6.1 用例方案 #
群集一般分为以下两种类别:
双节点群集
包含两个以上节点的群集。这通常表示节点数是奇数。
添加不同的拓扑可以衍生不同的用例。下面是最常见的用例:
- 位于一个位置的双节点群集
配置:: FC SAN 或类似的共享储存,第 2 层网络。
使用方案:: 嵌入式群集,注重服务的高可用性,而不是实现数据冗余来进行数据复制。例如,此类设置可用于无线电台或装配生产线控制器。
- 位于两个位置的双节点群集(使用最广泛)
配置:: 对称的延伸群集,FC SAN,以及跨两个位置的第 2 层网络。
使用方案:: 典型的延伸群集,注重服务的高可用性和本地数据冗余。用于数据库和企业资源规划。过去数年来最流行的设置之一。
- 位于三个位置的奇数数目的节点
配置:: 2×N+1 个节点,FC SAN 跨两个主要位置第三个辅助站点不部署 FC SAN,而是充当多数仲裁者。第 2 层网络至少跨两个主要位置。
使用方案:: 典型的延伸群集,注重服务的高可用性和数据冗余。例如数据库和企业资源规划。
6.2 仲裁判定 #
当一个或多个节点与群集的剩余节点之间的通讯失败时,即会发生群集分区。这些节点只能与同一分区中的其他节点通讯,并不知道被隔开的节点的存在。如果群集分区具有多数节点(或投票),则将其定义为具有仲裁(是“具有法定票数的”)。通过仲裁计算来获得此结果。要实现屏蔽,就必须具有仲裁。
SUSE Linux Enterprise High Availability Extension 11 与 SUSE Linux Enterprise High Availability Extension 12 的仲裁计算方式有所不同。在 SUSE Linux Enterprise High Availability Extension 11 中,仲裁由 Pacemaker 计算。从 SUSE Linux Enterprise High Availability Extension 12 开始,Corosync 可以直接处理双节点群集的仲裁,而无需更改 Pacemaker 配置。
仲裁计算方式受以下因素的影响:
- 群集节点数
为使服务保持运行状态,包含两个以上节点的群集依赖法定票数(多数票决)来解决群集分区。根据以下公式,您可以计算群集正常运行所需的最小工作节点数目:
N ≥ C/2 + 1 N = minimum number of operational nodes C = number of cluster nodes
例如,五节点群集至少需要三个工作节点(或两个可以故障转移的节点)。
我们强烈建议使用双节点群集或奇数数目的群集节点。双节点群集适合跨两个站点的延伸设置。所含节点数为奇数的群集可以构建于单个站点上,也可以分散在三个站点之间。
- Corosync 配置
Corosync 是一个讯息交换和成员资格层,具体请参见第 6.2.4 节 “双节点群集的 Corosync 配置”和第 6.2.5 节 “N 节点群集的 Corosync 配置”。
6.2.1 全局群集选项 #
全局群集选项控制群集在遇到特定情况时的行为方式。它们被分成若干组,可通过 Hawk2 和 crm 外壳之类的群集管理工具来查看和修改。
通常可保留预定义值。但为了使群集的关键功能正常工作,需要在进行基本群集设置后调整以下参数:
6.2.2 全局选项 no-quorum-policy #
此全局选项定义在群集分区不具有法定票数(分区不具有多数节点投票)时应执行的操作。
允许的值有:
ignore将
no-quorum-policy设置为ignore可使群集的行为如同它具有仲裁一样。它仍会进行资源管理。在 SLES 11 中,建议对双节点群集使用此设置。此选项从 SLES 12 开始已过时。Corosync 依据配置和条件为群集节点或单个节点提供“仲裁” — 或者不提供仲裁。
对于双节点群集,唯一有意义的行为就是始终像失去仲裁一样来做出反应。第一个步骤始终应该是尝试屏蔽丢失的节点。
freeze如果失去法定票数,群集分区将会冻结。继续进行资源管理:正在运行的资源不会停止(但可能重启动以响应监视事件),但不会启动受影响分区中的任何其他资源。
如果群集中的某些资源依赖于与其他节点的通讯(例如,OCFS2 装入),建议对此类群集使用此设置。在这种情况下,默认设置
no-quorum-policy=stop没有任何作用,因为它将导致以下情况:在对等节点不可到达时将无法停止这些资源。反之,尝试停止这些资源最终将超时并导致stop failure,进而触发升级恢复和屏蔽。stop(默认值)如果失去法定票数,受影响群集分区中的所有资源都将以一种有序的方式停止。
suicide如果失去法定票数,受影响群集分区中的所有节点都将被屏蔽。此选项只能与 SBD 结合使用,具体请参见第 11 章 “储存保护和 SBD”。
6.2.3 全局选项 stonith-enabled #
此全局选项定义是否要应用屏蔽,以允许 STONITH 设备关闭发生故障的节点以及无法停止其资源的节点。默认情况下,此全局选项设置为 true,因为对于常规的群集操作,有必要使用 STONITH 设备。根据默认值,如果未定义 STONITH 资源,则群集将拒绝启动任何资源。
如果出于任何原因而需要禁用屏蔽,请将 stonith-enabled 设置为 false,但请注意,这会影响产品的支持状态。此外,在 stonith-enabled="false" 的情况下,分布式锁管理器 (DLM) 等资源以及依赖于 DLM 的所有服务(例如 cLVM、GFS2 和 OCFS2)都将无法启动。
重要:不支持无 STONITH 的配置
不支持无 STONITH 资源的群集。
6.2.4 双节点群集的 Corosync 配置 #
使用引导脚本时,Corosync 配置包含一个 quorum 段落,其中包含以下选项:
例 6.1︰ 双节点群集的 Corosync 配置摘录 #
quorum {
# Enable and configure quorum subsystem (default: off)
# see also corosync.conf.5 and votequorum.5
provider: corosync_votequorum
expected_votes: 2
two_node: 1
}
与 SUSE Linux Enterprise 11 相比,SUSE Linux Enterprise 12 中的 votequorum 子系统基于 Corosync 版本 2.x。这表示不得使用 no-quorum-policy=ignore 选项。
当设置了 two_node: 1 时,默认会自动启用 wait_for_all 选项。如果未启用 wait_for_all,则群集应在两个节点上并行启动。否则,第一个节点将对缺失的第二个节点执行启动屏蔽。
6.3 群集资源 #
作为群集管理员,您需要在群集中为服务器上运行的每个资源或应用程序创建群集资源。群集资源可以包括网站、电子邮件服务器、数据库、文件系统、虚拟机和任何其他基于服务器的应用程序或在任意时间对用户都可用的服务。
