|
Dies ist eine unveröffentlichte Dokumentation für SUSE® Storage 1.12 (Dev). |
ReadWriteMany (RWX) Volumes
SUSE Storage unterstützt ReadWriteMany (RWX) Volumes, indem reguläre Longhorn-Volumes über NFSv4-Server bereitgestellt werden, die in Share-Manager-Pods wohnen.
Einführung
SUSE Storage bietet zwei Arten von RWX-Volumes, die jeweils für unterschiedliche Arbeitslastanforderungen optimiert sind:
Generische (Nicht-migrierbare) RWX-Volumes
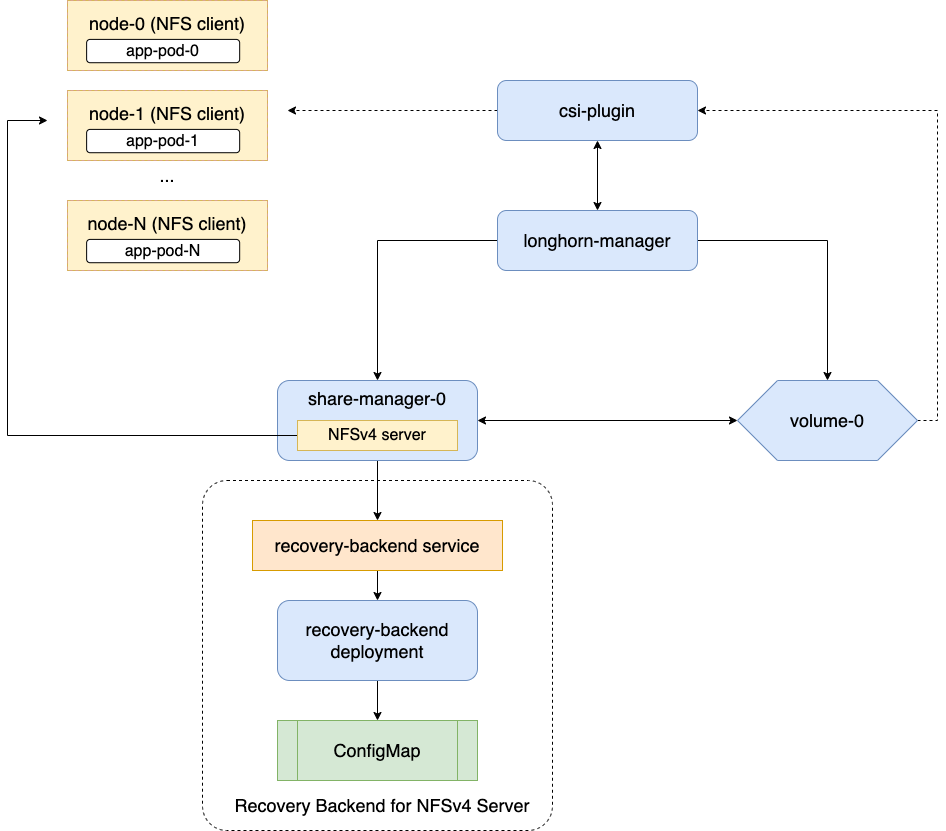
Generische RWX-Volumes bieten gemeinsamen Dateisystemzugriff über mehrere Knoten. share-manager-<volume-name> verwendet dedizierte NFSv4.1-Server, die in share-manager-<volume-name> Pods innerhalb des longhorn-system Namespace laufen. Jedes RWX-Volume ist mit einem entsprechenden Dienst gekoppelt, der den NFS-Endpunkt für Clients bereitstellt.
Diese Volumes sind ideal für Arbeitslasten, die gleichzeitigen Dateizugriff benötigen, aber keine Live-Migration unterstützen. Die Live-Migration ist der Prozess, bei dem eine laufende Arbeitslast von einem Quell-Host zu einem Ziel-Host ohne Dienstunterbrechung verschoben wird. Während der Migration sind die Volumes nur von der Quell-Arbeitslast zugänglich. Sobald die Migration abgeschlossen ist, übernimmt die Ziel-Arbeitslast den Zugriff, und die Quell-Arbeitslast wird beendet.
