|
Ce document a été traduit à l'aide d'une technologie de traduction automatique. Bien que nous nous efforcions de fournir des traductions exactes, nous ne fournissons aucune garantie quant à l'exhaustivité, l'exactitude ou la fiabilité du contenu traduit. En cas de divergence, la version originale anglaise prévaut et fait foi. |
|
Il s'agit d'une documentation non publiée pour SUSE® Storage 1.12 (Dev). |
Volumes ReadWriteMany (RWX)
SUSE Storage prend en charge les volumes ReadWriteMany (RWX) en exposant des volumes Longhorn réguliers via des serveurs NFSv4 qui résident dans des pods de gestion de partage.
Introduction
SUSE Storage fournit deux types de volumes RWX, chacun optimisé pour des exigences de charge de travail différentes :
Volumes RWX génériques (non migrables)
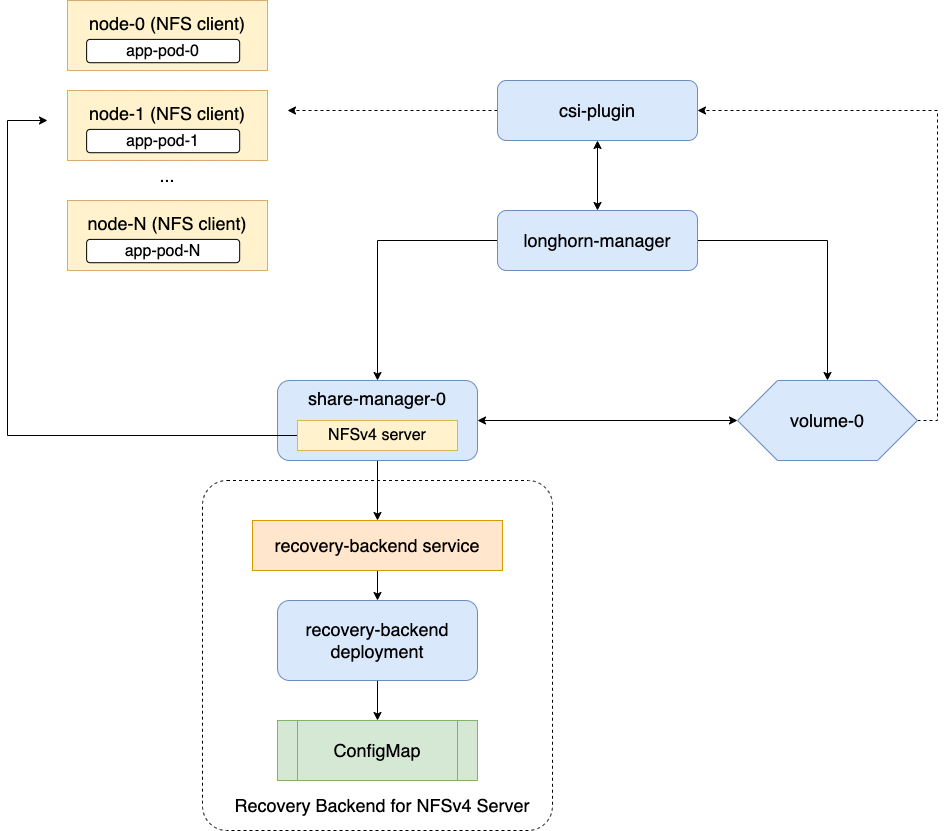
Les volumes RWX génériques offrent un accès au système de fichiers partagé sur plusieurs nœuds. Ils utilisent des serveurs NFSv4.1 dédiés qui fonctionnent dans share-manager-<volume-name> des pods au sein de l’espace de noms longhorn-system. Chaque volume RWX est associé à un Service correspondant qui expose le point de terminaison NFS aux clients.
Ces volumes sont idéaux pour les charges de travail nécessitant un accès concurrent aux fichiers mais ne prenant pas en charge la migration en direct. La migration en direct est le processus de déplacement d’une charge de travail en cours d’exécution d’un hôte source à un hôte de destination sans interruption de service. Pendant la migration, les volumes ne sont accessibles que depuis la charge de travail source. Une fois la migration terminée, la charge de travail de destination prend le relais de l’accès, et la charge de travail source est terminée.
Caractéristiques
-
Non capable de migration en direct.
-
Utilisez NFSv4.1 pour le partage basé sur le système de fichiers.
-
Convient pour le stockage partagé général et les charges de travail d’accès aux fichiers multi-nœuds.
|
Remarque : Mises à jour différées de l’image du pod de gestion de partage sur les volumes RWX actifs Suite à une mise à niveau du système Longhorn, lorsqu’un volume RWX générique (non migrable) reste attaché, les modifications apportées au |
Volumes RWX migrables
Les volumes RWX migrables sont conçus spécifiquement pour des charges de travail virtualisées telles que les machines virtuelles KubeVirt qui nécessitent une [migration en direct](https://kubevirt.io/user-guide/compute/live_migration/) tout en maintenant des opérations E/S en cours. Ces volumes permettent un déplacement fluide des machines virtuelles entre les nœuds pendant les opérations de maintenance, de basculement ou de rééquilibrage sans interruption de service.
Caractéristiques
-
Conçu pour des scénarios de migration en direct.
-
Nécessite
volumeMode: Block(Filesystemmode n’est pas pris en charge). -
Nécessite le mode d’accès ReadWriteMany et une StorageClass avec
migratable: "true"(qui définitvolume.spec.migratable=truesur le volume Longhorn). -
Non destiné aux charges de travail sur des systèmes de fichiers partagés généraux.
|
Vous pouvez distinguer les volumes RWX migrables en vérifiant le champ |
Exigences pour les volumes RWX génériques (non migrables)
-
Chaque nœud client NFS doit avoir un client NFSv4 installé.
Veuillez vous référer à Installation du client NFSv4 pour plus de détails sur l’installation.
Dépannage :Si le client NFSv4 n’est pas disponible sur le nœud, tenter de monter le volume entraîne un message d’erreur contenant le texte suivant :
for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program.
-
Le nom d’hôte de chaque nœud est unique dans le cluster Kubernetes.
Il existe un service de récupération backend dédié pour les serveurs NFS dans le système Longhorn. Lorsqu’un client se connecte à un serveur NFS, les informations du client, y compris son nom d’hôte, seront stockées dans le backend de récupération. Lorsqu’un Pod gestionnaire de partage ou un serveur NFS est terminé de manière anormale, SUSE Storage en créera un nouveau. Dans la période bonus de 90 secondes, les clients récupéreront les verrous en utilisant les informations du client stockées dans le backend de récupération.
Création et utilisation de volumes RWX génériques (non migrables)
|
Un volume RWX doit avoir le mode d’accès défini sur |
-
Pour les volumes Longhorn provisionnés dynamiquement, le mode d’accès est basé sur le mode d’accès du PVC.
-
Pour les volumes Longhorn créés manuellement (restauration, volume DR), le mode d’accès peut être spécifié lors de la création dans SUSE Storage l’interface.
-
Lors de la création d’un PV/PVC pour un volume Longhorn via l’interface, le mode d’accès du PV/PVC sera basé sur le mode d’accès du volume.
-
On peut changer le mode d’accès du volume Longhorn via l’interface si le volume n’est pas lié à un PVC.
-
Pour un volume Longhorn utilisé par un PVC RWX, le mode d’accès du volume sera changé en RWX.
Configuration de la localité des volumes pour les volumes RWX génériques (non migrables)
SUSE Storage fournit de nouveaux paramètres qui vous permettent de contrôler précisément la localité des données des volumes RWX (par l’identification des pods Share Manager associés). Ces paramètres granulaires fonctionnent avec les paramètres globaux associés pour offrir des performances optimales, une résilience et le respect des politiques ou contraintes organisationnelles.
shareManagerNodeSelector
Vous pouvez utiliser le paramètre StorageClass shareManagerNodeSelector pour spécifier des sélecteurs permettant d’identifier les nœuds sur lesquels les volumes RWX peuvent être planifiés. Ces sélecteurs sont fusionnés avec les paramètres globaux system-managed-components-node-selector et ensuite appliqués aux pods Share Manager des volumes RWX pour offrir un meilleur contrôle sur la localité des volumes.
Exemple :
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerNodeSelector: label-key1:label-value1;label-key2:label-value2
Dans cet exemple, les volumes RWX provisionnés avec le StorageClass spécifié seront planifiés sur des nœuds avec les étiquettes label-key1:label-value1 et label-key2:label-value2.
allowedTopologies
Longhorn convertit les paramètres storageClass.allowedTopologies en règles d’affinité pour les pods Share Manager des volumes RWX. Cela garantit que les pods sont planifiés sur des nœuds qui répondent aux exigences topologiques spécifiées (telles que les régions et les zones) et s’alignent avec la localité des volumes RWX.
