アーキテクチャと概念
SUSE Storageは、各ボリュームに専用のストレージコントローラを作成し、複数のノードに保存されている複数のレプリカ間でボリュームを同期レプリケートします。
ストレージコントローラとレプリカ自体はKubernetesを使用してオーケストレーションされます。
機能の概要については、このセクションを参照してください。
インストール要件については、このセクションを参照してください。
このセクションでは、Kubernetesの永続ストレージの概念に精通していることを前提としています。これらの概念に関する詳細情報については、付録を参照してください。このページで使用されている用語についてのヘルプは、このセクションを参照してください。
1.設計
設計には2つの階層があります:データプレーンとコントロールプレーン。Longhorn Engineはデータプレーンに対応するストレージコントローラであり、Longhorn Managerはコントロールプレーンに対応します。
1.1.Longhorn ManagerとLonghorn Engine
Longhorn Managerポッドは、SUSE Storageクラスター内の各ノードでKubernetesの デーモンセットとして実行されます。Kubernetesクラスター内でボリュームを作成および管理し、SUSE Storage UIまたはLonghorn CSIプラグインからのAPI呼び出しを処理します。Kubernetesコントローラパターンに従い、これは時折オペレータパターンと呼ばれます。
Longhorn Managerは、Kubernetes APIサーバーと通信して新しいSUSE Storageボリューム CRを作成します。その後、Longhorn ManagerはAPIサーバーの応答を監視し、Kubernetes APIサーバーが新しいSUSE StorageボリュームCRを作成したことを確認すると、Longhorn Managerは新しいボリュームを作成します。
Longhorn Managerがボリュームの作成を求められたとき、ボリュームが接続されているノードにLonghorn Engineのインスタンスを作成し、レプリカが配置される各ノードにレプリカを作成します。レプリカは最大の可用性を確保するために、別々のホストに配置する必要があります。
レプリカのための複数のデータパスは、Longhornボリュームの高可用性を確保します。レプリカまたはエンジンに問題が発生した場合、すべてのレプリカやポッドのボリュームへのアクセスに影響を与えることはありません。ポッドは通常通り機能し続けます。レプリカ数が`N`の特定のボリュームに対して、Longhornボリュームは最大`N-1`のレプリカ障害に耐えることができます。これは、ボリュームが稼働し続けるためには少なくとも1つの健康なレプリカが必要だからです。
Longhorn Engineは、SUSE Storageボリュームを使用するPodと同じノードで常に実行されます。それは、複数のノードに保存された複数のレプリカ間でボリュームを同期的に複製します。
エンジンとレプリカはKubernetesを使用してオーケストレーションされます。
以下の図では、
-
SUSE Storageボリュームを持つ3つのインスタンスがあります。
-
各ボリュームには、Longhorn Engineと呼ばれる専用のコントローラーがあります。V1ボリュームの場合、エンジンはLinuxプロセスとして実行され、V2ボリュームの場合はSPDK RAIDブロックデバイス(bdev)として動作します。
-
各SUSE Storageボリュームには2つのレプリカがあります。V1では、レプリカはLinuxプロセスとして実行され、V2ではSPDK論理ボリュームbdevとして実装されています。
-
図中の矢印は、ボリューム、コントローラーインスタンス、レプリカインスタンス、およびディスク間の読み取り/書き込みデータフローを示しています。
-
各ボリュームのために別々のLonghornエンジンを作成することにより、1つのコントローラーが故障しても、他のボリュームの機能には影響がありません。
図1。ボリューム、Longhorn Engine、レプリカインスタンス、およびディスク間の読み取り/書き込みデータフロー

1.2.マイクロサービスベースの設計の利点
各エンジンは1つのボリュームにのみサービスを提供する必要があり、ストレージコントローラーの設計が簡素化されます。コントローラーソフトウェアの障害ドメインは個々のボリュームに隔離されているため、コントローラーのクラッシュは1つのボリュームにのみ影響を与えます。
Longhorn Engineはシンプルで軽量であり、数千の別々のエンジンを作成することができます。Kubernetesはこれらの別々のエンジンをスケジュールし、共有ディスクセットからリソースを引き出し、SUSE Storageと連携して回復力のある分散ブロックストレージシステムを形成します。