Merkmale
-
Nicht fähig zu Live-Migration.
-
Verwenden Sie NFSv4.1 für dateisystembasierte Freigabe.
-
Geeignet für allgemeinen gemeinsamen Speicher und für Arbeitslasten mit Dateisystemzugriff über mehrere Knoten.
|
Hinweis: Verschobene Share-Manager-Pod-Image-Updates bei aktiven RWX-Volumes Nach einem Longhorn-Upgrade, wenn ein generisches (nicht-migrierbares) RWX-Volume angeschlossen bleibt, treten Änderungen am |
Migratable RWX-Volumes
Migratable RWX-Volumes sind speziell für virtualisierte Workloads wie KubeVirt-VMs konzipiert, die [Live-Migration](https://kubevirt.io/user-guide/compute/live_migration/) erfordern, während laufende I/O-Operationen aufrechterhalten werden. Diese Volumes ermöglichen eine nahtlose VM-Bewegung zwischen Knoten während Wartungs-, Failover- oder Rebalancing-Operationen, ohne dass es zu Dienstunterbrechungen kommt.
Merkmale
-
Entwickelt für Live-Migrationsszenarien.
-
Erfordert
volumeMode: Block(Filesystem-Modus wird nicht unterstützt). -
Erfordert den ReadWriteMany-Zugriffsmodus und eine StorageClass mit
migratable: "true"(dievolume.spec.migratable=trueauf dem Longhorn-Volume festlegt). -
Nicht für allgemeine Arbeitslasten, die ein gemeinsam genutztes Dateisystem erfordern, vorgesehen.
|
Sie können migrierbare RWX-Volumes unterscheiden, indem Sie das |
Anforderungen für generische (nicht-migrierbare) RWX-Volumes.
-
Jeder NFS-Client-Knoten muss einen NFSv4-Client installiert haben.
Bitte beziehen Sie sich auf Installation des NFSv4-Clients für weitere Installationsdetails.
Fehlerbehebung:Wenn der NFSv4-Client auf dem Knoten nicht verfügbar ist, führt der Versuch, das Volume zu mounten, zu einer Fehlermeldung, die den folgenden Text enthält:
for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program.
-
Der Hostname jedes Knotens ist im Kubernetes-Cluster einzigartig.
Es gibt einen speziellen Wiederherstellungs-Backend-Dienst für NFS-Server im Longhorn-System. Wenn sich ein Client mit einem NFS-Server verbindet, werden die Informationen des Clients, einschließlich seines Hostnamens, im Wiederherstellungs-Backend gespeichert. Wenn ein Share-Manager-Pod oder NFS-Server nicht ordnungsgemäß beendet wird, wird SUSE Storage einen neuen erstellen. Innerhalb des 90-sekündigen Kulanzzeitraums werden Clients die Sperren mit den im Wiederherstellungs-Backend gespeicherten Clientinformationen zurückfordern.
Erstellung und Nutzung von generischen (nicht-migrierbaren) RWX-Volumes.
|
Ein RWX-Volume muss den Zugriffsmodus auf |
-
Bei dynamisch bereitgestellten Longhorn-Volumes basiert der Zugriffsmodus auf dem Zugriffsmodus des PVC.
-
Für manuell erstellte Longhorn-Volumes (Wiederherstellung, DR-Volume) kann der Zugriffsmodus während der Erstellung in der SUSE Storage UI festgelegt werden.
-
Beim Erstellen eines PV/PVC für ein Longhorn-Volume über die UI basiert der Zugriffsmodus des PV/PVC auf dem Zugriffsmodus des Volumes.
-
Man kann den Zugriffsmodus des Longhorn-Volumes über die UI ändern, wenn das Volume nicht an ein PVC gebunden ist.
-
Für ein Longhorn-Volume, das von einem RWX-PVC verwendet wird, wird der Zugriffsmodus des Volumes auf RWX geändert.
Konfiguration der Volumenlokalität für generische (nicht-migrierbare) RWX-Volumes.
