- 1 Descripción conceptual
- 2 Ejemplos de uso
- 3 Requisitos
- 4 Descripción general de los guiones de bootstrap geográficos
- 5 Instalación como extensión
- 6 Configuración del primer sitio de un clúster geográfico
- 7 Adición de otro sitio a un clúster geográfico
- 8 Adición del árbitro
- 9 Supervisión de los sitios de clúster
- 10 Pasos siguientes
- 11 Información adicional
- 12 Información legal
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Inicio rápido de Geo Clustering #
Resumen#
Gracias a los clústeres geográficos, es posible contar con varios sitios dispersos geográficamente con un clúster local cada uno. El failover entre estos clústeres se coordina mediante una entidad de nivel superior: el gestor de tickets del clúster de booth. Este documento sirve como guía para la configuración básica de un clúster geográfico mediante los guiones de bootstrap geográficos proporcionados por el paquete ha-cluster-bootstrap.
- 1 Descripción conceptual
- 2 Ejemplos de uso
- 3 Requisitos
- 4 Descripción general de los guiones de bootstrap geográficos
- 5 Instalación como extensión
- 6 Configuración del primer sitio de un clúster geográfico
- 7 Adición de otro sitio a un clúster geográfico
- 8 Adición del árbitro
- 9 Supervisión de los sitios de clúster
- 10 Pasos siguientes
- 11 Información adicional
- 12 Información legal
- A GNU Licenses
1 Descripción conceptual #
Los clústeres geográficos basados en SUSE® Linux Enterprise High Availability Extension se pueden considerar clústeres de “superposición” en los que cada sitio de clúster se corresponde con un nodo de clúster en un clúster tradicional. El gestor de tickets del clúster de booth gestiona el clúster de superposición (en la instancia de booth al que se llama a continuación). Todas las partes implicadas en un clúster geográfico ejecutan un servicio, boothd. Este se conecta con los daemons de booth que se ejecuten en los demás sitios e intercambia detalles de conectividad. Para conseguir que los recursos del clúster tengan una alta disponibilidad en los sitios, la instancia de booth utiliza objetos de clúster denominados tickets. Un ticket otorga el derecho a ejecutar determinados recursos en un sitio de clúster específico. La instancia de booth garantiza que cada ticket solo se otorga a un único sitio a la vez.
Si se interrumpe la comunicación entre dos instancias de booth, puede deberse a una interrupción de la red entre los sitios de clúster o a una interrupción de un sitio de clúster. En tal caso, se necesita una instancia adicional (un tercer sitio de clúster o un árbitro) para llegar a un consenso sobre las decisiones (por ejemplo, el failover de los recursos entre los sitios). Los árbitros son equipos individuales (exteriores a los clústeres) en los que se ejecuta una instancia de booth de un modo especial. Cada clúster geográfico puede tener uno o varios árbitros.
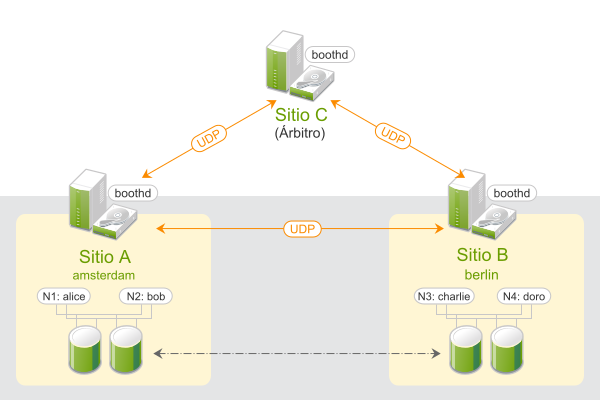
Figura 1: Clúster de dos sitios (2x2 nodos + árbitro) #
Para obtener más detalles sobre el concepto, los componentes y la gestión de tickets que se usan para los clústeres geográficos, consulte el Book “Geo Clustering Guide”, Chapter 2 “Conceptual Overview”.
