Operations Guide
- 1 Operations Overview
- 2 Tutorials
- 3 Third-Party Integrations
- 4 Managing Identity
- 5 Managing Compute
- 6 Managing ESX
- 7 Managing Block Storage
- 8 Managing Object Storage
- 9 Managing Networking
- 10 Managing the Dashboard
- 11 Managing Orchestration
- 12 Managing Monitoring, Logging, and Usage Reporting
- 13 System Maintenance
- 14 Backup and Restore
- 15 Troubleshooting Issues
5 Managing Compute
Information about managing and configuring the Compute service.
5.1 Managing Compute Hosts using Aggregates and Scheduler Filters #
OpenStack Nova has the concepts of availability zones and host aggregates that enable you to segregate your compute hosts. Availability zones are used to specify logical separation within your cloud based on the physical isolation or redundancy you have set up. Host aggregates are used to group compute hosts together based upon common features, such as operation system. For more information, read this topic.
OpenStack Nova has the concepts of availability zones and host aggregates that enable you to segregate your Compute hosts. Availability zones are used to specify logical separation within your cloud based on the physical isolation or redundancy you have set up. Host aggregates are used to group compute hosts together based upon common features, such as operation system. For more information, see Scaling and Segregating your Cloud.
The Nova scheduler also has a filter scheduler, which supports both filtering and weighting to make decisions on where new compute instances should be created. For more information, see Filter Scheduler and Scheduling.
This document is going to show you how to set up both a Nova host aggregate and configure the filter scheduler to further segregate your compute hosts.
5.1.1 Creating a Nova Aggregate #
These steps will show you how to create a Nova aggregate and how to add a compute host to it. You can run these steps on any machine that contains the NovaClient that also has network access to your cloud environment. These requirements are met by the Cloud Lifecycle Manager.
Log in to the Cloud Lifecycle Manager.
Source the administrative creds:
ardana >source ~/service.osrcList your current Nova aggregates:
ardana >nova aggregate-listCreate a new Nova aggregate with this syntax:
ardana >nova aggregate-create AGGREGATE-NAMEIf you wish to have the aggregate appear as an availability zone, then specify an availability zone with this syntax:
ardana >nova aggregate-create AGGREGATE-NAME AVAILABILITY-ZONE-NAMESo, for example, if you wish to create a new aggregate for your SUSE Linux Enterprise compute hosts and you wanted that to show up as the
SLEavailability zone, you could use this command:ardana >nova aggregate-create SLE SLEThis would produce an output similar to this:
+----+------+-------------------+-------+------------------+ | Id | Name | Availability Zone | Hosts | Metadata +----+------+-------------------+-------+--------------------------+ | 12 | SLE | SLE | | 'availability_zone=SLE' +----+------+-------------------+-------+--------------------------+
Next, you need to add compute hosts to this aggregate so you can start by listing your current hosts. You will want to limit the output of this command to only the hosts running the
computeservice, like this:ardana >nova host-list | grep computeYou can then add host(s) to your aggregate with this syntax:
ardana >nova aggregate-add-host AGGREGATE-NAME HOSTThen you can confirm that this has been completed by listing the details of your aggregate:
nova aggregate-details AGGREGATE-NAME
You can also list out your availability zones using this command:
ardana >nova availability-zone-list
5.1.2 Using Nova Scheduler Filters #
The Nova scheduler has two filters that can help with differentiating between different compute hosts that we'll describe here.
| Filter | Description |
|---|---|
| AggregateImagePropertiesIsolation |
Isolates compute hosts based on image properties and aggregate metadata. You can use commas to specify multiple values for the same property. The filter will then ensure at least one value matches. |
| AggregateInstanceExtraSpecsFilter |
Checks that the aggregate metadata satisfies any extra specifications
associated with the instance type. This uses
|
Using the AggregateImagePropertiesIsolation Filter
Log in to the Cloud Lifecycle Manager.
