- Informationen über dieses Handbuch
- I Ceph Dashboard
- 1 Infos zum Ceph Dashboard
- 2 Dashboard-Webbenutzeroberfläche
- 3 Verwalten von Ceph-Dashboard-Benutzern und -Rollen
- 4 Anzeigen von Cluster-internen Elementen
- 4.1 Anzeigen von Cluster-Knoten
- 4.2 Zugreifen auf das Clusterinventar
- 4.3 Anzeigen von Ceph Monitors
- 4.4 Anzeigen von Services
- 4.5 Anzeigen von Ceph OSDs
- 4.6 Anzeigen der Cluster-Konfiguration
- 4.7 Anzeigen der CRUSH Map
- 4.8 Anzeigen von Manager-Modulen
- 4.9 Anzeigen von Protokollen
- 4.10 Anzeigen der Überwachung
- 5 Verwalten von Pools
- 6 Verwalten von RADOS-Blockgeräten
- 7 Verwalten von NFS Ganesha
- 8 Verwalten von CephFS
- 9 Verwalten des Object Gateways
- 10 Manuelle Konfiguration
- 11 Verwalten von Benutzern und Rollen über die Kommandozeile
- II Clustervorgang
- 12 Ermitteln des Clusterzustands
- 12.1 Überprüfen des Status eines Clusters
- 12.2 Überprüfen der Clusterintegrität
- 12.3 Überprüfen der Nutzungsstatistik eines Clusters
- 12.4 Überprüfen des OSD-Status
- 12.5 Suchen nach vollen OSDs
- 12.6 Prüfen des Monitorstatus
- 12.7 Überprüfen des Zustands von Platzierungsgruppen
- 12.8 Speicherkapazität
- 12.9 Überwachen der OSDs und Platzierungsgruppen
- 13 Betriebsaufgaben
- 13.1 Ändern der Cluster-Konfiguration
- 13.2 Hinzufügen von Knoten
- 13.3 Entfernen von Knoten
- 13.4 OSD-Verwaltung
- 13.5 Verschieben des Salt Masters auf einen neuen Knoten
- 13.6 Aktualisieren der Cluster-Knoten
- 13.7 Aktualisieren von Ceph
- 13.8 Anhalten oder Neustarten des Clusters
- 13.9 Vollständiges Entfernen eines Ceph-Clusters
- 14 Betrieb von Ceph-Services
- 15 Sichern und Wiederherstellen
- 16 Überwachung und Warnungen
- 12 Ermitteln des Clusterzustands
- III Speichern von Daten in einem Cluster
- IV Zugreifen auf Cluster-Daten
- 21 Ceph Object Gateway
- 21.1 Object-Gateway-Beschränkungen und Benennungseinschränkungen
- 21.2 Bereitstellen des Object Gateways
- 21.3 Betrieb des Object Gateway Service
- 21.4 Konfigurationsoptionen
- 21.5 Verwalten des Zugriffs auf Object Gateway
- 21.6 HTTP-Frontends
- 21.7 Aktivieren von HTTPS/SSL für Object Gateways
- 21.8 Synchronisierungsmodule
- 21.9 LDAP-Authentifizierung
- 21.10 Bucket-Index-Sharding
- 21.11 Integration von OpenStack Keystone
- 21.12 Pool-Platzierung und Speicherklassen
- 21.13 Object Gateways an mehreren Standorten
- 22 Ceph iSCSI Gateway
- 23 Cluster-Dateisystem
- 24 Exportieren von Ceph-Daten mit Samba
- 25 NFS Ganesha
- 21 Ceph Object Gateway
- V Integration in Virtualisierungstools
- VI Konfigurieren eines Clusters
- A Ceph-Wartungsaktualisierungen auf der Grundlage von vorgeschalteten „Octopus“-Unterversionen
- B Aktualisierungen für die Dokumentation
- Glossar
- 2.1 Ceph-Dashboard-Anmeldebildschirm
- 2.2 Ceph-Dashboard-Startseite
- 2.3 Status-Widgets
- 2.4 Kapazitäts-Widgets
- 2.5 Leistungs-Widgets
- 3.1 Benutzerverwaltung
- 3.2 Hinzufügen eines Benutzers
- 3.3 Benutzerrollen
- 3.4 Hinzufügen einer Rolle
- 4.1 Hosts
- 4.2 Services
- 4.3 Ceph Monitors
- 4.4 Services
- 4.5 Ceph OSDs
- 4.6 OSD-Flags
- 4.7 OSD-Wiederherstellungspriorität
- 4.8 OSD-Details
- 4.9 OSDs erstellen
- 4.10 Hinzufügen von primären Geräten
- 4.11 OSDs mit hinzugefügten primären Geräten erstellen
- 4.12
- 4.13 Neu hinzugefügte OSDs
- 4.14 Cluster-Konfiguration
- 4.15 CRUSH Map
- 4.16 Manager-Module
- 4.17 Protokolle
- 5.1 Liste der Pools
- 5.2 Hinzufügen eines neuen Pools
- 6.1 Liste der RBD-Images
- 6.2 RBD-Details
- 6.3 RBD-Konfiguration
- 6.4 Hinzufügen eines neuen RBD
- 6.5 RBD-Snapshots
- 6.6 Ausführen von
rbd-mirror-Daemons - 6.7 Erstellen eines Pools mit der RBD-Anwendung
- 6.8 Konfigurieren des Reproduktionsmodus
- 6.9 Hinzufügen des Peer-Berechtigungsnachweises
- 6.10 Liste der reproduzierten Pools
- 6.11 Neues RBD-Image
- 6.12 Synchronisiertes neues RBD-Image
- 6.13 Reproduktionsstatus der RBD-Images
- 6.14 Liste der iSCSI-Ziele
- 6.15 Details zu iSCSI-Zielen
- 6.16 Hinzufügen eines neuen Ziels
- 7.1 Liste der NFS-Exporte
- 7.2 Details zu NFS-Exporten
- 7.3 Hinzufügen eines neuen NFS-Exports
- 7.4 Bearbeiten eines NFS-Exports
- 8.1 CephFS-Details
- 8.2 CephFS-Details
- 9.1 Gateway-Details
- 9.2 Gateway-Benutzer
- 9.3 Hinzufügen eines neuen Gateway-Benutzers
- 9.4 Gateway Bucket-Details
- 9.5 Bearbeiten der Bucket-Details
- 12.1 Ceph-Cluster
- 12.2 Peering-Schema
- 12.3 Statusangaben für Platzierungsgruppen
- 17.1 OSDs mit gemischten Geräteklassen
- 17.2 Beispielbaum
- 17.3 Methoden für den Austausch von Knoten
- 17.4 Platzierungsgruppen in einem Pool
- 17.5 Platzierungsgruppen und OSDs
- 18.1 Pools vor der Migration
- 18.2 Einrichtung der Cache-Ebene
- 18.3 Leeren von Daten
- 18.4 Festlegen der Überlagerung
- 18.5 Migration abgeschlossen
- 20.1 RADOS-Protokoll
- 22.1 Eigenschaften des iSCSI-Initiators
- 22.2 Zielportal ermitteln
- 22.3 Zielportale
- 22.4 Zielgruppen
- 22.5 Eigenschaften des iSCSI-Ziels
- 22.6 Gerätedetails
- 22.7 Assistent für neue Volumes
- 22.8 Eingabeaufforderung für Offline-Datenträger
- 22.9 Volume-Auswahl bestätigen
- 22.10 Eigenschaften des iSCSI-Initiators
- 22.11 Zielserver hinzufügen
- 22.12 Multipfadgeräte verwalten
- 22.13 Auflistung der Pfade für Multipfad
- 22.14 Dialogfeld „Speicher hinzufügen“
- 22.15 Benutzerdefinierte Speicherplatzeinstellung
- 22.16 Überblick zur iSCSI-Datenablage
- 25.1 NFS-Ganesha-Struktur
- 30.1 Einfache
cephx-Authentifizierung - 30.2 Authentifizierung mit
cephx - 30.3 Authentifizierung mit
cephx– MDS und OSD
- 12.1 Auffinden eines Objekts
- 13.1 Abstimmung nach Datenträgergröße
- 13.2 Einfache Einrichtung
- 13.3 Erweiterte Einrichtung
- 13.4 Erweiterte Einrichtung mit nicht einheitlichen Knoten
- 13.5 Experteneinrichtung
- 13.6 Komplexe (und unwahrscheinliche) Einrichtung
- 17.1
crushtool --reclassify-root - 17.2
crushtool --reclassify-bucket - 21.1 Trivial-Konfiguration
- 21.2 Nicht-Trivial-Konfiguration
- 28.1 Beispiel einer Beast-Konfiguration
- 28.2 CivetWeb-Beispielkonfiguration in
/etc/ceph/ceph.conf
Copyright © 2020–2023 SUSE LLC und Mitwirkende. Alle Rechte vorbehalten.
Sofern nicht anders angegeben, ist dieses Dokument unter Creative Commons Attribution-ShareAlike 4.0 International (CC-BY-SA 4.0) lizenziert: https://creativecommons.org/licenses/by-sa/4.0/legalcode.
Die SUSE-Marken finden Sie unter http://www.suse.com/company/legal/. Die Rechte für alle Marken von Drittanbietern liegen bei den jeweiligen Eigentümern. Markensymbole (®, ™ usw.) kennzeichnen Marken von SUSE und ihren Tochtergesellschaften. Sternchen (*) kennzeichnen Marken von Drittanbietern.
Alle Informationen in diesem Buch wurden mit größter Sorgfalt zusammengestellt. Auch hierdurch kann jedoch keine hundertprozentige Richtigkeit gewährleistet werden. Weder SUSE LLC, ihre Tochtergesellschaften, die Autoren noch die Übersetzer können für mögliche Fehler und deren Folgen haftbar gemacht werden.
Informationen über dieses Handbuch #
Dieses Handbuch konzentriert sich auf Routineaufgaben, die Sie als Administrator erledigen müssen, nachdem der grundlegende Ceph-Cluster bereitgestellt wurde (Vorgänge ab Tag 2). Außerdem werden alle unterstützten Möglichkeiten zum Zugriff auf die in einem Ceph-Cluster gespeicherten Daten beschrieben.
SUSE Enterprise Storage 7 ist eine Erweiterung zu SUSE Linux Enterprise Server 15 SP2. Es kombiniert die Funktion des Ceph(http://ceph.com/)-Speicherobjekts mit der Unternehmenstechnik und dem Support von SUSE. Mit SUSE Enterprise Storage 7 stellen IT-Organisationen eine dezentrale Speicherarchitektur bereit, die eine Reihe von Anwendungsfällen auf kommerziellen Hardwareplattformen unterstützt.
1 Verfügbare Dokumentation #
Die Dokumentation für unsere Produkte steht unter https://documentation.suse.com bereit. Hier finden Sie außerdem die neuesten Aktualisierungen und können die Dokumentation durchsuchen oder in verschiedenen Formaten herunterladen. Die neuesten Aktualisierungen der Dokumentation finden Sie in der englischen Sprachversion.
Darüber hinaus befindet sich die Dokumentation auf dem installierten System im Verzeichnis /usr/share/doc/manual. Sie ist enthalten in einem RPM-Paket namens
ses-manual_LANG_CODE. Installieren Sie es, wenn es nicht bereits auf Ihrem System vorhanden ist. Beispiel:
root # zypper install ses-manual_enDie folgende Dokumentation ist für dieses Produkt verfügbar:
- Implementierungsleitfaden
Diese Anleitung konzentriert sich auf die Bereitstellung eines grundlegenden Ceph-Clusters und auf die Bereitstellung zusätzlicher Services. Außerdem werden die Schritte für ein Upgrade auf SUSE Enterprise Storage 7 von der vorherigen Produktversion beschrieben.
- Betriebs- und Verwaltungshandbuch
Dieses Handbuch konzentriert sich auf Routineaufgaben, die Sie als Administrator erledigen müssen, nachdem der grundlegende Ceph-Cluster bereitgestellt wurde (Vorgänge ab Tag 2). Außerdem werden alle unterstützten Möglichkeiten zum Zugriff auf die in einem Ceph-Cluster gespeicherten Daten beschrieben.
- Security Hardening Guide (Sicherheitshandbuch)
Diese Anleitung konzentriert sich darauf, wie Sie die Sicherheit Ihres Clusters gewährleisten können.
- Troubleshooting Guide (Handbuch zur Fehlersuche)
In diesem Leitfaden werden verschiedene häufige Probleme bei der Ausführung von SUSE Enterprise Storage 7 und andere Fragen zu relevanten Komponenten wie Ceph oder Object Gateway behandelt.
- SUSE Enterprise Storage for Windows Guide (Handbuch zu SUSE Enterprise Storage für Windows)
In diesem Handbuch wird die Integration, Installation und Konfiguration von Microsoft-Windows-Umgebungen und SUSE Enterprise Storage mithilfe des Windows-Treibers beschrieben.
2 Feedback #
Wir freuen uns über Rückmeldungen und Beiträge zu dieser Dokumentation. Hierfür gibt es mehrere Kanäle:
- Serviceanforderungen und Support
Informationen zu Services und Support-Optionen, die für Ihr Produkt verfügbar sind, finden Sie unter http://www.suse.com/support/.
Zum Öffnen einer Service-Anforderung benötigen Sie ein SUSE-Abonnement, das beim SUSE Customer Center registriert ist. Gehen Sie zu https://scc.suse.com/support/requests, melden Sie sich an und klicken Sie auf .
- Fehlerberichte
Melden Sie Probleme mit der Dokumentation unter https://bugzilla.suse.com/. Zum Melden von Problemen ist ein Bugzilla-Konto erforderlich.
Zur Vereinfachung dieses Vorgangs können Sie die Links (Fehler in der Dokumentation melden) neben den Überschriften in der HTML-Version dieses Dokuments verwenden. Dadurch werden das richtige Produkt und die Kategorie in Bugzilla vorab ausgewählt und ein Link zum aktuellen Abschnitt hinzugefügt. Sie können somit sofort mit der Eingabe Ihres Berichts beginnen.
- Beiträge
Verwenden Sie für einen Beitrag zu dieser Dokumentation die Links (Quelle bearbeiten) neben den Überschriften in der HTML-Version dieses Dokuments. Sie führen Sie zum Quellcode auf GitHub, wo Sie eine Pull-Anforderung öffnen können. Für Beiträge ist ein GitHub-Konto erforderlich.
Weitere Informationen zur Dokumentationsumgebung für diese Dokumentation finden Sie in der README des Repositorys unter https://github.com/SUSE/doc-ses.
Alternativ können Sie E-Mails mit Fehlerberichten und Feedback zur Dokumentation an <doc-team@suse.com> senden. Geben Sie den Titel der Dokumentation, die Produktversion und das Datum der Veröffentlichung der Dokumentation an. Geben Sie zudem die entsprechende Abschnittsnummer und den Titel (oder die URL) an und fügen Sie eine kurze Beschreibung des Problems hinzu.
3 Konventionen in der Dokumentation #
In der vorliegenden Dokumentation werden die folgenden Hinweise und typografischen Konventionen verwendet:
/etc/passwd: Verzeichnis- und DateinamenPLATZHALTER: Ersetzen Sie PLATZHALTER durch den tatsächlichen Wert.
PFAD: Eine Umgebungsvariablels,--help: Kommandos, Optionen und ParameterBenutzer: Der Name eines Benutzers oder einer Gruppename_des_pakets: Der Name eines Softwarepakets
Alt, Alt–F1: Eine zu drückende Taste bzw. Tastenkombination. Tasten werden wie auf einer Tastatur in Großbuchstaben dargestellt.
, › : Menüelemente, Schaltflächen
AMD/Intel Dieser Absatz ist nur für die Intel 64/AMD64-Architekturen von Bedeutung. Die Pfeile kennzeichnen den Anfang und das Ende des Textblocks.
IBM Z, POWER Dieser Absatz ist nur für die Architekturen
IBM ZundPOWERrelevant. Die Pfeile kennzeichnen den Anfang und das Ende des Textblocks.Kapitel 1, „Beispielkapitel“: Ein Querverweis auf ein anderes Kapitel in diesem Handbuch.
Kommandos, die mit
root-Privilegien ausgeführt werden müssen. Diesen Kommandos kann zur Ausführung als nicht privilegierter Benutzer auch häufig das Präfixsudovorangestellt sein.root #commandtux >sudocommandKommandos, die von Benutzern ohne Privilegien ausgeführt werden können.
tux >commandHinweise
 Warnung: Warnhinweis
Warnung: WarnhinweisWichtige Informationen, die Sie kennen müssen, bevor Sie fortfahren. Warnt vor Sicherheitsrisiken, potenziellen Datenverlusten, Beschädigung der Hardware oder physischen Gefahren.
 Wichtig: Wichtiger Hinweis
Wichtig: Wichtiger HinweisWichtige Informationen, die Sie beachten sollten, bevor Sie den Vorgang fortsetzen.
 Anmerkung: Anmerkung
Anmerkung: AnmerkungErgänzende Informationen, beispielsweise zu unterschiedlichen Softwareversionen.
 Tipp: Tipp
Tipp: TippHilfreiche Informationen, etwa als Richtlinie oder praktische Empfehlung.
Kompaktinfos
Ergänzende Informationen, beispielsweise zu unterschiedlichen Softwareversionen.
Hilfreiche Informationen, etwa als Richtlinie oder praktische Empfehlung.
4 Produktlebenszyklus und Support #
Verschiedene SUSE-Produkte haben unterschiedliche Produktlebenszyklen. Die genauen Lebenszyklusdaten für SUSE Enterprise Storage finden Sie unter https://www.suse.com/lifecycle/.
4.1 SUSE-Support – Definitionen #
Informationen zu unserer Support-Richtlinie und die entsprechenden Optionen finden Sie unter https://www.suse.com/support/policy.html und https://www.suse.com/support/programs/long-term-service-pack-support.html.
4.2 Erläuterung zum Support für SUSE Enterprise Storage #
Sie benötigen ein entsprechendes Abonnement bei SUSE, um Support zu erhalten. Gehen Sie zur Anzeige der für Sie verfügbaren spezifischen Support-Angebote zu https://www.suse.com/support/ und wählen Sie das betreffende Produkt aus.
Die Support-Stufen sind folgendermaßen definiert:
- L1
Problemermittlung: Technischer Support mit Informationen zur Kompatibilität, Nutzungs-Support, kontinuierliche Wartung, Informationssammlung und einfache Problembehandlung anhand der verfügbaren Dokumentation.
- L2
Problemisolierung: Technischer Support zur Datenanalyse, Reproduktion von Kundenproblemen, Isolierung von Problembereichen und Lösung für Probleme, die in Stufe 1 nicht gelöst wurden, sowie Vorbereitung für Stufe 3.
- L3
Problembehebung: Technischer Support zur Lösung von Problemen durch technische Maßnahmen zur Behebung von Produktfehlern, die durch den Support der Stufe 2 erkannt wurden.
Vertragskunden und Partner erhalten SUSE Enterprise Storage mit L3-Support für alle Pakete, ausgenommen:
Technologievorschauen
Audio, Grafik, Schriftarten und Artwork
Pakete, für die ein zusätzlicher Kundenvertrag erforderlich ist
Einige Pakete, die im Lieferumfang von Modul Workstation Extension enthalten sind, erhalten nur L2-Support.
Pakete mit dem Namensende -devel (die Header-Dateien und ähnliche Entwicklerressourcen enthalten) werden nur zusammen mit den entsprechenden Hauptpaketen unterstützt.
SUSE unterstützt nur die Nutzung von Originalpaketen, also unveränderten und nicht kompilierten Paketen.
4.3 Technologievorschauen #
Mit Technologievorschauen sind Pakete, Stacks oder Funktionen gemeint, die SUSE bereitstellt, um einen kurzen Einblick in bevorstehende Innovationen zu geben. Durch Technologievorschauen haben Sie die Möglichkeit, neue Technologien in Ihrer Umgebung zu testen. Über Ihr Feedback würden wir uns sehr freuen. Wenn Sie eine Technologievorschau testen, kontaktieren Sie bitte Ihre Ansprechpartner bei SUSE und teilen Sie ihnen Ihre Erfahrungen und Anwendungsfälle mit. Ihr Input ist für zukünftige Entwicklungen sehr hilfreich.
Technologievorschauen haben jedoch folgende Nachteile:
Technologievorschauen befinden sich noch in Entwicklung. Daher sind die Funktionen möglicherweise unvollständig oder auf andere Weise nicht für die Produktionsnutzung geeignet.
Technologievorschauen werden nicht unterstützt.
Technologievorschauen sind möglicherweise nur für bestimmte Hardwarearchitekturen verfügbar.
Details und Funktionen von Technologievorschauen sind Änderungen unterworfen. Upgrades auf Folgeversionen sind demnach nicht möglich und erfordern eine Neuinstallation.
Technologievorschauen können jederzeit aus einem Produkt entfernt werden. SUSE ist nicht verpflichtet, eine unterstützte Version dieser Technologie in der Zukunft bereitzustellen, zum Beispiel, wenn SUSE erkennt, dass eine Vorschau den Kunden- oder Marktanforderungen oder den Unternehmensstandards nicht entspricht.
Eine Übersicht der Technologievorschauen, die im Lieferumfang Ihres Produkts enthalten sind, finden Sie in den Versionshinweisen unter https://www.suse.com/releasenotes/x86_64/SUSE-Enterprise-Storage/7.
5 Mitwirkende bei Ceph #
Das Ceph-Projekt und dessen Dokumentation ist das Ergebnis der Arbeit von Hunderten von Mitwirkenden und Organisationen. Weitere Einzelheiten finden Sie in https://ceph.com/contributors/.
6 Kommandos und Kommandozeilen in diesem Handbuch #
Als Ceph-Cluster-Administrator können Sie das Cluster-Verhalten mit bestimmten Kommandos konfigurieren und anpassen. Hierzu benötigen Sie verschiedene Arten von Kommandos:
6.1 Salt-spezifische Kommandos #
Mit diesen Kommandos können Sie Ceph-Cluster-Knoten bereitstellen, Kommandos auf mehreren (oder allen) Cluster-Knoten gleichzeitig ausführen oder auch Cluster-Knoten hinzufügen oder entfernen. Die am häufigsten verwendeten Kommandos sind ceph-salt und ceph-salt config. Salt-Kommandos müssen auf dem Salt-Master-Knoten als root ausgeführt werden. Diese Kommandos werden in der folgenden Kommandozeile eingegeben:
root@master # Beispiel:
root@master # ceph-salt config ls6.2 Ceph-spezifische Kommandos #
Hierbei handelt es sich um Kommandos auf niedrigerer Ebene, mit denen alle Aspekte des Clusters und seiner Gateways auf der Kommandozeile konfiguriert und feinabgestimmt werden, zum Beispiel ceph, cephadm, rbd oder radosgw-admin.
Zum Ausführen von Ceph-spezifischen Kommandos benötigen Sie den Lesezugriff auf einen Ceph-Schlüssel. Die Capabilities des Schlüssels definieren dann Ihre Rechte in der Ceph-Umgebung. Sie können die Ceph-Kommandos als root (oder über sudo) ausführen und den uneingeschränkten Standard-Schlüsselbund „ceph.client.admin.key“ verwenden.
Als sicherere und empfohlene Alternative erstellen Sie je einen stärker eingeschränkten, individuellen Schlüssel für die einzelnen verwaltungsberechtigten Benutzer, den Sie dann in einem Verzeichnis ablegen, in dem die Benutzer ihn lesen können, beispielsweise:
~/.ceph/ceph.client.USERNAME.keyring
Sollen ein benutzerdefinierter verwaltungsberechtigter Benutzer und Schlüsselbund verwendet werden, müssen Sie den Benutzernamen und den Pfad des Schlüssels bei jeder Ausführung des Kommandos ceph mit den Optionen -n client angeben.USER_NAME und --keyring PATH/TO/KEYRING angeben.
Um dies zu vermeiden, nehmen Sie diese Optionen in die Variable CEPH_ARGS in den ~/.bashrc-Dateien der einzelnen Benutzer auf.
Ceph-spezifische Kommandos können auf jedem Cluster-Knoten ausgeführt werden. Es wird jedoch empfohlen, sie ausschließlich auf dem Admin-Knoten auszuführen. In dieser Dokumentation werden die Kommandos mit dem Benutzer cephuser ausgeführt. Die Kommandozeile lautet daher:
cephuser@adm > Beispiel:
cephuser@adm > ceph auth listWenn Sie laut Dokumentation ein Kommando für einen Cluster-Knoten mit einer bestimmten Rolle ausführen sollen, ist dies an der Bezeichnung der Kommandozeile ersichtlich. Beispiel:
cephuser@mon > 6.2.1 Ausführen von ceph-volume #
Ab SUSE Enterprise Storage 7 werden Ceph-Services containerisiert ausgeführt. Wenn Sie ceph-volume auf einem OSD-Knoten ausführen müssen, müssen Sie ihm das Kommando cephadm voranstellen. Beispiel:
cephuser@adm > cephadm ceph-volume simple scan6.3 Allgemeine Linux-Kommandos #
Linux-Kommandos, die nicht Ceph-spezifisch sind, wie zum Beispiel mount, cat oder openssl, werden entweder mit der Kommandozeile cephuser@adm > oder root # eingeführt. Dies hängt davon ab, welche Rechte für das entsprechende Kommando erforderlich sind.
6.4 Zusätzliche Informationen #
Weitere Informationen zur Ceph-Schlüsselverwaltung finden Sie in Abschnitt 30.2, „Schlüsselverwaltungsbereiche“.
Teil I Ceph Dashboard #
- 1 Infos zum Ceph Dashboard
Das Ceph Dashboard ist eine integrierte webbasierte Verwaltungs- und Überwachungsanwendung von Ceph, mit der verschiedene Aspekte und Objekte des Clusters verwaltet werden. Das Dashboard wird automatisch aktiviert, nachdem der Basis-Cluster bereitgestellt wurde. Weitere Informationen hierzu finden S…
- 2 Dashboard-Webbenutzeroberfläche
Öffnen Sie zum Anmelden bei Ceph Dashboard die zugehörige URL (unter Angabe der Portnummer). Führen Sie zum Abrufen der Adresse folgendes Kommando aus:
- 3 Verwalten von Ceph-Dashboard-Benutzern und -Rollen
Die Dashboard-Benutzerverwaltung mit Ceph-Kommandos wurde bereits in Kapitel 11, Verwalten von Benutzern und Rollen über die Kommandozeile vorgestellt.
- 4 Anzeigen von Cluster-internen Elementen
Über den Menüpunkt können Sie detaillierte Informationen über Ceph-Clusterhosts, Inventar, Ceph Monitors, Services, OSDs, Konfiguration, CRUSH-Zuordnung, Ceph Manager, Protokolle und Überwachungsdateien anzeigen.
- 5 Verwalten von Pools
Weitere allgemeine Informationen zu Ceph Pools finden Sie in Kapitel 18, Verwalten von Speicher-Pools. Spezifische Informationen zu Pools mit Löschcodierung finden Sie in Kapitel 19, Erasure Coded Pools.
- 6 Verwalten von RADOS-Blockgeräten
Klicken Sie zum Auflisten aller verfügbaren RADOS-Blockgeräte (RBDs) im Hauptmenü auf › .
- 7 Verwalten von NFS Ganesha
Weitere Informationen zu NFS Ganesha finden Sie in Kapitel 25, NFS Ganesha.
- 8 Verwalten von CephFS
Weitere Informationen zu CephFS finden Sie in Kapitel 23, Cluster-Dateisystem.
- 9 Verwalten des Object Gateways
Bevor Sie beginnen, wird möglicherweise die folgende Meldung angezeigt, wenn Sie versuchen, auf das Object-Gateway-Frontend im Ceph Dashboard zuzugreifen:
- 10 Manuelle Konfiguration
In diesem Abschnitt erhalten Sie erweiterte Informationen für Benutzer, die die Dashboard-Einstellungen manuell über die Kommandozeile konfigurieren möchten.
- 11 Verwalten von Benutzern und Rollen über die Kommandozeile
In diesem Abschnitt wird die Verwaltung von Benutzerkonten erläutert, die im Ceph Dashboard verwendet werden. Hier erhalten Sie Hilfestellung für die Erstellung oder Bearbeitung von Benutzerkonten sowie für die Festlegung der richtigen Benutzerrollen und Berechtigungen.
1 Infos zum Ceph Dashboard #
Das Ceph Dashboard ist eine integrierte webbasierte Verwaltungs- und Überwachungsanwendung von Ceph, mit der verschiedene Aspekte und Objekte des Clusters verwaltet werden. Das Dashboard wird automatisch aktiviert, nachdem der Basis-Cluster bereitgestellt wurde. Weitere Informationen hierzu finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.3 “Bereitstellen des Ceph-Clusters”.
Mit dem Ceph Dashboard für SUSE Enterprise Storage 7 wurden weitere webbasierte Verwaltungsfunktionen hinzugefügt. Sie vereinfachen die Verwaltung von Ceph, einschließlich der Überwachung und Anwendungsadministration für den Ceph Manager. Sie müssen Ihren Ceph-Cluster nicht mehr mit komplexen Ceph-spezifischen Kommandos verwalten und überwachen. Sie können entweder die intuitive Oberfläche des Ceph Dashboards nutzen oder die integrierte REST-API.
Das Ceph-Dashboard-Modul visualisiert Informationen und Statistiken zum Ceph-Cluster über einen von ceph-mgr gehosteten Webserver. Im Book “Implementierungsleitfaden”, Chapter 1 “SES und Ceph”, Section 1.2.3 “Ceph-Knoten und -Daemons” finden Sie weitere Details zum Ceph Manager.
2 Dashboard-Webbenutzeroberfläche #
2.1 Anmelden #
Öffnen Sie zum Anmelden bei Ceph Dashboard die zugehörige URL (unter Angabe der Portnummer). Führen Sie zum Abrufen der Adresse folgendes Kommando aus:
cephuser@adm > ceph mgr services | grep dashboard
"dashboard": "https://host:port/",Das Kommando gibt die URL für den Standort des Ceph Dashboards zurück. Falls Sie Probleme mit diesem Kommando haben, finden Sie eine Lösung im Book “Troubleshooting Guide”, Chapter 10 “Troubleshooting the Ceph Dashboard”, Section 10.1 “Locating the Ceph Dashboard”.

Melden Sie sich mit dem Berechtigungsnachweis an, den Sie während der Cluster-Bereitstellung erstellt haben (weitere Informationen finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.3.2.9 “Konfigurieren des Berechtigungsnachweises für die Anmeldung am Ceph Dashboard”).
Wenn Sie nicht über das Standardkonto admin auf das Ceph Dashboard zugreifen möchten, erstellen Sie ein benutzerdefiniertes Benutzerkonto mit Administratorrechten. Weitere Informationen finden Sie in Kapitel 11, Verwalten von Benutzern und Rollen über die Kommandozeile.
Die Benutzeroberfläche des Dashboards ist grafisch in mehrere Blöcke unterteilt: Dienstprogramm-Menü oben rechts auf dem Bildschirm, Hauptmenü auf der linken Seite und Inhaltsbereich.

2.2 Dienstprogramm-Menü #
Oben rechts im Bildschirm befindet sich ein Dienstprogramm-Menü. Es enthält allgemeine Aufgaben, die eher mit dem Dashboard selbst zusammenhängen als mit dem Ceph-Cluster. Über die Optionen gelangen Sie zu den folgenden Themen:
Ändern der Sprachoberfläche des Dashboards zu: Tschechisch, Deutsch, Englisch, Spanisch, Französisch, Indonesisch, Italienisch, Japanisch, Koreanisch, Polnisch, Portugiesisch (Brasilianisch) und Chinesisch
Aufgaben und Benachrichtigungen
Anzeigen der Dokumentation, der Informationen über die REST-API oder weiterer Informationen über das Dashboard
Benutzerverwaltung und Telemetriekonfiguration
AnmerkungAusführlichere Kommandozeilenbeschreibungen für Benutzerrollen finden Sie in Kapitel 11, Verwalten von Benutzern und Rollen über die Kommandozeile.
Anmeldekonfiguration. Ändern des Passworts oder Abmeldung
2.3 Hauptmenü #
Das Hauptmenü des Dashboards ist links im Bildschirm angeordnet. Hier finden Sie die folgenden Themen:
Zur Ceph-Dashboard-Startseite zurückkehren.
Detaillierte Informationen über Hosts, Inventar, Ceph Monitors, Services, Ceph OSDs, Cluster-Konfiguration, CRUSH Map, Ceph-Manager-Module, Protokolle und Überwachung anzeigen.
Cluster-Pools abrufen und verwalten.
Detaillierte Informationen anzeigen und RADOS-Blockgeräte-Images, Spiegelung und iSCSI verwalten.
NFS-Ganesha-Implementierungen abrufen und verwalten.
AnmerkungWenn NFS Ganesha nicht bereitgestellt ist, erscheint ein Hinweis darauf. Siehe Abschnitt 11.6, „Konfigurieren von NFS Ganesha im Ceph Dashboard“.
CephFSs abrufen und verwalten.
Object-Gateway-Daemons, -Benutzer und -Buckets abrufen und verwalten.
AnmerkungWenn Object Gateway nicht bereitgestellt ist, erscheint ein Hinweis darauf. Siehe Abschnitt 10.4, „Aktivieren des Verwaltungs-Frontends für das Object Gateway“.
2.4 Inhaltsbereich #
Der Inhaltsbereich belegt den Hauptteil des Dashboard-Bildschirms. Die Dashboard-Startseite enthält zahlreiche nützliche Widgets, mit denen Sie sich rasch über den aktuellen Status des Clusters, die Kapazität und die Leistung informieren können.
2.5 Allgemeine Funktionen der Webbenutzeroberfläche #
Im Ceph Dashboard arbeiten Sie oft mit Listen, beispielsweise Listen von Pools, OSD-Knoten oder RBD-Geräten. Alle Listen werden standardmäßig automatisch alle fünf Sekunden aktualisiert. Mit den folgenden allgemeinen Widgets verwalten Sie diese Listen oder passen Sie an:
Mit ![]() lösen Sie eine manuelle Aktualisierung der Liste aus.
lösen Sie eine manuelle Aktualisierung der Liste aus.
Klicken Sie auf ![]() , um einzelne Tabellenspalten anzuzeigen oder
auszublenden.
, um einzelne Tabellenspalten anzuzeigen oder
auszublenden.
Klicken Sie auf ![]() und geben Sie ein (oder wählen Sie aus), wie viele
Zeilen auf einer einzelnen Seite angezeigt werden sollen.
und geben Sie ein (oder wählen Sie aus), wie viele
Zeilen auf einer einzelnen Seite angezeigt werden sollen.
Klicken Sie in das Feld  und filtern Sie die Zeilen, indem Sie die Zeichenkette
eingeben, nach der gesucht werden soll.
und filtern Sie die Zeilen, indem Sie die Zeichenkette
eingeben, nach der gesucht werden soll.
Ändern Sie mit  die aktuell angezeigte Seite, wenn die Liste mehrere
Seiten umfasst.
die aktuell angezeigte Seite, wenn die Liste mehrere
Seiten umfasst.
2.6 Dashboard-Widgets #
Die einzelnen Dashboard-Widgets enthalten spezielle Statusinformationen zu einem bestimmten Aspekt eines aktiven Ceph-Clusters. Einige Widgets sind aktive Links. Wenn Sie darauf klicken, werden Sie zu einer detaillierten Seite des jeweiligen Themas weitergeleitet.
Bei einigen grafischen Widgets werden zusätzliche Informationen angezeigt, wenn Sie mit der Maus darauf zeigen.
2.6.1 Status-Widgets #
-Widgets geben Ihnen einen kurzen Überblick über den aktuellen Status des Clusters.

Grundlegende Informationen zum Zustand des Clusters.
Gesamtanzahl der Cluster-Knoten.
Anzahl der aktiven Monitors und deren Quorum.
Gesamtanzahl der OSDs sowie Anzahl der als up und in gekennzeichneten OSDs.
Anzahl der aktiven und im Standby befindlichen Ceph Manager Daemons.
Anzahl der aktiven Object Gateways.
Anzahl der Metadatenserver.
Anzahl der konfigurierten iSCSI-Gateways.
2.6.2 Kapazitäts-Widgets #
-Widgets bieten kurze Informationen zur Speicherkapazität.

Verhältnis der belegten und verfügbaren Rohspeicherkapazität.
Anzahl der im Cluster gespeicherten Datenobjekte.
Diagramm der Platzierungsgruppe gemäß ihrem Status.
Anzahl der Pools im Cluster.
Durchschnittliche Anzahl der Platzierungsgruppen pro OSD.
2.6.3 Leistungs-Widgets #
-Widgets liefern grundlegende Leistungsdaten der Ceph-Clients.

Die Anzahl der Lese-/Schreibvorgänge des Clients pro Sekunde.
Die Datenmenge in Byte pro Sekunde, die zu und von Ceph-Clients übertragen wird.
Der pro Sekunde wiederhergestellte Datendurchsatz.
Zeigt den Scrubbing-Status (weitere Informationen finden Sie in Abschnitt 17.4.9, „Scrubbing einer Platzierungsgruppe“). Er lautet entweder
inaktiv,aktiviertoderaktiv.
3 Verwalten von Ceph-Dashboard-Benutzern und -Rollen #
Die Dashboard-Benutzerverwaltung mit Ceph-Kommandos wurde bereits in Kapitel 11, Verwalten von Benutzern und Rollen über die Kommandozeile vorgestellt.
In diesem Abschnitt erfahren Sie, wie Sie Benutzerkonten über die Dashboard-Webbenutzeroberfläche verwalten.
3.1 Auflisten von Benutzern #
Klicken Sie im Dienstprogramm-Menü auf ![]() und wählen Sie .
und wählen Sie .
Die Liste enthält den Benutzernamen, den vollständigen Namen und die E-Mail-Adresse jedes Benutzers sowie eine Liste der zugewiesenen Rollen. Zudem ist angegeben, ob die Rolle aktiviert ist und wann das Passwort abläuft.

3.2 Hinzufügen neuer Benutzer #
Klicken Sie zum Hinzufügen eines neuen Benutzers oben links in der Tabellenüberschrift auf . Geben Sie den Benutzernamen, das Passwort sowie optional den vollständigen Namen und eine E-Mail-Adresse ein.

Klicken Sie auf das kleine Stiftsymbol und weisen Sie dem Benutzer vordefinierte Rollen zu. Bestätigen Sie mit .
3.3 Bearbeiten von Benutzern #
Klicken Sie zum Bearbeiten der Details zu einem Benutzer auf dessen Tabellenzeile und wählen Sie aus. Bestätigen Sie mit .
3.4 Löschen von Benutzern #
Klicken Sie auf die Tabellenzeile des Benutzers, um die Auswahl zu markieren. Wählen Sie die Dropdown-Schaltfläche neben und dann in der Liste die Option aus, um das Benutzerkonto zu löschen. Aktivieren Sie das Kontrollkästchen und bestätigen Sie mit .
3.5 Auflisten der Benutzerrollen #
Klicken Sie im Dienstprogramm-Menü auf ![]() und wählen Sie .
Klicken Sie dann auf die Registerkarte .
und wählen Sie .
Klicken Sie dann auf die Registerkarte .
Die Liste enthält den Namen und die Beschreibung der einzelnen Rollen sowie einen Hinweis, ob die betreffende Rolle eine Systemrolle ist.

3.6 Hinzufügen benutzerdefinierter Rollen #
Klicken Sie zum Hinzufügen einer neuen benutzerdefinierten Rolle oben links in der Tabellenüberschrift auf . Geben Sie den und die ein und wählen Sie neben die entsprechenden Berechtigungen aus.
Wenn Sie benutzerdefinierte Rollen erstellen und den Ceph-Cluster später
mit dem Kommando ceph-salt purge entfernen möchten,
müssen Sie zunächst die benutzerdefinierten Rollen bereinigen. Weitere
Informationen finden Sie in Abschnitt 13.9, „Vollständiges Entfernen eines Ceph-Clusters“.

Wenn Sie das Kontrollkästchen vor dem Namen eines Themas aktivieren, aktivieren Sie damit alle Berechtigungen für dieses Thema. Wenn Sie das Kontrollkästchen aktivieren, aktivieren Sie damit alle Berechtigungen für sämtliche Themen.
Bestätigen Sie mit .
3.7 Bearbeiten benutzerdefinierter Rollen #
Klicken Sie auf die Tabellenzeile eines Benutzers. Wählen Sie oben links in der Tabellenüberschrift die Option aus, um die Beschreibung und die Berechtigungen der benutzerdefinierten Rolle zu bearbeiten. Bestätigen Sie mit .
3.8 Löschen benutzerdefinierter Rollen #
Klicken Sie auf die Tabellenzeile einer Rolle, um die Auswahl zu markieren. Wählen Sie die Dropdown-Schaltfläche neben und dann in der Liste die Option aus, um die Rolle zu löschen. Aktivieren Sie das Kontrollkästchen und bestätigen Sie mit .
4 Anzeigen von Cluster-internen Elementen #
Über den Menüpunkt können Sie detaillierte Informationen über Ceph-Clusterhosts, Inventar, Ceph Monitors, Services, OSDs, Konfiguration, CRUSH-Zuordnung, Ceph Manager, Protokolle und Überwachungsdateien anzeigen.
4.1 Anzeigen von Cluster-Knoten #
Mit › rufen Sie eine Liste der Cluster-Knoten ab.

Klicken Sie auf den Dropdown-Pfeil neben einem Knotennamen in der Spalte , um die Leistungsdetails des Knotens anzuzeigen.
Die Spalte enthält alle Daemons, die auf den einzelnen zugehörigen Knoten ausgeführt werden. Zum Abrufen der ausführlichen Konfiguration eines Daemons klicken Sie auf den Namen dieses Daemons.
4.2 Zugreifen auf das Clusterinventar #
Mit › rufen Sie eine Liste der Geräte ab. Die Liste enthält den Gerätepfad, den Typ, die Verfügbarkeit, den Hersteller, das Modell, die Größe und die OSDs.
Klicken Sie in der Spalte einen Knotennamen zur Auswahl an. Klicken Sie nach der Auswahl auf , um das Gerät zu identifizieren, auf dem der Host ausgeführt wird. Dadurch wird das Gerät angewiesen, die LEDs blinken zu lassen. Wählen Sie für die Dauer dieser Aktion zwischen 1, 2, 5, 10 und 15 Minuten. Klicken Sie auf .

4.3 Anzeigen von Ceph Monitors #
Mit
›
rufen Sie eine Liste der Cluster-Knoten mit aktiven Ceph-Monitoren ab. Das
Inhaltsfenster ist in zwei Ansichten unterteilt: Status
und In Quorum oder Nicht in Quorum.
Die Tabelle enthält allgemeine Statistiken zu aktiven Ceph Monitors, einschließlich der folgenden:
Cluster-ID
Monmap geändert
Monmap-Epoche
quorum con
quorum mon
erforderliche Verbindung
erforderliche Überwachung
Die Bereiche In Quorum und Nicht in
Quorum enthalten die Namen der einzelnen Monitore, die Rangnummer,
die öffentliche IP-Adresse und die Anzahl der offenen Sitzungen.
Zum Abrufen der Ceph Monitor-Konfiguration eines Knotens klicken Sie auf den Namen dieses Knotens in der Spalte .

4.4 Anzeigen von Services #
Klicken Sie auf
› ,
um Details zu jedem der verfügbaren Services anzuzeigen:
crash, Ceph Manager und Ceph Monitors. Die Liste enthält
den Namen des Container-Images, die ID des Container-Images, den Status der
Services, die ausgeführt werden, sowie die Größe und den Zeitpunkt der
letzten Aktualisierung.
Klicken Sie auf den Dropdown-Pfeil neben einem Servicenamen in der Spalte , um die Details des Daemons anzuzeigen. Die Detailliste enthält den Hostnamen, den Daemon-Typ, die Daemon-ID, die Container-ID, den Container-Image-Namen, die Container-Image-ID, die Versionsnummer, den Status und den Zeitpunkt der letzten Aktualisierung.

4.5 Anzeigen von Ceph OSDs #
Mit › rufen Sie eine Liste der Knoten mit aktiven OSD-Daemons ab. Die Liste enthält die Namen der einzelnen Knoten, die ID, den Status, die Geräteklasse, die Anzahl der Platzierungsgruppen, die Größe, die Auslastung, ein Diagramm der Lese-/Schreibvorgänge im Zeitverlauf sowie die Rate der Lese-/Schreibvorgänge pro Sekunde.

Wählen Sie im Dropdown-Menü der in der Tabellenüberschrift den Eintrag aus, um ein Popup-Fenster zu öffnen. Dieser enthält eine Liste von Flags, die für den gesamten Cluster gelten. Sie können einzelne Flags aktivieren oder deaktivieren und dies dann mit bestätigen.

Wählen Sie im Dropdown-Menü der in der Tabellenüberschrift den Eintrag aus, um ein Popup-Fenster zu öffnen. Dieser enthält eine Liste von OSD-Wiederherstellungsprioritäten, die für den gesamten Cluster gelten. Sie können das bevorzugte Prioritätsprofil aktivieren und die einzelnen Werte darunter anpassen. Bestätigen Sie mit .

Klicken Sie auf den Dropdown-Pfeil neben einem Knotennamen in der Spalte , um eine erweiterte Tabelle mit Details zu den Geräteeinstellungen und der Leistung anzuzeigen. Auf den verschiedenen Karteireitern finden Sie Listen der , , , sowie ein grafisches der Schreib- und Lesevorgänge und die .

Nach dem Klicken auf einen OSD-Knotennamen wird die Tabellenzeile hervorgehoben. Dies bedeutet, dass Sie nun eine Aufgabe auf dem Knoten ausführen können. Sie können eine der folgenden Aktionen ausführen: , , , , , , , , , , oder .
Klicken Sie auf den Abwärtspfeil oben links in der Tabellenüberschrift neben der Schaltfläche und wählen Sie die gewünschte Aufgabe aus.
4.5.1 Hinzufügen von OSDs #
Führen Sie zum Hinzufügen neuer OSDs folgende Schritte aus:
Überprüfen Sie, ob einige Cluster-Knoten über Speichergeräte verfügen, deren Status
verfügbarlautet. Klicken Sie dann auf den Abwärtspfeil links oben in der Tabellenüberschrift und wählen Sie aus. Dadurch wird das Fenster geöffnet. Abbildung 4.9: OSDs erstellen #
Abbildung 4.9: OSDs erstellen #Klicken Sie zum Hinzufügen primärer Speichergeräte für OSDs auf . Bevor Sie Speichergeräte hinzufügen können, müssen Sie oben rechts in der Tabelle Filterkriterien angeben, z. B. . Bestätigen Sie Ihre Einstellung mit .
 Abbildung 4.10: Hinzufügen von primären Geräten #
Abbildung 4.10: Hinzufügen von primären Geräten #Fügen Sie im aktualisierten Fenster optional freigegebene WAL- und BD-Geräte hinzu oder aktivieren Sie die Geräteverschlüsselung.
 Abbildung 4.11: OSDs mit hinzugefügten primären Geräten erstellen #
Abbildung 4.11: OSDs mit hinzugefügten primären Geräten erstellen #Klicken Sie auf , um die Vorschau der DriveGroups-Spezifikation für die zuvor hinzugefügten Geräte anzuzeigen. Bestätigen Sie mit .
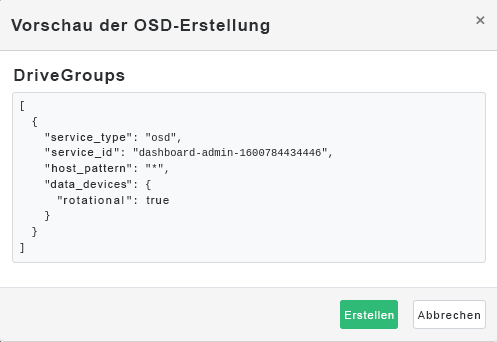 Abbildung 4.12: #
Abbildung 4.12: #Neue Geräte werden in die Liste der OSDs aufgenommen.
 Abbildung 4.13: Neu hinzugefügte OSDs #Anmerkung
Abbildung 4.13: Neu hinzugefügte OSDs #AnmerkungEine Fortschrittsvisualisierung des OSD-Erstellungsprozesses ist nicht vorhanden. Es dauert einige Zeit, bis die OSDs tatsächlich erstellt sind. Die OSDs werden nach dem Bereitstellen in der Liste angezeigt. Wenn Sie den Bereitstellungsstatus überprüfen möchten, zeigen Sie die Protokolle an, indem Sie auf › klicken.
4.6 Anzeigen der Cluster-Konfiguration #
Mit › erhalten Sie eine umfassende Liste der Ceph-Cluster-Konfigurationsoptionen. Die Liste enthält den Namen der Option, eine Kurzbeschreibung und die aktuellen und Standardwerte sowie die Angabe, ob die Option bearbeitbar ist.

Klicken Sie auf den Dropdown-Pfeil neben einer Konfigurationsoption in der Spalte , um eine erweiterte Tabelle mit detaillierten Informationen über die Option anzuzeigen, z. B. den Wertetyp, die minimal und maximal zulässigen Werte, ob sie zur Laufzeit aktualisiert werden kann und vieles mehr.
Ist eine bestimmte Option hervorgehoben, können Sie ihre(n) Wert(e) mit der Schaltfläche oben links in der Tabellenüberschrift bearbeiten. Bestätigen Sie die Änderungen mit .
4.7 Anzeigen der CRUSH Map #
Mit › rufen Sie eine CRUSH-Zuordnung des Clusters ab. Weitere allgemeine Informationen zu CRUSH-Zuordnungen finden Sie in Abschnitt 17.5, „Umgang mit der CRUSH-Zuordnung“.
Wenn Sie auf den Root, die Knoten oder die einzelnen OSDs klicken, werden ausführlichere Informationen angezeigt, z. B. das Crush-Gewicht, die Tiefe im Zuordnungsbaum, die Geräteklasse des OSD und vieles mehr.

4.8 Anzeigen von Manager-Modulen #
Mit › rufen Sie eine Liste der verfügbaren Ceph-Manager-Module ab. Die Zeilen enthalten jeweils einen Modulnamen sowie einen Hinweis, ob das Modul derzeit aktiviert ist oder nicht.

Klicken Sie auf den Dropdown-Pfeil neben einem Modul in der Spalte , um in der nachfolgenden Tabelle eine erweiterte Tabelle mit detaillierten Einstellungen anzuzeigen. Zum Bearbeiten klicken Sie oben links in der Tabellenüberschrift auf die Schaltfläche . Bestätigen Sie die Änderungen mit .
Klicken Sie auf den Dropdown-Pfeil neben der Schaltfläche oben links in der Tabellenüberschrift, um ein Modul zu oder zu .
4.9 Anzeigen von Protokollen #
Mit › rufen Sie eine Liste der letzten Protokolleinträge des Clusters ab. Die Zeilen enthalten jeweils einen Zeitstempel, den Typ des Protokolleintrags sowie die protokollierte Meldung selbst.
Auf der Registerkarte finden Sie die Protokolleinträge des Revisions-Subsystems. Kommandos zum Aktivieren oder Deaktivieren der Revision finden Sie in Abschnitt 11.5, „Revision von API-Anforderungen“.

4.10 Anzeigen der Überwachung #
Klicken Sie auf › , um Details zu Prometheus-Warnungen zu verwalten und anzuzeigen.
Wenn Prometheus aktiv ist, können Sie in diesem Bereich detaillierte Informationen zu , oder anzeigen.
Wenn Sie Prometheus noch nicht bereitgestellt haben, werden ein Informationsbanner und ein Link zur entsprechenden Dokumentation angezeigt.
5 Verwalten von Pools #
Weitere allgemeine Informationen zu Ceph Pools finden Sie in Kapitel 18, Verwalten von Speicher-Pools. Spezifische Informationen zu Pools mit Löschcodierung finden Sie in Kapitel 19, Erasure Coded Pools.
Klicken Sie zum Auflisten aller verfügbaren Pools im Hauptmenü auf .
Die Liste enthält den Namen, den Typ, die zugehörige Anwendung, den Platzierungsgruppenstatus, die Reproduktionsgröße, die letzte Änderung, das Profil mit Löschcodierung, den CRUSH-Regelsatz, die Auslastung sowie die Lese-/Schreibstatistik der einzelnen Pools.

Klicken Sie auf den Dropdown-Pfeil neben einem Poolnamen in der Spalte , um eine erweiterte Tabelle mit detaillierten Informationen zum Pool anzuzeigen, wie zum Beispiel die allgemeinen Details, die Leistungsdetails und die Konfiguration.
5.1 Hinzufügen eines neuen Pools #
Klicken Sie zum Hinzufügen eines neuen Pools oben links in der Tabelle der Pools auf . Im Pool-Formular können Sie den Namen des Pools, den Typ, seine Anwendungen, den Komprimierungsmodus und die Quoten einschließlich der maximalen Größe in Byte und der maximalen Anzahl der Objekte eingeben. Im Pool-Formular wird automatisch die optimale Anzahl der Platzierungsgruppen für diesen Pool berechnet. Die Berechnung beruht auf der Anzahl der OSDs im Cluster und dem ausgewählten Pool-Typ mit den zugehörigen Einstellungen. Sobald die Anzahl der Platzierungsgruppen manuell festgelegt wird, wird sie durch eine berechnete Anzahl ersetzt. Bestätigen Sie mit .

5.2 Löschen von Pools #
Wählen Sie einen zu löschenden Pool in der Tabellenzeile aus. Klicken Sie auf den Dropdown-Pfeil neben der Schaltfläche und dann auf .
5.3 Bearbeiten der Optionen eines Pools #
Wählen Sie zum Bearbeiten der Optionen eines Pools den Pool in der Tabellenzeile aus und klicken Sie oben links in der Tabelle der Pools auf .
Sie können den Namen des Pools ändern, die Anzahl der Platzierungsgruppen erhöhen sowie die Liste der Pool-Anwendungen und die Komprimierungseinstellungen ändern. Bestätigen Sie mit .
6 Verwalten von RADOS-Blockgeräten #
Klicken Sie zum Auflisten aller verfügbaren RADOS-Blockgeräte (RBDs) im Hauptmenü auf › .
In der Liste werden kurze Informationen über das Gerät angezeigt, wie der Name des Geräts, der zugehörige Poolname, der Namespace, die Größe des Geräts, die Anzahl und Größe der Objekte auf dem Gerät, Details zur Bereitstellung der Details sowie das übergeordnete Gerät.

6.1 Anzeigen von Details zu RBDs #
Zum Abrufen ausführlicher Informationen zu einem Gerät klicken Sie auf dessen Zeile in der Tabelle:

6.2 Anzeigen der RBD-Konfiguration #
Zum Abrufen der ausführlichen Konfiguration eines Geräts klicken Sie auf dessen Zeile in der Tabelle und dann in der unteren Tabelle auf die Registerkarte :

6.3 Erstellen von RBDs #
Klicken Sie zum Hinzufügen eines neuen Geräts oben links in der Tabellenüberschrift auf und verfahren Sie im Bildschirm folgendermaßen:

Geben Sie den Namen des neuen Geräts ein. Informationen zu Benennungseinschränkungen finden Sie im Book “Implementierungsleitfaden”, Chapter 2 “Hardwareanforderungen und Empfehlungen”, Section 2.11 “Namensbegrenzungen”.
Wählen Sie den Pool mit der zugewiesenen
rbd-Anwendung aus, von dem aus das neue RBD-Gerät erstellt werden soll.Geben Sie die Größe des neuen Geräts an.
Legen Sie zusätzliche Optionen für das Gerät fest. Zum Abstimmen der Geräteparameter klicken Sie auf und geben Sie Werte für die Objektgröße, die Stripe-Einheit oder die Stripe-Anzahl ein. Sollen Grenzwerte für Quality of Service (QoS) festgelegt werden, klicken Sie auf und geben Sie die Werte ein.
Bestätigen Sie mit .
6.4 Löschen von RBDs #
Wählen Sie ein zu löschendes Gerät in der Tabellenzeile aus. Klicken Sie auf den Dropdown-Pfeil neben der Schaltfläche und dann auf . Bestätigen Sie den Löschvorgang mit .
Das Löschen eines RBDs kann nicht rückgängig gemacht werden. Wenn Sie stattdessen die Option wählen, können Sie das Gerät später wiederherstellen. Wählen Sie das Gerät hierzu auf der Registerkarte der Haupttabelle aus und klicken Sie oben links in der Tabellenüberschrift auf .
6.5 Erstellen von Snapshots von RADOS-Blockgeräten #
Wählen Sie zum Erstellen eines RBD-Snapshots das Gerät in der Tabellenzeile aus, und das Inhaltsfenster für die detaillierte Konfiguration erscheint. Wählen Sie den Karteireiter aus und klicken Sie oben links in der Tabellenüberschrift auf . Geben Sie den Namen des Snapshots ein und bestätigen Sie mit .
Wenn Sie einen Snapshot ausgewählt haben, können Sie weitere Aktionen für das Gerät durchführen, z. B. Umbenennen, Schützen, Klonen, Kopieren oder Löschen. Mit wird der Zustand des Geräts vom aktuellen Snapshot wiederhergestellt.

6.6 RBD-Spiegelung #
RBD-Images können asynchron zwischen zwei Ceph-Clustern gespiegelt werden. Mit dem Ceph Dashboard können Sie die Reproduktion von RBD-Images zwischen mindestens zwei Clustern konfigurieren. Diese Funktion ist in zwei Modi verfügbar:
- Journal-basiert
Bei diesem Modus wird die Funktion des RBD-Journaling-Images verwendet, um die absturzkonsistente Reproduktion zwischen Clustern sicherzustellen.
- Snapshot-basiert
Dieser Modus verwendet periodisch geplante oder manuell erstellte RBD-Image-Spiegel-Snapshots, um absturzsichere RBD-Images zwischen Clustern zu reproduzieren.
Die Spiegelung wird innerhalb von Peer-Clustern pro Pool konfiguriert. Sie kann für eine bestimmte Untergruppe von Images innerhalb des Pools konfiguriert werden oder so, dass alle Images innerhalb eines Pools automatisch gespiegelt werden, wenn nur die Journal-basierte Spiegelung verwendet wird.
Die Spiegelung wird mit dem Kommando rbd konfiguriert,
das standardmäßig in SUSE Enterprise Storage 7 installiert ist. Der
rbd-mirror-Daemon ist dafür
zuständig, Image-Aktualisierungen aus dem Remote-Peer-Cluster zu entnehmen
und sie auf das Image im lokalen Cluster anzuwenden. In
Abschnitt 6.6.2, „Konfigurieren des rbd-mirror-Daemons“ finden Sie weitere Informationen
zum Aktivieren des
rbd-mirror-Daemons.
Abhängig von den gewünschten Anforderungen an die Reproduktion kann die RBD-Spiegelung entweder für eine einseitige oder für eine zweiseitige Reproduktion konfiguriert werden:
- Einseitige Reproduktion
Wenn Daten nur von einem primären Cluster auf einen sekundären Cluster gespiegelt werden, läuft der
rbd-mirror-Daemon nur auf dem sekundären Cluster.- Zweiseitige Reproduktion
Wenn Daten von primären Images auf einem Cluster auf nicht primäre Images auf einem anderen Cluster gespiegelt werden (und umgekehrt), wird der
rbd-mirror-Daemon auf beiden Clustern ausgeführt.
Jede Instanz des rbd-mirror-Daemons
muss in der Lage sein, sich gleichzeitig mit dem lokalen und dem entfernten
Ceph-Cluster zu verbinden, zum Beispiel mit allen Monitor- und OSD-Hosts.
Außerdem muss das Netzwerk über eine ausreichende Bandbreite zwischen den
beiden Rechenzentren verfügen, um die Spiegelung des Workloads zu
bewältigen.
Allgemeine Informationen und Anweisungen für die RADOS-Block-Device-Spiegelung über die Kommandozeile finden Sie in Abschnitt 20.4, „RBD-Image-Spiegel“.
6.6.1 Konfigurieren von primären und sekundären Clustern #
Im primären Cluster wird der ursprüngliche Pool mit Images erstellt. Im sekundären Cluster werden der Pool oder die Images aus dem primären Cluster reproduziert.
Die Bezeichnungen primär und sekundär sind im Zusammenhang mit der Reproduktion relativ, da sie sich eher auf einzelne Pools als auf Cluster beziehen. Bei einer bidirektionalen Reproduktion kann ein Pool beispielsweise aus dem primären in den sekundären Cluster gespiegelt werden, während ein anderer Pool aus dem sekundären in den primären Cluster gespiegelt wird.
6.6.2 Konfigurieren des rbd-mirror-Daemons #
Die folgenden Verfahren zeigen, wie einfache Verwaltungsaufgaben zum
Konfigurieren der Spiegelung mit dem rbd-Kommando
ausgeführt werden. Die Spiegelung wird pro Pool in den Ceph-Clustern
konfiguriert.
Die Schritte der Pool-Konfiguration sollten auf beiden Peer-Clustern durchgeführt werden. Bei diesen Verfahren wird der Einfachheit halber angenommen, dass von einem einzelnen Host aus auf zwei Cluster (den „primären“ und den „sekundären“) zugegriffen werden kann.
Der rbd-mirror-Daemon führt die
eigentliche Cluster-Datenreproduktion durch.
Benennen Sie die Datei
ceph.confund die Schlüsselbunddatei um und kopieren Sie sie vom primären Host auf den sekundären Host:cephuser@secondary >cp /etc/ceph/ceph.conf /etc/ceph/primary.confcephuser@secondary >cp /etc/ceph/ceph.admin.client.keyring \ /etc/ceph/primary.client.admin.keyringcephuser@secondary >scp PRIMARY_HOST:/etc/ceph/ceph.conf \ /etc/ceph/secondary.confcephuser@secondary >scp PRIMARY_HOST:/etc/ceph/ceph.client.admin.keyring \ /etc/ceph/secondary.client.admin.keyringGeben Sie zum Aktivieren der Spiegelung in einem Pool mit
rbddas Kommandomirror pool enable, den Poolnamen und den Spiegelungsmodus an:cephuser@adm >rbd mirror pool enable POOL_NAME MODEAnmerkungDer Spiegelungsmodus kann entweder
ImageoderPoollauten. Beispiel:cephuser@secondary >rbd --cluster primary mirror pool enable image-pool imagecephuser@secondary >rbd --cluster secondary mirror pool enable image-pool imageNavigieren Sie im Ceph Dashboard zu › . Die Tabelle links zeigt die aktiv ausgeführten
rbd-mirror-Daemons und ihren Zustand. Abbildung 6.6: Ausführen von
Abbildung 6.6: Ausführen vonrbd-mirror-Daemons #
6.6.3 Deaktivieren der Spiegelung #
Geben Sie zum Deaktivieren der Spiegelung in einem Pool mit
rbd das Kommando mirror pool disable
und den Poolnamen an:
cephuser@adm > rbd mirror pool disable POOL_NAMEWenn die Spiegelung auf diese Weise in einem Pool deaktiviert wird, dann wird sie auch in anderen Images (im Pool) deaktiviert, für die eine Spiegelung explizit aktiviert wurde.
6.6.4 Bootstrapping von Peers #
Damit der rbd-mirror-Daemon seinen
Peer-Cluster erkennen kann, muss der Peer im Pool registriert und ein
Benutzerkonto erstellt werden. Dieser Vorgang kann mit
rbd und den Kommandos mirror pool peer
bootstrap create und mirror pool peer bootstrap
import automatisiert werden.
Geben Sie zum Erstellen eines neues Bootstrap-Tokens mit
rbd das Kommando mirror pool peer bootstrap
create, einen Pool-Namen sowie einen optionalen Namen für den
Standort zur Beschreibung des lokalen Clusters an:
cephuser@adm > rbd mirror pool peer bootstrap create [--site-name local-site-name] pool-name
Die Ausgabe von mirror pool peer bootstrap create ist
ein Token, das dem Kommando mirror pool peer bootstrap
import übergeben werden sollte, beispielsweise am primären
Cluster:
cephuser@adm > rbd --cluster primary mirror pool peer bootstrap create --site-name primary
image-pool eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkL \
W1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1vbl9ob3N0I \
joiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
Geben Sie zum manuellen Importieren des von einem anderen Cluster
erstellten Bootstrap-Tokens mit dem Kommando rbd das
Kommando mirror pool peer bootstrap import, den
Poolnamen, einen Dateipfad zum erstellten Token (oder „-“, um von der
Standardeingabe zu lesen) sowie einen optionalen Standortnamen zur
Beschreibung des lokalen Clusters sowie eine Spiegelungsrichtung an
(standardmäßig rx-tx für eine bidirektionale Spiegelung,
kann aber auch auf rx-only für eine unidirektionale
Spiegelung festgelegt werden):
cephuser@adm > rbd mirror pool peer bootstrap import [--site-name local-site-name] \
[--direction rx-only or rx-tx] pool-name token-pathBeispielsweise am sekundären Cluster:
cephuser@adm >cat >>EOF < token eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW \ 1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1v \ bl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ== EOFcephuser@adm >rbd --cluster secondary mirror pool peer bootstrap import --site-name secondary image-pool token
6.6.5 Entfernen des Cluster-Peers #
Geben Sie zum Entfernen eines Ceph-Peer-Clusters für die Spiegelung mit dem
Kommando rbd das Kommando mirror pool peer
remove, den Poolnamen und die Peer-UUID (verfügbar über das
Kommando rbd mirror pool info) an:
cephuser@adm > rbd mirror pool peer remove pool-name peer-uuid6.6.6 Konfigurieren der Pool-Reproduktion im Ceph Dashboard #
Der rbd-mirror-Daemon benötigt
Zugriff auf den primären Cluster, damit die RBD-Images gespiegelt werden
können. Stellen Sie sicher, dass Sie die Schritte in
Abschnitt 6.6.4, „Bootstrapping von Peers“ befolgt haben, bevor Sie
fortfahren.
Erstellen Sie sowohl auf dem primären als auch auf dem sekundären Cluster Pools mit demselben Namen und weisen Sie ihnen die Anwendung
rbdzu. Weitere Informationen zum Erstellen eines neuen Pools finden Sie in Abschnitt 5.1, „Hinzufügen eines neuen Pools“. Abbildung 6.7: Erstellen eines Pools mit der RBD-Anwendung #
Abbildung 6.7: Erstellen eines Pools mit der RBD-Anwendung #Navigieren Sie im Dashboard des primären und des sekundären Clusters zu › . Klicken Sie in der Tabelle rechts auf den Namen des zu reproduzierenden Pools und dann auf und wählen Sie den Reproduktionsmodus aus. In diesem Beispiel wird der Pool-Reproduktionsmodus herangezogen, bei dem alle Images in einem bestimmten Pool reproduziert werden. Bestätigen Sie mit .
 Abbildung 6.8: Konfigurieren des Reproduktionsmodus #Wichtig: Fehler oder Warnung im primären Cluster
Abbildung 6.8: Konfigurieren des Reproduktionsmodus #Wichtig: Fehler oder Warnung im primären ClusterNach dem Aktualisieren des Reproduktionsmodus wird eine Fehler- oder Warnflagge in der entsprechenden rechten Spalte angezeigt. Der Grund hierfür ist, dass dem Pool bislang noch kein Peer-Benutzer für die Reproduktion zugewiesen wurde. Ignorieren Sie diese Flagge im primären Cluster, da der Peer-Benutzer ausschließlich im sekundären Cluster zugewiesen wird.
Navigieren Sie im Dashboard des sekundären Clusters zu › . Wählen Sie aus, um einen Pool-Spiegel-Peer hinzuzufügen. Geben Sie die Details für den primären Cluster an:
 Abbildung 6.9: Hinzufügen des Peer-Berechtigungsnachweises #
Abbildung 6.9: Hinzufügen des Peer-Berechtigungsnachweises #Eine willkürliche, eindeutige Zeichenkette, die den primären Cluster identifiziert, z. B. „primary“. Der Cluster-Name darf nicht mit dem tatsächlichen Namen des sekundären Clusters übereinstimmen.
Die Ceph-Benutzer-ID, die Sie als Spiegelungs-Peer erstellt haben. In diesem Beispiel lautet sie „rbd-mirror-peer“.
Kommagetrennte Liste von IP-Adressen der Ceph Monitor-Knoten des primären Clusters.
Schlüssel für die Peer-Benutzer-ID. Zum Abrufen führen Sie folgendes (Beispiel-)Kommando im primären Cluster aus:
cephuser@adm >ceph auth print_key pool-mirror-peer-name
Bestätigen Sie mit .
 Abbildung 6.10: Liste der reproduzierten Pools #
Abbildung 6.10: Liste der reproduzierten Pools #
6.6.7 Prüfen der Funktionsfähigkeit der RBD-Image-Reproduktion #
Wenn der rbd-mirror-Daemon
ausgeführt wird und die RBD-Image-Reproduktion im Ceph Dashboard
konfiguriert ist, können Sie prüfen, ob die Reproduktion tatsächlich
funktioniert:
Erstellen Sie im Ceph Dashboard des primären Clusters ein RBD-Image und geben Sie den Pool, den Sie bereits für die Reproduktion erstellt haben, als dessen übergeordneten Pool an. Aktivieren Sie die Funktionen
Exklusive SperreundJournalingfür das Image. Weitere Informationen zum Erstellen von RBD-Images finden Sie in Abschnitt 6.3, „Erstellen von RBDs“. Abbildung 6.11: Neues RBD-Image #
Abbildung 6.11: Neues RBD-Image #Sobald Sie das zu reproduzierende Image erstellt haben, öffnen Sie das Ceph Dashboard im sekundären Cluster und navigieren Sie zu › . Die Tabelle rechts zeigt die Veränderung in der Anzahl der -Images und die Anzahl der Images wird synchronisiert.
 Abbildung 6.12: Synchronisiertes neues RBD-Image #Tipp: Reproduktionsprozess
Abbildung 6.12: Synchronisiertes neues RBD-Image #Tipp: ReproduktionsprozessDie Tabelle unten auf der Seite zeigt den Reproduktionsstatus der RBD-Images. Auf der Registerkarte werden eventuelle Probleme angezeigt, die Registerkarte zeigt den Fortschritt der Image-Reproduktion und die Registerkarte enthält alle Images mit erfolgreicher Reproduktion.
 Abbildung 6.13: Reproduktionsstatus der RBD-Images #
Abbildung 6.13: Reproduktionsstatus der RBD-Images #Schreiben Sie im primären Cluster Daten in das RBD-Image. Navigieren Sie im Ceph Dashboard des sekundären Clusters zu › und prüfen Sie, ob die Größe des entsprechenden Images wächst, während die Daten im primären Cluster geschrieben werden.
6.7 Verwalten von iSCSI Gateways #
Weitere Informationen zu iSCSI-Gateways finden Sie in Kapitel 22, Ceph iSCSI Gateway.
Klicken Sie zum Auflisten aller verfügbaren Gateways und zugeordneten Images im Hauptmenü auf › . Die Registerkarte mit einer Liste der derzeit konfigurierten iSCSI-Gateways und zugeordneten RBD-Images wird geöffnet.
Die Tabelle enthält den Status der einzelnen Gateways, die Anzahl der iSCSI-Ziele und die Anzahl der Sitzungen. Die Tabelle enthält den Namen der einzelnen zugeordneten Images, den Backstore-Typ des zugehörigen Pool-Namens und weitere statistische Daten.
Die Registerkarte enthält eine Liste der derzeit konfigurierten iSCSI-Ziele.

Klicken Sie zum Anzeigen detaillierterer Informationen über ein Ziel auf den Dropdown-Pfeil in der Tabellenzeile des Ziels. Eine Baumstruktur mit den Datenträgern, Portalen, Initiatoren und Gruppen wird geöffnet. Wenn Sie auf ein Element klicken, wird es erweitert und sein Inhalt wird angezeigt, optional mit einer zugehörigen Konfiguration in der Tabelle rechts.

6.7.1 Hinzufügen von iSCSI-Zielen #
Klicken Sie zum Hinzufügen eines neuen iSCSI-Ziels links oben in der Tabelle auf und geben Sie die erforderlichen Informationen ein.

Geben Sie die Zieladresse des neuen Gateways ein.
Klicken Sie auf und wählen Sie ein oder mehrere iSCSI-Portale aus der Liste aus.
Klicken Sie auf und wählen Sie ein oder mehrere RBD-Images für das Gateway aus.
Wenn Sie für den Zugriff auf das Gateway eine Authentifizierung verwenden müssen, aktivieren Sie das Kontrollkästchen und geben Sie den Berechtigungsnachweis ein. Weitere erweiterte Authentifizierungsoptionen finden Sie nach Aktivieren von (Gegenseitige Authentifizierung) und (Ermittlungsauthentifizierung).
Bestätigen Sie mit .
6.7.2 Bearbeiten von iSCSI-Zielen #
Zum Bearbeiten eines vorhandenen iSCSI-Ziels klicken Sie auf dessen Zeile in der Tabelle und dann oben links in der Tabelle auf .
Sie können dann das iSCSI-Ziel bearbeiten, Portale hinzufügen oder löschen und entsprechende RBD-Images hinzufügen oder löschen. Außerdem haben Sie die Möglichkeit, die Authentifizierungsoptionen für das Gateway anzupassen.
6.7.3 Löschen von iSCSI-Zielen #
Wählen Sie zum Löschen eines iSCSI-Ziels die Tabellenzeile aus, klicken Sie auf den Dropdown-Pfeil neben der Schaltfläche und wählen Sie aus. Aktivieren Sie und bestätigen Sie mit .
6.8 RBD-Quality-of-Service (QoS) #
Allgemeine Informationen und eine Beschreibung der RBD-QoS-Konfigurationsoptionen finden Sie in Abschnitt 20.6, „QoS-Einstellungen“.
Die QoS-Optionen können auf verschiedenen Ebenen konfiguriert werden.
global
für einzelne Pools
für einzelne Images
Die globale Konfiguration befindet sich an oberster Stelle in der Liste und wird für alle neu erstellten RBD-Images herangezogen, außerdem für alle Images, in denen diese Werte in der Pool- oder RBD-Image-Schicht nicht überschrieben werden. Ein global festgelegter Optionswert kann für einzelne Pools oder Images überschrieben werden. Die für einen Pool festgelegten Optionen werden für alle RBD-Images dieses Pools übernommen, sofern sie nicht von einer Konfigurationsoption in einem Image überschrieben werden. Die für ein Image festgelegten Optionen überschreiben die für einen Pool festgelegten Optionen sowie die global festgelegten Optionen.
Auf diese Weise können Sie globale Standardwerte definieren, für alle RBD-Images eines bestimmten Pools anpassen und dann die Poolkonfiguration für einzelne RBD-Images überschreiben.
6.8.1 Globale Konfiguration von Optionen #
Wählen Sie für die globale Konfiguration von RBD-Optionen im Hauptmenü › aus.
Wählen Sie zum Auflisten aller verfügbaren globalen Konfigurationsoptionen neben die Option aus dem Dropdown-Menü.
Filtern Sie im Suchfeld die Ergebnisse der Tabelle nach
rbd_qos. Damit wird eine Liste aller verfügbaren Konfigurationsoptionen für QoS angezeigt.Klicken Sie zum Ändern eines Werts auf dessen Tabellenzeile und wählen Sie dann oben links in der Tabelle aus. Das Dialogfeld enthält sechs Felder für die Eingabe von Werten. Die RBD-Konfigurationsoptionswerte müssen im Textfeld angegeben werden.
AnmerkungIm Gegensatz zu anderen Dialogfeldern können Sie den Wert in diesem Dialogfeld nicht in bequemen Einheiten angeben. Sie müssen ihn entweder in Byte oder in IOPS angeben, je nach bearbeiteter Option.
6.8.2 Konfigurieren von Optionen für einen neuen Pool #
Zum Erstellen eines neuen Pools und zum Konfigurieren von
RBD-Konfigurationsoptionen klicken Sie auf
› . Wählen Sie den Pooltyp
aus. Ergänzen Sie den Pool dann mit dem
Anwendungs-Tag rbd, damit Sie die RBD-QoS-Optionen
konfigurieren können.
Bei einem Pool mit Löschcodierung können keine RBD-QoS-Konfigurationsoptionen konfiguriert werden. Zum Konfigurieren der RBD-QoS-Optionen für Pools mit Löschcodierung müssen Sie den reproduzierten Metadaten-Pool eines RBD-Images bearbeiten. Die Konfiguration wird dann für den Daten-Pool mit Löschcodierung dieses Images übernommen.
6.8.3 Konfigurieren von Optionen für einen vorhandenen Pool #
Zum Konfigurieren von RBD-QoS-Optionen für einen vorhandenen Pool klicken Sie auf , dann auf die Tabellenzeile des Pools und dann oben links in der Tabelle auf .
Im Dialogfeld wird der Abschnitt angezeigt, gefolgt vom Abschnitt .
Wenn weder der Abschnitt noch der Abschnitt angezeigt wird, bearbeiten Sie entweder einen Pool mit Löschcodierung, bei dem keine RBD-Konfigurationsoptionen festgelegt werden können, oder der Pool ist nicht für die Verwendung durch RBD-Images konfiguriert. Im letzteren Fall weisen Sie dem Pool das Anwendungs-Tag zu; hiermit werden die entsprechenden Konfigurationsabschnitte angezeigt.
6.8.4 Konfigurationsoptionen #
Erweitern Sie die Konfigurationsoptionen mit . Eine Liste aller verfügbaren Optionen wird angezeigt. Die Einheiten der Konfigurationsoptionen werden bereits in den Textfeldern angezeigt. Bei Optionen mit Byte pro Sekunde (BPS) können Sie Abkürzungen wie „1M“ oder „5G“ eingeben. Diese werden automatisch in „1 MB/s“ bzw. „5 GB/s“ umgewandelt.
Mit der Schaltfläche zum Zurücksetzen rechts neben den einzelnen Textfeldern können Sie die für den Pool festgelegten Werte entfernen. Die Konfigurationswerte für global konfigurierte Optionen oder für RBD-Images werden hiermit nicht entfernt.
6.8.5 Erstellen von RBD-QoS-Optionen mit einem neuen RBD-Image #
Zum Erstellen eines RBD-Images und zum Festlegen von RBD-QoS-Optionen für dieses Image klicken Sie auf › und dann auf . Klicken Sie auf , um den Abschnitt mit der erweiterten Konfiguration zu maximieren. Öffnen Sie alle verfügbaren Konfigurationsoptionen mit .
6.8.6 Bearbeiten von RBD-QoS-Optionen für vorhandene Images #
Zum Bearbeiten von RBD-QoS-Optionen für ein vorhandenes Image wählen Sie › , klicken auf die Tabellenzeile des Pools und schließlich auf . Das Dialogfeld „Bearbeiten“ wird geöffnet. Klicken Sie auf , um den Abschnitt mit der erweiterten Konfiguration zu maximieren. Öffnen Sie alle verfügbaren Konfigurationsoptionen mit .
6.8.7 Ändern von Konfigurationsoptionen beim Kopieren oder Klonen von Images #
Wenn ein RBD-Image geklont oder kopiert wird, werden die für dieses Image festgelegten Werte standardmäßig ebenfalls kopiert. Sollen diese Werte beim Kopieren oder Klonen geändert werden, geben Sie die aktualisierten Konfigurationswerte im Dialogfeld zum Kopieren/Klonen ein, ebenso wie beim Erstellen oder Bearbeiten eines RBD-Images. Hiermit werden ausschließlich die Werte für das zu kopierende oder zu klonende RBD-Image festgelegt (oder zurückgesetzt). Dieser Vorgang verändert weder die Konfiguration des Quell-RBD-Images noch die globale Konfiguration.
Wenn Sie den Optionswert beim Kopieren/Klonen zurücksetzen, wird in diesem Image kein Wert für diese Option festgelegt. Dies bedeutet, dass ein Wert für diese Option herangezogen wird, der für den übergeordneten Pool festgelegt wurde, sofern der betreffende Wert im übergeordneten Pool konfiguriert ist. Ansonsten wird der globale Standardwert verwendet.
7 Verwalten von NFS Ganesha #
Weitere Informationen zu NFS Ganesha finden Sie in Kapitel 25, NFS Ganesha.
Klicken Sie zum Auflisten aller verfügbaren NFS-Exporte im Hauptmenü auf .
In der Liste werden das Verzeichnis, der Daemon-Hostname, der Typ des Speicher-Back-Ends und der Zugriffstyp der einzelnen Exporte angezeigt.

Zum Abrufen ausführlicher Informationen zu einem NFS-Export klicken Sie auf dessen Tabellenzeile.

7.1 Erstellen eines NFS-Exports #
Klicken Sie zum Hinzufügen eines neuen NFS-Exports links oben in der Tabelle der Exporte auf und geben Sie die erforderlichen Informationen ein.

Wählen Sie mindestens einen NFS Ganesha Daemon aus, der den Export ausführen soll.
Wählen Sie ein Speicher-Back-End aus.
WichtigZurzeit werden nur NFS-Exporte unterstützt, die mit CephFS gesichert sind.
Wählen Sie eine Benutzer-ID aus und legen Sie andere Back-End-spezifische Optionen fest.
Geben Sie den Verzeichnispfad für den NFS-Export ein. Das Verzeichnis wird erstellt, falls es am Server noch nicht vorhanden ist.
Legen Sie andere NFS-spezifische Optionen fest, z. B. die unterstützte NFS-Protokollversion, den Zugriffstyp, Squashing oder das Transportprotokoll.
Wenn sie den Zugriff ausschließlich auf bestimmte Clients beschränken müssen, klicken Sie auf und fügen Sie deren IP-Adressen zusammen mit dem Zugriffstyp und den Squashing-Optionen hinzu.
Bestätigen Sie mit .
7.2 Löschen von NFS-Exporten #
Um einen Export zu löschen, wählen Sie den Export in der Tabellenzeile aus und markieren Sie ihn. Klicken Sie auf den Dropdown-Pfeil neben der Schaltfläche und wählen Sie aus. Aktivieren Sie das Kontrollkästchen und bestätigen Sie mit .
7.3 Bearbeiten von NFS-Exporten #
Um einen vorhandenen Export zu bearbeiten, wählen und markieren Sie den Export in der Tabellenzeile und klicken Sie oben links in der Exporttabelle auf .
Sie können dann alle Details des NFS-Exports anpassen.

8 Verwalten von CephFS #
Weitere Informationen zu CephFS finden Sie in Kapitel 23, Cluster-Dateisystem.
8.1 Anzeigen des CephFS-Überblicks #
Mit im Hauptmenü rufen Sie einen Überblick der konfigurierten Dateisysteme ab. Die Haupttabelle zeigt den Namen und das Erstellungsdatum der einzelnen Dateisysteme und gibt an, ob ein Dateisystem aktiviert ist oder nicht.
Wenn Sie auf die Tabellenzeile eines Dateisystems klicken, erhalten Sie Details zu dessen Rang und den Pools, die in das Dateisystem eingefügt wurden.

Unten im Bildschirm werden Statistiken mit der Anzahl der zugehörigen MDS-Inodes und Client-Anfragen in Echtzeit angezeigt.

9 Verwalten des Object Gateways #
Bevor Sie beginnen, wird möglicherweise die folgende Meldung angezeigt, wenn Sie versuchen, auf das Object-Gateway-Frontend im Ceph Dashboard zuzugreifen:
Information No RGW credentials found, please consult the documentation on how to enable RGW for the dashboard. Please consult the documentation on how to configure and enable the Object Gateway management functionality.
Das liegt daran, dass das Object Gateway nicht automatisch von cephadm für das Ceph Dashboard konfiguriert wurde. Wenn diese Meldung angezeigt wird, folgen Sie den Anweisungen in Abschnitt 10.4, „Aktivieren des Verwaltungs-Frontends für das Object Gateway“, um das Object-Gateway-Frontend für das Ceph Dashboard manuell zu aktivieren.
Weitere allgemeine Informationen zum Object Gateway finden Sie in Kapitel 21, Ceph Object Gateway.
9.1 Abrufen von Object Gateways #
Zum Abrufen einer Liste der konfigurierten Object Gateways klicken Sie auf › . Die Liste enthält die ID des Gateways, den Hostnamen des Cluster-Knotens, auf dem der Gateway Daemon ausgeführt wird, sowie die Versionsnummer des Gateways.
Klicken Sie auf den Dropdown-Pfeil neben dem Namen des Gateways, um detaillierte Informationen über das Gateway anzuzeigen. Die Registerkarte enthält Details zu Lese-/Schreiboperationen und Cache-Statistiken.

9.2 Verwalten von Object-Gateway-Benutzern #
Mit › erhalten Sie eine Liste der vorhandenen Object-Gateway-Benutzer.
Klicken Sie auf den Dropdown-Pfeil neben dem Benutzernamen, um Details zum Benutzerkonto anzuzeigen, wie zum Beispiel die Statusinformationen oder die Details zum Benutzer und zu den Bucket-Quoten.

9.2.1 Hinzufügen eines neuen Gateway-Benutzers #
Klicken Sie zum Hinzufügen eines neuen Gateway-Benutzers oben links in der Tabellenüberschrift auf . Geben Sie den Berechtigungsnachweis, Details zum S3-Schlüssel und die Benutzer- und Bucket-Quote ein und bestätigen Sie mit .

9.2.2 Löschen von Gateway-Benutzern #
Wählen und markieren Sie einen Gateway-Benutzer, den Sie löschen möchten. Klicken Sie auf die Dropdown-Schaltfläche neben und wählen Sie in der Liste aus, um das Benutzerkonto zu löschen. Aktivieren Sie das Kontrollkästchen und bestätigen Sie mit .
9.2.3 Bearbeiten von Gateway-Benutzerdetails #
Um Gateway-Benutzerdetails zu ändern, wählen Sie den Benutzer aus und markieren Sie ihn. Klicken Sie oben links in der Tabellenüberschrift auf .
Bearbeiten Sie die grundlegenden oder die zusätzlichen Benutzerinformationen, z. B. die Befähigungen, Schlüssel, Unterbenutzer und Kontingente. Bestätigen Sie mit .
Die Registerkarte enthält eine schreibgeschützte Liste der Gateway-Benutzer mit ihren Zugriffsschlüsseln und den geheimen Schlüsseln. Zum Abrufen der Schlüssel klicken Sie auf einen Benutzernamen in der Liste und dann oben links in der Tabellenüberschrift auf . Mit dem „Augensymbol“ im Dialogfeld blenden Sie die Schlüssel ein, mit dem Zwischenablagensymbol kopieren Sie den entsprechenden Schlüssel in die Zwischenablage.
9.3 Verwalten der Object-Gateway-Buckets #
Object Gateway(OGW)-Buckets setzen den Funktionsumfang von OpenStack-Swift-Containern um. Object-Gateway-Buckets fungieren als Container zum Speichern von Datenobjekten.
Klicken Sie auf › , um eine Liste der Object-Gateway-Buckets anzuzeigen.
9.3.1 Hinzufügen eines neuen Buckets #
Klicken Sie zum Hinzufügen eines neuen Object-Gateway-Buckets oben links in der Tabellenüberschrift auf . Geben Sie den Namen des Buckets ein, wählen Sie den Inhaber aus und legen Sie das Platzierungsziel fest. Bestätigen Sie mit .
In dieser Phase können Sie durch Auswahl von eine Sperre aktivieren. Sie können dies jedoch auch noch nach der Erstellung konfigurieren. Weitere Informationen zu diesem Thema finden Sie in Abschnitt 9.3.3, „Bearbeiten des Buckets“.
9.3.2 Anzeigen der Bucket-Details #
Klicken Sie auf den Dropdown-Pfeil neben dem Bucket-Namen, um detaillierte Informationen zu einem Object-Gateway-Bucket anzuzeigen.

Unterhalb der Tabelle werden Details zu den Bucket-Quoteneinstellungen angezeigt.
9.3.3 Bearbeiten des Buckets #
Wählen und markieren Sie einen Bucket und klicken Sie dann oben links in der Tabellenüberschrift auf .
Sie können den Inhaber des Buckets aktualisieren oder die Versionierung, die Multi-Faktor-Authentifizierung oder die Sperre aktivieren. Bestätigen Sie alle Änderungen mit .

