- Acerca de esta guía
- I Ceph Dashboard
- 1 Acerca de Ceph Dashboard
- 2 Interfaz de usuario Web de la consola
- 3 Gestión de usuarios y funciones de Ceph Dashboard
- 4 Visualización de elementos internos del clúster
- 4.1 Visualización de nodos de clúster
- 4.2 Acceso al inventario del clúster
- 4.3 Visualización de monitores Ceph Monitor
- 4.4 Visualización de servicios
- 4.5 Visualización de los OSD de Ceph
- 4.6 Visualización de la configuración del clúster
- 4.7 Visualización del mapa de CRUSH
- 4.8 Visualización de módulos del gestor
- 4.9 Visualización de registros
- 4.10 Visualización de la supervisión
- 5 Gestión de repositorios
- 6 Gestión de dispositivos de bloques RADOS
- 7 Gestión de NFS Ganesha
- 8 Gestión de CephFS
- 9 Gestión de Object Gateway
- 10 Configuración manual
- 11 Gestión de usuarios y funciones en la línea de comandos
- II Operación del clúster
- 12 Determinación del estado del clúster
- 12.1 Comprobación del estado de un clúster
- 12.2 Comprobación del estado del clúster
- 12.3 Comprobación de las estadísticas de uso de un clúster
- 12.4 Comprobación del estado de los OSD
- 12.5 Comprobación de OSD llenos
- 12.6 Comprobación del estado del monitor
- 12.7 Comprobación del estado de los grupos de colocación
- 12.8 Capacidad de almacenamiento
- 12.9 Supervisión de los OSD y los grupos de colocación
- 13 Tareas operativas
- 13.1 Modificación de la configuración del clúster
- 13.2 Adición de nodos
- 13.3 Eliminación de nodos
- 13.4 Gestión de OSD
- 13.5 Traslado del master de Salt a un nodo nuevo
- 13.6 Actualización de los nodos del clúster
- 13.7 Actualización de Ceph
- 13.8 Detención o reinicio del clúster
- 13.9 Eliminación de un clúster de Ceph completo
- 14 Funcionamiento de los servicios de Ceph
- 15 Copia de seguridad y recuperación
- 16 Supervisión y alertas
- 16.1 Configuración de imágenes personalizadas o locales
- 16.2 Actualización de los servicios de supervisión
- 16.3 Inhabilitación de la supervisión
- 16.4 Configuración de Grafana
- 16.5 Configuración del módulo de gestor de Prometheus
- 16.6 Modelo de seguridad de Prometheus
- 16.7 Receptor de alertas SNMP Alertmanager de Prometheus
- 12 Determinación del estado del clúster
- III Almacenamiento de datos en un clúster
- 17 Gestión de datos almacenados
- 18 Gestión de repositorios de almacenamiento
- 19 Repositorios codificados de borrado
- 20 Dispositivo de bloques RADOS
- 20.1 Comandos del dispositivo de bloques
- 20.2 Montaje y desmontaje
- 20.3 Instantáneas
- 20.4 Duplicados de imagen RBD
- 20.5 Ajustes de caché
- 20.6 Ajuste de QoS
- 20.7 Ajustes de lectura anticipada
- 20.8 Funciones avanzadas
- 20.9 Asignación del RBD utilizando clientes de kernel antiguos
- 20.10 Habilitación de dispositivos de bloques y Kubernetes
- IV Acceso a los datos del clúster
- 21 Ceph Object Gateway
- 21.1 Restricciones y limitaciones de denominación de Object Gateway
- 21.2 Distribución de Object Gateway
- 21.3 Funcionamiento del servicio de Object Gateway
- 21.4 Opciones de configuración
- 21.5 Gestión del acceso a Object Gateway
- 21.6 Procesadores frontales HTTP
- 21.7 Habilitación de HTTPS/SSL para pasarelas Object Gateway
- 21.8 Módulos de sincronización
- 21.9 Autenticación LDAP
- 21.10 Partición del índice de depósito
- 21.11 Integración con OpenStack Keystone
- 21.12 Colocación de repositorios y clases de almacenamiento
- 21.13 Pasarelas Object Gateway de varios sitios
- 22 Ceph iSCSI Gateway
- 23 Sistema de archivos en clúster
- 24 Exportación de datos de Ceph a través de Samba
- 25 NFS Ganesha
- 21 Ceph Object Gateway
- V Integración con herramientas de virtualización
- 26
libvirty Ceph - 27 Ceph como procesador final para la instancia de QEMU KVM
- 27.1 Instalación de
qemu-block-rbd - 27.2 Uso de QEMU
- 27.3 Creación de imágenes con QEMU
- 27.4 Cambio de tamaño de las imágenes con QEMU
- 27.5 Recuperación de información de la imagen con QEMU
- 27.6 Ejecución de QEMU con RBD
- 27.7 Habilitación de descartes y TRIM
- 27.8 Configuración de las opciones de caché de QEMU
- 27.1 Instalación de
- 26
- VI Configuración de un clúster
- A Actualizaciones de mantenimiento de Ceph basadas en versiones secundarias superiores de Octopus
- B Actualizaciones de la documentación
- Glosario
- 2.1 Pantalla de entrada a Ceph Dashboard
- 2.2 Página de inicio de Ceph Dashboard
- 2.3 Widgets de Estado
- 2.4 Widgets de Capacidad
- 2.5 Widgets de Rendimiento
- 3.1 Gestión de usuarios
- 3.2 Adición de un usuario
- 3.3 Funciones del usuario
- 3.4 Adición de una función
- 4.1 Hosts
- 4.2 Servicios
- 4.3 Monitores Ceph Monitor
- 4.4 Servicios
- 4.5 Daemons Ceph OSD
- 4.6 Indicadores de OSD
- 4.7 Prioridad de recuperación de OSD
- 4.8 Detalles de OSD
- 4.9 Crear OSDs
- 4.10 Adición de dispositivos primarios
- 4.11 Crear OSDs con dispositivos primarios añadidos
- 4.12
- 4.13 OSD recién añadidos
- 4.14 Configuración del clúster
- 4.15 Mapa de CRUSH
- 4.16 Módulos de gestor
- 4.17 Registros
- 5.1 Lista de repositorios
- 5.2 Adición de un repositorio nuevo
- 6.1 Lista de imágenes RBD
- 6.2 Detalles de RBD
- 6.3 Configuración de RBD
- 6.4 Adición de un RBD nuevo
- 6.5 Instantáneas de RBD
- 6.6 Ejecución de daemons
rbd-mirror - 6.7 Creación de un repositorio con la aplicación RBD
- 6.8 Configuración del modo de réplica
- 6.9 Adición de credenciales del par
- 6.10 Lista de repositorios replicados
- 6.11 Nueva imagen RBD
- 6.12 Nueva imagen RBD sincronizada
- 6.13 Estado de réplica de las imágenes RBD
- 6.14 Lista de destinos iSCSI
- 6.15 Detalles de destino iSCSI
- 6.16 Adición de un destino nuevo
- 7.1 Lista de exportaciones NFS
- 7.2 Detalles de la exportación NFS
- 7.3 Adición de una exportación NFS nueva
- 7.4 Edición de una exportación NFS
- 8.1 Detalles de CephFS
- 8.2 Detalles de CephFS
- 9.1 Detalles de la pasarela
- 9.2 Usuarios de pasarela
- 9.3 Adición de un nuevo usuario de pasarela
- 9.4 Detalles del depósito de pasarela
- 9.5 Edición de los detalles del depósito
- 12.1 Clúster de Ceph
- 12.2 Esquema de emparejamiento
- 12.3 Estado de los grupos de colocación
- 17.1 OSDs con clases de dispositivos mixtos
- 17.2 Árbol de ejemplo
- 17.3 Métodos de sustitución de nodos
- 17.4 Grupos de colocación en un repositorio
- 17.5 Grupos de colocación y OSDs
- 18.1 Repositorios antes de la migración
- 18.2 Configuración de los niveles de caché
- 18.3 Limpieza de datos
- 18.4 Configuración de la superposición
- 18.5 Migración completada
- 20.1 Protocolo RADOS
- 22.1 Propiedades del iniciador iSCSI
- 22.2 Descubrir portal de destino
- 22.3 Portales de destino
- 22.4 Destinos
- 22.5 Propiedades de destino iSCSI
- 22.6 Detalles del dispositivo
- 22.7 Nuevo asistente de volumen
- 22.8 Mensaje de disco sin conexión
- 22.9 Confirmación de las opciones del volumen
- 22.10 Propiedades del iniciador iSCSI
- 22.11 Adición de un servidor de destino
- 22.12 Gestión de dispositivos de múltiples rutas
- 22.13 Lista de vías para múltiples rutas
- 22.14 Recuadro de diálogo para añadir almacenamiento
- 22.15 Configuración de espacio personalizada
- 22.16 Resumen del almacén de datos iSCSI
- 25.1 Estructura de NFS Ganesha
- 30.1 Autenticación básica con
cephx - 30.2 Autenticación con
cephx - 30.3 Autenticación con
cephx: servidor de metadatos y OSD
- 12.1 Localización de un objeto
- 13.1 Filtrado por tamaño de disco
- 13.2 configuración sencilla
- 13.3 configuración avanzada
- 13.4 configuración avanzada con nodos no uniformes
- 13.5 configuración para expertos
- 13.6 configuración compleja (e improbable)
- 17.1
crushtool ‑‑reclassify‑root - 17.2
crushtool ‑‑reclassify‑bucket - 21.1 Configuración trivial
- 21.2 Configuración no trivial
- 28.1 Ejemplo de configuración de Beast
- 28.2 Ejemplo de configuración de Civetweb en
/etc/ceph/ceph.conf
Copyright © 2020–2023 SUSE LLC y colaboradores. Reservados todos los derechos.
Salvo que se indique lo contrario, este documento está sujeto a la licencia Creative Commons Attribution-ShareAlike 4.0 International (CC-BY-SA 4.0): https://creativecommons.org/licenses/by-sa/4.0/legalcode.
Para obtener información sobre las marcas comerciales de SUSE, consulte http://www.suse.com/company/legal/. Todas las marcas comerciales de otros fabricantes son propiedad de sus propietarios respectivos. Los símbolos de marca comercial (®,™ etc.) indican marcas comerciales de SUSE y sus afiliados. Los asteriscos (*) indican marcas comerciales de otros fabricantes.
Toda la información recogida en esta publicación se ha compilado prestando toda la atención posible al más mínimo detalle. Sin embargo, esto no garantiza una precisión total. Ni SUSE LLC, ni sus filiales, ni los autores o traductores serán responsables de los posibles errores o las consecuencias que de ellos pudieran derivarse.
Acerca de esta guía #
Esta guía se centra en las tareas rutinarias de las que usted, como administrador, debe ocuparse después de que se haya distribuido el clúster de Ceph básico (operaciones del día 2). También describe todas las formas admitidas para acceder a los datos almacenados en un clúster de Ceph.
SUSE Enterprise Storage 7 es una extensión para SUSE Linux Enterprise Server 15 SP2. Combina las funciones del proyecto de almacenamiento Ceph (http://ceph.com/) con la ingeniería empresarial y la asistencia de SUSE. SUSE Enterprise Storage 7 proporciona a las organizaciones de TI la capacidad de distribuir una arquitectura de almacenamiento distribuida que admite varios casos de uso mediante plataformas de hardware básicas.
1 Documentación disponible #
La documentación de nuestros productos está disponible en https://documentation.suse.com, donde también encontrará las actualizaciones más recientes y podrá explorar o descargar la documentación en diferentes formatos. Las últimas actualizaciones de la documentación se pueden encontrar en la versión en inglés.
Además, la documentación del producto también estará disponible en el sistema instalado, en la vía /usr/share/doc/manual. Se incluye en un paquete de RPM denominado
ses-manual_CÓDIGO_DE_IDIOMA. Instálelo si aún no está en el sistema, por ejemplo:
root # zypper install ses-manual_enLa documentación disponible para este producto es la siguiente:
- Guía de distribución
Esta guía se centra en la distribución de un clúster de Ceph básico y en cómo distribuir servicios adicionales. También se describen los pasos necesarios para actualizar a SUSE Enterprise Storage 7 desde la versión anterior del producto.
- Guía de administración y operaciones
Esta guía se centra en las tareas rutinarias de las que usted, como administrador, debe ocuparse después de que se haya distribuido el clúster de Ceph básico (operaciones del día 2). También describe todas las formas admitidas para acceder a los datos almacenados en un clúster de Ceph.
- Guía de protección de la seguridad
Esta guía se centra en cómo garantizar la seguridad del clúster.
- Guía de resolución de problemas
Esta guía describe varios problemas comunes al ejecutar SUSE Enterprise Storage 7 y otros problemas relacionados con los componentes relevantes, como Ceph u Object Gateway.
- Guía de SUSE Enterprise Storage para Windows
Esta guía describe la integración, instalación y configuración de entornos Microsoft Windows y SUSE Enterprise Storage mediante el controlador de Windows.
2 Proporcionar comentarios #
Agradecemos sus comentarios y contribuciones sobre esta documentación. Existen varios canales para enviarlos:
- Peticiones de servicio y asistencia técnica
Para obtener más información sobre los servicios y las opciones de asistencia técnica disponibles para el producto, consulte http://www.suse.com/support/.
Para abrir una petición de servicio, necesita una suscripción de SUSE registrada en el Centro de servicios al cliente de SUSE. Diríjase a https://scc.suse.com/support/requests, entre a la sesión y haga clic en (Crear nueva).
- Informes de errores
Puede informar sobre errores de la documentación en https://bugzilla.suse.com/. Para informar sobre errores, se requiere una cuenta de Bugzilla.
Para simplificar el proceso, puede utilizar los enlaces (Informar sobre errores de la documentación) que aparecen junto a los titulares de la versión HTML de este documento. De esta forma, se preseleccionan el producto y la categoría correctos en Bugzilla y se añade un enlace a la sección actual. Así, podrá empezar a escribir directamente el informe.
- Contribuciones
Para contribuir a esta documentación, utilice los enlaces (Editar origen) situados junto a los titulares de la versión HTML de este documento. Llevan al código fuente de GitHub, donde puede abrir una petición de extracción. Para contribuir, se requiere una cuenta de GitHub.
Para obtener más información sobre el entorno utilizado en esta documentación, consulte el archivo README (Léame) en https://github.com/SUSE/doc-ses.
- Correo
También puede informar sobre errores y enviar comentarios sobre la documentación a <doc-team@suse.com>. Por favor, incluya el título del documento, la versión del producto y la fecha de publicación de la documentación. También puede incluir el número de sección y título correspondientes (o proporcionar la URL), así como una descripción concisa del problema.
3 Convenciones de la documentación #
En este documento se utilizan los siguientes avisos y convenciones tipográficas:
/etc/passwd: nombres de directorio y nombres de archivos.ESPACIO RESERVADO: sustituya ESPACIO RESERVADO con el valor real.
VÍA: una variable de entorno.ls,‑‑help: comandos, opciones y parámetros.usuario: el nombre del usuario o grupo.nombre_de_paquete: el nombre de un paquete de software.
Alt, Alt–F1: tecla o combinación de teclas que pulsar. Las teclas se muestran en mayúsculas como en un teclado.
, › : elementos de menú, botones.
AMD/Intel Este párrafo solo es relevante para la arquitectura Intel 64/AMD64. Las flechas marcan el principio y el final del bloque de texto.
IBM Z, POWER Este párrafo solo es relevante para las arquitecturas
IBM ZyPOWER. Las flechas marcan el principio y el final del bloque de texto.Capítulo 1, “capítulo de ejemplo”: referencia cruzada a otro capítulo de esta guía.
Comandos que se deben ejecutar con privilegios de usuario
root. A menudo, también es posible añadir estos comandos como prefijos con el comandosudopara que un usuario sin privilegios los puedan ejecutar.root #commandtux >sudocommandComandos que pueden ejecutar los usuarios sin privilegios.
tux >commandNotificaciones
 Aviso: aviso de advertencia
Aviso: aviso de advertenciaInformación vital que debe tener en cuenta antes de continuar. Advierte acerca de problemas de seguridad, pérdida de datos potenciales, daños del hardware o peligros físicos.
 Importante: aviso importante
Importante: aviso importanteInformación importante que debe tener en cuenta antes de continuar.
 Nota: aviso de nota
Nota: aviso de notaInformación adicional, por ejemplo sobre las diferencias en las versiones de software.
 Sugerencia: aviso de sugerencia
Sugerencia: aviso de sugerenciaInformación útil, como una directriz o un consejo práctico.
Avisos compactos
Información adicional, por ejemplo sobre las diferencias en las versiones de software.
Información útil, como una directriz o un consejo práctico.
4 Ciclo de vida y asistencia del producto #
Los distintos productos de SUSE tienen distintos ciclos de vida. Para comprobar las fechas exactas del ciclo de vida de SUSE Enterprise Storage, consulte https://www.suse.com/lifecycle/.
4.1 Definiciones de asistencia técnica de SUSE #
Para obtener información sobre nuestra directiva de asistencia técnica y las opciones disponibles, consulte https://www.suse.com/support/policy.html y https://www.suse.com/support/programs/long-term-service-pack-support.html.
4.2 Declaración de asistencia técnica para SUSE Enterprise Storage #
Para recibir asistencia técnica, necesita disponer de una suscripción adecuada de SUSE. Para ver las ofertas de asistencia técnica específicas que tiene a su disposición, diríjase a https://www.suse.com/support/ y seleccione su producto.
Los niveles de asistencia se definen así:
- L1
Determinación de problemas; lo que significa que se ofrece asistencia técnica diseñada para proporcionar información de compatibilidad, asistencia sobre el uso, mantenimiento continuo, recopilación de información y resolución de problemas básicos con la documentación disponible.
- L2
Aislamiento de problemas; lo que significa que se ofrece asistencia técnica diseñada para analizar datos, reproducir los problemas del cliente, aislar el área del problema y proporcionar una resolución a los problemas que no se pueden resolver en el nivel 1 (L1) ni preparar para el nivel 3 (L3).
- L3
Resolución de problemas; lo que significa que se ofrece asistencia técnica diseñada para resolver los problemas mediante ingeniería y resolver los defectos que se han identificado en la asistencia de nivel 2 (L2).
En el caso de los clientes y socios con contrato, SUSE Enterprise Storage se suministra con asistencia L3 para todos los paquetes, excepto en los siguientes casos:
Tecnología en fase preliminar.
Sonido, gráficos, fuentes y material gráfico.
Paquetes que precisan de un contrato de clientes adicional.
Algunos paquetes incluidos como parte del módulo de extensión de estación de trabajo solo admiten asistencia L2.
Los paquetes con nombres que terminan en -devel (que contienen archivos de encabezado y recursos similares para desarrolladores) solo incluyen asistencia si van acompañados de sus paquetes principales.
SUSE solo admite el uso de paquetes originales. Es decir, paquetes que no hayan sido modificados ni recompilados.
4.3 Tecnología en fase preliminar #
Se considera como "tecnología en fase preliminar" cualquier paquete, pila o función proporcionada por SUSE para ofrecer un adelanto de las próximas innovaciones. Estos elementos se incluyen para ofrecer la oportunidad de probar nuevas tecnologías en su entorno. Le agradeceremos mucho sus comentarios. Si se dispone a probar una tecnología en fase preliminar, póngase en contacto con su representante de SUSE e infórmele de su experiencia y sus casos de uso. Sus comentarios nos resultarán útiles para desarrollar el producto.
Las tecnologías en fase preliminar tienen las limitaciones siguientes:
Están aún en proceso de desarrollo. En consecuencia, sus funciones pueden estar incompletas, ser inestables o no ser adecuadas de alguna otra forma para su uso en producción.
No se ofrece asistencia técnica para ellas.
Es posible que solo estén disponibles para arquitecturas de hardware específicas.
Sus detalles y funciones están sujetos a cambios. Como resultado, quizás no sea posible actualizar estas tecnologías en las versiones posteriores o que sea necesario realizar una instalación nueva.
Las tecnologías en fase preliminar se pueden eliminar de un producto en cualquier momento. SUSE no se compromete a facilitar una versión con asistencia técnica de dichas tecnologías en el futuro. Esto puede suceder, por ejemplo, si SUSE descubre que la tecnología en fase preliminar no cumple las necesidades del cliente o del mercado, o que no cumple con los estándares empresariales.
Para ver una descripción general de las tecnologías en fase preliminar incluidas con el producto, consulte la notas de la versión en https://www.suse.com/releasenotes/x86_64/SUSE-Enterprise-Storage/7.
5 Colaboradores de Ceph #
El proyecto Ceph y su documentación son el resultado del trabajo de cientos de colaboradores y organizaciones. Consulte https://ceph.com/contributors/ para obtener más información.
6 Comandos e indicadores de comandos utilizados en esta guía #
Como administrador de clústeres de Ceph, va a configurar y ajustar el comportamiento del clúster ejecutando comandos específicos. Necesitará varios tipos de comandos:
6.1 Comandos relacionados con Salt #
Estos comandos ayudan a distribuir los nodos de clúster de Ceph, a ejecutar comandos en varios nodos de clúster al mismo tiempo (o en todos ellos) o a ayudarle a añadir o quitar nodos de clúster. Los comandos más utilizados son ceph-salt y ceph-salt config. Los comandos de Salt se deben ejecutar en el nodo master de Salt como usuario root. Estos comandos se introducen con el siguiente símbolo del sistema:
root@master # Por ejemplo:
root@master # ceph-salt config ls6.2 Comandos relacionados con Ceph #
Se trata de comandos de nivel inferior para configurar y ajustar todos los aspectos del clúster y sus pasarelas en la línea de comandos, por ejemplo ceph, cephadm, rbd o radosgw-admin.
Para ejecutar comandos relacionados con Ceph, debe tener acceso de lectura a una clave de Ceph. Los privilegios que tiene en el entorno Ceph se definen en las capacidades de la clave. Una opción es ejecutar comandos de Ceph como usuario root (o mediante sudo) y utilizar el anillo de claves sin restricciones por defecto "ceph.client.admin.key".
La opción más segura y recomendada es crear una clave individual más restrictiva para cada usuario administrador y colocarla en un directorio donde los usuarios puedan leerla, por ejemplo:
~/.ceph/ceph.client.USERNAME.keyring
Para utilizar un usuario administrador y un anillo de claves personalizados, debe especificar el nombre de usuario y la vía a la clave cada vez que ejecute el comando ceph mediante las opciones -n client.NOMBRE_USUARIO y ‑‑keyring VÍA/A/ANILLO/DE/CLAVES.
Para evitarlo, incluya estas opciones en la variable CEPH_ARGS en los archivos ~/.bashrc de los usuarios individuales.
Aunque puede ejecutar comandos relacionados con Ceph en cualquier nodo de clúster, se recomienda hacerlo en el nodo de administración. Esta documentación utiliza al usuario cephuser para ejecutar los comandos, por lo tanto, se introducen con el siguiente símbolo del sistema:
cephuser@adm > Por ejemplo:
cephuser@adm > ceph auth listSi la documentación indica que ejecute un comando en un nodo de clúster con una función específica, el símbolo del sistema se encargará. Por ejemplo:
cephuser@mon > 6.2.1 Ejecución de ceph-volume #
A partir de SUSE Enterprise Storage 7, los servicios de Ceph se ejecutan en contenedores. Si necesita ejecutar ceph-volume en un nodo de OSD, debe anteponer el comando cephadm, por ejemplo:
cephuser@adm > cephadm ceph-volume simple scan6.3 Comandos generales de Linux #
Los comandos de Linux no relacionados con Ceph, como mount, cat o openssl se introducen con los símbolos del sistema cephuser@adm > o root #, dependiendo de los privilegios que requiera el comando relacionado.
6.4 Información adicional #
Para obtener más información sobre la gestión de claves de Ceph, consulte el Sección 30.2, “Áreas clave de gestión”.
Parte I Ceph Dashboard #
- 1 Acerca de Ceph Dashboard
Ceph Dashboard es una aplicación de supervisión y gestión de Ceph basada en Web que administra varios aspectos y objetos del clúster. La consola se habilita automáticamente después de distribuir el clúster básico en Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3 “Dist…
- 2 Interfaz de usuario Web de la consola
Para entrar a la sesión en Ceph Dashboard, abra su dirección URL en un navegador, incluido el número de puerto. Ejecute el comando siguiente para buscar la dirección:
- 3 Gestión de usuarios y funciones de Ceph Dashboard
En el Capítulo 11, Gestión de usuarios y funciones en la línea de comandos ya se describió la gestión de usuarios de la consola que se realiza mediante los comandos de Ceph en la línea de comandos.
- 4 Visualización de elementos internos del clúster
El elemento de menú permite ver información detallada acerca de los hosts del clúster de Ceph, el inventario, los monitores Ceph Monitor, los servicios, los OSD, la configuración, el mapa de CRUSH, Ceph Manager, los registros y los archivos de supervisión.
- 5 Gestión de repositorios
Para obtener información general sobre los repositorios de Ceph, consulte el Capítulo 18, Gestión de repositorios de almacenamiento. Para obtener información específica sobre los repositorios codificados de borrado, consulte el Capítulo 19, Repositorios codificados de borrado.
- 6 Gestión de dispositivos de bloques RADOS
Para mostrar todos los dispositivos de bloques RADOS (RBD) disponibles, haga clic en › en el menú principal.
- 7 Gestión de NFS Ganesha
Para obtener información general sobre NFS Ganesha, consulte el Capítulo 25, NFS Ganesha.
- 8 Gestión de CephFS
Para obtener información detallada sobre CephFS, consulte el Capítulo 23, Sistema de archivos en clúster
- 9 Gestión de Object Gateway
Antes de empezar, es posible que aparezca la siguiente notificación al intentar acceder al procesador frontal de Object Gateway en Ceph Dashboard:
- 10 Configuración manual
En esta sección se presenta información avanzada para los usuarios que prefieren configurar manualmente los valores de la consola en la línea de comandos.
- 11 Gestión de usuarios y funciones en la línea de comandos
En esta sección se describe cómo gestionar las cuentas de usuario utilizadas por la Ceph Dashboard. Sirve de ayuda para crear o modificar cuentas de usuario, así como para establecer las funciones y permisos de usuario adecuados.
1 Acerca de Ceph Dashboard #
Ceph Dashboard es una aplicación de supervisión y gestión de Ceph basada en Web que administra varios aspectos y objetos del clúster. La consola se habilita automáticamente después de distribuir el clúster básico en Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3 “Distribución del clúster de Ceph”.
En Ceph Dashboard para SUSE Enterprise Storage 7 se han añadido más funciones de gestión basadas en Web para facilitar la administración de Ceph, incluida la supervisión y la administración de aplicaciones en Ceph Manager. Ya no es necesario conocer comandos complejos relacionados con Ceph para gestionar y supervisar el clúster de Ceph. Puede utilizar la intuitiva interfaz de Ceph Dashboard o su API REST integrada.
El módulo Ceph Dashboard muestra información y estadísticas sobre el clúster de Ceph mediante un servidor Web alojado por ceph-mgr. Consulte Book “Guía de distribución”, Chapter 1 “SES y Ceph”, Section 1.2.3 “Nodos y daemons de Ceph” para obtener más información sobre Ceph Manager.
2 Interfaz de usuario Web de la consola #
2.1 Conexión #
Para entrar a la sesión en Ceph Dashboard, abra su dirección URL en un navegador, incluido el número de puerto. Ejecute el comando siguiente para buscar la dirección:
cephuser@adm > ceph mgr services | grep dashboard
"dashboard": "https://host:port/",El comando devuelve la URL donde se encuentra Ceph Dashboard. Si tiene problemas con este comando, consulte el Book “Troubleshooting Guide”, Chapter 10 “Troubleshooting the Ceph Dashboard”, Section 10.1 “Locating the Ceph Dashboard”.

Entre a la sesión con las credenciales que creó durante la distribución del clúster (consulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3.2.9 “Configuración de las credenciales de entrada de Ceph Dashboard”).
Si no desea utilizar la cuenta admin por defecto para acceder a Ceph Dashboard, cree una cuenta de usuario personalizada con privilegios de administrador. Consulte el Capítulo 11, Gestión de usuarios y funciones en la línea de comandos para obtener más información.
La interfaz de usuario de la consola se divide en varios bloques: el menú de utilidades en la parte superior derecha de la pantalla, el menú principal en la parte izquierda y el panel de contenido principal.

2.2 Menú de utilidades #
La parte superior derecha de la pantalla muestra un menú de utilidades. Incluye tareas generales relacionadas más con la consola que con el clúster de Ceph. Puede hacer clic en las opciones para acceder a los siguientes temas:
Cambiar la interfaz de idioma de la consola a: alemán, checo, chino, coreano, español, francés, indonesio, inglés, italiano, japonés, polaco o portugués (brasileño).
Tareas y notificaciones
Consultar la documentación, la información acerca de la API REST o información adicional acerca de la consola.
Gestionar a los usuarios y la configuración de telemetría.
NotaPara obtener una descripción más detalladas de las funciones de usuario de la línea de comandos, consulte el Capítulo 11, Gestión de usuarios y funciones en la línea de comandos.
Configuración de entrada a la sesión; cambiar la contraseña o cerrar la sesión.
2.3 Menú principal #
El menú principal de la consola ocupa la parte izquierda de la pantalla. Abarca los siguientes contenidos:
Vuelve a la página de inicio de Ceph Dashboard.
Muestra información detallada sobre los hosts, el inventario, los monitores Ceph Monitor, los servicios, los OSD de Ceph, la configuración del clúster, el mapa de CRUSH, los módulos de Ceph Manager, los registros y la supervisión.
Permite ver y gestionar repositorios de clústeres.
Muestra información detallada y permite gestionar las imágenes de dispositivos de bloques RADOS, la duplicación e iSCSI.
Permite ver y gestionar las distribuciones de NFS Ganesha.
NotaSi no se distribuye NFS Ganesha, aparece un aviso informativo. Consulte la Sección 11.6, “Configuración de NFS Ganesha en Ceph Dashboard”.
Permite ver y gestionar sistemas de archivos CephFS.
Permite ver y gestionar los daemons, usuarios y depósitos de Object Gateway.
NotaSi no se distribuye Object Gateway, aparece un aviso informativo. Consulte la Sección 10.4, “Habilitación del procesador frontal de gestión de Object Gateway”.
2.4 Panel de contenido #
El panel de contenidos ocupa gran parte de la pantalla de la consola. La página de inicio de la consola muestra numerosos widgets útiles para informar brevemente sobre el estado actual del clúster, su capacidad y el rendimiento.
2.5 Características comunes de la interfaz del usuario Web #
En Ceph Dashboard se suele trabajar con listas; por ejemplo, listas de repositorios, nodos de OSD o dispositivos RBD. Todas las listas se actualizan automáticamente por defecto cada cinco segundos. Los widgets comunes siguientes ayudan a gestionar o a ajustar estas listas:
Haga clic en ![]() para activar una actualización manual de la lista.
para activar una actualización manual de la lista.
Haga clic en ![]() para mostrar u ocultar columnas individuales.
para mostrar u ocultar columnas individuales.
Haga clic en ![]() e introduzca o seleccione el número de filas que desea
mostrar en cada página.
e introduzca o seleccione el número de filas que desea
mostrar en cada página.
Haga clic dentro de  y filtre las filas escribiendo una cadena de búsqueda.
y filtre las filas escribiendo una cadena de búsqueda.
Use  para cambiar la página que se muestra si la lista se
extiende por varias páginas.
para cambiar la página que se muestra si la lista se
extiende por varias páginas.
2.6 Widgets de consola #
Cada widget de consola muestra información de estado específica relacionada con un aspecto específico de un clúster de Ceph en ejecución. Algunos widgets son enlaces activos y, después de hacer clic en ellos, le redirigirán a una página con detalles sobre el tema que representan.
Algunos widgets gráficos muestran más detalles al mover el ratón sobre ellos.
2.6.1 Widgets de Estado #
Los widgets de ofrecen una breve descripción general sobre el estado actual del clúster.

Presenta información básica sobre el estado del clúster.
Muestra el número total de nodos del clúster.
Muestra el número de monitores en ejecución y su quórum.
Muestra el número total de OSD, así como el número de OSD con los estados up e in.
Muestra el número de daemons de Ceph Manager activos y en espera.
Muestra el número de pasarelas Object Gateway en ejecución.
Muestra el número de servidores de metadatos.
Muestra el número de pasarelas iSCSI Gateway configuradas.
2.6.2 Widgets de Capacidad #
Los widgets de muestran información breve sobre la capacidad de almacenamiento.

Muestra la proporción de capacidad de almacenamiento en bruto utilizada y disponible.
Muestra el número de objetos de datos almacenados en el clúster.
Muestra un gráfico de los grupos de colocación según su estado.
Muestra el número de repositorios del clúster.
Muestra el promedio de grupos de colocación por OSD.
2.6.3 Widgets de Rendimiento #
Los widgets de muestran datos básicos de rendimiento de los clientes de Ceph.

La cantidad de operaciones de lectura y escritura de los clientes por segundo.
La cantidad de datos transferidos a y desde los clientes de Ceph en bytes por segundo.
El rendimiento de los datos recuperados por segundo.
Muestra el estado de depuración (consulte la Sección 17.4.9, “Depuración de un grupo de colocación”). Puede ser
inactivo,habilitadooactivo.
3 Gestión de usuarios y funciones de Ceph Dashboard #
En el Capítulo 11, Gestión de usuarios y funciones en la línea de comandos ya se describió la gestión de usuarios de la consola que se realiza mediante los comandos de Ceph en la línea de comandos.
En esta sección se describe cómo gestionar cuentas de usuario mediante la interfaz de usuario Web de la consola.
3.1 Listas de usuarios #
Haga clic en ![]() en el menú de utilidades y seleccione .
en el menú de utilidades y seleccione .
La lista contiene el nombre de usuario de cada usuario, el nombre completo, el correo electrónico, una lista de funciones asignadas, si la función está habilitada y la fecha de caducidad de la contraseña.

3.2 Adición de nuevos usuarios #
Haga clic en en la parte superior izquierda del encabezado de la tabla para añadir un nuevo usuario. Introduzca su nombre de usuario, contraseña y, opcionalmente, un nombre completo y un correo electrónico.

Haga clic en el icono de lápiz pequeño para asignar funciones predefinidas al usuario. Para confirmar, haga clic en .
3.3 Edición de usuarios #
Haga clic en la fila de un usuario para resaltarlo. Seleccione para modificar los detalles del usuario. Para confirmar, haga clic en
3.4 Supresión de usuarios #
Haga clic en la fila de de un usuario para resaltarlo. Seleccione el botón desplegable situado junto a y seleccione en la lista para suprimir la cuenta de usuario. Active la casilla de verificación y haga clic en para confirmar.
3.5 Listado de las funciones de usuario #
Haga clic en ![]() en el menú de utilidades y seleccione . A continuación, haga clic en la pestaña
.
en el menú de utilidades y seleccione . A continuación, haga clic en la pestaña
.
La lista contiene el nombre y la descripción de cada función e indica si se trata de una función del sistema.

3.6 Adición de funciones personalizadas #
Haga clic en en la parte superior izquierda del encabezado de la tabla para añadir una nueva función personalizada. Introduzca los datos correspondientes en y y, junto a seleccione los permisos adecuados.
Si crea funciones de usuario personalizadas y tiene previsto eliminar el
clúster de Ceph con el comando ceph-salt purge más
adelante, primero debe limpiar las funciones personalizadas. Más detalles
en la Sección 13.9, “Eliminación de un clúster de Ceph completo”

Al activar la casilla de verificación que precede al nombre del tema, se activan todos los permisos para ese tema. Al activar la casilla de verificación se activan todos los permisos para todos los temas.
Para confirmar, haga clic en .
3.7 Edición de funciones personalizadas #
Haga clic en la fila de un usuario para resaltarlo. Seleccione en la parte superior izquierda del encabezado de la tabla para editar una descripción y los permisos de la función personalizada. Para confirmar, haga clic en
3.8 Supresión de funciones personalizadas #
Haga clic en la fila de una función para resaltarla. Seleccione el botón desplegable situado junto a y seleccione en la lista para suprimir la función. Active la casilla de verificación y haga clic en para confirmar.
4 Visualización de elementos internos del clúster #
El elemento de menú permite ver información detallada acerca de los hosts del clúster de Ceph, el inventario, los monitores Ceph Monitor, los servicios, los OSD, la configuración, el mapa de CRUSH, Ceph Manager, los registros y los archivos de supervisión.
4.1 Visualización de nodos de clúster #
Haga clic en › para ver una lista de nodos de clúster.

Haga clic en la flecha desplegable situada junto al nombre de un nodo en la columna para ver los detalles de rendimiento del nodo.
La columna muestra todos los daemons que se ejecutan en cada nodo relacionado. Haga clic en un nombre de daemon para ver su configuración detallada.
4.2 Acceso al inventario del clúster #
Haga clic en › para ver una lista de dispositivos. La lista incluye la vía del dispositivo, el tipo, la disponibilidad, el proveedor, el modelo, el tamaño y los OSD.
Haga clic para seleccionar un nombre de nodo en la columna . Si está seleccionado, haga clic en para identificar el dispositivo en el que se ejecuta el host. Esto indica al dispositivo que haga parpadear sus LED. Seleccione la duración de esta acción, que puede ser 1, 2, 5, 10 o 15 minutos. Haga clic en

4.3 Visualización de monitores Ceph Monitor #
Haga clic en
›
para ver una lista de nodos de clúster con monitores de Ceph en ejecución.
El panel de contenido se divide en dos vistas: Estado y
En quórum o Sin quórum.
La tabla muestra estadísticas generales sobre los monitores Ceph Monitor en ejecución, incluido lo siguiente:
ID del clúster
Mapa de supervisión modificado
Época de mapa de supervisión
quórum de con
quórum de mon
con requerido
mon requerido
Los paneles Con quórum y Sin quórum
incluyen el nombre de cada monitor, el número de rango, la dirección IP
pública y el número de sesiones abiertas.
Haga clic en un nombre de nodo en la columna para ver la configuración relacionada de Ceph Monitor.

4.4 Visualización de servicios #
Haga clic en
›
para ver los detalles de cada uno de los servicios disponibles:
crash, Ceph Manager y monitores Ceph Monitor. La lista
incluye el nombre de la imagen del contenedor, el ID de la imagen del
contenedor, el estado de lo que se está ejecutando, el tamaño y cuándo se
actualizó por última vez.
Haga clic en la flecha desplegable situada junto al nombre de un servicio en la columna para ver los detalles del daemon. La lista de detalles incluye el nombre de host, el tipo de daemon, el ID de daemon, el ID de contenedor, el nombre de la imagen del contenedor, el ID de la imagen del contenedor, el número de versión, el estado y cuándo se actualizó por última vez.

4.5 Visualización de los OSD de Ceph #
Haga clic en › para ver una lista de nodos con daemons de OSD en ejecución. La lista incluye el nombre de cada nodo, el ID, su estado, la clase de dispositivo, el número de grupos de colocación, el tamaño, el uso, el gráfico de lecturas/escrituras en el tiempo y la tasa de operaciones de lectura/escritura por segundo.

Seleccione en el menú desplegable en el encabezado de la tabla para abrir una ventana emergente. En ella verá una lista de indicadores que se aplican a todo el clúster. Puede activar o desactivar indicadores individuales. Para confirmar, haga clic en

Seleccione en el menú desplegable en el encabezado de la tabla para abrir una ventana emergente. En ella verá una lista de prioridades de recuperación de OSD que se aplican a todo el clúster. Puede activar el perfil de prioridad preferido y después ajustar los valores individuales. Para confirmar, haga clic en

Haga clic en la flecha desplegable situada junto a un nombre de nodo en la columna para ver una tabla extendida con detalles sobre la configuración y el rendimiento del dispositivo. En las distintas pestañas, es posible ver listas de , , el , y un gráfico de lecturas y escrituras, así como

Cuando se hace clic en el nombre de un nodo de OSD, la fila de la tabla se resalta. Esto significa que ahora se puede realizar una tarea en el nodo. Puede realizar cualquiera de las siguientes acciones: o
Haga clic en la flecha hacia abajo situada en la parte superior izquierda del encabezado de la tabla, junto al botón y seleccione la tarea que desea realizar.
4.5.1 Adición de OSD #
Para añadir nuevos OSD, siga estos pasos:
Verifique que algunos nodos del clúster tengan dispositivos de almacenamiento cuyo estado sea
disponible.A continuación, haga clic en la flecha hacia abajo situada en la parte superior izquierda del encabezado de la tabla y seleccione Se abrirá la ventana Figura 4.9: Crear OSDs #
Figura 4.9: Crear OSDs #Para añadir dispositivos de almacenamiento primarios para los OSD, haga clic en Antes de poder añadir dispositivos de almacenamiento, debe especificar criterios de filtrado en la parte superior derecha de la tabla por ejemplo, . Para confirmar, haga clic en
 Figura 4.10: Adición de dispositivos primarios #
Figura 4.10: Adición de dispositivos primarios #En la ventana actualizada, tiene la opción de añadir dispositivos WAL y BD compartidos, o bien de habilitar el cifrado de dispositivos.
 Figura 4.11: Crear OSDs con dispositivos primarios añadidos #
Figura 4.11: Crear OSDs con dispositivos primarios añadidos #Haga clic en para ver la vista previa de la especificación DriveGroups para los dispositivos que ha añadido anteriormente. Para confirmar, haga clic en
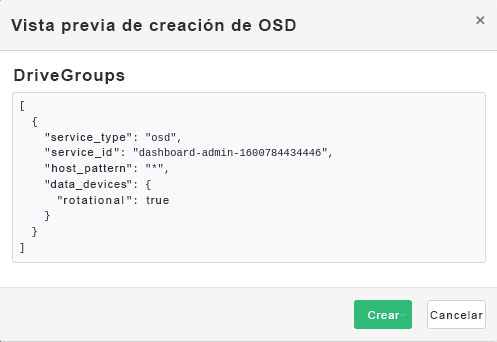 Figura 4.12: #
Figura 4.12: #Los dispositivos nuevos se añadirán a la lista de OSD.
 Figura 4.13: OSD recién añadidos #Nota
Figura 4.13: OSD recién añadidos #NotaNo es posible visualizar el progreso del proceso de creación de los OSD. Se tarda algún tiempo en crearlos. Los OSD aparecerán en la lista cuando se hayan distribuido. Si desea comprobar el estado de distribución, consulte los registros haciendo clic en › .
4.6 Visualización de la configuración del clúster #
Haga clic en › para ver una lista completa de las opciones de configuración del clúster de Ceph. La lista contiene el nombre de la opción, una descripción breve y sus valores actuales y por defecto. También se indica si la opción se puede editar.

Haga clic en la flecha desplegable situada junto a una opción de configuración en la columna para ver una tabla extendida con información detallada sobre la opción, como su tipo de valor, los valores mínimos y máximos permitidos, si se puede actualizar en el tiempo de ejecución y mucho más.
Después de resaltar una opción específica, puede editar sus valores haciendo clic en el botón en la parte superior izquierda del encabezado de la tabla. Para confirmar los cambios, haga clic en
4.7 Visualización del mapa de CRUSH #
Haga clic en › para ver un mapa de CRUSH del clúster. Para obtener información general sobre los mapas de CRUSH, consulte la Sección 17.5, “Manipulación del mapa de CRUSH”.
Haga clic en la raíz, los nodos o los OSD individuales para ver información más detallada, como el peso de CRUSH, la profundidad del árbol de mapa, la clase de dispositivo del OSD y mucho más.

4.8 Visualización de módulos del gestor #
Haga clic en › para ver una lista de los módulos de Ceph Manager disponibles. Cada línea está formada por nombre de módulo e información sobre si está habilitado actualmente.

Haga clic en la flecha desplegable situada junto a un módulo en la columna para ver una tabla extendida con detalles sobre la configuración en la tabla de abajo. Para editar los detalles, haciendo clic en en la parte superior izquierda del encabezado de la tabla. Para confirmar los cambios, haga clic en
Haga clic en la flecha desplegable situada junto al botón en la parte superior izquierda del encabezado de la tabla para o un módulo.
4.9 Visualización de registros #
Haga clic en › para ver una lista de las entradas de registro recientes del clúster. Cada línea está formada por una marca de tiempo, el tipo de la entrada de registro y el propio mensaje registrado.
Haga clic en la pestaña para ver las entradas de registro del subsistema de auditoría. Consulte en la Sección 11.5, “Auditoría de peticiones de API” los comandos necesarios para habilitar o inhabilitar la auditoría.

4.10 Visualización de la supervisión #
Haga clic en › para gestionar y ver los detalles de las alertas de Prometheus.
Si tiene Prometheus activo, en este panel de contenido puede ver información detallada sobre o
Si no ha distribuido Prometheus, aparecerá un anuncio con información y un enlace a la documentación pertinente.
5 Gestión de repositorios #
Para obtener información general sobre los repositorios de Ceph, consulte el Capítulo 18, Gestión de repositorios de almacenamiento. Para obtener información específica sobre los repositorios codificados de borrado, consulte el Capítulo 19, Repositorios codificados de borrado.
Para ver una lista de todos los repositorios disponibles, haga clic en en el menú principal.
La lista muestra el nombre y el tipo del repositorio, la aplicación relacionada, el estado del grupo de colocación, el tamaño de réplica, el último cambio, el perfil codificado de borrado, el conjunto de reglas de CRUSH y el uso y las estadísticas de lectura y escritura.

Haga clic en la flecha desplegable situada junto al nombre de un repositorio en la columna para ver una tabla extendida con información detallada sobre el repositorio, como los detalles generales, los detalles de rendimiento y la configuración.
5.1 Adición de un repositorio nuevo #
Para añadir un repositorio nuevo , haga clic en en la parte superior izquierda de la tabla de repositorios. En el formulario del repositorio, puede introducir el nombre del repositorio, el tipo, sus aplicaciones, el modo de compresión y las cuotas, incluido el número máximo de bytes y el número máximo de objetos. El propio formulario calcula el número de grupos de colocación que mejor se adapta a este repositorio específico. El cálculo se basa en la cantidad de OSD del clúster y el tipo de repositorio seleccionado con su configuración específica. Si se define manualmente el número de grupos de colocación, el número calculado se sustituirá. Para confirmar, haga clic en

5.2 Supresión de repositorios #
Para suprimir un repositorio, selecciónelo en la fila de la tabla. Haga clic en la flecha desplegable situada junto al botón y haga clic en
5.3 Edición de las opciones de un repositorio #
Para editar las opciones de un repositorio, seleccione el repositorio en la fila de la tabla y haga clic en en la parte superior izquierda de la tabla.
Puede cambiar el nombre del repositorio, aumentar el número de grupos de colocación, cambiar la lista de aplicaciones del repositorio y la configuración de compresión. Para confirmar, haga clic en
6 Gestión de dispositivos de bloques RADOS #
Para mostrar todos los dispositivos de bloques RADOS (RBD) disponibles, haga clic en › en el menú principal.
La lista muestra información breve sobre el dispositivo, como el nombre del dispositivo, el nombre del repositorio relacionado, el espacio de nombres, el tamaño del dispositivo, el número y el tamaño de los objetos del dispositivo, detalles sobre la provisión de los detalles y el padre.

6.1 Visualización de detalles de los RBD #
Para ver información más detallada sobre un dispositivo, haga clic en su fila en la tabla:

6.2 Visualización de la configuración de RBD #
Para ver la configuración detallada de un dispositivo, haga clic en su fila en la tabla y, a continuación, en la pestaña de la tabla inferior:

6.3 Creación de RBD #
Para añadir un dispositivo nuevo, haga clic en en la parte superior izquierda del encabezado de la tabla y haga lo siguiente en la pantalla

Introduzca el nombre del dispositivo nuevo. Consulte el Book “Guía de distribución”, Chapter 2 “Requisitos y recomendaciones de hardware”, Section 2.11 “Limitaciones de nombres” para conocer las limitaciones a la hora de asignar un nombre.
Seleccione el repositorio con la aplicación
rbdasignada desde la que se creará el nuevo dispositivo RBD.Especifique el tamaño del nuevo dispositivo.
Especifique las opciones adicionales para el dispositivo. Para ajustar los parámetros del dispositivo, haga clic en e introduzca valores para el tamaño del objeto, la unidad de repartición o el recuento de repartición. Para especificar los límites de calidad de servicio (QoS), haga clic en e introdúzcalos.
Para confirmar, haga clic en
6.4 Supresión de RBD #
Para suprimir un dispositivo, selecciónelo en la fila de la tabla. Haga clic en la flecha desplegable situada junto al botón y haga clic en Para confirmar, haga clic en
Suprimir un RBD es una acción irreversible. Si en su lugar, usa la opción podrá restaurar el dispositivo más adelante seleccionándolo en la pestaña de la tabla principal y haciendo clic en en la parte superior izquierda del encabezado de la tabla.
6.5 Creación de instantáneas de dispositivos de bloques RADOS #
Para crear una instantánea de dispositivo de bloques RADOS, seleccione el dispositivo en la fila de la tabla y aparecerá el panel de contenido de configuración detallada. Seleccione la pestaña y haga clic en en la parte superior izquierda del encabezado de la tabla. Escriba el nombre de la instantánea y haga clic en para confirmar.
Después de seleccionar una instantánea, puede realizar acciones adicionales en el dispositivo, como cambiar su nombre, protegerlo, clonarlo, copiarlo o suprimirlo. La opción (Deshacer) restaura el estado del dispositivo de la instantánea actual.

6.6 Duplicación de un RBD #
Los dispositivos de bloques de imágenes RADOS se pueden duplicar de forma asincrónica entre dos clústeres de Ceph. Puede usar Ceph Dashboard para configurar la réplica de imágenes RBD entre dos o más clústeres. Esta capacidad está disponible en dos modos:
- Basada en registro
Este modo utiliza las imágenes RBD transaccionales para garantizar la réplica protegida contra bloqueos de un momento concreto entre los clústeres.
- Basada en instantáneas
Este modo utiliza instantáneas de duplicación de imágenes RBD creadas de forma programada periódicamente o manualmente para replicar imágenes de RBD protegidas contra bloqueos entre clústeres.
La duplicación se configura en cada repositorio dentro de clústeres conectores y se puede configurar en un subconjunto específico de imágenes dentro del repositorio o para que refleje automáticamente todas las imágenes de un repositorio si se usa únicamente la duplicación transaccional.
La duplicación se configura mediante el comando rbd, que
se instala por defecto en SUSE Enterprise Storage 7. El daemon
rbd-mirror es el responsable de la
extracción de actualizaciones de imágenes del clúster conector remoto y de
aplicarlos a la imagen en el clúster local. Consulte la
Sección 6.6.2, “Habilitación del daemon rbd-mirror” para obtener más información
sobre cómo habilitar el daemon
rbd-mirror.
Dependiendo de la necesidad de réplica, la duplicación del dispositivo de bloques RADOS se puede configurar para la réplica unidireccional o bidireccional:
- Réplica unidireccional
Cuando los datos solo se duplican desde un clúster primario a un clúster secundario, el daemon
rbd-mirrorse ejecuta solo en el clúster secundario.- Réplica bidireccional
Cuando los datos se duplican desde imágenes primarias de un clúster a imágenes no primarias de otro clúster (y viceversa), el daemon
rbd-mirrorse ejecuta en ambos clústeres.
Cada instancia del daemon
rbd-mirror debe poder conectarse a
los clústeres de Ceph locales y remotos simultáneamente; por ejemplo, a
todos los monitores y los hosts OSD. Además, la red debe tener suficiente
ancho de banda entre los dos centros de datos para poder gestionar la carga
de trabajo de duplicación.
Para obtener información general y el enfoque de la línea de comandos para duplicar un dispositivo de bloques RADOS, consulte la Sección 20.4, “Duplicados de imagen RBD”.
6.6.1 Configuración de clústeres primarios y secundarios #
El clúster primario es aquel donde se crea el repositorio original con imágenes. El clúster secundario es donde se replican el repositorio o las imágenes desde el clúster primario.
Los términos primario y secundario pueden ser relativos en el contexto de la réplica, ya que están más relacionados con los repositorios individuales que con los clústeres. Por ejemplo, en la réplica bidireccional, un repositorio se puede duplicar desde el clúster primario al secundario, mientras que otro repositorio se puede duplicar desde el clúster secundario al primario.
6.6.2 Habilitación del daemon rbd-mirror #
Los siguientes procedimientos demuestran cómo llevar a cabo las tareas
administrativas básicas para configurar la duplicación mediante el comando
rbd. La duplicación se configura de forma independiente
para cada repositorio dentro de los clústeres de Ceph.
Los pasos para configurar el repositorio deben realizarse en ambos clústeres conectores. Para simplificar los ejemplos, en estos procedimientos se presupone que hay dos clústeres, denominados "primario" y "secundario, a los que se puede acceder desde un único host.
El daemon rbd-mirror realiza la
réplica de los datos del clúster.
Cambie el nombre de
ceph.confy de los archivos de anillo de claves y cópielos del host primario al secundario:cephuser@secondary >cp /etc/ceph/ceph.conf /etc/ceph/primary.confcephuser@secondary >cp /etc/ceph/ceph.admin.client.keyring \ /etc/ceph/primary.client.admin.keyringcephuser@secondary >scp PRIMARY_HOST:/etc/ceph/ceph.conf \ /etc/ceph/secondary.confcephuser@secondary >scp PRIMARY_HOST:/etc/ceph/ceph.client.admin.keyring \ /etc/ceph/secondary.client.admin.keyringPara habilitar la duplicación en un repositorio con
rbd, especifique el comandomirror pool enable, el nombre del repositorio y el modo de duplicación:cephuser@adm >rbd mirror pool enable POOL_NAME MODENotaEl modo de duplicación puede ser
imageopool. Por ejemplo:cephuser@secondary >rbd --cluster primary mirror pool enable image-pool imagecephuser@secondary >rbd --cluster secondary mirror pool enable image-pool imageEn Ceph Dashboard diríjase a › . La tabla de la izquierda muestra los daemons
rbd-mirrorque se ejecutan activamente y su estado. Figura 6.6: Ejecución de daemons
Figura 6.6: Ejecución de daemonsrbd-mirror#
6.6.3 Inhabilitación de la duplicación #
Para inhabilitar la duplicación en un repositorio con
rbd, especifique el comando mirror pool
disable y el nombre del repositorio:
cephuser@adm > rbd mirror pool disable POOL_NAMECuando se inhabilita la duplicación en un repositorio de esta forma, la duplicación también se inhabilitará en cualquier imagen (dentro del repositorio) para la que se haya habilitado la duplicación explícitamente.
6.6.4 Conectores de carga #
Para que rbd-mirror descubra su
clúster conector, este debe estar registrado en el repositorio y debe
crearse una cuenta de usuario. Este proceso se puede automatizar con
rbd mediante los comandos mirror pool peer
bootstrap create y mirror pool peer bootstrap
import.
Para crear manualmente un nuevo testigo de arranque con
rbd, especifique el comando mirror pool peer
bootstrap create, un nombre de repositorio y un nombre de sitio
opcional para describir el clúster local:
cephuser@adm > rbd mirror pool peer bootstrap create [--site-name local-site-name] pool-name
El resultado del comando mirror pool peer bootstrap
create será un testigo que se debe proporcionar al comando
mirror pool peer bootstrap import. Por ejemplo, en el
clúster primario:
cephuser@adm > rbd --cluster primary mirror pool peer bootstrap create --site-name primary
image-pool eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkL \
W1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1vbl9ob3N0I \
joiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
Para importar manualmente el testigo de arranque creado por otro clúster
con el comando rbd, especifique el comando
mirror pool peer bootstrap import, el nombre del
repositorio, una vía de archivo al testigo creado (o "-" para leer desde la
entrada estándar), junto con un nombre de sitio opcional para describir el
clúster local y una dirección de duplicación (por defecto es
rx-tx para la duplicación bidireccional, pero también se
puede definir como rx-only para la duplicación
unidireccional):
cephuser@adm > rbd mirror pool peer bootstrap import [--site-name local-site-name] \
[--direction rx-only or rx-tx] pool-name token-pathPor ejemplo, en el clúster secundario:
cephuser@adm >cat >>EOF < token eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW \ 1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1v \ bl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ== EOFcephuser@adm >rbd --cluster secondary mirror pool peer bootstrap import --site-name secondary image-pool token
6.6.5 Eliminación de un clúster conector #
Para eliminar un clúster conector duplicado de Ceph con el comando
rbd, especifique el comando mirror pool peer
remove, el nombre del repositorio y el UUID del conector
(disponible mediante el comando rbd mirror pool info):
cephuser@adm > rbd mirror pool peer remove pool-name peer-uuid6.6.6 Configuración de la réplica de repositorios en Ceph Dashboard #
El daemon rbd-mirror debe tener
acceso al clúster primario para poder duplicar imágenes RBD. Antes de
continuar, asegúrese de que ha seguido los pasos descritos en la
Sección 6.6.4, “Conectores de carga”.
Tanto en el clúster primario como en el secundario, cree repositorios con un nombre idéntico y asígneles la aplicación
rbd. Consulte la Sección 5.1, “Adición de un repositorio nuevo” para obtener más información sobre cómo crear un repositorio. Figura 6.7: Creación de un repositorio con la aplicación RBD #
Figura 6.7: Creación de un repositorio con la aplicación RBD #Tanto en la consola primaria como en la secundaria del clúster, diríjase a › . En la tabla de la derecha, haga clic en el nombre del repositorio que desea replicar y, después de hacer clic en , seleccione el modo de réplica. En este ejemplo, trabajaremos con un modo de réplica de repositorio, lo que significa que se replicarán todas las imágenes de un repositorio determinado. Para confirmar, haga clic en
 Figura 6.8: Configuración del modo de réplica #Importante: error o advertencia en el clúster primario
Figura 6.8: Configuración del modo de réplica #Importante: error o advertencia en el clúster primarioDespués de actualizar el modo de réplica, aparecerá un indicador de error o advertencia en la columna correspondiente de la derecha. Esto se debe a que el repositorio no tiene asignado todavía ningún usuario par para la réplica. Ignore este indicador para el clúster primario, ya que solo se asignará un usuario par al clúster secundario.
En la consola del clúster secundario, diríjase a › . Añada el par de duplicación del repositorio seleccionando . Proporcione los detalles del clúster primario:
 Figura 6.9: Adición de credenciales del par #
Figura 6.9: Adición de credenciales del par #Se trata de una cadena arbitraria exclusiva que identifica al clúster primario; por ejemplo, "primario". El nombre del clúster debe ser distinto del nombre real del clúster secundario.
El ID de usuario de Ceph que creó como par de duplicación. En este ejemplo es "rbd-mirror-peer".
Lista separada por comas de direcciones IP o nombres de host de los nodos de Ceph Monitor del clúster principal.
La clave relacionada con el ID de usuario par. Puede recuperarla ejecutando el siguiente comando de ejemplo en el clúster primario:
cephuser@adm >ceph auth print_key pool-mirror-peer-name
Para confirmar, haga clic en
 Figura 6.10: Lista de repositorios replicados #
Figura 6.10: Lista de repositorios replicados #
6.6.7 Verificación del funcionamiento de la réplica de la imagen RBD #
Cuando el daemon rbd-mirror esté en
ejecución y la réplica de la imagen RBD esté configurada en Ceph Dashboard,
podrá verificar si la réplica realmente funciona:
En Ceph Dashboard del clúster primario, cree una imagen RBD cuyo repositorio primario sea el repositorio que ya creó con fines de réplica. Habilite las funciones
Bloqueo exclusivoyEn diariode la imagen. Consulte la Sección 6.3, “Creación de RBD” para obtener más información sobre cómo crear imágenes RBD. Figura 6.11: Nueva imagen RBD #
Figura 6.11: Nueva imagen RBD #Después de crear la imagen que desea replicar, abra la Ceph Dashboard del clúster secundario y diríjase a › . La tabla de la derecha reflejará el cambio en el número de imágenes de y sincronizará el número de imágenes de .
 Figura 6.12: Nueva imagen RBD sincronizada #Sugerencia: progreso de la réplica
Figura 6.12: Nueva imagen RBD sincronizada #Sugerencia: progreso de la réplicaLa tabla de la parte inferior de la página muestra el estado de la réplica de las imágenes RBD. La pestaña incluye los problemas que se han podido producir, muestra el progreso de la réplica de la imagen y muestra todas las imágenes cuya réplica se ha realizado correctamente.
 Figura 6.13: Estado de réplica de las imágenes RBD #
Figura 6.13: Estado de réplica de las imágenes RBD #En el clúster primario, escriba datos en la imagen RBD. En la Ceph Dashboard del clúster secundario, diríjase a › y supervise si el tamaño de la imagen correspondiente aumenta a medida que se escriben los datos en el clúster primario.
6.7 Gestión de pasarelas iSCSI Gateway #
Para obtener información general sobre las pasarelas iSCSI Gateway, consulte el Capítulo 22, Ceph iSCSI Gateway.
Para mostrar todas las pasarelas disponibles y las imágenes asignadas, haga clic en › en el menú principal. Se abre una pestaña que muestra las pasarelas iSCSI Gateway configuradas actualmente y las imágenes RBD asignadas.
La tabla muestra el estado de cada pasarela, el número de destinos iSCSI y el número de sesiones. La tabla muestra el nombre de cada imagen asignada, el nombre del repositorio relacionado, el tipo de almacén y otros detalles estadísticos.
La pestaña muestra los destinos iSCSI configurados actualmente.

Para ver información más detallada acerca de un destino, haga clic en la flecha desplegable de la fila de la tabla de destino. Se abre un esquema estructurado en forma de árbol con los discos, los portales, los iniciadores y los grupos incluidos. Haga clic en un elemento para expandirlo y ver su contenido detallado, opcionalmente con la configuración relacionada en la tabla de la derecha.

6.7.1 Adición de destinos iSCSI #
Para añadir un destino iSCSI nuevo, haga clic en en la parte superior izquierda de la tabla e introduzca la información necesaria.

Escriba la dirección de destino de la nueva pasarela.
Haga clic en y seleccione uno o varios portales iSCSI de la lista.
Haga clic en y seleccione una o varias imágenes RBD para la pasarela.
Si necesita utilizar autenticación para acceder a la pasarela, marque la casilla de verificación e introduzca las credenciales. Encontrará opciones de autenticación más avanzadas después de activar y .
Para confirmar, haga clic en
6.7.2 Edición de destinos iSCSI #
Para editar un destino iSCSI existente, haga clic en su fila en la tabla y haga clic en en la parte superior izquierda de la tabla.
A continuación, puede modificar el destino iSCSI, añadir o suprimir portales y añadir o suprimir imágenes RBD relacionadas. También puede ajustar la información de autenticación para la pasarela.
6.7.3 Supresión de destinos iSCSI #
Para suprimir un destino iSCSI, seleccione la fila de la tabla, haga clic en la flecha desplegable situada junto al botón y seleccione Active la casilla de verificación y haga clic en para confirmar.
6.8 Calidad del servicio (QoS) de un RBD #
Para obtener información general y una descripción de las opciones de configuración de QoS de un RDB, consulte la Sección 20.6, “Ajuste de QoS”.
Las opciones de QoS se pueden configurar en diferentes niveles.
Globalmente
En cada repositorio
En cada imagen
La configuración global se encuentra en la parte superior de la lista y se utiliza para todas las imágenes RBD recién creadas y para aquellas imágenes que no sustituyen estos valores en la capa del repositorio o de la imagen RBD. Un valor especificado globalmente se puede sustituir en cada repositorio o imagen. Las opciones especificadas en un repositorio se aplicarán a todas las imágenes RBD de ese repositorio a menos que se sustituyan por una opción de configuración definida en una imagen. Las opciones especificadas en una imagen sustituyen a las opciones especificadas en un repositorio y a las especificadas globalmente.
De esta manera, es posible definir valores por defecto globalmente, adaptarlos para todas las imágenes de RBD de un repositorio específico y sustituir la configuración del repositorio para imágenes RBD individuales.
6.8.1 Configuración global de opciones #
Para configurar las opciones del dispositivo de bloques RADOS de forma global, seleccione › en el menú principal.
Para mostrar todas las opciones de configuración global disponibles, junto a seleccione en el menú desplegable.
Los resultados de la tabla se pueden filtrar por
rbd_qosen el campo de búsqueda. Esto muestra todas las opciones de configuración disponibles para QoS.Para cambiar un valor, haga clic en la fila de la tabla y seleccione en la parte superior izquierda de la tabla. El recuadro de diálogo contiene seis campos diferentes para especificar valores. Los valores de la opción de configuración de RBD se deben indicar en el recuadro de texto .
NotaA diferencia de otros recuadros de diálogo, este no permite especificar el valor en unidades según convenga. Debe establecer estos valores en bytes o IOPS, dependiendo de la opción que esté editando.
6.8.2 Configuración de opciones en un nuevo repositorio #
Para crear un nuevo repositorio y configurar las opciones de configuración
de RBD en él, haga clic en › . Seleccione
como tipo de repositorio. A continuación,
deberá añadir la etiqueta de aplicación rbd al
repositorio para poder configurar las opciones de QoS de RBD.
No es posible configurar las opciones de configuración de QoS de RBD en un repositorio codificado de borrado. Para configurar las opciones de QoS de RBD para los repositorios codificados de borrado, debe editar el repositorio de metadatos replicados de una imagen RBD. A continuación, la configuración se aplicará al repositorio codificado de borrado de esa imagen.
6.8.3 Configuración de opciones en un repositorio existente #
Para configurar las opciones de QoS de RBD en un repositorio existente, haga clic en , haga clic en la fila del repositorio en la tabla y seleccione en la parte superior izquierda de la tabla.
Debería ver la sección en el recuadro de diálogo, seguida de una sección .
Si no ve las secciones ni , es probable que esté editando un repositorio codificado de borrado, que no se puede usar para establecer opciones de configuración de RBD, o bien que el repositorio no esté configurado para que las imágenes RBD lo puedan usar. En este último caso, asigne la etiqueta de aplicación al repositorio y aparecerán las secciones de configuración correspondientes.
6.8.4 Opciones de configuración #
Haga clic en el signo + de para abrir todas las opciones de configuración disponibles. Aparecerá una lista de todas las opciones disponibles. Las unidades de las opciones de configuración ya se muestran en los recuadros de texto. En el caso de las opciones de bytes por segundo (BPS), es posible utilizar accesos directos tales como "1M" o "5G". Se convertirán automáticamente a "1 MB/s" y "5 GB/s", respectivamente.
Al hacer clic en el botón de restablecimiento situado a la derecha de cada recuadro de texto, se eliminará cualquier valor establecido en el repositorio. Esta acción no elimina los valores de configuración de las opciones configuradas globalmente o en una imagen RBD.
6.8.5 Creación de opciones de QoS de RBD con una imagen RBD nueva #
Para crear una imagen RBD con las opciones de QoS de RBD establecidas en esa imagen, seleccione › y haga clic en . Haga clic en para expandir la sección de configuración avanzada. Haga clic en para abrir todas las opciones de configuración disponibles.
6.8.6 Edición de las opciones de QoS de RBD en imágenes existentes #
Para editar las opciones de QoS de RBD en una imagen existente, seleccione › , haga clic en la fila del repositorio en la tabla y, por último, haga clic en . Aparecerá el recuadro de diálogo de edición. Haga clic en para expandir la sección de configuración avanzada. Haga clic en para abrir todas las opciones de configuración disponibles.
6.8.7 Cambio de las opciones de configuración al copiar o clonar imágenes #
Si se clona o se copia una imagen RBD, los valores establecidos en esa imagen en particular también se copiarán por defecto. Si desea cambiarlos durante la copia o la clonación, puede hacerlo especificando los valores de configuración actualizados en el recuadro de diálogo correspondiente, del mismo modo que cuando se crear o se edita una imagen RBD. Al realizar esta acción, solo establecerá (o restablecerá) los valores de la imagen RBD que se va a copiar o clonar. Esta operación no cambia ni la configuración de la imagen RBD de origen ni la configuración global.
Si decide restablecer el valor de la opción durante la copia o clonación, no se establecerá ningún valor para esa opción en esa imagen. Eso significa que cualquier valor de esa opción especificada para el repositorio padre se usará si el repositorio padre tiene el valor configurado. De lo contrario, se usará el valor por defecto global.
7 Gestión de NFS Ganesha #
Para obtener información general sobre NFS Ganesha, consulte el Capítulo 25, NFS Ganesha.
Para mostrar todas las exportaciones NFS disponibles, haga clic en en el menú principal.
La lista muestra el directorio de cada exportación, el nombre de host del daemon, el tipo de procesador final de almacenamiento y el tipo de acceso.

Para ver información más detallada sobre una exportación NFS, haga clic en su fila en la tabla:

7.1 Creación de exportaciones NFS #
Para añadir una exportación NFS nueva, haga clic en en la parte superior izquierda de la tabla de exportaciones e introduzca la información necesaria.

Seleccione uno o más daemons NFS Ganesha que ejecutarán la exportación.
Seleccione un procesador final de almacenamiento.
ImportanteEn este momento, solo se admiten las exportaciones NFS respaldadas por CephFS.
Seleccione un ID de usuario y otras opciones relacionadas con el procesador final de almacenamiento.
Introduzca la vía de la exportación NFS. Si el directorio no existe en el servidor, se creará.
Especifique las demás opciones relacionadas con NFS, como la versión del protocolo NFS compatible, las opciones de Pseudo, el tipo de acceso, la opción de squash o el protocolo de transporte.
Si necesita limitar el acceso solo a determinados clientes, haga clic en y añada sus direcciones IP junto con el tipo de acceso y las opciones de squash.
Para confirmar, haga clic en
7.2 Supresión de exportaciones NFS #
Para suprimir una exportación, seleccione y resalte la exportación en la fila de la tabla. Haga clic en la flecha desplegable situada junto al botón y seleccione Active la casilla de verificación y haga clic en para confirmar.
7.3 Edición de exportaciones NFS #
Para editar una exportación existente, seleccione y resalte la exportación en la fila de la tabla y haga clic en en la parte superior izquierda de la tabla de exportaciones.
A continuación, puede ajustar todos los detalles de la exportación NFS.

8 Gestión de CephFS #
Para obtener información detallada sobre CephFS, consulte el Capítulo 23, Sistema de archivos en clúster
8.1 Visualización del resumen de CephFS #
Haga clic en en el menú principal para ver un resumen de los sistemas de archivos configurados. La tabla principal muestra el nombre de cada sistema de archivos, la fecha de creación y si está habilitado o no.
Al hacer clic en una fila de la tabla del sistema de archivos, se muestran detalles sobre su rango y los repositorios añadidos al sistema de archivos.

En la parte inferior de la pantalla, se muestran estadísticas con el número de inodos MDS relacionados y las peticiones del cliente, recopiladas en tiempo real.

9 Gestión de Object Gateway #
Antes de empezar, es posible que aparezca la siguiente notificación al intentar acceder al procesador frontal de Object Gateway en Ceph Dashboard:
Information No RGW credentials found, please consult the documentation on how to enable RGW for the dashboard. Please consult the documentation on how to configure and enable the Object Gateway management functionality.
Esto se debe a que cephadm no ha configurado automáticamente Object Gateway para Ceph Dashboard. Si se muestra esta notificación, siga las instrucciones de la Sección 10.4, “Habilitación del procesador frontal de gestión de Object Gateway” para habilitar manualmente el procesador frontal de Object Gateway para Ceph Dashboard.
Para obtener información general sobre Object Gateway, consulte el Capítulo 21, Ceph Object Gateway.
9.1 Visualización de pasarelas Object Gateway #
Para ver una lista de pasarelas Object Gateway configuradas, haga clic en › . La lista incluye el ID de la pasarela, el nombre de host del nodo del clúster donde se ejecuta el daemon de la pasarela y el número de versión de la pasarela.
Haga clic en la flecha desplegable situada junto al nombre de la pasarela para ver información detallada sobre ella. La pestaña muestra detalles sobre las operaciones de lectura y escritura y las estadísticas de caché.

9.2 Gestión de usuarios de Object Gateway #
Haga clic en › para ver una lista de los usuarios existentes de Object Gateway.
Haga clic en la flecha desplegable situada junto al nombre de usuario para ver los detalles de la cuenta de usuario, como el estado o detalles de la cuota del usuario y del depósito.

9.2.1 Adición de un nuevo usuario de pasarela #
Para añadir un nuevo usuario de pasarela, haga clic en en la parte superior izquierda del encabezado de la tabla. Indique sus credenciales, los detalles sobre la clave S3 y las cuotas de usuario y depósito. A continuación, haga clic en para confirmar.

