Kurzanleitung zu Installation und Einrichtung
- 1 Einsatzszenario
- 2 Systemanforderungen
- 3 Überblick über die Bootstrap-Skripte
- 4 Installation von SUSE Linux Enterprise Server und High Availability Extension
- 5 Verwendung von SBD als Fencing-Mechanismus
- 6 Einrichtung des ersten Knotens
- 7 Hinzufügen des zweiten Knotens
- 8 Testen des Clusters
- 9 Weiterführende Informationen
- 10 Rechtliche Hinweise
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Kurzanleitung zu Installation und Einrichtung #
Zusammenfassung#
Dieses Dokument führt Sie durch die Einrichtung eines sehr einfachen Clusters mit zwei Knoten. Dabei werden Bootstrap-Skripte verwendet, die im Paket ha-cluster-bootstrap bereitgestellt werden. Bei diesem Vorgang müssen Sie unter anderem eine virtuelle IP-Adresse als Cluster-Ressource konfigurieren und SBD im gemeinsam genutzten Speicher als Fencing-Mechanismus (Abriegelung) verwenden.
- 1 Einsatzszenario
- 2 Systemanforderungen
- 3 Überblick über die Bootstrap-Skripte
- 4 Installation von SUSE Linux Enterprise Server und High Availability Extension
- 5 Verwendung von SBD als Fencing-Mechanismus
- 6 Einrichtung des ersten Knotens
- 7 Hinzufügen des zweiten Knotens
- 8 Testen des Clusters
- 9 Weiterführende Informationen
- 10 Rechtliche Hinweise
- A GNU Licenses
1 Einsatzszenario #
Mit den in diesem Dokument beschriebenen Verfahren erhalten Sie eine Minimaleinrichtung eines Clusters mit zwei Knoten, die folgende Eigenschaften aufweist:
Zwei Knoten:
alice(IP:192.168.1.1) undbob(IP:192.168.1.2), die über das Netzwerk miteinander verbunden sindDie virtuelle IP-Adresse (
192.168.2.1) nach dem Floating-IP-Prinzip, über die Clients eine Verbindung mit dem Service herstellen können, und zwar unabhängig davon, auf welchem physischen Knoten er ausgeführt wirdEin gemeinsam genutztes Speichergerät für den Einsatz als SBD-Fencing-Mechanismus Dadurch lassen sich Szenarien mit Systemspaltungen vermeiden.
Failover der Ressourcen von einem Knoten zum anderen, wenn der aktive Host ausfällt (Aktiv/Passiv-Einrichtung)
Nach der Einrichtung des Clusters mit den Bootstrap-Skripten überwachen wir den Cluster mit der grafischen HA Web Konsole (Hawk). Dabei handelt es sich um eines der Werkzeuge für die Cluster-Verwaltung, die im Lieferumfang von SUSE Linux Enterprise High Availability Extension enthalten sind. Die ordnungsgemäße Funktionsweise des Ressourcen-Failovers lässt sich ganz einfach testen, indem einer der Knoten in den Standby-Modus versetzt und geprüft wird, ob die virtuelle IP-Adresse zum zweiten Knoten migriert wird.
Sie können den aus zwei Knoten bestehenden Cluster zu Testzwecken oder als anfängliche Cluster-Minimalkonfiguration verwenden, die später erweitert werden kann. Bevor Sie den Cluster in einer Produktionsumgebung einsetzen, müssen Sie ihn Ihren Anforderungen entsprechend ändern.
2 Systemanforderungen #
In diesem Abschnitt erhalten Sie Informationen über die wichtigsten Systemanforderungen für das in Abschnitt 1, „Einsatzszenario“ beschriebene Szenario. Wenn Sie den Cluster für den Einsatz in einer Produktionsumgebung anpassen möchten, lesen Sie die ausführliche Liste der Systemanforderungen und Empfehlungen im Chapter 2, System Requirements and Recommendations.
Hardwareanforderungen #
- Server
Zwei Server mit der Software, die in Softwareanforderungen angegeben ist.
