- Informazioni su questa guida
- I Ceph Dashboard
- 1 Informazioni sul Ceph Dashboard
- 2 Interfaccia utente Web del dashboard
- 3 Gestione degli utenti e dei ruoli del Ceph Dashboard
- 4 Visualizzazione dei componenti interni del cluster
- 4.1 Visualizzazione dei nodi del cluster
- 4.2 Accesso all'inventario del cluster
- 4.3 Visualizzazione dei Ceph Monitor
- 4.4 Visualizzazione dei servizi
- 4.5 Visualizzazione dei Ceph OSD
- 4.6 Visualizzazione della configurazione del cluster
- 4.7 Visualizzazione della mappa CRUSH del
- 4.8 Visualizzazione dei moduli Manager
- 4.9 Visualizzazione dei log
- 4.10 Visualizzazione del monitoraggio
- 5 Gestione dei pool
- 6 Gestione del dispositivo di blocco RADOS (RADOS Block Device, RBD)
- 6.1 Visualizzazione dei dettagli sugli RBD
- 6.2 Visualizzazione della configurazione dell'RBD
- 6.3 Creazione di RBD
- 6.4 Eliminazione di RBD
- 6.5 Creazione di snapshot del dispositivo di blocco RADOS (RADOS Block Device, RBD)
- 6.6 Copia speculare RBD
- 6.7 Gestione di iSCSI Gateway
- 6.8 Qualità di servizio (QoS) RBD
- 7 Gestione di NFS Ganesha
- 8 Gestione di CephFS
- 9 Gestione di Object Gateway
- 10 Configurazione manuale
- 11 Gestione di utenti e ruoli sulla riga di comando
- II Funzionamento del cluster
- 12 Determinazione dello stato del cluster
- 12.1 Verifica dello stato di un cluster
- 12.2 Verifica dell'integrità del cluster
- 12.3 Verifica delle statistiche sull'utilizzo di un cluster
- 12.4 Verifica dello stato degli OSD
- 12.5 Verifica degli OSD pieni
- 12.6 Verifica dello stato del monitor
- 12.7 Verifica degli stati dei gruppi di posizionamento
- 12.8 Capacità di memorizzazione
- 12.9 Monitoraggio di OSD e gruppi di posizionamento
- 13 Task operativi
- 13.1 Modifica della configurazione del cluster
- 13.2 Aggiunta di nodi
- 13.3 Rimozione di nodi
- 13.4 Gestione degli OSD
- 13.5 Trasferimento del Salt Master a un nuovo nodo
- 13.6 Aggiornamento dei nodi del cluster
- 13.7 Aggiornamento di Ceph
- 13.8 Interruzione o riavvio del cluster
- 13.9 Rimozione dell'intero cluster Ceph
- 14 Funzionamento dei servizi Ceph
- 15 Backup e ripristino
- 16 Monitoraggio e creazione di avvisi
- 16.1 Configurazione di immagini personalizzate o locali
- 16.2 Aggiornamento dei servizi di monitoraggio
- 16.3 Disabilitazione del monitoraggio
- 16.4 Configurazione di Grafana
- 16.5 Configurazione del modulo Manager di Prometheus
- 16.6 Modello di sicurezza di Prometheus
- 16.7 Gateway SNMP di Prometheus Alertmanager
- 12 Determinazione dello stato del cluster
- III Memorizzazione dei dati in un cluster
- 17 Gestione dei dati memorizzati
- 18 Gestione dei pool di memorizzazione
- 19 Pool con codice di cancellazione
- 20 Dispositivo di blocco RADOS (RADOS Block Device, RBD)
- 20.1 Comandi dei dispositivi di blocco
- 20.2 Montaggio e smontaggio
- 20.3 Snapshot
- 20.4 Copie speculari delle immagini RBD
- 20.5 Impostazioni della cache
- 20.6 Impostazioni QoS
- 20.7 Impostazioni di lettura in avanti
- 20.8 Funzioni avanzate
- 20.9 Mappatura di RBD tramite i client kernel meno recenti
- 20.10 Abilitazione dei dispositivi di blocco e di Kubernetes
- IV Accesso ai dati del cluster
- 21 Ceph Object Gateway
- 21.1 Restrizioni e limitazioni di denominazione di Object Gateway
- 21.2 Distribuzione di Object Gateway
- 21.3 Attivazione del servizio Object Gateway
- 21.4 Opzioni di configurazione
- 21.5 Gestione dell'accesso a Object Gateway
- 21.6 Front-end HTTP
- 21.7 Abilitazione di HTTPS/SSL per gli Object Gateway
- 21.8 Moduli di sincronizzazione
- 21.9 Autenticazione LDAP
- 21.10 Partizionamento dell'indice del compartimento
- 21.11 Integrazione di OpenStack Keystone
- 21.12 Posizionamento di pool e classi di storage
- 21.13 Object Gateway multisito
- 22 Ceph iSCSI Gateway
- 23 File system in cluster
- 24 Esportazione dei dati Ceph tramite Samba
- 25 NFS Ganesha
- 21 Ceph Object Gateway
- V Integrazione con gli strumenti di virtualizzazione
- 26
libvirte Ceph - 27 Ceph come back-end per l'istanza QEMU KVM
- 27.1 Installazione
qemu-block-rbd - 27.2 Uso di QEMU
- 27.3 Creazione di immagini con QEMU
- 27.4 Ridimensionamento delle immagini con QEMU
- 27.5 Recupero delle informazioni sull'immagine con QEMU
- 27.6 Esecuzione di QEMU con RBD
- 27.7 Abilitazione dell'operazione di scarto e TRIM
- 27.8 Impostazione delle opzioni cache QEMU
- 27.1 Installazione
- 26
- VI Configurazione di un cluster
- A Aggiornamenti alla manutenzione di Ceph basati sulle release intermedie upstream "Pacific"
- Glossario
- 2.1 Schermata di login del Ceph Dashboard
- 2.2 Notifica di una nuova versione di SUSE Enterprise Storage
- 2.3 Home page del Ceph Dashboard
- 2.4 Widget Stato
- 2.5 Widget Capacità
- 2.6 Widget prestazioni
- 3.1 Gestione utenti
- 3.2 Aggiunta di un utente
- 3.3 Ruoli dell'utente
- 3.4 Aggiunta di un ruolo
- 4.1 Hosts
- 4.2 servizi
- 4.3 Ceph Monitor
- 4.4 servizi
- 4.5 Ceph OSD
- 4.6 Flag OSD
- 4.7 Priorità di recupero OSD
- 4.8 Dettagli OSD
- 4.9 Creazione di OSD
- 4.10 Aggiunta di dispositivi primari
- 4.11 Creazione di OSD con dispositivi primari aggiunti
- 4.12
- 4.13 OSD appena aggiunti
- 4.14 Configurazione del cluster
- 4.15 Mappa CRUSH
- 4.16 Moduli Manager
- 4.17 Log
- 5.1 Elenco di pool
- 5.2 Aggiunta di un nuovo pool
- 6.1 Elenco delle immagini RBD
- 6.2 Dettagli RBD
- 6.3 Configurazione RBD
- 6.4 Aggiunta di un nuovo RBD
- 6.5 Snapshot RBD
- 6.6 Esecuzione dei daemon
rbd-mirror - 6.7 Creazione di un pool con l'applicazione RBD
- 6.8 Configurazione della modalità di replica
- 6.9 Aggiunta delle credenziali del peer
- 6.10 Elenco dei pool replicati
- 6.11 Nuova immagine RBD
- 6.12 Nuova immagine RBD sincronizzata
- 6.13 Stato della replica delle immagini RBD
- 6.14 Elenco delle destinazioni iSCSI
- 6.15 Dettagli sulla destinazione iSCSI
- 6.16 Aggiunta di una nuova destinazione
- 7.1 Elenco di esportazioni NFS
- 7.2 Dettagli esportazione NFS
- 7.3 Aggiunta di una nuova esportazione NFS
- 7.4 Modifica di un'esportazione NFS
- 8.1 Dettagli CephFS
- 8.2 Dettagli CephFS
- 9.1 Dettagli Gateway
- 9.2 Utenti Gateway
- 9.3 Aggiunta di un nuovo utente Gateway
- 9.4 Dettagli compartimento Gateway
- 9.5 Modifica dei dettagli del compartimento
- 12.1 Cluster Ceph
- 12.2 Schema di peering
- 12.3 Stato dei gruppi di posizionamento
- 17.1 OSD con classi di dispositivi miste
- 17.2 Albero di esempio
- 17.3 Metodi di sostituzione dei nodi
- 17.4 Gruppi di posizionamento in un pool
- 17.5 Gruppi di posizionamento e OSD
- 18.1 Pool prima della migrazione
- 18.2 Configurazione del livello di cache
- 18.3 Svuotamento dei dati
- 18.4 Impostazione dell'overlay
- 18.5 Completamento della migrazione
- 20.1 Protocollo RADOS
- 22.1 Proprietà iniziatore iSCSI
- 22.2 Rilevazione portale di destinazione
- 22.3 Portali di destinazione
- 22.4 Destinazioni
- 22.5 Proprietà destinazione iSCSI
- 22.6 Dettagli dispositivo
- 22.7 Procedura guidata per il nuovo volume
- 22.8 Prompt del disco offline
- 22.9 Conferma selezioni volume
- 22.10 Proprietà iniziatore iSCSI
- 22.11 Aggiunta del server di destinazione
- 22.12 Gestione dei dispositivi multipath
- 22.13 Elenco dei percorsi per multipath
- 22.14 Finestra di dialogo Aggiungi memorizzazione
- 22.15 Impostazione spazio personalizzato
- 22.16 Panoramica dell'archivio dati iSCSI
- 25.1 Struttura di NFS Ganesha
- 30.1 Autenticazione
cephxdi base - 30.2
cephxautenticazione - 30.3 Autenticazione
cephx- MDS e OSD
- 12.1 Individuazione di un oggetto
- 13.1 Corrispondenza in base alle dimensioni del disco
- 13.2 Configurazione semplice
- 13.3 Configurazione avanzata
- 13.4 Configurazione avanzata con nodi non uniformi
- 13.5 Configurazione esperta
- 13.6 Configurazione complessa (e improbabile)
- 17.1
crushtool --reclassify-root - 17.2
crushtool --reclassify-bucket - 21.1 Configurazione semplice
- 21.2 Configurazione complessa
- 28.1 Configurazione oggetto Beast di esempio
- 28.2 Configurazione Civetweb di esempio in
/etc/ceph/ceph.conf
Copyright © 2020–2024 SUSE LLC e collaboratori. Tutti i diritti riservati.
Tranne laddove diversamente specificato, il presente documento è fornito con licenza Creative Commons Attribution-ShareAlike 4.0 International (CC-BY-SA 4.0): https://creativecommons.org/licenses/by-sa/4.0/legalcode
Per i marchi di fabbrica SUSE vedere http://www.suse.com/company/legal/. Tutti i marchi di fabbrica di terze parti appartengono ai rispettivi proprietari. I simboli dei marchi di fabbrica (®, ™, ecc.) indicano i marchi di fabbrica di SUSE e delle sue affiliate. Gli asterischi (*) indicano i marchi di fabbrica di terze parti.
Tutte le informazioni presenti nella presente pubblicazione sono state compilate con la massima attenzione ai dettagli. Ciò, tuttavia, non garantisce una precisione assoluta. SUSE LLC, le rispettive affiliate, gli autori e i traduttori non potranno essere ritenuti responsabili di eventuali errori o delle relative conseguenze.
Informazioni su questa guida #
Questa guida è incentrata sui task di routine che gli amministratori devono completare in seguito alla distribuzione del cluster Ceph di base (operazioni giorno 2). Descrive inoltre tutti i metodi supportati per l'accesso ai dati memorizzati in un cluster Ceph.
SUSE Enterprise Storage 7.1 è un'estensione per SUSE Linux Enterprise Server 15 SP3 che combina le funzionalità del progetto di storage Ceph (http://ceph.com/) con il supporto e l'ingegneria aziendale di SUSE. SUSE Enterprise Storage 7.1 fornisce alle organizzazioni IT la possibilità di installare un'architettura di storage distribuita in grado di supportare numerosi casi di utilizzo mediante piattaforme hardware commodity.
1 Documentazione disponibile #
La documentazione relativa ai nostri prodotti è disponibile all'indirizzo https://documentation.suse.com, dove sono disponibili anche gli ultimi aggiornamenti ed è possibile sfogliare ed effettuare il download della documentazione in vari formati. Gli ultimi aggiornamenti della documentazione sono disponibili in lingua inglese.
Inoltre, la documentazione dei prodotti è disponibile nel sistema installato in /usr/share/doc/manual. È inclusa in un pacchetto RPM denominato ses-manual_LANG_CODE. Installarlo se non è già presente nel sistema, ad esempio:
# zypper install ses-manual_enPer questo prodotto è disponibile la seguente documentazione:
- Guida all'installazione
Questa guida è incentrata sulla distribuzione di un cluster Ceph di base e di servizi aggiuntivi. Illustra inoltre le procedure da completare per eseguire l'upgrade a SUSE Enterprise Storage 7.1 dalla versione precedente.
- Guida all'amministrazione e alle operazioni
Questa guida è incentrata sui task di routine che gli amministratori devono completare in seguito alla distribuzione del cluster Ceph di base (operazioni giorno 2). Descrive inoltre tutti i metodi supportati per l'accesso ai dati memorizzati in un cluster Ceph.
- Guida alla sicurezza avanzata
Questa guida descrive le procedure per verificare la protezione del cluster.
- Guida alla soluzione dei problemi
Questa guida descrive diversi problemi comuni correlati all'esecuzione di SUSE Enterprise Storage 7.1 e altri problemi relativi ai componenti pertinenti, come Ceph oppure Object Gateway.
- Guida di SUSE Enterprise Storage per Windows
Questa guida descrive le procedure di integrazione, installazione e configurazione degli ambienti Microsoft Windows e SUSE Enterprise Storage tramite il driver di Windows.
2 Invio di feedback #
Qualsiasi feedback e contributo alla presente documentazione è ben accetto. È possibile lasciare il proprio feedback tramite tanti canali diversi:
- Richieste di servizio e supporto
Per verificare i servizi e le opzioni di supporto disponibili per il proprio prodotto, visitare http://www.suse.com/support/.
Per aprire una richiesta di servizio, è necessario l'abbonamento al SUSE Customer Center. Andare a https://scc.suse.com/support/requests, eseguire il login e fare clic su .
- Segnalazioni di bug
Segnalare i problemi relativi alla documentazione all'indirizzo https://bugzilla.suse.com/. Per la segnalazione dei problemi, è necessario un account Bugzilla.
Per semplificare il processo, è possibile utilizzare i collegamenti per la , accanto ai titoli nella versione HTML del presente documento, che preselezionano la categoria e il prodotto corretti in Bugzilla e indirizzano alla sezione corrente. È possibile iniziare a digitare subito la segnalazione di bug.
- Contributi
Per contribuire alla presente documentazione, utilizzare i collegamenti , accanto ai titoli nella versione HTML del documento, che indirizzano al codice sorgente su GitHub, dove è possibile aprire una richiesta pull. Per inviare un contributo, è necessario un account GitHub.
Per ulteriori informazioni sull'ambiente di documentazione utilizzato, vedere il file README dell'archivio all'indirizzo https://github.com/SUSE/doc-ses.
- Posta
È inoltre possibile segnalare errori e inviare feedback sulla documentazione scrivendo all'indirizzo <doc-team@suse.com>. Includere il titolo del documento, la versione del prodotto e la data di pubblicazione del documento. Inoltre, includere il titolo e il numero della sezione pertinente (o specificare l'URL) e fornire una breve descrizione del problema.
3 Convenzioni utilizzate nella documentazione #
Nel presente documento vengono utilizzati gli avvisi e le convenzioni tipografiche illustrati di seguito:
/etc/passwd: nomi di directory e fileSEGNAPOSTO: sostituire SEGNAPOSTO con il valore effettivo
PATH: variabile di ambientels,--help: comandi, opzioni e parametriuser: nome dell'utente o del gruppopackage_name: nome di un pacchetto software
Alt, Alt–F1: tasto da premere o combinazione di tasti. I tasti sono visualizzati in maiuscolo come se fossero sulla tastiera.
, › (Salva con nome): voci di menu, pulsanti
AMD/Intel Questo paragrafo si riferisce esclusivamente alle architetture AMD64/Intel 64. Le frecce contrassegnano l'inizio e la fine del blocco di testo.
IBM Z, POWER Questo paragrafo si riferisce esclusivamente alle architetture
IBM ZePOWER. Le frecce contrassegnano l'inizio e la fine del blocco di testo.Capitolo 1, «Capitolo di esempio»: riferimento incrociato a un altro capitolo della presente guida.
Comandi che devono essere eseguiti con privilegi di
root. Per eseguire tali comandi come utente senza privilegi, è spesso possibile anteporvi il prefissosudo.#command>sudocommandComandi che possono essere eseguiti anche da utenti senza privilegi.
>commandAvvisi
 Avvertimento: avvertenza
Avvertimento: avvertenzaInformazioni essenziali che è indispensabile conoscere prima di procedere. Segnala problemi di sicurezza, potenziali perdite di dati, danni hardware o pericoli fisici.
 Importante: avviso importante
Importante: avviso importanteInformazioni importanti che è consigliabile leggere prima di procedere.
 Nota: nota
Nota: notaInformazioni aggiuntive, che illustrano ad esempio le differenze tra le varie versioni del software.
 Suggerimento: suggerimento
Suggerimento: suggerimentoInformazioni utili, come linee guida o consigli pratici.
Avvisi compatti
Informazioni aggiuntive, che illustrano ad esempio le differenze tra le varie versioni del software.
Informazioni utili, come linee guida o consigli pratici.
4 Supporto #
Di seguito sono riportate l'Informativa sul supporto per SUSE Enterprise Storage e informazioni generali sulle anteprime della tecnologia. Per i dettagli sul ciclo di vita del prodotto, vedere il https://www.suse.com/lifecycle.
Se si ha diritto al supporto, ulteriori dettagli su come raccogliere informazioni per un ticket di supporto sono disponibili all'indirizzo https://documentation.suse.com/sles-15/html/SLES-all/cha-adm-support.html.
4.1 Informativa sul supporto per SUSE Enterprise Storage #
Per ricevere supporto, occorre una sottoscrizione idonea a SUSE. Per visualizzare le offerte di supporto specifiche disponibili, andare a https://www.suse.com/support/ e selezionare il prodotto in uso.
Di seguito sono riportate le definizioni dei livelli di supporto:
- L1
Individuazione del problema, ovvero supporto tecnico pensato per fornire informazioni di compatibilità, assistenza per l'utilizzo, operazioni di manutenzione, raccolta di informazioni e risoluzione dei problemi di base tramite la documentazione disponibile.
- L2
Isolamento del problema, ovvero supporto tecnico pensato per l'analisi dei dati, la riproduzione dei problemi dei clienti, l'isolamento dell'area del problema e la proposta di una risoluzione dei problemi non risolti al livello 1 o la loro preparazione per il livello 3.
- L3
Risoluzione del problema, ovvero supporto tecnico pensato per la risoluzione dei difetti del prodotto identificati al livello di supporto 2.
Per i clienti e i partner con contratto, SUSE Enterprise Storage è fornito con supporto L3 per tutti i pacchetti, a eccezione di quanto segue:
Anteprime della tecnologia.
Suoni, grafiche, tipi di carattere e oggetti grafici.
Pacchetti che richiedono un contratto con il cliente aggiuntivo.
Alcuni pacchetti rilasciati come parte del modulo Workstation Extension dispongono soltanto del supporto L2.
I pacchetti con nomi che terminano con -devel (contenenti file di intestazione e simili risorse per sviluppatori) sono supportati soltanto insieme ai relativi pacchetti principali.
SUSE supporterà soltanto l'utilizzo dei pacchetti originali. Vale a dire, i pacchetti non modificati e non ricompilati.
4.2 Anteprime della tecnologia #
Le anteprime della tecnologia sono pacchetti, stack o funzioni forniti da SUSE come anticipazioni sulle future innovazioni. Tramite le anteprime della tecnologia, i clienti hanno la possibilità di testare le nuove tecnologie all'interno del proprio ambiente. I feedback degli utenti sono bene accetti. Se si esegue il test di un'anteprima della tecnologia, contattare il proprio rappresentante SUSE per informarlo della propria esperienza utente e dei casi d'uso. I suggerimenti degli utenti sono molto utili per lo sviluppo futuro.
Le anteprime della tecnologia presentano le seguenti limitazioni:
Le anteprime della tecnologia sono ancora in fase di sviluppo. Di conseguenza, potrebbero essere incomplete a livello di funzioni, instabili o in altri modi non adatte per l'utilizzo nell'ambiente di produzione.
Le anteprime della tecnologia non dispongono di alcun supporto.
Le anteprime della tecnologia potrebbero essere disponibili soltanto per architetture hardware specifiche.
I dettagli e le funzionalità delle anteprime della tecnologia sono soggetti a modifica. Di conseguenza, potrebbe non essere possibile eseguire l'upgrade alle successive release di un'anteprima della tecnologia e potrebbe essere necessario eseguire una nuova installazione.
SUSE potrebbe rilevare che un'anteprima non soddisfa le esigenze dei clienti o del mercato o che non è confacente agli standard aziendali. Le anteprime della tecnologia possono essere rimosse da un prodotto in qualsiasi momento. SUSE non si impegna a fornire una versione supportata di tali tecnologie in futuro.
Per una panoramica delle anteprime della tecnologia fornite con il prodotto, vedere le note di rilascio all'indirizzo https://www.suse.com/releasenotes/x86_64/SUSE-Enterprise-Storage/7.1.
5 Collaboratori di Ceph #
Il progetto Ceph e la relativa documentazione sono il risultato del lavoro di centinaia di collaboratori e organizzazioni. Per ulteriori dettagli, consultare la pagina all'indirizzo https://ceph.com/contributors/.
6 Comandi e prompt dei comandi utilizzati nella presente guida #
Gli amministratori del cluster Ceph si occupano della configurazione e della modifica del comportamento del cluster tramite l'esecuzione di comandi specifici. Saranno necessari diversi tipi di comandi:
6.1 Comandi correlati a Salt #
Questi comandi consentono di distribuire i nodi del cluster Ceph, di eseguire comandi contemporaneamente su più (o su tutti i) nodi del cluster e semplificano l'aggiunta o la rimozione dei nodi del cluster. I comandi utilizzati più di frequente sono ceph-salt e ceph-salt config. È necessario eseguire i comandi Salt sul nodo del Salt Master come root. Questi comandi sono introdotti dal prompt seguente:
root@master # Esempio:
root@master # ceph-salt config ls6.2 Comandi correlati a Ceph #
Si tratta di comandi di livello inferiore per la configurazione e l'ottimizzazione di tutti gli aspetti del cluster e dei relativi gateway sulla riga di comando, ad esempio ceph, cephadm, rbd o radosgw-admin.
Per eseguire i comandi correlati a Ceph, è necessario disporre dell'accesso in lettura a una chiave Ceph. Le capacità della chiave definiscono i privilegi dell'utente all'interno dell'ambiente Ceph. Un'opzione consiste nell'eseguire i comandi di Ceph come root (o tramite sudo) e utilizzare il portachiavi di default senza restrizioni "ceph.client.admin.key".
L'opzione consigliata e più sicura consiste nel creare una chiave individuale più restrittiva per ogni utente amministratore e inserirla in una directory in cui gli utenti possano leggerla, ad esempio:
~/.ceph/ceph.client.USERNAME.keyring
Per utilizzare un utente amministratore e un portachiavi personalizzati, è necessario specificare il nome utente e il percorso della chiave ogni volta che si esegue il comando ceph tramite le opzioni -n client.USER_NAME e --keyring PATH/TO/KEYRING.
Per evitarlo, includere queste opzioni nella variabile CEPH_ARGS nei file ~/.bashrc dei singoli utenti.
I comandi correlati a Ceph possono essere eseguiti su qualsiasi nodo del cluster, ma è consigliabile eseguirli sul nodo admin. In questa documentazione, l'utente cephuser esegue i comandi, pertanto questi vengono introdotti dal prompt seguente:
cephuser@adm > Esempio:
cephuser@adm > ceph auth listSe nella documentazione è indicato di eseguire un comando su un nodo del cluster con un ruolo specifico, questo verrà indirizzato dal prompt. Esempio:
cephuser@mon > 6.2.1 Esecuzione di ceph-volume #
A partire da SUSE Enterprise Storage 7, i servizi Ceph vengono eseguiti in container. Se è necessario eseguire ceph-volume su un nodo OSD, occorre anteporlo con il comando cephadm, ad esempio:
cephuser@adm > cephadm ceph-volume simple scan6.3 Comandi Linux generali #
I comandi Linux non correlati a Ceph, come mount, cat o openssl, sono introdotti con i prompt cephuser@adm > o # , a seconda dei privilegi richiesti dal comando correlato.
6.4 Informazioni aggiuntive #
Per ulteriori informazioni sulla gestione della chiave Ceph, fare riferimento a Sezione 30.2, «Gestione delle chiavi».
Parte I Ceph Dashboard #
- 1 Informazioni sul Ceph Dashboard
Il Ceph Dashboard è un'applicazione di gestione e monitoraggio Ceph integrata e basata sul Web per l'amministrazione di diversi aspetti e oggetti del cluster. Il dashboard è abilitato automaticamente in seguito alla distribuzione del cluster di base come descritto nel Book “Guida alla distribuzione”…
- 2 Interfaccia utente Web del dashboard
Per eseguire il login al Ceph Dashboard, puntare il browser verso il relativo URL includendo il numero di porta. Eseguire il comando seguente per trovare l'indirizzo:
- 3 Gestione degli utenti e dei ruoli del Ceph Dashboard
La gestione degli utenti del dashboard tramite i comandi di Ceph sulla riga di comando è già stata illustrata nella Capitolo 11, Gestione di utenti e ruoli sulla riga di comando.
- 4 Visualizzazione dei componenti interni del cluster
La voce di menu consente di visualizzare informazioni dettagliate su host, inventario, Ceph Monitor, servizi, OSD, configurazione, mappa CRUSH, Ceph Manager, log e file di monitoraggio del cluster Ceph.
- 5 Gestione dei pool
Per informazioni generali sui pool Ceph, fare riferimento a Capitolo 18, Gestione dei pool di memorizzazione. Per informazioni specifiche sui pool con codice di cancellazione, fare riferimento al Capitolo 19, Pool con codice di cancellazione.
- 6 Gestione del dispositivo di blocco RADOS (RADOS Block Device, RBD)
Per visualizzare un elenco di tutti i dispositivi di blocco RADOS (RBD) disponibili, fare clic su › nel menu principale.
- 7 Gestione di NFS Ganesha
NFS Ganesha supporta NFS versione 4.1 e versioni successive. Non supporta NFS versione 3.
- 8 Gestione di CephFS
Per informazioni dettagliate su CephFS, fare riferimento al Capitolo 23, File system in cluster.
- 9 Gestione di Object Gateway
Prima di iniziare, quando si tenta di accedere al front-end di Object Gateway sul Ceph Dashboard, potrebbe essere visualizzata la notifica seguente:
- 10 Configurazione manuale
Questa sezione fornisce informazioni avanzate per gli utenti che preferiscono configurare manualmente le impostazioni del dashboard nella riga di comando.
- 11 Gestione di utenti e ruoli sulla riga di comando
Questa sezione descrive come gestire gli account utente utilizzati dal Ceph Dashboard e fornisce informazioni sulla creazione o modifica degli account utente, nonché sull'impostazione dei ruoli dell'utente e delle autorizzazioni corretti.
1 Informazioni sul Ceph Dashboard #
Il Ceph Dashboard è un'applicazione di gestione e monitoraggio Ceph integrata e basata sul Web per l'amministrazione di diversi aspetti e oggetti del cluster. Il dashboard è abilitato automaticamente in seguito alla distribuzione del cluster di base come descritto nel Book “Guida alla distribuzione”, Chapter 7 “Distribuzione del cluster di bootstrap mediante ceph-salt”.
Il Ceph Dashboard di SUSE Enterprise Storage 7.1 dispone di ulteriori funzionalità di gestione basate sul Web per semplificare l'amministrazione di Ceph, incluse le attività di monitoraggio e amministrazione dell'applicazione sul Ceph Manager. Per gestire e monitorare il cluster Ceph, non è più necessario conoscere i complessi comandi di Ceph. È possibile utilizzare l'intuitiva interfaccia o l'API REST integrata del Ceph Dashboard.
Il modulo del Ceph Dashboard visualizza informazioni e statistiche sul cluster Ceph tramite un server Web ospitato da ceph-mgr. Vedere Book “Guida alla distribuzione”, Chapter 1 “SES e Ceph”, Section 1.2.3 “Daemon e nodi Ceph” per ulteriori dettagli su Ceph Manager.
2 Interfaccia utente Web del dashboard #
2.1 Login #
Per eseguire il login al Ceph Dashboard, puntare il browser verso il relativo URL includendo il numero di porta. Eseguire il comando seguente per trovare l'indirizzo:
cephuser@adm > ceph mgr services | grep dashboard
"dashboard": "https://host:port/",Il comando restituisce l'URL su cui si trova il Ceph Dashboard. In caso di problemi con questo comando, vedere Book “Troubleshooting Guide”, Chapter 10 “Troubleshooting the Ceph Dashboard”, Section 10.1 “Locating the Ceph Dashboard”.

Eseguire il login con le credenziali create durante la distribuzione del cluster (vedere Book “Guida alla distribuzione”, Chapter 7 “Distribuzione del cluster di bootstrap mediante ceph-salt”, Section 7.2.9 “Configurazione delle credenziali di login del Ceph Dashboard”).
Se non si desidera utilizzare l'account admin di default per accedere al Ceph Dashboard, creare un account utente personalizzato con privilegi di amministratore. Per ulteriori dettagli, fare riferimento a Capitolo 11, Gestione di utenti e ruoli sulla riga di comando.
Non appena è disponibile un upgrade a una nuova versione principale di Ceph (nome in codice: Pacific), il Ceph Dashboard visualizza uno specifico messaggio nell'area di notifica superiore. Per eseguire l'upgrade, seguire le istruzioni indicate in Book “Guida alla distribuzione”, Chapter 11 “Upgrade da SUSE Enterprise Storage 7 a 7.1”.

L'interfaccia utente del dashboard è graficamente suddivisa in più blocchi: il menu dell'utility in alto a destra sulla schermata, il menu principale a sinistra e il pannello dei contenuti principale.

2.2 Menu dell'utility #
Il menu dell'utility occupa il lato superiore destro della schermata e include i task generali correlati più al dashboard che al cluster Ceph. Facendo clic sulle opzioni, è possibile:
Modificare la lingua dell'interfaccia del dashboard su: ceco, tedesco, inglese, spagnolo, francese, indonesiano, italiano, giapponese, coreano, polacco, portoghese (brasiliano) e cinese.
Accedere a task e notifiche.
Visualizzare la documentazione, le informazioni sull'API REST o ulteriori informazioni sul dashboard.
Accedere alla gestione utenti e alla configurazione di telemetria.
NotaPer descrizioni più dettagliate della riga di comando per i ruoli dell'utente, vedere il Capitolo 11, Gestione di utenti e ruoli sulla riga di comando.
Accedere alla configurazione del login; modificare la password o disconnettersi.
2.3 Menu principale #
Il menu principale del dashboard occupa il lato superiore sinistro della schermata e copre gli argomenti seguenti:
Per tornare alla home page del Ceph Dashboard.
Per visualizzare informazioni dettagliate su host, inventario, Ceph Monitor, servizi, Ceph OSD, configurazione del cluster, mappa CRUSH, moduli di Ceph Manager, log e monitoraggio.
Per visualizzare e gestire i pool del cluster.
Per visualizzare informazioni dettagliate e gestire le immagini del dispositivo di blocco RADOS (RADOS Block Device, RBD), la copia speculare e iSCSI.
Per visualizzare e gestire le distribuzioni di NFS Ganesha.
NotaSe NFS Ganesha non è distribuito, viene visualizzato un avviso. Vedere Sezione 11.6, «Configurazione di NFS Ganesha nel Ceph Dashboard».
Per visualizzare e gestire i CephFS.
Per visualizzare e gestire i daemon, gli utenti e i compartimenti di Object Gateway.
NotaSe Object Gateway non è distribuito, viene visualizzato un avviso. Vedere Sezione 10.4, «Abilitazione del front-end di gestione di Object Gateway».
2.4 Pannello dei contenuti #
Il pannello dei contenuti occupa la parte principale della schermata del dashboard. Nella home page del dashboard sono mostrati molti widget utili con informazioni sintetiche sullo stato corrente del cluster, sulla capacità e sulle prestazioni.
2.5 Funzioni dell'interfaccia utente Web comuni #
Spesso nel Ceph Dashboard si utilizzano elenchi: ad esempio, elenchi di pool, nodi OSD o dispositivi RBD. Tutti gli elenchi si aggiornano automaticamente per default ogni cinque secondi. I seguenti widget comuni consentono di gestire o regolare tali elenchi:
Fare clic su ![]() per attivare un aggiornamento manuale dell'elenco.
per attivare un aggiornamento manuale dell'elenco.
Fare clic su ![]() per visualizzare o nascondere colonne della tabella individuali.
per visualizzare o nascondere colonne della tabella individuali.
Fare clic su ![]() e immettere (o selezionare) il numero di righe da visualizzare in un'unica pagina.
e immettere (o selezionare) il numero di righe da visualizzare in un'unica pagina.
Fare clic all'interno di  e filtrare le righe digitando la stringa da ricercare.
e filtrare le righe digitando la stringa da ricercare.
Utilizzare  per modificare la pagina attualmente visualizzata se l'elenco è distribuito su più pagine.
per modificare la pagina attualmente visualizzata se l'elenco è distribuito su più pagine.
2.6 Widget del dashboard #
Ogni widget del dashboard mostra specifiche informazioni sullo stato relative a un determinato aspetto di un cluster Ceph in esecuzione. Alcuni widget sono collegamenti attivi che, dopo essere stati selezionati, reindirizzano l'utente a una pagina dettagliata dell'argomento a cui fanno riferimento.
Passando il mouse sopra alcuni widget grafici, è possibile visualizzare ulteriori dettagli.
2.6.1 Widget Stato #
I widget forniscono una breve panoramica sullo stato corrente del cluster.

Mostra le informazioni di base sullo stato del cluster.
Mostra il numero totale di nodi del cluster.
Mostra il numero di monitor in esecuzione e il relativo quorum.
Mostra il numero totale di OSD, oltre al numero di OSD negli stati up e in.
Mostra il numero di Ceph Manager Daemon attivi e in standby.
Mostra il numero di Object Gateway in esecuzione.
Mostra il numero di server di metadati.
Mostra il numero di iSCSI Gateway configurati.
2.6.2 Widget Capacità #
I widget mostrano brevi informazioni sulla capacità di storage.

Mostra il rapporto tra la capacità di storage nominale disponibile e quella utilizzata.
Mostra il numero di oggetti dati memorizzati nel cluster.
Visualizza un grafico dei gruppi di posizionamento in base al relativo stato.
Mostra il numero di pool nel cluster.
Mostra il numero medio di gruppi di posizionamento per OSD.
2.6.3 Widget Prestazioni #
I widget fanno riferimento ai dati di base sulle prestazioni dei client Ceph.

Numero di operazioni di lettura e scrittura dei client al secondo.
Quantità in byte al secondo di dati trasferiti ai e dai client Ceph.
Velocità effettiva dei dati recuperati al secondo.
Mostra lo stato della pulitura (vedere la Sezione 17.4.9, «Pulitura di un gruppo di posizionamento»). Lo stato può essere
inactive,enabledoactive(inattivo, abilitato o attivo).
3 Gestione degli utenti e dei ruoli del Ceph Dashboard #
La gestione degli utenti del dashboard tramite i comandi di Ceph sulla riga di comando è già stata illustrata nella Capitolo 11, Gestione di utenti e ruoli sulla riga di comando.
Questa sezione descrive come gestire gli account utente tramite l'interfaccia utente Web del dashboard.
3.1 Elenco degli utenti #
Fare clic su ![]() nel menu dell'utility e selezionare .
nel menu dell'utility e selezionare .
L'elenco contiene il nome utente, il nome completo, l'indirizzo e-mail, un elenco dei ruoli assegnati, le informazioni sullo stato di abilitazione del ruolo e la data di scadenza della password di ciascun utente.

3.2 Aggiunta di nuovi utenti #
Fare clic su in alto a sinistra nell'intestazione della tabella per aggiungere un nuovo utente. Immettere il nome utente e la password e facoltativamente il nome completo e l'e-mail.

Selezionare l'icona a forma di penna per assegnare i ruoli predefiniti all'utente. Confermare con .
3.3 Modifica di utenti #
Fare clic sulla riga di tabella corrispondente a un utente per evidenziarla. Selezionare per modificare i dettagli relativi all'utente. Confermare con .
3.4 Eliminazione di utenti #
Fare clic sulla riga di tabella corrispondente a un utente per evidenziarla. Selezionare la casella a discesa accanto a e selezionare dall'elenco per eliminare l'account utente. Attivare la casella di controllo e confermare con .
3.5 Elenco dei ruoli dell'utente #
Fare clic su ![]() nel menu dell'utility e selezionare . Quindi, fare clic sulla scheda .
nel menu dell'utility e selezionare . Quindi, fare clic sulla scheda .
L'elenco contiene il nome e la descrizione di ciascun ruolo e indica se si tratta di un ruolo di sistema.

3.6 Aggiunta di ruoli personalizzati #
Fare clic su in alto a sinistra nell'intestazione della tabella per aggiungere un nuovo ruolo personalizzato. Immettere il e la e, accanto ad , selezionare le autorizzazioni appropriate.
Se si creano ruoli dell'utente personalizzati e si intende rimuovere il cluster Ceph con il comando ceph-salt purge in un secondo momento, è necessario innanzitutto eliminare definitivamente i ruoli personalizzati. Ulteriori dettagli sono disponibili nella Sezione 13.9, «Rimozione dell'intero cluster Ceph».

Tramite l'attivazione della casella di controllo accanto al nome dell'argomento, si attivano tutte le autorizzazioni correlate a quest'ultimo. Se si attiva la casella di controllo , si attivano tutte le autorizzazioni correlate a tutti gli argomenti.
Confermare con .
3.7 Modifica dei ruoli personalizzati #
Fare clic sulla riga di tabella corrispondente a un utente per evidenziarla. Selezionare in alto a sinistra nell'intestazione della tabella per modificare la descrizione e le autorizzazioni di un ruolo personalizzato. Confermare con .
3.8 Eliminazione dei ruoli personalizzati #
Fare clic sulla riga di tabella corrispondente a un ruolo per evidenziarla. Selezionare la casella a discesa accanto a e selezionare dall'elenco per eliminare il ruolo. Attivare la casella di controllo e confermare con .
4 Visualizzazione dei componenti interni del cluster #
La voce di menu consente di visualizzare informazioni dettagliate su host, inventario, Ceph Monitor, servizi, OSD, configurazione, mappa CRUSH, Ceph Manager, log e file di monitoraggio del cluster Ceph.
4.1 Visualizzazione dei nodi del cluster #
Fare clic su › per visualizzare un elenco dei nodi del cluster.

Fare clic sulla freccia a discesa accanto al nome di un nodo nella colonna per visualizzare i dettagli sulle prestazioni del nodo.
Nella colonna sono elencati tutti i daemon in esecuzione in ogni nodo correlato. Fare clic sul nome di un daemon per visualizzare la relativa configurazione dettagliata.
4.2 Accesso all'inventario del cluster #
Fare clic su › per visualizzare un elenco dei dispositivi. L'elenco riporta il percorso, il tipo, la disponibilità, il produttore, il modello, la dimensione e gli OSD del dispositivo.
Fare clic per selezionare il nome di un nodo nella colonna . Quindi, fare clic su per identificare il dispositivo su cui è in esecuzione l'host. Questa operazione invia al dispositivo l'istruzione di far lampeggiare i LED. Selezionare la durata di questa azione su 1, 2, 5, 10 o 15 minuti. Fare clic su .

4.3 Visualizzazione dei Ceph Monitor #
Fare clic su › per visualizzare un elenco dei nodi del cluster con Ceph Monitor in esecuzione. Il pannello dei contenuti è suddiviso in due viste: Stato e Nel quorum o Non nel quorum.
Nella tabella sono riportate le statistiche generali relative ai Ceph Monitor in esecuzione, inclusi:
ID cluster
monmap modified
monmap epoch
quorum con
quorum mon
required con
required mon
I pannelli Nel quorum e Non nel quorum includono il nome, la classificazione, il numero, l'indirizzo IP pubblico e il numero di sessioni aperte di ogni monitor.
Fare clic sul nome di un nodo nella colonna per visualizzare la configurazione del Ceph Monitor correlato.

4.4 Visualizzazione dei servizi #
Fare clic su › per visualizzare i dettagli su ciascuno dei servizi disponibili: crash, Ceph Manager e Ceph Monitor. L'elenco include il nome dell'immagine del container, l'ID dell'immagine del container, lo stato degli elementi in esecuzione, la dimensione e l'ultimo aggiornamento.
Fare clic sulla freccia a discesa accanto al nome di un servizio nella colonna per visualizzare i dettagli sul daemon. Nell'elenco dei dettagli sono inclusi il nome host, il tipo di daemon, l'ID del daemon, l'ID del container, il nome dell'immagine del container, l'ID dell'immagine del container, il numero di versione, lo stato e l'ultimo aggiornamento.

4.5 Visualizzazione dei Ceph OSD #
Fare clic su › per visualizzare un elenco dei nodi con daemon OSD in esecuzione. Nell'elenco sono inclusi il nome, l'ID, lo stato, la classe del dispositivo, il numero di gruppi di posizionamento, le dimensioni, l'utilizzo, il grafico delle operazioni di lettura/scrittura nel tempo e la frequenza delle operazioni di lettura/scrittura al secondo di ogni nodo.

Selezionare dal menu a discesa nell'intestazione della tabella per aprire una finestra popup contenente un elenco dei flag che si applicano all'intero cluster. È possibile attivare o disattivare i singoli flag e confermare con .

Selezionare dal menu a discesa nell'intestazione della tabella per aprire una finestra popup contenente un elenco delle priorità di recupero OSD che si applicano all'intero cluster. È possibile attivare il profilo di priorità preferito e ottimizzare i singoli valori di seguito. Confermare con .

Fare clic sulla freccia a discesa accanto al nome di un nodo nella colonna per visualizzare una tabella estesa con i dettagli sulle impostazioni e le prestazioni del dispositivo. Sfogliando le diverse schede, è possibile visualizzare gli elenchi , , , , un delle operazioni di lettura e scrittura e .

Dopo aver fatto clic sul nome di un nodo OSD, la riga della tabella verrà evidenziata a indicare che è possibile eseguire task sul nodo. È possibile scegliere di eseguire una delle azioni seguenti: , , , , , , , , , , o .
Fare clic sulla freccia verso il basso in alto a sinistra nell'intestazione della tabella accanto al pulsante e selezionare il task che si desidera eseguire.
4.5.1 Aggiunta di OSD #
Per aggiungere nuovi OSD, seguire la procedura indicata di seguito:
Verificare che alcuni nodi del cluster dispongano di dispositivi di memorizzazione in stato
available(disponibile). Quindi, fare clic sulla freccia verso il basso in alto a sinistra nell'intestazione della tabella e selezionate . Si aprirà la finestra . Figura 4.9: Creazione di OSD #
Figura 4.9: Creazione di OSD #Per aggiungere dispositivi di memorizzazione primari per gli OSD, fare clic su . Prima che sia possibile aggiungere dispositivi di memorizzazione, è necessario specificare i criteri di filtro in alto a destra nella tabella , ad esempio . Confermare con .
 Figura 4.10: Aggiunta di dispositivi primari #
Figura 4.10: Aggiunta di dispositivi primari #Nella finestra aggiornata, è possibile aggiungere dispositivi WAL e DB condivisi o abilitare la cifratura dei dispositivi.
 Figura 4.11: Creazione di OSD con dispositivi primari aggiunti #
Figura 4.11: Creazione di OSD con dispositivi primari aggiunti #Fare clic su per visualizzare l'anteprima della specifica dei DriveGroups per i dispositivi aggiunti in precedenza. Confermare con il pulsante .
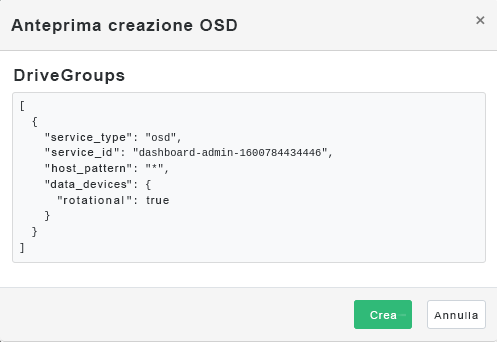 Figura 4.12: #
Figura 4.12: #I nuovi dispositivi verranno aggiunti all'elenco degli OSD.
 Figura 4.13: OSD appena aggiunti #Nota
Figura 4.13: OSD appena aggiunti #NotaLo stato di avanzamento del processo di creazione degli OSD non viene visualizzato. Per completare il processo, sono necessari diversi istanti. Gli OSD verranno visualizzati nell'elenco dopo essere stati distribuiti. Se si desidera controllare lo stato della distribuzione, aprire i log facendo clic su › .
4.6 Visualizzazione della configurazione del cluster #
Fare clic su › per visualizzare un elenco completo delle opzioni di configurazione del cluster Ceph. L'elenco contiene il nome dell'opzione, la descrizione breve, i valori attuali e di default e se l'opzione è modificabile.

Fare clic sulla freccia a discesa accanto a un'opzione di configurazione nella colonna per visualizzare una tabella estesa con le informazioni dettagliate sull'opzione, come il tipo di valore, i valori minimo e massimo consentiti, se è possibile aggiornarla al runtime e molto altro.
Dopo aver evidenziato un'opzione specifica, è possibile modificarne i valori facendo clic sul pulsante in alto a sinistra nell'intestazione della tabella. Confermare le modifiche con .
4.7 Visualizzazione della mappa CRUSH del #
Fare clic su › per visualizzare una mappa CRUSH del cluster. Per ulteriori informazioni generali sulle mappe CRUSH, fare riferimento alla Sezione 17.5, «Modifica della mappa CRUSH».
Fare clic sulla radice, sui nodi o sui singoli OSD per visualizzare altri dettagli, come il peso crush, la profondità nell'albero della mappa, la classe di dispositivi dell'OSD e molto altro.

4.8 Visualizzazione dei moduli Manager #
Fare clic su › per visualizzare un elenco dei moduli Ceph Manager disponibili. Ogni riga contiene il nome del modulo e informazioni sul suo stato di abilitazione o disabilitazione.

Fare clic sulla freccia a discesa accanto a un modulo nella colonna per visualizzare una tabella estesa con le impostazioni dettagliate nella tabella di seguito. Modificarle facendo clic sul pulsante in alto a sinistra nell'intestazione della tabella. Confermare le modifiche con .
Fare clic sulla freccia a discesa accanto al pulsante in alto a sinistra nell'intestazione della tabella per o un modulo.
4.9 Visualizzazione dei log #
Fare clic su › per visualizzare un elenco delle voci di log recenti del cluster. Ogni riga contiene la registrazione dell'orario, il tipo di voce del log e il messaggio registrato.
Fare clic sulla scheda per visualizzare le voci di log del sottosistema di revisione. Fare riferimento alla Sezione 11.5, «Controllo delle richieste API» per i comandi di abilitazione o disabilitazione della revisione.

4.10 Visualizzazione del monitoraggio #
Fare clic su › per gestire e visualizzare i dettagli sugli avvisi di Prometheus.
Se Prometheus è attivo, nel relativo pannello dei contenuti è possibile visualizzare le informazioni dettagliate su , o .
Se Prometheus non è stato distribuito, verranno visualizzati un'intestazione di informazioni e un collegamento alla documentazione pertinente.
5 Gestione dei pool #
Per informazioni generali sui pool Ceph, fare riferimento a Capitolo 18, Gestione dei pool di memorizzazione. Per informazioni specifiche sui pool con codice di cancellazione, fare riferimento al Capitolo 19, Pool con codice di cancellazione.
Per elencare tutti i pool disponibili, fare clic su nel menu principale.
Nell'elenco sono visualizzati il nome, il tipo, l'applicazione correlata, lo stato del gruppo di posizionamento, le dimensioni della replica, l'ultima modifica, il profilo con codice di cancellazione, il set di regole crush, l'utilizzo e le statistiche di lettura/scrittura relativi a ciascun pool.

Fare clic sulla freccia a discesa accanto a un nome del pool nella colonna per visualizzare una tabella estesa con informazioni dettagliate sul pool, come i dettagli generali, sulle prestazioni e la configurazione.
5.1 Aggiunta di un nuovo pool #
Per aggiungere un nuovo pool, fare clic su in alto a sinistra nella tabella dei pool. Nel modulo dei pool è possibile immettere il nome, il tipo, le applicazioni, la modalità di compressione e le quote relativi a un pool, incluso il numero massimo di byte e oggetti. Tale modulo calcola in anticipo il numero di gruppi di posizionamento più adatto per il pool specifico. Tale calcolo si basa sul numero di OSD nel cluster e sul tipo di pool selezionato con le relative impostazioni specifiche. Non appena viene impostato manualmente, il numero dei gruppi di posizionamento viene sostituito da un numero calcolato. Confermare con .

5.2 Eliminazione di pool #
Per eliminare un pool, selezionarlo nella riga della tabella. Fare clic sulla freccia a discesa accanto al pulsante e fare clic su .
5.3 Modifica delle opzioni di un pool #
Per modificare le opzioni di un pool, selezionare il pool nella riga della tabella e fare clic su in alto a sinistra nella tabella dei pool.
È possibile modificare il nome del pool, aumentare il numero di gruppi di posizionamento e modificare l'elenco delle applicazioni e delle impostazioni di compressione del pool. Confermare con .
6 Gestione del dispositivo di blocco RADOS (RADOS Block Device, RBD) #
Per visualizzare un elenco di tutti i dispositivi di blocco RADOS (RBD) disponibili, fare clic su › nel menu principale.
L'elenco mostra brevi informazioni sul dispositivo come il nome, il nome pool correlato, lo spazio dei nomi, le dimensioni del dispositivo, il numero e la dimensione degli oggetti sul dispositivo, i dettagli sul provisioning e il dispositivo superiore.

6.1 Visualizzazione dei dettagli sugli RBD #
Per visualizzare altri dettagli su un dispositivo, fare clic sulla relativa riga nella tabella:

6.2 Visualizzazione della configurazione dell'RBD #
Per visualizzare la configurazione dettagliata di un dispositivo, fare clic sulla relativa riga nella tabella e sulla scheda nella tabella inferiore:

6.3 Creazione di RBD #
Per aggiungere un nuovo dispositivo, fare clic su in alto a sinistra nell'intestazione della tabella ed eseguire quanto riportato di seguito nella schermata :

Immettere il nome del nuovo dispositivo. Per le restrizioni di denominazione, fare riferimento a Book “Guida alla distribuzione”, Chapter 2 “Requisiti hardware e raccomandazioni”, Section 2.11 “Limitazioni di denominazione”.
Selezionare il pool con l'applicazione
rbdassegnata da cui verrà creato il nuovo dispositivo RBD.Specificare le dimensioni del nuovo dispositivo.
Specificare le opzioni aggiuntive per il dispositivo. Per ottimizzare i parametri del dispositivo, fare clic su e immettere i valori relativi alle dimensioni dell'oggetto, all'unità di striping o al numero di striping. Per immettere i limiti di qualità del servizio (QoS, Quality of Service), fare clic su .
Confermare con .
6.4 Eliminazione di RBD #
Per eliminare un dispositivo, selezionarlo nella riga della tabella. Fare clic sulla freccia a discesa accanto al pulsante e fare clic su . Confermare l'eliminazione con (Elimina RBD).
L'eliminazione di un RBD è un'azione irreversibile. Se invece si seleziona l'opzione , è possibile ripristinare il dispositivo in un secondo momento selezionandolo nella scheda della tabella principale e facendo clic su in alto a sinistra nell'intestazione della tabella.
6.5 Creazione di snapshot del dispositivo di blocco RADOS (RADOS Block Device, RBD) #
Per creare uno snapshot del dispositivo di blocco RADOS (RADOS Block Device, RBD), selezionare il dispositivo nella riga della tabella per visualizzare il pannello dei contenuti relativo ai dettagli della configurazione. Selezionare la scheda e fare clic su in alto a sinistra nell'intestazione della tabella. Immettere il nome dello snapshot e confermare con .
Dopo aver selezionato una snapshot, è possibile eseguire ulteriori azioni sul dispositivo, ad esempio rinominarlo, proteggerlo, clonarlo, copiarlo o eliminarlo. L'opzione consente di ripristinare lo stato del dispositivo dallo snapshot attuale.

6.6 Copia speculare RBD #
È possibile eseguire la copia speculare delle immagini del dispositivo di blocco RADOS (RADOS Block Device, RBD) in modo asincrono tra due cluster Ceph. È possibile utilizzare il Ceph Dashboard per configurare la replica delle immagini RBD tra due o più cluster. Questa funzionalità è disponibile in due modalità:
- Basata sul journal
Questa modalità utilizza la funzione di journaling dell'immagine RBD per assicurare la replica temporizzata e con coerenza per arresto anomalo tra cluster.
- Basata su snapshot
Questa modalità utilizza snapshot di copia speculare dell'immagine RBD pianificati periodicamente o creati manualmente per eseguire la replica delle immagini RBD con coerenza per arresto anomalo tra cluster.
La copia speculare è configurata su ogni singolo pool all'interno dei cluster peer ed è possibile configurarla su un sottoinsieme specifico di immagini all'interno del pool o per fare in modo che esegua automaticamente la copia speculare di tutte le immagini del pool quando è in uso soltanto la modalità basata sul journal.
Per la configurazione della copia speculare si utilizza il comando rbd, installato per default in SUSE Enterprise Storage 7.1. Il daemon rbd-mirror è responsabile del pull degli aggiornamenti delle immagini dal cluster peer remoto e della loro applicazione all'immagine nel cluster locale. Vedere la Sezione 6.6.2, «Abilitazione del daemon rbd-mirror» per maggiori informazioni sull'abilitazione del daemon rbd-mirror.
A seconda delle necessità di replica, è possibile configurare la copia speculare del dispositivo di blocco RADOS (RADOS Block Device, RBD) sulla replica a una o due vie:
- Replica a una via
Quando la copia speculare dei dati avviene soltanto da un cluster primario a uno secondario, il daemon
rbd-mirrorviene eseguito solo sul cluster secondario.- Replica a due vie
Quando la copia speculare dei dati avviene dalle immagini primarie su un cluster alle immagini non primarie su un altro cluster (e viceversa), il daemon
rbd-mirrorviene eseguito su entrambi i cluster.
Ogni istanza del daemon rbd-mirror deve essere in grado di connettersi contemporaneamente al cluster Ceph local e remote, ad esempio a tutti i monitor e agli host OSD. Inoltre, la larghezza di banda della rete tra i due data center deve essere sufficiente per gestire il workload della copia speculare.
Per informazioni generali e sull'approccio della riga di comando alla copia speculare del dispositivo di blocco RADOS, fare riferimento alla Sezione 20.4, «Copie speculari delle immagini RBD».
6.6.1 Configurazione dei cluster primario e secondario #
Nel cluster primario viene creato il pool originale con le immagini. Nel cluster secondario vengono replicati il pool o le immagini dal cluster primario.
I termini primario e secondario possono essere relativi nel contesto della replica, perché fanno riferimento più ai singoli pool che ai cluster. Ad esempio, nella replica bidirezionale, è possibile eseguire la copia speculare di un pool dal cluster primario a quello secondario mentre è in corso la copia speculare di un altro pool dal cluster secondario a quello primario.
6.6.2 Abilitazione del daemon rbd-mirror #
Nelle procedure seguenti è illustrato come eseguire task amministrativi di base per configurare la copia speculare tramite il comando rbd. La copia speculare è configurata per ogni singolo pool nei cluster Ceph.
I passaggi di configurazione del pool devono essere eseguiti su entrambi i cluster peer. Per maggior chiarezza, in queste procedure si presuppone che due cluster, denominati "primary" e "secondary", siano accessibili da un singolo host.
Il daemon rbd-mirror esegue la replica effettiva dei dati del cluster.
Rinominare
ceph.confe i file di portachiavi e copiarli dall'host primario all'host secondario:cephuser@secondary >cp /etc/ceph/ceph.conf /etc/ceph/primary.confcephuser@secondary >cp /etc/ceph/ceph.admin.client.keyring \ /etc/ceph/primary.client.admin.keyringcephuser@secondary >scp PRIMARY_HOST:/etc/ceph/ceph.conf \ /etc/ceph/secondary.confcephuser@secondary >scp PRIMARY_HOST:/etc/ceph/ceph.client.admin.keyring \ /etc/ceph/secondary.client.admin.keyringPer abilitare la copia speculare su un pool con
rbd, specificare il comandomirror pool enable, il nome del pool e la modalità di copia speculare:cephuser@adm >rbd mirror pool enable POOL_NAME MODENotaLa modalità di copia speculare può essere
imageopool. Esempio:cephuser@secondary >rbd --cluster primary mirror pool enable image-pool imagecephuser@secondary >rbd --cluster secondary mirror pool enable image-pool imageNel Ceph Dashboard, andare a › . Nella tabella a sinistra vengono mostrati i daemon
rbd-mirrorin esecuzione e il relativo stato. Figura 6.6: Esecuzione dei daemon
Figura 6.6: Esecuzione dei daemonrbd-mirror#
6.6.3 Disabilitazione della copia speculare #
Per disabilitare la copia speculare con rbd, specificare il comando mirror pool disable e il nome del pool:
cephuser@adm > rbd mirror pool disable POOL_NAMEQuando si disabilita la copia speculare su un pool in questo modo, questa verrà disabilitata anche su qualsiasi immagine (nel pool) per la quale è stata abilitata esplicitamente la copia speculare.
6.6.4 Esecuzione del bootstrap dei peer #
Affinché rbd-mirror rilevi il rispettivo cluster peer, è necessario registrare il peer nel pool e creare un account utente. Questo processo può essere automatizzato con rbd tramite i comandi mirror pool peer bootstrap create e mirror pool peer bootstrap import.
Per creare manualmente un nuovo token di bootstrap con rbd, specificare il comando mirror pool peer bootstrap create, il nome del pool e un nome del sito facoltativo per la descrizione del cluster local:
cephuser@adm > rbd mirror pool peer bootstrap create [--site-name local-site-name] pool-name
L'output di mirror pool peer bootstrap create sarà un token che dovrà essere fornito al comando mirror pool peer bootstrap import. Ad esempio, sul cluster primario:
cephuser@adm > rbd --cluster primary mirror pool peer bootstrap create --site-name primary
image-pool eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkL \
W1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1vbl9ob3N0I \
joiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
Per importare manualmente il token di bootstrap creato da un altro cluster con il comando rbd, specificare il comando mirror pool peer bootstrap import, il nome del pool, il percorso del file al token creato (oppure "-" per leggere dall'input standard), insieme al nome del sito facoltativo per la descrizione del cluster local e a una direzione di copia speculare (l'impostazione di default è rx-tx per la copia speculare bidirezionale, ma è possibile configurare questa impostazione anche su rx-only per la copia speculare unidirezionale):
cephuser@adm > rbd mirror pool peer bootstrap import [--site-name local-site-name] \
[--direction rx-only or rx-tx] pool-name token-pathAd esempio, sul cluster secondario:
cephuser@adm >cat >>EOF < token eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW1pcn \ Jvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1vbl9ob3N0I \ joiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ== EOFcephuser@adm >rbd --cluster secondary mirror pool peer bootstrap import --site-name secondary image-pool token
6.6.5 Rimozione di un peer del cluster #
Per rimuovere un cluster Ceph peer in copia speculare con il comando rbd, specificare il comando mirror pool peer remove, il nome del pool e l'UUID del peer (disponibile dal comando rbd mirror pool info):
cephuser@adm > rbd mirror pool peer remove pool-name peer-uuid6.6.6 Configurazione della replica del pool nel Ceph Dashboard #
Il daemon rbd-mirror deve disporre dell'accesso al cluster primario per poter eseguire la copia speculare delle immagini RBD. Assicurarsi di aver seguito la procedura descritta nella Sezione 6.6.4, «Esecuzione del bootstrap dei peer» prima di continuare.
Nel cluster primario e secondario, creare pool con un nome identico e assegnarvi l'applicazione
rbd. Per ulteriori dettagli sulla creazione di un nuovo pool, fare riferimento alla Sezione 5.1, «Aggiunta di un nuovo pool». Figura 6.7: Creazione di un pool con l'applicazione RBD #
Figura 6.7: Creazione di un pool con l'applicazione RBD #Nei dashboard del cluster primario e secondario, andare a › . Nella tabella a destra, fare clic sul nome del pool da replicare e, dopo aver fatto clic su , selezionare la modalità di replica. In questo esempio, verrà utilizzata la modalità di replica pool, che indica che verranno replicate tutte le immagini all'interno di un determinato pool. Confermare con .
 Figura 6.8: Configurazione della modalità di replica #Importante: errore o avviso nel cluster primario
Figura 6.8: Configurazione della modalità di replica #Importante: errore o avviso nel cluster primarioIn seguito all'aggiornamento della modalità di replica, verrà visualizzato un errore o un flag di avviso nella colonna destra corrispondente. Ciò si verifica perché al pool non è stato ancora assegnato nessun utente peer per la replica. Ignorare questo flag per il cluster primario poiché l'utente peer viene assegnato soltanto al cluster secondario.
Nel dashboard del cluster secondario, andare a › . Aggiungere il peer di copia speculare del pool selezionando . Specificare i dettagli del cluster primario:
 Figura 6.9: Aggiunta delle credenziali del peer #
Figura 6.9: Aggiunta delle credenziali del peer #Stringa univoca arbitraria che identifica il cluster primario come "primary". Il nome del cluster deve essere diverso dal nome reale del cluster secondario.
ID utente Ceph creato come peer in copia speculare. In questo esempio è "rbd-mirror-peer".
Elenco separato da virgole degli indirizzi IP dei nodi Ceph Monitor del cluster primario.
Chiave correlata all'ID utente peer. È possibile recuperarla eseguendo sul cluster primario il comando di esempio seguente:
cephuser@adm >ceph auth print_key pool-mirror-peer-name
Confermare con .
 Figura 6.10: Elenco dei pool replicati #
Figura 6.10: Elenco dei pool replicati #
6.6.7 Verifica del funzionamento della replica dell'immagine RBD #
Una volta che il daemon rbd-mirror è in esecuzione e la replica dell'immagine RBD è configurata nel Ceph Dashboard, è il momento di verificare il funzionamento della replica:
Nel Ceph Dashboard del cluster primario, creare un'immagine RBD per fare in modo che il relativo pool superiore sia quello già creato per scopi di replica. Abilitare le funzioni
Blocco esclusivoeJournalingper l'immagine. Per i dettagli sulla creazione delle immagini RBD, fare riferimento alla Sezione 6.3, «Creazione di RBD». Figura 6.11: Nuova immagine RBD #
Figura 6.11: Nuova immagine RBD #Dopo aver creato l'immagine che si desidera replicare, aprire il Ceph Dashboard del cluster secondario e andare a › . La tabella a destra rifletterà la modifica del numero di immagini e sincronizzerà il numero di immagini .
 Figura 6.12: Nuova immagine RBD sincronizzata #Suggerimento: avanzamento della replica
Figura 6.12: Nuova immagine RBD sincronizzata #Suggerimento: avanzamento della replicaNella tabella in basso nella pagina viene mostrato lo stato della replica delle immagini RBD. La scheda include i possibili problemi, la scheda visualizza l'avanzamento della replica dell'immagine e la scheda elenca tutte le immagini di cui è riuscita la replica.
 Figura 6.13: Stato della replica delle immagini RBD #
Figura 6.13: Stato della replica delle immagini RBD #Nel cluster primario, scrivere i dati nell'immagine RBD. Nel Ceph Dashboard del cluster secondario, andare a › e controllare se le dimensioni dell'immagine corrispondente aumentano via via che i dati vengono scritti nel cluster primario.
6.7 Gestione di iSCSI Gateway #
Per ulteriori informazioni generali sugli iSCSI Gateway, fare riferimento al Capitolo 22, Ceph iSCSI Gateway.
Per visualizzare un elenco di tutti i gateway e le immagini mappate disponibili, fare clic su › nel menu principale. Si apre la scheda , in cui vengono elencati gli iSCSI Gateway attualmente configurati e le immagini RBD mappate.
Nella tabella dei sono elencati lo stato, il numero di destinazioni iSCSI e il numero di sessioni di ogni gateway. Nella tabella sono elencati il nome, il nome del pool correlato, il tipo di backstore e altri dettagli statistici di ciascuna immagine mappata.
Nella scheda sono elencate le destinazioni iSCSI attualmente configurate.

Per visualizzare ulteriori informazioni dettagliate su una destinazione, fare clic sulla freccia a discesa nella riga della tabella delle destinazioni. Si apre uno schema con struttura ad albero in cui sono elencati i dischi, i portali, gli iniziatori e i gruppi. Fare clic su un elemento per espanderlo e visualizzare i relativi contenuti dettagliati, facoltativamente insieme alla configurazione correlata, nella tabella a destra.

6.7.1 Aggiunta di destinazioni iSCSI #
Per aggiungere una nuova destinazione iSCSI, fare clic su in alto a sinistra nella tabella e immettere le informazioni richieste.

Immettere l'indirizzo di destinazione del nuovo gateway.
Fare clic su e selezionare uno o più portali iSCSI dall'elenco.
Fare clic su e selezionare una o più immagini RBD per il gateway.
Se è necessario utilizzare l'autenticazione per accedere al gateway, attivare la casella di controllo e immettere le credenziali. Ulteriori opzioni di autenticazione avanzata sono disponibili dopo l'attivazione di e .
Confermare con (Crea destinazione).
6.7.2 Modifica delle destinazioni iSCSI #
Per modificare una destinazione iSCSI esistente, fare clic sulla relativa riga nella tabella , quindi su in alto a sinistra nella tabella.
È quindi possibile modificare la destinazione iSCSI, aggiungere o eliminare portali e aggiungere o eliminare immagini RBD correlate. È inoltre possibile regolare le informazioni di autenticazione per il gateway.
6.7.3 Eliminazione delle destinazioni iSCSI #
Per eliminare una destinazione iSCSI, selezionare la riga della tabella e fare clic sulla freccia a discesa accanto al pulsante , quindi selezionare . Attivare la casella e confermare con .
6.8 Qualità di servizio (QoS) RBD #
Per ulteriori informazioni generali e per una descrizione delle opzioni di configurazione QoS RBD, fare riferimento alla Sezione 20.6, «Impostazioni QoS».
È possibile configurare le opzioni QoS a livelli diversi.
Globalmente
Per ogni singolo pool
Per ogni singola immagine
La configurazione globale si trova in cima all'elenco e verrà utilizzata per tutte le immagini RBD di nuova creazione e per quelle immagini che non ignorano tali valori sul livello di pool o di immagine RBD. Un valore di opzione specificato globalmente può essere ignorato per ogni singolo pool o per ogni singola immagine. Le opzioni specificate in un pool verranno applicate a tutte le immagini RBD di tale pool a meno che non siano sostituite da un'opzione di configurazione impostata in un'immagine. Le opzioni specificate in un'immagine sostituiranno quelle specificate globalmente e quelle specificate in un pool.
In questo modo, è possibile definire i valori di default globalmente, adattarli a tutte le immagini RBD di un pool specifico e sostituire la configurazione del pool per le singole immagini RBD.
6.8.1 Configurazione delle opzioni a livello globale #
Per configurare le opzioni del dispositivo di blocco RADOS (RADOS Block Device, RBD) a livello globale, selezionare › dal menu principale.
Per elencare tutte le opzioni di configurazione globale disponibili, accanto a , selezionare dal menu a discesa.
Filtrare i risultati della tabella applicando il filtro
rbd_qosnel campo di ricerca per visualizzare un elenco di tutte le opzioni di configurazione disponibili per QoS.Per modificare un valore, fare clic sulla relativa riga di tabella e selezionare in alto a sinistra nella tabella. La finestra di dialogo contiene sei campi diversi tramite cui è possibile specificare i valori. I valori dell'opzione di configurazione RBD sono obbligatori nella casella di testo
NotaA differenza di altre finestre di dialogo, questa non consente di specificare il valore nelle unità adeguate. È necessario impostare tali valori in byte o IOPS, a seconda dell'opzione che si sta modificando.
6.8.2 Configurazione delle opzioni in un nuovo pool #
Per creare un nuovo pool e configurarvi le opzioni di configurazione RBD, fare clic su › . Selezionare (replicato) come tipo di pool. Sarà quindi necessario aggiungere il tag applicazione rbd al pool per poter configurare le opzioni QoS RBD.
Non è possibile configurare le opzioni di configurazione QoS RBD sui pool con codice di cancellazione. A questo scopo, è necessario modificare il pool dei metadati replicato di un'immagine RBD. La configurazione verrà quindi applicata al pool di dati con codice di cancellazione di tale immagine.
6.8.3 Configurazione delle opzioni in un pool esistente #
Per configurare le opzioni QoS RBD in un pool esistente, fare clic su , quindi sulla riga di tabella corrispondente al pool e selezionare in alto a sinistra nella tabella.
Dovrebbe aprirsi la sezione nella finestra di dialogo, seguita dalla sezione .
Se le sezioni o non vengono visualizzate, è possibile che si stia modificando un pool con codice di cancellazione (erasure coded), il quale non può essere utilizzato per impostare le opzioni di configurazione RBD, o che il pool non sia configurato per l'utilizzo da parte delle immagini RBD. Nell'ultimo caso, assegnare il tag applicazione al pool per visualizzare le sezioni di configurazione corrispondenti.
6.8.4 Opzioni di configurazione #
Fare clic su per espandere le opzioni di configurazione. Verrà visualizzato un elenco di tutte le opzioni disponibili. Le unità delle opzioni di configurazione sono già visualizzate nelle caselle di testo. Se si seleziona l'opzione dei byte per secondo (BPS), è possibile utilizzare scorciatoie come "1M" o "5G". Tali valori verranno convertiti automaticamente in "1 MB/s" e "5 GB/s" rispettivamente.
Se si fa clic sul pulsante di reimpostazione a destra di ciascuna casella di testo, i valori impostati nel pool verranno rimossi. Questa azione non rimuove i valori di configurazione delle opzioni configurate a livello globale o in un'immagine RBD.
6.8.5 Creazione delle opzioni QoS RBD con una nuova immagine RBD #
Per creare un'immagine RBD con le opzioni QoS RBD impostate in quest'ultima, selezionare › e fare clic su . Fare clic su per espandere la sezione di configurazione avanzata. Fare clic su per aprire tutte le opzioni di configurazione disponibili.
6.8.6 Modifica delle opzioni QoS RBD sulle immagini esistenti #
Per modificare le opzioni QoS RBD in un'immagine esistente, selezionare › , fare clic sulla riga di tabella corrispondente al pool e quindi su . Verrà visualizzata la finestra di dialogo per la modifica. Fare clic su per espandere la sezione di configurazione avanzata. Fare clic su per aprire tutte le opzioni di configurazione disponibili.
6.8.7 Modifica delle opzioni di configurazione durante la copia o la clonazione delle immagini #
Se un'immagine RBD viene clonata o copiata, per default verranno copiati anche i valori impostati in tale immagine. Se si desidera modificarli durante la copia o la clonazione, specificare i valori di configurazione aggiornati nella finestra di dialogo di copia/clonazione seguendo gli stessi passaggi della procedura di creazione o modifica di un'immagine RBD. Questa operazione consente di impostare (o reimpostare) soltanto i valori dell'immagine RBD copiata o clonata e non influisce sulla configurazione dell'immagine RBD di origine o sulla configurazione globale.
Se si sceglie di reimpostare il valore di opzione durante la procedura di copia/clonazione, nell'immagine non verrà impostato alcun valore per tale opzione. Ciò vuol dire che verrà utilizzato il valore di tale opzione specificato per il pool superiore se in quest'ultimo è stato configurato tale valore. In caso contrario, verrà utilizzata l'impostazione di default globale.
7 Gestione di NFS Ganesha #
NFS Ganesha supporta NFS versione 4.1 e versioni successive. Non supporta NFS versione 3.
Per informazioni generali su NFS Ganesha, fare riferimento a Capitolo 25, NFS Ganesha.
Per elencare tutte le esportazioni NFS disponibili, fare clic su nel menu principale.
Nell'elenco sono visualizzati la directory, il nome host del daemon, il tipo di back-end di storage e il tipo di accesso di ciascuna esportazione.

Per visualizzare altri dettagli su un'esportazione NFS, fare clic sulla relativa riga di tabella.

7.1 Creazione di esportazioni NFS #
Per aggiungere una nuova esportazione NFS, fare clic su in alto a sinistra nella tabella delle esportazioni e immettere le informazioni richieste.

Selezionare uno o più daemon NFS Ganesha che eseguiranno l'esportazione.
Selezionare un back-end di storage.
ImportanteAttualmente, sono supportate soltanto le esportazioni NFS supportate da CephFS.
Selezionare un ID utente e altre opzioni di back-end.
Immettere il percorso della directory per l'esportazione NFS. Se la directory non esiste sul server, questa verrà creata.
Specificare altre opzioni correlate a NFS, come la versione del protocollo NFS supportata, l'opzione pseudo, il tipo di accesso, il tipo di squash o il protocollo di trasporto.
Se è necessario limitare l'accesso solo a client specifici, fare clic su e aggiungere i rispettivi indirizzi IP insieme alle opzioni del tipo di accesso e di squashing.
Confermare con il pulsante .
7.2 Eliminazione di esportazioni NFS #
Per eliminare un'esportazione, selezionarla ed evidenziarla nella riga della tabella. Fare clic sulla freccia a discesa accanto al pulsante e selezionare . Attivare la casella di controllo e confermare con .
7.3 Modifica di esportazioni NFS #
Per modificare un'esportazione esistente, selezionare ed evidenziare l'esportazione nella riga della tabella e fare clic su in alto a sinistra nella tabella delle esportazioni.
Quindi, è possibile regolare tutti i dettagli dell'esportazione NFS.

8 Gestione di CephFS #
Per informazioni dettagliate su CephFS, fare riferimento al Capitolo 23, File system in cluster.
8.1 Visualizzazione della panoramica su CephFS #
Fare clic su nel menu principale per visualizzare la panoramica dei file system configurati. Nella tabella principale viene mostrato il nome e la data di creazione di ciascun file system e informazioni sul relativo stato di abilitazione o disabilitazione.
Facendo clic sulla riga di tabella corrispondente a un file system, sarà possibile visualizzare i dettagli sulla classificazione e sui pool aggiunti a quest'ultimo.

Nella parte inferiore della schermata, è possibile visualizzare le statistiche con il numero in tempo reale degli inode MDS e delle richieste client correlati.

9 Gestione di Object Gateway #
Prima di iniziare, quando si tenta di accedere al front-end di Object Gateway sul Ceph Dashboard, potrebbe essere visualizzata la notifica seguente:
Information No RGW credentials found, please consult the documentation on how to enable RGW for the dashboard. Please consult the documentation on how to configure and enable the Object Gateway management functionality.
Questa notifica viene visualizzata perché Object Gateway non è stato configurato automaticamente da cephadm per il Ceph Dashboard. Se viene visualizzata questa notifica, seguire le istruzioni descritte nella Sezione 10.4, «Abilitazione del front-end di gestione di Object Gateway» per abilitare manualmente il front-end di Object Gateway per il Ceph Dashboard.
Per ulteriori informazioni generali su Object Gateway, fare riferimento al Capitolo 21, Ceph Object Gateway.
9.1 Visualizzazione degli Object Gateway #
Fare clic su › per visualizzare un elenco degli Object Gateway configurati. L'elenco include l'ID del gateway, il nome host del nodo del cluster su cui è in esecuzione il daemon del gateway e il numero di versione del gateway.
Fare clic sulla freccia a discesa accanto al nome del gateway per visualizzare le relative informazioni dettagliate. Nella scheda vengono mostrati i dettagli delle operazioni di lettura/scrittura e le statistiche sulla cache.

9.2 Gestione degli utenti di Object Gateway #
Fare clic su › per visualizzare un elenco degli utenti di Object Gateway esistenti.
Fare clic sulla freccia a discesa accanto al nome utente per visualizzare i dettagli sull'account utente, come le informazioni sullo stato o i dettagli sulla quota utenti o compartimenti.

9.2.1 Aggiunta di un nuovo utente Gateway #
Per aggiungere un nuovo utente Gateway, fare clic su in alto a sinistra nell'intestazione della tabella. Inserire le credenziali, i dettagli della chiave S3 e delle quote utenti e compartimenti, quindi confermare con .

