|
この文書は自動機械翻訳技術を使用して翻訳されています。 正確な翻訳を提供するように努めておりますが、翻訳された内容の完全性、正確性、信頼性については一切保証いたしません。 相違がある場合は、元の英語版 英語 が優先され、正式なテキストとなります。 |
ReadWriteMany (RWX) ボリューム
SUSE Storage は、共有マネージャーポッド内に存在する NFSv4 サーバーを介して、通常の Longhorn ボリュームを公開することにより、ReadWriteMany (RWX) ボリュームをサポートします。
概要
SUSE Storage は、異なるワークロード要件に最適化された 2 種類の RWX ボリュームを提供します:
一般的な(非移行可能)RWXボリューム
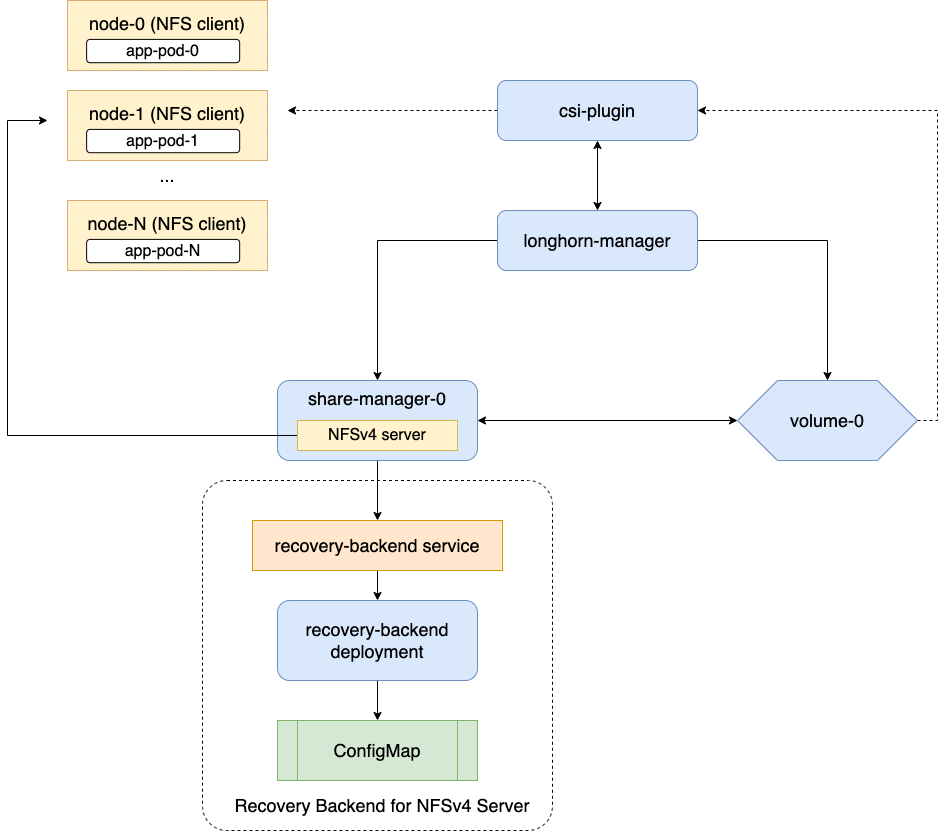
一般的な RWX ボリュームは、複数のノード間で共有ファイルシステムアクセスを提供します。それらは、longhorn-system ネームスペース内の share-manager-<volume-name> ポッドで稼働する専用 NFSv4.1 サーバーを使用します。各 RWX ボリュームは、クライアントに NFS エンドポイントを公開する対応するサービスとペアになっています。
これらのボリュームは、同時ファイルアクセスが必要なワークロードに最適ですが、ライブマイグレーションをサポートしていません。ライブマイグレーションは、サービスの中断なしに、実行中のワークロードをソースホストから宛先ホストに移動するプロセスです。移行中、ボリュームはソースワークロードからのみアクセス可能です。完了すると、宛先ワークロードがアクセスを引き継ぎ、ソースワークロードは終了します。
特性
-
ライブマイグレーション ができません。
-
ファイルシステムベースの共有には NFSv4.1 を使用します。
-
一般的な共有ストレージおよびマルチノードファイルアクセスワークロードに適しています。
|
注意:アクティブな RWX ボリューム上の共有マネージャーポッドのイメージ更新の遅延 Longhorn システムのアップグレード後、一般的な(非移行可能)RWXボリュームが接続されたままの場合、対応する |
移行可能なRWXボリューム
移行可能なRWXボリュームは、KubeVirt VMなどの仮想化ワークロード専用に設計されており、進行中のI/O操作を維持しながら[ライブマイグレーション](https://kubevirt.io/user-guide/compute/live_migration/)を必要とします。これらのボリュームは、メンテナンス、フェールオーバー、またはリバランス操作中にサービスの中断なしにノード間でVMをシームレスに移動できるようにします。
特性
-
ライブマイグレーションシナリオ用に設計されています。
-
`volumeMode: Block`が必要です(`Filesystem`モードはサポートされていません)。
-
ReadWriteManyアクセスモードが必要であり、
migratable: "true"(これによりLonghornボリュームで`volume.spec.migratable=true`が設定されます)を持つStorageClassも必要です。 -
一般的な共有ファイルシステムワークロードには意図されていません。
|
移行可能なRWXボリュームは、ボリューム仕様の`volume.spec.migratable`フィールドを確認することで区別できます。非移行可能なボリュームにはこのフィールドがありません。 |
一般的(非移行可能)RWXボリュームの要件
-
各NFSクライアントノードにはNFSv4クライアントがインストールされている必要があります。
インストールの詳細については、Installing NFSv4 clientを参照してください。
問題解決:ノードにNFSv4クライアントがない場合、ボリュームをマウントしようとすると、次のテキストを含むエラーメッセージが表示されます:
for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program.
-
各ノードのホスト名はKubernetesクラスター内で一意です。
LonghornシステムにはNFSサーバー用の専用リカバリバックエンドサービスがあります。クライアントがNFSサーバーに接続すると、クライアントのホスト名を含む情報がリカバリバックエンドに保存されます。シェアマネージャーポッドまたはNFSサーバーが異常終了した場合、SUSE Storageが新しいものを作成します。90秒の猶予期間内に、クライアントはリカバリバックエンドに保存されたクライアント情報を使用してロックを再取得します。
一般的な(非移行可能)RWXボリュームの作成と使用
|
RWXボリュームは、アクセスモードを`ReadWriteMany`に設定し、「移行可能」フラグを無効にする必要があります(parameters.migratable: `false`)。 |
-
動的にプロビジョニングされたLonghornボリュームの場合、アクセスモードはPVCのアクセスモードに基づきます。
-
手動で作成されたLonghornボリューム(復元、DRボリューム)の場合、アクセスモードはSUSE Storage UIで作成時に指定できます。
-
UIを介してLonghornボリュームのPV/PVCを作成する際、PV/PVCのアクセスモードはボリュームのアクセスモードに基づきます。
-
ボリュームがPVCにバインドされていない場合、UIを介してLonghornボリュームのアクセスモードを変更できます。
-
RWX PVCによって使用されるLonghornボリュームの場合、ボリュームのアクセスモードはRWXに変更されます。
一般的な(非移行可能)RWXボリュームのボリュームローカリティの設定
SUSE Storageは、RWXボリュームのデータローカリティを正確に制御するための新しい設定を提供します(関連するShare Managerポッドの特定を通じて)。これらの詳細な設定は、関連するグローバル設定と連携して、最適なパフォーマンス、耐障害性、および組織のポリシーや制約の遵守を提供します。
shareManagerNodeSelector
StorageClassパラメータ`shareManagerNodeSelector`を使用して、RWXボリュームがスケジュールできるノードを特定するためのセレクターを指定できます。これらのセレクターは、グローバル`system-managed-components-node-selector`設定と統合され、その後RWXボリュームのShare Managerポッドに適用され、ボリュームローカリティの制御を強化します。
例:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerNodeSelector: label-key1:label-value1;label-key2:label-value2
この例では、指定されたStorageClassでプロビジョニングされたRWXボリュームは、ラベル`label-key1:label-value1`と`label-key2:label-value2`を持つノードにスケジュールされます。
allowedTopologies
Longhornは、`storageClass.allowedTopologies`設定をRWXボリュームのShare Managerポッドのアフィニティルールに変換します。これにより、ポッドは指定されたトポロジー要件(地域やゾーンなど)を満たすノードにスケジュールされ、RWXボリュームのローカリティに一致します。
例:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
allowedTopologies:
- matchLabelExpressions:
- key: topology.kubernetes.io/region
values:
- us-west-1
この例では、Share ManagerポッドとRWXボリュームは`us-west-1`地域にスケジュールされます。
shareManagerTolerations
StorageClassパラメータ`shareManagerTolerations`を使用して、ノードのテイントに基づいてより柔軟なスケジューリングを許可することもできます。定義されたトレラレーションは、グローバル`taint-toleration`設定と統合され、その後Share Managerポッドに適用されます。
例:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerTolerations: nodetype=storage:NoSchedule
この例では、Share Managerポッドはノード上の`nodetype=storage:NoSchedule`テイントを許容し、それらのノードにスケジュール可能になります。
一般的な(非移行可能)RWXボリュームのボリュームマウントオプションの設定
RWXボリュームは、NFSを介してマウントされているときのみアクセス可能です。デフォルトでは、SUSE StorageはNFSバージョン4.1を使用し、`softerr`マウントオプション、`timeo`の値は"600"、`retrans`の値は"5"です。
