Configurar Prometheus y Grafana para Monitorizar SUSE® Storage
Longhorn expone métricas de forma nativa en formato de texto de Prometheus en un punto final REST http://LONGHORN_MANAGER_IP:PORT/metrics.
Puedes utilizar cualquier herramienta de recopilación como Prometheus, Graphite, Telegraf para extraer estas métricas y luego visualizar los datos recopilados con herramientas como Grafana.
Consulta Longhorn Métricas para Monitorización para las métricas disponibles.
Resumen de Alto Nivel
El sistema de monitorización utiliza Prometheus para recopilar datos y alertar, y Grafana para visualizar/crear paneles con los datos recopilados.
-
Servidor de Prometheus que extrae y almacena datos de series temporales desde los puntos finales de métricas de Longhorn. Prometheus también es responsable de generar alertas basadas en reglas configuradas y datos recopilados. Los servidores de Prometheus envían alertas a un Alertmanager.
-
AlertManager gestiona esas alertas, incluyendo el silencio, la inhibición, la agregación y el envío de notificaciones a través de métodos como correo electrónico, sistemas de notificación en llamada y plataformas de chat.
-
Grafana que consulta el servidor de Prometheus para obtener datos y dibuja un panel para la visualización.
La imagen de abajo describe la arquitectura detallada del sistema de monitorización.
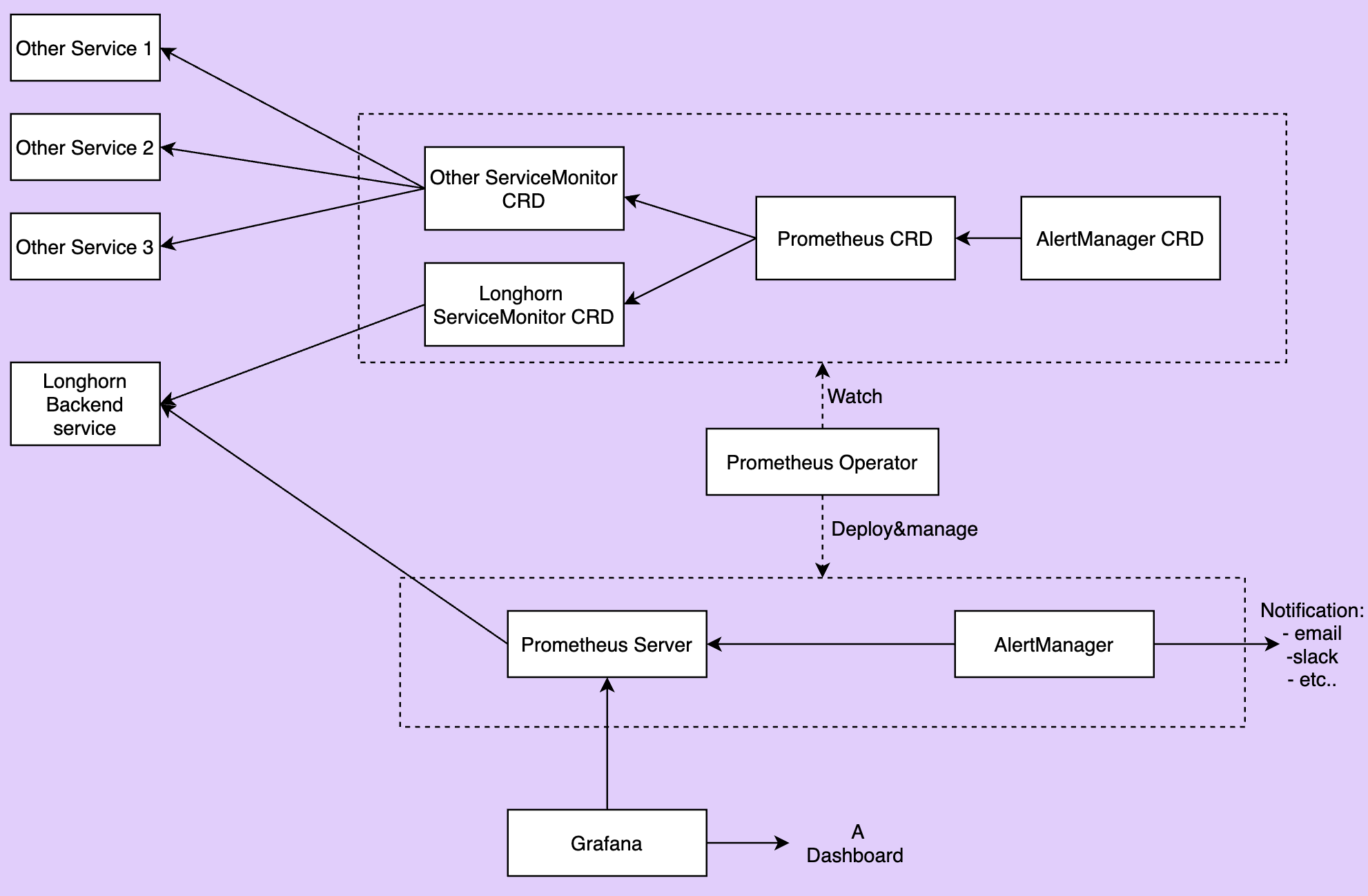
Hay 2 componentes no mencionados en la imagen anterior:
-
El servicio Backend de Longhorn es un servicio que apunta al conjunto de pods de Longhorn Manager. Las métricas de Longhorn se exponen en los pods de Longhorn Manager en el punto final
http://LONGHORN_MANAGER_IP:PORT/metrics. -