Bei den Servern kann es sich um Bare Metal-Server oder um virtuelle Rechner handeln. Sie müssen nicht unbedingt mit identischer Hardware (Arbeitsspeicher, Festplattenspeicher usw.) ausgestattet sein, die gleiche Architektur wird jedoch vorausgesetzt. Plattformübergreifende Cluster werden nicht unterstützt.
- Kommunikationskanäle
Mindestens zwei TCP/IP-Kommunikationsmedien pro Cluster-Knoten. Die Netzwerkausstattung muss die Kommunikationswege unterstützen, die Sie für die Cluster-Kommunikation verwenden möchten: Multicast oder Unicast. Die Kommunikationsmedien sollten eine Datenübertragungsrate von mindestens 100 MBit/s unterstützen. Für eine unterstützte Cluster-Einrichtung sind mindestens zwei redundante Kommunikationspfade erforderlich. Dies lässt sich durch folgende Methoden erreichen:
Über Network Device Bonding (bevorzugte Methode)
Über einen zweiten Kommunikationskanal in Corosync
Netzwerk-Fehlertoleranz in einer Infrastrukturschicht (z. B. Hypervisor).
- Knoten-Fencing/STONITH
Um das Szenario einer „Systemspaltung“ zu verhindern, benötigen Cluster einen Fencing-Mechanismus für Knoten. Wenn eine Systemspaltung vorliegt, werden Cluster-Knoten in zwei oder mehr Gruppen geteilt, die (aufgrund eines Hardware- bzw. Softwarefehlers oder einer unterbrochenen Netzwerkverbindung) keine Kenntnis voneinander haben. Ein Fencing-Mechanismus isoliert den fraglichen Knoten (in der Regel durch das Zurücksetzen oder Ausschalten des Knotens). Dies wird auch als STONITH („Shoot the other node in the head“, Englisch für „Schieß dem anderen Knoten in den Kopf“) bezeichnet. Als Fencing-Mechanismus für Knoten kann entweder ein physisches Gerät (ein Netzschalter) oder ein Mechanismus wie SBD (STONITH nach Festplatte) in Kombination mit einem Watchdog verwendet werden. Für SBD ist ein gemeinsam genutzter Speicher erforderlich.
Die folgende Software muss auf allen Knoten installiert werden, die dem Cluster angehören sollen:
Softwareanforderungen #
SUSE Linux Enterprise Server 12 SP5 (mit allen verfügbaren Online-Updates)
SUSE Linux Enterprise High Availability Extension 12 SP5 (mit allen verfügbaren Online-Updates)
Sonstige Anforderungen und Empfehlungen #
- Zeitsynchronisierung
Cluster-Knoten müssen mit einem NTP-Server außerhalb des Clusters synchronisiert werden. Weitere Informationen finden Sie unter https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Wenn die Knoten nicht synchronisiert werden, funktioniert der Cluster möglicherweise nicht ordnungsgemäß. Darüber hinaus wird die Analyse von Protokolldateien und Cluster-Berichten erheblich erschwert, wenn keine Synchronisierung erfolgt. Wenn Sie die Bootstrap-Skripte verwenden, werden Sie gewarnt, falls NTP noch nicht konfiguriert wurde.
- Hostname und IP-Adresse
Verwenden Sie statische IP-Adressen.
Listen Sie alle Cluster-Knoten in der Datei
/etc/hostsmit ihrem vollständig qualifizierten Hostnamen und der Kurzform des Hostnamens auf. Es ist sehr wichtig, dass sich die Cluster-Mitglieder untereinander anhand der Namen finden können. Wenn die Namen nicht verfügbar sind, tritt ein Fehler bei der internen Cluster-Kommunikation auf.
- SSH
Alle Cluster-Knoten müssen in der Lage sein, über SSH aufeinander zuzugreifen. Werkzeuge wie
crm report(zur Fehlerbehebung) und von Hawk2 erfordern einen passwortfreien SSH-Zugriff zwischen den Knoten, da sie andernfalls nur Daten vom aktuellen Knoten erfassen können.Wenn Sie die Bootstrap-Skripte für die Einrichtung des Clusters verwenden, werden die SSH-Schlüssel automatisch erstellt und kopiert.
3 Überblick über die Bootstrap-Skripte #
Alle Kommandos aus dem Paket ha-cluster-bootstrap führen Bootstrap-Skripte aus, für die nur wenig Zeit und kaum manuelle Eingriffe benötigt werden.
