Inicio rápido de Geo Clustering
- 1 Descripción conceptual
- 2 Ejemplos de uso
- 3 Requisitos
- 4 Descripción general de los guiones de bootstrap geográficos
- 5 Instalación como extensión
- 6 Configuración del primer sitio de un clúster geográfico
- 7 Adición de otro sitio a un clúster geográfico
- 8 Adición del árbitro
- 9 Supervisión de los sitios de clúster
- 10 Pasos siguientes
- 11 Información adicional
- 12 Información legal
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Inicio rápido de Geo Clustering #
Resumen#
Gracias a los clústeres geográficos, es posible contar con varios sitios dispersos geográficamente con un clúster local cada uno. El failover entre estos clústeres se coordina mediante una entidad de nivel superior: el gestor de tickets del clúster de booth. Este documento sirve como guía para la configuración básica de un clúster geográfico mediante los guiones de bootstrap geográficos proporcionados por el paquete ha-cluster-bootstrap.
- 1 Descripción conceptual
- 2 Ejemplos de uso
- 3 Requisitos
- 4 Descripción general de los guiones de bootstrap geográficos
- 5 Instalación como extensión
- 6 Configuración del primer sitio de un clúster geográfico
- 7 Adición de otro sitio a un clúster geográfico
- 8 Adición del árbitro
- 9 Supervisión de los sitios de clúster
- 10 Pasos siguientes
- 11 Información adicional
- 12 Información legal
- A GNU Licenses
1 Descripción conceptual #
Los clústeres geográficos basados en SUSE® Linux Enterprise High Availability Extension se pueden considerar clústeres de “superposición” en los que cada sitio de clúster se corresponde con un nodo de clúster en un clúster tradicional. El gestor de tickets del clúster de booth gestiona el clúster de superposición (en la instancia de booth al que se llama a continuación). Todas las partes implicadas en un clúster geográfico ejecutan un servicio, boothd. Este se conecta con los daemons de booth que se ejecuten en los demás sitios e intercambia detalles de conectividad. Para conseguir que los recursos del clúster tengan una alta disponibilidad en los sitios, la instancia de booth utiliza objetos de clúster denominados tickets. Un ticket otorga el derecho a ejecutar determinados recursos en un sitio de clúster específico. La instancia de booth garantiza que cada ticket solo se otorga a un único sitio a la vez.
Si se interrumpe la comunicación entre dos instancias de booth, puede deberse a una interrupción de la red entre los sitios de clúster o a una interrupción de un sitio de clúster. En tal caso, se necesita una instancia adicional (un tercer sitio de clúster o un árbitro) para llegar a un consenso sobre las decisiones (por ejemplo, el failover de los recursos entre los sitios). Los árbitros son equipos individuales (exteriores a los clústeres) en los que se ejecuta una instancia de booth de un modo especial. Cada clúster geográfico puede tener uno o varios árbitros.
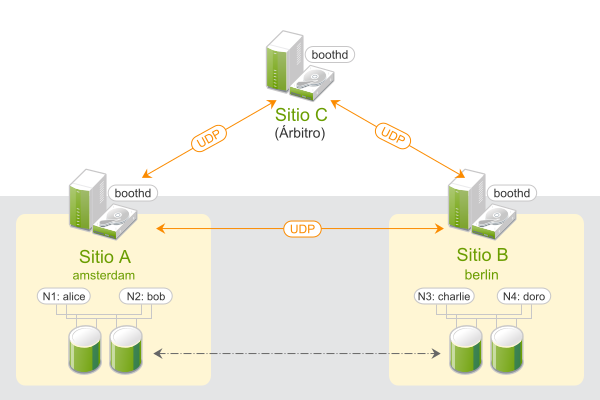
Figura 1: Clúster de dos sitios (2x2 nodos + árbitro) #
Para obtener más detalles sobre el concepto, los componentes y la gestión de tickets que se usan para los clústeres geográficos, consulte el Chapter 2, Conceptual Overview.
