- 1 Einsatzszenario
- 2 Systemanforderungen
- 3 Überblick über die Bootstrap-Skripte
- 4 Installation von SUSE Linux Enterprise Server und High Availability Extension
- 5 Verwendung von SBD als Fencing-Mechanismus
- 6 Einrichtung des ersten Knotens
- 7 Hinzufügen des zweiten Knotens
- 8 Testen des Clusters
- 9 Weiterführende Informationen
- 10 Rechtliche Hinweise
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Kurzanleitung zu Installation und Einrichtung #
Zusammenfassung#
Dieses Dokument führt Sie durch die Einrichtung eines sehr einfachen Clusters mit zwei Knoten. Dabei werden Bootstrap-Skripte verwendet, die im Paket ha-cluster-bootstrap bereitgestellt werden. Bei diesem Vorgang müssen Sie unter anderem eine virtuelle IP-Adresse als Cluster-Ressource konfigurieren und SBD im gemeinsam genutzten Speicher als Fencing-Mechanismus (Abriegelung) verwenden.
- 1 Einsatzszenario
- 2 Systemanforderungen
- 3 Überblick über die Bootstrap-Skripte
- 4 Installation von SUSE Linux Enterprise Server und High Availability Extension
- 5 Verwendung von SBD als Fencing-Mechanismus
- 6 Einrichtung des ersten Knotens
- 7 Hinzufügen des zweiten Knotens
- 8 Testen des Clusters
- 9 Weiterführende Informationen
- 10 Rechtliche Hinweise
- A GNU Licenses
1 Einsatzszenario #
Mit den in diesem Dokument beschriebenen Verfahren erhalten Sie eine Minimaleinrichtung eines Clusters mit zwei Knoten, die folgende Eigenschaften aufweist:
Zwei Knoten:
alice(IP:192.168.1.1) undbob(IP:192.168.1.2), die über das Netzwerk miteinander verbunden sindDie virtuelle IP-Adresse (
192.168.2.1) nach dem Floating-IP-Prinzip, über die Clients eine Verbindung mit dem Service herstellen können, und zwar unabhängig davon, auf welchem physischen Knoten er ausgeführt wirdEin gemeinsam genutztes Speichergerät für den Einsatz als SBD-Fencing-Mechanismus Dadurch lassen sich Szenarien mit Systemspaltungen vermeiden.
Failover der Ressourcen von einem Knoten zum anderen, wenn der aktive Host ausfällt (Aktiv/Passiv-Einrichtung)
Nach der Einrichtung des Clusters mit den Bootstrap-Skripten überwachen wir den Cluster mit der grafischen HA Web Konsole (Hawk). Dabei handelt es sich um eines der Werkzeuge für die Cluster-Verwaltung, die im Lieferumfang von SUSE Linux Enterprise High Availability Extension enthalten sind. Die ordnungsgemäße Funktionsweise des Ressourcen-Failovers lässt sich ganz einfach testen, indem einer der Knoten in den Standby-Modus versetzt und geprüft wird, ob die virtuelle IP-Adresse zum zweiten Knoten migriert wird.
Sie können den aus zwei Knoten bestehenden Cluster zu Testzwecken oder als anfängliche Cluster-Minimalkonfiguration verwenden, die später erweitert werden kann. Bevor Sie den Cluster in einer Produktionsumgebung einsetzen, müssen Sie ihn Ihren Anforderungen entsprechend ändern.
2 Systemanforderungen #
In diesem Abschnitt erhalten Sie Informationen über die wichtigsten Systemanforderungen für das in Abschnitt 1, „Einsatzszenario“ beschriebene Szenario. Wenn Sie den Cluster für den Einsatz in einer Produktionsumgebung anpassen möchten, lesen Sie die ausführliche Liste der Systemanforderungen und Empfehlungen im Book “Administration Guide”, Chapter 2 “System Requirements and Recommendations”.
Hardwareanforderungen #
- Server
Zwei Server mit der Software, die in Softwareanforderungen angegeben ist.
Bei den Servern kann es sich um Bare Metal-Server oder um virtuelle Rechner handeln. Sie müssen nicht unbedingt mit identischer Hardware (Arbeitsspeicher, Festplattenspeicher usw.) ausgestattet sein, die gleiche Architektur wird jedoch vorausgesetzt. Plattformübergreifende Cluster werden nicht unterstützt.
