Kurzanleitung zu Geo-Clustering
- 1 Konzeptüberblick
- 2 Einsatzszenario
- 3 Anforderungen
- 4 Überblick über die Geo-Bootstrap-Skripte
- 5 Installation als Erweiterung
- 6 Einrichten der ersten Site eines GeoClusters
- 7 Hinzufügen einer weiteren Site zu einem GeoCluster
- 8 Hinzufügen des Vermittlers
- 9 Überwachen der Cluster-Sites
- 10 Nächste Schritte
- 11 Weiterführende Informationen
- 12 Rechtliche Hinweise
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Kurzanleitung zu Geo-Clustering #
Zusammenfassung#
Mit Geo-Clustering können Sie mehrere geografisch verteilte Sites mit jeweils einem lokalen Cluster betreiben. Der Failover zwischen diesen Clustern wird von einer übergeordneten Entität koordiniert: dem Cluster-Ticket-Manager booth. Dieses Dokument führt Sie durch die grundlegende Einrichtung eines GeoClusters. Dabei werden Bootstrap-Skripte eingesetzt, die im Paket ha-cluster-bootstrap bereitgestellt werden.
- 1 Konzeptüberblick
- 2 Einsatzszenario
- 3 Anforderungen
- 4 Überblick über die Geo-Bootstrap-Skripte
- 5 Installation als Erweiterung
- 6 Einrichten der ersten Site eines GeoClusters
- 7 Hinzufügen einer weiteren Site zu einem GeoCluster
- 8 Hinzufügen des Vermittlers
- 9 Überwachen der Cluster-Sites
- 10 Nächste Schritte
- 11 Weiterführende Informationen
- 12 Rechtliche Hinweise
- A GNU Licenses
1 Konzeptüberblick #
GeoCluster, die auf SUSE Linux Enterprise High Availability Extension basieren, können als „Overlay“-Cluster betrachtet werden, wobei jede Cluster-Site einem Cluster-Knoten in einem traditionellen Cluster entspricht. Der Overlay-Cluster wird durch den Cluster-Ticket-Manager booth (im Folgenden booth) verwaltet. Alle in einen GeoCluster involvierten Parteien führen den Service boothd aus. Dieser stellt eine Verbindung mit den booth-Daemons her, die auf den anderen Sites ausgeführt werden, und tauscht Konnektivitätsinformationen mit ihnen aus. Damit Cluster-Ressourcen über Sites hinweg hochverfügbar werden, verwendet booth als Tickets bezeichnete Cluster-Objekte. Mit einem Ticket wird das Recht zum Ausführen bestimmter Ressourcen auf einer bestimmten Cluster-Site gewährt. Booth garantiert, dass jedes Ticket jeweils nur einer Site erteilt wird.
Wenn die Kommunikation zwischen zwei booth-Instanzen ausfällt, kann dies an einem Ausfall des Netzwerks zwischen den Cluster-Sites oder an einem Ausfall einer Cluster-Site liegen. In diesem Fall wird eine zusätzliche Instanz benötigt (eine dritte Cluster-Site bzw. ein Vermittler), um einen Konsens über Entscheidungen (wie Failover von Ressourcen zwischen den Sites) zu erzielen. Vermittler sind einzelne Rechner (außerhalb der Cluster), auf denen eine booth-Instanz in einem speziellen Modus ausgeführt wird. Jeder GeoCluster kann einen oder mehrere Vermittler besitzen.
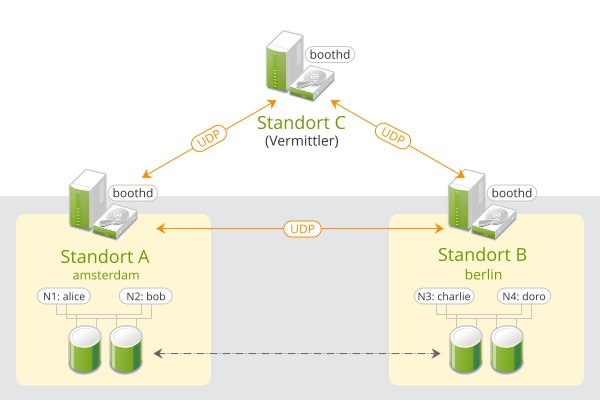
Abbildung 1: Cluster mit zwei Sites (2 x 2 Knoten + Vermittler) #
Weitere Details zum Konzept, zu den Komponenten und zur Ticketverwaltung für GeoCluster finden Sie im Chapter 2, Conceptual Overview.