2 Ejemplos de uso #
A continuación, vamos a configurar un clúster geográfico básico con dos sitios de clúster y un árbitro:
Los sitios de clúster se denominarán
amsterdamyberlin.Cada sitio estará compuesto por dos nodos. Los nodos
aliceybobpertenecen al clústeramsterdam. Los nodoscharlieydoropertenecen al clústerberlin.El sitio
amsterdamrecibirá la siguiente dirección IP virtual:192.168.201.100.El sitio
berlinrecibirá la siguiente dirección IP virtual:192.168.202.100.El árbitro tendrá la siguiente dirección IP:
192.168.203.100.
Antes de continuar, asegúrese de que se cumplen los siguientes requisitos:
Requisitos #
- Existen dos clústeres
Debe tener al menos dos clústeres que desea combinar en un clúster geográfico. Si necesita configurar dos clústeres en primer lugar, siga las instrucciones de Inicio rápido de instalación y configuración.
- Los clústeres tienen nombres descriptivos
Cada clúster debe tener un nombre descriptivo definido en
/etc/corosync/corosync.confque indique su ubicación.- Árbitro
Se ha instalado un tercer equipo que no forma parte de los clústeres existentes y que se usará como árbitro.
Para los requisitos detallados de cada elemento, consulte también la Sección 3, “Requisitos”.
3 Requisitos #
Requisitos de software #
Todos los equipos (nodos de clúster y árbitros) que formarán parte del clúster geográfico deben tener instalado el software siguiente:
SUSE® Linux Enterprise Server 12 SP5
SUSE Linux Enterprise High Availability Extension 12 SP5
Geo Clustering para SUSE Linux Enterprise High Availability Extension 12 SP5
Requisitos de red #
Todo el clúster geográfico debe tener acceso a las direcciones IP virtuales que se utilizarán para cada sitio de clúster.
Debe ser posible acceder a los sitios en un puerto UDP y TCP por cada instancia de booth. Esto significa que los cortafuegos y los túneles IPsec intermedios deben configurarse según corresponda.
Si se realiza otra instalación distinta, puede ser necesario abrir más puertos (por ejemplo, para DRBD o para la réplica de la base de datos).
Otros requisitos y recomendaciones #
Se deben sincronizar todos los nodos del clúster en todos los sitios con un servidor NTP fuera del clúster. Para obtener más información, consulte el https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Si no se sincronizan los nodos, resultará muy difícil analizar los archivos de registro y los informes del clúster.
Emplee un número impar de miembros en el clúster geográfico. Esto garantiza que, en caso de que la conexión de red se interrumpa, aún haya una mayoría de sitios (para evitar una situación de clúster con nodos malinformados). En caso de tener un número par de sitios de clúster, utilice un árbitro.
El clúster de cada sitio debe tener un nombre descriptivo, por ejemplo:
amsterdamyberlin.Los nombres de clúster de cada sitio se deben definir en los archivos
/etc/corosync/corosync.confrespectivos:totem { [...] cluster_name: amsterdam }Esto se puede realizar manualmente (editando
/etc/corosync/corosync.conf) o con el módulo de clúster YaST (cambiando a la categoría y definiendo un valor en ). Seguidamente, detenga e inicie el serviciopacemakerpara que los cambios entren en vigor:root #systemctlstop pacemakerroot #systemctlstart pacemaker
4 Descripción general de los guiones de bootstrap geográficos #
El guion
ha-cluster-geo-initconvierte un clúster en el primer sitio de un clúster geográfico. Toma algunos parámetros, como los nombres de los clústeres, al árbitro y uno o varios tickets, y crea el archivo/etc/booth/booth.confa partir de ellos. Copia la configuración de booth a todos los nodos del sitio de clúster actual. También configura los recursos del clúster necesarios para booth en el sitio de clúster actual.Para obtener información, consulte la Sección 6, “Configuración del primer sitio de un clúster geográfico”.
El guion
ha-cluster-geo-joinañade el clúster actual a un clúster geográfico existente. Copia la configuración de booth de un sitio de clúster existente y lo escribe en el archivo/etc/booth/booth.confen todos los nodos del sitio de clúster actual. También configura los recursos del clúster necesarios para booth en el sitio de clúster actual.Para obtener información, consulte la Sección 7, “Adición de otro sitio a un clúster geográfico”.