9.2.2 Eliminazione di utenti Gateway #
Per eliminare un utente Gateway, selezionarlo ed evidenziarlo. Fare clic sul pulsante a discesa accanto a e selezionare dall'elenco per eliminare l'account utente. Attivare la casella di controllo e confermare con .
9.2.3 Modifica dei dettagli di un utente Gateway #
Per modificare i dettagli di un utente Gateway, selezionare ed evidenziare tale utente. Fare clic su in alto a sinistra nell'intestazione della tabella.
Modificare le informazioni di base o aggiuntive dell'utente, come le informazioni su capacità, chiavi, sottoutenti e quota. Confermare con .
Nella scheda è incluso un elenco di sola lettura degli utenti Gateway e delle relative chiavi segrete e di accesso. Per visualizzare le chiavi, fare clic su un nome utente nell'elenco e selezionare in alto a sinistra nell'intestazione della tabella. Nella finestra di dialogo , fare clic sull'icona a forma di occhio per rendere visibili le chiavi oppure sull'icona degli appunti per copiare la chiave correlata negli appunti.
9.3 Gestione dei compartimenti Object Gateway #
I compartimenti Object Gateway (OGW) implementano la funzionalità dei container di OpenStack Swift e fungono da container per la memorizzazione degli oggetti dati.
Fare clic su › per visualizzare un elenco dei compartimenti Object Gateway.
9.3.1 Aggiunta di un nuovo compartimento #
Per aggiungere un nuovo compartimento Object Gateway, fare clic su in alto a sinistra nell'intestazione della tabella. Immettere il nome del compartimento, selezionare il proprietario e impostare la destinazione di posizionamento. Confermare con .
In questa fase è possibile inoltre abilitare il blocco selezionando ; a ogni modo, si tratta di un'impostazione che può essere configurata in seguito alla creazione. Consultare Sezione 9.3.3, «Modifica del compartimento» per maggiori informazioni.
9.3.2 Visualizzazione dei dettagli del compartimento #
Per visualizzare informazioni dettagliate su un compartimento Object Gateway, fare clic sulla freccia a discesa accanto al nome del compartimento.

Sotto la tabella , è possibile trovare i dettagli delle impostazioni relative al blocco e alla quota compartimenti.
9.3.3 Modifica del compartimento #
Selezionare ed evidenziare un compartimento, quindi fare clic su in alto a sinistra nell'intestazione della tabella.
È possibile aggiornare il proprietario del compartimento o abilitare il controllo versioni, l'autenticazione a più fattori o il blocco. Confermare le modifiche con .

9.3.4 Eliminazione di un compartimento #
Per eliminare un compartimento Object Gateway, selezionarlo ed evidenziarlo. Fare clic sul pulsante a discesa accanto a e selezionare dall'elenco per eliminare il compartimento. Attivare la casella di controllo e confermare con .
10 Configurazione manuale #
Questa sezione fornisce informazioni avanzate per gli utenti che preferiscono configurare manualmente le impostazioni del dashboard nella riga di comando.
10.1 Configurazione del supporto TLS/SSL #
Per default, tutte le connessioni HTTP al dashboard sono protette da TLS/SSL. Per la connessione sicura è necessario un certificato SSL. È possibile utilizzare un certificato firmato da se stessi o generarne uno e farlo firmare da un'autorità di certificazione (CA) nota.
In alcune situazioni, potrebbe essere opportuno disabilitare il supporto SSL. Ad esempio, se il dashboard è in esecuzione dietro un proxy che non supporta SSL.
Prestare attenzione quando si disabilita SSL poiché i nomi utente e le password verranno inviati al dashboard senza cifratura.
Per disabilitare SSL eseguire:
cephuser@adm > ceph config set mgr mgr/dashboard/ssl falseIn seguito alla modifica del certificato e della chiave SSL, è necessario riavviare manualmente i processi di Ceph Manager. Per farlo, eseguire
cephuser@adm > ceph mgr fail ACTIVE-MANAGER-NAMEo disabilitare e riabilitare il modulo del dashboard (questa azione comporta inoltre la rigenerazione del manager):
cephuser@adm >ceph mgr module disable dashboardcephuser@adm >ceph mgr module enable dashboard
10.1.1 Creazione di certificati autofirmati #
La procedura di creazione di un certificato firmato da se stessi per la comunicazione sicura è semplice. In questo modo è possibile rendere operativo il dashboard più rapidamente.
La maggior parte dei browser Web creerà un complain relativo al certificato firmato da se stessi e richiederà una conferma esplicita prima di stabilire una connessione sicura al dashboard.
Per generare e installare un certificato firmato da se stessi, utilizzare il seguente comando integrato:
cephuser@adm > ceph dashboard create-self-signed-cert10.1.2 Utilizzo dei certificati firmati dall'autorità di certificazione #
Per proteggere correttamente la connessione al dashboard ed eliminare i complain del browser Web per i certificati firmati da se stessi, si consiglia di utilizzare un certificato firmato da una CA.
È possibile generare una coppia di chiavi di certificato con un comando simile al seguente:
# openssl req -new -nodes -x509 \
-subj "/O=IT/CN=ceph-mgr-dashboard" -days 3650 \
-keyout dashboard.key -out dashboard.crt -extensions v3_ca
Il comando riportato sopra consente di generare i file dashboard.key e dashboard.crt. Dopo aver ottenuto il file dashboard.crt firmato dalla CA, abilitarlo per tutte le istanze di Ceph Manager eseguendo i comandi seguenti:
cephuser@adm >ceph dashboard set-ssl-certificate -i dashboard.crtcephuser@adm >ceph dashboard set-ssl-certificate-key -i dashboard.key
Se sono richiesti certificati diversi per ogni istanza di Ceph Manager, modificare i comandi e includere il nome dell'istanza come segue. Sostituire NAME con il nome dell'istanza di Ceph Manager (in genere il nome host correlato):
cephuser@adm >ceph dashboard set-ssl-certificate NAME -i dashboard.crtcephuser@adm >ceph dashboard set-ssl-certificate-key NAME -i dashboard.key
10.2 Modifica del nome host e del numero di porta #
Il Ceph Dashboard è associato a un indirizzo TCP/IP e a una porta TCP specifici. Per default, il Ceph Manager attualmente attivo che ospita il dashboard è associato alla porta TCP 8443 (o alla porta 8080 se SSL è disabilitato).
Se sugli host che eseguono Ceph Manager (e di conseguenza il Ceph Dashboard) è abilitato un firewall, potrebbe essere necessario modificare la configurazione per abilitare l'accesso a queste porte. Per ulteriori informazioni sulle impostazioni del firewall per Ceph, vedere Book “Troubleshooting Guide”, Chapter 13 “Hints and tips”, Section 13.7 “Firewall settings for Ceph”.
Per default, il Ceph Dashboard è associato a "::", corrispondente a tutti gli indirizzi IPv4 e IPv6 disponibili. È possibile modificare l'indirizzo IP e il numero di porta dell'applicazione Web per fare in modo che vengano applicati a tutte le istanze di Ceph Manager utilizzando i comandi seguenti:
cephuser@adm >ceph config set mgr mgr/dashboard/server_addr IP_ADDRESScephuser@adm >ceph config set mgr mgr/dashboard/server_port PORT_NUMBER
Dal momento che ogni daemon ceph-mgr ospita la propria istanza del dashboard, potrebbe essere necessario configurare separatamente tali istanze. Modificare l'indirizzo IP e il numero di porta di un'istanza del Manager specifica utilizzando i comandi seguenti (sostituire NAME con l'ID dell'istanza ceph-mgr):
cephuser@adm >ceph config set mgr mgr/dashboard/NAME/server_addr IP_ADDRESScephuser@adm >ceph config set mgr mgr/dashboard/NAME/server_port PORT_NUMBER
Il comando ceph mgr services consente di visualizzare tutti gli endpoint attualmente configurati. Cercare la chiave dashboard per ottenere l'URL per l'accesso al dashboard.
10.3 Regolazione dei nomi utente e delle password #
Se non si desidera utilizzare l'account amministratore di default, creare un account utente diverso e associarlo almeno a un ruolo. Viene fornito un set di ruoli di sistema predefiniti che è possibile utilizzare. Per ulteriori informazioni, fare riferimento a Capitolo 11, Gestione di utenti e ruoli sulla riga di comando.
Per creare un utente con privilegi di amministratore, utilizzare il comando seguente:
cephuser@adm > ceph dashboard ac-user-create USER_NAME PASSWORD administrator10.4 Abilitazione del front-end di gestione di Object Gateway #
Per utilizzare la funzionalità di gestione di Object Gateway del dashboard, è necessario immettere le credenziali di login di un utente con il flag system abilitato:
Se non si dispone di un utente con il flag
system, crearne uno:cephuser@adm >radosgw-admin user create --uid=USER_ID --display-name=DISPLAY_NAME --systemAnnotare le chiavi access_key e secret_key nell'output del comando.
È possibile inoltre ottenere le credenziali di un utente esistente utilizzando il comando
radosgw-admin:cephuser@adm >radosgw-admin user info --uid=USER_IDFornire al dashboard le credenziali ricevute in file separati:
cephuser@adm >ceph dashboard set-rgw-api-access-key ACCESS_KEY_FILEcephuser@adm >ceph dashboard set-rgw-api-secret-key SECRET_KEY_FILE
Per default, il firewall è abilitato in SUSE Linux Enterprise Server 15 SP3. Per ulteriori informazioni sulla configurazione del firewall, vedere Book “Troubleshooting Guide”, Chapter 13 “Hints and tips”, Section 13.7 “Firewall settings for Ceph”.
Vi sono diversi aspetti da considerare:
Il nome host e il numero di porta di Object Gateway vengono determinati automaticamente.
Se sono utilizzate più zone, l'host all'interno del gruppo di zone master e della zona master verrà determinato automaticamente. Queste impostazioni sono sufficienti per la maggior parte delle configurazioni, ma in alcuni casi è consigliabile impostare manualmente il nome host e la porta:
cephuser@adm >ceph dashboard set-rgw-api-host HOSTcephuser@adm >ceph dashboard set-rgw-api-port PORTPotrebbero essere necessarie queste impostazioni aggiuntive:
cephuser@adm >ceph dashboard set-rgw-api-scheme SCHEME # http or httpscephuser@adm >ceph dashboard set-rgw-api-admin-resource ADMIN_RESOURCEcephuser@adm >ceph dashboard set-rgw-api-user-id USER_IDSe si utilizza un certificato firmato da se stessi (Sezione 10.1, «Configurazione del supporto TLS/SSL») nella configurazione Object Gateway, disabilitare la verifica del certificato nel dashboard per evitare connessioni rifiutate a causa di certificati firmati da una CA sconosciuta o non corrispondenti al nome host:
cephuser@adm >ceph dashboard set-rgw-api-ssl-verify FalseSe Object Gateway impiega troppo tempo per elaborare le richieste e si verificano timeout sul dashboard, è possibile modificare il valore di timeout (impostato per default su 45 secondi):
cephuser@adm >ceph dashboard set-rest-requests-timeout SECONDS
10.5 Abilitazione della gestione iSCSI #
Il Ceph Dashboard gestisce le destinazioni iSCSI tramite l'API REST fornita dal servizio rbd-target-api di Ceph iSCSI Gateway. Assicurarsi che sia installata e abilitata sugli iSCSI Gateway.
La funzionalità di gestione di iSCSI del Ceph Dashboard dipende dalla versione 3 più recente del progetto ceph-iscsi. Assicurarsi che il sistema operativo fornisca la versione corretta, altrimenti il Ceph Dashboard non abiliterà le funzioni di gestione.
Se l'API REST ceph-iscsi è configurata in modalità HTTPS e utilizza un certificato autofirmato, configurare il dashboard in modo che eviti la verifica del certificato SSL durante l'accesso all'API ceph-iscsi.
Disabilitare la verifica SSL dell'API:
cephuser@adm > ceph dashboard set-iscsi-api-ssl-verification falseDefinire i gateway iSCSI disponibili:
cephuser@adm >ceph dashboard iscsi-gateway-listcephuser@adm >ceph dashboard iscsi-gateway-add scheme://username:password@host[:port]cephuser@adm >ceph dashboard iscsi-gateway-rm gateway_name
10.6 Abilitazione del Single Sign-On (SSO) #
Single Sign-On (SSO) è un metodo di controllo dell'accesso che consente agli utenti di eseguire contemporaneamente il login su più applicazioni utilizzando un solo ID e una sola password.
Il Ceph Dashboard supporta l'autenticazione esterna degli utenti tramite il protocollo SAML 2.0. Dal momento che l'autorizzazione viene comunque eseguita dal dashboard, è necessario innanzitutto creare gli account utente e associarli ai ruoli desiderati. Tuttavia, il processo di autenticazione può essere eseguito da un provider di identità (IdP) esistente.
Per configurare Single Sign-On, utilizzare il comando seguente:
cephuser@adm > ceph dashboard sso setup saml2 CEPH_DASHBOARD_BASE_URL \
IDP_METADATA IDP_USERNAME_ATTRIBUTE \
IDP_ENTITY_ID SP_X_509_CERT \
SP_PRIVATE_KEYParametri:
- CEPH_DASHBOARD_BASE_URL
URL di base da cui è accessibile il Ceph Dashboard (ad esempio "https://cephdashboard.local").
- IDP_METADATA
URL, percorso del file o contenuto del file XML dei metadati dell'IdP (ad esempio "https://myidp/metadata").
- IDP_USERNAME_ATTRIBUTE
Opzionale. Attributo che verrà utilizzato per ottenere il nome utente dalla risposta di autenticazione. L'impostazione di default è "uid".
- IDP_ENTITY_ID
Opzionale. Utilizzare quando è presente più di un'entità ID sui metadati dell'IdP.
- SP_X_509_CERT / SP_PRIVATE_KEY
Opzionale. Percorso del file o contenuto del certificato che verrà utilizzato dal Ceph Dashboard (provider di servizi) per l'accesso e la cifratura. Questi percorsi di file devono essere accessibili dall'istanza attiva di Ceph Manager.
Il valore dell'autorità di certificazione delle richieste SAML seguirà questo modello:
CEPH_DASHBOARD_BASE_URL/auth/saml2/metadata
Per visualizzare la configurazione SAML 2.0 corrente, eseguire:
cephuser@adm > ceph dashboard sso show saml2Per disabilitare Single Sign-On, eseguire:
cephuser@adm > ceph dashboard sso disablePer verificare se SSO è abilitato, eseguire:
cephuser@adm > ceph dashboard sso statusPer abilitare SSO eseguire:
cephuser@adm > ceph dashboard sso enable saml211 Gestione di utenti e ruoli sulla riga di comando #
Questa sezione descrive come gestire gli account utente utilizzati dal Ceph Dashboard e fornisce informazioni sulla creazione o modifica degli account utente, nonché sull'impostazione dei ruoli dell'utente e delle autorizzazioni corretti.
11.1 Gestione della policy password #
Per default, la funzione della policy password è abilitata insieme ai controlli seguenti:
La password supera N caratteri?
La nuova password è uguale a quella vecchia?
La funzione della policy password può essere attivata o disattivata:
cephuser@adm > ceph dashboard set-pwd-policy-enabled true|falseI singoli controlli seguenti possono essere attivati o disattivati:
cephuser@adm >ceph dashboard set-pwd-policy-check-length-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-oldpwd-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-username-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-exclusion-list-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-complexity-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-sequential-chars-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-repetitive-chars-enabled true|false
Inoltre, sono disponibili le opzioni seguenti per configurare il comportamento della policy password.
La lunghezza minima della password (il valore di default è 8):
cephuser@adm >ceph dashboard set-pwd-policy-min-length NLa complessità minima della password (il valore di default è 10):
cephuser@adm >ceph dashboard set-pwd-policy-min-complexity NLa complessità della password è calcolata tramite la classificazione di ciascun carattere da cui è composta.
Un elenco di parole separate da virgole che non è possibile utilizzare nella password:
cephuser@adm >ceph dashboard set-pwd-policy-exclusion-list word[,...]
11.2 Gestione degli account utente #
Il Ceph Dashboard supporta la gestione di più account utente. Ogni account utente include un nome utente, una password (memorizzata in formato cifrato tramite il comando bcrypt), un nome facoltativo e un indirizzo e-mail facoltativo.
Gli account utente sono memorizzati nel database di configurazione di Ceph Monitor e sono condivisi a livello globale su tutte le istanze di Ceph Manager.
Utilizzare i comandi seguenti per gestire gli account utente:
- Per mostrare gli utenti esistenti:
cephuser@adm >ceph dashboard ac-user-show [USERNAME]- Per creare un nuovo utente:
cephuser@adm >ceph dashboard ac-user-create USERNAME -i [PASSWORD_FILE] [ROLENAME] [NAME] [EMAIL]- Per eliminare un utente:
cephuser@adm >ceph dashboard ac-user-delete USERNAME- Per modificare la password di un utente:
cephuser@adm >ceph dashboard ac-user-set-password USERNAME -i PASSWORD_FILE- Per modificare il nome e l'e-mail di un utente:
cephuser@adm >ceph dashboard ac-user-set-info USERNAME NAME EMAIL- Per disabilitare un utente
cephuser@adm >ceph dashboard ac-user-disable USERNAME- Per abilitare un utente
cephuser@adm >ceph dashboard ac-user-enable USERNAME
11.3 Ruoli e autorizzazioni dell'utente #
Questa sezione descrive gli ambiti di sicurezza che è possibile assegnare a un ruolo dell'utente e come gestire i ruoli dell'utente e assegnarli agli account utente.
11.3.1 Definizione degli ambiti di sicurezza #
Gli account utente sono associati a un set di ruoli che definiscono le parti del dashboard accessibili dall'utente. Le parti del dashboard sono raggruppate all'interno di un ambito di sicurezza. Gli ambiti di sicurezza sono predefiniti e statici. Attualmente sono disponibili gli ambiti di sicurezza seguenti:
- hosts
Include tutte le funzioni relative alla voce di menu .
- config-opt
Include tutte le funzioni relative alla gestione delle opzioni di configurazione di Ceph.
- pool
Include tutte le funzioni relative alla gestione del pool.
- osd
Include tutte le funzioni relative alla gestione di Ceph OSD.
- monitor
Include tutte le funzioni relative alla gestione di Ceph Monitor.
- rbd-image
Include tutte le funzioni relative alla gestione delle immagini del dispositivo di blocco RADOS.
- rbd-mirroring
Include tutte le funzioni relative alla gestione della copia speculare del dispositivo di blocco RADOS.
- iscsi
Include tutte le funzioni relative alla gestione di iSCSI.
- rgw
Include tutte le funzioni relative alla gestione di Object Gateway.
- cephfs
Include tutte le funzioni relative alla gestione di CephFS.
- manager
Include tutte le funzioni relative alla gestione di Ceph Manager.
- log
Include tutte le funzioni relative alla gestione dei log di Ceph.
- grafana
Include tutte le funzioni relative al proxy Grafana.
- prometheus
Include tutte le funzioni relative alla gestione degli avvisi di Prometheus.
- dashboard-settings
Modifica le impostazioni del dashboard.
11.3.2 Specifica dei ruoli dell'utente #
Un ruolo consente di specificare un set di mappature tra un ambito di sicurezza e un set di autorizzazioni. Vi sono quattro tipi di autorizzazioni: "read" (lettura), "create" (creazione), "update" (aggiornamento) e "delete" (eliminazione).
Nell'esempio seguente viene specificato un ruolo in cui l'utente dispone delle autorizzazioni "read" e "create" per le funzioni relative alla gestione del pool e delle autorizzazioni complete per le funzioni relative alla gestione delle immagini RBD:
{
'role': 'my_new_role',
'description': 'My new role',
'scopes_permissions': {
'pool': ['read', 'create'],
'rbd-image': ['read', 'create', 'update', 'delete']
}
}Nel dashboard è già fornito un set di ruoli predefiniti denominati ruoli di sistema. È possibile utilizzarli immediatamente dopo l'installazione da zero del Ceph Dashboard:
- amministratore
Fornisce le autorizzazioni complete per tutti gli ambiti di sicurezza.
- sola lettura
Fornisce l'autorizzazione in lettura per tutti gli ambiti di sicurezza a eccezione delle impostazioni del dashboard.
- block-manager
Fornisce le autorizzazioni complete per gli ambiti "rbd-image", "rbd-mirroring" e "iscsi".
- rgw-manager
Fornisce le autorizzazioni complete per l'ambito "rgw".
- cluster-manager
Fornisce le autorizzazioni complete per gli ambiti "hosts", "osd", "monitor", "manager" e "config-opt".
- pool-manager
Fornisce le autorizzazioni complete per l'ambito "pool".
- cephfs-manager
Fornisce le autorizzazioni complete per l'ambito "cephfs".
11.3.2.1 Gestione dei ruoli personalizzati #
È possibile creare nuovi ruoli dell'utente utilizzando i comandi seguenti:
- Per creare un nuovo ruolo:
cephuser@adm >ceph dashboard ac-role-create ROLENAME [DESCRIPTION]- Per eliminare un ruolo:
cephuser@adm >ceph dashboard ac-role-delete ROLENAME- Per aggiungere autorizzazioni di ambito a un ruolo:
cephuser@adm >ceph dashboard ac-role-add-scope-perms ROLENAME SCOPENAME PERMISSION [PERMISSION...]- Per eliminare le autorizzazioni di ambito da un ruolo:
cephuser@adm >ceph dashboard ac-role-del-perms ROLENAME SCOPENAME
11.3.2.2 Assegnazione dei ruoli agli account utente #
Utilizzare i comandi seguenti per assegnare i ruoli agli utenti:
- Per impostare i ruoli dell'utente:
cephuser@adm >ceph dashboard ac-user-set-roles USERNAME ROLENAME [ROLENAME ...]- Per aggiungere ulteriori ruoli a un utente:
cephuser@adm >ceph dashboard ac-user-add-roles USERNAME ROLENAME [ROLENAME ...]- Per eliminare i ruoli da un utente:
cephuser@adm >ceph dashboard ac-user-del-roles USERNAME ROLENAME [ROLENAME ...]
Se si creano ruoli dell'utente personalizzati e si intende rimuovere il cluster Ceph con lo strumento di esecuzione ceph.purge in un secondo momento, è necessario innanzitutto eliminare definitivamente i ruoli personalizzati. Ulteriori dettagli sono disponibili nel Sezione 13.9, «Rimozione dell'intero cluster Ceph».
11.3.2.3 Esempio: creazione di un utente e di un ruolo personalizzato #
Questa sezione illustra la procedura di creazione di un account utente in grado di gestire le immagini RBD, visualizzare e creare pool Ceph e con l'accesso in sola lettura a qualsiasi altro ambito.
Creare un nuovo utente denominato
tux:cephuser@adm >ceph dashboard ac-user-create tux PASSWORDCreare un ruolo e specificare le autorizzazioni di ambito:
cephuser@adm >ceph dashboard ac-role-create rbd/pool-managercephuser@adm >ceph dashboard ac-role-add-scope-perms rbd/pool-manager \ rbd-image read create update deletecephuser@adm >ceph dashboard ac-role-add-scope-perms rbd/pool-manager pool read createAssociare i ruoli all'utente
tux:cephuser@adm >ceph dashboard ac-user-set-roles tux rbd/pool-manager read-only
11.4 Configurazione del proxy #
Se si desidera stabilire un URL fisso per raggiungere il Ceph Dashboard o se non si desidera consentire connessioni dirette ai nodi del manager, è possibile configurare un proxy per l'inoltro automatico delle richieste in entrata all'istanza ceph-mgr attualmente attiva.
11.4.1 Accesso al dashboard con proxy inversi #
Se si effettua l'accesso al dashboard tramite una configurazione di proxy inverso, potrebbe essere necessario fornirlo tramite un prefisso URL. Per fare in modo che il dashboard utilizzi i collegamenti ipertestuali che includono il prefisso specificato, è possibile configurare l'impostazione url_prefix:
cephuser@adm > ceph config set mgr mgr/dashboard/url_prefix URL_PREFIX
Quindi, è possibile accedere al dashboard all'indirizzo http://HOST_NAME:PORT_NUMBER/URL_PREFIX/.
11.4.2 Disabilitazione dei reindirizzamenti #
Se il Ceph Dashboard è protetto da un proxy per il bilanciamento del carico come HAProxy, disabilitare il comportamento di reindirizzamento per evitare situazioni in cui gli URL interni (non risolvibili) vengono pubblicati nel client di front-end. Utilizzare il comando seguente per fare in modo che il dashboard generi una risposta con un errore HTTP (500 per default) invece del reindirizzamento al dashboard attivo:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_behaviour "error"Per reimpostare l'impostazione sul comportamento di reindirizzamento di default, utilizzare il comando seguente:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_behaviour "redirect"11.4.3 Configurazione dei codici di stato di errore #
Se il comportamento di reindirizzamento è disabilitato, è necessario personalizzare il codice di stato HTTP dei dashboard di standby. A questo scopo, eseguire il comando seguente:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_error_status_code 50311.4.4 Configurazione HAProxy di esempio #
La configurazione di esempio seguente è da utilizzare per il pass-through TLS/SSL tramite HAProxy.
La configurazione è valida nelle condizioni seguenti: in caso di failover del dashboard, il client di front-end potrebbe ricevere una risposta di reindirizzamento HTTP (303) e verrà reindirizzato a un host non risolvibile.
Ciò avviene quando il failover si verifica durante due controlli di integrità di HAProxy. In questa situazione, il nodo del dashboard precedentemente attivo restituirà la risposta 303 che punta a un nuovo nodo attivo. Per evitare questa situazione, si consiglia di disabilitare il comportamento di reindirizzamento sui nodi di standby.
defaults
log global
option log-health-checks
timeout connect 5s
timeout client 50s
timeout server 450s
frontend dashboard_front
mode http
bind *:80
option httplog
redirect scheme https code 301 if !{ ssl_fc }
frontend dashboard_front_ssl
mode tcp
bind *:443
option tcplog
default_backend dashboard_back_ssl
backend dashboard_back_ssl
mode tcp
option httpchk GET /
http-check expect status 200
server x HOST:PORT ssl check verify none
server y HOST:PORT ssl check verify none
server z HOST:PORT ssl check verify none11.5 Controllo delle richieste API #
L'API REST del Ceph Dashboard è in grado di registrare le richieste PUT, POST e DELETE sul log di revisione di Ceph. La funzione di registrazione è disabilita per default, ma è possibile abilitarla con il comando seguente:
cephuser@adm > ceph dashboard set-audit-api-enabled trueSe abilitata, per ciascuna richiesta vengono registrati i parametri seguenti:
- from
Origine della richiesta, ad esempio "https://[::1]:44410".
- percorso
Percorso dell'API REST, ad esempio
/api/auth.- method
"PUT", "POST" o "DELETE".
- utente
Nome dell'utente (o "None").
Una voce di log di esempio ha il seguente aspetto:
2019-02-06 10:33:01.302514 mgr.x [INF] [DASHBOARD] \
from='https://[::ffff:127.0.0.1]:37022' path='/api/rgw/user/exu' method='PUT' \
user='admin' params='{"max_buckets": "1000", "display_name": "Example User", "uid": "exu", "suspended": "0", "email": "user@example.com"}'La registrazione del payload della richiesta (l'elenco degli argomenti e dei relativi valori) è abilitata per default. È possibile disabilitarla nel modo seguente:
cephuser@adm > ceph dashboard set-audit-api-log-payload false11.6 Configurazione di NFS Ganesha nel Ceph Dashboard #
Il Ceph Dashboard è in grado di gestire le esportazioni NFS Ganesha che utilizzano CephFS oppure Object Gateway come backstore. Il dashboard gestisce i file di configurazione di NFS Ganesha memorizzati negli oggetti RADOS sul cluster CephFS. NFS Ganesha deve memorizzare parte della loro configurazione nel cluster Ceph.
Eseguire il comando seguente per configurare l'ubicazione dell'oggetto di configurazione di NFS Ganesha.
cephuser@adm > ceph dashboard set-ganesha-clusters-rados-pool-namespace pool_name[/namespace]Adesso, è possibile gestire le esportazioni di NFS Ganesha tramite il Ceph Dashboard.
11.6.1 Configurazione di più cluster NFS Ganesha #
Il Ceph Dashboard supporta la gestione delle esportazioni di NFS Ganesha appartenenti a diversi cluster NFS Ganesha. Per isolare le singole configurazioni, è consigliabile che ogni cluster NFS Ganesha memorizzi i rispettivi oggetti di configurazione in uno spazio dei nomi/pool RADOS diverso.
Utilizzare il comando seguente per specificare l'ubicazione della configurazione di ciascun cluster NFS Ganesha:
cephuser@adm > ceph dashboard set-ganesha-clusters-rados-pool-namespace cluster_id:pool_name[/namespace](,cluster_id:pool_name[/namespace])*cluster_id è una stringa arbitraria che identifica in modo univoco il cluster NFS Ganesha.
Se il Ceph Dashboard viene configurato su più cluster NFS Ganesha, l'interfaccia utente Web consente automaticamente di selezionare il cluster a cui appartiene un'esportazione.
11.7 Plug-in di debug #
I plug-in del Ceph Dashboard estendono la funzionalità del dashboard. Il plug-in di debug consente la personalizzazione del comportamento del dashboard in base alla modalità di debug. È possibile abilitarlo, disabilitarlo o selezionarlo con il comando seguente:
cephuser@adm >ceph dashboard debug status Debug: 'disabled'cephuser@adm >ceph dashboard debug enable Debug: 'enabled'cephuser@adm >dashboard debug disable Debug: 'disabled'
Per default, è disabilitato. Si tratta dell'impostazione consigliata per le distribuzioni di produzione. Se necessario, è possibile abilitare la modalità di debug senza dover riavviare.
Parte II Funzionamento del cluster #
- 12 Determinazione dello stato del cluster
Quando un cluster è in esecuzione, è possibile utilizzare lo strumento
cephper monitorarlo. Per determinare lo stato del cluster, in genere occorre verificare lo stato dei Ceph OSD, di Ceph Monitor, dei gruppi di posizionamento e dei server di metadati.- 13 Task operativi
Per modificare la configurazione di un cluster Ceph esistente, seguire la procedura indicata di seguito:
- 14 Funzionamento dei servizi Ceph
È possibile utilizzare i servizi Ceph a livello di daemon, nodo o cluster. A seconda dell'approccio richiesto, utilizzare cephadm o il comando
systemctl.- 15 Backup e ripristino
Questo capitolo illustra quali parti del cluster Ceph sottoporre a backup per il ripristino della funzionalità.
- 16 Monitoraggio e creazione di avvisi
In SUSE Enterprise Storage 7.1, cephadm esegue la distribuzione di uno stack di monitoraggio e creazione di avvisi. Gli utenti devono definire i servizi (ad esempio Prometheus, Alertmanager e Grafana) da distribuire con cephadm in un file di configurazione YAML oppure distribuirli tramite l'interfac…
12 Determinazione dello stato del cluster #
Quando un cluster è in esecuzione, è possibile utilizzare lo strumento ceph per monitorarlo. Per determinare lo stato del cluster, in genere occorre verificare lo stato dei Ceph OSD, di Ceph Monitor, dei gruppi di posizionamento e dei server di metadati.
Per eseguire lo strumento ceph in modalità interattiva, digitare ceph nella riga di comando senza argomenti. La modalità interattiva è più pratica se si devono immettere più comandi ceph in una riga. Esempio:
cephuser@adm > ceph
ceph> health
ceph> status
ceph> quorum_status
ceph> mon stat12.1 Verifica dello stato di un cluster #
È possibile individuare lo stato immediato del cluster mediante ceph status o ceph -s:
cephuser@adm > ceph -s
cluster:
id: b4b30c6e-9681-11ea-ac39-525400d7702d
health: HEALTH_OK
services:
mon: 5 daemons, quorum ses-min1,ses-master,ses-min2,ses-min4,ses-min3 (age 2m)
mgr: ses-min1.gpijpm(active, since 3d), standbys: ses-min2.oopvyh
mds: my_cephfs:1 {0=my_cephfs.ses-min1.oterul=up:active}
osd: 3 osds: 3 up (since 3d), 3 in (since 11d)
rgw: 2 daemons active (myrealm.myzone.ses-min1.kwwazo, myrealm.myzone.ses-min2.jngabw)
task status:
scrub status:
mds.my_cephfs.ses-min1.oterul: idle
data:
pools: 7 pools, 169 pgs
objects: 250 objects, 10 KiB
usage: 3.1 GiB used, 27 GiB / 30 GiB avail
pgs: 169 active+cleanL'output fornisce le seguenti informazioni:
ID cluster
Stato di integrità del cluster
Epoca della mappa di monitoraggio e stato del quorum del monitoraggio
Epoca della mappa OSD e stato degli OSD
Stato di Ceph Manager
Stato di Object Gateway
Versione della mappa del gruppo di posizionamento
Numero di gruppi di posizionamento e pool
Quantità nozionale di dati memorizzati e numero di oggetti memorizzati
Quantità totale di dati memorizzati.
Il valore used riflette la quantità effettiva di spazio di memorizzazione non elaborato utilizzato. Il valore xxx GB / xxx GB indica la quantità disponibile (il numero inferiore) della capacità di memorizzazione complessiva del cluster. Il numero nozionale riflette le dimensioni dei dati memorizzati prima che vengano replicati, clonati o che ne venga eseguito lo snapshot. Pertanto, di norma la quantità di dati effettivamente memorizzata supera la quantità nozionale memorizzata, poiché Ceph crea repliche dei dati e può anche utilizzare capacità di memorizzazione per la clonazione e gli snapshot.
Altri comandi che consentono di visualizzare informazioni immediate sullo stato sono:
ceph pg statceph osd pool statsceph dfceph df detail
Per ottenere le informazioni aggiornate in tempo reale, inserire uno di questi comandi (incluso ceph -s) come argomento del comando watch:
# watch -n 10 'ceph -s'Premere Ctrl–C quando non si desidera più visualizzare le informazioni.
12.2 Verifica dell'integrità del cluster #
Dopo l'avvio del cluster e prima della lettura e/o scrittura dei dati, verificare lo stato di integrità del cluster:
cephuser@adm > ceph health
HEALTH_WARN 10 pgs degraded; 100 pgs stuck unclean; 1 mons down, quorum 0,2 \
node-1,node-2,node-3Se sono state specificate ubicazioni non di default per la configurazione o il portachiavi, è possibile specificarne le ubicazioni:
cephuser@adm > ceph -c /path/to/conf -k /path/to/keyring healthIl cluster Ceph restituisce uno dei seguenti codici di stato di integrità:
- OSD_DOWN
Uno o più OSD sono contrassegnati. È possibile che il daemon OSD sia stato interrotto o gli OSD peer potrebbero non essere in grado di raggiungere l'OSD nella rete. Tra le cause comuni sono inclusi un'interruzione o crash del daemon, un host inattivo o un'interruzione della rete.
Verificare che l'host sia integro, il daemon avviato e la rete funzionante. Se ha avuto luogo un crash del daemon, è possibile che il file di log del daemon (
/var/log/ceph/ceph-osd.*) contenga informazioni di debug.- OSD_crush type_DOWN, ad esempio OSD_HOST_DOWN
Tutti gli OSD in un determinato sottoalbero CRUSH vengono contrassegnati, ad esempio tutti gli OSD in un host.
- OSD_ORPHAN
Un OSD è un riferimento nella gerarchia della mappa CRUSH, ma non esiste. È possibile rimuovere l'OSD dalla gerarchia CRUSH con:
cephuser@adm >ceph osd crush rm osd.ID- OSD_OUT_OF_ORDER_FULL
Le soglie di utilizzo per backfillfull (il valore di default è 0,90), nearfull (il valore di default è 0,85), full (il valore di default è 0,95) e/o failsafe_full non sono crescenti. In particolare, ci si aspetta backfillfull < nearfull, nearfull < full e full < failsafe_full.
Per leggere i valori attuali, eseguire:
cephuser@adm >ceph health detail HEALTH_ERR 1 full osd(s); 1 backfillfull osd(s); 1 nearfull osd(s) osd.3 is full at 97% osd.4 is backfill full at 91% osd.2 is near full at 87%È possibile modificare le soglie con i comandi seguenti:
cephuser@adm >ceph osd set-backfillfull-ratio ratiocephuser@adm >ceph osd set-nearfull-ratio ratiocephuser@adm >ceph osd set-full-ratio ratio- OSD_FULL
Uno o più OSD hanno superato la soglia full e impediscono al cluster di fornire servizi di scrittura. È possibile verificare l'utilizzo da parte del pool con:
cephuser@adm >ceph dfÈ possibile visualizzare il rapporto full attualmente definito con:
cephuser@adm >ceph osd dump | grep full_ratioUna soluzione immediata per ripristinare la disponibilità di scrittura consiste nell'aumentare leggermente la soglia completa (full):
cephuser@adm >ceph osd set-full-ratio ratioAggiungere un nuovo spazio di memorizzazione al cluster installando più OSD, o eliminare i dati esistenti per liberare spazio.
- OSD_BACKFILLFULL
Uno o più OSD hanno superato la soglia backfillfull, impedendo il ribilanciamento dei dati nel dispositivo. Questo è un avviso preliminare che informa l'utente sull'impossibilità di completare il ribilanciamento e che il cluster è quasi pieno. È possibile verificare l'utilizzo da parte del pool con:
cephuser@adm >ceph df- OSD_NEARFULL
Uno o più OSD hanno superato la soglia nearfull. Questo è un avviso preliminare che informa l'utente che il cluster è quasi pieno. È possibile verificare l'utilizzo da parte del pool con:
cephuser@adm >ceph df- OSDMAP_FLAGS
Sono stati impostati uno o più flag del cluster interessato. Ad eccezione di full, è possibile impostare o eliminare i flag con:
cephuser@adm >ceph osd set flagcephuser@adm >ceph osd unset flagTali flag includono:
- full
Il cluster è contrassegnato come full (pieno) e non può fornire servizi di scrittura.
- pauserd, pausewr
Letture o scritture in pausa
- noup
Viene impedito l'avvio degli OSD.
- nodown
I rapporti sugli errori degli OSD vengono ignorati, ad esempio quando i monitoraggi non contrassegnano gli OSD come down (inattivi).
- noin
Gli OSD contrassegnati precedentemente come out non verranno contrassegnati di nuovo come in all'avvio.
- noout
Gli OSD down (inattivi) non verranno contrassegnati automaticamente come out dopo l'intervallo configurato.
- nobackfill, norecover, norebalance
Il recupero o il ribilanciamento dei dati è sospeso.
- noscrub, nodeep_scrub
La pulitura (vedere Sezione 17.6, «Pulitura dei gruppi di posizionamento») è disabilitata.
- notieragent
L'attività di suddivisione in livelli di cache è sospesa.
- OSD_FLAGS
Uno o più OSD presentano un flag per OSD del set di interesse. Tali flag includono:
- noup
All'OSD non è consentito l'avvio.
- nodown
I rapporti di errore per l'OSD specificato verranno ignorati.
- noin
Se precedentemente questo OSD è stato contrassegnato automaticamente come out in seguito a un errore, non verrà contrassegnato come in al suo avvio.
- noout
Se l'OSD è inattivo, non verrà contrassegnato automaticamente come out dopo l'intervallo configurato.
È possibile impostare ed eliminare i flag per OSD con:
cephuser@adm >ceph osd add-flag osd-IDcephuser@adm >ceph osd rm-flag osd-ID- OLD_CRUSH_TUNABLES
Nella mappa CRUSH vengono utilizzate impostazioni molto obsolete e deve essere aggiornata. Gli elementi ottimizzabili più obsoleti (vale a dire la versione client più vecchia in grado di connettersi al cluster) che è possibile utilizzare senza attivare questo avviso di stato di integrità vengono determinati dall'opzione di configurazione
mon_crush_min_required_version.- OLD_CRUSH_STRAW_CALC_VERSION
Nella mappa CRUSH viene utilizzato un metodo precedente, non ottimale per calcolare i valori del peso intermedio per i compartimenti straw. La mappa CRUSH deve essere aggiornata per utilizzare il metodo più recente (
straw_calc_version=1).- CACHE_POOL_NO_HIT_SET
Uno o più pool di cache non sono configurati con un set di accessi per controllare l'utilizzo, impedendo all'agente di suddivisione in livelli di identificare gli oggetti a caldo di essere svuotati o rimossi dalla cache. È possibile configurare i set di accessi nel pool di cache con:
cephuser@adm >ceph osd pool set poolname hit_set_type typecephuser@adm >ceph osd pool set poolname hit_set_period period-in-secondscephuser@adm >ceph osd pool set poolname hit_set_count number-of-hitsetscephuser@adm >ceph osd pool set poolname hit_set_fpp target-false-positive-rate- OSD_NO_SORTBITWISE
Nessun OSD di versione precedente a Luminous v12 in esecuzione, ma il flag
sortbitwisenon è stato impostato. È necessario impostare il flagsortbitwiseprima di poter avviare gli OSD Luminous v12 o versione più recente:cephuser@adm >ceph osd set sortbitwise- POOL_FULL
Uno o più pool hanno raggiunto la rispettiva quota e non consentono più le scritture. È possibile impostare le quote dei pool e l'utilizzo con:
cephuser@adm >ceph df detailÈ possibile aumentare la quota del pool con
cephuser@adm >ceph osd pool set-quota poolname max_objects num-objectscephuser@adm >ceph osd pool set-quota poolname max_bytes num-byteso eliminare alcuni dati esistenti per ridurre l'utilizzo.
- PG_AVAILABILITY
La disponibilità dei dati è ridotta, vale a dire che il cluster non è in grado di fornire servizi di richieste di potenziali letture o scritture per alcuni dati nel cluster. Nello specifico, è impossibile fornire servizi a uno o più gruppi di posizionamento il cui stato non consente richieste I/O. Gli stati dei gruppi di posizionamento problematici includono peering, stale (inattivo), incomplete (incompleto) e la mancanza di active (attivo) (se tali condizioni non vengono annullate rapidamente). Informazioni dettagliate sui gruppi di posizionamento interessati sono recuperabili da:
cephuser@adm >ceph health detailNella maggior parte dei casi, la causa radice risiede nell'attuale stato di inattività di uno o più OSD. È possibile interrogare lo stato di specifici gruppi di posizionamento problematici con:
cephuser@adm >ceph tell pgid query- PG_DEGRADED
La ridondanza dei dati è ridotta per alcuni dati, vale a dire che il cluster non dispone del numero desiderato di repliche per tutti i dati (per pool replicati) o di frammenti di codice di cancellazione (per pool con codice di cancellazione). Nello specifico, per uno o più gruppi di posizionamento è impostato il flag degraded o undersized (le istanze di tale gruppo di posizionamento nel cluster non sono sufficienti) oppure non è impostato il flag clean per un periodo di tempo. Informazioni dettagliate sui gruppi di posizionamento interessati sono recuperabili da:
cephuser@adm >ceph health detailNella maggior parte dei casi, la causa radice risiede nell'attuale stato di inattività di uno o più OSD. È possibile interrogare lo stato di specifici gruppi di posizionamento problematici con:
cephuser@adm >ceph tell pgid query- PG_DEGRADED_FULL
È possibile che la ridondanza dei dati può sia ridotta o a rischio per alcuni dati a causa della mancanza di spazio libero nel cluster. Nello specifico, per uno o più gruppi di posizionamento è impostato il flag backfill_toofull o recovery_toofull, vale a dire che il cluster non è in grado di eseguire la migrazione o recuperare i dati perché uno o più OSD superano la soglia backfillfull.
- PG_DAMAGED
In seguito alla pulitura dei dati (vedere Sezione 17.6, «Pulitura dei gruppi di posizionamento»), nel cluster sono stati rilevati alcuni problemi di incoerenza dei dati. Nello specifico, in uno o più gruppi di posizionamento è impostato il flag inconsistent o snaptrim_error, a indicare che a seguito di un'operazione di pulitura precedente è stato individuato un problema, oppure è impostato il flag repair, a indicare che attualmente è in corso una riparazione per tale incoerenza.
- OSD_SCRUB_ERRORS
Dalle puliture dell'OSD sono state rilevate incoerenze.
- CACHE_POOL_NEAR_FULL
Un pool di livelli di cache è quasi pieno. "Pieno" in questo contesto è determinato dalla proprietà target_max_bytes e target_max_objects nel pool di cache. Quando il pool raggiunge la soglia di destinazione, è possibile che le richieste di scrittura nel pool si blocchino quando i dati vengono svuotati e rimossi dalla cache, uno stato che di norma comporta latenze molto elevate e prestazioni scarse. È possibile regolare le dimensioni di destinazione del pool di cache con:
cephuser@adm >ceph osd pool set cache-pool-name target_max_bytes bytescephuser@adm >ceph osd pool set cache-pool-name target_max_objects objectsÈ inoltre possibile che le attività di svuotamento e rimozione siano bloccate a causa della disponibilità ridotta, delle prestazioni del livello base o a causa del carico complessivo del cluster.
- TOO_FEW_PGS
Il numero di gruppi di posizionamento in uso è sotto la soglia configurabile dei gruppi di posizionamento per OSD
mon_pg_warn_min_per_osd. Ciò può comportare una distribuzione e bilanciamento dei dati non ottimali negli OSD del cluster, riducendo le prestazioni complessive.- TOO_MANY_PGS
Il numero di gruppi di posizionamento in uso supera la soglia configurabile di gruppi di posizionamento per OSD
mon_pg_warn_max_per_osd. Ciò comporta un utilizzo della memoria maggiore per i daemon OSD, un peering più lento dopo le modifiche allo stato del cluster (ad esempio, riavvii, aggiunte o rimozioni di OSD) e un carico più elevato nei Ceph Manager e Ceph Monitor.È possibile ridurre il valore
pgp_num, ma non il valorepg_numper i pool esistenti. Ciò colloca effettivamente alcuni gruppi di posizionamento sugli stessi set di OSD, mitigando alcuni impatti negativi descritti sopra. È possibile regolare il valorepgp_numcon:cephuser@adm >ceph osd pool set pool pgp_num value- SMALLER_PGP_NUM
Il valore
pgp_numdi uno o più pool è inferiore apg_num. Di norma ciò indica che il numero di gruppi di posizionamento è stato incrementato senza incrementare anche comportamento del posizionamento. Di norma questo problema viene risolto impostandopgp_numin modo che corrisponda apg_num, attivando la migrazione dei dati, con:cephuser@adm >ceph osd pool set pool pgp_num pg_num_value- MANY_OBJECTS_PER_PG
Uno o più pool presentano un numero medio di oggetti per gruppo di posizionamento che è significativamente più elevato della media complessiva del cluster. La soglia specifica è controllata dal valore di configurazione
mon_pg_warn_max_object_skew. Di norma ciò indica che i pool che contengono la maggior parte dei dati nel cluster hanno un numero di gruppi di posizionamento insufficiente e/o che altri pool che non contengono una tale quantità di dati hanno troppi gruppi di posizionamento. È possibile aumentare la soglia per annullare l'avviso di stato di integrità regolando l'opzione di configurazionemon_pg_warn_max_object_skewnei monitoraggi.- POOL_APP_NOT_ENABLED
Un pool contiene uno o più oggetti, ma non è stato contrassegnato per l'utilizzo da parte di un'applicazione particolare. Risolvere questo avviso etichettando il pool per l'utilizzo da parte di un'applicazione. Ad esempio, se il pool viene utilizzato da RBD:
cephuser@adm >rbd pool init pool_nameSe il pool viene utilizzato da un'applicazione personalizzata "foo", è inoltre possibile etichettarla con il comando di livello basso:
cephuser@adm >ceph osd pool application enable foo- POOL_FULL
Uno o più pool hanno raggiunto (o sono prossimi a raggiungere) la rispettiva quota. La soglia per attivare questa condizione di errore è controllata dall'opzione di configurazione
mon_pool_quota_crit_threshold. È possibile regolare verso l'alto o verso il basso (o rimuovere) le quote dei pool con:cephuser@adm >ceph osd pool set-quota pool max_bytes bytescephuser@adm >ceph osd pool set-quota pool max_objects objectsImpostando il valore di quota a 0, questa verrà disabilitata.
- POOL_NEAR_FULL
Uno o più pool stanno per raggiungere la rispettiva quota. La soglia per attivare questa condizione di avviso è controllata dall'opzione di configurazione
mon_pool_quota_warn_threshold. È possibile regolare verso l'alto o verso il basso (o rimuovere) le quote dei pool con:cephuser@adm >ceph osd osd pool set-quota pool max_bytes bytescephuser@adm >ceph osd osd pool set-quota pool max_objects objectsImpostando il valore di quota a 0, questa verrà disabilitata.
- OBJECT_MISPLACED
Uno o più oggetti nel cluster non vengono memorizzati nel nodo specificato dal cluster. Ciò indica che la migrazione dei dati causata da una modifica recente del cluster non è stata ancora completata. La posizione errata dei dati non rappresenta una condizione pericolosa. La coerenza dei dati non è mai a rischio e le copie precedenti degli oggetti non vengono mai rimosse finché è presente il numero di copie nuove desiderato (nelle ubicazioni desiderate).
- OBJECT_UNFOUND
Impossibile individuare uno o più oggetti nel cluster. Nello specifico, gli OSD sanno che deve esistere una copia nuova o aggiornata di un oggetto, ma negli OSD attualmente attivi non è stata trovata una copia di tale versione dell'oggetto. Le richieste di lettura o scrittura negli oggetti "non trovati" verranno bloccate. Idealmente, è possibile riattivare l'OSD inattivo in cui è presente la copia più recente dell'oggetto non trovato. È possibile identificare gli OSD candidati in stato di peering per i gruppi di posizionamento responsabili dell'oggetto non trovato:
cephuser@adm >ceph tell pgid query- REQUEST_SLOW
Una o più richieste OSD impiegano molto tempo per l'elaborazione. Ciò può essere un'indicazione di carico estremo, dispositivo di memorizzazione lento o bug del software. È possibile interrogare la coda delle richieste sugli OSD in questione mediante l'esecuzione del seguente comando dall'host OSD:
cephuser@adm >cephadm enter --name osd.ID -- ceph daemon osd.ID opsÈ possibile visualizzare un riepilogo delle richieste recenti più lente:
cephuser@adm >cephadm enter --name osd.ID -- ceph daemon osd.ID dump_historic_opsÈ possibile individuare l'ubicazione di un OSD con:
cephuser@adm >ceph osd find osd.id- REQUEST_STUCK
Una o più richieste OSD sono state bloccate per un intervallo di tempo relativamente lungo, ad esempio 4.096 secondi. Ciò indica che lo stato del cluster non è integro da un periodo di tempo prolungato (ad esempio il numero di OSD in esecuzione o di gruppi di posizionamento inattivi non è sufficiente) o che sono presenti alcuni problemi interni dell'OSD.
- PG_NOT_SCRUBBED
Di recente non è stata eseguita la pulitura di uno o più gruppi di posizionamento (vedere la Sezione 17.6, «Pulitura dei gruppi di posizionamento»). Di norma la pulitura dei gruppi di posizionamento viene eseguita ogni
mon_scrub_intervalsecondi e questo avviso si attiva quando sono trascorsimon_warn_not_scrubbedsecondi senza che abbia avuto luogo una pulitura. La pulitura dei gruppi di posizionamento non verrà eseguita se questi non sono contrassegnati come puliti, il che può verificarsi se sono posizionati male o sono danneggiati (vedere PG_AVAILABILITY e PG_DEGRADED di cui sopra). È possibile avviare manualmente la pulitura di un gruppo di posizionamento pulito con:cephuser@adm >ceph pg scrub pgid- PG_NOT_DEEP_SCRUBBED
Di recente non è stata eseguita la pulitura approfondita di uno o più gruppi di posizionamento (vedere Sezione 17.6, «Pulitura dei gruppi di posizionamento»). Di norma la pulitura dei gruppi di posizionamento viene eseguita ogni
osd_deep_mon_scrub_intervalsecondi e questo avviso si attiva quando sono trascorsimon_warn_not_deep_scrubbedsecondi senza che abbia avuto luogo una pulitura. La pulitura (approfondita) dei gruppi di posizionamento non verrà eseguita se questi non sono contrassegnati come puliti, il che può verificarsi se sono posizionati male o sono danneggiati (vedere PG_AVAILABILITY e PG_DEGRADED di cui sopra). È possibile avviare manualmente la pulitura di un gruppo di posizionamento pulito con:cephuser@adm >ceph pg deep-scrub pgid
Se sono state specificate ubicazioni non di default per la configurazione o il portachiavi, è possibile specificarne le ubicazioni:
# ceph -c /path/to/conf -k /path/to/keyring health12.3 Verifica delle statistiche sull'utilizzo di un cluster #
Per verificare l'utilizzo e la distribuzione dei dati del cluster nei diversi pool, utilizzare il comando ceph df. Per ottenere ulteriori dettagli, utilizzare ceph df detail.
cephuser@adm > ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 30 GiB 27 GiB 121 MiB 3.1 GiB 10.40
TOTAL 30 GiB 27 GiB 121 MiB 3.1 GiB 10.40
--- POOLS ---
POOL ID STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 0 B 0 0 B 0 8.5 GiB
cephfs.my_cephfs.meta 2 1.0 MiB 22 4.5 MiB 0.02 8.5 GiB
cephfs.my_cephfs.data 3 0 B 0 0 B 0 8.5 GiB
.rgw.root 4 1.9 KiB 13 2.2 MiB 0 8.5 GiB
myzone.rgw.log 5 3.4 KiB 207 6 MiB 0.02 8.5 GiB
myzone.rgw.control 6 0 B 8 0 B 0 8.5 GiB
myzone.rgw.meta 7 0 B 0 0 B 0 8.5 GiB
Nella sezione RAW STORAGE dell'output è fornita una panoramica dello spazio di storage utilizzato dal cluster per i dati.
CLASS: classe di storage del dispositivo. Per ulteriori dettagli sulle classi di dispositivi, fare riferimento alla Sezione 17.1.1, «Classi di dispositivi».SIZE: capacità di memorizzazione complessiva del cluster.AVAIL: quantità di spazio libero disponibile nel cluster.USED: spazio (accumulato su tutti gli OSD) allocato esclusivamente per gli oggetti dati conservati nel dispositivo di blocco.RAW USED: somma tra lo spazio utilizzato ("USED") e quello allocato/riservato sul dispositivo di blocco per Ceph, ad esempio la parte BlueFS per BlueStore.% RAW USED: percentuale di spazio di memorizzazione di dati non elaborati utilizzato. Utilizzare questo numero insieme afull ratioenear full ratioper assicurarsi che non si stia raggiungendo la capacità del cluster. Per ulteriori dettagli, vedere la Sezione 12.8, «Capacità di memorizzazione».Nota: livello di riempimento del clusterQuando il livello di riempimento dello spazio di storage nominale si avvicina al 100%, è necessario aggiungere ulteriore spazio di storage al cluster. Un utilizzo più elevato può comportare a singoli OSD pieni e a problemi di integrità del cluster.
Utilizzare il comando
ceph osd df treeper elencare il livello di riempimento di tutti gli OSD.
Nella sezione POOLS dell'output è fornito un elenco di pool e l'utilizzo nozionale di ciascuno di essi. L'output di questa sezione non riflette repliche, cloni o snapshot. Ad esempio, se si memorizza un oggetto con 1 MB di dati, l'utilizzo nozionale sarà 1 MB, ma quello effettivo può essere di 2 MB o più a seconda del numero di repliche, cloni e snapshot.
POOL: nome del pool.ID: ID del pool.STORED: quantità di dati memorizzati dall'utente.OBJECTS: numero nozionale di oggetti memorizzati per pool.USED: quantità di spazio allocato esclusivamente ai dati da tutti i nodi OSD, indicato in KB.%USED: percentuale nozionale di spazio di memorizzazione utilizzato per ciascun pool.MAX AVAIL: spazio massimo disponibile nel pool specificato.
I numeri nella sezione POOLS sono nozionali. Non includono il numero di repliche, snapshot o cloni. Ne risulta che la somma delle quantità USED e %USED non verrà aggiunta alle quantità RAW USED e %RAW USED nella sezione RAW STORAGE dell'output.
12.4 Verifica dello stato degli OSD #
È possibile verificare lo stato degli OSD per assicurarsi che siano attivi e funzionanti eseguendo:
cephuser@adm > ceph osd statoppure
cephuser@adm > ceph osd dumpÈ inoltre possibile visualizzare gli OSD in base alla rispettiva posizione nella mappa CRUSH.
ceph osd tree eseguirà la stampa di un albero CRUSH con un host, i rispettivi OSD, se attivi, e il relativo peso:
cephuser@adm > ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 3 0.02939 root default
-3 3 0.00980 rack mainrack
-2 3 0.00980 host osd-host
0 1 0.00980 osd.0 up 1.00000 1.00000
1 1 0.00980 osd.1 up 1.00000 1.00000
2 1 0.00980 osd.2 up 1.00000 1.0000012.5 Verifica degli OSD pieni #
Ceph impedisce la scrittura in un OSD pieno in modo da evitare perdite di dati. In un cluster operativo, quando questo è prossimo al rispettivo rapporto di riempimento si riceve un avviso. L'impostazione di default di mon osd full ratio è 0,95 o 95% della capacità, prima che venga interrotta la scrittura dei dati da parte dei client. L'impostazione di default di mon osd nearfull ratio è 0,85 o 85% della capacità, quando viene generato avviso sullo stato di integrità.
I nodi OSD pieni verranno segnalati da ceph health:
cephuser@adm > ceph health
HEALTH_WARN 1 nearfull osds
osd.2 is near full at 85%oppure
cephuser@adm > ceph health
HEALTH_ERR 1 nearfull osds, 1 full osds
osd.2 is near full at 85%
osd.3 is full at 97%Il modo migliore per gestire un cluster pieno consiste nell'aggiungere nuovi host/dischi OSD che consentano al cluster di ridistribuire dati nello spazio di storage che si è appena reso disponibile.
Quando un OSD si riempie (utilizza il 100% del rispettivo spazio su disco), di norma questo si blocca rapidamente senza alcun avviso. Di seguito sono riportati alcuni suggerimenti utili per l'amministrazione dei nodi OSD.
È necessario posizionare lo spazio su disco di ciascun OSD (di norma montato in
/var/lib/ceph/osd/osd-{1,2..}) su un disco o una partizione dedicati sottostanti.Controllare i file di configurazione Ceph e assicurarsi che il log file Ceph non venga memorizzato nei dischi o nelle partizioni dedicati all'uso da parte degli OSD.
Assicurarsi che la scrittura nei dischi o nelle partizioni dedicati all'uso da parte degli OSD non venga eseguita da altri processi.
12.6 Verifica dello stato del monitor #
Dopo aver avviato il cluster e precedentemente alla prima lettura e/o scrittura dei dati, verificare lo stato del quorum dei Ceph Monitor. Se il cluster sta già provvedendo alle richieste, controllare periodicamente lo stato dei Ceph Monitor per assicurarsi che siano in esecuzione.
Per visualizzare la mappa del monitoraggio, eseguire quanto riportato di seguito:
cephuser@adm > ceph mon statoppure
cephuser@adm > ceph mon dumpPer verificare lo stato del quorum per il cluster di monitoraggio, eseguire quanto riportato di seguito:
cephuser@adm > ceph quorum_statusCeph restituirà lo stato del quorum. Ad esempio, un cluster Ceph costituito da tre monitoraggi può restituire quanto riportato di seguito:
{ "election_epoch": 10,
"quorum": [
0,
1,
2],
"monmap": { "epoch": 1,
"fsid": "444b489c-4f16-4b75-83f0-cb8097468898",
"modified": "2011-12-12 13:28:27.505520",
"created": "2011-12-12 13:28:27.505520",
"mons": [
{ "rank": 0,
"name": "a",
"addr": "192.168.1.10:6789\/0"},
{ "rank": 1,
"name": "b",
"addr": "192.168.1.11:6789\/0"},
{ "rank": 2,
"name": "c",
"addr": "192.168.1.12:6789\/0"}
]
}
}12.7 Verifica degli stati dei gruppi di posizionamento #
Oggetti della mappa dei gruppi di posizionamento negli OSD. Quando si monitorano i gruppi di posizionamento, questi dovranno essere active e clean. Per una discussione dettagliata, fare riferimento alla Sezione 12.9, «Monitoraggio di OSD e gruppi di posizionamento».
12.8 Capacità di memorizzazione #
Quando un cluster di memorizzazione Ceph si avvicina alla capacità massima, Ceph impedisce la scrittura o la lettura dai Ceph OSD come misura di sicurezza per evitare perdite di dati. Pertanto, non è consigliabile far avvicinare un cluster di produzione al rapporto di riempimento. Questa situazione andrebbe infatti a discapito dell'elevata disponibilità. Per default il rapporto di riempimento è impostato su 0,95, ovvero il 95% della capacità. Si tratta di un valore molto aggressivo per un cluster di test contenente un numero ridotto di OSD.
Durante il monitoraggio del cluster, prestare attenzione agli avvisi relativi alla percentuale nearfull. Ciò indica che nel caso di errori su alcuni OSD, potrebbe verificarsi una temporanea interruzione del servizio. Valutare la possibilità di aggiungere altri OSD per aumentare la capacità di storage.
In uno scenario comune per i cluster di prova, l'amministratore di sistema rimuove un Ceph OSD dal cluster di memorizzazione Ceph per osservare il ribilanciamento del cluster. Quindi, rimuove un altro Ceph OSD e così via fin quando il cluster non raggiunge il rapporto di riempimento e si blocca. Si consiglia di eseguire la pianificazione della capacità anche per il cluster di prova. In questo modo, sarà possibile calcolare la capacità di riserva necessaria per mantenere un'elevata disponibilità. Idealmente, è consigliabile pianificare una serie di errori dei Ceph OSD durante cui sia possibile recuperare il cluster e ripristinarlo allo stato active + clean senza sostituire immediatamente i Ceph OSD con errori. Anche se è possibile eseguire un cluster nello stato active + degraded, non è l'ideale per un normale funzionamento.
Nel diagramma seguente viene illustrato un cluster di memorizzazione Ceph semplificato che contiene 33 nodi Ceph e un Ceph OSD per host, ciascuno in grado di eseguire operazioni di lettura e scrittura su un'unità da 3 TB. La capacità effettiva di questo cluster di esempio è di 99 TB. L'opzione mon osd full ratio è impostata a 0,95. Se il cluster raggiunge i 5 TB di capacità rimanente, non consentirà ai client di leggere e scrivere dati. Di conseguenza, la capacità operativa del cluster di memorizzazione è 95 TB, non 99 TB.

In tale cluster, è normale che si verifichino errori su uno o due OSD. In uno scenario meno frequente ma possibile, può verificarsi un errore del router o dell'alimentazione del rack che causa la disattivazione simultanea di più OSD (ad esempio degli OSD da 7 a 12). In tale scenario, è consigliabile comunque puntare ad avere un cluster in grado di restare operativo e raggiungere lo stato active + clean, anche se ciò comporta l'aggiunta di alcuni host con ulteriori OSD in tempi brevi. Se l'utilizzo della capacità è troppo elevato, potrebbero verificarsi perdite di dati. Tuttavia, se l'utilizzo della capacità del cluster supera il rapporto di riempimento, è comunque preferibile scendere a compromessi sulla disponibilità dei dati per risolvere un'interruzione all'interno di un dominio di errore. Per questo motivo, si consiglia di effettuare una pianificazione seppur approssimativa della capacità.
Identificare due numeri per il cluster:
Il numero di OSD.
La capacità complessiva del cluster.
Se si divide la capacità totale del cluster per il numero di OSD contenuti, è possibile individuare la capacità media di un OSD del cluster. Moltiplicare questo numero per il numero di OSD su cui si prevede che si verificheranno errori in simultanea durante il normale funzionamento (un numero relativamente ridotto). Moltiplicare poi la capacità del cluster per il rapporto di riempimento fino a raggiungere la capacità operativa massima. Infine, sottrarre la quantità di dati degli OSD su cui si prevede che si verificheranno errori fino a raggiungere un rapporto di riempimento ragionevole. Ripetere la procedura indicata con un numero più elevato di errori sugli OSD (un rack di OSD) fino a ottenere un numero ragionevole per un rapporto di riempimento quasi completo.
Le impostazioni seguenti si applicano soltanto durante la creazione del cluster e vengono quindi memorizzate nella mappa OSD:
[global] mon osd full ratio = .80 mon osd backfillfull ratio = .75 mon osd nearfull ratio = .70
Queste impostazioni si applicano soltanto durante alla creazione del cluster. In seguito, è necessario modificarle nella mappa OSD utilizzando i comandi ceph osd set-nearfull-ratio e ceph osd set-full-ratio.
- mon osd full ratio
Percentuale di spazio su disco utilizzata prima che un OSD venga considerato pieno (
full). Il valore di default è 0,95- mon osd backfillfull ratio
Percentuale di spazio su disco utilizzata prima che un OSD venga considerato troppo pieno (
full) per il backfill. Il valore di default è 0,90- mon osd nearfull ratio
Percentuale di spazio su disco utilizzata prima che un OSD venga considerato quasi pieno (
nearfull). Il valore di default è 0,85
Se alcuni OSD sono nearfull, ma in altri è invece disponibile una capacità elevata, potrebbero verificarsi dei problemi con il peso CRUSH per gli OSD nearfull.
12.9 Monitoraggio di OSD e gruppi di posizionamento #
Per ottenere un'elevata disponibilità e un'alta affidabilità occorre adottare un approccio a tolleranza di errore nella gestione dei problemi hardware e software. Ceph non dispone di un single point of failure ed è in grado di provvedere alle richieste di dati nella modalità "degraded" (danneggiata). Il posizionamento dei dati di Ceph introduce un livello di riferimento indiretto per fare in modo che i dati non vengano direttamente associati a specifici indirizzi OSD. Vale a dire che per il controllo degli errori di sistema occorre individuare il gruppo di posizionamento e gli OSD sottostanti alla radice del problema.
Gli errori che si verificano in una parte del cluster possono impedire l'accesso a un determinato oggetto, ma non ad altri oggetti. Quando si verifica un errore, seguire la procedura di monitoraggio degli OSD e dei gruppi di posizionamento. Quindi, procedere con la risoluzione dei problemi.
Ceph in genere esegue il ripristino automatico. Tuttavia, se i problemi continuano a verificarsi, il monitoraggio degli OSD e dei gruppi di posizionamento consentirà di identificare il problema.
12.9.1 Monitoraggio degli OSD #
Un OSD può essere nello stato "in" (dentro il cluster) o nello stato "out" (fuori dal cluster). Contemporaneamente, può essere "up" (attivo e in esecuzione) o "down" (disattivato e non in esecuzione). Se un OSD è nello stato "up", può trovarsi dentro il cluster (sarà possibile leggere e scrivere i dati) o al di fuori di esso. Se si trovava all'interno del cluster e di recente è stato spostato al di fuori, Ceph eseguirà la migrazione dei gruppi di posizionamento in altri OSD. Se un OSD si trova fuori dal cluster, CRUSH non gli assegnerà alcun gruppo di posizionamento. Se un OSD è nello stato "down", deve essere anche "out".
Se un OSD è "down" e "in", è presente un problema e il cluster si trova nello stato non integro.
Se si esegue un comando come ceph health ceph -s o ceph -w, è possibile notare che il cluster non rimanda sempre lo stato HEALTH OK. Per quanto riguarda gli OSD, è prevedibile che il cluster non rimanderà lo stato HEALTH OK se:
Il cluster non è stato ancora avviato (non risponderà).
Il cluster è stato avviato o riavviato e non è ancora pronto, poiché è in corso la creazione dei gruppi di posizionamento e gli OSD sono in fase di peering.
Un OSD è stato aggiunto o rimosso.
La mappa del cluster è stata modificata.
Un aspetto importante del monitoraggio degli OSD consiste nell'assicurarsi che tutti gli OSD dentro il cluster siano attivi e in esecuzione quando lo è il cluster. Per verificare se tutti gli OSD sono in esecuzione, eseguire:
# ceph osd stat
x osds: y up, z in; epoch: eNNNN
Il risultato dovrebbe indicare il numero totale di OSD (x), quanti di questi sono nello stato "up" (y) e nello stato "in" (z) e l'epoca della mappa (eNNNN). Se il numero di OSD dentro il cluster ("in") superiore al numero di OSD attivi ("up"), eseguire il comando seguente per individuare i daemon ceph-osd non in esecuzione:
# ceph osd tree
#ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 2.00000 pool openstack
-3 2.00000 rack dell-2950-rack-A
-2 2.00000 host dell-2950-A1
0 ssd 1.00000 osd.0 up 1.00000 1.00000
1 ssd 1.00000 osd.1 down 1.00000 1.00000Ad esempio, se un OSD con ID 1 è inattivo, avviarlo:
cephuser@osd > sudo systemctl start ceph-CLUSTER_ID@osd.0.servicePer informazioni sui problemi associati agli OSD interrotti o che non verranno riavviati, vedere il Book “Troubleshooting Guide”, Chapter 4 “Troubleshooting OSDs”, Section 4.3 “OSDs not running”.
12.9.2 Assegnazione di insiemi di gruppi di posizionamento #
Quando CRUSH assegna i gruppi di posizionamento agli OSD, osserva il numero di repliche del pool e assegna il gruppo di posizionamento agli OSD in modo che ogni replica di tale gruppo venga assegnata a un OSD diverso. Ad esempio, se il pool richiede tre repliche di un gruppo di posizionamento, CRUSH potrebbe assegnarle rispettivamente a osd.1, osd.2 e osd.3. CRUSH in realtà individua un posizionamento pseudo-casuale che tiene conto dei domini di errore impostati nella mappa CRUSH. Di conseguenza, in un cluster di grandi dimensioni sarà raro vedere gruppi di posizionamento assegnati agli OSD più vicini. Il set di OSD che deve contenere le repliche di un determinato gruppo di posizionamento viene chiamato acting set. In alcuni casi, un OSD dell'acting set è disattivato oppure non è in grado di provvedere alle richieste relative agli oggetti nel gruppo di posizionamento. In queste situazioni, gli scenari potrebbero essere i seguenti:
Un OSD è stato aggiunto o rimosso. Quindi, CRUSH ha riassegnato il gruppo di posizionamento agli altri OSD e ha pertanto modificato la composizione dell'acting set, causando la migrazione dei dati con una procedura di "backfill".
Un OSD era nello stato "down", è stato riavviato ed è in corso di recupero.
Un OSD nell'acting set si trova nello stato "down" o non è in grado di provvedere alle richieste e un altro OSD ne assume provvisoriamente i compiti.
Ceph elabora una richiesta client tramite l'up set, ovvero il set degli OSD che provvederanno effettivamente alle richieste. Nella maggior parte dei casi, l'up set e l'acting set sono praticamente identici. Se differiscono, potrebbe significare che Ceph sta eseguendo la migrazione dei dati, che è in corso il recupero di un OSD o che si è verificato un problema (ad esempio, in tali scenari generalmente Ceph rimanda uno stato
HEALTH WARNcon il messaggio "stuck stale").
Per recuperare un elenco dei gruppi di posizionamento, eseguire:
cephuser@adm > ceph pg dumpPer visualizzare gli OSD che si trovano all'interno dell'acting set o dell'up set per un determinato gruppo di posizionamento, eseguire:
cephuser@adm > ceph pg map PG_NUM
osdmap eNNN pg RAW_PG_NUM (PG_NUM) -> up [0,1,2] acting [0,1,2]Il risultato dovrebbe indicare l'epoca di osdmap (eNNN), il numero di gruppi di posizionamento (PG_NUM), gli OSD nell'up set ("up") e quelli nell'acting set ("acting"):
Una mancata corrispondenza tra l'up set e l'acting set potrebbe indicare che è in corso il ribilanciamento del cluster o un suo potenziale problema.
12.9.3 Peering #
Prima che sia possibile scrivere dati su un gruppo di posizionamento, quest'ultimo deve essere negli stati active e clean. Affinché Ceph possa determinare lo stato corrente di un gruppo di posizionamento, l'OSD primario di tale gruppo (il primo OSD nell'acting set) esegue il peering con gli OSD secondario e terziario per accordarsi sullo stato corrente del gruppo di posizionamento (presupponendo che si tratti di un pool con tre repliche del gruppo di posizionamento).

