- 1 Présentation conceptuelle
- 2 Scénario d'utilisation
- 3 Configuration requise
- 4 Présentation des scripts d'amorçage Geo
- 5 Installation en tant qu'extension
- 6 Configuration du premier site d'une grappe géographique
- 7 Ajout d'un autre site à une grappe géographique
- 8 Ajout de l'arbitre
- 9 Surveillance des sites de grappe
- 10 Étapes suivantes
- 11 Complément d'informations
- 12 Mentions légales
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Démarrage rapide de Geo Clustering #
Résumé#
Geo Clustering vous permet d'avoir plusieurs sites dispersés géographiquement avec une grappe locale pour chacun. Le basculement entre ces grappes est coordonné par une entité de niveau supérieur : le gestionnaire de tickets de grappe booth. Le présent document explique la configuration de base d'une grappe géographique, à l'aide des scripts d'amorçage Geo fournis par le paquetage ha-cluster-bootstrap.
- 1 Présentation conceptuelle
- 2 Scénario d'utilisation
- 3 Configuration requise
- 4 Présentation des scripts d'amorçage Geo
- 5 Installation en tant qu'extension
- 6 Configuration du premier site d'une grappe géographique
- 7 Ajout d'un autre site à une grappe géographique
- 8 Ajout de l'arbitre
- 9 Surveillance des sites de grappe
- 10 Étapes suivantes
- 11 Complément d'informations
- 12 Mentions légales
- A GNU Licenses
1 Présentation conceptuelle #
Les grappes géographiques basées sur SUSE® Linux Enterprise High Availability Extension peuvent être considérées comme des grappes de « superposition », dans lesquelles chaque site de grappe correspond à un noeud d'une grappe traditionnelle. La grappe de superposition est gérée par le gestionnaire de ticket de grappe booth (appelé ci-après booth). Chacune des parties impliquées dans une grappe géographique exécute un service, le boothd. Celui-ci se connecte aux daemons booth en cours d'exécution sur les autres sites et échange des informations de connectivité. Pour rendre les ressources de grappe hautement disponibles entre les sites, le booth s'appuie sur les objets de grappe appelés tickets. Un ticket donne le droit d'exécuter certaines ressources sur un site de grappe spécifique. Le booth garantit que chaque ticket est accordé à un seul site à la fois.
En cas d'interruption de la communication entre deux instances de booth, cela peut provenir d'une défaillance du réseau entre les sites de grappe ou d'une indisponibilité d'un site de grappe. Dans ce cas, vous avez besoin d'une instance supplémentaire (un troisième site de grappe ou un arbitre) pour parvenir à un consensus sur les décisions (par exemple, le basculement des ressources entre les sites). Les arbitres sont des machines uniques (hors des grappes) qui exécutent une instance de booth dans un mode particulier. Chaque grappe géographique peut avoir un ou plusieurs arbitres.
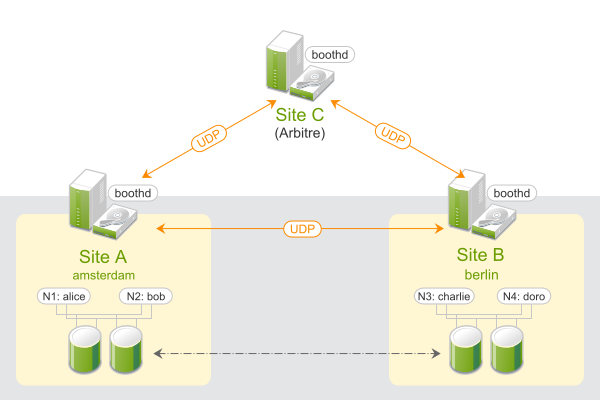
Figure 1 : grappe à deux sites (2x2 noeuds + arbitre) #
Pour plus de détails sur le concept, les composants et la gestion des tickets pour les grappes géographiques, reportez-vous au Book “Geo Clustering Guide”, Chapter 2 “Conceptual Overview”.