Mit
ha-cluster-initkönnen die grundlegenden Parameter definiert werden, die für eine Cluster-Kommunikation erforderlich sind. Sie erhalten dadurch einen aktiven Cluster mit einem Knoten.Mit
ha-cluster-joinkönnen Sie Ihrem Cluster weitere Knoten hinzufügen.Mit
ha-cluster-removekönnen Sie Knoten aus Ihrem Cluster entfernen.
Alle Bootstrap-Skripte protokollieren die zugehörigen Daten in der Datei /var/log/ha-cluster-bootstrap.log. In dieser Datei finden Sie alle Details des Bootstrap-Prozesses. Sämtliche Optionen, die während des Bootstrap-Prozesses festgelegt wurden, können später mit dem YaST-Cluster-Modul geändert werden. Weitere Informationen finden Sie im Section 3.1, “Manual Installation”.
Jedem Skript ist eine man-Seite zugeordnet, auf der Sie die verschiedenen Funktionen, die Optionen des Skripts und einen Überblick über die Dateien finden, die vom Skript erstellt und geändert werden können.
Das Bootstrap-Skript ha-cluster-init prüft und konfiguriert die folgenden Komponenten:
- NTP
Wenn NTP nicht für das Starten zur Boot-Zeit konfiguriert wurde, wird eine Nachricht angezeigt.
- SSH
Es erstellt SSH-Schlüssel für die passwortfreie Anmeldung zwischen Cluster-Knoten.
- Csync2
Es konfiguriert Csync2 für die Replikation der Konfigurationsdateien auf allen Knoten in einem Cluster.
- Corosync
Es konfiguriert das Cluster-Kommunikationssystem.
- SBD/Watchdog
Es prüft, ob ein Watchdog vorhanden ist, und fragt Sie, ob SBD als Fencing-Mechanismus für Knoten konfiguriert werden soll.
- Virtual Floating IP
Sie werden gefragt, ob eine virtuelle IP-Adresse für die Cluster-Verwaltung mit Hawk2 konfiguriert werden soll.
- Firewall
Es öffnet die Ports in der Firewall, die für die Cluster-Kommunikation benötigt werden.
- Clustername
Es definiert einen Namen für den Cluster. Standardmäßig lautet dieser
clusterNUMMER. Dies ist optional und für die meisten GeoCluster sinnvoll. In der Regel gibt der Cluster-Name den Standort an, was das Auffinden einer Site in einem GeoCluster erleichtert.
4 Installation von SUSE Linux Enterprise Server und High Availability Extension #
Die Pakete für die Konfiguration und Verwaltung eines Clusters mit High Availability Extension sind im Installationsschema High Availability enthalten. Damit dieses Schema verfügbar ist, müssen Sie SUSE Linux Enterprise High Availability Extension als Erweiterung von SUSE Linux Enterprise Server installieren.
Sie finden Informationen zur Installation von Erweiterungen im SUSE Linux Enterprise 12 SP5 Deployment Guide (Bereitstellungshandbuch für SUSE Linux Enterprise 12 SP2): https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Sollte das Schema noch nicht installiert sein, installieren Sie es mit dem Befehl zypper install -t pattern ha_sles. Alternativ können Sie das Schema auch mit YaST installieren. Führen Sie dazu die folgenden Schritte aus:
Prozedur 1: Schema „High Availability“ für hohe Verfügbarkeit installieren #
Starten Sie YaST und wählen Sie › .
Klicken Sie auf den Karteireiter und aktivieren Sie das Schema in der Schemaliste.
Klicken Sie auf , um mit der Installation der Pakete zu beginnen.
Installieren Sie das Schema „High Availability“ auf allen Rechnern, die Teil Ihres Clusters sein sollen.

Anmerkung: Installation der Softwarepakete bei allen Parteien
Für eine automatisierte Installation von SUSE Linux Enterprise Server 12 SP5 und SUSE Linux Enterprise High Availability Extension 12 SP5 müssen Sie zum Klonen von bestehenden Knoten AutoYaST verwenden. Weitere Informationen hierzu finden Sie im Section 3.2, “Mass Installation and Deployment with AutoYaST”.