12.9.4 Monitoraggio degli stati del gruppo di posizionamento #
Se si esegue un comando come ceph health, ceph -s o ceph -w, è possibile notare che il cluster non rimanda sempre il messaggio HEALTH OK. Dopo aver verificato che tutti gli OSD siano in esecuzione, controllare anche gli stati del gruppo di posizionamento.
È prevedibile che il cluster non rimanderà lo stato HEALTH OK in alcune circostanze correlate al peering del gruppo di posizionamento:
È stato creato un pool e non è stato ancora eseguito il peering dei gruppi di posizionamento.
È in corso il recupero dei gruppi di posizionamento.
Un OSD è stato aggiunto al cluster o rimosso da quest'ultimo.
La mappa CRUSH è stata modificata ed è in corso la migrazione dei gruppi di posizionamento.
Sono presenti dati incoerenti in repliche diverse di un gruppo di posizionamento.
Ceph sta eseguendo la pulitura delle repliche di un gruppo di posizionamento.
Ceph non dispone di sufficiente capacità di storage per il completamento delle operazioni di backfill.
Se a causa di una di queste circostanze Ceph rimanda il messaggio HEALTH WARN, non preoccuparsi. In molti casi, il cluster si ripristinerà automaticamente. In alcuni casi, può essere necessario intervenire. Un aspetto importante del monitoraggio dei gruppi di posizionamento consiste nell'assicurarsi che quando un cluster è attivo e in esecuzione, tutti i gruppi di posizionamento siano nello stato "active" e preferibilmente anche in quello "clean state". Per visualizzare lo stato di tutti i gruppi di posizionamento, eseguire:
cephuser@adm > ceph pg stat
x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB availIl risultato dovrebbe indicare il numero totale di gruppi di posizionamento (x), quanti di questi si trovano in un determinato stato, ad esempio "active+clean" (y), e la quantità di dati memorizzati (z).
Oltre agli stati del gruppo di posizionamento, Ceph rimanderà anche la capacità di storage utilizzata (aa), quella rimanente (bb) e la capacità di storage totale del gruppo di posizionamento. Tali valori possono essere importanti nei casi in cui:
Ci si sta avvicinando al valore impostato per
near full ratioofull ratio.I dati non vengono distribuiti nel cluster a causa di un errore nella configurazione CRUSH.
Gli ID dei gruppi di posizionamento sono costituiti dal numero del pool (e non dal nome) seguito da un punto (.) e dall'ID del gruppo di posizionamento (un numero esadecimale). È possibile visualizzare il numero e il nome del pool dall'output di ceph osd lspools. Ad esempio, il pool di default rbd corrisponde al numero di pool 0. Un ID del gruppo di posizionamento completo è strutturato nel modo seguente:
POOL_NUM.PG_ID
E in genere ha il seguente aspetto:
0.1f
Per recuperare un elenco dei gruppi di posizionamento, eseguire quanto riportato di seguito:
cephuser@adm > ceph pg dumpÈ inoltre possibile formattare l'output in formato JSON e salvarlo in un file:
cephuser@adm > ceph pg dump -o FILE_NAME --format=jsonPer interrogare un determinato gruppo di posizionamento, eseguire quanto riportato di seguito:
cephuser@adm > ceph pg POOL_NUM.PG_ID queryL'elenco seguente descrive in modo dettagliato gli stati dei gruppi di posizionamento più comuni.
- CREATING
Quando si crea un pool, quest'ultimo creerà il numero di gruppi di posizionamento specificato. Ceph rimanderà lo stato "creating" durante la creazione di uno o più gruppi di posizionamento. In seguito alla creazione, verrà avviato il peering degli OSD che fanno parte dell'acting set del gruppo di posizionamento. Al completamento del peering, lo stato del gruppo di posizionamento deve essere "active+clean", per indicare che un client Ceph può avviare la scrittura su tale gruppo.
 Figura 12.3: Stato dei gruppi di posizionamento #
Figura 12.3: Stato dei gruppi di posizionamento #- PEERING
Quando Ceph esegue il peering di un gruppo di posizionamento fa in modo che gli OSD che ne memorizzano le repliche concordino sullo stato degli oggetti e dei metadati contenuti nel gruppo. Quando Ceph completa il peering, vuol dire che gli OSD che memorizzano il gruppo di posizionamento concordano sullo stato corrente del gruppo di posizionamento. Tuttavia, il completamento del processo di peering non implica che in ogni replica siano presenti i contenuti più recenti.
Nota: cronologia autorevoleCeph non riconoscerà le operazioni di scrittura su un client finché tutti gli OSD dell'acting set non le salvano in modo permanente. Questa pratica consente di assicurare che almeno un membro dell'acting set conterrà un record di tutte le operazioni di scrittura riconosciute dall'ultima operazione di peering riuscita.
Tramite un record accurato delle operazioni di scrittura riconosciute, Ceph è in grado di creare e ampliare una nuova cronologia autorevole del gruppo di posizionamento, un set di operazioni completo e in corretta sequenza che, se eseguito, consente di aggiornare la copia dell'OSD di un gruppo di posizionamento.
- ACTIVE
Quando Ceph completa il processo di peering, il gruppo di posizionamento può passare allo stato
active. Lo statoactiveindica che i dati nel gruppo di posizionamento sono di norma disponibili all'interno del gruppo di posizionamento primario e nelle repliche delle operazioni di lettura e scrittura.- CLEAN
Quando un gruppo di posizionamento si trova nello stato
clean, l'OSD primario e gli OSD di replica hanno eseguito correttamente il peering e non sono presenti repliche residue relative al gruppo di posizionamento. Ceph ha eseguito la replica di tutti gli oggetti nel gruppo di posizionamento per il numero corretto di volte.- DEGRADED
Quando un client scrive un oggetto nell'OSD primario, questo è responsabile della scrittura delle repliche sugli OSD di replica. Quando l'OSD primario scrive l'oggetto nello storage, il gruppo di posizionamento rimane nello stato danneggiato ("degraded") finché gli OSD di replica non confermano all'OSD primario la riuscita della creazione degli oggetti di replica da parte di Ceph.
Il motivo per cui un gruppo di posizionamento può avere lo stato "active+degraded" è il fatto che un OSD può essere nello stato "active" anche se non contiene ancora tutti gli oggetti. Se un OSD diventa disattivato, Ceph contrassegna ciascun gruppo di posizionamento assegnato a tale OSD come "degraded". Quando l'OSD ritorna attivo, gli altri OSD devono ripetere il peering. Tuttavia, un client può comunque scrivere un nuovo oggetto in un gruppo di posizionamento danneggiato se si trova nello stato "active".
Se un OSD è nello stato "down" e la condizione "degraded" persiste, Ceph può contrassegnare l'OSD disattivato come esterno al cluster ("out") e rimappare i dati da questo OSD a un altro OSD. L'intervallo di tempo in cui un OSD viene contrassegnato dallo stato "down" a quello "out" è controllato dall'opzione
mon osd down out interval, impostata per default su 600 secondi.Inoltre, un gruppo di posizionamento può trovarsi nello stato "degraded" se Ceph non riesce a trovare uno o più oggetti al suo interno. Sebbene non sia possibile eseguire operazioni di lettura o scrittura sugli oggetti non trovati, sarà comunque possibile accedere a tutti gli altri oggetti nel gruppo di posizionamento nello stato "degraded".
- RECOVERING
Ceph è stato progettato per garantire una tolleranza agli errori su vasta scala in caso di problemi hardware e software. Quando un OSD diventa disattivato, i relativi contenuti potrebbero non essere aggiornati rispetto allo stato corrente delle altre repliche nei gruppi di posizionamento. Quando l'OSD ritorna attivo, i contenuti dei gruppi di posizionamento devono essere aggiornati per riflettere lo stato corrente. Durante questo intervallo di tempo, l'OSD potrebbe riportare lo stato "recovering".
La procedura di recupero non è sempre semplice, perché errori dell'hardware potrebbero causare errori a cascata in più OSD. Ad esempio, potrebbero verificarsi errori su uno switch di rete di un rack o di uno schedario a causa dei quali l'aggiornamento degli OSD di più computer host rispetto allo stato corrente del cluster non va a buon fine. Quando l'errore viene risolto, è necessario recuperare tutti gli OSD.
Ceph fornisce diverse impostazioni per bilanciare il conflitto delle risorse tra le nuove richieste di servizio e la necessità di recuperare gli oggetti dati e ripristinare i gruppi di posizionamento allo stato corrente. L'impostazione
osd recovery delay startconsente a un OSD di riavviarsi, ripetere il peering e persino elaborare alcune richieste di riproduzione prima di avviare il processo di recupero. L'impostazioneosd recovery thread timeoutconsente di impostare un timeout del thread, poiché più OSD potrebbero generare errori, riavviarsi e ripetere il peering a frequenza sfalsata. L'impostazioneosd recovery max activeconsente di limitare il numero di richieste di recupero che verranno elaborate contemporaneamente da un OSD per impedire errori di gestione delle richieste su tale OSD. L'impostazioneosd recovery max chunkconsente di limitare le dimensioni delle porzioni di dati recuperate per evitare un traffico eccessivo sulla rete.- BACK FILLING
Se viene aggiunto un nuovo OSD al cluster, CRUSH riassegnerà i gruppi di posizionamento dagli OSD già nel cluster a quello appena aggiunto. Se si forza il nuovo OSD ad accettare immediatamente i gruppi di posizionamento riassegnati, si può generare un carico eccessivo su quest'ultimo. Tramite il backfill dell'OSD con i gruppi di posizionamento, è possibile avviare questa procedura in background. Al completamento del backfill, il nuovo OSD inizierà a provvedere alle richieste quando sarà pronto.
Durante le operazioni di backfill, potrebbero essere visualizzati diversi stati: "backfill_wait" indica che un'operazione di backfill è in sospeso, ma non ancora in corso; "backfill" indica che un'operazione di backfill è in corso; "backfill_too_full" indica che un'operazione di backfill è stata richiesta, ma non è stato possibile completarla perché la capacità di storage è insufficiente. Se non è possibile eseguire il backfill di un gruppo di posizionamento, questo potrebbe essere considerato come incompleto ("incomplete").
In Ceph sono disponibili diverse impostazioni per la gestione del carico associato alla riassegnazione dei gruppi di posizionamento a un OSD (soprattutto ai nuovi OSD). Per default,
osd max backfillsconsente di impostare su 10 il numero massimo di operazioni di backfill simultanee verso o da un OSD. Conbackfill full ratioun OSD può rifiutare una richiesta di backfill se sta raggiungendo la percentuale di riempimento (90% per default) e apportare modifiche con il comandoceph osd set-backfillfull-ratio. Se un OSD rifiuta una richiesta di backfill, tramiteosd backfill retry intervall'OSD può ripetere la richiesta (per default dopo 10 secondi). Gli OSD possono inoltre impostare i valoriosd backfill scan mineosd backfill scan maxper gestire gli intervalli di scansione (impostati su 64 e 512 per default).- REMAPPED
Se l'acting set che gestisce un gruppo di posizionamento cambia, viene eseguita la migrazione dei dati dall'acting set precedente all'acting set nuovo. La gestione delle richieste da parte del nuovo OSD primario può richiedere del tempo. Il processo potrebbe quindi chiedere al precedente OSD primario di continuare a provvedere alle richieste fino al completamento della migrazione del gruppo di posizionamento. Al termine della migrazione dei dati, la mappatura utilizza l'OSD primario del nuovo acting set.
- STALE
Mentre Ceph utilizza gli heartbeat per verificare che gli host e i daemon siano in esecuzione, i daemon
ceph-osdpossono passare anche allo stato "stuck" e non segnalare statistiche in modo puntuale (ad esempio, in caso di un errore di rete temporaneo). Per default, i daemon OSD segnalano il relativo gruppo di posizionamento e le statistiche di avvio ed errori ogni mezzo secondo (0,5), ovvero con maggiore frequenza rispetto alle soglie di heartbeat. Se l'OSD primario dell'acting set di un gruppo di posizionamento non riesce a inviare segnalazioni al monitor o se gli altri OSD hanno segnalato l'OSD primario come disattivato, i monitor contrassegneranno il gruppo di posizionamento come inattivo ("stale").All'avvio del cluster, è normale visualizzare lo stato "stale" fino al completamento del processo di peering. Se il cluster è in esecuzione da un po' di tempo ma i gruppi di posizionamento continuano a essere nello stato "stale", vuol dire che l'OSD primario di tali gruppi di posizionamento è disattivato o non segnala al cluster monitoraggio le statistiche relative al gruppo.
12.9.5 Individuazione dell'ubicazione di un oggetto #
Per memorizzare i dati oggetto nel Ceph Object Store, il client Ceph deve impostare un nome oggetto e specificare un pool correlato. Il client Ceph recupera la mappa del cluster più recente, mentre l'algoritmo CRUSH calcola in che modo mappare l'oggetto a un gruppo di posizionamento e in che modo assegnare tale gruppo in modo dinamico a un OSD. Per individuare l'ubicazione dell'oggetto, servono solo il nome dell'oggetto e quello del pool. Esempio:
cephuser@adm > ceph osd map POOL_NAME OBJECT_NAME [NAMESPACE]
Procedere con la creazione di un oggetto di esempio. Specificare il nome oggetto "test-object-1", il percorso di un file di esempio "testfile.txt" contenente alcuni dati oggetto e il nome pool "data" tramite il comando rados put nella riga di comando:
cephuser@adm > rados put test-object-1 testfile.txt --pool=dataPer verificare che Ceph Object Store abbia memorizzato l'oggetto, eseguire quanto riportato di seguito:
cephuser@adm > rados -p data lsAdesso, individuare l'ubicazione dell'oggetto. L'output restituito da Ceph sarà l'ubicazione dell'oggetto:
cephuser@adm > ceph osd map data test-object-1
osdmap e537 pool 'data' (0) object 'test-object-1' -> pg 0.d1743484 \
(0.4) -> up ([1,0], p0) acting ([1,0], p0)
Per rimuovere l'oggetto di esempio, basta eliminarlo tramite il comando rados rm:
cephuser@adm > rados rm test-object-1 --pool=data13 Task operativi #
13.1 Modifica della configurazione del cluster #
Per modificare la configurazione di un cluster Ceph esistente, seguire la procedura indicata di seguito:
Esportare la configurazione attuale del cluster in un file:
cephuser@adm >ceph orch ls --export --format yaml > cluster.yamlModificare il file con la configurazione e aggiornare le righe pertinenti. In Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm” e nella Sezione 13.4.3, «Aggiunta di OSD tramite la specifica dei DriveGroups» sono disponibili esempi sulle specifiche.
Applicare la nuova configurazione:
cephuser@adm >ceph orch apply -i cluster.yaml
13.2 Aggiunta di nodi #
Per aggiungere un nuovo nodo a un cluster Ceph, seguire la procedura indicata di seguito:
Installare SUSE Linux Enterprise Server e SUSE Enterprise Storage sul nuovo host. Per ulteriori informazioni consultare Book “Guida alla distribuzione”, Chapter 5 “Installazione e configurazione di SUSE Linux Enterprise Server”.
Configurare l'host come Salt Minion di un Salt Master già esistente. Per ulteriori informazioni consultare Book “Guida alla distribuzione”, Chapter 6 “Distribuzione Salt”.
Aggiungere il nuovo host a
ceph-salte renderlo riconoscibile da cephadm, ad esempio:root@master #ceph-salt config /ceph_cluster/minions add ses-min5.example.comroot@master #ceph-salt config /ceph_cluster/roles/cephadm add ses-min5.example.comPer ulteriori informazioni consultare Book “Guida alla distribuzione”, Chapter 7 “Distribuzione del cluster di bootstrap mediante
ceph-salt”, Section 7.2.2 “Aggiunta di Salt Minion”.Verificare che il nodo sia stato aggiunto a
ceph-salt:root@master #ceph-salt config /ceph_cluster/minions ls o- minions ................................................. [Minions: 5] [...] o- ses-min5.example.com .................................... [no roles]Applicare la configurazione al nuovo host del cluster:
root@master #ceph-salt apply ses-min5.example.comVerificare che l'host appena aggiunto appartenga all'ambiente cephadm:
cephuser@adm >ceph orch host ls HOST ADDR LABELS STATUS [...] ses-min5.example.com ses-min5.example.com
13.3 Rimozione di nodi #
Se sul nodo da rimuovere sono in esecuzione degli OSD, rimuovere innanzitutto questi ultimi dal nodo e verificare che non ne siano rimasti altri in esecuzione. Per ulteriori dettagli sulla rimozione degli OSD, fare riferimento alla Sezione 13.4.4, «Rimozione degli OSD».
Per rimuovere un nodo da un cluster, procedere come segue:
Per tutti i tipi di servizio Ceph, ad eccezione di
node-exporterecrash, rimuovere il nome host del nodo dal file della specifica del posizionamento del cluster (ad esempiocluster.yml). Per ulteriori dettagli, fare riferimento a Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.2 “Specifica del servizio e del posizionamento”. Ad esempio, se si sta rimuovendo l'host denominatoses-min2, rimuovere tutte le occorrenze dises-min-2da tutte le sezioniplacement::Aggiornare
service_type: rgw service_id: EXAMPLE_NFS placement: hosts: - ses-min2 - ses-min3
in
service_type: rgw service_id: EXAMPLE_NFS placement: hosts: - ses-min3
Applicare le modifiche al file di configurazione:
cephuser@adm >ceph orch apply -i rgw-example.yamlRimuovere il nodo dall'ambiente cephadm:
cephuser@adm >ceph orch host rm ses-min2Se sul nodo sono in esecuzione i servizi
crash.osd.1ecrash.osd.2, rimuoverli eseguendo il comando seguente sull'host:root@minion >cephadm rm-daemon --fsid CLUSTER_ID --name SERVICE_NAMEEsempio:
root@minion >cephadm rm-daemon --fsid b4b30c6e... --name crash.osd.1root@minion >cephadm rm-daemon --fsid b4b30c6e... --name crash.osd.2Rimuovere tutti i ruoli dal minion che si desidera eliminare:
cephuser@adm >ceph-salt config /ceph_cluster/roles/tuned/throughput remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/tuned/latency remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/cephadm remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/admin remove ses-min2Se il minion che si desidera rimuovere è il minion di bootstrap, è necessario rimuovere anche il ruolo di bootstrap:
cephuser@adm >ceph-salt config /ceph_cluster/roles/bootstrap resetIn seguito alla rimozione di tutti gli OSD su un singolo host, rimuovere l'host dalla mappa CRUSH:
cephuser@adm >ceph osd crush remove bucket-nameNotaIl nome del compartimento deve coincidere con il nome host.
Adesso, è possibile rimuovere il minion dal cluster:
cephuser@adm >ceph-salt config /ceph_cluster/minions remove ses-min2
In caso di errore e se il minion che si sta tentando di rimuovere è nello stato di disattivazione permanente, sarà necessario rimuovere il nodo dal Salt Master:
root@master # salt-key -d minion_id
Quindi, rimuovere manualmente il nodo da pillar_root/ceph-salt.sls. In genere, questo si trova in /srv/pillar/ceph-salt.sls.
13.4 Gestione degli OSD #
Questa sezione descrive come aggiungere, cancellare o rimuovere gli OSD in un cluster Ceph.
13.4.1 Elenco dei dispositivi disco #
Per identificare i dispositivi disco utilizzati e non utilizzati su tutti i nodi del cluster, elencarli eseguendo il comando seguente:
cephuser@adm > ceph orch device ls
HOST PATH TYPE SIZE DEVICE AVAIL REJECT REASONS
ses-master /dev/vda hdd 42.0G False locked
ses-min1 /dev/vda hdd 42.0G False locked
ses-min1 /dev/vdb hdd 8192M 387836 False locked, LVM detected, Insufficient space (<5GB) on vgs
ses-min2 /dev/vdc hdd 8192M 450575 True13.4.2 Cancellazione dei dispositivi disco #
Per riutilizzare un dispositivo disco, è necessario innanzitutto cancellarlo (o rimuoverlo con zap):
ceph orch device zap HOST_NAME DISK_DEVICE
Esempio:
cephuser@adm > ceph orch device zap ses-min2 /dev/vdc
Se in precedenza l'utente ha distribuito gli OSD tramite i DriveGroups o l'opzione --all-available-devices mentre il flag unmanaged non era impostato, cephadm distribuirà automaticamente questi OSD in seguito alla loro cancellazione.
13.4.3 Aggiunta di OSD tramite la specifica dei DriveGroups #
I DriveGroups specificano i layout degli OSD nel cluster Ceph. Questi ultimi vengono definiti in un singolo file YAML. In questa sezione, verrà utilizzato drive_groups.yml come esempio.
L'amministratore deve specificare manualmente un gruppo di OSD correlati tra di loro (OSD ibridi distribuiti su unità HDD e SDD) o condividere le stesse opzioni di distribuzione (ad esempio lo stesso archivio dati, la stessa opzione di cifratura, gli stessi OSD stand-alone). Per evitare di elencare esplicitamente i dispositivi, i DriveGroups utilizzano un elenco di elementi di filtro che corrispondono ad alcuni campi selezionati dei rapporti di archivio di ceph-volume. In cephadm è fornito un codice che traduce tali DriveGroups in elenchi di dispositivi effettivi che l'utente potrà esaminare.
Il comando da eseguire per applicare la specifica OSD al cluster è:
cephuser@adm >ceph orch apply osd -idrive_groups.yml
Per visualizzare un'anteprima delle azioni e testare l'applicazione, è possibile utilizzare l'opzione --dry-run insieme al comando ceph orch apply osd. Esempio:
cephuser@adm >ceph orch apply osd -idrive_groups.yml--dry-run ... +---------+------+------+----------+----+-----+ |SERVICE |NAME |HOST |DATA |DB |WAL | +---------+------+------+----------+----+-----+ |osd |test |mgr0 |/dev/sda |- |- | |osd |test |mgr0 |/dev/sdb |- |- | +---------+------+------+----------+----+-----+
Se l'output di --dry-run soddisfa le aspettative, eseguire nuovamente il comando senza l'opzione --dry-run.
13.4.3.1 OSD non gestiti #
Tutti i dispositivi disco puliti disponibili corrispondenti alla specifica dei DriveGroups verranno utilizzati automaticamente come OSD dopo essere stati aggiunti al cluster. Per descrivere questo comportamento si parla di modalità gestita.
Per disabilitare la modalità gestita, aggiungere la riga unmanaged: true alle specifiche pertinenti, ad esempio:
service_type: osd service_id: example_drvgrp_name placement: hosts: - ses-min2 - ses-min3 encrypted: true unmanaged: true
Per modificare gli OSD già distribuiti dalla modalità gestita a quella non gestita, aggiungere le righe unmanaged: true dove applicabile durante la procedura descritta nella Sezione 13.1, «Modifica della configurazione del cluster».
13.4.3.2 Specifica dei DriveGroups #
Di seguito è riportato un file della specifica dei DriveGroups di esempio:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: drive_spec: DEVICE_SPECIFICATION db_devices: drive_spec: DEVICE_SPECIFICATION wal_devices: drive_spec: DEVICE_SPECIFICATION block_wal_size: '5G' # (optional, unit suffixes permitted) block_db_size: '5G' # (optional, unit suffixes permitted) encrypted: true # 'True' or 'False' (defaults to 'False')
L'opzione precedentemente chiamata "encryption" in DeepSea adesso si chiama "encrypted". Quando si applicano i DriveGroups in SUSE Enterprise Storage 7, assicurarsi di utilizzare questa nuova terminologia nella specifica del servizio, altrimenti ceph orch apply genererà un errore.
13.4.3.3 Creazione di corrispondenze dei dispositivi disco #
È possibile descrivere la specifica tramite i filtri seguenti:
In base al modello di disco:
model: DISK_MODEL_STRING
In base al produttore del disco:
vendor: DISK_VENDOR_STRING
SuggerimentoUtilizzare sempre caratteri minuscoli quando si immette il valore DISK_VENDOR_STRING.
Per ottenere dettagli sul produttore e il modello del disco, esaminare l'output del comando seguente:
cephuser@adm >ceph orch device ls HOST PATH TYPE SIZE DEVICE_ID MODEL VENDOR ses-min1 /dev/sdb ssd 29.8G SATA_SSD_AF34075704240015 SATA SSD ATA ses-min2 /dev/sda ssd 223G Micron_5200_MTFDDAK240TDN Micron_5200_MTFD ATA [...]Per indicare se si tratta di un disco rotativo o meno. Le unità SSD e NVME non sono rotative.
rotational: 0
Per distribuire un nodo utilizzando tutte le unità disponibili per gli OSD:
data_devices: all: true
Inoltre, tramite la limitazione del numero di dischi corrispondenti:
limit: 10
13.4.3.4 Aggiunta di filtri ai dispositivi in base alle dimensioni #
È possibile filtrare i dispositivi disco in base alle dimensioni (valore esatto o intervallo di dimensioni). Il parametro size: accetta gli argomenti nel formato seguente:
"10G" - include i dischi di dimensioni esatte.
"10G:40G" - include i dischi di dimensioni comprese nell'intervallo.
":10G" - include i dischi di dimensioni inferiori o uguali a 10 GB.
"40G" - include i dischi di dimensioni uguali o superiori a 40 GB.
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: size: '40TB:' db_devices: size: ':2TB'
Quando si utilizza il delimitatore ":", occorre racchiudere le dimensioni tra virgolette altrimenti il simbolo ":" verrà interpretato come un nuovo hash di configurazione.
Al posto di Gigabyte (G), è possibile specificare le dimensioni in Megabyte (M) o Terabyte (T).
13.4.3.5 Esempi di DriveGroups #
Questa sezione include esempi di diverse configurazioni OSD.
Questo esempio descrive due nodi con la stessa configurazione:
20 HDD
Produttore: Intel
Modello: SSD-123-foo
Dimensioni: 4 TB
2 SSD
Produttore: Micron
Modello: MC-55-44-ZX
Dimensioni: 512 GB
Il file drive_groups.yml corrispondente avrà l'aspetto seguente:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: model: SSD-123-foo db_devices: model: MC-55-44-XZ
Tale configurazione è semplice e valida. Tuttavia, in futuro un amministratore può aggiungere dischi di altri produttori che non verranno inclusi. È possibile ovviare a questo problema riducendo i filtri sulle proprietà di base delle unità:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: rotational: 1 db_devices: rotational: 0
Nell'esempio precedente, viene forzata la dichiarazione di tutti i dispositivi a rotazione come "dispositivi di dati" e tutti i dispositivi non a rotazione verranno utilizzati come "dispositivi condivisi" (wal, db).
Presupponendo che le unità di più di 2 TB saranno sempre i dispositivi di dati più lenti, è possibile applicare dei filtri in base alle dimensioni:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: size: '2TB:' db_devices: size: ':2TB'
Questo esempio descrive due configurazioni diverse: 20 HDD devono condividere 2 SSD, mentre 10 SSD devono condividere 2 NVMe.
20 HDD
Produttore: Intel
Modello: SSD-123-foo
Dimensioni: 4 TB
12 SSD
Produttore: Micron
Modello: MC-55-44-ZX
Dimensioni: 512 GB
2 NVMe
Produttore: Samsung
Modello: NVME-QQQQ-987
Dimensioni: 256 GB
È possibile definire tale configurazione con due layout come segue:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: MC-55-44-XZ
service_type: osd service_id: example_drvgrp_name2 placement: host_pattern: '*' data_devices: model: MC-55-44-XZ db_devices: vendor: samsung size: 256GB
Gli esempi precedenti sono basati sul presupposto che tutti i nodi dispongano delle stesse unità. Tuttavia, non è sempre questo il caso:
Nodi da 1 a 5:
20 HDD
Produttore: Intel
Modello: SSD-123-foo
Dimensioni: 4 TB
2 SSD
Produttore: Micron
Modello: MC-55-44-ZX
Dimensioni: 512 GB
Nodi da 6 a 10:
5 NVMe
Produttore: Intel
Modello: SSD-123-foo
Dimensioni: 4 TB
20 SSD
Produttore: Micron
Modello: MC-55-44-ZX
Dimensioni: 512 GB
È possibile utilizzare la chiave "target" nel layout per indirizzare nodi specifici. La notazione della destinazione Salt consente di non complicare la configurazione:
service_type: osd service_id: example_drvgrp_one2five placement: host_pattern: 'node[1-5]' data_devices: rotational: 1 db_devices: rotational: 0
seguito da
service_type: osd service_id: example_drvgrp_rest placement: host_pattern: 'node[6-10]' data_devices: model: MC-55-44-XZ db_devices: model: SSD-123-foo
In tutti i casi descritti in precedenza si presupponeva che i WAL e i DB utilizzassero lo stesso dispositivo. È tuttavia possibile anche distribuire i WAL su un dispositivo dedicato:
20 HDD
Produttore: Intel
Modello: SSD-123-foo
Dimensioni: 4 TB
2 SSD
Produttore: Micron
Modello: MC-55-44-ZX
Dimensioni: 512 GB
2 NVMe
Produttore: Samsung
Modello: NVME-QQQQ-987
Dimensioni: 256 GB
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: model: MC-55-44-XZ db_devices: model: SSD-123-foo wal_devices: model: NVME-QQQQ-987
Nella configurazione seguente, si tenterà di definire:
20 HDD supportati da 1 NVMe
2 HDD supportati da 1 SSD (db) e 1 NVMe (wal)
8 SSD supportati da 1 NVMe
2 SSD stand-alone (cifrati)
1 HDD è di riserva e non deve essere distribuito.
Di seguito è riportato il riepilogo delle unità utilizzate:
23 HDD
Produttore: Intel
Modello: SSD-123-foo
Dimensioni: 4 TB
10 SSD
Produttore: Micron
Modello: MC-55-44-ZX
Dimensioni: 512 GB
1 NVMe
Produttore: Samsung
Modello: NVME-QQQQ-987
Dimensioni: 256 GB
La definizione dei DriveGroups sarà la seguente:
service_type: osd service_id: example_drvgrp_hdd_nvme placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_hdd_ssd_nvme placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: MC-55-44-XZ wal_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_ssd_nvme placement: host_pattern: '*' data_devices: model: SSD-123-foo db_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_standalone_encrypted placement: host_pattern: '*' data_devices: model: SSD-123-foo encrypted: True
Rimarrà un'unità HDD, poiché il file viene analizzato dall'alto verso il basso.
13.4.4 Rimozione degli OSD #
Prima di rimuovere un nodo OSD dal cluster, verificare che lo spazio su disco disponibile sul cluster sia maggiore del disco OSD che verrà rimosso. Tenere presente che la rimozione di un OSD comporta il ribilanciamento dell'intero cluster.
Identificare l'OSD da rimuovere recuperandone l'ID:
cephuser@adm >ceph orch ps --daemon_type osd NAME HOST STATUS REFRESHED AGE VERSION osd.0 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.1 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.2 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.3 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ...Rimuovere uno o più OSD dal cluster:
cephuser@adm >ceph orch osd rm OSD1_ID OSD2_ID ...Esempio:
cephuser@adm >ceph orch osd rm 1 2È possibile interrogare lo stato dell'operazione di rimozione:
cephuser@adm >ceph orch osd rm status OSD_ID HOST STATE PG_COUNT REPLACE FORCE STARTED_AT 2 cephadm-dev done, waiting for purge 0 True False 2020-07-17 13:01:43.147684 3 cephadm-dev draining 17 False True 2020-07-17 13:01:45.162158 4 cephadm-dev started 42 False True 2020-07-17 13:01:45.162158
13.4.4.1 Interruzione della rimozione dell'OSD #
Se necessario, è possibile interrompere la rimozione di OSD dopo averla pianificata. Il comando seguente reimposterà lo stato iniziale dell'OSD e lo rimuoverà dalla coda:
cephuser@adm > ceph orch osd rm stop OSD_SERVICE_ID13.4.5 Sostituzione degli OSD #
Potrebbe essere necessario sostituire un disco OSD per diverse ragioni. Ad esempio:
Si sono verificati o si verificheranno a breve errori sul disco OSD in base alle informazioni SMART e il disco non può più essere utilizzato per memorizzare i dati in modo sicuro.
È necessario eseguire l'upgrade del disco OSD, ad esempio per aumentarne le dimensioni.
È necessario modificare il layout del disco OSD.
Si prevede di passare da un layout non LVM a un layout basato su LVM.
Per sostituire un OSD conservandone l'ID, eseguire:
cephuser@adm > ceph orch osd rm OSD_SERVICE_ID --replaceEsempio:
cephuser@adm > ceph orch osd rm 4 --replace
La procedura per la sostituzione di un OSD è identica a quella per la rimozione (vedere la Sezione 13.4.4, «Rimozione degli OSD» per ulteriori dettagli) con l'eccezione che l'OSD non viene rimosso definitivamente dalla gerarchia CRUSH e gli viene invece assegnato un flag destroyed.
Il flag destroyed è utilizzato per determinare gli ID degli OSD che verranno riutilizzati durante la successiva distribuzione degli OSD. Ai dischi appena aggiunti corrispondenti alla specifica dei DriveGroups (vedere la Sezione 13.4.3, «Aggiunta di OSD tramite la specifica dei DriveGroups» per ulteriori dettagli) verranno assegnati gli ID degli OSD della controparte corrispondente sostituita.
Aggiungendo l'opzione --dry-run, non verrà eseguita la sostituzione effettiva, ma verrà visualizzata in anteprima la procedura prevista.
In caso di sostituzione di un OSD dopo un errore, si consiglia vivamente di attivare una pulitura approfondita dei gruppi di posizionamento. Per ulteriori dettagli, vedere la Sezione 17.6, «Pulitura dei gruppi di posizionamento».
Per avviare una pulitura approfondita, eseguire il seguente comando:
cephuser@adm > ceph osd deep-scrub osd.OSD_NUMBERIn caso di errore di un dispositivo condiviso per DB/WAL, eseguire la procedura di sostituzione per tutti gli OSD che condividono il dispositivo in errore.
13.5 Trasferimento del Salt Master a un nuovo nodo #
Se è necessario sostituire l'host del Salt Master con uno nuovo, seguire la procedura indicata di seguito:
Esportare la configurazione del cluster ed eseguire il backup del file JSON esportato. Ulteriori dettagli sono disponibili nel Book “Guida alla distribuzione”, Chapter 7 “Distribuzione del cluster di bootstrap mediante
ceph-salt”, Section 7.2.14 “Esportazione delle configurazioni del cluster”.Se il Salt Master precedente è anche l'unico nodo di amministrazione nel cluster, spostare manualmente
/etc/ceph/ceph.client.admin.keyringe/etc/ceph/ceph.confnel nuovo Salt Master.Interrompere e disabilitare il servizio
systemddel Salt Master sul nodo del Salt Master precedente:root@master #systemctl stop salt-master.serviceroot@master #systemctl disable salt-master.serviceSe il nodo del Salt Master precedente non è più presente nel cluster, interrompere e disabilitare anche il servizio
systemddel Salt Minion:root@master #systemctl stop salt-minion.serviceroot@master #systemctl disable salt-minion.serviceAvvertimentoNon interrompere o disabilitare
salt-minion.servicese sul nodo del Salt Master precedente sono presenti daemon Ceph (MON, MGR, OSD, MDS, gateway, monitoraggio) in esecuzione.Installare SUSE Linux Enterprise Server 15 SP3 sul nuovo Salt Master seguendo la procedura descritta in Book “Guida alla distribuzione”, Chapter 5 “Installazione e configurazione di SUSE Linux Enterprise Server”.
Suggerimento: transizione del Salt MinionPer semplificare la transizione dei Salt Minion sul nuovo Salt Master, rimuovere la chiave pubblica originale del Salt Master da ciascuno di questi:
root@minion >rm /etc/salt/pki/minion/minion_master.pubroot@minion >systemctl restart salt-minion.serviceInstallare il pacchetto salt-master ed eventualmente il pacchetto salt-minion sul nuovo Salt Master.
Installare
ceph-saltsul nuovo nodo del Salt Master:root@master #zypper install ceph-saltroot@master #systemctl restart salt-master.serviceroot@master #salt '*' saltutil.sync_allImportanteAssicurarsi di eseguire tutti i tre comandi prima di continuare. I comandi sono idempotenti; non importa se vengono ripetuti.
Includere il nuovo Salt Master nel cluster come descritto in Book “Guida alla distribuzione”, Chapter 7 “Distribuzione del cluster di bootstrap mediante
ceph-salt”, Section 7.1 “Installazioneceph-salt”, Book “Guida alla distribuzione”, Chapter 7 “Distribuzione del cluster di bootstrap medianteceph-salt”, Section 7.2.2 “Aggiunta di Salt Minion” e Book “Guida alla distribuzione”, Chapter 7 “Distribuzione del cluster di bootstrap medianteceph-salt”, Section 7.2.4 “Specifica del nodo admin”.Importare la configurazione del cluster sottoposta a backup e applicarla:
root@master #ceph-salt import CLUSTER_CONFIG.jsonroot@master #ceph-salt applyImportanteRinominare il
minion iddel Salt Master nel fileCLUSTER_CONFIG.jsonesportato prima di importarlo.
13.6 Aggiornamento dei nodi del cluster #
Mantenere i nodi del cluster Ceph aggiornati applicando regolarmente gli aggiornamenti in sequenza.
13.6.1 Archivi software #
Prima di applicare le patch al cluster con i pacchetti software più recenti, verificare che tutti i nodi del cluster dispongano dell'accesso agli archivi pertinenti. Per un elenco completo degli archivi obbligatori, consultare questo riferimento: Book “Guida alla distribuzione”, Chapter 10 “Upgrade da SUSE Enterprise Storage 6 a 7.1”, Section 10.1.5.1 “Archivi software”.
13.6.2 Gestione provvisoria dell'archivio #
Se si utilizza uno strumento di gestione provvisoria, ad esempio SUSE Manager, Subscription Management Tool o RMT, tramite cui implementare gli archivi software sui nodi del cluster, verificare che le fasi degli archivi "Updates" di SUSE Linux Enterprise Server e SUSE Enterprise Storage vengano create nello stesso momento.
Si consiglia di utilizzare uno strumento di gestione temporanea per l'applicazione di patch con livelli di patch frozen o staged. In questo modo, sarà possibile assicurarsi che i nuovi nodi uniti al cluster dispongano dello stesso livello di patch dei nodi già in esecuzione al suo interno. Questo evita di dover applicare le patch più recenti a tutti i nodi del cluster prima che i nuovi nodi possano unirsi a quest'ultimo.
13.6.3 Tempo di fermo dei servizi Ceph #
A seconda della configurazione, i nodi del cluster potrebbero essere riavviati durante l'aggiornamento. Se è presente un single point of failure per servizi come Object Gateway, gateway Samba, NFS Ganesha o iSCSI, i computer del client potrebbero essere temporaneamente disconnessi dai servizi i cui nodi sono in corso di riavvio.
13.6.4 Esecuzione dell'aggiornamento #
Per aggiornare i pacchetti software su tutti i nodi del cluster alla versione più recente, eseguire il comando seguente:
root@master # ceph-salt update13.7 Aggiornamento di Ceph #
È possibile inviare a cephadm l'istruzione di aggiornare Ceph da una release di correzione di bug all'altra. L'aggiornamento automatico dei servizi Ceph rispetta l'ordine consigliato: inizia con i Ceph Manager, i Ceph Monitor e quindi continua sugli altri servizi, come Ceph OSD, Metadata Server e Object Gateway. Ogni daemon viene riavviato solo dopo che Ceph indica che il cluster resterà disponibile.
Nel processo di aggiornamento riportato di seguito è utilizzato il comando ceph orch upgrade. Tenere presente che le istruzioni seguenti illustrano come aggiornare il cluster Ceph con una versione del prodotto (ad esempio, un aggiornamento di manutenzione) e non spiegano come eseguire l'upgrade del cluster da una versione del prodotto all'altra.
13.7.1 Avvio dell'aggiornamento #
Prima di avviare l'aggiornamento, verificare che tutti i nodi siano online e che il cluster sia integro:
cephuser@adm > cephadm shell -- ceph -sPer eseguire l'aggiornamento a una release Ceph specifica:
cephuser@adm > ceph orch upgrade start --image REGISTRY_URLEsempio:
cephuser@adm > ceph orch upgrade start --image registry.suse.com/ses/7.1/ceph/ceph:latestEseguire l'upgrade dei pacchetti sugli host:
cephuser@adm > ceph-salt update13.7.2 Monitoraggio dell'aggiornamento #
Eseguire il comando seguente per determinare se è in corso un aggiornamento:
cephuser@adm > ceph orch upgrade statusMentre l'aggiornamento è in corso, nell'output dello stato di Ceph verrà visualizzata una barra di avanzamento:
cephuser@adm > ceph -s
[...]
progress:
Upgrade to registry.suse.com/ses/7.1/ceph/ceph:latest (00h 20m 12s)
[=======.....................] (time remaining: 01h 43m 31s)È inoltre possibile visualizzare il log cephadm:
cephuser@adm > ceph -W cephadm13.7.3 Annullamento dell'aggiornamento #
È possibile interrompere il processo di aggiornamento in qualsiasi momento:
cephuser@adm > ceph orch upgrade stop13.8 Interruzione o riavvio del cluster #
In alcuni casi può essere necessario interrompere o riavviare l'intero cluster. Si consiglia di verificare attentamente le dipendenze dei servizi in esecuzione. Nei passaggi successivi è descritto come interrompere e avviare il cluster:
Indicare al cluster Ceph di impostare il flag noout:
cephuser@adm >cephosd set nooutInterrompere daemon e nodi nel seguente ordine:
Client di memorizzazione
Gateway, ad esempio NFS Ganesha o Object Gateway
Metadata Server
Ceph OSD
Ceph Manager
Ceph Monitor
Se necessario, eseguire task di manutenzione.
Avviare nodi e server in ordine inverso rispetto al processo di spegnimento:
Ceph Monitor
Ceph Manager
Ceph OSD
Metadata Server
Gateway, ad esempio NFS Ganesha o Object Gateway
Client di memorizzazione
Rimuovere il flag noout:
cephuser@adm >cephosd unset noout
13.9 Rimozione dell'intero cluster Ceph #
Il comando ceph-salt purge consente di rimuovere l'intero cluster Ceph. Se sono stati distribuiti altri cluster Ceph, viene eliminato definitivamente quello segnalato da ceph -s. In questo modo è possibile pulire l'ambiente del cluster durante il test di diverse configurazioni.
Per evitare eliminazioni involontarie, lo strumento di coordinamento controlla se le misure di sicurezza sono disattivate. È possibile disattivare le misure di sicurezza e rimuovere il cluster Ceph eseguendo:
root@master #ceph-salt disengage-safetyroot@master #ceph-salt purge
14 Funzionamento dei servizi Ceph #
È possibile utilizzare i servizi Ceph a livello di daemon, nodo o cluster. A seconda dell'approccio richiesto, utilizzare cephadm o il comando systemctl.
14.1 Attivazione dei servizi singoli #
Se è necessario utilizzare un singolo servizio, per prima cosa individuarlo:
cephuser@adm > ceph orch ps
NAME HOST STATUS REFRESHED [...]
mds.my_cephfs.ses-min1.oterul ses-min1 running (5d) 8m ago
mgr.ses-min1.gpijpm ses-min1 running (5d) 8m ago
mgr.ses-min2.oopvyh ses-min2 running (5d) 8m ago
mon.ses-min1 ses-min1 running (5d) 8m ago
mon.ses-min2 ses-min2 running (5d) 8m ago
mon.ses-min4 ses-min4 running (5d) 7m ago
osd.0 ses-min2 running (61m) 8m ago
osd.1 ses-min3 running (61m) 7m ago
osd.2 ses-min4 running (61m) 7m ago
rgw.myrealm.myzone.ses-min1.kwwazo ses-min1 running (5d) 8m ago
rgw.myrealm.myzone.ses-min2.jngabw ses-min2 error 8m agoPer identificare un servizio su un nodo specifico, eseguire:
ceph orch ps NODE_HOST_NAME
Esempio:
cephuser@adm > ceph orch ps ses-min2
NAME HOST STATUS REFRESHED
mgr.ses-min2.oopvyh ses-min2 running (5d) 3m ago
mon.ses-min2 ses-min2 running (5d) 3m ago
osd.0 ses-min2 running (67m) 3m ago
Il comando ceph orch ps supporta diversi formati di output. Per modificare il formato, aggiungere l'opzione --format FORMAT, dove FORMAT indica uno tra i formati json, json-pretty o yaml. Esempio:
cephuser@adm > ceph orch ps --format yamlUna volta individuato il nome del servizio, è possibile avviarlo, riavviarlo o interromperlo:
ceph orch daemon COMMAND SERVICE_NAME
Ad esempio, per riavviare il servizio OSD con l'ID 0, eseguire:
cephuser@adm > ceph orch daemon restart osd.014.2 Attivazione dei tipi di servizio #
Se è necessario utilizzare un tipo di servizio specifico nell'intero cluster Ceph, immettere il comando seguente:
ceph orch COMMAND SERVICE_TYPE
Sostituire COMMAND con start, stop o restart.
Ad esempio, il comando seguente riavvia tutti i MON nel cluster, a prescindere dai nodi su cui sono effettivamente in esecuzione:
cephuser@adm > ceph orch restart mon14.3 Attivazione dei servizi su un singolo nodo #
Tramite il comando systemctl, è possibile utilizzare le destinazioni e i servizi systemd correlati a Ceph su un singolo nodo.
14.3.1 Identificazione di servizi e destinazioni #
Prima di utilizzare le destinazioni e i servizi systemd correlati a Ceph, individuare i nomi di file dei relativi file di unità. I nomi di file dei servizi seguono il modello seguente:
ceph-FSID@SERVICE_TYPE.ID.service
Esempio:
ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@mon.doc-ses-min1.service
ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@rgw.myrealm.myzone.doc-ses-min1.kwwazo.service
- FSID
ID univoco del cluster Ceph. È possibile trovarlo nell'output del comando
ceph fsid.- SERVICE_TYPE
Tipo di servizio, ad esempio
osd,monorgw.- ID
Stringa identificativa del servizio. Per gli OSD, si tratta del numero di ID del servizio. Per gli altri servizi, può corrispondere al nome host del nodo o a stringhe aggiuntive rilevanti per il tipo di servizio.
La porzione SERVICE_TYPE.ID è identica al contenuto della colonna NAME nell'output del comando ceph orch ps.
14.3.2 Attivazione di tutti i servizi su un nodo #
Tramite le destinazioni systemd di Ceph, è possibile utilizzare contemporaneamente tutti i servizi su un nodo oppure tutti i servizi appartenenti a un cluster identificato dal relativo FSID.
Ad esempio, per interrompere tutti i servizi Ceph su un nodo a prescindere dal cluster a cui appartengono, eseguire:
root@minion > systemctl stop ceph.target
Per riavviare tutti i servizi appartenenti a un cluster Ceph con ID b4b30c6e-9681-11ea-ac39-525400d7702d, eseguire:
root@minion > systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d.target14.3.3 Attivazione di un singolo servizio su un nodo #
Dopo aver identificato il nome di un servizio specifico, attivarlo come segue:
systemctl COMMAND SERVICE_NAME
Ad esempio, per riavviare un singolo servizio OSD con ID 1 su un cluster con ID b4b30c6e-9681-11ea-ac39-525400d7702d, eseguire:
# systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@osd.1.service14.3.4 Interrogazione dello stato del servizio #
È possibile interrogare systemd per lo stato dei servizi. Esempio:
# systemctl status ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@osd.0.service14.4 Spegnimento e riavvio dell'intero cluster Ceph #
Se è in programma un'interruzione di corrente, potrebbe essere necessario spegnere e riavviare il cluster. Per interrompere e riavviare senza problemi tutti i servizi correlati a Ceph, seguire la procedura indicata di seguito:
Spegnere o disconnettere i client con accesso al cluster.
Per impedire il ribilanciamento automatico del cluster da parte di CRUSH, impostare il cluster su
noout:cephuser@adm >ceph osd set nooutInterrompere tutti i servizi Ceph su tutti i nodi del cluster:
root@master #ceph-salt stopDisattivare tutti i nodi del cluster:
root@master #salt -G 'ceph-salt:member' cmd.run "shutdown -h"
Attivare il nodo admin.
Attivare i nodi Ceph Monitor.
Attivare i nodi Ceph OSD.
Annullare l'impostazione del flag
nooutconfigurata in precedenza:root@master #ceph osd unset nooutAttivare tutti i gateway configurati.
Attivare o connettere i client del cluster.
15 Backup e ripristino #
Questo capitolo illustra quali parti del cluster Ceph sottoporre a backup per il ripristino della funzionalità.
15.1 Backup della configurazione e dei dati del cluster #
15.1.1 Backup della configurazione ceph-salt #
Esportare la configurazione del cluster. Per ulteriori informazioni, vedere Book “Guida alla distribuzione”, Chapter 7 “Distribuzione del cluster di bootstrap mediante ceph-salt”, Section 7.2.14 “Esportazione delle configurazioni del cluster”.
15.1.2 Backup della configurazione Ceph #
Eseguire il backup della directory /etc/ceph contenente la configurazione fondamentale del cluster. Ad esempio, il backup di /etc/ceph sarà necessario quando occorre sostituire il nodo admin.
15.1.3 Backup della configurazione Salt #
È necessario eseguire il backup della directory /etc/salt contenente i file di configurazione Salt, ad esempio la chiave del Salt Master e le chiavi del client accettate.
I file Salt non sono obbligatori per il backup del nodo admin, ma semplificano la ridistribuzione del cluster Salt. Se il backup di tali file non è presente, minion è necessario registrare nuovamente i Salt minion nel nuovo nodo admin.
Verificare che il backup della chiave privata del Salt Master sia memorizzato in un'ubicazione sicura. La chiave del Salt Master può essere utilizzata per modificare tutti i nodi del cluster.
15.1.4 Backup delle configurazioni personalizzate #
Dati e personalizzazione di Prometheus.
Personalizzazione di Grafana.
Modifiche manuali alla configurazione iSCSI.
Chiavi Ceph.
Mappa CRUSH e regole CRUSH. Salvare la mappa CRUSH non compilata, incluse le regole CRUSH, in
crushmap-backup.txteseguendo il comando seguente:cephuser@adm >ceph osd getcrushmap | crushtool -d - -o crushmap-backup.txtConfigurazione del gateway Samba. Se si utilizza un gateway singolo, eseguire il backup di
/etc/samba/smb.conf. Se si utilizza una configurazione ad elevata disponibilità, eseguire il backup anche dei file di configurazione CTDB e Pacemaker. Fare riferimento al Capitolo 24, Esportazione dei dati Ceph tramite Samba per i dettagli sulla configurazione utilizzata dai gateway Samba.Configurazione di NFS Ganesha. Necessaria soltanto se si utilizza una configurazione ad elevata disponibilità. Fare riferimento al Capitolo 25, NFS Ganesha per i dettagli sulla configurazione utilizzata da NFS Ganesha.
15.2 Ripristino di un nodo Ceph #
Per recuperare un nodo dal backup reinstallare il nodo, sostituire i relativi file di configurazione e riorganizzare il cluster per fare in modo che venga nuovamente aggiunto il nodo di sostituzione.
Se è necessario ridistribuire il nodo admin, fare riferimento alla Sezione 13.5, «Trasferimento del Salt Master a un nuovo nodo».
Per i minion, è in genere più semplice eseguire una nuova ricompilazione e la ridistribuzione.
Reinstallare il nodo. Per ulteriori informazioni, vedere Book “Guida alla distribuzione”, Chapter 5 “Installazione e configurazione di SUSE Linux Enterprise Server”
Installare Salt. Per ulteriori informazioni, vedere Book “Guida alla distribuzione”, Chapter 6 “Distribuzione Salt”.
In seguito al ripristino della directory
/etc/saltdal backup, abilitare e riavviare i servizi Salt applicabili, ad esempio:root@master #systemctlenable salt-masterroot@master #systemctlstart salt-masterroot@master #systemctlenable salt-minionroot@master #systemctlstart salt-minionRimuovere la chiave master pubblica relativa al nodo Salt Master precedente da tutti i minion.
root@master #rm/etc/salt/pki/minion/minion_master.pubroot@master #systemctlrestart salt-minionRipristinare gli elementi locali nel nodo admin.
Importare la configurazione del cluster dal file JSON esportato in precedenza. Per ulteriori dettagli, fare riferimento a Book “Guida alla distribuzione”, Chapter 7 “Distribuzione del cluster di bootstrap mediante
ceph-salt”, Section 7.2.14 “Esportazione delle configurazioni del cluster”.Applicare la configurazione del cluster importata:
root@master #ceph-salt apply
16 Monitoraggio e creazione di avvisi #
In SUSE Enterprise Storage 7.1, cephadm esegue la distribuzione di uno stack di monitoraggio e creazione di avvisi. Gli utenti devono definire i servizi (ad esempio Prometheus, Alertmanager e Grafana) da distribuire con cephadm in un file di configurazione YAML oppure distribuirli tramite l'interfaccia riga di comando. Se sono distribuiti più servizi dello stesso tipo, viene eseguita una configurazione ad elevata disponibilità. L'utilità di esportazione dei nodi rappresenta un'eccezione a questa regola.
Tramite cephadm è possibile distribuire i servizi di monitoraggio seguenti:
Prometheus è il kit di strumenti per la creazione di avvisi e il monitoraggio. Raccoglie i dati forniti dalle utilità di esportazione di Prometheus e genera avvisi preconfigurati se vengono raggiunte delle soglie predefinite.
Alertmanager gestisce gli avvisi inviati dal server Prometheus. Deduplica, raggruppa e instrada gli avvisi al ricevitore corretto. Per default, il Ceph Dashboard sarà configurato automaticamente come ricevitore.
Grafana è il software di visualizzazione e creazione di avvisi. La funzionalità di creazione di avvisi di Grafana non è utilizzata da questo stack di monitoraggio. Per la creazione di avvisi, è utilizzato Alertmanager.
Node exporter è un'utilità di esportazione per Prometheus che fornisce i dati relativi al nodo su cui è installato. Si consiglia di installare questa utilità di esportazione dei nodi su tutti i nodi.
Il modulo Manager di Prometheus fornisce un'utilità di esportazione Prometheus da passare ai contatori delle prestazioni di Ceph dal punto di raccolta in ceph-mgr.
La configurazione di Prometheus, incluse le destinazioni di scrape (daemon che forniscono metriche), viene impostata automaticamente da cephadm. cephadm inoltre distribuisce un elenco di avvisi di default, ad esempio health error, 10% OSDs down o pgs inactive.
Per default, il traffico verso Grafana è cifrato tramite TLS. È possibile specificare un proprio certificato TLS o utilizzarne uno autofirmato. Se prima della distribuzione di Grafana non è stato configurato nessun certificato personalizzato, ne verrà creato e configurato automaticamente uno autofirmato per Grafana.
È possibile configurare i certificati personalizzati per Grafana seguendo la procedura indicata di seguito:
Configurare i file del certificato:
cephuser@adm >ceph config-key set mgr/cephadm/grafana_key -i $PWD/key.pemcephuser@adm >ceph config-key set mgr/cephadm/grafana_crt -i $PWD/certificate.pemRiavviare il servizio Ceph Manager:
cephuser@adm >ceph orch restart mgrRiconfigurare il servizio Grafana in modo che rifletta i nuovi percorsi del certificato e impostare l'URL corretto per Ceph Dashboard:
cephuser@adm >ceph orch reconfig grafana
Alertmanager gestisce gli avvisi inviati dal server Prometheus. Si occupa di deduplicarli, raggrupparli e instradarli al ricevitore corretto. È possibile silenziare gli eventi tramite Alertmanager, ma è possibile gestire i silenziamenti anche dal Ceph Dashboard.
Si consiglia di distribuire l'utilità Node exporter su tutti i nodi. A questo scopo, utilizzare il file monitoring.yaml con il tipo di servizio node-exporter. Per ulteriori informazioni sulla distribuzione dei servizi, vedere Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.3.8 “Distribuzione dello stack di monitoraggio”.
16.1 Configurazione di immagini personalizzate o locali #
Questa sezione descrive come modificare la configurazione delle immagini del container utilizzate durante la distribuzione o l'aggiornamento dei servizi. Non include i comandi da eseguire per la distribuzione o la ridistribuzione dei servizi.
Il metodo consigliato per la distribuzione dello stack di monitoraggio consiste nell'applicarne la specifica come descritto in Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.3.8 “Distribuzione dello stack di monitoraggio”.
Per distribuire le immagini del container personalizzate o locali, è necessario impostare tali immagini in cephadm. A questo scopo, è necessario eseguire il comando seguente:
cephuser@adm > ceph config set mgr mgr/cephadm/OPTION_NAME VALUEDove OPTION_NAME è uno dei nomi seguenti:
container_image_prometheus
container_image_node_exporter
container_image_alertmanager
container_image_grafana
Se non viene impostata alcuna opzione o se l'impostazione è stata rimossa, come VALUE vengono utilizzate le immagini seguenti:
registry.suse.com/ses/7.1/ceph/prometheus-server:2.32.1
registry.suse.com/ses/7.1/ceph/prometheus-node-exporter:1.1.2
registry.suse.com/ses/7.1/ceph/prometheus-alertmanager:0.21.0
registry.suse.com/ses/7.1/ceph/grafana:7.5.12
Esempio:
cephuser@adm > ceph config set mgr mgr/cephadm/container_image_prometheus prom/prometheus:v1.4.1Se viene impostata un'immagine personalizzata, il valore di default verrà sostituito (ma non sovrascritto). Il valore di default cambia quando sono disponibili degli aggiornamenti. Se si imposta un'immagine personalizzata, non sarà possibile aggiornare automaticamente il componente per cui è stata impostata tale immagine. Sarà necessario aggiornare manualmente la configurazione (tag e nome immagine) per poter installare gli aggiornamenti.
Se si sceglie di seguire invece le raccomandazioni, sarà possibile reimpostare l'immagine personalizzata impostata in precedenza. Dopodiché, il valore di default verrà utilizzato nuovamente. Utilizzare ceph config rm per reimpostare l'opzione di configurazione:
cephuser@adm > ceph config rm mgr mgr/cephadm/OPTION_NAMEEsempio:
cephuser@adm > ceph config rm mgr mgr/cephadm/container_image_prometheus16.2 Aggiornamento dei servizi di monitoraggio #
Come accennato nella Sezione 16.1, «Configurazione di immagini personalizzate o locali», cephadm è fornito con gli URL delle immagini del container consigliate e testate, che sono utilizzate per default.
Con l'aggiornamento dei pacchetti Ceph, potrebbero essere disponibili nuove versioni di tali URL. Questo aggiornamento si applica solo alla posizione da cui viene eseguito il pull delle immagini del container e non vale per i servizi.
In seguito all'aggiornamento degli URL delle nuove immagini del container (manualmente come descritto nella Sezione 16.1, «Configurazione di immagini personalizzate o locali» o automaticamente tramite l'aggiornamento del pacchetto Ceph), è possibile aggiornare i servizi di monitoraggio.
A questo scopo, utilizzare ceph orch reconfig nel modo seguente:
cephuser@adm >ceph orch reconfig node-exportercephuser@adm >ceph orch reconfig prometheuscephuser@adm >ceph orch reconfig alertmanagercephuser@adm >ceph orch reconfig grafana
Al momento, non esiste nessun comando singolo che consenta di aggiornare tutti i servizi di monitoraggio. L'ordine in cui i servizi vengono aggiornati non ha importanza.
Se si utilizzano immagini del container personalizzate, gli URL specificati per i servizi di monitoraggio non cambieranno automaticamente se i pacchetti Ceph vengono aggiornati. Se sono state specificate immagini del container personalizzate, sarà necessario immettere manualmente gli URL delle nuove immagini del container. Ad esempio, ciò si applica nel caso in cui si utilizzi un registro del container locale.
Alla Sezione 16.1, «Configurazione di immagini personalizzate o locali», è possibile trovare gli URL delle immagini del container consigliate per l'utilizzo.
16.3 Disabilitazione del monitoraggio #
Per disabilitare lo stack di monitoraggio, eseguire i comandi seguenti:
cephuser@adm >ceph orch rm grafanacephuser@adm >ceph orch rm prometheus --force # this will delete metrics data collected so farcephuser@adm >ceph orch rm node-exportercephuser@adm >ceph orch rm alertmanagercephuser@adm >ceph mgr module disable prometheus
16.4 Configurazione di Grafana #
Per poter verificare la presenza dei dashboard di Grafana prima che questi vengano caricati dal front-end, il back-end del Ceph Dashboard richiede l'URL Grafana. A causa del metodo applicato per l'implementazione di Grafana nel Ceph Dashboard, ciò vuol dire che sono necessarie due connessioni attive per poter visualizzare i grafici di Grafana nel Ceph Dashboard:
Il back-end (modulo Ceph MGR) deve verificare l'esistenza del grafico richiesto. Se la richiesta va a buon fine, comunica al front-end che può accedere a Grafana in sicurezza.
Il front-end richiede quindi i grafici di Grafana direttamente dal browser dell'utente tramite un
iframe. L'accesso all'istanza di Grafana viene eseguito direttamente dal Ceph Dashboard senza deviazioni.
A questo punto, l'ambiente potrebbe rendere difficile al browser dell'utente l'accesso diretto all'URL configurato nel Ceph Dashboard. Per risolvere questo problema, è possibile configurare un URL separato che verrà utilizzato esclusivamente per comunicare al front-end (il browser dell'utente) quale URL utilizzare per accedere a Grafana.
Per modificare l'URL restituito al front-end, immettere il comando seguente:
cephuser@adm > ceph dashboard set-grafana-frontend-api-url GRAFANA-SERVER-URLSe per questa opzione non è impostato alcun valore, verrà semplicemente eseguito il fallback al valore dell'opzione GRAFANA_API_URL, impostato automaticamente e aggiornato su base periodica da cephadm. Se è presente un valore impostato, il browser riceverà l'istruzione di utilizzare questo URL per accedere a Grafana.
16.5 Configurazione del modulo Manager di Prometheus #
Il modulo Manager di Prometheus è un modulo interno di Ceph che ne estende le funzionalità. Il modulo legge i (meta)dati di Ceph relativi allo stato e all'integrità e fornisce a Prometheus tali dati (sottoposti a scrape) in un formato utilizzabile.
Per applicare le modifiche alla configurazione, è necessario riavviare il modulo Manager di Prometheus.
16.5.1 Configurazione dell'interfaccia di rete #
Per default, il modulo Manager di Prometheus accetta le richieste HTTP sulla porta 9283 su tutti gli indirizzi IPv4 e IPv6 sull'host. È possibile configurare la porta e l'indirizzo di ascolto con ceph config-key set, con le chiavi mgr/prometheus/server_addr e mgr/prometheus/server_port. Questa porta è registrata nel registro di Prometheus.
Per aggiornare il valore di server_addr, eseguire il comando seguente:
cephuser@adm > ceph config set mgr mgr/prometheus/server_addr 0.0.0.0
Per aggiornare il valore di server_port, eseguire il comando seguente:
cephuser@adm > ceph config set mgr mgr/prometheus/server_port 928316.5.2 Configurazione del valore di scrape_interval #
Per default, il modulo Manager di Prometheus è configurato su un intervallo di scraping di 15 secondi. Si sconsiglia di utilizzare un intervallo di scraping inferiore a 10 secondi. Per impostare un diverso intervallo di scraping nel modulo di Prometheus, impostare scrape_interval sul valore desiderato:
Per garantire il corretto funzionamento del modulo, il relativo valore di scrape_interval impostato deve corrispondere sempre all'intervallo di scraping di Prometheus.
cephuser@adm > ceph config set mgr mgr/prometheus/scrape_interval 1516.5.3 Configurazione della cache #
Sui cluster di grandi dimensioni (più di 1000 OSD), può essere necessario molto tempo per completare il recupero delle metriche. Senza la cache, il modulo Manager di Prometheus potrebbe sovraccaricare il manager e causare l'arresto anomalo o il blocco delle istanze di Ceph Manager. Di conseguenza, la cache è abilitata per default e non è possibile disabilitarla, ma ciò implica che può diventare obsoleta. La cache è considerata obsoleta quando l'intervallo di tempo impiegato per il recupero delle metriche da Ceph supera il valore impostato per scrape_interval.
In questo caso, viene registrato un avviso e il modulo reagirà in uno dei modi seguenti:
Risponderà con un codice di stato 503 HTTP (servizio non disponibile).
Restituirà i contenuti della cache, anche se potrebbero essere obsoleti.
Questo comportamento può essere configurato con i comandi ceph config set.
Per inviare al modulo l'istruzione di rispondere con i dati verosimilmente obsoleti, impostarlo su return:
cephuser@adm > ceph config set mgr mgr/prometheus/stale_cache_strategy return
Per inviare al modulo l'istruzione di rispondere con l'errore service unavailable, impostarlo su fail:
cephuser@adm > ceph config set mgr mgr/prometheus/stale_cache_strategy fail16.5.4 Abilitazione del monitoraggio dell'immagine RBD #
Tramite l'abilitazione dei contatori delle prestazioni dinamiche dell'OSD, il modulo Manager di Prometheus può facoltativamente raccogliere le statistiche I/O per ogni singola immagine RBD. Tali statistiche vengono raccolte per tutte le immagini all'interno dei pool specificati nel parametro di configurazione mgr/prometheus/rbd_stats_pools.
Il parametro è un elenco di voci pool[/namespace] separate da virgole o spazi. Se lo spazio dei nomi non è specificato, vengono raccolte le statistiche relative a tutti gli spazi dei nomi nel pool.
Esempio:
cephuser@adm > ceph config set mgr mgr/prometheus/rbd_stats_pools "pool1,pool2,poolN"
Il modulo effettua la scansione dei pool e degli spazi dei nomi specificati e crea un elenco di tutte le immagini disponibili e lo aggiorna periodicamente. È possibile configurare l'intervallo tramite il parametro mgr/prometheus/rbd_stats_pools_refresh_interval (secondi), impostato per default su 300 secondi (cinque minuti).
Ad esempio, se l'intervallo di sincronizzazione è stato modificato in 10 minuti:
cephuser@adm > ceph config set mgr mgr/prometheus/rbd_stats_pools_refresh_interval 60016.6 Modello di sicurezza di Prometheus #
Il modello di sicurezza di Prometheus presume che utenti non attendibili dispongano dell'accesso ai log e all'endpoint HTTP di Prometheus. Gli utenti non attendibili dispongono dell'accesso a tutti i (meta)dati raccolti da Prometheus e contenuti nel database, oltre a una serie di informazioni operative e di debug.
Tuttavia l'API HTTP di Prometheus è limitata alle operazioni di sola lettura. Non è possibile modificare le configurazioni utilizzando l'API e i segreti non vengono esposti. Inoltre, Prometheus dispone di misure integrate per attenuare l'impatto degli attacchi Denial of Service.
16.7 Gateway SNMP di Prometheus Alertmanager #
Se si desidera ricevere notifiche sugli avvisi di Prometheus tramite trap SNMP, è possibile installare il gateway SNMP di Prometheus Alertmanager tramite cephadm o il Ceph Dashboard. A tale scopo, ad esempio per SNMPv2c, è necessario creare un file della specifica del posizionamento e del servizio con i contenuti seguenti:
Per ulteriori informazioni sui file del servizio e del posizionamento, vedere Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.2 “Specifica del servizio e del posizionamento”.
service_type: snmp-gateway
service_name: snmp-gateway
placement:
ADD_PLACEMENT_HERE
spec:
credentials:
snmp_community: ADD_COMMUNITY_STRING_HERE
snmp_destination: ADD_FQDN_HERE:ADD_PORT_HERE
snmp_version: V2cIn alternativa, è possibile utilizzare il Ceph Dashboard per distribuire il servizio del gateway SNMP per SNMPv2c e SNMPv3. Per ulteriori informazioni, fare riferimento al Sezione 4.4, «Visualizzazione dei servizi».
Parte III Memorizzazione dei dati in un cluster #
- 17 Gestione dei dati memorizzati
L'algoritmo CRUSH determina la modalità di storage e recupero dei dati mediante il calcolo delle ubicazioni di memorizzazione dati. CRUSH consente ai client Ceph di comunicare direttamente con gli OSD piuttosto che tramite un server centralizzato o un broker. Grazie ad un sistema per lo storage e il…
- 18 Gestione dei pool di memorizzazione
Ceph memorizza i dati nei pool. I pool sono gruppi logici per la memorizzazione di oggetti. Quando inizialmente si installa un cluster senza creare un pool, Ceph utilizza i pool di default per la memorizzazione dei dati. Gli elementi di rilievo più importanti riportati di seguito sono relativi ai po…
- 19 Pool con codice di cancellazione
Ceph fornisce un'alternativa alla replica normale dei dati nei pool denominata pool di cancellazione o con codice di cancellazione. I pool di cancellazione non forniscono le funzionalità complete dei pool replicati (ad esempio, non sono in grado di memorizzare i metadati dei pool RBD), ma richiedono…
- 20 Dispositivo di blocco RADOS (RADOS Block Device, RBD)
Un blocco è una sequenza di byte, ad esempio un blocco di dati da 4 MB. Le interfacce di memorizzazione basate su blocchi rappresentano il modo più comune per memorizzare i dati con supporti rotanti, come dischi rigidi, CD, dischi floppy. L'ubiquità delle interfacce dei dispositivi di blocco rende u…
17 Gestione dei dati memorizzati #
L'algoritmo CRUSH determina la modalità di storage e recupero dei dati mediante il calcolo delle ubicazioni di memorizzazione dati. CRUSH consente ai client Ceph di comunicare direttamente con gli OSD piuttosto che tramite un server centralizzato o un broker. Grazie ad un sistema per lo storage e il recupero dei dati basato su algoritmi, Ceph consente di evitare single point of failure, colli di bottiglia delle prestazioni e limiti fisici alla rispettiva scalabilità.
Per CRUSH è richiesta una mappa del cluster e viene utilizzata la mappa CRUSH per memorizzare e recuperare dati negli OSD in modo pressoché casuale, con una distribuzione uniforme dei dati nel cluster.
Le mappe CRUSH contengono: un elenco di OSD, un elenco di "compartimenti" per aggregare i dispositivi in ubicazioni fisiche e un elenco di regole che indicano a CRUSH come replicare i dati nei pool di un cluster Ceph. Riflettendo l'organizzazione fisica dell'installazione sottostante, CRUSH è in grado di modellare, e quindi di risolvere, potenziali origini di errori dei dispositivi correlati. Tra le origini tipiche sono incluse la prossimità fisica, un'alimentazione condivisa e una rete condivisa. Mediante la codifica di queste informazioni nella mappa del cluster, le policy di posizionamento di CRUSH possono separare le repliche di oggetti in vari domini di errore, continuando a mantenere la distribuzione desiderata. Ad esempio, per risolvere la possibilità di errori simultanei, può essere necessario assicurare che le repliche dei dati siano su dispositivi che utilizzano scaffali, rack, alimentatori, controller e/o ubicazioni fisiche.
Dopo aver distribuito un cluster Ceph cluster, viene generata una mappa CRUSH di default. Questa è adatta per l'ambiente sandbox Ceph. Quando tuttavia si distribuisce un cluster di dati su larga scala, considerare attentamente lo sviluppo di una mappa CRUSH personalizzata da utilizzare per gestire il cluster, migliorare le prestazioni e garantire la sicurezza dei dati.
Se ad esempio un OSD si interrompe, può essere utile una mappa CRUSH per individuare il data center fisico, la stanza, la fila e il rack dell'host con l'OSD non riuscito nel caso in cui sia necessario utilizzare un supporto on site o sostituire l'hardware.
In modo analogo, CRUSH può consentire di identificare gli errori più rapidamente. Ad esempio, se tutti gli OSD in un determinato rack si interrompono simultaneamente, è possibile che l'errore risieda in un interruttore di rete o nell'alimentazione del rack oppure nell'interruttore di rete piuttosto che negli OSD stessi.
Una mappa CRUSH personalizzata consente inoltre di identificare le ubicazioni fisiche in cui Ceph memorizza le copie ridondanti dei dati quando i gruppi di posizionamento (consultare Sezione 17.4, «Gruppi di posizionamento») associati a un host con errori si trovano in stato danneggiato.
In una mappa CRUSH sono presenti tre sezioni principali.
Dispositivi OSD: qualsiasi Object Storage Device corrispondente a un daemon
ceph-osd.Compartimenti aggregazione gerarchica delle ubicazioni di memorizzazione (ad esempio file, rack, host e così via) e relativi pesi assegnati.
Set di regole: modo in cui vengono selezionati i compartimenti.
17.1 Dispositivi OSD #
Per mappare i gruppi di posizionamento negli OSD, per la mappa CRUSH è richiesto un elenco di dispositivi OSD (il nome del daemon OSD). L'elenco dei dispositivi viene visualizzato prima nella mappa CRUSH.
#devices device NUM osd.OSD_NAME class CLASS_NAME
Esempio:
#devices device 0 osd.0 class hdd device 1 osd.1 class ssd device 2 osd.2 class nvme device 3 osd.3 class ssd
Come regola generale, un daemon OSD viene mappato in un disco singolo.
17.1.1 Classi di dispositivi #
La flessibilità della mappa CRUSH in termini di controllo del posizionamento dei dati è uno dei punti di forza di Ceph. È anche uno degli aspetti più complessi da gestire del cluster. Le classi di dispositivi automatizzano le modifiche più comuni apportate alle mappe CRUSH che l'amministratore in precedenza doveva eseguire manualmente.
17.1.1.1 Il problema della gestione CRUSH #
Spesso, i cluster Ceph sono compilati con più tipi di dispositivi di memorizzazione: HDD, SSD, NVMe o persino con classi miste delle tipologie appena elencate. Questi diversi tipi di dispositivi di memorizzazione sono chiamati classi di dispositivi per evitare confusione tra la proprietà type dei compartimenti CRUSH (ad esempio host, rack, row; vedere la Sezione 17.2, «Compartimenti» per ulteriori dettagli). I Ceph OSD supportati dai dispositivi SSD sono molto più veloci di quelli supportati dai dischi a rotazione e sono pertanto più adatti per determinati carichi di lavoro. Ceph semplifica la creazione di pool RADOS per dataset o carichi di lavoro diversi e l'assegnazione di regole CRUSH differenti per il controllo del posizionamento dei dati per questi pool.

La configurazione delle regole CRUSH per il posizionamento dei dati soltanto su una determinata classe di dispositivi è tuttavia un'operazione lunga e noiosa. Le regole si basano sulla gerarchia CRUSH, ma se negli stessi host o rack sono presenti dispositivi di diversi tipi (come nella gerarchia di esempio riportata sopra), tali dispositivi verranno (per default) mescolati e visualizzati negli stessi sottoalberi della gerarchia. Nelle versioni precedenti di SUSE Enterprise Storage, la separazione manuale dei dispositivi in alberi diversi comportava la creazione di più versioni di ciascun nodo intermedio per ogni classe di dispositivi.
17.1.1.2 Classi di dispositivi #
Una comoda soluzione offerta da Ceph è la possibilità di aggiungere una proprietà denominata device class a ciascun OSD. Per default, gli OSD impostano automaticamente le relative classi di dispositivi su "hdd", "ssd" o "nvme" in base alle proprietà hardware esposte dal kernel Linux. Queste classi di dispositivi sono indicate in una nuova colonna dell'output del comando ceph osd tree:
cephuser@adm > ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 83.17899 root default
-4 23.86200 host cpach
2 hdd 1.81898 osd.2 up 1.00000 1.00000
3 hdd 1.81898 osd.3 up 1.00000 1.00000
4 hdd 1.81898 osd.4 up 1.00000 1.00000
5 hdd 1.81898 osd.5 up 1.00000 1.00000
6 hdd 1.81898 osd.6 up 1.00000 1.00000
7 hdd 1.81898 osd.7 up 1.00000 1.00000
8 hdd 1.81898 osd.8 up 1.00000 1.00000
15 hdd 1.81898 osd.15 up 1.00000 1.00000
10 nvme 0.93100 osd.10 up 1.00000 1.00000
0 ssd 0.93100 osd.0 up 1.00000 1.00000
9 ssd 0.93100 osd.9 up 1.00000 1.00000
Se il rilevamento automatico della classe di dispositivi non riesce, ad esempio perché il driver del dispositivo non espone correttamente le informazioni sul dispositivo tramite sys/block, è possibile modificare le classi di dispositivi dalla riga di comando:
cephuser@adm >ceph osd crush rm-device-class osd.2 osd.3 done removing class of osd(s): 2,3cephuser@adm >ceph osd crush set-device-class ssd osd.2 osd.3 set osd(s) 2,3 to class 'ssd'
17.1.1.3 Impostazione delle regole di posizionamento CRUSH #
Tramite le regole CRUSH, è possibile limitare il posizionamento a una classe di dispositivi specifica. Ad esempio, è possibile creare un pool replicato "fast" per distribuire i dati soltanto sui dischi SSD tramite l'esecuzione del comando seguente:
cephuser@adm > ceph osd crush rule create-replicated RULE_NAME ROOT FAILURE_DOMAIN_TYPE DEVICE_CLASSEsempio:
cephuser@adm > ceph osd crush rule create-replicated fast default host ssdCreare un pool denominato "fast_pool" e assegnarlo alla regola "fast":
cephuser@adm > ceph osd pool create fast_pool 128 128 replicated fastLa procedura di creazione delle regole del codice di cancellazione è leggermente diversa. Innanzitutto, occorre creare un profilo con codice di cancellazione che includa una proprietà per la classe di dispositivi desiderata. Quindi, utilizzare tale profilo durante la creazione del pool con codice di cancellazione:
cephuser@adm >ceph osd erasure-code-profile set myprofile \ k=4 m=2 crush-device-class=ssd crush-failure-domain=hostcephuser@adm >ceph osd pool create mypool 64 erasure myprofile
Se occorre modificare manualmente la mappa CRUSH per personalizzare la regola, è possibile specificare la classe di dispositivi tramite la sintassi estesa. Ad esempio, la regola CRUSH generata dai comandi riportati sopra è la seguente:
rule ecpool {
id 2
type erasure
min_size 3
max_size 6
step set_chooseleaf_tries 5
step set_choose_tries 100
step take default class ssd
step chooseleaf indep 0 type host
step emit
}La differenza fondamentale qui è che il comando "take" include il suffisso aggiuntivo "class CLASS_NAME".
17.1.1.4 Comandi aggiuntivi #
Per visualizzare un elenco delle classi di dispositivi utilizzate in una mappa CRUSH, eseguire:
cephuser@adm > ceph osd crush class ls
[
"hdd",
"ssd"
]Per visualizzare un elenco delle regole CRUSH esistenti, eseguire:
cephuser@adm > ceph osd crush rule ls
replicated_rule
fastPer visualizzare i dettagli della regola CRUSH denominata "fast", eseguire:
cephuser@adm > ceph osd crush rule dump fast
{
"rule_id": 1,
"rule_name": "fast",
"ruleset": 1,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -21,
"item_name": "default~ssd"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}Per visualizzare un elenco degli OSD appartenenti a una classe "ssd", eseguire:
cephuser@adm > ceph osd crush class ls-osd ssd
0
117.1.1.5 Esecuzione della migrazione da una regola SSD esistente alle classi di dispositivi #
Nelle versioni di SUSE Enterprise Storage precedenti alla 5, occorreva modificare manualmente la mappa CRUSH e mantenere una gerarchia parallela per ogni tipo di dispositivo specializzato (ad esempio SSD) se si volevano scrivere le regole applicabili a tali dispositivi. Da SUSE Enterprise Storage 5 in poi, la funzione della classe di dispositivi ha reso possibile questa procedura in modo invisibile all'utente.
Tramite il comando crushtool, è possibile trasformare una regola e una gerarchia esistenti nelle nuove regole basate sulla classe. Sono possibili diversi tipi di trasformazione:
crushtool --reclassify-root ROOT_NAME DEVICE_CLASSQuesto comando include tutti gli elementi della gerarchia al di sotto di ROOT_NAME e modifica le regole che fanno riferimento a tale radice tramite
take ROOT_NAME
in
take ROOT_NAME class DEVICE_CLASS
Rinumera i compartimenti per fare in modo che gli ID obsoleti vengano utilizzati per lo "shadow tree" della classe specificata. Di conseguenza, non si verificano spostamenti di dati.
Esempio 17.1:crushtool --reclassify-root#Prendere in considerazione la seguente regola esistente:
rule replicated_ruleset { id 0 type replicated min_size 1 max_size 10 step take default step chooseleaf firstn 0 type rack step emit }Se si riclassifica la radice "default" come classe "hdd", la regola diventerà
rule replicated_ruleset { id 0 type replicated min_size 1 max_size 10 step take default class hdd step chooseleaf firstn 0 type rack step emit }crushtool --set-subtree-class BUCKET_NAME DEVICE_CLASSQuesto metodo contrassegna ogni dispositivo nel sottoalbero con radice BUCKET_NAME con la classe di dispositivi specificata.
L'opzione
--set-subtree-classviene in genere utilizzata insieme all'opzione--reclassify-rootper assicurarsi che tutti i dispositivi in tale radice siano etichettati con la classe corretta. Tuttavia, alcuni di questi dispositivi possono avere intenzionalmente una classe diversa e pertanto non è necessario etichettarli nuovamente. In questi casi, escludere l'opzione--set-subtree-class. Tenere presente che la nuova mappatura non sarà perfetta, perché la regola precedente è distribuita ai dispositivi di più classi, ma le regole modificate effettueranno la mappatura soltanto ai dispositivi della classe specificata.crushtool --reclassify-bucket MATCH_PATTERN DEVICE_CLASS DEFAULT_PATTERNQuesto metodo consente di unire una gerarchia parallela specifica del tipo con la gerarchia normale. Ad esempio, molti utenti dispongono di mappe CRUSH simili alla seguente:
Esempio 17.2:crushtool --reclassify-bucket#host node1 { id -2 # do not change unnecessarily # weight 109.152 alg straw hash 0 # rjenkins1 item osd.0 weight 9.096 item osd.1 weight 9.096 item osd.2 weight 9.096 item osd.3 weight 9.096 item osd.4 weight 9.096 item osd.5 weight 9.096 [...] } host node1-ssd { id -10 # do not change unnecessarily # weight 2.000 alg straw hash 0 # rjenkins1 item osd.80 weight 2.000 [...] } root default { id -1 # do not change unnecessarily alg straw hash 0 # rjenkins1 item node1 weight 110.967 [...] } root ssd { id -18 # do not change unnecessarily # weight 16.000 alg straw hash 0 # rjenkins1 item node1-ssd weight 2.000 [...] }Questa funzione riclassifica ogni compartimento corrispondente a un modello specificato. Il modello può essere simile a
%suffixo aprefix%. Nell'esempio riportato sopra, è utilizzato il modello%-ssd. Per ciascun compartimento corrispondente, la porzione rimanente del nome che corrisponde al carattere jolly "%" specifica il compartimento di base. Tutti i dispositivi nel compartimento corrispondente vengono etichettati con la classe di dispositivi specificata e quindi spostati nel compartimento di base. Se quest'ultimo non esiste (ad esempio se "node12-ss" esiste, ma "node12" non esiste), viene creato e collegato al di sotto del compartimento superiore di default specificato. Gli ID dei compartimenti obsoleti vengono conservati per i nuovi compartimenti replicati al fine di impedire il trasferimento dei dati. Le regole con i passaggitakeche fanno riferimento ai compartimenti obsoleti vengono modificate.crushtool --reclassify-bucket BUCKET_NAME DEVICE_CLASS BASE_BUCKETÈ possibile utilizzare l'opzione
--reclassify-bucketsenza caratteri jolly per mappare un compartimento singolo. Nell'esempio precedente, si intende mappare il compartimento "ssd" al compartimento di default.Il comando finale per la conversione della mappa, compresi i frammenti riportati sopra, è il seguente:
cephuser@adm >ceph osd getcrushmap -o originalcephuser@adm >crushtool -i original --reclassify \ --set-subtree-class default hdd \ --reclassify-root default hdd \ --reclassify-bucket %-ssd ssd default \ --reclassify-bucket ssd ssd default \ -o adjustedPer verificare la correttezza della conversione, è disponibile l'opzione
--compareche consente di testare un ampio campione di input della mappa CRUSH e di verificare che vengano restituiti gli stessi risultati. Questi input sono controllati dalle stesse opzioni che si applicano all'opzione--test. Per l'esempio riportato sopra, il comando è il seguente:cephuser@adm >crushtool -i original --compare adjusted rule 0 had 0/10240 mismatched mappings (0) rule 1 had 0/10240 mismatched mappings (0) maps appear equivalentSuggerimentoIn caso di differenze, tra parentesi viene indicata la percentuale degli input di cui è stata ripetuta la mappatura.
Dopo aver apportato tutte le modifiche desiderate alla mappa CRUSH, sarà possibile applicarla al cluster:
cephuser@adm >ceph osd setcrushmap -i adjusted
17.1.1.6 Ulteriori informazioni #
Nella Sezione 17.5, «Modifica della mappa CRUSH» sono disponibili ulteriori dettagli sulle mappe CRUSH.
Nel Capitolo 18, Gestione dei pool di memorizzazione sono disponibili ulteriori informazioni generali sui pool Ceph.
Nel Capitolo 19, Pool con codice di cancellazione sono disponibili ulteriori dettagli sui pool con codice di cancellazione.
17.2 Compartimenti #
Le mappe CRUSH contengono un elenco di OSD che è possibile organizzare in una struttura ad albero di compartimenti, in modo da aggregare i dispositivi in ubicazioni fisiche. I singoli OSD comprendono le foglie dell'albero.
|
0 |
osd |
Un dispositivo specifico oppure OSD ( |
|
1 |
host |
Nome di un host contenente uno o più OSD. |
|
2 |
chassis |
Identificatore dello chassis del rack contenente l' |
|
3 |
rack |
Un rack per computer. L'impostazione di default è |
|
4 |
row |
Una fila in una serie di rack. |
|
5 |
pdu |
Abbreviazione di "Power Distribution Unit" (unità di distribuzione di alimentazione). |
|
6 |
pod |
Abbreviazione di "Point of Delivery" (punto di consegna): in questo contesto, un gruppo di PDU o un gruppo di righe di rack. |
|
7 |
room |
Una stanza contenente righe di rack. |
|
8 |
datacenter |
Un data center fisico contenente uno o più stanze. |
|
9 |
region |
Area geografica del mondo (ad esempio, NAM, LAM, EMEA, APAC ecc). |
|
10 |
root |
Il nodo radice dell'albero dei compartimenti OSD (in genere impostato su |
È possibile modificare i tipi di compartimenti esistenti e crearne altri personalizzati.
Gli strumenti di distribuzione di Ceph generano una mappa CRUSH contenente un compartimento per ciascun host e una radice denominata "default", utile per il pool rbd di default. I tipi di compartimenti rimanenti sono un mezzo per memorizzare le informazioni sull'ubicazione fisica di nodi/compartimenti, che rende l'amministrazione del cluster molto più semplice in caso di malfunzionamento degli OSD, degli host o dell'hardware di rete e l'amministratore deve accedere all'hardware fisico.
I compartimenti dispongono di un tipo, un nome univoco (stringa), un ID univoco espresso come numero intero negativo, un peso relativo alla capacità totale/capacità degli elementi corrispondenti, un algoritmo di compartimento (straw2 per default) e l'hash (0 per default, che riflette l'hash CRUSH rjenkins1). Un compartimento può contenere uno o più elementi. Gli elementi possono essere costituiti da altri compartimenti o OSD. Gli elementi possono avere un peso che riflette quello relativo dell'elemento.
[bucket-type] [bucket-name] {
id [a unique negative numeric ID]
weight [the relative capacity/capability of the item(s)]
alg [the bucket type: uniform | list | tree | straw2 | straw ]
hash [the hash type: 0 by default]
item [item-name] weight [weight]
}Nell'esempio seguenti è illustrato come utilizzare i compartimenti per aggregare un pool e ubicazioni fisiche come un data center, una stanza, un rack e una fila.
host ceph-osd-server-1 {
id -17
alg straw2
hash 0
item osd.0 weight 0.546
item osd.1 weight 0.546
}
row rack-1-row-1 {
id -16
alg straw2
hash 0
item ceph-osd-server-1 weight 2.00
}
rack rack-3 {
id -15
alg straw2
hash 0
item rack-3-row-1 weight 2.00
item rack-3-row-2 weight 2.00
item rack-3-row-3 weight 2.00
item rack-3-row-4 weight 2.00
item rack-3-row-5 weight 2.00
}
rack rack-2 {
id -14
alg straw2
hash 0
item rack-2-row-1 weight 2.00
item rack-2-row-2 weight 2.00
item rack-2-row-3 weight 2.00
item rack-2-row-4 weight 2.00
item rack-2-row-5 weight 2.00
}
rack rack-1 {
id -13
alg straw2
hash 0
item rack-1-row-1 weight 2.00
item rack-1-row-2 weight 2.00
item rack-1-row-3 weight 2.00
item rack-1-row-4 weight 2.00
item rack-1-row-5 weight 2.00
}
room server-room-1 {
id -12
alg straw2
hash 0
item rack-1 weight 10.00
item rack-2 weight 10.00
item rack-3 weight 10.00
}
datacenter dc-1 {
id -11
alg straw2
hash 0
item server-room-1 weight 30.00
item server-room-2 weight 30.00
}
root data {
id -10
alg straw2
hash 0
item dc-1 weight 60.00
item dc-2 weight 60.00
}17.3 Set di regole #
Le mappe CRUSH supportano la nozione delle "regole CRUSH", che sono regole che determinano il posizionamento dei dati per un pool. Per i cluster di grandi dimensioni è probabile che vengano creati numerosi pool, ciascuno dei quali presenta set di regole e regole CRUSH propri. Per default, la mappa CRUSH dispone di una regola per la radice di default. Se sono necessarie più radici e più regole, occorre crearle in un secondo momento. In alternativa, queste verranno create automaticamente insieme ai nuovi pool.
Nella maggior parte dei casi non sarà necessario modificare le regole di default. Quando si crea un nuovo pool, il rispettivo set di regole di default è 0.
Una regola è strutturata nel modo seguente:
rule rulename {
ruleset ruleset
type type
min_size min-size
max_size max-size
step step
}- ruleset
Un numero intero. Classifica una regola come appartenente a un set di regole. Attivato mediante l'impostazione del set di regole in un pool. Questa opzione è obbligatoria. Il valore di default è
0.- tipo
Stringa. Descrive una regola per un pool con codice "replicated" o "coded". Questa opzione è obbligatoria. L'impostazione di default è
replicated.- min_size
Un numero intero. Se un gruppo di pool crea un numero di repliche inferiore a questo numero, CRUSH NON selezionerà questa regola. Questa opzione è obbligatoria. Il valore di default è
2.- max_size
Un numero intero. Se un gruppo di pool crea un numero di repliche superiore a questo numero, CRUSH NON selezionerà questa regola. Questa opzione è obbligatoria. Il valore di default è
10.- step take bucket
Prende un compartimento specificato tramite nome e avvia l'iterazione lungo l'albero. Questa opzione è obbligatoria. Per una spiegazione sull'iterazione nell'albero, vedere Sezione 17.3.1, «Iterazione dell'albero di nodi».
- step targetmodenum type bucket-type
target può essere sia
choosesiachooseleaf. Quando impostata suchoose, viene selezionato un numero di compartimenti.chooseleafseleziona direttamente gli OSD (nodi foglia) dal sottoalbero di ciascun compartimento nel set di compartimenti.mode può essere sia
firstnsiaindep. Vedere Sezione 17.3.2, «firstn e indep».Seleziona il numero di compartimenti di un determinato tipo. Dove N è il numero delle opzioni disponibili, se num > 0 && < N, scegliere tale numero di compartimenti; se num < 0, significa N - num; e se num == 0, scegliere N compartimenti (tutti disponibili). Segue
step takeostep choose.- step emit
Genera il valore corrente e svuota lo stack. Di norma utilizzata alla fine di una regola, ma può essere impiegata per formare alberi diversi nell'ambito della stessa regola. Segue
step choose.
17.3.1 Iterazione dell'albero di nodi #
È possibile visualizzare la struttura definita nei compartimenti sotto forma di albero di nodi. I compartimenti sono nodi e gli OSD sono foglie nell'albero.
Le regole nella mappa CRUSH definiscono il modo in cui gli OSD vengono selezionati dall'albero. Una regola inizia con un nodo, quindi effettua un'iterazione lungo l'albero per restituire un set di OSD. Non è possibile definire quale diramazione selezionare. L'algoritmo CRUSH assicura invece che il set di OSD soddisfi i requisiti di replica e distribuisca uniformemente i dati.
Con step take bucket l'iterazione nell'albero di noti inizia in un determinato compartimento (non in un tipo di compartimento). Se gli OSD provenienti da tutte le diramazioni nell'albero vengono restituiti, il compartimento deve essere il compartimento radice. Altrimenti per gli "step" seguenti l'iterazione ha luogo tramite un sottoalbero.
Dopo step take nella definizione della regola seguono una o più voci step choose. Ogni step choose sceglie un numero definito di nodi (o diramazioni) dal nodo superiore selezionato precedentemente.
Alla fine gli OSD selezionati vengono restituiti con step emit.
step chooseleaf è una pratica funzione che consente di selezionare direttamente gli OSD dalle diramazioni del compartimento specificato.
La Figura 17.2, «Albero di esempio» è un esempio di come viene utilizzato step per l'iterazione in un albero. Le frecce e i numeri arancioni corrispondono a example1a e example1b, mentre quelli blu corrispondono a example2 nelle seguenti definizioni delle regole.