operador de Prometheus facilita mucho la ejecución de Prometheus sobre Kubernetes. El operador supervisa 3 recursos personalizados: ServiceMonitor, Prometheus y AlertManager. Cuando creas esos recursos personalizados, el Operador de Prometheus despliega y gestiona el servidor de Prometheus y AlertManager con las configuraciones especificadas por el usuario.
Instalación
Este documento utiliza el espacio de nombres default para el sistema de monitorización. Para instalar en un espacio de nombres diferente, cambia el campo namespace: <OTHER_NAMESPACE> en los manifiestos.
Instala el Operador de Prometheus
Sigue las instrucciones en Operador de Prometheus - Guía Rápida.
NOTA: Es posible que necesites elegir una versión que sea compatible con la versión de Kubernetes del clúster.
Instala el ServiceMonitor de Longhorn
Instala el ServiceMonitor de Longhorn con Kubectl
Crea un ServiceMonitor para Longhorn Manager.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: longhorn-prometheus-servicemonitor
namespace: default
labels:
name: longhorn-prometheus-servicemonitor
spec:
selector:
matchLabels:
app: longhorn-manager
namespaceSelector:
matchNames:
- longhorn-system
endpoints:
- port: managerInstala el ServiceMonitor de Longhorn con Helm
-
Modifica el archivo YAML
longhorn/chart/values.yaml.metrics: serviceMonitor: # -- Setting that allows the creation of a [Prometheus Operator](https://prometheus-operator.dev/) ServiceMonitor resource for Longhorn Manager components. enabled: true -
Crea un ServiceMonitor para Longhorn Manager utilizando Helm.
helm upgrade longhorn longhorn/longhorn --namespace longhorn-system -f values.yaml
El ServiceMonitor de Longhorn es un recurso personalizado de Operador de Prometheus. Esta configuración permite que el servidor de Prometheus descubra todos los pods de Longhorn Manager y sus respectivos puntos finales.
Puedes utilizar el selector de etiquetas app: longhorn-manager para seleccionar el servicio longhorn-backend, que apunta al conjunto de pods de Longhorn Manager.