各ボリュームには独自のコントローラーがあるため、各ボリュームのコントローラーとレプリカインスタンスは、IO操作に目立った中断を引き起こすことなくアップグレードできます。
SUSE Storageは、システムの進行中の操作を中断することなく、すべてのライブボリュームのアップグレードを調整するための長時間実行されるジョブを作成できます。アップグレードが予期しない問題を引き起こさないようにするために、SUSE Storageはボリュームの小さなサブセットをアップグレードし、アップグレード中に何か問題が発生した場合には古いバージョンにロールバックすることを選択できます。
1.3.CSIドライバー
Longhorn CSIドライバーはブロックデバイスを取得し、フォーマットしてノードにマウントします。次に、 kubeletがKubernetes Pod内にデバイスをバインドマウントします。これにより、PodはSUSE Storageボリュームにアクセスできます。
必要なKubernetes CSIドライバーイメージは、Longhornドライバーデプロイヤーによって自動的にデプロイされます。 SUSE Storageをエアギャップ環境にインストールするには、このセクションを参照してください。
1.4.CSIプラグイン
SUSE Storageは、 CSIプラグイン。を介してKubernetesで管理されます。これにより、プラグインの簡単なインストールが可能になります。
Kubernetes CSIプラグインは、Kubernetesワークロードのために永続データを作成するためにボリュームを作成するためにSUSE Storageを呼び出します。CSIプラグインは、ボリュームの作成、削除、アタッチ、デタッチ、マウント、およびボリュームのスナップショットを取得する機能を提供します。SUSE Storageによって提供される他のすべての機能は、UIを通じて実装されています。
Kubernetesクラスターは、内部的にCSIインターフェースを使用してLonghorn CSIプラグインと通信します。Longhorn CSIプラグインは、Longhorn APIを使用してLonghorn Managerと通信します。
v1ボリュームの場合、SUSE StorageはiSCSIを使用し、ノードに追加の設定が必要な場合があります。
-
Linux配布パッケージに応じて、`open-iscsi`または`iscsiadm`のいずれかをインストールする必要があります。
対照的に、v2ボリュームは構成に応じて異なる前提条件があります。
-
`vfio_pci`や`uio_pci_generic`のようなカーネルモジュールが必要です。
-
NVMe-TCPフロントエンドには、`nvme_tcp`モジュールが必要です。
1.5.UI
UIはLonghorn APIを介してLonghorn Managerと対話し、Kubernetesの補完として機能します。UIを通じて、スナップショット、バックアップ、ノード、ディスクを管理できます。
さらに、クラスターのワーカーノードのスペース使用量が収集され、UIによって示されます。詳しくは、こちらをご覧ください。
2.ボリュームとプライマリストレージ
ボリュームを作成する際、Longhorn ManagerはLonghorn Engineマイクロサービスと各ボリュームのレプリカをマイクロサービスとして作成します。これらのマイクロサービスは一緒にSUSE Storageボリュームを形成します。各レプリカは異なるノードまたは異なるディスクに配置する必要があります。
Longhorn ManagerによってLonghorn Engineが作成された後、それはレプリカに接続します。Engineは、Podが実行されている同じノード上にブロックデバイスを公開します。
SUSE Storageボリュームはkubectlを使用して作成できます。
2.1.スリムプロビジョニングとボリュームサイズ
SUSE Storageはスリムプロビジョニングされたストレージシステムです。これは、SUSE Storageボリュームがその時点で必要なスペースのみを占有することを意味します。例えば、20 GBのボリュームを割り当てたが、そのうち1 GBしか使用していない場合、ディスク上の実際のデータサイズは1 GBになります。UIのボリューム詳細で実際のデータサイズを確認できます。
SUSE Storageボリューム自体は、ボリュームからコンテンツを削除してもサイズを縮小することはできません。例えば、20 GBのボリュームを作成し、10 GBを使用し、その後9 GBのコンテンツを削除した場合、ディスク上の実際のサイズは1 GBではなく、依然として10 GBになります。これは、SUSE Storageがブロックレベルで動作し、ファイルシステムレベルではないため、SUSE Storageはユーザーによってコンテンツが削除されたかどうかを認識できないからです。その情報は主にファイルシステムレベルで保持されます。
ボリュームサイズに関連する概念についての詳細は、このdocを参照してください。
2.2.メンテナンスモードでのボリュームの復元
UIからボリュームが接続されると、メンテナンスモードのチェックボックスがあります。これは主にスナップショットからボリュームを復元するために使用されます。
このオプションは、ボリューム接続中に誰もデータにアクセスできないよう、フロントエンド(ブロックデバイスまたはiSCSI)を有効にせずにボリュームを接続するものです。
v0.6.0以降、スナップショット復元操作にはボリュームがメンテナンスモードであることが必要です。これは、ボリュームがマウントされているか使用されている間にブロックデバイスの内容が変更されると、ファイルシステムの破損を引き起こすためです。
データが誤ってアクセスされることを心配せずにボリュームの状態を検査するのにも役立ちます。
2.3.Replicas
各レプリカは、SUSE Storageボリュームのスナップショットのチェーンを含んでいます。スナップショットは画像の層のようなもので、最も古いスナップショットがベース層として使用され、新しいスナップショットがその上に重ねられます。データは、古いスナップショットのデータを上書きする場合にのみ、新しいスナップショットに含まれます。スナップショットのチェーンは、データの現在の状態を示します。
各SUSE Storageボリュームについて、Kubernetesクラスター内で複数のレプリカが異なるノードで実行されるべきです。すべてのレプリカは同じように扱われ、Longhorn Engineは常にポッドと同じノードで実行され、ポッドはボリュームの消費者でもあります。そのようにして、ポッドがダウンしても、エンジンを別のポッドに移動でき、サービスは中断されずに続行されます。
デフォルトのレプリカ数は、設定。で変更できます。ボリュームが接続されると、UIでボリュームのレプリカ数を変更できます。
現在の正常なレプリカ数が指定されたレプリカ数より少ない場合、SUSE Storageは新しいレプリカの再構築を開始します。
現在の正常なレプリカ数が指定されたレプリカ数より多い場合、レプリカの自動バランスとデータのローカリティは無効になり、SUSE Storageは何もしません。この状況では、レプリカが失敗したり削除された場合、正常なレプリカ数が指定されたレプリカ数を下回らない限り、SUSE Storageは新しいレプリカの再構築を開始しません。レプリカの自動バランスまたはデータのローカリティが設定されている場合、SUSE Storageはレプリカの1つを削除する可能性があります。
SUSE Storageレプリカは、スリムプロビジョニングをサポートするLinux スパースファイル,を使用して構築されます。
2.3.1。レプリカの読み取りおよび書き込み操作の動作
ボリュームのレプリカからデータが読み取られるとき、ライブデータにそのデータが見つかれば、そのデータが使用されます。見つからない場合は、最新のスナップショットが読み取られます。データが最新のスナップショットに見つからない場合、次に古いスナップショットが読み取られ、最古のスナップショットが読み取られるまで続きます。
スナップショットを取得すると、 差分ディスクが作成されます。スナップショットの数が増えるにつれて、差分ディスクチェーン(スナップショットのチェーンとも呼ばれる)はかなり長くなる可能性があります。読み取り性能を向上させるために、SUSE Storageは各4Kストレージブロックに対して有効なデータを保持する差分ディスクを記録する読み取りインデックスを維持します。
次の図では、ボリュームには8つのブロックがあります。読み取りインデックスには8つのエントリがあり、読み取り操作が行われると遅延的に埋められます。
書き込み操作は読み取りインデックスをリセットし、ライブデータを指すようにします。ライブデータは、いくつかのインデックスにデータがあり、他のインデックスには空きスペースがあるデータで構成されています。
読み取りインデックスを超えて、現在使用されているブロックを示す追加のメタデータは維持していません。
図2。読み取りインデックスがどのスナップショットが最新のデータを保持しているかを追跡する方法
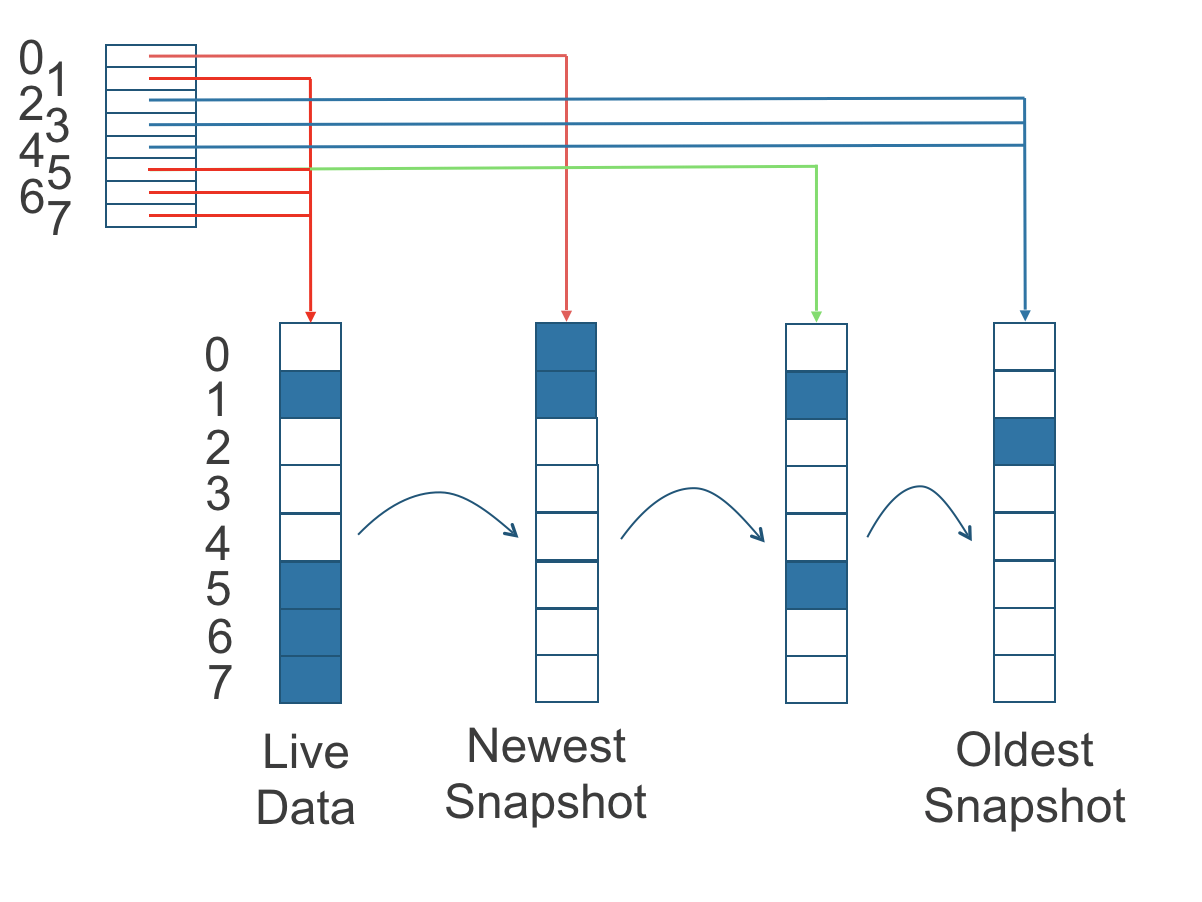
上の図は、読み取りインデックスに従って最新のデータを含むブロックを示すために色分けされており、最新のデータのソースも下の表に示されています:
| 読み取りインデックス | 最新のデータのソース |
|---|---|
0 |
最新のスナップショット |
1 |
ライブデータ |
2 |
最古のスナップショット |
3 |
最古のスナップショット |
4 |
最古のスナップショット |
5 |
ライブデータ |
6 |
ライブデータ |
7 |
ライブデータ |
上の図に示されている緑の矢印が示すように、読み取りインデックスのインデックス5は以前、最新のデータのソースとして2番目に古いスナップショットを指していましたが、インデックス5の4Kストレージブロックがライブデータによって上書きされたときにライブデータを指すように変更されました。
読み取りインデックスはメモリに保持され、各4Kブロックに対して1バイトを消費します。バイトサイズの読み取りインデックスは、各ボリュームに対して254スナップショットまで取得できることを意味します。
読み取りインデックスは、各レプリカに対して一定量のメモリ内データ構造を消費します。例えば、1 TBのボリュームは、256 MBのメモリ内読み取りインデックスを消費します。
2.3.2 新しいレプリカの追加方法
新しいレプリカが追加されると、既存のレプリカは新しいレプリカに同期されます。最初のレプリカは、ライブデータから新しいスナップショットを取得することによって作成されます。
以下のステップは、SUSE Storageが新しいレプリカを追加する方法の詳細な内訳を示しています:
-
Longhorn Engineは一時停止されます。
-
レプリカ内のスナップショットのチェーンがライブデータとスナップショットで構成されていると仮定しましょう。新しいレプリカが作成されると、ライブデータは最新の(2番目の)スナップショットとなり、新しい空のライブデータのバージョンが作成されます。
-
新しいレプリカはWO(書き込み専用)モードで作成されます。
-
Longhorn Engineは再開されます。
-
すべてのスナップショットが同期されます。
-
新しいレプリカはRW(読み書き可能)モードに設定されます。
2.3.3.故障したレプリカの再構築方法
SUSE Storageは、各ボリュームに対して常に指定された数の健全なレプリカを維持しようとします。
コントローラーがそのレプリカの1つで障害を検出すると、そのレプリカはエラー状態としてマークされます。Longhorn Managerは、故障したレプリカの再構築プロセスを開始し、調整する責任があります。
故障したレプリカを再構築するために、Longhorn Managerは空のレプリカを作成し、Longhorn Engineに空のレプリカをボリュームのレプリカセットに追加するよう呼び出します。
空のレプリカを追加するために、エンジンは以下の操作を実行します:
-
すべての読み取りおよび書き込み操作を一時停止します。
-
空のレプリカをWO(書き込み専用)モードで追加します。
-
すべての既存のレプリカのスナップショットを取得し、現在はその先頭に空の差分ディスクがあります。
-
すべての読み取りおよび書き込み操作の一時停止を解除します。新しく追加されたレプリカには、書き込み操作のみが送信されます。
-
良好なレプリカから空のレプリカに、最新の差分ディスクを除くすべてを同期するバックグラウンドプロセスを開始します。
-
同期が完了すると、すべてのレプリカは一貫したデータを持ち、ボリュームマネージャーは新しいレプリカをRW(読み書き)モードに設定します。
最後に、Longhorn ManagerがLonghorn Engineを呼び出して、故障したレプリカをレプリカセットから削除します。
2.4.スナップショット
スナップショット機能により、ボリュームを特定の履歴の時点に戻すことができます。セカンダリストレージのバックアップもスナップショットから作成できます。
ボリュームがスナップショットから復元されると、スナップショットが作成された時点でのボリュームの状態が反映されます。
スナップショット機能は、SUSE Storage 再構築プロセスの一部でもあります。SUSE Storage がレプリカのダウンを検出するたびに、自動的に(システム)スナップショットを取得し、別のノードで再構築を開始します。
2.4.1。スナップショットの仕組み
スナップショットは画像の層のようなもので、最も古いスナップショットがベース層として使用され、新しいスナップショットがその上に重ねられます。データは、古いスナップショットのデータを上書きする場合にのみ、新しいスナップショットに含まれます。スナップショットのチェーンは、データの現在の状態を示します。レプリカからデータがどのように読み取られるかの詳細な内訳については、レプリカの読み取りおよび書き込み操作に関するセクションを参照してください。
スナップショットは作成後に変更できませんが、スナップショットが削除されると、その変更は次に最近のスナップショットと統合されます。新しいデータは常にライブバージョンに書き込まれます。新しいスナップショットは常にライブデータから作成されます。
新しいスナップショットを作成するには、ライブデータが最新のスナップショットになります。その後、古いライブデータの代わりに新しい空のライブデータのバージョンが作成されます。
2.4.2。定期的スナップショット
スナップショットが占めるスペースを削減するために、ユーザーは保持するスナップショットの数を指定して定期的なスナップショットまたはバックアップをスケジュールすることができ、これによりスケジュールに従って新しいスナップショット/バックアップが自動的に作成され、その後、過剰なスナップショット/バックアップがクリーンアップされます。
2.4.3。スナップショットの削除
不要なスナップショットは、UIを通じて手動で削除できます。システム生成のスナップショットは、いずれかのスナップショットの削除がトリガーされた場合、自動的に削除対象としてマークされます。
最新のスナップショットは削除できません。これは、スナップショットが削除されるたびに、SUSE Storageがその内容を次のスナップショットと統合するため、次のスナップショットおよびその後のスナップショットが正しい内容を保持するためです。
しかし、SUSE Storageは最新のスナップショットに対してそれを行うことはできません。なぜなら、削除されたスナップショットと統合される最近のスナップショットが存在しないからです。最新のスナップショットの次の"`snapshot`"は、現在ユーザーによって読み書きされているライブボリューム(ボリュームヘッド)であるため、統合プロセスは発生できません。
代わりに、最新のスナップショットは削除済みとしてマークされ、次回可能なときにクリーンアップされます。
最新のスナップショットをクリーンアップするには、新しいスナップショットを作成し、その後、以前の「最新」スナップショットを削除できます。
2.4.4。スナップショットの保存
スナップショットは、各ボリュームのレプリカの一部としてローカルに保存されます。それらはKubernetesクラスター内のノードのディスクに保存されます。 スナップショットは、ホストの物理ディスク上のボリュームデータと同じ場所に保存されます。
2.4.5。クラッシュ整合性
SUSE Storageはクラッシュ整合性のあるブロックストレージソリューションです。
OSがブロックストレージに書き込む前にキャッシュに内容を保持するのは通常のことです。これは、すべてのレプリカがダウンしている場合、SUSE Storageがシャットダウンの直前に発生した変更を含まない可能性があることを意味します。なぜなら、内容はOSレベルのキャッシュに保持されており、まだSUSE Storageシステムに転送されていなかったからです。
この問題は、デスクトップコンピュータが停電によりシャットダウンした場合に発生する可能性のある問題に似ています。電源を再開した後、ハードドライブにいくつかの破損したファイルが見つかるかもしれません。
データを任意の瞬間にブロックストレージに書き込むためには、ノードで手動でsyncコマンドを実行するか、ディスクをアンマウントすることができます。いずれの状況でも、OSはキャッシュからブロックストレージに内容を書き込みます。
SUSE Storageはスナップショットを作成する前に自動的にsyncコマンドを実行します。
3.バックアップとセカンダリストレージ
バックアップは、Kubernetesクラスターの外部にあるNFSまたはS3互換のオブジェクトストアであるバックアップストア内のオブジェクトです。バックアップはセカンダリストレージの一形態を提供し、Kubernetesクラスターが利用できなくなってもデータを取得できるようにします。
ボリュームのレプリケーションが同期されており、低レイテンシがあるため、クロスリージョンレプリケーションを行うのは難しいです。バックアップストアは、この問題に対処するための手段としても使用されます。
バックアップターゲットがUIに設定されると(バックアップと復元 → バックアップターゲット)、SUSE Storageはバックアップストアに接続し、*バックアップ*画面に既存のバックアップのリストを表示できます。
SUSE Storageが第二のKubernetesクラスターで実行されている場合、セカンダリストレージのバックアップに災害復旧ボリュームを同期することもでき、データを第二のKubernetesクラスターでより迅速に回復できます。
3.1.バックアップの仕組み
バックアップは、1つのスナップショットをソースとして使用して作成され、そのスナップショットが作成された時点でのボリュームのデータの状態を反映します。バックアップはクラスターの外部にリモートで保存されます。
スナップショットとは対照的に、バックアップはスナップショットのチェーンを平坦化したバージョンと考えることができます。階層化されたイメージがフラットなイメージに変換されるときに情報が失われるのと同様に、スナップショットのチェーンがバックアップに変換されるときにもデータが失われます。両方の変換において、上書きされたデータは失われます。
バックアップにはスナップショットが含まれていないため、ボリュームデータの変更履歴も含まれていません。バックアップからボリュームを復元すると、ボリュームには最初に1つのスナップショットが含まれます。このスナップショットは、元のチェーン内のすべてのスナップショットを統合したバージョンであり、バックアップが作成された時点でのボリュームのライブデータを反映しています。
スナップショットは数百ギガバイトになることがありますが、バックアップは2 MBのファイルで構成されています。
同じ元のボリュームの各新しいバックアップは増分であり、スナップショット間の変更されたブロックを検出して送信します。これは比較的簡単な作業です。なぜなら、各スナップショットは 差分ファイルであり、最後のスナップショットからの変更のみを保存するからです。この設計は、ブロックが変更されていない場合にバックアップが取得されると、そのバックアップがバックアップストアで0バイトとして表示されることを意味します。しかし、そのバックアップから復元すると、バックアップストアにすでに存在する必要なブロックを復元するため、完全なボリュームデータが含まれます。
非常に多くの小さなストレージブロックを保存しないようにするために、SUSE Storageは2 MBブロックを使用してバックアップ操作を実行します。これは、2 MBの境界内の任意の4Kブロックが変更された場合、SUSE Storageが全体の2 MBブロックをバックアップすることを意味します。これは、管理のしやすさと効率のバランスを提供します。
図3。二次ストレージのバックアップと一次ストレージのスナップショットの関係
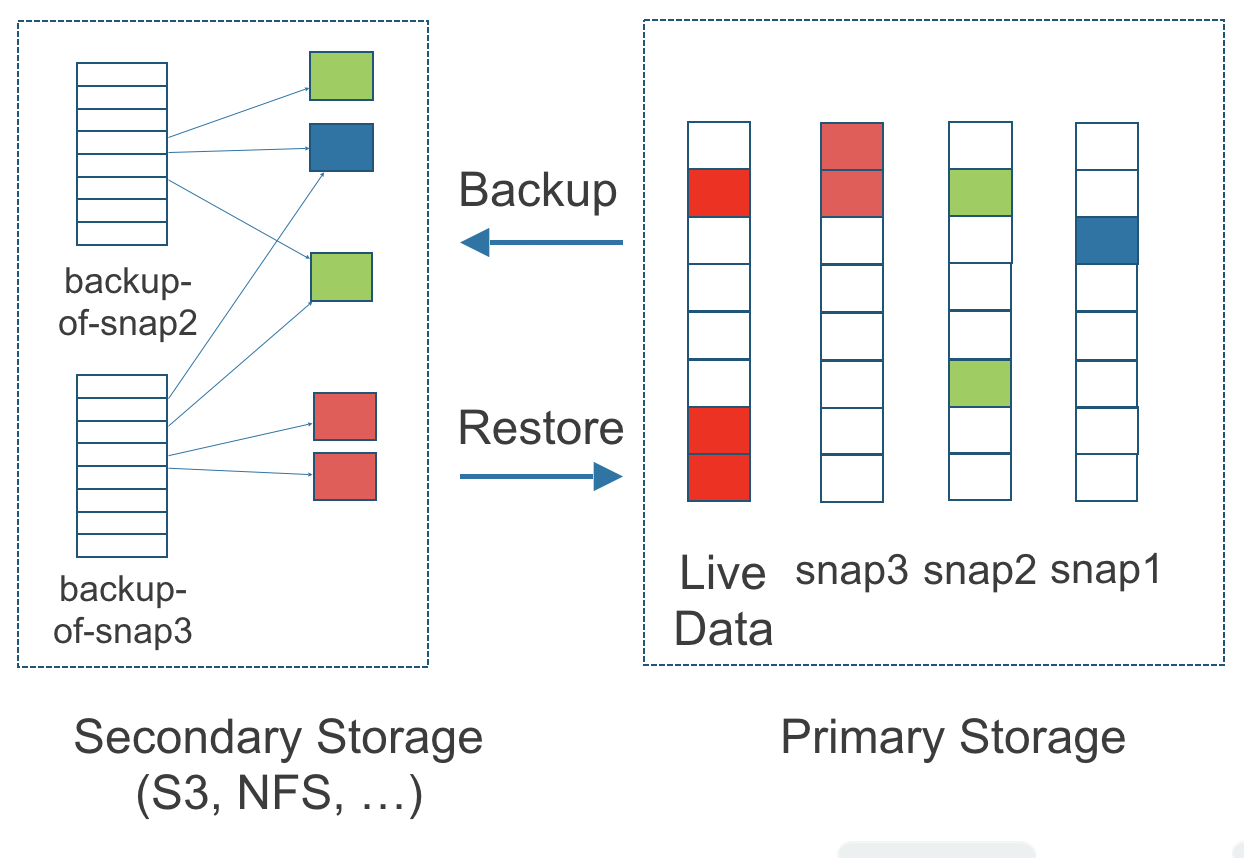
上記の図は、スナップショットからバックアップがどのように作成されるかを示しています:
-
図のプライマリストレージ側には、Kubernetesクラスター内のSUSE Storageボリュームの1つのレプリカが表示されています。レプリカは4つのスナップショットのチェーンで構成されています。最新から最古の順に、スナップショットはライブデータ、snap3、snap2、snap1です。
-
図のセカンダリストレージ側には、S3などの外部オブジェクトストレージサービスに2つのバックアップが表示されています。
-
セカンダリストレージでは、backup-from-snap2の色分けは、snap1からの青い変更とsnap2からの緑の変更の両方が含まれていることを示しています。snap2からの変更はsnap1のデータを上書きしなかったため、snap1とsnap2の両方の変更がbackup-from-snap2に含まれています。
-
backup-from-snap3という名前のバックアップは、snap3が作成された時点でのボリュームのデータの状態を反映しています。色分けと矢印は、backup-from-snap3がsnap3からのすべての濃い赤の変更を含んでいることを示していますが、snap2からの緑の変更は1つだけです。これは、snap3の赤の変更の1つがsnap2の緑の変更の1つを上書きしたためです。これは、バックアップが変更の完全な履歴を含まないことを示しています。なぜなら、バックアップはそれ以前のスナップショットと混同されるからです。
-
各バックアップは独自の2 MB ブロックのセットを保持します。各2 MB ブロックは一度だけバックアップされます。2つのバックアップは1つの緑のブロックと1つの青のブロックを共有します。
バックアップが二次ストレージから削除されると、SUSE Storageは使用しているすべてのブロックを削除しません。代わりに、定期的にガーベジコレクションを実行して、二次ストレージから未使用のブロックをクリーンアップします。
同じボリュームに属するすべてのバックアップの2 MB ブロックは共通のディレクトリに保存されるため、複数のバックアップ間で共有できます。
スペースを節約するために、バックアップ間で変更されなかった2 MB ブロックは、二次ストレージで同じバックアップボリュームを共有する複数のバックアップに再利用できます。チェックサムを使用して2 MB ブロックにアドレスを付けるため、同じボリューム内の2 MB ブロックに対してある程度の重複排除を達成します。
ボリュームレベルのメタデータはvolume.cfgに保存されます。各バックアップのメタデータファイル(例:snap2.cfg)は比較的小さく、バックアップ内のすべての2 MB ブロックの オフセットと チェックサムのみを含んでいます。
各2 MB ブロック(.blkファイル)は圧縮されています。
3.2.定期バックアップ
バックアップ操作は、定期スナップショットおよびバックアップ機能を使用してスケジュールできますが、必要に応じて実行することもできます。
ボリュームの定期バックアップをスケジュールすることをお勧めします。バックアップストアが利用できない場合は、定期的なスナップショットをスケジュールすることをお勧めします。
バックアップの作成は、ネットワークを通じてデータをコピーすることを含むため、時間がかかります。
3.3.災害復旧ボリューム
災害復旧(DR)ボリュームは、メインクラスター全体がダウンした場合に備えて、バックアップクラスターにデータを保存する特別なボリュームです。DRボリュームは、SUSE Storageボリュームのレジリエンシーを高めるために使用されます。
DRボリュームの主な目的はバックアップからデータを復元することなので、このタイプのボリュームはアクティブ化される前に以下のアクションをサポートしていません:
-
スナップショットの作成、削除、および復元
-
バックアップの作成
-
永続ボリュームの作成
-
永続ボリュームクレームの作成
DRボリュームは、バックアップストアのボリュームのバックアップから作成できます。DRボリュームが作成された後、SUSE Storageはその元のバックアップボリュームを監視し、最新のバックアップから段階的に復元します。バックアップボリュームは、同じボリュームの複数のバックアップを含むバックアップストア内のオブジェクトです。
メインクラスターの元のボリュームがダウンした場合、DRボリュームはバックアップクラスターで即座にアクティブ化でき、バックアップストアからバックアップクラスター内のボリュームへのデータ復元に必要な時間を短縮します。
DRボリュームがアクティブ化されると、SUSE Storageは元のボリュームの最後のバックアップを確認します。そのバックアップがすでに復元されていない場合、復元が開始され、アクティブ化アクションは失敗します。ユーザーは復元が完了するまで待ってから再試行する必要があります。
設定のバックアップターゲットは、DRボリュームが存在する場合は更新できません。
DRボリュームがアクティブ化された後、それは通常のSUSE Storageボリュームになり、非アクティブ化することはできません。
3.4.バックアップストアの更新間隔、RTO、およびRPO
増分復元は通常、定期的なバックアップストアの更新によってトリガーされます。バックアップターゲット設定画面で更新間隔を設定できます(バックアップと復元 → バックアップターゲット)。
この間隔は、回復時間目標(RTO)に影響を与える可能性があることに注意してください。間隔が長すぎると、災害復旧ボリュームが復元するためのデータ量が多くなり、時間がかかる可能性があります。
回復ポイント目標(RPO)は、バックアップボリュームの定期的なバックアップスケジュールによって決まります。通常のボリュームAの定期的なバックアップスケジュールが毎時バックアップを作成する場合、RPOは1時間です。ここで、SUSE Storageにおける定期バックアップのハウツーを確認できます。
以下の分析は、ボリュームが毎時バックアップを作成し、1つのバックアップからのデータの増分復元に5分かかると仮定しています:
-
バックアップストアのポーリング間隔が30分の場合、最後の復元以降、最大で1つのバックアップ分のデータがあります。1つのバックアップを復元するのにかかる時間は5分なので、RTOは5分になります。
-
バックアップストアのポーリング間隔が12時間の場合、最後の復元以降、最大で12個のバックアップ分のデータがあります。バックアップを復元するのにかかる時間は5 * 12 = 60分なので、RTOは60分になります。
付録:Kubernetesにおける永続ストレージの仕組み
Kubernetesにおける永続ストレージを理解するためには、ボリューム、永続ボリューム、永続ボリュームクレーム、およびストレージクラスを理解し、それらがどのように連携しているかを理解することが重要です。
Kubernetesボリュームの重要な特性の1つは、それが属するポッドと同じライフサイクルを持つことです。ポッドが消えると、ボリュームも失われます。対照的に、永続ボリュームは、ユーザーが削除するまでシステム内に存在し続けます。ボリュームは、同じポッド内のコンテナ間でデータを共有するためにも使用できますが、通常、ユーザーはポッドごとに1つのコンテナしか持たないため、これが主な使用ケースではありません。
Kubernetesクラスターにおける 永続ボリューム(PV) は、永続的なストレージの一部であり、 永続ボリュームクレーム(PVC) はストレージのリクエストです。 ストレージクラス は、ワークロードの要求に応じて新しいストレージを動的にプロビジョニングすることを可能にします。
Kubernetesワークロードが新しい永続ストレージと既存の永続ストレージをどのように使用するか
広く言えば、Kubernetesで永続ストレージを使用する主な方法は二つあります:
-
既存の永続ボリュームを使用する
-
新しい永続ボリュームを動的にプロビジョニングする
既存のストレージプロビジョニング
既存のPVを使用するには、アプリケーションがPVにバインドされたPVCを使用する必要があり、PVはPVCが要求する最小リソースを含む必要があります。
言い換えれば、Kubernetesで既存のストレージを設定するための典型的なワークフローは次のようになります:
-
アクセス可能な物理的または仮想的なストレージの意味で、永続ストレージボリュームを設定します。
-
永続ストレージを参照するPVを追加します。
-
PVを参照するPVCを追加します。
-
ワークロード内でPVCをボリュームとしてマウントします。
PVCがストレージの一部を要求すると、Kubernetes APIサーバーは、そのPVCを事前に割り当てられたPVと一致させようとします。一致が見つかれば、PVCはPVにバインドされ、ユーザーはその事前に割り当てられたストレージを使用し始めます。
一致するボリュームが存在しない場合、PersistentVolumeClaimsは無期限にバインドされないままとなります。例えば、50 GiのPVが多数プロビジョニングされたクラスターは、100 Giを要求するPVCと一致しません。100 GiのPVがクラスターに追加されると、PVCはバインドされる可能性があります。
言い換えれば、無限にPVCを作成できますが、KubernetesコントロールプレーンがPVCが要求するディスクスペース以上の十分なPVを見つけられた場合にのみ、PVにバインドされます。
動的ストレージプロビジョニング
動的ストレージプロビジョニングのために、アプリケーションはストレージクラスにバインドされたPVCを使用する必要があります。StorageClassは、新しい永続ボリュームをプロビジョニングするための権限を含んでいます。
Kubernetesにおける新しいストレージを動的にプロビジョニングするための全体的なワークフローには、StorageClassリソースが含まれます。
-
StorageClassを追加し、アクセス可能なストレージから新しいストレージを自動的にプロビジョニングするように設定します。
-
StorageClassを参照するPVCを追加します。
-
PVCをワークロードのボリュームとしてマウントします。
Kubernetesクラスターの管理者は、提供するストレージの"`classes`"を説明するためにKubernetes StorageClassを使用できます。StorageClassは、異なる容量制限、異なるIOPS、またはプロビジョナーがサポートする他の任意のパラメータを持つことができます。ストレージベンダー特有のプロビジョナーは、StorageClassと共に使用され、StorageClassオブジェクトに設定されたパラメータに従ってPVを自動的に割り当てます。また、プロビジョナーは、ユーザーのリソースクォータと権限要件を強制する能力を持っています。この設計では、管理者はPVの必要性を予測し、それを割り当てるという不必要な作業から解放されます。
StorageClassが使用されると、Kubernetes管理者はすべてのストレージを割り当てる責任を負いません。管理者は、特定のストレージプールへのアクセス権をユーザーに与え、ユーザーのクォータを決定するだけで済みます。その後、ユーザーはストレージプールから必要なストレージの部分を切り出すことができます。
StorageClassは、KubernetesでStorageClassオブジェクトを明示的に作成せずに使用することもできます。StorageClassはPVCとPVを一致させるために使用されるフィールドでもあるため、カスタムStorageClass名でPVを手動で作成し、そのStorageClass名を持つPVを要求するPVCを作成することができます。Kubernetesは、StorageClassオブジェクトがKubernetesリソースとして存在しなくても、指定されたStorageClass名でPVCをPVにバインドできます。
SUSE Storageは、Kubernetesワークロードが必要に応じて永続ストレージの部分を切り出すことができるようにStorageClassを導入します。
永続ストレージを持つKubernetesワークロードのための水平スケーリング
VolumeClaimTemplateはStatefulSetの仕様プロパティであり、ブロックストレージソリューションがKubernetesワークロードのために水平にスケールする方法を提供します。
このプロパティは、StatefulSetによって作成されたPodのために一致するPVとPVCを作成するために使用できます。
これらのPVCはStorageClassを使用して作成されるため、StatefulSetがスケールアップすると自動的に設定されます。
StatefulSetがスケールダウンすると、余分なPV/PVCはクラスターに保持され、StatefulSetが再びスケールアップする際に再利用されます。
VolumeClaimTemplateは、EBSやSUSE Storageのようなブロックストレージソリューションにとって重要です。これらのソリューションは本質的に ReadWriteOnce,であるため、ポッド間で共有することはできません。
デプロイメントは、永続データを持つ複数のポッドが実行されている場合、永続ストレージとうまく機能しません。複数のポッドがある場合は、StatefulSetを使用する必要があります。