# orange arrows
rule example1a {
ruleset 0
type replicated
min_size 2
max_size 10
# orange (1)
step take rack1
# orange (2)
step choose firstn 0 host
# orange (3)
step choose firstn 1 osd
step emit
}
rule example1b {
ruleset 0
type replicated
min_size 2
max_size 10
# orange (1)
step take rack1
# orange (2) + (3)
step chooseleaf firstn 0 host
step emit
}
# blue arrows
rule example2 {
ruleset 0
type replicated
min_size 2
max_size 10
# blue (1)
step take room1
# blue (2)
step chooseleaf firstn 0 rack
step emit
}17.3.2
Una regola CRUSH definisce le sostituzioni per i nodi o gli OSD non riusciti (vedere Sezione 17.3, «Set di regole»). Per lo step della parola chiave è richiesto firstn o indep come parametro. Figura 17.3, «Metodi di sostituzione dei nodi» fornisce un esempio.
firstn aggiunge i nodi di sostituzione alla fine dell'elenco dei nodi attivi. Nel caso di un nodo non riuscito, i seguenti nodi integri vengono spostati a sinistra per colmare il vuoto lasciato dal nodo non riuscito. Questo è il metodo di default e desiderato per i pool replicati, perché un nodo secondario contiene già tutti i dati e può essere impiegato immediatamente per svolgere i compiti del nodo primario.
indep seleziona i nodi di sostituzione per ciascun nodo attivo. La sostituzione di un nodo non riuscito non cambia l'ordine dei nodi rimanenti. Ciò è adatto per i pool con codice di cancellazione. Nei pool con codice di cancellazione, i dati memorizzati in un nodo dipendono dalla rispettiva posizione nella selezione del nodo. Quando l'ordine dei nodi cambia, tutti i dati nei nodi interessati devono essere trasferiti.

17.4 Gruppi di posizionamento #
Ceph mappa gli oggetti ai gruppi di posizionamento (PG). I gruppi di posizionamento sono partizionamenti o frammenti di un pool di oggetti logico che posizionano gli oggetti sotto forma di gruppi negli OSD. I gruppi di posizionamento riducono la quantità di metadati per oggetto quando Ceph memorizza i dati negli OSD. Più è alto il numero di gruppi di posizionamento (ad esempio 100 per OSD), migliore sarà il bilanciamento.
17.4.1 Utilizzo dei gruppi di posizionamento #
Un gruppo di posizionamento (PG) aggrega gli oggetti all'interno di un pool. Il motivo principale risiede nel fatto che il controllo del posizionamento degli oggetti e dei metadati per i singoli oggetti è un'attività onerosa per le risorse di elaborazione. Ad esempio, un sistema con milioni di oggetti non è in grado di controllare direttamente il posizionamento di ciascuno di questi oggetti.

Il client Ceph calcola il gruppo di posizionamento a cui apparterrà un oggetto. Per farlo, esegue l'hashing dell'ID dell'oggetto e applica un'operazione basata sul numero di gruppi di posizionamento presenti nel pool specificato e sull'ID del pool.
I contenuti dell'oggetto all'interno di un gruppo di posizionamento sono memorizzati in un set di OSD. Ad esempio, in un pool replicato di dimensione due, ogni gruppo di posizionamento memorizzerà gli oggetti su due OSD:

Se sull'OSD num. 2 si verificano degli errori, un altro OSD verrà assegnato al gruppo di posizionamento num. 1 e verrà compilato con le copie di tutti gli oggetti nell'OSD num. 1. Se la dimensione del pool viene modificata da due a tre, al gruppo di posizionamento verrà assegnato un altro OSD che riceverà le copie di tutti gli oggetti nel gruppo di posizionamento.
I gruppi di posizionamento non possiedono l'OSD, ma lo condividono con altri gruppi di posizionamento dello stesso pool o persino di altri pool. Se si verificano degli errori sull'OSD num. 2, il gruppo di posizionamento num. 2 dovrà ripristinare le copie degli oggetti utilizzando l'OSD num. 3.
Se il numero di gruppi di posizionamento aumenta, i nuovi gruppi verranno assegnati agli OSD. Anche il risultato della funzione CRUSH cambierà e alcuni oggetti dei gruppi di posizionamento precedenti verranno copiati sui nuovi gruppi di posizionamento e rimossi da quelli precedenti.
17.4.2 Determinazione del valore di PG_NUM #
A partire da Ceph Nautilus (v14.x), è possibile utilizzare il modulo pg_autoscaler di Ceph Manager per il dimensionamento automatico dei gruppi di posizionamento in base alle esigenze. Se si desidera abilitare questa funzione, fare riferimento a Book “Deploying and Administering SUSE Enterprise Storage with Rook”, Chapter 8 “Configuration”, Section 8.1.1.1 “Default PG and PGP counts”.
Durante la creazione di un nuovo pool, è comunque possibile impostare manualmente il valore di PG_NUM:
# ceph osd pool create POOL_NAME PG_NUMPG_NUM non può essere calcolato automaticamente. Di seguito sono elencati alcuni valori utilizzati di frequente, a seconda del numero di OSD nel cluster:
- Meno di 5 OSD:
Impostare PG_NUM su 128.
- Tra 5 e 10 OSD:
Impostare PG_NUM su 512.
- Tra 10 e 50 OSD:
Impostare PG_NUM su 1024.
Via via che il numero di OSD aumenta, diventa sempre più importante scegliere un valore corretto per PG_NUM. PG_NUM influisce sul comportamento del cluster e sulla durata dei dati in caso di errore dell'OSD.
17.4.2.1 Calcolo dei gruppi di posizionamento per più di 50 OSD #
Se si hanno meno di 50 OSD, utilizzare la preselezione descritta nella Sezione 17.4.2, «Determinazione del valore di PG_NUM». Se si hanno più di 50 OSD, si consiglia di utilizzare circa 50-100 gruppi di posizionamento per OSD per bilanciare l'uso delle risorse, la durata dei dati e la distribuzione. Per un pool di oggetti singolo, è possibile utilizzare la formula seguente per ottenere una linea di base:
total PGs = (OSDs * 100) / POOL_SIZE
Dove POOL_SIZE rappresenta il numero di repliche dei pool replicati o la somma "k"+"m" dei pool con codice di cancellazione restituita dal comando ceph osd erasure-code-profile get. Arrotondare il risultato alla potenza più vicina di 2. Si consiglia di arrotondare l'algoritmo CRUSH per bilanciare equamente il numero di oggetti tra i gruppi di posizionamento.
Ad esempio, per un cluster con 200 OSD e con una dimensione pool di 3 repliche, calcolare il numero di gruppi di posizionamento come segue:
(200 * 100) / 3 = 6667
La potenza più vicina di 2 è 8192.
Se si utilizzano più pool di dati per la memorizzazione degli oggetti, occorre assicurarsi di bilanciare il numero di gruppi di posizionamento per ogni pool con il numero di gruppi di posizionamento per ogni OSD. Occorre raggiungere un numero totale di gruppi di posizionamento ragionevole che fornisca una varianza abbastanza ridotta per OSD senza gravare sulle risorse di sistema o rallentare troppo il processo di peering.
Ad esempio, un cluster di 10 pool, ciascuno con 512 gruppi di posizionamento in 10 OSD, ha un totale di 5120 gruppi di posizionamento suddivisi in più di 10 OSD, ovvero 512 gruppi di posizionamento per OSD. In una configurazione di questo tipo non viene utilizzato un numero elevato di risorse. Tuttavia, se venissero creati 1000 pool con 512 gruppi di posizionamento ciascuno, gli OSD gestirebbero circa 50.000 gruppi di posizionamento ciascuno e sarebbero necessari molte più risorse e molto più tempo per il peering.
17.4.3 Impostazione del numero di gruppi di posizionamento #
A partire da Ceph Nautilus (v14.x), è possibile utilizzare il modulo pg_autoscaler di Ceph Manager per il dimensionamento automatico dei gruppi di posizionamento in base alle esigenze. Se si desidera abilitare questa funzione, fare riferimento a Book “Deploying and Administering SUSE Enterprise Storage with Rook”, Chapter 8 “Configuration”, Section 8.1.1.1 “Default PG and PGP counts”.
Se occorre tuttavia specificare manualmente il numero di gruppi di posizionamento all'interno di un pool, è necessario farlo al momento della creazione di quest'ultimo (vedere la Sezione 18.1, «Creazione di un pool»). Dopo aver impostato i gruppi di posizionamento per un pool, è possibile aumentarne il numero con il comando seguente:
# ceph osd pool set POOL_NAME pg_num PG_NUM
Dopo aver aumentato il numero di gruppi di posizionamento, è necessario aumentare anche il numero di gruppi di posizionamento per il posizionamento (PGP_NUM) per ribilanciare il cluster. PGP_NUM corrisponderà al numero di gruppi di posizionamento che verranno calcolati per il posizionamento dall'algoritmo CRUSH. L'aumento di PG_NUM comporta la suddivisione dei gruppi di posizionamento, ma la migrazione dei dati nei nuovi gruppi di posizionamento non sarà eseguita finché non verrà aumentato il valore di PGP_NUM. PGP_NUM deve essere uguale a PG_NUM. Per aumentare il numero dei gruppi di posizionamento per il posizionamento, eseguire quanto riportato di seguito:
# ceph osd pool set POOL_NAME pgp_num PGP_NUM17.4.4 Individuazione del numero di gruppi di posizionamento #
Per individuare il numero dei gruppi di posizionamento in un pool, eseguire il comando get seguente:
# ceph osd pool get POOL_NAME pg_num17.4.5 Individuazione delle statistiche dei gruppi di posizionamento di un cluster #
Per individuare le statistiche dei gruppi di posizionamento nel cluster, eseguire il comando seguente:
# ceph pg dump [--format FORMAT]I formati validi sono "plain" (default) e "json".
17.4.6 Individuazione delle statistiche dei gruppi di posizionamento bloccati #
Per individuare le statistiche di tutti i gruppi di posizionamento bloccati in uno stato specifico, eseguire quanto riportato di seguito:
# ceph pg dump_stuck STATE \
[--format FORMAT] [--threshold THRESHOLD]
STATE può indicare uno stato tra "inactive" (i gruppi di posizionamento non sono in grado di elaborare le operazioni di lettura o scrittura perché sono in attesa di un OSD con i dati più recenti), "unclean" (i gruppi di posizionamento contengono oggetti non replicati per il numero di volte desiderato), "stale" (i gruppi di posizionamento si trovano in uno stato sconosciuto; gli OSD che li ospitano non hanno informato il cluster di monitoraggio entro l'intervallo di tempo specificato dall'opzione mon_osd_report_timeout), "undersized" o "degraded".
I formati validi sono "plain" (default) e "json".
La soglia definisce il numero minimo di secondi in cui il gruppo di posizionamento resta bloccato prima di essere incluso nelle statistiche (l'impostazione di default è 300 secondi).
17.4.7 Ricerca della mappa di un gruppo di posizionamento #
Per cercare la mappa di un determinato gruppo di posizionamento, eseguire quanto riportato di seguito:
# ceph pg map PG_IDCeph restituirà la mappa del gruppo di posizionamento, il gruppo di posizionamento e lo stato dell'OSD:
# ceph pg map 1.6c
osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]17.4.8 Recupero delle statistiche dei gruppi di posizionamento #
Per recuperare le statistiche di un determinato gruppo di posizionamento, eseguire quanto riportato di seguito:
# ceph pg PG_ID query17.4.9 Pulitura di un gruppo di posizionamento #
Per pulire (Sezione 17.6, «Pulitura dei gruppi di posizionamento») un gruppo di posizionamento, eseguire quanto riportato di seguito:
# ceph pg scrub PG_IDCeph controlla il nodo primario e di replica, genera un catalogo di tutti gli oggetti del gruppo di posizionamento e li confronta per verificare che non ci siano oggetti mancanti o non corrispondenti e che i contenuti siano coerenti. Presupponendo la corrispondenza di tutte le repliche, una pulizia semantica finale assicura che tutti i metadati di oggetto relativi alla snapshot siano coerenti. Gli errori vengono segnalati tramite i log.
17.4.10 Assegnazione della priorità al backfill e al recupero dei gruppi di posizionamento #
In alcune situazioni può capitare di dover recuperare e/o eseguire il backfill di più gruppi di posizionamento, alcuni dei quali contengono dati più importanti di altri. Ad esempio, questi gruppi di posizionamento possono contenere dati di immagini utilizzati dai computer in esecuzione, mentre altri gruppi possono essere utilizzati da computer inattivi o da dati meno pertinenti. In questo caso, è consigliabile assegnare la priorità al recupero di questi gruppi per ripristinare per prime la disponibilità e le prestazioni dei dati memorizzati in questi gruppi. Per contrassegnare determinati gruppi di posizionamento come prioritari durante il backfill o il recupero, eseguire quanto riportato di seguito:
#ceph pg force-recovery PG_ID1 [PG_ID2 ... ]#ceph pg force-backfill PG_ID1 [PG_ID2 ... ]
In questo modo, Ceph eseguirà innanzitutto il recupero o il backfill dei gruppi di posizionamento specificati prima di passare agli altri gruppi. Questa impostazione non interrompe i processi di recupero o backfill in corso, ma fa in modo che i gruppi di posizionamento specificati vengano elaborati il prima possibile. Se si cambia idea o si assegna priorità ai gruppi errati, annullare la definizione della priorità:
#ceph pg cancel-force-recovery PG_ID1 [PG_ID2 ... ]#ceph pg cancel-force-backfill PG_ID1 [PG_ID2 ... ]
I comandi cancel-* rimuovono il flag "force" dai gruppi di posizionamento che vengono quindi elaborati nell'ordine di default. Di nuovo, questa impostazione non influisce sui gruppi di posizionamento in corso di elaborazione, ma soltanto su quelli che si trovano in coda. Il flag "force" viene cancellato automaticamente al termine del processo di recupero o backfill del gruppo.
17.4.11 Ripristino degli oggetti persi #
Se il cluster ha perso uno o più oggetti e l'utente ha deciso di abbandonare la ricerca dei dati persi, occorre contrassegnare gli oggetti non trovati come "lost".
Se gli oggetti ancora non si trovano dopo aver interrogato tutte le ubicazioni disponibili, è possibile che non si possano individuare. Ciò è possibile date le insolite combinazioni di errori che consentono al cluster di raccogliere informazioni sulle operazioni di scrittura effettuate prima del loro recupero.
Attualmente, l'unica opzione supportata è "revert", che consente di ripristinare una versione precedente dell'oggetto o di eliminarla completamente se si tratta di un nuovo oggetto. Per contrassegnare gli oggetti "unfound" come "lost", eseguire quanto riportato di seguito:
cephuser@adm > ceph pg PG_ID mark_unfound_lost revert|delete17.4.12 Abilitazione dell'utilità di dimensionamento automatico del gruppo di posizionamento #
I gruppi di posizionamento rappresentano un dettaglio di implementazione interno della modalità di distribuzione dei dati da parte di Ceph. Abilitando il dimensionamento automatico dei gruppi di posizionamento, si consente al cluster di creare oppure ottimizzare automaticamente i gruppi di posizionamento in base alla modalità di utilizzo del cluster stesso.
Ogni pool nel sistema dispone di una proprietà pg_autoscale_mode che può essere impostata su off, on o warn:
L'utilità di dimensionamento automatico è configurata per ogni singolo pool e può essere eseguita in tre modalità:
- off
Per disabilitare il dimensionamento automatico per il pool selezionato. L'amministratore dovrà scegliere un numero di gruppi di posizionamento adeguato per ogni pool.
- on
Per abilitare le regolazioni automatiche del numero di gruppi di posizionamento per un determinato pool.
- warn
Per inviare avvisi sull'integrità quando occorre regolare il numero di gruppi di posizionamento.
Per impostare la modalità di dimensionamento automatico per i pool esistenti:
cephuser@adm > ceph osd pool set POOL_NAME pg_autoscale_mode mode
È inoltre possibile configurare la modalità pg_autoscale_mode di default da applicare ai pool creati in futuro con:
cephuser@adm > ceph config set global osd_pool_default_pg_autoscale_mode MODEÈ possibile visualizzare ciascun pool, il relativo utilizzo e le eventuali modifiche del numero di gruppi di posizionamento suggerite con questo comando:
cephuser@adm > ceph osd pool autoscale-status17.5 Modifica della mappa CRUSH #
In questa sezione vengono presentati i modi con cui apportare modifiche di base alla mappa CRUSH, come la modifica di una mappa CRUSH, dei parametri della mappa CRUSH e l'aggiunta, lo spostamento o la rimozione di un OSD.
17.5.1 Modifica di una mappa CRUSH #
Per modificare una mappa CRUSH esistente, procedere come indicato di seguito:
Ottenere una mappa CRUSH. Per ottenere la mappa CRUSH per il cluster, eseguire quanto riportato di seguito:
cephuser@adm >ceph osd getcrushmap -o compiled-crushmap-filenameL'output Ceph (
-o) sarà una mappa CRUSH compilata nel nome file specificato. Poiché la mappa CRUSH è compilata, è necessario decompilarla prima di poterla modificare.Decompilare una mappa CRUSH. Per decompilare una mappa CRUSH, eseguire quanto riportato di seguito:
cephuser@adm >crushtool -d compiled-crushmap-filename \ -o decompiled-crushmap-filenameCeph decompilerà (
-d) la mappa CRUSH compilata e la genererà (-o) nel nome file specificato.Modificare almeno uno dei parametri di dispositivi, compartimenti e regole.
Compilare una mappa CRUSH. Per compilare una mappa CRUSH, eseguire quanto riportato di seguito:
cephuser@adm >crushtool -c decompiled-crush-map-filename \ -o compiled-crush-map-filenameCeph memorizzerà la mappa CRUSH compilata nel nome file specificato.
Impostare una mappa CRUSH. Per impostare la mappa CRUSH per il cluster, eseguire quanto riportato di seguito:
cephuser@adm >ceph osd setcrushmap -i compiled-crushmap-filenameCeph immetterà la mappa CRUSH compilata del nome file specificato come mappa CRUSH per il cluster.
Utilizzare un sistema di controllo versioni, come git o svn, per i file della mappa CRUSH esportati e modificati per semplificare un possibile rollback.
Testare la nuova mappa CRUSH modificata tramite il comando crushtool --test e confrontarla con lo stato prima di applicarla. Le seguenti opzioni di comando potrebbero risultare utili: --show-statistics, --show-mappings, --show-bad-mappings, ‑‑show-utilization, --show-utilization-all, --show-choose-tries
17.5.2 Aggiunta o spostamento di un OSD #
Per aggiungere o spostare un OSD nella mappa CRUSH di un cluster in esecuzione, eseguire quanto riportato di seguito:
cephuser@adm > ceph osd crush set id_or_name weight root=pool-name
bucket-type=bucket-name ...- id
Un numero intero. L'ID numerico dell'OSD. Questa opzione è obbligatoria.
- nome
Stringa. Indica il nome completo dell'OSD. Questa opzione è obbligatoria.
- weight
Valore doppio. Il peso CRUSH per l'OSD. Questa opzione è obbligatoria.
- root
Una coppia di chiavi/valori. Per default, la gerarchia CRUSH contiene il default del pool come rispettiva radice. Questa opzione è obbligatoria.
- bucket-type
Coppia di chiavi/valori. È possibile specificare l'ubicazione dell'OSD nella gerarchia CRUSH.
Nell'esempio seguente viene aggiunto osd.0 alla gerarchia o viene spostato l'OSD da un'ubicazione precedente.
cephuser@adm > ceph osd crush set osd.0 1.0 root=data datacenter=dc1 room=room1 \
row=foo rack=bar host=foo-bar-117.5.3 Differenza tra ceph osd reweight e ceph osd crush reweight #
Vi sono due comandi simili che cambiano la variabile "weight" di un Ceph OSD. Il loro contesto d'uso è diverso e può generare confusione.
17.5.3.1 ceph osd reweight #
Utilizzo:
cephuser@adm > ceph osd reweight OSD_NAME NEW_WEIGHT
ceph osd reweight imposta il peso sostitutivo sul Ceph OSD. Questo valore è compreso tra 0 e 1 e forza CRUSH a riposizionare i dati che altrimenti risiederebbero in questa unità. Non cambia i pesi assegnati ai compartimenti sopra l'OSD ed è una misura correttiva in caso di cattivo funzionamento della normale distribuzione CRUSH. Ad esempio, se uno degli OSD si trova al 90% e gli altri al 40%, è possibile ridurre il peso per provare a compensarlo.
Tenere presente che ceph osd reweight non è un'impostazione permanente. Quando un OSD non viene contrassegnato, il suo peso viene impostato a 0 e cambia su 1 quando il dispositivo viene contrassegnato nuovamente.
17.5.3.2 ceph osd crush reweight #
Utilizzo:
cephuser@adm > ceph osd crush reweight OSD_NAME NEW_WEIGHT
ceph osd crush reweight imposta il peso CRUSH dell'OSD. Si tratta di un valore arbitrario, che in genere corrisponde alle dimensioni del disco in TB, e controlla la quantità di dati che il sistema tenta di allocare sull'OSD.
17.5.4 Rimozione di un OSD #
Per rimuovere un OSD dalla mappa CRUSH di un cluster in esecuzione, eseguire quanto riportato di seguito:
cephuser@adm > ceph osd crush remove OSD_NAME17.5.5 Aggiunta di un compartimento #
Per aggiungere un compartimento alla mappa CRUSH di un cluster in esecuzione, eseguire il comando ceph osd crush add-bucket:
cephuser@adm > ceph osd crush add-bucket BUCKET_NAME BUCKET_TYPE17.5.6 Spostamento di un compartimento #
Per spostare un compartimento in un'altra ubicazione o posizione nella gerarchia della mappa CRUSH, eseguire quanto riportato di seguito:
cephuser@adm > ceph osd crush move BUCKET_NAME BUCKET_TYPE=BUCKET_NAME [...]Esempio:
cephuser@adm > ceph osd crush move bucket1 datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-117.5.7 Rimozione di un compartimento #
Per rimuovere un compartimento dalla gerarchia della mappa CRUSH, eseguire quanto riportato di seguito:
cephuser@adm > ceph osd crush remove BUCKET_NAMEI compartimenti devono essere vuoti per poter essere rimossi dalla gerarchia CRUSH.
17.6 Pulitura dei gruppi di posizionamento #
Oltre alla creazione di più copie di oggetti, Ceph assicura l'integrità dei dati tramite la pulitura dei gruppi di posizionamento. Per ulteriori informazioni su questi gruppi, consultare questo riferimento: Book “Guida alla distribuzione”, Chapter 1 “SES e Ceph”, Section 1.3.2 “Gruppi di posizionamento”. La pulitura Ceph è analoga all'esecuzione di fsck nel strato di memorizzazione degli oggetti. Per ciascun gruppo di posizionamento, Ceph genera un catalogo di tutti gli oggetti e confronta ciascun oggetto e le rispettive repliche per assicurare che non vi siano oggetti mancanti o non corrispondenti. Con la pulitura durante il giorno, vengono verificati le dimensioni e gli attributi degli oggetti, mentre con una pulitura settimanale più approfondita si effettua la lettura dei dati e mediante l'uso di checksum ne garantisce l'integrità.
La pulitura è importante per mantenere l'integrità dei dati, ma può ridurre le prestazioni. È possibile regolare le impostazioni seguenti per aumentare o diminuire le operazioni di pulitura:
osd max scrubsNumero massimo di operazioni di pulitura simultanee per un Ceph OSD. Il valore di default è 1.
osd scrub begin hour,osd scrub end hourOre del giorno (da 0 a 24) che definiscono una finestra temporale durante cui può avvenire la pulitura. Per default, questa finestra inizia alle ore 0 e termina alle ore 24.
ImportanteSe l'intervallo di pulitura del gruppo di posizionamento supera il valore dell'impostazione
osd scrub max interval, la pulitura verrà eseguita indipendentemente dalla finestra temporale definita per la stessa.osd scrub during recoveryConsente le operazioni di pulitura durante il recupero. Se si imposta su 'false' la pianificazione di nuove operazioni di pulitura verrà disabilitata durante un recupero attivo. Le operazioni di pulitura già in esecuzione continueranno normalmente. Questa opzione è utile per ridurre il carico di cluster trafficati. L'impostazione di default è "true".
osd scrub thread timeoutNumero massimo di secondi prima del timeout della pulitura. Il valore di default è 60.
osd scrub finalize thread timeoutIntervallo di tempo massimo espresso in secondi prima del time out del thread di completamento della pulitura. Il valore di default è 60*10.
osd scrub load thresholdCarico massimo normalizzato. Ceph non eseguirà la pulitura quando il carico del sistema (come definito dal rapporto
getloadavg()/numero dionline cpus) supera tale numero. Il valore di default è 0,5.osd scrub min intervalIntervallo minimo espresso in secondi per la pulitura di Ceph OSD quando il carico del cluster Ceph è basso. Il valore di default è 60*60*24 (una volta al giorno).
osd scrub max intervalIntervallo massimo espresso in secondi per la pulitura del Ceph OSD, a prescindere dal carico del cluster. Il valore di default è 7*60*60*24 (una volta alla settimana).
osd scrub chunk minNumero minimo di porzioni di archivio dati da pulire durante un'operazione singola. Ceph blocca le operazioni di scrittura su una porzione singola mentre è in corso la pulitura. Il valore di default è 5.
osd scrub chunk maxNumero massimo di porzioni di archivio dati da pulire durante un'operazione singola. Il valore di default è 25.
osd scrub sleepTempo di inattività prima della pulitura del gruppo successivo di porzioni. Se questo valore viene aumentato, l'operazione di pulitura risulta rallentata, mentre le operazioni del client sono meno influenzate. Il valore di default è 0.
osd deep scrub intervalIntervallo per la pulitura "approfondita" (lettura completa di tutti i dati). L'opzione
osd scrub load thresholdnon influisce su questa impostazione. Il valore di default è 60*60*24*7 (una volta alla settimana).osd scrub interval randomize ratioConsente di aggiungere un ritardo casuale al valore
osd scrub min intervalquando si pianifica il lavoro di pulitura successivo per un gruppo di posizionamento. Il ritardo è un valore casuale più piccolo rispetto al risultato diosd scrub min interval*osd scrub interval randomized ratio. Pertanto, l'impostazione di default distribuisce le puliture praticamente in modo casuale nella finestra temporale consentita di [1, 1,5] *osd scrub min interval. Il valore di default è 0,5.osd deep scrub strideConsente di leggere le dimensioni quando si effettua una pulitura approfondita. Il valore di default è 524288 (512 kB).
18 Gestione dei pool di memorizzazione #
Ceph memorizza i dati nei pool. I pool sono gruppi logici per la memorizzazione di oggetti. Quando inizialmente si installa un cluster senza creare un pool, Ceph utilizza i pool di default per la memorizzazione dei dati. Gli elementi di rilievo più importanti riportati di seguito sono relativi ai pool Ceph:
Resilienza: i pool Ceph forniscono resilienza tramite la replica o la codifica dei dati contenuti al loro interno. È possibile impostare ciascun pool come replicato (
replicated) o con codice di cancellazione (erasure coding). Per i pool replicati, è possibile impostare anche il numero di repliche, o copie, di cui disporrà ogni oggetto dati all'interno del pool. Il numero di copie (OSD, compartimenti/foglie CRUSH) che possono andare perse è inferiore di uno rispetto al numero delle repliche. Con il codice di cancellazione, è possibile impostare i valori dikem, dovekè il numero di porzioni di dati emè il numero di porzioni di codice. Per i pool con codice di cancellazione, il numero di porzioni di codice determina quanti OSD (compartimenti/foglie CRUSH) possono andare persi senza causare la perdita dei dati.Gruppi di posizionamento: è possibile impostare il numero di gruppi di posizionamento per il pool. In una configurazione tipica si utilizzano circa 100 gruppi di posizionamento per OSD per fornire il bilanciamento ottimale senza utilizzare troppe risorse di calcolo. Quando si configurano più pool, assicurarsi di impostare un numero ragionevole di gruppi di posizionamento per entrambi il pool e il cluster insieme.
Regole CRUSH: quando si memorizzano dati in un pool, gli oggetti e le relative repliche (o porzioni, nel caso dei pool con codice di cancellazione) vengono posizionati in base al set di regole CRUSH mappate al pool. È possibile creare una regola CRUSH personalizzata per il pool.
Snapshot: quando si creano snapshot con
ceph osd pool mksnap, si crea effettivamente uno snapshot di un determinato pool.
Per organizzare i dati nei pool, è possibile elencare, creare e rimuovere pool. È inoltre possibile visualizzare le statistiche di utilizzo per ciascun pool.
18.1 Creazione di un pool #
È possibile creare un pool replicato (replicated), per il recupero degli OSD persi mantenendo più copie degli oggetti, o di cancellazione (erasure) per ottenere la funzionalità RAID5 o 6 generalizzata. Per i pool replicati è necessario maggior spazio di storage nominale rispetto a quello necessario per i pool con codice di cancellazione. L'impostazione di default è replicated. Per ulteriori informazioni sui pool con codice di cancellazione, vedere il Capitolo 19, Pool con codice di cancellazione.
Per creare un pool replicato, eseguire:
cephuser@adm > ceph osd pool create POOL_NAMEL'utilità di dimensionamento automatico si occuperà della gestione degli argomenti facoltativi rimanenti. Per ulteriori informazioni, vedere Sezione 17.4.12, «Abilitazione dell'utilità di dimensionamento automatico del gruppo di posizionamento».
Per creare un pool con codice di cancellazione, eseguire:
cephuser@adm > ceph osd pool create POOL_NAME erasure CRUSH_RULESET_NAME \
EXPECTED_NUM_OBJECTS
Se si supera il limite di gruppi di posizionamento per OSD, è possibile che il comando ceph osd pool create si concluda con un errore. Il limite viene impostato con l'opzione mon_max_pg_per_osd.
- POOL_NAME
Indica il nome del pool. Deve essere univoco. Questa opzione è obbligatoria.
- POOL_TYPE
Indica il tipo di pool, che può essere sia
replicato, per recuperare dagli OSD persi mantenendo più copie degli oggetti, o dicancellazioneper ottenere un tipo di capacità RAID5 generalizzata. Per i pool replicati è richiesto uno spazio di memorizzazione non elaborato maggiore, ma consentono di implementare tutte le operazioni Ceph. Per i pool di cancellazione è richiesto uno spazio di memorizzazione non elaborato minore, ma è possibile implementare solo un sottoinsieme delle operazioni disponibili. L'impostazione di default perPOOL_TYPEèreplicated.- CRUSH_RULESET_NAME
Indica il nome del set di regole CRUSH per il pool. Se il set di regole specificato non esiste, la creazione dei pool replicati si concluderà con un errore con -ENOENT. Per i pool replicati, si tratta del set di regole specificato dalla variabile di configurazione
osd pool default CRUSH replicated ruleset. Questo set di regole deve esistere. Nel caso dei pool con codice di cancellazione, si tratta del set di regole "erasure-code", se è utilizzato il profilo con codice di cancellazione di default, oppure di POOL_NAME. Questo set di regole verrà creato in modo implicito se non esiste già.- erasure_code_profile=profile
Solo per i pool con codice di cancellazione. Utilizzare il profilo del codice di cancellazione. Deve essere un profilo esistente, come definito da
osd erasure-code-profile set.NotaSe per qualsiasi motivo l'utilità di dimensionamento automatico è stata disabilitata (
pg_autoscale_modeimpostata su off) su un pool, è possibile calcolare e impostare manualmente il numero di gruppi di posizionamento. Per informazioni più dettagliate sul calcolo del numero appropriato di gruppi di posizionamento per il pool, vedere Sezione 17.4, «Gruppi di posizionamento» (in lingua inglese).- EXPECTED_NUM_OBJECTS
Indica il numero di oggetti previsto per il pool. Quando questo valore viene impostato (insieme a una
soglia di unione del filestore), al momento della creazione del pool si verifica la suddivisione della cartella del gruppo di posizionamento. In tal modo si evita l'impatto di latenza con una suddivisione della cartella di runtime.
18.2 Elenco di pool #
Per elencare il pool del cluster, eseguire:
cephuser@adm > ceph osd pool ls18.3 Ridenominazione di un pool #
Per rinominare un pool, eseguire:
cephuser@adm > ceph osd pool rename CURRENT_POOL_NAME NEW_POOL_NAMESe si rinomina un pool e si dispone di funzionalità specifiche per il pool per un utente autenticato, è necessario aggiornare le funzionalità dell'utente con il nuovo nome pool.
18.4 Eliminazione di un pool #
I pool possono contenere dati importanti. L'eliminazione di un pool comporta la cancellazione di tutti i dati in esso contenuti e non è possibile recuperarli in alcun modo.
Poiché l'eliminazione involontaria di un pool è un pericolo effettivo, Ceph implementa due meccanismi che impediscono che ciò accada. Prima di poter eliminare un pool è necessario disabilitare entrambi i meccanismi.
Il primo di questi è il flag NODELETE. Ciascun pool è dotato di questo flag, il cui valore di default è "false". Per scoprire il valore di questo flag su un pool, eseguire il seguente comando:
cephuser@adm > ceph osd pool get pool_name nodelete
Se l'output è nodelete: true, non è possibile eliminare il pool fino a quando non si modifica il flag con il seguente comando:
cephuser@adm > ceph osd pool set pool_name nodelete false
Il secondo meccanismo è il parametro di configurazione esteso a tutto il cluster mon allow pool delete, il cui valore di default è "false". Vale a dire che per default non è possibile eliminare un pool. Il messaggio di errore visualizzato è:
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
Per eliminare il pool malgrado questa impostazione di sicurezza, è possibile impostare temporaneamente mon allow pool delete su "true", eliminare il pool e riportare il parametro su "false":
cephuser@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=truecephuser@adm >ceph osd pool delete pool_name pool_name --yes-i-really-really-mean-itcephuser@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=false
Con il comando injectargs viene visualizzato il seguente messaggio:
injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
Ciò conferma semplicemente che il comando è stato eseguito correttamente. Non si tratta di un errore.
Se sono stati creati set di regole propri e regole per un pool creato precedentemente, considerare di rimuovere tali regole quando il pool non è più necessario.
18.5 Altre operazioni #
18.5.1 Associazione di pool a un'applicazione #
Prima di utilizzare i pool, è necessario associare loro un'applicazione. I pool che verranno utilizzati con CephFS o quelli creati automaticamente da Object Gateway vengono associati automaticamente.
Negli altri casi, è possibile associare manualmente un nome applicazione in formato libero a un pool:
cephuser@adm > ceph osd pool application enable POOL_NAME APPLICATION_NAME
CephFS utilizza il nome applicazione cephfs, per il RADOS Block Device (dispositivo di blocco RADOS) viene utilizzato rbd e per Object Gateway viene utilizzato rgw.
È possibile associare un pool a più applicazioni, ciascuna delle quali può disporre di metadati propri. Per elencare l'applicazione (o le applicazioni) associata a un pool, immettere il comando seguente:
cephuser@adm > ceph osd pool application get pool_name18.5.2 Impostazione delle quote del pool #
È possibile impostare le quote del pool per il numero massimo di byte e/o il numero massimo di oggetti per pool.
cephuser@adm > ceph osd pool set-quota POOL_NAME MAX_OBJECTS OBJ_COUNT MAX_BYTES BYTESEsempio:
cephuser@adm > ceph osd pool set-quota data max_objects 10000Per rimuovere una quota, impostarne il valore a 0.
18.5.3 Visualizzazione delle statistiche del pool #
Per visualizzare le statistiche di utilizzo di un pool, eseguire:
cephuser@adm > rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.rgw.root 768 KiB 4 0 12 0 0 0 44 44 KiB 4 4 KiB 0 B 0 B
cephfs_data 960 KiB 5 0 15 0 0 0 5502 2.1 MiB 14 11 KiB 0 B 0 B
cephfs_metadata 1.5 MiB 22 0 66 0 0 0 26 78 KiB 176 147 KiB 0 B 0 B
default.rgw.buckets.index 0 B 1 0 3 0 0 0 4 4 KiB 1 0 B 0 B 0 B
default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B 0 B 0 B
default.rgw.log 0 B 207 0 621 0 0 0 5372132 5.1 GiB 3579618 0 B 0 B 0 B
default.rgw.meta 961 KiB 6 0 18 0 0 0 155 140 KiB 14 7 KiB 0 B 0 B
example_rbd_pool 2.1 MiB 18 0 54 0 0 0 3350841 2.7 GiB 118 98 KiB 0 B 0 B
iscsi-images 769 KiB 8 0 24 0 0 0 1559261 1.3 GiB 61 42 KiB 0 B 0 B
mirrored-pool 1.1 MiB 10 0 30 0 0 0 475724 395 MiB 54 48 KiB 0 B 0 B
pool2 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
pool3 333 MiB 37 0 111 0 0 0 3169308 2.5 GiB 14847 118 MiB 0 B 0 B
pool4 1.1 MiB 13 0 39 0 0 0 1379568 1.1 GiB 16840 16 MiB 0 B 0 BDi seguito è riportata una descrizione delle singole colonne:
- USED
Numero di byte utilizzati dal pool.
- OBJECTS
Numero di oggetti memorizzati nel pool.
- CLONES
Numero di cloni memorizzati nel pool. Quando viene creata una snapshot e si scrive su un oggetto, invece di modificare l'oggetto originale, ne viene creato un clone per evitare che il contenuto dell'oggetto originale acquisito tramite snapshot venga modificato.
- COPIES
Numero di repliche dell'oggetto. Ad esempio, se un pool replicato con fattore di replica di 3 contiene "x" oggetti, in genere disporrà di 3 * x copie.
- MISSING_ON_PRIMARY
Numero di oggetti in stato danneggiato (non esistono tutte le copie) mentre la copia è mancante sull'OSD primario.
- UNFOUND
Numero di oggetti non trovati.
- DEGRADED
Numero di oggetti danneggiati.
- RD_OPS
Numero totale di operazioni di lettura richieste per il pool.
- RD
Numero totale di byte letti dal pool.
- WR_OPS
Numero totale di operazioni di scrittura richieste per il pool.
- WR
Numero totale di byte scritti sul pool. Tenere presente che questo valore non corrisponde all'utilizzo del pool, poiché è possibile scrivere sullo stesso oggetto per più volte. Come risultato, il valore di utilizzo del pool rimarrà invariato, ma il numero di byte scritti nel pool aumenterà.
- USED COMPR
Numero di byte allocati per i dati compressi.
- UNDER COMPR
Numero di byte occupati dai dati compressi quando non lo sono.
18.5.4 Ottenimento dei valori del pool #
Per ottenere un valore da un pool, eseguire il comando get seguente:
cephuser@adm > ceph osd pool get POOL_NAME KEYÈ possibile ottenere valori per le chiavi elencate nella Sezione 18.5.5, «Impostazione dei valori del pool» oltre che per le chiavi seguenti:
- PG_NUM
Indica il numero di gruppi di posizionamento per il pool.
- PGP_NUM
Indica il numero effettivo dei gruppi di posizionamento da utilizzare quando si calcola il posizionamento dei dati. L'intervallo valido è uguale o minore di
PG_NUM.
Per visualizzare un elenco di tutti i valori correlati a un pool specifico, eseguire:
cephuser@adm > ceph osd pool get POOL_NAME all18.5.5 Impostazione dei valori del pool #
Per impostare un valore a un pool, eseguire:
cephuser@adm > ceph osd pool set POOL_NAME KEY VALUEDi seguito è riportato un elenco dei valori del pool ordinati per tipo di pool:
- crash_replay_interval
Indica il numero di secondi da consentire ai client per riprodurre richieste riconosciute, ma non sottoposte a commit.
- pg_num
Indica il numero di gruppi di posizionamento per il pool. Se si aggiungono nuovi OSD al cluster, verificare il valore dei gruppi di posizionamento su tutti i pool utilizzati come destinazione per i nuovi OSD.
- pgp_num
Indica il numero effettivo dei gruppi di posizionamento da utilizzare quando si calcola il posizionamento dei dati.
- crush_ruleset
Indica il set di regole da utilizzare per la mappatura del posizionamento oggetti nel cluster.
- hashpspool
Impostare (1) o annullare l'impostazione (0) del flag HASHPSPOOL su un determinato pool. Se si abilita questo flag, l'algoritmo viene modificato per distribuire meglio i gruppi di posizionamento agli OSD. Dopo aver abilitato questo flag in un pool il cui flag HASHPSPOOL è stato impostato sul valore 0 di default, nel cluster viene avviato il processo di backfill per fare in modo che il posizionamento di tutti i gruppi di posizionamento sia nuovamente corretto. Si tenga presente che questa procedura potrebbe generare un notevole carico I/O su un cluster, pertanto non abilitare il flag da 0 a 1 sui cluster di produzione con carico elevato.
- nodelete
Impedisce la rimozione del pool.
- nopgchange
Impedisce di modificare i valori
pg_numepgp_numdel pool.- noscrub,nodeep-scrub
Disabilita la pulitura (approfondita) dei dati per un pool specifico per risolvere carichi I/O temporaneamente elevati.
- write_fadvise_dontneed
Impostare o annullare l'impostazione del flag
WRITE_FADVISE_DONTNEEDsulle richieste di lettura/scrittura di un determinato pool per evitare l'inserimento dei dati nella cache. L'impostazione di default èfalse. Si applica a entrambi i pool replicati ed EC.- scrub_min_interval
Intervallo minimo espresso in secondi per la pulitura dei pool quando il carico del cluster è basso. Il valore di default
0significa che viene utilizzato il valoreosd_scrub_min_intervalricavato dal file di configurazione Ceph.- scrub_max_interval
Intervallo massimo espresso in secondi per la pulitura dei pool, indipendentemente dal carico del cluster. Il valore di default
0significa che viene utilizzato il valoreosd_scrub_max_intervalricavato dal file di configurazione Ceph.- deep_scrub_interval
Intervallo espresso in secondi per la pulitura approfondita del pool. Il valore di default
0significa che viene utilizzato il valoreosd_deep_scrubricavato dal file di configurazione Ceph.
- dimensione
Imposta il numero di repliche per gli oggetti nel pool. Per ulteriori informazioni, vedere Sezione 18.5.6, «Impostazione del numero di repliche di oggetti». Solo pool replicati.
- min_size
Imposta il numero minimo di repliche richiesto per I/O. Per ulteriori informazioni, vedere Sezione 18.5.6, «Impostazione del numero di repliche di oggetti». Solo pool replicati.
- nosizechange
Impedisce di modificare le dimensioni del pool. Durante la creazione di un pool, il valore di default è ricavato dal valore del parametro
osd_pool_default_flag_nosizechange, impostato sufalseper default. Si applica soltanto ai pool replicati perché non è possibile modificare le dimensioni dei pool EC.- hit_set_type
Consente di controllare i set di accessi per i pool di cache. Per ulteriori informazioni, vedere Bloom Filter (in lingua inglese). Questa opzione può contenere i seguenti valori:
bloom,explicit_hash,explicit_object. Il valore di default èbloom, gli altri valori sono solo ai fini dei test.- hit_set_count
Indica il numero di set di accessi per i pool di cache. Più elevato è il numero, maggiore è il consumo di RAM da parte del daemon
ceph-osd. Il valore di default è0.- hit_set_period
Indica la durata, espressa in secondi, di un periodo di set di accessi per i pool di cache. Più elevato è il numero, maggiore è il consumo di RAM da parte del daemon
ceph-osd. Durante la creazione di un pool, il valore di default è ricavato dal valore del parametroosd_tier_default_cache_hit_set_period, impostato su1200per default. Si applica soltanto ai pool replicati perché non è possibile utilizzare i pool EC come livello di cache.- hit_set_fpp
Probabilità falsa positiva per il tipo di set di accessi bloom. Per ulteriori informazioni, vedere Bloom Filter (in lingua inglese). L'intervallo valido è da 0,0 a 1,0; il valore di default è
0,05- use_gmt_hitset
Forza gli OSD a utilizzare le registrazioni dell'orario GMT (ora di Greenwich) quando si crea un set di accessi per la suddivisione in livelli di cache. In tal modo ci si assicura che i nodi in fusi orari diversi restituiscano lo stesso risultato. Il valore di default è
1. Tale valore non deve essere modificato.- cache_target_dirty_ratio
Indica la percentuale del pool di cache contenente oggetti modificati prima che l'agente di suddivisione in livelli di cache li svuoti nel pool di memorizzazione di supporto. Il valore di default è
0.4.- cache_target_dirty_high_ratio
Indica la percentuale del pool di cache contenente oggetti modificati prima che l'agente di suddivisione in livelli di cache li svuoti nel pool di memorizzazione di supporto con una velocità più elevata. Il valore di default è
0.6.- cache_target_full_ratio
Indica la percentuale del pool di cache contenente oggetti non modificati prima che l'agente di suddivisione in livelli di cache li rimuova dal pool di cache. Il valore di default è
0.8.- target_max_bytes
Ceph inizierà lo svuotamento o la rimozione degli oggetti quando viene attivata la soglia
max_bytes.- target_max_objects
Ceph inizierà lo svuotamento o la rimozione degli oggetti quando viene attivata la soglia
max_objects.- hit_set_grade_decay_rate
Grado di decadimento della temperatura tra due
hit_setconsecutivi. Il valore di default è20.- hit_set_search_last_n
Numero massimo
Ndi visualizzazioni neglihit_setper il calcolo della temperatura. Il valore di default è1.- cache_min_flush_age
Tempo (in secondi) prima che l'agente di suddivisione in livelli di cache svuoti un oggetto dal pool di cache nel pool di memorizzazione.
- cache_min_evict_age
Tempo (in secondi) prima che l'agente di suddivisione in livelli di cache rimuova un oggetto dal pool di cache.
- fast_read
Se questo flag è abilitato nei pool con codice di cancellazione, la richiesta di lettura emette sottoletture a tutte le partizioni e attende di ricevere un numero sufficiente di partizioni da decodificare per servire il client. Nel caso dei plug-in di cancellazione jerasure e isa, quando vengono restituite le prime risposte
K, la richiesta del client viene eseguita immediatamente utilizzando i dati decodificati da tali risposte. Questo approccio causa un maggiore carico sulla CPU e un minore carico sul disco/sulla rete. Attualmente il flag è supportato solo per i pool con codice di cancellazione. Il valore di default è0.
18.5.6 Impostazione del numero di repliche di oggetti #
Per impostare il numero di repliche di oggetti in un pool replicato, eseguire quanto riportato di seguito:
cephuser@adm > ceph osd pool set poolname size num-replicasIn num-replicas è incluso l'oggetto stesso. Se ad esempio si desiderano l'oggetto e due copie dello stesso per un totale di tre istanze dell'oggetto, specificare 3.
Se si imposta num-replicas a 2, si otterrà solo una copia dei dati. Se si perde un'istanza oggetto, è necessario confidare nel fatto che l'altra copia non sia corrotta, ad esempio dall'ultima pulitura effettuata durante il recupero (fare riferimento alla Sezione 17.6, «Pulitura dei gruppi di posizionamento»).
L'impostazione di un pool a una replica significa che nel pool è presente una istanza esatta dell'oggetto Dati. In caso di errore dell'OSD, i dati vengono persi. Un utilizzo possibile di un pool con una replica consiste nella memorizzazione temporanea dei dati per un breve periodo.
Se vengono impostate 4 repliche per un pool, è possibile aumentare l'affidabilità del 25%.
Nel caso di due data center, è necessario impostare almeno 4 repliche per un pool affinché siano presenti due copie in ciascun data center per fare in modo che, se un data center viene perso, ne esistano comunque due copie e i dati vengano conservati anche in caso di perdita di un disco.
Un oggetto potrebbe accettare I/O danneggiati con meno di pool size repliche. Per impostare un numero minimo di repliche obbligatorie per I/O, si deve utilizzare l'impostazione min_size. Esempio:
cephuser@adm > ceph osd pool set data min_size 2
In tal modo ci si assicura che nessun oggetto nel pool di dati riceva I/O con meno di min_size repliche.
Per ottenere il numero di repliche di oggetti, eseguire quanto riportato di seguito:
cephuser@adm > ceph osd dump | grep 'replicated size'
Ceph elencherà i pool, con l'attributo replicated size evidenziato. Per default, Ceph crea due repliche di un oggetto (per un totale di tre copie o una dimensione pari a 3).
18.6 Migrazione del pool #
Quando si crea un pool (vedere Sezione 18.1, «Creazione di un pool») è necessario specificarne i parametri iniziali, come il tipo di pool o il numero dei gruppi di posizionamento. Se in un secondo momento si decide di modificare uno di questi parametri, ad esempio durante la conversione di un pool replicato in uno con codice di cancellazione o se si riduce il numero di gruppi di posizionamento, è necessario eseguire la migrazione dei dati del pool su un altro i cui parametri sono adatti alla distribuzione attualmente attiva.
Questa sezione descrive due metodi di migrazione: il metodo del livello di cache, per la migrazione dei dati generali del pool, e il metodo basato sui sottocomandi rbd migrate, per la migrazione delle immagini RBD a un nuovo pool. Ogni metodo presenta le proprie specifiche e limitazioni.
18.6.1 Limitazioni #
È possibile utilizzare il metodo del livello di cache per eseguire la migrazione da un pool replicato a un pool EC o a un altro pool replicato. La migrazione da un pool EC non è supportata.
Non è possibile eseguire la migrazione delle immagini RBD e delle esportazioni CephFS da un pool replicato a un pool EC. Il motivo di questa limitazione risiede nel fatto che i pool EC non supportano
omap, laddove invece RBD e CephFS utilizzanoomapper memorizzare i metadati. Ad esempio, lo svuotamento dell'oggetto intestazione dell'RBD non riuscirà correttamente. Tuttavia, è possibile eseguire la migrazione dei dati a un pool EC, lasciando i metadati in un pool replicato.Il metodo
rbd migrationconsente di eseguire la migrazione delle immagini con un tempo di fermo del client minimo. È necessario soltanto interrompere il client prima del passaggiopreparee avviarlo in seguito. Tenere presente che solo un clientlibrbdche supporta questa funzione (Ceph Nautilus o più recenti) sarà in grado di aprire l'immagine subito dopo il passaggioprepare, mentre i clientlibrbdmeno recenti o i clientkrbdnon saranno in grado di aprire l'immagine finché non viene eseguita la fasecommit.
18.6.2 Esecuzione della migrazione con il livello di cache #
Il principio è semplice: includere il pool di cui eseguire la migrazione in un livello di cache in ordine inverso. Nell'esempio seguente viene eseguita la migrazione di un pool replicato denominato "testpool" a un pool con codice di cancellazione:
Creare un novo pool con codice di cancellazione denominato "newpool". Fare riferimento alla Sezione 18.1, «Creazione di un pool» per una spiegazione dettagliata dei parametri di creazione del pool.
cephuser@adm >ceph osd pool create newpool erasure defaultVerificare che il portachiavi del client utilizzato fornisca per "newpool" almeno le stesse capacità di "testpool".
Adesso si hanno due pool: quello originale replicato "testpool" compilato con i dati e il nuovo pool con codice di cancellazione vuoto "newpool":
 Figura 18.1: Pool prima della migrazione #
Figura 18.1: Pool prima della migrazione #Impostare il livello di cache e configurare il pool replicato "testpool" come pool di cache. L'opzione
-force-nonemptyconsente di aggiungere un livello di cache anche se il pool contiene già dei dati:cephuser@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=1'cephuser@adm >ceph osd tier add newpool testpool --force-nonemptycephuser@adm >ceph osd tier cache-mode testpool proxy Figura 18.2: Configurazione del livello di cache #
Figura 18.2: Configurazione del livello di cache #Forzare il pool di cache in modo che tutti gli oggetti vengano spostati nel nuovo pool:
cephuser@adm >rados -p testpool cache-flush-evict-all Figura 18.3: Svuotamento dei dati #
Figura 18.3: Svuotamento dei dati #Fino a quando lo svuotamento di tutti i dati nel pool con codice di cancellazione non è completato, è necessario specificare un overlay in modo che la ricerca degli oggetti venga eseguita nel pool precedente:
cephuser@adm >ceph osd tier set-overlay newpool testpoolCon l'overlay, tutte le operazioni vengono inoltrate al "testpool" replicato precedente:
 Figura 18.4: Impostazione dell'overlay #
Figura 18.4: Impostazione dell'overlay #Adesso è possibile commutare tutti i client agli oggetti di accesso nel nuovo pool.
Dopo la migrazione di tutti i dati nel "newpool" con codice di cancellazione, rimuovere l'overlay e il pool di cache "testpool" precedente:
cephuser@adm >ceph osd tier remove-overlay newpoolcephuser@adm >ceph osd tier remove newpool testpool Figura 18.5: Completamento della migrazione #
Figura 18.5: Completamento della migrazione #Esegui
cephuser@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=0'
18.6.3 Esecuzione della migrazione di immagini RBD #
Di seguito è indicata la modalità consigliata per eseguire la migrazione delle immagini RBD da un pool replicato a un altro.
Interrompere l'accesso dei client (ad esempio le macchine virtuali) all'immagine RBD.
Creare una nuova immagine nel pool di destinazione, con l'elemento superiore impostato sull'immagine di origine:
cephuser@adm >rbd migration prepare SRC_POOL/IMAGE TARGET_POOL/IMAGESuggerimento: migrazione soltanto dei dati a un pool con codice di cancellazioneSe è necessario eseguire la migrazione soltanto dei dati dell'immagine a un nuovo pool EC e lasciare i metadati nel pool replicato originale, eseguire invece il comando seguente:
cephuser@adm >rbd migration prepare SRC_POOL/IMAGE \ --data-pool TARGET_POOL/IMAGEConcedere ai client l'accesso all'immagine nel pool di destinazione.
Eseguire la migrazione dei dati al pool di destinazione:
cephuser@adm >rbd migration execute SRC_POOL/IMAGERimuovere l'immagine meno recente:
cephuser@adm >rbd migration commit SRC_POOL/IMAGE
18.7 Snapshot del pool #
Gli snapshot del pool riprendono lo stato dell'interno pool Ceph. Con gli snapshot del pool è possibile mantenere la cronologia dello stato del pool. La creazione di snapshot del pool consuma spazio di storage in modo proporzionale alle dimensioni del pool. Verificare sempre che lo spazio su disco nello spazio di memorizzazione correlato sia sufficiente prima di creare lo snapshot di un pool.
18.7.1 Creazione dello snapshot di un pool #
Per creare una snapshot di un pool, eseguire:
cephuser@adm > ceph osd pool mksnap POOL-NAME SNAP-NAMEEsempio:
cephuser@adm > ceph osd pool mksnap pool1 snap1
created pool pool1 snap snap118.7.2 Elenco di snapshot di un pool #
Per visualizzare un elenco delle snapshot esistenti di un pool, eseguire:
cephuser@adm > rados lssnap -p POOL_NAMEEsempio:
cephuser@adm > rados lssnap -p pool1
1 snap1 2018.12.13 09:36:20
2 snap2 2018.12.13 09:46:03
2 snaps18.7.3 Rimozione dello snapshot di un pool #
Per rimuovere una snapshot di un pool, eseguire:
cephuser@adm > ceph osd pool rmsnap POOL-NAME SNAP-NAME18.8 Compressione dei dati #
Per risparmiare spazio su disco, in BlueStore (ulteriori dettagli nel riferimento Book “Guida alla distribuzione”, Chapter 1 “SES e Ceph”, Section 1.4 “BlueStore”) è disponibile la compressione rapida dei dati. Il rapporto di compressione dipende dai dati memorizzati nel sistema. Tenere presente che per le attività di compressione/decompressione è richiesta una potenza della CPU aggiuntiva.
È possibile configurare la compressione dei dati a livello globale (vedere la Sezione 18.8.3, «Opzioni di compressione globali») e quindi sostituire le impostazioni di compressione specifiche per ciascun pool individuale.
È possibile abilitare o disabilitare la compressione dei dati del pool o modificare l'algoritmo e la modalità di compressione in qualsiasi momento, a prescindere dal fatto che il pool contenga o meno dati.
Dopo aver abilitato la compressione del pool, non verrà applicata alcuna compressione ai dati esistenti.
Dopo aver disabilitato la compressione di un pool, tutti i relativi dati verranno decompressi.
18.8.1 Abilitazione della compressione #
Per abilitare la compressione dei dati per un pool denominato POOL_NAME, eseguire il comando seguente:
cephuser@adm >cephosd pool set POOL_NAME compression_algorithm COMPRESSION_ALGORITHMcephuser@adm >cephosd pool set POOL_NAME compression_mode COMPRESSION_MODE
Per disabilitare la compressione dei dati per un pool, utilizzare "none" come algoritmo di compressione:
cephuser@adm >cephosd pool set POOL_NAME compression_algorithm none
18.8.2 Opzioni di compressione del pool #
Elenco completo delle opzioni di compressione:
- compression_algorithm
I valori possibili sono
none,zstd,snappy. L'impostazione di default èsnappy.L'algoritmo di compressione da utilizzare dipenda dal caso di utilizzo specifico. Di seguito sono riportati alcuni suggerimenti:
Utilizzare il valore di default
snappya meno che non sia necessario modificarlo per qualche motivo.zstdoffre un buon rapporto di compressione, ma causa un elevato overhead della CPU durante la compressione di piccole quantità di dati.Eseguire un benchmark di questi algoritmi su un campione dei dati effettivi continuando a osservare la CPU e il consumo di memoria del cluster.
- compression_mode
I valori possibili sono
none,aggressive,passive,force. L'impostazione di default ènone.none: la compressione non viene eseguita maipassive: la compressione viene eseguita se suggerita comeCOMPRESSIBLEaggressive: la compressione viene eseguita a meno che non sia suggerita comeINCOMPRESSIBLEforce: la compressione viene eseguita sempre
- compression_required_ratio
Valore: doppio, rapporto = SIZE_COMPRESSED / SIZE_ORIGINAL. Il valore di default è
0,875, che indica che l'oggetto non verrà compresso se la compressione non riduce lo spazio occupato di almeno il 12,5%.Gli oggetti al di sopra di tale rapporto non verranno memorizzati compressi a causa del basso guadagno netto.
- compression_max_blob_size
Valore: intero non firmato, dimensioni in byte. Default:
0Dimensioni massime degli oggetti che vengono compressi.
- compression_min_blob_size
Valore: intero non firmato, dimensioni in byte. Default:
0Dimensioni massime degli oggetti che vengono compressi.
18.8.3 Opzioni di compressione globali #
È possibile impostare le seguenti opzioni di configurazione nella configurazione di Ceph e applicarle a tutti gli OSD, non solo a un singolo pool. La configurazione specifica per il pool indicata nella Sezione 18.8.2, «Opzioni di compressione del pool» ha la precedenza.
- bluestore_compression_algorithm
Vedere compression_algorithm
- bluestore_compression_mode
Vedere compression_mode
- bluestore_compression_required_ratio
Vedere compression_required_ratio
- bluestore_compression_min_blob_size
Valore: intero non firmato, dimensioni in byte. Default:
0Dimensioni massime degli oggetti che vengono compressi. L'impostazione viene ignorata per default a favore di
bluestore_compression_min_blob_size_hddebluestore_compression_min_blob_size_ssd. Ha la precedenza quando viene impostata su un valore diverso da zero.- bluestore_compression_max_blob_size
Valore: intero non firmato, dimensioni in byte. Default:
0Dimensioni massime degli oggetti compressi prima che vengano suddivisi in porzioni più piccole. L'impostazione viene ignorata per default a favore di
bluestore_compression_max_blob_size_hddebluestore_compression_max_blob_size_ssd. Ha la precedenza quando viene impostata su un valore diverso da zero.- bluestore_compression_min_blob_size_ssd
Valore: intero non firmato, dimensioni in byte. Default:
8 KDimensioni minime degli oggetti che vengono compressi e memorizzati su un'unità SSD.
- bluestore_compression_max_blob_size_ssd
Valore: intero non firmato, dimensioni in byte. Default:
64 KDimensioni massime degli oggetti compressi e memorizzati nell'unità a stato solito prima che vengano suddivisi in porzioni più piccole.
- bluestore_compression_min_blob_size_hdd
Valore: intero non firmato, dimensioni in byte. Default:
128 KDimensioni minime degli oggetti che vengono compressi e memorizzati su dischi rigidi.
- bluestore_compression_max_blob_size_hdd
Valore: intero non firmato, dimensioni in byte. Default:
512 KDimensioni massime degli oggetti compressi e memorizzati nei dischi rigidi prima che vengano suddivisi in porzioni più piccole.
19 Pool con codice di cancellazione #
Ceph fornisce un'alternativa alla replica normale dei dati nei pool denominata pool di cancellazione o con codice di cancellazione. I pool di cancellazione non forniscono le funzionalità complete dei pool replicati (ad esempio, non sono in grado di memorizzare i metadati dei pool RBD), ma richiedono meno spazio di storage nominale. Un pool di cancellazione di default con 1 TB di storage di dati richiede 1,5 TB di spazio di storage nominale e prevede un solo errore del disco. Si tratta sicuramente di un vantaggio rispetto al pool replicato, che richiede 2 TB di spazio di storage nominale per lo stesso scopo.
Per ulteriori informazioni sul codice di cancellazione, vedere https://en.wikipedia.org/wiki/Erasure_code.
Per un elenco dei valori del pool relativo ai pool EC, fare riferimento a Valori del pool con codice di cancellazione.
19.1 Prerequisiti dei pool con codice di cancellazione #
Per utilizzare il codice di cancellazione, è necessario:
Definire una regola di cancellazione nella mappa CRUSH.
Definire un profilo con codice di cancellazione che specifichi l'algoritmo da utilizzare.
Creare un pool utilizzando la regola e il profilo menzionati in precedenza.
Tenere presente che non sarà possibile modificare il profilo e i relativi dettagli in seguito alla creazione del pool e all'aggiunta di dati.
Assicurarsi che le regole CRUSH per i pool di cancellazione utilizzino indep per step. Per informazioni, vedere Sezione 17.3.2, «firstn e indep».
19.2 Creazione di un pool con codice di cancellazione di esempio #
Il pool con codice di cancellazione più semplice equivale a RAID5 e richiede almeno tre host. In questa procedura è illustrato come creare un pool ai fini del test.
Il comando
ceph osd pool createviene utilizzato per creare un pool di tipo cancellazione.12sta per il numero di gruppi di posizionamento. Con i parametri di default, il pool è in grado di gestire gli errori di un OSD.cephuser@adm >ceph osd pool create ecpool 12 12 erasure pool 'ecpool' createdLa stringa
ABCDEFGHIviene scritta in un oggetto denominatoNYAN.cephuser@adm >echo ABCDEFGHI | rados --pool ecpool put NYAN -Ai fini del test, adesso è possibile disabilitare gli OSD, ad esempio disconnettendoli dalla rete.
Per verificare se il pool è in grado di gestire gli errori dei dispositivi, è possibile accedere al contenuto del file mediante il comando
rados.cephuser@adm >rados --pool ecpool get NYAN - ABCDEFGHI
19.3 Profili dei codici di cancellazione #
Quando si richiama il comando ceph osd pool create per creare un pool di cancellazione, viene utilizzato il profilo di default a meno che non se ne specifichi un altro. I profili definiscono la ridondanza dei dati. A tal fine impostare due parametri, denominati arbitrariamente k ed m. k ed m definiscono il numero di porzioni in cui vengono suddivisi i dati e quante porzioni di codifica vengono create. Le porzioni ridondanti vengono quindi memorizzate in OSD diversi.
Definizioni necessarie per i profili dei pool di cancellazione:
- chunk
quando si richiama la funzione di codifica, vengono restituite porzioni della stessa dimensione: le porzioni di dati che è possibile concatenare per ricostruire l'oggetto originale e le porzioni di codifica che è possibile utilizzare per ricompilare una porzione persa.
- k
il numero di porzioni di dati, ovvero il numero di porzioni in cui è suddiviso l'oggetto originale. Ad esempio, se
k = 2, un oggetto da 10 KB verrà suddiviso inkoggetti da 5 KB ciascuno. Il valoremin_sizedi default nei pool con codice di cancellazione èk + 1. Tuttavia, si consiglia di impostare il valoremin_sizesu almenok + 2per evitare la perdita di dati e operazioni di scrittura.- m
il numero di porzioni di codifica, ovvero il numero di porzioni aggiuntive calcolato dalle funzioni di codifica. Esistono 2 porzioni di codifica, vale a dire che 2 OSD possono essere fuori senza perdere dati.
- crush-failure-domain
definisce a quali dispositivi vengono distribuite le porzioni. È necessario impostare come valore un tipo di compartimento. Per tutti i tipi di compartimenti, vedere Sezione 17.2, «Compartimenti». Se il dominio dell'errore è
rack, le porzioni saranno memorizzate in rack diversi al fine di aumentare la resilienza in caso di errore dei rack. Tenere presente che ciò richiede dei rack k+m.
Con il profilo con codice di cancellazione di default utilizzato in Sezione 19.2, «Creazione di un pool con codice di cancellazione di esempio», i dati del cluster non andranno persi in caso di errore di un singolo OSD o di un host. Pertanto, per memorizzare 1 TB di dati è necessario uno spazio di memorizzazione effettivo di altri 0,5 TB. Ciò vuol dire che per 1 TB di dati sono necessari 1,5 TB di spazio di storage nominale (perché k=2, m=1). Ciò equivale a una normale configurazione RAID 5. Un pool replicato necessita invece di 2 TB di spazio di storage nominale per memorizzare 1 TB di dati.
È possibile visualizzare le impostazioni del profilo di default con:
cephuser@adm > ceph osd erasure-code-profile get default
directory=.libs
k=2
m=1
plugin=jerasure
crush-failure-domain=host
technique=reed_sol_vanÈ importante scegliere il profilo giusto perché non è possibile modificarlo dopo la creazione del pool. È necessario creare un nuovo pool con un profilo diverso e trasferirvi tutti gli oggetti del pool precedente (vedere la Sezione 18.6, «Migrazione del pool»).
I parametri più importanti del profilo sono k, m e crush-failure-domain in quanto definiscono l'overhead di memorizzazione e la durata dei dati. Ad esempio, se l'architettura desiderata deve sostenere la perdita di due rack con un overhead di storage del 66%, è possibile definire il profilo seguente. Tenere presente che ciò si applica solo alle mappe CRUSH contenenti compartimenti di tipo "rack":
cephuser@adm > ceph osd erasure-code-profile set myprofile \
k=3 \
m=2 \
crush-failure-domain=rackÈ possibile ripetere l'esempio della Sezione 19.2, «Creazione di un pool con codice di cancellazione di esempio» con questo nuovo profilo:
cephuser@adm >ceph osd pool create ecpool 12 12 erasure myprofilecephuser@adm >echo ABCDEFGHI | rados --pool ecpool put NYAN -cephuser@adm >rados --pool ecpool get NYAN - ABCDEFGHI
L'oggetto NYAN verrà diviso in tre (k=3) e verranno create due porzioni aggiuntive (m=2). Il valore di m definisce quanti OSD è possibile perdere simultaneamente senza perdere alcun dato. Con il comando crush-failure-domain=rack verrà creato un set di regole CRUSH che garantisce che le due porzioni non vengano memorizzate nello stesso rack.