2 Scénario d'utilisation #
Dans l'exemple suivant, nous allons configurer une grappe géographique de base avec deux sites de grappe et un arbitre :
Supposons que les sites de grappe soient nommés
amsterdametberlin.Supposons que chaque site se compose de deux noeuds. Les noeuds
aliceetbobappartiennent à la grappeamsterdam. Les noeudscharlieetdoroappartiennent à la grappeberlin.Le site
amsterdamrecevra l'adresse IP virtuelle suivante :192.168.201.100.Le site
berlinrecevra l'adresse IP virtuelle suivante :192.168.202.100.Supposons que l'arbitre a l'adresse IP suivante :
192.168.203.100.
Avant de poursuivre, assurez-vous que les conditions suivantes sont remplies :
Configuration requise #
- Deux grappes existantes
Vous avez au moins deux grappes existantes que vous souhaitez combiner dans une grappe géographique. (Si vous devez configurer deux grappes d'abord, suivez les instructions du manuel Article “Démarrage rapide de l'installation et de la configuration”.)
- Noms de grappe pertinents
Chaque grappe possède un nom de grappe pertinent défini dans le fichier
/etc/corosync/corosync.confqui reflète son emplacement.- Arbitre
Vous avez installé une troisième machine qui ne fait partie d'aucune grappe existante et doit être utilisée en tant qu'arbitre.
Pour plus de détails sur chaque élément, reportez-vous également à la Section 3, « Configuration requise ».
3 Configuration requise #
Configuration logicielle requise #
Toutes les machines (noeuds de grappe et arbitres) qui feront partie de la grappe géographique sont équipés des logiciels suivants :
SUSE® Linux Enterprise Server 12 SP5
SUSE Linux Enterprise High Availability Extension 12 SP5
Geo Clustering for SUSE Linux Enterprise High Availability Extension 12 SP5
Configuration du réseau #
Les adresses IP virtuelles à utiliser pour chaque site de grappe doivent être accessibles dans la grappe géographique.
Les sites doivent être accessibles sur un port UDP et un port TCP par instance de booth. En d'autres termes, les éventuels pare-feux ou tunnels IPsec intermédiaires doivent être configurés en conséquence.
D'autres décisions de configuration peuvent nécessiter l'ouverture de ports supplémentaires (par exemple, pour la réplication de base de données ou DRBD).
Autres conditions requises et recommandations #
Tous les noeuds de grappe sur tous les sites doivent être synchronisés avec un serveur NTP en dehors de la grappe. Pour plus d'informations, consultez le site https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Si les noeuds ne sont pas synchronisés, les fichiers journaux et les rapports de grappe sont très difficiles à analyser.
Utilisez un nombre impair de membres dans votre grappe géographique. En cas d'interruption de la connexion réseau, cela permet de garantir qu'il y a toujours une majorité de sites (afin d'éviter les scénarios de vues de grappe divergentes). Si vous disposez d'un nombre pair de sites de grappe, utilisez un arbitre.
La grappe sur chaque site a un nom pertinent, par exemple :
amsterdametberlin.Les noms de grappe pour chaque site sont définis dans leur fichier
/etc/corosync/corosync.confrespectif :totem { [...] cluster_name: amsterdam }Cette opération peut être réalisée soit manuellement (en modifiant le fichier
/etc/corosync/corosync.conf), soit avec le module de grappe YaST (en basculant sur la catégorie et en définissant un ). Ensuite, arrêtez et démarrez le servicepacemakerpour appliquer les modifications :root #systemctlstop pacemakerroot #systemctlstart pacemaker
4 Présentation des scripts d'amorçage Geo #
À l'aide du script
ha-cluster-geo-init, configurez une grappe en tant que premier site d'une grappe géographique. Le script utilise certains paramètres tels que les noms des grappes, l'arbitre et un ou plusieurs tickets pour créer le fichier/etc/booth/booth.conf. Il copie la configuration booth sur tous les noeuds du site de grappe actuel. Il configure également les ressources de grappe nécessaires pour le booth sur le site de grappe actuel.Pour plus de détails, reportez-vous à la Section 6, « Configuration du premier site d'une grappe géographique ».
