|
Este documento ha sido traducido utilizando tecnología de traducción automática. Si bien nos esforzamos por proporcionar traducciones precisas, no ofrecemos garantías sobre la integridad, precisión o confiabilidad del contenido traducido. En caso de discrepancia, la versión original en inglés prevalecerá y constituirá el texto autorizado. |
Actualiza de v1.4.0 a v1.4.1
Información general
Un botón de actualizar aparece en la pantalla Dashboard cada vez que aparece una nueva SUSE Virtualization versión a la que se puede actualizar. Para más información, consulta Iniciar la actualización.
Para entornos aislados, consulta Preparar una actualización en entorno aislado.
|
Verifica el uso del disco de las imágenes del sistema operativo en cada nodo antes de iniciar la actualización. Para hacer esto, accede al nodo a través de SSH y ejecuta el comando Ejemplo: Si
|
Actualiza la extensión de Harvester UI en SUSE Rancher Prime v2.10.1
Debes usar v1.0.3 de la extensión de Harvester UI para importar clústeres SUSE Virtualization v1.4.1 en Rancher v2.10.1.
-
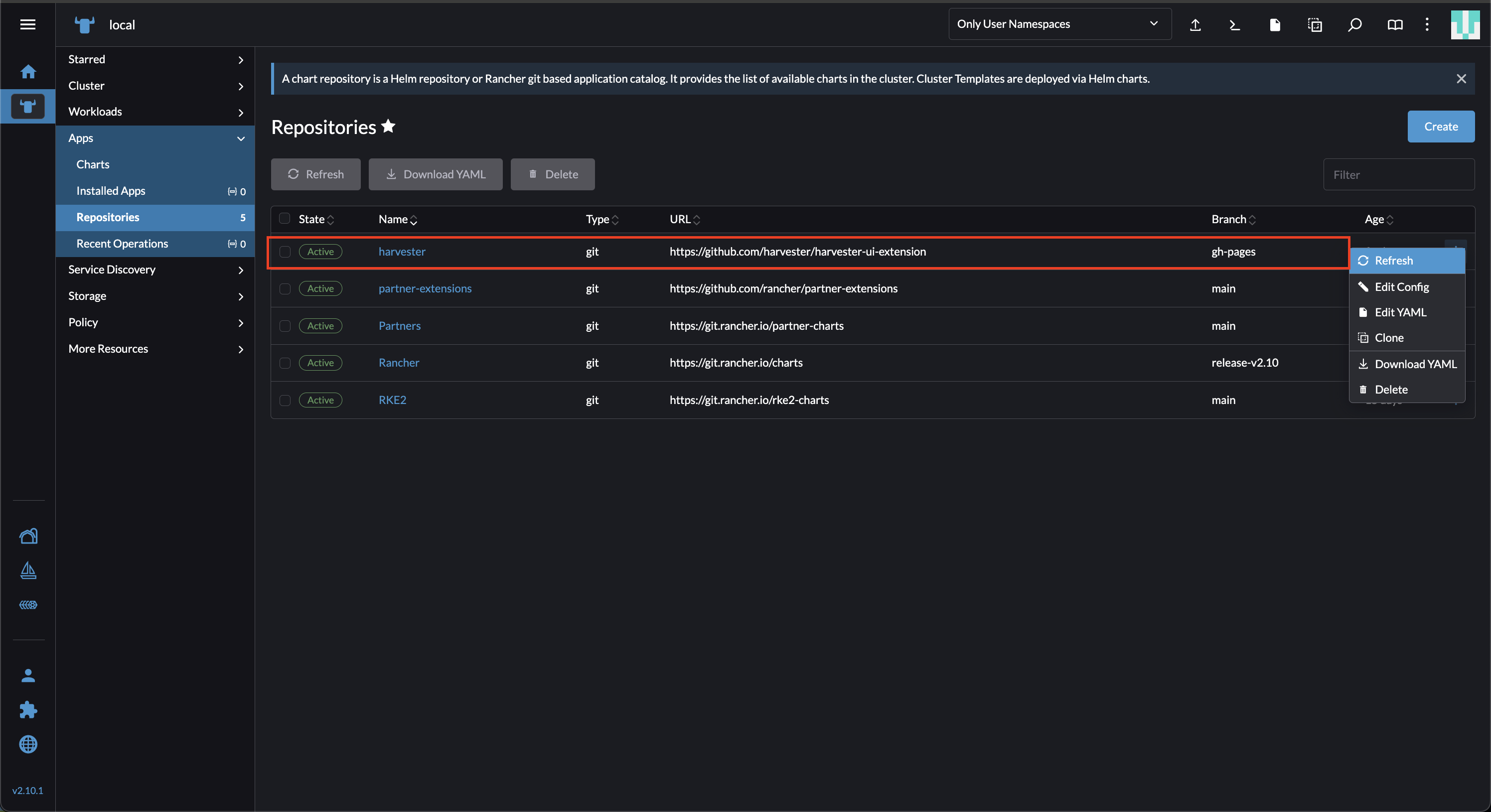
En la interfaz de Rancher, ve a local → Apps → Repositorios.
-
Localiza el repositorio llamado harvester, y luego selecciona ⋮ → Actualizar.
Este repositorio tiene las siguientes propiedades:
-
Rama: gh-pages
-
Ve a la pantalla Extensiones.
-
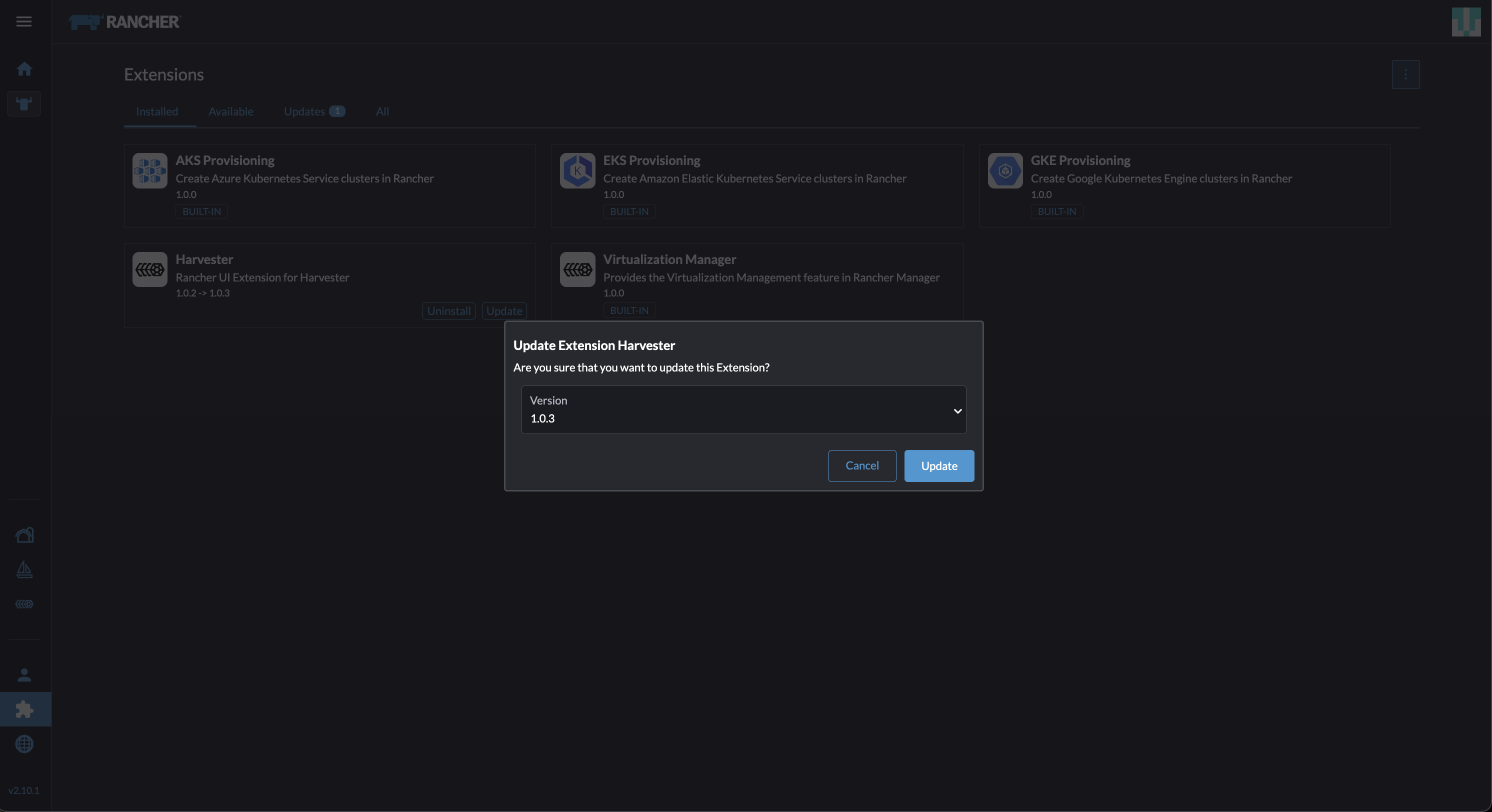
Localiza la extensión llamada Harvester, y luego haz clic en Actualizar.
-
Selecciona la versión 1.0.3, y luego haz clic en Actualizar.
-
Permite un tiempo para que la extensión se actualice y luego actualiza la pantalla.
|