2 Einsatzszenario #
Im Folgenden richten wir einen einfachen GeoCluster mit zwei Cluster-Sites und einem Vermittler ein:
Die Cluster-Sites erhalten die Namen
amsterdamundberlin.Jede Site besteht aus zwei Knoten. Die Knoten
aliceundbobgehören zum Clusteramsterdam. Die Knotencharlieunddorogehören zum Clusterberlin.Die Site
amsterdamerhält folgende virtuelle IP-Adresse:192.168.201.100.Die Site
berlinerhält folgende virtuelle IP-Adresse:192.168.202.100.Der Vermittler besitzt folgende IP-Adresse:
192.168.203.100.
Bevor Sie fortfahren, müssen Sie sicherstellen, dass folgende Voraussetzungen erfüllt sind:
Anforderungen #
- Zwei vorhandene Cluster
Sie haben mindestens zwei vorhandene Cluster, die Sie in einem GeoCluster kombinieren möchten. (Falls Sie zuerst zwei Cluster einrichten müssen, folgen Sie der Anleitung in der Kurzanleitung zu Installation und Einrichtung).
- Aussagekräftige Cluster-Namen
Für jeden Cluster wird in
/etc/corosync/corosync.confein aussagekräftiger Cluster-Name definiert, der den Standort angibt.- Vermittler
Sie haben einen dritten Rechner installiert, der nicht Teil eines vorhandenen Clusters ist und als Vermittler verwendet werden kann.
Detaillierte Informationen zu den einzelnen Anforderungen finden Sie auch in Abschnitt 3, „Anforderungen“.
3 Anforderungen #
Softwareanforderungen #
Auf allen Rechnern (Cluster-Knoten und Vermittlern), die Teil des GeoClusters sein werden, muss folgende Software installiert sein:
SUSE® Linux Enterprise Server 12 SP5
SUSE Linux Enterprise High Availability Extension 12 SP5
Geo-Clustering für SUSE Linux Enterprise High Availability Extension 12 SP5
Netzwerkvoraussetzungen #
Auf die virtuellen IPs, die für die einzelnen Cluster-Sites verwendet werden, muss ein Zugriff über den GeoCluster möglich sein.
Die Sites müssen pro booth-Instanz über einen UDP- und einen TCP-Port erreichbar sein. Folglich müssen Firewalls oder IPSec-Tunnel zwischen ihnen entsprechend konfiguriert sein.
Weitere Entscheidungen bezüglich der Einrichtung machen es möglicherweise erforderlich, weitere Ports zu öffnen (z. B. für DRBD oder Datenbankreplikation).
Sonstige Anforderungen und Empfehlungen #
Alle Cluster-Knoten auf allen Sites sollten mit einem NTP-Server außerhalb des Clusters synchronisiert werden. Weitere Informationen finden Sie unter https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Wenn Knoten nicht synchronisiert sind, ist es sehr schwierig, Protokolldateien und Cluster-Berichte zu analysieren.
Verwenden Sie in Ihrem GeoCluster eine ungerade Anzahl an Mitgliedern. Dadurch wird im Fall eines Ausfalls der Netzwerkverbindung sichergestellt, dass weiterhin eine Mehrheit von Sites gebildet werden kann (um das Szenario der Systemspaltung zu vermeiden). Falls Sie eine gerade Anzahl von Cluster-Sites haben, verwenden Sie einen Vermittler.
