Replica Rebuilding
Cuando SUSE Storage detecta una réplica fallida o eliminada, inicia automáticamente un proceso de reconstrucción. Este documento describe el flujo de trabajo de reconstrucción de réplicas para el motor de datos v1, incluyendo los métodos de reconstrucción completa, delta y rápida. También explica las limitaciones asociadas a cada método.
La reconstrucción no comenzará en los siguientes escenarios:
-
El volumen se está migrando a otro nodo.
-
El volumen es un volumen de restauración/DR antiguo.
-
El volumen está aumentando de tamaño.
Flujo de Trabajo de Reconstrucción de Réplicas
La reconstrucción de réplicas puede ocurrir en los siguientes escenarios para el motor de datos v1:
-
Un nodo se reinicia, se drena o se expulsa.
-
Una réplica se vuelve no saludable o es eliminada.
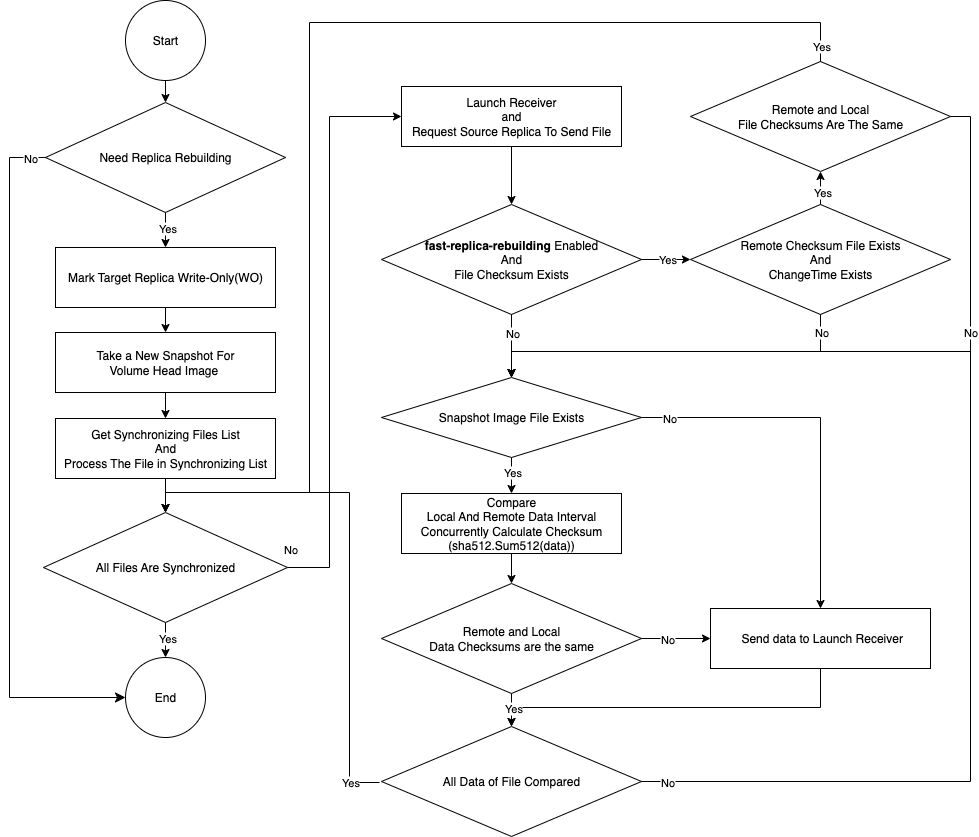
-
Marcar la réplica objetivo con modo
WO(solo escritura). -
Crear una nueva instantánea que sirva como punto de referencia de la cabecera del volumen para las comprobaciones de integridad de datos.
-
Generar la lista de archivos de sincronización para la cabecera del volumen y los archivos de instantánea.
Para el Motor de Datos V1
-
Iniciar un servidor receptor en la réplica objetivo para cada instantánea.
-
Instruir a la réplica fuente para que comience la sincronización de datos.
-
Para cada instantánea:
-
Verifica si el archivo de la instantánea existe en el directorio de datos de la réplica de destino.
-
Si no, transfiere todos los datos de la instantánea desde la réplica de origen a la réplica de destino. Consulte [_full_replica_rebuilding].
-
Si sí, verifica si los archivos de suma de comprobación de la instantánea existen, y si el tiempo de modificación y las sumas de comprobación son idénticos entre las réplicas de destino y origen.