La interfaz de usuario Rancher muestra un mensaje de error después de que se actualiza la extensión. El mensaje de error desaparece cuando actualizas la pantalla. Este problema, que existe en Rancher v2.10.0 y v2.10.1, se solucionará en v2.10.2. |
Problemas conocidos
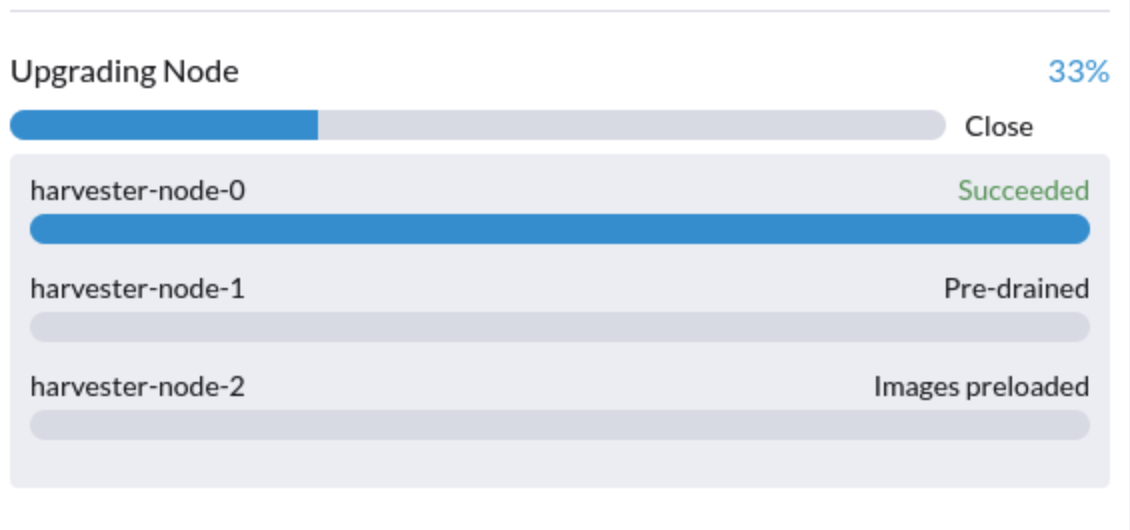
1. Actualización atascada en estado "Pre-drained"
El proceso de actualización puede quedar atascado en el estado "Pre-drained". Se supone que Kubernetes debe drenar la carga de trabajo en el nodo, pero algunos factores pueden causar que el proceso se detenga.