À l'aide du script
ha-cluster-geo-join, ajoutez la grappe actuelle à une grappe géographique existante. Le script copie la configuration booth d'un site de grappe existant et l'écrit dans le fichier/etc/booth/booth.confsur tous les noeuds du site de grappe actuel. Il configure également les ressources de grappe nécessaires pour le booth sur le site de grappe actuel.Pour plus de détails, reportez-vous à la Section 7, « Ajout d'un autre site à une grappe géographique ».
À l'aide du script
ha-cluster-geo-init-arbitrator, configurez la machine actuelle en tant qu'arbitre pour la grappe géographique. Le script copie de la configuration booth d'un site de grappe existant et l'écrit dans le fichier/etc/booth/booth.conf.Pour plus de détails, reportez-vous à la Section 8, « Ajout de l'arbitre ».
Tous les scripts d'amorçage consignent des données dans le fichier/var/log/ha-cluster-bootstrap.log. Pour toute information à propos du processus d'amorçage, consultez le fichier journal. Toutes les options définies lors du processus d'amorçage peuvent être modifiées ultérieurement (en changeant les paramètres booth, les ressources, etc.). Pour plus de détails, consultez le Book “Geo Clustering Guide”.
5 Installation en tant qu'extension #
La prise en charge de l'utilisation de grappes à haute disponibilité sur des distances illimitées est disponible sous forme d'extension distincte, appelée Geo Clustering for SUSE Linux Enterprise High Availability Extension.
Pour configurer une grappe géographique, vous avez besoin des paquetages inclus dans les modèles d'installation suivants :
Haute disponibilitéGeo Clustering for High Availability
Ces deux modèles sont disponibles uniquement si vous avez enregistré votre système auprès du SUSE Customer Center (ou d'un serveur d'enregistrement local) et ajouté les canaux de produit ou supports d'installation en tant qu'extension. Pour plus d'informations sur l'installation des extensions, reportez-vous au SUSE Linux Enterprise 12 SP5 Deployment Guide (Guide de déploiement de SUSE Linux Enterprise 12 SP5) : https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Procédure 1 : Installation des paquetages #
Pour installer les paquetages des deux modèles via la ligne de commande, utilisez Zypper :
root #zypperinstall -t pattern ha_sles ha_geoVous pouvez aussi utiliser YaST pour une installation graphique :
Démarrez YaST en tant qu'utilisateur
rootet sélectionnez › .Cliquez sur › et activez les modèles suivants :
Haute disponibilitéGeo Clustering for High Availability
Cliquez sur pour démarrer l'installation des paquetages.
Important : installation des paquetages logiciels sur toutes les parties
Les paquetages logiciels nécessaires pour la haute disponibilité et les grappes géographiques ne sont pas copiés automatiquement sur les noeuds de grappe.
Installez SUSE Linux Enterprise Server 12 SP5 ainsi que les modèles
Haute disponibilitéetGeo Clustering for High Availabilitysur toutes les machines qui feront partie de votre grappe Geo.Au lieu d'installer manuellement les paquetages sur toutes les machines qui feront partie de votre grappe, utilisez AutoYaST pour cloner des noeuds existants. Pour plus d'informations, reportez-vous au Book “Administration Guide”, Chapter 3 “Installing the High Availability Extension”, Section 3.2 “Mass Installation and Deployment with AutoYaST”.
Toutefois, l'extension Geo Clustering doit être installée manuellement sur toutes les machines faisant partie de la grappe géographique. AutoYaST n'est pas encore pris en charge pour Geo Clustering for SUSE Linux Enterprise High Availability Extension.