- Kommunikationskanäle
Mindestens zwei TCP/IP-Kommunikationsmedien pro Cluster-Knoten. Die Netzwerkausstattung muss die Kommunikationswege unterstützen, die Sie für die Cluster-Kommunikation verwenden möchten: Multicast oder Unicast. Die Kommunikationsmedien sollten eine Datenübertragungsrate von mindestens 100 MBit/s unterstützen. Für eine unterstützte Cluster-Einrichtung sind mindestens zwei redundante Kommunikationspfade erforderlich. Dies lässt sich durch folgende Methoden erreichen:
Über Network Device Bonding (bevorzugte Methode)
Über einen zweiten Kommunikationskanal in Corosync
Netzwerk-Fehlertoleranz in einer Infrastrukturschicht (z. B. Hypervisor).
- Knoten-Fencing/STONITH
Um das Szenario einer „Systemspaltung“ zu verhindern, benötigen Cluster einen Fencing-Mechanismus für Knoten. Wenn eine Systemspaltung vorliegt, werden Cluster-Knoten in zwei oder mehr Gruppen geteilt, die (aufgrund eines Hardware- bzw. Softwarefehlers oder einer unterbrochenen Netzwerkverbindung) keine Kenntnis voneinander haben. Ein Fencing-Mechanismus isoliert den fraglichen Knoten (in der Regel durch das Zurücksetzen oder Ausschalten des Knotens). Dies wird auch als STONITH („Shoot the other node in the head“, Englisch für „Schieß dem anderen Knoten in den Kopf“) bezeichnet. Als Fencing-Mechanismus für Knoten kann entweder ein physisches Gerät (ein Netzschalter) oder ein Mechanismus wie SBD (STONITH nach Festplatte) in Kombination mit einem Watchdog verwendet werden. Für SBD ist ein gemeinsam genutzter Speicher erforderlich.
Die folgende Software muss auf allen Knoten installiert werden, die dem Cluster angehören sollen:
Softwareanforderungen #
SUSE Linux Enterprise Server 12 SP5 (mit allen verfügbaren Online-Updates)
SUSE Linux Enterprise High Availability Extension 12 SP5 (mit allen verfügbaren Online-Updates)
Sonstige Anforderungen und Empfehlungen #
- Zeitsynchronisierung
Cluster-Knoten müssen mit einem NTP-Server außerhalb des Clusters synchronisiert werden. Weitere Informationen finden Sie unter https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Wenn die Knoten nicht synchronisiert werden, funktioniert der Cluster möglicherweise nicht ordnungsgemäß. Darüber hinaus wird die Analyse von Protokolldateien und Cluster-Berichten erheblich erschwert, wenn keine Synchronisierung erfolgt. Wenn Sie die Bootstrap-Skripte verwenden, werden Sie gewarnt, falls NTP noch nicht konfiguriert wurde.
- Hostname und IP-Adresse
Verwenden Sie statische IP-Adressen.
Listen Sie alle Cluster-Knoten in der Datei
/etc/hostsmit ihrem vollständig qualifizierten Hostnamen und der Kurzform des Hostnamens auf. Es ist sehr wichtig, dass sich die Cluster-Mitglieder untereinander anhand der Namen finden können. Wenn die Namen nicht verfügbar sind, tritt ein Fehler bei der internen Cluster-Kommunikation auf.
- SSH
Alle Cluster-Knoten müssen in der Lage sein, über SSH aufeinander zuzugreifen. Werkzeuge wie
crm report(zur Fehlerbehebung) und von Hawk2 erfordern einen passwortfreien SSH-Zugriff zwischen den Knoten, da sie andernfalls nur Daten vom aktuellen Knoten erfassen können.Wenn Sie die Bootstrap-Skripte für die Einrichtung des Clusters verwenden, werden die SSH-Schlüssel automatisch erstellt und kopiert.
3 Überblick über die Bootstrap-Skripte #
Alle Kommandos aus dem Paket ha-cluster-bootstrap führen Bootstrap-Skripte aus, für die nur wenig Zeit und kaum manuelle Eingriffe benötigt werden.
Mit
ha-cluster-initkönnen die grundlegenden Parameter definiert werden, die für eine Cluster-Kommunikation erforderlich sind. Sie erhalten dadurch einen aktiven Cluster mit einem Knoten.Mit
ha-cluster-joinkönnen Sie Ihrem Cluster weitere Knoten hinzufügen.Mit
ha-cluster-removekönnen Sie Knoten aus Ihrem Cluster entfernen.
