|
本文档采用自动化机器翻译技术翻译。 尽管我们力求提供准确的译文,但不对翻译内容的完整性、准确性或可靠性作出任何保证。 若出现任何内容不一致情况,请以原始 英文 版本为准,且原始英文版本为权威文本。 |
ReadWriteMany (RWX) 卷
SUSE Storage 通过在 share-manager Pod 中运行的 NFSv4 服务器来暴露常规 Longhorn 卷,从而支持 ReadWriteMany (RWX) 卷。
简介
SUSE Storage 提供两种类型的 RWX 卷,针对不同的工作负载需求进行了优化:
通用(不可迁移)RWX 卷
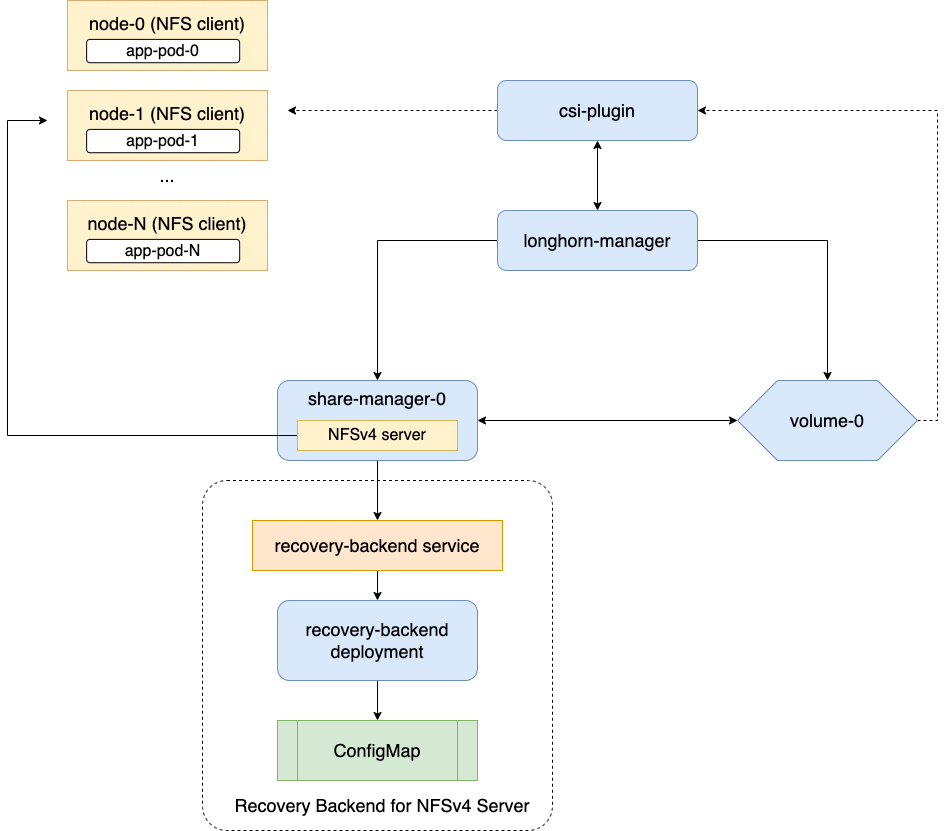
通用 RWX 卷在多个节点之间提供共享文件系统访问。它们使用在 share-manager-<volume-name> Pod 中运行的专用 NFSv4.1 服务器,位于 longhorn-system 名称空间内。每个 RWX 卷都与一个相应的服务配对,该服务向客户端暴露 NFS 端点。
这些卷非常适合需要并发文件访问但不支持实时迁移的工作负载。实时迁移是将正在运行的工作负载从源主机移动到目标主机的过程,而不会中断服务。在迁移过程中,卷仅可从源工作负载访问。一旦完成,目标工作负载接管访问,源工作负载被终止。
特性
-
不支持 实时迁移。
-
使用 NFSv4.1 进行基于文件系统的共享。
-
适用于一般共享存储和多节点文件访问工作负载。
|
注意:在活动 RWX 卷上延迟的 Share-Manager Pod 映像更新 在 Longhorn 系统升级后,当通用(不可迁移)RWX 卷保持附加状态时,对相应 |
可迁移的 RWX 卷
可迁移的 RWX 卷专为虚拟化工作负载设计,例如需要在保持持续 I/O 操作的同时进行 [实时迁移](https://kubevirt.io/user-guide/compute/live_migration/) 的 KubeVirt 虚拟机。这些卷在维护、故障转移或重新平衡操作期间,能够在节点之间无缝移动虚拟机,而不会中断服务。
通用(不可迁移)RWX 卷的要求
-
每个 NFS 客户端节点需要安装 NFSv4 客户端。
有关更多安装细节,请参阅 安装 NFSv4 客户端。
查错:如果节点上没有 NFSv4 客户端,尝试挂载卷将导致错误消息,其中包含以下文本:
for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program.
