- 關於本指南
- I Ceph Dashboard
- II 叢集操作
- III 在叢集中儲存資料
- IV 存取叢集資料
- V 與虛擬化工具整合
- VI 設定叢集
- A 以上游「Octopus」小數點版本為基礎的 Ceph 維護更新
- B 文件更新
- 辭彙表
- 2.1 Ceph Dashboard 登入畫面
- 2.2 Ceph Dashboard 首頁
- 2.3 狀態工具集
- 2.4 容量工具集
- 2.5 效能工具集
- 3.1 使用者管理
- 3.2 新增使用者
- 3.3 使用者角色
- 3.4 新增角色
- 4.1 主機
- 4.2 服務
- 4.3 Ceph 監控程式
- 4.4 服務
- 4.5 Ceph OSD
- 4.6 OSD 旗標
- 4.7 OSD 復原優先程度
- 4.8 OSD 詳細資料
- 4.9 建立 OSD
- 4.10 新增主要裝置
- 4.11 建立新增了主要裝置的 OSD
- 4.12
- 4.13 新增的 OSD
- 4.14 叢集組態
- 4.15 CRUSH 地圖
- 4.16 管理員模組
- 4.17 記錄
- 5.1 池清單
- 5.2 新增新池
- 6.1 RBD 影像清單
- 6.2 RBD 詳細資料
- 6.3 RBD 組態
- 6.4 新增新的 RBD
- 6.5 RBD 快照
- 6.6 執行中
rbd-mirror精靈 - 6.7 建立具有 RBD 應用程式的池
- 6.8 設定複製模式
- 6.9 新增對等身分證明
- 6.10 複本池清單
- 6.11 新 RBD 影像
- 6.12 同步的新 RBD 影像
- 6.13 RBD 影像的複製狀態
- 6.14 iSCSI 目標清單
- 6.15 iSCSI 目標詳細資料
- 6.16 新增新目標
- 7.1 NFS 輸出項清單
- 7.2 NFS 輸出項詳細資料
- 7.3 新增新的 NFS 輸出項
- 7.4 編輯 NFS 輸出項
- 8.1 CephFS 詳細資料
- 8.2 CephFS 詳細資料
- 9.1 閘道的詳細資料
- 9.2 閘道使用者
- 9.3 新增新閘道使用者
- 9.4 閘道桶詳細資料
- 9.5 編輯桶的詳細資料
- 12.1 Ceph 叢集
- 12.2 互聯綱要
- 12.3 放置群組狀態
- 17.1 使用混合裝置類別的 OSD
- 17.2 範例樹
- 17.3 節點取代方法
- 17.4 池中的放置群組
- 17.5 放置群組和 OSD
- 18.1 移轉前的池
- 18.2 快取層設定
- 18.3 資料衝洗
- 18.4 設定重疊層
- 18.5 完成移轉
- 20.1 RADOS 通訊協定
- 22.1 iSCSI 啟動器內容
- 22.2 探索目標入口
- 22.3 目標入口
- 22.4 目標
- 22.5 iSCSI 目標內容
- 22.6 裝置詳細資料
- 22.7 新磁碟區精靈
- 22.8 離線磁碟提示
- 22.9 確認選取的磁碟區設定
- 22.10 iSCSI 啟動器內容
- 22.11 新增目標伺服器
- 22.12 管理多重路徑裝置
- 22.13 多重路徑的路徑清單
- 22.14 新增儲存對話方塊
- 22.15 自定空間設定
- 22.16 iSCSI 資料儲存綜覽
- 25.1 NFS Ganesha 結構
- 30.1
cephx基本驗證 - 30.2
cephx驗證 - 30.3
cephx驗證 - MDS 和 OSD
版權所有 © 2020–2023 SUSE LLC 和貢獻者。版權所有。
除非另有說明,否則本文件依據創用 CC 姓名標示-相同方式分享 4.0 國際 (Creative Commons Attribution-ShareAlike 4.0 International, CC-BY-SA 4.0) 獲得授權:https://creativecommons.org/licenses/by-sa/4.0/legalcode。
如需 SUSE 商標,請參閱 http://www.suse.com/company/legal/。所有的協力廠商商標均為其各別擁有廠商的財產。®、™ 等商標符號表示 SUSE 及其關係企業的商標。星號 (*) 表示協力廠商的商標。
本手冊中所有資訊在編輯時,都已全力注意各項細節。但這不保證百分之百的正確性。因此,SUSE LLC 及其關係企業、作者或譯者都不需對任何錯誤或造成的結果負責。
關於本指南 #
本指南重點介紹在部署基本 Ceph 叢集 (第 2 天操作) 之後,做為管理員需要處理的例行任務。此外,還介紹了存取 Ceph 叢集中所儲存資料的所有支援方法。
SUSE Enterprise Storage 7 是 SUSE Linux Enterprise Server 15 SP2 的一個延伸。它結合了 Ceph (http://ceph.com/) 儲存專案的功能與 SUSE 的企業工程和支援。憑藉 SUSE Enterprise Storage 7,IT 組織能夠部署可以支援一些使用商用硬體平台的使用案例的分散式儲存架構。
1 可用文件 #
我們的產品文件可從 https://documentation.suse.com 獲取,您也可以在此處找到最新更新,以及瀏覽或下載各種格式的文件。最新的文件更新以英語版本提供。
此外,您安裝的系統的 /usr/share/doc/manual 下會提供產品文件。該文件包含在名為
ses-manual_LANG_CODE的 RPM 套件中。如果系統上尚未安裝該套件,請進行安裝,例如:
root # zypper install ses-manual_en針對本產品提供的文件如下:
- 部署指南
本指南重點介紹如何部署基本 Ceph 叢集以及如何部署其他服務。此外,還介紹了從先前的產品版本升級至 SUSE Enterprise Storage 7 的步驟。
- 管理和操作指南
本指南重點介紹在部署基本 Ceph 叢集 (第 2 天操作) 之後,做為管理員需要處理的例行任務。此外,還介紹了存取 Ceph 叢集中所儲存資料的所有支援方法。
- 安全強化指南
本指南重點介紹如何確保叢集的安全。
- Troubleshooting Guide
本指南將引導您瞭解執行 SUSE Enterprise Storage 7 時的各種常見問題以及與 Ceph 或物件閘道等相關元件有關的其他問題。
- SUSE Enterprise Storage for Windows 指南
本指南介紹如何使用 Windows 驅動程式整合、安裝和設定 Microsoft Windows 環境和 SUSE Enterprise Storage。
2 提供回饋 #
歡迎您對本文件提供回饋和貢獻。回饋管道包括:
- 服務要求和支援
如需產品可用的服務與支援選項,請參閱 http://www.suse.com/support/。
若要開啟服務要求,需要在 SUSE Customer Center 註冊一個 SUSE 訂閱。請移至 https://scc.suse.com/support/requests 並登入,然後按一下。
- 錯誤報告
在 https://bugzilla.suse.com/ 中報告文件問題。報告問題需要有 Bugzilla 帳戶。
若要簡化此程序,可以使用本文件 HTML 版本中的標題旁邊的連結。如此會在 Bugzilla 中預先選取正確的產品和類別,並新增目前章節的連結。然後,您便可以立即開始輸入錯誤報告。
- 協助改進
若要協助我們改進本文件,請使用本文件 HTML 版本中的標題旁邊的連結。這些連結會將您移至 GitHub 上的原始碼,在其中您可以開啟提取要求。參與貢獻需要有 GitHub 帳戶。
如需本文件使用的文件環境的詳細資訊,請參閱儲存庫的讀我檔案(網址:https://github.com/SUSE/doc-ses)。
- 郵件
您也可以將有關本文件中的錯誤以及相關回饋傳送至:<doc-team@suse.com>。請在其中包含文件標題、產品版本以及文件發行日期。此外,請包含相關的章節編號和標題 (或者提供 URL),並提供問題的簡要描述。
3 文件慣例 #
本文件中使用以下注意事項與排版慣例:
/etc/passwd:目錄名稱和檔案名稱PLACEHOLDER:以實際的值來取代 PLACEHOLDER
PATH:環境變數ls、--help:指令、選項和參數user:使用者或群組的名稱package_name:軟體套件的名稱
Alt、Alt–F1:按鍵或鍵組合。按鍵以大寫字母顯示,與鍵盤上的相同。
、 › :功能表項目、按鈕
AMD/Intel 本段僅與 Intel 64/AMD64 架構有關。箭頭標示了文字區塊的開頭與結尾。
IBM Z, POWER 本段內容僅與
IBM Z和POWER架構相關。箭頭標示了文字區塊的開頭與結尾。第 1 章「範例章節」:轉到本指南中另一章節的交互參照。
必須具有
root權限才能執行的指令。通常,您也可以在這些指令前加上sudo指令,以非特權使用者身分來執行它們。root #commandtux >sudocommand沒有權限的使用者也可以執行的指令。
tux >command注意事項
 警告:警告通知
警告:警告通知繼續操作之前必須瞭解的重要資訊。提醒您注意安全問題、可能的資料遺失、硬體損毀或者實際危險。
 重要:重要通知
重要:重要通知繼續操作之前應該瞭解的重要資訊。
 注意:注意通知
注意:注意通知其他資訊,例如各軟體版本之間的區別。
 提示:提示通知
提示:提示通知有用的資訊,例如一條準則或實用的建議。
精簡通知
其他資訊,例如各軟體版本之間的區別。
有用的資訊,例如一條準則或實用的建議。
4 產品生命週期和支援 #
不同的 SUSE 產品具有不同的產品生命週期。若要查看 SUSE Enterprise Storage 的確切生命週期日期,請參閱 https://www.suse.com/lifecycle/。
4.1 SUSE 支援定義 #
如需我們的支援政策和選項的資訊,請參閱 https://www.suse.com/support/policy.html 和 https://www.suse.com/support/programs/long-term-service-pack-support.html。
4.2 SUSE Enterprise Storage 支援聲明 #
若要獲得支援,您需要一個適當的 SUSE 訂閱。若要檢視為您提供的特定支援服務,請移至 https://www.suse.com/support/ 並選取您的產品。
支援層級的定義如下:
- L1
問題判斷,該技術支援層級旨在提供相容性資訊、使用支援、持續維護、資訊收集,以及使用可用文件進行基本疑難排解。
- L2
問題隔離,該技術支援層級旨在分析資料、重現客戶問題、隔離問題區域,並針對層級 1 不能解決的問題提供解決方法,或做為層級 3 的準備層級。
- L3
問題解決,該技術支援層級旨在借助工程方法解決層級 2 支援所確認的產品缺陷。
對於簽約的客戶與合作夥伴,SUSE Enterprise Storage 將為除以下套件外的其他所有套件提供 L3 支援:
技術預覽
音效、圖形、字型和作品
需要額外客戶合約的套件
模組 Workstation Extension 隨附的某些套件僅可享受 L2 支援。
名稱以 -devel 結尾的套件 (包含標題檔案和類似的開發人員資源) 只能與其主套件一起接受支援。
SUSE 僅支援使用原始套件,即,未發生變更且未重新編譯的套件。
4.3 技術預覽 #
技術預覽是 SUSE 提供的旨在讓使用者大略體驗未來創新的各種套件、堆疊或功能。隨附這些技術預覽只是為了提供方便,讓您有機會在自己的環境中測試新的技術。非常希望您能提供回饋!如果您測試了技術預覽,請聯絡 SUSE 代表,將您的體驗和使用案例告知他們。您的回饋對於我們的未來開發非常有幫助。
技術預覽存在以下限制:
技術預覽仍處於開發階段。因此,它們的功能可能不完整、不穩定,或者在其他方面不適合實際生產用途。
技術預覽不受支援。
技術預覽可能僅適用於特定的硬體架構。
技術預覽的詳細資料和功能可能隨時會發生變化。因此,可能無法升級至技術預覽的後續版本,而需要進行全新安裝。
可隨時從產品中移除技術預覽。SUSE 不承諾未來將提供此類技術的受支援版本。例如,如果 SUSE 發現某個預覽不符合客戶或市場需求,或者不符合企業標準,則可能會移除該預覽。
如需產品隨附的技術預覽綜覽,請參閱 https://www.suse.com/releasenotes/x86_64/SUSE-Enterprise-Storage/7 上的版本說明。
5 Ceph 參與者 #
Ceph 專案及其文件是數百個參與者和組織辛勤工作的成果。請參閱 https://ceph.com/contributors/,以取得詳細資料。
6 本指南中使用的指令和指令提示符 #
做為 Ceph 叢集管理員,您需要透過執行特定指令來設定和調整叢集行為。您將需要執行以下幾種類型的指令:
6.1 與 Salt 相關的指令 #
這些指令可協助您部署 Ceph 叢集節點、同時在數個 (或所有) 叢集節點上執行指令,或在您新增或移除叢集節點時為您提供協助。最常用的指令是 ceph-salt 和 ceph-salt config。您需要以 root 身分在 Salt Master 節點上執行 Salt 指令。透過以下提示符來引入這些指令:
root@master # 例如:
root@master # ceph-salt config ls6.2 與 Ceph 相關的指令 #
這些是較低層級的指令,用於在指令行上設定和微調叢集及其閘道的所有方面,例如 ceph、cephadm、rbd 或 radosgw-admin。
若要執行與 Ceph 相關的指令,您需要擁有 Ceph 金鑰的讀取存取權,而金鑰的功能則定義您在 Ceph 環境內的權限。一種方案是以 root 身分 (或透過 sudo) 執行 Ceph 指令,並使用不受限制的預設金鑰圈「ceph.client.admin.key」。
建議您使用更安全的方案,即為每個管理員使用者建立限制性更高的個別金鑰,並將其存放在使用者可讀取的目錄中,例如:
~/.ceph/ceph.client.USERNAME.keyring
若要使用自訂管理員使用者和金鑰圈,每次執行 ceph 指令 (使用 -n client.USER_NAME 和 --keyring PATH/TO/KEYRING 選項) 時,都需要指定該金鑰的使用者名稱和路徑。
為避免出現此情況,請將這些選項包含在各個使用者的 ~/.bashrc 檔案中的 CEPH_ARGS 變數中。
儘管您可以在任何叢集節點上執行與 Ceph 相關的指令,但我們建議您在管理節點上執行。本文件使用 cephuser 使用者來執行指令,因此透過以下提示符來引入指令:
cephuser@adm > 例如:
cephuser@adm > ceph auth list如果文件指示您在叢集節點上以特定角色來執行指令,應透過該提示符來定址。例如:
cephuser@mon > 6.2.1 執行 ceph-volume #
從 SUSE Enterprise Storage 7 開始,Ceph 服務以容器化方式執行。如果您需要在 OSD 節點上執行 ceph-volume,則需要在其前面加上 cephadm 指令,例如:
cephuser@adm > cephadm ceph-volume simple scan6.3 一般的 Linux 指令 #
與 Ceph 無關的 Linux 指令 (例如 mount、cat 或 openssl) 可透過 cephuser@adm > 或 root # 提示符來引入,具體取決於相關指令所需的權限。
6.4 其他資訊 #
如需 Ceph 金鑰管理的詳細資訊,請參閱第 30.2 節 「主要管理」。
第 I 部分 Ceph Dashboard #
- 1 關於 Ceph Dashboard
Ceph Dashboard 是一種內建的基於 Web 的 Ceph 管理和監控應用程式,負責管理叢集的各個方面和物件。在Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3 “部署 Ceph 叢集”中部署基本叢集後,將自動啟用該儀表板。
- 2 儀表板的 Web 使用者介面
若要登入 Ceph Dashboard,請將瀏覽器指向其 URL,包括連接埠號碼。執行以下指令可尋找位址:
- 3 管理 Ceph Dashboard 使用者和角色
如需在指令行上使用 Ceph 指令執行儀表板使用者管理的說明,請參閱第 11 章 「在指令行上管理使用者和角色」。
- 4 檢視叢集內部
您可以透過功能表項目檢視有關 Ceph 叢集主機、庫存、Ceph 監控程式、服務、OSD、組態、CRUSH 地圖、Ceph 管理員、記錄和監控檔案的詳細資訊。
- 5 管理池
如需 Ceph 池的更多一般資訊,請參閱第 18 章 「管理儲存池」。如需糾刪碼池特定的資訊,請參閱第 19 章 「糾刪碼池」。
- 6 管理 RADOS 區塊裝置
若要列出所有可用的 RADOS 區塊裝置 (RBD),請按一下主功能表中的 › 。
- 7 管理 NFS Ganesha
如需 NFS Ganesha 的更多一般資訊,請參閱第 25 章 「NFS Ganesha」。
- 8 管理 CephFS
若要檢視有關 CephFS 的詳細資訊,請參閱第 23 章 「叢集檔案系統」。
- 9 管理物件閘道
開始之前,在嘗試存取 Ceph Dashboard 上的物件閘道前端時,您可能會收到以下通知:
- 10 手動設定
本節為更喜歡在指令行上手動設定儀表板設定的使用者提供了進階資訊。
- 11 在指令行上管理使用者和角色
本節說明如何管理 Ceph Dashboard 使用的使用者帳戶。該工具可協助您建立或修改使用者帳戶,以及設定正確的使用者角色和許可權。
1 關於 Ceph Dashboard #
Ceph Dashboard 是一種內建的基於 Web 的 Ceph 管理和監控應用程式,負責管理叢集的各個方面和物件。在Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3 “部署 Ceph 叢集”中部署基本叢集後,將自動啟用該儀表板。
Ceph Dashboard for SUSE Enterprise Storage 7 新增了更多基於 Web 的管理功能 (包括對 Ceph 管理員的監控和應用程式管理),讓 Ceph 管理變得更輕鬆。現在,您不必瞭解複雜的 Ceph 相關指令,便可輕鬆管理和監控您的 Ceph 叢集。您可以使用 Ceph Dashboard 的直觀介面,也可以使用其內建的 REST API。
Ceph Dashboard 模組使用 ceph-mgr 代管的 Web 伺服器直觀呈現有關 Ceph 叢集的資訊和統計資料。如需 Ceph 管理員的更多詳細資料,請參閱Book “部署指南”, Chapter 1 “SES 和 Ceph”, Section 1.2.3 “Ceph 節點和精靈”。
2 儀表板的 Web 使用者介面 #
2.1 登入 #
若要登入 Ceph Dashboard,請將瀏覽器指向其 URL,包括連接埠號碼。執行以下指令可尋找位址:
cephuser@adm > ceph mgr services | grep dashboard
"dashboard": "https://host:port/",該指令將傳回 Ceph Dashboard 所在的 URL。如果您有與此指令相關的問題,請參閱Book “Troubleshooting Guide”, Chapter 10 “Troubleshooting the Ceph Dashboard”, Section 10.1 “Locating the Ceph Dashboard”。

使用您在叢集部署期間建立的身分證明登入 (參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3.2.9 “設定 Ceph Dashboard 登入身分證明”)。
如果您不想使用預設的 admin 帳戶存取 Ceph Dashboard,請建立擁有管理員權限的自訂使用者帳戶。如需更多詳細資料,請參閱第 11 章 「在指令行上管理使用者和角色」。
儀表板使用者介面以圖形方式分為數個區塊:螢幕右上方的公用程式功能表,左側的主功能表以及主要的內容窗格。

2.2 公用程式功能表 #
公用程式功能表位於螢幕右上方。該功能表包含與儀表板更為相關 (相較於 Ceph 叢集) 的一般任務。按一下相應選項可以存取以下主題:
將儀表板的語言介面變更為:捷克語、德語、英語、西班牙語、法語、印尼語、義大利語、日語、韓語、波蘭語、葡萄牙語 (巴西) 和中文。
任務與通知
檢視文件、有關 REST API 的資訊或有關儀表板的更多資訊。
使用者管理和遙測組態。
登入組態;變更密碼或登出。
2.3 主功能表 #
儀表板的主功能表位於螢幕左側。它涵蓋下列主題:
回到 Ceph Dashboard 首頁。
檢視有關主機、庫存、Ceph 監控程式、服務、Ceph OSD、叢集組態、CRUSH 地圖、Ceph 管理員模組、記錄和監控的詳細資訊。
檢視並管理叢集池。
檢視詳細資訊並管理 RADOS 區塊裝置影像、鏡像和 iSCSI。
檢視並管理 NFS Ganesha 部署。
檢視並管理 CephFS。
檢視並管理物件閘道的精靈、使用者和桶。
2.4 內容窗格 #
內容窗格佔據儀表板螢幕的主要部分。儀表板首頁上顯示了很多有用的工具集,為您提供叢集目前狀態、容量及效能的簡要資訊。
2.5 常用 Web UI 功能 #
在 Ceph Dashboard 中,您經常會用到清單 — 例如,池清單、OSD 節點清單或 RBD 裝置清單。所有清單預設每五秒會自動重新整理一次。下列常用工具集可協助您管理或調整這些清單:
按一下 ![]() 可手動觸發清單的重新整理。
可手動觸發清單的重新整理。
按一下 ![]() 可顯示或隱藏表的個別欄。
可顯示或隱藏表的個別欄。
按一下 ![]() 並輸入 (或選取) 要在一頁上顯示的列數。
並輸入 (或選取) 要在一頁上顯示的列數。
在  中按一下並輸入要搜尋的字串以過濾列。
中按一下並輸入要搜尋的字串以過濾列。
如果清單跨多頁顯示,可使用  來變更目前顯示的頁。
來變更目前顯示的頁。
2.6 儀表板工具集 #
每個儀表板工具集顯示與執行中 Ceph 叢集特定方面相關的特定狀態資訊。有些工具集是使用中連結,按一下它們會將您重新導向至其所代表主題的相關詳細頁面。
有些圖形工具集會在您將滑鼠移至其上時顯示更多詳細資料。
2.6.1 狀態工具集 #
工具集為您提供有關叢集目前狀態的簡要綜覽。

顯示有關叢集狀態的基本資訊。
顯示叢集節點的總數。
顯示執行中監控程式的數量及其仲裁。
顯示 OSD 的總數及處於 up 和 in 狀態的 OSD 數量。
顯示使用中和待命 Ceph 管理員精靈的數量。
顯示執行中物件閘道的數量。
顯示中繼資料伺服器的數量。
顯示設定的 iSCSI 閘道的數量。
2.6.2 容量工具集 #
工具集顯示有關儲存容量的簡要資訊。

顯示已用與可用原始儲存容量的比率。
顯示叢集中儲存的資料物件數量。
顯示依照狀態分組的放置群組圖表。
顯示叢集中池的數量。
顯示每個 OSD 的平均放置群組數量。
2.6.3 效能工具集 #
工具集提供 Ceph 用戶端的基本效能資料。

每秒用戶端讀取和寫入操作次數。
每秒與 Ceph 用戶端之間傳輸的資料數量 (以位元組計)。
每秒復原的資料輸送量。
顯示整理 (參閱第 17.4.9 節 「整理放置群組」) 狀態。其狀態可以是
inactive、enabled或active。
3 管理 Ceph Dashboard 使用者和角色 #
如需在指令行上使用 Ceph 指令執行儀表板使用者管理的說明,請參閱第 11 章 「在指令行上管理使用者和角色」。
本節介紹如何使用儀表板 Web 使用者介面來管理使用者帳戶。
3.1 列出使用者 #
按一下公用程式功能表中的 ![]() ,然後選取。
,然後選取。
該清單包含每個使用者的使用者名稱、全名、電子郵件、已指定角色的清單、角色是否啟用以及密碼過期日期。

3.2 新增新使用者 #
按一下表標題左上方的可新增新使用者。輸入其使用者名稱、密碼、全名 (選擇性) 和電子郵件。

按一下鉛筆小圖示可為使用者指定預先定義的角色。按一下進行確認。
3.3 編輯使用者 #
按一下表中某個使用者對應的列以反白顯示所選項。選取,即可編輯該使用者的詳細資料。按一下進行確認。
3.4 刪除使用者 #
按一下表中某個使用者對應的列以反白顯示所選項。選取旁的下拉式按鈕,然後從清單中選取,即可刪除使用者帳戶。啟用核取方塊,然後按一下進行確認。
3.5 列出使用者角色 #
按一下公用程式功能表中的 ![]() ,然後選取。然後按一下索引標籤。
,然後選取。然後按一下索引標籤。
該清單包含每個角色的名稱、描述及其是否屬於系統角色。

3.6 新增自訂角色 #
按一下表標題左上方的可新增新的自訂角色。輸入和,然後在旁選取適當的許可權。
如果您建立了自訂使用者角色,並打算以後使用 ceph-salt purge 指令移除 Ceph
叢集,則需要先清除自訂角色。如需更多詳細資料,請參閱第 13.9 節 「移除整個 Ceph 叢集」。

透過啟用主題名稱前的核取方塊,您可以啟用針對該主題的所有許可權。透過啟用核取方塊,您可以啟用針對所有主題的所有許可權。
按一下進行確認。
3.7 編輯自訂角色 #
按一下表中某個自訂角色對應的列以反白顯示所選項。選取表標題左上方的,即可編輯自訂角色的描述和許可權。按一下進行確認。
3.8 刪除自訂角色 #
按一下表中某個角色對應的列以反白顯示所選項。選取旁的下拉式按鈕,然後從清單中選取,即可刪除角色。啟用核取方塊,然後按一下進行確認。
4 檢視叢集內部 #
您可以透過功能表項目檢視有關 Ceph 叢集主機、庫存、Ceph 監控程式、服務、OSD、組態、CRUSH 地圖、Ceph 管理員、記錄和監控檔案的詳細資訊。
4.1 檢視叢集節點 #
按一下 › 可檢視叢集節點清單。

按一下欄中某個節點名稱旁的下拉式箭頭可檢視節點的效能詳細資料。
欄中會列出每個相關節點上的所有執行中精靈。按一下精靈名稱可檢視其詳細組態。
4.2 存取叢集庫存 #
按一下 › 可檢視裝置清單。該清單包含裝置路徑、類型、可用性、廠商、型號、大小和 OSD。
按一下以在欄中選取節點名稱。選取後,按一下以識別正在執行主機的裝置。這會讓相應裝置上的 LED 閃爍。選取此動作的持續時間 (介於 1、2、5、10 或 15 分鐘之間)。按一下。

4.3 檢視 Ceph 監控程式 #
按一下 › 可檢視具有執行中
Ceph
監控程式的叢集節點清單。內容窗格分為兩個檢視窗:狀態和仲裁成員或非仲裁成員。
表顯示有關執行中 Ceph 監控程式的一般統計資料,包括以下各項:
叢集 ID
monmap 修改時間
monmap 版本編號
仲裁 con
仲裁 mon
所需 con
所需 mon
仲裁成員和非仲裁成員窗格包含每個監控程式的名稱、階層編號、公用 IP
位址和開啟的工作階段數。
按一下欄中的節點名稱可檢視相關的 Ceph 監控程式組態。

4.4 顯示服務 #
按一下 › 可檢視每個可用服務的詳細資料:crash、Ceph
管理員和 Ceph 監控程式。該清單包含容器影像名稱、容器影像 ID、正在執行項目的狀態、大小以及上次重新整理時間。
按一下欄中某個服務名稱旁的下拉式箭頭可檢視精靈的詳細資料。詳細資料清單包含主機名稱、精靈類型、精靈 ID、容器 ID、容器影像名稱、容器影像 ID、版本號碼、狀態以及上次重新整理時間。

4.5 顯示 Ceph OSD #
按一下 › 可檢視具有執行中 OSD 精靈的節點清單。該清單包含每個節點的名稱、ID、狀態、裝置類別、放置群組數量、大小、使用率、不同時間的讀取/寫入圖表,以及每秒讀取/寫入操作次數。

從表標題中的下拉式功能表中選取,可開啟一個快顯視窗。此視窗包含適用於整個叢集的旗標清單。您可以啟用或停用個別旗標,然後按一下進行確認。

從表標題中的下拉式功能表中選取,可開啟一個快顯視窗。此視窗包含適用於整個叢集的 OSD 復原優先程度清單。您可以啟用偏好的優先程度設定檔,並對下面的個別值進行微調。按一下以確認。

按一下欄中某個節點名稱旁的下拉式箭頭可檢視延伸表,其中包含有關裝置設定和效能的詳細資料。您可以在數個索引標籤之間切換,以便查看、、、的各個清單、讀取/寫入操作次數的圖形,以及。

按一下某個 OSD 節點名稱後,將反白顯示表中的對應列。這表示現在您可以在該節點上執行任務。您可以選擇執行以下任何動作:、、、、、、、、、、或。
按一下表標題左上方按鈕旁的向下箭頭,然後選取要執行的任務。
4.5.1 新增 OSD #
若要新增新的 OSD,請執行以下步驟:
確認某些叢集節點的儲存裝置的狀態為
可用。然後按一下表標題左上方的向下箭頭並選取。此動作將開啟 視窗。 圖 4.9︰ 建立 OSD #
圖 4.9︰ 建立 OSD #若要為 OSD 新增主要儲存裝置,請按一下。在新增儲存裝置之前,需要在表的右上方指定過濾準則,例如 。請按加以確認。
 圖 4.10︰ 新增主要裝置 #
圖 4.10︰ 新增主要裝置 #在更新的 視窗中,可以選擇新增共用的 WAL 和 BD 裝置,或者啟用裝置加密。
 圖 4.11︰ 建立新增了主要裝置的 OSD #
圖 4.11︰ 建立新增了主要裝置的 OSD #按一下可檢視您先前已新增裝置的 DriveGroups 規格預覽。按一下以確認。
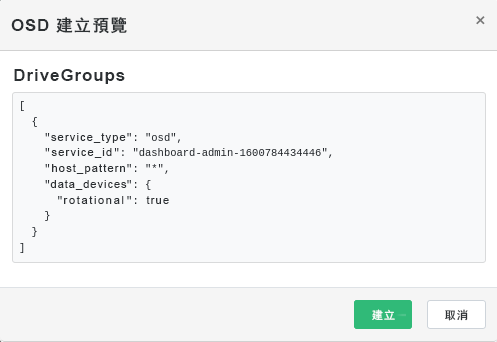 圖 4.12︰ #
圖 4.12︰ #新裝置將被新增至 OSD 清單中。
 圖 4.13︰ 新增的 OSD #注意
圖 4.13︰ 新增的 OSD #注意無法查看 OSD 建立程序的進度。實際建立 OSD 需要一些時間。OSD 部署完畢後,它們將顯示在清單中。如果您要檢查部署狀態,請按一下 › 檢視相關記錄。
4.6 檢視叢集組態 #
按一下 › 可檢視 Ceph 叢集組態選項的完整清單。該清單包含選項的名稱、其簡短描述、目前值和預設值以及選項是否可編輯。

按一下欄中某個組態選項旁的下拉式箭頭可檢視延伸表,其中包含有關該選項的詳細資訊,例如其值類型、允許的最小值和最大值、是否可以在執行時期更新等。
反白特定選項後,您可以透過按一下表標題左上方的按鈕來編輯它的值。按一下確認變更。
4.7 檢視 CRUSH 地圖 #
按一下 › 可檢視叢集的 CRUSH 地圖。如需 CRUSH 地圖的更多一般資訊,請參閱第 17.5 節 「CRUSH 地圖操作」。
按一下根、節點或個別 OSD 可檢視更多詳細資訊,例如 CRUSH 權數、地圖樹狀結構的深度、OSD 的裝置類別等等。

4.8 檢視管理員模組 #
按一下 › 可檢視可用 Ceph 管理員模組的清單。每行包含模組名稱以及該模組目前啟用與否的資訊。

按一下欄中某個模組旁的下拉式箭頭,可在下面的表中檢視包含詳細設定的延伸表。按一下表標題左上方的按鈕可進行編輯。按一下確認變更。
按一下表標題左上方按鈕旁的下拉式箭頭,可或模組。
4.9 檢視記錄 #
按一下 › 可檢視叢集的最近記錄項目清單。每行包含一個時戳、記錄項目的類型及自身所記錄的訊息。
按一下索引標籤可檢視稽核子系統的記錄項目。如需啟用或停用稽核的指令,請參閱第 11.5 節 「稽核 API 要求」。

4.10 檢視監控 #
按一下 › 可管理和檢視有關 Prometheus 警示的詳細資料。
如果您啟用了 Prometheus,則在此內容窗格中,您可以檢視有關、或的詳細資訊。
如果您未部署 Prometheus,則會顯示一個資訊標題頁以及相關文件的連結。
5 管理池 #
若要列出所有可用的池,請按一下主功能表中的。
該清單顯示每個池的名稱、類型、相關應用程式、放置群組狀態、複本大小、上次變更時間、糾刪碼設定檔、crush 規則集、使用率以及讀取/寫入統計資料。

按一下欄中某個池名稱旁的下拉式箭頭可檢視延伸表,其中包含有關池的詳細資訊,例如一般詳細資料、效能詳細資料和組態。
5.1 新增新池 #
若要新增新池,請按一下池表左上方的。在池表單中,您可以輸入池的名稱、類型、其應用程式、壓縮模式和定額 (包括位元組數上限和物件數量上限)。池表單會自行預先計算最適合此特定池的放置群組數量。計算以叢集中的 OSD 數量和所選池類型及其特定設定為依據。如果手動設定了放置群組數量,計算出的數量會取代設定的數量。按一下進行確認。

5.2 刪除池 #
若要刪除池,請選取並反白顯示表中該池對應的列。按一下按鈕旁的下拉式箭頭,然後按一下。
5.3 編輯池的選項 #
若要編輯池選項,請選取表中該池對應的列,然後按一下池表左上方的。
您可以變更池的名稱、增加放置群組的數量、變更池的應用程式清單和壓縮設定。按一下進行確認。
6 管理 RADOS 區塊裝置 #
若要列出所有可用的 RADOS 區塊裝置 (RBD),請按一下主功能表中的 › 。
該清單顯示有關裝置的簡要資訊,例如裝置名稱、相關池名稱、名稱空間、裝置大小、裝置上的物件數量和大小、有關詳細資料佈建的詳細資料以及父項。

6.1 檢視有關 RBD 的詳細資料 #
若要檢視某部裝置的更多詳細資訊,請按一下表中對應的列:

6.2 檢視 RBD 的組態 #
若要檢視某部裝置的詳細組態,請按一下表中對應的列,然後按一下下方表中的索引標籤:

6.3 建立 RBD #
若要新增新裝置,請按一下表標題左上方的,然後在 螢幕上執行以下操作:

輸入新裝置的名稱。請參閱Book “部署指南”, Chapter 2 “硬體要求和建議”, Section 2.11 “名稱限制”以瞭解命名限制。
選取要在其中建立新 RBD 裝置且指定了
rbd應用程式的池。指定新裝置的大小。
為裝置指定其他選項。若要微調裝置參數,請按一下,然後輸入物件大小、分割單位或分割計數的值。若要輸入服務品質 (QoS) 限制,請按一下,然後輸入限制。
按一下 進行確認。
6.4 刪除 RBD #
若要刪除裝置,請選取表中該裝置對應的列。按一下按鈕旁的下拉式箭頭,然後按一下。按一下 確認刪除。
刪除 RBD 的動作無法復原。如果您選擇將裝置,那麼稍後還可以將其還原,只需在主表的索引標籤上選取該裝置,然後按一下表標題左上方的。
6.5 建立 RADOS 區塊裝置快照 #
若要建立 RADOS 區塊裝置快照,請選取表中該裝置對應的列,將會顯示詳細的組態內容窗格。選取索引標籤,然後按一下表標題左上方的。輸入快照的名稱,然後按一下進行確認。
選取快照後,您可以在裝置上執行其他動作,例如重新命名、保護、克隆、複製或刪除。可根據目前的快照還原裝置的狀態。

6.6 RBD 鏡像 #
RADOS 區塊裝置影像可以在兩個 Ceph 叢集之間以非同步方式鏡像。您可以使用 Ceph Dashboard 在兩個或更多叢集之間設定 RBD 影像複製。此功能有兩種模式:
- 基於記錄
此模式使用 RBD 記錄影像功能來確保叢集之間的複製在時間點和當機時保持一致。
- 基於快照
此模式使用定期排程或手動建立的 RBD 影像鏡像快照,以在叢集之間複製當機時保持一致的 RBD 影像。
鏡像是基於對等叢集中的每個池進行設定的,可以對池中的特定影像子集進行設定,也可以設定為在僅使用基於記錄的鏡像時自動鏡像池中的所有影像。
鏡像是使用 rbd 指令設定的,依預設,SUSE Enterprise Storage 7
中會安裝該應用程式。rbd-mirror
精靈負責從遠端對等叢集提取影像更新,並將它們套用於本地叢集中的影像。如需啟用
rbd-mirror
精靈的詳細資訊,請參閱第 6.6.2 節 「啟用 rbd-mirror 精靈」。
依據複製需求,RBD 區塊裝置鏡像可以設定為單向或雙向複製:
- 單向複製
當資料僅會從主要叢集鏡像到次要叢集時,
rbd-mirror精靈僅在次要叢集上執行。- 雙向複製
當資料從一個叢集上的主要影像鏡像到另一個叢集上的非主要影像 (反之亦然) 時,
rbd-mirror精靈將在兩個叢集上執行。
rbd-mirror 精靈的每個例項都必須能夠同時連接至本地和遠端
Ceph 叢集,例如所有監控程式和 OSD 主機。此外,網路必須在兩個資料中心之間具有足夠的頻寬來處理鏡像工作負載。
6.6.1 設定主要叢集和次要叢集 #
主要叢集是用於建立包含影像的原始池的叢集。次要叢集是用於從主要叢集複製池或影像的叢集。
在複製情境中,主要與次要這兩個術語有可能是相對的,因為相較於叢集來說,它們與個別池更為相關。例如,在雙向複製中,可將一個池從主要叢集鏡像到次要叢集,與此同時,也可以將另一個池從次要叢集鏡像到主要叢集。
6.6.2 啟用 rbd-mirror 精靈 #
下面的程序展示如何使用 rbd 指令來執行設定鏡像的基本管理任務。在 Ceph 叢集中依池來設定鏡像。
兩個對等叢集上都應執行池設定步驟。為清楚起見,這些程序假設可從單部主機存取名為「primary」和「secondary」的兩個叢集。
rbd-mirror 精靈負責執行實際的叢集資料複製。
重新命名
ceph.conf和金鑰圈檔案,並將其從主要主機複製到次要主機:cephuser@secondary >cp /etc/ceph/ceph.conf /etc/ceph/primary.confcephuser@secondary >cp /etc/ceph/ceph.admin.client.keyring \ /etc/ceph/primary.client.admin.keyringcephuser@secondary >scp PRIMARY_HOST:/etc/ceph/ceph.conf \ /etc/ceph/secondary.confcephuser@secondary >scp PRIMARY_HOST:/etc/ceph/ceph.client.admin.keyring \ /etc/ceph/secondary.client.admin.keyring若要使用
rbd針對池啟用鏡像,請指定mirror pool enable、池名稱和鏡像模式:cephuser@adm >rbd mirror pool enable POOL_NAME MODE注意鏡像模式可以是
image或pool。例如:cephuser@secondary >rbd --cluster primary mirror pool enable image-pool imagecephuser@secondary >rbd --cluster secondary mirror pool enable image-pool image在 Ceph Dashboard 上,導覽至 › 。表的左側會顯示處於使用中狀態的執行中
rbd-mirror精靈及其狀態。 圖 6.6︰ 執行中
圖 6.6︰ 執行中rbd-mirror精靈 #
6.6.3 停用鏡像 #
若要使用 rbd 針對池停用鏡像,請指定 mirror pool
disable 指令和池名稱:
cephuser@adm > rbd mirror pool disable POOL_NAME使用這種方法對池停用鏡像時,還會對已為其明確啟用鏡像的所有影像 (該池中) 停用鏡像。
6.6.4 開機對等 #
為了使 rbd-mirror
探查其對等叢集,需要將對等註冊到池,並需要建立使用者帳戶。此程序可以使用 rbd 透過
mirror pool peer bootstrap create 和 mirror pool
peer bootstrap import 指令自動完成。
若要使用 rbd 手動建立新的開機記號,請指定 mirror pool peer
bootstrap create 指令、池名稱以及描述本地叢集的選擇性站台名稱:
cephuser@adm > rbd mirror pool peer bootstrap create [--site-name local-site-name] pool-name
mirror pool peer bootstrap create 的輸出將為應提供給
mirror pool peer bootstrap import 指令的記號。例如,在主要叢集上:
cephuser@adm > rbd --cluster primary mirror pool peer bootstrap create --site-name primary
image-pool eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkL \
W1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1vbl9ob3N0I \
joiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
若要使用 rbd 指令手動輸入另一個叢集建立的開機記號,請指定 mirror pool
peer bootstrap import 指令、池名稱、所建立記號的檔案路徑
(或設定為「-」以從標準輸入讀取),以及描述本地叢集的選擇性站台名稱和鏡像方向 (預設設定為 rx-tx
以進行雙向鏡像,但也可設定為 rx-only 以進行單向鏡像):
cephuser@adm > rbd mirror pool peer bootstrap import [--site-name local-site-name] \
[--direction rx-only or rx-tx] pool-name token-path例如,在次要叢集上:
cephuser@adm >cat >>EOF < token eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW \ 1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1v \ bl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ== EOFcephuser@adm >rbd --cluster secondary mirror pool peer bootstrap import --site-name secondary image-pool token
6.6.5 移除叢集對等 #
若要使用 rbd 指令移除鏡像對等 Ceph 叢集,請指定 mirror pool peer
remove 指令、池名稱和對等 UUID (可透過 rbd mirror pool
info 指令獲得):
cephuser@adm > rbd mirror pool peer remove pool-name peer-uuid6.6.6 在 Ceph Dashboard 中設定池複製 #
rbd-mirror 精靈需要擁有主要叢集的存取權,才能鏡像 RBD
影像。繼續之前,請確定已依據第 6.6.4 節 「開機對等」中的步驟進行操作。
在主要和次要兩個叢集上,建立名稱相同的池,並為其指定
rbd應用程式。如需建立新池的更多詳細資料,請參閱第 5.1 節 「新增新池」。 圖 6.7︰ 建立具有 RBD 應用程式的池 #
圖 6.7︰ 建立具有 RBD 應用程式的池 #在主要和次要兩個叢集的儀表板上,導覽至 › 。在表右側按一下要複製的池的名稱,然後按一下,並選取複製模式。在此範例中,我們將使用池複製模式,也就是說,將複製給定池中的所有影像。按一下進行確認。
 圖 6.8︰ 設定複製模式 #重要:主要叢集上的錯誤或警告
圖 6.8︰ 設定複製模式 #重要:主要叢集上的錯誤或警告更新複製模式後,右側相應的欄中會顯示錯誤或警告旗標。這是因為尚未為池指定用於複製的對等使用者。對於主要叢集,請省略此旗標,因為我們僅需為次要叢集指定對等使用者。
在次要叢集的儀表板上,導覽至 › 。透過選取來新增池鏡像對等。提供主要叢集的詳細資料:
 圖 6.9︰ 新增對等身分證明 #
圖 6.9︰ 新增對等身分證明 #用於識別主要叢集的任意唯一字串,例如「primary」。該叢集名稱不得與實際環境中次要叢集的名稱相同。
您建立做為鏡像對等的 Ceph 使用者 ID。此範例中為「rbd-mirror-peer」。
主要叢集 Ceph 監控程式節點的 IP 位址的逗號分隔清單。
與對等使用者 ID 相關的金鑰。您可以透過在主要叢集上執行以下範例指令來擷取該金鑰:
cephuser@adm >ceph auth print_key pool-mirror-peer-name
按一下以確認。
 圖 6.10︰ 複本池清單 #
圖 6.10︰ 複本池清單 #
6.6.7 確認 RBD 影像複製是否有效 #
如果 rbd-mirror 精靈正在執行,在 Ceph
Dashboard 上設定 RBD 影像複製後,就需要確認複製實際上是否有效:
在主要叢集的 Ceph Dashboard 上建立 RBD 影像,並將您已建立用於複製目的的池設為其父池。為影像啟用
獨佔鎖定和記錄功能。如需如何建立 RBD 影像的詳細資料,請參閱第 6.3 節 「建立 RBD」。 圖 6.11︰ 新 RBD 影像 #
圖 6.11︰ 新 RBD 影像 #建立要複製的影像後,開啟次要叢集的 Ceph Dashboard,並導覽至 › 。右側的表將在中所示數量的影像中反映該變更,並會同步中所示數量的影像。
 圖 6.12︰ 同步的新 RBD 影像 #
圖 6.12︰ 同步的新 RBD 影像 #在主要叢集上,將資料寫入 RBD 影像。在次要叢集的 Ceph Dashboard 上,導覽至 › ,並監控相應影像大小的增長是否與主要叢集上寫入的資料一致。

6.7 管理 iSCSI 閘道 #
若要列出所有可用閘道和對應的影像,請按一下主功能表中的 › 。索引標籤即會開啟,列出目前設定的 iSCSI 閘道和對應的 RBD 影像。
表列出每個閘道的狀態、iSCSI 目標數量及工作階段數量。表列出每個對應影像的名稱、相關池名稱、後備儲存類別,以及其他統計資料詳細資訊。
索引標籤列出目前設定的 iSCSI 目標。

若要檢視有關目標的更多詳細資訊,請按一下表中該目標對應的列上的下拉式箭頭。一個樹狀結構綱要即會開啟,列出磁碟、入口網站、啟動器和群組。按一下某一項可將其展開並檢視詳細內容,右側的表中也可能會顯示其相關組態。

6.7.1 新增 iSCSI 目標 #
若要新增新的 iSCSI 目標,請按一下表左上方的,並輸入所需資訊。

輸入新閘道的目標位址。
按一下,然後從清單中選取一或多個 iSCSI 入口網站。
按一下,然後為閘道選取一或多個 RBD 影像。
如果您需要使用驗證才能存取閘道,請啟用 核取方塊並輸入身分證明。選取和之後,您可看到更多進階驗證選項。
按一下進行確認。
6.7.2 編輯 iSCSI 目標 #
若要編輯某個現有 iSCSI 目標,請按一下表中對應的列,然後按一下表左上方的。
然後,您便可以修改 iSCSI 目標、新增或刪除入口網站,以及新增或刪除相關 RBD 影像。您還可以調整閘道的驗證資訊。
6.7.3 刪除 iSCSI 目標 #
若要刪除 iSCSI 目標,請選取表中其所對應的列並按一下按鈕旁的下拉式箭頭,然後選取。啟用,然後按一下進行確認。
6.8 RBD 服務品質 (QoS) #
您可以在不同層級設定 QoS 選項。
全域
基於每個池
基於每個影像
全域組態位於清單頂部,將用於所有新建立的 RBD 影像,以及不會覆寫池或 RBD 影像層相應值的影像。基於每個池或影像設定的值可能會覆寫全域指定的選項值。針對某個池指定的選項將套用至該池的所有 RBD 影像,除非被針對某個影像設定的組態選項所覆寫。對影像指定的選項將覆寫對池指定的選項以及全域指定的選項。
因此可以如此操作:全域定義預設值,對預設值進行調整以適合特定池的所有 RBD 影像,然後覆寫個別 RBD 影像的池組態。
6.8.1 全域設定選項 #
若要全域設定 RADOS 區塊裝置選項,請從主功能表中選取 › 。
若要列出所有可用的全域組態選項,請在旁從下拉式功能表中選擇。
在搜尋欄位中過濾
rbd_qos,以過濾表的結果。QoS 的所有可用組態選項即會列出。若要變更某個值,請按一下表中該值對應的列,然後選取表左上方的。對話方塊包含 6 個不同的欄位供您指定值。在 文字方塊中,RBD 組態選項值是必填的。
注意此對話方塊與其他對話方塊不同,不允許您使用方便的單位指定值。您只能使用位元組或 IOPS 單位設定這些值,具體取決於您要編輯的選項。
6.8.2 針對新池設定選項 #
若要建立新池並對其設定 RBD 組態選項,請按一下 › 。選取做為池類型。然後,您需要將
rbd 應用程式標記新增至池,這樣才能設定 RBD QoS 選項。
對於糾刪碼池是無法設定 RBD QoS 組態選項的。若要為糾刪碼池設定 RBD QoS 選項,您需要編輯 RBD 影像的複本中繼資料池。該組態隨後將套用於該影像的糾刪碼資料池。
6.8.3 針對現有池設定選項 #
若要對某個現有池設定 RBD QoS 選項,請按一下,然後按一下表中該池對應的列,並選取表左上方的。
對話方塊中應該就會顯示 區段,下方是區段。
如果 和區段均未顯示,則可能是因為您正在編輯無法用於設定 RBD 組態選項的糾刪碼池,或該池未設定為供 RBD 影像使用。在下一個案例中,將為池指定 應用程式標記,相應的組態區段將會顯示。
6.8.4 組態選項 #
按一下 以展開組態選項。所有可用選項的清單即會顯示。文字方塊中已顯示組態選項的單位。對於任何每秒位元組數 (BPS) 選項,您可以選擇使用「1M」或「5G」之類的捷徑。系統會自動將其轉換為對應的「1 MB/s」和「5 GB/s」。
按一下每個文字方塊右側的重設按鈕,將移除對該池設定的所有值。此操作不會移除全域設定或對 RBD 影像所設定選項的組態值。
6.8.5 使用新 RBD 影像建立 RBD QoS 選項 #
若要建立 RBD 影像並對該影像設定 RBD QoS 選項,請選取 › ,然後按一下。按一下可展開進階組態區段。按一下 可開啟所有可用組態選項。
6.8.6 編輯現有影像的 RBD QoS 選項 #
若要編輯現有影像的 RBD QoS 選項,請選取 › ,然後按一下表中該池對應的列,最後按一下。編輯對話方塊隨即顯示。按一下可展開進階組態區段。按一下 可開啟所有可用組態選項。
6.8.7 在複製或克隆影像時變更組態選項 #
如果克隆或複製了 RBD 影像,系統預設還會複製對該特定影像設定的值。如果您想在複製或克隆期間變更這些值,可透過在複製/克隆對話方塊中指定更新的組態值來進行變更,此程序與建立或編輯 RBD 影像時的方式相同。執行此操作只能設定 (或重設) 所複製或克隆的 RBD 影像的值,無法變更來源 RBD 影像組態,也無法變更全域組態。
如果您選擇在複製/克隆時重設選項值,系統將不會對該影像設定該選項的值。這表示系統將使用為父池指定的該選項的任何值 (如果為父池設定了相應值)。如果沒有為父池設定相應值,則將使用全域預設值。
7 管理 NFS Ganesha #
若要列出所有可用的 NFS 輸出項,請按一下主功能表中的 。
該清單會顯示每個輸出的目錄、精靈主機名稱、儲存後端類型以及存取類型。

若要檢視某個 NFS 輸出的更多詳細資訊,請按一下表中對應的列。

7.1 建立 NFS 輸出項 #
若要新增新的 NFS 輸出項,請按一下輸出項表左上方的並輸入所需的資訊。

選取一或多個將執行輸出的 NFS Ganesha 精靈。
選取儲存後端。
重要目前,僅支援由 CephFS 提供支援的 NFS 輸出項。
選取使用者 ID 及與後端相關的其他選項。
輸入 NFS 輸出項的目錄路徑。如果該目錄在伺服器上不存在,系統將建立該目錄。
指定與 NFS 相關的其他選項,例如支援的 NFS 通訊協定版本、虛擬、存取類型、匿名存取或傳輸通訊協定。
如果您需要設定限制,以便僅允許特定的用戶端存取,請按一下,並新增它們的 IP 位址以及存取類型和匿名存取選項。
按一下進行確認。
7.2 刪除 NFS 輸出項 #
若要刪除輸出項,請選取並反白顯示表中該輸出項對應的列。按一下按鈕旁的下拉式箭頭,然後選取。啟用核取方塊,然後按一下進行確認。
7.3 編輯 NFS 輸出項 #
若要編輯現有輸出項,請選取並反白顯示表中該輸出項對應的列,然後按一下輸出項表左上方的。
然後,您便可以調整 NFS 輸出項的所有詳細資料。

8 管理 CephFS #
8.1 檢視 CephFS 綜覽 #
在主功能表中按一下可檢視所設定檔案系統的綜覽。主表會顯示每個檔案系統的名稱、建立日期,以及檔案系統是否已啟用。
按一下表中某個檔案系統對應的列,可檢視其階層以及新增至其中的池的詳細資料。

您可在螢幕底部查看即時收集的相關 MDS Inode 及用戶端要求數量統計資料。

9 管理物件閘道 #
開始之前,在嘗試存取 Ceph Dashboard 上的物件閘道前端時,您可能會收到以下通知:
Information No RGW credentials found, please consult the documentation on how to enable RGW for the dashboard. Please consult the documentation on how to configure and enable the Object Gateway management functionality.
這是因為 cephadm 沒有為 Ceph Dashboard 自動設定物件閘道。如果您收到此通知,請依照第 10.4 節 「啟用物件閘道管理前端」中的說明手動啟用 Ceph Dashboard 的物件閘道前端。
9.1 檢視物件閘道 #
若要檢視設定的物件閘道清單,請按一下 › 。該清單包含閘道的 ID、執行閘道精靈的叢集節點的主機名稱,以及閘道的版本號碼。
按一下閘道名稱旁的下拉式箭頭可檢視有關該閘道的詳細資訊。索引標籤顯示有關讀取/寫入操作及快取統計資料的詳細資料。

9.2 管理物件閘道使用者 #
按一下 › 可檢視現有物件閘道使用者的清單。
按一下使用者名稱旁的下拉式箭頭可檢視有關使用者帳戶的詳細資料,例如狀態資訊或使用者和桶定額詳細資料。

9.2.1 新增新閘道使用者 #
若要新增新閘道使用者,請按一下表標題左上方的。填寫其身分證明、有關 S3 金鑰及使用者和桶定額的詳細資料,然後按一下進行確認。

9.2.2 刪除閘道使用者 #
若要刪除閘道使用者,請選取並反白顯示該使用者。按一下旁的下拉式按鈕,然後從清單中選取,即可刪除使用者帳戶。啟用核取方塊,然後按一下進行確認。
9.2.3 編輯閘道使用者詳細資料 #
若要變更閘道使用者詳細資料,請選取並反白顯示該使用者。按一下表標題左上方的。
修改基本或附加使用者資訊,例如其功能、金鑰、子使用者和定額資訊。按一下進行確認。
索引標籤包含唯讀的閘道使用者清單,以及這些使用者的存取金鑰和機密金鑰。若要檢視這些金鑰,請按一下清單中的使用者名稱,然後選取表標題左上方的。在 對話方塊中,按一下眼睛圖示可顯示金鑰,按一下剪貼板圖示可將相關金鑰複製到剪貼板。
9.3 管理物件閘道桶 #
物件閘道 (OGW) 桶實作了 OpenStack Swift 容器的功能。物件閘道桶可充當儲存資料物件的容器。
按一下 › 可檢視物件閘道桶清單。
9.3.1 新增新的桶 #
若要新增新的物件閘道桶,請按一下表標題左上方的。輸入桶的名稱,選取擁有者,並設定放置目標。按一下進行確認。
9.3.2 檢視桶詳細資料 #
若要檢視有關物件閘道桶的詳細資訊,請按一下桶名稱旁的下拉式箭頭。

您可以在表下方查看有關桶定額和鎖定設定的詳細資料。
9.3.3 編輯桶 #
選取並反白顯示桶,然後按一下表標題左上方的。
您可以更新桶的擁有者,或者啟用版本設定、多因素驗證或鎖定功能。按一下確認任何變更。