Alle Bootstrap-Skripte protokollieren die zugehörigen Daten in der Datei /var/log/ha-cluster-bootstrap.log. In dieser Datei finden Sie alle Details des Bootstrap-Prozesses. Sämtliche Optionen, die während des Bootstrap-Prozesses festgelegt wurden, können später mit dem YaST-Cluster-Modul geändert werden. Weitere Informationen finden Sie im Book “Administration Guide”, Chapter 3 “Installing the High Availability Extension”, Section 3.1 “Manual Installation”.
Jedem Skript ist eine man-Seite zugeordnet, auf der Sie die verschiedenen Funktionen, die Optionen des Skripts und einen Überblick über die Dateien finden, die vom Skript erstellt und geändert werden können.
Das Bootstrap-Skript ha-cluster-init prüft und konfiguriert die folgenden Komponenten:
- NTP
Wenn NTP nicht für das Starten zur Boot-Zeit konfiguriert wurde, wird eine Nachricht angezeigt.
- SSH
Es erstellt SSH-Schlüssel für die passwortfreie Anmeldung zwischen Cluster-Knoten.
- Csync2
Es konfiguriert Csync2 für die Replikation der Konfigurationsdateien auf allen Knoten in einem Cluster.
- Corosync
Es konfiguriert das Cluster-Kommunikationssystem.
- SBD/Watchdog
Es prüft, ob ein Watchdog vorhanden ist, und fragt Sie, ob SBD als Fencing-Mechanismus für Knoten konfiguriert werden soll.
- Virtual Floating IP
Sie werden gefragt, ob eine virtuelle IP-Adresse für die Cluster-Verwaltung mit Hawk2 konfiguriert werden soll.
- Firewall
Es öffnet die Ports in der Firewall, die für die Cluster-Kommunikation benötigt werden.
- Clustername
Es definiert einen Namen für den Cluster. Standardmäßig lautet dieser
clusterNUMMER. Dies ist optional und für die meisten GeoCluster sinnvoll. In der Regel gibt der Cluster-Name den Standort an, was das Auffinden einer Site in einem GeoCluster erleichtert.
4 Installation von SUSE Linux Enterprise Server und High Availability Extension #
Die Pakete für die Konfiguration und Verwaltung eines Clusters mit High Availability Extension sind im Installationsschema High Availability enthalten. Damit dieses Schema verfügbar ist, müssen Sie SUSE Linux Enterprise High Availability Extension als Erweiterung von SUSE Linux Enterprise Server installieren.
Sie finden Informationen zur Installation von Erweiterungen im SUSE Linux Enterprise 12 SP5 Deployment Guide (Bereitstellungshandbuch für SUSE Linux Enterprise 12 SP2): https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Sollte das Schema noch nicht installiert sein, installieren Sie es mit dem Befehl zypper install -t pattern ha_sles. Alternativ können Sie das Schema auch mit YaST installieren. Führen Sie dazu die folgenden Schritte aus:
Prozedur 1: Schema „High Availability“ für hohe Verfügbarkeit installieren #
Starten Sie YaST und wählen Sie › .
Klicken Sie auf den Karteireiter und aktivieren Sie das Schema in der Schemaliste.
Klicken Sie auf , um mit der Installation der Pakete zu beginnen.
Installieren Sie das Schema „High Availability“ auf allen Rechnern, die Teil Ihres Clusters sein sollen.

Anmerkung: Installation der Softwarepakete bei allen Parteien
Für eine automatisierte Installation von SUSE Linux Enterprise Server 12 SP5 und SUSE Linux Enterprise High Availability Extension 12 SP5 müssen Sie zum Klonen von bestehenden Knoten AutoYaST verwenden. Weitere Informationen hierzu finden Sie im Book “Administration Guide”, Chapter 3 “Installing the High Availability Extension”, Section 3.2 “Mass Installation and Deployment with AutoYaST”.
Registrieren Sie die Rechner beim SUSE Customer Center. Weitere Informationen finden Sie unter https://documentation.suse.com/sles-12/html/SLES-all/cha-update-offline.html#sec-update-registersystem.
5 Verwendung von SBD als Fencing-Mechanismus #
Falls Sie über einen gemeinsam genutzten Speicher wie beispielsweise ein SAN (Storage Area Network) verfügen, können Sie damit Szenarien einer Systemspaltung verhindern, indem Sie SBD als Fencing-Mechanismus für Knoten konfigurieren. SBD verwendet eine Watchdog-Unterstützung und den STONITH-Ressourcenagenten external/sbd.