19.3.1 Creazione di un nuovo profilo con codice di cancellazione #
Il comando seguente consente di creare un nuovo profilo con codice di cancellazione:
# ceph osd erasure-code-profile set NAME \
directory=DIRECTORY \
plugin=PLUGIN \
stripe_unit=STRIPE_UNIT \
KEY=VALUE ... \
--force- DIRECTORY
Opzionale. Impostare il nome della directory da cui viene caricato il plug-in del codice di cancellazione. Quello di default è
/usr/lib/ceph/erasure-code.- PLUGIN
Opzionale. Utilizzare il plug-in del codice di cancellazione per calcolare le porzioni di codifica e recuperare quelle mancanti. I plug-in disponibili sono "jerasure", "isa", "lrc" e "shes". Il plug-in di default è "jerasure".
- STRIPE_UNIT
Opzionale. La quantità di dati in una porzione di dati per segmento. Ad esempio, un profilo con 2 porzioni di dati e stripe_unit=4K inserisce l'intervallo 0-4K nella porzione 0, 4K-8K nella porzione 1 e quindi 8K-12K nuovamente nella porzione 0. Per le migliori prestazioni, deve essere un multiplo di 4K. Il valore di default viene estrapolato dall'opzione di configurazione di monitoraggio
osd_pool_erasure_code_stripe_unital momento della creazione di un pool. Il valore "stripe_width" di un pool che utilizza questo profilo sarà il numero delle porzioni di dati moltiplicato per questo valore di "stripe_unit".- KEY=VALUE
Le coppie di opzioni di chiavi/valori specifiche per il plug-in del codice di cancellazione selezionato.
- --force
Opzionale. Ignora un profilo esistente con lo stesso nome e consente l'impostazione di una stripe_unit non allineata a 4K.
19.3.2 Rimozione di un profilo con codice di cancellazione #
Il comando seguente consente di rimuovere un profilo con codice di cancellazione identificato dal relativo nome (NAME):
# ceph osd erasure-code-profile rm NAMESe è presente un pool che fa riferimento al profilo, l'eliminazione non riesce.
19.3.3 Visualizzazione dei dettagli di un profilo con codice di cancellazione #
Il comando seguente consente di visualizzare i dettagli di un profilo con codice di cancellazione identificato dal relativo nome (NAME):
# ceph osd erasure-code-profile get NAME19.3.4 Elenco dei profili con codice di cancellazione #
Il comando seguente consente di visualizzare un elenco dei nomi di tutti i profili con codice di cancellazione:
# ceph osd erasure-code-profile ls19.4 Contrassegno dei pool con codice di cancellazione con il dispositivo di blocco RADOS (RADOS Block Device, RBD) #
Per contrassegnare un pool EC come pool RBD, applicare il rispettivo tag:
cephuser@adm > ceph osd pool application enable rbd ec_pool_nameRBD può memorizzare data immagine nei pool EC. Tuttavia, l'intestazione di immagine e i metadati devono comunque essere memorizzati in un pool replicato. A tal fine, presupporre di disporre di un pool denominato "rbd":
cephuser@adm > rbd create rbd/image_name --size 1T --data-pool ec_pool_nameÈ possibile utilizzare normalmente l'immagine come qualsiasi altra, con la differenza che tutti i dati saranno memorizzati nel pool ec_pool_name al posto del pool "rbd".
20 Dispositivo di blocco RADOS (RADOS Block Device, RBD) #
Un blocco è una sequenza di byte, ad esempio un blocco di dati da 4 MB. Le interfacce di memorizzazione basate su blocchi rappresentano il modo più comune per memorizzare i dati con supporti rotanti, come dischi rigidi, CD, dischi floppy. L'ubiquità delle interfacce dei dispositivi di blocco rende un dispositivo di blocco virtuale un candidato ideale per interagire con un sistema di memorizzazione di massa come Ceph.
I dispositivi di blocco Ceph consentono la condivisione di risorse fisiche e sono ridimensionabili. Questi dispositivi memorizzano i dati suddivisi in più OSD in un cluster Ceph. I dispositivi di blocco Ceph sfruttano le funzionalità RADOS come la creazione di snapshot, replica e coerenza. I RADOS Block Device (RBD, dispositivi di blocco RADOS) di Ceph interagiscono con gli OSD utilizzando i moduli del kernel o la libreria librbd.