Exemple :
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
allowedTopologies:
- matchLabelExpressions:
- key: topology.kubernetes.io/region
values:
- us-west-1
Dans cet exemple, les pods Share Manager et les volumes RWX seront planifiés dans la région us-west-1.
shareManagerTolerations
Vous pouvez également utiliser le paramètre StorageClass shareManagerTolerations pour permettre une planification plus flexible basée sur les marquages des nœuds. Les tolérances définies sont fusionnées avec les paramètres globaux taint-toleration et ensuite appliquées aux pods Share Manager.
Exemple :
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-rwx
provisioner: driver.longhorn.io
parameters:
shareManagerTolerations: nodetype=storage:NoSchedule
Dans cet exemple, les pods Share Manager toléreront le marquage nodetype=storage:NoSchedule sur les nœuds, leur permettant d’être planifiés sur ces nœuds.
Configuration des options de montage des volumes pour les volumes RWX génériques (non migrables)
Un volume RWX n’est accessible que lorsqu’il est monté via NFS. Par défaut, SUSE Storage utilise la version 4.1 de NFS avec l’option de montage softerr, une valeur timeo de "600", et une valeur retrans de "5".
Si le serveur NFS devient inaccessible, les demandes des clients NFS sont réessayées selon la valeur retrans configurée. Des événements de longue durée tels que des coupures de courant et des facteurs tels que des partitions réseau provoquent finalement l’échec des demandes. Une erreur NFS (ETIMEDOUT pour l’option de montage softerr) est renvoyée à l’application appelante et une perte de données peut se produire. Si softerr n’est pas pris en charge, SUSE Storage utilise automatiquement l’option de montage soft à la place, qui renvoie un EIO en tant qu’erreur.
Vous pouvez utiliser des options de montage spécifiques pour de nouveaux volumes. Tout d’abord, créez une StorageClass personnalisée avec un paramètre nfsOptions, puis créez des PVC pour des volumes RWX en utilisant cette StorageClass spécifique.
Exemple :
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-test
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "2880"
fromBackup: ""
fsType: "ext4"
nfsOptions: "vers=4.2,noresvport,softerr,timeo=600,retrans=5"|
Pour créer des PVC pour des volumes RWX en utilisant la StorageClass d’exemple, remplacez la chaîne |
Notes
-
Vous devez fournir l’ensemble complet des options souhaitées. Toute option non fournie utilisera les valeurs par défaut du côté serveur NFS, et non celles de SUSE Storage.
-
SUSE Storage ne valide pas la chaîne
nfsOptions, donc les valeurs erronées et les erreurs typographiques ne sont pas signalées. Lorsque la chaîne est invalide, le montage est rejeté par le serveur NFS et le volume n’est ni créé ni attaché. -
Dans SUSE Storage v1.4.0 à 1.4.3 et v1.5.0 à 1.5.1, les volumes dans un pod de gestion de partage (spécifiquement, à l’étape
NodeStageVolume) sont montés en mode hard par défaut par le plugin Longhorn CSI. Le montage en mode hard permet à SUSE Storage de réessayer de manière persistante l’envoi de demandes NFS, garantissant que les E/S n’échouent pas même lorsque le serveur NFS devient inaccessible pendant un certain temps. Les E/S reprennent sans interruption lorsque le serveur retrouve la connectivité ou qu’un serveur de remplacement est créé.Cependant, ce mécanisme pour garantir l’intégrité des données comporte certains risques. Pour maintenir la stabilité, le noyau Linux n’autorise pas le démontage d’un système de fichiers tant que toutes les E/S en attente ne sont pas terminées. C’est une préoccupation car le système ne peut pas s’éteindre tant que tous les systèmes de fichiers ne sont pas démontés. Si le serveur NFS est incapable de récupérer, les nœuds clients doivent subir un redémarrage forcé.
Pour atténuer le problème, mettez à niveau vers v1.4.4, v1.5.2 ou une version ultérieure. Après la mise à niveau, soit
softerrsoitsoftest automatiquement appliqué au paramètrenfsOptionschaque fois que les volumes RWX sont réattachés (si les paramètres par défaut ne sont pas remplacés). -
Vous pouvez toujours utiliser l’option de montage
hard(via le mécanisme de remplacementnfsOptions), mais les volumes montés en dur sont soumis aux risques décrits.
Pour plus d’informations, reportez-vous à #6655.
Gestion des erreurs pour les volumes RWX génériques (non migrables)
-
Le Pod share-manager est terminé de manière anormale
Les entrées/sorties du client seront bloquées jusqu’à ce que SUSE Storage crée un nouveau Pod share-manager et le volume associé. Une fois le Pod créé avec succès, la période bonus de 90 secondes pour la récupération des verrous commence, et les utilisateurs s’attendraient à ce que
-
Avant la fin de la période bonus, les entrées/sorties du client vers le volume RWX seront toujours bloquées.