Registrieren Sie die Rechner beim SUSE Customer Center. Weitere Informationen finden Sie unter https://documentation.suse.com/sles-12/html/SLES-all/cha-update-offline.html#sec-update-registersystem.
5 Verwendung von SBD als Fencing-Mechanismus #
Falls Sie über einen gemeinsam genutzten Speicher wie beispielsweise ein SAN (Storage Area Network) verfügen, können Sie damit Szenarien einer Systemspaltung verhindern, indem Sie SBD als Fencing-Mechanismus für Knoten konfigurieren. SBD verwendet eine Watchdog-Unterstützung und den STONITH-Ressourcenagenten external/sbd.
5.1 Anforderungen für SBD #
Sie können während der Einrichtung des ersten Knotens mit ha-cluster-init entscheiden, ob Sie SBD verwenden möchten. Falls ja, müssen Sie den Pfad zum gemeinsam genutzten Speichergerät eingeben. ha-cluster-init erstellt standardmäßig automatisch eine kleine Partition auf dem Gerät, die für die Verwendung durch SBD vorgesehen ist.
Wenn Sie SBD verwenden möchten, müssen folgende Anforderungen erfüllt sein:
Der Pfad zum gemeinsam genutzten Speichergerät muss auf allen Knoten im Cluster persistent und konsistent sein. Verwenden Sie feste Gerätenamen wie
/dev/disk/by-id/dm-uuid-part1-mpath-abcedf12345.Das SBD-Gerät darf hostbasiertes RAID oder cLVM2 nicht verwenden und sich nicht auf einer DRBD-Instanz befinden.
Sie finden Details zur Einrichtung des gemeinsam genutzten Speichers im Storage Administration Guide (Administrationshandbuch zum Speicher) für SUSE Linux Enterprise Server 12 SP5: https://documentation.suse.com/sles-12/html/SLES-all/stor-admin.html.
5.2 Einrichtung von softdog-Watchdog und SBD #
In SUSE Linux Enterprise Server ist die Watchdog-Unterstützung im Kernel standardmäßig aktiviert: Die Auslieferung erfolgt mit mehreren Kernel-Modulen, die hardwarespezifische Watchdog-Treiber bereitstellen. In der High Availability Extension wird der SBD-Daemon als die Softwarekomponente verwendet, die Daten in den Watchdog „einspeist“.
Im folgenden Verfahren wird der softdog-Watchdog verwendet.
Wichtig: softdog-Einschränkungen
Der softdog-Treiber geht davon aus, dass noch mindestens eine CPU ausgeführt wird. Wenn alle CPUs ausgefallen sind, kann der im softdog-Treiber enthaltene Code, der das System neu starten soll, nicht ausgeführt werden. Ein Hardware-Watchdog arbeitet hingegen auch dann, wenn alle CPUs ausgefallen sind.
Bevor Sie den Cluster in einer Produktionsumgebung verwenden, ist es dringend empfohlen, das softdog-Modul durch das am besten zu Ihrer Hardware passende Hardwaremodul zu ersetzen.
Falls für Ihre Hardware jedoch kein passender Watchdog verfügbar ist, kann das softdog-Modul als Kernel-Watchdog-Modul verwendet werden.
Erstellen Sie mithilfe der Beschreibung im Abschnitt 5.1, „Anforderungen für SBD“, einen persistenten, gemeinsam genutzten Speicher.
Aktivieren Sie den softdog-Watchdog:
root #echosoftdog > /etc/modules-load.d/watchdog.confroot #systemctlrestart systemd-modules-loadTesten Sie, ob das softdog-Modul richtig geladen wurde:
root #lsmod| egrep "(wd|dog)" softdog 16384 1Initialisieren Sie auf
bobdie SBD-Partition:root #sbd-d /dev/SBDDEVICE createStarten Sie SBD, damit die Empfangsbereitschaft auf dem SBD-Gerät aktiviert ist:
root #sbd-d /dev/SBDDEVICE watchSenden Sie auf
aliceeine Testnachricht:root #sbd-d /dev/SBDDEVICE message bob testPrüfen Sie auf
bobmitsystemctlden Status; Sie sollten die empfangene Nachricht sehen:root #systemctlstatus sbd [...] info: Received command test from alice on disk SBDDEVICEBeenden Sie die Überwachung des SBD-Geräts auf
bobwie folgt:root #systemctlstop sbd
Es wird dringend empfohlen, die ordnungsgemäße Funktionsweise des SBD-Fencing-Mechanismus zu testen, wenn die Situation einer Systemspaltung eintritt. Ein derartiger Test kann durch die Blockierung der Corosync-Cluster-Kommunikation durchgeführt werden.