Edit the
~/openstack/my_cloud/config/nova/nova.conf.j2file and addAggregateImagePropertiesIsolationto the scheduler_filters section. Example below, in bold:# Scheduler ... scheduler_available_filters = nova.scheduler.filters.all_filters scheduler_default_filters = AvailabilityZoneFilter,RetryFilter,ComputeFilter, DiskFilter,RamFilter,ImagePropertiesFilter,ServerGroupAffinityFilter, ServerGroupAntiAffinityFilter,ComputeCapabilitiesFilter,NUMATopologyFilter, AggregateImagePropertiesIsolation ...Optionally, you can also add these lines:
aggregate_image_properties_isolation_namespace = <a prefix string>
aggregate_image_properties_isolation_separator = <a separator character>
(defaults to
.)If these are added, the filter will only match image properties starting with the name space and separator - for example, setting to
my_name_spaceand:would mean the image propertymy_name_space:image_type=SLEmatches metadataimage_type=SLE, butan_other=SLEwould not be inspected for a match at all.If these are not added all image properties will be matched against any similarly named aggregate metadata.
Add image properties to images that should be scheduled using the above filter
Commit the changes to git:
ardana >git add -Aardana >git commit -a -m "editing nova schedule filters"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlRun the ready deployment playbook:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the Nova reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts nova-reconfigure.yml
Using the AggregateInstanceExtraSpecsFilter Filter
Log in to the Cloud Lifecycle Manager.
Edit the
~/openstack/my_cloud/config/nova/nova.conf.j2file and addAggregateInstanceExtraSpecsFilterto the scheduler_filters section. Example below, in bold:# Scheduler ... scheduler_available_filters = nova.scheduler.filters.all_filters scheduler_default_filters = AvailabilityZoneFilter,RetryFilter,ComputeFilter, DiskFilter,RamFilter,ImagePropertiesFilter,ServerGroupAffinityFilter, ServerGroupAntiAffinityFilter,ComputeCapabilitiesFilter,NUMATopologyFilter, AggregateInstanceExtraSpecsFilter ...There is no additional configuration needed because the following is true:
The filter assumes
:is a separatorThe filter will match all simple keys in extra_specs plus all keys with a separator if the prefix is
aggregate_instance_extra_specs- for example,image_type=SLEandaggregate_instance_extra_specs:image_type=SLEwill both be matched against aggregate metadataimage_type=SLE
Add
extra_specsto flavors that should be scheduled according to the above.Commit the changes to git:
ardana >git add -Aardana >git commit -a -m "Editing nova scheduler filters"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlRun the ready deployment playbook:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the Nova reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts nova-reconfigure.yml
5.2 Using Flavor Metadata to Specify CPU Model #
Libvirt is a collection of software used in OpenStack to
manage virtualization. It has the ability to emulate a host CPU model in a
guest VM. In HPE Helion OpenStack Nova, the ComputeCapabilitiesFilter limits this
ability by checking the exact CPU model of the compute host against the
requested compute instance model. It will only pick compute hosts that have
the cpu_model requested by the instance model, and if the
selected compute host does not have that cpu_model, the
ComputeCapabilitiesFilter moves on to find another compute host that matches,
if possible. Selecting an unavailable vCPU model may cause Nova to fail
with no valid host found.
To assist, there is a Nova scheduler filter that captures
cpu_models as a subset of a particular CPU family. The
filter determines if the host CPU model is capable of emulating the guest
CPU model by maintaining the mapping of the vCPU models and comparing it with
the host CPU model.
There is a limitation when a particular cpu_model is
specified with hw:cpu_model via a compute flavor: the
cpu_mode will be set to custom. This
mode ensures that a persistent guest virtual machine will see the same
hardware no matter what host physical machine the guest virtual machine is
booted on. This allows easier live migration of virtual machines. Because of
this limitation, only some of the features of a CPU are exposed to the guest.
Requesting particular CPU features is not supported.
5.2.1 Editing the flavor metadata in the Horizon dashboard #
These steps can be used to edit a flavor's metadata in the Horizon
dashboard to add the extra_specs for a
cpu_model:
Access the Horizon dashboard and log in with admin credentials.