6.3.1 资源管理 #
必须先设置群集中的资源,然后才能使用它。例如,要使用 Apache 服务器作为群集资源,请先设置 Apache 服务器并完成 Apache 配置,然后才能在群集中启动相应的资源。
如果资源有特定环境要求,请确保这些要求已得到满足并且在所有群集节点上均相同。这种配置不由 High Availability Extension 管理。您必须自行管理。
注意:不要处理由群集管理的服务
使用 High Availability Extension 管理资源时,不得以其他方式(在群集外,例如手动或在引导时或重引导时)启动或停止同一资源。High Availability Extension 软件负责所有服务的启动或停止操作。
如果当服务已在群集控制下运行后您需要执行测试或维护任务,请确保先将资源、节点或整个群集置于维护模式,然后再进行手动处理。有关细节,请参见第 16.2 节 “用于维护任务的不同选项”。
配置群集中的资源后,请使用群集管理工具手动启动、停止、清理、删除或迁移资源。有关如何使用首选群集管理工具执行此操作的细节:
crmsh:第 8 章 “配置和管理群集资源(命令行)”
6.3.2 支持的资源代理类 #
对于添加的每个群集资源,需要定义资源代理需遵守的标准。资源代理提取它们提供的服务并显示群集的确切状态,以使群集对其管理的资源不作确答。群集依赖于资源代理在收到启动、停止或监视命令时作出相应反应。
通常,资源代理的形式为外壳脚本。High Availability Extension 支持以下类别的资源代理:
- Open Cluster Framework (OCF) 资源代理
OCF RA 代理最适合用于高可用性,特别是当您需要多状态资源或特殊监视功能时。这些代理通常位于
/usr/lib/ocf/resource.d/provider/中。其功能与 LSB 脚本的功能相似。但是,始终使用环境变量进行配置,这样可轻松接受和处理参数。OCF 规范(由于它与资源代理相关)可在 https://github.com/ClusterLabs/OCF-spec/blob/master/ra/1.0/resource-agent-api.md 中找到。OCF 规范有严格的定义,其中包括操作必须返回退出码,请参见第 9.3 节 “OCF 返回码和故障恢复”。群集严格遵循这些规范。要求所有 OCF 资源代理至少包含操作
start、stop、status、monitor和meta-data。meta-data操作可检索有关如何配置代理的信息。例如,如果要了解提供程序heartbeat的IPaddr代理的更多信息,请使用以下命令:OCF_ROOT=/usr/lib/ocf /usr/lib/ocf/resource.d/heartbeat/IPaddr meta-data
输出是 XML 格式的信息,包括多个部分(代理的常规描述、可用参数和可用操作)。
或者,也可以使用 crmsh 来查看有关 OCF 资源代理的信息。有关细节,请参见第 8.1.3 节 “显示有关 OCF 资源代理的信息”。
- Linux Standards Base (LSB) 脚本
LSB 资源代理一般由操作系统/分发包提供,并可在
/etc/init.d中找到。要用于群集,它们必须遵守 LSB init 脚本规范。例如,它们必须实施了多个操作,至少包括start、stop、restart、reload、force-reload和status。有关详细信息,请参见 http://refspecs.linuxbase.org/LSB_4.1.0/LSB-Core-generic/LSB-Core-generic/iniscrptact.html。这些服务的配置没有标准化。如果要将 LSB 脚本用于 High Availability,请确保您了解如何配置相关脚本。通常,您可以在
/usr/share/doc/packages/PACKAGENAME中的相关包文档中找到配置此类脚本的信息。- Systemd
从 SUSE Linux Enterprise 12 起,systemd 取代了常用的 System V init 守护程序。Pacemaker 可以管理 systemd 服务(如果有)。systemd 不使用 init 脚本,而是使用单元文件。通常,服务(或单元文件)由操作系统提供。如果您要转换现有的 init 脚本,可访问 http://0pointer.de/blog/projects/systemd-for-admins-3.html 找到更多信息。
- 服务
当前同时存在许多“通用”类型的系统服务:
LSB(属于 System V init)、systemd和(在某些分发版中提供的)upstart。因此,Pacemaker 支持使用特殊别名,这样可智能识别要将哪个服务应用到给定的群集节点。当群集中混合使用 systemd、upstart 和 LSB 服务时,此功能尤其有用。Pacemaker 将尝试按以下顺序查找指定服务:LSB (SYS-V) init 脚本、Systemd 单元文件或 Upstart 作业。- Nagios
使用监视插件(以前称为 Nagios 插件)可以监视远程主机上的服务。Pacemaker 可以使用监视插件(如果有)来执行远程监视。有关详细信息,请参见第 6.6.1 节 “使用监视插件监视远程主机上的服务”。
- STONITH(屏蔽)资源代理
此类仅用于与屏蔽相关的资源。有关详细信息,参见第 10 章 “屏障和 STONITH”。
随 High Availability Extension 提供的代理已写入 OCF 规范。
6.3.3 资源类型 #
可创建以下类型的资源:
- 原始资源
基元资源是最基本的资源类型。
了解如何使用首选群集管理工具创建原始资源:
Hawk2:过程 7.5 “添加原始资源”
crmsh:第 8.4.2 节 “创建群集资源”
- 组
组包含一组需要放在一起、按顺序启动和按相反顺序停止的资源。有关更多信息,请参见第 6.3.5.1 节 “组”。
- 克隆资源
克隆是可以在多个主机上处于活动状态的资源。如果各个资源代理支持,则任何资源均可克隆。有关更多信息,请参见第 6.3.5.2 节 “克隆资源”。
- 多状态资源(以前称为主/从资源)
多状态资源是一种特殊类型的克隆资源,它们可具有多个模式。有关更多信息,请参见第 6.3.5.3 节 “多状态资源”。
6.3.4 资源模板 #
如果希望创建具有类似配置的多个资源,则定义资源模板是最简单的方式。定义后,就可以在基元资源或特定类型的约束中引用该模板,请参见第 6.5.3 节 “资源模板和约束”。
如果在原始资源中引用了模板,则该原始资源将继承在模板中定义的所有操作、实例属性(参数)、元属性和利用率属性。此外,还可以为原始资源定义特定的操作或属性。如果在模板和原始资源中都定义了以上内容,则原始资源中定义的值将优先于模板中定义的值。
了解如何使用首选群集配置工具定义资源模板:
Hawk2:过程 7.6 “添加资源模板”
crmsh:第 8.4.3 节 “创建资源模板”
6.3.5 高级资源类型 #
基元资源是最简单的一种资源,易于配置,不过对于群集配置,您可能还需要更多高级资源类型,如组、克隆资源或多状态资源。
6.3.5.1 组 #
某些群集资源依赖于其他组件或资源,它们要求每个组件或资源都按特定顺序启动并在同一服务器上与它所依赖的资源一起运行。要简化此配置,可以使用群集资源组。
例 6.3︰ Web 服务器的资源组 #
资源组示例可以是需要 IP 地址和文件系统的 Web 服务器。在本例中,每个组件都是组成群集资源组的一个单独资源。资源组将在一台或多台服务器上运行。在发生软件或硬件故障时,资源组会将故障转移到群集中的另一台服务器,这一点与单个群集资源类似。
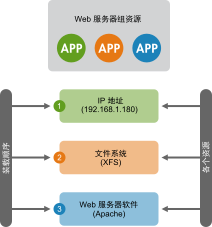
图 6.1︰ 组资源 #
组具有以下属性:
- 启动和停止
资源按其显示顺序启动并按相反顺序停止。
- 相关性
如果组中某个资源在某处无法运行,则该组中位于其之后的任何资源都不允许运行。
- 内容
组可能仅包含一些原始群集资源。组必须包含至少一个资源,否则配置无效。要引用组资源的子级,请使用子级 ID 而不是组 ID。
- 限制
尽管在约束中可以引用组的子代,但通常倾向于使用组的名称。
- 粘性
粘性在组中可以累加。每个活动的组成员可以将其粘性值累加到组的总分中。因此,如果
resource-stickiness的默认值是100,且组中有 7 个成员(其中 5 个成员处于活动状态),那么整个组首选其当前位置(分数为500)。- 资源监视
要为组启用资源监视,必须为组中每个要监视的资源分别配置监视。
了解如何使用首选群集管理工具创建组:
Hawk2:过程 7.9 “添加资源组”
crmsh:第 8.4.10 节 “配置群集资源组”
6.3.5.2 克隆资源 #
您可能希望某些资源在群集的多个节点上同时运行。为此,必须将资源配置为克隆资源。可以配置为克隆的资源示例包括群集文件系统(如 OCFS2)。可以克隆提供的任何资源。资源的资源代理支持此操作。克隆资源的配置甚至也有不同,具体取决于资源驻留的节点。
资源克隆有三种类型:
- 匿名克隆
这是最简单的克隆类型。这种克隆类型在所有位置上的运行方式都相同。因此,每台计算机上只能有一个匿名克隆实例是活动的。
- 全局唯一克隆
这些资源各不相同。一个节点上运行的克隆实例与另一个节点上运行的实例不同,同一个节点上运行的任何两个实例也不同。
- 状态克隆(多状态资源)
这些资源的活动实例分为两种状态:主动和被动。有时也称为主要和辅助,或主和从。状态克隆可以是匿名克隆也可以是全局唯一克隆。另请参见第 6.3.5.3 节 “多状态资源”。
克隆资源必须正好包含一组或一个常规资源。
配置资源监视或约束时,克隆资源与简单资源具有不同的要求。有关细节,请参见 http://www.clusterlabs.org/doc/ 上的《Pacemaker Explained》(Pacemaker 配置说明)。请参见“Clones - Resources That Get Active on Multiple Hosts”(克隆资源 - 在多个主机上处于活动状态的资源)一节。
了解如何使用首选群集管理工具创建克隆资源:
Hawk2:过程 7.10 “添加克隆资源”
crmsh:第 8.4.11 节 “配置克隆资源”。
6.3.5.3 多状态资源 #
多状态资源是克隆的特殊形式。它们允许实例处于两种操作模式中的一种(即 master 或 slave,不过您也可以按照自己的想法来命名这些模式)。多状态资源只能包含一个组或一个常规资源。
配置资源监视或约束时,多状态资源与简单资源具有不同的要求。有关细节,请参见 http://www.clusterlabs.org/doc/ 上的《Pacemaker Explained》(Pacemaker 配置说明)。请参见“Multi-state - Resources That Have Multiple Modes”(多状态 - 具有多个节点的资源)一节。
6.3.6 资源选项(元属性) #
您可以为添加的每个资源定义选项。群集使用这些选项来决定资源的行为方式,它们会告知 CRM 如何对待特定的资源。可以使用 crm_resource --meta 命令或者按过程 7.5 “添加原始资源”中所述使用 Hawk2 来设置资源选项。
表 6.1︰ 原始资源选项 #
|
选项 |
描述 |
默认值 |
|---|---|---|
|
|
如果不允许所有的资源都处于活动状态,群集会停止优先级较低的资源以便让优先级较高的资源处于活动状态。 |
|
|
|
群集应在哪种状态下尝试保留此资源?允许的值有: |
|
|
|
是否允许群集启动和停止资源?允许的值: |
|
|
|
是否可以手动处理资源?允许的值: |
|
|
|
资源留在所处位置的自愿程度如何? |
calculated |
|
|
节点上的此资源应发生多少故障后才能确定该节点没有资格主管此资源? |
|
|
|
如果群集发现资源在多个节点上处于活动状态,应执行什么操作?允许的值: |
|
|
|
在恢复为如同未发生故障一样正常工作(并允许资源返回它发生故障的节点)之前,需要等待几秒钟? |
|
|
|
允许对支持 |
|
|
|
此资源定义的远程节点的名称。这会将资源作为远程节点启用,同时定义唯一的名称用于标识该远程节点。如果未设置其他参数,则此值还会被假定为要在
警告:使用唯一 ID此值不得与任何现有资源 ID 或节点 ID 重复。 |
none(已禁用) |
|
|
guest 与 pacemaker_remote 建立连接时使用的自定义端口。 |
|
|
|
当远程节点的名称不是 guest 的主机名时要连接到的 IP 地址或主机名。 |
|
|
|
待发 guest 连接在超时之前的等待时间。 |
|
6.3.7 实例属性(参数) #
可为所有资源类的脚本指定参数,这些参数可确定脚本的行为方式和所控制的服务实例。如果资源代理支持参数,则可使用 crm_resource 命令或按过程 7.5 “添加原始资源”中所述使用 Hawk2 来添加这些参数。在 crm 命令行实用程序和 Hawk2 中,实例属性分别称为 params 和 Parameter。通过以 root 身份执行以下命令,可找到 OCF 脚本支持的实例属性列表:
root #crmra info [class:[provider:]]resource_agent
或(无可选部分):
root #crmra info resource_agent
输出列出了所有支持的属性及其用途和默认值。
例如,命令
root #crmra info IPaddr
返回以下输出:
Manages virtual IPv4 addresses (portable version) (ocf:heartbeat:IPaddr)
This script manages IP alias IP addresses
It can add an IP alias, or remove one.