9.3.4 刪除桶 #
若要刪除物件閘道桶,請選取並反白顯示該桶。按一下旁的下拉式按鈕,然後從清單中選取,即可刪除桶。啟用核取方塊,然後按一下進行確認。
10 手動設定 #
本節為更喜歡在指令行上手動設定儀表板設定的使用者提供了進階資訊。
10.1 設定 TLS/SSL 支援 #
所有連至儀表板的 HTTP 連接預設均使用 TLS/SSL 來保障安全。安全連接需要 SSL 證書。您可以使用自行簽署的證書,也可以產生證書並讓知名證書管理中心 (CA) 簽署該證書。
您可能會出於某種原因需要停用 SSL 支援。例如,如果儀表板是在不支援 SSL 的代理之後執行。
停用 SSL 要慎重,因為停用 SSL 後,使用者名稱和密碼將以未加密的形式傳送至儀表板。
若要停用 SSL,請執行以下指令:
cephuser@adm > ceph config set mgr mgr/dashboard/ssl false變更 SSL 證書和金鑰後,您需要手動重新啟動 Ceph 管理員程序。您可以透過執行以下指令
cephuser@adm > ceph mgr fail ACTIVE-MANAGER-NAME或停用儀表板模組之後再重新將其啟用的方式來執行此操作,如此還會觸發管理員自行重新繁衍:
cephuser@adm >ceph mgr module disable dashboardcephuser@adm >ceph mgr module enable dashboard
10.1.1 建立自行簽署的證書 #
為了安全通訊而建立自行簽署的證書的過程非常簡單。採用這種方式可迅速讓儀表板執行起來。
大多數網頁瀏覽器都將對自行簽署的證書發起控訴,並需要在建立與儀表板的安全連接前進行明確確認。
若要產生並安裝自行簽署的證書,請使用以下內建指令:
cephuser@adm > ceph dashboard create-self-signed-cert10.1.2 使用 CA 簽署的證書 #
為了正確保障連至儀表板的連接安全,以及消除網頁瀏覽器對自行簽署的證書的控訴,我們建議使用 CA 簽署的證書。
您可以使用如下指令產生證書金鑰組:
root # openssl req -new -nodes -x509 \
-subj "/O=IT/CN=ceph-mgr-dashboard" -days 3650 \
-keyout dashboard.key -out dashboard.crt -extensions v3_ca
以上指令會輸出 dashboard.key 和 dashboard.key.crt 檔案。獲得 CA 簽署的 dashboard.key.crt 檔案後,請執行以下指令為所有 Ceph 管理員例項啟用該證書:
cephuser@adm >ceph config-key set mgr/dashboard/crt -i dashboard.crtcephuser@adm >ceph config-key set mgr/dashboard/key -i dashboard.key
如果您需要為每個 Ceph 管理員例項使用不同的證書,請依如下所示修改指令,並在其中指定例項的名稱。以 Ceph 管理員例項的名稱 (通常是相關的主機名稱) 取代 NAME:
cephuser@adm >ceph config-key set mgr/dashboard/NAME/crt -i dashboard.crtcephuser@adm >ceph config-key set mgr/dashboard/NAME/key -i dashboard.key
10.2 變更主機名稱和連接埠號碼 #
Ceph Dashboard 結合至特定 TCP/IP 位址和 TCP 連接埠。依預設,代管儀表板的目前使用中 Ceph 管理員會結合至 TCP 連接埠 8443 (如果停用 SSL,則結合至 8080 連接埠)。
如果在執行 Ceph 管理員 (以及 Ceph Dashboard) 的主機上啟用了防火牆,則您可能需要變更組態以啟用對這些連接埠的存取。如需 Ceph 防火牆設定的詳細資訊,請參閱Book “Troubleshooting Guide”, Chapter 13 “Hints and tips”, Section 13.7 “Firewall settings for Ceph”。
Ceph Dashboard 預設結合至「::」,該符號表示所有可用的 IPv4 和 IPv6 位址。您可以使用以下指令變更 Web 應用程式的 IP 位址和連接埠號碼,以使它們適用於所有 Ceph 管理員例項:
cephuser@adm >ceph config set mgr mgr/dashboard/server_addr IP_ADDRESScephuser@adm >ceph config set mgr mgr/dashboard/server_port PORT_NUMBER
因為每個 ceph-mgr 精靈都代管著各自的儀表板例項,您可能需要單獨設定每個 Ceph 管理員例項。使用以下指令 (以 ceph-mgr 例項的 ID 取代 NAME) 變更特定管理員例項的 IP 位址和連接埠號碼:
cephuser@adm >ceph config set mgr mgr/dashboard/NAME/server_addr IP_ADDRESScephuser@adm >ceph config set mgr mgr/dashboard/NAME/server_port PORT_NUMBER
ceph mgr services 指令會顯示目前設定的所有端點。尋找 dashboard 鍵可獲取用於存取儀表板的 URL。
10.3 調整使用者名稱和密碼 #
如果您不想使用預設管理員帳戶,可建立其他使用者帳戶,並將其與至少一個角色相關聯。我們提供了一組預先定義的系統角色供您使用。如需詳細資訊,請參閱第 11 章 「在指令行上管理使用者和角色」。
若要建立具有管理員權限的使用者,請使用以下指令:
cephuser@adm > ceph dashboard ac-user-create USER_NAME PASSWORD administrator10.4 啟用物件閘道管理前端 #
若要使用儀表板的物件閘道管理功能,您需要提供啟用了 system 旗標的使用者的登入身分證明:
如果您沒有帶
system旗標的使用者,請建立一個:cephuser@adm >radosgw-admin user create --uid=USER_ID --display-name=DISPLAY_NAME --system記下指令輸出中的 access_key 和 secret_key 金鑰。
您還可以使用
radosgw-admin指令來獲取現有使用者的身分證明:cephuser@adm >radosgw-admin user info --uid=USER_ID向儀表板提供收到的身分證明:
cephuser@adm >ceph dashboard set-rgw-api-access-key ACCESS_KEYcephuser@adm >ceph dashboard set-rgw-api-secret-key SECRET_KEY
依預設,SUSE Linux Enterprise Server 15 SP2 中會啟用防火牆。如需防火牆組態的詳細資訊,請參閱Book “Troubleshooting Guide”, Chapter 13 “Hints and tips”, Section 13.7 “Firewall settings for Ceph”。
請注意以下幾點事項:
系統會自動確定物件閘道的主機名稱和連接埠號碼。
如果使用多個區域,物件閘道會自動確定主區域群組和主區域內的主機。此方式足以符合大部分設定的需求,但在某些情況下,您可能需要手動設定主機名稱和連接埠:
cephuser@adm >ceph dashboard set-rgw-api-host HOSTcephuser@adm >ceph dashboard set-rgw-api-port PORT您可能需要進行的額外設定如下:
cephuser@adm >ceph dashboard set-rgw-api-scheme SCHEME # http or httpscephuser@adm >ceph dashboard set-rgw-api-admin-resource ADMIN_RESOURCEcephuser@adm >ceph dashboard set-rgw-api-user-id USER_ID如果您在物件閘道設定中使用的是自行簽署的證書 (第 10.1 節 「設定 TLS/SSL 支援」),請在儀表板中停用證書驗證,以避免發生因證書是由未知 CA 簽署或與主機名稱不符而導致連接遭拒。
cephuser@adm >ceph dashboard set-rgw-api-ssl-verify False如果物件閘道處理要求所花的時間過長,導致儀表板逾時,則可調整逾時值 (預設為 45 秒):
cephuser@adm >ceph dashboard set-rest-requests-timeout SECONDS
10.5 啟用 iSCSI 管理 #
Ceph Dashboard 使用 Ceph iSCSI 閘道的 rbd-target-api 服務所提供的 REST API 管理 iSCSI 目標。確定已在 iSCSI 閘道上安裝並啟用它。
Ceph Dashboard 的 iSCSI 管理功能取決於 ceph-iscsi 專案的最新版本 3。請確定您的作業系統提供了正確的版本,否則 Ceph Dashboard 將無法啟用管理功能。
如果 ceph-iscsi REST API 以 HTTPS 模式設定並使用自行簽署的證書,請設定該儀表板以避免在存取 ceph-iscsi API 時發生 SSL 證書驗證。
停用 API SSL 驗證:
cephuser@adm > ceph dashboard set-iscsi-api-ssl-verification false定義可用的 iSCSI 閘道:
cephuser@adm >ceph dashboard iscsi-gateway-listcephuser@adm >ceph dashboard iscsi-gateway-add scheme://username:password@host[:port]cephuser@adm >ceph dashboard iscsi-gateway-rm gateway_name
10.6 啟用單一登入 #
單一登入 (SSO) 是一種允許使用者以單個 ID 和密碼同時登入多個應用程式的存取控制方法。
Ceph Dashboard 支援透過 SAML 2.0 通訊協定對使用者進行外部驗證。由於仍由儀表板負責進行授權,因此您需要先建立使用者帳戶,並將其與所需角色相關聯。不過,可由現有身分提供者 (IdP) 來執行驗證。
若要設定單一登入,請使用以下指令:
cephuser@adm > ceph dashboard sso setup saml2 CEPH_DASHBOARD_BASE_URL \
IDP_METADATA IDP_USERNAME_ATTRIBUTE \
IDP_ENTITY_ID SP_X_509_CERT \
SP_PRIVATE_KEY參數:
- CEPH_DASHBOARD_BASE_URL
可用於存取 Ceph Dashboard 的基本 URL (例如「https://cephdashboard.local」)。
- IDP_METADATA
IdP 中繼資料 XML 的 URL、檔案路徑或內容 (例如「https://myidp/metadata」)。
- IDP_USERNAME_ATTRIBUTE
選擇性。將用於從驗證回應中獲取使用者名稱的屬性。預設為「uid」。
- IDP_ENTITY_ID
選擇性。當 IdP 中繼資料上存在多個實體 ID 時,請使用該參數。
- SP_X_509_CERT / SP_PRIVATE_KEY
選擇性。Ceph Dashboard (服務提供者) 進行簽署和加密時將使用的證書的檔案路徑或內容。
SAML 要求的發出者值將採用以下格式:
CEPH_DASHBOARD_BASE_URL/auth/saml2/metadata
若要顯示目前的 SAML 2.0 組態,請執行以下指令:
cephuser@adm > ceph dashboard sso show saml2若要停用單一登入,請執行以下指令:
cephuser@adm > ceph dashboard sso disable若要檢查是否啟用了 SSO,請執行以下指令:
cephuser@adm > ceph dashboard sso status若要啟用 SSO,請執行以下指令:
cephuser@adm > ceph dashboard sso enable saml211 在指令行上管理使用者和角色 #
本節說明如何管理 Ceph Dashboard 使用的使用者帳戶。該工具可協助您建立或修改使用者帳戶,以及設定正確的使用者角色和許可權。
11.1 管理密碼規則 #
依預設會啟用密碼規則功能,包括以下檢查:
密碼長度是否超過 N 個字元?
舊密碼和新密碼是否相同?
可以完全開啟或關閉密碼規則功能:
cephuser@adm > ceph dashboard set-pwd-policy-enabled true|false可以開啟或關閉以下個別檢查:
cephuser@adm >ceph dashboard set-pwd-policy-check-length-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-oldpwd-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-username-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-exclusion-list-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-complexity-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-sequential-chars-enabled true|falsecephuser@adm >ceph dashboard set-pwd-policy-check-repetitive-chars-enabled true|false
此外,可使用以下選項設定密碼規則行為。
最短密碼長度 (預設值為 8):
cephuser@adm >ceph dashboard set-pwd-policy-min-length N最小密碼複雜性 (預設值為 10):
cephuser@adm >ceph dashboard set-pwd-policy-min-complexity N密碼複雜性是透過對密碼中的每個字元進行分類來計算的。
密碼中不允許使用的逗號分隔的單字清單:
cephuser@adm >ceph dashboard set-pwd-policy-exclusion-list word[,...]
11.2 管理使用者帳戶 #
Ceph Dashboard 支援管理多個使用者帳戶。每個使用者帳戶包含使用者名稱、密碼 (使用 bcrypt 以加密形式儲存)、選用名稱和選用電子郵件地址。
系統將使用者帳戶儲存在 Ceph 管理員的組態資料庫中,並在所有 Ceph 管理員例項之間全域共用該資訊。
使用以下指令可管理使用者帳戶:
- 顯示現有使用者:
cephuser@adm >ceph dashboard ac-user-show [USERNAME]- 建立新使用者:
cephuser@adm >ceph dashboard ac-user-create USERNAME [PASSWORD] [ROLENAME] [NAME] [EMAIL]- 刪除使用者:
cephuser@adm >ceph dashboard ac-user-delete USERNAME- 更改使用者的密碼:
cephuser@adm >ceph dashboard ac-user-set-password USERNAME PASSWORD- 修改使用者名稱和電子郵件:
cephuser@adm >ceph dashboard ac-user-set-info USERNAME NAME EMAIL- 停用使用者
cephuser@adm >ceph dashboard ac-user-disable USERNAME- 啟用使用者
cephuser@adm >ceph dashboard ac-user-enable USERNAME
11.3 使用者角色和許可權 #
本節介紹您可為使用者角色指定的安全性範圍、如何管理使用者角色,以及如何為使用者帳戶指定角色。
11.3.1 定義安全性範圍 #
使用者帳戶與一組角色相關聯,這些角色定義了該使用者可以存取儀表板的哪些部分。儀表板的各個部分均會劃分在某個安全性範圍內。安全性範圍已預先定義且固定不變。目前可用的安全性範圍如下:
- hosts
包含與功能表項目相關的所有功能。
- config-opt
包含與 Ceph 組態選項管理相關的所有功能。
- pool
包含與池管理相關的所有功能。
- osd
包含與 Ceph OSD 管理相關的所有功能。
- monitor
包含與 Ceph 監控程式管理相關的所有功能。
- rbd-image
包含與 RADOS 區塊裝置影像管理相關的所有功能。
- rbd-mirroring
包含與 RADOS 區塊裝置鏡像管理相關的所有功能。
- iscsi
包含與 iSCSI 管理相關的所有功能。
- rgw
包含與物件閘道管理相關的所有功能。
- cephfs
包含與 CephFS 管理相關的所有功能。
- manager
包含與 Ceph 管理員管理相關的所有功能。
- log
包含與 Ceph 記錄管理相關的所有功能。
- grafana
包含與 Grafana 代理相關的所有功能。
- prometheus
包含與 Prometheus 警示管理相關的所有功能。
- dashboard-settings
允許變更儀表板設定。
11.3.2 指定使用者角色 #
角色指定了一個安全性範圍與一組許可權之間的一組對應。許可權分為四種類型:「read」、「create」、「update」和「delete」。
下面的範例指定了一個角色,具有該角色的使用者擁有池管理相關功能的「read」和「create」許可權,以及 RBD 影像管理相關功能的完整許可權:
{
'role': 'my_new_role',
'description': 'My new role',
'scopes_permissions': {
'pool': ['read', 'create'],
'rbd-image': ['read', 'create', 'update', 'delete']
}
}儀表板提供了一組預先定義的角色,我們稱之為系統角色。全新安裝 Ceph Dashboard 後即可使用這些角色:
- administrator
提供針對所有安全性範圍的完整許可權。
- read-only
提供針對儀表板設定以外的其他所有安全性範圍的讀取許可權。
- block-manager
提供針對「rbd-image」、「rbd-mirroring」和「iscsi」範圍的完整許可權。
- rgw-manager
提供針對「rgw」範圍的完整許可權。
- cluster-manager
提供針對「hosts」、「osd」、「monitor」、「manager」和「config-opt」範圍的完整許可權。
- pool-manager
提供針對「pool」範圍的完整許可權。
- cephfs-manager
提供針對「cephfs」範圍的完整許可權。
11.3.2.1 管理自訂角色 #
您可以使用以下指令建立新使用者角色:
- 建立新角色:
cephuser@adm >ceph dashboard ac-role-create ROLENAME [DESCRIPTION]- 刪除角色:
cephuser@adm >ceph dashboard ac-role-delete ROLENAME- 新增範圍許可權至角色:
cephuser@adm >ceph dashboard ac-role-add-scope-perms ROLENAME SCOPENAME PERMISSION [PERMISSION...]- 從角色中刪除範圍許可權:
cephuser@adm >ceph dashboard ac-role-del-perms ROLENAME SCOPENAME
11.3.2.2 為使用者帳戶指定角色 #
使用以下指令可為使用者指定角色:
- 設定使用者角色:
cephuser@adm >ceph dashboard ac-user-set-roles USERNAME ROLENAME [ROLENAME ...]- 新增其他角色至使用者:
cephuser@adm >ceph dashboard ac-user-add-roles USERNAME ROLENAME [ROLENAME ...]- 刪除使用者的角色:
cephuser@adm >ceph dashboard ac-user-del-roles USERNAME ROLENAME [ROLENAME ...]
如果您建立了自訂使用者角色,並打算以後使用 ceph.purge 執行程式移除 Ceph 叢集,則需要先清除自訂角色。如需更多詳細資料,請參閱第 13.9 節 「移除整個 Ceph 叢集」。
11.3.2.3 範例:建立使用者和自訂角色 #
本節說明建立具有以下功能的使用者帳戶的程序:可管理 RBD 影像、檢視和建立 Ceph 池,並擁有針對任何其他範圍的唯讀存取權。
建立名為
tux的新使用者:cephuser@adm >ceph dashboard ac-user-create tux PASSWORD建立角色並指定範圍許可權:
cephuser@adm >ceph dashboard ac-role-create rbd/pool-managercephuser@adm >ceph dashboard ac-role-add-scope-perms rbd/pool-manager \ rbd-image read create update deletecephuser@adm >ceph dashboard ac-role-add-scope-perms rbd/pool-manager pool read create將角色與
tux使用者相關聯:cephuser@adm >ceph dashboard ac-user-set-roles tux rbd/pool-manager read-only
11.4 代理組態 #
如果您要建立固定 URL 以連接 Ceph Dashboard,或者不允許直接連接至管理員節點,可以設定一個代理將內送要求轉到目前使用中 ceph-mgr 例項。
11.4.1 使用反向代理存取儀表板 #
如果您要透過反向代理組態存取儀表板,則可能需要使用 URL 字首來存取。若要讓儀表板使用包含您字首的超連結,您可以進行 url_prefix 設定:
cephuser@adm > ceph config set mgr mgr/dashboard/url_prefix URL_PREFIX
然後,便可透過網址 http://HOST_NAME:PORT_NUMBER/URL_PREFIX/ 來存取儀表板。
11.4.2 停用重新導向 #
如果 Ceph Dashboard 位於 HAProxy 等負載平衡代理之後,請停用重新導向行為,以防止出現將內部 (無法解析的) URL 發佈到前端用戶端的情況。使用以下指令可讓儀表板以 HTTP 錯誤 (預設為500) 進行回應,而不是重新導向至使用中儀表板:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_behaviour "error"若要將設定重設為預設的重新導向行為,請使用以下指令:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_behaviour "redirect"11.4.3 設定錯誤狀態代碼 #
如果停用了重新導向行為,則應自訂待命儀表板的 HTTP 狀態代碼。為此,請執行以下指令:
cephuser@adm > ceph config set mgr mgr/dashboard/standby_error_status_code 50311.4.4 HAProxy 範例組態 #
以下範例組態適用於使用 HAProxy 的 TLS/SSL 傳遞。
該組態適用於以下情況:如果儀表板發生容錯移轉,前端用戶端可能會收到 HTTP 重新導向 (303) 回應,並將重新導向至無法解析的主機。
兩次 HAProxy 狀況檢查期間發生容錯移轉時,便會發生此情況。在這種情況下,先前處於使用中狀態的儀表板節點現在將以 303 進行回應,從而指向新使用中節點。為避免出現該情況,您應該考慮停用待命節點上的重新導向行為。
defaults
log global
option log-health-checks
timeout connect 5s
timeout client 50s
timeout server 450s
frontend dashboard_front
mode http
bind *:80
option httplog
redirect scheme https code 301 if !{ ssl_fc }
frontend dashboard_front_ssl
mode tcp
bind *:443
option tcplog
default_backend dashboard_back_ssl
backend dashboard_back_ssl
mode tcp
option httpchk GET /
http-check expect status 200
server x HOST:PORT ssl check verify none
server y HOST:PORT ssl check verify none
server z HOST:PORT ssl check verify none11.5 稽核 API 要求 #
Ceph Dashboard 的 REST API 可將 PUT、POST 和 DELETE 要求記錄至 Ceph 稽核記錄中。記錄功能預設處於停用狀態,但您可使用以下指令將其啟用:
cephuser@adm > ceph dashboard set-audit-api-enabled true如果記錄功能處於啟用狀態,將會記錄每個要求的以下參數:
- from
要求的來源,例如「https://[::1]:44410」。
- path
REST API 路徑,例如
/api/auth。- method
「PUT」、「POST」或「DELETE」。
- user
使用者的名稱 (或「None」)。
範例記錄項目如下所示:
2019-02-06 10:33:01.302514 mgr.x [INF] [DASHBOARD] \
from='https://[::ffff:127.0.0.1]:37022' path='/api/rgw/user/exu' method='PUT' \
user='admin' params='{"max_buckets": "1000", "display_name": "Example User", "uid": "exu", "suspended": "0", "email": "user@example.com"}'要求封包內容 (引數及其值的清單) 的記錄功能預設處於啟用狀態。您可以依照如下方式停用該功能:
cephuser@adm > ceph dashboard set-audit-api-log-payload false11.6 在 Ceph Dashboard 中設定 NFS Ganesha #
Ceph Dashboard 可以管理使用 CephFS 或物件閘道做為其後備儲存的 NFS Ganesha 輸出項。該儀表板用於管理儲存在 CephFS 叢集上的 RADOS 物件中的 NFS Ganesha 組態檔案。NFS Ganesha 必須將其部分組態儲存在 Ceph 叢集中。
執行以下指令以設定 NFS Ganesha 組態物件的位置:
cephuser@adm > ceph dashboard set-ganesha-clusters-rados-pool-namespace pool_name[/namespace]現在您便可以使用 Ceph Dashboard 管理 NFS Ganesha 輸出項。
11.6.1 設定多個 NFS Ganesha 叢集 #
Ceph Dashboard 支援管理屬於不同 NFS Ganesha 叢集的 NFS Ganesha 輸出項。建議每個 NFS Ganesha 叢集將其組態物件儲存在不同的 RADOS 池/名稱空間中,以便相互隔離各自組態。
使用以下指令可指定每個 NFS Ganesha 叢集的組態位置:
cephuser@adm > ceph dashboard set-ganesha-clusters-rados-pool-namespace cluster_id:pool_name[/namespace](,cluster_id:pool_name[/namespace])*cluster_id 是唯一識別 NFS Ganesha 叢集的任意字串。
使用多個 NFS Ganesha 叢集設定 Ceph Dashboard 時,Web UI 會自動讓您選擇輸出項所屬的叢集。
11.7 除錯外掛程式 #
Ceph Dashboard 外掛程式延伸了儀表板的功能。除錯外掛程式允許依據除錯模式來自訂儀表板的行為。可以使用以下指令啟用、停用或檢查除錯外掛程式:
cephuser@adm >ceph dashboard debug status Debug: 'disabled'cephuser@adm >ceph dashboard debug enable Debug: 'enabled'cephuser@adm >dashboard debug disable Debug: 'disabled'
錯外掛程式預設處於停用狀態。這是適用於生產部署的建議設定。如果需要,可以啟用除錯模式,而無需重新啟動。
第 II 部分 叢集操作 #
- 12 確定叢集狀態
當叢集正在執行時,您可以使用
ceph工具來監控它。若要確定叢集狀態,通常需要檢查 Ceph OSD、Ceph 監控程式、放置群組和中繼資料伺服器的狀態。- 13 操作任務
若要修改現有 Ceph 叢集的組態,請執行以下步驟:
- 14 Ceph 服務的操作
您可以在精靈、節點或叢集層級操作 Ceph 服務。依據您需要的方法,使用 cephadm 或
systemctl指令。- 15 備份及還原
本章說明您應當備份 Ceph 叢集的哪些部分才能還原叢集功能。
- 16 監控和警示
在 SUSE Enterprise Storage 7 中,cephadm 會部署一個監控和警示堆疊。使用者需要在 YAML 組態檔案中定義要使用 cephadm 部署的服務 (例如 Prometheus、警示管理員和 Grafana),也可以使用 CLI 來部署這些服務。當部署多個相同類型的服務時,會部署高可用性設定。但 Node Exporter 不適用於此規則。
12 確定叢集狀態 #
當叢集正在執行時,您可以使用 ceph 工具來監控它。若要確定叢集狀態,通常需要檢查 Ceph OSD、Ceph
監控程式、放置群組和中繼資料伺服器的狀態。
若要以互動模式執行 ceph 工具,請不帶任何引數在指令行中輸入
ceph。如果要在一行中輸入多條 ceph
指令,則使用互動模式較為方便。例如:
cephuser@adm > ceph
ceph> health
ceph> status
ceph> quorum_status
ceph> mon stat12.1 檢查叢集的狀態 #
您可以使用 ceph status 或 ceph -s 瞭解叢集的即時狀態:
cephuser@adm > ceph -s
cluster:
id: b4b30c6e-9681-11ea-ac39-525400d7702d
health: HEALTH_OK
services:
mon: 5 daemons, quorum ses-min1,ses-master,ses-min2,ses-min4,ses-min3 (age 2m)
mgr: ses-min1.gpijpm(active, since 3d), standbys: ses-min2.oopvyh
mds: my_cephfs:1 {0=my_cephfs.ses-min1.oterul=up:active}
osd: 3 osds: 3 up (since 3d), 3 in (since 11d)
rgw: 2 daemons active (myrealm.myzone.ses-min1.kwwazo, myrealm.myzone.ses-min2.jngabw)
task status:
scrub status:
mds.my_cephfs.ses-min1.oterul: idle
data:
pools: 7 pools, 169 pgs
objects: 250 objects, 10 KiB
usage: 3.1 GiB used, 27 GiB / 30 GiB avail
pgs: 169 active+clean輸出內容提供了以下資訊:
叢集 ID
叢集執行狀態
監控程式地圖版本編號和監控程式仲裁的狀態
OSD 地圖版本編號和 OSD 的狀態
Ceph 管理員的狀態
物件閘道的狀態
放置群組地圖版本
放置群組和池數量
理論上儲存的資料量和儲存的物件數量
所儲存資料的總量。
used 值反映實際使用的原始儲存量。xxx GB / xxx GB
值表示叢集可用容量
(兩者中的較小數值),以及叢集的整體儲存容量。理論數量反映在複製所儲存資料或建立其快照前這些資料的大小。因此,實際儲存的資料量一般會超出理論上的儲存量,因為
Ceph 會建立資料的複本,可能還會將儲存容量用於複製和建立快照。
顯示即時狀態資訊的其他指令如下:
ceph pg statceph osd pool statsceph dfceph df detail
若要即時更新資訊,請在 watch 指令中以引數的方式使用以上任意指令 (包括 ceph
-s):
root # watch -n 10 'ceph -s'如果您看累了,請按 Ctrl–C。
12.2 檢查叢集狀況 #
在啟動叢集後到開始讀取和/或寫入資料期間,檢查叢集的狀態:
cephuser@adm > ceph health
HEALTH_WARN 10 pgs degraded; 100 pgs stuck unclean; 1 mons down, quorum 0,2 \
node-1,node-2,node-3如果之前為您的組態或金鑰圈指定了非預設位置,則此時可以指定它們的位置:
cephuser@adm > ceph -c /path/to/conf -k /path/to/keyring healthCeph 叢集會傳回下列狀態代碼之一:
- OSD_DOWN
一或多個 OSD 標示為已停機。OSD 精靈可能已停止,或對等 OSD 可能無法透過網路連接 OSD。常見原因包括精靈已停止或已當機、主機已停機或網路中斷。
驗證主機是否執行良好,精靈是否已啟動,並且網路是否正常運作。如果精靈已當機,精靈記錄檔案 (
/var/log/ceph/ceph-osd.*) 可能會包含除錯資訊。- OSD_crush type_DOWN,例如 OSD_HOST_DOWN
特定 CRUSH 子樹中的所有 OSD (例如主機上的所有 OSD) 均標示為已停機。
- OSD_ORPHAN
在 CRUSH 地圖階層中參考了 OSD,但它不存在。可使用以下指令從 CRUSH 階層中移除 OSD:
cephuser@adm >ceph osd crush rm osd.ID- OSD_OUT_OF_ORDER_FULL
以下各項的使用率閾值並不是遞增的:backfillfull (預設值為 0.90)、nearfull (預設值為 0.85)、full (預設值為 0.95)、failsafe_full。特別是,我們需要 backfillfull < nearfull,nearfull < full 且 full < failsafe_full。
若要讀取最新的值,請執行以下指令:
cephuser@adm >ceph health detail HEALTH_ERR 1 full osd(s); 1 backfillfull osd(s); 1 nearfull osd(s) osd.3 is full at 97% osd.4 is backfill full at 91% osd.2 is near full at 87%可以使用以下指令調整閾值:
cephuser@adm >ceph osd set-backfillfull-ratio ratiocephuser@adm >ceph osd set-nearfull-ratio ratiocephuser@adm >ceph osd set-full-ratio ratio- OSD_FULL
一或多個 OSD 超出了 full 閾值,阻止叢集處理寫入操作。可使用以下指令檢查各池的使用量:
cephuser@adm >ceph df可使用以下指令查看目前定義的 full 比率:
cephuser@adm >ceph osd dump | grep full_ratio還原寫入可用性的臨時解決辦法是稍稍提高 full 閾值:
cephuser@adm >ceph osd set-full-ratio ratio請透過部署更多 OSD 將新的儲存新增至叢集,或者刪除現有資料來騰出空間。
- OSD_BACKFILLFULL
一或多個 OSD 超出了 backfillfull 閾值,因而不允許將資料重新平衡到此裝置。這是一則預警,表示重新平衡可能無法完成,並且叢集將滿。可使用以下指令檢查各池的使用量:
cephuser@adm >ceph df- OSD_NEARFULL
一或多個 OSD 超出了 nearfull 閾值。這是一則預警,表示叢集將滿。可使用以下指令檢查各池的使用量:
cephuser@adm >ceph df- OSDMAP_FLAGS
已設定一或多個所需的叢集旗標。可使用以下指令設定或清除這些旗標 (full 除外):
cephuser@adm >ceph osd set flagcephuser@adm >ceph osd unset flag這些旗標包括:
- full
叢集標記為已滿,無法處理寫入操作。
- pauserd、pausewr
已暫停讀取或寫入。
- noup
不允許 OSD 啟動。
- nodown
將會忽略 OSD 故障報告,如此監控程式便不會將 OSD 標示為 down。
- noin
先前標示為 out 的 OSD 在啟動時將不會重新標示為 in。
- noout
停機的 OSD 在設定間隔過後將不會自動標示為 out。
- nobackfill、norecover、norebalance
復原或資料重新平衡程序已暫停。
- noscrub、nodeep_scrub
整理程序已停用 (請參閱第 17.6 節 「整理放置群組」)。
- notieragent
快取分層活動已暫停。
- OSD_FLAGS
一或多個 OSD 設定了所需的每 OSD 旗標。這些旗標包括:
- noup
不允許 OSD 啟動。
- nodown
將會忽略此 OSD 的故障報告。
- noin
如果此 OSD 先前在發生故障後自動標示為 out,當它啟動時將不會標示為 in。
- noout
如果此 OSD 已停機,則在設定的間隔過後,它將不會自動標示為 out。
可使用以下指令來設定和清除每 OSD 旗標:
cephuser@adm >ceph osd add-flag osd-IDcephuser@adm >ceph osd rm-flag osd-ID- OLD_CRUSH_TUNABLES
CRUSH 地圖目前使用的設定很舊,應予以更新。
mon_crush_min_required_version組態選項可確定使用時不會觸發此狀態警告的最舊可調參數 (即能夠連接到叢集的最舊用戶端版本)。- OLD_CRUSH_STRAW_CALC_VERSION
CRUSH 地圖目前使用較舊的非最佳方法來計算 straw 桶的中間權數值。應該更新 CRUSH 地圖,以使用較新的方法 (
straw_calc_version=1)。- CACHE_POOL_NO_HIT_SET
一或多個快取池未設定命中集來追蹤使用量,這使分層代理程式無法識別要從快取中衝洗和逐出的冷物件。可使用以下指令對快取池設定命中集︰
cephuser@adm >ceph osd pool set poolname hit_set_type typecephuser@adm >ceph osd pool set poolname hit_set_period period-in-secondscephuser@adm >ceph osd pool set poolname hit_set_count number-of-hitsetscephuser@adm >ceph osd pool set poolname hit_set_fpp target-false-positive-rate- OSD_NO_SORTBITWISE
未在執行 Luminous 12 以下版本的 OSD,但是尚未設定
sortbitwise旗標。您需要先設定sortbitwise旗標,Luminous 12 或更新版本的 OSD 才能啟動:cephuser@adm >ceph osd set sortbitwise- POOL_FULL
一或多個池已達到其定額,不再允許寫入。您可使用以下指令來設定池定額和使用量:
cephuser@adm >ceph df detail您可以使用以下指令來提高池定額
cephuser@adm >ceph osd pool set-quota poolname max_objects num-objectscephuser@adm >ceph osd pool set-quota poolname max_bytes num-bytes或者刪除一些現有資料以減少使用量。
- PG_AVAILABILITY
資料可用性下降,這表示叢集無法處理針對叢集中某些資料的潛在讀取或寫入要求。具體而言,一或多個 PG 處於不允許處理 I/O 要求的狀態。有問題的 PG 狀態包括互聯建立中、陳舊、不完整和不處於使用中 (如果不迅速解決這些狀況)。執行以下指令可獲得有關哪些 PG 受影響的詳細資訊:
cephuser@adm >ceph health detail大多數情況下,出現此情形的根本原因在於一或多個 OSD 目前已停機。可使用以下指令來查詢特定的有問題 PG 的狀態:
cephuser@adm >ceph tell pgid query- PG_DEGRADED
某些資料的資料備援降低,這表示叢集沒有所需數量的複本用於所有資料 (對於副本池) 或糾刪碼片段 (對於糾刪碼池)。具體而言,一或多個 PG 設定了 degraded 或 undersized 旗標 (叢集中沒有該放置群組的足夠例項),或者有一段時間未設定 clean 旗標。執行以下指令可獲得有關哪些 PG 受影響的詳細資訊:
cephuser@adm >ceph health detail大多數情況下,出現此情形的根本原因在於一或多個 OSD 目前已停機。可使用以下指令來查詢特定的有問題 PG 的狀態:
cephuser@adm >ceph tell pgid query- PG_DEGRADED_FULL
由於叢集中的可用空間不足,某些資料的資料備援可能已降低或面臨風險。具體而言,一或多個 PG 設定了 backfill_toofull 或 recovery_tooful 旗標,這表示叢集無法移轉或復原資料,原因是一或多個 OSD 高於 backfillfull 閾值。
- PG_DAMAGED
資料整理 (請參閱第 17.6 節 「整理放置群組」) 程序探查到叢集中存在某些資料一致性問題。具體而言,一或多個 PG 設定了 inconsistent 或 snaptrim_error 旗標 (表示某個較早的整理操作發現問題),或者設定了 repair 旗標 (表示目前正在修復此類不一致問題)。
- OSD_SCRUB_ERRORS
最近的 OSD 整理操作發現了不一致問題。
- CACHE_POOL_NEAR_FULL
快取層池將滿。此環境中的「滿」由快取池的 target_max_bytes 和 target_max_objects 內容確定。當池達到目標閾值時,如果正在從快取衝洗和逐出資料,寫入池的要求可能會被阻擋,出現常會導致延遲很高且效能變差的狀態。可使用以下指令調整快取池目標大小:
cephuser@adm >ceph osd pool set cache-pool-name target_max_bytes bytescephuser@adm >ceph osd pool set cache-pool-name target_max_objects objects正常的快取衝洗和逐出活動還可能因基礎層級可用性或效能下降或者叢集的整體負載較高而受到限制。
- TOO_FEW_PGS
使用中的 PG 數量低於每個 OSD 的 PG 數的可設定閾值
mon_pg_warn_min_per_osd。這可能導致叢集中各 OSD 間的資料分發和平衡未達到最佳,以致降低整體效能。- TOO_MANY_PGS
使用中的 PG 數量高於每個 OSD 的 PG 數的可設定閾值
mon_pg_warn_max_per_osd。這可能導致 OSD 精靈的記憶體使用率較高,叢集狀態變更 (例如 OSD 重新啟動、新增或移除) 之後互聯速度降低,並且 Ceph 管理員和 Ceph 監控程式上的負載較高。雖然不能減少現有池的
pg_num值,但可以減少pgp_num值。這樣可有效地將一些 PG 併置在同組 OSD 上,從而減輕上述的一些負面影響。可使用以下指令調整pgp_num值:cephuser@adm >ceph osd pool set pool pgp_num value- SMALLER_PGP_NUM
一或多個池的
pgp_num值小於pg_num。這通常表示 PG 計數有所提高,但未同時提升放置行為。使用以下指令設定pgp_num,使其與觸發資料移轉的pg_num相符,通常便可解決此問題:cephuser@adm >ceph osd pool set pool pgp_num pg_num_value- MANY_OBJECTS_PER_PG
一或多個池的每 PG 平均物件數大大高於叢集的整體平均值。透過
mon_pg_warn_max_object_skew組態值來控制該特定閾值。這通常表示包含叢集中大部分資料的池所具有的 PG 太少,以及/或者不包含這麼多資料的其他池具有的 PG 太多。可透過調整監控程式上的mon_pg_warn_max_object_skew組態選項提高閾值,來消除該狀態警告。- POOL_APP_NOT_ENABLED
存在包含一或多個物件,但尚未標記為供特定應用程式使用的池。將池標記為供某個應用程式使用即可消除此警告。例如,如果池由 RBD 使用:
cephuser@adm >rbd pool init pool_name如果池正由自訂應用程式「foo」使用,您還可以使用低層級指令標記它:
cephuser@adm >ceph osd pool application enable foo- POOL_FULL
一或多個池已達到 (或幾乎要達到) 其定額。透過
mon_pool_quota_crit_threshold組態選項來控制觸發此錯誤狀況的閾值。可使用以下指令上調、下調 (或移除) 池定額:cephuser@adm >ceph osd pool set-quota pool max_bytes bytescephuser@adm >ceph osd pool set-quota pool max_objects objects將定額值設定為 0 將停用定額。
- POOL_NEAR_FULL
一或多個池接近其定額。透過
mon_pool_quota_warn_threshold組態選項來控制觸發此警告狀況的閾值。可使用以下指令上調、下調 (或移除) 池定額:cephuser@adm >ceph osd osd pool set-quota pool max_bytes bytescephuser@adm >ceph osd osd pool set-quota pool max_objects objects將定額值設定為 0 將停用定額。
- OBJECT_MISPLACED
叢集中的一或多個物件未儲存在叢集希望儲存的節點上。這表示叢集最近的某項變更導致的資料移轉尚未完成。誤放的資料本質上不屬於危險狀況。資料一致性方面永遠不會有風險,僅當所需位置放置了物件所需份數的新副本之後,系統才會移除物件的舊副本。
- OBJECT_UNFOUND
找不到叢集中的一或多個物件。具體而言,OSD 知道物件的新複本或更新複本應該存在,但在目前啟用的 OSD 上卻找不到該版物件的複本。系統將阻止對「未找到」物件的讀取或寫入要求。從理論上講,可以將具有未找到物件最近複本的已停機 OSD 重新啟用。可透過負責處理未找到物件的 PG 的互聯狀態識別候選 OSD:
cephuser@adm >ceph tell pgid query- REQUEST_SLOW
正花費很長的時間處理一或多個 OSD 要求。這可能表示負載極重、儲存裝置速度緩慢或有軟體錯誤。您可以從 OSD 主機上執行以下指令,來查詢有問題的 OSD 上的要求佇列:
cephuser@adm >ceph daemon osd.id ops您可以查看近期最慢的要求摘要:
cephuser@adm >ceph daemon osd.id dump_historic_ops可使用以下指令尋找 OSD 的位置:
cephuser@adm >ceph osd find osd.id- REQUEST_STUCK
已將一或多個 OSD 要求阻擋一段相當長的時間,例如 4096 秒。這表示叢集已有很長一段時間處於狀況不良狀態 (例如,沒有足夠的執行中 OSD 或非使用中 PG),或者 OSD 存在某種內部問題。
- PG_NOT_SCRUBBED
最近未整理 (請參閱第 17.6 節 「整理放置群組」) 一或多個 PG。通常每
mon_scrub_interval秒整理一次 PG,當mon_warn_not_scrubbed這類間隔已過但未進行整理時,就會觸發此警告。如果 PG 未標記為清理,系統將不會整理它們。如果 PG 放置錯誤或已降級,就會出現這種情況 (請參閱上文中的 PG_AVAILABILITY 和 PG_DEGRADED)。您可使用以下指令手動對標記為清理的 PG 啟動整理:cephuser@adm >ceph pg scrub pgid- PG_NOT_DEEP_SCRUBBED
最近未深層整理 (請參閱第 17.6 節 「整理放置群組」) 一或多個 PG。系統通常每
osd_deep_scrub_interval秒整理一次 PG,當mon_warn_not_deep_scrubbed秒已過但未進行整理時,就會觸發此警告。如果 PG 未標記為清理,系統將不會 (深層) 整理它們。如果 PG 放置錯誤或已降級,就會出現這種情況 (請參閱上文中的 PG_AVAILABILITY 和 PG_DEGRADED)。您可使用以下指令手動對標記為清理的 PG 啟動整理:cephuser@adm >ceph pg deep-scrub pgid
如果之前為您的組態或金鑰圈指定了非預設位置,則此時可以指定它們的位置:
root # ceph -c /path/to/conf -k /path/to/keyring health12.3 檢查叢集的使用率統計資料 #
若要檢視叢集的資料使用率以及資料在多個池之間的分佈,請使用 ceph df 指令。若要獲取更多詳細資料,請使用
ceph df detail。
cephuser@adm > ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 30 GiB 27 GiB 121 MiB 3.1 GiB 10.40
TOTAL 30 GiB 27 GiB 121 MiB 3.1 GiB 10.40
--- POOLS ---
POOL ID STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 0 B 0 0 B 0 8.5 GiB
cephfs.my_cephfs.meta 2 1.0 MiB 22 4.5 MiB 0.02 8.5 GiB
cephfs.my_cephfs.data 3 0 B 0 0 B 0 8.5 GiB
.rgw.root 4 1.9 KiB 13 2.2 MiB 0 8.5 GiB
myzone.rgw.log 5 3.4 KiB 207 6 MiB 0.02 8.5 GiB
myzone.rgw.control 6 0 B 8 0 B 0 8.5 GiB
myzone.rgw.meta 7 0 B 0 0 B 0 8.5 GiB
輸出中的 RAW STORAGE 區段提供叢集用於資料的儲存空間容量綜覽。
CLASS:裝置的儲存類別。如需裝置類別的更多詳細資料,請參閱第 17.1.1 節 「裝置類別」。SIZE:叢集的整體儲存容量。AVAIL:叢集中的可用空間容量。USED:單純為區塊裝置中儲存的資料物件配置的空間 (所有 OSD 上的累計空間)。RAW USED:「USED」空間與區塊裝置上為實現 Ceph 而配置/保留的空間 (例如 BlueStore 的 BlueFS 部分) 之和。% RAW USED:已用的原始儲存量百分比。將此數字與full ratio和near full ratio結合使用,可確保您不會用完叢集的容量。如需其他詳細資料,請參閱第 12.8 節 「儲存容量」。注意:叢集填滿程度當原始儲存填滿層級接近 100% 時,您需要新增新儲存空間至叢集。較高的使用量可能導致單個 OSD 填滿,叢集處於不良狀態。
使用指令
ceph osd df tree可列出所有 OSD 的填滿程度。
輸出內容的 POOLS
區段提供了池清單和每個池的理論使用量。此區段的輸出不反映複本、複製品或快照。例如,如果您儲存含 1MB
資料的物件,理論使用量將是 1MB,但是根據複本、複製品或快照數量,實際使用量可能是 2MB 或更多。
POOL:池的名稱。ID:池 ID。STORED:使用者儲存的資料量。OBJECTS:每個池的理論已儲存物件數。USED:所有 OSD 節點單純為儲存資料配置的空間容量 (以 kB 計)。%USED:每個池的理論已用儲存百分比。MAX AVAIL:給定池中的最大可用空間。
POOLS 區段中的數字是理論上的。它們不包括複本、快照或複製品數量。因此,USED 與
%USED 數量之和不會加總到輸出內容 RAW STORAGE 區段中的
RAW USED 和 %RAW USED 數量中。
12.4 檢查 OSD 狀態 #
您可透過執行以下指令來檢查 OSD,以確定它們已啟動且正在執行:
cephuser@adm > ceph osd stat或
cephuser@adm > ceph osd dump您也可以根據 OSD 在 CRUSH 地圖中的位置檢視 OSD。
ceph osd tree 將列印 CRUSH 樹及主機、它的 OSD、OSD 是否已啟動及其權數:
cephuser@adm > ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 3 0.02939 root default
-3 3 0.00980 rack mainrack
-2 3 0.00980 host osd-host
0 1 0.00980 osd.0 up 1.00000 1.00000
1 1 0.00980 osd.1 up 1.00000 1.00000
2 1 0.00980 osd.2 up 1.00000 1.0000012.5 檢查填滿的 OSD #
Ceph 可阻止您向填滿的 OSD 寫入資料,以防遺失資料。在正常運作的叢集中,當叢集接近其填滿比率時,您會收到警告。mon osd
full ratio 預設設為容量的 0.95 (95%),達到該比率後,叢集會阻止用戶端寫入資料。mon osd
nearfull ratio 預設設為容量的 0.85 (85%),達到該比率時,叢集會產生狀態警告。
可透過 ceph health 指令報告填滿的 OSD 節點:
cephuser@adm > ceph health
HEALTH_WARN 1 nearfull osds
osd.2 is near full at 85%或
cephuser@adm > ceph health
HEALTH_ERR 1 nearfull osds, 1 full osds
osd.2 is near full at 85%
osd.3 is full at 97%處理填滿的叢集的最佳方法是新增新的 OSD 主機/磁碟,以便讓叢集將資料重新分佈到新的可用儲存空間。
OSD 變滿 (即用完 100% 的磁碟空間) 之後,往往會迅速當機而不發出警告。管理 OSD 節點時需記住下面幾點提示。
每個 OSD 的磁碟空間 (通常掛接於
/var/lib/ceph/osd/osd-{1,2..}下) 需放置在專屬的基礎磁碟或分割區上。檢查 Ceph 組態檔案,確定 Ceph 不會將其記錄檔案儲存在專供 OSD 使用的磁碟/分割區上。
確定沒有其他程序寫入專供 OSD 使用的磁碟/分割區。
12.6 檢查監控程式狀態 #
啟動叢集後,請在第一次讀取和/或寫入資料之前檢查 Ceph 監控程式的仲裁狀態。如果叢集已在處理要求,請定期檢查 Ceph 監控程式的狀態,以確定其正在執行。
若要顯示監控程式地圖,請執行以下指令:
cephuser@adm > ceph mon stat或
cephuser@adm > ceph mon dump若要檢查監控程式叢集的仲裁狀態,請執行以下指令:
cephuser@adm > ceph quorum_statusCeph 將傳回仲裁狀態。例如,由三個監控程式組成的 Ceph 叢集可能傳回以下內容:
{ "election_epoch": 10,
"quorum": [
0,
1,
2],
"monmap": { "epoch": 1,
"fsid": "444b489c-4f16-4b75-83f0-cb8097468898",
"modified": "2011-12-12 13:28:27.505520",
"created": "2011-12-12 13:28:27.505520",
"mons": [
{ "rank": 0,
"name": "a",
"addr": "192.168.1.10:6789\/0"},
{ "rank": 1,
"name": "b",
"addr": "192.168.1.11:6789\/0"},
{ "rank": 2,
"name": "c",
"addr": "192.168.1.12:6789\/0"}
]
}
}12.7 檢查放置群組狀態 #
放置群組會將物件對應到 OSD。監控放置群組時,您希望它們處於 active 和
clean 狀態。如需詳細內容,請參閱第 12.9 節 「監控 OSD 和放置群組」。
12.8 儲存容量 #
做為防止資料遺失的安全措施,當 Ceph 儲存叢集接近其容量上限時,Ceph 將阻止您向 Ceph OSD 寫入或從中讀取資料。因此,讓生產叢集接近其填滿比率不是一種好的做法,因為這樣會犧牲高可用性。預設的填滿比率設定為 0.95,即容量的 95%。對於所含 OSD 數量較少的測試叢集而言,如此設定是非常激進的。
在監控叢集時,請注意與 nearfull 比率相關的警示。出現該警示表示,如果一或多個 OSD 發生故障,某些
OSD 的故障可能會導致服務暫時中斷。請考慮新增更多 OSD 以增加儲存容量。
測試叢集的一種常見情境是,系統管理員從 Ceph 儲存叢集中移除 Ceph OSD,等待叢集重新達到平衡。然後再移除另一個 Ceph
OSD,依此類推,直至叢集最終達到填滿比率並鎖死。我們建議即使使用測試叢集時也進行一定的容量規劃。透過規劃,您可以預估維持高可用性所需的備用容量。從理論上講,您需要規劃能夠應對一系列
Ceph OSD 發生故障的情況的方案,使叢集無需立即取代這些 Ceph OSD 也可復原到 active +
clean 狀態。您可以執行 active + degraded
狀態的叢集,但這不適合正常運作狀態。
下圖展示了一個包含 33 個 Ceph 節點的簡化 Ceph 儲存叢集,其中每個主機有一個 Ceph OSD,每個 Ceph OSD 從 3 TB
磁碟機讀取以及向其中寫入資料。此範例叢集實際的容量上限為 99 TB。mon osd full ratio 選項設定為
0.95。如果叢集的剩餘容量降至 5 TB,叢集將不允許用戶端讀取和寫入資料。因此,儲存叢集的運作容量為 95 TB,而不是 99 TB。

在這樣的叢集中,有一或兩個 OSD 發生故障屬於正常現象。一種不常發生但合乎常理的情況是機架的路由器或電源發生故障,導致多個 OSD (例如 OSD
7-12) 同時停機。在這種情況下,您仍然應該設法使叢集保持正常執行並達到 active + clean
狀態,即使這表示需要立即新增一些主機及額外的
OSD。如果容量使用率過高,您可能不會遺失資料。但是,如果叢集的容量使用率超過填滿比率,您雖然解決了故障網域內發生的中斷問題,卻可能會損失資料可用性。因此,我們建議至少進行大致的容量規劃。
針對您的叢集確定以下兩個數值:
OSD 的數量。
叢集的總容量。
如果您將叢集的總容量除以叢集中的 OSD 數量,將得到叢集內單個 OSD 的平均容量。將該數值與您預期正常運作期間將同時發生故障的 OSD 數量 (一個相對較小的數值) 相乘。最後,將叢集容量與填滿比率相乘得到運作容量上限。然後,減去您預期將發生故障的 OSD 中的資料量,即可得到一個合理的填滿比率。使用更高的 OSD 故障數 (整個機架的 OSD) 重複上述過程,即可得到一個合理的接近填滿比率數值。
以下設定僅在建立叢集時適用,隨後會儲存在 OSD 地圖中:
[global] mon osd full ratio = .80 mon osd backfillfull ratio = .75 mon osd nearfull ratio = .70
這些設定僅在建立叢集時適用。此後,需要使用 ceph osd set-nearfull-ratio 和
ceph osd set-full-ratio 指令在 OSD 地圖中變更這些設定。
- mon osd full ratio
在將 OSD 視為
已滿之前使用的磁碟空間百分比。預設值為 0.95- mon osd backfillfull ratio
在將 OSD 視為過
滿而無法回填之前使用的磁碟空間百分比。預設值為 0.90- mon osd nearfull ratio
在將 OSD 視為
將滿之前使用的磁碟空間百分比。預設值為 0.85
如果某些 OSD 將滿,但其他 OSD 的容量充足,則表示將滿 OSD 的
CRUSH 權數可能有問題。
12.9 監控 OSD 和放置群組 #
高可用性和高可靠性要求採用容錯方法來管理硬體和軟體問題。Ceph 沒有單一故障點,並且可以在「已降級」模式下處理資料要求。Ceph 的資料放置引入了一個間接層,以確定資料不會直接結合至特定 OSD 位址。這表示追蹤系統故障原因需要找到屬於問題根源的放置群組和基礎 OSD。
如果叢集的某個組件發生故障,叢集可能會阻止您存取某個特定物件,但這並不表示您無法存取其他物件。遇到故障時,請執行相關步驟來監控 OSD 和放置群組。然後開始進行疑難排解。
Ceph 一般情況下會進行自我修復。但如果問題仍然存在,監控 OSD 和放置群組將有助於您找到問題所在。
12.9.1 監控 OSD #
OSD 可能處於在叢集內 (「in」) 狀態,也可能處於在叢集外 (「out」) 狀態。同時,它也可能處於啟用並執行中 (「up」) 或 停機且未執行 (「down」) 狀態。如果某個 OSD 處於「up」狀態,則它可能在叢集內 (您可以讀取和寫入資料),也可能在叢集外。如果該 OSD 之前在叢集內,最近已移出叢集,則 Ceph 會將放置群組移轉至其他 OSD。如果某個 OSD 在叢集外,CRUSH 將不會為其指定放置群組。如果某個 OSD 處於「down」狀態,則它應該也處於「out」狀態。
如果某個 OSD 處於「down」和「in」狀態,則表示存在問題,並且叢集將處於狀況不良狀態。
如果您執行 ceph health、ceph -s 或
ceph -w 等指令,可能會注意到叢集並非永遠回應 HEALTH
OK。對於 OSD,您應當預期叢集在以下情況下不會回應 HEALTH
OK:
您尚未啟動叢集 (它不會回應)。
您已啟動或重新啟動叢集,但它尚未準備就緒,因為系統正在建立放置群組,並且 OSD 正在互聯。
您已新增或移除某個 OSD。
您已修改叢集地圖。
監控 OSD 的一個重要目的是確定當叢集已啟用且在執行時,叢集中的所有 OSD 也已啟用且在執行。若要確定是否所有 OSD 都在執行,請執行以下指令:
root # ceph osd stat
x osds: y up, z in; epoch: eNNNN
結果應顯示 OSD 總數 (x)、處於「up」狀態的 OSD 數量 (y)、處於「in」狀態的 OSD 數量 (z),以及地圖版本編號
(eNNNN)。如果在叢集內 (「in」) 的 OSD 數量大於處於「up」狀態的 OSD 數量,請執行以下指令來確定未在執行的
ceph-osd 精靈:
root # ceph osd tree
#ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 2.00000 pool openstack
-3 2.00000 rack dell-2950-rack-A
-2 2.00000 host dell-2950-A1
0 ssd 1.00000 osd.0 up 1.00000 1.00000
1 ssd 1.00000 osd.1 down 1.00000 1.00000例如,如果 ID 為 1 的 OSD 處於停機狀態,請將其啟動:
cephuser@osd > sudo systemctl start ceph-CLUSTER_ID@osd.0.service對於與已停止或不會重新啟動的 OSD 相關的問題,請參閱Book “Troubleshooting Guide”, Chapter 4 “Troubleshooting OSDs”, Section 4.3 “OSDs not running”。
12.9.2 指定放置群組集 #
CRUSH 向 OSD 指定放置群組時,會查看池的複本數量,然後再為 OSD 指定放置群組,以便將每個放置群組複本都指定給不同的
OSD。例如,如果池需要三個放置群組複本,CRUSH 可能會將這三個複本分別指定給
osd.1、osd.2 和
osd.3。CRUSH 實際上會尋找一種虛擬隨機放置方法,這種方法會將您在 CRUSH
地圖中設定的故障網域納入考量,因此在大型叢集中,您很少會看到放置群組指定給最鄰近的 OSD 的情況。我們將應包含特定放置群組的複本的 OSD
集稱為在任集。在某些情況下,在任集中的 OSD
會處於停機狀態,或者無法處理要存取放置群組中的物件的要求。當以下其中一種情況發生時,可能會出現這些情況:
您新增或移除了某個 OSD。CRUSH 隨後會將放置群組重新指定給其他 OSD,因而變更了在任集的組成部分,導致系統透過「回填」程序移轉資料。
某個 OSD 之前處於「down」狀態、之前進行了重新啟動,而現在正在復原。
在任集中的某個 OSD 處於「down」狀態,或者無法處理要求,並且另一個 OSD 已暫代其職。
Ceph 使用啟用集來處理用戶端要求,啟用集是實際處理要求的 OSD 集。在大多數情況下,啟用集和在任集幾乎完全相同。當兩者不同時,可能表示 Ceph 正在移轉資料、某個 OSD 正在復原,或者叢集存在問題 (例如,在此類情況下,Ceph 通常會回應
HEALTH WARN狀態及「stuck stale」訊息)。
若要擷取放置群組清單,請執行以下指令:
cephuser@adm > ceph pg dump若要檢視哪些 OSD 在給定放置群組的在任集或啟用集內,請執行以下指令:
cephuser@adm > ceph pg map PG_NUM
osdmap eNNN pg RAW_PG_NUM (PG_NUM) -> up [0,1,2] acting [0,1,2]結果應該會顯示 OSD 地圖版本編號 (eNNN)、放置群組數量 (PG_NUM)、啟用集 (「up」) 中的 OSD,以及在任集 (「acting」) 中的 OSD:
如果啟用集與在任集不相符,則可能表示叢集正在自行重新平衡,或者叢集可能存在問題。
12.9.3 建立互聯 #
放置群組必須處於 active 及 clean
狀態,您才能將資料寫入其中。為了讓 Ceph 確定某個放置群組的目前狀態,該放置群組的主 OSD
(在任集中的第一個 OSD) 會與第二個和第三個 OSD 建立互聯,以便就放置群組的目前狀態達成一致
(假設池中包含三個放置群組複本)。