Instala y configura el AlertManager de Prometheus
-
Crea un despliegue de Alertmanager altamente disponible con 3 instancias.
apiVersion: monitoring.coreos.com/v1 kind: Alertmanager metadata: name: longhorn namespace: default spec: replicas: 3 -
Las instancias de Alertmanager no se iniciarán a menos que se proporcione una configuración válida. Consulta Prometheus - Configuración para más explicaciones.
global: resolve_timeout: 5m route: group_by: [alertname] receiver: email_and_slack receivers: - name: email_and_slack email_configs: - to: <the email address to send notifications to> from: <the sender address> smarthost: <the SMTP host through which emails are sent> # SMTP authentication information. auth_username: <the username> auth_identity: <the identity> auth_password: <the password> headers: subject: 'Longhorn-Alert' text: |- {{ range .Alerts }} *Alert:* {{ .Annotations.summary }} - `{{ .Labels.severity }}` *Description:* {{ .Annotations.description }} *Details:* {{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}` {{ end }} {{ end }} slack_configs: - api_url: <the Slack webhook URL> channel: <the channel or user to send notifications to> text: |- {{ range .Alerts }} *Alert:* {{ .Annotations.summary }} - `{{ .Labels.severity }}` *Description:* {{ .Annotations.description }} *Details:* {{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}` {{ end }} {{ end }}Guarda la configuración de Alertmanager anterior en un archivo llamado
alertmanager.yamly crea un secreto a partir de él utilizando kubectl.Las instancias de Alertmanager requieren que el nombre del recurso secreto siga el formato
alertmanager-<ALERTMANAGER_NAME>. En el paso anterior, el nombre del Alertmanager eslonghorn, por lo que el nombre del secreto debe seralertmanager-longhorn.$ kubectl create secret generic alertmanager-longhorn --from-file=alertmanager.yaml -n default -
Para poder ver la interfaz web del Alertmanager, expónlo a través de un Servicio. Una forma sencilla de hacerlo es utilizar un Servicio de tipo NodePort.
apiVersion: v1 kind: Service metadata: name: alertmanager-longhorn namespace: default spec: type: NodePort ports: - name: web nodePort: 30903 port: 9093 protocol: TCP targetPort: web selector: alertmanager: longhornDespués de crear el servicio anterior, puedes acceder a la interfaz web del Alertmanager a través de la IP de un Nodo y el puerto 30903.
Utiliza el servicio
NodePortanterior solo para una verificación rápida, ya que no se comunica a través de la conexión TLS. Puede que desees cambiar el tipo de servicio aClusterIPy configurar un controlador de Ingress para exponer la interfaz web del Alertmanager a través de una conexión TLS.
Instala y configura el servidor de Prometheus.
-
Crea un recurso personalizado PrometheusRule para definir las condiciones de alerta. Consulta más ejemplos sobre las reglas de alerta de Longhorn en Ejemplos de Reglas de Alerta de Longhorn.
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: prometheus: longhorn role: alert-rules name: prometheus-longhorn-rules namespace: default spec: groups: - name: longhorn.rules rules: - alert: LonghornVolumeUsageCritical annotations: description: Longhorn volume {{$labels.volume}} on {{$labels.node}} is at {{$value}}% used for more than 5 minutes. summary: Longhorn volume capacity is over 90% used. expr: 100 * (longhorn_volume_usage_bytes / longhorn_volume_capacity_bytes) > 90 for: 5m labels: issue: Longhorn volume {{$labels.volume}} usage on {{$labels.node}} is critical. severity: criticalConsulta Prometheus - Reglas de alerta para más información.
-
Si la autorización RBAC está activada, crea un ClusterRole y un ClusterRoleBinding para los Pods de Prometheus.
apiVersion: v1 kind: ServiceAccount metadata: name: prometheus namespace: defaultapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus namespace: default rules: - apiGroups: [""] resources: - nodes - services - endpoints - pods verbs: ["get", "list", "watch"] - apiGroups: [""] resources: - configmaps verbs: ["get"] - nonResourceURLs: ["/metrics"] verbs: ["get"]apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: default -
Crea un recurso personalizado de Prometheus. Observa que seleccionamos el monitor de servicio de Longhorn y las reglas de Longhorn en la especificación.
apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: name: longhorn namespace: default spec: replicas: 2 serviceAccountName: prometheus alerting: alertmanagers: - namespace: default name: alertmanager-longhorn port: web serviceMonitorSelector: matchLabels: name: longhorn-prometheus-servicemonitor ruleSelector: matchLabels: prometheus: longhorn role: alert-rules -
Para poder ver la interfaz web del servidor de Prometheus, expónlo a través de un Servicio. Una forma sencilla de hacerlo es utilizar un Servicio de tipo NodePort.
apiVersion: v1 kind: Service metadata: name: prometheus-longhorn namespace: default spec: type: NodePort ports: - name: web nodePort: 30904 port: 9090 protocol: TCP targetPort: web selector: prometheus: longhornDespués de crear el servicio anterior, puedes acceder a la interfaz web del servidor de Prometheus a través de la IP de un nodo y el puerto 30904.
En este punto, deberías poder ver todos los objetivos de Longhorn Manager, así como las reglas de Longhorn en la sección de objetivos y reglas de la interfaz del servidor de Prometheus.
Utiliza el servicio NodePort anterior solo para una verificación rápida, ya que no se comunica a través de la conexión TLS. Puede que desees cambiar el tipo de servicio a
ClusterIPy configurar un controlador de Ingress para exponer la interfaz web del servidor de Prometheus a través de una conexión TLS.
Setup Grafana
-
Crea el ConfigMap de la fuente de datos de Grafana.
apiVersion: v1 kind: ConfigMap metadata: name: grafana-datasources namespace: default data: prometheus.yaml: |- { "apiVersion": 1, "datasources": [ { "access":"proxy", "editable": true, "name": "prometheus-longhorn", "orgId": 1, "type": "prometheus", "url": "http://prometheus-longhorn.default.svc:9090", "version": 1 } ] }NOTA: cambia el campo
urlsi estás instalando el stack de monitorización en un espacio de nombres diferente.+http://prometheus-longhorn.<NAMESPACE>.svc:9090" -
Crea el despliegue de Grafana.
apiVersion: apps/v1 kind: Deployment metadata: name: grafana namespace: default labels: app: grafana spec: replicas: 1 selector: matchLabels: app: grafana template: metadata: name: grafana labels: app: grafana spec: containers: - name: grafana image: grafana/grafana:7.1.5 ports: - name: grafana containerPort: 3000 resources: limits: memory: "500Mi" cpu: "300m" requests: memory: "500Mi" cpu: "200m" volumeMounts: - mountPath: /var/lib/grafana name: grafana-storage - mountPath: /etc/grafana/provisioning/datasources name: grafana-datasources readOnly: false volumes: - name: grafana-storage emptyDir: {} - name: grafana-datasources configMap: defaultMode: 420 name: grafana-datasources -
Crea el servicio de Grafana.
apiVersion: v1 kind: Service metadata: name: grafana namespace: default spec: selector: app: grafana type: ClusterIP ports: - port: 3000 targetPort: 3000 -
Expón Grafana en NodePort
32000.kubectl -n default patch svc grafana --type='json' -p '[{"op":"replace","path":"/spec/type","value":"NodePort"},{"op":"replace","path":"/spec/ports/0/nodePort","value":32000}]'Utiliza el servicio NodePort anterior solo para una verificación rápida, ya que no se comunica a través de la conexión TLS. Puede que desees cambiar el tipo de servicio a ClusterIP y configurar un controlador de Ingress para exponer Grafana a través de una conexión TLS.
