Geo Clustering Guide
- 1 Challenges for Geo Clusters
- 2 Conceptual Overview
- 3 Requirements
- 4 Setting Up the Booth Services
- 5 Synchronizing Configuration Files Across All Sites and Arbitrators
- 6 Configuring Cluster Resources and Constraints
- 7 Setting Up IP Relocation via DNS Update
- 8 Managing Geo Clusters
- 9 Troubleshooting
- 10 Upgrading to the Latest Product Version
- 11 For More Information
- A GNU Licenses
2 Conceptual Overview #
Abstract#
Geo clusters based on SUSE® Linux Enterprise High Availability Extension can be considered “overlay” clusters where each cluster site corresponds to a cluster node in a traditional cluster. The overlay cluster is managed by the booth cluster ticket manager (in the following called booth).
Each of the parties involved in a Geo cluster runs a service, the boothd.
It connects to the booth daemons running at the other sites and exchanges
connectivity details. For making cluster resources highly available across
sites, booth relies on cluster objects called tickets. A ticket grants the
right to run certain resources on a specific cluster site. Booth guarantees
that every ticket is granted to no more than one site at a time.
If the communication between two booth instances breaks down, it might be
because of a network breakdown between the cluster sites
or because of
an outage of one cluster site. In this case, you need an additional instance
(a third cluster site or an
arbitrator) to
reach consensus about decisions (such as failover of resources across sites).
Arbitrators are single machines (outside of the clusters) that run a booth
instance in a special mode. Each Geo cluster can have one or multiple
arbitrators.
The most common scenario probably is a Geo cluster with two sites and a single arbitrator on a third site. This requires three booth instances, see Figure 2.1, “Two-Site Cluster (2x2 Nodes + Arbitrator)”.
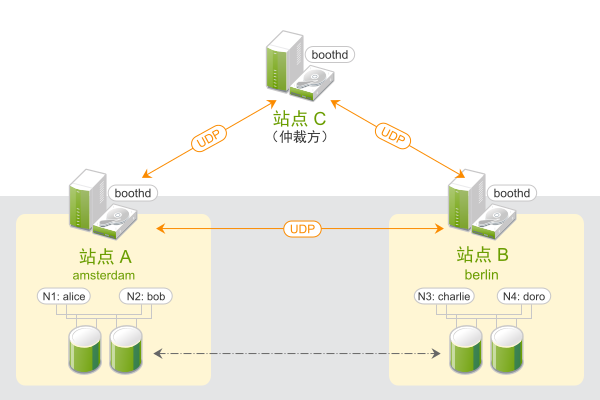
Figure 2.1: Two-Site Cluster (2x2 Nodes + Arbitrator) #
The following list explains the components and mechanisms for Geo clusters in more detail.
- Arbitrator
Each site runs one booth instance that is responsible for communicating with the other sites. If you have a setup with an even number of sites, you need an additional instance to reach consensus about decisions such as failover of resources across sites. In this case, add one or more arbitrators running at additional sites. Arbitrators are single machines that run a booth instance in a special mode. As all booth instances communicate with each other, arbitrators help to make more reliable decisions about granting or revoking tickets. Arbitrators cannot hold any tickets.
An arbitrator is especially important for a two-site scenario: For example, if site
Acan no longer communicate with siteB, there are two possible causes for that:A network failure between
AandB.Site
Bis down.
However, if site
C(the arbitrator) can still communicate with siteB, siteBmust still be up and running.- Booth Cluster Ticket Manager
Booth is the instance managing the ticket distribution, and thus, the failover process between the sites of a Geo cluster. Each of the participating clusters and arbitrators runs a service, the
boothd. It connects to the booth daemons running at the other sites and exchanges connectivity details. After a ticket has been granted to a site, the booth mechanism can manage the ticket automatically: If the site that holds the ticket is out of service, the booth daemons will vote which of the other sites will get the ticket. To protect against brief connection failures, sites that lose the vote (either explicitly or implicitly by being disconnected from the voting body) need to relinquish the ticket after a time-out. Thus, it is made sure that a ticket will only be redistributed after it has been relinquished by the previous site. See also Dead Man Dependency (loss-policy="fence").For a Geo cluster with two sites and arbitrator, you need 3 booth instances: one instance per site plus the instance running on the arbitrator.

Note: Limited Number of Booth Instances
The upper limit is (currently) 16 booth instances.
- Dead Man Dependency (
loss-policy="fence") After a ticket is revoked, it can take a long time until all resources depending on that ticket are stopped, especially in case of cascaded resources. To cut that process short, the cluster administrator can configure a
loss-policy(together with the ticket dependencies) for the case that a ticket gets revoked from a site. If the loss-policy is set tofence, the nodes that are hosting dependent resources are fenced.
Warning: Potential Loss of Data
On the one hand,
loss-policy="fence"considerably speeds up the recovery process of the cluster and makes sure that resources can be migrated more quickly.On the other hand, it can lead to loss of all unwritten data, such as:
Data lying on shared storage (for example, DRBD).
Data in a replicating database (for example, MariaDB or PostgreSQL) that has not yet reached the other site, because of a slow network link.
- Ticket
A ticket grants the right to run certain resources on a specific cluster site. A ticket can only be owned by one site at a time. Initially, none of the sites has a ticket—each ticket must be granted once by the cluster administrator. After that, tickets are managed by the booth for automatic failover of resources. But administrators may also intervene and grant or revoke tickets manually.
After a ticket is administratively revoked, it is not managed by booth anymore. For booth to start managing the ticket again, the ticket must be again granted to a site.
Resources can be bound to a certain ticket by dependencies. Only if the defined ticket is available at a site, the respective resources are started. Vice versa, if the ticket is removed, the resources depending on that ticket are automatically stopped.
The presence or absence of tickets for a site is stored in the CIB as a cluster status. With regard to a certain ticket, there are only two states for a site:
true(the site has the ticket) orfalse(the site does not have the ticket). The absence of a certain ticket (during the initial state of the Geo cluster) is not treated differently from the situation after the ticket has been revoked. Both are reflected by the valuefalse.A ticket within an overlay cluster is similar to a resource in a traditional cluster. But in contrast to traditional clusters, tickets are the only type of resource in an overlay cluster. They are primitive resources that do not need to be configured or cloned.
- Ticket Failover
If the ticket gets lost, which means other booth instances do not hear from the ticket owner in a sufficiently long time, one of the remaining sites will acquire the ticket. This is what is called ticket failover. If the remaining members cannot form a majority, then the ticket cannot fail over.