Inicialização Rápida do Geo Clustering
- 1 Visão geral conceitual
- 2 Cenário de uso
- 3 Requisitos
- 4 Visão geral dos scripts de boot Geo
- 5 Instalação como extensão
- 6 Configurando o primeiro site de um cluster Geo
- 7 Adicionando outro site a um cluster Geo
- 8 Adicionando o arbitrador
- 9 Monitorando sites do cluster
- 10 Próximas etapas
- 11 Para obter mais informações
- 12 Informações Legais
- A GNU Licenses
SUSE Linux Enterprise High Availability Extension 12 SP5
Inicialização Rápida do Geo Clustering #
Resumo#
O Geo Clustering permite ter vários sites distribuídos geograficamente, cada um com um cluster local. O failover entre esses clusters é coordenado por uma entidade de nível mais alto: o gerenciador de tickets de cluster de booth. Este documento orienta você na configuração básica de um cluster Geo, usando os scripts de boot Geo incluídos no pacote ha-cluster-bootstrap.
- 1 Visão geral conceitual
- 2 Cenário de uso
- 3 Requisitos
- 4 Visão geral dos scripts de boot Geo
- 5 Instalação como extensão
- 6 Configurando o primeiro site de um cluster Geo
- 7 Adicionando outro site a um cluster Geo
- 8 Adicionando o arbitrador
- 9 Monitorando sites do cluster
- 10 Próximas etapas
- 11 Para obter mais informações
- 12 Informações Legais
- A GNU Licenses
1 Visão geral conceitual #
Os clusters Geo baseados na SUSE® Linux Enterprise High Availability Extension podem ser considerados clusters “sobrepostos”, em que cada site do cluster corresponde a um nó em um cluster tradicional. O cluster sobreposto é administrado pelo gerenciador de tickets de cluster de booth (mencionado a seguir como booth). Cada uma das partes envolvidas em um cluster Geo executa um serviço, o boothd. Ele se conecta aos daemons de booth executados em outros sites e troca detalhes de conectividade. Para tornar os recursos de cluster altamente disponíveis em todos os sites, o booth usa como base objetos do cluster denominados tickets. Um ticket concede o direito de executar determinados recursos em um site de cluster específico. O booth garante que cada ticket seja concedido a, no máximo, um site por vez.
Se a comunicação entre duas instâncias de booth falhar, talvez seja por causa de uma queda na rede entre os sites do cluster ou uma interrupção de um site do cluster. Neste caso, é necessária uma instância adicional (um terceiro site do cluster ou um arbitrador) para chegar a um consenso sobre as decisões (por exemplo, o failover de recursos em todos os sites). Arbitradores são máquinas únicas (fora dos clusters) que executam uma instância de booth em um modo especial. Cada cluster Geo pode ter um ou vários arbitradores.
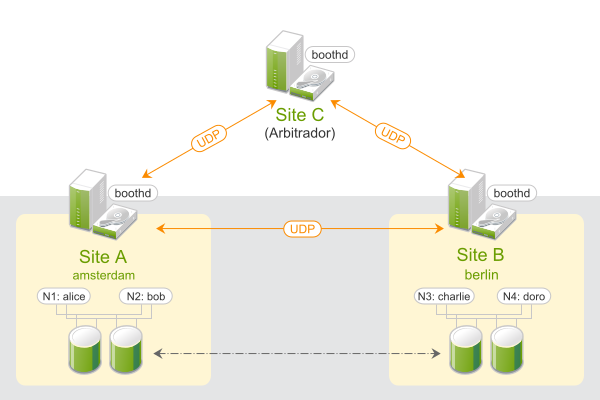
Figura 1: Cluster de Dois Sites (2x2 Nós + Arbitrador) #
Para obter mais detalhes sobre o conceito, os componentes e o gerenciamento de tickets usado para clusters Geo, consulte o Chapter 2, Conceptual Overview.
