SUSE Linux Enterprise High Availability Extension 12 SP5
Geo Clusteringのクイックスタート #
概要#
Geoクラスタリングを使用すると、それぞれ1つのローカルクラスタを備えた地理的に分散された複数のサイトを運用できます。これらのクラスタ間のフェールオーバーは、より高いレベルのエンティティであるブースクラスタチケットマネージャによって調整されます。このマニュアルでは、ha-cluster-bootstrapパッケージで提供されているGeoブートストラップスクリプトを使用して、基本的なGeoクラスタをセットアップする手順を説明します。
1 概念の概要 #
SUSE® Linux Enterprise High Availability Extensionを基にしたGeoクラスタは、各クラスタサイトが従来のクラスタ内の1つのクラスタノードに対応する「オーバーレイ」クラスタであると考えることができます。オーバーレイクラスタは、ブースクラスタチケットマネージャ(以後「ブース」と呼びます)によって管理されます。Geoクラスタ内のそれぞれの参加クラスタがboothdというサービスを実行します。これは、他のサイトで実行されているブースデーモンに接続し、接続性の詳細を交換します。サイト全体でクラスタリソースを高可用性にするため、ブースはチケットと呼ばれるクラスタオブジェクトに依存します。チケットは指定のクラスタサイトの特定のリソースを実行する権利を付与します。ブースはすべてのチケットが一度に1サイトにのみ付与されることを保証します。
2つのブースインスタンス間の通信が途切れる場合、クラスタサイト間のネットワークの障害か、または一方のクラスタサイトの停止が原因と考えられます。この場合、決定(サイト間のリソースのフェールオーバーなど)について合意状態に達するための追加のインスタンス(3つ目のクラスタサイトまたはアービトレータ)が必要です。アービトレータは特殊なモードでブースインスタンスを実行する(クラスタ外の)単一マシンです。各Geoクラスタは1つまたは複数のアービトレータを持つことができます。
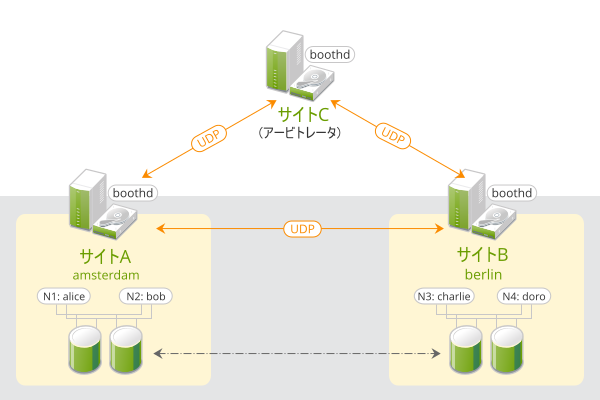
図 1: 2サイトクラスタ(2x2ノード + アービトレータ) #
Geoクラスタの概念とコンポーネント、およびGeoクラスタで採用されているチケット管理の詳細については、Chapter 2, Conceptual Overviewを参照してください。
2 使用シナリオ #
以下では、2つのクラスタサイトおよび1つのアービトレータを含む基本的なGeoクラスタを設定します。
クラスタサイトが
amsterdamおよびberlinという名前であることを想定しています。また、各サイトは2つのノードで構成されていることを想定しています。ノードの
aliceとbobは、クラスタamsterdamに属しています。ノードのcharlieとdoroは、クラスタberlinに属しています。サイト
amsterdamは、仮想IPアドレス192.168.201.100を取得します。サイト
berlinは、仮想IPアドレス192.168.202.100を取得します。アービトレータにはIPアドレス
192.168.203.100が設定されていることを想定しています。
続行する前に、次の要件が満たされているかどうか確認してください。
要件 #
- 2つの既存のクラスタ
Geoクラスタに結合する既存のクラスタを少なくとも2つ持っている(2つのクラスタを最初に設定する必要がある場合は、インストールおよびセットアップクイックスタートの手順に従ってください)。
- 意味のあるクラスタ名
各クラスタに、その場所を反映した、
/etc/corosync/corosync.confに定義されている意味のあるクラスタ名が付いている。- アービトレータ
既存のクラスタの一部ではなく、アービトレータとして使用される3つ目のマシンを設置している。
各項目の詳細要件については、3項 「要件」も参照してください。
3 要件 #
ソフトウェア要件 #
Geoクラスタの一部になるすべてのマシン(クラスタノードおよびアービトレータ)に次のソフトウェアがインストールされている。
SUSE® Linux Enterprise Server 12 SP5
SUSE Linux Enterprise High Availability Extension 12 SP5
