|
Dieses Dokument wurde mithilfe automatisierter maschineller Übersetzungstechnologie übersetzt. Wir bemühen uns um korrekte Übersetzungen, übernehmen jedoch keine Gewähr für die Vollständigkeit, Richtigkeit oder Zuverlässigkeit der übersetzten Inhalte. Im Falle von Abweichungen ist die englische Originalversion maßgebend und stellt den verbindlichen Text dar. |
Upgrade von v1.4.2 oder v1.4.3 auf v1.5.0
Allgemeine Informationen
Ein Upgrade-Button erscheint auf dem Dashboard-Bildschirm, wann immer eine neue SUSE Virtualization Version verfügbar wird, auf die Sie upgraden können. Für weitere Informationen, sehen Sie sich Starten Sie ein Upgrade an.
Sie können direkt von v1.4.2 auf v1.5.0 upgraden, da SUSE Virtualization maximal ein Upgrade auf eine Nebenversion der zugrunde liegenden Komponenten zulässt. SUSE Virtualization v1.4.2 und v1.4.3 verwenden dieselbe Nebenversion von SUSE® Rancher Prime: RKE2 (v1.31), während SUSE Virtualization v1.5.0 die nächste Nebenversion (v1.32) verwendet.
Für Informationen zum Upgrade von SUSE Virtualization in Air-Gapped-Umgebungen, siehe Bereiten Sie ein Air-Gapped-Upgrade vor.
Aktualisieren Sie die Harvester UI-Erweiterung auf SUSE Rancher Prime v2.11.0
Sie müssen v1.5.0 der Harvester UI-Erweiterung verwenden, um SUSE Virtualization v1.5.0 Cluster auf Rancher v2.11.0 zu importieren.
-
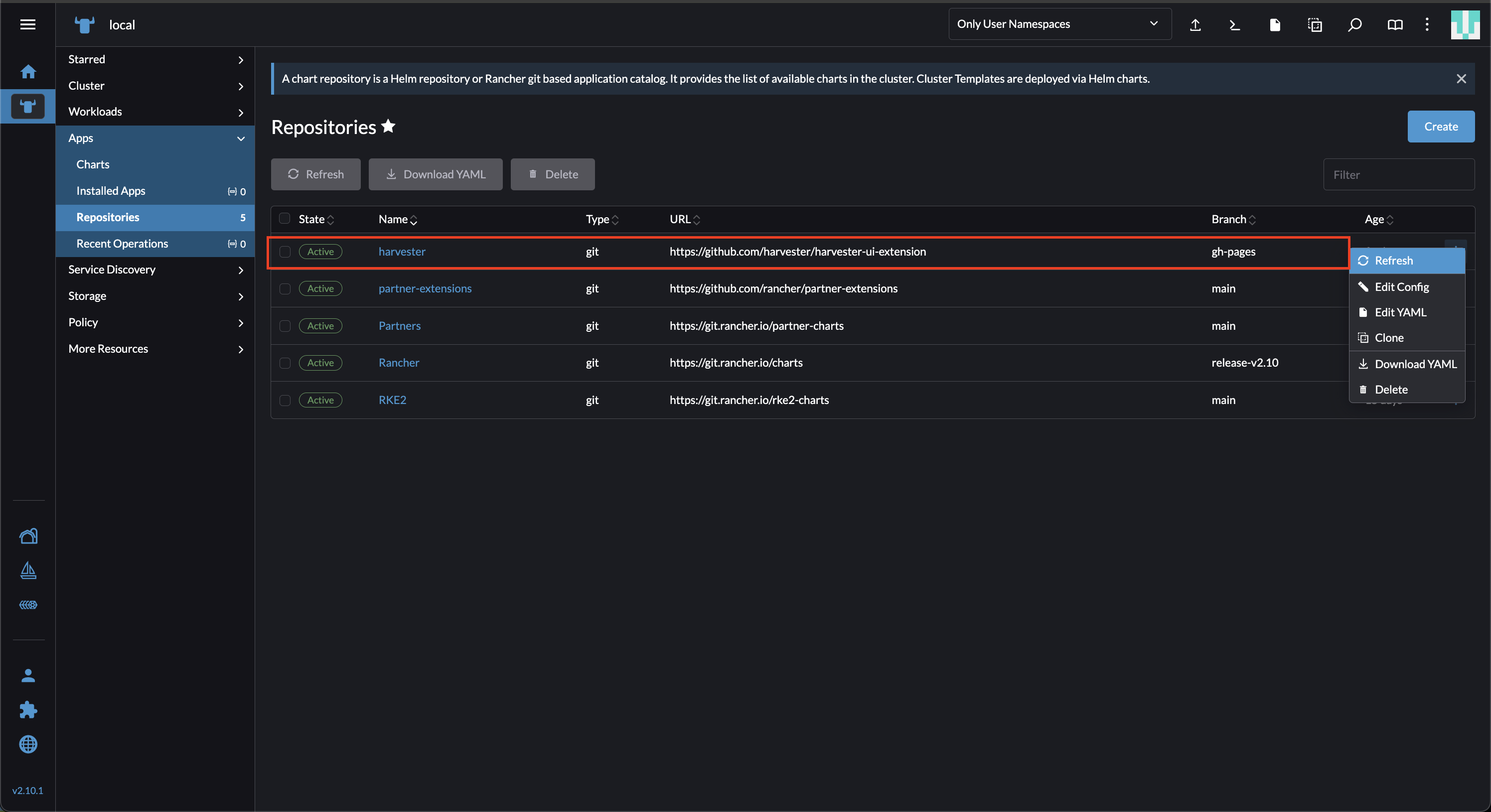
Gehen Sie auf der Rancher UI zu lokalen → Apps → Repositories.
-
Suchen Sie das Repository mit dem Namen harvester und wählen Sie dann ⋮ → Aktualisieren aus.
Dieses Repository hat die folgenden Eigenschaften:
-
Branch: gh-pages
-
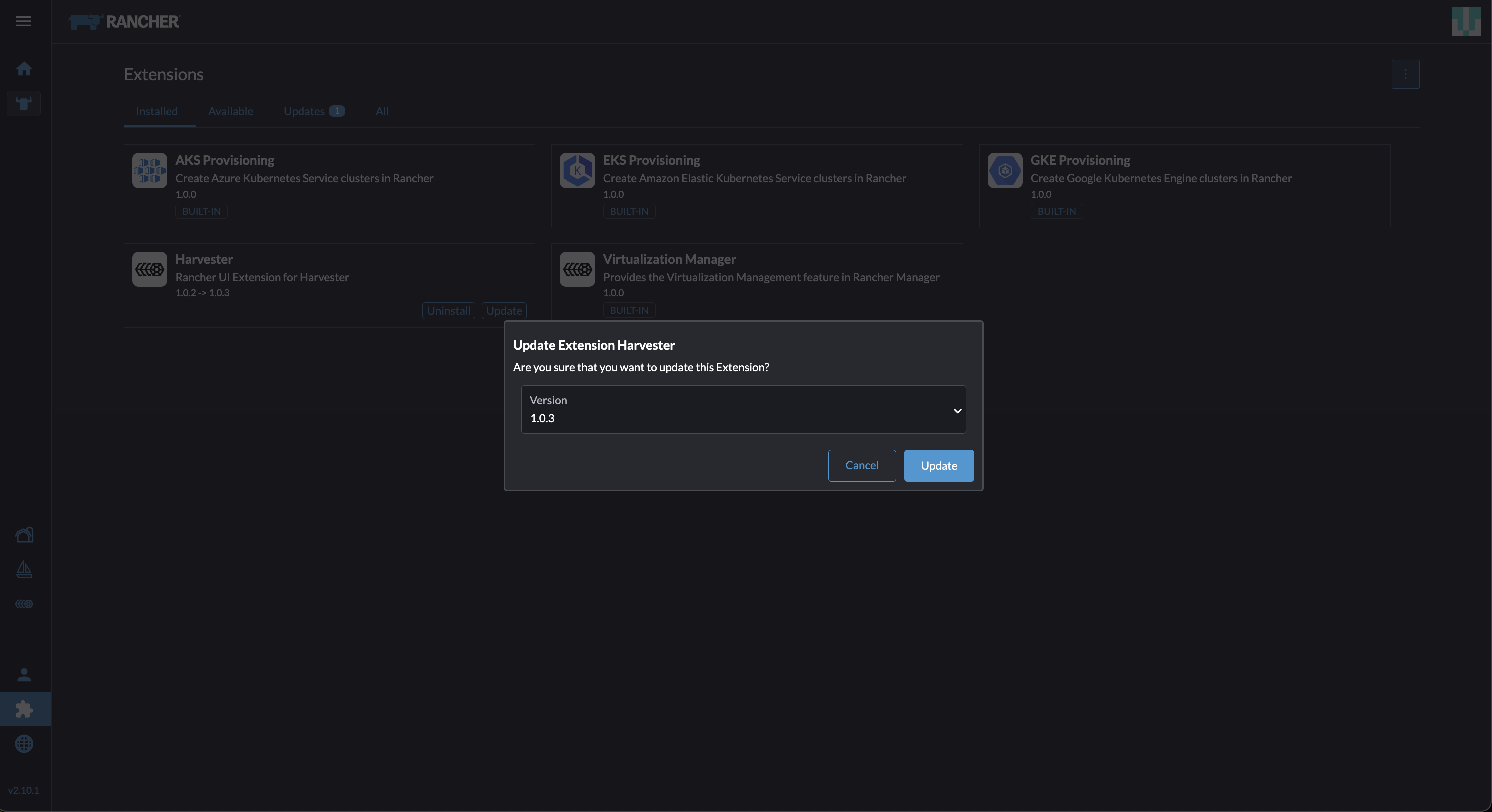
Gehen Sie zum Erweiterungen-Bildschirm.
-
Suchen Sie die Erweiterung mit dem Namen Harvester und klicken Sie dann auf Aktualisieren.
-
Wählen Sie die Version 1.5.0 aus und klicken Sie dann auf Aktualisieren.
-
Lassen Sie etwas Zeit für die Aktualisierung der Erweiterung und aktualisieren Sie dann den Bildschirm.
Bekannte Probleme
1. Der Status der Management-URL ist während des Upgrades "NichtBereit"
Die SUSE Virtualization Konsole auf einigen Knoten kann Status: NotReady anzeigen, während das Upgrade im Gange ist.
Der korrekte Status wird angezeigt, nachdem das Upgrade auf v1.5.0 abgeschlossen ist.
Verwandtes Problem: #7963
2. Air-gapped Upgrade bleibt mit einem ImagePullBackOff-Fehler in den Fluentd- und Fluent Bit Pods hängen.
Das Upgrade kann zu Beginn des Prozesses stecken bleiben, wie durch 0 % Fortschritt und Elemente, die im Ausstehend-Dialogfeld der SUSE Virtualization UI markiert sind, sowie im Upgrade-Dialogfeld.