2 Ejemplos de uso #
A continuación, vamos a configurar un clúster geográfico básico con dos sitios de clúster y un árbitro:
Los sitios de clúster se denominarán
amsterdamyberlin.Cada sitio estará compuesto por dos nodos. Los nodos
aliceybobpertenecen al clústeramsterdam. Los nodoscharlieydoropertenecen al clústerberlin.El sitio
amsterdamrecibirá la siguiente dirección IP virtual:192.168.201.100.El sitio
berlinrecibirá la siguiente dirección IP virtual:192.168.202.100.El árbitro tendrá la siguiente dirección IP:
192.168.203.100.
Antes de continuar, asegúrese de que se cumplen los siguientes requisitos:
Requisitos #
- Existen dos clústeres
Debe tener al menos dos clústeres que desea combinar en un clúster geográfico. Si necesita configurar dos clústeres en primer lugar, siga las instrucciones de Article “Inicio rápido de instalación y configuración”.
- Los clústeres tienen nombres descriptivos
Cada clúster debe tener un nombre descriptivo definido en
/etc/corosync/corosync.confque indique su ubicación.- Árbitro
Se ha instalado un tercer equipo que no forma parte de los clústeres existentes y que se usará como árbitro.
Para los requisitos detallados de cada elemento, consulte también la Sección 3, “Requisitos”.
3 Requisitos #
Requisitos de software #
Todos los equipos (nodos de clúster y árbitros) que formarán parte del clúster geográfico deben tener instalado el software siguiente:
SUSE® Linux Enterprise Server 12 SP5
SUSE Linux Enterprise High Availability Extension 12 SP5
Geo Clustering para SUSE Linux Enterprise High Availability Extension 12 SP5
Requisitos de red #
Todo el clúster geográfico debe tener acceso a las direcciones IP virtuales que se utilizarán para cada sitio de clúster.
Debe ser posible acceder a los sitios en un puerto UDP y TCP por cada instancia de booth. Esto significa que los cortafuegos y los túneles IPsec intermedios deben configurarse según corresponda.
Si se realiza otra instalación distinta, puede ser necesario abrir más puertos (por ejemplo, para DRBD o para la réplica de la base de datos).
Otros requisitos y recomendaciones #
Se deben sincronizar todos los nodos del clúster en todos los sitios con un servidor NTP fuera del clúster. Para obtener más información, consulte el https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Si no se sincronizan los nodos, resultará muy difícil analizar los archivos de registro y los informes del clúster.
Emplee un número impar de miembros en el clúster geográfico. Esto garantiza que, en caso de que la conexión de red se interrumpa, aún haya una mayoría de sitios (para evitar una situación de clúster con nodos malinformados). En caso de tener un número par de sitios de clúster, utilice un árbitro.
El clúster de cada sitio debe tener un nombre descriptivo, por ejemplo:
amsterdamyberlin.Los nombres de clúster de cada sitio se deben definir en los archivos
/etc/corosync/corosync.confrespectivos:totem { [...] cluster_name: amsterdam }Esto se puede realizar manualmente (editando
/etc/corosync/corosync.conf) o con el módulo de clúster YaST (cambiando a la categoría y definiendo un valor en ). Seguidamente, detenga e inicie el serviciopacemakerpara que los cambios entren en vigor:root #systemctlstop pacemakerroot #systemctlstart pacemaker
4 Descripción general de los guiones de bootstrap geográficos #
El guion
ha-cluster-geo-initconvierte un clúster en el primer sitio de un clúster geográfico. Toma algunos parámetros, como los nombres de los clústeres, al árbitro y uno o varios tickets, y crea el archivo/etc/booth/booth.confa partir de ellos. Copia la configuración de booth a todos los nodos del sitio de clúster actual. También configura los recursos del clúster necesarios para booth en el sitio de clúster actual.Para obtener información, consulte la Sección 6, “Configuración del primer sitio de un clúster geográfico”.