2 Cenário de uso #
A seguir, configuraremos um cluster Geo básico com dois sites do cluster e um arbitrador:
Vamos supor que os nomes dos sites do cluster são
amsterdameberlin.Imagine que cada site tenha dois nós. Os nós
aliceebobpertencem ao clusteramsterdam. Os nóscharlieedoropertencem ao clusterberlin.O site
amsterdamterá o seguinte endereço IP virtual:192.168.201.100.O site
berlinterá o seguinte endereço IP virtual:192.168.202.100.Suponha que o arbitrador tenha o seguinte endereço IP:
192.168.203.100.
Antes de prosseguir, verifique se os seguintes requisitos foram atendidos:
Requisitos #
- Dois clusters existentes
Você tem pelo menos dois clusters existentes para combinar em um cluster Geo. (Se você primeiro precisa configurar dois clusters, siga as instruções na Inicialização Rápida de Instalação e Configuração.)
- Nomes de cluster significativos
Cada cluster tem um nome significativo definido em
/etc/corosync/corosync.confque reflete seu local.- Arbitrador
Você instalou uma terceira máquina que não faz parte de nenhum cluster existente e deve ser usada como arbitrador.
Para obter os requisitos detalhados de cada item, consulte também a Seção 3, “Requisitos”.
3 Requisitos #
Requisitos de software #
Todas as máquinas (nós do cluster e arbitradores) que farão parte do cluster Geo têm o seguinte software instalado:
SUSE® Linux Enterprise Server 12 SP5
SUSE Linux Enterprise High Availability Extension 12 SP5
Geo Clustering for SUSE Linux Enterprise High Availability Extension 12 SP5
Requisitos de rede #
Os IPs virtuais a serem usados para cada site do cluster devem estar acessíveis no cluster Geo.
Os sites devem ser acessíveis em uma porta UDP e TCP por instância de booth. Isso significa que qualquer firewall ou túnel IPsec intermediário deve ser configurado adequadamente.
Outras decisões de configuração podem exigir a abertura de mais portas (por exemplo, para replicação de banco de dados ou do DRBD).
Outros requisitos e recomendações #
Todos os nós do cluster em todos os sites devem ser sincronizados com um servidor NTP fora do cluster. Para obter mais informações, consulte o https://documentation.suse.com/sles-12/html/SLES-all/cha-netz-xntp.html.
Se os nós não estiverem sincronizados, será muito difícil de analisar os arquivos de registro e os relatórios do cluster.
Use um número ímpar de membros no cluster Geo. Em caso de falha na conexão, esse procedimento garante que ainda exista uma maioria dos sites (para evitar um cenário de split brain). Caso você tenha um número par de sites do cluster, use um arbitrador.
O cluster em cada site tem um nome significativo, por exemplo:
amsterdameberlin.Os nomes dos clusters de cada site são definidos nos respectivos arquivos
/etc/corosync/corosync.conf:totem { [...] cluster_name: amsterdam }Isso pode ser feito manualmente (editando
/etc/corosync/corosync.conf) ou com o módulo de cluster do YaST (alternando para a categoria e definindo um ). Na sequencia, pare e inicie o serviçopacemakerpara as mudanças entrarem em vigor:root #systemctlstop pacemakerroot #systemctlstart pacemaker
4 Visão geral dos scripts de boot Geo #
Com o
ha-cluster-geo-init, transforme um cluster no primeiro site de um cluster Geo. O script usa alguns parâmetros, como os nomes dos clusters, o arbitrador e um ou vários tickets, e cria o arquivo/etc/booth/booth.confcom base neles. Ele copia a configuração de booth para todos os nós no site do cluster atual. Ele também configura os recursos de cluster necessários para o booth no site do cluster atual.Para obter os detalhes, consulte a Seção 6, “Configurando o primeiro site de um cluster Geo”.
Com o
ha-cluster-geo-join, adicione o cluster atual a um cluster Geo existente. O script copia a configuração de booth de um site do cluster existente e grava-a no/etc/booth/booth.confem todos os nós no site do cluster atual. Ele também configura os recursos de cluster necessários para o booth no site do cluster atual.Para obter os detalhes, consulte a Seção 7, “Adicionando outro site a um cluster Geo”.