Geo Clustering for SUSE Linux Enterprise High Availability Extension 12 SP5
ネットワーク要件 #
各クラスタサイトに使用される仮想IPはGeoクラスタ間でアクセスできる必要があります。
ブースインスタンスあたり1つのUDPポートと1つのTCPポートを通じて、サイトにアクセスできる必要があります。すなわち、間に配置されているすべてのファイアウォールとIPsesトンネルをこの要件に合わせて設定する必要があります。
セットアップに関する他の決定によって、さらに多くのポートを開く必要が生じることがあります(たとえばDRBDやデータベースレプリケーション用など)。
その他の要件と推奨事項 #
すべてのサイト上のすべてのクラスタノードはクラスタ外のNTPサーバと同期する必要があります。詳細については、https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.htmlを参照してください。
ノードが同期されていない場合、ログファイルまたはクラスタレポートは分析が難しくなります。
Geoクラスタでは、「偶数」のメンバーを使用します。これにより、ネットワーク接続が途切れた場合に、引き続きサイトの過半数が確実に存在するようにします(スプリットブレインシナリオを回避するため)。偶数のクラスタサイトがある場合には、アービトレータを使用します。
各サイトのクラスタには、
amsterdamやberlinなどの、意味のある名前があります。各サイトのクラスタ名はそれぞれの
/etc/corosync/corosync.confファイルで指定されています。totem { [...] cluster_name: amsterdam }これは、手動で実行するか(
/etc/corosync/corosync.confを編集します)、またはYaSTクラスタモジュールを使用して実行することができます(カテゴリに切り替え、を定義します)。その後、変更を有効にするため、pacemakerサービスを停止してから開始してください。root #systemctlstop pacemakerroot #systemctlstart pacemaker
4 Geoブートストラップスクリプトの概要 #
ha-cluster-geo-initを使用して、あるクラスタをGeoクラスタの最初のサイトにします。このスクリプトは、クラスタの名前、アービトレータ、1つまたは複数のチケットなどのパラメータを取得し、それらから/etc/booth/booth.confを作成します。ブース設定を現在のクラスタサイトのすべてのノードにコピーします。また、現在のクラスタサイトのブースに必要なクラスタリソースも設定します。詳細については、6項 「Geoクラスタの最初のサイトの設定」を参照してください。
ha-cluster-geo-joinを使用して、現在のクラスタを既存のGeoクラスタに追加します。このスクリプトは既存のクラスタサイトからブース設定をコピーし、それを現在のクラスタサイトのすべてのノード上の/etc/booth/booth.confに書き込みます。また、現在のクラスタサイトのブースに必要なクラスタリソースも設定します。詳細については、7項 「Geoクラスタへの別のサイトの追加」を参照してください。
ha-cluster-geo-init-arbitratorを使用して、現在のマシンをGeoクラスタのアービトレータにします。このスクリプトは既存のクラスタサイトからブース設定をコピーし、それを/etc/booth/booth.confに書き込みます。詳細については、8項 「アービトレータの追加」を参照してください。
すべてのブートストラップスクリプトは/var/log/ha-cluster-bootstrap.logにログを記録します。ブートストラッププロセスの詳細については、ログファイルを確認してください。ブートストラッププロセス中に設定されたオプションは後で変更できます(ブース設定の変更やリソースの変更など)。詳細については、「Geo Clustering Guide」を参照してください。
5 拡張としてのインストール #
Geo Clustering for SUSE Linux Enterprise High Availability Extensionという別個の拡張を使用することで、無制限の距離にまたがってHigh Availabilityクラスタを使用できるようになります。
Geoクラスタを設定するには、次のインストールパターンに含まれているパッケージが必要です。