5.1 Anforderungen für SBD #
Sie können während der Einrichtung des ersten Knotens mit ha-cluster-init entscheiden, ob Sie SBD verwenden möchten. Falls ja, müssen Sie den Pfad zum gemeinsam genutzten Speichergerät eingeben. ha-cluster-init erstellt standardmäßig automatisch eine kleine Partition auf dem Gerät, die für die Verwendung durch SBD vorgesehen ist.
Wenn Sie SBD verwenden möchten, müssen folgende Anforderungen erfüllt sein:
Der Pfad zum gemeinsam genutzten Speichergerät muss auf allen Knoten im Cluster persistent und konsistent sein. Verwenden Sie feste Gerätenamen wie
/dev/disk/by-id/dm-uuid-part1-mpath-abcedf12345.Das SBD-Gerät darf hostbasiertes RAID oder cLVM2 nicht verwenden und sich nicht auf einer DRBD-Instanz befinden.
Sie finden Details zur Einrichtung des gemeinsam genutzten Speichers im Storage Administration Guide (Administrationshandbuch zum Speicher) für SUSE Linux Enterprise Server 12 SP5: https://documentation.suse.com/sles-12/html/SLES-all/stor-admin.html.
5.2 Einrichtung von softdog-Watchdog und SBD #
In SUSE Linux Enterprise Server ist die Watchdog-Unterstützung im Kernel standardmäßig aktiviert: Die Auslieferung erfolgt mit mehreren Kernel-Modulen, die hardwarespezifische Watchdog-Treiber bereitstellen. In der High Availability Extension wird der SBD-Daemon als die Softwarekomponente verwendet, die Daten in den Watchdog „einspeist“.
Im folgenden Verfahren wird der softdog-Watchdog verwendet.
Wichtig: softdog-Einschränkungen
Der softdog-Treiber geht davon aus, dass noch mindestens eine CPU ausgeführt wird. Wenn alle CPUs ausgefallen sind, kann der im softdog-Treiber enthaltene Code, der das System neu starten soll, nicht ausgeführt werden. Ein Hardware-Watchdog arbeitet hingegen auch dann, wenn alle CPUs ausgefallen sind.
Bevor Sie den Cluster in einer Produktionsumgebung verwenden, ist es dringend empfohlen, das softdog-Modul durch das am besten zu Ihrer Hardware passende Hardwaremodul zu ersetzen.
Falls für Ihre Hardware jedoch kein passender Watchdog verfügbar ist, kann das softdog-Modul als Kernel-Watchdog-Modul verwendet werden.
Erstellen Sie mithilfe der Beschreibung im Abschnitt 5.1, „Anforderungen für SBD“, einen persistenten, gemeinsam genutzten Speicher.
Aktivieren Sie den softdog-Watchdog:
root #echosoftdog > /etc/modules-load.d/watchdog.confroot #systemctlrestart systemd-modules-loadTesten Sie, ob das softdog-Modul richtig geladen wurde:
root #lsmod| egrep "(wd|dog)" softdog 16384 1Initialisieren Sie auf
bobdie SBD-Partition:root #sbd-d /dev/SBDDEVICE createStarten Sie SBD, damit die Empfangsbereitschaft auf dem SBD-Gerät aktiviert ist:
root #sbd-d /dev/SBDDEVICE watchSenden Sie auf
aliceeine Testnachricht:root #sbd-d /dev/SBDDEVICE message bob testPrüfen Sie auf
bobmitsystemctlden Status; Sie sollten die empfangene Nachricht sehen:root #systemctlstatus sbd [...] info: Received command test from alice on disk SBDDEVICEBeenden Sie die Überwachung des SBD-Geräts auf
bobwie folgt:root #systemctlstop sbd
Es wird dringend empfohlen, die ordnungsgemäße Funktionsweise des SBD-Fencing-Mechanismus zu testen, wenn die Situation einer Systemspaltung eintritt. Ein derartiger Test kann durch die Blockierung der Corosync-Cluster-Kommunikation durchgeführt werden.
6 Einrichtung des ersten Knotens #
Richten Sie den ersten Knoten mit dem Skript ha-cluster-init ein. Dies dauert nicht lange und erfordert nur wenige manuelle Eingriffe.