El guion
ha-cluster-geo-joinañade el clúster actual a un clúster geográfico existente. Copia la configuración de booth de un sitio de clúster existente y lo escribe en el archivo/etc/booth/booth.confen todos los nodos del sitio de clúster actual. También configura los recursos del clúster necesarios para booth en el sitio de clúster actual.Para obtener información, consulte la Sección 7, “Adición de otro sitio a un clúster geográfico”.
El guion
ha-cluster-geo-init-arbitratorconvierte el equipo actual en un árbitro para el clúster geográfico. Copia la configuración de booth de un sitio de clúster existente y lo escribe en el archivo/etc/booth/booth.conf.Para obtener información, consulte la Sección 8, “Adición del árbitro”.
Todos los guiones de bootstrap se registran en /var/log/ha-cluster-bootstrap.log. Consulte el archivo de registro para obtener información sobre el proceso de bootstrap. Las opciones establecidas durante el proceso de bootstrap pueden modificarse más adelante (modificando la configuración de booth, los recursos, etc.). Para obtener más información, consulte Book “Geo Clustering Guide”.
5 Instalación como extensión #
Hay disponible capacidad para usar clústeres de alta disponibilidad a distancias ilimitadas como una extensión independiente, denominada Geo Clustering para SUSE Linux Enterprise High Availability Extension.
Para configurar un clúster geográfico, se necesitan los paquetes incluidos en los patrones de instalación siguientes:
Alta disponibilidadGeoCluster para alta disponibilidad
Ambos patrones solo están disponibles si ha registrado el sistema en el Centro de servicios al cliente de SUSE (o en un servidor de registro local) y ha añadido los canales de producto correspondientes o los medios de instalación como una extensión. Para obtener información sobre cómo instalar extensiones, consulte la Guía de distribución de SUSE Linux Enterprise 12 SP5: https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Procedimiento 1: instalación de los paquetes #
Para instalar los paquetes de ambos patrones mediante la línea de comandos, utilice Zypper:
root #zypperinstall -t pattern ha_sles ha_geoComo alternativa, utilice YaST para realizar una instalación gráfica:
Inicie YaST como usuario
Rooty seleccione › .Haga clic en › y active los patrones siguientes:
Alta disponibilidadGeoCluster para alta disponibilidad
Haga clic en para iniciar la instalación de los paquetes.
Importante: instalación de paquetes de software en todas las partes
Los paquetes de software necesarios para los clústeres de alta disponibilidad y geográficos no se copian automáticamente en los nodos del clúster.
Instale SUSE Linux Enterprise Server 12 SP5 y los patrones
Alta disponibilidadyGeoCluster para alta disponibilidaden todos los equipos que formarán parte del clúster geográfico.Si no desea instalar los paquetes de forma manual en todos los equipos que formarán parte del clúster, utilice AutoYaST para duplicar los nodos existentes. Hay más información disponible en el Book “Administration Guide”, Chapter 3 “Installing the High Availability Extension”, Section 3.2 “Mass Installation and Deployment with AutoYaST”.
Sin embargo, la extensión de clústeres geográficos debe instalarse manualmente en todos los equipos que formarán parte del clúster geográfico. La compatibilidad de AutoYaST con Geo Clustering para SUSE Linux Enterprise High Availability Extension aún no está disponible.
6 Configuración del primer sitio de un clúster geográfico #
Utilice el guion ha-cluster-geo-init para convertir un clúster existente en el primer sitio de un clúster geográfico.