高可用性Geo Clustering for High Availability
両方のパターンを使用できるための条件は、お使いのシステムをSUSEカスタマセンター(またはローカル登録サーバ)に登録済みであること、かつそれぞれの製品チャネルまたはインストールメディアを拡張として追加済みであることです。拡張のインストール方法については、『SUSE Linux Enterprise 12 SP5導入ガイド』 (https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html)を参照してください。
手順 1: パッケージのインストール #
コマンドラインを通じて両方のパターンからパッケージをインストールするには、Zypperを使用します。
root #zypperinstall -t pattern ha_sles ha_geo代わりの方法として、グラフィカルインタフェースを通じてインストールするには、YaSTを使用します。
YaSTを
rootユーザとして開始し、 › の順に選択します。› の順にクリックして、以下のパターンをアクティブ化します。
高可用性Geo Clustering for High Availability
をクリックして、パッケージのインストールを開始します。
重要: すべてのパーティへのソフトウェアパッケージのインストール
High AvailabilityクラスタおよびGeoクラスタに必要なソフトウェアパッケージは、クラスタノードに自動的にコピー「されません」。
SUSE Linux Enterprise Server 12 SP5と、
High AvailabilityパターンおよびGeo Clustering for High Availabilityパターンを、Geoクラスタの一部となる「すべての」マシンにインストールします。クラスタの一部となるすべてのマシンにパッケージを手動でインストールする代わりに、AutoYaSTを使用して既存のノードのクローンを作成します。詳細については、3.2項 「AutoYaSTによる大量インストールと展開」を参照してください。
ただし、Geo Clustering拡張機能は、Geoクラスタの一部となるすべてのマシン上に「手動で」インストールする必要があります。AutoYaSTでは、Geo Clustering for SUSE Linux Enterprise High Availability Extensionはまだサポートされていません。
6 Geoクラスタの最初のサイトの設定 #
ha-cluster-geo-initスクリプトを使用して、既存のクラスタをGeoクラスタの最初のサイトにします。
手順 2: ha-cluster-geo-initを使用した最初のサイト(amsterdam)の設定 #
サイトへのアクセスに使用可能なクラスタサイトごとの仮想IPを定義します。この目的のために
192.168.201.100および192.168.202.100を使用することを想定しています。仮想IPをクラスタリソースとして設定する必要はまだありません。これはブートストラップスクリプトによって実行されます。クラスタサイトで特定のリソースを実行する権利を付与する少なくとも1つのチケットの名前を定義します。チケットに依存するリソースを反映する、意味のある名前を使用します(たとえば、
ticket-nfs)。ブートストラップスクリプトはチケット名のみが必要です。10項 「次の手順」で説明されるように、後で既存の詳細(リソースのチケット依存関係)を定義できます。既存のクラスタのノードにログインします(たとえば、クラスタ
amsterdamのノードalice)。ha-cluster-geo-initを実行します。たとえば、次のオプションを使用します。root #ha-cluster-geo-init\ --clusters1 "amsterdam=192.168.201.100 berlin=192.168.202.100" \ --tickets2 ticket-nfs \ --arbitrator3 192.168.203.100
ブートストラップスクリプトはブース設定ファイルを作成し、それをクラスタサイト間で同期します。また、ブースに必要な基本的なクラスタリソースも作成します。手順 2のステップ 4の結果、次のブース設定およびクラスタリソースが作成されます。
例 1: ha-cluster-geo-initによって作成されたブース設定 #