9.2.2 Supresión de usuarios de pasarela #
Para suprimir un usuario de pasarela, seleccione y resalte al usuario. Haga clic en el botón desplegable situado junto a y seleccione en la lista para suprimir la cuenta de usuario. Active la casilla de verificación y haga clic en para confirmar.
9.2.3 Edición de los detalles del usuario de pasarela #
Para cambiar los detalles del usuario de pasarela, seleccione y resalte al usuario. Haga clic en en la parte superior izquierda del encabezado de la tabla.
Puede modificar la información básica o adicional del usuario, como sus capacidades, las claves, los subusuarios y la información de cuota. Para confirmar, haga clic en
La pestaña incluye una lista de solo lectura de los usuarios de la pasarela y sus claves de acceso y secreta. Para ver las claves, haga clic en el nombre de un usuario en la lista y, a continuación, seleccione en la parte superior izquierda del encabezado de la tabla. En recuadro de diálogo , haga clic en el icono del "ojo" para mostrar las claves, o bien haga clic en el icono del portapapeles para copiar la clave relacionada en el portapapeles.
9.3 Gestión de depósitos de Object Gateway #
Los depósitos de Object Gateway (OGW) implementan la funcionalidad de los contenedores de OpenStack Swift. Los depósitos de Object Gateway sirven como contenedores para almacenar objetos de datos.
Haga clic en › para ver una lista de depósitos de Object Gateway.
9.3.1 Adición de un depósito nuevo #
Para añadir un depósito nuevo de Object Gateway, haga clic en en la parte superior izquierda del encabezado de la tabla. Introduzca el nombre del depósito, seleccione el propietario y defina el destino de colocación. Para confirmar, haga clic en
En esta fase también puede habilitar el bloqueo seleccionando ; sin embargo, se puede configurar después de la creación. Consulte la Sección 9.3.3, “Edición del depósito” para obtener más información.
9.3.2 Visualización de detalles del depósito #
Para ver información detallada sobre un depósito de Object Gateway, haga clic en la flecha desplegable situada junto al nombre del depósito

Debajo de la tabla , puede encontrar detalles sobre la cuota de depósito y la configuración de bloqueo.
9.3.3 Edición del depósito #
Seleccione y resalte un depósito y, a continuación, haga clic en en la parte superior izquierda del encabezado de la tabla.
Puede actualizar el propietario del depósito o habilitar el control de versiones, la autenticación multifactor o el bloqueo. Para confirmar los cambios, haga clic en

9.3.4 Supresión de un depósito #
Para suprimir un depósito de Object Gateway, selecciónelo y resáltelo. Haga clic en el botón desplegable situado junto a y seleccione en la lista para suprimir el depósito. Active la casilla de verificación y haga clic en para confirmar.
10 Configuración manual #
En esta sección se presenta información avanzada para los usuarios que prefieren configurar manualmente los valores de la consola en la línea de comandos.
10.1 Configuración de la compatibilidad con TLS/SSL #
Todas las conexiones HTTP a la consola están protegidas por defecto con TLS/SSL. Una conexión segura requiere un certificado SSL. Puede usar un certificado autofirmado o generar un certificado y hacer que una entidad de certificación (CA) conocida lo firme.
A veces puede ser necesario inhabilitar SSL por algún motivo. Por ejemplo, si la consola se ejecuta mediante un proxy que no admite SSL.
Tenga cuidado al inhabilitar SSL, ya que los nombres de usuario y las contraseñas se enviarán a la consola sin cifrar.
Para inhabilitar SSL, ejecute:
cephuser@adm > ceph config set mgr mgr/dashboard/ssl falseDebe reiniciar los procesos de Ceph Manager manualmente después de cambiar el certificado SSL y la clave. Puede hacerlo ejecutando:
cephuser@adm > ceph mgr fail ACTIVE-MANAGER-NAMEo inhabilitando y volviendo a habilitar el módulo de consola, lo que también activa que el gestor se vuelva a reproducir a sí mismo:
cephuser@adm >ceph mgr module disable dashboardcephuser@adm >ceph mgr module enable dashboard
10.1.1 Creación de certificados autofirmados #
Crear un certificado autofirmado para establecer comunicaciones seguras es sencillo. Es una manera rápida de conseguir poner en funcionamiento la consola.
La mayoría de los navegadores Web producen una advertencia sobre los certificados autofirmados y requerirán que se confirmen explícitamente antes de establecer una conexión segura con la consola.
Para generar e instalar un certificado autofirmado, utilice el siguiente comando integrado:
cephuser@adm > ceph dashboard create-self-signed-cert10.1.2 Uso de certificados firmados por una CA #
Para proteger correctamente la conexión a la consola y eliminar las advertencias de los navegadores Web sobre los certificados autofirmados, se recomienda usar un certificado firmado por una CA.
Puede generar un par de claves de certificado con un comando similar al siguiente:
root # openssl req -new -nodes -x509 \
-subj "/O=IT/CN=ceph-mgr-dashboard" -days 3650 \
-keyout dashboard.key -out dashboard.crt -extensions v3_ca
El comando anterior genera los archivos dashboard.key y dashboard.crt. Después de que una CA haya firmado el archivo dashboard.crt, habilítelo para todas las instancias de Ceph Manager ejecutando los comandos siguientes:
cephuser@adm >ceph config-key set mgr/dashboard/crt -i dashboard.crtcephuser@adm >ceph config-key set mgr/dashboard/key -i dashboard.key
Si necesita certificados diferentes para cada instancia de Ceph Manager, modifique los comandos e incluya el nombre de la instancia de la siguiente manera. Sustituya NAME por el nombre de la instancia de Ceph Manager (normalmente es el nombre de host relacionado):
cephuser@adm >ceph config-key set mgr/dashboard/NAME/crt -i dashboard.crtcephuser@adm >ceph config-key set mgr/dashboard/NAME/key -i dashboard.key
10.2 Cambio del nombre del host y el número del puerto #
Ceph Dashboard se asocia con una dirección TCP/IP y un puerto TCP específicos. Por defecto, la instancia de Ceph Manager activa actualmente donde se aloja la consola se vincula al puerto TCP 8443 (o al 8080 si SSL está inhabilitado).
Si hay un cortafuegos habilitado en los hosts en los que se ejecuta Ceph Manager (y, por lo tanto, Ceph Dashboard), es posible que deba cambiar la configuración para habilitar el acceso a estos puertos. Para obtener más información sobre la configuración del cortafuegos para Ceph, consulte el Book “Troubleshooting Guide”, Chapter 13 “Hints and tips”, Section 13.7 “Firewall settings for Ceph”.
Ceph Dashboard se asocia por defecto con "::", que corresponde a todas las direcciones IPv4 e IPv6 disponibles. Es posible cambiar la dirección IP y el número de puerto de la aplicación Web para que se apliquen a todas las instancias de Ceph Manager mediante los siguientes comandos:
cephuser@adm >ceph config set mgr mgr/dashboard/server_addr IP_ADDRESScephuser@adm >ceph config set mgr mgr/dashboard/server_port PORT_NUMBER
Dado que cada daemon ceph-mgr aloja su propia instancia de la consola, es posible que deba configurarlos por separado. Cambie la dirección IP y el número de puerto de una instancia específica del gestor mediante los comandos siguientes (sustituya NAME por el ID de la instancia de ceph-mgr):
cephuser@adm >ceph config set mgr mgr/dashboard/NAME/server_addr IP_ADDRESScephuser@adm >ceph config set mgr mgr/dashboard/NAME/server_port PORT_NUMBER
El comando ceph mgr services muestra todos los puestos finales que están configurados actualmente. Busque la clave dashboard para obtener la dirección URL con la que acceder a la consola.
10.3 Ajuste de nombres de usuario y contraseñas #
Si no desea utilizar la cuenta de administrador por defecto, cree una cuenta de usuario diferente y asóciela con al menos una función. Proporcionamos un conjunto de funciones de sistema predefinidos que puede usar. Para obtener más información, consulte el Capítulo 11, Gestión de usuarios y funciones en la línea de comandos.
Para crear un usuario con privilegios de administrador, utilice el comando siguiente:
cephuser@adm > ceph dashboard ac-user-create USER_NAME PASSWORD administrator10.4 Habilitación del procesador frontal de gestión de Object Gateway #
Para utilizar la funcionalidad de gestión de Object Gateway de la consola, debe proporcionar las credenciales de entrada de un usuario con el indicador system habilitado:
Si no tiene ningún usuario con el indicador
system, cree uno:cephuser@adm >radosgw-admin user create --uid=USER_ID --display-name=DISPLAY_NAME --systemTome nota de las claves access_key y secret_key del resultado del comando.
También puede obtener las credenciales de un usuario existente mediante el comando
radosgw-admin:cephuser@adm >radosgw-admin user info --uid=USER_IDProporcione las credenciales recibidas a la consola:
cephuser@adm >ceph dashboard set-rgw-api-access-key ACCESS_KEYcephuser@adm >ceph dashboard set-rgw-api-secret-key SECRET_KEY
Por defecto, el cortafuegos está habilitado en SUSE Linux Enterprise Server 15 SP2. Para obtener más información acerca de la configuración del cortafuegos, consulte Book “Troubleshooting Guide”, Chapter 13 “Hints and tips”, Section 13.7 “Firewall settings for Ceph”.
Se deben tener en cuenta varios puntos:
El nombre de host y el número de puerto de Object Gateway se determinan automáticamente.
Si se utilizan varias zonas, el host se determinará automáticamente dentro del grupo de zonas maestras y la zona maestra. Esto es suficiente para la mayoría de configuraciones, pero en algunas circunstancias es posible que sea necesario definir el nombre de host y el puerto manualmente:
cephuser@adm >ceph dashboard set-rgw-api-host HOSTcephuser@adm >ceph dashboard set-rgw-api-port PORTPodría necesitar estos ajustes adicionales:
cephuser@adm >ceph dashboard set-rgw-api-scheme SCHEME # http or httpscephuser@adm >ceph dashboard set-rgw-api-admin-resource ADMIN_RESOURCEcephuser@adm >ceph dashboard set-rgw-api-user-id USER_IDSi utiliza un certificado autofirmado (Sección 10.1, “Configuración de la compatibilidad con TLS/SSL”) en la configuración de Object Gateway, inhabilite la verificación del certificado en la consola para evitar que se rechacen conexiones debido a que haya certificados firmados por una CA desconocida o a que no coincidan con el nombre de host:
cephuser@adm >ceph dashboard set-rgw-api-ssl-verify FalseSi Object Gateway tarda demasiado en procesar las peticiones y se agota el tiempo de espera en la consola, el valor del tiempo de espera se puede ajustar (por defecto es de 45 segundos):
cephuser@adm >ceph dashboard set-rest-requests-timeout SECONDS
10.5 Habilitación de la gestión de iSCSI #
Ceph Dashboard gestiona los destinos iSCSI mediante la API REST proporcionada por el servicio rbd-target-api de Ceph iSCSI Gateway. Asegúrese de que está instalado y habilitado en las pasarelas iSCSI.
La funcionalidad de gestión de iSCSI de Ceph Dashboard depende de la última versión 3 del proyecto ceph-iscsi. Asegúrese de que el sistema operativo proporciona la versión correcta; de lo contrario, Ceph Dashboard no habilitará las funciones de gestión.
Si la API REST ceph-iscsi está configurada en modo HTTPS y utiliza un certificado autofirmado, configure la consola para evitar la verificación del certificado SSL al acceder a la API ceph-iscsi.
Inhabilite la verificación SSL de la API:
cephuser@adm > ceph dashboard set-iscsi-api-ssl-verification falseDefina las pasarelas iSCSI disponibles:
cephuser@adm >ceph dashboard iscsi-gateway-listcephuser@adm >ceph dashboard iscsi-gateway-add scheme://username:password@host[:port]cephuser@adm >ceph dashboard iscsi-gateway-rm gateway_name
10.6 Habilitación de Single Sign-On #
Single Sign-On (SSO) es un método de control de acceso que permite a los usuarios entrar a la sesión mediante un único identificador y una contraseña en varias aplicaciones simultáneamente.
Ceph Dashboard admite la autenticación externa de usuarios a través del protocolo SAML 2.0. Dado que la autorización la sigue realizando la consola, primero debe crear cuentas de usuario y asociarlas a las funciones deseadas. Sin embargo, el proceso de autenticación lo puede realizar un proveedor de identidades (IdP) existente.
Para configurar Single Sign-On, utilice el siguiente comando:
cephuser@adm > ceph dashboard sso setup saml2 CEPH_DASHBOARD_BASE_URL \
IDP_METADATA IDP_USERNAME_ATTRIBUTE \
IDP_ENTITY_ID SP_X_509_CERT \
SP_PRIVATE_KEYParámetros:
- CEPH_DASHBOARD_BASE_URL
La URL base desde la que se puede acceder a la Ceph Dashboard (por ejemplo, "https://consolaceph.local").
- IDP_METADATA
La URL, la vía o el contenido del XML de metadatos del IdP (por ejemplo, "https://miidp/metadatos").
- IDP_USERNAME_ATTRIBUTE
Opcional. El atributo que se usará para obtener el nombre de usuario de la respuesta de autenticación. El valor por defecto es "uid".
- IDP_ENTITY_ID
Opcional. Se usa cuando existe más de un ID de entidad en los metadatos del IdP.
- SP_X_509_CERT / SP_PRIVATE_KEY
Opcional. Vía o contenido del certificado que usará la Ceph Dashboard (el proveedor de servicios) para la firma y el cifrado.
Este patrón irá seguido del valor del emisor de las peticiones SAML:
CEPH_DASHBOARD_BASE_URL/auth/saml2/metadata
Para mostrar la configuración actual de SAML 2.0, ejecute:
cephuser@adm > ceph dashboard sso show saml2Para inhabilitar Single Sign-On, ejecute:
cephuser@adm > ceph dashboard sso disablePara comprobar si SSO está habilitado, ejecute:
cephuser@adm > ceph dashboard sso statusPara habilitar SSO, ejecute:
cephuser@adm > ceph dashboard sso enable saml211 Gestión de usuarios y funciones en la línea de comandos #
En esta sección se describe cómo gestionar las cuentas de usuario utilizadas por la Ceph Dashboard. Sirve de ayuda para crear o modificar cuentas de usuario, así como para establecer las funciones y permisos de usuario adecuados.
11.1 Gestión de la directiva de contraseñas #
Por defecto, la función de directiva de contraseñas está habilitada, incluidas las siguientes comprobaciones:
¿La contraseña tiene más de N caracteres?
¿Son iguales la contraseña antigua y la nueva?
La función de directiva de contraseñas se puede activar o desactivar por completo:
cephuser@adm > ceph dashboard set-pwd-policy-enabled true|falseLas siguientes comprobaciones individuales se pueden activar o desactivar:
cephuser@adm >ceph dashboard set-pwd-policy-check-length-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-oldpwd-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-username-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-exclusion-list-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-complexity-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-sequential-chars-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-repetitive-chars-enabled true|false
Además, las siguientes opciones están disponibles para configurar el comportamiento de la directiva de contraseñas.
La longitud mínima de la contraseña (por defecto es 8):
cephuser@adm >ceph dashboard set-pwd-policy-min-length NLa complejidad mínima de la contraseña (por defecto es 10):
cephuser@adm >ceph dashboard set-pwd-policy-min-complexity NLa complejidad de la contraseña se calcula clasificando cada carácter de la contraseña.
Una lista de palabras separadas por comas que no se pueden utilizar en una contraseña:
cephuser@adm >ceph dashboard set-pwd-policy-exclusion-list word[,...]
11.2 Gestión de cuentas de usuario #
Ceph Dashboard admite la gestión de varias cuentas de usuario. Cada cuenta de usuario está formada por un nombre de usuario, una contraseña (almacenada cifrada mediante bcrypt), un nombre opcional y una dirección de correo electrónico opcional.
Las cuentas de usuario se almacenan en la base de datos de configuración de Ceph Monitor y se comparten de forma global entre todas las instancias de Ceph Manager.
Utilice los comandos siguientes para gestionar cuentas de usuario:
- Mostrar usuarios existentes:
cephuser@adm >ceph dashboard ac-user-show [USERNAME]- Crear un usuario:
cephuser@adm >ceph dashboard ac-user-create USERNAME [PASSWORD] [ROLENAME] [NAME] [EMAIL]- Suprimir un usuario:
cephuser@adm >ceph dashboard ac-user-delete USERNAME- Cambiar la contraseña de un usuario:
cephuser@adm >ceph dashboard ac-user-set-password USERNAME PASSWORD- Modificar el nombre y el correo electrónico de un usuario:
cephuser@adm >ceph dashboard ac-user-set-info USERNAME NAME EMAIL- Inhabilitar un usuario:
cephuser@adm >ceph dashboard ac-user-disable USERNAME- Habilitar un usuario:
cephuser@adm >ceph dashboard ac-user-enable USERNAME
11.3 Funciones y permisos de usuario #
En esta sección se describen los ámbitos de seguridad que puede asignar a una función de usuario, y se explica cómo gestionar funciones de usuario y cómo asignarlas a cuentas de usuario.
11.3.1 Definición de ámbitos de seguridad #
Las cuentas de usuario están asociadas a un conjunto de funciones que definen a qué partes de la consola puede tener acceso el usuario. Las distintas partes de la consola se agrupan dentro de un ámbito de seguridad. Los ámbitos de seguridad están predefinidos y son estáticos. Actualmente están disponibles los siguientes ámbitos de seguridad:
- hosts
Incluye todas las características relacionadas con la entrada del menú .
- config-opt
Incluye todas las características relacionadas con las gestión de las opciones de configuración de Ceph.
- pool
Incluye todas las características relacionadas con la gestión de repositorios.
- osd
Incluye todas las funciones relacionadas con la gestión de Ceph OSD.
- monitor
Incluye todas las características relacionadas con la gestión de Ceph Monitor.
- rbd-image
Incluye todas las funciones relacionadas con la gestión de imágenes de dispositivos de bloques RADOS.
- rbd-mirroring
Incluye todas las funciones relacionadas con la gestión de duplicados de dispositivos de bloques RADOS.
- iscsi
Incluye todas las características relacionadas con la gestión de iSCSI.
- rgw
Incluye todas las características relacionadas con la gestión de Object Gateway.
- cephfs
Incluye todas las características relacionadas con la gestión de CephFS.
- manager
Incluye todas las características relacionadas con la gestión de Ceph Manager.
- log
Incluye todas las características relacionadas con la gestión de los registros de Ceph.
- grafana
Incluye todas las características relacionadas con el proxy de Grafana.
- prometheus
Incluye todas las funciones relacionadas con la gestión de alertas Prometheus.
- dashboard-settings
Permite cambiar la configuración de la consola.
11.3.2 Especificación de funciones de usuario #
Una función especifica un conjunto de asignaciones entre un ámbito de seguridad y un conjunto de permisos. Hay cuatro tipos de permisos: "leer", "crear", "actualizar" y "suprimir".
En el ejemplo siguiente se especifica una función en la que un usuario tiene los permisos "leer" y "crear" para las características relacionadas con la gestión de repositorios, y tiene permisos completos para las características relacionadas con la gestión de imágenes RBD:
{
'role': 'my_new_role',
'description': 'My new role',
'scopes_permissions': {
'pool': ['read', 'create'],
'rbd-image': ['read', 'create', 'update', 'delete']
}
}La consola ya proporciona un conjunto de funciones predefinidas que llamamos funciones del sistema. Puede usarlas de inmediato después de instalar la Ceph Dashboard:
- administrator
Proporciona permisos completos para todos los ámbitos de seguridad.
- read-only
Proporciona permiso de lectura para todos los ámbitos de seguridad, excepto para la configuración de la consola.
- block-manager
Proporciona permisos completos para los ámbitos "rbd-image", "rbd-mirroring" e "iscsi".
- rgw-manager
Proporciona permisos completos para el ámbito "rgw".
- cluster-manager
Proporciona permisos completos para los ámbitos "hosts", "osd", "monitor", "manager" y "config-opt".
- pool-manager
Proporciona permisos completos para el ámbito "pool".
- cephfs-manager
Proporciona permisos completos para el ámbito "cephfs".
11.3.2.1 Gestión de funciones personalizadas #
Puede crear nuevas funciones de usuario mediante los siguientes comandos:
- Crear una función:
cephuser@adm >ceph dashboard ac-role-create ROLENAME [DESCRIPTION]- Suprimir una función:
cephuser@adm >ceph dashboard ac-role-delete ROLENAME- Añadir permisos de ámbito a una función:
cephuser@adm >ceph dashboard ac-role-add-scope-perms ROLENAME SCOPENAME PERMISSION [PERMISSION...]- Suprimir permisos de ámbito de una función:
cephuser@adm >ceph dashboard ac-role-del-perms ROLENAME SCOPENAME
11.3.2.2 Asignación de funciones a cuentas de usuario #
Utilice los comandos siguientes para asignar funciones a los usuarios:
- Definir funciones de usuario:
cephuser@adm >ceph dashboard ac-user-set-roles USERNAME ROLENAME [ROLENAME ...]- Añadir funciones adicionales a un usuario:
cephuser@adm >ceph dashboard ac-user-add-roles USERNAME ROLENAME [ROLENAME ...]- Suprimir funciones de un usuario:
cephuser@adm >ceph dashboard ac-user-del-roles USERNAME ROLENAME [ROLENAME ...]
Si crea funciones de usuario personalizadas y tiene previsto eliminar el clúster de Ceph con el runner ceph.purge más adelante, primero debe limpiar las funciones personalizadas. Más detalles en la Sección 13.9, “Eliminación de un clúster de Ceph completo”
11.3.2.3 Ejemplo: creación de un usuario y una función personalizada #
En esta sección se describe un procedimiento para crear una cuenta de usuario capaz de gestionar imágenes RBD, ver y crear repositorios de Ceph y tener acceso de solo lectura a cualquier otro ámbito.
Cree un usuario llamado
tux:cephuser@adm >ceph dashboard ac-user-create tux PASSWORDCree una función y especifique los permisos de ámbito:
cephuser@adm >ceph dashboard ac-role-create rbd/pool-managercephuser@adm >ceph dashboard ac-role-add-scope-perms rbd/pool-manager \ rbd-image read create update deletecephuser@adm >ceph dashboard ac-role-add-scope-perms rbd/pool-manager pool read createAsocie las funciones con el usuario
tux:cephuser@adm >ceph dashboard ac-user-set-roles tux rbd/pool-manager read-only
11.4 Configuración de proxy: #
Si desea establecer una URL fija para acceder a Ceph Dashboard, o si no desea permitir conexiones directas con los nodos del gestor, puede configurar un servidor proxy que reenvíe automáticamente las peticiones entrantes a la instancia de ceph-mgr activa.
11.4.1 Acceso a la consola con proxies inversos #
Si accede a la consola a través de una configuración de proxy inverso, es posible que deba darle servicio mediante un prefijo de URL. Para que la consola pueda usar hipervínculos que incluyan el prefijo, puede definir el valor de url_prefix:
cephuser@adm > ceph config set mgr mgr/dashboard/url_prefix URL_PREFIX
A continuación, podrá acceder a la consola en http://NOMBRE_HOST:NÚMERO_PUERTO/PREFIJO_URL/.
11.4.2 Inhabilitación de redirecciones #
Si Ceph Dashboard se encuentra detrás de un servidor proxy de equilibrio de carga como HAProxy, inhabilite el comportamiento de redirección para evitar situaciones en las que las URL internas (que no se pueden resolver) se publiquen en el cliente de procesador frontal. Utilice el comando siguiente para que la consola responda con un error HTTP (500 por defecto) en lugar de redirigir a la consola activa:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_behaviour "error"Para restablecer el ajuste al comportamiento de redirección por defecto, utilice el comando siguiente:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_behaviour "redirect"11.4.3 Configuración de códigos de estado de error #
Si el comportamiento de redirección está inhabilitado, debe personalizar el código de estado HTTP de las consolas en espera. Para ello, ejecute el comando siguiente:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_error_status_code 50311.4.4 Configuración de ejemplo de HAProxy #
El siguiente ejemplo de configuración es para la transferencia directa TLS/SSL mediante HAProxy.
La configuración funciona en las siguientes condiciones: si la consola falla, el cliente de procesador frontal puede recibir una respuesta de redirección HTTP (303) y se le redirigirá a un host que no se puede resolver.
Esto ocurre cuando se produce un failover durante dos comprobaciones de estado de HAProxy. En este caso, el nodo de consola anteriormente activo responderá ahora con un 303, que señala al nuevo nodo activo. Para evitarlo, puede inhabilitar el comportamiento de redirección en los nodos en espera.
defaults
log global
option log-health-checks
timeout connect 5s
timeout client 50s
timeout server 450s
frontend dashboard_front
mode http
bind *:80
option httplog
redirect scheme https code 301 if !{ ssl_fc }
frontend dashboard_front_ssl
mode tcp
bind *:443
option tcplog
default_backend dashboard_back_ssl
backend dashboard_back_ssl
mode tcp
option httpchk GET /
http-check expect status 200
server x HOST:PORT ssl check verify none
server y HOST:PORT ssl check verify none
server z HOST:PORT ssl check verify none11.5 Auditoría de peticiones de API #
La API REST de Ceph Dashboard puede registrar peticiones PUT, POST y DELETE en el registro de auditoría de Ceph. El registro está inhabilitado por defecto, pero es posible habilitarlo con el siguiente comando:
cephuser@adm > ceph dashboard set-audit-api-enabled trueSi está habilitado, se registran los parámetros siguientes por cada petición:
- from
El origen de la petición, por ejemplo "https://[::1]:44410".
- path
La vía de la API REST, por ejemplo
/api/auth.- method
"PUT", "POST" o "DELETE".
- user
El nombre del usuario (o "Ninguno").
Una entrada de registro de ejemplo tiene este aspecto:
2019-02-06 10:33:01.302514 mgr.x [INF] [DASHBOARD] \
from='https://[::ffff:127.0.0.1]:37022' path='/api/rgw/user/exu' method='PUT' \
user='admin' params='{"max_buckets": "1000", "display_name": "Example User", "uid": "exu", "suspended": "0", "email": "user@example.com"}'El registro de la carga útil de la petición (la lista de argumentos y sus valores) está habilitado por defecto. Puede inhabilitarlo de la siguiente manera:
cephuser@adm > ceph dashboard set-audit-api-log-payload false11.6 Configuración de NFS Ganesha en Ceph Dashboard #
Ceph Dashboard puede gestionar las exportaciones de NFS Ganesha que utilizan CephFS u Object Gateway como almacén secundario. La consola gestiona los archivos de configuración de NFS Ganesha almacenados en objetos RADOS en el clúster de CephFS. NFS Ganesha debe almacenar parte de su configuración en el clúster de Ceph.
Ejecute el comando siguiente para configurar la ubicación del objeto de configuración de NFS Ganesha:
cephuser@adm > ceph dashboard set-ganesha-clusters-rados-pool-namespace pool_name[/namespace]Ahora puede gestionar las exportaciones de NFS Ganesha mediante Ceph Dashboard.
11.6.1 Configuración de varios clústeres de NFS Ganesha #
Ceph Dashboard admite la gestión de exportaciones de NFS Ganesha que pertenecen a diferentes clústeres de NFS Ganesha. Se recomienda que cada clúster de NFS Ganesha almacene sus objetos de configuración en un repositorio o espacio de nombres RADOS diferente para aislar las configuraciones entre sí.
Utilice el comando siguiente para especificar las ubicaciones de la configuración de cada clúster de NFS Ganesha:
cephuser@adm > ceph dashboard set-ganesha-clusters-rados-pool-namespace cluster_id:pool_name[/namespace](,cluster_id:pool_name[/namespace])*La cadena cluster_id es arbitraria e identifica de forma exclusiva el clúster de NFS Ganesha.
Al configurar Ceph Dashboard con varios clústeres de NFS Ganesha, la interfaz de usuario Web permite elegir automáticamente a qué clúster pertenece una exportación.
11.7 Depuración de complementos #
Los complementos de Ceph Dashboard amplían la funcionalidad de la consola. El complemento de depuración permite personalizar el comportamiento de la consola según el modo de depuración. Puede habilitarse, inhabilitarse o comprobarse con el comando siguiente:
cephuser@adm >ceph dashboard debug status Debug: 'disabled'cephuser@adm >ceph dashboard debug enable Debug: 'enabled'cephuser@adm >dashboard debug disable Debug: 'disabled'
Por defecto, está inhabilitado. Este es el valor recomendado para las distribuciones de producción. Si es necesario, se puede habilitar el modo de depuración sin necesidad de reiniciar.
Parte II Operación del clúster #
- 12 Determinación del estado del clúster
Si dispone de un clúster en ejecución, puede utilizar la herramienta
cephpara supervisarlo. Normalmente, determinar el estado del clúster implica el estado de los daemons Ceph OSD, los monitores Ceph Monitor, los grupos de colocación y los servidores de metadatos.- 13 Tareas operativas
Para modificar la configuración de un clúster de Ceph existente, siga estos pasos:
- 14 Funcionamiento de los servicios de Ceph
Puede hacer funcionar los servicios de Ceph en el nivel de los daemons, los nodos o los clústeres. Según el enfoque que necesite, utilice cephadm o el comando
systemctl.- 15 Copia de seguridad y recuperación
En este capítulo se explica de qué partes del clúster de Ceph se debe realizar una copia de seguridad para poder restaurarlo.
- 16 Supervisión y alertas
En SUSE Enterprise Storage 7, cephadm distribuye una pila de alertas y supervisión. Los usuarios deben definir los servicios (como Prometheus, Alertmanager y Grafana) que desean distribuir con cephadm en un archivo de configuración YAML, o bien pueden utilizar la interfaz de línea de comandos para d…
12 Determinación del estado del clúster #
Si dispone de un clúster en ejecución, puede utilizar la herramienta
ceph para supervisarlo. Normalmente, determinar el estado
del clúster implica el estado de los daemons Ceph OSD, los monitores Ceph
Monitor, los grupos de colocación y los servidores de metadatos.
Para ejecutar la herramienta ceph en el modo interactivo,
escriba ceph en la línea de comandos sin ningún
argumento. El modo interactivo es más cómodo si se van a introducir más
comandos ceph en una fila. Por ejemplo:
cephuser@adm > ceph
ceph> health
ceph> status
ceph> quorum_status
ceph> mon stat12.1 Comprobación del estado de un clúster #
Puede averiguar el estado inmediato del clúster mediante ceph
status o ceph -s:
cephuser@adm > ceph -s
cluster:
id: b4b30c6e-9681-11ea-ac39-525400d7702d
health: HEALTH_OK
services:
mon: 5 daemons, quorum ses-min1,ses-master,ses-min2,ses-min4,ses-min3 (age 2m)
mgr: ses-min1.gpijpm(active, since 3d), standbys: ses-min2.oopvyh
mds: my_cephfs:1 {0=my_cephfs.ses-min1.oterul=up:active}
osd: 3 osds: 3 up (since 3d), 3 in (since 11d)
rgw: 2 daemons active (myrealm.myzone.ses-min1.kwwazo, myrealm.myzone.ses-min2.jngabw)
task status:
scrub status:
mds.my_cephfs.ses-min1.oterul: idle
data:
pools: 7 pools, 169 pgs
objects: 250 objects, 10 KiB
usage: 3.1 GiB used, 27 GiB / 30 GiB avail
pgs: 169 active+cleanLa salida proporciona la siguiente información:
ID del clúster
Estado del clúster
Valor epoch de la asignación de monitores y estado del quórum de monitores
Valor epoch de asignación de OSD y estado de los OSD
El estado de las instancias de Ceph Manager
El estado de las pasarelas Object Gateway
La versión de asignación del grupo de colocación
El número de grupos de colocación y de repositorios
La cantidad teórica de datos almacenados y el número de objetos almacenados
La cantidad total de datos almacenados
El valor used (utilizado) refleja la cantidad real de
almacenamiento en bruto utilizado. El número menor del valor xxx
GB / xxx GB indica la cantidad disponible de la capacidad de
almacenamiento global del clúster. El número teórico refleja el tamaño de
los datos almacenados antes de que se repliquen, se clonen o se capturen en
una instantánea. Por lo tanto, la cantidad de datos que se almacena
realmente suele superar el almacenamiento teórico, dado que Ceph crea
réplicas de los datos y también puede utilizar la capacidad de
almacenamiento para tareas de clonación y de captura de instantáneas.
Otros comandos que muestran la información de estado inmediato son los siguientes:
ceph pg statceph osd pool statsceph dfceph df detail
Para obtener la información actualizada en tiempo real, coloque cualquiera
de estos comandos (incluyendo ceph -s) como argumento del
comando watch:
root # watch -n 10 'ceph -s'Pulse Control–C cuando quiera detener la visualización.
12.2 Comprobación del estado del clúster #
Una vez iniciado el clúster y antes de empezar a leer o escribir datos, compruebe su estado:
cephuser@adm > ceph health
HEALTH_WARN 10 pgs degraded; 100 pgs stuck unclean; 1 mons down, quorum 0,2 \
node-1,node-2,node-3Si ha especificado ubicaciones distintas de las establecidas por defecto para la configuración o el anillo de claves, puede indicarlas:
cephuser@adm > ceph -c /path/to/conf -k /path/to/keyring healthEl clúster de Ceph devolverá uno de los siguientes códigos de estado:
- OSD_DOWN
Uno o varios OSD están señalados como inactivos. Se ha detenido el daemon OSD o los pares OSD no pueden acceder al OSD a través de la red. Algunas de las causas pueden ser un daemon detenido o bloqueado, un host caído o una interrupción de la red.
Compruebe que el host está en buen estado, el daemon se inicia y la red está funcionando. Si el daemon se ha bloqueado, el archivo de registro de daemon (
/var/log/ceph/ceph-osd.*) puede contener información de depuración.- OSD_tipo de bloqueo_DOWN; por ejemplo: OSD_HOST_DOWN
Todos los OSD con un determinado subárbol CRUSH se marcan como inactivos, por ejemplo, todos los OSD de un host.
- OSD_ORPHAN
Se hace referencia a un OSD en la jerarquía de asignaciones CRUSH, pero no existe. El OSD se puede quitar de la jerarquía CRUSH con:
cephuser@adm >ceph osd crush rm osd.ID- OSD_OUT_OF_ORDER_FULL
Los umbrales de uso para backfillfull (el valor por defecto es 0,90), nearfull (por defecto, 0,85), full (por defecto, 0,95) o failsafe_full no son ascendentes. En concreto, esperamos backfillfull < nearfull, nearfull < full y full < failsafe_full.
Para leer los valores actuales, ejecute:
cephuser@adm >ceph health detail HEALTH_ERR 1 full osd(s); 1 backfillfull osd(s); 1 nearfull osd(s) osd.3 is full at 97% osd.4 is backfill full at 91% osd.2 is near full at 87%Los umbrales se pueden ajustar con los comandos siguientes:
cephuser@adm >ceph osd set-backfillfull-ratio ratiocephuser@adm >ceph osd set-nearfull-ratio ratiocephuser@adm >ceph osd set-full-ratio ratio- OSD_FULL
Uno o varios OSD han excedido el umbral full, lo que impide que el clúster de servicio a las operaciones de escritura. El uso del repositorio se puede comprobar con:
cephuser@adm >ceph dfLa proporción de full definida actualmente se puede consultar con:
cephuser@adm >ceph osd dump | grep full_ratioUna solución a corto plazo para restaurar la disponibilidad de las operaciones de escritura es aumentar el umbral "full" en una pequeña cantidad:
cephuser@adm >ceph osd set-full-ratio ratioAñada nuevo espacio de almacenamiento al clúster mediante la implantación de más OSD o suprima datos existentes para liberar espacio.
- OSD_BACKFILLFULL
Uno o varios OSD han excedido el umbral backfillfull, lo que impide que los datos se puedan reequilibrar en este dispositivo. Se trata de una advertencia previa de que podría resultar imposible completar el reequilibrio y de que el clúster está casi lleno. El uso del repositorio se puede comprobar con:
cephuser@adm >ceph df- OSD_NEARFULL
Uno o varios OSD han excedido el umbral nearfull. Se trata de una advertencia previa de que el clúster está casi lleno. El uso del repositorio se puede comprobar con:
cephuser@adm >ceph df- OSDMAP_FLAGS
Se han definido uno o varios indicadores de interés en el clúster. Con la excepción de full, estos indicadores se pueden establecer o borrar con:
cephuser@adm >ceph osd set flagcephuser@adm >ceph osd unset flagLos indicadores son los siguientes:
- full
El clúster se marca como lleno y no permite realizar operaciones de escritura.
- pauserd, pausewr
Operaciones de lectura o de escritura en pausa.
- noup
No se pueden iniciar los OSD.
- nodown
Se omiten los informes de fallo de los OSD, de modo que los monitores no marquen los OSD como caídos (down).
- noin
Los OSD que se hayan marcado como out (fuera) no se volverán a marcar como in (dentro) cuando se inicien.
- noout
Los OSD caídos (down) no se marcarán automáticamente como out (fuera) después del intervalo configurado.
- nobackfill, norecover, norebalance
Las operaciones de recuperación o de reequilibrio de datos están suspendidas.
- noscrub, nodeep_scrub
Las operaciones de borrado seguro (consulte la Sección 17.6, “Depuración de grupos de colocación”) están inhabilitadas.
- notieragent
Las actividades de niveles de caché están suspendidas.
- OSD_FLAGS
Uno o varios OSD tienen establecido un indicador de interés por OSD. Los indicadores son los siguientes:
- noup
El OSD no se puede iniciar.
- nodown
Se omitirán los informes de errores para este OSD.
- noin
Si este OSD se ha marcado anteriormente como out (fuera) tras un fallo, no se marcará como in (dentro) cuando se inicie.
- noout
Si este OSD está apagado, no se marcará automáticamente como out (fuera) después del intervalo configurado.
Los indicadores por OSD se pueden definir y desactivar con:
cephuser@adm >ceph osd add-flag osd-IDcephuser@adm >ceph osd rm-flag osd-ID- OLD_CRUSH_TUNABLES
La asignación CRUSH utiliza una configuración muy antigua y se debe actualizar. Los tunables más antiguos que se pueden utilizar (es decir, es la versión más antigua del cliente que se puede conectar al clúster) sin que se active esta advertencia de estado está determinada por la opción de configuración
mon_crush_min_required_version.- OLD_CRUSH_STRAW_CALC_VERSION
La asignación CRUSH utiliza un método más antiguo y no óptimo para calcular los valores de peso intermedio para el ordenamiento por casilleros. La asignación CRUSH debe actualizarse para utilizar el método más reciente (
straw_calc_version=1).- CACHE_POOL_NO_HIT_SET
Uno o varios repositorios de caché no están configurados con un conjunto de resultados para realizar el seguimiento del uso, lo que impide que el agente de niveles de caché identifique los objetos fríos que debe limpiar y expulsar del caché. Los conjuntos de resultados se pueden configurar en el repositorio de caché con:
cephuser@adm >ceph osd pool set poolname hit_set_type typecephuser@adm >ceph osd pool set poolname hit_set_period period-in-secondscephuser@adm >ceph osd pool set poolname hit_set_count number-of-hitsetscephuser@adm >ceph osd pool set poolname hit_set_fpp target-false-positive-rate- OSD_NO_SORTBITWISE
No hay ningún OSD anterior a Luminous versión 12 en ejecución, pero no se ha definido el indicador
sortbitwise. Debe definir el indicadorsortbitwisepara que se puedan iniciar los OSD de Luminous 12 o versiones más recientes:cephuser@adm >ceph osd set sortbitwise- POOL_FULL
Uno o varios repositorios han alcanzado su cuota y ya no permiten más operaciones de escritura. Es posible definir cuotas de repositorio y límites de uso con:
cephuser@adm >ceph df detailPuede aumentar la cuota de repositorio con
cephuser@adm >ceph osd pool set-quota poolname max_objects num-objectscephuser@adm >ceph osd pool set-quota poolname max_bytes num-byteso suprimir algunos datos para reducir el uso.
- PG_AVAILABILITY
Hay una disponibilidad reducida de los datos, lo que significa que el clúster no puede responder a posibles peticiones de lectura o escritura de algunos de los datos del clúster. En particular, uno o varios grupos de colocación se encuentran en un estado que no permite atender las peticiones de E/S. Los estados de los grupos de colocación afectados son peering (emparejando), stale (detenido), incomplete (incompleto) y la ausencia de active (activo) (si dichos estados no desaparecen rápidamente). Encontrará información detallada sobre los grupos de colocación afectados en:
cephuser@adm >ceph health detailEn la mayoría de los casos, la causa raíz es que uno o varios OSD están caídos. Se puede consultar el estado de los grupos de colocación afectados específicos con:
cephuser@adm >ceph tell pgid query- PG_DEGRADED
Se reduce la redundancia de algunos datos, lo que significa que el clúster no tiene el número deseado de réplicas de todos los datos (para los repositorios replicados) o fragmentos de código de borrado (para los repositorios codificados de borrado). En concreto, uno o varios grupos de colocación tienen establecido el indicador degraded (degradado) o undersized (tamaño insuficiente) (no hay suficientes instancias de ese grupo de colocación en el clúster), o bien hace tiempo que no cuenta con el indicador clean (limpio). Encontrará información detallada sobre los grupos de colocación afectados en:
cephuser@adm >ceph health detailEn la mayoría de los casos, la causa raíz es que uno o varios OSD están caídos. Se puede consultar el estado de los grupos de colocación afectados específicos con:
cephuser@adm >ceph tell pgid query- PG_DEGRADED_FULL
La redundancia de datos se puede reducir o estar en peligro para algunos datos debido a la falta de espacio disponible en el clúster. En concreto, uno o varios grupos de colocación tienen establecidos los indicadores backfill_toofull o recovery_toofull, lo que significa que el clúster no puede migrar o recuperar datos debido a que uno o varios OSD superan el umbral backfillfull.
- PG_DAMAGED
El proceso de borrado seguro de datos (consulte la Sección 17.6, “Depuración de grupos de colocación”) ha detectado problemas con la coherencia de los datos en el clúster. Específicamente, hay uno o varios grupos de colocación con el indicador inconsistent o snaptrim_error, que indican que una operación anterior de borrado seguro ha detectado un problema, o bien se ha establecido el indicador repair, lo que significa que hay una reparación de dicha incoherencia en curso.
- OSD_SCRUB_ERRORS
Los procesos de borrado seguro de OSD recientes han revelado incoherencias.
- CACHE_POOL_NEAR_FULL
Un repositorio de nivel de caché está casi lleno. La capacidad en este contexto está determinada por las propiedades target_max_bytes y target_max_objects que aparecen en el repositorio de caché. Cuando el repositorio alcanza el umbral objetivo, las peticiones de escritura para el repositorio podrían bloquearse hasta que los datos se limpien y se expulsen del caché, un estado que suele producir latencias muy altas y un rendimiento deficiente. El objetivo de tamaño del repositorio de caché se puede ajustar con:
cephuser@adm >ceph osd pool set cache-pool-name target_max_bytes bytescephuser@adm >ceph osd pool set cache-pool-name target_max_objects objectsLas actividades normales de limpieza y expulsión del caché también se pueden atascar por una reducción de la disponibilidad o el rendimiento del nivel base o por la carga global del clúster.
- TOO_FEW_PGS
El número de grupos de colocación en uso está por debajo del umbral configurable de grupos de colocación por OSD (
mon_pg_warn_min_per_osd). Esto puede producir una distribución y reequilibrio de datos subóptimo entre los OSD del clúster y reducir el rendimiento general.- TOO_MANY_PGS
El número de grupos de colocación en uso está por encima del umbral configurable de grupos de colocación por OSD (
mon_pg_warn_max_per_osd). Esto puede dar lugar a un uso más elevado de memoria para los daemons de OSD, un emparejamiento más lento después de cambios de estado del clúster (por ejemplo, reinicios, incorporaciones o eliminaciones de OSD) y una mayor carga mayor en los gestores y monitores de Ceph.Aunque no es posible reducir el valor de
pg_numpara los repositorios existentes, sí se puede reducir el valor depgp_num. A efectos prácticos, esto sitúa algunos grupos de colocación en los mismos conjuntos de OSD, mitigando algunos de los impactos negativos descritos anteriormente. El valorpgp_numse puede ajustar con:cephuser@adm >ceph osd pool set pool pgp_num value- SMALLER_PGP_NUM
Uno o varios repositorios tienen un valor
pgp_numinferior apg_num. Por lo general, esto suele indicar que se ha aumentado el número de grupos de colocación sin aumentar al mismo tiempo el comportamiento de colocación. Normalmente, el problema se resuelve definiendopgp_numpara que coincida conpg_num, lo que activa la migración de datos:cephuser@adm >ceph osd pool set pool pgp_num pg_num_value- MANY_OBJECTS_PER_PG
Uno o varios repositorios tienen un número medio de objetos por grupo de colocación significativamente superior al promedio general del clúster. El umbral específico se controla mediante el valor de configuración
mon_pg_warn_max_object_skew. Esto suele indicar que los repositorios que contienen la mayoría de los datos del clúster disponen de muy pocos grupos de colocación o que los demás repositorios, que no contienen tantos datos, tienen demasiados grupos de colocación. Se puede elevar el umbral para silenciar la advertencia de estado; para ello, ajuste la opción de configuraciónmon_pg_warn_max_object_skewen los monitores.- POOL_APP_NOT_ENABLED
Existe un repositorio que contiene uno o varios objetos, pero no se ha etiquetado para su uso por parte de una aplicación determinada. Para resolver esta advertencia, etiquete el repositorio para su uso por parte de una aplicación. Por ejemplo, si el repositorio lo utiliza RBD:
cephuser@adm >rbd pool init pool_nameSi el repositorio está siendo utilizado por una aplicación personalizada "foo", también se puede etiquetar mediante el comando de bajo nivel:
cephuser@adm >ceph osd pool application enable foo- POOL_FULL
Uno o varios repositorios han alcanzado su cuota (o van a alcanzarla muy pronto). El umbral para que se active esta situación de error depende de la opción de configuración
mon_pool_quota_crit_threshold. Las cuotas del repositorio se pueden aumentar, reducir o eliminar con:cephuser@adm >ceph osd pool set-quota pool max_bytes bytescephuser@adm >ceph osd pool set-quota pool max_objects objectsSi define el valor de la cuota como 0, la cuota se inhabilitará.
- POOL_NEAR_FULL
Uno o varios repositorios se están aproximando a su cuota. El umbral para que se active esta situación de advertencia depende de la opción de configuración
mon_pool_quota_warn_threshold. Las cuotas del repositorio se pueden aumentar, reducir o eliminar con:cephuser@adm >ceph osd osd pool set-quota pool max_bytes bytescephuser@adm >ceph osd osd pool set-quota pool max_objects objectsSi define el valor de la cuota como 0, la cuota se inhabilitará.
- OBJECT_MISPLACED
Uno o varios objetos del clúster no se almacenan en el nodo en el que clúster pretende hacerlo. Esto indica que una migración de datos debida a algunos cambios recientes del clúster aún no se ha completado. El almacenamiento de datos en el lugar equivocado no es una situación peligrosa por sí misma. La coherencia de los datos nunca corre peligro y las copias antiguas de los objetos no se eliminan hasta que se alcanza el número de copias nuevas deseadas (en las ubicaciones correctas).
- OBJECT_UNFOUND
No es posible encontrar uno o más objetos en el clúster. En concreto, los OSD saben que debe existir una copia nueva o actualizada de un objeto, pero no se ha encontrado ninguna copia de esa versión del objeto en los OSD que están actualmente activos. Las peticiones de lectura o escritura a los objetos "unfound" (no encontrados) se bloquean. Idealmente, el OSD inactivo que tiene la copia más reciente del objeto no encontrado se puede volver a activar. Los OSD candidatos se pueden identificar a partir del estado de emparejamiento de los grupos de colocación responsables del objeto no encontrado:
cephuser@adm >ceph tell pgid query- REQUEST_SLOW
Una o varias peticiones de OSD tardan mucho tiempo en procesarse. Esto puede indicar un nivel de carga extremo, un dispositivo de almacenamiento lento o un fallo de software. Puede consultar la cola de peticiones de los OSD en cuestión ejecutando el siguiente comando desde el host OSD:
cephuser@adm >ceph daemon osd.id opsPuede consultar un resumen de las peticiones más lentas realizadas recientemente:
cephuser@adm >ceph daemon osd.id dump_historic_opsPuede consultar la ubicación de un OSD con:
cephuser@adm >ceph osd find osd.id- REQUEST_STUCK
Una o más peticiones de OSD se han bloqueado durante un tiempo relativamente largo, por ejemplo 4096 segundos. Esto indica que el clúster lleva un periodo prolongado de tiempo en un estado incorrecto (por ejemplo, no hay suficientes OSD en ejecución o grupos de colocación inactivos) o que hay algún problema interno con el OSD.
- PG_NOT_SCRUBBED
A uno o varios de los grupos de colocación no se les ha aplicado el borrado seguro (consulte la Sección 17.6, “Depuración de grupos de colocación”) recientemente. Normalmente, a los grupos de colocación se les aplica el borrado seguro cuando transcurre el número de segundos indicado en
mon_scrub_interval; esta advertencia se activa cuando transcurren los intervalos indicados enmon_warn_not_scrubbedsin que se realice un borrado seguro. A los grupos de colocación no se les aplicará el borrado seguro si no están marcados como limpios; esto puede ocurrir si se extravían o se degradan (consulte PG_AVAILABILITY y PG_DEGRADED más arriba). Puede iniciar manualmente el borrado seguro de un grupo de colocación limpio con:cephuser@adm >ceph pg scrub pgid- PG_NOT_DEEP_SCRUBBED
Uno o varios grupos de colocación no se han sometido a un borrado seguro profundo (consulte la Sección 17.6, “Depuración de grupos de colocación”) recientemente. Normalmente, a los grupos de colocación se les aplica un borrado seguro profundo cuando transcurre el número de segundos indicado en
osd_deep_mon_scrub_interval; esta advertencia se activa cuando transcurren los segundos indicados enmon_warn_not_deep_scrubbedsin que se realice un borrado seguro profundo. A los grupos de colocación no se les aplicará el borrado seguro profundo si no están marcados como limpios; esto puede ocurrir si se extravían o se degradan (consulte PG_AVAILABILITY y PG_DEGRADED más arriba). Puede iniciar manualmente el borrado seguro de un grupo de colocación limpio con:cephuser@adm >ceph pg deep-scrub pgid
Si ha especificado ubicaciones distintas de las establecidas por defecto para la configuración o el anillo de claves, puede indicarlas:
root # ceph -c /path/to/conf -k /path/to/keyring health12.3 Comprobación de las estadísticas de uso de un clúster #
Para comprobar el uso de datos de un clúster y la distribución de datos
entre los repositorios, utilice el comando ceph df. Para
obtener más detalles, utilice ceph df detail.
cephuser@adm > ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 30 GiB 27 GiB 121 MiB 3.1 GiB 10.40
TOTAL 30 GiB 27 GiB 121 MiB 3.1 GiB 10.40
--- POOLS ---
POOL ID STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 0 B 0 0 B 0 8.5 GiB
cephfs.my_cephfs.meta 2 1.0 MiB 22 4.5 MiB 0.02 8.5 GiB
cephfs.my_cephfs.data 3 0 B 0 0 B 0 8.5 GiB
.rgw.root 4 1.9 KiB 13 2.2 MiB 0 8.5 GiB
myzone.rgw.log 5 3.4 KiB 207 6 MiB 0.02 8.5 GiB
myzone.rgw.control 6 0 B 8 0 B 0 8.5 GiB
myzone.rgw.meta 7 0 B 0 0 B 0 8.5 GiB
La sección RAW STORAGE del resultado proporciona una
descripción general de la cantidad de almacenamiento que utiliza el clúster
para los datos.
CLASS: la clase de almacenamiento del dispositivo. Consulte la Sección 17.1.1, “Clases de dispositivos” para obtener más información sobre las clases de dispositivos.SIZE: capacidad de almacenamiento global del clúster.AVAIL: cantidad de espacio disponible en el clúster.USED: el espacio (acumulado en todos los OSD) asignado exclusivamente para objetos de datos conservados en el dispositivo de bloques.RAW USED: la suma del espacio "USED" y el espacio asignado/reservado en el dispositivo de bloques para propósitos de Ceph, por ejemplo la parte BlueFS para BlueStore.% RAW USED: porcentaje de almacenamiento en bruto utilizado. Utilice este número junto confull ratio(lleno) ynear full ratio(casi lleno) para asegurarse de que no se alcanza la capacidad de su clúster. Consulte la Sección 12.8, “Capacidad de almacenamiento” para obtener más información.Nota: nivel de llenado de clústerCuando un nivel de llenado de almacenamiento en bruto se acerca al 100 %, debe añadir nuevo almacenamiento al clúster. Un nivel de uso más elevado puede provocar que algunos OSD se llenen y se produzcan problemas de estado del clúster.
Utilice el comando
ceph osd df treepara que se muestre el nivel de llenado de todos los OSD.
La sección POOLS de la salida proporciona una lista de
los repositorios y el uso teórico de cada uno de ellos. La salida de esta
sección no refleja las réplicas, las clonaciones ni las
instantáneas. Por ejemplo, si almacena un objeto con 1 MB de datos, el uso
teórico es de 1 MB, pero el uso real puede ser de 2 MB o más, según el
número de réplicas, clonaciones e instantáneas.
POOL: el nombre del repositorio.ID: ID del repositorio.STORED: la cantidad de datos almacenados por el usuario.OBJECTS: el número teórico de objetos almacenados por repositorio.USED: la cantidad de espacio asignado exclusivamente para los datos por todos los nodos de OSD, en kB.%USED: el porcentaje teórico del almacenamiento utilizado por repositorio.MAX AVAIL: el espacio máximo disponible en el repositorio especificado.
Las cifras de la sección POOLS son teóricas. No incluyen el número de
réplicas, clonaciones o instantáneas. Por lo tanto, la suma de las
cantidades de USED y %USED no se
sumará a las cantidades de RAW USED y %RAW
USED de la sección RAW STORAGE del resultado.
12.4 Comprobación del estado de los OSD #
Para comprobar los OSD y asegurarse de que estén activos y conectados, ejecute:
cephuser@adm > ceph osd statO bien
cephuser@adm > ceph osd dumpTambién puede ver los OSD según su posición en la asignación de CRUSH.
ceph osd tree imprime un árbol de CRUSH con un host, sus
OSD, su estado de funcionamiento y su peso:
cephuser@adm > ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 3 0.02939 root default
-3 3 0.00980 rack mainrack
-2 3 0.00980 host osd-host
0 1 0.00980 osd.0 up 1.00000 1.00000
1 1 0.00980 osd.1 up 1.00000 1.00000
2 1 0.00980 osd.2 up 1.00000 1.0000012.5 Comprobación de OSD llenos #
Ceph impide escribir en un OSD lleno para que no se pierden datos. En un
clúster en funcionamiento, debería aparecer una advertencia cuando el
clúster se esté aproximando al máximo de su capacidad. El valor por defecto
de mon osd full ratio es de 0,95 o un 95 % de capacidad
para impedir la escritura de datos a los clientes. El valor por defecto de
mon osd nearfull ratio es de 0,85 o 85 % de capacidad
para generar una advertencia de estado.
El comando ceph health informa de los nodos de OSD
llenos:
cephuser@adm > ceph health
HEALTH_WARN 1 nearfull osds
osd.2 is near full at 85%O bien
cephuser@adm > ceph health
HEALTH_ERR 1 nearfull osds, 1 full osds
osd.2 is near full at 85%
osd.3 is full at 97%La mejor forma de ocuparse de un clúster lleno es añadir hosts de OSD o discos para que el clúster redistribuya los datos en el nuevo espacio de almacenamiento disponible.
Si un OSD se llena (usa el 100 % de su espacio de disco), normalmente se bloqueará de inmediato y sin previo aviso. A continuación indicamos algunos consejos que conviene recordar al administrar nodos de OSD.
El espacio de disco de cada OSD (normalmente montado en
/var/lib/ceph/osd/osd-{1,2..}) debe colocarse en un disco o en una partición de uso dedicado.Compruebe los archivos de configuración de Ceph y asegúrese de que Ceph no almacena el archivo de registro en las particiones o los discos cuyo uso esté dedicado a los OSD.
Asegúrese de que ningún otro proceso escribe en los discos o en las particiones de uso dedicado de los OSD.
12.6 Comprobación del estado del monitor #
Después de iniciar el clúster y antes de leer o escribir datos por primera vez, compruebe el estado de quórum de los monitores Ceph Monitor. Si el clúster ya está sirviendo peticiones, compruebe periódicamente el estado de los monitores Ceph Monitor para asegurarse de que se están ejecutando.
Para ver la asignación de monitores, ejecute lo siguiente:
cephuser@adm > ceph mon statO bien
cephuser@adm > ceph mon dumpPara comprobar el estado de quórum del clúster de monitores, ejecute lo siguiente:
cephuser@adm > ceph quorum_statusCeph devolverá el estado de quórum. Por ejemplo, un clúster de Ceph que consta de tres monitores podría devolver lo siguiente:
{ "election_epoch": 10,
"quorum": [
0,
1,
2],
"monmap": { "epoch": 1,
"fsid": "444b489c-4f16-4b75-83f0-cb8097468898",
"modified": "2011-12-12 13:28:27.505520",
"created": "2011-12-12 13:28:27.505520",
"mons": [
{ "rank": 0,
"name": "a",
"addr": "192.168.1.10:6789\/0"},
{ "rank": 1,
"name": "b",
"addr": "192.168.1.11:6789\/0"},
{ "rank": 2,
"name": "c",
"addr": "192.168.1.12:6789\/0"}
]
}
}12.7 Comprobación del estado de los grupos de colocación #
Los grupos de colocación asignan objetos a los OSD. Al supervisar los grupos
de colocación, es conveniente que tengan los estados
active (activo) y clean (limpio). Para
obtener información detallada, consulte la Sección 12.9, “Supervisión de los OSD y los grupos de colocación”.
12.8 Capacidad de almacenamiento #
Cuando un clúster de almacenamiento de Ceph se acerca a su capacidad máxima, Ceph impide escribir o leer desde los Ceph OSD como medida de seguridad para evitar la pérdida de datos. Por lo tanto, permitir que un clúster de producción se acerque a su máximo de capacidad no es una buena práctica, ya que se sacrifica la alta disponibilidad. El máximo de capacidad por defecto se define en .95, lo que significa el 95 % de la capacidad. Se trata de un valor muy agresivo para un clúster de pruebas con un número pequeño de OSD.
Al supervisar el clúster, esté alerta a las advertencias relacionadas con
la proporción de nearfull (casi lleno). Significa que un
error de algunos OSD podría dar lugar a una interrupción temporal del
servicio si se produce un error en uno o más OSD. Considere la posibilidad
de añadir más OSD para aumentar la capacidad de almacenamiento.
Un escenario habitual para los clústeres de prueba es la de un administrador
del sistema que elimina un Ceph OSD del clúster de almacenamiento de Ceph
para observar el reequilibrio del clúster. A continuación, quita otro Ceph
OSD, y así sucesivamente hasta que el clúster finalmente alcanza su máxima
capacidad y se bloquea. Se recomienda cierta planificación de la capacidad
incluso en el caso de un clúster de pruebas. La planificación permite
estimar la capacidad de repuesto que se necesitará para poder mantener la
alta disponibilidad. En una situación ideal, desea planear una serie de
errores del Ceph OSD en los que el clúster puede recuperarse a un estado
activo + limpio sin tener que sustituir esos Ceph OSD de
inmediato. Puede ejecutar un clúster en un estado activo +
degradado, pero no es lo ideal para condiciones de funcionamiento
normales.
En el diagrama siguiente se muestra un clúster de almacenamiento de Ceph
simplificado que contiene 33 nodos Ceph con un Ceph OSD por host. Cada uno
de ellos lee y escribe en una unidad de 3 TB. Este clúster de ejemplo tiene
una capacidad real máxima de 99 TB. La opción mon osd full
ratio se define en 0,95. Si el clúster cae por debajo de los 5 TB
de capacidad restante, no permitirá que los clientes lean y escriban datos.
Por lo tanto, la capacidad operativa del clúster de almacenamiento es de
95 TB, no de 99 TB.

En este tipo de clúster, es normal que uno o dos OSD fallen. Un escenario
menos frecuente, aunque razonable, implica que el router o la fuente de
alimentación de un bastidor falle, lo que desactiva varios OSD
simultáneamente (por ejemplo, los OSD del 7 al 12). En esa situación, debe
seguir intentando que un clúster pueda permanecer operativo y logre un
estado activo + limpio, incluso si eso significa añadir
algunos hosts con OSD adicionales a corto plazo. Si el uso de la capacidad
es demasiado alto, es posible que no pierda datos. Sin embargo, aún podría
sacrificar la disponibilidad de los datos y resolver al mismo tiempo una
interrupción dentro de un dominio de error si el uso de capacidad del
clúster supera el máximo. Por este motivo, se recomienda que se realice al
menos una planificación aproximada de la capacidad.
Identifique dos valores para el clúster:
El número de OSD.
La capacidad total del clúster.
Si divide la capacidad total del clúster por el número de OSD del clúster, encontrará la capacidad media de un OSD dentro del clúster. También puede multiplicar ese número por el número de OSD que espera que fallen simultáneamente durante las operaciones normales (un número relativamente pequeño). Por último, multiplique la capacidad del clúster por la capacidad máxima para descubrir la capacidad operativa máxima. A continuación, reste la cantidad de datos de los OSD que espera que no lleguen al máximo de capacidad razonable. Repita el proceso anterior con un mayor número de errores de OSD (un bastidor de OSD) para llegar a un número razonable capacidad casi máxima.
Los valores siguiente solo se aplica durante la creación del clúster y, después, se almacena en el mapa de OSD:
[global] mon osd full ratio = .80 mon osd backfillfull ratio = .75 mon osd nearfull ratio = .70
Estos valores solo se aplican durante la creación del clúster. Después
deben cambiarse en el mapa de OSD utilizando los comandos ceph osd
set-nearfull-ratio y ceph osd set-full-ratio.
- mon osd full ratio
El porcentaje de espacio en disco utilizado antes de un OSD se considera que está
lleno. El valor por defecto es .95.- mon osd backfillfull ratio
El porcentaje de espacio en disco utilizado antes de un OSD se considera que está demasiado
llenopara la reposición. El valor por defecto es .90.- mon osd nearfull ratio
El porcentaje de espacio en disco utilizado antes de un OSD se considera que está
casi lleno. El valor por defecto es .85.
Si algunos OSD están casi llenos, pero otros tienen
mucha capacidad, es posible que tenga un problema con el peso de CRUSH para
los OSD casi llenos.
12.9 Supervisión de los OSD y los grupos de colocación #
La alta disponibilidad y la alta confiabilidad requieren un enfoque tolerante a fallos para gestionar problemas de hardware y software. Ceph no tiene un único punto de error y puede atender peticiones de datos en un modo "degradado". La colocación de datos de Ceph introduce una capa de direccionamiento indirecto para garantizar que los datos no se enlacen directamente a determinadas direcciones de OSD. Eso significa que para el seguimiento de los errores del sistema es necesario buscar el grupo de colocación y los OSD subyacentes en la raíz del problema.
Un error en una parte del clúster puede impedir que se acceda a un objeto determinado. Eso no significa que no se pueda acceder a otros objetos. Si encuentra un error, siga los pasos para supervisar los OSD y los grupos de colocación. A continuación, comience el proceso de solución de problemas.
Ceph, generalmente, se puede autorreparar. Sin embargo, si los problemas persisten, la supervisión de los OSD y los grupos de colocación ayudará a identificar el problema.
12.9.1 Supervisión de OSD #
El estado de un OSD se encuentra en el clúster ("in") o fuera del clúster ("out"). Al mismo tiempo, está en activo y en ejecución ("up") o desactivado y sin ejecutarse ("down"). Si un OSD está "up", puede estar en el clúster (es posible leer y escribir datos) o fuera del clúster. Si estaba en el clúster y se movió recientemente fuera del clúster, Ceph migrará los grupos de colocación a otros OSD. Si un OSD está fuera del clúster, CRUSH no le asignará grupos de colocación. Si un OSD está "down", también debe estar "out".
Si un OSD está "down" e "in", hay un problema y el clúster no estará en un estado correcto.
Si ejecuta un comando como ceph health, ceph
-s o ceph -w, puede darse el caso de que el
clúster no siempre devuelva el estado HEALTH OK. Con
respecto a los OSD, debe esperar que el clúster no
devuelva HEALTH OK en las siguientes circunstancias:
Todavía no ha iniciado el clúster (no responderá).
Ha iniciado o reiniciado el clúster y aún no está listo, ya que se están creando los grupos de colocación y los OSD están en proceso de emparejamiento.
Ha añadido o eliminado un OSD.
Ha modificado el mapa del clúster.
Un aspecto importante de la supervisión de los OSD es asegurarse de que cuando el clúster está activo y en ejecución, todos los OSD del clúster también lo estén. Para comprobar si todos los OSD se están ejecutando, ejecute:
root # ceph osd stat
x osds: y up, z in; epoch: eNNNN
El resultado debería indicarle el número total de OSD (x), cuántos están
"up" (y), cuántos están "in" (z) y la época del mapa (eNNNN). Si el número
de OSD que están "in" en el clúster es mayor que el número de OSD que están
"up", ejecute el comando siguiente para identificar los daemons
ceph-osd que no se están ejecutando:
root # ceph osd tree
#ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 2.00000 pool openstack
-3 2.00000 rack dell-2950-rack-A
-2 2.00000 host dell-2950-A1
0 ssd 1.00000 osd.0 up 1.00000 1.00000
1 ssd 1.00000 osd.1 down 1.00000 1.00000Por ejemplo, si un OSD con ID 1 está inactivo, para iniciarlo:
cephuser@osd > sudo systemctl start ceph-CLUSTER_ID@osd.0.serviceConsulte el Book “Troubleshooting Guide”, Chapter 4 “Troubleshooting OSDs”, Section 4.3 “OSDs not running” para consultar los problemas asociados con los OSD que se han detenido o que no se reinician.
12.9.2 Asignación de conjuntos de grupos de colocación #
Cuando CRUSH asigna grupos de colocación a los OSD, examina el número de
réplicas del repositorio y asigna el grupo de colocación a los OSD de forma
que cada réplica del grupo de colocación se asigne a un OSD diferente. Por
ejemplo, si el repositorio requiere tres réplicas de un grupo de
colocación, CRUSH puede asignarlas a osd.1,
osd.2 y osd.3 respectivamente. CRUSH
en realidad intenta realizar una colocación seudoaleatoria que tenga en
cuenta los dominios de error que establezca en su mapa de CRUSH, por lo que
rara vez verá grupos de colocación asignados a los OSD vecinos más cercanos
en un clúster grande. El conjunto de OSD que deben contener las réplicas de
un grupo de colocación determinado se conoce como conjunto que
actúa. En algunos casos, un OSD del conjunto que actúa está
inactivo o no puede atender las peticiones de objetos del grupo de
colocación. Si se da ese caso, puede deberse a uno de los siguientes
escenarios:
Ha añadido o eliminado un OSD. En tal caso, CRUSH reasignó el grupo de colocación a otros OSD y, por lo tanto, cambió la composición del conjunto que actúa, lo que provocó la migración de datos con un proceso de "reposición".
Un OSD con el estado "down", se ha reiniciado y ahora se está recuperando.
Un OSD del conjunto que actúa tiene el estado "down" o no puede atender peticiones, y otro OSD ha asumido temporalmente sus funciones.
Ceph procesa la petición de un cliente con conjunto activo, que es el conjunto de OSD que realmente controlarán las peticiones. En la mayoría de los casos, el conjunto activo y el conjunto que actúa son prácticamente idénticos. Cuando no lo son, puede indicar que Ceph está migrando datos, que un OSD se está recuperando o que hay un problema (por ejemplo, Ceph suele responde a un estado
HEALTH WARNcon un mensaje "bloqueo obsoleto" en tales casos).
Para recuperar una lista de grupos de colocación, ejecute:
cephuser@adm > ceph pg dumpPara ver qué OSD están dentro del conjunto que actúa o del conjunto activo para un grupo de colocación determinado, ejecute:
cephuser@adm > ceph pg map PG_NUM
osdmap eNNN pg RAW_PG_NUM (PG_NUM) -> up [0,1,2] acting [0,1,2]El resultado debe indicar la época de osdmap (eNNN), el número del grupo de colocación (PG_NUM), los OSD del conjunto activo ("up") y los OSD del conjunto que actúa ("acting"):
Si el conjunto activo y el conjunto que actúa no coinciden, puede ser un indicador de que el clúster se está reequilibrando o de que hay un posible problema con el clúster.
12.9.3 Emparejamiento #
Para poder escribir datos en un grupo de colocación, este debe estar en un
estado activo y es recomendable que esté en un estado
limpio. Para que Ceph determine el estado actual de un
grupo de colocación, el OSD primario del grupo de colocación (el primer OSD
del conjunto que actúa) se empareja con los OSD
secundario y terciario para establecer un acuerdo sobre el estado actual
del grupo de colocación (suponiendo que el repositorio tenga tres réplicas
del grupo de colocación).

12.9.4 Supervisión de los estados del grupo de colocación #
Si ejecuta un comando como ceph health, ceph
-s o ceph -w, puede darse el caso de que el
clúster no siempre devuelva el mensaje HEALTH OK.
Después de comprobar si los OSD se están ejecutando, también debe comprobar
los estados del grupo de colocación.
Es previsible que el clúster no devuelva
HEALTH OK en varias circunstancias relacionadas con el
emparejamiento del grupo de colocación:
Ha creado un repositorio y los grupos de colocación aún no se han emparejado.
Los grupos de colocación se están recuperando.
Ha añadido o ha eliminado un OSD del clúster.
Ha modificado el mapa de CRUSH y los grupos de colocación están migrando.
Hay datos incoherentes en diferentes réplicas de un grupo de colocación.
Ceph está borrando de forma segura las réplicas de un grupo de colocación.
Ceph no tiene suficiente capacidad de almacenamiento para completar las operaciones de reposición.
Si una de las circunstancias mencionadas hace que Ceph devuelva el estado
HEALTH WARN, no se preocupe. En muchos casos, el clúster
se recuperará por sí solo. En algunos casos, es posible que deba tomar
alguna medida. Un aspecto importante a la hora de supervisar los grupos de
colocación es que debe asegurarse de que cuando el clúster esté activo y en
funcionamiento, todos los grupos de colocación deben estar "activos" y,
preferiblemente, en un "estado limpio". Para ver el estado de todos los
grupos de colocación, ejecute:
cephuser@adm > ceph pg stat
x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB availEl resultado debe indicar el número total de grupos de colocación (x); cuántos grupos de colocación están en un estado determinado, como "activo+limpio" (y) y la cantidad de datos almacenados (z).
Además de los estados del grupo de colocación, Ceph también devolverá la cantidad de capacidad de almacenamiento utilizada (aa), la cantidad de capacidad de almacenamiento restante (bb) y la capacidad de almacenamiento total para el grupo de colocación. Estos valores pueden ser importantes en algunos casos:
Cuando se está alcanzando la
capacidad casi máximao lacapacidad máxima.Cuando los datos no se están distribuyendo por el clúster debido a un error en la configuración de CRUSH.
Los ID de grupo de colocación constan del número de repositorio (no el
nombre del repositorio ) seguido de un punto (.) y el ID del grupo de
colocación (un número hexadecimal). Puede ver los números de repositorio y
sus nombres en el resultado de ceph osd lspools. Por
ejemplo, el repositorio por defecto rbd corresponde al
número de repositorio 0. Un ID de grupo de colocación completo tiene el
siguiente formato:
POOL_NUM.PG_ID
Y, normalmente, este aspecto:
0.1f
Para recuperar una lista de grupos de colocación, ejecute lo siguiente:
cephuser@adm > ceph pg dumpTambién puede dar al resultado formato JSON y guardarlo en un archivo:
cephuser@adm > ceph pg dump -o FILE_NAME --format=jsonPara consultar un grupo de colocación determinado, ejecute lo siguiente:
cephuser@adm > ceph pg POOL_NUM.PG_ID queryEn la lista siguiente se describen en detalle los estados habituales del grupo de colocación.
- CREATING (CREACIÓN)
Cuando se crea un repositorio, se crea el número de grupos de colocación especificados. Ceph devolverá el mensaje "creating" cuando está creando uno o más grupos de colocación. Cuando se creen, los OSD que formen parte del conjunto que actúa del grupo de colocación se emparejarán. Cuando el emparejamiento se haya completado, el estado del grupo de colocación debe ser "activo+limpio", lo que significa que un cliente de Ceph puede comenzar a escribir en el grupo de colocación.
 Figura 12.3: Estado de los grupos de colocación #
Figura 12.3: Estado de los grupos de colocación #- PEERING (EMPAREJAMIENTO)
Cuando Ceph empareja un grupo de colocación, está poniendo de acuerdo los OSD donde se almacenan las réplicas del grupo de colocación sobre el estado de los objetos y los metadatos del grupo de colocación. Cuando Ceph completa el emparejamiento, significa que los OSD donde se almacenan el grupo de colocación están de acuerdo sobre el estado actual de dicho grupo. Sin embargo, que el proceso de emparejamiento haya finalizado no significa que cada réplica tenga el contenido más reciente.
Nota: historial oficialCeph no reconocerá una operación de escritura a un cliente hasta que todos los OSD del conjunto que actúa persistan en la operación de escritura. Esta práctica garantiza que al menos un miembro del conjunto que actúa tendrá un registro de cada operación de escritura reconocida desde la última operación de emparejamiento correcta.
Con un registro preciso de cada operación de escritura reconocida, Ceph puede construir y ampliar un nuevo historial oficial del grupo de colocación: un conjunto completo y completamente ordenado de operaciones que, si se realiza, actualizaría una copia del OSD de un grupo de colocación.
- ACTIVE (ACTIVO)
Cuando Ceph completa el proceso de emparejamiento, un grupo de colocación puede convertirse en
activo. El estadoactivosignifica que los datos del grupo de colocación están generalmente disponibles en el grupo de colocación primario y en las réplicas para las operaciones de lectura y escritura.- CLEAN (LIMPIO)
Cuando un grupo de colocación está en estado
limpio, el OSD primario y los OSD de réplica se han emparejado correctamente y no hay réplicas perdidas para el grupo de colocación. Ceph ha replicado todos los objetos del grupo de colocación el número correcto de veces.- DEGRADED (DEGRADADO)
Si un cliente escribe un objeto en el OSD primario, este es responsable de escribir las réplicas en los OSD de réplica. Después de que el OSD primario escriba el objeto en el almacenamiento, el grupo de colocación permanecerá en un estado "degradado" hasta que el OSD primario haya recibido una confirmación de los OSD de réplica de que Ceph ha creado los objetos de réplica correctamente.
La razón por la que un grupo de colocación puede tener el estado "activo+degradado" es que un OSD puede estar "activo" aunque aún no contenga todos los objetos. Si un OSD deja de estar activo, Ceph marca cada grupo de colocación asignado al OSD como "degradado". Los OSD deben emparejarse de nuevo cuando el OSD vuelva a funcionar. Sin embargo, un cliente todavía puede escribir un objeto nuevo en un grupo de colocación degradado si su estado es "activo".
Si un OSD está "inactivo" y la condición "degradado" persiste, Ceph puede marcar el OSD inactivo como "externo" al clúster y volver a asignar los datos del OSD "inactivo" a otro OSD. El tiempo que transcurre entre que se marca como "inactivo" y se marca como "externo" se controla mediante la opción
mon osd out interval, que se establece en 600 segundos por defecto.Un grupo de colocación también puede estar "degradado" porque Ceph no pueda encontrar uno o varios objetos que deberían estar en el grupo de colocación. Aunque no puede leer ni escribir en objetos no encontrados, puede acceder a todos los demás objetos del grupo de colocación "degradado".
- RECOVERING (EN RECUPERACIÓN)
Ceph se ha diseñado para la tolerancia a fallos a una escala en la que los problemas de hardware y software son continuos. Cuando un OSD está "inactivo", su contenido puede quedar obsoleto respecto al de otras réplicas de los grupos de colocación. Cuando el OSD vuelve a estar "activo", el contenido de los grupos de colocación debe actualizarse para reflejar el estado actual. Durante ese período de tiempo, el OSD puede mostrar el estado de "en recuperación".
La recuperación no siempre es sencilla, ya que un error de hardware puede provocar un error en cascada de varios OSD. Por ejemplo, puede fallar un conmutador de red de un bastidor o un archivador, lo que puede provocar que el estado actual de los OSD de varias máquinas host quede retrasado respecto al clúster. Cada uno de los OSD debe recuperarse cuando se resuelva el error.
Ceph proporciona varios ajustes para equilibrar la contención de los recursos entre las peticiones de servicio nuevas y la necesidad de recuperar objetos de datos y restaurar los grupos de colocación al estado actual. El valor
osd recovery delay startpermite que un OSD se reinicie, vuelva a emparejarse e, incluso, que procese algunas peticiones de respuesta antes de iniciar el proceso de recuperación. El valorosd recovery thread timeoutdefine un tiempo límite del hilo, ya que varios OSD pueden fallar, reiniciarse y volver a emparejarse escalonadamente. El valorosd recovery max activelimita el número de peticiones de recuperación que un OSD procesará simultáneamente para evitar que el OSD no pueda atender las peticiones. El valorosd recovery max chunklimita el tamaño de los fragmentos de datos recuperados para evitar la congestión de la red.- BACK FILLING (EN REPOSICIÓN)
Cuando un nuevo OSD se une al clúster, CRUSH reasignará los grupos de colocación de los OSD del clúster al OSD recién añadido. Forzar al nuevo OSD a aceptar los grupos de colocación reasignados de inmediato, podría suponer una carga excesiva en el OSD nuevo. Al reponer los grupos de colocación en el OSD, este proceso puede comenzar en segundo plano. Una vez completado la reposición, el nuevo OSD comenzará a atender las peticiones cuando esté listo.
Durante las operaciones de reposición, es posible que vea uno de estos estados: "backfill_wait" indica que una operación de reposición está pendiente, pero aún no está en curso; "backfill" indica que una operación de reposición está en curso; "backfill_too_full" indica que se ha solicitado una operación de reposición, pero no se ha podido completar debido a que no hay capacidad de almacenamiento suficiente. Si no se puede realizar la reposición de un grupo de colocación, puede considerarse como "incompleto".
Ceph proporciona varios ajustes para gestionar la carga asociada con la reasignación de grupos de colocación a un OSD (especialmente un OSD nuevo). Por defecto,
osd max backfillsdefine que el número máximo de reposiciones simultáneas hacia o desde un OSD sea de 10. El valorbackfill full ratiopermite que un OSD rechace una petición de reposición si el OSD se acerca a su capacidad máxima (90 %, por defecto), que se cambia conceph osd set-backfillfull-ratio. Si un OSD rechaza una petición de reposición, el valorosd backfill retry intervalpermite que un OSD vuelva a intentar la petición (después de 10 segundos, por defecto). También es posible definir en los OSD los valoresosd backfill scan minyosd backfill scan maxpara gestionar los intervalos de escaneo (64 y 512, por defecto).- REMAPPED (REASIGNADO)
Cuando cambia el conjunto que actúa que atiende a un grupo de colocación, los datos migran del conjunto que actúa antiguo al nuevo. El nuevo OSD primario puede tardar algún tiempo en atender las peticiones de servicio. Por lo tanto, puede pedir al OSD primario antiguo que continúe atendiendo las peticiones hasta que se complete la migración del grupo de colocación. Cuando se completa la migración de los datos, la asignación utiliza el OSD primario del conjunto que actúa nuevo.
- STALE (OBSOLETO)
Mientras Ceph utiliza subejecución de réplica para asegurarse de que los hosts y los daemons se están ejecutando, los daemons
ceph-osdtambién pueden entrar en estado "bloqueo", en el que no informan sobre las estadísticas a tiempo (por ejemplo, si se produce un error temporal de la red). Por defecto, los daemons de OSD informan de las estadísticas de su grupo de colocación, del arranque y de los errores cada medio segundo (0,5), que es una frecuencia mayor a la de los umbrales de subejecución de réplica. Si el OSD primario del conjunto que actúa de un grupo de colocación no informa al monitor, o si otros OSD han informado de que el OSD primario está "inactivo", los monitores marcarán el grupo de colocación como "obsoleto".Al iniciar el clúster, es común ver el estado "obsoleto" hasta que se completa el proceso de emparejamiento. Después de que el clúster se haya estado ejecutando durante un tiempo, ver grupos de colocación con el estado "obsoleto" indica que el OSD primario para esos grupos de colocación está inactivo o no informa sobre las estadísticas del grupo de colocación al monitor.
12.9.5 Búsqueda de una ubicación de objeto #
Para almacenar datos de objetos en el almacén de objetos de Ceph, es preciso que un cliente de Ceph defina un nombre de objeto y que especifique un repositorio relacionado. El cliente de Ceph recupera el mapa más reciente del clúster y el algoritmo CRUSH calcula cómo asignar el objeto a un grupo de colocación. A continuación, calcula cómo asignar el grupo de colocación a un OSD dinámicamente. Para localizar la ubicación del objeto, solo se necesita el nombre del objeto y el nombre del repositorio. Por ejemplo:
cephuser@adm > ceph osd map POOL_NAME OBJECT_NAME [NAMESPACE]
Como ejemplo, vamos a crear un objeto. Especifique el nombre de objeto
"test-object-1", una vía al archivo de ejemplo "testfile.txt" que contiene
algunos datos de objeto y el nombre de repositorio "data". Para ellos
utilizaremos el comando rados put en la línea de
comandos:
cephuser@adm > rados put test-object-1 testfile.txt --pool=dataPara verificar que el almacén de objetos de Ceph ha almacenado el objeto, ejecute lo siguiente:
cephuser@adm > rados -p data lsAhora, identifique la ubicación del objeto. Ceph generará la ubicación del objeto:
cephuser@adm > ceph osd map data test-object-1
osdmap e537 pool 'data' (0) object 'test-object-1' -> pg 0.d1743484 \
(0.4) -> up ([1,0], p0) acting ([1,0], p0)
Para eliminar el objeto de ejemplo, basta con eliminarlo usando el comando
rados rm:
cephuser@adm > rados rm test-object-1 --pool=data13 Tareas operativas #
13.1 Modificación de la configuración del clúster #
Para modificar la configuración de un clúster de Ceph existente, siga estos pasos:
Exporte la configuración actual del clúster a un archivo:
cephuser@adm >ceph orch ls --export --format yaml > cluster.yamlEdite el archivo con la configuración y actualice las líneas pertinentes. Encontrará ejemplos de especificaciones en el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4 “Distribución de servicios y pasarelas” y en la Sección 13.4.3, “Adición de OSD mediante la especificación DriveGroups”.
Aplique la nueva configuración:
cephuser@adm >ceph orch apply -i cluster.yaml
13.2 Adición de nodos #
Para añadir un nodo nuevo a un clúster de Ceph, siga estos pasos:
Instale SUSE Linux Enterprise Server y SUSE Enterprise Storage en el nuevo host. Consulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.1 “Instalación y configuración de SUSE Linux Enterprise Server” para obtener más información.
Configure el host como un minion de Salt de un master de Salt ya existente. Consulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.2 “Distribución de Salt” para obtener más información.
Añada el nuevo host a
ceph-salty haga que cephadm lo reconozca, por ejemplo:root@master #ceph-salt config /ceph_cluster/minions add ses-min5.example.comroot@master #ceph-salt config /ceph_cluster/roles/cephadm add ses-min5.example.comConsulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3.2.2 “Adición de minions de Salt” para obtener más información.
Verifique que el nodo se ha añadido a
ceph-salt:root@master #ceph-salt config /ceph_cluster/minions ls o- minions ................................................. [Minions: 5] [...] o- ses-min5.example.com .................................... [no roles]Aplique la configuración al nuevo host del clúster:
root@master #ceph-salt apply ses-min5.example.comVerifique que el host recién añadido pertenece ahora al entorno de cephadm:
cephuser@adm >ceph orch host ls HOST ADDR LABELS STATUS [...] ses-min5.example.com ses-min5.example.com
13.3 Eliminación de nodos #
Si el nodo que va a eliminar ejecuta OSD, elimínelos primero y compruebe que no hay ningún OSD en ejecución en ese nodo. Consulte la Sección 13.4.4, “Eliminación de OSD” para obtener más información sobre la eliminación de OSD.
Para eliminar un nodo de un clúster, haga lo siguiente:
Para todos los tipos de servicio de Ceph, excepto
node-exporterycrash, elimine el nombre de host del nodo del archivo de especificación de colocación del clúster (por ejemplo,cluster.yml). Consulte Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.2 “Especificación del servicio y la colocación” para obtener más información. Por ejemplo, si va a eliminar el host denominadoses-min2, elimine todas las apariciones de- ses-min2de todas las seccionesplacement:.Actualice
service_type: rgw service_id: EXAMPLE_NFS placement: hosts: - ses-min2 - ses-min3
a
service_type: rgw service_id: EXAMPLE_NFS placement: hosts: - ses-min3
Aplique los cambios al archivo de configuración:
cephuser@adm >ceph orch apply -i rgw-example.yamlElimine el nodo del entorno de cephadm:
cephuser@adm >ceph orch host rm ses-min2Si el nodo ejecuta los servicios
crash.osd.1ycrash.osd.2, elimínelos ejecutando el siguiente comando en el host:root@minion >cephadm rm-daemon --fsid CLUSTER_ID --name SERVICE_NAMEPor ejemplo:
root@minion >cephadm rm-daemon --fsid b4b30c6e... --name crash.osd.1root@minion >cephadm rm-daemon --fsid b4b30c6e... --name crash.osd.2Elimine todas las funciones del minion que desee suprimir:
cephuser@adm >ceph-salt config /ceph_cluster/roles/tuned/throughput remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/tuned/latency remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/cephadm remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/admin remove ses-min2Si el minion que desea suprimir es el minion de arranque, también debe eliminar la función bootstrap:
cephuser@adm >ceph-salt config /ceph_cluster/roles/bootstrap resetDespués de eliminar todos los OSD de un solo host, elimine el host del mapa de CRUSH:
cephuser@adm >ceph osd crush remove bucket-nameNotaEl nombre del depósito debe ser el mismo que el nombre del host.
Ahora puede eliminar el minion del clúster:
cephuser@adm >ceph-salt config /ceph_cluster/minions remove ses-min2
En caso de que se produzca un fallo y el minion que está intentando eliminar se encuentre apagado permanentemente, deberá eliminar el nodo del master de Salt:
root@master # salt-key -d minion_id
A continuación, elimine manualmente el nodo de raíz_pilar/ceph-salt.sls. Normalmente se encuentra en /srv/pillar/ceph-salt.sls.
13.4 Gestión de OSD #
En esta sección se describe cómo añadir, borrar o eliminar OSD en un clúster de Ceph.
13.4.1 Listado de dispositivos de disco #
Para identificar los dispositivos de disco usados y sin usar en todos los nodos del clúster, muéstrelos ejecutando el comando siguiente:
cephuser@adm > ceph orch device ls
HOST PATH TYPE SIZE DEVICE AVAIL REJECT REASONS
ses-master /dev/vda hdd 42.0G False locked
ses-min1 /dev/vda hdd 42.0G False locked
ses-min1 /dev/vdb hdd 8192M 387836 False locked, LVM detected, Insufficient space (<5GB) on vgs
ses-min2 /dev/vdc hdd 8192M 450575 True13.4.2 Borrado de dispositivos de disco #
Para reutilizar un dispositivo de disco, primero debe borrarlo (comando zap):
ceph orch device zap HOST_NAME DISK_DEVICE
Por ejemplo:
cephuser@adm > ceph orch device zap ses-min2 /dev/vdc
Si ha distribuido previamente los OSD mediante DriveGroups o con la opción --all-available-devices sin que se haya definido el indicador unmanaged, cephadm distribuirá estos OSD automáticamente después de borrarlos.
13.4.3 Adición de OSD mediante la especificación DriveGroups #
DriveGroups especifica los diseños de los OSD del clúster de Ceph. Se definen en un único archivo YAML. En esta sección, utilizaremos drive_groups.yml como ejemplo.
Un administrador debe especificar manualmente un grupo de OSD que estén interrelacionados (OSD híbridos que se distribuyen en una mezcla de unidades HDD y SDD) o que compartan opciones de distribución idénticas (por ejemplo, el mismo almacén de objetos, la misma opción de cifrado y varios OSD independientes). Para no tener que mostrar explícitamente los dispositivos, DriveGroups utiliza una lista de elementos de filtro que corresponden a algunos campos seleccionados de los informes de inventario de ceph-volume. cephadm proporciona código que traduce esta especificación DriveGroups en listas de dispositivos reales para que el usuario las pueda inspeccionar.
El comando para aplicar la especificación de OSD al clúster es:
cephuser@adm >ceph orch apply osd -idrive_groups.yml
Para ver una vista previa de las acciones y probar la aplicación, puede utilizar la opción --dry-run junto con el comando ceph orch apply osd. Por ejemplo:
cephuser@adm >ceph orch apply osd -idrive_groups.yml--dry-run ... +---------+------+------+----------+----+-----+ |SERVICE |NAME |HOST |DATA |DB |WAL | +---------+------+------+----------+----+-----+ |osd |test |mgr0 |/dev/sda |- |- | |osd |test |mgr0 |/dev/sdb |- |- | +---------+------+------+----------+----+-----+
Si el resultado de --dry-run cumple sus expectativas, solo tiene que volver a ejecutar el comando sin la opción --dry-run.
13.4.3.1 OSD no gestionados #
Todos los dispositivos de disco limpios disponibles que coincidan con la especificación DriveGroups se utilizarán automáticamente como OSD después de añadirlos al clúster. Este comportamiento se denomina modo gestionado.
Para inhabilitar el modo gestionado, añada la línea unmanaged: true a las especificaciones relevantes, por ejemplo:
service_type: osd service_id: example_drvgrp_name placement: hosts: - ses-min2 - ses-min3 encrypted: true unmanaged: true
Para cambiar los OSD ya distribuidos del modo gestionado al modo no gestionado, añada las líneas unmanaged: true cuando corresponda durante el procedimiento descrito en la Sección 13.1, “Modificación de la configuración del clúster”.
13.4.3.2 Especificación DriveGroups #
A continuación se muestra un ejemplo de archivo de especificación DriveGroups:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: drive_spec: DEVICE_SPECIFICATION db_devices: drive_spec: DEVICE_SPECIFICATION wal_devices: drive_spec: DEVICE_SPECIFICATION block_wal_size: '5G' # (optional, unit suffixes permitted) block_db_size: '5G' # (optional, unit suffixes permitted) encrypted: true # 'True' or 'False' (defaults to 'False')
La opción denominada anteriormente "encryption" en DeepSea ahora se llama "encrypted". Al aplicar DriveGroups en SUSE Enterprise Storage 7, asegúrese de utilizar esta nueva terminología en la especificación del servicio; de lo contrario, la operación ceph orch apply fallará.
13.4.3.3 Filtrado de dispositivos de disco #
Puede describir la especificación utilizando los filtros siguientes:
Por modelo del disco:
model: DISK_MODEL_STRING
Por proveedor del disco:
vendor: DISK_VENDOR_STRING
SugerenciaEscriba siempre DISK_VENDOR_STRING en minúsculas.
Para obtener detalles sobre el modelo de disco y el proveedor, examine el resultado del siguiente comando:
cephuser@adm >ceph orch device ls HOST PATH TYPE SIZE DEVICE_ID MODEL VENDOR ses-min1 /dev/sdb ssd 29.8G SATA_SSD_AF34075704240015 SATA SSD ATA ses-min2 /dev/sda ssd 223G Micron_5200_MTFDDAK240TDN Micron_5200_MTFD ATA [...]Indica si un disco es giratorio o no. Las unidades SSD y NVMe no son giratorias.
rotational: 0
Distribuya un nodo utilizando todas las unidades disponibles para los OSD:
data_devices: all: true
También puede limitar el número de discos que coinciden:
limit: 10
13.4.3.4 Filtrado de dispositivos por tamaño #
Es posible filtrar los dispositivos de disco por su tamaño, ya sea por un tamaño exacto o por un intervalo de tamaños. El parámetro size: acepta argumentos con el formato siguiente:
'10G': incluye discos de un tamaño exacto.
'10G:40G': incluye discos cuyo tamaño está dentro del intervalo indicado.
':10G': incluye discos de 10 GB o menos.
'40G:': incluye discos de 40 GB o más.
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: size: '40TB:' db_devices: size: ':2TB'
Si se usa el delimitador ":", debe incluir el tamaño entre comillas simples, de lo contrario el signo ":" se interpretará como un nuevo hash de configuración.
En lugar de gigabytes (G), puede especificar el tamaño en megabytes (M) o en terabytes (T).
13.4.3.5 Ejemplos de DriveGroups #
Esta sección incluye ejemplos de diferentes configuraciones de OSD.
Este ejemplo describe dos nodos con la misma configuración:
20 discos duros
Proveedor: Intel
Modelo: SSD-123-foo
Tamaño: 4 TB
2 discos SSD
Proveedor: Micron
Modelo: MC-55-44-ZX
Tamaño: 512 GB
El archivo drive_groups.yml correspondiente será el siguiente:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: model: SSD-123-foo db_devices: model: MC-55-44-XZ
Esta configuración es sencilla y válida. El problema es que un administrador puede añadir discos de diferentes proveedores en el futuro, y estos no se incluirán. Puede mejorarla reduciendo los filtros en las propiedades principales de las unidades:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: rotational: 1 db_devices: rotational: 0
En el ejemplo anterior, estamos imponiendo que se declaren todos los dispositivos giratorios como "dispositivos de datos" y todos los dispositivos no giratorios se utilizarán como "dispositivos compartidos" (wal, db).
Si sabe que las unidades de más de 2 TB siempre serán los dispositivos de datos más lentos, puede filtrar por tamaño:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: size: '2TB:' db_devices: size: ':2TB'
En este ejemplo se describen dos configuraciones distintas: 20 discos duros deben compartir 2 unidades SSD, mientras que 10 unidades SSD deben compartir 2 NVMe.
20 discos duros
Proveedor: Intel
Modelo: SSD-123-foo
Tamaño: 4 TB
12 discos SSD
Proveedor: Micron
Modelo: MC-55-44-ZX
Tamaño: 512 GB
2 NVMe
Proveedor: Samsung
Modelo: NVME-QQQQ-987
Tamaño: 256 GB
Esta configuración se puede definir con dos diseños de la siguiente manera:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: MC-55-44-XZ
service_type: osd service_id: example_drvgrp_name2 placement: host_pattern: '*' data_devices: model: MC-55-44-XZ db_devices: vendor: samsung size: 256GB
En los ejemplos anteriores se suponía que todos los nodos tienen las mismas unidades. Sin embargo, eso no siempre es así:
Nodos 1-5:
20 discos duros
Proveedor: Intel
Modelo: SSD-123-foo
Tamaño: 4 TB
2 discos SSD
Proveedor: Micron
Modelo: MC-55-44-ZX
Tamaño: 512 GB
Nodos 6-10:
5 NVMe
Proveedor: Intel
Modelo: SSD-123-foo
Tamaño: 4 TB
20 discos SSD
Proveedor: Micron
Modelo: MC-55-44-ZX
Tamaño: 512 GB
Puede utilizar la clave "target" en el diseño para asignar nodos específicos a un destino. La notación del destino de Salt ayuda a simplificar las cosas:
service_type: osd service_id: example_drvgrp_one2five placement: host_pattern: 'node[1-5]' data_devices: rotational: 1 db_devices: rotational: 0
seguido de
service_type: osd service_id: example_drvgrp_rest placement: host_pattern: 'node[6-10]' data_devices: model: MC-55-44-XZ db_devices: model: SSD-123-foo
En todos los casos anteriores se presuponía que los WAL y DB usaban el mismo dispositivo. Sin embargo, también es posible distribuir el WAL en un dispositivo dedicado:
20 discos duros
Proveedor: Intel
Modelo: SSD-123-foo
Tamaño: 4 TB
2 discos SSD
Proveedor: Micron
Modelo: MC-55-44-ZX
Tamaño: 512 GB
2 NVMe
Proveedor: Samsung
Modelo: NVME-QQQQ-987
Tamaño: 256 GB
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: model: MC-55-44-XZ db_devices: model: SSD-123-foo wal_devices: model: NVME-QQQQ-987
En la siguiente configuración, tratamos de definir lo siguiente:
20 discos duros respaldados por 1 NVMe
2 discos duros respaldados por 1 SSD (db) y 1 NVMe (wal)
8 discos SSD respaldados por 1 NVMe
2 discos SSD independientes (cifrados)
1 disco duro es de repuesto y no debe distribuirse
El resumen de las unidades usadas es el siguiente:
23 discos duros
Proveedor: Intel
Modelo: SSD-123-foo
Tamaño: 4 TB
10 discos SSD
Proveedor: Micron
Modelo: MC-55-44-ZX
Tamaño: 512 GB
1 NVMe
Proveedor: Samsung
Modelo: NVME-QQQQ-987
Tamaño: 256 GB
La definición de DriveGroups será la siguiente:
service_type: osd service_id: example_drvgrp_hdd_nvme placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_hdd_ssd_nvme placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: MC-55-44-XZ wal_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_ssd_nvme placement: host_pattern: '*' data_devices: model: SSD-123-foo db_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_standalone_encrypted placement: host_pattern: '*' data_devices: model: SSD-123-foo encrypted: True
Se conservará un disco duro porque el archivo se está analizando de arriba abajo.
13.4.4 Eliminación de OSD #
Antes de eliminar un nodo de OSD del clúster, verifique que el clúster tiene más espacio libre en disco que el disco del OSD que va a eliminar. Tenga en cuenta que, si se elimina un OSD, todo el clúster se reequilibra.
Identifique qué OSD desea eliminar obteniendo su ID:
cephuser@adm >ceph orch ps --daemon_type osd NAME HOST STATUS REFRESHED AGE VERSION osd.0 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.1 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.2 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.3 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ...Elimine uno o varios OSD del clúster:
cephuser@adm >ceph orch osd rm OSD1_ID OSD2_ID ...Por ejemplo:
cephuser@adm >ceph orch osd rm 1 2Puede consultar el estado de la operación de eliminación:
cephuser@adm >ceph orch osd rm status OSD_ID HOST STATE PG_COUNT REPLACE FORCE STARTED_AT 2 cephadm-dev done, waiting for purge 0 True False 2020-07-17 13:01:43.147684 3 cephadm-dev draining 17 False True 2020-07-17 13:01:45.162158 4 cephadm-dev started 42 False True 2020-07-17 13:01:45.162158
13.4.4.1 Detención de la eliminación de OSD #
Después de programar la eliminación de un OSD, puede detener la eliminación si es necesario. El siguiente comando restablecerá el estado inicial del OSD y lo eliminará de la cola:
cephuser@adm > ceph orch osd rm stop OSD_SERVICE_ID13.4.5 Sustitución de OSD #
Para sustituir un OSD conservando su ID, ejecute:
cephuser@adm > ceph orch osd rm OSD_SERVICE_ID --replacePor ejemplo:
cephuser@adm > ceph orch osd rm 4 --replace
Sustituir un OSD es igual que eliminar un OSD (consulte la Sección 13.4.4, “Eliminación de OSD” para obtener más información), con la excepción de que el OSD no se elimina permanentemente de la jerarquía de CRUSH y se le asigna un indicador destroyed.
El indicador destroyed se utiliza para determinar los ID de OSD que se reutilizarán durante la siguiente distribución de OSD. A los discos recién añadidos que coincidan con la especificación DriveGroups (consulte la Sección 13.4.3, “Adición de OSD mediante la especificación DriveGroups” para obtener más información) se les asignarán los ID de OSD de su equivalente sustituido.
Al añadir la opción --dry-run no se ejecutará la sustitución real, pero se mostrarán los pasos que se llevarían a cabo normalmente.
13.5 Traslado del master de Salt a un nodo nuevo #
Si necesita sustituir el host del master de Salt por uno nuevo, siga estos pasos:
Exporte la configuración del clúster y realice una copia de seguridad del archivo JSON exportado. Más detalles en el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3.2.15 “Exportación de configuraciones de clúster”
Si el master de Salt antiguo es también el único nodo de administración del clúster, traslade manualmente
/etc/ceph/ceph.client.admin.keyringy/etc/ceph/ceph.confal nuevo master de Salt.Detenga e inhabilite el servicio
systemddel master de Salt en el nodo del master de Salt antiguo:root@master #systemctl stop salt-master.serviceroot@master #systemctl disable salt-master.serviceSi el nodo del master de Salt antiguo ya no está en el clúster, detenga e inhabilite también el servicio
systemddel minion de Salt:root@master #systemctl stop salt-minion.serviceroot@master #systemctl disable salt-minion.serviceAvisono detenga ni inhabilite
salt-minion.servicesi el nodo del master de Salt antiguo tiene algún daemon de Ceph (MON, MGR, OSD, MDS, pasarela, supervisión) en ejecución.Instale SUSE Linux Enterprise Server 15 SP2 en el nuevo master de Salt siguiendo el procedimiento descrito en el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.1 “Instalación y configuración de SUSE Linux Enterprise Server”.
Sugerencia: transición de los minions de SaltPara simplificar la transición de los minions de Salt al nuevo master de Salt, elimine la clave pública del master de Salt original de cada minion:
root@minion >rm /etc/salt/pki/minion/minion_master.pubroot@minion >systemctl restart salt-minion.serviceInstale el paquete salt-master y, si procede, el paquete salt-minion en el nuevo master de Salt.
Instale
ceph-salten el nuevo nodo del master de Salt:root@master #zypper install ceph-saltroot@master #systemctl restart salt-master.serviceroot@master #salt '*' saltutil.sync_allImportanteAsegúrese de ejecutar los tres comandos antes de continuar. Los comandos son idempotentes; no importa si se repiten.
Incluya el nuevo master de Salt en el clúster, como se describe en el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3.1 “Instalación de
ceph-salt”, el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3.2.2 “Adición de minions de Salt” y el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3.2.4 “Especificación del nodo de administración”.Importe la copia de seguridad de la configuración del clúster y aplíquela:
root@master #ceph-salt import CLUSTER_CONFIG.jsonroot@master #ceph-salt applyImportanteCambie el nombre del minion del master de Salt
minion iddel archivoCLUSTER_CONFIG.jsonexportado antes de importarlo.
13.6 Actualización de los nodos del clúster #
Para mantener actualizados los nodos del clúster de Ceph, aplique actualizaciones periódicas.
13.6.1 Repositorios de software #
Antes de aplicar al clúster los paquetes de software más recientes como parches, compruebe que todos los nodos del clúster tienen acceso a los repositorios relevantes. Consulte el Book “Guía de distribución”, Chapter 7 “Actualización desde una versión anterior”, Section 7.1.5.1 “Repositorios de software” para obtener una lista completa de los repositorios necesarios.
13.6.2 División en etapas del repositorio #
Si utiliza una herramienta de división en etapas (por ejemplo, SUSE Manager, o la herramienta de gestión de repositorios o RMT) que provea repositorios de software a los nodos del clúster, verifique que las etapas de los repositorios "de actualizaciones" de SUSE Linux Enterprise Server y SUSE Enterprise Storage se crean en el mismo momento.
Se recomienda encarecidamente utilizar una herramienta de división en etapas para aplicar parches con los niveles de parches inmovilizados o preconfigurados. Esto garantiza que los nuevos nodos que se unen al clúster tengan el mismo nivel de parche que los nodos que ya se ejecutan en el clúster. De ese modo, no será necesario aplicar los parches más recientes a todos los nodos del clúster antes de que los nuevos nodos se puedan unir al clúster.
13.6.3 Tiempo de inactividad de servicios de Ceph #
Dependiendo de la configuración, los nodos del clúster podrían reiniciarse durante la actualización. Si hay un punto único de error para servicios como Object Gateway, Samba Gateway, NFS Ganesha o iSCSI, los equipos cliente podrían desconectarse temporalmente de los servicios cuyos nodos se van a reiniciar.
13.6.4 Ejecución de la actualización #
Para actualizar los paquetes de software de todos los nodos del clúster a la versión más reciente, ejecute el comando siguiente:
root@master # ceph-salt update13.7 Actualización de Ceph #
Puede indicar a cephadm que actualice Ceph a partir de una versión de corrección de errores a otra. La actualización automatizada de los servicios de Ceph respeta el orden recomendado: comienza con Ceph Managers, después Ceph Monitors y continúa con otros servicios como Ceph OSD, servidores de metadatos y Object Gateways. Cada daemon solo se reinicia después de que Ceph indique que el clúster seguirá estando disponible.
El siguiente procedimiento de actualización utiliza el comando ceph orch upgrade. Tenga en cuenta que las instrucciones siguientes detallan cómo actualizar el clúster de Ceph con una versión de producto (por ejemplo, una actualización de mantenimiento), pero no proporcionan instrucciones sobre cómo actualizar el clúster de una versión de producto a otra.
13.7.1 Inicio de la actualización #
Antes de iniciar la actualización, compruebe que todos los nodos están en línea y que el clúster funciona correctamente:
cephuser@adm > cephadm shell -- ceph -sPara actualizar a una versión de Ceph específica:
cephuser@adm > ceph orch upgrade start --image REGISTRY_URLPor ejemplo:
cephuser@adm > ceph orch upgrade start --image registry.suse.com/ses/7/ceph/ceph:latestActualice los paquetes en los hosts:
cephuser@adm > ceph-salt update13.7.2 Supervisión de la actualización #
Ejecute el comando siguiente para determinar si hay una actualización en curso:
cephuser@adm > ceph orch upgrade statusMientras la actualización está en curso, verá una barra de progreso en el estado de Ceph:
cephuser@adm > ceph -s
[...]
progress:
Upgrade to registry.suse.com/ses/7/ceph/ceph:latest (00h 20m 12s)
[=======.....................] (time remaining: 01h 43m 31s)También puede ver el registro de cephadm:
cephuser@adm > ceph -W cephadm13.7.3 Cancelación de una actualización #
Puede detener el proceso de actualización en cualquier momento:
cephuser@adm > ceph orch upgrade stop13.8 Detención o reinicio del clúster #
En algunos casos, puede ser necesario detener o reiniciar el clúster completo. Recomendamos comprobar atentamente las dependencias de los servicios en ejecución. Los siguientes pasos se pueden usar como esquema de inicio y detención del clúster:
Indique al clúster de Ceph que no marque los OSD como "out":
cephuser@adm >cephosd set nooutDetenga los daemons y los nodos en el siguiente orden:
Clientes de almacenamiento
Gateways, por ejemplo, NFS Ganesha u Object Gateway
Servidor de metadatos
Ceph OSD
Ceph Manager
Ceph Monitor
Si es necesario, realice las tareas de mantenimiento.
Inicie los nodos y los servidores en el orden inverso al del proceso de apagado:
Ceph Monitor
Ceph Manager
Ceph OSD
Servidor de metadatos
Gateways, por ejemplo, NFS Ganesha u Object Gateway
Clientes de almacenamiento
Elimine el indicador de noout:
cephuser@adm >cephosd unset noout
13.9 Eliminación de un clúster de Ceph completo #
El comando ceph-salt purge elimina todo el clúster de Ceph. Si hay más clústeres de Ceph distribuidos, se limpia el notificado por ceph -s. De esta manera, puede limpiar el entorno del clúster cuando pruebe diferentes configuraciones.
Para evitar la supresión accidental, la orquestación comprueba si la seguridad está desactivada. Puede desactivar las medidas de seguridad y eliminar el clúster de Ceph ejecutando:
root@master #ceph-salt disengage-safetyroot@master #ceph-salt purge
14 Funcionamiento de los servicios de Ceph #
Puede hacer funcionar los servicios de Ceph en el nivel de los daemons, los nodos o los clústeres. Según el enfoque que necesite, utilice cephadm o el comando systemctl.
14.1 Funcionamiento de servicios individuales #
Si necesita hacer funcionar un servicio individual, identifíquelo primero:
cephuser@adm > ceph orch ps
NAME HOST STATUS REFRESHED [...]
mds.my_cephfs.ses-min1.oterul ses-min1 running (5d) 8m ago
mgr.ses-min1.gpijpm ses-min1 running (5d) 8m ago
mgr.ses-min2.oopvyh ses-min2 running (5d) 8m ago
mon.ses-min1 ses-min1 running (5d) 8m ago
mon.ses-min2 ses-min2 running (5d) 8m ago
mon.ses-min4 ses-min4 running (5d) 7m ago
osd.0 ses-min2 running (61m) 8m ago
osd.1 ses-min3 running (61m) 7m ago
osd.2 ses-min4 running (61m) 7m ago
rgw.myrealm.myzone.ses-min1.kwwazo ses-min1 running (5d) 8m ago
rgw.myrealm.myzone.ses-min2.jngabw ses-min2 error 8m agoPara identificar un servicio en un nodo específico, ejecute:
ceph orch ps NODE_HOST_NAME
Por ejemplo:
cephuser@adm > ceph orch ps ses-min2
NAME HOST STATUS REFRESHED
mgr.ses-min2.oopvyh ses-min2 running (5d) 3m ago
mon.ses-min2 ses-min2 running (5d) 3m ago
osd.0 ses-min2 running (67m) 3m ago
El comando ceph orch ps admite varios formatos de salida. Para cambiarlo, añada la opción --format FORMAT al final, donde FORMAT es uno de estas opciones: json, json-pretty o yaml. Por ejemplo:
cephuser@adm > ceph orch ps --format yamlUna vez que sepa el nombre del servicio, puede iniciarlo, reiniciarlo o detenerlo:
ceph orch daemon COMMAND SERVICE_NAME
Por ejemplo, para reiniciar el servicio OSD con el ID 0, ejecute:
cephuser@adm > ceph orch daemon restart osd.014.2 Funcionamiento de tipos de servicios #
Si necesita hacer funcionar un tipo específico de servicio en todo el clúster de Ceph, utilice el comando siguiente:
ceph orch COMMAND SERVICE_TYPE
Sustituya COMMAND por start, stop o restart.
Por ejemplo, el comando siguiente reinicia todos los MON del clúster, independientemente de los nodos en los que se ejecuten:
cephuser@adm > ceph orch restart mon14.3 Funcionamiento de servicios en un único nodo #
Mediante el comando systemctl, puede hacer funcionar los servicios y destinos de systemd relacionados con Ceph en un único nodo.
14.3.1 Identificación de servicios y destinos #
Antes de hacer funcionar los servicios y destinos de systemd relacionados con Ceph, debe identificar los nombres de archivo de sus archivos de unidad. Los nombres de archivo de los servicios tienen el siguiente patrón:
ceph-FSID@SERVICE_TYPE.ID.service
Por ejemplo:
ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@mon.doc-ses-min1.service
ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@rgw.myrealm.myzone.doc-ses-min1.kwwazo.service
- FSID
ID exclusivo del clúster de Ceph. Lo encontrará en el resultado del comando
ceph fsid.- SERVICE_TYPE
El tipo de servicio, por ejemplo,
osd,monorgw.- ID
Cadena de identificación del servicio. Para los OSD, es el número de ID del servicio. Para otros servicios, puede ser un nombre de host del nodo o cadenas adicionales relevantes para el tipo de servicio.
La parte de SERVICE_TYPE.ID es idéntica al contenido de la columna NAME del resultado del comando ceph orch ps.
14.3.2 Funcionamiento de todos los servicios en un nodo #
Al usar los destinos de systemd de Ceph, puede hacer funcionar simultáneamente todos los servicios en un nodo, o bien todos los servicios que pertenecen a un clúster identificado por su FSID.
Por ejemplo, para detener todos los servicios de Ceph en un nodo independientemente del clúster al que pertenezcan los servicios, ejecute:
root@minion > systemctl stop ceph.target
Para reiniciar todos los servicios que pertenecen a un clúster de Ceph con el ID b4b30c6e-9681-11ea-ac39-525400d7702d, ejecute:
root@minion > systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d.target14.3.3 Funcionamiento de un servicio individual en un nodo #
Después de identificar el nombre de un servicio específico, utilícelo de la siguiente manera:
systemctl COMMAND SERVICE_NAME
Por ejemplo, para reiniciar un único servicio OSD con el ID 1 en un clúster con el ID b4b30c6e-9681-11ea-ac39-525400d7702d, ejecute:
root # systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@osd.1.service14.3.4 Consulta del estado del servicio #
Puede consultar systemd para conocer el estado de los servicios. Por ejemplo:
root # systemctl status ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@osd.0.service14.4 Apagado y reinicio de todo el clúster de Ceph #
Es posible que sea necesario apagar y reiniciar el clúster en caso de que se vaya a producir un corte de energía programado. Para detener todos los servicios relacionados con Ceph y reiniciar sin problemas, siga los pasos siguientes.
Apague o desconecte cualquier cliente que acceda al clúster.
Para evitar que CRUSH reequilibre automáticamente el clúster, defina el clúster en
noout:cephuser@adm >ceph osd set nooutDetenga todos los servicios de Ceph en todos los nodos del clúster:
root@master #ceph-salt stoptodos los nodos del clúster:
root@master #salt -G 'ceph-salt:member' cmd.run "shutdown -h"
Encienda el nodo de administración.
Encienda los nodos de Ceph Monitor.
Encienda los nodos de OSD de Ceph.
Anule la definición del indicador
nooutdefinido anteriormente:root@master #ceph osd unset nooutEncienda todas las pasarelas configuradas.
Encienda o conecte los clientes del clúster.
15 Copia de seguridad y recuperación #
En este capítulo se explica de qué partes del clúster de Ceph se debe realizar una copia de seguridad para poder restaurarlo.
15.1 Copia de seguridad de la configuración y los datos del clúster #
15.1.1 Copia de seguridad de la configuración de ceph-salt #
Exporte la configuración del clúster. Encontrará más información en Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3.2.15 “Exportación de configuraciones de clúster”.
15.1.2 Copia de seguridad de la configuración de Ceph #
Realice una copia de seguridad del directorio /etc/ceph. Contiene configuración crucial del clúster. Por ejemplo, necesitará una copia de seguridad de /etc/ceph cuando deba sustituir el nodo de administración.
15.1.3 Copia de seguridad de la configuración de Salt #
Debe realizar una copia de seguridad del directorio /etc/salt/. Contiene los archivos de configuración de Salt, por ejemplo la clave del master de Salt y las claves de cliente aceptadas.
No es estrictamente necesario incluir los archivos de Salt al realizar una copia de seguridad del nodo de administración, pero facilita la posterior redistribución del clúster de Salt. Si no se hace una copia de seguridad de estos archivos, los minions de Salt deben registrarse de nuevo en el nuevo nodo de administración.
Asegúrese de que la copia de seguridad de la clave privada del master de Salt se guarda en una ubicación segura. La clave del master de Salt puede emplearse para manipular todos los nodos del clúster.
15.1.4 Copia de seguridad de configuraciones personalizadas #
Datos y personalizaciones de Prometheus.
Personalizaciones de Grafana.
Cambios manuales en la configuración de iSCSI.
Claves de ceph.
Mapa y reglas de CRUSH. Guarde el mapa de CRUSH descompilado, incluidas las reglas de CRUSH, en
crushmap-backup.txtejecutando el siguiente comando:cephuser@adm >ceph osd getcrushmap | crushtool -d - -o crushmap-backup.txtConfiguración de Samba Gateway. Si utiliza una única pasarela, realice una copia de seguridad de
/etc/samba/smb.conf. Si utiliza una configuración de alta disponibilidad, realice también una copia de seguridad de los archivos de configuración de CTDB y Pacemaker. Consulte el Capítulo 24, Exportación de datos de Ceph a través de Samba para ver detalles sobre la configuración que se usa en las pasarelas Samba Gateway.Configuración de NFS Ganesha. Solo se necesita si se utiliza una configuración de alta disponibilidad. Consulte el Capítulo 25, NFS Ganesha para ver detalles sobre la configuración que se usa en NFS Ganesha.
15.2 Restauración de un nodo de Ceph #
El procedimiento para recuperar un nodo de la copia de seguridad consiste en volver a instalar el nodo, sustituir sus archivos de configuración y, a continuación, volver a organizar el clúster para que se vuelva a añadir el nodo de sustitución.
Si necesita volver a distribuir el nodo de administración, consulte la Sección 13.5, “Traslado del master de Salt a un nodo nuevo”.
En el caso de los minions, suele ser más fácil volver a crearlos y distribuirlos.
Vuelva a instalar el nodo. Encontrará más información en Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.1 “Instalación y configuración de SUSE Linux Enterprise Server”
Instale Salt. Encontrará más información en Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.2 “Distribución de Salt”
Después de restaurar el directorio
/etc/saltdesde una copia de seguridad, habilite y reinicie los servicios de Salt aplicables, por ejemplo:root@master #systemctlenable salt-masterroot@master #systemctlstart salt-masterroot@master #systemctlenable salt-minionroot@master #systemctlstart salt-minionElimine la clave principal pública del nodo del master de Salt de todos los minions.
root@master #rm/etc/salt/pki/minion/minion_master.pubroot@master #systemctlrestart salt-minionRestaure cualquier elemento que fuera local en el nodo de administración.
Importe la configuración del clúster desde el archivo JSON exportado anteriormente. Consulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.3.2.15 “Exportación de configuraciones de clúster” para obtener más información.
Aplique la configuración de clúster importada:
root@master #ceph-salt apply
16 Supervisión y alertas #
En SUSE Enterprise Storage 7, cephadm distribuye una pila de alertas y supervisión. Los usuarios deben definir los servicios (como Prometheus, Alertmanager y Grafana) que desean distribuir con cephadm en un archivo de configuración YAML, o bien pueden utilizar la interfaz de línea de comandos para distribuirlos. Cuando se distribuyen varios servicios del mismo tipo, se distribuye una configuración de alta disponibilidad. El exportador de nodos es una excepción a esta regla.
Los siguientes servicios de supervisión se pueden distribuir con cephadm:
Prometheus es el kit de herramientas de supervisión y alertas. Recopila los datos proporcionados por los exportadores de Prometheus y activa alertas preconfiguradas si se alcanzan los umbrales predefinidos.
Alertmanager gestiona las alertas enviadas por el servidor de Prometheus. Desduplica, agrupa y dirige las alertas al receptor correcto. Por defecto, Ceph Dashboard se configura automáticamente como receptor.
Grafana es el software de visualización y alertas. Esta pila de supervisión no utiliza la función de alertas de Grafana. Para las alertas, se utiliza Alertmanager.
El exportador de nodos es un exportador de Prometheus que proporciona datos sobre el nodo en el que está instalado. Se recomienda instalar el exportador de nodos en todos los nodos.
El módulo de gestor de Prometheus proporciona un exportador de Prometheus para pasar los contadores de rendimiento de Ceph desde el punto de recopilación en ceph-mgr.
La configuración de Prometheus, incluidos los destinos de scrape (métricas que proporcionan daemons), se configura automáticamente mediante cephadm. cephadm también distribuye una lista de alertas por defecto, por ejemplo, error de estado, 10% de OSD inactivos o pgs inactivos.
Por defecto, el tráfico a Grafana se cifra con TLS. Puede proporcionar su propio certificado TLS o utilizar uno autofirmado. Si no se ha configurado ningún certificado personalizado antes de la distribución de Grafana, se crea y se configura automáticamente un certificado autofirmado para Grafana.
Los certificados personalizados para Grafana se pueden configurar mediante los comandos siguientes:
cephuser@adm >ceph config-key set mgr/cephadm/grafana_key -i $PWD/key.pemcephuser@adm >ceph config-key set mgr/cephadm/grafana_crt -i $PWD/certificate.pem
Alertmanager gestiona las alertas enviadas por el servidor de Prometheus. Se encarga de desduplicarlos, agruparlos y enrutarlos al receptor correcto. Las alertas se pueden silenciar mediante el Alertmanager, pero los silencios también se pueden gestionar mediante Ceph Dashboard.
Se recomienda que el exportador de nodos se distribuya en todos los nodos. Esto se puede hacer mediante el archivo monitoring.yaml con el tipo de servicio node-exporter. Consulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.3.8 “Distribución de la pila de supervisión” para obtener más información sobre la distribución de servicios.
16.1 Configuración de imágenes personalizadas o locales #
En esta sección se describe cómo cambiar la configuración de las imágenes de contenedor que se utilizan al distribuir o actualizar los servicios. No incluye los comandos necesarios para distribuir o volver a distribuir servicios.
El método recomendado para distribuir la pila de supervisión consiste en aplicar su especificación como se describe en el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.3.8 “Distribución de la pila de supervisión”.
Para distribuir imágenes de contenedor personalizadas o locales, las imágenes deben definirse en cephadm. Para ello, deberá ejecutar el comando siguiente:
cephuser@adm > ceph config set mgr mgr/cephadm/OPTION_NAME VALUEDonde OPTION_NAME es uno de estos nombres:
container_image_prometheus
container_image_node_exporter
container_image_alertmanager
container_image_grafana
Si no se ha definido ninguna opción o si se ha eliminado el ajuste, se utilizan las imágenes siguientes como VALUE:
registry.suse.com/caasp/v4.5/prometheus-server:2.18.0
registry.suse.com/caasp/v4.5/prometheus-node-exporter:0.18.1
registry.suse.com/caasp/v4.5/prometheus-alertmanager:0.16.2
registry.suse.com/ses/7/ceph/grafana:7.0.3
Por ejemplo:
cephuser@adm > ceph config set mgr mgr/cephadm/container_image_prometheus prom/prometheus:v1.4.1Al definir una imagen personalizada, el valor por defecto se anula (pero no se sobrescribe). El valor por defecto cambia cuando hay actualizaciones disponibles. Al definir una imagen personalizada, no podrá actualizar automáticamente el componente para el que ha definido la imagen personalizada. Deberá actualizar manualmente la configuración (el nombre de la imagen y la etiqueta) para poder instalar actualizaciones.
Si decide seguir las recomendaciones, puede restablecer la imagen personalizada que haya definido anteriormente. Después, se volverá a utilizar el valor por defecto. Utilice ceph config rm para restablecer la opción de configuración:
cephuser@adm > ceph config rm mgr mgr/cephadm/OPTION_NAMEPor ejemplo:
cephuser@adm > ceph config rm mgr mgr/cephadm/container_image_prometheus16.2 Actualización de los servicios de supervisión #
Como se menciona en la Sección 16.1, “Configuración de imágenes personalizadas o locales”, cephadm incluye las URL de las imágenes de contenedor recomendadas y probadas, que se utilizan por defecto.
Al actualizar los paquetes de Ceph, se pueden incluir nuevas versiones de estas URL. Esto solo actualiza de dónde se extraen las imágenes del contenedor, pero no actualiza ningún servicio.
Después de actualizar las URL de las nuevas imágenes de contenedor, ya sea manualmente como se describe en la Sección 16.1, “Configuración de imágenes personalizadas o locales”, o automáticamente mediante una actualización del paquete de Ceph, los servicios de supervisión se pueden actualizar.
Para ello, utilice ceph orch redeploy así:
cephuser@adm >ceph orch redeploy node-exportercephuser@adm >ceph orch redeploy prometheuscephuser@adm >ceph orch redeploy alertmanagercephuser@adm >ceph orch redeploy grafana
Actualmente no existe un comando único para actualizar todos los servicios de supervisión. El orden en el que se actualizan estos servicios no es importante.
Si utiliza imágenes de contenedor personalizadas, las URL especificadas para los servicios de supervisión no cambiarán automáticamente si se actualizan los paquetes de Ceph. Si ha especificado imágenes de contenedor personalizadas, deberá especificar manualmente las URL de las nuevas imágenes de contenedor. Este puede ser el caso si utiliza un registro de contenedor local.
En la Sección 16.1, “Configuración de imágenes personalizadas o locales”, encontrará las URL de las imágenes de contenedor recomendadas.
16.3 Inhabilitación de la supervisión #
Para inhabilitar la pila de supervisión, ejecute los comandos siguientes:
cephuser@adm >ceph orch rm grafanacephuser@adm >ceph orch rm prometheus --force # this will delete metrics data collected so farcephuser@adm >ceph orch rm node-exportercephuser@adm >ceph orch rm alertmanagercephuser@adm >ceph mgr module disable prometheus
16.4 Configuración de Grafana #
El procesador final de Ceph Dashboard requiere la URL de Grafana para poder verificar la existencia de consolas de Grafana antes de que el procesador frontal las cargue. Debido a cómo se implementa Grafana en Ceph Dashboard, esto significa que se requieren dos conexiones en funcionamiento para poder ver los gráficos de Grafana en Ceph Dashboard:
El procesador final (módulo Ceph MGR) debe verificar la existencia del gráfico solicitado. Si esta petición se realiza correctamente, el procesador frontal sabe que puede acceder a Grafana de forma segura.
A continuación, el procesador frontal pide los gráficos de Grafana directamente desde el navegador del usuario mediante un
iframe. Se accede directamente a la instancia de Grafana sin ningún desvío a través de Ceph Dashboard.
Ahora bien, puede darse el caso de que su entorno dificulte el acceso directo del navegador del usuario a la URL configurada en Ceph Dashboard. Para solucionar este problema, es posible configurar una URL independiente que se utilizará únicamente para indicar al procesador frontal (el navegador del usuario) qué URL debe utilizar para acceder a Grafana.
Para cambiar la URL que se devuelve al procesador frontal, emita el comando siguiente:
cephuser@adm > ceph dashboard set-grafana-frontend-api-url GRAFANA-SERVER-URLSi no se define ningún valor para esa opción, simplemente se recurrirá al valor de la opción GRAFANA_API_URL, que cephadm define de forma automática y actualiza periódicamente. Si se define, indicará al navegador que utilice esta URL para acceder a Grafana.
16.5 Configuración del módulo de gestor de Prometheus #
El módulo de gestor de Prometheus es un módulo de Ceph que amplía la funcionalidad de Ceph. El módulo lee metadatos de Ceph acerca de su estado y actividad, proporcionando los datos extraídos en un formato que Prometheus puede consumir.
Es necesario reiniciar el módulo de gestor de Prometheus para que se apliquen los cambios de configuración.
16.5.1 Configuración de la interfaz de red #
Por defecto, el módulo de gestor de Prometheus acepta peticiones HTTP en el puerto 9283 en todas las direcciones IPv4 e IPv6 del host. El puerto y la dirección de escucha se pueden configurar con ceph config-key set, con las claves mgr/prometheus/server_addr y mgr/prometheus/server_port. Este puerto está indicado en el registro de Prometheus.
Para actualizar server_addr, ejecute el comando siguiente:
cephuser@adm > ceph config set mgr mgr/prometheus/server_addr 0.0.0.0
Para actualizar server_port, ejecute el comando siguiente:
cephuser@adm > ceph config set mgr mgr/prometheus/server_port 928316.5.2 Configuración de scrape_interval #
Por defecto, el módulo de gestor de Prometheus se configura con un intervalo de scrape de 15 segundos. No se recomienda utilizar un intervalo inferior a 10 segundos. Para definir un intervalo diferente en el módulo de Prometheus, defina el valor que desee en scrape_interval:
Para que funcione correctamente y no se produzcan problemas, el valor de scrape_interval de este módulo siempre debe coincidir con el intervalo de scrape de Prometheus.
cephuser@adm > ceph config set mgr mgr/prometheus/scrape_interval 1516.5.3 Configuración de caché #
En clústeres grandes (de más de 1000 OSD), el tiempo necesario para obtener las métricas puede ser considerable. Sin la memoria caché, el módulo de gestor de Prometheus puede sobrecargar el gestor y provocar que las instancias de Ceph Manager no respondan o se bloqueen. Como resultado, la memoria caché está habilitada por defecto y no se puede inhabilitar, pero esto significa que la caché puede quedarse obsoleta. Se considera obsoleta cuando el tiempo para obtener las métricas de Ceph supera el valor de scrape_interval configurado.
Si este es el caso, se registrará una advertencia y el módulo:
Responde con un código de estado HTTP 503 (servicio no disponible).
Devuelve el contenido de la caché, aunque esté obsoleta.
Este comportamiento se puede configurar mediante los comandos ceph config set.
Para pedirle al módulo que responda con la indicación de que los datos posiblemente estén obsoletos, añada return:
cephuser@adm > ceph config set mgr mgr/prometheus/stale_cache_strategy return
Para pedirle al módulo que responda con servicio no disponible, añada fail:
cephuser@adm > ceph config set mgr mgr/prometheus/stale_cache_strategy fail16.5.4 Habilitación de la supervisión de imágenes RBD #
El módulo de gestor de Prometheus puede recopilar, opcionalmente, estadísticas de E/S por imagen RBD habilitando contadores de rendimiento de OSD dinámicos. Las estadísticas se recopilan para todas las imágenes de los repositorios especificados en el parámetro de configuración mgr/prometheus/rbd_stats_pools.
El parámetro es una lista separada por comas o espacios de entradas pool[/namespace]. Si no se especifica el espacio de nombres, las estadísticas se recopilan para todos los espacios de nombres del repositorio.
Por ejemplo:
cephuser@adm > ceph config set mgr mgr/prometheus/rbd_stats_pools "pool1,pool2,poolN"
El módulo explora los repositorios y espacios de nombres especificados, crea una lista de todas las imágenes disponibles y la actualiza periódicamente. El intervalo se puede configurar mediante el parámetro mgr/prometheus/rbd_stats_pools_refresh_interval (en segundos) y es de 300 segundos (cinco minutos) por defecto
Por ejemplo, si cambia el intervalo de sincronización a 10 minutos:
cephuser@adm > ceph config set mgr mgr/prometheus/rbd_stats_pools_refresh_interval 60016.6 Modelo de seguridad de Prometheus #
El modelo de seguridad de Prometheus presupone que los usuarios que no son de confianza tienen acceso al puesto final HTTP y los registros de Prometheus. Los usuarios que no son de confianza tienen acceso a todos los metadatos que Prometheus recopila y que se encuentran en la base de datos, además de a distinta información operativa y de depuración.
Sin embargo, la API HTTP de Prometheus está limitada a operaciones de solo lectura. Las configuraciones no se pueden cambiar mediante la API y los secretos no se revelan. Además, Prometheus tiene medidas integradas para mitigar el impacto de los ataques de denegación de servicio.
16.7 Receptor de alertas SNMP Alertmanager de Prometheus #
Si desea recibir una notificación sobre las alertas de Prometheus mediante alertas SNMP, puede instalar el receptor de alertas SNMP Alertmanager de Prometheus a través de cephadm. Para ello, debe crear un archivo de especificación de servicio y colocación con el contenido siguiente:
Para obtener más información sobre los archivos de servicio y colocación, consulte Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.2 “Especificación del servicio y la colocación”.
service_type: container
service_id: prometheus-webhook-snmp
placement:
ADD_PLACEMENT_HERE
image: registry.suse.com/ses/7/prometheus-webhook-snmp:latest
args:
- "--publish 9099:9099"
envs:
- ARGS="--debug --snmp-host=ADD_HOST_GATEWAY_HERE"
- RUN_ARGS="--metrics"
EOFUtilice esta especificación de servicio para que el servicio se ejecute con sus ajustes por defecto.
Debe publicar el puerto en el que escucha el receptor de Prometheus mediante el argumento de línea de comandos --publish PUERTO_DE_HOST:PUERTO_DE_CONTENEDOR cuando se ejecuta el servicio, ya que el contenedor no expone automáticamente el puerto. Esto se puede hacer añadiendo las líneas siguientes a la especificación:
args:
- "--publish 9099:9099"
Como alternativa, conecte el contenedor a la red del host mediante el argumento de línea de comandos --network=host.
args:
- "--network=host"Si el receptor de mensajes de alerta SNMP no está instalado en el mismo host que el contenedor, también debe especificar el nombre completo del host SNMP. Utilice la pasarela de red del contenedor para poder recibir mensajes de alerta SNMP fuera del contenedor/host:
envs:
- ARGS="--debug --snmp-host=CONTAINER_GATEWAY"16.7.1 Configuración del servicio prometheus-webhook-snmp #
El contenedor se puede configurar mediante variables de entorno o mediante un archivo de configuración.
Para las variables de entorno, utilice ARGS para definir las opciones globales y RUN_ARGS para las opciones del comando run. Debe adaptar la especificación de servicio de la siguiente manera:
envs:
- ARGS="--debug --snmp-host=CONTAINER_GATEWAY"
- RUN_ARGS="--metrics --port=9101"Para utilizar un archivo de configuración, la especificación de servicio debe adaptarse de la siguiente forma:
files:
etc/prometheus-webhook-snmp.conf:
- "debug: True"
- "snmp_host: ADD_HOST_GATEWAY_HERE"
- "metrics: True"
volume_mounts:
etc/prometheus-webhook-snmp.conf: /etc/prometheus-webhook-snmp.confPara distribuir, ejecute el comando siguiente:
cephuser@adm > ceph orch apply -i SERVICE_SPEC_FILEConsulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.3 “Distribución de servicios de Ceph” para obtener más información.
16.7.2 Configuración de Alertmanager de Prometheus para SNMP #
Por último, Alertmanager de Prometheus debe configurarse específicamente para las alertas SNMP. Si este servicio aún no se ha distribuido, cree un archivo de especificación de servicio. Debe sustituir IP_OR_FQDN por la dirección IP o el nombre completo del host en el que se ha instalado el receptor de alertas SNMP Alertmanager de Prometheus. Por ejemplo:
Si ya ha distribuido este servicio, para asegurarse de que Alertmanager está configurado correctamente para SNMP, vuelva a distribuirlo con los ajustes siguientes:
service_type: alertmanager
placement:
hosts:
- HOSTNAME
webhook_configs:
- 'http://IP_OR_FQDN:9099/'Aplique la especificación de servicio con el comando siguiente:
cephuser@adm > ceph orch apply -i SERVICE_SPEC_FILEParte III Almacenamiento de datos en un clúster #
- 17 Gestión de datos almacenados
El algoritmo CRUSH determina cómo se deben almacenar y recuperar los datos. Para ello, calcula las ubicaciones de almacenamiento. CRUSH aporta a los clientes de Ceph la capacidad de comunicarse con los OSD directamente, en lugar de hacerlo a través de un servidor centralizado o un intermediario. Con…
- 18 Gestión de repositorios de almacenamiento
Ceph almacena los datos en repositorios. Los repositorios son grupos lógicos en los que se almacenan objetos. Al distribuir un clúster por primera vez sin crear un repositorio, Ceph utiliza los repositorios por defecto para almacenar los datos. Los siguientes aspectos importantes están relacionados …
- 19 Repositorios codificados de borrado
Ceph ofrece una alternativa a la réplica normal de datos en repositorios denominada borrado o repositorio codificado de borrado. Los repositorios de borrado no proporcionan todas las funciones de los repositorios replicados (por ejemplo, no pueden almacenar metadatos para los repositorios RBD), pero…
- 20 Dispositivo de bloques RADOS
Un bloque es una secuencia de bytes, por ejemplo, un bloque de 4 MB de datos. Las interfaces de almacenamiento basadas en bloques son la forma más habitual de almacenar los datos en soportes de uso rotativo, como discos duros, CD o disquetes. La ubicuidad de las interfaces de dispositivos de bloques…
17 Gestión de datos almacenados #
El algoritmo CRUSH determina cómo se deben almacenar y recuperar los datos. Para ello, calcula las ubicaciones de almacenamiento. CRUSH aporta a los clientes de Ceph la capacidad de comunicarse con los OSD directamente, en lugar de hacerlo a través de un servidor centralizado o un intermediario. Con un método de almacenamiento y recuperación de datos determinado mediante un algoritmo, Ceph evita que haya un punto único de error, un cuello de botella de rendimiento y un límite físico a su capacidad de ampliación.
CRUSH requiere un mapa del clúster y usa el mapa de CRUSH para almacenar y recuperar de forma pseudoaleatoria los datos de los OSD con una distribución uniforme de los datos por el clúster.
Los mapas de CRUSH contienen una lista de los OSD, una lista de "depósitos" para agregar los dispositivos en ubicaciones físicas, y una lista de reglas que indican a CRUSH cómo se deben replicar los datos en los repositorios del clúster de Ceph. Al reflejar la organización física subyacente de la instalación, CRUSH puede modelar, y por lo tanto solucionar, causas potenciales de errores de dispositivo correlacionados. Las causas habituales suelen ser la proximidad física, una fuente de alimentación compartida y una red compartida. Mediante la codificación de esta información en un mapa del clúster, las directivas de colocación de CRUSH pueden separar las réplicas del objeto en dominios de fallo diferentes, al tiempo que se mantiene la distribución que se desea. Por ejemplo, para prepararse en caso de que se produzcan fallos simultáneos, puede ser conveniente asegurarse de que las réplicas de datos se encuentran en dispositivos que utilizan diferentes estantes, bastidores, fuente de alimentación, controladores o ubicaciones físicas.
Después de distribuir un clúster de Ceph, se genera un mapa de CRUSH por defecto. Resulta adecuado para el entorno de la zona protegida de Ceph. Sin embargo, si se distribuye un clúster de datos a gran escala, debe planificarse concienzudamente cómo desarrollar un mapa de CRUSH personalizado, ya que le ayudará a gestionar el clúster de Ceph, a mejorar el rendimiento y a garantizar la seguridad de los datos.
Por ejemplo, si falla un OSD, un mapa de CRUSH puede ayudarle a localizar el centro de datos físico, la sala, la fila y el bastidor del host donde se encuentra el OSD que ha fallado, en caso de que necesite asistencia técnica in situ o sustituir el hardware.
Del mismo modo, CRUSH puede ayudarle a identificar los errores más rápidamente. Por ejemplo, si todos los OSD en un bastidor determinado fallan al mismo tiempo, el error podría encontrarse en un conmutador de red o en la fuente de alimentación del bastidor, o en el conmutador de red, en lugar de estar en los propios OSD.
Un mapa de CRUSH personalizado también ayuda a identificar las ubicaciones físicas donde Ceph almacena las copias redundantes de los datos si los grupos de colocación (consulte la Sección 17.4, “Grupos de colocación”) asociados con un host que falla se encuentran en un estado degradado.
Hay tres secciones principales en un mapa de CRUSH.
Los Dispositivos OSD son cualquier dispositivo de almacenamiento de objetos correspondiente a un daemon
ceph osd.Los Depósitos están formados por una agregación jerárquica de ubicaciones de almacenamiento (por ejemplo, filas, bastidores, hosts, etc.) y sus pesos asignados.
Los Conjuntos de reglas son una forma de seleccionar depósitos.
17.1 Dispositivos OSD #
Para asignar grupos de colocación a los OSD, un mapa de CRUSH requiere una lista de los dispositivos OSD (el nombre del daemon OSD). La lista de dispositivos aparece primero en el mapa de CRUSH.
#devices device NUM osd.OSD_NAME class CLASS_NAME
Por ejemplo:
#devices device 0 osd.0 class hdd device 1 osd.1 class ssd device 2 osd.2 class nvme device 3 osd.3class ssd
Como regla general, un daemon OSD se asigna a un solo disco.
17.1.1 Clases de dispositivos #
La flexibilidad del mapa de CRUSH para controlar la colocación de los datos es uno de los puntos fuertes de Ceph. También es una de las partes más difíciles de gestionar del clúster. Las clases de dispositivos automatizan los cambios más comunes en los mapas de CRUSH que, antes, el administrador debía realizar manualmente.
17.1.1.1 El problema de la gestión de CRUSH #
Los clústeres de Ceph se crean con frecuencia con varios tipos de dispositivos de almacenamiento: discos duros, unidades SSD, NVMe o incluso con combinaciones de estos. Llamamos a estos diferentes tipos de dispositivos de almacenamiento clases de dispositivos, para evitar confusiones entre la propiedad type de las depósitos CRUSH (por ejemplo, host, bastidor o fila; consulte la Sección 17.2, “Depósitos” para obtener detalles). Los Ceph OSD respaldados por unidades SSD son mucho más rápidos que los respaldados por discos giratorios, por lo que son más adecuados para ciertas cargas de trabajo. Ceph facilita la creación de repositorios RADOS para diferentes conjuntos de datos o cargas de trabajo, así como para asignar las diferentes reglas de CRUSH que sirven para controlar la colocación de datos para esos repositorios.

Sin embargo, configurar las reglas de CRUSH para colocar datos solo en una determinada clase de dispositivo resulta tedioso. Las reglas funcionan en términos de la jerarquía de CRUSH, pero si los dispositivos se mezclan en los mismos hosts o bastidores (como en la jerarquía de ejemplo anterior), se mezclarán (por defecto) y aparecerán en los mismos subárboles de la jerarquía. Separarlos manualmente en árboles independientes implicaba crear varias versiones de cada nodo intermedio para cada clase de dispositivo en las versiones anteriores de SUSE Enterprise Storage.
17.1.1.2 Clases de dispositivos #
Una solución elegante que ofrece Ceph es añadir una propiedad denominada
clase de dispositivo a cada OSD. Por defecto, los OSD
definirán automáticamente sus clases de dispositivo como "hdd", "ssd" o
"nvme", en función de las propiedades de hardware expuestas por el kernel
de Linux. Estas clases de dispositivo se indican en una columna nueva del
resultado del comando ceph osd tree:
cephuser@adm > ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 83.17899 root default
-4 23.86200 host cpach
2 hdd 1.81898 osd.2 up 1.00000 1.00000
3 hdd 1.81898 osd.3 up 1.00000 1.00000
4 hdd 1.81898 osd.4 up 1.00000 1.00000
5 hdd 1.81898 osd.5 up 1.00000 1.00000
6 hdd 1.81898 osd.6 up 1.00000 1.00000
7 hdd 1.81898 osd.7 up 1.00000 1.00000
8 hdd 1.81898 osd.8 up 1.00000 1.00000
15 hdd 1.81898 osd.15 up 1.00000 1.00000
10 nvme 0.93100 osd.10 up 1.00000 1.00000
0 ssd 0.93100 osd.0 up 1.00000 1.00000
9 ssd 0.93100 osd.9 up 1.00000 1.00000
Si se produce un error al detectar automáticamente la clase de
dispositivo, por ejemplo porque el controlador del dispositivo no exponga
correctamente la información sobre el dispositivo mediante
/sys/block, puede ajustar las clases de dispositivo
desde la línea de comandos:
cephuser@adm >ceph osd crush rm-device-class osd.2 osd.3 done removing class of osd(s): 2,3cephuser@adm >ceph osd crush set-device-class ssd osd.2 osd.3 set osd(s) 2,3 to class 'ssd'
17.1.1.3 Definición de las reglas de colocación de CRUSH #
Las reglas de CRUSH pueden restringir la colocación a una clase de dispositivo específica. Por ejemplo, puede crear un repositorio "fast" (rápido) replicado que distribuya datos solo a través de discos SSD ejecutando el siguiente comando:
cephuser@adm > ceph osd crush rule create-replicated RULE_NAME ROOT FAILURE_DOMAIN_TYPE DEVICE_CLASSPor ejemplo:
cephuser@adm > ceph osd crush rule create-replicated fast default host ssdCree un repositorio denominado "fast_pool" y asígnelo a la regla "fast":
cephuser@adm > ceph osd pool create fast_pool 128 128 replicated fastEl proceso para crear reglas codificadas de borrado es ligeramente diferente. En primer lugar, cree un perfil codificado de borrado que incluya una propiedad para la clase de dispositivo deseada. A continuación, utilice ese perfil al crear el repositorio codificado de borrado:
cephuser@adm >ceph osd erasure-code-profile set myprofile \ k=4 m=2 crush-device-class=ssd crush-failure-domain=hostcephuser@adm >ceph osd pool create mypool 64 erasure myprofile
En caso de que necesite editar manualmente el mapa de CRUSH para personalizar la regla, la sintaxis se ha ampliado para permitir que se especifique la clase de dispositivo. Por ejemplo, la regla de CRUSH generada por los comandos anteriores tiene el siguiente aspecto:
rule ecpool {
id 2
type erasure
min_size 3
max_size 6
step set_chooseleaf_tries 5
step set_choose_tries 100
step take default class ssd
step chooseleaf indep 0 type host
step emit
}La diferencia importante aquí es que el comando "take" incluye el sufijo adicional "class NOMBRE_CLASE".
17.1.1.4 Comandos adicionales #
Para mostrar las clases de dispositivo utilizadas en un mapa de CRUSH, ejecute:
cephuser@adm > ceph osd crush class ls
[
"hdd",
"ssd"
]Para mostrar las reglas de CRUSH existentes, ejecute:
cephuser@adm > ceph osd crush rule ls
replicated_rule
fastPara ver los detalles de la regla de CRUSH denominada "fast", ejecute:
cephuser@adm > ceph osd crush rule dump fast
{
"rule_id": 1,
"rule_name": "fast",
"ruleset": 1,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -21,
"item_name": "default~ssd"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}Para mostrar los OSD que pertenecen a una clase "ssd", ejecute:
cephuser@adm > ceph osd crush class ls-osd ssd
0
117.1.1.5 Migración de una regla de SSD heredada a las clases de dispositivos #
En versiones de SUSE Enterprise Storage anteriores a la 5 era necesario editar manualmente el mapa de CRUSH y mantener una jerarquía paralela para cada tipo de dispositivo especializado (como SSD) para poder escribir reglas que se aplicaran a esos dispositivos. Desde SUSE Enterprise Storage 5, la característica de clase de dispositivo hace que escribir esas reglas se pueda hacer de forma transparente.
Es posible transformar una regla y una jerarquía heredadas a las nuevas
reglas basadas en clases mediante el comando crushtool.
Hay varios tipos de transformación posibles:
crushtool ‑‑reclassify‑root ROOT_NAME DEVICE_CLASSEste comando toma todos los elementos de la jerarquía situados bajo ROOT_NAME (nombre de raíz) y ajusta las reglas que hacen referencia a esa raíz mediante
take ROOT_NAME
y las sustituya por
take ROOT_NAME class DEVICE_CLASS
Vuelve a numerar los depósitos para que los ID anteriores se utilicen para el "árbol paralelo" de la clase especificada. Como consecuencia, no se produce ningún movimiento de datos.
Ejemplo 17.1:crushtool ‑‑reclassify‑root#Veamos la siguiente regla existente:
rule replicated_ruleset { id 0 type replicated min_size 1 max_size 10 step take default step chooseleaf firstn 0 type rack step emit }Si reclasifica la raíz "default" como clase "hdd", la regla se convertirá en:
rule replicated_ruleset { id 0 type replicated min_size 1 max_size 10 step take default class hdd step chooseleaf firstn 0 type rack step emit }crushtool ‑‑set‑subtree‑class BUCKET_NAME DEVICE_CLASSEste método marca todos los dispositivos del subárbol enraizados en BUCKET_NAME con la clase de dispositivo especificada.
‑‑set-subtree-classse utiliza normalmente junto con la opción‑‑reclassify-rootpara garantizar que todos los dispositivos de esa raíz están etiquetados con la clase correcta. Sin embargo, algunos de esos dispositivos pueden tener una clase diferente de forma intencionada y, por lo tanto, no desea volver a etiquetarlos. En tales casos, excluya la opción‑‑set-subtree-class. Tenga en cuenta que dicha reasignación no será perfecta, ya que la regla anterior se distribuye entre dispositivos de varias clases, pero las reglas ajustadas solo se asignan a los dispositivos de la clase de dispositivo especificada.crushtool ‑‑reclassify‑bucket MATCH_PATTERN DEVICE_CLASS DEFAULT_PATTERNEste método permite combinar una jerarquía paralela específica de tipo con la jerarquía normal. Por ejemplo, muchos usuarios tienen mapas de CRUSH similares a los siguientes:
Ejemplo 17.2:crushtool ‑‑reclassify‑bucket#host node1 { id -2 # do not change unnecessarily # weight 109.152 alg straw hash 0 # rjenkins1 item osd.0 weight 9.096 item osd.1 weight 9.096 item osd.2 weight 9.096 item osd.3 weight 9.096 item osd.4 weight 9.096 item osd.5 weight 9.096 [...] } host node1-ssd { id -10 # do not change unnecessarily # weight 2.000 alg straw hash 0 # rjenkins1 item osd.80 weight 2.000 [...] } root default { id -1 # do not change unnecessarily alg straw hash 0 # rjenkins1 item node1 weight 110.967 [...] } root ssd { id -18 # do not change unnecessarily # weight 16.000 alg straw hash 0 # rjenkins1 item node1-ssd weight 2.000 [...] }Esta función reclasifica cada depósito que coincide con un patrón determinado. El patrón puede ser de tipo
%sufijooprefijo%. En el ejemplo anterior, se usaría el patrón%-ssd. Para cada depósito coincidente, la parte restante del nombre que coincida con el comodín "%" especifica el depósito base. Todos los dispositivos del depósito coincidente se etiquetan con la clase de dispositivo especificada y, a continuación, se mueven al depósito base. Si el depósito base no existe (por ejemplo, si "node12-ssd" existe, pero "node12" no), se crea y se vincula debajo del depósito padre por defecto especificado. Los ID de depósito antiguos se conservan para los nuevos depósitos paralelos a fin de evitar que haya que mover datos. Las reglas con los pasostake(tomar) que hagan referencia a depósitos antiguos se ajustan.crushtool ‑‑reclassify‑bucket BUCKET_NAME DEVICE_CLASS BASE_BUCKETPuede utilizar la opción
‑‑reclassify-bucketsin un comodín para asignar un solo depósito. Por ejemplo, en el ejemplo anterior, queremos que el depósito "ssd" se asigne al depósito por defecto.El comando final para convertir el mapa compuesto por los fragmentos anteriores sería el siguiente:
cephuser@adm >ceph osd getcrushmap -o originalcephuser@adm >crushtool -i original --reclassify \ --set-subtree-class default hdd \ --reclassify-root default hdd \ --reclassify-bucket %-ssd ssd default \ --reclassify-bucket ssd ssd default \ -o adjustedPara verificar que la conversión sea correcta, hay una opción
‑‑compareque prueba una muestra cuantiosa de entradas al mapa de CRUSH y comprueba si vuelve a salir el mismo resultado. Estas entradas se controlan mediante las mismas opciones que se aplican a‑‑test. Para el ejemplo anterior, el comando sería el siguiente:cephuser@adm >crushtool -i original --compare adjusted rule 0 had 0/10240 mismatched mappings (0) rule 1 had 0/10240 mismatched mappings (0) maps appear equivalentSugerenciaSi hubiera diferencias, vería qué proporción de entradas se reasignan entre paréntesis.
Si el mapa de CRUSH ajustado es el que desea, puede aplicarlo al clúster:
cephuser@adm >ceph osd setcrushmap -i adjusted
17.1.1.6 información adicional #
Encontrará más detalles sobre los mapas de CRUSH en la Sección 17.5, “Manipulación del mapa de CRUSH”.
Encontrará más detalles sobre los repositorios de Ceph en general en el Capítulo 18, Gestión de repositorios de almacenamiento.
Encontrará más detalles sobre los repositorios codificados de borrado en el Capítulo 19, Repositorios codificados de borrado.
17.2 Depósitos #
Los mapas de CRUSH contienen una lista de los OSD, que se pueden organizar en una estructura de árbol de los depósitos para agregar los dispositivos en ubicaciones físicas. Los OSD individuales forman las hojas del árbol.
|
0 |
osd |
Un dispositivo u OSD específico ( |
|
1 |
host |
El nombre de un host que contiene uno o más OSD. |
|
2 |
chassis |
Identificador del chasis del bastidor que contiene el
|
|
3 |
rack |
El bastidor de un equipo. El valor por defecto es
|
|
4 |
row |
Una fila de una serie de bastidores. |
|
5 |
pdu |
Abreviatura de "Power Distribution Unit", unidad de distribución de energía. |
|
6 |
pod |
Abreviatura de "Point of Delivery", punto de entrega. En este contexto, un grupo de PDU o un grupo de filas de bastidores. |
|
7 |
room |
Una sala que contiene filas de bastidores. |
|
8 |
datacenter |
Un centro de datos físico que contiene una o más salas. |
|
9 |
region |
Región geográfica del mundo (por ejemplo, NAM, LAM, EMEA, APAC, etc.). |
|
10 |
root |
El nodo raíz del árbol de depósitos OSD (normalmente definido como
|
Puede modificar los tipos existentes y crear los suyos propios.
Las herramientas de distribución de Ceph generan un mapa de CRUSH que
contiene un depósito para cada host y una raíz denominada "default", lo que
resulta útil para el repositorio rbd por defecto. El
resto de tipos de depósitos ofrecen un medio para almacenar información
acerca de la ubicación física de los nodos/depósitos, lo que facilita la
administración del clúster cuando los OSD, los hosts, o el hardware de red
funcionan erróneamente y el administrador necesita acceder al hardware
físico.
Una depósito tiene un tipo, un nombre exclusivo (cadena), un ID único que se
expresa como un número entero negativo, un peso relativo a la capacidad
total dividida entre la capacidad de sus elementos, el algoritmo de depósito
(por defecto, straw2) y el hash (0 por
defecto, que refleja el hash de CRUSH rjenkins1). Un
depósito puede tener uno o varios elementos. Los elementos pueden estar
formados por otros depósitos o por OSD. Los elementos pueden tener un peso
relativo.
[bucket-type] [bucket-name] {
id [a unique negative numeric ID]
weight [the relative capacity/capability of the item(s)]
alg [the bucket type: uniform | list | tree | straw2 | straw ]
hash [the hash type: 0 by default]
item [item-name] weight [weight]
}En el siguiente ejemplo se muestra cómo se pueden utilizar depósitos para agregar un repositorio y ubicaciones físicas como un centro de datos, una sala, un bastidor y una fila.
host ceph-osd-server-1 {
id -17
alg straw2
hash 0
item osd.0 weight 0.546
item osd.1 weight 0.546
}
row rack-1-row-1 {
id -16
alg straw2
hash 0
item ceph-osd-server-1 weight 2.00
}
rack rack-3 {
id -15
alg straw2
hash 0
item rack-3-row-1 weight 2.00
item rack-3-row-2 weight 2.00
item rack-3-row-3 weight 2.00
item rack-3-row-4 weight 2.00
item rack-3-row-5 weight 2.00
}
rack rack-2 {
id -14
alg straw2
hash 0
item rack-2-row-1 weight 2.00
item rack-2-row-2 weight 2.00
item rack-2-row-3 weight 2.00
item rack-2-row-4 weight 2.00
item rack-2-row-5 weight 2.00
}
rack rack-1 {
id -13
alg straw2
hash 0
item rack-1-row-1 weight 2.00
item rack-1-row-2 weight 2.00
item rack-1-row-3 weight 2.00
item rack-1-row-4 weight 2.00
item rack-1-row-5 weight 2.00
}
room server-room-1 {
id -12
alg straw2
hash 0
item rack-1 weight 10.00
item rack-2 weight 10.00
item rack-3 weight 10.00
}
datacenter dc-1 {
id -11
alg straw2
hash 0
item server-room-1 weight 30.00
item server-room-2 weight 30.00
}
root data {
id -10
alg straw2
hash 0
item dc-1 weight 60.00
item dc-2 weight 60.00
}17.3 Conjuntos de reglas #
Los mapas de CRUSH admiten la noción de "reglas de CRUSH", que son las reglas que determinan la colocación de los datos de un repositorio. En clústeres de gran tamaño, es probable que cree muchos repositorios y que cada uno de ellos tenga sus propios conjuntos de reglas y reglas de CRUSH. El mapa de CRUSH por defecto tiene una regla para la raíz por defecto. Si desea más raíces y más reglas, debe crearlas más adelante o se crearán automáticamente cuando se creen nuevos repositorios.
En la mayoría de los casos, no será necesario modificar las reglas por defecto. Cuando se crea un repositorio nuevo, el conjunto de reglas por defecto es 0.
Una regla tiene el siguiente formato:
rule rulename {
ruleset ruleset
type type
min_size min-size
max_size max-size
step step
}- ruleset
Un número entero. Clasifica una regla para que pertenezca a un conjunto de reglas. Se activa definiendo el conjunto de reglas en un repositorio. Esta opción es obligatoria. El valor por defecto es
0.- type
Una cadena. Describe una regla para un repositorio codificado de réplica ("replicated)" o de borrado ("erasure"). Esta opción es obligatoria. El valor por defecto es
replicated(replicada).- min_size
Un número entero. Si un grupo de repositorios realiza un número inferior de réplicas que el indicado por este número, CRUSH NO selecciona esta regla. Esta opción es obligatoria. El valor por defecto es
2.- max_size
Un número entero. Si un grupo de repositorios realiza un número superior de réplicas que el indicado por este número, CRUSH NO selecciona esta regla. Esta opción es obligatoria. El valor por defecto es
10.- step take bucket
Toma un depósito especificado por su nombre e inicia una iteración hacia abajo por el árbol. Esta opción es obligatoria. Para obtener una explicación acerca de la iteración por el árbol, consulte la Sección 17.3.1, “Iteración del árbol de nodos”.
- step targetmodenum type bucket-type
target puede ser
chooseochooseleaf. Si se define comochoose, se seleccionan varios depósitos.chooseleafselecciona directamente los OSD (nodos hoja) del subárbol de cada depósito en el conjunto de depósitos.mode puede ser
firstnoindep. Consulte la Sección 17.3.2, “firstn e indep”.Selecciona el número de depósitos del tipo especificado. Donde N es el número de opciones disponibles, si num > 0 && < N, seleccione ese número de depósitos; si num < 0, significa N - num; y si num == 0, selecciona N depósitos (todos los disponibles). Se usa después de
step takeo astep choose.- step emit
Devuelve el valor actual y vacía la pila. Se suele usar al final de una regla, pero también puede utilizarse para formar árboles diferentes en la misma regla. Se usa después de
step choose.
17.3.1 Iteración del árbol de nodos #
La estructura definida con los depósitos se puede ver como un árbol de nodos. Los depósitos son nodos y los OSD son hojas de ese árbol.
Las reglas del mapa de CRUSH definen cómo se seleccionan los OSD del árbol. Una regla empieza con un nodo y se itera hacia abajo por el árbol para devolver un conjunto de OSD. No es posible definir la rama que se debe seleccionar. En su lugar, el algoritmo CRUSH garantiza que el conjunto de OSD cumple los requisitos de réplica y distribuye los datos de forma homogénea.
Con step take bucket, la
iteración por el árbol de nodos comienza en el depósito indicado (no en el
tipo de depósito). Si se deben devolver OSD de todas las ramas del árbol,
se debe indicar el depósito raíz. De lo contrario, la iteración de los
pasos siguientes solo se producirá por un subárbol.
Después de step take, se usan una o varias entradas
step choose en la definición de la regla. Cada
step choose elige un número definido de nodos (o ramas)
del nodo superior seleccionado anteriormente.
Al final, los OSD seleccionados se devuelven con step
emit.
step chooseleaf es una función de conveniencia que
selecciona directamente los OSD de ramas de un depósito determinado.
En la Figura 17.2, “Árbol de ejemplo” se proporciona un
ejemplo de cómo se usa step para producir la iteración
por un árbol. Las flechas naranjas y los números corresponden a
example1a y example1b, mientras que
las azules corresponden a example2 en las siguientes
definiciones de regla.