Prozedur 2: Ersten Knoten (alice) mit ha-cluster-init einrichten #
Melden Sie sich als
rootan dem physischen oder virtuellen Rechner an, den Sie als Cluster-Knoten verwenden möchten.Starten Sie das Bootstrap-Skript, indem Sie Folgendes ausführen:
root #ha-cluster-init--name CLUSTERNAMEErsetzen Sie den Platzhalter CLUSTERNAME durch einen aussagekräftigen Namen, wie den geografischen Standort Ihres Clusters (z. B.
amsterdam). Dies ist besonders hilfreich, wenn Sie daraus später einen GeoCluster erstellen möchten, da eine Site so leicht identifizierbar ist. Sollten Sie den Befehl ohne die Option--nameausführen, lautet der Standardnamehacluster.Falls Sie für Ihre Cluster-Kommunikation anstelle von Multicast (Standard) Unicast benötigen, verwenden Sie hierzu die Option
-u. Nach der Installation finden Sie in der Datei/etc/corosync/corosync.confden Wertudpu. Wennha-cluster-initeinen Knoten erkennt, der in Amazon Web Services (AWS) ausgeführt wird, verwendet das Skript automatisch Unicast als Standard für die Cluster-Kommunikation.Das Skript führt eine Prüfung im Hinblick auf die NTP-Konfiguration und einen Hardware-Watchdog-Service durch. Es generiert die öffentlichen und privaten SSH-Schlüssel, die für den SSH-Zugriff und die Csync2-Synchronisierung verwendet werden, und startet die entsprechenden Services.
Konfigurieren Sie die Cluster-Kommunikationsschicht (Corosync):
Geben Sie eine Netzwerkadresse ein, an die eine Bindung erfolgen soll. Das Skript schlägt standardmäßig die Netzwerkadresse
eth0vor. Alternativ dazu können Sie auch eine andere Netzwerkadresse wie beispielsweise die Adressebond0eingeben.Geben Sie eine Multicast-Adresse ein. Das Skript schlägt eine Zufallsadresse vor, die Sie als Standard verwenden können. Voraussetzung ist natürlich, dass diese Multicast-Adresse von Ihrem jeweiligen Netzwerk unterstützt wird.
Geben Sie einen Multicast-Port ein. Das Skript schlägt
5405als Standard vor.
Schließlich startet das Skript den Pacemaker-Service, um den aus einem Knoten bestehenden Cluster online zu schalten und Hawk2 zu aktivieren. Die URL, die für Hawk2 verwendet werden muss, wird auf dem Bildschirm angezeigt.
Richten Sie SBD als Fencing-Mechanismus für Knoten ein:
Bestätigen Sie mit
y, dass Sie SBD verwenden möchten.Geben Sie einen persistenten Pfad zu der Partition Ihres Blockgeräts ein, die Sie für SBD verwenden möchten. Weitere Informationen hierzu finden Sie in Abschnitt 5, „Verwendung von SBD als Fencing-Mechanismus“. Der Pfad muss bei allen Knoten im Cluster konsistent sein.
Konfigurieren Sie eine virtuelle IP-Adresse für die Cluster-Verwaltung mit Hawk2. (Mit dieser virtuellen IP-Ressource werden wir später testen, ob der Failover erfolgreich ist.)
Bestätigen Sie mit
y, dass Sie eine virtuelle IP-Adresse konfigurieren möchten.Geben Sie eine nicht verwendete IP-Adresse ein, die Sie als Verwaltungs-IP für Hawk2 verwenden möchten:
192.168.2.1Sie können auch eine Verbindung mit der virtuellen IP-Adresse herstellen, statt sich an einem einzelnen Cluster-Knoten mit Hawk2 anzumelden.
Sie verfügen jetzt über einen aktiven Cluster mit einem Knoten. Gehen Sie wie folgt vor, um seinen Status anzuzeigen:
Prozedur 3: Anmeldung an der Hawk2-Weboberfläche #
Starten Sie auf einem beliebigen Rechner einen Webbrowser und aktivieren Sie JavaScript und Cookies.
Geben Sie als URL die IP-Adresse oder den Hostnamen eines Cluster-Knotens ein, auf dem der Hawk-Web-Service ausgeführt wird. Sie können alternativ auch die virtuelle IP-Adresse eingeben, die Sie in Schritt 6 unter Prozedur 2, „Ersten Knoten (
alice) mitha-cluster-initeinrichten“ konfiguriert haben:https://HAWKSERVER:7630/
Anmerkung: Warnmeldung bezüglich des Zertifikats
Wenn bei Ihrem ersten Zugriff auf die URL eine Warnmeldung hinsichtlich des Zertifikats angezeigt wird, wird ein eigensigniertes Zertifikat verwendet. Eigensignierte Zertifikate gelten standardmäßig nicht als vertrauenswürdig.
Bitten Sie den Cluster-Operator um die Details des Zertifikats, damit Sie es überprüfen können.
Falls Sie dennoch fortfahren möchten, können Sie im Browser eine Ausnahme hinzufügen und die Warnmeldung auf diese Weise umgehen.