Der Cluster der einzelnen Sites besitzt einen aussagekräftigen Namen, z. B.:
amsterdamundberlin.Die Cluster-Namen für die einzelnen Sites sind jeweils in der Datei
/etc/corosync/corosync.confdefiniert:totem { [...] cluster_name: amsterdam }Dies kann manuell durchgeführt werden (indem Sie
/etc/corosync/corosync.confbearbeiten) oder mit dem Cluster-Modul YaST (indem Sie in der Kategorie einen definieren). Stoppen und starten Sie anschließend den Servicepacemakerneu, damit die Änderungen wirksam werden:root #systemctlstop pacemakerroot #systemctlstart pacemaker
4 Überblick über die Geo-Bootstrap-Skripte #
Mit
ha-cluster-geo-initmachen Sie einen Cluster zur ersten Site eines GeoClusters. Das Skript übernimmt einige Parameter, wie die Namen der Cluster, den Vermittler und eines oder mehrere Tickets und erstellt daraus/etc/booth/booth.conf. Es kopiert die booth-Konfiguration auf alle Knoten auf der aktuellen Cluster-Site. Außerdem konfiguriert es die Cluster-Ressourcen, die auf der aktuellen Cluster-Site für booth erforderlich sind.Weitere Informationen finden Sie in Abschnitt 6, „Einrichten der ersten Site eines GeoClusters“.
Mit
ha-cluster-geo-joinfügen Sie den aktuellen Cluster zu einem vorhandenen GeoCluster hinzu. Das Skript kopiert die booth-Konfiguration von einer vorhandenen Cluster-Site und schreibt diese auf allen Knoten auf der aktuellen Cluster-Site in/etc/booth/booth.conf. Außerdem konfiguriert es die Cluster-Ressourcen, die auf der aktuellen Cluster-Site für booth erforderlich sind.Weitere Informationen finden Sie in Abschnitt 7, „Hinzufügen einer weiteren Site zu einem GeoCluster“.
Mit
ha-cluster-geo-init-arbitratormachen Sie den aktuellen Rechner zum Vermittler für den GeoCluster. Das Skript kopiert die booth-Konfiguration von einer vorhandenen Cluster-Site und schreibt diese in/etc/booth/booth.conf.Weitere Informationen finden Sie in Abschnitt 8, „Hinzufügen des Vermittlers“.
Alle Bootstrap-Skripte protokollieren die zugehörigen Daten in der Datei /var/log/ha-cluster-bootstrap.log. In der Protokolldatei finden Sie alle Details des Bootstrap-Prozesses. Alle während des Bootstrap-Prozesses festgelegten Optionen können später geändert werden (durch Änderung der booth-Einstellungen, der Ressourcen usw.). Weitere Informationen finden Sie unter Geo Clustering Guide.
5 Installation als Erweiterung #
Unterstützung für Hochverfügbarkeits-Cluster über unbegrenzte Entfernungen ist als separate Erweiterung mit dem Namen „Geo-Clustering für SUSE Linux Enterprise High Availability Extension“ verfügbar.
Um einen GeoCluster einzurichten, benötigen Sie die in den folgenden Installationsschemata enthaltenen Pakete:
Hohe VerfügbarkeitGeoCluster-Bildung für hohe Verfügbarkeit
Beide Schemata sind nur verfügbar, wenn Sie Ihr System beim SUSE Customer Center (oder bei einem lokalen Registrierungsserver) registriert und die jeweiligen Produktkanäle oder Installationsmedien als Erweiterung hinzugefügt haben. Sie finden Informationen zur Installation von Erweiterungen im SUSE Linux Enterprise 12 SP5 Deployment Guide (Bereitstellungshandbuch für SUSE Linux Enterprise 12 SP2): https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Prozedur 1: Installieren der Pakete #
Verwenden Sie zum Installieren der Pakete beider Schemata über die Kommandozeile Zypper:
root #zypperinstall -t pattern ha_sles ha_geoAlternativ können Sie mit YaST eine grafische Installation ausfFühren:
Starten Sie YaST als Benutzer
rootund wählen Sie › aus.Klicken Sie auf › und aktivieren Sie folgende Schemata:
Hohe VerfügbarkeitGeoCluster-Bildung für hohe Verfügbarkeit
Klicken Sie auf , um mit der Installation der Pakete zu beginnen.
Wichtig: Installation der Softwarepakete bei allen Parteien
Die für hohe Verfügbarkeit und GeoCluster benötigten Softwarepakete werden nicht automatisch auf die Cluster-Knoten kopiert.
Installieren Sie SUSE Linux Enterprise Server 12 SP5 und die Schemata
Hohe VerfügbarkeitundGeoCluster-Bildung für hohe Verfügbarkeitauf allen Rechnern, die zu Ihrem GeoCluster gehören sollen.Statt die Pakete manuell auf allen Rechnern zu installieren, die Teil Ihres Clusters sein werden, können Sie mit AutoYaST vorhandene Knoten klonen. Weitere Informationen finden Sie im Section 3.2, “Mass Installation and Deployment with AutoYaST”.