Com o
ha-cluster-geo-init-arbitrator, transforme a máquina atual em um arbitrador para o cluster Geo. O script copia a configuração de booth de um site do cluster existente e grava-a no/etc/booth/booth.conf.Para obter os detalhes, consulte a Seção 8, “Adicionando o arbitrador”.
Todos os scripts de boot são registrados em /var/log/ha-cluster-bootstrap.log. Consulte o arquivo de registro para obter todos os detalhes do processo de boot. Quaisquer opções definidas durante o processo de boot podem ser modificadas posteriormente (modificando configurações de booth, recursos, etc.). Para obter detalhes, consulte o Geo Clustering Guide.
5 Instalação como extensão #
O suporte para uso de clusters de Alta Disponibilidade a distâncias ilimitadas está disponível como uma extensão separada, denominada Geo Clustering for SUSE Linux Enterprise High Availability Extension.
Para configurar um cluster Geo, você precisa dos pacotes incluídos nos seguintes padrões de instalação:
High AvailabilityGeo Clustering for High Availability
Ambos os padrões estão disponíveis apenas se você registrou seu sistema no SUSE Customer Center (ou em um servidor de registro local) e adicionou os respectivos canais do produto ou a mídia de instalação como uma extensão. Para obter informações sobre como instalar extensões, consulte o Guia de Implantação do SUSE Linux Enterprise 12 SP5: https://documentation.suse.com/sles-12/html/SLES-all/cha-add-ons.html.
Procedimento 1: Instalando os pacotes #
Para instalar os pacotes de ambos os padrões por meio da linha de comando, use o Zypper:
root #zypperinstall -t pattern ha_sles ha_geoSe preferir, use o YaST para uma instalação gráfica:
Inicie o YaST como usuário
roote selecione › .Clique em › e ative os seguintes padrões:
High AvailabilityGeo Clustering for High Availability
Clique em para iniciar a instalação dos pacotes.
Importante: Instalando pacotes de software em todas as partes
Os pacotes de software necessários para os clusters High Availability e Geo não são copiados automaticamente para os nós do cluster.
Instale o SUSE Linux Enterprise Server 12 SP5 e os padrões
High AvailabilityeGeo Clustering for High Availabilityem todas as máquinas que farão parte do cluster Geo.Em vez de instalar manualmente os pacotes em todas as máquinas que farão parte do cluster, use o AutoYaST para clonar nós existentes. Encontre mais informações no Section 3.2, “Mass Installation and Deployment with AutoYaST”.
No entanto, a extensão de cluster Geo deve ser instalada manualmente em todas as máquinas que farão parte do cluster Geo. O suporte do AutoYaST para a Geo Clustering for SUSE Linux Enterprise High Availability Extension ainda não está disponível.
6 Configurando o primeiro site de um cluster Geo #
Use o script ha-cluster-geo-init para transformar um cluster existente no primeiro site de um cluster Geo.
Procedimento 2: Configurando o Primeiro Site (amsterdam) com ha-cluster-geo-init #
Defina um IP virtual por site do cluster que pode ser usado para acessar o site. Consideramos que
192.168.201.100e192.168.202.100são usados para esta finalidade. Você ainda não precisa configurar os IPs virtuais como recursos de cluster. Isso será feito pelos scripts de boot.Defina o nome de pelo menos um ticket que concederá o direito de executar determinados recursos em um site do cluster. Use um nome significativo que corresponda aos recursos que dependem do ticket (por exemplo,
ticket-nfs). Os scripts de boot precisam apenas do nome do ticket. Você pode definir os detalhes restantes (dependências de ticket dos recursos) posteriormente, conforme descrito na Seção 10, “Próximas etapas”.Efetue login no nó de um cluster existente (por exemplo, no nó
alicedo clusteramsterdam).Execute
ha-cluster-geo-init. Por exemplo, use as seguintes opções:root #ha-cluster-geo-init\ --clusters1 "amsterdam=192.168.201.100 berlin=192.168.202.100" \ --tickets2 ticket-nfs \ --arbitrator3 192.168.203.100Os nomes dos sites do cluster (conforme definido em
/etc/corosync/corosync.conf) e os endereços IP virtuais que você deseja usar para cada site do cluster. Neste caso, temos dois sites do cluster (amsterdameberlin), cada um com um endereço IP virtual.O nome de um ou vários tickets.