6 Configuration du premier site d'une grappe géographique #
Utilisez le script ha-cluster-geo-init pour configurer une grappe existante en tant que premier site d'une grappe géographique.
Procédure 2 : configuration du premier site (amsterdam) avec le script ha-cluster-geo-init #
Définissez une adresse IP virtuelle par site de grappe qui peut être utilisée pour accéder au site. Supposons que nous utilisons
192.168.201.100et192.168.202.100à cet effet. Vous ne devez pas encore configurer les adresses IP virtuelles en tant que ressources de grappe. Les scripts d'amorçage s'en chargeront.Définissez le nom d'au moins un ticket qui accordera les droits pour l'exécution de certaines ressources sur un site de grappe. Utilisez un nom pertinent qui reflète les ressources qui dépendront du ticket (par exemple,
ticket-nfs). Les scripts d'amorçage ont uniquement besoin du nom de ticket, vous pouvez définir les détails restants (dépendances de ticket des ressources) plus tard, comme décrit à la Section 10, « Étapes suivantes ».Connectez-vous à un noeud d'une grappe existante (par exemple, au noeud
alicede la grappeamsterdam).Exécutez le script
ha-cluster-geo-init. Par exemple, utilisez les options suivantes :root #ha-cluster-geo-init\ --clusters1 "amsterdam=192.168.201.100 berlin=192.168.202.100" \ --tickets2 ticket-nfs \ --arbitrator3 192.168.203.100Les noms des sites de grappe (comme définis dans le fichier
/etc/corosync/corosync.conf) et les adresses IP virtuelles que vous souhaitez utiliser pour chaque site de grappe. Dans ce cas, nous avons deux sites de grappe (amsterdametberlin) avec une adresse IP virtuelle pour chacun.Le nom d'un ou de plusieurs tickets.
Le nom d'hôte ou l'adresse IP d'une machine en dehors des grappes.
Le script d'amorçage crée le fichier de configuration booth et le synchronise pour les différents sites de grappe. Il crée également les ressources de grappe de base nécessaires pour le booth. L'Étape 4 de la Procédure 2 conduirait à la configuration booth et aux ressources de grappe suivantes :
Exemple 1 : configuration booth créée par le script ha-cluster-geo-init #
# The booth configuration file is "/etc/booth/booth.conf". You need to # prepare the same booth configuration file on each arbitrator and # each node in the cluster sites where the booth daemon can be launched. # "transport" means which transport layer booth daemon will use. # Currently only "UDP" is supported. transport="UDP" port="9929" arbitrator="192.168.203.100" site="192.168.201.100" site="192.168.202.100" authfile="/etc/booth/authkey" ticket="ticket-nfs" expire="600"
Exemple 2 : ressources de grappe créées par le script ha-cluster-geo-init #
primitive1 booth-ip IPaddr2 \ params rule #cluster-name eq amsterdam ip=192.168.201.100 \ params rule #cluster-name eq berlin ip=192.168.202.100 \ primitive2 booth-site ocf:pacemaker:booth-site \ meta resource-stickiness=INFINITY \ params config=booth \ op monitor interval=10s group3 g-booth booth-ip booth-site \ meta target-role=Stopped4
Une adresse IP virtuelle pour chaque site de grappe. Elle est requise par les daemons booth qui ont besoin d'une adresse IP persistante sur chaque site de grappe. | |
Une ressource primitive pour le daemon booth. Elle communique avec les daemons booth sur les autres sites de grappe. Le daemon peut être démarré sur n'importe quel noeud du site, mais, pour que la ressource reste sur le même noeud, si possible, la permanence de la ressource doit être définie sur | |
Un groupe de ressources de grappe pour les deux primitives. Avec cette configuration, chaque daemon de booth sera disponible sur son adresse IP individuelle, indépendamment du noeud sur lequel le daemon est exécuté. | |
Le groupe de ressources de grappe n'est pas démarré par défaut. Après vérification de la configuration de vos ressources de grappe (et l'ajout des ressources nécessaires pour terminer votre configuration), vous devez démarrer le groupe de ressources. Reportez-vous à la section Étapes requises pour terminer la configuration d'une grappe géographique pour plus d'informations. |
7 Ajout d'un autre site à une grappe géographique #
Après avoir initialisé le premier site de votre grappe géographique, ajoutez la deuxième grappe avec le script ha-cluster-geo-join, comme décrit dans la Procédure 3. Le script doit avoir un accès SSH à un site de grappe déjà configuré et ajoutera la grappe actuelle à la grappe géographique.
Procédure 3 : ajout du deuxième site (berlin) avec le script ha-cluster-geo-join #
Connectez-vous à un noeud du site de grappe que vous souhaitez ajouter (par exemple, au noeud
charliede la grappeberlin).Exécutez la commande
ha-cluster-geo-join. Par exemple :root #ha-cluster-geo-join\ --cluster-node1 192.168.201.100\ --clusters2 "amsterdam=192.168.201.100 berlin=192.168.202.100"Indique à partir de quel emplacement le système doit copier la configuration booth. Utilisez l'adresse IP ou le nom d'hôte d'un noeud d'un site de grappe géographique déjà configuré. Vous pouvez également utiliser l'adresse IP virtuelle d'un site de grappe déjà existant (comme dans cet exemple). Vous pouvez aussi utiliser l'adresse IP ou le nom d'hôte d'un arbitre déjà configuré pour votre grappe géographique.
Les noms des sites de grappe (comme définis dans le fichier
/etc/corosync/corosync.conf) et les adresses IP virtuelles que vous souhaitez utiliser pour chaque site de grappe. Dans ce cas, nous avons deux sites de grappe (amsterdametberlin) avec une adresse IP virtuelle pour chacun.
Le script ha-cluster-geo-join copie la configuration booth à partir de 1 (voir Exemple 1). En outre, il crée les ressources de grappe nécessaires pour le booth (voir Exemple 2).
8 Ajout de l'arbitre #
Une fois que vous avez configuré tous les sites de votre grappe géographique avec les scripts ha-cluster-geo-init et ha-cluster-geo-join, définissez l'arbitre avec le script ha-cluster-geo-init-arbitrator.
Procédure 4 : configuration de l'arbitre avec le script ha-cluster-geo-init-arbitrator #
Connectez-vous à la machine que vous souhaitez utiliser en tant qu'arbitre.
Exécutez la commande suivante. Par exemple :
root #ha-cluster-geo-init-arbitrator--cluster-node1 192.168.201.100Indique à partir de quel emplacement le système doit copier la configuration booth. Utilisez l'adresse IP ou le nom d'hôte d'un noeud d'un site de grappe géographique déjà configuré. Vous pouvez également utiliser l'adresse IP virtuelle d'un site de grappe déjà existant (comme dans cet exemple).
Le script ha-cluster-geo-init-arbitrator copie la configuration booth à partir de 1 (voir Exemple 1). Il active et démarre également le service de booth sur l'arbitre. Ainsi, l'arbitre est prêt à communiquer avec les instances de booth sur les sites de grappe dès que les services de booth y sont aussi en cours d'exécution.
9 Surveillance des sites de grappe #
Pour afficher les deux sites de grappe avec les ressources et le ticket que vous avez créés au cours du processus d'amorçage, utilisez Hawk2. L'interface Web Hawk2 vous permet de surveiller et de gérer plusieurs grappes (indépendantes) et grappes géographiques.
Conditions préalables #
Toutes les grappes à surveiller à partir du de Hawk2 doivent exécuter SUSE Linux Enterprise High Availability Extension 12 SP5.
Si vous n'avez pas encore remplacé le certificat auto-signé pour Hawk2 par votre propre certificat (ou un certificat signé par une autorité de certification officielle) sur chaque noeud de grappe, effectuez l'opération suivante : connectez-vous à Hawk2 sur chaque noeud dans chaque grappe au moins une fois. Vérifiez le certificat (ou ajoutez une exception dans le navigateur afin d'ignorer l'avertissement). Sans cela, Hawk2 ne peut pas se connecter à la grappe.
Procédure 5 : utilisation du tableau de bord Hawk2 #
Démarrez un navigateur Web et entrez l'adresse IP virtuelle de votre premier site de grappe,
amsterdam:https://192.168.201.100:7630/
Vous pouvez également utiliser l'adresse IP ou le nom d'hôte du noeud
aliceoubob. Si vous avez configuré les deux noeuds avec les scripts d'amorçage, le servicehawkdoit s'exécuter sur les deux noeuds.Connectez-vous à l'interface Web de Hawk2.
Dans la barre de navigation de gauche, sélectionnez .
Hawk2 affiche une vue d'ensemble des noeuds et ressources sur le site de grappe actuel. En outre, il indique les qui ont été configurés pour la grappe géographique. Si vous avez besoin d'informations sur les icônes utilisées dans cette vue, cliquez sur (Légende).

Figure 2 : tableau de bord Hawk2 avec un site de grappe (
amsterdam) #Pour ajouter un tableau de bord pour le deuxième site de grappe, cliquez sur .
Entrez le permettant d'identifier la grappe dans le . Dans ce cas, il s'agit de
berlin.Entrez le nom d'hôte complet de l'un des noeuds de la grappe (dans ce cas,
charlieoudoro).Cliquez sur . Hawk2 affiche un deuxième onglet pour le site de grappe nouvellement ajouté avec une vue d'ensemble de ses noeuds et ressources.
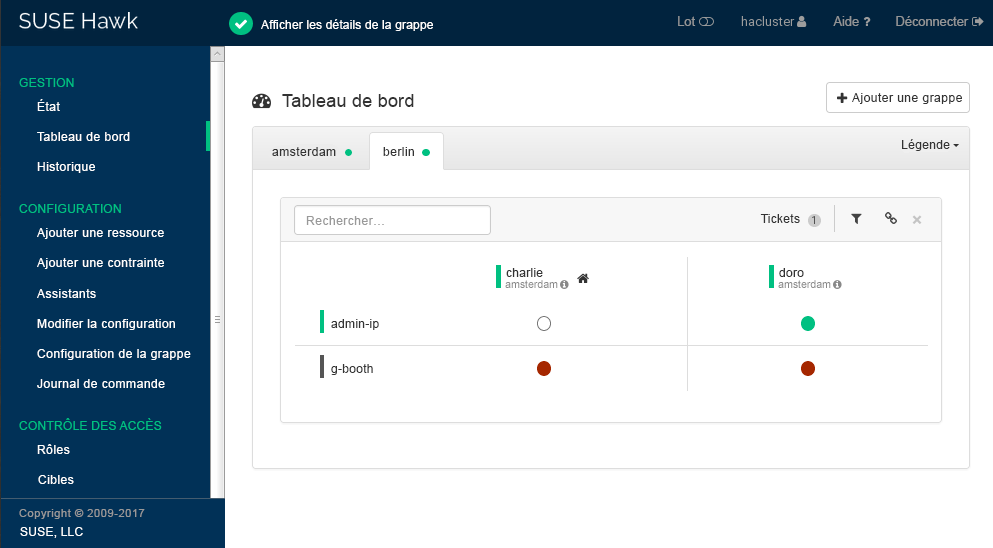
Figure 3 : tableau de bord Hawk2 avec deux sites de grappe #
Pour afficher plus de détails sur un site de grappe ou sur sa gestion, basculez vers l'onglet du site et cliquez sur l'icône de la chaîne.
Hawk2 ouvre la vue de ce site dans une nouvelle fenêtre de navigateur ou un nouvel onglet. Cette vue vous permet d'administrer cette partie de la grappe géographique.