6 Einrichtung des ersten Knotens #
Richten Sie den ersten Knoten mit dem Skript ha-cluster-init ein. Dies dauert nicht lange und erfordert nur wenige manuelle Eingriffe.
Prozedur 2: Ersten Knoten (alice) mit ha-cluster-init einrichten #
Melden Sie sich als
rootan dem physischen oder virtuellen Rechner an, den Sie als Cluster-Knoten verwenden möchten.Starten Sie das Bootstrap-Skript, indem Sie Folgendes ausführen:
root #ha-cluster-init--name CLUSTERNAMEErsetzen Sie den Platzhalter CLUSTERNAME durch einen aussagekräftigen Namen, wie den geografischen Standort Ihres Clusters (z. B.
amsterdam). Dies ist besonders hilfreich, wenn Sie daraus später einen GeoCluster erstellen möchten, da eine Site so leicht identifizierbar ist. Sollten Sie den Befehl ohne die Option--nameausführen, lautet der Standardnamehacluster.Falls Sie für Ihre Cluster-Kommunikation anstelle von Multicast (Standard) Unicast benötigen, verwenden Sie hierzu die Option
-u. Nach der Installation finden Sie in der Datei/etc/corosync/corosync.confden Wertudpu. Wennha-cluster-initeinen Knoten erkennt, der in Amazon Web Services (AWS) ausgeführt wird, verwendet das Skript automatisch Unicast als Standard für die Cluster-Kommunikation.Das Skript führt eine Prüfung im Hinblick auf die NTP-Konfiguration und einen Hardware-Watchdog-Service durch. Es generiert die öffentlichen und privaten SSH-Schlüssel, die für den SSH-Zugriff und die Csync2-Synchronisierung verwendet werden, und startet die entsprechenden Services.
Konfigurieren Sie die Cluster-Kommunikationsschicht (Corosync):
Geben Sie eine Netzwerkadresse ein, an die eine Bindung erfolgen soll. Das Skript schlägt standardmäßig die Netzwerkadresse
eth0vor. Alternativ dazu können Sie auch eine andere Netzwerkadresse wie beispielsweise die Adressebond0eingeben.Geben Sie eine Multicast-Adresse ein. Das Skript schlägt eine Zufallsadresse vor, die Sie als Standard verwenden können. Voraussetzung ist natürlich, dass diese Multicast-Adresse von Ihrem jeweiligen Netzwerk unterstützt wird.
Geben Sie einen Multicast-Port ein. Das Skript schlägt
5405als Standard vor.
Schließlich startet das Skript den Pacemaker-Service, um den aus einem Knoten bestehenden Cluster online zu schalten und Hawk2 zu aktivieren. Die URL, die für Hawk2 verwendet werden muss, wird auf dem Bildschirm angezeigt.
Richten Sie SBD als Fencing-Mechanismus für Knoten ein:
Bestätigen Sie mit
y, dass Sie SBD verwenden möchten.Geben Sie einen persistenten Pfad zu der Partition Ihres Blockgeräts ein, die Sie für SBD verwenden möchten. Weitere Informationen hierzu finden Sie in Abschnitt 5, „Verwendung von SBD als Fencing-Mechanismus“. Der Pfad muss bei allen Knoten im Cluster konsistent sein.
Konfigurieren Sie eine virtuelle IP-Adresse für die Cluster-Verwaltung mit Hawk2. (Mit dieser virtuellen IP-Ressource werden wir später testen, ob der Failover erfolgreich ist.)