# orange arrows
rule example1a {
ruleset 0
type replicated
min_size 2
max_size 10
# orange (1)
step take rack1
# orange (2)
step choose firstn 0 host
# orange (3)
step choose firstn 1 osd
step emit
}
rule example1b {
ruleset 0
type replicated
min_size 2
max_size 10
# orange (1)
step take rack1
# orange (2) + (3)
step chooseleaf firstn 0 host
step emit
}
# blue arrows
rule example2 {
ruleset 0
type replicated
min_size 2
max_size 10
# blue (1)
step take room1
# blue (2)
step chooseleaf firstn 0 rack
step emit
}17.3.2
Una regla de CRUSH define las sustituciones de los nodos o los OSD que
fallan (consulte la Sección 17.3, “Conjuntos de reglas”). La palabra clave
step requiere el parámetro firstn o
indep. En la
Figura 17.3, “Métodos de sustitución de nodos” se muestra un
ejemplo.
Con firstn se añaden nodos de sustitución al final de la
lista de nodos activos. En el caso de un nodo que ha fallado, los nodos en
buen estado siguientes se desplazan a la izquierda para cubrir el hueco del
nodo erróneo. Se trata del método por defecto, y el recomendado, para los
repositorios replicados, ya que un nodo secundario ya
tiene todos los datos y, por lo tanto, puede hacerse cargo de las tareas
del nodo principal de inmediato.
Con indep se seleccionan nodos de sustitución fijos para
cada nodo activo. La sustitución de un nodo con fallos no cambia el orden
de los nodos restantes. Este es el comportamiento recomendado para los
repositorios codificados de borrado. En los
repositorios codificados de borrado, los datos almacenados en un nodo
dependen de su posición en la selección de nodos. Cuando se cambia el orden
de los nodos, todos los datos de los nodos afectados deben recolocarse.

17.4 Grupos de colocación #
Ceph asigna objetos a los grupos de colocación. Los grupos de colocación son fragmentos de un repositorio de objetos lógicos que colocan objetos como un grupo en los OSD. Los grupos de colocación reducen la cantidad de metadatos por objeto cuando Ceph almacena los datos en los OSD. Disponer de un mayor número de grupos de colocación (por ejemplo, 100 por OSD) produce que haya un mejor equilibrio.
17.4.1 Uso de los grupos de colocación #
Un grupo de colocación (PG) agrega objetos dentro de un repositorio. La razón principal es que realizar un seguimiento de la ubicación de los objetos y de los metadatos de cada objeto es costoso desde el punto de vista computacional. Por ejemplo, un sistema con millones de objetos no puede realizar directamente un seguimiento de la ubicación de cada uno de esos objetos.

El cliente de Ceph calculará a qué grupo de colocación pertenecerá un objeto. Para ello, aplica el hash del ID de objeto y aplica una operación basada en el número grupos de colocación del repositorio definido y el ID del repositorio.
El contenido de un objeto situado dentro de un grupo de colocación se almacena en un conjunto de OSDs. Por ejemplo, en un repositorio replicado con un tamaño de dos, cada grupo de colocación almacenará objetos en dos OSD:

Si se produce un error en el OSD 2, otro OSD se asignará al grupo de colocación 1 y se rellenará con copias de todos los objetos de OSD 1. Si el tamaño del repositorio cambia de dos a tres, se asignará un OSD adicional al grupo de colocación y recibirá copias de todos los objetos del grupo de colocación.
Los grupos de colocación no son propietarios del OSD; lo comparten con otros grupos de colocación del mismo repositorio, o incluso con otros repositorios. Si se produce un error en el OSD 2, el grupo de colocación 2 también tendrá que restaurar copias de los objetos, mediante el OSD 3.
Cuando aumenta el número de grupos de colocación, se asignan OSD a los nuevos grupos de colocación. El resultado de la función CRUSH también cambia y algunos objetos de los grupos de colocación anteriores se copian en los nuevos grupos de colocación y se eliminan de los antiguos.
17.4.2 Determinación del valor de PG_NUM #
Desde Ceph Nautilus (v14.x), puede utilizar el módulo
pg_autoscaler de Ceph Manager para escalar
automáticamente los grupos de colocación según sea necesario. Si desea
habilitar esta función, consulte el
Book “Deploying and Administering SUSE Enterprise Storage with Rook”, Chapter 6 “Configuration”, Section 6.1.1.1 “Default PG and PGP counts”.
Al crear un repositorio nuevo, se puede elegir el valor de PG_NUM manualmente:
root # ceph osd pool create POOL_NAME PG_NUMEl valor de PG_NUM no se puede calcular automáticamente. A continuación se muestran algunos valores de uso común según el número de OSDs del clúster:
- Menos de 5 OSD:
En PG_NUM, defina el valor 128.
- Entre 5 y 10 OSD:
En PG_NUM, defina el valor 512.
- Entre 10 y 50 OSD:
En PG_NUM, defina el valor 1024.
A medida que aumenta el número de OSD, seleccionar el valor adecuado para PG_NUM se vuelve cada vez más importante. El valor de PG_NUM afecta considerablemente al comportamiento del clúster, así como a la durabilidad de los datos en caso de error del OSD.
17.4.2.1 Cálculo de los grupos de colocación para más de 50 OSD #
Si tiene menos de 50 OSD, utilice el valor preseleccionado descrito en la Sección 17.4.2, “Determinación del valor de PG_NUM”. Si tiene más de 50 OSD, se recomienda disponer de entre 50 y 100 grupos de colocación por OSD para equilibrar el uso de los recursos, la durabilidad de los datos y la distribución. Para un único repositorio de objetos, puede utilizar la siguiente fórmula para obtener una línea base:
total PGs = (OSDs * 100) / POOL_SIZE
Donde POOL_SIZE es el número de réplicas para
repositorios replicados o la suma "k"+"m" para lo repositorios codificados
de borrado, según el resultado del comando ceph osd
erasure-code-profile get. Debe redondear el resultado hasta la
potencia más cercana de 2. Se recomienda redondear hacia arriba para que
el algoritmo CRUSH equilibre uniformemente el número de objetos entre los
grupos de colocación.
Por ejemplo, para un clúster con 200 OSD y un tamaño de repositorio de 3 réplicas, el número de grupos de colocación se calcularía de la siguiente manera:
(200 * 100) / 3 = 6667
La potencia más cercana de 2 es 8192.
Si se usan varios repositorios de datos para almacenar objetos, debe equilibrar el número de grupos de colocación por repositorio con el número de grupos de colocación por OSD. Se debe alcanzar un número total razonable de grupos de colocación que proporcione una varianza razonablemente baja por OSD sin que afecte negativamente a los recursos del sistema ni provocar que el proceso de emparejamiento sea demasiado lento.
Por ejemplo, un clúster de 10 repositorios, cada uno con 512 grupos de colocación en 10 OSD da un total de 5120 grupos de colocación repartidos en 10 OSD; es decir, 512 grupos de colocación por OSD. Tal configuración no utilizaría demasiados recursos. Sin embargo, si se crearan 1000 repositorios con 512 grupos de colocación cada uno, los OSD controlarían aproximadamente 50 000 grupos de colocación cada uno y requerirían muchos más recursos y tiempo para el emparejamiento.
17.4.3 Definición del número de grupos de colocación #
Desde Ceph Nautilus (v14.x), puede utilizar el módulo
pg_autoscaler de Ceph Manager para escalar
automáticamente los grupos de colocación según sea necesario. Si desea
habilitar esta función, consulte el
Book “Deploying and Administering SUSE Enterprise Storage with Rook”, Chapter 6 “Configuration”, Section 6.1.1.1 “Default PG and PGP counts”.
Si aún necesita especificar el número de grupos de colocación en un repositorio manualmente, deberá especificarlos en el momento en el que cree el repositorio (consulte la Sección 18.1, “Creación de un repositorio”). Después de haber establecido los grupos de colocación para un repositorio, puede aumentar el número de grupos de colocación ejecutando el comando siguiente:
root # ceph osd pool set POOL_NAME pg_num PG_NUM
Después de aumentar el número de grupos de colocación, también debe
aumentar el número de grupos de colocación de la ubicación
(PGP_NUM) antes de que el clúster se reequilibre. El valor
de PGP_NUM será el número de grupos de colocación que el
algoritmo CRUSH tendrá en cuenta para la colocación. Al aumentar el valor
de PG_NUM, se dividen los grupos de colocación, pero los
datos no se migran a los grupos de colocación más recientes hasta que se
aumenta este valor de PG_NUM. El valor de
PGP_NUM debe ser igual al de PG_NUM. Para
aumentar el número de grupos de colocación de la ubicación, ejecute lo
siguiente:
root # ceph osd pool set POOL_NAME pgp_num PGP_NUM17.4.4 Obtención del número de grupos de colocación #
Para averiguar el número de grupos de colocación de un repositorio, ejecute
el comando get siguiente:
root # ceph osd pool get POOL_NAME pg_num17.4.5 Obtención de estadísticas del grupo de colocación de un clúster #
Para obtener las estadísticas de los grupos de colocación del clúster, ejecute el comando siguiente:
root # ceph pg dump [--format FORMAT]Los formatos válidos son "plain" (por defecto) y "json".
17.4.6 Obtención de estadísticas de los grupos de colocación atascados #
Para obtener las estadísticas de todos los grupos de colocación atascados en un estado especificado, ejecute lo siguiente:
root # ceph pg dump_stuck STATE \
[--format FORMAT] [--threshold THRESHOLD]
El valor de STATE puede ser "inactive"
(inactivo, los grupos de colocación no pueden procesar lecturas ni
escrituras porque están a la espera de que aparezca un OSD con los datos
más actualizados), "unclean" (no limpio, los grupos de colocación contienen
objetos que no se replican el número deseado de veces), "stale" (obsoleto,
los grupos de colocación están en un estado desconocido: los OSD donde se
alojan no han informado al clúster de supervisión en un intervalo de tiempo
especificado por la opción mon_osd_report_timeout,
"undersized" (tamaño insuficiente) o "degraded" (degradado).
Los formatos válidos son "plain" (por defecto) y "json".
El umbral define el número mínimo de segundos que el grupo de colocación debe estar atascado antes de que se incluya en las estadísticas (300 segundos por defecto).
17.4.7 Búsqueda de un mapa de grupos de colocación #
Para obtener el mapa de un grupo de colocación determinado, ejecute lo siguiente:
root # ceph pg map PG_IDCeph devolverá el mapa del grupo de colocación, el grupo de colocación y el estado del OSD:
root # ceph pg map 1.6c
osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]17.4.8 Obtención de estadísticas de los grupos de colocación #
Para recuperar estadísticas de un grupo de colocación determinado, ejecute lo siguiente:
root # ceph pg PG_ID query17.4.9 Depuración de un grupo de colocación #
Para borrar de forma segura un grupo de colocación (Sección 17.6, “Depuración de grupos de colocación”), ejecute lo siguiente:
root # ceph pg scrub PG_IDCeph comprueba los nodos primario y de réplica, genera un catálogo de todos los objetos del grupo de colocación y los compara para asegurarse de que no falta ningún objeto, que no coinciden y que su contenido es coherente. Suponiendo que todas las réplicas coincidan, un barrido semántico final garantiza que todos los metadatos de objetos relacionados con instantáneas sean coherentes. Los errores se notifican a través de los registros.
17.4.10 Priorización de la reposición y la recuperación de los grupos de colocación #
Puede encontrarse con una situación en la que varios grupos de colocación requieran una recuperación o una reposición, y algunos grupos contienen datos más importantes que otros. Por ejemplo, unos grupos de colocación pueden contener datos para las imágenes utilizadas por las máquinas en ejecución, mientras que otros pueden ser utilizados por máquinas inactivas o contener datos menos relevantes. En este caso, es posible que desee dar prioridad a la recuperación de los primeros grupos para que el rendimiento y la disponibilidad de los datos almacenados en aquellos grupos se restaure antes. Para marcar grupos de colocación concretos como prioritarios durante la reposición o la recuperación, ejecute lo siguiente:
root #ceph pg force-recovery PG_ID1 [PG_ID2 ... ]root #ceph pg force-backfill PG_ID1 [PG_ID2 ... ]
Esto hará que Ceph lleve a cabo la recuperación o la reposición en los grupos de colocación especificados, antes que en los demás. No se interrumpen las operaciones de reposición o recuperación que haya en curso, sino que los grupos de colocación especificados se procesan lo antes posible. Si cambia de opinión o se equivoca de grupo para priorizar, puede cancelar la priorización:
root #ceph pg cancel-force-recovery PG_ID1 [PG_ID2 ... ]root #ceph pg cancel-force-backfill PG_ID1 [PG_ID2 ... ]
Los comandos cancel‑* eliminan el indicador "force" de
los grupos de colocación para que se procesen en el orden por defecto. Una
vez más, esto no afecta a los grupos de colocación que ya se están
procesando, solo a los que todavía están en cola. El indicador "force" se
borra automáticamente después de que se realice la recuperación o la
reposición del grupo.
17.4.11 Reversión de objetos perdidos #
Si el clúster ha perdido uno o más objetos y ha decidido abandonar la búsqueda de los datos perdidos, debe marcar los objetos no encontrados como "perdidos".
Si los objetos siguen perdidos después de haber consultado todas las ubicaciones posibles, es posible que deba darlos definitivamente por perdidos. Esto puede ocurrir si se da una combinación inusual de errores en la que se permite al clúster obtener información sobre las escrituras que se realizaron antes de que se recuperaran las escrituras en sí.
Actualmente, la única opción admitida es "revert", que revertirá a una versión anterior del objeto, o que se ignorará por completo en caso de un objeto nuevo. Para marcar los objetos "unfound" (no encontrados) como "lost" (perdidos), ejecute lo siguiente:
cephuser@adm > ceph pg PG_ID mark_unfound_lost revert|delete17.4.12 Habilitación del escalador automático de grupos de colocación #
Los grupos de colocación (PG) son un detalle de implementación interno de cómo Ceph distribuye los datos. Al habilitar pg-autoscaling, puede permitir que el clúster cree o ajuste automáticamente los grupos de colocación en función de cómo se utilice el clúster.
Cada repositorio del sistema tiene una propiedad
pg_autoscale_mode que se puede establecer en
off, on o warn:
El escalador automático se configura para cada repositorio y se puede ejecutar en tres modos:
- off
Inhabilita la escala automática para este repositorio. Depende del administrador elegir un número de grupos de colocación adecuado para cada repositorio.
- on
Habilita los ajustes automáticos del recuento de grupos de colocación para el repositorio indicado.
- warn
Genera alertas de estado que indican cuando se debe ajustar el recuento de grupos de colocación.
Para definir el modo escala automático para los repositorios existentes:
cephuser@adm > ceph osd pool set POOL_NAME pg_autoscale_mode mode
También puede configurar la propiedad por defecto de
pg_autoscale_mode que se aplica a cualquier repositorio
que se cree en el futuro con:
cephuser@adm > ceph config set global osd_pool_default_pg_autoscale_mode MODEPuede ver cada repositorio, su utilización relativa y los cambios sugeridos en el recuento de grupos de colocación con este comando:
cephuser@adm > ceph osd pool autoscale-status17.5 Manipulación del mapa de CRUSH #
En esta sección se describen formas para manipular de forma básica el mapa de CRUSH: por ejemplo, para editar un mapa de CRUSH; cambiar los parámetros del mapa de CRUSH y añadir, mover o eliminar un OSD.
17.5.1 Edición de un mapa de CRUSH #
Para editar un mapa de CRUSH existente, haga lo siguiente:
Obtenga un mapa de CRUSH. Para obtener el mapa de CRUSH de su clúster, ejecute lo siguiente:
cephuser@adm >ceph osd getcrushmap -o compiled-crushmap-filenameCeph da como resultado (
-o) un mapa de CRUSH compilado con el nombre de archivo que especifique. Puesto que el mapa de CRUSH está compilado, debe descompilarlo antes de que se pueda editar.Descompilación de un mapa de CRUSH. Para descompilar un mapa de CRUSH, ejecute lo siguiente:
cephuser@adm >crushtool -d compiled-crushmap-filename \ -o decompiled-crushmap-filenameCeph descompilará (
-d) el mapa de CRUSH compilado y lo obtendrá como resultado (‑o) con el nombre de archivo que especifique.Edite al menos uno de los parámetros de dispositivos, depósitos o reglas.
Compile un mapa de CRUSH. Para hacerlo, ejecute lo siguiente:
cephuser@adm >crushtool -c decompiled-crush-map-filename \ -o compiled-crush-map-filenameCeph almacenará un mapa de CRUSH compilado con el nombre de archivo que especifique.
Defina un mapa de CRUSH. Para definir el mapa de CRUSH de su clúster, ejecute lo siguiente:
cephuser@adm >ceph osd setcrushmap -i compiled-crushmap-filenameCeph introducirá el mapa de CRUSH compilado con el nombre de archivo que ha especificado como el mapa de CRUSH del clúster.
Utilice un sistema de control de versiones, como git o svn, para los archivos de mapa de CRUSH exportados y modificados. Con ellos, una posible reversión es más sencilla.
Pruebe el nuevo mapa de CRUSH ajustado con el comando crushtool
‑‑test y compárelo con el estado anterior a la aplicación del
nuevo mapa de CRUSH. Encontrará útiles los siguientes conmutadores de
comandos: ‑‑show‑statistics,
‑‑show‑mappings, ‑‑show‑bad‑mappings,
‑‑show‑utilization,
‑‑show‑utilization‑all,
‑‑show‑choose‑tries.
17.5.2 Adición o traslado de un OSD #
Para añadir o trasladar un OSD en el mapa de CRUSH de un clúster en ejecución, ejecute lo siguiente:
cephuser@adm > ceph osd crush set id_or_name weight root=pool-name
bucket-type=bucket-name ...- id
Un número entero. El ID numérico del OSD. Esta opción es obligatoria.
- name
Una cadena. El nombre completo del OSD. Esta opción es obligatoria.
- weight
Un valor doble. El peso de CRUSH para el OSD. Esta opción es obligatoria.
- root
Un par de clave y valor. Por defecto, la jerarquía de CRUSH contiene como raíz el repositorio por defecto. Esta opción es obligatoria.
- bucket-type
Pares clave-valor. Puede especificar la ubicación del OSD en la jerarquía de CRUSH.
El ejemplo siguiente añade osd.0 a la jerarquía, o
traslada el OSD desde una ubicación anterior.
cephuser@adm > ceph osd crush set osd.0 1.0 root=data datacenter=dc1 room=room1 \
row=foo rack=bar host=foo-bar-117.5.3 Diferencia entre ceph osd reweight y ceph osd crush reweight #
Hay dos comandos similares que cambian el "peso" de un Ceph OSD. El contexto en el que se usan es diferente y puede causar confusión.
17.5.3.1 ceph osd reweight #
Uso:
cephuser@adm > ceph osd reweight OSD_NAME NEW_WEIGHT
ceph osd reweight define un peso de sustitución en el
Ceph OSD. Este valor está en el intervalo entre 0 y 1 e impone a CRUSH que
recoloque los datos que de otro modo estarían en esta unidad.
No cambia los pesos asignados a los
depósitos situados por encima del OSD. Se trata de una medida correctiva
en caso de que la distribución normal de CRUSH no funcione del todo bien.
Por ejemplo, si uno de los OSD está al 90 % y los demás están al 40 %,
podría reducir este peso para tratar de compensarlos.
Tenga en cuenta que ceph osd reweight no es un ajuste
persistente. Cuando un OSD se excluye, su peso se define en 0, y cuando
se incluye de nuevo, el peso cambia a 1.
17.5.3.2 ceph osd crush reweight #
Uso:
cephuser@adm > ceph osd crush reweight OSD_NAME NEW_WEIGHT
El valor ceph osd crush reweight permite definir el
peso de CRUSH del OSD. Este peso es un
valor arbitrario (generalmente el tamaño del disco en TB) y controla la
cantidad de datos que el sistema intenta asignar al OSD.
17.5.4 Eliminación de un OSD #
Para eliminar un OSD del mapa de CRUSH de un clúster en ejecución, ejecute lo siguiente:
cephuser@adm > ceph osd crush remove OSD_NAME17.5.5 Adición de un depósito #
Para añadir un depósito al mapa de CRUSH de un clúster en ejecución,
ejecute el comando ceph osd crush add-bucket:
cephuser@adm > ceph osd crush add-bucket BUCKET_NAME BUCKET_TYPE17.5.6 Traslado de un depósito #
Para trasladar un depósito a una ubicación diferente o colocarlo en la jerarquía del mapa de CRUSH, ejecute lo siguiente:
cephuser@adm > ceph osd crush move BUCKET_NAME BUCKET_TYPE=BUCKET_NAME [...]Por ejemplo:
cephuser@adm > ceph osd crush move bucket1 datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-117.5.7 Eliminación de un depósito #
Para eliminar un depósito de la jerarquía del mapa de CRUSH, ejecute lo siguiente:
cephuser@adm > ceph osd crush remove BUCKET_NAMEun depósito debe estar vacío para que se pueda eliminar de la jerarquía de CRUSH.
17.6 Depuración de grupos de colocación #
Además de realizar varias copias de los objetos, Ceph garantiza la
integridad de los datos realizando un borrado seguro de
los grupos de colocación (encontrará más información sobre los grupos de
colocación en el Book “Guía de distribución”, Chapter 1 “SES y Ceph”, Section 1.3.2 “Grupos de colocación”). El borrado
seguro de Ceph es análogo a ejecutar fsck en la capa de
almacenamiento de objetos. Para cada grupo de colocación, Ceph genera un
catálogo de todos los objetos y compara cada objeto primario y sus réplicas
para asegurarse de que no falta ningún objeto o que hay objetos que no
coinciden. Un borrado seguro ligero diario comprueba el tamaño y los
atributos del objeto, mientras que el borrado seguro profundo semanal lee
los datos y utiliza sumas de comprobación para garantizar la integridad de
los datos.
El borrado seguro es importante para mantener la integridad de los datos, pero puede reducir el rendimiento. Es posible ajustar los valores siguientes para aumentar o disminuir las operaciones de borrado seguro:
osd max scrubsEl número máximo de operaciones de borrado seguro simultáneas para un Ceph OSD. El valor por defecto es 1.
osd scrub begin hour,osd scrub end hourLas horas del día (de las 0 a 24) con las que se define una ventana temporal en la que se puede producir el borrado seguro. Por defecto, empieza a las 0 y termina a las 24.
ImportanteSi el intervalo de depuración del grupo de colocación supera el valor indicado en
osd scrub max interval, el borrado seguro se producirá independientemente de la ventana temporal que se defina.osd scrub during recoveryPermite el borrado seguro durante la recuperación. Si se establece el valor "false" (falso), se inhabilita la programación de borrados seguros nuevos mientras haya una recuperación activa. Los borrados seguros que ya estén en ejecución continuarán. Esta opción resulta útil para reducir la carga en clústeres muy ocupados. El valor por defecto es "true" (verdadero).
osd scrub thread timeoutEl tiempo máximo en segundos que debe transcurrir para que un hilo de borrado seguro llegue a su tiempo límite. El valor por defecto es 60.
osd scrub finalize thread timeoutEl tiempo máximo en segundos que debe transcurrir para que un hilo de finalización de borrado seguro llegue a su tiempo límite. El valor por defecto es 60*10.
osd scrub load thresholdLa carga máxima normalizada. Ceph no llevará a cabo un borrado seguro cuando la carga del sistema (como se define por el coeficiente de
getloadavg()/número deCPUs en línea) sea superior a este número. El valor por defecto es 0,5.osd scrub min intervalEl intervalo mínimo en segundos para el borrado seguro de Ceph OSD cuando la carga del clúster de Ceph sea pequeña. Por defecto es 60*60*24 (una vez al día).
osd scrub max intervalEl intervalo máximo en segundos para el borrado seguro del Ceph OSD, independientemente de la carga del clúster. Por defecto es 7*60*60*24 (una vez a la semana).
osd scrub chunk minEl número mínimo de porciones de almacenamiento de objetos que se deben borrar de forma segura durante una única operación. Ceph bloquea la escritura en una única porción durante el borrado seguro. El valor por defecto es 5.
osd scrub chunk maxEl número máximo de porciones de almacenamiento de objetos que se deben borrar de forma segura durante una única operación. El valor por defecto es 25.
osd scrub sleepEl tiempo de reposo antes de realizar el borrado seguro en el siguiente grupo de porciones. Al aumentar este valor, se ralentiza toda la operación de borrado seguro, mientras que las operaciones del cliente se ven menos afectadas. El valor por defecto es 0.
osd deep scrub intervalEl intervalo entre borrados seguros "profundos" (con lectura completa de todos los datos). La opción
osd scrub load thresholdno afecta a este valor. Por defecto es 60*60*24*7 (una vez a la semana).osd scrub interval randomize ratioAñade un retraso aleatorio al valor
osd scrub min intervalcuando se programa la siguiente tarea de borrado seguro para un grupo de colocación. El retraso es un valor aleatorio menor que el resultado deosd scrub min interval*osd scrub interval randomized ratio. Por lo tanto, el valor por defecto difunde de forma prácticamente aleatoria los procesos de borrado seguro durante la ventana temporal permitida de [1, 1,5] *osd scrub min interval. El valor por defecto es 0,5.osd deep scrub strideEl tamaño de lectura cuando se realiza un borrado seguro profundo. El valor por defecto es 524288 (512 kB).
18 Gestión de repositorios de almacenamiento #
Ceph almacena los datos en repositorios. Los repositorios son grupos lógicos en los que se almacenan objetos. Al distribuir un clúster por primera vez sin crear un repositorio, Ceph utiliza los repositorios por defecto para almacenar los datos. Los siguientes aspectos importantes están relacionados con los repositorios de Ceph:
Resiliencia: los repositorios de Ceph proporcionan resiliencia al replicar o codificar los datos que contienen. Cada repositorio se puede definir como
replicated(replicado) o comoerasure coding(codificación de borrado). En el caso de los repositorios replicados, debe definir el número de réplicas o copias que tendrá cada objeto de datos en el repositorio. El número de copias (OSD, depósitos/hojas de CRUSH) que se pueden perder es uno menos que el número de réplicas. Con la codificación de borrado, se definen los valores dekym, dondekes el número de fragmentos de datos ymes el número de fragmentos de codificación. Para los repositorios codificados de borrado, es el número de fragmentos de codificación lo que determina cuántos OSD (depósitos/hojas de CRUSH) se pueden perder sin perder datos.Grupos de colocación: puede establecer el número de grupos de colocación del repositorio. En una configuración típica, se utilizan aproximadamente 100 grupos de colocación por OSD para proporcionar el equilibrio óptimo sin necesidad de utilizar demasiados recursos informáticos. Al configurar varios repositorios, asegúrese de que ha definido un número razonable de grupos de colocación para el conjunto de repositorio y clúster.
Reglas de CRUSH: cuando se almacenan datos en un repositorio, los objetos y sus réplicas (o los fragmentos en caso de los repositorios codificados de borrado) se colocan según el conjunto de reglas de CRUSH asignado al repositorio. Puede crear una regla de CRUSH personalizada para el repositorio.
Instantáneas: al crear instantáneas con
ceph osd pool mksnap, se realiza una instantánea de un repositorio concreto.
Para organizar los datos en repositorios, puede enumerar, crear y eliminar repositorios. También puede ver las estadísticas de uso para cada repositorio.
18.1 Creación de un repositorio #
Los repositorios se pueden crear de tipo replicated
(replicado) para recuperar los OSD perdidos manteniendo varias copias de los
objetos o de tipo erasure (de borrado) para obtener
capacidad de tipo RAID5/6 generalizada. Los repositorios replicados
requieren más almacenamiento en bruto, mientras que los repositorios
codificados de borrado requieren menos. El tipo por defecto es
replicated. Para obtener más información sobre los
repositorios codificados de borrado, consulte el
Capítulo 19, Repositorios codificados de borrado.
Para crear un repositorio replicado, ejecute:
cephuser@adm > ceph osd pool create POOL_NAMEEl escalador automático se encargará del resto de los argumentos opcionales. Para obtener más información, consulte la Sección 17.4.12, “Habilitación del escalador automático de grupos de colocación”.
Para crear un repositorio codificado de borrado, ejecute:
cephuser@adm > ceph osd pool create POOL_NAME erasure CRUSH_RULESET_NAME \
EXPECTED_NUM_OBJECTS
El comando ceph osd pool create puede fallar si supera el
límite de grupos de colocación por OSD. El límite se establece con la opción
mon_max_pg_per_osd.
- POOL_NAME
Nombre del repositorio. Debe ser único. Esta opción es obligatoria.
- POOL_TYPE
El tipo de repositorio, que puede ser
replicated(replicado) para recuperar los OSD perdidos manteniendo varias copias de los objetos oerasure(de borrado) para obtener un tipo de capacidad RAID5 generalizada. Los repositorios replicados requieren más espacio de almacenamiento en bruto, pero implementan todas las operaciones de Ceph. Los repositorios de borrado requieren menos espacio de almacenamiento en bruto, pero solo implementan un subconjunto de las operaciones disponibles. El tipoPOOL_TYPEpor defecto esreplicated.- CRUSH_RULESET_NAME
El nombre de conjunto de reglas de CRUSH para el repositorio. Si el conjunto de reglas especificado no existe, se producirá un error -ENOENT al crear los repositorios replicados. Para los repositorios replicados es el conjunto de reglas especificado por la variable de configuración
osd pool default CRUSH replicated ruleset. Este conjunto de reglas debe existir. Para los repositorios de borrado, es "erasure-code" si se utiliza el perfil de código de borrado por defecto o POOL_NAME de lo contrario. Este conjunto de reglas de creará de forma implícita si aún no existe.- erasure_code_profile=perfil
Solo para los repositorios codificados de borrado. Utiliza el perfil de código de borrado. Debe ser un perfil existente, según se haya definido mediante
osd erasure-code-profile set.NotaSi por algún motivo el escalador automático se ha inhabilitado (
pg_autoscale_modedesactivado) en un repositorio, puede calcular y definir el número de grupos de colocación manualmente. Consulte la Sección 17.4, “Grupos de colocación” (Grupos de colocación) para obtener información sobre cómo calcular el número adecuado de grupos de colocación para su repositorio.- EXPECTED_NUM_OBJECTS
El número previsto de objetos para este repositorio. Al definir este valor (junto con un valor negativo en
filestore merge threshold), la división de carpetas del grupo de colocación se produce en el momento de la creación del repositorio. Esto evita el impacto de latencia cuando se divide una carpeta en tiempo de ejecución.
18.2 Listado de repositorios #
Para enumerar los repositorios de su clúster, ejecute:
cephuser@adm > ceph osd pool ls18.3 Cambio de nombre de un repositorio #
Para renombrar un repositorio, ejecute:
cephuser@adm > ceph osd pool rename CURRENT_POOL_NAME NEW_POOL_NAMESi ha renombrado de un repositorio y existen permisos por repositorio para los usuarios autenticados, debe actualizar los permisos con el nuevo nombre de repositorio.
18.4 Supresión de un repositorio #
Los repositorios pueden contener datos importantes. Si suprime un repositorio, desaparecerán todos sus datos y no habrá forma de recuperarlo.
Dado que la supresión accidental de un repositorio es un peligro real, Ceph implementa dos mecanismos que impiden suprimir los repositorios. Para suprimir un repositorio, primero es necesario inhabilitar ambos mecanismos.
El primero es el indicador NODELETE. Todos los
repositorios lo tienen y el valor por defecto es "false". Para averiguar el
valor de este indicador en un repositorio, ejecute el siguiente comando:
cephuser@adm > ceph osd pool get pool_name nodelete
Si la salida es nodelete: true, no podrá suprimir el
repositorio hasta que cambie el indicador mediante el siguiente comando:
cephuser@adm > ceph osd pool set pool_name nodelete false
El segundo mecanismo es el parámetro de configuración para todo el clúster
mon allow pool delete, que es "false" por defecto. Esto
significa que, por defecto, no es posible suprimir un repositorio. El
mensaje de error que se muestra es:
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
Para suprimir el repositorio a pesar de la configuración de seguridad, puede
definir temporalmente mon allow pool delete como "true",
suprimir el repositorio y, a continuación, volver a definir el parámetro
como "false":
cephuser@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=truecephuser@adm >ceph osd pool delete pool_name pool_name --yes-i-really-really-mean-itcephuser@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=false
El comando injectargs muestra el siguiente mensaje:
injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
Es una simple confirmación de que el comando se ha ejecutado correctamente. No es un error.
Si ha creado sus propios conjuntos de reglas y reglas para un repositorio que ha creado, plantéese la posibilidad de eliminar estos elementos cuando ya no necesite el repositorio.
18.5 Otras operaciones #
18.5.1 Asociación de repositorios a una aplicación #
Para utilizar los grupos, debe asociarlos a una aplicación. Los repositorios que se utilizarán con CephFS y los creados automáticamente por Object Gateway se asocian de forma automática.
En otros casos, se puede asociar manualmente un nombre de aplicación de formato libre al repositorio:
cephuser@adm > ceph osd pool application enable POOL_NAME APPLICATION_NAME
CephFS utiliza el nombre de aplicación cephfs, el
dispositivo de bloques RADOS utiliza rbd y Object
Gateway utiliza rgw.
Un repositorio se puede asociar a varias aplicaciones y cada aplicación puede tener sus propios metadatos. Para mostrar la aplicación (o las aplicaciones) asociadas a un repositorio, emita el comando siguiente:
cephuser@adm > ceph osd pool application get pool_name18.5.2 Definición de cuotas de repositorio #
Puede definir cuotas de repositorio para el número máximo de bytes o el número máximo de objetos por repositorio.
cephuser@adm > ceph osd pool set-quota POOL_NAME MAX_OBJECTS OBJ_COUNT MAX_BYTES BYTESPor ejemplo:
cephuser@adm > ceph osd pool set-quota data max_objects 10000Para eliminar una cuota, establezca su valor en 0.
18.5.3 Visualización de estadísticas de repositorios #
Para mostrar las estadísticas de uso de un repositorio, ejecute:
cephuser@adm > rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.rgw.root 768 KiB 4 0 12 0 0 0 44 44 KiB 4 4 KiB 0 B 0 B
cephfs_data 960 KiB 5 0 15 0 0 0 5502 2.1 MiB 14 11 KiB 0 B 0 B
cephfs_metadata 1.5 MiB 22 0 66 0 0 0 26 78 KiB 176 147 KiB 0 B 0 B
default.rgw.buckets.index 0 B 1 0 3 0 0 0 4 4 KiB 1 0 B 0 B 0 B
default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B 0 B 0 B
default.rgw.log 0 B 207 0 621 0 0 0 5372132 5.1 GiB 3579618 0 B 0 B 0 B
default.rgw.meta 961 KiB 6 0 18 0 0 0 155 140 KiB 14 7 KiB 0 B 0 B
example_rbd_pool 2.1 MiB 18 0 54 0 0 0 3350841 2.7 GiB 118 98 KiB 0 B 0 B
iscsi-images 769 KiB 8 0 24 0 0 0 1559261 1.3 GiB 61 42 KiB 0 B 0 B
mirrored-pool 1.1 MiB 10 0 30 0 0 0 475724 395 MiB 54 48 KiB 0 B 0 B
pool2 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
pool3 333 MiB 37 0 111 0 0 0 3169308 2.5 GiB 14847 118 MiB 0 B 0 B
pool4 1.1 MiB 13 0 39 0 0 0 1379568 1.1 GiB 16840 16 MiB 0 B 0 BA continuación se ofrece una descripción de cada columna:
- USED
El número de bytes utilizados por el repositorio.
- OBJECTS
El número de objetos almacenados en el repositorio.
- CLONES
El número de clones almacenados en el repositorio. Cuando se crea una instantánea y se escribe en un objeto, en lugar de modificar el objeto original, se crea su clon para que no se modifique el contenido del objeto original del que se ha hecho la instantánea.
- COPIES
El número de réplicas del objeto. Por ejemplo, si un repositorio replicado con el factor de réplica 3 tiene x objetos, normalmente tendrá 3 * x copias.
- MISSING_ON_PRIMARY
El número de objetos en estado degradado (no existen todas las copias) mientras falta la copia en el OSD primario.
- UNFOUND
El número de objetos no encontrados.
- DEGRADED
El número de objetos degradados.
- RD_OPS
El número total de operaciones de lectura pedidas para este repositorio.
- RD
El número total de bytes leídos de este repositorio.
- WR_OPS
El número total de operaciones de escritura pedidas para este repositorio.
- WR
El número total de bytes escritos en el repositorio. Tenga en cuenta que no es lo mismo que el uso del repositorio, ya que es posible escribir en el mismo objeto muchas veces. El resultado es que el uso del repositorio seguirá siendo el mismo, pero el número de bytes escritos en el repositorio aumentará.
- USED COMPR
El número de bytes asignados para datos comprimidos.
- UNDER COMPR
El número de bytes que ocupan los datos comprimidos cuando no están comprimidos
18.5.4 Obtención de valores de repositorio #
Para obtener un valor de un repositorio, ejecute el comando
get siguiente:
cephuser@adm > ceph osd pool get POOL_NAME KEYPuede obtener los valores de las claves indicadas en la Sección 18.5.5, “Definición de valores de repositorio”, además de las siguientes:
- PG_NUM
El número de grupos de colocación del repositorio.
- PGP_NUM
El número efectivo de grupos de colocación que se deben utilizar para calcular la colocación de los datos. El intervalo válido es igual o menor que
PG_NUM.
Para mostrar todos los valores relacionados con un repositorio específico, ejecute:
cephuser@adm > ceph osd pool get POOL_NAME all18.5.5 Definición de valores de repositorio #
Para definir un valor para un repositorio, ejecute:
cephuser@adm > ceph osd pool set POOL_NAME KEY VALUEA continuación se muestra una lista de valores de repositorio ordenados por tipo de repositorio:
- crash_replay_interval
El número de segundos que se debe permitir a los clientes que reproduzcan peticiones reconocidas, pero no confirmadas.
- pg_num
El número de grupos de colocación del repositorio. Si añade nuevos OSD al clúster, verifique el valor de los grupos de colocación en todos los repositorios de destino para los nuevos OSD.
- pgp_num
El número efectivo de grupos de colocación que se deben utilizar para calcular la colocación de los datos.
- crush_ruleset
El conjunto de reglas que se debe utilizar para asignar la colocación en el clúster.
- hashpspool
Establece (1) o anula (0) el indicador HASHPSPOOL en un repositorio. Cuando se habilita este indicador, el algoritmo cambia para mejorar la distribución de los grupos de colocación a los OSD. Después de habilitar el indicador en un repositorio cuyo indicador HASHPSPOOL se ha definido con el valor por defecto, 0, el clúster inicia la reposición para que todos los grupos vuelvan a la colocación correcta. Tenga en cuenta que esto puede crear una carga de E/S bastante sustancial en un clúster; por lo tanto, no habilite el indicador de 0 a 1 en clústeres de producción con mucha carga.
- nodelete
Impide la eliminación del repositorio.
- nopgchange
Impide que se modifiquen los valores
pg_numypgp_numdel repositorio.- noscrub,nodeep-scrub
Inhabilita la depuración (profunda) de los datos para el repositorio específico, a fin de resolver un pico temporal de carga de E/S.
- write_fadvise_dontneed
Defina o anule la definición del indicador
WRITE_FADVISE_DONTNEEDen las peticiones de lectura/escritura de un repositorio determinado para omitir la colocación de datos en el caché. El valor por defecto esfalse(falso). Se aplica tanto a los repositorios replicados como a los codificados de borrado.- scrub_min_interval
El intervalo mínimo en segundos para el borrado seguro de datos del repositorio cuando la carga del clúster es reducida. El valor
0por defecto significa que se utiliza el valorosd_scrub_min_intervaldel archivo de configuración de Ceph.- scrub_max_interval
El intervalo máximo en segundos para el borrado seguro de datos del repositorio, independientemente de la carga del clúster. El valor
0por defecto significa que se utiliza el valorosd_scrub_max_intervaldel archivo de configuración de Ceph.- deep_scrub_interval
El intervalo en segundos para el borrado seguro profundo del repositorio. El valor
0por defecto significa que se utiliza el valorosd_deep_scrubdel archivo de configuración de Ceph.
- size
Define el número de réplicas para los objetos del repositorio. Consulte la Sección 18.5.6, “Definición del número de réplicas de objetos” para obtener más información. Solo para repositorios replicados.
- min_size
Define el número mínimo de réplicas obligatorias para E/S. Consulte la Sección 18.5.6, “Definición del número de réplicas de objetos” para obtener más información. Solo para repositorios replicados.
- nosizechange
Impide que se modifique el tamaño del repositorio. Cuando se crea un repositorio, el valor por defecto se toma del valor del parámetro
osd_pool_default_flag_nosizechange, que esfalsepor defecto. Se aplica a los repositorios replicados solo porque no se puede cambiar el tamaño de los repositorios codificados de borrado.- hit_set_type
Habilita el seguimiento de conjuntos de resultados para repositorios de caché. Consulte este artículo sobre los filtros de Bloom para obtener más información. Esta opción puede tener los valores siguientes:
bloom,explicit_hashoexplicit_object. El valor por defecto esbloom, los demás solo se emplean para realizar pruebas.- hit_set_count
El número de conjuntos de resultados que se deben almacenar en los repositorios de caché. Cuanto mayor sea el número, más RAM consumirá el daemon
ceph-osd. El valor por defecto es0.- hit_set_period
La duración en segundos de un periodo de conjunto de resultados para los repositorios de caché. Cuanto mayor sea el número, más RAM consumirá el daemon
ceph-osd. Cuando se crea un repositorio, el valor por defecto se toma del valor del parámetroosd_tier_default_cache_hit_set_period, que es1200por defecto. Se aplica a los repositorios replicados solo porque los repositorios codificados de borrado no se pueden usar como nivel de caché.- hit_set_fpp
La probabilidad de falsos positivos para el tipo de conjunto de resultados del filtro de Bloom. Consulte este artículo sobre los filtros de Bloom para obtener más información. El intervalo válido es de 0.0 a 1.0; el valor predeterminado es
0.05- use_gmt_hitset
Forzar a los OSD para que utilicen marcas horarias GMT (hora del meridiano de Greenwich) al crear un conjunto de resultados para los niveles de caché. Esto garantiza que los nodos de distintas zonas horarias devuelvan el mismo resultado. El valor por defecto es
1. Este valor no debe cambiarse.- cache_target_dirty_ratio
El porcentaje del repositorio de caché que debe contener objetos modificados (sucios) para que el agente de niveles de caché los vacíe en el repositorio de almacenamiento. El valor por defecto es
0.4.- cache_target_dirty_high_ratio
El porcentaje del repositorio de caché que debe contener objetos modificados (sucios) para que el agente de niveles de caché los vacíe en el repositorio de almacenamiento a mayor velocidad. El valor por defecto es
0.6.- cache_target_full_ratio
El porcentaje del repositorio de caché que debe contener objetos no modificados (limpios) para que el agente de niveles de caché los expulse del repositorio de caché. El valor por defecto es
0.8.- target_max_bytes
Ceph comenzará a expulsar o limpiar objetos cuando se active el umbral establecido en
max_bytes.- target_max_objects
Ceph comenzará a expulsar o limpiar objetos cuando se active el umbral establecido en
max_objects.- hit_set_grade_decay_rate
Velocidad de caída de temperatura entre dos
hit_sets sucesivos. El valor por defecto es20.- hit_set_search_last_n
Deben contarse como máximo
Napariciones enhit_sets para calcular la temperatura. El valor por defecto es1.- cache_min_flush_age
El tiempo (en segundos) que debe transcurrir para que el agente de niveles de caché mueva un objeto del repositorio de caché al de almacenamiento.
- cache_min_evict_age
El tiempo (en segundos) que debe transcurrir para que el agente de niveles de caché expulse un objeto del repositorio de caché.
- fast_read
Si este indicador está habilitado en los repositorios codificados de borrado, las peticiones de lectura emite sublecturas a todos los shards y espera a recibir suficientes shards que descodificar para ofrecer servicio al cliente. En el caso de los complementos de borrado jerasure e isa, cuando vuelve la respuesta
K, la petición del cliente se atiende de inmediato con los datos descodificados a partir de estas respuestas. Este enfoque provoca más carga de CPU y menos carga de disco/red. Actualmente, este indicador solo se admite para los repositorios codificados de borrado. El valor por defecto es0.
18.5.6 Definición del número de réplicas de objetos #
Para establecer el número de réplicas de objetos en un repositorio replicado, ejecute lo siguiente:
cephuser@adm > ceph osd pool set poolname size num-replicasEl valor num-replicas incluye el objeto en sí. Por ejemplo, si quiere que existan el objeto y dos copias (tres instancias en total), especifique 3.
Si establece un valor de 2 en num-replicas, solo habrá una copia de los datos. Si pierde una instancia de un objeto, para recuperarlo debe poder confiar en que la otra copia no haya sufrido daños, por ejemplo, desde el último borrado seguro (consulte la Sección 17.6, “Depuración de grupos de colocación” para obtener más detalles).
Si establece solo una réplica en el repositorio, significa que habrá exactamente una única instancia del objeto de datos. Si el OSD falla, se perderán los datos. Un posible uso de un repositorio con una réplica es el almacenamiento temporal de datos durante poco tiempo.
Si se definen 4 réplicas para un repositorio, la fiabilidad aumenta en un 25%.
En el caso de dos centros de datos, debe definir al menos 4 réplicas para que un repositorio tenga dos copias en cada centro de datos. De este modo, si se pierde un centro de datos, aún existen dos copias y se puede perder un disco más sin que se pierdan datos.
Un objeto puede aceptar operaciones de E/S en modo degradado con menos
réplicas de las indicadas en pool size. Para configurar
un número mínimo de réplicas necesarias para las operaciones de E/S, debe
utilizar el valor min_size. Por ejemplo:
cephuser@adm > ceph osd pool set data min_size 2
Esto garantiza que ningún objeto del repositorio de datos recibirá
operaciones de E/S con menos réplicas de las indicadas en
min_size.
Para obtener el número de réplicas de objetos, ejecute lo siguiente:
cephuser@adm > ceph osd dump | grep 'replicated size'
Ceph enumerará los grupos con el atributo replicated
size destacado. Ceph crea por defecto dos réplicas de cada
objeto (un total de tres copias o un tamaño de 3).
18.6 Migración de repositorios #
Al crear un repositorio (consulte la Sección 18.1, “Creación de un repositorio”) debe especificar sus parámetros iniciales, como el tipo de repositorio o el número de grupos de colocación. Si más adelante decide cambiar cualquiera de estos parámetros (por ejemplo, al convertir un repositorio replicado en uno codificado de borrado o al disminuir el número de grupos de colocación), debe migrar los datos del repositorio a otro cuyos parámetros se adapten a la distribución.
En esta sección se describen dos métodos de migración: un método de
nivel de caché para la migración de datos de
repositorios generales y un método que utiliza los subcomandos rbd
migrate para migrar imágenes RBD a un repositorio nuevo. Cada
método tiene sus particularidades y limitaciones.
18.6.1 Limitaciones #
Puede usar el método de niveles de caché para migrar desde un repositorio replicado a un repositorio codificado de borrado o a otro repositorio replicado. No se admite la migración desde un repositorio codificado de borrado.
No se pueden migrar imágenes RBD ni exportaciones de CephFS de un repositorio replicado a un repositorio codificado de borrado. La razón es que los repositorios codificados de borrado no admiten
omap, mientras que RBD y CephFS utilizanomappara almacenar sus metadatos. Por ejemplo, el objeto de encabezado del RBD no se podrá vaciar. Sin embargo, es posible migrar los datos al repositorio codificado de borrado y dejar los metadatos en el repositorio replicado.El método
rbd migrationpermite migrar imágenes con el mínimo tiempo de inactividad del cliente. Solo es necesario detener el cliente antes del paso depreparacióne iniciarlo después. Tenga en cuenta que solo un clientelibrbdque admita esta característica (Ceph Nautilus o posterior) podrá abrir la imagen justo después del paso depreparación, mientras que los clienteslibrbdmás antiguos o los clienteskrbdno podrán abrir la imagen hasta que ejecute el paso deasignación.
18.6.2 Migración mediante el nivel de caché #
El principio básico es simple: incluir el repositorio que quiere migrar en un nivel de caché en orden inverso. En el ejemplo siguiente se migra un repositorio replicado denominado "testpool" a un repositorio codificado de borrado:
Cree un nuevo repositorio codificado de borrado y llámelo "newpool". Consulte la Sección 18.1, “Creación de un repositorio” para obtener una explicación detallada de los parámetros de creación de repositorios.
cephuser@adm >ceph osd pool create newpool erasure defaultVerifique que el anillo de claves de cliente utilizado proporcione al menos las mismas capacidades para "newpool" que para "testpool".
Ahora tiene dos repositorios: el original replicado y lleno de datos ("testpool") y el nuevo repositorio codificado de borrado vacío ("newpool"):
 Figura 18.1: Repositorios antes de la migración #
Figura 18.1: Repositorios antes de la migración #Configure los niveles de caché y establezca el repositorio replicado "testpool" como repositorio de caché. La opción
-force-nonemptypermite añadir un nivel de caché incluso si el repositorio ya tiene datos:cephuser@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=1'cephuser@adm >ceph osd tier add newpool testpool --force-nonemptycephuser@adm >ceph osd tier cache-mode testpool proxy Figura 18.2: Configuración de los niveles de caché #
Figura 18.2: Configuración de los niveles de caché #Ejecute un traslado forzoso de todos los objetos del repositorio de caché al nuevo repositorio:
cephuser@adm >rados -p testpool cache-flush-evict-all Figura 18.3: Limpieza de datos #
Figura 18.3: Limpieza de datos #Hasta que todos los datos se hayan movido al nuevo repositorio codificado de borrado, es preciso especificar una superposición para que los objetos se busquen en el repositorio antiguo:
cephuser@adm >ceph osd tier set-overlay newpool testpoolCon la superposición, todas las operaciones se reenvían al repositorio replicado antiguo ("testpool"):
 Figura 18.4: Configuración de la superposición #
Figura 18.4: Configuración de la superposición #Ahora puede configurar todos los clientes para que accedan a los objetos en el nuevo repositorio.
Una vez migrados todos los datos al repositorio codificado de borrado "newpool", elimine la superposición y el repositorio de caché antiguo ("testpool"):
cephuser@adm >ceph osd tier remove-overlay newpoolcephuser@adm >ceph osd tier remove newpool testpool Figura 18.5: Migración completada #
Figura 18.5: Migración completada #Ejecute:
cephuser@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=0'
18.6.3 Migración de imágenes RBD #
A continuación se muestra la forma recomendada de migrar imágenes RBD de un repositorio replicado a otro repositorio replicado.
Detenga el acceso de los clientes (como una máquina virtual) a la imagen RBD.
Cree una nueva imagen en el repositorio de destino, con la imagen de origen como elemento padre:
cephuser@adm >rbd migration prepare SRC_POOL/IMAGE TARGET_POOL/IMAGESugerencia: migración solo de datos a un repositorio codificado de borradoSi necesita migrar solo los datos de imagen a un nuevo repositorio codificado de borrado y dejar los metadatos en el repositorio replicado original, ejecute el siguiente comando:
cephuser@adm >rbd migration prepare SRC_POOL/IMAGE \ --data-pool TARGET_POOL/IMAGEPermita que los clientes accedan a la imagen en el repositorio de destino.
Migre los datos al repositorio de destino:
cephuser@adm >rbd migration execute SRC_POOL/IMAGEElimine la imagen antigua:
cephuser@adm >rbd migration commit SRC_POOL/IMAGE
18.7 Instantáneas de repositorios #
Las instantáneas de repositorios son instantáneas del estado del repositorio Ceph completo. Con las instantáneas de repositorios, es posible conservar el historial de estado del repositorio. Crear instantáneas de repositorio consume un espacio de almacenamiento proporcional al tamaño del repositorio. Compruebe siempre que hay espacio de almacenamiento suficiente antes de crear la instantánea de un repositorio.
18.7.1 Creación de una instantánea de un repositorio #
Para crear una instantánea de un repositorio, ejecute:
cephuser@adm > ceph osd pool mksnap POOL-NAME SNAP-NAMEPor ejemplo:
cephuser@adm > ceph osd pool mksnap pool1 snap1
created pool pool1 snap snap118.7.2 Lista de las instantáneas de un repositorio #
Para mostrar las instantáneas existentes de un repositorio, ejecute:
cephuser@adm > rados lssnap -p POOL_NAMEPor ejemplo:
cephuser@adm > rados lssnap -p pool1
1 snap1 2018.12.13 09:36:20
2 snap2 2018.12.13 09:46:03
2 snaps18.7.3 Eliminación de una instantánea de un repositorio #
Para eliminar una instantánea de un repositorio, ejecute:
cephuser@adm > ceph osd pool rmsnap POOL-NAME SNAP-NAME18.8 Compresión de datos #
BlueStore (encontrará más información en Book “Guía de distribución”, Chapter 1 “SES y Ceph”, Section 1.4 “BlueStore”) proporciona compresión de datos sobre la marcha para ahorrar espacio en disco. La relación de compresión depende de los datos almacenados en el sistema. Tenga en cuenta que la compresión/descompresión requiere potencia de CPU adicional.
Puede configurar la compresión de datos a nivel global (consulte la Sección 18.8.3, “Opciones de compresión global”) y, a continuación, sustituir la configuración específica para cada repositorio individual.
Es posible habilitar o inhabilitar la compresión de datos del repositorio o cambiar el algoritmo y el modo de compresión en cualquier momento, independientemente de si el repositorio contiene datos o no.
No se aplicará ninguna compresión a los datos existentes después de habilitar la compresión del repositorio.
Después de inhabilitar la compresión de un repositorio, todos sus datos se descomprimirán.
18.8.1 Habilitación de la compresión #
Para habilitar la compresión de datos para un repositorio denominado POOL_NAME, ejecute el siguiente comando:
cephuser@adm >cephosd pool set POOL_NAME compression_algorithm COMPRESSION_ALGORITHMcephuser@adm >cephosd pool set POOL_NAME compression_mode COMPRESSION_MODE
Para inhabilitar la compresión de datos para un repositorio, utilice "none" como algoritmo de compresión:
cephuser@adm >cephosd pool set POOL_NAME compression_algorithm none
18.8.2 Opciones de compresión de repositorios #
Este es un listado completo de las opciones de compresión:
- compression_algorithm
Los valores posibles son
none,zstdysnappy. El valor por defecto essnappy.El algoritmo de compresión utilizado depende del caso de uso específico. A continuación s ofrecen varias recomendaciones:
Utilice el valor por defecto,
snappy, si no tiene una buena razón para cambiarlo.zstdofrece una buena relación de compresión, pero causa una alta sobrecarga de CPU cuando comprime pequeñas cantidades de datos.Ejecute una comparativa de estos algoritmos en una muestra de sus datos reales y observe el uso de CPU y memoria en su clúster.
- compression_mode
Los valores posibles son
none,aggressive,passiveyforce. El valor por defecto esnone.none: no comprimir nuncapassive: comprimir si se sugiereCOMPRESSIBLEaggressive: comprimir a menos que se sugieraINCOMPRESSIBLEforce: comprimir siempre
- compression_required_ratio
Valor: doble, proporción = SIZE_COMPRESSED / SIZE_ORIGINAL. El valor por defecto es
0.875, lo que significa que si la compresión no reduce el espacio ocupado en al menos un 12,5 %, el objeto no se comprimirá.Los objetos por encima de esta proporción no se almacenarán comprimidos, ya que el beneficio neto es bajo.
- compression_max_blob_size
Valor: entero sin firmar, tamaño en bytes. Por defecto:
0El tamaño máximo de los objetos comprimidos.
- compression_min_blob_size
Valor: entero sin firmar, tamaño en bytes. Por defecto:
0El tamaño mínimo de los objetos comprimidos.
18.8.3 Opciones de compresión global #
Las siguientes opciones de configuración se pueden definir en la configuración de Ceph y se aplican a todos los OSD y no a un solo repositorio. La configuración específica del repositorio indicada en la Sección 18.8.2, “Opciones de compresión de repositorios” tendrá prioridad.
- bluestore_compression_algorithm
Consulte compression_algorithm
- bluestore_compression_mode
Consulte compression_mode
- bluestore_compression_required_ratio
Consulte compression_required_ratio
- bluestore_compression_min_blob_size
Valor: entero sin firmar, tamaño en bytes. Por defecto:
0El tamaño mínimo de los objetos comprimidos. La configuración se omite por defecto si se usa
bluestore_compression_min_blob_size_hddybluestore_compression_min_blob_size_ssd. Tiene prioridad cuando se define un valor distinto a cero.- bluestore_compression_max_blob_size
Valor: entero sin firmar, tamaño en bytes. Por defecto:
0El tamaño máximo de los objetos que se comprimen antes de dividirse en fragmentos más pequeños. La configuración se omite por defecto si se usa
bluestore_compression_max_blob_size_hddybluestore_compression_max_blob_size_ssd. Tiene prioridad cuando se define un valor distinto a cero.- bluestore_compression_min_blob_size_ssd
Valor: entero sin firmar, tamaño en bytes. Por defecto:
8KTamaño mínimo de los objetos comprimidos y almacenados en la unidad de estado sólido.
- bluestore_compression_max_blob_size_ssd
Valor: entero sin firmar, tamaño en bytes. Por defecto:
64KEl tamaño máximo de los objetos que se comprimen y se almacenan en unidades de estado sólido antes de dividirse en fragmentos más pequeños.
- bluestore_compression_min_blob_size_hdd
Valor: entero sin firmar, tamaño en bytes. Por defecto:
128KTamaño mínimo de los objetos comprimidos y almacenados en los discos duros.
- bluestore_compression_max_blob_size_hdd
Valor: entero sin firmar, tamaño en bytes. Por defecto:
512KEl tamaño máximo de los objetos que se comprimen y se almacenan en discos duros antes de dividirse en fragmentos más pequeños.
19 Repositorios codificados de borrado #
Ceph ofrece una alternativa a la réplica normal de datos en repositorios denominada borrado o repositorio codificado de borrado. Los repositorios de borrado no proporcionan todas las funciones de los repositorios replicados (por ejemplo, no pueden almacenar metadatos para los repositorios RBD), pero requieren menos almacenamiento en bruto. Un repositorio de borrado por defecto capaz de almacenar 1 TB de datos requiere 1,5 TB de almacenamiento en bruto, lo que permite un único fallo del disco. Esto es una ventaja respecto a un repositorio replicado, que necesita 2 TB de almacenamiento en bruto para el mismo propósito.
Para obtener información básica sobre la codificación de borrado, consulte https://en.wikipedia.org/wiki/Erasure_code.
Para obtener una lista de los valores de repositorio relacionados con los repositorios codificados de borrado, consulte Valores de repositorio codificado de borrado.
19.1 Requisitos previos para los repositorios codificados de borrado #
Para hacer uso de la codificación de borrado, debe hacer lo siguiente:
Defina una regla de borrado en el mapa de CRUSH.
Defina un perfil codificado de borrado que especifique el algoritmo de codificación que se debe utilizar.
Cree un repositorio utilizando la regla y el perfil mencionados anteriormente.
Tenga en cuenta que cambiar el perfil y sus detalles no será posible después de que se cree el repositorio y de que tenga datos.
Asegúrese de que las reglas de CRUSH para los repositorios de
borrado utilizan indep para
step. Para obtener información, consulte la
Sección 17.3.2, “firstn e indep”.
19.2 Creación de un repositorio codificado de borrado de ejemplo #
El repositorio codificado de borrado más sencillo es equivalente a RAID5 y requiere al menos tres hosts. Este procedimiento describe cómo crear un repositorio con fines de prueba.
El comando
ceph osd pool createse utiliza para crear un repositorio de tipo erasure. El12significa el número de grupos de colocación. Con los parámetros por defecto, el repositorio es capaz de gestionar situaciones en las que falle un OSD.cephuser@adm >ceph osd pool create ecpool 12 12 erasure pool 'ecpool' createdLa cadena
ABCDEFGHIse escribe en un objeto denominadoNYAN.cephuser@adm >echo ABCDEFGHI | rados --pool ecpool put NYAN -Con fines de prueba, los OSD se pueden inhabilitar ahora, por ejemplo, desconectándolos de la red.
Para probar si el repositorio puede gestionar el fallo de dispositivos, se puede acceder al contenido del archivo con el comando
rados.cephuser@adm >rados --pool ecpool get NYAN - ABCDEFGHI
19.3 Perfiles de código de borrado #
Cuando se invoca el comando ceph osd pool create para
crear un repositorio de borrado, se utiliza el perfil
por defecto, a menos que se especifique otro perfil distinto. Los perfiles
definen la redundancia de los datos. Para ello se definen dos parámetros,
que reciben el nombre arbitrario de k y
m. Los parámetros k y m definen en cuántas
porciones se divide un dato y cuántas porciones de
codificación se crean. Las porciones redundantes se almacenan en diferentes
OSD.
Definiciones necesarias para los perfiles de repositorio de borrado:
- porción
Cuando se llama a la función de codificación, se devuelven porciones del mismo tamaño: porciones de datos que pueden concatenarse para reconstruir el objeto original y porciones de codificación que se pueden usar para reconstruir una porción perdida.
- k
El número de porciones de datos, que es el número de porciones en las que se divide el objeto original. Por ejemplo, si
k = 2, un objeto de 10 kB se divide enkobjetos de 5 kB. El valor demin_sizepor defecto en los repositorios codificados de borrado esk + 1. Sin embargo, se recomienda quemin_sizeseak + 2o más para evitar la pérdida de escrituras y datos.- m
El número de porciones de codificación, que es el número de porciones adicionales calculadas por las funciones de codificación. Si hay 2 porciones de codificación, significa que pueden fallar dos OSD sin que se pierda ningún dato.
- crush-failure-domain
Define a qué dispositivos se distribuyen las porciones. Como valor se debe definir un tipo de depósito. Para ver todos los tipos de depósitos, consulte la Sección 17.2, “Depósitos”. Si el dominio de fallo es
rack, las porciones se almacenarán en bastidores diferentes para aumentar la capacidad de recuperación en caso de fallos del bastidor. Tenga en cuenta que esto requiere bastidores k + m.
Con el perfil codificado de borrado por defecto utilizado en la Sección 19.2, “Creación de un repositorio codificado de borrado de ejemplo”, no perderá datos del clúster si se produce un error en un único OSD o host. Por lo tanto, para almacenar 1 TB de datos, necesita otros 0,5 TB de almacenamiento en bruto. Eso significa que se necesitan 1,5 TB de almacenamiento en bruto para 1 TB de datos (dado que k = 2, m = 1). Esto equivale a una configuración RAID5 común. En comparación, un repositorio replicado necesita 2 TB de almacenamiento en bruto para almacenar 1 TB de datos.
Para mostrar los valores del perfil por defecto:
cephuser@adm > ceph osd erasure-code-profile get default
directory=.libs
k=2
m=1
plugin=jerasure
crush-failure-domain=host
technique=reed_sol_vanEs importante elegir el perfil correcto, ya que no se puede modificar después de que se cree el repositorio. Se debe crear un repositorio nuevo con un perfil distinto y todos los objetos del repositorio anterior se deben pasar al nuevo (consulte la Sección 18.6, “Migración de repositorios”).
Los parámetros más importantes del perfil son k,
m y crush-failure-domain, ya que
definen la sobrecarga de almacenamiento y la duración de los datos. Por
ejemplo, si la arquitectura debe aguantar la pérdida de dos bastidores con
una sobrecarga de almacenamiento del 66 %, puede definir el perfil
siguiente. Tenga en cuenta que esto solo es válido con un mapa de CRUSH que
tenga depósitos de tipo "bastidor":
cephuser@adm > ceph osd erasure-code-profile set myprofile \
k=3 \
m=2 \
crush-failure-domain=rackEl ejemplo de la Sección 19.2, “Creación de un repositorio codificado de borrado de ejemplo” se puede repetir con este nuevo perfil:
cephuser@adm >ceph osd pool create ecpool 12 12 erasure myprofilecephuser@adm >echo ABCDEFGHI | rados --pool ecpool put NYAN -cephuser@adm >rados --pool ecpool get NYAN - ABCDEFGHI
El objeto NYAN se dividirá en tres (k=3) y se crearán dos
porciones adicionales (m=2). El valor de
m define cuántos OSD pueden fallar al mismo tiempo sin
que se pierda ningún dato. El valor
crush-failure-domain=rack crea un conjunto de reglas de
CRUSH que garantiza que no se almacenarán dos porciones en el mismo
bastidor.

19.3.1 Creación de un nuevo perfil codificado de borrado #
El siguiente comando crea un nuevo perfil codificado de borrado:
root # ceph osd erasure-code-profile set NAME \
directory=DIRECTORY \
plugin=PLUGIN \
stripe_unit=STRIPE_UNIT \
KEY=VALUE ... \
--force- DIRECTORY
Opcional. Defina el nombre del directorio desde el que se carga el complemento codificado de borrado. El valor por defecto es
/usr/lib/ceph/erasure-code.- PLUGIN
Opcional. Utilice el complemento codificado de borrado para calcular fragmentos de codificación y recuperar fragmentos que falten. Los complementos disponibles son "jerasure", "isa", "lrc" y "shes". El valor por defecto es "jerasure".
- STRIPE_UNIT
Opcional. Indica la cantidad de datos de un fragmento de datos, por repartición. Por ejemplo, un perfil con 2 fragmentos de datos y el valor stripe_unit=4K colocaría el rango 0-4K en el fragmento 0, el rango 4K-8K en el fragmento 1 y el rango 8K-12K en el fragmento 0 de nuevo. Debe ser un múltiplo de 4K para obtener el mejor rendimiento. El valor por defecto se toma de la opción de configuración del monitor
osd_pool_erasure_code_stripe_unitcuando se crea un repositorio. El valor de "stripe_width" de un repositorio que utilice este perfil será el número de fragmentos de datos multiplicado por este valor de "stripe_unit".- KEY=VALUE
Los pares clave/valor de las opciones específicas del complemento codificado de borrado seleccionado.
- ‑‑force
Opcional. Sustituye un perfil existente con el mismo nombre y permite definir un valor de stripe_unit no alineado con 4K.
19.3.2 Eliminación de un perfil codificado de borrado #
El comando siguiente elimina un perfil codificado de borrado identificado por el valor de NAME (Nombre):
root # ceph osd erasure-code-profile rm NAMESi un repositorio hace referencia al perfil, la supresión fallará.
19.3.3 Visualización de los detalles de un perfil codificado de borrado #
El comando siguiente muestra los detalles de un perfil codificado de borrado identificado por el valor de NAME (Nombre):
root # ceph osd erasure-code-profile get NAME19.3.4 Listado de perfiles codificados de borrado #
El comando siguiente muestra los nombres de todos los perfiles codificado de borrado:
root # ceph osd erasure-code-profile ls19.4 Marcado de repositorios codificados de borrado con un dispositivo de bloques RADOS #
Para marcar un repositorio codificado de borrado como un repositorio RBD, etiquételo en consecuencia:
cephuser@adm > ceph osd pool application enable rbd ec_pool_nameRBD puede almacenar datos de imagen en repositorios codificados de borrado. Sin embargo, el encabezado de la imagen y los metadatos deberán almacenarse aún en un repositorio replicado. Suponiendo que el nombre del repositorio sea "rbd":
cephuser@adm > rbd create rbd/image_name --size 1T --data-pool ec_pool_namePuede utilizar la imagen con normalidad como cualquier otra, excepto por el hecho de que todos los datos se almacenarán en el repositorio ec_pool_name, en lugar de en el repositorio "rbd".
20 Dispositivo de bloques RADOS #
Un bloque es una secuencia de bytes, por ejemplo, un bloque de 4 MB de datos. Las interfaces de almacenamiento basadas en bloques son la forma más habitual de almacenar los datos en soportes de uso rotativo, como discos duros, CD o disquetes. La ubicuidad de las interfaces de dispositivos de bloques hacen que un dispositivo de bloques virtual sea el candidato idóneo para interactuar con un sistema de almacenamiento masivo de datos como Ceph.
Los dispositivos de bloques de Ceph permiten compartir recursos físicos y se
puede modificar su tamaño. Los datos se almacenan repartidos en varios OSD en
un clúster de Ceph. Los dispositivos de bloques de Ceph aprovechan las
funciones de RADOS, como la realización de instantáneas, las réplicas y la
comprobación de coherencia. Los dispositivos de bloques RADOS (RBD) de Ceph
interactúan con los OSD mediante módulos del kernel o la biblioteca
librbd.