SUSE Storage bietet neue Einstellungen, die es Ihnen ermöglichen, die Datenlokalität von RWX-Volumes präzise zu steuern (durch Identifizierung der zugehörigen Share-Manager-Pods). Diese granularen Einstellungen arbeiten mit den zugehörigen globalen Einstellungen zusammen, um optimale Leistung, Resilienz und Einhaltung von organisatorischen Richtlinien oder Einschränkungen zu gewährleisten.
shareManagerNodeSelector
Sie können den StorageClass-Parameter shareManagerNodeSelector verwenden, um Selektoren für die Identifizierung von Knoten anzugeben, auf denen RWX-Volumes geplant werden können. Diese Selektoren werden mit den globalen system-managed-components-node-selector Einstellungen zusammengeführt und dann auf die Share-Manager-Pods der RWX-Volumes angewendet, um mehr Kontrolle über die Volumenlokalität zu bieten.
Beispiel:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerNodeSelector: label-key1:label-value1;label-key2:label-value2
In diesem Beispiel werden RWX-Volumes, die mit der angegebenen StorageClass bereitgestellt werden, auf Knoten mit den Labels label-key1:label-value1 und label-key2:label-value2 eingeplant.
allowedTopologies
Longhorn wandelt die storageClass.allowedTopologies Einstellungen in Affinitätsregeln für die Share-Manager-Pods der RWX-Volumes um. Dies stellt sicher, dass die Pods auf Knoten eingeplant werden, die die angegebenen topologischen Anforderungen (wie Regionen und Zonen) erfüllen und mit der RWX-Volumenlokalität übereinstimmen.
Beispiel:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
allowedTopologies:
- matchLabelExpressions:
- key: topology.kubernetes.io/region
values:
- us-west-1
In diesem Beispiel werden die Share-Manager-Pods und RWX-Volumes in der Region us-west-1 eingeplant.
shareManagerTolerations
Sie können auch den StorageClass-Parameter shareManagerTolerations verwenden, um eine flexiblere Platzierung basierend auf Knoten-Taints zu ermöglichen. Die definierten Tolerations werden mit den globalen taint-toleration-Einstellungen zusammengeführt und dann auf die Share-Manager-Pods angewendet.
Beispiel:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerTolerations: nodetype=storage:NoSchedule
In diesem Beispiel werden die Share-Manager-Pods den nodetype=storage:NoSchedule-Taint auf Knoten tolerieren, was es ihnen ermöglicht, auf diesen Knoten eingeplant zu werden.
Konfiguration der Volume-Mount-Optionen für generische (nicht-migrierbare) RWX-Volumes.
Ein RWX-Volume ist nur zugänglich, wenn es über NFS eingebunden ist. Standardmäßig verwendet SUSE Storage die NFS-Version 4.1 mit der softerr-Mount-Option, einem timeo-Wert von "600" und einem retrans-Wert von "5".
Wenn der NFS-Server nicht mehr erreichbar ist, werden Anfragen von NFS-Clients gemäß dem konfigurierten retrans-Wert erneut versucht. Längere Ereignisse wie Stromausfälle und Faktoren wie Netzwerkpartitionen führen dazu, dass die Anfragen schließlich fehlschlagen. Ein NFS-Fehler (ETIMEDOUT für die softerr-Einbindungsoption) wird an die aufrufende Anwendung zurückgegeben, und es kann zu Datenverlust kommen. Wenn softerr nicht unterstützt wird, verwendet SUSE Storage automatisch stattdessen die soft-Einbindungsoption, die einen EIO als Fehler zurückgibt.
Sie können spezifische Einbindungsoptionen für neue Volumes verwenden. Zuerst erstellen Sie eine angepasste StorageClass mit einem nfsOptions-Parameter und erstellen dann PVCs für RWX-Volumes mit dieser spezifischen StorageClass.
