Inicio rápido de instalación y configuración
- 1 Ejemplos de uso
- 2 Requisitos del sistema
- 3 Descripción general de los guiones de bootstrap
- 4 Instalación de SUSE Linux Enterprise Server y High Availability Extension
- 5 Uso del SBD como mecanismo de “fencing”
- 6 Configuración del primer nodo
- 7 Adición del segundo nodo
- 8 Comprobación del clúster
- 9 Información adicional
- 10 Información legal
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Inicio rápido de instalación y configuración #
Resumen#
Este documento sirve como guía para la instalación de un clúster muy básico de dos nodos mediante los guiones de bootstrap proporcionados por el paquete ha-cluster-bootstrap. Esto incluye la configuración de una dirección IP virtual como recurso de clúster y el uso del SBD (del inglés Split Brain Detector, detector de inteligencia dividida) en el almacenamiento compartido como mecanismo de “fencing”.
- 1 Ejemplos de uso
- 2 Requisitos del sistema
- 3 Descripción general de los guiones de bootstrap
- 4 Instalación de SUSE Linux Enterprise Server y High Availability Extension
- 5 Uso del SBD como mecanismo de “fencing”
- 6 Configuración del primer nodo
- 7 Adición del segundo nodo
- 8 Comprobación del clúster
- 9 Información adicional
- 10 Información legal
- A GNU Licenses
1 Ejemplos de uso #
Los procedimientos descritos en este documento sirven para realizar una instalación mínima de un clúster de dos nodos con las siguientes propiedades:
Dos nodos:
alice(IP:192.168.1.1) ybob(IP:192.168.1.2), conectados entre sí a través de la red.Una dirección IP virtual flotante (
192.168.2.1) que permite a los clientes conectarse al servicio independientemente del nodo físico en el que se esté ejecutando.Un dispositivo de almacenamiento compartido, que se utiliza como mecanismo de “fencing” del SBD. Esto evita situaciones de clúster con nodos malinformados.
Failover (relevo de funciones multinodo) de recursos de un nodo a otro si el host activo se interrumpe (instalación activa/pasiva).
Después de instalar el clúster con los guiones de bootstrap, se supervisará el clúster con la interfaz gráfica HA Web Konsole (Hawk), una de las herramientas de gestión de clústeres incluidas en SUSE® Linux Enterprise High Availability Extension. Como prueba básica del funcionamiento del failover de recursos, se colocará uno de los nodos en modo En espera y se comprobará si la dirección IP virtual se migra al segundo nodo.
Puede utilizar el clúster de dos nodos con fines de prueba o como configuración de clúster mínima que puede ampliar más adelante. Antes de utilizar el clúster en un entorno de producción, modifíquelo según sus necesidades.
2 Requisitos del sistema #
En esta sección se informa sobre los principales requisitos del sistema para la situación descrita en la Sección 1, “Ejemplos de uso”. Si desea ajustar el clúster para usarlo en un entorno de producción, lea la lista completa de Requisitos y recomendaciones del sistema en Chapter 2, System Requirements and Recommendations.
Requisitos de hardware #
- Servidores
Dos servidores con el software especificado en la Requisitos de software.
Los servidores pueden ser equipos desde cero o máquinas virtuales. No es necesario que el hardware sea idéntico (memoria, espacio de disco, etc.), pero debe tener la misma arquitectura. No se admiten clústeres de distintas plataformas.
- Canales de comunicación
Se necesitan al menos dos medios de comunicación TCP/IP por nodo del clúster. El equipo de red debe ser compatible con los medios de comunicación que desee utilizar para las comunicaciones del clúster: multidifusión o difusión unidireccional. Los medios de comunicación deben admitir una velocidad de datos de 100 Mbit/s o superior. Para que la instalación del clúster sea compatible, se requieren dos o más vías de comunicación redundantes. Esto puede realizarse de las siguientes formas:
Con un vínculo de dispositivos de red (opción preferida)
Con un segundo canal de comunicación en Corosync
Tolerancia a fallos de red en el nivel de infraestructura (por ejemplo, hipervisor).
- “Fencing” de nodo o STONITH
Para evitar situaciones de “clústeres con nodos malinformados”, los clústeres necesitan un mecanismo de “fencing” de nodo. Si se produce una situación de clústeres con nodos malinformados, los nodos del clúster se dividen en dos o más grupos que no tienen constancia de los demás (debido a un fallo de hardware o software o debido a que se ha cortado la conexión de red). Un mecanismo de “fencing” aísla el nodo en cuestión (normalmente restableciendo o apagando el nodo). Esto también se denomina STONITH (“Shoot the other node in the head”, disparar al otro nodo en la cabeza). Un mecanismo de “fencing” de nodo puede ser un dispositivo físico (un conmutador de alimentación) o un mecanismo como SBD (STONITH por disco), en combinación con un vigilante. Para usar el SBD se requiere un almacenamiento compartido.
En todos los nodos que formarán parte del clúster debe instalarse el siguiente software:
Requisitos de software #
SUSE® Linux Enterprise Server 12 SP5 (con todas las actualizaciones en línea disponibles)
SUSE Linux Enterprise High Availability Extension 12 SP5 (con todas las actualizaciones en línea disponibles)
Otros requisitos y recomendaciones #
- Sincronización horaria
Los nodos del clúster deben sincronizarse con un servidor NTP externo al clúster. Para obtener más información, consulte el https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Si los nodos no se sincronizan, puede que el clúster no funcione correctamente. Asimismo, los archivos de registro y los informes del clúster son muy difíciles de analizar sin la sincronización. Si utiliza guiones de bootstrap, el sistema le avisará si NTP no está aún configurado.
- Nombre del host y dirección IP
Utilice direcciones IP estáticas.
Muestre todos los nodos del clúster en el archivo
/etc/hostscon su nombre de host completo y su nombre de host abreviado. Es esencial que los miembros del clúster puedan encontrarse unos a otros por su nombre. Si los nombres no están disponibles, se producirá un error de comunicación interna del clúster.
- SSH
Todos los nodos del clúster deben ser capaces de acceder a los demás mediante SSH. Herramientas como
crm report(para resolver problemas) y el de Hawk2 requieren acceso SSH sin contraseña entre los nodos; si no se proporciona, solo podrán recopilar datos del nodo actual.Si utiliza guiones de bootstrap para configurar el clúster, las claves SSH se crean y se copian automáticamente.
3 Descripción general de los guiones de bootstrap #
Todos los comandos del paquete ha-cluster-bootstrap ejecutan guiones de bootstrap que requieren solo un mínimo de tiempo y de intervención manual.
Con
ha-cluster-initpuede definir los parámetros básicos necesarios para la comunicación del clúster. Esto le deja con un clúster de un nodo en ejecución.Con
ha-cluster-joinpuede añadir más nodos al clúster.Con
ha-cluster-removepuede eliminar nodos del clúster.
Todos los guiones de bootstrap se registran en /var/log/ha-cluster-bootstrap.log. Consulte este archivo para obtener información sobre el proceso de bootstrap. Todas las opciones que se establecen durante el proceso de bootstrap se pueden modificar más adelante con el módulo de clúster de YaST. Consulte el Section 3.1, “Manual Installation” para obtener más información.
Cada guion incluye una página man donde se explican las distintas funciones y las opciones del guion y se ofrece una descripción general de los archivos que el guion puede crear y modificar.
El guion de bootstrap ha-cluster-init comprueba y configura los siguientes componentes:
- NTP
Si NTP no se ha configurado para iniciarse durante el arranque, aparece un mensaje.
- SSH
Crea claves SSH para la entrada sin contraseña entre los nodos del clúster.
- Csync2
Configura Csync2 para replicar los archivos de configuración en todos los nodos de un clúster.
- Corosync
Permite configurar el sistema de comunicación del clúster.
- SBD/vigilante
Comprueba si existe un vigilante y se le pregunta si desea configurar el SBD como mecanismo de “fencing” de nodo.
- IP virtual flotante
Le pregunta si desea configurar una dirección IP virtual para la administración del clúster con Hawk2.
- Cortafuegos
Abre los puertos del cortafuegos necesarios para la comunicación del clúster.
- Cluster Name (Nombre del clúster)
Permite definir un nombre para el clúster, que es, por defecto,
clusterNÚMERO. Este componente es opcional y resulta útil sobre todo para los clústeres geográficos. Normalmente, el nombre del clúster refleja la ubicación y permite que sea más fácil distinguir un sitio dentro de un clúster geográfico.
4 Instalación de SUSE Linux Enterprise Server y High Availability Extension #
Los paquetes para configurar y gestionar un clúster con High Availability Extension se incluyen en el patrón de instalación Alta disponibilidad. Este patrón solo está disponible si SUSE Linux Enterprise High Availability Extension se ha instalado como extensión de SUSE® Linux Enterprise Server.
Para obtener información sobre cómo instalar extensiones, consulte la Guía de distribución de SUSE Linux Enterprise 12 SP5: https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Si el patrón aún no está instalado, instálelo con el comando zypper install -t pattern ha_sles. Como alternativa, puede instalar el patrón con YaST. Proceda de la siguiente manera:
Procedimiento 1: instalación del patrón Alta disponibilidad #
Inicie YaST y seleccione › .
Haga clic en la pestaña y active el patrón en la lista.
Haga clic en para iniciar la instalación de los paquetes.
Instale el patrón Alta disponibilidad en todos los equipos que vayan a formar parte del clúster.

Nota: instalación de paquetes de software en todas las partes
Para realizar una instalación automática de SUSE Linux Enterprise Server 12 SP5 y SUSE Linux Enterprise High Availability Extension 12 SP5, utilice AutoYaST para clonar los nodos existentes. Para obtener más información, consulte el Section 3.2, “Mass Installation and Deployment with AutoYaST”.
Registre los equipos en el Centro de servicios al cliente de SUSE. Hay más información disponible en https://documentation.suse.com/sles-12/html/SLES-all/cha-update-offline.html#sec-update-registersystem.
5 Uso del SBD como mecanismo de “fencing” #
Si dispone de almacenamiento compartido, por ejemplo, una SAN (red de área de almacenamiento), puede utilizarla para evitar situaciones de clústeres con nodos malinformados mediante la configuración del SBD como mecanismo de “fencing” de nodo. El SBD utiliza la compatibilidad con el vigilante y el agente del recurso de STONITH external/sbd.
5.1 Requisitos del SBD #
Durante la instalación del primer nodo con ha-cluster-init, puede decidir si desea utilizar el SBD. Si responde afirmativamente, deberá introducir la vía al dispositivo de almacenamiento compartido. Por defecto, ha-cluster-init crea automáticamente una pequeña partición en el dispositivo que se va a usar para el SBD.
Para utilizar el SBD, deben cumplirse los siguientes requisitos:
La vía al dispositivo de almacenamiento compartido debe ser persistente y coherente en todos los nodos del clúster. Utilice nombres de dispositivo estables, como
/dev/disk/by-id/dm-uuid-part1-mpath-abcedf12345.El dispositivo SBD no debe utilizar RAID basado en host, cLVM2 ni residir en una instancia de DRBD*.
Para obtener información sobre cómo configurar el almacenamiento compartido, consulte la Guía de administración de almacenamiento de SUSE Linux Enterprise Server 12 SP5: https://documentation.suse.com/sles-12/html/SLES-all/stor-admin.html.
5.2 Configuración del vigilante softdog y del SBD #
En SUSE Linux Enterprise Server, la compatibilidad del vigilante en el núcleo está habilitada por defecto: incorpora varios módulos de núcleo que proporcionan controladores de vigilancia específicos de hardware. High Availability Extension utiliza el daemon de SBD como componente de software que “alimenta” al vigilante.
En el procedimiento siguiente se utiliza el vigilante softdog.
Importante: limitaciones de softdog
El controlador softdog presupone que sigue habiendo al menos una CPU en ejecución. Si todas las CPU están bloqueadas, el código del controlador softdog que debe rearrancar el sistema no se ejecuta nunca. Por el contrario, los vigilantes de hardware siguen en funcionamiento aunque todas las CPU estén bloqueadas.
Antes de utilizar el clúster en un entorno de producción, se recomienda encarecidamente sustituir el módulo softdog por el módulo de hardware correspondiente que mejor se adapte al hardware existente.
Sin embargo, si ningún vigilante coincide con el hardware, se puede usar softdog como módulo de vigilancia del núcleo.
Cree un almacenamiento compartido persistente, como se describe en la Sección 5.1, “Requisitos del SBD”.
Habilite el vigilante softdog:
root #echosoftdog > /etc/modules-load.d/watchdog.confroot #systemctlrestart systemd-modules-loadCompruebe que el módulo softdog está correctamente cargado:
root #lsmod| egrep "(wd|dog)" softdog 16384 1En
bob, inicialice la partición SBD:root #sbd-d /dev/SBDDEVICE createInicie el SBD para escuchar en el dispositivo SBD:
root #sbd-d /dev/SBDDEVICE watchEn
alice, envíe un mensaje de prueba:root #sbd-d /dev/SBDDEVICE message bob testEn
bob, compruebe el estado consystemctl. Debería ver el mensaje recibido:root #systemctlstatus sbd [...] info: Received command test from alice on disk SBDDEVICEDeje de vigilar el dispositivo SBD en
bobcon:root #systemctlstop sbd
Se recomienda encarecidamente comprobar que el mecanismo de “fencing” del SBD funciona correctamente en caso de que se produzca una situación de clúster con nodos malinformados. Esta prueba se puede realizar bloqueando la comunicación del clúster con Corosync.
6 Configuración del primer nodo #
Configure el primer nodo con el guion ha-cluster-init. Esto requiere solo un mínimo de tiempo y de intervención manual.
Procedimiento 2: configuración del primer nodo (alice) con ha-cluster-init #
Entre como usuario
rooten el equipo físico o virtual que desea utilizar como nodo de clúster.Para iniciar el guion de bootstrap, ejecute:
root #ha-cluster-init--name CLUSTERNAMESustituya el marcador de posición CLUSTERNAME por un nombre descriptivo, como la ubicación geográfica del clúster (por ejemplo,
amsterdam). Esto resulta especialmente útil si desea crear un clúster geográfico más adelante, ya que simplifica la identificación de un sitio. Si ejecuta el comando sin la opción--name, el nombre por defecto eshacluster.Si necesita unidifusión en lugar de multidifusión (valor por defecto) para la comunicación del clúster, utilice la opción
-u. Después de la instalación, busque el valorudpuen el archivo/etc/corosync/corosync.conf. Siha-cluster-initdetecta un nodo en ejecución en Amazon Web Services (AWS), el guion utilizará por defecto la unidifusión para la comunicación del clúster.Los guiones comprueban la configuración de NTP y si existe un servicio de vigilancia de hardware. Genera las claves SSH pública y privada usadas para el acceso SSH y la sincronización Csync2 e inicia los servicios respectivos.
Configure el nivel de comunicación del clúster (Corosync):
Introduzca la dirección de red con la que se debe enlazar. Por defecto, el guion propone la dirección de red
eth0. Si lo prefiere, especifique una dirección de red distinta; por ejemplo,bond0.Introduzca una dirección de multidifusión. El guion propone una dirección aleatoria que puede utilizar por defecto. Por supuesto, su red concreta debe admitir esta dirección de multidifusión.
Introduzca un puerto de multidifusión. El guion propone por defecto el puerto
5405.
Por último, el guion inicia el servicio Pacemaker para conectar el clúster de un nodo y habilitar Hawk2. La URL que se utilizará para Hawk2 se muestra en la pantalla.
Configure el SBD como mecanismo de “fencing” de nodo:
Haga clic en
spara confirmar que desea utilizar el SBD.Introduzca una vía persistente para la partición del dispositivo de bloques que desea utilizar para SBD, consulte la Sección 5, “Uso del SBD como mecanismo de “fencing””. La vía debe ser coherente en todos los nodos del clúster.
Configure una dirección IP virtual para la administración del clúster con Hawk2. (Esta IP virtual se usará para probar más adelante si el failover es correcto).
Haga clic en
spara confirmar que desea configurar una dirección IP virtual.Introduzca una dirección IP no utilizada que desee usar como IP de administración para Hawk2:
192.168.2.1.En lugar de entrar en un nodo de clúster individual con Hawk2, puede conectarse a la dirección IP virtual.
Ahora dispone de un clúster de un nodo en ejecución. Para ver su estado, haga lo siguiente:
Procedimiento 3: entrada a la sesión en la interfaz Web de Hawk2 #
En cualquier equipo, inicie un navegador Web y asegúrese de que las cookies y JavaScript están habilitados.
Como URL, introduzca la dirección IP o el nombre de host de cualquier nodo del clúster en el que se ejecute el servicio Web Hawk. Si lo prefiere, introduzca la dirección IP virtual que configuró en el Paso 6 del Procedimiento 2, “configuración del primer nodo (
alice) conha-cluster-init”:https://HAWKSERVER:7630/
Nota: advertencia de certificado
Si aparece una advertencia de certificado cuando intenta acceder a la URL por primera vez, se debe a que se está usando un certificado autofirmado. Los certificados autofirmados no se consideran de confianza por defecto.
Consulte a su operador de clúster los detalles del certificado para verificarlo.
Si desea continuar de todas formas, puede añadir una excepción en el navegador para omitir la advertencia.
En la pantalla de entrada de Hawk2, escriba el y la del usuario que se creó durante el proceso de bootstrap (usuario
haclustery contraseñalinux).
Importante: contraseña segura
Sustituya la contraseña por defecto por una segura tan pronto como sea posible:
root #passwdhaclusterHaga clic en Después de entrar a la sesión, en la interfaz Web de Hawk2 se abre por defecto la pantalla de estado, donde se muestra el estado del clúster actual:
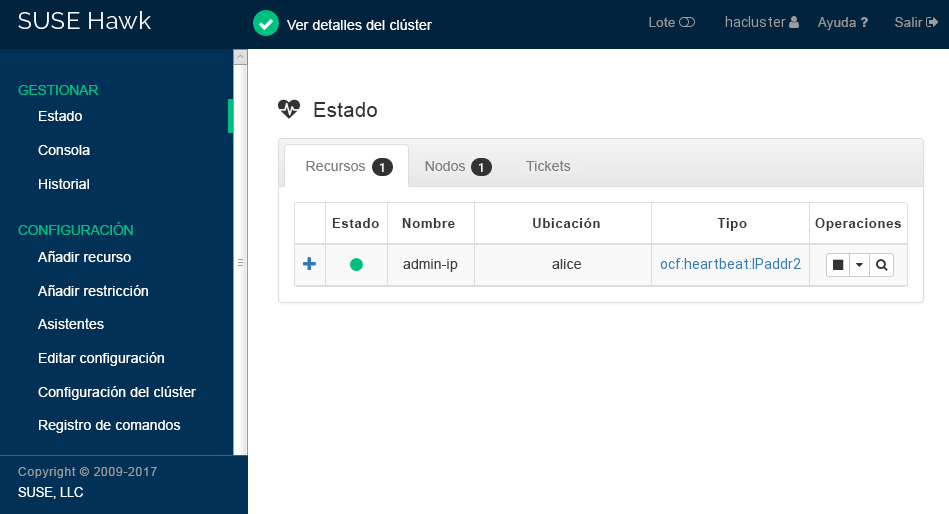
Figura 1: estado del clúster de un nodo en Hawk2 #
7 Adición del segundo nodo #
Si tiene un clúster de un nodo en ejecución, añada el segundo nodo de clúster con el guion de bootstrap ha-cluster-join, como se describe en el Procedimiento 4. El guion solo necesita acceso a un nodo de clúster existente y finalizará automáticamente la configuración básica en el equipo actual. Para obtener más detalles, consulte la página man ha-cluster-join.
Los guiones de bootstrap se encargan de cambiar la configuración específica a un clúster de dos nodos; por ejemplo, SBD y Corosync.
Procedimiento 4: Adición de un segundo nodo (bob) con ha-cluster-join #
Entre como usuario
rooten el equipo físico o virtual que se supone que debe unirse al clúster.Para iniciar el guion de bootstrap, ejecute:
root #ha-cluster-joinSi NTP no se ha configurado para iniciarse durante el arranque, aparece un mensaje. El guion también comprueba si hay un dispositivo de vigilancia de hardware (lo que es importante en caso de que desee configurar el SBD) y le notifica al respecto si no hay ninguno presente.
Si decide continuar de todas formas, se le pedirá la dirección IP de un nodo existente. Introduzca la dirección IP del primer nodo (
alice,192.168.1.1).Si aún no ha configurado el acceso SSH sin contraseña entre ambos equipos, también se le pedirá la contraseña del usuario
rootdel nodo existente.Después de entrar en el nodo especificado, el guion copia la configuración de Corosync, configura SSH y Csync2 y conecta el equipo actual como nodo de clúster nuevo. Además, inicia el servicio necesario para Hawk2.
Compruebe el estado del clúster en Hawk2. En › deberían aparecer dos nodos con estado verde (consulte la Figura 2, “estado del clúster de dos nodos”).
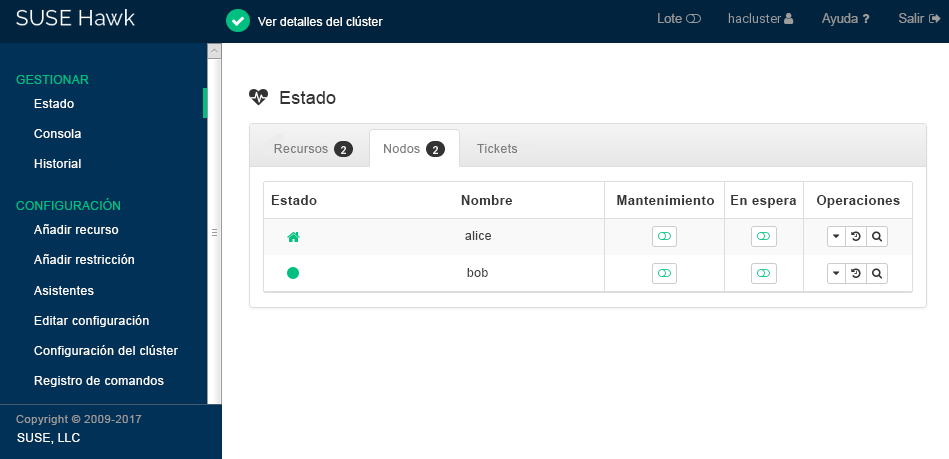
Figura 2: estado del clúster de dos nodos #
8 Comprobación del clúster #
El Procedimiento 5, “prueba de failover de recursos” es una sencilla prueba para comprobar si el clúster mueve la dirección IP virtual al otro nodo en caso de que el nodo que está ejecutando actualmente el recurso pase a modo En espera.
Sin embargo, una prueba realista implica casos de uso y situaciones específicos, incluida la prueba del mecanismo de “fencing” para evitar una situación de clúster con nodos malinformados. Si no ha configurado el mecanismo de “fencing” correctamente, es posible que el clúster no funcione de forma adecuada.
Antes de utilizar el clúster en un entorno de producción, pruébelo exhaustivamente en consonancia con sus casos de uso.
Procedimiento 5: prueba de failover de recursos #
Abra un terminal y ejecute un ping a
192.168.2.1, la dirección IP virtual:root #ping192.168.2.1Entre en el clúster, como se describe en el Procedimiento 3, “entrada a la sesión en la interfaz Web de Hawk2”.
En la opción › de Hawk2, marque el nodo en el que se está ejecutando la dirección IP virtual (recurso
admin_addr). Se presupone que el recurso se ejecuta enalice.Ponga
aliceen modo (consulte la Figura 3, “nodoaliceen modo En espera”).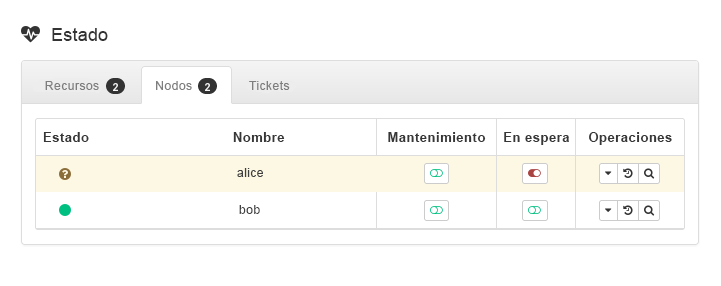
Figura 3: nodo
aliceen modo En espera #Haga clic en › . El recurso
admin_addrse ha migrado abob.
Durante la migración, se mostrará un flujo ininterrumpido de pings a la dirección IP virtual. Esto muestra que la configuración del clúster y la dirección IP flotante funcionan correctamente. Cancele el comando ping con Control–C.
9 Información adicional #
Encontrará más documentación sobre este producto en https://documentation.suse.com/sle-ha-12. La documentación también incluye una guía de administración completa de SUSE Linux Enterprise High Availability Extension. Consúltela para obtener más datos sobre las tareas de configuración y administración.
10 Información legal #
Copyright © 2006– 2026 SUSE LLC y colaboradores. Reservados todos los derechos.
Está permitido copiar, distribuir y modificar este documento según los términos de la licencia de documentación gratuita GNU, versión 1.2 o (según su criterio) versión 1.3. Este aviso de copyright y licencia deberán permanecer inalterados. En la sección titulada “GNU Free Documentation License” (Licencia de documentación gratuita GNU) se incluye una copia de la versión 1.2 de la licencia.
Para obtener información sobre las marcas comerciales de SUSE, consulte http://www.suse.com/company/legal/. Todas las marcas comerciales de otros fabricantes son propiedad de sus respectivas empresas. Los símbolos de marca comercial (®,™ etc.) indican marcas comerciales de SUSE y sus afiliados. Los asteriscos (*) indican marcas comerciales de otros fabricantes.
Toda la información recogida en esta publicación se ha compilado prestando toda la atención posible al más mínimo detalle. Sin embargo, esto no garantiza una precisión total. Ni SUSE LLC, ni sus filiales, ni los autores o traductores serán responsables de los posibles errores o las consecuencias que de ellos pudieran derivarse.