Parameters (* denotes required, [] the default):
ip* (string): IPv4 address
The IPv4 address to be configured in dotted quad notation, for example
"192.168.1.1".
nic (string, [eth0]): Network interface
The base network interface on which the IP address will be brought
online.
If left empty, the script will try and determine this from the
routing table.
Do NOT specify an alias interface in the form eth0:1 or anything here;
rather, specify the base interface only.
cidr_netmask (string): Netmask
The netmask for the interface in CIDR format. (ie, 24), or in
dotted quad notation 255.255.255.0).
If unspecified, the script will also try to determine this from the
routing table.
broadcast (string): Broadcast address
Broadcast address associated with the IP. If left empty, the script will
determine this from the netmask.
iflabel (string): Interface label
You can specify an additional label for your IP address here.
lvs_support (boolean, [false]): Enable support for LVS DR
Enable support for LVS Direct Routing configurations. In case a IP
address is stopped, only move it to the loopback device to allow the
local node to continue to service requests, but no longer advertise it
on the network.
local_stop_script (string):
Script called when the IP is released
local_start_script (string):
Script called when the IP is added
ARP_INTERVAL_MS (integer, [500]): milliseconds between gratuitous ARPs
milliseconds between ARPs
ARP_REPEAT (integer, [10]): repeat count
How many gratuitous ARPs to send out when bringing up a new address
ARP_BACKGROUND (boolean, [yes]): run in background
run in background (no longer any reason to do this)
ARP_NETMASK (string, [ffffffffffff]): netmask for ARP
netmask for ARP - in nonstandard hexadecimal format.
Operations' defaults (advisory minimum):
start timeout=90
stop timeout=100
monitor_0 interval=5s timeout=20s注意:组、克隆或多状态资源的实例属性
请注意,组、克隆和多状态资源没有实例属性。但是,任何实例属性集都将由组、克隆或多状态资源的子级继承。
6.3.8 资源操作 #
默认情况下,群集将不会确保您的资源一直正常。要指示群集执行此操作,需要将监视操作添加到资源定义中。可为所有类或资源代理添加监视操作。有关更多信息,请参见第 6.4 节 “资源监视”。
表 6.2︰ 资源操作属性 #
|
操作 |
描述 |
|---|---|
|
|
您的操作名称。必须是唯一的。(不会显示 ID)。 |
|
|
要执行的操作。常见值: |
|
|
执行操作的频率。单位:秒 |
|
|
需要等待多久才能声明操作失败。 |
|
|
需要满足哪些条件才会发生此操作。允许的值: |
|
|
此操作失败时执行的操作。允许的值:
|
|
|
如果值为 |
|
|
仅当资源具有此角色时才运行操作。 |
|
|
可全局设置或为单独资源设置。使 CIB 反映资源上“正在进行中的”操作的状态。 |
|
|
操作描述。 |
6.3.9 超时值 #
资源的超时值会受以下参数的影响:
op_defaults(操作的全局超时),在资源模板中定义的特定超时值,
为资源定义的特定超时值。
注意:值的优先级
如果为资源定义了特定值,则该值优先于全局默认值。资源的特定值也优先于在资源模板中定义的值。
获取超时值权限非常重要。将它们设置得太小会导致大量(不必要的)屏蔽操作,原因如下:
如果资源运行超时,它将失败,群集将尝试停止它。
如果停止资源也失败(例如,由于停止超时值设置得太小),群集将屏蔽该节点。发生此状况时所在的节点将被视为已失去控制。
您可以使用 crmsh 和 Hawk2 调整操作的全局默认值并设置任何特定的超时值。确定和设置超时值的最佳实践如下所示:
过程 6.1︰ 确定超时值 #
检查资源启动和停止(在负载状况下)所需的时间。
如果需要,请添加
op_defaults参数并相应地设置(默认)超时值:例如,将
default-action-timeout设置为60秒:crm(live)configure#op_defaults timeout=60对于需要更长时间期限的资源,则定义单独的超时值。
为资源配置操作时,添加单独的
start和stop操作。使用 Hawk2 配置操作时,它会针对这些操作提供有用的超时建议。
6.4 资源监视 #
如果要确保资源正在运行,必须为其配置资源监视。
如果资源监视程序检测到故障,将发生以下情况:
根据
/etc/corosync/corosync.conf中logging部分指定的配置生成日志文件消息。故障会在群集管理工具(Hawk2、
crm status)中和 CIB 状态部分反映出来。群集将启动重要的恢复操作,可包括停止资源以修复故障状态以及在本地或在其他节点上重启动资源。资源也可能不会重启动,具体取决于配置和群集状态。
