Démarrage rapide de Geo Clustering
- 1 Présentation conceptuelle
- 2 Scénario d'utilisation
- 3 Configuration requise
- 4 Présentation des scripts d'amorçage Geo
- 5 Installation en tant qu'extension
- 6 Configuration du premier site d'une grappe géographique
- 7 Ajout d'un autre site à une grappe géographique
- 8 Ajout de l'arbitre
- 9 Surveillance des sites de grappe
- 10 Étapes suivantes
- 11 Complément d'informations
- 12 Mentions légales
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Démarrage rapide de Geo Clustering #
Résumé#
Geo Clustering vous permet d'avoir plusieurs sites dispersés géographiquement avec une grappe locale pour chacun. Le basculement entre ces grappes est coordonné par une entité de niveau supérieur : le gestionnaire de tickets de grappe booth. Le présent document explique la configuration de base d'une grappe géographique, à l'aide des scripts d'amorçage Geo fournis par le paquetage ha-cluster-bootstrap.
- 1 Présentation conceptuelle
- 2 Scénario d'utilisation
- 3 Configuration requise
- 4 Présentation des scripts d'amorçage Geo
- 5 Installation en tant qu'extension
- 6 Configuration du premier site d'une grappe géographique
- 7 Ajout d'un autre site à une grappe géographique
- 8 Ajout de l'arbitre
- 9 Surveillance des sites de grappe
- 10 Étapes suivantes
- 11 Complément d'informations
- 12 Mentions légales
- A GNU Licenses
1 Présentation conceptuelle #
Les grappes géographiques basées sur SUSE® Linux Enterprise High Availability Extension peuvent être considérées comme des grappes de « superposition », dans lesquelles chaque site de grappe correspond à un noeud d'une grappe traditionnelle. La grappe de superposition est gérée par le gestionnaire de ticket de grappe booth (appelé ci-après booth). Chacune des parties impliquées dans une grappe géographique exécute un service, le boothd. Celui-ci se connecte aux daemons booth en cours d'exécution sur les autres sites et échange des informations de connectivité. Pour rendre les ressources de grappe hautement disponibles entre les sites, le booth s'appuie sur les objets de grappe appelés tickets. Un ticket donne le droit d'exécuter certaines ressources sur un site de grappe spécifique. Le booth garantit que chaque ticket est accordé à un seul site à la fois.
En cas d'interruption de la communication entre deux instances de booth, cela peut provenir d'une défaillance du réseau entre les sites de grappe ou d'une indisponibilité d'un site de grappe. Dans ce cas, vous avez besoin d'une instance supplémentaire (un troisième site de grappe ou un arbitre) pour parvenir à un consensus sur les décisions (par exemple, le basculement des ressources entre les sites). Les arbitres sont des machines uniques (hors des grappes) qui exécutent une instance de booth dans un mode particulier. Chaque grappe géographique peut avoir un ou plusieurs arbitres.
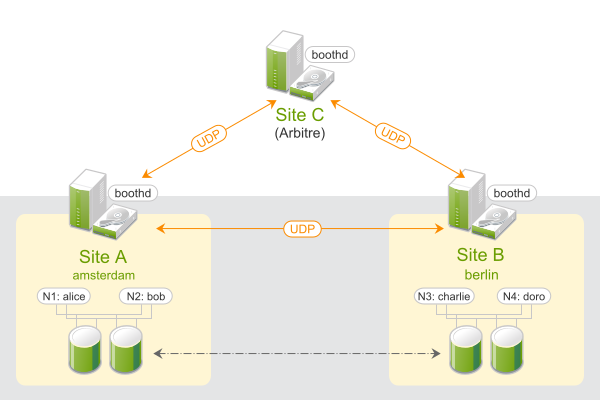
Figure 1 : grappe à deux sites (2x2 noeuds + arbitre) #
Pour plus de détails sur le concept, les composants et la gestion des tickets pour les grappes géographiques, reportez-vous au Chapter 2, Conceptual Overview.
2 Scénario d'utilisation #
Dans l'exemple suivant, nous allons configurer une grappe géographique de base avec deux sites de grappe et un arbitre :
Supposons que les sites de grappe soient nommés
amsterdametberlin.Supposons que chaque site se compose de deux noeuds. Les noeuds
aliceetbobappartiennent à la grappeamsterdam. Les noeudscharlieetdoroappartiennent à la grappeberlin.Le site
amsterdamrecevra l'adresse IP virtuelle suivante :192.168.201.100.Le site
berlinrecevra l'adresse IP virtuelle suivante :192.168.202.100.Supposons que l'arbitre a l'adresse IP suivante :
192.168.203.100.
Avant de poursuivre, assurez-vous que les conditions suivantes sont remplies :
Configuration requise #
- Deux grappes existantes
Vous avez au moins deux grappes existantes que vous souhaitez combiner dans une grappe géographique. (Si vous devez configurer deux grappes d'abord, suivez les instructions du manuel Démarrage rapide de l'installation et de la configuration.)
- Noms de grappe pertinents
Chaque grappe possède un nom de grappe pertinent défini dans le fichier
/etc/corosync/corosync.confqui reflète son emplacement.- Arbitre
Vous avez installé une troisième machine qui ne fait partie d'aucune grappe existante et doit être utilisée en tant qu'arbitre.
Pour plus de détails sur chaque élément, reportez-vous également à la Section 3, « Configuration requise ».
3 Configuration requise #
Configuration logicielle requise #
Toutes les machines (noeuds de grappe et arbitres) qui feront partie de la grappe géographique sont équipés des logiciels suivants :
SUSE® Linux Enterprise Server 12 SP5
SUSE Linux Enterprise High Availability Extension 12 SP5
Geo Clustering for SUSE Linux Enterprise High Availability Extension 12 SP5
Configuration du réseau #
Les adresses IP virtuelles à utiliser pour chaque site de grappe doivent être accessibles dans la grappe géographique.
Les sites doivent être accessibles sur un port UDP et un port TCP par instance de booth. En d'autres termes, les éventuels pare-feux ou tunnels IPsec intermédiaires doivent être configurés en conséquence.
D'autres décisions de configuration peuvent nécessiter l'ouverture de ports supplémentaires (par exemple, pour la réplication de base de données ou DRBD).
Autres conditions requises et recommandations #
Tous les noeuds de grappe sur tous les sites doivent être synchronisés avec un serveur NTP en dehors de la grappe. Pour plus d'informations, consultez le site https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Si les noeuds ne sont pas synchronisés, les fichiers journaux et les rapports de grappe sont très difficiles à analyser.
Utilisez un nombre impair de membres dans votre grappe géographique. En cas d'interruption de la connexion réseau, cela permet de garantir qu'il y a toujours une majorité de sites (afin d'éviter les scénarios de vues de grappe divergentes). Si vous disposez d'un nombre pair de sites de grappe, utilisez un arbitre.
La grappe sur chaque site a un nom pertinent, par exemple :
amsterdametberlin.Les noms de grappe pour chaque site sont définis dans leur fichier
/etc/corosync/corosync.confrespectif :totem { [...] cluster_name: amsterdam }Cette opération peut être réalisée soit manuellement (en modifiant le fichier
/etc/corosync/corosync.conf), soit avec le module de grappe YaST (en basculant sur la catégorie et en définissant un ). Ensuite, arrêtez et démarrez le servicepacemakerpour appliquer les modifications :root #systemctlstop pacemakerroot #systemctlstart pacemaker
4 Présentation des scripts d'amorçage Geo #
À l'aide du script
ha-cluster-geo-init, configurez une grappe en tant que premier site d'une grappe géographique. Le script utilise certains paramètres tels que les noms des grappes, l'arbitre et un ou plusieurs tickets pour créer le fichier/etc/booth/booth.conf. Il copie la configuration booth sur tous les noeuds du site de grappe actuel. Il configure également les ressources de grappe nécessaires pour le booth sur le site de grappe actuel.Pour plus de détails, reportez-vous à la Section 6, « Configuration du premier site d'une grappe géographique ».
À l'aide du script
ha-cluster-geo-join, ajoutez la grappe actuelle à une grappe géographique existante. Le script copie la configuration booth d'un site de grappe existant et l'écrit dans le fichier/etc/booth/booth.confsur tous les noeuds du site de grappe actuel. Il configure également les ressources de grappe nécessaires pour le booth sur le site de grappe actuel.Pour plus de détails, reportez-vous à la Section 7, « Ajout d'un autre site à une grappe géographique ».
À l'aide du script
ha-cluster-geo-init-arbitrator, configurez la machine actuelle en tant qu'arbitre pour la grappe géographique. Le script copie de la configuration booth d'un site de grappe existant et l'écrit dans le fichier/etc/booth/booth.conf.Pour plus de détails, reportez-vous à la Section 8, « Ajout de l'arbitre ».
Tous les scripts d'amorçage consignent des données dans le fichier/var/log/ha-cluster-bootstrap.log. Pour toute information à propos du processus d'amorçage, consultez le fichier journal. Toutes les options définies lors du processus d'amorçage peuvent être modifiées ultérieurement (en changeant les paramètres booth, les ressources, etc.). Pour plus de détails, consultez le Geo Clustering Guide.
5 Installation en tant qu'extension #
La prise en charge de l'utilisation de grappes à haute disponibilité sur des distances illimitées est disponible sous forme d'extension distincte, appelée Geo Clustering for SUSE Linux Enterprise High Availability Extension.
Pour configurer une grappe géographique, vous avez besoin des paquetages inclus dans les modèles d'installation suivants :
Haute disponibilitéGeo Clustering for High Availability
Ces deux modèles sont disponibles uniquement si vous avez enregistré votre système auprès du SUSE Customer Center (ou d'un serveur d'enregistrement local) et ajouté les canaux de produit ou supports d'installation en tant qu'extension. Pour plus d'informations sur l'installation des extensions, reportez-vous au SUSE Linux Enterprise 12 SP5 Deployment Guide (Guide de déploiement de SUSE Linux Enterprise 12 SP5) : https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Procédure 1 : Installation des paquetages #
Pour installer les paquetages des deux modèles via la ligne de commande, utilisez Zypper :
root #zypperinstall -t pattern ha_sles ha_geoVous pouvez aussi utiliser YaST pour une installation graphique :
Démarrez YaST en tant qu'utilisateur
rootet sélectionnez › .Cliquez sur › et activez les modèles suivants :
Haute disponibilitéGeo Clustering for High Availability
Cliquez sur pour démarrer l'installation des paquetages.
Important : installation des paquetages logiciels sur toutes les parties
Les paquetages logiciels nécessaires pour la haute disponibilité et les grappes géographiques ne sont pas copiés automatiquement sur les noeuds de grappe.
Installez SUSE Linux Enterprise Server 12 SP5 ainsi que les modèles
Haute disponibilitéetGeo Clustering for High Availabilitysur toutes les machines qui feront partie de votre grappe Geo.Au lieu d'installer manuellement les paquetages sur toutes les machines qui feront partie de votre grappe, utilisez AutoYaST pour cloner des noeuds existants. Pour plus d'informations, reportez-vous au Section 3.2, “Mass Installation and Deployment with AutoYaST”.
Toutefois, l'extension Geo Clustering doit être installée manuellement sur toutes les machines faisant partie de la grappe géographique. AutoYaST n'est pas encore pris en charge pour Geo Clustering for SUSE Linux Enterprise High Availability Extension.
6 Configuration du premier site d'une grappe géographique #
Utilisez le script ha-cluster-geo-init pour configurer une grappe existante en tant que premier site d'une grappe géographique.
Procédure 2 : configuration du premier site (amsterdam) avec le script ha-cluster-geo-init #
Définissez une adresse IP virtuelle par site de grappe qui peut être utilisée pour accéder au site. Supposons que nous utilisons
192.168.201.100et192.168.202.100à cet effet. Vous ne devez pas encore configurer les adresses IP virtuelles en tant que ressources de grappe. Les scripts d'amorçage s'en chargeront.Définissez le nom d'au moins un ticket qui accordera les droits pour l'exécution de certaines ressources sur un site de grappe. Utilisez un nom pertinent qui reflète les ressources qui dépendront du ticket (par exemple,
ticket-nfs). Les scripts d'amorçage ont uniquement besoin du nom de ticket, vous pouvez définir les détails restants (dépendances de ticket des ressources) plus tard, comme décrit à la Section 10, « Étapes suivantes ».Connectez-vous à un noeud d'une grappe existante (par exemple, au noeud
alicede la grappeamsterdam).Exécutez le script
ha-cluster-geo-init. Par exemple, utilisez les options suivantes :root #ha-cluster-geo-init\ --clusters1 "amsterdam=192.168.201.100 berlin=192.168.202.100" \ --tickets2 ticket-nfs \ --arbitrator3 192.168.203.100Les noms des sites de grappe (comme définis dans le fichier
/etc/corosync/corosync.conf) et les adresses IP virtuelles que vous souhaitez utiliser pour chaque site de grappe. Dans ce cas, nous avons deux sites de grappe (amsterdametberlin) avec une adresse IP virtuelle pour chacun.Le nom d'un ou de plusieurs tickets.