O nome de host ou endereço IP de uma máquina fora dos clusters.
O script de boot cria o arquivo de configuração de booth e o sincroniza com os sites do cluster. Ele também cria os recursos de cluster básicos necessários para o booth. A Etapa 4 do Procedimento 2 resulta na seguinte configuração de booth e recursos de cluster:
Exemplo 1: Configuração de Booth Criada por ha-cluster-geo-init #
# The booth configuration file is "/etc/booth/booth.conf". You need to # prepare the same booth configuration file on each arbitrator and # each node in the cluster sites where the booth daemon can be launched. # "transport" means which transport layer booth daemon will use. # Currently only "UDP" is supported. transport="UDP" port="9929" arbitrator="192.168.203.100" site="192.168.201.100" site="192.168.202.100" authfile="/etc/booth/authkey" ticket="ticket-nfs" expire="600"
Exemplo 2: Recursos de Cluster Criados por ha-cluster-geo-init #
primitive1 booth-ip IPaddr2 \ params rule #cluster-name eq amsterdam ip=192.168.201.100 \ params rule #cluster-name eq berlin ip=192.168.202.100 \ primitive2 booth-site ocf:pacemaker:booth-site \ meta resource-stickiness=INFINITY \ params config=booth \ op monitor interval=10s group3 g-booth booth-ip booth-site \ meta target-role=Stopped4
Um endereço IP virtual para cada site do cluster. Os daemons de booth exigem essa informação, pois precisam de um endereço IP persistente em cada site do cluster. | |
Um recurso primitivo para o daemon de booth. Ele se comunica com os daemons de booth nos outros sites do cluster. O daemon pode ser iniciado em qualquer nó do site, mas para que o recurso permaneça no mesmo nó, se possível, resource-stickiness é definido como | |
Um grupo de recursos de cluster para ambos os primitivos. Com essa configuração, cada daemon de booth está disponível em seu endereço IP individual, independentemente do nó em que o daemon é executado. | |
O grupo de recursos de cluster não é iniciado por padrão. Depois de verificar a configuração de recursos de cluster (e adicionar os recursos necessários para concluir a configuração), você precisará iniciar o grupo de recursos. Consulte Etapas necessárias para concluir a configuração do cluster Geo para obter os detalhes. |
7 Adicionando outro site a um cluster Geo #
Depois de inicializar o primeiro site do cluster Geo, adicione o segundo cluster com ha-cluster-geo-join, conforme descrito no Procedimento 3. O script precisa de acesso SSH a um site do cluster já configurado e adicionará o cluster atual ao cluster Geo.
Procedimento 3: Adicionando o Segundo Site (berlin) com ha-cluster-geo-join #
Efetue login no nó do site do cluster que você deseja adicionar (por exemplo, no nó
charliedo clusterberlin).Execute o comando
ha-cluster-geo-join. Por exemplo:root #ha-cluster-geo-join\ --cluster-node1 192.168.201.100\ --clusters2 "amsterdam=192.168.201.100 berlin=192.168.202.100"Especifica de onde copiar a configuração de booth. Use o nome de host ou endereço IP de um nó em um site do cluster Geo já configurado. Você também pode usar o endereço IP virtual de um site do cluster existente (como neste exemplo). Como alternativa, use o nome de host ou endereço IP de um arbitrador já configurado para o cluster Geo.
Os nomes dos sites do cluster (conforme definido em
/etc/corosync/corosync.conf) e os endereços IP virtuais que você deseja usar para cada site do cluster. Neste caso, temos dois sites do cluster (amsterdameberlin), cada um com um endereço IP virtual.