Geben Sie im Anmeldebildschirm von Hawk2 in und die Daten des Benutzers ein, der während des Bootstrap-Verfahrens erstellt wurde (Benutzer
hacluster, Passwortlinux).
Wichtig: Sicheres Passwort
Ersetzen Sie das Standardpasswort möglichst schnell durch ein sicheres Passwort:
root #passwdhaclusterKlicken Sie auf . Nach der Anmeldung wird auf der Hawk2-Weboberfläche standardmäßig der Status-Bildschirm angezeigt. Dort sehen Sie den aktuellen Cluster-Status auf einen Blick:
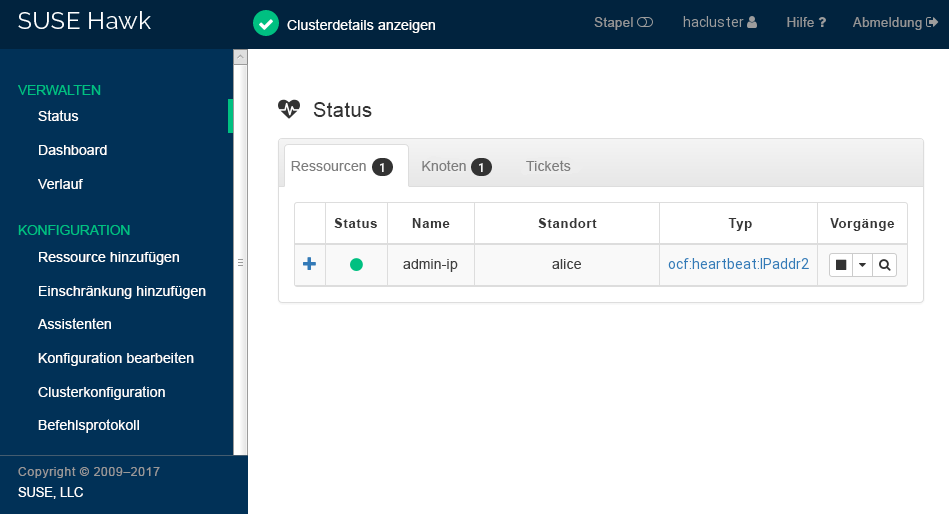
Abbildung 1: Status des aus einem Knoten bestehenden Clusters in Hawk2 #
7 Hinzufügen des zweiten Knotens #
Sobald der Cluster mit einem Knoten betriebsbereit ist, können Sie mit dem Bootstrap-Skript ha-cluster-join wie in Prozedur 4 beschrieben den zweiten Knoten hinzufügen. Das Skript benötigt lediglich Zugriff auf einen vorhandenen Cluster-Knoten. Es führt die grundlegende Einrichtung auf dem aktuellen Rechner automatisch durch. Ausführliche Informationen hierzu finden Sie auf der man-Seite ha-cluster-join.
Die Bootstrap-Skripte kümmern sich um die Änderung der für Cluster mit zwei Knoten spezifischen Konfiguration, wie SBD und Corosync.
Prozedur 4: Zweiten Knoten (bob) mit ha-cluster-join hinzufügen #
Melden Sie sich als
rootan dem physischen oder virtuellen Rechner an, der dem Cluster beitreten soll.Starten Sie das Bootstrap-Skript, indem Sie Folgendes ausführen:
root #ha-cluster-joinWenn NTP nicht für das Starten zur Boot-Zeit konfiguriert wurde, wird eine Nachricht angezeigt. Das Skript prüft außerdem, ob ein Hardware-Watchdog-Gerät vorhanden ist (dieses ist wichtig, falls Sie SBD konfigurieren möchten). Wenn keines gefunden wird, werden Sie in einer Warnmeldung darauf hingewiesen.
Falls Sie den Vorgang dennoch fortsetzen, werden Sie zur Eingabe der IP-Adresse eines vorhandenen Knotens aufgefordert. Geben Sie die IP-Adresse des ersten Knotens ein (
alice,192.168.1.1).Falls Sie noch keinen passwortfreien SSH-Zugriff zwischen beiden Rechnern konfiguriert haben, werden Sie außerdem zur Eingabe des
root-Passworts des bestehenden Knotens aufgefordert.Nach der Anmeldung an dem angegebenen Knoten kopiert das Skript die Corosync-Konfiguration. Anschließend konfiguriert es SSH und Csync2 und schaltet den aktuellen Rechner als neuen Cluster-Knoten online. Außerdem startet es den Service, der für Hawk2 erforderlich ist.