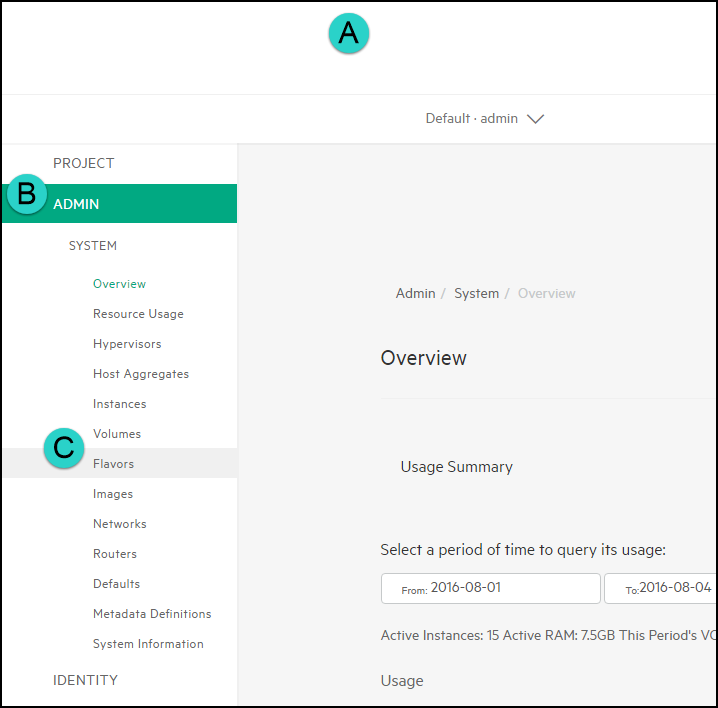
Access the Flavors menu by (A) clicking on the menu button, (B) navigating to the Admin section, and then (C) clicking on Flavors:
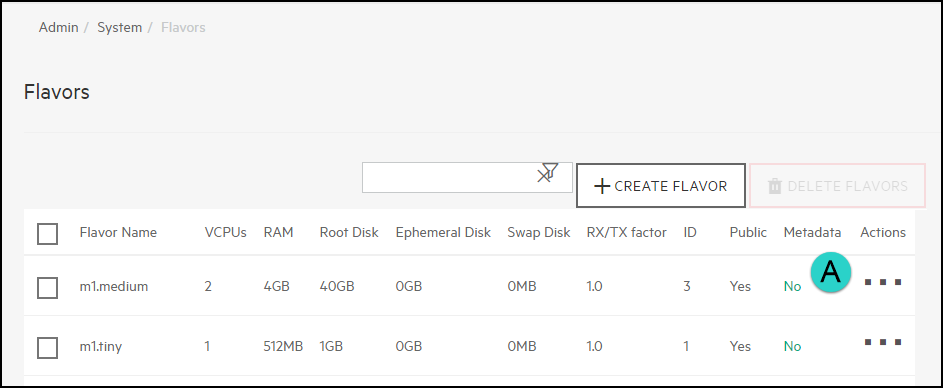
In the list of flavors, choose the flavor you wish to edit and click on the entry under the Metadata column:

Note
You can also create a new flavor and then choose that one to edit.
In the Custom field, enter
hw:cpu_modeland then click on the+(plus) sign to continue: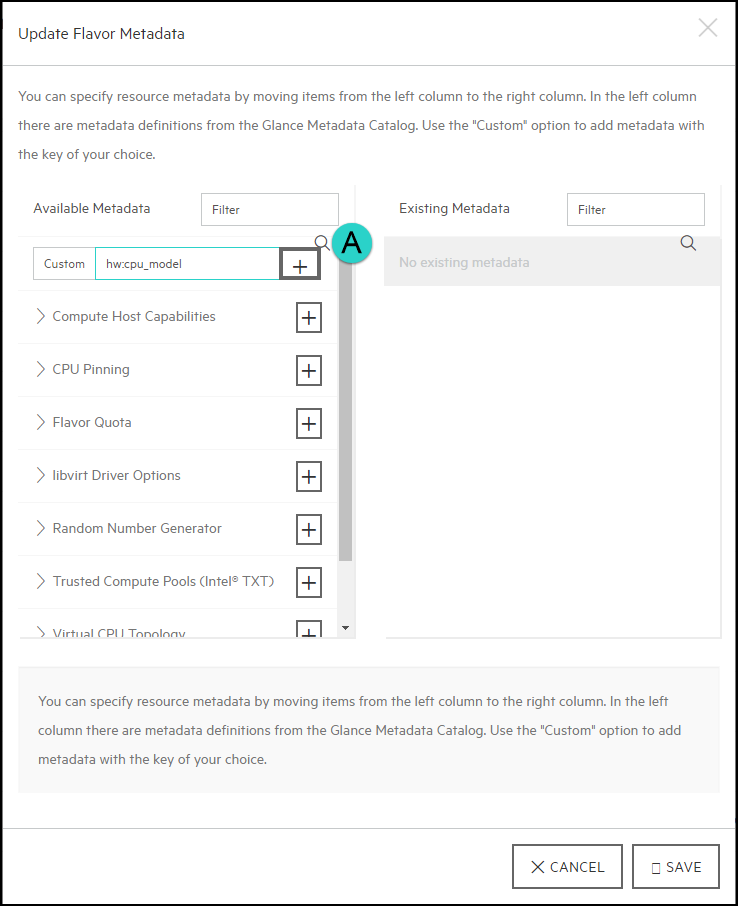
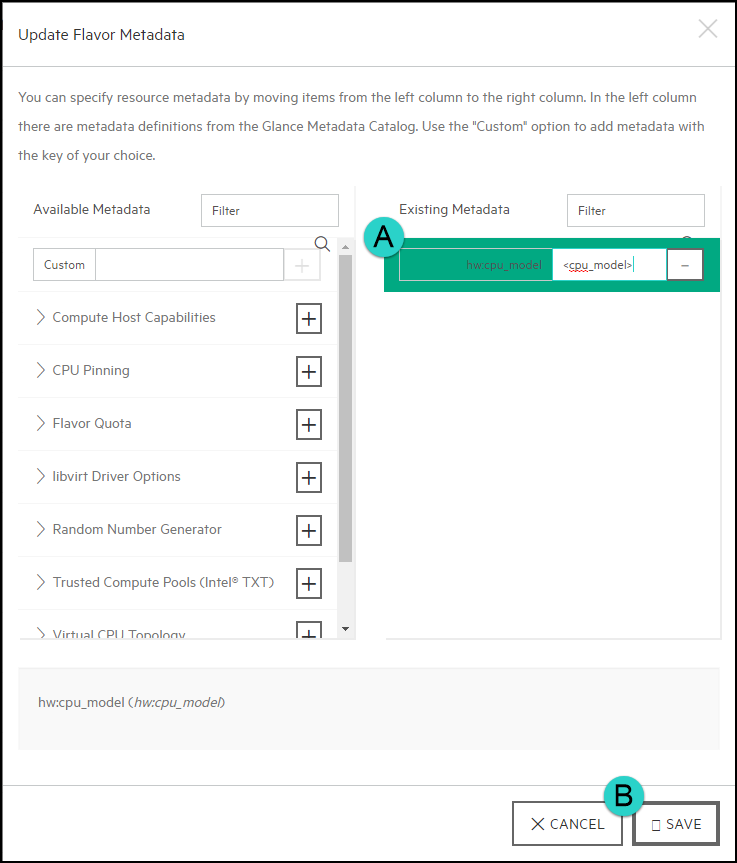
Then you will want to enter the CPU model into the field that you wish to use and then click Save:
5.3 Forcing CPU and RAM Overcommit Settings #
HPE Helion OpenStack supports overcommitting of CPU and RAM resources on compute nodes. Overcommitting is a technique of allocating more virtualized CPUs and/or memory than there are physical resources.