# The booth configuration file is "/etc/booth/booth.conf". You need to # prepare the same booth configuration file on each arbitrator and # each node in the cluster sites where the booth daemon can be launched. # "transport" means which transport layer booth daemon will use. # Currently only "UDP" is supported. transport="UDP" port="9929" arbitrator="192.168.203.100" site="192.168.201.100" site="192.168.202.100" authfile="/etc/booth/authkey" ticket="ticket-nfs" expire="600"
例 2: ha-cluster-geo-initによって作成されたクラスタリソース #
primitive1 booth-ip IPaddr2 \ params rule #cluster-name eq amsterdam ip=192.168.201.100 \ params rule #cluster-name eq berlin ip=192.168.202.100 \ primitive2 booth-site ocf:pacemaker:booth-site \ meta resource-stickiness=INFINITY \ params config=booth \ op monitor interval=10s group3 g-booth booth-ip booth-site \ meta target-role=Stopped4
各クラスタサイトの仮想IPアドレス。各クラスタサイトで持続的なIPアドレスを必要とするブースデーモンによって要求されます。 | |
ブースデーモンのプリミティブリソース。他のクラスタサイト上のブースデーモンと通信します。デーモンはサイトの任意のノード上で起動できますが、可能な場合、リソースが同じノード上にとどまるようにするため、resource-stickiness (リソースの固着性)を | |
両方のプリミティブのためのクラスタリソースグループ。この設定では、各ブースデーモンは、デーモンが実行しているノードとは関係なく、個々のIPアドレスで使用できます。 | |
クラスタリソースグループはデフォルトでは開始されません。クラスタリソースの設定を確認(およびセットアップを完了するために必要なリソースを追加)した後で、リソースグループを開始する必要があります。詳細については、Geoクラスタのセットアップを完了するために必要な手順を参照してください。 |
7 Geoクラスタへの別のサイトの追加 #
Geoクラスタの最初のサイトを初期化した後で、手順 3で説明されるように、2つ目のクラスタをha-cluster-geo-joinを使用して追加します。このスクリプトはすでに設定されているクラスタサイトへのSSHアクセスを必要とします。また、現在のクラスタをGeoクラスタに追加します。
手順 3: ha-cluster-geo-joinを使用した2つ目のサイト(berlin)の追加 #
追加するクラスタサイトのノードにログインします(たとえば、クラスタ
berlinのノードcharlie。)ha-cluster-geo-joinコマンドを実行します。次に例を示します。root #ha-cluster-geo-join\ --cluster-node1 192.168.201.100\ --clusters2 "amsterdam=192.168.201.100 berlin=192.168.202.100"
ha-cluster-geo-joinスクリプトは1からブース設定をコピーします。例 1を参照してください。また、ブースに必要なクラスタリソースを作成します(例 2を参照)。
8 アービトレータの追加 #
ha-cluster-geo-initおよびha-cluster-geo-joinを使用してGeoクラスタのすべてのサイトを設定した後で、ha-cluster-geo-init-arbitratorを使用してアービトレータを設定します。
手順 4: ha-cluster-geo-init-arbitratorを使用したアービトレータの設定 #
アービトレータとして使用するマシンにログインします。
次のコマンドを実行します。次に例を示します。
root #ha-cluster-geo-init-arbitrator--cluster-node1 192.168.201.100ブース設定のコピー元の場所を指定します。すでに設定されているGeoクラスタサイトのノードのIPアドレスまたはホスト名を使用します。または、(この例のように)既存のクラスタサイトの仮想IPアドレスを使用します。
ha-cluster-geo-init-arbitratorスクリプトは、ブース設定を1からコピーします。例 1を参照してください。また、アービトレータ上でブースサービスを有効化および開始します。このようにして、ブースサービスがクラスタサイトで実行されるとすぐに、アービトレータはそれらのサイトのブースインスタンスと通信する準備が整います。
9 クラスタサイトの監視 #
両方のクラスタサイトのブートストラッププロセス中に作成したリソースおよびチケットを表示するには、Hawk2を使用します。Hawk2 Webインタフェースは、複数の(無関係な)クラスタとGeoクラスタを監視および管理できます。
前提条件 #
Hawk5ので監視するすべてのクラスタでは、SUSE Linux Enterprise High Availability Extension 12 SP2を実行している必要があります。
すべてのクラスタノードにあるHawk2の自己署名証明書を独自の証明書(または公式認証局によって署名された証明書)で置き換えていない場合は、「すべての」クラスタの「すべての」ノードで、少なくとも1回はHawk2にログインします。証明書を検証します(または、ブラウザで例外を追加して警告をスキップします)。そうしない場合、Hawk2はクラスタに接続できません。
手順 5: Hawk2 ダッシュボードの使用 #
Webブラウザを起動し、最初のクラスタサイト
amsterdamの仮想IPを入力します。https://192.168.201.100:7630/
または、
aliceまたはbobのIPアドレスまたはホスト名を使用します。ブートストラップスクリプトを使用して両方のノードを設定している場合は、hawkサービスが両方のノードで実行されるはずです。Hawk2 Webインタフェースにログインします。
左のナビゲーションバーから、を選択します。
Hawk2に、現在のクラスタサイトのリソースとノードの概要が表示されます。また、Geoクラスタに設定されているすべてのが表示されます。このビューで使用されるアイコンに関する情報が必要な場合は、をクリックします。
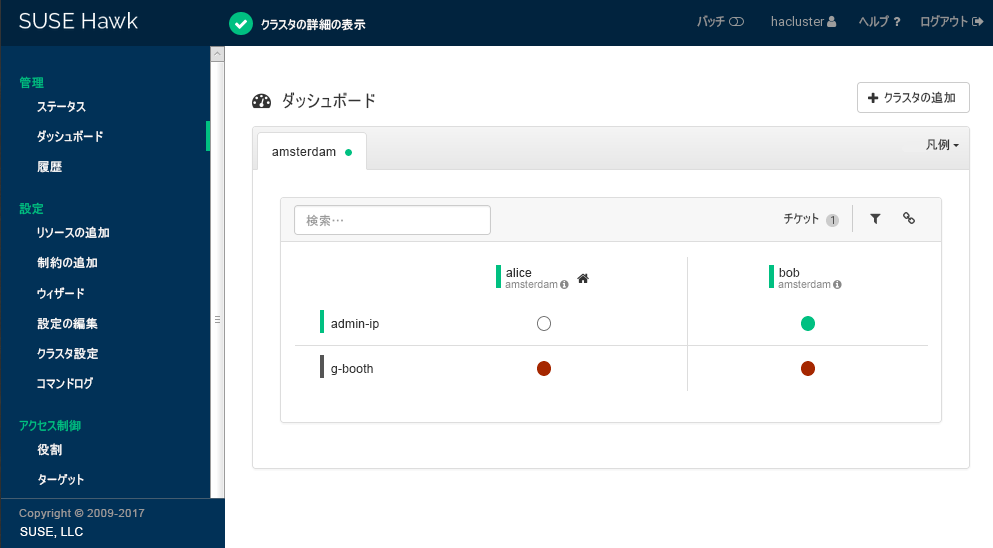
図 2: 最初のクラスタサイト(
amsterdam)を表示するHawk2 ダッシュボード #2つ目のクラスタサイトのダッシュボードを追加するには、をクリックします。
でクラスタを識別するためのを入力します。この場合は、
berlinです。一方のクラスタノードの完全修飾ホスト名を入力します(この場合、
charlieまたはdoro)。をクリックします。Hawk2に、新たに追加されたクラスタサイト用の2つ目のタブと、そのノードとリソースの概要が表示されます。
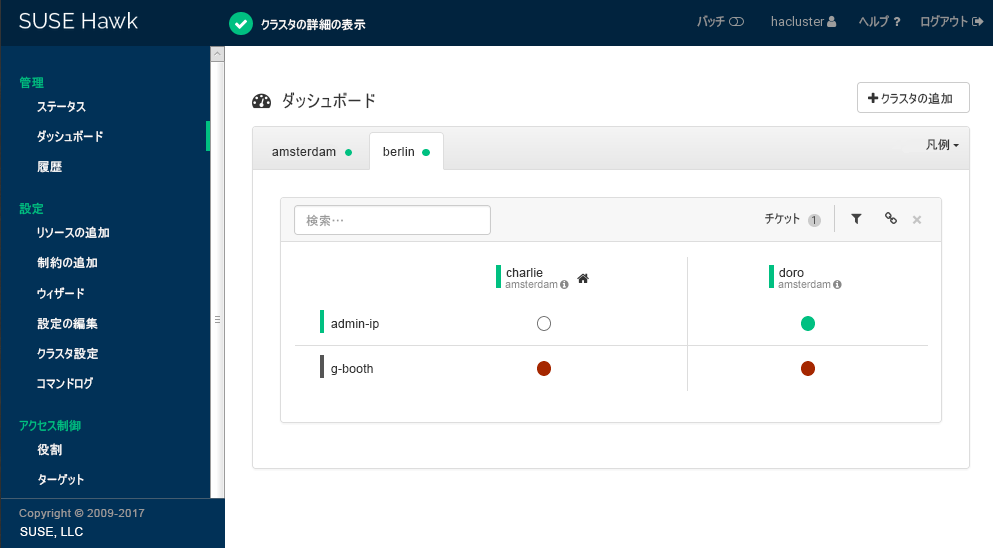
図 3: 両方のクラスタサイトが表示されたHawk2 ダッシュボード #
クラスタサイトの詳細を表示するか、クラスタサイトを管理するには、サイトのタブを切り替えて、チェーンアイコンをクリックします。
Hawk2はこのサイトのビューを新しいブラウザウィンドウかタブに表示します。このビューから、Geoクラスタへのこの参加を管理できます。
10 次の手順 #
Geoクラスタリングブートストラップスクリプトを使用すると、テスト目的で使用可能な基本的なGeoクラスタを迅速に設定できます。ただし、結果として生じたGeoクラスタを、運用環境で使用可能な機能するGeoクラスタに移行するには、さらに手順が必要です。Geoクラスタのセットアップを完了するために必要な手順を参照してください。
Geoクラスタのセットアップを完了するために必要な手順 #
- クラスタサイト上のブースサービスの開始
ブートストラッププロセスの後で、アービトレータブースサービスはまだクラスタサイト上のブースサービスと通信できません。クラスタサイト上のブースサービスは、デフォルトでは開始されないためです。
各クラスタサイト用のブースサービスは、ブースリソースグループ