Bestätigen Sie mit
y, dass Sie eine virtuelle IP-Adresse konfigurieren möchten.Geben Sie eine nicht verwendete IP-Adresse ein, die Sie als Verwaltungs-IP für Hawk2 verwenden möchten:
192.168.2.1Sie können auch eine Verbindung mit der virtuellen IP-Adresse herstellen, statt sich an einem einzelnen Cluster-Knoten mit Hawk2 anzumelden.
Sie verfügen jetzt über einen aktiven Cluster mit einem Knoten. Gehen Sie wie folgt vor, um seinen Status anzuzeigen:
Prozedur 3: Anmeldung an der Hawk2-Weboberfläche #
Starten Sie auf einem beliebigen Rechner einen Webbrowser und aktivieren Sie JavaScript und Cookies.
Geben Sie als URL die IP-Adresse oder den Hostnamen eines Cluster-Knotens ein, auf dem der Hawk-Web-Service ausgeführt wird. Sie können alternativ auch die virtuelle IP-Adresse eingeben, die Sie in Schritt 6 unter Prozedur 2, „Ersten Knoten (
alice) mitha-cluster-initeinrichten“ konfiguriert haben:https://HAWKSERVER:7630/
Anmerkung: Warnmeldung bezüglich des Zertifikats
Wenn bei Ihrem ersten Zugriff auf die URL eine Warnmeldung hinsichtlich des Zertifikats angezeigt wird, wird ein eigensigniertes Zertifikat verwendet. Eigensignierte Zertifikate gelten standardmäßig nicht als vertrauenswürdig.
Bitten Sie den Cluster-Operator um die Details des Zertifikats, damit Sie es überprüfen können.
Falls Sie dennoch fortfahren möchten, können Sie im Browser eine Ausnahme hinzufügen und die Warnmeldung auf diese Weise umgehen.
Geben Sie im Anmeldebildschirm von Hawk2 in und die Daten des Benutzers ein, der während des Bootstrap-Verfahrens erstellt wurde (Benutzer
hacluster, Passwortlinux).
Wichtig: Sicheres Passwort
Ersetzen Sie das Standardpasswort möglichst schnell durch ein sicheres Passwort:
root #passwdhaclusterKlicken Sie auf . Nach der Anmeldung wird auf der Hawk2-Weboberfläche standardmäßig der Status-Bildschirm angezeigt. Dort sehen Sie den aktuellen Cluster-Status auf einen Blick:
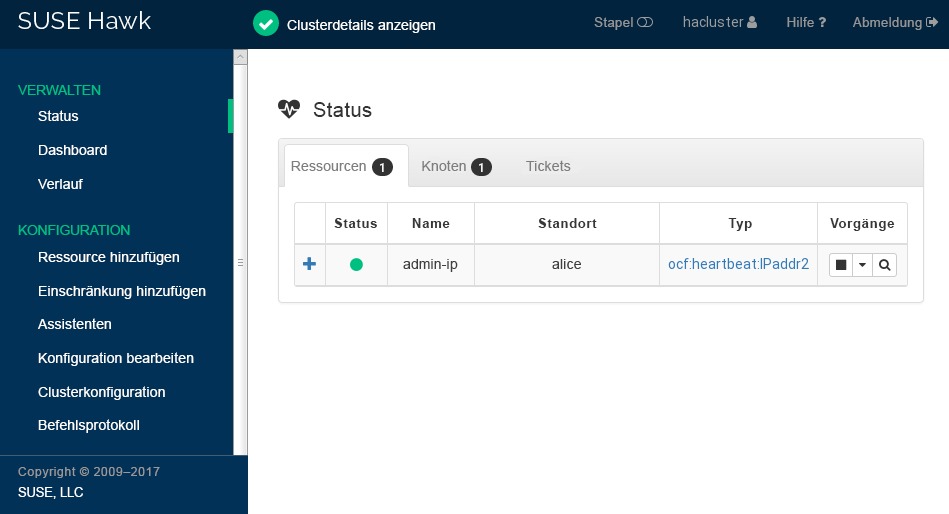
Abbildung 1: Status des aus einem Knoten bestehenden Clusters in Hawk2 #
7 Hinzufügen des zweiten Knotens #
Sobald der Cluster mit einem Knoten betriebsbereit ist, können Sie mit dem Bootstrap-Skript ha-cluster-join wie in Prozedur 4 beschrieben den zweiten Knoten hinzufügen. Das Skript benötigt lediglich Zugriff auf einen vorhandenen Cluster-Knoten. Es führt die grundlegende Einrichtung auf dem aktuellen Rechner automatisch durch. Ausführliche Informationen hierzu finden Sie auf der man-Seite ha-cluster-join.
