Configure o Prometheus e o Grafana para monitorar o SUSE® Storage
O Longhorn expõe nativamente métricas em formato de texto do Prometheus em um endpoint REST http://LONGHORN_MANAGER_IP:PORT/metrics.
Você pode usar qualquer ferramenta de coleta, como Prometheus, Graphite, Telegraf para coletar essas métricas e, em seguida, visualizar os dados coletados por ferramentas como Grafana.
Veja Métricas do Longhorn para Monitoramento para métricas disponíveis.
Visão Geral de Alto Nível
O sistema de monitoramento usa Prometheus para coletar dados e alertar, e Grafana para visualizar/dashboardar os dados coletados.
-
Servidor Prometheus que coleta e armazena dados de séries temporais dos endpoints de métricas do Longhorn. O Prometheus também é responsável por gerar alertas com base em regras configuradas e dados coletados. Os servidores Prometheus então enviam alertas para um Alertmanager.
-
O AlertManager então gerencia esses alertas, incluindo silenciamento, inibição, agregação e envio de notificações por métodos como e-mail, sistemas de notificação em plantão e plataformas de chat.
-
Grafana que consulta o servidor Prometheus por dados e cria um painel para visualização.
A imagem abaixo descreve a arquitetura detalhada do sistema de monitoramento.
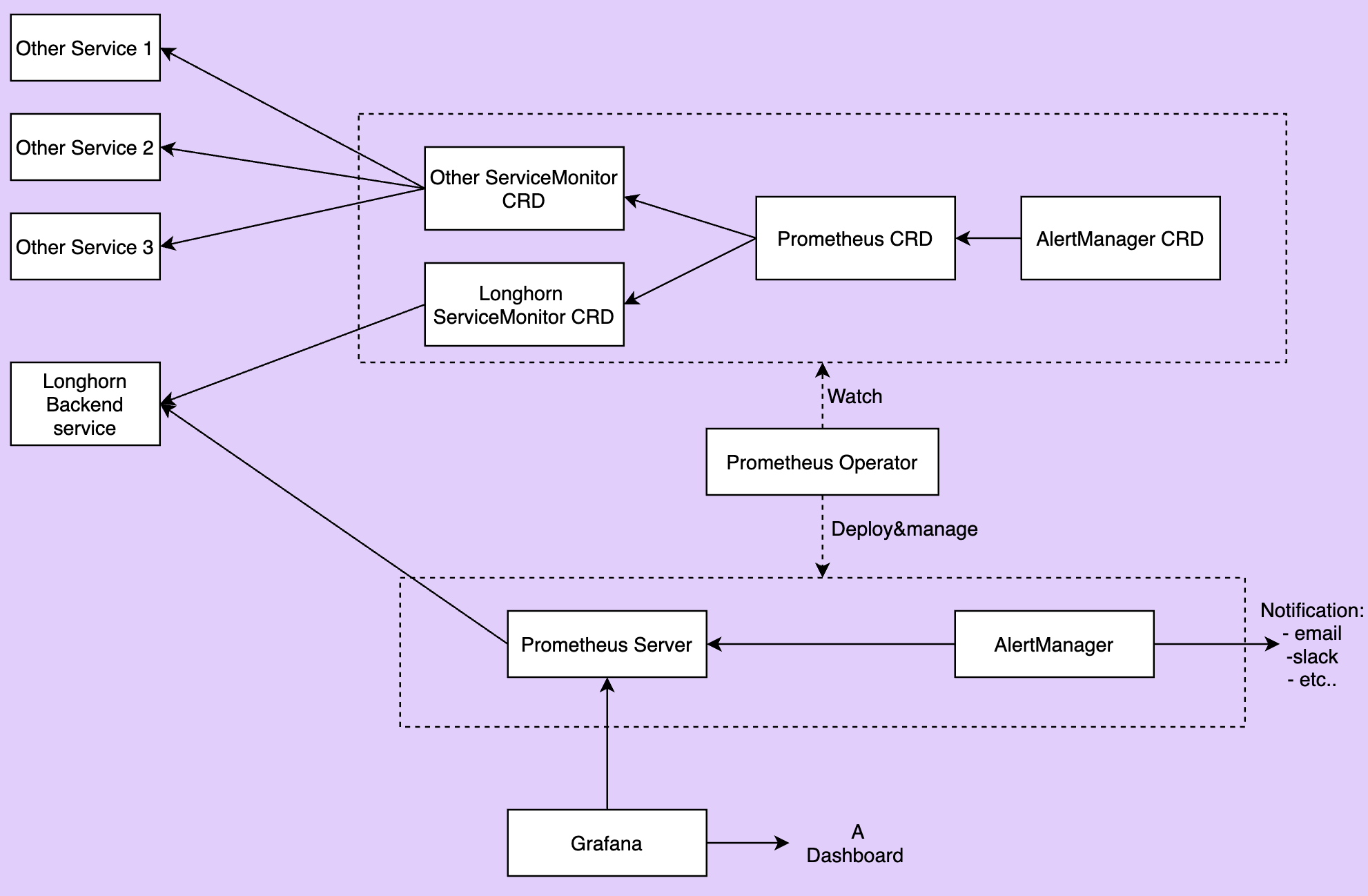
Existem 2 componentes não mencionados na imagem acima:
-
O serviço de backend do Longhorn é um serviço que aponta para o conjunto de pods do Longhorn Manager. As métricas do Longhorn são expostas nos pods do Longhorn Manager no endpoint
http://LONGHORN_MANAGER_IP:PORT/metrics. -
operador do Prometheus torna muito fácil executar o Prometheus sobre o Kubernetes. O operador observa 3 recursos personalizados: ServiceMonitor, Prometheus e AlertManager. Quando você cria esses recursos personalizados, o Operador do Prometheus implanta e gerencia o servidor Prometheus e o AlertManager com as configurações especificadas pelo usuário.