I dispositivi di blocco Ceph offrono prestazioni elevate con scalabilità infinita ai moduli del kernel. Supportano soluzioni di virtualizzazione come QEMU o sistemi di calcolo basati su cloud come OpenStack che fanno affidamento su libvirt. È possibile utilizzare lo stesso cluster per attivare Object Gateway, CephFS e RADOS Block Device (dispositivi di blocco RADOS) simultaneamente.
20.1 Comandi dei dispositivi di blocco #
Il comando rbd consente di creare, elencare, analizzare e rimuovere immagini dei dispositivi di blocco. È inoltre possibile utilizzarlo per clonare immagini, creare snapshot, eseguire il rollback di un'immagine in uno snapshot o visualizzare uno snapshot.
20.1.1 Creazione di un'immagine del dispositivo di blocco in un pool replicato #
Prima che sia possibile aggiungere un dispositivo di blocco a un client, è necessario creare un'immagine correlata in un pool esistente (vedere il Capitolo 18, Gestione dei pool di memorizzazione):
cephuser@adm > rbd create --size MEGABYTES POOL-NAME/IMAGE-NAMEAd esempio, per creare un'immagine da 1 GB denominata "myimage" le cui informazioni vengono memorizzate in un pool denominato "mypool", eseguire quanto riportato di seguito:
cephuser@adm > rbd create --size 1024 mypool/myimageSe si omette la scorciatoia dell'unità di dimensioni ("G" o "T"), le dimensioni dell'immagine vengono indicate in megabyte. Utilizzare "G" o "T" dopo le dimensioni per specificare gigabyte o terabyte.
20.1.2 Creazione di un'immagine del dispositivo di blocco in un pool con codice di cancellazione #
È possibile memorizzare i dati dell'immagine di un dispositivo di blocco direttamente nei pool con codice di cancellazione (EC, Erasure Coded). L'immagine di un dispositivo di blocco RADOS è costituita da due parti, dati e metadati. È possibile memorizzare solo la parte dati dell'immagine di un dispositivo di blocco RADOS (RADOS Block Device, RBD) in un pool EC. Il flag overwrite del pool deve essere impostato su true e ciò è possibile soltanto se tutti gli OSD in cui è memorizzato il pool utilizzano BlueStore.
Non è possibile memorizzare la parte metadati dell'immagine in un pool EC. È necessario specificare il pool replicato per memorizzare i metadati dell'immagine con l'opzione --pool= del comando rbd create oppure aggiungendo pool/ come prefisso del nome dell'immagine.
Creare un pool EC:
cephuser@adm >ceph osd pool create EC_POOL 12 12 erasurecephuser@adm >ceph osd pool set EC_POOL allow_ec_overwrites true
Specificare il pool replicato per la memorizzazione dei metadati:
cephuser@adm > rbd create IMAGE_NAME --size=1G --data-pool EC_POOL --pool=POOLOppure:
cephuser@adm > rbd create POOL/IMAGE_NAME --size=1G --data-pool EC_POOL20.1.3 Elenco delle immagini dei dispositivi di blocco #
Per visualizzare un elenco dei dispositivi di blocco in un pool denominato "mypool", eseguire quanto riportato di seguito:
cephuser@adm > rbd ls mypool20.1.4 Recupero delle informazioni sull'immagine #
Per recuperare le informazioni da un'immagine "myimage" in un pool denominato "mypool", eseguire quanto riportato di seguito:
cephuser@adm > rbd info mypool/myimage20.1.5 Ridimensionamento di un'immagine del dispositivo di blocco #
Le immagini del RADOS Block Device (dispositivo di blocco RADOS) sono sottoposte a thin provisioning, non utilizzano effettivamente alcuno spazio di memorizzazione fisico fino a quando non si inizia a salvare i dati in esse. Dispongono tuttavia di una capacità massima che è possibile impostare con l'opzione --size. Se si desidera aumentare (o diminuire) le dimensioni massime di un'immagine, eseguire quanto riportato di seguito:
cephuser@adm >rbd resize --size 2048 POOL_NAME/IMAGE_NAME # to increasecephuser@adm >rbd resize --size 2048 POOL_NAME/IMAGE_NAME --allow-shrink # to decrease
20.1.6 Rimozione di un'immagine del dispositivo di blocco #
Per rimuovere un dispositivo di blocco che corrisponde a un'immagine "myimage" in un pool denominato "mypool", eseguire quanto riportato di seguito:
cephuser@adm > rbd rm mypool/myimage20.2 Montaggio e smontaggio #
Dopo aver creato un dispositivo di blocco RADOS, è possibile utilizzarlo come qualsiasi altro dispositivo disco: formattarlo, montarlo in modo che sia in grado di scambiare file e smontarlo al termine dell'operazione.
L'impostazione di default del comando rbd è configurata sull'accesso al cluster tramite l'account utente admin di Ceph, che dispone dell'accesso amministrativo completo al cluster. Con questa impostazione vi è il rischio che gli utenti possano causare involontariamente danni, come quando si esegue il login come root a una workstation Linux. Pertanto, è preferibile creare account utente con meno privilegi e utilizzare tali account per il normale accesso in lettura/scrittura al dispositivo di blocco RADOS (RADOS Block Device, RBD).
20.2.1 Creazione di un account utente Ceph #
Per creare un nuovo account utente con le funzionalità Ceph Manager, Ceph Monitor e Ceph OSD, utilizzare il comando ceph con il sottocomando auth get-or-create:
cephuser@adm > ceph auth get-or-create client.ID mon 'profile rbd' osd 'profile profile name \
[pool=pool-name] [, profile ...]' mgr 'profile rbd [pool=pool-name]'Ad esempio, per creare un utente denominato qemu con accesso in lettura-scrittura al pool vms e accesso in sola lettura al pool images, eseguire quanto riportato di seguito:
ceph auth get-or-create client.qemu mon 'profile rbd' osd 'profile rbd pool=vms, profile rbd-read-only pool=images' \ mgr 'profile rbd pool=images'
L'output del comando ceph auth get-or-create sarà il portachiavi dell'utente specificato ed è possibile scriverlo in /etc/ceph/ceph.client.ID.keyring.
Quando si utilizza il comando rbd, è possibile specificare l'ID utente fornendo l'argomento facoltativo --id
ID.
Per ulteriori dettagli sulla gestione degli account utente Ceph, fare riferimento al Capitolo 30, Autenticazione con cephx.
20.2.2 Autenticazione utente #
Per specificare un nome utente, utilizzare --id user-name. Se si utilizza l'autenticazione cephx, è necessario specificare anche un segreto. Quest'ultimo potrebbe essere ricavato da un portachiavi o da un file contenente il segreto:
cephuser@adm > rbd device map --pool rbd myimage --id admin --keyring /path/to/keyringoppure
cephuser@adm > rbd device map --pool rbd myimage --id admin --keyfile /path/to/file20.2.3 Preparazione di un dispositivo di blocco RADOS (RADOS Block Device, RBD) per l'uso #
Accertarsi che nel cluster Ceph sia incluso un pool con l'immagine disco che si desidera mappare. Presupporre che il pool sia denominato
mypoole l'immaginemyimage.cephuser@adm >rbd list mypoolMappare l'immagine nel nuovo dispositivo di blocco:
cephuser@adm >rbd device map --pool mypool myimageElencare tutti i dispositivi mappati:
cephuser@adm >rbd device list id pool image snap device 0 mypool myimage - /dev/rbd0Il dispositivo che si desidera utilizzare è
/dev/rbd0.Suggerimento: percorso di dispositivo RBDAl posto di
/dev/rbdDEVICE_NUMBER, è possibile utilizzare/dev/rbd/POOL_NAME/IMAGE_NAMEcome percorso di dispositivo permanente. Esempio:/dev/rbd/mypool/myimage
Creare un file system XFS sul dispositivo
/dev/rbd0:#mkfs.xfs /dev/rbd0 log stripe unit (4194304 bytes) is too large (maximum is 256KiB) log stripe unit adjusted to 32KiB meta-data=/dev/rbd0 isize=256 agcount=9, agsize=261120 blks = sectsz=512 attr=2, projid32bit=1 = crc=0 finobt=0 data = bsize=4096 blocks=2097152, imaxpct=25 = sunit=1024 swidth=1024 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=0 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=8 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0Sostituire
/mntcon il proprio punto di montaggio, montare il dispositivo e verificare che sia montato correttamente:#mount /dev/rbd0 /mnt#mount | grep rbd0 /dev/rbd0 on /mnt type xfs (rw,relatime,attr2,inode64,sunit=8192,...Adesso è possibile spostare i dati nel e dal dispositivo come se questo fosse una directory locale.
Suggerimento: aumento delle dimensioni del dispositivo RBDSe le dimensioni del dispositivo RBD non sono più sufficienti, è possibile aumentarle.
Aumentare le dimensioni dell'immagine RBD, ad esempio fino a 10 GB.
cephuser@adm >rbd resize --size 10000 mypool/myimage Resizing image: 100% complete...done.Accrescere il file system in modo da riempire le nuove dimensioni del dispositivo:
#xfs_growfs /mnt [...] data blocks changed from 2097152 to 2560000
Una volta terminato l'accesso al dispositivo, è possibile annullare la mappatura e smontarlo.
cephuser@adm >rbd device unmap /dev/rbd0#unmount /mnt
Per semplificare i processi di mappatura e montaggio degli RBD dopo l'avvio e di smontaggio dopo l'arresto, vengono forniti uno script rbdmap e un'unità systemd. Vedere Sezione 20.2.4, «rbdmap: mappatura dei dispositivi RBD all'avvio».
20.2.4 rbdmap: mappatura dei dispositivi RBD all'avvio #
rbdmap è uno script della shell che consente di automatizzare le operazioni rbd map e rbd device unmap in una o più immagini RBD. Sebbene sia possibile eseguire manualmente lo script in qualsiasi momento, i principali vantaggi sono la mappatura automatica e il montaggio di immagini RBD all'avvio (e lo smontaggio e l'annullamento della mappatura all'arresto), attivati dal sistema Init. A tal fine è incluso un file di unità systemd, rbdmap.service con il pacchetto ceph-common.
Lo script impiega un singolo argomento, che può essere map o unmap. In entrambi i casi lo script analizza sintatticamente un file di configurazione. Il valore di default è /etc/ceph/rbdmap, ma è possibile ignorarlo tramite una variabile di ambiente RBDMAPFILE. Ciascuna riga del file di configurazione corrisponde a un'immagine RBD che deve anche essere mappata o non mappata.
Il file di configurazione presenta il seguente formato:
image_specification rbd_options
image_specificationPercorso di un'immagine in un pool. Specificare come pool_name/image_name.
rbd_optionsElenco di parametri facoltativo da passare al comando
rbd device mapsottostante. Questi parametri e i rispettivi valori devono essere specificati come stringa separata da virgola, ad esempio:PARAM1=VAL1,PARAM2=VAL2,...
Nell'esempio con lo script
rbdmapviene eseguito il seguente comando:cephuser@adm >rbd device map POOL_NAME/IMAGE_NAME --PARAM1 VAL1 --PARAM2 VAL2Nell'esempio seguente è possibile vedere come specificare un nome utente e un portachiavi con un segreto corrispondente:
cephuser@adm >rbdmap device map mypool/myimage id=rbd_user,keyring=/etc/ceph/ceph.client.rbd.keyring
Quando viene eseguito come rbdmap map, lo script analizza sintatticamente il file di configurazione e, per ogni immagine RBD specificata, prima tenta di mappare l'immagine (con il comando rbd device map), quindi ne esegue il montaggio.
Quando eseguito come rbdmap unmap, le immagini elencate nel file di configurazione il montaggio e la mappatura verranno annullati.
rbdmap unmap-all tenta di smontare e successivamente di annullare la mappatura di tutte le immagini RBD attualmente mappate, indipendentemente dalla loro presenza nell'elenco del file di configurazione.
Se ha esito positivo, l'operazione rbd device map mappa l'immagine a un dispositivo /dev/rbdX, quindi viene attivata una regola udev per creare un collegamento simbolico del nome del dispositivo /dev/rbd/pool_name/image_name che punta al dispositivo realmente mappato.
Affinché il montaggio e lo smontaggio abbiano esito positivo, il nome del dispositivo "intuitivo" deve avere una voce corrispondente in /etc/fstab. Quando si scrivono voci /etc/fstab per le immagini RBD, specificare l'opzione di montaggio "noauto" (o "nofail"). In tal modo si impedisce al sistema Init di tentare di montare il dispositivo troppo presto, perfino prima dell'esistenza del dispositivo in questione, poiché di norma rbdmap.service viene attivato piuttosto tardi nella sequenza di avvio.
Per un elenco completo di opzioni rbd, vedere la documentazione relativa a rbd (man 8 rbd).
Per alcuni esempi di utilizzo di rbdmap, vedere la documentazione relativa a rbdmap (man 8 rbdmap).
20.2.5 Aumento delle dimensioni dei dispositivi RBD #
Se le dimensioni del dispositivo RBD non sono più sufficienti, è possibile aumentarle.
Aumentare le dimensioni dell'immagine RBD, ad esempio fino a 10 GB.
cephuser@adm >rbd resize --size 10000 mypool/myimage Resizing image: 100% complete...done.Accrescere il file system in modo da riempire le nuove dimensioni del dispositivo.
#xfs_growfs /mnt [...] data blocks changed from 2097152 to 2560000
20.3 Snapshot #
Uno snapshot RBD è uno snapshot di un'immagine del RADOS Block Device (dispositivo di blocco RADOS). Gli snapshot consentono di conservare la cronologia dello stato dell'immagine. Ceph supporta anche il layering di snapshot, che consente di clonare rapidamente e facilmente immagini VM. Ceph supporta gli snapshot dei dispositivi di blocco mediante l'uso del comando rbd e molte interfacce di livello superiore, tra cui QEMU, libvirt, OpenStack e CloudStack.
Interrompere le operazioni di input e output e svuotare tutte le operazioni di scrittura in sospeso prima di creare una snapshot di un'immagine. Se l'immagine contiene un file system, questo deve presentare uno stato coerente al momento della creazione della snapshot.
20.3.1 Abilitazione e configurazione di cephx #
Quando cephx è abilitato, è necessario specificare un nome o un ID utente e un percorso del portachiavi contenente la chiave corrispondente dell'utente. Per ulteriori informazioni, vedere il Capitolo 30, Autenticazione con cephx. È inoltre possibile aggiungere la variabile di ambiente CEPH_ARGS per evitare di immettere di nuovo i seguenti parametri.
cephuser@adm >rbd --id user-ID --keyring=/path/to/secret commandscephuser@adm >rbd --name username --keyring=/path/to/secret commands
Ad esempio:
cephuser@adm >rbd --id admin --keyring=/etc/ceph/ceph.keyring commandscephuser@adm >rbd --name client.admin --keyring=/etc/ceph/ceph.keyring commands
Aggiungere l'utente e il segreto nella variabile di ambiente CEPH_ARGS in modo che non sia necessario immetterli ogni volta.
20.3.2 Nozioni di base sugli snapshot #
Nelle procedure seguenti è dimostrato come creare, elencare e rimuovere snapshot mediante l'uso del comando rbd sulla riga di comando.
20.3.2.1 Creazione di snapshot #
Per creare uno snapshot con rbd, specificare l'opzione snap create, il nome pool e il nome immagine.
cephuser@adm >rbd --pool pool-name snap create --snap snap-name image-namecephuser@adm >rbd snap create pool-name/image-name@snap-name
Esempio:
cephuser@adm >rbd --pool rbd snap create --snap snapshot1 image1cephuser@adm >rbd snap create rbd/image1@snapshot1
20.3.2.2 Elenco di snapshot #
Per elencare gli snapshot di un'immagine, specificare il nome pool e il nome immagine.
cephuser@adm >rbd --pool pool-name snap ls image-namecephuser@adm >rbd snap ls pool-name/image-name
Esempio:
cephuser@adm >rbd --pool rbd snap ls image1cephuser@adm >rbd snap ls rbd/image1
20.3.2.3 Rollback di snapshot #
Per eseguire il rollback a uno snapshot con rbd, specificare l'opzione snap rollback, il nome pool, il nome immagine e il nome snapshot.
cephuser@adm >rbd --pool pool-name snap rollback --snap snap-name image-namecephuser@adm >rbd snap rollback pool-name/image-name@snap-name
Esempio:
cephuser@adm >rbd --pool pool1 snap rollback --snap snapshot1 image1cephuser@adm >rbd snap rollback pool1/image1@snapshot1
Eseguire il rollback di un'immagine a uno snapshot significa sovrascrivere la versione attuale dell'immagine con i dati provenienti da uno snapshot. La durata di esecuzione di un rollback aumenta proporzionalmente alle dimensioni dell'immagine. È più rapido eseguire la clonazione da uno snapshot piuttosto che eseguire il rollback di un'immagine a uno snapshot; questo è inoltre il metodo preferito per tornare a uno stato preesistente.
20.3.2.4 Eliminazione di uno snapshot #
Per eliminare uno snapshot con rbd, specificare l'opzione snap rm, il nome pool, il nome immagine e il nome utente.
cephuser@adm >rbd --pool pool-name snap rm --snap snap-name image-namecephuser@adm >rbd snap rm pool-name/image-name@snap-name
Esempio:
cephuser@adm >rbd --pool pool1 snap rm --snap snapshot1 image1cephuser@adm >rbd snap rm pool1/image1@snapshot1
Nei Ceph OSD i dati vengono eliminati in modo asincrono, quindi con l'eliminazione di uno snapshot non si libera immediatamente spazio su disco.
20.3.2.5 Eliminazione definitiva di snapshot #
Per eliminare tutti gli snapshot di un'immagine con rbd, specificare l'opzione snap purge e il nome immagine.
cephuser@adm >rbd --pool pool-name snap purge image-namecephuser@adm >rbd snap purge pool-name/image-name
Esempio:
cephuser@adm >rbd --pool pool1 snap purge image1cephuser@adm >rbd snap purge pool1/image1
20.3.3 Layering degli snapshot #
Ceph supporta la creazione di più cloni copia su scrittura (copy-on-write, COW) di uno snapshot del dispositivo di blocco. Il layering degli snapshot consente ai client dei dispositivi di blocco Ceph di creare immagini molto rapidamente. Ad esempio, si può creare un'immagine del dispositivo di blocco con una Linux VM scritta al suo interno, quindi eseguire lo snapshot dell'immagine, proteggere lo snapshot e creare tutti i cloni copia su scrittura desiderati. Poiché gli snapshot sono di sola lettura, la clonazione di uno di essi semplifica la semantica e consente quindi di creare i cloni rapidamente.
I termini "parent" e "child" menzionati negli esempi di riga di comando riportati sotto significano uno snapshot del dispositivo di blocco Ceph (parent) e l'immagine corrispondente clonata dallo snapshot (child).
In ciascuna immagine clonata (child) è memorizzato il rifermento alla rispettiva immagine superiore, che consente all'immagine clonata di aprire e leggere lo snapshot superiore.
Un clone COW di uno snapshot si comporta esattamente come qualsiasi altra immagine del dispositivo di blocco Ceph. Nelle immagini clonate è possibile eseguire operazioni di lettura e scrittura ed è possibile clonarle e ridimensionarle. Con le immagini clonate non esistono restrizioni speciali. Il clone copia su scrittura di uno snapshot si riferisce tuttavia allo snapshot, quindi è necessario proteggere quest'ultimo prima di clonarlo.
--image-format 1 non supportata
Non è possibile creare snapshot di immagini create con l'opzione rbd create --image-format 1 obsoleta. Ceph supporta soltanto la clonazione delle immagini format 2 di default.
20.3.3.1 Introduzione al layering #
Il layering dei dispositivi di blocco Ceph è un processo semplice. È necessario disporre di un'immagine, creare uno snapshot dell'immagine, proteggere lo snapshot. Dopo aver eseguito questi passaggi, è possibile iniziare la clonazione dello snapshot.
L'immagine clonata fa riferimento allo snapshot superiore e include l'ID pool, l'ID immagine e l'ID snapshot. L'inclusione dell'ID pool significa che è possibile clonare snapshot da un pool nelle immagini in un altro pool.
Modello di immagine: un caso comune di layering dei dispositivi di blocco consiste nel creare un'immagine master e uno snapshot che funge da modello per i cloni. Ad esempio, un utente può creare un'immagine per una distribuzione Linux (ad esempio, SUSE Linux Enterprise Server) e creare uno snapshot corrispondente. Periodicamente, l'utente può aggiornare l'immagine e creare un nuovo snapshot (ad esempio,
zypper ref && zypper patchseguito darbd snap create). Ma mano che l'immagine matura, l'utente può clonare qualsiasi snapshot.Modello esteso: un caso più avanzato consiste nell'estensione di un'immagine modello che fornisce ulteriori informazioni rispetto all'immagine di base. Ad esempio, un utente può clonare un'immagine (un modello VM) e installare un software diverso (ad esempio un database, un sistema di gestione di contenuti o un sistema di analisi) ed eseguire quindi lo snapshot dell'immagine estesa, che a sua volta è possibile aggiornare allo stesso modo dell'immagine di base.
Pool di modelli: un metodo per utilizzare il layering dei dispositivi di blocco consiste nel creare un pool contenente immagini master che fungono da modelli e snapshot di tali modelli. È quindi possibile estendere i privilegi di sola lettura agli utenti in modo che possano clonare gli snapshot senza doverli scrivere o eseguire nel pool.
Migrazione/recupero dell'immagine: un metodo per utilizzare il layering dei dispositivi di blocco consiste nell'eseguire la migrazione o il recupero dei dati da un pool in un altro.
20.3.3.2 Protezione di uno snapshot #
I cloni accedono agli snapshot superiori. Tutti i cloni verrebbero interrotti se un utente eliminasse inavvertitamente lo snapshot superiore. Per impedire la perdita di dati, è necessario proteggere lo snapshot prima di poterlo clonare.
cephuser@adm >rbd --pool pool-name snap protect \ --image image-name --snap snapshot-namecephuser@adm >rbd snap protect pool-name/image-name@snapshot-name
Esempio:
cephuser@adm >rbd --pool pool1 snap protect --image image1 --snap snapshot1cephuser@adm >rbd snap protect pool1/image1@snapshot1
Non è possibile eliminare uno snapshot protetto.
20.3.3.3 Clonazione di uno snapshot #
Per clonare uno snapshot, è necessario specificare il pool superiore, l'immagine e lo snapshot, il pool secondario e il nome immagine. È necessario proteggere lo snapshot prima di poterlo clonare.
cephuser@adm >rbd clone --pool pool-name --image parent-image \ --snap snap-name --dest-pool pool-name \ --dest child-imagecephuser@adm >rbd clone pool-name/parent-image@snap-name \ pool-name/child-image-name
Esempio:
cephuser@adm > rbd clone pool1/image1@snapshot1 pool1/image2Si può clonare uno snapshot da un pool in un'immagine in un altro pool. Ad esempio, si possono mantenere immagini e snapshot di sola lettura come modelli in un pool e cloni scrivibili in un altro pool.
20.3.3.4 Annullamento della protezione di uno snapshot #
Prima di poter eliminare uno snapshot, è necessario annullarne la protezione. Inoltre, non è possibile eliminare snapshot con riferimenti dai cloni. È necessario appiattire ciascun clone di uno snapshot prima di poter eliminare quest'ultimo.
cephuser@adm >rbd --pool pool-name snap unprotect --image image-name \ --snap snapshot-namecephuser@adm >rbd snap unprotect pool-name/image-name@snapshot-name
Esempio:
cephuser@adm >rbd --pool pool1 snap unprotect --image image1 --snap snapshot1cephuser@adm >rbd snap unprotect pool1/image1@snapshot1
20.3.3.5 Elenco degli elementi secondari di uno snapshot #
Per elencare gli elementi secondari di uno snapshot, eseguire quanto riportato di seguito:
cephuser@adm >rbd --pool pool-name children --image image-name --snap snap-namecephuser@adm >rbd children pool-name/image-name@snapshot-name
Esempio:
cephuser@adm >rbd --pool pool1 children --image image1 --snap snapshot1cephuser@adm >rbd children pool1/image1@snapshot1
20.3.3.6 Appiattimento di un'immagine clonata #
Le immagini clonate mantengono un riferimento allo snapshot superiore. Quando si rimuove il riferimento dal clone secondario nello parent superiore, di fatto si "appiattisce" l'immagine copiando le informazioni dallo snapshot al clone. La durata di appiattimento di un clone aumenta proporzionalmente alle dimensioni dello snapshot. Per eliminare uno snapshot, prima è necessario appiattire le immagini secondarie.
cephuser@adm >rbd --pool pool-name flatten --image image-namecephuser@adm >rbd flatten pool-name/image-name
Esempio:
cephuser@adm >rbd --pool pool1 flatten --image image1cephuser@adm >rbd flatten pool1/image1
Poiché un'immagine appiattita contiene tutte le informazioni provenienti dallo snapshot, questa occuperà uno spazio di memorizzazione maggiore rispetto a un clone su più strati.
20.4 Copie speculari delle immagini RBD #
È possibile eseguire la copia speculare delle immagini RBD in modo asincrono tra due cluster Ceph. Questa funzionalità è disponibile in due modalità:
- Basata sul journal
Questa modalità utilizza la funzione di journaling dell'immagine RBD per assicurare la replica temporizzata e con coerenza per arresto anomalo tra cluster. Prima di modificare l'immagine effettiva, ogni operazione di scrittura sull'immagine RBD viene innanzitutto registrata sul journal associato. Il cluster
remoteleggerà dal journal e riprodurrà gli aggiornamenti nella relativa copia locale dell'immagine. Dal momento che ogni operazione di scrittura sull'immagine RBD risulta in due operazioni di scrittura sul cluster Ceph, prevedere un raddoppiamento delle latenze di scrittura quando si utilizza la funzione di journaling dell'immagine RBD.- Basata su snapshot
Questa modalità utilizza snapshot di copia speculare dell'immagine RBD pianificati periodicamente o creati manualmente per eseguire la replica delle immagini RBD con coerenza per arresto anomalo tra cluster. Il cluster
remotedeterminerà la presenza di eventuali aggiornamenti dei dati o dei metadati tra due snapshot di copia speculare e copierà i valori differenziali nella relativa copia locale dell'immagine. Con la funzione fast-diff dell'immagine RBD, è possibile calcolare rapidamente i blocchi di dati aggiornati senza dover effettuare la scansione dell'intera immagine RBD. Dal momento che questa modalità non garantisce coerenza temporizzata, sarà necessario sincronizzare il valore differenziale completo dello snapshot prima dell'uso in uno scenario di failover. Gli eventuali valori differenziali dello snapshot applicati parzialmente verranno sottoposti a rollback sull'ultimo snapshot di cui è stata completata la sincronizzazione.
La copia speculare è configurata per ogni singolo pool nei cluster peer e può essere configurata su un sottoinsieme specifico di immagini all'interno del pool o in modo che venga eseguita automaticamente la copia speculare di tutte le immagini di un pool quando è in uso soltanto la copia speculare basata sul journal. Per la configurazione della copia speculare si utilizza il comando rbd. Il daemon rbd-mirror è responsabile del pull degli aggiornamenti delle immagini dal cluster peer remote e della loro applicazione all'immagine nel cluster local.
A seconda delle necessità di replica, è possibile configurare la copia speculare RBD sulla replica a una o a due vie:
- Replica a una via
Quando la copia speculare dei dati avviene soltanto da un cluster primario a uno secondario, il daemon
rbd-mirrorviene eseguito solo sul cluster secondario.- Replica a due vie
Quando la copia speculare dei dati avviene dalle immagini primarie su un cluster alle immagini non primarie su un altro cluster (e viceversa), il daemon
rbd-mirrorviene eseguito su entrambi i cluster.
Ogni istanza del daemon rbd-mirror deve essere in grado di connettersi contemporaneamente a entrambi i cluster local e remote Ceph. Ad esempio, a tutti i monitor e agli host OSD. Inoltre, la larghezza di banda della rete tra i due data center deve essere sufficiente per gestire il workload della copia speculare.
20.4.1 Configurazione del pool #
Nelle procedure seguenti è illustrato come eseguire task amministrativi di base per configurare la copia speculare tramite il comando rbd. La copia speculare è configurata per ogni singolo pool nei cluster Ceph.
È necessario eseguire i passaggi della configurazione del pool su entrambi i cluster peer. Per maggior chiarezza, in queste procedure si presuppone che due cluster, denominati local e remote, siano accessibili da un singolo host.
Vedere la documentazione relativa a rbd (man 8 rbd) per ulteriori dettagli su come connettersi a cluster Ceph diversi.
Il nome del cluster negli esempi seguenti corrisponde a un file di configurazione Ceph omonimo /etc/ceph/remote.conf e al file del portachiavi Ceph omonimo /etc/ceph/remote.client.admin.keyring.
20.4.1.1 Abilitazione della copia speculare su un pool #
Per abilitare la copia speculare su un pool, specificare il sottocomando mirror pool enable, il nome pool e la modalità di esecuzione di copia speculare. La modalità di esecuzione di copia speculare può essere "pool" oppure "image":
- pool
Tutte le immagini nel pool in cui è abilitata la funzione di journaling vengono sottoposte a copia speculare.
- immagine
La copia speculare deve essere abilitata esplicitamente su ciascuna immagine. Consultare Sezione 20.4.2.1, «Abilitazione della copia speculare dell'immagine» per maggiori informazioni.
Esempio:
cephuser@adm >rbd --cluster local mirror pool enable POOL_NAME poolcephuser@adm >rbd --cluster remote mirror pool enable POOL_NAME pool
20.4.1.2 Disabilitazione della copia speculare #
Per disabilitare la copia speculare su un pool, specificare il sottocomando mirror pool disable e il nome pool. Quando si disabilita la copia speculare su un pool in questo modo, questa verrà disabilitata anche su qualsiasi immagine (nel pool) per la quale è stata abilitata esplicitamente la copia speculare.
cephuser@adm >rbd --cluster local mirror pool disable POOL_NAMEcephuser@adm >rbd --cluster remote mirror pool disable POOL_NAME
20.4.1.3 Esecuzione del bootstrap dei peer #
Affinché il daemon rbd-mirror rilevi il rispettivo cluster peer, è necessario registrare il peer nel pool e creare un account utente. Questo processo può essere automatizzato con rbd e i comandi mirror pool peer bootstrap create e mirror pool peer bootstrap import.
Per creare manualmente un nuovo token di bootstrap con rbd, specificare il comando mirror pool peer bootstrap create, il nome del pool e un nome descrittivo facoltativo del sito per la descrizione del cluster local:
cephuser@local > rbd mirror pool peer bootstrap create \
[--site-name LOCAL_SITE_NAME] POOL_NAME
L'output di mirror pool peer bootstrap create sarà un token che dovrà essere fornito al comando mirror pool peer bootstrap import. Ad esempio, sul cluster local:
cephuser@local > rbd --cluster local mirror pool peer bootstrap create --site-name local image-pool
eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW1pcnJvci1wZWVyIiwia2V5I \
joiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1vbl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
Per importare manualmente il token di bootstrap creato da un altro cluster con il comando rbd, utilizzare la sintassi seguente:
rbd mirror pool peer bootstrap import \ [--site-name LOCAL_SITE_NAME] \ [--direction DIRECTION \ POOL_NAME TOKEN_PATH
Dove:
- LOCAL_SITE_NAME
Nome descrittivo facoltativo del sito per la descrizione del cluster
local.- DIRECTION
Direzione della copia speculare. L'impostazione di default è
rx-txper la copia speculare bidirezionale, ma è possibile configurare questa impostazione anche surx-onlyper la copia speculare unidirezionale.- POOL_NAME
Nome del pool.
- TOKEN_PATH
Percorso del file al token creato (o
-per leggerlo dall'input standard).
Ad esempio, sul cluster remote:
cephuser@remote > cat <<EOF > token
eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1vbl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
EOFcephuser@adm > rbd --cluster remote mirror pool peer bootstrap import \
--site-name remote image-pool token20.4.1.4 Aggiunta manuale di un peer del cluster #
Come alternativa all'esecuzione del bootstrap dei peer descritta nella Sezione 20.4.1.3, «Esecuzione del bootstrap dei peer», è possibile specificare i peer manualmente. Per eseguire la copia speculare, il daemon rbd-mirror remoto necessita dell'accesso al cluster locale. Creare un nuovo utente Ceph locale che verrà utilizzato dal daemon rbd-mirror remoto, ad esempio rbd-mirror-peer:
cephuser@adm > ceph auth get-or-create client.rbd-mirror-peer \
mon 'profile rbd' osd 'profile rbd'
Utilizzare la sintassi seguente per aggiungere un cluster Ceph peer in copia speculare con il comando rbd:
rbd mirror pool peer add POOL_NAME CLIENT_NAME@CLUSTER_NAME
Esempio:
cephuser@adm >rbd --cluster site-a mirror pool peer add image-pool client.rbd-mirror-peer@site-bcephuser@adm >rbd --cluster site-b mirror pool peer add image-pool client.rbd-mirror-peer@site-a
Per default, il daemon rbd-mirror deve disporre dell'accesso al file di configurazione Ceph ubicato in /etc/ceph/.CLUSTER_NAME.conf, in cui sono specificati gli indirizzi IP dei MON del cluster peer e il portachiavi relativo a un client denominato CLIENT_NAME e ubicato nel percorso di ricerca del portachiavi di default o predefinito, ad esempio /etc/ceph/CLUSTER_NAME.CLIENT_NAME.keyring.
In alternativa, è possibile memorizzare in modo sicuro la chiave client e/o il MON del cluster peer nell'archivio config-key Ceph. Per specificare gli attributi di connessione del cluster peer durante l'aggiunta di un peer in copia speculare, utilizzare le opzioni --remote-mon-host e --remote-key-file. Esempio:
cephuser@adm >rbd --cluster site-a mirror pool peer add image-pool \ client.rbd-mirror-peer@site-b --remote-mon-host 192.168.1.1,192.168.1.2 \ --remote-key-file /PATH/TO/KEY_FILEcephuser@adm >rbd --cluster site-a mirror pool info image-pool --all Mode: pool Peers: UUID NAME CLIENT MON_HOST KEY 587b08db... site-b client.rbd-mirror-peer 192.168.1.1,192.168.1.2 AQAeuZdb...
20.4.1.5 Rimozione di un peer del cluster #
Per rimuovere un cluster peer in copia speculare, specificare il sottocomando mirror pool peer remove, il nome pool e l'UUID peer (reso disponibile dal comando rbd mirror pool info):
cephuser@adm >rbd --cluster local mirror pool peer remove POOL_NAME \ 55672766-c02b-4729-8567-f13a66893445cephuser@adm >rbd --cluster remote mirror pool peer remove POOL_NAME \ 60c0e299-b38f-4234-91f6-eed0a367be08
20.4.1.6 Pool di dati #
Durante la creazione di immagini nel cluster di destinazione, rbd-mirror seleziona un pool di dati come segue:
Se presente, verrà utilizzato il pool di dati di default configurato (con l'opzione di configurazione
rbd_default_data_pool) del cluster di destinazione.In caso contrario, se l'immagine di origine utilizza un pool di dati separato e sul cluster di destinazione esiste già un pool con lo stesso nome, verrà utilizzato tale pool.
Se nessuna delle due condizioni descritte sopra è applicabile, non verrà impostato alcun pool di dati.
20.4.2 Configurazione dell'immagine RBD #
Diversamente dalla configurazione del pool, la configurazione dell'immagine deve essere eseguita solo a fronte di un singolo cluster Ceph peer in copia speculare.
Le immagini RBD sottoposte a copia speculare sono designate come primarie o non primarie. Questa è una proprietà dell'immagine e non del pool. Non è possibile modificare le immagini designate come non primarie.
Le immagini vengono promosse automaticamente a primarie quando la copia speculare viene prima abilitata su un'immagine (implicitamente, se la modalità di copia speculare del pool è "pool" e la funzione di journaling dell'immagine è abilitata, oppure esplicitamente (vedere Sezione 20.4.2.1, «Abilitazione della copia speculare dell'immagine») mediante il comando rbd).
20.4.2.1 Abilitazione della copia speculare dell'immagine #
Se la copia speculare è configurata in modalità image, è necessario abilitarla esplicitamente per ciascuna immagine nel pool. Per abilitare la copia speculare per un'immagine specifica con rbd, specificare il sottocomando mirror image enable insieme al nome del pool e dell'immagine:
cephuser@adm > rbd --cluster local mirror image enable \
POOL_NAME/IMAGE_NAME
È possibile eseguire la copia speculare dell'immagine in modalità journal o snapshot:
- journal (default)
Se configurata nella modalità
journal, la copia speculare utilizzerà la funzione di journaling dell'immagine RBD per replicarne il contenuto. Tale funzione verrà abilitata automaticamente se non è stata ancora abilitata sull'immagine.- istantanea
Se configurata nella modalità
snapshot, la copia speculare utilizzerà gli snapshot di copia speculare dell'immagine RBD per replicarne il contenuto. Dopo l'abilitazione, verrà automaticamente creato un primo snapshot di copia speculare dell'immagine RBD e sarà possibile crearne altri con il comandorbd.
Esempio:
cephuser@adm >rbd --cluster local mirror image enable image-pool/image-1 snapshotcephuser@adm >rbd --cluster local mirror image enable image-pool/image-2 journal
20.4.2.2 Abilitazione della funzione di journaling dell'immagine #
Nella copia speculare RBD viene utilizzata la funzione di journaling RBD per assicurare che l'immagine replicata mantenga sempre con coerenza per arresto anomalo. Se si utilizza la modalità di copia speculare image, la funzione di journaling sarà abilitata automaticamente se sull'immagine è abilitata la copia speculare. Se si utilizza la modalità di copia speculare pool, prima che sia possibile sottoporre a copia speculare un'immagine su un cluster peer, occorre abilitare la funzione di journaling dell'immagine RBD. È possibile abilitare tale funzione al momento della creazione dell'immagine specificando l'opzione --image-feature exclusive-lock,journaling nel comando rbd.
In alternativa, è possibile abilitare dinamicamente la funzione di journaling sulle immagini RBD preesistenti. Per abilitare il journaling, specificare il sottocomando feature enable, il nome del pool e dell'immagine e il nome della funzione:
cephuser@adm >rbd --cluster local feature enable POOL_NAME/IMAGE_NAME exclusive-lockcephuser@adm >rbd --cluster local feature enable POOL_NAME/IMAGE_NAME journaling
La funzione journaling dipende dalla funzione exclusive-lock. Se la funzione exclusive-lock non è già stata abilitata, è necessario farlo prima di abilitare la funzione journaling.
È possibile abilitare per default il journaling su tutte le nuove immagini aggiungendo rbd default features = layering,exclusive-lock,object-map,deep-flatten,journaling al file di configurazione Ceph.
20.4.2.3 Creazione di snapshot di copia speculare dell'immagine #
Se si utilizza la copia speculare basata su snapshot, sarà necessario creare snapshot di copia speculare ogni volta che si desidera eseguire la copia speculare dei contenuti modificati dell'immagine RBD. Per creare manualmente uno snapshot di copia speculare con rbd, specificare il comando mirror image snapshot insieme al nome del pool e dell'immagine:
cephuser@adm > rbd mirror image snapshot POOL_NAME/IMAGE_NAMEEsempio:
cephuser@adm > rbd --cluster local mirror image snapshot image-pool/image-1
Per default, vengono creati solo tre snapshot di copia speculare per immagine. Se questo limite viene raggiunto, lo snapshot di copia speculare più recente viene eliminato automaticamente. Se necessario, è possibile ignorare questo limite con l'opzione di configurazione rbd_mirroring_max_mirroring_snapshots. Inoltre, gli snapshot di copia speculare vengono eliminati automaticamente quando l'immagine viene rimossa o quando la copia speculare viene disabilitata.
È inoltre possibile definire una pianificazione per la creazione automatica e periodica degli snapshot di copia speculare. Questi ultimi possono essere pianificati a livello globale, di singolo pool o di singola immagine. È possibile definire più pianificazioni di snapshot di copia speculare su qualsiasi livello, ma verranno eseguite soltanto le pianificazioni più specifiche corrispondenti a una singola immagine in copia speculare.
Per creare una pianificazione di snapshot di copia speculare con rbd, specificare il comando mirror snapshot schedule add insieme a un nome facoltativo del pool o dell'immagine, a un intervallo e a un'ora di inizio facoltativa.
L'intervallo può essere espresso in giorni, ore o minuti utilizzando rispettivamente i suffissi d, h o m. L'ora di inizio facoltativa può essere specificata utilizzando il formato di ora ISO 8601. Esempio:
cephuser@adm >rbd --cluster local mirror snapshot schedule add --pool image-pool 24h 14:00:00-05:00cephuser@adm >rbd --cluster local mirror snapshot schedule add --pool image-pool --image image1 6h
Per rimuovere una pianificazione di snapshot di copia speculare con rbd, specificare il comando mirror snapshot schedule remove con le opzioni corrispondenti al comando per l'aggiunta della pianificazione equivalente.
Per elencare tutte le pianificazioni di snapshot per un livello specifico (globale, pool o immagine) con rbd, immettere il comando mirror snapshot schedule ls insieme a un nome facoltativo del pool o dell'immagine. Inoltre, tramite l'opzione --recursive, è possibile elencare tutte le pianificazioni del livello specificato e dei livelli sottostanti. Esempio:
cephuser@adm > rbd --cluster local mirror schedule ls --pool image-pool --recursive
POOL NAMESPACE IMAGE SCHEDULE
image-pool - - every 1d starting at 14:00:00-05:00
image-pool image1 every 6h
Per verificare con rbd quando saranno creati i successivi snapshot per le immagini RBD con copia speculare basata su snapshot, specificare il comando mirror snapshot schedule status insieme a un nome facoltativo del pool o dell'immagine. Esempio:
cephuser@adm > rbd --cluster local mirror schedule status
SCHEDULE TIME IMAGE
2020-02-26 18:00:00 image-pool/image120.4.2.4 Disabilitazione della copia speculare dell'immagine #
Per disabilitare la copia speculare per un'immagine specifica, specificare il sottocomando mirror image disable insieme al nome del pool e dell'immagine:
cephuser@adm > rbd --cluster local mirror image disable POOL_NAME/IMAGE_NAME20.4.2.5 Promozione e abbassamento di livello delle immagini #
In uno scenario di failover in cui è necessario spostare la designazione primaria all'immagine nel cluster peer, è necessario interrompere l'accesso all'immagine primaria, abbassare di livello l'attuale immagine primaria, promuovere quella nuova e riprendere l'accesso all'immagine sul cluster alternativo.
È possibile forzare la promozione utilizzando l'opzione --force. La promozione forzata è necessaria quando è impossibile propagare l'abbassamento di livello al cluster peer (ad esempio, in caso di errore del cluster o di interruzione della comunicazione). Ne risulterà uno scenario split brain tra i due peer e l'immagine non viene più sincronizzata fino all'emissione di un sottocomando resync.
Per abbassare di livello un'immagine specifica a non primaria, specificare il sottocomando mirror image demote insieme al nome del pool e dell'immagine:
cephuser@adm > rbd --cluster local mirror image demote POOL_NAME/IMAGE_NAME
Per abbassare di livello tutte le immagini primarie in un pool a non primarie, specificare il sottocomando mirror pool demote insieme al nome del pool:
cephuser@adm > rbd --cluster local mirror pool demote POOL_NAME
Per promuovere un'immagine specifica a primaria, specificare il sottocomando mirror image promote insieme al nome del pool e dell'immagine:
cephuser@adm > rbd --cluster remote mirror image promote POOL_NAME/IMAGE_NAME
Per promuovere tutte le immagini primarie in un pool a primarie, specificare il sottocomando mirror pool promote insieme al nome del pool:
cephuser@adm > rbd --cluster local mirror pool promote POOL_NAMEPoiché lo stato di primaria o non primaria si riferisce a un'immagine singola, è possibile fare in modo che il carico I/O e il failover o il failback della fase vengano suddivisi tra due cluster.
20.4.2.6 Risincronizzazione forzata dell'immagine #
Se viene rilevato un evento split brain dal daemon rbd-mirror, non verrà effettuato alcun tentativo di copia speculare dell'immagine interessata finché non viene corretto. Per riprendere la copia speculare di un'immagine, prima abbassare di livello l'immagine definita obsoleta, quindi richiedere una risincronizzazione all'immagine primaria. Per richiedere una risincronizzazione dell'immagine, specificare il sottocomando mirror image resync insieme al nome del pool e dell'immagine:
cephuser@adm > rbd mirror image resync POOL_NAME/IMAGE_NAME20.4.3 Verifica dello stato della copia speculare #
Lo stato di replica del cluster peer viene memorizzato per ciascuna immagine primaria in copia speculare. È possibile recuperare tale stato mediante i sottocomandi mirror image status e mirror pool status:
Per richiedere lo stato dell'immagine speculare, specificare il sottocomando mirror image status insieme al nome del pool e dell'immagine:
cephuser@adm > rbd mirror image status POOL_NAME/IMAGE_NAME
Per richiedere lo stato di riepilogo del pool speculare, specificare il sottocomando mirror pool status insieme al nome del pool:
cephuser@adm > rbd mirror pool status POOL_NAME
Con l'aggiunta dell'opzione --verbose al sottocomando mirror pool status verranno generati ulteriori dettagli sullo stato di ciascuna immagine in copia speculare nel pool.
20.5 Impostazioni della cache #
L'implementazione dello spazio utente del dispositivo di blocco Ceph (librbd) non può servirsi della cache delle pagine Linux. Pertanto, dispone di memorizzazione nella cache integrata. Il comportamento della memorizzazione nella cache RBD è simile a quello della memorizzazione nella cache del disco rigido. Quando il sistema operativo invia una richiesta di sbarramento o di svuotamento, tutti i dati modificati vengono scritti sugli OSD. Ciò significa che la memorizzazione nella cache Write-back garantisce gli stessi livelli di sicurezza di un disco rigido fisico integro con una macchina virtuale che invia correttamente gli svuotamenti. La cache utilizza un algoritmo Least Recently Used (LRU) e, in modalità Write-back, è in grado di unire le richieste adiacenti per migliorare la velocità effettiva.
Ceph supporta la memorizzazione nella cache Write-back per RBD. Per abilitarla, eseguire
cephuser@adm > ceph config set client rbd_cache true
Per default, librbd non esegue alcuna memorizzazione nella cache. Le operazioni di scrittura e lettura vanno direttamente al cluster di memorizzazione e le operazioni di scrittura vengono restituite solo quando i dati si trovano sul disco in tutte le repliche. Se la memorizzazione nella cache è abilitata, le operazioni di scrittura vengono subito restituite, a meno che il numero di byte non svuotati non sia superiore a quello impostato nell'opzione rbd cache max dirty. In questo caso, l'operazione di scrittura attiva il writeback e si blocca finché non viene svuotato un numero sufficiente di byte.
Ceph supporta la memorizzazione nella cache Write-through per RBD. È possibile impostare le dimensioni della cache e le destinazioni e i limiti per passare dalla memorizzazione nella cache Write-back a quella Write-through. Per abilitare la modalità Write-through, eseguire
cephuser@adm > ceph config set client rbd_cache_max_dirty 0Ciò vuol dire che le operazioni di scrittura vengono restituite solo quando i dati si trovano sul disco in tutte le repliche, ma che le operazioni di lettura possono provenire dalla cache. La cache si trova nella memoria del client e ogni immagine RBD dispone della propria cache. Dal momento che la cache si trova in locale sul client, se altri accedono all'immagine, non vi è alcuna coerenza. Se la memorizzazione nella cache è abilitata, non sarà possibile eseguire OCFS o GFS su RBD.
I parametri seguenti influiscono sul comportamento dei dispositivi di blocco RADOS (RADOS Block Device, RBD). Per impostarli, utilizzare la categoria client:
cephuser@adm > ceph config set client PARAMETER VALUErbd cachePer abilitare la memorizzazione nella cache per il dispositivo di blocco RADOS (RBD). L'impostazione di default è "true".
rbd cache sizeDimensioni in byte della cache RBD. Il valore di default è 32 MB.
rbd cache max dirtyLimite di dati modificati espresso in byte in corrispondenza del quale la cache attiva il Write-back. Il valore di
rbd cache max dirtydeve essere inferiore arbd cache size. Se è impostato a 0, utilizza la memorizzazione nella cache Write-through. Il valore di default è 24 MB.rbd cache target dirtyDestinazione modificata prima che la cache inizi le operazioni di scrittura dei dati nel relativo storage. Non blocca le operazioni di scrittura nella cache. Il valore di default è 16 MB.
rbd cache max dirty ageNumero di secondi in cui i dati modificati si trovano nella cache prima dell'avvio del writeback. Il valore di default è 1.
rbd cache writethrough until flushSi avvia in modalità Write-through e passa alla modalità Write-back in seguito alla ricezione della prima richiesta di svuotamento. Si tratta di un'impostazione prudente ma sicura se le macchine virtuali in esecuzione su
rbdsono troppo obsolete per inviare richieste di svuotamento (ad esempio, nel caso del driver virtio in Linux prima del kernel 2.6.32). L'impostazione di default è "true".
20.6 Impostazioni QoS #
In genere, la Qualità di servizio (QoS, Quality of Service) fa riferimento ai metodi per la definizione della priorità del traffico e per la prenotazione delle risorse. È particolarmente importante per il trasporto del traffico con requisiti speciali.
Le impostazioni QoS seguenti sono utilizzate solo dall'implementazione dello spazio utente RBD librbd e non sono utilizzate dall'implementazione kRBD. Poiché iSCSI utilizza kRBD, non usa le impostazioni QoS. Tuttavia, per iSCSI è possibile configurare la QoS sul livello del dispositivo di blocco del kernel tramite le facility del kernel standard.
rbd qos iops limitLimite desiderato delle operazioni I/O al secondo. Il valore di default è 0 (nessun limite).
rbd qos bps limitLimite desiderato dei byte I/O al secondo. Il valore di default è 0 (nessun limite).
rbd qos read iops limitIl limite desiderato di operazioni di lettura al secondo. Il valore di default è 0 (nessun limite).
rbd qos write iops limitIl limite desiderato di operazioni di scrittura al secondo. Il valore di default è 0 (nessun limite).
rbd qos read bps limitIl limite desiderato di byte letti al secondo. Il valore di default è 0 (nessun limite).
rbd qos write bps limitIl limite desiderato di byte scritti al secondo. Il valore di default è 0 (nessun limite).
rbd qos iops burstLimite di burst desiderato delle operazioni I/O. Il valore di default è 0 (nessun limite).
rbd qos bps burstLimite di burst desiderato dei byte I/O. Il valore di default è 0 (nessun limite).
rbd qos read iops burstIl limite di burst desiderato delle operazioni di lettura. Il valore di default è 0 (nessun limite).
rbd qos write iops burstIl limite di burst desiderato delle operazioni di scrittura. Il valore di default è 0 (nessun limite).
rbd qos read bps burstIl limite di burst desiderato dei byte letti. Il valore di default è 0 (nessun limite).
rbd qos write bps burstIl limite di burst desiderato dei byte scritti. Il valore di default è 0 (nessun limite).
rbd qos schedule tick minTick di pianificazione minimo (in millisecondi) per QoS. Il valore di default è 50.
20.7 Impostazioni di lettura in avanti #
Il dispositivo di blocco RADOS supporta la lettura in avanti/prelettura per l'ottimizzazione delle operazioni di lettura piccole e sequenziali. Nel caso di una macchina virtuale, queste operazioni di lettura sono in genere gestite dal sistema operativo guest, anche se i boot loader potrebbero non generare letture efficaci. Se la memorizzazione nella cache è disabilitata, la lettura in avanti viene disabilitata automaticamente.
Le impostazioni di lettura in avanti seguenti sono utilizzate solo dall'implementazione dello spazio utente RBD librbd e non sono utilizzate dall'implementazione kRBD. Poiché iSCSI utilizza kRBD, non usa le impostazioni di lettura in avanti. Tuttavia, per iSCSI è possibile configurare la lettura in avanti sullo strato del dispositivo di blocco del kernel tramite le facility del kernel standard.
rbd readahead trigger requestsNumero di richieste di lettura sequenziali necessarie per attivare la lettura in avanti. Il valore di default è 10.
rbd readahead max bytesDimensioni massime della richiesta di lettura in avanti. Se è impostata su 0, la lettura in avanti è disabilitata. Il valore di default è 512 kB.
rbd readahead disable after bytesIn seguito alla lettura di questo numero di byte da un'immagine RBD, la lettura in avanti è disabilitata per tale immagine fino alla chiusura. In questo modo, il sistema operativo guest può subentrare alla lettura in avanti al momento dell'avvio. Se è impostata su 0, la lettura in avanti rimane abilitata. Il valore di default è 50 MB.
20.8 Funzioni avanzate #
Il dispositivo di blocco RADOS supporta le funzioni avanzate che consentono di migliorare la funzionalità delle immagini RBD. È possibile specificare le funzioni sulla riga di comando durante la creazione di un'immagine RBD oppure nel file di configurazione Ceph tramite l'opzione rbd_default_features.
È possibile specificare i valori dell'opzione rbd_default_features in due modi:
Come somma dei valori interni delle funzioni. Ogni funzione dispone di un proprio valore interno; ad esempio il valore di "layering" è 1 e quello di "fast-diff" è 16. Di conseguenza, per attivare queste due funzioni per default, includere quanto segue:
rbd_default_features = 17
Come elenco di funzioni separate da virgole. L'esempio precedente avrà l'aspetto seguente:
rbd_default_features = layering,fast-diff
Le immagini RBD con le funzioni seguenti non saranno supportate da iSCSI: deep-flatten, object-map, journaling, fast-diff, striping
Di seguito è riportato un elenco delle funzioni RBD avanzate:
layeringIl layering consente di utilizzare la funzione di clonazione.
Il valore interno è 1; quello di default è "yes".
stripingLo striping consente di distribuire i dati tra più oggetti e agevola il parallelismo dei workload sequenziali di lettura/scrittura. Consente di evitare la formazione di colli di bottiglia sui singoli nodi per dispositivi di blocco RADOS di grandi dimensioni oppure occupati.
Il valore interno è 2; quello di default è "yes".
exclusive-lockQuando abilitata, necessita di un client per ottenere un blocco su un oggetto prima di eseguire un'operazione di scrittura. Abilitare il blocco esclusivo solo quando un client singolo sta effettuando l'accesso a un'immagine nello stesso momento. Il valore interno è 4. L'impostazione di default è "yes".
object-mapIl supporto della mappa oggetti dipende dal supporto del blocco esclusivo. I dispositivi di blocco sono soggetti a thin provisioning e di conseguenza memorizzano soltanto i dati effettivamente esistenti. Il supporto della mappa oggetti consente di monitorare gli oggetti effettivamente esistenti (con dati memorizzati su un'unità). L'abilitazione del supporto della mappa oggetti consente di velocizzare le operazioni I/O per la clonazione, l'importazione e l'esportazione di un'immagine compilata in modo sparse e per l'eliminazione.
Il valore interno è 8; quello di default è "yes".
fast-diffIl supporto di fast-diff dipende dal supporto della mappa oggetti e del blocco esclusivo. Aggiunge un'altra proprietà alla mappa oggetti che la rende notevolmente più rapida nella creazione delle differenze tra le snapshot di un'immagine e l'utilizzo effettivo dei dati di una snapshot.
Il valore interno è 16; quello di default è "yes".
deep-flattenLa funzione deep-flatten attiva l'opzione
rbd flatten(vedere la Sezione 20.3.3.6, «Appiattimento di un'immagine clonata») su tutte le snapshot di un'immagine oltre che sull'immagine stessa. Senza di essa, le snapshot di un'immagine continueranno a dipendere da quella superiore e di conseguenza non sarà possibile eliminare tale immagine superiore finché non vengono eliminate anche le snapshot. Con l'impostazione deep-flatten, l'elemento superiore è reso indipendente dai cloni, anche se dispongono di snapshot.Il valore interno è 32; quello di default è "yes".
journalingIl supporto del journaling dipende dal supporto del blocco esclusivo. La funzione di journaling consente di registrare tutte le modifiche apportate a un'immagine nell'ordine in cui si verificano. La copia speculare RBD (vedere la Sezione 20.4, «Copie speculari delle immagini RBD») utilizza il journal per replicare un'immagine coerente con l'arresto anomalo in un cluster remoto.
Il valore interno è 64; quello di default è "yes".
20.9 Mappatura di RBD tramite i client kernel meno recenti #
I client meno recenti (ad esempio SLE11 SP4) potrebbero non essere in grado di mappare le immagini RBD poiché un cluster distribuito con SUSE Enterprise Storage 7.1 forza alcune funzioni (sia le funzioni a livello di immagine RBD che quelle a livello RADOS) non supportate dai client meno recenti. In questo caso, sui log OSD vengono visualizzati dei messaggi simili al seguente:
2019-05-17 16:11:33.739133 7fcb83a2e700 0 -- 192.168.122.221:0/1006830 >> \ 192.168.122.152:6789/0 pipe(0x65d4e0 sd=3 :57323 s=1 pgs=0 cs=0 l=1 c=0x65d770).connect \ protocol feature mismatch, my 2fffffffffff < peer 4010ff8ffacffff missing 401000000000000
Se si intende passare dal tipo di compartimento della mappa CRUSH "straw" a quello "straw2" e viceversa, procedere secondo una pianificazione. È prevedibile che questa operazione causi un impatto significativo sul carico del cluster, poiché la modifica del tipo di compartimento causerà un significativo ribilanciamento.
Disabilitare le funzioni dell'immagine RBD non supportate. Esempio:
cephuser@adm >rbd feature disable pool1/image1 object-mapcephuser@adm >rbd feature disable pool1/image1 exclusive-lockModificare il tipo di compartimento della mappa CRUSH da "straw2" a "straw":
Salvare la mappa CRUSH:
cephuser@adm >ceph osd getcrushmap -o crushmap.originalDecompilare la mappa CRUSH:
cephuser@adm >crushtool -d crushmap.original -o crushmap.txtModificare la mappa CRUSH e sostituire "straw2" con "straw".
Ricompilare la mappa CRUSH:
cephuser@adm >crushtool -c crushmap.txt -o crushmap.newImpostare la nuova mappa CRUSH:
cephuser@adm >ceph osd setcrushmap -i crushmap.new
20.10 Abilitazione dei dispositivi di blocco e di Kubernetes #
È possibile utilizzare i dispositivi di blocco RADOS Ceph con Kubernetes v1.13 e versioni successive tramite il driver ceph-csi, che esegue il provisioning dinamico delle immagini RBD sui volumi Kubernetes sottostanti e la mappatura di tali immagini sotto forma di dispositivi di blocco (facoltativamente montando un file system contenuto all'interno dell'immagine) ai nodi di lavoro su cui sono in esecuzione i pod che fanno riferimento a un volume con supporto RBD.
Per utilizzare i dispositivi di blocco Ceph con Kubernetes, è necessario installare e configurare ceph-csi all'interno dell'ambiente Kubernetes.
ceph-csi utilizza per default i moduli del kernel RBD, che potrebbero non supportare tutti gli elementi ottimizzabili CRUSH di Ceph o le funzioni dell'immagine RBD.
Per default, i dispositivi di blocco Ceph utilizzano il pool RBD. Creare un pool per la memorizzazione del volume Kubernetes. Assicurarsi che il cluster Ceph sia in esecuzione e creare il pool:
cephuser@adm >ceph osd pool create kubernetesUtilizzare lo strumento RBD per inizializzare il pool:
cephuser@adm >rbd pool init kubernetesCreare un nuovo utente per Kubernetes e
ceph-csi. Eseguire quanto riportato di seguito e registrare la chiave generata:cephuser@adm >ceph auth get-or-create client.kubernetes mon 'profile rbd' osd 'profile rbd pool=kubernetes' mgr 'profile rbd pool=kubernetes' [client.kubernetes] key = AQD9o0Fd6hQRChAAt7fMaSZXduT3NWEqylNpmg==Per definire gli indirizzi del Ceph Monitor per il cluster Ceph,
ceph-csinecessita di un oggetto ConfigMap memorizzato in Kubernetes. Raccogliere l'FSID e gli indirizzi del monitor univoci del cluster Ceph:cephuser@adm >ceph mon dump <...> fsid b9127830-b0cc-4e34-aa47-9d1a2e9949a8 <...> 0: [v2:192.168.1.1:3300/0,v1:192.168.1.1:6789/0] mon.a 1: [v2:192.168.1.2:3300/0,v1:192.168.1.2:6789/0] mon.b 2: [v2:192.168.1.3:3300/0,v1:192.168.1.3:6789/0] mon.cGenerare un file
csi-config-map.yamlsimile all'esempio riportato di seguito, sostituendo l'FSID perclusterIDe gli indirizzi dei monitor permonitors:kubectl@adm >cat <<EOF > csi-config-map.yaml --- apiVersion: v1 kind: ConfigMap data: config.json: |- [ { "clusterID": "b9127830-b0cc-4e34-aa47-9d1a2e9949a8", "monitors": [ "192.168.1.1:6789", "192.168.1.2:6789", "192.168.1.3:6789" ] } ] metadata: name: ceph-csi-config EOFQuindi, memorizzare il nuovo oggetto ConfigMap in Kubernetes:
kubectl@adm >kubectl apply -f csi-config-map.yamlPer la comunicazione con il cluster Ceph tramite
ceph-csi, sono necessarie le credenziali cephx. Generare un filecsi-rbd-secret.yamlsimile a quello nell'esempio riportato di seguito utilizzando l'ID utente Kubernetes e la chiave cephx appena creati:kubectl@adm >cat <<EOF > csi-rbd-secret.yaml --- apiVersion: v1 kind: Secret metadata: name: csi-rbd-secret namespace: default stringData: userID: kubernetes userKey: AQD9o0Fd6hQRChAAt7fMaSZXduT3NWEqylNpmg== EOFQuindi, memorizzare il nuovo oggetto segreto in Kubernetes:
kubectl@adm >kubectl apply -f csi-rbd-secret.yamlCreare il ServiceAccount e gli oggetti Kubernetes RBAC ClusterRole/ClusterRoleBinding richiesti. Questi oggetti non devono essere necessariamente personalizzati per il proprio ambiente Kubernetes e pertanto è possibile utilizzarli direttamente dai file YAML di distribuzione di
ceph-csi.kubectl@adm >kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-provisioner-rbac.yamlkubectl@adm >kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-nodeplugin-rbac.yamlCreare lo strumento di provisioning e i plug-in del nodo
ceph-csi:kubectl@adm >wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin-provisioner.yamlkubectl@adm >kubectl apply -f csi-rbdplugin-provisioner.yamlkubectl@adm >wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin.yamlkubectl@adm >kubectl apply -f csi-rbdplugin.yamlImportantePer default, i file YAML dello strumento di provisioning e del plug-in del nodo eseguiranno il pull della release di sviluppo del container
ceph-csi. È necessario aggiornare i file YAML per utilizzare la versione della release.
20.10.1 Uso dei dispositivi di blocco Ceph in Kubernetes #
La StorageClass Kubernetes definisce una classe di storage. È possibile creare più oggetti StorageClass per eseguire la mappatura a diversi livelli di qualità del servizio e funzioni. Si pensi ad esempio ai pool NVMe rispetto a quelli basati su HDD.
Per creare una StorageClass ceph-csi che mappi al pool Kubernetes creato sopra, è possibile utilizzare il file YAML seguente, dopo aver verificato che la proprietà clusterID corrisponda all'FSID del cluster Ceph:
kubectl@adm >cat <<EOF > csi-rbd-sc.yaml --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: csi-rbd-sc provisioner: rbd.csi.ceph.com parameters: clusterID: b9127830-b0cc-4e34-aa47-9d1a2e9949a8 pool: kubernetes csi.storage.k8s.io/provisioner-secret-name: csi-rbd-secret csi.storage.k8s.io/provisioner-secret-namespace: default csi.storage.k8s.io/node-stage-secret-name: csi-rbd-secret csi.storage.k8s.io/node-stage-secret-namespace: default reclaimPolicy: Delete mountOptions: - discard EOFkubectl@adm >kubectl apply -f csi-rbd-sc.yaml
Una PersistentVolumeClaim è una richiesta di risorse di memorizzazione astratte effettuata da un utente. La richiesta PersistentVolumeClaim viene quindi associata a una risorsa pod per il provisioning di un PersistentVolume, supportato da un'immagine del dispositivo di blocco Ceph. È possibile includere un valore volumeMode facoltativo per scegliere tra un file system montato (default) o un volume non elaborato basato sul dispositivo di blocco.
Con ceph-csi, specificando Filesystem per volumeMode, verranno supportate sia le richieste ReadWriteOnce che quelle ReadOnlyMany accessMode, mentre specificando Block per volumeMode, verranno supportate le richieste ReadWriteOnce, ReadWriteMany e ReadOnlyMany accessMode.
Ad esempio, per creare una richiesta PersistentVolumeClaim basata su blocchi in cui venga utilizzata la ceph-csi-based StorageClass creata sopra, è possibile usare il file YAML seguente per richiedere la memorizzazione del blocco non elaborato di csi-rbd-sc StorageClass:
kubectl@adm >cat <<EOF > raw-block-pvc.yaml --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: raw-block-pvc spec: accessModes: - ReadWriteOnce volumeMode: Block resources: requests: storage: 1Gi storageClassName: csi-rbd-sc EOFkubectl@adm >kubectl apply -f raw-block-pvc.yaml
Di seguito è riportato un esempio di associazione della richiesta PersistentVolumeClaim descritta sopra a una risorsa pod sotto forma di dispositivo di blocco non elaborato:
kubectl@adm >cat <<EOF > raw-block-pod.yaml --- apiVersion: v1 kind: Pod metadata: name: pod-with-raw-block-volume spec: containers: - name: fc-container image: fedora:26 command: ["/bin/sh", "-c"] args: ["tail -f /dev/null"] volumeDevices: - name: data devicePath: /dev/xvda volumes: - name: data persistentVolumeClaim: claimName: raw-block-pvc EOFkubectl@adm >kubectl apply -f raw-block-pod.yaml
Per creare una richiesta PersistentVolumeClaim basata su file system in cui venga utilizzata la ceph-csi-based StorageClass creata sopra, è possibile utilizzare il file YAML seguente per richiedere un file system montato (supportato da un'immagine RBD) di csi-rbd-sc StorageClass:
kubectl@adm >cat <<EOF > pvc.yaml --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: rbd-pvc spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 1Gi storageClassName: csi-rbd-sc EOFkubectl@adm >kubectl apply -f pvc.yaml
Di seguito è riportato un esempio di associazione della richiesta PersistentVolumeClaim descritta sopra a una risorsa pod sotto forma di file system montato:
kubectl@adm >cat <<EOF > pod.yaml --- apiVersion: v1 kind: Pod metadata: name: csi-rbd-demo-pod spec: containers: - name: web-server image: nginx volumeMounts: - name: mypvc mountPath: /var/lib/www/html volumes: - name: mypvc persistentVolumeClaim: claimName: rbd-pvc readOnly: false EOFkubectl@adm >kubectl apply -f pod.yaml
Parte IV Accesso ai dati del cluster #
- 21 Ceph Object Gateway
In questo capitolo vengono fornite ulteriori informazioni sui task amministrativi correlati a Object Gateway, come la verifica dello stato del servizio, la gestione degli account, i gateway multisito o l'autenticazione LDAP.
- 22 Ceph iSCSI Gateway
Questo capitolo è incentrato sui task amministrativi correlati a iSCSI Gateway. Per la procedura di distribuzione, fare riferimento a Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.3.5 “Distribuzione di iSCSI Gateway”.
- 23 File system in cluster
In questo capitolo sono descritti i task amministrativi che di norma vengono eseguiti dopo la configurazione del cluster e l'esportazione di CephFS. Per ulteriori informazioni sulla configurazione di CephFS, fare riferimento a Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti s…
- 24 Esportazione dei dati Ceph tramite Samba
Questo capitolo descrive come esportare i dati memorizzati in un cluster Ceph tramite una condivisione Samba/CIFS per potervi accedere con facilità dai computer client Windows*. Contiene inoltre informazioni utili per la configurazione di un gateway Samba Ceph in modo che si unisca ad Active Directo…
- 25 NFS Ganesha
NFS Ganesha è un server NFS che viene eseguito in uno spazio di indirizzamento dell'utente come parte del kernel del sistema operativo. Con NFS Ganesha, è possibile collegare un meccanismo di memorizzazione, come Ceph, e accedervi da qualsiasi client NFS. Per istruzioni sull'installazione, vedere Bo…
21 Ceph Object Gateway #
In questo capitolo vengono fornite ulteriori informazioni sui task amministrativi correlati a Object Gateway, come la verifica dello stato del servizio, la gestione degli account, i gateway multisito o l'autenticazione LDAP.
21.1 Restrizioni e limitazioni di denominazione di Object Gateway #
Di seguito è riportato un elenco di importanti limiti Object Gateway:
21.1.1 Limitazioni dei compartimenti #
Quando si inizia a utilizzare Object Gateway tramite l'API S3, i nomi dei compartimenti sono limitati ai nomi conformi a DNS in cui è consentito un trattino "-". Quando si inizia a utilizzare Object Gateway tramite l'API Swift, è possibile utilizzare una combinazione qualsiasi di caratteri UTF-8 supportati, tranne la barra "/". La lunghezza massima di un nome di compartimento è di 255 caratteri. I nomi dei compartimenti devono essere univoci.
Sebbene sia possibile utilizzare qualsiasi nome di compartimento basato su UTF-8 tramite l'API Swift, si consiglia di denominare i compartimenti tenendo in considerazione i limiti di denominazione S3 in modo da evitare problemi di accesso allo stesso compartimento tramite l'API S3.
21.1.2 Limitazioni degli oggetti memorizzati #
- Numero massimo di oggetti per utente
Per default, nessuna restrizione (limite definito da ~ 2^63).
- Numero massimo di oggetti per compartimento
Per default, nessuna restrizione (limite definito da ~ 2^63).
- Dimensioni massime di un oggetto di cui effettuare l'upload/da memorizzare
Gli upload singoli sono limitati a 5 GB. Utilizzare multipart per dimensioni grandi degli oggetti. Il numero massimo di porzioni multipart è 10000.
21.1.3 Limitazioni dell'intestazione HTTP #
L'intestazione HTTP e il limite di richiesta dipendono dalla front-end Web utilizzata. L'oggetto beast di default limita le dimensioni dell'intestazione HTTP a 16 KB.
21.2 Distribuzione di Object Gateway #
Analogamente agli altri servizi Ceph, Ceph Object Gateway viene distribuito tramite cephadm. Per ulteriori dettagli, fare riferimento a Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.2 “Specifica del servizio e del posizionamento”, nello specifico a Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.3.4 “Distribuzione degli Object Gateway”.
21.3 Attivazione del servizio Object Gateway #
In modo analogo agli altri servizi Ceph, gli Object Gateway vengono attivati identificando innanzitutto il nome del servizio con il comando ceph orch ps ed eseguendo quindi il comando di attivazione seguente, ad esempio:
ceph orch daemon restart OGW_SERVICE_NAME
Fare riferimento al Capitolo 14, Funzionamento dei servizi Ceph per informazioni complete sull'attivazione dei servizi Ceph.
21.4 Opzioni di configurazione #
Fare riferimento alla Sezione 28.5, «Ceph Object Gateway» per un elenco delle opzioni di configurazione di Object Gateway.
21.5 Gestione dell'accesso a Object Gateway #
È possibile comunicare con Object Gateway mediante l'interfaccia compatibile con S3 o Swift. L'interfaccia S3 è compatibile con un grande sottoinsieme dell'API Amazon S3 RESTful. L'interfaccia Swift è compatibile con un grande sottoinsieme dell'API OpenStack Swift.
Per entrambe le interfacce è richiesto di creare un utente specifico e installare il software client pertinente per comunicare con il gateway che utilizza la chiave segreta dell'utente.
21.5.1 Accesso a Object Gateway #
21.5.1.1 Accesso all'interfaccia S3 #
Per accedere all'interfaccia S3, è necessario un client REST. S3cmd è un client S3 della riga di comando. È possibile trovarlo in openSUSE Build Service (OBS) (in lingua inglese). L'archivio contiene versioni di entrambe le distribuzioni basate su SUSE Linux Enterprise e openSUSE.
Se si desidera testare l'accesso all'interfaccia S3, è anche possibile scrivere un piccolo script Python, che consentirà di eseguire la connessione a Object Gateway, creare un nuovo compartimento ed elencare tutti i compartimenti. I valori per aws_access_key_id e aws_secret_access_key sono ricavati dai valori di access_key e secret_key restituiti dal comando radosgw_admin di cui alla Sezione 21.5.2.1, «Aggiunta di utenti S3 e Swift».
Installare il pacchetto
python-boto:#zypper in python-botoCreare un nuovo script Python denominato
s3test.pycon il seguente contenuto:import boto import boto.s3.connection access_key = '11BS02LGFB6AL6H1ADMW' secret_key = 'vzCEkuryfn060dfee4fgQPqFrncKEIkh3ZcdOANY' conn = boto.connect_s3( aws_access_key_id = access_key, aws_secret_access_key = secret_key, host = 'HOSTNAME', is_secure=False, calling_format = boto.s3.connection.OrdinaryCallingFormat(), ) bucket = conn.create_bucket('my-new-bucket') for bucket in conn.get_all_buckets(): print "NAME\tCREATED".format( name = bucket.name, created = bucket.creation_date, )Sostituire
HOSTNAMEcon il nome host dell'host in cui è stato configurato il servizio Object Gateway, ad esempiogateway_host.Eseguire lo script:
python s3test.py
L'output dello script è simile a quanto riportato di seguito:
my-new-bucket 2015-07-22T15:37:42.000Z
21.5.1.2 Accesso all'interfaccia Swift #
Per accedere a Object Gateway tramite l'interfaccia Swift, è necessario il client della riga di comando swift. Nella relativa documentazione man 1 swift sono fornite ulteriori informazioni sulle rispettive opzioni della riga di comando.
Il pacchetto è incluso nel modulo "Public cloud" di SUSE Linux Enterprise 12 a partire da SP3 e di SUSE Linux Enterprise 15. Prima di installare il pacchetto, è necessario attivare il modulo e aggiornare l'archivio software:
# SUSEConnect -p sle-module-public-cloud/12/SYSTEM-ARCH
sudo zypper refreshOppure
#SUSEConnect -p sle-module-public-cloud/15/SYSTEM-ARCH#zypper refresh
Per installare il comando swift, eseguire quanto riportato di seguito:
# zypper in python-swiftclientPer l'accesso swift si utilizza la seguente sintassi:
> swift -A http://IP_ADDRESS/auth/1.0 \
-U example_user:swift -K 'SWIFT_SECRET_KEY' list
Sostituire IP_ADDRESS con l'indirizzo IP del server gateway e SWIFT_SECRET_KEY con il valore corrispondente dell'output del comando radosgw-admin key create eseguito per l'utente swift nella Sezione 21.5.2.1, «Aggiunta di utenti S3 e Swift».
Esempio:
> swift -A http://gateway.example.com/auth/1.0 -U example_user:swift \
-K 'r5wWIxjOCeEO7DixD1FjTLmNYIViaC6JVhi3013h' listL'output è:
my-new-bucket
21.5.2 Gestione degli account S3 e Swift #
21.5.2.1 Aggiunta di utenti S3 e Swift #
Per abilitare gli utenti finali all'iterazione con il gateway, è necessario creare un utente, una chiave di accesso e un segreto. Esistono due tipi di utenti: un utente e un sottoutente. Mentre gli utenti vengono utilizzati per l'iterazione con l'interfaccia S3, i sottoutenti sono gli utenti dell'interfaccia Swift. Ciascun sottoutente è associato a un utente.
Per creare un utente Swift, seguire la procedura indicata:
Per creare un utente Swift, che nella nostra terminologia è denominato sottoutente, prima è necessario creare l'utente associato.
cephuser@adm >radosgw-admin user create --uid=USERNAME \ --display-name="DISPLAY-NAME" --email=EMAILEsempio:
cephuser@adm >radosgw-admin user create \ --uid=example_user \ --display-name="Example User" \ --email=penguin@example.comPer creare un sottoutente (interfaccia Swift) per l'utente, occorre specificare l'ID utente (--uid=USERNAME) nonché l'ID e il livello di accesso del sottoutente.
cephuser@adm >radosgw-admin subuser create --uid=UID \ --subuser=UID \ --access=[ read | write | readwrite | full ]Esempio:
cephuser@adm >radosgw-admin subuser create --uid=example_user \ --subuser=example_user:swift --access=fullGenerare una chiave segreta per l'utente.
cephuser@adm >radosgw-admin key create \ --gen-secret \ --subuser=example_user:swift \ --key-type=swiftL'output di entrambi i comandi saranno i dati formattati per JSON in cui è visualizzato lo stato dell'utente. Osservare le righe seguenti e ricordare il valore di
secret_key:"swift_keys": [ { "user": "example_user:swift", "secret_key": "r5wWIxjOCeEO7DixD1FjTLmNYIViaC6JVhi3013h"}],
Se si accede a Object Gateway tramite l'interfaccia S3, è necessario creare un utente S3 eseguendo:
cephuser@adm > radosgw-admin user create --uid=USERNAME \
--display-name="DISPLAY-NAME" --email=EMAILEsempio:
cephuser@adm > radosgw-admin user create \
--uid=example_user \
--display-name="Example User" \
--email=penguin@example.com
Con questo comando si creano anche la chiave di accesso e la chiave segreta dell'utente. Verificare l'output per le parole chiave access_key e secret_key e i rispettivi valori:
[...]
"keys": [
{ "user": "example_user",
"access_key": "11BS02LGFB6AL6H1ADMW",
"secret_key": "vzCEkuryfn060dfee4fgQPqFrncKEIkh3ZcdOANY"}],
[...]21.5.2.2 Rimozione di utenti S3 e Swift #
La procedura di eliminazione degli utenti S3 e Swift è simile. Nel caso degli utenti Swift però potrebbe essere necessario eliminare l'utente e i rispettivi sottoutenti.
Per rimuovere un utente S3 o Swift (inclusi tutti i rispettivi sottoutenti), specificare user rm e l'ID utente nel seguente comando:
cephuser@adm > radosgw-admin user rm --uid=example_user
Per rimuovere un sottoutente, specificare subuser rm e l'ID sottoutente.
cephuser@adm > radosgw-admin subuser rm --uid=example_user:swiftÈ possibile utilizzare una delle seguenti opzioni:
- --purge-data
Elimina definitivamente tutti i dati associato all'ID utente.
- --purge-keys
Elimina definitivamente tutte le chiavi associate all'ID utente.
Quando si rimuove un sottoutente, si rimuove l'accesso all'interfaccia Swift. L'utente rimarrà nel sistema.
21.5.2.3 Modifica delle chiavi di accesso e segrete degli utenti S3 e Swift #
I parametri di access_key e secret_key identificano l'utente Object Gateway nel momento in cui accede al gateway. Modificare chiavi utente esistenti è come crearne di nuove, in quanto le chiavi precedenti vengono sovrascritte.
Per gli utenti S3, eseguire quanto riportato di seguito:
cephuser@adm > radosgw-admin key create --uid=EXAMPLE_USER --key-type=s3 --gen-access-key --gen-secretPer gli utenti Swift, eseguire quanto riportato di seguito:
cephuser@adm > radosgw-admin key create --subuser=EXAMPLE_USER:swift --key-type=swift --gen-secret--key-type=TYPESpecifica il tipo di chiave.
swiftos3.--gen-access-keyGenera una chiave di accesso casuale (di default per l'utente S3).
--gen-secretGenera una chiave segreta casuale.
--secret=KEYSpecifica una chiave segreta, ad esempio una chiave generata manualmente.
21.5.2.4 Abilitazione della gestione delle quote utente #
Ceph Object Gateway consente di impostare le quote su utenti e compartimenti di proprietà degli utenti. Le quote includono il numero massimo di oggetti in un compartimento e le dimensioni massime di memorizzazione espresse in megabyte.
Prima di abilitare una quota utente, è necessario impostarne i parametri:
cephuser@adm > radosgw-admin quota set --quota-scope=user --uid=EXAMPLE_USER \
--max-objects=1024 --max-size=1024--max-objectsSpecifica il numero massimo di oggetti. Con un numero negativo la verifica viene disabilitata.
--max-sizeSpecifica il numero massimo di byte. Con un numero negativo la verifica viene disabilitata.
--quota-scopeSpecifica l'ambito della quota. Le opzioni sono
bucketeuser. Le quote dei compartimenti si riferiscono ai compartimenti di proprietà di un utente. Le quote utente si riferiscono a un utente.
Una volta impostata una quota utente, è possibile abilitarla:
cephuser@adm > radosgw-admin quota enable --quota-scope=user --uid=EXAMPLE_USERPer disabilitare una quota:
cephuser@adm > radosgw-admin quota disable --quota-scope=user --uid=EXAMPLE_USERPer elencare le impostazioni della quota:
cephuser@adm > radosgw-admin user info --uid=EXAMPLE_USERPer aggiornare le statistiche della quota:
cephuser@adm > radosgw-admin user stats --uid=EXAMPLE_USER --sync-stats21.6 Front-end HTTP #
Ceph Object Gateway supporta due front-end HTTP integrati: oggetto beast e Civetweb.
Il front-end dell'oggetto beast utilizza la libreria Boost.Beast per l'analisi HTTP e la libreria Boost.Asio per l'I/O di rete asincrono.
Il front-end Civetweb utilizza la libreria HTTP Civetweb, che è un fork di Mongoose.
È possibile configurarli con l'opzione rgw_frontends. Fare riferimento alla Sezione 28.5, «Ceph Object Gateway» per un elenco delle opzioni di configurazione.
21.7 Abilitazione di HTTPS/SSL per gli Object Gateway #
Per abilitare la comunicazione sicura di Object Gateway tramite SSL, occorre disporre di un certificato emesso da un'autorità di certificazione o crearne uno autofirmato.
21.7.1 Creazione di un certificato autofirmato #
Ignorare questa sezione se si dispone già di un certificato valido firmato dalla CA.
Nella procedura seguente è illustrato come generare un certificato SSL autofirmato sul Salt Master.
Se è necessario che Object Gateway sia noto ad altre identità di oggetto, aggiungerle all'opzione
subjectAltNamenella sezione[v3_req]del file/etc/ssl/openssl.cnf:[...] [ v3_req ] subjectAltName = DNS:server1.example.com DNS:server2.example.com [...]
Suggerimento: indirizzi IP insubjectAltNamePer utilizzare gli indirizzi IP al posto dei nomi di dominio nell'opzione
subjectAltName, sostituire la riga di esempio con quanto segue:subjectAltName = IP:10.0.0.10 IP:10.0.0.11
Creare la chiave e il certificato utilizzando
openssl. Immettere tutti i dati che è necessario includere nel certificato. Si consiglia di immettere FQDN come nome comune. Prima di firmare il certificato, verificare che "X509v3 Subject Alternative Name:" sia incluso nelle estensioni richieste e che sia impostato nel certificato che viene generato.root@master #openssl req -x509 -nodes -days 1095 \ -newkey rsa:4096 -keyout rgw.key -out rgw.pemAggiungere la chiave al file di certificato:
root@master #cat rgw.key >> rgw.pem
21.7.2 Configurazione di Object Gateway con SSL #
Per configurare Object Gateway sull'uso dei certificati SSL, utilizzare l'opzione rgw_frontends. Esempio:
cephuser@adm > ceph config set WHO rgw_frontends \
beast ssl_port=443 ssl_certificate=config://CERT ssl_key=config://KEYSe le chiavi di configurazione CERT e KEY non vengono specificate, il servizio Object Gateway cercherà la chiave e il certificato SSL nelle chiavi di configurazione seguenti:
rgw/cert/RGW_REALM/RGW_ZONE.key rgw/cert/RGW_REALM/RGW_ZONE.crt
Se si desidera sostituire l'ubicazione della chiave e del certificato SSL di default, importarli nel database di configurazione utilizzando il comando seguente:
ceph config-key set CUSTOM_CONFIG_KEY -i PATH_TO_CERT_FILE
Quindi, utilizzare le chiavi di configurazione personalizzate con la direttiva config://.
21.8 Moduli di sincronizzazione #
Object Gateway viene distribuito come servizio multisito ed è possibile eseguire la copia speculare dei dati e dei metadati tra le zone. I moduli di sincronizzazione sono costruiti in cima al framework multisito che consente l'inoltro di dati e metadati a un livello esterno diverso. Un modulo di sincronizzazione consente di eseguire un set di azioni ogni volta che ha luogo una modifica dei dati (ad esempio, operazioni correlate ai metadati come la creazione di compartimenti o di utenti). Poiché le modifiche del multisito Object Gateway sono coerenti nei siti remoti, le modifiche vengono propagate in modo asincrono. Questo concetto comprende casi d'uso come il backup della memorizzazione di oggetti in un cluster cloud esterno, una soluzione di backup personalizzata in cui vengono utilizzate unità nastro o l'indicizzazione dei metadati in ElasticSearch.
21.8.1 Configurazione dei moduli di sincronizzazione #
Tutti i moduli di sincronizzazione vengono configurati in modo simile. È necessario creare una nuova zona (fare riferimento alla Sezione 21.13, «Object Gateway multisito» per ulteriori dettagli) e impostare la relativa opzione --tier_type, ad esempio --tier-type=cloud, per il modulo di sincronizzazione cloud:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--endpoints=http://endpoint1.example.com,http://endpoint2.example.com, [...] \
--tier-type=cloudÈ possibile configurare un livello specifico tramite il comando seguente:
cephuser@adm > radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--tier-config=KEY1=VALUE1,KEY2=VALUE2La variabile KEY della configurazione specifica la variabile di configurazione da aggiornare, mentre VALUE specifica il nuovo valore corrispondente. È possibile accedere ai valori nidificati utilizzando il punto. Esempio:
cephuser@adm > radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--tier-config=connection.access_key=KEY,connection.secret=SECRETÈ possibile accedere agli elementi della matrice aggiungendo delle parentesi quadre "[]" all'elemento a cui si fa riferimento. È possibile aggiungere un nuovo elemento della matrice utilizzando le parentesi quadre "[]". Il valore di indice -1 fa riferimento all'ultimo elemento della matrice. Non è possibile creare un nuovo elemento e farvi nuovamente riferimento nello stesso comando. Ad esempio, di seguito è riportato un comando per la creazione di un nuovo profilo per i compartimenti che iniziano con PREFIX:
cephuser@adm >radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \ --rgw-zone=ZONE-NAME \ --tier-config=profiles[].source_bucket=PREFIX'*'cephuser@adm >radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \ --rgw-zone=ZONE-NAME \ --tier-config=profiles[-1].connection_id=CONNECTION_ID,profiles[-1].acls_id=ACLS_ID
Tramite il parametro --tier-config-add==VALUE, è possibile aggiungere una nuova voce di configurazione del livello.
Per rimuovere una voce esistente, utilizzare --tier-config-rm=KEY.
21.8.2 Sincronizzazione delle zone #
La configurazione di un modulo di sincronizzazione viene eseguita a livello locale in una zona. Il modulo di sincronizzazione determina se i dati vengono esportati dalla zona o se questa utilizza solo dati modificati in un'altra zona. A partire da Luminous, i plug-in di sincronizzazione supportati sono ElasticSearch, rgw, il plug-in di sincronizzazione di default mediante il quale vengono sincronizzati i dati tra le zone, e log, un plug-in di sincronizzazione semplice che registra le operazioni dei metadati che hanno luogo nelle zone remote. Nelle sezioni seguenti è riportato l'esempio di una zona in cui viene utilizzato il modulo di sincronizzazione ElasticSearch. Il processo è simile a quello utilizzato per la configurazione di qualsiasi altro plug-in di sincronizzazione.
rgw è il plug-in di sincronizzazione di default e non è necessario configurarlo esplicitamente.
21.8.2.1 Requisiti e presupposti #
Si supponga una semplice configurazione multisito, come descritta nella Sezione 21.13, «Object Gateway multisito», costituita da 2 zone: us-east e us-west. Adesso si aggiunge una terza zona us-east-es nella quale vengono elaborati solo i metadati provenienti da altri siti. Questa zona può essere nello stesso cluster Ceph di us-east o in uno diverso. In questa zona vengono utilizzati solo i metadati provenienti da altre zone e gli Object Gateway in essa contenuti non serviranno direttamente alcuna richiesta dell'utente finale.
21.8.2.2 Configurazione delle zone #
Creare una terza zona simile a quelle descritte nella Sezione 21.13, «Object Gateway multisito», ad esempio
cephuser@adm >radosgw-adminzone create --rgw-zonegroup=us --rgw-zone=us-east-es \ --access-key=SYSTEM-KEY --secret=SECRET --endpoints=http://rgw-es:80È possibile configurare un modulo di sincronizzazione per questa zona nel modo seguente:
cephuser@adm >radosgw-adminzone modify --rgw-zone=ZONE-NAME --tier-type=TIER-TYPE \ --tier-config={set of key=value pairs}Ad esempio, nel modulo di sincronizzazione
ElasticSearchcephuser@adm >radosgw-adminzone modify --rgw-zone=ZONE-NAME --tier-type=elasticsearch \ --tier-config=endpoint=http://localhost:9200,num_shards=10,num_replicas=1Per le varie opzioni tier-config supportate, fare riferimento a Sezione 21.8.3, «Modulo di sincronizzazione ElasticSearch».
Infine, aggiornare il periodo
cephuser@adm >radosgw-adminperiod update --commitAdesso, avviare Object Gateway nella zona
cephuser@adm >ceph orch start rgw.REALM-NAME.ZONE-NAME
21.8.3 Modulo di sincronizzazione ElasticSearch #
Questo modulo di sincronizzazione consente di scrivere in ElasticSearch i metadati provenienti da altre zone. A partire da Luminous, è il formato JSON dei campi dei dati che attualmente vengono memorizzati in ElasticSearch.
{
"_index" : "rgw-gold-ee5863d6",
"_type" : "object",
"_id" : "34137443-8592-48d9-8ca7-160255d52ade.34137.1:object1:null",
"_score" : 1.0,
"_source" : {
"bucket" : "testbucket123",
"name" : "object1",
"instance" : "null",
"versioned_epoch" : 0,
"owner" : {
"id" : "user1",
"display_name" : "user1"
},
"permissions" : [
"user1"
],
"meta" : {
"size" : 712354,
"mtime" : "2017-05-04T12:54:16.462Z",
"etag" : "7ac66c0f148de9519b8bd264312c4d64"
}
}
}21.8.3.1 Parametri di configurazione di tipi di livelli ElasticSearch #
- endpoint
Specifica l'endpoint del server ElasticSearch cui accedere.
- num_shards
(numero intero) Numero di partizioni che verranno configurate da ElasticSearch con l'inizializzazione della sincronizzazione sui dati. Dopo l'inizializzazione non è possibile modificare tale numero. Per qualsiasi modifica sono richieste la ricompilazione dell'indice di ElasticSearch e la reinizializzazione del processo di sincronizzazione dei dati.
- num_replicas
(numero intero) Numero di repliche che verranno configurate da ElasticSearch con l'inizializzazione della sincronizzazione sui dati.
- explicit_custom_meta
(true | false) Specifica se tutti i metadati personalizzati dell'utente verranno indicizzati o se l'utente dovrà configurare (a livello di compartimento) quali voci dei metadati del cliente devono essere indicizzate. Per default, questa opzione è impostata su false.
- index_buckets_list
(elenco di stringhe separate da virgole) Se vuoti, tutti i compartimenti verranno indicizzati. Altrimenti, verranno indicizzati solo i compartimenti specificati qui. È possibile specificare i prefissi dei compartimenti (ad esempio "foo*") o i suffissi (ad esempio "*bar").
- approved_owners_list
(elenco di stringhe separate da virgole) Se vuoti, i compartimenti di tutti i proprietari verranno indicizzati (operazione soggetta ad altre restrizioni), altrimenti verranno indicizzati solo i compartimenti appartenenti ai proprietari specificati. È possibile specificare anche i suffissi e i prefissi.
- override_index_path
(stringa) Se non è vuota, la stringa verrà utilizzata come percorso di indice di ElasticSearch. Altrimenti il percorso di indice verrà determinato e generato al momento dell'inizializzazione della sincronizzazione.
- nomeutente
Specifica un nome utente per ElasticSearch se occorre effettuare l'autenticazione.
- password
Specifica una password per ElasticSearch se occorre effettuare l'autenticazione.
21.8.3.2 Interrogazioni dei metadati #
Poiché adesso nel cluster ElasticSearch vengono memorizzati metadati di oggetti, è importante che l'endpoint di ElasticSearch non sia esposto al pubblico e che sia accessibile solo dagli amministratori del cluster. Ciò rappresenta un problema per l'esposizione delle interrogazioni dei metadati all'utente finale, dato che l'utente dovrebbe interrogare solo i propri metadati e non quelli di altri utenti. Pertanto sarebbe opportuno che l'autenticazione degli utenti da parte del cluster ElasticSearch venga eseguita in modo simile a RGW, il che rappresenta un problema.
A partire da Luminous RGW, adesso nella zona master dei metadata master è possibile provvedere alle richieste degli utenti finali. In tal modo l'endpoint di ElasticSearch non viene esposto al pubblico e si risolve anche il problema di autenticazione e autorizzazione in quanto RGW stesso è in grado di autenticare le richieste degli utenti finali. A tal fine, RGW introduce una nuova interrogazione nelle API del compartimento che sono in grado di provvedere alle richieste ElasticSearch. Tutte queste richieste devono essere inviate alla zona master dei metadati.
- Ottenimento di un'interrogazione ElasticSearch
GET /BUCKET?query=QUERY-EXPR
parametri di richiesta:
max-keys: numero massimo di voci da restituire
marker: marker di impaginazione
expression := [(]<arg> <op> <value> [)][<and|or> ...]
op è uno dei seguenti: <, <=, ==, >=, >
Esempio:
GET /?query=name==foo
Verranno restituite tutte le chiavi indicizzate per le quali l'utente dispone l'autorizzazione in lettura e vengono denominate "foo". L'output sarà un elenco di chiavi in XML simile alla risposta dei compartimenti dell'elenco S3.
- Configurazione dei campi dei metadati personalizzati
Definire quali voci dei metadati personalizzati devono essere indicizzate (nel compartimento specificato) e quali sono i tipi di queste chiavi. Se si configura l'indicizzazione esplicita dei metadati personalizzati, tale operazione è necessaria affinché rgw indicizzi i valori dei metadati personalizzati specificati. Altrimenti è necessaria nei casi in cui le chiavi dei metadati indicizzati siano di tipo diverso dalla stringa.
POST /BUCKET?mdsearch x-amz-meta-search: <key [; type]> [, ...]
I campi di metadati multipli devono essere separati da virgole, è possibile forzare un tipo per un campo con un punto e virgola ";". I tipi attualmente consentiti sono stringa (default), numero intero e data. Ad esempio, se si desidera indicizzare i metadati di oggetto personalizzati x-amz-meta-year come int, x-amz-meta-date come tipo di data e x-amz-meta-title come stringa, procedere come indicato di seguito
POST /mybooks?mdsearch x-amz-meta-search: x-amz-meta-year;int, x-amz-meta-release-date;date, x-amz-meta-title;string
- Eliminazione della configurazione dei metadati personalizzati
Eliminare la configurazione del compartimento dei metadati personalizzati.
DELETE /BUCKET?mdsearch
- Ottenimento della configurazione dei metadati personalizzati
Recuperare la configurazione del compartimento dei metadati personalizzati.
GET /BUCKET?mdsearch
21.8.4 Modulo di sincronizzazione cloud #
Questa sezione descrive un modulo che effettua la sincronizzazione dei dati della zona con un servizio cloud remoto. La sincronizzazione è esclusivamente unidirezionale (ovvero la data non viene risincronizzata dalla zona remota). L'obiettivo principale di questo modulo è quello di abilitare la sincronizzazione dei dati con più provider di servizi cloud. Al momento, questo modulo supporta i provider cloud compatibili con AWS (S3).
Per sincronizzare i dati con un servizio cloud remoto, occorre configurare le credenziali utente. Poiché molti servizi cloud introducono dei limiti sul numero di compartimenti che ciascun utente può creare, è possibile configurare la mappatura dei compartimenti e degli oggetti di origine, delle diverse destinazioni su compartimenti diversi e dei prefissi dei compartimenti. Tenere presente che gli elenchi di accesso all'origine (ACL) non verranno conservati. È possibile mappare le autorizzazioni degli utenti di origine specifici a determinati utenti di destinazione.
A causa delle limitazioni dell'API, non è possibile conservare l'ora di modifica dell'oggetto originale e il tag dell'entità HTTP (ETag). Il modulo di sincronizzazione cloud memorizza queste informazioni come attributi di metadati sugli oggetti di destinazione.
21.8.4.1 Configurazione del modulo di sincronizzazione cloud #
Di seguito sono riportati degli esempi di configurazione semplice e complessa del modulo di sincronizzazione cloud. Tenere presente che la configurazione semplice può entrare in conflitto con quella complessa.
{
"connection": {
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style": path | virtual,
},
"acls": [ { "type": id | email | uri,
"source_id": SOURCE_ID,
"dest_id": DEST_ID } ... ],
"target_path": TARGET_PATH,
}{
"default": {
"connection": {
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style" path | virtual,
},
"acls": [
{
"type": id | email | uri, # optional, default is id
"source_id": ID,
"dest_id": ID
} ... ]
"target_path": PATH # optional
},
"connections": [
{
"connection_id": ID,
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style": path | virtual, # optional
} ... ],
"acl_profiles": [
{
"acls_id": ID, # acl mappings
"acls": [ {
"type": id | email | uri,
"source_id": ID,
"dest_id": ID
} ... ]
}
],
"profiles": [
{
"source_bucket": SOURCE,
"connection_id": CONNECTION_ID,
"acls_id": MAPPINGS_ID,
"target_path": DEST, # optional
} ... ],
}Di seguito è riportata la spiegazione dei termini di configurazione utilizzati:
- connessione
Rappresenta la connessione al servizio cloud remoto. Contiene "connection_id", "access_key", "secret", "endpoint", e "host_style".
- access_key
La chiave di accesso al cloud remoto che verrà utilizzata per la connessione specifica.
- secret
La chiave segreta del servizio cloud remoto.
- endpoint
URL dell'endpoint del servizio cloud remoto.
- host_style
Tipo di stile host ("path" o "virtual") da utilizzare per l'accesso all'endpoint cloud remoto. L'impostazione di default è "path".
- acls
Matrice delle mappature dell'elenco accessi.
- acl_mapping
Ciascuna struttura "acl_mapping" contiene "type", "source_id" e "dest_id". Questi valori definiscono la mutazione dell'ACL di ciascun oggetto. Le mutazioni dell'ACL consentono di convertire l'ID utente di origine in un ID di destinazione.
- tipo
Tipo di ACL: "id" definisce l'ID utente, "email" definisce l'utente tramite l'indirizzo e-mail e "uri" definisce l'utente in base all'uri (gruppo).
- source_id
ID dell'utente nella zona di origine.
- dest_id
ID dell'utente nella destinazione.
- target_path
Una stringa che definisce la modalità di creazione del percorso di destinazione. Il percorso di destinazione specifica un prefisso al quale viene aggiunto il nome dell'oggetto di origine. Il percorso di destinazione configurabile può includere una delle seguenti variabili:
- SID
Una stringa univoca che rappresenta l'ID dell'istanza di sincronizzazione.
- ZONEGROUP
Nome del gruppo di zone.
- ZONEGROUP_ID
ID del gruppo di zone.
- ZONE
Nome della zona.
- ZONE_ID
ID della zona.
- BUCKET
Nome del compartimento di origine.
- OWNER
ID del proprietario del compartimento di origine.
Ad esempio: target_path = rgwx-ZONE-SID/OWNER/BUCKET
- acl_profiles
Una matrice dei profili dell'elenco accessi.
- acl_profile
Ogni profilo contiene "acls_id", che rappresenta il profilo, e una matrice "acls" che contiene un elenco delle "acl_mappings".
- profili
Un elenco dei profili. Ogni profilo contiene quanto segue:
- source_bucket
Il nome o il prefisso di un compartimento (se termina con *) che definisce i compartimenti di origine per il profilo.
- target_path
Vedere sopra per la spiegazione.
- connection_id
ID della connessione che verrà utilizzato per questo profilo.
- acls_id
ID del profilo dell'ACL che verrà utilizzato per questo profilo.
21.8.4.2 Elementi configurabili specifici di S3 #
Il modulo di sincronizzazione cloud funziona soltanto con i back-end compatibili con AWS S3. È possibile utilizzare alcuni elementi configurabili per ottimizzarne il comportamento durante l'accesso ai servizi cloud S3:
{
"multipart_sync_threshold": OBJECT_SIZE,
"multipart_min_part_size": PART_SIZE
}- multipart_sync_threshold
Gli oggetti di dimensioni uguali o superiori a questo valore verranno sincronizzati con il servizio cloud tramite l'upload multipart.
- multipart_min_part_size
Dimensioni minime delle parti da utilizzare durante la sincronizzazione degli oggetti con l'upload multipart.
21.8.5 Modulo di sincronizzazione degli archivi #
Il modulo di sincronizzazione degli archivi utilizza la funzione del controllo versioni degli oggetti S3 in Object Gateway. È possibile configurare una zona di archiviazione per acquisire le diverse versioni degli oggetti S3 che hanno luogo nel corso del tempo nelle altre zone. Tramite i gateway associati alla zona di archiviazione, è possibile eliminare la cronologia delle versioni conservata nella zona stessa.
Grazie a questa architettura, diverse zone senza versione possono eseguire la copia speculare dei relativi dati e metadati tramite i propri gateway di zona fornendo elevata disponibilità agli utenti finali, mentre la zona di archiviazione acquisisce tutti gli aggiornamenti dei dati per consolidarli come versioni degli oggetti S3.
Includendo la zona di archiviazione in una configurazione multizona, è possibile ottenere in una zona la flessibilità della cronologia degli oggetti S3 risparmiando al contempo spazio che verrà utilizzato nelle zone rimanenti dalle repliche degli oggetti S3 con versione.
21.8.5.1 Configurazione del modulo di sincronizzazione degli archivi #
Fare riferimento alla Sezione 21.13, «Object Gateway multisito» per i dettagli sulla configurazione dei gateway multisito.
Fare riferimento alla Sezione 21.8, «Moduli di sincronizzazione» per i dettagli sulla configurazione dei moduli di sincronizzazione.
Per utilizzare il modulo di sincronizzazione degli archivi, occorre creare una nuova zona con tipo di livello impostato su archive:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME \
--rgw-zone=OGW_ZONE_NAME \
--endpoints=http://OGW_ENDPOINT1_URL[,http://OGW_ENDPOINT2_URL,...]
--tier-type=archive21.9 Autenticazione LDAP #
Oltre all'autenticazione utente locale di default, con Object Gateway si possono utilizzare i servizi del server LDAP per autenticare anche gli utenti.
21.9.1 Meccanismo di autenticazione #
Object Gateway estrae le credenziali LDAP dell'utente da un token. Dal nome utente viene costruito un filtro di ricerca. In Object Gateway si utilizza il servizio configurato per ricercare la directory di una voce corrispondente. Se si trova la voce, Object Gateway tenta di associare il nome distinto con la password ottenuta dal token. Se le credenziali sono valide, l'associazione avrà esito positivo e verrà concesso l'accesso a Object Gateway.
È possibile limitare gli utenti consentiti impostando la base per la ricerca a un'unità organizzativa specifica o definendo un filtro di ricerca personalizzato, ad esempio richiedendo l'appartenenza di un gruppo specifico, classi di oggetti personalizzati o attributi.
21.9.2 Requisiti #
LDAP o Active Directory: un'istanza LDAP in esecuzione accessibile da Object Gateway.
Account di servizio: credenziali LDAP che devono essere utilizzate da Object Gateway con autorizzazioni di ricerca.
Account utente: almeno un account utente nella directory LDAP.
Non utilizzare gli stessi nomi utente per gli utenti locali e per gli utenti che vengono autenticati mediante l'uso di LDAP. Object Gateway non è in grado di distinguerli e li considera come lo stesso utente.
Utilizzare l'utility ldapsearch per verificare l'account di servizio o la connessione LDAP. Esempio:
> ldapsearch -x -D "uid=ceph,ou=system,dc=example,dc=com" -W \
-H ldaps://example.com -b "ou=users,dc=example,dc=com" 'uid=*' dnAssicurarsi di utilizzare gli stessi parametri LDAP del file di configurazione Ceph per eliminare eventuali problemi.
21.9.3 Configurazione di Object Gateway per utilizzare l'autenticazione LDAP #
I seguenti parametri sono correlati all'autenticazione LDAP:
rgw_s3_auth_use_ldapImpostare questa opzione su
trueper abilitare l'autenticazione S3 con LDAP.rgw_ldap_uriSpecifica il server LDAP da utilizzare. Assicurarsi di utilizzare il parametro
ldaps://FQDN:PORTper evitare di trasmettere apertamente le credenziali come testo normale.rgw_ldap_binddnNome distinto (DN) dell'account di servizio utilizzato da Object Gateway.
rgw_ldap_secretPassword per l'account di servizio.
- rgw_ldap_searchdn
Specifica la base DIT (Directory Information Tree) per la ricerca degli utenti. Questa può essere l'unità organizzativa degli utenti o una più specifica.
rgw_ldap_dnattrAttributo che viene utilizzato nel filtro di ricerca costruito per la corrispondenza con un nome utente. A seconda del DIT, è probabile che tale attributo sia
uidocn.rgw_search_filterSe non è specificato, in Object Gateway il filtro di ricerca viene costruito automaticamente con l'impostazione
rgw_ldap_dnattr. Utilizzare questo parametro per restringere l'elenco degli utenti consentiti con la massima flessibilità. Consultare Sezione 21.9.4, «Utilizzo di un filtro di ricerca personalizzato per limitare l'accesso degli utenti» per ulteriori informazioni.
21.9.4 Utilizzo di un filtro di ricerca personalizzato per limitare l'accesso degli utenti #
È possibile utilizzare il parametro rgw_search_filter in due modi diversi.
21.9.4.1 Filtro parziale per limitare ulteriormente il filtro di ricerca costruito #
Di seguito è riportato un esempio di filtro parziale:
"objectclass=inetorgperson"
In Object Gateway il filtro di ricerca verrà generato come di consueto, con il nome dell'utente ottenuto dal token del valore di rgw_ldap_dnattr. Il filtro costruito viene quindi combinato con il filtro parziale dell'attributo rgw_search_filter. A seconda del nome utente e delle impostazioni, il filtro di ricerca finale può diventare:
"(&(uid=hari)(objectclass=inetorgperson))"
In tal caso, all'utente 'hari' verrà concesso l'accesso solo se è presente nella directory LDAP, dispone di una classe oggetto 'inetorgperson' e ha specificato una password valida.
21.9.4.2 Filtro completo #
Un filtro completo deve contenere un token USERNAME che verrà sostituito con il nome dell'utente durante il tentativo di autenticazione. In tal caso, il parametro rgw_ldap_dnattr non viene più utilizzato. Ad esempio, per limitare gli utenti validi a un gruppo specifico, utilizzare il filtro seguente:
"(&(uid=USERNAME)(memberOf=cn=ceph-users,ou=groups,dc=mycompany,dc=com))"
memberOf
Per utilizzare l'attributo memberOf nelle richieste LDAP è richiesto il supporto lato server dall'implementazione del server LDAP specificata.
21.9.5 Generazione di un token di accesso per l'autenticazione LDAP #
Il token di accesso viene generato dall'utility radosgw-token in base al nome utente e alla password LDAP. L'output è una stringa codificata base-64 che corrisponde al token di accesso effettivo. Utilizzare il client S3 preferito (fare riferimento a Sezione 21.5.1, «Accesso a Object Gateway»), specificare il token come chiave di accesso e utilizzare una chiave segreta vuota.
>export RGW_ACCESS_KEY_ID="USERNAME">export RGW_SECRET_ACCESS_KEY="PASSWORD"cephuser@adm >radosgw-token --encode --ttype=ldap
Il token di accesso è una struttura JSON codificata base-64 e contiene le credenziali LDAP non cifrate.
Per Active Directory, utilizzare il parametro --ttype=ad.
21.10 Partizionamento dell'indice del compartimento #
In Object Gateway i dati di indice del compartimento vengono memorizzati in un pool di indice, che per default è impostato su .rgw.buckets.index. Se si inseriscono troppi (centinaia di migliaia) oggetti in un singolo compartimento e la quota massima per il numero di oggetti per compartimento (rgw bucket default quota max objects) non è impostata, le prestazioni del pool di indice potrebbero essere compromesse. Il partizionamento dell'indice del compartimento impedisce tali riduzioni delle prestazioni e consente un numero maggiore di oggetti per compartimento.
21.10.1 Ripartizionamento dell'indice del compartimento #
Se un compartimento è diventato più grande e la rispettiva configurazione iniziale non è più sufficiente, è necessario ripartizionare il pool di indice del compartimento. È possibile utilizzare il ripartizionamento automatico dell'indice del compartimento online (fare riferimento alla Sezione 21.10.1.1, «Ripartizionamento dinamico») o eseguire manualmente il ripartizionamento dell'indice del compartimento offline (fare riferimento alla Sezione 21.10.1.2, «Ripartizionamento manuale»).
21.10.1.1 Ripartizionamento dinamico #
A partire da SUSE Enterprise Storage 5, è supportato il ripartizionamento del compartimento online. Viene rilevato se il numero di oggetti per compartimento raggiunge una determinata soglia e viene aumentato automaticamente il numero di partizioni utilizzate dall'indice del compartimento. Questo processo consente di ridurre il numero di voci in ciascuna partizione dell'indice del compartimento.
Il processo di rilevamento viene eseguito:
Quando vengono aggiunti nuovi oggetti al compartimento.
In un processo in background che esegue periodicamente la scansione di tutti i compartimenti. Questo è necessario per gestire i compartimenti esistenti che non vengono aggiornati.
Un compartimento per il quale è richiesto il ripartizionamento viene aggiunto alla coda reshard_log e verrà pianificato per un ripartizionamento successivo. I thread della ripartizione vengono eseguiti in background ed eseguono un ripartizionamento pianificato alla volta.
rgw_dynamic_reshardingAbilita o disabilita il ripartizionamento dinamico dell'indice del compartimento. I valori possibili sono "true" o "false". Il valore di default è "true".
rgw_reshard_num_logsNumero di partizioni per il log di ripartizionamento. Il valore di default è 16.
rgw_reshard_bucket_lock_durationDurata del bloccaggio nell'oggetto Compartimento durante il ripartizionamento. Il valore di default è 120 secondi.
rgw_max_objs_per_shardNumero massimo di oggetti per partizione dell'indice del compartimento. Il valore di default è 10.0000 oggetti.
rgw_reshard_thread_intervalDurata massima tra i cicli di elaborazione dei thread delle ripartizioni. Il valore di default è 600 secondi.
- Aggiungere un compartimento alla coda di ripartizionamento:
cephuser@adm >radosgw-admin reshard add \ --bucket BUCKET_NAME \ --num-shards NEW_NUMBER_OF_SHARDS- Elencare la coda di ripartizionamento:
cephuser@adm >radosgw-admin reshard list- Elaborare/pianificare un ripartizionamento del compartimento:
cephuser@adm >radosgw-admin reshard process- Visualizzare lo stato di ripartizionamento del compartimento:
cephuser@adm >radosgw-admin reshard status --bucket BUCKET_NAME- Annullare il ripartizionamento del compartimento in sospeso:
cephuser@adm >radosgw-admin reshard cancel --bucket BUCKET_NAME
21.10.1.2 Ripartizionamento manuale #
Il ripartizionamento dinamico di cui alla Sezione 21.10.1.1, «Ripartizionamento dinamico» è supportato solo per le configurazioni Object Gateway semplici. Per le configurazioni multisito, utilizzare il ripartizionamento manuale descritto nella presente sezione.
Per eseguire il ripartizionamento manuale dell'indice del compartimento offline, utilizzare il comando seguente:
cephuser@adm > radosgw-admin bucket reshard
Il comando bucket reshard consente di effettuare le seguenti operazioni:
Creare un nuovo set di oggetti Indice compartimento per l'oggetto specificato.
Distribuire tutte le voci di questi oggetti di indice.
Creare una nuova istanza del compartimento.
Collegare la nuova istanza del compartimento al compartimento in modo che tutte le nuove operazioni di indice passino attraverso i nuovi indici del compartimento.
Stampare il vecchio e il nuovo ID compartimento nell'output standard.
Quando si sceglie il numero di partizionamenti, non superare le 100.000 voci per partizionamento. I partizionamenti dell'indice del compartimento corrispondenti a numeri primi tendono a funzionare meglio in voci dell'indice del compartimento distribuite uniformemente nei partizionamenti. Ad esempio, invece di impostare 500 partizionamenti dell'indice del compartimento, è consigliabile impostarne 503, dal momento che questo è un numero primo.
Assicurarsi che tutte le operazioni nel compartimento vengano interrotte
Eseguire il backup dell'indice del compartimento originale:
cephuser@adm >radosgw-admin bi list \ --bucket=BUCKET_NAME \ > BUCKET_NAME.list.backupEseguire il ripartizionamento dell'indice del compartimento:
cephuser@adm >radosgw-admin bucket reshard \ --bucket=BUCKET_NAME \ --num-shards=NEW_SHARDS_NUMBERSuggerimento: ID compartimento precedenteCome parte del rispettivo output, questo comando consente inoltre di stampare l'ID compartimento nuovo e quello precedente.
21.10.2 Partizionamento dell'indice del compartimento per nuovi compartimenti #
Sono disponibili due opzioni che influenzano il partizionamento dell'indice del compartimento:
Utilizzare l'opzione
rgw_override_bucket_index_max_shardsper le configurazioni semplici.Utilizzare l'opzione
bucket_index_max_shardsper le configurazioni multisito.
Con l'impostazione delle opzioni su 0 si disabilita il partizionamento dell'indice del compartimento. Con un valore maggiore di 0 si abilita il partizionamento dell'indice del compartimento e si imposta il numero massimo di partizioni.
La formula seguente consente di calcolare il numero di partizioni consigliato:
number_of_objects_expected_in_a_bucket / 100000
Si tenga presente che il numero massimo di partizioni è 7877.
21.10.2.1 Configurazioni multisito #
Le configurazioni multisito possono avere un pool di indice diverso per la gestione dei failover. Per configurare un numero di partizioni coerente per le zone in un gruppo di zone, impostare l'opzione bucket_index_max_shards nella configurazione del gruppo di zone:
Esportare la configurazione del gruppo di zone nel file
zonegroup.json:cephuser@adm >radosgw-admin zonegroup get > zonegroup.jsonModificare il file
zonegroup.jsone impostare l'opzionebucket_index_max_shardsper ciascuna zona con nome.Reimpostare il gruppo di zone:
cephuser@adm >radosgw-admin zonegroup set < zonegroup.jsonAggiornare il periodo. Vedere Sezione 21.13.2.6, «Aggiornare il periodo».
21.11 Integrazione di OpenStack Keystone #
OpenStack Keystone è un servizio di gestione delle identità per il prodotto OpenStack. È possibile integrare Object Gateway con Keystone per configurare un gateway che accetti un token di autenticazione Keystone. Un utente autorizzato da Keystone ad accedere al gateway verrà verificato sul lato Ceph Object Gateway e verrà creato automaticamente se necessario. Object Gateway interroga Keystone periodicamente per un elenco di token revocati.
21.11.1 Configurazione di OpenStack #
Prima di configurare Ceph Object Gateway, è necessario configurare OpenStack Keystone all'abilitazione del servizio Swift e fare in modo questo che punti a Ceph Object Gateway:
Impostare il servizio Swift. Prima di poter utilizzare OpenStack per la convalida degli utenti Swift, creare il servizio Swift:
>openstack service create \ --name=swift \ --description="Swift Service" \ object-storeImpostare gli endpoint. Dopo aver creato il servizio Swift, fare in modo che punti a Ceph Object Gateway. Sostituire REGION_NAME con il nome del gruppo di zone o il nome dell'area del gateway.
>openstack endpoint create --region REGION_NAME \ --publicurl "http://radosgw.example.com:8080/swift/v1" \ --adminurl "http://radosgw.example.com:8080/swift/v1" \ --internalurl "http://radosgw.example.com:8080/swift/v1" \ swiftVerificare le impostazioni. Dopo aver creato il servizio Swift e impostati gli endpoint, visualizzare questi ultimi per verificare che tutte le impostazioni siano corrette.
>openstack endpoint show object-store
21.11.2 Configurazione di Ceph Object Gateway #
21.11.2.1 Configurazione dei certificati SSL #
Ceph Object Gateway interroga Keystone periodicamente per un elenco di token revocati. Tali richieste sono codificate e firmate. È inoltre possibile configurare Keystone in modo che vengano forniti token firmati da se stessi, a loro volta codificati e firmati. È necessario configurare il gateway in modo che possa decodificare e verificare tali messaggi firmati. Pertanto, è necessario convertire in formato "nss db" i certificati OpenSSL utilizzati da Keystone per creare le richieste:
#mkdir /var/ceph/nss#openssl x509 -in /etc/keystone/ssl/certs/ca.pem \ -pubkey | certutil -d /var/ceph/nss -A -n ca -t "TCu,Cu,Tuw"rootopenssl x509 -in /etc/keystone/ssl/certs/signing_cert.pem \ -pubkey | certutil -A -d /var/ceph/nss -n signing_cert -t "P,P,P"
Per consentire l'interazione tra Ceph Object Gateway e OpenStack Keystone, quest'ultimo può utilizzare un certificato SSL firmato da se stessi. Installare il certificato SSL di Keystone sul nodo sul quale è in esecuzione Ceph Object Gateway o in alternativa impostare il valore dell'opzione rgw keystone verify ssl su "false". L'impostazione di rgw keystone verify ssl su "false" significa che non verrà effettuato alcun tentativo di verifica del certificato da parte del gateway.
21.11.2.2 Configurazione delle opzioni di Object Gateway #
È possibile configurare l'integrazione di Keystone utilizzando le opzioni seguenti:
rgw keystone api versionVersione dell'API Keystone. Le opzioni valide sono 2 o 3. Il valore di default è 2.
rgw keystone urlURL e numero di porta dell'API amministrativa RESTful sul server Keystone. Segue il modello SERVER_URL:PORT_NUMBER.
rgw keystone admin tokenToken o segreto condiviso configurato all'interno di Keystone per le richieste amministrative.
rgw keystone accepted rolesRuoli richiesti per provvedere alle richieste. L'impostazione di default è "Member, admin".
rgw keystone accepted admin rolesElenco dei ruoli che consentono a un utente di ottenere privilegi amministrativi.
rgw keystone token cache sizeNumero massimo di voci nella cache dei token Keystone.
rgw keystone revocation intervalNumero di secondi prima della verifica dei token revocati. Il valore di default è 15 * 60.
rgw keystone implicit tenantsCrea nuovi utenti nei rispettivi tenant con lo stesso nome. L'impostazione di default è "false".
rgw s3 auth use keystoneSe impostata su "'true", Ceph Object Gateway eseguirà l'autenticazione degli utenti tramite Keystone. L'impostazione di default è "false".
nss db pathPercorso del database NSS.
È inoltre possibile configurare il tenant del servizio Keystone, l'utente e la password per Keystone (per la versione 2.0 di OpenStack Identity API) in modo simile a quanto avviene per la configurazione dei servizi OpenStack. In tal modo, è possibile evitare di impostare il segreto condiviso rgw keystone admin token nel file di configurazione, che deve essere disabilitato negli ambienti di produzione. Le credenziali del tenant del servizio devono disporre di privilegi amministrativi. Per ulteriori dettagli, fare riferimento alla documentazione ufficiale di OpenStack Keystone (in lingua inglese). Di seguito sono riportate le opzioni di configurazione correlate:
rgw keystone admin userNome utente amministratore Keystone.
rgw keystone admin passwordPassword utente amministratore Keystone.
rgw keystone admin tenantTenant utente amministratore Keystone versione 2.0.
Un utente Ceph Object Gateway viene mappato a un tenant Keystone. A un utente Keystone vengono assegnati diversi ruoli, possibilmente su più tenant. Quando Ceph Object Gateway ottiene il ticket, fa riferimento ai ruoli del tenant e dell'utente assegnati a tale ticket, quindi accetta o rifiuta la richiesta in base all'impostazione definita per l'opzione rgw keystone accepted roles.
Sebbene i tenant Swift vengano mappati per default all'utente Object Gateway, è possibile mapparli anche ai tenant OpenStack tramite l'opzione rgw keystone implicit tenants. In tal modo i container utilizzeranno lo spazio dei nomi dei tenant anziché quello globale uguale a S3 che è l'impostazione di default di Object Gateway. Per evitare di fare confusione, si consiglia di decidere il metodo di mappatura in fase di pianificazione. L'attivazione/disattivazione dell'opzione in un momento successivo influisce solo sulle richieste più recenti che vengono mappate a un tenant, mentre i compartimenti creati precedentemente continuano a risiedere in uno spazio dei nomi globale.
Per la versione 3 di OpenStack Identity API, si deve sostituire l'opzione rgw keystone admin tenant con:
rgw keystone admin domainDomino utente amministratore Keystone.
rgw keystone admin projectProgetto utente amministratore Keystone.
21.12 Posizionamento di pool e classi di storage #
21.12.1 Visualizzazione delle destinazioni di posizionamento #
Le destinazioni di posizionamento consentono di controllare quali pool sono associati a un determinato compartimento. La destinazione di posizionamento di un compartimento viene selezionata al momento della creazione e non può essere modificata. Per visualizzare la regola placement_rule corrispondente, utilizzare il comando seguente:
cephuser@adm > radosgw-admin bucket statsLa configurazione del gruppo di zone contiene un elenco di destinazioni di posizionamento con una destinazione iniziale denominata "default-placement". La configurazione della zona mappa quindi ogni nome della destinazione di posizionamento del gruppo di zone allo storage locale corrispondente. Queste informazioni sul posizionamento della zona includono il nome "index_pool" per l'indice del compartimento, il nome "data_extra_pool" per i metadati relativi agli upload multipart incompleti e il nome "data_pool" per ogni classe di storage.
21.12.2 Classi di storage #
Le classi di storage agevolano la personalizzazione del posizionamento dei dati di oggetto. Le regole di S3 Bucket Lifecycle consentono di automatizzare la transizione degli oggetti tra le classi di storage.
Le classi di storage vengono definite in termini di destinazioni di posizionamento. Per ogni destinazione di posizionamento del gruppo di zone sono elencate le relative classi di storage disponibili con una classe iniziale denominata "STANDARD". La configurazione della zona specifica il nome di pool "data_pool" per ciascuna delle classi di storage del gruppo di zone.
21.12.3 Configurazione dei gruppi di zone e delle zone #
Per configurare il posizionamento dei gruppi di zone e delle zone, utilizzare il comando radosgw-admin. È possibile interrogare la configurazione del posizionamento del gruppo di zone tramite il comando seguente:
cephuser@adm > radosgw-admin zonegroup get
{
"id": "ab01123f-e0df-4f29-9d71-b44888d67cd5",
"name": "default",
"api_name": "default",
...
"placement_targets": [
{
"name": "default-placement",
"tags": [],
"storage_classes": [
"STANDARD"
]
}
],
"default_placement": "default-placement",
...
}Per interrogare la configurazione del posizionamento della zona, eseguire:
cephuser@adm > radosgw-admin zone get
{
"id": "557cdcee-3aae-4e9e-85c7-2f86f5eddb1f",
"name": "default",
"domain_root": "default.rgw.meta:root",
...
"placement_pools": [
{
"key": "default-placement",
"val": {
"index_pool": "default.rgw.buckets.index",
"storage_classes": {
"STANDARD": {
"data_pool": "default.rgw.buckets.data"
}
},
"data_extra_pool": "default.rgw.buckets.non-ec",
"index_type": 0
}
}
],
...
}
Se in precedenza non è stata effettuata nessuna configurazione multisito, vengono creati un gruppo di zone e una zona "default" per l'utente e le relative modifiche apportate non saranno effettive fino al riavvio di Ceph Object Gateway. Se è stato creato un dominio per la configurazione multisito, le modifiche alla zona/al gruppo di zone verranno applicate dopo averle confermate tramite il comando radosgw-admin period update --commit.
21.12.3.1 Aggiunta di una destinazione di posizionamento #
Per creare una nuova destinazione di posizionamento denominata "temporary", iniziare aggiungendola al gruppo di zone:
cephuser@adm > radosgw-admin zonegroup placement add \
--rgw-zonegroup default \
--placement-id temporaryQuindi, fornire le informazioni sul posizionamento della zona per la destinazione specificata:
cephuser@adm > radosgw-admin zone placement add \
--rgw-zone default \
--placement-id temporary \
--data-pool default.rgw.temporary.data \
--index-pool default.rgw.temporary.index \
--data-extra-pool default.rgw.temporary.non-ec21.12.3.2 Aggiunta di una classe di storage #
Per aggiungere una nuova classe di storage denominata "COLD" alla destinazione "default-placement", iniziare aggiungendola al gruppo di zone:
cephuser@adm > radosgw-admin zonegroup placement add \
--rgw-zonegroup default \
--placement-id default-placement \
--storage-class COLDQuindi, fornire le informazioni sul posizionamento della zona per la classe di storage specificata:
cephuser@adm > radosgw-admin zone placement add \
--rgw-zone default \
--placement-id default-placement \
--storage-class COLD \
--data-pool default.rgw.cold.data \
--compression lz421.12.4 Personalizzazione del posizionamento #
21.12.4.1 Modifica del posizionamento del gruppo di zone di default #
Per default, i nuovi compartimenti utilizzeranno la destinazione default_placement del gruppo di zone. È possibile modificare questa impostazione del gruppo di zone con quanto segue:
cephuser@adm > radosgw-admin zonegroup placement default \
--rgw-zonegroup default \
--placement-id new-placement21.12.4.2 Modifica del posizionamento dell'utente di default #
Gli utenti di Ceph Object Gateway possono sostituire la destinazione di posizionamento di default del gruppo di zone impostando un campo default_placement non vuoto nella sezione delle informazioni utente. Analogamente, la classe default_storage_class può sostituire la classe di storage STANDARD applicata per default agli oggetti.
cephuser@adm > radosgw-admin user info --uid testid
{
...
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
...
}Se la destinazione di posizionamento di un gruppo di zone contiene tag, gli utenti non potranno creare compartimenti con questa destinazione, a meno che le relative informazioni non contengano almeno un tag corrispondente nel campo "placement_tags". Ciò può essere utile per limitare l'accesso a determinati tipi di storage.
Poiché il comando radosgw-admin non è in grado di modificare direttamente questi campi, è necessario modificare manualmente il formato JSON:
cephuser@adm >radosgw-admin metadata get user:USER-ID > user.json>vi user.json # edit the file as requiredcephuser@adm >radosgw-admin metadata put user:USER-ID < user.json
21.12.4.3 Modifica del posizionamento del compartimento S3 di default #
Durante la creazione di un compartimento con il protocollo S3, è possibile specificare una destinazione di posizionamento come parte del LocationConstraint al fine di sostituire le destinazioni di posizionamento di default per l'utente e il gruppo di zone.
In genere, il LocationConstraint deve corrispondere all'api_name del gruppo di zone:
<LocationConstraint>default</LocationConstraint>
È possibile aggiungere una destinazione di posizionamento personalizzata all'api_name dopo i due punti:
<LocationConstraint>default:new-placement</LocationConstraint>
21.12.4.4 Modifica del posizionamento del compartimento Swift #
Durante la creazione di un compartimento con il protocollo Swift, è possibile specificare una destinazione di posizionamento nell'X-Storage-Policy dell'intestazione HTTP:
X-Storage-Policy: NEW-PLACEMENT
21.12.5 Utilizzo delle classi di storage #
Tutte le destinazioni di posizionamento dispongono di una classe di storage STANDARD che viene applicata per default ai nuovi oggetti. È possibile sostituire questa classe di default con la relativa default_storage_class.
Per creare un oggetto in una classe di storage non di default, specificare il nome di tale classe in un'intestazione HTTP insieme alla richiesta. Il protocollo S3 utilizza l'intestazione X-Amz-Storage-Class, mentre il protocollo Swift utilizza l'intestazione X-Object-Storage-Class.
È possibile utilizzare S3 Object Lifecycle Management per spostare i dati degli oggetti tra le classi di storage con le azioni Transition.
21.13 Object Gateway multisito #
Ceph supporta diverse opzioni di configurazione multisito per Ceph Object Gateway:
- Multizona
Configurazione composta da un gruppo di zone e da più zone, ognuna delle quali con una o più istanze
ceph-radosgw. Ogni zona è supportata dal relativo cluster di memorizzazione Ceph. Le zone multiple all'interno di un gruppo di zone forniscono funzionalità di disaster recovery a quest'ultimo, se dovesse verificarsi un grave errore in una delle zone. Ogni zona è attiva e può ricevere operazioni di scrittura. Oltre alle funzioni di disaster recovery, più zone attive possono fungere anche da base per le reti per la consegna di contenuto.- Gruppo multizona
Ceph Object Gateway supporta più gruppi di zone, ciascuno costituito da una o più zone. Gli oggetti memorizzati nelle zone di un gruppo di zone all'interno dello stesso dominio di un altro gruppo di zone condividono uno spazio dei nomi di oggetto globale, per fare in modo che gli ID oggetto delle zone e dei gruppi di zone siano univoci.
NotaÈ importante tenere presente che i gruppi di zone sincronizzano i metadati soltanto tra di loro. I dati e i metadati vengono replicati tra le zone all'interno del gruppo di zone e non vengono condivisi nel dominio.
- Domini multipli
Ceph Object Gateway supporta la nozione dei domini, ovvero uno spazio dei nomi univoco a livello globale. I domini multipli sono supportati e possono contenere uno o più gruppi di zone.
È possibile configurare ciascun Object Gateway per l'esecuzione in una configurazione della zona attiva-attiva, al fine di consentire le operazioni di scrittura nelle zone non master. La configurazione multisito è memorizzata all'interno di un container denominato dominio. Il dominio memorizza gruppi di zone, zone e un intervallo di tempo con più epoche per il monitoraggio delle modifiche apportate alla configurazione. I daemon rgw gestiscono la sincronizzazione eliminando la necessità di utilizzare un agente di sincronizzazione separato. Questo approccio alla sincronizzazione consente il funzionamento di Ceph Object Gateway con una configurazione attiva-attiva invece che attiva-passiva.
21.13.1 Requisiti e presupposti #
Per una configurazione multisito sono necessari almeno due cluster di memorizzazione Ceph e almeno due istanze di Ceph Object Gateway, una per ogni cluster di memorizzazione Ceph. Nella configurazione riportata di seguito si presuppone la presenza di almeno due cluster di memorizzazione Ceph in ubicazioni geograficamente separate. Tuttavia, la configurazione può funzionare nello stesso sito. Ad esempio, le zone denominate rgw1 e rgw2.
Per la configurazione multisito sono necessari un gruppo di zone master e una zona master, che sarà l'origine di riferimento per quanto riguarda tutte le operazioni dei metadati in un cluster multisito. Inoltre, ogni gruppo di zone deve contenere una zona master. I gruppi di zone possono avere una o più zone non master o secondarie. Nella presente guida, l'host rgw1 funge da zona master del gruppo di zone master e l'host rgw2 funge da zona secondaria del gruppo di zone master.
21.13.2 Configurazione di una zona master #
Tutti i gateway di una configurazione multisito recuperano la rispettiva configurazione da un daemon ceph-radosgw su un host all'interno del gruppo di zone master e della zona master. Per configurare i gateway in una configurazione multisito, selezionare un'istanza ceph-radosgw per configurare il gruppo di zone master e la zona master.
21.13.2.1 Creazione di un dominio #
Un dominio rappresenta uno spazio dei nomi univoco a livello globale composto da uno o più gruppi di zone contenenti una o più zone. Le zone contengono i compartimenti, che a loro volta contengono gli oggetti. Tramite i domini, Ceph Object Gateway può supportare più spazi dei nomi e le relative configurazioni sullo stesso hardware. Un dominio contiene la nozione dei periodi. Ogni periodo rappresenta lo stato della configurazione del gruppo di zone e della zona nel tempo. Ogni volta che si apporta una modifica a un gruppo di zone o a una zona, aggiornare il periodo ed eseguirne il commit. Per default, Ceph Object Gateway non crea domini per la compatibilità con le versioni precedenti. Come best practice, si consiglia di creare i domini per i nuovi cluster.
Creare un nuovo dominio denominato gold per la configurazione multisito aprendo l'interfaccia della riga di comando su un host da utilizzare nel gruppo di zone e nella zona master. Quindi, eseguire quanto riportato di seguito:
cephuser@adm > radosgw-admin realm create --rgw-realm=gold --default
Se il cluster dispone di un dominio singolo, specificare il flag --default. Se il flag --default è specificato, radosgw-admin utilizza per default questo dominio. Se il flag --default non è specificato, per aggiungere gruppi di zone e zone occorre specificare i flag --rgw-realm o ‑‑realm-id per identificare il dominio durante l'aggiunta di gruppi di zone e zone.
In seguito alla creazione del dominio, radosgw-admin ne restituisce la configurazione:
{
"id": "4a367026-bd8f-40ee-b486-8212482ddcd7",
"name": "gold",
"current_period": "09559832-67a4-4101-8b3f-10dfcd6b2707",
"epoch": 1
}Ceph genera un ID univoco per il dominio, che ne consente la ridenominazione in caso di necessità.
21.13.2.2 Creazione di un gruppo di zone master #
All'interno di un dominio deve essere presente almeno un gruppo di zone che funge da gruppo di zone master del dominio stesso. Creare un nuovo gruppo di zone master per la configurazione multisito aprendo l'interfaccia della riga di comando su un host da utilizzare nel gruppo di zone e nella zona master. Creare un gruppo di zone master denominato us eseguendo quanto riportato di seguito:
cephuser@adm > radosgw-admin zonegroup create --rgw-zonegroup=us \
--endpoints=http://rgw1:80 --master --default
Se il dominio dispone di un singolo gruppo di zone, specificare il flag --default. Se il flag --default è specificato, radosgw-admin utilizza per default questo gruppo di zone per l'aggiunta di nuove zone. Se il flag --default non è specificato, per aggiungere le zone occorre specificare i flag --rgw-zonegroup o --zonegroup-id per identificare il gruppo di zone durante l'aggiunta o la modifica delle zone.
In seguito alla creazione del gruppo di zone master, radosgw-admin ne restituisce la configurazione: Esempio:
{
"id": "d4018b8d-8c0d-4072-8919-608726fa369e",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "",
"zones": [],
"placement_targets": [],
"default_placement": "",
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7"
}21.13.2.3 Creazione di una zona master #
Le zone devono essere create su un nodo Ceph Object Gateway che si trova all'interno della zona.
Creare una nuova zona master per la configurazione multisito aprendo l'interfaccia della riga di comando su un host da utilizzare nel gruppo di zone e nella zona master. Eseguire le operazioni seguenti:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-1 \
--endpoints=http://rgw1:80 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
Le opzioni --access-key e --secret non sono specificate nell'esempio precedente e vengono aggiunte alla zona al momento della creazione dell'utente nella sezione successiva.
In seguito alla creazione della zona master, radosgw-admin ne restituisce la configurazione. Esempio:
{
"id": "56dfabbb-2f4e-4223-925e-de3c72de3866",
"name": "us-east-1",
"domain_root": "us-east-1.rgw.meta:root",
"control_pool": "us-east-1.rgw.control",
"gc_pool": "us-east-1.rgw.log:gc",
"lc_pool": "us-east-1.rgw.log:lc",
"log_pool": "us-east-1.rgw.log",
"intent_log_pool": "us-east-1.rgw.log:intent",
"usage_log_pool": "us-east-1.rgw.log:usage",
"reshard_pool": "us-east-1.rgw.log:reshard",
"user_keys_pool": "us-east-1.rgw.meta:users.keys",
"user_email_pool": "us-east-1.rgw.meta:users.email",
"user_swift_pool": "us-east-1.rgw.meta:users.swift",
"user_uid_pool": "us-east-1.rgw.meta:users.uid",
"otp_pool": "us-east-1.rgw.otp",
"system_key": {
"access_key": "1555b35654ad1656d804",
"secret_key": "h7GhxuBLTrlhVUyxSPUKUV8r/2EI4ngqJxD7iBdBYLhwluN30JaT3Q=="
},
"placement_pools": [
{
"key": "us-east-1-placement",
"val": {
"index_pool": "us-east-1.rgw.buckets.index",
"storage_classes": {
"STANDARD": {
"data_pool": "us-east-1.rgw.buckets.data"
}
},
"data_extra_pool": "us-east-1.rgw.buckets.non-ec",
"index_type": 0
}
}
],
"metadata_heap": "",
"realm_id": ""
}21.13.2.4 Eliminazione del gruppo e della zona di default #
Nella procedura seguente si presuppone che sia stata eseguita una configurazione multisito tramite i sistemi appena installati che non hanno ancora iniziato a memorizzare i dati. Non eliminare la zona di default e i relativi pool se la si utilizza già per memorizzare i dati, altrimenti questi verranno eliminati e non sarà più possibile recuperarli.
L'installazione di default di Object Gateway crea un gruppo di zone di default denominato default. Eliminare la zona di default se presente. Rimuoverla innanzitutto dal gruppo di zone di default.
cephuser@adm > radosgw-admin zonegroup delete --rgw-zonegroup=defaultEliminare i pool di default dal cluster di memorizzazione Ceph, se presenti:
Nel passaggio seguente si presuppone che sia stata eseguita una configurazione multisito tramite i sistemi appena installati che non hanno ancora iniziato a memorizzare i dati. Non eliminare il gruppo di zone di default se lo si utilizza già per memorizzare i dati.
cephuser@adm >ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.meta default.rgw.meta --yes-i-really-really-mean-it
Se il gruppo di zone di default viene eliminato, verrà eliminato anche l'utente del sistema. Se le chiavi dell'utente amministratore non vengono propagate, la funzionalità di gestione di Object Gateway del Ceph Dashboard restituirà un errore. Andare alla sezione successiva per ricreare l'utente di sistema se si procede con questo passaggio.
21.13.2.5 Creazione di utenti di sistema #
I daemon ceph-radosgw devono eseguire l'autenticazione prima di eseguire il pull delle informazioni sul dominio e sul periodo. Nella zona master, creare un utente di sistema per semplificare l'autenticazione tra i daemon:
cephuser@adm > radosgw-admin user create --uid=zone.user \
--display-name="Zone User" --access-key=SYSTEM_ACCESS_KEY \
--secret=SYSTEM_SECRET_KEY --system
Annotare le variabili access_key e secret_key, poiché saranno necessarie per l'autenticazione delle zone secondarie nella zona master.
Aggiungere l'utente di sistema alla zona master:
cephuser@adm > radosgw-admin zone modify --rgw-zone=us-east-1 \
--access-key=ACCESS-KEY --secret=SECRETAggiornare il periodo per applicare le modifiche:
cephuser@adm > radosgw-admin period update --commit21.13.2.6 Aggiornare il periodo #
Dopo aver aggiornato la configurazione della zona master, aggiornare il periodo:
cephuser@adm > radosgw-admin period update --commit
In seguito all'aggiornamento del periodo, radosgw-admin ne restituisce la configurazione. Esempio:
{
"id": "09559832-67a4-4101-8b3f-10dfcd6b2707", "epoch": 1, "predecessor_uuid": "", "sync_status": [], "period_map":
{
"id": "09559832-67a4-4101-8b3f-10dfcd6b2707", "zonegroups": [], "short_zone_ids": []
}, "master_zonegroup": "", "master_zone": "", "period_config":
{
"bucket_quota": {
"enabled": false, "max_size_kb": -1, "max_objects": -1
}, "user_quota": {
"enabled": false, "max_size_kb": -1, "max_objects": -1
}
}, "realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7", "realm_name": "gold", "realm_epoch": 1
}Tramite l'aggiornamento del periodo viene modificata l'epoca e ci si assicura che le altre zone ricevano la configurazione aggiornata.
21.13.2.7 Avvio di Gateway #
Sull'host di Object Gateway, avviare e abilitare il servizio Ceph Object Gateway. Per identificare l'FSID univoco del cluster, eseguire ceph fsid. Per identificare il nome del daemon di Object Gateway, eseguire ceph orch ps --hostname HOSTNAME.
cephuser@ogw >systemctl start ceph-FSID@DAEMON_NAMEcephuser@ogw >systemctl enable ceph-FSID@DAEMON_NAME
21.13.3 Configurazione delle zone secondarie #
Le zone all'interno di un gruppo di zone replicano tutti i dati per fare in modo che in ogni zona siano presenti gli stessi dati. Durante la creazione di una zona secondaria, effettuare tutte le operazioni seguenti su un host identificato per servire tale zona.
Per aggiungere una terza zona, attenersi alle stesse procedure seguite per l'aggiunta della zona secondaria. Utilizzare un nome diverso per la zona.
Le operazioni dei metadati, come la creazione di un utente, devono essere eseguite su un host all'interno della zona master. La zona master e la zona secondaria possono ricevere le operazioni dei compartimenti, ma la zona secondaria reindirizza tali operazioni alla zona master. Se la zona master è inattiva, le operazioni dei compartimenti non andranno a buon fine.
21.13.3.1 Esecuzione del pull del dominio #
Utilizzando il percorso URL, la chiave di accesso e il segreto della zona master nel gruppo di zone master, importare la configurazione del dominio nell'host. Per importare un dominio non di default, specificare il dominio tramite le opzioni di configurazione --rgw-realm o --realm-id.
cephuser@adm > radosgw-admin realm pull --url=url-to-master-zone-gateway --access-key=access-key --secret=secretTramite l'importazione del dominio viene recuperata anche la configurazione corrente del periodo, che viene contrassegnato come attuale anche sull'host remoto.
Se questo dominio è il dominio di default o l'unico dominio, contrassegnarlo come dominio di default.
cephuser@adm > radosgw-admin realm default --rgw-realm=REALM-NAME21.13.3.2 Creazione di una zona secondaria #
Creare una zona secondaria per la configurazione multisito aprendo l'interfaccia della riga di comando su un host da utilizzare nella zona secondaria. Specificare l'ID del gruppo di zone, il nome della nuova zona e l'endpoint corrispondente. Non utilizzare il flag --master. Per default, tutte le zone vengono eseguite in una configurazione attiva-attiva. Se la zona secondaria non deve accettare le operazioni di scrittura, specificare il flag --read-only per creare una configurazione attiva-passiva tra la zona master e la zona secondaria. Inoltre, specificare le variabili access_key e secret_key dell'utente di sistema generato memorizzate nella zona master del gruppo di zone master. Eseguire le operazioni seguenti:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE-GROUP-NAME\
--rgw-zone=ZONE-NAME --endpoints=URL \
--access-key=SYSTEM-KEY --secret=SECRET\
--endpoints=http://FQDN:80 \
[--read-only]Esempio:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=us --endpoints=http://rgw2:80 \
--rgw-zone=us-east-2 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
{
"id": "950c1a43-6836-41a2-a161-64777e07e8b8",
"name": "us-east-2",
"domain_root": "us-east-2.rgw.data.root",
"control_pool": "us-east-2.rgw.control",
"gc_pool": "us-east-2.rgw.gc",
"log_pool": "us-east-2.rgw.log",
"intent_log_pool": "us-east-2.rgw.intent-log",
"usage_log_pool": "us-east-2.rgw.usage",
"user_keys_pool": "us-east-2.rgw.users.keys",
"user_email_pool": "us-east-2.rgw.users.email",
"user_swift_pool": "us-east-2.rgw.users.swift",
"user_uid_pool": "us-east-2.rgw.users.uid",
"system_key": {
"access_key": "1555b35654ad1656d804",
"secret_key": "h7GhxuBLTrlhVUyxSPUKUV8r\/2EI4ngqJxD7iBdBYLhwluN30JaT3Q=="
},
"placement_pools": [
{
"key": "default-placement",
"val": {
"index_pool": "us-east-2.rgw.buckets.index",
"data_pool": "us-east-2.rgw.buckets.data",
"data_extra_pool": "us-east-2.rgw.buckets.non-ec",
"index_type": 0
}
}
],
"metadata_heap": "us-east-2.rgw.meta",
"realm_id": "815d74c2-80d6-4e63-8cfc-232037f7ff5c"
}Nei passaggi seguenti si presuppone che sia stata eseguita una configurazione multisito tramite i sistemi appena installati che non hanno ancora iniziato a memorizzare i dati. Non eliminare la zona di default e i relativi pool se la si utilizza già per memorizzare i dati, altrimenti questi andranno persi e non sarà più possibile recuperarli.
Eliminare la zona di default se necessario:
cephuser@adm > radosgw-admin zone delete --rgw-zone=defaultEliminare i pool di default dal cluster di memorizzazione Ceph se necessario:
cephuser@adm >ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.users.uid default.rgw.users.uid --yes-i-really-really-mean-it
21.13.3.3 Aggiornamento del file di configurazione Ceph #
Aggiornare il file di configurazione Ceph sugli host della zona secondaria aggiungendo l'opzione di configurazione rgw_zone e il nome della zona secondaria alla voce dell'istanza.
Per farlo, eseguire il comando seguente:
cephuser@adm > ceph config set SERVICE_NAME rgw_zone us-west21.13.3.4 Aggiornamento del periodo #
Dopo aver aggiornato la configurazione della zona master, aggiornare il periodo:
cephuser@adm > radosgw-admin period update --commit
{
"id": "b5e4d3ec-2a62-4746-b479-4b2bc14b27d1",
"epoch": 2,
"predecessor_uuid": "09559832-67a4-4101-8b3f-10dfcd6b2707",
"sync_status": [ "[...]"
],
"period_map": {
"id": "b5e4d3ec-2a62-4746-b479-4b2bc14b27d1",
"zonegroups": [
{
"id": "d4018b8d-8c0d-4072-8919-608726fa369e",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"zones": [
{
"id": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"name": "us-east-1",
"endpoints": [
"http:\/\/rgw1:80"
],
"log_meta": "true",
"log_data": "false",
"bucket_index_max_shards": 0,
"read_only": "false"
},
{
"id": "950c1a43-6836-41a2-a161-64777e07e8b8",
"name": "us-east-2",
"endpoints": [
"http:\/\/rgw2:80"
],
"log_meta": "false",
"log_data": "true",
"bucket_index_max_shards": 0,
"read_only": "false"
}
],
"placement_targets": [
{
"name": "default-placement",
"tags": []
}
],
"default_placement": "default-placement",
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7"
}
],
"short_zone_ids": [
{
"key": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"val": 630926044
},
{
"key": "950c1a43-6836-41a2-a161-64777e07e8b8",
"val": 4276257543
}
]
},
"master_zonegroup": "d4018b8d-8c0d-4072-8919-608726fa369e",
"master_zone": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"period_config": {
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
}
},
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7",
"realm_name": "gold",
"realm_epoch": 2
}Tramite l'aggiornamento del periodo viene modificata l'epoca e ci si assicura che le altre zone ricevano la configurazione aggiornata.
21.13.3.5 Avvio di Object Gateway #
Sull'host di Object Gateway, avviare e abilitare il servizio Ceph Object Gateway:
cephuser@adm > ceph orch start rgw.us-east-221.13.3.6 Verifica dello stato di sincronizzazione #
Una volta configurata la zona secondaria, verificare lo stato di sincronizzazione. La sincronizzazione copia nella zona secondaria gli utenti e i compartimenti creati nella zona master.
cephuser@adm > radosgw-admin sync statusL'output fornisce lo stato delle operazioni di sincronizzazione. Esempio:
realm f3239bc5-e1a8-4206-a81d-e1576480804d (gold)
zonegroup c50dbb7e-d9ce-47cc-a8bb-97d9b399d388 (us)
zone 4c453b70-4a16-4ce8-8185-1893b05d346e (us-west)
metadata sync syncing
full sync: 0/64 shards
metadata is caught up with master
incremental sync: 64/64 shards
data sync source: 1ee9da3e-114d-4ae3-a8a4-056e8a17f532 (us-east)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with sourceLe zone secondarie accettano le operazioni dei compartimenti; tuttavia, le reindirizzano alla zona master ed eseguono la sincronizzazione con quest'ultima per ricevere i risultati di tali operazioni. Se la zona master è inattiva, le operazioni dei compartimenti eseguite sulla zona secondaria non andranno a buon fine, ma le operazioni degli oggetti riusciranno correttamente.
21.13.3.7 Verifica di un oggetto #
Per default, dopo che la sincronizzazione di un oggetto è riuscita non viene eseguita una nuova verifica degli oggetti. Per abilitare la verifica, impostare l'opzione rgw_sync_obj_etag_verify su true. Dopo l'abilitazione, gli oggetti facoltativi verranno sincronizzati. Un ulteriore checksum MD5 verificherà che il calcolo sia effettuato sull'origine e sulla destinazione. Questo consente di assicurare l'integrità degli oggetti recuperati da un server remoto su HTTP, inclusa la sincronizzazione multisito. L'opzione può ridurre le prestazioni degli RGW poiché è necessaria maggiore potenza di calcolo.
21.13.4 Manutenzione generale di Object Gateway #
21.13.4.1 Verifica dello stato di sincronizzazione #
È possibile interrogare le informazioni sullo stato della replica di una zona con:
cephuser@adm > radosgw-admin sync status
realm b3bc1c37-9c44-4b89-a03b-04c269bea5da (gold)
zonegroup f54f9b22-b4b6-4a0e-9211-fa6ac1693f49 (us)
zone adce11c9-b8ed-4a90-8bc5-3fc029ff0816 (us-west)
metadata sync syncing
full sync: 0/64 shards
incremental sync: 64/64 shards
metadata is behind on 1 shards
oldest incremental change not applied: 2017-03-22 10:20:00.0.881361s
data sync source: 341c2d81-4574-4d08-ab0f-5a2a7b168028 (us-east)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source
source: 3b5d1a3f-3f27-4e4a-8f34-6072d4bb1275 (us-3)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with sourceL'output può variare a seconda dello stato di sincronizzazione. Durante la sincronizzazione, i partizionamenti sono descritti come di due tipi diversi:
- Partizionamenti arretrati
I partizionamenti arretrati sono quelli che richiedono una sincronizzazione completa dei dati e quelli che richiedono una sincronizzazione dei dati incrementale perché non sono aggiornati.
- Partizionamenti di ripristino
I partizionamenti di ripristino sono quelli contrassegnati per un nuovo tentativo, poiché presentano un errore durante la sincronizzazione. L'errore riguarda principalmente problemi minori, come l'acquisizione di un blocco su un compartimento, e in genere si risolve da sé.
21.13.4.2 Controllo dei log #
Solo per la configurazione multisito, è possibile controllare il log dei metadati (mdlog), il log dell'indice del compartimento (bilog) e il log dei dati (datalog). È possibile elencarli e troncarli. Nella maggior parte dei casi, l'operazione non è necessaria poiché l'opzione rgw_sync_log_trim_interval è impostata per default a 20 minuti. Se l'opzione non è impostata manualmente su 0, non sarà mai necessario effettuare la troncatura, che può causare effetti collaterali.
21.13.4.3 Modifica della zona dei metadata master #
Prestare la massima attenzione quando si modifica la zona dei metadata master. Se una zona non ha terminato la sincronizzazione dei metadati dalla zona master corrente, non sarà in grado di servire alcuna voce rimanente quando viene promossa al ruolo di master e queste modifiche andranno perse. Per questo motivo, prima di promuoverla come master, si consiglia di attendere che lo stato di sincronizzazione radosgw-admin della zona raggiunga lo stesso livello della sincronizzazione dei metadati. Analogamente, se le modifiche ai metadati sono in corso di elaborazione nella zona master corrente, mentre è in corso la promozione di un'altra zona al ruolo di master, è probabile che queste modifiche andranno perse. Per evitarlo, si consiglia di disattivare le istanze di Object Gateway sulla zona master precedente. In seguito alla promozione di un'altra zona, il rispettivo nuovo periodo può essere recuperato con il pull del periodo di radosgw-admin ed è possibile riavviare i gateway.
Per promuovere una zona (ad esempio, la zona us-west nel gruppo di zone us) a metadata master, eseguire i comandi seguenti su tale zona:
cephuser@ogw >radosgw-admin zone modify --rgw-zone=us-west --mastercephuser@ogw >radosgw-admin zonegroup modify --rgw-zonegroup=us --mastercephuser@ogw >radosgw-admin period update --commit
In questo modo viene generato un nuovo periodo che verrà inviato ad altre zone dalle istanze di Object Gateway nella zona us-west.
21.13.5 Esecuzione del failover e del disaster recovery #
Qualora la zona master dovesse venire meno, eseguire il failover nella zona secondaria per il disaster recovery.
Rendere la zona secondaria la zona master e di default. Esempio:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --defaultPer default, Ceph Object Gateway viene eseguito in una configurazione attiva-attiva. Se si è configurato il cluster per l'esecuzione in una configurazione attiva-passiva, la zona secondaria è di sola lettura. Rimuovere lo stato
--read-onlyper consentire alla zona di ricevere le operazioni di scrittura. Esempio:cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --default \ --read-only=falseAggiornare il periodo per applicare le modifiche:
cephuser@adm >radosgw-admin period update --commitRiavviare Ceph Object Gateway:
cephuser@adm >ceph orch restart rgw
Se la zona master precedente viene recuperata, ripristinare l'operazione.
Dalla zona recuperata, eseguire il pull della configurazione del dominio più recente dall'attuale zona master.
cephuser@adm >radosgw-admin realm pull --url=URL-TO-MASTER-ZONE-GATEWAY \ --access-key=ACCESS-KEY --secret=SECRETRendere la zona recuperata la zona master e di default:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --defaultAggiornare il periodo per applicare le modifiche:
cephuser@adm >radosgw-admin period update --commitRiavviare Ceph Object Gateway nella zona recuperata:
cephuser@adm >ceph orch restart rgw@rgwSe la configurazione della zona secondaria deve essere in sola lettura, aggiornare la zona secondaria:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --read-onlyAggiornare il periodo per applicare le modifiche:
cephuser@adm >radosgw-admin period update --commitRiavviare Ceph Object Gateway nella zona secondaria:
cephuser@adm >ceph orch restart@rgw
22 Ceph iSCSI Gateway #
Questo capitolo è incentrato sui task amministrativi correlati a iSCSI Gateway. Per la procedura di distribuzione, fare riferimento a Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.3.5 “Distribuzione di iSCSI Gateway”.
22.1 Destinazioni gestite ceph-iscsi #
Questo capitolo illustra come eseguire la connessione a destinazioni gestite ceph-iscsi da client sui quali è in esecuzione Linux, Microsoft Windows o VMware.
22.1.1 Connessione a open-iscsi #
La connessione a destinazioni iSCSI supportate da ceph-iscsi con open-iscsi è un processo a due passaggi. Innanzi tutto l'iniziatore deve rilevare le destinazioni iSCSI disponibili sull'host gateway, quindi deve eseguire il login e mappare le unità logiche (LU) disponibili.
Per entrambi i passaggi è richiesto che il daemon open-iscsi sia in esecuzione. Il modo in cui si avvia il daemon open-iscsi dipende dalla distribuzione Linux corrente:
Sugli host SUSE Linux Enterprise Server (SLES) e Red Hat Enterprise Linux (RHEL), eseguire
systemctl start iscsid(oservice iscsid startsesystemctlnon è disponibile).Sugli host Debian e Ubuntu, eseguire
systemctl start open-iscsi(oservice open-iscsi start).
Se sull'host dell'iniziatore viene eseguito SUSE Linux Enterprise Server, consultare la pagina all'indirizzo https://documentation.suse.com/sles/15-SP1/single-html/SLES-storage/#sec-iscsi-initiator per ulteriori informazioni su come eseguire la connessione a una destinazione iSCSI.
Per qualsiasi altra distribuzione Linux che supporta open-iscsi, procedere per rilevare le destinazioni sul gateway ceph-iscsi in uso (in questo esempio viene utilizzato iscsi1.example.com come indirizzo del portale; per l'accesso multipath ripetere i passaggi con iscsi2.example.com):
# iscsiadm -m discovery -t sendtargets -p iscsi1.example.com
192.168.124.104:3260,1 iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvolQuindi, eseguire il login al portale. Se il login viene completato correttamente, tutte le unità logiche supportate da RBD presenti sul portale saranno immediatamente disponibili sul bus SCSI del sistema:
# iscsiadm -m node -p iscsi1.example.com --login
Logging in to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] (multiple)
Login to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] successful.Ripetere il processo per gli altri indirizzi IP o host del portale.
Se nel sistema è installata l'utility lsscsi, utilizzarla per enumerare i dispositivi SCSI disponibili nel sistema:
lsscsi [8:0:0:0] disk SUSE RBD 4.0 /dev/sde [9:0:0:0] disk SUSE RBD 4.0 /dev/sdf
In una configurazione multipath (dove due dispositivi iSCSI connessi rappresentano un'unica e medesima unità logica), è inoltre possibile esaminare lo stato del dispositivo multipath con l'utility multipath:
# multipath -ll
360014050cf9dcfcb2603933ac3298dca dm-9 SUSE,RBD
size=49G features='0' hwhandler='0' wp=rw
|-+- policy='service-time 0' prio=1 status=active
| `- 8:0:0:0 sde 8:64 active ready running
`-+- policy='service-time 0' prio=1 status=enabled
`- 9:0:0:0 sdf 8:80 active ready runningAdesso è possibile utilizzare il dispositivo multipath come qualsiasi dispositivo di blocco. Ad esempio, è possibile utilizzare il dispositivo come volume fisico per Linux Logical Volume Management (LVM) oppure è possibile creare semplicemente un file system su di esso. Nell'esempio riportato di seguito è illustrato come creare un file system XFS su un volume iSCSI multipath appena connesso:
# mkfs -t xfs /dev/mapper/360014050cf9dcfcb2603933ac3298dca
log stripe unit (4194304 bytes) is too large (maximum is 256KiB)
log stripe unit adjusted to 32KiB
meta-data=/dev/mapper/360014050cf9dcfcb2603933ac3298dca isize=256 agcount=17, agsize=799744 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=12800000, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=6256, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Poiché XFS è un file system non in cluster, è possibile montarlo solo su un singolo nodo dell'iniziatore iSCSI in un determinato momento.
Se ogni volta che si desidera interrompere l'uso delle unità logiche iSCSI associate a una determinata destinazione, eseguire il comando seguente:
# iscsiadm -m node -p iscsi1.example.com --logout
Logging out of session [sid: 18, iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260]
Logout of [sid: 18, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] successful.Come con la rilevazione e il login, è necessario ripetere la procedura di logout per tutti gli indirizzi IP o i nomi host del portale.
22.1.1.1 Configurazione multipath #
La configurazione multipath viene aggiornata sui client o sugli iniziatori ed è indipendente da qualsiasi configurazione ceph-iscsi. Selezionare una strategia prima di utilizzare la memorizzazione a blocchi. Dopo aver modificato /etc/multipath.conf, riavviare multipathd con
# systemctl restart multipathdPer una configurazione attiva-passiva con nomi intuitivi, aggiungere
defaults {
user_friendly_names yes
}
a /etc/multipath.conf. Dopo aver connesso le destinazioni, eseguire
# multipath -ll
mpathd (36001405dbb561b2b5e439f0aed2f8e1e) dm-0 SUSE,RBD
size=2.0G features='0' hwhandler='0' wp=rw
|-+- policy='service-time 0' prio=1 status=active
| `- 2:0:0:3 sdl 8:176 active ready running
|-+- policy='service-time 0' prio=1 status=enabled
| `- 3:0:0:3 sdj 8:144 active ready running
`-+- policy='service-time 0' prio=1 status=enabled
`- 4:0:0:3 sdk 8:160 active ready runningNotare lo stato di ciascun collegamento. Per una configurazione attiva-attiva, aggiungere
defaults {
user_friendly_names yes
}
devices {
device {
vendor "(LIO-ORG|SUSE)"
product "RBD"
path_grouping_policy "multibus"
path_checker "tur"
features "0"
hardware_handler "1 alua"
prio "alua"
failback "immediate"
rr_weight "uniform"
no_path_retry 12
rr_min_io 100
}
}
a /etc/multipath.conf. Riavviare multipathd ed eseguire
# multipath -ll
mpathd (36001405dbb561b2b5e439f0aed2f8e1e) dm-3 SUSE,RBD
size=2.0G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
`-+- policy='service-time 0' prio=50 status=active
|- 4:0:0:3 sdj 8:144 active ready running
|- 3:0:0:3 sdk 8:160 active ready running
`- 2:0:0:3 sdl 8:176 active ready running22.1.2 Connessione di Microsoft Windows (iniziatore iSCSI Microsoft) #
Per eseguire la connessione a una destinazione iSCSI SUSE Enterprise Storage da un server Windows 2012, seguire la procedura indicata di seguito:
Aprire Windows Server Manager. Da Dashboard, selezionare › . Viene visualizzata la finestra di dialogo . Selezionare la scheda :
 Figura 22.1: Proprietà iniziatore iSCSI #
Figura 22.1: Proprietà iniziatore iSCSI #Nella finestra di dialogo immettere il nome host o l'indirizzo IP della destinazione nel campo , quindi fare clic su :
 Figura 22.2: Rilevazione portale di destinazione #
Figura 22.2: Rilevazione portale di destinazione #Ripetere il processo per tutti gli altri nomi host o indirizzi IP del gateway Al termine, rivedere l'elenco :
 Figura 22.3: Portali di destinazione #
Figura 22.3: Portali di destinazione #Quindi, passare alla scheda e rivedere le destinazioni rilevate.
 Figura 22.4: Destinazioni #
Figura 22.4: Destinazioni #Fare clic su nella scheda . Viene visualizzata la finestra di dialogo . Selezionare la casella di controllo per abilitare I/O multipath (MPIO), quindi fare clic su :
Quando si chiude la finestra di dialogo , selezionare per rivedere le proprietà della destinazione:
 Figura 22.5: Proprietà destinazione iSCSI #
Figura 22.5: Proprietà destinazione iSCSI #Selezionare e fare clic su per rivedere la configurazione multipath I/O:
 Figura 22.6: Dettagli dispositivo #
Figura 22.6: Dettagli dispositivo #L'impostazione di default per è . Se si preferisce una configurazione solo failover, modificare l'impostazione in .
In tal modo si conclude la configurazione dell'iniziatore iSCSI. I volumi iSCSI adesso sono disponibili come qualsiasi altro dispositivo SCSI ed è possibile inizializzarli per utilizzarli come volumi e unità. Fare clic su per chiudere la finestra di dialogo e continuare con il ruolo nel dashboard di .
Osservare il volume appena connesso. Viene identificato come SUSE RBD SCSI Multi-Path Drive (Unità multipath SCSI RBD SUSE) sul bus iSCSI e inizialmente è contrassegnato con lo stato Offline e un tipo di tabella delle partizioni Sconosciuto. Se il nuovo volume non viene visualizzato immediatamente, selezionare dalla casella di riepilogo per effettuare di nuovo la scansione del bus iSCSI.
Fare clic con il pulsante destro del mouse sul volume iSCSI e selezionare dal menu di scelta rapida. Viene visualizzata la . Fare clic su , evidenziare il volume iSCSI appena connesso e fare clic su per iniziare.
 Figura 22.7: Procedura guidata per il nuovo volume #
Figura 22.7: Procedura guidata per il nuovo volume #Inizialmente il dispositivo è vuoto e non contiene una tabella delle partizioni. Quando richiesto, confermare la finestra di dialogo in cui viene indicato che il volume verrà inizializzato con una tabella delle partizioni GPT:
 Figura 22.8: Prompt del disco offline #
Figura 22.8: Prompt del disco offline #Selezionare le dimensioni del volume. Di norma si utilizza l'intera capacità del dispositivo. Assegnare quindi una lettera di unità o un nome directory in cui sarà disponibile il volume appena creato. Quindi, selezionare un a file system da creare sul nuovo volume e infine confermare le selezioni con per completare la creazione del volume:
 Figura 22.9: Conferma selezioni volume #
Figura 22.9: Conferma selezioni volume #Al termine del processo, rivedere i risultati e fare clic su per concludere l'inizializzazione dell'unità. Una volta completata l'inizializzazione, il volume (e il rispettivo file system NTFS) diventa disponibile come un'unità locale appena inizializzata.
22.1.3 Connessione di VMware #
Per eseguire la connessione a volumi iSCSI gestiti da
ceph-iscsi, è necessario che sia configurato un adattatore software iSCSI. Se nella configurazione vSphere non è presente alcun adattatore di questo tipo, crearne uno selezionando › › › .Quando disponibili, selezionare le proprietà dell'adattatore facendo clic con il pulsante destro del mouse sull'adattatore e selezionando dal menu di scelta rapida:
 Figura 22.10: Proprietà iniziatore iSCSI #
Figura 22.10: Proprietà iniziatore iSCSI #Nella finestra di dialogo , fare clic sul pulsante . Accedere quindi alla scheda e selezionare .
Immettere l'indirizzo IP o il nome host del gateway iSCSI
ceph-iscsi. Se si eseguono più servizi iSCSI Gateway in una configurazione di failover, ripetere il passaggio per tutti i gateway che vengono attivati. Figura 22.11: Aggiunta del server di destinazione #
Figura 22.11: Aggiunta del server di destinazione #Una volta eseguito l'accesso a tutti i servizi iSCSI Gateway, fare clic su nella finestra di dialogo per iniziare una nuova scansione dell'adattatore iSCSI.
Al completamento della nuova scansione, il nuovo dispositivo iSCSI viene visualizzato sotto l'elenco nel riquadro . Per i dispositivi multipath adesso è possibile fare clic con il pulsante destro del mouse sull'adattatore e selezionare nel menu di scelta rapida:
 Figura 22.12: Gestione dei dispositivi multipath #
Figura 22.12: Gestione dei dispositivi multipath #Adesso dovrebbero essere visualizzati tutti i percorsi con un indicatore luminoso verde in corrispondenza dello . Uno dei percorsi deve essere contrassegnato come e tutti gli altri semplicemente come :
 Figura 22.13: Elenco dei percorsi per multipath #
Figura 22.13: Elenco dei percorsi per multipath #Adesso è possibile passare da all'elemento etichettato . Nell'angolo in alto a destra del riquadro, selezionare per visualizzare la finestra di dialogo . Quindi, selezionare e fare clic su . Il dispositivo iSCSI appena creato viene visualizzato nell'elenco . Selezionarlo e fare clic su per continuare:
 Figura 22.14: Finestra di dialogo Aggiungi memorizzazione #
Figura 22.14: Finestra di dialogo Aggiungi memorizzazione #Fare clic su per accettare il layout del disco di default disk.
Nel riquadro , assegnare un nome al nuovo archivio dati e fare clic su . Accettare l'impostazione di default per utilizzare l'intero spazio del volume per l'archivio dati o selezionare per un archivio dati più piccolo:
 Figura 22.15: Impostazione spazio personalizzato #
Figura 22.15: Impostazione spazio personalizzato #Fare clic su per completare la creazione dell'archivio dati.
Il nuovo archivio dati viene visualizzato nell'elenco degli archivi dati ed è possibile selezionarlo per recuperare i dettagli. Adesso è possibile utilizzare il volume iSCSI supportato
ceph-iscsicome qualsiasi altro archivio dati vSphere. Figura 22.16: Panoramica dell'archivio dati iSCSI #
Figura 22.16: Panoramica dell'archivio dati iSCSI #
22.2 Conclusioni #
ceph-iscsi è un componente chiave di SUSE Enterprise Storage 7.1 che consente di accedere a uno storage a blocchi distribuito e altamente disponibile da qualsiasi server o client in grado di leggere il protocollo iSCSI. Mediante l'uso di ceph-iscsi su uno o più host gateway iSCSI, le immagini Ceph RBD diventano disponibili come unità logiche (LU) associate a destinazioni iSCSI, cui è possibile accedere nella modalità facoltativa di bilanciamento del carico ad elevata disponibilità.
Poiché tutta la configurazione ceph-iscsi è memorizzata nell'archivio dati Ceph RADOS, gli host gateway ceph-iscsi sono di conseguenza sprovvisti di stato permanente, pertanto è possibile sostituirli, aumentarli o ridurli in base alle esigenze. Come risultato, SUSE Enterprise Storage 7.1 consente ai clienti SUSE di eseguire una tecnologia di storage aziendale effettivamente distribuita, altamente disponibile, resiliente e con funzioni di riparazione automatica sull'hardware utilizzato e su una piattaforma interamente open source.
23 File system in cluster #
In questo capitolo sono descritti i task amministrativi che di norma vengono eseguiti dopo la configurazione del cluster e l'esportazione di CephFS. Per ulteriori informazioni sulla configurazione di CephFS, fare riferimento a Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.3.3 “Distribuzione dei Metadata Server”.
23.1 Montaggio di CephFS #
Una volta creato il file system ed MDS è attivo, si è pronti per montare il file da un host client.
23.1.1 Preparazione del client #
Se sull'host client è in esecuzione SUSE Linux Enterprise 12 SP2 o versioni successive, il sistema è pronto per il montaggio di CephFS senza alcuna configurazione aggiuntiva.
Se sull'host client è in esecuzione SUSE Linux Enterprise 12 SP1, è necessario applicare le patch più recenti prima di montare CephFS.
In ogni caso, tutto il necessario per montare CephFS è incluso in SUSE Linux Enterprise. Il prodotto SUSE Enterprise Storage 7.1 non è necessario.
Per supportare in modo completo la sintassi di mount, prima di tentare di montare CephFS deve essere installato il pacchetto ceph-common (fornito con SUSE Linux Enterprise).
Senza il pacchetto ceph-common (e pertanto senza l'helper mount.ceph), occorrerà utilizzare gli IP dei monitor al posto del loro nome, poiché il client kernel non sarà in grado di eseguire la risoluzione del nome.
La sintassi mount di base è:
# mount -t ceph MON1_IP[:PORT],MON2_IP[:PORT],...:CEPHFS_MOUNT_TARGET \
MOUNT_POINT -o name=CEPHX_USER_NAME,secret=SECRET_STRING23.1.2 Creazione di un file segreto #
Per default, quando il cluster Ceph è in esecuzione l'autenticazione è attivata. È necessario creare un file in cui archiviare la chiave segreta (non il portachiavi stesso). Per ottenere la chiave segreta per un determinato utente e creare il file, procedere come indicato di seguito:
Visualizzare la chiave per l'utente specificato in un file portachiavi:
cephuser@adm >cat /etc/ceph/ceph.client.admin.keyringCopiare la chiave dell'utente che utilizzerà il file system Ceph FS montato. Di norma, la chiave è simile a quanto riportato di seguito:
AQCj2YpRiAe6CxAA7/ETt7Hcl9IyxyYciVs47w==
Creare un file in cui il nome utente costituisce parte del nome file, ad esempio
/etc/ceph/admin.secretper l'utente admin.Incollare il valore della chiave nel file creato al passaggio precedente.
Impostare i diritti di accesso al file appropriati. L'utente deve essere il solo in grado di leggere il file, gli altri non possono avere alcun diritto di accesso.
23.1.3 Montaggio di CephFS #
È possibile montare CephFS utilizzando il comando mount. È necessario specificare il nome host di monitoraggio o l'indirizzo IP. Poiché in SUSE Enterprise Storage l'autenticazione cephx è abilitata per default, è necessario specificare un nome utente e il rispettivo segreto:
# mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secret=AQATSKdNGBnwLhAAnNDKnH65FmVKpXZJVasUeQ==Dato che il comando precedente rimane nella cronologia shell, la lettura del segreto da un file rappresenta un approccio più sicuro:
# mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secretIl file segreto deve contenere solo il segreto del portachiavi effettivo. Nell'esempio, il file conterrà quindi solo la riga seguente:
AQATSKdNGBnwLhAAnNDKnH65FmVKpXZJVasUeQ==
Qualora uno dei monitoraggi dovesse essere inattivo al momento del montaggio, è buona prassi specificare più monitoraggi separati da virgole nella riga di comando mount. Ciascun indirizzo di monitoraggio si presenta nella forma host[:port]. Se non si specifica la porta, per default viene utilizzata la 6789.
Creare il punto di montaggio nell'host locale:
# mkdir /mnt/cephfsMontaggio di CephFS:
# mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret
Se è necessario montare un sottoinsieme del file system, è possibile specificare una sottodirectory subdir:
# mount -t ceph ceph_mon1:6789:/subdir /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret
È possibile specificare più host di monitoraggio nel comando mount:
# mount -t ceph ceph_mon1,ceph_mon2,ceph_mon3:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secretSe si utilizzano client con restrizioni di percorso, tra le funzionalità MDS deve essere incluso l'accesso in lettura alla directory radice. Ad esempio, un portachiavi potrebbe presentare l'aspetto seguente:
client.bar key: supersecretkey caps: [mds] allow rw path=/barjail, allow r path=/ caps: [mon] allow r caps: [osd] allow rwx
la parte allow r path=/ significa che i client con restrizioni di percorso sono in grado di leggere il volume radice, ma non di scriverlo. Nei casi di utilizzo in cui l'isolamento completo è un requisito, ciò può rappresentare un problema.
23.2 Smontaggio di CephFS #
Per smontare CephFS, utilizzare il comando umount:
# umount /mnt/cephfs23.3 Montaggio di CephFS in /etc/fstab #
Per montare CephFS automaticamente all'avvio del client, inserire la riga corrispondente nella rispettiva tabella dei file system /etc/fstab:
mon1:6790,mon2:/subdir /mnt/cephfs ceph name=admin,secretfile=/etc/ceph/secret.key,noatime,_netdev 0 2
23.4 Più daemon MDS attivi (MDS attivo-attivo) #
Per default CephFS è configurato per un unico daemon MDS attivo. Per adattare le prestazioni dei metadati a sistemi su larga scala, è possibile abilitare più daemon MDS attivi in modo che il workload dei metadati venga condiviso con un altro.
23.4.1 Utilizzo dell'MDS attivo-attivo #
Quando le prestazioni dei metadati sull'MDS singolo di default si bloccano, prendere in considerazione l'eventualità di utilizzare più daemon MDS attivi.
L'aggiunta di ulteriori daemon non migliora le prestazioni su tutti i tipi di workload. Ad esempio, una singola applicazione in esecuzione su un unico client non sarà avvantaggiata da un maggior numero di daemon MDS, a meno che l'applicazione non esegua parallelamente molte operazioni di metadati.
I workload che di norma traggono vantaggi da un maggior numero di daemon MDS attivi sono quelli provvisti di numerosi client, che magari funzionano su molte directory separate.
23.4.2 Aumento delle dimensioni del cluster attivo MDS #
Ciascun file system CephFS presenta un'impostazione max_mds che controlla il numero di livelli che saranno creati. Il numero di livelli effettivo nel file system aumenterà solo se è disponibile un daemon di riserva da inserire nel nuovo livello. Se ad esempio è in esecuzione un solo daemon MDS e max_mds è impostato su due, non verrà creato un secondo livello.
Nell'esempio seguente, l'opzione max_mds viene impostata a 2 per creare un nuovo livello oltre a quello di default. Per visualizzare le modifiche, eseguire ceph status prima di impostare max_mds, quindi osservare la riga contenente fsmap:
cephuser@adm >cephstatus [...] services: [...] mds: cephfs-1/1/1 up {0=node2=up:active}, 1 up:standby [...]cephuser@adm >cephfs set cephfs max_mds 2cephuser@adm >cephstatus [...] services: [...] mds: cephfs-2/2/2 up {0=node2=up:active,1=node1=up:active} [...]
Il livello appena creato (1) passa dallo stato "creating" al rispettivo stato "active".
Anche con più daemon MDS attivi, in un sistema altamente disponibile è comunque richiesto che vengano impiegati daemon in standby se i server in esecuzione su un daemon attivo vengono meno.
Di conseguenza, il numero massimo effettivo di max_mds per i sistemi altamente disponibili è uno in meno rispetto al numero totale di server MDS presenti nel sistema. Per garantire la disponibilità qualora si verificassero più errori di server, aumentare il numero di daemon in standby nel sistema in modo che corrisponda al numero di errori di server necessario per poter rimanere attivi.
23.4.3 Riduzione del numero di livelli #
Tutti i livelli, inclusi quelli da rimuovere, devono prima essere attivi. Vale a dire che è necessario disporre di almeno max_mds daemon MDS disponibili.
In primo luogo, impostare max_mds a un numero inferiore. Ad esempio, tornare a un singolo MDS attivo:
cephuser@adm >cephstatus [...] services: [...] mds: cephfs-2/2/2 up {0=node2=up:active,1=node1=up:active} [...]cephuser@adm >cephfs set cephfs max_mds 1cephuser@adm >cephstatus [...] services: [...] mds: cephfs-1/1/1 up {0=node2=up:active}, 1 up:standby [...]
23.4.4 Aggiunta manuale di un albero della directory a un livello #
Per distribuire uniformemente il carico dei metadati nel cluster in configurazioni con vari server di metadati attivi, viene eseguito un bilanciamento. Di norma, questo metodo risulta sufficientemente efficace per la maggior parte degli utenti, ma talvolta è auspicabile sostituire il bilanciamento dinamico con mappature esplicite dei metadati in determinati livelli. In tal modo l'amministratore o gli utenti possono distribuire uniformemente il carico di applicazioni o limitare l'impatto delle richieste di metadati degli utenti sull'intero cluster.
Il meccanismo fornito a tale scopo è denominato "pin di esportazione". Si tratta di un attributo esteso delle directory il cui nome è ceph.dir.pin. Gli utenti possono impostare questo attributo mediante l'uso di comandi standard:
# setfattr -n ceph.dir.pin -v 2 /path/to/dir
Il valore (-v) dell'attributo esteso corrisponde al livello cui assegnare il sottoalbero della directory. Un valore di default pari a -1 indica che la directory non è stata aggiunta.
La directory superiore più vicina con pin di esportazione impostato, eredita il pin. Pertanto, l'impostazione del pin di esportazione in una directory influisce su tutte le rispettive directory secondarie. Il pin della directory superiore può essere sostituito impostando il pin di esportazione della directory secondaria. Esempio:
# mkdir -p a/b # "a" and "a/b" start with no export pin set.
setfattr -n ceph.dir.pin -v 1 a/ # "a" and "b" are now pinned to rank 1.
setfattr -n ceph.dir.pin -v 0 a/b # "a/b" is now pinned to rank 0
# and "a/" and the rest of its children
# are still pinned to rank 1.23.5 Gestione del failover #
Se un daemon MDS smette di comunicare con il monitoraggio, questo attenderà mds_beacon_grace secondi (valore di default 15 secondi) prima di contrassegnare il daemon come lento. È possibile configurare uno o più daemon "in standby" che verranno impiegati durante il failover del daemon MDS.
23.5.1 Configurazione della riproduzione in standby #
È possibile configurare ciascun file system CephFS per aggiungere daemon standby-replay. Questi daemon standby-replay seguono il journal dei metadati dell'MDS attivo per ridurre il tempo di failover nel caso in cui quest'ultimo dovesse diventare non disponibile. Ogni MDS attivo può essere seguito da un solo daemon standby-replay.
Configurare la riproduzione in standby su un file system con il comando seguente:
cephuser@adm > ceph fs set FS-NAME allow_standby_replay BOOLSe impostati, i monitor assegneranno i daemon standby-replay disponibili per fare in modo che seguano gli MDS attivi su tale file system.
Quando un MDS entra in stato di riproduzione in standby, verrà utilizzato solo come standby per il livello seguito. Se un altro livello genera un errore, il daemon standby-replay non verrà utilizzato come sostituto, anche se non ve ne sono altri in standby disponibili. Per questo motivo, se si utilizza la riproduzione in standby, è consigliabile che per ogni MDS attivo sia presente un daemon standby-replay.
23.6 Impostazione delle quote CephFS #
È possibile impostare le quote in qualsiasi sottodirectory del file system Ceph. La quota consente di limitare il numero di byte o file memorizzati al di sotto del punto specificato nella gerarchia della directory.
23.6.1 Limitazioni delle quote CephFS #
L'uso delle quote con CephFS pone le limitazioni seguenti:
- Le quote sono cooperative e non concorrenziali.
Le quote Ceph contano sul fatto che il client, al raggiungimento di uno specifico limite, interrompa la scrittura sul file system di cui esegue il montaggio. La parte server non può impedire a un client dannoso di scrivere quanti più dati possibile. Le quote non devono essere utilizzate per evitare il riempimento del file system negli ambienti con client completamente inattendibili.
- Le quote non sono precise.
I processi che scrivono sul file system verranno interrotti poco dopo il raggiungimento del limite di quota. Verrà loro inevitabilmente concesso di scrivere alcuni dati oltre il limite configurato. I client scrittori verranno interrotti entro alcuni decimi di secondo dopo il superamento di tale limite.
- Le quote sono implementate nel client kernel a partire dalla versione 4.17.
Le quote sono supportate dal client dello spazio utente (libcephfs, ceph-fuse). I client kernel Linux 4.17 e versioni successive supportano le quote CephFS sui cluster di SUSE Enterprise Storage 7.1. I client kernel (anche le versioni recenti) non sono in grado di gestire le quote sui cluster meno recenti, anche se possono impostarne gli attributi estesi. I kernel SLE12-SP3 (e versioni successive) includono già i backport necessari per la gestione delle quote.
- In presenza di restrizioni di montaggio basate sul percorso, prestare attenzione quando si configurano le quote.
Per applicare le quote, il client deve disporre dell'accesso all'inode della directory sulla quale sono configurate. Il client non applicherà la quota se dispone dell'accesso limitato a un percorso specifico (ad esempio
home/user) in base alla funzionalità MDS e se la quota è configurata su una directory antenato a cui il client non ha accesso (/home). Se si applicano restrizioni di accesso basate sul percorso, assicurarsi di configurare la quota sulla directory a cui il client può accedere (ad esempio/home/usero/home/user/quota_dir).
23.6.2 Configurazione delle quote CephFS #
È possibile configurare le quote CephFS tramite gli attributi estesi virtuali:
ceph.quota.max_filesConfigura un limite di file.
ceph.quota.max_bytesConfigura un limite di byte.
Se gli attributi vengono visualizzati su un inode della directory, la quota viene configurata in questa posizione. Se gli attributi non sono presenti, in questa directory non viene impostata nessuna quota (anche se potrebbe comunque esserne configurata una nella directory superiore).
Per impostare una quota di 100 MB, eseguire:
cephuser@mds > setfattr -n ceph.quota.max_bytes -v 100000000 /SOME/DIRECTORYPer impostare una quota di 10.000 file, eseguire:
cephuser@mds > setfattr -n ceph.quota.max_files -v 10000 /SOME/DIRECTORYPer visualizzare l'impostazione della quota, eseguire:
cephuser@mds > getfattr -n ceph.quota.max_bytes /SOME/DIRECTORYcephuser@mds > getfattr -n ceph.quota.max_files /SOME/DIRECTORYSe il valore dell'attributo esteso è "0", la quota non è impostata.
Per rimuovere una quota, eseguire:
cephuser@mds >setfattr -n ceph.quota.max_bytes -v 0 /SOME/DIRECTORYcephuser@mds >setfattr -n ceph.quota.max_files -v 0 /SOME/DIRECTORY
23.7 Gestione degli snapshot CephFS #
Le snapshot CephFS creano una vista di sola lettura del file system relativa al momento in cui vengono acquisite. È possibile creare una snapshot in qualsiasi directory. La snapshot includerà tutti i dati del file system nella directory specificata. In seguito alla creazione della snapshot, i dati memorizzati nel buffer vengono trasferiti in modo asincrono da diversi client. Di conseguenza, la creazione delle snapshot è un processo molto rapido.
Se sono presenti più file system CephFS che condividono un singolo pool (tramite spazi dei nomi), le relative snapshot entreranno in conflitto e l'eliminazione di una snapshot comporterà l'assenza di dati file su altre snapshot che condividono lo stesso pool.
23.7.1 Creazione di snapshot #
La funzione delle snapshot CephFS è abilitata per default sui nuovi file system. Per abilitarla sui file system esistenti, eseguire:
cephuser@adm > ceph fs set CEPHFS_NAME allow_new_snaps true
In seguito all'abilitazione delle snapshot, tutte le directory in CephFS avranno una sottodirectory.snap speciale.
Si tratta di una sottodirectory virtuale. Non è riportata nell'elenco di directory della directory superiore, ma il nome .snap non può essere utilizzato come nome di file o directory. Per accedere alla directory .snap, è necessario farlo esplicitamente, ad esempio:
> ls -la /CEPHFS_MOUNT/.snap/I client kernel CephFS hanno una limitazione: non sono in grado di gestire più di 400 snapshot in un file system. Il numero di snapshot deve essere sempre tenuto al di sotto di questo limite, a prescindere dal client utilizzato. Se si utilizzano client CephFS meno recenti, come SLE12-SP3, tenere presente che superare le 400 snapshot è dannoso per le operazioni perché si verificherà un arresto anomalo del client.
Configurare l'impostazione client snapdir per assegnare un nome diverso alla sottodirectory delle snapshot.
Per creare una snapshot, creare una sottodirectory nella directory .snap con un nome personalizzato. Ad esempio, per creare una snapshot della directory /CEPHFS_MOUNT/2/3/, eseguire:
> mkdir /CEPHFS_MOUNT/2/3/.snap/CUSTOM_SNAPSHOT_NAME23.7.2 Eliminazione degli snapshot #
Per eliminare una snapshot, rimuovere la relativa sottodirectory all'interno della directory .snap:
> rmdir /CEPHFS_MOUNT/2/3/.snap/CUSTOM_SNAPSHOT_NAME24 Esportazione dei dati Ceph tramite Samba #
Questo capitolo descrive come esportare i dati memorizzati in un cluster Ceph tramite una condivisione Samba/CIFS per potervi accedere con facilità dai computer client Windows*. Contiene inoltre informazioni utili per la configurazione di un gateway Samba Ceph in modo che si unisca ad Active Directory nel dominio Windows* per eseguire l'autenticazione e l'autorizzazione degli utenti.
A causa dell'aumento dell'overhead del protocollo e della latenza aggiuntiva causati dagli hop di rete extra tra il client e lo storage, l'accesso a CephFS tramite un gateway Samba potrebbe ridurre notevolmente le prestazioni dell'applicazione rispetto ai client Ceph nativi.
24.1 Esportazione di CephFS tramite la condivisione Samba #
I client CephFS e NFS nativi non sono limitati dai blocchi di file ottenuti tramite Samba e viceversa. I dati delle applicazioni basate sul blocco di file su più protocolli potrebbero risultare danneggiati se l'accesso ai percorsi della condivisione Samba supportati da CephFS viene effettuato in altri modi.
24.1.1 Configurazione ed esportazione dei pacchetti Samba #
Per configurare ed esportare una condivisione Samba, è necessario che siano installati i pacchetti seguenti: samba-ceph e samba-winbind. Installarli se non lo sono:
cephuser@smb > zypper install samba-ceph samba-winbind24.1.2 Esempio di gateway singolo #
Per prepararsi all'esportazione di una condivisione Samba, scegliere un nodo appropriato da utilizzare come gateway Samba. Il nodo deve disporre dell'accesso alla rete del client Ceph, oltre che di sufficienti risorse di CPU, memoria e networking.
La funzionalità di failover può essere fornita con CTDB e SUSE Linux Enterprise High Availability Extension. Per ulteriori informazioni sulla configurazione ad alta disponibilità, fare riferimento alla Sezione 24.1.3, «Configurazione dell'elevata disponibilità».
Accertare che nel cluster sia già esistente un CephFS operativo.
Creare un portachiavi gateway Samba specifico sul nodo admin Ceph e copiarlo in entrambi i nodi gateway Samba:
cephuser@adm >cephauth get-or-create client.samba.gw mon 'allow r' \ osd 'allow *' mds 'allow *' -o ceph.client.samba.gw.keyringcephuser@adm >scpceph.client.samba.gw.keyring SAMBA_NODE:/etc/ceph/Sostituire SAMBA_NODE con il nome del nodo gateway Samba.
I passaggi seguenti vengono eseguiti sul nodo gateway Samba. Installare Samba insieme al pacchetto di integrazione Ceph:
cephuser@smb >sudo zypper in samba samba-cephSostituire i contenuti di default del file
/etc/samba/smb.confcon quanto segue:[global] netbios name = SAMBA-GW clustering = no idmap config * : backend = tdb2 passdb backend = tdbsam # disable print server load printers = no smbd: backgroundqueue = no [SHARE_NAME] path = CEPHFS_MOUNT read only = no oplocks = no kernel share modes = no
Il percorso CEPHFS_MOUNT riportato sopra deve essere montato prima dell'avvio di Samba con una configurazione di condivisione del kernel CephFS. Vedere Sezione 23.3, «Montaggio di CephFS in
/etc/fstab».La configurazione di condivisione sopra utilizza il client CephFS del kernel Linux, consigliato per motivi di prestazioni. In alternativa, è possibile utilizzare anche il modulo
vfs_cephSamba per la comunicazione con il cluster Ceph. Le istruzioni sono riportate di seguito per scopi di legacy e non sono consigliate per nuove le distribuzioni Samba:[SHARE_NAME] path = / vfs objects = ceph ceph: config_file = /etc/ceph/ceph.conf ceph: user_id = samba.gw read only = no oplocks = no kernel share modes = no
Suggerimento: oplocks e modalità di condivisioneGli
oplocks(noti anche come lease SMB2+) consentono di ottenere migliori prestazioni tramite un'aggressiva memorizzazione nella cache del client, ma sono poco sicuri se Samba è distribuito con altri client CephFS, comemount.ceph, FUSE o NFS Ganesha del kernel.Se l'accesso al percorso del file system CephFS è gestito esclusivamente da Samba, è possibile abilitare il parametro degli
oplocksin sicurezza.Attualmente, è necessario disabilitare
kernel share modesnelle condivisioni in esecuzione con il modulo vfs di CephFS per consentire il corretto funzionamento del file serving.Importante: autorizzazione dell'accessoSamba mappa gli utenti e i gruppi SMB agli account locali. È possibile assegnare agli utenti locali una password per l'accesso alla condivisione Samba tramite:
#smbpasswd -a USERNAMEPer operazioni I/O corrette, l'elenco di controllo dell'accesso (ACL) del percorso della condivisione deve consentire l'accesso all'utente connesso tramite Samba. È possibile modificare l'ACL effettuando un montaggio temporaneo tramite il client del kernel CephFS e utilizzando le utility
chmod,chownosetfaclrispetto al percorso della condivisione. Ad esempio, per consentire l'accesso a tutti gli utenti, eseguire:#chmod 777 MOUNTED_SHARE_PATH
24.1.2.1 Avvio dei servizi Samba #
Avviare o riavviare i servizi Samba stand-alone utilizzando i comandi seguenti:
#systemctl restart smb.service#systemctl restart nmb.service#systemctl restart winbind.service
Per assicurarsi che i servizi Samba vengano avviati al momento dell'avvio, abilitarli tramite:
#systemctl enable smb.service#systemctl enable nmb.service#systemctl enable winbind.service
nmb e winbind facoltativi
Se non è necessaria l'esplorazione di condivisione di rete, non occorre abilitare e avviare il servizio nmb.
Il servizio winbind è necessario soltanto se viene configurato come membro del dominio Active Directory. Vedere Sezione 24.2, «Unione di gateway Samba e Active Directory».
24.1.3 Configurazione dell'elevata disponibilità #
Sebbene la disponibilità della distribuzione multi-nodo Samba + CTDB sia molto più elevata rispetto a quella a nodo singolo (vedere il Capitolo 24, Esportazione dei dati Ceph tramite Samba), il failover invisibile all'utente lato client non è supportato. In caso di errore del nodo gateway Samba, è probabile che si verifichi una breve interruzione delle attività delle applicazioni.
Questa sezione fornisce un esempio di come configurare una configurazione ad alta disponibilità a due nodi dei server Samba. La configurazione richiede SUSE Linux Enterprise High Availability Extension. I due nodi sono denominati earth (192.168.1.1) e mars (192.168.1.2).
Per informazioni su SUSE Linux Enterprise High Availability Extension, vedere https://documentation.suse.com/sle-ha/15-SP1/.
Inoltre, due indirizzi IP virtuali mobili consentono ai client di connettersi al servizio indipendentemente dal nodo fisico sul quale è in esecuzione. 192.168.1.10 è utilizzato per amministrazione del cluster con Hawk2 e 192.168.2.1 esclusivamente per esportazioni CIFS. Ciò semplifica la successiva applicazione delle limitazioni di sicurezza.
La procedura seguente descrive l'installazione di esempio. Ulteriori informazioni sono disponibili all'indirizzo https://documentation.suse.com/sle-ha/15-SP1/single-html/SLE-HA-install-quick/.
Creare un portachiavi gateway Samba specifico sul nodo admin e copiarlo su entrambi i nodi:
cephuser@adm >cephauth get-or-create client.samba.gw mon 'allow r' \ osd 'allow *' mds 'allow *' -o ceph.client.samba.gw.keyringcephuser@adm >scpceph.client.samba.gw.keyringearth:/etc/ceph/cephuser@adm >scpceph.client.samba.gw.keyringmars:/etc/ceph/La configurazione SLE ad elevata disponibilità richiede un dispositivo di isolamento per evitare una situazione split-brain quando i nodi del cluster attivi non sono più sincronizzati. A questo scopo, è possibile utilizzare un'immagine RBD Ceph con il dispositivo di blocco Stonith (SBD, Stonith Block Device). Per ulteriori dettagli, fare riferimento a https://documentation.suse.com/sle-ha/15-SP1/single-html/SLE-HA-guide/#sec-ha-storage-protect-fencing-setup.
Se non è ancora esistente, creare un pool RBD denominato
rbd(vedere la Sezione 18.1, «Creazione di un pool») e associarlo arbd(vedere la Sezione 18.5.1, «Associazione di pool a un'applicazione»). Quindi, creare un'immagine RBD correlata chiamatasbd01:cephuser@adm >ceph osd pool create rbdcephuser@adm >ceph osd pool application enable rbd rbdcephuser@adm >rbd -p rbd create sbd01 --size 64M --image-sharedPreparare
earthemarsper ospitare il servizio Samba:Prima di continuare, verificare che siano installati i seguenti pacchetti: ctdb, tdb-tools e samba.
#zypperin ctdb tdb-tools samba samba-cephAssicurarsi che i servizi Samba e CTDB siano interrotti e disabilitati:
#systemctl disable ctdb#systemctl disable smb#systemctl disable nmb#systemctl disable winbind#systemctl stop ctdb#systemctl stop smb#systemctl stop nmb#systemctl stop winbindAprire la porta
4379del firewall su tutti i nodi. Questo passaggio è necessario affinché CTDB comunichi con altri nodi del cluster.
Su
earth, creare i file di configurazione per Samba, che verranno in seguito sincronizzati conmars.Inserire un elenco di indirizzi IP privati dei nodi del gateway Samba nel file
/etc/ctdb/nodes. Alla pagina della documentazione (man 7 ctdb) sono disponibili ulteriori dettagli.192.168.1.1 192.168.1.2
Configurare Samba. Aggiungere le righe seguenti nella sezione
[global]di/etc/samba/smb.conf. Utilizzare il nome host prescelto al posto di CTDB-SERVER (tutti i nodi del cluster compaiono in effetti come un grande nodo con questo nome). Aggiungere inoltre una definizione della condivisione, ad esempio SHARE_NAME:[global] netbios name = SAMBA-HA-GW clustering = yes idmap config * : backend = tdb2 passdb backend = tdbsam ctdbd socket = /var/lib/ctdb/ctdb.socket # disable print server load printers = no smbd: backgroundqueue = no [SHARE_NAME] path = / vfs objects = ceph ceph: config_file = /etc/ceph/ceph.conf ceph: user_id = samba.gw read only = no oplocks = no kernel share modes = no
Tenere presente che i file
/etc/ctdb/nodese/etc/samba/smb.confdevono corrispondere in tutti i nodi gateway Samba.
Installare ed eseguire il bootstrap del cluster SUSE Linux Enterprise High Availability.
Registrare SUSE Linux Enterprise High Availability Extension su
earthemars:root@earth #SUSEConnect-r ACTIVATION_CODE -e E_MAILroot@mars #SUSEConnect-r ACTIVATION_CODE -e E_MAILInstallare ha-cluster-bootstrap su entrambi i nodi:
root@earth #zypperin ha-cluster-bootstraproot@mars #zypperin ha-cluster-bootstrapMappare l'immagine RBD
sbd01a entrambi i gateway Samba tramiterbdmap.service.Modificare
/etc/ceph/rbdmape aggiungere una voce per l'immagine SBD:rbd/sbd01 id=samba.gw,keyring=/etc/ceph/ceph.client.samba.gw.keyring
Abilitare e avviare
rbdmap.service:root@earth #systemctl enable rbdmap.service && systemctl start rbdmap.serviceroot@mars #systemctl enable rbdmap.service && systemctl start rbdmap.serviceIl dispositivo
/dev/rbd/rbd/sbd01deve essere disponibile su entrambi i gateway Samba.Inizializzare il cluster su
earthe lasciare chemarssi unisca.root@earth #ha-cluster-initroot@mars #ha-cluster-join-c earthImportanteDurante il processo di inizializzazione e unione del cluster, verrà richiesto se si desidera utilizzare SBD. Confermare con
ye specificare/dev/rbd/rbd/sbd01come percorso al dispositivo di memorizzazione.
Verificare lo stato del cluster. Dovrebbero essere visibili due nodi aggiunti al cluster:
root@earth #crmstatus 2 nodes configured 1 resource configured Online: [ earth mars ] Full list of resources: admin-ip (ocf::heartbeat:IPaddr2): Started earthEseguire i comandi seguenti su
earthper configurare la risorsa CTDB:root@earth #crmconfigurecrm(live)configure#primitivectdb ocf:heartbeat:CTDB params \ ctdb_manages_winbind="false" \ ctdb_manages_samba="false" \ ctdb_recovery_lock="!/usr/lib64/ctdb/ctdb_mutex_ceph_rados_helper ceph client.samba.gw cephfs_metadata ctdb-mutex" ctdb_socket="/var/lib/ctdb/ctdb.socket" \ op monitor interval="10" timeout="20" \ op start interval="0" timeout="200" \ op stop interval="0" timeout="100"crm(live)configure#primitivesmb systemd:smb \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#primitivenmb systemd:nmb \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#primitivewinbind systemd:winbind \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#groupg-ctdb ctdb winbind nmb smbcrm(live)configure#clonecl-ctdb g-ctdb meta interleave="true"crm(live)configure#commitSuggerimento: PrimitivenmbewinbindfacoltativiSe non è necessaria l'esplorazione di condivisione di rete, non occorre aggiungere il primitive
nmb.Il primitive
winbindè necessario soltanto se viene configurato come membro del dominio Active Directory. Vedere Sezione 24.2, «Unione di gateway Samba e Active Directory».Il binario
/usr/lib64/ctdb/ctdb_mutex_ceph_rados_helpernell'opzione di configurazionectdb_recovery_lockha i parametri CLUSTER_NAME, CEPHX_USER, RADOS_POOL, e RADOS_OBJECT in questo ordine.È possibile aggiungere un ulteriore parametro di timeout del blocco per ignorare il valore di default utilizzato (10 secondi). Un valore più elevato consentirà di aumentare la durata di failover del master di recupero CTDB, mentre se viene impostato un valore più basso, il master di recupero potrebbe venire rilevato erroneamente come disattivato, innescando ripetutamente il failover.
Aggiungere un indirizzo IP di cluster:
crm(live)configure#primitiveip ocf:heartbeat:IPaddr2 params ip=192.168.2.1 \ unique_clone_address="true" \ op monitor interval="60" \ meta resource-stickiness="0"crm(live)configure#clonecl-ip ip \ meta interleave="true" clone-node-max="2" globally-unique="true"crm(live)configure#colocationcol-with-ctdb 0: cl-ip cl-ctdbcrm(live)configure#ordero-with-ctdb 0: cl-ip cl-ctdbcrm(live)configure#commitSe
unique_clone_addressè impostato sutrue, l'agente della risorsa IPaddr2 aggiunge un ID clone all'indirizzo specificato, portando a tre diversi indirizzi IP, che non sono di solito necessari, ma aiutano per il bilanciamento di carico. Per ulteriori informazioni su questo argomento, vedere https://documentation.suse.com/sle-ha/15-SP1/single-html/SLE-HA-guide/#cha-ha-lb.Controllare il risultato:
root@earth #crmstatus Clone Set: base-clone [dlm] Started: [ factory-1 ] Stopped: [ factory-0 ] Clone Set: cl-ctdb [g-ctdb] Started: [ factory-1 ] Started: [ factory-0 ] Clone Set: cl-ip [ip] (unique) ip:0 (ocf:heartbeat:IPaddr2): Started factory-0 ip:1 (ocf:heartbeat:IPaddr2): Started factory-1Eseguire un test da un computer client. Su un client Linux, eseguire il seguente comando per vedere se è possibile copiare i file dal e nel sistema:
#smbclient//192.168.2.1/myshare
24.1.3.1 Riavvio delle risorse Samba ad elevata disponibilità #
Se la configurazione di Samba o CTBD viene modificata, potrebbe essere necessario riavviare le risorse ad elevata disponibilità per applicare tali modifiche. Questa operazione può essere eseguita tramite:
#crmresource restart cl-ctdb
24.2 Unione di gateway Samba e Active Directory #
È possibile configurare il gateway Samba Ceph come membro del dominio Samba con supporto Active Directory (AD). In qualità di membro del dominio Samba, è possibile utilizzare nei file e nelle directory del CephFS esportato i gruppi e gli utenti di dominio riportati negli elenchi di controllo dell'accesso (ACL) locali.
24.2.1 Preparazione dell'installazione di Samba #
Questa sezione presenta la procedura preliminare da seguire prima della configurazione di Samba. Se si inizia da un ambiente pulito, sarà possibile evitare confusione e assicurarsi che nessun file dell'installazione Samba precedente venga mischiato con la nuova installazione del membro del dominio.
Tutti gli orologi dei nodi gateway Samba devono essere sincronizzati con il controller del dominio Active Directory. Gli sfasamenti di orario possono comportare errori di autenticazione.
Verificare che non siano in esecuzione processi di Samba o di memorizzazione dei nomi nella cache:
cephuser@smb > ps ax | egrep "samba|smbd|nmbd|winbindd|nscd"
Se nell'output vengono elencati i processi samba, smbd, nmbd, winbindd o nscd, interromperli.
Se in precedenza è stata eseguita un'installazione Samba su questo host, rimuovere il file /etc/samba/smb.conf. Rimuovere inoltre tutti i file di database Samba, ad esempio i file *.tdb and *.ldb. Per visualizzare un elenco delle directory contenenti i database Samba, eseguire:
cephuser@smb > smbd -b | egrep "LOCKDIR|STATEDIR|CACHEDIR|PRIVATE_DIR"24.2.2 Verifica del DNS #
Active Directory (AD) utilizza il DNS per individuare altri controller del dominio (DC) e servizi, come Kerberos. Pertanto, i membri del domino e i server Active Directory devono essere in grado di risolvere le zone DNS di Active Directory.
Verificare che il DNS sia configurato correttamente e che la ricerca diretta e inversa vengano risolte correttamente, ad esempio:
cephuser@adm > nslookup DC1.domain.example.com
Server: 10.99.0.1
Address: 10.99.0.1#53
Name: DC1.domain.example.com
Address: 10.99.0.1cephuser@adm > 10.99.0.1
Server: 10.99.0.1
Address: 10.99.0.1#53
1.0.99.10.in-addr.arpa name = DC1.domain.example.com.24.2.3 Risoluzione dei record SRV #
Active Directory utilizza i record SRV per l'individuazione dei servizi, come Kerberos e LDAP. Per verificare che i record SRV vengano risolti correttamente, utilizzare la shell interattiva nslookup, ad esempio:
cephuser@adm > nslookup
Default Server: 10.99.0.1
Address: 10.99.0.1
> set type=SRV
> _ldap._tcp.domain.example.com.
Server: UnKnown
Address: 10.99.0.1
_ldap._tcp.domain.example.com SRV service location:
priority = 0
weight = 100
port = 389
svr hostname = dc1.domain.example.com
domain.example.com nameserver = dc1.domain.example.com
dc1.domain.example.com internet address = 10.99.0.124.2.4 Configurazione di Kerberos #
Samba supporta i back-end Heimdal e MIT Kerberos. Per configurare Kerberos sul membro del dominio, impostare quanto segue nel file /etc/krb5.conf:
[libdefaults] default_realm = DOMAIN.EXAMPLE.COM dns_lookup_realm = false dns_lookup_kdc = true
Nell'esempio precedente Kerberos viene configurato per il dominio DOMAIN.EXAMPLE.COM. Non si consiglia di impostare altri parametri nel file /etc/krb5.conf. Se il file /etc/krb5.conf contiene una riga include, non funzionerà: occorre rimuovere tale riga.
24.2.5 Risoluzione del nome host locale #
Quando viene eseguita l'unione a un host sul dominio, Samba tenta di registrare il nome host nella zona DNS di Active Directory. A questo scopo, l'utility net deve essere in grado di risolvere il nome host tramite DNS o utilizzando una voce corretta nel file /etc/hosts.
Per verificare che il nome host venga risolto correttamente, utilizzare il comando getent hosts:
cephuser@adm > getent hosts example-host
10.99.0.5 example-host.domain.example.com example-host
Il nome host e il nome di dominio completo (FQDN) non devono identificarsi con l'indirizzo IP 127.0.0.1 o altri indirizzi IP diversi da quello utilizzato nell'interfaccia LAN del membro del domino. Se non viene visualizzato nessun output o se l'host viene risolto sull'indirizzo IP errato e DHCP non è in uso, impostare la voce corretta nel file /etc/hosts:
127.0.0.1 localhost 10.99.0.5 example-host.samdom.example.com example-host
/etc/hosts
Se si utilizza DHCP, verificare che la riga "127.0.0.1" sia presente soltanto in /etc/hosts. Se continuano a verificarsi problemi, contattare l'amministratore del server DHCP.
Se occorre aggiungere alias al nome host del computer, aggiungerli alla fine della riga che inizia con l'indirizzo IP del computer (non alla riga "127.0.01").
24.2.6 Configurazione di Samba #
Questa sezione fornisce informazioni sulle specifiche opzioni di configurazione da includere nel di configurazione di Samba.
L'appartenenza al dominio Active Directory è configurata principalmente tramite l'impostazione di security = ADS insieme al dominio Kerberos e ai parametri di mappatura ID appropriati nella sezione [global] di /etc/samba/smb.conf.
[global] security = ADS workgroup = DOMAIN realm = DOMAIN.EXAMPLE.COM ...
24.2.6.1 Scelta del back-end per la mappatura ID in winbindd #
Se è necessario assegnare agli utenti diverse shell di login e/o diversi percorsi alla home directory Unix o se si desidera invece che gli utenti abbiano lo stesso ID in generale, utilizzare il back-end "ad" winbind e aggiungere gli attributi RFC2307 ad Active Directory.
Gli attributi RFC2307 non vengono aggiunti automaticamente durante la creazione di utenti o gruppi.
I numeri di ID rilevati su un controller del dominio (compresi nell'intervallo di 3000000) non sono attributi RFC2307 e non verranno utilizzati nei membri del dominio Unix. Se si necessita degli stessi numeri di ID in generale, aggiungere gli attributi uidNumber e gidNumber ad Active Directory e utilizzare il back-end "ad" winbind nei membri del dominio Unix. Se si decide di aggiungere gli attributi uidNumber e gidNumber ad Active Directory, non utilizzare i numeri nell'intervallo di 3000000.
Se gli utenti utilizzeranno il controller del dominio di Active Directory Samba soltanto per scopi di autenticazione e non per la memorizzazione dei dati o per eseguire il login, è possibile utilizzare il back-end "rid" winbind. Ciò consente di calcolare gli ID utente e gruppo dal RID Windows*. Se si utilizza la stessa sezione [global] di smb.conf in ogni membro del dominio Unix, si otterranno gli stessi ID. Se si utilizza il back-end "rid", non è necessario aggiungere nulla ad Active Directory e gli attributi RFC2307 verranno ignorati. Se si utilizza il back-end "rid", impostare i parametri template shell e template homedir in smb.conf. Queste impostazioni sono globali e tutti gli utenti ottengono la stessa shell di login e lo stesso percorso della home directory Unix (a differenza degli attributi RFC2307, in cui è possibile impostare shell e percorsi alla home directory Unix individuali).
È disponibile un'altra modalità di configurazione di Samba, relativa allo scenario in cui è necessario che gli utenti e i gruppi abbiano lo stesso ID in generale, ma che soltanto gli utenti dispongano della stessa shell di login e utilizzino lo stesso percorso della home directory Unix. In questo caso vengono utilizzati il back-end "ad" winbind e le righe modello in smb.conf. In questo modo, è necessario soltanto aggiungere gli attributi uidNumber e gidNumber ad Active Directory.
Altri dettagli e sui back-end di mappatura degli ID sono disponibili nella relativa documentazione: man 8 idmap_ad, man 8 idmap_rid e man 8 idmap_autorid.
24.2.6.2 Impostazione degli intervalli di ID utente e gruppo #
Dopo aver individuato il back-end winbind da utilizzare, è necessario specificare gli intervalli da applicare con l'opzione idmap config in smb.conf. Per default, su un membro del dominio Unix, sono presenti più blocchi di ID utente e gruppo:
| ID | Intervallo |
|---|---|
| 0-999 | Utenti e gruppi di sistema locali. |
| A partire da 1000 | Utenti e gruppi Unix locali. |
| A partire da 10000 | Utenti e gruppi DOMAIN. |
Come è possibile vedere dagli intervalli riportati sopra, è consigliabile non far iniziare gli intervalli "*" o "DOMAIN" da un valore inferiore a 999, poiché potrebbero interferire con gli utenti e i gruppi di sistema locali. Dal momento che è consigliabile inoltre lasciare uno spazio per gli utenti e i gruppi Unix locali, un buon compromesso è far iniziare gli intervalli idmap config da 3000.
È necessario stabilire un valore potenziale relativo alla crescita di "DOMAIN" e se si intendono creare domini attendibili. Quindi, è possibile impostare gli intervalli idmap config come segue:
| Dominio | Intervallo |
|---|---|
| * | 3000-7999 |
| DOMINIO | 10000-999999 |
| TRUSTED | 1000000-9999999 |
24.2.6.3 Mappatura dell'account dell'amministratore del dominio all'utente root locale #
Samba consente di mappare gli account di dominio a un account locale. Utilizzare questa funzione per eseguire operazioni di file sul file system del membro del domino come utente diverso dall'account che ha richiesto l'operazione sul client.
La mappatura dell'amministratore del dominio all'account root locale è facoltativa. Configurarla solo se l'amministratore del dominio deve poter eseguire operazioni di file sul membro del dominio tramite le autorizzazioni root. Tenere presente che la mappatura dell'amministratore all'account root non consente di eseguire il login come "Amministratore" ai membri del dominio Unix.
Per mappare l'amministratore del dominio all'account root locale, seguire la procedura indicata di seguito:
Aggiungere il parametro seguente alla sezione
[global]del filesmb.conf:username map = /etc/samba/user.map
Creare il file
/etc/samba/user.mapcon il contenuto seguente:!root = DOMAIN\Administrator
Se si utilizza il back-end di mappatura ID "ad", non impostare l'attributo uidNumber per l'account dell'amministratore del dominio. Se tale attributo è impostato per l'account, il valore sostituisce l'UID "0" locale dell'utente root e la mappatura non riesce.
Per ulteriori dettagli, vedere il parametro username map nella documentazione smb.conf (man 5 smb.conf).
24.2.7 Unione al dominio Active Directory #
Per unire l'host a un'Active Directory, eseguire:
cephuser@smb > net ads join -U administrator
Enter administrator's password: PASSWORD
Using short domain name -- DOMAIN
Joined EXAMPLE-HOST to dns domain 'DOMAIN.example.com'24.2.8 Configurazione del Name Service Switch #
Per rendere gli utenti e i gruppi del domino disponibili sul sistema locale, è necessario abilitare la libreria Name Service Switch (NSS). Aggiungere la voce winbind ai database seguenti nel file /etc/nsswitch.conf:
passwd: files winbind group: files winbind
Mantenere la voce
filescome prima origine di entrambi i database. In questo modo, NSS cercherà gli utenti e i gruppi del dominio nei file/etc/passwde/etc/groupprima di interrogare il serviziowinbind.Non aggiungere la voce
winbindal databaseshadowdi NSS, poiché potrebbe causare un errore dell'utilitywbinfo.Non utilizzare gli stessi nomi utente nel file
/etc/passwdlocale e nel dominio.
24.2.9 Avvio dei servizi #
In seguito alle modifiche della configurazione, riavviare i servizi Samba come descritto nella Sezione 24.1.2.1, «Avvio dei servizi Samba» o nella Sezione 24.1.3.1, «Riavvio delle risorse Samba ad elevata disponibilità».
24.2.10 Test della connettività di winbindd #
24.2.10.1 Invio di un ping winbindd #
Per verificare se il servizio winbindd è in grado di eseguire la connessione ai controller del dominio (DC) Active Directory o a un controller di dominio primario (PDC), immettere:
cephuser@smb > wbinfo --ping-dc
checking the NETLOGON for domain[DOMAIN] dc connection to "DC.DOMAIN.EXAMPLE.COM" succeeded
Se il comando precedente non riesce, verificare che il servizio winbindd sia in esecuzione e che il file smb.conf sia configurato correttamente.
24.2.10.2 Ricerca di utenti e gruppi del dominio #
Tramite la libreria libnss_winbind è possibile effettuare una ricerca degli utenti e dei gruppi del dominio. Ad esempio, per cercare l'utente del domino "DOMAIN\demo01":
cephuser@smb > getent passwd DOMAIN\\demo01
DOMAIN\demo01:*:10000:10000:demo01:/home/demo01:/bin/bashPer cercare il gruppo del domino "Domain Users":
cephuser@smb > getent group "DOMAIN\\Domain Users"
DOMAIN\domain users:x:10000:24.2.10.3 Assegnazione di autorizzazioni di file a utenti e gruppi del dominio #
Tramite la libreria NSS, è possibile utilizzare i gruppi e gli account utente del dominio nei comandi. Ad esempio, per impostare il proprietario di un file sull'utente del dominio "demo01" e il gruppo sul gruppo del dominio "Domain Users", immettere:
cephuser@smb > chown "DOMAIN\\demo01:DOMAIN\\domain users" file.txt25 NFS Ganesha #
NFS Ganesha è un server NFS che viene eseguito in uno spazio di indirizzamento dell'utente come parte del kernel del sistema operativo. Con NFS Ganesha, è possibile collegare un meccanismo di memorizzazione, come Ceph, e accedervi da qualsiasi client NFS. Per istruzioni sull'installazione, vedere Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.3.6 “Distribuzione di NFS Ganesha”.
A causa dell'aumento dell'overhead del protocollo e della latenza aggiuntiva causati dagli hop di rete extra tra il client e lo storage, l'accesso a Ceph tramite un gateway NFS potrebbe ridurre notevolmente le prestazioni dell'applicazione se confrontate con quelle del CephFS nativo.
Ogni servizio NFS Ganesha è composto da una gerarchia di configurazione contenente:
Un
ganesha.confdi bootstrapUn oggetto di configurazione comune RADOS per ciascun servizio
Un oggetto di configurazione RADOS per ciascuna esportazione
La configurazione di bootstrap è la configurazione minima per l'avvio del daemon nfs-ganesha all'interno di un container. Ciascuna configurazione di bootstrap conterrà una direttiva %url che include eventuali configurazioni aggiuntive dell'oggetto di configurazione comune RADOS. L'oggetto di configurazione comune può includere ulteriori direttive %url per ciascuna delle esportazioni NFS definite negli oggetti di configurazione RADOS di esportazione.

25.1 Creazione di un servizio NFS #
Per specificare la distribuzione dei servizi Ceph, si consiglia di creare un file con formattazione YAML contenente la specifica dei servizi da distribuire. È possibile creare un file della specifica separato per ogni tipo di servizio oppure specificare più tipi di servizi (o tutti) in un unico file.
A seconda dell'opzione scelta, per creare un servizio NFS Ganesha, sarà necessario aggiornare o creare un file con formattazione YAML pertinente. Per ulteriori informazioni sulla creazione del file, vedere Book “Guida alla distribuzione”, Chapter 8 “Distribuzione dei rimanenti servizi di base mediante cephadm”, Section 8.2 “Specifica del servizio e del posizionamento”.
Dopo aver aggiornato o creato il file eseguire quanto riportato di seguito per creare un servizio nfs-ganesha:
cephuser@adm > ceph orch apply -i FILE_NAME25.2 Avvio o riavvio di NFS Ganesha #
L'avvio del servizio NFS Ganesha non esporta automaticamente un file system CephFS. Per esportare un file system CephFS, creare un file di configurazione di esportazione. Per ulteriori dettagli, fare riferimento a Sezione 25.4, «Creazione di un'esportazione NFS».
Per avviare il servizio NFS Ganesha, eseguire:
cephuser@adm > ceph orch start nfs.SERVICE_IDPer riavviare il servizio NFS Ganesha, eseguire:
cephuser@adm > ceph orch restart nfs.SERVICE_IDSe si desidera riavviare soltanto un singolo daemon NFS Ganesha, eseguire:
cephuser@adm > ceph orch daemon restart nfs.SERVICE_IDQuando si avvia o riavvia NFS Ganesha, il timeout di tolleranza per NFS v4 è di 90 secondi. Durante la moratoria, le nuove richieste dai client vengono rifiutate attivamente. Pertanto, è possibile che i client subiscano un rallentamento delle richieste durante la moratoria di NFS.
25.3 Elenco di oggetti nel pool di recupero NFS #
Eseguire quanto riportato di seguito per elencare gli oggetti nel pool di recupero NFS:
cephuser@adm > rados --pool POOL_NAME --namespace NAMESPACE_NAME ls25.4 Creazione di un'esportazione NFS #
È possibile creare un'esportazione NFS nel Ceph Dashboard oppure manualmente, dalla riga di comando. Per creare l'esportazione mediante il Ceph Dashboard, fare riferimento al Capitolo 7, Gestione di NFS Ganesha e più specificamente alla Sezione 7.1, «Creazione di esportazioni NFS».
Per creare manualmente un'esportazione NFS, creare un file di configurazione per l'esportazione. Ad esempio, un file /tmp/export-1 con il seguente contenuto:
EXPORT {
export_id = 1;
path = "/";
pseudo = "/";
access_type = "RW";
squash = "no_root_squash";
protocols = 3, 4;
transports = "TCP", "UDP";
FSAL {
name = "CEPH";
user_id = "admin";
filesystem = "a";
secret_access_key = "SECRET_ACCESS_KEY";
}
}Dopo aver creato e salvato il file di configurazione per la nuova esportazione, eseguire il seguente comando per creare l'esportazione:
rados --pool POOL_NAME --namespace NAMESPACE_NAME put EXPORT_NAME EXPORT_CONFIG_FILE
Ad esempio:
cephuser@adm > rados --pool example_pool --namespace example_namespace put export-1 /tmp/export-1
Modificare il blocco FSAL in modo che includa l'ID utente cephx desiderato e la chiave di accesso segreta.
25.5 Verifica dell'esportazione NFS #
NFS v4 crea un elenco di esportazioni nella radice di uno pseudo file system. È possibile verificare che le condivisioni NFS vengano esportate montando / del nodo del server NFS Ganesha:
#mount-t nfs nfs_ganesha_server_hostname:/ /path/to/local/mountpoint#ls/path/to/local/mountpoint cephfs
Per default, cephadm configurerà un server NFS v4. NFS v4 non interagisce con rpcbind o con il daemon mountd. Gli strumenti del client NFS, come showmount, non visualizzeranno nessuna esportazione configurata.
25.6 Montaggio dell'esportazione NFS #
Per montare la condivisione NFS esportata su un host client, eseguire:
#mount-t nfs nfs_ganesha_server_hostname:/ /path/to/local/mountpoint
25.7 Cluster NFS Ganesha multipli #
È possibile definire più cluster NFS Ganesha per:
Separare i cluster NFS Ganesha per l'accesso a CephFS.
Parte V Integrazione con gli strumenti di virtualizzazione #
- 26
libvirte Ceph La libreria libvirt consente di creare uno strato di astrazione della macchina virtuale tra le interfacce dell'Hypervisor e le applicazioni software che le utilizzano. Con libvirt, sviluppatori e amministratori di sistema possono focalizzarsi su un framework di gestione, un'API e un'interfaccia shel…
- 27 Ceph come back-end per l'istanza QEMU KVM
Il caso di utilizzo Ceph più frequente riguarda l'inserimento di immagini di dispositivi di blocco nelle macchine virtuali. Ad esempio, un utente può creare un'immagine "golden" con un sistema operativo e qualsiasi software pertinente in una configurazione ideale. L'utente, quindi, effettua uno snap…
26 libvirt e Ceph #
La libreria libvirt consente di creare uno strato di astrazione della macchina virtuale tra le interfacce dell'Hypervisor e le applicazioni software che le utilizzano. Con libvirt, sviluppatori e amministratori di sistema possono focalizzarsi su un framework di gestione, un'API e un'interfaccia shell (virsh) comuni a Hypervisor diversi, tra cui QEMU/KVM, Xen, LXC o VirtualBox.
I dispositivi di blocco Ceph supportano QEMU/KVM. È possibile utilizzare i dispositivi di blocco Ceph con software che si interfaccia con libvirt. Nella soluzione cloud si utilizza libvirt per l'iterazione con QEMU/KVM e quest'ultimo esegue l'iterazione con i dispositivi di blocco Ceph tramite librbd.
Per creare macchine virtuali in cui vengono utilizzati dispositivi di blocco Ceph, seguire le procedure riportate nelle sezioni seguenti. Negli esempi, sono stati utilizzati libvirt-pool per il nome pool, client.libvirt per il nome utente e new-libvirt-image per il nome immagine. È possibile utilizzare qualsiasi valore desiderato, ma assicurarsi di sostituire tali valori quando si eseguono i comandi nelle procedure successive.
26.1 Configurazione di Ceph con libvirt #
Per configurare Ceph per l'uso con libvirt, eseguire i seguenti passaggi:
Creare un pool. Nell'esempio seguente viene utilizzato il nome pool
libvirt-poolcon 128 gruppi di posizionamento.cephuser@adm >ceph osd pool create libvirt-pool 128 128Verificare l'esistenza del pool.
cephuser@adm >ceph osd lspoolsCreare un utente Ceph. Nell'esempio seguente viene utilizzato il nome utente Ceph
client.libvirte si fa riferimento alibvirt-pool.cephuser@adm >ceph auth get-or-create client.libvirt mon 'profile rbd' osd \ 'profile rbd pool=libvirt-pool'Verificare l'esistenza del nome.
cephuser@adm >ceph auth listNota: nome utente o IDlibvirtaccederà a Ceph tramite l'IDlibvirt, non il nome Cephclient.libvirt. Per una spiegazione dettagliata della differenza tra ID e nome, vedere Sezione 30.2.1.1, «Utente» (in lingua inglese).Utilizzare QEMU per creare un'immagine nel pool RBD. Nell'esempio seguente viene utilizzato il nome immagine
new-libvirt-imagee si fa riferimento alibvirt-pool.Suggerimento: ubicazione del file portachiaviLa chiave utente
libvirtè memorizzata in un file portachiavi ubicato nella directory/etc/ceph. Occorre assegnare al file portachiavi un nome appropriato in cui sia incluso il nome del cluster Ceph a cui appartiene. Per il nome del cluster di default "ceph", il nome del file portachiavi è/etc/ceph/ceph.client.libvirt.keyring.Se il portachiavi non esiste, crearlo con:
cephuser@adm >ceph auth get client.libvirt > /etc/ceph/ceph.client.libvirt.keyring#qemu-img create -f raw rbd:libvirt-pool/new-libvirt-image:id=libvirt 2GVerificare l'esistenza dell'immagine.
cephuser@adm >rbd -p libvirt-pool ls
26.2 Preparazione del programma di gestione VM #
È possibile utilizzare libvirt senza un programma di gestione VM, ma è più semplice creare prima il dominio con virt-manager.
Installare un programma di gestione delle macchine virtuali.
#zypper in virt-managerPreparare/effettuare il download di un'immagine del sistema operativo che si desidera eseguire come virtualizzato.
Avviare il programma di gestione delle macchine virtuali.
virt-manager
26.3 Creazione di una macchina virtuale (VM) #
Per creare una VM con virt-manager, eseguire i passaggi seguenti:
Scegliere la connessione dall'elenco, fare clic con il pulsante destro del mouse su di essa e selezionare .
specificando il percorso di memorizzazione esistente. Specificare il tipo di sistema operativo, le impostazioni della memoria e il della macchina virtuale, ad esempio
libvirt-virtual-machine.Completare la configurazione e avviare la VM.
Verificare l'esistenza del dominio appena creato con
sudo virsh list. Se necessario, specificare la stringa di connessione, comevirsh -c qemu+ssh://root@vm_host_hostname/system listId Name State ----------------------------------------------- [...] 9 libvirt-virtual-machine runningEseguire il login alla VM e interromperla prima di configurarla per l'uso con Ceph.
26.4 Configurazione della macchina virtuale (VM) #
Questo capitolo è incentrato sulla configurazione delle VM per l'integrazione con Ceph mediante l'uso di virsh. Spesso per i comandi virsh sono richiesti i privilegi radice (sudo) e non verranno restituiti i risultati appropriati né notifiche in merito ai privilegi radice richiesti. Per informazioni sui comandi virsh, fare riferimento a man 1 virsh (è richiesta l'installazione del pacchetto libvirt-client).
Aprire il file di configurazione con
virsh editvm-domain-name.#virsh edit libvirt-virtual-machineIn <devices> deve essere presente una voce <disk>.
<devices> <emulator>/usr/bin/qemu-system-SYSTEM-ARCH</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw'/> <source file='/path/to/image/recent-linux.img'/> <target dev='vda' bus='virtio'/> <address type='drive' controller='0' bus='0' unit='0'/> </disk>Sostituire
/path/to/image/recent-linux.imgcon il percorso dell'immagine del sistema operativo.ImportanteUtilizzare
sudo virsh edital posto di un editor di testo. Se si modifica il file di configurazione in/etc/qemucon un editor di testo, è possibile chelibvirtlibvirt non riconosca la modifica. Se è presente una discrepanza tra i contenuti del file XML in/etc/libvirt/qemue il risultato disudo virsh dumpxmlvm-domain-name, la VM potrebbe non funzionare correttamente.Aggiungere l'immagine Ceph RBD creata precedentemente come voce <disk>.
<disk type='network' device='disk'> <source protocol='rbd' name='libvirt-pool/new-libvirt-image'> <host name='monitor-host' port='6789'/> </source> <target dev='vda' bus='virtio'/> </disk>Sostituire monitor-host con il nome host e sostituire il pool e/o il nome immagine secondo necessità. È possibile aggiungere più voci <host> per i Ceph Monitor. L'attributo
devè il nome dispositivo logico che verrà visualizzato nella directory/devdella VM. L'attributo bus facoltativo indica il tipo di dispositivo disco da emulare. Le impostazioni valide sono specifiche per il driver (ad esempio ide, scsi, virtio, xen, usb o sata).salvataggio del file.
Se nel cluster Ceph è abilitata l'autenticazione (impostazione di default), è necessario generare un segreto. Aprire l'editor desiderato e creare un file denominato
secret.xmlcon il contenuto seguente:<secret ephemeral='no' private='no'> <usage type='ceph'> <name>client.libvirt secret</name> </usage> </secret>Definire il segreto.
#virsh secret-define --file secret.xml <uuid of secret is output here>Ottenere la chiave
client.libvirte salvare la stringa chiave in un file.cephuser@adm >ceph auth get-key client.libvirt | sudo tee client.libvirt.keyImpostare l'UUID del segreto.
#virsh secret-set-value --secret uuid of secret \ --base64 $(cat client.libvirt.key) && rm client.libvirt.key secret.xmlÈ inoltre necessario impostare manualmente il segreto aggiungendo la seguente voce
<auth>all'elemento<disk>immesso precedentemente (sostituendo il valore uuid con il risultato dell'esempio della riga di comando di cui sopra).#virsh edit libvirt-virtual-machineQuindi, aggiungere l'elemento
<auth></auth>al file di configurazione del dominio:... </source> <auth username='libvirt'> <secret type='ceph' uuid='9ec59067-fdbc-a6c0-03ff-df165c0587b8'/> </auth> <target ...NotaL'ID di esempio è
libvirt, non il nome Cephclient.libvirtgenerato al passaggio 2 della Sezione 26.1, «Configurazione di Ceph conlibvirt». Assicurarsi di utilizzare il componente ID del nome Ceph generato. Se per qualche motivo è necessario generare di nuovo il segreto, si dovrà eseguiresudo virsh secret-undefineuuid prima di eseguire di nuovosudo virsh secret-set-value.
26.5 Riepilogo #
Una volta configurata la VM per l'uso con Ceph, è possibile avviarla. Per verificare che la VM e Ceph comunichino tra loro, è possibile eseguire la procedura seguente.
Verificare che Ceph sia in esecuzione:
cephuser@adm >ceph healthVerificare che la VM sia in esecuzione:
#virsh listVerificare che la VM stia comunicando con Ceph. Sostituire vm-domain-name con il nome di dominio della VM:
#virsh qemu-monitor-command --hmp vm-domain-name 'info block'Verificare che il dispositivo di
&target dev='hdb' bus='ide'/>venga visualizzato in/devo in/proc/partitions:>ls /dev>cat /proc/partitions
27 Ceph come back-end per l'istanza QEMU KVM #
Il caso di utilizzo Ceph più frequente riguarda l'inserimento di immagini di dispositivi di blocco nelle macchine virtuali. Ad esempio, un utente può creare un'immagine "golden" con un sistema operativo e qualsiasi software pertinente in una configurazione ideale. L'utente, quindi, effettua uno snapshot dell'immagine. Infine, l'utente clona lo snapshot (di solito molte volte, vedere Sezione 20.3, «Snapshot» per ulteriori informazioni). La capacità di creare cloni copia su scrittura di uno snapshot significa che Ceph è in grado di fornire rapidamente immagini di dispositivi di blocco alle macchine virtuali, perché il client non deve effettuare il download di un'immagine intera ogni volta che esegue lo spin-up di una nuova macchina virtuale.
I dispositivi di blocco Ceph possono essere integrati con le macchine virtuali QEMU. Per ulteriori informazioni su QEMU KVM, vedere https://documentation.suse.com/sles/15-SP1/single-html/SLES-virtualization/#part-virt-qemu (in lingua inglese).
27.1 Installazione qemu-block-rbd #
Per utilizzare i dispositivi di blocco Ceph, è necessario che in QEMU sia installato il driver appropriato. Verificare che il pacchetto qemu-block-rbd sia installato e installarlo se necessario:
# zypper install qemu-block-rbd27.2 Uso di QEMU #
Nella riga di comando QEMU ci si aspetta che venga specificato il nome pool e il nome immagine. È anche possibile specificare il nome di uno snapshot.
qemu-img command options \ rbd:pool-name/image-name@snapshot-name:option1=value1:option2=value2...
Ad esempio, se si specificano le opzioni id e conf si potrebbe ottenere:
qemu-img command options \
rbd:pool_name/image_name:id=glance:conf=/etc/ceph/ceph.conf27.3 Creazione di immagini con QEMU #
È possibile creare un'immagine del dispositivo di blocco da QEMU. Specificare rbd, il nome pool e il nome dell'immagine che si desidera creare. Si devono specificare anche le dimensioni dell'immagine.
qemu-img create -f raw rbd:pool-name/image-name size
Esempio:
qemu-img create -f raw rbd:pool1/image1 10G Formatting 'rbd:pool1/image1', fmt=raw size=10737418240 nocow=off cluster_size=0
Il formato dati raw è effettivamente la sola opzione di formato sensibile da utilizzare con RBD. Tecnicamente si potrebbero utilizzare altri formati supportati da QEMU, come qcow2, ma in tal modo si aggiungerebbe ulteriore overhead e il volume non sarebbe sicuro per la migrazione in tempo reale della macchina virtuale quando la memorizzazione nella cache è abilitata.
27.4 Ridimensionamento delle immagini con QEMU #
È possibile ridimensionare un'immagine del dispositivo di blocco da QEMU. Specificare rbd, il nome pool e il nome dell'immagine che si desidera ridimensionare. Si devono specificare anche le dimensioni dell'immagine.
qemu-img resize rbd:pool-name/image-name size
Esempio:
qemu-img resize rbd:pool1/image1 9G Image resized.
27.5 Recupero delle informazioni sull'immagine con QEMU #
È possibile recuperare informazioni sull'immagine del dispositivo di blocco da QEMU. Specificare rbd, il nome pool e il nome dell'immagine.
qemu-img info rbd:pool-name/image-name
Esempio:
qemu-img info rbd:pool1/image1 image: rbd:pool1/image1 file format: raw virtual size: 9.0G (9663676416 bytes) disk size: unavailable cluster_size: 4194304
27.6 Esecuzione di QEMU con RBD #
Con QEMU è possibile accedere a un'immagine come un dispositivo di blocco virtuale direttamente tramite librbd. In tal modo si evita un ulteriore passaggio contestuale ed è possibile sfruttare la memorizzazione nella cache RBD.
È possibile utilizzare qemu-img per convertire le immagini della macchina virtuale esistenti in immagini del dispositivo di blocco Ceph. Ad esempio, se si dispone di un'immagine qcow2, si potrebbe eseguire:
qemu-img convert -f qcow2 -O raw sles12.qcow2 rbd:pool1/sles12
Per eseguire un avvio della macchina virtuale da tale immagine, si potrebbe eseguire:
# qemu -m 1024 -drive format=raw,file=rbd:pool1/sles12
La memorizzazione nella cache RBD può migliorare le prestazioni in modo significativo. Le opzioni di cache QEMU controllano la memorizzazione nella cache librbd caching:
# qemu -m 1024 -drive format=rbd,file=rbd:pool1/sles12,cache=writebackPer ulteriori informazioni sulla memorizzazione nella cache RBD, fare riferimento alla Sezione 20.5, «Impostazioni della cache».
27.7 Abilitazione dell'operazione di scarto e TRIM #
I dispositivi di blocco Ceph supportano l'operazione di scarto. Vale a dire che un guest può inviare richieste TRIM per consentire a un dispositivo di blocco Ceph di recuperare spazio inutilizzato. Tale operazione può essere abilitata nel guest tramite il montaggio di XFS con l'opzione di scarto.
Affinché questa sia disponibile nel guest, è necessario abilitarla esplicitamente per il dispositivo di blocco. A tal fine, specificare una discard_granularity associata all'unità:
# qemu -m 1024 -drive format=raw,file=rbd:pool1/sles12,id=drive1,if=none \
-device driver=ide-hd,drive=drive1,discard_granularity=512Nell'esempio di cui sopra è utilizzato il driver IDE. Il driver virtio non supporta l'opzione di scarto.
Se si utilizza libvirt, modificare il file di configurazione del dominio libvirt utilizzando virsh edit per includere il valore xmlns:qemu. Aggiungere quindi un qemu:commandline block come secondario per tale dominio. Nell'esempio seguente è illustrato come impostare due dispositivi con qemu id= su valori discard_granularity diversi.
<domain type='kvm' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'> <qemu:commandline> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-0.discard_granularity=4096'/> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-1.discard_granularity=65536'/> </qemu:commandline> </domain>
27.8 Impostazione delle opzioni cache QEMU #
Le opzioni cache QEMU corrispondono alle seguenti impostazioni cache RBD Ceph.
Writeback:
rbd_cache = true
Write-through:
rbd_cache = true rbd_cache_max_dirty = 0
Nessuno:
rbd_cache = false
Le impostazioni cache QEMU sostituiscono le impostazioni di default Ceph (impostazioni non impostate esplicitamente nel file di configurazione Ceph). Se si impostano esplicitamente le impostazioni cache RBD nel file di configurazione Ceph, (fare riferimento alla Sezione 20.5, «Impostazioni della cache»), le impostazioni Ceph sostituiscono le impostazioni della cache QEMU. Se si configurano le impostazioni cache nella riga di comando QEMU, le rispettive impostazioni sostituiscono quelle del file di configurazione Ceph.
Parte VI Configurazione di un cluster #
- 28 Configurazione del cluster Ceph
Questo capitolo descrive come configurare il cluster Ceph utilizzando le opzioni apposite.
- 29 Moduli di Ceph Manager
L'architettura di Ceph Manager (per una breve presentazione, consultare questo riferimento: Book “Guida alla distribuzione”, Chapter 1 “SES e Ceph”, Section 1.2.3 “Daemon e nodi Ceph”) consente di estendere le sue funzionalità tramite i moduli, come "dashboard" (vedere il Parte I, «Ceph Dashboard»),…
- 30 Autenticazione con
cephx Per identificare i client e proteggerli da attacchi man-in-the-middle, in Ceph è disponibile il rispettivo sistema di autenticazione
cephx. I client in questo contesto sono utenti umani, come l'utente amministratore, o servizi/daemon correlati a Ceph, ad esempio OSD, monitoraggi o Object Gateway.
28 Configurazione del cluster Ceph #
Questo capitolo descrive come configurare il cluster Ceph utilizzando le opzioni apposite.
28.1 Configurazione del file ceph.conf #
cephadm utilizza un file ceph.conf di base che contiene soltanto un insieme minimo di opzioni per la connessione ai MON, l'autenticazione e il recupero delle informazioni di configurazione. Nella maggior parte dei casi, ciò è limitato all'opzione mon_host (anche se è possibile evitarlo utilizzando i record DNS SRV).
Il file ceph.conf non funge più da posizione centrale per la memorizzazione della configurazione del cluster, a favore del database di configurazione (vedere la Sezione 28.2, «Database di configurazione»).
Se tuttavia è necessario modificare la configurazione del cluster tramite il file ceph.conf, ad esempio perché si utilizza un client che non è in grado di supportare le opzioni di lettura dal database di configurazione, è necessario eseguire il comando seguente e mantenere e distribuire il file ceph.conf nell'intero cluster:
cephuser@adm > ceph config set mgr mgr/cephadm/manage_etc_ceph_ceph_conf false28.1.1 Accesso a ceph.conf nelle immagini del container #
Nonostante i daemon Ceph vengano eseguiti all'interno dei container, è possibile comunque accedere al relativo file di configurazione ceph.conf, montato in bind mount, come il file seguente sul sistema host:
/var/lib/ceph/CLUSTER_FSID/DAEMON_NAME/config
Sostituire CLUSTER_FSID con l'FSID univoco del cluster in esecuzione così come restituito dal comando ceph fsid e DAEMON_NAME con il nome del daemon specifico così come riportato dal comando ceph orch ps. Esempio:
/var/lib/ceph/b4b30c6e-9681-11ea-ac39-525400d7702d/osd.2/config
Per modificare la configurazione di un daemon, modificare il relativo file config e riavviarlo:
# systemctl restart ceph-CLUSTER_FSID-DAEMON_NAMEEsempio:
# systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d-osd.2Tutte le impostazioni personalizzate andranno perse dopo che cephadm ripeterà la distribuzione del daemon.
28.2 Database di configurazione #
I Ceph Monitor gestiscono un database centrale delle opzioni di configurazione che influiscono sul comportamento dell'intero cluster.
28.2.1 Sezioni e maschere di configurazione #
Le opzioni di configurazione archiviate dal MON possono risiedere in una sezione globale oppure in una sezione del tipo di daemon o di un daemon specifico. Le opzioni possono disporre inoltre di una maschera associata per limitare ulteriormente i daemon o i client a cui sono applicate. Le maschere presentano due forme:
TYPE:LOCATION, dove TYPE indica una proprietà CRUSH, come
rackoppurehost, e LOCATION indica un valore relativo a tale proprietà.Ad esempio,
host:example_hostlimiterà l'opzione soltanto ai daemon o ai client in esecuzione su un determinato host.CLASS:DEVICE_CLASS, dove DEVICE_CLASS indica il nome di una classe di dispositivi CRUSH, come
hddossd. Ad esempio,class:ssdlimiterà l'opzione soltanto agli OSD supportati dai dispositivi SSD. Questa maschera non ha alcun effetto sui daemon o i client non OSD.
28.2.2 Impostazione e lettura delle opzioni di configurazione #
Utilizzare i comandi seguenti per impostare o leggere le opzioni di configurazione del cluster. Il parametro WHO può essere il nome di una sezione, una maschera o entrambe, separate da una barra (/). Ad esempio, osd/rack:foo rappresenta tutti i daemon OSD nel rack denominato foo.
ceph config dumpEsegue il dump di tutto il database di configurazione per l'intero cluster.
ceph config get WHOEsegue il dump della configurazione per un daemon o client specifico (ad esempio,
mds.a) archiviato nel database di configurazione.ceph config set WHO OPTION VALUEImposta l'opzione di configurazione sul valore specificato nel database di configurazione.
ceph config show WHOMostra la configurazione in esecuzione segnalata per un daemon in esecuzione. Se sono in uso anche dei file di configurazione locali o se le opzioni sono state sostituite nella riga di comando o al runtime, queste impostazioni possono differire da quelle archiviate dai monitor. L'origine dei valori di opzione è riportata come parte dell'output.
ceph config assimilate-conf -i INPUT_FILE -o OUTPUT_FILEImporta un file di configurazione specificato come INPUT_FILE e archivia le opzioni valide nel database di configurazione. Le impostazioni non riconosciute, non valide o che non possono essere controllate dal monitor verranno restituite in un file abbreviato archiviato come OUTPUT_FILE. Questo comando è utile per eseguire la transizione dai file di configurazione esistenti alla configurazione centralizzata basata su monitor.
28.2.3 Configurazione dei daemon al runtime #
Nella maggior parte dei casi, Ceph consente di apportare modifiche alla configurazione di un daemon al runtime. Ciò è utile, ad esempio, se è necessario aumentare o diminuire il numero di output di log o durante l'ottimizzazione del cluster di runtime.
È possibile aggiornare i valori delle opzioni di configurazione con il comando seguente:
cephuser@adm > ceph config set DAEMON OPTION VALUEAd esempio, per regolare il livello di log di debug su un OSD specifico, eseguire:
cephuser@adm > ceph config set osd.123 debug_ms 20Se la stessa opzione è personalizzata anche in un file di configurazione locale, l'impostazione del monitor verrà ignorata poiché ha un livello di priorità inferiore rispetto al file di configurazione.
28.2.3.1 Sostituzione dei valori #
È possibile modificare temporaneamente un valore di opzione tramite i sottocomandi tell o daemon. Tale modifica influisce soltanto sul processo in esecuzione e viene eliminata in seguito al riavvio del daemon o del processo.
Esistono due modi per sostituire i valori:
Utilizzare il sottocomando
tellper inviare un messaggio a un daemon specifico da un qualsiasi nodo del cluster:cephuser@adm >ceph tell DAEMON config set OPTION VALUEEsempio:
cephuser@adm >ceph tell osd.123 config set debug_osd 20SuggerimentoIl sottocomando
tellaccetta i caratteri jolly come identificatori del daemon. Ad esempio, per regolare il livello di debug su tutti i daemon OSD, eseguire:cephuser@adm >ceph tell osd.* config set debug_osd 20Utilizzare il sottocomando
daemonper connettersi a un processo del daemon specifico tramite un socket in/var/run/cephdal nodo su cui è in esecuzione il processo:cephuser@adm >cephadm enter --name osd.ID -- ceph daemon DAEMON config set OPTION VALUEEsempio:
cephuser@adm >cephadm enter --name osd.4 -- ceph daemon osd.4 config set debug_osd 20
Durante la visualizzazione delle impostazioni di runtime con il comando ceph config show (vedere la Sezione 28.2.3.2, «Visualizzazione delle impostazioni di runtime»), i valori temporaneamente sostituiti vengono mostrati con un valore override di origine.
28.2.3.2 Visualizzazione delle impostazioni di runtime #
Per visualizzare tutte le opzioni impostate per un daemon:
cephuser@adm > ceph config show-with-defaults osd.0Per visualizzare tutte le opzioni non di default impostate per un daemon:
cephuser@adm > ceph config show osd.0Per ispezionare un'opzione specifica:
cephuser@adm > ceph config show osd.0 debug_osdÈ possibile inoltre connettersi a un daemon in esecuzione dal nodo su cui è in esecuzione tale processo e osservarne la configurazione:
cephuser@adm > cephadm enter --name osd.0 -- ceph daemon osd.0 config showPer visualizzare soltanto le impostazioni non di default:
cephuser@adm > cephadm enter --name osd.0 -- ceph daemon osd.0 config diffPer ispezionare un'opzione specifica:
cephuser@adm > cephadm enter --name osd.0 -- ceph daemon osd.0 config get debug_osd28.3 config-key memorizzazione #
config-key è un servizio per utilizzo generico offerto dai Ceph Monitor. Semplifica la gestione delle chiavi di configurazione tramite la memorizzazione permanente delle coppie di chiave-valore. config-key è utilizzato principalmente dagli strumenti e dai daemon Ceph.
Dopo aver aggiunto una nuova chiave o averne modificata una esistente, riavviare il servizio interessato per applicare le modifiche. Nel Capitolo 14, Funzionamento dei servizi Ceph è possibile trovare ulteriori dettagli sull'attivazione dei servizi Ceph.
Utilizzare il comando per eseguire l'archivio config-keyconfig-key. Il comando config-key utilizza i sottocomandi seguenti:
ceph config-key rm KEYElimina la chiave specificata.
ceph config-key exists KEYVerifica la presenza della chiave specificata.
ceph config-key get KEYRecupera il valore della chiave specificata.
ceph config-key lsElenca tutte le chiavi.
ceph config-key dumpEsegue il dump di tutte le chiavi e dei relativi valori.
ceph config-key set KEY VALUEArchivia la chiave specificata con il valore specificato.
28.3.1 iSCSI Gateway #
iSCSI Gateway utilizza l'archivio config-key per salvare o leggere le relative opzioni di configurazione. Tutte le chiavi relative a iSCSI Gateway dispongono del prefisso iscsi, ad esempio:
iscsi/trusted_ip_list iscsi/api_port iscsi/api_user iscsi/api_password iscsi/api_secure
Se ad esempio sono necessari due insiemi di opzioni di configurazione, estendere il prefisso con un'altra parola chiave descrittiva, come datacenterA e datacenterB:
iscsi/datacenterA/trusted_ip_list iscsi/datacenterA/api_port [...] iscsi/datacenterB/trusted_ip_list iscsi/datacenterB/api_port [...]
28.4 Ceph OSD e BlueStore #
28.4.1 Configurazione del ridimensionamento automatico della cache #
È possibile configurare BlueStore sul ridimensionamento automatico delle cache se tc_malloc è configurato come allocatore di memoria e l'impostazione bluestore_cache_autotune è abilitata. Attualmente, questa opzione è abilitata per default. BlueStore tenterà di mantenere l'utilizzo della memoria heap dell'OSD al di sotto delle dimensioni di destinazione definite tramite l'opzione di configurazione osd_memory_target. Si tratta di un algoritmo best-effort e le cache non si ridurranno oltre le dimensioni specificate da osd_memory_cache_min. I rapporti della cache verranno selezionati in base a una gerarchia di priorità. Se le informazioni di priorità non sono disponibili, vengono utilizzate come fallback le opzioni bluestore_cache_meta_ratio e bluestore_cache_kv_ratio.
- bluestore_cache_autotune
Ottimizza automaticamente i rapporti assegnati a diverse cache BlueStore restando nei valori minimi. L'impostazione di default è
True.- osd_memory_target
Se
tc_mallocebluestore_cache_autotunesono abilitate, cerca di mantenere questo numero di byte mappati alla memoria.NotaQuesto numero potrebbe non corrispondere esattamente all'utilizzo della memoria RSS del processo. Anche se di norma la quantità totale di memoria heap mappata dal processo non deve essere molto lontana da questo valore di destinazione, non vi sono garanzie che il kernel recupererà la memoria non mappata.
- osd_memory_cache_min
Se
tc_mallocebluestore_cache_autotunesono abilitate, consente di impostare la quantità minima di memoria utilizzata per le cache.NotaSe viene impostato un valore troppo basso, può verificarsi un notevole trashing della cache.
28.5 Ceph Object Gateway #
È possibile influenzare il comportamento di Object Gateway utilizzando diverse opzioni. Se un'opzione non viene specificata, ne viene utilizzato il valore di default. Di seguito è riportato un elenco completo delle opzioni di Object Gateway:
28.5.1 Impostazioni generali #
- rgw_frontends
Configura i front-end HTTP. Specificare più front-end in un elenco separato da virgole. Ogni configurazione di front-end può includere un elenco di opzioni separate da spazi, in cui ogni opzione è nel formato "key=value" o "key". L'impostazione di default è
beast port=7480.- rgw_data
Imposta l'ubicazione dei file di dati per Object Gateway. L'impostazione di default è
/var/lib/ceph/radosgw/CLUSTER_ID.- rgw_enable_apis
Abilita le API specificate. L'impostazione di default è "s3, swift, swift_auth, admin All APIs".
- rgw_cache_enabled
Abilita o disabilita la cache di Object Gateway. L'impostazione di default è
true.- rgw_cache_lru_size
Numero di voci nella cache di Object Gateway. Il valore di default è 10000.
- rgw_socket_path
Percorso del socket per il socket di dominio.
FastCgiExternalServerutilizza questo socket. Se non viene specificato nessun percorso del socket, Object Gateway non verrà eseguito come server esterno. Il percorso specificato qui deve essere lo stesso del percorso specificato nel filergw.conf.- rgw_fcgi_socket_backlog
Backlog del socket per fcgi. Il valore di default è 1024.
- rgw_host
Host dell'istanza di Object Gateway. Può essere un indirizzo IP o un nome host. Il valore di default è
0.0.0.0.- rgw_port
Numero di porta in cui l'istanza è in ascolto delle richieste. Se non è specificato, Object Gateway esegue il FastCGI esterno.
- rgw_dns_name
Nome DNS del dominio servito.
- rgw_script_uri
Valore alternativo di SCRIPT_URI se non impostato nella richiesta.
- rgw_request_uri
Valore alternativo di REQUEST_URI se non impostato nella richiesta.
- rgw_print_continue
Se attiva, abilitare 100-continue. L'impostazione di default è
true.- rgw_remote_addr_param
Parametro dell'indirizzo remoto. Ad esempio, il campo HTTP contenente l'indirizzo remoto o l'indirizzo X-Forwarded-For se è attivo un proxy inverso. L'impostazione di default è
REMOTE_ADDR.- rgw_op_thread_timeout
Timeout espresso in secondi per i thread aperti. Il valore di default è 600.
- rgw_op_thread_suicide_timeout
Timeout espresso in secondi prima del termine del processo di Object Gateway. Se è impostata a 0 (default), questa impostazione è disabilitata.
- rgw_thread_pool_size
Numero di thread per il server Oggetto beast. Aumentare il valore se è necessario provvedere a più richieste. Il valore di default è 100 thread.
- rgw_num_rados_handles
Numero di handle del cluster RADOS per Object Gateway. Adesso per ciascun thread di lavoro Object Gateway viene selezionato un handle RADOS permanente. Questa opzione potrebbe diventare obsoleta e rimossa dalle release future. Il valore di default è 1.
- rgw_num_control_oids
Numero di oggetti di notifica utilizzati per la sincronizzazione della cache tra diverse istanze di Object Gateway. Il valore di default è 8.
- rgw_init_timeout
Numero di secondi prima che Object Gateway smetta di tentare di effettuare l'inizializzazione. Il valore di default è 30.
- rgw_mime_types_file
Percorso e ubicazione dei tipi MIME. Utilizzata per il rilevamento automatico Swift dei tipi di oggetto. L'impostazione di default è
/etc/mime.types.- rgw_gc_max_objs
Numero massimo di oggetti che possono essere gestiti dal recupero spazio in un ciclo di elaborazione di recupero spazio. Il valore di default è 32.
- rgw_gc_obj_min_wait
Tempo di attesa minimo prima che l'oggetto venga rimosso e gestito dal processo di recupero spazio. Il valore di default è 2 * 3600.
- rgw_gc_processor_max_time
Durata massima tra l'inizio di due cicli di elaborazione di recupero spazio consecutivi. Il valore di default è 3600.
- rgw_gc_processor_period
Durata del ciclo di elaborazione di recupero spazio. Il valore di default è 3600.
- rgw_s3_success_create_obj_status
Risposta alternativa di stato riuscito per
create-obj. Il valore di default è 0.- rgw_resolve_cname
Determina se Object Gateway deve utilizzare il record DNS CNAME del campo del nome host della richiesta (se il nome host non è uguale al nome DNS di Object Gateway). L'impostazione di default è
false.- rgw_obj_stripe_size
Dimensioni di striping di oggetto per gli oggetti Object Gateway. Il valore di default è
4 << 20.- rgw_extended_http_attrs
Aggiunge un nuovo set di attributi che è possibile impostare su un'entità (ad esempio un utente, un compartimento o un oggetto). È possibile impostare tali attributi aggiuntivi tramite i campi dell'intestazione HTTP quando si inserisce o si modifica l'entità tramite il metodo POST. Se impostati, questi attributi verranno restituiti come campi HTTP durante la richiesta GET/HEAD sull'entità. L'impostazione di default è
content_foo, content_bar, x-foo-bar.- rgw_exit_timeout_secs
Numero di secondi in cui restare in attesa di un processo prima dell'uscita senza condizioni. Il valore di default è 120.
- rgw_get_obj_window_size
Dimensioni in byte della finestra di una singola richiesta di oggetto. Il valore di default è
16 << 20.- rgw_get_obj_max_req_size
Dimensioni massime della richiesta di una singola operazione GET inviata al cluster di memorizzazione Ceph. Il valore di default è
4 << 20.- rgw_relaxed_s3_bucket_names
Abilita le regole minime del nome del compartimento S3 per i compartimenti dell'area US. L'impostazione di default è
false.- rgw_list_buckets_max_chunk
Numero massimo di compartimenti da recuperare durante un'operazione singola quando vengono elencati i compartimenti dell'utente. Il valore di default è 1000.
- rgw_override_bucket_index_max_shards
Rappresenta il numero di partizioni dell'oggetto di indice del compartimento. Se viene impostata a 0 (default), il partizionamento non verrà eseguito. Si sconsiglia di impostare un valore troppo elevato (ad esempio 1000) poiché ciò aumenta i costi di creazione dell'elenco dei compartimenti. Impostare questa variabile nelle sezioni client o global per applicarla automaticamente ai comandi
radosgw-admin.- rgw_curl_wait_timeout_ms
Timeout espresso in millisecondi per determinate chiamate
curl. Il valore di default è 1000.- rgw_copy_obj_progress
Abilita l'output dell'avanzamento dell'oggetto durante le operazioni di copia più lunghe. L'impostazione di default è
true.- rgw_copy_obj_progress_every_bytes
Byte minimi tra gli output dell'avanzamento della copia. Il valore di default è 1024 * 1024.
- rgw_admin_entry
Punto di entrata di un URL della richiesta admin. L'impostazione di default è
admin.- rgw_content_length_compat
Abilita la gestione di compatibilità delle richieste FCGI con le opzioni CONTENT_LENGTH E HTTP_CONTENT_LENGTH impostate. L'impostazione di default è
false.- rgw_bucket_quota_ttl
Intervallo di tempo espresso in secondi durante il quale le informazioni sulla quota memorizzate nella cache sono attendibili. Dopo questo timeout, le informazioni sulla quota verranno recuperate nuovamente dal cluster. Il valore di default è 600.
- rgw_user_quota_bucket_sync_interval
Intervallo di tempo espresso in secondi durante il quale le informazioni sulla quota del compartimento vengono accumulate prima della sincronizzazione con il cluster. Durante questo intervallo, le altre istanze di Object Gateway non visualizzeranno le modifiche apportate alle statistiche sulla quota del compartimento relative alle operazioni su tale istanza. Il valore di default è 180.
- rgw_user_quota_sync_interval
Intervallo di tempo espresso in secondi durante il quale le informazioni sulla quota utenti vengono accumulate prima della sincronizzazione con il cluster. Durante questo intervallo, le altre istanze di Object Gateway non visualizzeranno le modifiche apportate alle statistiche sulla quota utenti relative alle operazioni su tale istanza. Il valore di default è 180.
- rgw_bucket_default_quota_max_objects
Numero massimo di default di oggetti per compartimento. Viene impostata per i nuovi utenti se non viene specificata nessuna quota e non ha effetto sugli utenti esistenti. Impostare questa variabile nelle sezioni client o global per applicarla automaticamente ai comandi
radosgw-admin. Il valore di default è -1.- rgw_bucket_default_quota_max_size
Capacità massima di default di ciascun compartimento espressa in byte. Viene impostata per i nuovi utenti se non viene specificata nessuna quota e non ha effetto sugli utenti esistenti. Il valore di default è -1.
- rgw_user_default_quota_max_objects
Numero massimo di default di oggetti per utente. Sono inclusi tutti gli oggetti in tutti i compartimenti di proprietà dell'utente. Viene impostata per i nuovi utenti se non viene specificata nessuna quota e non ha effetto sugli utenti esistenti. Il valore di default è -1.
- rgw_user_default_quota_max_size
Valore delle dimensioni massime della quota utenti espresso in byte impostato per i nuovi utenti se non viene specificata nessun'altra quota. Non ha effetto sugli utenti esistenti. Il valore di default è -1.
- rgw_verify_ssl
Verifica i certificati SSL durante la creazione delle richieste. L'impostazione di default è
true.- rgw_max_chunk_size
Dimensioni massime di una porzione di dati che verrà letta in una singola operazione. Se si aumenta il valore a 4 MB (4194304) si otterranno prestazioni migliori durante l'elaborazione di oggetti di grandi dimensioni. Il valore di default è 128 kB (131072).
- rgw_zone
Nome della zona per l'istanza del gateway. Se non viene impostata nessuna zona, è possibile configurare un valore di default in tutto il cluster con il comando
radosgw-admin zone default.- rgw_zonegroup
Nome del gruppo di zone per l'istanza del gateway. Se non viene impostato nessun gruppo di zone, è possibile configurare un valore di default in tutto il cluster con il comando
radosgw-admin zonegroup default.- rgw_realm
Nome del dominio per l'istanza del gateway. Se non viene impostato nessun dominio, è possibile configurare un valore di default in tutto il cluster con il comando
radosgw-admin realm default.- rgw_run_sync_thread
Se nel dominio sono presenti altre zone da cui eseguire la sincronizzazione, generare dei thread per gestire la sincronizzazione dei dati e dei metadati. L'impostazione di default è
true.- rgw_data_log_window
Finestra delle voci del log dei dati in secondi. Il valore di default è 30.
- rgw_data_log_changes_size
Numero di voci nella memoria da mettere in attesa per il log delle modifiche dei dati. Il valore di default è 1000.
- rgw_data_log_obj_prefix
Prefisso del nome di oggetto del log dei dati. L'impostazione di default è "data_log".
- rgw_data_log_num_shards
Numero di partizioni (oggetti) su cui conservare il log delle modifiche dei dati. Il valore di default è 128.
- rgw_md_log_max_shards
Numero massimo di partizioni per il log dei metadati. Il valore di default è 64.
- rgw_enforce_swift_acls
Applica le impostazioni dell'elenco di controllo dell'accesso (ACL) Swift. L'impostazione di default è
true.- rgw_swift_token_expiration
Tempo espresso in secondi per la scadenza di un token Swift. Il valore di default è 24 * 3600.
- rgw_swift_url
URL dell'API Swift di Ceph Object Gateway.
- rgw_swift_url_prefix
Prefisso URL dello StorageURL Swift che precede la porzione di testo "/v1". Ciò consente di eseguire più istanze del gateway sullo stesso host. Per ragioni di compatibilità, se per questa variabile di configurazione non viene impostato alcun valore, verrà utilizzato il valore "/swift" di default. Utilizzare il prefisso esplicito "/" come inizio dello StorageURL dalla radice.
AvvertimentoQuesta opzione non funzionerà se viene impostata su "/" e se l'API S3 è abilitata. Tenere presente che la disabilitazione di S3 non consentirà la distribuzione di Object Gateway nella configurazione multisito.
- rgw_swift_auth_url
URL di default per la verifica dei token di autenticazione v1 quando l'autenticazione Swift interna non è utilizzata.
- rgw_swift_auth_entry
Punto di entrata di un URL di autenticazione Swift. L'impostazione di default è
auth.- rgw_swift_versioning_enabled
Abilita il controllo versioni dell'oggetto dell'API Object Storage di OpenStack. Ciò consente ai client di inserire l'attributo
X-Versions-Locationsui container di cui deve essere creata una versione. L'attributo specifica il nome del container in cui sono memorizzate le versioni archiviate. Deve essere di proprietà dello stesso utente del container con versione per motivi di verifica del controllo dell'accesso (gli ACL non sono presi in considerazione). Non è possibile creare una versione per tali container con il meccanismo di controllo versioni dell'oggetto S3. L'impostazione di default èfalse.
- rgw_log_nonexistent_bucket
Abilita Object Gateway per il logging di una richiesta relativa a un compartimento inesistente. L'impostazione di default è
false.- rgw_log_object_name
Formato di registrazione di un nome oggetto. Per i dettagli sugli identificatori del formato, consultare la documentazione
man 1 date. L'impostazione di default è%Y-%m-%d-%H-%i-%n.- rgw_log_object_name_utc
Specifica se nel nome oggetto registrato è inclusa l'ora UTC. Se è impostata su
false(default), viene utilizzata l'ora locale.- rgw_usage_max_shards
Numero massimo di partizioni per la registrazione dell'utilizzo. Il valore di default è 32.
- rgw_usage_max_user_shards
Numero massimo di partizioni utilizzate per la registrazione dell'utilizzo di un singolo utente. Il valore di default è 1.
- rgw_enable_ops_log
Abilita la registrazione di ciascuna operazione Object Gateway riuscita. L'impostazione di default è
false.- rgw_enable_usage_log
Abilita il log di utilizzo. L'impostazione di default è
false.- rgw_ops_log_rados
Specifica se scrivere il log delle operazioni sul back-end del cluster di memorizzazione Ceph. L'impostazione di default è
true.- rgw_ops_log_socket_path
Socket del dominio Unix per i log delle operazioni di scrittura.
- rgw_ops_log_data_backlog
Dimensioni dei dati massime del backlog dei dati per i log delle operazioni scritte su un socket del dominio Unix. Il valore di default è 5 << 20.
- rgw_usage_log_flush_threshold
Numero di voci modificate unite nel log di utilizzo prima dello svuotamento sincrono. Il valore di default è 1024.
- rgw_usage_log_tick_interval
Svuota il log di utilizzo in sospeso ogni "n" secondi. Il valore di default è 30.
- rgw_log_http_headers
Elenco con valori separati da virgole delle intestazioni HTTP da includere nelle voci del log. I nomi delle intestazioni non fanno distinzione tra lettere maiuscole e minuscole e utilizzano il nome completo dell'intestazione con le parole separate da caratteri di sottolineatura. Ad esempio, "http_x_forwarded_for", "http_x_special_k".
- rgw_intent_log_object_name
Formato di registrazione del nome oggetto dell'intent log. Per i dettagli sugli identificatori del formato, consultare la documentazione
man 1 date. L'impostazione di default è "%Y-%m-%d-%i-%n".- rgw_intent_log_object_name_utc
Specifica se nel nome oggetto dell'intent log è inclusa l'ora UTC. Se è impostata su
false(default), viene utilizzata l'ora locale.
- rgw_keystone_url
URL del server Keystone.
- rgw_keystone_api_version
Versione (2 o 3) di OpenStack Identity API da utilizzare per la comunicazione con il server Keystone. Il valore di default è 2.
- rgw_keystone_admin_domain
Nome del dominio OpenStack con privilegi di amministratore quando è in uso OpenStack Identity API v3.
- rgw_keystone_admin_project
Nome del progetto OpenStack con privilegi di amministratore quando è in uso OpenStack Identity API v3. Se non viene impostata, verrà utilizzato il valore di
rgw keystone admin tenant.- rgw_keystone_admin_token
Token amministratore Keystone (segreto condiviso). In Object Gateway, l'autenticazione tramite il token amministratore ha la priorità sull'autenticazione con le credenziali di amministratore (opzioni
rgw keystone admin user,rgw keystone admin password,rgw keystone admin tenant,rgw keystone admin projectergw keystone admin domain). La funzione del token amministratore è considerata obsoleta.- rgw_keystone_admin_tenant
Nome del tenant OpenStack con privilegi di amministratore (tenant del servizio) quando è in uso OpenStack Identity API v2.
- rgw_keystone_admin_user
Nome dell'utente OpenStack con privilegi di amministratore per l'autenticazione Keystone (utente del servizio) quando è in uso OpenStack Identity API v2.
- rgw_keystone_admin_password
Password dell'utente amministratore OpenStack quando è in uso OpenStack Identity API v2.
- rgw_keystone_accepted_roles
Ruoli richiesti per provvedere alle richieste. L'impostazione di default è "Member, admin".
- rgw_keystone_token_cache_size
Numero massimo di voci in ciascuna cache dei token Keystone. Il valore di default è 10000.
- rgw_keystone_revocation_interval
Numero di secondi tra le verifiche della revoca dei token. Il valore di default è 15 * 60.
- rgw_keystone_verify_ssl
Verifica i certificati SSL durante la creazione di richieste di token per Keystone. L'impostazione di default è
true.
28.5.1.1 Note aggiuntive #
- rgw_dns_name
Consente ai client di utilizzare i compartimenti di tipo
vhost.L'accesso di tipo
vhostfa riferimento all'uso di bucketname.s3-endpoint/object-path, diverso dall'accesso di tipopath: s3-endpoint/bucket/object.Se
rgw dns nameè impostato, verificare che il client S3 sia configurato sull'indirizzamento delle richieste all'endpoint specificato dargw dns name.
28.5.2 Configurazione dei front-end HTTP #
28.5.2.1 Oggetto beast #
- port, ssl_port
Numeri di porte di attesa IPv4 e IPv6. È possibile specificare più numeri di porte:
port=80 port=8000 ssl_port=8080
Il valore di default è 80.
- endpoint, ssl_endpoint
Indirizzi di attesa nel formato "address[:port]", dove l'indirizzo è una stringa di indirizzo IPv4 in formato decimale separato da punti o un indirizzo IPv6 in notazione esadecimale racchiuso tra parentesi quadre. Se viene specificato un endpoint IPv6, verranno attesi solo indirizzi IPv6. Il numero di porta facoltativo di default è 80 per
endpointe 443 perssl_endpoint. È possibile specificare più indirizzi:endpoint=[::1] endpoint=192.168.0.100:8000 ssl_endpoint=192.168.0.100:8080
- ssl_private_key
Percorso facoltativo del file di chiave privata utilizzato per gli endpoint abilitati per SSL. Se non è specificato, viene utilizzato il file
ssl_certificatecome chiave privata.- tcp_nodelay
Se specificata, l'opzione del socket disabiliterà l'algoritmo Nagle sulla connessione. Vale a dire che i pacchetti verranno inviati non appena possibile invece di attendere un buffer o un timeout completo.
Il valore "1" disabilita l'algoritmo Nagle per tutti i socket.
Il valore "0" mantiene abilitato l'algoritmo Nagle (default).
cephuser@adm > ceph config set rgw.myrealm.myzone.ses-min1.kwwazo \
rgw_frontends beast port=8000 ssl_port=443 \
ssl_certificate=/etc/ssl/ssl.crt \
error_log_file=/var/log/radosgw/beast.error.log28.5.2.2 CivetWeb #
- porta
Numero di porta di attesa. Per le porte abilitate per SSL, aggiungere un suffisso "s" (ad esempio "443s"). Per associare un indirizzo IPv4 o IPv6 specifico, utilizzare il formato "address:port". È possibile specificare più endpoint aggiungendoli con il simbolo "+" o specificando diverse opzioni:
port=127.0.0.1:8000+443s port=8000 port=443s
Il valore di default è 7480.
- num_threads
Numero di thread generati da Civetweb per la gestione delle connessioni HTTP in entrata. Questa impostazione consente di limitare effettivamente il numero di connessioni simultanee di cui il front-end è in grado di occuparsi.
Il valore di default è quello specificato dall'opzione
rgw_thread_pool_size.- request_timeout_ms
Intervallo di tempo espresso in millisecondi durante il quale Civitweb resta in attesa di altri dati in entrata prima di abbandonare l'operazione.
Il valore di default è 30.000 millisecondi.
- access_log_file
Percorso del file di log di accesso. È possibile specificare un percorso completo o un percorso relativo alla directory di lavoro attuale. Se non è specificato (default), gli accessi non vengono registrati.
- error_log_ file
Percorso del file di log degli errori. È possibile specificare un percorso completo o un percorso relativo alla directory di lavoro attuale. Se non è specificato (default), gli errori non vengono registrati.
/etc/ceph/ceph.conf #cephuser@adm > ceph config set rgw.myrealm.myzone.ses-min2.ingabw \
rgw_frontends civetweb port=8000+443s request_timeout_ms=30000 \
error_log_file=/var/log/radosgw/civetweb.error.log28.5.2.3 Opzioni comuni #
- ssl_certificate
Percorso del file di certificato SSL utilizzato per gli endpoint abilitati per SSL.
- prefisso
Stringa di prefisso inserita nell'URI di tutte le richieste. Ad esempio, un front-end solo Swift può fornire un prefisso URI
/swift.
29 Moduli di Ceph Manager #
L'architettura di Ceph Manager (per una breve presentazione, consultare questo riferimento: Book “Guida alla distribuzione”, Chapter 1 “SES e Ceph”, Section 1.2.3 “Daemon e nodi Ceph”) consente di estendere le sue funzionalità tramite i moduli, come "dashboard" (vedere il Parte I, «Ceph Dashboard»), "prometheus" (vedere il Capitolo 16, Monitoraggio e creazione di avvisi) o "servizio di bilanciamento".
Per visualizzare un elenco di tutti i moduli disponibili, eseguire:
cephuser@adm > ceph mgr module ls
{
"enabled_modules": [
"restful",
"status"
],
"disabled_modules": [
"dashboard"
]
}Per abilitare o disabilitare un modulo specifico, eseguire:
cephuser@adm > ceph mgr module enable MODULE-NAMEEsempio:
cephuser@adm > ceph mgr module disable dashboardPer visualizzare un elenco dei servizi forniti dai moduli abilitati, eseguire:
cephuser@adm > ceph mgr services
{
"dashboard": "http://myserver.com:7789/",
"restful": "https://myserver.com:8789/"
}29.1 Servizio di bilanciamento #
Il modulo del servizio di bilanciamento consente di ottimizzare la distribuzione del gruppo di posizionamento (PG) sugli OSD per una distribuzione più bilanciata. Anche se attivato per default, il modulo è inattivo. Supporta le due modalità seguenti: crush-compat e upmap.
Per visualizzare le informazioni sulla configurazione e sullo stato attuali del servizio di bilanciamento, eseguire:
cephuser@adm > ceph balancer status29.1.1 Modalità "crush-compat" #
Nella modalità "crush-compat", il servizio di bilanciamento regola il valore reweight-sets degli OSD per ottenere una migliore distribuzione dei dati. Sposta i gruppi di posizionamento tra gli OSD, attivando temporaneamente lo stato HEALTH_WARN sul cluster derivante dalla posizione errata dei gruppi di posizionamento.
Anche se "crush-compat" è la modalità di default, si consiglia di attivarla esplicitamente:
cephuser@adm > ceph balancer mode crush-compat29.1.2 Pianificazione ed esecuzione del bilanciamento dei dati #
Tramite il modulo del servizio di bilanciamento, è possibile pianificare il bilanciamento dei dati. È quindi possibile eseguire manualmente tale pianificazione oppure impostare il bilanciamento continuo dei gruppi di posizionamento tramite il servizio di bilanciamento.
La scelta di eseguire il servizio di bilanciamento in modalità automatica o manuale dipende da diversi fattori, come lo squilibrio dei dati attuali, le dimensioni del cluster, il numero di gruppi di posizionamento o l'attività I/O. Si consiglia di creare una pianificazione iniziale e di eseguirla quando il carico I/O sul cluster è ridotto. Infatti, lo squilibrio iniziale sarà probabilmente notevole ed è quindi consigliabile mantenere basso l'impatto sui client. Dopo l'iniziale esecuzione manuale, considerare l'attivazione della modalità automatica e monitorare il traffico di ribilanciamento in condizioni di carico I/O normale. I miglioramenti apportati alla distribuzione del gruppo di posizionamento devono essere ponderati in base al traffico di ribilanciamento creato dal servizio di bilanciamento.
Durante il processo di bilanciamento, il modulo del servizio di bilanciamento limita i movimenti del gruppo di posizionamento per fare in modo che ne venga spostata soltanto una frazione configurabile. Il valore di default è 5% ed è possibile regolare la frazione, ad esempio sul 9%, eseguendo il comando seguente:
cephuser@adm > ceph config set mgr target_max_misplaced_ratio .09Per creare ed eseguire una pianificazione del bilanciamento, seguire la procedura indicata di seguito:
Controllare il punteggio del cluster corrente:
cephuser@adm >ceph balancer evalCreare una pianificazione. Ad esempio, "great_plan":
cephuser@adm >ceph balancer optimize great_planVerificare i cambiamenti implicati dall'uso di "great_plan":
cephuser@adm >ceph balancer show great_planControllare il punteggio potenziale del cluster se si dovesse decidere di applicare "great_plan":
cephuser@adm >ceph balancer eval great_planEseguire "great_plan" per una sola volta:
cephuser@adm >ceph balancer execute great_planOsservare il bilanciamento del cluster con il comando
ceph -s. Se si è soddisfatti del risultato, attivare il bilanciamento automatico:cephuser@adm >ceph balancer onSe in un secondo momento si decide di disattivare il bilanciamento automatico, eseguire:
cephuser@adm >ceph balancer off
È possibile attivare il bilanciamento automatico senza eseguire una pianificazione iniziale. In questo caso, l'esecuzione del ribilanciamento dei gruppi di posizionamento potrebbe impiegare molto tempo.
29.2 Abilitazione del modulo di telemetria #
Il plug-in di telemetria consente di inviare i dati anonimi del progetto Ceph relativi al cluster su cui è in esecuzione il plug-in.
Questo componente (che richiede il consenso esplicito) contiene contatori e statistiche sulla modalità di distribuzione del cluster, sulla versione di Ceph, sulla distribuzione degli host e su altri parametri, che consentono di comprendere meglio l'utilizzo di Ceph. Non contiene nessun dato sensibile come nomi dei pool, nomi e contenuto di oggetti o nomi host.
Lo scopo del modulo di telemetria consiste nel fornire agli sviluppatori un ciclo di feedback automatizzato per agevolare il calcolo dei tassi di adozione, il controllo o l'individuazione degli aspetti da approfondire o convalidare ulteriormente durante la configurazione per evitare risultati indesiderati.
Per essere in grado di inviare i dati su HTTPS ai server upstream, il modulo di telemetria richiede i nodi Ceph Manager. Assicurarsi che i firewall aziendali consentano questa azione.
Per abilitare il modulo di telemetria:
cephuser@adm >ceph mgr module enable telemetryNotaQuesto comando consente soltanto di visualizzare i dati a livello locale. Questo comando non condivide i dati con la community di Ceph.
Per consentire al modulo di telemetria di avviare la condivisione dei dati:
cephuser@adm >ceph telemetry onPer disabilitare la condivisione dei dati di telemetria:
cephuser@adm >ceph telemetry offPer generare un rapporto JSON stampabile:
cephuser@adm >ceph telemetry showPer aggiungere un contatto e una descrizione al rapporto:
cephuser@adm >ceph config set mgr mgr/telemetry/contact John Doe john.doe@example.comcephuser@adm >ceph config set mgr mgr/telemetry/description 'My first Ceph cluster'Per default, il modulo compila e invia un nuovo rapporto ogni 24 ore. Per modificare questo intervallo:
cephuser@adm >ceph config set mgr mgr/telemetry/interval HOURS
30 Autenticazione con cephx #
Per identificare i client e proteggerli da attacchi man-in-the-middle, in Ceph è disponibile il rispettivo sistema di autenticazione cephx. I client in questo contesto sono utenti umani, come l'utente amministratore, o servizi/daemon correlati a Ceph, ad esempio OSD, monitoraggi o Object Gateway.
Il protocollo cephx non indirizza la cifratura dati nel trasporto, come TLS/SSL.
30.1 Architettura di autenticazione #
cephx utilizza chiavi segrete condivise per l'autenticazione, vale a dire che sia il client che i Ceph Monitor dispongono di una copia della chiave segreta del client. Il protocollo di autenticazione consente a entrambe le parti di provare a vicenda l'esistenza di una copia della chiave senza rivelarla effettivamente. In tal modo se esegue un'autenticazione reciproca, che assicura sia all'utente sia al cluster che entrambi possiedono rispettivamente la chiave segreta e la copia della stessa.
Una funzione di scalabilità della chiave di Ceph consente di evitare un'interfaccia centralizzata nell'archivio dati Ceph. Ciò significa che i client Ceph possono interagire direttamente con gli OSD. Per proteggere i dati, in Ceph è disponibile il sistema di autenticazione cephx, che consente di autenticare i client Ceph.
Ciascun monitoraggio in grado di autenticare client e distribuire chiavi, pertanto non si verifica alcun single point of failure o collo di bottiglia quando si utilizza cephx. Il monitoraggio restituisce una struttura di dati di autenticazione nella quale è inclusa una chiave sessione quando si ottengono i servizi Ceph. Tale chiave sessione è cifrata con la chiave segreta permanente del client in modo che solo quest'ultimo sia in grado di richiedere servizi dai Ceph monitor. La chiave sessione viene quindi utilizzata dal client per richiedere i rispettivi servizi desiderati dal monitoraggio e questo a sua volta fornisce un ticket tramite il quale il client eseguirà l'autenticazione negli OSD in cui vengono effettivamente gestiti i dati. I Ceph monitor e gli OSD condividono un segreto in modo che il client possa utilizzare il ticket fornito dal monitoraggio con qualsiasi OSD o server di metadati nel cluster. Poiché i ticket cephx hanno una scadenza, l'autore di un attacco non può utilizzare un ticket scaduto o una chiave sessione ottenuti in modo illecito.
Per utilizzare cephx, l'amministratore deve prima configurare i client/gli utenti. Nel seguente diagramma, l'utente client.admin richiama ceph auth get-or-create-key dalla riga di comando per generare un nome utente e una chiave segreta. Nel sottosistema auth di Ceph vengono generati nome utente e chiave, quindi viene memorizzata una copia con il o i monitoraggio e il segreto dell'utente viene trasmesso di nuovo all'utente client.admin. Vale a dire che client e monitoraggio condividono una chiave segreta.

cephx di base #Per eseguire l'autenticazione con il monitoraggio, il client trasmette al monitoraggio il nome utente. Il monitoraggio genera una chiave sessione che viene cifrata con la chiave segreta associata al nome utente e il ticket cifrato viene trasmesso di nuovo al client. I dati con la chiave segreta condivisa vengono quindi decifrati nel client in modo da recuperare la chiave sessione. La chiave sessione consente di identificare l'utente per la sessione attuale. Il client richiede quindi un ticket correlato all'utente, che viene firmato dalla chiave sessione. Il monitoraggio genera un ticket, che viene poi cifrato con la chiave segreta dell'utente e trasmesso di nuovo al client. Il ticket viene quindi decifrato dal client e utilizzato per firmare le richieste agli OSD e ai server di metadati nel cluster.

cephx autenticazione #
Il protocollo cephx consente di autenticare le comunicazioni in corso tra il computer client e i server Ceph. Ciascun messaggio inviato tra un client e un server dopo l'autenticazione iniziale viene firmato mediante l'uso di un ticket che può essere verificato da monitoraggi, OSD, e server di metadati tramite il rispettivo segreto condiviso.

cephx - MDS e OSD #La protezione offerta da questa autenticazione viene applicata tra il client Ceph e gli host del cluster Ceph. L'autenticazione non viene estesa oltre il client Ceph. Se un utente accede al client Ceph da un host remoto, l'autenticazione Ceph non viene applicata alla connessione tra l'host dell'utente e l'host client.
30.2 Gestione delle chiavi #
In questa sezione sono descritti gli utenti del client Ceph e le rispettive autenticazioni e autorizzazioni con il cluster di memorizzazione Ceph. Gli utenti sono individui o attori di sistema, come le applicazioni, che utilizzano i client Ceph per interagire con i daemon del cluster di memorizzazione Ceph.
Quando Ceph viene eseguito con l'autenticazione e l'autorizzazione abilitate (abilitate per default), è necessario specificare un nome utente e un portachiavi contenente la chiave segreta dell'utente specificato (di solito tramite riga di comando). Se non si specifica un nome utente, Ceph utilizzerà client.admin come nome utente di default. Se non si specifica un portachiavi, Ceph ne ricercherà uno tramite l'impostazione del portachiavi nel file di configurazione Ceph. Ad esempio, se si esegue il comando ceph health senza specificare un nome utente o un portachiavi, il comando viene interpretato da Ceph nel seguente modo:
cephuser@adm > ceph -n client.admin --keyring=/etc/ceph/ceph.client.admin.keyring health
In alternativa, è possibile utilizzare la variabile di ambiente CEPH_ARGS per evitare di immettere di nuovo il nome utente e il segreto.
30.2.1 Informazioni di background #
Indipendentemente dal tipo di client Ceph (ad esempio, dispositivo di blocco, spazio di memorizzazione degli oggetti, file system, API nativa), Ceph memorizza tutti i dati come oggetti nei pool. Gli utenti Ceph devono disporre dell'accesso ai pool per leggere e scrivere i dati. Inoltre, gli utenti Ceph devono eseguire le autorizzazioni per utilizzare i comandi amministrativi Ceph. Di seguito sono spiegati i concetti per comprendere come gestire gli utenti Ceph.
30.2.1.1 Utente #
Un utente è un individuo o un attore di sistema, come ad esempio un'applicazione. La creazione di utenti consente di controllare chi (o cosa) può accedere al cluster di memorizzazione Ceph, ai rispettivi pool e ai dati in essi contenuti.
Ceph utilizza tipi di utenti. Ai fini della gestione degli utenti, il tipo sarà sempre client. Ceph identifica gli utenti nella forma delimitata da un punto (.), costituita dal tipo di utente e ID utente. Ad esempio, TYPE.ID, client.admin o client.user1. Il motivo dell'uso del tipo di utente sta nel fatto che anche i Ceph monitor, gli OSD e i server di metadati utilizzano il protocollo cephx, ma non sono client. La distinzione del tipo di utenti consente di distinguere gli utenti del client dagli altri, semplificando il controllo degli accessi, nonché il monitoraggio e la tracciabilità degli utenti.
A volte non è semplice capire qual è il tipo di utente. A seconda di come viene utilizzata, la riga di comando di Ceph consente infatti di specificare l'utente con o senza tipo. Se si specifica --user o --id, è possibile omettere il tipo. client.user1 può quindi essere immesso semplicemente come user1. Se si specifica --name o -n, è necessario indicare il tipo e il nome, ad esempio client.user1. Laddove possibile, come best practice si consiglia di utilizzare anche il tipo e il nome.
Un utente del cluster di memorizzazione Ceph non è lo stesso di un'unità di memorizzazione degli oggetti Ceph o di un utente del file system Ceph. Ceph Object Gateway utilizza un utente del cluster di memorizzazione Ceph per la comunicazione tra il daemon del gateway e il cluster di memorizzazione, ma il gateway dispone di una funzionalità di gestione degli utenti propria per gli utenti finali. Nel file system Ceph viene utilizzata la semantica POSIX. Lo spazio utente associato a esso non è lo stesso dell'utente di un cluster di memorizzazione Ceph.
30.2.1.2 Autorizzazione e funzionalità #
In Ceph, con il termine "capabilities" (caps, funzionalità) si intende l'autorizzazione di un utente autenticato a praticare la funzionalità di monitoraggio, OSD e server dei metadati. Le capacità possono inoltre limitare l'accesso ai dati all'interno di un pool o di uno spazio dei nomi del pool. Le funzionalità di un utente vengono impostate da un utente amministrativo Ceph durante la creazione o l'aggiornamento di un utente.
La sintassi delle funzionalità presenta la forma seguente:
daemon-type 'allow capability' [...]
Di seguito è riportato un elenco di funzionalità per ciascun tipo di servizio:
- Funzionalità di monitoraggio
includono
r,w,xeallow profile cap.mon 'allow rwx' mon 'allow profile osd'
- Funzionalità OSD
includono
r,w,x,class-read,class-writeeprofile osd. Le funzionalità OSD consentono inoltre le impostazioni di pool spazio dei nomi.osd 'allow capability' [pool=poolname] [namespace=namespace-name]
- Funzionalità MDS
richiedono semplicemente
allowo è possibile lasciare vuoto.mds 'allow'
Le voci seguenti descrivono ciascuna funzionalità:
- allow
Precede le impostazioni di accesso per un daemon. Implica
rwsolo per MDS.- r
Fornisce all'utente l'accesso in lettura. Richiesta con monitoraggi per il recupero della mappa CRUSH.
- w
Fornisce all'utente l'accesso in scrittura agli oggetti.
- x
Fornisce all'utente la funzionalità di chiamare metodi di classe (lettura e scrittura) per eseguire operazioni
authnei monitoraggi.- class-read
Fornisce all'utente la funzionalità di chiamare metodi di lettura di classe. Sottoinsieme di
x.- class-write
Fornisce all'utente la funzionalità di chiamare metodi di scrittura di classe. Sottoinsieme di
x.- *
Fornisce all'utente autorizzazioni per la lettura, scrittura ed esecuzione di un determinato daemon/pool, nonché la capacità di eseguire comandi amministrativi.
- profile osd
Fornisce all'utente le autorizzazioni per connettere un OSD ad altri OSD o monitoraggi. Concessa sugli OSD per abilitarli a gestire il traffico heartbeat delle repliche e le segnalazioni dello stato.
- profile mds
Fornisce all'utente le autorizzazioni per connettere un MDS ad altri MDS o monitoraggi.
- profile bootstrap-osd
Fornisce all'utente le autorizzazioni per eseguire il bootstrap su un OSD. Delegata agli strumenti di distribuzione in modo che dispongano delle autorizzazioni per aggiungere chiavi quando si esegue il bootstrap di un OSD.
- profile bootstrap-mds
Fornisce all'utente le autorizzazioni per eseguire il bootstrap su un server dei metadati. Delegata agli strumenti di distribuzione in modo che dispongano delle autorizzazioni per aggiungere chiavi quando si esegue il bootstrap di un server dei metadati.
30.2.1.3 Pool #
Un pool è una partizione logica in cui vengono memorizzati i dati degli utenti. Nelle distribuzioni Ceph, è prassi comune creare un pool come partizione logica per tipi di dati simili. Ad esempio, quando si distribuisce Ceph come back end per OpenStack, una distribuzione tipica comprende pool per volumi, immagini, backup, macchine virtuali e utenti come client.glance o client.cinder.
30.2.2 Gestione degli utenti #
La funzionalità di gestione degli utenti offre agli amministratori del cluster Ceph la possibilità di creare, aggiornare ed eliminare utenti direttamente nel cluster Ceph.
Quando si creano o si eliminano utenti nel cluster Ceph, potrebbe essere necessario distribuire chiavi ai client in modo che possano essere aggiunte ai portachiavi. Per informazioni, vedere Sezione 30.2.3, «Gestione dei portachiavi».
30.2.2.1 Elenco degli utenti #
Per elencare gli utenti nel cluster, eseguire quanto riportato di seguito:
cephuser@adm > ceph auth list
Ceph elencherà tutti gli utenti nel cluster. Ad esempio, in un cluster con due nodi, l'output ceph auth list ha un aspetto simile:
installed auth entries:
osd.0
key: AQCvCbtToC6MDhAATtuT70Sl+DymPCfDSsyV4w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQC4CbtTCFJBChAAVq5spj0ff4eHZICxIOVZeA==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQBHCbtT6APDHhAA5W00cBchwkQjh3dkKsyPjw==
caps: [mds] allow
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBICbtTOK9uGBAAdbe5zcIGHZL3T/u2g6EBww==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQBHCbtT4GxqORAADE5u7RkpCN/oo4e5W0uBtw==
caps: [mon] allow profile bootstrap-osd
Si noti che viene applicata la notazione TYPE.ID per gli utenti in modo che osd.0 specifichi un utente di tipo osd con ID 0. client.admin è un utente di tipo client con ID admin. Inoltre, ogni voce presenta una voce key: value e una o più voci caps:.
È possibile utilizzare l'opzione -o filename con ceph auth list per salvare l'output in un file.
30.2.2.2 Ottenimento delle informazioni sugli utenti #
Per recuperare un utente, una chiave e funzionalità specifiche, eseguire quanto riportato di seguito:
cephuser@adm > ceph auth get TYPE.IDEsempio:
cephuser@adm > ceph auth get client.admin
exported keyring for client.admin
[client.admin]
key = AQA19uZUqIwkHxAAFuUwvq0eJD4S173oFRxe0g==
caps mds = "allow"
caps mon = "allow *"
caps osd = "allow *"Gli sviluppatori possono eseguire anche:
cephuser@adm > ceph auth export TYPE.ID
Il comando auth export è identico a auth get, ma consente anche di stampare l'ID autenticazione interno.
30.2.2.3 Aggiunta di utenti #
Con l'aggiunta di un utente si creano un nome utente (TYPE.ID), una chiave segreta e tutte le funzionalità incluse nel comando utilizzato per creare l'utente.
La chiave di un utente consente a quest'ultimo di eseguire l'autenticazione con il cluster di memorizzazione Ceph. Le funzionalità dell'utente gli forniscono le autorizzazione in lettura, scrittura o esecuzione nei Ceph monitor (mon), Ceph OSD (osd) server dei metadati Ceph (mds).
Per aggiungere un utente sono disponibili alcuni comandi:
ceph auth addQuesto comando è il modo canonico per aggiungere un utente. Consente di creare l'utente, generare una chiave e aggiungere tutte le funzionalità specificate.
ceph auth get-or-createQuesto comando è spesso il modo più pratico per creare un utente perché restituisce un formato keyfile con nome utente (tra parentesi) e chiave. Se l'utente esiste già, questo comando restituisce semplicemente il nome utente e la chiave nel formato keyfile. È possibile utilizzare l'opzione
-o filenameper salvare l'output in un file.ceph auth get-or-create-keyQuesto comando è un modo pratico per creare un utente e restituire (solo) la chiave utente. È utile per i client per i quali è necessaria solo la chiave (ad esempio
libvirt). Se l'utente esiste già, questo comando restituisce semplicemente la chiave. È possibile utilizzare l'opzione-o filenameper salvare l'output in un file.
Quando si creano utenti del client, è possibile creare un utente senza alcuna funzionalità. Un utente privo di funzionalità può eseguire solo ed esclusivamente l'autenticazione. Tale client non è in grado di recuperare la mappa del cluster dal monitoraggio. È tuttavia possibile creare un utente senza funzionalità se si desidera rinviare l'aggiunta delle funzionalità in un momento successivo mediante l'uso del comando ceph auth caps.
Un utente tipico dispone almeno delle funzionalità di lettura sul Ceph monitor e delle funzionalità di lettura e scrittura sui Ceph OSD. Inoltre, le autorizzazioni OSD di un utente sono spesso limitate per l'accesso a un determinato pool.
cephuser@adm >ceph auth add client.john mon 'allow r' osd \ 'allow rw pool=liverpool'cephuser@adm >ceph auth get-or-create client.paul mon 'allow r' osd \ 'allow rw pool=liverpool'cephuser@adm >ceph auth get-or-create client.george mon 'allow r' osd \ 'allow rw pool=liverpool' -o george.keyringcephuser@adm >ceph auth get-or-create-key client.ringo mon 'allow r' osd \ 'allow rw pool=liverpool' -o ringo.key
Se si forniscono a un utente le funzionalità per gli OSD, ma non si limita l'accesso a un determinato pool, l'utente potrà accedere a tutti i pool nel cluster.
30.2.2.4 Modifica delle funzionalità utente #
Il comando ceph auth caps consente di specificare un utente e di modificarne le funzionalità. Quando si impostano nuove funzionalità, quelle attuali verranno sovrascritte. Per visualizzare le funzionalità attuali, eseguire ceph auth get USERTYPE.USERID. Per aggiungere funzionalità, è necessario specificare anche le funzionalità esistenti quando si utilizza la forma seguente:
cephuser@adm > ceph auth caps USERTYPE.USERID daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]' [daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]']Esempio:
cephuser@adm >ceph auth get client.johncephuser@adm >ceph auth caps client.john mon 'allow r' osd 'allow rw pool=prague'cephuser@adm >ceph auth caps client.paul mon 'allow rw' osd 'allow r pool=prague'cephuser@adm >ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
Per rimuovere una funzionalità, è possibile reimpostarla. Se si desidera che l'utente non disponga di alcun accesso a un determinato daemon impostato precedentemente, specificare una stringa vuota:
cephuser@adm > ceph auth caps client.ringo mon ' ' osd ' '30.2.2.5 Eliminazione di utenti #
Per eliminare un utente, utilizzare ceph auth del:
cephuser@adm > ceph auth del TYPE.ID
dove TYPE è un client, osd, mon o mds e ID è il nome utente o l'ID del daemon.
Se sono stati creati utenti con autorizzazioni esclusivamente per un pool non più esistente, considerare di eliminare anche tali utenti.
30.2.2.6 Stampa di una chiave utente #
Per stampare una chiave di autenticazione dell'utente nell'output standard, eseguire quanto riportato di seguito:
cephuser@adm > ceph auth print-key TYPE.ID
dove TYPE è un client, osd, mon o mds e ID è il nome utente o l'ID del daemon.
È utile stampare una chiave utente quando è necessario popolare il software del client con una chiave utente (come libvirt), come nell'esempio seguente:
# mount -t ceph host:/ mount_point \
-o name=client.user,secret=`ceph auth print-key client.user`30.2.2.7 Importazione di utenti #
Per importare uno o più utenti, utilizzare ceph auth import e specificare un portachiavi:
cephuser@adm > ceph auth import -i /etc/ceph/ceph.keyringNel cluster di memorizzazione Ceph verranno aggiunti nuovi utenti, le rispettive chiavi e funzionalità e verranno aggiornati gli utenti esistenti, insieme alle rispettive chiavi e funzionalità.
30.2.3 Gestione dei portachiavi #
Quando si accede a Ceph tramite il cliente Ceph, questo ricercherà un portachiavi locale. In Ceph l'impostazione dei portachiavi è preimpostata per default con i quattro nomi seguenti, quindi non è necessario impostarli nel file di configurazione Ceph a meno che non si desideri ignorare le impostazioni di default:
/etc/ceph/cluster.name.keyring /etc/ceph/cluster.keyring /etc/ceph/keyring /etc/ceph/keyring.bin
La metavariabile cluster è il nome del cluster Ceph definito dal nome del file di configurazione Ceph. ceph.conf significa che il nome del cluster è ceph, pertanto ceph.keyring. La metavariabile name è il tipo di utente e l'ID utente, ad esempio client.admin, pertanto ceph.client.admin.keyring.
Dopo aver creato un utente (ad esempio client.ringo), è necessario ottenere la chiave e aggiungerla a un portachiavi in un client Ceph in modo che l'utente possa accedere al cluster di memorizzazione Ceph.
Nella Sezione 30.2, «Gestione delle chiavi» è spiegato come elencare, ottenere, aggiungere, modificare ed eliminare utenti direttamente nel cluster di memorizzazione Ceph. Ceph, tuttavia, fornisce anche l'utility ceph-authtool per consentire la gestione dei portachiavi da un client Ceph.
30.2.3.1 Creazione di un portachiavi #
Quando si utilizzano le procedure indicate nella Sezione 30.2, «Gestione delle chiavi» per creare utenti, è necessario fornire chiavi utente ai client Ceph in modo che il client possa recuperare la chiave per l'utente specificato ed eseguire l'autenticazione con il cluster di memorizzazione Ceph. I client Ceph accedono ai portachiavi per ricercare un nome utente e recuperare la chiave dell'utente:
cephuser@adm > ceph-authtool --create-keyring /path/to/keyring
Quando si crea un portachiavi con più utenti, si consiglia di utilizzare il nome cluster (ad esempio cluster.keyring) per il nome file del portachiavi e salvarlo nella directory /etc/ceph, in modo che l'impostazione di default della configurazione del portachiavi selezioni il nome file senza doverlo specificare nella copia locale del file di configurazione Ceph. Ad esempio, creare ceph.keyring eseguendo quanto riportato di seguito:
cephuser@adm > ceph-authtool -C /etc/ceph/ceph.keyring
Quando si crea un portachiavi con un singolo utente, si consiglia di utilizzare il nome del cluster, il tipo di utente e il nome utente e salvarlo nella directory /etc/ceph. Ad esempio, ceph.client.admin.keyring per l'utente client.admin.
30.2.3.2 Aggiunta di un utente a un portachiavi #
Quando si aggiunge un utente al cluster di memorizzazione Ceph (vedere Sezione 30.2.2.3, «Aggiunta di utenti»), è possibile recuperare utente, chiave e funzionalità e salvare l'utente in un portachiavi.
Se si desidera solo utilizzare un utente per portachiavi, con il comando ceph auth get e l'opzione -o l'output verrà salvato nel formato file del portachiavi. Ad esempio, per creare un portachiavi per l'utente client.admin, eseguire quanto riportato di seguito:
cephuser@adm > ceph auth get client.admin -o /etc/ceph/ceph.client.admin.keyring
Quando si desidera importare utenti in un portachiavi, è possibile utilizzare ceph-authtool per specificare il portachiavi di destinazione e quello di origine:
cephuser@adm > ceph-authtool /etc/ceph/ceph.keyring \
--import-keyring /etc/ceph/ceph.client.admin.keyring
Se il portachiavi è compromesso, eliminare la chiave dalla directory /etc/ceph e crearne una nuova seguendo le stesse istruzioni della Sezione 30.2.3.1, «Creazione di un portachiavi».
30.2.3.3 Creazione di un utente #
In Ceph è disponibile il comando ceph auth add per creare un utente direttamente nel cluster di memorizzazione Ceph. È tuttavia possibile creare anche un utente, chiavi e funzionalità direttamente in un portachiavi client Ceph. Quindi, è possibile importare l'utente nel cluster di memorizzazione Ceph:
cephuser@adm > ceph-authtool -n client.ringo --cap osd 'allow rwx' \
--cap mon 'allow rwx' /etc/ceph/ceph.keyringÈ altresì possibile creare un portachiavi e aggiungervi un utente simultaneamente:
cephuser@adm > ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo \
--cap osd 'allow rwx' --cap mon 'allow rwx' --gen-key
Negli scenari precedenti, il nuovo utente client.ringo è presente solo nel portachiavi. Per aggiungere un nuovo utente al cluster di memorizzazione Ceph, è comunque necessario aggiungerlo al cluster:
cephuser@adm > ceph auth add client.ringo -i /etc/ceph/ceph.keyring30.2.3.4 Modifica di utenti #
Per modificare le funzionalità di un record utente in un portachiavi, specificare il portachiavi e l'utente seguiti dalle funzionalità:
cephuser@adm > ceph-authtool /etc/ceph/ceph.keyring -n client.ringo \
--cap osd 'allow rwx' --cap mon 'allow rwx'Per aggiornare l'utente modificato nell'ambiente cluster Ceph, è necessario importare le modifiche dal portachiavi alla voce utente nel cluster Ceph:
cephuser@adm > ceph auth import -i /etc/ceph/ceph.keyringVedere Sezione 30.2.2.7, «Importazione di utenti» per informazioni più dettagliate sull'aggiornamento di un cluster di memorizzazione Ceph da un portachiavi.
30.2.4 Utilizzo della riga di comando #
Il comando ceph supporta le seguenti opzioni correlate alla modifica del nome utente e del segreto:
--ido--userCeph identifica gli utenti con tipo e ID (TYPE.ID, come
client.adminoclient.user1). Le opzioniid,namee-nconsentono di specificare la parte ID del nome utente (ad esempioadminouser1). È possibile specificare l'utente con --id e omettere il tipo. Ad esempio, per specificare l'utente client.foo immettere quanto indicato di seguito:cephuser@adm >ceph --id foo --keyring /path/to/keyring healthcephuser@adm >ceph --user foo --keyring /path/to/keyring health--nameo-nCeph identifica gli utenti con tipo e ID (TYPE.ID, come
client.adminoclient.user1). Le opzioni--namee-nconsentono di specificare il nome utente completo. È necessario specificare il tipo di utente (di normaclient) con l'ID utente:cephuser@adm >ceph --name client.foo --keyring /path/to/keyring healthcephuser@adm >ceph -n client.foo --keyring /path/to/keyring health--keyringPercorso del portachiavi contenente uno o più nomi utente e segreti. L'opzione
--secretoffre la stessa funzionalità, ma non funzione con Object Gateway, in cui viene utilizzata--secretper altri scopi. È possibile recuperare un portachiavi conceph auth get-or-createe memorizzarlo localmente. Questo è l'approccio preferito perché è possibile cambiare i nomi utenti senza dover cambiare il percorso del portachiavi:cephuser@adm >rbd map --id foo --keyring /path/to/keyring mypool/myimage
A Aggiornamenti alla manutenzione di Ceph basati sulle release intermedie upstream "Pacific" #
Molti pacchetti di chiavi di SUSE Enterprise Storage 7.1 si basano sulle serie di release Pacific di Ceph. Quando vengono pubblicate dal progetto Ceph (https://github.com/ceph/ceph) nuove release intermedie nella serie Pacific, SUSE Enterprise Storage 7.1 viene aggiornato con le correzioni di bug e i backport delle funzioni upstream più recenti.
Questo capitolo contiene un riepilogo delle modifiche principali presenti in ogni release intermedia upstream che sono state o che verranno incluse nel prodotto.
Glossario #
Desktop
- Albero di instradamento #
Un termine assegnato a qualsiasi diagramma in cui vengono mostrati i diversi instradamenti che possono essere intrapresi da un ricevitore.
- Alertmanager #
Binario singolo che gestisce gli avvisi inviati dal server Prometheus e che invia notifiche all'utente finale.
- Ceph Dashboard #
Un'applicazione di gestione e monitoraggio Ceph integrata e basata sul Web per l'amministrazione di diversi aspetti e oggetti del cluster. Il dashboard viene implementato sotto forma di modulo di Ceph Manager.
- Ceph Manager #
Ceph Manager o MGR è il software del Ceph Manager che raccoglie tutte le informazioni sullo stato del cluster in un'unica posizione.
- Ceph Monitor #
Ceph Monitor o MON è il software del Ceph Monitor.
ceph-salt#Fornisce gli strumenti per la distribuzione dei cluster Ceph gestiti da cephdam tramite Salt.
- cephadm #
cephadm distribuisce e gestisce i cluster Ceph connettendosi agli host del daemon manager tramite SSH per aggiungere, rimuovere o aggiornare i container del daemon Ceph.
- CephFS #
File system Ceph.
- CephX #
Protocollo di autenticazione Ceph. Cephx opera come Kerberos, ma non dispone di nessun Single point of failure.
- Client Ceph #
Raccolta di componenti Ceph che possono accedere ai cluster di memorizzazione Ceph. Sono inclusi Object Gateway, il dispositivo di blocco Ceph, CephFS e le librerie, i moduli del kernel e i client FUSE corrispondenti.
- Cluster di memorizzazione Ceph #
Set di base del software di memorizzazione in cui vengono memorizzati i dati dell'utente. Tale set è costituito da Ceph monitor e OSD.
- Compartimento #
Punto in cui vengono aggregati altri nodi in una gerarchia di ubicazioni fisiche.
- CRUSH, mappa CRUSH #
Acronimo di Controlled Replication Under Scalable Hashing: un algoritmo che determina la modalità di storage e recupero dei dati mediante il calcolo delle ubicazioni di memorizzazione dati. Per CRUSH è richiesta una mappa del cluster per memorizzare e recuperare dati negli OSD in modo pressoché casuale, con una distribuzione uniforme dei dati nel cluster.
- Daemon Ceph OSD #
Il daemon
ceph-osdè il componente di Ceph responsabile della memorizzazione degli oggetti su un file system locale e della fornitura dell'accesso a questi ultimi sulla rete.- Dispositivo di blocco RADOS (RADOS Block Device, RBD) #
Componente di storage di blocco di Ceph. Noto anche come dispositivo di blocco Ceph.
- DriveGroups #
I DriveGroups sono una dichiarazione di uno o più layout OSD che è possibile mappare a unità fisiche. Il layout OSD definisce il modo in cui Ceph alloca fisicamente lo storage OSD sui supporti corrispondenti ai criteri specificati.
- Gateway Samba #
Il gateway Samba si unisce ad Active Directory nel dominio Windows per l'autenticazione e l'autorizzazione degli utenti.
- Grafana #
Soluzione di monitoraggio e analisi di database.
- Gruppo di zone #
- Memorizzazione degli oggetti Ceph #
"Prodotto", servizio o funzionalità di memorizzazione degli oggetti, costituiti da un cluster di memorizzazione Ceph e da un Ceph Object Gateway.
- Metadata Server #
Metadata Server o MDS è il software dei metadati Ceph.
- Modulo di sincronizzazione degli archivi #
Modulo che consente la creazione di una zona di Object Gateway in cui conservare la cronologia delle versioni degli oggetti S3.
- Multizona #
- Nodo #
Qualsiasi computer o server in un cluster Ceph.
- Nodo admin #
L'host dal quale si eseguono i comandi correlati a Ceph per amministrare gli host del cluster.
- Nodo OSD #
Un nodo del cluster in cui vengono memorizzati i dati, vengono gestiti la replica, il recupero e il ribilanciamento dei dati e vengono fornite alcune informazioni sul monitoraggio nei Ceph monitor mediante la verifica di altri daemon Ceph OSD.
- Object Gateway #
Il componente gateway S3/Swift per Ceph Object Store. Noto anche come RADOS Gateway (RGW).
- OSD #
Object Storage Device: unità di memorizzazione fisica o logica.
- PAG #
Gruppo di posizionamento: una sottodivisione di un pool, utilizzata per il perfezionamento delle prestazioni.
- Pool #
Partizioni logiche per la memorizzazione di oggetti come immagini disco.
- Prometheus #
Kit di strumenti per la creazione di avvisi e il monitoraggio del sistema.
- Regola CRUSH #
Regola di posizionamento dei dati CRUSH che si applica a determinati pool.
- Release intermedia #
Qualsiasi release ad hoc che include esclusivamente correzioni dei bug o per la sicurezza.
- Reliable Autonomic Distributed Object Store (RADOS) #
Set di base del software di memorizzazione in cui vengono memorizzati i dati dell'utente (MON+OSD).
- Samba #
Software di integrazione Windows.
- Set di regole #
Regole per determinare il posizionamento dei dati per un pool.