-
Si sí, SUSE Storage omite la transferencia de los datos de la instantánea. Esta optimización reduce el uso de CPU, la entrada/salida de disco, la entrada/salida de red y el tiempo total de reconstrucción. Consulte [_fast_replica_rebuilding].
-
Si no, SUSE Storage calcula y compara las sumas de comprobación a nivel de bloque utilizando el algoritmo SHA-512. Si se encuentran discrepancias, solo se sincronizan los bloques diferentes. Consulte Delta Replica Rebuilding.
-
-
-
-
Para el motor de datos V2
-
Expón las réplicas de origen y destino y prepara una copia superficial utilizando el motor SPDK.
-
Para cada instantánea:
-
Verifica si la marca de tiempo de la instantánea, el tamaño real y la suma de verificación coinciden entre el origen y el destino.
-
Si sí, SUSE Storage omite la transferencia de los datos de esa instantánea.
-
Si no, verifica si tanto las instantáneas de origen como las de destino contienen sumas de verificación en rango.
-
Si sí, recupera y compara las sumas de verificación en rango. Si existen discrepancias, solo se copian los rangos que no coinciden. Consulte [_fast_replica_rebuilding].
-
Si no, elimina la instantánea de destino existente. Luego, copia toda la instantánea desde la réplica de origen a la réplica de destino. Consulte [_full_replica_rebuilding].
-
-
-
Reconstrucción completa de la réplica
Si la réplica es irrecuperable o no tiene datos existentes, SUSE Storage sincroniza todos los datos desde una réplica saludable. Reconstruye la réplica transfiriendo toda la cadena de instantáneas.
La reconstrucción completa de réplicas consume un ancho de banda de red significativo y resulta en operaciones de escritura en disco pesadas en el nodo objetivo. Sin embargo, es necesaria cuando la réplica objetivo no tiene datos utilizables.
Delta Replica Rebuilding
La reconstrucción de réplicas delta es solo para el motor de datos v1. Comienza con una réplica fallida reutilizable y verifica la integridad de los datos para todos los snapshots, bloque por bloque.
-
Esto está disponible solo para la reutilización de réplicas fallidas, y hay un archivo de snapshot existente (con el mismo nombre) en el directorio de datos de la réplica fallida.
-
Cuando una instantánea no tiene suma de comprobación, SUSE Storage realiza la reconstrucción de réplicas delta para esta instantánea en su lugar.
-
Pros:
-
Reducir el consumo de ancho de banda de red.
-
-
Contras:
-
Aumento de la sobrecarga de CPU porque SUSE Storage calculará la suma de comprobación del bloque de datos de la instantánea, bloque por bloque, para la verificación de integridad de datos.
-
El tiempo de reconstrucción está influenciado por el rendimiento de la CPU.
-
Reconstrucción Rápida de Réplicas
La reconstrucción rápida de réplicas se habilita cuando se cumplen las siguientes condiciones:
-
La configuración de reconstrucción rápida de réplicas está habilitada:
fast-replica-rebuild-enabled: true -
Los archivos de suma de verificación de snapshots se crean (las sumas de verificación se precomputan) utilizando uno de los siguientes métodos:
-
snapshot-data-integrityestá configurado enenabled: Un trabajo programado calcula las sumas de verificación para todos los snapshots a intervalos configurados (por defecto: 7 días). -
snapshot-data-integrity-immediate-check-after-snapshot-creationestá configurado entrue: La suma de comprobación de la instantánea se calcula inmediatamente después de la creación de la instantánea.
-
|
Estos cálculos de suma de comprobación consumen recursos de almacenamiento y computación. El tiempo de cálculo es impredecible y puede afectar negativamente al rendimiento del almacenamiento. Para más información, consulta Integridad de Datos de Instantáneas. |
-
Pros:
-
Minimiza el consumo de ancho de banda de la red.
-
Minimiza la entrada/salida en disco.
-
-
Contras:
-
Calcular las sumas de comprobación de las instantáneas puede llevar mucho tiempo.
-
El momento del cálculo de la suma de comprobación es impredecible. Puede activarse incluso bajo una alta carga de entrada/salida.
-
Para más información, consulta Reconstrucción Rápida de Réplicas.
Factores que Afectan al Rendimiento de la Reconstrucción
-
Cabecera de volumen grande
-
Por qué es importante: La cabecera de volumen es un archivo especial que nunca tiene una suma de comprobación precomputada. Si una réplica falla, SUSE Storage siempre debe sincronizar la cabecera de volumen completa. Una cabecera de volumen más grande aumenta el tiempo de reconstrucción.