Una posible causa son los procesos relacionados con motores huérfanos del Longhorn Instance Manager. Para determinar si esto se aplica a tu situación, realiza los siguientes pasos:
-
Verifica el nombre del pod
instance-manageren el nodo atascado.Ejemplo:
El nodo atascado es
harvester-node-1, y el nombre del pod del Instance Manager esinstance-manager-d80e13f520e7b952f4b7593fc1883e2a.$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager instance-manager-d80e13f520e7b952f4b7593fc1883e2a 1/1 Running 0 3d8h -
Revisa los registros del Longhorn Manager en busca de mensajes informativos.
Ejemplo:
$ kubectl -n longhorn-system logs daemonsets/longhorn-manager ... time="2025-01-14T00:00:01Z" level=info msg="Node instance-manager-d80e13f520e7b952f4b7593fc1883e2a is marked unschedulable but removing harvester-node-1 PDB is blocked: some volumes are still attached InstanceEngines count 1 pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0" func="controller.(*InstanceManagerController).syncInstanceManagerPDB" file="instance_manager_controller.go:823" controller=longhorn-instance-manager node=harvester-node-1El pod
instance-managerno puede ser drenado debido al motorpvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0. -
Verifica si el motor sigue funcionando en el nodo atascado.
Ejemplo:
$ kubectl -n longhorn-system get engines.longhorn.io pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0 -o jsonpath='{"Current state: "}{.status.currentState}{"\nNode ID: "}{.spec.nodeID}{"\n"}' Current state: stopped Node ID:El problema probablemente existe si la salida muestra que el motor no está funcionando o no se encuentra.
-
Verifica si todos los volúmenes están saludables.
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'Todos los volúmenes deben estar marcados como
healthy. Si este no es el caso, informa del problema. -
Elimina el PodDisruptionBudget (PDB) del pod
instance-manager.Ejemplo:
kubectl delete pdb instance-manager-d80e13f520e7b952f4b7593fc1883e2a -n longhorn-system
2. Actualiza con una StorageClass predeterminada que no sea harvester-longhorn