g-boothによって管理されます(例2「ha-cluster-geo-initによって作成されたクラスタリソース」を参照)。サイトあたり1つのブースサービスインスタンスを開始するには、各クラスタサイト上でそれぞれのブースリソースグループを開始します。これにより、すべてのブースインスタンスが相互に通信できるようになります。- チケット依存関係と順序の制約の設定
リソースがGeoクラスタブートストラッププロセス中に作成したチケットに依存するようにするには、制約を設定します。制約ごとに、チケットがクラスタサイトから取り消された場合の各リソースの動作を定義する
loss-policyを設定します。詳細については、Chapter 6, Configuring Cluster Resources and Constraintsを参照してください。
- まずチケットをサイトに付与する
ブースがGeoクラスタ内の特定のチケットを管理するためには、まずチケットを手動でサイトに「付与」する必要があります。チケットを付与するには、ブースクライアントのコマンドラインツールまたはHawk2のいずれかを使用できます。
詳細については、Chapter 8, Managing Geo Clustersを参照してください。
ブートストラップスクリプトは、両方のクラスタサイトで同一のブースリソース、およびアービトレータを含むすべてのサイトで同一のブース設定ファイルを作成します。(運用環境へ移行するため) Geoクラスタセットアップを拡張するときは、多くの場合、ブート設定を微調整し、ブース関連のクラスタリソースの設定も変更します。その後、Geoクラスタの他のサイトへの変更を有効にするため、変更内容を同期する必要があります。
注記: クラスタサイト間での変更の同期
ブース設定の変更をすべてのクラスタサイト(アービトレータを含む)に同期するには、Csync2を使用します。詳細については、Chapter 5, Synchronizing Configuration Files Across All Sites and Arbitratorsを参照してください。
CIB (クラスタ情報データベース)は、Geoクラスタのクラスタサイト間で自動的に同期されません。つまり、すべてのクラスタサイトで必要なリソース設定の変更を他のサイトに手動で転送する必要があります。これを行うには、各リソースをタグ付けし、それらを現在のCIBからエクスポートして、他のクラスタサイト上のCIBにインポートします。詳細については、Section 6.4, “Transferring the Resource Configuration to Other Cluster Sites”を参照してください。
11 その他の情報 #
本製品の他のマニュアルは、https://documentation.suse.com/sle-ha-12/で入手できます。ここに掲載されているマニュアルの中には、包括的な『
Geo Clustering Guide』もあります。設定および管理タスクの詳細については、このマニュアルを参照してください。DRBDを介したGeoクラスタ間でのデータレプリケーションの方法の詳細を記載したドキュメントは、
SUSE Best Practicesシリーズで公開されています: https://documentation.suse.com/sbp/all/html/SBP-DRBD/index.html
12 保証と著作権 #
Copyright © 2006– 2026 SUSE LLC and contributors. All rights reserved.
この文書は、GNUフリー文書ライセンスのバージョン1.2または(オプションとして)バージョン1.3の条項に従って、複製、頒布、および/または改変が許可されています。ただし、この著作権表示およびライセンスは変更せずに記載すること。ライセンスバージョン1.2のコピーは、「GNUフリー文書ライセンス」セクションに含まれています。
SUSEの商標については、http://www.suse.com/company/legal/を参照してください。その他の製品名および会社名は、各社の商標または登録商標です。商標記号(®、 ™など)は、SUSEおよび関連会社の商標を示します。アスタリスク(*)は、第三者の商標を示します。
本書のすべての情報は、細心の注意を払って編集されています。しかし、このことは絶対に正確であることを保証するものではありません。SUSE LLC、その関係者、著者、翻訳者のいずれも誤りまたはその結果に対して一切責任を負いかねます。