10 Étapes suivantes #
Les scripts d'amorçage de mise en grappe géographique constituent un moyen rapide pour configurer une grappe géographique de base qui peut être utilisée à des fins de test. Toutefois, pour convertir la grappe géographique résultante en une grappe géographique opérationnelle pouvant être utilisée dans des environnements de production, d'autres étapes sont requises (voir Étapes requises pour terminer la configuration d'une grappe géographique).
Étapes requises pour terminer la configuration d'une grappe géographique #
- Démarrage des services de booth sur des sites de grappe
Après le processus d'amorçage, le service de booth de l'arbitre ne peut pas encore communiquer avec les services de booth des sites de grappe, car ils ne sont pas démarrés par défaut.
Le service de booth pour chaque site de grappe est géré par le groupe de ressources de booth
g-booth(voir Exemple 2, « ressources de grappe créées par le scriptha-cluster-geo-init»). Pour démarrer une instance du service de booth par site, démarrez le groupe de ressources de booth respectif sur chaque site de grappe. Cela permet à toutes les instances de booth de communiquer entre elles.- Configuration des dépendances de tickets et ordre des contraintes
Pour faire dépendre des ressources du ticket que vous avez créé au cours du processus d'amorçage de grappe géographique, configurez des contraintes. Pour chaque contrainte, définissez une
stratégie relative aux pertesqui définit ce qu'il arriverait aux ressources respectives si le ticket était révoqué d'un site de grappe.Pour plus de détails, reportez-vous au Book “Geo Clustering Guide”, Chapter 6 “Configuring Cluster Resources and Constraints”.
- Octroi initial d'un ticket à un site
Avant que le booth puisse gérer un certain ticket au sein de la grappe géographique, vous devez d'abord l'attribuer à un site manuellement. Pour accorder un ticket, vous pouvez utiliser l'outil de ligne de commande du client de booth ou Hawk2.
Pour plus de détails, reportez-vous au Book “Geo Clustering Guide”, Chapter 8 “Managing Geo Clusters”.
Les scripts d'amorçage créent les mêmes ressources de booth sur les deux sites de grappe et les mêmes fichiers de configuration booth sur tous les sites, y compris l'arbitre. Si vous étendez la configuration de grappe géographique (pour passer à un environnement de production), vous devrez probablement affiner la configuration booth et modifier la configuration des ressources de grappe liées au booth. Ensuite, vous devez synchroniser les modifications sur les autres sites de votre grappe géographique pour qu'elles soient prises en compte.
Remarque : synchronisation des modifications entre les différents sites de grappe
Pour synchroniser les modifications de la configuration booth sur tous les sites de grappe (y compris l'arbitre), utilisez Csync2. Pour plus d'informations, reportez-vous au Book “Geo Clustering Guide”, Chapter 5 “Synchronizing Configuration Files Across All Sites and Arbitrators”.
Le CIB (base d'informations de la grappe) n'est pas synchronisé automatiquement entre les différents sites d'une grappe géographique. Cela signifie que toutes les modifications de la configuration des ressources requises sur tous les sites de grappe doivent être transférées vers les autres sites manuellement. Pour ce faire, ajoutez des balises aux ressources respectives, exportez-les à partir du CIB actuel, puis importez-les dans le CIB sur les autres sites de grappe. Pour plus de détails, reportez-vous au Book “Geo Clustering Guide”, Chapter 6 “Configuring Cluster Resources and Constraints”, Section 6.4 “Transferring the Resource Configuration to Other Cluster Sites”.
11 Complément d'informations #
Pour plus de documentation sur ce produit, reportez-vous à l'adresse https://documentation.suse.com/sle-ha-12/. Vous y trouverez notamment un manuel complet
Geo Clustering Guide(Guide de mise en grappe géographique). Pour en savoir plus sur les tâches de configuration et d'administration, consultez ce manuel.Un document avec des informations détaillées sur la procédure de réplication des données via DRBD sur des grappes Geo a été publié dans la série
SUSE Best Practices(Meilleures pratiques SUSE) : https://documentation.suse.com/sbp/all/html/SBP-DRBD/index.html.
