Node Space Usage
Whole Cluster Space Usage
In Dashboard page, SUSE Storage shows you the cluster space usage info:
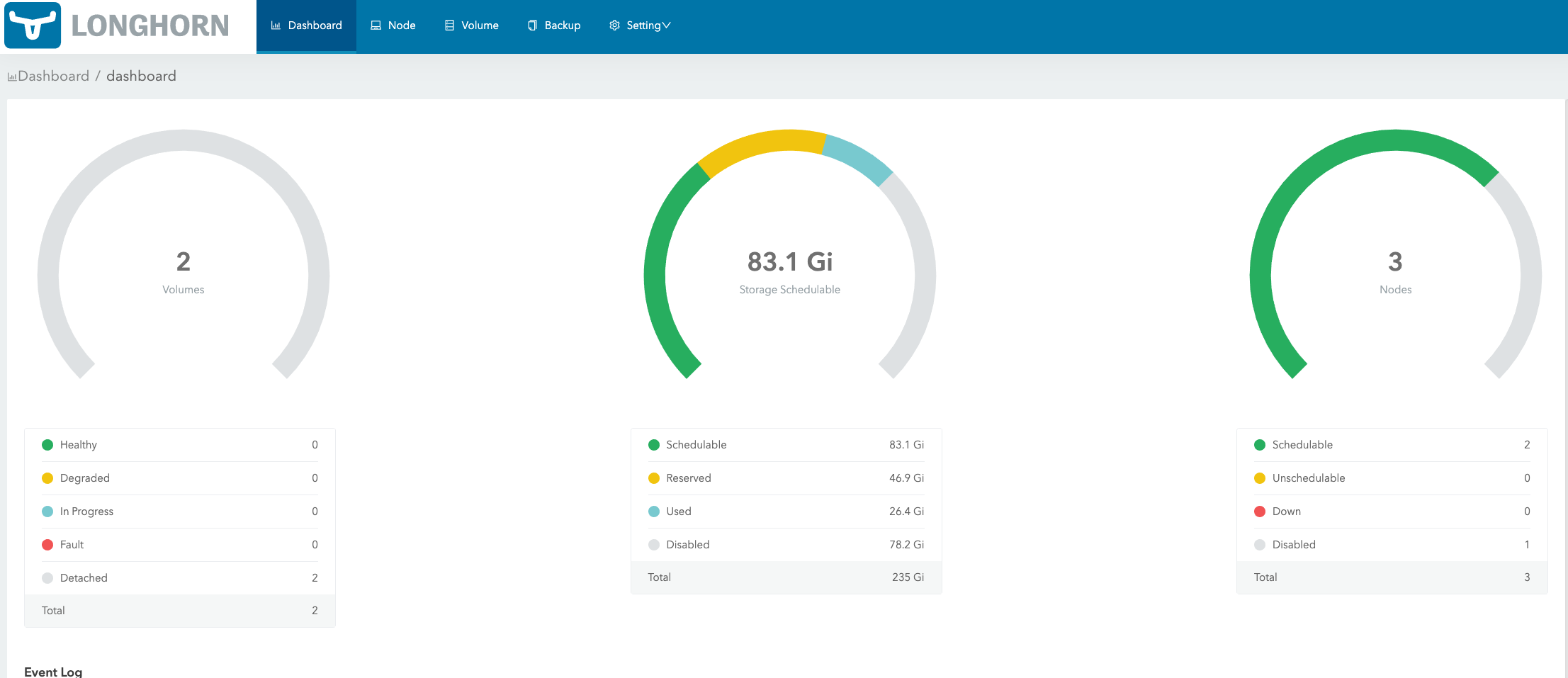
Schedulable: The actual space that can be used for Longhorn volume scheduling.
Reserved: The space reserved for other applications and system.
Used: The actual space that has been used by Longhorn system and other applications.
Disabled: The total space of the disks/nodes on which Longhorn volumes are not allowed for scheduling.
Space Usage of Each Node
In Nodes page, SUSE Storage show the space allocation, schedule and usage info for each node:
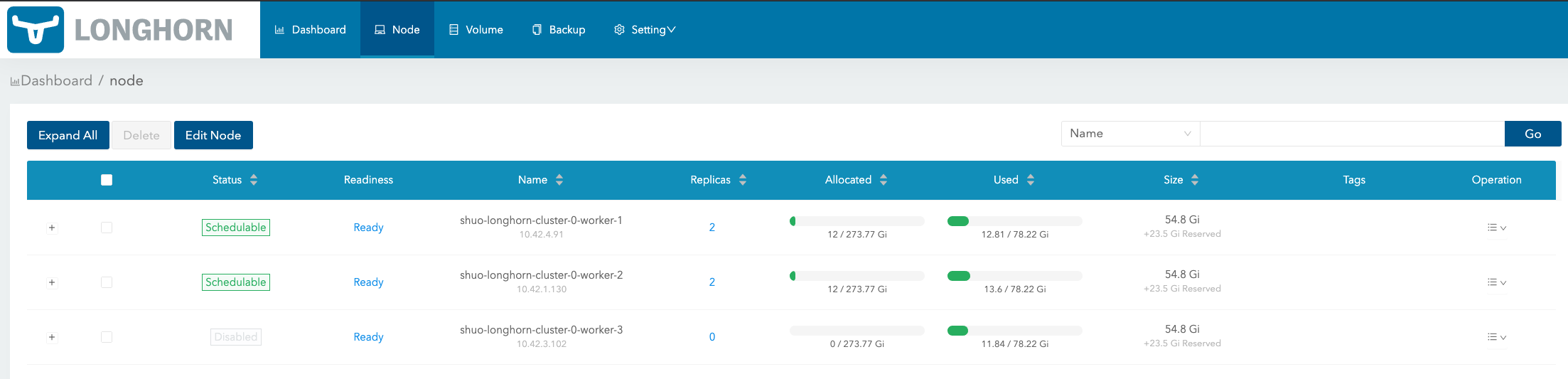
Size column: The max actual available space that can be used by Longhorn volumes. It equals the total disk space of the node minus reserved space.
Allocated column: The left number is the size that has been used for volume scheduling, and it does not mean the space has been used for the Longhorn volume data store. The right number is the max size for volume scheduling, which the result of Size multiplying Storage Over Provisioning Percentage. (In the above illustration, Storage Over Provisioning Percentage is 500.) Hence, the difference between the 2 numbers (let’s call it as the allocable space) determines if a volume replica can be scheduled to this node.
Used column: The left part indicates the currently used space of this node. The whole bar indicates the total space of the node.
Notice that the allocable space may be greater than the actual available space of the node when setting Storage Over Provisioning Percentage to a value greater than 100. If the volumes are heavily used and lots of historical data would be stored in the volume snapshots, please be careful about using a large value for this setting. For more info about the setting, see here for details.
Disk Schedulability Status and Troubleshooting Message
When a disk becomes unschedulable, SUSE Storage exposes the underlying reason directly in the UI.
On the Nodes page, if the internal Schedulable condition of the disk is False, the UI displays the exact message from node.diskStatus[x].conditions[Schedulable].
This information is essential for diagnosing issues related to space limits or over-provisioning.
Example Troubleshooting Message:
Disk default-disk-1030100000000 (/var/lib/longhorn/) on the node ip-192-168-203-144.ap-southeast-1.compute.internal is not schedulable for more replica; Scheduling space condition failed: ScheduledTotal = 4294967296 (Size + StorageScheduled) is greater than ProvisionedLimit = -64504221696 (100% of StorageMax - StorageReserved).How to interpret this message:
-
ScheduledTotal: The total space currently scheduled for replicas (both existing and pending) on this disk.This does not represent the actual disk usage.
-
ProvisionedLimit: The maximum allowed scheduling capacity for this disk. It is derived from:-
physical size of the disk (
StorageMax) -
its reserved space (
StorageReserved) -
multiplied by the
Storage Over Provisioning Percentageof the cluster
-
When ScheduledTotal exceeds ProvisionedLimit, the disk becomes unschedulable and will not accept new replicas until the disk configuration or cluster settings are adjusted.