如果不配置资源监视,则不会告知成功启动的资源故障,且群集始终显示资源状况正常。
- 监视已停止的资源
通常,只要资源在运行,就仅受群集监视。但是,为了检测并发违例,还需为停止的资源配置监视。例如:
primitive dummy1 ocf:heartbeat:Dummy \ op monitor interval="300s" role="Stopped" timeout="10s" \ op monitor interval="30s" timeout="10s"当资源
dummy1处于role="Stopped"状态时,此配置就会每300秒触发一次对该资源的监视操作。在运行时,针对它的监视间隔为30秒。- 检测
CRM 会对每个节点上的各个资源执行初始监视,也称为
探测。清理资源之后也会执行探测。如果为资源定义了多项监视操作,则 CRM 将选择间隔时间最小的一项操作,并会使用其超时值作为探测的默认超时值。如果未配置任何监视操作,则将应用整个群集的默认值。默认值为20秒(如果未通过配置op_defaults参数来指定其他默认值)。如果您不想依赖自动计算或op_defaults值,请为此资源的探测定义具体的监视操作。为此,可以添加一个监视操作并将interval设置为0,例如:crm(live)configure#primitiversc1 ocf:pacemaker:Dummy \ op monitor interval="0" timeout="60"rsc1的探测将在60 秒后超时,而不管op_defaults中定义的全局超时或者配置的任何其他操作超时如何。如果未设置interval="0"以指定相应资源的探测,CRM 将自动检查是否为该资源定义了任何其他监视操作,并按如上所述计算探测的超时值。
了解如何使用首选群集管理工具添加对资源的监视操作:
Hawk2:过程 7.13 “添加和修改操作”
crmsh:第 8.4.9 节 “配置资源监视”
6.5 资源约束 #
配置好所有资源只是完成了该任务的一部分。即便群集熟悉所有必需资源,它可能还无法进行正确处理。资源约束允许您指定在哪些群集节点上运行资源、以何种顺序装载资源,以及特定资源依赖于哪些其他资源。
6.5.1 约束类型 #
提供三种不同的约束:
- 资源位置
位置约束定义资源可以、不可以或首选在哪些节点上运行。
- 资源共置
共置约束告知群集哪些资源可以或不可以在一个节点上一起运行。
- 资源顺序
顺序约束定义操作的顺序。
重要:约束与特定资源类型的限制
不要为资源组的成员创建共置约束,而是应该创建指向整个资源组的共置约束。其他所有类型的约束可安全地用于资源组的成员。
不要对包含克隆资源或者应用了多状态资源的资源使用任何约束。约束必须应用于克隆资源或多状态资源,不能应用于子资源。
6.5.1.1 资源集 #
6.5.1.1.1 使用资源集定义约束 #
可以使用资源集作为定义位置、共置或顺序约束的备用格式,在资源集中,基元资源已被全部分组到一个集合中。以前,为了实现此目的,用户可以定义一个资源组(不一定总能准确表达设计意图),也可以将每种关系定义为单个约束。随着资源和组合数目的增加,后面这种做法会导致约束过度膨胀。通过资源集进行配置并不一定会减少复杂程度,但更易于理解和维护,如以下示例中所示。
例 6.4︰ 用于位置约束的资源集 #
例如,可以在 crmsh 中使用资源集 (loc-alice) 的以下配置,将两个虚拟 IP(vip1 和 vip2)置于同一个节点 alice:
crm(live)configure#primitivevip1 ocf:heartbeat:IPaddr2 params ip=192.168.1.5crm(live)configure#primitivevip1 ocf:heartbeat:IPaddr2 params ip=192.168.1.6crm(live)configure#locationloc-alice { vip1 vip2 } inf: alice
要使用资源集来替换共置约束的配置,请考虑以下两个示例:
例 6.5︰ 共置资源链 #
<constraints>
<rsc_colocation id="coloc-1" rsc="B" with-rsc="A" score="INFINITY"/>
<rsc_colocation id="coloc-2" rsc="C" with-rsc="B" score="INFINITY"/>
<rsc_colocation id="coloc-3" rsc="D" with-rsc="C" score="INFINITY"/>
</constraints>由资源集表示的相同配置:
<constraints>
<rsc_colocation id="coloc-1" score="INFINITY" >
<resource_set id="colocated-set-example" sequential="true">
<resource_ref id="A"/>
<resource_ref id="B"/>
<resource_ref id="C"/>
<resource_ref id="D"/>
</resource_set>
</rsc_colocation>
</constraints>如果想使用资源集来替换顺序约束的配置,请考虑以下两个示例:
例 6.6︰ 有序资源链 #
<constraints>
<rsc_order id="order-1" first="A" then="B" />
<rsc_order id="order-2" first="B" then="C" />
<rsc_order id="order-3" first="C" then="D" />
</constraints>可以使用包含有序资源的资源集来实现相同的目的:
例 6.7︰ 以资源集表示的有序资源链 #
<constraints>
<rsc_order id="order-1">
<resource_set id="ordered-set-example" sequential="true">
<resource_ref id="A"/>
<resource_ref id="B"/>
<resource_ref id="C"/>
<resource_ref id="D"/>
</resource_set>
</rsc_order>
</constraints>
资源集可以是有序的 (sequential=true),也可以是无序的 (sequential=false)。此外,可以使用 require-all 属性在 AND 与 OR 逻辑之间切换。
6.5.1.1.2 不带依赖项的共置约束的资源集 #
有时,将一组资源放置在同一个节点上(定义共置约束)会很有用,但前提是这些资源之间不存在硬依赖性。例如,您想要在同一个节点上放置两个资源,但不希望群集在其中一个资源发生故障时重启动另一个资源。可以在 crm 外壳中使用 weak bond 命令实现此目的。
了解如何使用首选群集管理工具设置这些“弱绑定”:
6.5.1.2 更多信息 #
了解如何使用首选群集管理工具添加各种约束:
Hawk2:第 7.6 节 “配置约束”
crmsh:第 8.4.5 节 “配置资源约束”