Procedimiento 2: configuración del primer sitio (amsterdam) mediante ha-cluster-geo-init #
Defina una dirección IP virtual por cada sitio de clúster que se pueda usar para acceder al sitio. Supongamos que usa
192.168.201.100y192.168.202.100para este propósito. Aún no es necesario configurar las direcciones IP virtuales como recursos del clúster. Eso lo harán los guiones de bootstrap.Defina el nombre de al menos un ticket que pueda otorgar el derecho a ejecutar ciertos recursos en un sitio de clúster. Utilice un nombre descriptivo que refleje los recursos que dependerán del ticket (por ejemplo,
ticket-nfs). Los guiones de bootstrap solo necesitan el nombre del ticket; puede definir los detalles restantes más tarde (como dependencias de ticket de los recursos), como se describe en la Sección 10, “Pasos siguientes”.Entre en un nodo de un clúster existente (por ejemplo, en el nodo
alicedel clústeramsterdam).Ejecute
ha-cluster-geo-init. Por ejemplo, use las siguientes opciones:root #ha-cluster-geo-init\ --clusters1 "amsterdam=192.168.201.100 berlin=192.168.202.100" \ --tickets2 ticket-nfs \ --arbitrator3 192.168.203.100Los nombres de los sitios de clúster (como se definen en
/etc/corosync/corosync.conf) y las direcciones IP virtuales que desea utilizar para cada sitio de clúster. En este caso, tenemos dos sitios de clúster (amsterdamyberlin) con una dirección IP virtual cada uno.El nombre de uno o varios tickets.
El nombre de host o la dirección IP de un equipo situado fuera de los clústeres.
El guion de bootstrap crea el archivo de configuración de booth y lo sincroniza con todos los sitios del clúster. También crea los recursos básicos del clúster necesarios para booth. El Paso 4 del Procedimiento 2 dará como resultado la siguiente configuración de booth y los siguientes recursos del clúster:
Ejemplo 1: Configuración de booth creada por ha-cluster-geo-init #
# The booth configuration file is "/etc/booth/booth.conf". You need to # prepare the same booth configuration file on each arbitrator and # each node in the cluster sites where the booth daemon can be launched. # "transport" means which transport layer booth daemon will use. # Currently only "UDP" is supported. transport="UDP" port="9929" arbitrator="192.168.203.100" site="192.168.201.100" site="192.168.202.100" authfile="/etc/booth/authkey" ticket="ticket-nfs" expire="600"
Ejemplo 2: Recursos del clúster creados por ha-cluster-geo-init #
primitive1 booth-ip IPaddr2 \ params rule #cluster-name eq amsterdam ip=192.168.201.100 \ params rule #cluster-name eq berlin ip=192.168.202.100 \ primitive2 booth-site ocf:pacemaker:booth-site \ meta resource-stickiness=INFINITY \ params config=booth \ op monitor interval=10s group3 g-booth booth-ip booth-site \ meta target-role=Stopped4
Una dirección IP virtual para cada sitio de clúster. Se requiere para los daemons de booth que necesitan una dirección IP persistente en cada sitio de clúster. | |
Un recurso primitivo para el daemon de booth. Se comunica con los daemons de booth en los demás sitios del clúster. El daemon puede iniciarse en cualquier nodo del sitio, pero para conseguir que el recurso permanezca en el mismo nodo, si es posible, en el parámetro resource-stickiness se define el valor | |
Un grupo de recursos del clúster para ambos recursos primitivos. Con esta configuración, cada daemon de booth estará disponible en su dirección IP individual, independientemente del nodo en el que se ejecute el daemon. | |
El grupo de recursos del clúster no se inicia por defecto. Después de verificar la configuración de los recursos del clúster (y añadir los recursos que necesita para completar la configuración), debe iniciar el grupo de recursos. Consulte Pasos necesarios para completar la configuración del clúster geográfico para obtener más información. |
7 Adición de otro sitio a un clúster geográfico #
Después de inicializar el primer sitio del clúster geográfico, añada un segundo clúster mediante ha-cluster-geo-join, como se describe en el Procedimiento 3. El guion necesita acceso SSH a un sitio de clúster ya configurado y añadirá el clúster actual al clúster geográfico.