12 Mentions légales #
Copyright © 2006– 2025 SUSE LLC et contributeurs. Tous droits réservés.
Il est autorisé de copier, distribuer et/ou modifier ce document conformément aux conditions de la licence de documentation libre GNU version 1.2 ou (à votre discrétion) 1.3, avec la section permanente qu'est cette mention de copyright et la licence. Une copie de la version de licence 1.2 est incluse dans la section intitulée « Licence de documentation libre GNU ».
Pour les marques commerciales SUSE, consultez le site Web http://www.suse.com/company/legal/. Toutes les autres marques de fabricants tiers sont la propriété de leur détenteur respectif. Les symboles de marque commerciale (®,™, etc.) indiquent des marques commerciales de SUSE et de ses filiales. Des astérisques (*) désignent des marques commerciales de fabricants tiers.
Toutes les informations de cet ouvrage ont été regroupées avec le plus grand soin. Cela ne garantit cependant pas sa complète exactitude. Ni SUSE LLC, ni les sociétés affiliées, ni les auteurs, ni les traducteurs ne peuvent être tenus responsables des erreurs possibles ou des conséquences qu'elles peuvent entraîner.
A GNU Licenses #
This appendix contains the GNU Free Documentation License version 1.2.
GNU Free Documentation License #
Copyright (C) 2000, 2001, 2002 Free Software Foundation, Inc. 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA. Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
0. PREAMBLE #
The purpose of this License is to make a manual, textbook, or other functional and useful document "free" in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
1. APPLICABILITY AND DEFINITIONS #
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The "Document", below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as "you". You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A "Modified Version" of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document's overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The "Invariant Sections" are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The "Cover Texts" are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A "Transparent" copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The "Title Page" means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, "Title Page" means the text near the most prominent appearance of the work's title, preceding the beginning of the body of the text.
A section "Entitled XYZ" means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as "Acknowledgements", "Dedications", "Endorsements", or "History".) To "Preserve the Title" of such a section when you modify the Document means that it remains a section "Entitled XYZ" according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
2. VERBATIM COPYING #
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
3. COPYING IN QUANTITY #
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document's license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
4. MODIFICATIONS #
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
State on the Title page the name of the publisher of the Modified Version, as the publisher.
Preserve all the copyright notices of the Document.
Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document's license notice.
Include an unaltered copy of this License.
Preserve the section Entitled "History", Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled "History" in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the "History" section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
For any section Entitled "Acknowledgements" or "Dedications", Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
Delete any section Entitled "Endorsements". Such a section may not be included in the Modified Version.
Do not retitle any existing section to be Entitled "Endorsements" or to conflict in title with any Invariant Section.
Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version's license notice. These titles must be distinct from any other section titles.
You may add a section Entitled "Endorsements", provided it contains nothing but endorsements of your Modified Version by various parties--for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
5. COMBINING DOCUMENTS #
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled "History" in the various original documents, forming one section Entitled "History"; likewise combine any sections Entitled "Acknowledgements", and any sections Entitled "Dedications". You must delete all sections Entitled "Endorsements".
6. COLLECTIONS OF DOCUMENTS #
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT WORKS #
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an "aggregate" if the copyright resulting from the compilation is not used to limit the legal rights of the compilation's users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document's Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
8. TRANSLATION #
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled "Acknowledgements", "Dedications", or "History", the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
9. TERMINATION #
You may not copy, modify, sublicense, or distribute the Document except as expressly provided for under this License. Any other attempt to copy, modify, sublicense or distribute the Document is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
10. FUTURE REVISIONS OF THIS LICENSE #
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License "or any later version" applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation.
ADDENDUM: How to use this License for your documents #
Copyright (c) YEAR YOUR NAME. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled “GNU Free Documentation License”.
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the “with...Texts.” line with this:
with the Invariant Sections being LIST THEIR TITLES, with the Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.