Beispiel:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-test
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "2880"
fromBackup: ""
fsType: "ext4"
nfsOptions: "vers=4.2,noresvport,softerr,timeo=600,retrans=5"|
Um PVCs für RWX-Volumes mit der Beispiel-StorageClass zu erstellen, ersetzen Sie die |
Anmerkungen
-
Sie müssen das vollständige Set der gewünschten Optionen bereitstellen. Alle nicht angegebenen Optionen verwenden die Standardwerte auf der NFS-Server-Seite, nicht die eigenen von SUSE Storage.
-
SUSE Storage validiert die
nfsOptions-Zeichenfolge nicht, sodass fehlerhafte Werte und Tippfehler nicht gekennzeichnet werden. Wenn die Zeichenfolge ungültig ist, wird die Einbindung vom NFS-Server abgelehnt und das Volume wird weder erstellt noch angehängt. -
In SUSE Storage v1.4.0 bis 1.4.3 und v1.5.0 bis v1.5.1 werden Volumes innerhalb eines Share-Manager-Pods (insbesondere im
NodeStageVolume-Schritt) standardmäßig vom Longhorn-CSI-Plugin hart eingebunden. Das harte Einbinden ermöglicht es SUSE Storage, NFS-Anfragen kontinuierlich erneut zu senden, sodass IOs nicht fehlschlagen, selbst wenn der NFS-Server für einige Zeit nicht erreichbar ist. IOs setzen nahtlos fort, wenn der Server die Konnektivität wiedererlangt oder ein Ersatzserver erstellt wird.Dieser Mechanismus zur Gewährleistung der Datenintegrität birgt jedoch einige Risiken. Um die Stabilität zu gewährleisten, erlaubt der Linux-Kernel das Aushängen eines Dateisystems nicht, bis alle ausstehenden IOs abgeschlossen sind. Dies ist ein Anliegen, da das System nicht heruntergefahren werden kann, bis alle Dateisysteme ausgehängt sind. Wenn der NFS-Server nicht in der Lage ist, sich zu erholen, müssen die Client-Knoten einen erzwungenen Neustart durchlaufen.
Um das Problem zu beheben, führen Sie ein Upgrade auf v1.4.4, v1.5.2 oder eine spätere Version durch. Nach der Aktualisierung wird entweder
softerrodersoftautomatisch auf dennfsOptions-Parameter angewendet, wann immer RWX-Volumes wieder angehängt werden (sofern die Standardeinstellungen nicht überschrieben werden). -
Sie können weiterhin die
hard-Mount-Option (über dennfsOptions-Überschreibmechanismus) verwenden, aber hart montierte Volumes sind den beschriebenen Risiken ausgesetzt.
Für weitere Informationen siehe #6655.
Fehlerbehandlung für generische (nicht migrierbare) RWX-Volumes
-
Der share-manager Pod wird nicht ordnungsgemäß beendet.
Client-IO wird blockiert, bis SUSE Storage einen neuen share-manager Pod und das zugehörige Volume erstellt. Sobald der Pod erfolgreich erstellt wurde, beginnt der 90-sekündige Kulanzzeitraum für die Rückforderung von Sperren, und die Benutzer würden erwarten
-
Vor Ablauf des Kulanzzeitraums wird Client-IO zum RWX-Volume weiterhin blockiert.
-
Der Server lehnt Lese- und Schreiboperationen sowie nicht zurückforderbare Sperranfragen mit einem Fehler von NFS4ERR_GRACE ab.
-
Der Kulanzzeitraum kann vorzeitig beendet werden, wenn alle Sperren erfolgreich zurückgefordert werden.
Nach Ablauf des Kulanzzeitraums setzen die IOs der Clients, die die Sperren erfolgreich zurückgefordert haben, ohne veraltete Dateihandle-Fehler oder IO-Fehler fort. Wenn eine Sperre innerhalb des Kulanzzeitraums nicht zurückgefordert werden kann, wird die Sperre verworfen, und der Server gibt einen IO-Fehler an den Client zurück. Der Client stellt eine neue Sperre wieder her. Die Anwendung sollte den IO-Fehler behandeln. Dennoch können nicht alle Anwendungen IO-Fehler aufgrund ihrer Implementierung behandeln. Daher kann dies zum Fehlschlagen der IO-Operation und zum Datenverlust führen. Die Datenkonsistenz kann ein Problem darstellen.