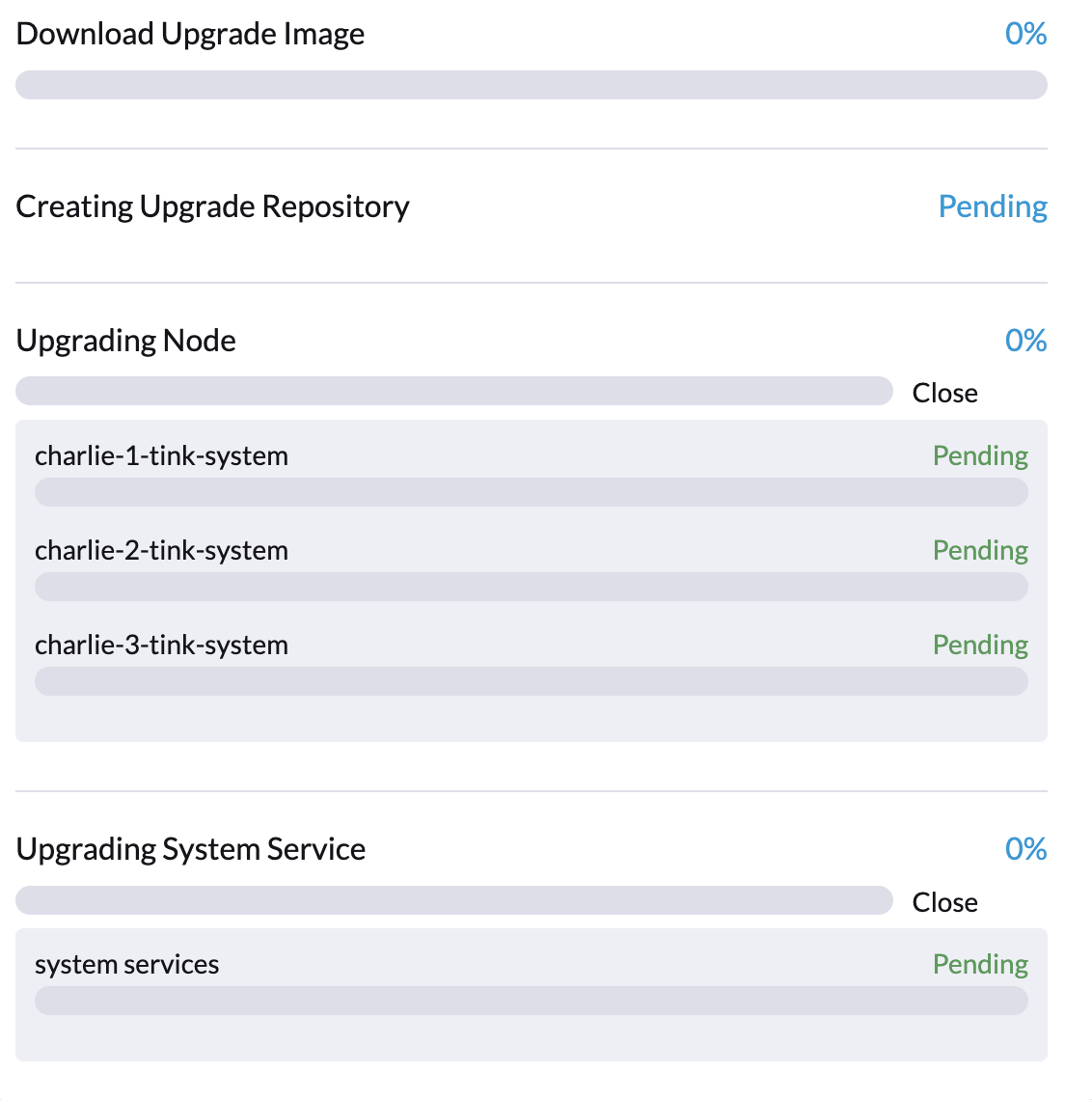
Insbesondere können Fluentd und Fluent Bit Pods im ImagePullBackOff Status stecken bleiben. Um den Status der Pods zu überprüfen, führen Sie die folgenden Befehle aus:
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-x2hz8 7m14s
$ kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=hvst-upgrade-x2hz8
NAME UPGRADE
hvst-upgrade-x2hz8-upgradelog hvst-upgrade-x2hz8
$ kubectl -n harvester-system get pods -l harvesterhci.io/upgradeLog=hvst-upgrade-x2hz8-upgradelog
NAME READY STATUS RESTARTS AGE
hvst-upgrade-x2hz8-upgradelog-downloader-6cdb864dd9-6bw98 1/1 Running 0 7m7s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-2nq7q 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-697wf 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-kd8kl 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentd-0 0/2 ImagePullBackOff 0 7m42sDies geschieht, weil die folgenden Container-Images weder in den Cluster-Knoten vorab geladen noch aus dem Internet heruntergeladen werden:
-
ghcr.io/kube-logging/fluentd:v1.15-ruby3 -
ghcr.io/kube-logging/config-reloader:v0.0.5 -
fluent/fluent-bit:2.1.8
Um das Problem zu beheben, führen Sie eine der folgenden Aktionen aus:
-
Aktualisieren Sie die Logging CR, um die bereits in den Cluster-Knoten vorab geladenen Images zu verwenden. Führen Sie dazu die folgenden Befehle auf dem Cluster aus:
# Get the Logging CR names OPERATOR_LOGGING_NAME=$(kubectl get loggings -l app.kubernetes.io/name=rancher-logging -o jsonpath="{.items[0].metadata.name}") INFRA_LOGGING_NAME=$(kubectl get loggings -l harvesterhci.io/upgradeLogComponent=infra -o jsonpath="{.items[0].metadata.name}") # Gather image info from operator's Logging CR FLUENTD_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.repository}") FLUENTD_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.tag}") FLUENTBIT_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.repository}") FLUENTBIT_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.tag}") CONFIG_RELOADER_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.repository}") CONFIG_RELOADER_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.tag}") # Patch the Logging CR kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentbit/image\",\"value\":{\"repository\":\"$FLUENTBIT_IMAGE_REPO\",\"tag\":\"$FLUENTBIT_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/image\",\"value\":{\"repository\":\"$FLUENTD_IMAGE_REPO\",\"tag\":\"$FLUENTD_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/configReloaderImage\",\"value\":{\"repository\":\"$CONFIG_RELOADER_IMAGE_REPO\",\"tag\":\"$CONFIG_RELOADER_IMAGE_TAG\"}}]"Der Status der Fluentd und Fluent Bit Pods sollte sich in Kürze auf
Runningändern und der Upgrade-Prozess sollte fortgesetzt werden, nachdem die Logging CR aktualisiert wurde. Wenn der Status des Fluentd Pods weiterhinImagePullBackOffist, können Sie den Pod löschen, um ihn zum Neustart zu zwingen.UPGRADE_NAME=$(kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o jsonpath='{.items[0].metadata.name}') UPGRADELOG_NAME=$(kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=$UPGRADE_NAME -o jsonpath='{.items[0].metadata.name}') kubectl -n harvester-system delete pods -l harvesterhci.io/upgradeLog=$UPGRADELOG_NAME,harvesterhci.io/upgradeLogComponent=aggregator -
Auf einem Computer mit Internetzugang ziehen Sie die erforderlichen Container-Images und exportieren Sie diese dann in eine TAR-Datei. Übertragen Sie als Nächstes die TAR-Datei auf die Cluster-Knoten und importieren Sie die Images, indem Sie die folgenden Befehle auf jedem Knoten ausführen:
# Pull down the three container images docker pull ghcr.io/kube-logging/fluentd:v1.15-ruby3 docker pull ghcr.io/kube-logging/config-reloader:v0.0.5 docker pull fluent/fluent-bit:2.1.8 # Export the images to a tar file docker save \ ghcr.io/kube-logging/fluentd:v1.15-ruby3 \ ghcr.io/kube-logging/config-reloader:v0.0.5 \ fluent/fluent-bit:2.1.8 > upgradelog-images.tar # After transferring the tar file to the cluster nodes, import the images (need to be run on each node) ctr -n k8s.io images import upgradelog-images.tarDer Upgrade-Prozess sollte fortgesetzt werden, nachdem die Images vorab geladen wurden.
-
(Nicht empfohlen) Starten Sie den Upgrade-Prozess mit deaktiviertem Logging neu. Stellen Sie sicher, dass das Kontrollkästchen Logging aktivieren im Upgrade Dialogfeld nicht ausgewählt ist.
-
Verwandtes Problem: #7955
3. Das Upgrade bleibt beim Warten auf das mcc-harvester Bundle CR hängen.
Wenn Sie von einer alten SUSE Virtualization Version (wie v1.0.x, v1.1.x und v1.2.x) upgraden, kann der Upgrade-Prozess beim Warten auf die Bereitstellung des mcc-harvester Bundle CR stecken bleiben.
> kubectl get bundles -n fleet-local
NAME BUNDLEDEPLOYMENTS-READY STATUS
mcc-harvester 0/1 Modified(1) [Cluster fleet-local/local]; kubevirt.kubevirt.io harvester-system/kubevirt modified {"spec":{"configuration":{"vmStateStorageClass":"vmstate-persistence"}}}Die Hauptursache ist, dass die neuesten dependency_charts CRDs nicht angewendet wurden, was geschah, weil Helm keine CRDs für SUSE Virtualization verwaltet. Um das Upgrade fortzusetzen, führen Sie das folgende Skript aus:
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/kubevirt-operator/crds/crd-kubevirt.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/csi-snapshotter/crds/volumesnapshotclasses.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/csi-snapshotter/crds/volumesnapshotcontents.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/csi-snapshotter/crds/volumesnapshots.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/whereabouts/crds/whereabouts.cni.cncf.io_ippools.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/whereabouts/crds/whereabouts.cni.cncf.io_overlappingrangeipreservations.yamlÜberprüfen Sie nach fünf Minuten den Status im mcc-harvester Bundle CR von bundle.fleet.cattle.io/v1alpha1. Wenn derselbe Fehler weiterhin angezeigt wird, müssen Sie das Bundle CR mit dem folgenden Skript erneut synchronisieren:
#!/bin/bash
patch_fleet_bundle() {
local bundleName=$1
local generation=$(kubectl get -n fleet-local bundle ${bundleName} -o jsonpath='{.spec.forceSyncGeneration}')
local new_generation=$((generation+1))
patch_manifest="$(mktemp)"
cat > "$patch_manifest" <<EOF
{
"spec": {
"forceSyncGeneration": $new_generation
}
}
EOF
echo "patch bundle to new generation: $new_generation"
kubectl patch -n fleet-local bundle ${bundleName} --type=merge --patch-file $patch_manifest
rm -f $patch_manifest
}
for bundle in mcc-harvester
do
patch_fleet_bundle ${bundle}
doneSie müssen auch sicherstellen, dass die cdi CRD existiert.
> kubectl get bundle -n fleet-local
NAMESPACE NAME BUNDLEDEPLOYMENTS-READY STATUS
fleet-local mcc-harvester 0/1 Modified(1) [Cluster fleet-local/local]; cdi.cdi.kubevirt.io cdi missingWenn die cdi CRD existiert, führen Sie das patch_fleet_bundle Skript aus, um das mcc-harvester Bundle CR erneut zu synchronisieren. Andernfalls führen Sie das folgende Skript aus, um die cdi CRD zu erstellen:
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/cdi/crds/cdi.yamlVerwandtes Problem: #8163
4. Virtuelle Maschinen, die migrierbare RWX-Volumes verwenden, starten unerwartet neu.
Virtuelle Maschinen, die migrierbare RWX-Volumes verwenden, starten unerwartet neu, wenn die CSI-Plugin-Pods neu gestartet werden. Dieses Problem betrifft SUSE Virtualization v1.4.x, v1.5.0 und v1.5.1.
Die Umgehungslösung besteht darin, die Einstellung Automatisch Arbeitslast-Pod löschen, wenn das Volume unerwartet getrennt wird im SUSE Storage UI vor dem Start des Upgrade zu deaktivieren. Sie müssen die Einstellung wieder aktivieren, sobald das Upgrade abgeschlossen ist.
Das Problem wird in SUSE Storage v1.8.3, v1.9.1 und späteren Versionen behoben sein. SUSE Virtualization v1.6.0 wird SUSE Storage v1.9.1 enthalten.