-
每个节点的主机名在 Kubernetes 集群中是唯一的。
Longhorn 系统中有一个专用的 NFS 服务器恢复后端服务。当客户端连接到 NFS 服务器时,客户端的信息,包括其主机名,将存储在恢复后端中。当 share-manager Pod 或 NFS 服务器异常终止时,SUSE Storage 将创建一个新的。在 90 秒的宽限期内,客户端将使用存储在恢复后端中的客户端信息重新获取锁。
通用(不可迁移)RWX 卷的创建和使用
|
RWX 卷的访问模式必须设置为`ReadWriteMany`,并且"可迁移"标志必须禁用(parameters.migratable: `false`)。 |
-
对于动态配置的 Longhorn 卷,访问模式基于 PVC 的访问模式。
-
对于手动创建的 Longhorn 卷(恢复、DR 卷),可以在 SUSE Storage UI 中创建时指定访问模式。
-
通过 UI 为 Longhorn 卷创建 PV/PVC 时,PV/PVC 的访问模式将基于卷的访问模式。
-
如果卷未绑定到 PVC,可以通过 UI 更改 Longhorn 卷的访问模式。
-
对于被 RWX PVC 使用的 Longhorn 卷,卷的访问模式将更改为 RWX。
为通用(非可迁移)RWX 卷配置卷本地性
SUSE Storage 提供了新的设置,允许您精确控制 RWX 卷的数据本地性(通过识别相关的 Share Manager Pod)。这些细粒度设置与相关的全局设置一起工作,以提供最佳性能、弹性以及遵循组织政策或约束。
shareManagerNodeSelector
您可以使用 StorageClass 参数 shareManagerNodeSelector 来指定选择器,以识别 RWX 卷可以调度的节点。这些选择器与全局 system-managed-components-node-selector 设置合并,然后应用于 RWX 卷的 Share Manager Pod,以提供对卷本地性的更多控制。
示例:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerNodeSelector: label-key1:label-value1;label-key2:label-value2
在此示例中,使用指定 StorageClass 配置的 RWX 卷将调度到具有标签 label-key1:label-value1 和 label-key2:label-value2 的节点上。
allowedTopologies
Longhorn 将 storageClass.allowedTopologies 设置转换为 RWX 卷的 Share Manager Pod 的亲和性规则。这确保了 pod 被调度到满足指定拓扑要求(如区域和可用区)的节点上,并与 RWX 卷的本地性对齐。
示例:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
allowedTopologies:
- matchLabelExpressions:
- key: topology.kubernetes.io/region
values:
- us-west-1
在此示例中,Share Manager Pod 和 RWX 卷将在 us-west-1 区域调度。
shareManagerTolerations
您还可以使用 StorageClass 参数 shareManagerTolerations,以便根据节点污点允许更灵活的调度。定义的容忍与全局 taint-toleration 设置合并,然后应用于 Share Manager Pod。
示例:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerTolerations: nodetype=storage:NoSchedule
在此示例中,Share Manager Pod 将容忍节点上的 nodetype=storage:NoSchedule 污点,从而允许它们在这些节点上调度。
为通用(非可迁移)RWX 卷配置卷挂载选项
RWX 卷仅在通过 NFS 挂载时可访问。默认情况下,SUSE Storage 使用NFS版本4.1,挂载选项为`softerr`,`timeo`值为“600”,`retrans`值为“5”。
如果 NFS 服务器变得不可访问,NFS 客户端的请求将根据配置的 retrans 值进行重试。持续时间较长的事件,例如停电,以及网络分区等因素,会导致请求最终失败。NFS 错误(ETIMEDOUT 对于 softerr 挂载选项)将返回给调用应用程序,并可能导致数据丢失。如果不支持 softerr,SUSE Storage 将自动使用 soft 挂载选项,返回 EIO 作为错误。
您可以为新卷使用特定的挂载选项。首先,创建一个带有 nfsOptions 参数的自定义 StorageClass,然后使用该特定 StorageClass 为 RWX 卷创建 PVC。
示例:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-test
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "2880"
fromBackup: ""
fsType: "ext4"
nfsOptions: "vers=4.2,noresvport,softerr,timeo=600,retrans=5"|
要使用示例 StorageClass 为 RWX 卷创建 PVC,请将 |
注意
-
您必须提供所需选项的完整集合。未提供的任何选项将使用 NFS 服务器端的默认值,而不是 SUSE Storage 自身的默认值。
-
SUSE Storage 不验证
nfsOptions字符串,因此错误值和拼写错误不会被标记。当字符串无效时,挂载将被 NFS 服务器拒绝,卷不会被创建或附加。 -