9.3.4 Löschen eines Buckets #
Wählen und markieren Sie den Object-Gateway-Bucket, den Sie löschen möchten. Klicken Sie auf die Dropdown-Schaltfläche neben und wählen Sie in der Liste aus, um den Bucket zu löschen. Aktivieren Sie das Kontrollkästchen und bestätigen Sie mit .
10 Manuelle Konfiguration #
In diesem Abschnitt erhalten Sie erweiterte Informationen für Benutzer, die die Dashboard-Einstellungen manuell über die Kommandozeile konfigurieren möchten.
10.1 Konfigurieren der TLS/SSL-Unterstützung #
Alle HTTP-Verbindungen zum Dashboard werden standardmäßig mit TLS/SSL gesichert. Für eine sichere Verbindung ist ein SSL-Zertifikat erforderlich. Sie können entweder ein eigensigniertes Zertifikat verwenden oder ein Zertifikat erzeugen und durch eine bekannte Zertifizierungsstelle (CA) signieren lassen.
Unter Umständen muss die SSL-Unterstützung deaktiviert werden. Dies ist beispielsweise der Fall, wenn das Dashboard hinter einem Proxy ausgeführt wird, der SSL nicht unterstützt.
Deaktivieren Sie SSL nur mit Bedacht, da die Benutzernamen und Passwörter damit unverschlüsselt an das Dashboard gesendet werden.
Mit folgendem Kommando deaktivieren Sie SSL:
cephuser@adm > ceph config set mgr mgr/dashboard/ssl falseDie Ceph-Manager-Prozesse müssen nach einer Änderung des SSL-Zertifikats und des Schlüssels manuell neu gestartet werden. Führen Sie hierzu entweder das folgende Kommando aus:
cephuser@adm > ceph mgr fail ACTIVE-MANAGER-NAMEoder deaktivieren Sie das Dashboard-Modul und aktivieren Sie es wieder, wodurch auch der Manager sich selbst wieder neu erzeugt:
cephuser@adm >ceph mgr module disable dashboardcephuser@adm >ceph mgr module enable dashboard
10.1.1 Erstellen von eigensignierten Zertifikaten #
Ein eigensigniertes Zertifikat für die sichere Kommunikation lässt sich schnell und einfach erstellen. So bringen Sie das Dashboard rasch in Gang.
Die meisten Webbrowser geben bei selbstsignierten Zertifikaten eine Fehlermeldung aus und fordern eine explizite Bestätigung, bevor eine sichere Verbindung zum Dashboard hergestellt wird.
Mit dem folgenden integrierten Kommando erzeugen und installieren Sie ein selbstsigniertes Zertifikat:
cephuser@adm > ceph dashboard create-self-signed-cert10.1.2 Verwenden von Zertifikaten, die von einer Zertifizierungsstelle signiert wurden #
Damit die Verbindung zum Dashboard ordnungsgemäß gesichert wird und Webbrowser-Fehlermeldungen zu selbstsignierten Zertifikaten unterbunden werden, wird empfohlen, ein Zertifikat zu verwenden, das von einer CA signiert ist.
Mit einem Kommando wie im folgenden Beispiel erzeugen Sie ein Zertifikat-Schlüsselpaar:
root # openssl req -new -nodes -x509 \
-subj "/O=IT/CN=ceph-mgr-dashboard" -days 3650 \
-keyout dashboard.key -out dashboard.crt -extensions v3_ca
Das obige Kommando gibt die Dateien dashboard.key und dashboard.crt aus. Sobald die Datei dashboard.crt von einer CA signiert wurde, aktivieren Sie es mit dem folgenden Kommando für alle Ceph-Manager-Instanzen:
cephuser@adm >ceph config-key set mgr/dashboard/crt -i dashboard.crtcephuser@adm >ceph config-key set mgr/dashboard/key -i dashboard.key
Wenn Sie unterschiedliche Zertifikate für die einzelnen Ceph-Manager-Instanzen benötigen, bearbeiten Sie die Kommandos und geben Sie den Namen der Instanz wie folgt an. Ersetzen Sie NAME durch den Namen der Ceph-Manager-Instanz (in der Regel der zugehörige Hostname):
cephuser@adm >ceph config-key set mgr/dashboard/NAME/crt -i dashboard.crtcephuser@adm >ceph config-key set mgr/dashboard/NAME/key -i dashboard.key
10.2 Ändern des Hostnamens und der Portnummer #
Ceph Dashboard bindet an eine bestimmte TCP/IP-Adresse und an einen bestimmten TCP-Port. Standardmäßig bindet der derzeit aktive Ceph Manager, auf dem das Dashboard gehostet wird, an den TCP-Port 8443 (oder 8080, wenn SSL deaktiviert ist).
Wenn auf den Hosts, auf denen Ceph Manager (und damit Ceph Dashboard) ausgeführt wird, eine Firewall aktiviert ist, müssen Sie möglicherweise die Konfiguration ändern, um den Zugriff auf diese Ports zu ermöglichen. Weitere Informationen zu den Firewall-Einstellungen für Ceph finden Sie im Book “Troubleshooting Guide”, Chapter 13 “Hints and tips”, Section 13.7 “Firewall settings for Ceph”.
Ceph Dashboard bindet standardmäßig an „::“, was allen verfügbaren IPv4- und IPv6-Adressen entspricht. Mit folgenden Kommandos können Sie die IP-Adresse und die Portnummer der Webanwendung ändern, sodass sie für alle Ceph-Manager-Instanzen gelten:
cephuser@adm >ceph config set mgr mgr/dashboard/server_addr IP_ADDRESScephuser@adm >ceph config set mgr mgr/dashboard/server_port PORT_NUMBER
Auf jedem ceph-mgr-Daemon wird eine eigene Dashboard-Instanz gehostet; unter Umständen müssen diese Instanzen daher separat konfiguriert werden. Mit folgenden Kommandos ändern Sie die IP-Adresse und die Portnummer für eine bestimmte Manager-Instanz (ersetzen Sie NAME mit der ID der ceph-mgr-Instanz):
cephuser@adm >ceph config set mgr mgr/dashboard/NAME/server_addr IP_ADDRESScephuser@adm >ceph config set mgr mgr/dashboard/NAME/server_port PORT_NUMBER
Das Kommando ceph mgr services gibt alle derzeit konfigurierten Endpunkte zurück. Über den Schlüssel dashboard erhalten Sie die URL für den Zugriff auf das Dashboard.
10.3 Anpassen der Benutzernamen und Passwörter #
Wenn Sie nicht das standardmäßige Administratorkonto verwenden möchten, erstellen Sie ein anderes Benutzerkonto und weisen Sie diesem Konto mindestens eine Rolle zu. Es steht eine Reihe vordefinierter Systemrollen zur Auswahl. Weitere Informationen finden Sie unter Kapitel 11, Verwalten von Benutzern und Rollen über die Kommandozeile.
Mit folgendem Kommando erstellen Sie einen Benutzer mit Administratorrechten:
cephuser@adm > ceph dashboard ac-user-create USER_NAME PASSWORD administrator10.4 Aktivieren des Verwaltungs-Frontends für das Object Gateway #
Sollen die Object-Gateway-Verwaltungsfunktionen des Dashboards genutzt werden, müssen Sie die Anmeldeberechtigung eines Benutzers mit dem aktivierten system-Flag angeben:
Falls kein Benutzer mit dem
system-Flag vorhanden ist, müssen Sie einen erstellen:cephuser@adm >radosgw-admin user create --uid=USER_ID --display-name=DISPLAY_NAME --systemBeachten Sie die Schlüssel access_key und secret_key in der Ausgabe des Kommandos.
Sie können die Berechtigungsnachweise eines vorhandenen Benutzers auch mit dem Kommando
radosgw-adminabrufen:cephuser@adm >radosgw-admin user info --uid=USER_IDGeben Sie den erhaltenen Berechtigungsnachweis im Dashboard an:
cephuser@adm >ceph dashboard set-rgw-api-access-key ACCESS_KEYcephuser@adm >ceph dashboard set-rgw-api-secret-key SECRET_KEY
Standardmäßig ist die Firewall in SUSE Linux Enterprise Server 15 SP2 aktiviert. Weitere Informationen zur Firewall-Konfiguration finden Sie im Book “Troubleshooting Guide”, Chapter 13 “Hints and tips”, Section 13.7 “Firewall settings for Ceph”.
Es sind mehrere Punkte zu beachten:
Der Hostname und die Portnummer des Object Gateways werden automatisch ermittelt.
Wenn mehrere Zonen verwendet werden, wird automatisch der Host in der Master-Zonengruppe und der Master-Zone ermittelt. Bei den meisten Einrichtungen reicht dies aus, doch unter bestimmten Umständen müssen Sie den Hostnamen und den Port manuell festlegen:
cephuser@adm >ceph dashboard set-rgw-api-host HOSTcephuser@adm >ceph dashboard set-rgw-api-port PORTSie benötigen ggf. die folgenden zusätzlichen Einstellungen:
cephuser@adm >ceph dashboard set-rgw-api-scheme SCHEME # http or httpscephuser@adm >ceph dashboard set-rgw-api-admin-resource ADMIN_RESOURCEcephuser@adm >ceph dashboard set-rgw-api-user-id USER_IDWenn die Object-Gateway-Einrichtung ein selbstsigniertes Zertifikat umfasst (Abschnitt 10.1, „Konfigurieren der TLS/SSL-Unterstützung“), deaktivieren Sie die Zertifikatsprüfung im Dashboard, sodass keine Verbindungen aufgrund von Zertifikaten, die von einer unbekannten CA signiert wurden oder nicht mit dem Hostnamen übereinstimmen, verweigert werden:
cephuser@adm >ceph dashboard set-rgw-api-ssl-verify FalseWenn die Verarbeitung von Anforderungen im Object Gateway zu lange dauert und eine Zeitüberschreitung im Dashboard auftritt, können Sie den Zeitüberschreitungswert anpassen (Standardwert 45 Sekunden):
cephuser@adm >ceph dashboard set-rest-requests-timeout SECONDS
10.5 Aktivieren der iSCSI-Verwaltung #
Das Ceph Dashboard verwaltet iSCSI-Ziele mithilfe der REST-API, die vom Service rbd-target-api des Ceph-iSCSI-Gateways bereitgestellt wird. Stellen Sie sicher, dass es auf iSCSI-Gateways installiert und aktiviert ist.
Die iSCSI-Verwaltungsfunktion des Ceph Dashboards hängt von der neuesten Version 3 des ceph-iscsi-Projekts ab. Stellen Sie sicher, dass Ihr Betriebssystem die richtige Version bereitstellt, da das Ceph Dashboard die Verwaltungsfunktionen andernfalls nicht aktiviert.
Wenn die ceph-iscsi-REST-API im HTTPS-Modus konfiguriert ist und ein eigensigniertes Zertifikat verwendet, konfigurieren Sie das Dashboard so, dass die Überprüfung des SSL-Zertifikats beim Zugriff auf die ceph-iscsi-API vermieden wird.
Deaktivieren Sie die API-SSL-Überprüfung:
cephuser@adm > ceph dashboard set-iscsi-api-ssl-verification falseDefinieren Sie die verfügbaren iSCSI-Gateways:
cephuser@adm >ceph dashboard iscsi-gateway-listcephuser@adm >ceph dashboard iscsi-gateway-add scheme://username:password@host[:port]cephuser@adm >ceph dashboard iscsi-gateway-rm gateway_name
10.6 Aktivieren von Single Sign-on #
Mit der Zugriffskontrollmethode Single Sign-on (SSO) können die Benutzer sich mit einer einzigen ID und einem einzigen Passwort bei mehreren Anwendungen gleichzeitig anmelden.
Das Ceph Dashboard unterstützt die externe Authentifizierung von Benutzern über das SAML-2.0-Protokoll. Da die Autorisierung weiterhin durch das Dashboard vorgenommen wird, müssen Sie zunächst Benutzerkonten erstellen und ihnen die gewünschten Rollen zuweisen. Der Authentifizierungsprozess kann jedoch von einem vorhandenen Identitätsanbieter (IdP) durchgeführt werden.
Mit folgendem Kommando konfigurieren Sie das Single Sign-on:
cephuser@adm > ceph dashboard sso setup saml2 CEPH_DASHBOARD_BASE_URL \
IDP_METADATA IDP_USERNAME_ATTRIBUTE \
IDP_ENTITY_ID SP_X_509_CERT \
SP_PRIVATE_KEYParameter:
- CEPH_DASHBOARD_BASE_URL
Basis-URL für den Zugriff auf Ceph Dashboard (z. B. „https://cephdashboard.local“).
- IDP_METADATA
URL, Dateipfad oder Inhalt der IdP-Metadaten-XML (z. B. „https://myidp/metadata“).
- IDP_USERNAME_ATTRIBUTE
Optional. Attribut, mit dem der Benutzername aus der Authentifizierungsantwort ermittelt wird. Der Standardwert lautet „uid“.
- IDP_ENTITY_ID
Optional. Für den Fall, dass die IdP-Metadaten mehrere Entitäts-IDs umfassen.
- SP_X_509_CERT / SP_PRIVATE_KEY
Optional. Dateipfad oder Inhalt des Zertifikats, mit dem das Ceph Dashboard (Service-Anbieter) die Signierung und Verschlüsselung vornimmt.
Für den Ausstellerwert der SAML-Anforderungen gilt folgende Syntax:
CEPH_DASHBOARD_BASE_URL/auth/saml2/metadata
Mit folgendem Kommando rufen Sie die aktuelle SAML-2.0-Konfiguration ab:
cephuser@adm > ceph dashboard sso show saml2Mit folgendem Kommando deaktivieren Sie Single Sign-on:
cephuser@adm > ceph dashboard sso disableMit folgendem Kommando prüfen Sie, ob SSO aktiviert ist:
cephuser@adm > ceph dashboard sso statusMit folgendem Kommando aktivieren Sie SSO:
cephuser@adm > ceph dashboard sso enable saml211 Verwalten von Benutzern und Rollen über die Kommandozeile #
In diesem Abschnitt wird die Verwaltung von Benutzerkonten erläutert, die im Ceph Dashboard verwendet werden. Hier erhalten Sie Hilfestellung für die Erstellung oder Bearbeitung von Benutzerkonten sowie für die Festlegung der richtigen Benutzerrollen und Berechtigungen.
11.1 Verwalten der Passwortrichtlinie #
Standardmäßig ist die Passwortrichtlinienfunktion einschließlich der folgenden Prüfungen aktiviert:
Ist das Passwort länger als N Zeichen?
Sind das alte und das neue Passwort identisch?
Die Passwortrichtlinienfunktion kann komplett ein- oder ausgeschaltet werden:
cephuser@adm > ceph dashboard set-pwd-policy-enabled true|falseDie folgenden Einzelprüfungen können ein- oder ausgeschaltet werden:
cephuser@adm >ceph dashboard set-pwd-policy-check-length-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-oldpwd-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-username-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-exclusion-list-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-complexity-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-sequential-chars-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-repetitive-chars-enabled true|false
Darüber hinaus stehen zum Konfigurieren des Verhaltens der Passwortrichtlinie die folgenden Optionen zur Verfügung.
Die minimale Passwortlänge (Standardwert ist 8):
cephuser@adm >ceph dashboard set-pwd-policy-min-length NDie minimale Passwortkomplexität (Standardwert ist 10):
cephuser@adm >ceph dashboard set-pwd-policy-min-complexity NDie Passwortkomplexität wird berechnet, indem jedes Zeichen im Passwort klassifiziert wird.
Eine Liste mit kommagetrennten Wörtern, die nicht in einem Passwort verwendet werden dürfen:
cephuser@adm >ceph dashboard set-pwd-policy-exclusion-list word[,...]
11.2 Verwalten von Benutzerkonten #
Das Ceph Dashboard unterstützt die Verwaltung mehrerer Benutzerkonten. Jedes Benutzerkonto umfasst einen Benutzernamen, ein Passwort (in verschlüsselter Form mit bcrypt gespeichert), einen optionalen Namen und eine optionale E-Mail-Adresse.
Die Benutzerkonten werden in der Konfigurationsdatenbank von Ceph Monitor gespeichert und global für alle Ceph-Manager-Instanzen freigegeben.
Mit folgenden Kommandos verwalten Sie die Benutzerkonten:
- Vorhandene Benutzer abrufen:
cephuser@adm >ceph dashboard ac-user-show [USERNAME]- Einen neuen Benutzer erstellen:
cephuser@adm >ceph dashboard ac-user-create USERNAME [PASSWORD] [ROLENAME] [NAME] [EMAIL]- Einen Benutzer löschen:
cephuser@adm >ceph dashboard ac-user-delete USERNAME- Benutzerpasswörter ändern:
cephuser@adm >ceph dashboard ac-user-set-password USERNAME PASSWORD- Name und E-Mail-Adresse eines Benutzers bearbeiten:
cephuser@adm >ceph dashboard ac-user-set-info USERNAME NAME EMAIL- Benutzer deaktivieren:
cephuser@adm >ceph dashboard ac-user-disable USERNAME- Benutzer aktivieren:
cephuser@adm >ceph dashboard ac-user-enable USERNAME
11.3 Benutzerrollen und Berechtigungen #
In diesem Abschnitt erfahren Sie, welche Sicherheitsbereiche Sie einer Benutzerrolle zuweisen können, wie Sie Benutzerrollen verwalten und wie Sie sie den Benutzerkonten zuweisen.
11.3.1 Definieren von Sicherheitsbereichen #
Benutzerkonten sind mit einer Gruppe von Rollen verknüpft, mit der definiert wird, auf welche Teile des Dashboards der Benutzer zugreifen kann. Die Dashboard-Teile sind in einem Sicherheitsbereich gruppiert. Sicherheitsbereiche sind vordefiniert und statisch. Die folgenden Sicherheitsbereiche sind derzeit verfügbar:
- hosts
Alle Funktionen für den Menüeintrag .
- config-opt
Alle Funktionen für die Verwaltung der Ceph-Konfigurationsoptionen.
- Speicherplatz auf dem Pool
Alle Funktionen für die Pool-Verwaltung.
- osd
Alle Funktionen für die Ceph OSD-Verwaltung.
- monitor
Alle Funktionen für die Ceph Monitor-Verwaltung.
- rbd-image
Alle Funktionen für die Verwaltung von RADOS-Block-Device-Images.
- rbd-mirroring
Alle Funktionen für die Verwaltung der RADOS-Block-Device-Spiegelung.
- iscsi
Alle Funktionen für die iSCSI-Verwaltung.
- rgw
Alle Funktionen für die Object-Gateway-Verwaltung.
- cephfs
Alle Funktionen für die CephFS-Verwaltung.
- manager
Alle Funktionen für die Ceph-Manager-Verwaltung.
- Protokoll
Alle Funktionen für die Verwaltung der Ceph-Protokolle.
- grafana
Alle Funktionen für den Grafana-Proxy.
- prometheus
Alle Funktionen für die Prometheus-Verwaltung.
- dashboard-settings
Zum Ändern der Dashboard-Einstellungen.
11.3.2 Festlegen von Benutzerrollen #
Eine Rolle bestimmt eine Reihe von Zuordnungen zwischen einem Sicherheitsbereich und einer Gruppe von Berechtigungen. Es gibt vier Arten von Berechtigungen: „read“, „create“, „update“ und „delete“.
Im folgenden Beispiel wird eine Rolle festgelegt, bei der ein Benutzer die Berechtigungen „read“ und „create“ für Funktionen im Rahmen der Pool-Verwaltung sowie uneingeschränkte Berechtigungen für Funktionen im Rahmen der RBD-Image-Verwaltung besitzt:
{
'role': 'my_new_role',
'description': 'My new role',
'scopes_permissions': {
'pool': ['read', 'create'],
'rbd-image': ['read', 'create', 'update', 'delete']
}
}Das Dashboard bietet bereits eine Gruppe vordefinierter Rollen, die als Systemrollen bezeichnet werden. Diese Rollen können Sie nach einer Neuinstallation des Ceph Dashboards sofort nutzen:
- Administrator
Uneingeschränkte Berechtigungen für alle Sicherheitsbereiche.
- Nur-Lesen
Leseberechtigung für alle Sicherheitsbereiche mit Ausnahme der Dashboard-Einstellungen.
- block-manager
Uneingeschränkte Berechtigungen für die Bereiche „rbd-image“, „rbd-mirroring“ und „iscsi“.
- rgw-manager
Uneingeschränkte Berechtigungen für den Bereich „rgw“.
- cluster-manager
Uneingeschränkte Berechtigungen für die Bereiche „hosts“, „osd“, „monitor“, „manager“ und „config-opt“.
- pool-manager
Uneingeschränkte Berechtigungen für den Bereich „pool“.
- cephfs-manager
Uneingeschränkte Berechtigungen für den Bereich „cephfs“.
11.3.2.1 Verwalten benutzerdefinierter Rollen #
Mit folgenden Kommandos können Sie neue Benutzerrollen erstellen:
- Eine neue Rolle erstellen:
cephuser@adm >ceph dashboard ac-role-create ROLENAME [DESCRIPTION]- Eine Rolle löschen:
cephuser@adm >ceph dashboard ac-role-delete ROLENAME- Bereichsberechtigungen für eine Rolle festlegen:
cephuser@adm >ceph dashboard ac-role-add-scope-perms ROLENAME SCOPENAME PERMISSION [PERMISSION...]- Bereichsberechtigungen einer Rolle löschen:
cephuser@adm >ceph dashboard ac-role-del-perms ROLENAME SCOPENAME
11.3.2.2 Zuweisen von Rollen zu Benutzerkonten #
Mit folgenden Kommandos weisen Sie die Rollen den Benutzern zu:
- Benutzerrollen festlegen:
cephuser@adm >ceph dashboard ac-user-set-roles USERNAME ROLENAME [ROLENAME ...]- Einem Benutzer zusätzliche Rollen zuweisen:
cephuser@adm >ceph dashboard ac-user-add-roles USERNAME ROLENAME [ROLENAME ...]- Rollen eines Benutzers löschen:
cephuser@adm >ceph dashboard ac-user-del-roles USERNAME ROLENAME [ROLENAME ...]
Wenn Sie benutzerdefinierte Rollen erstellen und den Ceph-Cluster später mit dem Ausführungsprogramm ceph.purge bereinigen möchten, müssen Sie zunächst die benutzerdefinierten Rollen bereinigen. Weitere Informationen finden Sie in Abschnitt 13.9, „Vollständiges Entfernen eines Ceph-Clusters“.
11.3.2.3 Beispiel: Erstellen eines Benutzers und einer benutzerdefinierten Regel #
In diesem Abschnitt wird das Verfahren zum Erstellen eines Benutzerkontos veranschaulicht, das RBD-Images verwalten und den Ceph-Pool abrufen kann sowie den Nur-Lese-Zugriff auf alle anderen Bereiche erhält.
Erstellen Sie einen neuen Benutzer namens
tux:cephuser@adm >ceph dashboard ac-user-create tux PASSWORDErstellen Sie eine Rolle und legen Sie die Bereichsberechtigungen fest:
cephuser@adm >ceph dashboard ac-role-create rbd/pool-managercephuser@adm >ceph dashboard ac-role-add-scope-perms rbd/pool-manager \ rbd-image read create update deletecephuser@adm >ceph dashboard ac-role-add-scope-perms rbd/pool-manager pool read createOrdnen Sie die Rollen dem Benutzer
tuxzu:cephuser@adm >ceph dashboard ac-user-set-roles tux rbd/pool-manager read-only
11.4 Proxy-Konfiguration #
Wenn Sie eine feste URL für das Ceph Dashboard festlegen möchten oder wenn Sie keine direkten Verbindungen zu den Manager-Knoten zulassen möchten, können Sie einen Proxy einrichten, der eingehende Anfragen automatisch an die aktuell aktive ceph-mgr-Instanz weiterleitet.
11.4.1 Zugriff auf das Dashboard über Reverse-Proxys #
Wenn Sie über eine Reverse-Proxy-Konfiguration auf das Dashboard zugreifen, muss ggf. ein URL-Präfix angegeben werden. Mit der Einstellung url_prefix legen Sie fest, dass das Dashboard Hyperlinks mit Ihrem Präfix nutzen soll:
cephuser@adm > ceph config set mgr mgr/dashboard/url_prefix URL_PREFIX
Anschließend können Sie unter http://HOST_NAME:PORT_NUMBER/URL_PREFIX/ auf das Dashboard zugreifen.
11.4.2 Deaktivieren von Umleitungen #
Wenn sich das Ceph Dashboard hinter einem Lastausgleichsproxy wie HAProxy befindet, deaktivieren Sie das Weiterleitungsverhalten, um Situationen zu vermeiden, in denen die internen (nicht auflösbaren) URLs an den Frontend-Client veröffentlicht werden. Mit folgendem Kommando antwortet das Dashboard mit einem HTTP-Fehler (standardmäßig 500), statt an das aktive Dashboard weiterzuleiten:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_behaviour "error"Setzen Sie die Einstellung mit folgendem Kommando auf das standardmäßige Weiterleitungsverhalten zurück:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_behaviour "redirect"11.4.3 Konfigurieren von Fehlerstatuscodes #
Wenn das Weiterleitungsverhalten deaktiviert ist, dann sollten Sie den HTTP-Statuscode von Standby-Dashboards anpassen. Führen Sie hierzu folgendes Kommando aus:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_error_status_code 50311.4.4 Beispiel einer HAProxy-Konfiguration #
Im folgenden Beispiel wird ein TLS/SSL-Durchlauf mit HAProxy konfiguriert.
Die Konfiguration funktioniert unter den folgenden Bedingungen: Wenn das Dashboard ausfällt, erhält der Frontend-Client möglicherweise eine HTTP-Weiterleitungsantwort (303) und wird an einen nicht auflösbaren Host weitergeleitet.
Dies geschieht, wenn die Ausfallsicherung während zweier HAProxy-Zustandsprüfungen auftritt. In dieser Situation antwortet der zuvor aktive Dashboard-Knoten nun mit einer 303, die auf den neuen aktiven Knoten zeigt. Um diese Situation zu vermeiden, sollten Sie erwägen, das Weiterleitungsverhalten auf Standby-Knoten zu deaktivieren.
defaults
log global
option log-health-checks
timeout connect 5s
timeout client 50s
timeout server 450s
frontend dashboard_front
mode http
bind *:80
option httplog
redirect scheme https code 301 if !{ ssl_fc }
frontend dashboard_front_ssl
mode tcp
bind *:443
option tcplog
default_backend dashboard_back_ssl
backend dashboard_back_ssl
mode tcp
option httpchk GET /
http-check expect status 200
server x HOST:PORT ssl check verify none
server y HOST:PORT ssl check verify none
server z HOST:PORT ssl check verify none11.5 Revision von API-Anforderungen #
Die REST-API des Ceph Dashboards kann PUT-, POST- und DELETE-Anforderungen im Ceph-Revisionsprotokoll festhalten. Die Protokollierung ist standardmäßig deaktiviert; mit folgendem Kommando können Sie sie jedoch aktivieren:
cephuser@adm > ceph dashboard set-audit-api-enabled trueNach der Aktivierung werden die folgenden Parameter für jede Anforderung protokolliert:
- Von
Ursprung der Anforderung, z. B. „https://[::1]:44410“.
- Pfad
Der REST API-Pfad, z. B
/api/auth.- Methode
„PUT“, „POST“ oder „DELETE“.
- benutzer
Name des Benutzers (oder „None“ [Keine]).
Beispiel für einen Protokolleintrag:
2019-02-06 10:33:01.302514 mgr.x [INF] [DASHBOARD] \
from='https://[::ffff:127.0.0.1]:37022' path='/api/rgw/user/exu' method='PUT' \
user='admin' params='{"max_buckets": "1000", "display_name": "Example User", "uid": "exu", "suspended": "0", "email": "user@example.com"}'Die Protokollierung der Anforderungsnutzlast (die Liste der Argumente und ihrer Werte) ist standardmäßig aktiviert. So können Sie sie deaktivieren:
cephuser@adm > ceph dashboard set-audit-api-log-payload false11.6 Konfigurieren von NFS Ganesha im Ceph Dashboard #
Das Ceph Dashboard kann NFS-Ganesha-Exporte verwalten, die CephFS oder Object Gateway als Backstore verwenden. Das Dashboard verwaltet NFS-Ganesha-Konfigurationsdateien, die in RADOS-Objekten auf dem CephFS-Cluster gespeichert sind. NFS Ganesha muss einen Teil ihrer Konfiguration im Ceph-Cluster speichern.
Konfigurieren Sie den Standort der Konfigurationsobjekte von NFS Ganesha mit folgendem Kommando:
cephuser@adm > ceph dashboard set-ganesha-clusters-rados-pool-namespace pool_name[/namespace]Sie können nun NFS-Ganesha-Exporte über das Ceph Dashboard verwalten.
11.6.1 Konfigurieren mehrerer NFS-Ganesha-Cluster #
Das Ceph Dashboard unterstützt die Verwaltung von NFS-Ganesha-Exporten, die zu verschiedenen NFS-Ganesha-Clustern gehören. Wir empfehlen, dass jeder NFS-Ganesha-Cluster seine Konfigurationsobjekte in einem anderen RADOS-Pool/Namespace speichert, um die Konfigurationen voneinander zu isolieren.
Geben Sie mit folgendem Kommando die Speicherorte der Konfiguration der einzelnen NFS-Ganesha-Cluster an:
cephuser@adm > ceph dashboard set-ganesha-clusters-rados-pool-namespace cluster_id:pool_name[/namespace](,cluster_id:pool_name[/namespace])*Die cluster_id ist eine beliebige Zeichenkette, die den NFS-Ganesha-Cluster eindeutig identifiziert.
Wenn Sie das Ceph Dashboard mit mehreren NFS-Ganesha-Clustern konfigurieren, können Sie in der Weboberfläche automatisch auswählen, zu welchem Cluster ein Export gehört.
11.7 Plugins zur Fehlersuche #
Ceph-Dashboard-Plugins erweitern die Funktionalität des Dashboards. Das Plugin zur Fehlersuche ermöglicht die Anpassung des Verhaltens des Dashboards entsprechend dem Fehlersuchmodus. Es kann mit folgendem Kommando aktiviert, deaktiviert oder überprüft werden:
cephuser@adm >ceph dashboard debug status Debug: 'disabled'cephuser@adm >ceph dashboard debug enable Debug: 'enabled'cephuser@adm >dashboard debug disable Debug: 'disabled'
Es ist standardmäßig deaktiviert. Dies ist die empfohlene Einstellung für Produktionsbereitstellungen. Bei Bedarf kann der Fehlersuchmodus aktiviert werden, ohne dass ein Neustart erforderlich ist.
Teil II Clustervorgang #
- 12 Ermitteln des Clusterzustands
Die Überwachung eines aktiven Clusters ist mit dem Werkzeug
cephmöglich. Zur Ermittlung des Cluster-Zustands wird in der Regel der Status der Ceph OSDs, Ceph Monitors, Platzierungsgruppen und Metadatenserver geprüft.- 13 Betriebsaufgaben
Gehen Sie zum Ändern der Konfiguration eines vorhandenen Ceph-Clusters folgendermaßen vor:
- 14 Betrieb von Ceph-Services
Sie können Ceph-Services auf Daemon-, Knoten- oder Clusterebene betreiben. Verwenden Sie je nach gewünschtem Ansatz cephadm oder das Kommando
systemctl.- 15 Sichern und Wiederherstellen
In diesem Kapitel wird erläutert, welche Teile des Ceph-Clusters gesichert werden müssen, damit die Funktion des Clusters wiederhergestellt werden kann.
- 16 Überwachung und Warnungen
In SUSE Enterprise Storage 7 stellt cephadm einen Überwachungs- und Warnungsstack bereit. Anwender müssen die Services (wie Prometheus, Alertmanager und Grafana), die sie mit cephadm bereitstellen wollen, entweder in einer YAML-Konfigurationsdatei definieren, oder sie können sie über die Kommandozei…
12 Ermitteln des Clusterzustands #
Die Überwachung eines aktiven Clusters ist mit dem Werkzeug
ceph möglich. Zur Ermittlung des Cluster-Zustands wird in
der Regel der Status der Ceph OSDs, Ceph Monitors, Platzierungsgruppen und
Metadatenserver geprüft.
Geben Sie zur Ausführung des Werkzeugs ceph im
interaktiven Modus ceph in der Kommandozeile ohne
Argumente ein. Der interaktive Modus ist praktischer, wenn Sie vorhaben,
mehrere ceph-Kommandos in einer Zeile einzugeben.
Beispiel:
cephuser@adm > ceph
ceph> health
ceph> status
ceph> quorum_status
ceph> mon stat12.1 Überprüfen des Status eines Clusters #
Mit ceph -s oder ceph -s rufen Sie den
aktuellen Zustand des Clusters ab:
cephuser@adm > ceph -s
cluster:
id: b4b30c6e-9681-11ea-ac39-525400d7702d
health: HEALTH_OK
services:
mon: 5 daemons, quorum ses-min1,ses-master,ses-min2,ses-min4,ses-min3 (age 2m)
mgr: ses-min1.gpijpm(active, since 3d), standbys: ses-min2.oopvyh
mds: my_cephfs:1 {0=my_cephfs.ses-min1.oterul=up:active}
osd: 3 osds: 3 up (since 3d), 3 in (since 11d)
rgw: 2 daemons active (myrealm.myzone.ses-min1.kwwazo, myrealm.myzone.ses-min2.jngabw)
task status:
scrub status:
mds.my_cephfs.ses-min1.oterul: idle
data:
pools: 7 pools, 169 pgs
objects: 250 objects, 10 KiB
usage: 3.1 GiB used, 27 GiB / 30 GiB avail
pgs: 169 active+cleanDie Ausgabe bietet die folgenden Informationen:
Cluster-ID
Cluster-Zustand
Die Monitor-Zuordnungsepoche und den Status des Monitor-Quorums
Die OSD-Zuordnungsepoche und den Status der OSDs
Status der Ceph Managers
Status der Object Gateways
Die Version der Placement-Group-Zuordnung
Die Anzahl der Placement Groups und Pools
Die nominelle Menge der gespeicherten Daten und die Anzahl der gespeicherten Objekte
Die Gesamtmenge der gespeicherten Daten
Der Wert used bezeichnet den tatsächlich belegten
Basisspeicherplatz. Der Wert xxx GB / xxx GB bezeichnet
den verfügbaren Speicherplatz (der kleinere Wert) der gesamten
Speicherkapazität des Clusters. Die nominelle Menge spiegelt die Menge der
gespeicherten Daten wider, bevor diese reproduziert oder geklont werden
oder ein Snapshot davon erstellt wird. Daher übersteigt die Menge der
tatsächlich gespeicherten Daten normalerweise die nominelle gespeicherte
Menge, weil Ceph Reproduktionen der Daten erstellt und die
Speicherkapazität möglicherweise auch zum Klonen und für Snapshots
verwendet.
Mit den folgenden Kommandos werden die Statusinformationen ebenfalls sofort angezeigt:
ceph pg statceph osd pool statsceph dfceph df detail
Sollen die Angaben in Echtzeit aktualisiert werden, geben Sie diese
Kommandos (auch ceph ‑s) als Argument für das Kommando
watch an:
root # watch -n 10 'ceph -s'Drücken Sie Strg–C, wenn Sie den Vorgang nicht länger beobachten möchten.
12.2 Überprüfen der Clusterintegrität #
Überprüfen Sie den Zustand Ihres Clusters nach dessen Start und bevor Sie mit dem Lesen und/oder Schreiben von Daten beginnen:
cephuser@adm > ceph health
HEALTH_WARN 10 pgs degraded; 100 pgs stuck unclean; 1 mons down, quorum 0,2 \
node-1,node-2,node-3Wenn Sie nicht standardmäßige Standorte für Ihre Konfiguration oder Ihren Schlüsselbund angegeben haben, können Sie diese angeben mit:
cephuser@adm > ceph -c /path/to/conf -k /path/to/keyring healthDer Ceph-Cluster gibt einen der folgenden Zustandscodes zurück:
- OSD_DOWN
Einer oder mehrere OSDs sind als inaktiv gekennzeichnet. Der OSD Daemon wurde möglicherweise gestoppt oder Peer-OSDs erreichen den OSD möglicherweise nicht über das Netzwerk. Üblicherweise handelt es sich dabei um einen gestoppten oder abgestürzten Daemon, einen inaktiven Host oder einen Netzwerkausfall.
Verifizieren Sie, dass sich der Host in einem ordnungsgemäßen Zustand befindet, der Daemon gestartet ist und das Netzwerk funktioniert. Falls der Daemon abgestürzt ist, enthält die Protokolldatei des Daemon (
/var/log/ceph/ceph-osd.*) möglicherweise Informationen zur Fehlersuche.- OSD_CRUSH-Typ_DOWN, beispielsweise OSD_HOST_DOWN
Alle OSDs in einem bestimmten CRUSH-Teilbaum sind als inaktiv gekennzeichnet, wie zum Beispiel alle OSDs auf einem Host.
- OSD_ORPHAN
In der CRUSH Map-Hierarchie wird auf einen OSD verwiesen, er ist jedoch nicht vorhanden. Der OSD kann aus der CRUSH-Hierarchie entfernt werden mit:
cephuser@adm >ceph osd crush rm osd.ID- OSD_OUT_OF_ORDER_FULL
Die Auslastungsgrenzwerte für backfillfull (Standardwert 0,90), nearfull (Standardwert 0,85), full (Standardwert 0,95) und/oder failsafe_full sind nicht aufsteigend. Insbesondere erwarten wir backfillfull < nearfull, nearfull < full und full < failsafe_full.
Mit folgendem Kommando lesen Sie die aktuellen Werte aus:
cephuser@adm >ceph health detail HEALTH_ERR 1 full osd(s); 1 backfillfull osd(s); 1 nearfull osd(s) osd.3 is full at 97% osd.4 is backfill full at 91% osd.2 is near full at 87%Die Grenzwerte können mit folgenden Kommandos angepasst werden:
cephuser@adm >ceph osd set-backfillfull-ratio ratiocephuser@adm >ceph osd set-nearfull-ratio ratiocephuser@adm >ceph osd set-full-ratio ratio- OSD_FULL
Einer oder mehrere OSDs haben den Grenzwert full überschritten, was verhindert, dass der Cluster Schreibvorgänge ausführt. Die Auslastung pro Pool wird überprüft mit:
cephuser@adm >ceph dfDer zurzeit definierte Grad full wird angezeigt mit:
cephuser@adm >ceph osd dump | grep full_ratioEine kurzfristige Behelfslösung zum Wiederherstellen der Schreibverfügbarkeit ist die geringfügige Erhöhung des Grenzwerts:
cephuser@adm >ceph osd set-full-ratio ratioFügen Sie neuen Speicherplatz zum Cluster hinzu, indem Sie weitere OSDs bereitstellen, oder löschen Sie bestehende Daten, um Speicherplatz freizugeben.
- OSD_BACKFILLFULL
Einer oder mehrere OSDs haben den Grenzwert backfillfull überschritten, wodurch verhindert wird, dass auf diesem Gerät ein Datenausgleich stattfindet. Hierbei handelt es sich um eine frühzeitige Warnung, dass der Ausgleich möglicherweise nicht durchgeführt werden kann und der Cluster fast voll ist. Die Auslastung pro Pool wird überprüft mit:
cephuser@adm >ceph df- OSD_NEARFULL
Einer oder mehrere OSDs haben den Grenzwert nearfull überschritten. Hierbei handelt es sich um eine frühzeitige Warnung, dass der Cluster fast voll ist. Die Auslastung pro Pool wird überprüft mit:
cephuser@adm >ceph df- OSDMAP_FLAGS
Eine oder mehrere interessante Cluster-Flags wurden gesetzt. Mit Ausnahme von full können diese Flags festgelegt oder gelöscht werden mit:
cephuser@adm >ceph osd set flagcephuser@adm >ceph osd unset flagDie folgenden Flags sind verfügbar:
- Vollständig
Der Cluster wird als voll gekennzeichnet und kann keine Schreibvorgänge mehr bedienen.
- pauserd, pausewr
Lese- und Schreibvorgänge werden ausgesetzt.
- noup
OSDs dürfen nicht gestartet werden.
- nodown
OSD-Fehlerberichte werden ignoriert, sodass die Monitors keine OSDs mit down kennzeichnen.
- noin
OSDs, die vorher mit out gekennzeichnet wurden, werden beim Starten nicht wieder mit in gekennzeichnet.
- noout
Down OSDs werden nach dem konfigurierten Intervall nicht automatisch mit out gekennzeichnet.
- nobackfill, norecover, norebalance
Wiederherstellung oder Datenausgleich ist angehalten.
- noscrub, nodeep_scrub
Scrubbing (Informationen hierzu finden Sie in Abschnitt 17.6, „Scrubbing von Platzierungsgruppen“) ist deaktiviert.
- notieragent
Die Cache-Tiering-Aktivität ist angehalten.
- OSD_FLAGS
Für eine oder mehrere OSDs wurde eine Interessensflagge pro OSD gesetzt. Die folgenden Flags sind verfügbar:
- noup
Der OSD darf nicht starten.
- nodown
Fehlerberichte für diesen OSD werden ignoriert.
- noin
Wenn dieser OSD vorher automatisch nach einem Fehler mit out markiert wurde, wird er beim Start nicht mit in gekennzeichnet.
- noout
Wenn dieser OSD inaktiv ist, wird er nach dem konfigurierten Intervall nicht automatisch mit out gekennzeichnet.
Pro-OSD-Flags werden gesetzt oder gelöscht mit:
cephuser@adm >ceph osd add-flag osd-IDcephuser@adm >ceph osd rm-flag osd-ID- OLD_CRUSH_TUNABLES
Die CRUSH Map verwendet sehr alte Einstellungen und sollte aktualisiert werden. Die ältesten Tunables, die verwendet werden können (d. h. die älteste Client-Version, die eine Verbindung zum Cluster herstellen kann), ohne diese Zustandswarnung auszulösen, werden durch die Konfigurationsoption
mon_crush_min_required_versionfestgelegt.- OLD_CRUSH_STRAW_CALC_VERSION
Die CRUSH Map verwendet eine ältere, nicht optimale Methode zur Berechnung von Gewichtungszwischenwerten für Straw Buckets. Die CRUSH Map sollte aktualisiert werden, um die neuere Methode zu verwenden (
straw_calc_version=1).- CACHE_POOL_NO_HIT_SET
Einer oder mehrere Cache Pools wurden nicht mit einem Treffersatz zum Verfolgen der Auslastung konfiguriert. Dadurch wird verhindert, dass der Tiering-Agent unbenutzte Objekte erkennt, die aus dem Cache entfernt werden müssen. Treffersätze werden im Cache Pool konfiguriert mit:
cephuser@adm >ceph osd pool set poolname hit_set_type typecephuser@adm >ceph osd pool set poolname hit_set_period period-in-secondscephuser@adm >ceph osd pool set poolname hit_set_count number-of-hitsetscephuser@adm >ceph osd pool set poolname hit_set_fpp target-false-positive-rate- OSD_NO_SORTBITWISE
Es werden keine OSDs vor Luminous Version 12 ausgeführt, doch das Flag
sortbitwisewurde nicht gesetzt. Das Flagsortbitwisemuss gesetzt werden, damit OSDs ab Luminous Version 12 starten:cephuser@adm >ceph osd set sortbitwise- POOL_FULL
Einer oder mehrere Pools haben das Kontingent erreicht und lassen keine weiteren Schreibvorgänge zu. Pool-Kontingente und Auslastungswerte werden mit folgendem Kommando festgelegt:
cephuser@adm >ceph df detailLegen Sie entweder das Pool-Kontingent mit
cephuser@adm >ceph osd pool set-quota poolname max_objects num-objectscephuser@adm >ceph osd pool set-quota poolname max_bytes num-bytesfest oder löschen Sie einige vorhandene Daten, um die Auslastung zu verringern.
- PG_AVAILABILITY
Die Datenverfügbarkeit ist reduziert. Dies bedeutet, dass der Cluster potenzielle Lese- oder Schreibanforderungen für einige Daten im Cluster nicht bedienen kann. Dies ist insbesondere dann der Fall, wenn sich mindestens eine PG in einem Zustand befindet, der die Ausführung von E/A-Anforderungen nicht zulässt. Problematische PG-Zustände sind peering, stale, incomplete und das Fehlen von active (wenn diese Zustände nicht schnell gelöscht werden). Detaillierte Informationen dazu, welche PGs betroffen sind, erhalten Sie durch Ausführen von:
cephuser@adm >ceph health detailIn den meisten Fällen besteht die Ursache darin, dass einer oder mehrere OSDs aktuell inaktiv sind. Der Zustand bestimmter problematischer PGs kann abgefragt werden mit:
cephuser@adm >ceph tell pgid query- PG_DEGRADED
Die Datenredundanz ist für einige Daten reduziert. Dies bedeutet, dass der Cluster nicht über die gewünschte Anzahl der Reproduktionen für alle Daten (für reproduzierte Pools) oder Erasure Code-Fragmente (für Erasure Coded Pools) verfügt. Dies ist insbesondere dann der Fall, wenn bei einer oder mehreren PGs das Flag degraded oder undersized gesetzt wurde (es sind nicht genügend Instanzen dieser Placement Group im Cluster vorhanden) oder wenn einige Zeit das Flag clean nicht gesetzt war. Detaillierte Informationen dazu, welche PGs betroffen sind, erhalten Sie durch Ausführen von:
cephuser@adm >ceph health detailIn den meisten Fällen besteht die Ursache darin, dass einer oder mehrere OSDs aktuell inaktiv sind. Der Zustand bestimmter problematischer PGs kann abgefragt werden mit:
cephuser@adm >ceph tell pgid query- PG_DEGRADED_FULL
Die Datenredundanz ist möglicherweise für einige Daten reduziert oder in Gefahr, weil freier Speicherplatz im Cluster fehlt. Dies ist insbesondere dann der Fall, wenn für eine oder mehrere PGs das Flag backfill_toofull oder recovery_toofull gesetzt wurde. Dies bedeutet, dass der Cluster keine Daten migrieren oder wiederherstellen kann, weil einer oder mehrere OSDs den Grenzwert backfillfull überschritten haben.
- PG_DAMAGED
Beim Daten-Scrubbing (weitere Informationen hierzu finden Sie in Abschnitt 17.6, „Scrubbing von Platzierungsgruppen“) wurden einige Probleme bezüglich der Datenkonsistenz im Cluster erkannt. Dies ist insbesondere dann der Fall, wenn für eine oder mehrere PGs das Flag inconsistent oder snaptrim_error gesetzt wurde. Dadurch wird angegeben, dass bei einem früheren Scrubbing-Vorgang ein Problem gefunden wurde. Möglicherweise wurde auch das Flag repair gesetzt, was bedeutet, dass eine derartige Inkonsistenz gerade repariert wird.
- OSD_SCRUB_ERRORS
Bei kürzlich durchgeführten OSD-Scrubbing-Vorgängen wurden Inkonsistenzen erkannt.
- CACHE_POOL_NEAR_FULL
Ein Cache-Schicht-Pool ist fast voll. In diesem Kontext wird „full“ durch die Eigenschaften target_max_bytes und target_max_objects des Caches Pools bestimmt. Wenn der Pool den Grenzwert erreicht, werden Schreibanforderungen an den Pool möglicherweise blockiert und Daten aus dem Cache entfernt und gelöscht. Dieser Zustand führt normalerweise zu sehr hohen Latenzen und schlechter Leistung. Der Grenzwert für die Größe des Pools kann angepasst werden mit:
cephuser@adm >ceph osd pool set cache-pool-name target_max_bytes bytescephuser@adm >ceph osd pool set cache-pool-name target_max_objects objectsDie normale Aktivität zum Leeren des Caches wird möglicherweise auch gedrosselt durch die reduzierte Verfügbarkeit oder Leistung der Basisschicht oder durch die Cluster-Last insgesamt.
- TOO_FEW_PGS
Die Anzahl der verwendeten PGs liegt unterhalb des konfigurierbaren Grenzwerts der
mon_pg_warn_min_per_osd-PGs pro OSD. Dies führt eventuell dazu, dass die Daten nicht optimal auf die OSDs im Cluster verteilt und ausgeglichen werden und die Leistung insgesamt verschlechtert wird.- TOO_MANY_PGS
Die Anzahl der verwendeten PGs liegt oberhalb des konfigurierbaren Grenzwerts der
mon_pg_warn_min_per_osd-PGs pro OSD. Dies führt möglicherweise zu höherer Arbeitsspeicherauslastung für OSD-Daemons, langsamerem Peering nach Änderungen des Cluster-Zustands (beispielsweise OSD-Neustarts, Hinzufügen oder Entfernen) sowie höherer Last für Ceph Managers und Ceph Monitors.Der Wert
pg_numfür bestehende Pools kann nicht reduziert werden, der Wertpgp_numjedoch schon. Dadurch werden einige PGs effizient auf denselben Gruppen von OSDs angeordnet, wodurch einige der oben beschriebenen negativen Auswirkungen abgeschwächt werden. Derpgp_num-Wert kann angepasst werden mit:cephuser@adm >ceph osd pool set pool pgp_num value- SMALLER_PGP_NUM
Bei einem oder mehreren Pools ist der
pgp_num-Wert kleiner als derpg_num-Wert. Dies ist normalerweise ein Anzeichen dafür, dass die PG-Anzahl erhöht wurde, ohne auch das Platzierungsverhalten zu erhöhen. Dieses Problem wird normalerweise dadurch behoben, dasspgp_nummitpg_numabgeglichen wird, was die Datenmigration auslöst. Verwenden Sie hierzu:cephuser@adm >ceph osd pool set pool pgp_num pg_num_value- MANY_OBJECTS_PER_PG
Bei mindestens einem Pool ist die durchschnittliche Anzahl von Objekten pro PG erheblich höher als der Durchschnitt im Cluster insgesamt. Der spezifische Grenzwert wird gesteuert durch den Konfigurationswert
mon_pg_warn_max_object_skew. Dies ist normalerweise ein Anzeichen dafür, dass die Pools mit den meisten Daten im Cluster zu wenige PGs enthalten und/oder dass andere Pools mit weniger Daten zu viele PGs enthalten. Um die Zustandswarnung abzustellen, kann der Grenzwert durch Anpassen der Konfigurationsoptionmon_pg_warn_max_object_skewan den Monitors erhöht werden.- POOL_APP_NOT_ENABLED¶
Es ist zwar ein Pool mit einem oder mehreren Objekten vorhanden, wurde jedoch nicht für die Verwendung durch eine bestimmte Anwendung gekennzeichnet. Heben Sie diese Warnmeldung auf, indem Sie den Pool für die Verwendung durch eine Anwendung kennzeichnen. Beispiel, wenn der Pool von RBD verwendet wird:
cephuser@adm >rbd pool init pool_nameWenn der Pool durch eine benutzerdefinierte Anwendung „foo“ verwendet wird, können Sie ihn auch mit dem Kommando der untersten Ebene kennzeichnen:
cephuser@adm >ceph osd pool application enable foo- POOL_FULL
Einer oder mehrere Pools haben das Kontingent erreicht (oder erreichen es bald). Der Grenzwert zum Auslösen dieser Fehlerbedingung wird durch die Konfigurationsoption
mon_pool_quota_crit_thresholdgesteuert. Pool-Kontingente werden nach oben oder unten angepasst (oder entfernt) mit:cephuser@adm >ceph osd pool set-quota pool max_bytes bytescephuser@adm >ceph osd pool set-quota pool max_objects objectsDurch Festlegen des Kontingentwerts auf 0 wird das Kontingent deaktiviert.
- POOL_NEAR_FULL
Einer oder mehrere Pools haben bald das Kontingent erreicht. Der Grenzwert zum Auslösen dieser Fehlerbedingung wird durch die Konfigurationsoption
mon_pool_quota_warn_thresholdgesteuert. Pool-Kontingente werden nach oben oder unten angepasst (oder entfernt) mit:cephuser@adm >ceph osd osd pool set-quota pool max_bytes bytescephuser@adm >ceph osd osd pool set-quota pool max_objects objectsDurch Festlegen des Kontingentwerts auf 0 wird das Kontingent deaktiviert.
- OBJECT_MISPLACED
Mindestens ein Objekt im Cluster ist nicht auf dem Knoten gespeichert, auf dem es laut Cluster gespeichert werden soll. Dies ist ein Anzeichen dafür, dass die Datenmigration aufgrund einer kürzlich vorgenommenen Änderung am Cluster noch nicht abgeschlossen ist. Falsch platzierte Daten stellen an sich keine Gefahr dar. Die Datenkonsistenz ist niemals in Gefahr und alte Kopien von Objekten werden niemals entfernt, bevor die gewünschte Anzahl an neuen Kopien (an den gewünschten Speicherorten) vorhanden ist.
- OBJECT_UNFOUND
Ein oder mehrere Objekte im Cluster werden nicht gefunden. Dies ist insbesondere dann der Fall, wenn die OSDs wissen, dass eine neue oder aktualisierte Kopie eines Objekts vorhanden sein sollte, jedoch keine Kopie dieser Version des Objekts auf OSDs gefunden wurden, die zurzeit aktiv sind. Lese- oder Schreibanforderungen an die „unfound“-Objekte werden blockiert. Im Idealfall kann das inaktive OSD, auf dem sich das aktuelle Exemplar des nicht gefundenen Objekts befindet, wieder aktiviert werden. Dafür in Frage kommende OSDs können anhand des Peering-Zustands für die PGs identifiziert werden, die für das nicht gefundene Objekt zuständig sind:
cephuser@adm >ceph tell pgid query- REQUEST_SLOW
Die Verarbeitung einer oder mehrerer OSD-Anforderungen dauert sehr lange. Dies ist möglicherweise ein Anzeichen für eine extreme Last, ein langsames Speichergerät oder einen Softwarefehler. Mit folgendem Kommando, das auf dem OSD-Host ausgeführt wird, fragen Sie die Anforderungswarteschlange auf den in Frage kommenden OSDs ab:
cephuser@adm >ceph daemon osd.id opsSie sehen eine Zusammenfassung der langsamsten kürzlich vorgenommenen Anforderungen:
cephuser@adm >ceph daemon osd.id dump_historic_opsSie finden den Standort eines OSDs mit:
cephuser@adm >ceph osd find osd.id- REQUEST_STUCK
Mindestens eine OSD-Anforderung wurde relativ lange Zeit blockiert, z. B. 4.096 Sekunden. Dies ist ein Anzeichen dafür, dass sich entweder der Cluster für einen längeren Zeitraum in einem fehlerhaften Zustand befindet (beispielsweise wenn nicht genügend OSDs ausgeführt werden oder inaktive PGs vorliegen) oder wenn interne Probleme am OSD aufgetreten sind.
- PG_NOT_SCRUBBED
Es wurde länger kein Scrubbing bei mindestens einer PG durchgeführt (weitere Informationen hierzu finden Sie in Abschnitt 17.6, „Scrubbing von Platzierungsgruppen“). Bei PGs wird normalerweise alle
mon_scrub_intervalSekunden ein Scrubbing durchgeführt und diese Warnmeldung wird ausgelöst, wenn diesemon_warn_not_scrubbed-Intervalle ohne Scrubbing abgelaufen sind. Bei PGs wird kein Scrubbing durchgeführt, wenn sie nicht als intakt („clean“) gekennzeichnet sind. Dies kann vorkommen, wenn sie falsch platziert wurden oder eingeschränkt leistungsfähig sind (weitere Informationen hierzu finden Sie oben unter PG_AVAILABILITY und PG_DEGRADED). Ein Scrubbing einer intakten PG wird manuell initiiert mit:cephuser@adm >ceph pg scrub pgid- PG_NOT_DEEP_SCRUBBED
Bei einer oder mehreren PGs wurden länger kein Deep Scrubbing durchgeführt (weitere Informationen hierzu finden Sie in Abschnitt 17.6, „Scrubbing von Platzierungsgruppen“). Bei PGs wird normalerweise alle
osd_deep_mon_scrub_intervalSekunden ein Scrubbing durchgeführt und diese Warnmeldung wird ausgelöst, wenn diesermon_warn_not_deep_scrubbed-Zeitraum ohne Scrubbing abgelaufen ist. Bei PGs wird kein (Deep) Scrubbing durchgeführt, wenn sie nicht als intakt („clean“) gekennzeichnet sind. Dies kann vorkommen, wenn sie falsch platziert wurden oder eingeschränkt leistungsfähig sind (weitere Informationen hierzu finden Sie oben unter PG_AVAILABILITY und PG_DEGRADED). Ein Scrubbing einer intakten PG wird manuell initiiert mit:cephuser@adm >ceph pg deep-scrub pgid
Wenn Sie nicht standardmäßige Standorte für Ihre Konfiguration oder Ihren Schlüsselbund angegeben haben, können Sie diese angeben mit:
root # ceph -c /path/to/conf -k /path/to/keyring health12.3 Überprüfen der Nutzungsstatistik eines Clusters #
Mit dem Kommando ceph df prüfen Sie die Datenauslastung
und Datenverteilung auf die Pools in einem Cluster. Mit ceph df
detail erhalten Sie weitere Details.
cephuser@adm > ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 30 GiB 27 GiB 121 MiB 3.1 GiB 10.40
TOTAL 30 GiB 27 GiB 121 MiB 3.1 GiB 10.40
--- POOLS ---
POOL ID STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 0 B 0 0 B 0 8.5 GiB
cephfs.my_cephfs.meta 2 1.0 MiB 22 4.5 MiB 0.02 8.5 GiB
cephfs.my_cephfs.data 3 0 B 0 0 B 0 8.5 GiB
.rgw.root 4 1.9 KiB 13 2.2 MiB 0 8.5 GiB
myzone.rgw.log 5 3.4 KiB 207 6 MiB 0.02 8.5 GiB
myzone.rgw.control 6 0 B 8 0 B 0 8.5 GiB
myzone.rgw.meta 7 0 B 0 0 B 0 8.5 GiB
Der Abschnitt RAW STORAGE der Ausgabe gibt einen
Überblick über den Speicherplatz, den Ihr Cluster für die Daten nutzt.
CLASS: Die Speicherklasse des Geräts. Weitere detaillierte Informationen zu Geräteklassen finden Sie in Abschnitt 17.1.1, „Geräteklassen“.SIZE: Die gesamte Speicherkapazität des Clusters.AVAIL: Der verfügbare freie Speicherplatz im Cluster.USED: Der Speicherplatz (über alle OSDs akkumuliert), der ausschließlich für Datenobjekte auf dem Blockgerät zugewiesen ist.RAW USED: Summe des belegten Speicherplatzes („USED“) und des Speicherplatzes auf dem Blockgerät, der für Ceph-Zwecke zugewiesen/reserviert ist, z. B. der BlueFS-Bereich für BlueStore.% RAW USED: Der Prozentsatz des genutzten Basisspeicherplatzes. Verwenden Sie diese Zahl in Verbindung mitfull ratioundnear full ratio, um sicherzustellen, dass die Kapazität des Clusters nicht voll ausgelastet wird. Weitere Informationen finden Sie in Abschnitt 12.8, „Speicherkapazität“.Anmerkung: Füllstand des ClustersWenn sich der Rohspeicherfüllstand dem Wert 100 % nähert, müssen Sie neuen Speicher in den Cluster aufnehmen. Eine höhere Auslastung führt möglicherweise zu einzelnen vollen OSDs und Problemen mit dem Cluster-Zustand.
Listen Sie mit dem Kommando
ceph osd df treeden Füllstand aller OSDs auf.
Im Abschnitt POOLS der Ausgabe finden Sie eine Liste der
Pools und die nominelle Auslastung der einzelnen Pools. Die Ausgabe in
diesem Abschnitt umfasst keine Reproduktionen, Klone
oder Snapshots. Beispiel: Wenn Sie ein Objekt mit 1 MB Daten speichern,
beträgt die nominelle Auslastung 1 MB. Die tatsächliche Auslastung beträgt
jedoch möglicherweise 2 MB oder mehr, je nach Anzahl der Reproduktionen,
Klone und Snapshots.
POOL: Der Name des Pools.ID: Die Pool-ID.STORED: Die vom Benutzer gespeicherte Datenmenge.OBJECTS: Die nominelle Anzahl der pro Pool gespeicherten Objekte.USED: Der Speicherplatz (in kB), der von allen OSD-Knoten ausschließlich für Daten zugewiesen ist.%USED: Der nominelle Prozentsatz des genutzten Speichers pro Pool.MAX AVAIL: Der maximal verfügbare Speicherplatz im jeweiligen Pool.
Die Zahlen im Abschnitt POOLS sind nominell. Sie sind nicht inklusive der
Anzahl der Reproduktionen, Snapshots oder Klone zu verstehen. Folglich
entspricht die Summe der Zahlen unter USED und
%USED nicht den Zahlen unter RAW USED
und %RAW USED im Abschnitt RAW
STORAGE der Ausgabe.
12.4 Überprüfen des OSD-Status #
Mit folgenden Kommandos prüfen Sie die OSDs, um sicherzustellen, dass sie aktiv sind:
cephuser@adm > ceph osd statoder
cephuser@adm > ceph osd dumpOSDs lassen sich auch entsprechend ihrer Position in der CRUSH-Map anzeigen.
Mit ceph osd tree werden ein CRUSH-Baum mit einem Host
und dessen OSDs, der Status der Aktivität und deren Gewicht ausgegeben:
cephuser@adm > ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 3 0.02939 root default
-3 3 0.00980 rack mainrack
-2 3 0.00980 host osd-host
0 1 0.00980 osd.0 up 1.00000 1.00000
1 1 0.00980 osd.1 up 1.00000 1.00000
2 1 0.00980 osd.2 up 1.00000 1.0000012.5 Suchen nach vollen OSDs #
Ceph verhindert, dass Sie an einen vollen OSD schreiben, damit Sie keine
Daten verlieren. In einem betriebsbereiten Cluster sollten Sie eine
Warnmeldung erhalten, wenn der Cluster annähernd voll ist. Der Wert für
mon osd full ratio beträgt standardmäßig 0,95 bzw. 95 %
der Kapazität. Wenn dieser Wert erreicht ist, werden die Clients davon
abgehalten, Daten zu schreiben. Der Wert mon osd nearfull
ratio beträgt standardmäßig 0,85 bzw. 85 % der Kapazität. Wenn
dieser Wert erreicht ist, wird eine Zustandswarnung generiert.
Volle OSD-Knoten werden durch ceph health gemeldet:
cephuser@adm > ceph health
HEALTH_WARN 1 nearfull osds
osd.2 is near full at 85%oder
cephuser@adm > ceph health
HEALTH_ERR 1 nearfull osds, 1 full osds
osd.2 is near full at 85%
osd.3 is full at 97%Am besten fügen Sie bei einem vollen Cluster neue OSD-Hosts/-Datenträger hinzu. Dadurch kann der Cluster Daten auf dem neu verfügbaren Speicherplatz verteilen.
Wenn ein OSD voll wird, also 100 % der Festplattenkapazität nutzt, stürzt er normalerweise schnell und ohne Warnmeldung ab. Nachfolgend sehen Sie einige Tipps, die Sie beim Verwalten von OSD-Knoten beachten sollten.
Der Festplattenspeicherplatz der einzelnen OSDs (normalerweise eingehängt unter
/var/lib/ceph/osd/osd-{1,2..}) muss jeweils auf eine dedizierte zugrundeliegende Festplatte oder Partition gestellt werden.Überprüfen Sie die Ceph-Konfigurationsdateien und stellen Sie sicher, dass Ceph die Protokolldatei nicht auf den Festplatten/Partitionen speichert, die explizit für die OSDs vorgesehen sind.
Vergewissern Sie sich, dass kein anderer Prozess auf die Festplatten/Partitionen schreibt, die explizit für die OSDs vorgesehen sind.
12.6 Prüfen des Monitorstatus #
Nachdem Sie den Cluster gestartet haben und bevor die ersten Daten gelesen und/oder geschrieben werden, prüfen Sie die Kontingentstatus der Ceph Monitors. Wenn der Cluster bereits Anforderungen verarbeitet, prüfen Sie den Status der Ceph Monitors regelmäßig, ob sie tatsächlich ausgeführt werden.
Führen Sie zum Anzeigen der Monitor-Zuordnung Folgendes aus:
cephuser@adm > ceph mon statoder
cephuser@adm > ceph mon dumpFühren Sie zum Prüfen des Quorum-Status für den Monitor-Cluster Folgendes aus:
cephuser@adm > ceph quorum_statusCeph gibt den Quorum-Status zurück. Beispielsweise gibt ein Ceph-Cluster, der aus drei Monitors besteht, möglicherweise Folgendes zurück:
{ "election_epoch": 10,
"quorum": [
0,
1,
2],
"monmap": { "epoch": 1,
"fsid": "444b489c-4f16-4b75-83f0-cb8097468898",
"modified": "2011-12-12 13:28:27.505520",
"created": "2011-12-12 13:28:27.505520",
"mons": [
{ "rank": 0,
"name": "a",
"addr": "192.168.1.10:6789\/0"},
{ "rank": 1,
"name": "b",
"addr": "192.168.1.11:6789\/0"},
{ "rank": 2,
"name": "c",
"addr": "192.168.1.12:6789\/0"}
]
}
}12.7 Überprüfen des Zustands von Platzierungsgruppen #
Placement Groups ordnen Objekte zu OSDs zu. Bei der Überwachung Ihrer
Placement Groups sollten diese active (aktiv) und
clean (intakt) sein. Ausführliche Informationen finden
Sie in Abschnitt 12.9, „Überwachen der OSDs und Platzierungsgruppen“.
12.8 Speicherkapazität #
Wenn sich ein Ceph-Speicher-Cluster seiner maximalen Kapazität annähert, unterbindet Ceph aus Sicherheitsgründen weitere Schreib- oder Lesevorgänge auf Ceph OSDs, damit kein Datenverlust eintritt. Es wird daher nicht empfohlen, die Quote eines Produktions-Clusters voll auszuschöpfen, da damit die Hochverfügbarkeit nicht mehr gewährleistet ist. Die standardmäßige „full“-Quote ist auf 0,95 eingestellt, also auf 95 % der Kapazität. Für einen Test-Cluster mit nur wenigen OSDs ist dies eine äußerst aggressive Einstellung.
Achten Sie bei der Überwachung des Clusters auf Warnmeldungen zur
nearfull-Quote. Dies bedeutet, dass ein Ausfall eines
(oder mehrerer) OSDs zu einer Serviceunterbrechung führen würde. Ziehen Sie
in Erwägung, weitere OSDs einzufügen und damit die Speicherkapazität zu
erhöhen.
In einem gängigen Szenario für Test-Cluster entfernt ein Systemadministrator
ein Ceph OSD aus dem Ceph-Speicher-Cluster und beobachtet dann den
Neuausgleich des Clusters. Anschließend wird ein weiterer Ceph OSD entfernt
usw., bis der Cluster schließlich die „full“-Quote erreicht und zum
Stillstand kommt. Selbst bei einem Test-Cluster wird eine gewisse
Kapazitätsplanung empfohlen. Durch die Planung können Sie einschätzen, wie
viel Ersatzkapazität Sie benötigen, damit die Hochverfügbarkeit
aufrechterhalten werden kann. Im Idealfall sollten Sie eine ganze Reihe von
Ceph OSD-Ausfällen einplanen, bei der Cluster wieder den Status
active + clean erreichen kann, ohne die betreffenden Ceph
OSDs austauschen zu müssen. Sie können einen Cluster im Status
active + degraded ausführen, doch unter normalen
Betriebsbedingungen ist dies nicht ideal.
Das nachfolgende Diagramm zeigt einen vereinfachten Ceph-Speicher-Cluster
mit 33 Ceph Knoten und je einem Ceph OSD pro Host, die jeweils Lese- und
Schreibvorgänge auf einem 3-TB-Laufwerk ausführen. Dieser Beispiel-Cluster
besitzt eine maximale Istkapazität von 99 TB. Die Option mon osd
full ratio ist auf 0,95 eingestellt. Sobald der Speicherplatz im
Cluster unter 5 TB der Restkapazität fällt, werden Lese- und Schreibvorgänge
der Clients unterbunden. Die Betriebskapazität des Speicher-Clusters liegt
also bei 95 TB, nicht bei 99 TB.

In einem solchen Cluster ist ein Ausfall von einem oder zwei OSDs durchaus
normal. In einem weniger häufigen, jedoch denkbaren Szenario fällt der
Router oder die Netzversorgung eines Racks aus, sodass mehrere OSDs
gleichzeitig ausfallen (z. B. OSDs 7–12). In einem solchen Szenario muss der
Cluster dennoch weiterhin betriebsbereit bleiben und den Status
active + clean erreichen – selbst wenn dafür einige Hosts
mit zusätzlichen OSDs in kürzester Zeit eingefügt werden müssen. Wenn die
Kapazitätsauslastung zu hoch ist, verlieren Sie unter Umständen keine Daten.
Doch beim Beheben eines Ausfalls in einer Fehlerdomäne ist die
Datenverfügbarkeit dennoch beeinträchtigt, wenn die Kapazitätsauslastung des
Clusters die für Code übersteigt. Aus diesem Grund wird zumindest eine grobe
Kapazitätsplanung empfohlen.
Ermitteln Sie zwei Zahlen für Ihren Cluster:
die Anzahl der OSDs,
die Gesamtkapazität des Clusters.
Wenn Sie die Gesamtkapazität des Clusters durch die Anzahl der OSDs im Cluster dividieren, erhalten Sie die Durchschnittskapazität eines OSDs im Cluster. Multiplizieren Sie diese Zahl ggf. mit der Anzahl der OSDs, die laut Ihren Erwartungen im Normalbetrieb gleichzeitig ausfallen könnten (relativ kleine Zahl). Multiplizieren Sie schließlich die Kapazität des Clusters mit der „full“-Quote. Damit erhalten Sie die maximale Betriebskapazität. Subtrahieren Sie dann die Datenmenge der OSDs, die vermutlich ausfallen werden, und Sie erhalten eine angemessene „full“-Quote. Wenn Sie den obigen Vorgang mit einer größeren Anzahl an OSD-Ausfällen (einem OSD-Rack) wiederholen, erhalten Sie eine angemessene Zahl für die „near full“-Quote.
Die folgenden Einstellungen gelten nur bei der Cluster-Erstellung und werden dann in der OSD-Karte gespeichert:
[global] mon osd full ratio = .80 mon osd backfillfull ratio = .75 mon osd nearfull ratio = .70
Diese Einstellungen gelten nur bei der Cluster-Erstellung. Später müssen
sie mit den Kommandos ceph osd set-nearfull-ratio und
ceph osd set-full-ratioin der OSD-Karte geändert werden.
- mon osd full ratio
Prozentsatz des belegten Datenträgerspeichers, bevor ein OSD als
fullgilt. Der Standardwert lautet 0,95.- mon osd backfillfull ratio
Prozentsatz des belegten Datenträgerspeichers, bevor ein OSD als zu
fullfür einen Abgleich gilt. Der Standardwert lautet 0,90.- mon osd nearfull ratio
Prozentsatz des belegten Datenträgerspeichers, bevor ein OSD als
nearfullgilt. Der Standardwert lautet 0,85.
Wenn einige OSDs nearfull sind, andere aber noch
reichlich Kapazität besitzen, liegt eventuell ein Problem mit dem
CRUSH-Gewicht für die nearfull-OSDs vor.
12.9 Überwachen der OSDs und Platzierungsgruppen #
Voraussetzung für Hochverfügbarkeit und hohe Zuverlässigkeit ist eine fehlertolerante Bearbeitung von Hardware- und Softwareproblemen. Ceph enthält keinen Single-Point-of-Failure und kann Anforderungen nach Daten in einem eingeschränkt leistungsfähigen Modus („degraded“) verarbeiten. Die Datenplatzierung bei Ceph umfasst eine Dereferenzierungsschicht, mit der gewährleistet wird, dass die Daten nicht direkt an bestimmte OSD-Adressen binden. Bei der Suche nach Systemfehlern bedeutet dies, dass die richtige Platzierungsgruppe und die zugrunde liegenden OSDs als Problemursache ermittelt werden müssen.
Bei einem Fehler in einem Teil des Clusters können Sie unter Umständen nicht auf ein bestimmtes Objekt zugreifen. Dies bedeutet nicht, dass Sie nicht auf andere Objekte zugreifen können. Wenn ein Fehler auftritt, befolgen Sie die Anweisungen für die Überwachung Ihrer OSDs und Platzierungsgruppen. Nehmen Sie dann die Fehlerbehebung vor.
Ceph repariert sich im Allgemeinen selbst. Bleiben Probleme jedoch längere Zeit bestehen, trägt die Überwachung der OSDs und Platzierungsgruppen dazu bei, das Problem zu erkennen.
12.9.1 Überwachen der OSDs #
Ein OSD befindet sich entweder im Cluster (Status „in“) oder außerhalb des Clusters („out“). Gleichzeitig ist er entweder betriebsbereit und aktiv („up“) oder nicht betriebsbereit und inaktiv („down“). Wenn ein OSD „up“ ist, befindet er sich entweder im Cluster (Sie können Daten lesen und schreiben) oder außerhalb des Clusters. Wenn er sich bis vor Kurzem im Cluster befand und dann aus dem Cluster heraus verschoben wurde, migriert Ceph die Platzierungsgruppen zu anderen OSDs. Befindet sich ein OSD außerhalb des Clusters, weist CRUSH diesem OSD keine Platzierungsgruppen zu. Wenn ein OSD „down“ ist, sollte er auch „out“ sein.
Ist ein OSD „down“ und „in“, liegt ein Problem vor und der Cluster ist nicht in einem einwandfreien Zustand.
Wenn Sie ein Kommando wie ceph health, ceph
-s oder ceph -w ausführen, meldet der Cluster
nicht immer HEALTH OK. Im Hinblick auf OSDs ist unter
den folgenden Umständen zu erwarten, dass der Cluster
nicht die Meldung HEALTH OK
zurückgibt:
Sie haben den Cluster noch nicht gestartet (er kann nicht antworten).
Sie haben den Cluster gestartet oder neu gestartet. Er ist jedoch noch nicht betriebsbereit, da die Platzierungsgruppen noch erstellt werden und die OSDs gerade den Peering-Prozess durchlaufen.
Sie haben ein OSD hinzugefügt oder entfernt.
Sie haben die Clusterzuordnung geändert.
Bei der Überwachung der OSDs ist in jedem Fall darauf zu achten, dass alle OSDs im Cluster betriebsbereit und aktiv sind, wenn der Cluster selbst betriebsbereit und aktiv ist. Mit folgendem Kommando prüfen Sie, ob alle OSDs aktiv sind:
root # ceph osd stat
x osds: y up, z in; epoch: eNNNN
Das Ergebnis umfasst die Gesamtanzahl der OSDs (x), die Anzahl der OSDs mit
dem Status „up“ (y), die Anzahl der OSDs mit dem Status „in“ (z) sowie die
Zuordnungsepoche (eNNNN). Wenn die Anzahl der „in“-OSDs höher ist als die
Anzahl der „up“-OSDs, ermitteln Sie die nicht aktiven
ceph-osd-Daemons mit folgendem Kommando:
root # ceph osd tree
#ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 2.00000 pool openstack
-3 2.00000 rack dell-2950-rack-A
-2 2.00000 host dell-2950-A1
0 ssd 1.00000 osd.0 up 1.00000 1.00000
1 ssd 1.00000 osd.1 down 1.00000 1.00000Wenn beispielsweise ein OSD mit ID 1 inaktiv ist, starten Sie es mit:
cephuser@osd > sudo systemctl start ceph-CLUSTER_ID@osd.0.serviceWeitere Informationen zu Problemen im Zusammenhang mit OSDs, die angehalten wurden oder sich nicht neu starten lassen, finden Sie im Book “Troubleshooting Guide”, Chapter 4 “Troubleshooting OSDs”, Section 4.3 “OSDs not running”.
12.9.2 Zuweisen von Platzierungsgruppen #
Beim Zuweisen von Platzierungsgruppen zu den OSDs prüft CRUSH die Anzahl
der Reproduktionen für den Pool und weist die Platzierungsgruppe den OSDs
so zu, dass jede Reproduktion dieser Platzierungsgruppe einem anderen OSD
zugeordnet wird. Wenn der Pool beispielsweise drei Reproduktionen einer
Platzierungsgruppe benötigt, weist CRUSH die Reproduktionen beispielsweise
osd.1, osd.2 und
osd.3 zu. CRUSH strebt dabei eine pseudozufällige
Platzierung an, bei der die in der CRUSH-Zuordnung festgelegten
Fehlerdomänen berücksichtigt werden, sodass Platzierungsgruppen nur in
seltenen Fällen den jeweils nächstgelegenen OSDs in einem großen Cluster
zugewiesen werden. Der OSD-Satz, in dem sich die Reproduktion einer
bestimmten Platzierungsgruppe befinden soll, wird als
„acting“-Satz bezeichnet. In einigen Fällen ist ein
OSD im „acting“-Satz nicht betriebsbereit oder kann anderweitig keine
Anforderungen nach Objekten in der Platzierungsgruppe verarbeiten. In
diesen Situationen liegt eines der folgenden Szenarien vor:
Sie haben ein OSD hinzugefügt oder entfernt. CRUSH hat die Platzierungsgruppe dann anderen OSDs zugewiesen und damit die Zusammensetzung des agierenden Satzes verändert, sodass die Migration der Daten im Rahmen eines „backfill“-Prozesses ausgelöst wurde.
Ein OSD war „down“, wurde neu gestartet und wird nunmehr wiederhergestellt.
Ein OSD im „acting“-Satz ist „down“ oder kann keine Anforderungen verarbeiten und ein anderer OSD hat vorübergehend dessen Aufgaben übernommen.
Ceph verarbeitet eine Client-Anforderung mit dem „up“-Satz, also dem Satz der OSDs, die die Anforderungen tatsächlich verarbeiten. In den meisten Fällen sind der „up“-Satz und der „acting“-Satz praktisch identisch. Ist dies nicht der Fall, kann dies darauf hinweisen, dass Ceph gerade Daten migriert, ein OSD wiederhergestellt wird oder ein Problem vorliegt (in diesen Szenarien gibt Ceph in der Regel den Status
HEALTH WARNmit der Meldung „stuck stale“ zurück).
Mit folgendem Kommando rufen Sie eine Liste der Platzierungsgruppen ab:
cephuser@adm > ceph pg dumpMit folgendem Kommando stellen Sie fest, welche OSDs sich im „acting“-Satz oder im „up“-Satz einer bestimmten Platzierungsgruppe befinden:
cephuser@adm > ceph pg map PG_NUM
osdmap eNNN pg RAW_PG_NUM (PG_NUM) -> up [0,1,2] acting [0,1,2]Das Ergebnis umfasst die osdmap-Epoche (eNNN), die Nummer der Platzierungsgruppe (PG_NUM), die OSDs im „up“-Satz („up“) sowie die OSDs im „acting“-Satz („acting“):
Wenn der „up“-Satz und der „acting“-Satz nicht übereinstimmen, kann dies darauf hinweisen, dass der Cluster sich gerade ausgleicht oder dass ein potenzielles Problem mit dem Cluster vorliegt.
12.9.3 Peering #
Bevor Sie Daten in eine Platzierungsgruppe schreiben können, muss sie den
Status active und auch den Status
clean aufweisen. Damit Ceph den aktuellen Status einer
Fertigungsgruppe feststellen kann, führt der primäre OSD der
Platzierungsgruppe (der erste OSD im „acting“-Satz)
ein Peering mit dem sekundären und dem tertiären OSD durch, sodass sie sich
über den aktuellen Status der Platzierungsgruppe abstimmen können (unter
der Annahme eines Pools mit drei Reproduktionen der PG).