El Harvester añade la anotación storageclass.kubernetes.io/is-default-class: "true" a harvester-longhorn, que es la StorageClass predeterminada original. Cuando reemplazas harvester-longhorn con otra StorageClass, ocurren lo siguiente:
-
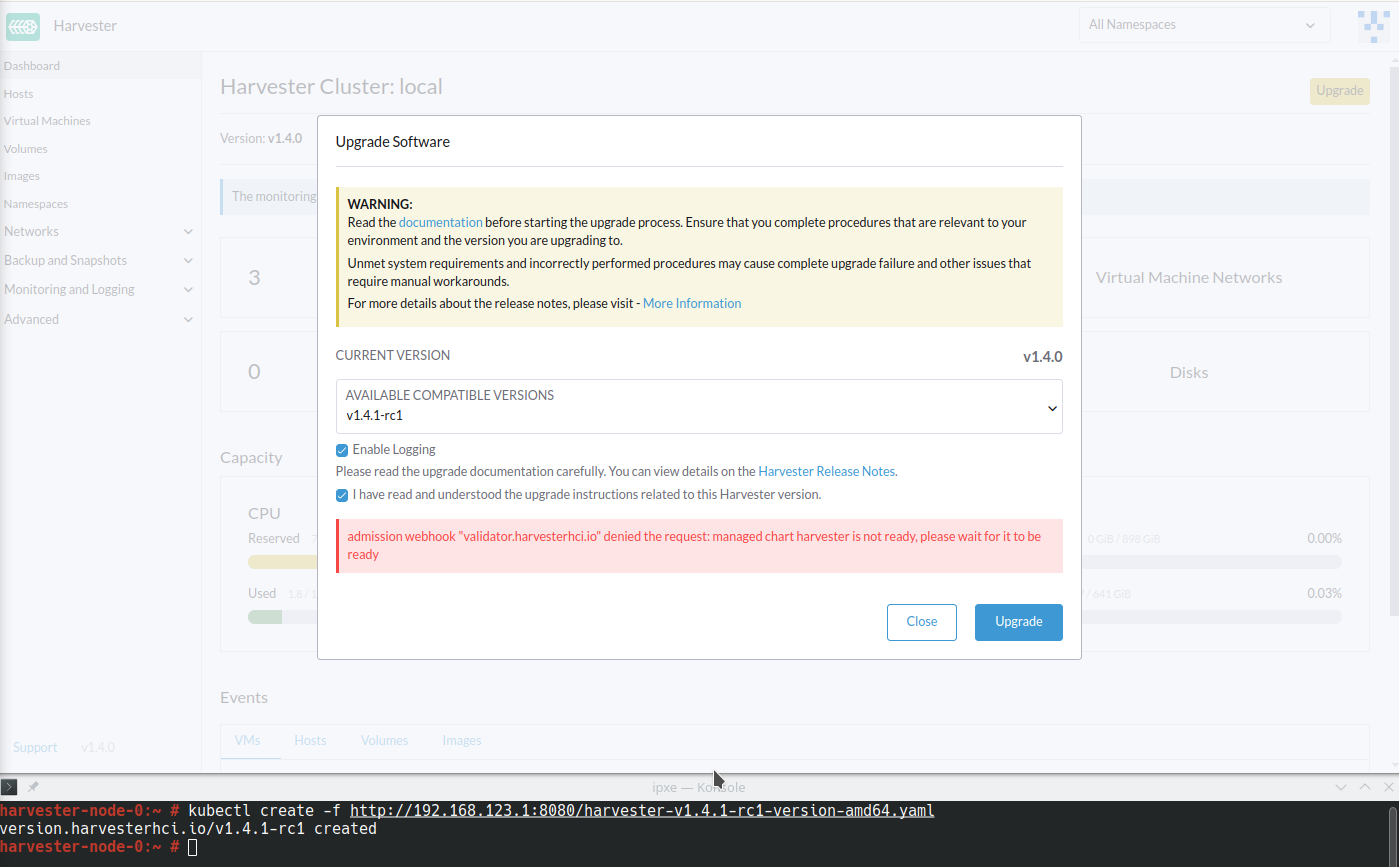
El ManagedChart de Harvester muestra el mensaje de error
cannot patch "harvester-longhorn" with kind StorageClass: admission webhook "validator.harvesterhci.io" denied the request: default storage class %!s(MISSING) already exists, please reset it first. -
El webhook deniega la solicitud de actualización.
Puedes realizar cualquiera de las siguientes soluciones alternativas:
-
Establece
harvester-longhorncomo la StorageClass predeterminada. -
Añade
spec.values.storageClass.defaultStorageClass: falseal ManagedChart deharvester.kubectl edit managedchart harvester -n fleet-local -
Añade
timeoutSeconds: 600a la especificación del ManagedChart de Harvester.kubectl edit managedchart harvester -n fleet-local
Problema relacionado: #7375
3. Actualización atascada en estado "Esperando reinicio"
El proceso de actualización puede quedar atascado en el estado "Esperando reinicio" después de que la imagen de Harvester v1.4.1 se instale en un nodo y se inicie un reinicio. En este punto, el controlador de actualización observa si el sistema operativo de Harvester v1.4.1 está en funcionamiento.
Si la imagen de Harvester v1.4.1 (en adelante denominada active.img) no arranca por ningún motivo, el nodo se reinicia automáticamente en modo de recuperación y arranca la imagen de Harvester v1.4.0 previamente instalada (en adelante denominada passive.img). El controlador de actualización no puede detectar el sistema operativo esperado, por lo que la actualización permanece atascada hasta que un administrador solucione el problema con active.img.
active.img puede volverse corrupto e inarrancable debido a la falta de espacio en disco en la partición COS_STATE durante la actualización. Esto ocurre si Harvester v1.4.0 se instaló originalmente en el nodo y el sistema se configuró para usar un disco de datos separado. El problema no ocurre en las siguientes situaciones:
-
El sistema tiene un único disco que es compartido por el sistema operativo y los datos.