O script ha-cluster-geo-join copia a configuração de booth de 1. Consulte o Exemplo 1. Além disso, ele cria os recursos de cluster necessários para o booth (consulte o Exemplo 2).
8 Adicionando o arbitrador #
Depois de configurar todos os sites do cluster Geo com o ha-cluster-geo-init e o ha-cluster-geo-join, configure o arbitrador com o ha-cluster-geo-init-arbitrator.
Procedimento 4: Configurando o Arbitrador com ha-cluster-geo-init-arbitrator #
Efetue login na máquina que você deseja usar como arbitrador.
Execute o seguinte comando. Por exemplo:
root #ha-cluster-geo-init-arbitrator--cluster-node1 192.168.201.100Especifica de onde copiar a configuração de booth. Use o nome de host ou endereço IP de um nó em um site do cluster Geo já configurado. Se preferir, use o endereço IP virtual de um site do cluster existente (como neste exemplo).
O script ha-cluster-geo-init-arbitrator copia a configuração de booth de 1. Consulte o Exemplo 1. Ele também habilita e inicia o serviço de booth no arbitrador. Dessa forma, o arbitrador está pronto para se comunicar com as instâncias de booth nos sites do cluster assim que os serviços de booth são executados neles também.
9 Monitorando sites do cluster #
Para ver os dois sites do cluster com os recursos e o ticket que você criou durante o processo de boot, use o Hawk2. A interface da Web do Hawk2 permite monitorar e gerenciar vários clusters (não relacionados) e clusters Geo.
Pré-requisitos #
Todos os clusters que serão monitorados do do Hawk5 devem executar a SUSE Linux Enterprise High Availability Extension 12 SP2.
Se você ainda não substituiu o certificado autoassinado para o Hawk2 em cada nó do cluster pelo seu próprio certificado (ou um certificado assinado por uma Autoridade de Certificação oficial), faça o seguinte: Efetue login no Hawk2 em cada nó em cada cluster pelo menos uma vez. Verifique o certificado (ou adicione uma exceção ao browser para ignorar o aviso). Do contrário, o Hawk2 não poderá se conectar ao cluster.
Procedimento 5: Usando o painel de controle do Hawk2 #
Inicie um browser da Web e insira o IP virtual do seu primeiro site do cluster,
amsterdam:https://192.168.201.100:7630/
Se preferir, use o nome de host ou endereço IP de
aliceoubob. Se você configurou ambos os nós com os scripts de boot, o serviçohawkdeve ser executado em ambos os nós.Efetue login na interface da Web do Hawk2.
Na barra de navegação esquerda, selecione .
O Hawk2 mostra uma visão geral dos recursos e nós no site do cluster atual. Além disso, ele mostra quaisquer que foram configurados para o cluster Geo. Se você precisar de informações sobre os ícones usados nesta tela, clique em .
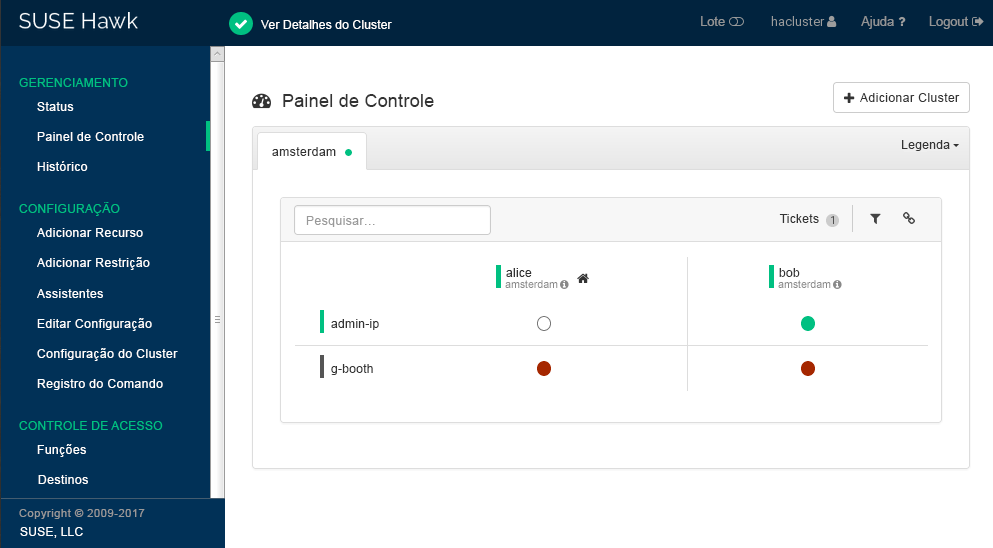
Figura 2: Painel de Controle do Hawk2 com Um Site do Cluster (
amsterdam) #Para adicionar um painel de controle para o segundo site do cluster, clique em .