12.9.4 Überwachen des Zustands von Platzierungsgruppen #
Wenn Sie ein Kommando wie ceph health, ceph
-s oder ceph -w ausführen, gibt der Cluster
nicht immer die Meldung HEALTH OK zurück. Sobald Sie
geprüft haben, ob die OSDs aktiv sind, prüfen Sie auch den Status der
Platzierungsgruppen.
Unter verschiedenen, mit dem Platzierungsgruppen-Peering zusammenhängenden
Umständen ist zu erwarten, dass der Cluster
nicht die Meldung HEALTH
OK zurückgibt:
Sie haben einen Pool erstellt, und die Platzierungsgruppen haben noch nicht das Peering durchgeführt.
Die Platzierungsgruppen werden wiederhergestellt.
Sie haben einen OSD in einen Cluster eingefügt oder daraus entfernt.
Sie haben die CRUSH-Zuordnung geändert, und Ihre Platzierungsgruppen werden migriert.
Die verschiedenen Reproduktionen einer Platzierungsgruppe enthalten inkonsistente Daten.
Ceph führt das Scrubbing der Reproduktionen einer Platzierungsgruppe durch.
Die Speicherkapazität reicht nicht für die Ausgleichsoperationen von Ceph aus.
Wenn Ceph aus den obigen Gründen die Meldung HEALTH WARN
ausgibt, ist dies kein Grund zur Sorge. In zahlreichen Fällen kann sich der
Cluster selbst wiederherstellen. In bestimmten Fällen müssen Sie jedoch
selbst gewisse Maßnahmen ergreifen. Bei der Überwachung der OSDs ist in
jedem Fall darauf zu achten, dass alle Platzierungsgruppen den Status
„active“ und nach Möglichkeit auch den Status „clean“ besitzen, wenn der
Cluster selbst betriebsbereit und aktiv ist. Mit folgendem Kommando rufen
Sie den Status aller Platzierungsgruppen ab:
cephuser@adm > ceph pg stat
x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB availDas Ergebnis umfasst die Gesamtanzahl der Platzierungsgruppen (x), die Anzahl der Platzierungsgruppen in einem bestimmten Status, z. B. „active+clean“ (y) sowie die gespeicherte Datenmenge (z).
Neben dem Status der Platzierungsgruppen gibt Ceph außerdem die belegte Speicherkapazität (aa), die verbleibende Speicherkapazität (bb) und die Gesamtspeicherkapazität für die Platzierungsgruppe zurück. Diese Zahlen sind in einigen Fällen von großer Bedeutung:
Sie nähern sich dem Wert für
near full ratiooderfull ratio.Die Daten werden aufgrund eines Fehlers in der CRUSH-Konfiguration nicht im Cluster verteilt.
Die Platzierungsgruppen-IDs bestehen aus der Pool-Nummer (nicht dem
Pool-Namen), gefolgt von einem Punkt (.) und der eigentlichen
Platzierungsgruppen-ID (eine hexadezimale Zahl). Die Pool-Nummern und
zugehörige Namen sind in der Ausgabe des Kommandos ceph osd
lspools ersichtlich. Der Standard-Pool rbd
entspricht beispielsweise der Pool-Nummer 0. Eine vollständige
Platzierungsgruppen-ID weist das folgende Format auf:
POOL_NUM.PG_ID
und sieht in der Regel wie folgt aus:
0.1f
Mit folgendem Kommando rufen Sie eine Liste der Platzierungsgruppen ab:
cephuser@adm > ceph pg dumpSie können auch die Ausgabe im JSON-Format formatieren und in einer Datei speichern:
cephuser@adm > ceph pg dump -o FILE_NAME --format=jsonMit folgendem Kommando fragen Sie eine bestimmte Platzierungsgruppe ab:
cephuser@adm > ceph pg POOL_NUM.PG_ID queryIn der nachfolgenden Liste werden die gängigen Statusangaben für Platzierungsgruppen näher beschrieben.
- CREATING
Beim Erstellen eines Pools wird die angegebene Anzahl der Platzierungsgruppen erstellt. Ceph gibt „creating“ zurück, während eine Platzierungsgruppe erstellt wird. Beim Erstellen führen die OSDs im „acting“-Satz der Platzierungsgruppe das Peering durch. Nach dem Peering sollte die Platzierungsgruppe den Status „active+clean“ aufweisen, sodass ein Ceph-Client in die Platzierungsgruppe schreiben kann.
 Abbildung 12.3: Statusangaben für Platzierungsgruppen #
Abbildung 12.3: Statusangaben für Platzierungsgruppen #- PEERING
Beim Peering einer Platzierungsgruppe stimmt Ceph die OSDs, auf denen die Reproduktionen der Platzierung gespeichert sind, hinsichtlich des Status der Objekte und Metadaten in der Platzierungsgruppe ab. Nach dem Peering zeigen also alle OSDs, auf denen die Platzierungsgruppe gespeichert ist, den aktuellen Status dieser Gruppe. Der Abschluss des Peering-Prozesses bedeutet jedoch nicht, dass jede Reproduktion den aktuellen Inhalt enthält.
Anmerkung: Maßgeblicher VerlaufCeph bestätigt nur dann einen Schreibvorgang auf einen Client, wenn alle OSDs im „acting“-Satz den Schreibvorgang dauerhaft speichern. Auf diese Weise ist sichergestellt, dass mindestens ein Mitglied des „acting“-Satzes einen Datensatz pro bestätigtem Schreibvorgang seit dem letzten erfolgreichen Peering-Vorgang besitzt.
Anhand der sorgfältigen Aufzeichnungen der einzelnen bestätigten Schreiboperationen kann Ceph einen neuen maßgeblichen Verlauf der Platzierungsgruppe aufstellen und fortführen – also einen vollständigen, geordneten Satz von Operationen, mit dem das Exemplar einer Platzierungsgruppe, die sich auf einem OSD befindet, auf den neuesten Stand gebracht werden kann.
- AKTIV
Nach Abschluss des Peering-Prozesses kann eine Platzierungsgruppe den Status
activeerhalten. Im Statusactivestehen die Daten in der Platzierungsgruppe im Allgemeinen in der primären Platzierungsgruppe zur Verfügung, die Reproduktionen dagegen für Lese- und Schreiboperationen.- CLEAN
Wenn eine Platzierungsgruppe den Status
cleanaufweist, haben der primäre OSD und die Reproduktions-OSDs das Peering erfolgreich beendet, und es gibt keine nicht zugeordneten Reproduktionen für die Platzierungsgruppe. Ceph hat alle Objekte in der Platzierungsgruppe so oft wie gefordert reproduziert.- DEGRADED
Wenn ein Client ein Objekt in den primären OSD schreibt, ist der primäre OSD dafür zuständig, die Reproduktionen in die Reproduktions-OSDs zu schreiben. Sobald der primäre OSD das Objekt in den Speicher geschrieben hat, verbleibt die Platzierungsgruppe so lange im Status „degraded“, bis der primäre OSD eine Bestätigung von den Reproduktions-OSDs erhält, dass Ceph die Reproduktionsobjekte erfolgreich erstellt hat.
Eine Platzierungsgruppe kann dann den Status „active+degraded“ aufweisen, wenn ein OSD den Status „active“ besitzt, obwohl er noch nicht alle Objekte enthält. Wenn ein OSD ausfällt, kennzeichnet Ceph die einzelnen Platzierungsgruppen, die diesem OSD zugewiesen sind, als „degraded“. Sobald der OSD wieder funktionsfähig ist, müssen die OSDs das Peering wiederholen. Wenn eine eingeschränkt leistungsfähige Platzierungsgruppe den Status „active“ aufweist, kann ein Client jedoch weiterhin in ein neues Objekt in dieser Gruppe schreiben.
Wenn ein OSD den Status „down“ aufweist und die Bedingung „degraded“ weiterhin vorliegt, kennzeichnet Ceph den ausgefallenen OSD als außerhalb des Clusters („out“) und ordnet die Daten des „down“-OSDs einem anderen OSD zu. Der Zeitraum zwischen der Kennzeichnung als „down“ und der Kennzeichnung als „out“ wird durch die Option
mon osd down out intervalgesteuert (Standardwert 600 Sekunden).Eine Platzierungsgruppe kann auch dann den Status „degraded“ erhalten, wenn Ceph mindestens ein Objekt, das sich in der Platzierungsgruppe befinden sollte, nicht auffinden kann. Es ist zwar nicht möglich, in nicht gefundenen Objekten zu lesen oder zu schreiben, doch Sie können weiterhin auf alle anderen Objekte in der „degraded“-Platzierungsgruppe zugreifen.
- RECOVERING
Ceph ist für die Fehlertoleranz in Situationen mit anhaltenden Hardware- und Softwareproblemen ausgelegt. Wenn ein OSD ausfällt („down“), bleibt sein Inhalt hinter dem Status anderer Reproduktionen in den Platzierungsgruppen zurück. Sobald der OSD wieder funktionsfähig ist („up“), muss der Inhalt der Platzierungsgruppen gemäß dem aktuellen Stand aktualisiert werden. In diesem Zeitraum befindet sich der OSD im Status „recovering“.
Die Wiederherstellung ist nicht unbedingt trivial, da ein Hardwarefehler durchaus eine Kettenreaktion mit Ausfall mehrerer OSDs auslösen kann. Wenn beispielsweise ein Netzwerkschalter für ein Rack oder einen Schrank ausfällt, können die OSDs zahlreicher Hostmaschinen unter Umständen hinter den aktuellen Status des Clusters zurückfallen. Sobald der Fehler behoben wurde, muss jeder einzelne OSD wiederhergestellt werden.
Ceph bietet verschiedene Einstellungen für den Ausgleich der Ressourcenkonflikte zwischen neuen Serviceanforderungen und der Notwendigkeit, Datenobjekte wiederherzustellen und die Platzierungsgruppen wieder auf den neuesten Stand zu bringen. Mit der Einstellung
osd recovery delay startkann ein OSD vor Beginn des Wiederherstellungsprozesses neu starten, das Peering erneut durchführen und sogar einige Wiederholungsanforderungen verarbeiten. Die Einstellungosd recovery thread timeoutlegt eine Thread-Zeitüberschreitung fest, da mehrere OSDs gestaffelt ausfallen, neu starten und das Peering erneut durchführen können. Die Einstellungosd recovery max activebeschränkt die Anzahl der Wiederherstellungsanforderungen, die ein OSD gleichzeitig verarbeitet, damit der OSD nicht ausfällt. Die Einstellungosd recovery max chunkbeschränkt die Größe der wiederhergestellten Datenblöcke, sodass eine Überlastung des Netzwerks verhindert wird.- BACK FILLING
Wenn ein neuer OSD in den Cluster eintritt, weist CRUSH die Platzierungsgruppen von den OSDs im Cluster zum soeben hinzugefügten OSD zu. Wird die sofortige Annahme der neu zugewiesenen Platzierungsgruppen durch den neuen OSD erzwungen, kann dies den OSD immens belasten. Durch den Ausgleich des OSD mit den Platzierungsgruppen kann dieser Prozess im Hintergrund beginnen. Nach erfolgtem Ausgleich verarbeitet der neue OSD die ersten Anforderungen, sobald er dazu bereit ist.
Während des Ausgleichs werden ggf. verschiedene Statusangaben angezeigt: „backfill_wait“, bedeutet, dass ein Ausgleichsvorgang aussteht, jedoch noch nicht gestartet wurde; „backfill“ bedeutet, dass ein Ausgleichsvorgang läuft; „backfill_too_full“ bedeutet, dass ein Ausgleichsvorgang angefordert wurde, jedoch aufgrund unzureichender Speicherkapazität nicht ausgeführt werden konnte. Wenn der Ausdruck einer Platzierungsgruppe nicht durchgeführt werden kann, gilt sie als „unvollständig“.
Ceph bietet verschiedene Einstellungen für die Bewältigung der Belastung im Zusammenhang mit der Neuzuweisung von Placement Groups zu einem OSD (insbesondere zu einem neuen OSD). Standardmäßig beschränkt
osd max backfillsdie Anzahl gleichzeitiger Ausgleichsvorgänge mit einem OSD auf maximal 10 Vorgänge. Mitbackfill full ratiokann ein OSD eine Ausgleichsanforderung verweigern, wenn der OSD sich seiner „full“-Quote nähert (standardmäßig 90 %). Dieser Wert kann mit dem Kommandoceph osd set-backfillfull-ratiogeändert werden. Wenn ein OSD eine Ausgleichsanforderung verweigert, kann der OSD die Anforderung mitosd backfill retry intervalwiederholen (standardmäßig nach 10 Sekunden). Die OSDs können außerdem die Scanintervalle (standardmäßig 64 und 512) mitosd backfill scan minundosd backfill scan maxverwalten.- REMAPPED
Wenn sich der „acting“-Satz ändert, der für eine Platzierungsgruppe zuständig ist, werden die Daten vom bisherigen „acting“-Satz zum neuen „acting“-Satz migriert. Ein neuer primärer OSD kann unter Umständen erst nach einiger Zeit die ersten Anforderungen verarbeiten. In diesem Fall weist er den bisherigen primären OSD an, weiterhin die Anforderungen zu verarbeiten, bis die Migration der Platzierungsgruppe abgeschlossen ist. Nach erfolgter Datenmigration greift die Zuordnung auf den primären OSD des neuen „acting“-Satzes zurück.
- INAKTIV
Obwohl Ceph mithilfe von Heartbeats prüft, ob die Hosts und Daemons ausgeführt werden, können die
ceph-osd-Daemons in den Status „stuck“ gelangen, in dem sie die Statistiken nicht zeitnah melden (z. B. bei einem vorübergehenden Netzwerkfehler). Standardmäßig melden die OSD-Daemons in Abständen von einer halben Sekunde (0,5) ihre Statistiken zu Platzierungsgruppen, Startvorgängen und Fehlern, also in deutlich kürzeren Abständen als die Heartbeat-Grenzwerte. Wenn der primäre OSD im „acting“-Satz keine Meldung an den Monitor übergibt oder wenn andere OSDs den primären OSD als „down“ gemeldet haben, kennzeichnen die Monitors die Platzierungsgruppe als „stale“.Beim Starten des Clusters wird häufig der Status „stale“ angezeigt, bis der Peering-Prozess abgeschlossen ist. Wenn der Cluster eine Weile aktiv war, weisen Platzierungsgruppen mit dem Status „stale“ darauf hin, dass der primäre OSD dieser Platzierungsgruppen ausgefallen ist oder keine Platzierungsgruppenstatistiken an den Monitor meldet.
12.9.5 Auffinden des Speicherorts eines Objekts #
Zum Speichern von Objektdaten im Ceph Object Store muss ein Ceph-Client einen Objektnamen festlegen und einen zugehörigen Pool angeben. Der Ceph-Client ruft die aktuelle Cluster-Zuordnung ab. Der CRUSH-Algorithmus berechnet, wie das Objekt einer Platzierungsgruppe zugeordnet werden soll, und dann, wie die Platzierungsgruppe dynamisch einem OSD zugewiesen werden soll. Zum Auffinden des Objektspeicherorts benötigen Sie lediglich den Objektnamen und den Poolnamen. Beispiel:
cephuser@adm > ceph osd map POOL_NAME OBJECT_NAME [NAMESPACE]
Erstellen Sie für dieses Beispiel zunächst ein Objekt. Geben Sie den
Objektnamen „test-object-1“, den Pfad zur Beispieldatei „testfile.txt“ mit
einigen Objektdaten sowie den Poolnamen „data“ mit dem Kommando
rados put in der Kommandozeile an:
cephuser@adm > rados put test-object-1 testfile.txt --pool=dataPrüfen Sie mit folgendem Kommando, ob das Objekt im Ceph Object Store gespeichert wurde:
cephuser@adm > rados -p data lsErmitteln Sie nun den Objektspeicherort. Ceph gibt den Speicherort des Objekts zurück:
cephuser@adm > ceph osd map data test-object-1
osdmap e537 pool 'data' (0) object 'test-object-1' -> pg 0.d1743484 \
(0.4) -> up ([1,0], p0) acting ([1,0], p0)
Löschen Sie das Beispielobjekt mit dem Kommando rados
rm:
cephuser@adm > rados rm test-object-1 --pool=data13 Betriebsaufgaben #
13.1 Ändern der Cluster-Konfiguration #
Gehen Sie zum Ändern der Konfiguration eines vorhandenen Ceph-Clusters folgendermaßen vor:
Exportieren Sie die aktuelle Konfiguration des Clusters in eine Datei:
cephuser@adm >ceph orch ls --export --format yaml > cluster.yamlBearbeiten Sie die Datei mit der Konfiguration und aktualisieren Sie die entsprechenden Zeilen. Beispiele der Spezifikation finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4 “Bereitstellen von Services und Gateways” sowie in Abschnitt 13.4.3, „Hinzufügen von OSDs mit der DriveGroups-Spezifikation“.
Wenden Sie die neue Konfiguration an:
cephuser@adm >ceph orch apply -i cluster.yaml
13.2 Hinzufügen von Knoten #
Führen Sie zum Hinzufügen eines neuen Knotens zu einem Ceph-Cluster folgende Schritte aus:
Installieren Sie SUSE Linux Enterprise Server und SUSE Enterprise Storage auf dem neuen Host. Weitere Informationen finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.1 “Installieren und Konfigurieren von SUSE Linux Enterprise Server”.
Konfigurieren Sie den Host als Salt Minion eines bereits vorhandenen Salt Masters. Weitere Informationen finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.2 “Bereitstellen von Salt”.
Fügen Sie den neuen Host zu
ceph-salthinzu und machen Sie cephadm darauf aufmerksam:root@master #ceph-salt config /ceph_cluster/minions add ses-min5.example.comroot@master #ceph-salt config /ceph_cluster/roles/cephadm add ses-min5.example.comWeitere Informationen finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.3.2.2 “Hinzufügen von Salt Minions”.
Überprüfen Sie, ob der Knoten zu
ceph-salthinzugefügt wurde:root@master #ceph-salt config /ceph_cluster/minions ls o- minions ................................................. [Minions: 5] [...] o- ses-min5.example.com .................................... [no roles]Wenden Sie die Konfiguration auf den neuen Clusterhost an:
root@master #ceph-salt apply ses-min5.example.comStellen Sie sicher, dass der neu hinzugefügte Host nun zur cephadm-Umgebung gehört:
cephuser@adm >ceph orch host ls HOST ADDR LABELS STATUS [...] ses-min5.example.com ses-min5.example.com
13.3 Entfernen von Knoten #
Wenn der Knoten, den Sie entfernen möchten, OSDs ausführt, entfernen Sie zuerst die OSDs und überprüfen Sie, dass keine OSDs auf diesem Knoten ausgeführt werden. Weitere detaillierte Informationen zum Entfernen von OSDs finden Sie in Abschnitt 13.4.4, „Entfernen von OSDs“.
Gehen Sie zum Entfernen eines Knotens von einem Cluster folgendermaßen vor:
Entfernen Sie bei allen Ceph-Servicetypen mit Ausnahme von
node-exporterundcrashden Hostnamen des Knotens aus der Spezifikationsdatei für die Clusterplatzierung (z. B.cluster.yml). Weitere Informationen finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.2 “Service- und Platzierungsspezifikation”. Wenn Sie beispielsweise den Host namensses-min2entfernen, müssen Sie alle Vorkommen von- ses-min2aus allenplacement:-Abschnitten entfernen:Aktualisieren Sie
service_type: rgw service_id: EXAMPLE_NFS placement: hosts: - ses-min2 - ses-min3
zu
service_type: rgw service_id: EXAMPLE_NFS placement: hosts: - ses-min3
Wenden Sie die Änderungen an der Konfigurationsdatei an:
cephuser@adm >ceph orch apply -i rgw-example.yamlEntfernen Sie den Knoten aus der Umgebung von cephadm:
cephuser@adm >ceph orch host rm ses-min2Wenn auf dem Knoten die Services
crash.osd.1undcrash.osd.2ausgeführt werden, entfernen Sie sie, indem Sie folgendes Kommando auf dem Host ausführen:root@minion >cephadm rm-daemon --fsid CLUSTER_ID --name SERVICE_NAMEBeispiel:
root@minion >cephadm rm-daemon --fsid b4b30c6e... --name crash.osd.1root@minion >cephadm rm-daemon --fsid b4b30c6e... --name crash.osd.2Entfernen Sie alle Rollen von dem Minion, den Sie löschen möchten:
cephuser@adm >ceph-salt config /ceph_cluster/roles/tuned/throughput remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/tuned/latency remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/cephadm remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/admin remove ses-min2Wenn der zu entfernende Minion der Bootstrap-Minion ist, müssen Sie auch die Bootstrap-Rolle entfernen:
cephuser@adm >ceph-salt config /ceph_cluster/roles/bootstrap resetNachdem Sie alle OSDs auf einem einzelnen Host entfernt haben, entfernen Sie den Host aus der CRUSH-Zuordnung:
cephuser@adm >ceph osd crush remove bucket-nameAnmerkungDer Bucket-Name sollte mit dem Hostnamen identisch sein.
Sie können den Minion nun aus dem Cluster entfernen:
cephuser@adm >ceph-salt config /ceph_cluster/minions remove ses-min2
Wenn ein Fehler auftritt und sich der zu entfernende Minion in einem dauerhaft ausgeschalteten Zustand befindet, müssen Sie den Knoten vom Salt Master entfernen:
root@master # salt-key -d minion_id
Entfernen Sie dann den Knoten manuell aus pillar_root/ceph-salt.sls. Er befindet sich normalerweise in /srv/pillar/ceph-salt.sls.
13.4 OSD-Verwaltung #
In diesem Abschnitt wird beschrieben, wie Sie OSDs in einem Ceph-Cluster hinzufügen, löschen oder entfernen.
13.4.1 Auflisten von Datenträgergeräten #
Um verwendete und nicht verwendete Datenträgergeräte auf allen Cluster-Knoten zu identifizieren, listen Sie sie mit folgendem Kommando auf:
cephuser@adm > ceph orch device ls
HOST PATH TYPE SIZE DEVICE AVAIL REJECT REASONS
ses-master /dev/vda hdd 42.0G False locked
ses-min1 /dev/vda hdd 42.0G False locked
ses-min1 /dev/vdb hdd 8192M 387836 False locked, LVM detected, Insufficient space (<5GB) on vgs
ses-min2 /dev/vdc hdd 8192M 450575 True13.4.2 Löschen von Datenträgergeräten #
Um ein Datenträgergerät wieder zu verwenden, müssen Sie es zuerst löschen (oder zappen):
ceph orch device zap HOST_NAME DISK_DEVICE
Beispiel:
cephuser@adm > ceph orch device zap ses-min2 /dev/vdc
Wenn Sie zuvor OSDs mithilfe von DriveGroups oder der Option --all-available-devices bereitgestellt haben und das Flag unmanaged dabei nicht gesetzt war, stellt cephadm diese OSDs automatisch bereit, nachdem Sie sie gelöscht haben.
13.4.3 Hinzufügen von OSDs mit der DriveGroups-Spezifikation #
DriveGroups bestimmen das Layout der OSDs im Ceph-Cluster. Sie werden in einer einzigen YAML-Datei definiert. In diesem Abschnitt wird die Datei drive_groups.yml als Beispiel herangezogen.
Ein Administrator muss manuell eine Gruppe von OSDs erstellen, die zusammenhängen (Hybrid-OSDs, die auf einer Mischung von HDDs und SDDs implementiert sind) oder dieselben Bereitstellungsoptionen aufweisen (z. B. gleicher Objektspeicher, gleiche Verschlüsselungsoption, Stand-Alone-OSDs). Damit die Geräte nicht explizit aufgelistet werden müssen, werden sie in den DriveGroups anhand einer Liste von Filterelementen gefiltert, die einigen wenigen ausgewählten Feldern in den ceph-volume-Bestandsberichten entsprechen. Der Code in cephadm wandelt diese DriveGroups in Gerätelisten um, die dann vom Benutzer geprüft werden können.
Das Kommando zum Anwenden der OSD-Spezifikation auf den Cluster lautet:
cephuser@adm >ceph orch apply osd -idrive_groups.yml
Für eine Vorschau der Aktionen und einen Test der Anwendung können Sie die Option --dry-run zusammen mit dem Kommando ceph orch apply osd verwenden. Beispiel:
cephuser@adm >ceph orch apply osd -idrive_groups.yml--dry-run ... +---------+------+------+----------+----+-----+ |SERVICE |NAME |HOST |DATA |DB |WAL | +---------+------+------+----------+----+-----+ |osd |test |mgr0 |/dev/sda |- |- | |osd |test |mgr0 |/dev/sdb |- |- | +---------+------+------+----------+----+-----+
Wenn die --dry-run-Ausgabe Ihren Erwartungen entspricht, führen Sie das Kommando einfach erneut ohne die Option --dry-run aus.
13.4.3.1 Nicht verwaltete OSDs #
Alle verfügbaren fehlerfreien Datenträgergeräte, die der DriveGroups-Spezifikation entsprechen, werden automatisch als OSDs verwendet, nachdem Sie sie dem Cluster hinzugefügt haben. Dieses Verhalten wird als verwalteter Modus bezeichnet.
Fügen Sie zum Deaktivieren des verwalteten Modus beispielsweise die Zeile unmanaged: true zu den entsprechenden Spezifikationen hinzu:
service_type: osd service_id: example_drvgrp_name placement: hosts: - ses-min2 - ses-min3 encrypted: true unmanaged: true
Um bereits bereitgestellte OSDs vom verwalteten zum nicht verwalteten Modus zu ändern, fügen Sie während des in Abschnitt 13.1, „Ändern der Cluster-Konfiguration“ beschriebenen Vorgangs die Zeilen unmanaged: true an den entsprechenden Stellen hinzu.
13.4.3.2 DriveGroups-Spezifikation #
Es folgt ein Beispiel für eine DriveGroups-Spezifikationsdatei:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: drive_spec: DEVICE_SPECIFICATION db_devices: drive_spec: DEVICE_SPECIFICATION wal_devices: drive_spec: DEVICE_SPECIFICATION block_wal_size: '5G' # (optional, unit suffixes permitted) block_db_size: '5G' # (optional, unit suffixes permitted) encrypted: true # 'True' or 'False' (defaults to 'False')
Die bisher als „Verschlüsselung“ bezeichnete Option in DeepSea wurde in „verschlüsselt“ umbenannt. Stellen Sie beim Anwenden von DriveGroups in SUSE Enterprise Storage 7 sicher, dass Sie diese neue Terminologie in Ihrer Servicespezifikation verwenden, da sonst der ceph orch apply-Vorgang fehlschlägt.
13.4.3.3 Abstimmung von Datenträgergeräten #
Sie können die Spezifikation mit folgenden Filtern beschreiben:
Nach Datenträgermodell:
model: DISK_MODEL_STRING
Nach Datenträgerhersteller:
vendor: DISK_VENDOR_STRING
TippGeben Sie den DISK_VENDOR_STRING immer in Kleinbuchstaben ein.
Details zu Datenträgermodell und Hersteller erhalten Sie in der Ausgabe des folgenden Kommandos:
cephuser@adm >ceph orch device ls HOST PATH TYPE SIZE DEVICE_ID MODEL VENDOR ses-min1 /dev/sdb ssd 29.8G SATA_SSD_AF34075704240015 SATA SSD ATA ses-min2 /dev/sda ssd 223G Micron_5200_MTFDDAK240TDN Micron_5200_MTFD ATA [...]Angabe, ob ein rotierender oder ein nicht rotierender Datenträger vorliegt. SSDs und NVMe-Laufwerke sind keine rotierenden Datenträger.
rotational: 0
Implementieren Sie einen Knoten mit allen verfügbaren Laufwerken für OSDs:
data_devices: all: true
Zusätzlich mit Einschränkung der Anzahl passender Datenträger
limit: 10
13.4.3.4 Filtern von Geräten nach Größe #
Sie können die Datenträgergeräte nach ihrer Größe filtern – wahlweise nach einer genauen Größenangabe oder einem Größenbereich. Der Parameter size: akzeptiert Argumente wie folgt:
„10G“ – Datenträger mit einer bestimmten Größe.
„10G:40G“ – Datenträger mit einer Größe im angegebenen Bereich.
„:10G“ – Datenträger mit einer Größe von maximal 10 GB.
„40G:“ – Datenträger mit einer Größe von mindestens 40 GB.
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: size: '40TB:' db_devices: size: ':2TB'
Beim Begrenzer „:“ müssen Sie die Größe in Anführungszeichen setzen, da das Zeichen „:“ ansonsten als neuer Konfiguration-Hash interpretiert wird.
Anstelle von Gigabyte (G) können Sie die Größen auch in Megabyte (M) oder Terabyte (T) angeben.
13.4.3.5 Beispiele für DriveGroups #
Dieser Abschnitt enthält Beispiele verschiedener OSD-Einrichtungen.
Dieses Beispiel zeigt zwei Knoten mit derselben Einrichtung:
20 HDDs
Hersteller: Intel
Modell: SSD-123-foo
Größe: 4 TB
2 SSDs
Hersteller: Micron
Modell: MC-55-44-ZX
Größe: 512 GB
Die entsprechende Datei drive_groups.yml sieht wie folgt aus:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: model: SSD-123-foo db_devices: model: MC-55-44-XZ
Eine solche Konfiguration ist unkompliziert und zulässig. Es stellt sich allerdings das Problem, dass ein Administrator in Zukunft eventuell Datenträger von anderen Herstellern einfügt, die dann nicht berücksichtigt werden. Zur Verbesserung geben Sie weniger Filter für die wesentlichen Eigenschaften der Laufwerke an:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: rotational: 1 db_devices: rotational: 0
Im vorherigen Beispiel wird die Deklaration aller rotierenden Geräte als „Datengeräte“ erzwungen und alle nicht rotierenden Geräte werden als „freigegebene Geräte“ (wal, db) genutzt.
Wenn Laufwerke mit mehr als 2 TB stets als langsamere Datengeräte eingesetzt werden sollen, können Sie nach Größe filtern:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: size: '2TB:' db_devices: size: ':2TB'
Dieses Beispiel umfasst zwei getrennte Einrichtungen: 20 HDDs sollen gemeinsam 2 SSDs nutzen und 10 SSDs nutzen gemeinsam 2 NVMes.
20 HDDs
Hersteller: Intel
Modell: SSD-123-foo
Größe: 4 TB
12 SSDs
Hersteller: Micron
Modell: MC-55-44-ZX
Größe: 512 GB
2 NVMes
Hersteller: Samsung
Modell: NVME-QQQQ-987
Größe: 256 GB
Eine solche Einrichtung kann wie folgt mit zwei Layouts definiert werden:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: MC-55-44-XZ
service_type: osd service_id: example_drvgrp_name2 placement: host_pattern: '*' data_devices: model: MC-55-44-XZ db_devices: vendor: samsung size: 256GB
In den vorherigen Beispielen wurde angenommen, dass alle Knoten dieselben Laufwerke umfassen. Dies ist jedoch nicht immer der Fall:
Knoten 1–5:
20 HDDs
Hersteller: Intel
Modell: SSD-123-foo
Größe: 4 TB
2 SSDs
Hersteller: Micron
Modell: MC-55-44-ZX
Größe: 512 GB
Knoten 6–10:
5 NVMes
Hersteller: Intel
Modell: SSD-123-foo
Größe: 4 TB
20 SSDs
Hersteller: Micron
Modell: MC-55-44-ZX
Größe: 512 GB
Mit dem „target“-Schlüssel im Layout können Sie bestimmte Knoten adressieren. Die Salt-Zielnotation trägt zur Vereinfachung bei:
service_type: osd service_id: example_drvgrp_one2five placement: host_pattern: 'node[1-5]' data_devices: rotational: 1 db_devices: rotational: 0
gefolgt von:
service_type: osd service_id: example_drvgrp_rest placement: host_pattern: 'node[6-10]' data_devices: model: MC-55-44-XZ db_devices: model: SSD-123-foo
In allen vorherigen Fällen wird angenommen, dass die WALs und DBs dasselbe Gerät nutzen. Es ist jedoch auch möglich, WAL auf einem dedizierten Gerät zu implementieren:
20 HDDs
Hersteller: Intel
Modell: SSD-123-foo
Größe: 4 TB
2 SSDs
Hersteller: Micron
Modell: MC-55-44-ZX
Größe: 512 GB
2 NVMes
Hersteller: Samsung
Modell: NVME-QQQQ-987
Größe: 256 GB
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: model: MC-55-44-XZ db_devices: model: SSD-123-foo wal_devices: model: NVME-QQQQ-987
In der folgenden Einrichtung soll Folgendes definiert werden:
20 HDDs mit 1 NVMe
2 HDDs mit 1 SSD(db) und 1 NVMe(wal)
8 SSDs mit 1 NVMe
2 Stand-Alone-SSDs (verschlüsselt)
1 HDD fungiert als Ersatz und soll nicht bereitgestellt werden
Zusammenfassung der verwendeten Datenträger:
23 HDDs
Hersteller: Intel
Modell: SSD-123-foo
Größe: 4 TB
10 SSDs
Hersteller: Micron
Modell: MC-55-44-ZX
Größe: 512 GB
1 NVMe
Hersteller: Samsung
Modell: NVME-QQQQ-987
Größe: 256 GB
Die DriveGroups-Definition lautet:
service_type: osd service_id: example_drvgrp_hdd_nvme placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_hdd_ssd_nvme placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: MC-55-44-XZ wal_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_ssd_nvme placement: host_pattern: '*' data_devices: model: SSD-123-foo db_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_standalone_encrypted placement: host_pattern: '*' data_devices: model: SSD-123-foo encrypted: True
Eine HDD verbleibt, da die Datei von oben nach unten analysiert wird.
13.4.4 Entfernen von OSDs #
Vergewissern Sie sich vor dem Entfernen eines OSD-Knotens aus dem Cluster, dass der Cluster über mehr freien Festplattenspeicher verfügt als der OSD-Datenträger, den Sie entfernen möchten. Bedenken Sie, dass durch Entfernen eines OSDs ein Ausgleich des gesamten Clusters durchgeführt wird.
Identifizieren Sie das zu entfernende OSD, indem Sie dessen ID ermitteln:
cephuser@adm >ceph orch ps --daemon_type osd NAME HOST STATUS REFRESHED AGE VERSION osd.0 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.1 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.2 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.3 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ...Entfernen Sie ein oder mehrere OSDs aus dem Cluster:
cephuser@adm >ceph orch osd rm OSD1_ID OSD2_ID ...Beispiel:
cephuser@adm >ceph orch osd rm 1 2Sie können den Status des Entfernungsvorgangs abfragen:
cephuser@adm >ceph orch osd rm status OSD_ID HOST STATE PG_COUNT REPLACE FORCE STARTED_AT 2 cephadm-dev done, waiting for purge 0 True False 2020-07-17 13:01:43.147684 3 cephadm-dev draining 17 False True 2020-07-17 13:01:45.162158 4 cephadm-dev started 42 False True 2020-07-17 13:01:45.162158
13.4.4.1 Anhalten der OSD-Entfernung #
Nach dem Planen einer OSD-Entfernung können Sie die Entfernung bei Bedarf stoppen. Mit folgendem Kommando wird der Ausgangszustand des OSDs zurückgesetzt und es wird aus der Warteschlange entfernt:
cephuser@adm > ceph orch osd rm stop OSD_SERVICE_ID13.4.5 Ersetzen von OSDs #
Ersetzen Sie ein OSD unter Beibehaltung seiner ID mit folgendem Kommando:
cephuser@adm > ceph orch osd rm OSD_SERVICE_ID --replaceBeispiel:
cephuser@adm > ceph orch osd rm 4 --replace
Der Vorgang zum Ersetzen eines OSDs ist identisch mit dem Vorgang zum Entfernen eines OSDs (weitere Details finden Sie in Abschnitt 13.4.4, „Entfernen von OSDs“). Allerdings wird beim Ersetzen das OSD nicht dauerhaft aus der CRUSH-Hierarchie entfernt und stattdessen ein Flag destroyed gesetzt.
Durch das Flag destroyed werden OSD-IDs ermittelt, die beim nächsten OSD-Einsatz wiederverwendet werden. Neu hinzugefügte Datenträger, die der DriveGroups-Spezifikation entsprechen (weitere Details finden Sie in Abschnitt 13.4.3, „Hinzufügen von OSDs mit der DriveGroups-Spezifikation“), erhalten die OSD-IDs des ersetzten Gegenstücks.
Durch Anhängen der Option --dry-run wird die eigentliche Ersetzung nicht ausgeführt, sondern es wird eine Vorschau der Schritte angezeigt, die normalerweise ablaufen würden.
13.5 Verschieben des Salt Masters auf einen neuen Knoten #
Wenn Sie den Salt-Master-Host durch einen neuen ersetzen müssen, führen Sie folgende Schritte aus:
Exportieren Sie die Cluster-Konfiguration und sichern Sie die exportierte JSON-Datei. Weitere Informationen finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.3.2.15 “Exportieren von Cluster-Konfigurationen”.
Wenn der alte Salt Master auch der einzige Verwaltungsknoten im Cluster ist, dann verschieben Sie
/etc/ceph/ceph.client.admin.keyringund/etc/ceph/ceph.confmanuell auf den neuen Salt Master.Stoppen und deaktivieren Sie den Salt Master
systemd-Service auf dem alten Salt-Master-Knoten:root@master #systemctl stop salt-master.serviceroot@master #systemctl disable salt-master.serviceWenn der alte Salt-Master-Knoten nicht mehr im Cluster ist, stoppen und deaktivieren Sie auch den
systemd-Service des Salt Minion:root@master #systemctl stop salt-minion.serviceroot@master #systemctl disable salt-minion.serviceWarnungStoppen oder deaktivieren Sie den
salt-minion.servicenicht, wenn auf dem alten Salt-Master-Knoten irgendwelche Ceph-Daemons (MON, MGR, OSD, MDS, Gateway, Monitoring) ausgeführt werden.Installieren Sie SUSE Linux Enterprise Server 15 SP2 auf dem neuen Salt Master entsprechend dem im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.1 “Installieren und Konfigurieren von SUSE Linux Enterprise Server” beschriebenen Verfahren.
Tipp: Übergang der Salt MinionsDamit der Übergang der Salt Minions auf den neuen Salt Master erleichtert wird, entfernen Sie den öffentlichen Schlüssel des ursprünglichen Salt Masters aus allen Minions:
root@minion >rm /etc/salt/pki/minion/minion_master.pubroot@minion >systemctl restart salt-minion.serviceInstallieren Sie das salt-master -Paket und gegebenenfalls das salt-minion -Paket auf dem neuen Salt Master.
Installieren Sie
ceph-saltauf dem neuen Salt-Master-Knoten:root@master #zypper install ceph-saltroot@master #systemctl restart salt-master.serviceroot@master #salt '*' saltutil.sync_allWichtigStellen Sie sicher, dass Sie alle drei Kommandos ausführen, bevor Sie fortfahren. Die Befehle sind idempotent. Es spielt keine Rolle, ob sie wiederholt werden.
Fügen Sie den neuen Salt Master im Cluster hinzu, wie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.3.1 “Installieren von
ceph-salt”, im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.3.2.2 “Hinzufügen von Salt Minions” und im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.3.2.4 “Festlegen des Admin Knoten” beschrieben.Importieren Sie die gesicherte Cluster-Konfiguration und wenden Sie sie an:
root@master #ceph-salt import CLUSTER_CONFIG.jsonroot@master #ceph-salt applyWichtigBenennen Sie die
minion iddes Salt Masters in der exportierten DateiCLUSTER_CONFIG.jsonum, bevor Sie sie importieren.
13.6 Aktualisieren der Cluster-Knoten #
Wenden Sie regelmäßig Updates im laufenden Betrieb an, damit die Ceph-Cluster-Knoten auf dem neuesten Stand bleiben.
13.6.1 Software-Repositorys #
Bevor Sie den Cluster mit den aktuellen Software-Paketen patchen, prüfen Sie, ob alle Cluster-Knoten auf die relevanten Repositorys zugreifen können. Eine Liste aller erforderlichen Repositorys finden Sie in Book “Implementierungsleitfaden”, Chapter 7 “Upgrade von einer früheren Version”, Section 7.1.5.1 “Software-Repositorys”.
13.6.2 Repository-Staging #
Wenn Sie mit einem Repository-Staging-System arbeiten (z. B. SUSE Manager, Repository Management Tool oder RMT), mit dem die Software-Repositorys für die Cluster-Knoten bereitgestellt werden, müssen die Phasen für beide „Aktualisierungen“-Repositorys für SUSE Linux Enterprise Server und SUSE Enterprise Storage zum gleichen Zeitpunkt erstellt werden.
Wir empfehlen dringend, ein Staging-Tool zu verwenden, um Patches mit eingefrorenen oder gestaffelten Patch-Stufen anzuwenden. Damit wird gewährleistet, dass die neu in den Cluster eintretenden Knoten dieselbe Patchstufe aufweisen wie die Knoten, die sich bereits im Cluster befinden. So müssen Sie nicht mehr die aktuellen Patches auf alle Cluster-Knoten anwenden, bevor neue Knoten in den Cluster aufgenommen werden können.
13.6.3 Ausfallzeit von Ceph-Services #
Je nach Konfiguration werden die Cluster-Knoten während der Aktualisierung ggf. neu gestartet. Wenn ein Single-Point-of-Failure für Services wie Object Gateway, Samba Gateway, NFS Ganesha oder iSCSI vorliegt, werden die Client-Computer unter Umständen vorübergehend von Services getrennt, dessen Knoten neu gestartet werden.
13.6.4 Ausführen der Aktualisierung #
Aktualisieren Sie mit folgendem Kommando die Softwarepakete auf allen Cluster-Knoten auf die aktuelle Version:
root@master # ceph-salt update13.7 Aktualisieren von Ceph #
Sie können cephadm anweisen, Ceph von einer Bugfix-Version auf eine andere zu aktualisieren. Die automatische Aktualisierung der Ceph-Services hält sich an die empfohlene Reihenfolge. Sie beginnt mit Ceph Managers, Ceph Monitors und geht dann weiter zu anderen Services wie Ceph OSDs, Metadatenservern und Object Gateways. Jeder Daemon wird erst dann neu gestartet, wenn Ceph anzeigt, dass der Cluster verfügbar bleibt.
Die folgende Aktualisierung wird mit dem Kommando ceph orch upgrade ausgeführt. Beachten Sie, dass in den folgenden Anweisungen detailliert beschrieben ist, wie Sie Ihren Ceph-Cluster mit einer Produktversion aktualisieren (z. B. einem Wartungsupdate). Sie erhalten darin keine Informationen, wie Sie Ihren Cluster von einer Produktversion auf eine andere aktualisieren.
13.7.1 Starten der Aktualisierung #
Vergewissern Sie sich vor dem Starten der Aktualisierung, dass alle Knoten zurzeit online sind und der Cluster integer ist:
cephuser@adm > cephadm shell -- ceph -sSo aktualisieren Sie auf eine bestimmte Ceph-Version:
cephuser@adm > ceph orch upgrade start --image REGISTRY_URLBeispiel:
cephuser@adm > ceph orch upgrade start --image registry.suse.com/ses/7/ceph/ceph:latestRüsten Sie die Pakete auf den Hosts auf:
cephuser@adm > ceph-salt update13.7.2 Überwachen der Aktualisierung #
Ermitteln Sie mit folgendem Kommando, ob eine Aktualisierung durchgeführt wird:
cephuser@adm > ceph orch upgrade statusWährend des Aktualisierungsvorgangs sehen Sie in der Ceph-Statusausgabe einen Fortschrittsbalken:
cephuser@adm > ceph -s
[...]
progress:
Upgrade to registry.suse.com/ses/7/ceph/ceph:latest (00h 20m 12s)
[=======.....................] (time remaining: 01h 43m 31s)Sie können auch das cephadm-Protokoll beobachten:
cephuser@adm > ceph -W cephadm13.7.3 Abbrechen einer Aktualisierung #
Sie können den Aktualisierungsvorgang jederzeit stoppen:
cephuser@adm > ceph orch upgrade stop13.8 Anhalten oder Neustarten des Clusters #
In einigen Fällen muss möglicherweise der gesamte Cluster angehalten oder neugestartet werden. Wir empfehlen, sorgfältig nach Abhängigkeiten von aktiven Services zu suchen. Die folgenden Schritte beschreiben den Vorgang zum Stoppen und Starten des Clusters:
Weisen Sie den Ceph-Cluster an, für OSDs das Flag „noout“ zu setzen:
cephuser@adm >cephosd set nooutStoppen Sie die Daemons und Knoten in der folgenden Reihenfolge:
Speicher-Clients
Gateways wie NFS Ganesha oder Object Gateway
Metadata Server
Ceph OSD
Ceph Manager
Ceph Monitor
Führen Sie Wartungsaufgaben aus, falls erforderlich.
Starten Sie die Knoten und Server in umgekehrter Reihenfolge des Herunterfahrens:
Ceph Monitor
Ceph Manager
Ceph OSD
Metadata Server
Gateways wie NFS Ganesha oder Object Gateway
Speicher-Clients
Entfernen Sie das Flag „noout“:
cephuser@adm >cephosd unset noout
13.9 Vollständiges Entfernen eines Ceph-Clusters #
Mit dem Kommando ceph-salt purge wird der gesamte Cluster entfernt. Wenn weitere Ceph-Cluster bereitgestellt sind, wird der von ceph -s gemeldete Cluster bereinigt. Auf diese Weise können Sie die kleinste menschliche Umgebung bereinigen, wenn Sie verschiedene Einrichtungen testen.
Damit nicht versehentlich ein Löschvorgang durchgeführt wird, prüft die Orchestrierung, ob die Sicherheitsmaßnahmen deaktiviert sind. Mit folgendem Kommando können Sie die Sicherheitsmaßnahmen deaktivieren und den Ceph-Cluster entfernen:
root@master #ceph-salt disengage-safetyroot@master #ceph-salt purge
14 Betrieb von Ceph-Services #
Sie können Ceph-Services auf Daemon-, Knoten- oder Clusterebene betreiben. Verwenden Sie je nach gewünschtem Ansatz cephadm oder das Kommando systemctl.
14.1 Betrieb einzelner Services #
Wenn Sie einen individuellen Service betreiben müssen, identifizieren Sie diesen zuerst:
cephuser@adm > ceph orch ps
NAME HOST STATUS REFRESHED [...]
mds.my_cephfs.ses-min1.oterul ses-min1 running (5d) 8m ago
mgr.ses-min1.gpijpm ses-min1 running (5d) 8m ago
mgr.ses-min2.oopvyh ses-min2 running (5d) 8m ago
mon.ses-min1 ses-min1 running (5d) 8m ago
mon.ses-min2 ses-min2 running (5d) 8m ago
mon.ses-min4 ses-min4 running (5d) 7m ago
osd.0 ses-min2 running (61m) 8m ago
osd.1 ses-min3 running (61m) 7m ago
osd.2 ses-min4 running (61m) 7m ago
rgw.myrealm.myzone.ses-min1.kwwazo ses-min1 running (5d) 8m ago
rgw.myrealm.myzone.ses-min2.jngabw ses-min2 error 8m agoFühren Sie zum Identifizieren eines Service auf einem bestimmten Knoten folgendes Kommando aus:
ceph orch ps NODE_HOST_NAME
Beispiel:
cephuser@adm > ceph orch ps ses-min2
NAME HOST STATUS REFRESHED
mgr.ses-min2.oopvyh ses-min2 running (5d) 3m ago
mon.ses-min2 ses-min2 running (5d) 3m ago
osd.0 ses-min2 running (67m) 3m ago
Das Kommando ceph orch ps unterstützt mehrere Ausgabeformate. Hängen Sie zum Ändern die Option --format FORMAT an, wobei FORMAT entweder json, json-pretty oder yaml sein kann. Beispiel:
cephuser@adm > ceph orch ps --format yamlSobald Sie den Namen des Service kennen, können Sie ihn starten, neu starten oder stoppen:
ceph orch daemon COMMAND SERVICE_NAME
Führen Sie folgendes Kommando aus, um beispielsweise den OSD-Service mit der ID 0 neu zu starten:
cephuser@adm > ceph orch daemon restart osd.014.2 Betrieb der Servicetypen #
Verwenden Sie folgendes Kommando, wenn Sie einen bestimmten Servicetyp im gesamten Ceph-Cluster betreiben müssen:
ceph orch COMMAND SERVICE_TYPE
Ersetzen Sie COMMAND durch start, stop oder restart.
Mit folgendem Kommando werden beispielsweise alle MONs im Cluster neu gestartet, unabhängig davon, auf welchen Knoten sie tatsächlich ausgeführt werden:
cephuser@adm > ceph orch restart mon14.3 Betrieb von Services auf einem einzelnen Knoten #
Mit dem Kommando systemctl betreiben Sie Ceph-bezogene systemd-Services und -Ziele auf einem einzelnen Knoten.
14.3.1 Identifizieren von Services und Zielen #
Bevor Sie Ceph-bezogene systemd-Services und -Ziele betreiben, müssen Sie die Dateinamen der zugehörigen Einheitendateien identifizieren. Die Dateinamen der Services werden nach folgendem Muster erstellt:
ceph-FSID@SERVICE_TYPE.ID.service
Beispiel:
ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@mon.doc-ses-min1.service
ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@rgw.myrealm.myzone.doc-ses-min1.kwwazo.service
- FSID
Eindeutige ID des Ceph-Clusters. Sie finden sie in der Ausgabe des Kommandos
ceph fsid.- SERVICE_TYPE
Typ des Service, beispielsweise
osd,monoderrgw.- ID
Identifikationszeichenkette des Service. Bei OSDs ist es die ID-Nummer des Service. Bei anderen Services kann es sich entweder um einen Hostnamen des Knotens oder um zusätzliche für den Servicetyp relevante Zeichenketten handeln.
Der Teil SERVICE_TYPE.ID ist in der Ausgabe des Kommandos ceph orch ps identisch mit dem Inhalt der Spalte NAME.
14.3.2 Betrieb aller Services auf einem Knoten #
Mit den systemd-Zielen von Ceph können Sie entweder alle Services auf einem Knoten oder alle Services, die zu einem durch seine FSID identifizierten Cluster gehören, gleichzeitig betreiben.
Führen Sie folgendes Kommando aus, um beispielsweise alle Ceph-Services auf einem Knoten zu stoppen, unabhängig davon, zu welchem Cluster die Services gehören:
root@minion > systemctl stop ceph.target
Führen Sie folgendes Kommando aus, um alle Services neu zu starten, die zu einem Ceph-Cluster mit ID b4b30c6e-9681-11ea-ac39-525400d7702d gehören:
root@minion > systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d.target14.3.3 Betrieb eines einzelnen Service auf einem Knoten #
Nachdem Sie den Namen eines bestimmten Service identifiziert haben, betreiben Sie ihn auf folgende Weise:
systemctl COMMAND SERVICE_NAME
Führen Sie folgendes Kommando aus, um beispielsweise einen einzelnen OSD-Service mit ID 1 auf einem Cluster mit ID b4b30c6e-9681-11ea-ac39-525400d7702d neu zu starten:
root # systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@osd.1.service14.3.4 Abfragen des Servicestatus #
Eine Abfrage mit systemd ermittelt den Status von Services. Beispiel:
root # systemctl status ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@osd.0.service14.4 Herunterfahren und Neustarten des gesamten Ceph-Clusters #
Das Herunterfahren und Neustarten des Clusters kann bei einem geplanten Stromausfall erforderlich sein. Führen Sie folgende Schritte aus, um alle Ceph-bezogenen Services zu stoppen und ohne Probleme neu zu starten.
Fahren Sie alle Clients herunter, die auf den Cluster zugreifen, oder trennen Sie deren Verbindung.
Legen Sie den Cluster auf
nooutfest, um zu verhindern, dass CRUSH den Cluster automatisch neu ausbalanciert:cephuser@adm >ceph osd set nooutStoppen Sie alle Ceph-Services auf allen Cluster-Knoten:
root@master #ceph-salt stopSchalten Sie alle Cluster-Knoten aus:
root@master #salt -G 'ceph-salt:member' cmd.run "shutdown -h"
Schalten Sie den Admin-Knoten ein.
Schalten Sie die Ceph Monitor-Knoten ein.
Schalten Sie die Ceph OSD-Knoten ein.
Entfernen Sie das vorher festgelegte Flag
noout:root@master #ceph osd unset nooutSchalten Sie alle konfigurierten Gateways ein.
Schalten Sie die Cluster-Clients ein oder verbinden Sie sie.
15 Sichern und Wiederherstellen #
In diesem Kapitel wird erläutert, welche Teile des Ceph-Clusters gesichert werden müssen, damit die Funktion des Clusters wiederhergestellt werden kann.
15.1 Sichern von Cluster-Konfiguration und -Daten #
15.1.1 Sichern der ceph-salt-Konfiguration #
Exportieren Sie die Cluster-Konfiguration. Weitere Informationen finden Sie in Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.3.2.15 “Exportieren von Cluster-Konfigurationen”.
15.1.2 Sichern der Ceph-Konfiguration #
Sichern Sie das Verzeichnis /etc/ceph. Es enthält wichtige Cluster-Konfigurationsdaten. Beispielsweise ist die /etc/ceph-Sicherung dann erforderlich, wenn Sie den Admin-Knoten ersetzen müssen.
15.1.3 Sichern der Salt-Konfiguration #
Sichern Sie das Verzeichnis /etc/salt/. Es enthält die Salt-Konfigurationsdateien, beispielsweise den Salt-Master-Schlüssel und die akzeptierten Client-Schlüssel.
Die Salt-Dateien sind zum Sichern des Admin-Knotens nicht unbedingt erforderlich, doch die erneute Bereitstellung des Salt Clusters wird dadurch einfacher. Wenn diese Dateien nicht gesichert sind, müssen die Salt Minions erneut beim neuen Admin-Knoten registriert werden.
Vergewissern Sie sich, dass die Sicherungskopien des privaten Salt-Master-Schlüssels an einem sicheren Ort verwahrt sind. Mit dem Salt-Master-Schlüssel können alle Cluster-Knoten manipuliert werden.
15.1.4 Sichern benutzerdefinierter Konfigurationen #
Prometheus-Daten und -Anpassung
Grafana-Anpassung
Manuelle Änderungen an der iSCSI-Konfiguration
Ceph-Schlüssel
CRUSH-Zuordnung und CRUSH-Regeln Mit folgendem Kommando speichern Sie die dekompilierte CRUSH-Zuordnung zusammen mit den CRUSH-Regeln in
crushmap-backup.txt:cephuser@adm >ceph osd getcrushmap | crushtool -d - -o crushmap-backup.txtSamba-Gateway-Konfiguration. Wenn Sie ein einzelnes Gateway nutzen, sichern Sie
/etc/samba/smb.conf. Wenn Sie eine Hochverfügbarkeitseinrichtung verwenden, müssen Sie auch die CTDB- und Pacemaker-Konfigurationsdateien sichern. Weitere Informationen zur verwendeten Konfiguration der Samba Gateways finden Sie in Kapitel 24, Exportieren von Ceph-Daten mit Samba.NFS-Ganesha-Konfiguration. Nur bei einer Hochverfügbarkeitseinrichtung erforderlich. Weitere Informationen zur verwendeten Konfiguration von NFS Ganesha finden Sie in Kapitel 25, NFS Ganesha.
15.2 Wiederherstellen eines Ceph-Knotens #
Das Verfahren zur Wiederherstellung eines Knotens aus der Sicherung besteht darin, den Knoten neu zu installieren, seine Konfigurationsdateien zu ersetzen und dann den Cluster neu zu orchestrieren, so dass der Ersatzknoten wieder hinzugefügt wird.
Wenn Sie den Admin-Knoten neu bereitstellen müssen, finden Sie Informationen hierzu in Abschnitt 13.5, „Verschieben des Salt Masters auf einen neuen Knoten“.
Bei Minions ist es in der Regel einfacher, sie einfach wieder aufzubauen und neu zu verteilen.
Installieren Sie den Knoten neu. Weitere Informationen finden Sie in Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.1 “Installieren und Konfigurieren von SUSE Linux Enterprise Server”.
Weitere Informationen zum Installieren von Salt finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.2 “Bereitstellen von Salt”.
Aktivieren Sie nach dem Wiederherstellen des Verzeichnisses
/etc/saltaus einer Sicherung die entsprechenden Salt-Services und starten Sie sie neu. Beispiel:root@master #systemctlenable salt-masterroot@master #systemctlstart salt-masterroot@master #systemctlenable salt-minionroot@master #systemctlstart salt-minionEntfernen Sie den öffentlichen Master-Schlüssel für den alten Salt-Master-Knoten aus allen Minions.
root@master #rm/etc/salt/pki/minion/minion_master.pubroot@master #systemctlrestart salt-minionStellen Sie alles wieder her, was sich lokal auf dem Admin-Knoten befand.
Importieren Sie die Cluster-Konfiguration aus der zuvor exportierten JSON-Datei. Weitere Informationen finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.3.2.15 “Exportieren von Cluster-Konfigurationen”.
Wenden Sie die importierte Cluster-Konfiguration an:
root@master #ceph-salt apply
16 Überwachung und Warnungen #
In SUSE Enterprise Storage 7 stellt cephadm einen Überwachungs- und Warnungsstack bereit. Anwender müssen die Services (wie Prometheus, Alertmanager und Grafana), die sie mit cephadm bereitstellen wollen, entweder in einer YAML-Konfigurationsdatei definieren, oder sie können sie über die Kommandozeilenschnittstelle bereitstellen. Wenn mehrere Services desselben Typs bereitgestellt werden, wird eine hochverfügbare Einrichtung bereitgestellt. Der Node Exporter stellt eine Ausnahme von dieser Regel dar.
Die folgenden Überwachungsservices können mit cephadm bereitgestellt werden:
Prometheus ist das Überwachungs- und Warnmeldungs-Toolkit. Es sammelt die von Prometheus-Exportern bereitgestellten Daten und löst vorkonfigurierte Warnungen aus, wenn vordefinierte Schwellenwerte erreicht wurden.
Alertmanager verarbeitet die durch den Prometheus-Server gesendeten Warnmeldungen. Es dedupliziert und gruppiert die Warnungen und leitet sie an den richtigen Empfänger weiter. Standardmäßig wird das Ceph Dashboard automatisch als Empfänger konfiguriert.
Grafana ist die Visualisierungs- und Warnmeldungs-Software. Die Warnungsfunktion von Grafana wird von diesem Überwachungs-Stack nicht genutzt. Für Warnungen wird der Alertmanager verwendet.
Der Node Exporter ist ein Exporter für Prometheus, der Daten über den Knoten liefert, auf dem er installiert ist. Es wird empfohlen, den Node Exporter auf allen Knoten zu installieren.
Das Prometheus-Manager-Modul stellt einen Prometheus-Exporter bereit, um Ceph-Leistungszähler von der Sammelstelle in ceph-mgr weiterzugeben.
Die Prometheus-Konfiguration, einschließlich der Scrape-Ziele (Daemons, die Kennzahlen bereitstellen), wird automatisch von cephadm eingerichtet. cephadm stellt außerdem eine Liste standardmäßiger Warnungen bereit, z. B. health error (Zustandsfehler), 10% OSDs down (10 % der OSDs inaktiv) oder pgs inactive (PGs inaktiv).
Standardmäßig wird der Datenverkehr zu Grafana mit TLS verschlüsselt. Sie können entweder ein eigenes TLS-Zertifikat bereitstellen oder ein eigensigniertes Zertifikat verwenden. Wenn vor dem Bereitstellen von Grafana kein benutzerdefiniertes Zertifikat konfiguriert wurde, dann wird automatisch ein eigensigniertes Zertifikat erstellt und für Grafana konfiguriert.
Benutzerdefinierte Zertifikate für Grafana können mit den folgenden Kommandos konfiguriert werden:
cephuser@adm >ceph config-key set mgr/cephadm/grafana_key -i $PWD/key.pemcephuser@adm >ceph config-key set mgr/cephadm/grafana_crt -i $PWD/certificate.pem
Alertmanager verarbeitet die durch den Prometheus-Server gesendeten Warnmeldungen. Hiermit werden die Warnmeldungen dedupliziert, gruppiert und an den richtigen Empfänger geleitet. Warnungen können über den Alertmanager stummgeschaltet werden. Stummschaltungen können aber auch über das Ceph Dashboard verwaltet werden.
Es wird empfohlen, den Node Exporter auf allen Knoten zu installieren. Dies kann über die Datei monitoring.yaml mit dem Servicetyp node-exporter erfolgen. Im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.3.8 “Bereitstellen des Überwachungs-Stacks” finden Sie weitere Informationen zum Bereitstellen von Services.
16.1 Konfigurieren von benutzerdefinierten oder lokalen Images #
In diesem Abschnitt wird beschrieben, wie Sie die Konfiguration von Container-Images ändern, die beim Bereitstellen oder Aktualisieren von Services verwendet werden. Er enthält nicht die Kommandos, die zum Bereitstellen oder erneuten Bereitstellen von Services erforderlich sind.
Die empfohlene Methode zum Bereitstellen des Überwachungs-Stacks besteht in der Anwendung seiner Spezifikation, wie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.3.8 “Bereitstellen des Überwachungs-Stacks”beschrieben.
Zum Bereitstellen benutzerdefinierter oder lokaler Container-Images müssen die Images in cephadm festgelegt werden. Dazu müssen Sie folgendes Kommando ausführen:
cephuser@adm > ceph config set mgr mgr/cephadm/OPTION_NAME VALUEOPTION_NAME bezeichnet einen der folgenden Namen:
container_image_prometheus
container_image_node_exporter
container_image_alertmanager
container_image_grafana
Wenn keine Option festgelegt ist oder wenn die Einstellung entfernt wurde, werden die folgenden Images als VALUE verwendet:
registry.suse.com/caasp/v4.5/prometheus-server:2.18.0
registry.suse.com/caasp/v4.5/prometheus-node-exporter:0.18.1
registry.suse.com/caasp/v4.5/prometheus-alertmanager:0.16.2
registry.suse.com/ses/7/ceph/grafana:7.0.3
Beispiel:
cephuser@adm > ceph config set mgr mgr/cephadm/container_image_prometheus prom/prometheus:v1.4.1Durch Festlegen eines benutzerdefinierten Image wird der Standardwert außer Kraft gesetzt (aber nicht überschrieben). Der Standardwert ändert sich, wenn Aktualisierungen verfügbar sind. Wenn Sie ein benutzerdefiniertes Bild festlegen, können Sie die Komponente, für die Sie das benutzerdefinierte Image festgelegt haben, nicht automatisch aktualisieren. Sie müssen die Konfiguration (Image-Namen und Tag) manuell aktualisieren, um Aktualisierungen installieren zu können.
Wenn Sie sich stattdessen für die Empfehlungen entscheiden, können Sie das zuvor festgelegte benutzerdefinierte Image zurücksetzen. Danach wird wieder der Standardwert verwendet. Verwenden Sie ceph config rm, um die Konfigurationsoption zurückzusetzen:
cephuser@adm > ceph config rm mgr mgr/cephadm/OPTION_NAMEBeispiel:
cephuser@adm > ceph config rm mgr mgr/cephadm/container_image_prometheus16.2 Aktualisieren von Überwachungsservices #
Wie in Abschnitt 16.1, „Konfigurieren von benutzerdefinierten oder lokalen Images“ erwähnt, sind im Lieferumfang von cephadm die URLs der empfohlenen und getesteten Container-Images vorhanden. Diese werden standardmäßig verwendet.
In Aktualisierungen der Ceph-Pakete können neue Versionen dieser URLs bereitgestellt werden. Dadurch wird nur aktualisiert, woher die Container-Images abgerufen werden, es werden aber keine Services aktualisiert.
Die Überwachungsservices können aktualisiert werden, nachdem die URLs zu den neuen Container-Images aktualisiert wurden – entweder manuell, wie in Abschnitt 16.1, „Konfigurieren von benutzerdefinierten oder lokalen Images“ beschrieben, oder automatisch durch eine Aktualisierung des Ceph-Pakets.
Verwenden Sie dazu ceph orch redeploy wie folgt:
cephuser@adm >ceph orch redeploy node-exportercephuser@adm >ceph orch redeploy prometheuscephuser@adm >ceph orch redeploy alertmanagercephuser@adm >ceph orch redeploy grafana
Zurzeit gibt es kein einzelnes Kommando zum Aktualisieren aller Überwachungsservices. Die Reihenfolge, in der diese Services aktualisiert werden, ist nicht wichtig.
Wenn Sie benutzerdefinierte Container-Images verwenden, werden die für die Überwachungsservices angegebenen URLs nicht automatisch geändert, wenn die Ceph-Pakete aktualisiert werden. Wenn Sie benutzerdefinierte Container-Images angegeben haben, müssen Sie die URLs der neuen Container-Images manuell angeben. Dies kann der Fall sein, wenn Sie eine lokale Container-Registrierung verwenden.
Die URLs der empfohlenen Container-Images, die Sie verwenden sollten, finden Sie in Abschnitt 16.1, „Konfigurieren von benutzerdefinierten oder lokalen Images“.
16.3 Deaktivieren der Überwachung #
Deaktivieren Sie den Überwachungs-Stack mit folgenden Kommandos:
cephuser@adm >ceph orch rm grafanacephuser@adm >ceph orch rm prometheus --force # this will delete metrics data collected so farcephuser@adm >ceph orch rm node-exportercephuser@adm >ceph orch rm alertmanagercephuser@adm >ceph mgr module disable prometheus
16.4 Konfigurieren von Grafana #
Das Ceph-Dashboard-Back-End benötigt die Grafana-URL, um das Vorhandensein von Grafana-Dashboards zu verifizieren, noch bevor das Frontend sie lädt. Aufgrund der Art und Weise, wie Grafana in Ceph Dashboard implementiert ist, bedeutet dies, dass zwei funktionierende Verbindungen erforderlich sind, um Grafana-Graphe in Ceph Dashboard sehen zu können:
Das Back-End (Ceph MGR-Modul) muss prüfen, ob der angeforderte Graph vorhanden ist. Wenn diese Anfrage erfolgreich ist, teilt es dem Frontend mit, dass es sicher auf Grafana zugreifen kann.
Das Frontend fordert dann die Grafana-Graphen direkt vom Browser des Benutzers über einen
iframean. Der Zugriff auf die Grafana-Instanz erfolgt direkt und ohne Umweg über das Ceph Dashboard.
In Ihrer Umgebung kann der Browser des Benutzers womöglich nicht direkt auf die im Ceph Dashboard konfigurierte URL zugreifen. Um dieses Problem zu lösen, kann eine separate URL konfiguriert werden, die ausschließlich dazu dient, dem Frontend (dem Browser des Benutzers) mitzuteilen, welche URL es für den Zugriff auf Grafana verwenden soll.
Mit folgendem Kommando ändern Sie die URL, die an das Frontend zurückgegeben wird:
cephuser@adm > ceph dashboard set-grafana-frontend-api-url GRAFANA-SERVER-URLWenn kein Wert für diese Option festgelegt ist, wird einfach auf den Wert der Option GRAFANA_API_URL zurückgegriffen. Er wird automatisch festgelegt und regelmäßig von cephadm aktualisiert. Wenn er festgelegt ist, wird der Browser angewiesen, diese URL für den Zugriff auf Grafana zu verwenden.
16.5 Konfigurieren des Prometheus-Manager-Moduls #
Das Prometheus-Manager-Modul ist ein Modul innerhalb von Ceph, mit dem die Funktionalität von Ceph erweitert wird. Das Modul liest (Meta-)Daten von Ceph über seinen Status und Zustand und stellt die (gescrapten) Daten in einem verwertbaren Format für Prometheus bereit.
Das Prometheus-Manager-Modul muss neu gestartet werden, damit die Konfigurationsänderungen übernommen werden.
16.5.1 Konfigurieren der Netzwerkschnittstelle #
Standardmäßig akzeptiert das Prometheus-Manager-Modul HTTP-Anfragen an Port 9283 auf allen IPv4- und IPv6-Adressen des Hosts. Der Port und die Überwachungsadresse sind beide mit ceph config-key set konfigurierbar, mit den Schlüsseln mgr/prometheus/server_addr und mgr/prometheus/server_port. Dieser Port ist in der Registrierung von Prometheus registriert.
Aktualisieren Sie die server_addr mit folgendem Kommando:
cephuser@adm > ceph config set mgr mgr/prometheus/server_addr 0.0.0.0
Aktualisieren Sie den server_port mit folgendem Kommando:
cephuser@adm > ceph config set mgr mgr/prometheus/server_port 928316.5.2 Konfigurieren des scrape_interval #
Standardmäßig ist das Prometheus-Manager-Modul mit einem Scrape-Intervall von 15 Sekunden konfiguriert. Ein Scrape-Intervall unter 10 Sekunden ist nicht zu empfehlen. Legen Sie scrape_interval auf den gewünschten Wert fest, um ein anderes Scrape-Intervall im Prometheus-Modul festzulegen:
Für eine korrekte und problemlose Funktionsweise sollte das scrape_interval dieses Moduls immer so festgelegt werden, dass es dem Prometheus-Scrape-Intervall entspricht.
cephuser@adm > ceph config set mgr mgr/prometheus/scrape_interval 1516.5.3 Konfigurieren des Caches #
Bei großen Clustern (mehr als 1000 OSDs) kann das Abrufen der Kennzahlen viel Zeit in Anspruch nehmen. Ohne den Cache kann das Prometheus-Manager-Modul den Manager überlasten und zu nicht reagierenden oder abstürzenden Ceph-Manager-Instanzen führen. Daher ist der Cache standardmäßig aktiviert und kann nicht deaktiviert werden, was jedoch zu einem veralteten Cache führen kann. Der Cache wird als veraltet angesehen, wenn die Zeit zum Abrufen der Kennzahlen von Ceph das konfigurierte scrape_interval überschreitet.
Wenn dies der Fall ist, wird eine Warnung protokolliert und das Modul reagiert auf zwei mögliche Arten:
Es antwortet mit einem 503-HTTP-Statuscode (Service nicht verfügbar).
Es gibt den Inhalt des Caches zurück, auch wenn er womöglich veraltet ist.
Dieses Verhalten kann mit den ceph config set-Kommandos konfiguriert werden.
Legen Sie das Modul auf return fest, um es anzuweisen, mit möglicherweise veralteten Daten zu antworten:
cephuser@adm > ceph config set mgr mgr/prometheus/stale_cache_strategy return
Legen Sie das Modul auf fail fest, um es anzuweisen, mit service unavailable zu antworten:
cephuser@adm > ceph config set mgr mgr/prometheus/stale_cache_strategy fail16.5.4 Aktivieren der RBD-Image-Überwachung #
Durch Aktivieren der dynamischen OSD-Leistungszähler kann das Prometheus-Manager-Modul optional RBD-pro-Image-Statistiken sammeln. Die Statistiken werden für alle Images in den Pools gesammelt, die im Konfigurationsparameter mgr/prometheus/rbd_stats_pools angegeben sind.
Der Parameter ist eine durch Komma oder Leerzeichen getrennte Liste von pool[/namespace]-Einträgen. Wenn der Namespace nicht angegeben ist, wird die Statistik für alle Namespaces im Pool gesammelt.
Beispiel:
cephuser@adm > ceph config set mgr mgr/prometheus/rbd_stats_pools "pool1,pool2,poolN"
Das Modul sucht die angegebenen Pools und Namespaces ab, erstellt eine Liste aller verfügbaren Images und aktualisiert sie in regelmäßigen Abständen. Das Intervall ist über den Parameter mgr/prometheus/rbd_stats_pools_refresh_interval konfigurierbar (in Sekunden) und beträgt standardmäßig 300 Sekunden (fünf Minuten).
Wenn Sie beispielsweise das Synchronisierungsintervall auf 10 Minuten geändert haben:
cephuser@adm > ceph config set mgr mgr/prometheus/rbd_stats_pools_refresh_interval 60016.6 Prometheus-Sicherheitsmodell #
Das Sicherheitsmodell von Prometheus geht davon aus, dass nicht vertrauenswürdige Benutzer Zugriff auf den Prometheus-HTTP-Endpunkt und die Protokolle haben. Nicht vertrauenswürdige Benutzer haben Zugriff auf alle (Meta-)Daten, die Prometheus sammelt und die in der Datenbank enthalten sind, sowie auf eine Vielzahl von Betriebs- und Debugging-Informationen.
Die HTTP-API von Prometheus ist jedoch auf reine Lesevorgänge beschränkt. Konfigurationen können nicht über die API geändert werden, und Geheimnisse werden nicht offengelegt. Darüber hinaus verfügt Prometheus über einige integrierte Maßnahmen zur Abschwächung der Auswirkungen von Denial-of-Service-Angriffen.
16.7 Prometheus Alertmanager SNMP-Webhook #
Wenn Sie mithilfe von SNMP-Traps über Prometheus-Warnungen benachrichtigt werden möchten, können Sie den Prometheus-Alertmanager-SNMP-Webhook über cephadm installieren. Dazu müssen Sie eine Service- und Platzierungsspezifikationsdatei mit folgendem Inhalt erstellen:
Weitere Informationen zum Erstellen von Service- und Platzierungsspezifikationsdateien finden Sie in Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.2 “Service- und Platzierungsspezifikation”.
service_type: container
service_id: prometheus-webhook-snmp
placement:
ADD_PLACEMENT_HERE
image: registry.suse.com/ses/7/prometheus-webhook-snmp:latest
args:
- "--publish 9099:9099"
envs:
- ARGS="--debug --snmp-host=ADD_HOST_GATEWAY_HERE"
- RUN_ARGS="--metrics"
EOFVerwenden Sie diese Servicespezifikation, um den Service mit seinen Standardeinstellungen auszuführen.
Sie müssen den Port, auf dem der Prometheus-Empfänger überwacht, mit dem Kommandozeilenargument --publish HOST_PORT:CONTAINER_PORT veröffentlichen, wenn Sie den Service ausführen, da der Port nicht automatisch vom Container sichtbar gemacht wird. Dies kann durch Hinzufügen der folgenden Zeilen zur Spezifikation erreicht werden:
args:
- "--publish 9099:9099"
Alternativ können Sie mit dem Kommandozeilenargument --network=host den Container mit dem Host-Netzwerk verbinden.
args:
- "--network=host"Wenn der SNMP-Trap-Empfänger nicht auf demselben Host wie der Container installiert ist, müssen Sie auch den FQDN des SNMP-Hosts angeben. Verwenden Sie das Netzwerk-Gateway des Containers, um SNMP-Traps außerhalb des Containers/Hosts zu empfangen:
envs:
- ARGS="--debug --snmp-host=CONTAINER_GATEWAY"16.7.1 Konfigurieren des Service prometheus-webhook-snmp #
Der Container kann über Umgebungsvariablen oder über eine Konfigurationsdatei konfiguriert werden.
Verwenden Sie für die Umgebungsvariablen ARGS, um globale Optionen festzulegen, und RUN_ARGS für die run-Optionen. Die Servicespezifikation muss folgendermaßen angepasst werden:
envs:
- ARGS="--debug --snmp-host=CONTAINER_GATEWAY"
- RUN_ARGS="--metrics --port=9101"Für eine Konfigurationsdatei muss die Servicespezifikation folgendermaßen angepasst werden:
files:
etc/prometheus-webhook-snmp.conf:
- "debug: True"
- "snmp_host: ADD_HOST_GATEWAY_HERE"
- "metrics: True"
volume_mounts:
etc/prometheus-webhook-snmp.conf: /etc/prometheus-webhook-snmp.confFühren Sie zur Bereitstellung folgendes Kommando aus:
cephuser@adm > ceph orch apply -i SERVICE_SPEC_FILEWeitere Informationen zu diesem Thema finden Sie unter dem Stichwort Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.3 “Bereitstellen von Ceph-Services”.
16.7.2 Konfigurieren des Prometheus Alertmanager für SNMP #
Schließlich muss der Prometheus Alertmanager speziell für SNMP-Traps konfiguriert werden. Wenn dieser Service noch nicht bereitgestellt wurde, erstellen Sie eine Servicespezifikationsdatei. Sie müssen IP_OR_FQDN durch die IP-Adresse oder den FQDN des Hosts ersetzen, auf dem der Prometheus Alertmanager SNMP-Webhook installiert wurde. Beispiel:
Wenn Sie diesen Service bereits bereitgestellt haben, dann stellen Sie ihn mit folgenden Einstellungen erneut bereit, um sicherzustellen, dass der Alertmanager korrekt für SNMP eingerichtet ist.
service_type: alertmanager
placement:
hosts:
- HOSTNAME
webhook_configs:
- 'http://IP_OR_FQDN:9099/'Wenden Sie die Servicespezifikation mit folgendem Kommando an:
cephuser@adm > ceph orch apply -i SERVICE_SPEC_FILETeil III Speichern von Daten in einem Cluster #
- 17 Verwaltung gespeicherter Daten
Der CRUSH-Algorithmus bestimmt, wie Daten gespeichert und abgerufen werden, indem er die Datenspeicherorte berechnet. CRUSH ist die Grundlage für die direkte Kommunikation der Ceph-Clients mit OSDs, ansonsten müssten sie über einen zentralen Server oder Broker kommunizieren. Mit einer algorithmisch …
- 18 Verwalten von Speicher-Pools
Ceph speichert Daten in Pools. Pools sind logische Gruppen für Speicherobjekte. Wenn Sie zunächst einen Cluster bereitstellen, ohne einen Pool zu erstellen, verwendet Ceph die Standard-Pools zum Speichern von Daten. Für Ceph-Pools gelten die folgenden wichtigen Punkte:
- 19 Erasure Coded Pools
Ceph bietet eine Alternative zur normalen Reproduktion von Daten in Pools, die als Erasure oder Erasure Coded Pool bezeichnet wird. Erasure Pools bieten nicht alle Funktionen der reproduzierten Pools (sie können beispielsweise keine Metadaten für RBD-Pools speichern), belegen jedoch weniger Basisspe…
- 20 RADOS Block Device
Ein Block ist eine Folge von Byte, beispielsweise ein 4-MB-Datenblock. Blockbasierte Speicherschnittstellen werden am häufigsten zum Speichern von Daten auf rotierenden Medien wie Festplatten, CDs, Disketten verwendet. Angesichts der Omnipräsenz von Blockgeräteschnittstellen ist ein virtuelles Block…
17 Verwaltung gespeicherter Daten #
Der CRUSH-Algorithmus bestimmt, wie Daten gespeichert und abgerufen werden, indem er die Datenspeicherorte berechnet. CRUSH ist die Grundlage für die direkte Kommunikation der Ceph-Clients mit OSDs, ansonsten müssten sie über einen zentralen Server oder Broker kommunizieren. Mit einer algorithmisch festgelegten Methode zum Speichern und Abrufen von Daten vermeidet Ceph einen Single-Point-of-Failure, einen Leistungsengpass und eine physische Beschränkung der Skalierbarkeit.
CRUSH benötigt eine Zuordnung Ihres Clusters und verwendet die CRUSH-Zuordnung zum pseudozufälligen Speichern und Abrufen von Daten in OSDs gleichmäßiger Datenverteilung im Cluster.
CRUSH-Zuordnungen enthalten eine Liste von OSDs, eine Liste der „Buckets“ zum Aggregieren der Geräte an physischen Standorten sowie eine Liste der Regeln, die CRUSH anweisen, wie es Daten in den Pools eines Ceph-Clusters reproduzieren soll. Durch Widerspiegeln der zugrundeliegenden physischen Struktur der Installation kann CRUSH potenzielle Ursachen von korrelierten Gerätefehlern nachbilden und somit eine Lösung suchen. Zu den typischen Ursachen zählen die physische Umgebung, eine gemeinsame Energiequelle und ein gemeinsames Netzwerk. Durch Verschlüsseln dieser Informationen in die Cluster-Zuordnung können CRUSH-Platzierungsrichtlinien Objektreproduktionen auf verschiedene Fehlerdomänen auslagern und gleichzeitig die gewünschte Verteilung beibehalten. Um beispielsweise für den Fall gleichzeitig auftretender Fehler vorzusorgen, sollte am besten sichergestellt werden, dass sich Datenreproduktionen auf Geräten mit unterschiedlichen Ablagefächern, Racks, Netzanschlüssen, Controllern und/oder physischen Speicherorten befinden.
Nach Bereitstellung eines Ceph-Clusters wird eine standardmäßige CRUSH-Zuordnung generiert. Sie eignet sich sehr gut für Ihre Ceph Sandbox-Umgebung. Wenn Sie jedoch einen sehr großen Daten-Cluster bereitstellen, sollten Sie die Entwicklung einer benutzerdefinierten CRUSH-Zuordnung ernsthaft in Erwägung ziehen, weil sie Ihnen die Verwaltung Ihres Ceph-Clusters erleichtert, die Leistung verbessert und die Datensicherheit gewährleistet.
Wenn beispielsweise ein OSD ausfällt, können Sie anhand der CRUSH-Zuordnung das physische Rechenzentrum, den Raum, die Reihe und das Rack des Hosts mit dem fehlerhaften OSD finden, für den Fall, dass Sie Support vor Ort benötigen oder die Hardware austauschen müssen.
Entsprechend kann CRUSH Ihnen auch dabei helfen, Fehler schneller zu finden. Wenn beispielsweise alle OSDs in einem bestimmten Rack gleichzeitig ausfallen, liegt der Fehler möglicherweise bei einem Netzwerkschalter oder der Energiezufuhr zum Rack bzw. am Netzwerkschalter statt an den OSDs selbst.
Eine benutzerdefinierte CRUSH-Zuordnung kann Ihnen auch dabei helfen, die physischen Standorte zu finden, an denen Ceph redundante Kopien der Daten speichert, wenn sich die Platzierungsgruppen (siehe Abschnitt 17.4, „Platzierungsgruppen“), die mit einem fehlerhaften Host verknüpft sind, in einem eingeschränkt leistungsfähigen Zustand befinden.
Eine CRUSH-Zuordnung setzt sich aus drei Hauptabschnitten zusammen.
OSD-Geräte umfassen alle Objektspeichergeräte, die einem
ceph-osd-Daemon entsprechen.Buckets sind eine hierarchische Ansammlung von Speicherorten (beispielsweise Reihen, Racks, Hosts etc.) und deren zugewiesenem Gewicht.
Regelsatz bezeichnen die Art und Weise, wie Buckets ausgewählt werden.
17.1 OSD-Geräte #
Zum Zuordnen von Platzierungsgruppen zu OSDs benötigt eine CRUSH-Zuordnung eine Liste von OSD-Geräten (den Namen des OSD Daemons). Die Liste der Geräte erscheint in der CRUSH-Zuordnung an erster Stelle.
#devices device NUM osd.OSD_NAME class CLASS_NAME
Beispiel:
#devices device 0 osd.0 class hdd device 1 osd.1 class ssd device 2 osd.2 class nvme device 3 osd.3class ssd
In der Regel wird ein OSD-Daemon einer einzelnen Festplatte zugeordnet.
17.1.1 Geräteklassen #
Die flexible Steuerung der Datenplatzierung mithilfe der CRUSH-Zuordnung zählt zu Cephs Stärken. Gleichzeitig ist dies mit der schwierigste Teil bei der Clusterverwaltung. Geräteklassen automatisieren die häufigsten Änderungen an CRUSH-Zuordnungen, die der Administrator bisher manuell vornehmen musste.
17.1.1.1 Das CRUSH-Verwaltungsproblem #
Ceph-Cluster setzen sich häufig aus verschiedenen Typen von Speichergeräten zusammen, also HDD, SSD, NVMe oder sogar gemischten Klassen dieser Geräte. Diese unterschiedlichen Speichergerättypen werden hier als Geräteklassen bezeichnet, sodass eine Verwechslung mit der Eigenschaft type der CRUSH-Buckets verhindert wird (z. B. „host“, „rack“, „row“; siehe Abschnitt 17.2, „Buckets“). SSD-gestützte Ceph-OSDs sind deutlich schneller als OSDs mit drehbaren Scheiben und damit für bestimmte Workloads besser geeignet. Mit Ceph können Sie ganz einfach RADOS-Pools für unterschiedliche Datenmengen oder Workloads erstellen und unterschiedliche CRUSH-Regeln für die Datenplatzierung in diesen Pools zuweisen.

Es ist jedoch mühsam, die CRUSH-Regeln so einzurichten, dass die Daten nur auf eine bestimmte Geräteklasse platziert werden. Die Regeln folgen der CRUSH-Hierarchie, doch wenn die Geräte in den Hosts oder Racks gemischt angeordnet sind (wie in der Beispielhierarchie oben), werden sie (standardmäßig) miteinander vermischt, sodass sie in den gleichen Unterbäumen der Hierarchie auftreten. In früheren Versionen von SUSE Enterprise Storage mussten sie manuell in separate Bäume sortiert werden, wobei für jede Geräteklasse mehrere Versionen der einzelnen Zwischen-Knoten erstellt werden mussten.
17.1.1.2 Geräteklassen #
Für diese Situation bietet Ceph eine elegante Lösung: Jedem OSD wird eine
Geräteklasse als Eigenschaft zugewiesen.
Standardmäßig stellen die OSDs ihre jeweilige Geräteklasse automatisch auf
„hdd“, „ssd“ oder „nvme“ ein, abhängig von den Hardware-Eigenschaften, die
der Linux-Kernel bereitstellt. Diese Geräte werden in der Ausgabe des
Kommandos ceph osd tree in einer neuen Spalte
aufgeführt:
cephuser@adm > ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 83.17899 root default
-4 23.86200 host cpach
2 hdd 1.81898 osd.2 up 1.00000 1.00000
3 hdd 1.81898 osd.3 up 1.00000 1.00000
4 hdd 1.81898 osd.4 up 1.00000 1.00000
5 hdd 1.81898 osd.5 up 1.00000 1.00000
6 hdd 1.81898 osd.6 up 1.00000 1.00000
7 hdd 1.81898 osd.7 up 1.00000 1.00000
8 hdd 1.81898 osd.8 up 1.00000 1.00000
15 hdd 1.81898 osd.15 up 1.00000 1.00000
10 nvme 0.93100 osd.10 up 1.00000 1.00000
0 ssd 0.93100 osd.0 up 1.00000 1.00000
9 ssd 0.93100 osd.9 up 1.00000 1.00000
Wenn die automatische Erkennung der Geräteklasse fehlschlägt, da
beispielsweise der Gerätetreiber die Daten zum Gerät nicht ordnungsgemäß
über /sys/block bereitstellt, können Sie die
Geräteklassen über die Kommandozeile anpassen:
cephuser@adm >ceph osd crush rm-device-class osd.2 osd.3 done removing class of osd(s): 2,3cephuser@adm >ceph osd crush set-device-class ssd osd.2 osd.3 set osd(s) 2,3 to class 'ssd'
17.1.1.3 Festlegen von CRUSH-Platzierungsregeln #
CRUSH-Regeln beschränken die Platzierung auf eine bestimmte Geräteklasse. Mit folgendem Kommando können Sie beispielsweise einen „schnell“ reproduzierten Pool erstellen, der die Daten ausschließlich auf SSD-Datenträger verteilt:
cephuser@adm > ceph osd crush rule create-replicated RULE_NAME ROOT FAILURE_DOMAIN_TYPE DEVICE_CLASSBeispiel:
cephuser@adm > ceph osd crush rule create-replicated fast default host ssdErstellen Sie einen Pool mit der Bezeichnung „fast_pool“ und weisen Sie ihn der Regel „fast“ zu:
cephuser@adm > ceph osd pool create fast_pool 128 128 replicated fastDie Erstellung von Löschcode-Regeln läuft geringfügig anders ab. Zunächst erstellen Sie ein Löschcode-Profil mit einer Eigenschaft für die gewünschte Geräteklasse. Anschließend legen Sie den Pool mit Löschcodierung an:
cephuser@adm >ceph osd erasure-code-profile set myprofile \ k=4 m=2 crush-device-class=ssd crush-failure-domain=hostcephuser@adm >ceph osd pool create mypool 64 erasure myprofile
Die Syntax wurde erweitert, sodass Sie die Geräteklasse auch manuell eingeben können, falls die CRUSH-Zuordnung manuell bearbeitet werden muss. Die obigen Kommandos erzeugen beispielsweise die folgende CRUSH-Regel:
rule ecpool {
id 2
type erasure
min_size 3
max_size 6
step set_chooseleaf_tries 5
step set_choose_tries 100
step take default class ssd
step chooseleaf indep 0 type host
step emit
}Der wichtige Unterschied: Das Kommando „take“ umfasst hier das zusätzliche Suffix „class CLASS_NAME“.
17.1.1.4 Zusätzliche Kommandos #
Mit folgendem Kommando rufen Sie eine Liste der Geräte in einer CRUSH-Zuordnung ab:
cephuser@adm > ceph osd crush class ls
[
"hdd",
"ssd"
]Mit folgendem Kommando rufen Sie eine Liste der vorhandenen CRUSH-Regeln ab:
cephuser@adm > ceph osd crush rule ls
replicated_rule
fastMit folgendem Kommando rufen Sie Details zur CRUSH-Regel „+++fast“ ab:
cephuser@adm > ceph osd crush rule dump fast
{
"rule_id": 1,
"rule_name": "fast",
"ruleset": 1,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -21,
"item_name": "default~ssd"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}Mit folgendem Kommando rufen Sie eine Liste der OSDs ab, die zur Klasse „ssd“ gehören:
cephuser@adm > ceph osd crush class ls-osd ssd
0
117.1.1.5 Migration von einer Legacy-SSD-Regel zu Geräteklassen #
In SUSE Enterprise Storage vor Version 5 mussten Sie die CRUSH-Zuordnung manuell bearbeiten und parallele Hierarchien für jeden einzelnen Gerätetyp (z. B. SSD) pflegen, damit Sie überhaupt Regeln für diese Regeln schreiben konnten. Seit SUSE Enterprise Storage 5 ist dies mit der Geräteklassenfunktion transparent möglich.
Mit dem Kommando crushtool wandeln Sie eine
Legacy-Regel und -Hierarchie in die neuen klassenbasierten Regeln um. Für
die Umwandlung stehen mehrere Möglichkeiten zur Auswahl:
crushtool --reclassify-root ROOT_NAME DEVICE_CLASSDieses Kommando erfasst alle Elemente in der Hierarchie unterhalb von ROOT_NAME und ersetzt alle Regeln, die mit
take ROOT_NAME
auf diesen Root verweisen, durch
take ROOT_NAME class DEVICE_CLASS
Die Buckets werden neu nummeriert, so dass die bisherigen IDs in den „Schattenbaum“ der jeweiligen Klasse übernommen werden. Somit werden keine Daten verschoben.
Beispiel 17.1:crushtool --reclassify-root#Betrachten Sie die folgende vorhandene Regel:
rule replicated_ruleset { id 0 type replicated min_size 1 max_size 10 step take default step chooseleaf firstn 0 type rack step emit }Wenn Sie den Root „default“ als Klasse „hdd“ neu klassifizieren, lautet die Regel nunmehr
rule replicated_ruleset { id 0 type replicated min_size 1 max_size 10 step take default class hdd step chooseleaf firstn 0 type rack step emit }crushtool --set-subtree-class BUCKET_NAME DEVICE_CLASSMit dieser Methode werden alle Geräte im Teilbaum mit dem Root BUCKET_NAME und der angegebenen Geräteklasse gekennzeichnet.
--set-subtree-classwird in der Regel gemeinsam mit der Option--reclassify-rootherangezogen, damit alle Geräte im betreffenden Root mit der richtigen Klasse gekennzeichnet werden. Einige Geräte, denen bewusst eine andere Klasse zugewiesen wurde, sollen jedoch nicht neu gekennzeichnet werden. In diesen Fällen lassen Sie die Option--set-subtree-classweg. Beachten Sie, dass diese Neuzuordnung nicht völlig einwandfrei ist, da die bisherige Regel auf Geräte mehrerer Klassen verteilt ist, während die angepassten Regeln lediglich Geräten der angegebenen Geräteklasse zugeordnet werden.crushtool --reclassify-bucket MATCH_PATTERN DEVICE_CLASS DEFAULT_PATTERNMit dieser Methode lässt sich eine parallele typenspezifische Hierarchie mit der normalen Hierarchie zusammenführen. Bei vielen Benutzern sehen die CRUSH-Zuordnungen beispielsweise so oder ähnlich aus:
Beispiel 17.2:crushtool --reclassify-bucket#host node1 { id -2 # do not change unnecessarily # weight 109.152 alg straw hash 0 # rjenkins1 item osd.0 weight 9.096 item osd.1 weight 9.096 item osd.2 weight 9.096 item osd.3 weight 9.096 item osd.4 weight 9.096 item osd.5 weight 9.096 [...] } host node1-ssd { id -10 # do not change unnecessarily # weight 2.000 alg straw hash 0 # rjenkins1 item osd.80 weight 2.000 [...] } root default { id -1 # do not change unnecessarily alg straw hash 0 # rjenkins1 item node1 weight 110.967 [...] } root ssd { id -18 # do not change unnecessarily # weight 16.000 alg straw hash 0 # rjenkins1 item node1-ssd weight 2.000 [...] }Mit dieser Funktion werden alle Buckets neu klassifiziert, die mit einem bestimmten Muster übereinstimmen. Dieses Muster lautet beispielsweise
%suffixoderprefix%. Im obigen Beispiel würden Sie das Muster%-ssdheranziehen. Bei jedem passenden Bucket bezeichnet der verbleibende Teil des Namens, also der Teil im Platzhalter „%“, den Basis-Bucket. Alle Geräte im passenden Bucket werden mit der angegebenen Geräteklasse gekennzeichnet und dann in den Basis-Bucket verschoben. Wenn der Basis-Bucket noch nicht vorhanden ist („node12-ssd“ liegt beispielsweise vor, „node12“ dagegen nicht), wird er erstellt und unter dem angegebenen standardmäßigen übergeordneten Bucket verknüpft. Die bisherigen Bucket-IDs werden für die neuen Shadow-Buckets beibehalten, wodurch keine Daten verschoben werden müssen. Regeln mittake-Schritten, die auf die bisherigen Buckets verweisen, werden angepasst.crushtool --reclassify-bucket BUCKET_NAME DEVICE_CLASS BASE_BUCKETMit der Option
--reclassify-bucketohne Platzhalter können Sie einen einzelnen Bucket zuordnen. Im obigen Beispiel soll beispielsweise der Bucket „ssd“ dem Standard-Bucket zugeordnet werden.Das Kommando, mit dem die Zuordnung mit den obigen Fragmenten endgültig konvertiert wird, lautet dann:
cephuser@adm >ceph osd getcrushmap -o originalcephuser@adm >crushtool -i original --reclassify \ --set-subtree-class default hdd \ --reclassify-root default hdd \ --reclassify-bucket %-ssd ssd default \ --reclassify-bucket ssd ssd default \ -o adjustedMit der Option
--comparekönnen Sie prüfen, ob die Konvertierung fehlerfrei durchgeführt wurde. Hiermit wird eine große Anzahl von Eingaben in die CRUSH-Zuordnung getestet und es wird verglichen, ob wieder das gleiche Ergebnis erzielt wird. Diese Eingaben werden mit denselben Optionen gesteuert wie--test. Im obigen Beispiel lautet das Kommando dann:cephuser@adm >crushtool -i original --compare adjusted rule 0 had 0/10240 mismatched mappings (0) rule 1 had 0/10240 mismatched mappings (0) maps appear equivalentTippBei Abweichungen würde das Verhältnis der neu zugeordneten Eingaben in Klammern angegeben.
Wenn Sie mit der angepassten CRUSH-Zuordnung zufrieden sind, können Sie sie auf den Cluster anwenden:
cephuser@adm >ceph osd setcrushmap -i adjusted
17.1.1.6 Weitere Informationen #
Weitere Informationen zu CRUSH-Zuordnungen finden Sie in Abschnitt 17.5, „Umgang mit der CRUSH-Zuordnung“.
Weitere Informationen zu Ceph Pools im Allgemeinen finden Sie in Kapitel 18, Verwalten von Speicher-Pools.
Weitere Informationen zu Pools mit Löschcodierung finden Sie in Kapitel 19, Erasure Coded Pools.
17.2 Buckets #
CRUSH-Zuordnungen enthalten eine Liste von OSDs, die in einer Baumstruktur von Buckets angeordnet werden können, um die Geräte an physischen Standorten zu aggregieren. Die einzelnen OSDs stellen die Blätter am Baum dar.
|
0 |
osd |
Ein spezifisches Gerät oder OSD ( |
|
1 |
Host |
Der Name eines Hosts mit einem oder mehreren OSDs. |
|
2 |
chassis |
Kennung dafür, welches Chassis im Rack den |
|
3 |
rack |
Ein Computer-Rack. Der Standardwert ist |
|
4 |
row |
Eine Reihe in einer Serie von Racks. |
|
5 |
pdu |
Abkürzung für „Power Distribution Unit“ (Stromversorgungseinheit). |
|
6 |
pod |
Abkürzung für „Point of Delivery“ (Zustellort): in diesem Zusammenhang eine Gruppe von PDUs oder eine Gruppe von Rackreihen. |
|
7 |
room |
Ein Raum mit Rackreihen. |
|
8 |
Rechenzentrum |
Ein physisches Rechenzentrum mit einem oder mehreren Räumen. |
|
9 |
region |
Geografische Region der Welt (z. B. NAM, LAM, EMEA, APAC usw.) |
|
10 |
root |
Der Stammknoten des Baums der OSD-Buckets (normalerweise auf
|
Sie können die vorhandenen Typen bearbeiten und eigene Bucket-Typen erstellen.
Die Bereitstellungswerkzeuge von Ceph generieren eine CRUSH-Zuordnung, die
einen Bucket für jeden Host sowie den Pool „default“ enthält, was für den
standardmäßigen rbd-Pool nützlich ist. Die restlichen
Bucket-Typen dienen zum Speichern von Informationen zum physischen Standort
von Knoten/Buckets. Dadurch wird die Cluster-Verwaltung erheblich
erleichtert, wenn bei OSDs, Hosts oder Netzwerkhardware Störungen auftreten
und der Administrator Zugriff auf die physische Hardware benötigt.
Ein Bucket umfasst einen Typ, einen eindeutigen Namen (Zeichenkette), eine
eindeutige als negative Ganzzahl ausgedrückte ID, ein Gewicht relativ zur
Gesamtkapazität/Capability seiner Elemente, den Bucket-Algorithmus
(standardmäßig straw) sowie den Hash (standardmäßig
0, was dem CRUSH Hash rjenkins1
entspricht). Ein Bucket kann ein oder mehrere Elemente enthalten. Die
Elemente bestehen möglicherweise aus anderen Buckets oder OSDs. Elemente
können ein Gewicht aufweisen, das dem relativen Gewicht des Elements
entspricht.
[bucket-type] [bucket-name] {
id [a unique negative numeric ID]
weight [the relative capacity/capability of the item(s)]
alg [the bucket type: uniform | list | tree | straw2 | straw ]
hash [the hash type: 0 by default]
item [item-name] weight [weight]
}Das folgende Beispiel veranschaulicht, wie Sie Buckets zum Aggregieren eines Pools und der physischen Standorte wie Rechenzentrum, Raum, Rack und Reihe verwenden.
host ceph-osd-server-1 {
id -17
alg straw2
hash 0
item osd.0 weight 0.546
item osd.1 weight 0.546
}
row rack-1-row-1 {
id -16
alg straw2
hash 0
item ceph-osd-server-1 weight 2.00
}
rack rack-3 {
id -15
alg straw2
hash 0
item rack-3-row-1 weight 2.00
item rack-3-row-2 weight 2.00
item rack-3-row-3 weight 2.00
item rack-3-row-4 weight 2.00
item rack-3-row-5 weight 2.00
}
rack rack-2 {
id -14
alg straw2
hash 0
item rack-2-row-1 weight 2.00
item rack-2-row-2 weight 2.00
item rack-2-row-3 weight 2.00
item rack-2-row-4 weight 2.00
item rack-2-row-5 weight 2.00
}
rack rack-1 {
id -13
alg straw2
hash 0
item rack-1-row-1 weight 2.00
item rack-1-row-2 weight 2.00
item rack-1-row-3 weight 2.00
item rack-1-row-4 weight 2.00
item rack-1-row-5 weight 2.00
}
room server-room-1 {
id -12
alg straw2
hash 0
item rack-1 weight 10.00
item rack-2 weight 10.00
item rack-3 weight 10.00
}
datacenter dc-1 {
id -11
alg straw2
hash 0
item server-room-1 weight 30.00
item server-room-2 weight 30.00
}
root data {
id -10
alg straw2
hash 0
item dc-1 weight 60.00
item dc-2 weight 60.00
}17.3 Regelsatz #
CRUSH-Zuordnungen unterstützen das Konzept der „CRUSH-Regeln“. Dabei handelt es sich um die Regeln, die die Datenplatzierung für einen Pool bestimmen. Bei großen Clustern erstellen Sie wahrscheinlich viele Pools und jeder Pool verfügt über einen eigenen CRUSH-Regelsatz und Regeln. Die standardmäßige CRUSH-Zuordnung umfasst eine Regel für den Standard-Root. Wenn Sie weitere Roots und Regeln benötigen, erstellen Sie sie später. Ansonsten werden sie automatisch angelegt, sobald neue Pools eingerichtet werden.
In den meisten Fällen müssen Sie die Standardregeln nicht ändern. Beim Erstellen eines neuen Pools lautet der Standardregelsatz 0.
Eine Regel sieht folgendermaßen aus:
rule rulename {
ruleset ruleset
type type
min_size min-size
max_size max-size
step step
}- ruleset
Eine Ganzzahl. Klassifiziert eine Regel als Teil einer Gruppe von Regeln. Wird dadurch aktiviert, dass der Regelsatz in einem Pool festgelegt wird. Diese Option muss aktiviert sein. Der Standardwert ist
0.- type
Eine Zeichenkette. Beschreibt eine Regel für einen „reproduzierten“ oder einen „Erasure“ Coded Pool. Diese Option muss aktiviert sein. Die Standardeinstellung ist
replicated.- min_size
Eine Ganzzahl. CRUSH wählt diese Regel NICHT aus, wenn eine Poolgruppe weniger Reproduktionen erstellt als diese Zahl. Diese Option muss aktiviert sein. Die Standardeinstellung ist
2.- max_size
Eine Ganzzahl. CRUSH wählt diese Regel NICHT aus, wenn eine Poolgruppe mehr Reproduktionen erstellt als diese Zahl. Diese Option muss aktiviert sein. Die Standardeinstellung ist
10.- step take bucket
Nimmt einen Bucket, der durch einen Namen angegeben wird, und beginnt, den Baum nach unten zu durchlaufen. Diese Option muss aktiviert sein. Eine Erläuterung zum Durchlaufen des Baums finden Sie in Abschnitt 17.3.1, „Durchlaufen des Knoten-Baums“.
- step targetmodenum type bucket-type
target ist entweder
chooseoderchooseleaf. Wenn der Wert aufchoosefestgelegt ist, wird eine Reihe von Buckets ausgewählt.chooseleafwählt direkt die OSDs (Blatt-Knoten) aus dem Teilbaum der einzelnen Buckets in der Gruppe der Buckets aus.mode ist entweder
firstnoderindep. Siehe Abschnitt 17.3.2, „firstn und indep“.Wählt die Anzahl der Buckets des angegebenen Typs aus. Wenn N die Anzahl der verfügbaren Optionen ist und num > 0 && < N, wählen Sie genauso viele Buckets. num < 0 bedeutet N - num. Bei num == 0 wählen Sie N Buckets (alle verfügbar). Folgt auf
step takeoderstep choose.- step emit
Gibt den aktuellen Wert aus und leert den Stack. Wird normalerweise am Ende einer Regel verwendet, kann jedoch auch zum Erstellen unterschiedlicher Bäume in derselben Regel verwendet werden. Folgt auf
step choose.
17.3.1 Durchlaufen des Knoten-Baums #
Die mit den Buckets definierte Struktur kann als Knoten-Baum angezeigt werden. Buckets sind Knoten und OSDs sind Blätter an diesem Baum.
Die Regeln in der CRUSH-Zuordnung definieren, wie OSDs aus diesem Baum ausgewählt werden. Eine Regel beginnt mit einem Knoten und durchläuft dann den Baum nach unten, um eine Reihe von OSDs zurückzugeben. Es ist nicht möglich, zu definieren, welcher Zweig ausgewählt werden muss. Stattdessen wird durch den CRUSH-Algorithmus sichergestellt, dass die Gruppe der OSDs die Reproduktionsanforderungen erfüllt und die Daten gleichmäßig verteilt.
Bei step take bucket beginnt
der Durchlauf des Knoten-Baums am angegebenen Bucket (nicht am Bucket-Typ).
Wenn OSDs aus allen Zweigen am Baum zurückgegeben werden müssen, dann muss
der Bucket der Root Bucket sein. Andernfalls durchlaufen die folgenden
Schritte nur einen Teilbaum.
In der Regeldefinition folgen nach step take ein oder
zwei step choose-Einträge. Mit jedem step
choose wird eine definierte Anzahl von Knoten (oder Zweigen) aus
dem vorher ausgewählten oberen Knoten gewählt.
Am Ende werden die ausgewählten OSDs mit step emit
zurückgegeben.
step chooseleaf ist eine praktische Funktion, mit der
OSDs direkt aus Zweigen des angegebenen Buckets ausgewählt werden.
Abbildung 17.2, „Beispielbaum“ zeigt ein Beispiel, wie
step zum Durchlaufen eines Baums verwendet wird. In den
folgenden Regeldefinitionen entsprechen die orangen Pfeile und Zahlen
example1a und example1b und die
blauen Pfeile example2.