NFSサーバーがアクセスできなくなると、NFSクライアントからのリクエストは設定された`retrans`の値に従って再試行されます。電力障害やネットワーク分断などの長時間のイベントにより、リクエストは最終的に失敗します。NFSエラー(`ETIMEDOUT`は`softerr`マウントオプションのため)は呼び出し元のアプリケーションに返され、データ損失が発生する可能性があります。`softerr`がサポートされていない場合、SUSE Storageは自動的に`soft`マウントオプションを使用し、その結果`EIO`がエラーとして返されます。
新しいボリュームに特定のマウントオプションを使用できます。まず、`nfsOptions`パラメータを持つカスタマイズされたStorageClassを作成し、その後、その特定のStorageClassを使用してRWXボリュームのPVCを作成します。
例:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-test
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "2880"
fromBackup: ""
fsType: "ext4"
nfsOptions: "vers=4.2,noresvport,softerr,timeo=600,retrans=5"|
サンプルStorageClassを使用してRWXボリュームのPVCを作成するには、`nfsOptions`文字列をカスタマイズされたカンマ区切りの合法的なオプションのリストに置き換えます。 |
備考
-
希望するオプションの完全なセットを提供する必要があります。提供されていないオプションは、NFSサーバー側のデフォルトを使用し、SUSE Storageの独自のものではありません。
-
SUSE Storageは`nfsOptions`文字列を検証しないため、誤った値やタイプミスはフラグされません。文字列が無効な場合、マウントはNFSサーバーによって拒否され、ボリュームは作成されず、接続されません。
-
SUSE Storageのv1.4.0から1.4.3およびv1.5.0からv1.5.1では、共有マネージャーポッド内のボリューム(具体的には`NodeStageVolume`ステップで)は、Longhorn CSIプラグインによってデフォルトでハードマウントされます。ハードマウントにより、SUSE StorageはNFSリクエストの送信を持続的に再試行でき、NFSサーバーが一時的にアクセスできなくなってもIOが失敗しないことが保証されます。サーバーが接続を回復するか、代替サーバーが作成されると、IOはシームレスに再開されます。
ただし、データの整合性を保証するこのメカニズムにはいくつかのリスクが伴います。安定性を維持するために、Linuxカーネルはすべての保留中のIOが完了するまでファイルシステムのアンマウントを許可しません。これは、すべてのファイルシステムがアンマウントされるまでシステムがシャットダウンできないため、懸念事項です。NFSサーバーが回復できない場合、クライアントノードは強制再起動を行う必要があります。
問題を軽減するために、v1.4.4、v1.5.2、またはそれ以降のバージョンにアップグレードしてください。アップグレード後、RWXボリュームが再接続されるたびに、`softerr`または`soft`が`nfsOptions`パラメータに自動的に適用されます(デフォルト設定が上書きされない場合)。
-
`hard`マウントオプション(`nfsOptions`上書きメカニズムを介して)を引き続き使用できますが、ハードマウントされたボリュームは、記載されたリスクの対象となります。
詳細については、 #6655を参照してください。
一般的な(移行不可能な)RWXボリュームのエラー処理
-
share-manager Podが異常終了しました
クライアントのIOは、SUSE Storageが新しいshare-manager Podと関連するボリュームを作成するまでブロックされます。Podが正常に作成されると、ロック回収のための90秒の猶予期間が開始され、ユーザーは期待します。
-
猶予期間が終了する前に、RWXボリュームへのクライアントのIOは依然としてブロックされます。
-
サーバーは、NFS4ERR_GRACEのエラーでREADおよびWRITE操作と非回収ロック要求を拒否します。
-
すべてのロックが正常に回収されれば、猶予期間は早期に終了することがあります。
猶予期間を終了した後、ロックを正常に回収したクライアントのIOは、古いファイルハンドルエラーやIOエラーなしで続行されます。猶予期間内にロックを回収できない場合、ロックは破棄され、サーバーはクライアントにIOエラーを返します。クライアントは新しいロックを再確立します。アプリケーションはIOエラーを処理する必要があります。それにもかかわらず、すべてのアプリケーションがその実装のためにIOエラーを処理できるわけではありません。したがって、IO操作のエラーやデータ損失を引き起こす可能性があります。データの整合性が問題になる可能性があります。
+ ここにRWXボリュームを使用したDaemonSetの例があります。
+ DaemonSetの各PodはRWXボリュームにデータを書き込んでいます。共有マネージャー Pod が実行されているノードがダウンしている場合、別のノードに新しい共有マネージャー Pod が作成されます。ダウンノードにあるクライアントの一つが消失したため、残りのクライアントのロックが正常に回収されても、ロック回収プロセスは90秒の猶予期間より早く終了することはできません。これらのクライアントの IO は、猶予期間が終了した後も続きます。
-
-
Kubernetes DNS サービスがダウンした場合、共有マネージャー Pod は longhorn-nfs-recovery-backend と通信できなくなります。
共有マネージャー Pod 内の NFS-ganesha サーバーは、サービス
longhorn-recovery-backendの IP を介してlonghorn-nfs-recovery-backendと通信します。DNS サービスが利用できない場合、RWX ボリュームの作成および削除、ならびに NFS サーバーの回復は操作できなくなります。したがって、通信障害を避けるために DNS サービスの高可用性が推奨されます。 -
迅速なフェールオーバー機能。
SUSE Storage は、ボリュームの共有マネージャー NFS サーバー Pod が実行されているノードの障害からの回復にかかる時間を短縮することで可用性を向上させる機能をサポートしています。この機能は、サーバーを監視するために直接ハートビートを使用します。サーバーが応答しない場合、通常の手順よりも早く新しいサーバーを作成するように動作します。また、NFS サーバーを異なる設定にし、回復猶予期間を90秒から30秒に短縮します。
詳細は RWX ボリュームの迅速なフェールオーバー にあります。
以前の外部プロビジョナーからの移行
以下の PVC は、あるボリュームから別のボリュームにデータをコピーできる Kubernetes ジョブを作成します。
-
data-source-pvcを、Kubernetes によって作成された以前の NFSv4 RWX PVC の名前に置き換えてください。 -
data-target-pvcを、新しいワークロードに使用したい新しい RWX PVC の名前に置き換えてください。
手動で新しい RWX Longhorn ボリューム + PVC/PV を作成するか、RWX PVC を作成して Longhorn に動的にボリュームをプロビジョニングさせることができます。
両方の PVC は同じネームスペースに存在する必要があります。デフォルトとは異なるネームスペースを使用している場合は、以下のジョブのネームスペースを変更してください。
apiVersion: batch/v1
kind: Job
metadata:
namespace: default # namespace where the PVC's exist
name: volume-migration
spec:
completions: 1
parallelism: 1
backoffLimit: 3
template:
metadata:
name: volume-migration
labels:
name: volume-migration
spec:
restartPolicy: Never
containers:
- name: volume-migration
image: ubuntu:xenial
tty: true
command: [ "/bin/sh" ]
args: [ "-c", "cp -r -v /mnt/old /mnt/new" ]
volumeMounts:
- name: old-vol
mountPath: /mnt/old
- name: new-vol
mountPath: /mnt/new
volumes:
- name: old-vol
persistentVolumeClaim:
claimName: data-source-pvc # change to data source PVC
- name: new-vol
persistentVolumeClaim:
claimName: data-target-pvc # change to data target PVC