+ Hier ist ein Beispiel für ein DaemonSet, das ein RWX-Volume verwendet.
+ Jeder Pod des DaemonSets schreibt Daten in das RWX-Volume. Wenn der Knoten, auf dem der Share-Manager-Pod läuft, ausfällt, wird ein neuer Share-Manager-Pod auf einem anderen Knoten erstellt. Da einer der Clients, der sich auf dem ausgefallenen Knoten befindet, nicht mehr vorhanden ist, kann der Lock-Reclaim-Prozess nicht früher als nach dem 90-sekündigen Kulanzzeitraum beendet werden, auch wenn die Sperren der verbleibenden Clients erfolgreich zurückgefordert wurden. Die IOs dieser Clients setzen sich fort, nachdem der Kulanzzeitraum abgelaufen ist.
-
-
Wenn der Kubernetes-DNS-Dienst ausfällt, können die Share-Manager-Pods nicht mit longhorn-nfs-recovery-backend kommunizieren.
Der NFS-Ganesha-Server in einem Share-Manager-Pod kommuniziert mit
longhorn-nfs-recovery-backendüber die IP des Diensteslonghorn-recovery-backend. Wenn der DNS-Dienst nicht verfügbar ist, sind die Erstellung und Löschung von RWX-Volumes sowie die Wiederherstellung von NFS-Servern nicht möglich. Daher wird eine hohe Verfügbarkeit des DNS-Dienstes empfohlen, um Kommunikationsausfälle zu vermeiden. -
Fast-Failover-Funktion.
SUSE Storage unterstützt eine Funktion, die die Verfügbarkeit verbessern kann, indem die Zeit verkürzt wird, die benötigt wird, um sich von einem Ausfall des Knotens, auf dem der Share-Manager-NFS-Server-Pod des Volumes läuft, zu erholen. Die Funktion verwendet einen direkten Takt, um den Server zu überwachen. Wenn der Server nicht reagiert, wird schneller als in der üblichen Reihenfolge ein neuer erstellt. Er konfiguriert auch den NFS-Server anders, um den Kulanzzeitraum von 90 auf 30 Sekunden zu verkürzen.
Weitere Details finden Sie unter RWX Volume Fast Failover.
Migration vom vorherigen externen Bereitsteller.
Der untenstehende PVC erstellt einen Kubernetes-Job, der Daten von einem Volume auf ein anderes kopieren kann.
-
Ersetzen Sie
data-source-pvcdurch den Namen des vorherigen NFSv4 RWX PVC, der von Kubernetes erstellt wurde. -
Ersetzen Sie
data-target-pvcdurch den Namen des neuen RWX PVC, den Sie für Ihre neuen Workloads verwenden möchten.
Sie können manuell ein neues RWX Longhorn-Volume + PVC/PV erstellen oder einfach ein RWX PVC erstellen und dann Longhorn dynamisch ein Volume für Sie bereitstellen lassen.
Beide PVCs müssen im selben Namespace existieren. Wenn Sie einen anderen Namespace als den Standard verwenden, ändern Sie den Namespace des Jobs unten.
apiVersion: batch/v1
kind: Job
metadata:
namespace: default # namespace where the PVC's exist
name: volume-migration
spec:
completions: 1
parallelism: 1
backoffLimit: 3
template:
metadata:
name: volume-migration
labels:
name: volume-migration
spec:
restartPolicy: Never
containers:
- name: volume-migration
image: ubuntu:xenial
tty: true
command: [ "/bin/sh" ]
args: [ "-c", "cp -r -v /mnt/old /mnt/new" ]
volumeMounts:
- name: old-vol
mountPath: /mnt/old
- name: new-vol
mountPath: /mnt/new
volumes:
- name: old-vol
persistentVolumeClaim:
claimName: data-source-pvc # change to data source PVC
- name: new-vol
persistentVolumeClaim:
claimName: data-target-pvc # change to data target PVC