Le nom d'hôte ou l'adresse IP d'une machine en dehors des grappes.
Le script d'amorçage crée le fichier de configuration booth et le synchronise pour les différents sites de grappe. Il crée également les ressources de grappe de base nécessaires pour le booth. L'Étape 4 de la Procédure 2 conduirait à la configuration booth et aux ressources de grappe suivantes :
Exemple 1 : configuration booth créée par le script ha-cluster-geo-init #
# The booth configuration file is "/etc/booth/booth.conf". You need to # prepare the same booth configuration file on each arbitrator and # each node in the cluster sites where the booth daemon can be launched. # "transport" means which transport layer booth daemon will use. # Currently only "UDP" is supported. transport="UDP" port="9929" arbitrator="192.168.203.100" site="192.168.201.100" site="192.168.202.100" authfile="/etc/booth/authkey" ticket="ticket-nfs" expire="600"
Exemple 2 : ressources de grappe créées par le script ha-cluster-geo-init #
primitive1 booth-ip IPaddr2 \ params rule #cluster-name eq amsterdam ip=192.168.201.100 \ params rule #cluster-name eq berlin ip=192.168.202.100 \ primitive2 booth-site ocf:pacemaker:booth-site \ meta resource-stickiness=INFINITY \ params config=booth \ op monitor interval=10s group3 g-booth booth-ip booth-site \ meta target-role=Stopped4
Une adresse IP virtuelle pour chaque site de grappe. Elle est requise par les daemons booth qui ont besoin d'une adresse IP persistante sur chaque site de grappe. | |
Une ressource primitive pour le daemon booth. Elle communique avec les daemons booth sur les autres sites de grappe. Le daemon peut être démarré sur n'importe quel noeud du site, mais, pour que la ressource reste sur le même noeud, si possible, la permanence de la ressource doit être définie sur | |
Un groupe de ressources de grappe pour les deux primitives. Avec cette configuration, chaque daemon de booth sera disponible sur son adresse IP individuelle, indépendamment du noeud sur lequel le daemon est exécuté. | |
Le groupe de ressources de grappe n'est pas démarré par défaut. Après vérification de la configuration de vos ressources de grappe (et l'ajout des ressources nécessaires pour terminer votre configuration), vous devez démarrer le groupe de ressources. Reportez-vous à la section Étapes requises pour terminer la configuration d'une grappe géographique pour plus d'informations. |
7 Ajout d'un autre site à une grappe géographique #
Après avoir initialisé le premier site de votre grappe géographique, ajoutez la deuxième grappe avec le script ha-cluster-geo-join, comme décrit dans la Procédure 3. Le script doit avoir un accès SSH à un site de grappe déjà configuré et ajoutera la grappe actuelle à la grappe géographique.
Procédure 3 : ajout du deuxième site (berlin) avec le script ha-cluster-geo-join #
Connectez-vous à un noeud du site de grappe que vous souhaitez ajouter (par exemple, au noeud
charliede la grappeberlin).Exécutez la commande
ha-cluster-geo-join. Par exemple :root #ha-cluster-geo-join\ --cluster-node1 192.168.201.100\ --clusters2 "amsterdam=192.168.201.100 berlin=192.168.202.100"Indique à partir de quel emplacement le système doit copier la configuration booth. Utilisez l'adresse IP ou le nom d'hôte d'un noeud d'un site de grappe géographique déjà configuré. Vous pouvez également utiliser l'adresse IP virtuelle d'un site de grappe déjà existant (comme dans cet exemple). Vous pouvez aussi utiliser l'adresse IP ou le nom d'hôte d'un arbitre déjà configuré pour votre grappe géographique.
Les noms des sites de grappe (comme définis dans le fichier
/etc/corosync/corosync.conf) et les adresses IP virtuelles que vous souhaitez utiliser pour chaque site de grappe. Dans ce cas, nous avons deux sites de grappe (amsterdametberlin) avec une adresse IP virtuelle pour chacun.
Le script ha-cluster-geo-join copie la configuration booth à partir de 1 (voir Exemple 1). En outre, il crée les ressources de grappe nécessaires pour le booth (voir Exemple 2).
8 Ajout de l'arbitre #
Une fois que vous avez configuré tous les sites de votre grappe géographique avec les scripts ha-cluster-geo-init et ha-cluster-geo-join, définissez l'arbitre avec le script ha-cluster-geo-init-arbitrator.
Procédure 4 : configuration de l'arbitre avec le script ha-cluster-geo-init-arbitrator #
Connectez-vous à la machine que vous souhaitez utiliser en tant qu'arbitre.
Exécutez la commande suivante. Par exemple :
root #ha-cluster-geo-init-arbitrator--cluster-node1 192.168.201.100Indique à partir de quel emplacement le système doit copier la configuration booth. Utilisez l'adresse IP ou le nom d'hôte d'un noeud d'un site de grappe géographique déjà configuré. Vous pouvez également utiliser l'adresse IP virtuelle d'un site de grappe déjà existant (comme dans cet exemple).
Le script ha-cluster-geo-init-arbitrator copie la configuration booth à partir de 1 (voir Exemple 1). Il active et démarre également le service de booth sur l'arbitre. Ainsi, l'arbitre est prêt à communiquer avec les instances de booth sur les sites de grappe dès que les services de booth y sont aussi en cours d'exécution.
9 Surveillance des sites de grappe #
Pour afficher les deux sites de grappe avec les ressources et le ticket que vous avez créés au cours du processus d'amorçage, utilisez Hawk2. L'interface Web Hawk2 vous permet de surveiller et de gérer plusieurs grappes (indépendantes) et grappes géographiques.
Conditions préalables #
Toutes les grappes à surveiller à partir du de Hawk2 doivent exécuter SUSE Linux Enterprise High Availability Extension 12 SP5.
Si vous n'avez pas encore remplacé le certificat auto-signé pour Hawk2 par votre propre certificat (ou un certificat signé par une autorité de certification officielle) sur chaque noeud de grappe, effectuez l'opération suivante : connectez-vous à Hawk2 sur chaque noeud dans chaque grappe au moins une fois. Vérifiez le certificat (ou ajoutez une exception dans le navigateur afin d'ignorer l'avertissement). Sans cela, Hawk2 ne peut pas se connecter à la grappe.
Procédure 5 : utilisation du tableau de bord Hawk2 #
Démarrez un navigateur Web et entrez l'adresse IP virtuelle de votre premier site de grappe,
amsterdam:https://192.168.201.100:7630/
Vous pouvez également utiliser l'adresse IP ou le nom d'hôte du noeud
aliceoubob. Si vous avez configuré les deux noeuds avec les scripts d'amorçage, le servicehawkdoit s'exécuter sur les deux noeuds.Connectez-vous à l'interface Web de Hawk2.
Dans la barre de navigation de gauche, sélectionnez .
Hawk2 affiche une vue d'ensemble des noeuds et ressources sur le site de grappe actuel. En outre, il indique les qui ont été configurés pour la grappe géographique. Si vous avez besoin d'informations sur les icônes utilisées dans cette vue, cliquez sur (Légende).
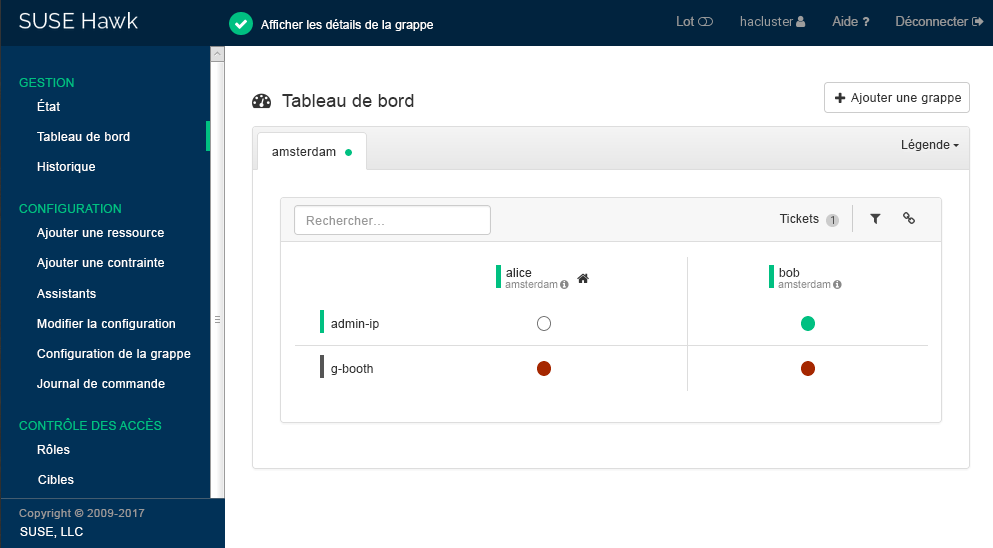
Figure 2 : tableau de bord Hawk2 avec un site de grappe (
amsterdam) #Pour ajouter un tableau de bord pour le deuxième site de grappe, cliquez sur .
Entrez le permettant d'identifier la grappe dans le . Dans ce cas, il s'agit de
berlin.Entrez le nom d'hôte complet de l'un des noeuds de la grappe (dans ce cas,
charlieoudoro).Cliquez sur . Hawk2 affiche un deuxième onglet pour le site de grappe nouvellement ajouté avec une vue d'ensemble de ses noeuds et ressources.
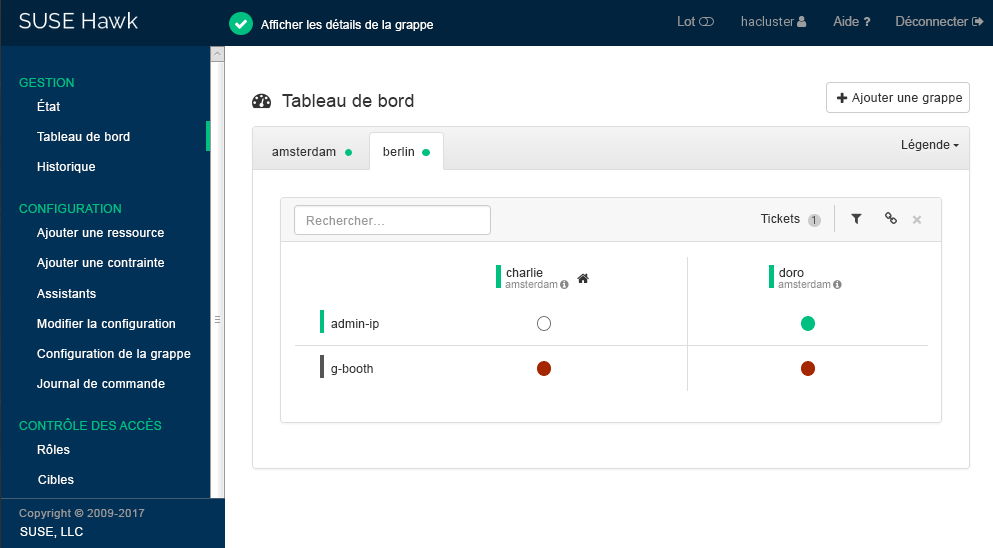
Figure 3 : tableau de bord Hawk2 avec deux sites de grappe #
Pour afficher plus de détails sur un site de grappe ou sur sa gestion, basculez vers l'onglet du site et cliquez sur l'icône de la chaîne.
Hawk2 ouvre la vue de ce site dans une nouvelle fenêtre de navigateur ou un nouvel onglet. Cette vue vous permet d'administrer cette partie de la grappe géographique.
10 Étapes suivantes #
Les scripts d'amorçage de mise en grappe géographique constituent un moyen rapide pour configurer une grappe géographique de base qui peut être utilisée à des fins de test. Toutefois, pour convertir la grappe géographique résultante en une grappe géographique opérationnelle pouvant être utilisée dans des environnements de production, d'autres étapes sont requises (voir Étapes requises pour terminer la configuration d'une grappe géographique).
Étapes requises pour terminer la configuration d'une grappe géographique #
- Démarrage des services de booth sur des sites de grappe
Après le processus d'amorçage, le service de booth de l'arbitre ne peut pas encore communiquer avec les services de booth des sites de grappe, car ils ne sont pas démarrés par défaut.
Le service de booth pour chaque site de grappe est géré par le groupe de ressources de booth
g-booth(voir Exemple 2, « ressources de grappe créées par le scriptha-cluster-geo-init»). Pour démarrer une instance du service de booth par site, démarrez le groupe de ressources de booth respectif sur chaque site de grappe. Cela permet à toutes les instances de booth de communiquer entre elles.- Configuration des dépendances de tickets et ordre des contraintes
Pour faire dépendre des ressources du ticket que vous avez créé au cours du processus d'amorçage de grappe géographique, configurez des contraintes. Pour chaque contrainte, définissez une
stratégie relative aux pertesqui définit ce qu'il arriverait aux ressources respectives si le ticket était révoqué d'un site de grappe.Pour plus de détails, reportez-vous au Chapter 6, Configuring Cluster Resources and Constraints.
- Octroi initial d'un ticket à un site
Avant que le booth puisse gérer un certain ticket au sein de la grappe géographique, vous devez d'abord l'attribuer à un site manuellement. Pour accorder un ticket, vous pouvez utiliser l'outil de ligne de commande du client de booth ou Hawk2.
Pour plus de détails, reportez-vous au Chapter 8, Managing Geo Clusters.
Les scripts d'amorçage créent les mêmes ressources de booth sur les deux sites de grappe et les mêmes fichiers de configuration booth sur tous les sites, y compris l'arbitre. Si vous étendez la configuration de grappe géographique (pour passer à un environnement de production), vous devrez probablement affiner la configuration booth et modifier la configuration des ressources de grappe liées au booth. Ensuite, vous devez synchroniser les modifications sur les autres sites de votre grappe géographique pour qu'elles soient prises en compte.
Remarque : synchronisation des modifications entre les différents sites de grappe
Pour synchroniser les modifications de la configuration booth sur tous les sites de grappe (y compris l'arbitre), utilisez Csync2. Pour plus d'informations, reportez-vous au Chapter 5, Synchronizing Configuration Files Across All Sites and Arbitrators.
Le CIB (base d'informations de la grappe) n'est pas synchronisé automatiquement entre les différents sites d'une grappe géographique. Cela signifie que toutes les modifications de la configuration des ressources requises sur tous les sites de grappe doivent être transférées vers les autres sites manuellement. Pour ce faire, ajoutez des balises aux ressources respectives, exportez-les à partir du CIB actuel, puis importez-les dans le CIB sur les autres sites de grappe. Pour plus de détails, reportez-vous au Section 6.4, “Transferring the Resource Configuration to Other Cluster Sites”.
11 Complément d'informations #
Pour plus de documentation sur ce produit, reportez-vous à l'adresse https://documentation.suse.com/sle-ha-12/. Vous y trouverez notamment un manuel complet
Geo Clustering Guide(Guide de mise en grappe géographique). Pour en savoir plus sur les tâches de configuration et d'administration, consultez ce manuel.Un document avec des informations détaillées sur la procédure de réplication des données via DRBD sur des grappes Geo a été publié dans la série
SUSE Best Practices(Meilleures pratiques SUSE) : https://documentation.suse.com/sbp/all/html/SBP-DRBD/index.html.
12 Mentions légales #
Copyright © 2006– 2026 SUSE LLC et contributeurs. Tous droits réservés.
Il est autorisé de copier, distribuer et/ou modifier ce document conformément aux conditions de la licence de documentation libre GNU version 1.2 ou (à votre discrétion) 1.3, avec la section permanente qu'est cette mention de copyright et la licence. Une copie de la version de licence 1.2 est incluse dans la section intitulée « Licence de documentation libre GNU ».
Pour les marques commerciales SUSE, consultez le site Web http://www.suse.com/company/legal/. Toutes les autres marques de fabricants tiers sont la propriété de leur détenteur respectif. Les symboles de marque commerciale (®,™, etc.) indiquent des marques commerciales de SUSE et de ses filiales. Des astérisques (*) désignent des marques commerciales de fabricants tiers.
Toutes les informations de cet ouvrage ont été regroupées avec le plus grand soin. Cela ne garantit cependant pas sa complète exactitude. Ni SUSE LLC, ni les sociétés affiliées, ni les auteurs, ni les traducteurs ne peuvent être tenus responsables des erreurs possibles ou des conséquences qu'elles peuvent entraîner.