Configurer Prometheus et Grafana pour surveiller SUSE® Storage.
Longhorn expose nativement des métriques au format texte Prometheus sur un point de terminaison REST http://LONGHORN_MANAGER_IP:PORT/metrics.
Vous pouvez utiliser n’importe quel outil de collecte tel que Prometheus, Graphite, Telegraf pour extraire ces métriques puis visualiser les données collectées par des outils tels que Grafana.
Voir Longhorn Metrics for Monitoring pour consulter les métriques disponibles.
Aperçu général
Le système de surveillance utilise Prometheus pour collecter des données et envoyer des alertes, et Grafana pour visualiser/créer un tableau de bord des données collectées.
-
Le serveur Prometheus extrait et stocke les données de séries temporelles à partir des points de terminaison de métriques Longhorn. Prometheus est également responsable de la génération d’alertes basées sur des règles configurées et sur les données collectées. Les serveurs Prometheus envoient ensuite des alertes à un Alertmanager.
-
AlertManager gère ensuite ces alertes, y compris la mise en silence, l’inhibition, l’agrégation et l’envoi de notifications par des méthodes telles que l’e-mail, les systèmes de notification d’appel et les plateformes de chat.
-
Grafana qui interroge le serveur Prometheus pour des données et dessine un tableau de bord pour la visualisation.
L’image ci-dessous décrit l’architecture détaillée du système de surveillance.
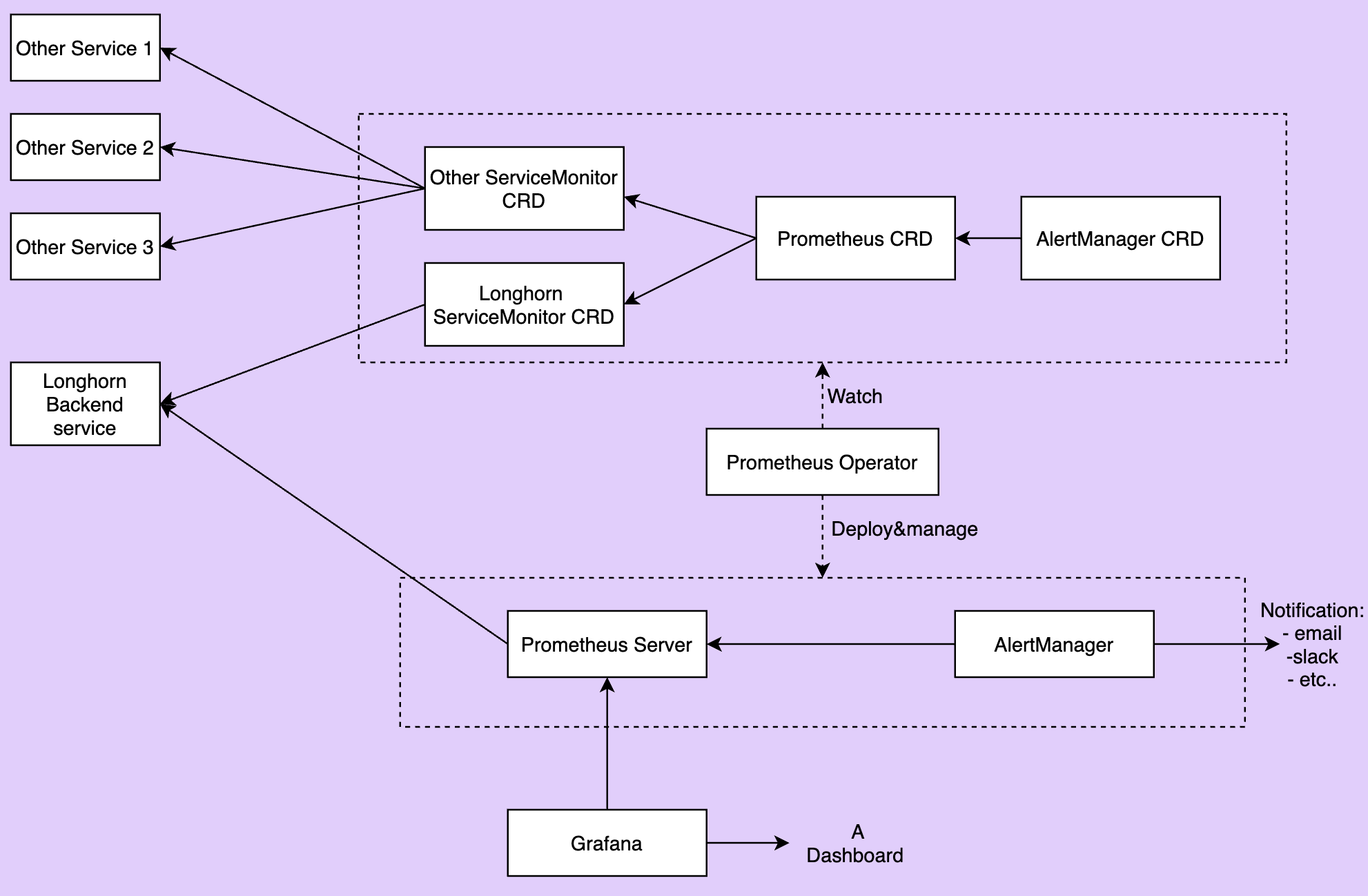
Il y a 2 composants non mentionnés dans l’image ci-dessus :
-
Le service backend Longhorn est un service pointant vers l’ensemble des pods Longhorn Manager. Les métriques de Longhorn sont exposées dans les pods Longhorn Manager au point de terminaison
http://LONGHORN_MANAGER_IP:PORT/metrics. -
Prometheus Operator facilite grandement l’exécution de Prometheus sur Kubernetes. L’opérateur surveille 3 ressources personnalisées : ServiceMonitor, Prometheus et AlertManager. Lorsque vous créez ces ressources personnalisées, l’opérateur Prometheus déploie et gère le serveur Prometheus ainsi qu’AlertManager, en utilisant les configurations spécifiées par l’utilisateur.
Installation
Ce document utilise l’espace de noms default pour le système de surveillance. Pour installer dans un espace de noms différent, modifiez le champ namespace: <OTHER_NAMESPACE> dans les manifestes.
Installez le Prometheus Operator.
Suivez les instructions dans Prometheus Operator - Quickstart.
REMARQUE : Vous devrez peut-être choisir une version compatible avec la version de Kubernetes du cluster.
Installez Longhorn ServiceMonitor.
Installez Longhorn ServiceMonitor avec Kubectl.
Créez un ServiceMonitor pour Longhorn Manager.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: longhorn-prometheus-servicemonitor
namespace: default
labels:
name: longhorn-prometheus-servicemonitor
spec:
selector:
matchLabels:
app: longhorn-manager
namespaceSelector:
matchNames:
- longhorn-system
endpoints:
- port: managerInstallez Longhorn ServiceMonitor avec Helm.
-
Modifiez le fichier YAML
longhorn/chart/values.yaml.metrics: serviceMonitor: # -- Setting that allows the creation of a [Prometheus Operator](https://prometheus-operator.dev/) ServiceMonitor resource for Longhorn Manager components. enabled: true -
Créez un ServiceMonitor pour Longhorn Manager en utilisant Helm.
helm upgrade longhorn longhorn/longhorn --namespace longhorn-system -f values.yaml
Longhorn ServiceMonitor est une ressource personnalisée Prometheus Operator. Cette configuration permet au serveur Prometheus de découvrir tous les pods Longhorn Manager et leurs points de terminaison respectifs.
Vous pouvez utiliser le sélecteur d’étiquettes app: longhorn-manager pour sélectionner le service longhorn-backend, qui pointe vers l’ensemble des pods Longhorn Manager.
Installez et configurez Prometheus AlertManager.
-
Créez un déploiement Alertmanager hautement disponible avec 3 instances.
apiVersion: monitoring.coreos.com/v1 kind: Alertmanager metadata: name: longhorn namespace: default spec: replicas: 3 -
Les instances d’Alertmanager ne démarreront pas à moins qu’une configuration valide ne soit fournie. Voir Prometheus - Configuration pour plus d’explications.
global: resolve_timeout: 5m route: group_by: [alertname] receiver: email_and_slack receivers: - name: email_and_slack email_configs: - to: <the email address to send notifications to> from: <the sender address> smarthost: <the SMTP host through which emails are sent> # SMTP authentication information. auth_username: <the username> auth_identity: <the identity> auth_password: <the password> headers: subject: 'Longhorn-Alert' text: |- {{ range .Alerts }} *Alert:* {{ .Annotations.summary }} - `{{ .Labels.severity }}` *Description:* {{ .Annotations.description }} *Details:* {{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}` {{ end }} {{ end }} slack_configs: - api_url: <the Slack webhook URL> channel: <the channel or user to send notifications to> text: |- {{ range .Alerts }} *Alert:* {{ .Annotations.summary }} - `{{ .Labels.severity }}` *Description:* {{ .Annotations.description }} *Details:* {{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}` {{ end }} {{ end }}Enregistrez la configuration d’Alertmanager ci-dessus dans un fichier appelé
alertmanager.yamlet créez un secret à partir de celui-ci en utilisant kubectl.Les instances d’Alertmanager nécessitent que le nom de la ressource secrète suive le format
alertmanager-<ALERTMANAGER_NAME>. Dans l’étape précédente, le nom de l’Alertmanager estlonghorn, donc le nom du secret doit êtrealertmanager-longhorn.$ kubectl create secret generic alertmanager-longhorn --from-file=alertmanager.yaml -n default -
Pour pouvoir visualiser l’interface web de l’Alertmanager, exposez-le via un Service. Une manière simple de le faire est d’utiliser un Service de type NodePort.
apiVersion: v1 kind: Service metadata: name: alertmanager-longhorn namespace: default spec: type: NodePort ports: - name: web nodePort: 30903 port: 9093 protocol: TCP targetPort: web selector: alertmanager: longhornAprès avoir créé le service ci-dessus, vous pouvez accéder à l’interface web de l’Alertmanager via l’adresse IP d’un nœud et le port 30903.
Utilisez
NodePortle service ci-dessus uniquement pour une vérification rapide car il ne communique pas via la connexion TLS. Vous souhaiterez peut-être changer le type de service enClusterIPet configurer un contrôleur Ingress pour exposer l’interface web de l’Alertmanager via une connexion TLS.
Installez et configurez le serveur Prometheus.
-
Créez une ressource personnalisée PrometheusRule pour définir les conditions d’alerte. Voir plus d’exemples concernant les règles d’alerte Longhorn à Exemples de règles d’alerte Longhorn.
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: prometheus: longhorn role: alert-rules name: prometheus-longhorn-rules namespace: default spec: groups: - name: longhorn.rules rules: - alert: LonghornVolumeUsageCritical annotations: description: Longhorn volume {{$labels.volume}} on {{$labels.node}} is at {{$value}}% used for more than 5 minutes. summary: Longhorn volume capacity is over 90% used. expr: 100 * (longhorn_volume_usage_bytes / longhorn_volume_capacity_bytes) > 90 for: 5m labels: issue: Longhorn volume {{$labels.volume}} usage on {{$labels.node}} is critical. severity: criticalVoir Prometheus - Règles d’alerte pour plus d’informations.
-
Si l’autorisation RBAC est activée, créez un ClusterRole et un ClusterRoleBinding pour les Pods Prometheus.
apiVersion: v1 kind: ServiceAccount metadata: name: prometheus namespace: defaultapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus namespace: default rules: - apiGroups: [""] resources: - nodes - services - endpoints - pods verbs: ["get", "list", "watch"] - apiGroups: [""] resources: - configmaps verbs: ["get"] - nonResourceURLs: ["/metrics"] verbs: ["get"]apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: default -
Créez une ressource personnalisée Prometheus. Remarquez que nous sélectionnons le Longhorn ServiceMonitor et les règles Longhorn dans la spécification.
apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: name: longhorn namespace: default spec: replicas: 2 serviceAccountName: prometheus alerting: alertmanagers: - namespace: default name: alertmanager-longhorn port: web serviceMonitorSelector: matchLabels: name: longhorn-prometheus-servicemonitor ruleSelector: matchLabels: prometheus: longhorn role: alert-rules -
Pour pouvoir visualiser l’interface web du serveur Prometheus, exposez-le via un Service. Une manière simple de le faire est d’utiliser un Service de type NodePort.
apiVersion: v1 kind: Service metadata: name: prometheus-longhorn namespace: default spec: type: NodePort ports: - name: web nodePort: 30904 port: 9090 protocol: TCP targetPort: web selector: prometheus: longhornAprès avoir créé le service ci-dessus, vous pouvez accéder à l’interface web du serveur Prometheus via l’adresse IP d’un nœud et le port 30904.
À ce stade, vous devriez être en mesure de voir toutes les cibles de Longhorn Manager ainsi que les règles Longhorn dans la section cibles et règles de l’interface du serveur Prometheus.
Utilisez le service NodePort ci-dessus uniquement pour une vérification rapide car il ne communique pas via la connexion TLS. Vous souhaiterez peut-être changer le type de service en
ClusterIPet configurer un contrôleur Ingress pour exposer l’interface web du serveur Prometheus via une connexion TLS.
Configurez Grafana.
-
Créez le ConfigMap de la source de données Grafana.
apiVersion: v1 kind: ConfigMap metadata: name: grafana-datasources namespace: default data: prometheus.yaml: |- { "apiVersion": 1, "datasources": [ { "access":"proxy", "editable": true, "name": "prometheus-longhorn", "orgId": 1, "type": "prometheus", "url": "http://prometheus-longhorn.default.svc:9090", "version": 1 } ] }NOTE: changez le champ
urlsi vous installez la pile de surveillance dans un espace de noms différent.+http://prometheus-longhorn.<NAMESPACE>.svc:9090" -
Créez le déploiement Grafana.
apiVersion: apps/v1 kind: Deployment metadata: name: grafana namespace: default labels: app: grafana spec: replicas: 1 selector: matchLabels: app: grafana template: metadata: name: grafana labels: app: grafana spec: containers: - name: grafana image: grafana/grafana:7.1.5 ports: - name: grafana containerPort: 3000 resources: limits: memory: "500Mi" cpu: "300m" requests: memory: "500Mi" cpu: "200m" volumeMounts: - mountPath: /var/lib/grafana name: grafana-storage - mountPath: /etc/grafana/provisioning/datasources name: grafana-datasources readOnly: false volumes: - name: grafana-storage emptyDir: {} - name: grafana-datasources configMap: defaultMode: 420 name: grafana-datasources -
Créez le service Grafana.
apiVersion: v1 kind: Service metadata: name: grafana namespace: default spec: selector: app: grafana type: ClusterIP ports: - port: 3000 targetPort: 3000 -
Exposez Grafana sur NodePort
32000.kubectl -n default patch svc grafana --type='json' -p '[{"op":"replace","path":"/spec/type","value":"NodePort"},{"op":"replace","path":"/spec/ports/0/nodePort","value":32000}]'Utilisez le service NodePort ci-dessus uniquement pour une vérification rapide car il ne communique pas via la connexion TLS. Vous voudrez peut-être changer le type de service en ClusterIP et configurer un contrôleur Ingress pour exposer Grafana via une connexion TLS.
-
Accédez au tableau de bord Grafana en utilisant n’importe quelle IP de nœud sur le port
32000.# Default Credential User: admin Pass: admin -
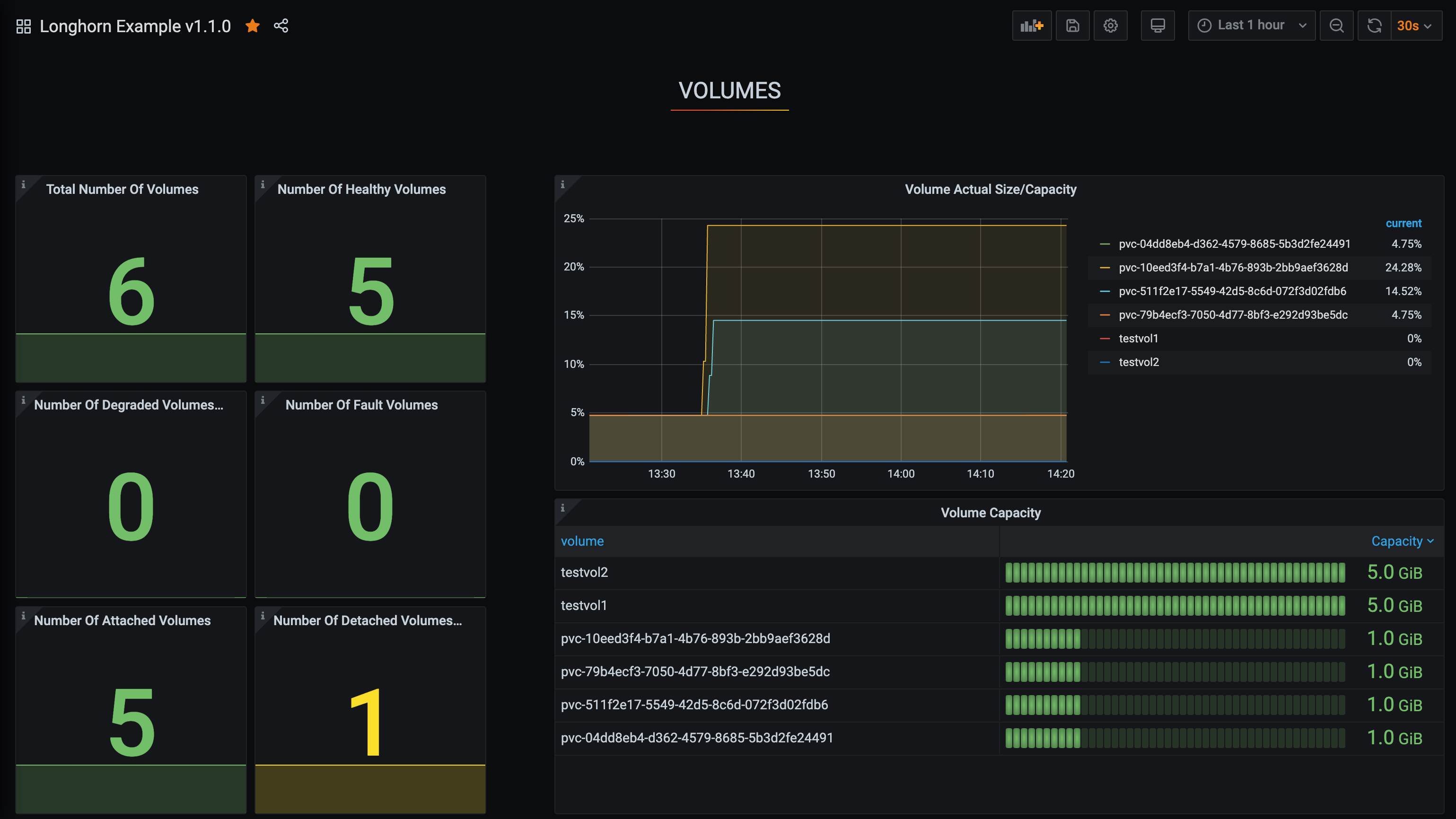
Configurez le tableau de bord Longhorn.
Une fois dans Grafana, importez le tableau de bord d’exemple préconstruit Longhorn example dashboard.
Voir Grafana Lab - Export and import pour des instructions sur la façon d’importer un tableau de bord Grafana.
Vous devriez voir le tableau de bord suivant lors d’une configuration réussie :