有关配置约束的更多信息以及顺序和共置基本概念的详细背景信息,请参见以下文档。可以从 http://www.clusterlabs.org/doc/ 访问这些文档:
《Pacemaker Explained》(Pacemaker 配置说明),“Resource Constraints”(资源约束)一章
《Colocation Explained》(共置说明)
《Ordering Explained》(顺序说明)
6.5.2 分数和无限值 #
定义约束时,还需要指定分数。各种分数是群集工作方式的重要组成部分。其实,从迁移资源到决定在已降级群集中停止哪些资源的整个过程是通过以某种方式操纵分数来实现的。分数按每个资源来计算,资源分数为负的任何节点都无法运行该资源。计算资源的分数后,群集会选择分数最高的节点。
INFINITY(无穷大)目前定义为 1,000,000。提高或降低分数需遵循以下三个基本规则:
任何值 + 无穷大 = 无穷大
任何值 - 无穷大 = -无穷大
无穷大 - 无穷大 = -无穷大
定义资源约束时,需为每个约束指定一个分数。分数表示您指派给此资源约束的值。分数较高的约束先应用,分数较低的约束后应用。通过使用不同的分数为既定资源创建更多位置约束,可以指定资源要故障转移至的目标节点的顺序。
6.5.3 资源模板和约束 #
如果定义了资源模板(请参见第 6.3.4 节 “资源模板”),则可在以下类型的约束中引用该模板:
顺序约束
共置约束
rsc_ticket 约束(用于 Geo 群集)。
但是,共置约束不得包含多个对模板的引用。资源集不得包含对模板的引用。
在约束中引用的资源模板代表派生自该模板的所有原始资源。这意味着,约束将应用于引用资源模板的所有原始资源。在约束中引用资源模板是资源集的备用方式,它可以显著简化群集配置。有关资源集的细节,请参见过程 7.17 “为约束使用资源集”。
6.5.4 故障转移节点 #
资源在出现故障时会自动重启动。如果在当前节点上无法实现此操作,或者此操作在当前节点上失败了 N 次,它将尝试故障转移到其他节点。每次资源失败时,其失败计数都会增加。您可以多次定义资源的故障次数(migration-threshold),在该值之后资源会迁移到新节点。如果群集中存在两个以上的节点,则特定资源故障转移的节点由 High Availability 软件选择。
但可以通过为资源配置一个或多个位置约束和一个 migration-threshold 来指定此资源将故障转移到的节点。
了解如何使用首选群集管理工具指定故障转移节点:
Hawk2:第 7.6.6 节 “指定资源故障转移节点”
crmsh:第 8.4.6 节 “指定资源故障转移节点”
例 6.8︰ 迁移阈值 - 流程 #
例如,假设您已经为 rsc1 资源配制了一个首选在 alice 节点上运行的位置约束。如果那里失败了,系统会检查 migration-threshold 并与故障计数进行比较。如果故障计数 >= migration-threshold,会将资源迁移到下一个自选节点。
一旦达到阈值,节点将不再能运行失败资源,直到重设置资源的 failcount 为止。这可以由群集管理员手动执行或通过设置资源的 failure-timeout 选项执行。
例如,设置 migration-threshold=2 和 failure-timeout=60s 会导致资源在发生两次故障后迁移到新节点。允许该资源在一分钟后移回(具体取决于粘性和约束分数)。
迁移阈值概念有两个异常,发生在资源启动失败或停止失败时:
启动失败将失败计数设置为
INFINITY,因此总是会导致立即迁移。停止故障会导致屏蔽(
stonith-enabled设置为true时,这是默认设置)。如果不定义 STONITH 资源(或
stonith-enabled设置为false),则该资源不会迁移。
有关配合首选群集管理工具使用迁移阈值和重置故障计数的详细信息,请参见:
Hawk2:第 7.6.6 节 “指定资源故障转移节点”
crmsh:第 8.4.6 节 “指定资源故障转移节点”
6.5.5 故障回复节点 #
当原始节点恢复联机并位于群集中时,资源可能会故障回复到该节点。为防止资源故障回复到之前运行它的节点,或者要指定让该资源故障回复到其他节点,请更改其资源粘性值。可以在创建资源时或之后指定资源粘性。
指定资源粘性值时请考虑以下含义:
- 值为
0: 这是默认选项。资源放置在系统中的最适合位置。这意味着当负载能力“较好”或较差的节点变得可用时才转移资源。此选项的作用几乎等同于自动故障回复,只是资源可能会转移到非之前活动的节点上。
- 值大于
0: 资源更愿意留在当前位置,但是如果有更合适的节点可用时会移动。值越高表示资源越愿意留在当前位置。
- 值小于
0: 资源更愿意移离当前位置。绝对值越高表示资源越愿意离开当前位置。
- 值为
INFINITY: 如果不是因节点不适合运行资源(节点关机、节点待机、达到
migration-threshold或配置更改)而强制资源转移,资源总是留在当前位置。此选项的作用几乎等同于完全禁用自动故障回复。- 值为
-INFINITY: 资源总是移离当前位置。
6.5.6 根据资源负载影响放置资源 #
并非所有资源都相等。某些资源(如 Xen guest)需要托管它们的节点满足其容量要求。如果所放置资源的总需求超过了提供的容量,则资源性能将降低(或甚至失败)。
要考虑此情况,可使用 High Availability Extension 指定以下参数:
特定节点提供的容量。
特定资源需要的容量。
资源放置整体策略。
了解如何使用首选群集管理工具配置这些设置:
Hawk2:第 7.6.8 节 “根据负载影响配置资源放置”
crmsh:第 8.4.8 节 “根据负载影响配置资源放置”
如果节点有充足的可用容量来满足资源要求,则此节点将被视为此资源的有效节点。容量的性质对 High Availability Extension 而言完全无关紧要;它只是确保在将资源移到节点上之前满足资源的所有容量要求。
要手动配置资源要求和节点提供的容量,请使用利用率属性。可根据个人喜好命名利用率属性,并根据配置需要定义多个名称/值对。但是,属性值必须是整数。
如果将具有利用率属性的多个资源组合或设置共置约束,则 High Availability Extension 会考虑此情况。如有可能,资源将被放置到可以满足所有容量要求的节点上。
注意:组的利用率属性
无法直接为资源组设置利用率属性。但是,为了简化组的配置,可以使用组中所有资源所需的总容量添加利用率属性。
High Availability Extension 还提供了方法来自动检测和配置节点容量和资源要求:
NodeUtilization 资源代理检查节点的容量(与 CPU 和 RAM 有关)。要配置自动检测,请创建类、提供程序和类型如下的克隆资源:ocf:pacemaker:NodeUtilization。每个节点上应都有一个克隆实例在运行。实例启动后,利用率部分将添加到节点的 CIB 配置中。
为了自动检测资源的最低要求(与 RAM 和 CPU 有关),Xen 资源代理已得到改善。启动 Xen 资源后,它将反映 RAM 和 CPU 的使用情况。利用率属性将自动添加到资源配置中。