Instalação
Este documento utiliza o namespace default para o sistema de monitoramento. Para instalar em um namespace diferente, altere o campo namespace: <OTHER_NAMESPACE> nos manifests.
Instale o Prometheus Operator
Siga as instruções em Prometheus Operator - Quickstart.
NOTA: Você pode precisar escolher uma versão que seja compatível com a versão do Kubernetes do cluster.
Instale o Longhorn ServiceMonitor
Instale o Longhorn ServiceMonitor com Kubectl
Crie um ServiceMonitor para o Longhorn Manager.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: longhorn-prometheus-servicemonitor
namespace: default
labels:
name: longhorn-prometheus-servicemonitor
spec:
selector:
matchLabels:
app: longhorn-manager
namespaceSelector:
matchNames:
- longhorn-system
endpoints:
- port: managerInstale o Longhorn ServiceMonitor com Helm
-
Modifique o arquivo YAML
longhorn/chart/values.yaml.metrics: serviceMonitor: # -- Setting that allows the creation of a [Prometheus Operator](https://prometheus-operator.dev/) ServiceMonitor resource for Longhorn Manager components. enabled: true -
Crie um ServiceMonitor para o Longhorn Manager usando Helm.
helm upgrade longhorn longhorn/longhorn --namespace longhorn-system -f values.yaml
O Longhorn ServiceMonitor é um recurso personalizado do Prometheus Operator. Esta configuração permite que o servidor Prometheus descubra todos os pods do Longhorn Manager e seus respectivos endpoints.
Você pode usar o seletor de rótulos app: longhorn-manager para selecionar o serviço longhorn-backend, que aponta para o conjunto de pods do Longhorn Manager.