-
Accede al panel de Grafana utilizando cualquier IP de nodo en el puerto
32000.# Default Credential User: admin Pass: admin -
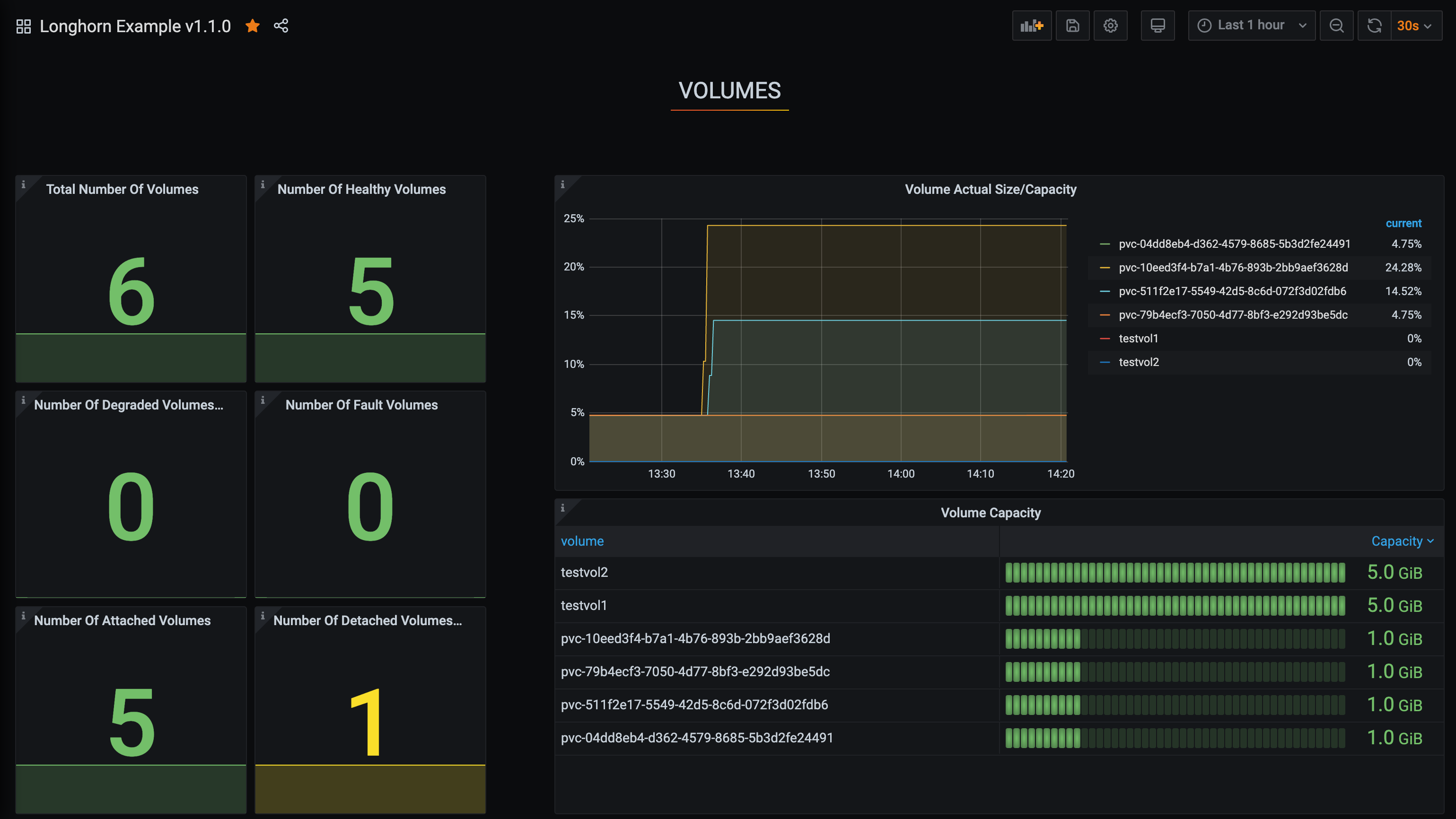
Configura el panel de Longhorn.
Una vez dentro de Grafana, importa el panel de ejemplo preconstruido Longhorn example dashboard.
Consulta Grafana Lab - Exportar e importar para obtener instrucciones sobre cómo importar un panel de Grafana.
Deberías ver el siguiente panel en la configuración: