Protokollierung
Es ist wichtig zu wissen, was im Harvester Cluster passiert/ist passiert.
Harvester sammelt die cluster running log, Kubernetes audit und event Protokolle direkt nach dem Einschalten des Clusters, was hilfreich für Überwachung, Protokollierung, Prüfung und Fehlersuche ist.
Harvester unterstützt das Senden dieser Protokolle an verschiedene Arten von Protokollservern.
|
Die Größe der Protokolldaten hängt von der Clustergröße, der Arbeitslast und anderen Faktoren ab. |
Die Protokollierungsfunktion ist jetzt mit einem Add-on implementiert und standardmäßig in neuen Installationen deaktiviert.
Benutzer können das rancher-logging Add-on über die Harvester-Benutzeroberfläche nach der Installation aktivieren/deaktivieren.
Benutzer können das rancher-logging Add-on in ihrer Harvester-Installation auch aktivieren/deaktivieren, indem sie die Konfigurationsdatei anpassen.
Für Harvester-Cluster, die von Version v1.1.x aktualisiert wurden, wird die Protokollierungsfunktion automatisch in ein Add-on umgewandelt und bleibt wie zuvor aktiviert.
Übersicht über die Architektur
Sowohl Harvester als auch Rancher verwenden den Logging Operator, um spezifische Komponenten und Operationen der internen Protokollierungsinfrastruktur zu verwalten.
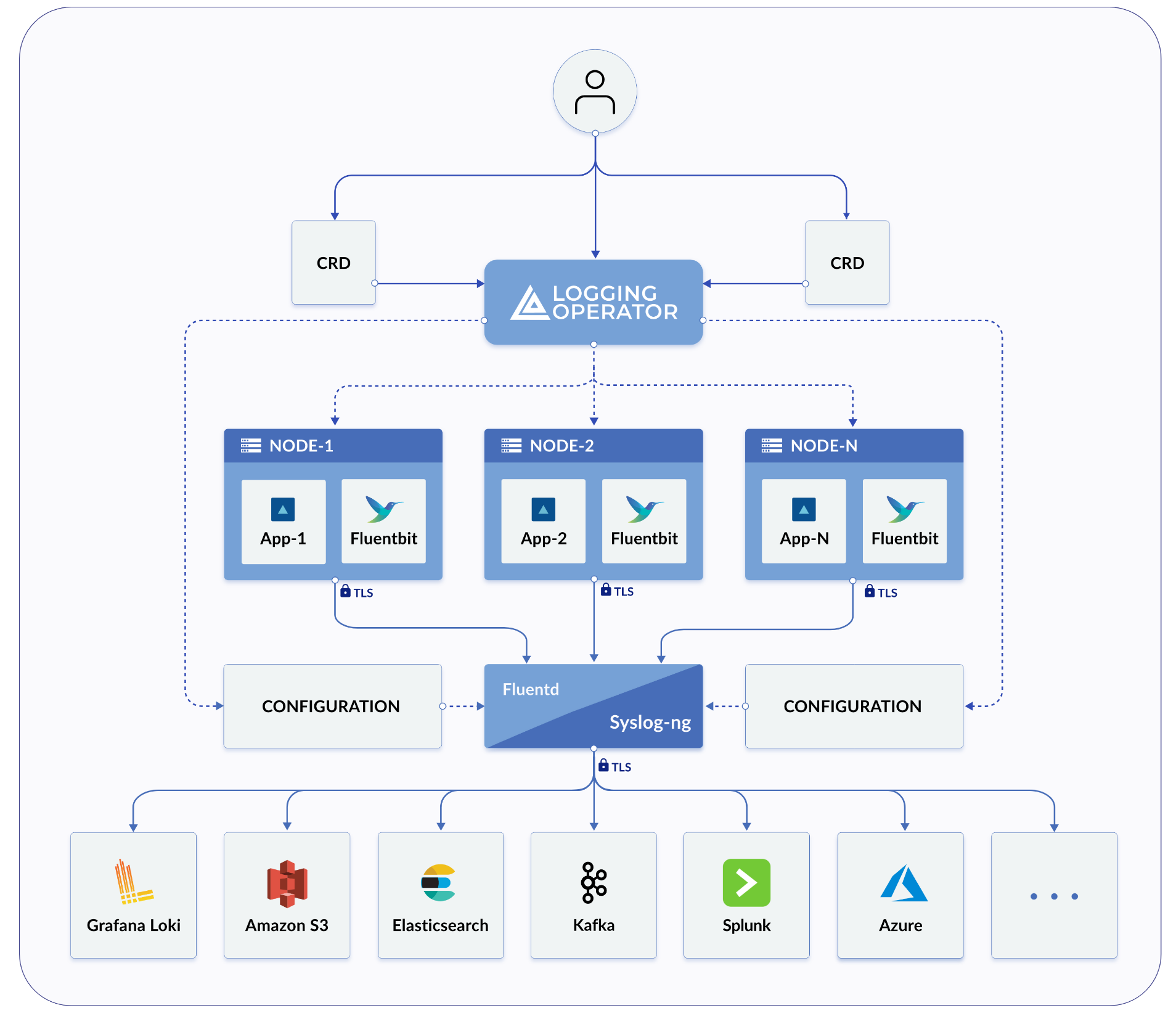
In der Praxis von Harvester nutzen Logging, Audit und Event eine gemeinsame Architektur, wobei Logging die Infrastruktur darstellt und Audit sowie Event darauf aufbauen.
Protokollierung
Die Protokollierungsinfrastruktur von Harvester ermöglicht es Ihnen, Harvester-Protokolle in einen externen Dienst wie Graylog, Elasticsearch, Splunk, Grafana Loki und andere zu aggregieren.
Gesammelte Protokolle
Siehe unten für eine Liste der gesammelten Protokolle:
-
Protokolle von allen Clustern
Pods -
Kernel-Protokolle von jedem
node -
Protokolle von ausgewählten systemd-Diensten von jedem Knoten
-
rke2-server -
rke2-agent -
rancherd -
rancher-system-agent -
NetworkManager -
iscsid
-
|
Benutzer können konfigurieren und ändern, wohin die aggregierten Protokolle gesendet werden, sowie einige grundlegende Filter anwenden. Es wird nicht unterstützt, die Auswahl der zu sammelnden Protokolle zu ändern. |
Konfigurieren von Protokollressourcen
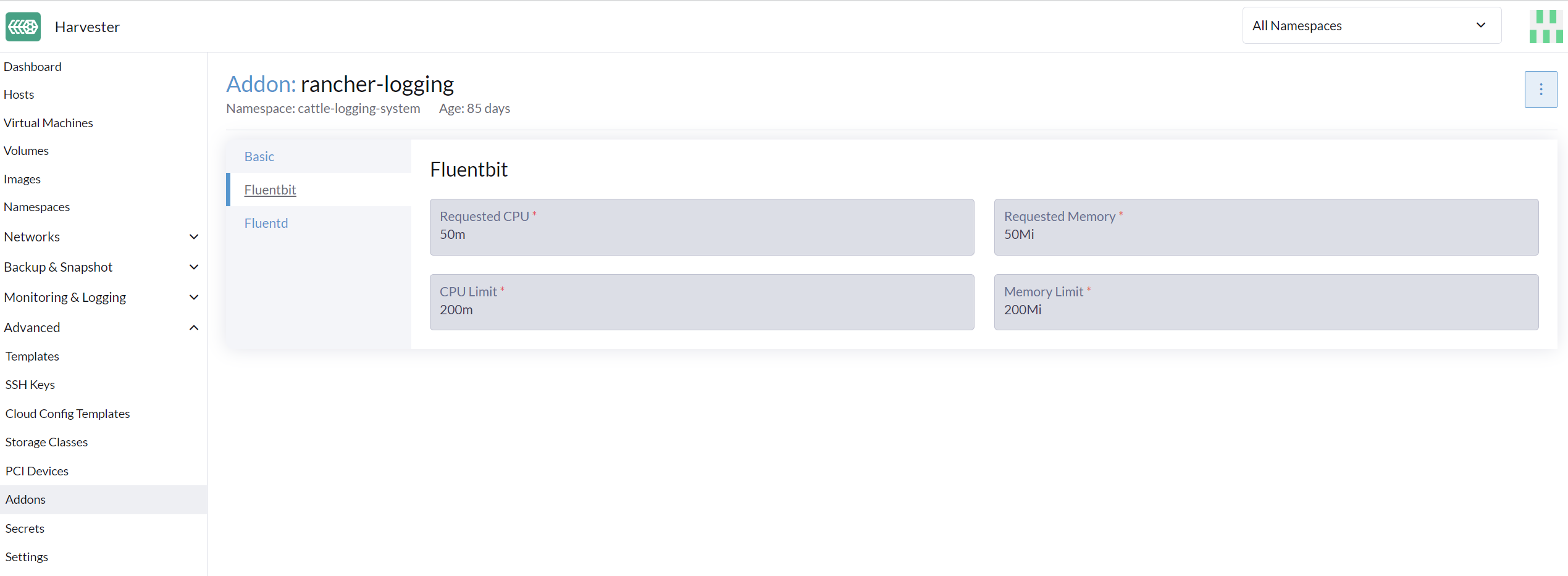
Unter dem Logging-Operator befinden sich Fluentd und Fluent Bit, die für die Protokollsammlung und -weiterleitung zuständig sind. Falls gewünscht, können Sie anpassen, wie viele Ressourcen diesen Komponenten zugewiesen werden.
Von der Benutzeroberfläche
-
Gehen Sie zur Seite Erweitert > Addons und wählen Sie das rancher-logging Addon aus.
-
Wechseln Sie zum Tab Fluentbit und ändern Sie die Ressourcennachfragen und -limits.
-
Wechseln Sie zum Tab Fluentd und ändern Sie die Ressourcennachfragen und -limits.
-
Wählen Sie Speichern, wenn Sie mit dem Konfigurieren der Einstellungen für das rancher-logging Add-on fertig sind.
|
Die Konfiguration der Benutzeroberfläche ist nur sichtbar, wenn das rancher-logging Add-on aktiviert ist. |
Von der Kommandozeilenschnittstelle
Sie können den folgenden kubectl Befehl verwenden, um die Ressourcenkonfigurationen für das rancher-logging Add-on zu ändern: kubectl edit addons.harvesterhci.io -n cattle-logging-system rancher-logging.
Der Ressourcenpfad und die Standardwerte sind wie folgt.
apiVersion: harvesterhci.io/v1beta1
kind: Addon
metadata:
name: rancher-logging
namespace: cattle-logging-system
spec:
valuesContent: |
fluentbit:
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 50m
memory: 50Mi
fluentd:
resources:
limits:
cpu: 1000m
memory: 800Mi
requests:
cpu: 100m
memory: 200Mi
|
Sie können weiterhin Konfigurationsanpassungen vornehmen, wenn das Add-on deaktiviert ist. Diese Änderungen treten jedoch erst in Kraft, wenn Sie das Add-on wieder aktivieren. |
Überprüfung von nicht verwendeten Ressourcen
Beim Aktivieren des rancher-logging Add-ons kann der folgende Fehler auftreten:
Sie können auch beobachten, dass die Implementierungen, die mit dem Add-on verbunden sind, nicht vollständig ausgerollt sind.
Um zu verhindern, dass der Fehler erneut auftritt, führen Sie die folgenden Aktionen aus, bevor Sie das Add-on aktivieren:
-
Aktualisieren oder löschen Sie die betroffenen nicht verwendeten Ressourcen.
-
Fügen Sie die Annotation
harvesterhci.io/skipRancherLoggingAddonWebhookCheck: "true"zum Add-on hinzu.
Konfigurieren von Protokollzielen
Protokollierungsoperationen werden durch den Logging Operator unterstützt und mithilfe von Fluentd-Ressourcen gesteuert, insbesondere Flow und ClusterFlow sowie Output und ClusterOutput. Sie können Protokolle routen und filtern, indem Sie diese CRDs auf den Harvester-Cluster anwenden.
Beim Anwenden neuer Outputs und Flows auf den Cluster kann es einige Zeit dauern, bis der Logging-Operator sie effektiv anwendet. Bitte erlauben Sie daher einige Minuten, bis die Protokolle beginnen zu fließen.
Clustered vs Namespaced
Eine wichtige Sache, die man beim Routen von Protokollen verstehen sollte, ist der Unterschied zwischen ClusterFlow vs Flow und ClusterOutput vs Output. Der Hauptunterschied zwischen der clusterbasierten und der nicht-clusterbasierten Version besteht darin, dass letztere in Namespaces organisiert sind.
Die größte Auswirkung davon ist, dass Flows nur auf Outputs zugreifen kann, die sich im selben Namespace befinden, aber dennoch auf beliebige ClusterOutput zugreifen kann.
Weitere Informationen finden Sie in der Dokumentation:
Von der Benutzeroberfläche
|
UI-Bilder sind für |
Erstellen von Ausgaben
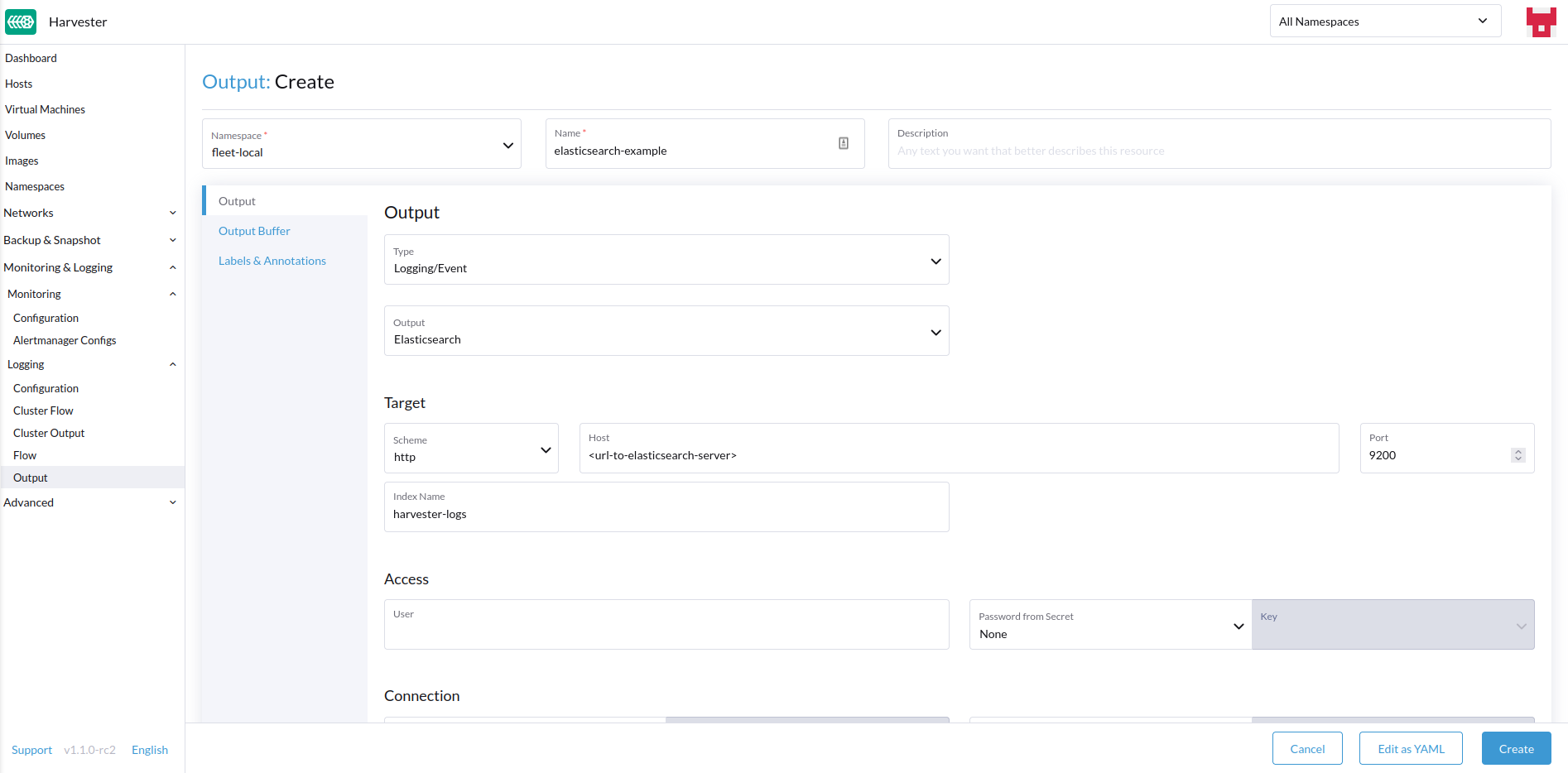
-
Wählen Sie die Option, um ein neues
OutputoderClusterOutputzu erstellen. -
Wenn Sie ein
Outputerstellen, wählen Sie den gewünschten Namespace aus. -
Fügen Sie einen Namen für die Ressourcen hinzu.
-
Wählen Sie den Protokolltyp.
-
Wählen Sie den Protokollausgabetyp.
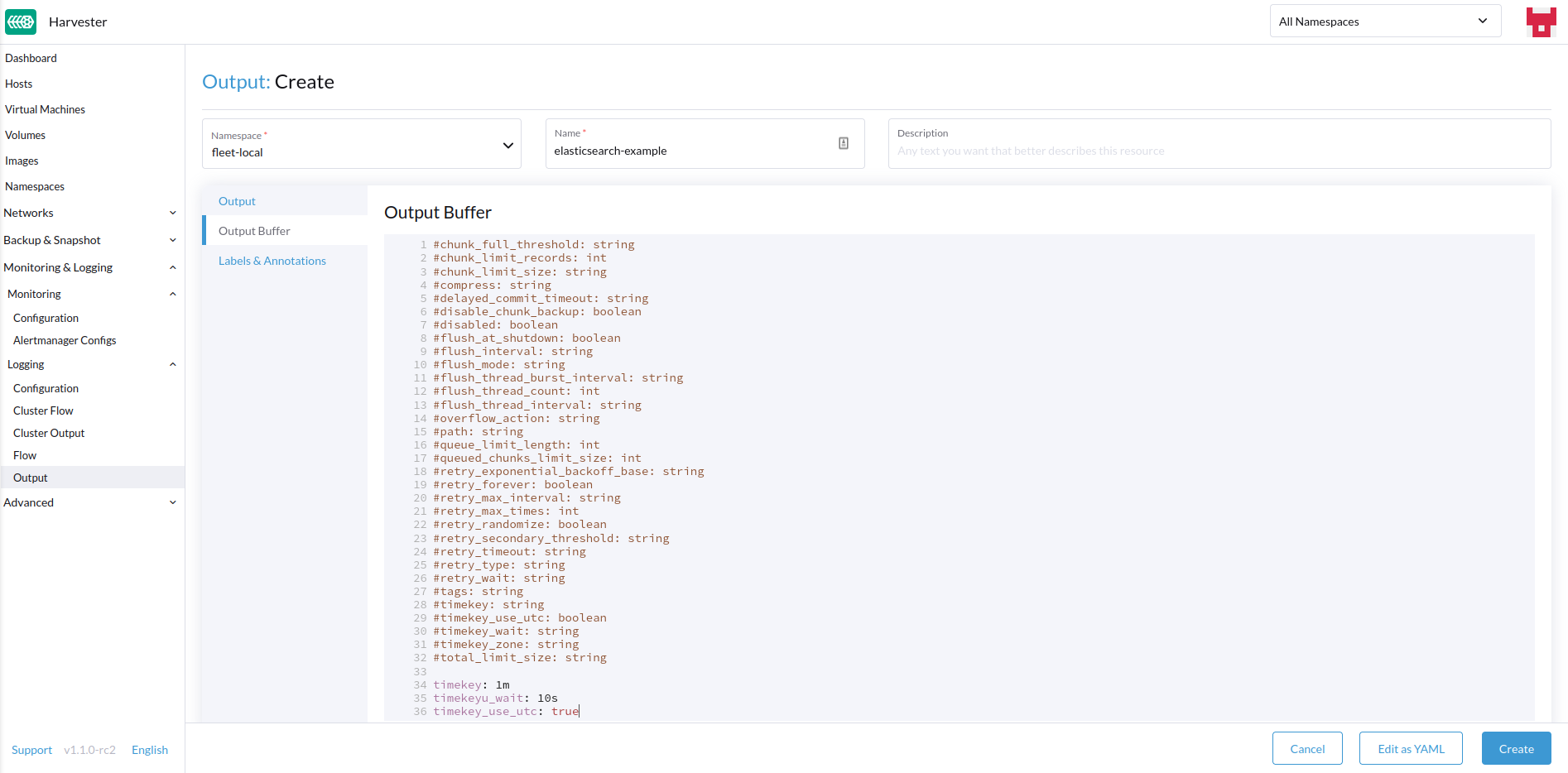
-
Konfigurieren Sie den Ausgabepuffer, falls erforderlich.
-
Fügen Sie beliebige Labels oder Anmerkungen hinzu.
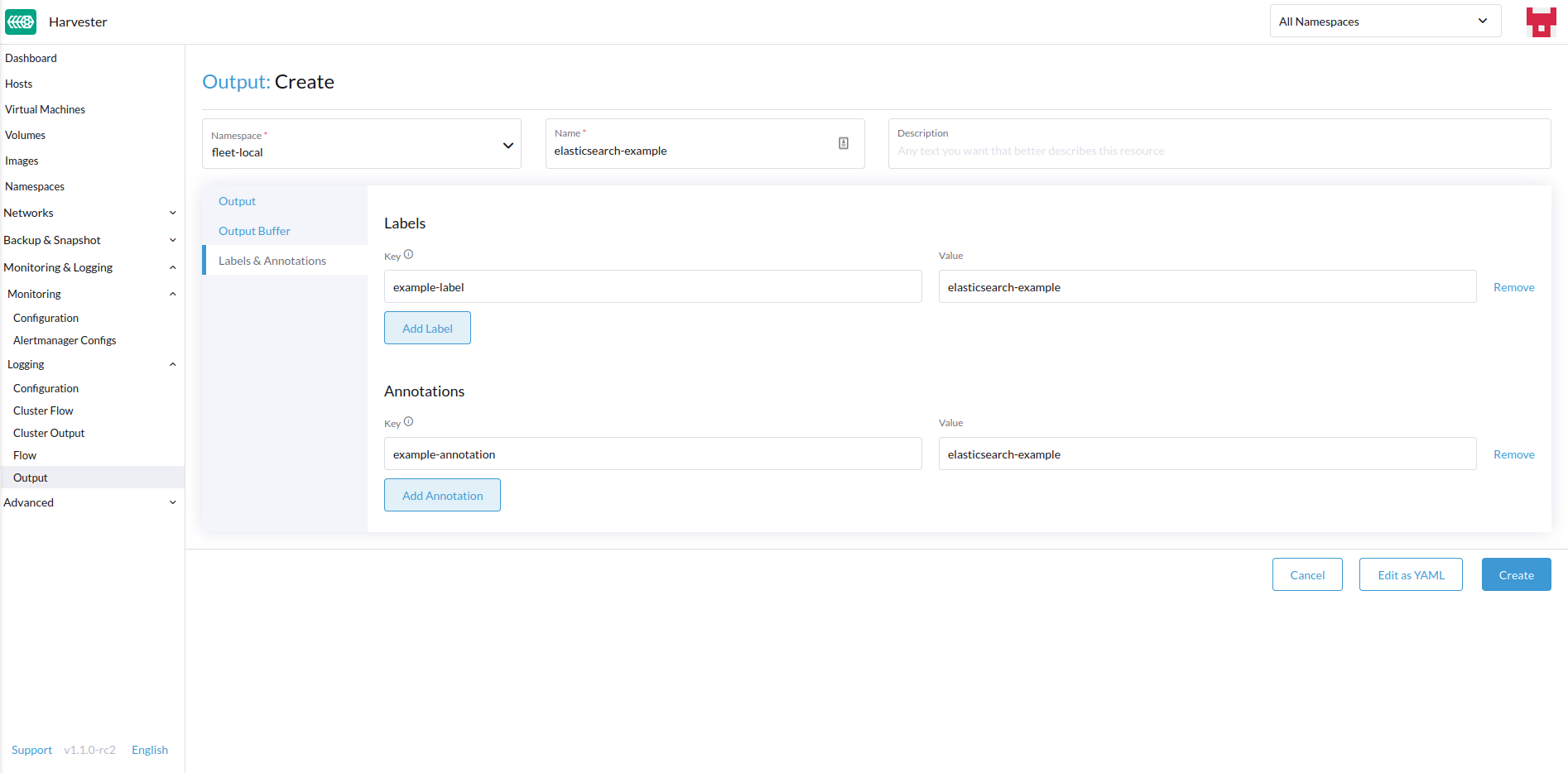
-
Sobald Sie fertig sind, klicken Sie
Createunten rechts.
|
Je nach ausgewählter Ausgabe (Splunk, Elasticsearch usw.) gibt es zusätzliche Felder, die im Formular angegeben werden müssen. |
Ausgabe
Das Formular zeigt die Felder an, die für die ausgewählte Ausgabe verfügbar sind.
Ausgabepuffer
Der Editor ermöglicht es Ihnen, das bevorzugte Verhalten des Ausgabepuffers mithilfe verschiedener Felder zu beschreiben.
Flows erstellen
-
Wählen Sie die Option, um ein neues
FlowoderClusterFlowzu erstellen. -
Wenn Sie ein
Flowerstellen, wählen Sie den gewünschten Namespace aus. -
Fügen Sie einen Namen für die Ressource hinzu.
-
Wählen Sie beliebige Knoten aus, deren Protokolle ein- oder ausgeschlossen werden sollen.
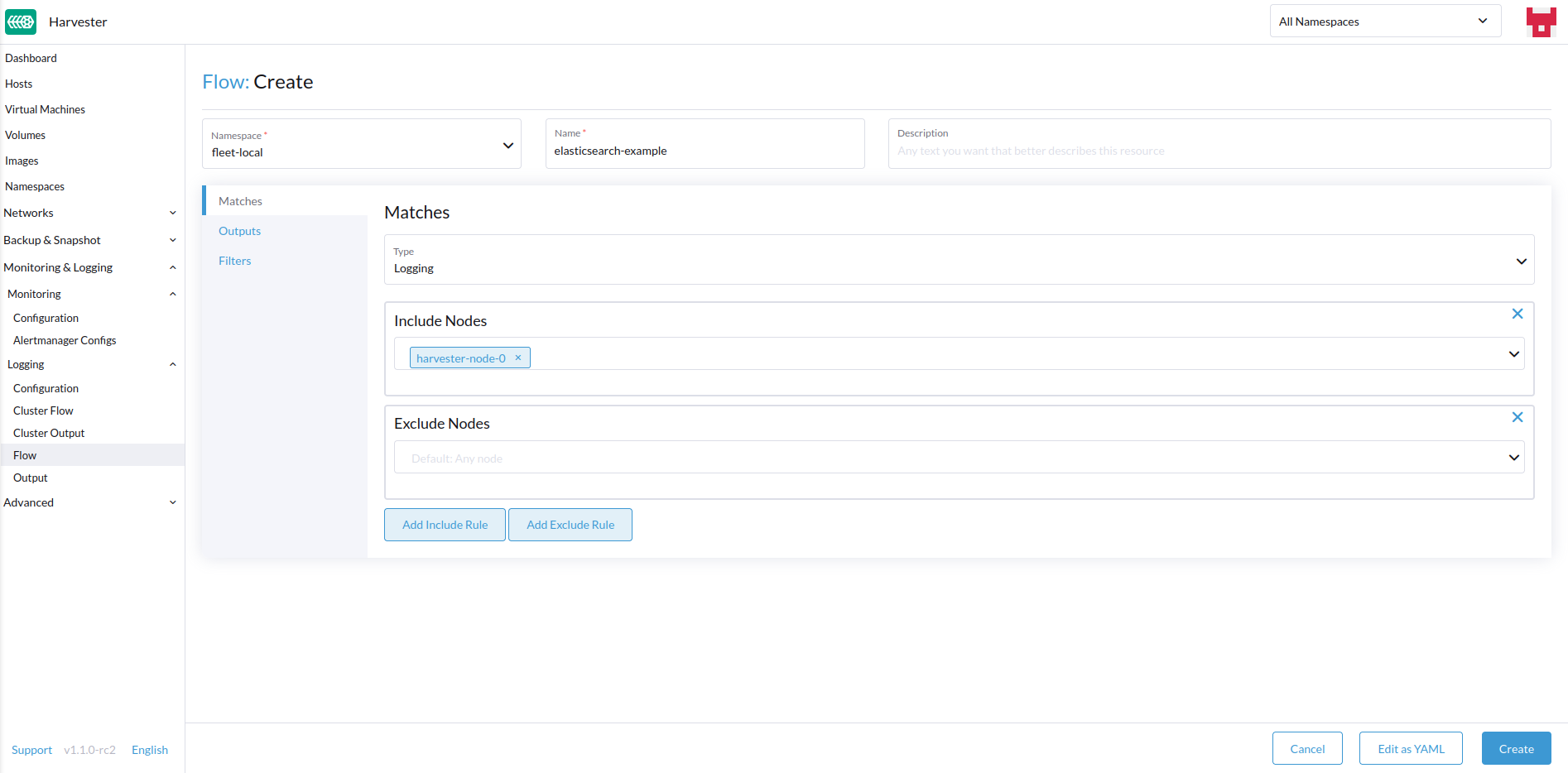
-
Wählen Sie Ziel
OutputsundClusterOutputsaus.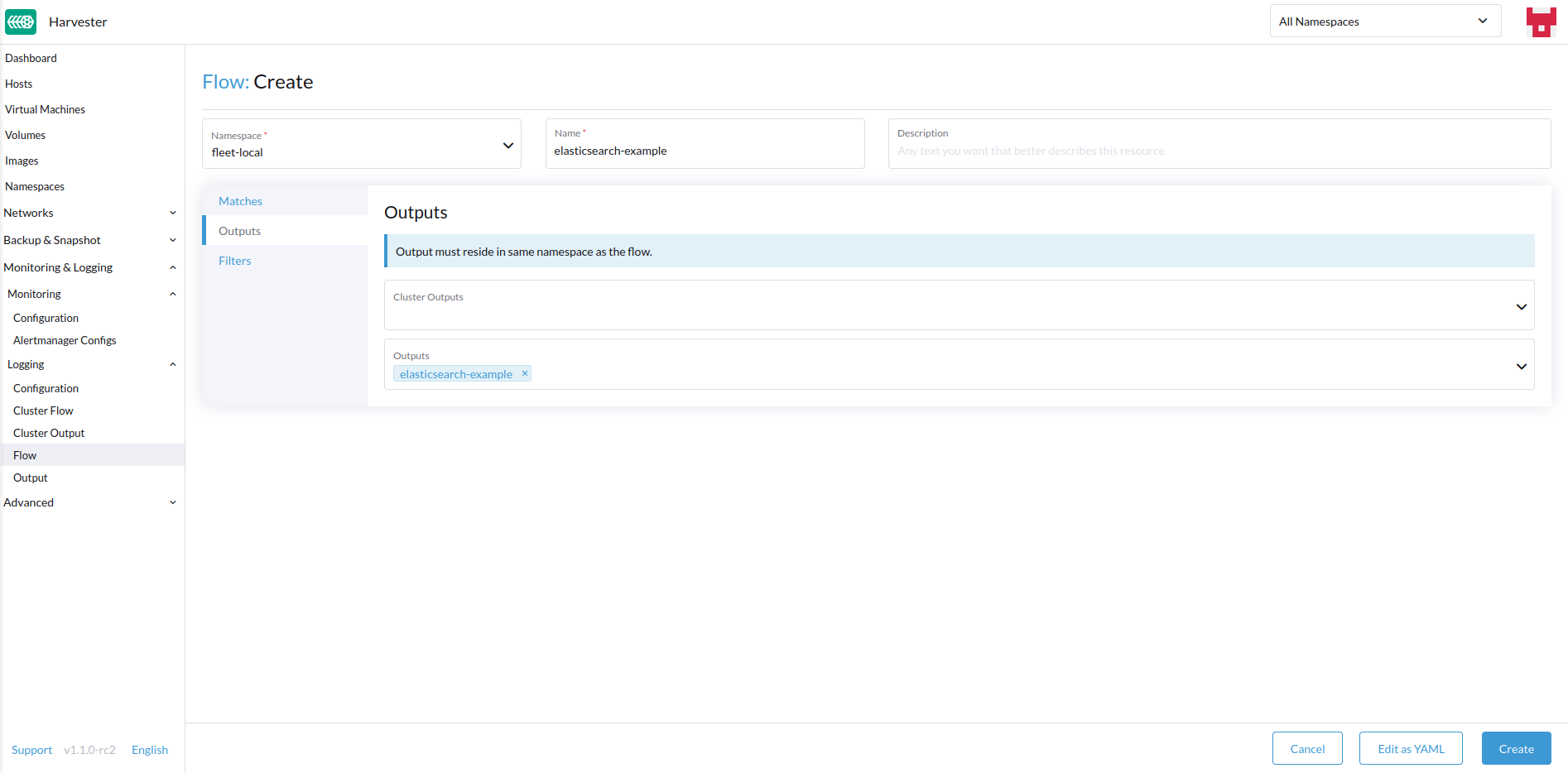
-
Fügen Sie bei Bedarf Filter hinzu.
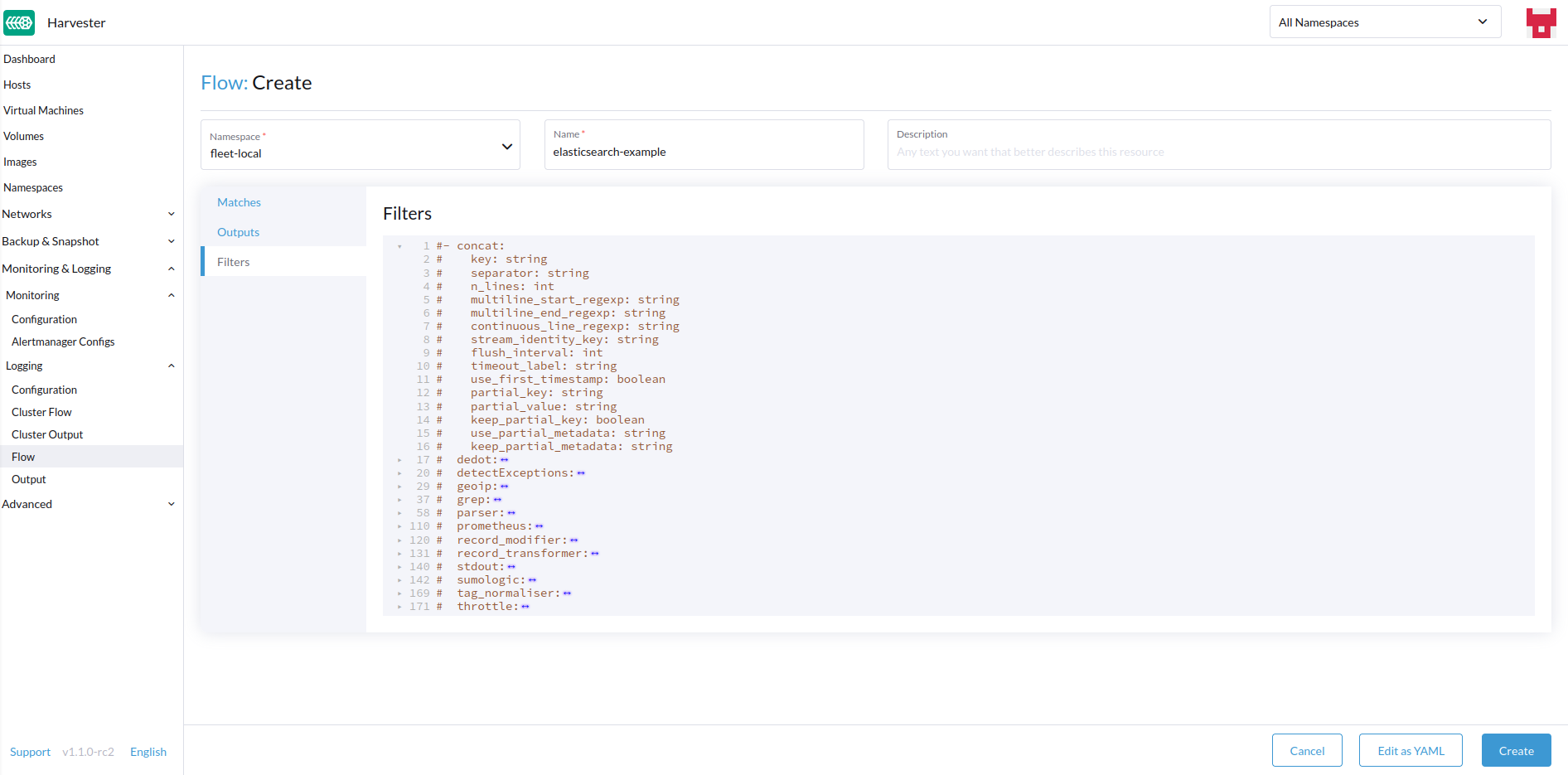
-
Sobald Sie fertig sind, klicken Sie
Createunten links.
Entspricht
Übereinstimmungen ermöglichen es Ihnen, zu filtern, welche Protokolle Sie in die Flow einbeziehen möchten. Das Formular erlaubt nur das Ein- oder Ausschließen von Knotenprotokollen, aber falls erforderlich, können Sie andere von der Ressource unterstützte Übereinstimmungsregeln hinzufügen, indem Sie Edit as YAML auswählen.
Für weitere Informationen zur Übereinstimmungsanweisung siehe Übereinstimmungsanweisung.
Ausgaben
Ausgaben ermöglichen es Ihnen, eine oder mehrere OutputRefs auszuwählen, um die aggregierten Protokolle zu senden. Beim Erstellen oder Bearbeiten eines Flow / ClusterFlow ist es erforderlich, dass der Benutzer mindestens eine Output auswählt.
|
Es muss mindestens eine vorhandene |
Filter
Filter ermöglichen es Ihnen, die Protokolle zu transformieren, zu verarbeiten und zu verändern. Für weitere Informationen siehe die Liste der unterstützten Filter.
Von der Kommandozeile
Um Protokollrouten über die Befehlszeile zu konfigurieren, müssen Sie nur die YAML-Dateien für die relevanten Ressourcen definieren:
# elasticsearch-logging.yaml
apiVersion: logging.banzaicloud.io/v1beta1
kind: Output
metadata:
name: elasticsearch-example
namespace: fleet-local
labels:
example-label: elasticsearch-example
annotations:
example-annotation: elasticsearch-example
spec:
elasticsearch:
host: <url-to-elasticsearch-server>
port: 9200
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: elasticsearch-example
namespace: fleet-local
spec:
match:
- select: {}
globalOutputRefs:
- elasticsearch-exampleUnd dann anwenden:
kubectl apply -f elasticsearch-logging.yamlVerweisen auf Geheimnisse
Sie können geheime Werte (im YAML-Format) mit einer der folgenden Methoden definieren:
Die einfachste Möglichkeit ist die Verwendung des value-Schlüssels, der einen einfachen Stringwert für das gewünschte Geheimnis darstellt. Diese Methode sollte nur zu Testzwecken und niemals in der Produktion verwendet werden:
aws_key_id:
value: "secretvalue"Die nächste Möglichkeit ist die Verwendung von valueFrom, die es ermöglicht, einen bestimmten Wert aus einem Geheimnis durch ein Name- und Schlüssel-Paar zu referenzieren:
aws_key_id:
valueFrom:
secretKeyRef:
name: <kubernetes-secret-name>
key: <kubernetes-secret-key>Einige Plugins benötigen eine Datei, aus der sie lesen, anstatt einfach einen Wert aus dem Geheimnis zu erhalten (dies ist oft der Fall bei CA-Zertifikatdateien). In diesen Fällen müssen Sie mountFrom verwenden, das das Geheimnis als Datei in die zugrunde liegende fluentd-Implementierung einbindet und das Plugin auf die Datei verweist. Die valueFrom- und mountFrom-Objekte sehen gleich aus:
tls_cert_path:
mountFrom:
secretKeyRef:
name: <kubernetes-secret-name>
key: <kubernetes-secret-key>Für weitere Informationen siehe Geheimnisdefinition.
Beispiel Outputs
-
Elasticsearch
-
Graylog
-
Splunk
-
Loki
Für die einfachste Implementierung können Sie Elasticsearch auf Ihrem lokalen System mit Docker bereitstellen:
sudo docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e xpack.security.enabled=false -e node.name=es01 -e discovery.type=single-node -it docker.elastic.co/elasticsearch/elasticsearch:8.16.6|
Um Elasticsearch mit SUSE Virtualization v1.5.0 zu verwenden, stellen Sie sicher, dass der Elasticsearch-Server Version 8.11.0 oder höher läuft. Sie müssen Elasticsearch upgraden, wenn der |
Stellen Sie sicher, dass Sie vm.max_map_count auf >= 262144 gesetzt haben, da der oben genannte Docker-Befehl sonst fehlschlägt. Sobald der Elasticsearch-Server läuft, können Sie die YAML-Datei für ClusterOutput und ClusterFlow erstellen:
cat << EOF > elasticsearch-example.yaml
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: elasticsearch-example
namespace: cattle-logging-system
spec:
elasticsearch:
host: 192.168.0.119
port: 9200
buffer:
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: elasticsearch-example
namespace: cattle-logging-system
spec:
match:
- select: {}
globalOutputRefs:
- elasticsearch-example
EOFUnd wenden Sie die Datei an:
kubectl apply -f elasticsearch-example.yamlNachdem Sie etwas Zeit gewährt haben, damit der Logging-Operator die Ressourcen anwenden kann, können Sie testen, ob die Protokolle fließen:
$ curl localhost:9200/fluentd/_search
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 11603,
"max_score": 1,
"hits": [
{
"_index": "fluentd",
"_type": "fluentd",
"_id": "yWHr0oMBXcBggZRJgagY",
"_score": 1,
"_source": {
"stream": "stderr",
"logtag": "F",
"message": "I1013 02:29:43.020384 1 csi_handler.go:248] Attaching \"csi-974b4a6d2598d8a7a37b06d06557c428628875e077dabf8f32a6f3aa2750961d\"",
"kubernetes": {
"pod_name": "csi-attacher-5d4cc8cfc8-hd4nb",
"namespace_name": "longhorn-system",
"pod_id": "c63c2014-9556-40ce-a8e1-22c55de12e70",
"labels": {
"app": "csi-attacher",
"pod-template-hash": "5d4cc8cfc8"
},
"annotations": {
"cni.projectcalico.org/containerID": "857df09c8ede7b8dee786a8c8788e8465cca58f0b4d973c448ed25bef62660cf",
"cni.projectcalico.org/podIP": "10.52.0.15/32",
"cni.projectcalico.org/podIPs": "10.52.0.15/32",
"k8s.v1.cni.cncf.io/network-status": "[{\n \"name\": \"k8s-pod-network\",\n \"ips\": [\n \"10.52.0.15\"\n ],\n \"default\": true,\n \"dns\": {}\n}]",
"k8s.v1.cni.cncf.io/networks-status": "[{\n \"name\": \"k8s-pod-network\",\n \"ips\": [\n \"10.52.0.15\"\n ],\n \"default\": true,\n \"dns\": {}\n}]",
"kubernetes.io/psp": "global-unrestricted-psp"
},
"host": "harvester-node-0",
"container_name": "csi-attacher",
"docker_id": "f10e4449492d4191376d3e84e39742bf077ff696acbb1e5f87c9cfbab434edae",
"container_hash": "sha256:03e115718d258479ce19feeb9635215f98e5ad1475667b4395b79e68caf129a6",
"container_image": "docker.io/longhornio/csi-attacher:v3.4.0"
}
}
},
...
]
}
}Sie können den Anweisungen hier folgen, um Clusterprotokolle über Graylog bereitzustellen und anzuzeigen:
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: "all-logs-gelf-hs"
namespace: "cattle-logging-system"
spec:
globalOutputRefs:
- "example-gelf-hs"
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: "example-gelf-hs"
namespace: "cattle-logging-system"
spec:
gelf:
host: "192.168.122.159"
port: 12202
protocol: "udp"Sie können den Anweisungen hier folgen, um Clusterprotokolle über Splunk bereitzustellen und anzuzeigen.
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: harvester-logging-splunk
namespace: cattle-logging-system
spec:
splunkHec:
hec_host: 192.168.122.101
hec_port: 8088
insecure_ssl: true
index: harvester-log-index
hec_token:
valueFrom:
secretKeyRef:
key: HECTOKEN
name: splunk-hec-token2
buffer:
chunk_limit_size: 3MB
timekey: 2m
timekey_wait: 1m
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: harvester-logging-splunk
namespace: cattle-logging-system
spec:
filters:
- tag_normaliser: {}
match:
globalOutputRefs:
- harvester-logging-splunkSie können die Anweisungen im Logging HEP zur Bereitstellung und Anzeige von Clusterprotokollen über Grafana Loki befolgen.
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: harvester-loki
namespace: cattle-logging-system
spec:
match:
- select: {}
globalOutputRefs:
- harvester-loki
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: harvester-loki
namespace: cattle-logging-system
spec:
loki:
url: http://loki-stack.cattle-logging-system.svc:3100
extra_labels:
logOutput: harvester-lokiRevision
Harvester sammelt Kubernetes audit und kann die audit an verschiedene Arten von Protokollservern senden.
Die Richtliniendatei zur Anleitung von kube-apiserver ist hier.
Audit-Definition
In kubernetes werden die Audit-Daten von kube-apiserver gemäß der definierten Richtlinie generiert.
... Audit policy Audit policy defines rules about what events should be recorded and what data they should include. The audit policy object structure is defined in the audit.k8s.io API group. When an event is processed, it's compared against the list of rules in order. The first matching rule sets the audit level of the event. The defined audit levels are: None - don't log events that match this rule. Metadata - log request metadata (requesting user, timestamp, resource, verb, etc.) but not request or response body. Request - log event metadata and request body but not response body. This does not apply for non-resource requests. RequestResponse - log event metadata, request and response bodies. This does not apply for non-resource requests.
Audit-Protokollformat
Audit-Protokollformat in Kubernetes
Kubernetes apiserver protokolliert Audit im folgenden JSON-Format in eine lokale Datei.
{
"kind":"Event",
"apiVersion":"audit.k8s.io/v1",
"level":"Metadata",
"auditID":"13d0bf83-7249-417b-b386-d7fc7c024583",
"stage":"RequestReceived",
"requestURI":"/apis/flowcontrol.apiserver.k8s.io/v1beta2/prioritylevelconfigurations?fieldManager=api-priority-and-fairness-config-producer-v1",
"verb":"create",
"user":{"username":"system:apiserver","uid":"d311c1fe-2d96-4e54-a01b-5203936e1046","groups":["system:masters"]},
"sourceIPs":["::1"],
"userAgent":"kube-apiserver/v1.24.7+rke2r1 (linux/amd64) kubernetes/e6f3597",
"objectRef":{"resource":"prioritylevelconfigurations",
"apiGroup":"flowcontrol.apiserver.k8s.io",
"apiVersion":"v1beta2"},
"requestReceivedTimestamp":"2022-10-19T18:55:07.244781Z",
"stageTimestamp":"2022-10-19T18:55:07.244781Z"
}Audit-Protokollausgabe/Clusterausgabe
Um auditbezogene Protokolle auszugeben, erfordert der Output/ClusterOutput den Wert von loggingRef, um harvester-kube-audit-log-ref zu sein.
Wenn Sie vom Harvester-Dashboard aus konfigurieren, wird das Feld automatisch hinzugefügt.
Wählen Sie den Typ Audit Only aus der Dropdown-Liste Type aus.
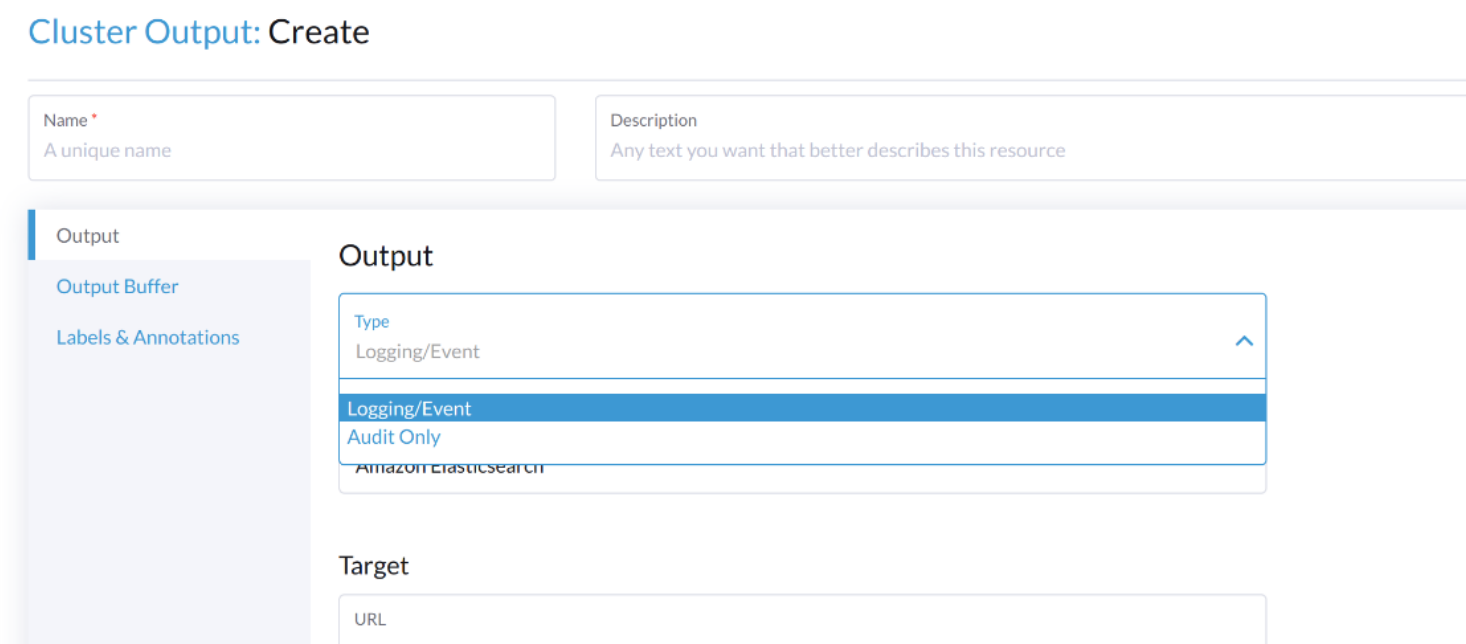
Wenn Sie über die Kommandozeilenschnittstelle konfigurieren, fügen Sie bitte das Feld manuell hinzu.
Beispiel:
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: "harvester-audit-webhook"
namespace: "cattle-logging-system"
spec:
http:
endpoint: "http://192.168.122.159:8096/"
open_timeout: 3
format:
type: "json"
buffer:
chunk_limit_size: 3MB
timekey: 2m
timekey_wait: 1m
loggingRef: harvester-kube-audit-log-ref # this reference is fixed and must be here
Audit-Protokollfluss/Clusterfluss
Um auditbezogene Protokolle zu leiten, erfordert der Flow/ClusterFlow den Wert von loggingRef, um harvester-kube-audit-log-ref zu sein.
Wenn Sie vom Harvester-Dashboard aus konfigurieren, wird das Feld automatisch hinzugefügt.
Wählen Sie den Typ Audit aus.
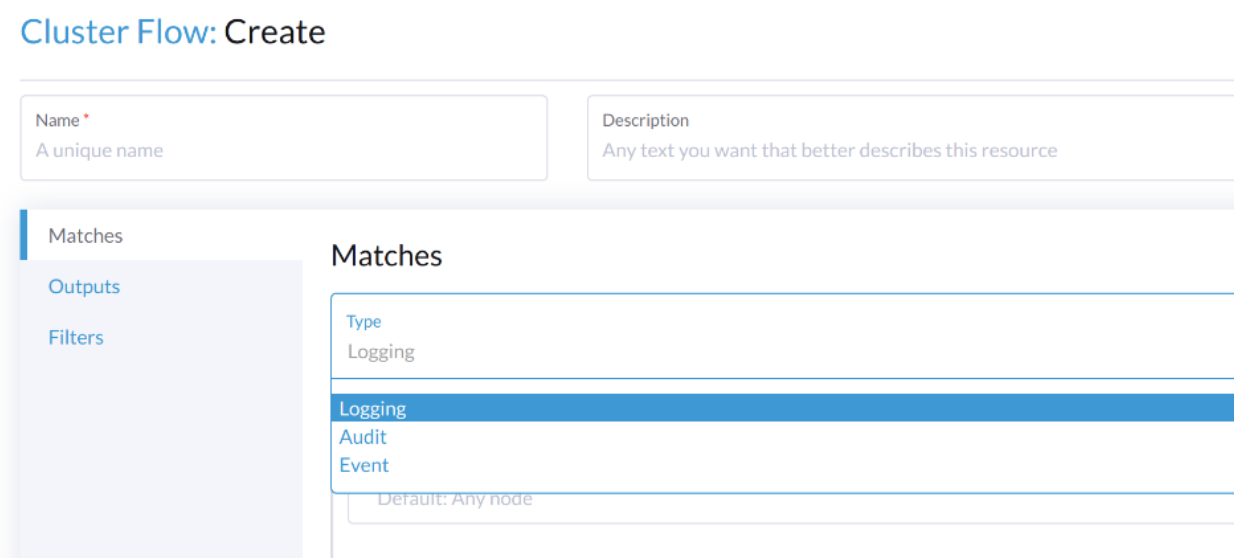
Wenn Sie über die Kommandozeilenschnittstelle konfigurieren, fügen Sie bitte das Feld manuell hinzu.
Beispiel:
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: "harvester-audit-webhook"
namespace: "cattle-logging-system"
spec:
globalOutputRefs:
- "harvester-audit-webhook"
loggingRef: harvester-kube-audit-log-ref # this reference is fixed and must be here
Ereignis
Harvester sammelt Kubernetes event und kann die event an verschiedene Arten von Protokollservern senden.
Ereignisdefinition
Kubernetes events sind Objekte, die Ihnen zeigen, was innerhalb eines Clusters passiert, wie z.B. welche Entscheidungen vom Scheduler getroffen wurden oder warum einige Pods vom Knoten entfernt wurden. Alle Kernelkomponenten und Erweiterungen (Operatoren/Controller) können über den API-Server Ereignisse erstellen.
Ereignisse haben keine direkte Beziehung zu Protokollnachrichten, die von den verschiedenen Komponenten generiert werden, und sind nicht vom Protokoll-Verbosity-Level betroffen. Wenn eine Komponente ein Ereignis erstellt, gibt sie oft eine entsprechende Protokollnachricht aus. Ereignisse werden vom API-Server nach kurzer Zeit (typischerweise nach einer Stunde) bereinigt, was bedeutet, dass sie verwendet werden können, um Probleme zu verstehen, die auftreten, aber Sie müssen sie sammeln, um vergangene Ereignisse zu untersuchen.
Ereignisse sind das Erste, worauf man bei Anwendungen sowie Infrastrukturoperationen achten sollte, wenn etwas nicht wie erwartet funktioniert. Sie für einen längeren Zeitraum aufzubewahren, ist entscheidend, wenn der Fehler das Ergebnis früherer Ereignisse ist oder bei der Durchführung einer Post-Mortem-Analyse.
Ereignisprotokollformat
Ereignisprotokollformat in Kubernetes
Ein kubernetes event Beispiel:
{
"apiVersion": "v1",
"count": 1,
"eventTime": null,
"firstTimestamp": "2022-08-24T11:17:35Z",
"involvedObject": {
"apiVersion": "kubevirt.io/v1",
"kind": "VirtualMachineInstance",
"name": "vm-ide-1",
"namespace": "default",
"resourceVersion": "604601",
"uid": "1bd4133f-5aa3-4eda-bd26-3193b255b480"
},
"kind": "Event",
"lastTimestamp": "2022-08-24T11:17:35Z",
"message": "VirtualMachineInstance defined.",
"metadata": {
"creationTimestamp": "2022-08-24T11:17:35Z",
"name": "vm-ide-1.170e43cbdd833b62",
"namespace": "default",
"resourceVersion": "604626",
"uid": "0114f4e7-1d4a-4201-b0e5-8cc8ede202f4"
},
"reason": "Created",
"reportingComponent": "",
"reportingInstance": "",
"source": {
"component": "virt-handler",
"host": "harv1"
},
"type": "Normal"
},
Ereignisprotokollformat, bevor es an Protokollserver gesendet wird.
Jeder event log hat das Format: {"stream":"","logtag":"F","message":"","kubernetes":{""}}. Das kubernetes event befindet sich im Feld message.
{
"stream":"stdout",
"logtag":"F",
"message":"{
\\"verb\\":\\"ADDED\\",
\\"event\\":{\\"metadata\\":{\\"name\\":\\"vm-ide-1.170e446c3f890433\\",\\"namespace\\":\\"default\\",\\"uid\\":\\"0b44b6c7-b415-4034-95e5-a476fcec547f\\",\\"resourceVersion\\":\\"612482\\",\\"creationTimestamp\\":\\"2022-08-24T11:29:04Z\\",\\"managedFields\\":[{\\"manager\\":\\"virt-controller\\",\\"operation\\":\\"Update\\",\\"apiVersion\\":\\"v1\\",\\"time\\":\\"2022-08-24T11:29:04Z\\"}]},\\"involvedObject\\":{\\"kind\\":\\"VirtualMachineInstance\\",\\"namespace\\":\\"default\\",\\"name\\":\\"vm-ide-1\\",\\"uid\\":\\"1bd4133f-5aa3-4eda-bd26-3193b255b480\\",\\"apiVersion\\":\\"kubevirt.io/v1\\",\\"resourceVersion\\":\\"612477\\"},\\"reason\\":\\"SuccessfulDelete\\",\\"message\\":\\"Deleted PodDisruptionBudget kubevirt-disruption-budget-hmmgd\\",\\"source\\":{\\"component\\":\\"disruptionbudget-controller\\"},\\"firstTimestamp\\":\\"2022-08-24T11:29:04Z\\",\\"lastTimestamp\\":\\"2022-08-24T11:29:04Z\\",\\"count\\":1,\\"type\\":\\"Normal\\",\\"eventTime\\":null,\\"reportingComponent\\":\\"\\",\\"reportingInstance\\":\\"\\"}
}",
"kubernetes":{"pod_name":"harvester-default-event-tailer-0","namespace_name":"cattle-logging-system","pod_id":"d3453153-58c9-456e-b3c3-d91242580df3","labels":{"app.kubernetes.io/instance":"harvester-default-event-tailer","app.kubernetes.io/name":"event-tailer","controller-revision-hash":"harvester-default-event-tailer-747b9d4489","statefulset.kubernetes.io/pod-name":"harvester-default-event-tailer-0"},"annotations":{"cni.projectcalico.org/containerID":"aa72487922ceb4420ebdefb14a81f0d53029b3aec46ed71a8875ef288cde4103","cni.projectcalico.org/podIP":"10.52.0.178/32","cni.projectcalico.org/podIPs":"10.52.0.178/32","k8s.v1.cni.cncf.io/network-status":"[{\\n \\"name\\": \\"k8s-pod-network\\",\\n \\"ips\\": [\\n \\"10.52.0.178\\"\\n ],\\n \\"default\\": true,\\n \\"dns\\": {}\\n}]","k8s.v1.cni.cncf.io/networks-status":"[{\\n \\"name\\": \\"k8s-pod-network\\",\\n \\"ips\\": [\\n \\"10.52.0.178\\"\\n ],\\n \\"default\\": true,\\n \\"dns\\": {}\\n}]","kubernetes.io/psp":"global-unrestricted-psp"},"host":"harv1","container_name":"harvester-default-event-tailer-0","docker_id":"455064de50cc4f66e3dd46c074a1e4e6cfd9139cb74d40f5ba00b4e3e2a7ab2d","container_hash":"docker.io/banzaicloud/eventrouter@sha256:6353d3f961a368d95583758fa05e8f4c0801881c39ed695bd4e8283d373a4262","container_image":"docker.io/banzaicloud/eventrouter:v0.1.0"}
}
Ereignisprotokollausgabe/ClusterAusgabe
Ereignisse teilen sich das Output/ClusterOutput mit Logging.
Wählen Sie Logging/Event aus der Type Dropdownliste aus.
Ereignisprotokollfluss/ClusterFluss
Im Vergleich zur normalen Protokollierung Flow/ClusterFlow hat das Event-bezogene Flow/ClusterFlow ein zusätzliches Übereinstimmungsfeld mit dem Wert event-tailer.
Wenn Sie vom Harvester-Dashboard aus konfigurieren, wird das Feld automatisch hinzugefügt.
Wählen Sie Event aus der Type Dropdownliste aus.
Wenn Sie über die Kommandozeilenschnittstelle konfigurieren, fügen Sie bitte das Feld manuell hinzu.
Beispiel:
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: harvester-event-webhook
namespace: cattle-logging-system
spec:
filters:
- tag_normaliser: {}
match:
- select:
labels:
app.kubernetes.io/name: event-tailer
globalOutputRefs:
- harvester-event-webhook