Instale e configure o Prometheus AlertManager
-
Crie uma implantação do Alertmanager altamente disponível com 3 instâncias.
apiVersion: monitoring.coreos.com/v1 kind: Alertmanager metadata: name: longhorn namespace: default spec: replicas: 3 -
As instâncias do Alertmanager não iniciarão a menos que uma configuração válida seja fornecida. Veja Prometheus - Configuração para mais explicações.
global: resolve_timeout: 5m route: group_by: [alertname] receiver: email_and_slack receivers: - name: email_and_slack email_configs: - to: <the email address to send notifications to> from: <the sender address> smarthost: <the SMTP host through which emails are sent> # SMTP authentication information. auth_username: <the username> auth_identity: <the identity> auth_password: <the password> headers: subject: 'Longhorn-Alert' text: |- {{ range .Alerts }} *Alert:* {{ .Annotations.summary }} - `{{ .Labels.severity }}` *Description:* {{ .Annotations.description }} *Details:* {{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}` {{ end }} {{ end }} slack_configs: - api_url: <the Slack webhook URL> channel: <the channel or user to send notifications to> text: |- {{ range .Alerts }} *Alert:* {{ .Annotations.summary }} - `{{ .Labels.severity }}` *Description:* {{ .Annotations.description }} *Details:* {{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}` {{ end }} {{ end }}Salve a configuração do Alertmanager acima em um arquivo chamado
alertmanager.yamle crie um segredo a partir dele usando kubectl.As instâncias do Alertmanager exigem que o nome do recurso Secret siga o formato
alertmanager-<ALERTMANAGER_NAME>. No passo anterior, o nome do Alertmanager élonghorn, então o nome do segredo deve seralertmanager-longhorn$ kubectl create secret generic alertmanager-longhorn --from-file=alertmanager.yaml -n default -
Para poder visualizar a interface web do Alertmanager, exponha-a através de um Serviço. Uma maneira simples de fazer isso é usar um Serviço do tipo NodePort.
apiVersion: v1 kind: Service metadata: name: alertmanager-longhorn namespace: default spec: type: NodePort ports: - name: web nodePort: 30903 port: 9093 protocol: TCP targetPort: web selector: alertmanager: longhornApós criar o serviço acima, você pode acessar a interface web do Alertmanager através do IP de um Node e da porta 30903.
Use o serviço
NodePortacima apenas para verificação rápida, pois ele não se comunica pela conexão TLS. Você pode querer mudar o tipo de serviço paraClusterIPe configurar um controlador de Ingress para expor a interface web do Alertmanager através de uma conexão TLS.
Instale e configure o servidor Prometheus
-
Crie um recurso personalizado PrometheusRule para definir as condições de alerta. Veja mais exemplos sobre regras de alerta do Longhorn em Exemplos de Regras de Alerta do Longhorn.
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: prometheus: longhorn role: alert-rules name: prometheus-longhorn-rules namespace: default spec: groups: - name: longhorn.rules rules: - alert: LonghornVolumeUsageCritical annotations: description: Longhorn volume {{$labels.volume}} on {{$labels.node}} is at {{$value}}% used for more than 5 minutes. summary: Longhorn volume capacity is over 90% used. expr: 100 * (longhorn_volume_usage_bytes / longhorn_volume_capacity_bytes) > 90 for: 5m labels: issue: Longhorn volume {{$labels.volume}} usage on {{$labels.node}} is critical. severity: criticalVeja Prometheus - Regras de Alerta para mais informações.
-
Se a autorização RBAC estiver ativada, crie um ClusterRole e um ClusterRoleBinding para os Pods do Prometheus.
apiVersion: v1 kind: ServiceAccount metadata: name: prometheus namespace: defaultapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus namespace: default rules: - apiGroups: [""] resources: - nodes - services - endpoints - pods verbs: ["get", "list", "watch"] - apiGroups: [""] resources: - configmaps verbs: ["get"] - nonResourceURLs: ["/metrics"] verbs: ["get"]apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: default -
Crie um recurso personalizado do Prometheus. Observe que selecionamos o monitor de serviço do Longhorn e as regras do Longhorn na especificação.
apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: name: longhorn namespace: default spec: replicas: 2 serviceAccountName: prometheus alerting: alertmanagers: - namespace: default name: alertmanager-longhorn port: web serviceMonitorSelector: matchLabels: name: longhorn-prometheus-servicemonitor ruleSelector: matchLabels: prometheus: longhorn role: alert-rules -
Para poder visualizar a interface web do servidor Prometheus, exponha-o através de um Serviço. Uma maneira simples de fazer isso é usar um Serviço do tipo NodePort.
apiVersion: v1 kind: Service metadata: name: prometheus-longhorn namespace: default spec: type: NodePort ports: - name: web nodePort: 30904 port: 9090 protocol: TCP targetPort: web selector: prometheus: longhornApós criar o serviço acima, você pode acessar a interface web do servidor Prometheus através do IP de um Node e da porta 30904.
Neste ponto, você deve ser capaz de ver todos os alvos do Longhorn Manager, bem como as regras do Longhorn na seção de alvos e regras da interface do servidor Prometheus.
Use o serviço NodePort acima apenas para verificação rápida, pois ele não se comunica pela conexão TLS. Você pode querer mudar o tipo de serviço para
ClusterIPe configurar um controlador de Ingress para expor a interface web do servidor Prometheus através de uma conexão TLS.
Configure o Grafana
-
Crie o ConfigMap da fonte de dados do Grafana.
apiVersion: v1 kind: ConfigMap metadata: name: grafana-datasources namespace: default data: prometheus.yaml: |- { "apiVersion": 1, "datasources": [ { "access":"proxy", "editable": true, "name": "prometheus-longhorn", "orgId": 1, "type": "prometheus", "url": "http://prometheus-longhorn.default.svc:9090", "version": 1 } ] }NOTA: altere o campo
urlse você estiver instalando a pilha de monitoramento em um namespace diferente.+http://prometheus-longhorn.<NAMESPACE>.svc:9090" -
Crie a implantação do Grafana.
apiVersion: apps/v1 kind: Deployment metadata: name: grafana namespace: default labels: app: grafana spec: replicas: 1 selector: matchLabels: app: grafana template: metadata: name: grafana labels: app: grafana spec: containers: - name: grafana image: grafana/grafana:7.1.5 ports: - name: grafana containerPort: 3000 resources: limits: memory: "500Mi" cpu: "300m" requests: memory: "500Mi" cpu: "200m" volumeMounts: - mountPath: /var/lib/grafana name: grafana-storage - mountPath: /etc/grafana/provisioning/datasources name: grafana-datasources readOnly: false volumes: - name: grafana-storage emptyDir: {} - name: grafana-datasources configMap: defaultMode: 420 name: grafana-datasources -
Crie o Serviço do Grafana.
apiVersion: v1 kind: Service metadata: name: grafana namespace: default spec: selector: app: grafana type: ClusterIP ports: - port: 3000 targetPort: 3000 -
Exponha o Grafana no NodePort
32000.kubectl -n default patch svc grafana --type='json' -p '[{"op":"replace","path":"/spec/type","value":"NodePort"},{"op":"replace","path":"/spec/ports/0/nodePort","value":32000}]'Use o serviço NodePort acima apenas para verificação rápida, pois ele não se comunica pela conexão TLS. Você pode querer alterar o tipo de serviço para ClusterIP e configurar um controlador de Ingress para expor o Grafana por meio de uma conexão TLS.
-
Acesse o painel do Grafana usando qualquer IP de nó na porta
32000.# Default Credential User: admin Pass: admin -
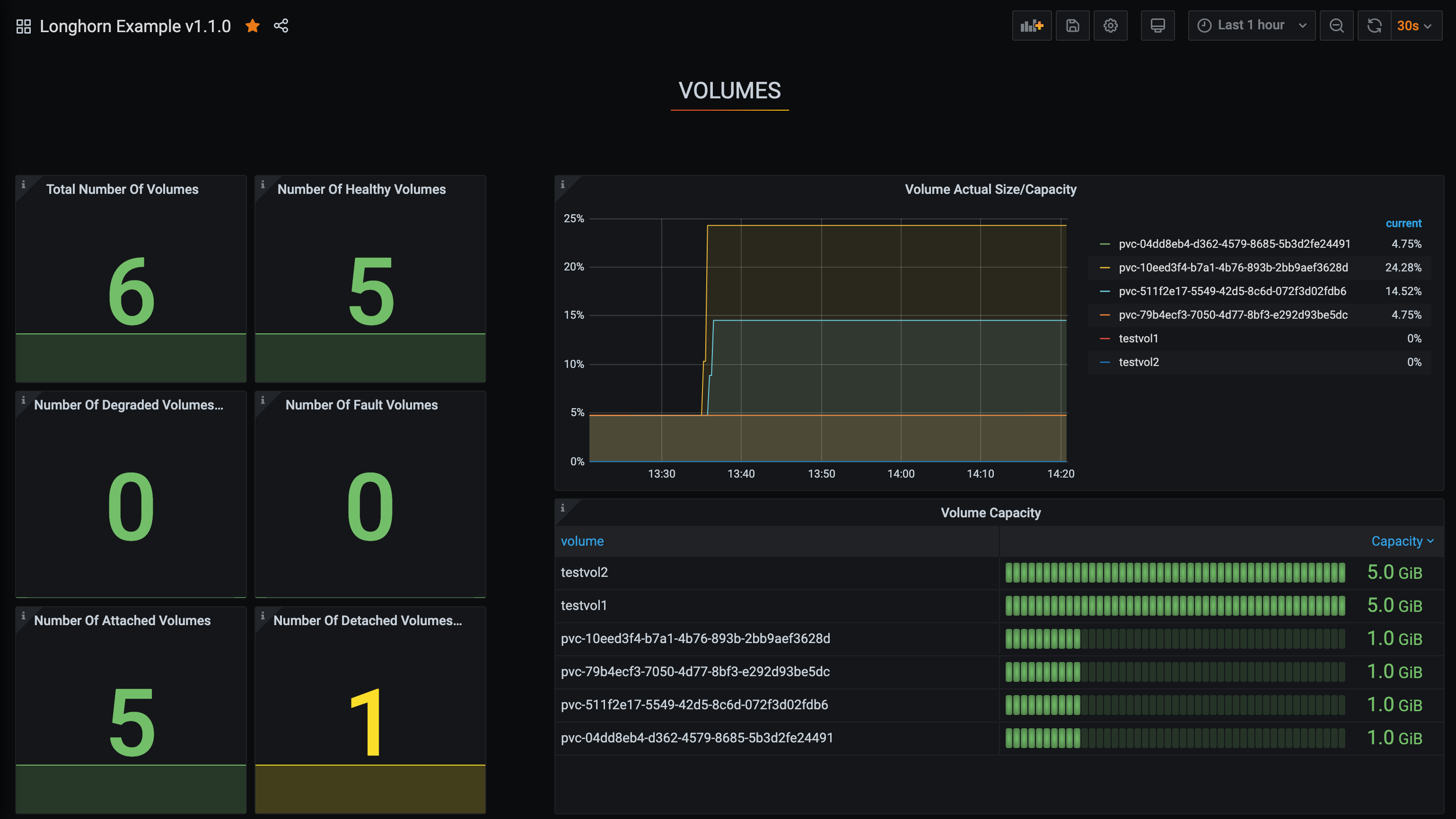
Configure o painel do Longhorn.
Uma vez dentro do Grafana, importe o painel de exemplo do Longhorn pré-construído.
Veja Laboratório do Grafana - Exportar e importar para instruções sobre como importar um painel do Grafana.
Você deve ver o seguinte painel após a configuração bem-sucedida: