Inicialização Rápida de Instalação e Configuração
- 1 Cenário de uso
- 2 Requisitos do sistema
- 3 Visão geral dos scripts de boot
- 4 Instalando a SUSE Linux Enterprise Server e a High Availability Extension
- 5 Usando o SBD como mecanismo de fencing
- 6 Configurando o primeiro nó
- 7 Adicionando o segundo nó
- 8 Testando o cluster
- 9 Para obter mais informações
- 10 Informações Legais
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Inicialização Rápida de Instalação e Configuração #
Resumo#
Este documento orienta na configuração de um cluster muito básico de dois nós usando os scripts de boot incluídos no pacote ha-cluster-bootstrap. Isso inclui a configuração de um endereço IP virtual como um recurso de cluster e o uso do SBD em armazenamento compartilhado como mecanismo de fencing.
- 1 Cenário de uso
- 2 Requisitos do sistema
- 3 Visão geral dos scripts de boot
- 4 Instalando a SUSE Linux Enterprise Server e a High Availability Extension
- 5 Usando o SBD como mecanismo de fencing
- 6 Configurando o primeiro nó
- 7 Adicionando o segundo nó
- 8 Testando o cluster
- 9 Para obter mais informações
- 10 Informações Legais
- A GNU Licenses
1 Cenário de uso #
Os procedimentos neste documento conduzem a configuração mínima de um cluster de dois nós com as seguintes propriedades:
Dois nós:
alice(IP:192.168.1.1) ebob(IP:192.168.1.2), conectados um ao outro pela rede.Um endereço IP virtual flutuante (
192.168.2.1) que permite aos clientes se conectarem ao serviço independentemente do nó físico no qual estão sendo executados.Um dispositivo de armazenamento compartilhado usado como mecanismo de fencing SBD. Isso evita cenários de split brain.
Failover de recursos de um nó para outro em caso de falha no host ativo (configuração ativo/passivo).
Após a instalação do cluster com os scripts de boot, ele será monitorado com o Hawk (HA Web Konsole) gráfico, uma das ferramentas de gerenciamento de cluster incluídas na SUSE® Linux Enterprise High Availability Extension. Como um teste básico para verificar se o failover de recursos funciona, colocaremos um dos nós no modo standby e verificaremos se o endereço IP virtual será migrado para o segundo nó.
Você pode usar o cluster de dois nós para fins de teste ou como uma configuração de cluster mínima que pode ser estendida posteriormente. Antes de usar o cluster em um ambiente de produção, modifique-o de acordo com os seus requisitos.
2 Requisitos do sistema #
Esta seção informa você sobre os principais requisitos do sistema para o cenário descrito na Seção 1, “Cenário de uso”. Para ajustar o cluster para uso em um ambiente de produção, leia a lista completa de Requisitos e recomendações do sistema no Chapter 2, System Requirements and Recommendations.
Requisitos de hardware #
- Servidores
Dois servidores com software conforme especificado na Requisitos de software.
Os servidores podem ser completamente vazios ou máquinas virtuais. Eles não exigem hardware idêntico (memória, espaço em disco, etc.), mas devem ter a mesma arquitetura. Clusters compatíveis com várias plataformas não são suportados.
- Canais de comunicação
No mínimo, duas mídias de comunicação TCP/IP por nó do cluster. O equipamento de rede deve suportar os meios de comunicação que você deseja usar para comunicação do cluster: multicast ou unicast. A mídia de comunicação deve suportar uma taxa de dados de 100 Mbit/s ou superior. Para uma configuração de cluster compatível, são necessários pelo menos dois caminhos de comunicação redundantes. Isso pode ser feito por meio de:
Ligação de Dispositivo de Rede (preferencial)
Um segundo canal de comunicação no Corosync
Tolerância a falhas de rede na camada da infraestrutura (por exemplo, hipervisor).
- Fencing de nó/STONITH
Para evitar um cenário de “split brain”, os clusters precisam de um mecanismo de fencing de nó. Em um cenário de split brain, os nós do cluster são divididos em dois ou mais grupos que não sabem a respeito um do outro (devido a uma falha de hardware ou de software ou a uma conexão de rede interrompida). Um mecanismo de fencing isola o nó em questão (geralmente, redefinindo ou desligando o nó). Isso também é chamado de STONITH (“Shoot the other node in the head” – Atirar na cabeça do outro nó). O mecanismo de fencing de nó pode ser um dispositivo físico (switch de energia) ou um mecanismo como SBD (STONITH por disco) em combinação com um watchdog. O uso do SBD requer armazenamento compartilhado.
Em todos os nós que farão parte do cluster, é necessário instalar o seguinte software:
Requisitos de software #
SUSE® Linux Enterprise Server 12 SP5 (com todas as atualizações online disponíveis)
SUSE Linux Enterprise High Availability Extension 12 SP5 (com todas as atualizações online disponíveis)
Outros requisitos e recomendações #
- Sincronização de horário
Os nós do cluster devem ser sincronizados com um servidor NTP fora do cluster. Para obter mais informações, consulte o https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Se os nós não forem sincronizados, o cluster poderá não funcionar apropriadamente. Além disso, os arquivos de registro e os relatórios do cluster são muito difíceis de analisar sem a sincronização. Se você usar os scripts de boot, será avisado caso o NTP ainda não tenha sido configurado.
- Nome de host e endereço IP
Use endereços IP estáticos.
Liste todos os nós do cluster no arquivo
etc/hostscom o respectivo nome completo e abreviado do host. É essencial que os membros do cluster possam encontrar uns aos outros pelo nome. Se os nomes não estiverem disponíveis, haverá falha na comunicação interna do cluster.
- SSH
Todos os nós do cluster devem ser capazes de acessar uns aos outros por SSH. Ferramentas como o
crm report(para solução de problemas) e o do Hawk2 exigem acesso por SSH sem senha entre os nós; do contrário, elas apenas poderão coletar dados do nó atual.Se você usar os scripts de boot para configurar o cluster, as chaves SSH serão automaticamente criadas e copiadas.
3 Visão geral dos scripts de boot #
Todos os comandos do pacote ha-cluster-bootstrap executam scripts de boot que exigem apenas um mínimo de intervenção manual e de tempo.
Com o
ha-cluster-init, defina os parâmetros básicos necessários para a comunicação do cluster. Dessa forma, você tem um cluster de um nó em execução.Com o
ha-cluster-join, adicione mais nós ao cluster.Com o
ha-cluster-remove, remova nós do cluster.
Todos os scripts de boot são registrados em /var/log/ha-cluster-bootstrap.log. Consulte esse arquivo para obter todos os detalhes do processo de boot. As opções definidas durante o processo de boot podem ser modificadas posteriormente com o módulo de cluster do YaST. Consulte o Section 3.1, “Manual Installation” para obter os detalhes.
Cada script vem com uma página de manual que abrange a variedade de funções, as opções do script e uma visão geral dos arquivos que o script pode criar e modificar.
O script de boot ha-cluster-init verifica e configura os seguintes componentes:
- NTP
Se o NTP não foi configurado para ser iniciado no momento da inicialização, uma mensagem é exibida.
- SSH
Ele cria chaves SSH para login sem senha entre os nós do cluster.
- Csync2
Ele configura o Csync2 para replicar os arquivos de configuração para todos os nós em um cluster.
- Corosync
Ele configura o sistema de comunicação do cluster.
- SBD/Watchdog
Ele verifica se há um watchdog e pergunta se é para configurar o SBD como mecanismo de fencing de nó.
- IP flutuante virtual
Ele pergunta se é para configurar um endereço IP virtual para administração do cluster com o Hawk2.
- Firewall
Ele abre as portas no firewall que são necessárias para a comunicação do cluster.
- Nome do cluster
Ele define um nome para o cluster, por padrão
clusterNÚMERO. Isso é opcional e é útil principalmente para clusters Geo. Geralmente, o nome do cluster reflete a localização e facilita distinguir um site dentro de um cluster Geo.
4 Instalando a SUSE Linux Enterprise Server e a High Availability Extension #
Os pacotes para configurar e gerenciar um cluster com a High Availability Extension estão incluídos no padrão de instalação High Availability (Alta Disponibilidade). Esse padrão apenas estará disponível após a instalação da SUSE Linux Enterprise High Availability Extension como uma extensão ao SUSE® Linux Enterprise Server.
Para obter informações sobre como instalar extensões, consulte o Guia de Implantação do SUSE Linux Enterprise 12 SP5: https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Se o padrão ainda não foi instalado, instale-o com o comando zypper install -t pattern ha_sles. Se preferir, instale o padrão com o YaST. Proceda da seguinte maneira:
Procedimento 1: Instalando o padrão High Availability #
Inicie o YaST e selecione › .
Clique na guia e ative o padrão na lista de padrões.
Clique em para iniciar a instalação dos pacotes.
Instale o padrão High Availability em todas as máquinas que farão parte do cluster.

Nota: Instalando pacotes de software em todas as partes
Para uma instalação automatizada do SUSE Linux Enterprise Server 12 SP5 e da SUSE Linux Enterprise High Availability Extension 12 SP5, use o AutoYaST para clonar os nós existentes. Para obter mais informações, consulte o Section 3.2, “Mass Installation and Deployment with AutoYaST”.
Registre as máquinas no SUSE Customer Center. Encontre mais informações em https://documentation.suse.com/sles-12/html/SLES-all/cha-update-offline.html#sec-update-registersystem.
5 Usando o SBD como mecanismo de fencing #
Se você tem armazenamento compartilhado, como uma SAN (Storage Area Network), pode usá-lo para evitar cenários de split brain configurando o SBD como mecanismo de fencing de nó. O SBD usa o suporte a watchdog e o agente de recurso external/sbd do STONITH.
5.1 Requisitos do SBD #
Durante a configuração do primeiro nó com ha-cluster-init, você decide se vai usar o SBD. Em caso afirmativo, será necessário digitar o caminho para o dispositivo de armazenamento compartilhado. Por padrão, o ha-cluster-init cria automaticamente uma pequena partição no dispositivo que será usado para o SBD.
Para usar o SBD, os seguintes requisitos devem ser atendidos:
O caminho para o dispositivo de armazenamento compartilhado deve ser persistente e consistente em todos os nós no cluster. Use nomes de dispositivos estáveis, como
/dev/disk/by-id/dm-uuid-part1-mpath-abcedf12345.O dispositivo SBD não deve usar RAID baseado em host, cLVM2 nem residir em uma instância DRBD*.
Para obter detalhes sobre a configuração do armazenamento compartilhado, consulte o Guia de Administração de Armazenamento do SUSE Linux Enterprise Server 12 SP5: https://documentation.suse.com/sles-12/html/SLES-all/stor-admin.html.
5.2 Configurando o watchdog do Softdog e o SBD #
No SUSE Linux Enterprise Server, o suporte a watchdog no kernel está habilitado por padrão: Ele está incluído em vários módulos do kernel que fornecem drivers de watchdog específicos do hardware. A High Availability Extension usa o daemon SBD como o componente de software que “alimenta” o watchdog.
O procedimento a seguir usa o watchdog do softdog.
Importante: Limitações do softdog
O driver softdog supõe que pelo menos uma CPU ainda esteja em execução. Se todas as CPUs estiverem travadas, o código no driver softdog que deve reinicializar o sistema nunca será executado. Por outro lado, os watchdogs do hardware continuarão funcionando mesmo se todas as CPUs estiverem travadas.
Antes de usar o cluster em um ambiente de produção, é altamente recomendável substituir o módulo softdog pelo módulo correspondente mais adequado ao seu hardware.
No entanto, se nenhum watchdog corresponder ao seu hardware, o softdog poderá ser usado como o módulo watchdog do kernel.
Crie um armazenamento compartilhado persistente conforme descrito na Seção 5.1, “Requisitos do SBD”.
Habilite o watchdog do softdog:
root #echosoftdog > /etc/modules-load.d/watchdog.confroot #systemctlrestart systemd-modules-loadTeste se o módulo softdog foi carregado corretamente:
root #lsmod| egrep "(wd|dog)" softdog 16384 1Em
bob, inicialize a partição SBD:root #sbd-d /dev/SBDDEVICE createInicie o SBD para escutar no dispositivo SBD:
root #sbd-d /dev/SBDDEVICE watchEm
alice, envie uma mensagem de teste:root #sbd-d /dev/SBDDEVICE message bob testEm
bob, verifique o status com o comandosystemctl, e a mensagem recebida deve ser exibida:root #systemctlstatus sbd [...] info: Received command test from alice on disk SBDDEVICEPare de monitorar o dispositivo SBD em
bobcom:root #systemctlstop sbd
É altamente recomendável testar se o mecanismo de fencing SBD funciona de maneira apropriada em caso de split brain. Esse tipo de teste pode ser feito bloqueando a comunicação do cluster Corosync.
6 Configurando o primeiro nó #
Configure o primeiro nó com o script ha-cluster-init. Isso exige apenas um mínimo de intervenção manual e de tempo.
Procedimento 2: Configurando o primeiro nó (alice) com ha-cluster-init #
Efetue login como
rootna máquina virtual ou física que você deseja usar como nó do cluster.Inicie o script de boot executando:
root #ha-cluster-init--name CLUSTERNAMESubstitua o marcador CLUSTERNAME por um nome significativo, como a localização geográfica do seu cluster (por exemplo,
amsterdam). Isso é útil principalmente para criar um cluster Geo no futuro, pois ele simplifica a identificação de um site. Se você executar o comando sem a opção--name, o nome padrão seráhacluster.Se você precisar de unicast em vez de multicast (padrão) para a comunicação com o cluster, use a opção
-u. Após a instalação, localize o valorudpuno arquivo/etc/corosync/corosync.conf. Seha-cluster-initdetectar um nó em execução na AWS (Amazon Web Services), o script usará unicast automaticamente como padrão para comunicação com o cluster.O script verifica se há um serviço watchdog de hardware e uma configuração do NTP. Ele gera as chaves SSH públicas e privadas usadas para acesso SSH e sincronização Csync2 e inicia os respectivos serviços.
Configure a camada de comunicação do cluster (Corosync):
Digite um endereço de rede ao qual vincular. Por padrão, o script propõe o endereço de rede de
eth0. Se preferir, digite um endereço de rede diferente, por exemplo, o endereço debond0.Digite um endereço multicast. O script propõe um endereço aleatório que você pode usar como padrão. A sua rede particular precisa suportar esse endereço multicast.
Digite uma porta de multicast. Como padrão, o script propõe
5405.
Por fim, o script inicia o serviço Pacemaker para colocar o cluster de um nó online e habilitar o Hawk2. O URL a ser usado no Hawk2 é exibido na tela.
Configure o SBD como mecanismo de fencing de nó:
Pressione
ypara confirmar que você deseja usar o SBD.Digite um caminho persistente para a partição do dispositivo de blocos que você deseja usar para o SBD. Consulte a Seção 5, “Usando o SBD como mecanismo de fencing”. O caminho deve ser consistente em todos os nós no cluster.
Configure um endereço IP virtual para administração do cluster com o Hawk2. (Usaremos esse recurso de IP virtual para testar o failover bem-sucedido mais adiante.)
Pressione
ypara confirmar que você deseja configurar um endereço IP virtual.Digite um endereço IP não utilizado que você deseja usar como o IP de administração no Hawk2:
192.168.2.1Em vez de efetuar login em um nó de cluster individual com o Hawk2, você pode se conectar ao endereço IP virtual.
Agora, você tem um cluster de um nó em execução. Para ver seu status, faça o seguinte:
Procedimento 3: Efetuando login na interface da Web do Hawk2 #
Em qualquer máquina, inicie um browser da Web e verifique se o JavaScript e os cookies estão habilitados.
Como URL, digite o endereço IP ou nome de host de qualquer nó do cluster que executa o serviço Web Hawk. Se preferir, digite o endereço IP virtual que foi configurado na Etapa 6 do Procedimento 2, “Configurando o primeiro nó (
alice) comha-cluster-init”:https://HAWKSERVER:7630/
Nota: Aviso de Certificado
Se um aviso de certificado for exibido quando você tentar acessar o URL pela primeira vez, um certificado autoassinado estará em uso. Os certificados autoassinados não são considerados confiáveis por padrão.
Solicite ao operador do cluster os detalhes do certificado para verificá-lo.
Para continuar mesmo assim, você pode adicionar uma exceção ao browser para ignorar o aviso.
Na tela de login do Hawk2, digite o e a do usuário que foi criado durante o procedimento de boot (usuário
hacluster, senhalinux).
Importante: Senha de Segurança
Substitua a senha padrão por uma segura assim que possível:
root #passwdhaclusterClique em . Após o login, a interface da Web do Hawk2 mostrará a tela Status por padrão, exibindo o status atual do cluster imediatamente:
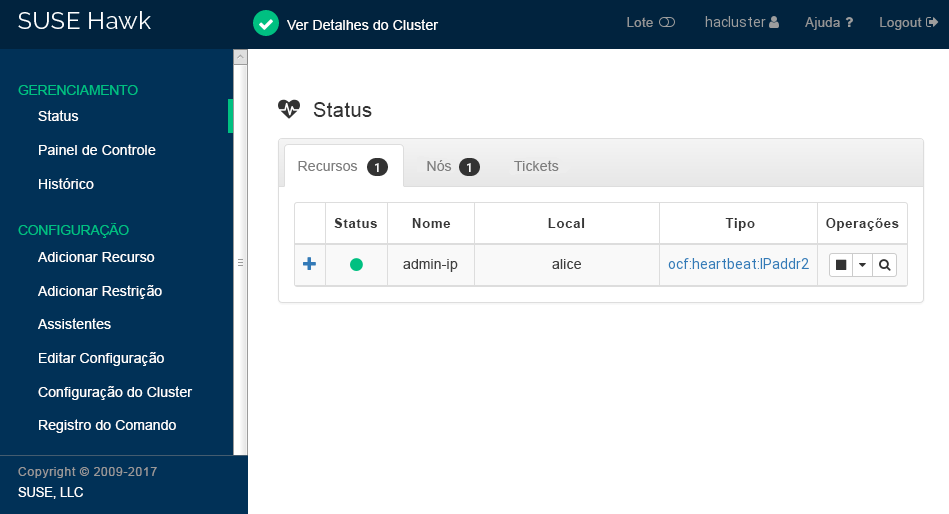
Figura 1: Status do Cluster de um Nó no Hawk2 #
7 Adicionando o segundo nó #
Se você tem um cluster de um nó ativo em execução, adicione o segundo nó do cluster com o script de boot ha-cluster-join, conforme descrito no Procedimento 4. O script precisa apenas de acesso a um nó do cluster existente para concluir a configuração básica na máquina atual automaticamente. Para obter detalhes, consulte a página de manual do ha-cluster-join.
Os scripts de boot ficam encarregados de mudar a configuração específica para um cluster de dois nós, por exemplo, SBD e Corosync.
Procedimento 4: Adicionando o segundo nó (bob) com ha-cluster-join #
Efetue login como
rootna máquina virtual ou física que deve se unir ao cluster.Inicie o script de boot executando:
root #ha-cluster-joinSe o NTP não foi configurado para ser iniciado no momento da inicialização, uma mensagem é exibida. O script também verifica se há um dispositivo de watchdog de hardware (que é importante para configurar o SBD) e avisará você se não houver nenhum.
Se você continuar mesmo assim, será solicitado a digitar o endereço IP de um nó existente. Digite o endereço IP do primeiro nó (
alice,192.168.1.1).Se você ainda não configurou o acesso SSH sem senha entre as duas máquinas, também será solicitado a digitar a senha de
rootdo nó existente.Após efetuar login no nó especificado, o script copiará a configuração do Corosync, definirá o SSH e o Csync2 e colocará a máquina atual online como novo nó do cluster. Além disso, ele iniciará o serviço necessário no Hawk2.
Verifique o status do cluster no Hawk2. Em › , dois nós são exibidos com um status verde (consulte a Figura 2, “Status do Cluster de Dois Nós”).
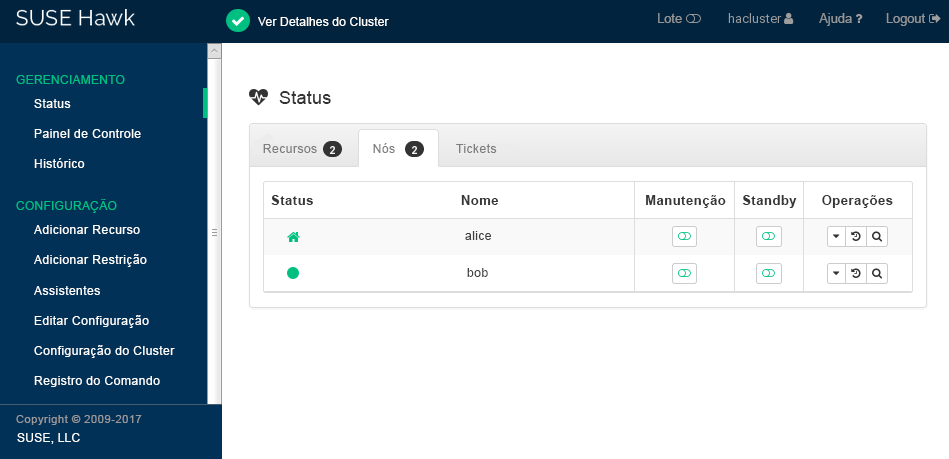
Figura 2: Status do Cluster de Dois Nós #
8 Testando o cluster #
O Procedimento 5, “Testando o failover de recursos” é um teste simples para verificar se o cluster move o endereço IP virtual para o outro nó caso o nó que executa o recurso atualmente esteja definido como standby.
No entanto, um teste realista envolve casos de uso e cenários específicos, incluindo testes do mecanismo de fencing para evitar uma situação de split brain. Se você não configurar o mecanismo de fencing corretamente, o cluster não funcionará de maneira apropriada.
Antes de usar o cluster em um ambiente de produção, teste-o completamente de acordo com os seus casos de uso.
Procedimento 5: Testando o failover de recursos #
Abra um terminal e execute o ping de
192.168.2.1, seu endereço IP virtual:root #ping192.168.2.1Efetue login no seu cluster conforme descrito no Procedimento 3, “Efetuando login na interface da Web do Hawk2”.
No Hawk2, › , verifique em qual nó o endereço IP virtual (recurso
admin_addr) está sendo executado. Consideramos que o recurso esteja sendo executado emalice.Coloque
aliceno modo (consulte a Figura 3, “Nóaliceno Modo Standby”).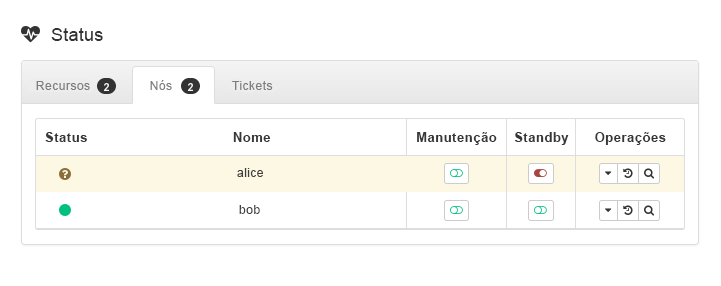
Figura 3: Nó
aliceno Modo Standby #Clique em › . O recurso
admin_addrfoi migrado parabob.
Durante a migração, é exibido um fluxo contínuo de pings para o endereço IP virtual. Isso mostra que a configuração do cluster e o IP flutuante funcionam corretamente. Cancele o comando ping com Ctrl–C.
9 Para obter mais informações #
Encontre mais documentação para este produto em https://documentation.suse.com/sle-ha-12. A documentação também inclui um Guia de Administração completo para a SUSE Linux Enterprise High Availability Extension. Consulte-o para ver mais tarefas de configuração e administração.
10 Informações Legais #
Copyright © 2006– 2026 SUSE LLC e colaboradores. Todos os direitos reservados.
Permissão concedida para copiar, distribuir e/ou modificar este documento sob os termos da Licença GNU de Documentação Livre, Versão 1.2 ou (por sua opção) versão 1.3; com a Seção Invariante sendo estas informações de copyright e a licença. Uma cópia da versão 1.2 da licença está incluída na seção intitulada “GNU Free Documentation License” (Licença GNU de Documentação Livre).
Para ver as marcas registradas da SUSE, visite http://www.suse.com/company/legal/. Todas as marcas comerciais de terceiros pertencem a seus respectivos proprietários. Os símbolos de marca registrada (®,™ etc.) representam marcas registradas da SUSE e suas afiliadas. Os asteriscos (*) indicam marcas registradas de terceiros.
Todas as informações deste manual foram compiladas com a maior atenção possível aos detalhes. Entretanto, isso não garante uma precisão absoluta. A SUSE LLC, suas afiliadas, os autores ou tradutores não serão responsáveis por possíveis erros nem pelas consequências resultantes de tais erros.