Procedimiento 3: adición del segundo sitio (berlin) mediante ha-cluster-geo-join #
Entre en un nodo del sitio de clúster que desee añadir (por ejemplo, en el nodo
charliedel clústerberlin).Ejecute el comando
ha-cluster-geo-join. Por ejemplo:root #ha-cluster-geo-join\ --cluster-node1 192.168.201.100\ --clusters2 "amsterdam=192.168.201.100 berlin=192.168.202.100"Especifica de dónde se debe copiar la configuración de booth. Utilice la dirección IP o el nombre de host de un nodo de un sitio de clúster geográfico ya configurado. También puede usar la dirección IP virtual de un sitio de clúster ya existente (como en este ejemplo). Como alternativa, use la dirección IP o el nombre de host de un árbitro ya configurado para el clúster geográfico.
Los nombres de los sitios de clúster (como se definen en
/etc/corosync/corosync.conf) y las direcciones IP virtuales que desea utilizar para cada sitio de clúster. En este caso, tenemos dos sitios de clúster (amsterdamyberlin) con una dirección IP virtual cada uno.
El guion ha-cluster-geo-join copia la configuración de booth de 1, consulte el Ejemplo 1. Además, crea los recursos del clúster necesarios para la instancia de booth (consulte el Ejemplo 2).
8 Adición del árbitro #
Después de configurar todos los sitios del clúster geográfico mediante ha-cluster-geo-init y ha-cluster-geo-join, configure el árbitro mediante ha-cluster-geo-init-arbitrator.
Procedimiento 4: configuración del árbitro mediante ha-cluster-geo-init-arbitrator #
Entre en el equipo que desea utilizar como árbitro.
Ejecute el comando siguiente. Por ejemplo:
root #ha-cluster-geo-init-arbitrator--cluster-node1 192.168.201.100Especifica de dónde se debe copiar la configuración de booth. Utilice la dirección IP o el nombre de host de un nodo de un sitio de clúster geográfico ya configurado. Como alternativa, puede usar la dirección IP virtual de un sitio de clúster ya existente (como en este ejemplo).
El guion ha-cluster-geo-init-arbitrator copia la configuración de booth de 1, consulte el Ejemplo 1. También habilita e inicia el servicio de booth en el árbitro. Por lo tanto, el árbitro está listo para comunicarse con las instancias de booth de los sitios de clúster en cuanto los servicios de booth se ejecutan allí.
9 Supervisión de los sitios de clúster #
Para ver ambos sitios de clúster con los recursos y el ticket que ha creado durante el proceso de bootstrap, utilice Hawk2. La interfaz Web Hawk2 permite supervisar y gestionar varios clústeres (no relacionados) y clústeres geográficos.
Requisitos previos #
En todos los clústeres que se van a supervisar con la de Hawk5 se debe ejecutar SUSE Linux Enterprise High Availability Extension 12 SP2.
Si aún no ha sustituido el certificado autofirmado de Hawk2 en cada nodo de clúster por su propio certificado (o por un certificado firmado por una autoridad certificadora oficial), haga lo siguiente: entre en Hawk2 en cada nodo y en cada clúster al menos una vez. Verifique el certificado (o añada una excepción en el navegador para omitir la advertencia). De lo contrario, Hawk2 no podrá conectarse al clúster.
Procedimiento 5: uso de la consola de Hawk2 #
Abra un navegador Web y escriba la dirección IP virtual del primer sitio de clúster,
amsterdam:https://192.168.201.100:7630/
Como alternativa, utilice la dirección IP o el nombre de host de los nodos
aliceobob. Si ha configurado ambos nodos con los guiones de bootstrap, el serviciohawkdebe ejecutarse en ambos nodos.Entre en la interfaz Web de Hawk2.
En la barra de navegación izquierda, seleccione
Hawk2 muestra un resumen de los nodos y los recursos del sitio de clúster actual. Además, muestra todos los que se han configurado para el clúster geográfico. Si necesita información acerca de los iconos utilizados en esta vista, haga clic en .
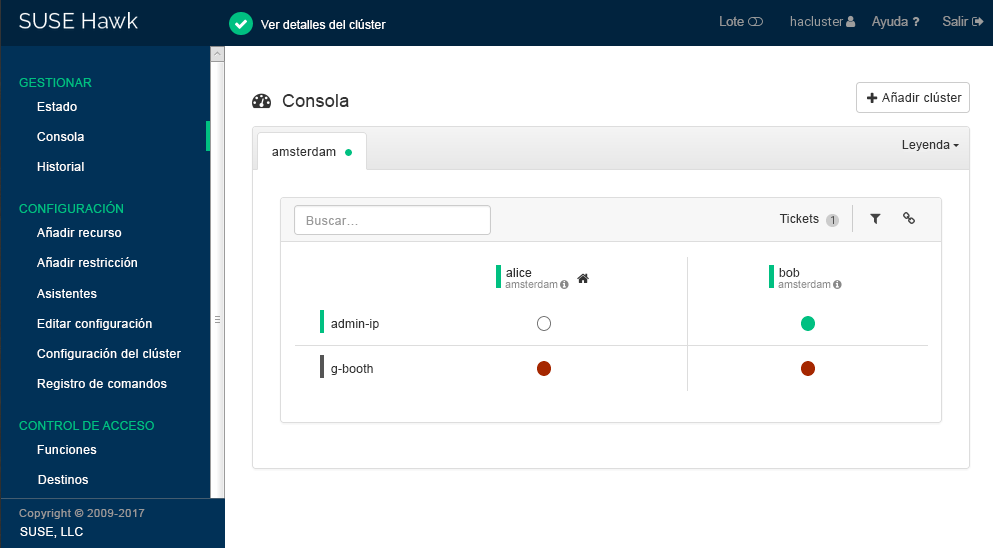
Figura 2: consola de Hawk2 con un sitio de clúster (
amsterdam) #Para añadir una consola del segundo sitio de clúster, haga clic en .
Introduzca un valor en para identificar el clúster en la . En este caso,
berlin.Escriba el nombre de host completo de uno de los nodos del clúster (en este caso,
charlieodoro).Haga clic en . Hawk2 mostrará una segunda pestaña para el sitio de clúster recién añadido con un resumen de sus nodos y recursos.
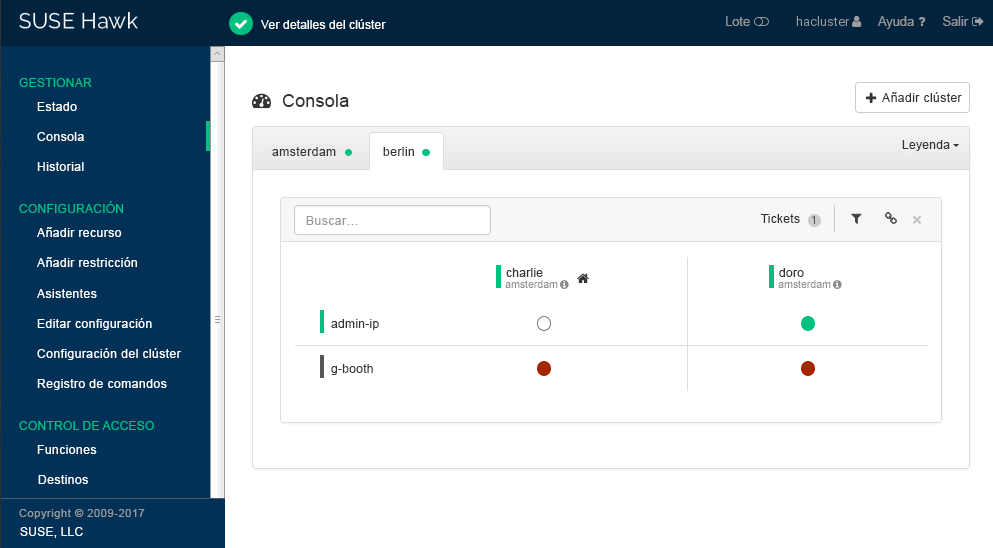
Figura 3: consola de Hawk2 con ambos sitios de clúster #
Para ver más detalles sobre un sitio de clúster, o para gestionarlo, cambie a la pestaña del sitio y haga clic en el icono de cadena.
Hawk2 abre la vista de ese sitio en una nueva ventana o pestaña del navegador. Allí, podrá administrar esa parte del clúster geográfico.
10 Pasos siguientes #
Los guiones de bootstrap de los clústeres geográficos proporcionan una forma rápida de configurar un clúster geográfico básico que puede utilizarse con fines de prueba. Sin embargo, para convertir el clúster geográfico resultante en un clúster geográfico funcional que pueda usarse en entornos de producción, son necesarios más pasos, consulte Pasos necesarios para completar la configuración del clúster geográfico.
Pasos necesarios para completar la configuración del clúster geográfico #
- Inicio de los servicios de booth en sitios de clúster
Después del proceso de bootstrap, el servicio booth del árbitro aún no puede comunicarse con los servicios booth de los sitios de clúster, ya que no se inician por defecto.
El servicio booth de cada sitio de clúster se gestiona mediante el grupo de recursos de booth
g-booth(consulte el Ejemplo 2, “Recursos del clúster creados porha-cluster-geo-init”). Para iniciar una instancia del servicio de booth en cada sitio, inicie el grupo de recursos de booth correspondiente en cada sitio de clúster. Esto permite que todas las instancias de booth se comuniquen entre sí.- Configuración de las dependencias del ticket y petición de restricciones
Para hacer que los recursos dependan del ticket que ha creado durante el proceso de bootstrap del clúster geográfico, debe configurar restricciones. Para cada restricción, defina una
directiva de pérdidaque defina qué debe ocurrir con los recursos respectivos si se revoca el ticket desde un sitio de clúster.Para obtener información, consulte el Book “Geo Clustering Guide”, Chapter 6 “Configuring Cluster Resources and Constraints”.
- Concesión inicial de un ticket a un sitio
Antes de que la instancia de booth pueda gestionar un ticket determinado en el clúster geográfico, debe otorgarlo a un sitio manualmente. Puede utilizar la herramienta de línea de comandos del cliente de booth o Hawk2 para otorgar un ticket.
Para obtener información, consulte el Book “Geo Clustering Guide”, Chapter 8 “Managing Geo Clusters”.
Los guiones de bootstrap crean los mismos recursos de booth en ambos sitios de clúster, además de los mismos archivos de configuración de booth en todos los sitios, incluido el árbitro. Si extiende la configuración del clúster geográfico (para convertirlo en un entorno de producción), es probable que ajuste los detalles de la configuración de booth y que cambie la configuración de los recursos del clúster relacionados con la instancia de booth. Después, debe sincronizar los cambios realizados con los demás sitios del clúster geográfico para que entren en vigor.
Nota: sincronización de los cambios en todos los sitios de clúster
Para sincronizar los cambios de la configuración de booth en todos los sitios de clúster (incluido el árbitro), utilice Csync2. Hay más información disponible en el Book “Geo Clustering Guide”, Chapter 5 “Synchronizing Configuration Files Across All Sites and Arbitrators”.
La CIB (base de datos de información del clúster) no se sincroniza automáticamente con los sitios de clúster de un clúster geográfico. Esto significa que los cambios en la configuración del recurso que se necesiten en todos los sitios de clúster deben transferirse a los demás sitios manualmente. Para hacerlo, etiquete los recursos respectivos, expórtelos desde la CIB actual e impórtelos a la CIB de los demás sitios de clúster. Para obtener información, consulte el Book “Geo Clustering Guide”, Chapter 6 “Configuring Cluster Resources and Constraints”, Section 6.4 “Transferring the Resource Configuration to Other Cluster Sites”.
11 Información adicional #
Hay disponible más documentación sobre este producto en https://documentation.suse.com/sle-ha-12/. La documentación también incluye una completa
guía sobre los clústeres geográficos. Consúltela para obtener más datos sobre las tareas de configuración y administración.Se ha publicado un documento con información detallada sobre cómo replicar los datos a través de DRBD entre clústeres geográficos en la serie
SUSE Best Practices(Prácticas recomendadas de SUSE): https://documentation.suse.com/sbp/all/html/SBP-DRBD/index.html
12 Información legal #
Copyright © 2006– 2025 SUSE LLC y colaboradores. Reservados todos los derechos.
Está permitido copiar, distribuir y modificar este documento según los términos de la licencia de documentación gratuita GNU, versión 1.2 o (según su criterio) versión 1.3. Este aviso de copyright y licencia deberán permanecer inalterados. En la sección titulada “GNU Free Documentation License” (Licencia de documentación gratuita GNU) se incluye una copia de la versión 1.2 de la licencia.
Para obtener información sobre las marcas comerciales de SUSE, consulte http://www.suse.com/company/legal/. Todas las marcas comerciales de otros fabricantes son propiedad de sus respectivas empresas. Los símbolos de marca comercial (®,™ etc.) indican marcas comerciales de SUSE y sus afiliados. Los asteriscos (*) indican marcas comerciales de otros fabricantes.
Toda la información recogida en esta publicación se ha compilado prestando toda la atención posible al más mínimo detalle. Sin embargo, esto no garantiza una precisión total. Ni SUSE LLC, ni sus filiales, ni los autores o traductores serán responsables de los posibles errores o las consecuencias que de ellos pudieran derivarse.
A GNU Licenses #
This appendix contains the GNU Free Documentation License version 1.2.
GNU Free Documentation License #
Copyright (C) 2000, 2001, 2002 Free Software Foundation, Inc. 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA. Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
0. PREAMBLE #
The purpose of this License is to make a manual, textbook, or other functional and useful document "free" in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
1. APPLICABILITY AND DEFINITIONS #
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The "Document", below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as "you". You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A "Modified Version" of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document's overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The "Invariant Sections" are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The "Cover Texts" are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A "Transparent" copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The "Title Page" means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, "Title Page" means the text near the most prominent appearance of the work's title, preceding the beginning of the body of the text.
A section "Entitled XYZ" means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as "Acknowledgements", "Dedications", "Endorsements", or "History".) To "Preserve the Title" of such a section when you modify the Document means that it remains a section "Entitled XYZ" according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
2. VERBATIM COPYING #
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
3. COPYING IN QUANTITY #
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document's license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
4. MODIFICATIONS #
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
State on the Title page the name of the publisher of the Modified Version, as the publisher.
Preserve all the copyright notices of the Document.
Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document's license notice.
Include an unaltered copy of this License.
Preserve the section Entitled "History", Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled "History" in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the "History" section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
For any section Entitled "Acknowledgements" or "Dedications", Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
Delete any section Entitled "Endorsements". Such a section may not be included in the Modified Version.
Do not retitle any existing section to be Entitled "Endorsements" or to conflict in title with any Invariant Section.
Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version's license notice. These titles must be distinct from any other section titles.
You may add a section Entitled "Endorsements", provided it contains nothing but endorsements of your Modified Version by various parties--for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
5. COMBINING DOCUMENTS #
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled "History" in the various original documents, forming one section Entitled "History"; likewise combine any sections Entitled "Acknowledgements", and any sections Entitled "Dedications". You must delete all sections Entitled "Endorsements".
6. COLLECTIONS OF DOCUMENTS #
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT WORKS #
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an "aggregate" if the copyright resulting from the compilation is not used to limit the legal rights of the compilation's users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document's Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
8. TRANSLATION #
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled "Acknowledgements", "Dedications", or "History", the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
9. TERMINATION #
You may not copy, modify, sublicense, or distribute the Document except as expressly provided for under this License. Any other attempt to copy, modify, sublicense or distribute the Document is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
10. FUTURE REVISIONS OF THIS LICENSE #
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License "or any later version" applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation.
ADDENDUM: How to use this License for your documents #
Copyright (c) YEAR YOUR NAME. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled “GNU Free Documentation License”.
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the “with...Texts.” line with this:
with the Invariant Sections being LIST THEIR TITLES, with the Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.