-
Una versión anterior de Harvester fue instalada originalmente y luego actualizada a la v1.4.0.
Para comprobar si el problema existe en tu entorno, realiza los siguientes pasos:
-
Accede al nodo a través de SSH e inicia sesión utilizando la cuenta de root.
-
Ejecuta los comandos
cat /proc/cmdlineyhead -n1 /etc/harvester-release.yaml.Ejemplo:
# cat /proc/cmdline BOOT_IMAGE=(loop0)/boot/vmlinuz console=tty1 root=LABEL=COS_STATE cos-img/filename=/cOS/passive.img panic=0 net.ifnames=1 rd.cos.oemlabel=COS_OEM rd.cos.mount=LABEL=COS_OEM:/oem rd.cos.mount=LABEL=COS_PERSISTENT:/usr/local rd.cos.oemtimeout=120 audit=1 audit_backlog_limit=8192 intel_iommu=on amd_iommu=on iommu=pt multipath=off upgrade_failure # head -n1 /etc/harvester-release.yaml harvester: v1.4.0La presencia de
cos-img/filename=/cOS/passive.imgyupgrade_failureen la salida indica que el sistema se inició en modo de recuperación. La versión de Harvester en/etc/harvester-release.yamlconfirma que el sistema está utilizando actualmente la imagen v1.4.0. -
Comprueba si
active.imgestá corrupto ejecutando el comandofsck.ext2 -nf /run/initramfs/cos-state/cOS/active.img.Ejemplo:
# fsck.ext2 -nf /run/initramfs/cos-state/cOS/active.img e2fsck 1.46.4 (18-Aug-2021) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure [...a list of various different errors may appear here...] e2fsck: aborted COS_ACTIVE: ********** WARNING: Filesystem still has errors ********** -
Verifica los tamaños de las particiones ejecutando el comando
lsblk -o NAME,LABEL,SIZE.Ejemplo:
# lsblk -o NAME,LABEL,SIZE NAME LABEL SIZE loop0 COS_ACTIVE 3G sr0 1024M vda 250G ├─vda1 COS_GRUB 64M ├─vda2 COS_OEM 64M ├─vda3 COS_RECOVERY 4G ├─vda4 COS_STATE 8G └─vda5 COS_PERSISTENT 237.9G vdb HARV_LH_DEFAULT 128GLa salida en el ejemplo muestra una partición
COS_STATEque tiene un tamaño de 8G. En este caso específico, que implica un intento fallido de actualización y unactive.imgcorrupto, es probable que la partición no tuviera suficiente espacio libre para que la actualización tuviera éxito.
Para solucionar el problema, realiza los siguientes pasos:
-
Si tu clúster tiene dos o más nodos, accede a los nodos restantes a través de SSH y verifica el uso del disco de
active.imgypassive.img.# du -sh /run/initramfs/cos-state/cOS/* 1.7G /run/initramfs/cos-state/cOS/active.img 3.1G /run/initramfs/cos-state/cOS/passive.imgSi
passive.imgconsume 3.1G de espacio en disco, ejecuta los siguientes comandos utilizando la cuenta de root:# mount -o remount,rw /run/initramfs/cos-state # fallocate --dig-holes /run/initramfs/cos-state/cOS/passive.img # mount -o remount,ro /run/initramfs/cos-statepassive.imgse convierte en un archivo disperso, que solo debería consumir 1.7G de espacio en disco (lo mismo queactive.img). Esto asegura que los otros nodos tengan suficiente espacio libre, evitando que el proceso de actualización se quede atascado de nuevo. -
Accede al nodo atascado a través de SSH, y luego ejecuta los siguientes comandos utilizando la cuenta de root:
# mount -o remount,rw /run/initramfs/cos-state # cp /run/initramfs/cos-state/cOS/passive.img \ /run/initramfs/cos-state/cOS/active.img # tune2fs -L COS_ACTIVE /run/initramfs/cos-state/cOS/active.img # mount -o remount,ro /run/initramfs/cos-stateEl
passive.imgexistente (limpio) se copia sobre elactive.imgcorrupto, y la etiqueta se establece correctamente. -
Reinicia el nodo atascado, y luego selecciona la primera entrada (Harvester v1.4.1) en la pantalla de arranque de GRUB.
La pantalla de arranque de GRUB muestra inicialmente Harvester v1.4.1 (fallback) por defecto. A pesar de la versión mostrada, el sistema arranca en Harvester v1.4.0.
-
Copia
rootfs.squashfsdesde el ISO de Harvester v1.4.1 a una ubicación conveniente en el nodo atascado.El ISO se puede montar en el nodo atascado o en otro sistema. Puedes copiar el archivo utilizando el comando
scp. -
Accede al nodo atascado a través de SSH, y luego ejecuta los siguientes comandos utilizando la cuenta de root:
# mkdir /tmp/manual-os-upgrade # mkdir /tmp/manual-os-upgrade/config # mkdir /tmp/manual-os-upgrade/rootfs # mount -o loop rootfs.squashfs /tmp/manual-os-upgrade/rootfs # cat > /tmp/manual-os-upgrade/config/config.yaml <<EOF upgrade: system: size: 3072 EOF # elemental upgrade \ --logfile /tmp/manual-os-upgrade/upgrade.log \ --directory /tmp/manual-os-upgrade/rootfs \ --config-dir /tmp/manual-os-upgrade/config \ --debugDebes reemplazar la ruta de muestra en la cuarta línea con la ruta real del
rootfs.squashfscopiado.Se genera un nuevo
active.img(limpio) basado en la imagen raíz del ISO de Harvester v1.4.1.Si ocurre algún error, guarda una copia de
/tmp/manual-os-upgrade/upgrade.log. -
ejecute los comandos siguientes:
# umount /tmp/manual-os-upgrade/rootfs # rebootEl nodo debería arrancar correctamente en Harvester v1.4.1, y la actualización debería proceder como se espera.
4. La actualización de versión se reinicia inesperadamente después de hacer clic en el botón "Descartar".
Cuando utilizas Rancher para actualizar versión SUSE Virtualization, la interfaz de usuario Rancher muestra un diálogo con un botón etiquetado como "Descartar". Hacer clic en este botón puede resultar en los siguientes problemas:
-
La sección
statusdel CRharvesterhci.io/v1beta1/upgradese borra, causando la pérdida de toda la información importante sobre la actualización de versión. -
El proceso de actualización de versión se reinicia inesperadamente.
Este problema afecta a Rancher v2.10.x, que utiliza v1.0.2, v1.0.3 y v1.0.4 de Harvester UI extensión. Todas SUSE Virtualization las versiones de la UI no se ven afectadas. El problema se soluciona en Harvester UI extensión v1.0.5 y v1.5.0.
Para evitar este problema, realiza cualquiera de las siguientes acciones:
-
Utiliza la SUSE Virtualization UI para las actualizaciones de versión. Hacer clic en el botón "Descartar" en la SUSE Virtualization UI no resulta en un comportamiento inesperado.
-
En lugar de hacer clic en el botón en la Rancher UI, ejecuta el siguiente comando contra el clúster:
kubectl -n harvester-system label upgrades -l harvesterhci.io/latestUpgrade=true harvesterhci.io/read-message=true
Problema relacionado: #7791
5. Las máquinas virtuales que utilizan volúmenes RWX migrables se reinician inesperadamente
Las máquinas virtuales que utilizan volúmenes RWX migrables se reinician inesperadamente cuando se reinician los pods del plugin CSI. Este problema afecta a SUSE Virtualization v1.4.x, v1.5.0 y v1.5.1.
La solución alternativa es desactivar la configuración Eliminar automáticamente el pod de carga de trabajo cuando el volumen se desmonte inesperadamente en la SUSE Storage UI antes de iniciar la actualización de versión. Debes habilitar de nuevo la configuración una vez que se haya completado la actualización.
El problema se solucionará en SUSE Storage v1.8.3, v1.9.1 y versiones posteriores. SUSE Virtualization v1.6.0 incluirá SUSE Storage v1.9.1.