在 SUSE Storage v1.4.0 到 1.4.3 和 v1.5.0 到 v1.5.1 中,共享管理器 pod 内的卷(具体来说,在
NodeStageVolume步骤中)默认由 Longhorn CSI 插件进行硬挂载。硬挂载允许SUSE Storage持续重试发送NFS请求,确保即使NFS服务器在一段时间内不可访问,IOs也不会失败。当服务器恢复连接或创建替代服务器时,IOs将无缝恢复。然而,这种保证数据完整性的机制存在一定风险。为了保持稳定,Linux 内核不允许卸载文件系统,直到所有待处理的 I/O 完成。这是一个问题,因为系统在所有文件系统卸载之前无法关闭。如果 NFS 服务器无法恢复,客户端节点必须进行强制重启。
为了解决此问题,请升级到 v1.4.4、v1.5.2 或更高版本。升级后,每当 RWX 卷重新附加时,
softerr或soft会自动应用于nfsOptions参数(如果未覆盖默认设置)。 -
您仍然可以使用
hard挂载选项(通过nfsOptions覆盖机制),但硬挂载卷会面临所述风险。
有关更多信息,请参见 #6655。
通用(不可迁移)RWX 卷的故障处理
-
share-manager Pod 异常终止
客户端 IO 将被阻塞,直到 SUSE Storage 创建一个新的 share-manager Pod 及相关卷。一旦 Pod 成功创建,锁回收的 90 秒宽限期将开始,用户会期望
-
在宽限期结束之前,对 RWX 卷的客户端 IO 仍将被阻塞。
-
服务器拒绝读取和写入操作以及非回收锁请求,并返回 NFS4ERR_GRACE 错误。
-
如果所有锁成功回收,宽限期可以提前终止。
在宽限期结束后,成功回收锁的客户端的 IO 将继续进行,不会出现过期文件句柄错误或 IO 错误。如果在宽限期内无法回收锁,则锁将被丢弃,服务器将向客户端返回 IO 错误。客户端重新建立一个新的锁。应用程序应处理 IO 错误。然而,并非所有应用程序都能处理 IO 错误,具体取决于它们的实现。因此,这可能导致 IO 操作的故障和数据丢失。数据一致性可能会成为一个问题。
+ 以下是使用 RWX 卷的 DaemonSet 示例。
+ DaemonSet 的每个 Pod 都在向 RWX 卷写入数据。如果运行 share-manager Pod 的节点出现故障,则会在另一个节点上创建一个新的 share-manager Pod。由于位于故障节点上的一个客户端已离开,锁回收过程不能在 90 秒的宽限期之前终止,即使剩余客户端的锁已成功回收。这些客户端的 IO 在宽限期结束后继续进行。
-
-
如果Kubernetes DNS服务出现故障,share-manager Pods将无法与longhorn-nfs-recovery-backend进行通信。
share-manager Pod中的NFS-ganesha服务器通过服务`longhorn-recovery-backend`的IP与`longhorn-nfs-recovery-backend`进行通信。如果DNS服务不可用,RWX卷的创建和删除以及NFS服务器的恢复将无法进行。因此,建议确保DNS服务的高可用性,以避免通信故障。
-
快速故障转移功能。
SUSE Storage支持一种功能,该功能通过缩短卷上 share-manager NFS 服务器 Pod 所在节点出现故障后恢复所需的时间来提高可用性。该功能使用直接检测信号来监控服务器。如果服务器无响应,它会比通常的顺序更快地创建一个新的服务器。它还以不同的方式配置NFS服务器,将恢复宽限期从90秒缩短到30秒。
更多详细信息请参见RWX卷快速故障转移。
从之前的外部供应器迁移
以下PVC创建一个Kubernetes作业,可以将数据从一个卷复制到另一个卷。
-
将`data-source-pvc`替换为之前由Kubernetes创建的NFSv4 RWX PVC的名称。
-
将`data-target-pvc`替换为您希望用于新工作负载的新RWX PVC的名称。
您可以手动创建一个新的RWX Longhorn卷 + PVC/PV,或者只需创建一个RWX PVC,然后让Longhorn动态为您提供一个卷。
两个PVC需要存在于同一个名称空间中。如果您使用的名称空间与默认名称空间不同,请在下面更改作业的名称空间。
apiVersion: batch/v1
kind: Job
metadata:
namespace: default # namespace where the PVC's exist
name: volume-migration
spec:
completions: 1
parallelism: 1
backoffLimit: 3
template:
metadata:
name: volume-migration
labels:
name: volume-migration
spec:
restartPolicy: Never
containers:
- name: volume-migration
image: ubuntu:xenial
tty: true
command: [ "/bin/sh" ]
args: [ "-c", "cp -r -v /mnt/old /mnt/new" ]
volumeMounts:
- name: old-vol
mountPath: /mnt/old
- name: new-vol
mountPath: /mnt/new
volumes:
- name: old-vol
persistentVolumeClaim:
claimName: data-source-pvc # change to data source PVC
- name: new-vol
persistentVolumeClaim:
claimName: data-target-pvc # change to data target PVC