-
Cómo prevenir: Toma instantáneas regularmente para reducir el tamaño de la cabecera de volumen. Programa instantáneas antes del mantenimiento planificado para minimizar el tiempo de reconstrucción.
-
-
No existen instantáneas
-
Por qué es importante: Sin instantáneas, SUSE Storage no puede omitir la transferencia de datos ni reutilizar datos existentes. Si se crea una instantánea del volumen pero su suma de comprobación no está lista, SUSE Storage debe realizar la reconstrucción delta. Esto aumenta el uso de CPU debido a las comparaciones de suma de verificación bloque por bloque.
-
Cómo prevenir:
-
Habilita
snapshot-data-integrity-immediate-check-after-snapshot-creationosnapshot-data-integritypara precomputar sumas de verificación. Compensación: Aumenta el uso de CPU, la entrada/salida de disco y el uso de almacenamiento durante la computación. -
Utiliza un trabajo recurrente para crear instantáneas regularmente.
-
-
-
Instantánea purgada
-
Por qué es importante: Cuando comienza la purga de instantáneas, las instantáneas generadas por el sistema se fusionan en la siguiente instantánea. Esto invalida la suma de verificación de la siguiente instantánea.
-
Cómo prevenir:
-
Habilita
snapshot-data-integrity-immediate-check-after-snapshot-creationpara asegurar que las sumas de comprobación se calculen después de la purga. -
Crea proactivamente una instantánea y permite tiempo para la generación de la suma de comprobación antes de realizar actualizaciones o reconstrucciones.
-
-
-
Reconstrucciones concurrentes
-
Por qué es importante: Ejecutar múltiples reconstrucciones en el mismo nodo puede sobreutilizar la CPU, la E/S de disco y la E/S de red, afectando el rendimiento.
-
Cómo prevenir: Ajusta el número de reconstrucciones concurrentes utilizando la configuración
concurrent-replica-rebuild-per-node-limit.
-
-
Fallos múltiples de réplicas
-
Por qué es importante: Aumenta el tiempo y la complejidad de la reconstrucción. Si
auto-cleanup-system-generated-snapshotestruey no existen instantáneas creadas por el usuario, dos réplicas fallidas pueden desencadenar al menos una transferencia completa de datos.Para más detalles, consulta Avoid "full data transfer" when rebuilding two failed replicas.
-
Cómo prevenir:
-
Desactiva
auto-cleanup-system-generated-snapshotantes de realizar el mantenimiento. -
Crea instantáneas de usuario de todos los volúmenes antes de comenzar el mantenimiento.
-
Utiliza un trabajo recurrente para tomar instantáneas regularmente.
-
-
-
Reconstrucción de Réplicas a Escala
-
Por qué es importante:
La reconstrucción de réplicas a escala permite que una réplica en reconstrucción obtenga instantáneas de múltiples réplicas sanas de forma concurrente, mejorando significativamente el rendimiento de reconstrucción para ciertos patrones de carga de trabajo.
-
Cómo habilitar:
Establece
replica-rebuild-concurrent-sync-limit> 1 para permitir que múltiples réplicas sanas inicien servidores de sincronización. La réplica en reconstrucción obtiene diferentes instantáneas de diferentes réplicas fuente simultáneamente. Esta función es particularmente beneficiosa para volúmenes con pequeños fragmentos de datos dispersos y huecos en sus instantáneas.Para más detalles, consulta Reconstrucción de Réplicas a Escala.
-
Casos de Uso
Reinicio de Nodo Durante la Actualización de Versión
Cuando un nodo trabajador con réplicas se reinicia como parte de una actualización planificada:
-
La réplica en ese nodo se vuelve temporalmente no disponible y falla, pero las operaciones de lectura y escritura continúan.
-
Si el nodo se recupera dentro de
replica-replenishment-wait-interval, SUSE Storage inicia una reconstrucción utilizando la réplica fallida reutilizable.
Durante el proceso de reconstrucción:
-
SUSE Storage selecciona la última réplica fallida reutilizable si hay múltiples réplicas fallidas reutilizables disponibles.
-
Basado en el escenario de reconstrucción:
-
Si la reconstrucción rápida de réplicas está habilitada y todas las sumas de comprobación de instantáneas existen: SUSE Storage activa [_fast_replica_rebuilding]. Solo se sincronizan los bloques cambiados en la cabeza del volumen, evitando tanto la reconstrucción completa como la delta.
-
Si la reconstrucción rápida de réplicas está habilitada pero faltan algunas sumas de comprobación de instantáneas: SUSE Storage activa Delta Replica Rebuilding. Los bloques cambiados de instantáneas sin sumas de comprobación se sincronizan, evitando la reconstrucción completa.
-
Si la reconstrucción rápida de réplicas está desactivada: SUSE Storage realiza la reconstrucción delta sincronizando los bloques cambiados de todas las instantáneas, evitando la reconstrucción completa.
-
Drenaje de Nodo a Corto Plazo
Si un nodo trabajador se drena para mantenimiento a corto plazo y luego se restaura rápidamente:
-
La réplica en el nodo drenado se marca como fallida de inmediato.
-
Si el nodo se vuelve a habilitar antes de que expire el
replica-replenishment-wait-interval, SUSE Storage intenta reutilizar la réplica fallida. -
El comportamiento de reconstrucción sigue la misma lógica que se describe en el caso de uso anterior.
Configuraciones Relevantes
| Valor | Default | Descripción |
|---|---|---|
|
|
Habilita la reconstrucción rápida de réplicas. Se basa en sumas de comprobación de instantáneas precomputadas. |
|
Calcula los hashes de los archivos de disco de instantáneas solo si no tienen hash o si su tiempo de modificación ha cambiado. |
|
|
|
Programa de Cron para calcular sumas de comprobación para todas las instantáneas. Por defecto: cada 7 días. |
|
|
Si está habilitado, calcula las sumas de comprobación inmediatamente después de la creación de la instantánea. |
|
|
Tiempo en segundos para esperar antes de crear una nueva réplica. Permite la reutilización de réplicas fallidas. |
|
|
Limita el número de reconstrucciones de réplicas concurrentes por nodo. |
|
|
Número máximo de réplicas saludables que pueden sincronizarse con una réplica en reconstrucción de forma concurrente. Rango: 1-5. Al establecerlo en 1, se desactiva la reconstrucción a escala. |
|
|
Determina si las réplicas degradadas se reconstruyen mientras el volumen está desconectado. |
Análisis de Compensaciones de Configuración
-
-
enabled: Salta la transferencia de datos de instantáneas si las sumas de comprobación están actualizadas. Proporciona reconstrucciones rápidas pero no revalida los datos. -
disabled: Realiza reconstrucciones delta utilizando comparaciones de bloques. Más lento, pero asegura la integridad de los datos de la instantánea.
-
-
-
enabled: Por defecto, calcula las sumas de comprobación de las instantáneas cada 7 días. Aumenta el uso de CPU, E/S de disco y recursos.
-
-
snapshot-data-integrity-cronjob
-
Por defecto:
0 0 */7 * *Si
snapshot-data-integrityestá habilitado, esto define cuándo se recalculan las sumas de comprobación de las instantáneas. Las instantáneas creadas entre ejecuciones de cron pueden carecer de sumas de comprobación.
-
-
snapshot-data-integrity-immediate-check-after-snapshot-creation
-
true: Calcula inmediatamente las sumas de comprobación de las instantáneas después de la creación. Aumenta el uso de CPU y E/S de disco. El tiempo de finalización es impredecible. -
false: Las instantáneas pueden no tener sumas de comprobación hasta la siguiente ejecución de cron. Se requerirá reconstrucción delta si faltan las sumas de comprobación.
-
-
replica-replenishment-wait-interval
-
Por defecto:
600segundos-
Intervalo corto: Puede omitir la reutilización de réplicas fallidas y activar reconstrucciones completas.
-
Intervalo largo: Espera más tiempo para reutilizar réplicas fallidas, pero puede retrasar la recuperación.
-
-
-
concurrent-replica-rebuild-per-node-limit
-
Por defecto:
5-
Límite alto: Puede sobrecargar los recursos del nodo, ralentizando las reconstrucciones y las cargas de trabajo activas.
-
Límite bajo: Reduce la contención de recursos, pero aumenta el tiempo de reconstrucción debido a la cola.
-
-
-
replica-rebuild-concurrent-sync-limit
-
Por defecto:
1-
Cuando se establece en
1, la reconstrucción a escala está desactivada y solo se utiliza la reconstrucción tradicional de una sola fuente con un consumo mínimo de recursos. Cuando se establece en los valores 2-5, se habilita la reconstrucción a escala con múltiples réplicas de origen, proporcionando una mejora significativa en el rendimiento para los volúmenes. Sin embargo, los valores más altos aumentan el consumo de CPU en las réplicas de origen y destino. -
Esta configuración puede ser anulada por
volume.spec.RebuildConcurrentSyncLimitpor volumen.
-
-