Die Bootstrap-Skripte kümmern sich um die Änderung der für Cluster mit zwei Knoten spezifischen Konfiguration, wie SBD und Corosync.
Prozedur 4: Zweiten Knoten (bob) mit ha-cluster-join hinzufügen #
Melden Sie sich als
rootan dem physischen oder virtuellen Rechner an, der dem Cluster beitreten soll.Starten Sie das Bootstrap-Skript, indem Sie Folgendes ausführen:
root #ha-cluster-joinWenn NTP nicht für das Starten zur Boot-Zeit konfiguriert wurde, wird eine Nachricht angezeigt. Das Skript prüft außerdem, ob ein Hardware-Watchdog-Gerät vorhanden ist (dieses ist wichtig, falls Sie SBD konfigurieren möchten). Wenn keines gefunden wird, werden Sie in einer Warnmeldung darauf hingewiesen.
Falls Sie den Vorgang dennoch fortsetzen, werden Sie zur Eingabe der IP-Adresse eines vorhandenen Knotens aufgefordert. Geben Sie die IP-Adresse des ersten Knotens ein (
alice,192.168.1.1).Falls Sie noch keinen passwortfreien SSH-Zugriff zwischen beiden Rechnern konfiguriert haben, werden Sie außerdem zur Eingabe des
root-Passworts des bestehenden Knotens aufgefordert.Nach der Anmeldung an dem angegebenen Knoten kopiert das Skript die Corosync-Konfiguration. Anschließend konfiguriert es SSH und Csync2 und schaltet den aktuellen Rechner als neuen Cluster-Knoten online. Außerdem startet es den Service, der für Hawk2 erforderlich ist.
Prüfen Sie den Cluster-Status in Hawk2. Unter › sollten zwei Knoten mit einem grün dargestellten Status angezeigt werden (siehe Abbildung 2, „Status des aus zwei Knoten bestehenden Clusters“).
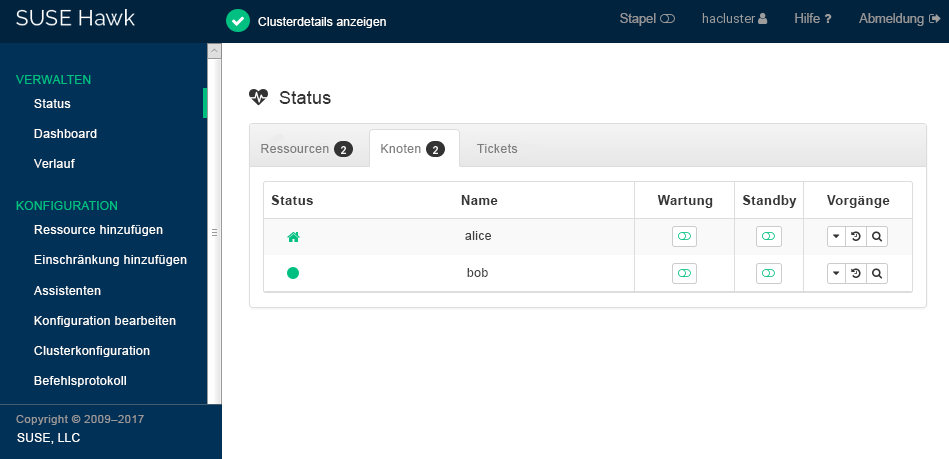
Abbildung 2: Status des aus zwei Knoten bestehenden Clusters #
8 Testen des Clusters #
Prozedur 5, „Testen des Ressourcen-Failovers“ ist ein einfacher Test zur Prüfung, ob der Cluster die virtuelle IP-Adresse zu dem anderen Knoten verschiebt, wenn der Knoten, der die Ressource zurzeit ausführt, auf Standby gesetzt wird.