Insira o para identificá-lo no . Neste caso,
berlim.Insira o nome completo do host de um dos nós do cluster (neste caso,
charlieoudoro).Clique em . O Hawk2 exibirá uma segunda guia para o site do cluster recém-adicionado com uma visão geral de seus nós e recursos.
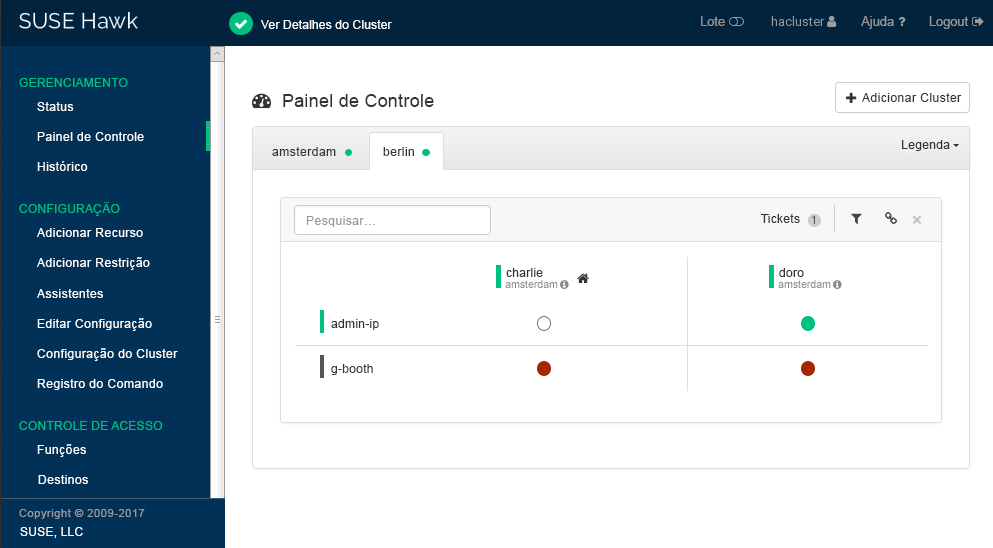
Figura 3: Painel de Controle do Hawk2 com os Dois Sites do Cluster #
Para ver mais detalhes para um site do cluster ou para gerenciá-lo, alterne para a guia do site e clique no ícone de corrente.
O Hawk2 abre a tela referente a esse site em uma nova janela ou guia do browser. Neste local, você pode administrar esta parte do cluster Geo.
10 Próximas etapas #
Os scripts de boot de cluster Geo são um meio rápido para configurar um cluster Geo básico que pode ser usado para fins de teste. No entanto, para mover o cluster Geo resultante para um cluster Geo funcional que pode ser usado em ambientes de produção, mais etapas são necessárias. Consulte Etapas necessárias para concluir a configuração do cluster Geo.
Etapas necessárias para concluir a configuração do cluster Geo #
- Iniciando os serviços de booth em sites do cluster
Após o processo de boot, o serviço de booth do arbitrador ainda não poderá se comunicar com os serviços de booth nos sites do cluster, porque eles não são iniciados por padrão.
