Replica Rebuilding
When SUSE Storage detects a failed or deleted replica, it automatically initiates a rebuilding process. This document outlines the replica rebuilding workflow for v1 data engine, including full, delta, and fast rebuilding methods. It also explains the limitations associated with each method.
Rebuilding will not start in the following scenarios:
-
The volume is migrating to another node.
-
The volume is an old restore/DR volume.
-
The volume is expanding in size.
Replica Rebuilding Workflow
Replica rebuilding may occur in the following scenarios for the v1 data engine:
-
A node is rebooted, drained, or evicted.
-
A replica becomes unhealthy or is deleted.
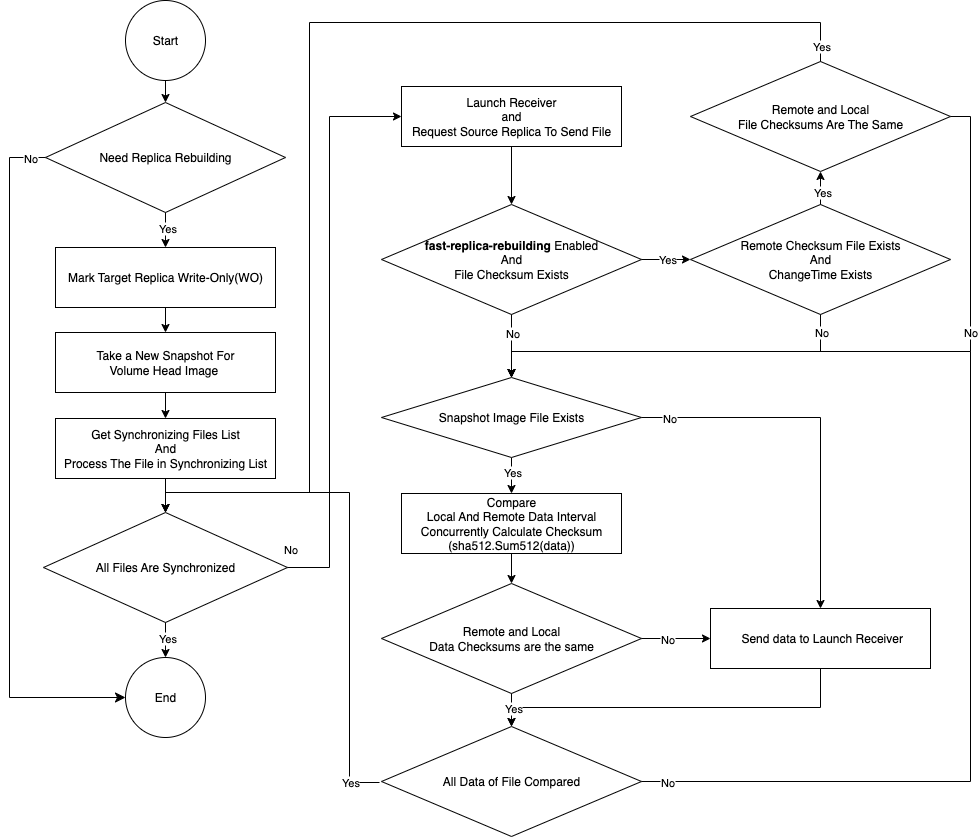
-
Mark the target replica with
WO(write-only) mode. -
Create a new snapshot to serve as the volume head reference point for data integrity checks.
-
Generate the synchronization file list for the volume head and snapshot files.
For V1 Data Engine
-
Start a receiver server on the target replica for each snapshot.
-
Instruct the source replica to begin data synchronization.
-
For each snapshot:
-
Check if the snapshot file exists in the data directory of the target replica.
-
If no, transfer the entire snapshot data from the source replica to the target replica. See Full Replica Rebuilding.
-
If yes, check whether the snapshot checksum files exist, and whether the modification time and checksums are identical between the target and source replicas.
-
If yes, SUSE Storage skips transferring the data of the snapshot. This optimization reduces CPU usage, disk I/O, network I/O, and total rebuild time. See Fast Replica Rebuilding.
-
If no, SUSE Storage calculates and compares block-level checksums using the SHA-512 algorithm. If mismatches are found, only the differing blocks are synchronized. See Delta Replica Rebuilding.
-
-
-
-
For V2 Data Engine
-
Expose the source and target replicas and prepare a shallow copy using the SPDK engine.
-
For each snapshot:
-
Check if the snapshot timestamp, actual size, and checksum match between the source and target.
-
If yes, SUSE Storage skips transferring the data of that snapshot.
-
If no, check whether both the source and target snapshots contain ranged checksums.
-
If yes, fetch and compare the range checksums. If mismatches exist, only the mismatched ranges are copied. See Fast Replica Rebuilding.
-
If no, delete the existing target snapshot. Then, copy the entire snapshot from the source replica to the target replica. See Full Replica Rebuilding.
-
-
-
Full Replica Rebuilding
If the replica is unrecoverable or has no existing data, SUSE Storage synchronizes all data from a healthy replica. It reconstructs the replica by transferring the full snapshot chain.
Full replica rebuilding consumes significant network bandwidth and results in heavy disk write operations on the target node. However, it is required when the target replica has no usable data.
Delta Replica Rebuilding
Delta replica rebuilding is only for v1 data engine. It starts with a reusable failed replica, and it checks the data integrity for all snapshots' data block by block.
-
This is available for failed replica reuse only, and there is an existing snapshot file (with the same name) in the failed replica data directory
-
When a snapshot has no checksum, SUSE Storage performs delta replica rebuilding for this snapshot instead.
-
Pros:
-
Reduce network bandwidth consumption.
-
-
Cons:
-
Increased CPU overhead because SUSE Storage will compute the checksum of the snapshot data block by block for data integrity check.
-
Rebuilding time is influenced by CPU performance.
-
Fast Replica Rebuilding
Fast replica rebuilding is enabled when the following conditions are met:
-
The fast replica rebuild setting is enabled:
fast-replica-rebuild-enabled: true -
Snapshot checksum files are created (checksums are precomputed) using one of the following methods:
-
snapshot-data-integrityis set toenabled: A scheduled job calculates checksums for all snapshots at a configured interval (default: 7 days). -
snapshot-data-integrity-immediate-check-after-snapshot-creationis set totrue: The snapshot checksum is calculated immediately after snapshot creation.
-
|
These checksum calculations consume storage and computing resources. The calculation time is unpredictable and may negatively impact storage performance. For more information, see Snapshot Data Integrity. |
-
Pros:
-
Minimizes network bandwidth consumption.
-
Minimizes disk I/O.
-
-
Cons:
-
Calculating snapshot checksums can be time-consuming.
-
The timing of checksum calculation is unpredictable. It may trigger even under high I/O load.
-
For more information, see Fast Replica Rebuilding.
Factors That Affect Rebuilding Performance
-
Large volume head
-
Why it matters: The volume head is a special file that never has a precomputed checksum. If a replica fails, SUSE Storage must always synchronize the entire volume head. A larger volume head increases rebuild time.
-
How to prevent: Take snapshots regularly to reduce the volume head’s size. Schedule snapshots before planned maintenance to minimize rebuild time.
-
-
No snapshots exist
-
Why it matters: Without snapshots, SUSE Storage cannot skip data transfer or reuse existing data. If a volume head snapshot is created but its checksum isn’t ready, SUSE Storage must perform delta rebuilding. This increases CPU usage due to block-by-block checksum comparisons.
-
How to prevent:
-
Enable
snapshot-data-integrity-immediate-check-after-snapshot-creationorsnapshot-data-integrityto precompute checksums. Trade-off: Increases CPU, disk I/O, and storage usage during computation. -
Use a recurring job to create snapshots regularly.
-
-
-
Snapshot purged
-
Why it matters: When snapshot purging starts, system-generated snapshots are coalesced into the next snapshot. This invalidates the checksum of next snapshot.
-
How to prevent:
-
Enable
snapshot-data-integrity-immediate-check-after-snapshot-creationto ensure checksums are computed after purging. -
Proactively create a snapshot and allow time for checksum generation before performing upgrades or rebuilds.
-
-
-
Concurrent rebuilds
-
Why it matters: Running multiple rebuilds on the same node can overuse CPU, disk input-output, and network input-output, impacting performance.
-
How to prevent: Tune the number of concurrent rebuilds using the
concurrent-replica-rebuild-per-node-limitsetting.
-
-
Multiple replica failures
-
Why it matters: Increases rebuild time and complexity. If
auto-cleanup-system-generated-snapshotistrueand no user-created snapshots exist, two failed replicas may trigger at least one full data transfer.For more details, see Avoid "full data transfer" when rebuilding two failed replicas.
-
How to prevent:
-
Disable
auto-cleanup-system-generated-snapshotbefore performing maintenance. -
Create user snapshots of all volumes before starting maintenance.
-
Use a recurring job to take snapshots regularly.
-
-
Use Cases
Node Reboot During Upgrade
When a worker node with replicas is rebooted as part of a planned upgrade:
-
The replica on that node becomes temporarily unavailable and fails, but read and write operations continue.
-
If the node recovers within the
replica-replenishment-wait-interval, SUSE Storage initiates a rebuild using the reusable failed replica.
During the rebuilding process:
-
SUSE Storage selects the latest reusable failed replica if multiple reusable failed replicas are available.
-
Based on the rebuild scenario:
-
If fast replica rebuilding is enabled and all snapshot checksums exist: SUSE Storage triggers Fast Replica Rebuilding. Only changed blocks in the volume head are synced, avoiding both full and delta rebuilding.
-
If fast replica rebuilding is enabled but some snapshot checksums are missing: SUSE Storage triggers Delta Replica Rebuilding. Changed blocks from snapshots without checksums are synced, avoiding full rebuilding.
-
If fast replica rebuilding is disabled: SUSE Storage performs delta rebuilding by syncing changed blocks of all snapshots, avoiding full rebuilding.
-
Short-Term Node Drain
If a worker node is drained for short-term maintenance and then quickly restored:
-
The replica on the drained node is marked as failed immediately.
-
If the node is uncordoned before the
replica-replenishment-wait-intervalexpires, SUSE Storage attempts to reuse the failed replica. -
Rebuild behavior follows the same logic as described in the previous use case.
Relevant Settings
| Setting | Default | Description |
|---|---|---|
|
|
Enables fast replica rebuilding. Relies on precomputed snapshot checksums. |
|
Hashes snapshot disk files only if they are unhashed or their modification time has changed. |
|
|
|
Cron schedule to compute checksums for all snapshots. Default: every 7 days. |
|
|
If enabled, computes checksums immediately after snapshot creation. |
|
|
Time in seconds to wait before creating a new replica. Allows reuse of failed replicas. |
|
|
Limits the number of concurrent replica rebuilds per node. |
|
|
Determines whether degraded replicas are rebuilt while the volume is detached. |
Settings Trade-Off Analysis
-
-
enabled: Skips snapshot data transfer if checksums are current. Provides fast rebuilds but doesn’t revalidate data. -
disabled: Performs delta rebuilding using block comparisons. Slower, but ensures snapshot data integrity.
-
-
-
enabled: By default, calculates snapshot checksums every 7 days. Increases CPU, disk I/O, and resource usage.
-
-
snapshot-data-integrity-cronjob
-
Default:
0 0 */7 * *If
snapshot-data-integrityis enabled, this defines when snapshot checksums are recalculated. Snapshots created between cron runs may lack checksums.
-
-
snapshot-data-integrity-immediate-check-after-snapshot-creation
-
true: Immediately computes snapshot checksums after creation. Increases CPU and disk I/O usage. Completion time is unpredictable. -
false: Snapshots may not have checksums until the next cron run. Delta rebuilding will be required if checksums are missing.
-
-
replica-replenishment-wait-interval
-
Default:
600seconds-
Short interval: May skip reusing failed replicas and trigger full rebuilds.
-
Long interval: Waits longer to reuse failed replicas but may delay recovery.
-
-
-
concurrent-replica-rebuild-per-node-limit
-
Default:
5-
High limit: May overload node resources, slowing down rebuilds and active workloads.
-
Low limit: Reduces resource contention but increases rebuild time due to queueing.
-
-