-
Le serveur rejette les opérations de LECTURE et d’ÉCRITURE ainsi que les demandes de verrouillage non récupérables avec une erreur de NFS4ERR_GRACE.
-
La période bonus peut être terminée plus tôt si tous les verrous sont récupérés avec succès.
Après la sortie de la période bonus, les E/S des clients ayant récupéré avec succès les verrous se poursuivent sans erreurs liées aux poignées de fichiers obsolètes ni d’erreurs d’entrée/sortie. Si un verrou ne peut pas être récupéré dans la période bonus, le verrou est abandonné, et le serveur renvoie une erreur d’entrée/sortie au client. Le client rétablit un nouveau verrou. L’application doit gérer l’erreur d’entrée/sortie. Néanmoins, certaines applications ne parviennent pas à gérer les erreurs d’entrée/sortie en raison de leur implémentation. Ainsi, cela peut entraîner l’échec de l’opération d’entrée/sortie et la perte de données. La cohérence des données peut poser problème.
+ Voici un exemple d’un DaemonSet utilisant un volume RWX.
+ Chaque Pod du DaemonSet écrit des données dans le volume RWX. Si le nœud où le Pod share-manager s’exécute est hors service, un nouveau Pod share-manager est créé sur un autre nœud. Puisqu’un des clients situés sur le nœud en panne est parti, le processus de récupération de verrou ne peut pas être terminé avant la période bonus de 90 secondes, même si les verrous des clients restants ont été récupérés avec succès. Les E/S de ces clients continuent après l’expiration de la période bonus.
-
-
Si le service DNS de Kubernetes tombe en panne, les Pods de gestion de partage ne pourront pas communiquer avec longhorn-nfs-recovery-backend.
Le serveur NFS-ganesha dans un Pod share-manager communique avec
longhorn-nfs-recovery-backendvia l’adresse IP du servicelonghorn-recovery-backend. Si le service DNS est hors service, la création et la suppression de volumes RWX ainsi que la récupération des serveurs NFS seront inopérables. Ainsi, la haute disponibilité du service DNS est recommandée pour éviter l’échec de communication. -
Fonctionnalité de basculement rapide.
SUSE Storage prend en charge une fonctionnalité qui peut améliorer la disponibilité en réduisant le temps nécessaire pour se remettre d’un échec du nœud sur lequel s’exécute le Pod share-manager du serveur NFS du volume. La fonctionnalité utilise une pulsation directe pour surveiller le serveur. Si le serveur ne répond pas, il agit pour en créer un nouveau plus rapidement que la séquence habituelle. Il configure également le serveur NFS différemment, pour réduire la période bonus de récupération de 90 à 30 secondes.
Plus de détails sont disponibles à RWX Volume Fast Failover.
Migration depuis le provisionneur externe précédent.
Le PVC ci-dessous crée un job Kubernetes qui peut copier des données d’un volume à un autre.
-
Remplacez le
data-source-pvcpar le nom du PVC RWX NFSv4 précédent qui a été créé par Kubernetes. -
Remplacez le
data-target-pvcpar le nom du nouveau PVC RWX que vous souhaitez utiliser pour vos nouvelles charges de travail.
Vous pouvez créer manuellement un nouveau volume Longhorn RWX + PVC/PV, ou simplement créer un PVC RWX et laisser Longhorn provisionner dynamiquement un volume pour vous.
Les deux PVC doivent exister dans le même espace de noms. Si vous utilisiez un espace de noms différent de celui par défaut, changez l’espace de noms du job ci-dessous.
apiVersion: batch/v1
kind: Job
metadata:
namespace: default # namespace where the PVC's exist
name: volume-migration
spec:
completions: 1
parallelism: 1
backoffLimit: 3
template:
metadata:
name: volume-migration
labels:
name: volume-migration
spec:
restartPolicy: Never
containers:
- name: volume-migration
image: ubuntu:xenial
tty: true
command: [ "/bin/sh" ]
args: [ "-c", "cp -r -v /mnt/old /mnt/new" ]
volumeMounts:
- name: old-vol
mountPath: /mnt/old
- name: new-vol
mountPath: /mnt/new
volumes:
- name: old-vol
persistentVolumeClaim:
claimName: data-source-pvc # change to data source PVC
- name: new-vol
persistentVolumeClaim:
claimName: data-target-pvc # change to data target PVC