Los dispositivos de bloques de Ceph ofrecen un alto rendimiento con infinitas
posibilidades de escalabilidad para los módulos de kernel. Son compatibles
con soluciones de virtualización como QEMU o sistemas informáticos basados en
la nube que dependen de libvirt,
como OpenStack. Puede utilizar el mismo clúster para gestionar Object
Gateway, CephFS y los dispositivos de bloques RADOS al mismo tiempo.
20.1 Comandos del dispositivo de bloques #
El comando rbd permite crear, enumerar, examinar y
eliminar imágenes de los dispositivos de bloques. También se puede emplear,
por ejemplo, para clonar imágenes, crear instantáneas, revertir una imagen
al estado de una instantánea o ver una instantánea.
20.1.1 Creación de una imagen del dispositivo de bloques en un repositorio replicado #
Antes de poder añadir un dispositivo de bloques a un cliente, debe crear una imagen relacionada en un repositorio existente (consulte el Capítulo 18, Gestión de repositorios de almacenamiento):
cephuser@adm > rbd create --size MEGABYTES POOL-NAME/IMAGE-NAMEPor ejemplo, para crear una imagen de 1 GB denominada "myimage" que almacena información en un repositorio llamado "mypool", ejecute lo siguiente:
cephuser@adm > rbd create --size 1024 mypool/myimageSi omite un acceso directo de unidad de tamaño ("G" o "T"), el tamaño de la imagen se indicará en megabytes. Utilice "G" o "T" después del número de tamaño para especificar gigabytes o terabytes.
20.1.2 Creación de una imagen del dispositivo de bloques en un repositorio codificado de borrado #
Es posible almacenar datos de una imagen de dispositivo de bloques
directamente en repositorios codificados de borrado. Una imagen de
dispositivo de bloques RADOS está formada por elementos de
datos y metadatos. Solo se puede
almacenar la parte de datos de una imagen de dispositivo de bloques RADOS
en un repositorio codificado de borrado. El repositorio debe tener en el
indicador overwrite el valor true
definido, y eso solo es posible si todos los OSD donde se almacena el
repositorio utilizan BlueStore.
No es posible almacenar la parte de metadatos de la imagen en un
repositorio codificado de borrado. Puede especificar el repositorio
replicado para almacenar los metadatos de la imagen con la opción
--pool= del comando rbd create o
especificar pool/ como prefijo del nombre de la imagen.
Cree un repositorio codificado de borrado:
cephuser@adm >ceph osd pool create EC_POOL 12 12 erasurecephuser@adm >ceph osd pool set EC_POOL allow_ec_overwrites true
Especifique el repositorio replicado para almacenar los metadatos:
cephuser@adm > rbd create IMAGE_NAME --size=1G --data-pool EC_POOL --pool=POOLO bien:
cephuser@adm > rbd create POOL/IMAGE_NAME --size=1G --data-pool EC_POOL20.1.3 Listado de imágenes de dispositivos de bloques #
Para mostrar los dispositivos de bloques en un repositorio denominado "mypool", ejecute lo siguiente:
cephuser@adm > rbd ls mypool20.1.4 Recuperación de información de la imagen #
Para recuperar información de una imagen denominada "myimage" dentro de un repositorio denominado "mypool", ejecute lo siguiente:
cephuser@adm > rbd info mypool/myimage20.1.5 Cambio de tamaño de la imagen de un dispositivo de bloques #
Las imágenes de los dispositivos de bloques RADOS emplean un sistema de
provisión ligera, lo que significa que no emplean espacio físico real hasta
que empieza a guardar datos en ellos. No obstante, tienen una capacidad
máxima que se define mediante la opción ‑‑size. Si desea
aumentar (o reducir) el tamaño máximo de la imagen (o disminuir), ejecute
lo siguiente:
cephuser@adm >rbd resize --size 2048 POOL_NAME/IMAGE_NAME # to increasecephuser@adm >rbd resize --size 2048 POOL_NAME/IMAGE_NAME --allow-shrink # to decrease
20.1.6 Eliminación de una imagen de dispositivo de bloques #
Para eliminar un dispositivo de bloques que se corresponde con una imagen llamada "myimage" en un repositorio denominado "mypool", ejecute lo siguiente:
cephuser@adm > rbd rm mypool/myimage20.2 Montaje y desmontaje #
Después de crear un dispositivo de bloques RADOS, puede usarlo como cualquier otro dispositivo de disco: formatearlo, montarlo para que permita el intercambio de archivos y desmontarlo cuando haya terminado.
El comando rbd accede por defecto al clúster mediante la
cuenta de usuario admin de Ceph. Esta cuenta tiene acceso
administrativo completo al clúster. Esto aumenta el riesgo de causar daños
accidentalmente, como ocurre cuando se entra en una estación de trabajo
Linux como usuario root. Por lo
tanto, es preferible crear cuentas de usuario con menos privilegios y
utilizar estas cuentas para el acceso normal de lectura/escritura a
dispositivos de bloques RADOS.
20.2.1 Creación de una cuenta de usuario de Ceph #
Para crear una nueva cuenta de usuario con las capacidades de Ceph Manager,
Ceph Monitor y Ceph OSD, utilice el comando ceph con el
subcomando auth get-or-create:
cephuser@adm > ceph auth get-or-create client.ID mon 'profile rbd' osd 'profile profile name \
[pool=pool-name] [, profile ...]' mgr 'profile rbd [pool=pool-name]'Por ejemplo, para crear un usuario llamado qemu con acceso de lectura y escritura al repositorio vms y acceso de solo lectura al repositorio images, ejecute lo siguiente:
ceph auth get-or-create client.qemu mon 'profile rbd' osd 'profile rbd pool=vms, profile rbd-read-only pool=images' \ mgr 'profile rbd pool=images'
El resultado del comando ceph auth get-or-create será el
anillo de claves del usuario especificado, que se puede escribir en
/etc/ceph/ceph.client.ID.keyring.
Al utilizar el comando rbd, puede especificar el ID de
usuario proporcionando el argumento opcional --id
ID.
Para obtener más información sobre la gestión de cuentas de usuario de
Ceph, consulte el Capítulo 30, Autenticación con cephx.
20.2.2 Autenticación de usuarios #
Para especificar un nombre de usuario, utilice ‑‑id
nombre de usuario. Si utiliza la
autenticación de cephx, también debe especificar
un secreto. Puede proceder de un anillo de claves o de un archivo que
contenga el secreto:
cephuser@adm > rbd device map --pool rbd myimage --id admin --keyring /path/to/keyringO bien
cephuser@adm > rbd device map --pool rbd myimage --id admin --keyfile /path/to/file20.2.3 Preparación de un dispositivo de bloques RADOS para su uso #
Asegúrese de que el clúster de Ceph incluye un repositorio con la imagen de disco que desea asignar. Supongamos que el repositorio se denomina
mypooly la imagenmyimage.cephuser@adm >rbd list mypoolAsigne la imagen a un nuevo dispositivo de bloques:
cephuser@adm >rbd device map --pool mypool myimageEnumerar todos los dispositivos asignados:
cephuser@adm >rbd device list id pool image snap device 0 mypool myimage - /dev/rbd0El dispositivo en el que queremos trabajar es
/dev/rbd0.Sugerencia: vía del dispositivo RBDEn lugar de
/dev/rbdNÚMERO_DISPOSITIVO, puede utilizar/dev/rbd/NOMBRE_REPOSITORIO/NOMBRE_IMAGENcomo vía persistente del dispositivo. Por ejemplo:/dev/rbd/mypool/myimage
Cree un sistema de archivos XFS en el dispositivo
/dev/rbd0:root #mkfs.xfs /dev/rbd0 log stripe unit (4194304 bytes) is too large (maximum is 256KiB) log stripe unit adjusted to 32KiB meta-data=/dev/rbd0 isize=256 agcount=9, agsize=261120 blks = sectsz=512 attr=2, projid32bit=1 = crc=0 finobt=0 data = bsize=4096 blocks=2097152, imaxpct=25 = sunit=1024 swidth=1024 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=0 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=8 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0Sustituyendo
/mntpor el punto de montaje, monte el dispositivo y compruebe que está montado correctamente:root #mount /dev/rbd0 /mntroot #mount | grep rbd0 /dev/rbd0 on /mnt type xfs (rw,relatime,attr2,inode64,sunit=8192,...Ya puede mover datos al dispositivo y desde él como si fuese un directorio local.
Sugerencia: aumento del tamaño del dispositivo RBDSi descubre que el tamaño del dispositivo RBD es insuficiente, puede aumentarlo con facilidad.
Aumente el tamaño de la imagen RBD, por ejemplo, hasta 10 GB.
cephuser@adm >rbd resize --size 10000 mypool/myimage Resizing image: 100% complete...done.Aumente el sistema de archivos hasta llenar el nuevo tamaño del dispositivo:
root #xfs_growfs /mnt [...] data blocks changed from 2097152 to 2560000
Cuando termine de acceder al dispositivo, puede desasignarlo y desmontarlo.
cephuser@adm >rbd device unmap /dev/rbd0root #unmount /mnt
Se proporciona un guion rbdmap y una unidad
systemd para facilitar el proceso
de asignación y montaje de los RBD después del arranque, así como de
desmontarlos antes del apagado. Consulte la
Sección 20.2.4, “rbdmap: asignación de dispositivos RBD durante el arranque”.
20.2.4 rbdmap: asignación de dispositivos RBD durante el arranque #
rbdmap es un guion de shell que automatiza las
operaciones rbd map y rbd device
unmap en una o varias imágenes RBD. Aunque es posible ejecutar el
guion manualmente en cualquier momento, la ventaja principal consiste en
asignar y montar automáticamente las imágenes RBD durante el arranque (y
desmontarlas y desasignarlas al apagar el equipo), activándose mediante el
sistema Init. Con este fin, el paquete ceph-common
incluye el archivo de unidad
systemd
rbdmap.service.
El guion solo acepta un argumento, que puede ser map o
unmap. En ambos casos, el guion analiza un archivo de
configuración. Se utiliza /etc/ceph/rbdmap por
defecto, pero se puede anular mediante una variable de entorno
RBDMAPFILE. Cada línea del archivo de configuración se
corresponde con una imagen RBD que se debe asignar o desasignar.
El archivo de configuración tiene el formato siguiente:
image_specification rbd_options
image_specificationVía a una imagen dentro de un repositorio. Se debe especificar como nombre_repositorio/nombre_imagen.
rbd_optionsUna lista opcional de parámetros que se puedan pasar al comando
rbd device mapsubyacente. Estos parámetros y sus valores se deben especificar como una cadena separada por comas, por ejemplo:PARAM1=VAL1,PARAM2=VAL2,...
El ejemplo hace que el guion
rbdmapejecute el siguiente comando:cephuser@adm >rbd device map POOL_NAME/IMAGE_NAME --PARAM1 VAL1 --PARAM2 VAL2En el ejemplo siguiente puede se explica cómo especificar un nombre de usuario y un anillo de claves con un secreto correspondiente:
cephuser@adm >rbdmap device map mypool/myimage id=rbd_user,keyring=/etc/ceph/ceph.client.rbd.keyring
Si se ejecuta como rbdmap map, el guion analiza el
archivo de configuración y, para cada imagen RBD especificada, primero
intenta asignar la imagen (mediante el comando rbd device
map) y luego montarla.
Si se ejecuta como rbdmap unmap, las imágenes enumeradas
en el archivo de configuración se desmontarán y se desasignarán.
rbdmap unmap-all intenta desmontar y posteriormente
desasignar todas las imágenes RBD asignadas actualmente, independientemente
de que estén enumeradas o no en el archivo de configuración.
Si la operación se realiza correctamente, rbd device map
asigna la imagen a un dispositivo /dev/rbdX, momento
en el que se activa una regla udev para crear un enlace simbólico de nombre
de dispositivo de confianza
/dev/rbd/nombre_repositorio/nombre_imagen
que señala al dispositivo real asignado.
Para que las operaciones de montaje y desmontaje se lleven a cabo
correctamente, el nombre del dispositivo de confianza debe tener una
entrada correspondiente en /etc/fstab. Al escribir
entradas /etc/fstab para imágenes RBD, especifique la
opción de montaje "noauto" (o "nofail"). Esto impide que el sistema Init
intente montar el dispositivo demasiado pronto, antes de que el dispositivo
en cuestión aún exista, ya que rbdmap.service
normalmente se activa bastante tarde en la secuencia de arranque.
Para una lista completa de opciones de rbd, consulte la
página man de rbd (man 8 rbd).
Para consultar ejemplos de uso de rbdmap, consulte la
página man de rbdmap (man 8 rbdmap).
20.2.5 Aumento del tamaño de dispositivos RBD #
Si descubre que el tamaño del dispositivo RBD es insuficiente, puede aumentarlo con facilidad.
Aumente el tamaño de la imagen RBD, por ejemplo, hasta 10 GB.
cephuser@adm >rbd resize --size 10000 mypool/myimage Resizing image: 100% complete...done.Aumente el sistema de archivos hasta llenar el nuevo tamaño del dispositivo.
root #xfs_growfs /mnt [...] data blocks changed from 2097152 to 2560000
20.3 Instantáneas #
Una instantánea RBD es una instantánea de una imagen de dispositivo de
bloques RADOS. Las instantáneas permiten conservar un historial de los
estados de la imagen. Ceph también es compatible con capas de instantáneas,
lo que permite clonar imágenes de máquinas virtuales de forma rápida y
sencilla. Ceph admite las instantáneas de dispositivos de bloques mediante
el comando rbd y muchas interfaces de alto nivel,
incluidas QEMU, libvirt, OpenStack y CloudStack.
Detenga las operaciones de entrada y salida y vacíe todas las escrituras pendientes antes de tomar una instantánea de una imagen. Si la imagen contiene un sistema de archivos, este debe tener un estado coherente en el momento de realizar la instantánea.
20.3.1 Habilitación y configuración de cephx #
Si cephx está habilitado, debe especificar un
nombre de usuario o ID y una vía al anillo de claves que contiene la clave
correspondiente para el usuario. Consulte el
Capítulo 30, Autenticación con cephx para obtener más información. También
puede añadir la variable de entorno CEPH_ARGS para
evitar la reintroducción de los siguientes parámetros.
cephuser@adm >rbd --id user-ID --keyring=/path/to/secret commandscephuser@adm >rbd --name username --keyring=/path/to/secret commands
Por ejemplo:
cephuser@adm >rbd --id admin --keyring=/etc/ceph/ceph.keyring commandscephuser@adm >rbd --name client.admin --keyring=/etc/ceph/ceph.keyring commands
Añada el usuario y el secreto a la variable de entorno
CEPH_ARGS para no tener que introducir estos
datos en cada ocasión.
20.3.2 Conceptos básicos sobre instantáneas #
Los procedimientos siguientes muestran cómo crear, enumerar y eliminar
instantáneas mediante el comando rbd en la línea de
comandos.
20.3.2.1 Creación de instantáneas #
Para crear una instantánea con rbd, especifique la
opción snap create, el nombre del repositorio y el nombre
de la imagen.
cephuser@adm >rbd --pool pool-name snap create --snap snap-name image-namecephuser@adm >rbd snap create pool-name/image-name@snap-name
Por ejemplo:
cephuser@adm >rbd --pool rbd snap create --snap snapshot1 image1cephuser@adm >rbd snap create rbd/image1@snapshot1
20.3.2.2 Listado de instantáneas #
Para enumerar las instantáneas de una imagen, especifique el nombre del repositorio y el de la imagen.
cephuser@adm >rbd --pool pool-name snap ls image-namecephuser@adm >rbd snap ls pool-name/image-name
Por ejemplo:
cephuser@adm >rbd --pool rbd snap ls image1cephuser@adm >rbd snap ls rbd/image1
20.3.2.3 Reversión de instantáneas #
Para revertir una instantánea con rbd, especifique la
opción snap rollback, el nombre del repositorio, el
nombre de la imagen y el nombre de la instantánea.
cephuser@adm >rbd --pool pool-name snap rollback --snap snap-name image-namecephuser@adm >rbd snap rollback pool-name/image-name@snap-name
Por ejemplo:
cephuser@adm >rbd --pool pool1 snap rollback --snap snapshot1 image1cephuser@adm >rbd snap rollback pool1/image1@snapshot1
Revertir una imagen a una instantánea significa sobrescribir la versión actual de la imagen con los datos de la instantánea. El tiempo necesario para ejecutar una reversión aumenta según el tamaño de la imagen. Es más rápido clonar una instantánea que revertir una imagen a una instantánea, por lo que es el método preferible para volver a un estado preexistente.
20.3.2.4 Supresión de una instantánea #
Para suprimir una instantánea con rbd, especifique la
opción snap rm, el nombre del repositorio, el nombre de
la imagen y el nombre de usuario.
cephuser@adm >rbd --pool pool-name snap rm --snap snap-name image-namecephuser@adm >rbd snap rm pool-name/image-name@snap-name
Por ejemplo:
cephuser@adm >rbd --pool pool1 snap rm --snap snapshot1 image1cephuser@adm >rbd snap rm pool1/image1@snapshot1
Los OSD de Ceph suprimen los datos de forma asíncrona, por lo que al suprimir una instantánea, no se libera el espacio de disco inmediatamente.
20.3.2.5 Limpieza de instantáneas #
Para suprimir todas las instantáneas de una imagen con
rbd, especifique la opción snap purge
y el nombre de la imagen.
cephuser@adm >rbd --pool pool-name snap purge image-namecephuser@adm >rbd snap purge pool-name/image-name
Por ejemplo:
cephuser@adm >rbd --pool pool1 snap purge image1cephuser@adm >rbd snap purge pool1/image1
20.3.3 Capas de instantáneas #
Ceph admite la posibilidad de crear varios clones de copia de escritura (COW, por sus siglas en inglés) de una instantánea de dispositivo de bloques. Las capas de instantáneas permiten que los clientes de dispositivos de bloques de Ceph creen imágenes muy rápidamente. Por ejemplo, puede crear una imagen de dispositivo de bloques con una máquina virtual Linux escrita en él y, a continuación, realizar una instantánea de la imagen, protegerla y crear tantos clones de copia de escritura como desee. Las instantáneas son de solo lectura, por lo que clonar una instantánea simplifica la semántica y permite crear clones rápidamente.
Los términos "parent" (padre) y "child" (hijo) mencionados en los siguientes ejemplos de la línea de comandos hacen referencia a una instantánea de un dispositivo de bloques de Ceph (padre) y la imagen correspondiente clonada de la instantánea (hijo).
Cada imagen clonada (hijo) almacena una referencia a su imagen padre que permite que la imagen clonada abra la instantánea padre y la lea.
Un clon COW de una instantánea se comporta exactamente igual que cualquier otra imagen de dispositivo de bloques de Ceph. Puede leer las imágenes clonadas, escribir en ellas, clonarlas y redimensionarlas. No existen restricciones especiales que afecten a las imágenes clonadas. No obstante, la clonación de copia de escritura de una instantánea hace referencia a la instantánea, por lo que debe proteger la instantánea antes de clonarla.
‑‑image-format 1 no se admite
No es posible crear instantáneas de imágenes creadas con la opción
obsoleta rbd create ‑‑image-format 1. Ceph solo admite
la clonación de las imágenes format 2 por defecto.
20.3.3.1 Procedimientos iniciales con las capas #
La aplicación de capas a un dispositivo de bloques de Ceph es un proceso sencillo. Debe disponer de una imagen. Debe crear una instantánea de la imagen. Debe proteger la instantánea. Una vez realizados estos pasos, puede empezar a clonar la instantánea.
La imagen clonada tendrá una referencia a la instantánea padre e incluirá el ID del repositorio, el ID de la imagen y el ID de la instantánea. La inclusión del ID del repositorio significa que se pueden clonar instantáneas de un repositorio como imágenes en un repositorio distinto.
Plantilla de imagen: un ejemplo de uso habitual para crear capas de dispositivos de bloques es crear una imagen principal y una instantánea que sirva como plantilla para los clones. Por ejemplo, un usuario puede crear una imagen de una distribución de Linux (como SUSE Linux Enterprise Server) y crear una instantánea para ella. El usuario puede actualizar periódicamente la imagen y crear una instantánea nueva (por ejemplo,
zypper ref && zypper patch, seguido derbd snap create). A medida que la imagen crezca, el usuario puede clonar cualquiera de las instantáneas.Plantilla extendida: un ejemplo de uso más avanzado implica la posibilidad de extender una imagen de plantilla para que proporcione más información que una imagen base. Por ejemplo, un usuario puede clonar una imagen (una plantilla de máquina virtual) e instalar otro software (por ejemplo, una base de datos, un sistema de gestión de contenido o un sistema de análisis) y, a continuación, realizar una instantánea de la imagen extendida, que a su vez se puede actualizar de la misma manera que la imagen base.
Repositorio de plantillas: una manera de utilizar capas de dispositivos de bloques es crear un repositorio que contenga imágenes principales que actúen como plantillas e instantáneas de dichas plantillas. A continuación, puede ampliar los privilegios de solo lectura a los usuarios, de modo que tengan la posibilidad de clonar las instantáneas sin la capacidad de escribir o ejecutar dentro del repositorio.
Migración y recuperación de imágenes: una manera de utilizar capas de dispositivos de bloques consiste en migrar o recuperar datos de un repositorio a otro.
20.3.3.2 Protección de una instantánea #
Los clones acceden a las instantáneas padre. Todos los clones dejarán de funcionar si un usuario suprime por error la instantánea padre. Para evitar la pérdida de datos, debe proteger la instantánea antes de clonarla.
cephuser@adm >rbd --pool pool-name snap protect \ --image image-name --snap snapshot-namecephuser@adm >rbd snap protect pool-name/image-name@snapshot-name
Por ejemplo:
cephuser@adm >rbd --pool pool1 snap protect --image image1 --snap snapshot1cephuser@adm >rbd snap protect pool1/image1@snapshot1
No es posible suprimir una instantánea protegida.
20.3.3.3 Clonación de una instantánea #
Para clonar una instantánea, debe especificar el repositorio padre, la imagen, la instantánea, el repositorio hijo y el nombre de la imagen. Debe proteger la instantánea para poder clonarla.
cephuser@adm >rbd clone --pool pool-name --image parent-image \ --snap snap-name --dest-pool pool-name \ --dest child-imagecephuser@adm >rbd clone pool-name/parent-image@snap-name \ pool-name/child-image-name
Por ejemplo:
cephuser@adm > rbd clone pool1/image1@snapshot1 pool1/image2Puede clonar una instantánea de un repositorio como una imagen de otro repositorio. Por ejemplo, puede mantener imágenes e instantáneas de solo lectura como plantillas en un repositorio y clones con acceso de escritura en otro.
20.3.3.4 Desprotección de una instantánea #
Para suprimir una instantánea, primero debe desprotegerla. Además, no puede suprimir instantáneas que tengan referencias de clones. Debe aplanar todos los clones de una instantánea para poder eliminarla.
cephuser@adm >rbd --pool pool-name snap unprotect --image image-name \ --snap snapshot-namecephuser@adm >rbd snap unprotect pool-name/image-name@snapshot-name
Por ejemplo:
cephuser@adm >rbd --pool pool1 snap unprotect --image image1 --snap snapshot1cephuser@adm >rbd snap unprotect pool1/image1@snapshot1
20.3.3.5 Listado de los hijos de una instantánea #
Para enumerar los hijos de una instantánea, ejecute lo siguiente:
cephuser@adm >rbd --pool pool-name children --image image-name --snap snap-namecephuser@adm >rbd children pool-name/image-name@snapshot-name
Por ejemplo:
cephuser@adm >rbd --pool pool1 children --image image1 --snap snapshot1cephuser@adm >rbd children pool1/image1@snapshot1
20.3.3.6 Aplanamiento de una imagen clonada #
Las imágenes clonadas retienen una referencia a la instantánea padre. Si elimina la referencia del clon a la instantánea padre, la imagen se "aplana" copiando la información de la instantánea en el clon. El tiempo que se tarda en aplanar un clon aumenta según el tamaño de la instantánea. Para suprimir una instantánea, primero debe aplanar las imágenes hijo.
cephuser@adm >rbd --pool pool-name flatten --image image-namecephuser@adm >rbd flatten pool-name/image-name
Por ejemplo:
cephuser@adm >rbd --pool pool1 flatten --image image1cephuser@adm >rbd flatten pool1/image1
Dado que una imagen plana contiene toda la información de la instantánea, ocupará más espacio de almacenamiento que un clon con capas.
20.4 Duplicados de imagen RBD #
Las imágenes RBD se pueden duplicar de forma asincrónica entre dos clústeres de Ceph. Esta capacidad está disponible en dos modos:
- Basada en registro
Este modo utiliza las imágenes RBD transaccionales para garantizar la réplica protegida contra bloqueos de un momento concreto entre los clústeres. Cada escritura en la imagen RBD se guarda primero en el registro asociado antes de modificar la imagen real. El clúster
remotoleerá el registro y reproducirá las actualizaciones en su copia local de la imagen. Dado que cada escritura en la imagen RBD dará como resultado dos escrituras en el clúster de Ceph, se espera que la latencia de escritura casi se duplique cuando se utiliza la función de imagen RBD transaccional.- Basada en instantáneas
Este modo utiliza instantáneas de duplicación de imágenes RBD creadas de forma programada periódicamente o manualmente para replicar imágenes de RBD protegidas contra bloqueos entre clústeres. El clúster
remotodeterminará las actualizaciones de datos o metadatos entre dos instantáneas de duplicación y copiará los deltas en su copia local de la imagen. Con la ayuda de la función de imagen fast-diff de RBD, los bloques de datos actualizados se pueden calcular rápidamente sin necesidad de explorar la imagen RBD completa. Dado que este modo no es coherente en un momento determinado, será necesario sincronizar el delta completo de la instantánea antes de utilizarlo durante una situación de failover. Cualquier delta de instantánea aplicado parcialmente se revertirá a la última instantánea totalmente sincronizada antes de su uso.
La duplicación se configura de forma independiente para cada repositorio
dentro de los clústeres conectores. Esto se puede configurar en un
subconjunto específico de imágenes dentro del repositorio, o para que
refleje automáticamente todas las imágenes de un repositorio si se usa
únicamente la duplicación transaccional. La duplicación se configura
mediante el comando rbd. El daemon
rbd-mirror es el responsable de la
extracción de actualizaciones de imágenes del clúster conector
remoto y de aplicarlos a la imagen en el clúster
local.
Dependiendo de las necesidades de réplica, la duplicación del RBD se puede configurar para la réplica unidireccional o bidireccional:
- Réplica unidireccional
Cuando los datos solo se duplican desde un clúster primario a un clúster secundario, el daemon
rbd-mirrorse ejecuta solo en el clúster secundario.- Réplica bidireccional
Cuando los datos se duplican desde imágenes primarias de un clúster a imágenes no primarias de otro clúster (y viceversa), el daemon
rbd-mirrorse ejecuta en ambos clústeres.
Cada instancia del daemon
rbd-mirror debe poder conectarse a
los clústeres de Ceph locales y
remotos simultáneamente. Por ejemplo, todos los hosts de
monitor y OSD. Además, la red debe tener suficiente ancho de banda entre
los dos centros de datos para poder gestionar la carga de trabajo de
duplicación.
20.4.1 Configuración del repositorio #
Los siguientes procedimientos demuestran cómo llevar a cabo las tareas
administrativas básicas para configurar la duplicación mediante el comando
rbd. La duplicación se configura de forma independiente
para cada repositorio dentro de los clústeres de Ceph.
Debe llevar a cabo los pasos de configuración del repositorio en ambos
clústeres conectores. Para simplificar los ejemplos, en estos
procedimientos se presupone que hay dos clústeres, denominados
local y remote a los que se puede
acceder desde un único host.
Consulte la página man de rbd (man 8
rbd) para obtener información adicional acerca de cómo conectarse
a clústeres de Ceph diferentes.
En los siguientes ejemplos, el nombre del clúster corresponde a un archivo
de configuración de Ceph con el mismo nombre
/etc/ceph/remote.conf y a un archivo de anillo de
claves de Ceph con el mismo nombre
/etc/ceph/remote.client.admin.keyring.
20.4.1.1 Habilitación de la duplicación en un repositorio #
Para habilitar la duplicación en un repositorio, especifique el subcomando
mirror pool enable, el nombre del repositorio y el modo
de duplicación. El modo de duplicación puede ser de repositorio o de
imagen:
- pool
Se duplican todas las imágenes del repositorio con el registro transaccional habilitado.
- image
La duplicación se debe habilitar explícitamente en cada imagen. Consulte la Sección 20.4.2.1, “Habilitación de la duplicación de imágenes” para obtener más información.
Por ejemplo:
cephuser@adm >rbd --cluster local mirror pool enable POOL_NAME poolcephuser@adm >rbd --cluster remote mirror pool enable POOL_NAME pool
20.4.1.2 Inhabilitación de la duplicación #
Para inhabilitar la duplicación en un repositorio, especifique el
subcomando mirror pool disable y el nombre del
repositorio. Cuando se inhabilita la duplicación en un repositorio de esta
forma, la duplicación también se inhabilitará en cualquier imagen (dentro
del repositorio) para la que se haya habilitado la duplicación
explícitamente.
cephuser@adm >rbd --cluster local mirror pool disable POOL_NAMEcephuser@adm >rbd --cluster remote mirror pool disable POOL_NAME
20.4.1.3 Conectores de carga #
Para que el daemon rbd-mirror
descubra su clúster conector, el conector debe estar registrado en el
repositorio y se debe crear una cuenta de usuario. Este proceso se puede
automatizar con rbd y con los comandos mirror
pool peer bootstrap create y mirror pool peer bootstrap
import.
Para crear manualmente un nuevo testigo de arnque con
rbd, especifique el comando mirror pool peer
bootstrap create, un nombre de repositorio y un nombre de sitio
descriptivo opcional para describir el clúster local:
cephuser@local > rbd mirror pool peer bootstrap create \
[--site-name LOCAL_SITE_NAME] POOL_NAME
El resultado del comando mirror pool peer bootstrap
create será un testigo que se debe proporcionar al comando
mirror pool peer bootstrap import. Por ejemplo, en el
clúster local:
cephuser@local > rbd --cluster local mirror pool peer bootstrap create --site-name local image-pool
eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW \
1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1v \
bl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
Para importar manualmente el testigo de arranque creado por otro clúster
con el comando rbd, utilice la siguiente sintaxis:
rbd mirror pool peer bootstrap import \ [--site-name LOCAL_SITE_NAME] \ [--direction DIRECTION \ POOL_NAME TOKEN_PATH
Dónde:
- LOCAL_SITE_NAME
Un nombre de sitio descriptivo opcional para describir el clúster
local.- DIRECTION
Una dirección de duplicación. El valor por defecto es
rx-txpara la duplicación bidireccional, pero también se puede definir comorx-onlypara la duplicación unidireccional.- POOL_NAME
El nombre del repositorio.
- TOKEN_PATH
Una vía de archivo al testigo creado (o
-para leerlo desde la entrada estándar).
Por ejemplo, en el clúster remote:
cephuser@remote > cat <<EOF > token
eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW \
1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1v \
bl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
EOFcephuser@adm > rbd --cluster remote mirror pool peer bootstrap import \
--site-name remote image-pool token20.4.1.4 Adición manual de un conector de clúster #
Como alternativa al procedimiento descrito en la
Sección 20.4.1.3, “Conectores de carga”, puede especificar
conectores de forma manual. El daemon remoto
rbd-mirror necesitará acceso al
clúster local para realizar la duplicación. Cree un nuevo usuario local de
Ceph, que utilizará el daemon remoto
rbd-mirror; por ejemplo,
rbd-mirror-peer:
cephuser@adm > ceph auth get-or-create client.rbd-mirror-peer \
mon 'profile rbd' osd 'profile rbd'
Utilice la siguiente sintaxis para añadir un clúster de Ceph conector
duplicado con el comando rbd:
rbd mirror pool peer add POOL_NAME CLIENT_NAME@CLUSTER_NAME
Por ejemplo:
cephuser@adm >rbd --cluster site-a mirror pool peer add image-pool client.rbd-mirror-peer@site-bcephuser@adm >rbd --cluster site-b mirror pool peer add image-pool client.rbd-mirror-peer@site-a
Por defecto, el daemon rbd-mirror
debe tener acceso al archivo de configuración de Ceph ubicado en
/etc/ceph/.NOMBRE_CLÚSTER.conf.
Proporciona las direcciones IP de los MON del clúster conector y un anillo
de claves para un cliente denominado
NOMBRE_CLIENTE ubicado en las vías de búsqueda
por defecto o personalizadas del anillo de claves; por ejemplo
/etc/ceph/NOMBRE_CLUSTER.NOMBRE_CLIENTE.keyring.
Como alternativa, el MON del clúster conector o la clave de cliente se
pueden almacenar de forma segura en el almacén de claves de configuración
de Ceph local. Para especificar los atributos de conexión del clúster
conector al añadir un conector de duplicación, utilice las opciones
--remote-mon-host y --remote-key-file.
Por ejemplo:
cephuser@adm >rbd --cluster site-a mirror pool peer add image-pool \ client.rbd-mirror-peer@site-b --remote-mon-host 192.168.1.1,192.168.1.2 \ --remote-key-file /PATH/TO/KEY_FILEcephuser@adm >rbd --cluster site-a mirror pool info image-pool --all Mode: pool Peers: UUID NAME CLIENT MON_HOST KEY 587b08db... site-b client.rbd-mirror-peer 192.168.1.1,192.168.1.2 AQAeuZdb...
20.4.1.5 Eliminación de un clúster conector #
Para eliminar un clúster conector duplicado, especifique el subcomando
mirror pool peer remove, el nombre del repositorio y el
UUID del conector (disponible mediante el comando rbd mirror pool
info):
cephuser@adm >rbd --cluster local mirror pool peer remove POOL_NAME \ 55672766-c02b-4729-8567-f13a66893445cephuser@adm >rbd --cluster remote mirror pool peer remove POOL_NAME \ 60c0e299-b38f-4234-91f6-eed0a367be08
20.4.1.6 Repositorios de datos #
Al crear imágenes en el clúster de destino,
rbd-mirror selecciona un
repositorio de datos de la siguiente manera:
Si el clúster de destino tiene un repositorio de datos por defecto configurado (con la opción de configuración
rbd_default_data_pool), se utilizará.De lo contrario, si la imagen de origen utiliza un repositorio de datos independiente y existe un repositorio con el mismo nombre en el clúster de destino, se utilizará dicho repositorio.
Si no se cumple ninguna de estas condiciones, no se definirá ningún repositorio de datos.
20.4.2 Configuración de la imagen RBD #
A diferencia de la configuración del repositorio, la configuración de la imagen solo se debe realizar en un único clúster conector duplicado de Ceph.
Las imágenes RBD duplicadas se designan como primary (principal) o non-primary (no principal). Se trata de una propiedad de la imagen, no del repositorio. Las imágenes designadas como no principales no se pueden modificar.
Las imágenes suben de nivel a principal automáticamente cuando la
duplicación se habilita por primera vez en una imagen (ya sea implícita, si
el modo de duplicación del repositorio es "pool" [repositorio] y la imagen
cuenta con la función de imagen transaccional habilitada, o explícita
[consulte la Sección 20.4.2.1, “Habilitación de la duplicación de imágenes”], mediante
el comando rbd).
20.4.2.1 Habilitación de la duplicación de imágenes #
Si la duplicación está configurada en el modo image, es
necesario habilitar explícitamente la duplicación para cada imagen del
repositorio. Para habilitar la duplicación de una imagen concreta con
rbd, especifique el subcomando mirror image
enable junto con el nombre del repositorio y el de la imagen:
cephuser@adm > rbd --cluster local mirror image enable \
POOL_NAME/IMAGE_NAME
El modo de imagen duplicada puede ser journal
(registro) o snapshot (instantánea):
- journal (modo por defecto)
Cuando se configura en el modo
journal, la duplicación utilizará la función de imagen RBD transaccional para replicar el contenido de la imagen. Si esta función aún no está habilitada en la imagen, se habilitará automáticamente.- snapshot
Cuando se configura en el modo de
snapshot, la duplicación utilizará instantáneas de duplicación de la imagen RBD para replicar el contenido de la imagen. Una vez habilitada, se creará automáticamente una instantánea de duplicación inicial. Se pueden crear instantáneas adicionales mediante el comandorbd.
Por ejemplo:
cephuser@adm >rbd --cluster local mirror image enable image-pool/image-1 snapshotcephuser@adm >rbd --cluster local mirror image enable image-pool/image-2 journal
20.4.2.2 Habilitación de la función transaccional de imágenes #
La duplicación RBD utiliza las imágenes RBD transaccionales para
garantizar que la imagen replicada siempre esté protegida contra fallos.
Cuando se utiliza el modo de duplicación image, la
función transaccional se habilita automáticamente si la duplicación está
habilitada en la imagen. Cuando se utiliza el modo de duplicación
pool, antes de que una imagen se pueda duplicar en un
clúster conector, la función de imagen RBD transaccional debe estar
habilitada. Se puede habilitar en el momento de crear la imagen
proporcionando la opción ‑‑image-feature
exclusive-lock,journaling al comando rbd.
Como alternativa, la función de registro transaccional se puede habilitar
de forma dinámica en las imágenes RBD preexistentes. Para habilitar el
registro transaccional, especifique el subcomando feature
enable, el nombre del repositorio y la imagen y el nombre de la
función:
cephuser@adm >rbd --cluster local feature enable POOL_NAME/IMAGE_NAME exclusive-lockcephuser@adm >rbd --cluster local feature enable POOL_NAME/IMAGE_NAME journaling
La función journaling (registro transaccional) depende
de la función exclusive-lock (bloqueo exclusivo). Si la
función exclusive-lock no está habilitada, deberá
habilitarla antes que la función journaling.
Puede habilitar la función transaccional en todas las imágenes nuevas por
defecto añadiendo rbd default features =
layering,exclusive-lock,object-map,deep-flatten,journaling al
archivo de configuración de Ceph.
20.4.2.3 Creación de instantáneas de duplicación de la imagen #
Si se utiliza la duplicación basada en instantáneas, será necesario crear
instantáneas de duplicación siempre que se desee duplicar el contenido
modificado de la imagen RBD. Para crear una instantánea de duplicación
manualmente con rbd, especifique el comando
mirror image snapshot junto con el nombre del
repositorio y la imagen:
cephuser@adm > rbd mirror image snapshot POOL_NAME/IMAGE_NAMEPor ejemplo:
cephuser@adm > rbd --cluster local mirror image snapshot image-pool/image-1
Por defecto, solo se crearán tres instantáneas de duplicación por imagen.
La instantánea de duplicación más reciente se elimina automáticamente si
se alcanza el límite. El límite se puede anular mediante la opción de
configuración rbd_mirroring_max_mirroring_snapshots si es
necesario. Además, las instantáneas de duplicación se suprimen
automáticamente cuando se elimina la imagen o cuando se inhabilita la
duplicación.
Las instantáneas de duplicación también se pueden crear automáticamente de forma periódica si se programa. La instantánea de duplicación se puede programar a nivel global, por repositorio o por imagen. Se pueden definir varias programaciones de instantáneas de duplicación en cualquier nivel, pero solo se ejecutarán las programaciones más específicas que coincidan con una imagen duplicada individual.
Para crear una programación de instantáneas de duplicación con
rbd, especifique el comando mirror snapshot
schedule add junto con un nombre de repositorio o imagen
opcional, un intervalo y una hora de inicio opcional.
El intervalo se puede especificar en días, horas o minutos mediante los
sufijos d, h o m,
respectivamente. La hora de inicio opcional se puede especificar mediante
el formato de hora ISO 8601. Por ejemplo:
cephuser@adm >rbd --cluster local mirror snapshot schedule add --pool image-pool 24h 14:00:00-05:00cephuser@adm >rbd --cluster local mirror snapshot schedule add --pool image-pool --image image1 6h
Para eliminar una programación de instantáneas de duplicación con
rbd, especifique el comando mirror snapshot
schedule remove con opciones que coincidan con el comando
correspondiente para añadir una programación.
Para todas las programaciones de instantáneas para un nivel específico
(global, repositorio o imagen) con rbd, especifique el
comando mirror snapshot schedule ls junto con un nombre
de repositorio o imagen opcional. Además, se puede especificar la opción
--recursive para mostrar todas las programaciones en el
nivel especificado e inferior. Por ejemplo:
cephuser@adm > rbd --cluster local mirror schedule ls --pool image-pool --recursive
POOL NAMESPACE IMAGE SCHEDULE
image-pool - - every 1d starting at 14:00:00-05:00
image-pool image1 every 6h
Para saber cuándo se crearán las siguientes instantáneas para las imágenes
RBD de duplicación basadas en instantáneas con rbd,
especifique el comando mirror snapshot schedule status
junto con un nombre de repositorio o imagen opcional. Por ejemplo:
cephuser@adm > rbd --cluster local mirror schedule status
SCHEDULE TIME IMAGE
2020-02-26 18:00:00 image-pool/image120.4.2.4 Inhabilitación de la duplicación de imágenes #
Para habilitar la duplicación de una imagen concreta, especifique el
subcomando mirror image disable junto con el nombre del
repositorio y el de la imagen:
cephuser@adm > rbd --cluster local mirror image disable POOL_NAME/IMAGE_NAME20.4.2.5 Subida y bajada de nivel de imágenes #
En una situación de failover en la que sea necesario mover la designación primara a la imagen del clúster conector, debe detener el acceso a la imagen principal, bajarla de nivel, subir el nivel de la nueva imagen principal y reanudar el acceso a la imagen en el clúster alternativo.
Puede forzar la subida de nivel mediante la opción
‑‑force. Es necesario forzar la subida de nivel cuando
la bajada de nivel no se puede propagar al clúster conector (por ejemplo,
en caso de fallo del clúster o interrupción de la comunicación). Esto
provocará una situación de división entre ambos conectores y la imagen
dejará de sincronizarse hasta que se emita un subcomando
resync.
Para bajar de nivel una imagen y convertirla en no principal, especifique
el subcomando mirror image demote junto con el nombre
del repositorio y el de la imagen:
cephuser@adm > rbd --cluster local mirror image demote POOL_NAME/IMAGE_NAME
Para bajar de nivel todas las imágenes principales de un repositorio a no
principales, especifique el subcomando mirror pool
demote junto con el nombre del repositorio:
cephuser@adm > rbd --cluster local mirror pool demote POOL_NAME
Para subir de nivel una imagen y convertirla en principal, especifique el
subcomando mirror image promote junto con el nombre del
repositorio y el de la imagen:
cephuser@adm > rbd --cluster remote mirror image promote POOL_NAME/IMAGE_NAME
Para subir de nivel todas las imágenes de un repositorio a principales,
especifique el subcomando mirror pool promote junto con
el nombre del repositorio:
cephuser@adm > rbd --cluster local mirror pool promote POOL_NAMEPuesto que el estado primario o no primario se establece para cada imagen, es posible que haya dos clústeres que dividan la carga de E/S y el failover o failback por fases.
20.4.2.6 Forzado de la resincronización de la imagen #
Si el daemon rbd-mirror detecta un
evento dividido, no intentará duplicar la imagen afectada hasta que se
corrija. Para reanudar la duplicación de una imagen, primero baje de nivel
la imagen considerada obsoleta y, a continuación, realice una petición de
resincronización de la imagen principal. Para pedir una resincronización
de la imagen, especifique el subcomando mirror image
resync junto con el nombre del repositorio y el de la imagen:
cephuser@adm > rbd mirror image resync POOL_NAME/IMAGE_NAME20.4.3 Comprobación del estado de la duplicación #
El estado de replicación de clúster conector se almacena para cada imagen
principal duplicada. Este estado se puede recuperar mediante los
subcomandos mirror image status y mirror pool
status:
Para pedir el estado de la imagen duplicada, especifique el subcomando
mirror image status junto con el nombre del repositorio
y el de la imagen:
cephuser@adm > rbd mirror image status POOL_NAME/IMAGE_NAME
Para pedir el estado resumido del repositorio de duplicación, especifique
el subcomando mirror pool status junto con el nombre del
repositorio:
cephuser@adm > rbd mirror pool status POOL_NAME
Si se añade la opción ‑‑verbose al subcomando
mirror pool status, también se mostrará la información
de estado de todas las imágenes duplicadas del repositorio.
20.5 Ajustes de caché #
La implementación del espacio de usuario del dispositivo de bloques Ceph
(librbd) no puede hacer uso del caché de paginación
de Linux. Por lo tanto, incluye su propio almacenamiento en caché en
memoria. El almacenamiento en caché de RBD tiene un comportamiento similar
al almacenamiento en caché del disco duro. Cuando el sistema operativo envía
una barrera o una petición de vaciado, todos los datos "sucios" se escriben
en los OSD. Esto significa que el uso del almacenamiento en caché en modo
write-back es tan seguro como usar un disco duro físico de buen
comportamiento con una máquina virtual que envía correctamente los vaciados.
La memoria caché utiliza un algoritmo LRU (del inglés
Least Recently Used, menos usadas recientemente) y, en el modo write-back,
puede combinar peticiones adyacentes para obtener un mejor rendimiento.
Ceph admite el modo write-back de almacenamiento en caché para los RBD. Para habilitarlo, ejecute:
cephuser@adm > ceph config set client rbd_cache true
Por defecto, librbd no realiza ningún
almacenamiento en caché. Las escrituras y lecturas van directamente al
clúster de almacenamiento. Las escrituras solo se devuelven cuando los datos
están en el disco en todas las réplicas. Con el almacenamiento en caché
habilitado, las escrituras se devuelven de inmediato, a menos que haya más
bytes sin vaciar de los definidos en la opción rbd cache max
dirty. En tal caso, la escritura activa la escritura diferida y se
bloquea hasta que se vacían suficientes bytes.
Ceph admite el modo write-through de almacenamiento en caché para los RBD. Es posible definir el tamaño de la memoria caché y establecer destinos y límites para cambiar del modo write-back al modo write-through de almacenamiento en caché. Para habilitar el modo write-through, ejecute:
cephuser@adm > ceph config set client rbd_cache_max_dirty 0Esto significa que las escrituras solo se devuelven cuando los datos están en el disco en todas las réplicas, pero las lecturas pueden provenir de la memoria caché. La memoria caché está en memoria en el cliente y cada imagen RBD tiene su propia memoria caché. Puesto que la memoria caché es local para el cliente, si hay otros usuarios que acceden a la imagen, la coherencia se pierde. Ejecutar GFS u OCFS sobre el RBD no funcionará si el almacenamiento en caché está habilitado.
Los siguientes parámetros afectan al comportamiento de los dispositivos de
bloques RADOS. Para definirlos, utilice la categoría
client:
cephuser@adm > ceph config set client PARAMETER VALUErbd cacheHabilita el almacenamiento en caché para el dispositivo de bloques RADOS (RBD). El valor por defecto es "true" (verdadero).
rbd cache sizeEl tamaño de la memoria caché del RBD en bytes. El valor por defecto es 32 MB.
rbd cache max dirtyEl límite de bytes "sucios" en el que la memoria caché activa el modo write-back. El valor de
rbd cache max dirtydebe ser menor que el derbd cache size. Si se define en 0, se utiliza el almacenamiento en caché en modo write-through. El valor por defecto es 24 MB.rbd cache target dirtyEl "destino sucio" antes de que la memoria caché comience a escribir datos en el almacenamiento de datos. No bloquea las escrituras en la memoria caché. El valor por defecto es 16 MB.
rbd cache max dirty ageEl número de segundos que los datos sucios están en la memoria caché antes de que se inicie la escritura diferida. El valor por defecto es 1.
rbd cache writethrough until flushComienza en modo write-through y cambia al modo write-back después de que se reciba la primera petición de vaciado. Habilitar esta opción es una medida conservadora pero segura en caso de que las máquinas virtuales que se ejecutan en
rbdsean demasiado antiguas para enviar vaciados (por ejemplo, el controlador virtio de Linux antes del kernel 2.6.32). El valor por defecto es "true" (verdadero).
20.6 Ajuste de QoS #
Por norma general, la calidad de servicio (QoS) hace referencia a los métodos de priorización del tráfico y de reserva de recursos. Es particularmente importante para el transporte del tráfico con requisitos especiales.
Los ajustes de QoS siguientes solo se utilizan en la implementación
librbd del RBD de espacio de
nombres, pero no por la implementación
kRBD. Dado que iSCSI utiliza
kRBD, no utiliza los valores de QoS. Sin embargo,
para iSCSI puede configurar QoS en la capa de dispositivo de bloques del
kernel mediante instalaciones del kernel estándar.
rbd qos iops limitEl límite deseado de operaciones de E/S por segundo. El valor por defecto es 0 (sin límite).
rbd qos bps limitEl límite deseado de bytes de E/S por segundo. El valor por defecto es 0 (sin límite).
rbd qos read iops limitEl límite deseado de operaciones de lectura por segundo. El valor por defecto es 0 (sin límite).
rbd qos write iops limitEl límite deseado de operaciones de escritura por segundo. El valor por defecto es 0 (sin límite).
rbd qos read bps limitEl límite deseado de bytes de lectura por segundo. El valor por defecto es 0 (sin límite).
rbd qos write bps limitEl límite deseado de bytes de escritura por segundo. El valor por defecto es 0 (sin límite).
rbd qos iops burstEl límite de ráfaga deseado de operaciones de E/S. El valor por defecto es 0 (sin límite).
rbd qos bps burstEl límite de ráfaga deseado de bytes de E/S. El valor por defecto es 0 (sin límite).
rbd qos read iops burstEl límite de ráfaga deseado de operaciones de lectura. El valor por defecto es 0 (sin límite).
rbd qos write iops burstEl límite de ráfaga deseado de operaciones de escritura. El valor por defecto es 0 (sin límite).
rbd qos read bps burstEl límite de ráfaga deseado de bytes de lectura. El valor por defecto es 0 (sin límite).
rbd qos write bps burstEl límite de ráfaga deseado de bytes de escritura. El valor por defecto es 0 (sin límite).
rbd qos schedule tick minLa pulsación de programación mínima (en milisegundos) para QoS. El valor por defecto es 50.
20.7 Ajustes de lectura anticipada #
El dispositivo de bloques RADOS admite la lectura anticipada y la captura previa para optimizar las lecturas pequeñas y secuenciales. Normalmente, el sistema operativo invitado se encargaría de gestionar esta función en una máquina virtual, pero es posible que los cargadores de arranque no emitan lecturas eficientes. La lectura anticipada se inhabilita automáticamente si el almacenamiento en caché está inhabilitado.
Los ajustes de lectura anticipada siguientes solo se utilizan en la
implementación librbd del RBD de
espacio de nombres, pero no por la implementación
kRBD. Dado que iSCSI utiliza
kRBD, no utiliza los ajustes de lectura
anticipada. Sin embargo, para iSCSI puede configurar la lectura anticipada
en la capa de dispositivo de bloques del kernel mediante instalaciones del
kernel estándar.
rbd readahead trigger requestsEl número de peticiones de lectura secuenciales necesarias para activar la lectura anticipada. El valor por defecto es 10.
rbd readahead max bytesEl tamaño máximo de una petición de lectura anticipada. Si se define en 0, la lectura anticipada estará inhabilitada. El valor por defecto es 512 kB.
rbd readahead disable after bytesDespués de que se hayan leído este número de bytes de una imagen RBD, la lectura anticipada se inhabilita para esa imagen hasta que se cierra. Esto permite que el sistema operativo invitado recupere la función de lectura anticipada cuando se arranca. Si se define en 0, la lectura anticipada sigue habilitada. El valor por defecto es 50 MB.
20.8 Funciones avanzadas #
El dispositivo de bloques RADOS admite funciones avanzadas que mejoran la
funcionalidad de las imágenes RBD. Puede especificar las funciones en la
línea de comandos cuando se crea una imagen RBD o en el archivo de
configuración de Ceph mediante la opción
rbd_default_features.
Es posible especificar los valores de la opción
rbd_default_features de dos maneras:
Como una suma de los valores internos de las funciones. Cada función tiene su propio valor interno; por ejemplo, la "layering" tiene 1 y "fast-diff" tiene 16. Por lo tanto, para activar estas dos funciones por defecto, incluya lo siguiente:
rbd_default_features = 17
Como una lista separada por comas de funciones. El ejemplo anterior tendrá el siguiente aspecto:
rbd_default_features = layering,fast-diff
Las imágenes RBD con las siguientes funciones no son compatibles con iSCSI:
deep-flatten, object-map,
journaling, fast-diff y
striping
A continuación se muestra una lista de funciones avanzadas de RBD:
layeringLa disposición en capas permite utilizar la clonación.
El valor interno es 1, el valor por defecto es "sí".
stripingLa repartición striping distribuye los datos entre varios objetos y ayuda a las cargas de trabajo de lectura y escritura secuenciales mediante paralelismo. Evita los cuellos de botella en un solo nodo en dispositivos de bloques RADOS de gran volumen u ocupación.
El valor interno es 2, el valor por defecto es "sí".
exclusive-lockSi está habilitado, requiere que un cliente obtenga un bloqueo en un objeto antes de realizar una escritura. Habilita el bloqueo exclusivo solo si un único cliente accede a una imagen al mismo tiempo. El valor interno es 4. El valor por defecto es "sí".
object-mapLa compatibilidad con el mapa de objetos depende de la compatibilidad con el bloqueo exclusivo. Los dispositivos de bloque son de provisión ligera, lo que significa que solo almacenan datos que realmente existen. La compatibilidad con el mapa de objetos ayuda a realizar un seguimiento de los objetos que realmente existen (que tienen datos almacenados en una unidad). Al habilitar la compatibilidad con el mapa de objetos, se aceleran las operaciones de E/S para clonar, importar y exportar una imagen escasamente poblada y suprimirla.
El valor interno es 8, el valor por defecto es "sí".
fast-diffLa compatibilidad con diff rápida depende de la compatibilidad con el mapa de objetos y con el bloqueo exclusivo. Añade otra propiedad al mapa de objetos, lo que hace que sea mucho más rápido generar diffs entre las instantáneas de una imagen y el uso de datos real de una instantánea.
El valor interno es 16, el valor por defecto es "sí".
deep-flattenEl aplanamiento profundo hace que
rbd flatten(consulte la Sección 20.3.3.6, “Aplanamiento de una imagen clonada”) funcione en todas las instantáneas de una imagen, además de en la propia imagen. Sin él, las instantáneas de una imagen seguirían dependiendo de la imagen padre y, por lo tanto, no se podría suprimir la imagen padre hasta que se eliminaran las instantáneas. El aplanamiento profundo provoca que una imagen padre sea independiente de sus clones, incluso si tienen instantáneas.El valor interno es 32, el valor por defecto es "sí".
journalingLa compatibilidad con el registro transaccional depende de la compatibilidad con el bloqueo exclusivo. El registro transaccional guarda todas las modificaciones en una imagen en el orden en el que se producen. La duplicación del RBD (consulte la Sección 20.4, “Duplicados de imagen RBD”) utiliza el diario para replicar una imagen coherente con la detención por fallo en un clúster remoto.
El valor interno es 64 y el valor por defecto es "no".
20.9 Asignación del RBD utilizando clientes de kernel antiguos #
Es posible que los clientes antiguos (por ejemplo, SLE11 SP4) no puedan asignar imágenes RBD porque un clúster distribuido con SUSE Enterprise Storage 7 aplica algunas funciones (tanto funciones de nivel de imagen RBD como funciones de nivel de RADOS) que estos clientes antiguos no admiten. Si esto sucede, los registros del OSD mostrarán mensajes similares a los siguientes:
2019-05-17 16:11:33.739133 7fcb83a2e700 0 -- 192.168.122.221:0/1006830 >> \ 192.168.122.152:6789/0 pipe(0x65d4e0 sd=3 :57323 s=1 pgs=0 cs=0 l=1 c=0x65d770).connect \ protocol feature mismatch, my 2fffffffffff < peer 4010ff8ffacffff missing 401000000000000
Si tiene previsto cambiar los tipos de depósito del mapa de CRUSH entre "straw" y "straw2", hágalo de una manera planificada. Tenga previsto que el impacto en la carga del clúster será significativo, ya que provocará un reequilibrio masivo del clúster.
Inhabilite las funciones de la imagen RBD que no sean compatibles. Por ejemplo:
cephuser@adm >rbd feature disable pool1/image1 object-mapcephuser@adm >rbd feature disable pool1/image1 exclusive-lockCambie los tipos de depósito del mapa de CRUSH de "straw2" a "straw":
Guarde el mapa de CRUSH:
cephuser@adm >ceph osd getcrushmap -o crushmap.originalDescompile el mapa de CRUSH.
cephuser@adm >crushtool -d crushmap.original -o crushmap.txtEdite el mapa de CRUSH y sustituya "straw2" por "straw".
Vuelva a compilar el mapa de CRUSH:
cephuser@adm >crushtool -c crushmap.txt -o crushmap.newDefina el nuevo mapa de CRUSH:
cephuser@adm >ceph osd setcrushmap -i crushmap.new
20.10 Habilitación de dispositivos de bloques y Kubernetes #
Puede usar RBD de Ceph con Kubernetes 1.13 y versiones posteriores mediante
el controlador ceph-csi. Este controlador proporciona
imágenes RBD de forma dinámica para respaldar los volúmenes de Kubernetes y
asigna estas imágenes RBD como dispositivos de bloques (montando
opcionalmente un sistema de archivos incluido en la imagen) en nodos de
trabajo que ejecutan pods que hacen referencia a un volumen respaldado por
RBD.
Para utilizar dispositivos de bloques de Ceph con Kubernetes, debe instalar
y configurar ceph-csi en el entorno de Kubernetes.
ceph-csi utiliza los módulos del kernel de RBD por
defecto, que quizás no admitan todos los elementos ajustables de Ceph CRUSH
o las funciones de imagen RBD.
Por defecto, los dispositivos de bloques de Ceph utilizan el repositorio de RBD. Cree un repositorio para el almacenamiento de volúmenes de Kubernetes. Asegúrese de que el clúster de Ceph se está ejecutando y, a continuación, cree el repositorio:
cephuser@adm >ceph osd pool create kubernetesUtilice la herramienta RBD para inicializar el repositorio:
cephuser@adm >rbd pool init kubernetesCree un nuevo usuario para Kubernetes y
ceph-csi. Ejecute lo siguiente y guarde la clave generada:cephuser@adm >ceph auth get-or-create client.kubernetes mon 'profile rbd' osd 'profile rbd pool=kubernetes' mgr 'profile rbd pool=kubernetes' [client.kubernetes] key = AQD9o0Fd6hQRChAAt7fMaSZXduT3NWEqylNpmg==ceph-csirequiere un objeto ConfigMap almacenado en Kubernetes para definir las direcciones del monitor de Ceph para el clúster de Ceph. Recopile tanto el fsid exclusivo del clúster de Ceph como las direcciones del monitor:cephuser@adm >ceph mon dump <...> fsid b9127830-b0cc-4e34-aa47-9d1a2e9949a8 <...> 0: [v2:192.168.1.1:3300/0,v1:192.168.1.1:6789/0] mon.a 1: [v2:192.168.1.2:3300/0,v1:192.168.1.2:6789/0] mon.b 2: [v2:192.168.1.3:3300/0,v1:192.168.1.3:6789/0] mon.cGenere un archivo
csi-config-map.yamlsimilar al ejemplo siguiente, sustituyendo el FSID porclusterIDy las direcciones de monitor pormonitors.kubectl@adm >cat <<EOF > csi-config-map.yaml --- apiVersion: v1 kind: ConfigMap data: config.json: |- [ { "clusterID": "b9127830-b0cc-4e34-aa47-9d1a2e9949a8", "monitors": [ "192.168.1.1:6789", "192.168.1.2:6789", "192.168.1.3:6789" ] } ] metadata: name: ceph-csi-config EOFCuando se genere, almacene el nuevo objeto ConfigMap en Kubernetes:
kubectl@adm >kubectl apply -f csi-config-map.yamlceph-csirequiere las credenciales de cephx para comunicarse con el clúster de Ceph. Genere un archivocsi-rbd-secret.yamlsimilar al ejemplo siguiente, utilizando el ID de usuario de Kubernetes y la clave de cephx recién creados:kubectl@adm >cat <<EOF > csi-rbd-secret.yaml --- apiVersion: v1 kind: Secret metadata: name: csi-rbd-secret namespace: default stringData: userID: kubernetes userKey: AQD9o0Fd6hQRChAAt7fMaSZXduT3NWEqylNpmg== EOFCuando se genere, guarde el nuevo objeto de secreto en Kubernetes:
kubectl@adm >kubectl apply -f csi-rbd-secret.yamlCree los objetos ServiceAccount y RBAC ClusterRole/ClusterRoleBinding necesarios de Kubernetes. No es obligatorio personalizar estos objetos para el entorno de Kubernetes y, por lo tanto, se pueden utilizar directamente desde los archivos YAML de distribución de
ceph-csi:kubectl@adm >kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-provisioner-rbac.yamlkubectl@adm >kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-nodeplugin-rbac.yamlCree el aprovisionador
ceph-csiy los complementos de nodo:kubectl@adm >wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin-provisioner.yamlkubectl@adm >kubectl apply -f csi-rbdplugin-provisioner.yamlkubectl@adm >wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin.yamlkubectl@adm >kubectl apply -f csi-rbdplugin.yamlImportantePor defecto, los archivos YAML del aprovisionador y del complemento de nodo extraerán la versión de desarrollo del contenedor de
ceph-csi. Los archivos YAML deben actualizarse para utilizar una versión de lanzamiento.
20.10.1 Uso de dispositivos de bloques de Ceph en Kubernetes #
Kubernetes StorageClass define una clase de almacenamiento. Se pueden crear varios objetos StorageClass para asignarlos a diferentes niveles y funciones de calidad de servicio. Por ejemplo, NVMe frente a los repositorios basados en discos duros.
Para crear un objeto StorageClass de ceph-csi que se
asigne al repositorio de Kubernetes creado anteriormente, se puede usar el
siguiente archivo YAML, después de asegurarse de que la propiedad
clusterID coincide con el FSID del clúster de Ceph:
kubectl@adm >cat <<EOF > csi-rbd-sc.yaml --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: csi-rbd-sc provisioner: rbd.csi.ceph.com parameters: clusterID: b9127830-b0cc-4e34-aa47-9d1a2e9949a8 pool: kubernetes csi.storage.k8s.io/provisioner-secret-name: csi-rbd-secret csi.storage.k8s.io/provisioner-secret-namespace: default csi.storage.k8s.io/node-stage-secret-name: csi-rbd-secret csi.storage.k8s.io/node-stage-secret-namespace: default reclaimPolicy: Delete mountOptions: - discard EOFkubectl@adm >kubectl apply -f csi-rbd-sc.yaml
Una PersistentVolumeClaim es una petición de recursos de
almacenamiento abstractos por parte de un usuario. La
PersistentVolumeClaim se asociará a un recurso de pod
para aprovisionar un PersistentVolume, que estaría
respaldado por una imagen de bloque de Ceph. Se puede incluir un
volumeMode opcional para seleccionar entre un sistema de
archivos montado (por defecto) o un volumen basado en dispositivos de
bloques en bruto.
Con ceph-csi, especificando Filesystem
para volumeMode puede admitir peticiones tanto
ReadWriteOnce como ReadOnlyMany
accessMode; y especificando Block para
volumeMode puede admitir peticiones
ReadWriteOnce, ReadWriteMany y
ReadOnlyMany accessMode.
Por ejemplo, para crear una petición
PersistentVolumeClaim basada en bloques que utilice la
ceph-csi-based StorageClass creada anteriormente, se
puede utilizar el siguiente archivo YAML para pedir almacenamiento de
bloques en bruto desde csi-rbd-sc StorageClass:
kubectl@adm >cat <<EOF > raw-block-pvc.yaml --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: raw-block-pvc spec: accessModes: - ReadWriteOnce volumeMode: Block resources: requests: storage: 1Gi storageClassName: csi-rbd-sc EOFkubectl@adm >kubectl apply -f raw-block-pvc.yaml
A continuación, se muestra un ejemplo de asociación de la
PersistentVolumeClaim anterior a un recurso de pod como
dispositivo de bloques en bruto:
kubectl@adm >cat <<EOF > raw-block-pod.yaml --- apiVersion: v1 kind: Pod metadata: name: pod-with-raw-block-volume spec: containers: - name: fc-container image: fedora:26 command: ["/bin/sh", "-c"] args: ["tail -f /dev/null"] volumeDevices: - name: data devicePath: /dev/xvda volumes: - name: data persistentVolumeClaim: claimName: raw-block-pvc EOFkubectl@adm >kubectl apply -f raw-block-pod.yaml
Para crear una PersistentVolumeClaim basad en un sistema
de archivos que utilice la clase cceph-csi-based
StorageClass creada anteriormente, se puede utilizar el siguiente
archivo YAML para pedir un sistema de archivos montado (respaldado por una
imagen RBD) desde la clase csi-rbd-sc StorageClass:
kubectl@adm >cat <<EOF > pvc.yaml --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: rbd-pvc spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 1Gi storageClassName: csi-rbd-sc EOFkubectl@adm >kubectl apply -f pvc.yaml
A continuación, se muestra un ejemplo de asociación de la
PersistentVolumeClaim anterior a un recurso de pod como
sistema de archivos montado:
kubectl@adm >cat <<EOF > pod.yaml --- apiVersion: v1 kind: Pod metadata: name: csi-rbd-demo-pod spec: containers: - name: web-server image: nginx volumeMounts: - name: mypvc mountPath: /var/lib/www/html volumes: - name: mypvc persistentVolumeClaim: claimName: rbd-pvc readOnly: false EOFkubectl@adm >kubectl apply -f pod.yaml
Parte IV Acceso a los datos del clúster #
- 21 Ceph Object Gateway
En este capítulo se presentan las tareas de administración relacionadas con Object Gateway, como la comprobación del estado del servicio, la gestión de cuentas, las pasarelas de varios sitios o la autenticación LDAP.
- 22 Ceph iSCSI Gateway
Este capítulo se centra en las tareas de administración relacionadas con iSCSI Gateway. Para consultar el procedimiento de distribución, consulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.3.5 “Distribución de pasarelas iSCSI Gateway”.
- 23 Sistema de archivos en clúster
En este capítulo se describen las tareas de administración que normalmente se llevan a cabo después de configurar el clúster y exportar CephFS. Si necesita más información sobre cómo configurar CephFS, consulte Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.3.3 “Distr…
- 24 Exportación de datos de Ceph a través de Samba
En este capítulo se describe cómo exportar datos almacenados en un clúster de Ceph a través de un recurso compartido Samba/CIFS, de forma que se pueda acceder fácilmente a ellos desde equipos cliente Windows.* También incluye información que le ayudará a configurar una pasarela Samba de Ceph para un…
- 25 NFS Ganesha
NFS Ganesha es un servidor NFS que se ejecuta en un espacio de dirección de usuario, en lugar de hacerlo como parte del kernel del sistema operativo. Con NFS Ganesha, puede poner en marcha su propio mecanismo de almacenamiento, como Ceph, y acceder a él desde cualquier cliente NFS. Para obtener inst…
21 Ceph Object Gateway #
En este capítulo se presentan las tareas de administración relacionadas con Object Gateway, como la comprobación del estado del servicio, la gestión de cuentas, las pasarelas de varios sitios o la autenticación LDAP.
21.1 Restricciones y limitaciones de denominación de Object Gateway #
A continuación encontrará una lista de limitaciones importantes de Object Gateway.
21.1.1 Limitaciones de los depósitos #
Cuando se accede a Object Gateway a través de la API de S3, los nombres de depósito deben ser nombres compatibles con DNS y solo se permite el carácter de guión "-". Cuando se accede a Object Gateway a través de la API de Swift, puede utilizar cualquier combinación de caracteres UTF-8 compatibles, excepto el carácter de barra "/". La longitud máxima de los nombres de depósito es de 255 caracteres. Los nombres de depósitos deben ser exclusivos.
Aunque puede utilizar cualquier nombre de depósito basado en UTF-8 en la API de Swift, se recomienda respetar la limitación existente para los nombre en S3, a fin de evitar problemas al acceder al mismo depósito a través de la API de S3.
21.1.2 Limitaciones de los objetos almacenados #
- Número máximo de objetos por usuario
No hay restricciones por defecto (limitado a ~2^63).
- Número máximo de objetos por depósito
No hay restricciones por defecto (limitado a ~2^63).
- Tamaño máximo de un objeto para cargar o almacenar
Las cargas sencillas están restringidas a 5 GB. Divida varias partes para objetos más grandes. El número máximo de porciones de varias partes es 10 000.
21.1.3 Limitaciones de los encabezados HTTP #
El encabezado HTTP y la limitación de la petición dependen de la interfaz Web que se utilice. La instancia por defecto de Beast restringe el tamaño del encabezado HTTP a 16 kB.
21.2 Distribución de Object Gateway #
La distribución de Ceph Object Gateway sigue el mismo procedimiento que la distribución de otros servicios de Ceph, mediante cephadm. Para obtener más información, consulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.2 “Especificación del servicio y la colocación”, específicamente el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.3.4 “Distribución de pasarelas Object Gateways”.
21.3 Funcionamiento del servicio de Object Gateway #
Puede utilizar las pasarelas Object Gateway de la misma forma que otros servicios de Ceph: identificando primero el nombre del servicio con el comando ceph orch ps y ejecutando el comando siguiente para los servicios operativos, por ejemplo:
ceph orch daemon restart OGW_SERVICE_NAME
Consulte el Capítulo 14, Funcionamiento de los servicios de Ceph para obtener información completa sobre el funcionamiento de los servicios de Ceph.
21.4 Opciones de configuración #
Consulte en la Sección 28.5, “Ceph Object Gateway” una lista de opciones de configuración de Object Gateway.
21.5 Gestión del acceso a Object Gateway #
Es posible comunicarse con Object Gateway mediante una interfaz compatible con S3 o con Swift. La interfaz de S3 es compatible con un gran subconjunto de la API RESTful de Amazon S3. La interfaz de Swift es compatible con un gran subconjunto de la API de OpenStack Swift.
Ambas interfaces requieren que cree un usuario específico y que instale el software cliente relevante para comunicarse con la pasarela mediante la clave de secreto del usuario.
21.5.1 Acceso a Object Gateway #
21.5.1.1 Acceso a la interfaz de S3 #
Para acceder a la interfaz de S3, necesita un cliente de REST. S3cmd es un cliente de S3 de línea de comandos. Lo encontrará en OpenSUSE Build Service. El repositorio contiene versiones tanto para SUSE Linux Enterprise como para distribuciones basadas en openSUSE.
Si desea probar el acceso a la interfaz de S3, también puede escribir un pequeño guion de Python. El guion se conectará con Object Gateway, creará un depósito nuevo y mostrará todos los depósitos. Los valores de aws_access_key_id y aws_secret_access_key se toman de los valores de access_key y secret_key devueltos por el comando radosgw_admin de la Sección 21.5.2.1, “Adición de usuarios de S3 y Swift”.
Instale el paquete
python-boto:root #zypper in python-botoCree un nuevo guion de Python denominado
s3test.pycon el siguiente contenido:import boto import boto.s3.connection access_key = '11BS02LGFB6AL6H1ADMW' secret_key = 'vzCEkuryfn060dfee4fgQPqFrncKEIkh3ZcdOANY' conn = boto.connect_s3( aws_access_key_id = access_key, aws_secret_access_key = secret_key, host = 'HOSTNAME', is_secure=False, calling_format = boto.s3.connection.OrdinaryCallingFormat(), ) bucket = conn.create_bucket('my-new-bucket') for bucket in conn.get_all_buckets(): print "NAME\tCREATED".format( name = bucket.name, created = bucket.creation_date, )Sustituya
HOSTNAMEpor el nombre del host donde haya configurado el servicio de Object Gateway; por ejemplogateway_host.Ejecute el guion:
python s3test.py
El guion da como resultado algo parecido a lo siguiente:
my-new-bucket 2015-07-22T15:37:42.000Z
21.5.1.2 Acceso a la interfaz de Swift #
Para acceder a Object Gateway a través de una interfaz de Swift, necesita el cliente de línea de comandos swift. La página man 1 swift incluye más información sobre las opciones de la línea de comandos.
El paquete se incluye en el módulo "Nube pública" de SUSE Linux Enterprise 12 de la versión SP3 y en SUSE Linux Enterprise 15. Antes de instalar el paquete, debe activar el módulo y actualizar el repositorio de software:
root # SUSEConnect -p sle-module-public-cloud/12/SYSTEM-ARCH
sudo zypper refreshO bien
root #SUSEConnect -p sle-module-public-cloud/15/SYSTEM-ARCHroot #zypper refresh
Para instalar el comando swift, ejecute lo siguiente:
root # zypper in python-swiftclientEl acceso swift utiliza la sintaxis siguiente:
tux > swift -A http://IP_ADDRESS/auth/1.0 \
-U example_user:swift -K 'SWIFT_SECRET_KEY' list
Sustituya IP_ADDRESS por la dirección IP del servidor de pasarela, y SWIFT_SECRET_KEY por el valor de la clave de secreto de Swift que se obtiene al ejecutar el comando radosgw-admin key create para el usuario de swift en la Sección 21.5.2.1, “Adición de usuarios de S3 y Swift”.
Por ejemplo:
tux > swift -A http://gateway.example.com/auth/1.0 -U example_user:swift \
-K 'r5wWIxjOCeEO7DixD1FjTLmNYIViaC6JVhi3013h' listEl resultado es:
my-new-bucket
21.5.2 Gestión de cuentas de S3 y Swift #
21.5.2.1 Adición de usuarios de S3 y Swift #
Debe crear un usuario, una clave de acceso y un secreto para permitir que los usuarios finales puedan interactuar con la pasarela. Existen dos tipos de usuarios: usuario y subusuario. Los usuarios se utilizan cuando se interactúa con la interfaz de S3, mientras que los subusuarios son usuarios de la interfaz de Swift. Cada subusuario está asociado a un usuario.
Para crear un usuario de Swift, siga estos pasos:
Para crear un usuario de Swift, que es un subusuario en nuestra terminología, debe crear primero el usuario asociado.
cephuser@adm >radosgw-admin user create --uid=USERNAME \ --display-name="DISPLAY-NAME" --email=EMAILPor ejemplo:
cephuser@adm >radosgw-admin user create \ --uid=example_user \ --display-name="Example User" \ --email=penguin@example.comPara crear un subusuario (interfaz de Swift) para el usuario, debe especificar el ID de usuario (‑‑uid=USERNAME), el ID de subusuario y el nivel de acceso para el subusuario.
cephuser@adm >radosgw-admin subuser create --uid=UID \ --subuser=UID \ --access=[ read | write | readwrite | full ]Por ejemplo:
cephuser@adm >radosgw-admin subuser create --uid=example_user \ --subuser=example_user:swift --access=fullGenere una clave de secreto para el usuario.
cephuser@adm >radosgw-admin key create \ --gen-secret \ --subuser=example_user:swift \ --key-type=swiftAmbos comandos darán como resultado datos con formato JSON que muestran el estado del usuario. Fíjese en las siguientes líneas y recuerde el valor de
secret_key:"swift_keys": [ { "user": "example_user:swift", "secret_key": "r5wWIxjOCeEO7DixD1FjTLmNYIViaC6JVhi3013h"}],
Cuando acceda a Object Gateway a través de la interfaz de S3, deberá crear un usuario de S3 ejecutando:
cephuser@adm > radosgw-admin user create --uid=USERNAME \
--display-name="DISPLAY-NAME" --email=EMAILPor ejemplo:
cephuser@adm > radosgw-admin user create \
--uid=example_user \
--display-name="Example User" \
--email=penguin@example.com
El comando también crea la clave de acceso y la clave de secreto del usuario. Compruebe el resultado de las palabras clave access_key y secret_key y sus valores correspondientes:
[...]
"keys": [
{ "user": "example_user",
"access_key": "11BS02LGFB6AL6H1ADMW",
"secret_key": "vzCEkuryfn060dfee4fgQPqFrncKEIkh3ZcdOANY"}],
[...]21.5.2.2 Eliminación de usuarios de S3 y Swift #
El procedimiento para suprimir usuarios es similar para los usuarios de S3 y de Swift. Pero en el caso de los usuarios de Swift, puede ser necesario suprimir el usuario incluyendo sus subusuarios.
Para eliminar un usuario de S3 o Swift (incluidos todos sus subusuarios), especifique user rm y el ID de usuario en el siguiente comando:
cephuser@adm > radosgw-admin user rm --uid=example_user
Para eliminar un subusuario, especifique subuser rm y el ID de subusuario.
cephuser@adm > radosgw-admin subuser rm --uid=example_user:swiftPuede usar las siguientes opciones:
- --purge-data
Limpia todos los datos asociados al ID de usuario.
- --purge-keys
Limpia todas las claves asociadas al ID de usuario.
Cuando se elimina un subusuario, se elimina el acceso a la interfaz de Swift. El usuario permanecerá en el sistema.
21.5.2.3 Cambio del acceso de usuario y las claves de secreto de S3 y Swift #
Los parámetros access_key y secret_key identifican al usuario de Object Gateway cuando se accede a la pasarela. Cambiar las claves de usuario existentes es igual a crear otras nuevas, ya que las claves antiguas se sobrescriben.
Para los usuarios de S3, ejecute lo siguiente:
cephuser@adm > radosgw-admin key create --uid=EXAMPLE_USER --key-type=s3 --gen-access-key --gen-secretPara los usuarios de Swift, ejecute lo siguiente:
cephuser@adm > radosgw-admin key create --subuser=EXAMPLE_USER:swift --key-type=swift --gen-secret‑‑key-type=TYPEEspecifica el tipo de clave. Puede ser
swiftos3.--gen-access-keyGenera una clave de acceso aleatoria (por defecto, para el usuario de S3).
--gen-secretGenera una clave de secreto aleatoria.
‑‑secret=KEYEspecifica una clave de secreto; por ejemplo, una generada manualmente.
21.5.2.4 Habilitación de la gestión de cuotas de usuario #
Ceph Object Gateway permite definir cuotas en usuarios y depósitos que pertenezcan a los usuarios. Las cuotas incluyen el número máximo de objetos de un depósito y el tamaño de almacenamiento máximo en megabytes.
Antes de habilitar una cuota de usuario, debe definir los parámetros correspondientes:
cephuser@adm > radosgw-admin quota set --quota-scope=user --uid=EXAMPLE_USER \
--max-objects=1024 --max-size=1024--max-objectsEspecifica el número máximo de objetos. Un valor negativo inhabilita la comprobación.
--max-sizeEspecifica el número máximo de bytes. Un valor negativo inhabilita la comprobación.
--quota-scopeDefine el ámbito para la cuota. Las opciones son
depósitoyusuario. Las cuotas de depósito se aplican a los depósitos que posee un usuario. Las cuotas de usuario se aplican a un usuario.
Una vez definida una cuota de usuario, se puede habilitar:
cephuser@adm > radosgw-admin quota enable --quota-scope=user --uid=EXAMPLE_USERPara inhabilitar una cuota:
cephuser@adm > radosgw-admin quota disable --quota-scope=user --uid=EXAMPLE_USERPara mostrar la configuración de la cuota:
cephuser@adm > radosgw-admin user info --uid=EXAMPLE_USERPara actualizar las estadísticas de la cuota:
cephuser@adm > radosgw-admin user stats --uid=EXAMPLE_USER --sync-stats21.6 Procesadores frontales HTTP #
Ceph Object Gateway admite dos front-ends HTTP incrustados: Beast y Civetweb.
El front-end Beast utiliza la biblioteca Boost.Beast para el análisis HTTP y la biblioteca Boost.Asio para la E/S de red asincrónica.
El front-end Civetweb utiliza la biblioteca HTTP Civetweb, que es una derivación de Mongoose.
Puede configurarlos con la opción rgw_frontends. Consulte la Sección 28.5, “Ceph Object Gateway” para obtener una lista de las opciones de configuración.
21.7 Habilitación de HTTPS/SSL para pasarelas Object Gateway #
Para permitir que Object Gateway se pueda comunicar de forma segura mediante SSL, debe tener un certificado emitido por una CA o crear uno autofirmado.
21.7.1 Creación de certificados autofirmados #
Omita esta sección si ya dispone de un certificado válido firmado por una CA.
El siguiente procedimiento describe cómo generar un certificado SSL autofirmado en el master de Salt.
Si necesita que identidades de sujeto adicionales conozcan Object Gateway, añádalas a la opción
subjectAltNameen la sección[v3_req]del archivo/etc/ssl/openssl.cnf:[...] [ v3_req ] subjectAltName = DNS:server1.example.com DNS:server2.example.com [...]
Sugerencia: direcciones IP ensubjectAltNamePara utilizar direcciones IP en lugar de nombres de dominio en la opción
subjectAltName, sustituya la línea de ejemplo por lo siguiente:subjectAltName = IP:10.0.0.10 IP:10.0.0.11
Cree la clave y el certificado con
openssl. Introduzca todos los datos que necesite incluir en el certificado. Es recomendable introducir el nombre completo como nombre común. Antes de firmar el certificado, verifique que en las extensiones pedidas se incluye "X509v3 Subject Alternative Name:" y que el certificado resultante tiene definido "X509v3 Subject Alternative Name:".root@master #openssl req -x509 -nodes -days 1095 \ -newkey rsa:4096 -keyout rgw.key -out rgw.pemAñada la clave al final del archivo de certificado:
root@master #cat rgw.key >> rgw.pem
21.7.2 Configuración de Object Gateway con SSL #
Para configurar Object Gateway para que utilice certificados SSL, utilice la opción rgw_frontends. Por ejemplo:
cephuser@adm > ceph config set WHO rgw_frontends \
beast ssl_port=443 ssl_certificate=config://CERT ssl_key=config://KEYSi no especifica las claves de configuración CERT y KEY, el servicio de Object Gateway buscará el certificado SSL y la clave en las siguientes claves de configuración:
rgw/cert/RGW_REALM/RGW_ZONE.key rgw/cert/RGW_REALM/RGW_ZONE.crt
Si desea anular la clave SSL por defecto y la ubicación del certificado, impórtelos a la base de datos de configuración mediante el comando siguiente:
ceph config-key set CUSTOM_CONFIG_KEY -i PATH_TO_CERT_FILE
A continuación, utilice las claves de configuración personalizadas mediante la directiva config://.
21.8 Módulos de sincronización #
Object Gateway se distribuye como un servicio multisitio y puede duplicar datos y metadatos entre las zonas. Los módulos de sincronización se crean sobre la infraestructura de varios sitios y permiten el envío de datos y metadatos a un nivel externo diferente. Con un módulo de sincronización es posible realizar un conjunto de acciones siempre que se produzca un cambio en los datos (por ejemplo, las operaciones de metadatos como la creación de depósitos o usuarios). Como los cambios en varios sitios de Object Gateway al final acaban siendo consistentes en los sitios remotos, estos cambios se propagan de forma asíncrona. Esto cubre situaciones de uso como realizar una copia de seguridad del almacenamiento de objetos en un clúster de nube externa o una solución de copia de seguridad personalizada mediante unidades de cinta; o también indexar metadatos en ElasticSearch,
21.8.1 Configuración de módulos de sincronización #
Todos los módulos de sincronización se configuran de forma similar. Debe crear una zona nueva (consulte la Sección 21.13, “Pasarelas Object Gateway de varios sitios” para obtener más detalles) y defina su opción ‑‑tier_type, por ejemplo ‑‑tier-type-cloud para el módulo de sincronización en la nube:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--endpoints=http://endpoint1.example.com,http://endpoint2.example.com, [...] \
--tier-type=cloudPuede configurar el nivel específico mediante el siguiente comando:
cephuser@adm > radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--tier-config=KEY1=VALUE1,KEY2=VALUE2El elemento KEY de la configuración especifica la variable de configuración que desea actualizar y VALUE especifica su nuevo valor. Es posible acceder a los valores anidados usando un punto. Por ejemplo:
cephuser@adm > radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--tier-config=connection.access_key=KEY,connection.secret=SECRETPuede acceder a las entradas de matriz añadiendo corchetes "[]" detrás de la entrada a la que se hace referencia. Es posible añadir una entrada de matriz nueva utilizando corchetes "[]". El valor de índice de -1 hace referencia a la última entrada de la matriz. No es posible crear una entrada nueva y volver a hacer referencia a ella en el mismo comando. Por ejemplo, se muestra un comando para crear un perfil nuevo para depósitos que empiecen con PREFIX:
cephuser@adm >radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \ --rgw-zone=ZONE-NAME \ --tier-config=profiles[].source_bucket=PREFIX'*'cephuser@adm >radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \ --rgw-zone=ZONE-NAME \ --tier-config=profiles[-1].connection_id=CONNECTION_ID,profiles[-1].acls_id=ACLS_ID
Puede añadir una nueva entrada de configuración de nivel con el parámetro ‑‑tier-config-add=KEY=VALUE.
Para quitar una entrada existente, use ‑‑tier-config-rm=KEY.
21.8.2 Sincronización de zonas #
La configuración del módulo de sincronización es local en una zona. El módulo de sincronización determina si la zona exporta los datos o si solo puede utilizar los datos que se ha modificado en otra zona. A partir de la versión Luminous, los complementos de sincronización compatibles son ElasticSearch, rgw (el complemento por defecto que sincroniza los datos entre las zonas) y log, un complemento de sincronización trivial que registra la operación de metadatos que se produce en las zonas remotas. Las secciones siguientes muestran como ejemplo una zona con el módulo de sincronización ElasticSearch. El proceso será similar para configurar cualquier otro complemento de sincronización.
El complemento de sincronización por defecto es rgw y no es necesario configurarlo de forma explícita.
21.8.2.1 Requisitos y supuestos #
Supongamos que tenemos una configuración sencilla de varios sitios, descrita en la Sección 21.13, “Pasarelas Object Gateway de varios sitios”, formada por 2 zonas: us-east y us-west. Se añade una tercera zona us-east-es, que es una zona que solo procesa metadatos de los otros sitios. Esta zona puede estar en el mismo clúster de Ceph o en uno distinto a us-east. Esta zona solo consumirá metadatos de otras zonas y la pasarela Object Gateway de esta zona no atenderá directamente a ninguna petición del usuario final.
21.8.2.2 Configuración de zonas #
Cree una tercera zona similar a la que se describe en la Sección 21.13, “Pasarelas Object Gateway de varios sitios”, por ejemplo:
cephuser@adm >radosgw-adminzone create --rgw-zonegroup=us --rgw-zone=us-east-es \ --access-key=SYSTEM-KEY --secret=SECRET --endpoints=http://rgw-es:80Puede configurar un módulo de sincronización para esta zona así:
cephuser@adm >radosgw-adminzone modify --rgw-zone=ZONE-NAME --tier-type=TIER-TYPE \ --tier-config={set of key=value pairs}Por ejemplo, en el módulo de sincronización
ElasticSearch:cephuser@adm >radosgw-adminzone modify --rgw-zone=ZONE-NAME --tier-type=elasticsearch \ --tier-config=endpoint=http://localhost:9200,num_shards=10,num_replicas=1Para las distintas opciones de configuración de niveles admitidas, consulte la Sección 21.8.3, “Módulo de sincronización ElasticSearch”.
Por último, actualice el período:
cephuser@adm >radosgw-adminperiod update --commitInicie ahora Object Gateway en la zona:
cephuser@adm >ceph orch start rgw.REALM-NAME.ZONE-NAME
21.8.3 Módulo de sincronización ElasticSearch #
Este módulo de sincronización escribe los metadatos de otras zonas en ElasticSearch. A partir de la versión Luminous, este es el código JSON de campos de datos que se almacenan en ElasticSearch.
{
"_index" : "rgw-gold-ee5863d6",
"_type" : "object",
"_id" : "34137443-8592-48d9-8ca7-160255d52ade.34137.1:object1:null",
"_score" : 1.0,
"_source" : {
"bucket" : "testbucket123",
"name" : "object1",
"instance" : "null",
"versioned_epoch" : 0,
"owner" : {
"id" : "user1",
"display_name" : "user1"
},
"permissions" : [
"user1"
],
"meta" : {
"size" : 712354,
"mtime" : "2017-05-04T12:54:16.462Z",
"etag" : "7ac66c0f148de9519b8bd264312c4d64"
}
}
}21.8.3.1 Parámetros de configuración de tipo de nivel de ElasticSearch #
- endpoint
Especifica el puesto final del servidor de ElasticSearch al que se accede.
- num_shards
(número entero) El número de particiones con las que se configurará ElasticSearch al inicializar la sincronización de datos. Tenga en cuenta que este valor no se puede cambiar después de la inicialización. Cualquier cambio que se haga aquí requiere que se vuelva a crear el índice de ElasticSearch y se reinicialice el proceso de sincronización de datos.
- num_replicas
(número entero) El número de réplicas con las que se configurará ElasticSearch al inicializar la sincronización de datos.
- explicit_custom_meta
(true | false) Especifica si se indexarán todos los metadatos personalizados del usuario, o si el usuario deberá configurar (en el nivel de depósitos) las entradas de metadatos del cliente que se deben indexar. La opción por defecto es "false" (falso).
- index_buckets_list
(lista de cadenas separadas por comas) Si está vacío, todos los depósitos se indexarán. De lo contrario, solo se indexarán los depósitos que se especifiquen aquí. Es posible proporcionar prefijos de depósito (por ejemplo, "foo*") o sufijos de depósito (por ejemplo, "*bar").
- approved_owners_list
(lista de cadenas separadas por comas) Si está vacío, se indexarán los depósitos de todos los propietarios (esto está sujeto a otras restricciones). En caso contrario, se indexarán solo los depósitos de los propietarios especificados. También es posible proporcionar prefijos y sufijos.
- override_index_path
(cadena) Si no está vacío, esta cadena se utilizará como la vía de índice de ElasticSearch. De lo contrario, la vía de índice se determinará y se generará durante la inicialización de la sincronización.
- username
Indica un nombre de usuario para ElasticSearch si se requiere autenticación.
- password
Indica una contraseña para ElasticSearch si se requiere autenticación.
21.8.3.2 Consultas de metadatos #
Dado que el clúster de ElasticSearch almacena ahora metadatos de objeto, es importante que el puesto final de ElasticSearch no esté expuesto al público y solo puedan acceder los administradores de clúster. Exponer las consultas de metadatos a los usuarios finales plantea un problema, ya que queremos que los usuarios solo puedan consultar sus propios metadatos y no los de otros usuarios. Esto último requeriría que el clúster de ElasticSearch autenticara a los usuarios de forma similar a como lo hace RGW, lo que supone un problema.
A partir de la versión Luminous, la instancia de RGW de la zona principal de metadatos puede atender a las peticiones del usuario final. De este modo, no se expone el puesto final de ElasticSearch al público y también se resuelve el problema de la autenticación y la autorización, ya que RGW realiza estas labores para las peticiones del usuario final. Por este motivo, RGW presenta una nueva consulta en las API de depósito que pueden atender las peticiones de ElasticSearch. Todas estas peticiones deben enviarse a la zona principal de metadatos.
- Cómo obtener una consulta de ElasticSearch
GET /BUCKET?query=QUERY-EXPR
Parámetros de la petición:
max-keys: el número máximo de entradas que se deben devolver.
marker: el marcador de paginación.
expression := [(]<arg> <op> <value> [)][<and|or> ...]
El operador "op" es uno de los siguientes: <, <=, ==, >=, >
Por ejemplo:
GET /?query=name==foo
devolverá todas las claves indexadas para las que el usuario tiene permiso de lectura y que tienen como nombre "foo". El resultado será una lista de claves en formato XML similar a la respuesta de lista de depósitos de S3.
- Cómo configurar campos de metadatos personalizados
Defina las entradas de metadatos personalizados que se deben indexar (en el depósito especificado) y cuáles son los tipos de estas claves. Si se ha configurado el indexado explícito de metadatos personalizados, esto es obligatorio para que rgw indexe los valores de los metadatos personalizados especificados. También es necesario en casos en los que las claves de metadatos indexadas sean de un tipo distinto a cadena.
POST /BUCKET?mdsearch x-amz-meta-search: <key [; type]> [, ...]
Si hay varios campos de metadatos, deben separarse con comas. Es posible aplicar un tipo para un campo con punto y coma ";". Los tipos permitidos actualmente son string (valor por defecto), integer y date. Por ejemplo, si desea indexar un metadato de objeto personalizado x-amz-meta-year como int, x-amz-meta-date como fecha de tipo y x-amz-meta-title como cadena, debería hacer lo siguiente:
POST /mybooks?mdsearch x-amz-meta-search: x-amz-meta-year;int, x-amz-meta-release-date;date, x-amz-meta-title;string
- Cómo suprimir una configuración personalizada de metadatos
Puede suprimir una configuración personalizada de metadatos.
DELETE /BUCKET?mdsearch
- Cómo obtener una configuración personalizada de metadatos
Puede recuperar una configuración personalizada de metadatos.
GET /BUCKET?mdsearch
21.8.4 Módulo de sincronización en la nube #
En esta sección se presenta un módulo que sincroniza los datos de zona con un servicio remoto en la nube. La sincronización es unidireccional: la fecha no se sincroniza de nuevo desde la zona remota. El objetivo principal de este módulo es habilitar la sincronización de datos con varios proveedores de servicios en la nube. Actualmente es compatible con proveedores de nube compatibles con AWS (S3).
Para sincronizar los datos con un servicio remoto en la nube, debe configurar las credenciales de usuario. Dado que muchos servicios en la nube incluyen límites en el número de depósitos que puede crear cada usuario, es posible configurar la asignación de objetos y depósitos de origen, diferentes destinos para a distintos depósitos y prefijos de depósito. Tenga en cuenta que las listas de acceso de origen (ACL) no se conservarán. Es posible asignar permisos de usuarios de origen específicos a usuarios de destino concretos.
Debido a las limitaciones de la API, no hay manera de conservar la hora de modificación del objeto original ni la etiqueta de entidad HTTP (ETag). El módulo de sincronización en la nube los almacena como atributos de metadatos en los objetos de destino.
21.8.4.1 Configuración del módulo de sincronización en la nube #
A continuación se muestran ejemplos de una configuración trivial y no trivial para el módulo de sincronización en la nube. Tenga en cuenta que la configuración trivial puede presentar conflictos con la no trivial.
{
"connection": {
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style": path | virtual,
},
"acls": [ { "type": id | email | uri,
"source_id": SOURCE_ID,
"dest_id": DEST_ID } ... ],
"target_path": TARGET_PATH,
}{
"default": {
"connection": {
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style" path | virtual,
},
"acls": [
{
"type": id | email | uri, # optional, default is id
"source_id": ID,
"dest_id": ID
} ... ]
"target_path": PATH # optional
},
"connections": [
{
"connection_id": ID,
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style": path | virtual, # optional
} ... ],
"acl_profiles": [
{
"acls_id": ID, # acl mappings
"acls": [ {
"type": id | email | uri,
"source_id": ID,
"dest_id": ID
} ... ]
}
],
"profiles": [
{
"source_bucket": SOURCE,
"connection_id": CONNECTION_ID,
"acls_id": MAPPINGS_ID,
"target_path": DEST, # optional
} ... ],
}A continuación se explican los términos de configuración utilizados:
- connection
Representa una conexión con el servicio remoto en la nube. Contiene "connection_id", "access_key", "secret", "endpoint" y "host_style".
- access_key
La clave de acceso remoto a la nube que se usará para la conexión específica.
- secret
La clave secreta para el servicio remoto en la nube.
- endpoint
Dirección URL del puesto final del servicio remoto en la nube.
- host_style
El tipo de estilo del host ("path" o "virtual") que se usará al acceder de forma remota al puesto final en la nube. El valor por defecto es "path".
- acls
La matriz de asignaciones de la lista de acceso.
- acl_mapping
Cada estructura "acl_mapping" contiene "type", "source_id" y "dest_id". Estos elementos definen la mutación de la ACL para cada objeto. Una mutación de la ACL permite convertir el ID de usuario de origen en un ID de destino.
- type
El tipo de ACL: "id" define el ID de usuario, "email" define al usuario por correo electrónico y "uri" define al usuario por uri (grupo).
- source_id
El ID de usuario en la zona de origen.
- dest_id
El ID de usuario en el destino.
- target_path
Cadena que define cómo se crea la vía de destino. La vía de destino especifica un prefijo al que se anexa el nombre del objeto de origen. La vía de destino configurable puede incluir cualquiera de las variables siguientes:
- SID
Una cadena exclusiva que representa el ID de instancia de sincronización.
- ZONEGROUP
El nombre del grupo de zonas.
- ZONEGROUP_ID
El ID de grupo de zonas.
- ZONE
Nombre de zona.
- ZONE_ID
El ID de zona.
- BUCKET
El nombre del depósito de origen.
- OWNER
El ID de propietario del depósito de origen.
Por ejemplo: target_path = rgwx-ZONA-SID/PROPIETARIO/DEPÓSITO
- acl_profiles
Una matriz de perfiles de lista de acceso.
- acl_profile
Cada perfil contiene "acls_id", que representa el perfil y una matriz "acls" que contiene una lista "acl_mappings".
- profiles
Una lista de perfiles. Cada perfil contiene lo siguiente:
- source_bucket
Un nombre de depósito o un prefijo de depósito (si termina con *) que define los depósitos de origen para este perfil.
- target_path
Consulte arriba la explicación.
- connection_id
El ID de la conexión que se utilizará para este perfil.
- acls_id
El ID del perfil de ACL que se utilizará para este perfil.
21.8.4.2 Elementos configurables específicos de S3 #
El módulo de sincronización en la nube solo funciona con back-ends compatibles con AWS S3. Hay algunos elementos configurables que se pueden utilizar para ajustar su comportamiento al acceder a los servicios en la nube de S3:
{
"multipart_sync_threshold": OBJECT_SIZE,
"multipart_min_part_size": PART_SIZE
}- multipart_sync_threshold
Los objetos cuyo tamaño sea igual o mayor que este valor se sincronizarán con el servicio en la nube mediante la carga de varias partes.
- multipart_min_part_size
El tamaño mínimo de las partes que se debe utilizar al sincronizar objetos mediante la carga de varias partes.
21.8.5 Módulo de sincronización de archivador #
El módulo archive sync module usa la característica de control de versiones de objetos S3 en Object Gateway. Puede configurar una zona de archivador que capture las diferentes versiones de los objetos S3 a medida que se producen en otras zonas. El historial de versiones que conserva la zona de archivador solo se puede eliminar a través de pasarelas asociadas con la zona de archivador.
Con esta arquitectura, es posible que varias zonas sin versiones pueden duplicar sus datos y metadatos a través de sus pasarelas de zona, lo que proporciona alta disponibilidad a los usuarios finales, mientras que la zona de archivador captura todas las actualizaciones de datos para consolidarlos como versiones de objetos S3.
Al incluir la zona de archivador en una configuración multizona, se consigue la flexibilidad de un historial de objetos dS3 en una zona, al tiempo que se ahorra el espacio que las réplicas de los objetos S3 versionados consumirían en las zonas restantes.
21.8.5.1 Configuración del módulo de sincronización de archivador #
Consulte la Sección 21.13, “Pasarelas Object Gateway de varios sitios” para obtener más información sobre la configuración de pasarelas de varios sitios.
Consulte la Sección 21.8, “Módulos de sincronización” para obtener información detallada sobre cómo configurar los módulos de sincronización.
Para utilizar el módulo de sincronización de archivador, debe crear una zona nueva cuyo tipo de nivel esté definido como archive:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME \
--rgw-zone=OGW_ZONE_NAME \
--endpoints=http://OGW_ENDPOINT1_URL[,http://OGW_ENDPOINT2_URL,...]
--tier-type=archive21.9 Autenticación LDAP #
Aparte de la autenticación de usuario local por defecto, Object Gateway también puede utilizar servicios del servidor LDAP para autenticar a los usuarios.
21.9.1 Mecanismo de autenticación #
Object Gateway extrae las credenciales LDAP del usuario de un testigo. Se construye un filtro de búsqueda a partir del nombre de usuario. Object Gateway utiliza la cuenta del servicio configurado para buscar una entrada que coincida en el directorio. Si se encuentra una entrada, Object Gateway intenta vincularse al nombre completo encontrado con la contraseña del testigo. Si las credenciales son válidas, la vinculación se realizará correctamente y Object Gateway otorgará acceso.
Puede limitar los usuarios permitidos estableciendo como base para la búsqueda una unidad organizativa específica o especificando un filtro de búsqueda personalizado; por ejemplo, un filtro que requiera la pertenencia a un grupo específico, clases de objetos personalizados o atributos.
21.9.2 Requisitos #
LDAP o Active Directory: una instancia de LDAP en ejecución a la que Object Gateway pueda acceder.
Cuenta de servicio: credenciales LDAP que utilizará Object Gateway con los permisos de búsqueda.
Cuenta de usuario: al menos una cuenta de usuario en el directorio LDAP.
No debe utilizar los mismos nombres de usuario para los usuarios locales y los usuarios que se van a autenticar mediante LDAP. Object Gateway no puede distinguirlos y los trata como el mismo usuario.
Emplee la utilidad ldapsearch para verificar la cuenta de servicio o la conexión LDAP. Por ejemplo:
tux > ldapsearch -x -D "uid=ceph,ou=system,dc=example,dc=com" -W \
-H ldaps://example.com -b "ou=users,dc=example,dc=com" 'uid=*' dnAsegúrese de utilizar los mismos parámetros LDAP del archivo de configuración de Ceph para eliminar posibles problemas.
21.9.3 Configuración de Object Gateway para utilizar la autenticación LDAP #
Los siguientes parámetros están relacionados con la autenticación LDAP:
rgw_ldap_uriEspecifica el servidor LDAP que se debe usar. Asegúrese de usar el parámetro
ldaps://nombre_completo:puertopara evitar la transmisión de credenciales de forma abierta en formato de texto sin cifrar.rgw_ldap_binddnEl nombre completo (DN) de la cuenta de servicio que utiliza Object Gateway.
rgw_ldap_secretLa contraseña de la cuenta de servicio.
rgw_ldap_searchdnEspecifica la base en el árbol de información del directorio para buscar usuarios. Puede tratarse de la unidad organizativa de los usuarios o alguna unidad organizativa (OU) más específica.
rgw_ldap_dnattrEl atributo que se utiliza en el filtro de búsqueda construido para que coincida con un nombre de usuario. Dependiendo de su árbol de información de directorio (DIT), probablemente será
uidocn.rgw_search_filterSi no se especifica, Object Gateway crea automáticamente el filtro de búsqueda con el valor
rgw_ldap_dnattr. Este parámetro se puede usar para restringir la lista de usuarios permitidos de formas muy flexibles. Consulte la Sección 21.9.4, “Uso de un filtro de búsqueda personalizado para limitar el acceso de usuario” para obtener más información.
21.9.4 Uso de un filtro de búsqueda personalizado para limitar el acceso de usuario #
Existen dos formas de utilizar el parámetro rgw_search_filter.
21.9.4.1 Filtro parcial para restringir aún más el filtro de búsqueda construido #
Un ejemplo de un filtro parcial:
"objectclass=inetorgperson"
Object Gateway generará el filtro de búsqueda de la forma habitual con el nombre de usuario tomado del testigo y el valor de rgw_ldap_dnattr. El filtro construido se combina a continuación con el filtro parcial del atributo rgw_search_filter. Según el nombre de usuario y la configuración, el filtro de búsqueda final puede ser:
"(&(uid=hari)(objectclass=inetorgperson))"
En este caso, solo se otorgará acceso al usuario "hari" si se encuentra en el directorio LDAP, tiene la clase de objeto "inetorgperson" y ha especificado una contraseña válida.
21.9.4.2 Filtro completo #
Un filtro completo debe contener un testigo USERNAME que se sustituirá por el nombre de usuario durante el intento de autenticación. El parámetro rgw_ldap_dnattr ya no se usa en este caso. Por ejemplo, para limitar los usuarios válidos a un grupo específico, utilice el filtro siguiente:
"(&(uid=USERNAME)(memberOf=cn=ceph-users,ou=groups,dc=mycompany,dc=com))"
memberOf
Para poder usar el atributo memberOf en las búsquedas LDAP se requiere compatibilidad en el servidor LDAP específico implementado.
21.9.5 Generación de un testigo de acceso para la autenticación LDAP #
La utilidad radosgw-token genera el testigo de acceso en función del nombre de usuario y la contraseña LDAP. Cree una cadena codificada en base 64 que es el testigo de acceso real. Utilice su cliente de S3 favorito (consulte la Sección 21.5.1, “Acceso a Object Gateway”) y especifique el testigo como clave de acceso y utilice una clave de secreto vacía.