# orange arrows
rule example1a {
ruleset 0
type replicated
min_size 2
max_size 10
# orange (1)
step take rack1
# orange (2)
step choose firstn 0 host
# orange (3)
step choose firstn 1 osd
step emit
}
rule example1b {
ruleset 0
type replicated
min_size 2
max_size 10
# orange (1)
step take rack1
# orange (2) + (3)
step chooseleaf firstn 0 host
step emit
}
# blue arrows
rule example2 {
ruleset 0
type replicated
min_size 2
max_size 10
# blue (1)
step take room1
# blue (2)
step chooseleaf firstn 0 rack
step emit
}17.3.2
Eine CRUSH-Regel definiert den Ersatz für fehlerhafte Knoten oder OSDs
(weitere Informationen finden Sie in Abschnitt 17.3, „Regelsatz“). Für
das Schlüsselwort step ist entweder
firstn oder indep als Parameter
erforderlich. Abbildung 17.3, „Methoden für den Austausch von Knoten“ zeigt
ein Beispiel.
firstn fügt Ersatz-Knoten am Ende der Liste der aktiven
Knoten hinzu. Im Fall eines fehlerhaften Knotens werden die folgenden
fehlerfreien Knoten nach links verschoben, um die Lücke der fehlerhaften
Knoten zu schließen. Dies ist die standardmäßige und erwünschte Methode für
reproduzierte Pools, weil ein sekundärer Knoten
bereits alle Daten enthält und daher die Aufgaben des primären Knoten
sofort übernehmen kann.
indep wählt feste Ersatz-Knoten für jeden aktiven Knoten
aus. Der Ersatz für einen fehlerhaften Knoten ändert nicht die Reihenfolge
der anderen Knoten. Dies ist die erwünschte Methode für Erasure
Coded Pools. In Erasure Coded Pools hängen die in einem Knoten
gespeicherten Daten von ihrer Position in der Knoten-Auswahl ab. Wenn sich
die Reihenfolge der Knoten ändert, müssen alle Daten in den betroffenen
Knoten neu platziert werden.

17.4 Platzierungsgruppen #
Ceph ordnet die Objekte bestimmten Platzierungsgruppen (PGs) zu. Die Platzierungsgruppen sind Shards oder Fragmente einer logischen Gruppe, mit der Objekte als Gruppe in OSDs platziert werden. Platzierungsgruppen verringern die Menge der Metadaten pro Objekt, wenn Ceph die Daten in OSDs speichert. Eine größere Anzahl von Platzierungsgruppen – beispielsweise 100 pro OSD – bewirkt einen besseren Ausgleich.
17.4.1 Verwenden von Platzierungsgruppen #
Eine Platzierungsgruppe (PG) aggregiert Objekte in einem Pool. Der wichtigste Grund: Die Nachverfolgung der Objektplatzierung und der Metadaten für einzelne Objekte ist rechnerisch aufwendig. In einem System mit Millionen von Objekten ist es beispielsweise nicht möglich, die Platzierung einzelner Objekte direkt zu verfolgen.

Der Ceph-Client berechnet die Platzierungsgruppe, zu der ein Objekt gehört. Hierzu erhält die Objekt-ID ein Hash und es wird eine Aktion aufgeführt, die auf der Anzahl der PGs im definierten Pool und auf der ID des Pools beruht.
Der Inhalt des Objekts in einer Platzierungsgruppe wird in einer Gruppe von OSDs gespeichert. In einem reproduzierten Pool der Größe 2 werden Objekte durch die Platzierungsgruppen beispielsweise auf zwei OSDs gespeichert:

Wenn OSD 2 ausfällt, wird der Platzierungsgruppe 1 ein anderes OSD zugewiesen, auf dem dann Kopien aller Objekte auf OSD 1 abgelegt werden. Wird die Poolgröße von 2 auf 3 erhöht, wird der Platzierungsgruppe ein zusätzliches OSD zugewiesen, das dann Kopien aller Objekte in der Platzierungsgruppe erhält.
Platzierungsgruppen fungieren nicht als Eigentümer des OSD, sondern nutzen es gemeinsam mit anderen Platzierungsgruppen aus demselben Pool oder sogar aus anderen Pools. Wenn OSD 2 ausfällt, muss die Platzierungsgruppe 2 ebenfalls Kopien der Objekte wiederherstellen, wobei OSD 3 herangezogen wird.
Wenn die Anzahl der Platzierungsgruppen wächst, werden den neuen Platzierungsgruppen entsprechend OSDs zugewiesen. Auch das Ergebnis der CRUSH-Funktion ändert sich und einige Objekte aus den bisherigen Platzierungsgruppen werden in die neuen Platzierungsgruppen kopiert und aus den bisherigen Gruppen entfernt.
17.4.2 Ermitteln des Werts für PG_NUM #
Seit Ceph Nautilus (v14.x) können Sie das Ceph-Manager-Modul
pg_autoscaler verwenden, um die PGs bei Bedarf
automatisch zu skalieren. Wenn Sie diese Funktion aktivieren möchten,
lesen Sie im Book “Deploying and Administering SUSE Enterprise Storage with Rook”, Chapter 7 “Configuration”, Section 7.1.1.1 “Default PG and PGP counts” nach.
Beim Erstellen eines neuen Pools können Sie den Wert von PG_NUM noch manuell wählen:
root # ceph osd pool create POOL_NAME PG_NUMPG_NUM kann nicht automatisch berechnet werden. Die folgenden Werte kommen häufig zum Einsatz, je nach Anzahl der OSDs im Cluster:
- Weniger als 5 OSDs:
Legen Sie PG_NUM auf 128 fest.
- Zwischen 5 und 10 OSDs:
Legen Sie PG_NUM auf 512 fest.
- Zwischen 10 und 50 OSDs:
Legen Sie PG_NUM auf 1.024 fest.
Mit wachsender Anzahl der OSDs wird die Auswahl des richtigen Werts für PG_NUM immer wichtiger. PG_NUM wirkt sich stark auf das Verhalten des Clusters und auf die Haltbarkeit der Daten bei einem OSD-Fehler aus.
17.4.2.1 Berechnen der Platzierungsgruppen für mehr als 50 OSDs #
Wenn Sie weniger als 50 OSDs nutzen, beachten Sie die Vorauswahl unter Abschnitt 17.4.2, „Ermitteln des Werts für PG_NUM“. Wenn Sie mehr als 50 OSDs nutzen, werden etwa 50–100 Platzierungsgruppen pro OSD empfohlen, sodass die Ressourcenauslastung, die Datenhaltbarkeit und die Verteilung ausgeglichen sind. Bei einem einzelnen Pool mit Objekten können Sie mit der folgenden Formel einen Referenzwert berechnen:
total PGs = (OSDs * 100) / POOL_SIZE
POOL_SIZE bezeichnet hierbei entweder die
Anzahl der Reproduktionen bei reproduzierten Pools oder die Summe aus
„k“+„m“ bei Pools mit Löschcodierung, die durch das Kommando ceph
osd erasure-code-profile get zurückgegeben wird. Runden Sie das
Ergebnis auf die nächste Zweierpotenz auf. Das Aufrunden wird empfohlen,
damit der CRUSH-Algorithmus die Anzahl der Objekte gleichmäßig auf die
Platzierungsgruppen verteilen kann.
Für einen Cluster mit 200 OSDs und einer Poolgröße von 3 Reproduktionen würden Sie die Anzahl der PGs beispielsweise wie folgt näherungsweise ermitteln:
(200 * 100) / 3 = 6667
Die nächste Zweierpotenz ist 8.192.
Wenn Objekte in mehreren Daten-Pools gespeichert werden, müssen Sie die Anzahl der Platzierungsgruppen pro Pool in jedem Fall mit der Anzahl der Platzierungsgruppen pro OSD abgleichen. Dabei müssen Sie eine sinnvolle Gesamtanzahl der Platzierungsgruppen erreichen, die eine angemessen niedrige Varianz pro OSD gewährleistet, ohne die Systemressourcen überzustrapazieren oder den Peering-Prozess zu stark zu verlangsamen.
Ein Cluster mit 10 Pools mit je 512 Platzierungsgruppen auf 10 OSDs umfasst beispielsweise insgesamt 5.120 Platzierungsgruppen auf 10 OSDs, also 512 Platzierungsgruppen pro OSD. Eine solche Einrichtung verbraucht nicht allzu viele Ressourcen. Würden jedoch 1.000 Pools mit je 512 Platzierungsgruppen erstellt, müssten die OSDs je etwa 50.000 Platzierungsgruppen verarbeiten, was die Ressourcenauslastung und den Zeitaufwand für das Peering erheblich erhöhen würde.
17.4.3 Festlegen der Anzahl der Platzierungsgruppen #
Seit Ceph Nautilus (v14.x) können Sie das Ceph-Manager-Modul
pg_autoscaler verwenden, um die PGs bei Bedarf
automatisch zu skalieren. Wenn Sie diese Funktion aktivieren möchten,
lesen Sie im Book “Deploying and Administering SUSE Enterprise Storage with Rook”, Chapter 7 “Configuration”, Section 7.1.1.1 “Default PG and PGP counts” nach.
Wenn Sie die Anzahl der Platzierungsgruppen in einem Pool noch manuell festlegen müssen, müssen Sie sie zum Zeitpunkt der Poolerstellung angeben (weitere Informationen finden Sie in Abschnitt 18.1, „Erstellen eines Pools“). Die festgelegte Anzahl der Platzierungsgruppen für einen Pool kann mit folgendem Kommando erhöht werden:
root # ceph osd pool set POOL_NAME pg_num PG_NUM
Wenn Sie die Anzahl der Platzierungsgruppen erhöhen, müssen Sie auch die
Anzahl der zu platzierenden Platzierungsgruppen (PGP_NUM)
erhöhen, damit der Cluster neu ausgeglichen werden kann.
PGP_NUM ist die Anzahl der Platzierungsgruppen, die der
CRUSH-Algorithmus zur Platzierung berücksichtigt. Wird
PG_NUM erhöht, werden die Platzierungsgruppen geteilt; die
Daten werden allerdings erst dann zu den neueren Platzierungsgruppen
migriert, wenn PGP_NUM erhöht wird.
PGP_NUM muss gleich PG_NUM sein. Mit
folgendem Kommando erhöhen Sie die Anzahl der Platzierungsgruppen zur
Platzierung:
root # ceph osd pool set POOL_NAME pgp_num PGP_NUM17.4.4 Feststellen der Anzahl der Platzierungsgruppen #
Führen Sie folgendes get-Kommando aus, um die Anzahl der
Platzierungsgruppen in einem Pool festzustellen:
root # ceph osd pool get POOL_NAME pg_num17.4.5 Feststellen der PG-Statistiken für einen Cluster #
Mit folgendem Kommando stellen Sie die Statistik für die Platzierungsgruppen in Ihrem Cluster fest:
root # ceph pg dump [--format FORMAT]Zulässige Formate sind „plain“ (Standard) und „json“.
17.4.6 Feststellen von Statistiken für hängen gebliebene PGs #
Mit folgendem Kommando stellen Sie die Statistiken für alle Platzierungsgruppen fest, die in einem bestimmten Status hängen geblieben sind:
root # ceph pg dump_stuck STATE \
[--format FORMAT] [--threshold THRESHOLD]
STATE lautet „inactive“ (PGs können keine Lese-
oder Schreibvorgänge verarbeiten, da sie darauf warten, dass ein OSD die
jeweils neuesten Daten bereitstellt), „unclean“ (PGs enthalten Objekte, die
nicht so oft wie gefordert reproduziert wurden), „stale“ (PGs besitzen
einen unbekannten Status – die OSDs, auf denen sie gehostet werden, haben
den Status nicht im Zeitraum zurückgegeben, der in der Option
mon_osd_report_timeout festgelegt ist), „undersized“ oder
„degraded“.
Zulässige Formate sind „plain“ (Standard) und „json“.
Der Schwellwert definiert den Mindestzeitraum (in Sekunden), über den die Platzierungsgruppe hängen geblieben sein muss, bevor sie in die zurückgegebenen Statistiken aufgenommen wird (standardmäßig 300 Sekunden).
17.4.7 Suchen einer Platzierungsgruppenzuordnung #
Mit folgendem Kommando suchen Sie die Platzierungsgruppenzuordnung für eine bestimmte Platzierungsgruppe:
root # ceph pg map PG_IDCeph gibt die Platzierungsgruppenzuordnung, die Platzierungsgruppe und den OSD-Status zurück:
root # ceph pg map 1.6c
osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]17.4.8 Abrufen einer Platzierungsgruppenstatistik #
Mit folgendem Kommando rufen Sie die Statistiken für eine bestimmte Platzierungsgruppe ab:
root # ceph pg PG_ID query17.4.9 Scrubbing einer Platzierungsgruppe #
Mit folgendem Kommando führen Sie das Scrubbing (Abschnitt 17.6, „Scrubbing von Platzierungsgruppen“) einer Platzierungsgruppe aus:
root # ceph pg scrub PG_IDCeph prüft die primären Knoten und die Reproduktionsknoten, erzeugt einen Katalog aller Objekte der Platzierungsgruppe und führt einen Vergleich aus, mit dem gewährleistet wird, dass keine Objekte fehlen oder fehlerhaft zugeordnet wurden und dass die Inhalte der Objekte konsistent sind. Unter der Voraussetzung, dass alle Reproduktionen übereinstimmen, wird mit einem abschließenden semantischen Durchlauf geprüft, ob alle snapshotspezifischen Objekt-Metadaten konsistent sind. Fehler werden in Protokollen erfasst.
17.4.10 Priorisierung des Abgleichs und der Wiederherstellung von Platzierungsgruppen #
Unter Umständen müssen mehrere Platzierungsgruppen wiederhergestellt und/oder abgeglichen werden, deren Daten unterschiedlich wichtig sind. Die PGs enthalten beispielsweise Daten für Images, die auf derzeit laufenden Computern verwendet werden, andere PGs dagegen werden von inaktiven Computern herangezogen oder enthalten weniger relevante Daten. In diesem Fall muss die Wiederherstellung der betreffenden Gruppen priorisiert werden, sodass die Leistung und Verfügbarkeit der in diesen Gruppen gespeicherten Daten rascher wieder bereitstehen. Mit folgendem Kommando markieren Sie bestimmte Platzierungsgruppen bei einem Abgleich oder einer Wiederherstellung als priorisiert:
root #ceph pg force-recovery PG_ID1 [PG_ID2 ... ]root #ceph pg force-backfill PG_ID1 [PG_ID2 ... ]
Hiermit führt Ceph zuerst die Wiederherstellung oder den Abgleich der angegebenen Platzierungsgruppen durch und verarbeitet dann erst andere Platzierungsgruppen. Laufende Abgleich- oder Wiederherstellungsvorgänge werden nicht unterbrochen, sondern die angegebenen PGs werden so rasch wie möglich verarbeitet. Wenn Sie Ihre Meinung ändern oder nicht die richtigen Gruppen priorisiert haben, können Sie die Priorisierung abbrechen:
root #ceph pg cancel-force-recovery PG_ID1 [PG_ID2 ... ]root #ceph pg cancel-force-backfill PG_ID1 [PG_ID2 ... ]
Mit den Kommandos cancel-* wird das Flag „force“ aus den
PGs entfernt, sodass sie in der standardmäßigen Reihenfolge verarbeitet
werden. Auch dieser Vorgang wirkt sich nicht auf die derzeit verarbeiten
Platzierungsgruppen aus, sondern lediglich auf Gruppen, die sich noch in
der Warteschlange befinden. Nach der Wiederherstellung oder dem Abgleich
der Gruppe wird das Flag „force“ automatisch gelöscht.
17.4.11 Wiederherstellen verlorener Objekte #
Wenn mindestens ein Objekt im Cluster verloren gegangen ist und Sie nicht mehr weiter nach den verlorenen Daten suchen möchten, müssen Sie die nicht gefundenen Objekte als „verloren“ markieren.
Können die Objekte auch nach Abfrage aller denkbaren Speicherorte nicht abrufen werden, müssen Sie die verlorenen Objekte ggf. aufgeben. Dieser Fall kann bei außergewöhnlichen Fehlerkombinationen auftreten, bei denen Informationen über Schreibvorgänge an den Cluster weitergegeben werden, bevor die Schreibvorgänge selbst wiederhergestellt werden.
Derzeit wird ausschließlich die Option „revert“ unterstützt, mit der entweder ein Abgleich mit einer früheren Version des Objekts erfolgt oder das Objekt „vergessen“ wird (sofern ein neues Objekt vorliegt). Mit folgendem Kommando markieren Sie die nicht gefundenen („unfound“) Objekte als verloren („lost“):
cephuser@adm > ceph pg PG_ID mark_unfound_lost revert|delete17.4.12 Aktivieren der PG-Autoskalierung #
Platzierungsgruppen (PGs) sind ein internes Implementierungsdetail zur Verteilung der Daten durch Ceph. Wenn Sie die PG-Autoskalierung aktivieren, können Sie zulassen, dass der Cluster PGs entweder selbst erstellt oder automatisch einstellt, je nachdem, wie der Cluster genutzt wird.
Jeder Pool im System verfügt über eine Eigenschaft
pg_autoscale_mode, die auf off,
on oder warn festgelegt werden kann:
Die Autoskalierung wird auf einer Pro-Pool-Basis konfiguriert und kann in drei Modi ausgeführt werden:
- off
Deaktiviert die Autoskalierung für diesen Pool. Es liegt im Ermessen des Administrators, eine geeignete PG-Nummer für jeden Pool zu wählen.
- on
Aktiviert die automatische Anpassung der PG-Anzahl für den angegebenen Pool.
- warn
Löst Zustandswarnungen aus, wenn die PG-Anzahl angepasst werden sollte.
So legen Sie den Autoskalierungsmodus für bestehende Pools fest:
cephuser@adm > ceph osd pool set POOL_NAME pg_autoscale_mode mode
Mit folgendem Kommando können Sie auch den Standardmodus
pg_autoscale_mode konfigurieren, der auf alle zukünftig
erstellten Pools angewendet wird:
cephuser@adm > ceph config set global osd_pool_default_pg_autoscale_mode MODEMit diesem Kommando können Sie jeden Pool, seine relative Auslastung und alle vorgeschlagenen Änderungen an der PG-Anzahl anzeigen:
cephuser@adm > ceph osd pool autoscale-status17.5 Umgang mit der CRUSH-Zuordnung #
In diesem Abschnitt werden grundlegende Methoden zum Umgang mit der CRUSH-Zuordnung vorgestellt, wie Bearbeiten einer CRUSH-Zuordnung, Ändern der CRUSH-Zuordnungs-Parameter und Hinzufügen/Verschieben/Entfernen eines OSD.
17.5.1 Bearbeiten einer CRUSH-Zuordnung #
Gehen Sie zum Bearbeiten einer bestehenden CRUSH-Zuordnung folgendermaßen vor:
Rufen Sie eine CRUSH-Zuordnung ab. Führen Sie folgendes Kommando aus, um die CRUSH-Zuordnung für Ihren Cluster abzurufen:
cephuser@adm >ceph osd getcrushmap -o compiled-crushmap-filenameCeph gibt (
-o) eine kompilierte CRUSH-Zuordnung an den angegebenen Dateinamen aus. Da die CRUSH-Zuordnung in kompilierter Form vorliegt, muss sie vor der Bearbeitung zunächst dekompiliert werden.Dekompilieren Sie eine CRUSH-Zuordnung. Führen Sie zum Dekompilieren einer CRUSH-Zuordnung folgendes Kommando aus:
cephuser@adm >crushtool -d compiled-crushmap-filename \ -o decompiled-crushmap-filenameCeph dekompiliert (
-d) die kompilierte CRUSH-Zuordnung und gibt Sie (-o) an den angegebenen Dateinamen aus.Bearbeiten Sie mindestens einen der Geräte-, Buckets- und Regel-Parameter.
Kompilieren Sie eine CRUSH-Zuordnung. Führen Sie zum Kompilieren einer CRUSH-Zuordnung folgendes Kommando aus:
cephuser@adm >crushtool -c decompiled-crush-map-filename \ -o compiled-crush-map-filenameCeph speichert eine kompilierte CRUSH-Zuordnung an den angegebenen Dateinamen.
Legen Sie eine CRUSH-Zuordnung fest. Führen Sie folgendes Kommando aus, um die CRUSH-Zuordnung für Ihren Cluster festzulegen:
cephuser@adm >ceph osd setcrushmap -i compiled-crushmap-filenameCeph gibt die CRUSH-Zuordnung des angegebenen Dateinamens als CRUSH-Zuordnung für den Cluster ein.
Verwenden Sie ein Versionierungssystem (z. B. git oder svn) für die exportierten und bearbeiteten CRUSH-Zuordnung-Dateien. Damit wird ein etwaiger Abgleich vereinfacht.
Testen Sie die neue, angepasste CRUSH-Zuordnung mit dem Kommando
crushtool --test und vergleichen Sie sie mit dem Status
vor Anwendung der neuen CRUSH-Zuordnung. Nützliche Kommandoschalter:
--show-statistics, --show-mappings,
--show-bad-mappings, --show-utilization,
--show-utilization-all,
--show-choose-tries
17.5.2 Hinzufügen oder Verschieben eines OSD #
Führen Sie zum Hinzufügen eines OSD in der CRUSH-Zuordnung des aktiven Clusters folgendes Kommando aus:
cephuser@adm > ceph osd crush set id_or_name weight root=pool-name
bucket-type=bucket-name ...- id
Eine Ganzzahl. Die numerische ID des OSD. Diese Option muss aktiviert sein.
- Name
Eine Zeichenkette. Der vollständige Name des OSD. Diese Option muss aktiviert sein.
- weight
Der Gleitkomma-Datentyp „double“. Das CRUSH-Gewicht für den OSD. Diese Option muss aktiviert sein.
- root
Ein Schlüssel-Wert-Paar. Standardmäßig enthält die CRUSH-Hierarchie den Pool-Standardwert als Root. Diese Option muss aktiviert sein.
- bucket-type
Schlüssel-Wert-Paare. Sie haben die Möglichkeit, den Standort des OSD in der CRUSH-Hierarchie anzugeben.
Im folgenden Beispiel wird osd.0 zur Hierarchie
hinzugefügt oder der OSD wird von einem vorigen Standort verschoben.
cephuser@adm > ceph osd crush set osd.0 1.0 root=data datacenter=dc1 room=room1 \
row=foo rack=bar host=foo-bar-117.5.3 Unterschied zwischen ceph osd reweight und ceph osd crush reweight #
Das „Gewicht“ eines Ceph OSD kann mit zwei ähnlichen Kommandos geändert werden. Die Kommandos unterscheiden sich durch ihren Nutzungskontext, was zu Verwirrung führen kann.
17.5.3.1 ceph osd reweight #
Wert:
cephuser@adm > ceph osd reweight OSD_NAME NEW_WEIGHT
Mit ceph osd reweight wird ein überschreibendes Gewicht
für das Ceph OSD festgelegt. Dieser Wert im Bereich 0 bis 1 zwingt CRUSH,
die Daten zu verlagern, die sich ansonsten auf diesem Laufwerk befinden
würden. Das Gewicht, das den Buckets oberhalb des OSD zugewiesen ist, wird
hiermit nicht geändert. Dieser Vorgang
fungiert als Korrekturmaßnahme für den Fall, dass die normale
CRUSH-Distribution nicht ordnungsgemäß funktioniert. Wenn beispielsweise
ein OSD bei 90 % steht und die anderen bei 40 %, können Sie dieses Gewicht
senken und das Ungleichgewicht damit beheben.
Beachten Sie, dass ceph osd reweight keine dauerhafte
Einstellung ist. Wird ein OSD als „out“ gekennzeichnet, wird sein Gewicht
auf 0 festgelegt; sobald es wieder als „in“ gekennzeichnet wird, erhält
das Gewicht den Wert 1.
17.5.3.2 ceph osd crush reweight #
Wert:
cephuser@adm > ceph osd crush reweight OSD_NAME NEW_WEIGHT
Mit ceph osd crush reweight wird das
CRUSH-Gewicht des OSD festgelegt. Dieses
Gewicht ist ein willkürlicher Wert (im Allgemeinen die Größe der
Festplatte in TB) und steuert die Datenmenge, die das System dem OSD
zuordnet.
17.5.4 Entfernen eines OSD #
Führen Sie zum Entfernen eines OSD in der CRUSH-Zuordnung eines aktiven Clusters folgendes Kommando aus:
cephuser@adm > ceph osd crush remove OSD_NAME17.5.5 Hinzufügen eines Buckets #
Mit dem Kommando ceph osd crush add-bucket fügen Sie der
CRUSH-Zuordnung eines aktiven Clients einen Bucket hinzu:
cephuser@adm > ceph osd crush add-bucket BUCKET_NAME BUCKET_TYPE17.5.6 Verschieben eines Buckets #
Mit folgendem Kommando verschieben Sie einen Bucket an einen anderen Standort oder eine andere Position in der CRUSH-Zuordnung-Hierarchie:
cephuser@adm > ceph osd crush move BUCKET_NAME BUCKET_TYPE=BUCKET_NAME [...]Beispiel:
cephuser@adm > ceph osd crush move bucket1 datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-117.5.7 Entfernen eines Buckets #
Mit folgendem Kommando entfernen Sie einen Bucket:
cephuser@adm > ceph osd crush remove BUCKET_NAMEEin Bucket kann nur dann aus der CRUSH-Hierarchie entfernt werden, wenn er leer ist.
17.6 Scrubbing von Platzierungsgruppen #
Ceph legt nicht nur mehrere Kopien der Objekte an, sondern schützt die
Datenintegrität durch Scrubbing der Platzierungsgruppen
(für weitere Informationen zu Platzierungsgruppen, siehe das
Book “Implementierungsleitfaden”, Chapter 1 “SES und Ceph”, Section 1.3.2 “Platzierungsgruppen”). Ceph Scrubbing ist analog zur
Ausführung von fsck auf Objektspeicherebene zu verstehen.
Ceph generiert für jede Placement Group einen Katalog aller Objekte und
vergleicht jedes primäre Objekt und dessen Reproduktionen, um
sicherzustellen, dass keine Objekte fehlen oder falsch abgeglichen wurden.
Beim täglichen Light Scrubbing werden die Objektgröße und Attribute geprüft.
Beim wöchentlichen Deep Scrubbing werden die Daten gelesen und die
Datenintegrität wird anhand von Prüfsummen sichergestellt.
Scrubbing ist wichtig zur Sicherung der Datenintegrität, kann jedoch die Leistung beeinträchtigen. Passen Sie die folgenden Einstellungen an, um mehr oder weniger Scrubbing-Vorgänge festzulegen:
osd max scrubsDie maximale Anzahl der gleichzeitig ausgeführten Scrubbing-Operationen für ein Ceph OSD. Der Standardwert ist 1.
osd scrub begin hour,osd scrub end hourDie Stunden am Tag (0 bis 24), die ein Zeitfenster für das Scrubbing definieren. Beginnt standardmäßig bei 0 und endet bei 24.
WichtigWenn das Scrubbing-Intervall der Platzierungsgruppe die Einstellung
osd scrub max intervalüberschreitet, wird das Scrubbing ungeachtet des für ein Scrubbing definierten Zeitfensters durchgeführt.osd scrub during recoveryLässt Scrubbing-Vorgänge bei der Wiederherstellung zu. Wird diese Option auf „false“ festgelegt, wird die Planung neuer Scrubbing-Vorgänge während einer aktiven Wiederherstellung deaktiviert. Bereits laufende Scrubbing-Vorgänge werden fortgesetzt. Diese Option ist nützlich, um die Last ausgelasteter Cluster zu reduzieren. Die Standardeinstellung ist „true“.
osd scrub thread timeoutDer maximale Zeitraum in Sekunden vor der Zeitüberschreitung eines Scrubbing Threads. Der Standardwert ist 60.
osd scrub finalize thread timeoutDer maximale Zeitraum in Sekunden vor der Zeitüberschreitung eines Scrubbing Finalize Threads. Der Standardwert ist 60*10.
osd scrub load thresholdDie normalisierte Maximallast. Ceph führt kein Scrubbing durch, wenn die Systemlast (definiert durch das Verhältnis von
getloadavg()/ Anzahl vononline cpus) höher ist als dieser Wert. Der Standardwert ist 0.5.osd scrub min intervalDas Mindestintervall in Sekunden für Scrubbing-Vorgänge am Ceph OSD, wenn die Ceph-Cluster-Last gering ist. Der Standardwert ist 60*60*24 (einmal täglich).
osd scrub max intervalDas maximale Intervall in Sekunden für Scrubbing-Vorgänge am Ceph OSD ungeachtet der Cluster-Last. Der Standardwert ist 7*60*60*24 (einmal pro Woche).
osd scrub chunk minDie maximale Anzahl der Objektspeicher-Datenblöcke für einen einzelnen Scrubbing-Vorgang. Ceph blockiert Schreibvorgänge an einen einzelnen Datenblock während eines Scrubbing-Vorgangs. Der Standardwert ist 5.
osd scrub chunk maxDie Mindestanzahl der Objektspeicher-Datenblöcke für einen einzelnen Scrubbing-Vorgang. Der Standardwert ist 25.
osd scrub sleepRuhezeit vor dem Scrubbing der nächsten Gruppe von Datenblöcken. Durch Erhöhen dieses Werts wird der gesamte Scrubbing-Vorgang verlangsamt. Die Client-Vorgänge insgesamt werden dadurch weniger beeinträchtigt. Der Standardwert ist 0.
osd deep scrub intervalDas Intervall für ein Deep Scrubbing (alle Daten werden vollständig gelesen). Die Option
osd scrub load thresholdhat keinen Einfluss auf diese Einstellung. Der Standardwert ist 60*60*24*7 (einmal pro Woche).osd scrub interval randomize ratioFügen Sie beim Planen des nächsten Scrubbing-Auftrags für eine Placement Group eine zufällige Verzögerung zum Wert
osd scrub min intervalhinzu. Die Verzögerung ist ein Zufallswert kleiner als das Ergebnis ausosd scrub min interval*osd scrub interval randomized ratio. Daher werden mit dem Standardwert die Scrubbing-Vorgänge praktisch zufällig auf das zulässige Zeitfenster von [1, 1,5] *osd scrub min intervalverteilt. Der Standardwert ist 0.5.osd deep scrub strideLesegröße für ein Deep Scrubbing. Der Standardwert ist 524288 (512 kB).
18 Verwalten von Speicher-Pools #
Ceph speichert Daten in Pools. Pools sind logische Gruppen für Speicherobjekte. Wenn Sie zunächst einen Cluster bereitstellen, ohne einen Pool zu erstellen, verwendet Ceph die Standard-Pools zum Speichern von Daten. Für Ceph-Pools gelten die folgenden wichtigen Punkte:
Stabilität: Mit Ceph-Pools wird Stabilität erreicht, da die darin enthaltenen Daten reproduziert oder verschlüsselt werden. Jeder Pool kann auf
reproduziertodermit Löschcodierungfestgelegt werden. Bei reproduzierten Pools legen Sie außerdem die Anzahl der Reproduktionen oder Kopien für jedes Datenobjekt innerhalb des Pools fest. Die Anzahl der Kopien (OSDs, CRUSH-Buckets/Blätter), die verloren gehen können, ist eins weniger als die Anzahl der Reproduktionen. Bei der Löschcodierung legen Sie die Werte vonkundmfest, wobeikdie Anzahl der Datenblöcke undmdie Anzahl der Datenblöcke für die Codierung darstellt. Bei Pools mit Löschcodierung bestimmt die Anzahl der Datenblöcke für die Codierung, wie viele OSDs (CRUSH-Buckets/Blätter) ohne Datenverlust verloren gehen können.Platzierungsgruppen: Sie können die Anzahl der Platzierungsgruppen für den Pool festlegen. Bei einer normalen Konfiguration sind etwa 100 Placement Groups pro OSD vorhanden. Dadurch wird ein optimaler Ausgleich ermöglicht, ohne zu viel Rechnerressourcen zu verbrauchen. Achten Sie bei der Einrichtung von mehreren Pools sorgfältig darauf, dass Sie eine vernünftige Anzahl von Placement Groups sowohl für den Pool als auch den Cluster insgesamt festlegen.
CRUSH-Regeln: Wenn Sie Daten in einem Pool speichern, werden die Objekte und deren Reproduktionen (bzw. Blöcke bei Pools mit Löschcodierung) gemäß dem CRUSH-Regelsatz platziert, der dem Pool zugeordnet ist. Es ist auch möglich, eine benutzerdefinierte CRUSH-Regel für Ihren Pool zu erstellen.
Snapshots: Wenn Sie einen Snapshot mit
ceph osd pool mksnaperstellen, machen Sie im Grunde einen Snapshot von einem bestimmten Pool.
Zum Strukturieren der Daten in Pools können Sie Pools auflisten, erstellen und entfernen. Es ist auch möglich, die Auslastungsstatistik für jeden Pool anzuzeigen.
18.1 Erstellen eines Pools #
Ein Pool kann entweder als reproduziert erstellt werden,
um eine Wiederherstellung verlorener OSDs durch Beibehaltung mehrerer Kopien
von Objekten zu ermöglichen, oder als Löschcodierung, um
eine Art von genereller RAID5/6-Funktion zu erhalten. Reproduzierte Pools
belegen mehr Rohspeicher, Pools mit Löschcodierung dagegen weniger
Rohspeicher. Die Standardeinstellung lautet reproduziert.
Weitere Informationen zu Pools mit Löschcodierung finden Sie in
Kapitel 19, Erasure Coded Pools.
Führen Sie zum Erstellen eines reproduzierten Pools Folgendes aus:
cephuser@adm > ceph osd pool create POOL_NAMEDie Autoskalierung verarbeitet die restlichen optionalen Argumente. Weitere Informationen finden Sie Abschnitt 17.4.12, „Aktivieren der PG-Autoskalierung“.
Führen Sie zum Erstellen eines Erasure Coded Pools Folgendes aus:
cephuser@adm > ceph osd pool create POOL_NAME erasure CRUSH_RULESET_NAME \
EXPECTED_NUM_OBJECTS
Das Kommando ceph osd pool create wird möglicherweise
nicht ausgeführt, wenn Sie die zulässige Anzahl der Platzierungsgruppen pro
OSD überschreiten. Der Grenzwert wird mit der Option
mon_max_pg_per_osd festgelegt.
- POOL_NAME
Der Name des Pools. Er muss eindeutig sein. Diese Option muss aktiviert sein.
- POOL_TYPE
Der Pool-Typ, entweder
replicated(reproduziert), um eine Wiederherstellung verlorener OSDs durch Beibehaltung mehrerer Kopien von Objekten zu ermöglich, odererasure, um eine Art von genereller RAID5-Funktion zu erhalten. Reproduzierte Pools benötigen zwar mehr Basisspeicher, implementieren jedoch alle Ceph-Operationen. Erasure Pools benötigen weniger Basisspeicher, implementieren jedoch nur eine Teilmenge der verfügbaren Operationen. Die Standardeinstellung fürPOOL_TYPElautetreproduziert.- CRUSH_RULESET_NAME
Der Name des CRUSH-Regelsatzes für diesen Pool. Wenn der angegebene Regelsatz nicht vorhanden ist, werden die reproduzierten Pools nicht erstellt und -ENOENT wird ausgegeben. Bei reproduzierten Pools ist es der Regelsatz, der in der Konfigurationsvariablen
osd pool default CRUSH replicated rulesetangegeben ist. Dieser Regelsatz muss vorhanden sein. Bei Erasure Pools ist dies „erasure-code“, wenn das standardmäßige Löschcode-Profil verwendet, wird, ansonsten POOL_NAME. Falls dieser Regelsatz nicht bereits vorhanden ist, wird er implizit erstellt.- erasure_code_profile=profile
Nur für Erasure Coded Pools. Verwenden Sie das Erasure Code Profil. Es muss ein vorhandenes Profil sein, das durch
osd erasure-code-profile setdefiniert wurde.AnmerkungWenn aus irgendeinem Grund die Autoskalierung in einem Pool deaktiviert wurde (
pg_autoscale_modeauf „off“ festgelegt), können Sie die PG-Nummern manuell berechnen und festlegen. Unter Abschnitt 17.4, „Platzierungsgruppen“ finden Sie detaillierte Informationen zur Berechnung einer angemessenen Anzahl von Placement Groups für Ihren Pool.- EXPECTED_NUM_OBJECTS
Die erwartete Anzahl von Objekten für diesen Pool. Wenn Sie diesen Wert festlegen (zusammen mit einem negativen Wert für
filestore merge threshold), wird der PG-Ordner zum Zeitpunkt der Pool-Erstellung aufgeteilt. Dadurch werden die negativen Auswirkungen der Latenz vermieden, die bei einer Aufteilung bei Laufzeit auftritt.
18.2 Auflisten der Pools #
Führen Sie zum Auflisten der Pools Ihres Clusters Folgendes aus:
cephuser@adm > ceph osd pool ls18.3 Umbenennen eines Pools #
Führen Sie zum Umbenennen eines Pools folgendes Kommando aus:
cephuser@adm > ceph osd pool rename CURRENT_POOL_NAME NEW_POOL_NAMEWenn Sie einen Pool umbenennen und Capabilities pro Pool für einen authentifizierten Benutzer festgelegt haben, müssen Sie die Capabilities des Benutzer mit dem neuen Pool-Namen aktualisieren.
18.4 Löschen eines Pools #
Pools enthalten möglicherweise wichtige Daten. Durch Löschen eines Pools gehen alle Daten im Pool verloren und es gibt keine Möglichkeit, sie wiederherzustellen.
Da die unbeabsichtigte Löschung von Pools eine echte Gefahr darstellt, implementiert Ceph zwei Mechanismen, durch die eine Löschung verhindert wird. Beide Mechanismen müssen deaktiviert werden, bevor ein Pool gelöscht werden kann.
Der erste Mechanismus ist das Flag NODELETE. Diese Flagge
ist bei jedem Pool gesetzt und der Standardwert ist „false“. Führen Sie
folgendes Kommando aus, um den Wert dieser Flagge an einem Pool
festzustellen:
cephuser@adm > ceph osd pool get pool_name nodelete
Wenn das Kommando nodelete: true ausgibt, ist es erst
möglich, den Pool zu löschen, wenn Sie das Flag mit folgendem Kommando
ändern:
cephuser@adm > ceph osd pool set pool_name nodelete false
Der zweite Mechanismus ist der Cluster-weite Konfigurationsparameter
mon allow pool delete, der standardmäßig auf „false“
festgelegt ist. Dies bedeutet, dass es standardmäßig nicht möglich ist,
einen Pool zu löschen. Die angezeigte Fehlermeldung sieht folgendermaßen
aus:
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
Zum Löschen des Pools trotz der Sicherheitseinstellung legen Sie
vorübergehend mon allow pool delete auf „true“ fest,
löschen den Pool und legen den Parameter dann wieder auf „false“ fest:
cephuser@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=truecephuser@adm >ceph osd pool delete pool_name pool_name --yes-i-really-really-mean-itcephuser@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=false
Das Kommando injectargs zeigt die folgende Meldung an:
injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
Dadurch wird einfach nur bestätigt, dass das Kommando erfolgreich ausgeführt wurde. Dies ist kein Fehler.
Wenn Sie für einen erstellten Pool eigene Regelsätze und Regeln festgelegt haben, sollten Sie diese entfernen, wenn Sie den Pool nicht länger benötigen.
18.5 Sonstige Vorgänge #
18.5.1 Verknüpfen von Pools mit einer Anwendung #
Bevor Sie Pools verwenden, müssen Sie sie mit einer Anwendung verknüpfen. Mit dem CephFS verwendete Pools oder automatisch von Object Gateway erstellte Pools werden automatisch verknüpft.
In anderen Fällen können Sie manuell einen frei formulierten Anwendungsnamen mit einem Pool verknüpfen:
cephuser@adm > ceph osd pool application enable POOL_NAME APPLICATION_NAME
CephFS verwendet den Anwendungsnamen cephfs, RADOS
Block Device verwendet rbd und Object Gateway verwendet
rgw.
Ein Pool kann mit mehreren Anwendungen verknüpft werden und jede Anwendung kann eigene Metadaten enthalten. Listen Sie die mit einem Pool verknüpften Anwendungen mit folgendem Kommando auf:
cephuser@adm > ceph osd pool application get pool_name18.5.2 Festlegen von Pool-Kontingenten #
Pool-Kontingente können für die maximale Anzahl von Byte und/oder die maximale Anzahl von Objekten pro Pool festgelegt werden.
cephuser@adm > ceph osd pool set-quota POOL_NAME MAX_OBJECTS OBJ_COUNT MAX_BYTES BYTESBeispiel:
cephuser@adm > ceph osd pool set-quota data max_objects 10000Zum Entfernen eines Kontingents legen Sie den entsprechenden Wert auf 0 fest.
18.5.3 Anzeigen von Pool-Statistiken #
Führen Sie zum Anzeigen der Auslastungsstatistik eines Pools folgendes Kommando aus:
cephuser@adm > rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.rgw.root 768 KiB 4 0 12 0 0 0 44 44 KiB 4 4 KiB 0 B 0 B
cephfs_data 960 KiB 5 0 15 0 0 0 5502 2.1 MiB 14 11 KiB 0 B 0 B
cephfs_metadata 1.5 MiB 22 0 66 0 0 0 26 78 KiB 176 147 KiB 0 B 0 B
default.rgw.buckets.index 0 B 1 0 3 0 0 0 4 4 KiB 1 0 B 0 B 0 B
default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B 0 B 0 B
default.rgw.log 0 B 207 0 621 0 0 0 5372132 5.1 GiB 3579618 0 B 0 B 0 B
default.rgw.meta 961 KiB 6 0 18 0 0 0 155 140 KiB 14 7 KiB 0 B 0 B
example_rbd_pool 2.1 MiB 18 0 54 0 0 0 3350841 2.7 GiB 118 98 KiB 0 B 0 B
iscsi-images 769 KiB 8 0 24 0 0 0 1559261 1.3 GiB 61 42 KiB 0 B 0 B
mirrored-pool 1.1 MiB 10 0 30 0 0 0 475724 395 MiB 54 48 KiB 0 B 0 B
pool2 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
pool3 333 MiB 37 0 111 0 0 0 3169308 2.5 GiB 14847 118 MiB 0 B 0 B
pool4 1.1 MiB 13 0 39 0 0 0 1379568 1.1 GiB 16840 16 MiB 0 B 0 BBeschreibung der einzelnen Spalten:
- USED
Speicherplatz (in Byte), der durch den Pool belegt wird.
- OBJECTS
Anzahl der im Pool gespeicherten Objekte.
- CLONES
Anzahl der im Pool gespeicherten Klone. Wenn Sie einen Snapshot erstellen und in ein Objekt schreiben, wird nicht das ursprüngliche Objekt geändert, sondern es wird ein Klon erstellt, sodass der ursprünglich im Snapshot festgehaltene Objektinhalt nicht geändert wird.
- KOPIEN
Anzahl der Objektreproduktionen. Wenn beispielsweise ein reproduzierter Pool mit dem Reproduktionsfaktor 3 „x“ Objekte umfasst, enthält er in der Regel 3 * x Exemplare.
- MISSING_ON_PRIMARY
Anzahl von Objekten im eingeschränkt leistungsfähigen Status (nicht alle Exemplare vorhanden), wobei das Exemplar auf dem primären OSD fehlt.
- UNFOUND
Anzahl der nicht gefundenen Objekte.
- DEGRADED
Anzahl der eingeschränkt leistungsfähigen Objekte.
- RD_OPS
Gesamtanzahl der für diesen Pool angeforderten Leseoperationen.
- RD
Datenmenge (in Byte), die aus diesem Pool ausgelesen wurde.
- WR_OPS
Gesamtanzahl der für diesen Pool angeforderten Schreiboperationen.
- WR
Datenmenge (in Byte), die in diesen Pool geschrieben wurde. Dieser Wert ist nicht mit der Auslastung des Pools identisch, da Sie mehrfach in ein einzelnes Objekt schreiben können. Die Pool-Auslastung bleibt dabei unverändert, die in den Pool geschriebene Datenmenge (in Byte) steigt jedoch an.
- USED COMPR
Speicherplatz (in Byte), der für komprimierte Daten zugewiesen ist.
- UNDER COMPR
Speicherplatz (in Byte), den die komprimierten Daten belegen, wenn sie nicht komprimiert sind.
18.5.4 Abrufen von Pool-Werten #
Rufen Sie einen Wert von einem Pool mit folgendem
get-Kommando ab:
cephuser@adm > ceph osd pool get POOL_NAME KEYSie können die Werte für Schlüssel abrufen, die in Abschnitt 18.5.5, „Festlegen von Pool-Werten“ aufgelistet sind, und zudem folgende Schlüssel:
- PG_NUM
Die Anzahl der Placement Groups für den Pool.
- PGP_NUM
Die effektive Anzahl von Placement Groups zum Berechnen der Datenplatzierung. Der gültige Bereich ist gleich oder kleiner
PG_NUM.
Mit folgendem Kommando rufen Sie alle Werte für einen bestimmten Pool ab:
cephuser@adm > ceph osd pool get POOL_NAME all18.5.5 Festlegen von Pool-Werten #
Führen Sie zum Festlegen des Werts für einen Pool folgendes Kommando aus:
cephuser@adm > ceph osd pool set POOL_NAME KEY VALUEDie folgende Liste zeigt die Pool-Werte sortiert nach Pool-Typ:
- crash_replay_interval
Der Zeitraum in Sekunden, für den Clients bestätigte, aber noch nicht zugewiesene Anforderungen erneut wiedergeben können.
- pg_num
Die Anzahl der Placement Groups für den Pool. Wenn Sie neue OSDs in den Cluster aufnehmen, prüfen Sie den Wert für die Platzierungsgruppen in allen Pools, die für die neuen OSDs vorgesehen sind.
- pgp_num
Die effektive Anzahl von Placement Groups zum Berechnen der Datenplatzierung.
- crush_ruleset
Der zu verwendende Regelsatz für die Zuordnung der Objektplatzierung im Cluster.
- hashpspool
Setzen Sie das Flag HASHPSPOOL an einem angegebenen Pool (1) oder entfernen Sie sie (0). Durch Aktivieren dieses Flags wird der Algorithmus geändert, um PGs besser auf OSDs zu verteilen. Nach Aktivierung dieses Flags für einen Pool, dessen HASHPSPOOL-Flag auf den Standardwert 0 festgelegt wurde, beginnt der Cluster einen Abgleich, um erneut eine korrekte Platzierung aller PGs zu erreichen. Dies kann zu einer erheblichen E/A-Belastung auf einem Cluster führen. Aktivieren Sie diese Flagge daher nicht in stark ausgelasteten Produktions-Clustern (Umstellung von 0 auf 1).
- nodelete
Verhindert, dass der Pool entfernt wird.
- nopgchange
Verhindert, dass die Werte
pg_numundpgp_numdes Pools geändert werden.- noscrub,nodeep-scrub
Deaktiviert (Deep-)Scrubbing der Daten für den entsprechenden Pool, um eine vorübergehend hohe E/A-Last zu vermeiden.
- write_fadvise_dontneed
Legt das Flag
WRITE_FADVISE_DONTNEEDbei Lese-/Schreibanforderungen eines bestimmten Pools fest oder entfernt sie, um das Ablegen von Daten in den Cache zu umgehen. Die Standardeinstellung istfalse. Gilt sowohl für reproduzierte als auch für EC-Pools.- scrub_min_interval
Das Mindestintervall in Sekunden für ein Pool Scrubbing, wenn die Cluster-Last gering ist. Der Standardwert
0bedeutet, dass der Wertosd_scrub_min_intervalaus der Ceph-Konfigurationsdatei verwendet wird.- scrub_max_interval
Das maximale Intervall in Sekunden für ein Pool Scrubbing, unabhängig von der Cluster-Last. Der Standardwert
0bedeutet, dass der Wertosd_scrub_max_intervalaus der Ceph-Konfigurationsdatei verwendet wird.- deep_scrub_interval
Das Intervall in Sekunden für ein deep Scrubbing des Pools. Der Standardwert
0bedeutet, dass der Wertosd_deep_scrubaus der Ceph-Konfigurationsdatei verwendet wird.
- Größe
Legt die Anzahl der Reproduktionen für Objekte im Pool fest. Weitere Informationen finden Sie in Abschnitt 18.5.6, „Festlegen der Anzahl der Objektreproduktionen“. Nur reproduzierte Pools.
- min_size
Legt die Mindestanzahl von Reproduktionen fest, die für E/A benötigt werden. Weitere Informationen finden Sie in Abschnitt 18.5.6, „Festlegen der Anzahl der Objektreproduktionen“. Nur reproduzierte Pools.
- nosizechange
Verhindert, dass die Größe des Pools geändert wird. Beim Erstellen eines Pools wird der Standardwert aus dem Wert des Parameters
osd_pool_default_flag_nosizechangeübernommen, der standardmäßigfalselautet. Gilt nur für reproduzierte Pools, da Sie die Größe für EC-Pools nicht ändern können.- hit_set_type
Aktiviert die Treffersatz-Verfolgung für Cache Pools. Weitere Informationen finden Sie unter Bloomfilter. Für diese Option sind die folgenden Werte möglich:
bloom,explicit_hash,explicit_object. Der Standardwert istbloom, die anderen Werte sind nur für Testzwecke vorgesehen.- hit_set_count
Die Anzahl der Treffersätze, die für Cache Pools gespeichert werden sollen. Je höher die Anzahl, desto mehr RAM wird vom
ceph-osd-Daemon belegt. Der Standardwert ist0.- hit_set_period
Die Dauer einer Treffersatz-Periode in Sekunden für Cache Pools. Je höher die Anzahl, desto mehr RAM wird vom
ceph-osd-Daemon belegt. Beim Erstellen eines Pools wird der Standardwert aus dem Wert des Parametersosd_tier_default_cache_hit_set_periodübernommen, der standardmäßig1200lautet. Gilt nur für reproduzierte Pools, da EC-Pools nicht als Cache-Ebene verwendet werden können.- hit_set_fpp
Die falsch positive Wahrscheinlichkeit für den Bloom-Treffersatz-Typ. Weitere Informationen finden Sie unter Bloomfilter. Der gültige Bereich ist 0,0 bis 1,0. Der Standardwert ist
0,05.- use_gmt_hitset
Erzwingen Sie bei Erstellung eines Treffersatzes für das Cache Tiering, dass OSDs die MGZ-Zeitstempel (mittlere Greenwich-Zeit) verwenden. Dadurch wird sichergestellt, dass Knoten in verschiedenen Zeitzonen dasselbe Ergebnis zurückgeben. Der Standardwert ist
1. Dieser Wert darf nicht geändert werden.- cache_target_dirty_ratio
Der Prozentsatz der bearbeiteten (fehlerhaften) Objekte im Cache Pool, der erreicht sein muss, bevor der Cache Tiering Agent diese Objekte in den Hintergrundspeicher-Pool verschiebt. Der Standardwert ist
0.4.- cache_target_dirty_high_ratio
Der Prozentsatz der bearbeiteten (fehlerhaften) Objekte im Cache Pool, der erreicht sein muss, bevor der Cache Tiering Agent diese Objekte mit höherer Geschwindigkeit in den Hintergrundspeicher-Pool verschiebt. Der Standardwert ist
0.6.- cache_target_full_ratio
Der Prozentsatz der unbearbeiteten (intakten) Objekte im Cache Pool, der erreicht sein muss, bevor der Cache Tiering Agent diese Objekte aus dem Cache Pool entfernt. Der Standardwert ist
0.8.- target_max_bytes
Ceph beginnt mit dem Verschieben oder Entfernen von Objekten, wenn der Grenzwert
max_bytesausgelöst wird.- target_max_objects
Ceph beginnt mit dem Verschieben oder Entfernen von Objekten, wenn der Grenzwert
max_objectsausgelöst wird.- hit_set_grade_decay_rate
Temperaturzerfallsrate zwischen zwei aufeinanderfolgenden
hit_set. Der Standardwert ist20.- hit_set_search_last_n
Anzahl der meisten
N-Vorkommen inhit_sets für die Temperaturberechnung. Der Standardwert ist1.- cache_min_flush_age
Die Zeit (in Sekunden), bevor der Cache Tiering Agent ein Objekt vom Cache Pool in den Speicher-Pool verschiebt.
- cache_min_evict_age
Die Zeit (in Sekunden), bevor der Cache Tiering Agent ein Objekt aus dem Cache Pool entfernt.
- fast_read
Wenn dieses Flag bei Erasure Coding Pools aktiviert wird, stellt die Leseanforderung Teil-Lesevorgänge an alle Shards aus und wartet, bis sie genügend Shards zum Decodieren erhält, die für den Client verarbeitet werden. Wenn im Fall von jerasure- und isa-Erasure-Plugins die ersten
K-Antworten zurückgegeben werden, dann wird die Anforderung des Clients sofort anhand der von diesen Antworten decodierten Daten verarbeitet. Diese Vorgehensweise erhöht die CPU-Auslastung und senkt die Datenträger-/Netzwerkauslastung. Diese Flagge wird aktuell nur für Erasure Coded Pools unterstützt. Der Standardwert ist0.
18.5.6 Festlegen der Anzahl der Objektreproduktionen #
Führen Sie folgendes Kommando aus, um die Anzahl der Objektreproduktionen in einem reproduzierten Pool festzulegen:
cephuser@adm > ceph osd pool set poolname size num-replicasIn num-replicas ist das Objekt selbst enthalten. Geben Sie 3 an, wenn Sie beispielsweise das Objekt und zwei Kopien des Objekts für insgesamt drei Instanzen des Objekts wünschen.
Wenn Sie num-replicas auf 2 festlegen, wird nur eine Kopie Ihrer Daten erstellt. Wenn Sie eine Objektinstanz verlieren, müssen Sie sich darauf verlassen, dass die andere Kopie seit dem letzten Scrubbing bei der Wiederherstellung nicht beschädigt wurde (ausführliche Informationen siehe Abschnitt 17.6, „Scrubbing von Platzierungsgruppen“).
Wenn der Pool auf eine Reproduktion festgelegt wird, bedeutet dies, dass genau eine Instanz des Datenobjekts im Pool vorhanden ist. Wenn der OSD ausfällt, verlieren Sie die Daten. Ein Pool mit einer Reproduktion wird normalerweise verwendet, wenn temporäre Daten für kurze Zeit gespeichert werden.
Wenn Sie 4 Reproduktionen für einen Pool festlegen, erhöht dies die Zuverlässigkeit um 25 %.
Bei zwei Rechenzentren müssen Sie mindestens 4 Reproduktionen für einen Pool festlegen, damit sich je zwei Exemplare in jedem Rechenzentrum befinden. Sollte dann ein Rechenzentrum ausfallen, sind weiterhin zwei Exemplare vorhanden, sodass noch ein weiterer Datenträger verloren gehen kann, ohne dass Datenverlust eintritt.
Ein Objekt akzeptiert möglicherweise E/As im eingeschränkt
leistungsfähigen Modus mit weniger als pool size
Reproduktionen. Sie sollten die Einstellung min_size
verwenden, um eine Mindestanzahl erforderlicher Reproduktionen für E/A
festzulegen. Beispiel:
cephuser@adm > ceph osd pool set data min_size 2
Dadurch wird sichergestellt, dass kein Objekt im Daten-Pool E/A mit
weniger Reproduktionen als min_size erhält.
Führen Sie folgendes Kommando aus, um die Anzahl der Objektreproduktionen abzurufen:
cephuser@adm > ceph osd dump | grep 'replicated size'
Ceph listet die Pools mit hervorgehobenem Attribut replicated
size auf. Standardmäßig erstellt Ceph zwei Reproduktionen eines
Objekts (insgesamt drei Kopien oder eine Größe von 3).
18.6 Pool-Migration #
Beim Erstellen eines Pools (Informationen hierzu finden Sie in Abschnitt 18.1, „Erstellen eines Pools“) müssen Sie die ersten Parameter wie den Pool-Typ oder die Anzahl der Placement Groups angeben. Wenn Sie sich später entscheiden, diese Parameter zu ändern (z. B. einen reproduzierten Pool in einen Pool mit Löschcodierung umwandeln oder die Anzahl der Platzierungsgruppen verringern), müssen Sie die Pool-Daten zu einem anderen Pool migrieren, dessen Parameter zur gewünschten Implementierung passen.
In diesem Abschnitt werden zwei Migrationsmethoden beschrieben: eine
Cache-Ebene-Methode für die allgemeine
Pool-Datenmigration und eine Methode, die rbd
migrate-Unterkommandos verwendet, um RBD-Images in einen neuen
Pool zu migrieren. Jede Methode hat ihre Eigenheiten und Grenzen.
18.6.1 Nutzungsbeschränkungen #
Mit der Cache-Ebene-Methode können Sie einen reproduzierten Pool entweder zu einem Pool mit Löschcodierung oder zu einem anderen reproduzierten Pool migrieren. Die Migration von einem Pool mit Löschcodierung wird nicht unterstützt.
Sie können keine RBD-Images und CephFS-Exporte aus einem reproduzierten Pool zu einem EC-Pool migrieren. Der Grund ist, dass EC-Pools
omapnicht unterstützen, während RBD und CephFSomapzum Speichern ihrer Metadaten verwenden. Beispielsweise kann das Header-Objekt des RBD nicht geleert werden. Sie können jedoch Daten in den EC-Pool migrieren und die Metadaten im reproduzierten Pool belassen.Mit der
rbd migration-Methode können Images mit minimaler Client-Ausfallzeit migriert werden. Sie müssen den Client lediglich vor demprepare-Schritt anhalten und danach wieder starten. Hierbei ist zu beachten, dass nur einlibrbd-Client, der diese Funktion unterstützt (Ceph Nautilus oder höher), das Image direkt nach demprepare-Schritt öffnen kann, älterelibrbd-Clients oder diekrbd-Clients dagegen erst nach demcommit-Schritt.
18.6.2 Migrieren mit der Cache-Ebene #
Das Prinzip ist einfach: Stellen Sie den Pool, der migriert werden soll, in umgekehrter Reihenfolge in eine Cache-Schicht. Das folgende Beispiel zeigt die Migration des reproduzierten Pools „testpool“ zu einem Pool mit Löschcodierung:
Erstellen Sie einen neuen Pool mit Löschcodierung mit der Bezeichnung „newpool“. Eine ausführliche Erläuterung der Parameter für die Pool-Erstellung finden Sie in Abschnitt 18.1, „Erstellen eines Pools“.
cephuser@adm >ceph osd pool create newpool erasure defaultPrüfen Sie, ob der verwendete Client-Schlüsselbund für „newpool“ mindestens dieselben Funktionen bietet wie für „testpool“.
Nun verfügen Sie über zwei Pools: den ursprünglichen reproduzierten „testpool“ mit Daten und den neuen leeren Erasure Coded „newpool“:
 Abbildung 18.1: Pools vor der Migration #
Abbildung 18.1: Pools vor der Migration #Richten Sie die Cache-Schicht ein und konfigurieren Sie den reproduzierten „testpool“ als Cache Pool. Mit der Option
-force-nonemptykönnen Sie selbst dann eine Cache-Schicht hinzufügen, wenn der Pool bereits Daten enthält:cephuser@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=1'cephuser@adm >ceph osd tier add newpool testpool --force-nonemptycephuser@adm >ceph osd tier cache-mode testpool proxy Abbildung 18.2: Einrichtung der Cache-Ebene #
Abbildung 18.2: Einrichtung der Cache-Ebene #Erzwingen Sie, dass der Cache Pool alle Objekte in den neuen Pool verschiebt:
cephuser@adm >rados -p testpool cache-flush-evict-all Abbildung 18.3: Leeren von Daten #
Abbildung 18.3: Leeren von Daten #Solange nicht alle Daten geleert und zum neuen Erasure Coded Pool verschoben sind, müssen Sie eine Überlagerung angeben, sodass Objekte noch im alten Pool gesucht werden:
cephuser@adm >ceph osd tier set-overlay newpool testpoolBei einer Überlagerung werden alle Operationen an den alten reproduzierten „testpool“ weitergeleitet:
 Abbildung 18.4: Festlegen der Überlagerung #
Abbildung 18.4: Festlegen der Überlagerung #Nun können Sie alle Clients auf den Zugriff von Objekten im neuen Pool umstellen.
Wenn alle Daten zum Erasure Coded „newpool“ migriert sind, entfernen Sie die Überlagerung und den alten Cache Pool „testpool“:
cephuser@adm >ceph osd tier remove-overlay newpoolcephuser@adm >ceph osd tier remove newpool testpool Abbildung 18.5: Migration abgeschlossen #
Abbildung 18.5: Migration abgeschlossen #Führen Sie folgendes Kommando aus:
cephuser@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=0'
18.6.3 Migrieren von RBD-Images #
Für die Migration von RBD-Images aus einem reproduzierten Pool zu einem anderen reproduzierten Pool wird folgende Vorgehensweise empfohlen:
Beenden Sie den Zugriff von Clients (z. B. von einer virtuellen Maschine) auf das RBD-Image.
Erstellen Sie ein neues Image im Ziel-Pool und legen Sie das Quell-Image als übergeordnetes Image fest:
cephuser@adm >rbd migration prepare SRC_POOL/IMAGE TARGET_POOL/IMAGETipp: Migrieren Sie nur Daten zu einem Pool mit LöschcodierungSollen lediglich die Image-Daten zu einem neuen EC-Pool migriert werden und die Metadaten im ursprünglichen reproduzierten Pool verbleiben, führen Sie stattdessen folgendes Kommando aus:
cephuser@adm >rbd migration prepare SRC_POOL/IMAGE \ --data-pool TARGET_POOL/IMAGEGeben Sie den Clients den Zugriff auf das Image im Ziel-Pool.
Migrieren Sie die Daten zum Ziel-Pool:
cephuser@adm >rbd migration execute SRC_POOL/IMAGEEntfernen Sie das bisherige Image:
cephuser@adm >rbd migration commit SRC_POOL/IMAGE
18.7 Pool Snapshots #
Pool Snapshots sind Snapshots vom Zustand des gesamten Ceph Pools. Mit Pool Snapshots behalten Sie den Verlauf des Pool-Zustands bei. Die Erstellung von Pool Snapshots belegt Speicherplatz proportional zur Pool-Größe. Prüfen Sie immer zunächst, ob im betreffenden Speicher genügend Festplattenspeicherplatz vorhanden ist, bevor Sie einen Snapshot eines Pools erstellen.
18.7.1 Erstellen eines Pool Snapshots #
Mit folgendem Kommando erstellen Sie einen Snapshot eines Pools:
cephuser@adm > ceph osd pool mksnap POOL-NAME SNAP-NAMEBeispiel:
cephuser@adm > ceph osd pool mksnap pool1 snap1
created pool pool1 snap snap118.7.2 Auflisten der Snapshots eines Pools #
Mit folgendem Kommando rufen Sie die vorhandenen Snapshots eines Pools ab:
cephuser@adm > rados lssnap -p POOL_NAMEBeispiel:
cephuser@adm > rados lssnap -p pool1
1 snap1 2018.12.13 09:36:20
2 snap2 2018.12.13 09:46:03
2 snaps18.7.3 Entfernen eines Snapshots eines Pools #
Mit folgendem Kommando entfernen Sie einen Snapshot eines Pools:
cephuser@adm > ceph osd pool rmsnap POOL-NAME SNAP-NAME18.8 Datenkomprimierung #
BlueStore (siehe Book “Implementierungsleitfaden”, Chapter 1 “SES und Ceph”, Section 1.4 “BlueStore”) bietet eine direkte Datenkomprimierung, mit der Sie Speicherplatz sparen. Das Komprimierungsverhältnis ist abhängig von den im System gespeicherten Daten. Beachten Sie, dass für die Komprimierung/die Dekomprimierung zusätzliche CPU-Leistung erforderlich ist.
Sie können die Datenkomprimierung global konfigurieren (siehe Abschnitt 18.8.3, „Globale Komprimierungsoptionen“) und dann bestimmte Komprimierungseinstellungen für die einzelnen Pools überschreiben.
Sie können die Komprimierung der Pool-Daten aktivieren oder deaktivieren und auch jederzeit den Komprimierungsalgorithmus und -modus ändern, unabhängig davon, ob der Pool Daten enthält oder nicht.
Vorhandene Daten werden nach Aktivierung der Pool-Komprimierung nicht komprimiert.
Wenn Sie die Komprimierung für einen Pool deaktivieren, werden dessen Daten alle dekomprimiert.
18.8.1 Aktivieren der Komprimierung #
Mit folgendem Kommando aktivieren Sie die Datenkomprimierung für den Pool POOL_NAME:
cephuser@adm >cephosd pool set POOL_NAME compression_algorithm COMPRESSION_ALGORITHMcephuser@adm >cephosd pool set POOL_NAME compression_mode COMPRESSION_MODE
Zum Deaktivieren der Datenkomprimierung für einen Pool geben Sie „none“ als Komprimierungsalgorithmus an:
cephuser@adm >cephosd pool set POOL_NAME compression_algorithm none
18.8.2 Optionen der Pool-Komprimierung #
Eine vollständige Liste der Komprimierungseinstellungen:
- compression_algorithm
Zulässige Werte sind
none,zstdundsnappy. Die Standardeinstellung lautetsnappy.Der zu verwendende Komprimierungsalgorithmus hängt vom einzelnen Anwendungsfall ab. Einige Empfehlungen:
Behalten Sie die Standardeinstellung
snappybei, sofern es keinen guten Grund gibt, diese Einstellung zu ändern.zstdbietet ein gutes Komprimierungsverhältnis, verursacht jedoch beim Komprimieren kleiner Datenmengen einen hohen CPU-Overhead.Vergleichen Sie diese Algorithmen anhand eines Beispiels Ihrer realen Daten und beobachten Sie dabei die CPU- und Arbeitsspeicherauslastung Ihres Clusters.
- compression_mode
Zulässige Werte sind
none,aggressive,passiveundforce. Die Standardeinstellung lautetnone.none: Niemals komprimierenpassive: Komprimieren bei Hinweis aufCOMPRESSIBLEaggressive: Komprimieren, falls kein Hinweis aufINCOMPRESSIBLEforce: Immer komprimieren
- compression_required_ratio
Wert: Gleitkomma „double“, Grad = SIZE_COMPRESSED / SIZE_ORIGINAL. Der Standardwert lautet
0,875; wenn die Komprimierung also den belegten Speicherplatz um mindestens 12,5 % verringert, wird das Objekt nicht komprimiert.Objekte mit einem höheren Grad werden nicht komprimiert gespeichert, weil der Nutzen insgesamt sehr gering ist.
- compression_max_blob_size
Wert: Ganzzahl ohne Vorzeichen, Größe in Byte. Standardeinstellung:
0Maximale Größe der Objekte, die komprimiert werden.
- compression_min_blob_size
Wert: Ganzzahl ohne Vorzeichen, Größe in Byte. Standardeinstellung:
0Mindestgröße der Objekte, die komprimiert werden.
18.8.3 Globale Komprimierungsoptionen #
Die folgenden Konfigurationsoptionen können in der Ceph-Konfiguration festgelegt werden und gelten für alle OSDs und nicht nur für einen einzelnen Pool. Die in Abschnitt 18.8.2, „Optionen der Pool-Komprimierung“ aufgelistete für den Pool spezifische Konfiguration hat Vorrang.
- bluestore_compression_algorithm
Siehe compression_algorithm.
- bluestore_compression_mode
Siehe compression_mode.
- bluestore_compression_required_ratio
Siehe compression_required_ratio.
- bluestore_compression_min_blob_size
Wert: Ganzzahl ohne Vorzeichen, Größe in Byte. Standardeinstellung:
0Mindestgröße der Objekte, die komprimiert werden. Die Einstellung wird standardmäßig zugunsten von
bluestore_compression_min_blob_size_hddundbluestore_compression_min_blob_size_ssdignoriert. Wenn ein Wert ungleich null festgelegt ist, erhält sie Vorrang.- bluestore_compression_max_blob_size
Wert: Ganzzahl ohne Vorzeichen, Größe in Byte. Standardeinstellung:
0Maximale Größe von komprimierten Objekten, bevor sie in kleinere Blöcke aufgeteilt werden. Die Einstellung wird standardmäßig zugunsten von
bluestore_compression_max_blob_size_hddundbluestore_compression_max_blob_size_ssdignoriert. Wenn ein Wert ungleich null festgelegt ist, erhält sie Vorrang.- bluestore_compression_min_blob_size_ssd
Wert: Ganzzahl ohne Vorzeichen, Größe in Byte. Standardeinstellung:
8KMindestgröße der Objekte, die komprimiert und auf Festkörperlaufwerk gespeichert werden.
- bluestore_compression_max_blob_size_ssd
Wert: Ganzzahl ohne Vorzeichen, Größe in Byte. Standardeinstellung:
64KMaximale Größe von komprimierten, auf einem Solid-State-Laufwerk gespeicherten Objekten, bevor sie in kleinere Blöcke aufgeteilt werden.
- bluestore_compression_min_blob_size_hdd
Wert: Ganzzahl ohne Vorzeichen, Größe in Byte. Standardeinstellung:
128KMindestgröße der Objekte, die komprimiert und auf Festplatten gespeichert werden.
- bluestore_compression_max_blob_size_hdd
Wert: Ganzzahl ohne Vorzeichen, Größe in Byte. Standardeinstellung:
512KMaximale Größe von komprimierten, auf einer Festplatte gespeicherten Objekten, bevor sie in kleinere Blöcke aufgeteilt werden.
19 Erasure Coded Pools #
Ceph bietet eine Alternative zur normalen Reproduktion von Daten in Pools, die als Erasure oder Erasure Coded Pool bezeichnet wird. Erasure Pools bieten nicht alle Funktionen der reproduzierten Pools (sie können beispielsweise keine Metadaten für RBD-Pools speichern), belegen jedoch weniger Basisspeicherplatz. Ein standardmäßiger Erasure Pool, in dem 1 TB Daten gespeichert werden können, erfordert 1,5 TB Basisspeicherplatz für einen einzelnen Festplattenausfall. Im Vergleich dazu benötigt ein reproduzierter Pool einen Basisspeicherplatz von 2 TB für denselben Zweck.
Hintergrundinformationen zu dem Begriff Erasure Code finden Sie unter https://en.wikipedia.org/wiki/Erasure_code.
Eine Liste der Pool-Werte für EC-Pools finden Sie im Abschnitt Werte der Pools mit Löschcodierung.
19.1 Voraussetzungen für Erasure Coded Pools #
Zur Nutzung von Erasure Coding muss Folgendes ausgeführt werden:
Definieren Sie eine Löschregel in der CRUSH-Zuordnung.
Definieren Sie ein Löschcode-Profil, in dem der zu verwendende Codierungsalgorithmus angegeben ist.
Erstellen Sie einen Pool mit der obigen Regel und dem Profil.
Denken Sie daran, dass das Profil und die Details im Profil nicht mehr geändert werden können, sobald der Pool erstellt wurde und Daten in den Pool aufgenommen wurden.
Stellen Sie sicher, dass die CRUSH-Regeln für Erasure
Pools indep für step
verwenden. Weitere Informationen finden Sie in
Abschnitt 17.3.2, „firstn und indep“.
19.2 Erstellen eines Pools mit Löschcodierung für Testzwecke #
Der einfachste Erasure Coded Pool entspricht RAID5 und benötigt mindestens drei Hosts. Dieser Vorgang beschreibt die Erstellung eines Pools für Testzwecke.
Mit dem Kommando
ceph osd pool createwird ein Pool vom Typ erasure erstellt. Die Zahl12steht für die Anzahl der Placement Groups. Mit den Standardparametern kann der Pool den Ausfall eines OSD verarbeiten.cephuser@adm >ceph osd pool create ecpool 12 12 erasure pool 'ecpool' createdDie Zeichenkette
ABCDEFGHIwird in ein Objekt namensNYANgeschrieben.cephuser@adm >echo ABCDEFGHI | rados --pool ecpool put NYAN -Für Testzwecke können die OSDs nun deaktiviert werden, zum Beispiel durch Trennen vom Netzwerk.
Auf den Inhalt der Datei wird mit dem Kommando
radoszugegriffen, um zu testen, ob der Pool den Ausfall von Geräten verarbeiten kann.cephuser@adm >rados --pool ecpool get NYAN - ABCDEFGHI
19.3 Löschcode-Profile #
Wird das Kommando ceph osd pool create zum Erstellen
eines erasure pool aufgerufen, dann wird das
Standardprofil verwendet, es sei denn ein anderes Profil wird angegeben.
Profile definieren die Redundanz von Daten. Dies erfolgt durch Festlegen von
zwei Parametern, die willkürlich als k und
m bezeichnet werden. k und m definieren, in wie viele
Datenblöcke eine bestimmte Datenmenge aufgeteilt und wie
viele Codierungs-Datenblöcke erstellt werden. Redundante Datenblöcke werden
dann auf verschiedenen OSDs gespeichert.
Für Erasure Pool-Profile erforderliche Definitionen:
- chunk
Wenn die Verschlüsselungsfunktion aufgerufen wird, gibt sie Datenblöcke der selben Größe zurück: Datenblöcke, die verkettet werden können, um das ursprüngliche Objekt zu rekonstruieren, sowie Codierungs-Datenblöcke, mit denen ein verlorener Datenblock neu aufgebaut werden kann.
- k
Die Anzahl der Datenblöcke, d. h. die Anzahl der Blöcke, in die das ursprüngliche Objekt aufgeteilt wurde. Bei einem Wert von beispielsweise
k=2wird ein Objekt von 10 KB inkObjekte zu je 5 KB aufgeteilt. Der Standardwert fürmin_sizefür Erasure Coded Pools lautetk + 1. Es wird jedoch empfohlen,min_sizeauf einen Wert von mindestensk + 2festzulegen, damit keine Schreib- und Datenverluste eintreten.- m
Die Anzahl der Codierungs-Datenblöcke, d. h. die Anzahl der zusätzlichen Blöcke, die durch die Verschlüsselungsfunktionen berechnet werden. Bei 2 Codierungs-Datenblöcken können 2 OSDs ausfallen, ohne dass Daten verloren gehen.
- crush-failure-domain
Definiert, an welche Geräte die Datenblöcke verteilt werden. Ein Bucket-Typ muss als Wert festgelegt werden. Alle Bucket-Typen finden Sie in Abschnitt 17.2, „Buckets“. Wenn die Fehlerdomäne
racklautet, werden die Datenblöcke in verschiedenen Racks gespeichert, um die Stabilität im Fall von Rack-Fehlern zu erhöhen. Denken Sie daran, das hierfür k+m Racks erforderlich sind.
Mit dem in Abschnitt 19.2, „Erstellen eines Pools mit Löschcodierung für Testzwecke“ verwendeten standardmäßigen Löschcode-Profil verlieren Sie keine Cluster-Daten, wenn ein einzelnes OSD oder ein einzelner Host ausfällt. Daher benötigt es zum Speichern von 1 TB Daten weitere 0,5 TB Basisspeicherplatz. Für 1 TB Daten sind daher 1,5 TB Basisspeicherplatz erforderlich (k=2, m=1). Dies entspricht einer allgemeinen RAID5-Konfiguration. Zum Vergleich: Ein reproduzierter Pool benötigt 2 TB Basisspeicherplatz zum Speichern von 1 TB Daten.
Die Einstellungen des Standardprofils werden angezeigt mit:
cephuser@adm > ceph osd erasure-code-profile get default
directory=.libs
k=2
m=1
plugin=jerasure
crush-failure-domain=host
technique=reed_sol_vanEs ist wichtig, das richtige Profil zu wählen, weil es nach Erstellung des Pools nicht mehr geändert werden kann. Ein neuer Pool mit einem anderen Profil muss erstellt und alle Objekte müssen vom vorigen Pool in den neuen Pool verschoben werden (siehe Abschnitt 18.6, „Pool-Migration“).
Die wichtigsten Parameter des Profils sind k,
m und crush-failure-domain, weil sie
den Speicher-Overhead und die Datenhaltbarkeit definieren. Wenn
beispielsweise die gewünschte Architektur den Verlust von zwei Racks mit
einem Speicher-Overhead von 66 % kompensieren muss, kann das folgende Profil
definiert werden. Dies gilt jedoch nur für eine CRUSH-Zuordnung mit Buckets
vom Typ „rack“:
cephuser@adm > ceph osd erasure-code-profile set myprofile \
k=3 \
m=2 \
crush-failure-domain=rackDas Beispiel in Abschnitt 19.2, „Erstellen eines Pools mit Löschcodierung für Testzwecke“ kann mit diesem neuen Profil wiederholt werden:
cephuser@adm >ceph osd pool create ecpool 12 12 erasure myprofilecephuser@adm >echo ABCDEFGHI | rados --pool ecpool put NYAN -cephuser@adm >rados --pool ecpool get NYAN - ABCDEFGHI
Das NYAN-Objekt wird in drei Datenblöcke aufgeteilt (k=3)
und zwei weitere Datenblöcke werden erstellt (m=2). Der
Wert von m definiert, wie viele OSDs gleichzeitig
ausfallen können, ohne dass Daten verloren gehen. Mit
crush-failure-domain=rack wird ein CRUSH-Regelsatz
erstellt, der sicherstellt, dass keine zwei Datenblöcke im selben Rack
gespeichert werden.

19.3.1 Erstellen eines neuen Löschcode-Profils #
Mit folgendem Kommando erstellen Sie ein neues Löschcode-Profil:
root # ceph osd erasure-code-profile set NAME \
directory=DIRECTORY \
plugin=PLUGIN \
stripe_unit=STRIPE_UNIT \
KEY=VALUE ... \
--force- VERZEICHNIS
Optional. Legen Sie den Namen des Verzeichnisses fest, aus dem das Löschcode-Plugin geladen werden soll. Der Standardwert lautet
/usr/lib/ceph/erasure-code.- PLUGIN
Optional. Mit dem Löschcode-Plugin können Sie Codierungsblöcke berechnen und fehlende Blöcke wiederherstellen. Verfügbare Plugins: „jerasure“, „isa“, „lrc“ und „shes“. Der Standardwert lautet „jerasure“.
- STRIPE_UNIT
Optional. Datenmenge in einem Datenblock pro Stripe. Bei einem Profil mit 2 Datenblöcken und dem Wert „stripe_unit=4K“ wird beispielsweise der Bereich 0–4K in Block 0 abgelegt, 4K–8K in Block 1 und 8K–12K wieder in Block 0. Dieser Wert muss ein Vielfaches von 4K sein, damit die bestmögliche Leistung erzielt wird. Der Standardwert wird beim Erstellen eines Pools aus der Monitor-Konfigurationsoption
osd_pool_erasure_code_stripe_unitabgerufen. Der Wert für „stripe_width“ eines Pools mit diesem Profil entspricht der Anzahl der Datenblöcke, multipliziert mit diesem Wert für „stripe_unit“.- KEY=VALUE
Schlüssel-/Wertepaare von Optionen für das ausgewählte Löschcode-Plugin.
- --force
Optional. Überschreibt ein vorhandenes Profil mit demselben Namen und ermöglicht die Einstellung eines nicht durch 4K teilbaren Werts für „stripe_unit“.
19.3.2 Entfernen eines Löschcode-Profils #
Mit folgendem Kommando entfernen Sie das unter NAME angegebene Löschcode-Profil:
root # ceph osd erasure-code-profile rm NAMEWenn ein Pool auf das Profil verweist, kann das Profil nicht gelöscht werden.
19.3.3 Abrufen der Details eines Löschcode-Profils #
Mit folgendem Kommando rufen Sie Details für das unter NAME angegebene Löschcode-Profil ab:
root # ceph osd erasure-code-profile get NAME19.3.4 Auflisten von Löschcode-Profilen #
Mit folgendem Kommando rufen Sie eine Liste der Namen aller Löschcode-Profile ab:
root # ceph osd erasure-code-profile ls19.4 Markieren von Erasure Coded Pools mit RADOS-Blockgerät #
Setzen Sie ein entsprechendes Tag, wenn Sie einen EC Pool als RBD-Pool kennzeichnen möchten:
cephuser@adm > ceph osd pool application enable rbd ec_pool_nameRBD kann Image-Daten in EC Pools speichern. Der Image Header und die Metadaten müssen jedoch weiterhin in einem reproduzierten Pool gespeichert werden. Nehmen wir an, Sie verfügen zu diesem Zweck über einen Pool namens „rbd“:
cephuser@adm > rbd create rbd/image_name --size 1T --data-pool ec_pool_nameSie können das Image normalerweise wie jedes andere Image verwenden, außer dass alle Daten im Pool ec_pool_name gespeichert werden statt im „rbd“-Pool.
20 RADOS Block Device #
Ein Block ist eine Folge von Byte, beispielsweise ein 4-MB-Datenblock. Blockbasierte Speicherschnittstellen werden am häufigsten zum Speichern von Daten auf rotierenden Medien wie Festplatten, CDs, Disketten verwendet. Angesichts der Omnipräsenz von Blockgeräteschnittstellen ist ein virtuelles Blockgerät für ein Massenspeichersystem wie Ceph hervorragend zur Interaktion geeignet.
Ceph-Blockgeräte lassen die gemeinsame Nutzung physischer Ressourcen zu und
ihre Größe kann geändert werden. Sie speichern Daten auf mehreren OSDs in
einem Ceph-Cluster verteilt. Ceph-Blockgeräte nutzen die RADOS-Funktionen wie
Snapshotting, Reproduktion und Konsistenz. Cephs RADOS Block Devices (RBD)
interagieren mit OSDs über Kernel-Module oder die
librbd-Bibliothek.

Die Blockgeräte von Ceph sind sehr leistungsfähig und unbegrenzt auf
Kernel-Module skalierbar. Sie unterstützen Virtualisierungslösungen wie QEMU
oder Cloud-basierte Rechnersysteme wie OpenStack, die auf
libvirt basieren. Sie können Object
Gateway, CephFS und RADOS Block Devices gleichzeitig am selben Cluster
ausführen.
20.1 Kommandos für Blockgeräte #
Mit dem Kommando rbd werden Blockgeräte-Images erstellt,
aufgelistet, intern geprüft und entfernt. Sie können es beispielsweise auch
zum Klonen von Images, zum Erstellen von Snapshots, für ein Rollback eines
Image zu einem Snapshot oder zum Anzeigen eines Snapshots verwenden.
20.1.1 Erstellen eines Blockgeräte-Image in einem reproduzierten Pool #
Bevor Sie ein Blockgerät in einen Client aufnehmen können, müssen Sie ein zugehöriges Image in einem vorhandenen Pool erstellen (siehe Kapitel 18, Verwalten von Speicher-Pools):
cephuser@adm > rbd create --size MEGABYTES POOL-NAME/IMAGE-NAMEMit folgendem Kommando erstellen Sie beispielsweise das 1-GB-Image „myimage“, in dem Informationen aus dem Pool „mypool“ gespeichert werden:
cephuser@adm > rbd create --size 1024 mypool/myimageWenn Sie die Abkürzung einer Größeneinheit („G“ oder „T“) auslassen, wird die Größe des Images in Megabyte angegeben. Mit „G“ oder „T“ nach der Zahl geben Sie Gigabyte oder Terabyte an.
20.1.2 Erstellen eines Blockgeräte-Image in einem Pool mit Löschcodierung #
Daten eines Blockgeräte-Image können direkt in Pools mit Löschcodierung
(EC-Pools) gespeichert werden. Ein RADOS-Block-Device-Image besteht aus
einem Data- und einem
metadata-Teil. Sie können lediglich den Datenteil
eines RADOS Blockgeräte-Image in einem EC-Pool speichern. Das Flag
overwrite des Pools muss auf true
festgelegt sein. Dies ist nur möglich, wenn alle OSDs, auf denen der Pool
gespeichert ist, mit BlueStore arbeiten.
Es ist nicht möglich, den Metadaten-Teil des Image in einem EC-Pool zu
speichern. Sie können den reproduzierten Pool zum Speichern der Metadaten
des Image mit der Option --pool= des Kommandos
rbd create angeben oder pool/ als
Präfix vor dem Imagenamen angeben.
Erstellen Sie einen EC-Pool:
cephuser@adm >ceph osd pool create EC_POOL 12 12 erasurecephuser@adm >ceph osd pool set EC_POOL allow_ec_overwrites true
Geben Sie den reproduzierten Pool zum Speichern von Metadaten an:
cephuser@adm > rbd create IMAGE_NAME --size=1G --data-pool EC_POOL --pool=POOLoder:
cephuser@adm > rbd create POOL/IMAGE_NAME --size=1G --data-pool EC_POOL20.1.3 Auflisten von Blockgeräte-Images #
Mit folgendem Kommando rufen Sie die Blockgeräte im Pool „mypool“ ab:
cephuser@adm > rbd ls mypool20.1.4 Abrufen von Image-Informationen #
Mit folgendem Kommando rufen Sie Informationen aus dem Image „myimage“ im Pool „mypool“ ab:
cephuser@adm > rbd info mypool/myimage20.1.5 Ändern der Größe eines Blockgeräte-Image #
RADOS-Block-Device-Images werden schlank bereitgestellt, was bedeutet, dass
Sie erst physischen Speicherplatz belegen, wenn Sie damit beginnen, Daten
darin zu speichern. Ihre Kapazität ist jedoch auf den Wert beschränkt, den
Sie mit der Option --size festlegen. Führen Sie folgendes
Kommando aus, wenn Sie die maximale Größe des Image erhöhen (oder
verringern) möchten:
cephuser@adm >rbd resize --size 2048 POOL_NAME/IMAGE_NAME # to increasecephuser@adm >rbd resize --size 2048 POOL_NAME/IMAGE_NAME --allow-shrink # to decrease
20.1.6 Entfernen eines Blockgeräte-Image #
Mit folgendem Kommando entfernen Sie ein Blockgerät, das dem Image „myimage“ im Pool „mypool“ entspricht:
cephuser@adm > rbd rm mypool/myimage20.2 Ein- und Aushängen #
Nach Erstellung eines RADOS Block Device können Sie es wie jedes andere Datenträgergerät nutzen: Sie können es formatieren, für den Dateiaustausch einhängen und danach wieder aushängen.
Das Kommando rbd greift standardmäßig mit dem
Ceph-Admin-Benutzerkonto auf den Cluster zu. Dieses Konto
hat vollen Verwaltungszugriff auf den Cluster. Dadurch besteht die Gefahr,
dass versehentlich Schaden angerichtet wird, ähnlich wie bei der Anmeldung
an einem Linux-Arbeitsplatzrechner als
root. Daher ist es vorzuziehen,
Benutzerkonten mit weniger Rechten zu erstellen und diese Konten für den
normalen Lese-/Schreibzugriff auf RADOS-Blockgeräte zu verwenden.
20.2.1 Erstellen eines Ceph-Benutzerkontos #
Erstellen Sie ein neues Benutzerkonto mit Ceph-Manager-, Ceph-Monitor- und
Ceph-OSD-Funktionen über das Kommando ceph mit dem
Unterkommando auth get-or-create:
cephuser@adm > ceph auth get-or-create client.ID mon 'profile rbd' osd 'profile profile name \
[pool=pool-name] [, profile ...]' mgr 'profile rbd [pool=pool-name]'Erstellen Sie beispielsweise einen Benutzer namens qemu mit Lese- und Schreibzugriff auf die Pool-vms und Nur-Lese-Zugriff auf die Pool-Images mit folgendem Kommando:
ceph auth get-or-create client.qemu mon 'profile rbd' osd 'profile rbd pool=vms, profile rbd-read-only pool=images' \ mgr 'profile rbd pool=images'
Die Ausgabe des Kommandos ceph auth get-or-create ist
der Schlüsselring für den angegebenen Benutzer, der in
/etc/ceph/ceph.client.Id.keyring.keyring
geschrieben werden kann.
Wenn Sie das Kommando rbd verwenden, können Sie die
Benutzer-ID mit dem optionalen Argument --id
ID angeben.
Weitere Details zur Verwaltung von Ceph-Benutzerkonten finden Sie in
Kapitel 30, Authentifizierung mit cephx.
20.2.2 Benutzerauthentifizierung #
Geben Sie einen Benutzernamen mit --id
user-name an. Bei der
cephx-Authentifizierung müssen Sie außerdem ein
Geheimnis angeben. Es kann von einem Schlüsselbund stammen oder aus einer
Datei, die das Geheimnis enthält:
cephuser@adm > rbd device map --pool rbd myimage --id admin --keyring /path/to/keyringoder
cephuser@adm > rbd device map --pool rbd myimage --id admin --keyfile /path/to/file20.2.3 Vorbereiten eines RADOS-Blockgeräts für den Einsatz #
Stellen Sie sicher, dass Ihr Ceph-Cluster einen Pool mit dem Festplatten-Image enthält, das zugeordnet werden soll. Nehmen wir an, der Name des Pools lautet
mypoolund das Image istmyimage.cephuser@adm >rbd list mypoolOrdnen Sie das Image einem neuen Blockgerät zu:
cephuser@adm >rbd device map --pool mypool myimageListen Sie alle zugeordneten Geräte auf:
cephuser@adm >rbd device list id pool image snap device 0 mypool myimage - /dev/rbd0Das Gerät, mit dem wir arbeiten möchten, heißt
/dev/rbd0.Tipp: RBD-GerätepfadStatt
/dev/rbdDEVICE_NUMBERkönnen Sie/dev/rbd/POOL_NAME/IMAGE_NAMEals dauerhaften Gerätepfad verwenden. Beispiel:/dev/rbd/mypool/myimage
Erstellen Sie am Gerät namens
/dev/rbd0ein XFS-Dateisystem:root #mkfs.xfs /dev/rbd0 log stripe unit (4194304 bytes) is too large (maximum is 256KiB) log stripe unit adjusted to 32KiB meta-data=/dev/rbd0 isize=256 agcount=9, agsize=261120 blks = sectsz=512 attr=2, projid32bit=1 = crc=0 finobt=0 data = bsize=4096 blocks=2097152, imaxpct=25 = sunit=1024 swidth=1024 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=0 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=8 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0Ersetzen Sie
/mntdurch Ihren Einhängepunkt, hängen Sie das Gerät ein und prüfen Sie, ob es korrekt eingehängt ist:root #mount /dev/rbd0 /mntroot #mount | grep rbd0 /dev/rbd0 on /mnt type xfs (rw,relatime,attr2,inode64,sunit=8192,...Nun können Sie Daten auf das und vom Gerät verschieben, als wäre es ein lokales Verzeichnis.
Tipp: Vergrößern des RBD-GerätsWenn sich herausstellt, dass die Größe des RBD-Geräts nicht mehr ausreicht, lässt es sich leicht vergrößern.
Vergrößern Sie das RBD-Image, beispielsweise auf 10 GB.
cephuser@adm >rbd resize --size 10000 mypool/myimage Resizing image: 100% complete...done.Erweitern Sie das Dateisystem, bis es die neue Größe des Geräts ausfüllt:
root #xfs_growfs /mnt [...] data blocks changed from 2097152 to 2560000
Wenn Sie Ihre Arbeit an dem Gerät beenden, können Sie dessen Zuordnung aufheben und das Gerät aushängen.
cephuser@adm >rbd device unmap /dev/rbd0root #unmount /mnt
Ein rbdmap-Skript und eine
systemd-Einheit werden
bereitgestellt, um den Prozess des Zuordnens und Einhängens von RBDs nach
dem Booten und des Aushängens vor dem Herunterfahren reibungsloser zu
gestalten. Weitere Informationen finden Sie unter
Abschnitt 20.2.4, „Rbdmap – Zuordnen von RBD-Geräten beim Booten“.
20.2.4 Rbdmap – Zuordnen von RBD-Geräten beim Booten #
Das Shell-Skript rbdmap automatisiert die Operationen
rbd map und rbd device unmap an einem
oder mehreren RBD-Images. Obwohl Sie das Skript jederzeit manuell ausführen
können, ist sein wichtigster Vorteil, es automatisch zuordnen und die
RBD-Images beim Booten einhängen (und sie beim Herunterfahren aushängen und
die Zuordnung aufheben) zu können. Dieser Vorgang wird vom Init-System
ausgelöst. Zu diesem Zweck ist eine Datei für die
systemd-Einheit
(rbdmap.service) im Paket
ceph-common enthalten.
Das Skript nimmt ein einzelnes Argument, entweder map oder
unmap. In beiden Fällen analysiert das Skript eine
Konfigurationsdatei. Die Standardeinstellung
/etc/ceph/rbdmap kann mit der Umgebungsvariablen
RBDMAPFILE überschrieben werden. Jede Zeile der
Konfigurationsdatei entspricht einem RBD-Image, das zugeordnet oder dessen
Zuordnung aufgehoben werden soll.
Die Konfigurationsdatei hat das folgende Format:
image_specification rbd_options
image_specificationPfad zu einem Image in einem Pool. Geben Sie diesen als pool_name/image_name an.
rbd_optionsEine optionale Liste der Parameter, die an das zugrunde liegende Kommando
rbd device mapweitergegeben werden sollen. Diese Parameter und ihre Werte sollten als durch Komma getrennte Zeichenkette angegeben werden, wie zum Beispiel:PARAM1=VAL1,PARAM2=VAL2,...
Im Beispiel führt das Skript
rbdmapfolgendes Kommando aus:cephuser@adm >rbd device map POOL_NAME/IMAGE_NAME --PARAM1 VAL1 --PARAM2 VAL2Im folgenden Beispiel wird erläutert, wie Sie einen Benutzernamen und einen Schlüsselbund mit zugehörigem Geheimnis angeben:
cephuser@adm >rbdmap device map mypool/myimage id=rbd_user,keyring=/etc/ceph/ceph.client.rbd.keyring
Wenn das Skript als rbdmap map ausgeführt wird,
analysiert es die Konfigurationsdatei und versucht, für jedes angegebene
RBD-Image zunächst das Image zuzuordnen (mit dem Kommando rbd
device map) und dann das Image einzuhängen.
Wenn es als rbdmap unmap ausgeführt wird, werden die in
der Konfigurationsdatei aufgelisteten Images ausgehängt und ihre
Zuordnungen werden aufgehoben.
rbdmap unmap-all versucht, alle aktuell zugeordneten
RBD-Images auszuhängen und danach deren Zuordnungen aufzuheben, unabhängig
davon, ob sie in der Konfigurationsdatei aufgelistet sind.
Bei erfolgreicher Ausführung wird mit dem Vorgang rbd device
map das Image einem /dev/rbdX-Gerät
zugeordnet. Zu diesem Zeitpunkt wird eine udev-Regel ausgelöst, um einen
symbolischen Link zu einem Geräteanzeigenamen
/dev/rbd/pool_name/image_name
zu erstellen, der auf das reale zugeordnete Gerät zeigt.
Damit das Einhängen und Aushängen erfolgreich ausgeführt wird, muss der
Anzeigename des Geräts einen entsprechenden Eintrag in
/etc/fstab haben. Geben Sie beim Schreiben von
/etc/fstab-Einträgen für RBD-Images die Einhängeoption
„noauto“ (oder „nofail“) an. Dadurch wird verhindert, dass das Init-System
das Gerät zu früh einhängt, also noch bevor das betreffende Gerät überhaupt
vorhanden ist, weil rbdmap.service normalerweise
ziemlich spät in der Boot-Sequenz ausgelöst wird.
Eine vollständige Liste der rbd-Optionen finden Sie auf
der rbd-Handbuchseite (man 8 rbd).
Beispiele zur Anwendung von rbdmap finden Sie auf der
rbdmap-Handbuchseite (man 8 rbdmap).
20.2.5 Vergrößern von RBD-Geräten #
Wenn sich herausstellt, dass die Größe des RBD-Geräts nicht mehr ausreicht, lässt es sich leicht vergrößern.
Vergrößern Sie das RBD-Image, beispielsweise auf 10 GB
cephuser@adm >rbd resize --size 10000 mypool/myimage Resizing image: 100% complete...done.Erweitern Sie das Dateisystem, bis es die neue Größe des Geräts ausfüllt.
root #xfs_growfs /mnt [...] data blocks changed from 2097152 to 2560000
20.3 Aufnahmen #
Ein RBD-Image ist eine Snapshot eines RADOS-Block-Device-Image. Mit
Snapshots behalten Sie den Verlauf des Zustands eines Image bei: Ceph
unterstützt auch ein Snapshot Layering zum schnellen und einfachen Klonen
von VM-Images. Ceph unterstützt Blockgeräte-Snapshots mit dem Kommando
rbd sowie viele übergeordnete Schnittstellen wie QEMU,
libvirt, OpenStack und CloudStack.
Halten Sie die Eingabe- und Ausgabeoperationen an und entfernen Sie alle ausstehenden Schreibvorgänge, bevor Sie einen Snapshot eines Images anfertigen. Wenn das Image ein Dateisystem enthält, muss sich das Dateisystem zum Zeitpunkt der Snapshot-Erstellung in einem konsistenten Zustand befinden.
20.3.1 Aktivieren und Konfigurieren von cephx #
Wenn cephx aktiviert ist, dann müssen Sie einen
Benutzernamen oder eine ID und einen Pfad zum Schlüsselbund mit dem
entsprechenden Schlüssel für den Benutzer angeben. Weitere Einzelheiten
finden Sie unter Kapitel 30, Authentifizierung mit cephx. Es ist auch möglich,
die Umgebungsvariable CEPH_ARGS hinzuzufügen, um
die erneute Eingabe der folgenden Parameter zu verhindern.
cephuser@adm >rbd --id user-ID --keyring=/path/to/secret commandscephuser@adm >rbd --name username --keyring=/path/to/secret commands
Beispiel:
cephuser@adm >rbd --id admin --keyring=/etc/ceph/ceph.keyring commandscephuser@adm >rbd --name client.admin --keyring=/etc/ceph/ceph.keyring commands
Fügen Sie den Benutzer und das Geheimnis zur Umgebungsvariable
CEPH_ARGS hinzu, damit Sie diese Informationen
nicht jedes Mal neu eingeben müssen.
20.3.2 Allgemeine Informationen zu Snapshots #
Das folgende Verfahren zeigt, wie Snapshots mit dem Kommando
rbd in der Kommandozeile erstellt, aufgelistet und
entfernt werden.
20.3.2.1 Erstellen von Snapshots #
Geben Sie zum Erstellen eines Snapshots mit rbd die
Option snap create, den Pool-Namen und den Image-Namen
an.
cephuser@adm >rbd --pool pool-name snap create --snap snap-name image-namecephuser@adm >rbd snap create pool-name/image-name@snap-name
Beispiel:
cephuser@adm >rbd --pool rbd snap create --snap snapshot1 image1cephuser@adm >rbd snap create rbd/image1@snapshot1
20.3.2.2 Auflisten von Snapshots #
Geben Sie zum Auflisten von Snapshots eines Image den Pool-Namen und den Image-Namen an.
cephuser@adm >rbd --pool pool-name snap ls image-namecephuser@adm >rbd snap ls pool-name/image-name
Beispiel:
cephuser@adm >rbd --pool rbd snap ls image1cephuser@adm >rbd snap ls rbd/image1
20.3.2.3 Rollback von Snapshots #
Geben Sie zur Durchführung eines Rollbacks zu einem Snapshot mit
rbd die Option snap rollback, den
Pool-Namen, den Image-Namen und den Namen des Snapshots an.
cephuser@adm >rbd --pool pool-name snap rollback --snap snap-name image-namecephuser@adm >rbd snap rollback pool-name/image-name@snap-name
Beispiel:
cephuser@adm >rbd --pool pool1 snap rollback --snap snapshot1 image1cephuser@adm >rbd snap rollback pool1/image1@snapshot1
Bei einem Rollback eines Image zu einem Snapshot wird die aktuelle Version des Image mit den Daten aus einem Snapshot überschrieben. Ein Rollback dauert umso länger je größer das Image ist. Einen Snapshot zu klonen ist schneller als ein Rollback eines Image zu einem Snapshot durchzuführen und ist die bevorzugte Methode, wenn zu einem früheren Zustand zurückgekehrt werden soll.
20.3.2.4 Löschen eines Snapshots #
Geben Sie zum Löschen eines Snapshots mit rbd die
Option snap rm, den Pool-Namen, den Image-Namen und den
Benutzernamen an.
cephuser@adm >rbd --pool pool-name snap rm --snap snap-name image-namecephuser@adm >rbd snap rm pool-name/image-name@snap-name
Beispiel:
cephuser@adm >rbd --pool pool1 snap rm --snap snapshot1 image1cephuser@adm >rbd snap rm pool1/image1@snapshot1
Ceph OSDs löschen Daten asynchron. Daher wird beim Löschen eines Snapshots nicht sofort Festplattenspeicherplatz frei.
20.3.2.5 Bereinigen von Snapshots #
Geben Sie zum Entfernen aller Snapshots für ein Image mit
rbd die Option snap purge und den
Image-Namen an.
cephuser@adm >rbd --pool pool-name snap purge image-namecephuser@adm >rbd snap purge pool-name/image-name
Beispiel:
cephuser@adm >rbd --pool pool1 snap purge image1cephuser@adm >rbd snap purge pool1/image1
20.3.3 Snapshot-Layering #
Ceph unterstützt die Möglichkeit zur Erstellung mehrerer COW(copy-on-write)-Klone eines Blockgeräte-Snapshots. Durch ein Snapshot Layering können Ceph-Blockgeräte-Clients Images sehr schnell erstellen. Beispielsweise könnten Sie ein Blockgeräte-Image mit einem darauf geschriebenen Linux VM und danach einen Snapshot von diesem Image erstellen, dann den Snapshot schützen und beliebig viele COW-Klone erstellen. Ein Snapshot ist schreibgeschützt. Daher vereinfacht ein Snapshot die Semantik und ermöglicht es, Klone schnell zu erstellen.
Die im folgenden Kommandozeilenbeispiel genannten Elemente „parent“ (übergeordnet) und „child“ (untergeordnet) beziehen sich auf einen Ceph-Blockgeräte-Snapshot (parent) und das entsprechende Image, das vom Snapshot geklont wurde (child).
Jedes geklonte Image (child) speichert einen Verweis auf das übergeordnete Image (parent), wodurch das geklonte Image den übergeordneten Snapshot (parent) öffnen und lesen kann.
Ein COW-Klon eines Snapshots verhält sich exakt genauso wie jedes andere Ceph-Blockgeräte-Image. Geklonte Images können gelesen, geschrieben und geklont werden und ihre Größe lässt sich ändern. Geklonte Images haben keine besonderen Einschränkungen. Der COW-Klon eines Snapshots verweist jedoch auf den Snapshot. Daher müssen Sie den Snapshot schützen, bevor Sie ihn klonen.
--image-format 1 wird nicht unterstützt
Sie können keine Snapshots von Images anfertigen, die mit der veralteten
Option rbd create --image-format 1 erstellt wurden.
Ceph unterstützt lediglich das Klonen der standardmäßigen format
2-Images.
20.3.3.1 Erste Schritte mit Layering #
Ceph-Blockgeräte-Layering ist ein einfacher Prozess. Sie benötigen ein Image. Sie müssen einen Snapshot vom Image erstellen. Sie müssen den Snapshot schützen. Nach Ausführung dieser Schritte beginnen Sie mit dem Klonen des Snapshots.
Das geklonte Image verweist auf den übergeordneten Snapshot und enthält Pool-ID, Image-ID und Snapshot-ID. Durch die enthaltene Pool-ID können Snapshots von einem Pool zu Images in einem anderen Pool geklont werden.
Image-Schablone: Bei einem üblichen Anwendungsfall für Blockgeräte-Layering wird ein Master Image erstellt und ein Snapshot, der als Schablone für Klone dient. Beispielsweise erstellt ein Benutzer ein Image für eine Linux-Distribution (zum Beispiel SUSE Linux Enterprise Server) und dann einen Snapshot dafür. Der Benutzer aktualisiert möglicherweise das Image regelmäßig und erstellt einen neuen Snapshot (zum Beispiel
zypper ref && zypper patchgefolgt vonrbd snap create). So wie sich das Image weiterentwickelt, kann der Benutzer beliebige einzelne Snapshots klonen.Erweiterte Schablone: Bei einem anspruchsvolleren Anwendungsfall wird ein Schablonen-Image erweitert, das mehr Informationen als eine Basis-Image enthält. Beispielsweise könnte ein Benutzer ein Image (eine VM-Schablone) klonen und weitere Software installieren (beispielsweise eine Datenbank, ein Content-Management-System oder ein Analysesystem) und dann einen Snapshot des erweiterten Image erstellen, das genauso wie das Basis-Image aktualisiert wird.
Schablonen-Pool: Eine Methode des Blockgeräte-Layerings ist die Erstellung eines Pools, der Master-Images enthält, die als Schablonen fungieren, sowie Snapshots dieser Schablonen. Sie könnten dann Nur-Lesen-Berechtigungen an Benutzer verteilen. Die Benutzer haben dadurch die Möglichkeit, die Snapshots zu klonen, dürfen jedoch nicht im Pool schreiben oder Vorgänge ausführen.
Image-Migration/Wiederherstellung: Eine Methode des Blockgeräte-Layerings ist die Migration oder Wiederherstellung von Daten von einem Pool in einen anderen Pool.
20.3.3.2 Schützen eines Snapshots #
Klone greifen auf die übergeordneten Snapshots zu. Alle Klone würden zerstört werden, wenn ein Benutzer versehentlich den übergeordneten Snapshot löscht. Sie müssen den Snapshot schützen, bevor Sie ihn klonen, um Datenverlust zu verhindern.
cephuser@adm >rbd --pool pool-name snap protect \ --image image-name --snap snapshot-namecephuser@adm >rbd snap protect pool-name/image-name@snapshot-name
Beispiel:
cephuser@adm >rbd --pool pool1 snap protect --image image1 --snap snapshot1cephuser@adm >rbd snap protect pool1/image1@snapshot1
Geschützte Snapshots können nicht gelöscht werden.
20.3.3.3 Klonen eines Snapshots #
Zum Klonen eines Snapshots müssen Sie den übergeordneten Pool, das Image, den Snapshot, den untergeordneten Pool und den Image-Namen angeben. Der Snapshot muss vor dem Klonen geschützt werden.
cephuser@adm >rbd clone --pool pool-name --image parent-image \ --snap snap-name --dest-pool pool-name \ --dest child-imagecephuser@adm >rbd clone pool-name/parent-image@snap-name \ pool-name/child-image-name
Beispiel:
cephuser@adm > rbd clone pool1/image1@snapshot1 pool1/image2Ein Snapshot kann von einem Pool zu einem Image in einem anderen Pool geklont werden. Sie könnten beispielsweise schreibgeschützte Images und Snapshots als Schablonen in einem Pool beibehalten und beschreibbare Klone in einem anderen Pool.
20.3.3.4 Aufheben des Schutzes eines Snapshots #
Vor dem Löschen eines Snapshots muss zunächst dessen Schutz aufgehoben werden. Außerdem dürfen Sie keine Snapshots löschen, die Verweise von Klonen enthalten. Sie müssen jeden Klon eines Snapshots vereinfachen, bevor Sie den Snapshot löschen.
cephuser@adm >rbd --pool pool-name snap unprotect --image image-name \ --snap snapshot-namecephuser@adm >rbd snap unprotect pool-name/image-name@snapshot-name
Beispiel:
cephuser@adm >rbd --pool pool1 snap unprotect --image image1 --snap snapshot1cephuser@adm >rbd snap unprotect pool1/image1@snapshot1
20.3.3.5 Auflisten der untergeordneten Klone eines Snapshots #
Führen Sie zum Auflisten der untergeordneten Klone eines Snapshots folgendes Kommando aus:
cephuser@adm >rbd --pool pool-name children --image image-name --snap snap-namecephuser@adm >rbd children pool-name/image-name@snapshot-name
Beispiel:
cephuser@adm >rbd --pool pool1 children --image image1 --snap snapshot1cephuser@adm >rbd children pool1/image1@snapshot1
20.3.3.6 Vereinfachen eines geklonten Images #
Geklonte Images behalten einen Verweis auf den übergeordneten Snapshot bei. Wenn Sie den Verweis vom untergeordneten Klon zum übergeordneten Snapshot entfernen, wird das Image tatsächlich „vereinfacht“, indem die Informationen vom Snapshot zum Klon kopiert werden. Die Vereinfachung eines Klons dauert umso länger je größer der Snapshot ist. Zum Löschen eines Snapshots müssen Sie zunächst die untergeordneten Images vereinfachen.
cephuser@adm >rbd --pool pool-name flatten --image image-namecephuser@adm >rbd flatten pool-name/image-name
Beispiel:
cephuser@adm >rbd --pool pool1 flatten --image image1cephuser@adm >rbd flatten pool1/image1
Da ein vereinfachtes Image alle Informationen des Snapshots enthält, belegt ein vereinfachtes Image mehr Speicherplatz als ein Layering-Klon.
20.4 RBD-Image-Spiegel #
RBD-Images können asynchron zwischen zwei Ceph-Clustern gespiegelt werden. Diese Funktion ist in zwei Modi verfügbar:
- Journal-basiert
Bei diesem Modus wird die Funktion des RBD-Journaling-Image verwendet, um die absturzkonsistente Reproduktion zwischen Clustern sicherzustellen. Jeder Schreibvorgang in das RBD-Image wird zunächst im zugehörigen Journal aufgezeichnet, bevor das eigentliche Image geändert wird. Der
Remote-Cluster liest aus dem Journal und gibt die Aktualisierungen in seiner lokalen Kopie des Image wieder. Da jeder Schreibvorgang auf das RBD-Image zu zwei Schreibvorgängen auf dem Ceph-Cluster führt, müssen Sie bei Verwendung der RBD-Journaling-Image-Funktion mit nahezu doppelt so langen Schreiblatenzen rechnen.- Snapshot-basiert
Dieser Modus verwendet periodisch geplante oder manuell erstellte RBD-Image-Spiegel-Snapshots, um absturzsichere RBD-Images zwischen Clustern zu reproduzieren. Der
Remote-Cluster ermittelt alle Daten- oder Metadaten-Aktualisierungen zwischen zwei Spiegel-Snapshots und kopiert die Deltas in seine lokale Kopie des Image. Mit Hilfe der RBD-Image-Funktion „fast-diff“ können aktualisierte Datenblöcke schnell berechnet werden, ohne dass das gesamte RBD-Image abgesucht werden muss. Da dieser Modus nicht zeitpunktkonsistent ist, muss das vollständige Snapshot-Delta vor der Verwendung in einem Failover-Szenario synchronisiert werden. Alle teilweise angewendeten Snapshot-Deltas werden vor der Verwendung auf den letzten vollständig synchronisierten Snapshot zurückgesetzt.
Die Spiegelung wird pro Pool in den Peer-Clustern konfiguriert. Dies kann
für eine bestimmte Untergruppe von Images innerhalb des Pools konfiguriert
werden oder so, dass alle Images innerhalb eines Pools automatisch
gespiegelt werden, wenn nur die Journal-basierte Spiegelung verwendet wird.
Die Spiegelung wird mit dem rbd-Kommando ausgeführt. Der
rbd-mirror-Daemon ist dafür
zuständig, Image-Aktualisierungen aus dem
Remote-Peer-Cluster zu entnehmen und sie auf das Image im
lokalen Cluster anzuwenden.
Abhängig von den gewünschten Anforderungen an die Reproduktion kann die RBD-Spiegelung entweder für eine ein- oder zweiseitige Reproduktion konfiguriert werden:
- Einseitige Reproduktion
Wenn Daten nur von einem primären Cluster auf einen sekundären Cluster gespiegelt werden, läuft der
rbd-mirror-Daemon nur auf dem sekundären Cluster.- Zweiseitige Reproduktion
Wenn Daten von primären Images auf einem Cluster auf nicht primäre Images auf einem anderen Cluster gespiegelt werden (und umgekehrt), wird der
rbd-mirror-Daemon auf beiden Clustern ausgeführt.
Jede Instanz des rbd-mirror-Daemons
muss in der Lage sein, sich gleichzeitig mit dem lokalen
und dem Remote-Ceph-Cluster zu verbinden, beispielsweise
mit allen Überwachungs- und OSD-Hosts. Außerdem muss das Netzwerk über eine
ausreichende Bandbreite zwischen den beiden Rechenzentren verfügen, um die
Spiegelung des Workloads zu bewältigen.
20.4.1 Pool-Konfiguration #
Die folgenden Verfahren zeigen, wie einfache Verwaltungsaufgaben zum
Konfigurieren der Spiegelung mit dem rbd-Kommando
ausgeführt werden. Die Spiegelung wird pro Pool in den Ceph-Clustern
konfiguriert.
Sie müssen die Schritte zur Pool-Konfiguration an beiden Peer-Clustern
ausführen. Bei diesen Verfahren wird der Einfachheit halber angenommen,
dass von einem einzelnen Host aus auf zwei Cluster
(lokal und Remote) zugegriffen werden
kann.
Weitere detaillierte Informationen zum Herstellen einer Verbindung zu
verschiedenen Ceph-Clustern finden Sie auf der
rbd-Handbuchseite (man 8 rbd).
Der Clustername in den folgenden Beispielen entspricht einer
Ceph-Konfigurationsdatei mit dem gleichen Namen
/etc/ceph/remote.conf und einer
Ceph-Schlüsselbunddatei mit dem gleichen Namen
/etc/ceph/remote.client.admin.keyring.
20.4.1.1 Aktivieren der Spiegelung für einen Pool #
Geben Sie zum Aktivieren der Spiegelung in einem Pool das Unterkommando
mirror pool enable, den Pool-Namen und den
Spiegelungsmodus an. Der Spiegelungsmodus kann entweder „pool“ oder
„image“ lauten:
- Speicherplatz auf dem Pool
Alle Images im Pool mit aktivierter Journaling-Funktion werden gespiegelt.
- Image
Die Spiegelung muss auf jedem Image explizit aktiviert werden. Weitere Informationen zu diesem Thema finden Sie unter dem Stichwort Abschnitt 20.4.2.1, „Aktivieren der Image-Spiegelung“.
Beispiel:
cephuser@adm >rbd --cluster local mirror pool enable POOL_NAME poolcephuser@adm >rbd --cluster remote mirror pool enable POOL_NAME pool
20.4.1.2 Deaktivieren der Spiegelung #
Geben Sie zum Deaktivieren der Spiegelung in einem Pool das Unterkommando
mirror pool disable und den Pool-Namen an. Wenn die
Spiegelung auf diese Weise in einem Pool deaktiviert wird, dann wird sie
auch in anderen Images (im Pool) deaktiviert, für die eine Spiegelung
explizit aktiviert wurde.
cephuser@adm >rbd --cluster local mirror pool disable POOL_NAMEcephuser@adm >rbd --cluster remote mirror pool disable POOL_NAME
20.4.1.3 Bootstrapping von Peers #
Damit der rbd-mirror-Daemon seinen
Peer-Cluster erkennen kann, muss der Peer im Pool registriert und ein
Benutzerkonto angelegt werden. Dieser Vorgang kann mit
rbd und den Kommandos mirror pool peer
bootstrap create und mirror pool peer bootstrap
import automatisiert werden.
Um ein neues Bootstrap-Token mit rbd manuell zu
erstellen, geben Sie das Kommando mirror pool peer bootstrap
create, einen Pool-Namen sowie einen optionalen Anzeigenamen für
den Standort zur Beschreibung des lokalen Clusters an:
cephuser@local > rbd mirror pool peer bootstrap create \
[--site-name LOCAL_SITE_NAME] POOL_NAME
Die Ausgabe von mirror pool peer bootstrap create ist
ein Token, das dem Kommando mirror pool peer bootstrap
import übergeben werden sollte, beispielsweise am
lokalen Cluster:
cephuser@local > rbd --cluster local mirror pool peer bootstrap create --site-name local image-pool
eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW \
1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1v \
bl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
Importieren Sie über folgende Syntax mit dem Kommando
rbd das von einem anderen Cluster erstellte
Bootstrap-Token manuell:
rbd mirror pool peer bootstrap import \ [--site-name LOCAL_SITE_NAME] \ [--direction DIRECTION \ POOL_NAME TOKEN_PATH
Ort:
- LOCAL_SITE_NAME
Ein optionaler Anzeigename für den Standort zum Beschreiben des
lokalenClusters.- DIRECTION
Eine Spiegelrichtung. Die Standardeinstellung ist
rx-txfür die zweiseitige Spiegelung, kann aber auch aufrx-onlyfür die einseitige Spiegelung festgelegt werden.- POOL_NAME
Name des Pools.
- TOKEN_PATH
Ein Dateipfad zum erstellten Token (oder
-, um es von der Standardeingabe zu lesen),
beispielsweise am Remote-Cluster:
cephuser@remote > cat <<EOF > token
eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW \
1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1v \
bl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
EOFcephuser@adm > rbd --cluster remote mirror pool peer bootstrap import \
--site-name remote image-pool token20.4.1.4 Manuelles Hinzufügen eines Cluster-Peers #
Alternativ zum Bootstrapping von Peers, wie in
Abschnitt 20.4.1.3, „Bootstrapping von Peers“ beschrieben, können Sie
Peers auch manuell angeben. Der entfernte
rbd-mirror-Daemon benötigt zur
Durchführung der Spiegelung Zugriff auf den lokalen Cluster. Erstellen Sie
einen neuen lokalen Ceph-Benutzer, den der entfernte
rbd-mirror-Daemon verwendet, z. B.
rbd-mirror-peer:
cephuser@adm > ceph auth get-or-create client.rbd-mirror-peer \
mon 'profile rbd' osd 'profile rbd'
Verwenden Sie die folgende Syntax, um einen Spiegelungs-Peer-Ceph-Cluster
mit dem Kommando rbd hinzuzufügen:
rbd mirror pool peer add POOL_NAME CLIENT_NAME@CLUSTER_NAME
Beispiel:
cephuser@adm >rbd --cluster site-a mirror pool peer add image-pool client.rbd-mirror-peer@site-bcephuser@adm >rbd --cluster site-b mirror pool peer add image-pool client.rbd-mirror-peer@site-a
Standardmäßig muss der
rbd-mirror-Daemon Zugriff auf die
Ceph-Konfigurationsdatei haben, die sich unter
/etc/ceph/.CLUSTER_NAME.conf
befindet. Es stellt IP-Adressen der MONs des Peer-Clusters und einen
Schlüsselring für einen Client namens
CLIENT_NAME bereit, der sich in den Standard-
oder benutzerdefinierten Schlüsselring-Suchpfaden befindet, z. B.
/etc/ceph/CLUSTER_NAME.CLIENT_NAME.keyring.
Alternativ kann der MON- und/oder Client-Schlüssel des Peer-Clusters
sicher im lokalen config-Schlüsselspeicher von Ceph gespeichert werden.
Geben Sie die Verbindungsattribute des Peer-Clusters beim Hinzufügen eines
Spiegelungs-Peers mit den Optionen --remote-mon-host und
--remote-key-file an. Beispiel:
cephuser@adm >rbd --cluster site-a mirror pool peer add image-pool \ client.rbd-mirror-peer@site-b --remote-mon-host 192.168.1.1,192.168.1.2 \ --remote-key-file /PATH/TO/KEY_FILEcephuser@adm >rbd --cluster site-a mirror pool info image-pool --all Mode: pool Peers: UUID NAME CLIENT MON_HOST KEY 587b08db... site-b client.rbd-mirror-peer 192.168.1.1,192.168.1.2 AQAeuZdb...
20.4.1.5 Entfernen des Cluster-Peers #
Geben Sie zum Entfernen eines Peer Clusters für die Spiegelung das
Unterkommando mirror pool peer remove, den Pool-Namen
und die Peer-UUID (verfügbar über das Kommando rbd mirror pool
info) an:
cephuser@adm >rbd --cluster local mirror pool peer remove POOL_NAME \ 55672766-c02b-4729-8567-f13a66893445cephuser@adm >rbd --cluster remote mirror pool peer remove POOL_NAME \ 60c0e299-b38f-4234-91f6-eed0a367be08
20.4.1.6 Datenpools #
Beim Erstellen von Images im Zielcluster wählt
rbd-mirror einen Datenpool wie
folgt aus:
Wenn der Ziel-Cluster einen Standard-Datenpool konfiguriert hat (mit der Konfigurationsoption
rbd_default_data_pool), wird dieser verwendet.Andernfalls, wenn das Quell-Image einen separaten Datenpool verwendet und ein Pool mit demselben Namen auf dem Ziel-Cluster vorhanden ist, wird dieser Pool verwendet.
Wenn keiner der beiden oben genannten Punkte zutrifft, wird kein Datenpool festgelegt.
20.4.2 RBD-Image-Konfiguration #
Im Gegensatz zur Pool-Konfiguration muss die Image-Konfiguration nur für einen einzigen für die Spiegelung vorgesehenen Peer Ceph-Cluster durchgeführt werden.
Gespiegelte RBD-Images werden entweder als primär oder nicht primär ausgewiesen. Dies ist eine Eigenschaft des Image und nicht des Pools. Als nicht primär ausgewiesene Images können nicht bearbeitet werden.
Images werden automatisch zu primären Images hochgestuft, wenn die
Spiegelung zuvor für ein Image aktiviert wird (entweder implizit mit dem
Pool-Spiegelungsmodus „pool“ und durch Aktivieren der Journaling-Funktion
für das Image oder explizit (Informationen hierzu finden Sie in
Abschnitt 20.4.2.1, „Aktivieren der Image-Spiegelung“) mit dem
rbd-Kommando).
20.4.2.1 Aktivieren der Image-Spiegelung #
Wenn eine Spiegelung im Modus Image konfiguriert ist,
muss die Spiegelung für jedes Image im Pool explizit aktiviert werden.
Geben Sie zum Aktivieren der Spiegelung für ein bestimmtes Image mit
rbd das Unterkommando mirror image
enable zusammen mit dem Pool- und dem Image-Namen an:
cephuser@adm > rbd --cluster local mirror image enable \
POOL_NAME/IMAGE_NAME
Der Spiegel-Image-Modus kann entweder Journal oder
Snapshot lauten:
- Journal (Standardeinstellung)
Wenn die Spiegelung im
Journal-Modus konfiguriert ist, wird mit der RBD-Journaling-Image-Funktion der Image-Inhalt reproduziert. Wenn die RBD-Journaling-Image-Funktion noch nicht für das Image aktiviert ist, wird sie automatisch aktiviert.- Snapshot
Wenn die Spiegelung im
Snapshot-Modus konfiguriert ist, verwendet sie RBD-Image-Spiegel-Snapshots zum Reproduzieren des Image-Inhalts. Sobald diese Option aktiviert ist, wird automatisch ein erster Spiegel-Snapshot erstellt. Zusätzliche RBD-Image-Spiegel-Snapshots können mit dem Kommandorbderstellt werden.
Beispiel:
cephuser@adm >rbd --cluster local mirror image enable image-pool/image-1 snapshotcephuser@adm >rbd --cluster local mirror image enable image-pool/image-2 journal
20.4.2.2 Aktivieren der Image-Journaling-Funktion #
Bei der RBD-Spiegelung wird immer die RBD Journaling-Funktion verwendet,
um sicherzustellen, dass das reproduzierte Image immer absturzkonsistent
bleibt. Bei Verwendung des Image-Spiegelungsmodus wird
die Journaling-Funktion automatisch aktiviert, wenn die Spiegelung auf dem
Image aktiviert ist. Wenn Sie den Pool-Spiegelungsmodus
verwenden, muss die RBD-Image-Journaling-Funktion aktiviert sein, bevor
ein Image auf einen Peer-Cluster gespiegelt werden kann. Die Funktion kann
bei der Image-Erstellung durch Angabe der Option --image-feature
exclusive-lock,journaling für das rbd-Kommando
aktiviert werden.
Alternativ kann die Journaling-Funktion für bereits vorhandene RBD-Images
dynamisch aktiviert werden. Geben Sie zum Aktivieren des Journaling den
Unterbefehl feature enable, den Pool-Namen, den
Image-Namen und den Namen der Funktion an:
cephuser@adm >rbd --cluster local feature enable POOL_NAME/IMAGE_NAME exclusive-lockcephuser@adm >rbd --cluster local feature enable POOL_NAME/IMAGE_NAME journaling
Die Funktion journaling hängt von der Funktion
exclusive-lock ab. Wenn die Funktion
exclusive-lock nicht bereits aktiviert ist, müssen Sie
diese vor Aktivierung der Funktion journaling
aktivieren.
Sie können das Journaling für alle neuen Images standardmäßig aktivieren,
indem Sie rbd default features =
layering,exclusive-lock,object-map,deep-flatten,journaling zu
Ihrer Ceph-Konfigurationsdatei hinzufügen.
20.4.2.3 Erstellen von Image-Spiegel-Snapshots #
Bei der Snapshot-basierten Spiegelung müssen immer dann Spiegel-Snapshots
erstellt werden, wenn der geänderte Inhalt des RBD-Image gespiegelt werden
soll. Geben Sie zum manuellen Erstellen eines Spiegel-Snapshots mit
rbd das Kommando mirror image
snapshot zusammen mit dem Pool- und dem Image-Namen an:
cephuser@adm > rbd mirror image snapshot POOL_NAME/IMAGE_NAMEBeispiel:
cephuser@adm > rbd --cluster local mirror image snapshot image-pool/image-1
Standardmäßig werden nur drei Spiegel-Snapshots pro Image erstellt. Der
letzte Spiegel-Snapshot wird automatisch entfernt, wenn das Limit erreicht
ist. Das Limit kann bei Bedarf über die Konfigurationsoption
rbd_mirroring_max_mirroring_snapshots außer Kraft gesetzt
werden. Außerdem werden Spiegel-Snapshots automatisch gelöscht, wenn das
Image entfernt oder die Spiegelung deaktiviert wird.
Spiegel-Snapshots können auch automatisch auf periodischer Basis erstellt werden, wenn Spiegel-Snapshot-Zeitpläne definiert sind. Der Spiegel-Snapshot kann auf globaler Ebene, pro Pool oder pro Image geplant werden. Es können zwar mehrere Zeitpläne für Spiegel-Snapshots auf jeder Ebene definiert werden, doch nur die spezifischsten Snapshot-Zeitpläne, die zu einem einzelnen gespiegelten Image passen, werden ausgeführt.
Geben Sie zum Erstellen eines Spiegel-Snapshot-Zeitplans mit
rbd das Kommando mirror snapshot schedule
add zusammen mit einem optionalen Pool- oder Image-Namen, einem
Intervall und einer optionalen Startzeit an.
Das Intervall kann in Tagen, Stunden oder Minuten mit den entsprechenden
Suffixen d, h oder m
angegeben werden. Die optionale Startzeit wird im ISO 8601-Zeitformat
angegeben. Beispiel:
cephuser@adm >rbd --cluster local mirror snapshot schedule add --pool image-pool 24h 14:00:00-05:00cephuser@adm >rbd --cluster local mirror snapshot schedule add --pool image-pool --image image1 6h
Geben Sie zum Entfernen eines Spiegel-Snapshot-Zeitplans mit
rbd das Kommando mirror snapshot schedule
remove mit Optionen an, die dem entsprechenden Kommando „add
schedule“ entsprechen.
Geben Sie zum Auflisten aller Snapshot-Zeitpläne für eine bestimmte Ebene
(global, Pool oder Image) mit rbd das Kommando
mirror snapshot schedule ls zusammen mit einem
optionalen Pool- oder Image-Namen an. Zusätzlich kann die Option
--recursive angegeben werden, um alle Zeitpläne auf der
angegebenen Ebene und darunter aufzulisten. Beispiel:
cephuser@adm > rbd --cluster local mirror schedule ls --pool image-pool --recursive
POOL NAMESPACE IMAGE SCHEDULE
image-pool - - every 1d starting at 14:00:00-05:00
image-pool image1 every 6h
Um herauszufinden, wann die nächsten Snapshots für die Snapshot-basierte
Spiegelung von RBD-Images mit rbd erstellt werden,
geben Sie das Kommando mirror snapshot schedule status
zusammen mit einem optionalen Pool- oder Image-Namen an. Beispiel:
cephuser@adm > rbd --cluster local mirror schedule status
SCHEDULE TIME IMAGE
2020-02-26 18:00:00 image-pool/image120.4.2.4 Aktivieren der Image-Spiegelung #
Geben Sie zum Deaktivieren der Spiegelung für ein bestimmtes Image das
Unterkommando mirror image disable zusammen mit dem
Pool- und Image-Namen an:
cephuser@adm > rbd --cluster local mirror image disable POOL_NAME/IMAGE_NAME20.4.2.5 Hoch- und Herabstufen von Images #
In einem Failover-Szenario, in dem die primäre Bezeichnung zum Image im Peer Cluster verschoben werden muss, müssen Sie den Zugriff auf das primäre Image stoppen, das aktuelle primäre Image herabstufen, das neue primäre Image hochstufen und den Zugriff auf das Image am alternativen Cluster wieder aufnehmen.
Die Hochstufung wird mit der Option --force erzwungen.
Die erzwungene Hochstufung ist erforderlich, wenn die Herabstufung nicht
auf den Peer Cluster übertragen werden kann (beispielsweise im Fall eines
Cluster-Fehlers oder Kommunikationsausfalls). Dies führt zu einem
Split-Brain-Szenario zwischen den beiden Peers und das Image wird nicht
mehr synchronisiert, bis ein Unterkommando resync
ausgestellt wird.
Geben Sie zum Herabstufen eines bestimmten Image zu „nicht primär“ das
Unterkommando mirror image demote zusammen mit dem
Pool- und Image-Namen an:
cephuser@adm > rbd --cluster local mirror image demote POOL_NAME/IMAGE_NAME
Geben Sie zum Herabstufen aller primären Images in einem Pool zu „nicht
primär“ das Unterkommando mirror pool demote zusammen
mit dem Pool-Namen an:
cephuser@adm > rbd --cluster local mirror pool demote POOL_NAME
Geben Sie zum Hochstufen eines bestimmten Image zu „primär“ das
Unterkommando mirror image promote zusammen mit dem
Pool- und Image-Namen an:
cephuser@adm > rbd --cluster remote mirror image promote POOL_NAME/IMAGE_NAME
Geben Sie zum Hochstufen aller primären Images in einem Pool zu „primär“
das Unterkommando mirror pool promote zusammen mit dem
Pool-Namen an:
cephuser@adm > rbd --cluster local mirror pool promote POOL_NAMEDa der Status „primär“ oder „nicht primär“ pro Image gilt, ist es möglich, die E/A-Last auf zwei Cluster aufzuteilen und dort ein Failover oder Failback durchzuführen.
20.4.2.6 Erzwingen der erneuten Image-Synchronisierung #
Wenn der rbd-mirror-Daemon ein
Split Brain-Szenario erkennt, versucht er erst wieder, das betreffende
Image zu spiegeln, wenn das Problem behoben ist. Um die Spiegelung für ein
Image wieder aufzunehmen, müssen Sie zunächst das Image, das als veraltet
ermittelt wurde, herabstufen und dann eine erneute Synchronisierung mit
dem primären Image anfordern. Geben Sie zum Anfordern einer erneuten
Synchronisierung des Image das Unterkommando mirror image
resync zusammen mit dem Pool- und Image-Namen an:
cephuser@adm > rbd mirror image resync POOL_NAME/IMAGE_NAME20.4.3 Prüfen des Spiegelungsstatus #
Der Reproduktionsstatus des Peer Clusters wird für jedes primäre
gespiegelte Image gespeichert. Dieser Status wird mit den Unterkommandos
mirror image status und mirror pool
status abgerufen:
Geben Sie zum Anfordern des Spiegel-Image-Status das Unterkommando
mirror image status zusammen mit dem Pool- und
Image-Namen an:
cephuser@adm > rbd mirror image status POOL_NAME/IMAGE_NAME
Geben Sie zum Anfordern einer Übersicht zum Spiegel-Pool-Status das
Unterkommando mirror pool status zusammen mit dem
Pool-Namen an:
cephuser@adm > rbd mirror pool status POOL_NAME
Durch Hinzufügen der Option --verbose zum Unterkommando
mirror pool status werden zusätzlich Statusdetails für
jedes Spiegel-Image im Pool ausgegeben.
20.5 Cache-Einstellungen #
Die Implementierung des Benutzerbereichs auf dem Ceph-Blockgerät
(librbd) kann den Linux-Seiten-Cache nicht nutzen.
Sie umfasst daher ein eigenes Caching im Speicher. Das RBD-Caching läuft
ähnlich ab wie das Festplatten-Caching. Wenn das Betriebssystem eine Sperre
oder eine Verschiebungsanforderung sendet, werden alle kürzlich bearbeiteten
(„dirty“) Daten auf die OSDs geschrieben. Dies bedeutet, dass das Caching
mit Zurückschreiben ebenso sicher ist wie eine wohldefinierte physische
Festplatte mit einer VM, die ordnungsgemäß Verschiebungen sendet. Der Cache
beruht auf einem Least-Recently-Used(LRU)-Algorithmus;
im Zurückschreiben-Modus kann er nebeneinanderliegende Anforderungen
zusammenführen und damit den Durchsatz erhöhen.
Ceph unterstützt das Caching mit Zurückschreiben für RBD. Aktivieren Sie es mit
cephuser@adm > ceph config set client rbd_cache true
Standardmäßig nimmt librbd kein Caching vor.
Schreib- und Lesevorgänge gehen direkt in den Speicher-Cluster und
Schreibvorgänge werden nur dann zurückgegeben, wenn sich die Daten in allen
Reproduktionen auf dem Datenträger befinden. Bei aktiviertem Caching werden
Schreibvorgänge sofort zurückgegeben, außer die Menge der nicht verschobenen
Daten (in Byte) ist höher als der Wert der Option rbd cache max
dirty. Der Schreibvorgang löst in diesem Fall das Zurückschreiben
aus und bleibt so lange gesperrt, bis eine ausreichende Datenmenge
verschoben wurde.
Ceph unterstützt das Caching mit Durchschreiben für RBD. Sie können die Größe des Caches festlegen und auch die Ziele und Einschränkungen vom Caching mit Zurückschreiben auf das Caching mit Durchschreiben umstellen. Aktivieren Sie den Durchschreiben-Modus mit
cephuser@adm > ceph config set client rbd_cache_max_dirty 0Dies bedeutet, dass Schreibvorgänge nur dann zurückgegeben werden, wenn sich die Daten in allen Reproduktionen auf dem Datenträger befinden; Lesevorgänge können dagegen aus dem Cache stammen. Der Cache befindet sich im Speicher auf dem Client und jedes RBD-Image umfasst einen eigenen Cache. Da sich der Cache lokal auf dem Client befindet, ist keine Kohärenz gegeben, wenn andere auf das Image zugreifen. Bei aktiviertem Caching können GFS oder OCFS nicht zusätzlich zu RBD ausgeführt werden.
Die folgenden Parameter beeinflussen das Verhalten von RADOS-Blockgeräten.
Legen Sie sie mit der Client-Kategorie fest:
cephuser@adm > ceph config set client PARAMETER VALUErbd cacheCaching für RADOS Block Device (RBD) aktivieren. Die Standardeinstellung ist „true“.
rbd cache sizeGröße des RBD-Caches (in Byte). Standardwert ist 32 MB.
rbd cache max dirtyGrenzwert für die Menge der kürzlich bearbeiteten („dirty“) Daten, bei dem der Cache das Zurückschreiben auslöst.
rbd cache max dirtymuss kleiner alsrbd cache sizesein. Beim Wert 0 wird das Caching mit Durchschreiben herangezogen. Standardwert ist 24 MB.rbd cache target dirtyDas kürzlich bearbeitete Ziel („dirty target“), bevor der Cache die ersten Daten in den Datenspeicher schreibt. Blockiert keine Schreibvorgänge in den Cache. Standardwert ist 16 MB.
rbd cache max dirty ageZeitraum (in Sekunden), über den soeben bearbeitete Daten im Cache verbleiben, bevor das Zurückschreiben beginnt. Der Standardwert ist 1.
rbd cache writethrough until flushDer Vorgang beginnt im Durchschreiben-Modus und wechselt zum Zurückschreiben, sobald die erste Verschiebungsanforderung eingeht. Dies ist eine konservative, jedoch sichere Einstellung für den Fall, dass virtuelle Maschinen mit
rbdzu alt sind, um Verschiebungen zu senden (z. B. der Virtio-Treiber in Linux vor Kernel 2.6.32). Die Standardeinstellung ist „true“.
20.6 QoS-Einstellungen #
„Quality of Service“ (QoS) bezeichnet im Allgemeinen verschiedene Methoden, mit denen der Datenverkehr priorisiert und Ressourcen reserviert werden. Dies ist insbesondere für Datenverkehr mit besonderen Anforderungen von Bedeutung.
Die folgenden QoS-Einstellungen werden ausschließlich durch die
Benutzerbereichs-RBD-Implementierung
librbd verwendet,
nicht jedoch von der
kRBD-Implementierung. iSCSI greift auf
kRBD zurück und nutzt daher nicht die
QoS-Einstellungen. Für iSCSI können Sie jedoch QoS mit den standardmäßigen
Kernel-Funktionen in der Kernel-Blockgeräteschicht konfigurieren.
rbd qos iops limitGewünschter Grenzwert für die E/A-Operationen pro Sekunde. Der Standardwert ist 0 (keine Einschränkung).
rbd qos bps limitGewünschter Grenzwert für die E/A-Datenmenge (in Byte) pro Sekunde. Der Standardwert ist 0 (keine Einschränkung).
rbd qos read iops limitGewünschter Grenzwert für die Leseoperationen pro Sekunde. Der Standardwert ist 0 (keine Einschränkung).
rbd qos write iops limitGewünschter Grenzwert für die Schreiboperationen pro Sekunde. Der Standardwert ist 0 (keine Einschränkung).
rbd qos read bps limitGewünschter Grenzwert für die gelesene Datenmenge (in Byte) pro Sekunde. Der Standardwert ist 0 (keine Einschränkung).
rbd qos write bps limitGewünschter Grenzwert für die geschriebene Datenmenge (in Byte) pro Sekunde. Der Standardwert ist 0 (keine Einschränkung).
rbd qos iops burstGewünschter Blockgrenzwert für E/A-Operationen. Der Standardwert ist 0 (keine Einschränkung).
rbd qos bps burstGewünschter Blockgrenzwert für die E/A-Datenmenge (in Byte). Der Standardwert ist 0 (keine Einschränkung).
rbd qos read iops burstGewünschter Blockgrenzwert für Leseoperationen. Der Standardwert ist 0 (keine Einschränkung).
rbd qos write iops burstGewünschter Blockgrenzwert für Schreiboperationen. Der Standardwert ist 0 (keine Einschränkung).
rbd qos read bps burstGewünschter Blockgrenzwert für die gelesene Datenmenge (in Byte). Der Standardwert ist 0 (keine Einschränkung).
rbd qos write bps burstGewünschter Blockgrenzwert für die geschriebene Datenmenge (in Byte). Der Standardwert ist 0 (keine Einschränkung).
rbd qos schedule tick minMinimaler Zeitplanimpuls (in Millisekunden) für QoS. Der Standardwert ist 50.
20.7 Read-Ahead-Einstellungen #
RADOS Block Device unterstützt das Read-Ahead/Prefetching zur Optimierung kleiner, sequenzieller Lesevorgänge. Bei einer virtuellen Maschine wird dies in der Regel durch das Gast-Betriebssystem abgewickelt, doch Bootloader geben unter Umständen keine effizienten Lesevorgänge aus. Das Read-Ahead wird automatisch deaktiviert, wenn das Caching aktiviert ist.
Die folgenden Read-Ahead-Einstellungen werden ausschließlich durch die
Benutzerbereichs-RBD-Implementierung
librbd verwendet,
nicht jedoch von der
kRBD-Implementierung. iSCSI greift auf
kRBD zurück und nutzt daher nicht die
Read-Ahead-Einstellungen. Für iSCSI können Sie jedoch Read-Ahead mit den
standardmäßigen Kernel-Funktionen in der Kernel-Blockgeräteschicht
konfigurieren.
rbd readahead trigger requestsAnzahl der sequenziellen Leseanforderungen, die zum Auslösen des Read-Ahead erforderlich sind. Der Standardwert ist 10.
rbd readahead max bytesMaximale Größe einer Read-Ahead-Anforderung. Beim Wert 0 ist das Read-Ahead deaktiviert. Der Standardwert ist 512 KB.
rbd readahead disable after bytesSobald die angegebene Datenmenge (in Byte) aus einem RBD-Image gelesen wurde, wird das Read-Ahead für dieses Image deaktiviert, bis es geschlossen wird. Damit kann das Gast-Betriebssystem das Read-Ahead beim Starten übernehmen. Beim Wert 0 bleibt das Read-Ahead aktiviert. Der Standardwert ist 50 MB.
20.8 Erweiterte Funktionen #
RADOS Block Device unterstützt erweiterte Funktionen, die den
Funktionsumfang von RBD-Images vergrößern. Sie können die Funktionen
entweder in der Kommandozeile beim Erstellen eines RBD-Images angeben oder
in der Ceph-Konfigurationsdatei mit der Option
rbd_default_features.
Die Werte für die Option rbd_default_features können auf
zwei Arten angegeben werden:
als Summe der internen Werte der Funktion. Jede Funktion besitzt einen eigenen internen Wert – „layering“ beispielsweise den Wert 1 und „fast-diff“ den Wert 16. Sollen diese beiden Funktionen standardmäßig aktiviert werden, geben Sie daher Folgendes an:
rbd_default_features = 17
als durch Komma getrennte Liste mit Funktionen. Das obige Beispiel sieht wie folgt aus:
rbd_default_features = layering,fast-diff
RBD-Images mit den folgenden Funktionen werden nicht durch iSCSI
unterstützt: deep-flatten, object-map,
journaling, fast-diff,
striping
Liste der erweiterten RBD-Funktionen:
layeringMit dem Layering können Sie Elemente klonen.
Der interne Wert ist gleich 1, die Standardeinstellung lautet „yes“.
stripingDas Striping verteilt Daten auf mehrere Objekte und bewirkt Parallelität für sequenzielle Lese-/Schreib-Workloads. Damit werden Engpässe durch einzelne Knoten bei großen oder stark ausgelasteten RADOS Block Devices verhindert.
Der interne Wert ist gleich 2, die Standardeinstellung lautet „yes“.
exclusive-lockWenn diese Option aktiviert ist, muss ein Client eine Sperre für ein Objekt erwirken, bevor ein Schreibvorgang ausgeführt werden kann. Aktivieren Sie die exklusive Sperre nur dann, wenn nur ein einzelner Client auf ein bestimmtes Image zugreift, nicht mehrere Clients gleichzeitig. Der interne Wert ist gleich 4. Die Standardeinstellung lautet „yes“.
object-mapDie Objektzuordnungsunterstützung ist abhängig von der Unterstützung der exklusiven Sperre. Blockgeräte werden per Thin Provisioning bereitgestellt; dies bedeutet, dass lediglich Daten auf diesen Geräten gespeichert werden, die tatsächlich vorhanden sind. Die Objektzuordnungsunterstützung hilft bei der Ermittlung, welche Objekte tatsächlich vorhanden sind (für welche Objekte also Daten auf einem Server gespeichert sind). Wird die Objektzuordnungsunterstützung aktiviert, beschleunigt dies die E/A-Operationen beim Klonen, Importieren und Exportieren eines kaum gefüllten Images sowie den Löschvorgang.
Der interne Wert ist gleich 8, die Standardeinstellung lautet „yes“.
fast-diffDie Fast-diff-Unterstützung ist abhängig von der Objektzuordnungsunterstützung und der Unterstützung der exklusiven Sperre. Hiermit wird eine zusätzliche Eigenschaft in die Objektzuordnung aufgenommen, die die Erzeugung von Vergleichen zwischen Snapshots eines Images und der tatsächlichen Datennutzung eines Snapshots erheblich beschleunigt.
Der interne Wert ist gleich 16, die Standardeinstellung lautet „yes“.
deep-flatten„deep-flatten“ sorgt dafür, dass
rbd flatten(siehe Abschnitt 20.3.3.6, „Vereinfachen eines geklonten Images“) für alle Snapshots eines Images und zusätzlich für das Image selbst ausgeführt werden kann. Ohne diese Option beruhen Snapshots eines Images weiterhin auf dem übergeordneten Image, sodass Sie das übergeordnete Image erst dann löschen können, wenn die Snapshots gelöscht wurden. Mit „deep-flatten“ wird die Abhängigkeit eines übergeordneten Elements von seinen Klonen aufgehoben, selbst wenn sie Snapshots umfassen.Der interne Wert ist gleich 32, die Standardeinstellung lautet „yes“.
JournalDie Journaling-Unterstützung ist abhängig von der Unterstützung der exklusiven Sperre. Mit dem Journaling werden alle Änderungen an einem Image in der Reihenfolge festgehalten, in der sie vorgenommen wurden. Die RBD-Spiegelung (siehe Abschnitt 20.4, „RBD-Image-Spiegel“) reproduziert anhand des Journals ein absturzkonsistentes Image auf einem Remote-Cluster.
Der interne Wert ist gleich 64, die Standardeinstellung lautet „yes“.
20.9 RBD-Zuordnung mit älteren Kernel-Clients #
Ältere Clients (z. B. SLE11 SP4) können RBD-Images unter Umständen nicht zuordnen, da ein mit SUSE Enterprise Storage 7 bereitgestellter Cluster bestimmte Funktionen erzwingt (sowohl auf Ebene der RBD-Images als auch auf RADOS-Ebene), die diese älteren Clients nicht unterstützen. In diesem Fall enthalten die OSD-Protokolle die folgenden oder ähnliche Meldungen:
2019-05-17 16:11:33.739133 7fcb83a2e700 0 -- 192.168.122.221:0/1006830 >> \ 192.168.122.152:6789/0 pipe(0x65d4e0 sd=3 :57323 s=1 pgs=0 cs=0 l=1 c=0x65d770).connect \ protocol feature mismatch, my 2fffffffffff < peer 4010ff8ffacffff missing 401000000000000
Sollen die CRUSH-Zuordnung-Bucket-Typen zwischen „straw“ und „straw2“ gewechselt werden, gehen Sie dabei wohlgeplant vor. Erwarten Sie erhebliche Auswirkungen auf die Cluster-Last, da eine Änderung des Bucket-Typs einen massiven Cluster-Ausgleich auslöst.
Deaktivieren Sie alle nicht unterstützten RBD-Image-Funktionen. Beispiel:
cephuser@adm >rbd feature disable pool1/image1 object-mapcephuser@adm >rbd feature disable pool1/image1 exclusive-lockStellen Sie die CRUSH-Zuordnung-Bucket-Typen von „straw2“ auf „straw“ um:
Speichern Sie die CRUSH-Zuordnung:
cephuser@adm >ceph osd getcrushmap -o crushmap.originalDekompilieren Sie die CRUSH-Zuordnung:
cephuser@adm >crushtool -d crushmap.original -o crushmap.txtBearbeiten Sie die CRUSH-Zuordnung und ersetzen Sie „straw2“ durch „straw“.
Kompilieren Sie die CRUSH-Zuordnung neu:
cephuser@adm >crushtool -c crushmap.txt -o crushmap.newLegen Sie die neue CRUSH-Zuordnung fest:
cephuser@adm >ceph osd setcrushmap -i crushmap.new
20.10 Aktiveren von Blockgeräten und Kubernetes #
Sie können Ceph RBD mit Kubernetes v1.13 und höher über den
ceph-csi-Treiber verwenden. Dieser Treiber stellt
RBD-Images dynamisch für Kubernetes-Volumes bereit und ordnet diese
RBD-Images als Blockgeräte (und optionales Einhängen eines im Image
enthaltenen Dateisystems) zu Arbeitsknoten zu, auf denen Pods ausgeführt
werden, die auf ein RBD-gestütztes Volume verweisen.
Um Ceph-Blockgeräte mit Kubernetes zu verwenden, müssen Sie
ceph-csi in Ihrer Kubernetes-Umgebung installieren und
konfigurieren.
ceph-csi verwendet standardmäßig die RBD-Kernelmodule,
die möglicherweise nicht alle Ceph CRUSH-Tunables oder RBD-Image-Funktionen
unterstützen.
Ceph-Blockgeräte verwenden standardmäßig den RBD-Pool. Erstellen Sie einen Pool für Kubernetes-Volume-Speicher. Stellen Sie sicher, dass Ihr Ceph-Cluster ausgeführt wird, und erstellen Sie dann den Pool:
cephuser@adm >ceph osd pool create kubernetesInitialisieren Sie den Pool mit dem RBD-Werkzeug:
cephuser@adm >rbd pool init kubernetesErstellen Sie einen neuen Benutzer für Kubernetes und
ceph-csi. Führen Sie folgendes Kommando aus und zeichnen Sie den generierten Schlüssel auf:cephuser@adm >ceph auth get-or-create client.kubernetes mon 'profile rbd' osd 'profile rbd pool=kubernetes' mgr 'profile rbd pool=kubernetes' [client.kubernetes] key = AQD9o0Fd6hQRChAAt7fMaSZXduT3NWEqylNpmg==Für
ceph-csiist ein in Kubernetes gespeichertes ConfigMap-Objekt erforderlich, um die Ceph-Monitoradressen für den Ceph-Cluster zu definieren. Erfassen Sie sowohl die eindeutige FSID des Ceph-Clusters als auch die Monitoradressen:cephuser@adm >ceph mon dump <...> fsid b9127830-b0cc-4e34-aa47-9d1a2e9949a8 <...> 0: [v2:192.168.1.1:3300/0,v1:192.168.1.1:6789/0] mon.a 1: [v2:192.168.1.2:3300/0,v1:192.168.1.2:6789/0] mon.b 2: [v2:192.168.1.3:3300/0,v1:192.168.1.3:6789/0] mon.cGenerieren Sie eine
csi-config-map.yaml-Datei ähnlich dem folgenden Beispiel und ersetzen Sie die FSID durchclusterIDund die Monitoradressen durchmonitors:kubectl@adm >cat <<EOF > csi-config-map.yaml --- apiVersion: v1 kind: ConfigMap data: config.json: |- [ { "clusterID": "b9127830-b0cc-4e34-aa47-9d1a2e9949a8", "monitors": [ "192.168.1.1:6789", "192.168.1.2:6789", "192.168.1.3:6789" ] } ] metadata: name: ceph-csi-config EOFSpeichern Sie nach der Generierung das neue ConfigMap-Objekt in Kubernetes:
kubectl@adm >kubectl apply -f csi-config-map.yamlFür
ceph-csiist der cephx-Berechtigungsnachweis für die Kommunikation mit dem Ceph-Cluster erforderlich. Generieren Sie einecsi-rbd-secret.yaml-Datei ähnlich dem folgenden Beispiel mit der neu erstellten Kubernetes-Benutzer-ID und dem cephx-Schlüssel:kubectl@adm >cat <<EOF > csi-rbd-secret.yaml --- apiVersion: v1 kind: Secret metadata: name: csi-rbd-secret namespace: default stringData: userID: kubernetes userKey: AQD9o0Fd6hQRChAAt7fMaSZXduT3NWEqylNpmg== EOFSpeichern Sie das generierte neue geheime Objekt in Kubernetes:
kubectl@adm >kubectl apply -f csi-rbd-secret.yamlErstellen Sie die erforderlichen Kubernetes-Objekte ServiceAccount und RBAC ClusterRole/ClusterRoleBinding. Diese Objekte müssen nicht unbedingt für Ihre Kubernetes-Umgebung angepasst werden und können daher direkt aus den
ceph-csi-YAML-Bereitstellungsdateien verwendet werden:kubectl@adm >kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-provisioner-rbac.yamlkubectl@adm >kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-nodeplugin-rbac.yamlErstellen Sie das
ceph-csi-Bereitstellungsprogramm und die Knoten-Plugins:kubectl@adm >wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin-provisioner.yamlkubectl@adm >kubectl apply -f csi-rbdplugin-provisioner.yamlkubectl@adm >wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin.yamlkubectl@adm >kubectl apply -f csi-rbdplugin.yamlWichtigStandardmäßig wird mit den YAML-Dateien des Bereitstellungsprogramms und des Knoten-Plugins die Entwicklungsversion des
ceph-csi-Containers abgerufen. Die YAML-Dateien sollten zur Verwendung einer Freigabeversion aktualisiert werden.
20.10.1 Verwenden von Ceph-Blockgeräten in Kubernetes #
Die Kubernetes StorageClass definiert eine Speicherklasse. Es können mehrere StorageClass-Objekte erstellt werden, um verschiedene Quality-of-Service-Stufen und Funktionen zuzuordnen. Zum Beispiel NVMe- versus HDD-basierte Pools.
Um eine ceph-csi-StorageClass zu erstellen, die auf den
oben erstellten Kubernetes-Pool zugeordnet wird, kann die folgende
YAML-Datei verwendet werden, nachdem sichergestellt wurde, dass die
Eigenschaft clusterID mit der FSID Ihres Ceph-Clusters
übereinstimmt:
kubectl@adm >cat <<EOF > csi-rbd-sc.yaml --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: csi-rbd-sc provisioner: rbd.csi.ceph.com parameters: clusterID: b9127830-b0cc-4e34-aa47-9d1a2e9949a8 pool: kubernetes csi.storage.k8s.io/provisioner-secret-name: csi-rbd-secret csi.storage.k8s.io/provisioner-secret-namespace: default csi.storage.k8s.io/node-stage-secret-name: csi-rbd-secret csi.storage.k8s.io/node-stage-secret-namespace: default reclaimPolicy: Delete mountOptions: - discard EOFkubectl@adm >kubectl apply -f csi-rbd-sc.yaml
Ein PersistentVolumeClaim ist eine Anforderung von
abstrakten Speicherressourcen durch einen Benutzer. Der
PersistentVolumeClaim würde dann einer Pod-Ressource
zugeordnet werden, um ein PersistentVolume
bereitzustellen, das durch ein Ceph-Block-Image gesichert wird. Ein
optionaler volumeMode kann eingeschlossen werden, um
zwischen einem eingehängten Dateisystem (Standard) oder einem Volume auf
Basis eines Basisblockgeräts zu wählen.
Bei ceph-csi kann die Angabe von
Filesystem für volumeMode die Forderungen
ReadWriteOnce und ReadOnlyMany
accessMode unterstützen. Die Angabe von Block
für volumeMode kann die Forderungen
ReadWriteOnce, ReadWriteMany und
ReadOnlyMany accessMode unterstützen.
Um beispielsweise einen blockbasierten
PersistentVolumeClaim zu erstellen, der die oben
erstellte ceph-csi-basierte StorageClass verwendet, kann
die folgende YAML-Datei verwendet werden, um Basisblockspeicher von der
csi-rbd-sc StorageClass anzufordern:
kubectl@adm >cat <<EOF > raw-block-pvc.yaml --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: raw-block-pvc spec: accessModes: - ReadWriteOnce volumeMode: Block resources: requests: storage: 1Gi storageClassName: csi-rbd-sc EOFkubectl@adm >kubectl apply -f raw-block-pvc.yaml
Im Folgenden wird ein Beispiel für die Bindung des obigen
PersistentVolumeClaim an eine Pod-Ressource als
Basisblockgerät gezeigt:
kubectl@adm >cat <<EOF > raw-block-pod.yaml --- apiVersion: v1 kind: Pod metadata: name: pod-with-raw-block-volume spec: containers: - name: fc-container image: fedora:26 command: ["/bin/sh", "-c"] args: ["tail -f /dev/null"] volumeDevices: - name: data devicePath: /dev/xvda volumes: - name: data persistentVolumeClaim: claimName: raw-block-pvc EOFkubectl@adm >kubectl apply -f raw-block-pod.yaml
Um einen dateisystembasierten PersistentVolumeClaim zu
erstellen, der die oben erstellte ceph-csi-basierte
StorageClass verwendet, kann die folgende YAML-Datei verwendet
werden, um ein eingehängtes (von einem RBD-Image gesichertes) Dateisystem
von der csi-rbd-sc StorageClass anzufordern:
kubectl@adm >cat <<EOF > pvc.yaml --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: rbd-pvc spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 1Gi storageClassName: csi-rbd-sc EOFkubectl@adm >kubectl apply -f pvc.yaml
Im Folgenden wird ein Beispiel für die Bindung des obigen
PersistentVolumeClaim an eine Pod-Ressource als
eingehängtes Dateisystem gezeigt:
kubectl@adm >cat <<EOF > pod.yaml --- apiVersion: v1 kind: Pod metadata: name: csi-rbd-demo-pod spec: containers: - name: web-server image: nginx volumeMounts: - name: mypvc mountPath: /var/lib/www/html volumes: - name: mypvc persistentVolumeClaim: claimName: rbd-pvc readOnly: false EOFkubectl@adm >kubectl apply -f pod.yaml
Teil IV Zugreifen auf Cluster-Daten #
- 21 Ceph Object Gateway
Dieses Kapitel enthält detaillierte Informationen zu Verwaltungsaufgaben, die für Object Gateway relevant sind, wie Prüfen des Servicestatus, Verwalten der Konten, Gateways an mehreren Standorten oder LDAP-Authentifizierung.
- 22 Ceph iSCSI Gateway
In diesem Kapitel befassen wir uns hauptsächlich mit Verwaltungsaufgaben, die für das iSCSI Gateway relevant sind. Das Verfahren zur Bereitstellung wird im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.3.5 “Bereitstellen von iSCSI-Gateways” erläutert.
- 23 Cluster-Dateisystem
In diesem Kapitel werden Verwaltungsaufgaben beschrieben, die normalerweise nach der Einrichtung des Clusters und dem Export des CephFS ausgeführt werden. Weitere Informationen zum Einrichten des CephFS finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5…
- 24 Exportieren von Ceph-Daten mit Samba
Mit diesem Kapitel wird erläutert, wie Sie Daten, die in einem Ceph-Cluster gespeichert sind, über eine Samba-/CIFS-Freigabe exportieren, sodass Sie problemlos von Windows*-Client-Computern darauf zugreifen können. Hier erfahren Sie außerdem, wie Sie ein Ceph-Samba-Gateway für die Einbindung in Acti…
- 25 NFS Ganesha
NFS Ganesha ist ein NFS-Server, der in einem Benutzeradressenbereich statt als Teil des Betriebssystem-Kernels ausgeführt wird. Mit NFS Ganesha binden Sie Ihren eigenen Speichermechanismus ein, wie zum Beispiel Ceph, und greifen von einem beliebigen NFS Client darauf zu. Die Installationsanweisungen…
21 Ceph Object Gateway #
Dieses Kapitel enthält detaillierte Informationen zu Verwaltungsaufgaben, die für Object Gateway relevant sind, wie Prüfen des Servicestatus, Verwalten der Konten, Gateways an mehreren Standorten oder LDAP-Authentifizierung.
21.1 Object-Gateway-Beschränkungen und Benennungseinschränkungen #
Nachfolgend sehen Sie eine Liste der wichtigen Object-Gateway-Beschränkungen:
21.1.1 Bucket-Einschränkungen #
Wenn Sie Object Gateway über die S3 API verwenden, sind Bucket-Namen auf DNS-fähige Namen mit einem Bindestrich „-“ beschränkt. Wenn Sie Object Gateway über die Swift API verwenden, können Sie jede beliebige Kombination aus durch UTF-8 unterstützten Zeichen verwenden, mit Ausnahme des Schrägstrichs „/“. Die maximale Länge eines Bucket-Namens beträgt 255 Zeichen. Bucket-Namen müssen eindeutig sein.
Auch wenn Sie auf UTF-8 basierende Bucket-Namen über die Swift API verwenden, empfehlen wir, Buckets unter Berücksichtigung der S3-Benennungseinschränkungen zu benennen, um Probleme beim Zugriff auf diesen Bucket über die S3 API zu vermeiden.
21.1.2 Einschränkungen für gespeicherte Objekte #
- Maximale Anzahl der Objekte pro Benutzer
Standardmäßig keine Einschränkung (beschränkt durch ~ 2^63).
- Maximale Anzahl der Objekte pro Bucket
Standardmäßig keine Einschränkung (beschränkt durch ~ 2^63).
- Maximale Größe eines Objekts zum Heraufladen/Speichern
Einzelne Uploads sind auf 5 GB beschränkt. Verwenden Sie Multipart für größere Objekte. Die maximale Anzahl der Multipart-Datenblöcke beträgt 10.000.
21.1.3 HTTP-Header-Beschränkungen #
Beschränkungen für HTTP-Header und Anforderungen hängen vom verwendeten Web-Frontend ab. In Beast ist die Größe des HTTP-Headers auf 16 kB beschränkt.
21.2 Bereitstellen des Object Gateways #
Die Bereitstellung von Ceph Object Gateway erfolgt nach dem gleichen Verfahren wie die Bereitstellung anderer Ceph-Services, nämlich mit cephadm. Weitere Informationen finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.2 “Service- und Platzierungsspezifikation” und insbesondere im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.3.4 “Bereitstellen von Object Gateways”.
21.3 Betrieb des Object Gateway Service #
Sie können die Object Gateways wie andere Ceph-Services betreiben. Identifizieren Sie dazu zunächst den Servicenamen mit dem Kommando ceph orch ps und führen Sie folgendes Kommando für den Betrieb von Services aus. Beispiel:
ceph orch daemon restart OGW_SERVICE_NAME
In Kapitel 14, Betrieb von Ceph-Services finden Sie alle Informationen über den Betrieb von Ceph-Services.
21.4 Konfigurationsoptionen #
Unter Abschnitt 28.5, „Ceph Object Gateway“ finden Sie eine Liste der Object-Gateway-Konfigurationsoptionen.
21.5 Verwalten des Zugriffs auf Object Gateway #
Die Kommunikation mit Object Gateway ist entweder über eine S3-fähige Schnittstelle oder eine Swift-fähige Schnittstelle möglich. Die S3-Schnittstelle ist kompatibel mit einer großen Teilmenge der S3 RESTful API. Die Swift-Schnittstelle ist kompatibel mit einer großen Teilmenge der OpenStack Swift API.
Bei beiden Schnittstellen müssen Sie einen bestimmten Benutzer erstellen und die relevante Client-Software installieren, um mit dem Gateway unter Verwendung des geheimen Schlüssels des Benutzers zu kommunizieren.
21.5.1 Zugreifen auf Object Gateway #
21.5.1.1 Zugriff auf die S3-Schnittstelle #
Für den Zugriff auf die S3-Schnittstelle benötigen Sie einen REST Client. S3cmd ist ein Kommandozeilen-S3 Client. Sie finden ihn im OpenSUSE Build Service. Das Repository enthält Versionen für SUSE Linux Enterprise und für openSUSE-basierte Distributionen.
Wenn Sie Ihren Zugriff auf die S3-Schnittstelle testen möchten, können Sie ein kleines Python-Skript schreiben. Das Skript stellt eine Verbindung zum Object Gateway her, erstellt einen neuen Bucket und listet alle Buckets auf. Die Werte für aws_access_key_id und aws_secret_access_key werden den Werten für access_key und secret_key entnommen, die vom Kommando radosgw_admin in Abschnitt 21.5.2.1, „Hinzufügen von S3- und Swift-Benutzern“ zurückgegeben wurden.
Installieren Sie das Paket
phyton-boto:root #zypper in python-botoErstellen Sie ein neues Python-Skript namens
s3test.pymit folgendem Inhalt:import boto import boto.s3.connection access_key = '11BS02LGFB6AL6H1ADMW' secret_key = 'vzCEkuryfn060dfee4fgQPqFrncKEIkh3ZcdOANY' conn = boto.connect_s3( aws_access_key_id = access_key, aws_secret_access_key = secret_key, host = 'HOSTNAME', is_secure=False, calling_format = boto.s3.connection.OrdinaryCallingFormat(), ) bucket = conn.create_bucket('my-new-bucket') for bucket in conn.get_all_buckets(): print "NAME\tCREATED".format( name = bucket.name, created = bucket.creation_date, )Ersetzen Sie
HOSTNAMEdurch den Hostnamen des Hosts, auf dem Sie den Object-Gateway-Service konfiguriert haben, beispielsweisegateway_host.Führen Sie das Skript aus:
python s3test.py
Das Skript gibt in etwa Folgendes aus:
my-new-bucket 2015-07-22T15:37:42.000Z
21.5.1.2 Zugriff auf die Swift-Schnittstelle #
Für den Zugriff auf das Object Gateway über die Swift-Schnittstelle benötigen Sie den swift-Kommandozeilen-Client. In der entsprechenden Handbuchseite man 1 swift erfahren Sie mehr über dessen Kommandozeilenoptionen.
Das Paket befindet sich im Modul „Public Cloud“ für SUSE Linux Enterprise 12 ab SP3 und SUSE Linux Enterprise 15. Vor der Installation des Pakets müssen Sie das Modul aktivieren und das Software Repository aktualisieren:
root # SUSEConnect -p sle-module-public-cloud/12/SYSTEM-ARCH
sudo zypper refreshoder
root #SUSEConnect -p sle-module-public-cloud/15/SYSTEM-ARCHroot #zypper refresh
Führen Sie zur Installation des swift-Pakets folgendes Kommando aus:
root # zypper in python-swiftclientBeim Swift-Zugang wird die folgende Syntax verwendet:
tux > swift -A http://IP_ADDRESS/auth/1.0 \
-U example_user:swift -K 'SWIFT_SECRET_KEY' list
Ersetzen Sie IP_ADDRESS durch die IP-Adresse des Gateway Servers und SWIFT_SECRET_KEY durch dessen Wert der Ausgabe des Kommandos radosgw-admin key create, das für den swift-Benutzer in Abschnitt 21.5.2.1, „Hinzufügen von S3- und Swift-Benutzern“ ausgeführt wurde.
Beispiel:
tux > swift -A http://gateway.example.com/auth/1.0 -U example_user:swift \
-K 'r5wWIxjOCeEO7DixD1FjTLmNYIViaC6JVhi3013h' listDie Ausgabe ist:
my-new-bucket
21.5.2 Verwalten von S3- und Swift-Konten #
21.5.2.1 Hinzufügen von S3- und Swift-Benutzern #
Sie müssen einen Benutzer, einen Zugriffsschlüssel und ein Geheimnis erstellen, um Endbenutzer für die Interaktion mit dem Gateway zu aktivieren. Es gibt zwei Arten von Benutzern: einen Benutzer und einen Unterbenutzer. Benutzer werden für die Interaktion mit der S3-Schnittstelle verwendet, während Unterbenutzer Benutzer der Swift-Schnittstelle sind. Jeder Unterbenutzer ist einem Benutzer zugeordnet.
Führen Sie zum Erstellen eines Swift-Benutzers folgende Schritte aus:
Zum Erstellen eines Swift-Benutzers (in unserer Terminologie ein Unterbenutzer) müssen Sie zunächst den zugeordneten Benutzer erstellen.
cephuser@adm >radosgw-admin user create --uid=USERNAME \ --display-name="DISPLAY-NAME" --email=EMAILBeispiel:
cephuser@adm >radosgw-admin user create \ --uid=example_user \ --display-name="Example User" \ --email=penguin@example.comZum Erstellen eines Unterbenutzers (Swift-Schnittstelle) für den Benutzer müssen Sie die Benutzer-ID (--uid=USERNAME), eine Unterbenutzer-ID und die Zugriffsstufe für den Unterbenutzer angeben.
cephuser@adm >radosgw-admin subuser create --uid=UID \ --subuser=UID \ --access=[ read | write | readwrite | full ]Beispiel:
cephuser@adm >radosgw-admin subuser create --uid=example_user \ --subuser=example_user:swift --access=fullGenerieren Sie einen geheimen Schlüssel für den Benutzer.
cephuser@adm >radosgw-admin key create \ --gen-secret \ --subuser=example_user:swift \ --key-type=swiftBeide Kommandos geben JSON-formatierte Daten mit dem Benutzerstatus aus. Notieren Sie sich die folgenden Zeilen und merken Sie sich den Wert des
secret_key:"swift_keys": [ { "user": "example_user:swift", "secret_key": "r5wWIxjOCeEO7DixD1FjTLmNYIViaC6JVhi3013h"}],
Beim Zugriff auf das Object Gateway über die S3-Schnittstelle müssen Sie einen S3-Benutzer erstellen, indem Sie folgendes Kommando ausführen:
cephuser@adm > radosgw-admin user create --uid=USERNAME \
--display-name="DISPLAY-NAME" --email=EMAILBeispiel:
cephuser@adm > radosgw-admin user create \
--uid=example_user \
--display-name="Example User" \
--email=penguin@example.com
Das Kommando erstellt auch den Zugriff und geheimen Schlüssel des Benutzers. Überprüfen Sie dessen Ausgabe nach den Schlüsselwörtern access_key und secret_key und deren Werte:
[...]
"keys": [
{ "user": "example_user",
"access_key": "11BS02LGFB6AL6H1ADMW",
"secret_key": "vzCEkuryfn060dfee4fgQPqFrncKEIkh3ZcdOANY"}],
[...]21.5.2.2 Entfernen von S3- und Swift-Benutzern #
Das Verfahren zum Löschen von Benutzern ist bei S3- und Swift-Benutzern in etwa gleich. Im Fall von Swift-Benutzern müssen Sie jedoch möglicherweise den Benutzer einschließlich dessen Unterbenutzer löschen.
Geben Sie zum Entfernen eines S3- oder Swift-Benutzers (einschließlich aller Unterbenutzer) user rm und die Benutzer-ID im folgenden Kommando an:
cephuser@adm > radosgw-admin user rm --uid=example_user
Geben Sie zum Entfernen eines Unterbenutzers subuser rm und die Unterbenutzer-ID an.
cephuser@adm > radosgw-admin subuser rm --uid=example_user:swiftDie folgenden Optionen stehen Ihnen zur Verfügung:
- --purge-data
Löscht alle Daten, die der Benutzer-ID zugeordnet sind.
- --purge-keys
Löscht alle Schlüssel, die der Benutzer-ID zugeordnet sind.
Wenn Sie einen Unterbenutzer entfernen, dann entfernen Sie auch den Zugriff auf die Swift-Schnittstelle. Der Benutzer bleibt im System.
21.5.2.3 Ändern des Zugriffs und der geheimen Schlüssel von S3- und Swift-Benutzern #
Die Parameter access_key und secret_key kennzeichnen den Object-Gateway-Benutzer für den Zugriff auf das Gateway. Das Ändern der bestehenden Benutzerschlüssel ist identisch mit dem Erstellen neuer Schlüssel, weil die alten Schlüssel überschrieben werden.
Führen Sie für S3-Benutzer folgendes Kommando aus:
cephuser@adm > radosgw-admin key create --uid=EXAMPLE_USER --key-type=s3 --gen-access-key --gen-secretFühren Sie für Swift-Benutzer folgendes Kommando aus:
cephuser@adm > radosgw-admin key create --subuser=EXAMPLE_USER:swift --key-type=swift --gen-secret--key-type=TYPEGibt den Typ des Schlüssels an, entweder
swiftoders3.--gen-access-keyGeneriert einen Zugriffsschlüssel nach dem Zufallsprinzip (für S3-Benutzer standardmäßig).
--gen-secretGeneriert einen geheimen Schlüssel nach dem Zufallsprinzip.
--secret=KEYGibt einen geheimen Schlüssel an, beispielsweise einen manuell generierten.
21.5.2.4 Aktivieren der Verwaltung von Benutzerquoten #
Mit dem Ceph Object Gateway können Sie Kontingente für Benutzer und Buckets für Benutzer festlegen. Kontingente umfassen die maximale Anzahl der Objekte in einem Bucket sowie die maximale Speichergröße in Megabyte.
Vor dem Aktivieren einer Benutzerquote müssen Sie zunächst deren Parameter festlegen:
cephuser@adm > radosgw-admin quota set --quota-scope=user --uid=EXAMPLE_USER \
--max-objects=1024 --max-size=1024--max-objectsGibt die maximale Anzahl von Objekten an. Durch einen negativen Wert wird die Prüfung deaktiviert.
--max-sizeGibt die maximale Anzahl von Bytes an. Durch einen negativen Wert wird die Prüfung deaktiviert.
--quota-scopeLegt das Volumen für das Kontingent fest. Die Optionen sind
bucketunduser. Bucket-Quoten gelten für Buckets, die ein Benutzer besitzt. Benutzerquoten gelten für einen Benutzer.
Sobald Sie eine Benutzerquote festgelegt haben, können Sie sie aktivieren:
cephuser@adm > radosgw-admin quota enable --quota-scope=user --uid=EXAMPLE_USERSo deaktivieren Sie ein Kontingent:
cephuser@adm > radosgw-admin quota disable --quota-scope=user --uid=EXAMPLE_USERSo listen Sie Kontingenteinstellungen auf:
cephuser@adm > radosgw-admin user info --uid=EXAMPLE_USERSo aktualisieren Sie die Kontingentstatistik:
cephuser@adm > radosgw-admin user stats --uid=EXAMPLE_USER --sync-stats21.6 HTTP-Frontends #
Das Ceph Object Gateway unterstützt zwei eingebettete HTTP-Front-Ends: Beast und Civetweb.
Das Beast-Front-End führt das HTTP-Parsing mit der Boost.Beast-Bibliothek und die asynchrone Netzwerk-E/A mit der Boost.Asio-Bibliothek durch.
Das Civetweb-Front-End greift auf die Civetweb-HTTP-Bibliothek zurück (ein Mongoose-Fork).
Sie können diese über die Option rgw_frontends konfigurieren. Unter Abschnitt 28.5, „Ceph Object Gateway“ finden Sie eine Liste der Konfigurationsoptionen.
21.7 Aktivieren von HTTPS/SSL für Object Gateways #
Zur Aktivierung des Object Gateways für die sichere Kommunikation über SSL benötigen Sie entweder ein von einer Zertifizierungsstelle ausgestelltes Zertifikat oder Sie müssen ein eigensigniertes Zertifikat erstellen.
21.7.1 Erstellen eines eigensignierten Zertifikats #
Überspringen Sie diesen Abschnitt, wenn Sie bereits über ein gültiges Zertifikat verfügen, das von einer Zertifizierungsstelle signiert wurde.
Das folgende Verfahren beschreibt, wie ein eigensigniertes SSL-Zertifikat im Salt Master generiert wird.
Wenn Ihr Object Gateway auch unter weiteren Subjektidentitäten bekannt sein soll, tragen Sie sie in die Option
subjectAltNameim Abschnitt[v3_req]in der Datei/etc/ssl/openssl.cnfein:[...] [ v3_req ] subjectAltName = DNS:server1.example.com DNS:server2.example.com [...]
Tipp: IP-Adressen insubjectAltNameSollen IP-Adressen anstelle von Domänennamen in der Option
subjectAltNameangegeben werden, ersetzen Sie die Beispielzeile wie folgt:subjectAltName = IP:10.0.0.10 IP:10.0.0.11
Erstellen Sie den Schlüssel und das Zertifikat mit
openssl. Geben Sie alle Daten ein, die in Ihrem Zertifikat enthalten sein sollen. Wir empfehlen die Eingabe des FQDN als Eigenname. Verifizieren Sie vor dem Signieren des Zertifikats, dass 'X509v3 Subject Alternative Name:' in den angeforderten Erweiterungen enthalten ist und dass für das resultierende Zertifikat "X509v3 Subject Alternative Name:" festgelegt wurde.root@master #openssl req -x509 -nodes -days 1095 \ -newkey rsa:4096 -keyout rgw.key -out rgw.pemHängen Sie den Schlüssel an die Zertifikatsdatei an:
root@master #cat rgw.key >> rgw.pem
21.7.2 Konfigurieren von Object Gateway mit SSL #
Konfigurieren Sie Object Gateway für die Verwendung von SSL-Zertifikaten über die Option rgw_frontends. Beispiel:
cephuser@adm > ceph config set WHO rgw_frontends \
beast ssl_port=443 ssl_certificate=config://CERT ssl_key=config://KEYWenn Sie die Konfigurationsschlüssel CERT und KEY nicht angeben, sucht der Object-Gateway-Service das SSL-Zertifikat und den Schlüssel unter den folgenden Konfigurationsschlüsseln:
rgw/cert/RGW_REALM/RGW_ZONE.key rgw/cert/RGW_REALM/RGW_ZONE.crt
Wenn Sie den Standard-SSL-Schlüssel und -Zertifikatsspeicherort außer Kraft setzen möchten, importieren Sie sie mit dem folgenden Kommando in die Konfigurationsdatenbank:
ceph config-key set CUSTOM_CONFIG_KEY -i PATH_TO_CERT_FILE
Verwenden Sie dann die benutzerdefinierten Konfigurationsschlüssel mit der Anweisung config://.
21.8 Synchronisierungsmodule #
Object Gateway wird als Service für mehrere Standorte bereitgestellt, wobei Sie Daten und Metadaten zwischen den Zonen spiegeln können. Synchronisierungsmodule werden auf das Framework für mehrere Standorte aufgesetzt und lassen die Weiterleitung von Daten und Metadaten zu einer anderen externen Schicht zu. Mit einem Synchronisierungsmodul kann eine Reihe von Aktionen durchgeführt werden, sobald eine Datenänderung vorgenommen wird (beispielsweise Metadaten-Operationen wie die Erstellung von Buckets oder Benutzern). Da die Object-Gateway-Änderungen an mehreren Standorten letztendlich an Remote-Standorten konsistent sind, werden die Änderungen asynchron verteilt. Damit sind Anwendungsfälle wie das Sichern des Objektspeichers in einem externen Cloud Cluster, eine benutzerdefinierte Sicherungslösung mit Bandlaufwerken oder die Indizierung von Metadaten in ElasticSearch abgedeckt.
21.8.1 Konfigurieren von Synchronisierungsmodulen #
Alle Synchronisierungsmodule werden auf ähnliche Weise konfiguriert. Sie müssen eine neue Zone erstellen (weitere Informationen siehe Abschnitt 21.13, „Object Gateways an mehreren Standorten“) und die Option --tier_type für diese Zone festlegen, beispielsweise --tier-type=cloud für das Cloud-Synchronisierungsmodul:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--endpoints=http://endpoint1.example.com,http://endpoint2.example.com, [...] \
--tier-type=cloudMit folgendem Kommando konfigurieren Sie die jeweilige Schicht:
cephuser@adm > radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--tier-config=KEY1=VALUE1,KEY2=VALUE2KEY in der Konfiguration bezeichnet die zu aktualisierende Konfigurationsvariable und VALUE bezeichnet den neuen Wert. Verschachtelte Werte können mithilfe von Punkten angegeben werden. Beispiel:
cephuser@adm > radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--tier-config=connection.access_key=KEY,connection.secret=SECRETMatrixeinträge können mithilfe von eckigen Klammern „[]“ um den referenzierten Eintrag angegeben werden. Soll ein neuer Matrixeintrag eingefügt werden, setzen Sie den Eintrag in eckige Klammern „[]“. Ein Indexwert von -1 verweist auf den letzten Eintrag in der Matrix. Es ist nicht möglich, einen neuen Eintrag anzulegen und im gleichen Kommando auf diesen Eintrag zu verweisen. Mit folgendem Kommando erstellen Sie beispielsweise ein neues Profil für Buckets, die mit PREFIX beginnen:
cephuser@adm >radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \ --rgw-zone=ZONE-NAME \ --tier-config=profiles[].source_bucket=PREFIX'*'cephuser@adm >radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \ --rgw-zone=ZONE-NAME \ --tier-config=profiles[-1].connection_id=CONNECTION_ID,profiles[-1].acls_id=ACLS_ID
Mit dem Parameter --tier-config-add=KEY=VALUE fügen Sie einen neuen Schichtkonfigurationseintrag ein.
Mit --tier-config-rm=KEY entfernen Sie einen vorhandenen Eintrag.
21.8.2 Synchronisieren von Zonen #
Die Konfiguration eines Synchronisierungsmoduls wird lokal in einer Zone vorgenommen. Das Synchronisierungsmodul bestimmt, ob die Zone Daten exportiert oder in einer anderen Zone geänderte Daten nur nutzen darf. Ab Luminous sind die unterstützten Synchronisierungs-Plugins ElasticSearch, rgw (das standardmäßige Synchronisierungs-Plugin zum Synchronisieren von Daten zwischen den Zonen) und log (ein Trivial-Synchronisierungs-Plugin zum Protokollieren der Metadaten-Operation in den Remote-Zonen). In den folgenden Abschnitten verwenden wir das Beispiel einer Zone mit dem Synchronisierungsmodul ElasticSearch. Bei·der·Konfiguration·eines·anderen·Synchronisierungs-Plugins wäre das Verfahren ähnlich.
rgw ist das standardmäßige Synchronisierungs-Plugin. Es muss nicht explizit konfiguriert werden.
21.8.2.1 Anforderungen und Annahmen #
Nehmen wir eine einfache Konfiguration für mehrere Standorte an, wie in Abschnitt 21.13, „Object Gateways an mehreren Standorten“ beschrieben. Sie besteht aus zwei Zonen: us-east und us-west. Nun fügen wir eine dritte Zone us-east-es hinzu. Diese Zone verarbeitet nur die Metadaten der anderen Standorte. Diese Zone kann sich im selben Ceph-Cluster befinden wie us-east oder auch in einer anderen Zone. Diese Zone würde nur die Metadaten aus anderen Zonen nutzen. Object Gateways in dieser Zone verarbeiten Endbenutzeranforderungen nicht direkt.
21.8.2.2 Konfigurieren von Zonen #
Erstellen Sie die dritte Zone so ähnlich wie die Zonen, die in Abschnitt 21.13, „Object Gateways an mehreren Standorten“ beschrieben sind. Beispiel:
cephuser@adm >radosgw-adminzone create --rgw-zonegroup=us --rgw-zone=us-east-es \ --access-key=SYSTEM-KEY --secret=SECRET --endpoints=http://rgw-es:80Ein Synchronisierungsmodul kann für diese Zone mit folgendem Kommando konfiguriert werden:
cephuser@adm >radosgw-adminzone modify --rgw-zone=ZONE-NAME --tier-type=TIER-TYPE \ --tier-config={set of key=value pairs}Beispiel im Synchronisierungsmodul
ElasticSearch:cephuser@adm >radosgw-adminzone modify --rgw-zone=ZONE-NAME --tier-type=elasticsearch \ --tier-config=endpoint=http://localhost:9200,num_shards=10,num_replicas=1Die verschiedenen unterstützten „tier-config“-Optionen finden Sie in Abschnitt 21.8.3, „Synchronisierungsmodul ElasticSearch“.
Aktualisieren Sie schließlich den Zeitraum:
cephuser@adm >radosgw-adminperiod update --commitStarten Sie das Object Gateway in der Zone:
cephuser@adm >ceph orch start rgw.REALM-NAME.ZONE-NAME
21.8.3 Synchronisierungsmodul ElasticSearch #
Dieses Synchronisierungsmodul schreibt die Metadaten aus anderen Zonen zu ElasticSearch. Ab Luminous ist es die JSON-Datei der Datenfelder, die aktuell in ElasticSearch gespeichert ist.
{
"_index" : "rgw-gold-ee5863d6",
"_type" : "object",
"_id" : "34137443-8592-48d9-8ca7-160255d52ade.34137.1:object1:null",
"_score" : 1.0,
"_source" : {
"bucket" : "testbucket123",
"name" : "object1",
"instance" : "null",
"versioned_epoch" : 0,
"owner" : {
"id" : "user1",
"display_name" : "user1"
},
"permissions" : [
"user1"
],
"meta" : {
"size" : 712354,
"mtime" : "2017-05-04T12:54:16.462Z",
"etag" : "7ac66c0f148de9519b8bd264312c4d64"
}
}
}21.8.3.1 Parameter zur Konfiguration des ElasticSearch-Schichttyps #
- endpoint
Gibt den ElasticSearch Server-Endpunkt für den Zugriff an.
- num_shards
(Ganzzahl) Die Anzahl der Shards, mit denen ElasticSearch beim Initialisieren der Datensynchronisierung konfiguriert wird. Beachten Sie, dass dies nach der Initialisierung nicht mehr geändert werden kann. Zum Ändern muss der ElasticSearch-Index neu aufgebaut und der Datensynchronisierungsvorgang neu initialisiert werden.
- num_replicas
(Ganzzahl) Die Anzahl der Reproduktionen, mit denen ElasticSearch beim Initialisieren der Datensynchronisierung konfiguriert wird.
- explicit_custom_meta
(true | false) Gibt an, ob alle benutzerdefinierten Metadaten der Benutzer indiziert werden oder ob Benutzer (auf Bucket-Ebene) konfigurieren müssen, welche Kundenmetadaten-Einträge indiziert werden sollten. Standardmäßig ist dies auf „false“ festgelegt.
- index_buckets_list
(durch Komma getrennte Liste von Zeichenketten) Falls leer, werden alle Buckets indiziert. Andernfalls werden nur die hier genannten Buckets indiziert. Es ist möglich, Bucket-Präfixe (zum Beispiel „foo*“) oder Bucket-Suffixe (zum Beispiel „*bar“) anzugeben.
- approved_owners_list
(durch Komma getrennte Liste von Zeichenketten) Falls leer, werden die Buckets aller Eigentümer indiziert (falls keine anderen Einschränkungen vorhanden sind). Andernfalls werden nur die Buckets bestimmter Eigentümer indiziert. Suffixe und Präfixe können ebenfalls angegeben werden.
- override_index_path
(Zeichenkette) Falls nicht leer, wird diese Zeichenkette als ElasticSearch-Indexpfad verwendet. Andernfalls wird der Indexpfad bei Initialisierung der Synchronisierung festgelegt und generiert.
- benutzername
Gibt einen Benutzernamen für ElasticSearch an, falls eine Authentifizierung erforderlich ist.
- kennwort
Gibt ein Passwort für ElasticSearch an, falls eine Authentifizierung erforderlich ist.
21.8.3.2 Metadatenabfragen #
Da der ElasticSearch Cluster nun Objekt-Metadaten speichert, ist es wichtig, dass der ElasticSearch-Endpunkt nicht öffentlich gemacht wird und nur für Cluster-Administratoren zugänglich ist. Die Anzeige von Metadaten-Abfragen für den Endbenutzer selbst ist problematisch, weil der Benutzer nur seine Metadaten abfragen soll und nicht die Metadaten anderer Benutzer. Der ElasticSearch Cluster müsste Benutzer ähnlich wie RGW authentifizieren, was ein Problem darstellt.
Ab Luminous kann RGW in der Metadaten-Masterzone nun die Endbenutzeranforderungen verarbeiten. Dadurch ist es möglich, dass der ElasticSearch-Endpunkt nicht öffentlich zugänglich ist und gleichzeitig das Authentifizierungs- und Autorisierungsproblem gelöst ist, weil RGW selbst die Endbenutzeranforderungen authentifizieren kann. Zu diesem Zweck führt RGW eine neue Abfrage in den Bucket APIs ein, die ElasticSearch-Anforderungen verarbeiten können. Diese Anforderungen müssen an die Metadaten-Masterzone gesendet werden.
- Abrufen einer ElasticSearch-Abfrage
GET /BUCKET?query=QUERY-EXPR
Anforderungsparameter:
max-keys: maximale Anzahl der Einträge, die zurückgegeben werden sollen
marker: Kennzeichnung für die Paginierung
expression := [(]<arg> <op> <value> [)][<and|or> ...]
„op“ steht für eines der folgenden Zeichen: <, <=, ==, >=, >
Beispiel:
GET /?query=name==foo
Gibt alle indizierten Schlüssel zurück, für die der Benutzer über Berechtigungen verfügt. Sie werden als „foo“ bezeichnet. Die Ausgabe ist eine Liste von Schlüsseln im XML-Format, die der S3-Antwort auf die Anforderung zum Auflisten von Buckets ähnlich ist.
- Konfigurieren benutzerdefinierter Metadatenfelder
Definieren Sie, welche benutzerdefinierten Metadateneinträge (unter dem angegebenen Bucket) indiziert werden und welchen Typ diese Schlüssel haben sollen. Dies ist erforderlich, damit RGW die angegebenen benutzerdefinierten Metadatenwerte indiziert, wenn die explizite Indizierung von benutzerdefinierten Metadaten konfiguriert ist. Andernfalls ist es erforderlich in Fällen, in denen die indizierten Metadatenschlüssel keine Zeichenketten sind.
POST /BUCKET?mdsearch x-amz-meta-search: <key [; type]> [, ...]
Mehrere Metadatenfelder müssen durch Komma getrennt werden. Ein Typ kann für ein Feld mit „;“ erzwungen werden. Derzeit sind Zeichenketten (Standard), Ganzzahlen und Datumsangaben als Typen zulässig. Mit folgendem Kommando indizieren Sie beispielsweise die Metadaten eines benutzerdefinierten Objekts („x-amz-meta-year“ als Ganzzahl, „x-amz-meta-date“ als Datum und „x-amz-meta-title“ als Zeichenkette):
POST /mybooks?mdsearch x-amz-meta-search: x-amz-meta-year;int, x-amz-meta-release-date;date, x-amz-meta-title;string
- Löschen einer benutzerdefinierten Metadatenkonfiguration
Löschen Sie eine benutzerdefinierte Konfiguration eines Metadaten-Buckets.
DELETE /BUCKET?mdsearch
- Abrufen einer benutzerdefinierten Metadatenkonfiguration
Rufen Sie eine benutzerdefinierte Konfiguration eines Metadaten-Buckets ab.
GET /BUCKET?mdsearch
21.8.4 Cloud-Synchronisierungsmodul #
In diesem Abschnitt erhalten Sie Informationen zu einem Modul, mit dem die Zonendaten mit einem Remote-Cloud-Service synchronisiert werden. Die Synchronisierung läuft nur in eine Richtung ab – die Daten werden nicht aus der Remote-Zone zurück synchronisiert. Dieses Modul sorgt hauptsächlich dafür, dass Daten mit mehreren Cloud-Service-Anbietern synchronisiert werden können. Derzeit werden Cloud-Anbieter unterstützt, die mit AWS (S3) kompatibel sind.
Für die Synchronisierung von Daten mit einem Remote-Cloud-Service müssen Sie Berechtigungsnachweise für Benutzer konfigurieren. Zahlreiche Cloud-Services beschränken die maximale Anzahl der Buckets, die von den einzelnen Benutzern erstellt werden können. Sie können daher die Zuordnung von Quellobjekten und Buckets, verschiedenen Zielen und verschiedenen Buckets sowie von Bucket-Präfixen konfigurieren. Die Quell-Zugriffslisten (ACLs) werden dabei nicht beibehalten. Sie können Berechtigungen bestimmter Quellbenutzer zu bestimmten Zielbenutzern zuordnen.
Aufgrund der API-Einschränkungen ist es nicht möglich, die ursprüngliche Bearbeitungszeit und das HTTP-Entitäts-Tag (ETag) des Objekts beizubehalten. Das Cloud-Synchronisierungsmodul speichert diese Angaben als Metadaten-Attribute in den Zielobjekten.
21.8.4.1 Konfigurieren des Cloud-Synchronisierungsmoduls #
Die folgenden Beispiele zeigen eine Trivial- und eine Nicht-Trivial-Konfiguration für das Cloud-Synchronisierungsmodul. Hierbei ist zu beachten, dass die Trivial-Konfiguration mit der Nicht-Trivial-Konfiguration in Konflikt kommen kann.
{
"connection": {
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style": path | virtual,
},
"acls": [ { "type": id | email | uri,
"source_id": SOURCE_ID,
"dest_id": DEST_ID } ... ],
"target_path": TARGET_PATH,
}{
"default": {
"connection": {
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style" path | virtual,
},
"acls": [
{
"type": id | email | uri, # optional, default is id
"source_id": ID,
"dest_id": ID
} ... ]
"target_path": PATH # optional
},
"connections": [
{
"connection_id": ID,
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style": path | virtual, # optional
} ... ],
"acl_profiles": [
{
"acls_id": ID, # acl mappings
"acls": [ {
"type": id | email | uri,
"source_id": ID,
"dest_id": ID
} ... ]
}
],
"profiles": [
{
"source_bucket": SOURCE,
"connection_id": CONNECTION_ID,
"acls_id": MAPPINGS_ID,
"target_path": DEST, # optional
} ... ],
}Erläuterung der Konfigurationsbegriffe:
- Verbindung
Eine Verbindung zum Remote-Cloud-Service. Umfasst „connection_id“, „access_key“, „secret“, „endpoint“ und „host_style“.
- access_key
Remote-Cloud-Zugriffsschlüssel für die jeweilige Verbindung.
- secret
Geheimschlüssel für den Remote-Cloud-Service.
- endpoint
URL für den Endpunkt des Remote-Cloud-Service.
- host_style
Hosttyp („path“ oder „virtual“) für den Zugriff auf den Remote-Cloud-Endpunkt. Der Standardwert lautet „path“.
- acls
Matrix der Zugriffslistenzuordnungen.
- acl_mapping
Jede „acl_mapping“-Struktur umfasst „type“, „source_id“ und „dest_id“. Hiermit wird die ACL-Mutation für die einzelnen Objekte definiert. Mit einer ACL-Mutation kann die Quellbenutzer-ID in eine Ziel-ID umgewandelt werden.
- type
ACL-Typ: „id“ definiert die Benutzer-ID, „email“ definiert den Benutzer nach E-Mail und „uri“ definiert den Benutzer nach URI (Gruppe).
- source_id
ID des Benutzers in der Quellzone.
- dest_id
ID des Benutzers im Ziel.
- target_path
Mit dieser Zeichenkette wird definiert, wie der Zielpfad erstellt wird. Der Zielpfad umfasst ein Präfix, an das der Quellobjektname angehängt wird. Das konfigurierbare Element für den Zielpfad kann die folgenden Variablen umfassen:
- SID
Eindeutige Zeichenkette für die ID der Synchronisierungsinstanz.
- ZONEGROUP
Name der Zonengruppe.
- ZONEGROUP_ID
ID der Zonengruppe.
- ZONE
Name der Zone.
- ZONE_ID
ID der Zone.
- BUCKET
Name des Quell-Buckets.
- OWNER
ID für den Eigentümer des Quell-Buckets.
Beispiel: target_path = rgwx-ZONE-SID/OWNER/BUCKET
- acl_profiles
Matrix mit Zugriffslistenprofilen.
- acl_profile
Jedes Profil umfasst „acls_id“ für das Profil sowie eine „acls“-Matrix mit einer Liste der „acl_mappings“.
- Profile
Liste mit Profilen. Jedes Profil umfasst Folgendes:
- source_bucket
Entweder der Name eines Buckets oder ein Bucket-Präfix (Endung auf *), mit dem der oder die Quell-Bucket(s) für dieses Profil definiert werden.
- target_path
Erläuterung siehe oben.
- connection_id
ID der Verbindung für dieses Profil.
- acls_id
ID des ACL-Profils für dieses Profil.
21.8.4.2 S3-spezifische konfigurierbare Elemente #
Das Cloud-Synchronisierungsmodul arbeitet lediglich mit Back-Ends zusammen, die mit AWS S3 kompatibel sind. Dieses Verhalten kann beim Zugriff auf S3-Cloud-Services mithilfe bestimmter konfigurierbarer Elemente beeinflusst werden:
{
"multipart_sync_threshold": OBJECT_SIZE,
"multipart_min_part_size": PART_SIZE
}- multipart_sync_threshold
Objekte mit einer Größe größer oder gleich diesem Wert werden per Multipart-Upload mit dem Cloud-Service synchronisiert.
- multipart_min_part_size
Mindestgröße der Teile für die Synchronisierung von Objekten per Multipart-Upload.
21.8.5 Archiv-Synchronisierungsmodul #
Das Archiv-Synchronisierungsmodul verwendet die Versionierungsfunktion von S3-Objekten im Object Gateway. Sie können eine Archivzone konfigurieren, in der die verschiedenen Versionen von S3-Objekten erfasst werden, die im Lauf der Zeit in anderen Zonen auftreten. Der Versionsverlauf in der Archivzone kann nur mithilfe von Gateways beseitigt werden, die der Archivzone zugeordnet sind.
Bei einer solchen Architektur können verschiedene nichtversionierte Zonen ihre Daten und Metadaten über die jeweiligen Zonen-Gateways spiegeln, sodass Hochverfügbarkeit für die Endbenutzer erzielt wird, während in der Archivzone alle Datenaktualisierungen erfasst und als Versionen der S3-Objekte konsolidiert werden.
Wenn Sie die Archivzone in eine Mehrzonen-Konfiguration einbinden, erhalten Sie die Flexibilität eines S3-Objektverlaufs in einer einzelnen Zone, wobei Sie den Speicherplatz einsparen, den die Reproduktionen der versionierten S3-Objekte in den verbleibenden Zonen belegen würden.
21.8.5.1 Konfigurieren des Archiv-Synchronisierungsmoduls #
Weitere Informationen zum Konfigurieren von Gateways für mehrere Standorte finden Sie in Abschnitt 21.13, „Object Gateways an mehreren Standorten“.
Weitere Informationen zum Konfigurieren von Synchronisierungsmodulen finden Sie in Abschnitt 21.8, „Synchronisierungsmodule“.
Zur Nutzung des Archiv-Synchronisierungsmoduls erstellen Sie eine neue Zone mit dem Schichttyp archive:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME \
--rgw-zone=OGW_ZONE_NAME \
--endpoints=http://OGW_ENDPOINT1_URL[,http://OGW_ENDPOINT2_URL,...]
--tier-type=archive21.9 LDAP-Authentifizierung #
Abgesehen von der standardmäßigen Authentifizierung lokaler Benutzer kann Object Gateway Benutzer auch über LDAP Server Services authentifizieren.
21.9.1 Beglaubigungsverfahren #
Das Object Gateway extrahiert den Berechtigungsnachweis des Benutzers aus einem Token. Ein Suchfilter wird aus dem Benutzernamen erstellt. Das Object Gateway durchsucht anhand des konfigurierten Servicekontos das Verzeichnis nach einem passenden Eintrag. Wird ein Eintrag gefunden, versucht das Object Gateway, eine Bindung zum gefundenen eindeutigen Namen mit dem Passwort aus dem Token herzustellen. Wenn der Berechtigungsnachweis gültig ist, wird die Bindung hergestellt und das Object Gateway gewährt den Zugriff.
Die Anzahl der Benutzer lässt sich begrenzen. Legen Sie dazu die Basis für die Suche auf eine bestimmte organisatorische Einheit fest oder geben Sie einen benutzerdefinierten Suchfilter an, beispielsweise eine bestimmte Gruppenmitgliedschaft, benutzerdefinierte Objektklassen oder Attribute.
21.9.2 Anforderungen #
LDAP oder Active Directory: Eine aktive LDAP-Instanz, auf die Object Gateway zugreifen kann.
Servicekonto: LDAP-Berechtigungen, die vom Object Gateway mit Suchberechtigungen verwendet werden sollen.
Benutzerkonto: Mindestens ein Benutzerkonto im LDAP-Verzeichnis.
Für lokale Benutzer und für Benutzer, die mit LDAP authentifiziert werden, sollten nicht dieselben Benutzernamen verwendet werden. Das Object Gateway kann sie nicht unterscheiden und behandelt sie als ein und denselben Benutzer.
Verifizieren Sie das Servicekonto oder die LDAP-Verbindung mit dem Dienstprogramm ldapsearch. Beispiel:
tux > ldapsearch -x -D "uid=ceph,ou=system,dc=example,dc=com" -W \
-H ldaps://example.com -b "ou=users,dc=example,dc=com" 'uid=*' dnVergewissern Sie sich, dass Sie dieselben LDAP-Parameter verwenden wie in der Ceph-Konfigurationsdatei, um mögliche Probleme zu vermeiden.
21.9.3 Konfigurieren des Object Gateways zur Verwendung der LDAP-Authentifizierung #
Die folgenden Parameter beziehen sich auf die LDAP-Authentifizierung:
rgw_ldap_uriGibt den zu verwendenden LDAP-Server an. Vergewissern Sie sich, dass Sie den Parameter
ldaps://FQDN:portverwenden, um die offene Übertragung des Berechtigungsnachweises in Klartext zu verhindern.rgw_ldap_binddnDer vom Object Gateway verwendete eindeutige Name des Servicekontos.
rgw_ldap_secretDas Passwort für das Service-Konto.
- rgw_ldap_searchdn
Gibt die Basis im Verzeichnisinformationsbaum zum Suchen von Benutzern an. Sie könnte die organisatorische Einheit Ihrer Benutzer oder eine spezifischere organisatorische Einheit sein.
rgw_ldap_dnattrDas Attribut, das im konstruierten Suchfilter zum Abgleich eines Benutzernamens verwendet wird. Abhängig von Ihrem Verzeichnisinformationsbaum (Directory Information Tree, DIT) wäre es wahrscheinlich
uidodercn.rgw_search_filterWenn dieser Parameter nicht angegeben ist, konstruiert das Object Gateway automatisch den Suchfilter mit der Einstellung
rgw_ldap_dnattr. Mit diesem Parameter engen Sie die Liste der zulässigen Benutzer auf sehr flexible Weise ein. Weitere Details finden Sie in Abschnitt 21.9.4, „Verwenden eines benutzerdefinierten Suchfilters zur Begrenzung des Benutzerzugriffs“.
21.9.4 Verwenden eines benutzerdefinierten Suchfilters zur Begrenzung des Benutzerzugriffs #
Den Parameter rgw_search_filter können Sie auf unterschiedliche Weise verwenden.
21.9.4.1 Teilfilter zur weiteren Beschränkung des konstruierten Suchfilters #
Beispiel eines Teilfilters:
"objectclass=inetorgperson"
Das Object Gateway generiert den Suchfilter wie üblich mit dem Benutzernamen aus dem Token und dem Wert von rgw_ldap_dnattr. Der konstruierte Filter wird dann mit dem Teilfilter aus dem Attribut rgw_search_filter kombiniert. Abhängig vom Benutzernamen und den Einstellungen sieht der finale Suchfilter möglicherweise folgendermaßen aus:
"(&(uid=hari)(objectclass=inetorgperson))"
In diesem Fall erhält der Benutzer „hari“ nur dann Zugriff, wenn er im LDAP-Verzeichnis gefunden wird, über die Objektklasse „inetorgperson“ verfügt und ein gültiges Passwort angegeben hat.
21.9.4.2 Vollständiger Filter #
Ein vollständiger Filter muss einen Token USERNAME enthalten, der beim Authentifizierungsversuch durch den Benutzernamen ersetzt wird. Der Parameter rgw_ldap_dnattr wird in diesem Fall nicht mehr verwendet. Verwenden Sie beispielsweise folgenden Filter, um die gültigen Benutzer auf eine bestimmte Gruppe zu beschränken:
"(&(uid=USERNAME)(memberOf=cn=ceph-users,ou=groups,dc=mycompany,dc=com))"
memberOf
Für die Verwendung des Attributs memberOf in LDAP-Suchen ist die serverseitige Unterstützung Ihrer spezifischen LDAP Server-Implementierung erforderlich.
21.9.5 Generieren eines Zugriffstokens für die LDAP-Authentifizierung #
Das Dienstprogramm radosgw-token generiert den Zugriffstoken basierend auf LDAP-Benutzername und Passwort. Es gibt eine mit base-64 verschlüsselte Zeichenkette aus, die der eigentliche Zugriffstoken ist. Verwenden Sie Ihren bevorzugten S3 Client (weitere Informationen hierzu finden Sie in Abschnitt 21.5.1, „Zugreifen auf Object Gateway“), geben Sie den Token als Zugriffsschlüssel an und verwenden Sie einen leeren geheimen Schlüssel.
tux >export RGW_ACCESS_KEY_ID="USERNAME"tux >export RGW_SECRET_ACCESS_KEY="PASSWORD"cephuser@adm >radosgw-token --encode --ttype=ldap
Der Zugriffstoken ist eine mit base-64 verschlüsselte JSON-Struktur und enthält den LDAP-Berechtigungsnachweis als Klartext.
Verwenden Sie für Active Directory den Parameter --ttype=ad.
21.10 Bucket-Index-Sharding #
Das Object Gateway speichert Bucket-Indexdaten in einem Index-Pool, der standardmäßig .rgw.buckets.index lautet. Wenn Sie zu viele (hunderttausende) Objekte in einen einzelnen Bucket stellen und das Kontingent für die maximale Anzahl der Objekte pro Bucket (rgw bucket default quota max objects) nicht festgelegt ist, dann verschlechtert sich möglicherweise die Leistung des Index-Pools. Ein Bucket-Index-Sharding verhindert derartige Leistungseinbußen und ermöglicht eine hohe Anzahl von Objekten pro Bucket.
21.10.1 Bucket-Index-Resharding #
Wenn ein Bucket groß geworden ist und die anfängliche Konfiguration nicht mehr ausreicht, muss für den Indexpool des Buckets ein Resharding durchgeführt werden. Sie können entweder das automatische Online-Resharding für den Bucket-Index durchführen (Informationen hierzu finden Sie in Abschnitt 21.10.1.1, „Dynamisches Resharding“) oder ein manuelles Offline-Resharding des Bucket-Index (Informationen hierzu finden Sie in Abschnitt 21.10.1.2, „Manuelles Resharding“).
21.10.1.1 Dynamisches Resharding #
Seit SUSE Enterprise Storage 5 unterstützen wir das Online-Bucket-Resharding. Es erkennt, wenn die Anzahl der Objekte pro Bucket einen bestimmten Schwellwert erreicht, und erhöht automatisch die Anzahl der vom Bucket-Index verwendeten Shards. Dieser Vorgang reduziert die Anzahl der Einträge in jedem Bucket-Index-Shard.
Der Erkennungsvorgang wird in folgenden Fällen ausgeführt:
Wenn neue Objekte zum Bucket hinzugefügt werden.
In einem Hintergrundprozess, der regelmäßig alle Buckets absucht. Dies ist erforderlich, um bestehende Buckets zu verarbeiten, die nicht aktualisiert werden.
Ein Bucket, für den ein Resharding durchgeführt werden muss, wird zur Warteschlange reshard_log hinzugefügt und das Resharding wird für später geplant. Die Reshard-Threads werden im Hintergrund ausgeführt und führen das geplante Resharding für die einzelnen Buckets nacheinander durch.
rgw_dynamic_reshardingAktiviert oder deaktiviert das dynamische Index-Resharding. Mögliche Werte sind „true“ und „false“. Die Standardeinstellung ist „true“.
rgw_reshard_num_logsAnzahl der Shards für das Resharding-Protokoll. Der Standardwert ist 16.
rgw_reshard_bucket_lock_durationDauer der Sperre des Bucket-Objekts beim Resharding. Die Standardeinstellung ist 120 Sekunden.
rgw_max_objs_per_shardMaximale Anzahl der Objekte pro Bucket-Index-Shard. Der Standardwert ist 100.000 Objekte.
rgw_reshard_thread_intervalMaximale Zeit zwischen den Verarbeitungsrunden des Reshard-Threads. Die Standardeinstellung ist 600 Sekunden.
- Fügen Sie ein Bucket zur Resharding-Warteschlange hinzu mit:
cephuser@adm >radosgw-admin reshard add \ --bucket BUCKET_NAME \ --num-shards NEW_NUMBER_OF_SHARDS- Listen Sie die Resharding-Warteschlange auf mit:
cephuser@adm >radosgw-admin reshard list- Verarbeiten/planen Sie ein Bucket-Resharding mit:
cephuser@adm >radosgw-admin reshard process- Zeigen Sie den Bucket-Resharding-Status an mit:
cephuser@adm >radosgw-admin reshard status --bucket BUCKET_NAME- Brechen Sie das ausstehende Bucket-Resharding ab mit:
cephuser@adm >radosgw-admin reshard cancel --bucket BUCKET_NAME
21.10.1.2 Manuelles Resharding #
Das in Abschnitt 21.10.1.1, „Dynamisches Resharding“ erwähnte dynamische Resharding wird nur für einfache Object-Gateway-Konfigurationen unterstützt. Bei Konfigurationen mit mehreren Standorten müssen Sie das in diesem Abschnitt erläuterte manuelle Resharding verwenden.
Führen Sie für ein manuelles Offline-Resharding des Bucket-Index folgendes Kommando aus:
cephuser@adm > radosgw-admin bucket reshard
Das Kommando bucket reshard führt Folgendes aus:
Es erstellt einen neuen Satz von Bucket-Index-Objekten für das angegebene Objekt.
Es verteilt alle Einträge dieser Indexobjekte.
Es erstellt eine neue Bucket-Instanz.
Es verknüpft die neue Bucket-Instanz mit dem Bucket, sodass alle neuen Index-Operationen durch die neuen Bucket-Indizes gehen.
Gibt die alte und die neue Bucket-ID an die Standardausgabe aus.
Bei der Wahl der Anzahl der Shards dürfen Sie nicht mehr als 100.000 Einträge pro Shard vorsehen. Bucket-Index-Shards, die Primzahlen sind, funktionieren tendenziell besser bei der gleichmäßigen Verteilung von Bucket-Indexeinträgen auf die Shards. Zum Beispiel sind 503 Bucket-Index-Shards besser als 500, da erstere Zahl eine Primzahl ist.
Vergewissern Sie sich, dass alle Operationen zum Bucket gestoppt sind.
Sichern Sie den ursprünglichen Bucket-Index:
cephuser@adm >radosgw-admin bi list \ --bucket=BUCKET_NAME \ > BUCKET_NAME.list.backupFühren Sie ein Resharding des Bucket-Index aus:
cephuser@adm >radosgw-admin bucket reshard \ --bucket=BUCKET_NAME \ --num-shards=NEW_SHARDS_NUMBERTipp: Alte Bucket-IDAls Teil seiner Ausgabe gibt dieses Kommando auch die neue und alte Bucket-ID aus.
21.10.2 Bucket-Index-Sharding für neue Buckets #
Für ein Bucket-Index-Sharding stehen zwei Optionen zur Verfügung:
Verwenden Sie bei einfachen Konfigurationen die Option
rgw_override_bucket_index_max_shards.Verwenden Sie bei Konfigurationen mit mehreren Standorten die Option
bucket_index_max_shards.
Das Bucket-Index-Sharding wird deaktiviert, wenn die Optionen auf 0 festgelegt sind. Ein Wert größer 0 aktiviert das Bucket-Index-Sharding und legt die maximale Anzahl von Shards fest.
Die folgende Formel unterstützt Sie beim Berechnen der empfohlenen Anzahl von Shards:
number_of_objects_expected_in_a_bucket / 100000
Beachten Sie, dass maximal 7877 Shards möglich sind.
21.10.2.1 Konfigurationen für mehrere Standorte #
Konfigurationen für mehrere Standorte können einen anderen Index-Pool zum Verwalten von Failover haben. Legen Sie zum Konfigurieren einer konsistenten Anzahl von Shards für Zonen in einer Zonengruppe die Option bucket_index_max_shards in der Konfiguration der Zonengruppe fest:
Exportieren Sie die Zonengruppenkonfiguration in die Datei
zonegroup.json:cephuser@adm >radosgw-admin zonegroup get > zonegroup.jsonBearbeiten Sie die Datei
zonegroup.jsonund legen Sie die Optionbucket_index_max_shardsfür jede benannte Zone fest.Setzen Sie die Zonengruppe zurück:
cephuser@adm >radosgw-admin zonegroup set < zonegroup.jsonAktualisieren Sie den Zeitraum mit. Siehe Abschnitt 21.13.2.6, „Aktualisieren Sie den Zeitraum mit“.
21.11 Integration von OpenStack Keystone #
OpenStack Keystone ist ein Identitätsservice für das OpenStack-Produkt. Sie können das Object Gateway mit Keystone integrieren, um ein Gateway einzurichten, das einen Keystone-Authentifizierungstoken akzeptiert. Ein Benutzer, der durch Keystone für den Zugriff auf das Gateway autorisiert ist, wird am Ceph Object Gateway verifiziert und gegebenenfalls automatisch erstellt. Das Object Gateway fragt Keystone regelmäßig nach einer Liste der entzogenen Token ab.
21.11.1 Konfigurieren von OpenStack #
Vor dem Konfigurieren des Ceph Gateways müssen Sie OpenStack Keystone konfigurieren, um den Swift Service zu aktivieren und auf das Ceph Object Gateway auszurichten:
Festlegen des Swift Service. Sie müssen zunächst den Swift Service erstellen, um OpenStack zur Validierung von Swift-Benutzern zu verwenden:
tux >openstack service create \ --name=swift \ --description="Swift Service" \ object-storeFestlegen der Endpunkte. Nach dem Erstellen des Swift Service müssen Sie diesen auf das Ceph Object Gateway ausrichten. Ersetzen Sie REGION_NAME durch den Zonengruppennamen oder Regionsnamen des Gateways.
tux >openstack endpoint create --region REGION_NAME \ --publicurl "http://radosgw.example.com:8080/swift/v1" \ --adminurl "http://radosgw.example.com:8080/swift/v1" \ --internalurl "http://radosgw.example.com:8080/swift/v1" \ swiftVerifizieren der Einstellungen. Nach dem Erstellen des Swift Service und dem Festlegen der Endpunkte müssen Sie die Endpunkte anzeigen, um zu verifizieren, dass alle Einstellungen korrekt sind.
tux >openstack endpoint show object-store
21.11.2 Konfigurieren des Ceph Object Gateways #
21.11.2.1 Konfigurieren der SSL-Zertifikate #
Das Ceph Object Gateway fragt Keystone regelmäßig nach einer Liste der entzogenen Token ab. Diese Anforderungen sind verschlüsselt und signiert. Keystone kann ebenfalls konfiguriert werden, um eigensignierte Token bereitzustellen, die ebenfalls verschlüsselt und signiert sind. Sie müssen das Gateway so konfigurieren, dass es diese signierten Nachrichten entschlüsseln und verifizieren kann. Daher müssen die OpenSSL-Zertifikate, die Keystone zum Erstellen der Anforderungen verwendet, in das Format „nss db“ konvertiert werden:
root #mkdir /var/ceph/nssroot #openssl x509 -in /etc/keystone/ssl/certs/ca.pem \ -pubkey | certutil -d /var/ceph/nss -A -n ca -t "TCu,Cu,Tuw"rootopenssl x509 -in /etc/keystone/ssl/certs/signing_cert.pem \ -pubkey | certutil -A -d /var/ceph/nss -n signing_cert -t "P,P,P"
OpenStack Keystone kann über ein eigensigniertes SSL-Zertifikat mit dem Ceph Object Gateway interagieren. Installieren Sie entweder das SSL-Zertifikat von Keystone im Knoten, auf dem das Ceph Object Gateway ausgeführt wird, oder legen Sie alternativ den Wert der Option rgw keystone verify ssl auf „false“ fest. Wenn Sie rgw keystone verify ssl auf „false“ festlegen, versucht das Gateway nicht, das Zertifikat zu verifizieren.
21.11.2.2 Konfigurieren der Optionen des Object Gateways #
Die Keystone-Integration wird mit folgenden Optionen konfiguriert:
rgw keystone api versionVersion der Keystone-API. Gültige Optionen sind 2 oder 3. Der Standardwert ist 2.
rgw keystone urlDie URL und Portnummer der administrativen RESTful API am Keystone-Server. Folgt dem Schema SERVER_URL:PORTNUMMER.
rgw keystone admin tokenDer Token oder das gemeinsame Geheimnis, der/das intern in Keystone für administrative Anforderungen konfiguriert wird.
rgw keystone accepted rolesDie Rollen zur Verarbeitung der Anforderungen. Die Standardeinstellung ist „Member, admin“.
rgw keystone accepted admin rolesDie Liste der Rollen, mit denen Benutzer Verwaltungsrechte erhalten können.
rgw keystone token cache sizeDie maximale Anzahl der Einträge im Keystone-Token-Cache.
rgw keystone revocation intervalDie Dauer in Sekunden, bevor entzogene Token überprüft werden. Der Standardwert ist 15 * 60.
rgw keystone implicit tenantsNeue Benutzer werden in ihren eigenen Mandanten mit demselben Namen erstellt. Die Standardeinstellung ist „false“.
rgw s3 auth use keystoneWird diese Option auf „true“ festgelegt, authentifiziert das Ceph Object Gateway Benutzer mit Keystone. Die Standardeinstellung ist „false“.
nss db pathDer Pfad zur NSS-Datenbank.
Es ist auch möglich, den Keystone Service-Mandanten, den Benutzer und das Passwort für Keystone (für Version 2.0 der OpenStack Identity API) auf ähnliche Weise zu konfigurieren wie OpenStack Services normalerweise konfiguriert werden. Dadurch vermeiden Sie, das gemeinsame Geheimnis rgw keystone admin token in der Konfigurationsdatei festzulegen, das in Produktionsumgebungen deaktiviert sein sollte. Die Anmeldedaten des Service-Mandanten sollten Administratorrechte enthalten. Weitere Details finden Sie in der offiziellen OpenStack Keystone-Dokumentation. Die entsprechenden Konfigurationsoptionen sind wie folgt:
rgw keystone admin userDer Benutzername des verwaltungsberechtigten Keystone-Benutzers.
rgw keystone admin passwordDas Passwort des verwaltungsberechtigten Keystone-Benutzers.
rgw keystone admin tenantDer Mandant des verwaltungsberechtigten Benutzers von Keystone Version 2.0.
Ein Ceph Object-Gateway-Benutzer wird einem Keystone-Mandanten zugeordnet. Einem Keystone-Benutzer sind verschiedene Rollen zugewiesen, möglicherweise zu mehr als einem Mandanten. Wenn das Ceph Object Gateway das Ticket erhält, sieht es sich den Mandanten und die Benutzerrollen an, die diesem Ticket zugewiesen sind, und akzeptiert die Anforderung oder weist sie zurück, je nach Einstellung der Option rgw keystone accepted roles.
Obgleich Swift-Mandanten standardmäßig zum Object-Gateway-Benutzer zugeordnet werden, ist mit der Option rgw keystone implicit tenants auch deren Zuordnung zu OpenStack-Mandanten möglich. Dadurch verwenden Container den Mandanten-Namespace statt des S3-ähnlichen globalen Namespace, das standardmäßig für Object Gateway verwendet wird. Wir empfehlen, die Zuordnungsmethode in der Planungsphase festzulegen, um Verwirrung zu vermeiden. Wenn eine Option später gewechselt wird, betrifft dies nur neuere Anforderungen, die unter einem Mandanten zugeordnet werden. Ältere Buckets, die vorher erstellt wurden, sind weiterhin in einem globalen Namespace enthalten.
Bei Version 3 der OpenStack Identity API sollten Sie die Option rgw keystone admin tenant ersetzen durch:
rgw keystone admin domainDie Domäne des verwaltungsberechtigten Keystone-Benutzers.
rgw keystone admin projectDas Projekt des verwaltungsberechtigten Keystone-Benutzers.
21.12 Pool-Platzierung und Speicherklassen #
21.12.1 Anzeigen von Platzierungszielen #
Mit Platzierungszielen wird gesteuert, welche Pools einem bestimmten Bucket zugeordnet werden. Das Platzierungsziel eines Buckets wird beim Erstellen festgelegt und kann nicht geändert werden. Mit folgendem Kommando rufen Sie die zugehörige placement_rule ab:
cephuser@adm > radosgw-admin bucket statsDie Zonengruppenkonfiguration umfasst eine Liste von Platzierungszielen mit dem anfänglichen Ziel „default-placement“. Anschließend ordnet die Zonenkonfiguration die Namen der einzelnen Zonengruppen-Platzierungsziele dem lokalen Speicher zu. Diese Zonenplatzierungsdaten umfassen den Namen „index_pool“ für den Bucket-Index, den Namen „data_extra_pool“ für Metadaten zu unvollständigen Multipart-Uploads sowie je einen Namen „data_pool“ für die einzelnen Speicherklassen.
21.12.2 Speicherklassen #
Speicherklassen tragen dazu bei, die Platzierung von Objektdaten individuell anzupassen. Mithilfe von S3-Bucket-Lebenszyklusregeln lässt sich der Übergang von Objekten zwischen Speicherklassen automatisieren.
Speicherklassen werden anhand von Platzierungszielen definiert. In den einzelnen Platzierungszielen der Zonengruppe sind die verfügbaren Speicherklassen jeweils mit der Anfangsklasse „STANDARD“ aufgelistet. Die Zonenkonfiguration stellt jeweils den Pool-Namen „data_pool“ für die einzelnen Speicherklassen der Zonengruppe bereit.
21.12.3 Konfigurieren von Zonengruppen und Zonen #
Mit dem Kommando radosgw-admin konfigurieren Sie die Platzierung der Zonengruppen und Zonen. Mit folgendem Kommando rufen Sie die Platzierungskonfiguration der Zonengruppe ab:
cephuser@adm > radosgw-admin zonegroup get
{
"id": "ab01123f-e0df-4f29-9d71-b44888d67cd5",
"name": "default",
"api_name": "default",
...
"placement_targets": [
{
"name": "default-placement",
"tags": [],
"storage_classes": [
"STANDARD"
]
}
],
"default_placement": "default-placement",
...
}Mit folgendem Kommando rufen Sie die Platzierungskonfiguration der Zone ab:
cephuser@adm > radosgw-admin zone get
{
"id": "557cdcee-3aae-4e9e-85c7-2f86f5eddb1f",
"name": "default",
"domain_root": "default.rgw.meta:root",
...
"placement_pools": [
{
"key": "default-placement",
"val": {
"index_pool": "default.rgw.buckets.index",
"storage_classes": {
"STANDARD": {
"data_pool": "default.rgw.buckets.data"
}
},
"data_extra_pool": "default.rgw.buckets.non-ec",
"index_type": 0
}
}
],
...
}
Falls Sie bislang noch keine Konfiguration mit mehreren Standorten vorgenommen haben, wird je eine „standardmäßige“ Zone und Zonengruppe erstellt. Änderungen an der Zone/Zonengruppe treten erst dann in Kraft, wenn Sie die Ceph Object Gateways neu starten. Wenn Sie einen Bereich für mehrere Standorte angelegt haben, treten Änderungen an der Zone/Zonengruppe in Kraft, sobald Sie diese Änderungen mit dem Kommando radosgw-admin period update --commit übergeben.
21.12.3.1 Hinzufügen eines Platzierungsziels #
Soll ein neues Platzierungsziel mit dem Namen „temporary“ erstellt werden, fügen Sie das Ziel zunächst in die Zonengruppe ein:
cephuser@adm > radosgw-admin zonegroup placement add \
--rgw-zonegroup default \
--placement-id temporaryGeben Sie dann die Zonenplatzierungsdaten für dieses Ziel an:
cephuser@adm > radosgw-admin zone placement add \
--rgw-zone default \
--placement-id temporary \
--data-pool default.rgw.temporary.data \
--index-pool default.rgw.temporary.index \
--data-extra-pool default.rgw.temporary.non-ec21.12.3.2 Hinzufügen einer Speicherklasse #
Soll eine neue Speicherklasse mit dem Namen „COLD“ in das Ziel „default-placement“ eingefügt werden, fügen Sie die Klasse zunächst in die Zonengruppe ein:
cephuser@adm > radosgw-admin zonegroup placement add \
--rgw-zonegroup default \
--placement-id default-placement \
--storage-class COLDGeben Sie dann die Zonenplatzierungsdaten für diese Speicherklasse an:
cephuser@adm > radosgw-admin zone placement add \
--rgw-zone default \
--placement-id default-placement \
--storage-class COLD \
--data-pool default.rgw.cold.data \
--compression lz421.12.4 Anpassung der Platzierung #
21.12.4.1 Bearbeiten der standardmäßigen Zonengruppenplatzierung #
Neue Buckets greifen standardmäßig auf das Ziel default_placement der Zonengruppe zurück. Mit folgendem Kommando können Sie diese Zonengruppeneinstellung ändern:
cephuser@adm > radosgw-admin zonegroup placement default \
--rgw-zonegroup default \
--placement-id new-placement21.12.4.2 Bearbeiten der standardmäßigen Benutzerplatzierung #
Ein Ceph Object-Gateway-Benutzer kann ein nicht leeres Feld default_placement in den Benutzerinformationen festlegen und ist damit in der Lage, das standardmäßige Platzierungsziel der Zonengruppe zu überschreiben. Ebenso kann default_storage_class die Speicherklasse STANDARD überschreiben, die standardmäßig auf Objekte angewendet wird.
cephuser@adm > radosgw-admin user info --uid testid
{
...
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
...
}Wenn das Platzierungsziel einer Zonengruppe Tags enthält, können die Benutzer nur dann Buckets mit diesem Platzierungsziel erstellen, wenn ihre Benutzerinformationen mindestens ein passendes Tag im Feld „placement_tags“ umfassen. Damit ist es möglich, den Zugriff auf bestimmte Speichertypen einzuschränken.
Diese Felder können nicht direkt mit dem Kommando radosgw-admin bearbeitet werden. Sie müssen das JSON-Format daher manuell bearbeiten:
cephuser@adm >radosgw-admin metadata get user:USER-ID > user.jsontux >vi user.json # edit the file as requiredcephuser@adm >radosgw-admin metadata put user:USER-ID < user.json
21.12.4.3 Bearbeiten der standardmäßigen S3-Bucket-Platzierung #
Wird ein Bucket mit dem S3-Protokoll erstellt, kann ein Platzierungsziel als Teil von LocationConstraint angegeben werden, sodass die standardmäßigen Platzierungsziele des Benutzers und der Zonengruppe überschrieben werden.
In der Regel muss LocationConstraint mit api_name der Zonengruppe übereinstimmen:
<LocationConstraint>default</LocationConstraint>
Sie können nach api_name einen Doppelpunkt und ein benutzerdefiniertes Platzierungsziel einfügen:
<LocationConstraint>default:new-placement</LocationConstraint>
21.12.4.4 Bearbeiten der Swift-Bucket-Platzierung #
Wird ein Bucket mit dem Swift-Protokoll erstellt, können Sie ein Platzierungsziel im HTTP-Header unter X-Storage-Policy angeben:
X-Storage-Policy: NEW-PLACEMENT
21.12.5 Verwenden von Speicherklassen #
Alle Platzierungsziele umfassen eine Speicherklasse STANDARD, die standardmäßig auf neue Objekte angewendet wird. Diesen Standardwert können Sie mit default_storage_class überschreiben.
Soll ein Objekt in einer nicht standardmäßigen Speicherklasse erstellt werden, geben Sie den Namen dieser Speicherklasse in einem HTTP-Header in der Anforderung an. Das S3-Protokoll greift auf den Header X-Amz-Storage-Class zurück, das Swift-Protokoll dagegen auf den Header X-Object-Storage-Class.
In S3 Object Lifecycle Management können Sie Objektdaten zwischen Speicherklassen mithilfe von Transition-Aktionen verschieben.
21.13 Object Gateways an mehreren Standorten #
Ceph unterstützt verschiedene Optionen zur Konfiguration für mehrere Standorte für das Ceph Object Gateway:
- Mehrere Zonen
Eine Konfiguration, die aus einer Zonengruppe und mehreren Zonen besteht, jede Zone mit einer oder mehreren
ceph-radosgw-Instanzen. Jede Zone wird durch einen eigenen Ceph Storage Cluster unterstützt. Mehrere Zonen in einer Zonengruppe bieten eine Disaster Recovery für die Zonengruppe, wenn in einer der Zonen ein erheblicher Fehler auftritt. Jede Zone ist aktiv und kann Schreibvorgänge empfangen. Neben der Disaster Recovery können mehrere aktive Zonen auch als Grundlage für Content Delivery Networks dienen.- Mehrfach-Zonengruppe
Ceph Object Gateway unterstützt mehrere Zonengruppen, jede Zonengruppe mit einer oder mehreren Zonen. Objekte, die in Zonen in einer Zonengruppe innerhalb desselben Bereichs wie eine andere Zonengruppe gespeichert sind, teilen sich einen globalen Objekt-Namespace, wodurch eindeutige Objekt-IDs über Zonengruppen und Zonen hinweg gewährleistet werden.
AnmerkungEs ist wichtig, zu beachten, dass Zonengruppen Metadaten nur untereinander synchronisieren. Daten und Metadaten werden zwischen den Zonen innerhalb der Zonengruppe repliziert. Es werden keine Daten oder Metadaten über einen Bereich hinweg gemeinsam genutzt.
- Mehrere Bereiche
Ceph Object Gateway unterstützt das Konzept der Bereiche; ein global eindeutiger Namespace. Es werden mehrere Bereiche unterstützt, die einzelne oder mehrere Zonengruppen umfassen können.
Sie können jedes Object Gateway so konfigurieren, dass es in einer Aktiv/Aktiv-Zonenkonfiguration arbeitet und Schreibvorgänge in Nicht-Master-Zonen zulässt. Die Konfiguration für mehrere Standorte wird in einem Container gespeichert, der Bereich genannt wird. Der Bereich speichert Zonengruppen, Zonen und einen Zeitraum mit mehreren Epochen zur Verfolgung von Änderungen an der Konfiguration. Die rgw-Daemons übernehmen die Synchronisierung, so dass kein separater Synchronisierungsagent erforderlich ist. Dieser Ansatz zur Synchronisierung ermöglicht es dem Ceph Object Gateway, mit einer Aktiv/Aktiv-Konfiguration anstelle von Aktiv/Passiv zu arbeiten.
21.13.1 Anforderungen und Annahmen #
Für eine Konfiguration für mehrere Standorte sind mindestens zwei Ceph-Speichercluster erforderlich sowie mindestens zwei Ceph Object-Gateway-Instanzen, eine für jeden Ceph-Speichercluster. Die folgende Konfiguration setzt voraus, dass sich mindestens zwei Ceph-Speichercluster an geografisch getrennten Standorten befinden. Die Konfiguration kann jedoch am gleichen Standort funktionieren. Zum Beispiel mit den Namen rgw1 und rgw2.
Für eine Konfiguration für mehrere Standorte sind eine Master-Zonengruppe und eine Master-Zone erforderlich. Eine Master-Zone ist die Quelle der Wahrheit in Bezug auf alle Metadatenoperationen in einem Cluster mit mehreren Standorten. Zusätzlich benötigt jede Zonengruppe eine Master-Zone. Zonengruppen können eine oder mehrere Neben- oder Nicht-Master-Zonen umfassen. In dieser Anleitung dient der Host rgw1 als Master-Zone der Master-Zonengruppe und der Host rgw2 als sekundäre Zone der Master-Zonengruppe.
21.13.2 Konfigurieren einer Master-Zone #
Alle Gateways in einer Konfiguration für mehrere Standorte rufen ihre Konfiguration von einem ceph-radosgw-Daemon auf einem Host innerhalb der Master-Zonengruppe und der Master-Zone ab. Wählen Sie zur Konfiguration Ihrer Gateways in einer Konfiguration für mehrere Standorte eine ceph-radosgw-Instanz aus, um die Master-Zonengruppe und die Master-Zone zu konfigurieren.
21.13.2.1 Erstellen eines Bereichs #
Ein Bereich stellt einen global eindeutigen Namespace dar, der aus einer oder mehreren Zonengruppen mit einer oder mehreren Zonen besteht. Zonen enthalten Buckets, die ihrerseits Objekte enthalten. Durch einen Bereich kann das Ceph Object Gateway mehrere Namespaces und deren Konfiguration auf derselben Hardware unterstützen. Ein Bereich umfasst das Konzept von Zeiträumen. Jeder Zeitraum stellt den Zustand der Zonengruppe und der Zonenkonfiguration in der Zeit dar. Jedes Mal, wenn Sie eine Änderung an einer Zonengruppe oder Zone vornehmen, müssen Sie den Zeitraum aktualisieren und bestätigen. Standardmäßig erstellt das Ceph Object Gateway aus Gründen der Abwärtskompatibilität keinen Bereich. Als bewährtes Verfahren empfehlen wir, Bereiche für neue Cluster zu erstellen.
Erstellen Sie einen neuen Bereich namens Gold für die Konfiguration für mehrere Standorte. Öffnen Sie dazu eine Kommandozeilenschnittstelle auf einem Host, der für die Master-Zonengruppe und -Zone identifiziert wurde. Führen Sie dann folgendes Kommando aus:
cephuser@adm > radosgw-admin realm create --rgw-realm=gold --default
Wenn der Cluster einen einzigen Bereich umfasst, geben Sie das Flag --default an. Wenn ‑‑default angegeben wird, verwendet radosgw-admin standardmäßig diesen Bereich. Wenn ‑‑default nicht angegeben ist, muss beim Hinzufügen von Zonengruppen und Zonen entweder das Flag --rgw-realm oder das Flag --realm-id angegeben werden, um den Bereich zu identifizieren.
Nach dem Erstellen des Bereichs gibt radosgw-admin die Bereichskonfiguration zurück:
{
"id": "4a367026-bd8f-40ee-b486-8212482ddcd7",
"name": "gold",
"current_period": "09559832-67a4-4101-8b3f-10dfcd6b2707",
"epoch": 1
}Ceph generiert eine eindeutige ID für den Bereich, die bei Bedarf die Umbenennung eines Bereichs ermöglicht.
21.13.2.2 Erstellen einer Master-Zonengruppe #
Ein Bereich muss mindestens eine Zonengruppe enthalten, die als Master-Zonengruppe für den Bereich dient. Erstellen Sie eine neue Master-Zonengruppe für die Konfiguration für mehrere Standorte. Öffnen Sie dazu eine Kommandozeilenschnittstelle auf einem Host, der für die Master-Zonengruppe und -Zone identifiziert wurde. Erstellen Sie mit folgendem Kommando eine Master-Zonengruppe mit dem Namen us:
cephuser@adm > radosgw-admin zonegroup create --rgw-zonegroup=us \
--endpoints=http://rgw1:80 --master --default
Wenn der Bereich eine einzige Zonengruppe umfasst, geben Sie das Flag --default an. Wenn --default angegeben ist, verwendet radosgw-admin beim Hinzufügen neuer Zonen standardmäßig diese Zonengruppe. Wenn --default nicht angegeben ist, muss beim Hinzufügen von Zonen entweder das Flag --rgw-zonegroup oder das Flag --zonegroup-id angegeben werden, um den Bereich zu identifizieren.
Nach dem Erstellen der Master-Zonengruppe gibt radosgw-admin die Zonengruppenkonfiguration zurück. Beispiel:
{
"id": "d4018b8d-8c0d-4072-8919-608726fa369e",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "",
"zones": [],
"placement_targets": [],
"default_placement": "",
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7"
}21.13.2.3 Erstellen einer Master-Zone #
Zonen müssen auf einem Ceph Object-Gateway-Knoten erstellt werden, der sich innerhalb der Zone befindet.
Erstellen Sie eine neue Master-Zone für die Konfiguration für mehrere Standorte. Öffnen Sie dazu eine Kommandozeilenschnittstelle auf einem Host, der für die Master-Zonengruppe und -Zone identifiziert wurde. Führen Sie Folgendes aus:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-1 \
--endpoints=http://rgw1:80 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
Die Optionen --access-key und --secret sind im obigen Beispiel nicht angegeben. Diese Einstellungen werden der Zone hinzugefügt, wenn im nächsten Abschnitt der Benutzer erstellt wird.
Nach dem Erstellen der Master-Zone gibt radosgw-admin die Zonenkonfiguration zurück. Beispiel:
{
"id": "56dfabbb-2f4e-4223-925e-de3c72de3866",
"name": "us-east-1",
"domain_root": "us-east-1.rgw.meta:root",
"control_pool": "us-east-1.rgw.control",
"gc_pool": "us-east-1.rgw.log:gc",
"lc_pool": "us-east-1.rgw.log:lc",
"log_pool": "us-east-1.rgw.log",
"intent_log_pool": "us-east-1.rgw.log:intent",
"usage_log_pool": "us-east-1.rgw.log:usage",
"reshard_pool": "us-east-1.rgw.log:reshard",
"user_keys_pool": "us-east-1.rgw.meta:users.keys",
"user_email_pool": "us-east-1.rgw.meta:users.email",
"user_swift_pool": "us-east-1.rgw.meta:users.swift",
"user_uid_pool": "us-east-1.rgw.meta:users.uid",
"otp_pool": "us-east-1.rgw.otp",
"system_key": {
"access_key": "1555b35654ad1656d804",
"secret_key": "h7GhxuBLTrlhVUyxSPUKUV8r/2EI4ngqJxD7iBdBYLhwluN30JaT3Q=="
},
"placement_pools": [
{
"key": "us-east-1-placement",
"val": {
"index_pool": "us-east-1.rgw.buckets.index",
"storage_classes": {
"STANDARD": {
"data_pool": "us-east-1.rgw.buckets.data"
}
},
"data_extra_pool": "us-east-1.rgw.buckets.non-ec",
"index_type": 0
}
}
],
"metadata_heap": "",
"realm_id": ""
}21.13.2.4 Löschen der Standardzone und -gruppe #
Die folgenden Schritte gehen von einer Konfiguration für mehrere Standorte mit neu installierten Systemen aus, in denen noch keine Daten gespeichert sind. Löschen Sie nicht die Standardzone und ihre Pools, wenn Sie sie bereits zum Speichern von Daten verwenden. Ansonsten werden die Daten gelöscht und können nicht wiederhergestellt werden.
Die Standardinstallation von Object Gateway erstellt die Standard-Zonengruppe namens default. Löschen Sie die Standardzone, falls sie vorhanden ist. Stellen Sie sicher, dass Sie sie zuerst aus der Standard-Zonengruppe entfernen.
cephuser@adm > radosgw-admin zonegroup delete --rgw-zonegroup=defaultLöschen Sie die Standard-Pools in Ihrem Ceph-Speichercluster, falls sie vorhanden sind:
Im folgenden Schritt wird von einer Konfiguration für mehrere Standorte mit neu installierten Systemen ausgegangen, in denen aktuell noch keine Daten gespeichert sind. Löschen Sie nicht die Standard-Zonengruppe, wenn Sie sie bereits zum Speichern von Daten verwenden.
cephuser@adm >ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.meta default.rgw.meta --yes-i-really-really-mean-it
Wenn Sie die Standard-Zonengruppe löschen, löschen Sie auch den Systembenutzer. Wenn Ihre Admin-Benutzerschlüssel nicht verteilt sind, schlägt die Object-Gateway-Verwaltungsfunktion des Ceph Dashboards fehl. Wenn Sie mit diesem Schritt fortfahren, machen Sie mit dem nächsten Abschnitt zum Neuerstellen des Systembenutzers weiter.
21.13.2.5 Erstellen von Systembenutzern #
Die ceph-radosgw-Daemons müssen sich authentifizieren, bevor sie Bereichs- und Zeitrauminformationen abrufen. Erstellen Sie in der Master-Zone einen Systembenutzer, um die Authentifizierung zwischen den Daemons zu vereinfachen:
cephuser@adm > radosgw-admin user create --uid=zone.user \
--display-name="Zone User" --access-key=SYSTEM_ACCESS_KEY \
--secret=SYSTEM_SECRET_KEY --system
Notieren Sie sich den access_key und den secret_key, da die sekundären Zonen sie zur Authentifizierung bei der Master-Zone benötigen.
Fügen Sie den Systembenutzer zur Master-Zone hinzu:
cephuser@adm > radosgw-admin zone modify --rgw-zone=us-east-1 \
--access-key=ACCESS-KEY --secret=SECRETAktualisieren Sie die Periode, damit die Änderungen wirksam werden:
cephuser@adm > radosgw-admin period update --commit21.13.2.6 Aktualisieren Sie den Zeitraum mit #
Aktualisieren Sie nach der Aktualisierung der Master-Zonenkonfiguration den Zeitraum:
cephuser@adm > radosgw-admin period update --commit
Nach dem Aktualisieren des Zeitraums gibt radosgw-admin die Zeitraumkonfiguration zurück. Beispiel:
{
"id": "09559832-67a4-4101-8b3f-10dfcd6b2707", "epoch": 1, "predecessor_uuid": "", "sync_status": [], "period_map":
{
"id": "09559832-67a4-4101-8b3f-10dfcd6b2707", "zonegroups": [], "short_zone_ids": []
}, "master_zonegroup": "", "master_zone": "", "period_config":
{
"bucket_quota": {
"enabled": false, "max_size_kb": -1, "max_objects": -1
}, "user_quota": {
"enabled": false, "max_size_kb": -1, "max_objects": -1
}
}, "realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7", "realm_name": "gold", "realm_epoch": 1
}Durch Aktualisieren des Zeitraums wird die Epoche geändert und sichergestellt, dass andere Zonen die aktualisierte Konfiguration erhalten.
21.13.2.7 Starten des Gateways #
Starten und aktivieren Sie den Ceph Object-Gateway-Service auf dem Object-Gateway-Host. Ermitteln Sie mit dem Kommando ceph fsid die eindeutige FSID des Clusters. Ermitteln Sie den Namen des Object-Gateway-Daemons mit dem Kommando ceph orch ps --hostname HOSTNAME.
cephuser@ogw >systemctl start ceph-FSID@DAEMON_NAMEcephuser@ogw >systemctl enable ceph-FSID@DAEMON_NAME
21.13.3 Konfigurieren sekundärer Zonen #
In den Zonen einer Zonengruppe werden alle Daten reproduziert, sodass gewährleistet ist, dass alle Zonen dieselben Daten umfassen. Beim Erstellen der sekundären Zone führen Sie alle nachfolgenden Operationen auf einem Host aus, der für die sekundäre Zone vorgesehen ist.
Gehen Sie zum Hinzufügen einer dritten Zone genauso vor wie beim Hinzufügen der zweiten Zone. Verwenden Sie einen anderen Zonennamen.
Sie müssen Metadatenvorgänge, wie beispielsweise die Erstellung von Benutzern, auf einem Host innerhalb der Master-Zone ausführen. Die Master-Zone und die sekundäre Zone können Bucket-Vorgänge empfangen, doch die sekundäre Zone leitet Bucket-Vorgänge an die Master-Zone weiter. Wenn die Master-Zone inaktiv ist, schlagen Bucket-Vorgänge fehl.
21.13.3.1 Importieren des Bereichs #
Importieren Sie die Bereichskonfiguration mit dem URL-Pfad, dem Zugriffsschlüssel und dem Geheimnis der Masterzone in der Master-Zonengruppe auf den Host. Geben Sie zum Importieren eines nicht standardmäßigen Bereichs den Bereich mit den Konfigurationsoptionen --rgw-realm oder --realm-id an.
cephuser@adm > radosgw-admin realm pull --url=url-to-master-zone-gateway --access-key=access-key --secret=secretDurch Importieren des Bereichs wird auch die aktuelle Zeitraumkonfiguration des entfernten Hosts abgerufen und zum aktuellen Zeitraum auch auf diesem Host gemacht.
Wenn dieser Bereich der Standardbereich oder der einzige Bereich ist, machen Sie den Bereich zum Standardbereich.
cephuser@adm > radosgw-admin realm default --rgw-realm=REALM-NAME21.13.3.2 Erstellen einer sekundären Zone #
Erstellen Sie eine neue sekundäre Zone für die Konfiguration für mehrere Standorte. Öffnen Sie dazu eine Kommandozeilenschnittstelle auf einem Host, der für die sekundäre Zone identifiziert wurde. Geben Sie die Zonengruppen-ID, den neuen Zonennamen und einen Endpunkt für die Zone an. Verwenden Sie nicht das Flag --master. Alle Zonen werden standardmäßig in einer Aktiv/Aktiv-Konfiguration ausgeführt. Wenn die sekundäre Zone keine Schreibvorgänge akzeptieren soll, geben Sie das Flag --read-only an. Dadurch wird eine Aktiv/Passiv-Konfiguration zwischen der Master-Zone und der sekundären Zone erstellt. Geben Sie zusätzlich den access_key und den secret_key des generierten Systembenutzers an, der in der Master-Zone der Master-Zonengruppe gespeichert ist. Führen Sie Folgendes aus:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE-GROUP-NAME\
--rgw-zone=ZONE-NAME --endpoints=URL \
--access-key=SYSTEM-KEY --secret=SECRET\
--endpoints=http://FQDN:80 \
[--read-only]Beispiel:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=us --endpoints=http://rgw2:80 \
--rgw-zone=us-east-2 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
{
"id": "950c1a43-6836-41a2-a161-64777e07e8b8",
"name": "us-east-2",
"domain_root": "us-east-2.rgw.data.root",
"control_pool": "us-east-2.rgw.control",
"gc_pool": "us-east-2.rgw.gc",
"log_pool": "us-east-2.rgw.log",
"intent_log_pool": "us-east-2.rgw.intent-log",
"usage_log_pool": "us-east-2.rgw.usage",
"user_keys_pool": "us-east-2.rgw.users.keys",
"user_email_pool": "us-east-2.rgw.users.email",
"user_swift_pool": "us-east-2.rgw.users.swift",
"user_uid_pool": "us-east-2.rgw.users.uid",
"system_key": {
"access_key": "1555b35654ad1656d804",
"secret_key": "h7GhxuBLTrlhVUyxSPUKUV8r\/2EI4ngqJxD7iBdBYLhwluN30JaT3Q=="
},
"placement_pools": [
{
"key": "default-placement",
"val": {
"index_pool": "us-east-2.rgw.buckets.index",
"data_pool": "us-east-2.rgw.buckets.data",
"data_extra_pool": "us-east-2.rgw.buckets.non-ec",
"index_type": 0
}
}
],
"metadata_heap": "us-east-2.rgw.meta",
"realm_id": "815d74c2-80d6-4e63-8cfc-232037f7ff5c"
}Die folgenden Schritte gehen von einer Konfiguration für mehrere Standorte mit neu installierten Systemen aus, in denen noch keine Daten gespeichert sind. Löschen Sie nicht die Standardzone und ihre Pools, wenn Sie sie bereits zum Speichern von Daten verwenden. Andernfalls gehen die Daten verloren und können nicht wiederhergestellt werden.
Löschen Sie die Standardzone, falls erforderlich:
cephuser@adm > radosgw-admin zone rm --rgw-zone=defaultLöschen Sie die Standard-Pools in Ihrem Ceph-Speichercluster, falls erforderlich:
cephuser@adm >ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.users.uid default.rgw.users.uid --yes-i-really-really-mean-it
21.13.3.3 Aktualisieren der Ceph-Konfigurationsdatei #
Aktualisieren Sie die Ceph-Konfigurationsdatei auf den Hosts der sekundären Zone. Fügen Sie dazu die Konfigurationsoption rgw_zone und den Namen der sekundären Zone zum Instanzeintrag hinzu.
Führen Sie hierzu folgendes Kommando aus:
cephuser@adm > ceph config set SERVICE_NAME rgw_zone us-west21.13.3.4 Aktualisieren des Zeitraums #
Aktualisieren Sie nach der Aktualisierung der Master-Zonenkonfiguration den Zeitraum:
cephuser@adm > radosgw-admin period update --commit
{
"id": "b5e4d3ec-2a62-4746-b479-4b2bc14b27d1",
"epoch": 2,
"predecessor_uuid": "09559832-67a4-4101-8b3f-10dfcd6b2707",
"sync_status": [ "[...]"
],
"period_map": {
"id": "b5e4d3ec-2a62-4746-b479-4b2bc14b27d1",
"zonegroups": [
{
"id": "d4018b8d-8c0d-4072-8919-608726fa369e",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"zones": [
{
"id": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"name": "us-east-1",
"endpoints": [
"http:\/\/rgw1:80"
],
"log_meta": "true",
"log_data": "false",
"bucket_index_max_shards": 0,
"read_only": "false"
},
{
"id": "950c1a43-6836-41a2-a161-64777e07e8b8",
"name": "us-east-2",
"endpoints": [
"http:\/\/rgw2:80"
],
"log_meta": "false",
"log_data": "true",
"bucket_index_max_shards": 0,
"read_only": "false"
}
],
"placement_targets": [
{
"name": "default-placement",
"tags": []
}
],
"default_placement": "default-placement",
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7"
}
],
"short_zone_ids": [
{
"key": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"val": 630926044
},
{
"key": "950c1a43-6836-41a2-a161-64777e07e8b8",
"val": 4276257543
}
]
},
"master_zonegroup": "d4018b8d-8c0d-4072-8919-608726fa369e",
"master_zone": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"period_config": {
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
}
},
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7",
"realm_name": "gold",
"realm_epoch": 2
}Durch Aktualisieren des Zeitraums wird die Epoche geändert und sichergestellt, dass andere Zonen die aktualisierte Konfiguration erhalten.
21.13.3.5 Starten des Object Gateways #
Starten und aktivieren Sie auf dem Object-Gateway-Host den Ceph Object-Gateway-Service:
cephuser@adm > ceph orch start rgw.us-east-221.13.3.6 Prüfen des Synchronisierungsstatus #
Prüfen Sie den Synchronisierungsstatus, wenn die sekundäre Zone aktiv ist. Durch die Synchronisierung werden Benutzer und Buckets, die in der Master-Zone erstellt wurden, in die sekundäre Zone kopiert.
cephuser@adm > radosgw-admin sync statusDie Ausgabe gibt den Status der Synchronisierungsvorgänge an. Beispiel:
realm f3239bc5-e1a8-4206-a81d-e1576480804d (gold)
zonegroup c50dbb7e-d9ce-47cc-a8bb-97d9b399d388 (us)
zone 4c453b70-4a16-4ce8-8185-1893b05d346e (us-west)
metadata sync syncing
full sync: 0/64 shards
metadata is caught up with master
incremental sync: 64/64 shards
data sync source: 1ee9da3e-114d-4ae3-a8a4-056e8a17f532 (us-east)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with sourceSekundäre Zonen akzeptieren zwar Bucket-Vorgänge, leiten allerdings Bucket-Vorgänge an die Master-Zone um. Dann synchronisieren sie sich mit der Master-Zone, um das Ergebnis der Bucket-Vorgänge zu erhalten. Wenn die Master-Zone inaktiv ist, schlagen Bucket-Vorgänge, die in der sekundären Zone ausgeführt werden, fehl. Objektvorgänge sollten jedoch erfolgreich sein.
21.13.4 Allgemeine Objekt-Gateway-Wartung #
21.13.4.1 Prüfen des Synchronisierungsstatus #
Informationen über den Reproduktionsstatus einer Zone können abgefragt werden mit:
cephuser@adm > radosgw-admin sync status
realm b3bc1c37-9c44-4b89-a03b-04c269bea5da (gold)
zonegroup f54f9b22-b4b6-4a0e-9211-fa6ac1693f49 (us)
zone adce11c9-b8ed-4a90-8bc5-3fc029ff0816 (us-west)
metadata sync syncing
full sync: 0/64 shards
incremental sync: 64/64 shards
metadata is behind on 1 shards
oldest incremental change not applied: 2017-03-22 10:20:00.0.881361s
data sync source: 341c2d81-4574-4d08-ab0f-5a2a7b168028 (us-east)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source
source: 3b5d1a3f-3f27-4e4a-8f34-6072d4bb1275 (us-3)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source21.13.4.2 Ändern der Metadaten-Master-Zone #
Seien Sie vorsichtig, wenn Sie die Zone ändern, die der Metadaten-Master ist. Wenn eine Zone die Synchronisierung der Metadaten mit der aktuellen Master-Zone noch nicht abgeschlossen hat, kann sie bei der Hochstufung zum Master keine verbleibenden Einträge mehr verarbeiten und diese Änderungen gehen verloren. Aus diesem Grund empfehlen wir, zu warten, bis der radosgw-admin-Synchronisierungsstatus einer Zone die Metadaten-Synchronisierung abgeschlossen hat, bevor sie zum Master hochgestuft wird. Ähnlich verhält es sich, wenn Änderungen an Metadaten von der aktuellen Master-Zone verarbeitet werden, während eine andere Zone zum Master hochgestuft wird. Diese Änderungen gehen wahrscheinlich verloren. Um dies zu vermeiden, empfehlen wir, alle Object-Gateway-Instanzen in der vorherigen Master-Zone herunterzufahren. Nach dem Hochstufen einer anderen Zone kann deren neuer Zeitraum mit radosgw-admin abgerufen werden und die Gateways können neu gestartet werden.
Führen Sie zum Hochstufen einer Zone (z. B. Zone us-west in der Zonengruppe us) zum Metadaten-Master folgende Kommandos für diese Zone aus:
cephuser@ogw >radosgw-admin zone modify --rgw-zone=us-west --mastercephuser@ogw >radosgw-admin zonegroup modify --rgw-zonegroup=us --mastercephuser@ogw >radosgw-admin period update --commit
Dadurch wird ein neuer Zeitraum generiert, und die Object-Gateway-Instanzen in der Zone us-west senden diesen Zeitraum an andere Zonen.
21.13.5 Durchführen von Failover und Disaster Recovery #
Falls die Master-Zone ausfällt, führen Sie zum Zweck eines Disaster Recovery ein Failover zur sekundären Zone durch.
Machen Sie die sekundäre Zone zur Master- und Standardzone. Beispiel:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --defaultStandardmäßig wird das Ceph Object Gateway in einer Aktiv/Aktiv-Konfiguration ausgeführt. Wenn der Cluster zur Ausführung in einer Aktiv/Passiv-Konfiguration konfiguriert wurde, ist die sekundäre Zone eine schreibgeschützte Zone. Entfernen Sie den Status
‑‑read-only, damit die Zone Schreibvorgänge empfangen kann. Beispiel:cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --default \ --read-only=falseAktualisieren Sie die Periode, damit die Änderungen wirksam werden:
cephuser@adm >radosgw-admin period update --commitStarten Sie das Ceph Object Gateway neu:
cephuser@adm >ceph orch restart rgw
Wenn die frühere Master-Zone wiederhergestellt ist, setzen Sie die Operation zurück.
Rufen Sie in der wiederhergestellten Zone den Zeitraum von der aktuellen Master-Zone ab.
cephuser@adm >radosgw-admin realm pull --url=URL-TO-MASTER-ZONE-GATEWAY \ --access-key=ACCESS-KEY --secret=SECRETMachen Sie die wiederhergestellte Zone zur Master- und Standardzone:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --defaultAktualisieren Sie die Periode, damit die Änderungen wirksam werden:
cephuser@adm >radosgw-admin period update --commitStarten Sie das Ceph Object Gateway in der wiederhergestellten Zone neu:
cephuser@adm >ceph orch restart rgw@rgwWenn die sekundäre Zone eine schreibgeschützte Konfiguration sein muss, aktualisieren Sie die sekundäre Zone:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --read-onlyAktualisieren Sie die Periode, damit die Änderungen wirksam werden:
cephuser@adm >radosgw-admin period update --commitStarten Sie das Ceph Object Gateway in der sekundären Zone neu:
cephuser@adm >ceph orch restart@rgw
22 Ceph iSCSI Gateway #
In diesem Kapitel befassen wir uns hauptsächlich mit Verwaltungsaufgaben, die für das iSCSI Gateway relevant sind. Das Verfahren zur Bereitstellung wird im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.3.5 “Bereitstellen von iSCSI-Gateways” erläutert.
22.1 Mit ceph-iscsi verwaltete Ziele #
In diesem Kapitel wird erläutert, wie Sie eine Verbindung zu
ceph-iscsi-verwalteten Zielen von
Clients aus herstellen, auf denen Linux, Microsoft Windows oder VMware
ausgeführt wird.
22.1.1 Herstellen einer Verbindung zu open-iscsi #
Die Herstellung einer Verbindung zu
ceph-iscsi-gestützten iSCSI-Zielen
mit open-iscsi erfolgt in zwei Schritten. Zunächst
muss der Initiator die iSCSI-Ziele ermitteln, die am Gateway-Host verfügbar
sind. Dann muss er sich anmelden und die verfügbaren logischen Einheiten
(Logical Unit, LU) zuordnen.
Für beide Schritte muss der open-iscsi-Daemon
aktiv sein. Die Art und Weise, wie Sie den
open-iscsi-Daemon starten, hängt von Ihrer
Linux-Distribution ab:
Führen Sie auf SUSE Linux Enterprise Server (SLES)- und Red Hat Enterprise Linux (RHEL)-Hosts
systemctl start iscsidaus (oderservice iscsid start, fallssystemctlnicht verfügbar ist).Führen Sie auf Debian- und Ubuntu-Hosts
systemctl start open-iscsiaus (oderservice open-iscsi start).
Wenn Ihr Initiator-Host SUSE Linux Enterprise Server ausführt, sehen Sie sich die detaillierten Informationen unter https://documentation.suse.com/sles/15-SP2/html/SLES-all/cha-iscsi.html#sec-iscsi-initiator an, um zu erfahren, wie Sie eine Verbindung zu einem iSCSI-Ziel herstellen.
Fahren Sie bei allen anderen Linux-Distributionen, die
open-iscsi unterstützen, damit fort, Ziele in
Ihrem ceph-iscsi-Gateway zu
ermitteln (in diesem Beispiel verwenden wir „iscsi1.example.com“ als
Portaladresse. Wiederholen Sie für einen Multipfadzugriff diese Schritte
mit „iscsi2.example.com“):
root # iscsiadm -m discovery -t sendtargets -p iscsi1.example.com
192.168.124.104:3260,1 iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvolMelden Sie sich dann beim Portal an. Nach erfolgreicher Anmeldung stehen sofort alle RBD-unterstützten logischen Einheiten auf dem Portal im System SCSI-Bus zur Verfügung:
root # iscsiadm -m node -p iscsi1.example.com --login
Logging in to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] (multiple)
Login to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] successful.Wiederholen Sie diesen Vorgang für andere Portal-IP-Adressen oder Hosts.
Wenn auf Ihrem System das Dienstprogramm lsscsi
installiert ist, zählen Sie damit die verfügbaren SCSI-Geräte auf Ihrem
System auf:
lsscsi [8:0:0:0] disk SUSE RBD 4.0 /dev/sde [9:0:0:0] disk SUSE RBD 4.0 /dev/sdf
In einer Multipfadkonfiguration (bei der zwei verbundene iSCSI-Geräte ein
und dieselbe logische Einheit darstellen) können Sie auch den Zustand des
Multipfadgeräts mit dem Dienstprogramm multipath
untersuchen:
root # multipath -ll
360014050cf9dcfcb2603933ac3298dca dm-9 SUSE,RBD
size=49G features='0' hwhandler='0' wp=rw
|-+- policy='service-time 0' prio=1 status=active
| `- 8:0:0:0 sde 8:64 active ready running
`-+- policy='service-time 0' prio=1 status=enabled
`- 9:0:0:0 sdf 8:80 active ready runningDaraufhin kann dieses Multipfadgerät wie jedes andere Blockgerät verwendet werden. Sie können dieses Gerät beispielsweise als physisches Volume für Linux Logical Volume Management (LVM) verwenden oder einfach darauf ein Dateisystem erstellen. Im folgenden Beispiel sehen Sie, wie ein XFS-Dateisystem auf dem neu verbundenen Multipfad-iSCSI-Volume erstellt wird:
root # mkfs -t xfs /dev/mapper/360014050cf9dcfcb2603933ac3298dca
log stripe unit (4194304 bytes) is too large (maximum is 256KiB)
log stripe unit adjusted to 32KiB
meta-data=/dev/mapper/360014050cf9dcfcb2603933ac3298dca isize=256 agcount=17, agsize=799744 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=12800000, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=6256, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Beachten Sie, dass XFS ein nicht geclustertes Dateisystem ist und daher zu einem gegebenen Zeitpunkt nur auf einem einzelnen iSCSI-Initiator eingehängt werden darf.
Führen Sie folgendes Kommando aus, wenn Sie die mit einem bestimmten Ziel verknüpften iSCSI-LUs irgendwann nicht mehr weiter verwenden möchten:
root # iscsiadm -m node -p iscsi1.example.com --logout
Logging out of session [sid: 18, iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260]
Logout of [sid: 18, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] successful.Bei der Ermittlung und Anmeldung müssen Sie die Abmeldeschritte für alle Portal-IP-Adressen oder Hostnamen wiederholen.
22.1.1.1 Multipfadkonfiguration #
Die Multipfadkonfiguration wird auf den Clients oder Initiatoren
beibehalten und ist unabhängig von anderen
ceph-iscsi-Konfigurationen. Wählen
Sie vor Verwendung der Blockspeicherung eine Strategie aus. Starten Sie
nach dem Bearbeiten der Datei /etc/multipath.conf die
Option multipathd neu mit
root # systemctl restart multipathdFügen Sie für eine Aktiv/Passiv-Konfiguration mit Anzeigenamen
defaults {
user_friendly_names yes
}
zu Ihrer Datei /etc/multipath.conf hinzu. Führen Sie
nach erfolgreicher Herstellung einer Verbindung zu den Zielen folgendes
Kommando aus:
root # multipath -ll
mpathd (36001405dbb561b2b5e439f0aed2f8e1e) dm-0 SUSE,RBD
size=2.0G features='0' hwhandler='0' wp=rw
|-+- policy='service-time 0' prio=1 status=active
| `- 2:0:0:3 sdl 8:176 active ready running
|-+- policy='service-time 0' prio=1 status=enabled
| `- 3:0:0:3 sdj 8:144 active ready running
`-+- policy='service-time 0' prio=1 status=enabled
`- 4:0:0:3 sdk 8:160 active ready runningBeachten Sie den Status der einzelnen Links. Fügen Sie für eine Aktiv/Aktiv-Konfiguration
defaults {
user_friendly_names yes
}
devices {
device {
vendor "(LIO-ORG|SUSE)"
product "RBD"
path_grouping_policy "multibus"
path_checker "tur"
features "0"
hardware_handler "1 alua"
prio "alua"
failback "immediate"
rr_weight "uniform"
no_path_retry 12
rr_min_io 100
}
}
zu Ihrer Datei /etc/multipath.conf hinzu. Starten Sie
multipathd neu und führen Sie folgendes Kommando
aus:
root # multipath -ll
mpathd (36001405dbb561b2b5e439f0aed2f8e1e) dm-3 SUSE,RBD
size=2.0G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
`-+- policy='service-time 0' prio=50 status=active
|- 4:0:0:3 sdj 8:144 active ready running
|- 3:0:0:3 sdk 8:160 active ready running
`- 2:0:0:3 sdl 8:176 active ready running22.1.2 Herstellen einer Verbindung zu Microsoft Windows (Microsoft iSCSI-Initiator) #
Führen Sie zum Herstellen einer Verbindung zum SUSE Enterprise Storage iSCSI-Ziel auf einem Windows 2012 Server folgende Schritte aus:
Öffnen Sie Windows Server Manager. Wählen Sie am Desktop › aus. Das Dialogfeld (iSCSI-Initiator-Eigenschaften) wird angezeigt. Wählen Sie die Registerkarte aus:
 Abbildung 22.1: Eigenschaften des iSCSI-Initiators #
Abbildung 22.1: Eigenschaften des iSCSI-Initiators #Geben Sie im Dialogfeld (Zielportal ermitteln) den Hostnamen oder die IP-Adresse im Feld ein und klicken Sie auf :
 Abbildung 22.2: Zielportal ermitteln #
Abbildung 22.2: Zielportal ermitteln #Wiederholen Sie diesen Vorgang für alle Gateway-Hostnamen oder IP-Adressen. Überprüfen Sie nach Fertigstellung die Liste (Zielportale):
 Abbildung 22.3: Zielportale #
Abbildung 22.3: Zielportale #Wechseln Sie anschließend zur Registerkarte und prüfen Sie die ermittelten Ziele.
 Abbildung 22.4: Zielgruppen #
Abbildung 22.4: Zielgruppen #Klicken Sie auf (Verbinden) auf der Registerkarte . Das Dialogfeld (Mit Ziel verbinden) wird angezeigt. Aktivieren Sie das Kontrollkästchen für (Multipfad aktivieren), um die Multipfad-E/A (MPIO) zu aktivieren und klicken Sie anschließend auf :
Wenn das Dialogfeld (Mit Ziel verbinden) geschlossen wird, wählen Sie aus, um die Eigenschaften des Ziels zu prüfen:
 Abbildung 22.5: Eigenschaften des iSCSI-Ziels #
Abbildung 22.5: Eigenschaften des iSCSI-Ziels #Wählen Sie aus und klicken Sie auf , um die Multipath-Konfiguration zu überprüfen:
 Abbildung 22.6: Gerätedetails #
Abbildung 22.6: Gerätedetails #Die standardmäßige (Lastausgleichrichtlinie) ist (Round-Robin mit Teilmenge). Wenn Sie eine reine Failover-Konfiguration bevorzugen, ändern Sie die Einstellung zu (Nur Failover).
Damit ist die iSCSI-Initiator-Konfiguration abgeschlossen. Die iSCSI-Volumes sind nun verfügbar wie alle anderen SCSI-Geräte und können zur Verwendung als Volumes und Laufwerke initialisiert werden. Klicken Sie auf , um das Dialogfeld (Eigenschaften des iSCSI-Initiators) zu schließen und fahren Sie mit der Rolle (Datei- und Speicherdienste) am -Dashboard fort.
Beobachten Sie das neu verbundene Volume. Es ist am iSCSI-Bus als SUSE RBD SCSI Multi-Path Drive (SUSE RBD SCSI-Multipfadlaufwerk) gekennzeichnet. Es ist zu Beginn mit einem Offline-Status markiert und einem Partitionstabellentyp Unbekannt. Wenn das neue Volume nicht sofort angezeigt wird, wählen Sie (Speicher neu absuchen) aus dem Dropdown-Feld (Aufgaben) aus, um den iSCSI-Bus neu abzusuchen.
Klicken Sie mit der rechten Maustaste auf das iSCSI-Volume und wählen Sie im Kontextmenü (Neues Volume) aus. Der (Assistent für neue Volumes) wird angezeigt. Klicken Sie auf , heben Sie das neu verbundene iSCSI-Volume hervor und klicken Sie auf , um zu beginnen.
 Abbildung 22.7: Assistent für neue Volumes #
Abbildung 22.7: Assistent für neue Volumes #Zu Beginn ist das Gerät leer und enthält keine Partitionstabelle. Wenn Sie dazu aufgefordert werden, bestätigen Sie den Dialog und geben Sie an, dass das Volume mit einer GPT-Partitionstabelle initialisiert wird:
 Abbildung 22.8: Eingabeaufforderung für Offline-Datenträger #
Abbildung 22.8: Eingabeaufforderung für Offline-Datenträger #Wählen Sie die Volume-Größe aus. Normalerweise würden Sie die volle Kapazität des Geräts nutzen. Weisen Sie in diesem Fall einen Laufwerkbuchstaben oder Verzeichnisnamen zu, in dem das neu erstellte Volumen verfügbar sein soll. Wählen Sie dann ein Dateisystem aus, das am neuen Volume erstellt werden soll. Bestätigen Sie schließlich Ihre Auswahl mit , um die Erstellung des Volumes abzuschließen:
 Abbildung 22.9: Volume-Auswahl bestätigen #
Abbildung 22.9: Volume-Auswahl bestätigen #Überprüfen Sie die Ergebnisse nach Abschluss des Vorgangs, klicken Sie dann auf , um die Laufwerkinitialisierung abzuschließen. Nach Abschluss der Initialisierung steht das Volume (und dessen NTFS-Dateisystem) wie ein neu initialisiertes lokales Laufwerk zur Verfügung.
22.1.3 Herstellen einer Verbindung zu VMware #
Sie benötigen zur Herstellung einer Verbindung zu
ceph-iscsi-verwalteten iSCSI-Volumen einen konfigurierten iSCSI-Softwareadapter. Wenn in Ihrer vSphere-Konfiguration kein derartiger Adapter verfügbar ist, erstellen Sie einen Adapter, indem Sie die Optionsfolge › › › auswählen.Wählen Sie die Eigenschaften des Adapters aus, falls verfügbar. Klicken Sie dazu mit der rechten Maustaste auf den Adapter und wählen Sie im Kontextmenü die Option aus:
 Abbildung 22.10: Eigenschaften des iSCSI-Initiators #
Abbildung 22.10: Eigenschaften des iSCSI-Initiators #Klicken Sie im Dialogfeld (iSCSI-Software-Initiator) auf die Schaltfläche (Konfigurieren). Gehen Sie dann zur Registerkarte (Dynamische Ermittlung) und wählen Sie (Hinzufügen) aus.
Geben Sie die IP-Adresse oder den Hostnamen Ihres
ceph-iscsi-iSCSI-Gateways ein. Wenn Sie mehrere iSCSI-Gateways in einer Failover-Konfiguration ausführen, wiederholen Sie diesen Schritt für alle vorhandenen Gateways. Abbildung 22.11: Zielserver hinzufügen #
Abbildung 22.11: Zielserver hinzufügen #Klicken Sie nach Eingabe aller iSCSI-Gateways im Dialogfeld auf , um eine erneute Absuche des iSCSI-Adapters zu initiieren.
Nach Abschluss der Neuabsuche wird das neue iSCSI-Gerät unterhalb der Liste (Speicheradapter) im Fensterbereich angezeigt. Für Multipfadgeräte können Sie nun mit der rechten Maustaste auf den Adapter klicken und im Kontextmenü (Pfade verwalten) auswählen:
 Abbildung 22.12: Multipfadgeräte verwalten #
Abbildung 22.12: Multipfadgeräte verwalten #Sie sollten nun alle Pfade mit einer grünen Anzeige unter sehen. Einer Ihrer Pfade sollte mit (Aktiv (E/A)) gekennzeichnet sein und alle anderen einfach mit (Aktiv):
 Abbildung 22.13: Auflistung der Pfade für Multipfad #
Abbildung 22.13: Auflistung der Pfade für Multipfad #Sie können nun von (Speicheradapter) zum Element mit dem Label (Speicher) wechseln. Wählen Sie oben rechts im Fensterbereich (Speicher hinzufügen...) aus, um das Dialogfeld (Speicher hinzufügen) zu öffnen. Wählen Sie dann (Datenträger/LUN) aus und klicken Sie auf . Das neu hinzugefügte iSCSI-Gerät erscheint in der Liste (Datenträger/LUN auswählen). Wählen Sie es aus und klicken Sie dann auf , um fortzufahren:
 Abbildung 22.14: Dialogfeld „Speicher hinzufügen“ #
Abbildung 22.14: Dialogfeld „Speicher hinzufügen“ #Klicken Sie auf , um das standardmäßige Datenträger-Layout zu übernehmen.
Weisen Sie im Fensterbereich der neuen Datenablage einen Namen zu und klicken Sie auf . Akzeptieren Sie die Standardeinstellung zur Verwendung des gesamten Speicherplatzes des Volumes für die Datenablage oder wählen Sie (Benutzerdefinierte Speicherplatzeinstellung) für eine kleinere Datenablage aus:
 Abbildung 22.15: Benutzerdefinierte Speicherplatzeinstellung #
Abbildung 22.15: Benutzerdefinierte Speicherplatzeinstellung #Klicken Sie auf (Fertig stellen), um die Erstellung der Datenablage abzuschließen.
Die neue Datenablage wird nun in der Datenablageliste angezeigt. Wählen Sie sie aus, um die Details abzurufen. Nun sind Sie in der Lage, das
ceph-iscsi-unterstützte iSCSI-Volume wie jede andere vSphere-Datenablage zu verwenden. Abbildung 22.16: Überblick zur iSCSI-Datenablage #
Abbildung 22.16: Überblick zur iSCSI-Datenablage #
22.2 Fazit #
ceph-iscsi ist eine
Schlüsselkomponente von SUSE Enterprise Storage 7, die den Zugriff auf
dezentrale, hochverfügbare Blockspeicher von jedem Server oder Client aus
ermöglicht, der das iSCSI-Protokoll versteht. Durch Verwendung von
ceph-iscsi auf mindestens einem
iSCSI-Gateway-Host werden Ceph RBD-Images als logische Einheiten (Logical
Units, LUs) verfügbar, die mit iSCSI-Zielen verknüpft sind. Auf diese kann
auf optional lastausgeglichene, hochverfügbare Weise zugegriffen werden.
Da die gesamte Konfiguration von
ceph-iscsi im Ceph
RADOS-Objektspeicher gespeichert ist, weisen
ceph-iscsi-Gateway-Hosts von Natur
aus keinen dauerhaften Zustand auf und können daher nach Belieben ersetzt,
verbessert oder reduziert werden. SUSE Enterprise Storage 7 ermöglicht es
SUSE-Kunden folglich, eine echte dezentrale, hochverfügbare, stabile und
selbstreparierende Unternehmensspeichertechnologie auf frei erhältlicher
Hardware und einer Open Source-Plattform auszuführen.
23 Cluster-Dateisystem #
In diesem Kapitel werden Verwaltungsaufgaben beschrieben, die normalerweise nach der Einrichtung des Clusters und dem Export des CephFS ausgeführt werden. Weitere Informationen zum Einrichten des CephFS finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.3.3 “Bereitstellen von Metadatenservern”.
23.1 Einhängen von CephFS #
Wenn das Dateisystem erstellt und der MDS aktiv ist, sind Sie bereit, das Dateisystem von einem Client-Host aus einzuhängen.
23.1.1 Vorbereiten des Clients #
Wenn auf dem Client-Host SUSE Linux Enterprise 12 SP2 oder höher ausgeführt wird, ist das System bereit, das CephFS ohne weitere Anpassung einzuhängen.
Wenn auf dem Client-Host SUSE Linux Enterprise 12 SP1 ausgeführt wird, müssen Sie alle neuesten Patches anwenden, bevor Sie das CephFS einhängen.
In jedem Fall ist in SUSE Linux Enterprise alles enthalten, was zum Einhängen von CephFS benötigt wird. SUSE Enterprise Storage 7 wird nicht benötigt.
Zur Unterstützung der vollständigen mount-Syntax sollte das Paket
ceph-common (das im Lieferumfang von SUSE Linux Enterprise enthalten ist) installiert werden, bevor Sie versuchen, CephFS einzuhängen.
Ohne das Paket ceph-common (und somit ohne mount.ceph-Helper) müssen die IPs der Monitors anstelle ihrer Namen verwendet werden. Dies liegt daran, dass der Kernel-Client keine Namensauflösung durchführen kann.
Die grundlegende Einhängesyntax lautet:
root # mount -t ceph MON1_IP[:PORT],MON2_IP[:PORT],...:CEPHFS_MOUNT_TARGET \
MOUNT_POINT -o name=CEPHX_USER_NAME,secret=SECRET_STRING23.1.2 Erstellen einer geheimen Datei #
Der Ceph-Cluster wird mit standardmäßig eingeschalteter Authentifizierung ausgeführt. Sie sollten eine Datei erstellen, in der Ihr geheimer Schlüssel (nicht der Schlüsselbund selbst) gespeichert wird. Gehen Sie folgendermaßen vor, um den geheimen Schlüssel für einen bestimmten Benutzer abzurufen und dann die Datei zu erstellen:
Sehen Sie sich den Schlüssel für den bestimmten Benutzer in einer Schlüsselbunddatei an:
cephuser@adm >cat /etc/ceph/ceph.client.admin.keyringKopieren Sie den Schlüssel des Benutzers, der das eingehängte Ceph FS-Dateisystem verwenden wird. Normalerweise sieht der Schlüssel in etwa so aus:
AQCj2YpRiAe6CxAA7/ETt7Hcl9IyxyYciVs47w==
Erstellen Sie eine Datei mit dem Benutzernamen als Teil des Dateinamens, wie zum Beispiel
/etc/ceph/admin.secretfür den Benutzer admin.Fügen Sie den Schlüsselwert in der im vorigen Schritt erstellten Datei ein.
Legen Sie die ordnungsgemäßen Zugriffsrechte für die Datei fest. Ausschließlich der Benutzer sollte die Datei lesen können. Andere dürfen keine Zugriffsrechte dafür erhalten.
23.1.3 Einhängen von CephFS #
CephFS wird mit dem Befehl mount eingehängt. Sie müssen den Hostnamen oder die IP-Adresse des Monitors angeben. Da in SUSE Enterprise Storage standardmäßig die cephx-Authentifizierung aktiviert ist, müssen Sie einen Benutzernamen und das entsprechende Geheimnis angeben:
root # mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secret=AQATSKdNGBnwLhAAnNDKnH65FmVKpXZJVasUeQ==Da das vorige Kommando im Shell-Verlauf bleibt, ist es sicherer, das Geheimnis aus einer Datei zu lesen:
root # mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secretBeachten Sie, dass die Geheimnisdatei nur das tatsächliche Schlüsselbundgeheimnis enthalten sollte. In unserem Beispiel enthält die Datei dann nur die folgende Zeile:
AQATSKdNGBnwLhAAnNDKnH65FmVKpXZJVasUeQ==
Es ist sinnvoll, in der mount-Kommandozeile mehrere Monitors durch Komma getrennt anzugeben, für den Fall, dass zum Zeitpunkt des Einhängens ein Monitor zufällig inaktiv ist. Jede Monitoradresse hat die Form host[:port]. Wenn der Port nicht angegeben wird, ist es standardmäßig Port 6789.
Erstellen sie den Einhängepunkt am lokalen Host:
root # mkdir /mnt/cephfsHängen Sie das CephFS ein:
root # mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret
Ein Unterverzeichnis subdir kann angegeben werden, wenn eine Teilmenge des Dateisystems eingehängt werden soll:
root # mount -t ceph ceph_mon1:6789:/subdir /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret
Sie können mehr als einen Monitor-Host im Kommando mount angeben:
root # mount -t ceph ceph_mon1,ceph_mon2,ceph_mon3:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secretWenn Clients mit Pfadbeschränkungen verwendet werden, muss der MDS Lesezugriff auf das Stammverzeichnis enthalten. Ein Schlüsselbund sieht beispielsweise in etwa wie folgt aus:
client.bar key: supersecretkey caps: [mds] allow rw path=/barjail, allow r path=/ caps: [mon] allow r caps: [osd] allow rwx
Der Abschnitt allow r path=/ bedeutet, dass pfadbeschränkte Clients das Root-Volume sehen können, jedoch nicht darauf schreiben dürfen. In Anwendungsfällen, in denen die vollständige Isolierung vorausgesetzt wird, könnte dies ein Problem darstellen.
23.2 Aushängen von CephFS #
CephFS wird mit dem Kommando umount ausgehängt:
root # umount /mnt/cephfs23.3 Einhängen von CephFS in /etc/fstab #
Fügen Sie zum automatischen Einhängen von CephFS bei Client-Start die entsprechende Zeile in die Tabelle /etc/fstab seines Dateisystems ein:
mon1:6790,mon2:/subdir /mnt/cephfs ceph name=admin,secretfile=/etc/ceph/secret.key,noatime,_netdev 0 2
23.4 Mehrere aktive MDS-Daemons (Aktiv/Aktiv-MDS) #
CephFS wird standardmäßig für einen einzelnen aktiven MDS-Daemon konfiguriert. Zum Skalieren der Metadatenleistung für große Systeme können Sie mehrere aktive MDS-Daemons aktivieren. Dadurch wird der Metadaten-Workload untereinander aufgeteilt.
23.4.1 Verwenden von Aktiv/Aktiv-MDS #
Erwägen Sie, mehrere aktive MDS-Daemons zu verwenden, falls Ihre Metadatenleistung bei einem standardmäßigen einzelnen MDS einen Engpass erfahren würde.
Das Hinzufügen weiterer Daemons erhöht nicht die Leistung bei allen Workload-Typen. Beispielsweise profitiert eine Einzelanwendung, die auf einem einzelnen Client ausgeführt wird, nicht von einer höheren Anzahl von MDS-Daemons, es sei denn, die Anwendung führt sehr viele Metadaten-Operationen gleichzeitig aus.
Workloads, die normalerweise von einer höheren Anzahl aktiver MDS-Daemons profitieren, sind Workloads mit vielen Clients, die eventuell in vielen verschiedenen Verzeichnissen arbeiten.
23.4.2 Vergrößern des aktiven MDS-Clusters #
Jedes CephFS-Dateisystem verfügt über eine max_mds-Einstellung, die steuert, wie viele Rangstufen erstellt werden. Die tatsächliche Anzahl der Rangstufen im Dateisystem wird nur dann erhöht, wenn ein Ersatz-Daemon verfügbar ist, der die neue Rangstufe übernehmen kann. Wenn beispielsweise nur ein MDS-Daemon ausgeführt wird und max_mds auf „2“ festgelegt ist, wird keine zweite Rangstufe erstellt.
Im folgenden Beispiel legen wir die Option max_mds auf „2“ fest, um eine neue Rangstufe abgesehen von der standardmäßigen Rangstufe zu erstellen. Führen Sie zum Anzeigen der Änderungen ceph status aus bevor und nachdem Sie max_mds festlegen und beobachten Sie die Zeile, die fsmap enthält:
cephuser@adm >cephstatus [...] services: [...] mds: cephfs-1/1/1 up {0=node2=up:active}, 1 up:standby [...]cephuser@adm >cephfs set cephfs max_mds 2cephuser@adm >cephstatus [...] services: [...] mds: cephfs-2/2/2 up {0=node2=up:active,1=node1=up:active} [...]
Die neu erstellte Rangstufe (1) durchläuft den Zustand „wird erstellt“ und wird dann in den Zustand „aktiv“ versetzt.
Auch bei mehreren aktiven Daemons benötigt ein hochverfügbares System weiterhin Standby-Daemons, die übernehmen, wenn einer der Server, auf dem ein aktiver Daemon ausgeführt wird, ausfällt.
Folglich ist die praktische maximale Anzahl von max_mds bei hochverfügbaren Systemen ein Server weniger als die Gesamtanzahl der MDS-Server in Ihrem System. Um im Fall mehrerer Serverausfälle verfügbar zu bleiben, müssen Sie die Anzahl der Standby-Daemons im System entsprechend der Anzahl der Serverausfälle anpassen, die sie kompensieren müssen.
23.4.3 Reduzieren der Anzahl von Rangstufen #
Alle Rangstufen, einschließlich der zu entfernenden Rangstufen, müssen zunächst aktiv sein. Dies bedeutet, dass mindestens max_mds MDS-Daemons verfügbar sein müssen.
Legen Sie zunächst max_mds auf eine kleinere Anzahl fest. Gehen Sie beispielsweise zu einem einzelnen aktiven MDS zurück:
cephuser@adm >cephstatus [...] services: [...] mds: cephfs-2/2/2 up {0=node2=up:active,1=node1=up:active} [...]cephuser@adm >cephfs set cephfs max_mds 1cephuser@adm >cephstatus [...] services: [...] mds: cephfs-1/1/1 up {0=node2=up:active}, 1 up:standby [...]
23.4.4 Manuelles Anheften von Verzeichnisbäumen an eine Rangstufe #
Bei Konfigurationen mit mehreren aktiven Metadaten-Servern wird ein Ausgleichsprogramm ausgeführt, das die Metadatenlast gleichmäßig im Cluster verteilt. Dies funktioniert normalerweise bei den meisten Benutzern ganz gut, doch manchmal ist es wünschenswert, das dynamische Ausgleichsprogramm durch explizite Zuordnungen von Metadaten zu bestimmten Rangstufen außer Kraft zu setzen. Dadurch erhalten der Administrator oder die Benutzer die Möglichkeit, die Anwendungslast gleichmäßig zu verteilen oder die Auswirkungen auf die Metadatenanforderungen der Benutzer auf den gesamten Cluster einzuschränken.
Der zu diesem Zweck bereitgestellte Mechanismus wird „Export-Pin“ genannt. Es handelt sich um ein erweitertes Attribut von Verzeichnissen. Der Name dieses erweiterten Attributs ist ceph.dir.pin. Benutzer können dieses Attribut mit Standardkommandos festlegen:
root # setfattr -n ceph.dir.pin -v 2 /path/to/dir
Der Wert (-v) des erweiterten Attributs ist die Rangstufe, zu dem der Verzeichnisunterbaum zugewiesen wird. Ein Standardwert von -1 gibt an, dass das Verzeichnis nicht angeheftet wird.
Ein Verzeichnisexport-Pin wird vom nächstgelegenen übergeordneten Verzeichnis mit einem festgelegten Export-Pin übernommen. Daher betrifft die Festlegung eines Export-Pins auch alle untergeordneten Verzeichnisse. Der Pin des übergeordneten Verzeichnisses kann jedoch durch Festlegen des Verzeichnisexport-Pins des untergeordneten Verzeichnisses außer Kraft gesetzt werden. Beispiel:
root # mkdir -p a/b # "a" and "a/b" start with no export pin set.
setfattr -n ceph.dir.pin -v 1 a/ # "a" and "b" are now pinned to rank 1.
setfattr -n ceph.dir.pin -v 0 a/b # "a/b" is now pinned to rank 0
# and "a/" and the rest of its children
# are still pinned to rank 1.23.5 Failover-Verwaltung #
Wenn ein MDS-Daemon die Kommunikation mit dem Monitor stoppt, dann wartet der Monitor mds_beacon_grace Sekunden (standardmäßig 15 Sekunden), bevor er den Daemon als laggy (langsam) kennzeichnet. Sie können einen oder mehrere „standby“-Daemons konfigurieren, die bei einem MDS-Daemon-Failover übernehmen.
23.5.1 Konfigurieren von Standby-Replay #
Jedes CephFS-Dateisystem kann so konfiguriert werden, dass es Standby-Replay-Daemons hinzufügt. Diese Standby-Daemons folgen dem Metadatenjournal des aktiven MDS, um die Failover-Zeit zu reduzieren, falls der aktive MDS nicht mehr verfügbar ist. Jeder aktive MDS darf nur einen Standby-Replay-Daemon haben, der ihm folgt.
Konfigurieren Sie Standby-Replay auf einem Dateisystem mit folgendem Kommando:
cephuser@adm > ceph fs set FS-NAME allow_standby_replay BOOLWenn diese Option aktiviert ist, weisen die Monitore verfügbare Standby-Daemons zu, die den aktiven MDS in diesem Dateisystem folgen.
Wenn ein Daemon den Status Standby-Replay aufweist, wird er nur als Standby für die Rangstufe verwendet, der er folgt. Wenn eine andere Rangstufe ausfällt, wird dieser Standby-Replay-Daemon nicht als Ersatz verwendet, auch wenn keine anderen Standbys verfügbar sind. Aus diesem Grund ist es ratsam, dass jeder aktive MDS über einen Standby-Replay-Daemon verfügt, wenn Standby-Replay verwendet wird.
23.6 Festlegen von CephFS-Kontingenten #
Sie können Kontingente für beliebige Unterverzeichnisse des Ceph-Dateisystems anlegen. Das Kontingent beschränkt entweder die Anzahl der Byte oder die Anzahl der Dateien, die unterhalb des angegebenen Punkts in der Verzeichnishierarchie gespeichert werden können.
23.6.1 Einschränkungen von CephFS-Kontingenten #
Kontingente in CephFS unterliegen folgenden Einschränkungen:
- Kontingente sind kooperativ und konkurrieren nicht untereinander.
Ceph-Kontingente sind darauf angewiesen, dass der Client, der das Dateisystem einhängt, nicht mehr darin schreibt, sobald ein bestimmter Grenzwert erreicht ist. Der Server-Teil kann nicht verhindern, dass ein böswilliger Client beliebig viele Daten schreibt. Es ist nicht zulässig, das Füllen des Dateisystems in Umgebungen, in denen die Clients als überhaupt nicht verbürgt gelten, mithilfe von Kontingenten zu verhindern.
- Kontingente sind nicht absolut genau.
Prozesse, die in das Dateisystem schreiben, werden kurz nach Erreichen des Kontingentgrenzwerts angehalten. Es ist nicht zu verhindern, dass eine gewisse Datenmenge geschrieben wird, die den konfigurierten Grenzwert übersteigt. Client-Schreibvorgänge werden innerhalb weniger Zehntelsekunden nach dem Überschreiten des konfigurierten Grenzwerts angehalten.
- Kontingente werden ab Version 4.17 im Kernel-Client implementiert.
Kontingente werden durch den Benutzerbereichs-Client (libcephfs, ceph-fuse) unterstützt. Die Linux-Kernel-Clients 4.17 und höher unterstützen CephFS-Kontingente auf Clustern mit SUSE Enterprise Storage 7. Kernel-Clients (selbst die neueren Versionen) können Kontingente nicht auf älteren Clustern verarbeiten, auch wenn sie die erweiterten Attribute der Kontingente festlegen können. Kernel ab SLE12-SP3 enthalten bereits die erforderlichen Backports zur Verarbeitung von Kontingenten.
- Konfigurieren Sie die Kontingente nur mit Vorsicht, wenn pfadbasierte Einhängeeinschränkungen gelten.
Der Client kann die Kontingente nur dann durchsetzen, wenn er den Zugriff auf den Verzeichnis-Inode besitzt, auf dem die Kontingente konfiguriert sind. Wenn der Zugriff des Clients auf einen bestimmten Pfad (z. B.
/home/user) gemäß der MDS-Capability eingeschränkt ist und Sie ein Kontingent für ein übergeordnetes Verzeichnis konfigurieren, auf das der Client nicht zugreifen kann (/home), kann der Client das Kontingent nicht erzwingen. Wenn Sie pfadbasierte Zugriffsbeschränkungen verwenden, stellen Sie sicher, dass Sie die Kontingente für das Verzeichnis konfigurieren, auf das der Client zugreifen kann (z. B./home/useroder/home/user/quota_dir).
23.6.2 Konfigurieren von CephFS-Kontingenten #
CephFS-Kontingente werden mit virtuellen erweiterten Attributen konfiguriert:
ceph.quota.max_filesKonfiguriert einen Grenzwert für die Anzahl der Dateien.
ceph.quota.max_bytesKonfiguriert einen Grenzwert für die Anzahl der Bytes.
Wenn Attribute für einen Verzeichnis-Inode angezeigt werden, ist dort ein Kontingent konfiguriert. Fehlen die Attribute, wurde kein Kontingent für das Verzeichnis festgelegt (eventuell jedoch für ein übergeordnetes Verzeichnis).
Mit folgendem Kommando legen Sie ein Kontingent von 100 MB fest:
cephuser@mds > setfattr -n ceph.quota.max_bytes -v 100000000 /SOME/DIRECTORYMit folgendem Kommando legen Sie ein Kontingent von 10.000 Dateien fest:
cephuser@mds > setfattr -n ceph.quota.max_files -v 10000 /SOME/DIRECTORYMit folgendem Kommando rufen Sie die Kontingenteinstellung ab:
cephuser@mds > getfattr -n ceph.quota.max_bytes /SOME/DIRECTORYcephuser@mds > getfattr -n ceph.quota.max_files /SOME/DIRECTORYWenn das erweiterte Attribut den Wert „0“ aufweist, ist kein Kontingent festgelegt.
Mit folgendem Kommando entfernen Sie ein Kontingent:
cephuser@mds >setfattr -n ceph.quota.max_bytes -v 0 /SOME/DIRECTORYcephuser@mds >setfattr -n ceph.quota.max_files -v 0 /SOME/DIRECTORY
23.7 Verwalten von CephFS-Snapshots #
Ein CephFS-Snapshot ist eine schreibgeschützte Ansicht des Dateisystems zu dem Zeitpunkt, zu dem der Snapshot erstellt wurde. Sie können Snapshots in beliebigen Verzeichnissen erstellen. Der Snapshot deckt alle Daten im Dateisystem unter dem angegebenen Verzeichnis ab. Nach dem Erstellen des Snapshots werden die zwischengespeicherten Daten asynchron von verschiedenen Clients verschoben. Die Snapshot-Erstellung ist daher sehr schnell.
Greifen mehrere CephFS-Dateisysteme auf einen einzelnen Pool zu (über Namespaces), prallen ihre Snapshots aufeinander. Wenn Sie dann einen einzelnen Snapshot löschen, fehlen die entsprechenden Daten in anderen Snapshots, die denselben Pool nutzen.
23.7.1 Erstellen von Snapshots #
Die CephFS-Snapshot-Funktion ist auf neuen Dateisystemen standardmäßig aktiviert. Mit folgendem Kommando aktivieren Sie die Funktion auf vorhandenen Dateisystemen:
cephuser@adm > ceph fs set CEPHFS_NAME allow_new_snaps true
Sobald Sie die Snapshots aktiviert haben, enthalten alle Verzeichnisse im CephFS das besondere Unterverzeichnis .snap.
Dies ist ein virtuelles Unterverzeichnis. Es erscheint nicht in der Verzeichnisliste des übergeordneten Verzeichnisses, aber der Name .snap kann nicht als Datei- oder Verzeichnisname verwendet werden. Der Zugriff auf das Verzeichnis .snap muss explizit erfolgen. Beispiel:
tux > ls -la /CEPHFS_MOUNT/.snap/Für CephFS-Kernel-Clients gilt eine Einschränkung: Sie können maximal 400 Snapshots in einem Dateisystem verarbeiten. Halten Sie die Anzahl der Snapshots stets unter diesem Grenzwert, unabhängig vom tatsächlichen Client. Wenn Sie mit älteren CephFS-Clients arbeiten (z. B. mit SLE12-SP3), bedenken Sie, dass eine Anzahl von mehr als 400 Snapshots zum Absturz des Clients führt und damit die Abläufe erheblich beeinträchtigt.
Mit der Einstellung client snapdir können Sie einen anderen Namen für das Snapshot-Unterverzeichnis konfigurieren.
Zum Erstellen eines Snapshots legen Sie ein Unterverzeichnis mit einem benutzerdefinierten Namen unter dem Verzeichnis .snap an. Mit folgendem Kommando erstellen Sie beispielsweise einen Snapshot des Verzeichnisses /CEPHFS_MOUNT/2/3/:
tux > mkdir /CEPHFS_MOUNT/2/3/.snap/CUSTOM_SNAPSHOT_NAME23.7.2 Löschen von Snapshots #
Soll ein Snapshot gelöscht werden, entfernen Sie das zugehörige Unterverzeichnis aus dem Verzeichnis .snap:
tux > rmdir /CEPHFS_MOUNT/2/3/.snap/CUSTOM_SNAPSHOT_NAME24 Exportieren von Ceph-Daten mit Samba #
Mit diesem Kapitel wird erläutert, wie Sie Daten, die in einem Ceph-Cluster gespeichert sind, über eine Samba-/CIFS-Freigabe exportieren, sodass Sie problemlos von Windows*-Client-Computern darauf zugreifen können. Hier erfahren Sie außerdem, wie Sie ein Ceph-Samba-Gateway für die Einbindung in Active Directory in der Windows*-Domäne konfigurieren, sodass Benutzer damit authentifiziert und autorisiert werden können.
Angesichts des erhöhten Protokoll-Overheads und der zusätzlichen Latenz durch zusätzliche Netzwerk-Hops zwischen Client und Speicher kann ein Zugriff auf CephFS über einen Samba Gateway die Anwendungsleistung im Vergleich zu nativen CephFS- oder Object-Gateway-Clients erheblich senken.
24.1 Exportieren von CephFS über eine Samba-Freigabe #
Native CephFS- und NFS-Clients sind nicht durch Dateisperren in Samba eingeschränkt und umgekehrt. In Anwendungen, die auf der protokollübergreifenden Dateisperre beruhen, können dort Beschädigungen auftreten, wenn der Zugriff auf CephFS-gestützte Samba-Freigabepfade auf andere Weise erfolgt.
24.1.1 Konfigurieren und Exportieren von Samba-Paketen #
Für die Konfiguration und den Export einer Samba-Freigabe müssen die folgenden Pakete installiert werden: samba-ceph und samba-winbind. Wenn diese Pakete nicht installiert sind, installieren Sie sie:
cephuser@smb > zypper install samba-ceph samba-winbind24.1.2 Beispiel mit einem einzelnen Gateway #
Zur Vorbereitung auf den Export einer Samba-Freigabe wählen Sie einen geeigneten Knoten, der als Samba Gateway fungieren soll. Der Knoten benötigt den Zugriff auf das Ceph-Client-Netzwerk sowie ausreichende CPU-, Arbeitsspeicher- und Netzwerkressourcen.
Die Failover-Funktionalität kann mit CTDB und mit der SUSE Linux Enterprise High Availability Extension zur Verfügung gestellt werden. Weitere Informationen zur HA-Einrichtung finden Sie in Abschnitt 24.1.3, „Konfigurieren von Hochverfügbarkeit“.
Vergewissern Sie sich, dass sich in Ihrem Cluster bereits ein funktionierendes CephFS befindet.
Erstellen Sie einen für Samba Gateway spezifischen Schlüsselbund auf dem Ceph-Admin-Knoten und kopieren Sie ihn in beide Samba-Gateway-Knoten:
cephuser@adm >cephauth get-or-create client.samba.gw mon 'allow r' \ osd 'allow *' mds 'allow *' -o ceph.client.samba.gw.keyringcephuser@adm >scpceph.client.samba.gw.keyring SAMBA_NODE:/etc/ceph/Ersetzen Sie SAMBA_NODE durch den Namen des Samba-Gateway-Knotens.
Die folgenden Schritte werden im Samba-Gateway-Knoten ausgeführt. Installieren Sie Samba zusammen mit dem Ceph-Integrationspaket:
cephuser@smb >sudo zypper in samba samba-cephErsetzen Sie den Standardinhalt der Datei
/etc/samba/smb.confwie folgt:[global] netbios name = SAMBA-GW clustering = no idmap config * : backend = tdb2 passdb backend = tdbsam # disable print server load printers = no smbd: backgroundqueue = no [SHARE_NAME] path = CEPHFS_MOUNT read only = no oplocks = no kernel share modes = no
Der obige CEPHFS_MOUNT-Pfad muss vor dem Start von Samba mit einer Kernel-CephFS-Freigabekonfiguration eingehängt werden. Siehe Abschnitt 23.3, „Einhängen von CephFS in
/etc/fstab“.Die obige Freigabekonfiguration verwendet den Linux-Kernel-CephFS-Client, der aus Leistungsgründen empfohlen wird. Alternativ kann auch das Samba-Modul
vfs_cephzur Kommunikation mit dem Ceph-Cluster verwendet werden. Die folgenden Anweisungen sind für ältere Versionen gedacht und werden für neue Samba-Installationen nicht empfohlen:[SHARE_NAME] path = / vfs objects = ceph ceph: config_file = /etc/ceph/ceph.conf ceph: user_id = samba.gw read only = no oplocks = no kernel share modes = no
Tipp: Oplocks und Freigabemodioplocks(auch als SMB2+-Leases bezeichnet) steigern die Leistung durch aggressives Client-Caching, sind jedoch derzeit unsicher, wenn Samba gemeinsam mit anderen CephFS-Clients bereitgestellt wird, z. B. Kernel-mount.ceph, FUSE oder NFS Ganesha.Wenn der gesamte Zugriff auf die Pfade im CephFS-Dateisystem ausschließlich über Samba abläuft, kann der Parameter
oplocksgefahrlos aktiviert werden.In einer Freigabe, die mit dem vfs-Modul von CephFS ausgeführt wird, müssen die
Kernel-Freigabemodiderzeit deaktiviert werden, damit die Dateibereitstellung fehlerfrei erfolgt.Wichtig: Zulassen des ZugriffsSamba ordnet SMB-Benutzer und -Gruppen lokalen Konten zu. Lokalen Benutzern kann mit folgendem Kommando ein Passwort für den Zugriff auf Samba-Freigaben zugewiesen werden:
root #smbpasswd -a USERNAMEFür eine erfolgreiche E/A muss die Zugriffssteuerungsliste (ACL) des Freigabepfads den Zugriff des über Samba verbundenen Benutzers zulassen. Zum Bearbeiten der ACL können Sie eine temporäre Einhängung über den CephFS-Kernel-Client vornehmen und die Dienstprogramme
chmod,chownodersetfaclauf den Freigabepfad anwenden. Mit folgendem Kommando gestatten Sie beispielsweise den Zugriff aller Benutzer:root #chmod 777 MOUNTED_SHARE_PATH
24.1.2.1 Starten von Samba-Services #
Starten Sie eigenständige Samba-Services mit den folgenden Kommandos oder starten Sie sie neu:
root #systemctl restart smb.serviceroot #systemctl restart nmb.serviceroot #systemctl restart winbind.service
Um sicherzustellen, dass die Samba-Services beim Booten starten, aktivieren Sie sie mit:
root #systemctl enable smb.serviceroot #systemctl enable nmb.serviceroot #systemctl enable winbind.service
nmb- und winbind-Services
Wenn Sie keine Netzwerkfreigaben durchsuchen müssen, brauchen Sie den nmb-Service nicht zu aktivieren und zu starten.
Der winbind-Service wird nur benötigt, wenn er als Active Directory-Domänenmitglied konfiguriert ist. Siehe Abschnitt 24.2, „Verbinden von Samba-Gateway und Active Directory“.
24.1.3 Konfigurieren von Hochverfügbarkeit #
Eine Implementierung mit Samba + CTDB und mehreren Knoten bietet eine höhere Verfügbarkeit als ein Einzelknoten (siehe Kapitel 24, Exportieren von Ceph-Daten mit Samba), doch ein clientseitiges, transparentes Failover wird nicht unterstützt. Der Ausfall eines Samba-Gateway-Knotens führt mit großer Wahrscheinlichkeit zu einer kurzen Unterbrechung für die Anwendungen.
In diesem Abschnitt finden Sie ein Beispiel, wie eine Hochverfügbarkeitskonfiguration aus Samba-Servern mit zwei Knoten eingerichtet wird. Für die Einrichtung ist die SUSE Linux Enterprise High Availability Extension erforderlich. Die beiden Knoten werden earth (192.168.1.1) und mars (192.168.1.2) genannt.
Detaillierte Informationen zu SUSE Linux Enterprise High Availability Extension finden Sie unter https://documentation.suse.com/sle-ha/15-SP1/.
Außerdem können Clients über zwei virtuelle IP-Adressen nach dem Floating-IP-Prinzip eine Verbindung mit dem Service herstellen, und zwar unabhängig davon, auf welchem physischen Knoten er ausgeführt wird. 192.168.1.10 wird für die Cluster-Verwaltung mit Hawk2 verwendet und 192.168.2.1 exklusiv für die CIFS-Exporte. Dies erleichtert später die Anwendung von Sicherheitsbeschränkungen.
Das folgende Verfahren beschreibt das Installationsbeispiel. Weitere Informationen finden Sie unter https://documentation.suse.com/sle-ha/15-SP2/html/SLE-HA-all/art-sleha-install-quick.html.
Erstellen Sie einen für das Samba Gateway spezifischen Schlüsselbund auf dem Admin-Knoten und kopieren Sie ihn in beide Knoten:
cephuser@adm >cephauth get-or-create client.samba.gw mon 'allow r' \ osd 'allow *' mds 'allow *' -o ceph.client.samba.gw.keyringcephuser@adm >scpceph.client.samba.gw.keyringearth:/etc/ceph/cephuser@adm >scpceph.client.samba.gw.keyringmars:/etc/ceph/Für die Einrichtung von SLE-HA ist ein Fencing-Gerät erforderlich, um eine Split Brain-Situation zu verhindern, wenn aktive Cluster-Knoten nicht mehr synchronisiert sind. Zu diesem Zweck können Sie ein Ceph RBD-Image mit Stonith Block Device (SBD) verwenden. Weitere Informationen finden Sie in https://documentation.suse.com/sle-ha/15-SP2/html/SLE-HA-all/cha-ha-storage-protect.html#sec-ha-storage-protect-fencing-setup.
Falls es noch nicht vorhanden ist, erstellen Sie einen RBD-Pool namens
rbd(weitere Informationen finden Sie in Abschnitt 18.1, „Erstellen eines Pools“) und verknüpfen Sie ihn mitrbd(weitere Informationen finden Sie in Abschnitt 18.5.1, „Verknüpfen von Pools mit einer Anwendung“). Erstellen Sie dann ein entsprechendes RBD-Image namenssbd01:cephuser@adm >ceph osd pool create rbdcephuser@adm >ceph osd pool application enable rbd rbdcephuser@adm >rbd -p rbd create sbd01 --size 64M --image-sharedBereiten Sie
earthundmarsdarauf vor, den Samba Service zu hosten:Vergewissern Sie sich, dass die folgenden Pakete installiert sind, bevor Sie fortfahren: ctdb, tdb-tools, und samba.
root #zypperin ctdb tdb-tools samba samba-cephStellen Sie sicher, dass die Samba- und CTDB-Services gestoppt und deaktiviert sind:
root #systemctl disable ctdbroot #systemctl disable smbroot #systemctl disable nmbroot #systemctl disable winbindroot #systemctl stop ctdbroot #systemctl stop smbroot #systemctl stop nmbroot #systemctl stop winbindÖffnen Sie Port
4379Ihrer Firewall in allen Knoten. Dies ist erforderlich, damit CTDB mit anderen Cluster-Knoten kommunizieren kann.
Erstellen Sie die Konfigurationsdateien für Samba in
earth. Diese werden später automatisch mitmarssynchronisiert.Fügen Sie eine Liste der privaten IP-Adressen der Samba-Gateway-Knoten in die Datei
/etc/ctdb/nodesein. Weitere Informationen finden Sie auf der CTDB-Handbuch-Seite (man 7 ctdb).192.168.1.1 192.168.1.2
Konfigurieren Sie Samba. Fügen Sie die folgenden Zeilen im Abschnitt
[global]von/etc/samba/smb.confhinzu. Wählen Sie den gewünschten Hostnamen anstelle CTDB-SERVER (alle Knoten im Cluster werden sinnvollerweise als ein großer Knoten mit diesem Namen angezeigt). Tragen Sie auch eine Freigabedefinition ein (Beispiel unter SHARE_NAME):[global] netbios name = SAMBA-HA-GW clustering = yes idmap config * : backend = tdb2 passdb backend = tdbsam ctdbd socket = /var/lib/ctdb/ctdb.socket # disable print server load printers = no smbd: backgroundqueue = no [SHARE_NAME] path = / vfs objects = ceph ceph: config_file = /etc/ceph/ceph.conf ceph: user_id = samba.gw read only = no oplocks = no kernel share modes = no
Hierbei ist zu beachten, dass die Dateien
/etc/ctdb/nodesund/etc/samba/smb.confauf allen Samba-Gateway-Knoten identisch sein müssen.
Installieren Sie den SUSE Linux Enterprise High Availability Cluster und führen Sie ein Bootstrap durch.
Registrieren Sie die SUSE Linux Enterprise High Availability Extension in
earthundmars:root@earth #SUSEConnect-r ACTIVATION_CODE -e E_MAILroot@mars #SUSEConnect-r ACTIVATION_CODE -e E_MAILInstallieren ha-cluster-bootstrap in beiden Knoten:
root@earth #zypperin ha-cluster-bootstraproot@mars #zypperin ha-cluster-bootstrapOrdnen Sie das RBD-Image
sbd01auf beiden Samba-Gateways überrbdmap.servicezu.Bearbeiten Sie
/etc/ceph/rbdmapund fügen Sie einen Eintrag für das SBD-Image hinzu:rbd/sbd01 id=samba.gw,keyring=/etc/ceph/ceph.client.samba.gw.keyring
Aktivieren und starten Sie
rbdmap.service:root@earth #systemctl enable rbdmap.service && systemctl start rbdmap.serviceroot@mars #systemctl enable rbdmap.service && systemctl start rbdmap.serviceDas Gerät
/dev/rbd/rbd/sbd01sollte auf beiden Samba-Gateways verfügbar sein.Initialisieren Sie den Cluster auf
earthund nehmen Siemarsdarin auf.root@earth #ha-cluster-initroot@mars #ha-cluster-join-c earthWichtigWährend des Vorgangs der Initialisierung und der Aufnahme im Cluster werden Sie interaktiv gefragt, ob Sie SBD verwenden möchten. Bestätigen Sie mit
jund geben Sie dann/dev/rbd/rbd/sbd01als Pfad zum Speichergerät an.
Prüfen Sie den Status des Clusters. Sie sollten zwei Knoten sehen, die im Cluster hinzugefügt wurden:
root@earth #crmstatus 2 nodes configured 1 resource configured Online: [ earth mars ] Full list of resources: admin-ip (ocf::heartbeat:IPaddr2): Started earthFühren Sie die folgenden Kommandos in
earthaus, um die CTDB-Ressource zu konfigurieren:root@earth #crmconfigurecrm(live)configure#primitivectdb ocf:heartbeat:CTDB params \ ctdb_manages_winbind="false" \ ctdb_manages_samba="false" \ ctdb_recovery_lock="!/usr/lib64/ctdb/ctdb_mutex_ceph_rados_helper ceph client.samba.gw cephfs_metadata ctdb-mutex" ctdb_socket="/var/lib/ctdb/ctdb.socket" \ op monitor interval="10" timeout="20" \ op start interval="0" timeout="200" \ op stop interval="0" timeout="100"crm(live)configure#primitivesmb systemd:smb \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#primitivenmb systemd:nmb \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#primitivewinbind systemd:winbind \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#groupg-ctdb ctdb winbind nmb smbcrm(live)configure#clonecl-ctdb g-ctdb meta interleave="true"crm(live)configure#commitTipp: Optionalenmb- undwinbind-PrimitiveWenn Sie keine Netzwerkfreigaben durchsuchen müssen, brauchen Sie das
nmb-Primitiv nicht zu aktivieren und zu starten.Das
winbind-Primitiv wird nur benötigt, wenn es als Active Directory-Domänenmitglied konfiguriert ist. Siehe Abschnitt 24.2, „Verbinden von Samba-Gateway und Active Directory“.Die Binärdatei
/usr/lib64/ctdb/ctdb_mutex_rados_helperin der Konfigurationsoptionctdb_recovery_lockenthält die Parameter CLUSTER_NAME, CEPHX_USER, RADOS_POOL und RADOS_OBJECT (in dieser Reihenfolge).Wenn Sie einen zusätzlichen Parameter für die Sperren-Zeitüberschreitung anhängen, können Sie den Standardwert (10 Sekunden) überschreiben. Bei einem höheren Wert wird die Failover-Zeit des CTDB Recovery Master verlängert, bei einem niedrigeren Wert wird der Recovery Master dagegen unter Umständen fälschlich als ausgefallen erkannt, sodass ein ungeplantes Failover ausgeführt wird.
Fügen Sie eine geclusterte IP-Adresse hinzu:
crm(live)configure#primitiveip ocf:heartbeat:IPaddr2 params ip=192.168.2.1 \ unique_clone_address="true" \ op monitor interval="60" \ meta resource-stickiness="0"crm(live)configure#clonecl-ip ip \ meta interleave="true" clone-node-max="2" globally-unique="true"crm(live)configure#colocationcol-with-ctdb 0: cl-ip cl-ctdbcrm(live)configure#ordero-with-ctdb 0: cl-ip cl-ctdbcrm(live)configure#commitWenn
unique_clone_addressauftruefestgelegt ist, fügt der Ressourcenagent IPaddr2 eine Klon-ID zur angegebenen Adresse hinzu, was zu drei verschiedenen IP-Adressen führt. Diese werden normalerweise nicht benötigt, sind jedoch nützlich beim Lastausgleich. Weitere Informationen zu diesem Thema finden Sie unter https://documentation.suse.com/sle-ha/15-SP2/html/SLE-HA-all/cha-ha-lb.html.Überprüfen Sie das Ergebnis:
root@earth #crmstatus Clone Set: base-clone [dlm] Started: [ factory-1 ] Stopped: [ factory-0 ] Clone Set: cl-ctdb [g-ctdb] Started: [ factory-1 ] Started: [ factory-0 ] Clone Set: cl-ip [ip] (unique) ip:0 (ocf:heartbeat:IPaddr2): Started factory-0 ip:1 (ocf:heartbeat:IPaddr2): Started factory-1Testen Sie es an einem Client-Rechner. Führen Sie auf einem Linux Client das folgende Kommando aus, um zu sehen, ob Sie Dateien vom und zum System kopieren können:
root #smbclient//192.168.2.1/myshare
24.1.3.1 Neustart der Hochverfügbarkeits-Samba-Ressourcen #
Nach einer Änderung der Samba- oder CTDB-Konfiguration müssen die Hochverfügbarkeits-Ressourcen möglicherweise neu gestartet werden, damit die Änderungen wirksam werden. Dies lässt sich durch folgende Methoden erreichen:
root #crmresource restart cl-ctdb
24.2 Verbinden von Samba-Gateway und Active Directory #
Sie können den Ceph Samba Gateway als Mitglied der Samba-Domäne mit Active Directory(AD)-Unterstützung konfigurieren. Als Samba-Domänenmitglied können Sie Domänenbenutzer und Gruppen in lokalen Zugriffssteuerungslisten (ACLs) für Dateien und Verzeichnisse aus dem exportierten CephFS verwenden.
24.2.1 Vorbereiten der Samba-Konfiguration #
Dieser Abschnitt enthält die vorbereitenden Schritte vor der eigentlichen Samba-Konfiguration. Der Einstieg mit einer sauberen Umgebung trägt dazu bei, eventuelle Verwirrungen zu vermeiden, und sorgt dafür, dass keine Dateien aus der früheren Samba-Installation mit der neuen Domänenmitglieds-Installation vermischt werden.
Die Uhren aller Samba Gateway Knoten müssen mit dem Active Directory-Domänencontroller synchronisiert werden. Ein Taktversatz kann zu Authentifizierungsfehlern führen.
Es dürfen keine Samba- oder Name-Caching-Prozesse ausgeführt werden:
cephuser@smb > ps ax | egrep "samba|smbd|nmbd|winbindd|nscd"
Wenn samba-, smbd-, nmbd-, winbindd- oder nscd-Prozesse in der Ausgabe aufgeführt werden, halten Sie diese Prozesse.
Wenn zuvor eine Samba-Installation auf diesem Host ausgeführt wurde, entfernen Sie die Datei /etc/samba/smb.conf. Entfernen Sie auch alle Samba-Datenbankdateien, z. B. *.tdb- und *.ldb-Dateien. Mit folgendem Kommando rufen Sie eine Liste der Verzeichnisse ab, in denen sich Samba-Datenbanken befinden:
cephuser@smb > smbd -b | egrep "LOCKDIR|STATEDIR|CACHEDIR|PRIVATE_DIR"24.2.2 Überprüfen des DNS #
Active Directory (AD) sucht mithilfe des DNS nach anderen Domänencontrollern (DCs) und Services wie Kerberos. Die AD-Domänenmitglieder und Server müssen daher in der Lage sein, die AD-DNS-Zonen aufzulösen.
Prüfen Sie, ob der DNS ordnungsgemäß konfiguriert wurde und ob sowohl die Vorwärts- als auch die Rückwärtssuche fehlerfrei aufgelöst werden, beispielsweise:
cephuser@adm > nslookup DC1.domain.example.com
Server: 10.99.0.1
Address: 10.99.0.1#53
Name: DC1.domain.example.com
Address: 10.99.0.1cephuser@adm > 10.99.0.1
Server: 10.99.0.1
Address: 10.99.0.1#53
1.0.99.10.in-addr.arpa name = DC1.domain.example.com.24.2.3 Auflösen von SRV-Datensätzen #
AD sucht mithilfe des SRV nach Services wie Kerberos und LDAP. Prüfen Sie mit der interaktiven nslookup-Shell, ob die SRV-Datensätze fehlerfrei aufgelöst werden, beispielsweise:
cephuser@adm > nslookup
Default Server: 10.99.0.1
Address: 10.99.0.1
> set type=SRV
> _ldap._tcp.domain.example.com.
Server: UnKnown
Address: 10.99.0.1
_ldap._tcp.domain.example.com SRV service location:
priority = 0
weight = 100
port = 389
svr hostname = dc1.domain.example.com
domain.example.com nameserver = dc1.domain.example.com
dc1.domain.example.com internet address = 10.99.0.124.2.4 Kerberos konfigurieren #
Samba unterstützt Heimdal- und MIT-Kerberos-Back-Ends. Zum Konfigurieren von Kerberos auf dem Domänenmitglied legen Sie Folgendes in der Datei /etc/krb5.conf fest:
[libdefaults] default_realm = DOMAIN.EXAMPLE.COM dns_lookup_realm = false dns_lookup_kdc = true
Im obigen Exempel wird Kerberos für den Bereich DOMAIN.EXAMPLE.COM konfiguriert. Es wird nicht empfohlen, weitere Parameter in der Datei /etc/krb5.conf festzulegen. Wenn die Datei /etc/krb5.conf eine Zeile include enthält, funktioniert sie nicht; Sie müssen diese Zeile entfernen.
24.2.5 Auflösen des Namens des lokalen Hosts #
Wenn Sie einen Host in die Domäne aufnehmen, versucht Samba, den Hostnamen in der AT-DNS-Zone zu registrieren. Hierzu muss das Dienstprogramm net in der Lage sein, den Hostnamen mit DNS oder mit einem passenden Eintrag in der Datei /etc/hosts aufzulösen.
Prüfen Sie mit dem Kommando getent hosts, ob der Hostname fehlerfrei aufgelöst wird:
cephuser@adm > getent hosts example-host
10.99.0.5 example-host.domain.example.com example-host
Der Hostname und der FQDN dürfen nicht zur IP-Adresse 127.0.0.1 oder zu einer anderen IP-Adresse aufgelöst werden, die nicht mit der IP-Adresse der LAN-Schnittstelle des Domänenmitglieds übereinstimmt. Wenn keine Ausgabe angezeigt oder der Host zu einer falschen IP-Adresse aufgelöst wird und Sie nicht mit DHCP arbeiten, legen Sie den richtigen Eintrag in der Datei /etc/hosts fest:
127.0.0.1 localhost 10.99.0.5 example-host.samdom.example.com example-host
/etc/hosts
Wenn Sie DHCP verwenden, darf /etc/hosts nur die Zeile „127.0.0.1“ enthalten. Bleiben die Probleme weiterhin bestehen, wenden Sie sich an den Administrator Ihres DHCP-Servers.
Sollen Aliasnamen für den Namen des Computers eingefügt werden, tragen Sie sie am Ende der Zeile ein, die mit der IP-Adresse des Computers beginnt, nicht in die Zeile „127.0.0.1“.
24.2.6 Konfigurieren von Samba #
In diesem Abschnitt werden spezielle Konfigurationsoptionen vorgestellt, die Sie in die Samba-Konfiguration aufnehmen müssen.
Die Active Directory-Domänenmitgliedschaft wird in erster Linie durch die Einstellung Sicherheit = ADS zusammen mit den entsprechenden Parametern für die Zuordnung von Kerberos-Bereich und ID im Abschnitt [global] der Datei /etc/samba/smb.conf konfiguriert.
[global] security = ADS workgroup = DOMAIN realm = DOMAIN.EXAMPLE.COM ...
24.2.6.1 Auswahl des Back-Ends für die ID-Zuordnung in winbindd #
Wenn die Benutzer unterschiedliche Login-Shells und/oder Unix-Basisverzeichnispfade erhalten oder stets dieselbe ID nutzen sollen, verwenden Sie das winbind-Back-End „ad“ und nehmen Sie RFC2307-Attribute in AD auf.
Die RFC2307-Attribute werden beim Erstellen von Benutzern oder Gruppen nicht automatisch hinzugefügt.
Die ID-Nummern auf einem DC (Nummern im Bereich ab 3.000.000) sind keine RFC2307-Attribute und werden nicht auf Unix-Domänenmitgliedern verwendet. Sollen stets dieselben ID-Nummern gelten, nehmen Sie die Attribute uidNumber und gidNumber in AD auf und verwenden Sie das winbind-Back-End „ad“ auf Unix-Domänenmitgliedern. Sollen die Attribute uidNumber und gidNumber dennoch in AD aufgenommen werden, geben Sie keine Zahlen im Bereich ab 3.000.000 an.
Wenn Ihre Benutzer den Samba-AD-DC lediglich zur Authentifizierung heranziehen, also keine Daten dort speichern und sich nicht dort anmelden, können Sie das winbind-Back-End „rid“ heranziehen. Hiermit werden die Benutzer- und Gruppen-IDs über die Windows*-RID berechnet. Wenn Sie auf jedem Unix-Domänenmitglied denselben Abschnitt [global] in der Datei smb.conf nutzen, erhalten Sie stets dieselben IDs. Beim Back-End „rid“ müssen Sie keine Ergänzungen in AD vornehmen und die RFC2307-Attribute werden ignoriert. Legen Sie beim Back-End „rid“ die Parameter template shell und template homedir in smb.conf fest. Diese Einstellungen gelten global und alle Benutzer erhalten dieselbe Login-Shell und denselben Unix-Basisverzeichnispfad (im Gegensatz zu den RFC2307-Attributen, mit denen Sie individuelle Unix-Basisverzeichnispfade und Shells angeben können).
Für die Einrichtung von Samba steht eine weitere Möglichkeit zur Auswahl: Ihre Benutzer und Gruppen erhalten stets dieselbe ID, doch nur die Benutzer erhalten jeweils dieselbe Login-Shell und denselben Unix-Basisverzeichnispfad. Dies erreichen Sie mit dem winbind-Back-End „ad“ und den Schablonenzeilen in smb.conf. So müssen Sie lediglich die Attribute uidNumber und gidNumber in AD aufnehmen.
Weitere Informationen zu den verfügbaren Back-Ends für die ID-Zuordnung finden Sie auf den jeweiligen Handbuchseiten: man 8 idmap_ad, man 8 idmap_rid und man 8 idmap_autorid.
24.2.6.2 Einrichten der Benutzer- und Gruppen-ID-Bereiche #
Sobald Sie sich für ein winbind-Back-End entschieden haben, legen Sie die Bereiche für die Option idmap config in smb.conf fest. Auf einem Unix-Domänenmitglied sind standardmäßig mehrere Blöcke mit Benutzer- und Gruppen-IDs reserviert:
| IDs | Bereich |
|---|---|
| 0-999 | Lokale Systembenutzer und -gruppen. |
| Ab 1.000 | Lokale UNIX-Benutzer und -Gruppen. |
| Ab 10.000 | DOMAIN-Benutzer und -Gruppen. |
Wie aus den obigen Bereichen hervorgeht, darf weder der Bereich „*“ noch der Bereich „DOMAIN“ bei 999 oder weniger beginnen, da diese IDs mit den lokalen Systembenutzern und -gruppen in Konflikt kämen. Lassen Sie außerdem genug Platz für lokale Unix-Benutzer und -Gruppen. idmap config-Bereiche ab 3.000 sind daher ein guter Kompromiss.
Überlegen Sie, inwieweit Ihre „DOMAIN“ noch wachsen wird und ob Sie verbürgte Domänen einplanen sollten. Anschließend können Sie die idmap config-Bereiche wie folgt festlegen:
| Domäne | Bereich |
|---|---|
| * | 3000-7999 |
| DOMAIN | 10000-999999 |
| TRUSTED | 1000000-9999999 |
24.2.6.3 Zuordnen des Domänenadministrator-Kontos zum lokalen root-Benutzer #
In Samba können Sie Domänenkonten einem lokalen Konto zuordnen. Mit dieser Funktion können Sie Dateioperationen als ein anderer Benutzer auf dem Dateisystem des Domänenmitglieds ausführen, also nicht mit dem Konto, das die betreffende Operation auf dem Client angefordert hat.
Die Zuordnung des Domänenadministrators zum lokalen root-Konto ist optional. Konfigurieren Sie die Zuordnung nur dann, wenn der Domänenadministrator in der Lage sein muss, Dateioperationen auf dem Domänenmitglied mit root-Berechtigungen auszuführen. Beachten Sie, dass Sie sich auch nach Zuordnung des Administrators zum root-Konto nicht als „Administrator“ bei Unix-Domänenmitgliedern anmelden können.
So ordnen Sie den Domänenadministrator dem lokalen root-Konto zu:
Tragen Sie den folgenden Parameter im Abschnitt
[global]der Dateismb.confein:username map = /etc/samba/user.map
Erstellen Sie die Datei
/etc/samba/user.mapmit folgendem Inhalt:!root = DOMAIN\Administrator
Wenn Sie das ID-Zuordnungs-Back-End „ad“ verwenden, legen Sie nicht das Attribut uidNumber für das Domänenadministratorkonto fest. Ist das Attribut für das Konto festgelegt, überschreibt der Wert die lokale UID „0“ des root-Benutzers und die Zuordnung schlägt fehl.
Weitere Informationen finden Sie unter dem Parameter username map auf der Handbuchseite zu smb.conf (man 5 smb.conf).
24.2.7 Einbindung in die Active Directory-Domäne #
Mit folgendem Kommando binden Sie den Host in Active Directory ein:
cephuser@smb > net ads join -U administrator
Enter administrator's password: PASSWORD
Using short domain name -- DOMAIN
Joined EXAMPLE-HOST to dns domain 'DOMAIN.example.com'24.2.8 Konfigurieren des Name Service Switch (NSS) #
Domänenbenutzer und -gruppen stehen nur dann im lokalen System zur Verfügung, wenn Sie die NSS-Bibliothek (Name Service Switch) aktivieren. Ergänzen Sie die folgenden Datenbanken in der Datei /etc/nsswitch.conf mit dem Eintrag winbind:
passwd: files winbind group: files winbind
Behalten Sie den Eintrag
filesals erste Quelle für beide Datenbanken bei. So kann NSS die Domänenbenutzer und -gruppen in den Dateien/etc/passwdund/etc/groupnachschlagen, bevor eine Abfrage an denwinbind-Dienst erfolgt.Nehmen Sie den Eintrag
winbindnicht in die NSS-Shadow-Datenbank auf. Dies kann dazu führen, dass daswbinfo-Dienstprogramm fehlschlägt.Verwenden Sie in der lokalen Datei
/etc/passwdnicht dieselben Benutzernamen wie in der Domäne.
24.2.9 Starten der Services #
Starten Sie nach den Änderungen an der Konfiguration die Samba-Services neu. Weitere Informationen hierzu finden Sie in Abschnitt 24.1.2.1, „Starten von Samba-Services“ oder in Abschnitt 24.1.3.1, „Neustart der Hochverfügbarkeits-Samba-Ressourcen“.
24.2.10 Testen der winbindd-Konnektivität #
24.2.10.1 Senden eines winbindd-Pings #
So prüfen Sie, ob der winbindd-Service eine Verbindung zu AD-Domänencontrollern (DC) oder zu einem Primärdomänencontroller (PDC) herstellen kann:
cephuser@smb > wbinfo --ping-dc
checking the NETLOGON for domain[DOMAIN] dc connection to "DC.DOMAIN.EXAMPLE.COM" succeeded
Falls das obige Kommando fehlschlägt, prüfen Sie, ob der winbindd-Service ausgeführt wird und die Datei smb.conf ordnungsgemäß eingerichtet ist.
24.2.10.2 Nachschlagen von Domänenbenutzern und -gruppen #
Mithilfe der Bibliothek libnss_winbind können Sie Domänenbenutzer und -gruppen nachschlagen. So schlagen Sie beispielsweise den Domänenbenutzer „DOMAIN\demo01“ nach:
cephuser@smb > getent passwd DOMAIN\\demo01
DOMAIN\demo01:*:10000:10000:demo01:/home/demo01:/bin/bashSo schlagen Sie die Domänengruppe „Domain Users“ nach:
cephuser@smb > getent group "DOMAIN\\Domain Users"
DOMAIN\domain users:x:10000:24.2.10.3 Zuweisen von Dateiberechtigungen zu Domänenbenutzern und -gruppen #
Mithilfe der NSS-Bibliothek (Name Service Switch) können Sie Domänenbenutzerkonten und -gruppen in Kommandos heranziehen. So legen Sie beispielsweise den Domänenbenutzer „demo01“ als Eigentümer einer Datei und die Domänengruppe „Domain Users“ als Gruppe fest:
cephuser@smb > chown "DOMAIN\\demo01:DOMAIN\\domain users" file.txt25 NFS Ganesha #
NFS Ganesha ist ein NFS-Server, der in einem Benutzeradressenbereich statt als Teil des Betriebssystem-Kernels ausgeführt wird. Mit NFS Ganesha binden Sie Ihren eigenen Speichermechanismus ein, wie zum Beispiel Ceph, und greifen von einem beliebigen NFS Client darauf zu. Die Installationsanweisungen finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.3.6 “Bereitstellen von NFS Ganesha”.
Angesichts des erhöhten Protokoll-Overheads und der zusätzlichen Latenz durch zusätzliche Netzwerk-Hops zwischen Client und Speicher kann ein Zugriff auf Ceph über einen NFS-Gateway die Anwendungsleistung im Vergleich zu einem nativen CephFS erheblich senken.
Jeder NFS-Ganesha-Dienst besteht aus einer Konfigurationshierarchie, die Folgendes enthält:
Einen Bootstrap
ganesha.confEin gemeinsames RADOS-Konfigurationsobjekt pro Service
Ein RADOS-Konfigurationsobjekt pro Export
Die Bootstrap-Konfiguration ist die Minimalkonfiguration zum Starten des nfs-ganesha-Daemons innerhalb eines Containers. Jede Bootstrap-Konfiguration enthält eine %url-Anweisung, die jede zusätzliche Konfiguration aus dem gemeinsamen RADOS-Konfigurationsobjekt enthält. Das gemeinsame Konfigurationsobjekt kann zusätzliche %url-Anweisungen für jeden der NFS-Exporte enthalten, die in den RADOS-Konfigurationsobjekten definiert sind.

25.1 Erstellen eines NFS-Service #
Die Spezifikation der Bereitstellung von Ceph-Services erfolgt am besten durch Erstellen einer YAML-formatierten Datei mit der Spezifikation der Services, die Sie bereitstellen möchten. Sie können für jeden Servicetyp eine eigene Spezifikationsdatei erstellen, oder Sie geben mehrere (oder alle) Servicetypen in einer Datei an.
Je nachdem, wofür Sie sich entschieden haben, müssen Sie eine entsprechende YAML-formatierte Datei aktualisieren oder erstellen, um einen NFS-Ganesha-Dienst anzulegen. Weitere Informationen zum Erstellen der Datei finden Sie im Book “Implementierungsleitfaden”, Chapter 5 “Bereitstellung mit cephadm”, Section 5.4.2 “Service- und Platzierungsspezifikation”.
Nachdem Sie die Datei aktualisiert oder erstellt haben, erstellen Sie mit folgendem Kommando einen nfs-ganesha-Dienst:
cephuser@adm > ceph orch apply -i FILE_NAME25.2 Starten oder Neustarten von NFS Ganesha #
Führen Sie zum Starten des NFS-Ganesha-Diensts folgendes Kommando aus:
cephuser@adm > ceph orch start nfs.SERVICE_IDFühren Sie für einen Neustart des NFS-Ganesha-Diensts folgendes Kommando aus:
cephuser@adm > ceph orch restart nfs.SERVICE_IDFalls Sie nur einen einzelnen NFS-Ganesha-Daemon neu starten möchten, führen Sie folgendes Kommando aus:
cephuser@adm > ceph orch daemon restart nfs.SERVICE_IDWenn NFS Ganesha gestartet oder neu gestartet wird, hat es eine Kulanzzeitüberschreitung von 90 Sekunden für NFS v4. Während des Kulanzzeitraums werden neue Anforderungen von Clients aktiv abgelehnt. Somit werden die Anforderungen der Clients möglicherweise verzögert, wenn sich NFS im Kulanzzeitraum befindet.
25.3 Auflisten von Objekten im NFS-Wiederherstellungspool #
Listen Sie die Objekte im NFS-Widerherstellungspool mit folgendem Kommando auf:
cephuser@adm > rados --pool POOL_NAME --namespace NAMESPACE_NAME ls25.4 Erstellen eines NFS-Exports #
Erstellen Sie einen NFS-Export mit folgendem Kommando.
Der FSAL-Block sollte so geändert werden, dass er die gewünschte cephx-Benutzer-ID und den geheimen Zugangsschlüssel enthält.
cephuser@adm > rados --pool POOL_NAME --namespace NAMESPACE_NAME put export-1 export-125.5 Überprüfen des NFS-Exports #
NFS v4 erstellt eine Liste von Exporten im Stamm eines Pseudodateisystems. Sie können überprüfen, ob die NFS-Freigaben exportiert werden. Hängen Sie dazu / des NFS-Ganesha-Serverknotens ein:
root #mount-t nfs nfs_ganesha_server_hostname:/ /path/to/local/mountpointroot #ls/path/to/local/mountpoint cephfs
Standardmäßig konfiguriert cephadm einen NFS-v4-Server. NFS v4 interagiert weder mit rpcbind noch mit dem mountd-Daemon. NFS-Client-Tools wie showmount zeigen keine konfigurierten Exporte an.
25.6 Einhängen des NFS-Exports #
Führen Sie zum Einhängen der exportierten NFS-Freigabe auf einem Client-Host folgendes Kommando aus:
root #mount-t nfs nfs_ganesha_server_hostname:/ /path/to/local/mountpoint
25.7 Mehrere NFS-Ganesha-Cluster #
Es können mehrere NFS-Ganesha-Cluster definiert werden. Dies ermöglicht:
Getrennte NFS-Ganesha-Cluster für den Zugriff auf CephFS.
Teil V Integration in Virtualisierungstools #
- 26
libvirtund Ceph Die libvirt-Bibliothek erstellt eine Abstraktionsschicht einer virtuellen Maschine zwischen den Hypervisor-Schnittstellen und den Softwareanwendungen, die sie verwenden. Mit libvirt können sich Entwickler und Systemadministratoren auf ein gemeinsames Verwaltungs-Framework, eine gemeinsame API und di…
- 27 Ceph als Back-End für die QEMU KVM-Instanz
Der häufigste Anwendungsfall von Ceph ist die Bereitstellung von Blockgeräte-Images für virtuelle Maschinen. Ein Benutzer erstellt beispielsweise ein Klon-Image („Golden Image“) mit Betriebssystem und der relevanten Software in einer idealen Konfiguration. Dann erstellt der Benutzer einen Snapshot d…
26 libvirt und Ceph #
Die libvirt-Bibliothek erstellt eine Abstraktionsschicht einer virtuellen Maschine zwischen den Hypervisor-Schnittstellen und den Softwareanwendungen, die sie verwenden. Mit libvirt können sich Entwickler und Systemadministratoren auf ein gemeinsames Verwaltungs-Framework, eine gemeinsame API und die gemeinsame Shell-Schnittstelle (virsh) zu vielen verschiedenen Hypervisoren konzentrieren, einschließlich QEMU/KVM, Xen, LXC oder VirtualBox.
Ceph-Blockgeräte unterstützen QEMU/KVM. Ceph-Blockgeräte können mit Software verwendet werden, die eine Schnittstelle zu libvirt darstellen. Die Cloud-Lösung verwendet libvirt zur Interaktion mit QEMU/KVM, das wiederum mit Ceph-Blockgeräten über librbd interagiert.
Erstellen Sie VMs, die Ceph-Blockgeräte verwenden, anhand der folgenden Verfahren. In den Beispielen haben wir libvirt-pool als Poolnamen, client.libvirt als Benutzernamen und new-libvirt-image als Image-Namen verwendet. Sie können jeden gewünschten Wert verwenden, doch ersetzen Sie auf jeden Fall diese Werte, wenn sie Kommandos in den folgenden Verfahren ausführen.
26.1 Konfigurieren von Ceph mit libvirt #
Führen Sie zum Konfigurieren von Ceph zur Verwendung mit libvirt die folgenden Schritte aus:
Erstellen Sie einen Pool. Im folgenden Beispiel wird der Poolname
libvirt-poolmit 128 Placement Groups verwendet.cephuser@adm >ceph osd pool create libvirt-pool 128 128Verifizieren Sie, dass der Pool vorhanden ist.
cephuser@adm >ceph osd lspoolsErstellen Sie einen Ceph-Benutzer. Das folgende Beispiel verwendet den Ceph-Benutzernamen
client.libvirtund verweist auflibvirt-pool.cephuser@adm >ceph auth get-or-create client.libvirt mon 'profile rbd' osd \ 'profile rbd pool=libvirt-pool'Verifizieren Sie, dass der Name vorhanden ist.
cephuser@adm >ceph auth listAnmerkung: Benutzername oder IDlibvirtgreift auf Ceph mit der IDlibvirtzu, nicht mit dem Ceph-Namenclient.libvirt. Unter Abschnitt 30.2.1.1, „Benutzer“ finden Sie eine detaillierte Erklärung zum Unterschied zwischen ID und Name.Erstellen Sie ein Image in Ihrem RBD-Pool mit QEMU. Das folgende Beispiel verwendet den Image-Namen
new-libvirt-imageund verweist auflibvirt-pool.Tipp: Speicherort der SchlüsselbunddateiDer Benutzerschlüssel
libvirtist in einer Schlüsselbunddatei im Verzeichnis/etc/cephgespeichert. Die Schlüsselbunddatei muss einen geeigneten Namen aufweisen, der den Namen des Ceph-Clusters enthält, zu dem sie gehört. Für den Standard-Cluster-Namen „ceph“ lautet der Name der Schlüsselbunddatei/etc/ceph/ceph.client.libvirt.keyring.Wenn der Schlüsselbund nicht vorhanden ist, erstellen Sie ihn mit:
cephuser@adm >ceph auth get client.libvirt > /etc/ceph/ceph.client.libvirt.keyringroot #qemu-img create -f raw rbd:libvirt-pool/new-libvirt-image:id=libvirt 2GVerifizieren Sie, dass das Image vorhanden ist.
cephuser@adm >rbd -p libvirt-pool ls
26.2 Vorbereiten des VM-Managers #
libvirt kann zwar ohne VM-Manager verwendet werden, doch es ist möglicherweise für Sie einfacher, wenn Sie Ihre erste Domäne mitvirt-manager erstellen.
Installieren Sie einen Manager für virtuelle Maschinen.
root #zypper in virt-managerBereiten Sie ein Betriebssystem-Image des Systems vor, das Sie virtualisiert ausführen möchten, oder laden Sie es herunter.
Starten Sie den VM-Manager.
virt-manager
26.3 Erstellen einer VM #
Führen Sie zum Erstellen einer VM mit virt-manager die folgenden Schritte aus:
Wählen Sie die Verbindung aus der Liste aus, klicken Sie mit der rechten Maustaste darauf und wählen Sie aus.
, indem Sie den Pfad zum bestehenden Speicher angeben. Geben Sie den Betriebssystemtyp, die Arbeitsspeichereinstellungen und den der virtuellen Maschine an, beispielsweise
libvirt-virtual-machine.Stellen Sie die Konfiguration fertig und starten Sie die VM.
Verifizieren Sie mit
sudo virsh list, dass die neu erstellte Domäne vorhanden ist. Geben Sie die Verbindungszeichenkette wie folgt an, falls erforderlich:virsh -c qemu+ssh://root@vm_host_hostname/system listId Name State ----------------------------------------------- [...] 9 libvirt-virtual-machine runningMelden Sie sich bei der VM an und stoppen Sie sie, bevor Sie sie zur Verwendung mit Ceph konfigurieren.
26.4 Konfigurieren der VM #
In diesem Kapitel konzentrieren wir uns auf die Konfiguration von VMs zur Integration in Ceph über virsh. Für virsh-Kommandos werden oft Root-Berechtigungen (sudo) benötigt. Sie geben außerdem nicht die entsprechenden Ergebnisse zurück und benachrichtigen Sie auch nicht, dass Root-Berechtigungen erforderlich sind. Weitere Informationen zu den virsh-Kommandos finden Sie unter man 1 virsh (das Paket libvirt-client muss installiert sein).
Öffnen Sie die Konfigurationsdatei mit
virsh editvm-domain-name.root #virsh edit libvirt-virtual-machineUnter <devices> sollte ein <disk>-Eintrag vorhanden sein.
<devices> <emulator>/usr/bin/qemu-system-SYSTEM-ARCH</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw'/> <source file='/path/to/image/recent-linux.img'/> <target dev='vda' bus='virtio'/> <address type='drive' controller='0' bus='0' unit='0'/> </disk>Ersetzen Sie
/path/to/image/recent-linux.imgdurch den Pfad zum Betriebssystem-Image.WichtigVerwenden Sie
sudo virsh editanstelle eines Texteditors. Wenn Sie die Konfigurationsdatei unter/etc/libvirt/qemumit einem Texteditor ändern, erkenntlibvirtdie Änderung möglicherweise nicht. Wenn eine Diskrepanz zwischen dem Inhalt der XML-Datei unter/etc/libvirt/qemuund dem Ergebnis aussudo virsh dumpxmlvm-domain-name auftritt, funktioniert Ihre VM möglicherweise nicht ordnungsgemäß.Fügen Sie das vorher erstellte Ceph RBD-Image als <disk>-Eintrag hinzu.
<disk type='network' device='disk'> <source protocol='rbd' name='libvirt-pool/new-libvirt-image'> <host name='monitor-host' port='6789'/> </source> <target dev='vda' bus='virtio'/> </disk>Ersetzen Sie monitor-host durch den Namen Ihres Hosts und ersetzen Sie den Pool und/oder den Image-Namen wie erforderlich. Sie haben die Möglichkeit, für Ihre Ceph Monitors mehrere <Host>-Einträge hinzuzufügen. Das
dev-Attribut ist der logische Gerätename, der unter dem/dev-Verzeichnis Ihrer VM angezeigt wird. Das optionale Busattribut gibt den Typ des zu emulierenden Datenträgergeräts an. Die gültigen Einstellungen sind treiberspezifisch (zum Beispiel ide, scsi, virtio, xen, usb oder sata).Datei speichern.
Wenn bei Ihrem Ceph-Cluster die Authentifizierung aktiviert ist (was standardmäßig der Fall ist), dann müssen Sie ein Geheimnis generieren. Öffnen Sie den Editor Ihrer Wahl und erstellen Sie eine Datei namens
secret.xmlmit folgendem Inhalt:<secret ephemeral='no' private='no'> <usage type='ceph'> <name>client.libvirt secret</name> </usage> </secret>Definieren Sie das Geheimnis.
root #virsh secret-define --file secret.xml <uuid of secret is output here>Rufen Sie den
client.libvirt-Schlüssel ab und speichern Sie die Schlüsselzeichenkette in eine Datei.cephuser@adm >ceph auth get-key client.libvirt | sudo tee client.libvirt.keyLegen Sie die UUID für das Geheimnis fest.
root #virsh secret-set-value --secret uuid of secret \ --base64 $(cat client.libvirt.key) && rm client.libvirt.key secret.xmlSie müssen auch das Geheimnis manuell festlegen. Fügen Sie dazu den folgenden
<auth>-Eintrag zum vorher eingegebenen<disk>-Element hinzu (was den UUID-Wert durch das Ergebnis aus dem oben genannten Kommandozeilenbeispiel ersetzt).root #virsh edit libvirt-virtual-machineFügen Sie dann das
<auth></auth>-Element zur Konfigurationsdatei der Domäne hinzu:... </source> <auth username='libvirt'> <secret type='ceph' uuid='9ec59067-fdbc-a6c0-03ff-df165c0587b8'/> </auth> <target ...AnmerkungDie Beispiel-ID ist
libvirt, nicht der Ceph-Nameclient.libvirtwie in Schritt 2 in Abschnitt 26.1, „Konfigurieren von Ceph mitlibvirt“ generiert. Stellen Sie sicher, dass Sie die ID-Komponente des generierten Ceph-Namens verwenden. Wenn Sie aus irgendeinem Grund das Geheimnis neu generieren müssen, dann müssen Siesudo virsh secret-undefineuuid ausführen, bevor Siesudo virsh secret-set-valueerneut ausführen.
26.5 Zusammenfassung #
Sie können die VM starten, sobald Sie die VM zur Verwendung mit Ceph konfiguriert haben. Führen Sie die folgenden Schritte aus, um zu verifizieren, dass die VM und Ceph miteinander kommunizieren.
Prüfen Sie, ob Ceph ausgeführt wird:
cephuser@adm >ceph healthPrüfen Sie, ob die VM ausgeführt wird:
root #virsh listPrüfen Sie, ob die VM mit Ceph kommuniziert: Ersetzen Sie vm-domain-name durch den Namen Ihrer VM-Domäne:
root #virsh qemu-monitor-command --hmp vm-domain-name 'info block'Überprüfen Sie, ob das Gerät vom
&target dev='hdb' bus='ide'/>unter/devoder unter/proc/partitionserscheint:tux >ls /devtux >cat /proc/partitions
27 Ceph als Back-End für die QEMU KVM-Instanz #
Der häufigste Anwendungsfall von Ceph ist die Bereitstellung von Blockgeräte-Images für virtuelle Maschinen. Ein Benutzer erstellt beispielsweise ein Klon-Image („Golden Image“) mit Betriebssystem und der relevanten Software in einer idealen Konfiguration. Dann erstellt der Benutzer einen Snapshot des Image. Schließlich klont der Benutzer den Snapshot (normalerweise viele Male, weitere detaillierte Informationen finden Sie in Abschnitt 20.3, „Aufnahmen“). Die Fähigkeit zum Erstellen von Klonen aus Snapshots durch Kopien beim Schreibvorgang bedeutet, dass Ceph schnell Blockgeräte-Images für virtuelle Maschinen bereitstellen kann, weil der Client nicht bei jeder Erstellung einer neuen virtuellen Maschine ein gesamtes Image herunterladen muss.
Ceph-Blockgeräte können in virtuelle QEMU-Maschinen integriert werden. Weitere Informationen zu QEMU KVM finden Sie unter https://documentation.suse.com/sles/15-SP2/html/SLES-all/part-virt-qemu.html.
27.1 Installieren von qemu-block-rbd #
Zur Verwendung von Ceph-Blockgeräten muss für QEMU der entsprechende Treiber installiert sein. Prüfen Sie, ob das Paket qemu-block-rbd installiert ist und installieren Sie es, falls erforderlich:
root # zypper install qemu-block-rbd27.2 Verwenden von QEMU #
In der QEMU-Kommandozeile müssen Sie den Poolnamen und den Image-Namen angeben. Sie können außerdem auch einen Snapshot-Namen angeben.
qemu-img command options \ rbd:pool-name/image-name@snapshot-name:option1=value1:option2=value2...
Beispielsweise könnte die Angabe der Optionen id und conf wie folgt aussehen:
qemu-img command options \
rbd:pool_name/image_name:id=glance:conf=/etc/ceph/ceph.conf27.3 Erstellen von Images mit QEMU #
Sie können ein Blockgeräte-Image von QEMU aus erstellen. Sie müssen rbd, den Poolnamen und den Namen des zu erstellenden Image angeben. Sie müssen auch die Größe des Image angeben.
qemu-img create -f raw rbd:pool-name/image-name size
Beispiel:
qemu-img create -f raw rbd:pool1/image1 10G Formatting 'rbd:pool1/image1', fmt=raw size=10737418240 nocow=off cluster_size=0
Das Datenformat raw ist wirklich die einzige sinnvolle Formatoption für RBD. Eigentlich könnten Sie auch andere QEMU-unterstützte Formate verwenden wie qcow2, doch das würde zusätzlichen Overhead bedeuten. Außerdem würde bei Live-Migration der virtuellen Maschine das Volume unsicher, wenn Caching aktiviert ist.
27.4 Ändern der Größe von Images mit QEMU #
Sie können die Größe eines Blockgeräte-Images von QEMU aus ändern. Sie müssen rbd, den Poolnamen und den Namen des Image angeben, dessen Größe geändert werden soll. Sie müssen auch die Größe des Image angeben.
qemu-img resize rbd:pool-name/image-name size
Beispiel:
qemu-img resize rbd:pool1/image1 9G Image resized.
27.5 Abrufen von Image-Informationen mit QEMU #
Sie können die Informationen zum Blockgeräte-Image von QEMU aus abrufen. Sie müssen dazu rbd, den Poolnamen und den Namen des Image angeben.
qemu-img info rbd:pool-name/image-name
Beispiel:
qemu-img info rbd:pool1/image1 image: rbd:pool1/image1 file format: raw virtual size: 9.0G (9663676416 bytes) disk size: unavailable cluster_size: 4194304
27.6 Ausführen von QEMU mit RBD #
QEMU kann auf ein Image als virtuelles Blockgerät direkt über librbd zugreifen. Dadurch wird ein zusätzlicher Kontextschalter vermieden und Sie können vom RBD-Caching profitieren.
Zum Konvertieren der bestehenden Images von virtuellen Maschinen zu Ceph-Blockgeräte-Images kann qemu-img verwendet werden. Wenn Sie beispielsweise über ein qcow2-Image verfügen, könnten Sie folgendes Kommando ausführen:
qemu-img convert -f qcow2 -O raw sles12.qcow2 rbd:pool1/sles12
Mit folgendem Kommando könnten Sie eine virtuelle Maschine von diesem Image booten:
root # qemu -m 1024 -drive format=raw,file=rbd:pool1/sles12
RBD Caching kann die Leistung erheblich verbessern. Die Cache-Optionen von QEMU steuern das librbd-Caching:
root # qemu -m 1024 -drive format=rbd,file=rbd:pool1/sles12,cache=writebackWeitere Informationen zum RBD-Caching finden Sie in Abschnitt 20.5, „Cache-Einstellungen“.
27.7 Aktivieren und Verwerfen und TRIM #
Ceph-Blockgeräte unterstützen die Verwerfen-Operation. Dies bedeutet, dass ein Gast TRIM-Anforderungen senden kann, damit ein Ceph-Blockgerät nicht genutzten Speicherplatz freigibt. Dies kann beim Gast durch Einhängen von XFS mit der Verwerfen-Option aktiviert werden.
Damit dies für den Gast verfügbar ist, muss es explizit für das Blockgerät aktiviert sein. Dazu müssen Sie eine discard_granularity angeben, die mit dem Laufwerk verknüpft ist:
root # qemu -m 1024 -drive format=raw,file=rbd:pool1/sles12,id=drive1,if=none \
-device driver=ide-hd,drive=drive1,discard_granularity=512Im obigen Beispiel wird ein IDE-Treiber verwendet. Der virtio-Treiber unterstützt keine Verwerfen-Vorgänge.
Wenn Sie libvirt verwenden, bearbeiten Sie die Konfigurationsdatei Ihrer libvirt-Domäne mit virsh edit, um den Wert xmlns:qemu hinzuzufügen. Fügen Sie dann einen qemu:commandline block als untergeordnetes Element dieser Domäne hinzu. Im folgenden Beispiel sehen Sie, wie zwei Geräte mit qemu id= auf verschiedene discard_granularity-Werte festgelegt werden.
<domain type='kvm' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'> <qemu:commandline> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-0.discard_granularity=4096'/> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-1.discard_granularity=65536'/> </qemu:commandline> </domain>
27.8 Festlegen von QEMU-Cache-Optionen #
Die Cache-Optionen von QEMU entsprechen den folgenden Ceph RBD-Cache-Einstellungen.
Writeback:
rbd_cache = true
Writethrough:
rbd_cache = true rbd_cache_max_dirty = 0
kein Befehl:
rbd_cache = false
Die Cache-Einstellungen von QEMU überschreiben die Standardeinstellungen von Ceph (Einstellungen, die nicht explizit in der Ceph-Konfigurationsdatei festgelegt sind). Wenn Sie explizit die RBD Cache-Einstellungen in Ihrer Ceph-Konfigurationsdatei festlegen (siehe Abschnitt 20.5, „Cache-Einstellungen“), überschreiben Ihre Ceph-Einstellungen die QEMU-Cache-Einstellungen. Wenn Sie die Cache-Einstellungen in der QEMU-Kommandozeile festlegen, überschreiben die Einstellungen der QEMU-Kommandozeile die Einstellungen der Ceph-Konfigurationsdatei.
Teil VI Konfigurieren eines Clusters #
- 28 Konfiguration des Ceph-Clusters
In diesem Kapitel wird beschrieben, wie Sie den Ceph-Cluster mithilfe von Konfigurationsoptionen konfigurieren.
- 29 Ceph-Manager-Module
Der Funktionsumfang des Ceph Managers (kurze Einführung siehe Book “Implementierungsleitfaden”, Chapter 1 “SES und Ceph”, Section 1.2.3 “Ceph-Knoten und -Daemons”) kann dank seiner Architektur mithilfe von Modulen erweitert werden, z. B. „dashboard“ (siehe Teil I, „Ceph Dashboard“), „prometheus“ (si…
- 30 Authentifizierung mit
cephx Das Authentifizierungssystem cephx von Ceph dient dazu, Clients zu identifizieren und sie gegen Man-in-the-Middle-Angriffe zu schützen. Clients in diesem Kontext sind entweder Benutzer (wie zum Beispiel Administratoren) oder auf Ceph bezogene Services/Daemons (beispielsweise OSDs, Monitors oder Obje…
28 Konfiguration des Ceph-Clusters #
In diesem Kapitel wird beschrieben, wie Sie den Ceph-Cluster mithilfe von Konfigurationsoptionen konfigurieren.
28.1 Konfigurieren der Datei ceph.conf #
cephadm verwendet eine einfache ceph.conf-Datei, die nur einen minimalen Satz von Optionen für die Verbindung mit MONs, die Authentifizierung und das Abrufen von Konfigurationsinformationen enthält. In den meisten Fällen ist dies auf die Option mon_host beschränkt (obwohl dies durch die Verwendung von DNS-SRV-Datensätzen verhindert werden kann).
Die Datei ceph.conf dient nicht mehr als zentraler Ort zum Speichern der Cluster-Konfiguration, sondern zum Speichern der Konfigurationsdatenbank (weitere Informationen hierzu finden Sie in Abschnitt 28.2, „Konfigurationsdatenbank“).
Wenn Sie die Cluster-Konfiguration dennoch über die Datei ceph.conf ändern müssen (zum Beispiel, weil Sie einen Client verwenden, der das Lesen von Optionen aus der Konfigurationsdatenbank nicht unterstützt), müssen Sie folgendes Kommando ausführen und sich um die Pflege und Verteilung der Datei ceph.conf im gesamten Cluster kümmern:
cephuser@adm > ceph config set mgr mgr/cephadm/manage_etc_ceph_ceph_conf false28.1.1 Zugreifen auf ceph.conf innerhalb der Container-Images #
Obwohl Ceph-Daemons innerhalb von Containern ausgeführt werden, können Sie dennoch auf deren Konfigurationsdatei ceph.conf zugreifen. Sie ist auf dem Hostsystem als folgende Datei gebunden und eingehängt:
/var/lib/ceph/CLUSTER_FSID/DAEMON_NAME/config
Ersetzen Sie CLUSTER_FSID durch die eindeutige FSID des aktiven Clusters, wie sie vom Kommando ceph fsid zurückgegeben wird, und DAEMON_NAME durch den Namen des spezifischen Daemons, wie er vom Kommando ceph orch ps aufgeführt wird. Beispiel:
/var/lib/ceph/b4b30c6e-9681-11ea-ac39-525400d7702d/osd.2/config
Um die Konfiguration eines Daemons zu ändern, bearbeiten Sie seine config-Datei und starten Sie ihn neu:
root # systemctl restart ceph-CLUSTER_FSID-DAEMON_NAMEBeispiel:
root # systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d-osd.2Alle benutzerdefinierten Einstellungen gehen verloren, nachdem cephadm den Daemon neu bereitgestellt hat.
28.2 Konfigurationsdatenbank #
Ceph Monitors verwalten eine zentrale Datenbank mit Konfigurationsoptionen, die das Verhalten des gesamten Clusters beeinflussen.
28.2.1 Konfigurieren von Abschnitten und Masken #
Die vom MON gespeicherten Konfigurationsoptionen können sich in einem globalen Abschnitt, einem Abschnitt für den Daemon-Typ oder einem Abschnitt für den spezifischen Daemon befinden. Darüber hinaus können Optionen auch mit einer Maske verknüpft sein, um weiter einzuschränken, für welche Daemons oder Clients die Option gilt. Es gibt zwei Arten von Masken:
TYPE:LOCATION, wobei TYPE eine CRUSH-Eigenschaft wie
rackoderhostist, während LOCATION einen Wert für diese Eigenschaft bezeichnet.Zum Beispiel schränkt
host:example_hostdie Option nur auf Daemons oder Clients ein, die auf einem bestimmten Host ausgeführt werden.CLASS:DEVICE_CLASS, wobei DEVICE_CLASS für den Namen einer CRUSH-Geräteklasse steht wie
HDDoderSSD. Zum Beispiel beschränktclass:ssddie Option nur auf OSDs, die von SSDs gesichert werden. Für Nicht-OSD-Daemons oder -Clients hat diese Maske keine Wirkung.
28.2.2 Festlegen und Lesen von Konfigurationsoptionen #
Mit folgenden Kommandos legen Sie Cluster-Konfigurationsoptionen fest oder lesen sie: Der WHO-Parameter kann ein Abschnittsname, eine Maske oder eine Kombination aus beidem sein, getrennt durch einen Schrägstrich (/). Zum Beispiel steht osd/rack:foo für alle OSD-Daemons im Rack mit dem Namen foo.
ceph config dumpGibt die gesamte Konfigurationsdatenbank für einen ganzen Cluster aus.
ceph config get WHOGibt die Konfiguration für einen bestimmten Daemon oder Client (z. B.
mds.a) aus, wie sie in der Konfigurationsdatenbank gespeichert ist.ceph config set WHO OPTION VALUELegt die Konfigurationsoption auf den angegebenen Wert in der Konfigurationsdatenbank fest.
ceph config show WHOZeigt die gemeldete aktive Konfiguration für einen aktiven Daemon an. Diese Einstellungen können von denen abweichen, die von den Monitoren gespeichert werden, wenn auch lokale Konfigurationsdateien verwendet werden oder Optionen auf der Kommandozeile oder zur Laufzeit außer Kraft gesetzt wurden. Die Quelle der Optionswerte wird als Teil der Ausgabe gemeldet.
ceph config assimilate-conf -i INPUT_FILE -o OUTPUT_FILEImportiert eine als INPUT_FILE angegebene Konfigurationsdatei und speichert alle gültigen Optionen in der Konfigurationsdatenbank. Alle Einstellungen, die nicht erkannt werden, ungültig sind oder vom Monitor nicht gesteuert werden können, werden in einer verkürzten Datei zurückgegeben, die als OUTPUT_FILE gespeichert wird. Dieses Kommando ist nützlich für die Umstellung von älteren Konfigurationsdateien auf die zentralisierte monitorbasierte Konfiguration.
28.2.3 Konfigurieren von Daemons zur Laufzeit #
In den meisten Fällen lässt Ceph es zu, dass Sie Änderungen an der Konfiguration eines Daemons zur Laufzeit vornehmen. Dies ist beispielsweise nützlich, wenn Sie die Menge der Protokollierungsausgabe erhöhen oder verringern müssen oder wenn Sie eine Clusteroptimierung der Laufzeit durchführen.
Sie können die Werte von Konfigurationsoptionen mit folgendem Kommando aktualisieren:
cephuser@adm > ceph config set DAEMON OPTION VALUEFühren Sie zum Anpassen der Protokollstufe für die Fehlersuche zu einem bestimmten OSD folgendes Kommando aus:
cephuser@adm > ceph config set osd.123 debug_ms 20Wenn dieselbe Option auch in einer lokalen Konfigurationsdatei angepasst ist, wird die Monitoreinstellung ignoriert, da sie eine niedrigere Priorität als die Konfigurationsdatei hat.
28.2.3.1 Überschreiben von Werten #
Sie können einen Optionswert vorübergehend mit den Unterkommandos tell oder daemon ändern. Solche Änderungen wirken sich nur auf den laufenden Prozess aus und werden nach dem Neustart des Daemons oder Prozesses verworfen.
Zum Überschreiben von Werten haben Sie zwei Möglichkeiten:
Senden Sie mit dem Unterkommando
telleine Nachricht von einem beliebigen Cluster-Knoten aus an einen bestimmten Daemon:cephuser@adm >ceph tell DAEMON config set OPTION VALUEBeispiel:
cephuser@adm >ceph tell osd.123 config set debug_osd 20TippMit dem Unterkommando
tellwerden Platzhalter als Daemon-Bezeichner akzeptiert. Führen Sie zum Anpassen der Fehlersuchestufe für alle OSD-Daemons folgendes Kommando aus:cephuser@adm >ceph tell osd.* config set debug_osd 20Stellen Sie mit dem Unterkommando
daemoneine Verbindung zu einem bestimmten Daemon-Prozess über einen Socket in/var/run/cephvon dem Knoten aus her, auf dem der Prozess ausgeführt wird:cephuser@adm >ceph daemon DAEMON config set OPTION VALUEBeispiel:
cephuser@adm >ceph daemon osd.4 config set debug_osd 20
Bei der Anzeige von Laufzeiteinstellungen mit dem Kommando ceph config show (weitere Informationen hierzu finden Sie in Abschnitt 28.2.3.2, „Anzeigen der Laufzeiteinstellungen“) werden temporär überschriebene Werte mit der Quelle override angezeigt.
28.2.3.2 Anzeigen der Laufzeiteinstellungen #
So zeigen Sie alle für einen Daemon festgelegten Optionen an:
cephuser@adm > ceph config show-with-defaults osd.0So zeigen Sie alle für einen Daemon festgelegten nicht standardmäßigen Optionen an:
cephuser@adm > ceph config show osd.0So prüfen Sie eine bestimmte Option:
cephuser@adm > ceph config show osd.0 debug_osdSie können auch eine Verbindung zu einem aktiven Daemon von dem Knoten aus herstellen, auf dem sein Prozess ausgeführt wird, und seine Konfiguration beobachten:
cephuser@adm > ceph daemon osd.0 config showSo zeigen Sie nicht standardmäßige Einstellungen an:
cephuser@adm > ceph daemon osd.0 config diffSo prüfen Sie eine bestimmte Option:
cephuser@adm > ceph daemon osd.0 config get debug_osd28.3 config-key-Speicher #
config-key ist ein Service von Ceph Monitors für allgemeine Zwecke. Er vereinfacht die Verwaltung von Konfigurationsschlüsseln durch die permanente Speicherung von Schlüssel-Wert-Paaren. config-key wird hauptsächlich von Ceph-Werkzeugen und -Daemons verwendet.
Nachdem Sie einen neuen Schlüssel hinzugefügt oder einen vorhandenen Schlüssel geändert haben, starten Sie den betroffenen Service neu, damit die Änderungen wirksam werden. Weitere Details zum Betrieb von Ceph-Services finden Sie in Kapitel 14, Betrieb von Ceph-Services.
Mit dem Kommando config-key betreiben Sie den config-key-Speicher. Das Kommando config-key verwendet folgende Unterkommandos:
ceph config-key rm KEYLöscht den angegebenen Schlüssel.
ceph config-key exists KEYPrüft, ob der angegebene Schlüssel vorhanden ist.
ceph config-key get KEYRuft den Wert des angegebenen Schlüssels ab.
ceph config-key lsListet alle Schlüssel auf.
ceph config-key dumpGibt alle Schlüssel und deren Werte aus.
ceph config-key set KEY VALUESpeichert den angegebenen Schlüssel mit dem entsprechenden Wert.
28.3.1 iSCSI Gateway #
Das iSCSI Gateway speichert oder liest seine Konfigurationsoptionen im config-key-Speicher. Allen auf das iSCSI Gateway bezogenen Schlüsseln wird die Zeichenkette iscsi vorangestellt, wie zum Beispiel:
iscsi/trusted_ip_list iscsi/api_port iscsi/api_user iscsi/api_password iscsi/api_secure
Wenn Sie beispielsweise zwei Sätze von Konfigurationsoptionen benötigen, erweitern Sie das Präfix um ein weiteres beschreibendes Schlüsselwort, z. B. datacenterA und datacenterB:
iscsi/datacenterA/trusted_ip_list iscsi/datacenterA/api_port [...] iscsi/datacenterB/trusted_ip_list iscsi/datacenterB/api_port [...]
28.4 Ceph OSD und BlueStore #
28.4.1 Konfigurieren der automatischen Cache-Größe #
BlueStore kann so konfiguriert werden, dass die Größe der Caches automatisch geändert wird, wenn tc_malloc als Arbeitsspeicherzuordner konfiguriert und die Einstellung bluestore_cache_autotune aktiviert ist. Diese Option ist derzeit standardmäßig aktiviert. BlueStore versucht mit der Konfigurationsoption osd_memory_target, die Auslastung des OSD-Heap-Speichers unter einer bestimmten Zielgröße zu halten. Dies ist ein Best-Effort-Algorithmus und die Caches werden nicht auf eine Größe unter dem mit osd_memory_cache_min angegebenen Wert verkleinert. Die Cache-Verhältnisse werden auf der Grundlage einer Prioritätenhierarchie festgelegt. Wenn keine Prioritätsdaten vorliegen, werden die Optionen bluestore_cache_meta_ratio und bluestore_cache_kv_ratio herangezogen.
- bluestore_cache_autotune
Passt automatisch die Verhältnisse an, die verschiedenen BlueStore-Caches zugewiesen sind, und beachtet dabei die Mindestwerte. Die Standardeinstellung ist
true.- osd_memory_target
Wenn
tc_mallocundbluestore_cache_autotuneaktiviert sind, wird versucht, die Zuordnung dieser Datenmenge (in Byte) im Speicher beizubehalten.AnmerkungDies ist nicht völlig mit der RSS-Speichernutzung des Prozesses identisch. Die Gesamtmenge an Heap-Speicher, die durch den Prozess zugeordnet wird, sollte im Allgemeinen nahe an diesem Ziel legen. Es gibt jedoch keine Garantie, dass der Kernel den Speicher, dessen Zuordnung aufgehoben wurde, tatsächlich freigibt.
- osd_memory_cache_min
Wenn
tc_mallocundbluestore_cache_autotuneaktiviert sind, legen Sie die Mindestspeichermenge für Caches fest.AnmerkungEin zu niedriger Wert kann zu einer erheblichen Cache-Überlastung führen.
28.5 Ceph Object Gateway #
Sie können das Verhalten des Object Gateways durch eine Reihe von Optionen beeinflussen. Wenn eine Option nicht angegeben ist, wird ihr Standardwert verwendet. Liste aller Object-Gateway-Optionen:
28.5.1 Allgemeine Einstellungen #
- rgw_frontends
Konfiguriert das oder die HTTP-Front-Ends. Geben Sie mehrere Front-Ends in einer durch Komma getrennten Liste an. Die einzelnen Front-End-Konfigurationen können eine Liste mit Optionen umfassen, die durch Leerzeichen getrennt sind. Die Optionen werden jeweils in der Form „Schlüssel=Wert“ oder „Schlüssel“ angegeben. Der Standardwert ist
beast port=7480.- rgw_data
Bestimmt den Speicherort der Datendateien für das Object Gateway. Die Standardeinstellung ist
/var/lib/ceph/radosgw/CLUSTER_ID.- rgw_enable_apis
Aktiviert die angegebenen APIs. Die Standardeinstellung ist „s3, swift, swift_auth, admin All APIs“.
- rgw_cache_enabled
Aktiviert oder deaktiviert den Object-Gateway-Cache. Die Standardeinstellung ist
true.- rgw_cache_lru_size
Anzahl der Einträge im Object-Gateway-Cache. Der Standardwert ist 10000.
- rgw_socket_path
Socket-Pfad für den Domänen-Socket.
FastCgiExternalServernutzt diesen Socket. Wenn Sie keinen Socket-Pfad angeben, wird das Object Gateway nicht als externer Server ausgeführt. Hier muss derselbe Pfad angegeben werden wie in der Dateirgw.conf.- rgw_fcgi_socket_backlog
Socket-Backlog für fcgi. Der Standardwert ist 1024.
- rgw_host
Host für die Object-Gateway-Instanz. Dies kann eine IP-Adresse oder ein Hostname sein. Der Standardwert ist
0.0.0.0.- rgw_port
Portnummer, die die Instanz auf Anforderungen überwacht. Falls hier kein Wert angegeben ist, wird externes FastCGI auf dem Object Gateway ausgeführt.
- rgw_dns_name
DNS-Name der bedienten Domäne.
- rgw_script_uri
Alternativwert für die SCRIPT_URI, falls dieser in der Anforderung nicht angegeben ist.
- rgw_request_uri
Alternativwert für die REQUEST_URI, falls dieser in der Anforderung nicht angegeben ist.
- rgw_print_continue
Bei Betriebsbereitschaft aktivieren Sie „100-continue“. Die Standardeinstellung ist
true.- rgw_remote_addr_param
Remote-Adressparameter. Dies ist beispielsweise das HTTP-Feld mit der Remote-Adresse oder die X-Forwarded-For-Adresse, wenn ein Reverse-Proxy verwendet wird. Die Standardeinstellung ist
REMOTE_ADDR.- rgw_op_thread_timeout
Zeitüberschreitung (in Sekunden) für offene Threads. Der Standardwert ist 600.
- rgw_op_thread_suicide_timeout
Zeitüberschreitung (in Sekunden), bevor der Object-Gateway-Prozess abgebrochen wird. Beim Wert 0 (Standard) ist dies deaktiviert.
- rgw_thread_pool_size
Anzahl der Threads für den Beast-Server. Erhöhen Sie den Wert, wenn Sie mehr Anforderungen verarbeiten müssen. Der Standardwert ist 100 Threads.
- rgw_num_rados_handles
Anzahl der RADOS-Cluster-Zugriffsnummern für das Object Gateway. Jeder Object-Gateway-Worker-Thread kann nun eine RADOS-Zugriffsnummer für seine Gültigkeitsdauer auswählen. Diese Option wird unter Umständen aus künftigen Versionen als veraltet entfernt. Der Standardwert ist 1.
- rgw_num_control_oids
Anzahl der Benachrichtigungsobjekte für die Cache-Synchronisierung zwischen verschiedenen Object-Gateway-Instanzen. Der Standardwert ist 8.
- rgw_init_timeout
Zeitraum (in Sekunden), bevor das Object Gateway die Initialisierung abbricht. Der Standardwert ist 30.
- rgw_mime_types_file
Pfad und Speicherort der MIME-Typen. Für die Swift-Autoerkennung von Objekttypen. Die Standardeinstellung ist
/etc/mime.types.- rgw_gc_max_objs
Maximale Anzahl der Objekte, die durch die Speicherbereinigung in einem einzelnen Speicherbereinigungszyklus verarbeitet werden kann. Der Standardwert ist 32.
- rgw_gc_obj_min_wait
Minimale Wartezeit, bevor das Objekt entfernt und durch die Speicherbereinigung verarbeitet werden kann. Der Standardwert ist 2 * 3.600.
- rgw_gc_processor_max_time
Maximaler Zeitraum zwischen dem Beginn zweier aufeinanderfolgender Speicherbereinigungszyklen. Der Standardwert ist 3600.
- rgw_gc_processor_period
Zyklusdauer für die Speicherbereinigung. Der Standardwert ist 3600.
- rgw_s3_success_create_obj_status
Alternative Erfolgsstatusantwort für
create-obj. Der Standardwert ist 0.- rgw_resolve_cname
Angabe, ob das Object Gateway den Datensatz DNS CNAME aus dem Feld für den Hostnamen in der Anforderung heranziehen soll (falls der Hostname nicht mit dem DNS-Namen des Object Gateways übereinstimmt). Die Standardeinstellung ist
false.- rgw_obj_stripe_size
Größe eines Objekt-Stripes für Object-Gateway-Objekte. Der Standardwert ist
4 << 20.- rgw_extended_http_attrs
Fügt einen neuen Attributsatz ein, der für eine Entität festgelegt werden kann (z. B. einen Benutzer, einen Bucket oder ein Objekt). Diese zusätzlichen Attribute können mithilfe von HTTP-Header-Feldern festgelegt werden, wenn die Entität platziert oder mit der POST-Methode bearbeitet wird. Wenn diese Option aktiviert ist, werden diese Attribute als HTTP-Felder zurückgegeben, wenn GET/HEAD für die Entität angefordert wird. Die Standardeinstellung ist
content_foo, content_bar, x-foo-bar.- rgw_exit_timeout_secs
Wartezeit (in Sekunden) für einen Prozess, bevor er uneingeschränkt beendet wird. Der Standardwert ist 120.
- rgw_get_obj_window_size
Fenstergröße (in Byte) für eine einzelne Objektanforderung. Der Standardwert ist
16 << 20.- rgw_get_obj_max_req_size
Maximale Anforderungsgröße einer einzelnen GET-Operation, die an den Ceph Storage Cluster gesendet wird. Der Standardwert ist
4 << 20.- rgw_relaxed_s3_bucket_names
Aktiviert lockere Namensregeln für S3-Buckets in der US-Region. Die Standardeinstellung ist
false.- rgw_list_buckets_max_chunk
Maximale Anzahl an Buckets, die in einer einzelnen Operation zum Auflisten der Benutzer-Buckets abgerufen werden soll. Der Standardwert ist 1000.
- rgw_override_bucket_index_max_shards
Anzahl der Shards für das Bucket-Indexobjekt. Bei der Einstellung 0 (Standard) wird kein Sharding durchgeführt. Ein zu hoher Wert (z. B. 1.000) wird nicht empfohlen, da dies die Kosten für die Bucket-Auflistung erhöht. Diese Variable ist im Client-Abschnitt oder im globalen Abschnitt festzulegen, damit sie bei einem Kommando
radosgw-adminautomatisch übernommen wird.- rgw_curl_wait_timeout_ms
Zeitüberschreitung (in Millisekunden) für bestimmte
curl-Aufrufe. Der Standardwert ist 1000.- rgw_copy_obj_progress
Aktiviert die Ausgabe des Objektfortschritts bei umfangreichen Kopiervorgängen. Die Standardeinstellung ist
true.- rgw_copy_obj_progress_every_bytes
Minimale Datenmenge (in Byte) zwischen zwei Ausgaben des Kopierfortschritts. Der Standardwert ist 1.024 * 1.024.
- rgw_admin_entry
Der Einstiegspunkt für eine Admin-Anforderungs-URL. Die Standardeinstellung ist
admin.- rgw_content_length_compat
Aktiviert die Kompatibilitätsverarbeitung von FCGI-Anforderungen, bei denen sowohl CONTENT_LENGTH als auch HTTP_CONTENT_LENGTH festgelegt ist. Die Standardeinstellung ist
false.- rgw_bucket_quota_ttl
Zeitraum (in Sekunden), über den die im Cache gespeicherten Kontingentdaten als verbürgt gelten. Nach Ablauf dieser Zeitüberschreitung werden die Kontingentdaten erneut aus dem Cluster abgerufen. Der Standardwert ist 600.
- rgw_user_quota_bucket_sync_interval
Zeitraum (Sekunden), über den die Bucket-Kontingentdaten akkumuliert werden, bevor sie mit dem Cluster synchronisiert werden. In diesem Zeitraum können andere Object-Gateway-Instanzen die Veränderungen an der Bucket-Kontingentstatistik im Zusammenhang mit Operationen für diese Instanz nicht sehen. Der Standardwert ist 180.
- rgw_user_quota_sync_interval
Zeitraum (Sekunden), über den die Benutzer-Kontingentdaten akkumuliert werden, bevor sie mit dem Cluster synchronisiert werden. In diesem Zeitraum können andere Object-Gateway-Instanzen die Veränderungen an der Benutzer-Kontingentstatistik im Zusammenhang mit Operationen für diese Instanz nicht sehen. Der Standardwert ist 180.
- rgw_bucket_default_quota_max_objects
Standardmäßige maximale Anzahl der Objekte pro Bucket. Dieser Wert wird für neue Benutzer festgelegt, wenn kein anderes Kontingent angegeben wurde. Er wirkt sich nicht auf vorhandene Benutzer aus. Diese Variable ist im Client-Abschnitt oder im globalen Abschnitt festzulegen, damit sie bei einem Kommando
radosgw-adminautomatisch übernommen wird. Der Standardwert ist -1.- rgw_bucket_default_quota_max_size
Standardmäßige maximale Kapazität pro Bucket (in Byte). Dieser Wert wird für neue Benutzer festgelegt, wenn kein anderes Kontingent angegeben wurde. Er wirkt sich nicht auf vorhandene Benutzer aus. Der Standardwert ist -1.
- rgw_user_default_quota_max_objects
Standardmäßige maximale Anzahl der Objekte für einen Benutzer. Hierzu zählen alle Objekte in allen Buckets, die im Eigentum des Benutzers stehen. Dieser Wert wird für neue Benutzer festgelegt, wenn kein anderes Kontingent angegeben wurde. Er wirkt sich nicht auf vorhandene Benutzer aus. Der Standardwert ist -1.
- rgw_user_default_quota_max_size
Wert für das benutzerspezifische maximale Größenkontingent (in Byte). Dieser Wert wird für neue Benutzer festgelegt, wenn kein anderes Kontingent angegeben wurde. Er wirkt sich nicht auf vorhandene Benutzer aus. Der Standardwert ist -1.
- rgw_verify_ssl
Überprüft SSL-Zertifikate im Rahmen von Anforderungen. Die Standardeinstellung ist
true.- rgw_max_chunk_size
Die maximale Größe eines Datenblocks, der bei einer einzelnen Operation gelesen wird. Die Leistung bei der Verarbeitung von großen Objekten wird verbessert, wenn der Wert auf 4 MB (4194304) erhöht wird. Der Standardwert ist 128 KB (131072).
- rgw_zone
Name der Zone für die Gateway-Instanz. Wenn keine Zone festgelegt ist, können Sie mit dem Kommando
radosgw-admin zone defaulteine clusterweite Standardeinstellung festlegen.- rgw_zonegroup
Name der Zonengruppe für die Gateway-Instanz. Wenn keine Zonengruppe festgelegt ist, können Sie mit dem Kommando
radosgw-admin zonegroup defaulteine clusterweite Standardeinstellung festlegen.- rgw_realm
Name des Bereichs für die Gateway-Instanz. Wenn kein Bereich festgelegt ist, können Sie mit dem Kommando
radosgw-admin realm defaulteine clusterweite Standardeinstellung festlegen.- rgw_run_sync_thread
Wenn der Bereich weitere Zonen für die Synchronisierung umfasst, werden Threads erzeugt, die die Synchronisierung der Daten und Metadaten übernehmen. Die Standardeinstellung ist
true.- rgw_data_log_window
Zeitfenster (in Sekunden) für Datenprotokolleinträge. Der Standardwert ist 30.
- rgw_data_log_changes_size
Anzahl der Einträge im Speicher, die für das Datenänderungsprotokoll beibehalten werden sollen. Der Standardwert ist 1000.
- rgw_data_log_obj_prefix
Objektnamenpräfix für das Datenprotokoll. Die Standardeinstellung ist „data_log“.
- rgw_data_log_num_shards
Anzahl der Shards (Objekte), in denen das Datenänderungsprotokoll abgelegt werden soll. Der Standardwert ist 128.
- rgw_md_log_max_shards
Maximale Anzahl der Shards für das Metadaten-Protokoll. Der Standardwert ist 64.
- rgw_enforce_swift_acls
Erzwingt die Swift-Einstellungen für die Zugriffssteuerungsliste (ACL). Die Standardeinstellung ist
true.- rgw_swift_token_expiration
Zeitraum (in Sekunden), nach dem ein Swift-Token abläuft. Der Standardwert ist 24 * 3.600.
- rgw_swift_url
URL für die Swift-API des Ceph Object Gateway.
- rgw_swift_url_prefix
URL-Präfix für Swift StorageURL, das dem Teil „/v1“ vorangestellt wird. Hiermit können mehrere Gateway-Instanzen auf demselben Host ausgeführt werden. Wenn diese Konfigurationsvariable leer bleibt, wird aus Kompatibilitätsgründen die Standardeinstellung „/swift“ verwendet. Mit dem expliziten Präfix „/“ wird StorageURL im Root-Verzeichnis gestartet.
WarnungEs ist nicht möglich, „/“ für diese Option festzulegen, wenn die S3-API aktiviert ist. Wichtiger Hinweis: Wenn S3 deaktiviert wird, kann das Object Gateway nicht in der Konfiguration für mehrere Standorte implementiert werden.
- rgw_swift_auth_url
Standard-URL die Überprüfung der v1-Authentifizierungs-Token, wenn die interne Swift-Authentifizierung nicht verwendet wird.
- rgw_swift_auth_entry
Einstiegspunkt für eine Swift-Authentifizierungs-URL. Die Standardeinstellung ist
auth.- rgw_swift_versioning_enabled
Aktiviert die Objektversionierung der OpenStack Object Storage-API. Damit können Clients das Attribut
X-Versions-Locationfür Container festlegen, die versioniert werden sollen. Das Attribut bestimmt den Namen des Containers, in dem die archivierten Versionen gespeichert werden. Aus Gründen der Zugriffssteuerungsprüfung muss dieser Container im Eigentum desselben Benutzers stehen wie der versionierte Container – ACLs werden nicht berücksichtigt. Diese Container können nicht mit dem S3-Mechanismus zur Objektversionierung versioniert werden. Die Standardeinstellung istfalse.
- rgw_log_nonexistent_bucket
Hiermit kann das Object Gateway eine Anforderung nach einem nicht vorhandenen Bucket protokollieren. Die Standardeinstellung ist
false.- rgw_log_object_name
Protokollierungsformat für einen Objektnamen. Weitere Informationen zu Formatspezifizierern finden Sie auf der Handbuchseite
man 1 date. Die Standardeinstellung ist%Y-%m-%d-%H-%i-%n.- rgw_log_object_name_utc
Angabe, ob ein protokollierter Objektname eine UTC-Zeit enthält. Bei der Einstellung
false(Standard) wird die Ortszeit verwendet.- rgw_usage_max_shards
Maximale Anzahl der Shards für die Auslastungsprotokollierung. Der Standardwert ist 32.
- rgw_usage_max_user_shards
Maximale Anzahl der Shards für die Auslastungsprotokollierung für einen einzelnen Benutzer . Der Standardwert ist 1.
- rgw_enable_ops_log
Aktiviert die Protokollierung für jede erfolgreiche Object-Gateway-Operation. Die Standardeinstellung ist
false.- rgw_enable_usage_log
Aktiviert das Auslastungsprotokoll. Die Standardeinstellung ist
false.- rgw_ops_log_rados
Angabe, ob das Operationsprotokoll in das Ceph Storage ClusterࢮBack-End geschrieben werden soll. Die Standardeinstellung ist
true.- rgw_ops_log_socket_path
Unix-Domänen-Socket für das Schreiben der Operationsprotokolle.
- rgw_ops_log_data_backlog
Maximale Datengröße des Daten-Backlogs für Operationsprotokolle, die auf einen Unix-Domänen-Socket geschrieben werden. Der Standardwert ist 5 << 20.
- rgw_usage_log_flush_threshold
Anzahl der kürzlich bearbeiteten („dirty“) zusammengeführten Einträge im Auslastungsprotokoll, bevor sie synchron verschoben werden. Der Standardwert ist 1024.
- rgw_usage_log_tick_interval
Auslastungsprotokolldaten zu ausstehenden Verschiebungen alle „n“ Sekunden. Der Standardwert ist 30.
- rgw_log_http_headers
Durch Komma getrennte Liste der HTTP-Header, die in Protokolleinträge aufgenommen werden sollen. Bei Header-Namen wird nicht zwischen Groß- und Kleinschreibung unterschieden. Geben Sie den vollständigen Header-Namen ein und trennen Sie die einzelnen Wörter jeweils durch Unterstrich. Beispiel: „http_x_forwarded_for“, „http_x_special_k“.
- rgw_intent_log_object_name
Protokollierungsformat für den Intent-Protokollobjektnamen. Weitere Informationen zu Formatspezifizierern finden Sie auf der Handbuchseite
man 1 date. Die Standardeinstellung ist „%Y-%m-%d-%i-%n“.- rgw_intent_log_object_name_utc
Angabe, ob der Intent-Protokollobjektname eine UTC-Zeit enthält. Bei der Einstellung
false(Standard) wird die Ortszeit verwendet.
- rgw_keystone_url
URL für den Keystone-Server.
- rgw_keystone_api_version
Version (2 oder 3) der OpenStack Identity-API, über die die Kommunikation mit dem Keystone-Server abgewickelt werden soll. Der Standardwert ist 2.
- rgw_keystone_admin_domain
Name der OpenStack-Domäne mit Administratorberechtigung bei Verwendung der OpenStack Identity-API v3.
- rgw_keystone_admin_project
Name des OpenStack-Projekts mit Administratorberechtigung bei Verwendung der OpenStack Identity-API v3. Falls kein Wert angegeben ist, wird stattdessen der Wert für
rgw keystone admin tenantverwendet.- rgw_keystone_admin_token
Keystone-Administrator-Token (gemeinsames Geheimnis). Im Object Gateway hat die Authentifizierung mit dem Administrator-Token den Vorrang vor der Authentifizierung mit dem Administrator-Berechtigungsnachweis (Optionen
rgw keystone admin user,rgw keystone admin password,rgw keystone admin tenant,rgw keystone admin projectundrgw keystone admin domain). Die Administrator-Token-Funktion gilt als veraltet.- rgw_keystone_admin_tenant
Name des OpenStack-Mandanten mit Administratorberechtigung (Servicemandant) bei Verwendung der OpenStack Identity-API v2.
- rgw keystone admin user
Name des OpenStack-Benutzers mit Administratorberechtigung für die Keystone-Authentifizierung (Servicebenutzer) bei Verwendung der OpenStack Identity-API v2.
- rgw_keystone_admin_password
Passwort für den verwaltungsberechtigten OpenStack-Benutzer bei Verwendung der OpenStack Identity-API v2.
- rgw_keystone_accepted_roles
Die Rollen zur Verarbeitung der Anforderungen. Die Standardeinstellung ist „Member“, „admin“.
- rgw_keystone_token_cache_size
Maximale Anzahl der Einträge pro Keystone-Token-Cache. Der Standardwert ist 10000.
- rgw_keystone_revocation_interval
Zeitraum (in Sekunden) zwischen zwei Überprüfungen, ob Token entzogen wurden. Der Standardwert ist 15 * 60.
- rgw_keystone_verify_ssl
Überprüft SSL-Zertifikate im Rahmen von Token-Anforderungen an Keystone. Die Standardeinstellung ist
true.
28.5.1.1 Weitere Hinweise #
- rgw_dns_name
Ermöglicht Clients die Verwendung von
vhost-Buckets.Der
vhost-Zugriff bezieht sich auf die Verwendung des bucketname.s3-endpoint/object-path. Dies ist im Vergleich zumpath-Zugriff: s3-endpoint/bucket/objectWenn der
rgw dns namefestgelegt ist, müssen Sie überprüfen, ob der S3 Client so konfiguriert ist, dass er Anforderungen zu dem Endpunkt leitet, der durchrgw dns nameangegeben ist.
28.5.2 Konfigurieren von HTTP-Frontends #
28.5.2.1 Beast #
- port, ssl_port
Portnummern der zu überwachenden IPv4- und IPv6-Ports. Sie können mehrere Portnummern angeben:
port=80 port=8000 ssl_port=8080
Der Standardwert ist 80.
- endpoint, ssl_endpoint
Zu überwachende Adressen in der Form „address[:port]“, wobei die Adresse als IPv4-Adresszeichenkette mit Dezimalziffern und Punkten oder als IPv6-Adresse mit hexadezimaler Schreibweise in eckigen Klammern angegeben wird. Wenn Sie hier einen IPv6-Endpunkt angeben, wird lediglich IPv6 überwacht. Die optionale Portnummer lautet standardmäßig 80 für
endpointund 443 fürssl_endpoint. Sie können mehrere Adressen angeben:endpoint=[::1] endpoint=192.168.0.100:8000 ssl_endpoint=192.168.0.100:8080
- ssl_private_key
Optionaler Pfad zur Datei mit dem privaten Schlüssel für SSL-fähige Endpunkte. Wenn hier kein Wert angegeben ist, wird die Datei
ssl_certificateals privater Schlüssel herangezogen.- tcp_nodelay
Wenn hier ein Wert angegeben ist, deaktiviert die Socket-Option den Nagle-Algorithmus für die Verbindung. Dies bedeutet, dass Pakete so bald wie möglich gesendet werden, statt abzuwarten, bis der Puffer gefüllt ist oder eine Zeitüberschreitung eintritt.
Mit dem Wert „1“ wird der Nagle-Algorithmus für alle Sockets deaktiviert.
Mit dem Wert „0“ bleibt der Nagle-Algorithmus aktiviert (Standard).
cephuser@adm > ceph config set rgw.myrealm.myzone.ses-min1.kwwazo \
rgw_frontends beast port=8000 ssl_port=443 \
ssl_certificate=/etc/ssl/ssl.crt \
error_log_file=/var/log/radosgw/beast.error.log28.5.2.2 CivetWeb #
- Anschluss
Portnummer des zu überwachenden Ports. Bei SSL-fähigen Ports hängen Sie das Suffix „s“ an (z. B. „443s“). Soll eine bestimmte IPv4- oder IPv6-Adresse gebunden werden, beachten Sie die Form „address:port“. Sie können mehrere Endpunkte angeben. Verbinden Sie sie wahlweise mit „+“ oder legen Sie mehrere Optionen fest:
port=127.0.0.1:8000+443s port=8000 port=443s
Der Standardwert ist 7480.
- num_threads
Anzahl der Threads, die CivetWeb zur Verarbeitung eingehender HTTP-Verbindungen erzeugt. Hiermit wird letztlich die Anzahl der gleichzeitigen Verbindungen verringert, die durch das Front-End verarbeitet werden können.
Der Standardwert ist der Wert der Option
rgw_thread_pool_size.- request_timeout_ms
Zeitraum (in Millisekunden), über den CivetWeb auf weitere eingehende Daten wartet, bevor der Vorgang abgebrochen wird.
Der Standardwert ist 30.000 Millisekunden.
- access_log_file
Pfad der Zugriffsprotokolldatei. Sie können entweder einen vollständigen Pfad angeben oder einen Pfad relativ zum aktuellen Arbeitsverzeichnis. Wenn hier kein Wert angegeben ist (Standard), werden die Zugriffe nicht protokolliert.
- error_log_file
Pfad der Fehlerprotokolldatei. Sie können entweder einen vollständigen Pfad angeben oder einen Pfad relativ zum aktuellen Arbeitsverzeichnis. Wenn hier kein Wert angegeben ist (Standard), werden die Fehler nicht protokolliert.
/etc/ceph/ceph.conf #cephuser@adm > ceph config set rgw.myrealm.myzone.ses-min2.ingabw \
rgw_frontends civetweb port=8000+443s request_timeout_ms=30000 \
error_log_file=/var/log/radosgw/civetweb.error.log28.5.2.3 Allgemeine Optionen #
- ssl_certificate
Pfad zur SSL-Zertifikatsdatei für SSL-fähige Endpunkte.
- Präfix
Eine Präfixzeichenkette, die in die URI aller Anforderungen eingefügt wird. Ein Frontend, das ausschließlich mit Swift arbeitet, könnte beispielsweise das URI-Präfix
/swiftausgeben.
29 Ceph-Manager-Module #
Der Funktionsumfang des Ceph Managers (kurze Einführung siehe Book “Implementierungsleitfaden”, Chapter 1 “SES und Ceph”, Section 1.2.3 “Ceph-Knoten und -Daemons”) kann dank seiner Architektur mithilfe von Modulen erweitert werden, z. B. „dashboard“ (siehe Teil I, „Ceph Dashboard“), „prometheus“ (siehe Kapitel 16, Überwachung und Warnungen) oder „balancer“.
Mit folgendem Kommando rufen Sie eine Liste aller verfügbaren Module ab:
cephuser@adm > ceph mgr module ls
{
"enabled_modules": [
"restful",
"status"
],
"disabled_modules": [
"dashboard"
]
}Mit folgendem Kommando aktivieren oder deaktivieren Sie ein bestimmtes Modul:
cephuser@adm > ceph mgr module enable MODULE-NAMEBeispiel:
cephuser@adm > ceph mgr module disable dashboardMit folgendem Kommando rufen Sie eine Liste der Services ab, die die aktivierten Module anbieten:
cephuser@adm > ceph mgr services
{
"dashboard": "http://myserver.com:7789/",
"restful": "https://myserver.com:8789/"
}29.1 Ausgleichsprogramm #
Das Ausgleichsprogramm-Modul optimiert die Verteilung der Platzierungsgruppen (PG) auf die OSDs, sodass die Implementierung ausgeglichener wird. Das Modul ist standardmäßig aktiviert, ist jedoch inaktiv. Es unterstützt die Modi crush-compat und upmap.
Mit folgendem Kommando zeigen Sie die Informationen zum Status und der Konfiguration des aktuellen Ausgleichsprogramms an:
cephuser@adm > ceph balancer status29.1.1 Modus „crush-compat“ #
Im Modus „crush-compat“ passt das Ausgleichsprogramm die Neugewichtungs-Sets der OSDs an, sodass eine verbesserte Verteilung der Daten erzielt wird. Die PGs werden zwischen den OSDs verschoben, so dass vorübergehend der Cluster-Status HEALTH_WARN aufgrund von falsch platzierten PGs eintritt.
Auch wenn „crush-compat“ der Standardmodus ist, wird empfohlen, ihn explizit zu aktivieren:
cephuser@adm > ceph balancer mode crush-compat29.1.2 Planen und Ausführen des Datenausgleichs #
Mit dem Ausgleichsprogramm-Modul können Sie einen Plan für den Datenausgleich aufstellen. Anschließend können Sie den Plan manuell ausführen oder die PGs fortlaufend durch das Ausgleichsprogramm ausgleichen lassen.
Die Entscheidung, ob das Ausgleichsprogramm im manuellen oder automatischen Modus ausgeführt werden soll, ist von verschiedenen Faktoren abhängig, z. B. vom aktuellen Ungleichgewicht der Daten, von der Cluster-Größe, der PG-Anzahl oder der E/A-Aktivität. Es wird empfohlen, einen anfänglichen Plan aufzustellen und in einem Zeitraum mit niedrigerer E/A-Belastung im Cluster auszuführen. Zu Beginn liegt in der Regel ein erhebliches Ungleichgewicht vor und es ist dringend zu empfehlen, die Auswirkungen auf die Clients so gering wie möglich zu halten. Nach der ersten manuellen Ausführung können Sie ggf. den automatischen Modus aktivieren und den Ausgleichsdatenverkehr bei normaler E/A-Belastung überwachen. Die Verbesserungen bei der PG-Verteilung sind gegen den Ausgleichsdatenverkehr abzuwägen, der durch das Ausgleichsprogramm verursacht wird.
Während des Ausgleichsprozesses schränkt das Ausgleichsprogramm die PG-Verschiebungen ein, sodass nur ein konfigurierbarer Anteil der PGs verschoben wird. Der Standardwert ist 5 %. Mit folgendem Kommando erhöhen Sie den Anteil beispielsweise auf 9 %:
cephuser@adm > ceph config set mgr target_max_misplaced_ratio .09So können Sie einen Ausgleichsplan aufstellen und umsetzen:
Prüfen Sie die aktuelle Cluster-Bewertung:
cephuser@adm >ceph balancer evalStellen Sie einen Plan auf. Beispielsweise „great_plan“:
cephuser@adm >ceph balancer optimize great_planBetrachten Sie die Veränderungen, die „great_plan“ mit sich bringen wird:
cephuser@adm >ceph balancer show great_planPrüfen Sie die potentielle Clusterbewertung, wenn Sie sich entscheiden, „great_plan“ umzusetzen:
cephuser@adm >ceph balancer eval great_planFühren Sie „great_plan“ einmalig aus:
cephuser@adm >ceph balancer execute great_planBeobachten Sie den Cluster-Ausgleich mit dem Kommando
ceph -s. Wenn Sie mit dem Ergebnis zufrieden sind, aktivieren Sie den automatischen Ausgleich:cephuser@adm >ceph balancer onMit folgendem Kommando deaktivieren Sie den automatischen Ausgleich später:
cephuser@adm >ceph balancer off
Sie können den automatischen Ausgleich aktivieren, ohne einen anfänglichen Plan umzusetzen. In diesem Fall müssen Sie damit rechnen, dass der Ausgleich der Platzierungsgruppen unter Umständen lange dauert.
29.2 Aktivieren des Telemetriemoduls #
Das Telemetrie-Plugin sendet anonyme Daten zum Cluster, in dem das Plugin ausgeführt wird, an das Ceph-Projekt.
Diese (Opt-in-)Komponente umfasst Zähler und Statistiken zur Implementierung des Clusters, außerdem die Ceph-Version, die Verteilung der Hosts und andere Parameter, die dem Projekt einen besseren Einblick in die Nutzung von Ceph eröffnen. Vertrauliche Daten wie Pool-Namen, Objektnamen, Objektinhalte oder Hostnamen werden nicht übermittelt.
Das Telemetriemodul fungiert als automatisierte Feedback-Schleife für die Entwickler und trägt dazu bei, die Akzeptanz zu ermitteln, das Tracking umzusetzen und Punkte festzustellen, die im Rahmen der Konfiguration besser erklärt oder eingehender geprüft werden müssen, damit unerwünschte Ergebnisse verhindert werden.
Zur Nutzung des Telemetriemoduls müssen die Ceph-Manager-Knoten in der Lage sein, Daten über HTTPS an die vorgeschalteten Server zu übermitteln. Ihre Unternehmens-Firewalls müssen diesen Vorgang zulassen.
So aktivieren Sie das Telemetriemodul:
cephuser@adm >ceph mgr module enable telemetryAnmerkungMit diesem Kommando können Sie Ihre Daten lediglich lokal abrufen. Dieses Kommando gibt Ihre Daten nicht an die Ceph-Community weiter.
So lassen Sie die Weitergabe von Daten durch das Telemetriemodul zu:
cephuser@adm >ceph telemetry onSo deaktivieren Sie die Weitergabe der Telemetriedaten:
cephuser@adm >ceph telemetry offSo erzeugen Sie einen druckbaren JSON-Bericht:
cephuser@adm >ceph telemetry showSo ergänzen Sie den Bericht mit einem Ansprechpartner und einer Beschreibung:
cephuser@adm >ceph config set mgr mgr/telemetry/contact John Doe john.doe@example.comcephuser@adm >ceph config set mgr mgr/telemetry/description 'My first Ceph cluster'Das Modul erstellt und sendet standardmäßig alle 24 Stunden einen neuen Bericht. So passen Sie diesen Zeitabstand an:
cephuser@adm >ceph config set mgr mgr/telemetry/interval HOURS
30 Authentifizierung mit cephx #
Das Authentifizierungssystem cephx
von Ceph dient dazu, Clients zu identifizieren und sie gegen
Man-in-the-Middle-Angriffe zu schützen. Clients in
diesem Kontext sind entweder Benutzer (wie zum Beispiel Administratoren) oder
auf Ceph bezogene Services/Daemons (beispielsweise OSDs, Monitors oder Object
Gateways).
Das cephx-Protokoll befasst sich
nicht mit der Datenverschlüsselung bei der Übertragung, wie zum Beispiel
TLS/SSL.
30.1 Authentifizierungsarchitektur #
cephx verwendet gemeinsame geheime
Schlüssel zur Authentifizierung. Dies bedeutet, dass sowohl der Client als
auch die Ceph Monitors eine Kopie des geheimen Schlüssels des Clients
besitzen. Anhand des Authentifizierungsprotokolls weisen beide Parteien
nach, dass sie eine Kopie des Schlüssels besitzen, ohne ihn tatsächlich
anzuzeigen. Dies sorgt für gegenseitige Authentifizierung, was bedeutet, der
Cluster ist sicher, dass der Benutzer einen geheimen Schlüssel besitzt, und
der Benutzer ist sicher, dass der Cluster ebenfalls über eine Kopie des
geheimen Schlüssels verfügt.
Eine wichtige Skalierbarkeitsfunktion von Ceph besteht darin, eine
zentralisierte Schnittstelle zum Ceph-Objektspeicher zu vermeiden. Dies
bedeutet, dass Ceph-Clients direkt mit OSDs interagieren. Zum Schutz der
Daten steht das Authentifizierungssystem
cephx von Ceph zur Verfügung, das
die Ceph-Clients authentifiziert.
Jeder Monitor kann Clients authentifizieren und Schlüssel verteilen. Daher
gibt es bei der Verwendung von
cephx keinen
Single-Point-of-Failure oder Engpass. Der Monitor gibt eine
Authentifizierungsdatenstruktur zurück, die einen Sitzungsschlüssel enthält,
mit dem Ceph Services abgerufen werden. Dieser Sitzungsschlüssel wird
wiederum mit dem permanenten geheimen Schlüssel des Clients verschlüsselt.
Dadurch ist es nur dem Client möglich, Services von den Ceph Monitors
anzufordern. Der Client fordert dann mit dem Sitzungsschlüssel die
gewünschten Services vom Monitor ab und der Monitor stellt dem Client ein
Ticket aus. Dieses Ticket authentifiziert den Client bei den OSDs, die
tatsächlich die Daten verarbeiten. Ceph Monitors und OSDs haben ein
gemeinsames Geheimnis, sodass der Client das Ticket vom Monitor für jeden
OSD oder Metadata Server im Cluster verwenden kann.
cephx-Tickets laufen ab, sodass ein
abgelaufenes Ticket oder ein Sitzungsschlüssel einem Angreifer, der es sich
widerrechtlich angeeignet hat, nichts nützt.
Für cephx muss ein Administrator
zunächst Clients/Benutzer einrichten. In der folgenden Grafik ruft der
client.admin das Kommando
ceph auth get-or-create-key in der Kommandozeile auf, um
einen Benutzernamen und einen geheimen Schlüssel zu generieren. Das
Teilsystem auth von Ceph generiert den Benutzernamen und
Schlüssel, speichert eine Kopie bei den Monitors und überträgt das Geheimnis
des Benutzers zurück an den
client.admin-Benutzer. Dies
bedeutet, dass der Client und der Monitor über einen gemeinsamen geheimen
Schlüssel verfügen.

cephx-Authentifizierung #Zur Authentifizierung beim Monitor gibt der Client den Benutzernamen an den Monitor weiter. Der Monitor generiert einen Sitzungsschlüssel und verschlüsselt diesen mit dem geheimen Schlüssel, der mit dem Benutzernamen verknüpft ist. Danach überträgt er das verschlüsselte Ticket zurück an den Client. Der Client entschlüsselt dann die Daten mit dem gemeinsamen geheimen Schlüssel, um den Sitzungsschlüssel abzurufen. Der Sitzungsschlüssel identifiziert den Benutzer für die aktuelle Sitzung. Der Client fordert dann ein Ticket an, das sich auf den Benutzer bezieht. Dieses Ticket wird durch den Sitzungsschlüssel signiert. Der Monitor generiert ein Ticket, verschlüsselt es mit dem geheimen Schlüssel des Benutzers und überträgt es zurück an den Client. Der Client entschlüsselt das Ticket und signiert damit Anforderungen an OSDs und Metadata Server im gesamten Cluster.

cephx #
Das cephx-Protokoll authentifiziert
die fortlaufende Kommunikation zwischen dem Client-Rechner und den Ceph
Servern. Jede nach der ersten Authentifizierung zwischen einem Client und
einem Server gesendete Nachricht wird mit einem Ticket signiert, das die
Monitors, OSDs und Metadata Server mit ihrem gemeinsamen geheimen Schlüssel
verifizieren können.

cephx – MDS und OSD #Der durch diese Authentifizierung erreichte Schutz besteht zwischen dem Ceph-Client und den Ceph-Cluster-Hosts. Die Authentifizierung wird nicht über den Ceph-Client hinaus erweitert. Wenn der Benutzer von einem Remote-Host aus auf den Ceph-Client zugreift, wird die Ceph-Authentifizierung nicht auf die Verbindung zwischen dem Host des Benutzers und dem Client-Host angewendet.
30.2 Schlüsselverwaltungsbereiche #
In diesem Abschnitt werden die Ceph-Client-Benutzer und deren Authentifizierung und Autorisierung beim Ceph Storage Cluster erläutert. Benutzer sind entweder Einzelpersonen oder Systemaktoren wie Anwendungen, die Ceph-Clients für die Interaktion mit den Ceph Storage Cluster Daemons nutzen.
Wenn Ceph mit aktivierter Authentifizierung und Autorisierung ausgeführt
wird (standardmäßig aktiviert), dann müssen Sie einen Benutzernamen angeben
und einen Schlüsselbund, der den geheimen Schlüssel des angegebenen
Benutzers enthält (normalerweise über die Kommandozeile). Wenn Sie keinen
Benutzernamen angeben, verwendet Ceph
client.admin als standardmäßigen
Benutzernamen. Wenn Sie keinen Schlüsselbund angeben, sucht Ceph nach einem
Schlüsselbund über die Schlüsselbundeinstellung in der
Ceph-Konfigurationsdatei. Wenn Sie beispielsweise das Kommando ceph
health ausführen, ohne einen Benutzernamen oder Schlüsselbund
anzugeben, dann interpretiert Ceph das Kommando folgendermaßen:
cephuser@adm > ceph -n client.admin --keyring=/etc/ceph/ceph.client.admin.keyring health
Alternativ können Sie mit der CEPH_ARGS-Umgebungsvariable
die wiederholte Eingabe von Benutzername und Geheimnis vermeiden.
30.2.1 Hintergrundinformation #
Ungeachtet des Typs des Ceph-Clients (beispielsweise Blockgerät, Objektspeicher, Dateisystem, systemeigene API) speichert Ceph alle Daten als Objekte in Pools. Ceph-Benutzer benötigen zum Lesen und Schreiben von Daten Zugriff auf die Pools. Außerdem müssen Ceph-Benutzer über Ausführungsberechtigungen verfügen, um die Verwaltungskommandos von Ceph zu verwenden. Die Ceph-Benutzerverwaltung verstehen Sie am besten anhand der folgenden Konzepte.
30.2.1.1 Benutzer #
Ein Benutzer ist entweder eine Einzelperson oder ein Systemaktor wie eine Anwendung. Durch die Erstellung von Benutzern steuern Sie, wer (oder was) auf Ihren Ceph Storage Cluster, dessen Pools und die Daten in den Pools Zugriff hat.
Ceph verwendet Typen von Benutzern. Zum Zweck der
Benutzerverwaltung lautet der Typ immer client. Ceph
kennzeichnet Benutzer durch (.) getrennt und bestehend aus Benutzertyp und
Benutzer-ID. Beispiel: TYPE.ID,
client.admin oder client.user1. Der
Grund dafür besteht darin, dass Ceph Monitors, OSDs und Metadata Server
ebenfalls das cephx-Protokoll verwenden, jedoch keine „clients“ sind.
Durch unterschiedliche Benutzertypen wird zwischen Client-Benutzern und
anderen Benutzern unterschieden, was die Zugriffskontrolle, die
Benutzerüberwachung und Nachverfolgbarkeit verbessert.
Der Benutzertyp von Ceph kann unter Umständen verwirrend erscheinen, da
Sie in der Ceph-Kommandozeile einen Benutzer mit oder ohne Typ angeben
können, je nach Ihrer Nutzung der Kommandozeile. Bei
--user oder --id können Sie den Typ
weglassen. client.user1 kann also einfach als
user1 eingegeben werden. Bei --name
oder -n müssen Sie den Typ und den Namen angeben, z. B.
client.user1. Als optimales Verfahren wird empfohlen,
nach Möglichkeit stets den Typ und den Namen anzugeben.
Ein Ceph Storage Cluster-Benutzer ist nicht dasselbe wie ein Ceph Object Storage-Benutzer oder ein Ceph-Dateisystembenutzer. Das Ceph Object Gateway nutzt einen Ceph Storage Cluster-Benutzer für die Kommunikation zwischen dem Gateway Daemon und dem Storage Cluster, doch das Gateway verfügt über eine eigene Benutzerverwaltungsfunktion für Endbenutzer. Das Ceph-Dateisystem verwendet die POSIX-Semantik. Der damit verknüpfte Benutzerbereich entspricht nicht einem Ceph Storage Cluster-Benutzer.
30.2.1.2 Autorisierung und Befähigungen #
Mit dem Begriff „Capabilities“ (Caps) beschreibt Ceph die Autorisierung eines authentifizierten Benutzers zur Ausführung der Funktionalität der Monitors, OSDs und Metadata Servers. Die „Capabilities“ können außerdem den Zugriff auf Daten in einem Pool oder Pool-Namespace einschränken. Ein verwaltungsbefugter Benutzer von Ceph legt die Capabilities eines Benutzers bei dessen Erstellung oder Aktualisierung fest.
Die Syntax der Capabilities entspricht der folgenden Form:
daemon-type 'allow capability' [...]
Hier sehen Sie eine Liste der Capabilities für die einzelnen Service-Typen:
- Monitor-Capabilities
sind
r,w,xundallow profile cap.mon 'allow rwx' mon 'allow profile osd'
- OSD-Capabilities
sind
r,w,x,class-read,class-writeundprofile osd. Außerdem sind bei OSD-Capabilities auch Pool- und Namespace-Einstellungen möglich.osd 'allow capability' [pool=poolname] [namespace=namespace-name]
- MDS-Capability
Dafür ist nur
allowerforderlich oder es erfolgt kein Eintrag.mds 'allow'
Die folgenden Einträge beschreiben die einzelnen Capabilities:
- allow
Geht den Zugriffseinstellungen für einen Daemon voran. Schließt
rwnur für MDS ein.- r
Gewährt Benutzern Lesezugriff. Erforderlich bei Monitors zum Abrufen der CRUSH Map.
- w
Gewährt Benutzern Schreibzugriff auf Objekte.
- x
Gewährt Benutzern die Capability zum Aufrufen von Klassenmethoden (Lesen und Schreiben) und zur Ausführung von
auth-Operationen an Monitors.- class-read
Gewährt Benutzern die Capability zum Aufrufen von Methoden zum Lesen für Klassen. Teilmenge von
x.- class-write
Gewährt Benutzern die Capability zum Aufrufen von Methoden zum Schreiben für Klassen. Teilmenge von
x.- *
Gewährt Benutzern Lese-, Schreib- und Ausführungsberechtigungen für einen bestimmten Daemon/Pool sowie die Möglichkeit zum Ausführen von Admin-Kommandos.
- profile osd
Gewährt Benutzern Berechtigungen zum Herstellen einer Verbindung als OSD mit anderen OSDs oder Monitors. Wird OSDs gewährt, um OSDs die Verarbeitung von Heartbeat-Datenverkehr und Statusberichterstellung für Reproduktionen zu ermöglichen.
- profile mds
Gewährt Benutzern Berechtigungen zum Herstellen einer Verbindung als MDS mit anderen MDSs oder Monitors.
- profile bootstrap-osd
Gewährt Benutzern Berechtigungen für OSD-Bootstraps. Übertragen an Bereitstellungswerkzeuge, damit diese berechtigt sind, beim Bootstrapping eines OSDs Schlüssel hinzuzufügen.
- profile bootstrap-mds
Gewährt Benutzern Berechtigungen für Metadata Server-Bootstraps. Übertragen an Bereitstellungswerkzeuge, damit diese berechtigt sind, beim Bootstrapping eines Metadata Servers Schlüssel hinzuzufügen.
30.2.1.3 Pools #
Ein Pool ist eine logische Partition, in der Benutzer Daten speichern. Bei
Ceph-Bereitstellungen ist es üblich, einen Pool als logische Partition für
ähnliche Datentypen zu erstellen. Wenn beispielsweise Ceph als Back-End
für OpenStack bereitgestellt wird, dann würde eine typische Bereitstellung
Pools für Volumes, Images, Sicherungen und virtuelle Maschinen umfassen
sowie Benutzer wie client.glance
oder client.cinder.
30.2.2 Benutzer verwalten #
Die Benutzerverwaltungsfunktion ermöglicht es Ceph-Cluster-Administratoren, Benutzer direkt im Ceph-Cluster zu erstellen, zu aktualisieren und zu löschen.
Wenn Sie Benutzer im Ceph-Cluster erstellen oder löschen, müssen Sie möglicherweise Schlüssel an Clients verteilen, damit diese zu Schlüsselbunden hinzugefügt werden können. Ausführliche Informationen finden Sie unter Abschnitt 30.2.3, „Verwalten von Schlüsselbunden“.
30.2.2.1 Auflisten von Benutzern #
Führen Sie folgendes Kommando aus, um die Benutzer in Ihrem Cluster aufzulisten:
cephuser@adm > ceph auth list
Ceph listet alle Benutzer in Ihrem Cluster auf. In einem Cluster mit zwei
Knoten beispielsweise sieht die Ausgabe von ceph auth
list folgendermaßen aus:
installed auth entries:
osd.0
key: AQCvCbtToC6MDhAATtuT70Sl+DymPCfDSsyV4w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQC4CbtTCFJBChAAVq5spj0ff4eHZICxIOVZeA==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQBHCbtT6APDHhAA5W00cBchwkQjh3dkKsyPjw==
caps: [mds] allow
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBICbtTOK9uGBAAdbe5zcIGHZL3T/u2g6EBww==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQBHCbtT4GxqORAADE5u7RkpCN/oo4e5W0uBtw==
caps: [mon] allow profile bootstrap-osd
Beachten Sie, dass die Schreibweise TYPE.ID für
Benutzer so angewendet wird, dass osd.0 einen Benutzer
vom Typ osd und dessen ID 0
bezeichnet. client.admin ist ein Benutzer vom Typ
client und seine ID lautet admin.
Beachten Sie auch, dass sich jeder Eintrag aus einem Eintrag
key: value und einem oder
mehreren Einträgen caps: zusammensetzt.
Speichern Sie die Ausgabe mit der Option -o
filename und ceph auth
list in eine Datei.
30.2.2.2 Abrufen von Informationen zu Benutzern #
Führen Sie folgendes Kommando aus, um einen bestimmten Benutzer, Schlüssel und Capabilities abzurufen:
cephuser@adm > ceph auth get TYPE.IDBeispiel:
cephuser@adm > ceph auth get client.admin
exported keyring for client.admin
[client.admin]
key = AQA19uZUqIwkHxAAFuUwvq0eJD4S173oFRxe0g==
caps mds = "allow"
caps mon = "allow *"
caps osd = "allow *"Entwickler können auch Folgendes ausführen:
cephuser@adm > ceph auth export TYPE.ID
Das Kommando auth export entspricht auth
get und gibt außerdem die interne Authentifizierungs-ID aus.
30.2.2.3 Hinzufügen von Benutzern #
Durch Hinzufügen eines Benutzers wird ein Benutzername
(TYPE.ID) erstellt sowie ein geheimer Schlüssel und die
Capabilities, die im Kommando enthalten sind, mit dem sie den Benutzer
erstellen.
Benutzerschlüssel ermöglichen es Benutzern, sich beim Ceph Storage Cluster zu authentifizieren. Durch ihre Capabilities sind Benutzer autorisiert, an Ceph Monitors (mon), Ceph OSDs (osd) oder Ceph Metadata Server (mds) zu lesen, zu schreiben und Vorgänge auszuführen.
Zum Hinzufügen von Benutzern stehen einige Kommandos zur Verfügung:
ceph auth addDieses Kommando ist die herkömmliche Methode zum Hinzufügen von Benutzern. Es erstellt den Benutzer, generiert einen Schlüssel und fügt beliebige angegebene Capabilities hinzu.
ceph auth get-or-createDieses Kommando ist oft die bequemste Methode zum Erstellen eines Benutzers, weil es ein Schlüsseldateiformat mit dem Benutzernamen (in Klammern) und dem Schlüssel zurückgibt. Wenn der Benutzer bereits vorhanden ist, gibt dieses Kommando einfach den Benutzernamen und den Schlüssel im Schlüsseldateiformat zurück. Speichern Sie die Ausgabe mit der Option
-o filenamein eine Datei.ceph auth get-or-create-keyDieses Kommando ist eine bequeme Methode zum Erstellen eines Benutzers. Es gibt (nur) den Schlüssel des Benutzers zurück. Dies ist nützlich für Clients, die nur den Schlüssel benötigen (beispielsweise
libvirt). Wenn der Benutzer bereits vorhanden ist, gibt dieses Kommando einfach den Schlüssel zurück. Speichern Sie die Ausgabe mit der Option-o filenamein eine Datei.
Beim Erstellen von Client-Benutzern können Sie auch einen Benutzer ohne
Capabilities erstellen. Ein Benutzer ohne Capabilities kann nichts anderes
als authentifizieren. Ein derartiger Client kann nicht die
Cluster-Zuordnung vom Monitor abrufen. Es ist jedoch möglich, einen
Benutzer ohne Capabilities zu erstellen, wenn Sie später Capabilities mit
dem Kommando ceph auth caps hinzufügen möchten.
Ein normaler Benutzer verfügt zumindest über Lese-Capabilities für den Ceph Monitor und Lese- und Schreib-Capabilities für Ceph OSDs. Außerdem sind die OSD-Berechtigungen eines Benutzers oft auf den Zugriff auf einen bestimmten Pool beschränkt.
cephuser@adm >ceph auth add client.john mon 'allow r' osd \ 'allow rw pool=liverpool'cephuser@adm >ceph auth get-or-create client.paul mon 'allow r' osd \ 'allow rw pool=liverpool'cephuser@adm >ceph auth get-or-create client.george mon 'allow r' osd \ 'allow rw pool=liverpool' -o george.keyringcephuser@adm >ceph auth get-or-create-key client.ringo mon 'allow r' osd \ 'allow rw pool=liverpool' -o ringo.key
Wenn Sie einem Benutzer die Capabilities für OSDs gewähren, aber nicht den Zugriff auf bestimmte Pools beschränken, dann hat der Benutzer Zugriff auf alle Pools im Cluster.
30.2.2.4 Bearbeiten der Befähigungen für Benutzer #
Mit dem Kommando ceph auth caps können Sie einen
Benutzer angeben und die Capabilities dieses Benutzers ändern. Wenn Sie
neue Capabilities festlegen, werden die aktuellen damit überschrieben.
Führen Sie das Kommando ceph auth get
USERTYPE aus, um die aktuellen Capabilities
anzuzeigen.BENUTZER-ID. Zum
Hinzufügen von Capabilities müssen Sie auch die bestehenden Capabilities
angeben, wenn Sie folgende Form verwenden:
cephuser@adm > ceph auth caps USERTYPE.USERID daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]' [daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]']Beispiel:
cephuser@adm >ceph auth get client.johncephuser@adm >ceph auth caps client.john mon 'allow r' osd 'allow rw pool=prague'cephuser@adm >ceph auth caps client.paul mon 'allow rw' osd 'allow r pool=prague'cephuser@adm >ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
Zum Entfernen einer Capability können Sie diese zurücksetzen. Wenn der Benutzer auf einen bestimmten Daemon, auf den er vorher zugreifen konnte, keinen Zugriff mehr haben soll, geben Sie eine leere Zeichenkette an:
cephuser@adm > ceph auth caps client.ringo mon ' ' osd ' '30.2.2.5 Löschen von Benutzern #
Einen Benutzer löschen Sie mit ceph auth del:
cephuser@adm > ceph auth del TYPE.ID
Dabei steht TYPE für client,
osd, mon oder mds
und ID ist der Benutzername oder die ID des
Daemon.
Wenn Sie Benutzer mit Berechtigungen genau für einen Pool erstellt haben, der nicht mehr vorhanden ist, sollten Sie diese Benutzer ebenfalls löschen.
30.2.2.6 Ausgabe des Benutzerschlüssels #
Führen Sie folgendes Kommando aus, um die Authentifizierungsschlüssel eines Benutzers in der Standardausgabe auszugeben:
cephuser@adm > ceph auth print-key TYPE.ID
Dabei steht TYPE für client,
osd, mon oder mds
und ID ist der Benutzername oder die ID des
Daemon.
Die Ausgabe eines Benutzerschlüssels ist nützlich, wenn Sie in einer
Client-Software einen Benutzerschlüssel (wie zum Beispiel
libvirt) angeben müssen.
Beispiel:
root # mount -t ceph host:/ mount_point \
-o name=client.user,secret=`ceph auth print-key client.user`30.2.2.7 Importieren von Benutzern #
Importieren Sie einen oder mehrere Benutzer mit ceph auth
import und geben Sie einen Schlüsselbund an:
cephuser@adm > ceph auth import -i /etc/ceph/ceph.keyringDer Ceph Storage Cluster fügt neue Benutzer, deren Schlüssel und Capabilities hinzu und aktualisiert bestehende Benutzer, deren Schlüssel und Capabilities.
30.2.3 Verwalten von Schlüsselbunden #
Wenn Sie über einen Ceph-Client auf Ceph zugreifen, sucht der Cient nach einem lokalen Schlüsselbund. Ceph legt standardmäßig in der Schlüsselbundeinstellung vorab die folgenden vier Schlüsselbundnamen fest. Sie müssen diese daher nicht in der Ceph-Konfigurationsdatei festlegen, es sei denn, Sie möchten die Standardwerte überschreiben:
/etc/ceph/cluster.name.keyring /etc/ceph/cluster.keyring /etc/ceph/keyring /etc/ceph/keyring.bin
Die Metavariable cluster ist Ihr
Ceph-Cluster-Name, der durch den Namen in der Ceph-Konfigurationsdatei
definiert ist. ceph.conf bedeutet, dass der
Cluster-Name ceph lautet, was
ceph.keyring ergibt. Die Metavariable
name ist der Benutzertyp und die Benutzer-ID,
wie zum Beispiel client.admin, was
ceph.client.admin.keyring ergibt.
Nach Erstellung eines Benutzers (zum Beispiel
client.ringo) müssen Sie den
Schlüssel abrufen und diesen zu einem Schlüsselbund auf einem Ceph-Client
hinzufügen, sodass der Benutzer Zugriff auf den Ceph Storage Cluster hat.
In Abschnitt 30.2, „Schlüsselverwaltungsbereiche“ finden Sie detaillierte
Informationen zum Auflisten, Abrufen, Hinzufügen, Bearbeiten und Löschen
von Benutzern direkt im Ceph Storage Cluster. Ceph stellt jedoch auch das
ceph-authtool-Dienstprogramm zur Verfügung, mit dem
Schlüsselbunde von einem Ceph-Client aus verwaltet werden.
30.2.3.1 Erstellen eines Schlüsselbunds #
Wenn Sie zum Erstellen von Benutzern wie in Abschnitt 30.2, „Schlüsselverwaltungsbereiche“ beschrieben vorgehen, dann müssen Sie den Ceph-Clients Benutzerschlüssel zur Verfügung stellen. Die Clients rufen den Schlüssel für den angegebenen Benutzer ab und authentifizieren diesen im Ceph Storage Cluster. Ceph-Clients greifen auf Schlüsselbunde zu, um einen Benutzernamen zu ermitteln und den Schlüssel des Benutzer abzurufen:
cephuser@adm > ceph-authtool --create-keyring /path/to/keyring
Wir empfehlen, beim Erstellen eines Schlüsselbunds mit mehreren Benutzern
den Cluster-Namen (beispielsweise
cluster.keyring) als Schlüsselbunddateinamen zu
verwenden und diesen im Verzeichnis /etc/ceph zu
speichern. Die Standardeinstellung der Schlüsselbundkonfiguration
übernimmt den Dateinamen, ohne dass Sie diesen in der lokalen Kopie Ihrer
Ceph-Konfigurationsdatei angeben müssen. Erstellen Sie beispielsweise
ceph.keyring mit dem folgenden Kommando:
cephuser@adm > ceph-authtool -C /etc/ceph/ceph.keyring
Wir empfehlen, beim Erstellen eines Schlüsselbunds für einen einzelnen
Benutzer den Cluster-Namen, den Benutzertyp und Benutzernamen zu verwenden
und im Verzeichnis /etc/ceph zu speichern,
beispielsweise ceph.client.admin.keyring für den
client.admin-Benutzer.
30.2.3.2 Hinzufügen eines Benutzers zu einem Schlüsselbund #
Beim Hinzufügen eines Benutzers zum Ceph Storage Cluster (weitere Informationen hierzu finden Sie in Abschnitt 30.2.2.3, „Hinzufügen von Benutzern“) können Sie den Benutzer, den Schlüssel und die Capabilities abrufen und den Benutzer in einem Schlüsselbund speichern.
Wenn Sie nur einen Benutzer pro Schlüsselbund verwenden möchten, dann
speichern Sie die Ausgabe im Schlüsselbunddateiformat mit dem Kommando
ceph auth get und der Option -o.
Führen Sie beispielsweise zum Erstellen eines Schlüsselbunds für den
client.admin-Benutzer folgendes
Kommando aus:
cephuser@adm > ceph auth get client.admin -o /etc/ceph/ceph.client.admin.keyring
Wenn Sie Benutzer in einen Schlüsselbund importieren möchten, dann geben
Sie mit ceph-authtool den Ziel-Schlüsselbund und den
Ursprungs-Schlüsselbund an:
cephuser@adm > ceph-authtool /etc/ceph/ceph.keyring \
--import-keyring /etc/ceph/ceph.client.admin.keyring
Wenn Ihr Schlüsselbund beschädigt ist, löschen Sie Ihren Schlüssel aus
dem Verzeichnis /etc/ceph und erstellen Sie einen
neuen Schlüssel mit denselben Anweisungen aus
Abschnitt 30.2.3.1, „Erstellen eines Schlüsselbunds“.
30.2.3.3 Erstellen eines Benutzers #
Ceph stellt das Kommando ceph auth add zum Erstellen
eines Benutzers direkt im Ceph Storage Cluster zur Verfügung. Sie können
jedoch auch einen Benutzer, die Schlüssel und Capabilities direkt im
Ceph-Client-Schlüsselbund erstellen. Danach importieren Sie den Benutzer
im Ceph Storage Cluster:
cephuser@adm > ceph-authtool -n client.ringo --cap osd 'allow rwx' \
--cap mon 'allow rwx' /etc/ceph/ceph.keyringEs ist auch möglich, einen Schlüsselbund zu erstellen und gleichzeitig einen neuen Benutzer zum Schlüsselbund hinzuzufügen:
cephuser@adm > ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo \
--cap osd 'allow rwx' --cap mon 'allow rwx' --gen-key
In den obigen Szenarien ist der neue Benutzer
client.ringo nur im
Schlüsselbund vorhanden. Zum Hinzufügen des neuen Benutzers zum Ceph
Storage Cluster müssen Sie den neuen Benutzer noch zum Cluster hinzufügen:
cephuser@adm > ceph auth add client.ringo -i /etc/ceph/ceph.keyring30.2.3.4 Bearbeiten von Benutzern #
Geben Sie zum Bearbeiten der Capabilities eines Benutzerdatensatzes in einem Schlüsselbund den Schlüsselbund und den Benutzer gefolgt von den Capabilities an:
cephuser@adm > ceph-authtool /etc/ceph/ceph.keyring -n client.ringo \
--cap osd 'allow rwx' --cap mon 'allow rwx'Zum Aktualisieren des bearbeiteten Benutzers in der Ceph-Cluster-Umgebung müssen Sie die Änderungen aus dem Schlüsselbund in den Benutzereintrag im Ceph-Cluster importieren:
cephuser@adm > ceph auth import -i /etc/ceph/ceph.keyringDetaillierte Informationen zum Aktualisieren eines Benutzers im Ceph Storage Cluster von einem Schlüsselbund aus finden Sie in Abschnitt 30.2.2.7, „Importieren von Benutzern“.
30.2.4 Nutzung der Kommandozeile #
Das Kommando ceph unterstützt die folgenden Optionen in
Bezug auf die Bearbeitung von Benutzername und Geheimnis:
--idoder--userCeph kennzeichnet Benutzer mit einem Typ und einer ID (TYPE.ID, wie
client.adminoderclient.user1). Mit den Optionenid,nameund-ngeben Sie den ID-Teil des Benutzernamens an (beispielsweiseadminoderuser1). Sie können den Benutzer mit ‑‑id angeben und den Typ auslassen. Geben Sie beispielsweise zum Angeben des Benutzers „client.foo“ Folgendes ein:cephuser@adm >ceph --id foo --keyring /path/to/keyring healthcephuser@adm >ceph --user foo --keyring /path/to/keyring health--nameoder-nCeph kennzeichnet Benutzer mit einem Typ und einer ID (TYPE.ID, wie
client.adminoderclient.user1). Die Optionen--nameund-nermöglichen es Ihnen, den vollständigen Benutzernamen anzugeben. Sie müssen den Benutzertyp angeben (normalerweiseclient) mit der Benutzer-ID:cephuser@adm >ceph --name client.foo --keyring /path/to/keyring healthcephuser@adm >ceph -n client.foo --keyring /path/to/keyring health--keyringDer Pfad zum Schlüsselbund mit einem oder mehreren Benutzernamen und Geheimnissen. Die Option
--secrethat zwar dieselbe Funktion, funktioniert jedoch nicht bei Object Gateway, weil dort--secreteinem anderen Zweck dient. Es ist möglich, einen Schlüsselbund mitceph auth get-or-createabzurufen und ihn lokal zu speichern. Diese Vorgehensweise wird bevorzugt, weil Sie Benutzernamen wechseln können, ohne den Schlüsselbundpfad zu ändern:cephuser@adm >rbd map --id foo --keyring /path/to/keyring mypool/myimage
A Ceph-Wartungsaktualisierungen auf der Grundlage von vorgeschalteten „Octopus“-Unterversionen #
Mehrere wesentliche Pakete in SUSE Enterprise Storage 7 beruhen auf der Octopus-Versionsserie von Ceph. Wenn das Ceph-Projekt (https://github.com/ceph/ceph) neue Unterversionen in der Octopus-Serie veröffentlicht, wird SUSE Enterprise Storage 7 aktualisiert, damit das Produkt von den aktuellen vorgeschalteten Bugfixes und Funktions-Backports profitiert.
In diesem Kapitel erhalten Sie einen Überblick über wichtige Änderungen in den einzelnen vorgeschalteten Unterversionen, die bereits in das Produkt aufgenommen wurden oder künftig aufgenommen werden.
Octopus-Unterversion 15.2.5#
Die Octopus-Unterversion 15.2.5 brachte die folgenden Korrekturen und weitere Änderungen:
CephFS: Die Richtlinien für die automatische statische Teilbaumpartitionierung können jetzt unter Verwendung der neuen erweiterten Attribute für verteiltes und zufälliges kurzlebiges Anheften von Verzeichnissen konfiguriert werden. Weitere Informationen finden Sie in der folgenden Dokumentation: https://docs.ceph.com/docs/master/cephfs/multimds/
Für Monitore ist nun die Konfigurationsoption
mon_osd_warn_num_repairedverfügbar, die standardmäßig auf 10 festgelegt ist. Wenn ein OSD mehr als diese Anzahl von E/A-Fehlern in den gespeicherten Daten repariert hat, wird die ZustandswarnungOSD_TOO_MANY_REPAIRSgeneriert.Jetzt werden geplante Scrubs vom Typ „deaktiviert“ abgebrochen, wenn global oder pro Pool die Flags
no scrubund/oderno deep-scrubgesetzt sind. Alle vom Benutzer initiierten Scrubs werden NICHT unterbrochen.Ein Problem wurde behoben, bei dem OSD-Zuordnungen in einem fehlerfreien Cluster nicht optimiert wurden.
Octopus-Unterversion 15.2.4#
Die Octopus-Unterversion 15.2.4 brachte die folgenden Korrekturen und weitere Änderungen:
CVE-2020-10753: rgw: sanitize newlines in s3 CORSConfiguration’s ExposeHeader
Object Gateway: Die Unterkommandos
radosgw-admin, die sich auf bezugslose Einheiten beziehen (radosgw-admin orphans find,radosgw-admin orphans finishundradosgw-admin orphans list-jobs), wurden als veraltet entfernt. Sie wurden nicht aktiv gewartet, und da sie Zwischenergebnisse auf dem Cluster speichern, könnten sie potenziell einen fast vollen Cluster füllen. Sie wurden durch das Werkzeugrgw-orphan-listersetzt, das derzeit noch als experimentell betrachtet wird.RBD: Der Name des RBD-Pool-Objekts, das zum Speichern des Zeitplans zum Bereinigen des RBD-Papierkorbs verwendet wird, wurde von
rbd_trash_trash_purge_schedulezurbd_trash_purge_schedulegeändert. Benutzer, die bereits mit der Funktion des Zeitplans zum Bereinigen des RBD-Papierkorbs begonnen und Zeitpläne pro Pool oder Namespace konfiguriert haben, sollten vor dem Upgrade das Objektrbd_trash_trash_purge_schedulenachrbd_trash_purge_schedulekopieren undrbd_trash_purge_schedulemit den folgenden Kommandos in jedem RBD-Pool und -Namespace entfernen, in denen zuvor ein Zeitplan zur Bereinigung des Papierkorbs konfiguriert war:rados -p pool-name [-N namespace] cp rbd_trash_trash_purge_schedule rbd_trash_purge_schedule rados -p pool-name [-N namespace] rm rbd_trash_trash_purge_schedule
Alternativ können Sie den Zeitplan nach der Aktualisierung auf eine andere Ihnen genehme Weise wiederherstellen.
Octopus-Unterversion 15.2.3#
Die Octopus-Unterversion 15.2.3 war eine Hot Fix-Version zur Behebung eines Problems, bei dem das WAL beschädigt wurde, wenn
bluefs_preextend_wal_filesundbluefs_buffered_iogleichzeitig aktiviert waren. Der Fix in 15.2.3 ist nur eine vorübergehende Maßnahme (Änderung des Standardwertes vonbluefs_preextend_wal_fileszufalse). Die dauerhafte Lösung besteht darin, die Optionbluefs_preextend_wal_fileskomplett zu entfernen. Diese Lösung wird wahrscheinlich in der Zwischenversion 15.2.6 erscheinen.
Octopus-Unterversion 15.2.2#
Mit der Octopus-Unterversion 15.2.2 wurde eine Sicherheitslücke gepatcht:
CVE-2020-10736: Autorisierungsumgehung in MONs und MGRs behoben
Octopus-Unterversion 15.2.1#
In Octopus-Unterversion 15.2.1 wurde ein Problem behoben, bei dem ein schnelles Upgrade von Luminous (SES5.5) zu Nautilus (SES6) zu Octopus (SES7) zum Absturz von OSDs führte. Darüber hinaus wurden zwei Sicherheitslücken gepatcht, die in der ursprünglichen Octopus-Version (15.2.0) vorhanden waren:
CVE-2020-1759: Nonce-Wiederverwendung im sicheren Modus von msgr V2 behoben
CVE-2020-1760: XSS aufgrund von RGW GetObject-Header-Splitting behoben
B Aktualisierungen für die Dokumentation #
In diesem Kapitel werden inhaltliche Änderungen für dieses Dokument aufgeführt, die für die aktuelle SUSE Enterprise Storage-Version gelten.
Das Ceph-Dashboard-Kapitel (Teil I, „Ceph Dashboard“) wurde in der Buchhierarchie um eine Ebene nach oben verschoben, so dass seine detaillierten Themen direkt im Inhaltsverzeichnis durchsucht werden können.
Die Struktur des Book “Betriebs- und Verwaltungshandbuch” wurde aktualisiert, um sie an die aktuellen Handbücher anzupassen. Einige Kapitel wurden in andere Handbücher verschoben (jsc#SES-1397).
Glossar #
Allgemein
- Admin-Knoten #
Der Host, von dem aus Sie die Ceph-bezogenen Befehle zur Verwaltung von Cluster-Hosts ausführen.
- Alertmanager #
Einzelne Binärdatei, die die vom Prometheus-Server gesendeten Warnmeldungen verarbeitet und die Endbenutzer benachrichtigt.
- Archiv-Synchronisierungsmodul #
Modul, mit dem eine Object-Gateway-Zone erstellt werden kann, in der der Verlauf der S3-Objektversionen abgelegt wird.
- Bucket #
Punkt, der andere Knoten in eine Hierarchie physischer Standorte aggregiert.
- Ceph Dashboard #
Eine integrierte webbasierte Verwaltungs- und Überwachungsanwendung von Ceph, mit der verschiedene Aspekte und Objekte des Clusters verwaltet werden. Das Dashboard wird als Ceph-Manager-Modul implementiert.
- Ceph Manager #
Ceph Manager oder MGR ist die Ceph-Manager-Software, die den gesamten Status des ganzen Clusters an einem Ort sammelt.
- Ceph Monitor #
Ceph Monitor oder MON ist die Ceph-Monitorsoftware.
- Ceph Object Storage #
Das Objektspeicher-„Produkt“, der Service oder die Fähigkeiten, die aus einem Ceph Storage Cluster und einem Ceph Object Gateway bestehen.
- Ceph Storage Cluster #
Ein zentraler Satz von Speichersoftwareprogrammen, die die Daten des Benutzers speichern. Ein derartiger Satz besteht aus Ceph Monitors und OSDs.
- Ceph-Client #
Die Sammlung von Ceph-Komponenten, die auf einen Ceph Storage Cluster zugreifen können. Dazu gehören das Object Gateway, das Ceph-Blockgerät, das CephFS und die entsprechenden Bibliotheken, Kernel-Module und FUSE-Clients.
- Ceph-OSD-Daemon #
Der
ceph-osd-Daemon ist als Ceph-Komponente dafür zuständig, Objekte in einem lokalen Dateisystem zu speichern und den Zugriff auf diese Objekte über das Netzwerk bereitzustellen.ceph-salt#Stellt Werkzeuge für die Bereitstellung von Ceph-Clustern bereit, die von cephadm mit Salt verwaltet werden.
- cephadm #
Mit cephadm wird ein Ceph-Cluster bereitgestellt und verwaltet. Dazu wird vom Manager-Daemon über SSH eine Verbindung zu den Hosts hergestellt, um Ceph-Daemon-Container hinzuzufügen, zu entfernen oder zu aktualisieren.
- CephFS #
Das Ceph-Dateisystem.
- CephX #
Das Ceph-Authentifizierungsprotokoll. Cephx funktioniert wie Kerberos, hat aber keinen Single-Point-of-Failure.
- CRUSH, CRUSH Map #
Controlled Replication Under Scalable Hashing: Dieser Algorithmus berechnet Datenspeicherorte und bestimmt damit, wie Daten gespeichert und abgerufen werden. CRUSH benötigt eine Karte (Map) des Clusters zum pseudozufälligen Speichern und Abrufen von Daten in OSDs mit gleichmäßiger Datenverteilung im Cluster.
- CRUSH-Regel #
Die CRUSH-Datenplatzierungsregel, die für einen bestimmten Pool oder mehrere Pools gilt.
- DriveGroups #
DriveGroups sind eine Deklaration von einem oder mehreren OSD-Layouts, die auf physische Laufwerke abgebildet werden können. Ein OSD-Layout definiert, wie Ceph OSD-Speicher auf den Medien, die den angegebenen Kriterien entsprechen, physisch zuweist.
- Grafana #
Lösung für die Datenbankanalyse und -überwachung.
- Knoten #
Ein einzelner Rechner oder Server in einem Ceph-Cluster.
- Mehrere Zonen #
- Metadata Server #
Metadata Server oder MDS ist die Ceph-Metadatensoftware.
- Object Gateway #
Die S3/Swift-Gateway-Komponente für Ceph Object Store. Auch bekannt als RADOS Gateway (RGW).
- OSD #
Object Storage Device (Objektspeichergerät): Eine physische oder logische Speichereinheit.
- OSD-Knoten #
Ein Cluster-Knoten, der Daten speichert, Reproduktion, Wiederherstellung, Backfilling und Ausgleich der Daten verarbeitet und Überwachungsinformationen für Ceph-Monitore zur Verfügung stellt, indem er andere Ceph OSD-Daemons überprüft.
- PG #
Platzierungsgruppe: Teilbereich eines Pools zur Leistungsanpassung.
- Pool #
Logische Partitionen zum Speichern von Objekten wie Festplatten-Images.
- Prometheus #
Toolkit für die Systemüberwachung und die Ausgabe von Warnmeldungen.
- RADOS-Blockgerät (RADOS Block Device, RBD) #
Die Blockspeicherkomponente von Ceph. Auch als Ceph-Blockgerät bekannt.
- Regelsatz #
Regeln zur Festlegung der Datenplatzierung für einen Pool.
- Reliable Autonomic Distributed Object Store (RADOS) #
Ein zentraler Satz von Speichersoftwareprogrammen, die die Daten des Benutzers (MON+OSD) speichern.
- Routing-Baum #
Bezeichnung für ein Diagramm mit den verschiedenen Wegen, die ein Empfänger durchlaufen kann.
- Samba #
Windows-Integrationssoftware.
- Samba Gateway #
Das Samba Gateway verbindet sich mit dem Active Directory in der Windows-Domäne, um Benutzer zu authentifizieren und zu autorisieren.
- Unterversion #
Jede Ad-hoc-Version, die nur Fehler- oder Sicherheitsbehebungen enthält.
- zonegroup #