Ein aussagekräftiger Test umfasst jedoch gezielte Anwendungsfälle und Szenarien. Beispielsweise sollte auch Ihr Fencing-Mechanismus getestet werden, damit Situationen einer Systemspaltung vermieden werden. Falls Sie Ihren Fencing-Mechanismus nicht ordnungsgemäß eingerichtet haben, funktioniert der Cluster nicht richtig.
Bevor Sie den Cluster in einer Produktionsumgebung einsetzen, müssen Sie ihn anhand Ihrer Anwendungsfälle gründlich testen.
Prozedur 5: Testen des Ressourcen-Failovers #
Öffnen Sie ein Terminal und setzen Sie ein Ping-Signal für Ihre virtuelle IP-Adresse
192.168.2.1ab:root #ping192.168.2.1Melden Sie sich wie in Prozedur 3, „Anmeldung an der Hawk2-Weboberfläche“ beschrieben an Ihrem Cluster an.
Prüfen Sie in Hawk2 unter › , auf welchem Knoten die virtuelle IP-Adresse (Ressource
admin_addr) ausgeführt wird. Im vorliegenden Fall wird vorausgesetzt, dass die Ressource aufaliceausgeführt wird.Versetzen Sie
alicein den -Modus (siehe Abbildung 3, „Knotenaliceim Standby-Modus“).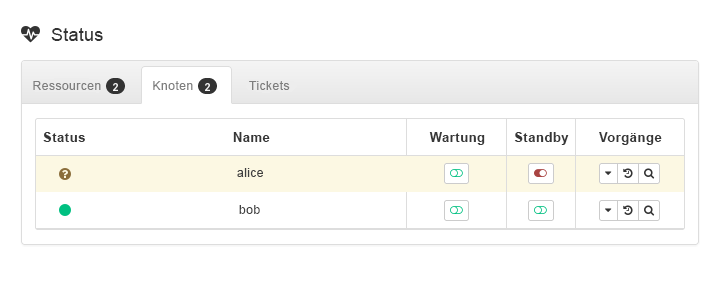
Abbildung 3: Knoten
aliceim Standby-Modus #Klicken Sie auf › . Die Ressource
admin_addrwurde zubobmigriert.
Während der Migration sollte ein ununterbrochener Fluss an Ping-Signalen an die virtuelle IP-Adresse zu beobachten sein. Dies zeigt, dass die Cluster-Einrichtung und die Floating-IP ordnungsgemäß funktionieren. Brechen Sie das ping-Kommando mit Strg– C ab.
9 Weiterführende Informationen #
Sie finden die sonstige Dokumentation zu diesem Produkt unter https://documentation.suse.com/sle-ha-12. Die Dokumentation beinhaltet unter anderem ein umfassendes Administrationshandbuch für SUSE Linux Enterprise High Availability Extension. Dort werden weitere Konfigurations- und Verwaltungsaufgaben beschrieben.
10 Rechtliche Hinweise #
Copyright © 2006– 2026 SUSE LLC und Mitwirkende. Alle Rechte vorbehalten.
Es wird die Genehmigung erteilt, dieses Dokument unter den Bedingungen der GNU Free Documentation License, Version 1.2 oder (optional) Version 1.3 zu vervielfältigen, zu verbreiten und/oder zu verändern; die unveränderlichen Abschnitte hierbei sind der Urheberrechtshinweis und die Lizenzbedingungen. Eine Kopie dieser Lizenz (Version 1.2) finden Sie im Abschnitt „GNU Free Documentation License“.
Die SUSE-Marken finden Sie unter http://www.suse.com/company/legal/. Alle anderen Marken von Drittanbietern sind Besitz ihrer jeweiligen Eigentümer. Markensymbole (®, ™ usw.) kennzeichnen Marken von SUSE und der Tochtergesellschaften. Sternchen (*) kennzeichnen Marken von Drittanbietern.
Alle Informationen in diesem Buch wurden mit größter Sorgfalt zusammengestellt. Doch auch dadurch kann hundertprozentige Richtigkeit nicht gewährleistet werden. Weder SUSE LLC noch ihre Tochtergesellschaften noch die Autoren noch die Übersetzer können für mögliche Fehler und deren Folgen haftbar gemacht werden.