注意:适用于 Xen 和 libvirt 的不同资源代理
ocf:heartbeat:Xen 资源代理不应与 libvirt 搭配使用,因为 libvirt 需要能够修改计算机说明文件。
对于 libvirt,请使用 ocf:heartbeat:VirtualDomain 资源代理。
除了检测最低要求外,High Availability Extension 还允许通过 VirtualDomain 资源代理监视当前的利用率。它检测虚拟机的 CPU 和 RAM 使用情况。要使用此功能,请配置类、提供程序和类型如下的资源:ocf:heartbeat:VirtualDomain。可以使用以下实例属性: autoset_utilization_cpu 和
autoset_utilization_hv_memory。两者都默认为 true。这将在每个监视周期中更新 CIB 中的利用率值。
与手动或自动配置容量和要求无关,放置策略必须使用 placement-strategy 属性(在全局群集选项中)指定。可用值如下:
default(默认值)不考虑利用率值。根据位置得分分配资源。如果分数相等,资源将均匀分布在节点中。
utilization在确定节点是否有足够的可用容量来满足资源要求时考虑利用率值。但仍会根据分配给节点的资源数执行负载平衡。
minimal在确定节点是否有足够的可用容量来满足资源要求时考虑利用率值。尝试将资源集中到尽可能少的节点上(以节省其余节点上的能耗)。
balanced在确定节点是否有足够的可用容量来满足资源要求时考虑利用率值。尝试均匀分布资源,从而优化资源性能。
注意:配置资源优先级
可用的放置策略是最佳方法 - 它们不使用复杂的启发式解析程序即可始终实现最佳分配结果。确保正确设置资源优先级,以便首选调度最重要的资源。
例 6.9︰ 负载平衡放置配置示例 #
以下示例演示了配有四台虚拟机、节点数相等的三节点群集。
node alice utilization memory="4000"
node bob utilization memory="4000"
node charlie utilization memory="4000"
primitive xenA ocf:heartbeat:Xen utilization hv_memory="3500" \
params xmfile="/etc/xen/shared-vm/vm1"
meta priority="10"
primitive xenB ocf:heartbeat:Xen utilization hv_memory="2000" \
params xmfile="/etc/xen/shared-vm/vm2"
meta priority="1"
primitive xenC ocf:heartbeat:Xen utilization hv_memory="2000" \
params xmfile="/etc/xen/shared-vm/vm3"
meta priority="1"
primitive xenD ocf:heartbeat:Xen utilization hv_memory="1000" \
params xmfile="/etc/xen/shared-vm/vm4"
meta priority="5"
property placement-strategy="minimal"
如果三个节点都处于正常状态,那么资源 xenA 将首先放置到一个节点上,然后是 xenD。xenB 和 xenC 将分配在一起或者其中一个与 xenD 分配在一起。
如果一个节点出现故障,可用的总内存将不足以托管所有资源。将确保分配 xenA,xenD 同样如此。但是,只能再放置剩余资源 xenB 和 xenC 中的一个。由于它们的优先级相同,结果未定。要解决这种不确定性,需要为其中一个资源设置更高的优先级。
6.5.7 使用标记分组资源 #
标记是 Pacemaker 中最近新增的功能。使用标记可以一次性引用多个资源,而无需在这些资源之间创建任何共置或顺序关系。此功能十分适用于对概念上相关的资源进行分组。例如,如果有多个资源与某个数据库相关,您可以创建一个名为 databases 的标记,并将与该数据库相关的所有资源都添加到此标记。这样,只需使用一条命令就能停止或启动所有这些资源。
标记也可以用于约束。例如,loc-db-prefer 位置约束将应用到标记了 databases 的一组资源:
location loc-db-prefer databases 100: alice
了解如何使用首选群集管理工具创建标记:
Hawk2:过程 7.12 “添加标记”
crmsh:第 8.5.6 节 “分组/标记资源”
6.6 管理远程主机上的服务 #
在最近几年中,是否能够监视和管理远程主机上的服务已变得越来越重要。SUSE Linux Enterprise High Availability Extension 11 SP3 可让用户通过监视插件来密切监视远程主机上的服务。最近添加的 pacemaker_remote 服务现在允许 SUSE Linux Enterprise High Availability Extension
12 SP5 全面管理和监视远程主机上的资源,就如同这些资源是真实的群集节点一样,并且无需用户在远程计算机上安装群集堆栈。
6.6.1 使用监视插件监视远程主机上的服务 #
虚拟机的监视可以通过 VM 代理来完成(只有在超级管理程序中出现 guest 时才可选择 VM 代理),或者通过从 VirtualDomain 或 Xen 代理调用外部脚本来完成。直到现在为止,仍只有通过在虚拟机中对高可用性堆栈进行完全设置才能实现更细化的监视。
通过提供对监视插件(以前称为 Nagios 插件)的支持,High Availability Extension 现在还可让您监视远程主机上的服务。您可以收集 guest 上的外部状态,而无需修改 guest 映像。例如,VM guest 可能会运行需要能够访问的 Web 服务或简单的网络资源。现在,有了 Nagios 资源代理,您就可以监视 guest 上的 Web 服务或网络资源。如果这些服务再也无法访问,High Availability Extension 将触发相应 guest 的重启或迁移操作。
如果您的 guest 依赖于某项服务(例如,guest 要使用 NFS 服务器),则这项服务可以是由群集管理的普通资源,也可以是使用 Nagios 资源进行监视的外部服务。
要配置 Nagios 资源,必须在主机上安装以下包:
monitoring-pluginsmonitoring-plugins-metadata
必要时,YaST 或 Zypper 将解决对后续包的任何依赖性问题。
将监视插件配置为属于资源容器(通常是 VM)的资源便是其中一个典型用例。如果容器中有任何资源发生故障,则将重启该容器。有关配置示例,请参见例 6.10 “为监视插件配置资源”。或者,如果想使用 Nagios 资源代理通过网络监视主机或服务,还可将这些代理配置为普通资源。
例 6.10︰ 为监视插件配置资源 #
primitive vm1 ocf:heartbeat:VirtualDomain \
params hypervisor="qemu:///system" config="/etc/libvirt/qemu/vm1.xml" \
op start interval="0" timeout="90" \
op stop interval="0" timeout="90" \
op monitor interval="10" timeout="30"
primitive vm1-sshd nagios:check_tcp \
params hostname="vm1" port="22" \ 1
op start interval="0" timeout="120" \ 2
op monitor interval="10"
group g-vm1-and-services vm1 vm1-sshd \
meta container="vm1" 3
支持的参数与监视插件的长选项相同。监视插件通过参数 | |
因为启动 guest 操作系统并让其服务运行需要一段时间,所以必须设置足够长的监视资源启动超时。 | |
|
以上示例仅包含适用于 check_tcp 插件的一个 资源,但也可以针对不同的插件类型配置多个 资源(例如 check_http 或 check_udp)。
如果服务的主机名相同,还可以为组指定 hostname 参数,而无需为各个基元资源一一添加该参数。例如:
group g-vm1-and-services vm1 vm1-sshd vm1-httpd \
meta container="vm1" \
params hostname="vm1"
如果监视插件监视的任何服务在 VM 中发生故障,则群集会检测到该情况并重启容器资源 (VM)。可以通过指定服务监视操作的 on-fail 属性来配置在这种情况下要执行的操作。默认值为 restart-container。
在考虑 VM 的 migration-threshold 时,会将服务的故障计数考虑在内。
6.6.2 使用 pacemaker_remote 管理远程节点上的服务 #
使用 pacemaker_remote 服务可将高可用性群集扩展到虚拟节点或远程裸机计算机。这些虚拟节点或远程裸机无需运行群集堆栈就能成为群集的成员。
High Availability Extension 现在可以起动虚拟环境(KVM 和 LXC)以及驻留在这些虚拟环境中的资源,而无需虚拟环境运行 Pacemaker 或 Corosync。
对于同时要管理用作群集资源的虚拟机以及 VM 中驻留的资源的用例,您现在可以使用以下设置:
“常规”(裸机)群集节点运行 High Availability Extension。
虚拟机运行
pacemaker_remote服务(几乎不需要在 VM 端进行任何配置)。“常规”群集节点上的群集堆栈会起动 VM 并连接到 VM 上运行的
pacemaker_remote服务,以将 VM 作为远程节点集成到群集中。
由于远程节点上未安装群集堆栈,因此这意味着:
远程节点不参与仲裁。
远程节点无法成为 DC。
远程节点不受可伸缩性限制(Corosync 将成员数限制为 32 个节点)的约束。
您可以在 http://www.clusterlabs.org/doc/ 上的《Pacemaker Remote—Extending High Availability into Virtual Nodes》(Pacemaker 远程 - 将高可用性扩展到虚拟节点)中找到有关 remote_pacemaker 服务的更多信息,包括多个用例和详细的设置说明。
6.7 监视系统运行状况 #
为避免节点耗尽磁盘空间而使得系统无法管理已分配给该节点的任何资源,High Availability Extension 提供了一个资源代理 ocf:pacemaker:SysInfo。使用此代理可监视节点在磁盘分区的状况。SysInfo RA 会创建一个名为 #health_disk 的节点属性,如果任何受监视磁盘的可用空间低于指定限制,就会将其设置为 red。
要定义 CRM 在节点状况到达临界状态时应如何反应,请使用全局群集选项 node-health-strategy。
过程 6.2︰ 配置系统运行状况监视 #
要在某个节点耗尽磁盘空间时从该节点自动移除资源,请执行以下操作:
配置
ocf:pacemaker:SysInfo资源:primitive sysinfo ocf:pacemaker:SysInfo \ params disks="/tmp /var"1 min_disk_free="100M"2 disk_unit="M"3 \ op monitor interval="15s"要完成资源配置,请创建
ocf:pacemaker:SysInfo的克隆并在每个群集节点上启动此克隆。将
node-health-strategy设置为migrate-on-red:property node-health-strategy="migrate-on-red"
如果
#health_disk属性设置为red,则策略引擎会将-INF添加到该节点的资源分数中。此时将从此节点移除所有资源。STONITH 资源将是最后一个被停止的资源,但即使 STONITH 资源不再运行,仍可屏蔽该节点。屏蔽对 CIB 有直接访问权且将继续起作用。
当节点状况变成 red 状态后,解决会导致问题的状况。然后清除 red 状态,使节点能够再次运行资源。登录到群集节点并使用下列其中一种方法:
执行以下命令:
root #crmnode status-attr NODE delete #health_disk在该节点上重启动 Pacemaker。
重引导该节点。
该节点将恢复服务并可再次运行资源。
6.8 更多信息 #
- http://crmsh.github.io/
用于高可用性群集管理的高级命令行界面 crm 外壳 (crmsh) 的主页。
- http://crmsh.github.io/documentation
提供有关 crm 外壳的多份文档,包括使用 crmsh 完成基本群集设置的入门教程,以及 crm 外壳的综合性手册。后者可在 http://crmsh.github.io/man-2.0/ 上访问。http://crmsh.github.io/start-guide/ 上提供了相关教程。
- http://clusterlabs.org/
Pacemaker 主页,随 High Availability Extension 提供的群集资源管理器。
- http://www.clusterlabs.org/doc/
提供数个综合性手册,以及一些解释一般概念的简短文档。例如:
《Pacemaker Explained》(Pacemaker 说明):包含全面、详尽的参考信息。
《Configuring Fencing with crmsh》(使用 crmsh 配置屏蔽):如何配置和使用 STONITH 设备。
《Colocation Explained》(共置说明)
《Ordering Explained》(顺序说明)
- https://clusterlabs.org
高可用性 Linux 项目的主页。