12.9.4 監控放置群組狀態 #
如果您執行 ceph health、ceph -s 或
ceph -w 等指令,可能會注意到叢集並非永遠回應 HEALTH OK
訊息。檢查 OSD 是否正在執行之後,還應檢查放置群組狀態。
在一些與放置群組互聯相關的情況下,叢集預期將不會回應 HEALTH
OK:
您已建立池,並且放置群組尚未互聯。
放置群組正在復原。
您已向叢集新增了 OSD,或已從叢集中移除了 OSD。
您已修改 CRUSH 地圖,並且您的放置群組正在移轉。
在不同的放置群組複本中存在資料不一致的情況。
Ceph 正在整理放置群組的複本。
Ceph 的儲存容量不足,無法完成回填操作。
如果上述其中一種情況導致 Ceph 回應 HEALTH
WARN,請不要驚慌。叢集在許多情況下都會自行復原。在有些情況下,您可能需要採取措施。監控放置群組的一個重要目的是要確定當叢集已啟用且在執行時,所有放置群組都處於「active」狀態,並且最好處於「clean」狀態。若要查看所有放置群組的狀態,請執行以下指令:
cephuser@adm > ceph pg stat
x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB avail結果應該會顯示放置群組總數 (x)、處於特定狀態 (例如「active+clean」) 的放置群組數量 (y),以及儲存的資料量 (z)。
除了放置群組狀態之外,Ceph 還會回應使用的儲存容量 (aa)、剩餘的儲存容量 (bb),以及放置群組的總儲存容量。在以下情況下,這些數值可能非常重要:
已達到
near full ratio或full ratio。由於您的 CRUSH 組態中存在錯誤,您的資料未在叢集中分佈。
放置群組 ID 由池編號 (並非池名稱) 加一個句點 (.)和放置群組 ID (一個十六進位數) 組成。您可以在 ceph osd
lspools 的輸出中檢視池編號及其名稱。例如,預設池 rbd 與池編號 0
對應。完全合格的放置群組 ID 的格式如下:
POOL_NUM.PG_ID
通常顯示如下:
0.1f
若要擷取放置群組清單,請執行以下指令:
cephuser@adm > ceph pg dump您還可以將輸出內容設定為 JSON 格式,並將其儲存到檔案中:
cephuser@adm > ceph pg dump -o FILE_NAME --format=json若要查詢特定的放置群組,請執行以下指令:
cephuser@adm > ceph pg POOL_NUM.PG_ID query以下清單詳細說明了常見的放置群組狀態。
- CREATING (建立中)
當您建立池時,Ceph 會建立您指定數量的放置群組。Ceph 會在建立一或多個放置群組時回應「creating」。建立放置群組之後,屬於放置群組在任集的各 OSD 將會互聯。完成互聯程序時,放置群組狀態應該為「active+clean」,這表示 Ceph 用戶端可以開始向放置群組寫入資料。
 圖 12.3︰ 放置群組狀態 #
圖 12.3︰ 放置群組狀態 #- PEERING (正在互聯)
當 Ceph 在對放置群組執行互聯操作時,會在儲存放置群組複本的各 OSD 之間就該放置群組中物件和中繼資料的狀態達成一致。當 Ceph 完成互聯程序時,便表示儲存放置群組的各 OSD 之間就放置群組的目前狀態達成一致。不過,完成互聯程序並不表示每個複本都有最新的內容。
注意:權威歷程在在任集的所有 OSD 都持續進行寫入操作之前,Ceph 將不會向用戶端確認寫入操作。這樣做可確保在上次成功互聯之後,至少有一個在任集成員將擁有每個確認的寫入操作的記錄。
透過準確記錄每個確認的寫入操作,Ceph 可以建構並擴充一個新的權威放置群組歷程,即一個完整且完全有序的操作集,如果執行該操作集,會將 OSD 的放置群組複本更新至最新狀態。
- ACTIVE (使用中)
當 Ceph 完成互聯程序時,放置群組可能會變為
active狀態。active狀態表示一般可在主放置群組和複本中使用放置群組中的資料來進行讀取和寫入操作。- CLEAN (正常)
如果放置群組處於
clean狀態,則表示主 OSD 和複本 OSD 已成功互聯,並且該放置群組沒有流浪複本。Ceph 已將放置群組中的所有物件複製正確的次數。- DEGRADED (已降級)
當用戶端將物件寫入主 OSD 時,該主 OSD 負責將複本寫入複本 OSD。主 OSD 將物件寫入儲存空間之後,放置群組將保持「degraded」狀態,直至主 OSD 收到了複本 OSD 傳送的 Ceph 已成功建立複本物件的確認訊息。
放置群組有可能處於「active+degraded」狀態,這是因為即使 OSD 尚未儲存所有物件,它也可能處於「active」狀態。如果某個 OSD 變成停機狀態,Ceph 會將指定給該 OSD 的每個放置群組都標示為「degraded」。當該 OSD 恢復啟用狀態後,各 OSD 必須再次互聯。不過,如果某個已降級放置群組處於「active」狀態,用戶端仍然可以將新物件寫入該放置群組。
如果某個 OSD 處於「down」狀態,並且持續保持「degraded」狀況,Ceph 可能會將該停機的 OSD 標示為「out」(表示移出叢集),並將停機 (「down」) 的 OSD 的資料重新對應至另一個 OSD。透過
mon osd down out interval選項來控制從將 OSD 標示為「down」到將其標示為「out」相隔的時間,該選項預設設定為 600 秒。放置群組也可能處於「degraded」狀態,當 Ceph 找不到應在放置群組中的一或多個物件時,便會發生此情況。雖然您無法讀取未找到的物件或向其寫入資料,卻仍然可以存取「degraded」狀態的放置群組中的所有其他物件。
- RECOVERING (正在復原)
Ceph 設計用於在發生硬體和軟體問題時進行大規模容錯。當 OSD 變成「down」狀態時,其內容可能落後於放置群組中其他複本的目前狀態。當 OSD 恢復「up」狀態時,必須更新放置群組的內容,以反映最新狀態。在此期間,OSD 可能會顯現出「recovering」狀態。
復原並非永遠都是無足輕重的,因為硬體故障可能會導致多個 OSD 發生串聯故障。例如,一個機架或機櫃的網路交換器可能會發生故障,這可能會導致一些主機的 OSD 落後於叢集的目前狀態。解決故障之後,必須復原每個 OSD。
Ceph 提供了一些設定,用來平衡新服務要求與復原資料物件並將放置群組還原到最新狀態的需求之間的資源爭用。
osd recovery delay start設定允許 OSD 在啟動復原程序之前重新啟動、重新互聯,甚至處理一些重播要求。osd recovery thread timeout用於設定線串逾時,因為有可能會有多個 OSD 交錯發生故障、重新啟動以及重新互聯。osd recovery max active設定用於限制 OSD 將同時處理的復原要求數,以防止 OSD 無法處理要求。osd recovery max chunk設定用於限制復原的資料區塊大小,以避免出現網路阻塞。- BACK FILLING (正在回填)
當新 OSD 加入叢集時,CRUSH 會將叢集中 OSD 的放置群組重新指定給新增的 OSD。強制新 OSD 立即接受重新指定的放置群組可能會使新 OSD 過載。向 OSD 回填放置群組可讓此程序在背景中開始。完成回填後,新 OSD 將在準備就緒時開始處理要求。
在執行回填操作期間,系統可能會顯示以下其中一種狀態:「backfill_wait」表示回填操作待處理,但尚未進行;「backfill」表示正在進行回填操作;「backfill_too_full」表示已要求進行回填操作,但由於儲存容量不足而無法完成。如果無法回填某個放置群組,則可能會將其視為「incomplete」。
Ceph 提供了一些設定來管理與向某個 OSD (尤其是新 OSD) 重新指定放置群組有關的負載。
osd max backfills預設將向或從一個 OSD 同時進行的最大回填數設定為 10。backfill full ratio允許 OSD 在接近其填滿比率 (預設為 90%) 時拒絕回填要求,並使用ceph osd set-backfillfull-ratio指令進行變更。如果某個 OSD 拒絕回填要求,osd backfill retry interval可讓 OSD 重試要求 (預設在 10 秒後)。OSD 還可以設定osd backfill scan min和osd backfill scan max,以管理掃描間隔 (預設值分別為 64 和 512)。- REMAPPED (已重新對應)
當用於處理放置群組的在任集發生變化時,資料會從舊在任集移轉至新在任集。新主 OSD 可能需要一段時間才能處理要求。因此,新主 OSD 可能會要求舊主 OSD 繼續處理要求,直至放置群組移轉完成。資料移轉完成時,對應將使用新在任集的主 OSD。
- STALE (過時)
儘管 Ceph 使用活動訊號來確定主機和精靈正在執行,但
ceph-osd精靈也可能會卡住,無法及時報告統計資料 (例如,當發生暫時的網路故障時)。依預設,OSD 精靈每半秒鐘 (0.5) 報告一次其放置群組、開機及故障統計資料,這個頻率高於活動訊號閾值。如果某個放置群組在任集的主 OSD 未能向監控程式報告,或者其他 OSD 已將該主 OSD 報告為「down」,則監控程式會將該放置群組標示為「stale」。當您啟動叢集後,叢集常常會在互聯程序完成之前顯示為「stale」狀態。叢集執行一段時間之後,如果放置群組顯示為「stale」狀態,則表示這些放置群組的主 OSD 處於停機狀態,或者未向監控程式報告放置群組統計資料。
12.9.5 尋找物件位置 #
若要在 Ceph 物件儲存中儲存物件資料,Ceph 用戶端需要設定物件名稱並指定相關的池。Ceph 用戶端會擷取最新的叢集地圖,並且 CRUSH 演算法會計算如何將物件對應至放置群組,然後計算如何以動態方式將該放置群組指定給 OSD。若要尋找物件位置,您只需知道物件名稱和池名稱。例如:
cephuser@adm > ceph osd map POOL_NAME OBJECT_NAME [NAMESPACE]
做為範例,我們來建立一個物件。在指令行上使用 rados put
指令指定物件名稱「test-object-1」、包含一些物件資料的範例檔案「testfile.txt」的路徑,以及池名稱「data」。
cephuser@adm > rados put test-object-1 testfile.txt --pool=data若要確認 Ceph 物件儲存是否已儲存物件,請執行以下指令:
cephuser@adm > rados -p data ls現在,我們來確定物件位置。Ceph 將會輸出物件的位置:
cephuser@adm > ceph osd map data test-object-1
osdmap e537 pool 'data' (0) object 'test-object-1' -> pg 0.d1743484 \
(0.4) -> up ([1,0], p0) acting ([1,0], p0)
若要移除範例物件,只需使用 rados rm 指令將其刪除:
cephuser@adm > rados rm test-object-1 --pool=data13 操作任務 #
13.1 修改叢集組態 #
若要修改現有 Ceph 叢集的組態,請執行以下步驟:
將叢集的目前組態輸出至檔案:
cephuser@adm >ceph orch ls --export --format yaml > cluster.yaml編輯包含組態的檔案並更新相關行。可在Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4 “部署服務和閘道”和第 13.4.3 節 「使用 DriveGroups 規格新增 OSD。」中找到規格範例。
套用新組態:
cephuser@adm >ceph orch apply -i cluster.yaml
13.2 新增節點 #
若要向 Ceph 叢集新增新的節點,請執行以下步驟:
在新主機上安裝 SUSE Linux Enterprise Server 和 SUSE Enterprise Storage。如需相關資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.1 “安裝和設定 SUSE Linux Enterprise Server”。
將主機設定為已存在 Salt Master 的 Salt Minion。如需相關資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.2 “部署 Salt”。
將新主機新增至
ceph-salt並讓 cephadm 能識別它,例如:root@master #ceph-salt config /ceph_cluster/minions add ses-min5.example.comroot@master #ceph-salt config /ceph_cluster/roles/cephadm add ses-min5.example.com如需相關資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3.2.2 “新增 Salt Minion”。
確認節點是否已新增至
ceph-salt:root@master #ceph-salt config /ceph_cluster/minions ls o- minions ................................................. [Minions: 5] [...] o- ses-min5.example.com .................................... [no roles]將組態套用於新叢集主機:
root@master #ceph-salt apply ses-min5.example.com確認新增的主機現在是否屬於 cephadm 環境:
cephuser@adm >ceph orch host ls HOST ADDR LABELS STATUS [...] ses-min5.example.com ses-min5.example.com
13.3 移除節點 #
若要從叢集移除節點,請執行以下操作:
對於除
node-exporter和crash以外的所有 Ceph 服務類型,請從叢集放置規格檔案 (例如cluster.yml) 中移除節點的主機名稱。如需更多詳細資料,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.2 “服務和放置規格”。例如,如果您要移除名為ses-min2的主機,請從所有placement:區段中移除所有出現的- ses-min2:更新
service_type: rgw service_id: EXAMPLE_NFS placement: hosts: - ses-min2 - ses-min3
針對
service_type: rgw service_id: EXAMPLE_NFS placement: hosts: - ses-min3
將您的變更套用於組態檔案:
cephuser@adm >ceph orch apply -i rgw-example.yaml從 cephadm 的環境中移除節點:
cephuser@adm >ceph orch host rm ses-min2如果節點正在執行
crash.osd.1和crash.osd.2服務,請透過在主機上執行以下指令將其移除:root@minion >cephadm rm-daemon --fsid CLUSTER_ID --name SERVICE_NAME例如:
root@minion >cephadm rm-daemon --fsid b4b30c6e... --name crash.osd.1root@minion >cephadm rm-daemon --fsid b4b30c6e... --name crash.osd.2從您要刪除的 Minion 中移除所有角色:
cephuser@adm >ceph-salt config /ceph_cluster/roles/tuned/throughput remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/tuned/latency remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/cephadm remove ses-min2cephuser@adm >ceph-salt config /ceph_cluster/roles/admin remove ses-min2如果您要移除的 Minion 是開機 Minion,則還需要移除開機角色:
cephuser@adm >ceph-salt config /ceph_cluster/roles/bootstrap reset移除單部主機上的所有 OSD 後,從 CRUSH 地圖中移除該主機:
cephuser@adm >ceph osd crush remove bucket-name注意桶名稱應該與主機名稱相同。
現在您便可以從叢集中移除 Minion:
cephuser@adm >ceph-salt config /ceph_cluster/minions remove ses-min2
如果發生故障,並且您嘗試移除的 Minion 處於永久關閉電源狀態,則需要從 Salt Master 中移除節點:
root@master # salt-key -d minion_id
然後,手動從 pillar_root/ceph-salt.sls 中移除節點。它通常位於 /srv/pillar/ceph-salt.sls 中。
13.4 OSD 管理 #
本節介紹如何在 Ceph 叢集中新增、去除或移除 OSD。
13.4.1 列出磁碟裝置 #
若要識別所有叢集節點上已使用和未使用的磁碟裝置,請透過執行以下指令列出這些裝置:
cephuser@adm > ceph orch device ls
HOST PATH TYPE SIZE DEVICE AVAIL REJECT REASONS
ses-master /dev/vda hdd 42.0G False locked
ses-min1 /dev/vda hdd 42.0G False locked
ses-min1 /dev/vdb hdd 8192M 387836 False locked, LVM detected, Insufficient space (<5GB) on vgs
ses-min2 /dev/vdc hdd 8192M 450575 True13.4.2 去除磁碟裝置 #
若要重新使用磁碟裝置,需要先將其去除 (或清除):
ceph orch device zap HOST_NAME DISK_DEVICE
例如:
cephuser@adm > ceph orch device zap ses-min2 /dev/vdc
如果您先前在未設定 unmanaged 旗標的情況下使用 DriveGroups 或 --all-available-devices 選項部署了 OSD,cephadm 將在您去除這些 OSD 後再自動部署它們。
13.4.3 使用 DriveGroups 規格新增 OSD。 #
DriveGroups 用於指定 Ceph 叢集中 OSD 的配置。它們在單個 YAML 檔案中定義。在本節中,我們將使用 drive_groups.yml 做為範例。
管理員應手動指定一組相關的 OSD (部署在 HDD 和 SDD 組合上的混合 OSD),或一組使用相同部署選項的 OSD (例如,物件儲存、加密選項相同的各獨立 OSD)。為了避免明確列出裝置,DriveGroups 會使用與 ceph-volume 庫存報告中的幾個所選欄位對應的過濾項目清單。cephadm 將提供一些代碼,用於將這些 DriveGroups 轉換為供使用者檢查的實際裝置清單。
將 OSD 規格套用於叢集的指令是:
cephuser@adm >ceph orch apply osd -idrive_groups.yml
若要查看動作預覽並測試您的應用程式,您可以將 --dry-run 選項與 ceph orch apply osd 指令結合使用。例如:
cephuser@adm >ceph orch apply osd -idrive_groups.yml--dry-run ... +---------+------+------+----------+----+-----+ |SERVICE |NAME |HOST |DATA |DB |WAL | +---------+------+------+----------+----+-----+ |osd |test |mgr0 |/dev/sda |- |- | |osd |test |mgr0 |/dev/sdb |- |- | +---------+------+------+----------+----+-----+
如果 --dry-run 輸出符合您的預期,則只需重新執行指令而無需使用 --dry-run 選項。
13.4.3.1 未受管理 OSD #
將符合 DriveGroups 規格的所有可用的乾淨磁碟裝置新增至叢集後,它們將自動做為 OSD 使用。此行為稱為受管理模式。
若要停用受管理模式,請將 unmanaged: true 行新增至相關規格,例如:
service_type: osd service_id: example_drvgrp_name placement: hosts: - ses-min2 - ses-min3 encrypted: true unmanaged: true
13.4.3.2 DriveGroups 規格 #
下面是 DriveGroups 規格檔案的範例:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: drive_spec: DEVICE_SPECIFICATION db_devices: drive_spec: DEVICE_SPECIFICATION wal_devices: drive_spec: DEVICE_SPECIFICATION block_wal_size: '5G' # (optional, unit suffixes permitted) block_db_size: '5G' # (optional, unit suffixes permitted) encrypted: true # 'True' or 'False' (defaults to 'False')
先前在 DeepSea 中名為「加密」的選項已被重新命名為「已加密」。在 SUSE Enterprise Storage 7 中套用 DriveGroups 時,請確定在服務規格中使用此新術語,否則 ceph orch apply 操作將失敗。
13.4.3.3 相符磁碟裝置 #
您可以使用以下過濾器描述規格:
依磁碟型號:
model: DISK_MODEL_STRING
依磁碟廠商:
vendor: DISK_VENDOR_STRING
提示永遠以小寫形式輸入 DISK_VENDOR_STRING。
若要獲取有關磁碟型號和廠商的詳細資料,請檢查以下指令的輸出:
cephuser@adm >ceph orch device ls HOST PATH TYPE SIZE DEVICE_ID MODEL VENDOR ses-min1 /dev/sdb ssd 29.8G SATA_SSD_AF34075704240015 SATA SSD ATA ses-min2 /dev/sda ssd 223G Micron_5200_MTFDDAK240TDN Micron_5200_MTFD ATA [...]磁碟是否為旋轉式硬碟。SSD 和 NVMe 磁碟機不屬於旋轉式硬碟。
rotational: 0
部署將全部可用磁碟機皆用於 OSD 的節點:
data_devices: all: true
此外,還可透過限制相符磁碟的數量來過濾:
limit: 10
13.4.3.4 依大小過濾裝置 #
您可以依磁碟裝置大小對其過濾,可以依確切大小也可以依大小範圍來過濾。size: 參數接受使用下列格式的引數:
'10G' - 包括大小為該值的磁碟。
'10G:40G' - 包括大小在該範圍內的磁碟。
':10G' - 包括大小小於或等於 10 GB 的磁碟。
'40G:' - 包括大小等於或大於 40 GB 的磁碟。
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: size: '40TB:' db_devices: size: ':2TB'
如果使用「:」分隔符,您需要使用引號括住大小,否則系統會將「:」符號解譯為新組態雜湊。
您可以指定以百萬位元組 (M) 或兆位元組 (T) 計的大小,而不能指定以十億位元組 (G) 計的大小。
13.4.3.5 DriveGroups 範例 #
本節包含其他 OSD 設定的範例。
下面的範例描述了使用相同設定的兩個節點:
20 個 HDD
廠商:Intel
型號:SSD-123-foo
大小:4 TB
2 個 SSD
廠商:Micron
型號:MC-55-44-ZX
大小:512 GB
對應的 drive_groups.yml 檔案如下所示:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: model: SSD-123-foo db_devices: model: MC-55-44-XZ
這樣的組態簡單有效。但問題是管理員將來可能要新增來自不同廠商的磁碟,而這樣的磁碟不在可新增範圍內。您可以透過減少針對磁碟機核心內容的過濾器來予以改進。
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: rotational: 1 db_devices: rotational: 0
在上面的範例中,我們強制將所有旋轉式裝置宣告為「data devices」,將所有非旋轉式裝置當成「shared devices」(wal、db) 使用。
如果您知道大小超過 2 TB 的磁碟機將一律做為較慢的資料裝置,則可以依大小過濾:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: size: '2TB:' db_devices: size: ':2TB'
下面的範例描述了兩種不同的設定:20 個 HDD 將共用 2 個 SSD,而 10 個 SSD 將共用 2 個 NVMe。
20 個 HDD
廠商:Intel
型號:SSD-123-foo
大小:4 TB
12 個 SSD
廠商:Micron
型號:MC-55-44-ZX
大小:512 GB
2 個 NVMe
廠商:Samsung
型號:NVME-QQQQ-987
大小:256 GB
這樣的設定可使用如下兩個配置定義:
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: MC-55-44-XZ
service_type: osd service_id: example_drvgrp_name2 placement: host_pattern: '*' data_devices: model: MC-55-44-XZ db_devices: vendor: samsung size: 256GB
上述範例假設所有節點的磁碟機都相同,但情況並非總是如此:
節點 1-5:
20 個 HDD
廠商:Intel
型號:SSD-123-foo
大小:4 TB
2 個 SSD
廠商:Micron
型號:MC-55-44-ZX
大小:512 GB
節點 6-10:
5 個 NVMe
廠商:Intel
型號:SSD-123-foo
大小:4 TB
20 個 SSD
廠商:Micron
型號:MC-55-44-ZX
大小:512 GB
您可以在配置中使用「target」鍵來定位特定節點。Salt 定位標記可讓事情變得簡單:
service_type: osd service_id: example_drvgrp_one2five placement: host_pattern: 'node[1-5]' data_devices: rotational: 1 db_devices: rotational: 0
後接
service_type: osd service_id: example_drvgrp_rest placement: host_pattern: 'node[6-10]' data_devices: model: MC-55-44-XZ db_devices: model: SSD-123-foo
上述所有案例都假設 WAL 和 DB 使用相同裝置,但也有可能會在專屬裝置上部署 WAL:
20 個 HDD
廠商:Intel
型號:SSD-123-foo
大小:4 TB
2 個 SSD
廠商:Micron
型號:MC-55-44-ZX
大小:512 GB
2 個 NVMe
廠商:Samsung
型號:NVME-QQQQ-987
大小:256 GB
service_type: osd service_id: example_drvgrp_name placement: host_pattern: '*' data_devices: model: MC-55-44-XZ db_devices: model: SSD-123-foo wal_devices: model: NVME-QQQQ-987
在以下設定中,我們嘗試定義:
由 1 個 NVMe 支援 20 個 HDD
由 1 個 SSD (db) 和 1 個 NVMe (wal) 支援 2 個 HDD
由 1 個 NVMe 支援 8 個 SSD
2 個獨立 SSD (加密)
1 個 HDD 做為備用,不應部署
共使用如下數量的磁碟機:
23 個 HDD
廠商:Intel
型號:SSD-123-foo
大小:4 TB
10 個 SSD
廠商:Micron
型號:MC-55-44-ZX
大小:512 GB
1 個 NVMe
廠商:Samsung
型號:NVME-QQQQ-987
大小:256 GB
DriveGroups 定義如下所示:
service_type: osd service_id: example_drvgrp_hdd_nvme placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_hdd_ssd_nvme placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: MC-55-44-XZ wal_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_ssd_nvme placement: host_pattern: '*' data_devices: model: SSD-123-foo db_devices: model: NVME-QQQQ-987
service_type: osd service_id: example_drvgrp_standalone_encrypted placement: host_pattern: '*' data_devices: model: SSD-123-foo encrypted: True
在檔案的整個剖析過程中,一直會保留一個 HDD。
13.4.4 移除 OSD #
在從叢集中移除 OSD 節點之前,請確認該叢集中的可用磁碟空間是否比您要移除的 OSD 磁碟大。請注意,移除 OSD 會導致整個叢集進行重新平衡。
透過獲取其 ID 來識別要移除的 OSD:
cephuser@adm >ceph orch ps --daemon_type osd NAME HOST STATUS REFRESHED AGE VERSION osd.0 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.1 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.2 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ... osd.3 target-ses-090 running (3h) 7m ago 3h 15.2.7.689 ...從叢集中移除一或多個 OSD:
cephuser@adm >ceph orch osd rm OSD1_ID OSD2_ID ...例如:
cephuser@adm >ceph orch osd rm 1 2您可以查詢移除操作的狀態:
cephuser@adm >ceph orch osd rm status OSD_ID HOST STATE PG_COUNT REPLACE FORCE STARTED_AT 2 cephadm-dev done, waiting for purge 0 True False 2020-07-17 13:01:43.147684 3 cephadm-dev draining 17 False True 2020-07-17 13:01:45.162158 4 cephadm-dev started 42 False True 2020-07-17 13:01:45.162158
13.4.4.1 停止 OSD 移除 #
排程 OSD 移除後,您可以視需要停止移除。以下指令將重設 OSD 的初始狀態並將其從佇列中移除:
cephuser@adm > ceph orch osd rm stop OSD_SERVICE_ID13.4.5 取代 OSD #
若要在保留其 ID 的情況下取代 OSD,請執行:
cephuser@adm > ceph orch osd rm OSD_SERVICE_ID --replace例如:
cephuser@adm > ceph orch osd rm 4 --replace
取代 OSD 與移除 OSD 基本相同 (如需更多詳細資料,請參閱第 13.4.4 節 「移除 OSD」),只不過 OSD 不是從 CRUSH 階層中永久移除,而是被指定了一個 destroyed 旗標。
destroyed 旗標用於確定將在下一次 OSD 部署期間重複使用的 OSD ID。新增的符合 DriveGroups 規格的磁碟 (如需更多詳細資料,請參閱第 13.4.3 節 「使用 DriveGroups 規格新增 OSD。」) 將被指定其所取代之磁碟的 OSD ID。
附加 --dry-run 選項不會執行實際取代,而會預覽通常會發生的步驟。
13.5 將 Salt Master 移至新節點 #
如果需要以新 Salt Master 主機取代 Salt Master 主機,請執行以下步驟:
輸出叢集組態並備份輸出的 JSON 檔案。如需更多詳細資料,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3.2.15 “輸出叢集組態”。
如果舊的 Salt Master 也是叢集中的唯一管理節點,則需要將
/etc/ceph/ceph.client.admin.keyring和/etc/ceph/ceph.conf手動移至新 Salt Master。停止並停用舊 Salt Master 節點上的 Salt Master
systemd服務:root@master #systemctl stop salt-master.serviceroot@master #systemctl disable salt-master.service如果舊 Salt Master 節點不再位於叢集中,還要停止並停用 Salt Minion
systemd服務:root@master #systemctl stop salt-minion.serviceroot@master #systemctl disable salt-minion.service警告如果舊 Salt Master 節點上有任何執行中 Ceph 精靈 (MON、MGR、OSD、MDS、閘道、監控),請不要停止或停用
salt-minion.service。依據Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.1 “安裝和設定 SUSE Linux Enterprise Server”中所述的程序,在新的 Salt Master 上安裝 SUSE Linux Enterprise Server 15 SP2。
提示:轉換 Salt Minion為便於將 Salt Minion 轉換為新的 Salt Master,請從每個 Salt Minion 中移除原始 Salt Master 的公用金鑰:
root@minion >rm /etc/salt/pki/minion/minion_master.pubroot@minion >systemctl restart salt-minion.service將 salt-master 套件和 salt-minion 套件 (如適用) 安裝到新的 Salt Master。
在新的 Salt Master 節點上安裝
ceph-salt:root@master #zypper install ceph-saltroot@master #systemctl restart salt-master.serviceroot@master #salt '*' saltutil.sync_all重要確定在繼續之前執行所有三個指令。這些指令是等冪的;是否重複並不重要。
在叢集中包含新的 Salt Master,如Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3.1 “安裝
ceph-salt”、Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3.2.2 “新增 Salt Minion”和Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3.2.4 “指定管理節點”中所述。輸入備份的叢集組態並套用該組態:
root@master #ceph-salt import CLUSTER_CONFIG.jsonroot@master #ceph-salt apply重要輸入之前,請在輸出的
CLUSTER_CONFIG.json檔案中重新命名 Salt Master 的minion id。
13.6 更新叢集節點 #
定期套用滾存更新,以使 Ceph 叢集節點保持最新。
13.6.1 軟體儲存庫 #
使用最新的套裝軟體修補叢集之前,請確認叢集的所有節點均可存取相關的儲存庫。如需所需儲存庫的完整清單,請參閱Book “部署指南”, Chapter 7 “自前一版本升級”, Section 7.1.5.1 “軟體儲存庫”。
13.6.2 儲存庫暫存 #
如果您使用向叢集節點提供軟體儲存庫的暫存工具 (例如 SUSE Manager、儲存庫管理工具或 RMT),請確認 SUSE Linux Enterprise Server 和 SUSE Enterprise Storage 的「Updates」儲存庫的階段都是在同一時刻建立的。
強烈建議您使用暫存工具來套用修補程式層級為 frozen 或 staged 的修補程式。這樣可確保加入叢集的新節點具有與已在叢集中執行的節點相同的修補程式層級。透過這種方法,您無需向叢集的所有節點都套用最新修補程式,新節點也能加入叢集。
13.6.3 Ceph 服務停機時間 #
叢集節點可能會在更新期間重新開機,具體視組態而定。如果物件閘道、Samba 閘道、NFS Ganesha 或 iSCSI 等服務存在單一故障點,用戶端機器可能會暫時解除與相應節點正在重新開機的服務的連接。
13.6.4 執行更新 #
若要將所有叢集節點上的軟體套件更新至最新版本,請執行以下指令:
root@master # ceph-salt update13.7 更新 Ceph #
您可以指示 cephadm 將 Ceph 從一個錯誤修復版本更新至另一個版本。Ceph 服務的自動更新遵循建議的順序進行,即從 Ceph 管理員、Ceph 監控程式開始更新,然後繼續更新 Ceph OSD、中繼資料伺服器和物件閘道等其他服務。只有當 Ceph 指示叢集將仍然可用之後,才會重新啟動每個精靈。
以下更新程序使用 ceph orch upgrade 指令。請注意,以下說明詳細介紹了如何使用某個產品版本 (例如維護更新) 更新您的 Ceph 叢集,但未提供如何將叢集從一個產品版本升級至另一個產品版本的說明。
13.7.1 啟動更新 #
開始更新之前,請確認所有節點目前都處於線上狀態,並且叢集狀況良好:
cephuser@adm > cephadm shell -- ceph -s更新至某個特定的 Ceph 版本:
cephuser@adm > ceph orch upgrade start --image REGISTRY_URL例如:
cephuser@adm > ceph orch upgrade start --image registry.suse.com/ses/7/ceph/ceph:latest升級主機上的套件:
cephuser@adm > ceph-salt update13.7.2 監控更新 #
執行以下指令可確定是否正在進行更新:
cephuser@adm > ceph orch upgrade status如果正在進行更新,您將在 Ceph 狀態輸出中看到一個進度列:
cephuser@adm > ceph -s
[...]
progress:
Upgrade to registry.suse.com/ses/7/ceph/ceph:latest (00h 20m 12s)
[=======.....................] (time remaining: 01h 43m 31s)您還可以查看 cephadm 記錄:
cephuser@adm > ceph -W cephadm13.7.3 取消更新 #
您可以隨時停止更新程序:
cephuser@adm > ceph orch upgrade stop13.8 將叢集停止或重新開機 #
在某些情況下,可能需要將整個叢集停止或重新開機。建議您仔細檢查執行中服務的相依項。下列步驟簡要說明如何停止和啟動叢集:
告知 Ceph 叢集不要將 OSD 標示為 out:
cephuser@adm >cephosd set noout依下面的順序停止精靈和節點:
儲存用戶端
閘道,例如 NFS Ganesha 或物件閘道
中繼資料伺服器
Ceph OSD
Ceph 管理員
Ceph 監控程式
視需要執行維護任務。
依與關閉過程相反的順序啟動節點和伺服器:
Ceph 監控程式
Ceph 管理員
Ceph OSD
中繼資料伺服器
閘道,例如 NFS Ganesha 或物件閘道
儲存用戶端
移除 noout 旗標:
cephuser@adm >cephosd unset noout
13.9 移除整個 Ceph 叢集 #
ceph-salt purge 指令可移除整個 Ceph 叢集。如果部署了更多的 Ceph 叢集,則將清除 ceph -s 報告的叢集。這樣,您便可以在測試不同的設定時清理叢集環境。
為防止意外刪除,協調程序會檢查是否解除了安全措施。您可以透過執行以下指令來解除安全措施並移除 Ceph 叢集:
root@master #ceph-salt disengage-safetyroot@master #ceph-salt purge
14 Ceph 服務的操作 #
您可以在精靈、節點或叢集層級操作 Ceph 服務。依據您需要的方法,使用 cephadm 或 systemctl 指令。
14.1 操作個別服務 #
如果您需要操作個別服務,請先識別該服務:
cephuser@adm > ceph orch ps
NAME HOST STATUS REFRESHED [...]
mds.my_cephfs.ses-min1.oterul ses-min1 running (5d) 8m ago
mgr.ses-min1.gpijpm ses-min1 running (5d) 8m ago
mgr.ses-min2.oopvyh ses-min2 running (5d) 8m ago
mon.ses-min1 ses-min1 running (5d) 8m ago
mon.ses-min2 ses-min2 running (5d) 8m ago
mon.ses-min4 ses-min4 running (5d) 7m ago
osd.0 ses-min2 running (61m) 8m ago
osd.1 ses-min3 running (61m) 7m ago
osd.2 ses-min4 running (61m) 7m ago
rgw.myrealm.myzone.ses-min1.kwwazo ses-min1 running (5d) 8m ago
rgw.myrealm.myzone.ses-min2.jngabw ses-min2 error 8m ago若要識別特定節點上的服務,請執行:
ceph orch ps NODE_HOST_NAME
例如:
cephuser@adm > ceph orch ps ses-min2
NAME HOST STATUS REFRESHED
mgr.ses-min2.oopvyh ses-min2 running (5d) 3m ago
mon.ses-min2 ses-min2 running (5d) 3m ago
osd.0 ses-min2 running (67m) 3m ago
ceph orch ps 指令支援多種輸出格式。若要變更格式,請附加 --format FORMAT 選項,其中 FORMAT 是 json、json-pretty 或 yaml 其中之一。例如:
cephuser@adm > ceph orch ps --format yaml知道服務名稱後,您就可以啟動、重新啟動或停止該服務:
ceph orch daemon COMMAND SERVICE_NAME
例如,若要重新啟動 ID 為 0 的 OSD 服務,請執行:
cephuser@adm > ceph orch daemon restart osd.014.2 操作服務類型 #
如果您需要操作整個 Ceph 叢集中特定類型的服務,請使用以下指令:
ceph orch COMMAND SERVICE_TYPE
以 start、stop 或 restart 取代 COMMAND。
例如,以下指令會重新啟動叢集中的所有 MON,無論它們實際是在哪個節點上執行:
cephuser@adm > ceph orch restart mon14.3 操作單個節點上的服務 #
透過使用 systemctl 指令,您可以操作單個節點上與 Ceph 相關的 systemd 服務和目標。
14.3.1 識別服務和目標 #
在操作與 Ceph 相關的 systemd 服務和目標之前,您需要識別其單位檔案的檔案名稱。服務的檔案名稱具有以下格式:
ceph-FSID@SERVICE_TYPE.ID.service
例如:
ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@mon.doc-ses-min1.service
ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@rgw.myrealm.myzone.doc-ses-min1.kwwazo.service
- FSID
Ceph 叢集的唯一 ID。您可以在
ceph fsid指令的輸出中找到該 ID。- SERVICE_TYPE
服務的類型,例如
osd、mon或rgw。- ID
服務的識別字串。對於 OSD,它是服務的 ID 編號。對於其他服務,它可以是節點的主機名稱,也可以是與服務類型相關的其他字串。
SERVICE_TYPE.ID 部分與 ceph orch ps 指令輸出中的 NAME 欄的內容相同。
14.3.2 操作一個節點上所有服務 #
透過使用 Ceph 的 systemd 目標,您可以同時操作某個節點上的所有服務,或者同時操作屬於由其 FSID 識別的叢集的所有服務。
例如,若要停止某個節點上的所有 Ceph 服務,而不考慮服務所屬的叢集,請執行:
root@minion > systemctl stop ceph.target
若要重新啟動屬於 ID 為 b4b30c6e-9681-11ea-ac39-525400d7702d 的 Ceph 叢集的所有服務,請執行:
root@minion > systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d.target14.3.3 操作一個節點上的個別服務 #
識別特定服務的名稱後,請如下所示操作該服務:
systemctl COMMAND SERVICE_NAME
例如,若要重新啟動 ID 為 b4b30c6e-9681-11ea-ac39-525400d7702d 的叢集上 ID 為 1 的單個 OSD 服務,請執行:
root # systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@osd.1.service14.3.4 查詢服務狀態 #
您可以查詢 systemd 來瞭解服務的狀態。例如:
root # systemctl status ceph-b4b30c6e-9681-11ea-ac39-525400d7702d@osd.0.service14.4 關閉並重新啟動整個 Ceph 叢集 #
如果發生計劃電源中斷,可能需要關閉並重新啟動叢集。若要停止與 Ceph 相關的所有服務然後再重新啟動而不會出現問題,請遵循以下步驟進行操作。
關閉存取叢集的任何用戶端或斷開其連接。
若要阻止 CRUSH 自動重新平衡叢集,請將叢集設定為
noout:cephuser@adm >ceph osd set noout停止所有叢集節點上的所有 Ceph 服務:
root@master #ceph-salt stop關閉所有叢集節點的電源:
root@master #salt -G 'ceph-salt:member' cmd.run "shutdown -h"
開啟管理節點的電源。
開啟 Ceph 監控程式節點的電源。
開啟 Ceph OSD 節點的電源。
取消設定先前設定的
noout旗標:root@master #ceph osd unset noout開啟所有已設定閘道的電源。
開啟叢集用戶端的電源或連接叢集用戶端。
15 備份及還原 #
本章說明您應當備份 Ceph 叢集的哪些部分才能還原叢集功能。
15.1 備份叢集組態和資料 #
15.1.1 備份 ceph-salt 組態 #
輸出叢集組態。您可以在 Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3.2.15 “輸出叢集組態” 找到更多的資訊。
15.1.2 備份 Ceph 組態 #
備份 /etc/ceph 目錄。該目錄包含至關重要的叢集組態。例如,當您需要更換管理節點時,就需要備份 /etc/ceph。
15.1.3 備份 Salt 組態 #
您需要備份 /etc/salt/ 目錄。該目錄包含 Salt 組態檔案,例如 Salt Master 金鑰和已接受的用戶端金鑰。
從嚴格意義上來說,備份管理節點並不需要備份 Salt 檔案,但這些檔案能夠簡化 Salt 叢集的重新部署。如果不備份這些檔案,就需要在新管理節點上重新註冊 Salt Minion。
請務必將 Salt Master 私密金鑰的備份儲存在安全位置。Salt Master 金鑰可用於操縱所有叢集節點。
15.1.4 備份自訂組態 #
Prometheus 資料和自訂。
Grafana 自訂。
手動變更 iSCSI 組態。
Ceph 金鑰。
CRUSH 地圖和 CRUSH 規則。透過執行以下指令將包含 CRUSH 規則的反編譯 CRUSH 地圖儲存到
crushmap-backup.txt中:cephuser@adm >ceph osd getcrushmap | crushtool -d - -o crushmap-backup.txtSamba 閘道組態。如果您使用的是單一閘道,請備份
/etc/samba/smb.conf。如果您使用的是 HA 設定,還需要備份 CTDB 和 Pacemaker 組態檔案。如需 Samba 閘道所使用組態的詳細資料,請參閱第 24 章 「透過 Samba 輸出 Ceph 資料」。NFS Ganesha 組態。僅當使用 HA 設定時需要備份。如需 NFS Ganesha 所使用組態的詳細資料,請參閱第 25 章 「NFS Ganesha」。
15.2 還原 Ceph 節點 #
從備份中復原節點的程序就是重新安裝節點,更換其組態檔案,然後重新協調叢集,以便重新新增取代節點。
如果您需要重新部署管理節點,請參閱第 13.5 節 「將 Salt Master 移至新節點」。
對於 Minion,通常更易於簡化重建和重新部署。
重新安裝節點。如需詳細資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.1 “安裝和設定 SUSE Linux Enterprise Server”。
安裝 Salt。如需詳細資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.2 “部署 Salt”
從備份還原
/etc/salt目錄後,啟用並重新啟動適用的 Salt 服務,例如:root@master #systemctlenable salt-masterroot@master #systemctlstart salt-masterroot@master #systemctlenable salt-minionroot@master #systemctlstart salt-minion從所有 Minion 中移除舊 Salt Master 節點的公用 Master 金鑰。
root@master #rm/etc/salt/pki/minion/minion_master.pubroot@master #systemctlrestart salt-minion還原管理節點的所有本地內容。
從先前輸出的 JSON 檔案輸入叢集組態。如需更多詳細資料,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.3.2.15 “輸出叢集組態”。
套用輸入的叢集組態:
root@master #ceph-salt apply
16 監控和警示 #
在 SUSE Enterprise Storage 7 中,cephadm 會部署一個監控和警示堆疊。使用者需要在 YAML 組態檔案中定義要使用 cephadm 部署的服務 (例如 Prometheus、警示管理員和 Grafana),也可以使用 CLI 來部署這些服務。當部署多個相同類型的服務時,會部署高可用性設定。但 Node Exporter 不適用於此規則。
使用 cephadm 可以部署以下監控服務:
Prometheus 是監控和警示工具套件。它會收集 Prometheus 輸出程式提供的資料,並在達到預先定義的閾值時觸發預先設定的警示。
Alertmanager 用於處理 Prometheus 伺服器傳送的警示。它將負責重複資訊刪除、分組並將警示路由到正確的接收器。依預設,Ceph Dashboard 將自動設定為接收器。
Grafana 是虛擬化和警示軟體。此監控堆疊不使用 Grafana 的警示功能。而是使用警示管理員進行警示。
Node Exporter 是 Prometheus 的輸出程式,用於提供其所安裝到之節點的相關資料。建議您在所有節點上安裝 Node Exporter。
Prometheus 管理員模組提供了 Prometheus 輸出程式,可從 ceph-mgr 中的收集點傳遞 Ceph 效能計數器。
Prometheus 組態 (包括抓取目標 (度量提供精靈)) 由 cephadm 自動設定。cephadm 還會部署預設警示清單,例如 health error、10% OSDs down 或 pgs inactive。
依預設,傳送到 Grafana 的流量會使用 TLS 加密。您可以提供自己的 TLS 證書,也可以使用自行簽署的證書。如果在部署 Grafana 之前未設定自訂證書,則將自動為 Grafana 建立和設定自行簽署的證書。
可使用以下指令設定 Grafana 的自訂證書:
cephuser@adm >ceph config-key set mgr/cephadm/grafana_key -i $PWD/key.pemcephuser@adm >ceph config-key set mgr/cephadm/grafana_crt -i $PWD/certificate.pem
Alertmanager 處理 Prometheus 伺服器傳送的警示。它負責重複資訊刪除、分組,並將它們路由到正確的接收器。可以使用警示管理員消除警示,但也可以使用 Ceph Dashboard 管理靜默功能。
建議您在所有節點上部署 Node Exporter。可以使用含有 node-exporter 服務類型的 monitoring.yaml 檔案執行此操作。如需部署服務的詳細資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3.8 “部署監控堆疊”。
16.1 設定自訂或本地影像 #
本節說明如何變更部署或更新服務時所使用的容器影像組態。不包括部署或重新部署服務所需的指令。
部署監控堆疊的推薦方法是依據Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3.8 “部署監控堆疊”中所述套用其規格。
若要部署自訂或本地容器影像,需要在 cephadm 中設定影像。為此,您需要執行以下指令:
cephuser@adm > ceph config set mgr mgr/cephadm/OPTION_NAME VALUE其中,OPTION_NAME 為以下任何名稱:
container_image_prometheus
container_image_node_exporter
container_image_alertmanager
container_image_grafana
如果未設定任何選項或已移除該設定,則將使用以下影像做為 VALUE:
registry.suse.com/caasp/v4.5/prometheus-server:2.18.0
registry.suse.com/caasp/v4.5/prometheus-node-exporter:0.18.1
registry.suse.com/caasp/v4.5/prometheus-alertmanager:0.16.2
registry.suse.com/ses/7/ceph/grafana:7.0.3
例如:
cephuser@adm > ceph config set mgr mgr/cephadm/container_image_prometheus prom/prometheus:v1.4.1設定自訂影像將覆蓋預設值 (但並不會覆寫)。當有可用更新時,預設值將發生變更。設定自訂影像後,您將無法自動更新設定了自訂影像的元件。您需要手動更新組態 (影像名稱和標記) 才能安裝更新。
如果您選擇遵循這些建議,則可以重設先前設定的自訂影像。之後,將再次使用預設值。使用 ceph config rm 重設組態選項:
cephuser@adm > ceph config rm mgr mgr/cephadm/OPTION_NAME例如:
cephuser@adm > ceph config rm mgr mgr/cephadm/container_image_prometheus16.2 更新監控服務 #
依據第 16.1 節 「設定自訂或本地影像」中所述,cephadm 隨附了推薦且經過測試之容器影像的 URL,預設會使用這些 URL。
更新 Ceph 套件後,可能會隨附這些 URL 的新版本。如此只會更新容器影像的提取位置,而不會更新任何服務。
更新新容器影像的 URL (可以依據第 16.1 節 「設定自訂或本地影像」中所述執行手動更新,也可以透過更新 Ceph 套件進行自動更新) 後,便可以更新監控服務。
若要執行此操作,請使用 ceph orch redeploy 指令,如下所示:
cephuser@adm >ceph orch redeploy node-exportercephuser@adm >ceph orch redeploy prometheuscephuser@adm >ceph orch redeploy alertmanagercephuser@adm >ceph orch redeploy grafana
目前沒有可更新所有監控服務的單一指令。這些服務的更新順序並不重要。
如果您使用自訂容器影像,則在更新 Ceph 套件時為監控服務指定的 URL 將不會自動變更。如果您已指定自訂容器影像,則需要手動指定新容器影像的 URL。使用本地容器登錄時,可能會出現這種情況。
您可以在第 16.1 節 「設定自訂或本地影像」一節中找到要使用的推薦容器影像的 URL。
16.3 停用監控 #
若要停用監控堆疊,請執行以下指令:
cephuser@adm >ceph orch rm grafanacephuser@adm >ceph orch rm prometheus --force # this will delete metrics data collected so farcephuser@adm >ceph orch rm node-exportercephuser@adm >ceph orch rm alertmanagercephuser@adm >ceph mgr module disable prometheus
16.4 設定 Grafana #
Ceph Dashboard 後端要求 Grafana URL 能夠在前端均衡載入 Grafana 儀表板之前確認其是否存在。由於 Grafana 在 Ceph Dashboard 中實作方式的本質,意味著需要兩個有效連接才能在 Ceph Dashboard 中看到 Grafana 圖形:
後端 (Ceph MGR 模組) 需要確認所要求的圖形是否存在。如果此要求成功,便會告知前端它可以安全地存取 Grafana。
然後,前端會使用
iframe直接從使用者的瀏覽器要求 Grafana 圖形。可以直接存取 Grafana 例項,而無需再經由 Ceph Dashboard。
現在,您的環境可能會讓使用者的瀏覽器難以直接存取 Ceph Dashboard 中設定的 URL。為解決此問題,可以設定一個單獨的 URL,專用於告知前端 (使用者的瀏覽器) 應使用哪個 URL 來存取 Grafana。
若要變更傳回給前端的 URL,請發出以下指令:
cephuser@adm > ceph dashboard set-grafana-frontend-api-url GRAFANA-SERVER-URL如果沒有為該選項設定任何值,它將回復為 GRAFANA_API_URL 選項的值,該選項值自動設定並由 cephadm 定期更新。如果設定了值,它將指示瀏覽器使用此 URL 來存取 Grafana。
16.5 設定 Prometheus 管理員模組 #
Prometheus 管理員模組是一個 Ceph 內部模組,它延伸了 Ceph 的功能。該模組會從 Ceph 讀取有關其狀態和狀況的 (中繼) 資料,並以可使用的格式向 Prometheus 提供 (抓取的) 資料。
需要重新啟動 Prometheus 管理員模組才能套用組態變更。
16.5.1 設定網路介面 #
依預設,Prometheus 管理員模組接受主機上所有 IPv4 和 IPv6 位址的連接埠 9283 上的 HTTP 要求。連接埠和監聽位址都可使用 ceph config-key set 進行設定,並使用機碼 mgr/prometheus/server_addr 和 mgr/prometheus/server_port。此連接埠已在 Prometheus 的登錄中註冊。
若要更新 server_addr,請執行以下指令:
cephuser@adm > ceph config set mgr mgr/prometheus/server_addr 0.0.0.0
若要更新 server_port,請執行以下指令:
cephuser@adm > ceph config set mgr mgr/prometheus/server_port 928316.5.2 設定 scrape_interval #
依預設,Prometheus 管理員模組設定了 15 秒的抓取間隔。我們建議使用的抓取間隔不得少於 10 秒。若要在 Prometheus 模組中設定其他抓取間隔,請將 scrape_interval 設定為所需值:
若要正常運作而不會導致任何問題,此模組的 scrape_interval 應永遠依據 Prometheus 抓取間隔進行設定。
cephuser@adm > ceph config set mgr mgr/prometheus/scrape_interval 1516.5.3 設定快取 #
在大型叢集 (超過 1000 個 OSD) 上,擷取度量的時間可能會變得非常重要。如果沒有快取,Prometheus 管理員模組可能會令管理員超載,並導致 Ceph 管理員例項無回應或當機。因此,系統預設會啟用快取,並且不能停用快取,但這意味著快取可能會過時。當從 Ceph 擷取度量的時間超出所設定的 scrape_interval 時,快取將被視為過時。
如果發生此情況,系統將記錄一則警告,並且模組將:
以 503 HTTP 狀態代碼 (服務不可用) 回應。
傳回快取的內容,即使該內容可能已過時。
可使用 ceph config set 指令設定此行為。
若要告知模組以可能過時的資料進行回應,請將其設定為 return:
cephuser@adm > ceph config set mgr mgr/prometheus/stale_cache_strategy return
若要告知模組以 service unavailable 進行回應,請將其設定為 fail:
cephuser@adm > ceph config set mgr mgr/prometheus/stale_cache_strategy fail16.5.4 啟用 RBD 影像監控 #
Prometheus 管理員模組可以透過啟用動態 OSD 效能計數器來選擇性地收集 RBD 每個影像的 IO 統計資料。如此將為在 mgr/prometheus/rbd_stats_pools 組態參數中所指定池中的所有影像收集統計資料。
參數是以逗號或空格分隔的 pool[/namespace] 項目清單。如果未指定名稱空間,則將收集池中所有名稱空間的統計資料。
例如:
cephuser@adm > ceph config set mgr mgr/prometheus/rbd_stats_pools "pool1,pool2,poolN"
該模組會掃描指定的池和名稱空間,列出所有可用影像,並定期重新整理該清單。此間隔可透過 mgr/prometheus/rbd_stats_pools_refresh_interval 參數進行設定 (以秒計),預設值為 300 秒 (5 分鐘)。
例如,如果您將同步間隔變更為 10 分鐘:
cephuser@adm > ceph config set mgr mgr/prometheus/rbd_stats_pools_refresh_interval 60016.6 Prometheus 安全性模型 #
Prometheus 的安全性模型假設不受信任的使用者有權存取 Prometheus HTTP 端點和記錄。不受信任的使用者有權存取資料庫中包含的 Prometheus 收集的所有 (中繼) 資料,以及各種操作和除錯資訊。
不過,Prometheus 的 HTTP API 僅限唯讀操作。無法使用 API 變更組態,並且不會公開機密金鑰。此外,Prometheus 還有一些內建的措施可用於緩解拒絕服務攻擊的影響。
16.7 Prometheus 警示管理員 SNMP Webhook #
如果您想透過 SNMP 設陷接收有關 Prometheus 警示的通知,可以透過 cephadm 安裝 Prometheus 警示管理員 SNMP Webhook。為此,您需要使用以下內容建立服務和放置規格檔案:
如需服務和放置檔案的詳細資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.2 “服務和放置規格”。
service_type: container
service_id: prometheus-webhook-snmp
placement:
ADD_PLACEMENT_HERE
image: registry.suse.com/ses/7/prometheus-webhook-snmp:latest
args:
- "--publish 9099:9099"
envs:
- ARGS="--debug --snmp-host=ADD_HOST_GATEWAY_HERE"
- RUN_ARGS="--metrics"
EOF使用此服務規格可讓服務使用其預設設定來執行。
執行該服務時,您需要使用指令行引數 --publish HOST_PORT:CONTAINER_PORT 來發佈 Prometheus 接收器正在監聽的連接埠,因為容器不會自動公開該連接埠。可透過在規格中新增下面幾行來完成此操作:
args:
- "--publish 9099:9099"
或者,使用指令行引數 --network=host 將容器連接至主機網路。
args:
- "--network=host"如果未在與容器相同的主機上安裝 SNMP 設陷接收器,則還必須指定 SNMP 主機的 FQDN。使用容器的網路閘道可以接收容器/主機外部的 SNMP 設陷:
envs:
- ARGS="--debug --snmp-host=CONTAINER_GATEWAY"16.7.1 設定 prometheus-webhook-snmp 服務 #
可以透過環境變數或使用組態檔案來設定容器。
對於環境變數,請使用 ARGS 設定全域選項,並使用 RUN_ARGS 設定 run 指令選項。您需要如下所示調整服務規格:
envs:
- ARGS="--debug --snmp-host=CONTAINER_GATEWAY"
- RUN_ARGS="--metrics --port=9101"若要使用組態檔案,必須如下所示調整服務規格:
files:
etc/prometheus-webhook-snmp.conf:
- "debug: True"
- "snmp_host: ADD_HOST_GATEWAY_HERE"
- "metrics: True"
volume_mounts:
etc/prometheus-webhook-snmp.conf: /etc/prometheus-webhook-snmp.conf若要進行部署,請執行以下指令:
cephuser@adm > ceph orch apply -i SERVICE_SPEC_FILE如需詳細資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3 “部署 Ceph 服務”。
16.7.2 為 SNMP 設定 Prometheus 警示管理員 #
最後,需要為 SNMP 設陷設定專屬 Prometheus 警示管理員。如果尚未部署此服務,請建立服務規格檔案。您需要使用安裝了 Prometheus 警示管理員 SNMP Webhook 之主機的 IP 位址或 FQDN 來取代 IP_OR_FQDN。例如:
如果您已部署此服務,請確定為 SNMP 正確設定警示管理員,使用以下設定重新部署。
service_type: alertmanager
placement:
hosts:
- HOSTNAME
webhook_configs:
- 'http://IP_OR_FQDN:9099/'使用以下指令套用服務規格:
cephuser@adm > ceph orch apply -i SERVICE_SPEC_FILE第 III 部分 在叢集中儲存資料 #
- 17 儲存的資料管理
CRUSH 演算法透過運算資料儲存位置來確定如何儲存和擷取資料。利用 CRUSH,Ceph 用戶端無需透過集中式伺服器或仲介,即可直接與 OSD 通訊。借助演算法確定的資料儲存和擷取方法,Ceph 可避免單一故障點、效能瓶頸和延展性實體限制。
- 18 管理儲存池
Ceph 將資料儲存在池中。池是用於儲存物件的邏輯群組。如果您先部署叢集而不建立池,Ceph 會使用預設池來儲存資料。下面著重指出與 Ceph 池有關的重要特性:
- 19 糾刪碼池
Ceph 提供了一種在池中正常複製資料的替代方案,稱為糾刪池或糾刪碼池。糾刪碼池不能提供複本池的所有功能 (例如,它們無法儲存 RBD 池的中繼資料),但其所需的原始儲存空間更少。一個能夠儲存 1 TB 資料的預設糾刪碼池需要 1.5 TB 的原始儲存空間,以應對發生單個磁碟故障的情況。從這方面而言,糾刪碼池優於複本池,因為後者需要 2 TB 的原始儲存空間才能實現相同目的。
- 20 RADOS 區塊裝置
一個區塊就是由若干位元組組成的序列,例如 4 MB 的資料區塊。區塊式儲存介面是使用旋轉媒體 (例如硬碟、CD、軟碟) 儲存資料最常見的方式。區塊裝置介面的普及,也使得虛擬區塊裝置成為與大量資料儲存系統 (例如 Ceph) 進行互動的理想選擇。
17 儲存的資料管理 #
CRUSH 演算法透過運算資料儲存位置來確定如何儲存和擷取資料。利用 CRUSH,Ceph 用戶端無需透過集中式伺服器或仲介,即可直接與 OSD 通訊。借助演算法確定的資料儲存和擷取方法,Ceph 可避免單一故障點、效能瓶頸和延展性實體限制。
CRUSH 需要獲取叢集的地圖,它使用 CRUSH 地圖以虛擬隨機方式在 OSD 中儲存和擷取資料,並以一致的方式在整個叢集中分發資料。
CRUSH 地圖包含一個 OSD 清單、一個用於將裝置聚合到實體位置的「桶」清單,以及一個指示 CRUSH 應如何複製 Ceph 叢集池中資料的規則清單。透過反映安裝的基礎實體組織,CRUSH 可對相關裝置故障的潛在根源塑模,從而解決故障的根源。一般的根源包括實體距離、共用電源和共用網路。透過將這些資訊編碼到叢集地圖中,CRUSH 放置規則可將物件複本分隔在不同的故障網域中,同時維持所需的分發方式。例如,為了消除可能的並行故障,可能需要確定資料複本位於使用不同機架、機櫃、電源、控制器和/或實體位置的裝置上。
部署 Ceph 叢集後,將會產生預設的 CRUSH 地圖。這種模式適合 Ceph 沙箱環境。但是,在部署大規模的資料叢集時,強烈建議您考慮建立自訂 CRUSH 地圖,因為這樣做有助於管理 Ceph 叢集、提高效能並確保資料安全。
例如,如果某個 OSD 停機,而您需要使用現場支援或更換硬體,則 CRUSH 地圖可協助您定位到發生 OSD 故障的主機所在的實體資料中心、機房、裝置排和機櫃。
同樣,CRUSH 可以協助您更快地確定故障。例如,如果特定機櫃中的所有 OSD 同時停機,故障可能是由某個網路交換器或者機櫃或網路交換器的電源所致,而不是發生在 OSD 自身上。
當與故障主機關聯的放置群組 (請參閱第 17.4 節 「放置群組」) 處於降級狀態時,自訂 CRUSH 地圖還可協助您確定 Ceph 儲存資料備援副本的實體位置。
CRUSH 地圖包括三個主要部分。
17.1 OSD 裝置 #
為了將放置群組對應到 OSD,CRUSH 地圖需要 OSD 裝置 (OSD 精靈的名稱) 的清單。裝置清單顯示在 CRUSH 地圖的最前面。
#devices device NUM osd.OSD_NAME class CLASS_NAME
例如:
#devices device 0 osd.0 class hdd device 1 osd.1 class ssd device 2 osd.2 class nvme device 3 osd.3class ssd
一般而言,一個 OSD 精靈對應到一個磁碟。
17.1.1 裝置類別 #
Ceph 的優勢之一是 CRUSH 地圖能夠靈活控制資料的放置。這也是叢集最難管理的環節之一。裝置類別會自動對 CRUSH 地圖執行最常見的變更,先前這些變更都需要由管理員手動完成。
17.1.1.1 CRUSH 管理問題 #
Ceph 叢集常由多種類型的儲存裝置建構而成:HDD、SSD、NVMe,甚至是以上這些類別的混合。我們將這些不同的儲存裝置類型稱為裝置類別,以避免與 CRUSH 桶的類型內容 (例如 host、rack 和 row,請參閱第 17.2 節 「桶」以瞭解更多詳細資料) 產生混淆。受 SSD 支援的 Ceph OSD 比受旋轉式磁碟支援的 OSD 速度快得多,因此更適合特定工作負載。利用 Ceph,您可輕鬆為不同資料集或工作負載建立 RADOS 池,以及指定不同的 CRUSH 規則來控制這些池的資料放置。

不過,透過設定 CRUSH 規則將資料僅放置到特定類別的裝置這個過程十分枯燥。規則是針對 CRUSH 階層運作的,但如果將某些裝置混合到同一主機或機架中 (如上面的範例階層所示),則這些裝置預設會混合在一起並顯示在階層的同一子樹狀結構中。若要手動將它們分隔到單獨的樹狀結構中,需要針對先前版本的 SUSE Enterprise Storage 中的每個裝置類別,為每個中間節點建立多個版本。
17.1.1.2 裝置類別 #
Ceph 提供了一個較佳的解決方案,就是新增一個名為裝置類別的內容至每個 OSD。依預設,OSD 會依據
Linux 核心所公開的硬體內容,自動將自己的裝置類別設定為「hdd」、「ssd」或「nvme」。ceph osd
tree 指令輸出的新欄中會報告這些裝置類別:
cephuser@adm > ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 83.17899 root default
-4 23.86200 host cpach
2 hdd 1.81898 osd.2 up 1.00000 1.00000
3 hdd 1.81898 osd.3 up 1.00000 1.00000
4 hdd 1.81898 osd.4 up 1.00000 1.00000
5 hdd 1.81898 osd.5 up 1.00000 1.00000
6 hdd 1.81898 osd.6 up 1.00000 1.00000
7 hdd 1.81898 osd.7 up 1.00000 1.00000
8 hdd 1.81898 osd.8 up 1.00000 1.00000
15 hdd 1.81898 osd.15 up 1.00000 1.00000
10 nvme 0.93100 osd.10 up 1.00000 1.00000
0 ssd 0.93100 osd.0 up 1.00000 1.00000
9 ssd 0.93100 osd.9 up 1.00000 1.00000
如果裝置類別自動偵測失敗 (例如由於未透過 /sys/block
正確向裝置驅動程式公開裝置的相關資訊而導致失敗),您可以使用指令行調整裝置類別:
cephuser@adm >ceph osd crush rm-device-class osd.2 osd.3 done removing class of osd(s): 2,3cephuser@adm >ceph osd crush set-device-class ssd osd.2 osd.3 set osd(s) 2,3 to class 'ssd'
17.1.1.3 設定 CRUSH 放置規則 #
CRUSH 規則可限制對特定裝置類別執行放置操作。例如,您可以透過執行以下指令來建立僅將資料分佈在 SSD 磁碟上的「fast」複本池:
cephuser@adm > ceph osd crush rule create-replicated RULE_NAME ROOT FAILURE_DOMAIN_TYPE DEVICE_CLASS例如:
cephuser@adm > ceph osd crush rule create-replicated fast default host ssd建立名為「fast_pool」的池,並將其指定給「fast」規則:
cephuser@adm > ceph osd pool create fast_pool 128 128 replicated fast建立糾刪碼規則的程序略有不同。首先,建立包含所需裝置類別所對應內容的糾刪碼設定檔。然後,在建立糾刪碼池時使用該設定檔:
cephuser@adm >ceph osd erasure-code-profile set myprofile \ k=4 m=2 crush-device-class=ssd crush-failure-domain=hostcephuser@adm >ceph osd pool create mypool 64 erasure myprofile
為應對您需要手動編輯 CRUSH 地圖來自訂規則的情況,已將該語法進行擴充,以便允許指定裝置類別。例如,上述指令產生的 CRUSH 規則如下所示:
rule ecpool {
id 2
type erasure
min_size 3
max_size 6
step set_chooseleaf_tries 5
step set_choose_tries 100
step take default class ssd
step chooseleaf indep 0 type host
step emit
}此處的重要差異是,「take」指令包含額外的「class CLASS_NAME」尾碼。
17.1.1.4 其他指令 #
若要列出 CRUSH 地圖中使用的裝置類別,請執行以下指令:
cephuser@adm > ceph osd crush class ls
[
"hdd",
"ssd"
]若要列出現有的 CRUSH 規則,請執行以下指令:
cephuser@adm > ceph osd crush rule ls
replicated_rule
fast若要檢視名為「fast」的 CRUSH 規則的詳細資料,請執行以下指令:
cephuser@adm > ceph osd crush rule dump fast
{
"rule_id": 1,
"rule_name": "fast",
"ruleset": 1,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -21,
"item_name": "default~ssd"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}若要列出屬於「ssd」類別的 OSD,請執行以下指令:
cephuser@adm > ceph osd crush class ls-osd ssd
0
117.1.1.5 從舊版 SSD 規則移轉至裝置類別 #
在早於版本 5 的 SUSE Enterprise Storage 中,若要寫入適用於裝置的規則,您需要手動編輯 CRUSH 地圖,並為每個具體的裝置類型 (例如 SSD) 維護平行的階層。自 SUSE Enterprise Storage 5 起,裝置類別特性透明地實現了這一目的。
您可以使用 crushtool 指令將舊版規則和階層轉換為基於類別的新版規則。系統提供了以下幾種轉換類型:
crushtool --reclassify-root ROOT_NAME DEVICE_CLASS此指令會獲取 ROOT_NAME 下的階層中的所有內容,並將透過
take ROOT_NAME
參考該根的所有規則都調整為
take ROOT_NAME class DEVICE_CLASS
它會對桶重新編號,以便為指定類別的「shadow tree」使用舊 ID。因此不會移動資料。
範例 17.1︰crushtool --reclassify-root#假設存在以下現有規則:
rule replicated_ruleset { id 0 type replicated min_size 1 max_size 10 step take default step chooseleaf firstn 0 type rack step emit }如果您將根「default」重新分類為「hdd」類別,規則將變為
rule replicated_ruleset { id 0 type replicated min_size 1 max_size 10 step take default class hdd step chooseleaf firstn 0 type rack step emit }crushtool --set-subtree-class BUCKET_NAME DEVICE_CLASS此方法會將根目錄為 BUCKET_NAME 的子樹狀結構中的每部裝置標示為指定的裝置類別。
--set-subtree-class通常與--reclassify-root選項結合使用,以確定該根中的所有裝置均標為正確的類別。不過,其中一些裝置可能特意使用了不同的類別,因此您不需要重新對它們進行標記。在此類情況下,請勿使用--set-subtree-class選項。請記住,這樣的重新對應並不完美,因為之前的規則是跨多個類別的裝置配送的,而調整後的規則將僅對應至指定裝置類別的裝置。crushtool --reclassify-bucket MATCH_PATTERN DEVICE_CLASS DEFAULT_PATTERN此方法允許將類型特定的平行階層與一般階層合併。例如,許多使用者會具有類似如下的 CRUSH 地圖:
範例 17.2︰crushtool --reclassify-bucket#host node1 { id -2 # do not change unnecessarily # weight 109.152 alg straw hash 0 # rjenkins1 item osd.0 weight 9.096 item osd.1 weight 9.096 item osd.2 weight 9.096 item osd.3 weight 9.096 item osd.4 weight 9.096 item osd.5 weight 9.096 [...] } host node1-ssd { id -10 # do not change unnecessarily # weight 2.000 alg straw hash 0 # rjenkins1 item osd.80 weight 2.000 [...] } root default { id -1 # do not change unnecessarily alg straw hash 0 # rjenkins1 item node1 weight 110.967 [...] } root ssd { id -18 # do not change unnecessarily # weight 16.000 alg straw hash 0 # rjenkins1 item node1-ssd weight 2.000 [...] }此函數會將與給定模式相符的每個桶重新分類。模式的格式可能為
%suffix或prefix%。在上面的範例中,您需要使用%-ssd模式。對於每個相符的桶,與「%」萬用字元相符的名稱的其餘部分指定了基本桶。相符桶中的所有裝置都標示為指定的裝置類別,隨後會移至基本桶中。如果基本桶不存在 (例如,如果「node12-ssd」存在,但「node12」不存在),則系統會建立基本桶,並將其關聯到指定的預設父桶下。系統會為新的陰影桶保留舊桶 ID,以防資料移動。系統會對包含參考舊桶的take步驟的規則進行調整。crushtool --reclassify-bucket BUCKET_NAME DEVICE_CLASS BASE_BUCKET您可以使用不包含萬用字元的
--reclassify-bucket選項來對應單個桶。例如,在上面的範例中,我們希望將「ssd」桶對應至預設桶。用於轉換由上述片段組成的地圖的最後一個指令將如下所示:
cephuser@adm >ceph osd getcrushmap -o originalcephuser@adm >crushtool -i original --reclassify \ --set-subtree-class default hdd \ --reclassify-root default hdd \ --reclassify-bucket %-ssd ssd default \ --reclassify-bucket ssd ssd default \ -o adjusted若要確認轉換是否正確,可以使用
--compare選項。該選項會測試大量對 CRUSH 地圖的輸入,並比較是否會產生相同的結果。透過適用於--test的相同選項來控制這些輸入。對於上面的範例,指令將如下所示:cephuser@adm >crushtool -i original --compare adjusted rule 0 had 0/10240 mismatched mappings (0) rule 1 had 0/10240 mismatched mappings (0) maps appear equivalent提示如果存在差異,括號中將會顯示重新對應的輸入比率。
如果您對調整後的 CRUSH 地圖滿意,便可將其套用於叢集:
cephuser@adm >ceph osd setcrushmap -i adjusted
17.1.1.6 相關資訊 #
如需 CRUSH 地圖的更多詳細資料,請參閱第 17.5 節 「CRUSH 地圖操作」。
如需 Ceph 池的更多一般詳細資料,請參閱第 18 章 「管理儲存池」
如需糾刪碼池的更多詳細資料,請參閱第 19 章 「糾刪碼池」。
17.2 桶 #
CRUSH 地圖包含 OSD 的清單,可將這些 OSD 組織成桶的樹狀結構排列方式,以便將裝置聚合到實體位置。個別 OSD 組成樹狀結構上的葉。
|
0 |
osd |
特定裝置或 OSD ( |
|
1 |
host |
包含一或多個 OSD 之主機的主機名稱。 |
|
2 |
chassis |
機架中包含該 |
|
3 |
rack |
電腦機櫃。預設值為 |
|
4 |
row |
由一系列機櫃組成的裝置排。 |
|
5 |
pdu |
「Power Distribution Unit」(電源分配器) 的縮寫。 |
|
6 |
pod |
「Point of Delivery」(傳遞點) 的縮寫。在此情境中為一組 PDU 或一組機架列。 |
|
7 |
room |
包含多列機架的機房。 |
|
8 |
datacenter |
包含一或多個機房的實體資料中心。 |
|
9 |
region |
全球的地理區域 (例如 NAM、LAM、EMEA、APAC 等) |
|
10 |
root |
OSD 桶的樹狀結構根節點 (通常設定為 |
您可以修改現有類型,以及建立自己的桶類型。
Ceph 的部署工具可產生 CRUSH 地圖,其中包含每個主機的桶,以及名為「default」的根 (可用於預設的
rbd 池)。剩餘的桶類型提供了一種儲存有關節點/桶的實體位置資訊的方法,當
OSD、主機或網路硬體無法正常運作,並且管理員需要存取實體硬體時,這種方法可顯著簡化叢集管理工作。
桶具有類型、唯一的名稱 (字串)、以負整數表示的唯一的 ID、相對於其項目總容量/功能的權數、桶演算法 (預設為
straw2),以及雜湊 (預設為 0,代表 CRUSH 雜湊
rjenkins1)。一個桶可以包含一或多個項目。項目可由其他桶或 OSD
組成。項目可能會有一個權數來反映該項目的相對權數。
[bucket-type] [bucket-name] {
id [a unique negative numeric ID]
weight [the relative capacity/capability of the item(s)]
alg [the bucket type: uniform | list | tree | straw2 | straw ]
hash [the hash type: 0 by default]
item [item-name] weight [weight]
}下面的範例說明如何使用桶來聚合池,以及諸如資料中心、機房、機櫃和裝置排的實體位置。
host ceph-osd-server-1 {
id -17
alg straw2
hash 0
item osd.0 weight 0.546
item osd.1 weight 0.546
}
row rack-1-row-1 {
id -16
alg straw2
hash 0
item ceph-osd-server-1 weight 2.00
}
rack rack-3 {
id -15
alg straw2
hash 0
item rack-3-row-1 weight 2.00
item rack-3-row-2 weight 2.00
item rack-3-row-3 weight 2.00
item rack-3-row-4 weight 2.00
item rack-3-row-5 weight 2.00
}
rack rack-2 {
id -14
alg straw2
hash 0
item rack-2-row-1 weight 2.00
item rack-2-row-2 weight 2.00
item rack-2-row-3 weight 2.00
item rack-2-row-4 weight 2.00
item rack-2-row-5 weight 2.00
}
rack rack-1 {
id -13
alg straw2
hash 0
item rack-1-row-1 weight 2.00
item rack-1-row-2 weight 2.00
item rack-1-row-3 weight 2.00
item rack-1-row-4 weight 2.00
item rack-1-row-5 weight 2.00
}
room server-room-1 {
id -12
alg straw2
hash 0
item rack-1 weight 10.00
item rack-2 weight 10.00
item rack-3 weight 10.00
}
datacenter dc-1 {
id -11
alg straw2
hash 0
item server-room-1 weight 30.00
item server-room-2 weight 30.00
}
root data {
id -10
alg straw2
hash 0
item dc-1 weight 60.00
item dc-2 weight 60.00
}17.3 規則集 #
CRUSH 地圖支援「CRUSH 規則」概念,這些規則確定池的資料放置。對於大型叢集,您可能會建立許多池,其中每個池各自可能具有自己的 CRUSH 規則集和規則。預設 CRUSH 地圖具有適用於預設根的規則。如果您想使用更多根和更多規則,則需稍後自行建立,或者在建立新池時讓系統自動建立。
大多數情況下,您無需修改預設規則。建立新池時,該池的預設規則集為 0。
規則採用以下格式:
rule rulename {
ruleset ruleset
type type
min_size min-size
max_size max-size
step step
}- ruleset
一個整數。將規則分類,使其屬於一個規則集。透過在池中設定規則集來啟用。必須指定此選項。預設值為
0。- type
一個字串。描述了適用於「複本」或「糾刪碼」池的規則。必須指定此選項。預設值為
replicated。- min_size
一個整數。如果池群組建立的複本數小於此數字,CRUSH 將不選取此規則。必須指定此選項。預設值為
2。- max_size
一個整數。如果池群組建立的複本數大於此數字,CRUSH 將不選取此規則。必須指定此選項。預設值為
10。- step take bucket
採用以名稱指定的桶,並開始在樹狀結構中向下逐一查看。必須指定此選項。如需在樹中逐一查看的說明,請參閱第 17.3.1 節 「逐一查看節點樹」。
- step targetmodenum type bucket-type
target 可以是
choose或chooseleaf。如果設定為choose,則會選取許多桶。chooseleaf直接從桶集的每個桶的子樹中選取 OSD (葉節點)。mode 可以是
firstn或indep。請參閱第 17.3.2 節 「firstn 和 indep」。選取給定類型的桶的數量。其中,N 是可用選項的數量,如果 num > 0 且 < N,則選擇該數量的桶;如果 num < 0,則表示 N - 數量;如果 num = 0,則選擇 N 個桶 (全部可用)。跟在
step take或step choose後使用。- step emit
輸出目前的值並清空堆疊。一般在規則的結尾使用,但也可在同一規則中用來構成不同的樹。跟在
step choose後使用。
17.3.1 逐一查看節點樹 #
可採用節點樹的形式來檢視使用桶定義的結構。在此樹中,桶是節點,OSD 是葉。
CRUSH 地圖中的規則定義如何從此樹中選取 OSD。規則從某個節點開始,然後在樹中向下逐一查看,以傳回一組 OSD。無法定義需要選取哪個分支。CRUSH 演算法可保證 OSD 集能夠符合複製要求並均衡分發資料。
使用 step take bucket
時,在節點樹中從給定的桶 (而不是桶類型) 開始逐一查看。如果要傳回樹中所有分支上的 OSD,該桶必須是根桶。否則,以下步驟只會在子樹中逐一查看。
完成 step take 後,接下來會執行規則定義中的一或多個 step
choose 項目。每個 step choose 會從前面選定的上層節點中選擇指定數量的節點
(或分支)。
最後,使用 step emit 傳回選定的 OSD。
step chooseleaf 是一個便捷函數,可直接從給定桶的分支中選取 OSD。
圖形 17.2 「範例樹」中提供了展示如何使用
step 在樹中逐一查看的範例。在下面的規則定義中,橙色箭頭和數字與
example1a 和 example1b 對應,藍色箭頭和數字與
example2 對應。

# orange arrows
rule example1a {
ruleset 0
type replicated
min_size 2
max_size 10
# orange (1)
step take rack1
# orange (2)
step choose firstn 0 host
# orange (3)
step choose firstn 1 osd
step emit
}
rule example1b {
ruleset 0
type replicated
min_size 2
max_size 10
# orange (1)
step take rack1
# orange (2) + (3)
step chooseleaf firstn 0 host
step emit
}
# blue arrows
rule example2 {
ruleset 0
type replicated
min_size 2
max_size 10
# blue (1)
step take room1
# blue (2)
step chooseleaf firstn 0 rack
step emit
}17.3.2
CRUSH 規則定義有故障節點或 OSD 的取代項 (請參閱第 17.3 節 「規則集」)。關鍵字
step 要求使用 firstn 或
indep
參數。圖形 17.3 「節點取代方法」提供了範例。
firstn
將取代節點新增至使用中節點清單的結尾。如果某個節點發生故障,其後的正常節點會移位到左側,以填滿有故障節點留下的空缺。這是副本池的預設方法,也是需要採取的方法,因為次要節點已包含所有資料,因此可立即接管主要節點的職責。
indep
為每個使用中節點選取固定的取代節點。取代有故障節點不會變更剩餘節點的順序。這對於糾刪碼池而言是所需的行為。在糾刪碼池中,節點上儲存的資料取決於在選取節點時它所在的位置。如果節點的順序發生變化,受影響節點上的所有資料都需要重新放置。

17.4 放置群組 #
Ceph 會將物件對應至放置群組 (PG)。放置群組是指邏輯物件池的分區或片段,可將物件以群組形式放置到 OSD 中。放置群組可減少 Ceph 將資料儲存到 OSD 中時每個物件的中繼資料數量。如果放置群組的數量較多 (例如,每個 OSD 有 100 個放置群組),將可實現較佳的平衡。
17.4.1 使用放置群組 #
放置群組 (PG) 聚合了池內的物件。主要原因是基於每個物件來追蹤物件放置和中繼資料的計算成本較高。例如,包含數百萬個物件的系統無法直接追蹤各個物件的放置。

Ceph 用戶端負責計算物件將屬於哪個放置群組。它會對物件 ID 進行雜湊處理,並依據所定義池中的 PG 數及池的 ID 來套用操作。
系統會在一組 OSD 中儲存放置群組內的物件內容。例如,在大小為 2 的複本池中,每個放置群組將物件儲存到兩個 OSD 中:

如果 OSD 2 發生故障,則系統會將另一個 OSD 指定給放置群組 1,並在該 OSD 中填入 OSD 1 內所有物件的複本。如果池大小從 2 變為 3,則系統會向放置群組另外再指定一個 OSD,並在該 OSD 中填入放置群組內所有物件的複本。
放置群組並不擁有 OSD,它們與同一池甚至其他池內的其他放置群組共用 OSD。如果 OSD 2 發生故障,放置群組 2 也將需要使用 OSD 3 來還原物件的複本。
當放置群組的數量增加時,系統會向新放置群組指定 OSD。CRUSH 函數的結果也會發生變更,並且系統會將之前的放置群組的部分物件複製到新放置群組,並將它們從舊放置群組移除。
17.4.2 確定 PG_NUM 的值 #
從 Ceph Nautilus (v14.x) 開始,您可以使用 Ceph 管理員 pg_autoscaler
模組視需要自動調整 PG。如果要啟用此功能,請參閱Book “Deploying and Administering SUSE Enterprise Storage with Rook”, Chapter 6 “Configuration”, Section 6.1.1.1 “Default PG and PGP counts”。
建立新池時,您仍可手動選擇 PG_NUM 的值:
root # ceph osd pool create POOL_NAME PG_NUM系統無法自動計算 PG_NUM 的值。以下是一些常用的值,選擇哪個值取決於叢集中的 OSD 數量:
- 少於 5 個 OSD:
將 PG_NUM 設定為 128。
- 5 到 10 個 OSD:
將 PG_NUM 設定為 512。
- 10 到 50 個 OSD:
將 PG_NUM 設定為 1024。
隨著 OSD 數量的增加,選擇正確的 PG_NUM 值也變得愈加重要。PG_NUM 對叢集的行為以及 OSD 發生故障時的資料持久性具有很大影響。
17.4.2.1 計算超過 50 個 OSD 的放置群組 #
如果 OSD 數量低於 50,請使用第 17.4.2 節 「確定 PG_NUM 的值」中所述的預先選取的值。如果 OSD 數量超過 50,建議為每個 OSD 使用約 50 到 100 個放置群組,以平衡資源的使用、資料持久性和資料分佈。對於單個物件池,您可以使用以下公式來計算基線數量:
total PGs = (OSDs * 100) / POOL_SIZE
其中,POOL_SIZE 是複本的數量 (如果是複本池) 或 ceph
osd erasure-code-profile get 指令所傳回的「k」和「m」之和
(如果是糾刪碼池)。應將結果捨入至最接近的 2 的次方數。對於 CRUSH 演算法,建議進行捨入,以便均衡放置群組之間的物件數。
例如,如果叢集包含 200 個 OSD 和大小為 3 個複本的池,您需要依照如下方式預估 PG 數:
(200 * 100) / 3 = 6667
最接近的 2 的次方數為 8192。
使用多個資料池儲存物件時,您需要確保在每個池的放置群組數與每個 OSD 的放置群組數之間取得平衡。您需要採用合理的放置群組總數,在不過度佔用系統資源或導致互聯程序過慢的前提下,確保每個 OSD 的差異保持在合理的較低水平。
例如,如果叢集包含 10 個池,每個池有 512 個放置群組 (位於 10 個 OSD 中),則表示共有 5,120 個放置群組分佈於 10 個 OSD 中,即每個 OSD 有 512 個放置群組。這樣的設定不會使用過多資源。但是,如果建立了 1000 個池,且每個池有 512 個放置群組,那麼每個 OSD 需要處理約 50,000 個放置群組,這樣完成互聯所需的資源和時間便會顯著增加。
17.4.3 設定放置群組的數量 #
從 Ceph Nautilus (v14.x) 開始,您可以使用 Ceph 管理員 pg_autoscaler
模組視需要自動調整 PG。如果要啟用此功能,請參閱Book “Deploying and Administering SUSE Enterprise Storage with Rook”, Chapter 6 “Configuration”, Section 6.1.1.1 “Default PG and PGP counts”。
如果您仍需手動指定池中的放置群組數量,則需要在建立池時指定 (請參閱第 18.1 節 「建立池」)。為池設定放置群組後,您可以透過執行以下指令來增加放置群組的數量:
root # ceph osd pool set POOL_NAME pg_num PG_NUM
增加放置群組數量後,您還需要增加要放置的放置群組數量
(PGP_NUM),以便您的叢集重新達到平衡。PGP_NUM 是考慮要透過
CRUSH 演算法放置的放置群組數。增加 PG_NUM 會分割放置群組,但在增加
PGP_NUM 之前,資料不會移轉至較新的放置群組。PGP_NUM 應等於
PG_NUM。若要增加應放置的放置群組數量,請執行以下指令:
root # ceph osd pool set POOL_NAME pgp_num PGP_NUM17.4.4 獲取放置群組的數量 #
獲取某個池中放置群組的數量,請執行以下 get 指令:
root # ceph osd pool get POOL_NAME pg_num17.4.5 獲取叢集的 PG 統計資料 #
若要獲取叢集內放置群組的統計資料,請執行以下指令:
root # ceph pg dump [--format FORMAT]有效格式為「plain」(預設值) 和「json」。
17.4.6 獲取卡住的 PG 統計資料 #
若要獲取所有卡在指定狀態之放置群組的統計資料,請執行以下指令:
root # ceph pg dump_stuck STATE \
[--format FORMAT] [--threshold THRESHOLD]
可能的狀態有:「inactive」(PG 由於在等待擁有最新資料的 OSD
恢復啟用狀態而無法處理讀取或寫入)、「unclean」(PG 包含未複製所需次數的物件)、「stale」(PG 處於未知狀態,即代管 PG 的 OSD
未在 mon_osd_report_timeout
選項所指定的時間間隔內向監控程式叢集報告相關資訊)、「undersized」或「degraded」。
有效格式為「plain」(預設值) 和「json」。
該閾值定義放置群組至少卡住多少秒 (預設為 300 秒) 後,系統會將其包含到傳回的統計資料中。
17.4.7 搜尋放置群組地圖 #
若要搜尋特定放置群組的地圖,請執行以下指令:
root # ceph pg map PG_IDCeph 將傳回放置群組地圖、放置群組和 OSD 狀態:
root # ceph pg map 1.6c
osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]17.4.8 擷取放置群組統計資料 #
若要擷取特定放置群組的統計資料,請執行以下指令:
root # ceph pg PG_ID query17.4.9 整理放置群組 #
若要整理 (第 17.6 節 「整理放置群組」) 放置群組,請執行以下指令:
root # ceph pg scrub PG_IDCeph 會檢查主要節點和複本節點、產生放置群組內所有物件的目錄,並對它們進行比較,以確定沒有缺少或不符的物件且物件的內容均一致。假設所有複本均相符,最後的語意整理便可確定所有與快照相關的物件中繼資料均一致。系統透過記錄來報告錯誤。
17.4.10 設定放置群組回填和復原的優先程度 #
您可能會遇到數個放置群組需要復原和/或回填,而其中一些放置群組儲存的資料比其他放置群組更為重要的情況。例如,這些 PG 可能儲存著執行中機器所使用的影像資料,其他 PG 則可能儲存的是由非使用中機器使用的資料或相關度較低的資料。在該情況下,您可能需要優先復原這些放置群組,以便更早地還原這些放置群組中所儲存資料的效能和可用性。若要將特定放置群組標示為在回填或復原期間優先處理,請執行以下指令:
root #ceph pg force-recovery PG_ID1 [PG_ID2 ... ]root #ceph pg force-backfill PG_ID1 [PG_ID2 ... ]
這將導致 Ceph 先對指定放置群組執行復原或回填,然後再處理其他放置群組。這并不會中斷目前正在進行的回填或復原,而是會使指定的 PG 儘快得到處理。如果您改變了主意或將錯誤的放置群組設為優先處理,請使用以下指令取消優先程度:
root #ceph pg cancel-force-recovery PG_ID1 [PG_ID2 ... ]root #ceph pg cancel-force-backfill PG_ID1 [PG_ID2 ... ]
cancel-* 指令會移除 PG 的「force」旗標,這樣系統便會依預設順序處理這些
PG。同樣,這並不會影響目前正在處理的放置群組,只會影響仍排在佇列中的放置群組。完成放置群組復原或回填後,系統即會自動清除「force」旗標。
17.4.11 復原遺失的物件 #
如果叢集遺失了一或多個物件,而您已決定放棄搜尋遺失的資料,則需要將未找到的物件標示為「lost」。
如果在查詢過所有可能的位置後仍未找到這些物件,您可能需要放棄這些遺失的物件。這可能是由於幾種故障同時發生 (這種情況很少見) 所導致,致使叢集在寫入自身復原之前便得知寫入已執行。
目前唯一支援的選項為「revert」,該選項會復原到物件的先前版本,或在有新物件時完全忽略遺失物件。若要將「未找到」的物件標示為「lost」,請執行以下指令:
cephuser@adm > ceph pg PG_ID mark_unfound_lost revert|delete17.4.12 啟用 PG 自動調整器 #
放置群組 (PG) 是 Ceph 分佈資料方式的詳細內部實作。透過啟用 PG 自動調整功能,您可以允許叢集依據叢集的使用情況建立或自動調整 PG。
系統中的每個池都有一個 pg_autoscale_mode 內容,可將其設定為
off、on 或 warn:
自動調整器基於每個池設定,可在以下三種模式下執行:
- off
為此池停用自動調整功能。由管理員為每個池選擇適當的 PG 數量。
- on
為給定池啟用 PG 計數自動調整功能。
- warn
當 PG 計數應進行調整時,系統將發出狀況警示。
若要為現有池設定自動調整模式,請執行以下指令:
cephuser@adm > ceph osd pool set POOL_NAME pg_autoscale_mode mode
您也可以執行以下指令,以設定將套用至未來將建立之所有池的預設 pg_autoscale_mode:
cephuser@adm > ceph config set global osd_pool_default_pg_autoscale_mode MODE您可以執行以下指令來檢視每個池、其相關使用情況,以及對 PG 計數的任何變更建議:
cephuser@adm > ceph osd pool autoscale-status17.5 CRUSH 地圖操作 #
本節介紹基本的 CRUSH 地圖操作方法,例如編輯 CRUSH 地圖、變更 CRUSH 地圖參數,以及新增/移動/移除 OSD。
17.5.1 編輯 CRUSH 地圖 #
若要編輯現有的 CRUSH 地圖,請執行以下操作:
獲取 CRUSH 地圖。要獲取叢集的 CRUSH 地圖,請執行以下指令:
cephuser@adm >ceph osd getcrushmap -o compiled-crushmap-filenameCeph 會將編譯的 CRUSH 地圖輸出 (
-o) 至您指定名稱的檔案。由於該 CRUSH 地圖採用編譯格式,您必須先將其反編譯,才能對其進行編輯。反編譯 CRUSH 地圖。若要反編譯 CRUSH 地圖,請執行以下指令:
cephuser@adm >crushtool -d compiled-crushmap-filename \ -o decompiled-crushmap-filenameCeph 將對已編譯的 CRUSH 地圖進行反編譯 (
-d),並將其輸出 (-o) 至您指定名稱的檔案。至少編輯「裝置」、「桶」和「規則」中的其中一個參數。
編譯 CRUSH 地圖。若要編譯 CRUSH 地圖,請執行以下指令:
cephuser@adm >crushtool -c decompiled-crush-map-filename \ -o compiled-crush-map-filenameCeph 會將編譯的 CRUSH 地圖儲存至您指定名稱的檔案。
設定 CRUSH 地圖。若要設定叢集的 CRUSH 地圖,請執行以下指令:
cephuser@adm >ceph osd setcrushmap -i compiled-crushmap-filenameCeph 將輸入您所指定檔案名稱的已編譯 CRUSH 地圖,做為叢集的 CRUSH 地圖。
請為輸出並修改過的 CRUSH 地圖檔案使用諸如 git 或 svn 的版本設定系統。這可以讓可能發生的復原變得簡單。
請使用 crushtool --test 指令測試調整後的新 CRUSH 地圖,並與套用新 CRUSH
地圖之前的狀態進行比較。以下指令參數十分有用:--show-statistics、--show-mappings、--show-bad-mappings、--show-utilization、--show-utilization-all、--show-choose-tries
17.5.2 新增或移動 OSD #
若要在執行中叢集的 CRUSH 地圖中新增或移動 OSD,請執行以下指令:
cephuser@adm > ceph osd crush set id_or_name weight root=pool-name
bucket-type=bucket-name ...- id
一個整數。OSD 的數字 ID。必須指定此選項。
- name
一個字串。OSD 的全名。必須指定此選項。
- weight
一個雙精度浮點數。OSD 的 CRUSH 權數。必須指定此選項。
- root
一個鍵值組。依預設,CRUSH 階層包含 default 池做為根。必須指定此選項。
- bucket-type
多個鍵值組。您可在 CRUSH 階層中指定 OSD 的位置。
下面的範例將 osd.0 新增至階層,或移動先前某個位置的 OSD。
cephuser@adm > ceph osd crush set osd.0 1.0 root=data datacenter=dc1 room=room1 \
row=foo rack=bar host=foo-bar-117.5.3 ceph osd reweight 與 ceph osd crush reweight 之間的差異 #
有兩個相似的指令都可變更 Ceph OSD 的權數。它們的使用情境不同,可能會造成混淆。
17.5.3.1 ceph osd reweight #
用法:
cephuser@adm > ceph osd reweight OSD_NAME NEW_WEIGHT
ceph osd reweight 用於對 Ceph OSD 設定覆寫權數。此值介於 0 到 1 之間,會強制
CRUSH 重新放置此磁碟機上將以其他方式儲存的資料。該指令不會變更指定給 OSD
上方的桶的權數,它是一種在正常 CRUSH 分佈出現問題時的矯正措施。例如,如果您的其中一個 OSD 處於 90%,而其他 OSD 處於
40%,則您可縮小此權數,以嘗試對其進行補償。
請注意,ceph osd reweight 並非永久設定。將某個 OSD 標示為「out」時,它的權數將設為
0,一旦將它重新標示為「in」,其權數又會變更為 1。
17.5.3.2 ceph osd crush reweight #
用法:
cephuser@adm > ceph osd crush reweight OSD_NAME NEW_WEIGHT
ceph osd crush reweight 用於設定 OSD 的
CRUSH 權數。此權數可以是任意值 (通常是以 TB
計的磁碟大小),用於控制系統嘗試指定給 OSD 的資料量。
17.5.4 移除 OSD #
若要從執行中叢集的 CRUSH 地圖中移除 OSD,請執行以下指令:
cephuser@adm > ceph osd crush remove OSD_NAME17.5.5 新增桶 #
若要新增桶至執行中叢集的 CRUSH 地圖,請執行 ceph osd crush add-bucket 指令:
cephuser@adm > ceph osd crush add-bucket BUCKET_NAME BUCKET_TYPE17.5.6 移動桶 #
若要將某個桶移至 CRUSH 地圖階層中的不同位置,請執行以下指令:
cephuser@adm > ceph osd crush move BUCKET_NAME BUCKET_TYPE=BUCKET_NAME [...]例如:
cephuser@adm > ceph osd crush move bucket1 datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-117.5.7 移除桶 #
若要從 CRUSH 地圖階層中移除某個桶,請執行以下指令:
cephuser@adm > ceph osd crush remove BUCKET_NAME從 CRUSH 階層中只能移除空的桶。
17.6 整理放置群組 #
除了為物件建立多個複本外,Ceph 還可透過整理放置群組來確保資料完整性
(請參閱Book “部署指南”, Chapter 1 “SES 和 Ceph”, Section 1.3.2 “放置群組”以瞭解有關放置群組的詳細資訊)。Ceph
的整理類似於在物件儲存層上執行 fsck。對於每個放置群組,Ceph
都會產生一個包含所有物件的目錄,並比較每個主要物件及其複本,以確定不會有遺失或不相符的物件。每天的淺層整理會檢查物件大小和屬性,而每週的深層整理則會讀取資料,並使用檢查總數來確保資料完整性。
整理對於維護資料完整性非常重要,但該操作可能會降低效能。您可以透過調整以下設定來增加或減少整理操作:
osd max scrubs同時針對一個 Ceph OSD 執行的整理操作數量上限。預設值為 1。
osd scrub begin hour、osd scrub end hour依小時定義的一天內可以執行整理的時間段 (0 到 24)。預設開始時間為 0,結束時間為 24。
重要如果放置群組的整理間隔超出
osd scrub max interval設定的值,則無論您定義的整理時間段為何,都將執行整理。osd scrub during recovery允許復原期間執行整理。若將此選項設定為「false」,則當有復原程序處於使用中狀態時,將禁止排程新的整理。已在執行的整理將繼續執行。此選項有助於降低忙碌叢集上的負載。預設值為「true」。
osd scrub thread timeout整理線串逾時前的最長時間 (以秒計)。預設值為 60。
osd scrub finalize thread timeout整理完成線串逾時前的最長時間 (以秒計)。預設值為 60*10。
osd scrub load threshold正常化的最大負載。當系統負載 (由
getloadavg ()與online cpus數量之比定義) 高於此數字時,Ceph 將不會執行整理。預設值為 0.5。osd scrub min interval當 Ceph 叢集負載較低時,整理 Ceph OSD 的最短間隔 (以秒計)。預設值為 60*60*24 (一天一次)。
osd scrub max interval無論叢集負載如何都整理 Ceph OSD 的最長間隔 (以秒計)。預設值為 7*60*60*24 (一週一次)。
osd scrub chunk min單次操作期間要整理的物件儲存區塊數量下限。整理期間,Ceph 會阻止向單個區塊寫入資料。預設值為 5。
osd scrub chunk max單次操作期間要整理的物件儲存區塊數量上限。預設值為 25。
osd scrub sleep整理下一組區塊之前睡眠的時間。增大此值會降低整個整理操作的速度,但對用戶端操作的影響較小。預設值為 0。
osd deep scrub interval深層整理 (完整讀取所有資料) 的間隔。
osd scrub load threshold選項不會影響此設定。預設值為 60*60*24*7 (一週一次)。osd scrub interval randomize ratio在排程放置群組的下一次整理工作時,為
osd scrub min interval值新增一個隨機延遲。該延遲為一個隨機的值,小於osd scrub min interval*osd scrub interval randomized ratio所得結果。因此,該預設設定實際上是將整理隨機地排程在允許的時間範圍 [1, 1.5] *osd scrub min interval內執行。預設值為 0.5。osd deep scrub stride執行深層整理時讀取的大小。預設值為 524288 (512 kB)。
18 管理儲存池 #
Ceph 將資料儲存在池中。池是用於儲存物件的邏輯群組。如果您先部署叢集而不建立池,Ceph 會使用預設池來儲存資料。下面著重指出與 Ceph 池有關的重要特性:
復原能力:Ceph 池透過複製或編碼其中包含的資料來提供復原能力。可將每個池設定為
replicated或erasure coding。對於複本池,您可以進一步設定池中每個資料物件將擁有的複本數。可遺失的複本數 (OSD、CRUSH 桶/葉) 比複本數少一個。您可以使用糾刪碼設定k和m的值,其中k表示資料區塊的數量,m表示編碼區塊的數量。對於糾刪碼池,編碼區塊的數量決定了在不遺失資料的情況下可遺失的 OSD (CRUSH 桶/葉) 數量。放置群組:您可以設定池的放置群組數。一般的組態為每個 OSD 使用約 100 個放置群組,以提供最佳平衡而又不會耗費太多運算資源。設定多個池時,請務必將池和叢集做為整體進行考量,以確保設定合理的放置群組數。
CRUSH 規則:在池中儲存資料時,系統會依據對應至該池的 CRUSH 規則集來放置物件及其複本或區塊 (如果是糾刪碼池)。您可以為池建立自訂 CRUSH 規則。
快照:使用
ceph osd pool mksnap建立快照時,可高效建立特定池的快照。
若要將資料組織到池中,您可以列出、建立和移除池。您還可以檢視每個池的使用量統計資料。
18.1 建立池 #
可以建立 replicated (用於保留物件的多個複本,以便從遺失的 OSD 復原) 或
erasure (用於獲得通用 RAID 5 或 6 功能)
類型的池。複本池所需的原始儲存空間較多,而糾刪碼池所需的原始儲存空間較少。預設設定為
replicated。如需糾刪碼池的詳細資訊,請參閱第 19 章 「糾刪碼池」。
若要建立副本池,請執行以下指令:
cephuser@adm > ceph osd pool create POOL_NAME若要建立糾刪碼池,請執行以下指令:
cephuser@adm > ceph osd pool create POOL_NAME erasure CRUSH_RULESET_NAME \
EXPECTED_NUM_OBJECTS
如果超出了每個 OSD 的放置群組限制,則 ceph osd pool create 指令可能會失敗。使用
mon_max_pg_per_osd 選項可設定該限制。
- POOL_NAME
池的名稱,必須是唯一的。必須指定此選項。
- POOL_TYPE
池類型,可以是
replicated(用於保留物件的多個副本,以便從失敗的 OSD 復原) 或erasure(用於獲得某種通用 RAID5 功能)。副本池需要的原始儲存較多,但可實作所有 Ceph 操作。糾刪碼池需要的原始儲存較少,但僅實作部分可用的操作。預設POOL_TYPE設定為replicated。- CRUSH_RULESET_NAME
此池的 CRUSH 規則集名稱。如果所指定的規則集不存在,則建立複本池的操作將會失敗,並顯示 -ENOENT。對於複本池,它是由
osd pool default CRUSH replicated ruleset組態變數指定的規則集。此規則集必須存在。對於糾刪碼池,如果使用預設糾刪碼設定檔,則規則集為「erasure-code」,否則為 POOL_NAME。如果此規則集尚不存在,系統將隱式建立該規則集。- erasure_code_profile=profile
僅適用於糾刪碼池。使用糾刪碼設定檔。該設定檔必須是
osd erasure-code-profile set所定義的現有設定檔。注意如果出於任何原因停用了池上的自動調整器 (
pg_autoscale_mode設定為 off),您可以手動計算和設定 PG 數量。如需計算池的適當放置群組數的詳細資料,請參閱第 17.4 節 「放置群組」。- EXPECTED_NUM_OBJECTS
此池的預期物件數。如果設定此值 (與一個為負數的
filestore merge threshold值),系統在建立池時會分割 PG 資料夾。這可避免因執行時期資料夾拆分導致的延遲影響。
18.2 列出池 #
若要列出叢集的池,請執行以下指令:
cephuser@adm > ceph osd pool ls18.3 重新命名池 #
若要重新命名池,請執行以下指令:
cephuser@adm > ceph osd pool rename CURRENT_POOL_NAME NEW_POOL_NAME如果重新命名了某個池,且為經過驗證的使用者使用了依池能力,則必須用新的池名稱更新使用者的能力。
18.4 刪除池 #
池中可能包含重要資料。刪除池會導致池中的所有資料消失,且無法復原。
不小心刪除池十分危險,因此 Ceph 實作了兩個機制來防止刪除池。若要刪除池,必須先停用這兩個機制。
第一個機制是 NODELETE
旗標。每個池都有這個旗標,其預設值為「false」。若要確定某個池的此旗標值,請執行以下指令:
cephuser@adm > ceph osd pool get pool_name nodelete
如果指令輸出 nodelete: true,則只有在使用以下指令變更該旗標後,才能刪除池:
cephuser@adm > ceph osd pool set pool_name nodelete false
第二個機制是叢集範圍的組態參數 mon allow pool
delete,其預設值為「false」。這表示預設不能刪除池。顯示的錯誤訊息是:
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
若要規避此安全設定以刪除池,可以暫時將 mon allow pool delete
設定為「true」,刪除池,然後將該參數恢復為「false」:
cephuser@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=truecephuser@adm >ceph osd pool delete pool_name pool_name --yes-i-really-really-mean-itcephuser@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=false
injectargs 指令會顯示以下訊息:
injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
這主要用於確認該指令已成功執行。它不是錯誤。
如果為您建立的池建立了自己的規則集和規則,則應該考慮在不再需要該池時移除規則集和規則。
18.5 其他操作 #
18.5.1 將池與應用程式關聯 #
在使用池之前,需要將它們與應用程式關聯。將與 CephFS 搭配使用或由物件閘道自動建立的池會自動相關聯。
對於其他情況,可以手動將自由格式的應用程式名稱與池關聯:
cephuser@adm > ceph osd pool application enable POOL_NAME APPLICATION_NAME
CephFS 使用應用程式名稱 cephfs,RADOS 區塊裝置使用
rbd,物件閘道使用 rgw。
一個池可以與多個應用程式關聯,而每個應用程式都可具有自己的中繼資料。若要列出與池關聯的一個 (或多個) 應用程式,請發出以下指令:
cephuser@adm > ceph osd pool application get pool_name18.5.2 設定池定額 #
您可以設定池定額,限定每個池的最大位元組數和/或最大物件數。
cephuser@adm > ceph osd pool set-quota POOL_NAME MAX_OBJECTS OBJ_COUNT MAX_BYTES BYTES例如:
cephuser@adm > ceph osd pool set-quota data max_objects 10000若要移除定額,請將其值設定為 0。
18.5.3 顯示池統計資料 #
若要顯示池的使用量統計資料,請執行以下指令:
cephuser@adm > rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.rgw.root 768 KiB 4 0 12 0 0 0 44 44 KiB 4 4 KiB 0 B 0 B
cephfs_data 960 KiB 5 0 15 0 0 0 5502 2.1 MiB 14 11 KiB 0 B 0 B
cephfs_metadata 1.5 MiB 22 0 66 0 0 0 26 78 KiB 176 147 KiB 0 B 0 B
default.rgw.buckets.index 0 B 1 0 3 0 0 0 4 4 KiB 1 0 B 0 B 0 B
default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B 0 B 0 B
default.rgw.log 0 B 207 0 621 0 0 0 5372132 5.1 GiB 3579618 0 B 0 B 0 B
default.rgw.meta 961 KiB 6 0 18 0 0 0 155 140 KiB 14 7 KiB 0 B 0 B
example_rbd_pool 2.1 MiB 18 0 54 0 0 0 3350841 2.7 GiB 118 98 KiB 0 B 0 B
iscsi-images 769 KiB 8 0 24 0 0 0 1559261 1.3 GiB 61 42 KiB 0 B 0 B
mirrored-pool 1.1 MiB 10 0 30 0 0 0 475724 395 MiB 54 48 KiB 0 B 0 B
pool2 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
pool3 333 MiB 37 0 111 0 0 0 3169308 2.5 GiB 14847 118 MiB 0 B 0 B
pool4 1.1 MiB 13 0 39 0 0 0 1379568 1.1 GiB 16840 16 MiB 0 B 0 B各欄的描述如下:
- USED
池使用的位元組數。
- OBJECTS
池中儲存的物件數。
- CLONES
池中儲存的克隆數。如果在建立快照時某個用戶端向物件寫入資料,系統將會建立原始物件的克隆,而不是對該物件進行修改,這樣便不會修改已建立快照的原始物件內容。
- COPIES
物件複本的數量。例如,如果某個複製因數為 3 的複本池有「x」個物件,它通常將會有 3 * x 個複本。
- MISSING_ON_PRIMARY
當主 OSD 上的複本缺失時,處於降級狀態 (不是所有複本都存在) 的物件的數量。
- UNFOUND
未找到的物件數。
- DEGRADED
已降級的物件數。
- RD_OPS
針對此池要求的讀取操作總數。
- RD
從此池讀取的位元組總數。
- WR_OPS
針對此池要求的寫入操作總數。
- WR
寫入池的位元組總數。請注意,該數值與池的使用率不同,因為您可能會多次寫入同一物件。如此一來,池的使用率雖然不變,但寫入池的位元組數會增長。
- USED COMPR
為壓縮資料配置的位元組數。
- UNDER COMPR
壓縮資料在未壓縮時佔用的位元組數。
18.5.4 獲取池值 #
若要從池中獲取值,請執行以下 get 指令:
cephuser@adm > ceph osd pool get POOL_NAME KEY您可以獲取第 18.5.5 節 「設定池值」中所列鍵以及下列鍵的值:
- PG_NUM
池的放置群組數。
- PGP_NUM
計算資料放置時要使用的放置群組的有效數量。有效範圍等於或小於
PG_NUM。
若要列出與特定池相關的所有值,請執行以下指令:
cephuser@adm > ceph osd pool get POOL_NAME all18.5.5 設定池值 #
若要設定池的值,請執行以下指令:
cephuser@adm > ceph osd pool set POOL_NAME KEY VALUE以下是依據池類型排序的池值清單:
- crash_replay_interval
允許用戶端重送已確認但未提交的要求的秒數。
- pg_num
池的放置群組數。如果您將新 OSD 新增至叢集,請確認所有池上專用於新 OSD 的放置群組的值。
- pgp_num
計算資料放置時要使用的放置群組的有效數量。
- crush_ruleset
用於在叢集中對應物件放置的規則集。
- hashpspool
為給定池設定 (1) 或取消設定 (0) HASHPSPOOL 旗標。啟用此旗標會變更演算法,以採用更佳的方式將 PG 分佈到 OSD 之間。對之前 HASHPSPOOL 旗標設為預設值 0 的池啟用此旗標後,叢集會開始回填,以使所有 PG 恢復正確的放置狀態。請注意,此操作可能會在叢集上產生大量 I/O 負載,因此請勿對負載較高的生產叢集啟用該旗標 (由 0 變更為 1)。
- nodelete
防止移除池。
- nopgchange
防止變更池的
pg_num和pgp_num。- noscrub、nodeep-scrub
停用 (深層) 整理特定池的資料,以解決暫時性的高 I/O 負載問題。
- write_fadvise_dontneed
在給定池的讀取/寫入要求上設定或取消設定
WRITE_FADVISE_DONTNEED旗標,以繞過將資料放入快取。預設值為false。適用於複本池和 EC 池。- scrub_min_interval
叢集負載低時整理池的最小間隔 (以秒計)。預設值
0表示使用來自 Ceph 組態檔案的osd_scrub_min_interval值。- scrub_max_interval
無論叢集負載如何都整理池的最大間隔 (以秒計)。預設值
0表示使用來自 Ceph 組態檔案的osd_scrub_max_interval值。- deep_scrub_interval
深層整理池的間隔 (以秒計)。預設值
0表示使用來自 Ceph 組態檔案的osd_deep_scrub值。
- size
設定池中物件的複本數。如需更多詳細資料,請參閱第 18.5.6 節 「設定物件複本數」。僅限副本池。
- min_size
設定 I/O 所需的最小複本數。如需更多詳細資料,請參閱第 18.5.6 節 「設定物件複本數」。僅限副本池。
- nosizechange
防止變更池的大小。建立池時,預設值取自
osd_pool_default_flag_nosizechange參數的值,預設設定為false。僅適用於複本池,因為無法變更 EC 池的大小。- hit_set_type
對快取池啟用命中集追蹤。請參閱布隆過濾器以瞭解更多資訊。此選項可用的值如下:
bloom、explicit_hash、explicit_object。預設值為bloom,其他值僅用於測試。- hit_set_count
要為快取池儲存的命中集數。該數值越高,
ceph-osd精靈耗用的 RAM 越多。預設值為0。- hit_set_period
快取池的命中集期間的時長 (以秒計)。該數值越高,
ceph-osd精靈耗用的 RAM 越多。建立池時,預設值取自osd_tier_default_cache_hit_set_period參數的值,預設設定為1200。僅適用於複本池,因為 EC 池不能做為快取層使用。- hit_set_fpp
布隆命中集類型的誤報率。請參閱布隆過濾器以瞭解更多資訊。有效範圍是 0.0 - 1.0,預設值為
0.05- use_gmt_hitset
為快取分層建立命中集時,強制 OSD 使用 GMT (格林威治標準時間) 時戳。這可確保在不同時區中的節點傳回相同的結果。預設值為
1。不應該變更此值。- cache_target_dirty_ratio
在快取分層代理程式將已修改 (髒) 物件衝洗到後備儲存池之前,包含此類物件的快取池百分比。預設值為
0.4。- cache_target_dirty_high_ratio
在快取分層代理程式將已修改 (髒) 物件衝洗到速度更快的後備儲存池之前,包含此類物件的快取池百分比。預設值為
0.6。- cache_target_full_ratio
在快取分層代理程式將未修改 (乾淨) 物件從快取池逐出之前,包含此類物件的快取池百分比。預設值為
0.8。- target_max_bytes
觸發
max_bytes閾值後,Ceph 將會開始衝洗或逐出物件。- target_max_objects
觸發
max_objects閾值後,Ceph 將會開始衝洗或逐出物件。- hit_set_grade_decay_rate
兩次連續的
hit_set之間的溫度降低率。預設值為20。- hit_set_search_last_n
計算溫度時在
hit_set中對出現的項最多計N次。預設值為1。- cache_min_flush_age
在快取分層代理程式將物件從快取池衝洗到儲存池之前的時間 (以秒計)。
- cache_min_evict_age
在快取分層代理程式將物件從快取池中逐出之前的時間 (以秒計)。
- fast_read
如果對糾刪碼池啟用此旗標,則讀取要求會向所有分區發出子讀取指令,並一直等到接收到足夠解碼的分區,才會為用戶端提供服務。對於 jerasure 和 isa 糾刪外掛程式,前
K個複本傳回時,就會使用從這些複本解碼的資料立即處理用戶端的要求。採用此方法會產生較高的 CPU 負載,而磁碟/網路負載則較低。目前,此旗標僅支援用於糾刪碼池。預設值為0。
18.5.6 設定物件複本數 #
若要設定副本池上的物件複本數,請執行以下指令:
cephuser@adm > ceph osd pool set poolname size num-replicasnum-replicas 包括物件自身。例如,如果您想用物件和物件的兩個複本組成物件的三個例項,請指定 3。
如果將 num-replicas 設定為 2,資料將只有一個副本。例如,如果一個物件例項發生故障,則需要在復原期間確定自上次整理後,另一個複本沒有損毀 (如需詳細資料,請參閱第 17.6 節 「整理放置群組」)。
將池設定為具有一個複本意味著池中的資料物件只有一個例項。如果 OSD 發生故障,您將遺失資料。若要短時間儲存臨時資料,可能就會用到只有一個副本的池。
為池設定 4 個複本可將可靠性提高 25%。
如果有兩個資料中心,您至少需要為池設定 4 個複本,使每個資料中心都有兩個複本。如此,當其中一個資料中心發生故障時,仍有兩個複本存在,並且如果又有一個磁碟發生故障,您仍可確保不會遺失資料。
物件可接受降級模式下複本數量低於 pool size 的 I/O。若要設定 I/O
所需複本的最小數量,您應該使用 min_size 設定。例如:
cephuser@adm > ceph osd pool set data min_size 2
這可確保資料池中沒有物件會接收到複本數量低於 min_size 的 I/O。
若要獲取物件複本數,請執行以下指令:
cephuser@adm > ceph osd dump | grep 'replicated size'
Ceph 將列出池,並反白顯示 replicated size 屬性。Ceph 預設會建立物件的兩個複本
(共三個副本,或者大小為 3)。
18.6 池移轉 #
建立池 (請參閱第 18.1 節 「建立池」) 時,您需要指定池的初始參數,例如池類型或放置群組數量。如果您稍後決定變更其中的任一參數 (例如將複本池轉換為糾刪碼池,或者減少放置群組數量),您需要將池資料移轉至參數適合您的部署的另一個池。
本節介紹兩種移轉方法:用於一般池資料移轉的快取層方法,以及使用 rbd
migrate 子指令將 RBD 影像移轉至新池的方法。每種方法都包含特定設定和限制。
18.6.1 限制 #
您可以使用快取層方法,從複本池移轉至 EC 池或另一個複本池。不支援從 EC 池移轉。
您無法將 RBD 影像和 CephFS 輸出從複本池移轉至糾刪碼池。原因是 EC 池不支援
omap,而 RBD 和 CephFS 會使用omap來儲存其中繼資料。例如,系統將無法衝洗 RBD 的標題物件。但您可以將資料移轉至 EC 池,而將中繼資料保留在複本池中。使用
rbd migration方法可確保在移轉影像時最大限度地減少用戶端停機時間。您只需在prepare步驟之前停止用戶端,在此之後再將其啟動。請注意,只有支援此功能的librbd用戶端 (Ceph Nautilus 或更新版本) 才能在prepare步驟之後開啟影像,而較舊的librbd用戶端或krbd用戶端在執行commit步驟之前將無法開啟影像。
18.6.2 使用快取層移轉 #
該方法的原理十分簡單,只需將需要移轉的池依相反的順序加入快取層中即可。下面是將名為「testpool」的複本池移轉至糾刪碼池的範例:
建立一個名為「newpool」的新糾刪碼池。如需池建立參數的詳細說明,請參閱第 18.1 節 「建立池」。
cephuser@adm >ceph osd pool create newpool erasure default確認使用的用戶端金鑰圈所提供的針對「newpool」的功能至少與針對「testpool」的相同。
您現在有兩個池,即填滿資料的原始副本池「testpool」和新的空白糾刪碼池「newpool」:
 圖 18.1︰ 移轉前的池 #
圖 18.1︰ 移轉前的池 #設定快取層,並將複本池「testpool」設定為快取池。透過使用
-force-nonempty選項,即使池已有資料,您也可以新增快取層:cephuser@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=1'cephuser@adm >ceph osd tier add newpool testpool --force-nonemptycephuser@adm >ceph osd tier cache-mode testpool proxy 圖 18.2︰ 快取層設定 #
圖 18.2︰ 快取層設定 #強制快取池將所有物件移到新池中:
cephuser@adm >rados -p testpool cache-flush-evict-all 圖 18.3︰ 資料衝洗 #
圖 18.3︰ 資料衝洗 #您需要指定一個重疊層,以便在舊池中搜尋物件,直到所有資料都已衝洗到新的糾刪碼池。
cephuser@adm >ceph osd tier set-overlay newpool testpool有了重疊層,所有操作都會轉到舊的副本池「testpool」:
 圖 18.4︰ 設定重疊層 #
圖 18.4︰ 設定重疊層 #現在,您可以將所有用戶端都切換為存取新池中的物件。
所有資料都移轉至糾刪碼池「newpool」後,移除重疊層和舊快取池「testpool」:
cephuser@adm >ceph osd tier remove-overlay newpoolcephuser@adm >ceph osd tier remove newpool testpool 圖 18.5︰ 完成移轉 #
圖 18.5︰ 完成移轉 #執行
cephuser@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=0'
18.6.3 移轉 RBD 影像 #
建議採用如下方式將 RBD 影像從一個複本池移轉至另一個複本池。
禁止用戶端 (例如虛擬機器) 存取 RBD 影像。
在目標池中建立新影像,並將其父項設定為來源影像:
cephuser@adm >rbd migration prepare SRC_POOL/IMAGE TARGET_POOL/IMAGE提示:僅將資料移轉至糾刪碼池如果您只需將影像資料移轉至新的 EC 池,而將中繼資料保留在原始複本池中,請改為執行以下指令:
cephuser@adm >rbd migration prepare SRC_POOL/IMAGE \ --data-pool TARGET_POOL/IMAGE讓用戶端存取目標池中的影像。
將資料移轉至目標池:
cephuser@adm >rbd migration execute SRC_POOL/IMAGE移除舊影像:
cephuser@adm >rbd migration commit SRC_POOL/IMAGE
18.7 池快照 #
池快照是整個 Ceph 池的狀態快照。透過池快照,您可以保留池狀態的歷程。建立池快照會佔用與池大小成正比的儲存空間。在建立池快照之前,請務必檢查相關儲存是否有足夠的磁碟空間。
18.7.1 建立池快照 #
若要建立池快照,請執行以下指令:
cephuser@adm > ceph osd pool mksnap POOL-NAME SNAP-NAME例如:
cephuser@adm > ceph osd pool mksnap pool1 snap1
created pool pool1 snap snap118.7.2 列出池快照 #
若要列出池的現有快照,請執行以下指令:
cephuser@adm > rados lssnap -p POOL_NAME例如:
cephuser@adm > rados lssnap -p pool1
1 snap1 2018.12.13 09:36:20
2 snap2 2018.12.13 09:46:03
2 snaps18.7.3 移除池快照 #
若要移除池的某個快照,請執行以下指令:
cephuser@adm > ceph osd pool rmsnap POOL-NAME SNAP-NAME18.8 資料壓縮 #
BlueStore (如需更多詳細資料,請參閱Book “部署指南”, Chapter 1 “SES 和 Ceph”, Section 1.4 “BlueStore”) 提供即時資料壓縮,以節省磁碟空間。壓縮率取決於系統中儲存的資料。請注意,壓縮/解壓縮需要額外的 CPU 資源。
您可以全域設定資料壓縮 (請參閱第 18.8.3 節 「全域壓縮選項」),然後覆寫每個個別池的特定壓縮設定。
無論池是否包含資料,您都可以啟用或停用池資料壓縮,或者隨時變更壓縮演算法和模式。
啟用池壓縮之後,將不會向現有資料套用壓縮。
停用某個池的壓縮之後,將會解壓縮該池的所有資料。
18.8.1 啟用壓縮 #
若要對名為 POOL_NAME 的池啟用資料壓縮,請執行以下指令:
cephuser@adm >cephosd pool set POOL_NAME compression_algorithm COMPRESSION_ALGORITHMcephuser@adm >cephosd pool set POOL_NAME compression_mode COMPRESSION_MODE
若要對池停用資料壓縮,請使用「none」壓縮演算法:
cephuser@adm >cephosd pool set POOL_NAME compression_algorithm none
18.8.2 池壓縮選項 #
完整的壓縮設定清單:
- compression_algorithm
可用的值有
none、zstd、snappy。預設值為snappy。使用的壓縮演算法取決於特定使用案例。以下是一些相關的建議:
只要您沒有充分的理由變更預設值
snappy,就請使用該值。zstd可提供較佳的壓縮率,但當壓縮少量資料時,會導致 CPU 負擔較高。針對實際資料的樣本執行這些演算法的基準測試,同時觀察叢集的 CPU 和記憶體使用率。
- compression_mode
可用的值有
none、aggressive、passive、force。預設值為none。none:永不壓縮passive:如果提示COMPRESSIBLE,則壓縮aggressive:除非提示INCOMPRESSIBLE,才壓縮force:永遠都壓縮
- compression_required_ratio
值:雙精度浮點數,比率 = SIZE_COMPRESSED / SIZE_ORIGINAL。預設值為
0.875,這表示如果壓縮未將佔用空間至少減少 12.5%,將不會壓縮物件。由於淨增益低,儲存高於此比率的物件時不會壓縮。
- compression_max_blob_size
值:不帶正負號的整數,大小以位元組計。預設值:
0所壓縮物件的最大大小。
- compression_min_blob_size
值:不帶正負號的整數,大小以位元組計。預設值:
0所壓縮物件的最小大小。
18.8.3 全域壓縮選項 #
可在 Ceph 組態中設定以下組態選項,並將其套用於所有 OSD 而不僅僅是單個池。第 18.8.2 節 「池壓縮選項」中列出的池特定組態優先。
- bluestore_compression_algorithm
- bluestore_compression_mode
請參閱 compression_mode
- bluestore_compression_required_ratio
- bluestore_compression_min_blob_size
值:不帶正負號的整數,大小以位元組計。預設值:
0所壓縮物件的最小大小。系統預設會忽略該設定,並使用
bluestore_compression_min_blob_size_hdd和bluestore_compression_min_blob_size_ssd的值。如果設定為非零值,則該設定優先。- bluestore_compression_max_blob_size
值:不帶正負號的整數,大小以位元組計。預設值:
0在將物件分割為更小的區塊之前,所壓縮物件的大小上限。系統預設會忽略該設定,並使用
bluestore_compression_max_blob_size_hdd和bluestore_compression_max_blob_size_ssd的值。如果設定為非零值,則該設定優先。- bluestore_compression_min_blob_size_ssd
值:不帶正負號的整數,大小以位元組計。預設值:
8K壓縮並儲存在固態硬碟上的物件的最小大小。
- bluestore_compression_max_blob_size_ssd
值:不帶正負號的整數,大小以位元組計。預設值:
64K在將物件分割為更小的區塊之前,在固態硬碟上壓縮並儲存的物件的大小上限。
- bluestore_compression_min_blob_size_hdd
值:不帶正負號的整數,大小以位元組計。預設值:
128K壓縮並儲存在普通硬碟上的物件的最小大小。
- bluestore_compression_max_blob_size_hdd
值:不帶正負號的整數,大小以位元組計。預設值:
512K在將物件分割為更小的區塊之前,在硬碟上壓縮並儲存的物件的大小上限。
19 糾刪碼池 #
Ceph 提供了一種在池中正常複製資料的替代方案,稱為糾刪池或糾刪碼池。糾刪碼池不能提供複本池的所有功能 (例如,它們無法儲存 RBD 池的中繼資料),但其所需的原始儲存空間更少。一個能夠儲存 1 TB 資料的預設糾刪碼池需要 1.5 TB 的原始儲存空間,以應對發生單個磁碟故障的情況。從這方面而言,糾刪碼池優於複本池,因為後者需要 2 TB 的原始儲存空間才能實現相同目的。
如需糾刪碼的背景資訊,請參閱 https://en.wikipedia.org/wiki/Erasure_code。
如需 EC 池相關的池值清單,請參閱糾刪碼池值。
19.1 糾刪碼池的先決條件 #
若要使用糾刪碼,您需要:
在 CRUSH 地圖中定義糾刪碼規則。
定義用於指定要使用的編碼演算法的糾刪碼設定檔。
建立使用上述規則和設定檔的池。
請記住,一旦建立好池且池中包含資料,便無法變更設定檔和設定檔中的詳細資料。
確定糾刪池的 CRUSH 規則對 step 使用
indep。如需詳細資料,請參閱第 17.3.2 節 「firstn 和 indep」。
19.2 建立範例糾刪碼池 #
最簡單的糾刪碼池相當於 RAID5,至少需要三個主機。以下程序介紹如何建立用於測試的池。
ceph osd pool create指令用於建立類型為糾刪的池。12表示放置群組的數量。使用預設參數時,該池能夠處理一個 OSD 的故障。cephuser@adm >ceph osd pool create ecpool 12 12 erasure pool 'ecpool' created字串
ABCDEFGHI將寫入名為NYAN的物件。cephuser@adm >echo ABCDEFGHI | rados --pool ecpool put NYAN -為了進行測試,現在可以停用 OSD,例如,透過斷開其網路連接來停用。
若要測試該池是否可以處理多部裝置發生故障的情況,可以使用
rados指令來存取檔案的內容。cephuser@adm >rados --pool ecpool get NYAN - ABCDEFGHI
19.3 糾刪碼設定檔 #
呼叫 ceph osd pool create
指令來建立糾刪池時,除非指定了其他設定檔,否則會使用預設的設定檔。設定檔定義資料備援。若要進行此定義,可以設定隨意命名為
k 和 m 的兩個參數。k 和 m
定義要將資料片段拆分成多少個區塊,以及要建立多少個編碼區塊。之後,備援區塊即會儲存在不同的 OSD 上。
糾刪池設定檔所需的定義:
- chunk
如果呼叫該編碼函數,它會傳回相同大小的區塊:可串連起來以重新建構原始物件的資料區塊,以及可用於重建所遺失區塊的編碼區塊。
- k
資料區塊的數量,即要將原始物件分割成的區塊數量。例如,如果
k = 2,則會將一個 10 kB 物件分割成各為 5 kB 的k個物件。糾刪碼池的預設min_size為k + 1。不過,我們建議將min_size設定為k + 2或更大的值,以避免寫入操作和資料遺失。- m
編碼區塊的數量,即編碼函數運算的額外區塊數量。如果有 2 個編碼區塊,則表示可以移出 2 個 OSD,而不會遺失資料。
- crush-failure-domain
定義要將區塊分佈到的裝置。其值需要設定為某個桶類型。如需所有的桶類型,請參閱第 17.2 節 「桶」。如果故障網域為
機櫃,則會將區塊儲存在不同的機櫃上,以提高機櫃發生故障時的復原能力。請記住,這需要 k+m 個機架。
使用第 19.2 節 「建立範例糾刪碼池」中所用的預設糾刪碼設定檔時,如果單個 OSD 或主機發生故障,叢集資料將不會遺失。因此,若要儲存 1 TB 資料,需要額外提供 0.5 TB 原始儲存空間。也就是說,需要 1.5 TB 原始儲存空間才能儲存 1 TB 資料 (因為 k=2、m=1)。這相當於常見的 RAID 5 組態。做為對比,複本池需要 2 TB 原始儲存空間才能儲存 1 TB 資料。
可使用以下指令來顯示預設設定檔的設定:
cephuser@adm > ceph osd erasure-code-profile get default
directory=.libs
k=2
m=1
plugin=jerasure
crush-failure-domain=host
technique=reed_sol_van選擇適當的設定檔非常重要,因為在建立池後便無法修改設定檔。需要建立使用不同設定檔的新池,並將之前的池中的所有物件移到新池 (請參閱第 18.6 節 「池移轉」)。
設定檔最重要的幾個參數是 k、m 和
crush-failure-domain,因為它們定義儲存負擔和資料持久性。例如,如果在兩個機架發生故障並且儲存負擔達到
66% 的情況下,必須能夠維繫所需的架構,您可定義以下設定檔。請注意,這僅適用於擁有「rack」類型的桶的 CRUSH 地圖:
cephuser@adm > ceph osd erasure-code-profile set myprofile \
k=3 \
m=2 \
crush-failure-domain=rack對於此新設定檔,可以重複第 19.2 節 「建立範例糾刪碼池」中的範例:
cephuser@adm >ceph osd pool create ecpool 12 12 erasure myprofilecephuser@adm >echo ABCDEFGHI | rados --pool ecpool put NYAN -cephuser@adm >rados --pool ecpool get NYAN - ABCDEFGHI
NYAN 物件將分割成三個 (k=3),並將建立兩個額外的區塊
(m=2)。m 值定義可以同時遺失多少個 OSD
而不會遺失任何資料。crush-failure-domain=rack 將建立一個 CRUSH
規則集,用於確保不會將兩個區塊儲存在同一個機櫃中。

19.3.1 建立新糾刪碼設定檔 #
以下指令可建立新糾刪碼設定檔:
root # ceph osd erasure-code-profile set NAME \
directory=DIRECTORY \
plugin=PLUGIN \
stripe_unit=STRIPE_UNIT \
KEY=VALUE ... \
--force- DIRECTORY
選擇性。設定從中載入糾刪碼外掛程式的目錄名稱。預設為
/usr/lib/ceph/erasure-code。- PLUGIN
選擇性。使用糾刪碼外掛程式可計算編碼區塊和復原遺失的區塊。可用的外掛程式有「jerasure」、「isa」、「lrc」和「shes」。預設為「jerasure」。
- STRIPE_UNIT
選擇性。資料區塊中每個分割區的資料量。例如,如果設定檔有 2 個資料區塊,且 stripe_unit 等於 4K,則系統會將範圍 0-4K 的資料置於區塊 0 中,將 4K-8K 置於區塊 1 中,然後再將 8K-12K 置於區塊 0 中。需要有多個 4K 才能實現最佳效能。預設值取自建立池時的監控程式組態選項
osd_pool_erasure_code_stripe_unit。使用此設定檔的池的「stripe_width」等於資料區塊的數量乘以此「stripe_unit」。- KEY=VALUE
選定糾刪碼外掛程式特定的選項鍵值組。
- --force
選擇性。覆寫名稱相同的現有設定檔,並允許設定不依 4K 對齊的 stripe_unit。
19.3.2 移除糾刪碼設定檔 #
以下指令可依 NAME 所識別的糾刪碼設定檔移除相應設定檔:
root # ceph osd erasure-code-profile rm NAME如果某個池參考了該設定檔,則刪除將會失敗。
19.3.3 顯示糾刪碼設定檔的詳細資料 #
以下指令可依 NAME 所識別的糾刪碼設定檔顯示其詳細資料:
root # ceph osd erasure-code-profile get NAME19.3.4 列出糾刪碼設定檔 #
以下指令可列出所有糾刪碼設定檔的名稱:
root # ceph osd erasure-code-profile ls19.4 標示含 RADOS 區塊裝置的糾刪碼池 #
若要將 EC 池標示為 RBD 池,請對其進行相應標記:
cephuser@adm > ceph osd pool application enable rbd ec_pool_nameRBD 可在 EC 池中儲存影像資料。但是,影像標題和中繼資料仍需要儲存在複本池中。為此,假設您的池命名為「rbd」:
cephuser@adm > rbd create rbd/image_name --size 1T --data-pool ec_pool_name您可以如同使用任何其他影像一般正常使用該影像,只不過所有資料都將儲存在 ec_pool_name 池而非「rbd」池中。
20 RADOS 區塊裝置 #
一個區塊就是由若干位元組組成的序列,例如 4 MB 的資料區塊。區塊式儲存介面是使用旋轉媒體 (例如硬碟、CD、軟碟) 儲存資料最常見的方式。區塊裝置介面的普及,也使得虛擬區塊裝置成為與大量資料儲存系統 (例如 Ceph) 進行互動的理想選擇。
Ceph 區塊裝置允許共用實體資源,並且可以調整大小。它們會將儲存資料在 Ceph 叢集中的多個 OSD 上進行分割。Ceph 區塊裝置會利用 RADOS
功能,例如建立快照、複製和一致性。Ceph 的 RADOS 區塊裝置 (RBD) 使用核心模組或
librbd 程式庫與 OSD 互動。

Ceph 的區塊裝置為核心模組提供高效能及無限的延展性。它們支援虛擬化解決方案 (例如 QEMU),或依賴於
libvirt 的雲端運算系統 (例如
OpenStack)。您可以使用同一個叢集來同時操作物件閘道、CephFS 和 RADOS 區塊裝置。
20.1 區塊裝置指令 #
使用 rbd
指令可建立、列出、內省和移除區塊裝置影像。您還可以使用它來執行其他操作,例如,複製影像、建立快照、將影像復原到快照,或檢視快照。
20.1.1 在複本池中建立區塊裝置影像 #
將區塊裝置新增至用戶端之前,您需要在現有池中建立一個相關的影像 (請參閱第 18 章 「管理儲存池」):
cephuser@adm > rbd create --size MEGABYTES POOL-NAME/IMAGE-NAME例如,若要建立名為「myimage」的 1 GB 影像,並使其將資訊儲存在名為「mypool」的池中,請執行以下指令:
cephuser@adm > rbd create --size 1024 mypool/myimage如果您省略了大小單位捷徑 (「G」或「T」),影像大小將以百萬位元組計。請在大小數值之後使用「G」或「T」來指定十億位元組或兆位元組。
20.1.2 在糾刪碼池中建立區塊裝置影像 #
可以將區塊裝置影像的資料直接儲存在糾刪碼 (EC) 池中。RADOS
區塊裝置影像由資料和中繼資料兩部分組成。您只能將 RADOS
區塊裝置影像的資料部分儲存在 EC 池中。若要這麼做,池的 overwrite 旗標需要設定為
true,並且用於儲存池的所有 OSD 都必須使用 BlueStore。
不能將影像的中繼資料部分儲存在 EC 池中。您可以使用 rbd create 指令的
--pool= 選項指定用於儲存影像中繼資料的複本池,也可以將 pool/
指定為影像名稱字首。
建立 EC 池:
cephuser@adm >ceph osd pool create EC_POOL 12 12 erasurecephuser@adm >ceph osd pool set EC_POOL allow_ec_overwrites true
指定用於儲存中繼資料的複本池:
cephuser@adm > rbd create IMAGE_NAME --size=1G --data-pool EC_POOL --pool=POOL或:
cephuser@adm > rbd create POOL/IMAGE_NAME --size=1G --data-pool EC_POOL20.1.3 列出區塊裝置影像 #
若要列出名為「mypool」的池中的區塊裝置,請執行以下指令:
cephuser@adm > rbd ls mypool20.1.4 擷取影像資訊 #
若要從名為「mypool」的池內的影像「myimage」擷取資訊,請執行以下指令:
cephuser@adm > rbd info mypool/myimage20.1.5 調整區塊裝置影像的大小 #
RADOS 區塊裝置影像是簡易佈建的 — 在您開始將資料儲存到這些影像之前,它們實際上並不會使用任何實體儲存。但是,這些影像具有您使用
--size 選項設定的最大容量。如果您要增大 (或減小) 影像的最大大小,請執行以下指令:
cephuser@adm >rbd resize --size 2048 POOL_NAME/IMAGE_NAME # to increasecephuser@adm >rbd resize --size 2048 POOL_NAME/IMAGE_NAME --allow-shrink # to decrease
20.1.6 移除區塊裝置影像 #
若要移除「mypool」池內的影像「myimage」所對應的區塊裝置,請執行以下指令:
cephuser@adm > rbd rm mypool/myimage20.2 掛接和卸載 #
建立 RADOS 區塊裝置之後,便可以像任何其他磁碟裝置一般使用它:進行格式化、將其掛接以便能夠交換檔案,以及在完成時將其卸載。
rbd 指令預設使用 Ceph admin
使用者帳戶存取叢集。此帳戶擁有叢集的完整管理存取權。這會帶來導致損害的意外風險,類似於以
root 身分登入 Linux
工作站之類。因此,最好建立具有較少權限的使用者帳戶,並將這些帳戶用於正常的讀取/寫入 RADOS 區塊裝置存取。
20.2.1 建立 Ceph 使用者帳戶 #
若要建立擁有 Ceph 管理員、Ceph 監控程式和 Ceph OSD 能力的新使用者帳戶,請將 ceph
指令與 auth get-or-create 子指令結合使用:
cephuser@adm > ceph auth get-or-create client.ID mon 'profile rbd' osd 'profile profile name \
[pool=pool-name] [, profile ...]' mgr 'profile rbd [pool=pool-name]'例如,若要建立一個名為 qemu 的使用者,該使用者擁有對池 vms 的讀取寫入存取權以及對池 images 的唯讀存取權,請執行以下指令:
ceph auth get-or-create client.qemu mon 'profile rbd' osd 'profile rbd pool=vms, profile rbd-read-only pool=images' \ mgr 'profile rbd pool=images'
ceph auth get-or-create 指令的輸出將是指定使用者的金鑰圈,可將其寫入
/etc/ceph/ceph.client.ID.keyring。
使用 rbd 指令時,可以透過提供選擇性的 --id
ID 引數來指定使用者 ID。
如需管理 Ceph 使用者帳戶的更多詳細資料,請參閱第 30 章 「使用 cephx 進行驗證」。
20.2.2 使用者驗證 #
若要指定使用者名稱,請使用 --id
user-name。如果您使用
cephx 驗證,則還需要指定機密。該機密可能來自金鑰圈,或某個包含機密的檔案:
cephuser@adm > rbd device map --pool rbd myimage --id admin --keyring /path/to/keyring或
cephuser@adm > rbd device map --pool rbd myimage --id admin --keyfile /path/to/file20.2.3 準備 RADOS 區塊裝置以供使用 #
確定您的 Ceph 叢集的池中包含要對應的磁碟影像。假設池名為
mypool,影像名為myimage。cephuser@adm >rbd list mypool將影像對應至新的區塊裝置:
cephuser@adm >rbd device map --pool mypool myimage列出所有對應的裝置:
cephuser@adm >rbd device list id pool image snap device 0 mypool myimage - /dev/rbd0我們要使用的裝置是
/dev/rbd0。提示:RBD 裝置路徑您可以使用
/dev/rbd/POOL_NAME/IMAGE_NAME做為永久裝置路徑來取代/dev/rbdDEVICE_NUMBER。例如:/dev/rbd/mypool/myimage
在
/dev/rbd0裝置上建立 XFS 檔案系統:root #mkfs.xfs /dev/rbd0 log stripe unit (4194304 bytes) is too large (maximum is 256KiB) log stripe unit adjusted to 32KiB meta-data=/dev/rbd0 isize=256 agcount=9, agsize=261120 blks = sectsz=512 attr=2, projid32bit=1 = crc=0 finobt=0 data = bsize=4096 blocks=2097152, imaxpct=25 = sunit=1024 swidth=1024 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=0 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=8 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0以您的掛接點取代
/mnt,掛接裝置並檢查其是否正確掛接:root #mount /dev/rbd0 /mntroot #mount | grep rbd0 /dev/rbd0 on /mnt type xfs (rw,relatime,attr2,inode64,sunit=8192,...現在,您便可以將資料移入和移出裝置,就如同它是本地目錄一樣。
提示:增大 RBD 裝置的大小如果您發現 RBD 裝置的大小不再夠用,可以輕鬆增大大小。
增大 RBD 影像的大小,例如增大到 10GB。
cephuser@adm >rbd resize --size 10000 mypool/myimage Resizing image: 100% complete...done.擴充檔案系統以填入裝置的新大小:
root #xfs_growfs /mnt [...] data blocks changed from 2097152 to 2560000
當您存取完裝置後,可以將其取消對應並卸載。
cephuser@adm >rbd device unmap /dev/rbd0root #unmount /mnt
提供了 rbdmap 程序檔和
systemd 單位,以更加順暢地在開機後對應和掛接
RBD,並在關機前將其卸載。參閱第 20.2.4 節 「rbdmap:在開機時對應 RBD 裝置」。
20.2.4 rbdmap:在開機時對應 RBD 裝置 #
rbdmap 是一個外圍程序程序檔,可對一或多個 RBD 影像自動執行 rbd
map 和 rbd device unmap
操作。雖然您隨時都可以手動執行該程序檔,但其主要優勢是在開機時自動對應和掛接 RBD 影像 (以及在關機時卸載和取消對應),此操作由 Init
系統觸發。ceph-common 套件中隨附了一個
systemd 單位檔案
rbdmap.service 用於執行此操作。
該程序檔使用單個引數,可以是 map 或
unmap。使用任一引數時,該程序檔都會剖析組態檔案。它預設為
/etc/ceph/rbdmap,但可透過環境變數
rbdmapFILE 覆寫。該組態檔案的每一行相當於一個要對應或取消對應的 RBD 影像。
組態檔案採用以下格式:
image_specification rbd_options
image_specification池中影像的路徑。以 pool_name/image_name 格式指定。
rbd_options要傳遞給基礎
rbd device map指令的參數的選擇性清單。應該以逗號分隔的字串指定這些參數及其值,例如:PARAM1=VAL1,PARAM2=VAL2,...
該範例讓
rbdmap程序檔執行以下指令:cephuser@adm >rbd device map POOL_NAME/IMAGE_NAME --PARAM1 VAL1 --PARAM2 VAL2下面的範例中介紹了如何使用相應的金鑰指定使用者名稱和金鑰圈:
cephuser@adm >rbdmap device map mypool/myimage id=rbd_user,keyring=/etc/ceph/ceph.client.rbd.keyring
以 rbdmap map 形式執行時,該程序檔會剖析組態檔案,並且對於每個指定的 RBD
影像,它會嘗試先對應影像 (使用 rbd device map 指令),然後再掛接影像。
以 rbdmap unmap 形式執行時,將卸載並取消對應組態檔案中列出的影像。
rbdmap unmap-all 會嘗試卸載然後取消對應所有目前已對應的 RBD
影像,而不論它們是否列在組態檔案中。
如果成功,rbd device map 操作會將影像對應至
/dev/rbdX 裝置,此時會觸發 udev 規則,以建立易記的裝置名稱符號連結
/dev/rbd/pool_name/image_name,該連結指向實際對應的裝置。
為了使掛接和卸載成功,「易記的」裝置名稱在 /etc/fstab 中需有對應項。寫入 RBD 影像的
/etc/fstab 項目時,指定「noauto」(或「nofail」) 掛接選項。這可防止 Init
系統過早 (尚未出現有問題的裝置時) 嘗試掛接裝置,因為 rbdmap.service
一般在開機序列中相當靠後的時間觸發。
如需 rbd 選項的完整清單,請參閱 rbd 手冊頁
(man 8 rbd)。
如需 rbdmap 用法的範例,請參閱 rbdmap 手冊頁
(man 8 rbdmap)。
20.2.5 增大 RBD 裝置的大小 #
如果您發現 RBD 裝置的大小不再夠用,可以輕鬆增大大小。
增大 RBD 影像的大小,例如增大到 10GB。
cephuser@adm >rbd resize --size 10000 mypool/myimage Resizing image: 100% complete...done.擴充檔案系統以填入裝置的新大小。
root #xfs_growfs /mnt [...] data blocks changed from 2097152 to 2560000
20.3 快照 #
RBD 快照是 RADOS 區塊裝置影像的快照。透過快照,您可以保留影像狀態的歷程。Ceph
還支援快照分層,這可讓您輕鬆快捷地複製虛擬機器影像。Ceph 使用 rbd 指令和許多高階介面 (包括
QEMU、libvirt、OpenStack 和 CloudStack) 支援區塊裝置快照。
在建立影像的快照之前,請停止輸入和輸出操作,並衝洗所有待處理寫入操作。如果影像包含檔案系統,則在建立快照時,檔案系統必須處於一致狀態。
20.3.1 啟用和設定 cephx #
如果啟用了 cephx,則必須指定使用者名稱或
ID,以及包含使用者相應金鑰的金鑰圈的路徑。請參閱第 30 章 「使用 cephx 進行驗證」,以取得詳細資料。您還可以新增
CEPH_ARGS 環境變數,以免重新輸入以下參數。
cephuser@adm >rbd --id user-ID --keyring=/path/to/secret commandscephuser@adm >rbd --name username --keyring=/path/to/secret commands
例如:
cephuser@adm >rbd --id admin --keyring=/etc/ceph/ceph.keyring commandscephuser@adm >rbd --name client.admin --keyring=/etc/ceph/ceph.keyring commands
將使用者和機密新增至 CEPH_ARGS 環境變數,如此您便無需每次都輸入它們。
20.3.2 快照基礎知識 #
下面的程序展示如何在指令行上使用 rbd 指令來建立、列出和移除快照。
20.3.2.1 建立快照 #
若要使用 rbd 建立快照,請指定 snap create
選項、池名稱和影像名稱。
cephuser@adm >rbd --pool pool-name snap create --snap snap-name image-namecephuser@adm >rbd snap create pool-name/image-name@snap-name
例如:
cephuser@adm >rbd --pool rbd snap create --snap snapshot1 image1cephuser@adm >rbd snap create rbd/image1@snapshot1
20.3.2.2 列出快照 #
若要列出影像的快照,請指定池名稱和影像名稱。
cephuser@adm >rbd --pool pool-name snap ls image-namecephuser@adm >rbd snap ls pool-name/image-name
例如:
cephuser@adm >rbd --pool rbd snap ls image1cephuser@adm >rbd snap ls rbd/image1
20.3.2.3 復原快照 #
若要使用 rbd 復原快照,請指定 snap rollback
選項、池名稱、影像名稱和快照名稱。
cephuser@adm >rbd --pool pool-name snap rollback --snap snap-name image-namecephuser@adm >rbd snap rollback pool-name/image-name@snap-name
例如:
cephuser@adm >rbd --pool pool1 snap rollback --snap snapshot1 image1cephuser@adm >rbd snap rollback pool1/image1@snapshot1
將影像復原到快照意味著會使用快照中的資料覆寫目前版本的影像。執行復原所需的時間將隨影像大小的增加而延長。從快照複製較快,而從影像到快照的復原較慢,因此複製是恢復到先前存在狀態的慣用方法。
20.3.2.4 刪除快照 #
若要使用 rbd 刪除快照,請指定 snap rm
選項、池名稱、影像名稱和使用者名稱。
cephuser@adm >rbd --pool pool-name snap rm --snap snap-name image-namecephuser@adm >rbd snap rm pool-name/image-name@snap-name
例如:
cephuser@adm >rbd --pool pool1 snap rm --snap snapshot1 image1cephuser@adm >rbd snap rm pool1/image1@snapshot1
Ceph OSD 會以非同步方式刪除資料,因此刪除快照不能立即釋放磁碟空間。
20.3.2.5 清除快照 #
若要使用 rbd 刪除影像的所有快照,請指定 snap purge
選項和影像名稱。
cephuser@adm >rbd --pool pool-name snap purge image-namecephuser@adm >rbd snap purge pool-name/image-name
例如:
cephuser@adm >rbd --pool pool1 snap purge image1cephuser@adm >rbd snap purge pool1/image1
20.3.3 快照分層 #
Ceph 支援為一個區塊裝置快照建立多個寫入時複製 (COW) 克隆的功能。快照分層可讓 Ceph 區塊裝置用戶端能夠極快地建立影像。例如,您可以建立區塊裝置影像並將 Linux 虛擬機器寫入其中,然後建立影像的快照、保護快照,並建立您所需數量的「寫入時複製」複製品。快照是唯讀的,因此複製快照簡化了語意,如此可快速建立複製品。
下面的指令行範例中提到的「父」和「子」這兩個術語是指 Ceph 區塊裝置快照 (父) 和從快照複製的相應影像 (子)。
每個複製的影像 (子) 都儲存了對其父影像的參考,這可讓複製的影像開啟父快照並讀取其內容。
快照的 COW 複製品運作方式與任何其他 Ceph 區塊裝置影像完全相同。您可針對複製的影像執行讀取、寫入、複製和調整大小操作。系統對複製的影像沒有特殊限制。但是,快照的寫入時複製複製品會參考快照,因此您必須在複製快照之前保護快照。
--image-format 1
您無法為透過已取代的 rbd create --image-format 1 選項建立的影像建立快照。Ceph
僅支援克隆預設的 format 2 影像。
20.3.3.1 分層入門 #
Ceph 區塊裝置分層是一個簡單的過程。您必須有一個影像。您必須建立影像的快照。您必須保護快照。在您執行這些步驟之後,就可以開始複製快照了。
複製的影像具有對父快照的參考,並且包含池 ID、影像 ID 和快照 ID。包含池 ID 表示您可以將快照從一個池複製到另一個池中的影像。
影像範本:一種常見的區塊裝置分層使用案例是建立主影像和當成複製品範本使用的快照。例如,使用者可為 Linux 套裝作業系統 (如 SUSE Linux Enterprise Server) 建立影像並為它建立快照。使用者可以定期更新影像和建立新的快照 (例如,先執行
zypper ref && zypper patch,接著執行rbd snap create)。隨著影像日趨成熟,使用者可以複製任何一個快照。延伸的範本:更進階的使用案例包括延伸比基礎影像提供的資訊更多的範本影像。例如,使用者可以複製影像 (虛擬機器範本) 並安裝其他軟體 (例如,資料庫、內容管理系統或分析系統),然後建立延伸影像的快照,這個延伸影像可以如基礎影像一般更新。
範本池:使用區塊裝置分層的一種方法是建立包含主影像 (用做範本) 的池,然後建立這些範本的快照。之後,您便可以擴充使用者的唯讀特權,使他們可以複製快照,卻不能寫入池或在池中執行。
影像移轉/復原:使用區塊裝置分層的一種方法是將資料從一個池移轉或復原到另一個池。
20.3.3.2 保護快照 #
複製品會存取父快照。如果使用者意外刪除了父快照,則所有複製品都會損毀。為了防止資料遺失,您需要先保護快照,然後才能複製它。
cephuser@adm >rbd --pool pool-name snap protect \ --image image-name --snap snapshot-namecephuser@adm >rbd snap protect pool-name/image-name@snapshot-name
例如:
cephuser@adm >rbd --pool pool1 snap protect --image image1 --snap snapshot1cephuser@adm >rbd snap protect pool1/image1@snapshot1
您無法刪除受保護的快照。
20.3.3.3 克隆快照 #
若要複製快照,您需要指定父池、影像、快照、子池和影像名稱。您需要先保護快照,然後才能複製它。
cephuser@adm >rbd clone --pool pool-name --image parent-image \ --snap snap-name --dest-pool pool-name \ --dest child-imagecephuser@adm >rbd clone pool-name/parent-image@snap-name \ pool-name/child-image-name
例如:
cephuser@adm > rbd clone pool1/image1@snapshot1 pool1/image2您可以將快照從一個池複製到另一個池中的影像。例如,可以在一個池中將唯讀影像和快照做為範本維護,而在另一個池中維護可寫入複製品。
20.3.3.4 取消保護快照 #
您必須先取消保護快照,然後才能刪除它。另外,您無法刪除複製品所參考的快照。您需要先壓平快照的每個複製品,然後才能刪除快照。
cephuser@adm >rbd --pool pool-name snap unprotect --image image-name \ --snap snapshot-namecephuser@adm >rbd snap unprotect pool-name/image-name@snapshot-name
例如:
cephuser@adm >rbd --pool pool1 snap unprotect --image image1 --snap snapshot1cephuser@adm >rbd snap unprotect pool1/image1@snapshot1
20.3.3.5 列出快照的子項 #
若要列出快照的子項,請執行以下指令:
cephuser@adm >rbd --pool pool-name children --image image-name --snap snap-namecephuser@adm >rbd children pool-name/image-name@snapshot-name
例如:
cephuser@adm >rbd --pool pool1 children --image image1 --snap snapshot1cephuser@adm >rbd children pool1/image1@snapshot1
20.3.3.6 壓平克隆的影像 #
複製的影像會保留對父快照的參考。移除子複製品對父快照的參考時,可透過將資訊從快照複製到複製品,高效「壓平」影像。壓平複製品所需的時間隨快照大小的增加而延長。若要刪除快照,必須先壓平子影像。
cephuser@adm >rbd --pool pool-name flatten --image image-namecephuser@adm >rbd flatten pool-name/image-name
例如:
cephuser@adm >rbd --pool pool1 flatten --image image1cephuser@adm >rbd flatten pool1/image1
由於壓平的影像包含快照中的所有資訊,壓平的影像佔用的儲存空間將比分層複製品多。
20.4 RBD 影像鏡像 #
RBD 影像可以在兩個 Ceph 叢集之間以非同步方式鏡像。此功能有兩種模式:
- 基於記錄
此模式使用 RBD 記錄影像功能來確保叢集之間的複製在時間點和當機時保持一致。在修改實際影像之前,向 RBD 影像的每次寫入都會先記錄到關聯記錄中。
remote叢集將從記錄中讀取並向其本地影像複本重播更新。由於向 RBD 影像的每次寫入都將導致向 Ceph 叢集的兩次寫入,因此在使用 RBD 記錄影像功能時,預期寫入延遲將增加近一倍。- 基於快照
此模式使用定期排程或手動建立的 RBD 影像鏡像快照,以在叢集之間複製當機時保持一致的 RBD 影像。
remote叢集將決定兩個鏡像快照之間的任何資料或中繼資料更新,並將增量複製到影像的本地複本。利用 RBD fast-diff 影像功能,可以快速運算更新的資料區塊,而無需掃描完整的 RBD 影像。由於此模式不確保在時間點保持一致,因此在容錯移轉期間使用該模式之前,需要同步完整的快照增量。任何部分套用的快照增量都將復原到使用該模式前最後一個完全同步的快照。
基於對等叢集中的每個池設定鏡像。可以對池中特定影像子集進行設定,也可以設定為在僅使用基於記錄的鏡像時自動鏡像池中的所有影像。使用
rbd
指令來設定鏡像。rbd-mirror 精靈負責從
remote 對等叢集提取影像更新,並將它們套用於 local
叢集中的影像。
依據所需的複製需求,RBD 鏡像可以設定為單向或雙向複製:
- 單向複製
當資料僅會從主要叢集鏡像到次要叢集時,
rbd-mirror精靈僅在次要叢集上執行。- 雙向複製
當資料從一個叢集上的主要影像鏡像到另一個叢集上的非主要影像 (反之亦然) 時,
rbd-mirror精靈將在兩個叢集上執行。
rbd-mirror 精靈的每個例項需要能夠同時連接至
local 和 remote Ceph 叢集。例如,所有監控程式和 OSD
主機。此外,網路需要兩個資料中心之間具有足夠的頻寬來處理鏡像工作負載。
20.4.1 池組態 #
下面的程序展示如何使用 rbd 指令來執行設定鏡像的基本管理任務。在 Ceph 叢集中依池來設定鏡像。
您需要在兩個對等叢集上執行池組態步驟。為清楚起見,這些程序假設可從單部主機存取名為 local 和
remote 的兩個叢集。
如需如何連接到不同 Ceph 叢集的更多詳細資料,請參閱 rbd 手冊頁 (man 8
rbd)。
以下範例中的叢集名稱對應於同名 /etc/ceph/remote.conf 的 Ceph 組態檔案以及同名
/etc/ceph/remote.client.admin.keyring 的 Ceph 金鑰圈檔案。
20.4.1.1 在池上啟用鏡像 #
若要針對池啟用鏡像,請指定 mirror pool enable
子指令、池名稱和鏡像模式。鏡像模式可以是池或影像:
- pool
系統會鏡像啟用了記錄功能的池中的所有影像。
- image
需要針對每個影像明確啟用鏡像。如需詳細資訊,請參閱第 20.4.2.1 節 「啟用影像鏡像」。
例如:
cephuser@adm >rbd --cluster local mirror pool enable POOL_NAME poolcephuser@adm >rbd --cluster remote mirror pool enable POOL_NAME pool
20.4.1.2 停用鏡像 #
若要對池停用鏡像,請指定 mirror pool disable
子指令和池名稱。使用這種方法對池停用鏡像時,還會對已為其明確啟用鏡像的所有影像 (該池中) 停用鏡像。
cephuser@adm >rbd --cluster local mirror pool disable POOL_NAMEcephuser@adm >rbd --cluster remote mirror pool disable POOL_NAME
20.4.1.3 開機對等 #
為了使 rbd-mirror
精靈探查其對等叢集,需要將對等註冊到池,並需要建立使用者帳戶。此程序可以透過
rbd、mirror pool peer bootstrap
create 和 mirror pool peer bootstrap import
指令自動完成。
若要使用 rbd 手動建立新的開機記號,請指定 mirror pool peer
bootstrap create 指令、池名稱以及描述 local
叢集的選擇性易記站台名稱:
cephuser@local > rbd mirror pool peer bootstrap create \
[--site-name LOCAL_SITE_NAME] POOL_NAME
mirror pool peer bootstrap create 的輸出將為應提供給
mirror pool peer bootstrap import 指令的記號。例如,在
local 叢集上:
cephuser@local > rbd --cluster local mirror pool peer bootstrap create --site-name local image-pool
eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW \
1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1v \
bl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
若要使用 rbd 指令手動輸入另一個叢集所建立的開機記號,請使用以下語法:
rbd mirror pool peer bootstrap import \ [--site-name LOCAL_SITE_NAME] \ [--direction DIRECTION \ POOL_NAME TOKEN_PATH
地點:
- LOCAL_SITE_NAME
用於描述
local叢集的選擇性易記站台名稱。- DIRECTION
鏡像方向。預設設定為
rx-tx進行雙向鏡像,但也可設定為rx-only進行單向鏡像。- POOL_NAME
池名稱。
- TOKEN_PATH
指向所建立記號的檔案路徑 (或設定為
-以從標準輸入讀取)。
例如,在 remote 叢集上:
cephuser@remote > cat <<EOF > token
eyJmc2lkIjoiOWY1MjgyZGItYjg5OS00NTk2LTgwOTgtMzIwYzFmYzM5NmYzIiwiY2xpZW50X2lkIjoicmJkLW \
1pcnJvci1wZWVyIiwia2V5IjoiQVFBUnczOWQwdkhvQmhBQVlMM1I4RmR5dHNJQU50bkFTZ0lOTVE9PSIsIm1v \
bl9ob3N0IjoiW3YyOjE5Mi4xNjguMS4zOjY4MjAsdjE6MTkyLjE2OC4xLjM6NjgyMV0ifQ==
EOFcephuser@adm > rbd --cluster remote mirror pool peer bootstrap import \
--site-name remote image-pool token20.4.1.4 手動新增叢集對等 #
除了依據第 20.4.1.3 節 「開機對等」中所述開機對等之外,您還可以手動指定對等。遠端
rbd-mirror 精靈需要存取本地叢集才能執行鏡像。建立遠端
rbd-mirror 精靈將使用的新本地 Ceph 使用者,例如
rbd-mirror-peer:
cephuser@adm > ceph auth get-or-create client.rbd-mirror-peer \
mon 'profile rbd' osd 'profile rbd'
使用以下語法透過 rbd 指令新增鏡像對等 Ceph 叢集:
rbd mirror pool peer add POOL_NAME CLIENT_NAME@CLUSTER_NAME
例如:
cephuser@adm >rbd --cluster site-a mirror pool peer add image-pool client.rbd-mirror-peer@site-bcephuser@adm >rbd --cluster site-b mirror pool peer add image-pool client.rbd-mirror-peer@site-a
依預設,rbd-mirror 精靈需要有權存取位於
/etc/ceph/.CLUSTER_NAME.conf
的 Ceph 組態檔案。它提供對等叢集之 MON 的 IP 位址和名為 CLIENT_NAME
之用戶端的金鑰圈 (位於預設或自訂金鑰圈搜尋路徑中,例如
/etc/ceph/CLUSTER_NAME.CLIENT_NAME.keyring)。
或者,對等叢集的 MON 和/或用戶端金鑰可以安全地儲存在本地 Ceph config-key
儲存區中。若要在新增鏡像對等時指定對等叢集連接屬性,請使用 --remote-mon-host 和
--remote-key-file 選項。例如:
cephuser@adm >rbd --cluster site-a mirror pool peer add image-pool \ client.rbd-mirror-peer@site-b --remote-mon-host 192.168.1.1,192.168.1.2 \ --remote-key-file /PATH/TO/KEY_FILEcephuser@adm >rbd --cluster site-a mirror pool info image-pool --all Mode: pool Peers: UUID NAME CLIENT MON_HOST KEY 587b08db... site-b client.rbd-mirror-peer 192.168.1.1,192.168.1.2 AQAeuZdb...
20.4.1.5 移除叢集對等 #
若要移除鏡像對等叢集,請指定 mirror pool peer remove 子指令、池名稱和對等 UUID
(可透過 rbd mirror pool info 指令獲得):
cephuser@adm >rbd --cluster local mirror pool peer remove POOL_NAME \ 55672766-c02b-4729-8567-f13a66893445cephuser@adm >rbd --cluster remote mirror pool peer remove POOL_NAME \ 60c0e299-b38f-4234-91f6-eed0a367be08
20.4.1.6 資料池 #
在目標叢集中建立影像時,rbd-mirror
會依如下所述選取資料池:
如果目標叢集設定了預設資料池 (使用
rbd_default_data_pool組態選項),則會使用該預設資料池。否則,如果來源影像使用單獨的資料池,並且目標叢集上存在同名的池,則將使用該池。
如果以上兩種情況都不成立,將不會設定資料池。
20.4.2 RBD 影像組態 #
與池組態不同,影像組態只需要針對單個鏡像對等 Ceph 叢集執行。
系統會將鏡像的 RBD 影像指定為主要或非主要。這是影像的內容,而不是池的內容。不能修改指定為非主要的影像。
當首次對某個影像啟用鏡像時 (如果池鏡像模式是「池」並且影像已啟用記錄影像功能,則暗示已啟用,或者可透過 rbd
指令明確啟用
(請參閱第 20.4.2.1 節 「啟用影像鏡像」)),影像會自動升級為主要影像。
20.4.2.1 啟用影像鏡像 #
如果鏡像設定為使用 image 模式,則需要為池中的每個影像明確啟用鏡像。若要使用
rbd 為特定影像啟用鏡像,請指定 mirror image
enable 子指令以及池和影像名稱:
cephuser@adm > rbd --cluster local mirror image enable \
POOL_NAME/IMAGE_NAME
鏡像影像模式可以是 journal,也可以是 snapshot:
- journal (預設模式)
如果設定為使用
journal模式,鏡像將使用 RBD 記錄影像功能來複製影像內容。如果尚未在影像上啟用 RBD 記錄影像功能,該功能將自動啟用。- snapshot
如果設定為使用
snapshot模式,鏡像將使用 RBD 影像鏡像快照來複製影像內容。啟用後,將自動建立初始鏡像快照。可透過rbd指令建立其他 RBD 影像鏡像快照。
例如:
cephuser@adm >rbd --cluster local mirror image enable image-pool/image-1 snapshotcephuser@adm >rbd --cluster local mirror image enable image-pool/image-2 journal
20.4.2.2 啟用影像記錄功能 #
RBD 鏡像使用 RBD 記錄功能來確保複製的影像永遠在當機時保持一致狀態。使用 image
鏡像模式時,如果在影像上啟用了鏡像,則將自動啟用記錄功能。使用 pool 鏡像模式時,必須先啟用 RBD
影像記錄功能,然後才能將影像鏡像到對等叢集。在建立影像時,可以透過將 --image-feature
exclusive-lock,journaling 選項提供給 rbd 指令來啟用該功能。
您也可以針對預先存在的 RBD 影像動態啟用記錄功能。若要啟用記錄,請指定 feature enable
子指令、池和影像名稱以及功能名稱:
cephuser@adm >rbd --cluster local feature enable POOL_NAME/IMAGE_NAME exclusive-lockcephuser@adm >rbd --cluster local feature enable POOL_NAME/IMAGE_NAME journaling
journaling 功能依賴於 exclusive-lock 功能。如果
exclusive-lock 功能尚未啟用,您需要先啟用它,再啟用
journaling 功能。
依預設,您可以透過將 rbd default features =
layering,exclusive-lock,object-map,deep-flatten,journaling 新增至
Ceph 組態檔案,在所有新影像上啟用記錄功能。
20.4.2.3 建立影像鏡像快照 #
使用基於快照的鏡像時,每當要鏡像 RBD 影像的已變更內容,都需要建立鏡像快照。若要使用 rbd
手動建立鏡像快照,請指定 mirror image snapshot 指令以及池和影像名稱:
cephuser@adm > rbd mirror image snapshot POOL_NAME/IMAGE_NAME例如:
cephuser@adm > rbd --cluster local mirror image snapshot image-pool/image-1
依預設,每個影像僅可建立三個鏡像快照。如果達到此限制,將自動剪除最近的鏡像快照。可以視需要透過
rbd_mirroring_max_mirroring_snapshots
組態選項覆寫該限制。此外,移除影像或停用鏡像時,會自動刪除鏡像快照。
如果定義了鏡像快照排程,也可以定期自動建立鏡像快照。可以在全域、池或影像層級排程鏡像快照。可以在任何層級定義多個鏡像快照排程,但只有與個別鏡像影像相符的最特定的快照排程才會執行。
若要使用 rbd 建立鏡像快照排程,請指定 mirror snapshot schedule
add 指令以及選擇性的池或影像名稱、間隔和選擇性的開始時間。
可以分別使用尾碼 d、h 或 m
指定以天、小時或分鐘計的間隔。可使用 ISO 8601 時間格式指定選擇性的開始時間。例如:
cephuser@adm >rbd --cluster local mirror snapshot schedule add --pool image-pool 24h 14:00:00-05:00cephuser@adm >rbd --cluster local mirror snapshot schedule add --pool image-pool --image image1 6h
若要使用 rbd 移除鏡像快照排程,請指定 mirror snapshot schedule
remove 指令以及與相應的新增排程指令相符的選項。
若要使用 rbd 列出特定層級 (全域、池或影像) 的所有快照排程,請指定 mirror
snapshot schedule ls 指令以及選擇性的池或影像名稱。此外,還可以指定
--recursive 選項,以列出指定及以下層級的所有排程。例如:
cephuser@adm > rbd --cluster local mirror schedule ls --pool image-pool --recursive
POOL NAMESPACE IMAGE SCHEDULE
image-pool - - every 1d starting at 14:00:00-05:00
image-pool image1 every 6h
若要獲取使用 rbd 為基於快照的鏡像 RBD 影像建立下一個快照的時間,請指定
mirror snapshot schedule status 指令以及選擇性的池或影像名稱。例如:
cephuser@adm > rbd --cluster local mirror schedule status
SCHEDULE TIME IMAGE
2020-02-26 18:00:00 image-pool/image120.4.2.4 停用影像鏡像 #
若要為特定影像停用鏡像,請指定 mirror image disable 子指令以及池和影像名稱:
cephuser@adm > rbd --cluster local mirror image disable POOL_NAME/IMAGE_NAME20.4.2.5 升級和降級影像 #
在需要將主要指定移動到對等叢集中影像的容錯移轉情況下,您需要停止存取主要影像、降級目前主要影像、升級新的主要影像,然後繼續存取替代叢集上的影像。
可以使用 --force 選項強制升級。降級不能傳播到對等叢集時
(例如,當叢集發生故障或通訊中斷時),就需要強制升級。這將導致兩個對等叢集之間出現電腦分裂的情況,並且影像將不再同步,直到發出了
resync 子指令。
若要將特定影像降級為非主要影像,請指定 mirror image demote 子指令以及池和影像名稱:
cephuser@adm > rbd --cluster local mirror image demote POOL_NAME/IMAGE_NAME
若要將池中的所有主要影像都降級為非主要影像,請指定 mirror pool demote 子指令以及池名稱:
cephuser@adm > rbd --cluster local mirror pool demote POOL_NAME
若要將特定影像升級為主要影像,請指定 mirror image promote 子指令以及池和影像名稱:
cephuser@adm > rbd --cluster remote mirror image promote POOL_NAME/IMAGE_NAME
若要將池中的所有非主要影像都升級為主要影像,請指定 mirror pool promote 子指令以及池名稱:
cephuser@adm > rbd --cluster local mirror pool promote POOL_NAME因為主要或非主要狀態是針對影像的,所以可以使用兩個叢集來分割 I/O 負載,並進行容錯移轉或錯誤回復。
20.4.2.6 強制影像重新同步 #
如果 rbd-mirror
精靈偵測到電腦分裂事件,則在該情況解決之前,它不會嘗試鏡像受影響的影像。若要繼續鏡像影像,請先降級確定已過期的影像,然後要求與主要影像重新同步。若要要求影像重新同步,請指定
mirror image resync 子指令以及池和影像名稱:
cephuser@adm > rbd mirror image resync POOL_NAME/IMAGE_NAME20.4.3 檢查鏡像狀態 #
系統會儲存每個主要鏡像影像的對等叢集複製狀態。可使用 mirror image status 和
mirror pool status 子指令來擷取此狀態:
若要要求鏡像影像狀態,請指定 mirror image status 子指令以及池和影像名稱:
cephuser@adm > rbd mirror image status POOL_NAME/IMAGE_NAME
若要要求鏡像池摘要狀態,請指定 mirror pool status 子指令以及池名稱:
cephuser@adm > rbd mirror pool status POOL_NAME
將 --verbose 選項新增至 mirror pool status
子指令會額外地輸出池中每個鏡像影像的狀態詳細資料。
20.5 快取設定 #
Ceph 區塊裝置的使用者空間實作 (librbd) 無法利用 Linux
頁面快取。因此,它具有自己的記憶體內部快取。RBD 快取的行為與硬碟快取類似。當作業系統傳送屏障或衝洗要求時,所有「改動」資料都會寫入
OSD。這表示只要虛擬機器可以正確傳送衝洗要求,使用寫回快取與使用執行良好的實體硬碟一樣安全。該快取運用最久未使用
(LRU) 演算法,並且在寫回模式下可以合併相鄰要求,以提高輸送量。
Ceph 支援為 RBD 提供寫回快取。若要啟用該功能,請執行
cephuser@adm > ceph config set client rbd_cache true
librbd
預設不會執行任何快取。寫入和讀取都直接到達儲存叢集,並且只有當資料的所有複本都寫入磁碟後,寫入操作才會傳回。如果啟用了快取,寫入操作會立即傳回,除非未衝洗的位元組數大於
rbd cache max dirty
選項中設定的數值。在此情況下,寫入操作會觸發寫回機制並一直阻塞,直至衝洗了足夠多的位元組。
Ceph 支援為 RBD 提供直寫快取。您可以設定快取的大小,以及從寫回快取切換到直寫快取的目標和限值。若要啟用直寫模式,請執行
cephuser@adm > ceph config set client rbd_cache_max_dirty 0這表示只有當資料的所有複本都寫入磁碟後,寫入操作才會傳回,但可能會從快取中讀取資料。快取資訊儲存在用戶端的記憶體中,並且每個 RBD 都有自己的快取。由於對用戶端而言快取位於本地,因此如果有其他用戶端存取影像,不會存在快取一致性的問題。如果啟用了快取,在 RBD 上將不能執行 GFS 或 OCFS。
以下參數會影響 RADOS 區塊裝置的行為。若要設定這些參數,請使用 client 類別:
cephuser@adm > ceph config set client PARAMETER VALUErbd cache對 RADOS 區塊裝置 (RBD) 啟用快取。預設值為「true」。
rbd cache sizeRBD 快取大小 (以位元組計)。預設值為 32 MB。
rbd cache max dirty使快取觸發寫回機制的「改動」資料限值 (以位元組計)。
rbd cache max dirty的值必須小於rbd cache size的值。如果設定為 0,將使用直寫快取。預設值為 24 MB。rbd cache target dirty達到該「改動資料目標」後,快取即會開始向資料儲存空間寫入資料。該設定不會使寫入快取的操作阻塞。預設值為 16 MB。
rbd cache max dirty age寫回開始前,改動資料在快取中暫存的時間 (以秒計)。預設值為 1。
rbd cache writethrough until flush開始進入直寫模式,在收到第一個衝洗要求後切換到寫回模式。啟用此設定雖然較為保守,但卻是一種安全的做法,如此可應對在
rbd上執行的虛擬機器太舊而無法傳送衝洗要求的情況 (例如,核心早於 2.6.32 的 Linux 中的 Virtio 驅動程式)。預設值為「true」。
20.6 QoS 設定 #
一般而言,服務品質 (QoS) 指的是設定流量優先順序和資源保留方法。它對於具有特殊要求的流量傳輸尤為重要。
只有使用者空間 RBD 實作 librbd 會使用下列 QoS
設定,kRBD 實作不使用這些設定。由於 iSCSI
使用的是 kRBD,因此不使用 QoS 設定。不過,對於
iSCSI,您可以使用標準核心工具在核心區塊裝置層上設定 QoS。
rbd qos iops limit指定的每秒 I/O 操作次數上限。預設值為 0 (無上限)。
rbd qos bps limit指定的每秒 I/O 位元組數上限。預設值為 0 (無上限)。
rbd qos read iops limit指定的每秒讀取操作次數上限。預設值為 0 (無上限)。
rbd qos write iops limit指定的每秒寫入操作次數上限。預設值為 0 (無上限)。
rbd qos read bps limit指定的每秒內讀取的位元組數上限。預設值為 0 (無上限)。
rbd qos write bps limit指定的每秒內寫入的位元組數上限。預設值為 0 (無上限)。
rbd qos iops burst指定的 I/O 操作次數高載上限。預設值為 0 (無上限)。
rbd qos bps burst指定的 I/O 位元組數高載上限。預設值為 0 (無上限)。
rbd qos read iops burst指定的讀取操作次數高載上限。預設值為 0 (無上限)。
rbd qos write iops burst指定的寫入操作次數高載上限。預設值為 0 (無上限)。
rbd qos read bps burst指定的讀取的位元組數高載上限。預設值為 0 (無上限)。
rbd qos write bps burst指定的寫入的位元組數高載上限。預設值為 0 (無上限)。
rbd qos schedule tick minQoS 的最小排程刻點 (以毫秒計)。預設值為 50。
20.7 預先讀取設定 #
RADOS 區塊裝置支援預先讀取/預先擷取功能,以最佳化小區塊的循序讀取。如果使用虛擬機器,此操作通常應由客體作業系統處理,但開機載入程式可能不會發出有效的讀取要求。如果停用快取,則會自動停用預先讀取功能。
只有使用者空間 RBD 實作 librbd
會使用下列預先讀取設定,kRBD 實作不使用這些設定。由於
iSCSI 使用的是 kRBD,因此不使用預先讀取設定。不過,對於
iSCSI,您可以使用標準核心工具在核心區塊裝置層上設定預先讀取。
rbd readahead trigger requests觸發預先讀取所必需的循序讀取要求數。預設值為 10。
rbd readahead max bytes預先讀取要求的大小上限。如果設定為 0,則會停用預先讀取功能。預設值為 512kB。
rbd readahead disable after bytes從 RBD 影像讀取此數量的位元組後,該影像的預先讀取功能將會停用,直至其關閉。使用此設定,客體作業系統開機時便可接管預先讀取工作。如果設定為 0,預先讀取將永遠處於啟用狀態。預設值為 50 MB。
20.8 進階功能 #
RADOS 區塊裝置支援可增強 RBD 影像功能的進階功能。您可以在建立 RBD 影像時在指令行上指定這些功能,或者在 Ceph 組態檔案中使用
rbd_default_features 選項來指定。
您可以透過以下兩種方式指定 rbd_default_features 選項的值:
指定為相應功能的內部值之和。每項功能都有自己的內部值,例如,「layering」的內部值為 1,「fast-diff」的內部值為 16。因此,如果想要預設啟用這兩項功能,請指定以下選項:
rbd_default_features = 17
指定為各功能的逗號分隔清單。上面的範例應如下所示:
rbd_default_features = layering,fast-diff
iSCSI 不支援具有以下功能的 RBD
影像:deep-flatten、object-map、journaling、fast-diff、striping
以下是 RBD 的進階功能清單:
layering分層允許您使用克隆。
內部值為 1,預設值為「yes」。
striping分割功能會將資料分佈在多個物件之間,有助於平行處理循序讀取/寫入工作負載。它可防止大型或繁忙的 RADOS 區塊裝置出現單節點瓶頸。
內部值為 2,預設值為「yes」。
exclusive-lock如果啟用,用戶端需要在寫入資料之前鎖定物件。僅當一次只有一個用戶端在存取影像時,才應啟用獨佔鎖定。內部值為 4。預設值為「yes」。
object-map物件對應支援相依於獨佔鎖定支援。區塊裝置採用的是簡易佈建,也就是說這些裝置僅儲存實際存在的資料。物件對應支援有助於追蹤哪些物件實際存在 (在磁碟機上儲存了資料)。啟用物件對應支援可以加快克隆、輸入和輸出資料稀疏的影像,以及刪除所需的 I/O 操作。
內部值為 8,預設值為「yes」。
fast-diffFast-diff 支援相依於物件對應支援和獨佔鎖定支援。它會新增另一個內容至物件對應,使其更快地產生影像各快照之間的差異以及快照的實際資料使用率。
內部值為 16,預設值為「yes」。
deep-flattenDeep-flatten 使
rbd flatten(請參閱第 20.3.3.6 節 「壓平克隆的影像」) 除了對影像自身有作用外,還對影像的所有快照有作用。如果沒有該功能,影像的快照將仍然相依於其父影像,因而如果未刪除快照,您將無法刪除父影像。Deep-flatten 使父影像可獨立於其克隆,即使這些克隆有快照也不例外。內部值為 32,預設值為「yes」。
journaling記錄支援相依於獨佔鎖定支援。記錄會依修改發生的順序記錄影像的所有修改。RBD 鏡像 (請參閱第 20.4 節 「RBD 影像鏡像」) 會使用記錄將當機一致性影像複製到
遠端叢集。內部值為 64,預設值為「no」。
20.9 使用舊核心用戶端對應 RBD #
舊用戶端 (例如 SLE11 SP4) 可能無法對應 RBD 影像,因為使用 SUSE Enterprise Storage 7 部署的叢集會強制執行一些舊用戶端不支援的功能 (RBD 影像層級功能和 RADOS 層級功能)。發生此情況時,OSD 記錄將顯示類似如下的訊息:
2019-05-17 16:11:33.739133 7fcb83a2e700 0 -- 192.168.122.221:0/1006830 >> \ 192.168.122.152:6789/0 pipe(0x65d4e0 sd=3 :57323 s=1 pgs=0 cs=0 l=1 c=0x65d770).connect \ protocol feature mismatch, my 2fffffffffff < peer 4010ff8ffacffff missing 401000000000000
如果您打算在 CRUSH 地圖桶類型「straw」與「straw2」之間切換,請做好相應規劃。這樣做預計會對叢集負載產生重大影響,因為變更桶類型將導致叢集大規模重新平衡。
停用任何不支援的 RBD 影像功能。例如:
cephuser@adm >rbd feature disable pool1/image1 object-mapcephuser@adm >rbd feature disable pool1/image1 exclusive-lock將 CRUSH 地圖桶類型由「straw2」變更為「straw」:
儲存 CRUSH 地圖:
cephuser@adm >ceph osd getcrushmap -o crushmap.original反編譯 CRUSH 地圖:
cephuser@adm >crushtool -d crushmap.original -o crushmap.txt編輯 CRUSH 地圖,並以「straw」取代「straw2」。
重新編譯 CRUSH 地圖:
cephuser@adm >crushtool -c crushmap.txt -o crushmap.new設定新 CRUSH 地圖:
cephuser@adm >ceph osd setcrushmap -i crushmap.new
20.10 啟用區塊裝置和 Kubernetes #
您可以透過 ceph-csi 驅動程式將 Ceph RBD 與 Kubernetes v1.13
及更新版本結合使用。此驅動程式會動態佈建 RBD 影像以支援 Kubernetes 磁碟區,並在參考 RBD 支援磁碟區的背景工作節點執行中 pod
上做為區塊裝置對應這些 RBD 影像 (選取性地掛接影像中包含的檔案系統)。
若要將 Ceph 區塊裝置與 Kubernetes 結合使用,必須在您的 Kubernetes 環境中安裝和設定
ceph-csi。
ceph-csi 預設使用 RBD 核心模組,它可能不支援所有 Ceph CRUSH 可調參數或 RBD
影像功能。
依預設,Ceph 區塊裝置使用 RBD 池。為 Kubernetes 磁碟區儲存建立池。確定 Ceph 叢集正在執行,然後建立池:
cephuser@adm >ceph osd pool create kubernetes使用 RBD 工具啟始化池:
cephuser@adm >rbd pool init kubernetes為 Kubernetes 和
ceph-csi建立一個新使用者。執行以下指令並記錄產生的金鑰:cephuser@adm >ceph auth get-or-create client.kubernetes mon 'profile rbd' osd 'profile rbd pool=kubernetes' mgr 'profile rbd pool=kubernetes' [client.kubernetes] key = AQD9o0Fd6hQRChAAt7fMaSZXduT3NWEqylNpmg==ceph-csi需要儲存在 Kubernetes 中的 ConfigMap 物件來定義 Ceph 叢集的 Ceph 監控程式位址。收集 Ceph 叢集的唯一 fsid 和監控程式位址:cephuser@adm >ceph mon dump <...> fsid b9127830-b0cc-4e34-aa47-9d1a2e9949a8 <...> 0: [v2:192.168.1.1:3300/0,v1:192.168.1.1:6789/0] mon.a 1: [v2:192.168.1.2:3300/0,v1:192.168.1.2:6789/0] mon.b 2: [v2:192.168.1.3:3300/0,v1:192.168.1.3:6789/0] mon.c產生
csi-config-map.yaml檔案,取代clusterID的 FSID,並取代monitors的監控程式位址,如下例所示:kubectl@adm >cat <<EOF > csi-config-map.yaml --- apiVersion: v1 kind: ConfigMap data: config.json: |- [ { "clusterID": "b9127830-b0cc-4e34-aa47-9d1a2e9949a8", "monitors": [ "192.168.1.1:6789", "192.168.1.2:6789", "192.168.1.3:6789" ] } ] metadata: name: ceph-csi-config EOF產生後,將新的 ConfigMap 物件儲存在 Kubernetes 中:
kubectl@adm >kubectl apply -f csi-config-map.yamlceph-csi需要 cephx 身分證明來與 Ceph 叢集通訊。使用新建立的 Kubernetes 使用者 ID 和 cephx 金鑰產生csi-rbd-secret.yaml檔案,如下例所示:kubectl@adm >cat <<EOF > csi-rbd-secret.yaml --- apiVersion: v1 kind: Secret metadata: name: csi-rbd-secret namespace: default stringData: userID: kubernetes userKey: AQD9o0Fd6hQRChAAt7fMaSZXduT3NWEqylNpmg== EOF產生後,將新的機密金鑰物件儲存在 Kubernetes 中:
kubectl@adm >kubectl apply -f csi-rbd-secret.yaml建立所需的 ServiceAccount 和 RBAC ClusterRole/ClusterRoleBinding Kubernetes 物件。這些物件不一定需要依據您的 Kubernetes 環境進行自訂,因此可以直接從
ceph-csi部署 YAML 檔案使用:kubectl@adm >kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-provisioner-rbac.yamlkubectl@adm >kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-nodeplugin-rbac.yaml建立
ceph-csi佈建程式和節點外掛程式:kubectl@adm >wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin-provisioner.yamlkubectl@adm >kubectl apply -f csi-rbdplugin-provisioner.yamlkubectl@adm >wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin.yamlkubectl@adm >kubectl apply -f csi-rbdplugin.yaml重要依預設,佈建程式和節點外掛程式 YAML 檔案將提取
ceph-csi容器的開發版本。應更新 YAML 檔案以使用發行版本。
20.10.1 在 Kubernetes 中使用 Ceph 區塊裝置 #
Kubernetes StorageClass 定義了一個儲存類別。可以建立多個 StorageClass 物件,以對應至不同的服務品質層級和功能。例如,NVMe 與基於 HDD 的池對應。
若要建立對應至上面所建立 Kubernetes 池的 ceph-csi StorageClass,請在確定
clusterID 內容與您的 Ceph 叢集 FSID 相符之後,可以使用以下 YAML檔案:
kubectl@adm >cat <<EOF > csi-rbd-sc.yaml --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: csi-rbd-sc provisioner: rbd.csi.ceph.com parameters: clusterID: b9127830-b0cc-4e34-aa47-9d1a2e9949a8 pool: kubernetes csi.storage.k8s.io/provisioner-secret-name: csi-rbd-secret csi.storage.k8s.io/provisioner-secret-namespace: default csi.storage.k8s.io/node-stage-secret-name: csi-rbd-secret csi.storage.k8s.io/node-stage-secret-namespace: default reclaimPolicy: Delete mountOptions: - discard EOFkubectl@adm >kubectl apply -f csi-rbd-sc.yaml
PersistentVolumeClaim
是使用者發出的抽象儲存資源要求。然後,PersistentVolumeClaim 將與 pod 資源相關聯以佈建
PersistentVolume,它將由 Ceph 區塊影像提供支援。可以包含選擇性的
volumeMode,以便在掛接的檔案系統 (預設) 或原始的基於區塊裝置的磁碟區之間進行選取。
使用 ceph-csi,為 volumeMode 指定
Filesystem 可支援 ReadWriteOnce 和
ReadOnlyMany accessMode 聲明,為 volumeMode
指定 Block 可支援
ReadWriteOnce、ReadWriteMany 和
ReadOnlyMany accessMode 聲明。
例如,若要建立使用上面建立的 ceph-csi-based StorageClass 之基於區塊的
PersistentVolumeClaim,可以使用以下 YAML 檔案從
csi-rbd-sc StorageClass 要求原始區塊儲存:
kubectl@adm >cat <<EOF > raw-block-pvc.yaml --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: raw-block-pvc spec: accessModes: - ReadWriteOnce volumeMode: Block resources: requests: storage: 1Gi storageClassName: csi-rbd-sc EOFkubectl@adm >kubectl apply -f raw-block-pvc.yaml
下面的範例說明如何將上述 PersistentVolumeClaim 做為原始區塊裝置結合至 pod 資源:
kubectl@adm >cat <<EOF > raw-block-pod.yaml --- apiVersion: v1 kind: Pod metadata: name: pod-with-raw-block-volume spec: containers: - name: fc-container image: fedora:26 command: ["/bin/sh", "-c"] args: ["tail -f /dev/null"] volumeDevices: - name: data devicePath: /dev/xvda volumes: - name: data persistentVolumeClaim: claimName: raw-block-pvc EOFkubectl@adm >kubectl apply -f raw-block-pod.yaml
若要建立使用上面建立的 ceph-csi-based StorageClass 之基於檔案系統的
PersistentVolumeClaim,可以使用以下 YAML 檔案從
csi-rbd-sc StorageClass 要求掛接的檔案系統 (由 RBD 影像提供支援):
kubectl@adm >cat <<EOF > pvc.yaml --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: rbd-pvc spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 1Gi storageClassName: csi-rbd-sc EOFkubectl@adm >kubectl apply -f pvc.yaml
下面的範例說明如何將上述 PersistentVolumeClaim 做為掛接的檔案系統結合至 pod 資源:
kubectl@adm >cat <<EOF > pod.yaml --- apiVersion: v1 kind: Pod metadata: name: csi-rbd-demo-pod spec: containers: - name: web-server image: nginx volumeMounts: - name: mypvc mountPath: /var/lib/www/html volumes: - name: mypvc persistentVolumeClaim: claimName: rbd-pvc readOnly: false EOFkubectl@adm >kubectl apply -f pod.yaml
第 IV 部分 存取叢集資料 #
- 21 Ceph 物件閘道
本章介紹物件閘道相關管理任務的詳細資料,例如,檢查服務的狀態,管理帳戶、多站台閘道或 LDAP 驗證。
- 22 Ceph iSCSI 閘道
本章重點介紹與 iSCSI 閘道相關的管理任務。如需部署程序,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3.5 “部署 iSCSI 閘道”。
- 23 叢集檔案系統
本章介紹通常應在完成叢集設定與輸出 CephFS 後執行的管理任務。如需有關設定 CephFS 的詳細資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3.3 “部署中繼資料伺服器”。
- 24 透過 Samba 輸出 Ceph 資料
本章介紹如何透過 Samba/CIFS 共用輸出 Ceph 叢集中儲存的資料,以便您可從 Windows* 用戶端機器輕鬆存取這些資料。另外還介紹了有助於您將 Ceph Samba 閘道設定為加入到 Windows* 網域中的 Active Directory,以進行使用者驗證和授權的資訊。
- 25 NFS Ganesha
NFS Ganesha 是一部 NFS 伺服器,它在使用者位址空間中執行,而不是做為作業系統核心的一部分執行。憑藉 NFS Ganesha,您可以插入自己的儲存機制 (例如 Ceph),並從任何 NFS 用戶端存取它。如需安裝說明,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3.6 “部署 NFS Ganesha”。
21 Ceph 物件閘道 #
本章介紹物件閘道相關管理任務的詳細資料,例如,檢查服務的狀態,管理帳戶、多站台閘道或 LDAP 驗證。
21.1 物件閘道限制和命名限制 #
下面列出了物件閘道的一些重要限制:
21.1.1 桶限制 #
透過 S3 API 存取物件閘道時,桶名稱必須符合 DNS 且允許使用虛線字元「-」。當透過 Swift API 存取物件閘道時,您可使用支援 UTF-8 的字元 (斜線字元「/」除外) 的任何組合。桶名稱最多可包含 255 個字元。桶名稱必須是唯一的。
雖然透過 Swift API 存取時,可使用任何基於 UTF-8 的桶名稱,但仍建議您根據 S3 命名限制對桶命名,以免在透過 S3 API 存取同一個桶時發生問題。
21.1.2 儲存之物件的限制 #
- 每個使用者的物件數量上限
預設無限制 (大約不超過 2^63)。
- 每個桶的物件數量上限
預設無限制 (大約不超過 2^63)。
- 要上傳/儲存的物件的最大大小
單次上傳的上限為 5GB。更大的物件可分為多個部分上傳。多部分區塊的最大數量為 10000。
21.1.3 HTTP 標題限制 #
HTTP 標頭和要求限制取決於所使用的 Web 前端。預設 Beast 會將 HTTP 標題大小限制為 16 kB。
21.2 部署物件閘道 #
Ceph 物件閘道採用與其他 Ceph 服務相同的程序進行部署,即使用 cephadm。如需詳細資料,具體請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.2 “服務和放置規格”到Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3.4 “部署物件閘道”。
21.3 操作物件閘道服務 #
您可以如同操作其他 Ceph 服務一般來操作物件閘道,首先使用 ceph orch ps 指令識別服務名稱,然後執行以下指令來操作服務,例如:
ceph orch daemon restart OGW_SERVICE_NAME
如需操作 Ceph 服務的完整資訊,請參閱第 14 章 「Ceph 服務的操作」。
21.4 組態選項 #
如需物件閘道組態選項的清單,請參閱第 28.5 節 「Ceph 物件閘道」。
21.5 管理物件閘道的存取 #
您可以使用與 S3 或 Swift 相容的介面來與物件閘道通訊。S3 介面與大部分 Amazon S3 RESTful API 都相容。Swift 介面與大部分 OpenStack Swift API 都相容。
這兩個介面都要求您建立特定的使用者,並安裝相關的用戶端軟體,以使用該使用者的機密金鑰來與閘道通訊。
21.5.1 存取物件閘道 #
21.5.1.1 S3 介面存取 #
若要存取 S3 介面,您需要有 REST 用戶端。S3cmd 是一個指令行 S3 用戶端。您可以在 OpenSUSE Build Service 中找到它。該儲存庫包含既適用於 SUSE Linux Enterprise 套裝作業系統又適用於基於 openSUSE 的套裝作業系統的版本。
如果您想測試自己是否能夠存取 S3 介面,也可以編寫一個簡短的 Python 程序檔。該程序檔將連接到物件閘道,建立新桶,並列出所有桶。aws_access_key_id 和 aws_secret_access_key 的值取自第 21.5.2.1 節 「新增 S3 和 Swift 使用者」中所述 radosgw_admin 指令傳回的 access_key 和 secret_key 的值。
安裝
python-boto套件:root #zypper in python-boto建立名為
s3test.py的新 Python 程序檔,並在其中包含以下內容:import boto import boto.s3.connection access_key = '11BS02LGFB6AL6H1ADMW' secret_key = 'vzCEkuryfn060dfee4fgQPqFrncKEIkh3ZcdOANY' conn = boto.connect_s3( aws_access_key_id = access_key, aws_secret_access_key = secret_key, host = 'HOSTNAME', is_secure=False, calling_format = boto.s3.connection.OrdinaryCallingFormat(), ) bucket = conn.create_bucket('my-new-bucket') for bucket in conn.get_all_buckets(): print "NAME\tCREATED".format( name = bucket.name, created = bucket.creation_date, )請以您在其上設定了物件閘道服務的主機的主機名稱來取代
HOSTNAME,例如gateway_host。執行程序檔:
python s3test.py
該程序檔將輸出類似下方內容的資訊:
my-new-bucket 2015-07-22T15:37:42.000Z
21.5.1.2 Swift 介面存取 #
若要透過 Swift 介面存取物件閘道,需要使用 swift 指令行用戶端。該介面的手冊頁 man 1 swift 介紹了有關其指令行選項的詳細資訊。
從 SUSE Linux Enterprise 12 SP3 到 SUSE Linux Enterprise 15 的「Public Cloud」模組中都隨附了該套件。在安裝該套件之前,需要啟動該模組並重新整理軟體儲存庫:
root # SUSEConnect -p sle-module-public-cloud/12/SYSTEM-ARCH
sudo zypper refresh或
root #SUSEConnect -p sle-module-public-cloud/15/SYSTEM-ARCHroot #zypper refresh
若要安裝 swift 指令,請執行以下指令:
root # zypper in python-swiftclient使用以下語法進行 swift 存取:
tux > swift -A http://IP_ADDRESS/auth/1.0 \
-U example_user:swift -K 'SWIFT_SECRET_KEY' list
請以閘道伺服器的 IP 位址取代 IP_ADDRESS,以在第 21.5.2.1 節 「新增 S3 和 Swift 使用者」中針對 swift 使用者執行 radosgw-admin key create 指令所產生輸出中的相應值取代 SWIFT_SECRET_KEY。
例如:
tux > swift -A http://gateway.example.com/auth/1.0 -U example_user:swift \
-K 'r5wWIxjOCeEO7DixD1FjTLmNYIViaC6JVhi3013h' list輸出為:
my-new-bucket
21.5.2 管理 S3 和 Swift 帳戶 #
21.5.2.1 新增 S3 和 Swift 使用者 #
您需要建立使用者、存取金鑰和機密才能讓最終使用者與閘道互動。使用者分兩種類型:使用者和子使用者。與 S3 介面互動時使用使用者,子使用者是 Swift 介面的使用者。每個子使用者都與某個使用者相關聯。
若要建立 Swift 使用者,請執行以下步驟:
若要建立 Swift 使用者 (在我們的術語中稱作子使用者),您需要先建立關聯的使用者。
cephuser@adm >radosgw-admin user create --uid=USERNAME \ --display-name="DISPLAY-NAME" --email=EMAIL例如:
cephuser@adm >radosgw-admin user create \ --uid=example_user \ --display-name="Example User" \ --email=penguin@example.com若要建立使用者的子使用者 (用於 Swift 介面),必須指定使用者 ID (--uid=USERNAME)、子使用者 ID 和該子使用者的存取層級。
cephuser@adm >radosgw-admin subuser create --uid=UID \ --subuser=UID \ --access=[ read | write | readwrite | full ]例如:
cephuser@adm >radosgw-admin subuser create --uid=example_user \ --subuser=example_user:swift --access=full為使用者產生機密金鑰。
cephuser@adm >radosgw-admin key create \ --gen-secret \ --subuser=example_user:swift \ --key-type=swift這兩個指令都會輸出 JSON 格式的資料,其中顯示了使用者狀態。請注意以下幾行,並記住
secret_key值:"swift_keys": [ { "user": "example_user:swift", "secret_key": "r5wWIxjOCeEO7DixD1FjTLmNYIViaC6JVhi3013h"}],
透過 S3 介面存取物件閘道時,需要執行以下指令來建立 S3 使用者:
cephuser@adm > radosgw-admin user create --uid=USERNAME \
--display-name="DISPLAY-NAME" --email=EMAIL例如:
cephuser@adm > radosgw-admin user create \
--uid=example_user \
--display-name="Example User" \
--email=penguin@example.com
該指令還會建立使用者的存取金鑰和機密金鑰。檢查該指令輸出中的 access_key 和 secret_key 關鍵字及其值:
[...]
"keys": [
{ "user": "example_user",
"access_key": "11BS02LGFB6AL6H1ADMW",
"secret_key": "vzCEkuryfn060dfee4fgQPqFrncKEIkh3ZcdOANY"}],
[...]21.5.2.2 移除 S3 和 Swift 使用者 #
刪除 S3 使用者與刪除 Swift 使用者的程序類似。不過,在刪除 Swift 使用者時,您可能需要同時刪除該使用者及其子使用者。
若要移除 S3 或 Swift 使用者 (包括其所有子使用者),請在以下指令中指定 user rm 和使用者 ID:
cephuser@adm > radosgw-admin user rm --uid=example_user
若要移除子使用者,請指定 subuser rm 和子使用者 ID。
cephuser@adm > radosgw-admin subuser rm --uid=example_user:swift您可使用以下選項:
- --purge-data
清除與該使用者 ID 關聯的所有資料。
- --purge-keys
清除與該使用者 ID 關聯的所有金鑰。
移除某個子使用者時,移除的是其對 Swift 介面的存取權限。該使用者仍會保留在系統中。
21.5.2.3 變更 S3 和 Swift 使用者的存取金鑰與機密金鑰 #
存取閘道時,access_key 和 secret_key 參數用於識別物件閘道使用者。變更現有使用者金鑰的過程與建立新使用者金鑰的過程相同,舊金鑰會被覆寫。
對於 S3 使用者,請執行以下指令:
cephuser@adm > radosgw-admin key create --uid=EXAMPLE_USER --key-type=s3 --gen-access-key --gen-secret對於 Swift 使用者,請執行以下指令:
cephuser@adm > radosgw-admin key create --subuser=EXAMPLE_USER:swift --key-type=swift --gen-secret--key-type=TYPE指定金鑰的類型。值為
swift或s3。--gen-access-key產生隨機存取金鑰 (預設針對 S3 使用者)。
--gen-secret產生隨機機密金鑰。
--secret=KEY指定機密金鑰,例如手動產生的金鑰。
21.5.2.4 啟用使用者定額管理 #
Ceph 物件閘道允許您針對使用者以及使用者擁有的桶設定定額。定額包括一個桶中的最大物件數,以及最大儲存大小 (MB)。
在啟用使用者定額之前,需要先設定定額的參數:
cephuser@adm > radosgw-admin quota set --quota-scope=user --uid=EXAMPLE_USER \
--max-objects=1024 --max-size=1024--max-objects指定最大物件數。指定負值會停用檢查。
--max-size指定最大位元組數。指定負值會停用檢查。
--quota-scope設定定額的範圍。選項包括
bucket和user。桶定額將套用到使用者擁有的桶。使用者定額將套用到使用者。
設定使用者定額後,可啟用該定額:
cephuser@adm > radosgw-admin quota enable --quota-scope=user --uid=EXAMPLE_USER若要停用定額:
cephuser@adm > radosgw-admin quota disable --quota-scope=user --uid=EXAMPLE_USER若要列出定額設定:
cephuser@adm > radosgw-admin user info --uid=EXAMPLE_USER若要更新定額統計資料:
cephuser@adm > radosgw-admin user stats --uid=EXAMPLE_USER --sync-stats21.6 HTTP 前端 #
Ceph 物件閘道支援兩個內嵌式 HTTP 前端:Beast 和 Civetweb。
Beast 前端使用 Boost.Beast 程式庫處理 HTTP 剖析,使用 Boost.Asio 程式庫處理非同步網路 I/O。
Civetweb 前端使用 Civetweb HTTP 程式庫,該程式庫屬於 Mongoose 的分支。
您可以使用 rgw_frontends 選項來設定它們。如需組態選項的清單,請參閱第 28.5 節 「Ceph 物件閘道」。
21.7 為物件閘道啟用 HTTPS/SSL #
若要讓物件閘道可使用 SSL 進行安全通訊,您需要擁有 CA 核發的證書,或建立自行簽署的證書。
21.7.1 建立自行簽署的證書 #
如果您已擁有 CA 簽署的有效證書,請跳過本節。
以下程序說明如何在 Salt Master 上產生自行簽署的 SSL 證書。
如果您需要透過其他主體身分來識別您的物件閘道,請將這些身分新增至
/etc/ssl/openssl.cnf檔案[v3_req]區段的subjectAltName選項中:[...] [ v3_req ] subjectAltName = DNS:server1.example.com DNS:server2.example.com [...]
提示:subjectAltName中的 IP 位址若要在
subjectAltName選項中使用 IP 位址而非網域名稱,請使用下面一行取代範例行:subjectAltName = IP:10.0.0.10 IP:10.0.0.11
使用
openssl建立金鑰和證書。輸入需要包含在證書中的所有資料。建議您輸入 FQDN 做為通用名稱。簽署證書前,確認「X509v3 Subject Alternative Name:」包含在要求的延伸中,並且產生的證書中設定了「X509v3 Subject Alternative Name:」。root@master #openssl req -x509 -nodes -days 1095 \ -newkey rsa:4096 -keyout rgw.key -out rgw.pem向證書檔案附加金鑰:
root@master #cat rgw.key >> rgw.pem
21.7.2 設定使用 SSL 的物件閘道 #
若要將物件閘道設定為使用 SSL 證書,請使用 rgw_frontends 選項。例如:
cephuser@adm > ceph config set WHO rgw_frontends \
beast ssl_port=443 ssl_certificate=config://CERT ssl_key=config://KEY如果您未指定 CERT 和 KEY 組態機碼,物件閘道服務將在以下組態機碼中尋找 SSL 證書和金鑰:
rgw/cert/RGW_REALM/RGW_ZONE.key rgw/cert/RGW_REALM/RGW_ZONE.crt
如果您要覆寫預設的 SSL 金鑰和證書位置,請使用以下指令將它們輸入至組態資料庫:
ceph config-key set CUSTOM_CONFIG_KEY -i PATH_TO_CERT_FILE
然後透過 config:// 指令使用您的自訂組態機碼。
21.8 同步模組 #
物件閘道部署為多站台服務,您可以在不同區域之間鏡像其資料和中繼資料。同步模組建立在多站台架構的基礎上,可將資料和中繼資料轉遞到不同的外部層。利用同步模組,可讓系統在每當有資料發生變更 (例如執行桶或使用者建立等中繼資料操作) 時即執行一組動作。當物件閘道多站台變更最終在遠端站台上保持一致時,變更將以非同步方式傳播。因而很多情況下都適合使用同步模組,例如,將物件儲存備份到外部雲端叢集、使用磁帶機的自訂備份解決方案,或在 ElasticSearch 中為中繼資料編制索引。
21.8.1 設定同步模組 #
所有同步模組的設定方式都是相似的。您需要建立一個新區域 (請參閱第 21.13 節 「多站台物件閘道」以瞭解更多詳細資料) 並為其設定 --tier_type 選項,例如針對雲端同步模組設定 --tier-type=cloud:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--endpoints=http://endpoint1.example.com,http://endpoint2.example.com, [...] \
--tier-type=cloud您可以使用以下指令來設定特定層:
cephuser@adm > radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--tier-config=KEY1=VALUE1,KEY2=VALUE2組態中的 KEY 指定您希望更新的組態變數,VALUE 指定該變數的新值。使用句點可存取巢狀的值。例如:
cephuser@adm > radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \
--rgw-zone=ZONE-NAME \
--tier-config=connection.access_key=KEY,connection.secret=SECRET您可以透過附加方括號「[]」及參考的項目來存取相應陣列項目。您可以使用方括號「[]」來新增新的陣列項目。索引值 -1 參考的是陣列中的最後一個項目。在同一個指令中無法建立新項目並再次參考該項目。例如,用於為以 PREFIX 開頭的桶建立新設定檔的指令如下所示:
cephuser@adm >radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \ --rgw-zone=ZONE-NAME \ --tier-config=profiles[].source_bucket=PREFIX'*'cephuser@adm >radosgw-admin zone modify --rgw-zonegroup=ZONE-GROUP-NAME \ --rgw-zone=ZONE-NAME \ --tier-config=profiles[-1].connection_id=CONNECTION_ID,profiles[-1].acls_id=ACLS_ID
您可以使用 --tier-config-add=KEY=VALUE 參數來新增新的層組態項目。
您可以使用 --tier-config-rm=KEY 移除現有的項目。
21.8.2 同步區域 #
同步模組組態對於區域而言位於本地。同步模組會確定區域是要輸出資料,還是只能使用已在另一區域中修改的資料。從 Luminous 版本開始,支援的同步外掛程式有 ElasticSearch、rgw 和 log,其中 rgw 是在區域之間同步資料的預設同步外掛程式,log 是記錄遠端區域中發生的中繼資料操作的一般同步外掛程式。以下各節內容包含了使用 ElasticSearch 同步模組的區域範例。其程序與設定任何其他同步外掛程式的程序均相似。
rgw 是預設的同步外掛程式,不需要明確設定。
21.8.2.1 要求和假設 #
我們假設已依據第 21.13 節 「多站台物件閘道」中所述設定了一個簡單的多站台,它由 us-east 和 us-west 這兩個區域組成。現在,我們新增第三個區域 us-east-es,此區域只處理來自其他站台的中繼資料。此區域可與 us-east 位於同一 Ceph 叢集中,也可位於不同的叢集中。此區域只使用來自其他區域的中繼資料,並且此區域中的物件閘道不會直接處理任何最終使用者要求。
21.8.2.2 設定區域 #
建立類似於第 21.13 節 「多站台物件閘道」中所述區域的第三個區域,例如
cephuser@adm >radosgw-adminzone create --rgw-zonegroup=us --rgw-zone=us-east-es \ --access-key=SYSTEM-KEY --secret=SECRET --endpoints=http://rgw-es:80可透過以下指令為此區域設定同步模組:
cephuser@adm >radosgw-adminzone modify --rgw-zone=ZONE-NAME --tier-type=TIER-TYPE \ --tier-config={set of key=value pairs}例如,在
ElasticSearch同步模組中執行以下指令cephuser@adm >radosgw-adminzone modify --rgw-zone=ZONE-NAME --tier-type=elasticsearch \ --tier-config=endpoint=http://localhost:9200,num_shards=10,num_replicas=1如需支援的各個 tier-config 選項,請參閱第 21.8.3 節 「ElasticSearch 同步模組」。
最後,更新期間
cephuser@adm >radosgw-adminperiod update --commit現在,在區域中啟動物件閘道
cephuser@adm >ceph orch start rgw.REALM-NAME.ZONE-NAME
21.8.3 ElasticSearch 同步模組 #
此同步模組會將來自其他區域的中繼資料寫入 ElasticSearch。從 Luminous 版本開始,這些中繼資料就是我們目前儲存在 ElasticSearch 中的資料欄位的 JSON。
{
"_index" : "rgw-gold-ee5863d6",
"_type" : "object",
"_id" : "34137443-8592-48d9-8ca7-160255d52ade.34137.1:object1:null",
"_score" : 1.0,
"_source" : {
"bucket" : "testbucket123",
"name" : "object1",
"instance" : "null",
"versioned_epoch" : 0,
"owner" : {
"id" : "user1",
"display_name" : "user1"
},
"permissions" : [
"user1"
],
"meta" : {
"size" : 712354,
"mtime" : "2017-05-04T12:54:16.462Z",
"etag" : "7ac66c0f148de9519b8bd264312c4d64"
}
}
}21.8.3.1 ElasticSearch 層類型組態參數 #
- endpoint
指定要存取的 ElasticSearch 伺服器端點。
- num_shards
(整數) 資料同步啟始化時將為 ElasticSearch 設定的分區數量。請注意,啟始化之後將無法變更此數量。在此處進行任何變更都需要重建 ElasticSearch 索引,並需要重新啟始化資料同步程序。
- num_replicas
(整數) 資料同步啟始化時將為 ElasticSearch 設定的複本數量。
- explicit_custom_meta
(true | false) 指定是否將為所有使用者自訂中繼資料編製索引,或者使用者是否需要 (在桶層級) 設定應為哪些客戶中繼資料項目編製索引。此參數預設為 false
- index_buckets_list
(逗號分隔的字串清單) 如果為空白,將會為所有桶編製索引。否則,將只為此處指定的桶編製索引。可以提供桶字首 (例如「foo*」) 或桶字尾 (例如「*bar」)。
- approved_owners_list
(逗號分隔的字串清單) 如果為空白,將會為所有擁有者的桶編製索引 (需遵守其他限制);否則,將只為指定擁有者擁有的桶編製索引。也可以提供字尾和字首。
- override_index_path
(字串) 如果非空白,則此字串將做為 ElasticSearch 索引路徑。否則,將在同步啟始化時確定並產生索引路徑。
- username
指定 ElasticSearch 的使用者名稱 (如果需要驗證)。
- password
指定 ElasticSearch 的密碼 (如果需要驗證)。
21.8.3.2 中繼資料查詢 #
由於 ElasticSearch 叢集現在儲存物件中繼資料,因此務必確定 ElasticSearch 端點不會向公眾公開,只有叢集管理員可存取它們。向最終使用者自己公開中繼資料查詢會造成問題,因為我們希望該使用者只查詢自己的中繼資料,而不能查詢任何其他使用者的中繼資料,這要求 ElasticSearch 叢集如同 RGW 所做的那樣來對使用者進行驗證,而這就導致了問題發生。
從 Luminous 版本開始,中繼資料主區域中的 RGW 可處理最終使用者要求。這樣就無需向公眾公開 ElasticSearch 端點,同時也解決了驗證和授權問題,因為 RGW 自身就能對最終使用者要求進行驗證。出於此目的,RGW 在桶 API 中引入了可處理 ElasticSearch 要求的新查詢。所有這些要求都必須傳送到中繼資料主區域。
- 獲取 ElasticSearch 查詢
GET /BUCKET?query=QUERY-EXPR
要求參數:
max-keys:要傳回的最大項目數
marker:分頁標記
expression := [(]<arg> <op> <value> [)][<and|or> ...]
運算子為下列其中一項:<、<=、==、>=、>
例如:
GET /?query=name==foo
將傳回使用者有權讀取且編製了索引、名為「foo」的所有鍵。輸出內容將是 XML 格式的鍵清單,與 S3 的「列出桶」要求的回應類似。
- 設定自訂中繼資料欄位
定義應該 (在指定的桶中) 為哪些自訂中繼資料項目編製索引,以及這些鍵的類型是什麼。如果設定了明確的自訂中繼資料索引,則需要此定義,以便 rgw 為指定的自訂中繼資料值編製索引。如果未設定,在已編製索引的中繼資料鍵類型不是字串的情況下,也需要此定義。
POST /BUCKET?mdsearch x-amz-meta-search: <key [; type]> [, ...]
若中繼資料欄位有多個,則必須使用逗號加以分隔,可以使用分號「;」強制指定欄位的類型。目前允許的類型有字串 (預設)、整數和日期。例如,如果您想要將自訂物件中繼資料 x-amz-meta-year 以整數類型編入索引,將 x-amz-meta-date 以日期類型編入索引,並將 x-amz-meta-title 以字串類型編入索引,您需要執行以下指令:
POST /mybooks?mdsearch x-amz-meta-search: x-amz-meta-year;int, x-amz-meta-release-date;date, x-amz-meta-title;string
- 刪除自訂中繼資料組態
刪除自訂中繼資料桶組態。
DELETE /BUCKET?mdsearch
- 獲取自訂中繼資料組態
擷取自訂中繼資料桶組態。
GET /BUCKET?mdsearch
21.8.4 雲端同步模組 #
本節介紹用於將區域資料同步到遠端雲端服務的模組。該同步是單向的,無法將資料從遠端區域同步回其本地區域。此模組的主要目的是實現面向多個雲端服務提供者的資料同步,目前僅支援與 AWS (S3) 相容的雲端提供者。
若要將資料同步到遠端雲端服務,您需要設定使用者身分證明。由於許多雲端服務都對每個使用者可建立的桶數量設定了限制,因此您可以設定來源物件與桶的對應,以使不同的目標對應至不同的桶和桶字首。請注意,系統不會保留來源存取清單 (ACL)。可以將特定來源使用者的許可權對應至特定目的地使用者。
由於 API 存在限制,因此無法保留原始物件修改時間和 HTTP 實體標記 (ETag)。雲端同步模組會將它們儲存為目的地物件的中繼資料屬性。
21.8.4.1 設定雲端同步模組 #
下面提供了一些一般和非一般雲端同步模組組態範例。請注意,一般組態可能會與非一般組態發生衝突。
{
"connection": {
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style": path | virtual,
},
"acls": [ { "type": id | email | uri,
"source_id": SOURCE_ID,
"dest_id": DEST_ID } ... ],
"target_path": TARGET_PATH,
}{
"default": {
"connection": {
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style" path | virtual,
},
"acls": [
{
"type": id | email | uri, # optional, default is id
"source_id": ID,
"dest_id": ID
} ... ]
"target_path": PATH # optional
},
"connections": [
{
"connection_id": ID,
"access_key": ACCESS,
"secret": SECRET,
"endpoint": ENDPOINT,
"host_style": path | virtual, # optional
} ... ],
"acl_profiles": [
{
"acls_id": ID, # acl mappings
"acls": [ {
"type": id | email | uri,
"source_id": ID,
"dest_id": ID
} ... ]
}
],
"profiles": [
{
"source_bucket": SOURCE,
"connection_id": CONNECTION_ID,
"acls_id": MAPPINGS_ID,
"target_path": DEST, # optional
} ... ],
}下面是對所用組態術語的解釋:
- connection
表示與遠端雲端服務的連接。包含「connection_id」、「access_key」、「secret」、「endpoint」和「host_style」。
- access_key
將用於特定連接的遠端雲端存取金鑰。
- secret
遠端雲端服務的機密金鑰。
- endpoint
遠端雲端服務端點的 URL。
- host_style
存取遠端雲端端點時要使用的主機類型 (「path」或「virtual」)。預設值為「path」。
- acls
存取清單對應陣列。
- acl_mapping
每個「acl_mapping」結構都包含「type」、「source_id」和「dest_id」。它們將定義每個物件的 ACL 變動。ACL 變動允許將來源使用者 ID 轉換為目的地 ID。
- type
ACL 類型:「id」定義使用者 ID,「email」依電子郵件定義使用者,「uri」依 uri (群組) 定義使用者。
- source_id
來源區域中的使用者 ID。
- dest_id
目的地中的使用者 ID。
- target_path
用於定義目標路徑建立方式的字串。目標路徑指定附加至來源物件名稱的字首。可對目標路徑進行設定,以使其包含以下任何變數:
- SID
表示同步例項 ID 的唯一字串。
- ZONEGROUP
區域群組名稱。
- ZONEGROUP_ID
區域群組 ID。
- ZONE
區域名稱。
- ZONE_ID
區域 ID。
- BUCKET
來源桶名稱。
- OWNER
來源桶擁有者 ID。
例如:target_path = rgwx-ZONE-SID/OWNER/BUCKET
- acl_profiles
存取清單設定檔陣列。
- acl_profile
每個設定檔均包含代表設定檔的「acls_id」和用於儲存「acl_mappings」清單的「acls」陣列。
- profiles
設定檔清單。每個設定檔均包含以下變數:
- source_bucket
用於定義此設定檔來源桶的桶名稱或桶字首 (如果以 * 結尾)。
- target_path
請參閱上文的相關解釋。
- connection_id
將用於此設定檔的連接 ID。
- acls_id
將用於此設定檔的 ACL 設定檔 ID。
21.8.4.2 S3 特定的可設定項 #
雲端同步模組僅適用於與 AWS S3 相容的後端。該模組提供了一些可設定項,用來調整它在存取 S3 雲端服務時的行為:
{
"multipart_sync_threshold": OBJECT_SIZE,
"multipart_min_part_size": PART_SIZE
}- multipart_sync_threshold
針對大小大於或等於此值的物件,將使用多部分上傳來與雲端服務進行同步。
- multipart_min_part_size
透過多部分上傳同步物件時所使用的部分大小下限。
21.8.5 歸檔同步模組 #
歸檔同步模組利用了物件閘道中 S3 物件的版本設定功能。您可以設定一個歸檔區域,用來擷取其他區域中一段時間內出現的 S3 物件的不同版本。只能透過與歸檔區域關聯的閘道來刪除歸檔區域保留的版本歷程。
借助這樣的架構,一些沒有建立版本的區域可以透過自身的區域閘道來鏡像它們的資料和中繼資料,以便向最終使用者提供高可用性,同時,歸檔區域會擷取所有資料更新,以便將它們合併為 S3 物件的版本。
透過在多區域組態中包含歸檔區域,您可以靈活地在一個區域中保留 S3 物件歷程,同時能夠節省其餘區域中已建立版本的 S3 物件的複本原本會需要的空間。
21.8.5.1 設定歸檔同步模組 #
若要使用歸檔同步模組,您需要建立一個新區域,並將其層類型設定為 archive:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME \
--rgw-zone=OGW_ZONE_NAME \
--endpoints=http://OGW_ENDPOINT1_URL[,http://OGW_ENDPOINT2_URL,...]
--tier-type=archive21.9 LDAP authentication #
除了預設的本地使用者驗證之外,物件閘道還能利用 LDAP 伺服器服務來對使用者進行驗證。
21.9.1 驗證機制 #
物件閘道從記號擷取使用者的 LDAP 身分證明。可以根據使用者名稱建構搜尋過濾器。物件閘道使用設定的服務帳戶在目錄中搜尋相符項。如果找到了某個項目,物件閘道會嘗試使用記號中的密碼結合到所找到的可辨識名稱。如果身分證明有效,結合將會成功,並且物件閘道會授予存取權。
您可以透過將搜尋範圍設定為特定的組織單位,或者指定自訂搜尋過濾器 (例如,要求特定的群組成員資格、自訂物件類別或屬性),來限制允許的使用者。
21.9.2 要求 #
LDAP 或 Active Directory:物件閘道可存取的執行中 LDAP 例項。
服務帳戶:物件閘道要使用且擁有搜尋權限的 LDAP 身分證明。
使用者帳戶:LDAP 目錄中的至少一個使用者帳戶。
不得對本地使用者以及要使用 LDAP 進行驗證的使用者使用相同的使用者名稱。物件閘道無法區分兩者,會將它們視為同一個使用者。
使用 ldapsearch 公用程式可驗證服務帳戶或 LDAP 連接。例如:
tux > ldapsearch -x -D "uid=ceph,ou=system,dc=example,dc=com" -W \
-H ldaps://example.com -b "ou=users,dc=example,dc=com" 'uid=*' dn請務必在 Ceph 組態檔案中使用相同的 LDAP 參數,以杜絕可能的問題。
21.9.3 將物件閘道設定為使用 LDAP 驗證 #
以下參數與 LDAP 驗證相關:
rgw_ldap_uri指定要使用的 LDAP 伺服器。請務必使用
ldaps://FQDN:PORT參數,以免公開傳輸純文字身分證明。rgw_ldap_binddn物件閘道使用的服務帳戶的可辨識名稱 (DN)。
rgw_ldap_secret服務帳戶的密碼。
- rgw_ldap_searchdn
指定在目錄資訊樹狀結構中搜尋使用者的範圍,可以是使用者的組織單位,或某個更具體的組織單位 (OU)。
rgw_ldap_dnattr在建構的搜尋過濾器中用來比對某個使用者名稱的屬性。根據所用的目錄資訊樹狀結構 (DIT),可能會是
uid或cn。rgw_search_filter如果未指定,則物件閘道會使用
rgw_ldap_dnattr設定自動建構搜尋過濾器。使用此參數能非常靈活地縮小所允許使用者清單的範圍。如需詳細資料,請參閱第 21.9.4 節 「使用自訂搜尋過濾器來限制使用者存取權」。
21.9.4 使用自訂搜尋過濾器來限制使用者存取權 #
可透過兩種方式使用 rgw_search_filter 參數。
21.9.4.1 用於進一步限制所建構搜尋過濾器的部分過濾器 #
部分過濾器的範例:
"objectclass=inetorgperson"
物件閘道將照常使用記號中的使用者名稱和 rgw_ldap_dnattr 的值產生搜尋過濾器。然後,建構的過濾器將與 rgw_search_filter 屬性中的部分過濾器合併。根據所用的使用者名稱和設定,最終的搜尋過濾器可能會變成:
"(&(uid=hari)(objectclass=inetorgperson))"
在這種情況下,僅當在 LDAP 目錄中找到了使用者「hari」,該使用者具有物件類別「inetorgperson」並且確實指定了有效密碼時,才向他授予存取權。
21.9.4.2 完整過濾器 #
完整過濾器必須包含 USERNAME 記號,在嘗試驗證期間,將以使用者名稱取代該記號。在這種情況下,不再使用 rgw_ldap_dnattr 參數。例如,若要將有效使用者限制為特定的群組,可使用以下過濾器:
"(&(uid=USERNAME)(memberOf=cn=ceph-users,ou=groups,dc=mycompany,dc=com))"
memberOf 屬性
若要在 LDAP 搜尋中使用 memberOf 屬性,您的特定 LDAP 伺服器實作需要提供伺服器端支援。
21.9.5 產生用於 LDAP 驗證的存取記號 #
radosgw-token 公用程式根據 LDAP 使用者名稱和密碼產生存取記號。它會輸出 base-64 編碼字串,即實際的存取記號。請使用偏好的 S3 用戶端 (請參閱第 21.5.1 節 「存取物件閘道」),將該記號指定為存取金鑰,並使用空白機密金鑰。
tux >export RGW_ACCESS_KEY_ID="USERNAME"tux >export RGW_SECRET_ACCESS_KEY="PASSWORD"cephuser@adm >radosgw-token --encode --ttype=ldap
存取記號是一個 base-64 編碼的 JSON 結構,並包含純文字形式的 LDAP 身分證明。
對於 Active Directory,請使用 --ttype=ad 參數。
21.10 桶索引分區 #
物件閘道在索引池中儲存桶索引資料,該池預設為 .rgw.buckets.index。如果將太多 (數十萬個) 物件放入單個桶中,並且不設定每個桶的最大物件數量定額 (rgw bucket default quota max objects),索引池的效能可能會下降。桶索引分區可在允許每個桶中放入大量物件的同時,防止出現此類效能下降的情況。
21.10.1 桶索引重新分區 #
如果隨著桶的增大,其初始組態不再能符合需求,則需要對桶的索引池進行重新分區。您可以使用自動線上桶索引重新分區功能 (請參閱第 21.10.1.1 節 「動態重新分區」),也可以手動離線執行桶索引重新分區 (請參閱第 21.10.1.2 節 「手動重新分區」)。
21.10.1.1 動態重新分區 #
從 SUSE Enterprise Storage 5 開始,我們支援線上桶重新分區功能。此功能會偵測每個桶的物件數量是否達到某個閾值,如果達到該閾值,將會相應地自動增加桶索引使用的分區數量。此程序會減少每個桶索引分區中的項目數。
該偵測程序在以下情況和環境中執行:
當有新的物件新增至桶中時。
在定期掃描所有桶的背景程序中。掃描的目的是為了處理未在更新的現有桶。
需要重新分區的桶會新增至 reshard_log 佇列,且將排程於稍後進行重新分區。重新分區線串在背景中執行,並將逐個執行已排程的重新分區。
rgw_dynamic_resharding啟用或停用動態桶索引重新分區。可用的值為「true」或「false」。預設設為「true」。
rgw_reshard_num_logs重新分區記錄的分區數。預設設為 16。
rgw_reshard_bucket_lock_duration重新分區期間將桶物件鎖定的持續時間。預設設為 120 秒。
rgw_max_objs_per_shard每個桶索引分區的最大物件數。預設設為 100000 個物件。
rgw_reshard_thread_interval兩輪重新分區線串處理間隔的最長時間。預設設為 600 秒。
- 將桶新增至重新分區佇列:
cephuser@adm >radosgw-admin reshard add \ --bucket BUCKET_NAME \ --num-shards NEW_NUMBER_OF_SHARDS- 列出重新分區佇列:
cephuser@adm >radosgw-admin reshard list- 處理/排程桶重新分區:
cephuser@adm >radosgw-admin reshard process- 顯示桶重新分區狀態:
cephuser@adm >radosgw-admin reshard status --bucket BUCKET_NAME- 取消等待中的桶重新分區:
cephuser@adm >radosgw-admin reshard cancel --bucket BUCKET_NAME
21.10.1.2 手動重新分區 #
第 21.10.1.1 節 「動態重新分區」所述的動態重新分區僅適用於簡單物件閘道組態。對於多站台組態,請使用本節所述的手動重新分區。
若要手動對桶索引執行離線重新分區,請使用以下指令:
cephuser@adm > radosgw-admin bucket reshard
bucket reshard 指令執行以下操作:
為指定物件建立一組新的桶索引物件。
分散這些索引物件的所有項目。
建立新的桶例項。
列出新的桶例項以及桶,以便所有新的索引操作都能夠套用到新的桶索引。
將舊的和新的桶 ID 列印到標準輸出。
選擇分區數量時,請注意以下幾點:確定每個分區不超過 100000 個項目。如果在各個分區中均勻分佈桶索引項目,使用質數數量的桶索引分區通常效果更佳。例如,使用 503 個桶索引分區會比使用 500 個的效果更佳,因為前者為質數。
確定對桶執行的所有操作都已停止。
備份原始桶索引:
cephuser@adm >radosgw-admin bi list \ --bucket=BUCKET_NAME \ > BUCKET_NAME.list.backup對桶索引重新分區:
cephuser@adm >radosgw-admin bucket reshard \ --bucket=BUCKET_NAME \ --num-shards=NEW_SHARDS_NUMBER提示:舊桶 ID此指令還會將新的和舊的桶 ID 列印到其輸出中。
21.10.2 新桶的桶索引分區 #
有兩個選項會影響桶索引分區:
對於簡單組態,請使用
rgw_override_bucket_index_max_shards選項。對於多站台組態,請使用
bucket_index_max_shards選項。
將選項設為 0 將停用桶索引分區。如果將其設為大於 0 的值,則會啟用桶索引分區,並設定最大分區數。
下面的公式可協助您計算建議的分區數:
number_of_objects_expected_in_a_bucket / 100000
注意,分區的最大數量為 7877。
21.10.2.1 多站台組態 #
多站台組態可能會使用另一個索引池來管理容錯移轉。若要為一個區域群組內的區域設定一致的分區數量,請在該區域群組的組態中設定 bucket_index_max_shards 選項:
將區域群組組態輸出至
zonegroup.json檔案:cephuser@adm >radosgw-admin zonegroup get > zonegroup.json編輯
zonegroup.json檔案,為每個指定的區域設定bucket_index_max_shards選項。重設區域群組:
cephuser@adm >radosgw-admin zonegroup set < zonegroup.json更新期間。請參閱第 21.13.2.6 節 「更新期間」。
21.11 OpenStack Keystone 整合 #
OpenStack Keystone 是一項用於 OpenStack 產品的身分服務。您可以將物件閘道與 Keystone 相整合,以設定接受 Keystone 驗證記號的閘道。Ceph 物件閘道端將會對 Keystone 授權可存取閘道的使用者進行驗證,並視需要自動建立使用者。物件閘道會定期查詢 Keystone,以獲取已撤銷記號清單。
21.11.1 設定 OpenStack #
設定 Ceph 物件閘道前,需要先設定 OpenStack Keystone 以啟用 Swift 服務,並將其指向 Ceph 物件閘道:
設定 Swift 服務。若要使用 OpenStack 來驗證 Swift 使用者,請先建立 Swift 服務:
tux >openstack service create \ --name=swift \ --description="Swift Service" \ object-store設定端點。建立 Swift 服務後,指向 Ceph 物件閘道。以閘道的區域群組名稱或區域名稱取代 REGION_NAME。
tux >openstack endpoint create --region REGION_NAME \ --publicurl "http://radosgw.example.com:8080/swift/v1" \ --adminurl "http://radosgw.example.com:8080/swift/v1" \ --internalurl "http://radosgw.example.com:8080/swift/v1" \ swift驗證設定。建立 Swift 服務並設定端點後,顯示端點以確認所有設定正確無誤。
tux >openstack endpoint show object-store
21.11.2 設定 Ceph 物件閘道 #
21.11.2.1 設定 SSL 證書 #
Ceph 物件閘道會定期查詢 Keystone,以獲取已撤銷記號清單。系統會對這些要求加以編碼並簽署。還可設定 Keystone 以提供自行簽署的記號,這些記號同樣經過編碼和簽署。您需要設定閘道以便其可以解碼並驗證這些已簽署訊息。因此,需要將 Keystone 用於建立要求的 OpenSSL 證書轉換為「nss db」格式:
root #mkdir /var/ceph/nssroot #openssl x509 -in /etc/keystone/ssl/certs/ca.pem \ -pubkey | certutil -d /var/ceph/nss -A -n ca -t "TCu,Cu,Tuw"rootopenssl x509 -in /etc/keystone/ssl/certs/signing_cert.pem \ -pubkey | certutil -A -d /var/ceph/nss -n signing_cert -t "P,P,P"
為允許 Ceph 物件閘道與 OpenStack Keystone 互動,OpenStack Keystone 可使用自行簽署的 SSL 證書。可在執行 Ceph 物件閘道的節點上安裝 Keystone 的 SSL 證書,也可以將選項 rgw keystone verify ssl 的值設為「false」。將 rgw keystone verify ssl 設為「false」表示閘道將不會嘗試驗證證書。
21.11.2.2 設定物件閘道的選項 #
您可以使用以下選項設定 Keystone 整合:
rgw keystone api versionKeystone API 的版本。有效選項為 2 或 3。預設設為 2。
rgw keystone urlKeystone 伺服器上管理 RESTful API 的 URL 和連接埠號碼。採用 SERVER_URL:PORT_NUMBER 模式。
rgw keystone admin token在 Keystone 內部為管理要求設定的記號或共用機密。
rgw keystone accepted roles處理要求需要具有的角色。預設設為「Member, admin」。
rgw keystone accepted admin roles允許使用者獲取管理特權的角色清單。
rgw keystone token cache sizeKeystone 記號快取中的最大項目數。
rgw keystone revocation interval檢查已撤銷記號前間隔的秒數。預設設為 15 * 60。
rgw keystone implicit tenants在各自的同名租用戶中建立新使用者。預設設為「false」。
rgw s3 auth use keystone如果設為「true」,Ceph 物件閘道將使用 Keystone 對使用者進行驗證。預設設為「false」。
nss db pathNSS 資料庫的路徑。
還可以設定 Keystone 服務租用戶、Keystone 的使用者和密碼 (適用於 OpenStack Identity API 2.0 版本),設定方法與設定 OpenStack 服務的方法類似。使用此方法可避免在組態檔案中設定共用機密 rgw keystone admin token,生產環境中應停用該共用機密。服務租用戶身分證明應具有管理員權限。如需更多詳細資料,請參閱官方 OpenStack Keystone 文件。相關組態選項如下:
rgw keystone admin userKeystone 管理員使用者名稱。
rgw keystone admin passwordKeystone 管理員使用者密碼。
rgw keystone admin tenantKeystone 2.0 版管理員使用者租用戶。
Ceph 物件閘道使用者與 Keystone 租用戶一一對應。系統會為一個 Keystone 使用者指定不同的角色,這些角色可能分佈在不止一個租用戶上。當 Ceph 物件閘道收到票證時,會查看為該票證指定的租用戶和使用者角色,並根據 rgw keystone accepted roles 選項的設定接受或拒絕要求。
雖然 Swift 租用戶預設會對應到物件閘道使用者,但也可透過 rgw keystone implicit tenants 選項將其對應到 OpenStack 租用戶。如此會讓容器使用租用戶名稱空間,而不是物件閘道預設採用的 S3 之類全域名稱空間。建議在規劃階段就決定好對應方法,以免產生混淆。這是因為以後切換選項只會影響租用戶下所對應的較新要求,而先前建立的舊桶仍將繼續放在全域名稱空間中。
對於 OpenStack Identity API 3 版本,您應使用以下選項取代 rgw keystone admin tenant 選項:
rgw keystone admin domainKeystone 管理員使用者網域。
rgw keystone admin projectKeystone 管理員使用者專案。
21.12 池放置和儲存類別 #
21.12.1 顯示放置目標 #
放置目標用於控制哪些池與特定桶相關聯。桶的放置目標是在建立桶時選取的,無法修改。您可透過執行以下指令來顯示桶的 placement_rule:
cephuser@adm > radosgw-admin bucket stats區域群組組態包含一個放置目標清單,其中初始目標名為「default-placement」。區域組態隨後會將每個區域群組放置目標名稱對應至其本地儲存。此區域放置資訊包括表示桶索引的「index_pool」名稱、表示不完整多部分上傳相關中繼資料的「data_extra_pool」名稱,以及表示每個儲存類別的「data_pool」名稱。
21.12.2 儲存類別 #
儲存類別有助於自訂物件資料的放置。S3 桶生命週期規則可自動轉換物件的儲存類別。
依據放置目標來定義儲存類別。每個區域群組放置目標會列出它的可用儲存類別,其中初始類別名為「STANDARD」。區域組態負責為每個區域群組的儲存類別提供「data_pool」池名稱。
21.12.3 設定區域群組和區域 #
您可以對區域群組和區域使用 radosgw-admin 指令來設定其放置。可以使用以下指令來查詢區域群組放置組態:
cephuser@adm > radosgw-admin zonegroup get
{
"id": "ab01123f-e0df-4f29-9d71-b44888d67cd5",
"name": "default",
"api_name": "default",
...
"placement_targets": [
{
"name": "default-placement",
"tags": [],
"storage_classes": [
"STANDARD"
]
}
],
"default_placement": "default-placement",
...
}若要查詢區域放置組態,請執行以下指令:
cephuser@adm > radosgw-admin zone get
{
"id": "557cdcee-3aae-4e9e-85c7-2f86f5eddb1f",
"name": "default",
"domain_root": "default.rgw.meta:root",
...
"placement_pools": [
{
"key": "default-placement",
"val": {
"index_pool": "default.rgw.buckets.index",
"storage_classes": {
"STANDARD": {
"data_pool": "default.rgw.buckets.data"
}
},
"data_extra_pool": "default.rgw.buckets.non-ec",
"index_type": 0
}
}
],
...
}
如果您之前未進行過任何多站台組態,系統將會為您建立「default」區域和區域群組,並且您必須重新啟動 Ceph 物件閘道,對該區域/區域群組所做的變更才會生效。如果您已建立過多站台領域,則當您使用 radosgw-admin period update --commit 指令提交對區域/區域群組的變更後,變更即會生效。
21.12.3.1 新增放置目標 #
若要建立一個名為「temporary」的新放置目標,首先請將該放置目標新增至區域群組:
cephuser@adm > radosgw-admin zonegroup placement add \
--rgw-zonegroup default \
--placement-id temporary然後為該目標提供區域放置資訊:
cephuser@adm > radosgw-admin zone placement add \
--rgw-zone default \
--placement-id temporary \
--data-pool default.rgw.temporary.data \
--index-pool default.rgw.temporary.index \
--data-extra-pool default.rgw.temporary.non-ec21.12.3.2 新增儲存類別 #
若要新增一個名為「COLD」的新儲存類別至「default-placement」目標,首先請將該儲存類別新增至區域群組:
cephuser@adm > radosgw-admin zonegroup placement add \
--rgw-zonegroup default \
--placement-id default-placement \
--storage-class COLD然後為該儲存類別提供區域放置資訊:
cephuser@adm > radosgw-admin zone placement add \
--rgw-zone default \
--placement-id default-placement \
--storage-class COLD \
--data-pool default.rgw.cold.data \
--compression lz421.12.4 放置自訂 #
21.12.4.1 編輯預設區域群組放置 #
新桶預設會使用區域群組的 default_placement 目標。您可以使用以下指令變更此區域群組設定:
cephuser@adm > radosgw-admin zonegroup placement default \
--rgw-zonegroup default \
--placement-id new-placement21.12.4.2 編輯預設使用者放置 #
Ceph 物件閘道使用者可以透過在使用者資訊中設定非空白 default_placement 欄位,來覆寫區域群組的預設放置目標。同樣,default_storage_class 也可以覆寫預設套用於物件的 STANDARD 儲存類別。
cephuser@adm > radosgw-admin user info --uid testid
{
...
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
...
}如果區域群組的放置目標包含任何標記,則除非使用者資訊的「placement_tags」欄位中至少包含一個相符的標記,否則使用者將無法建立具有該放置目標的桶。這有助於限制對某些特定儲存類型的存取。
radosgw-admin 無法直接修改這些欄位,因此您需要手動編輯 JSON 格式:
cephuser@adm >radosgw-admin metadata get user:USER-ID > user.jsontux >vi user.json # edit the file as requiredcephuser@adm >radosgw-admin metadata put user:USER-ID < user.json
21.12.4.3 編輯 S3 預設桶放置 #
採用 S3 通訊協定建立桶時,可在 LocationConstraint 選項中提供放置目標,以覆寫使用者和區域群組的預設放置目標。
通常,LocationConstraint 需要與區域群組的 api_name 相符:
<LocationConstraint>default</LocationConstraint>
您可以新增自訂放置目標至 api_name (需在該自訂目標前加上一個冒號):
<LocationConstraint>default:new-placement</LocationConstraint>
21.12.4.4 編輯 Swift 桶放置 #
採用 Swift 通訊協定建立桶時,您可以在 HTTP 標題的 X-Storage-Policy 中提供放置目標:
X-Storage-Policy: NEW-PLACEMENT
21.12.5 使用儲存類別 #
所有放置目標均具有 STANDARD 儲存類別,這是系統預設為新物件套用的儲存類別。您可以使用物件的 default_storage_class 覆寫此預設值。
若要建立不屬於預設儲存類別的物件,請在要求的 HTTP 標題中提供所需的儲存類別名稱。S3 通訊協定使用 X-Amz-Storage-Class 標題,而 Swift 通訊協定則使用 X-Object-Storage-Class 標題。
憑藉 S3 物件生命週期管理,您可以使用轉換操作來切換物件資料的儲存類別。
21.13 多站台物件閘道 #
Ceph 支援為 Ceph 物件閘道選擇以下多種多站台組態選項:
- 多區域
由一個區域群組和多個區域組成的組態,每個區域有一或多個
ceph-radosgw例項。每個區域由各自的 Ceph 儲存叢集提供支援。當區域群組中的其中一個區域出現嚴重故障時,該區域群組中的其他區域可為區域群組提供災難備援。每個區域都處於使用中狀態且可接收寫入操作。除了災難備援外,多個使用中區域還可做為內容傳遞網路的基礎。- 多區域群組
Ceph 物件閘道支援多個區域群組,每個區域群組有一或多個區域。物件會儲存到一個區域群組中的多個區域,而同屬於一個領域的另一個區域群組會共用全域物件名稱空間,以確保物件 ID 在各個區域群組和區域間保持唯一。
注意請務必注意,區域群組只會在各個區域群組之間同步中繼資料。區域群組內的各個區域之間會複製資料和中繼資料。但任何資料和中繼資料均不會在領域中共用。
- 多個領域
Ceph 物件閘道支援領域 (即全域唯一的名稱空間) 概念。支援使用多個領域,每個領域可包含一或多個區域群組。
您可以將每個物件閘道設定為以主動/主動區域組態執行,以便允許向非主區域寫入資料。多站台組態儲存在名為領域的容器內。領域中會儲存區域群組、區域和包含多個版本編號 (用於追蹤對組態的變更) 的期間。rgw 精靈負責處理同步,因而不需要另行提供同步代理程式。這種同步方法可讓 Ceph 物件閘道以主動/主動組態 (而非主動/被動組態) 執行。
21.13.1 要求和假設 #
多站台組態至少需要兩個 Ceph 儲存叢集以及兩個 Ceph 物件閘道例項,每個 Ceph 物件閘道例項對應一個 Ceph 儲存叢集。以下組態假設至少有兩個 Ceph 儲存叢集分佈在不同的地理位置。但該組態也可在同一站台執行。例如,有兩個名為 rgw1 和 rgw2 的主機。
多站台組態需要有一個主區域群組和一個主區域。主區域是與多站台叢集中所有中繼資料操作相關的信任資料來源。此外,每個區域群組都需要有一個主區域。區域群組可以有一或多個次要區域或非主區域。在本指南中,rgw1 主機做為主區域群組的主區域,rgw2 主機做為主區域群組的次要區域。
21.13.2 設定主區域 #
多站台組態中的所有閘道都要從主區域群組和主區域內主機上的 ceph-radosgw 精靈擷取其組態。若要在多站台組態中設定您的閘道,請選取 ceph-radosgw 例項以設定主區域群組和主區域。
21.13.2.1 建立領域 #
領域表示全域唯一的名稱空間,由包含一或多個區域的一或多個區域群組組成。區域包含桶,而桶包含物件。憑藉領域,Ceph 物件閘道可以在相同硬體上支援多個名稱空間及其組態。領域包含期間概念。每個期間表示不同時間的區域群組和區域組態的狀態。每次您變更區域群組或區域時,請更新期間並提交更新。出於反向相容性考慮,Ceph 物件閘道預設不會建立領域。做為最佳實務,我們建議您為新叢集建立領域。
若要為多站台組態建立名為 gold 的新領域,請在識別為用於主區域群組和主區域中的主機上開啟指令行介面。然後執行以下指令:
cephuser@adm > radosgw-admin realm create --rgw-realm=gold --default
如果叢集只有一個領域,請指定 --default 旗標。如果指定了 --default,radosgw-admin 會預設為使用此領域。如果未指定 --default,新增區域群組和區域時需要指定 --rgw-realm 或 --realm-id 旗標以識別相應的領域。
建立領域後,使用 radosgw-admin 可傳回領域組態:
{
"id": "4a367026-bd8f-40ee-b486-8212482ddcd7",
"name": "gold",
"current_period": "09559832-67a4-4101-8b3f-10dfcd6b2707",
"epoch": 1
}Ceph 會為領域產生唯一的 ID,因此允許使用者在需要時重新命名領域。
21.13.2.2 建立主區域群組 #
領域必須至少有一個區域群組做為該領域的主區域群組。若要為多站台組態建立新的主區域群組,請在識別為用於主區域群組和主區域中的主機上開啟指令行介面。透過執行以下指令建立名為 us 的主區域群組:
cephuser@adm > radosgw-admin zonegroup create --rgw-zonegroup=us \
--endpoints=http://rgw1:80 --master --default
如果領域只有一個區域群組,請指定 --default 旗標。如果指定了 --default,radosgw-admin 在新增新區域時預設會使用此區域群組。如果未指定 --default,新增區域時需要指定 --rgw-zonegroup 或 --zonegroup-id 旗標以識別新增或修改區域時的相應區域群組。
建立主區域群組後,使用 radosgw-admin 可傳回區域群組組態。例如:
{
"id": "d4018b8d-8c0d-4072-8919-608726fa369e",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "",
"zones": [],
"placement_targets": [],
"default_placement": "",
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7"
}21.13.2.3 建立主區域 #
需要在將要置於區域內的 Ceph 物件閘道節點上建立區域。
若要為多站台組態建立新的主區域,請在識別為用於主區域群組和主區域中的主機上開啟指令行介面。執行以下項目:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-1 \
--endpoints=http://rgw1:80 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
上面的範例中未指定 --access-key 和 --secret 選項。在下一節中建立使用者時會將這些設定新增至區域中。
建立主區域後,使用 radosgw-admin 可傳回區域組態。例如:
{
"id": "56dfabbb-2f4e-4223-925e-de3c72de3866",
"name": "us-east-1",
"domain_root": "us-east-1.rgw.meta:root",
"control_pool": "us-east-1.rgw.control",
"gc_pool": "us-east-1.rgw.log:gc",
"lc_pool": "us-east-1.rgw.log:lc",
"log_pool": "us-east-1.rgw.log",
"intent_log_pool": "us-east-1.rgw.log:intent",
"usage_log_pool": "us-east-1.rgw.log:usage",
"reshard_pool": "us-east-1.rgw.log:reshard",
"user_keys_pool": "us-east-1.rgw.meta:users.keys",
"user_email_pool": "us-east-1.rgw.meta:users.email",
"user_swift_pool": "us-east-1.rgw.meta:users.swift",
"user_uid_pool": "us-east-1.rgw.meta:users.uid",
"otp_pool": "us-east-1.rgw.otp",
"system_key": {
"access_key": "1555b35654ad1656d804",
"secret_key": "h7GhxuBLTrlhVUyxSPUKUV8r/2EI4ngqJxD7iBdBYLhwluN30JaT3Q=="
},
"placement_pools": [
{
"key": "us-east-1-placement",
"val": {
"index_pool": "us-east-1.rgw.buckets.index",
"storage_classes": {
"STANDARD": {
"data_pool": "us-east-1.rgw.buckets.data"
}
},
"data_extra_pool": "us-east-1.rgw.buckets.non-ec",
"index_type": 0
}
}
],
"metadata_heap": "",
"realm_id": ""
}21.13.2.4 刪除預設區域和群組 #
下列步驟假設多站台組態使用的是新安裝的系統,即其中尚未儲存任何資料。如果您已在使用預設區域及其池儲存資料,請勿刪除該區域及其池,否則資料將被刪除且無法復原。
採用預設設定安裝物件閘道時會建立名為 default 的預設區域群組。刪除預設區域 (如果存在)。請務必先將其從預設區域群組中移除。
cephuser@adm > radosgw-admin zonegroup delete --rgw-zonegroup=default刪除 Ceph 儲存叢集中的預設池 (如果存在):
下列步驟假設多站台組態使用的是新安裝的系統,即目前未儲存任何資料。如果您已在使用預設區域群組儲存資料,請勿刪除該區域群組。
cephuser@adm >ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.meta default.rgw.meta --yes-i-really-really-mean-it
如果您刪除預設區域群組,則將同時刪除系統使用者。如果未傳播您的管理員使用者金鑰,Ceph Dashboard 的物件閘道管理功能將會失效。如您執行此步驟,請遵循下一節的操作,以重新建立您的系統使用者。
21.13.2.5 建立系統使用者 #
ceph-radosgw 精靈在提取領域和期間資訊前必須進行驗證。在主區域中,建立系統使用者以簡化精靈之間的驗證:
cephuser@adm > radosgw-admin user create --uid=zone.user \
--display-name="Zone User" --access-key=SYSTEM_ACCESS_KEY \
--secret=SYSTEM_SECRET_KEY --system
記下 access_key 和 secret_key,因為次要區域需要使用它們向主區域進行驗證。
將系統使用者新增至主區域:
cephuser@adm > radosgw-admin zone modify --rgw-zone=us-east-1 \
--access-key=ACCESS-KEY --secret=SECRET更新期間,以使變更生效:
cephuser@adm > radosgw-admin period update --commit21.13.2.6 更新期間 #
更新主區域組態後,請更新期間:
cephuser@adm > radosgw-admin period update --commit
更新期間後,使用 radosgw-admin 可傳回期間組態。例如:
{
"id": "09559832-67a4-4101-8b3f-10dfcd6b2707", "epoch": 1, "predecessor_uuid": "", "sync_status": [], "period_map":
{
"id": "09559832-67a4-4101-8b3f-10dfcd6b2707", "zonegroups": [], "short_zone_ids": []
}, "master_zonegroup": "", "master_zone": "", "period_config":
{
"bucket_quota": {
"enabled": false, "max_size_kb": -1, "max_objects": -1
}, "user_quota": {
"enabled": false, "max_size_kb": -1, "max_objects": -1
}
}, "realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7", "realm_name": "gold", "realm_epoch": 1
}更新期間會變更版本編號,並會確保其他區域可收到更新的組態。
21.13.2.7 啟動閘道 #
在物件閘道主機上,啟動並啟用 Ceph 物件閘道服務。若要識別叢集的唯一 FSID,請執行 ceph fsid。若要識別物件閘道精靈名稱,請執行 ceph orch ps --hostname HOSTNAME。
cephuser@ogw >systemctl start ceph-FSID@DAEMON_NAMEcephuser@ogw >systemctl enable ceph-FSID@DAEMON_NAME
21.13.3 設定次要區域 #
區域群組內的區域會複製所有資料,以確保各區域都具有相同資料。建立次要區域時,請在指定為次要區域提供服務的主機上執行以下所有操作。
若要新增第三個區域,請執行與新增次要區域相同的程序。請使用不同的區域名稱。
您必須在主區域內的主機上執行中繼資料操作 (例如建立使用者)。主區域及次要區域均可接收桶操作,但次要區域會將桶操作重新導向至主區域。如果主區域處於停機狀態,桶操作將會失敗。
21.13.3.1 提取領域 #
使用主區域群組中的主區域的 URL 路徑、存取金鑰和機密金鑰將領域組態提取至主機。若要提取非預設領域,請使用 --rgw-realm 或 --realm-id 組態選項指定該領域。
cephuser@adm > radosgw-admin realm pull --url=url-to-master-zone-gateway --access-key=access-key --secret=secret提取領域會同時擷取遠端的目前期間組態,並將其設定為此主機上的目前期間。
如果此領域為預設領域或唯一的領域,請將其設定為預設領域。
cephuser@adm > radosgw-admin realm default --rgw-realm=REALM-NAME21.13.3.2 建立次要區域 #
若要為多站台組態建立次要區域,請在識別為用於次要區域的主機上開啟指令行介面。為區域指定區域群組 ID、新區域名稱和端點。請勿使用 --master 旗標。所有區域預設均以主動/主動組態執行。如果次要區域不應接受寫入操作,請指定 --read-only 旗標以在主區域和次要區域之間建立主動/被動組態。此外,還需提供所產生系統使用者的 access_key 和 secret_key,這些資料儲存在主區域群組的主區域中。執行以下項目:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=ZONE-GROUP-NAME\
--rgw-zone=ZONE-NAME --endpoints=URL \
--access-key=SYSTEM-KEY --secret=SECRET\
--endpoints=http://FQDN:80 \
[--read-only]例如:
cephuser@adm > radosgw-admin zone create --rgw-zonegroup=us --endpoints=http://rgw2:80 \
--rgw-zone=us-east-2 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
{
"id": "950c1a43-6836-41a2-a161-64777e07e8b8",
"name": "us-east-2",
"domain_root": "us-east-2.rgw.data.root",
"control_pool": "us-east-2.rgw.control",
"gc_pool": "us-east-2.rgw.gc",
"log_pool": "us-east-2.rgw.log",
"intent_log_pool": "us-east-2.rgw.intent-log",
"usage_log_pool": "us-east-2.rgw.usage",
"user_keys_pool": "us-east-2.rgw.users.keys",
"user_email_pool": "us-east-2.rgw.users.email",
"user_swift_pool": "us-east-2.rgw.users.swift",
"user_uid_pool": "us-east-2.rgw.users.uid",
"system_key": {
"access_key": "1555b35654ad1656d804",
"secret_key": "h7GhxuBLTrlhVUyxSPUKUV8r\/2EI4ngqJxD7iBdBYLhwluN30JaT3Q=="
},
"placement_pools": [
{
"key": "default-placement",
"val": {
"index_pool": "us-east-2.rgw.buckets.index",
"data_pool": "us-east-2.rgw.buckets.data",
"data_extra_pool": "us-east-2.rgw.buckets.non-ec",
"index_type": 0
}
}
],
"metadata_heap": "us-east-2.rgw.meta",
"realm_id": "815d74c2-80d6-4e63-8cfc-232037f7ff5c"
}下列步驟假設多站台組態使用的是新安裝的系統,即其中尚未儲存任何資料。如果您已在使用預設區域及其池儲存資料,請勿刪除該區域及其池,否則資料將會遺失且無法復原。
視需要刪除預設區域:
cephuser@adm > radosgw-admin zone rm --rgw-zone=default視需要刪除 Ceph 儲存叢集中的預設池:
cephuser@adm >ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-itcephuser@adm >ceph osd pool rm default.rgw.users.uid default.rgw.users.uid --yes-i-really-really-mean-it
21.13.3.3 更新 Ceph 組態檔案 #
透過在相應例項項目中新增 rgw_zone 組態選項和次要區域名稱,來更新次要區域主機上的 Ceph 組態檔案。
為此,請執行以下指令:
cephuser@adm > ceph config set SERVICE_NAME rgw_zone us-west21.13.3.4 更新期間 #
更新主區域組態後,請更新期間:
cephuser@adm > radosgw-admin period update --commit
{
"id": "b5e4d3ec-2a62-4746-b479-4b2bc14b27d1",
"epoch": 2,
"predecessor_uuid": "09559832-67a4-4101-8b3f-10dfcd6b2707",
"sync_status": [ "[...]"
],
"period_map": {
"id": "b5e4d3ec-2a62-4746-b479-4b2bc14b27d1",
"zonegroups": [
{
"id": "d4018b8d-8c0d-4072-8919-608726fa369e",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"zones": [
{
"id": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"name": "us-east-1",
"endpoints": [
"http:\/\/rgw1:80"
],
"log_meta": "true",
"log_data": "false",
"bucket_index_max_shards": 0,
"read_only": "false"
},
{
"id": "950c1a43-6836-41a2-a161-64777e07e8b8",
"name": "us-east-2",
"endpoints": [
"http:\/\/rgw2:80"
],
"log_meta": "false",
"log_data": "true",
"bucket_index_max_shards": 0,
"read_only": "false"
}
],
"placement_targets": [
{
"name": "default-placement",
"tags": []
}
],
"default_placement": "default-placement",
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7"
}
],
"short_zone_ids": [
{
"key": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"val": 630926044
},
{
"key": "950c1a43-6836-41a2-a161-64777e07e8b8",
"val": 4276257543
}
]
},
"master_zonegroup": "d4018b8d-8c0d-4072-8919-608726fa369e",
"master_zone": "83859a9a-9901-4f00-aa6d-285c777e10f0",
"period_config": {
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
}
},
"realm_id": "4a367026-bd8f-40ee-b486-8212482ddcd7",
"realm_name": "gold",
"realm_epoch": 2
}更新期間會變更版本編號,並會確保其他區域可收到更新的組態。
21.13.3.5 啟動物件閘道 #
在物件閘道主機上,啟動並啟用 Ceph 物件閘道服務:
cephuser@adm > ceph orch start rgw.us-east-221.13.3.6 檢查同步狀態 #
在次要區域啟用並執行時,檢查同步狀態。同步操作會將主區域中建立的使用者和桶複製到次要區域。
cephuser@adm > radosgw-admin sync status下面的輸出提供了同步操作的狀態。例如:
realm f3239bc5-e1a8-4206-a81d-e1576480804d (gold)
zonegroup c50dbb7e-d9ce-47cc-a8bb-97d9b399d388 (us)
zone 4c453b70-4a16-4ce8-8185-1893b05d346e (us-west)
metadata sync syncing
full sync: 0/64 shards
metadata is caught up with master
incremental sync: 64/64 shards
data sync source: 1ee9da3e-114d-4ae3-a8a4-056e8a17f532 (us-east)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source次要區域會接受桶操作,但會將它們重新導向至主區域,然後會與主區域同步以接收桶操作的結果。如果主區域處於停機狀態,對次要區域執行的桶操作將會失敗,但物件操作應該會成功完成。
21.13.4 一般物件閘道維護 #
21.13.4.1 檢查同步狀態 #
您可以使用以下指令查詢區域複製狀態的相關資訊:
cephuser@adm > radosgw-admin sync status
realm b3bc1c37-9c44-4b89-a03b-04c269bea5da (gold)
zonegroup f54f9b22-b4b6-4a0e-9211-fa6ac1693f49 (us)
zone adce11c9-b8ed-4a90-8bc5-3fc029ff0816 (us-west)
metadata sync syncing
full sync: 0/64 shards
incremental sync: 64/64 shards
metadata is behind on 1 shards
oldest incremental change not applied: 2017-03-22 10:20:00.0.881361s
data sync source: 341c2d81-4574-4d08-ab0f-5a2a7b168028 (us-east)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source
source: 3b5d1a3f-3f27-4e4a-8f34-6072d4bb1275 (us-3)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source21.13.4.2 變更中繼資料主區域 #
變更中繼資料的主區域時請小心。如果某個區域未完成與目前主區域的中繼資料同步,將其升級為主區域時,它將無法處理剩餘的項目,這些變更將會遺失。因此,我們建議等到區域的 radosgw-admin 同步狀態跟上中繼資料同步後,再將該區域升級為主區域。同樣,如果目前主區域正在處理對中繼資料的變更,此時若將另一個區域升級為主區域,這些變更也可能會遺失。為避免此情況,我們建議關閉先前主區域上的所有物件閘道例項。升級另一個區域後,可以使用 radosgw-admin 期間提取指令擷取它的新期間,然後可以重新啟動閘道。
若要將一個區域 (例如,us 區域群組中的 us-west 區域) 升級為中繼資料的主區域,請在該區域執行以下指令:
cephuser@ogw >radosgw-admin zone modify --rgw-zone=us-west --mastercephuser@ogw >radosgw-admin zonegroup modify --rgw-zonegroup=us --mastercephuser@ogw >radosgw-admin period update --commit
這樣會產生一個新期間,並且 us-west 區域中的物件閘道例項會將此期間傳送到其他區域。
21.13.5 執行容錯移轉和災難備援 #
如果主區域發生故障,將容錯移轉至次要區域,以實現災難備援。
將次要區域設為主區域和預設區域。例如:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --default依預設,Ceph 物件閘道以主動/主動組態執行。如果已將叢集設定為以主動/被動組態執行,則次要區域是唯讀區域。移除
--read-only狀態可允許區域接收寫入操作。例如:cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --default \ --read-only=false更新期間,以使變更生效:
cephuser@adm >radosgw-admin period update --commit重新啟動 Ceph 物件閘道:
cephuser@adm >ceph orch restart rgw
如果之前的主區域已復原,請還原操作。
在已復原的區域中,從目前主區域提取最新的領域組態。
cephuser@adm >radosgw-admin realm pull --url=URL-TO-MASTER-ZONE-GATEWAY \ --access-key=ACCESS-KEY --secret=SECRET將已復原的區域設定為主區域和預設區域:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --master --default更新期間,以使變更生效:
cephuser@adm >radosgw-admin period update --commit在已復原的區域中重新啟動 Ceph 物件閘道:
cephuser@adm >ceph orch restart rgw@rgw如果次要區域需要採用唯讀組態,請更新次要區域:
cephuser@adm >radosgw-admin zone modify --rgw-zone=ZONE-NAME --read-only更新期間,以使變更生效:
cephuser@adm >radosgw-admin period update --commit在次要區域中重新啟動 Ceph 物件閘道:
cephuser@adm >ceph orch restart@rgw
22 Ceph iSCSI 閘道 #
本章重點介紹與 iSCSI 閘道相關的管理任務。如需部署程序,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3.5 “部署 iSCSI 閘道”。
22.1 ceph-iscsi 管理的目標 #
本節介紹如何從執行 Linux、Microsoft Windows 或 VMware 的用戶端連接至
ceph-iscsi 管理的目標。
22.1.1 連接 open-iscsi #
使用 open-iscsi 連接
ceph-iscsi 支援的 iSCSI
目標需要執行兩個步驟。首先,啟動器必須探查閘道主機上可用的 iSCSI 目標,然後必須登入並對應可用的邏輯單位 (LU)。
這兩個步驟都需要 open-iscsi 精靈處於執行狀態。啟動
open-iscsi 精靈的方式取決於您的 Linux 套裝作業系統:
在 SUSE Linux Enterprise Server (SLES) 和 Red Hat Enterprise Linux (RHEL) 主機上,執行
systemctl start iscsid(如果systemctl不可用,請執行service iscsid start)。在 Debian 和 Ubuntu 主機上,執行
systemctl start open-iscsi(或service open-iscsi start)。
如果啟動器主機執行 SUSE Linux Enterprise Server,請參閱 https://documentation.suse.com/sles/15-SP2/html/SLES-all/cha-iscsi.html#sec-iscsi-initiator 以瞭解有關如何連接至 iSCSI 目標的詳細資料。
對於支援 open-iscsi 的任何其他 Linux 套裝作業系統,請繼續探查
ceph-iscsi 閘道上的目標 (本範例使用
iscsi1.example.com 做為入口網站位址;對於多重路徑存取,請使用 iscsi2.example.com 重複這些步驟):
root # iscsiadm -m discovery -t sendtargets -p iscsi1.example.com
192.168.124.104:3260,1 iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol然後登入該入口網站。如果登入成功完成,則入口網站中所有受 RBD 支援的邏輯單位將立即在系統 SCSI 匯流排上變為可用:
root # iscsiadm -m node -p iscsi1.example.com --login
Logging in to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] (multiple)
Login to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] successful.針對其他入口網站 IP 位址或主機重複此過程。
如果系統上已安裝 lsscsi 公用程式,您可以使用它來列舉系統上可用的 SCSI 裝置:
lsscsi [8:0:0:0] disk SUSE RBD 4.0 /dev/sde [9:0:0:0] disk SUSE RBD 4.0 /dev/sdf
在多重路徑組態 (其中兩個已連接的 iSCSI 裝置代表一個相同的 LU) 中,您還可以使用
multipath 公用程式檢查多重路徑裝置狀態:
root # multipath -ll
360014050cf9dcfcb2603933ac3298dca dm-9 SUSE,RBD
size=49G features='0' hwhandler='0' wp=rw
|-+- policy='service-time 0' prio=1 status=active
| `- 8:0:0:0 sde 8:64 active ready running
`-+- policy='service-time 0' prio=1 status=enabled
`- 9:0:0:0 sdf 8:80 active ready running現在,您可視需要將此多重路徑裝置當成任何區塊裝置使用。例如,可將該裝置當成 Linux 邏輯磁碟區管理 (LVM) 的實體磁碟區使用,或者直接在該裝置上建立檔案系統。下面的範例說明如何在新連接的多重路徑 iSCSI 磁碟區上建立 XFS 檔案系統:
root # mkfs -t xfs /dev/mapper/360014050cf9dcfcb2603933ac3298dca
log stripe unit (4194304 bytes) is too large (maximum is 256KiB)
log stripe unit adjusted to 32KiB
meta-data=/dev/mapper/360014050cf9dcfcb2603933ac3298dca isize=256 agcount=17, agsize=799744 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=12800000, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=6256, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0請注意,由於 XFS 是非叢集檔案系統,無論何時,您都只能將它掛接到單個 iSCSI 啟動器節點上。
任何時候若要停止使用與特定目標關聯的 iSCSI LU,請執行以下指令:
root # iscsiadm -m node -p iscsi1.example.com --logout
Logging out of session [sid: 18, iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260]
Logout of [sid: 18, target: iqn.2003-01.org.linux-iscsi.iscsi.SYSTEM-ARCH:testvol, portal: 192.168.124.104,3260] successful.與執行探查和登入時一樣,必須針對所有入口網站 IP 位址或主機名稱重複登出步驟。
22.1.1.1 設定多重路徑 #
多重路徑組態保留在用戶端或啟動器上,並不相依於任何
ceph-iscsi 組態。在使用區塊儲存之前,請選取一項策略。編輯
/etc/multipath.conf 之後,請使用以下指令重新啟動
multipathd
root # systemctl restart multipathd對於包含易記名稱的主動/被動組態,請將
defaults {
user_friendly_names yes
}
新增至 /etc/multipath.conf。成功連接目標後,請執行
root # multipath -ll
mpathd (36001405dbb561b2b5e439f0aed2f8e1e) dm-0 SUSE,RBD
size=2.0G features='0' hwhandler='0' wp=rw
|-+- policy='service-time 0' prio=1 status=active
| `- 2:0:0:3 sdl 8:176 active ready running
|-+- policy='service-time 0' prio=1 status=enabled
| `- 3:0:0:3 sdj 8:144 active ready running
`-+- policy='service-time 0' prio=1 status=enabled
`- 4:0:0:3 sdk 8:160 active ready running注意每個連結的狀態。對於主動/主動組態,請將
defaults {
user_friendly_names yes
}
devices {
device {
vendor "(LIO-ORG|SUSE)"
product "RBD"
path_grouping_policy "multibus"
path_checker "tur"
features "0"
hardware_handler "1 alua"
prio "alua"
failback "immediate"
rr_weight "uniform"
no_path_retry 12
rr_min_io 100
}
}
新增至 /etc/multipath.conf。重新啟動
multipathd 並執行
root # multipath -ll
mpathd (36001405dbb561b2b5e439f0aed2f8e1e) dm-3 SUSE,RBD
size=2.0G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
`-+- policy='service-time 0' prio=50 status=active
|- 4:0:0:3 sdj 8:144 active ready running
|- 3:0:0:3 sdk 8:160 active ready running
`- 2:0:0:3 sdl 8:176 active ready running22.1.2 連接 Microsoft Windows (Microsoft iSCSI 啟動器) #
若要從 Windows 2012 伺服器連接 SUSE Enterprise Storage iSCSI 目標,請執行以下步驟:
開啟 Windows 伺服器管理員。在儀表板中,選取 › 。對話方塊隨即顯示。選取索引標籤:
 圖 22.1︰ iSCSI 啟動器內容 #
圖 22.1︰ iSCSI 啟動器內容 #在對話方塊中的欄位內,輸入目標的主機名稱或 IP 位址,然後按一下:
 圖 22.2︰ 探索目標入口 #
圖 22.2︰ 探索目標入口 #針對所有其他閘道主機名稱或 IP 位址重複此過程。完成後,查看清單:
 圖 22.3︰ 目標入口 #
圖 22.3︰ 目標入口 #接下來,切換到索引標籤並查看已探索的目標。
 圖 22.4︰ 目標 #
圖 22.4︰ 目標 #在索引標籤中按一下。對話方塊隨即顯示。選取核取方塊以啟用多重路徑 I/O (MPIO),然後按一下:
對話方塊關閉後,選取以查看目標的內容:
 圖 22.5︰ iSCSI 目標內容 #
圖 22.5︰ iSCSI 目標內容 #選取,然後按一下 以查看多重路徑 I/O 組態:
 圖 22.6︰ 裝置詳細資料 #
圖 22.6︰ 裝置詳細資料 #預設的為。如果您偏好單純的容錯移轉組態,請將規則變更為。
iSCSI 啟動器的組態設定到此結束。現在,可以像使用任何其他 SCSI 裝置一樣使用 iSCSI 磁碟區,並可將其啟始化,使其可當成磁碟區和磁碟機使用。按一下以關閉 對話方塊,然後繼續在儀表板中設定角色。
觀察新連接的磁碟區。該磁碟區識別為 iSCSI 匯流排上的 SUSE RBD SCSI 多重路徑磁碟機,並且最初標示為離線狀態,其分割區表類型為未知。如果新磁碟區未立即顯示,請從下拉式方塊中選取,以重新掃描 iSCSI 匯流排。
以滑鼠右鍵按一下 iSCSI 磁碟區,然後從快顯功能表中選取。隨即顯示。按一下,反白新連接的 iSCSI 磁碟區,然後按一下開始建立新磁碟區。
 圖 22.7︰ 新磁碟區精靈 #
圖 22.7︰ 新磁碟區精靈 #該裝置最初是空的,不包含任何分割區表。當出現對話方塊指出將要使用 GPT 分割區表啟始化磁碟區時,確認該操作:
 圖 22.8︰ 離線磁碟提示 #
圖 22.8︰ 離線磁碟提示 #選取磁碟區大小。使用者一般會使用裝置的全部容量。然後,指定新建立磁碟區將在其上變為可用狀態的磁碟機代號或目錄名稱。接下來,選取要在新磁碟區上建立的檔案系統。最後,按一下以確認所做的選擇並完成磁碟區的建立:
 圖 22.9︰ 確認選取的磁碟區設定 #
圖 22.9︰ 確認選取的磁碟區設定 #完成該過程後,請檢查結果,然後按一下以結束磁碟機啟始化。完成啟始化後,便可以像使用新啟始化的本地磁碟機一般使用該磁碟區 (及其 NTFS 檔案系統)。
22.1.3 連接 VMware #
若要連接至
ceph-iscsi管理的 iSCSI 磁碟區,需要有設定好的 iSCSI 軟體介面卡。如果 vSphere 組態中未提供此類介面卡,請選取 › › › 來建立一個介面卡。如果適用,請以滑鼠右鍵按一下該介面卡並從快顯功能表中選取,來選取該介面卡的內容:
 圖 22.10︰ iSCSI 啟動器內容 #
圖 22.10︰ iSCSI 啟動器內容 #在 對話方塊中,按一下按鈕。然後移至索引標籤並選取。
輸入
ceph-iscsiiSCSI 閘道的 IP 位址或主機名稱。如果您在容錯移轉組態中執行多個 iSCSI 閘道,請針對要操作的所有閘道重複此步驟。 圖 22.11︰ 新增目標伺服器 #
圖 22.11︰ 新增目標伺服器 #輸入所有 iSCSI 閘道後,請在對話方塊中按一下,以發起對 iSCSI 介面卡的重新掃描。
重新掃描完成後,新的 iSCSI 裝置會顯示在窗格中的清單下。對於多重路徑裝置,您現在可以在該介面卡上按一下滑鼠右鍵,然後從快顯功能表中選取:
 圖 22.12︰ 管理多重路徑裝置 #
圖 22.12︰ 管理多重路徑裝置 #您現在應該會看到,所有路徑的下面都帶有綠燈。其中一個路徑應該已標示為,其他所有路徑只是標示為:
 圖 22.13︰ 多重路徑的路徑清單 #
圖 22.13︰ 多重路徑的路徑清單 #現在,您可以從切換到標為的項目。在窗格右上角選取,以開啟對話方塊。然後選取 並按一下。新增的 iSCSI 裝置會顯示在 清單中。選取該裝置,然後按一下繼續:
 圖 22.14︰ 新增儲存對話方塊 #
圖 22.14︰ 新增儲存對話方塊 #按一下以接受預設的磁碟配置。
在窗格中,為新資料儲存指定名稱,然後按一下。接受將磁碟區的整個空間用於資料儲存的預設設定,或者選取以建立較小的資料儲存:
 圖 22.15︰ 自定空間設定 #
圖 22.15︰ 自定空間設定 #按一下以完成資料儲存的建立。
新資料儲存現在即會顯示在資料儲存清單中,您可以選取它來擷取詳細資料。現在,您可以如同使用任何其他 vSphere 資料儲存一般使用
ceph-iscsi支援的 iSCSI 磁碟區。 圖 22.16︰ iSCSI 資料儲存綜覽 #
圖 22.16︰ iSCSI 資料儲存綜覽 #
22.2 結論 #
ceph-iscsi 是 SUSE Enterprise Storage
7 的一個關鍵元件,使用它可以從任何支援 iSCSI 通訊協定的伺服器或用戶端存取高度可用的分散式區塊儲存。在一或多個 iSCSI 閘道主機上使用
ceph-iscsi,可將 Ceph RBD 影像當成與 iSCSI
目標關聯的邏輯單位 (LU) 使用,並可視需要以負載平衡且高度可用的方式來存取該邏輯單位。
由於系統將所有 ceph-iscsi 組態都儲存在 Ceph RADOS
物件儲存中,ceph-iscsi
閘道主機先天就不具有持久性狀態,因而可以任意對其進行取代或者增減。因此,憑藉 SUSE Enterprise Storage 7,SUSE
客戶可在商用硬體和完全開放原始碼的平台上執行真正的分散式、高度可用、有復原能力且可自我修復的企業儲存技術。
23 叢集檔案系統 #
本章介紹通常應在完成叢集設定與輸出 CephFS 後執行的管理任務。如需有關設定 CephFS 的詳細資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3.3 “部署中繼資料伺服器”。
23.1 掛接 CephFS #
建立檔案系統後,如果 MDS 處於使用中狀態,您便可以從用戶端主機掛接檔案系統。
23.1.1 準備用戶端 #
如果用戶端主機執行的是 SUSE Linux Enterprise 12 SP2 或更新版本,系統無需額外設定即可掛接 CephFS。
如果用戶端主機執行的是 SUSE Linux Enterprise 12 SP1,您需要套用所有最新的修補程式,才能掛接 CephFS。
無論是哪一種情況,SUSE Linux Enterprise 中都包含了掛接 CephFS 需要的所有項目。不需要 SUSE Enterprise Storage 7 產品。
為了支援完整的 mount 語法,在嘗試掛接 CephFS 之前,應該先安裝
ceph-common 套件 (於 SUSE Linux Enterprise 中隨附)。
如果不安裝 ceph-common 套件 (因而也就未安裝 mount.ceph 輔助程式),將需要使用監控程式的 IP 而非其名稱。因為核心用戶端將無法執行名稱解析。
基本掛接語法如下:
root # mount -t ceph MON1_IP[:PORT],MON2_IP[:PORT],...:CEPHFS_MOUNT_TARGET \
MOUNT_POINT -o name=CEPHX_USER_NAME,secret=SECRET_STRING23.1.2 建立機密金鑰檔案 #
Ceph 叢集執行時預設會開啟驗證功能。您應該建立一個可用於儲存您的機密金鑰 (不是金鑰圈自身) 的檔案。請執行以下操作,以獲取特定使用者的機密金鑰並建立該檔案:
在金鑰圈檔案中檢視特定使用者的金鑰:
cephuser@adm >cat /etc/ceph/ceph.client.admin.keyring複製要使用所掛接 Ceph FS 檔案系統的使用者的金鑰。金鑰的格式通常類似下方所示:
AQCj2YpRiAe6CxAA7/ETt7Hcl9IyxyYciVs47w==
為使用者 admin 建立一個檔案名稱包含使用者名稱的檔案,例如
/etc/ceph/admin.secret。將金鑰值貼至上一步中建立的檔案中。
設定對該檔案的適當存取權限。該使用者應該是唯一有權讀取該檔案的使用者,其他人不能有任何存取權限。
23.1.3 掛接 CephFS #
可以使用 mount 指令掛接 CephFS。您需要指定監控程式的主機名稱或 IP 位址。由於 SUSE Enterprise Storage 中預設會啟用 cephx 驗證,因此,您還需要指定一個使用者名稱及其相關的機密:
root # mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secret=AQATSKdNGBnwLhAAnNDKnH65FmVKpXZJVasUeQ==由於上一個指令會保留在外圍程序歷程中,因此更安全的做法是從檔案讀取機密:
root # mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret請注意,機密檔案應該僅包含實際的金鑰圈機密。因此,在本範例中,該檔案僅包含下行:
AQATSKdNGBnwLhAAnNDKnH65FmVKpXZJVasUeQ==
最好能在 mount 指令行中指定多個監控程式並以逗號分隔,以避免某個監控程式在掛接時剛好發生停機的情況。每個監控程式的位址採用主機[:連接埠] 格式。如果未指定連接埠,預設會使用連接埠 6789。
在本地主機上建立掛接點:
root # mkdir /mnt/cephfs掛接 CephFS:
root # mount -t ceph ceph_mon1:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret
如果要掛接檔案系統的某個子集,可以指定子目錄 subdir:
root # mount -t ceph ceph_mon1:6789:/subdir /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret
可在 mount 指令中指定多個監控程式主機:
root # mount -t ceph ceph_mon1,ceph_mon2,ceph_mon3:6789:/ /mnt/cephfs \
-o name=admin,secretfile=/etc/ceph/admin.secret如果使用實施了路徑限制的用戶端,則 MDS 功能需要包含對根目錄的讀取存取權。例如,金鑰圈的格式可能如下所示:
client.bar key: supersecretkey caps: [mds] allow rw path=/barjail, allow r path=/ caps: [mon] allow r caps: [osd] allow rwx
allow r path=/ 部分表示路徑受限的用戶端能夠查看根磁碟區,但無法寫入資料至其中。在要求完全隔離的使用情況下,這可能會造成問題。
23.2 卸載 CephFS #
若要卸載 CephFS,請使用 umount 指令:
root # umount /mnt/cephfs23.3 在 /etc/fstab 中掛接 CephFS #
若要在用戶端啟動時自動掛接 CephFS,請在其檔案系統表 /etc/fstab 中插入相應的行:
mon1:6790,mon2:/subdir /mnt/cephfs ceph name=admin,secretfile=/etc/ceph/secret.key,noatime,_netdev 0 2
23.4 多個使用中 MDS 精靈 (主動/主動 MDS) #
依預設,CephFS 是針對單個使用中 MDS 精靈設定的。若要調整大規模系統的中繼資料效能,您可以啟用多個使用中 MDS 精靈,以便互相分擔中繼資料工作負載。
23.4.1 使用主動/主動 MDS #
如果依預設設定使用單個 MDS 時中繼資料效能出現瓶頸,可考慮使用多個使用中 MDS 精靈。
增加精靈數量並不會提高所有工作負載類型的效能。例如,增加 MDS 精靈的數量不會讓單個用戶端上執行的單個應用程式受益,除非該應用程式在同時執行大量中繼資料操作。
一般而言,能夠因大量使用中 MDS 精靈受益的工作負載是使用許多用戶端的工作負載,也許是在許多獨立目錄中運作的工作負載。
23.4.2 增加 MDS 使用中叢集的大小 #
每個 CephFS 檔案系統都有一項 max_mds 設定,用於控制將要建立的階層數。僅當某個備用精靈可用於承擔新階層時,檔案系統中的實際階層數才會增加。例如,如果只有執行一個 MDS 精靈,而 max_mds 設定為兩個,則將不會建立另一個階層。
在下面的範例中,我們將 max_mds 選項設定為 2,以便在保留預設階層的情況下再建立一個新階層。若要查看變更,請在設定 max_mds 之前和之後執行 ceph status,然後觀察包含 fsmap 的行:
cephuser@adm >cephstatus [...] services: [...] mds: cephfs-1/1/1 up {0=node2=up:active}, 1 up:standby [...]cephuser@adm >cephfs set cephfs max_mds 2cephuser@adm >cephstatus [...] services: [...] mds: cephfs-2/2/2 up {0=node2=up:active,1=node1=up:active} [...]
新建立的階層 (1) 會經歷「正在建立」狀態,然後進入「使用中」狀態。
即使具有多個使用中 MDS 精靈,當任何在執行使用中精靈的伺服器發生故障時,高可用性系統也仍會要求待命精靈接管工作。
因此,高可用性系統的 max_mds 合理最大值比系統中的 MDS 伺服器總數小 1。若要在發生多次伺服器故障時保持可用性,可增加系統中待命精靈的數量,使之與不會導致失去可用性的伺服器故障數相符。
23.4.3 減小階層數 #
所有階層 (包括要移除的階層) 首先必須是使用中的。這表示至少需要有 max_mds 個 MDS 精靈可用。
首先,將 max_mds 設為一個較小的數字。例如,我們重新使用單個使用中 MDS:
cephuser@adm >cephstatus [...] services: [...] mds: cephfs-2/2/2 up {0=node2=up:active,1=node1=up:active} [...]cephuser@adm >cephfs set cephfs max_mds 1cephuser@adm >cephstatus [...] services: [...] mds: cephfs-1/1/1 up {0=node2=up:active}, 1 up:standby [...]
23.4.4 手動將目錄樹關聯到階層 #
在多個使用中中繼資料伺服器組態中,將會執行一個平衡器,用於在叢集中均衡分配中繼資料負載。這種模式通常足以符合大多數使用者的需求,但有時,使用者需要使用中繼資料到特定階層的明確對應來覆寫動態平衡器。這樣,管理員或使用者便可以在整個叢集上均衡地分攤應用程式負載,或限制使用者的中繼資料要求對整個叢集的影響。
針對此目的提供的機制稱為「輸出關聯」。它是目錄的延伸屬性。此延伸屬性名為 ceph.dir.pin。使用者可以使用標準指令來設定此屬性:
root # setfattr -n ceph.dir.pin -v 2 /path/to/dir
延伸屬性的值 (-v) 是要將目錄子樹指定到的階層。預設值 -1 表示不關聯該目錄。
目錄輸出關聯從設定了輸出關聯的最近的父級繼承。因此,對某個目錄設定輸出關聯會影響該目錄的所有子項。但是,可以透過設定子目錄輸出關聯來覆寫父級的關聯。例如:
root # mkdir -p a/b # "a" and "a/b" start with no export pin set.
setfattr -n ceph.dir.pin -v 1 a/ # "a" and "b" are now pinned to rank 1.
setfattr -n ceph.dir.pin -v 0 a/b # "a/b" is now pinned to rank 0
# and "a/" and the rest of its children
# are still pinned to rank 1.23.5 管理容錯移轉 #
如果 MDS 精靈停止與監控程式通訊,監控程式會等待 mds_beacon_grace 秒 (預設為 15 秒),然後將精靈標示為 laggy。可以設定一或多個「待命」精靈,用於在 MDS 精靈容錯移轉期間接管工作。
23.5.1 設定待命重播 #
可以設定每個 CephFS 檔案系統,以新增待命重播精靈。這些待命精靈會追蹤使用中 MDS 的中繼資料記錄,以減少使用中 MDS 變為無法使用時的容錯移轉時間。每個使用中 MDS 只能有一個追隨它的待命重播精靈。
您可以使用以下指令在檔案系統上設定待命重播:
cephuser@adm > ceph fs set FS-NAME allow_standby_replay BOOL設定待命重播後,監控程式將會指定該檔案系統中可用於追隨使用中 MDS 的待命精靈。
當某個 MDS 進入待命重播狀態後,它只會做為所追隨階層的待命精靈。如果另一個階層發生故障,系統不會使用此待命重播精靈來取代前者,即使沒有其他可用的待命精靈也是如此。因此,如果使用了待命重播,則建議每個使用中 MDS 都應有一個待命重播精靈。
23.6 設定 CephFS 定額 #
您可以對 Ceph 檔案系統的任何子目錄設定定額。定額可限制目錄階層中指定點下所儲存的位元組或檔案數。
23.6.1 CephFS 定額限制 #
CephFS 的定額設定具有以下限制:
- 定額是合作性而非競爭性的。
達到限制時,Ceph 定額依賴於掛接檔案系統的用戶端來停止向其寫入資料。伺服器端無法阻止惡意用戶端寫入所需數量的資料。在用戶端完全不受信任的環境中,請勿使用定額來阻止填入檔案系統。
- 定額並不精確。
在達到定額限制不久後,系統便會停止向檔案系統寫入資料的程序。這樣便會不可避免地允許這些程序在超出設定的限制後又寫入一定數量的資料。系統將會在超出所設定限制後的十分之一秒內停止用戶端寫入程序。
- 自 4.17 版本起,即在核心用戶端中實作了定額。
定額受使用者空間用戶端 (libcephfs、ceph-fuse) 支援。4.17 及更新版本的 Linux 核心用戶端支援 SUSE Enterprise Storage 7 叢集上的 CephFS 定額。核心用戶端 (甚至最近的版本) 無法處理較舊叢集的定額,即使它們可以設定定額延伸屬性也是如此。SLE12-SP3 (及更新版本) 核心永遠包含所需的向後移植能力,以處理定額。
- 與基於路徑的掛接限制配合使用時,需謹慎設定定額。
用戶端需要有權存取設定了定額的目錄 Inode,才能強制執行這些定額。如果依據 MDS 功能,用戶端對特定路徑 (例如
/home/user) 的存取受到限制,並且對其無權存取的上階目錄 (/home) 設定了定額,則用戶端將無法強制執行該定額。使用基於路徑的存取限制時,請務必對用戶端可以存取的目錄 (例如/home/user或/home/user/quota_dir) 設定定額。
23.6.2 設定 CephFS 定額 #
您可以使用虛擬延伸屬性來設定 CephFS 定額:
ceph.quota.max_files設定檔案限制。
ceph.quota.max_bytes設定位元組限制。
如果某個目錄 Inode 存在這些屬性,即表示對該位置設定了定額。如果不存在,則表示未對該目錄設定定額 (即使可能對父目錄設定了定額)。
若要設定 100 MB 的定額,請執行以下指令:
cephuser@mds > setfattr -n ceph.quota.max_bytes -v 100000000 /SOME/DIRECTORY若要設定 10,000 個檔案的定額,請執行以下指令:
cephuser@mds > setfattr -n ceph.quota.max_files -v 10000 /SOME/DIRECTORY若要檢視定額設定,請執行以下指令:
cephuser@mds > getfattr -n ceph.quota.max_bytes /SOME/DIRECTORYcephuser@mds > getfattr -n ceph.quota.max_files /SOME/DIRECTORY如果延伸屬性的值為「0」,則表示未設定定額。
若要移除定額,請執行以下指令:
cephuser@mds >setfattr -n ceph.quota.max_bytes -v 0 /SOME/DIRECTORYcephuser@mds >setfattr -n ceph.quota.max_files -v 0 /SOME/DIRECTORY
23.7 管理 CephFS 快照 #
在建立 CephFS 快照時,快照會建立此時間點檔案系統的唯讀檢視。您可以在任何目錄中建立快照。快照將涵蓋檔案系統中指定目錄下的所有資料。建立快照後,系統會從各用戶端非同步衝洗緩衝區資料。因此,建立快照的速度十分快。
如果您有多個 CephFS 檔案系統在共用一個池 (透過名稱空間),則這些檔案系統的快照將會發生衝突,並且刪除其中一個快照將會導致共用同一個池的其他快照遺失檔案資料。
23.7.1 建立快照 #
對於新檔案系統,系統預設會啟用 CephFS 快照功能。若要對現有檔案系統啟用該功能,請執行以下指令:
cephuser@adm > ceph fs set CEPHFS_NAME allow_new_snaps true
啟用快照後,CephFS 中的所有目錄都將包含一個特殊的 .snap 子目錄。
這是個虛擬子目錄。它不會出現在父目錄的目錄清單中,但您不能使用 .snap 名稱做為檔案或目錄名稱。若要存取 .snap 目錄,需要採用明確存取方式,例如:
tux > ls -la /CEPHFS_MOUNT/.snap/CephFS 核心用戶端有一個限制:一旦檔案系統中所含快照數量超過 400 個,它們將無法處理。快照的數量應永遠低於此上限,無論使用哪個用戶端均如此。如果使用較舊的 CephFS 用戶端 (例如 SLE12-SP3),請記住,快照數量超過 400 個對運作十分有害,因為這會導致用戶端當機。
您可以透過進行 client snapdir 設定來為快照子目錄設定其他名稱。
若要建立快照,請以自訂名稱在 .snap 目錄下建立子目錄。例如,若要建立目錄 /CEPHFS_MOUNT/2/3/ 的快照,請執行以下指令:
tux > mkdir /CEPHFS_MOUNT/2/3/.snap/CUSTOM_SNAPSHOT_NAME23.7.2 刪除快照 #
若要刪除某個快照,請在 .snap 目錄中刪除該快照的子目錄:
tux > rmdir /CEPHFS_MOUNT/2/3/.snap/CUSTOM_SNAPSHOT_NAME24 透過 Samba 輸出 Ceph 資料 #
本章介紹如何透過 Samba/CIFS 共用輸出 Ceph 叢集中儲存的資料,以便您可從 Windows* 用戶端機器輕鬆存取這些資料。另外還介紹了有助於您將 Ceph Samba 閘道設定為加入到 Windows* 網域中的 Active Directory,以進行使用者驗證和授權的資訊。
由於用戶端與儲存區之間的額外網路躍程會導致通訊協定負擔增加並產生額外的延遲,因此與使用原生 Ceph 用戶端相比,透過 Samba 閘道存取 CephFS 可能會使應用程式效能大幅降低。
24.1 透過 Samba 共用輸出 CephFS #
原生 CephFS 和 NFS 用戶端不受透過 Samba 獲取的檔案鎖定限制,反之亦然。如果透過其他方式存取 CephFS 支援的 Samba 共用路徑,則依賴跨通訊協定檔案鎖定的應用程式可能會出現資料損毀。
24.1.1 設定和輸出 Samba 套件 #
若要設定和輸出 Samba 共用,需要安裝以下套件: samba-ceph 和 samba-winbind。若尚未安裝這些套件,請執行以下指令進行安裝:
cephuser@smb > zypper install samba-ceph samba-winbind24.1.2 單一閘道範例 #
在輸出 Samba 共用的準備過程中,需要選擇用於充當 Samba 閘道的合適節點。該節點必須能存取 Ceph 用戶端網路,同時要有足夠的 CPU、記憶體和網路資源。
您可以透過 CTDB 和 SUSE Linux Enterprise High Availability Extension 提供容錯移轉功能。如需 HA 設定的詳細資訊,請參閱第 24.1.3 節 「設定高可用性」。
請確定叢集中已存在一個正常運作的 CephFS。
在 Ceph 管理節點上建立一個特定於 Samba 閘道的金鑰圈,並將其複製到兩個 Samba 閘道節點:
cephuser@adm >cephauth get-or-create client.samba.gw mon 'allow r' \ osd 'allow *' mds 'allow *' -o ceph.client.samba.gw.keyringcephuser@adm >scpceph.client.samba.gw.keyring SAMBA_NODE:/etc/ceph/使用 Samba 閘道節點的名稱取代 SAMBA_NODE。
在 Samba 閘道節點上執行以下步驟。將 Samba 連同 Ceph 整合套件一併安裝:
cephuser@smb >sudo zypper in samba samba-ceph使用以下內容取代
/etc/samba/smb.conf檔案的預設內容:[global] netbios name = SAMBA-GW clustering = no idmap config * : backend = tdb2 passdb backend = tdbsam # disable print server load printers = no smbd: backgroundqueue = no [SHARE_NAME] path = CEPHFS_MOUNT read only = no oplocks = no kernel share modes = no
在啟動具有核心 CephFS 共用組態的 Samba 之前,必須先掛接上面的 CEPHFS_MOUNT 路徑。請參閱第 23.3 節 「在
/etc/fstab中掛接 CephFS」。上面的共用組態使用 Linux 核心 CephFS 用戶端,這是出於效能原因建議使用的用戶端。做為替代方案,也可以使用 Samba
vfs_ceph模組與 Ceph 叢集通訊。以下指示僅適用於舊版,不建議用於新的 Samba 部署:[SHARE_NAME] path = / vfs objects = ceph ceph: config_file = /etc/ceph/ceph.conf ceph: user_id = samba.gw read only = no oplocks = no kernel share modes = no
提示:Oplocks 和共用模式oplocks(也稱為 SMB2+ 租用) 可透過加速用戶端快取來提升效能,不過如果將其他 CephFS 用戶端 (例如核心mount.ceph、FUSE 或 NFS Ganesha) 與 Samba 一併部署,該機制目前並不安全。如果由 Samba 專門處理所有 CephFS 檔案系統路徑存取,則可安全啟用
oplocks參數。目前,在使用 CephFS vfs 模組執行的共用中,需要停用
kernel share modes,檔案處理才能正常運作。重要:允許存取Samba 可將 SMB 使用者和群組對應至本地帳戶。可以透過以下指令為本地使用者指定 Samba 共用存取的密碼:
root #smbpasswd -a USERNAME對於成功的 I/O,共用路徑的存取控制清單 (ACL) 需要允許存取透過 Samba 連接的使用者。您可以透過 CephFS 核心用戶端暫時掛接,並對共用路徑使用
chmod、chown或setfacl公用程式來修改 ACL。例如,若要允許所有使用者進行存取,請執行以下指令:root #chmod 777 MOUNTED_SHARE_PATH
24.1.2.1 啟動 Samba 服務 #
使用以下指令可啟動或重新啟動獨立的 Samba 服務:
root #systemctl restart smb.serviceroot #systemctl restart nmb.serviceroot #systemctl restart winbind.service
若要確定會在開機時啟動 Samba 服務,請透過以下指令將其啟用:
root #systemctl enable smb.serviceroot #systemctl enable nmb.serviceroot #systemctl enable winbind.service
nmb 和 winbind 服務
如果不需要瀏覽網路共用,則無需啟用和啟動 nmb 服務。
僅當設定為 Active Directory 網域成員時才需要 winbind 服務。請參閱第 24.2 節 「加入 Samba 閘道和 Active Directory」。
24.1.3 設定高可用性 #
儘管多節點 Samba + CTDB 部署比單節點部署的高可用性更佳 (請參閱第 24 章 「透過 Samba 輸出 Ceph 資料」),但它並不支援用戶端透明容錯移轉。應用程式可能會在 Samba 閘道節點發生故障時出現短暫的中斷。
本節提供一個範例來展示如何設定 Samba 伺服器的雙節點高可用性組態。該設定需要 SUSE Linux Enterprise High Availability Extension。兩個節點分別名為 earth (192.168.1.1) 和 mars (192.168.1.2)。
如需 SUSE Linux Enterprise High Availability Extension 的詳細資料,請參閱 https://documentation.suse.com/sle-ha/15-SP1/。
此外,使用兩個浮動的虛擬 IP 位址可讓用戶端連接到服務,而不管該服務在哪個實體節點上執行。192.168.1.10 用於透過 Hawk2 進行叢集管理,192.168.2.1 專門用於 CIFS 輸出。如此可讓日後能更輕鬆地套用安全性限制。
以下程序說明範例安裝。https://documentation.suse.com/sle-ha/15-SP2/html/SLE-HA-all/art-sleha-install-quick.html 上提供了更多詳細資料。
在管理節點上建立一個特定於 Samba 閘道的金鑰圈,並將其複製到上述兩個節點上:
cephuser@adm >cephauth get-or-create client.samba.gw mon 'allow r' \ osd 'allow *' mds 'allow *' -o ceph.client.samba.gw.keyringcephuser@adm >scpceph.client.samba.gw.keyringearth:/etc/ceph/cephuser@adm >scpceph.client.samba.gw.keyringmars:/etc/ceph/SLE-HA 設定需要一個圍籬區隔裝置,以避免在使用中叢集節點變為未同步時出現電腦分裂情況。為此,您可以將 Ceph RBD 影像與 Stonith 區塊裝置 (SBD) 結合使用。如需更多詳細資料,請參閱 https://documentation.suse.com/sle-ha/15-SP2/html/SLE-HA-all/cha-ha-storage-protect.html#sec-ha-storage-protect-fencing-setup。
如果該影像尚不存在,請建立一個名為
rbd的 RBD 池 (參閱第 18.1 節 「建立池」),並將其與rbd相關聯 (參閱第 18.5.1 節 「將池與應用程式關聯」)。然後建立一個名為sbd01的相關 RBD 影像:cephuser@adm >ceph osd pool create rbdcephuser@adm >ceph osd pool application enable rbd rbdcephuser@adm >rbd -p rbd create sbd01 --size 64M --image-shared準備好
earth和mars,以代管 Samba 服務:繼續操作前,請確定已安裝下列套件: ctdb、 tdb-tools及 samba。
root #zypperin ctdb tdb-tools samba samba-ceph確定已停止並停用 Samba 和 CTDB 服務:
root #systemctl disable ctdbroot #systemctl disable smbroot #systemctl disable nmbroot #systemctl disable winbindroot #systemctl stop ctdbroot #systemctl stop smbroot #systemctl stop nmbroot #systemctl stop winbind在所有節點上開啟防火牆的連接埠
4379。這是為了使 CTDB 能夠與其他叢集節點通訊。
在
earth上建立 Samba 的組態檔案。這些檔案稍後將自動同步到mars。在
/etc/ctdb/nodes檔案中插入 Samba 閘道節點的私人 IP 位址清單。如需更多詳細資料,請參閱 ctdb 手冊頁 (man 7 ctdb)。192.168.1.1 192.168.1.2
設定 Samba。在
/etc/samba/smb.conf的[global]區段中新增以下行。使用所選的主機名稱取代 CTDB-SERVER (叢集中的所有節點將顯示為一個使用此名稱的大節點,以方便操作)。另外,新增一個共用定義,以 SHARE_NAME 為例:[global] netbios name = SAMBA-HA-GW clustering = yes idmap config * : backend = tdb2 passdb backend = tdbsam ctdbd socket = /var/lib/ctdb/ctdb.socket # disable print server load printers = no smbd: backgroundqueue = no [SHARE_NAME] path = / vfs objects = ceph ceph: config_file = /etc/ceph/ceph.conf ceph: user_id = samba.gw read only = no oplocks = no kernel share modes = no
請注意,
/etc/ctdb/nodes和/etc/samba/smb.conf檔案需要在所有 Samba 閘道節點上都相符。
安裝並開機 SUSE Linux Enterprise High Availability 叢集。
在
earth和mars上註冊 SUSE Linux Enterprise High Availability Extension:root@earth #SUSEConnect-r ACTIVATION_CODE -e E_MAILroot@mars #SUSEConnect-r ACTIVATION_CODE -e E_MAIL安裝 ha-cluster-bootstrap :
root@earth #zypperin ha-cluster-bootstraproot@mars #zypperin ha-cluster-bootstrap透過
rbdmap.service在兩個 Samba 閘道上對應 RBD 影像sbd01。編輯
/etc/ceph/rbdmap並新增 SBD 影像的項目:rbd/sbd01 id=samba.gw,keyring=/etc/ceph/ceph.client.samba.gw.keyring
啟用並啟動
rbdmap.service:root@earth #systemctl enable rbdmap.service && systemctl start rbdmap.serviceroot@mars #systemctl enable rbdmap.service && systemctl start rbdmap.service/dev/rbd/rbd/sbd01裝置應在兩個 Samba 閘道上都可用。啟始化
earth上的叢集並讓mars加入它。root@earth #ha-cluster-initroot@mars #ha-cluster-join-c earth重要在啟始化和加入叢集的過程中,會以互動方式詢問您是否使用 SBD。按一下
y進行確認,然後將/dev/rbd/rbd/sbd01指定為儲存裝置的路徑。
檢查叢集的狀態。您應該會看到兩個節點都已新增至叢集中:
root@earth #crmstatus 2 nodes configured 1 resource configured Online: [ earth mars ] Full list of resources: admin-ip (ocf::heartbeat:IPaddr2): Started earth在
earth上執行以下指令,以設定 CTDB 資源:root@earth #crmconfigurecrm(live)configure#primitivectdb ocf:heartbeat:CTDB params \ ctdb_manages_winbind="false" \ ctdb_manages_samba="false" \ ctdb_recovery_lock="!/usr/lib64/ctdb/ctdb_mutex_ceph_rados_helper ceph client.samba.gw cephfs_metadata ctdb-mutex" ctdb_socket="/var/lib/ctdb/ctdb.socket" \ op monitor interval="10" timeout="20" \ op start interval="0" timeout="200" \ op stop interval="0" timeout="100"crm(live)configure#primitivesmb systemd:smb \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#primitivenmb systemd:nmb \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#primitivewinbind systemd:winbind \ op start timeout="100" interval="0" \ op stop timeout="100" interval="0" \ op monitor interval="60" timeout="100"crm(live)configure#groupg-ctdb ctdb winbind nmb smbcrm(live)configure#clonecl-ctdb g-ctdb meta interleave="true"crm(live)configure#commit提示:選擇性的nmb和winbind原始如果不需要瀏覽網路共用,則無需新增
nmb原始。僅當設定為 Active Directory 網域成員時才需要
winbind原始。請參閱第 24.2 節 「加入 Samba 閘道和 Active Directory」。組態選項
ctdb_recovery_lock中的二進位檔案/usr/lib64/ctdb/ctdb_mutex_ceph_rados_helper中依如下順序包含以下參數:CLUSTER_NAME、CEPHX_USER、RADOS_POOL 和 RADOS_OBJECT。可附加一個額外的鎖定逾時參數來覆寫所用的預設值 (10 秒)。使用更高的值將會增加 CTDB 復原主節點的容錯移轉時間,然而使用更低的值可能會導致不正確地將復原主節點偵測為停機狀態,以致觸發翻動容錯移轉。
新增叢集化 IP 位址:
crm(live)configure#primitiveip ocf:heartbeat:IPaddr2 params ip=192.168.2.1 \ unique_clone_address="true" \ op monitor interval="60" \ meta resource-stickiness="0"crm(live)configure#clonecl-ip ip \ meta interleave="true" clone-node-max="2" globally-unique="true"crm(live)configure#colocationcol-with-ctdb 0: cl-ip cl-ctdbcrm(live)configure#ordero-with-ctdb 0: cl-ip cl-ctdbcrm(live)configure#commit如果
unique_clone_address設定為true,IPaddr2 資源代辦會向指定的位址新增一個複製品 ID,從而導致出現三個不同的 IP 位址。這些位址通常是不需要的,但有助於實現負載平衡。如需有關此主題的詳細資訊,請參閱 https://documentation.suse.com/sle-ha/15-SP2/html/SLE-HA-all/cha-ha-lb.html。檢查結果:
root@earth #crmstatus Clone Set: base-clone [dlm] Started: [ factory-1 ] Stopped: [ factory-0 ] Clone Set: cl-ctdb [g-ctdb] Started: [ factory-1 ] Started: [ factory-0 ] Clone Set: cl-ip [ip] (unique) ip:0 (ocf:heartbeat:IPaddr2): Started factory-0 ip:1 (ocf:heartbeat:IPaddr2): Started factory-1從用戶端機器執行測試。在 Linux 用戶端上執行以下指令,確定是否可以將檔案複製到系統或從系統複製檔案:
root #smbclient//192.168.2.1/myshare
24.1.3.1 重新啟動 HA Samba 資源 #
發生任何 Samba 或 CTDB 組態變更後,可能需要重新啟動 HA 資源才能使變更生效。可透過以下指令來實現:
root #crmresource restart cl-ctdb
24.2 加入 Samba 閘道和 Active Directory #
您可以將 Ceph Samba 閘道設定為支援 Active Directory (AD) 的 Samba 網域成員。做為 Samba 網域成員,您可以針對來自輸出 CephFS 的檔案和目錄在本地存取清單 (ACL) 中使用網域使用者和群組。
24.2.1 準備 Samba 安裝 #
本節介紹在設定 Samba 自身之前,您需要執行的一些準備步驟。首先,您需要準備一個乾淨的環境,這樣有助於防止混淆,並可確認以前所安裝的 Samba 系統中的檔案未與新安裝的網域成員混用。
所有 Samba 閘道節點的時鐘都需要與 Active Directory 網域控制器保持同步。時鐘誤差可能會導致驗證失敗。
確認沒有執行中的 Samba 或名稱快取程序:
cephuser@smb > ps ax | egrep "samba|smbd|nmbd|winbindd|nscd"
如果輸出列出了任何 samba、smbd、nmbd、winbindd 或 nscd 程序,請將其停止。
如果您之前在此主機上執行過 Samba 安裝,請移除 /etc/samba/smb.conf 檔案。另外,請移除所有 Samba 資料庫檔案 (例如 *.tdb 和 *.ldb 檔案)。若要列出包含 Samba 資料庫的目錄,請執行以下指令:
cephuser@smb > smbd -b | egrep "LOCKDIR|STATEDIR|CACHEDIR|PRIVATE_DIR"24.2.2 確認 DNS #
Active Directory (AD) 使用 DNS 來尋找網域控制器 (DC) 和服務 (例如 Kerberos)。因此,AD 網域成員和伺服器需要能夠解析 AD DNS 區域。
確認已正確設定 DNS 且正向和反向尋找均可正確解析,例如:
cephuser@adm > nslookup DC1.domain.example.com
Server: 10.99.0.1
Address: 10.99.0.1#53
Name: DC1.domain.example.com
Address: 10.99.0.1cephuser@adm > 10.99.0.1
Server: 10.99.0.1
Address: 10.99.0.1#53
1.0.99.10.in-addr.arpa name = DC1.domain.example.com.24.2.3 解析 SRV 記錄 #
AD 使用 SRV 記錄尋找服務 (例如 Kerberos 和 LDAP)。若要確認能否正確解析 SRV 記錄,請使用 nslookup 互動外圍程序,例如:
cephuser@adm > nslookup
Default Server: 10.99.0.1
Address: 10.99.0.1
> set type=SRV
> _ldap._tcp.domain.example.com.
Server: UnKnown
Address: 10.99.0.1
_ldap._tcp.domain.example.com SRV service location:
priority = 0
weight = 100
port = 389
svr hostname = dc1.domain.example.com
domain.example.com nameserver = dc1.domain.example.com
dc1.domain.example.com internet address = 10.99.0.124.2.4 設定 Kerberos #
Samba 支援 Heimdal 和 MIT Kerberos 後端。若要對網域成員設定 Kerberos,請在您的 /etc/krb5.conf 檔案中進行以下設定:
[libdefaults] default_realm = DOMAIN.EXAMPLE.COM dns_lookup_realm = false dns_lookup_kdc = true
上面的範例為 DOMAIN.EXAMPLE.COM 領域設定了 Kerberos。我們不建議在 /etc/krb5.conf 檔案中設定任何進一步的參數。如果您的 /etc/krb5.conf 中包含 include 行,則您必須移除此行,否則該檔案將無法運作。
24.2.5 解析本地主機名稱 #
當您將主機加入網域中時,Samba 會嘗試在 AD DNS 區域中註冊其主機名稱。為此,net 公用程式需要能夠使用 DNS 或 /etc/hosts 檔案中的正確項目來解析主機名稱。
若要確認您的主機名稱解析正確,請使用 getent hosts 指令:
cephuser@adm > getent hosts example-host
10.99.0.5 example-host.domain.example.com example-host
主機名稱和 FQDN 不得解析為 127.0.0.1 IP 位址,或與網域成員的 LAN 介面上所用 IP 位址不同的任何 IP 位址。如果未顯示輸出或主機解析為錯誤的 IP 位址,而您未在使用 DHCP,請在 /etc/hosts 檔案中設定正確的項目:
127.0.0.1 localhost 10.99.0.5 example-host.samdom.example.com example-host
/etc/hosts
如果您在使用 DHCP,請檢查 /etc/hosts 是否僅包含「127.0.0.1」行。如果仍然有問題,請聯絡 DHCP 伺服器的管理員。
如果您需要新增機器主機名稱的別名,請將別名新增至以機器 IP 位址開頭的行的末尾,切勿新增至「127.0.0.1」行。
24.2.6 設定 Samba #
本節描述有關您需要在 Samba 組態中包含的特定組態選項的資訊。
Active Directory 網域成員資格主要透過在 /etc/samba/smb.conf 的 [global] 區段中設定 security = ADS 以及相應的 Kerberos 領域和 ID 對應參數進行設定。
[global] security = ADS workgroup = DOMAIN realm = DOMAIN.EXAMPLE.COM ...
24.2.6.1 選擇 winbindd 中用於 ID 對應的後端 #
如果您需要讓您的使用者使用不同的登入外圍程序和/或 Unix 主目錄路徑,或者讓他們在任何地方都使用相同的 ID,您需要使用 winbind「ad」後端並將 RFC2307 屬性新增至 AD 中。
建立使用者或群組時,系統不會自動新增 RFC2307 屬性。
DC 上找到的 ID 編號 (3000000 範圍內的編號) 不是 RFC2307 屬性,Unix 網域成員上將不會使用該編號。如果您需要在任何地方都使用相同的 ID 編號,請將 uidNumber 和 gidNumber 屬性新增至 AD 中,並在 Unix 網域成員上使用 winbind「ad」後端。如果您決定將 uidNumber 和 gidNumber 屬性新增至 AD 中,請不要使用 3000000 範圍內的編號。
如果您的使用者僅將 Samba AD DC 用於驗證目的,而不會在其上儲存資料或登入其中,則您可使用 winbind「rid」後端。如此,系統會依據 Windows* RID 來計算使用者和群組 ID。如果您在每個 Unix 網域成員上的 smb.conf 中都使用相同的 [global] 區段,您將會獲得相同的 ID。如果您使用「rid」後端,則不需要向 AD 新增任何內容,系統將會忽略 RFC2307 屬性。使用「rid」後端時,請在 smb.conf 中設定 template shell 和 template homedir 參數。它們是全域設定,會為所有使用者設定相同的登入外圍程序和 Unix 主目錄路徑 (RFC2307 屬性則不同,可用來設定個別的 Unix 主目錄路徑和外圍程序)。
如果您需要讓您的使用者和群組在任何地方都使用相同的 ID,但只需要為他們設定相同的登入外圍程序和相同的 Unix 主目錄路徑,還可使用另一種方法來設定 Samba。您可以透過使用 winbind「ad」後端並在 smb.conf 中使用範本行來實現此目的。使用此方法時,您僅需將 uidNumber 和 gidNumber 屬性新增至 AD 中。
如需可用 ID 對應後端的更多詳細資訊,請參閱下列相關手冊頁:man 8 idmap_ad、man 8 idmap_rid 和 man 8 idmap_autorid。
24.2.6.2 設定使用者和群組 ID 範圍 #
決定好使用哪個 winbind 後端後,您需要在 smb.conf 中設定 idmap config 選項來指定要使用的範圍。依預設,Unix 網域成員上保留有多個使用者和群組 ID 區塊:
| ID | 範圍 |
|---|---|
| 0-999 | 本地系統使用者和群組。 |
| 從 1000 開始 | 本地 Unix 使用者和群組。 |
| 從 10000 開始 | DOMAIN 使用者和群組。 |
依據上述範圍,您不應將「*」或「DOMAIN」範圍設定為 999 以內,因為它們會與本地系統使用者和群組發生衝突。您還應為任何本地 Unix 使用者和群組留出餘地,因此將 idmap config 範圍設定為從 3000 開始是不錯的折衷方法。
您需要確定「DOMAIN」可能會增長到多大,並決定是否打算建立任何受信任的網域。然後,便可依如下所示來設定 idmap config 範圍:
| 領域 | 範圍 |
|---|---|
| * | 3000-7999 |
| DOMAIN | 10000-999999 |
| TRUSTED | 1000000-9999999 |
24.2.6.3 將網域管理員帳戶對應至本地 root 使用者 #
Samba 可讓您將網域帳戶對應至本地帳戶。透過此功能,您可以用不同於用戶端上要求執行操作的帳戶的使用者身分在網域成員的檔案系統上執行檔案操作。
將網域管理員對應至本地 root 帳戶屬於選擇性操作。請僅在網域管理員需要能夠使用 root 許可權在網域成員上執行檔案操作時設定該對應。請注意,將 Administrator 對應至 root 帳戶後,其便不能以「Administrator」身分登入 Unix 網域成員。
若要將網域管理員對應至本地 root 帳戶,請執行以下步驟:
將以下參數新增至
smb.conf檔案的[global]區段:username map = /etc/samba/user.map
建立包含以下內容的
/etc/samba/user.map檔案:!root = DOMAIN\Administrator
使用「ad」ID 對應後端時,請不要為網域管理員帳戶設定 uidNumber 屬性。如果為網域管理員帳戶設定了該屬性,其值會覆寫 root 使用者的本地 UID「0」,因而會導致對應失敗。
如需更多詳細資料,請參閱 smb.conf 手冊頁 (man 5 smb.conf) 中的 username map 參數。
24.2.7 加入 Active Directory 網域 #
若要將主機加入 Active Directory,請執行以下指令:
cephuser@smb > net ads join -U administrator
Enter administrator's password: PASSWORD
Using short domain name -- DOMAIN
Joined EXAMPLE-HOST to dns domain 'DOMAIN.example.com'24.2.8 設定名稱服務參數 #
若要使網域使用者和群組可供本地系統使用,您需要啟用名稱服務參數 (NSS) 程式庫。在 /etc/nsswitch.conf 檔案中,將 winbind 項目附加到以下資料庫:
passwd: files winbind group: files winbind
將
files項目指定為這兩個資料庫的第一個來源。這可讓 NSS 在查詢winbind服務之前,先從/etc/passwd和/etc/group檔案中尋找網域使用者和群組。不要將
winbind項目新增至 NSSshadow資料庫中。這樣做可能會導致wbinfo公用程式失敗。不要在本地
/etc/passwd檔案中使用與網域中相同的使用者名稱。
24.2.9 啟動服務 #
在組態發生變更後,依據第 24.1.2.1 節 「啟動 Samba 服務」或第 24.1.3.1 節 「重新啟動 HA Samba 資源」中所述重新啟動 Samba 服務。
24.2.10 測試 winbindd 連接性 #
24.2.10.1 傳送 winbindd ping #
若要驗證 winbindd 服務能否連接至 AD 網域控制器 (DC) 或主要網域控制器 (PDC),請輸入以下指令:
cephuser@smb > wbinfo --ping-dc
checking the NETLOGON for domain[DOMAIN] dc connection to "DC.DOMAIN.EXAMPLE.COM" succeeded
如果前一條指令失敗,請確認 winbindd 服務正在執行,且正確設定了 smb.conf 檔案。
24.2.10.2 尋找網域使用者和群組 #
您可以使用 libnss_winbind 程式庫尋找網域使用者和群組。例如,若要尋找網域使用者「DOMAIN\demo01」,請執行以下指令:
cephuser@smb > getent passwd DOMAIN\\demo01
DOMAIN\demo01:*:10000:10000:demo01:/home/demo01:/bin/bash若要尋找網域群組「Domain Users」,請執行以下指令:
cephuser@smb > getent group "DOMAIN\\Domain Users"
DOMAIN\domain users:x:10000:24.2.10.3 為網域使用者和群組指定檔案許可權 #
利用名稱服務參數 (NSS) 程式庫,您可以在指令中使用網域使用者帳戶和群組。例如,若要將檔案的擁有者設定為「demo01」網域使用者,並將群組設定為「Domain Users」網域群組,請輸入以下指令:
cephuser@smb > chown "DOMAIN\\demo01:DOMAIN\\domain users" file.txt25 NFS Ganesha #
NFS Ganesha 是一部 NFS 伺服器,它在使用者位址空間中執行,而不是做為作業系統核心的一部分執行。憑藉 NFS Ganesha,您可以插入自己的儲存機制 (例如 Ceph),並從任何 NFS 用戶端存取它。如需安裝說明,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.3.6 “部署 NFS Ganesha”。
由於用戶端與儲存區之間的額外網路躍程會導致通訊協定負擔新增並產生額外的延遲,因此與使用原生 CephFS 相比,透過 NFS 閘道存取 Ceph 可能會使應用程式效能大幅降低。
每個 NFS Ganesha 服務都含有一個組態階層,其中包含:
開機
ganesha.conf每個服務的 RADOS 通用組態物件
每個輸出的 RADOS 組態物件
開機組態是要在容器中啟動 nfs-ganesha 精靈的最低組態。每個開機組態都將包含一個 %url 指令,該指令中包含來自 RADOS 通用組態物件的任何額外組態。通用組態物件可以為輸出 RADOS 組態物件中定義的每個 NFS 輸出包含額外的 %url 指令。

25.1 建立 NFS 服務 #
指定 Ceph 服務部署的推薦方法是建立一個 YAML 格式的檔案,其中包含所要部署服務的規格。您可以為每種類型的服務建立單獨的規格檔案,也可以在一個檔案中指定多個 (或所有) 服務類型。
依據您的選擇,您將需要更新或建立相關的 YAML 格式檔案來建立 NFS Ganesha 服務。如需建立該檔案的詳細資訊,請參閱Book “部署指南”, Chapter 5 “使用 cephadm 進行部署”, Section 5.4.2 “服務和放置規格”。
更新或建立該檔案之後,請執行以下指令以建立 nfs-ganesha 服務:
cephuser@adm > ceph orch apply -i FILE_NAME25.2 啟動或重新啟動 NFS Ganesha #
若要啟動 NFS Ganesha 服務,請執行:
cephuser@adm > ceph orch start nfs.SERVICE_ID若要重新啟動 NFS Ganesha 服務,請執行:
cephuser@adm > ceph orch restart nfs.SERVICE_ID如果您只想重新啟動單個 NFS Ganesha 精靈,請執行:
cephuser@adm > ceph orch daemon restart nfs.SERVICE_ID啟動或重新啟動 NFS Ganesha 時,NFS v4 會有 90 秒的逾時寬限期間。在寬限期間,系統會主動拒絕來自用戶端的新要求。因此,當 NFS 處於寬限期內,用戶端可能會發生要求處理速度變慢的情況。
25.3 列出 NFS 復原池中的物件 #
執行以下指令以列出 NFS 復原池中的物件:
cephuser@adm > rados --pool POOL_NAME --namespace NAMESPACE_NAME ls25.4 建立 NFS 輸出 #
執行以下指令以建立 NFS 輸出。
應修改 FSAL 區塊以包含所需的 cephx 使用者 ID 和機密存取金鑰。
cephuser@adm > rados --pool POOL_NAME --namespace NAMESPACE_NAME put export-1 export-125.5 確認 NFS 輸出 #
NFS v4 將在虛擬檔案系統的根目錄下構建輸出清單。您可以透過掛接 NFS Ganesha 伺服器節點的 / 來確認 NFS 共用是否已輸出:
root #mount-t nfs nfs_ganesha_server_hostname:/ /path/to/local/mountpointroot #ls/path/to/local/mountpoint cephfs
依預設,cephadm 將設定 NFS v4 伺服器。NFS v4 不會與 rpcbind 或 mountd 精靈進行互動。NFS 用戶端工具 (例如 showmount) 將不會顯示任何已設定的輸出。
25.6 掛接 NFS 輸出 #
若要在用戶端主機上掛接輸出的 NFS 共用,請執行:
root #mount-t nfs nfs_ganesha_server_hostname:/ /path/to/local/mountpoint
25.7 多個 NFS Ganesha 叢集 #
可以定義多個 NFS Ganesha 叢集。如此便可:
分隔 NFS Ganesha 叢集,以便存取 CephFS。
第 V 部分 與虛擬化工具整合 #
- 26
libvirt和 Ceph libvirt程式庫在監管程式介面與使用這些介面的軟體應用程式之間建立了一個虛擬機器抽象層。使用libvirt,開發人員和系統管理員可將工作重心放在通用管理架構、通用 API、通用外圍程序介面 (virsh),以及諸多不同的監管程式 (包括 QEMU/KVM、Xen、LXC 或 VirtualBox) 上。- 27 Ceph 做為 QEMU KVM 例項的後端
最常見的 Ceph 使用案例涉及到向虛擬機器提供區塊裝置影像。例如,在理想的組態中,使用者可以建立包含 OS 和所有相關軟體的「黃金」影像。然後,使用者可以建立該影像的快照。最後,使用者可以複製該快照 (通常要複製多次,如需詳細資料,請參閱第 20.3 節 「快照」)。能夠建立快照的寫入時複製複製品,就表示 Ceph 能夠快速向虛擬機器佈建區塊裝置影像,因為用戶端不需要在每次運轉新的虛擬機器時都下載整個影像。
26 libvirt 和 Ceph #
libvirt 程式庫在監管程式介面與使用這些介面的軟體應用程式之間建立了一個虛擬機器抽象層。使用 libvirt,開發人員和系統管理員可將工作重心放在通用管理架構、通用 API、通用外圍程序介面 (virsh),以及諸多不同的監管程式 (包括 QEMU/KVM、Xen、LXC 或 VirtualBox) 上。
Ceph 區塊裝置支援 QEMU/KVM。您可以透過與 libvirt 連接的軟體來使用 Ceph 區塊裝置。雲端解決方案使用 libvirt 來與 QEMU/KVM 互動,而 QEMU/KVM 透過 librbd 來與 Ceph 區塊裝置互動。
若要建立使用 Ceph 區塊裝置的虛擬機器,請依以下各節所述的程序操作。在範例中,我們分別使用了 libvirt-pool、client.libvirt 和 new-libvirt-image 做為池名稱、使用者名稱和影像名稱。您可以根據個人喜好使用任何值,但在執行後續程序中的指令時,請務必取代這些值。
26.1 設定 Ceph 與 libvirt 搭配使用 #
若要將 Ceph 設定為與 libvirt 搭配使用,請執行以下步驟:
建立池。下面的範例使用池名稱
libvirt-pool和 128 個放置群組。cephuser@adm >ceph osd pool create libvirt-pool 128 128驗證該池是否存在。
cephuser@adm >ceph osd lspools建立 Ceph 使用者。下面的範例使用 Ceph 使用者名稱
client.libvirt並參考libvirt-pool。cephuser@adm >ceph auth get-or-create client.libvirt mon 'profile rbd' osd \ 'profile rbd pool=libvirt-pool'驗證該名稱是否存在。
cephuser@adm >ceph auth list注意:使用者名稱或 IDlibvirt將使用 IDlibvirt,而不是 Ceph 名稱client.libvirt來存取 Ceph。如需 ID 與名稱之間的差別的詳細說明,請參閱第 30.2.1.1 節 「使用者」。使用 QEMU 在 RBD 池中建立影像。下面的範例使用影像名稱
new-libvirt-image並參考libvirt-pool。提示:金鑰圈檔案位置libvirt使用者金鑰儲存在/etc/ceph目錄下的金鑰圈檔案中。需要為金鑰圈檔案指定適當的名稱,其中應包含其所屬 Ceph 叢集的名稱。如果叢集名稱為預設名稱「ceph」,則金鑰圈檔案名稱為/etc/ceph/ceph.client.libvirt.keyring。如果該金鑰圈不存在,請使用以下指令建立它:
cephuser@adm >ceph auth get client.libvirt > /etc/ceph/ceph.client.libvirt.keyringroot #qemu-img create -f raw rbd:libvirt-pool/new-libvirt-image:id=libvirt 2G驗證該影像是否存在。
cephuser@adm >rbd -p libvirt-pool ls
26.2 準備虛擬機器管理員 #
雖然您可以單獨使用 libvirt,而不藉助虛擬機器管理員,但您可能會發現,使用 virt-manager 來建立第一個網域會更簡單。
安裝虛擬機器管理員。
root #zypper in virt-manager準備/下載要執行虛擬化的系統的 OS 影像。
啟動虛擬機器管理員。
virt-manager
26.3 建立虛擬機器 #
若要使用 virt-manager 建立虛擬機器,請執行以下步驟:
從清單中選擇連接,在其上按一下滑鼠右鍵,然後選取。
透過提供現有儲存的路徑來。指定 OS 類型和記憶體設定,並為虛擬機器,例如
libvirt-virtual-machine。完成組態並啟動虛擬機器。
使用
sudo virsh list驗證新建立的網域是否存在。如果需要,請指定連接字串,例如virsh -c qemu+ssh://root@vm_host_hostname/system listId Name State ----------------------------------------------- [...] 9 libvirt-virtual-machine running在將虛擬機器設定為與 Ceph 搭配使用前,登入虛擬機器並將其停止。
26.4 設定虛擬機器 #
本章重點介紹如何使用 virsh 設定虛擬機器,以與 Ceph 整合。virsh 指令通常需要 root 特權 (sudo),它不會傳回相應的結果,也不會告知您需要 root 特權。如需 virsh 指令的參考資訊,請參閱 man 1 virsh (需要安裝 libvirt-client )。
使用
virsh editvm-domain-name 開啟組態檔案。root #virsh edit libvirt-virtual-machine<devices> 下面應該包含 <disk> 項目。
<devices> <emulator>/usr/bin/qemu-system-SYSTEM-ARCH</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw'/> <source file='/path/to/image/recent-linux.img'/> <target dev='vda' bus='virtio'/> <address type='drive' controller='0' bus='0' unit='0'/> </disk>以 OS 影像的路徑取代
/path/to/image/recent-linux.img。重要請使用
sudo virsh edit,不要使用文字編輯器。如果使用文字編輯器編輯/etc/libvirt/qemu下的組態檔案,libvirt可能無法辨識變更。如果/etc/libvirt/qemu下的 XML 檔案內容與sudo virsh dumpxmlvm-domain-name 傳回的結果有差異,則表示虛擬機器可能沒有正常運作。將先前建立的 Ceph RBD 影像新增為 <disk> 項目。
<disk type='network' device='disk'> <source protocol='rbd' name='libvirt-pool/new-libvirt-image'> <host name='monitor-host' port='6789'/> </source> <target dev='vda' bus='virtio'/> </disk>以您主機的名稱取代 monitor-host,並視需要取代池名稱和/或影像名稱。您可為 Ceph 監控程式新增多個 <host> 項目。
dev屬性是邏輯裝置名稱,將顯示在虛擬機器的/dev目錄下。選擇性 bus 屬性表示要模擬的磁碟裝置類型。有效的設定都是驅動程式特定的 (例如 ide、scsi、virtio、xen、usb 或 sata)。儲存檔案。
如果 Ceph 叢集已啟用驗證 (預設會啟用),您必須產生一個機密。開啟所選的編輯器,並建立包含以下內容的
secret.xml檔案:<secret ephemeral='no' private='no'> <usage type='ceph'> <name>client.libvirt secret</name> </usage> </secret>定義機密。
root #virsh secret-define --file secret.xml <uuid of secret is output here>獲取
client.libvirt金鑰,並將金鑰字串儲存到某個檔案中。cephuser@adm >ceph auth get-key client.libvirt | sudo tee client.libvirt.key設定機密的 UUID。
root #virsh secret-set-value --secret uuid of secret \ --base64 $(cat client.libvirt.key) && rm client.libvirt.key secret.xml此外,必須透過將以下
<auth>項目新增至前面輸入的<disk>元素 (請以上述指令行範例的結果取代 uuid 值),來手動設定機密。root #virsh edit libvirt-virtual-machine然後,將
<auth></auth>元素新增至網域組態檔案:... </source> <auth username='libvirt'> <secret type='ceph' uuid='9ec59067-fdbc-a6c0-03ff-df165c0587b8'/> </auth> <target ...注意示範的 ID 為
libvirt,而不是在第 26.1 節 「設定 Ceph 與libvirt搭配使用」的步驟 2 中產生的 Ceph 名稱client.libvirt。請務必使用所產生 Ceph 名稱的 ID 組成部分。如果您出於某個原因需要重新產生機密,則在再次執行sudo virsh secret-set-value之前,需要執行sudo virsh secret-undefineuuid。
26.5 摘要 #
設定要與 Ceph 搭配使用的虛擬機器之後,便可啟動該虛擬機器。若要驗證虛擬機器與 Ceph 是否可相互通訊,可執行以下程序。
檢查 Ceph 是否在執行:
cephuser@adm >ceph health檢查虛擬機器是否在執行:
root #virsh list檢查虛擬機器是否在與 Ceph 通訊。以虛擬機器網域的名稱取代 vm-domain-name:
root #virsh qemu-monitor-command --hmp vm-domain-name 'info block'檢查
/dev或/proc/partitions下是否存在&target dev='hdb' bus='ide'/>中的裝置:tux >ls /devtux >cat /proc/partitions
27 Ceph 做為 QEMU KVM 例項的後端 #
最常見的 Ceph 使用案例涉及到向虛擬機器提供區塊裝置影像。例如,在理想的組態中,使用者可以建立包含 OS 和所有相關軟體的「黃金」影像。然後,使用者可以建立該影像的快照。最後,使用者可以複製該快照 (通常要複製多次,如需詳細資料,請參閱第 20.3 節 「快照」)。能夠建立快照的寫入時複製複製品,就表示 Ceph 能夠快速向虛擬機器佈建區塊裝置影像,因為用戶端不需要在每次運轉新的虛擬機器時都下載整個影像。
Ceph 區塊裝置可與 QEMU 虛擬機器相整合。如需 QEMU KVM 的詳細資訊,請參閱 https://documentation.suse.com/sles/15-SP2/html/SLES-all/part-virt-qemu.html。
27.1 安裝 qemu-block-rbd #
若要使用 Ceph 區塊裝置,需在 QEMU 上安裝相應的驅動程式。請檢查是否已安裝 qemu-block-rbd 套件,若未安裝,則予以安裝:
root # zypper install qemu-block-rbd27.2 使用 QEMU #
使用 QEMU 指令行時,您需要指定池名稱和影像名稱。您也可以指定快照名稱。
qemu-img command options \ rbd:pool-name/image-name@snapshot-name:option1=value1:option2=value2...
例如,可依如下所示指定 id 和 conf 選項:
qemu-img command options \
rbd:pool_name/image_name:id=glance:conf=/etc/ceph/ceph.conf27.3 使用 QEMU 建立影像 #
您可以透過 QEMU 建立區塊裝置影像。必須指定 rbd、池名稱,以及要建立的影像名稱。此外,還必須指定影像的大小。
qemu-img create -f raw rbd:pool-name/image-name size
例如:
qemu-img create -f raw rbd:pool1/image1 10G Formatting 'rbd:pool1/image1', fmt=raw size=10737418240 nocow=off cluster_size=0
事實上,raw 資料格式是可對 RBD 使用的唯一合理格式選項。從技術上講,您也可以使用 QEMU 支援的其他格式 (例如 qcow2),但這會增加額外的負擔,如果啟用了快取,還會在即時移轉虛擬機器時讓磁碟區變得不安全。
27.4 使用 QEMU 調整影像大小 #
您可以透過 QEMU 調整區塊裝置影像的大小。必須指定 rbd、池名稱,以及要調整大小的影像名稱。此外,還必須指定影像的大小。
qemu-img resize rbd:pool-name/image-name size
例如:
qemu-img resize rbd:pool1/image1 9G Image resized.
27.5 使用 QEMU 擷取影像資訊 #
您可以透過 QEMU 擷取區塊裝置影像的資訊。必須指定 rbd、池名稱和影像名稱。
qemu-img info rbd:pool-name/image-name
例如:
qemu-img info rbd:pool1/image1 image: rbd:pool1/image1 file format: raw virtual size: 9.0G (9663676416 bytes) disk size: unavailable cluster_size: 4194304
27.6 使用 RBD 執行 QEMU #
QEMU 可以透過 librbd 直接將影像做為虛擬區塊裝置來存取。這可以避免額外的網路位置切換,並可利用 RBD 快取的優勢。
您可以使用 qemu-img 將現有的虛擬機器影像轉換成 Ceph 區塊裝置影像。例如,如果您有一個 qcow2 影像,則可以執行:
qemu-img convert -f qcow2 -O raw sles12.qcow2 rbd:pool1/sles12
若要執行從該影像開機的虛擬機器,您可以執行:
root # qemu -m 1024 -drive format=raw,file=rbd:pool1/sles12
RBD 快取可大幅提高效能。QEMU 的快取選項可控制 librbd 快取:
root # qemu -m 1024 -drive format=rbd,file=rbd:pool1/sles12,cache=writeback如需 RBD 快取的詳細資訊,請參閱第 20.5 節 「快取設定」。
27.7 啟用丟棄和 TRIM #
Ceph 區塊裝置支援丟棄操作。這表示客體可以傳送 TRIM 要求,以便讓 Ceph 區塊裝置回收未使用的空間。可以透過結合丟棄選項掛接 XFS,在客體中啟用此功能。
若要讓客體可使用此功能,必須明確為區塊裝置啟用此功能。為此,您必須指定與磁碟機關聯的 discard_granularity:
root # qemu -m 1024 -drive format=raw,file=rbd:pool1/sles12,id=drive1,if=none \
-device driver=ide-hd,drive=drive1,discard_granularity=512上面的範例使用 IDE 驅動程式。Virtio 驅動程式不支援丟棄功能。
如果您在使用 libvirt,請使用 virsh edit 編輯 libvirt 網域的組態檔案,以包含 xmlns:qemu 值。然後,將 qemu:commandline block 新增為該網域的子級。下面的範例展示如何將包含 qemu id= 的兩部裝置設定為不同的 discard_granularity 值。
<domain type='kvm' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'> <qemu:commandline> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-0.discard_granularity=4096'/> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-1.discard_granularity=65536'/> </qemu:commandline> </domain>
27.8 設定 QEMU 快取選項 #
QEMU 的快取選項與以下 Ceph RBD 快取設定對應。
寫回:
rbd_cache = true
寫入:
rbd_cache = true rbd_cache_max_dirty = 0
無:
rbd_cache = false
QEMU 的快取設定會覆寫 Ceph 的預設設定 (未在 Ceph 組態檔案中明確指定的設定)。如果在 Ceph 組態檔案中明確指定了 RBD 快取設定 (請參閱第 20.5 節 「快取設定」),您的 Ceph 設定將會覆寫 QEMU 快取設定。如果您在 QEMU 指令行中指定了快取設定,則 QEMU 指令行設定會覆寫 Ceph 組態檔案設定。
第 VI 部分 設定叢集 #
- 28 Ceph 叢集組態
本章介紹如何透過組態選項設定 Ceph 叢集。
- 29 Ceph 管理員模組
Ceph 管理員的架構 (請參閱Book “部署指南”, Chapter 1 “SES 和 Ceph”, Section 1.2.3 “Ceph 節點和精靈”中的簡短介紹) 允許您透過「儀表板」(請參閱第 I 部分 「Ceph Dashboard」)、「prometheus」(請參閱第 16 章 「監控和警示」) 或「平衡器」等模組來延伸其功能。
- 30 使用
cephx進行驗證 為了識別用戶端並防禦中間人攻擊,Ceph 提供了
cephx驗證系統。在此環境中,用戶端表示人類使用者 (例如 admin 使用者) 或 Ceph 相關的服務/精靈 (例如 OSD、監控程式或物件閘道)。
28 Ceph 叢集組態 #
本章介紹如何透過組態選項設定 Ceph 叢集。
28.1 設定 ceph.conf 檔案 #
cephadm 使用基本 ceph.conf 檔案,該檔案中僅包含用於連接至 MON、驗證和擷取組態資訊的最小選項集。在大多數情況下,這僅限於 mon_host 選項 (雖然可以透過使用 DNS SRV 記錄來避免該限制)。
ceph.conf 檔案不再充當儲存叢集組態的中心位置,而是支援組態資料庫 (參閱第 28.2 節 「組態資料庫」)。
如果您仍然需要透過 ceph.conf 檔案變更叢集組態 (例如,由於您使用的用戶端不支援從組態資料庫讀取選項),則需要執行以下指令,並負責在整個叢集維護和分發 ceph.conf 檔案:
cephuser@adm > ceph config set mgr mgr/cephadm/manage_etc_ceph_ceph_conf false28.1.1 存取容器影像內部的 ceph.conf #
雖然 Ceph 精靈在容器內執行,您仍然可以存取其 ceph.conf 組態檔案。它做為主機系統上的以下檔案結合掛接:
/var/lib/ceph/CLUSTER_FSID/DAEMON_NAME/config
以 ceph fsid 指令所傳回的執行中叢集的唯一 FSID 取代 CLUSTER_FSID,並以 ceph orch ps 指令列出的特定精靈的名稱取代 DAEMON_NAME。例如:
/var/lib/ceph/b4b30c6e-9681-11ea-ac39-525400d7702d/osd.2/config
若要修改某個精靈的組態,請編輯其 config 檔案並重新啟動該精靈:
root # systemctl restart ceph-CLUSTER_FSID-DAEMON_NAME例如:
root # systemctl restart ceph-b4b30c6e-9681-11ea-ac39-525400d7702d-osd.2cephadm 重新部署精靈後,所有自訂設定都將遺失。
28.2 組態資料庫 #
Ceph 監控程式負責管理影響整個叢集行為的組態選項的中央資料庫。
28.2.1 設定區段和遮罩 #
MON 儲存的組態選項可以位於全域區段、精靈類型區段或特定精靈區段中。此外,選項還可以具有與其關聯的遮罩,以進一步限制選項適用的精靈或用戶端範圍。遮罩具有以下兩種格式:
TYPE:LOCATION,其中 TYPE 為
rack或host等 CRUSH 內容,而 LOCATION 為該內容的值。例如,
host:example_host會將該選項僅限用於在某個特定主機上執行的精靈或用戶端。CLASS:DEVICE_CLASS,其中 DEVICE_CLASS 為
hdd或ssd等 CRUSH 裝置類別的名稱。例如,class:ssd會將該選項僅限用於由 SSD 支援的 OSD。此遮罩對非 OSD 精靈或用戶端無效。
28.2.2 設定和讀取組態選項 #
使用以下指令可設定或讀取叢集組態選項。WHO 參數可以是區段名稱、遮罩或兩者的組合,用斜線 (/) 字元分隔。例如,osd/rack:foo 表示機架中名為 foo 的所有 OSD 精靈。
ceph config dump傾印整個叢集的整個組態資料庫。
ceph config get WHO傾印儲存在組態資料庫中的特定精靈或用戶端 (例如,
mds.a) 的組態。ceph config set WHO OPTION VALUE將組態選項設定為組態資料庫中的指定值。
ceph config show WHO顯示某個執行中精靈的已報告執行中組態。如果還使用了本地組態檔案,或者在指令行上或執行時期覆寫了選項,則這些設定可能與監控程式所儲存的設定有所不同。選項值的來源會做為輸出的一部分進行報告。
ceph config assimilate-conf -i INPUT_FILE -o OUTPUT_FILE輸入指定為 INPUT_FILE 的組態檔案,並將任何有效選項儲存到組態資料庫中。任何無法識別、無效或監控程式無法控制的設定都將在儲存為 OUTPUT_FILE 的縮寫檔案中傳回。此指令對於從舊組態檔案轉換為基於監控程式的集中式組態非常有用。
28.2.3 在執行時期設定精靈 #
在大多數情況下,Ceph 允許您在執行時期變更精靈的組態。例如,當您需要增加或減少記錄輸出數量時,或者在執行執行時期叢集最佳化時,這會非常有用。
您可以使用以下指令更新組態選項的值:
cephuser@adm > ceph config set DAEMON OPTION VALUE例如,若要調整某個特定 OSD 上的除錯記錄層級,請執行:
cephuser@adm > ceph config set osd.123 debug_ms 20如果在本地組態檔案中還自訂了相同的選項,則將忽略監控程式設定,因為它的優先程度低於組態檔案。
28.2.3.1 覆寫值 #
您可以使用 tell 或 daemon 子指令暫時修改選項值。此類修改只會影響執行中程序,並會在精靈或程序重新啟動後被丟棄。
有兩種方法可以覆寫值:
使用
tell子指令從任何叢集節點向某個特定精靈傳送訊息:cephuser@adm >ceph tell DAEMON config set OPTION VALUE例如:
cephuser@adm >ceph tell osd.123 config set debug_osd 20提示tell子指令接受使用萬用字元做為精靈識別碼。例如,若要調整所有 OSD 精靈上的除錯層級,請執行:cephuser@adm >ceph tell osd.* config set debug_osd 20使用
daemon子指令透過/var/run/ceph中的通訊端從執行程序的節點連接至某個特定精靈程序:cephuser@adm >ceph daemon DAEMON config set OPTION VALUE例如:
cephuser@adm >ceph daemon osd.4 config set debug_osd 20
28.2.3.2 檢視執行時期設定 #
檢視某個精靈的所有選項設定:
cephuser@adm > ceph config show-with-defaults osd.0檢視某個精靈的的所有非預設選項設定:
cephuser@adm > ceph config show osd.0檢查某個特定選項:
cephuser@adm > ceph config show osd.0 debug_osd您還可以從執行其程序的節點連接至某個執行中精靈,並觀察其組態:
cephuser@adm > ceph daemon osd.0 config show僅檢視非預設設定:
cephuser@adm > ceph daemon osd.0 config diff檢查某個特定選項:
cephuser@adm > ceph daemon osd.0 config get debug_osd28.3 config-key 儲存 #
config-key 是 Ceph 監控程式提供的一般用途的服務。它透過永久儲存機碼值組簡化了組態機碼的管理。config-key 主要由 Ceph 工具和精靈使用。
使用 config-key 指令可操作 config-key 儲存。config-key 指令使用以下子指令:
ceph config-key rm KEY刪除指定機碼。
ceph config-key exists KEY檢查指定機碼是否存在。
ceph config-key get KEY擷取指定機碼的值。
ceph config-key ls列出所有機碼。
ceph config-key dump傾印所有機碼及其值。
ceph config-key set KEY VALUE儲存具有給定值的指定機碼。
28.3.1 iSCSI 閘道 #
iSCSI 閘道使用 config-key 儲存來儲存或讀取其組態選項。所有與 iSCSI 閘道相關的機碼都以 iscsi 字串做為字首,例如:
iscsi/trusted_ip_list iscsi/api_port iscsi/api_user iscsi/api_password iscsi/api_secure
例如,如果需要兩組組態選項,請使用另一個描述性關鍵字 (例如 datacenterA 和 datacenterB) 來延伸字首:
iscsi/datacenterA/trusted_ip_list iscsi/datacenterA/api_port [...] iscsi/datacenterB/trusted_ip_list iscsi/datacenterB/api_port [...]
28.4 Ceph OSD 和 BlueStore #
28.4.1 設定自動快取大小調整 #
如果 tc_malloc 設定為記憶體配置器並且啟用了 bluestore_cache_autotune 設定,可將 BlueStore 設定為自動調整其快取大小。目前,此選項預設處於啟用狀態。BlueStore 會嘗試將 OSD 堆積記憶體使用率維持在 osd_memory_target 組態選項指定的目標大小之下。這是一種最優演算法,而且快取不會縮減到小於 osd_memory_cache_min 所指定的大小。系統將依據優先程度的階層選擇快取率。如果無法獲取優先程度資訊,將使用 bluestore_cache_meta_ratio 和 bluestore_cache_kv_ratio 選項做為備選。
- bluestore_cache_autotune
在遵循最小值的要求下,自動調整為不同 BlueStore 快取指定的比率。預設值為
True。- osd_memory_target
如果啟用了
tc_malloc和bluestore_cache_autotune,該選項將嘗試在記憶體中對應此數量的位元組。注意此數量可能與程序的 RSS 記憶體使用率並不完全相符。雖然程序對應的堆積記憶體總量一般應該保持為接近此目標的數量,但並不能保證核心會真正收回已取消對應的記憶體。
- osd_memory_cache_min
如果啟用了
tc_malloc和bluestore_cache_autotune,該選項可設定用於快取的最小記憶體量。注意將此值設定得過小可能會導致嚴重的快取猛移。
28.5 Ceph 物件閘道 #
您可以透過多個選項來影響物件閘道行為。如果未指定選項,將使用預設值。完整的物件閘道選項清單如下:
28.5.1 一般設定 #
- rgw_frontends
設定 HTTP 前端。請以逗號分隔的清單指定多個前端。每個前端組態可能包含一組以空格分隔的選項,每個選項的格式均為「鍵=值」或「鍵」。預設值為
beast port=7480。- rgw_data
為物件閘道設定資料檔案的位置。預設值為
/var/lib/ceph/radosgw/CLUSTER_ID。- rgw_enable_apis
啟用指定的 API。預設值為「s3, swift, swift_auth, admin All APIs」。
- rgw_cache_enabled
啟用或停用物件閘道快取。預設值為
true。- rgw_cache_lru_size
物件閘道快取中的項目數。預設值為 10000。
- rgw_socket_path
網域通訊端的通訊端路徑。
FastCgiExternalServer使用此通訊端。如果您未指定通訊端路徑,物件閘道將不會做為外部伺服器執行。您在此處指定的路徑須與rgw.conf檔案中指定的路徑相同。- rgw_fcgi_socket_backlog
fcgi 的通訊端積存資料。預設值為 1024。
- rgw_host
物件閘道例項的主機,可以是 IP 位址或主機名稱。預設值為
0.0.0.0。- rgw_port
例項用於監聽要求的連接埠號碼。如果未指定,物件閘道將執行外部 FastCGI。
- rgw_dns_name
所處理的網域的 DNS 名稱。
- rgw_script_uri
如果要求中未設定 SCRIPT_URI,則做為其備用值。
- rgw_request_uri
如果要求中未設定 REQUEST_URI,則做為其備用值。
- rgw_print_continue
啟用 100-continue (如果可正常運作)。預設值為
true。- rgw_remote_addr_param
遠端位址參數。例如,包含遠端位址的 HTTP 欄位或 X-Forwarded-For 位址 (如果反向代理可正常運作)。預設值為
REMOTE_ADDR。- rgw_op_thread_timeout
開啟的線串的逾時 (以秒計)。預設值為 600。
- rgw_op_thread_suicide_timeout
物件閘道程序停止前逾時的時間 (以秒計)。如果設定為 0 (預設值),則表示停用。
- rgw_thread_pool_size
Beast 伺服器的線串數。如果需要處理更多要求,請設定更高的值。預設為 100 個線串。
- rgw_num_rados_handles
物件閘道的 RADOS 叢集控制代碼數量。現在,每個物件閘道工作線串都可以選取一個 RADOS 控制代碼並在其有效期內保留。未來版本中可能會取代並移除此選項。預設值為 1。
- rgw_num_control_oids
不同物件閘道例項之間用於快取同步的通知物件數量。預設值為 8。
- rgw_init_timeout
物件閘道放棄啟始化前經過的秒數。預設值為 30。
- rgw_mime_types_file
MIME 類型的路徑和位置。用於物件類型的 Swift 自動偵測。預設值為
/etc/mime.types。- rgw_gc_max_objs
垃圾回收在一個垃圾回收處理週期內可處理的最大物件數量。預設值為 32。
- rgw_gc_obj_min_wait
垃圾回收處理可移除和處理物件前需等待的最短時間。預設值為 2 * 3600。
- rgw_gc_processor_max_time
兩次連續的垃圾回收處理週期開始時所間隔的最長時間。預設值為 3600。
- rgw_gc_processor_period
垃圾回收處理的週期時間。預設值為 3600。
- rgw_s3_success_create_obj_status
create-obj的備用成功狀態回應。預設值為 0。- rgw_resolve_cname
物件閘道是否應使用要求主機名稱欄位的 DNS CNAME 記錄 (如果主機名稱與物件閘道 DNS 名稱不同)。預設值為
false。- rgw_obj_stripe_size
物件閘道物件的物件分割大小。預設值為
4 << 20。- rgw_extended_http_attrs
新增可對實體 (例如,使用者、桶或物件) 設定的一組新屬性。使用 POST 方法放置或修改實體時,可透過 HTTP 標題欄位設定這些額外的屬性。如果設定了這些屬性,當對實體發出 GET/HEAD 要求時,它們將做為 HTTP 欄位傳回。預設值為
content_foo, content_bar, x-foo-bar。- rgw_exit_timeout_secs
無條件結束前等待程序的秒數。預設值為 120。
- rgw_get_obj_window_size
單個物件要求的視窗大小 (以位元組計)。預設值為
16 << 20。- rgw_get_obj_max_req_size
傳送到 Ceph 儲存叢集的單次 GET 操作的要求大小上限。預設值為
4 << 20。- rgw_relaxed_s3_bucket_names
為 US 區域桶啟用寬鬆 S3 桶名稱規則。預設值為
false。- rgw_list_buckets_max_chunk
列出使用者桶時,在一次操作中擷取的桶數量上限。預設值為 1000。
- rgw_override_bucket_index_max_shards
表示桶索引物件的分區數量。設為 0 (預設值) 表示沒有分區。不建議將此值設定得太大 (例如 1000),因為這樣會增加列出桶的成本。應在用戶端或全域區段中設定此變數,以便將其自動套用至
radosgw-admin指令。- rgw_curl_wait_timeout_ms
某些
curl呼叫的逾時時間 (以毫秒計)。預設值為 1000。- rgw_copy_obj_progress
啟用在費時較長的複製操作期間輸出物件進度的功能。預設值為
true。- rgw_copy_obj_progress_every_bytes
兩次複製進度輸出相隔的最小位元組數。預設值為 1024 * 1024。
- rgw_admin_entry
管理要求 URL 的進入點。預設值為
admin。- rgw_content_length_compat
為設定了 CONTENT_LENGTH 和 HTTP_CONTENT_LENGTH 的 FCGI 要求啟用相容性處理。預設值為
false。- rgw_bucket_quota_ttl
已快取定額資訊的受信任時長 (以秒計)。經過此逾時時間後,將從叢集重新擷取定額資訊。預設值為 600。
- rgw_user_quota_bucket_sync_interval
同步到叢集前,桶定額資訊的累計時長 (以秒計)。在此期間,其他物件閘道例項將不會看到與此例項上的操作相關的桶定額統計資料發生的變更。預設值為 180。
- rgw_user_quota_sync_interval
同步到叢集前,使用者定額資訊的累計時長 (以秒計)。在此期間,其他物件閘道例項將不會看到與此例項上的操作相關的使用者定額統計資料發生的變更。預設值為 180。
- rgw_bucket_default_quota_max_objects
每個桶的預設物件數量上限。如果未指定其他定額,此上限將對新使用者設定,對現有使用者無效。應在用戶端或全域區段中設定此變數,以便將其自動套用至
radosgw-admin指令。預設值為 -1。- rgw_bucket_default_quota_max_size
每個桶的預設容量上限 (以位元組計)。如果未指定其他定額,此上限將對新使用者設定,對現有使用者無效。預設值為 -1。
- rgw_user_default_quota_max_objects
使用者的預設物件數量上限。這個數量包括該使用者擁有的所有桶中的全部物件。如果未指定其他定額,此上限將對新使用者設定,對現有使用者無效。預設值為 -1。
- rgw_user_default_quota_max_size
如果未指定其他定額,使用者定額大小上限值 (以位元組計) 將對新使用者設定,對現有使用者無效。預設值為 -1。
- rgw_verify_ssl
發出要求時驗證 SSL 證書。預設值為
true。- rgw_max_chunk_size
將在單個操作中讀取的最大資料區塊大小。將值增至 4MB (4194304) 可以在處理大型物件時提高效能。預設值為 128kB (131072)。
- rgw_zone
閘道例項所在區域的名稱。如果未設定區域,可使用
radosgw-admin zone default指令設定叢集範圍的預設值。- rgw_zonegroup
閘道例項所在區域群組的名稱。如果未設定區域群組,可使用
radosgw-admin zonegroup default指令設定叢集範圍的預設值。- rgw_realm
閘道例項所在領域的名稱。如果未設定領域,可使用
radosgw-admin realm default指令設定叢集範圍的預設值。- rgw_run_sync_thread
如果領域中有其他要依據其同步的區域,則繁衍線串來處理資料和中繼資料的同步。預設值為
true。- rgw_data_log_window
資料記錄項目時段 (以秒計)。預設值為 30。
- rgw_data_log_changes_size
要為資料變更記錄儲存的記憶體內項目數。預設值為 1000。
- rgw_data_log_obj_prefix
資料記錄的物件名稱字首。預設值為「data_log」。
- rgw_data_log_num_shards
儲存資料變更記錄的分區 (物件) 數。預設值為 128。
- rgw_md_log_max_shards
中繼資料記錄的分區數量上限。預設值為 64。
- rgw_enforce_swift_acls
強制執行 Swift 存取控制清單 (ACL) 設定。預設值為
true。- rgw_swift_token_expiration
Swift 記號過期時間 (以秒計)。預設值為 24 * 3600。
- rgw_swift_url
Ceph Object Gateway Swift API 的 URL。
- rgw_swift_url_prefix
Swift StorageURL 中位於「/v1」部分前的 URL 字首。此設定允許在同一主機上執行多個閘道例項。出於相容性考慮,請將此組態變數設為空白,以便使用預設值「/swift」。使用明確的字首「/」會在根目錄啟動 StorageURL。
警告如果啟用了 S3 API,將此選項設為「/」將不起作用。請注意,如果停用 S3,將無法在多站台組態中部署物件閘道。
- rgw_swift_auth_url
未使用內部 Swift 驗證時,用於驗證 v1 驗證記號的預設 URL。
- rgw_swift_auth_entry
Swift 驗證 URL 的進入點。預設值為
auth。- rgw_swift_versioning_enabled
啟用 OpenStack Object Storage API 的物件版本設定。此選項可讓用戶端對應當建立版本的容器設定
X-Versions-Location屬性。該屬性指定儲存已歸檔版本的容器名稱。出於存取控制驗證 (ACL 不在考慮範圍之內) 的原因,必須由已建立版本的容器所屬的同一使用者擁有該屬性。無法透過 S3 物件版本設定機制來為這些容器建立版本。預設值為false。
- rgw_log_nonexistent_bucket
允許物件閘道記錄針對不存在的桶的要求。預設值為
false。- rgw_log_object_name
物件名稱的記錄格式。如需格式指定元的詳細資料,請參閱
man 1 date手冊頁。預設值為%Y-%m-%d-%H-%i-%n。- rgw_log_object_name_utc
記錄的物件名稱是否包含 UTC 時間。如果設定為
false(預設值),則會使用本地時間。- rgw_usage_max_shards
用於使用率記錄的分區數量上限。預設值為 32。
- rgw_usage_max_user_shards
用於單個使用者的使用率記錄的分區數量上限。預設值為 1。
- rgw_enable_ops_log
啟用記錄每個成功物件閘道操作的功能。預設值為
false。- rgw_enable_usage_log
啟用使用率記錄。預設值為
false。- rgw_ops_log_rados
是否應將操作記錄寫入 Ceph 儲存叢集後端。預設值為
true。- rgw_ops_log_socket_path
用於寫入操作記錄的 Unix 網域通訊端。
- rgw_ops_log_data_backlog
寫入 Unix 網域通訊端的操作記錄的資料積存大小上限。預設值為 5 << 20。
- rgw_usage_log_flush_threshold
同步衝洗前使用率記錄中已合併的改動項目數量。預設值為 1024。
- rgw_usage_log_tick_interval
每隔「n」秒衝洗待處理使用率記錄資料。預設值為 30。
- rgw_log_http_headers
要在記錄項目中包含的 HTTP 標題的逗號分隔清單。標題名稱不區分大小寫,使用完整標題名稱格式,且各單字間以底線分隔。例如「http_x_forwarded_for」、「http_x_special_k」。
- rgw_intent_log_object_name
要記錄的記錄物件名稱的記錄格式。如需格式指定元的詳細資料,請參閱
man 1 date手冊頁。預設值為「%Y-%m-%d-%i-%n」。- rgw_intent_log_object_name_utc
要記錄的記錄物件名稱是否包含 UTC 時間。如果設定為
false(預設值),則會使用本地時間。
- rgw_keystone_url
Keystone 伺服器的 URL。
- rgw_keystone_api_version
應用於與 Keystone 伺服器通訊的 OpenStack Identity API 的版本 (2 或 3)。預設值為 2。
- rgw_keystone_admin_domain
使用 OpenStack Identity API v3 時,具有管理員權限的 OpenStack 網域名稱。
- rgw_keystone_admin_project
使用 OpenStack Identity API v3 時,具有管理員權限的 OpenStack 專案名稱。如果未設定,將使用
rgw keystone admin tenant的值取代。- rgw_keystone_admin_token
Keystone 管理員記號 (共享秘密)。在物件閘道中,使用管理員記號的驗證的優先程度高於使用管理員身分證明的驗證 (選項
rgw keystone admin user、rgw keystone admin password、rgw keystone admin tenant、rgw keystone admin project和rgw keystone admin domain)。系統將管理員記號功能視為已取代。- rgw_keystone_admin_tenant
使用 OpenStack Identity API v2 時,具有管理員權限的 OpenStack 租用戶 (服務租用戶) 的名稱。
- rgw_keystone_admin_user
使用 OpenStack Identity API v2 時,具有管理員權限的 OpenStack 使用者 (服務使用者) 的名稱。
- rgw_keystone_admin_password
使用 OpenStack Identity API v2 時 OpenStack 管理員使用者的密碼。
- rgw_keystone_accepted_roles
處理要求需要具有的角色。預設值為「Member, admin」。
- rgw_keystone_token_cache_size
每個 Keystone 記號快取中的項目數上限。預設值為 10000。
- rgw_keystone_revocation_interval
記號撤銷檢查間隔的時間 (以秒計)。預設值為 15 * 60。
- rgw_keystone_verify_ssl
向 Keystone 發出記號要求時,驗證 SSL 證書。預設值為
true。
28.5.1.1 補充說明 #
- rgw_dns_name
允許用戶端使用
vhost類型的桶。vhost類型存取表示使用 bucketname.s3-endpoint/object-path。與之相對,path類型存取使用:s3-endpoint/bucket/object如果設定了
rgw dns name,請確認 S3 用戶端是否設定為將要求轉到rgw dns name指定的端點。
28.5.2 設定 HTTP 前端 #
28.5.2.1 Beast #
- port、ssl_port
IPv4 和 IPv6 監聽連接埠號碼。您可以指定多個連接埠號碼:
port=80 port=8000 ssl_port=8080
預設值為 80。
- endpoint、ssl_endpoint
監聽位址採用「位址[:連接埠]」格式,其中,位址為採用點分隔十進位格式的 IPv4 位址字串,或是採用以方括號括住的十六進位標記法表示的 IPv6 位址。指定將僅監聽 IPv6 的 IPv6 端點。
endpoint和ssl_endpoint的選用連接埠號碼分別預設為 80 和 443。您可以指定多個位址:endpoint=[::1] endpoint=192.168.0.100:8000 ssl_endpoint=192.168.0.100:8080
- ssl_private_key
此為選擇性設定,指定用於啟用了 SSL 的端點的私密金鑰檔案路徑。如果未指定,將使用
ssl_certificate檔案做為私密金鑰。- tcp_nodelay
如果指定該選項,通訊端選項將針對連接停用 Nagle 的演算法。這表示將會儘快傳送封包,而不會等到發生緩衝區滿載或逾時才傳送。
「1」會對所有通訊端停用 Nagle 的演算法。
「0」會使 Nagle 的演算法保持啟用狀態 (預設值)。
cephuser@adm > ceph config set rgw.myrealm.myzone.ses-min1.kwwazo \
rgw_frontends beast port=8000 ssl_port=443 \
ssl_certificate=/etc/ssl/ssl.crt \
error_log_file=/var/log/radosgw/beast.error.log28.5.2.2 CivetWeb #
- port
監聽連接埠號碼。對啟用了 SSL 的連接埠新增「s」尾碼 (例如「443s」)。若要結合特定 IPv4 或 IPv6 位址,請使用「位址:連接埠」格式。您可以透過使用「+」聯結多個端點或透過提供多個選項,來指定多個端點:
port=127.0.0.1:8000+443s port=8000 port=443s
預設值為 7480。
- num_threads
Civetweb 所繁衍以處理內送 HTTP 連接的線串數。此設定可有效限制前端可處理的並行連接數。
預設為
rgw_thread_pool_size選項所指定的值。- request_timeout_ms
Civetweb 在放棄前需等待更多內送資料的時長 (以毫秒計)。
預設值為 30000 毫秒。
- access_log_file
存取記錄檔案的路徑。您可以指定完整路徑,或目前工作目錄的相對路徑。如果未指定 (預設設定),將不會記錄存取。
- error_log_file
錯誤記錄檔案的路徑。您可以指定完整路徑,或目前工作目錄的相對路徑。如果未指定 (預設設定),將不會記錄錯誤。
/etc/ceph/ceph.conf 中的範例 Civetweb 組態 #cephuser@adm > ceph config set rgw.myrealm.myzone.ses-min2.ingabw \
rgw_frontends civetweb port=8000+443s request_timeout_ms=30000 \
error_log_file=/var/log/radosgw/civetweb.error.log28.5.2.3 通用選項 #
- ssl_certificate
用於啟用了 SSL 的端點的 SSL 證書檔案路徑。
- prefix
要插入到所有要求的 URI 中的字首字串。例如,僅支援 Swift 的前端可能會提供一個
/swift的 URI 字首。
29 Ceph 管理員模組 #
Ceph 管理員的架構 (請參閱Book “部署指南”, Chapter 1 “SES 和 Ceph”, Section 1.2.3 “Ceph 節點和精靈”中的簡短介紹) 允許您透過「儀表板」(請參閱第 I 部分 「Ceph Dashboard」)、「prometheus」(請參閱第 16 章 「監控和警示」) 或「平衡器」等模組來延伸其功能。
若要列出所有可用的模組,請執行:
cephuser@adm > ceph mgr module ls
{
"enabled_modules": [
"restful",
"status"
],
"disabled_modules": [
"dashboard"
]
}若要啟用或停用特定模組,請執行:
cephuser@adm > ceph mgr module enable MODULE-NAME例如:
cephuser@adm > ceph mgr module disable dashboard若要列出已啟用模組所提供的服務,請執行:
cephuser@adm > ceph mgr services
{
"dashboard": "http://myserver.com:7789/",
"restful": "https://myserver.com:8789/"
}29.1 平衡器 #
平衡器模組可最佳化各 OSD 之間的放置群組 (PG) 分佈,以實現更平衡的部署。儘管預設會啟用該模組,但它將處於非使用中狀態。它支援 crush-compat 和 upmap 這兩種模式。
若要檢視目前的平衡器狀態和組態資訊,請執行:
cephuser@adm > ceph balancer status29.1.1 「crush-compat」模式 #
在「crush-compat」模式下,平衡器會調整 OSD 的重設權數集,以改進資料分佈。它會將 PG 在 OSD 之間移動,因此會暫時出現由 PG 錯放所導致的 HEALTH_WARN 叢集狀態。
儘管「crush-compat」為預設模式,但我們仍建議明確將其啟用:
cephuser@adm > ceph balancer mode crush-compat29.1.2 資料平衡的規劃和執行 #
您可以使用平衡器模組建立資料平衡計畫。隨後,您可以手動執行該計畫,或讓平衡器持續平衡 PG。
若要決定是以手動還是自動模式來執行平衡器,需要考慮諸如目前資料的不平衡情況、叢集大小、PG 計數或 I/O 活動等多項因素。我們建議選擇在叢集中的 I/O 負載較低時建立和執行初始計畫。原因是初始的不平衡情況可能會非常嚴重,因此最好將對用戶端的影響保持在較低程度。初始的手動執行完成後,建議您啟用自動模式,並監控正常 I/O 負載下的重新平衡流量。需要對照平衡器所導致的重新平衡流量來權衡 PG 分佈的改進。
在平衡過程中,平衡器模組會節流 PG 的移動,以便僅移動可設定的 PG 部分。該部分預設為 5%,您可透過執行以下指令調整該部分 (例如,調整為 9%):
cephuser@adm > ceph config set mgr target_max_misplaced_ratio .09若要建立和執行平衡計畫,請執行以下步驟:
檢查目前的叢集分數:
cephuser@adm >ceph balancer eval建立計畫,例如「great_plan」:
cephuser@adm >ceph balancer optimize great_plan查看「great_plan」將引發的變更:
cephuser@adm >ceph balancer show great_plan檢查潛在的叢集分數 (如果您決定套用「great_plan」):
cephuser@adm >ceph balancer eval great_plan執行「great_plan」一次:
cephuser@adm >ceph balancer execute great_plan使用
ceph -s指令觀察叢集平衡情況。如果您對結果滿意,請啟用自動平衡:cephuser@adm >ceph balancer on如果您稍後決定停用自動平衡,請執行:
cephuser@adm >ceph balancer off
您可以不執行初始計畫,直接啟用自動平衡。在此情況下,放置群組的重新平衡用時可能會非常長。
29.2 啟用遙測模組 #
遙測外掛程式可傳送有關執行其的叢集的 Ceph 專案匿名資料。
此 (選擇加入) 元件包含有關叢集部署方式、Ceph 版本、主機分佈,以及其他有助於專案更好地瞭解 Ceph 使用方式的參數的計數器和統計資料。它不包含任何諸如池名稱、物件名稱、物件內容或主機名稱等敏感性資料。
遙測模組用於為開發人員提供自動化回饋迴路,以協助其量化採用率、追蹤情況,或指出為避免出現不良後果而需在組態期間以更佳方式進行解釋或驗證的內容。
遙測模組需要 Ceph 管理員節點能夠透過 HTTPS 將資料推入至上游伺服器。請確定您的企業防火牆允許此動作。
若要啟用遙測模組,請執行以下指令:
cephuser@adm >ceph mgr module enable telemetry注意此指令只能讓您在本地檢視您的資料。它並不會將您的資料與 Ceph 社群共用。
若要允許遙測模組開始共用資料,請執行以下指令:
cephuser@adm >ceph telemetry on若要停用遙測資料共用,請執行以下指令:
cephuser@adm >ceph telemetry off若要產生可列印的 JSON 報告,請執行以下指令:
cephuser@adm >ceph telemetry show若要新增聯絡資訊和描述至報告,請執行以下指令:
cephuser@adm >ceph config set mgr mgr/telemetry/contact John Doe john.doe@example.comcephuser@adm >ceph config set mgr mgr/telemetry/description 'My first Ceph cluster'該模組預設每 24 小時編譯並傳送一次新報告。若要調整此間隔,請執行以下指令:
cephuser@adm >ceph config set mgr mgr/telemetry/interval HOURS
30 使用 cephx 進行驗證 #
為了識別用戶端並防禦中間人攻擊,Ceph 提供了 cephx
驗證系統。在此環境中,用戶端表示人類使用者 (例如 admin 使用者) 或 Ceph 相關的服務/精靈 (例如
OSD、監控程式或物件閘道)。
cephx 通訊協定不會處理 TLS/SSL 之類的傳輸中資料加密。
30.1 驗證架構 #
cephx 使用共用機密金鑰進行驗證,這表示用戶端和 Ceph
監控程式都有用戶端機密金鑰的副本。驗證通訊協定可讓雙方互相證明各自擁有金鑰的副本,且無需真正透露金鑰。這樣就實現了雙向驗證,即,叢集可確定使用者擁有機密金鑰,而使用者亦可確定叢集擁有機密金鑰的副本。
Ceph 的一項重要延展性功能就是不需要透過集中式介面即可與 Ceph 物件儲存互動。這表示 Ceph 用戶端可直接與 OSD
互動。為了保護資料,Ceph 提供了 cephx 驗證系統來對
Ceph 用戶端進行驗證。
每個監控程式都可對用戶端進行驗證並分發金鑰,因此,在使用 cephx
時,不會出現單一故障點或瓶頸。監控程式會傳回驗證資料結構,其中包含獲取 Ceph
服務時要用到的工作階段金鑰。此工作階段金鑰自身已使用用戶端的永久機密金鑰進行了加密,因此,只有用戶端才能向 Ceph
監控程式要求服務。然後,用戶端會使用工作階段金鑰向監控程式要求所需的服務,監控程式會為用戶端提供一個票證,用於向實際處理資料的 OSD
驗證用戶端。Ceph 監控程式和 OSD 共用一個機密,因此,用戶端可使用監控程式提供的票證向叢集中的任何 OSD
或中繼資料伺服器表明身分。cephx
票證有過期時間,因此,攻擊者無法使用已過期的票證或以不當方式獲取的工作階段金鑰。
若要使用
cephx,管理員必須先設定用戶端/使用者。在下圖中,client.admin
使用者從指令行呼叫 ceph auth get-or-create-key 來產生使用者名稱和機密金鑰。Ceph
的 auth 子系統會產生該使用者名稱和金鑰,在監控程式中儲存一個副本,並將該使用者的機密傳回給
client.admin
使用者。這表示用戶端和監控程式共用一個機密金鑰。