tux >export RGW_ACCESS_KEY_ID="USERNAME"tux >export RGW_SECRET_ACCESS_KEY="PASSWORD"cephuser@adm >radosgw-token --encode --ttype=ldap
El testigo de acceso es una estructura JSON codificada en base 64 y contiene las credenciales LDAP en texto sin cifrar.
Para Active Directory, utilice el parámetro ‑‑type=ad.
21.10 Partición del índice de depósito #
Object Gateway almacena los datos del índice de depósito en un repositorio de índice, que usa por defecto .rgw.buckets.index. Si coloca demasiados objetos (cientos de miles) en un único depósito y no se define la cuota del número máximo de objetos por depósito (rgw bucket default quota max objects), el rendimiento del repositorio de índice se puede degradar. La partición del índice de depósito evita esa disminución del rendimiento y permite un número elevado de objetos por depósito.
21.10.1 Nueva partición del índice de depósito #
Si un depósito ha crecido mucho y su configuración inicial ya no es suficiente, es preciso volver a partir el repositorio de índice del depósito. Se puede usar la partición de índice de depósito en línea automática (consulte la Sección 21.10.1.1, “Partición dinámica”, o partir el índice de depósito manualmente sin conexión (consulte la Sección 21.10.1.2, “Partición manual”).
21.10.1.1 Partición dinámica #
Desde SUSE Enterprise Storage 5, se admite la partición de depósito en línea. Esto detecta si el número de objetos por depósito alcanza un umbral determinado y aumenta automáticamente el número de particiones utilizado por el índice de depósito. Este proceso reduce el número de entradas de cada partición de índice de depósito.
El proceso de detección se ejecuta en estos casos:
Cuando se añaden nuevos objetos al depósito.
En un proceso en segundo plano que explora periódicamente todos los depósitos. Esto es necesario para tratar con los depósitos existentes que no se van a actualizar.
Si un depósito requiere partición, se añade a la cola reshard_log y se programa para su partición más tarde. Los hilos de partición se ejecutan en segundo plano y ejecutan la partición programada de una en una.
rgw_dynamic_reshardingHabilita o inhabilita la partición del índice de depósito dinámica. Los valores válidos son "true" (verdadero) o "false" (falso). Por defecto es "true" (verdadero).
rgw_reshard_num_logsEl número de particiones para el registro. Se usa el valor por defecto de 16.
rgw_reshard_bucket_lock_durationDuración del bloqueo en el objeto de depósito durante la partición. Se usa el valor por defecto de 120 segundos.
rgw_max_objs_per_shardEl número máximo de objetos por partición de índice de depósito. Por defecto es 100 000 objetos.
rgw_reshard_thread_intervalEl tiempo máximo entre las rondas de procesamiento de hilos de partición. Se usa el valor por defecto de 600 segundos.
- Añadir un depósito a la cola de partición:
cephuser@adm >radosgw-admin reshard add \ --bucket BUCKET_NAME \ --num-shards NEW_NUMBER_OF_SHARDS- Mostrar la cola de partición:
cephuser@adm >radosgw-admin reshard list- Procesar o programar una partición de depósito:
cephuser@adm >radosgw-admin reshard process- Mostrar el estado de partición del depósito:
cephuser@adm >radosgw-admin reshard status --bucket BUCKET_NAME- Cancelar las particiones de depósito pendientes:
cephuser@adm >radosgw-admin reshard cancel --bucket BUCKET_NAME
21.10.1.2 Partición manual #
La partición dinámica mencionada en la Sección 21.10.1.1, “Partición dinámica” solo se admite en configuraciones sencilla de Object Gateway. Para las configuraciones de varios sitios, utilice la partición manual que se describe en esta sección.
Para particionar manualmente el índice de depósito sin conexión, utilice el comando siguiente:
cephuser@adm > radosgw-admin bucket reshard
El comando bucket reshard realiza las acciones siguientes:
Crea un nuevo conjunto de objetos de índice de depósito para el objeto especificado.
Distribuye todas las entradas de estos objetos de índice.
Crea una nueva instancia del depósito.
Enlaza la nueva instancia del depósito con el depósito para que todas las operaciones de índice nuevas pasen por los nuevos índices de depósito.
Imprime el ID de depósito antiguo y el nuevo en una salida estándar.
Cuando elija un número de particiones, tenga en cuenta lo siguiente: no debe haber más de 100.000 entradas por partición. Las particiones del índice de depósito que son números primos tienden a funcionar mejor para distribuir uniformemente las entradas de índice de depósito entre las particiones. Por ejemplo, tener 503 particiones de índice de depósito es mejor que tener 500, ya que 503 es un número primo.
Asegúrese de que se han detenido todas las operaciones dirigidas al depósito.
Realice una copia de seguridad del índice de depósito original:
cephuser@adm >radosgw-admin bi list \ --bucket=BUCKET_NAME \ > BUCKET_NAME.list.backupVuelva a particionar el índice de depósito:
cephuser@adm >radosgw-admin bucket reshard \ --bucket=BUCKET_NAME \ --num-shards=NEW_SHARDS_NUMBERSugerencia: ID de depósito antiguoComo parte del resultado, este comando también imprime los ID nuevo y antiguo.
21.10.2 Partición de índice de depósito para depósitos nuevos #
Existen dos opciones que afectan a la partición de índice de depósito:
Utilice la opción
rgw_override_bucket_index_max_shardspara las configuraciones sencillas.Utilice la opción
bucket_index_max_shardspara las configuraciones de varios sitios.
Si se define el valor 0 en las opciones, se inhabilita la partición de índice de depósito. Un valor mayor que 0 permite la partición de índice de depósito y establece el número máximo de particiones.
La fórmula siguiente le permitirá calcular el número recomendado de particiones:
number_of_objects_expected_in_a_bucket / 100000
Tenga en cuenta que el número máximo de particiones es de 7877.
21.10.2.1 Configuraciones de varios sitios #
Las configuraciones de varios sitios pueden tener un repositorio de índice diferente para gestionar el failover. Para configurar un número de particiones coherente para las zonas de un grupo de zonas, defina la opción bucket_index_max_shards en la configuración del grupo de zonas:
Exporte la configuración del grupo de zonas al archivo
zonegroup.json:cephuser@adm >radosgw-admin zonegroup get > zonegroup.jsonEdite el archivo
zonegroup.jsony defina la opciónbucket_index_max_shardspara cada zona con nombre.Restablezca el grupo de zonas:
cephuser@adm >radosgw-admin zonegroup set < zonegroup.jsonActualice el período. Consulte la Sección 21.13.2.6, “Actualice el período”.
21.11 Integración con OpenStack Keystone #
OpenStack Keystone es un servicio de identidad para el producto OpenStack. Puede integrar Object Gateway con Keystone a fin de configurar una pasarela que acepte un testigo de autenticación de Keystone. Un usuario autorizado por Keystone para acceder a la pasarela se verificará en Ceph Object Gateway y, si fuera necesario, se creará automáticamente. Object Gateway pide periódicamente a Keystone una lista de los testigos revocados.
21.11.1 Configuración de OpenStack #
Antes de configurar Ceph Object Gateway, debe configurar OpenStack Keystone para habilitar el servicio de Swift y dirigirlo a Ceph Object Gateway:
Defina el servicio de Swift.Para utilizar OpenStack a fin de validar usuarios de Swift, cree primero el servicio de Swift:
tux >openstack service create \ --name=swift \ --description="Swift Service" \ object-storeDefina los puestos finales.Después de crear el servicio de Swift, diríjalo a Ceph Object Gateway. Sustituya REGION_NAME por el nombre del grupo de zonas o el nombre de la región de la pasarela.
tux >openstack endpoint create --region REGION_NAME \ --publicurl "http://radosgw.example.com:8080/swift/v1" \ --adminurl "http://radosgw.example.com:8080/swift/v1" \ --internalurl "http://radosgw.example.com:8080/swift/v1" \ swiftVerifique los ajustes.Después de crear el servicio de Swift y definir los puestos finales, muestre los puestos finales para verificar que todos los valores son correctos.
tux >openstack endpoint show object-store
21.11.2 Configuración de Ceph Object Gateway #
21.11.2.1 Configuración de certificados SSL #
Ceph Object Gateway pide periódicamente a Keystone una lista de los testigos revocados. Estas peticiones están codificadas y firmadas. Keystone también puede configurarse para que proporcione testigos autofirmados, que también están codificados y firmados. Debe configurar la pasarela para que pueda descodificar y verificar estos mensajes firmados. Por lo tanto, los certificados OpenSSL que Keystone utiliza para crear las peticiones deben convertirse al formato "nss db":
root #mkdir /var/ceph/nssroot #openssl x509 -in /etc/keystone/ssl/certs/ca.pem \ -pubkey | certutil -d /var/ceph/nss -A -n ca -t "TCu,Cu,Tuw"rootopenssl x509 -in /etc/keystone/ssl/certs/signing_cert.pem \ -pubkey | certutil -A -d /var/ceph/nss -n signing_cert -t "P,P,P"
Para permitir que Ceph Object Gateway interactúe con OpenStack Keystone, OpenStack Keystone puede utilizar un certificado SSL autofirmado. Instale el certificado SSL de Keystone en el nodo donde se ejecuta Ceph Object Gateway o, de forma alternativa, defina el valor de la opción rgw keystone verify ssl como "false" (falso). Si define rgw keystone verify ssl como "false", la pasarela no intentará verificar el certificado.
21.11.2.2 Configuración de las opciones de Object Gateway #
Puede configurar la integración de Keystone utilizando las siguientes opciones:
rgw keystone api versionVersión de la API de Keystone. Las opciones válidas son 2 o 3. Se usa el valor por defecto de 2.
rgw keystone urlLa URL y el número de puerto de la API RESTful administrativa en el servidor de Keystone. Sigue el patrón URL_SERVIDOR:NÚMERO_PUERTO.
rgw keystone admin tokenEl testigo o secreto compartido que se configura internamente en Keystone para las peticiones administrativas.
rgw keystone accepted rolesLas funciones necesarias para atender las peticiones. Por defecto es "Member, admin".
rgw keystone accepted admin rolesLa lista de funciones que permiten a un usuario obtener privilegios administrativos.
rgw keystone token cache sizeEl número máximo de entradas en el caché de testigo de Keystone.
rgw keystone revocation intervalEl número de segundos antes de comprobar los testigos revocados. Por defecto es 15 * 60.
rgw keystone implicit tenantsCrea nuevos usuarios en sus propios inquilinos del mismo nombre. Se usa el valor por defecto, "false" (falso).
rgw s3 auth use keystoneSi se establece como "true" (verdadero), Ceph Object Gateway autenticará a los usuarios mediante Keystone. Se usa el valor por defecto, "false" (falso).
nss db pathLa vía a la base de datos NSS.
También es posible configurar el inquilino del servicio de Keystone, el usuario y la contraseña para Keystone (para la versión 2.0 de la API de identidades de OpenStack), de modo similar a cómo se suelen configurar los servicios de OpenStack. De este modo, puede evitar establecer el secreto compartido rgw keystone admin token en el archivo de configuración, que se debe inhabilitar en entornos de producción. Las credenciales del inquilino de servicio deben tener privilegios de administrador. Para obtener más información, consulte la documentación oficial de OpenStack Keystone. A continuación se muestran las opciones de configuración relacionadas:
rgw keystone admin userEl nombre de usuario del administrador de Keystone.
rgw keystone admin passwordLa contraseña del usuario administrador de Keystone.
rgw keystone admin tenantEl inquilino del usuario administrador de Keystone versión 2.0.
Se asigna un usuario de Ceph Object Gateway a un inquilino de Keystone. Un usuario de Keystone tiene diferentes funciones asignadas, posiblemente en más de un inquilino. Cuando Ceph Object Gateway obtiene el ticket, busca en las funciones de inquilino y usuario que se han asignado a dicho ticket y acepta o rechaza la petición de acuerdo con el valor de la opción rgw keystone accepted roles.
Aunque los inquilinos de Swift se asignan por defecto al usuario de Object Gateway, también pueden asignarse a inquilinos de OpenStack mediante la opción rgw keystone implicit tenants. Esto hará que los contenedores usen el espacio de nombres del inquilino en lugar del espacio de nombres global de S3, que es la opción por defecto de Object Gateway. Se recomienda decidir de antemano el método de asignación en la fase de planificación para evitar confusiones. La razón es que si se cambia la opción más tarde, solo se verán afectadas las peticiones nuevas que se asignen bajo un inquilino, mientras que los depósitos antiguos creados anteriormente seguirán en el espacio de nombres global.
En la versión 3 de la API de identidades de OpenStack, deber sustituir la opción rgw keystone admin tenant por:
rgw keystone admin domainEl dominio de usuario administrador de Keystone.
rgw keystone admin projectEl proyecto de usuario administrador de Keystone.
21.12 Colocación de repositorios y clases de almacenamiento #
21.12.1 Visualización de destinos de colocación #
Los destinos de colocación controlan qué repositorios están asociados con un depósito determinado. El destino de colocación de un depósito se selecciona durante la creación y no se puede modificar. Es posible mostrar su valor de placement_rule ejecutando el siguiente comando:
cephuser@adm > radosgw-admin bucket statsLa configuración del grupo de zonas contiene una lista de destinos de colocación con un destino inicial denominado "default-placement". A continuación, la configuración de zona asigna cada nombre de destino de la colocación del grupo de zona a su almacenamiento local. Esta información de colocación de zona incluye el nombre "index_pool" para el índice del depósito, el nombre "data_extra_pool" para los metadatos sobre cargas de varias incompletas y un nombre de "data_pool" para cada clase de almacenamiento.
21.12.2 Clases de almacenamiento #
Las clases de almacenamiento ayudan a personalizar la colocación de los datos de objeto. Las reglas del ciclo de vida del depósito S3 pueden automatizar la transición de objetos entre clases de almacenamiento.
Las clases de almacenamiento se definen en términos de destinos de colocación. Cada destino de colocación de grupo de zonas muestra sus clases de almacenamiento disponibles con una clase inicial denominada "STANDARD". La configuración de zona es responsable de proporcionar un nombre de repositorio "data_pool" para cada una de las clases de almacenamiento del grupo de zonas.
21.12.3 Configuración de grupos de zonas y zonas #
Utilice el comando radosgw-admin en los grupos de zona y las zonas para configurar su colocación. Puede consultar la configuración de la colocación del grupo de zonas con el comando siguiente:
cephuser@adm > radosgw-admin zonegroup get
{
"id": "ab01123f-e0df-4f29-9d71-b44888d67cd5",
"name": "default",
"api_name": "default",
...
"placement_targets": [
{
"name": "default-placement",
"tags": [],
"storage_classes": [
"STANDARD"
]
}
],
"default_placement": "default-placement",
...
}Para consultar la configuración de colocación de la zona, ejecute:
cephuser@adm > radosgw-admin zone get
{
"id": "557cdcee-3aae-4e9e-85c7-2f86f5eddb1f",
"name": "default",
"domain_root": "default.rgw.meta:root",
...
"placement_pools": [
{
"key": "default-placement",
"val": {
"index_pool": "default.rgw.buckets.index",
"storage_classes": {
"STANDARD": {
"data_pool": "default.rgw.buckets.data"
}
},
"data_extra_pool": "default.rgw.buckets.non-ec",
"index_type": 0
}
}
],
...
}
Si no ha realizado ninguna configuración de varios sitios anterior, se crean automáticamente una zona por defecto ("default") y un grupo de zonas. Los cambios en el grupo de zonas o las zonas no tendrán efecto hasta que reinicie Ceph Object Gateway. Si ha creado un reino para varios sitios, los cambios de la zona o el grupo de zonas surtirán efecto después de confirmar los cambios con el comando radosgw-admin period update ‑‑commit.
21.12.3.1 Adición de un destino de colocación #
Para crear un nuevo destino de colocación denominado "temporary", comience añadiéndolo al grupo de zonas:
cephuser@adm > radosgw-admin zonegroup placement add \
--rgw-zonegroup default \
--placement-id temporaryA continuación, proporcione la información de colocación de zona para ese destino:
cephuser@adm > radosgw-admin zone placement add \
--rgw-zone default \
--placement-id temporary \
--data-pool default.rgw.temporary.data \
--index-pool default.rgw.temporary.index \
--data-extra-pool default.rgw.temporary.non-ec21.12.3.2 Adición de una clase de almacenamiento #
Para añadir una nueva clase de almacenamiento denominada "COLD" al destino "default-placement", empiece añadiéndola al grupo de zonas:
cephuser@adm > radosgw-admin zonegroup placement add \
--rgw-zonegroup default \
--placement-id default-placement \
--storage-class COLDA continuación, proporcione la información de colocación de zona para esa clase de almacenamiento:
cephuser@adm > radosgw-admin zone placement add \
--rgw-zone default \
--placement-id default-placement \
--storage-class COLD \
--data-pool default.rgw.cold.data \
--compression lz421.12.4 Personalización de colocación #
21.12.4.1 Edición de la colocación del grupo de zonas por defecto #
Por defecto, los nuevos depósitos utilizan el destino default_placement del grupo de zonas. Puede cambiar este valor del grupo de zonas con:
cephuser@adm > radosgw-admin zonegroup placement default \
--rgw-zonegroup default \
--placement-id new-placement21.12.4.2 Edición de la colocación del usuario por defecto #
Un usuario de Ceph Object Gateway puede sustituir el destino de la colocación por defecto del grupo de zonas definiendo un campo default_placement no vacío en la información del usuario. De forma similar, el valor de default_storage_class puede sustituir la clase de almacenamiento STANDARD aplicada a los objetos por defecto.
cephuser@adm > radosgw-admin user info --uid testid
{
...
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
...
}Si el destino de colocación de un grupo de zonas contiene etiquetas, los usuarios no podrán crear depósitos con ese destino de colocación a menos que su información de usuario contenga al menos una etiqueta que coincida en su campo "placement_tags". Esto puede ser útil para restringir el acceso a ciertos tipos de almacenamiento.
El comando radosgw-admin no puede modificar estos campos directamente; por lo tanto, debe editar el formato JSON manualmente:
cephuser@adm >radosgw-admin metadata get user:USER-ID > user.jsontux >vi user.json # edit the file as requiredcephuser@adm >radosgw-admin metadata put user:USER-ID < user.json
21.12.4.3 Edición de la colocación del depósito por S3 por defecto #
Al crear un depósito con el protocolo S3, es posible proporcionar un destino de colocación como parte de LocationConstraint para sustituir los destinos de colocación por defecto del usuario y del grupo de zonas.
Normalmente, LocationConstraint debe coincidir con el valor de api_name del grupo de zonas:
<LocationConstraint>default</LocationConstraint>
Puede añadir un destino de colocación personalizado a api_name detrás de un signo de dos puntos:
<LocationConstraint>default:new-placement</LocationConstraint>
21.12.4.4 Edición de la colocación del depósito por Swift #
Cuando se crea un depósito con el protocolo Swift, es posible proporcionar un destino de colocación en el parámetro X-Storage-Policy del encabezado HTTP:
X-Storage-Policy: NEW-PLACEMENT
21.12.5 Uso de clases de almacenamiento #
Todos los destinos de colocación tienen una clase de almacenamiento STANDARD que se aplica por defecto a los nuevos objetos. Puede sustituir este valor por defecto con su valor de default_storage_class.
Para crear un objeto en una clase de almacenamiento que no sea la clase por defecto, proporcione ese nombre de clase de almacenamiento en un encabezado HTTP con la petición. El protocolo S3 utiliza el encabezado X-Amz-Storage-Class, mientras que el protocolo Swift utiliza el encabezado X-Object-Storage-Class.
Puede utilizar la gestión del ciclo de vida del objeto S3 para mover datos de objetos entre clases de almacenamiento mediante acciones de transición.
21.13 Pasarelas Object Gateway de varios sitios #
Ceph admite varias opciones de configuración de varios sitios para Ceph Object Gateway:
- Multizona
Una configuración que consta de un grupo de zonas y varias zonas, y cada zona tiene una o más instancias de
ceph-radosgw. Cada zona tiene el respaldo de su propio clúster de almacenamiento de Ceph. Varias zonas de un grupo de zonas proporcionan recuperación tras fallos para el grupo de zonas en caso de que una de las zonas experimente un fallo importante. Todas las zonas están activas y pueden recibir operaciones de escritura. Además de la recuperación tras fallos, varias zonas activas también pueden servir como base para las redes de distribución de contenido.- Grupo multizona
Ceph Object Gateway admite varios grupos de zonas, cada grupo de zonas con una o más zonas. Los objetos almacenados en zonas de un grupo de zonas dentro del mismo dominio que otro grupo de zonas comparten un espacio de nombres de objeto global, lo que garantiza que haya ID de objeto exclusivos en los grupos de zonas y las zonas.
NotaEs importante tener en cuenta que los grupos de zonas solo sincronizan metadatos entre sí. Los datos y los metadatos se replican entre las zonas del grupo de zonas. No se comparten datos ni metadatos en un dominio.
- Varios dominios
Ceph Object Gateway admite la noción de dominios; un espacio de nombres exclusivo global. Se admiten varios dominios que pueden abarcar uno o varios grupos de zonas.
Puede configurar cada instancia de Object Gateway para que funcione con una configuración de zona activa-activa, lo que permite la escritura en zonas no principales. La configuración de varios sitios se almacena en un contenedor denominado "dominio". El dominio almacena grupos de zonas, zonas y un período de tiempo con varias épocas para realizar un seguimiento de los cambios en la configuración. Los daemons rgw gestionan la sincronización, eliminando la necesidad de un agente de sincronización independiente. Este enfoque de la sincronización permite que Ceph Object Gateway funcione con una configuración activa-activa, en lugar de con una activa-pasiva.
21.13.1 Requisitos y supuestos #
Una configuración de varios sitios requiere al menos dos clústeres de almacenamiento de Ceph y al menos dos instancias de Ceph Object Gateway, una para cada clúster de almacenamiento de Ceph. En la siguiente configuración se presupone que hay al menos dos clústeres de almacenamiento de Ceph en ubicaciones separadas geográficamente. Sin embargo, la configuración puede funcionar en el mismo sitio. Por ejemplo, se pueden llamar rgw1 y rgw2.
Una configuración de varios sitios requiere un grupo de zonas principal y una zona principal. Una zona principal es la fuente de información con respecto a todas las operaciones de metadatos de un clúster de varios sitios. Además, cada grupo de zonas requiere una zona principal. Los grupos de zonas pueden tener una o más zonas secundarias o no principales. En esta guía, el host rgw1 actúa como zona principal del grupo de zonas principal y el host rgw2 actúa como zona secundaria del grupo de zonas principal.
21.13.2 Configuración de una zona principal #
Todas las pasarelas de una configuración de varios sitios recuperan su configuración de un daemon ceph-radosgw situado en un host dentro del grupo de zonas principal y la zona principal. Para configurar las pasarelas en una configuración de varios sitios, seleccione una instancia de ceph-radosgw para configurar el grupo de zonas principal y la zona principal.
21.13.2.1 Creación de un dominio #
Un dominio representa un espacio de nombres único global que consta de uno o más grupos de zonas, que a su vez contienen una o más zonas. Las zonas contienen depósitos, que a su vez contienen objetos. Un dominio permite que Ceph Object Gateway admita varios espacios de nombres y su configuración en el mismo hardware. Un dominio contiene la noción de períodos. Cada período representa el estado del grupo de zonas y la configuración de la zona en el tiempo. Cada vez que realice un cambio en un grupo de zonas o en una zona, debe actualizar el período y asignarlo. Por defecto, Ceph Object Gateway no crea un dominio para la compatibilidad con versiones anteriores. Como práctica recomendada, se recomienda crear dominios para los clústeres nuevos.
Cree un nuevo dominio denominado gold para la configuración de varios sitios abriendo una interfaz de línea de comandos en un host identificado para servir en el grupo de zonas principal y la zona. A continuación, ejecute lo siguiente:
cephuser@adm > radosgw-admin realm create --rgw-realm=gold --default
Si el clúster tiene un solo dominio, especifique el indicador --default. Si se especifica ‑‑default, radosgw-admin utiliza este dominio por defecto. Si no se especifica --default, para añadir grupos de zonas y zonas es necesario especificar el indicador --rgw-realm o el indicador --realm-id para identificar el dominio al añadir grupos de zonas y zonas.
Después de crear el dominio, radosgw-admin devuelve la configuración del dominio:
{
"id": "4a367026-bd8f-40ee-b486-8212482ddcd7",
"name": "gold",
"current_period": "09559832-67a4-4101-8b3f-10dfcd6b2707",
"epoch": 1
}Ceph genera un ID exclusivo para el dominio, que permite renombrar el dominio si es necesario.
21.13.2.2 Creación de un grupo de zonas principal #
Un dominio debe tener al menos un grupo de zonas para servir como grupo de zonas principal para el dominio. Cree un nuevo grupo de zonas principal para la configuración de varios sitios abriendo una interfaz de línea de comandos en un host identificado para servir en el grupo de zonas principal y la zona. Cree un grupo de zonas principal llamado us ejecutando lo siguiente:
cephuser@adm > radosgw-admin zonegroup create --rgw-zonegroup=us \
--endpoints=http://rgw1:80 --master --default
Si el dominio solo tiene un grupo de zonas, especifique el indicador --default. Si se especifica --default, radosgw-admin utiliza este grupo de zonas por defecto al añadir nuevas zonas. Si no se especifica --default, para añadir zonas se necesitará el indicador --rgw-zonegroup o el indicador --zonegroup-id para identificar el grupo de zonas al añadir o modificar zonas.
Después de crear el grupo de zonas principal, radosgw-admin devuelve la configuración del grupo de zonas. Por ejemplo:
{
"id": "d4018b8d-8c0d-4072-8919-608726fa369e",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "",
"zones": [],
"placement_targets": [],
"default_placement": "",
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7"
}21.13.2.3 Creación de una zona principal #
Las zonas deben crearse en un nodo de Ceph Object Gateway que se encuentre dentro de la zona.
Cree una nueva zona principal para la configuración de varios sitios abriendo una interfaz de línea de comandos en un host identificado para servir en el grupo de zonas principal y la zona. Realice lo siguiente:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-1 \
--endpoints=http://rgw1:80 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
Las opciones --access-key y --secret no se especifican en el ejemplo anterior. Estos ajustes se añaden a la zona cuando se crea el usuario en la siguiente sección.
Después de crear la zona principal, radosgw-admin devuelve la configuración de la zona. Por ejemplo:
{
"id": "56dfabbb-2f4e-4223-925e-de3c72de3866",
"name": "us-east-1",
"domain_root": "us-east-1.rgw.meta:root",
"control_pool": "us-east-1.rgw.control",
"gc_pool": "us-east-1.rgw.log:gc",
"lc_pool": "us-east-1.rgw.log:lc",
"log_pool": "us-east-1.rgw.log",
"intent_log_pool": "us-east-1.rgw.log:intent",
"usage_log_pool": "us-east-1.rgw.log:usage",
"reshard_pool": "us-east-1.rgw.log:reshard",
"user_keys_pool": "us-east-1.rgw.meta:users.keys",
"user_email_pool": "us-east-1.rgw.meta:users.email",
"user_swift_pool": "us-east-1.rgw.meta:users.swift",
"user_uid_pool": "us-east-1.rgw.meta:users.uid",
"otp_pool": "us-east-1.rgw.otp",
"system_key": {
"access_key": "1555b35654ad1656d804",
"secret_key": "h7GhxuBLTrlhVUyxSPUKUV8r/2EI4ngqJxD7iBdBYLhwluN30JaT3Q=="
},
"placement_pools": [
{
"key": "us-east-1-placement",
"val": {
"index_pool": "us-east-1.rgw.buckets.index",
"storage_classes": {
"STANDARD": {
"data_pool": "us-east-1.rgw.buckets.data"
}
},
"data_extra_pool": "us-east-1.rgw.buckets.non-ec",
"index_type": 0
}
}
],
"metadata_heap": "",
"realm_id": ""
}21.13.2.4 Supresión de la zona y el grupo de zonas por defecto #
En los siguientes pasos se presupone que hay una configuración de varios sitios que utiliza sistemas recién instalados en los que aún no se almacenan datos. No suprima la zona por defecto ni sus repositorios si ya la está utilizando para almacenar datos, o los datos se suprimirán y no se podrán recuperar.
La instalación por defecto de Object Gateway crea el grupo de zonas por defecto denominado default. Suprima la zona por defecto si existe. Asegúrese de eliminarla primero del grupo de zonas por defecto.
cephuser@adm > radosgw-admin zonegroup delete --rgw-zonegroup=defaultSuprima los repositorios por defecto del clúster de almacenamiento de Ceph, si existen:
En el siguiente paso se presupone que hay una configuración de varios sitios que utiliza sistemas recién instalados en los que no se almacenan datos. No suprima el grupo de zonas por defecto si ya lo está utilizando para almacenar datos.
cephuser@adm >ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.meta default.rgw.meta --yes-i-really-really-mean-it
Si suprime el grupo de zonas por defecto, también está suprimiendo el usuario del sistema. Si las claves del usuario administrador no se propagan, la funcionalidad de gestión de Object Gateway de Ceph Dashboard fallará. Continúe en la siguiente sección para volver a crear el usuario del sistema si continúa con este paso.
21.13.2.5 Creación de usuarios del sistema #
Los daemons ceph-radosgw deben autenticarse antes de extraer información del dominio y el período. En la zona principal, cree un usuario del sistema para simplificar la autenticación entre los daemons:
cephuser@adm > radosgw-admin user create --uid=zone.user \
--display-name="Zone User" --access-key=SYSTEM_ACCESS_KEY \
--secret=SYSTEM_SECRET_KEY --system
Anote la clave de acceso y la clave secreta, ya que las zonas secundarias deben autenticarse con la zona principal.
Añada el usuario del sistema a la zona principal:
cephuser@adm > radosgw-admin zone modify --rgw-zone=us-east-1 \
--access-key=ACCESS-KEY --secret=SECRETActualice el período para que los cambios surtan efecto:
cephuser@adm > radosgw-admin period update --commit21.13.2.6 Actualice el período #
Después de actualizar la configuración de la zona principal, actualice el período:
cephuser@adm > radosgw-admin period update --commit
Después de actualizar el período, radosgw-admin devuelve la configuración del período. Por ejemplo:
{
"id": "09559832-67a4-4101-8b3f-10dfcd6b2707", "epoch": 1, "predecessor_uuid": "", "sync_status": [], "period_map":
{
"id": "09559832-67a4-4101-8b3f-10dfcd6b2707", "zonegroups": [], "short_zone_ids": []
}, "master_zonegroup": "", "master_zone": "", "period_config":
{
"bucket_quota": {
"enabled": false, "max_size_kb": -1, "max_objects": -1
}, "user_quota": {
"enabled": false, "max_size_kb": -1, "max_objects": -1
}
}, "realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7", "realm_name": "gold", "realm_epoch": 1
}La actualización del período cambia la época y garantiza que otras zonas reciban la configuración actualizada.
21.13.2.7 Inicio de Gateway #
En el host de Object Gateway, inicie y habilite el servicio Ceph Object Gateway. Para identificar el FSID exclusivo del clúster, ejecute ceph fsid. Para identificar el nombre del daemon de Object Gateway, ejecute ceph orch ps --hostname NOMBREHOST.
cephuser@ogw >systemctl start ceph-FSID@DAEMON_NAMEcephuser@ogw >systemctl enable ceph-FSID@DAEMON_NAME
21.13.3 Configuración de zonas secundarias #
Las zonas de un grupo de zonas replican todos los datos para asegurarse de que cada zona tiene los mismos datos. Cuando cree la zona secundaria, ejecute todas las operaciones siguientes en un host identificado para servir a la zona secundaria.
Para añadir una tercera zona, siga los mismos procedimientos que para añadir la zona secundaria. Utilice un nombre de zona diferente.
Debe realizar las operaciones de metadatos, como crear usuarios, en un host de la zona principal. La zona principal y la zona secundaria pueden recibir operaciones de depósito, pero la zona secundaria redirige las operaciones de depósito a la zona principal. Si la zona principal está inactiva, las operaciones de depósito fallarán.
21.13.3.1 Extracción del dominio #
Mediante la vía URL, la clave de acceso y el secreto de la zona principal del grupo de zonas principal, extraiga la configuración del dominio en el host. Para extraer un dominio que no sea el dominio por defecto, especifique el dominio mediante las opciones de configuración --rgw-realm o --realm-id.
cephuser@adm > radosgw-admin realm pull --url=url-to-master-zone-gateway --access-key=access-key --secret=secretAl importar el dominio, también se recupera la configuración del período actual del host remoto, que se convierte también en el período actual en este host.
Si este dominio es el dominio por defecto, o el único dominio, conviértalo en el dominio por defecto.
cephuser@adm > radosgw-admin realm default --rgw-realm=REALM-NAME21.13.3.2 Creación de una zona secundaria #
Cree una zona secundaria para la configuración de varios sitios abriendo una interfaz de línea de comandos en un host identificado para servir a la zona secundaria. Especifique el ID del grupo de zonas, el nombre de la nueva zona y un puesto final para la zona. No utilice el indicador ‑‑master. Todas las zonas se ejecutan con una configuración activa-activa por defecto. Si la zona secundaria no debe aceptar operaciones de escritura, especifique el indicador --read-only para crear una configuración activa-pasiva entre la zona principal y la zona secundaria. Además, proporcione la clave de acceso y la clave secreta del usuario del sistema generado almacenado en la zona principal del grupo de zonas principal. Realice lo siguiente:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE-GROUP-NAME\
--rgw-zone=ZONE-NAME --endpoints=URL \
--access-key=SYSTEM-KEY --secret=SECRET\
--endpoints=http://FQDN:80 \
[--read-only]Por ejemplo:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=us --endpoints=http://rgw2:80 \
--rgw-zone=us-east-2 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
{
"id": "950c1a43-6836-41a2-a161-64777e07e8b8",
"name": "us-east-2",
"domain_root": "us-east-2.rgw.data.root",
"control_pool": "us-east-2.rgw.control",
"gc_pool": "us-east-2.rgw.gc",
"log_pool": "us-east-2.rgw.log",
"intent_log_pool": "us-east-2.rgw.intent-log",
"usage_log_pool": "us-east-2.rgw.usage",
"user_keys_pool": "us-east-2.rgw.users.keys",
"user_email_pool": "us-east-2.rgw.users.email",
"user_swift_pool": "us-east-2.rgw.users.swift",
"user_uid_pool": "us-east-2.rgw.users.uid",
"system_key": {
"access_key": "1555b35654ad1656d804",
"secret_key": "h7GhxuBLTrlhVUyxSPUKUV8r\/2EI4ngqJxD7iBdBYLhwluN30JaT3Q=="
},
"placement_pools": [
{
"key": "default-placement",
"val": {
"index_pool": "us-east-2.rgw.buckets.index",
"data_pool": "us-east-2.rgw.buckets.data",
"data_extra_pool": "us-east-2.rgw.buckets.non-ec",
"index_type": 0
}
}
],
"metadata_heap": "us-east-2.rgw.meta",
"realm_id": "815d74c2-80d6-4e63-8cfc-232037f7ff5c"
}En los pasos siguientes se presupone que hay una configuración de varios sitios en la que se usan sistemas recién instalados en los que aún no se almacenan datos. No suprima la zona por defecto ni sus repositorios si ya la está utilizando para almacenar datos, o los datos se perderán y no se podrán recuperar.
Suprima la zona por defecto si es necesario:
cephuser@adm > radosgw-admin zone rm --rgw-zone=defaultSuprima los repositorios por defecto del clúster de almacenamiento de Ceph si es necesario:
cephuser@adm >ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.users.uid default.rgw.users.uid --yes-i-really-really-mean-it
21.13.3.3 Actualización del archivo de configuración de Ceph #
Actualice el archivo de configuración de Ceph en los hosts de la zona secundaria añadiendo la opción de configuración rgw_zone y el nombre de la zona secundaria a la entrada de la instancia.
Para ello, ejecute el comando siguiente:
cephuser@adm > ceph config set SERVICE_NAME rgw_zone us-west21.13.3.4 Actualización del período #
Después de actualizar la configuración de la zona principal, actualice el período:
cephuser@adm > radosgw-admin period update --commit
{
"id": "b5e4d3ec-2a62-4746-b479-4b2bc14b27d1",
"epoch": 2,
"predecessor_uuid": "09559832-67a4-4101-8b3f-10dfcd6b2707",
"sync_status": [ "[...]"
],
"period_map": {
"id": "b5e4d3ec-2a62-4746-b479-4b2bc14b27d1",
"zonegroups": [
{
"id": "d4018b8d-8c0d-4072-8919-608726fa369e",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"zones": [
{
"id": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"name": "us-east-1",
"endpoints": [
"http:\/\/rgw1:80"
],
"log_meta": "true",
"log_data": "false",
"bucket_index_max_shards": 0,
"read_only": "false"
},
{
"id": "950c1a43-6836-41a2-a161-64777e07e8b8",
"name": "us-east-2",
"endpoints": [
"http:\/\/rgw2:80"
],
"log_meta": "false",
"log_data": "true",
"bucket_index_max_shards": 0,
"read_only": "false"
}
],
"placement_targets": [
{
"name": "default-placement",
"tags": []
}
],
"default_placement": "default-placement",
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7"
}
],
"short_zone_ids": [
{
"key": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"val": 630926044
},
{
"key": "950c1a43-6836-41a2-a161-64777e07e8b8",
"val": 4276257543
}
]
},
"master_zonegroup": "d4018b8d-8c0d-4072-8919-608726fa369e",
"master_zone": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"period_config": {
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
}
},
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7",
"realm_name": "gold",
"realm_epoch": 2
}La actualización del período cambia la época y garantiza que otras zonas reciban la configuración actualizada.
21.13.3.5 Inicio de Object Gateway #
En el host de Object Gateway, inicie y habilite el servicio Ceph Object Gateway:
cephuser@adm > ceph orch start rgw.us-east-221.13.3.6 Comprobación del estado de sincronización #
Cuando la zona secundaria esté activa y en ejecución, compruebe el estado de sincronización. La sincronización copia los usuarios y depósitos creados en la zona principal en la zona secundaria.
cephuser@adm > radosgw-admin sync statusLa salida proporciona el estado de las operaciones de sincronización. Por ejemplo:
realm f3239bc5-e1a8-4206-a81d-e1576480804d (gold)
zonegroup c50dbb7e-d9ce-47cc-a8bb-97d9b399d388 (us)
zone 4c453b70-4a16-4ce8-8185-1893b05d346e (us-west)
metadata sync syncing
full sync: 0/64 shards
metadata is caught up with master
incremental sync: 64/64 shards
data sync source: 1ee9da3e-114d-4ae3-a8a4-056e8a17f532 (us-east)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with sourceLas zonas secundarias aceptan operaciones de depósito; sin embargo, las zonas secundarias redirigen las operaciones de depósito a la zona principal y, a continuación, se sincronizan con la zona principal para recibir el resultado de las operaciones de depósito. Si la zona principal está inactiva, las operaciones de depósito que se ejecuten en la zona secundaria fallarán, pero las operaciones de objeto deberían realizarse correctamente.
21.13.4 Mantenimiento general de Object Gateway #
21.13.4.1 Comprobación del estado de sincronización #
La información sobre el estado de réplica de una zona se puede consultar con:
cephuser@adm > radosgw-admin sync status
realm b3bc1c37-9c44-4b89-a03b-04c269bea5da (gold)
zonegroup f54f9b22-b4b6-4a0e-9211-fa6ac1693f49 (us)
zone adce11c9-b8ed-4a90-8bc5-3fc029ff0816 (us-west)
metadata sync syncing
full sync: 0/64 shards
incremental sync: 64/64 shards
metadata is behind on 1 shards
oldest incremental change not applied: 2017-03-22 10:20:00.0.881361s
data sync source: 341c2d81-4574-4d08-ab0f-5a2a7b168028 (us-east)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source
source: 3b5d1a3f-3f27-4e4a-8f34-6072d4bb1275 (us-3)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source21.13.4.2 Cambio de la zona principal de metadatos #
Tenga cuidado cuando cambie qué zona es la principal para los metadatos. Si una zona no ha terminado de sincronizar los metadatos de la zona principal actual, no puede servir las entradas restantes cuando se asciende a principal, y esos cambios se pierden. Por este motivo, se recomienda esperar a que el estado de sincronización radosgw-admin de una zona se ponga al día con la sincronización de los metadatos antes de subirla a zona principal. Del mismo modo, si la zona principal actual está procesando cambios en los metadatos mientras otra zona se está subiendo a principal, es probable que se pierdan dichos cambios. Para evitarlo, se recomienda cerrar todas las instancias de Object en la zona principal anterior. Después de subir de nivel otra zona, su nuevo período se puede recuperar con la el comando de extracción de período radosgw-admin y se las pasarelas se pueden reiniciar.
Para subir de nivel una zona (por ejemplo, la zona us-west del grupo de zonas us) a zona principal de metadatos, ejecute los comandos siguientes en esa zona:
cephuser@ogw >radosgw-admin zone modify --rgw-zone=us-west --mastercephuser@ogw >radosgw-admin zonegroup modify --rgw-zonegroup=us --mastercephuser@ogw >radosgw-admin period update --commit
Esto genera un nuevo período y las instancias de Object Gateway de la zona us-west envían este período a otras zonas.
21.13.5 Realización de failover y recuperación tras fallos #
Si la zona principal fallara, realice un failover a la zona secundaria para recuperarse tras los fallos.
Convierta la zona secundaria en la zona principal y por defecto. Por ejemplo:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --defaultPor defecto, Ceph Object Gateway ejecuta una configuración activa-activa. Si el clúster se ha configurado para ejecutarse en una configuración activa-pasiva, la zona secundaria será una zona de solo lectura. Elimine el estado
--read-onlypara permitir que la zona reciba operaciones de escritura. Por ejemplo:cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --default \ --read-only=falseActualice el período para que los cambios surtan efecto:
cephuser@adm >radosgw-admin period update --commitReinicie Ceph Object Gateway:
cephuser@adm >ceph orch restart rgw
Si la zona principal anterior se recupera, revierta la operación.
Desde la zona recuperada, extraiga la última configuración de dominio de la zona principal actual.
cephuser@adm >radosgw-admin realm pull --url=URL-TO-MASTER-ZONE-GATEWAY \ --access-key=ACCESS-KEY --secret=SECRETConvierta la zona recuperada en la zona principal y por defecto:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --defaultActualice el período para que los cambios surtan efecto:
cephuser@adm >radosgw-admin period update --commitReinicie Ceph Object Gateway en la zona recuperada:
cephuser@adm >ceph orch restart rgw@rgwSi la zona secundaria debe tener una configuración de solo lectura, actualice la zona secundaria:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --read-onlyActualice el período para que los cambios surtan efecto:
cephuser@adm >radosgw-admin period update --commitReinicie Ceph Object Gateway en la zona secundaria:
cephuser@adm >ceph orch restart@rgw
22 Ceph iSCSI Gateway #
Este capítulo se centra en las tareas de administración relacionadas con iSCSI Gateway. Para consultar el procedimiento de distribución, consulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.3.5 “Distribución de pasarelas iSCSI Gateway”.
22.1 Destinos gestionados con ceph-iscsi #
En este capítulo se describe cómo conectar destinos gestionados
ceph-iscsi desde clientes con
VMware, Microsoft Windows o Linux.
22.1.1 Conexión a open-iscsi #
La conexión a destinos iSCSI compatibles con
ceph-iscsi mediante
open-iscsi es un proceso de dos pasos. En primer
lugar, el iniciador debe descubrir los destinos iSCSI disponibles en el
host de la pasarela y, a continuación, debe entrar y asignar las unidades
lógicas disponibles
Ambos pasos requieren que el daemon open-iscsi
esté en ejecución. La forma en que inicie el daemon
open-iscsi depende de su distribución Linux:
En hosts con SUSE Linux Enterprise Server (SLES) y Red Hat Enterprise Linux (RHEL), ejecute
systemctl start iscsid(oservice iscsid startsisystemctlno está disponible).En hosts con Debian y Ubuntu, ejecute
systemctl start open-iscsi(oservice open-iscsi start).
Si el sistema operativo del host del iniciador es SUSE Linux Enterprise Server, consulte https://documentation.suse.com/sles/15-SP2/html/SLES-all/cha-iscsi.html#sec-iscsi-initiator para obtener información sobre cómo conectarse a un destino iSCSI.
Para cualquier otra distribución Linux compatible con
open-iscsi, descubra los destinos en la pasarela
ceph-iscsi. En este ejemplo se
utiliza iscsi1.example.com como dirección del portal. Para el acceso de
múltiples rutas, repita los pasos con iscsi2.example.com:
root # iscsiadm -m discovery -t sendtargets -p iscsi1.example.com
192.168.124.104:3260,1 iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvolA continuación, entre en el portal. Si la entrada se completa correctamente, las unidades lógicas con RBD del portal estarán disponibles de inmediato en el bus SCSI del sistema:
root # iscsiadm -m node -p iscsi1.example.com --login
Logging in to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] (multiple)
Login to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] successful.Repita este proceso con las demás direcciones IP o hosts del portal.
Si su sistema tiene la utilidad lsscsi instalada,
se utiliza para mostrar los dispositivos SCSI disponibles en el sistema:
lsscsi [8:0:0:0] disk SUSE RBD 4.0 /dev/sde [9:0:0:0] disk SUSE RBD 4.0 /dev/sdf
En una configuración de múltiples rutas (donde dos dispositivos iSCSI
conectados representan la misma unidad lógica), también puede examinar el
estado del dispositivo de múltiples vías con la utilidad
multipath:
root # multipath -ll
360014050cf9dcfcb2603933ac3298dca dm-9 SUSE,RBD
size=49G features='0' hwhandler='0' wp=rw
|-+- policy='service-time 0' prio=1 status=active
| `- 8:0:0:0 sde 8:64 active ready running
`-+- policy='service-time 0' prio=1 status=enabled
`- 9:0:0:0 sdf 8:80 active ready runningAhora puede utilizar este dispositivo de múltiples rutas igual que cualquier otro dispositivo de bloques. Por ejemplo, puede utilizar el dispositivo como volumen físico para la gestión de volúmenes lógicos (LVM) de Linux o, simplemente, puede crear un sistema de archivos en él. El ejemplo siguiente muestra cómo crear un sistema de archivos XFS en el volumen iSCSI de múltiples rutas recién conectado:
root # mkfs -t xfs /dev/mapper/360014050cf9dcfcb2603933ac3298dca
log stripe unit (4194304 bytes) is too large (maximum is 256KiB)
log stripe unit adjusted to 32KiB
meta-data=/dev/mapper/360014050cf9dcfcb2603933ac3298dca isize=256 agcount=17, agsize=799744 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=12800000, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=6256, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Tenga en cuenta que puesto que XFS un sistema de archivos no agrupados en clúster, es posible que solo sea capaz de montar un único nodo de iniciador iSCSI en un momento dado.
Si en cualquier momento desea dejar de utilizar las unidades lógicas iSCSI asociadas con un destino concreto, ejecute el siguiente comando:
root # iscsiadm -m node -p iscsi1.example.com --logout
Logging out of session [sid: 18, iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260]
Logout of [sid: 18, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] successful.Como ocurre con el descubrimiento y la entrada, debe repetir los pasos de salida para todas las direcciones IP y nombres de host del portal.
22.1.1.1 Configuración de múltiples rutas #
La configuración de múltiples rutas se conserva en los clientes o los
iniciadores y es independiente de cualquier configuración de
ceph-iscsi. Seleccione una
estrategia antes de utilizar el almacenamiento de bloques. Después de
editar /etc/multipath.conf, reinicie
multipathd con
root # systemctl restart multipathdPara una configuración activa-pasiva con nombres descriptivos, añada
defaults {
user_friendly_names yes
}
a /etc/multipath.conf. Después de conectarse
correctamente a los destinos, ejecute
root # multipath -ll
mpathd (36001405dbb561b2b5e439f0aed2f8e1e) dm-0 SUSE,RBD
size=2.0G features='0' hwhandler='0' wp=rw
|-+- policy='service-time 0' prio=1 status=active
| `- 2:0:0:3 sdl 8:176 active ready running
|-+- policy='service-time 0' prio=1 status=enabled
| `- 3:0:0:3 sdj 8:144 active ready running
`-+- policy='service-time 0' prio=1 status=enabled
`- 4:0:0:3 sdk 8:160 active ready runningTenga en cuenta el estado de cada enlace. Para una configuración activa-activa, añada
defaults {
user_friendly_names yes
}
devices {
device {
vendor "(LIO-ORG|SUSE)"
product "RBD"
path_grouping_policy "multibus"
path_checker "tur"
features "0"
hardware_handler "1 alua"
prio "alua"
failback "immediate"
rr_weight "uniform"
no_path_retry 12
rr_min_io 100
}
}
a /etc/multipath.conf. Reinicie
multipathd y ejecute
root # multipath -ll
mpathd (36001405dbb561b2b5e439f0aed2f8e1e) dm-3 SUSE,RBD
size=2.0G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
`-+- policy='service-time 0' prio=50 status=active
|- 4:0:0:3 sdj 8:144 active ready running
|- 3:0:0:3 sdk 8:160 active ready running
`- 2:0:0:3 sdl 8:176 active ready running22.1.2 Conexión de Microsoft Windows (iniciador de Microsoft iSCSI) #
Para conectarse a un destino iSCSI de SUSE Enterprise Storage desde un servidor Windows 2012, siga estos pasos:
Abra Windows Server Manager. En la consola, seleccione › . Se abre el recuadro de diálogo . Seleccione la pestaña :
 Figura 22.1: Propiedades del iniciador iSCSI #
Figura 22.1: Propiedades del iniciador iSCSI #En el recuadro de diálogo , introduzca el nombre de host o la dirección IP del destino en el campo y haga clic en :
 Figura 22.2: Descubrir portal de destino #
Figura 22.2: Descubrir portal de destino #Repita este proceso con todas las demás direcciones IP o nombres de host de la pasarela. Cuando haya terminado, revise la lista :
 Figura 22.3: Portales de destino #
Figura 22.3: Portales de destino #A continuación, cambie a la pestaña y revise los destinos que ha descubierto.
 Figura 22.4: Destinos #
Figura 22.4: Destinos #Haga clic en en la pestaña . Se abre el recuadro de diálogo . Marque la casilla de verificación para habilitar múltiples rutas de E/S (MPIO) y, a continuación, haga clic en :
Cuando se cierre el recuadro de diálogo , seleccione para revisar las propiedades del destino:
 Figura 22.5: Propiedades de destino iSCSI #
Figura 22.5: Propiedades de destino iSCSI #Seleccione y haga clic en para revisar la configuración de múltiples rutas de E/S:
 Figura 22.6: Detalles del dispositivo #
Figura 22.6: Detalles del dispositivo #La opción por defecto para es . Si prefiere una configuración de failover, cambie este valor a
Así concluye la configuración del iniciador iSCSI. Los volúmenes iSCSI están ahora disponibles como cualquier otro dispositivo SCSI y se pueden iniciar para usarse como volúmenes y unidades. Haga clic en para cerrar el recuadro de diálogo y continúe con la función en la consola .
Observe el volumen recién conectado. Se identifica como SUSE RBD SCSI Multi-Path Drive en el bus iSCSI e inicialmente se marca con el estado Sin conexión y el tipo de tabla de partición Desconocido. Si el nuevo volumen no aparece de inmediato, seleccione en la lista desplegable para volver a explorar el bus iSCSI
Haga clic con el botón derecho en el volumen iSCSI y seleccione en el menú contextual. Se abre . Haga clic en , resalte el volumen iSCSI recién conectado y haga clic en para comenzar.
 Figura 22.7: Nuevo asistente de volumen #
Figura 22.7: Nuevo asistente de volumen #Inicialmente, el dispositivo está vacío y no incluye una tabla de particiones. Cuando se le solicite, confirme el recuadro de diálogo que indica que se inicializará el volumen con una tabla de particiones GPT:
 Figura 22.8: Mensaje de disco sin conexión #
Figura 22.8: Mensaje de disco sin conexión #Seleccione el tamaño del volumen. Por lo general, utilizará toda la capacidad del dispositivo. Después, asigne una letra de unidad o un nombre de directorio donde estará disponible el volumen recién creado. A continuación, seleccione el sistema de archivos que se va a crear en el volumen nuevo y, por último, confirme la selección con la opción para terminar de crear el volumen:
 Figura 22.9: Confirmación de las opciones del volumen #
Figura 22.9: Confirmación de las opciones del volumen #Cuando termine el proceso, revise los resultados y haga clic en para concluir la inicialización de la unidad. Después de que finalice la inicialización, el volumen (y su sistema de archivos NTFS) estarán disponibles como una unidad local recién inicializada.
22.1.3 Conexión de VMware #
Para conectarse a volúmenes iSCSI gestionados con
ceph-iscsi, necesita un adaptador de software iSCSI configurado. Si no hay ningún adaptador de ese tipo disponible en la configuración de vSphere, cree uno seleccionando › › › .Si está disponible, haga clic con el botón derecho en el adaptador y seleccione en el menú contextual:
 Figura 22.10: Propiedades del iniciador iSCSI #
Figura 22.10: Propiedades del iniciador iSCSI #En el recuadro de diálogo haga clic en el botón A continuación, acceda a la pestaña y seleccione .
Introduzca la dirección IP o el nombre de host de su pasarela iSCSI
ceph-iscsi. Si ejecuta varias pasarelas iSCSI en una configuración de failover, repita este paso para todas las pasarelas con las que trabaje. Figura 22.11: Adición de un servidor de destino #
Figura 22.11: Adición de un servidor de destino #Cuando haya introducido todas las pasarelas iSCSI, haga clic en en el recuadro de diálogo para iniciar una nueva exploración del adaptador iSCSI.
Cuando finalice la nueva exploración, el nuevo dispositivo iSCSI aparece al final de la lista en el panel . Para dispositivos de múltiples rutas, ahora puede hacer clic con el botón derecho en el adaptador y seleccionar en el menú contextual:
 Figura 22.12: Gestión de dispositivos de múltiples rutas #
Figura 22.12: Gestión de dispositivos de múltiples rutas #Ahora debería ver todas las rutas con una luz verde en . Una de las rutas debe estar marcada como y todas las demás simplemente como :
 Figura 22.13: Lista de vías para múltiples rutas #
Figura 22.13: Lista de vías para múltiples rutas #Ahora puede cambiar de al elemento etiquetado como . Seleccione en la esquina superior derecha del panel para abrir el recuadro de diálogo . A continuación, seleccione y haga clic en . El dispositivo iSCSI recién añadido aparece en la lista . Selecciónelo y haga clic en para continuar:
 Figura 22.14: Recuadro de diálogo para añadir almacenamiento #
Figura 22.14: Recuadro de diálogo para añadir almacenamiento #Haga clic en para aceptar el diseño de disco por defecto.
En el panel , asigne un nombre al nuevo almacén de datos y haga clic en . Acepte la configuración por defecto para utilizar todo el espacio del volumen para el almacén de datos, o bien seleccione para definir un almacén de datos más pequeño:
 Figura 22.15: Configuración de espacio personalizada #
Figura 22.15: Configuración de espacio personalizada #Haga clic en para completar la creación del almacén de datos.
El nuevo almacén de datos aparece ahora en la lista de almacenes de datos y se puede seleccionar para recuperar la información. Ahora puede usar el volumen iSCSI con
ceph-iscsicomo cualquier otro almacén de datos de vSphere. Figura 22.16: Resumen del almacén de datos iSCSI #
Figura 22.16: Resumen del almacén de datos iSCSI #
22.2 Conclusión #
ceph-iscsi es un componente clave de
SUSE Enterprise Storage 7 que permite acceder al almacenamiento de bloques
distribuido y de alta disponibilidad desde cualquier servidor o cliente
capaz de comunicarse con el protocolo iSCSI. Mediante el uso de
ceph-iscsi en uno o varios hosts de
iSCSI Gateway, las imágenes de Ceph RBD están disponibles como unidades
lógicas asociados con destinos iSCSI, a los que se puede acceder de forma
opcional con equilibrio de carga y con alta disponibilidad.
Dado que toda la configuración de
ceph-iscsi se almacena en el almacén
de objetos de Ceph RADOS, los hosts de pasarela
ceph-iscsi son inherentemente no
persistentes y, por lo tanto se pueden reemplazar, aumentar o reducir a
voluntad. Como resultado, SUSE Enterprise Storage 7 permite a los clientes
de SUSE ejecutar una tecnología de almacenamiento empresarial verdaderamente
distribuida, de alta disponibilidad, resistente y autorreparable en hardware
no especializado y en una plataforma completamente de código abierto.
23 Sistema de archivos en clúster #
En este capítulo se describen las tareas de administración que normalmente se llevan a cabo después de configurar el clúster y exportar CephFS. Si necesita más información sobre cómo configurar CephFS, consulte Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.3.3 “Distribución de servidores de metadatos”.
23.1 Montaje de CephFS #
Cuando se crea el sistema de archivos y el servidor de metadatos está activo, estará preparado para montar el sistema de archivos desde un host de cliente.
23.1.1 Preparación del cliente #
Si el host del cliente ejecuta SUSE Linux Enterprise 12 SP2 o una versión posterior, el sistema ya está preparado para montar CephFS sin preparativos adicionales.
Si el host de cliente ejecuta SUSE Linux Enterprise 12 SP1, debe aplicar todos los parches más recientes antes de montar CephFS.
En cualquier caso, todo lo necesario para montar CephFS se incluye en SUSE Linux Enterprise. El producto SUSE Enterprise Storage 7 no es necesario.
Para admitir la sintaxis completa de mount, el paquete
ceph-common (que se incluye con SUSE Linux Enterprise) debe estar instalado antes de intentar montar CephFS.
Sin el paquete ceph-common (y, por tanto, sin el ayudante mount.ceph), será necesario utilizar las direcciones IP de los monitores en lugar de sus nombres. Esto se debe a que el cliente del kernel no podrá resolver los nombres.
La sintaxis básica de montaje es:
root # mount -t ceph MON1_IP[:PORT],MON2_IP[:PORT],...:CEPHFS_MOUNT_TARGET \
MOUNT_POINT -o name=CEPHX_USER_NAME,secret=SECRET_STRING23.1.2 Creación de un archivo secreto #
El clúster de Ceph se ejecuta con la autenticación activada por defecto. Debe crear un archivo donde se almacene la clave de secreto (no el anillo de claves en sí). Para obtener la clave de secreto para un usuario concreto y, a continuación, crear el archivo, haga lo siguiente:
Muestre la clave para el usuario concreto en un archivo de anillo de claves:
cephuser@adm >cat /etc/ceph/ceph.client.admin.keyringCopie la clave del usuario que va a utilizar el sistema de archivos CephFS montado. Normalmente, la clave tiene un aspecto similar al siguiente:
AQCj2YpRiAe6CxAA7/ETt7Hcl9IyxyYciVs47w==
Cree un archivo con el nombre de usuario como parte del nombre de archivo; por ejemplo,
/etc/ceph/admin.secretpara el usuario admin.Pegue el valor de la clave en el archivo creado en el paso anterior.
Defina los derechos de acceso adecuados en el archivo. El usuario debe ser el único que pueda leer el archivo: los demás usuarios no deben tener ningún derecho de acceso.
23.1.3 Montaje de CephFS #
Puede montar CephFS con el comando mount. Es preciso especificar el nombre de host o la dirección IP del monitor. Dado que la autenticación cephx está habilitada por defecto en SUSE Enterprise Storage, debe especificar también un nombre de usuario y su secreto relacionado:
root # mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secret=AQATSKdNGBnwLhAAnNDKnH65FmVKpXZJVasUeQ==Como el comando anterior permanece en el historial de shell, un enfoque más seguro es leer el secreto desde un archivo:
root # mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secretTenga en cuenta que el archivo de secreto solo debe contener el secreto del anillo de claves actual. En nuestro ejemplo, el archivo solo contendrá la línea siguiente:
AQATSKdNGBnwLhAAnNDKnH65FmVKpXZJVasUeQ==
Resulta recomendable especificar varios monitores separados por comas en la línea del comando mount por si un monitor se desactiva en algún momento del montaje. Las direcciones de los monitores tiene el formato host[:puerto]. Si no se especifica el puerto, se utiliza por defecto el 6789.
Cree el punto de montaje en el host local:
root # mkdir /mnt/cephfsMonte CephFS:
root # mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret
Es posible especificar un subdirectorio subdir si se va a montar un subconjunto del sistema de archivos:
root # mount -t ceph ceph_mon1:6789:/subdir /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret
Puede especificar más de un host de monitor en el comando mount:
root # mount -t ceph ceph_mon1,ceph_mon2,ceph_mon3:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secretSi se usan clientes con restricciones de vía, es preciso incluir acceso de lectura al directorio raíz en los permisos del servidor de metadatos. Por ejemplo, un anillo de claves puede tener este aspecto:
client.bar key: supersecretkey caps: [mds] allow rw path=/barjail, allow r path=/ caps: [mon] allow r caps: [osd] allow rwx
La parte allow r path=/ significa que los clientes que tienen vías restringidas podrán ver el volumen raíz, pero no escribir en él. Esto puede ser un problema para los casos en los que se requiera aislamiento completo.
23.2 Desmontaje de CephFS #
Para desmontar CephFS, utilice el comando umount:
root # umount /mnt/cephfs23.3 Montaje de CephFS en /etc/fstab #
Para montar CephFS automáticamente durante el inicio del cliente, inserte la línea correspondiente en la tabla de su sistema de archivos /etc/fstab:
mon1:6790,mon2:/subdir /mnt/cephfs ceph name=admin,secretfile=/etc/ceph/secret.key,noatime,_netdev 0 2
23.4 Varios daemons de servidor de metadatos activos (MDS activo-activo) #
CephFS está configurado por defecto para un solo daemon de servidor de metadatos activo. Para ampliar el rendimiento de los metadatos en sistemas a gran escala, puede habilitar varios daemons de servidor de metadatos activos: compartirán la carga de trabajo de los metadatos entre sí.
23.4.1 Uso de servidor de metadatos activo-activo #
Puede ser útil usar varios daemons de servidor de metadatos activos si el rendimiento de los metadatos sufre un cuello de botella en el servidor de metadatos único por defecto.
Añadir más daemons no mejora el rendimiento de todos los tipos de cargas de trabajo. Por ejemplo, una única aplicación que se ejecute en un único cliente no se beneficiará de un número mayor de daemons de servidor de metadatos; a menos que la aplicación lleve a cabo muchas operaciones de metadatos en paralelo.
Las cargas de trabajo que suelen beneficiarse de que haya un número mayor de daemons de servidor de metadatos activos son las que tienen muchos clientes, quizás funcionando en muchos directorios diferentes.
23.4.2 Aumento del tamaño del clúster activo del servidor de metadatos #
Cada sistema de archivos CephFS tiene un valor max_mds que controla el número de rangos que se van a crear. El número real de rangos en el sistema de archivos solo aumentará si hay un daemon de repuesto disponible para hacerse cargo del nuevo rango. Por ejemplo, si hay solo un daemon de servidor de metadatos en ejecución y en max_mds se define el valor 2, no se creará un segundo rango.
En el ejemplo siguiente, la opción max_mds se define con el valor 2 para crear un nuevo rango aparte del rango por defecto. Para ver los cambios, ejecute ceph status antes y, después de definir max_mds, observe la línea que contiene fsmap:
cephuser@adm >cephstatus [...] services: [...] mds: cephfs-1/1/1 up {0=node2=up:active}, 1 up:standby [...]cephuser@adm >cephfs set cephfs max_mds 2cephuser@adm >cephstatus [...] services: [...] mds: cephfs-2/2/2 up {0=node2=up:active,1=node1=up:active} [...]
El rango recién creado (1) pasa por el estado de "creación" y entra en su estado "activo".
Incluso con varios daemons de servidor de metadatos activos, un sistema de alta disponibilidad sigue necesitando daemons en espera para que entren en acción si falla alguno de los servidores en los que se ejecuta un daemon activo.
En consecuencia, el número máximo práctico de max_mds para sistemas de alta disponibilidad es uno menos que el número total de servidores de metadatos del sistema. Para seguir estando disponible en caso de que varios servidores fallen, aumente el número de daemons en espera del sistema para que sea igual al número de servidores que se pueda admitir que fallen.
23.4.3 Reducción del número de rangos #
Todos los rangos, incluidos los que se van a eliminar, deben estar activos en primer lugar. Esto significa que debe tener al menos el número de max_mds de daemons de servidor de metadatos disponibles.
En primer lugar, defina en max_mds un número inferior. Por ejemplo, vuelva a tener un único servidor de metadatos activo:
cephuser@adm >cephstatus [...] services: [...] mds: cephfs-2/2/2 up {0=node2=up:active,1=node1=up:active} [...]cephuser@adm >cephfs set cephfs max_mds 1cephuser@adm >cephstatus [...] services: [...] mds: cephfs-1/1/1 up {0=node2=up:active}, 1 up:standby [...]
23.4.4 Fijación manual de árboles de directorio a un rango #
En las configuraciones con varios servidores de metadatos activos, se ejecuta un mecanismo de equilibrio que funciona para distribuir la carga de los metadatos de forma uniforme en el clúster. Esto suele ser suficientemente para la mayoría de los usuarios pero, en ocasiones, es aconsejable sustituir el mecanismo de equilibrio dinámico por asignaciones explícitas de metadatos para rangos concreto. De esta forma, se permite que el administrador o los usuarios puedan distribuir uniformemente la carga de la aplicación o limitar el impacto de las peticiones de metadatos de los usuarios en todo el clúster.
El mecanismo proporcionado para este propósito se denomina "fijación de exportación". Se trata de un atributo extendido de los directorios. El nombre de este atributo extendido es ceph.dir.pin. Los usuarios pueden definir este atributo mediante comandos estándar:
root # setfattr -n ceph.dir.pin -v 2 /path/to/dir
El valor (- v) del atributo extendido es el rango al que se debe asignar el subárbol de directorio. Un valor por defecto de -1 indica que el directorio no está fijado.
La fijación de exportación de directorio se hereda de su padre más próximo que cuente con una fijación de exportación definido. Por lo tanto, definir la fijación de exportación en un directorio, afecta a todos sus hijos. Sin embargo, la fijación padre se puede sustituir definiendo fijaciones de exportación en el directorio hijo. Por ejemplo:
root # mkdir -p a/b # "a" and "a/b" start with no export pin set.
setfattr -n ceph.dir.pin -v 1 a/ # "a" and "b" are now pinned to rank 1.
setfattr -n ceph.dir.pin -v 0 a/b # "a/b" is now pinned to rank 0
# and "a/" and the rest of its children
# are still pinned to rank 1.23.5 Gestión del failover #
Si un daemon de servidor de metadatos deja de comunicarse con el monitor, este espera el número de segundos definido en mds_beacon_grace (por defecto, 15 segundos) antes de marcar el daemon como retrasado. Es posible configurar uno o varios daemons en espera que se harán cargo del trabajo durante un failover del daemon de servidor de metadatos.
23.5.1 Configuración reserva-respuesta #
Cada sistema de archivos CephFS puede configurarse para añadir daemons de reserva-respuesta. Estos daemons de reserva siguen el registro de metadatos del MDS activo para reducir el tiempo de failover en caso de que el MDS activo deje de estar disponible. Cada MDS activo puede tener solo un daemon de reserva-respuesta siguiéndolo.
Para configurar un daemon de reserva-respuesta en un sistema de archivos, ejecute el comando siguiente:
cephuser@adm > ceph fs set FS-NAME allow_standby_replay BOOLCuando se definen los monitores, se asignan daemons de reserva-respuesta disponibles para seguir los MDS activos en ese sistema de archivos.
Si un MDS ha entrado en estado de reserva-respuesta, solo se utilizará como daemon de reserva para el rango al que sigue. Si otro rango falla, este daemon de reserva-respuesta no se utilizará como sustituto, aunque no haya ningún otro daemon de reserva disponible. Por este motivo, se recomienda que si se utiliza este sistema, todos los MDS activos deben tener un daemon de reserva-respuesta.
23.6 Configuración de cuotas de CephFS #
Puede establecer cuotas en cualquier subdirectorio del sistema de archivos de Ceph. La cuota restringe el número de bytes o de archivos almacenados debajo del punto especificado en la jerarquía de directorios.
23.6.1 Limitaciones de cuotas de CephFS #
El uso de cuotas con CephFS tiene las siguientes limitaciones:
- Las cuotas son cooperativas y no compiten.
Las cuotas de Ceph dependen de que el cliente que está montando el sistema de archivos deje de escribir en él cuando se alcance un límite. La parte del servidor no puede impedir que un cliente malintencionado escriba tantos datos como necesite. No utilice cuotas para evitar que se rellene el sistema de archivos en entornos en los que los clientes no sean de total confianza.
- Las cuotas son imprecisas.
Los procesos que se escriben en el sistema de archivos se detienen poco después de que se alcance el límite de cuota. Inevitablemente se les permitirá escribir cierta cantidad de datos por encima del límite configurado. Los escritores del cliente se detendrán décimas de segundos después de superar el límite configurado.
- Las cuotas se implementan en el cliente del kernel a partir de la versión 4.17.
Las cuotas son compatibles con el cliente de espacio de usuario (libcephfs, ceph-fuse). Los clientes del kernel de Linux de la versión 4.17 y superiores admiten cuotas de CephFS en clústeres de SUSE Enterprise Storage 7. Los clientes del kernel (incluso de las versiones recientes) no podrán controlar las cuotas en clústeres más antiguos, incluso si son capaces de establecer los atributos extendidos de las cuotas. Los kernel SLE12-SP3 (y versiones posteriores) ya incluyen las adaptaciones necesarias para gestionar cuotas.
- Configure las cuotas cuidadosamente cuando se utilicen con restricciones de montaje basadas en vías.
El cliente necesita tener acceso al inodo del directorio en el cual se configuran las cuotas para aplicarlas. Si el cliente tiene acceso restringido a una vía específica (por ejemplo
/home/user) según la capacidad del MDS y se configura una cuota en un directorio antecesor al que no tienen acceso (/home), el cliente no la aplicará. Si utiliza restricciones de acceso basadas en vías, asegúrese de configurar la cuota en el directorio al que puede acceder el cliente (por ejemplo,/home/usero/home/user/quota_dir).
23.6.2 Configuración de cuotas de CephFS #
Puede configurar cuotas de CephFS mediante atributos extendidos virtuales:
ceph.quota.max_filesConfigura un límite de archivos.
ceph.quota.max_bytesConfigura un límite debytes.
Si los atributos aparecen en un inodo de directorio, allí se configura una cuota. Si no están presentes, no se establece ninguna cuota en ese directorio (aunque se podría configurar una en un directorio padre).
Para establecer una cuota de 100 MB, ejecute:
cephuser@mds > setfattr -n ceph.quota.max_bytes -v 100000000 /SOME/DIRECTORYPara establecer una cuota de 10.000 archivos, ejecute:
cephuser@mds > setfattr -n ceph.quota.max_files -v 10000 /SOME/DIRECTORYPara ver la configuración de cuota, ejecute:
cephuser@mds > getfattr -n ceph.quota.max_bytes /SOME/DIRECTORYcephuser@mds > getfattr -n ceph.quota.max_files /SOME/DIRECTORYSi el valor del atributo extendido es "0", no se establece la cuota.
Para eliminar una cuota, ejecute:
cephuser@mds >setfattr -n ceph.quota.max_bytes -v 0 /SOME/DIRECTORYcephuser@mds >setfattr -n ceph.quota.max_files -v 0 /SOME/DIRECTORY
23.7 Gestión de instantáneas de CephFS #
Las instantáneas de CephFS crean una vista de solo lectura del sistema de archivos del momento en que se toman. Puede crear una instantánea en cualquier directorio. La instantánea cubrirá todos los datos del sistema de archivos del directorio especificado. Después de crear una instantánea, los datos almacenados en búfer se vacían de forma asincrónica desde varios clientes. Como resultado, crear una instantánea es muy rápido.
Si tiene varios sistemas de archivos CephFS que comparten un único repositorio (mediante espacios de nombres), sus instantáneas tendrán un conflicto y si se suprime una instantánea, faltarán datos de archivo en otras instantáneas que compartan el mismo repositorio.
23.7.1 Creación de instantáneas #
La función de instantáneas de CephFS está habilitada por defecto en los nuevos sistemas de archivos. Para habilitarla en sistemas de archivos existentes, ejecute:
cephuser@adm > ceph fs set CEPHFS_NAME allow_new_snaps true
Después de habilitar las instantáneas, todos los directorios de CephFS tendrán un subdirectorio .snap especial.
Este es un subdirectorio virtual. No aparece en la lista de directorios del directorio padre, pero el nombre .snap no se puede utilizar como nombre de archivo ni directorio. Para acceder al directorio .snap es necesario acceder a él explícitamente, por ejemplo:
tux > ls -la /CEPHFS_MOUNT/.snap/Los clientes del kernel de CephFS tienen una limitación: no pueden gestionar más de 400 instantáneas en un sistema de archivos. El número de instantáneas siempre debe mantenerse por debajo de este límite, independientemente del cliente que se esté utilizando. Si se utilizan clientes de CephFS más antiguos, como SLE12-SP3, tenga en cuenta que tener más 400 instantáneas es perjudicial para las operaciones, ya que el cliente se detendrá por fallo.
Puede configurar un nombre diferente para el subdirectorio de instantáneas definiendo el valor client snapdir.
Para crear una instantánea, cree un subdirectorio en el directorio .snap con un nombre personalizado. Por ejemplo, para crear una instantánea del directorio /CEPHFS_MOUNT/2/3/, ejecute:
tux > mkdir /CEPHFS_MOUNT/2/3/.snap/CUSTOM_SNAPSHOT_NAME23.7.2 Supresión de instantáneas #
Para suprimir una instantánea, elimine su subdirectorio dentro del directorio .snap:
tux > rmdir /CEPHFS_MOUNT/2/3/.snap/CUSTOM_SNAPSHOT_NAME24 Exportación de datos de Ceph a través de Samba #
En este capítulo se describe cómo exportar datos almacenados en un clúster de Ceph a través de un recurso compartido Samba/CIFS, de forma que se pueda acceder fácilmente a ellos desde equipos cliente Windows.* También incluye información que le ayudará a configurar una pasarela Samba de Ceph para unirse a Active Directory en el dominio de Windows* para autenticar y autorizar a los usuarios.
Debido al aumento de la sobrecarga de protocolo y a la latencia adicional causados por saltos de red adicionales entre el cliente y el almacenamiento, el acceso a CephFS a través de una pasarela Samba puede reducir de forma significativa el rendimiento de la aplicación en comparación con los clientes de Ceph nativos.
24.1 Exportación de CephFS mediante un recurso compartido Samba #
Los clientes nativos de CephFS y NFS no están restringidos por los bloqueos de archivos obtenidos a través de Samba, y viceversa. Las aplicaciones que se basan en el bloqueo de archivos con varios protocolos pueden sufrir daños en los datos si se accede a las vías compartidas de Samba respaldadas por CephFS a través de otros medios.
24.1.1 Configuración y exportación de paquetes de Samba #
Para configurar y exportar un recurso compartido Samba, es necesario instalar los paquetes siguientes: samba-ceph y samba-winbind. Instale estos paquetes si no lo están:
cephuser@smb > zypper install samba-ceph samba-winbind24.1.2 Ejemplo de pasarela única #
Para preparar la exportación de un recurso compartido Samba, elija un nodo adecuado para que actúe como pasarela Samba. El nodo debe tener acceso a la red del cliente de Ceph, así como suficientes recursos de CPU, memoria y redes.
Es posible proporcionar funcionalidad de failover con CTDB y SUSE Linux Enterprise High Availability Extension. Consulte la Sección 24.1.3, “Configuración de alta disponibilidad” para obtener más información sobre la configuración de alta disponibilidad.
Asegúrese de que ya existe una instancia de CephFS en funcionamiento en el clúster.
Cree un anillo de claves específico para la pasarela Samba en nodo de administración de Ceph y cópielo en ambos nodos de pasarela Samba:
cephuser@adm >cephauth get-or-create client.samba.gw mon 'allow r' \ osd 'allow *' mds 'allow *' -o ceph.client.samba.gw.keyringcephuser@adm >scpceph.client.samba.gw.keyring SAMBA_NODE:/etc/ceph/Sustituya SAMBA_NODE con el nombre del nodo de pasarela de Samba.
Los pasos siguientes se ejecutan en el nodo de pasarela Samba. Instale Samba junto con el paquete de integración de Ceph:
cephuser@smb >sudo zypper in samba samba-cephSustituya el contenido por defecto del archivo
/etc/samba/smb.confpor lo siguiente:[global] netbios name = SAMBA-GW clustering = no idmap config * : backend = tdb2 passdb backend = tdbsam # disable print server load printers = no smbd: backgroundqueue = no [SHARE_NAME] path = CEPHFS_MOUNT read only = no oplocks = no kernel share modes = no
La vía CEPHFS_MOUNT anterior debe montarse antes de iniciar Samba con una configuración de recurso compartido CephFS del kernel. Consulte la Sección 23.3, “Montaje de CephFS en
/etc/fstab”.La configuración de recursos compartidos anterior utiliza el cliente CephFS del kernel de Linux, lo que se recomienda por motivos de rendimiento. Como alternativa, el módulo Samba
vfs_cephtambién se puede utilizar para comunicarse con el clúster de Ceph. Las instrucciones se muestran a continuación para sistemas heredados, pero no se recomiendan para distribuciones nuevas de Samba:[SHARE_NAME] path = / vfs objects = ceph ceph: config_file = /etc/ceph/ceph.conf ceph: user_id = samba.gw read only = no oplocks = no kernel share modes = no
Sugerencia: Oplocks y modos compartidosLos
oplocks(también conocidos como arrendamientos SMB2+) mejoran el rendimiento gracias al almacenamiento en caché agresivo del cliente, pero actualmente no son seguros si Samba se distribuye junto con otros clientes de CephFS, como el kernelmount.ceph, FUSE o NFS Ganesha.Si Samba controla en exclusiva todo el acceso a la vía del sistema de archivos CephFS, el parámetro
oplocksse puede habilitar de forma segura.Actualmente,
kernel share modesdebe estar inhabilitado en un recurso compartido que se ejecute con el módulo CephFS vfs para que la provisión de archivos funcione correctamente.Importante: permitir el accesoSamba asigna usuarios y grupos de SMB a cuentas locales. A los usuarios locales se les puede asignar una contraseña para el acceso compartido de Samba mediante:
root #smbpasswd -a USERNAMEPara que la E/S se realice correctamente, la lista de control de acceso (ACL) de la vía compartida debe permitir el acceso al usuario conectado a través de Samba. Puede modificar la ACL montándola temporalmente a través del cliente del kernel de CephFS y utilizando las utilidades
chmod,chownosetfaclen la vía del recurso compartido. Por ejemplo, para permitir el acceso a todos los usuarios, ejecute:root #chmod 777 MOUNTED_SHARE_PATH
24.1.2.1 Inicio de los servicios de Samba #
Inicie o reinicie los servicios Samba independientes mediante los comandos siguientes:
root #systemctl restart smb.serviceroot #systemctl restart nmb.serviceroot #systemctl restart winbind.service
Para garantizar que los servicios de Samba se inician al arrancar, habilítelos mediante:
root #systemctl enable smb.serviceroot #systemctl enable nmb.serviceroot #systemctl enable winbind.service
nmb y winbind opcionales
Si no necesita examinar el recurso compartido de red, no es necesario que habilite e inicie el servicio nmb.
El servicio winbind solo es necesario cuando se configura como miembro del dominio de Active Directory. Consulte la Sección 24.2, “Unión de pasarela Samba y Active Directory”.
24.1.3 Configuración de alta disponibilidad #
Aunque una distribución de varios nodos de Samba + CTDB tiene mayor disponibilidades que un nodo único (consulte el Capítulo 24, Exportación de datos de Ceph a través de Samba), no se admite el failover transparente en el cliente. Es probable que las aplicaciones experimenten una breve interrupción por el error del nodo de pasarela Samba.
En esta sección se proporciona un ejemplo de cómo establecer una configuración de dos nodos de alta disponibilidad de los servidores de Samba. La configuración requiere SUSE Linux Enterprise High Availability Extension. Los dos nodos se denominan earth (192.168.1.1) y mars (192.168.1.2).
Para obtener información sobre SUSE Linux Enterprise High Availability Extension, consulte https://documentation.suse.com/sle-ha/15-SP1/.
Asimismo, dos direcciones IP virtuales flotantes permiten a los clientes conectarse al servicio independientemente del nodo físico en el que se estén ejecutando. 192.168.1.10 se usa para la administración del clúster con Hawk2 y 192.168.2.1 se usa exclusivamente para las exportaciones CIFS. De esta forma es más fácil aplicar más tarde restricciones de seguridad.
El procedimiento siguiente describe la instalación de ejemplo. Encontrará más información en https://documentation.suse.com/sle-ha/15-SP2/html/SLE-HA-all/art-sleha-install-quick.html.
Cree un anillo de claves específico de la pasarela Samba en el nodo de administración y cópielo en ambos nodos:
cephuser@adm >cephauth get-or-create client.samba.gw mon 'allow r' \ osd 'allow *' mds 'allow *' -o ceph.client.samba.gw.keyringcephuser@adm >scpceph.client.samba.gw.keyringearth:/etc/ceph/cephuser@adm >scpceph.client.samba.gw.keyringmars:/etc/ceph/La configuración de SLE-HA requiere un dispositivo de aislamiento para evitar una situación de clúster con nodos malinformados cuando los nodos de clúster activos dejen de estar sincronizados. Para ello, puede utilizar una imagen Ceph RBD con un dispositivo de bloques Stonith (SBD). Consulte https://documentation.suse.com/sle-ha/15-SP2/html/SLE-HA-all/cha-ha-storage-protect.html#sec-ha-storage-protect-fencing-setup para obtener más información.
Si aún no existe, cree un repositorio RBD denominado
rbd(consulte la Sección 18.1, “Creación de un repositorio”) y asócielo conrbd(consulte la Sección 18.5.1, “Asociación de repositorios a una aplicación”). A continuación, cree una imagen RBD relacionada llamadasbd01:cephuser@adm >ceph osd pool create rbdcephuser@adm >ceph osd pool application enable rbd rbdcephuser@adm >rbd -p rbd create sbd01 --size 64M --image-sharedPrepare
earthymarspara que alojen el servicio de Samba:Asegúrese de que los paquetes siguientes están instalados antes de continuar: ctdb, tdb-toolsy samba.
root #zypperin ctdb tdb-tools samba samba-cephAsegúrese de que los servicios Samba y CTDB están detenidos e inhabilitados:
root #systemctl disable ctdbroot #systemctl disable smbroot #systemctl disable nmbroot #systemctl disable winbindroot #systemctl stop ctdbroot #systemctl stop smbroot #systemctl stop nmbroot #systemctl stop winbindAbra el puerto
4379del cortafuegos en todos los nodos. Esto es necesario para que CTDB pueda comunicarse con los demás nodos del clúster.
En
earth, cree los archivos de configuración de Samba. Más adelante, se sincronizarán automáticamente conmars.Inserte una lista de direcciones IP privadas de los nodos de pasarela Samba en el archivo
/etc/ctdb/node. Encontrará más información en la página de manual de ctdb (man 7 ctdb).192.168.1.1 192.168.1.2
Configure Samba. Añada las líneas siguientes en la sección
[global]de/etc/samba/smb.conf. Utilice el nombre de host que desee en lugar de CTDB-SERVER (en realidad, todos los nodos del clúster aparecerán como un nodo extenso con este nombre): Añada también una definición de recurso compartido, como ejemplo, puede usar SHARE_NAME:[global] netbios name = SAMBA-HA-GW clustering = yes idmap config * : backend = tdb2 passdb backend = tdbsam ctdbd socket = /var/lib/ctdb/ctdb.socket # disable print server load printers = no smbd: backgroundqueue = no [SHARE_NAME] path = / vfs objects = ceph ceph: config_file = /etc/ceph/ceph.conf ceph: user_id = samba.gw read only = no oplocks = no kernel share modes = no
Tenga en cuenta que los archivos
/etc/ctdb/nodesy/etc/samba/smb.confdeben coincidir en todos los nodos de pasarela Samba.
Instale y cargue el clúster de SUSE Linux Enterprise High Availability.
Registre SUSE Linux Enterprise High Availability Extension en
earthymars:root@earth #SUSEConnect-r ACTIVATION_CODE -e E_MAILroot@mars #SUSEConnect-r ACTIVATION_CODE -e E_MAILInstale ha-cluster-bootstrap en ambos nodos:
root@earth #zypperin ha-cluster-bootstraproot@mars #zypperin ha-cluster-bootstrapAsigne la imagen RBD
sbd01en ambas pasarelas Samba medianterbdmap.service.Edite
/etc/ceph/rbdmapy añada una entrada para la imagen SBD:rbd/sbd01 id=samba.gw,keyring=/etc/ceph/ceph.client.samba.gw.keyring
Habilite e inicie
rbdmap.service:root@earth #systemctl enable rbdmap.service && systemctl start rbdmap.serviceroot@mars #systemctl enable rbdmap.service && systemctl start rbdmap.serviceEl dispositivo
/dev/rbd/rbd/sbd01debe estar disponible en ambas pasarelas Samba.Inicialice el clúster en
earthy deje quemarsse una a él.root@earth #ha-cluster-initroot@mars #ha-cluster-join-c earthImportanteDurante el proceso de inicialización y unión al clúster, se le preguntará de forma interactiva si desea utilizar SBD. Confirme con
yy, a continuación, especifique/dev/rbd/rbd/sbd01como vía al dispositivo de almacenamiento.
Compruebe el estado del clúster. Debería observar que se han añadido dos nodos al clúster:
root@earth #crmstatus 2 nodes configured 1 resource configured Online: [ earth mars ] Full list of resources: admin-ip (ocf::heartbeat:IPaddr2): Started earthEjecute los comandos siguientes en
earthpara configurar el recurso CTDB:root@earth #crmconfigurecrm(live)configure#primitivectdb ocf:heartbeat:CTDB params \ ctdb_manages_winbind="false" \ ctdb_manages_samba="false" \ ctdb_recovery_lock="!/usr/lib64/ctdb/ctdb_mutex_ceph_rados_helper ceph client.samba.gw cephfs_metadata ctdb-mutex" ctdb_socket="/var/lib/ctdb/ctdb.socket" \ op monitor interval="10" timeout="20" \ op start interval="0" timeout="200" \ op stop interval="0" timeout="100"crm(live)configure#primitivesmb systemd:smb \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#primitivenmb systemd:nmb \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#primitivewinbind systemd:winbind \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#groupg-ctdb ctdb winbind nmb smbcrm(live)configure#clonecl-ctdb g-ctdb meta interleave="true"crm(live)configure#commitSugerencia: primitivasnmbywinbindopcionalesSi no necesita examinar el recurso compartido de red, no es necesario añadir el primitivo
nmb.El primitivo
winbindsolo es necesario si se configura como miembro del dominio de Active Directory. Consulte la Sección 24.2, “Unión de pasarela Samba y Active Directory”.El archivo binario
/usr/lib64/ctdb/ctdb_mutex_ceph_rados_helperde la opción de configuraciónctdb_recovery_locktiene los parámetros CLUSTER_NAME CEPHX_USER RADOS_POOL y RADOS_OBJECT, en este orden.Es posible anexar un parámetro de tiempo de espera de bloqueo adicional para sustituir el valor por defecto utilizado (10 segundos). Un valor más alto aumentará el tiempo de failover del master de recuperación CTDB, mientras que un valor más bajo puede dar lugar a que se detecte incorrectamente que el master de recuperación está inactivo, lo que desencadenaría conmutaciones por error sucesivas.
Añada una dirección IP agrupada en clúster:
crm(live)configure#primitiveip ocf:heartbeat:IPaddr2 params ip=192.168.2.1 \ unique_clone_address="true" \ op monitor interval="60" \ meta resource-stickiness="0"crm(live)configure#clonecl-ip ip \ meta interleave="true" clone-node-max="2" globally-unique="true"crm(live)configure#colocationcol-with-ctdb 0: cl-ip cl-ctdbcrm(live)configure#ordero-with-ctdb 0: cl-ip cl-ctdbcrm(live)configure#commitSi
unique_clone_addressse define comotrue(verdadero), el agente de recurso IPaddr2 añade un ID de clonación a la dirección especificada, lo que da como resultado que haya tres direcciones IP distintas. Normalmente, no son necesarias, pero ayudan a la hora de equilibrar la carga. Para obtener más información sobre este tema, consulte https://documentation.suse.com/sle-ha/15-SP2/html/SLE-HA-all/cha-ha-lb.html.Compruebe el resultado:
root@earth #crmstatus Clone Set: base-clone [dlm] Started: [ factory-1 ] Stopped: [ factory-0 ] Clone Set: cl-ctdb [g-ctdb] Started: [ factory-1 ] Started: [ factory-0 ] Clone Set: cl-ip [ip] (unique) ip:0 (ocf:heartbeat:IPaddr2): Started factory-0 ip:1 (ocf:heartbeat:IPaddr2): Started factory-1Realice una prueba desde un equipo cliente. En un cliente Linux, ejecute el comando siguiente para comprobar si puede copiar archivos desde el sistema y en el sistema:
root #smbclient//192.168.2.1/myshare
24.1.3.1 Reinicio de recursos de Samba de alta disponibilidad #
Después de cualquier cambio en la configuración de Samba o CTDB, es posible que sea necesario reiniciar los recursos de alta disponibilidad para que los cambios surtan efecto. Esto puede hacerse así:
root #crmresource restart cl-ctdb
24.2 Unión de pasarela Samba y Active Directory #
Puede configurar la pasarela Samba de Ceph para que se convierta en miembro del dominio de Samba compatible con Active Directory (AD). Como miembro del dominio de Samba, puede usar usuarios y grupos de dominio en listas de acceso local (ACL) en archivos y directorios del sistema CephFS exportado.
24.2.1 Preparación de la instalación de Samba #
En esta sección se presenta los pasos preparatorios que debe tener en cuenta antes de configurar Samba. Empezar con un entorno limpio ayuda a evitar confusiones y permite verificar que no se mezcla ningún archivo de la instalación anterior de Samba con la nueva instalación del miembro de dominio.
Todos los relojes de los nodos de la pasarela Samba deben sincronizarse con el controlador de dominio de Active Directory. La diferencia de hora puede provocar errores de autenticación.
Compruebe que no se esté ejecutando ningún proceso de Samba ni de almacenamiento en caché de nombres:
cephuser@smb > ps ax | egrep "samba|smbd|nmbd|winbindd|nscd"
Si en el resultado aparece algún proceso samba, smbd, nmbd, winbindd o nscd, deténgalos.
Si ha ejecutado previamente una instalación de Samba en este host, elimine el archivo /etc/samba/smb.conf. Elimine también todos los archivos de base de datos de Samba, como los archivos *.tdb y *.ldb. Para mostrar directorios que contienen bases de datos Samba, ejecute:
cephuser@smb > smbd -b | egrep "LOCKDIR|STATEDIR|CACHEDIR|PRIVATE_DIR"24.2.2 Verificación de DNS #
Active Directory (AD) utiliza DNS para localizar otros controladores de dominio (CD) y servicios, como Kerberos. Por lo tanto, los miembros del dominio de AD y los servidores deben poder resolver las zonas DNS de AD.
Verifique que DNS esté configurado correctamente y que tanto la búsqueda directa como la inversa den resultados correctamente, por ejemplo:
cephuser@adm > nslookup DC1.domain.example.com
Server: 10.99.0.1
Address: 10.99.0.1#53
Name: DC1.domain.example.com
Address: 10.99.0.1cephuser@adm > 10.99.0.1
Server: 10.99.0.1
Address: 10.99.0.1#53
1.0.99.10.in-addr.arpa name = DC1.domain.example.com.24.2.3 Resolución de registros SRV #
AD utiliza registros SRV para localizar servicios, como Kerberos y LDAP. Para comprobar si los registros SRV se resuelven correctamente, utilice la shell interactiva nslookup, por ejemplo:
cephuser@adm > nslookup
Default Server: 10.99.0.1
Address: 10.99.0.1
> set type=SRV
> _ldap._tcp.domain.example.com.
Server: UnKnown
Address: 10.99.0.1
_ldap._tcp.domain.example.com SRV service location:
priority = 0
weight = 100
port = 389
svr hostname = dc1.domain.example.com
domain.example.com nameserver = dc1.domain.example.com
dc1.domain.example.com internet address = 10.99.0.124.2.4 Configuración de Kerberos #
Samba admite los back-ends Kerberos Heimdal y MIT. Para configurar Kerberos en el miembro de dominio, defina lo siguiente en el archivo /etc/krb5.conf:
[libdefaults] default_realm = DOMAIN.EXAMPLE.COM dns_lookup_realm = false dns_lookup_kdc = true
En el ejemplo anterior, Kerberos se configura para el reino DOMAIN.EXAMPLE.COM. No se recomienda definir ningún parámetro adicional en el archivo /etc/krb5.conf. Si /etc/krb5.conf contiene una línea include, no funcionará; debe eliminar esta línea.
24.2.5 Resolución del nombre del host local #
Cuando se une un host al dominio, Samba intenta registrar el nombre de host en la zona DNS de AD. Para ello, la utilidad net debe ser capaz de resolver el nombre de host mediante DNS o con una entrada correcta en el archivo /etc/hosts.
Para verificar que el nombre de host se resuelve correctamente, utilice el comando getent hosts:
cephuser@adm > getent hosts example-host
10.99.0.5 example-host.domain.example.com example-host
El nombre de host y el nombre completo no deben resolverse en la dirección IP 127.0.0.1 ni en ninguna dirección IP que no sea la utilizada en la interfaz LAN del miembro de dominio. Si no se muestra ningún resultado o el host se resuelve en la dirección IP incorrecta y no está utilizando DHCP, defina la entrada correcta en el archivo /etc/hosts:
127.0.0.1 localhost 10.99.0.5 example-host.samdom.example.com example-host
/etc/hosts
Si utiliza DHCP, compruebe que /etc/hosts solo contiene la línea "127.0.0.1". Si sigue teniendo problemas, póngase en contacto con el administrador del servidor DHCP.
Si necesita añadir alias al nombre de host del equipo, añádalos al final de la línea que comienza con la dirección IP del equipo, no a la línea "127.0.0.1".
24.2.6 Configuración de Samba #
En esta sección se presenta información sobre las opciones de configuración específicas que debe incluir en la configuración de Samba.
La pertenencia al dominio de Active Directory se configura principalmente con el ajuste security = ADS junto con los parámetros de asignación de ID y del dominio de Kerberos adecuados en la sección [global] de /etc/samba/smb.conf.
[global] security = ADS workgroup = DOMAIN realm = DOMAIN.EXAMPLE.COM ...
24.2.6.1 Elección del procesador final para la asignación de ID en winbindd #
Si necesita que los usuarios tengan diferentes shells de entrada a la sesión o vías de directorio de inicio de Unix, o si desea que tengan el mismo ID en todas partes, deberá usar el back-end winbind "ad" y añadir atributos RFC2307 a AD.
Los atributos RFC2307 no se añaden automáticamente cuando se crean usuarios o grupos.
Los números de ID presentes en un controlador de dominio (números en el rango 3000000) no son atributos RFC2307 y no se utilizarán en los miembros de dominio de Unix. Si necesita tener los mismos números de ID en todas partes, añada los atributos uidNumber y gidNumber a AD y utilice el back-end winbind "ad" en los miembros de dominio de Unix. Si decide añadir los atributos uidNumber y gidNumber a AD, no utilice números en el rango 3000000.
Si los usuarios solo usarán el controlador de dominio de AD de Samba para la autenticación y no almacenarán datos ni entrarán a la sesión en él, puede usar el back-end winbind "rid". Esto calcula los ID de usuario y grupo del RID de Windows*. Si utiliza la misma sección [global] de smb.conf en cada miembro de dominio de Unix, obtendrá los mismos ID. Si utiliza el back-end "rid", no es necesario añadir nada a AD y los atributos RFC2307 se omitirán. Cuando utilice el back-end "rid", defina los parámetros template shell y template homedir en smb.conf. Este valor es global y todos los usuarios obtienen la misma shell de entrada a la sesión y la misma vía del directorio de inicio de Unix (a diferencia de los atributos RFC2307, donde es posible definir shells y vías del directorio de inicio de Unix individuales).
Hay otra forma de configurar Samba: si necesita que los usuarios y grupos tengan el mismo ID en todas partes, pero solo necesitan que los usuarios tengan la mismo shell de entrada a la sesión y usen la misma vía de directorio de inicio de Unix. Puede hacerlo utilizando el back-end winbind "ad" y las líneas de plantilla en smb.conf. De esta forma solo necesita añadir los atributos uidNumber y gidNumber a AD.
Encontrará información detallada sobre los back-end de asignación de ID disponibles en las páginas man relacionadas: man 8 idmap_ad, man 8 idmap_rid y man 8 idmap_autorid.
24.2.6.2 Configuración de rangos de ID de usuario y grupo #
Después de decidir qué back-end winbind se va a utilizar, debe especificar los rangos que se deben usar con la opción idmap config en smb.conf. Por defecto, hay varios bloques de ID de usuarios y grupos en un miembro de dominio de Unix:
| ID | Rango |
|---|---|
| 0-999 | Usuarios y grupos del sistema local. |
| A partir de 1000 | Usuarios y grupos de Unix local. |
| A partir de 10000 | Usuarios y grupos del dominio |
Como puede ver en los rangos anteriores, no debe definir que los rangos "*" ni "DOMAIN" comiencen en 999 o un valor más bajo, ya que interferirían con los usuarios y grupos del sistema local. También debe dejar un espacio para cualquier usuario y grupo local de Unix, por lo que una buena opción podría ser iniciar los rangos de idmap config en 3000.
Debe decidir cuánto podría crecer "DOMAIN" y si tiene previsto tener dominios de confianza. A continuación, puede definir los rangos de idmap config de la siguiente manera:
| Dominio | Rango |
|---|---|
| * | 3000-7999 |
| DOMINIO | 10000-999999 |
| DE CONFIANZA | 1000000-9999999 |
24.2.6.3 Asignación de la cuenta de administrador de dominio al usuario root local #
Samba permite asignar cuentas de dominio a una cuenta local. Utilice esta función para ejecutar operaciones de archivo en el sistema de archivos del miembro del dominio como un usuario diferente que el de la cuenta que pidió la operación en el cliente.
La asignación del administrador de dominio a la cuenta raíz local es opcional. Configure solo la asignación si el administrador de dominio necesita ser capaz de ejecutar operaciones de archivo en el miembro de dominio con permisos de usuario root. Tenga en cuenta que asignar el administrador a la cuenta raíz no permite entrar a la sesión en los miembros del dominio Unix como "Administrador".
Para asignar el administrador del dominio a la cuenta raíz local, siga estos pasos:
Añada el siguiente parámetro a la sección
[global]del archivosmb.conf:username map = /etc/samba/user.map
Cree el archivo
/etc/samba/user.mapcon el siguiente contenido:!root = DOMAIN\Administrator
Si utiliza el back-end de asignación de ID "ad", no defina el atributo uidNumber para la cuenta de administrador de dominio. Si la cuenta tiene el atributo definido, el valor sustituye el UID local "0" del usuario root y, por lo tanto, se produce un error en la asignación.
Para obtener más información, consulte el parámetro username map en la página man de smb.conf (man 5 smb.conf).
24.2.7 Unión al dominio de Active Directory #
Para unir el host a Active Directory, ejecute:
cephuser@smb > net ads join -U administrator
Enter administrator's password: PASSWORD
Using short domain name -- DOMAIN
Joined EXAMPLE-HOST to dns domain 'DOMAIN.example.com'24.2.8 Configuración del conmutador de servicio de nombres #
Para hacer que los usuarios y grupos de dominio estén disponibles en el sistema local, debe habilitar la biblioteca del conmutador de servicio de nombres (NSS). Añada la entrada winbind al final de las siguientes bases de datos en el archivo /etc/nsswitch.conf:
passwd: files winbind group: files winbind
Conserve la entrada
filescomo el primer origen para ambas bases de datos. Esto permite al NSS buscar usuarios y grupos de dominio desde los archivos/etc/passwdy/etc/groupantes de consultar el serviciowinbind.No añada la entrada
winbinda la base de datosshadowdel NSS. Esto puede causar que la utilidadwbinfofalle.No utilice los mismos nombres de usuario en el archivo
/etc/passwdlocal que en el dominio.
24.2.9 Inicio de los servicios #
Tras los cambios de configuración, reinicie los servicios de Samba según se explica en la Sección 24.1.2.1, “Inicio de los servicios de Samba” o en la Sección 24.1.3.1, “Reinicio de recursos de Samba de alta disponibilidad”.
24.2.10 Prueba de la conectividad de winbindd #
24.2.10.1 Envío de un ping de winbindd #
Para verificar si el servicio winbindd puede conectarse a los controladores de dominio de AD o a un controlador de dominio primario, escriba:
cephuser@smb > wbinfo --ping-dc
checking the NETLOGON for domain[DOMAIN] dc connection to "DC.DOMAIN.EXAMPLE.COM" succeeded
Si se produce un error en el comando anterior, verifique que el servicio winbindd se está ejecutando y que el archivo smb.conf está configurado correctamente.
24.2.10.2 Búsqueda de usuarios y grupos de dominios #
La biblioteca libnss_winbind permite buscar usuarios y grupos de dominio. Por ejemplo, para buscar el usuario de dominio "DOMAIN\demo01":
cephuser@smb > getent passwd DOMAIN\\demo01
DOMAIN\demo01:*:10000:10000:demo01:/home/demo01:/bin/bashPara buscar el grupo de dominio "Domain Users":
cephuser@smb > getent group "DOMAIN\\Domain Users"
DOMAIN\domain users:x:10000:24.2.10.3 Asignación de permisos de archivos a usuarios y grupos de dominio #
La biblioteca del conmutador del servicio de nombres (NSS) permite usar cuentas de usuario de dominio y grupos en los comandos. Por ejemplo, para definir como propietario de un archivo al usuario de dominio "demo01" y como grupo de dominio a "Domain Users", escriba:
cephuser@smb > chown "DOMAIN\\demo01:DOMAIN\\domain users" file.txt25 NFS Ganesha #
NFS Ganesha es un servidor NFS que se ejecuta en un espacio de dirección de usuario, en lugar de hacerlo como parte del kernel del sistema operativo. Con NFS Ganesha, puede poner en marcha su propio mecanismo de almacenamiento, como Ceph, y acceder a él desde cualquier cliente NFS. Para obtener instrucciones sobre la instalación, consulte Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.3.6 “Distribución de NFS Ganesha”.
Debido al aumento de la sobrecarga de protocolo y a la latencia adicional causados por saltos de red adicionales entre el cliente y el almacenamiento, el acceso a Ceph a través de una pasarela de NFS puede reducir de forma significativa el rendimiento de la aplicación en comparación con los clientes nativos de CephFS.
Cada servicio de NFS Ganesha consta de una jerarquía de configuración que contiene:
Un archivo de carga (bootstrap)
ganesha.confUn objeto de configuración común RADOS por servicio
Un objeto de configuración RADOS por exportación
La configuración de carga es la configuración mínima para iniciar el daemon nfs-ganesha dentro de un contenedor. Cada configuración de carga contendrá una directiva %url que incluya cualquier configuración adicional del objeto de configuración común RADOS. El objeto de configuración común puede incluir directivas %url adicionales para cada una de las exportaciones NFS definidas en los objetos de configuración RADOS de exportación.

25.1 Creación de un servicio NFS #
La forma recomendada de especificar la distribución de los servicios de Ceph es crear un archivo con formato YAML con la especificación de los servicios que desea distribuir. Puede crear un archivo de especificación independiente para cada tipo de servicio, o bien especificar varios (o todos) los tipos de servicios en un archivo.
Dependiendo de lo que haya decidido hacer, deberá actualizar o crear un archivo con formato YAML relevante para crear un servicio de NFS Ganesha. Para obtener más información sobre la creación del archivo, consulte el Book “Guía de distribución”, Chapter 5 “Distribución con cephadm”, Section 5.4.2 “Especificación del servicio y la colocación”.
Una vez que haya actualizado o creado el archivo, ejecute lo siguiente para crear un servicio nfs-ganesha:
cephuser@adm > ceph orch apply -i FILE_NAME25.2 Inicio o reinicio de NFS Ganesha #
Para iniciar el servicio de NFS Ganesha, ejecute:
cephuser@adm > ceph orch start nfs.SERVICE_IDPara reiniciar el servicio de NFS Ganesha, ejecute:
cephuser@adm > ceph orch restart nfs.SERVICE_IDSi solo desea reiniciar un único daemon de NFS Ganesha, ejecute:
cephuser@adm > ceph orch daemon restart nfs.SERVICE_IDCuando se inicia o se reinicia NFS Ganesha, tiene un tiempo límite de gracia de 90 segundos para NFS v4. Durante el período de gracia, las peticiones nuevas de los clientes se rechazan de forma activa. Por lo tanto, los clientes pueden observar una ralentización de las peticiones cuando NFS se encuentra en período de gracia.
25.3 Listado de objetos en el repositorio de recuperación NFS #
Ejecute lo siguiente para mostrar los objetos del repositorio de recuperación de NFS:
cephuser@adm > rados --pool POOL_NAME --namespace NAMESPACE_NAME ls25.4 Creación de una exportación NFS #
Ejecute lo siguiente para crear una exportación NFS.
El bloque FSAL debe modificarse para incluir el ID de usuario de cephx deseado y la clave de acceso secreta.
cephuser@adm > rados --pool POOL_NAME --namespace NAMESPACE_NAME put export-1 export-125.5 Verificación de la exportación NFS #
NFS v4 creará una lista de exportaciones en la raíz de un sistema de archivos simulado. Puede verificar que los recursos compartidos NFS se exportan montando la raíz (/) del nodo del servidor NFS Ganesha:
root #mount-t nfs nfs_ganesha_server_hostname:/ /path/to/local/mountpointroot #ls/path/to/local/mountpoint cephfs
Por defecto, cephadm configura un servidor NFS v4. NFS v4 no interactúa con rpcbind ni con el daemon mountd. Las herramientas del cliente NFS, como showmount, no muestran ninguna exportación configurada.
25.6 Montaje de la exportación NFS #
Para montar el recurso compartido NFS exportado en un host de cliente, ejecute:
root #mount-t nfs nfs_ganesha_server_hostname:/ /path/to/local/mountpoint
25.7 Varios clústeres de NFS Ganesha #
Es posible definir varios clústeres de NFS Ganesha, lo que permite:
Clústeres de NFS Ganesha separados para acceder a CephFS.
Parte V Integración con herramientas de virtualización #
- 26
libvirty Ceph La biblioteca libvirt crea una capa de abstracción de máquina virtual entre las interfaces de hipervisor y las aplicaciones de software que las utilizan. Con libvirt, los desarrolladores y administradores del sistema pueden centrarse en un marco de gestión común, API comunes y una interfaz de shell …
- 27 Ceph como procesador final para la instancia de QEMU KVM
El caso de uso más frecuente de Ceph implica proporcionar imágenes de dispositivo de bloques a máquinas virtuales. Por ejemplo, un usuario puede crear una imagen lista para usar con un sistema operativo y cualquier software relevante en una configuración ideal. A continuación, el usuario toma una in…
26 libvirt y Ceph #
La biblioteca libvirt crea una capa de abstracción de máquina virtual entre las interfaces de hipervisor y las aplicaciones de software que las utilizan. Con libvirt, los desarrolladores y administradores del sistema pueden centrarse en un marco de gestión común, API comunes y una interfaz de shell también común (virsh) para muchos hipervisores distintos, incluidos QEMU/KVM, Xen, LXC y VirtualBox.
Los dispositivos de bloques de Ceph admiten QEMU/KVM. Es posible utilizar dispositivos de bloques de Ceph con software que se conecte con libvirt. La solución de nube utiliza libvirt para interactuar con QEMU/KVM, y QEMU/KVM interactúa con los dispositivos de bloques de Ceph a través de librbd.
Para crear máquinas virtuales que utilicen dispositivos de bloques de Ceph, utilice los procedimientos de las siguientes secciones. En los ejemplos, hemos utilizado libvirt-pool para el nombre del repositorio, client.libvirt para el nombre de usuario y new-libvirt-image para el nombre de la imagen. Puede utilizar cualquier nombre que desee, pero asegúrese de sustituirlos cuando ejecute los comandos en los procedimientos siguientes.
26.1 Configuración de Ceph con libvirt #
Para configurar Ceph para su uso con libvirt, realice los pasos siguientes:
Cree un repositorio. En el ejemplo siguiente se utiliza el nombre de repositorio
libvirt-poolcon 128 grupos de colocación.cephuser@adm >ceph osd pool create libvirt-pool 128 128Compruebe que el repositorio existe.
cephuser@adm >ceph osd lspoolsCree un usuario de Ceph. El siguiente ejemplo utiliza el nombre de usuario de Ceph
client.libvirty hace referencia alibvirt-pool.cephuser@adm >ceph auth get-or-create client.libvirt mon 'profile rbd' osd \ 'profile rbd pool=libvirt-pool'Verifique que el nombre existe.
cephuser@adm >ceph auth listNota: nombre de usuario o IDlibvirtaccederá a Ceph utilizando el IDlibvirt, no el nombre de Cephclient.libvirt. Consulte la Sección 30.2.1.1, “Usuario” para obtener una explicación detallada de la diferencia entre el ID y el nombre.Utilice QEMU para crear una imagen en el repositorio RBD. El siguiente ejemplo utiliza el nombre de imagen
new-libvirt-imagey hace referencia alibvirt-pool.Sugerencia: ubicación del archivo de anillo de clavesLa clave de usuario
libvirtse almacena en un archivo de claves colocado en el directorio/etc/ceph. El archivo de claves debe tener un nombre adecuado que incluya el nombre del clúster de Ceph al que pertenece. Para el nombre de clúster por defecto "ceph", el nombre del archivo de claves es/etc/ceph/ceph.client.libvirt.keyring.Si el anillo de claves no existe, créelo con:
cephuser@adm >ceph auth get client.libvirt > /etc/ceph/ceph.client.libvirt.keyringroot #qemu-img create -f raw rbd:libvirt-pool/new-libvirt-image:id=libvirt 2GVerifique que la imagen existe.
cephuser@adm >rbd -p libvirt-pool ls
26.2 Preparación del gestor de máquina virtual #
Puede utilizar libvirt sin un gestor de máquina virtual, pero le resultará más fácil crear el primer dominio con virt-manager.
Instale un gestor de máquina virtual.
root #zypper in virt-managerPrepare o descargue una imagen de sistema operativo del sistema que desea ejecutar de forma virtualizada.
Lance el gestor de máquina virtual.
virt-manager
26.3 Creación de una máquina virtual #
Para crear una máquina virtual con virt-manager, realice los siguientes pasos:
Elija la conexión en la lista, haga clic con el botón derecho en ella y seleccione (Nuevo).
Para proporcione la vía al almacenamiento actual. Especifique el tipo de sistema operativo, los valores de memoria y el de la máquina virtual, por ejemplo
libvirt-virtual-machine.Finalice la configuración e inicie la máquina virtual.
Verifique que el dominio recién creado existe con
sudo virsh list. Si es necesario, especifique la cadena de conexión, como:virsh -c qemu+ssh://root@vm_host_hostname/system listId Name State ----------------------------------------------- [...] 9 libvirt-virtual-machine runningEntre en la máquina virtual y deténgala antes de configurarla para su uso con Ceph.
26.4 Configuración de la máquina virtual #
En este capítulo nos centramos en la configuración de máquinas virtuales para su integración con Ceph mediante virsh. Los comandos de virsh suelen requerir privilegios de usuario root (sudo) y, si no se tienen esos privilegios, no proporcionan resultados adecuados ni notifican de que esos privilegios son necesarios. Para obtener información sobre los comandos de virsh, consulte man 1 virsh (se requiere el paquete libvirt-client para instalarse).
Abra el archivo de configuración con
virsh editvm-domain-name.root #virsh edit libvirt-virtual-machineEn <devices> debe haber una entrada <disk>.
<devices> <emulator>/usr/bin/qemu-system-SYSTEM-ARCH</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw'/> <source file='/path/to/image/recent-linux.img'/> <target dev='vda' bus='virtio'/> <address type='drive' controller='0' bus='0' unit='0'/> </disk>Sustituya
/path/to/image/recent-linux.imgpor la vía a la imagen del sistema operativo.ImportanteUse
sudo virsh editen lugar de un editor de textos. Si edita el archivo de configuración en/etc/libvirt/qemucon un editor de textos,libvirtpuede que no reconozca el cambio. Si hay discrepancias entre el contenido del archivo XML de/etc/libvirt/qemuy el resultado desudo virsh dumpxmlvm-domain-name, puede que la máquina virtual no funcione correctamente.Añada la imagen de Ceph RBD que ha creado anteriormente como una entrada <disk>.
<disk type='network' device='disk'> <source protocol='rbd' name='libvirt-pool/new-libvirt-image'> <host name='monitor-host' port='6789'/> </source> <target dev='vda' bus='virtio'/> </disk>Sustituya monitor-host por el nombre de host y sustituya el nombre del repositorio y el nombre de la imagen según sea necesario. Puede añadir varias entradas <host> para los monitores de Ceph. El atributo
deves el nombre del dispositivo lógico que aparecerá en el directorio/devde la máquina virtual. El atributo de bus opcional indica el tipo de dispositivo de disco que se debe emular. Los valores válidos son específicos de cada controlador (por ejemplo ide, scsi, virtio, xen, usb o sata).Guarde el archivo.
Si el clúster de Ceph tiene la autenticación habilitada (lo está por defecto), debe generar un secreto. Abra el editor que quiera y cree un archivo denominado
secret.xmlcon el contenido siguiente:<secret ephemeral='no' private='no'> <usage type='ceph'> <name>client.libvirt secret</name> </usage> </secret>Defina el secreto.
root #virsh secret-define --file secret.xml <uuid of secret is output here>Obtenga la clave
client.libvirty guarde la cadena de clave en un archivo.cephuser@adm >ceph auth get-key client.libvirt | sudo tee client.libvirt.keyDefina el UUID del secreto.
root #virsh secret-set-value --secret uuid of secret \ --base64 $(cat client.libvirt.key) && rm client.libvirt.key secret.xmlTambién debe definir el secreto manualmente añadiendo la siguiente entrada
<auth>al elemento<disk>que introdujo antes (sustituya el valor de uuid con el resultado de la línea de comandos del ejemplo anterior).root #virsh edit libvirt-virtual-machineA continuación, añada el elemento
<auth></auth>al archivo de configuración de dominio:... </source> <auth username='libvirt'> <secret type='ceph' uuid='9ec59067-fdbc-a6c0-03ff-df165c0587b8'/> </auth> <target ...NotaEl ID del ejemplo es
libvirt, no el nombre de Cephclient.libvirt, como se generó en el paso 2 de la Sección 26.1, “Configuración de Ceph conlibvirt”. Asegúrese de utilizar el componente ID del nombre de Ceph que ha generado. Si por algún motivo necesita volver a generar el secreto, deberá ejecutarsudo virsh secret-undefineuuid antes de ejecutarsudo virsh secret-set-valuede nuevo.
26.5 Resumen #
Después de configurar la máquina virtual para usarla con Ceph, puede iniciarla. Para verificar que la máquina virtual y Ceph se comunican, puede llevar a cabo los procedimientos siguientes.
Compruebe que se está ejecutando Ceph:
cephuser@adm >ceph healthCompruebe que se está ejecutando la máquina virtual:
root #virsh listCompruebe que la máquina virtual se comunica con Ceph. Sustituya vm-domain-name por el nombre de su dominio de máquina virtual:
root #virsh qemu-monitor-command --hmp vm-domain-name 'info block'Compruebe que el dispositivo de
&target dev='hdb' bus='ide'/>aparece en/devo en/proc/partitions:tux >ls /devtux >cat /proc/partitions
27 Ceph como procesador final para la instancia de QEMU KVM #
El caso de uso más frecuente de Ceph implica proporcionar imágenes de dispositivo de bloques a máquinas virtuales. Por ejemplo, un usuario puede crear una imagen lista para usar con un sistema operativo y cualquier software relevante en una configuración ideal. A continuación, el usuario toma una instantánea de la imagen. Por último, el usuario clona la instantánea (normalmente muchas veces, consulte la Sección 20.3, “Instantáneas” para más información). La capacidad para crear clones de copia de escritura de una instantánea significa que Ceph puede provisionar imágenes de dispositivos de bloques a máquinas virtuales rápidamente, ya que el cliente no necesita descargar una imagen completa cada vez que invoca una máquina virtual nueva.
Los dispositivos de bloques de Ceph pueden integrarse con máquinas virtuales QEMU. Para obtener más información sobre QEMU KVM, consulte https://documentation.suse.com/sles/15-SP2/html/SLES-all/part-virt-qemu.html.
27.1 Instalación de qemu-block-rbd #
Para poder utilizar dispositivos de bloques de Ceph, QEMU debe tener instalado el controlador adecuado. Compruebe si el paquete qemu-block-rbd está instalado e instálelo si fuera necesario:
root # zypper install qemu-block-rbd27.2 Uso de QEMU #
La línea de comandos de QEMU espera que se especifique el nombre de repositorio y el nombre de imagen. También puede especificar un nombre de instantánea.
qemu-img command options \ rbd:pool-name/image-name@snapshot-name:option1=value1:option2=value2...
Por ejemplo, si especifica las opciones id y conf, se puede obtener un resultado parecido al siguiente:
qemu-img command options \
rbd:pool_name/image_name:id=glance:conf=/etc/ceph/ceph.conf27.3 Creación de imágenes con QEMU #
Puede crear una imagen de dispositivo de bloques en QEMU. Debe especificar el rbd, el nombre del repositorio y el nombre de la imagen que desea crear. También debe especificar el tamaño de la imagen.
qemu-img create -f raw rbd:pool-name/image-name size
Por ejemplo:
qemu-img create -f raw rbd:pool1/image1 10G Formatting 'rbd:pool1/image1', fmt=raw size=10737418240 nocow=off cluster_size=0
El formato de datos raw es en realidad la única opción que se puede usar con RBD. Técnicamente, se podrían utilizar otros formatos compatibles con QEMU, como qcow2, pero se requiere mucha más supervisión y haría que el volumen no fuera seguro para la migración en directo de la máquina virtual si el almacenamiento en caché está habilitado.
27.4 Cambio de tamaño de las imágenes con QEMU #
Puede cambiar el tamaño de una imagen de dispositivo de bloques en QEMU. Debe especificar el rbd, el nombre del repositorio y el nombre de la imagen cuyo tamaño desea cambiar. También debe especificar el tamaño de la imagen.
qemu-img resize rbd:pool-name/image-name size
Por ejemplo:
qemu-img resize rbd:pool1/image1 9G Image resized.
27.5 Recuperación de información de la imagen con QEMU #
Puede recuperar información de la imagen del dispositivo de bloques en QEMU. Debe especificar el rbd, el nombre del repositorio y el nombre de la imagen.
qemu-img info rbd:pool-name/image-name
Por ejemplo:
qemu-img info rbd:pool1/image1 image: rbd:pool1/image1 file format: raw virtual size: 9.0G (9663676416 bytes) disk size: unavailable cluster_size: 4194304
27.6 Ejecución de QEMU con RBD #
QEMU puede acceder a una imagen como dispositivo de bloques virtual directamente a través de librbd. Esto evita una conmutación de contexto adicional y puede aprovechar las ventajas del almacenamiento en caché de RBD.
Puede utilizar qemu-img para convertir las imágenes de la máquina virtual existentes a imágenes de dispositivos de bloques de Ceph. Por ejemplo, si dispone de una imagen qcow2, ejecute:
qemu-img convert -f qcow2 -O raw sles12.qcow2 rbd:pool1/sles12
Para ejecutar un arranque de la máquina virtual desde esa imagen, ejecute:
root # qemu -m 1024 -drive format=raw,file=rbd:pool1/sles12
El almacenamiento en caché de RBD puede mejorar significativamente el rendimiento. Las opciones de caché de QEMU controlan el almacenamiento en caché de librbd:
root # qemu -m 1024 -drive format=rbd,file=rbd:pool1/sles12,cache=writebackPara obtener más información sobre el almacenamiento en caché de RBD, consulte la Sección 20.5, “Ajustes de caché”.
27.7 Habilitación de descartes y TRIM #
Los dispositivos de bloques de Ceph admiten la operación de descarte. Esto significa que un invitado puede enviar peticiones TRIM para permitir que un dispositivo de bloques de Ceph reclame espacio no utilizado. Esto se puede habilitar en el invitado montando XFS con la opción de descarte.
Para que esto esté disponible para el invitado, se debe habilitar explícitamente para el dispositivo de bloques. Para ello, debe especificar una opción discard_granularity asociada a la unidad:
root # qemu -m 1024 -drive format=raw,file=rbd:pool1/sles12,id=drive1,if=none \
-device driver=ide-hd,drive=drive1,discard_granularity=512En el ejemplo anterior se utiliza el controlador IDE. El controlador virtio no admite el descarte.
Si utiliza libvirt, edite el archivo de configuración del dominio de libvirt con el comando virsh edit e incluya el valor xmlns:qemu. A continuación, añada qemu:commandline block como hijo de dicho dominio. El siguiente ejemplo muestra cómo definir dos dispositivos con qemu id= con valores discard_granularity distintos.
<domain type='kvm' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'> <qemu:commandline> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-0.discard_granularity=4096'/> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-1.discard_granularity=65536'/> </qemu:commandline> </domain>
27.8 Configuración de las opciones de caché de QEMU #
Las opciones de caché de QEMU se corresponden con los siguientes valores de caché de Ceph RBD.
Writeback (actualización de la memoria a través de datos de caché):
rbd_cache = true
WriteThrough (escritura integral caché-memoria):
rbd_cache = true rbd_cache_max_dirty = 0
None (Ninguna):
rbd_cache = false
Los valores de caché de QEMU sustituyen a los valores por defecto de Ceph (los valores que no se definan explícitamente en el archivo de configuración de Ceph). Si define explícitamente los valores de caché de RBD en el archivo de configuración de Ceph (consulte la Sección 20.5, “Ajustes de caché”), los valores de Ceph sustituirán a los valores de caché de QEMU. Si define los valores de caché en la línea de comandos de QEMU, los valores de la línea de comandos de QEMU sustituyen a los valores del archivo de configuración de Ceph.
Parte VI Configuración de un clúster #
- 28 Configuración del clúster de Ceph
En este capítulo se describe cómo configurar el clúster de Ceph mediante las opciones de configuración.
- 29 Módulos de Ceph Manager
La arquitectura de Ceph Manager (consulte Book “Guía de distribución”, Chapter 1 “SES y Ceph”, Section 1.2.3 “Nodos y daemons de Ceph” para obtener una breve introducción) permite ampliar su funcionalidad mediante módulos, como la "consola" (consulte la Parte I, “Ceph Dashboard”), "prometheus" (cons…
- 30 Autenticación con
cephx Para identificar a los clientes y protegerlos frente a ataques de tipo "man-in-the-middle", Ceph proporciona su propio sistema de autenticación: cephx. En este contexto, los clientes son usuarios humanos (por ejemplo, el usuario administrador) o servicios/daemons relacionados con Ceph (por ejemplo, …
28 Configuración del clúster de Ceph #
En este capítulo se describe cómo configurar el clúster de Ceph mediante las opciones de configuración.
28.1 Configuración del archivo ceph.conf #
cephadm utiliza un archivo ceph.conf básico que solo contiene un conjunto mínimo de opciones para conectarse a los MON, autenticarse y obtener información de configuración. En la mayoría de los casos, esto se limita a la opción mon_host (aunque se puede evitar mediante el uso de registros SRV de DNS).
El archivo ceph.conf ya no sirve como lugar central para almacenar la configuración del clúster. Ahora se usa la base de datos de configuración (consulte la Sección 28.2, “Base de datos de configuración”).
Si aún necesita cambiar la configuración del clúster mediante el archivo ceph.conf (por ejemplo, porque utiliza un cliente que no admite opciones de lectura de la base de datos de configuración), debe ejecutar el comando siguiente y encargarse de mantener y distribuir el archivo ceph.conf en todo el clúster:
cephuser@adm > ceph config set mgr mgr/cephadm/manage_etc_ceph_ceph_conf false28.1.1 Acceso a ceph.conf dentro de imágenes de contenedor #
Aunque los daemons de Ceph se ejecutan en contenedores, aún puede acceder a su archivo de configuración ceph.conf. Se monta mediante asociación como el siguiente archivo en el sistema host:
/var/lib/ceph/CLUSTER_FSID/DAEMON_NAME/config
Sustituya CLUSTER_FSID por el FSID exclusivo del clúster en ejecución tal y como lo devuelve el comando ceph fsid y DAEMON_NAME por el nombre del daemon específico que aparece en el comando ceph orch ps. Por ejemplo:
/var/lib/ceph/b4b30c6e-9681-11ea-ac39-525400d7702d/osd.2/config
Para modificar la configuración de un daemon, edite su archivo config y reinícielo:
root # systemctl restart ceph-CLUSTER_FSID-DAEMON_NAMEPor ejemplo:
root # systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d-osd.2Todos los ajustes personalizados se perderán después de que cephadm vuelva a distribuir el daemon.
28.2 Base de datos de configuración #
Los monitores Ceph Monitor gestionan una base de datos central de opciones de configuración que afectan al comportamiento de todo el clúster.
28.2.1 Configuración de secciones y máscaras #
Las opciones de configuración almacenadas por MON pueden encontrarse en una sección global, de tipo de daemon o de daemon específico. Además, las opciones también pueden tener una máscara asociada para restringir aún más a qué daemons o clientes se aplica la opción. Las máscaras tienen dos formas:
TIPO:UBICACIÓN, donde TIPO es una propiedad de CRUSH como
rackohost, y UBICACIÓN es un valor para esa propiedad.Por ejemplo,
host: host_de_ejemplolimitará la opción solo a los daemons o clientes que se ejecutan en ese host concreto.CLASE:CLASE_DE_DISPOSITiVO, donde CLASE_DE_DISPOSITIVO es el nombre de una clase de dispositivo CRUSH como
hddossd. Por ejemplo,class:ssdlimitará la opción solo a los OSD respaldados por SSD. Esta máscara no tiene ningún efecto en los daemons o clientes que no sean OSD.
28.2.2 Ajuste y lectura de opciones de configuración #
Utilice los comandos siguientes para definir o leer las opciones de configuración del clúster. El parámetro WHO puede ser un nombre de sección, una máscara o una combinación de ambos separados por un carácter de barra (/). Por ejemplo, osd/rack:foo representa todos los daemons OSD del bastidor denominado foo.
ceph config dumpVuelca toda la base de datos de configuración de un clúster completo.
ceph config get WHOVuelca la configuración de un daemon o cliente específicos (por ejemplo,
mds.a), tal como se almacena en la base de datos de configuración.ceph config set WHO OPTION VALUEEstablece el valor especificado en la opción de configuración de la base de datos de configuración.
ceph config show WHOMuestra la configuración en ejecución notificada para un daemon en ejecución. Estos ajustes pueden diferir de los almacenados por los monitores si también hay en uso archivos de configuración locales o si se han anulado opciones en la línea de comandos o en el tiempo de ejecución. El origen de los valores de la opción se notifica como parte del resultado.
ceph config assimilate-conf -i INPUT_FILE -o OUTPUT_FILEImporta un archivo de configuración especificado como INPUT_FILE y almacena las opciones válidas en la base de datos de configuración. Cualquier ajuste que no se reconozca, que no sea válido o que el monitor no pueda controlar se devolverá en un archivo abreviado almacenado como OUTPUT_FILE. Este comando es útil para realizar la transición de archivos de configuración legados a una configuración centralizada basada en monitor.
28.2.3 Configuración de daemons en tiempo de ejecución #
En la mayoría de los casos, Ceph permite realizar cambios en la configuración de un daemon en tiempo de ejecución. Esto es útil, por ejemplo, cuando necesita aumentar o disminuir el volumen de salida del registro, o cuando se realiza la optimización del clúster en tiempo de ejecución.
Puede actualizar los valores de las opciones de configuración con el comando siguiente:
cephuser@adm > ceph config set DAEMON OPTION VALUEPor ejemplo, para ajustar el nivel de registro de depuración en un OSD específico, ejecute:
cephuser@adm > ceph config set osd.123 debug_ms 20Si la misma opción también se personaliza en un archivo de configuración local, el ajuste del monitor se ignorará porque tiene menos prioridad que el archivo de configuración.
28.2.3.1 Anulación de valores #
Es posible modificar temporalmente el valor de una opción mediante los subcomandos tell o daemon. Dicha modificación solo afecta al proceso en ejecución y se descarta después de que el daemon o el proceso se reinicien.
Existen dos formas de anular valores:
Utilice el subcomando
tellpara enviar un mensaje a un daemon específico desde cualquier nodo del clúster:cephuser@adm >ceph tell DAEMON config set OPTION VALUEPor ejemplo:
cephuser@adm >ceph tell osd.123 config set debug_osd 20SugerenciaEl subcomando
tellacepta comodines como identificadores de daemon. Por ejemplo, para ajustar el nivel de depuración en todos los daemons de OSD, ejecute:cephuser@adm >ceph tell osd.* config set debug_osd 20Utilice el subcomando
daemonpara conectarse a un proceso de daemon específico mediante un zócalo en/var/run/cephdesde el nodo donde se ejecuta el proceso:cephuser@adm >ceph daemon DAEMON config set OPTION VALUEPor ejemplo:
cephuser@adm >ceph daemon osd.4 config set debug_osd 20
Al visualizar los ajustes de tiempo de ejecución con el comando ceph config show (consulte la Sección 28.2.3.2, “Visualización de los ajustes del tiempo de ejecución”), los valores anulados temporalmente se mostrarán con override en origen.
28.2.3.2 Visualización de los ajustes del tiempo de ejecución #
Para ver todas las opciones definidas para un daemon:
cephuser@adm > ceph config show-with-defaults osd.0Para ver todas las opciones que no están definidas por defecto para un daemon:
cephuser@adm > ceph config show osd.0Para inspeccionar una opción específica:
cephuser@adm > ceph config show osd.0 debug_osdTambién puede conectarse a un daemon en ejecución desde el nodo donde se está ejecutando su proceso y observar su configuración:
cephuser@adm > ceph daemon osd.0 config showPara ver solo los ajustes que no son los ajustes por defecto:
cephuser@adm > ceph daemon osd.0 config diffPara inspeccionar una opción específica:
cephuser@adm > ceph daemon osd.0 config get debug_osd28.3 Almacén config-key #
config-key es un servicio de uso general que ofrecen los monitores Ceph Monitor. Simplifica la gestión de las claves de configuración al almacenar pares clave-valor de forma permanente. config-key se utiliza principalmente en herramientas y daemons de Ceph.
Después de añadir una clave nueva o modificar una existente, reinicie el servicio afectado para que los cambios surtan efecto. Encontrará más información sobre el funcionamiento de los servicios de Ceph en el Capítulo 14, Funcionamiento de los servicios de Ceph.
Utilice el comando config-key para hacer funcionar el almacén config-key. El comando config-key utiliza los siguientes subcomandos:
ceph config-key rm KEYSuprime la clave especificada.
ceph config-key exists KEYComprueba si la clave especificada existe.
ceph config-key get KEYRecupera el valor de la clave especificada.
ceph config-key lsMuestra todas las claves.
ceph config-key dumpVuelca todas las claves y sus valores.
ceph config-key set KEY VALUEAlmacena la clave especificada con el valor especificado.
28.3.1 iSCSI Gateway #
iSCSI Gateway utiliza el almacén config-key para guardar o leer sus opciones de configuración. Todas las claves relacionadas con iSCSI Gateway tienen como prefijo la cadena iscsi, por ejemplo:
iscsi/trusted_ip_list iscsi/api_port iscsi/api_user iscsi/api_password iscsi/api_secure
Si necesita, por ejemplo, dos conjuntos de opciones de configuración, extienda el prefijo con otra palabra clave descriptiva; por ejemplo, datacenterA y datacenterB:
iscsi/datacenterA/trusted_ip_list iscsi/datacenterA/api_port [...] iscsi/datacenterB/trusted_ip_list iscsi/datacenterB/api_port [...]
28.4 Ceph OSD y BlueStore #
28.4.1 Configuración del tamaño automático del caché #
BlueStore se puede configurar para que cambie automáticamente el tamaño de sus cachés si se configura tc_malloc como asignador de memoria y el valor bluestore_cache_autotune está habilitado. Esta opción está habilitada por defecto. BlueStore intentará mantener el uso de memoria del montón OSD por debajo de un tamaño de destino designado mediante la opción de configuración osd_memory_target. Se trata de un algoritmo de mejor esfuerzo y las memorias caché no se reducirán a un tamaño más pequeño que el indicado por el valor de osd_memory_cache_min. Las relaciones de caché se elegirán en función de una jerarquía de prioridades. Si la información de prioridad no está disponible, las opciones bluestore_cache_meta_ratio y bluestore_cache_kv_ratio se utilizan como reserva.
- bluestore_cache_autotune
Ajusta automáticamente las relaciones asignadas a diferentes cachés de BlueStore respetando los valores mínimos. El valor por defecto es
True(verdadero).- osd_memory_target
Si
tc_mallocybluestore_cache_autotuneestán habilitados, intenta mantener al menos este número de bytes asignados en la memoria.NotaEsto podría no coincidir exactamente con el uso de memoria de RSS del proceso. Aunque la cantidad total de memoria de montón asignada por el proceso generalmente debe ser aproximadamente la de este destino, no existe garantía alguna de que el kernel recupere la memoria cuya asignación se ha anulado.
- osd_memory_cache_min
Si
tc_mallocybluestore_cache_autotuneestán habilitados, define la cantidad mínima de memoria que se utiliza para las memorias caché.NotaSi se define un valor demasiado bajo en esta opción, se podría producir una hiperpaginación significativa de caché.
28.5 Ceph Object Gateway #
Puede influir en el comportamiento de Object Gateway mediante varias opciones. Si no se especifica ninguna opción, se utiliza su valor por defecto. A continuación se muestra una lista completa de las opciones de Object Gateway:
28.5.1 Valores generales #
- rgw_frontends
Configura los front-ends HTTP. Puede especificar varios front-ends en una lista delimitada por comas. Cada configuración de front-end puede incluir una lista de opciones separadas por espacios, donde cada opción tiene el formato "clave-valor" o "clave". El valor por defecto es
beast port=7480.- rgw_data
Define la ubicación de los archivos de datos para Object Gateway. El valor por defecto es
/var/lib/ceph/radosgw/ID_CLÚSTER.- rgw_enable_apis
Habilita las API especificadas. El valor por defecto es "s3, swift, swift_auth, admin All APIs".
- rgw_cache_enabled
Habilita o inhabilita el caché de Object Gateway. El valor por defecto es
true(verdadero).- rgw_cache_lru_size
El número de entradas en caché de Object Gateway. El valor por defecto es 10000.
- rgw_socket_path
La vía del zócalo de dominio.
FastCgiExternalServerutiliza este zócalo. Si no especifica una vía de zócalo, Object Gateway no se ejecutará como servidor externo. La vía que especifique aquí debe ser la misma que la especificada en el archivorgw.conf.- rgw_fcgi_socket_backlog
El backlog del zócalo para fcgi. El valor por defecto es 1024.
- rgw_host
El host de la instancia de Object Gateway. Puede ser una dirección IP o un nombre de host. El valor por defecto es
0.0.0.0.- rgw_port
El número de puerto en el que la instancia escucha las peticiones. Si no se especifica, Object Gateway ejecuta FastCGI externo.
- rgw_dns_name
El nombre DNS del dominio provisto.
- rgw_script_uri
El valor alternativo para SCRIPT_URI si no se establece en la petición.
- rgw_request_uri
El valor alternativo para REQUEST_URI si no se establece en la petición.
- rgw_print_continue
Habilite 100-continue si está operativo. El valor por defecto es
true(verdadero).- rgw_remote_addr_param
El parámetro de dirección remota. Por ejemplo, el campo HTTP que contiene la dirección remota o la dirección X-Forwarded-For si hay un proxy inverso operativo. El valor por defecto es
REMOTE_ADDR.- rgw_op_thread_timeout
El tiempo límite en segundos para los hilos abiertos. El valor por defecto es 600.
- rgw_op_thread_suicide_timeout
El tiempo límite en segundos antes de que el proceso de Object Gateway se interrumpa. Este valor está inhabilitado si se establece en 0 (por defecto).
- rgw_thread_pool_size
El número de hilos para el servidor de Beast. Se incrementa a un valor superior si necesita atender más peticiones. Por defecto es 100 hilos.
- rgw_num_rados_handles
El número de referencias de clúster de RADOS para Object Gateway. Cada hilo de trabajo de Object Gateway elige ahora una referencia de RADOS para toda su vida útil. Esta opción puede quedar obsoleta y eliminarse en futuras versiones. El valor por defecto es 1.
- rgw_num_control_oids
El número de objetos de notificación utilizados para la sincronización de caché entre diferentes instancias de Object Gateway. El valor por defecto es 8.
- rgw_init_timeout
El número de segundos antes de que Object Gateway renuncie a la inicialización. El valor por defecto es 30.
- rgw_mime_types_file
La vía y la ubicación de los tipos MIME. Se utiliza para la detección automática de Swift de tipos de objetos. El valor por defecto es
/etc/mime.types.- rgw_gc_max_objs
El número máximo de objetos que puede controlar la recopilación de elementos no utilizados en un ciclo de procesamiento de recopilación de elementos no utilizados. El valor por defecto es 32.
- rgw_gc_obj_min_wait
El tiempo de espera mínimo antes de que el objeto se puede eliminar y controlar mediante el procesamiento de recopilación de elementos no utilizados. El valor por defecto es 2*3600.
- rgw_gc_processor_max_time
El tiempo máximo entre el comienzo de dos ciclos de procesamiento de recopilación de elementos no utilizados consecutivos. El valor por defecto es 3600.
- rgw_gc_processor_period
El tiempo de ciclo del procesamiento de recopilación de elementos no utilizados. El valor por defecto es 3600.
- rgw_s3_success_create_obj_status
La respuesta alternativa del estado de éxito para
create-obj. El valor por defecto es 0.- rgw_resolve_cname
Indica si Object Gateway debe usar el registro CNAME DNS del campo de nombre de host de la petición (si el nombre de host no es igual al nombre DNS de Object Gateway). El valor por defecto es
false(falso).- rgw_obj_stripe_size
El tamaño de una repartición de objetos de Object Gateway. El valor por defecto es
4 << 20.- rgw_extended_http_attrs
Añade un nuevo conjunto de atributos que se pueden definir en una entidad (por ejemplo, un usuario, un depósito o un objeto). Estos atributos adicionales se pueden definir mediante campos de encabezado HTTP al colocar la entidad o modificarla mediante el método POST. Si se definen, estos atributos se devolverán como campos HTTP cuando se pida el GET/HEAD de la entidad. El valor por defecto es
content_foo, content_bar, x-foo-bar.- rgw_exit_timeout_secs
Número de segundos que se esperará un proceso antes de salir incondicionalmente. El valor por defecto es 120.
- rgw_get_obj_window_size
El tamaño de la ventana, en bytes, para una petición de un solo objeto. El valor por defecto es
16 << 20.- rgw_get_obj_max_req_size
El tamaño máximo de petición de una sola operación GET enviada al clúster de almacenamiento de Ceph. El valor por defecto es
4 << 20.- rgw_relaxed_s3_bucket_names
Habilita las reglas de nombre de depósito de S3 en expansión para depósitos de la región de EE. UU. El valor por defecto es
false(falso).- rgw_list_buckets_max_chunk
El número máximo de depósitos que se van a recuperar en una sola operación al mostrar las depósitos de usuario. El valor por defecto es 1000.
- rgw_override_bucket_index_max_shards
Representa el número de fragmentos para el objeto de índice de depósito. El valor 0 (por defecto) indica que no hay partición. No se recomienda definir un valor demasiado grande (por ejemplo 1000) ya que aumenta el coste de la lista de depósitos. Esta variable se debe establecer en las secciones del cliente o en las globales, de forma que se aplique automáticamente a los comandos
radosgw-admin.- rgw_curl_wait_timeout_ms
El tiempo de espera en milisegundos para determinadas llamadas
curl. El valor por defecto es 1000.- rgw_copy_obj_progress
Habilita los resultados del progreso del objeto durante las operaciones de copia largas. El valor por defecto es
true(verdadero).- rgw_copy_obj_progress_every_bytes
Los bytes mínimos entre los resultados de progreso de las operaciones de copia. El valor por defecto es 1024*1024.
- rgw_admin_entry
El punto de entrada de una dirección URL de petición de administrador. El valor por defecto es
admin.- rgw_content_length_compat
Habilita el control de compatibilidad de las peticiones FCGI con CONTENT_LENGTH y HTTP_CONTENT_LENGTH definidos. El valor por defecto es
false(falso).- rgw_bucket_quota_ttl
El tiempo en segundos durante el cual la información de cuota almacenada en caché es de confianza. Cuando transcurre este tiempo límite, la información de cuota se vuelve a recuperar del clúster. El valor por defecto es 600.
- rgw_user_quota_bucket_sync_interval
El tiempo en segundos durante el cual se acumula la información de cuota del depósito antes de sincronizarse con el clúster. Durante este tiempo, las demás instancias de Object Gateway no verán los cambios en las estadísticas de cuota de depósito relacionados con las operaciones de esta instancia. El valor por defecto es 180.
- rgw_user_quota_sync_interval
El tiempo en segundos durante el cual se acumula la información de cuota de usuario antes de sincronizarla con el clúster. Durante este tiempo, las demás instancias de Object Gateway no verán los cambios en las estadísticas de cuota de usuario relacionados con las operaciones de esta instancia. El valor por defecto es 180.
- rgw_bucket_default_quota_max_objects
Número máximo por defecto de objetos por depósito. Se establece en los nuevos usuarios si no se especifica ninguna otra cuota y no tiene ningún efecto sobre los usuarios existentes. Esta variable se debe establecer en las secciones del cliente o en las globales, de forma que se aplique automáticamente a los comandos
radosgw-admin. El valor por defecto es -1.- rgw_bucket_default_quota_max_size
Capacidad máxima por defecto por depósito en bytes. Se establece en los nuevos usuarios si no se especifica ninguna otra cuota y no tiene ningún efecto sobre los usuarios existentes. El valor por defecto es -1.
- rgw_user_default_quota_max_objects
Número máximo por defecto de objetos para un usuario. Esto incluye todos los objetos de todos los depósitos propiedad del usuario. Se establece en los nuevos usuarios si no se especifica ninguna otra cuota y no tiene ningún efecto sobre los usuarios existentes. El valor por defecto es -1.
- rgw_user_default_quota_max_size
El valor de la cuota de tamaño máximo de usuario en bytes definido en los nuevos usuarios si no se especifica ninguna otra cuota. No tiene ningún efecto sobre los usuarios existentes. El valor por defecto es -1.
- rgw_verify_ssl
Verifique los certificados SSL mientras realiza las peticiones. El valor por defecto es
true(verdadero).- rgw_max_chunk_size
El tamaño máximo de una porción de datos que se leerá en una única operación. Si se aumenta el valor a 4 MB (4194304) se conseguirá un mejor rendimiento al procesar objetos grandes. El valor por defecto es 128 kB (131072).
- rgw_zone
El nombre de la zona de la instancia de pasarela. Si no se define ninguna zona, es posible configurar un valor por defecto para todo el clúster con el comando
radosgw-admin zone default.- rgw_zonegroup
El nombre del grupo de zonas de la instancia de pasarela. Si no se define ningún grupo de zonas, es posible configurar un valor por defecto para todo el clúster con el comando
radosgw-admin zonegroup default.- rgw_realm
El nombre del reino de la instancia de pasarela. Si no se define ningún reino, es posible configurar un valor por defecto para todo el clúster con el comando
radosgw-admin realm default.- rgw_run_sync_thread
Si hay otras zonas en el reino desde las que se deba sincronizar, genere hilos para controlar la sincronización de datos y metadatos. El valor por defecto es
true(verdadero).- rgw_data_log_window
La ventana de entradas del registro de datos en segundos. El valor por defecto es 30.
- rgw_data_log_changes_size
El número de entradas en memoria que se deben conservar para el registro de cambios de datos. El valor por defecto es 1000.
- rgw_data_log_obj_prefix
El prefijo del nombre de objeto para el registro de datos. El valor por defecto es "data_log".
- rgw_data_log_num_shards
El número de fragmentos (objetos) de los que se debe mantener el registro de cambios de datos. El valor por defecto es 128.
- rgw_md_log_max_shards
El número máximo de fragmentos para el registro de metadatos. El valor por defecto es 64.
- rgw_enforce_swift_acls
Aplica los valores de la lista de control de acceso (ACL) de Swift. El valor por defecto es
true(verdadero).- rgw_swift_token_expiration
El tiempo en segundos que falta para que caduque el testigo de Swift. El valor por defecto es 24*3600.
- rgw_swift_url
La URL de la API de Swift de Ceph Object Gateway.
- rgw_swift_url_prefix
El prefijo de URL para StorageURL de Swift que precede a "/v1". Esto permite ejecutar varias instancias de pasarela en el mismo host. Por motivos de compatibilidad, si esta variable de configuración se deja vacía, se utilizará el indicador "/swift" por defecto. Utilice el prefijo explícito "/" para iniciar StorageURL en la raíz.
AvisoDefinir "/" en esta opción no funcionará si la API de S3 está habilitada. Tenga en cuenta que inhabilitar S3 hará que sea imposible distribuir Object Gateway en la configuración de varios sitios.
- rgw_swift_auth_url
La URL por defecto para verificar los testigos de autenticación v1 si no se utiliza la autenticación interna de Swift.
- rgw_swift_auth_entry
El punto de entrada para una dirección URL de autenticación de Swift. El valor por defecto es
auth.- rgw_swift_versioning_enabled
Habilita el control de versiones de objetos de la API de almacenamiento de objetos de OpenStack. Esto permite a los clientes colocar el atributo
X-Versions-Locationen los contenedores que se deben versionar. El atributo especifica el nombre del contenedor donde se almacenan las versiones archivadas. Por motivos de verificación del control de acceso, debe ser propiedad del mismo usuario que el contenedor versionado: las ACL no se tienen en cuenta. Esos contenedores no pueden versionarse mediante el mecanismo de control de versiones de objetos de S3. El valor por defecto esfalse(falso).
- rgw_log_nonexistent_bucket
Permite que Object Gateway registre una petición para un depósito inexistente. El valor por defecto es
false(falso).- rgw_log_object_name
El formato de registro de un nombre de objeto. Consulte la página man
man 1 datepara obtener más información sobre los especificadores de formato. El valor por defecto es%Y-%m-%d-%H-%i-%n.- rgw_log_object_name_utc
Indica si un nombre de objeto registrado incluye una hora UTC. Si se establece en
false(valor por defecto), utiliza la hora local.- rgw_usage_max_shards
El número máximo de fragmentos para el registro de uso. El valor por defecto es 32.
- rgw_usage_max_user_shards
El número máximo de fragmentos utilizados para el registro de uso de un solo usuario. El valor por defecto es 1.
- rgw_enable_ops_log
Habilita el registro de cada operación de Object Gateway correcta. El valor por defecto es
false(falso).- rgw_enable_usage_log
Habilita el registro de uso. El valor por defecto es
false(falso).- rgw_ops_log_rados
Indica si el registro de operaciones debe escribirse en el back-end del clúster de almacenamiento de Ceph. El valor por defecto es
true(verdadero).- rgw_ops_log_socket_path
El zócalo de dominio Unix para escribir registros de operaciones.
- rgw_ops_log_data_backlog
El tamaño máximo de datos de backlog de datos para los registros de operaciones escritos en un zócalo de dominio Unix. El valor por defecto es 5 << 20.
- rgw_usage_log_flush_threshold
El número de entradas combinadas sucias en el registro de uso antes de vaciarlas de forma sincrónica. El valor por defecto es 1024.
- rgw_usage_log_tick_interval
Vacía los datos de registro de uso pendientes cada "n" segundos. El valor por defecto es 30.
- rgw_log_http_headers
Lista delimitada por comas de encabezados HTTP que se deben incluir en las entradas de registro. Los nombres de encabezado no distinguen mayúsculas de minúsculas y usan el nombre de encabezado completo con palabras separadas por guiones bajos. Por ejemplo, "http_x_forwarded_for", "http_x_special_k".
- rgw_intent_log_object_name
El formato de registro para el nombre del objeto de registro de intent. Consulte la página man
man 1 datepara obtener más información sobre los especificadores de formato. El valor por defecto es "%Y-%m-%d-%i-%n".- rgw_intent_log_object_name_utc
Indica si el nombre del objeto de registro de intent incluye una hora UTC. Si se establece en
false(valor por defecto), utiliza la hora local.
- rgw_keystone_url
La URL del servidor de Keystone.
- rgw_keystone_api_version
La versión (2 o 3) de la API de identidad de OpenStack que se debe utilizar para la comunicación con el servidor de Keystone. El valor por defecto es 2.
- rgw_keystone_admin_domain
El nombre del dominio de OpenStack con privilegios de administrador al utilizar la versión 3 de la API de identidad de OpenStack.
- rgw_keystone_admin_project
El nombre del proyecto de OpenStack con privilegios de administrador al utilizar la versión 3 de la API de identidad de OpenStack. Si no se define, se usará en su lugar el valor de
rgw keystone admin tenant.- rgw_keystone_admin_token
El testigo de administrador de Keystone (secreto compartido). En Object Gateway, la autenticación con el testigo de administrador tiene prioridad sobre la autenticación con las credenciales de administrador (opciones
rgw keystone admin user,rgw keystone admin password,rgw keystone admin tenant,rgw keystone admin projectyrgw keystone admin domain). Se considera que la función de testigo de administrador está obsoleta.- rgw_keystone_admin_tenant
El nombre del inquilino de OpenStack con privilegios de administrador (inquilino de servicio) al utilizar la versión 2 de la API de identidad de OpenStack.
- rgw_keystone_admin_user
El nombre del usuario de OpenStack con privilegios de administrador para la autenticación de Keystone (usuario de servicio) al utilizar la versión 2 de la API de identidad de OpenStack.
- rgw_keystone_admin_password
La contraseña del usuario administrador de OpenStack al utilizar la versión 2 de la API de identidad de OpenStack.
- rgw_keystone_accepted_roles
Las funciones necesarias para atender las peticiones. Por defecto es "Member, admin".
- rgw_keystone_token_cache_size
El número máximo de entradas en cada caché del testigo de Keystone. El valor por defecto es 10000.
- rgw_keystone_revocation_interval
El número de segundos entre comprobaciones de revocación del testigo. El valor por defecto es 15*60.
- rgw_keystone_verify_ssl
Verifica los certificados SSL mientras se realizan peticiones de testigo a Keystone. El valor por defecto es
true(verdadero).
28.5.1.1 Notas adicionales #
- rgw_dns_name
Permite a los clientes utilizar depósitos de estilo
vhost.El acceso al estilo
vhosthace referencia al uso bucketname.s3-endpoint/object-path. Esto es en comparación con el acceso de estilopath: s3-endpoint/bucket/objectSi se define
rgw dns name, verifique que el cliente de S3 está configurado para dirigir las peticiones al puesto final especificado porrgw dns name.
28.5.2 Configuración de procesadores frontales HTTP #
28.5.2.1 Beast #
- port, ssl_port
Los números de puerto de escucha IPv4 e IPv6. Puede especificar varios números de puerto:
port=80 port=8000 ssl_port=8080
El valor por defecto es 80.
- endpoint, ssl_endpoint
Las direcciones de escucha con el formato "dirección[:puerto]", donde "dirección" es una cadena de dirección IPv4 en formato decimal con puntos o una dirección IPv6 en notación hexadecimal entre corchetes. Si se especifica un puesto final IPv6, solo se escucharían direcciones IPv6. El número de puerto opcional es por defecto el 80 para
endpointy el 443 parassl_endpoint. Puede especificar varias direcciones:endpoint=[::1] endpoint=192.168.0.100:8000 ssl_endpoint=192.168.0.100:8080
- ssl_private_key
Vía opcional al archivo de clave privada utilizado para los puestos finales habilitados para SSL. Si no se especifica, se usa el archivo
ssl_certificatecomo clave privada.- tcp_nodelay
Si se especifica, la opción de zócalo inhabilitará el algoritmo de Nagle en la conexión. Significa que los paquetes se enviarán tan pronto como sea posible, en lugar de esperar a que se complete el búfer o a que se agote el tiempo límite.
"1" inhabilita el algoritmo de Nagle para todos los zócalos.
"0" mantiene habilitado el algoritmo de Nagle (opción por defecto).
cephuser@adm > ceph config set rgw.myrealm.myzone.ses-min1.kwwazo \
rgw_frontends beast port=8000 ssl_port=443 \
ssl_certificate=/etc/ssl/ssl.crt \
error_log_file=/var/log/radosgw/beast.error.log28.5.2.2 Civetweb #
- port
El número del puerto de escucha. En el caso de los puertos habilitados para SSL, añada un sufijo "s" (por ejemplo, "443s"). Para vincular una dirección IPv4 o IPv6 específica, utilice el formato "dirección:puerto". Puede especificar varios puestos finales uniéndolos con "+" o proporcionando varias opciones:
port=127.0.0.1:8000+443s port=8000 port=443s
El valor por defecto es 7480.
- num_threads
El número de hilos generados por Civetweb para controlar las conexiones HTTP entrantes. Esto limita de manera eficaz el número de conexiones simultáneas que el front-end puede atender.
El valor por defecto es el valor especificado por la opción
rgw_thread_pool_size.- request_timeout_ms
El tiempo en milisegundos que Civetweb esperará más datos entrantes antes de darse por vencido.
El valor por defecto es 30000 milisegundos.
- access_log_file
Vía al archivo de registro de accesos. Puede especificar una vía completa o una relativa al directorio de trabajo actual. Si no se especifica (opción por defecto), los accesos no se registran.
- error_log_file
Vía al archivo de registro de errores. Puede especificar una vía completa o una relativa al directorio de trabajo actual. Si no se especifica (opción por defecto), los errores no se registran.
/etc/ceph/ceph.conf #cephuser@adm > ceph config set rgw.myrealm.myzone.ses-min2.ingabw \
rgw_frontends civetweb port=8000+443s request_timeout_ms=30000 \
error_log_file=/var/log/radosgw/civetweb.error.log28.5.2.3 Opciones comunes #
- ssl_certificate
Vía al archivo de certificado SSL utilizado para los puestos finales habilitados para SSL.
- prefix
Cadena de prefijo que se inserta en el URI de todas las peticiones. Por ejemplo, un procesador frontal solo de Swift podría proporcionar el prefijo de URI
/swift.
29 Módulos de Ceph Manager #
La arquitectura de Ceph Manager (consulte Book “Guía de distribución”, Chapter 1 “SES y Ceph”, Section 1.2.3 “Nodos y daemons de Ceph” para obtener una breve introducción) permite ampliar su funcionalidad mediante módulos, como la "consola" (consulte la Parte I, “Ceph Dashboard”), "prometheus" (consulte el Capítulo 16, Supervisión y alertas), o el "equilibrador".
Para mostrar todos los módulos disponibles, ejecute:
cephuser@adm > ceph mgr module ls
{
"enabled_modules": [
"restful",
"status"
],
"disabled_modules": [
"dashboard"
]
}Para habilitar o inhabilitar un módulo específico, ejecute:
cephuser@adm > ceph mgr module enable MODULE-NAMEPor ejemplo:
cephuser@adm > ceph mgr module disable dashboardPara mostrar los servicios que proporcionan los módulos habilitados, ejecute:
cephuser@adm > ceph mgr services
{
"dashboard": "http://myserver.com:7789/",
"restful": "https://myserver.com:8789/"
}29.1 Equilibrador #
El módulo del equilibrador optimiza la distribución del grupo de colocación (PG) entre los OSD para conseguir una distribución más equilibrada. Aunque el módulo se activa por defecto, está inactivo. Admite los dos modos siguientes: crush-compat y upmap.
Para ver el estado actual del equilibrador y los datos de configuración, ejecute:
cephuser@adm > ceph balancer status29.1.1 Modo "crush-compat" #
En el modo "crush-compat", el equilibrador ajusta los conjuntos de reequilibrio de peso de los OSD para lograr una mejor distribución de los datos. Mueve los grupos de colocación por los OSD, lo que causa que el clúster tenga temporalmente el estado HEALTH_WARN debido a los grupos de colocación descolocados.
Aunque "crush-compat" es el modo por defecto, se recomienda activarlo explícitamente:
cephuser@adm > ceph balancer mode crush-compat29.1.2 Planificación y ejecución del equilibrado de datos #
Mediante el módulo de equilibrador, puede crear un plan para equilibrar los datos. A continuación, puede ejecutar el plan manualmente o dejar que los grupos de colocación se equilibren continuamente de forma automática.
La decisión de ejecutar el equilibrador en modo manual o automático depende de varios factores, como el desequilibrio actual de los datos, el tamaño del clúster, el número de grupos de colocación o la actividad de E/S. Se recomienda crear un plan inicial y ejecutarlo en un momento de baja carga de E/S en el clúster. El motivo es que, probablemente, el desequilibrio inicial será considerable y es una buena práctica para reducir el impacto en los clientes. Después de una ejecución manual inicial, considere la posibilidad de activar el modo automático y de supervisar el tráfico de reequilibrio bajo una carga de E/S normal. Deben sopesarse las mejoras en la distribución del grupo de colocación frente al tráfico de reequilibrio causado por el equilibrador.
Durante el proceso de equilibrio, el módulo de equilibrador regula los movimientos de los grupos de colocación para que solo se mueva una fracción configurable de ellos. El valor por defecto es el 5 %, y se puede ajustar, por ejemplo al 9 %, ejecutando el comando siguiente:
cephuser@adm > ceph config set mgr target_max_misplaced_ratio .09Para crear y ejecutar un plan de equilibrio, siga estos pasos:
Compruebe la puntuación actual del clúster:
cephuser@adm >ceph balancer evalCree un plan. Por ejemplo, "great_plan":
cephuser@adm >ceph balancer optimize great_planVea qué cambios implicará el plan "great_plan":
cephuser@adm >ceph balancer show great_planCompruebe la puntuación potencial del clúster si decide aplicar el plan "great_plan":
cephuser@adm >ceph balancer eval great_planEjecute el plan "great_plan" una sola vez:
cephuser@adm >ceph balancer execute great_planObserve el equilibrio del clúster con el comando
ceph -s. Si el resultado es satisfactorio, active el equilibrio automático:cephuser@adm >ceph balancer onSi más adelante decide desactivar el equilibrio automático, ejecute:
cephuser@adm >ceph balancer off
Es posible activar el equilibrio automático sin ejecutar un plan inicial. En tal caso, el reequilibrio de los grupos de colocación puede tardar bastante tiempo.
29.2 Habilitación del módulo de telemetría #
El complemento de telemetría envía datos anónimos del proyecto Ceph sobre el clúster en el que se ejecuta el complemento.
Este componente (que hay que aceptar explícitamente) incluye contadores y estadísticas sobre cómo se ha distribuido el clúster, la versión de Ceph, la distribución de los hosts y otros parámetros que ayudan al proyecto a comprender mejor la forma en que se usa Ceph. No contiene datos confidenciales como nombres de repositorios, nombres de objetos, contenido de objetos ni nombres de host.
El propósito del módulo de telemetría es proporcionar comentarios automatizado para que los desarrolladores puedan cuantificar las tasas de adopción y el seguimiento o detectar los elementos que deben explicarse o validarse mejor durante la configuración para evitar resultados no deseados.
El módulo de telemetría requiere que los nodos de Ceph Manager tengan la capacidad de enviar datos a través de HTTPS a los servidores de fases anteriores. Asegúrese de que su cortafuegos corporativos permita esta acción.
Para habilitar el módulo de telemetría:
cephuser@adm >ceph mgr module enable telemetryNotaEste comando solo permite ver los datos localmente. No comparte datos con la comunidad de Ceph.
Para permitir que el módulo de telemetría comience a compartir datos:
cephuser@adm >ceph telemetry onPara inhabilitar el uso compartido de los datos de telemetría:
cephuser@adm >ceph telemetry offPara generar un informe JSON que se pueda imprimir:
cephuser@adm >ceph telemetry showPara añadir un contacto y una descripción al informe:
cephuser@adm >ceph config set mgr mgr/telemetry/contact John Doe john.doe@example.comcephuser@adm >ceph config set mgr mgr/telemetry/description 'My first Ceph cluster'El módulo compila y envía un informe nuevo cada 24 horas por defecto. Para ajustar este intervalo:
cephuser@adm >ceph config set mgr mgr/telemetry/interval HOURS
30 Autenticación con cephx #
Para identificar a los clientes y protegerlos frente a ataques de tipo
"man-in-the-middle", Ceph proporciona su propio sistema de autenticación:
cephx. En este contexto, los
clientes son usuarios humanos (por ejemplo, el usuario
administrador) o servicios/daemons relacionados con Ceph (por ejemplo, los
OSD, los monitores o las pasarelas Object Gateway).
El protocolo cephx no se hace cargo
del cifrado de datos durante el transporte, como SSL/TLS.
30.1 Arquitectura de autenticación #
cephx utiliza claves de secreto
compartido para la autenticación, lo que significa que tanto el cliente como
monitores Ceph Monitor tienen una copia de la clave de secreto del cliente.
El protocolo de autenticación permite a ambas partes probarse entre sí que
disponen de una copia de la clave sin revelarla. Esto proporciona
autenticación mutua, lo que significa que el clúster está seguro de que el
usuario posee la clave de secreto, y el usuario está seguro de que el
clúster también tiene una copia.
Una característica fundamental para la capacidad de ampliación de Ceph es
que se evita una interfaz centralizada en el almacén de objetos de Ceph.
Esto significa que los clientes de Ceph pueden interactuar directamente con
los OSD. Para proteger los datos, Ceph proporciona su propio sistema de
autenticación, cephx, que autentica
a los clientes de Ceph.
Cada monitor puede autenticar a los clientes y distribuir claves, por lo que
no hay un punto único de error ni cuellos de botella cuando se utiliza
cephx. El monitor devuelve una
estructura de datos de autenticación que contiene una clave de sesión que se
usará para obtener los servicios de Ceph. Esta clave de sesión está cifrada
a su vez con la clave de secreto permanente del cliente, de forma que solo
el cliente puede pedir servicios de los monitores de Ceph. El cliente
utiliza entonces la clave de sesión para pedir los servicios que desea del
monitor, y el monitor proporciona al cliente un ticket que autenticará al
cliente en los OSD donde se gestionan realmente los datos. Los monitores de
Ceph y los OSD comparten un secreto, por lo que el cliente puede utilizar el
ticket proporcionado por el monitor con cualquier OSD o servidor de
metadatos del clúster. Los tickets de
cephx caducan, por lo que un
atacante no puede utilizar un ticket caducado ni una clave de sesión que
haya obtenido de forma fraudulenta.
Para utilizar cephx, un
administrador debe configurar primero clientes o usuarios. En el siguiente
diagrama, el usuario client.admin
invoca ceph auth get-o-create-key en la línea de comandos
para generar un nombre de usuario y una clave de secreto. El subsistema
auth de Ceph genera el nombre de usuario y la clave,
almacena una copia con los monitores y transmite el secreto del usuario de
nuevo al usuario client.admin.
Esto significa que el cliente y el monitor comparten una clave de secreto.

cephx #Para autenticarse con el monitor, el cliente pasa el nombre de usuario al monitor. El monitor genera una clave de sesión, la cifra con la clave de secreto asociada con el nombre de usuario y transmite el ticket cifrado de vuelta al cliente. El cliente descifra los datos con la clave de secreto compartida para recuperar la clave de sesión. La clave de sesión identifica al usuario para la sesión actual. A continuación, el cliente pide un ticket relacionado con el usuario, que está firmado por la clave de sesión. El monitor genera un ticket, lo cifra con la clave de secreto del usuario y lo transmite al cliente. El cliente descifra el ticket y lo utiliza para firmar las peticiones a los OSD y los servidores de metadatos en todo el clúster.

cephx #
El protocolo cephx autentica
continuamente las comunicaciones entre el equipo del cliente y los
servidores de Ceph. Cada mensaje que se envía entre un cliente y un servidor
después de la autenticación inicial se firma con un ticket que los
monitores, los OSD y los servidores de metadatos pueden verificar con su
secreto compartido.

cephx: servidor de metadatos y OSD #La protección que ofrece esta autenticación se produce entre el cliente de Ceph y los hosts del clúster de Ceph. La autenticación no se extiende más allá del cliente de Ceph. Si el usuario accede al cliente de Ceph desde un host remoto, la autenticación de Ceph no se aplica a la conexión entre el host del usuario y el host del cliente.
30.2 Áreas clave de gestión #
En esta sección se describen los usuarios del cliente de Ceph, así como su autenticación y autorización con el clúster de almacenamiento de Ceph. Los usuarios son personas o actores del sistema, como aplicaciones, que utilizan los clientes de Ceph para interactuar con los daemons del clúster de almacenamiento de Ceph.
Cuando se ejecuta Ceph con la autenticación y la autorización habilitadas
(lo están por defecto), debe especificar un nombre de usuario y un anillo de
claves que contenga la clave de secreto del usuario especificado (por lo
general, a través de la línea de comandos). Si no especifica un nombre de
usuario, Ceph usará client.admin
como nombre de usuario por defecto. Si no especifica un anillo de claves,
Ceph buscará un anillo de claves mediante el valor correspondiente del
archivo de configuración de Ceph. Por ejemplo, si ejecuta el comando
ceph health sin especificar un nombre de usuario o un
anillo de claves, Ceph interpreta el comando así:
cephuser@adm > ceph -n client.admin --keyring=/etc/ceph/ceph.client.admin.keyring health
Si lo prefiere, puede utilizar la variable de entorno
CEPH_ARGS para evitar tener que introducir de nuevo el
nombre de usuario y el secreto.
30.2.1 Información básica #
Independientemente del tipo de cliente de Ceph (por ejemplo, un dispositivo de bloques, almacenamiento de objetos, sistema de archivos o API nativa), Ceph almacena todos los datos como objetos en repositorios. Los usuarios de Ceph necesitan tener acceso a los repositorios a fin de poder leer y escribir los datos. Además, los usuarios de Ceph deben tener permisos de ejecución para usar los comandos de administración de Ceph. Los siguientes conceptos le ayudarán a comprender mejor la gestión de usuarios de Ceph.
30.2.1.1 Usuario #
Un usuario es una persona o un actor del sistema, como una aplicación. Crear usuarios permite controlar quién (o qué) puede acceder a su clúster de almacenamiento de Ceph, sus repositorios y los datos de los repositorios.
Ceph usa tipos de usuarios. Para la gestión de los
usuarios, el tipo siempre será client. Ceph identifica
a los usuarios con un formato delimitado por punto (.), formado por el
tipo de usuario y el ID de usuario. Por ejemplo,
TYPE.ID, client.admin o
client.user1. Este formato se usa porque los monitores
de Ceph, los OSD y los servidores de metadatos también utilizan el
protocolo cephx, pero no son clientes. Distinguir el tipo de usuario ayuda
a diferenciar entre los usuarios cliente y otros usuarios, además de
optimizar el control de acceso, la supervisión del usuario y el
seguimiento.
A veces, el tipo de usuario de Ceph puede parecer confuso, ya que la línea
de comandos de Ceph permite especificar un usuario con o sin el tipo,
dependiendo del uso que se haga de la línea de comandos. Si especifica
‑‑user o ‑‑id, puede omitir el tipo. Por
lo tanto, client.user1 se puede introducir simplemente
como user1. Si especifica ‑‑name o
-no, debe especificar el tipo y el nombre, como
client.user1. Se recomienda usar el tipo y el nombre
como práctica recomendada siempre que sea posible.
Un usuario de clúster de almacenamiento de Ceph no es lo mismo que un usuario de almacenamiento de objetos de Ceph ni un usuario de sistema de archivos de Ceph. Ceph Object Gateway utiliza un usuario de clúster de almacenamiento de Ceph para la comunicación entre el daemon de pasarela y el clúster de almacenamiento, pero la pasarela tiene sus propias funciones de gestión de usuarios para los usuarios finales. El sistema de archivos de Ceph utiliza la semántica de POSIX. El espacio de usuarios asociado a ese sistema no es igual que un usuario de clúster de almacenamiento de Ceph.
30.2.1.2 Autorización y permisos #
Ceph usa el término permisos (caps, o "capabilities" en inglés) para describir la autorización de un usuario autenticado para que pueda trabajar con los monitores, los OSD y los servidores de metadatos. Los permisos también pueden restringir el acceso a los datos de un repositorio o a un espacio de nombres de repositorio. Un usuario administrativo de Ceph define los permisos del usuario cuando lo crea o lo actualiza.
La sintaxis de los permisos sigue este formato:
daemon-type 'allow capability' [...]
A continuación encontrará una lista de permisos para cada tipo de servicio:
- Permisos de monitor
Incluye
r,w,xyallow profile permiso.mon 'allow rwx' mon 'allow profile osd'
- Permisos de OSD
Incluye
r,w,x,class-read,class-writeyprofile osd. Además, los permisos de OSD también permiten configurar el repositorio y el espacio de nombres.osd 'allow capability' [pool=poolname] [namespace=namespace-name]
- Permiso de servidor de metadatos
Solo es
allowo se deja vacío.mds 'allow'
Las siguientes entradas describen cada permiso:
- allow
Precede a la configuración de acceso para un daemon. Implica
rwsolo para el servidor de metadatos.- r
Proporciona al usuario acceso de lectura. Es necesario para que los monitores puedan recuperar el mapa de CRUSH.
- w
Proporciona al usuario acceso de escritura a los objetos.
- x
Proporciona al usuario el permiso para llamar a métodos de clase (tanto de lectura como de escritura) y para llevar a cabo operaciones
authen los monitores.- class-read
Proporciona al usuario el permiso para llamar a métodos de lectura de clase. Subconjunto de
x.- class-write
Proporciona al usuario el permiso para llamar a métodos de escritura de clase. Subconjunto de
x.- *
Proporciona al usuario permisos de lectura, escritura y ejecución para un daemon o repositorio concreto, así como la capacidad de ejecutar comandos de administración.
- profile osd
Proporciona a un usuario permiso para conectarse como un OSD a otros OSD o monitores. Se otorga en los OSD para permitirles gestionar el tráfico de subejecución de réplica y la elaboración de informes de estado.
- profile mds
Proporciona a un usuario permiso para conectarse como un servidor de metadatos a otros servidores de metadatos o monitores.
- profile bootstrap-osd
Proporciona a un usuario permisos para cargar un OSD. Se delega a las herramientas de distribución para que tengan permisos para añadir claves cuando se carga un OSD.
- profile bootstrap-mds
Proporciona a un usuario permisos para cargar un servidor de metadatos. Se delega a las herramientas de distribución para que tengan permisos para añadir claves cuando se carga un servidor de metadatos.
30.2.1.3 Repositorios #
Un repositorio es una partición lógica donde los usuarios almacenan los
datos. En distribuciones de Ceph, es común crear un repositorio como una
partición lógica para tipos similares de datos. Por ejemplo, al distribuir
Ceph como procesador final para OpenStack, una distribución típica tendría
repositorios para los volúmenes, las imágenes, las copias de seguridad,
las máquinas virtuales y los usuarios como
client.glance o
client.cinder.
30.2.2 Gestión de usuarios #
La funcionalidad de gestión de usuarios proporciona a los administradores de clústeres de Ceph la capacidad de crear, actualizar y suprimir usuarios directamente en el clúster de Ceph.
Al crear o suprimir usuarios en el clúster de Ceph, puede ser necesario distribuir claves a los clientes para que se puedan añadir a anillos de claves. Para obtener más información, consulte: Sección 30.2.3, “Gestión de anillos de claves”.
30.2.2.1 Listas de usuarios #
Para obtener una lista de los usuarios del clúster, ejecute lo siguiente:
cephuser@adm > ceph auth list
Ceph mostrará a todos los usuarios del clúster. Por ejemplo, en un clúster
de dos nodos, ceph auth list da como resultado algo
parecido a esto:
installed auth entries:
osd.0
key: AQCvCbtToC6MDhAATtuT70Sl+DymPCfDSsyV4w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQC4CbtTCFJBChAAVq5spj0ff4eHZICxIOVZeA==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQBHCbtT6APDHhAA5W00cBchwkQjh3dkKsyPjw==
caps: [mds] allow
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBICbtTOK9uGBAAdbe5zcIGHZL3T/u2g6EBww==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQBHCbtT4GxqORAADE5u7RkpCN/oo4e5W0uBtw==
caps: [mon] allow profile bootstrap-osd
Tenga en cuenta que se aplica la notación TYPE.ID para
los usuarios, de forma que osd.0 especifica un usuario
de tipo osd cuyo ID es 0.
client.admin es un usuario de tipo
client cuyo ID es admin. Tenga en
cuenta también que cada entrada tiene una entrada key:
valor y una o más entradas
caps:.
Puede utilizar la opción -o nombre de
archivo con ceph auth list para
guardar el resultado en un archivo.
30.2.2.2 Obtención de información sobre los usuarios #
Para recuperar información de un usuario, una clave y permisos concretos, ejecute lo siguiente:
cephuser@adm > ceph auth get TYPE.IDPor ejemplo:
cephuser@adm > ceph auth get client.admin
exported keyring for client.admin
[client.admin]
key = AQA19uZUqIwkHxAAFuUwvq0eJD4S173oFRxe0g==
caps mds = "allow"
caps mon = "allow *"
caps osd = "allow *"Los desarrolladores también pueden ejecutar lo siguiente:
cephuser@adm > ceph auth export TYPE.ID
El comando auth export es idéntico al comando
auth get, pero también imprime el ID de autenticación
interno.
30.2.2.3 Adición de usuarios #
Al añadir un usuario, se crea un nombre de usuario
(TYPE.ID), una clave de secreto y cualquier permiso
incluido en el comando que se utiliza para crear el usuario.
La clave del usuario permite a este autenticarse con el clúster de almacenamiento de Ceph. Los permisos del usuario autorizan a este a leer, escribir o ejecutar en los monitores de Ceph (mon), los OSD de Ceph (osd) o los servidores de metadatos de Ceph (mds).
Hay varios comandos disponibles para añadir un usuario:
ceph auth addEste comando es la manera canónica de añadir un usuario. Crea el usuario, genera una clave y añade cualquier permiso especificado.
ceph auth get-or-createEste comando suele ser la forma más cómoda de crear un usuario, ya que devuelve un formato de archivo de clave con el nombre de usuario (entre corchetes) y la clave. Si el usuario ya existe, este comando simplemente devuelve el nombre de usuario y la clave con formato de archivo de clave. Puede utilizar la opción
-o nombre de archivopara guardar el resultado en un archivo.ceph auth get-or-create-keyEste comando es un método sencillo de crear un usuario y devolver (solo) la clave del usuario. Resulta útil para clientes que solo necesitan la clave (por ejemplo,
libvirt). Si el usuario ya existe, este comando solo devuelve la clave. Puede utilizar la opción-o nombre de archivopara guardar el resultado en un archivo.
Cuando se crean usuarios de cliente, puede crear un usuario sin permisos.
Un usuario sin permisos puede autenticarse, pero nada más. Un cliente de
este tipo no puede recuperar el mapa del clúster del monitor. Sin embargo,
puede crear un usuario sin permisos si desea añadir los permisos más tarde
con el comando ceph auth caps.
Un usuario típico tiene al menos el permiso de lectura en el monitor de Ceph y de lectura y escritura en los OSD de Ceph. Además, los permisos de OSD de un usuario a menudo están restringidos al acceso a un repositorio concreto.
cephuser@adm >ceph auth add client.john mon 'allow r' osd \ 'allow rw pool=liverpool'cephuser@adm >ceph auth get-or-create client.paul mon 'allow r' osd \ 'allow rw pool=liverpool'cephuser@adm >ceph auth get-or-create client.george mon 'allow r' osd \ 'allow rw pool=liverpool' -o george.keyringcephuser@adm >ceph auth get-or-create-key client.ringo mon 'allow r' osd \ 'allow rw pool=liverpool' -o ringo.key
Si proporciona a un usuario permisos para los OSD, pero no restringe el acceso a repositorios concretos, el usuario tendrá acceso a todos los repositorios del clúster.
30.2.2.4 Modificación de los permisos de usuario #
El comando ceph auth caps permite especificar un
usuario y cambiar sus permisos. Al definir nuevos permisos, se
sobrescribirán los existentes. Para ver los permisos actuales, ejecute
ceph auth get
USERTYPE.USERID.
Para añadir permisos, también debe especificar los permisos existentes con
el formato siguiente:
cephuser@adm > ceph auth caps USERTYPE.USERID daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]' [daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]']Por ejemplo:
cephuser@adm >ceph auth get client.johncephuser@adm >ceph auth caps client.john mon 'allow r' osd 'allow rw pool=prague'cephuser@adm >ceph auth caps client.paul mon 'allow rw' osd 'allow r pool=prague'cephuser@adm >ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
Para eliminar un permiso, puede restablecerlo. Si desea que el usuario no tenga acceso a un daemon concreto que se ha definido previamente, especifique una cadena vacía:
cephuser@adm > ceph auth caps client.ringo mon ' ' osd ' '30.2.2.5 Supresión de usuarios #
Para suprimir un usuario, utilice ceph auth del:
cephuser@adm > ceph auth del TYPE.ID
donde TYPE es client,
osd, mon o mds, e
ID es el nombre del usuario o el ID del daemon.
Si ha creado usuarios con permisos estrictamente para un repositorio que ya no existe, plantéese también la posibilidad de suprimir dichos usuarios.
30.2.2.6 Impresión de la clave de un usuario #
Para imprimir la clave de autenticación de un usuario con una salida estándar, ejecute lo siguiente:
cephuser@adm > ceph auth print-key TYPE.ID
donde TYPE es client,
osd, mon o mds, e
ID es el nombre del usuario o el ID del daemon.
Imprimir la clave de un usuario resulta útil si necesita completar el
software de cliente con la clave de un usuario (por ejemplo,
libvirt), tal y como se muestra
en el siguiente ejemplo:
root # mount -t ceph host:/ mount_point \
-o name=client.user,secret=`ceph auth print-key client.user`30.2.2.7 Importación de usuarios #
Para importar uno o varios usuarios, utilice ceph auth
import y especifique un anillo de claves:
cephuser@adm > ceph auth import -i /etc/ceph/ceph.keyringEl clúster de almacenamiento de Ceph añadirá los nuevos usuarios, sus claves y sus permisos, además de actualizar los usuarios existentes, sus claves y sus permisos.
30.2.3 Gestión de anillos de claves #
Si accede a Ceph a través de un cliente de Ceph, el cliente buscará un anillo de claves local. Ceph incluye cuatro nombres de anillos de claves por defecto, por lo que no es necesario definirlos en el archivo de configuración de Ceph, a menos que desee sustituir esos valores por defecto:
/etc/ceph/cluster.name.keyring /etc/ceph/cluster.keyring /etc/ceph/keyring /etc/ceph/keyring.bin
La metavariable cluster es el nombre de su
clúster de Ceph definido en el archivo de configuración de Ceph.
ceph.conf significa que el nombre del clúster es
ceph, como en ceph.keyring. La
metavariable name es el tipo de usuario y el ID
de usuario; por ejemplo, client.admin, como en
ceph.client.admin.keyring.
Después de crear un usuario (por ejemplo,
client.ringo), debe obtener la
clave y añadirla a un anillo de claves en un cliente de Ceph para que el
usuario pueda acceder el clúster de almacenamiento de Ceph.
En la Sección 30.2, “Áreas clave de gestión” se detalla cómo mostrar una
lista de usuario y obtener, añadir, modificar y suprimir usuarios
directamente en el clúster de almacenamiento de Ceph. Sin embargo, Ceph
también proporciona la utilidad ceph-authtool, que
permite gestionar anillos de claves desde un cliente de Ceph.
30.2.3.1 Creación de un anillo de claves #
Cuando se utilizan los procedimientos de la Sección 30.2, “Áreas clave de gestión” para crear usuarios, debe proporcionar las claves de usuario a los clientes de Ceph para que puedan recuperar la clave para el usuario especificado y autenticarse con el clúster de almacenamiento de Ceph. Los clientes de Ceph acceden a los anillos de claves para buscar un nombre de usuario y recuperar la clave del usuario:
cephuser@adm > ceph-authtool --create-keyring /path/to/keyring
Cuando se crea un anillo de claves con varios usuarios, es recomendable
utilizar el nombre del clúster (por ejemplo
cluster.keyring) para el nombre de archivo del
anillo de claves y guardarlo en el directorio
/etc/ceph. De esta forma, la configuración por
defecto del anillo de claves tomará el nombre de archivo sin que sea
necesario especificarlo en la copia local del archivo de configuración de
Ceph. Por ejemplo, para crear ceph.keyring, ejecute
lo siguiente:
cephuser@adm > ceph-authtool -C /etc/ceph/ceph.keyring
Cuando se crea un anillo de claves con un solo usuario, se recomienda usar
el nombre del clúster, el tipo de usuario y el nombre de usuario y
guardarlo en el directorio /etc/ceph. Por ejemplo,
ceph.client.admin.keyring para el usuario
client.admin.
30.2.3.2 Adición de un usuario a un anillo de claves #
Cuando se añade un usuario al clúster de almacenamiento de Ceph (consulte la Sección 30.2.2.3, “Adición de usuarios”), puede recuperar el usuario, la clave y los permisos, y guardar el usuario en un anillo de claves.
Si solo desea utilizar un usuario por anillo de claves, el comando
ceph auth get con la opción -o
guardará el resultado en el formato de archivo del anillo de claves. Por
ejemplo, para crear un anillo de claves para el usuario
client.admin, ejecute lo
siguiente:
cephuser@adm > ceph auth get client.admin -o /etc/ceph/ceph.client.admin.keyring
Si desea importar usuarios en un anillo de claves, puede utilizar
ceph-authtool para especificar el anillo de claves de
destino y el anillo de claves de origen:
cephuser@adm > ceph-authtool /etc/ceph/ceph.keyring \
--import-keyring /etc/ceph/ceph.client.admin.keyring
Si el anillo de claves está en peligro, suprima la clave del directorio
/etc/ceph y vuelva a crear una clave nueva siguiendo
las mismas instrucciones de la Sección 30.2.3.1, “Creación de un anillo de claves”.
30.2.3.3 Creación de un usuario #
Ceph proporciona el comando ceph auth add para crear un
usuario directamente en el clúster de almacenamiento de Ceph. Sin embargo,
también puede crear un usuario, las claves y los permisos directamente en
un anillo de claves del cliente de Ceph. A continuación, puede importar el
usuario en el clúster de almacenamiento de Ceph:
cephuser@adm > ceph-authtool -n client.ringo --cap osd 'allow rwx' \
--cap mon 'allow rwx' /etc/ceph/ceph.keyringTambién puede crear un anillo de claves y añadirle simultáneamente un usuario nuevo:
cephuser@adm > ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo \
--cap osd 'allow rwx' --cap mon 'allow rwx' --gen-key
En las situaciones anteriores, el nuevo usuario
client.ringo está solo en el
anillo de claves. Para añadir el nuevo usuario al clúster de
almacenamiento de Ceph, sigue siendo necesario añadir el nuevo usuario al
clúster:
cephuser@adm > ceph auth add client.ringo -i /etc/ceph/ceph.keyring30.2.3.4 Modificación de usuarios #
Para modificar los permisos de un registro de usuario en un anillo de claves, especifique el anillo de claves y el usuario seguidos de los permisos:
cephuser@adm > ceph-authtool /etc/ceph/ceph.keyring -n client.ringo \
--cap osd 'allow rwx' --cap mon 'allow rwx'Para actualizar el usuario modificado en el entorno de clúster de Ceph, debe importar los cambios desde el anillo de claves en la entrada de usuario del clúster de Ceph:
cephuser@adm > ceph auth import -i /etc/ceph/ceph.keyringConsulte la Sección 30.2.2.7, “Importación de usuarios” para obtener información sobre cómo actualizar el clúster de almacenamiento de Ceph desde un anillo de claves.
30.2.4 Uso de la línea de comandos #
El comando ceph admite las siguientes opciones
relacionadas con el nombre de usuario y la manipulación del secreto:
‑‑ido‑‑userCeph identifica a los usuarios con un tipo y un ID (TYPE.ID; por ejemplo,
client.adminoclient.user1). Las opcionesid,namey-npermiten especificar la parte del ID del nombre de usuario (por ejemplo,adminouser1). Puede especificar el usuario con la opción ‑‑id y omitir el tipo. Por ejemplo, para especificar el usuario client.foo, escriba lo siguiente:cephuser@adm >ceph --id foo --keyring /path/to/keyring healthcephuser@adm >ceph --user foo --keyring /path/to/keyring health‑‑nameo‑nCeph identifica a los usuarios con un tipo y un ID (TYPE.ID; por ejemplo,
client.adminoclient.user1). Las opciones‑‑namey‑npermiten especificar el nombre completo del usuario. Debe especificar el tipo de usuario (generalmente,client) con el ID de usuario:cephuser@adm >ceph --name client.foo --keyring /path/to/keyring healthcephuser@adm >ceph -n client.foo --keyring /path/to/keyring health‑‑keyringLa vía al anillo de claves que contiene uno o más nombres de usuario y secretos. La opción
‑‑secretofrece las mismas funciones, pero no funciona con Object Gateway, que utiliza‑‑secretpara otro fin. Puede recuperar un anillo de claves conauth ceph get-or-createy almacenarlo localmente. Se trata del enfoque preferido, ya que permite cambiar de nombres de usuario sin tener que cambiar la vía del anillo de claves:cephuser@adm >rbd map --id foo --keyring /path/to/keyring mypool/myimage
A Actualizaciones de mantenimiento de Ceph basadas en versiones secundarias superiores de Octopus #
Varios paquetes clave de SUSE Enterprise Storage 7 se basan en las distintas versiones de Octopus de Ceph. Cuando el proyecto Ceph (https://github.com/ceph/ceph) publica nuevas versiones secundarias de la serie Octopus, SUSE Enterprise Storage 7 se actualiza para garantizar que el producto se beneficia de las últimas correcciones de solucionar errores y actualizaciones retroactivas de características de esas versiones.
Este capítulo contiene un resumen de los principales cambios incluidos en cada versión secundaria posterior que se ha incluido en el producto, o que se tiene previsto incluir.
Octopus 15.2.5#
La versión 15.2.5 de Octopus aporta las siguientes correcciones y otros cambios:
CephFS: las directivas de partición de subárbol estático automáticas ahora se pueden configurar mediante los nuevos atributos extendidos de fijación efímera aleatoria y distribuida en los directorios. Para obtener más datos, consulte la documentación siguiente: https://docs.ceph.com/docs/master/cephfs/multimds/
Los monitores tienen ahora una opción de configuración
mon_osd_warn_num_repaired, que está definida en 10 por defecto. Si algún OSD ha reparado más errores de E/S en los datos almacenados de los indicados por esta cifra, se genera una advertencia de estadoOSD_TOO_MANY_REPAIRS.Ahora, si los indicadores
no scrubono deep-scrubse definen globalmente o por repositorio, la depuración programada del tipo inhabilitado se interrumpirán. Las depuraciones iniciadas por el usuario NO se interrumpen.Se ha solucionado un problema por el que osdmaps no se optimizaba en un clúster en buen estado.
Octopus 15.2.4#
La versión 15.2.4 de Octopus aporta las siguientes correcciones y otros cambios:
CVE-2020-10753: rgw: se han saneado las nuevas líneas en el encabezado ExposeHeader de s3 CORSConfiguration
Object Gateway: los subcomandos
radosgw-adminrelacionados con huérfanos (radosgw-admin orphans find,radosgw-admin orphans finishyradosgw-admin orphans list-jobs) han quedado obsoletos. No se han mantenido de forma activa y, dado que almacenan resultados intermedios en el clúster, podrían llegar a ocupar un clúster casi por completo. Se han sustituido por una herramienta,rgw-orphan-list, que actualmente se considera experimental.RBD: el nombre del objeto de repositorio RBD que se utiliza para almacenar la programación de limpieza de la papelera de RBD ha cambiado de
rbd_trash_trash_purge_schedulearbd_trash_purge_schedule. Los usuarios que ya han comenzado a utilizar la función de programación de limpieza de papelera de RBD y tienen programas por repositorio o por espacio de nombres configuradas deben copiar el objetorbd_trash_trash_purge_scheduleenrbd_trash_purge_scheduleantes de la actualización y eliminarrbd_trash_purge_schedulemediante los comandos siguientes en cada repositorio RBD y espacio de nombres configurado anteriormente:rados -p pool-name [-N namespace] cp rbd_trash_trash_purge_schedule rbd_trash_purge_schedule rados -p pool-name [-N namespace] rm rbd_trash_trash_purge_schedule
También puede utilizar cualquier otra forma conveniente de restaurar la programación después de la actualización.
Octopus 15.2.3#
La versión 15.2.3 de Octopus era una versión Hot Fix para solucionar un problema en el que se detectaban daños en WAL cuando se habilitaban
bluefs_preextend_wal_filesybluefs_bufferen_ioal mismo tiempo. La corrección de 15.2.3 es solo una medida temporal (que cambia el valor por defecto debluefs_preextend_wal_filesafalse). La solución permanente será eliminar por completo la opciónbluefs_preextend_wal_files: lo más probable es que esta solución llegue en la versión 15.2.6.
Octopus 15.2.2#
La versión 15.2.2 de Octopus solucionó una vulnerabilidad de seguridad:
CVE-2020-10736: se ha corregido una omisión de autorización en MON y MGR.
Octopus 15.2.1#
La versión 15.2.1 de Octopus solucionó un problema por el cual la actualización rápida de Luminous (SES5.5) a Nautilus (SES6) a Octopus (SES7) provocaba que los OSD se bloquearan. Además, se aplicaron parches a dos vulnerabilidades de seguridad presentes en la versión inicial de Octopus (15.2.0):
CVE-2020-1759: se ha corregido la reutilización de nonce en el modo seguro de msgr V2.
CVE-2020-1760: XSS corregido debido a la división de encabezado GetObject de RGW.
B Actualizaciones de la documentación #
En este capítulo se describen los cambios de contenido de este documento que se aplican a la versión actual de SUSE Enterprise Storage.
El capítulo sobre Ceph Dashboard (Parte I, “Ceph Dashboard”) se ha subido un nivel en la jerarquía del libro para que los temas detallados se puedan buscar directamente en la tabla de contenido.
La estructura del Book “Guía de administración y operaciones” se ha actualizado para que coincida con el rango actual de guías. Algunos capítulos se han trasladado a otras guías (jsc#SES-1397).
Glosario #
General
- Alertmanager #
Un binario que gestiona las alertas enviadas por el servidor Prometheus y notifica al usuario final.
- Almacenamiento de objetos de Ceph #
El "producto", el servicio o las capacidades de almacenamiento de objetos, formado por un clúster de almacenamiento de Ceph y Ceph Object Gateway.
- Árbol de enrutamiento #
Un término dado a cualquier diagrama que muestre las diversas rutas que un receptor puede ejecutar.
- Ceph Dashboard #
Una aplicación integrada de gestión y supervisión de Ceph basada en Web para administrar varios aspectos y objetos del clúster. La consola se implementa como un módulo de Ceph Manager.
- Ceph Manager #
Ceph Manager, o MGR, es el software de gestión de Ceph, que recopila todo el estado de todo el clúster en un solo lugar.
- Ceph Monitor #
Ceph Monitor, o MON, es el software de supervisión de Ceph.
ceph-salt#Proporciona herramientas para distribuir clústeres de Ceph gestionados por cephadm mediante Salt.
- cephadm #
cephadm distribuye y gestiona un clúster de Ceph conectándose a hosts desde el daemon del gestor a través de SSH para añadir, eliminar o actualizar contenedores de daemon de Ceph.
- CephFS #
El sistema de archivos de Ceph.
- CephX #
El protocolo de autenticación de Ceph. Cephx funciona como Kerberos, pero no tiene un punto único de fallo.
- Cliente de Ceph #
Colección de componentes de Ceph que pueden acceder a un clúster de almacenamiento de Ceph. Entre ellos se incluyen Object Gateway, Ceph Block Device, CephFS y sus correspondientes bibliotecas, módulos del kernel y clientes FUSE.
- Clúster de almacenamiento de Ceph #
El conjunto principal de software de almacenamiento donde se almacenan los datos del usuario' Dicho conjunto está formado por los monitores Ceph Monitor y los OSD.
- Conjunto de reglas #
Las reglas para determinar la ubicación de los datos de un repositorio.
- CRUSH, mapa de CRUSH #
CRUSH: Controlled Replication Under Scalable Hashing (réplica controlada bajo hash escalable) es un algoritmo que determina cómo se deben almacenar y recuperar los datos calculando las ubicaciones de almacenamiento de los datos. CRUSH requiere un mapa del clúster para almacenar de forma pseudoaleatoria y recuperar los datos de los OSD con una distribución uniforme de los datos por el clúster.
- Daemon Ceph OSD #
El daemon
ceph-osdes el componente de Ceph responsable de almacenar objetos en un sistema de archivos local y de proporcionar acceso a ellos a través de la red.- Depósito #
Un punto que añade otros nodos en una jerarquía de ubicaciones físicas.
- Dispositivo de bloques RADOS (RBD) #
El componente de almacenamiento de bloques de Ceph. También conocido como dispositivo de bloques de Ceph.
- DriveGroups #
DriveGroups es una declaración de uno o varios diseños de OSD que se pueden asignar a unidades físicas. Un diseño de OSD define cómo Ceph asigna físicamente el almacenamiento de OSD en los medios que coinciden con criterios especificados.
- Grafana #
Solución de análisis y supervisión de bases de datos.
- grupo de zona #
- Módulo de sincronización de archivos #
Módulo que permite crear una zona de Object Gateway para mantener el historial de versiones de objetos de S3.
- Multizona #
- Nodo #
Cualquier equipo o servidor único de un clúster de Ceph.
- Nodo de administración #
El host desde el que se ejecutan los comandos relacionados con Ceph para administrar los hosts del clúster.
- Nodo de OSD #
Un nodo de clúster donde se almacenan los datos; se gestiona la réplica de los datos, la recuperación, la reposición y el reequilibrio, y que proporciona detalles de supervisión a los monitores Ceph Monitor mediante la comprobación de otros daemons Ceph OSD.
- Object Gateway #
El componente de pasarela S3/Swift para el almacén de objetos de Ceph. También conocido como pasarela RADOS (RGW).
- OSD #
Dispositivo de almacenamiento de objetos: unidad de almacenamiento física o lógica.
- PG #
Grupo de colocación: una subdivisión de un repositorio que se utiliza para ajustar el rendimiento.
- Prometheus #
Kit de herramientas de supervisión y alerta de sistemas.
- RADOS (Reliable Autonomic Distributed Object Store, almacén de objetos distribuido automático fiable) #
El conjunto principal de software de almacenamiento donde se almacenan los datos del usuario (MON+OSD).
- Regla de CRUSH #
La regla de colocación de datos de CRUSH que se aplica a uno o varios repositorios concretos.
- Repositorio #
Las particiones lógicas para almacenar los objetos, como las imágenes de disco.
- Samba #
Software de integración de Windows.
- Samba Gateway #
Samba Gateway se une a Active Directory en el dominio de Windows para autenticar y autorizar a los usuarios.
- Servidor de metadatos #
El servidor de metadatos, o MDS, es el software de metadatos de Ceph.
- Versión secundaria #
Cualquier versión ad hoc que incluye solo correcciones de errores o de seguridad.