The default settings for this are:
| Setting | Default Value | Description |
|---|---|---|
| cpu_allocation_ratio | 16 |
Virtual CPU to physical CPU allocation ratio which affects all CPU filters. This configuration specifies a global ratio for CoreFilter. For AggregateCoreFilter, it will fall back to this configuration value if no per-aggregate setting found. Note
This can be set per-compute, or if set to |
| ram_allocation_ratio | 1.0 |
Virtual RAM to physical RAM allocation ratio which affects all RAM filters. This configuration specifies a global ratio for RamFilter. For AggregateRamFilter, it will fall back to this configuration value if no per-aggregate setting found. Note
This can be set per-compute, or if set to |
| disk_allocation_ratio | 1.0 |
This is the virtual disk to physical disk allocation ratio used by the disk_filter.py script to determine if a host has sufficient disk space to fit a requested instance. A ratio greater than 1.0 will result in over-subscription of the available physical disk, which can be useful for more efficiently packing instances created with images that do not use the entire virtual disk,such as sparse or compressed images. It can be set to a value between 0.0 and 1.0 in order to preserve a percentage of the disk for uses other than instances. Note
This can be set per-compute, or if set to |
5.3.1 Changing the overcommit ratios for your entire environment #
If you wish to change the CPU and/or RAM overcommit ratio settings for your entire environment then you can do so via your Cloud Lifecycle Manager with these steps.
Log in to the Cloud Lifecycle Manager.
Edit the Nova configuration settings located in this file:
~/openstack/my_cloud/config/nova/nova.conf.j2
Add or edit the following lines to specify the ratios you wish to use:
cpu_allocation_ratio = 16 ram_allocation_ratio = 1.0
Commit your configuration to the Git repository (Book “Installing with Cloud Lifecycle Manager”, Chapter 10 “Using Git for Configuration Management”), as follows:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "setting Nova overcommit settings"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlUpdate your deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the Nova reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts nova-reconfigure.yml
5.4 Enabling the Nova Resize and Migrate Features #
The Nova resize and migrate features are disabled by default. If you wish to utilize these options, these steps will show you how to enable it in your cloud.
The two features below are disabled by default:
Resize - this feature allows you to change the size of a Compute instance by changing its flavor. See the OpenStack User Guide for more details on its use.
Migrate - read about the differences between "live" migration (enabled by default) and regular migration (disabled by default) in Section 13.1.3.3, “Live Migration of Instances”.
These two features are disabled by default because they require passwordless SSH access between Compute hosts with the user having access to the file systems to perform the copy.
5.4.1 Enabling Nova Resize and Migrate #
If you wish to enable these features, use these steps on your lifecycle
manager. This will deploy a set of public and private SSH keys to the
Compute hosts, allowing the nova user SSH access between
each of your Compute hosts.
Log in to the Cloud Lifecycle Manager.
Run the Nova reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts nova-reconfigure.yml --extra-vars nova_migrate_enabled=trueTo ensure that the resize and migration options show up in the Horizon dashboard, run the Horizon reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts horizon-reconfigure.yml
5.4.2 Disabling Nova Resize and Migrate #
This feature is disabled by default. However, if you have previously enabled
it and wish to re-disable it, you can use these steps on your lifecycle
manager. This will remove the set of public and private SSH keys that were
previously added to the Compute hosts, removing the nova
users SSH access between each of your Compute hosts.
Log in to the Cloud Lifecycle Manager.
Run the Nova reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts nova-reconfigure.yml --extra-vars nova_migrate_enabled=falseTo ensure that the resize and migrate options are removed from the Horizon dashboard, run the Horizon reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts horizon-reconfigure.yml
5.5 Enabling ESX Compute Instance(s) Resize Feature #
The resize of ESX compute instance is disabled by default. If you want to utilize this option, these steps will show you how to configure and enable it in your cloud.
The following feature is disabled by default:
Resize - this feature allows you to change the size of a Compute instance by changing its flavor. See the OpenStack User Guide for more details on its use.
5.5.1 Procedure #
If you want to configure and re-size ESX compute instance(s), perform the following steps:
Log in to the Cloud Lifecycle Manager.
Edit the
~ /openstack/my_cloud/config/nova/nova.conf.j2to add the following parameter under Policy:# Policy allow_resize_to_same_host=True
Commit your configuration:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "<commit message>"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlUpdate your deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlBy default the nova resize feature is disabled. To enable nova resize, refer to Section 5.4, “Enabling the Nova Resize and Migrate Features”.
By default an ESX console log is not set up. For more details about its setup, refer to VMware vSphere.
5.6 Configuring the Image Service #
The image service, based on OpenStack Glance, works out of the box and does not need any special configuration. However, we show you how to enable Glance image caching as well as how to configure your environment to allow the Glance copy-from feature if you choose to do so. A few features detailed below will require some additional configuration if you choose to use them.
Warning
Glance images are assigned IDs upon creation, either automatically or specified by the user. The ID of an image should be unique, so if a user assigns an ID which already exists, a conflict (409) will occur.
This only becomes a problem if users can publicize or share images with
others. If users can share images AND cannot publicize images then your
system is not vulnerable. If the system has also been purged (via
glance-manage db purge) then it is possible for deleted
image IDs to be reused.
If deleted image IDs can be reused then recycling of public and shared images becomes a possibility. This means that a new (or modified) image can replace an old image, which could be malicious.
If this is a problem for you, please contact Professional Services.
5.6.1 How to enable Glance image caching #
In HPE Helion OpenStack 8, by default, the Glance image caching option is not enabled. You have the option to have image caching enabled and these steps will show you how to do that.
The main benefits to using image caching is that it will allow the Glance service to return the images faster and it will cause less load on other services to supply the image.
In order to use the image caching option you will need to supply a logical volume for the service to use for the caching.
If you wish to use the Glance image caching option, you will see the
section below in your
~/openstack/my_cloud/definition/data/disks_controller.yml
file. You will specify the mount point for the logical volume you wish to
use for this.
Log in to the Cloud Lifecycle Manager.
Edit your
~/openstack/my_cloud/definition/data/disks_controller.ymlfile and specify the volume and mount point for yourglance-cache. Here is an example:# Glance cache: if a logical volume with consumer usage glance-cache # is defined Glance caching will be enabled. The logical volume can be # part of an existing volume group or a dedicated volume group. - name: glance-vg physical-volumes: - /dev/sdx logical-volumes: - name: glance-cache size: 95% mount: /var/lib/glance/cache fstype: ext4 mkfs-opts: -O large_file consumer: name: glance-api usage: glance-cacheIf you are enabling image caching during your initial installation, prior to running
site.ymlthe first time, then continue with the installation steps. However, if you are making this change post-installation then you will need to commit your changes with the steps below.Commit your configuration to the Git repository (Book “Installing with Cloud Lifecycle Manager”, Chapter 10 “Using Git for Configuration Management”), as follows:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlUpdate your deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the Glance reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts glance-reconfigure.yml
An existing volume image cache is not properly deleted when Cinder detects the source image has changed. After updating any source image, delete the cache volume so that the cache is refreshed.
The volume image cache must be deleted before trying to use the associated
source image in any other volume operations. This includes creating bootable
volumes or booting an instance with create volume enabled
and the updated image as the source image.
5.6.2 Allowing the Glance copy-from option in your environment #
When creating images, one of the options you have is to copy the image from
a remote location to your local Glance store. You do this by specifying the
--copy-from option when creating the image. To use this
feature though you need to ensure the following conditions are met:
The server hosting the Glance service must have network access to the remote location that is hosting the image.
There cannot be a proxy between Glance and the remote location.
The Glance v1 API must be enabled, as v2 does not currently support the
copy-fromfunction.The http Glance store must be enabled in the environment, following the steps below.
Enabling the HTTP Glance Store
Log in to the Cloud Lifecycle Manager.
Edit the
~/openstack/my_cloud/config/glance/glance-api.conf.j2file and addhttpto the list of Glance stores in the[glance_store]section as seen below in bold:[glance_store] stores = {{ glance_stores }}, httpCommit your configuration to the Git repository (Book “Installing with Cloud Lifecycle Manager”, Chapter 10 “Using Git for Configuration Management”), as follows:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlUpdate your deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the Glance reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts glance-reconfigure.ymlRun the Horizon reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts horizon-reconfigure.yml