El guion
ha-cluster-geo-init-arbitratorconvierte el equipo actual en un árbitro para el clúster geográfico. Copia la configuración de booth de un sitio de clúster existente y lo escribe en el archivo/etc/booth/booth.conf.Para obtener información, consulte la Sección 8, “Adición del árbitro”.
Todos los guiones de bootstrap se registran en /var/log/ha-cluster-bootstrap.log. Consulte el archivo de registro para obtener información sobre el proceso de bootstrap. Las opciones establecidas durante el proceso de bootstrap pueden modificarse más adelante (modificando la configuración de booth, los recursos, etc.). Para obtener más información, consulte Geo Clustering Guide.
5 Instalación como extensión #
Hay disponible capacidad para usar clústeres de alta disponibilidad a distancias ilimitadas como una extensión independiente, denominada Geo Clustering para SUSE Linux Enterprise High Availability Extension.
Para configurar un clúster geográfico, se necesitan los paquetes incluidos en los patrones de instalación siguientes:
Alta disponibilidadGeoCluster para alta disponibilidad
Ambos patrones solo están disponibles si ha registrado el sistema en el Centro de servicios al cliente de SUSE (o en un servidor de registro local) y ha añadido los canales de producto correspondientes o los medios de instalación como una extensión. Para obtener información sobre cómo instalar extensiones, consulte la Guía de distribución de SUSE Linux Enterprise 12 SP5: https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Procedimiento 1: instalación de los paquetes #
Para instalar los paquetes de ambos patrones mediante la línea de comandos, utilice Zypper:
root #zypperinstall -t pattern ha_sles ha_geoComo alternativa, utilice YaST para realizar una instalación gráfica:
Inicie YaST como usuario
Rooty seleccione › .Haga clic en › y active los patrones siguientes:
Alta disponibilidadGeoCluster para alta disponibilidad
Haga clic en para iniciar la instalación de los paquetes.
Importante: instalación de paquetes de software en todas las partes
Los paquetes de software necesarios para los clústeres de alta disponibilidad y geográficos no se copian automáticamente en los nodos del clúster.
Instale SUSE Linux Enterprise Server 12 SP5 y los patrones
Alta disponibilidadyGeoCluster para alta disponibilidaden todos los equipos que formarán parte del clúster geográfico.Si no desea instalar los paquetes de forma manual en todos los equipos que formarán parte del clúster, utilice AutoYaST para duplicar los nodos existentes. Hay más información disponible en el Section 3.2, “Mass Installation and Deployment with AutoYaST”.
Sin embargo, la extensión de clústeres geográficos debe instalarse manualmente en todos los equipos que formarán parte del clúster geográfico. La compatibilidad de AutoYaST con Geo Clustering para SUSE Linux Enterprise High Availability Extension aún no está disponible.
6 Configuración del primer sitio de un clúster geográfico #
Utilice el guion ha-cluster-geo-init para convertir un clúster existente en el primer sitio de un clúster geográfico.
Procedimiento 2: configuración del primer sitio (amsterdam) mediante ha-cluster-geo-init #
Defina una dirección IP virtual por cada sitio de clúster que se pueda usar para acceder al sitio. Supongamos que usa
192.168.201.100y192.168.202.100para este propósito. Aún no es necesario configurar las direcciones IP virtuales como recursos del clúster. Eso lo harán los guiones de bootstrap.Defina el nombre de al menos un ticket que pueda otorgar el derecho a ejecutar ciertos recursos en un sitio de clúster. Utilice un nombre descriptivo que refleje los recursos que dependerán del ticket (por ejemplo,
ticket-nfs). Los guiones de bootstrap solo necesitan el nombre del ticket; puede definir los detalles restantes más tarde (como dependencias de ticket de los recursos), como se describe en la Sección 10, “Pasos siguientes”.Entre en un nodo de un clúster existente (por ejemplo, en el nodo
alicedel clústeramsterdam).Ejecute
ha-cluster-geo-init. Por ejemplo, use las siguientes opciones:root #ha-cluster-geo-init\ --clusters1 "amsterdam=192.168.201.100 berlin=192.168.202.100" \ --tickets2 ticket-nfs \ --arbitrator3 192.168.203.100Los nombres de los sitios de clúster (como se definen en
/etc/corosync/corosync.conf) y las direcciones IP virtuales que desea utilizar para cada sitio de clúster. En este caso, tenemos dos sitios de clúster (amsterdamyberlin) con una dirección IP virtual cada uno.El nombre de uno o varios tickets.
El nombre de host o la dirección IP de un equipo situado fuera de los clústeres.
El guion de bootstrap crea el archivo de configuración de booth y lo sincroniza con todos los sitios del clúster. También crea los recursos básicos del clúster necesarios para booth. El Paso 4 del Procedimiento 2 dará como resultado la siguiente configuración de booth y los siguientes recursos del clúster:
Ejemplo 1: Configuración de booth creada por ha-cluster-geo-init #
# The booth configuration file is "/etc/booth/booth.conf". You need to # prepare the same booth configuration file on each arbitrator and # each node in the cluster sites where the booth daemon can be launched. # "transport" means which transport layer booth daemon will use. # Currently only "UDP" is supported. transport="UDP" port="9929" arbitrator="192.168.203.100" site="192.168.201.100" site="192.168.202.100" authfile="/etc/booth/authkey" ticket="ticket-nfs" expire="600"
Ejemplo 2: Recursos del clúster creados por ha-cluster-geo-init #
primitive1 booth-ip IPaddr2 \ params rule #cluster-name eq amsterdam ip=192.168.201.100 \ params rule #cluster-name eq berlin ip=192.168.202.100 \ primitive2 booth-site ocf:pacemaker:booth-site \ meta resource-stickiness=INFINITY \ params config=booth \ op monitor interval=10s group3 g-booth booth-ip booth-site \ meta target-role=Stopped4
Una dirección IP virtual para cada sitio de clúster. Se requiere para los daemons de booth que necesitan una dirección IP persistente en cada sitio de clúster. | |
Un recurso primitivo para el daemon de booth. Se comunica con los daemons de booth en los demás sitios del clúster. El daemon puede iniciarse en cualquier nodo del sitio, pero para conseguir que el recurso permanezca en el mismo nodo, si es posible, en el parámetro resource-stickiness se define el valor | |
Un grupo de recursos del clúster para ambos recursos primitivos. Con esta configuración, cada daemon de booth estará disponible en su dirección IP individual, independientemente del nodo en el que se ejecute el daemon. | |
El grupo de recursos del clúster no se inicia por defecto. Después de verificar la configuración de los recursos del clúster (y añadir los recursos que necesita para completar la configuración), debe iniciar el grupo de recursos. Consulte Pasos necesarios para completar la configuración del clúster geográfico para obtener más información. |
7 Adición de otro sitio a un clúster geográfico #
Después de inicializar el primer sitio del clúster geográfico, añada un segundo clúster mediante ha-cluster-geo-join, como se describe en el Procedimiento 3. El guion necesita acceso SSH a un sitio de clúster ya configurado y añadirá el clúster actual al clúster geográfico.
Procedimiento 3: adición del segundo sitio (berlin) mediante ha-cluster-geo-join #
Entre en un nodo del sitio de clúster que desee añadir (por ejemplo, en el nodo
charliedel clústerberlin).Ejecute el comando
ha-cluster-geo-join. Por ejemplo:root #ha-cluster-geo-join\ --cluster-node1 192.168.201.100\ --clusters2 "amsterdam=192.168.201.100 berlin=192.168.202.100"Especifica de dónde se debe copiar la configuración de booth. Utilice la dirección IP o el nombre de host de un nodo de un sitio de clúster geográfico ya configurado. También puede usar la dirección IP virtual de un sitio de clúster ya existente (como en este ejemplo). Como alternativa, use la dirección IP o el nombre de host de un árbitro ya configurado para el clúster geográfico.
Los nombres de los sitios de clúster (como se definen en
/etc/corosync/corosync.conf) y las direcciones IP virtuales que desea utilizar para cada sitio de clúster. En este caso, tenemos dos sitios de clúster (amsterdamyberlin) con una dirección IP virtual cada uno.
El guion ha-cluster-geo-join copia la configuración de booth de 1, consulte el Ejemplo 1. Además, crea los recursos del clúster necesarios para la instancia de booth (consulte el Ejemplo 2).
8 Adición del árbitro #
Después de configurar todos los sitios del clúster geográfico mediante ha-cluster-geo-init y ha-cluster-geo-join, configure el árbitro mediante ha-cluster-geo-init-arbitrator.
Procedimiento 4: configuración del árbitro mediante ha-cluster-geo-init-arbitrator #
Entre en el equipo que desea utilizar como árbitro.
Ejecute el comando siguiente. Por ejemplo:
root #ha-cluster-geo-init-arbitrator--cluster-node1 192.168.201.100Especifica de dónde se debe copiar la configuración de booth. Utilice la dirección IP o el nombre de host de un nodo de un sitio de clúster geográfico ya configurado. Como alternativa, puede usar la dirección IP virtual de un sitio de clúster ya existente (como en este ejemplo).
El guion ha-cluster-geo-init-arbitrator copia la configuración de booth de 1, consulte el Ejemplo 1. También habilita e inicia el servicio de booth en el árbitro. Por lo tanto, el árbitro está listo para comunicarse con las instancias de booth de los sitios de clúster en cuanto los servicios de booth se ejecutan allí.
9 Supervisión de los sitios de clúster #
Para ver ambos sitios de clúster con los recursos y el ticket que ha creado durante el proceso de bootstrap, utilice Hawk2. La interfaz Web Hawk2 permite supervisar y gestionar varios clústeres (no relacionados) y clústeres geográficos.
Requisitos previos #
En todos los clústeres que se van a supervisar con la de Hawk5 se debe ejecutar SUSE Linux Enterprise High Availability Extension 12 SP2.
Si aún no ha sustituido el certificado autofirmado de Hawk2 en cada nodo de clúster por su propio certificado (o por un certificado firmado por una autoridad certificadora oficial), haga lo siguiente: entre en Hawk2 en cada nodo y en cada clúster al menos una vez. Verifique el certificado (o añada una excepción en el navegador para omitir la advertencia). De lo contrario, Hawk2 no podrá conectarse al clúster.
Procedimiento 5: uso de la consola de Hawk2 #
Abra un navegador Web y escriba la dirección IP virtual del primer sitio de clúster,
amsterdam:https://192.168.201.100:7630/
Como alternativa, utilice la dirección IP o el nombre de host de los nodos
aliceobob. Si ha configurado ambos nodos con los guiones de bootstrap, el serviciohawkdebe ejecutarse en ambos nodos.Entre en la interfaz Web de Hawk2.
En la barra de navegación izquierda, seleccione
Hawk2 muestra un resumen de los nodos y los recursos del sitio de clúster actual. Además, muestra todos los que se han configurado para el clúster geográfico. Si necesita información acerca de los iconos utilizados en esta vista, haga clic en .
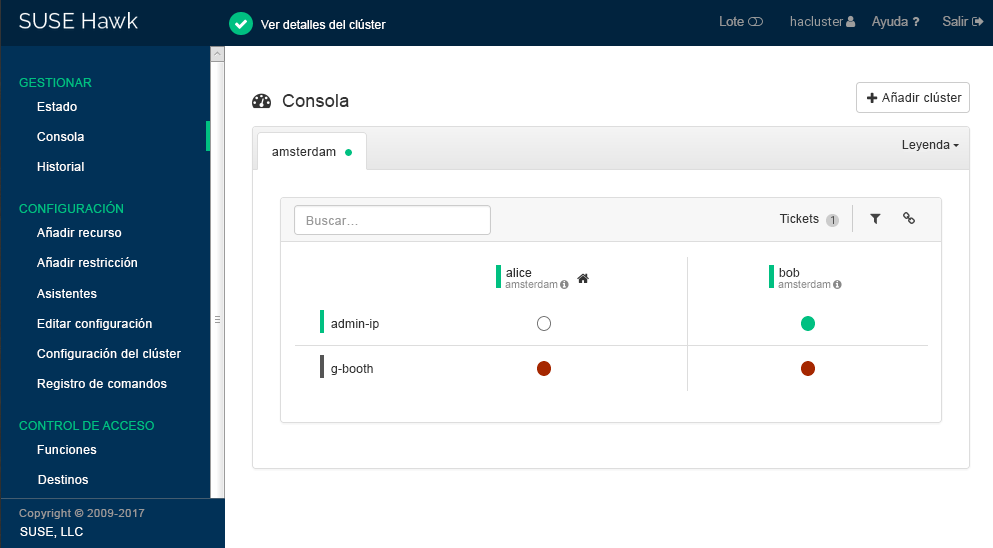
Figura 2: consola de Hawk2 con un sitio de clúster (
amsterdam) #Para añadir una consola del segundo sitio de clúster, haga clic en .
Introduzca un valor en para identificar el clúster en la . En este caso,
berlin.Escriba el nombre de host completo de uno de los nodos del clúster (en este caso,
charlieodoro).Haga clic en . Hawk2 mostrará una segunda pestaña para el sitio de clúster recién añadido con un resumen de sus nodos y recursos.
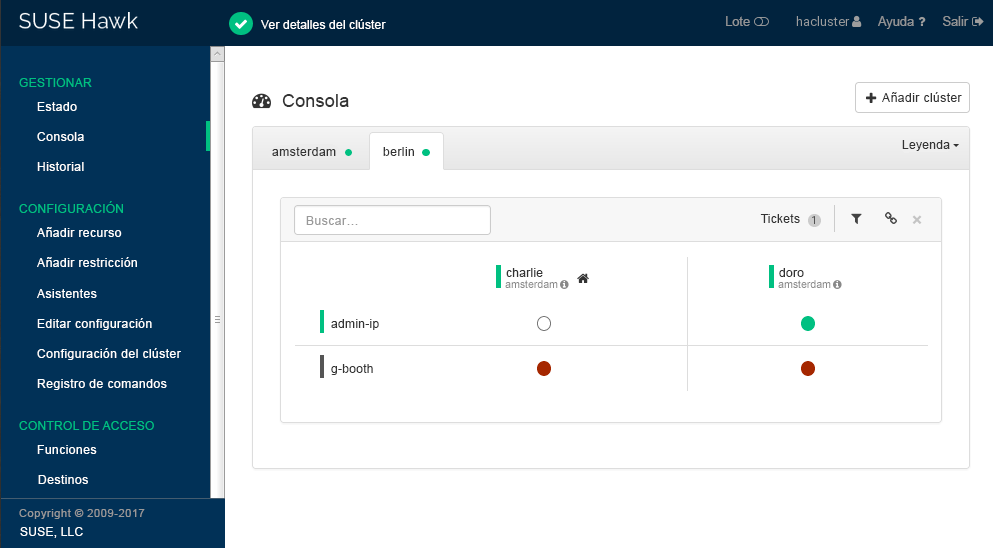
Figura 3: consola de Hawk2 con ambos sitios de clúster #
Para ver más detalles sobre un sitio de clúster, o para gestionarlo, cambie a la pestaña del sitio y haga clic en el icono de cadena.
Hawk2 abre la vista de ese sitio en una nueva ventana o pestaña del navegador. Allí, podrá administrar esa parte del clúster geográfico.
10 Pasos siguientes #
Los guiones de bootstrap de los clústeres geográficos proporcionan una forma rápida de configurar un clúster geográfico básico que puede utilizarse con fines de prueba. Sin embargo, para convertir el clúster geográfico resultante en un clúster geográfico funcional que pueda usarse en entornos de producción, son necesarios más pasos, consulte Pasos necesarios para completar la configuración del clúster geográfico.
Pasos necesarios para completar la configuración del clúster geográfico #
- Inicio de los servicios de booth en sitios de clúster
Después del proceso de bootstrap, el servicio booth del árbitro aún no puede comunicarse con los servicios booth de los sitios de clúster, ya que no se inician por defecto.
El servicio booth de cada sitio de clúster se gestiona mediante el grupo de recursos de booth
g-booth(consulte el Ejemplo 2, “Recursos del clúster creados porha-cluster-geo-init”). Para iniciar una instancia del servicio de booth en cada sitio, inicie el grupo de recursos de booth correspondiente en cada sitio de clúster. Esto permite que todas las instancias de booth se comuniquen entre sí.- Configuración de las dependencias del ticket y petición de restricciones
Para hacer que los recursos dependan del ticket que ha creado durante el proceso de bootstrap del clúster geográfico, debe configurar restricciones. Para cada restricción, defina una
directiva de pérdidaque defina qué debe ocurrir con los recursos respectivos si se revoca el ticket desde un sitio de clúster.Para obtener información, consulte el Chapter 6, Configuring Cluster Resources and Constraints.
- Concesión inicial de un ticket a un sitio
Antes de que la instancia de booth pueda gestionar un ticket determinado en el clúster geográfico, debe otorgarlo a un sitio manualmente. Puede utilizar la herramienta de línea de comandos del cliente de booth o Hawk2 para otorgar un ticket.
Para obtener información, consulte el Chapter 8, Managing Geo Clusters.
Los guiones de bootstrap crean los mismos recursos de booth en ambos sitios de clúster, además de los mismos archivos de configuración de booth en todos los sitios, incluido el árbitro. Si extiende la configuración del clúster geográfico (para convertirlo en un entorno de producción), es probable que ajuste los detalles de la configuración de booth y que cambie la configuración de los recursos del clúster relacionados con la instancia de booth. Después, debe sincronizar los cambios realizados con los demás sitios del clúster geográfico para que entren en vigor.
Nota: sincronización de los cambios en todos los sitios de clúster
Para sincronizar los cambios de la configuración de booth en todos los sitios de clúster (incluido el árbitro), utilice Csync2. Hay más información disponible en el Chapter 5, Synchronizing Configuration Files Across All Sites and Arbitrators.
La CIB (base de datos de información del clúster) no se sincroniza automáticamente con los sitios de clúster de un clúster geográfico. Esto significa que los cambios en la configuración del recurso que se necesiten en todos los sitios de clúster deben transferirse a los demás sitios manualmente. Para hacerlo, etiquete los recursos respectivos, expórtelos desde la CIB actual e impórtelos a la CIB de los demás sitios de clúster. Para obtener información, consulte el Section 6.4, “Transferring the Resource Configuration to Other Cluster Sites”.
11 Información adicional #
Hay disponible más documentación sobre este producto en https://documentation.suse.com/sle-ha-12/. La documentación también incluye una completa
guía sobre los clústeres geográficos. Consúltela para obtener más datos sobre las tareas de configuración y administración.Se ha publicado un documento con información detallada sobre cómo replicar los datos a través de DRBD entre clústeres geográficos en la serie
SUSE Best Practices(Prácticas recomendadas de SUSE): https://documentation.suse.com/sbp/all/html/SBP-DRBD/index.html
12 Información legal #
Copyright © 2006– 2026 SUSE LLC y colaboradores. Reservados todos los derechos.
Está permitido copiar, distribuir y modificar este documento según los términos de la licencia de documentación gratuita GNU, versión 1.2 o (según su criterio) versión 1.3. Este aviso de copyright y licencia deberán permanecer inalterados. En la sección titulada “GNU Free Documentation License” (Licencia de documentación gratuita GNU) se incluye una copia de la versión 1.2 de la licencia.
Para obtener información sobre las marcas comerciales de SUSE, consulte http://www.suse.com/company/legal/. Todas las marcas comerciales de otros fabricantes son propiedad de sus respectivas empresas. Los símbolos de marca comercial (®,™ etc.) indican marcas comerciales de SUSE y sus afiliados. Los asteriscos (*) indican marcas comerciales de otros fabricantes.
Toda la información recogida en esta publicación se ha compilado prestando toda la atención posible al más mínimo detalle. Sin embargo, esto no garantiza una precisión total. Ni SUSE LLC, ni sus filiales, ni los autores o traductores serán responsables de los posibles errores o las consecuencias que de ellos pudieran derivarse.