Die Geo-Clustering-Erweiterung muss jedoch manuell auf allen Rechnern installiert werden, die zum GeoCluster gehören sollen. AutoYaST wird für Geo-Clustering für SUSE Linux Enterprise High Availability Extension noch nicht unterstützt.
6 Einrichten der ersten Site eines GeoClusters #
Verwenden Sie das Skript ha-cluster-geo-init, um einen vorhandenen Cluster zur ersten Site eines GeoClusters zu machen.
Prozedur 2: Einrichten der ersten Site (amsterdam) mit ha-cluster-geo-init #
Definieren Sie pro Cluster-Site eine virtuelle IP, über die auf die Site zugegriffen werden kann. Hierzu verwenden wir in diesem Beispiel
192.168.201.100und192.168.202.100. Es ist jetzt noch nicht erforderlich, die virtuellen IPs als Cluster-Ressourcen zu konfigurieren. Das erledigen die Bootstrap-Skripte.Definieren Sie einen Namen für mindestens ein Ticket, mit dem die Berechtigung erteilt wird, bestimmte Ressourcen auf einer Cluster-Site auszuführen. Verwenden Sie einen aussagekräftigen Namen, der auf die Ressourcen hinweist, die von dem Ticket abhängen (z. B.
ticket-nfs). Die Bootstrap-Skripte benötigen nur den Ticketnamen. Die weiteren Einzelheiten (Ticketabhängigkeiten der Ressourcen) können Sie später, wie in Abschnitt 10, „Nächste Schritte“ beschrieben, definieren.Melden Sie sich bei einem Knoten eines vorhandenen Clusters an (z. B. beim Knoten
alicedes Clustersamsterdam).Führen Sie
ha-cluster-geo-initaus. Verwenden Sie beispielsweise die folgenden Optionen:root #ha-cluster-geo-init\ --clusters1 "amsterdam=192.168.201.100 berlin=192.168.202.100" \ --tickets2 ticket-nfs \ --arbitrator3 192.168.203.100Die Namen der Cluster-Sites (die in
/etc/corosync/corosync.confdefiniert sind) und die virtuellen IP-Adressen, die Sie für die einzelnen Cluster-Sites verwenden möchten. In diesem Fall haben wir zwei Cluster-Sites (amsterdamundberlin), die je eine virtuelle IP-Adresse besitzen.Den Namen eines oder mehrerer Tickets.
Den Hostnamen oder die IP-Adresse eines Rechners außerhalb des Clusters.
Das Bootstrap-Skript erstellt die booth-Konfigurationsdatei und synchronisiert diese zwischen den Cluster-Sites. Es erstellt außerdem die für booth erforderlichen grundlegenden Cluster-Ressourcen. Schritt 4 aus Prozedur 2 erzeugt folgende booth-Konfiguration und Cluster-Ressourcen:
Beispiel 1: Durch ha-cluster-geo-init erstellte booth-Konfiguration #
# The booth configuration file is "/etc/booth/booth.conf". You need to # prepare the same booth configuration file on each arbitrator and # each node in the cluster sites where the booth daemon can be launched. # "transport" means which transport layer booth daemon will use. # Currently only "UDP" is supported. transport="UDP" port="9929" arbitrator="192.168.203.100" site="192.168.201.100" site="192.168.202.100" authfile="/etc/booth/authkey" ticket="ticket-nfs" expire="600"
Beispiel 2: Durch ha-cluster-geo-init erstellte Cluster-Ressourcen #
primitive1 booth-ip IPaddr2 \ params rule #cluster-name eq amsterdam ip=192.168.201.100 \ params rule #cluster-name eq berlin ip=192.168.202.100 \ primitive2 booth-site ocf:pacemaker:booth-site \ meta resource-stickiness=INFINITY \ params config=booth \ op monitor interval=10s group3 g-booth booth-ip booth-site \ meta target-role=Stopped4
Eine virtuelle IP-Adresse für jede Cluster-Site. Diese wird von den booth-Daemons benötigt, die für jede Cluster-Site eine persistente IP-Adresse voraussetzen. | |
Eine primitive Ressource für den booth-Daemon. Er kommuniziert mit den booth-Daemons auf den anderen Cluster-Sites. Der Daemon kann in einem beliebigen Knoten der Site gestartet werden, damit die Ressource jedoch in demselben Knoten bleibt, muss für „resource-stickiness“ möglichst | |
Eine Cluster-Ressourcengruppe für beide Primitive. Mit dieser Konfiguration ist jeder booth-Daemon an der jeweiligen IP-Adresse verfügbar, und zwar unabhängig von dem Knoten, auf dem der Daemon ausgeführt wird. | |
Die Cluster-Ressourcengruppe wird standardmäßig nicht gestartet. Nachdem Sie die Konfiguration Ihrer Cluster-Ressourcen überprüft (und die für Ihr Setup erforderlichen Ressourcen hinzugefügt) haben, müssen Sie die Ressourcengruppe starten. Weitere Informationen finden Sie in Erforderliche Schritte für den Abschluss des GeoCluster-Setups. |
7 Hinzufügen einer weiteren Site zu einem GeoCluster #
Nachdem Sie die erste Site Ihres GeoClusters initialisiert haben, fügen Sie mit ha-cluster-geo-join einen zweiten Cluster hinzu (in Prozedur 3 beschrieben). Das Skript benötigt SSH-Zugriff auf eine bereits konfigurierte Cluster-Site und fügt dann den aktuellen Cluster zum GeoCluster hinzu.
Prozedur 3: Hinzufügen der zweiten Site (berlin) mit ha-cluster-geo-join #
Melden Sie sich bei einem Knoten der Cluster-Site an, die Sie hinzufügen möchten (z. B. beim Knoten
charliedes Clustersberlin).Führen Sie den Befehl
ha-cluster-geo-joinaus. Beispiel:root #ha-cluster-geo-join\ --cluster-node1 192.168.201.100\ --clusters2 "amsterdam=192.168.201.100 berlin=192.168.202.100"Legt fest, von wo die booth-Konfiguration kopiert werden soll. Verwenden Sie die IP-Adresse oder den Hostnamen eines Knotens in einer bereits konfigurierten GeoCluster-Site. Sie können auch (wie in diesem Beispiel) die virtuelle IP-Adresse einer bereits vorhandenen Cluster-Site verwenden. Alternativ können Sie die IP-Adresse oder den Hostnamen eines bereits für Ihren GeoCluster konfigurierten Vermittlers verwenden.
Die Namen der Cluster-Sites (die in
/etc/corosync/corosync.confdefiniert sind) und die virtuellen IP-Adressen, die Sie für die einzelnen Cluster-Sites verwenden möchten. In diesem Fall haben wir zwei Cluster-Sites (amsterdamundberlin), die je eine virtuelle IP-Adresse besitzen.
Das Skript ha-cluster-geo-join kopiert die booth-Konfiguration von 1, siehe Beispiel 1. Außerdem erstellt es die für booth benötigten Cluster-Ressourcen (siehe Beispiel 2).
8 Hinzufügen des Vermittlers #
Nachdem Sie alle Sites Ihres GeoClusters mit ha-cluster-geo-init und ha-cluster-geo-join eingerichtet haben, richten Sie mit ha-cluster-geo-init-arbitrator den Vermittler ein.
Prozedur 4: Einrichten des Vermittlers mit ha-cluster-geo-init-arbitrator #
Melden Sie sich bei dem Rechner an, den Sie als Vermittler verwenden möchten.
Führen Sie den folgenden Befehl aus. Beispiel:
root #ha-cluster-geo-init-arbitrator--cluster-node1 192.168.201.100Legt fest, von wo die booth-Konfiguration kopiert werden soll. Verwenden Sie die IP-Adresse oder den Hostnamen eines Knotens in einer bereits konfigurierten GeoCluster-Site. Sie können alternativ (wie in diesem Beispiel) die virtuelle IP-Adresse einer bereits vorhandenen Cluster-Site verwenden.
Das Skript ha-cluster-geo-init-arbitrator kopiert die booth-Konfiguration von 1, siehe Beispiel 1. Außerdem aktiviert und startet es den booth-Service auf dem Vermittler. Der Vermittler ist damit bereit, mit den booth-Instanzen auf den Cluster-Sites zu kommunizieren, sobald auch dort der booth-Service ausgeführt wird.
9 Überwachen der Cluster-Sites #
Verwenden Sie Hawk2, um beide Cluster-Sites mit den Ressourcen und dem Ticket anzuzeigen, die Sie während des Bootstrap-Prozesses erstellt haben. Über die Hawk2-Weboberfläche können Sie mehrere (nicht zugeordnete) Cluster und GeoCluster überwachen und verwalten.
Voraussetzungen #
Auf allen Clustern, die über das von Hawk2 überwacht werden sollen, muss SUSE Linux Enterprise High Availability Extension 12 SP5 ausgeführt werden.
Wenn Sie das eigensignierte Zertifikat für Hawk2 noch nicht auf jedem Cluster-Knoten durch ein eigenes Zertifikat (oder ein von einer offiziellen Zertifizierungsstelle signiertes Zertifikat) ersetzt haben, gehen Sie wie folgt vor: Melden Sie sich auf jedem Knoten in jedem Cluster mindestens einmal bei Hawk2 an. Überprüfen Sie das Zertifikat (oder fügen Sie im Browser eine Ausnahme hinzu, um die Warnung zu umgehen). Andernfalls kann Hawk2 keine Verbindung mit dem Cluster herstellen.
Prozedur 5: Verwendung des Hawk2-Dashboards #
Starten Sie einen Webbrowser und geben Sie die virtuelle IP-Adresse Ihrer ersten Cluster-Site
amsterdamein:https://192.168.201.100:7630/
Alternativ können Sie die IP-Adresse oder den Hostnamen von
aliceoderbobverwenden. Wenn Sie beide Knoten mit den Bootstrap-Skripten eingerichtet haben, sollte in beiden Knoten der Servicehawkausgeführt werden.Melden Sie sich an der Hawk2-Weboberfläche an.
Wählen Sie auf der linken Navigationsleiste aus.
Hawk2 zeigt eine Übersicht der Ressourcen und Knoten auf der aktuellen Cluster-Site an. Außerdem zeigt Hawk2 alle an, die für den GeoCluster konfiguriert wurden. Informationen zu den in dieser Ansicht verwendeten Symbolen erhalten Sie, indem Sie auf klicken.
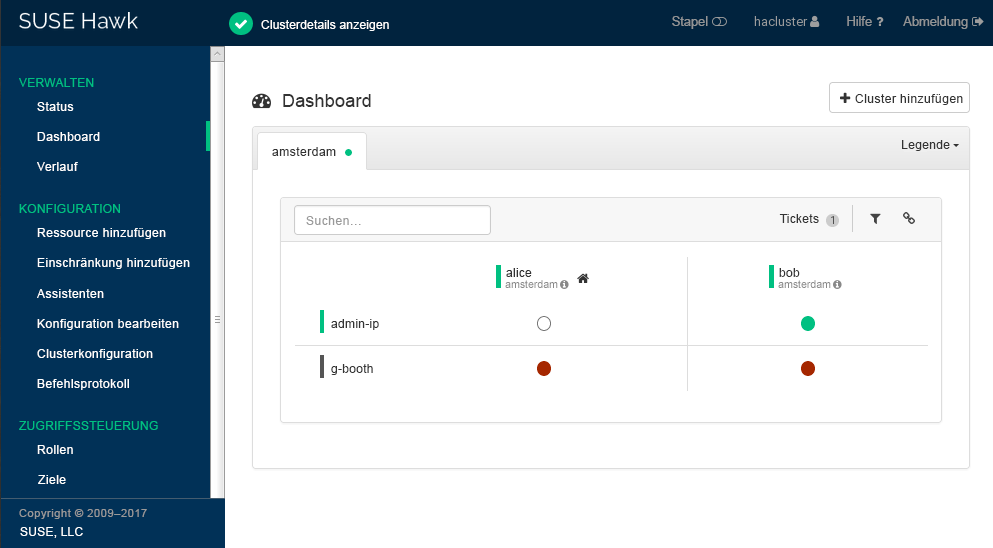
Abbildung 2: Hawk2-Dashboard mit einer Cluster-Site – (
amsterdam) #Klicken Sie auf , um ein Dashboard für die zweite Cluster-Site hinzuzufügen.
Geben Sie den ein, der den Cluster im identifiziert. In diesem Fall ist dies
berlin.Geben Sie den vollständigen Hostnamen einer der Cluster-Knoten ein (in diesem Fall
charlieoderdoro).Klicken Sie auf . Hawk2 zeigt für die neu hinzugefügte Cluster-Site eine zweite Registerkarte mit einer Übersicht der vorhandenen Knoten und Ressourcen an.
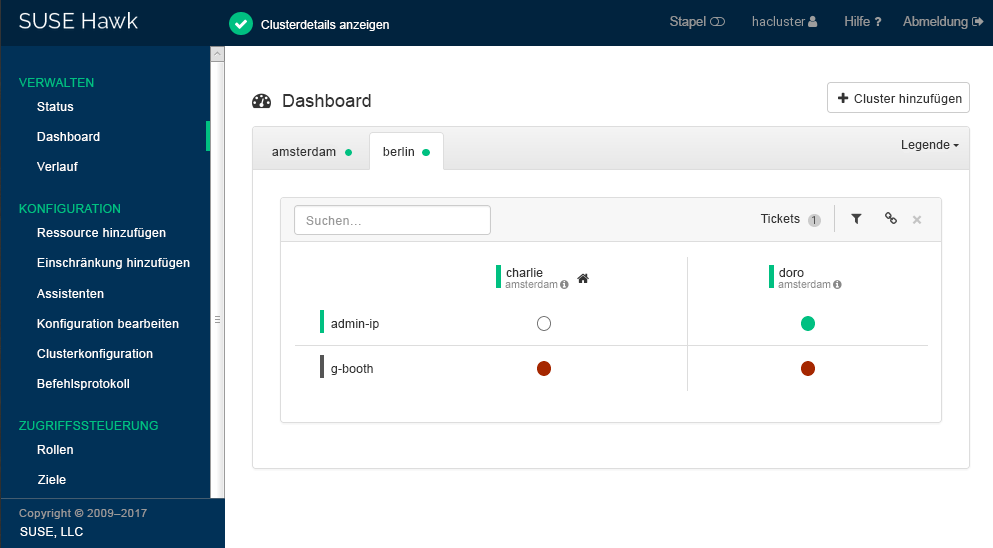
Abbildung 3: Hawk2-Dashboard mit beiden Cluster-Sites #
Um weitere Details anzuzeigen oder um eine Cluster-Site zu verwalten, wechseln Sie zur Registerkarte der Site und klicken Sie auf das Kettensymbol.
Hawk2 öffnet für die Site die in einem neuen Browserfenster oder Tab. Dort können Sie diesen Teil des GeoClusters verwalten.
10 Nächste Schritte #
Die Bootstrap-Skripte für das Geo-Clustering ermöglichen das schnelle Einrichten eines grundlegenden GeoClusters, der zu Testzwecken verwendet werden kann. Um einen solchen GeoCluster jedoch in einen funktionierenden GeoCluster zu überführen, der in einer Produktionsumgebung eingesetzt werden kann, sind weitere Schritte erforderlich. Siehe Erforderliche Schritte für den Abschluss des GeoCluster-Setups.
Erforderliche Schritte für den Abschluss des GeoCluster-Setups #
- Starten der booth-Services auf Cluster-Sites
Nach dem Bootstrap-Prozess kann der booth-Service des Vermittlers noch nicht mit den booth-Services auf den Cluster-Sites kommunizieren, da diese standardmäßig nicht gestartet werden.
Der booth-Service für jede Cluster-Site wird von der booth-Ressourcengruppe
g-boothverwaltet (siehe Beispiel 2, „Durchha-cluster-geo-initerstellte Cluster-Ressourcen“). Um eine Instanz des booth-Service pro Site zu starten, starten Sie die entsprechende booth-Ressourcengruppe auf den einzelnen Cluster-Sites. Damit sind alle booth-Instanzen in der Lage, miteinander zu kommunizieren.- Konfigurieren von Ticketabhängigkeiten und Einschränkungen
Um Ressourcen von dem von Ihnen während des Bootstrap-Prozesses für den GeoCluster erstellten Ticket abhängig zu machen, müssen Sie Einschränkungen konfigurieren. Legen Sie für jede Einschränkung mit
loss-policyeine Verlustrichtlinie fest, mit der Sie definieren, was mit den betroffenen Ressourcen passieren soll, wenn das Ticket von einer Cluster-Site zurückgezogen wird.Weitere Informationen finden Sie im Chapter 6, Configuring Cluster Resources and Constraints.
- Einer Site ein erstes Ticket gewähren
Bevor ein bestimmtes Ticket im GeoCluster von booth verwaltet werden kann, müssen Sie es einer Site einmal manuell gewähren. Um ein Ticket zu gewähren, können Sie entweder das Kommandozeilenwerkzeug „booth client“ oder Hawk2 verwenden.
Weitere Informationen finden Sie im Chapter 8, Managing Geo Clusters.
Die Bootstrap-Skripte erstellen auf beiden Cluster-Sites dieselben booth-Ressourcen und auf allen Sites, auch auf dem Vermittler, dieselben booth-Konfigurationsdateien. Wenn Sie das GeoCluster-Setup erweitern (um in eine Produktionsumgebung zu wechseln), werden Sie die booth-Konfiguration wahrscheinlich genauer abstimmen und auch die Konfiguration der zu booth gehörenden Cluster-Ressourcen ändern. Anschließend müssen Sie die Änderungen mit den anderen Sites Ihres GeoClusters synchronisieren, damit sie wirksam werden.
Anmerkung: Synchronisieren von Änderungen zwischen Cluster-Sites
Verwenden Sie Csync2, um Änderungen der booth-Konfiguration zwischen allen Cluster-Sites (einschließlich dem Vermittler) zu synchronisieren. Weitere Informationen finden Sie im Chapter 5, Synchronizing Configuration Files Across All Sites and Arbitrators.
Die CIB (Cluster Information Database) wird nicht automatisch zwischen den Cluster-Sites eines GeoClusters synchronisiert. Daher müssen alle Änderungen der Ressourcenkonfiguration, die auf allen Cluster-Sites benötigt werden, manuell auf die anderen Sites übertragen werden. Markieren Sie hierzu die entsprechenden Ressourcen, exportieren Sie sie aus der aktuellen CIB und importieren Sie sie in die CIBs auf den anderen Cluster-Sites. Weitere Informationen finden Sie im Section 6.4, “Transferring the Resource Configuration to Other Cluster Sites”.
11 Weiterführende Informationen #
Mehr Dokumentation zu diesem Produkt ist unter https://documentation.suse.com/sle-ha-12/ verfügbar. Zur Dokumentation gehört auch ein ausführliches
Geo-Clustering-Handbuch. Dort werden weitere Konfigurations- und Verwaltungsaufgaben beschrieben.In der Serie
SUSE Best Practiceswurde ein Dokument mit detaillierten Informationen zur Datenreplikation über DRBD zwischen GeoClustern veröffentlicht: https://documentation.suse.com/sbp/all/html/SBP-DRBD/index.html
12 Rechtliche Hinweise #
Copyright © 2006– 2026 SUSE LLC und Mitwirkende. Alle Rechte vorbehalten.
Es wird die Genehmigung erteilt, dieses Dokument unter den Bedingungen der GNU Free Documentation License, Version 1.2 oder (optional) Version 1.3 zu vervielfältigen, zu verbreiten und/oder zu verändern; die unveränderlichen Abschnitte hierbei sind der Urheberrechtshinweis und die Lizenzbedingungen. Eine Kopie dieser Lizenz (Version 1.2) finden Sie im Abschnitt „GNU Free Documentation License“.
Die SUSE-Marken finden Sie unter http://www.suse.com/company/legal/. Alle anderen Marken von Drittanbietern sind Besitz ihrer jeweiligen Eigentümer. Markensymbole (®, ™ usw.) kennzeichnen Marken von SUSE und der Tochtergesellschaften. Sternchen (*) kennzeichnen Marken von Drittanbietern.
Alle Informationen in diesem Buch wurden mit größter Sorgfalt zusammengestellt. Doch auch dadurch kann hundertprozentige Richtigkeit nicht gewährleistet werden. Weder SUSE LLC noch ihre Tochtergesellschaften noch die Autoren noch die Übersetzer können für mögliche Fehler und deren Folgen haftbar gemacht werden.