Prüfen Sie den Cluster-Status in Hawk2. Unter › sollten zwei Knoten mit einem grün dargestellten Status angezeigt werden (siehe Abbildung 2, „Status des aus zwei Knoten bestehenden Clusters“).
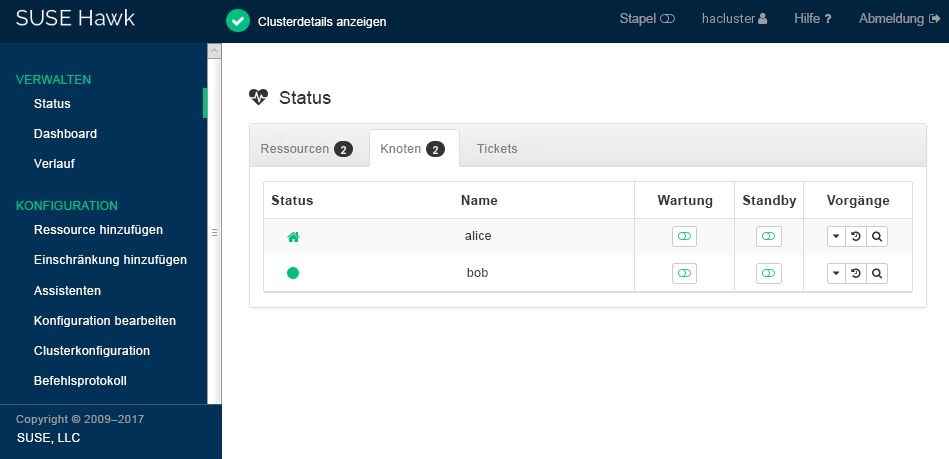
Abbildung 2: Status des aus zwei Knoten bestehenden Clusters #
8 Testen des Clusters #
Prozedur 5, „Testen des Ressourcen-Failovers“ ist ein einfacher Test zur Prüfung, ob der Cluster die virtuelle IP-Adresse zu dem anderen Knoten verschiebt, wenn der Knoten, der die Ressource zurzeit ausführt, auf Standby gesetzt wird.
Ein aussagekräftiger Test umfasst jedoch gezielte Anwendungsfälle und Szenarien. Beispielsweise sollte auch Ihr Fencing-Mechanismus getestet werden, damit Situationen einer Systemspaltung vermieden werden. Falls Sie Ihren Fencing-Mechanismus nicht ordnungsgemäß eingerichtet haben, funktioniert der Cluster nicht richtig.
Bevor Sie den Cluster in einer Produktionsumgebung einsetzen, müssen Sie ihn anhand Ihrer Anwendungsfälle gründlich testen.
Prozedur 5: Testen des Ressourcen-Failovers #
Öffnen Sie ein Terminal und setzen Sie ein Ping-Signal für Ihre virtuelle IP-Adresse
192.168.2.1ab:root #ping192.168.2.1Melden Sie sich wie in Prozedur 3, „Anmeldung an der Hawk2-Weboberfläche“ beschrieben an Ihrem Cluster an.
Prüfen Sie in Hawk2 unter › , auf welchem Knoten die virtuelle IP-Adresse (Ressource
admin_addr) ausgeführt wird. Im vorliegenden Fall wird vorausgesetzt, dass die Ressource aufaliceausgeführt wird.Versetzen Sie
alicein den -Modus (siehe Abbildung 3, „Knotenaliceim Standby-Modus“).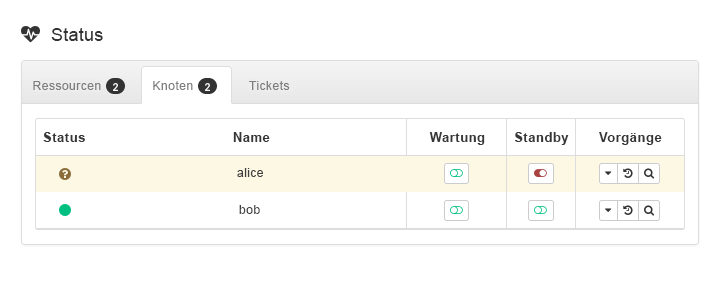
Abbildung 3: Knoten
aliceim Standby-Modus #Klicken Sie auf › . Die Ressource
admin_addrwurde zubobmigriert.
Während der Migration sollte ein ununterbrochener Fluss an Ping-Signalen an die virtuelle IP-Adresse zu beobachten sein. Dies zeigt, dass die Cluster-Einrichtung und die Floating-IP ordnungsgemäß funktionieren. Brechen Sie das ping-Kommando mit Strg– C ab.
9 Weiterführende Informationen #
Sie finden die sonstige Dokumentation zu diesem Produkt unter https://documentation.suse.com/sle-ha-12. Die Dokumentation beinhaltet unter anderem ein umfassendes Administrationshandbuch für SUSE Linux Enterprise High Availability Extension. Dort werden weitere Konfigurations- und Verwaltungsaufgaben beschrieben.
10 Rechtliche Hinweise #
Copyright © 2006– 2025 SUSE LLC und Mitwirkende. Alle Rechte vorbehalten.
Es wird die Genehmigung erteilt, dieses Dokument unter den Bedingungen der GNU Free Documentation License, Version 1.2 oder (optional) Version 1.3 zu vervielfältigen, zu verbreiten und/oder zu verändern; die unveränderlichen Abschnitte hierbei sind der Urheberrechtshinweis und die Lizenzbedingungen. Eine Kopie dieser Lizenz (Version 1.2) finden Sie im Abschnitt „GNU Free Documentation License“.
Die SUSE-Marken finden Sie unter http://www.suse.com/company/legal/. Alle anderen Marken von Drittanbietern sind Besitz ihrer jeweiligen Eigentümer. Markensymbole (®, ™ usw.) kennzeichnen Marken von SUSE und der Tochtergesellschaften. Sternchen (*) kennzeichnen Marken von Drittanbietern.
Alle Informationen in diesem Buch wurden mit größter Sorgfalt zusammengestellt. Doch auch dadurch kann hundertprozentige Richtigkeit nicht gewährleistet werden. Weder SUSE LLC noch ihre Tochtergesellschaften noch die Autoren noch die Übersetzer können für mögliche Fehler und deren Folgen haftbar gemacht werden.
A GNU Licenses #
This appendix contains the GNU Free Documentation License version 1.2.
GNU Free Documentation License #
Copyright (C) 2000, 2001, 2002 Free Software Foundation, Inc. 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA. Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
0. PREAMBLE #
The purpose of this License is to make a manual, textbook, or other functional and useful document "free" in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
1. APPLICABILITY AND DEFINITIONS #
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The "Document", below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as "you". You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A "Modified Version" of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document's overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The "Invariant Sections" are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The "Cover Texts" are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A "Transparent" copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The "Title Page" means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, "Title Page" means the text near the most prominent appearance of the work's title, preceding the beginning of the body of the text.
A section "Entitled XYZ" means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as "Acknowledgements", "Dedications", "Endorsements", or "History".) To "Preserve the Title" of such a section when you modify the Document means that it remains a section "Entitled XYZ" according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
2. VERBATIM COPYING #
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
3. COPYING IN QUANTITY #
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document's license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
4. MODIFICATIONS #
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
State on the Title page the name of the publisher of the Modified Version, as the publisher.
Preserve all the copyright notices of the Document.
Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document's license notice.
Include an unaltered copy of this License.
Preserve the section Entitled "History", Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled "History" in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the "History" section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
For any section Entitled "Acknowledgements" or "Dedications", Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
Delete any section Entitled "Endorsements". Such a section may not be included in the Modified Version.
Do not retitle any existing section to be Entitled "Endorsements" or to conflict in title with any Invariant Section.
Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version's license notice. These titles must be distinct from any other section titles.
You may add a section Entitled "Endorsements", provided it contains nothing but endorsements of your Modified Version by various parties--for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
5. COMBINING DOCUMENTS #
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled "History" in the various original documents, forming one section Entitled "History"; likewise combine any sections Entitled "Acknowledgements", and any sections Entitled "Dedications". You must delete all sections Entitled "Endorsements".
6. COLLECTIONS OF DOCUMENTS #
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT WORKS #
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an "aggregate" if the copyright resulting from the compilation is not used to limit the legal rights of the compilation's users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document's Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
8. TRANSLATION #
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled "Acknowledgements", "Dedications", or "History", the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
9. TERMINATION #
You may not copy, modify, sublicense, or distribute the Document except as expressly provided for under this License. Any other attempt to copy, modify, sublicense or distribute the Document is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
10. FUTURE REVISIONS OF THIS LICENSE #
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License "or any later version" applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation.
ADDENDUM: How to use this License for your documents #
Copyright (c) YEAR YOUR NAME. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled “GNU Free Documentation License”.
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the “with...Texts.” line with this:
with the Invariant Sections being LIST THEIR TITLES, with the Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.