O serviço de booth para cada site do cluster é gerenciado pelo grupo de recursos de booth
g-booth(consulte o Exemplo 2, “Recursos de Cluster Criados porha-cluster-geo-init”). Para iniciar uma instância do serviço de booth por site, inicie o respectivo grupo de recursos de booth em cada site do cluster. Isso permite que todas as instâncias de booth se comuniquem umas com as outras.- Configurando dependências de ticket e restrições de pedidos
Para tornar os recursos dependentes do ticket que você criou durante o processo de boot do cluster Geo, configure restrições. Para cada restrição, defina uma
loss-policy, que define o que deverá acontecer com os respectivos recursos se o ticket for revogado de um site do cluster.Para obter os detalhes, consulte o Chapter 6, Configuring Cluster Resources and Constraints.
- Concedendo inicialmente um ticket a um site
Antes que o booth possa gerenciar determinado ticket no cluster Geo, você precisa concedê-lo a um site manualmente. Você pode usar a ferramenta de linha de comando do cliente de booth ou o Hawk2 para conceder um ticket.
Para obter os detalhes, consulte o Chapter 8, Managing Geo Clusters.
Os scripts de boot criam os mesmos recursos de booth em ambos os sites do cluster, e os mesmos arquivos de configuração de booth em todos os sites, incluindo o arbitrador. Se você estender a configuração do cluster Geo (para mover para um ambiente de produção), provavelmente ajustará a configuração de booth e também mudará a configuração dos recursos de cluster relacionados ao booth. Depois disso, será necessário sincronizar as mudanças com os outros sites do cluster Geo para entrarem em vigor.
Nota: Sincronizando mudanças com todos os sites do cluster
Para sincronizar as alterações na configuração de booth com todos os sites do cluster (incluindo o arbitrador), use o Csync2. Encontre mais informações no Chapter 5, Synchronizing Configuration Files Across All Sites and Arbitrators.
O CIB (Cluster Information Database) não é sincronizado automaticamente com todos os sites de um cluster Geo. Isso significa que quaisquer mudanças na configuração de recursos necessárias em todos os sites do cluster precisam ser transferidas para os outros sites manualmente. Para isso, marque os respectivos recursos, exporte-os do CIB atual e importe-os para o CIB nos outros sites do cluster. Para obter os detalhes, consulte o Section 6.4, “Transferring the Resource Configuration to Other Cluster Sites”.
11 Para obter mais informações #
Há mais documentação para este produto disponível em https://documentation.suse.com/sle-ha-12/. A documentação também inclui um
Guia do Geo Clusteringcompleto. Consulte-o para ver mais tarefas de configuração e administração.Um documento com instruções detalhadas sobre replicação de dados por meio do DRBD em clusters Geo foi publicado na série
Melhores práticas do SUSE:https://documentation.suse.com/sbp/all/html/SBP-DRBD/index.html
12 Informações Legais #
Copyright © 2006– 2026 SUSE LLC e colaboradores. Todos os direitos reservados.
Permissão concedida para copiar, distribuir e/ou modificar este documento sob os termos da Licença GNU de Documentação Livre, Versão 1.2 ou (por sua opção) versão 1.3; com a Seção Invariante sendo estas informações de copyright e a licença. Uma cópia da versão 1.2 da licença está incluída na seção intitulada “GNU Free Documentation License” (Licença GNU de Documentação Livre).
Para ver as marcas registradas da SUSE, visite http://www.suse.com/company/legal/. Todas as marcas comerciais de terceiros pertencem a seus respectivos proprietários. Os símbolos de marca registrada (®,™ etc.) representam marcas registradas da SUSE e suas afiliadas. Os asteriscos (*) indicam marcas registradas de terceiros.
Todas as informações deste manual foram compiladas com a maior atenção possível aos detalhes. Entretanto, isso não garante uma precisão absoluta. A SUSE LLC, suas afiliadas, os autores ou tradutores não serão responsáveis por possíveis erros nem pelas consequências resultantes de tais erros.