cephx 基本驗證 #若要在監控程式中進行驗證,用戶端需將使用者名稱傳遞給監控程式。監控程式會產生一個工作階段金鑰,並使用與該使用者名稱關聯的機密金鑰來加密該工作階段金鑰,然後將加密的票證傳回給用戶端。之後,用戶端會使用共用的機密金鑰解密資料,以擷取工作階段金鑰。工作階段金鑰可識別目前工作階段的使用者。然後,用戶端會要求與該使用者相關、由工作階段金鑰簽署的票證。監控程式會產生一個票證,以使用者的機密金鑰對其加密,然後將其傳回給用戶端。用戶端解密該票證,並使用它來簽署傳至整個叢集中的 OSD 和中繼資料伺服器的要求。

cephx 驗證 #
cephx 通訊協定會對用戶端機器與 Ceph
伺服器之間進行的通訊進行驗證。完成初始驗證後,將使用監控程式、OSD
和中繼資料伺服器可透過共用機密進行驗證的票證,來簽署用戶端與伺服器之間傳送的每條訊息。

cephx 驗證 - MDS 和 OSD #這種驗證提供的保護僅限於 Ceph 用戶端與 Ceph 叢集主機之間,驗證不會延伸到 Ceph 用戶端以外。如果使用者從遠端主機存取 Ceph 用戶端,則不會對使用者主機與用戶端主機之間的連接套用 Ceph 驗證。
30.2 主要管理 #
本節介紹 Ceph 用戶端使用者,以及如何在 Ceph 儲存叢集中對其進行驗證和授權。使用者是指使用 Ceph 用戶端來與 Ceph 儲存叢集精靈互動的個人或系統參與者 (例如應用程式)。
Ceph 在啟用驗證和授權 (預設啟用) 的情況下執行時,您必須指定一個使用者名稱,以及包含所指定使用者的機密金鑰的金鑰圈
(通常透過指令行指定)。如果您未指定使用者名稱,Ceph 將使用
client.admin
做為預設使用者名稱。如果您未指定金鑰圈,Ceph 將透過 Ceph
組態檔案中的金鑰圈設定來尋找金鑰圈。例如,如果您在未指定使用者名稱或金鑰圈的情況下執行 ceph health
指令,Ceph 將依如下所示解釋該指令:
cephuser@adm > ceph -n client.admin --keyring=/etc/ceph/ceph.client.admin.keyring health
或者,您可以使用 CEPH_ARGS 環境變數來避免重複輸入使用者名稱和機密。
30.2.1 背景資訊 #
無論 Ceph 用戶端是何類型 (例如,區塊裝置、物件儲存、檔案系統、原生 API),Ceph 都會在池中將所有資料儲存為物件。Ceph 使用者需要擁有池存取權才能讀取和寫入資料。此外,Ceph 使用者必須擁有執行權限才能使用 Ceph 的管理指令。以下概念可協助您理解 Ceph 使用者管理。
30.2.1.1 使用者 #
使用者是指個人或系統參與者 (例如應用程式)。透過建立使用者,您可以控制誰 (或哪個參與者) 能夠存取您的 Ceph 儲存叢集、其池及池中的資料。
Ceph 使用多種類型的使用者。進行使用者管理時,將一律使用
client 類型。Ceph 透過句點 (.)分隔格式來識別使用者,該格式由使用者類型和使用者 ID
組成。例如,TYPE.ID、client.admin 或
client.user1。區分使用者類型的原因在於,Ceph 監控程式、OSD 和中繼資料伺服器也使用
cephx 通訊協定,但它們並非用戶端。區分使用者類型有助於將用戶端使用者與其他使用者區分開來,從而簡化存取控制、使用者監控和追溯性。
有時,Ceph 的使用者類型可能會令人混淆,因為依據指令行用法的不同,Ceph 指令行允許您指定具有類型的使用者或不具有類型的使用者。如果您指定
--user 或 --id,則可以省略類型。因此,可將
client.user1 簡單地輸入為 user1。如果您指定的是
--name 或 -n,則必須指定類型和名稱,例如
client.user1。做為最佳實務,我們建議儘可能使用類型和名稱。
Ceph 儲存叢集使用者與 Ceph 物件儲存使用者或 Ceph 檔案系統使用者均不同。Ceph 物件閘道使用 Ceph 儲存叢集使用者在閘道精靈與儲存叢集之間通訊,但閘道有自己的使用者管理功能來管理最終使用者。Ceph 檔案系統使用 POSIX 語意。與其關聯的使用者空間和 Ceph 儲存叢集使用者不同。
30.2.1.2 授權和能力 #
Ceph 使用「能力」(caps) 術語來描述對已驗證的使用者進行授權,允許其運用監控程式、OSD 和中繼資料伺服器的功能。功能還可限制對池或池名稱空間內的資料的存取。Ceph 管理使用者可在建立或更新使用者時設定使用者的能力。
能力語法的格式如下:
daemon-type 'allow capability' [...]
下面是每個服務類型的能力清單:
- 監控程式能力
包括
r、w、x和allow profile cap。mon 'allow rwx' mon 'allow profile osd'
- OSD 能力
包括
r、w、x、class-read、class-write和profile osd。此外,使用 OSD 能力還能進行池和名稱空間設定。osd 'allow capability' [pool=poolname] [namespace=namespace-name]
- MDS 能力
只需要
allow,或留為空白。mds 'allow'
以下各項描述了每個能力:
- allow
需先於精靈的存取設定指定。僅對 MDS 表示
rw。- r
向使用者授予讀取權限。存取監控程式以擷取 CRUSH 地圖時需具有此能力。
- w
向使用者授予對物件的寫入權限。
- x
授予使用者呼叫類別方法 (包括讀取和寫入) 的能力,以及在監控程式中執行
auth操作的能力。- class-read
授予使用者呼叫類別讀取方法的能力。
x的子集。- class-write
授予使用者呼叫類別寫入方法的能力。
x的子集。- *
授予使用者對特定精靈/池的讀取、寫入和執行權限,以及執行管理指令的能力。
- profile osd
授予使用者以某個 OSD 身分連接到其他 OSD 或監控程式的權限。授予 OSD 權限,使 OSD 能夠處理複製活動訊號流量和狀態報告。
- profile mds
授予使用者以某個 MDS 身分連接到其他 MDS 或監控程式的權限。
- profile bootstrap-osd
授予使用者將 OSD 開機的權限。授權給部署工具,使其在將 OSD 開機時有權新增金鑰。
- profile bootstrap-mds
授予使用者將中繼資料伺服器開機的權限。授權給部署工具,使其在將中繼資料伺服器開機時有權新增金鑰。
30.2.1.3 池 #
池是指使用者在其中儲存資料的邏輯分割區。在 Ceph 部署中,常見的做法是為相似類型的資料建立一個池做為邏輯分割區。例如,將 Ceph 部署為
OpenStack 的後端時,一般的部署方式是為磁碟區、影像、備份和虛擬機器以及使用者 (如
client.glance 或
client.cinder) 建立相應的池。
30.2.2 管理使用者 #
使用者管理功能可讓 Ceph 叢集管理員能夠直接在 Ceph 叢集中建立、更新和刪除使用者。
在 Ceph 叢集中建立或刪除使用者時,可能需要將金鑰分發到用戶端,以便可將金鑰新增至金鑰圈。請參閱第 30.2.3 節 「管理金鑰圈」,以獲得詳細資料。
30.2.2.1 列出使用者 #
若要列出叢集中的使用者,請執行以下指令:
cephuser@adm > ceph auth list
Ceph 將列出您叢集中的所有使用者。例如,在包含兩個節點的叢集中,ceph auth list
輸出類似下方所示:
installed auth entries:
osd.0
key: AQCvCbtToC6MDhAATtuT70Sl+DymPCfDSsyV4w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQC4CbtTCFJBChAAVq5spj0ff4eHZICxIOVZeA==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQBHCbtT6APDHhAA5W00cBchwkQjh3dkKsyPjw==
caps: [mds] allow
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBICbtTOK9uGBAAdbe5zcIGHZL3T/u2g6EBww==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQBHCbtT4GxqORAADE5u7RkpCN/oo4e5W0uBtw==
caps: [mon] allow profile bootstrap-osd
請注意,針對使用者採用 TYPE.ID 表示法,例如,osd.0 指定
osd 類型的使用者,其 ID 為
0。client.admin 是
client 類型的使用者,其 ID 為
admin。另請注意,每個項目都包含一個 key:
value 項目,以及一或多個
caps: 項目。
您可以將 -o filename 選項和
ceph auth list 結合使用,以將輸出儲存到某個檔案。
30.2.2.2 獲取有關使用者的資訊 #
若要擷取特定的使用者、金鑰和能力,請執行以下指令:
cephuser@adm > ceph auth get TYPE.ID例如:
cephuser@adm > ceph auth get client.admin
exported keyring for client.admin
[client.admin]
key = AQA19uZUqIwkHxAAFuUwvq0eJD4S173oFRxe0g==
caps mds = "allow"
caps mon = "allow *"
caps osd = "allow *"開發人員也可以執行以下指令:
cephuser@adm > ceph auth export TYPE.ID
auth export 指令與 auth get
相同,不過它還會列印內部驗證 ID。
30.2.2.3 新增使用者 #
新增使用者會建立使用者名稱 (TYPE.ID)、機密金鑰,以及包含在指令中用於建立該使用者的所有能力。
使用者可使用其金鑰向 Ceph 儲存叢集進行驗證。使用者的能力授予該使用者在 Ceph 監控程式 (mon)、Ceph OSD (osd) 或 Ceph 中繼資料伺服器 (mds) 上進行讀取、寫入或執行的能力。
可以使用以下幾個指令來新增使用者:
ceph auth add此指令是新增使用者的規範方法。它會建立使用者、產生金鑰,並新增所有指定的能力。
ceph auth get-or-create此指令往往是建立使用者的最便捷方法,因為它會傳回包含使用者名稱 (在方括號中) 和金鑰的金鑰檔案格式。如果該使用者已存在,此指令只以金鑰檔案格式傳回使用者名稱和金鑰。您可以使用
-o filename選項將輸出儲存到某個檔案。ceph auth get-or-create-key此指令是建立使用者並僅傳回使用者金鑰的便捷方式。對於只需要金鑰的用戶端 (例如
libvirt),此指令非常實用。如果該使用者已存在,此指令只傳回金鑰。您可以使用-o filename選項將輸出儲存到某個檔案。
建立用戶端使用者時,您可以建立不具有能力的使用者。不具有能力的使用者可以進行驗證,但不能執行其他操作。此類用戶端無法從監控程式擷取叢集地圖。但是,如果您希望稍後再新增能力,可以使用
ceph auth caps 指令建立一個不具有能力的使用者。
一般的使用者至少對 Ceph 監控程式具有讀取能力,並對 Ceph OSD 具有讀取和寫入能力。此外,使用者的 OSD 權限通常限制為只能存取特定的池。
cephuser@adm >ceph auth add client.john mon 'allow r' osd \ 'allow rw pool=liverpool'cephuser@adm >ceph auth get-or-create client.paul mon 'allow r' osd \ 'allow rw pool=liverpool'cephuser@adm >ceph auth get-or-create client.george mon 'allow r' osd \ 'allow rw pool=liverpool' -o george.keyringcephuser@adm >ceph auth get-or-create-key client.ringo mon 'allow r' osd \ 'allow rw pool=liverpool' -o ringo.key
如果您為某個使用者提供了對 OSD 的能力,但未限制只能存取特定池,則該使用者將有權存取叢集中的所有池。
30.2.2.4 修改使用者能力 #
使用 ceph auth caps
指令可以指定使用者以及變更該使用者的能力。設定新能力會覆寫目前的能力。若要檢視目前的能力,請執行 ceph auth get
USERTYPE。USERID。若要新增能力,使用以下格式時還需要指定現有能力:
cephuser@adm > ceph auth caps USERTYPE.USERID daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]' [daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]']例如:
cephuser@adm >ceph auth get client.johncephuser@adm >ceph auth caps client.john mon 'allow r' osd 'allow rw pool=prague'cephuser@adm >ceph auth caps client.paul mon 'allow rw' osd 'allow r pool=prague'cephuser@adm >ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
若要移除某個能力,可重設該能力。如果希望使用者無權存取以前設定的特定精靈,請指定一個空白字串:
cephuser@adm > ceph auth caps client.ringo mon ' ' osd ' '30.2.2.5 刪除使用者 #
若要刪除使用者,請使用 ceph auth del:
cephuser@adm > ceph auth del TYPE.ID
其中,TYPE 是
client、osd、mon 或
mds 之一,ID 是使用者名稱或精靈的 ID。
如果您建立了僅對不再存在的池具有權限的使用者,則應該考慮也刪除那些使用者。
30.2.2.6 列印使用者的金鑰 #
若要將使用者的驗證金鑰列印到標準輸出,請執行以下指令:
cephuser@adm > ceph auth print-key TYPE.ID
其中,TYPE 是
client、osd、mon 或
mds 之一,ID 是使用者名稱或精靈的 ID。
當您需要在用戶端軟體 (例如 libvirt)
中填入某個使用者的金鑰時,列印使用者的金鑰非常實用,如以下範例所示:
root # mount -t ceph host:/ mount_point \
-o name=client.user,secret=`ceph auth print-key client.user`30.2.2.7 輸入使用者 #
若要輸入一或多個使用者,請使用 ceph auth import 並指定金鑰圈:
cephuser@adm > ceph auth import -i /etc/ceph/ceph.keyringCeph 儲存叢集將新增新使用者及其金鑰和能力,並更新現有使用者及其金鑰和能力。
30.2.3 管理金鑰圈 #
當您透過 Ceph 用戶端存取 Ceph 時,該用戶端會尋找本地金鑰圈。依預設,Ceph 會使用以下四個金鑰圈名稱預先指定金鑰圈設定,因此,除非您要覆寫預設值,否則無需在 Ceph 組態檔案中設定這些名稱:
/etc/ceph/cluster.name.keyring /etc/ceph/cluster.keyring /etc/ceph/keyring /etc/ceph/keyring.bin
cluster 元變數是依 Ceph 組態檔案名稱定義的 Ceph
叢集名稱。ceph.conf 表示叢集名稱為
ceph,因此金鑰圈名稱為
ceph.keyring。name
元變數是使用者類型和使用者 ID (例如 client.admin),因此金鑰圈名稱為
ceph.client.admin.keyring。
建立使用者 (例如 client.ringo)
之後,必須獲取金鑰並將其新增至 Ceph 用戶端上的金鑰圈,以使該使用者能夠存取 Ceph 儲存叢集。
第 30.2 節 「主要管理」詳細介紹了如何直接在 Ceph
儲存叢集中列出、獲取、新增、修改和刪除使用者。不過,Ceph 還提供了 ceph-authtool
公用程式,可讓您從 Ceph 用戶端管理金鑰圈。
30.2.3.1 建立金鑰圈 #
當您依照第 30.2 節 「主要管理」中的程序建立使用者時,需要向 Ceph 用戶端提供使用者金鑰,以使用戶端能擷取指定使用者的金鑰,並向 Ceph 儲存叢集驗證身分。Ceph 用戶端將存取金鑰圈,以查閱使用者名稱並擷取使用者的金鑰:
cephuser@adm > ceph-authtool --create-keyring /path/to/keyring
建立包含多個使用者的金鑰圈時,我們建議使用叢集名稱 (例如 cluster.keyring)
做為金鑰圈檔案名稱,並將其儲存在 /etc/ceph 目錄中,如此,您無需在 Ceph
組態檔案的本地副本中指定檔案名稱,金鑰圈組態預設設定就會選取正確的檔案名稱。例如,可執行以下指令來建立
ceph.keyring:
cephuser@adm > ceph-authtool -C /etc/ceph/ceph.keyring
建立包含單個使用者的金鑰圈時,我們建議使用叢集名稱、使用者類型和使用者名稱,並將其儲存在
/etc/ceph 目錄中。例如,為
client.admin 使用者建立
ceph.client.admin.keyring。
30.2.3.2 將使用者新增至金鑰圈 #
將某個使用者新增至 Ceph 儲存叢集時 (請參閱第 30.2.2.3 節 「新增使用者」),您可以擷取該使用者、金鑰和能力,並將該使用者儲存到金鑰圈。
如果您只想對每個金鑰圈使用一個使用者,可以將 -o 選項與 ceph auth
get 指令結合使用,以金鑰圈檔案格式儲存輸出。例如,若要為
client.admin 使用者建立金鑰圈,請執行以下指令:
cephuser@adm > ceph auth get client.admin -o /etc/ceph/ceph.client.admin.keyring
若要將使用者輸入到金鑰圈,可以使用 ceph-authtool 來指定目的地金鑰圈和來源金鑰圈:
cephuser@adm > ceph-authtool /etc/ceph/ceph.keyring \
--import-keyring /etc/ceph/ceph.client.admin.keyring30.2.3.3 建立使用者 #
Ceph 提供 ceph auth add 指令用於直接在 Ceph
儲存叢集中建立使用者。不過,您也可以直接在 Ceph 用戶端金鑰圈中建立使用者、金鑰和能力。然後,可將使用者輸入到 Ceph 儲存叢集:
cephuser@adm > ceph-authtool -n client.ringo --cap osd 'allow rwx' \
--cap mon 'allow rwx' /etc/ceph/ceph.keyring您也可以在建立金鑰圈的同時將新使用者新增至該金鑰圈:
cephuser@adm > ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo \
--cap osd 'allow rwx' --cap mon 'allow rwx' --gen-key
在前面的方案中,新使用者 client.ringo
僅存放在金鑰圈中。若要將該新使用者新增至 Ceph 儲存叢集,您仍必須手動新增:
cephuser@adm > ceph auth add client.ringo -i /etc/ceph/ceph.keyring30.2.3.4 修改使用者 #
若要修改金鑰圈中某條使用者記錄的能力,請指定該金鑰圈和使用者,然後指定能力:
cephuser@adm > ceph-authtool /etc/ceph/ceph.keyring -n client.ringo \
--cap osd 'allow rwx' --cap mon 'allow rwx'若要在 Ceph 叢集環境中更新已修改的使用者,必須將金鑰圈中的變更輸入到 Ceph 叢集中的使用者項目:
cephuser@adm > ceph auth import -i /etc/ceph/ceph.keyring請參閱第 30.2.2.7 節 「輸入使用者」,瞭解有關根據金鑰圈更新 Ceph 儲存叢集使用者的詳細資料。
30.2.4 指令行用法 #
ceph 指令支援以下與使用者名稱和機密操作相關的選項:
--id或--userCeph 使用類型和 ID (TYPE.ID,例如
client.admin或client.user1) 來識別使用者。使用id、name和-n選項可以指定使用者名稱的 ID 部分 (例如admin或user1)。您可以使用 --id 指定使用者,並省略類型。例如,若要指定使用者 client.foo,請輸入以下指令:cephuser@adm >ceph --id foo --keyring /path/to/keyring healthcephuser@adm >ceph --user foo --keyring /path/to/keyring health--name或-nCeph 使用類型和 ID (TYPE.ID,例如
client.admin或client.user1) 來識別使用者。使用--name和-n選項可以指定完整的使用者名稱。您必須指定使用者類型 (一般為client) 和使用者 ID:cephuser@adm >ceph --name client.foo --keyring /path/to/keyring healthcephuser@adm >ceph -n client.foo --keyring /path/to/keyring health--keyring包含一或多個使用者名稱和機密的金鑰圈路徑。
--secret選項提供相同的功能,但它不適用於物件閘道,該閘道將--secret用於其他目的。您可以使用ceph auth get-or-create來擷取金鑰圈並將其儲存在本地。這是慣用的方法,因為您無需切換金鑰圈路徑就能切換使用者名稱:cephuser@adm >rbd map --id foo --keyring /path/to/keyring mypool/myimage
A 以上游「Octopus」小數點版本為基礎的 Ceph 維護更新 #
SUSE Enterprise Storage 7 中的幾個關鍵套件均以 Ceph 的 Octopus 版本系列為基礎。當 Ceph 專案 (https://github.com/ceph/ceph) 在 Octopus 系列中發佈新的小數點版本時,SUSE Enterprise Storage 7 即會更新,以確保產品套用最新的上游錯誤修復並可進行功能向後移植。
本章簡要介紹有關已經或計劃在產品中包含的每個上游小數點版本中的重要變更。
Octopus 15.2.5 小數點版本#
Octopus 15.2.5 小數點版本引入了以下修復和其他變更:
CephFS:現在可以使用目錄上新的分散式和隨機暫時關聯延伸屬性來設定自動靜態子樹分割規則。如需詳細資訊,請參閱以下文件:https://docs.ceph.com/docs/master/cephfs/multimds/
監控程式現有一個組態選項
mon_osd_warn_num_repaired,該選項預設設定為 10。如果任何 OSD 修復的儲存資料中的 I/O 錯誤數超過此數量,則會產生OSD_TOO_MANY_REPAIRS狀況警告。現在,如果在全域或在池層級設定了
no scrub和/或no deep-scrub旗標,將中止已停用類型的排程整理。所有使用者啟動的整理將不會中斷。修復了在狀態良好的叢集中不會修剪 osdmaps 的問題。
Octopus 15.2.4 小數點版本#
Octopus 15.2.4 小數點版本引入了以下修復和其他變更:
CVE-2020-10753:rgw: 處理 s3 CORSConfiguration 的 ExposeHeader 中的換行
物件閘道:處理未同步分割區的
radosgw-admin子指令 (radosgw-admin orphans find、radosgw-admin orphans finish和radosgw-admin orphans list-jobs) 已被取代。並不會主動維護這些子指令,並且由於它們會在叢集上儲存中間結果,因此可能會填入幾乎已滿的叢集。這些子指令已被工具rgw-orphan-list取代,該工具目前被視為是實驗性工具。RBD:用於儲存 RBD 垃圾桶清除排程的 RBD 池物件的名稱已由
rbd_trash_trash_purge_schedule變更為rbd_trash_purge_schedule。已開始使用 RBD 垃圾桶清除排程功能並設定了每個池或名稱空間排程的使用者,應在升級前將rbd_trash_trash_purge_schedule物件複製到rbd_trash_purge_schedule,並在先前設定了垃圾桶清除排程的每個 RBD 池和名稱空間中使用以下指令移除rbd_trash_purge_schedule:rados -p pool-name [-N namespace] cp rbd_trash_trash_purge_schedule rbd_trash_purge_schedule rados -p pool-name [-N namespace] rm rbd_trash_trash_purge_schedule
或者,使用任何其他簡便方法在升級後還原排程。
Octopus 15.2.3 小數點版本#
Octopus 15.2.3 小數點版本是一個 Hotfix 版本,用於解決在同時啟用
bluefs_preextend_wal_files和bluefs_buffered_io時發生的 WAL 損毀問題。15.2.3 中的修復只是一種暫時性措施 (將bluefs_preextend_wal_files的預設值變更為false)。永久性的修復將是完全移除bluefs_preextend_wal_files選項:此修復很可能會在 15.2.6 小數點版本中實現。
Octopus 15.2.2 小數點版本#
Octopus 15.2.2 小數點版本修補了一個安全性弱點:
CVE-2020-10736:修復了 MON 和 MGR 中的授權繞過問題
Octopus 15.2.1 小數點版本#
Octopus 15.2.1 小數點版本修復了從 Luminous (SES5.5) 到 Nautilus (SES6) 再到 Octopus (SES7) 的快速升級導致 OSD 當機的問題。此外,它還修補了 Octopus (15.2.0) 初始版本中存在的兩個安全性弱點:
CVE-2020-1759:修復了 msgrv2 安全模式下的 nonce 重複使用
CVE-2020-1760:修復了由於 RGW GetObject 標題分割而導致的 XSS
B 文件更新 #
本章列出了本文件中適用於目前 SUSE Enterprise Storage 版本的內容變更。
Ceph Dashboard 章節 (第 I 部分 「Ceph Dashboard」) 在手冊階層中上移了一級,以便可以直接在目錄中搜尋其詳細主題。
Book “操作和管理指南”的結構已更新,以與目前的指南範圍相符。一些章節被移至其他指南 (jsc#SES-1397)。
辭彙表 #
一般
- Alertmanager #
用於處理 Prometheus 伺服器傳送的警示並通知最終使用者的單個二進位檔案。
- Ceph Dashboard #
一種內建的基於 Web 的 Ceph 管理和監控應用程式,負責管理叢集的各個方面和物件。儀表板做為 Ceph 管理員模組實作。
- Ceph OSD 精靈 #
ceph-osd精靈是 Ceph 的元件,負責在本地檔案系統上儲存物件,並在網路中提供對它們的存取。- Ceph 儲存叢集 #
用於儲存使用者資料的儲存軟體的核心集合。此類集合由 Ceph 監控程式和 OSD 組成。
- Ceph 物件儲存 #
物件儲存「產品」、服務或功能,由 Ceph 儲存叢集和 Ceph 物件閘道組成。
- Ceph 用戶端 #
可以存取 Ceph 儲存叢集的 Ceph 元件集合。其中包括物件閘道、Ceph 區塊裝置、CephFS 及其相應的程式庫、核心模組和 FUSE 用戶端。
- Ceph 監控程式 #
Ceph 監控程式或 MON 是 Ceph 監控程式軟體。
- Ceph 管理員 #
Ceph 管理員或 MGR 是 Ceph 管理員軟體,會將整個叢集的所有狀態收集到一處。
ceph-salt#提供使用 Salt 部署由 cephadm 管理的 Ceph 叢集的工具。
- cephadm #
cephadm 用於部署和管理 Ceph 叢集,它會透過 SSH 從管理員精靈連接至主機以新增、移除或更新 Ceph 精靈容器。
- CephFS #
Ceph 檔案系統。
- CephX #
Ceph 驗證通訊協定。Cephx 操作與 Kerberos 類似,但它沒有單一故障點。
- CRUSH 規則 #
適用於某個特定池或多個池的 CRUSH 資料放置規則。
- CRUSH、CRUSH 地圖 #
基於可延展雜湊的受控複製:透過計算資料儲存位置來確定如何儲存和擷取資料的演算法。CRUSH 需要獲取叢集的地圖來以虛擬隨機的方式在 OSD 中儲存和擷取資料,並以一致的方式在整個叢集中分散資料。
- DriveGroups #
DriveGroups 是可對應至實體磁碟機的一或多個 OSD 配置的宣告。OSD 配置定義了 Ceph 如何在符合指定準則的媒體上實際配置 OSD 儲存。
- Grafana #
資料庫分析和監控解決方案。
- OSD #
物件儲存裝置:一個實體或邏輯儲存單位。
- OSD 節點 #
一個叢集節點,用於儲存資料、處理資料複製、復原、回填、重新平衡,以及透過檢查其他 Ceph OSD 精靈為 Ceph 監控程式提供某些監控資訊。
- Prometheus #
系統監控和警示工具套件。
- RADOS 區塊裝置 (RBD) #
Ceph 的區塊儲存元件。也稱為 Ceph 區塊裝置。
- Samba #
Windows 整合式軟體。
- Samba 閘道 #
Samba 閘道加入到 Windows 網域中的 Active Directory,以進行使用者驗證和授權。
- 中繼資料伺服器 #
中繼資料伺服器或 MDS 是 Ceph 中繼資料軟體。
- 儲存池 #
用於儲存物件 (例如磁碟影像) 的邏輯分割區。
- 區域群組 #
- 可靠自主分散式物件儲存 (RADOS) #
用於儲存使用者資料的儲存軟體的核心集合 (MON+OSD)。
- 多區域 #
- 小數點版本 #
任何只包含錯誤或安全修復的臨機操作版本。
- 放置群組 #
放置群組:池的細分,用於進行效能調整。
- 桶 #
將其他節點聚合成實體位置階層的一個點。
- 歸檔同步模組 #
允許建立物件閘道區域以保留 S3 物件版本歷程的模組。
- 物件閘道 #
Ceph 物件儲存的 S3/Swift 閘道元件。也稱為 RADOS 閘道 (RGW)。
- 管理節點 #
在其上執行與 Ceph 相關的指令以管理叢集主機的主機。
- 節點 #
Ceph 叢集中的任何一部機器或伺服器。
- 規則集 #
用於確定池的資料放置的規則。
- 路由樹狀結構 #
該術語指的是展示接收器可執行的不同路由的任何圖表。