Operations Guide
- 1 Operations Overview
- 2 Tutorials
- 3 Third-Party Integrations
- 4 Managing Identity
- 5 Managing Compute
- 6 Managing ESX
- 7 Managing Block Storage
- 8 Managing Object Storage
- 9 Managing Networking
- 10 Managing the Dashboard
- 11 Managing Orchestration
- 12 Managing Monitoring, Logging, and Usage Reporting
- 13 System Maintenance
- 14 Backup and Restore
- 15 Troubleshooting Issues
12 Managing Monitoring, Logging, and Usage Reporting
Information about the monitoring, logging, and metering services included with your HPE Helion OpenStack.
12.1 Monitoring #
The HPE Helion OpenStack Monitoring service leverages OpenStack Monasca, which is a multi-tenant, scalable, fault tolerant monitoring service.
12.1.1 Getting Started with Monitoring #
You can use the HPE Helion OpenStack Monitoring service to monitor the health of your cloud and, if necessary, to troubleshoot issues.
Monasca data can be extracted and used for a variety of legitimate purposes, and different purposes require different forms of data sanitization or encoding to protect against invalid or malicious data. Any data pulled from Monasca should be considered untrusted data, so users are advised to apply appropriate encoding and/or sanitization techniques to ensure safe and correct usage and display of data in a web browser, database scan, or any other use of the data.
12.1.1.1 Monitoring Service Overview #
12.1.1.1.1 Installation #
The monitoring service is automatically installed as part of the HPE Helion OpenStack installation.
No specific configuration is required to use Monasca. However, you can configure the database for storing metrics as explained in Section 12.1.2, “Configuring the Monitoring Service”.
12.1.1.1.2 Differences Between Upstream and HPE Helion OpenStack Implementations #
In HPE Helion OpenStack, the OpenStack monitoring service, Monasca, is included as the monitoring solution, except for the following which are not included:
Transform Engine
Events Engine
Anomaly and Prediction Engine
Note
Icinga was supported in previous HPE Helion OpenStack versions but it has been deprecated in HPE Helion OpenStack 8.
12.1.1.1.3 Diagram of Monasca Service #
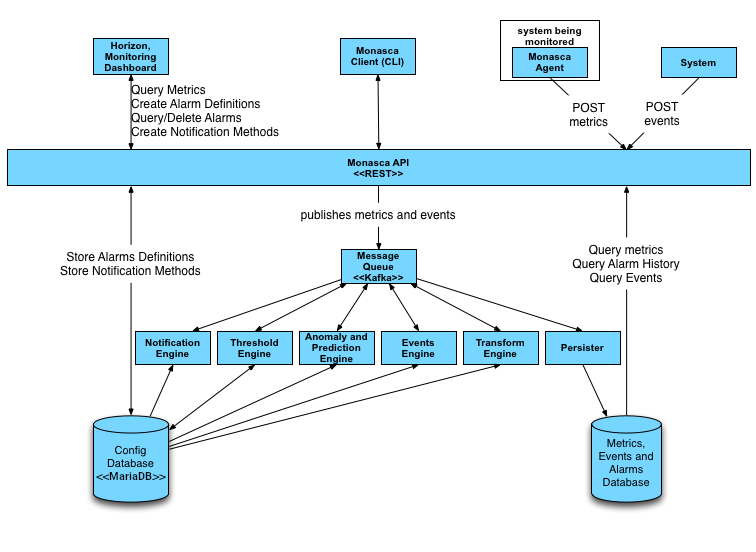
12.1.1.1.4 For More Information #
For more details on OpenStack Monasca, see Monasca.io
12.1.1.1.5 Back-end Database #
The monitoring service default metrics database is Cassandra, which is a highly-scalable analytics database and the recommended database for HPE Helion OpenStack.
You can learn more about Cassandra at Apache Cassandra.
12.1.1.2 Working with Monasca #
Monasca-Agent
The monasca-agent is a Python program that runs on the control plane nodes. It runs the defined checks and then sends data onto the API. The checks that the agent runs include:
System Metrics: CPU utilization, memory usage, disk I/O, network I/O, and filesystem utilization on the control plane and resource nodes.
Service Metrics: the agent supports plugins such as MySQL, RabbitMQ, Kafka, and many others.
VM Metrics: CPU utilization, disk I/O, network I/O, and memory usage of hosted virtual machines on compute nodes. Full details of these can be found https://github.com/openstack/monasca-agent/blob/master/docs/Plugins.md#per-instance-metrics.
For a full list of packaged plugins that are included HPE Helion OpenStack, see Monasca Plugins
You can further customize the monasca-agent to suit your needs, see Customizing the Agent
12.1.1.3 Accessing the Monitoring Service #
Access to the Monitoring service is available through a number of different interfaces.
12.1.1.3.1 Command-Line Interface #
For users who prefer using the command line, there is the python-monascaclient, which is part of the default installation on your Cloud Lifecycle Manager node.
For details on the CLI, including installation instructions, see Python-Monasca Client
Monasca API
If low-level access is desired, there is the Monasca REST API.
Full details of the Monasca API can be found on GitHub.
12.1.1.3.2 Operations Console GUI #
You can use the Operations Console (Ops Console) for HPE Helion OpenStack to view data about your HPE Helion OpenStack cloud infrastructure in a web-based graphical user interface (GUI) and ensure your cloud is operating correctly. By logging on to the console, HPE Helion OpenStack administrators can manage data in the following ways: Triage alarm notifications.
Alarm Definitions and notifications now have their own screens and are collected under the Alarm Explorer menu item which can be accessed from the Central Dashboard. Central Dashboard now allows you to customize the view in the following ways:
Rename or re-configure existing alarm cards to include services different from the defaults
Create a new alarm card with the services you want to select
Reorder alarm cards using drag and drop
View all alarms that have no service dimension now grouped in an Uncategorized Alarms card
View all alarms that have a service dimension that does not match any of the other cards -now grouped in an Other Alarms card
You can also easily access alarm data for a specific component. On the Summary page for the following components, a link is provided to an alarms screen specifically for that component:
Compute Instances: Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.3 “Managing Compute Hosts”
Object Storage: Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.4 “Managing Swift Performance”, Section 1.4.4 “Alarm Summary”
12.1.1.3.3 Connecting to the Operations Console #
To connect to Operations Console, perform the following:
Ensure your login has the required access credentials: Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.2 “Connecting to the Operations Console”, Section 1.2.1 “Required Access Credentials”
Connect through a browser: Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.2 “Connecting to the Operations Console”, Section 1.2.2 “Connect Through a Browser”
Optionally use a Host name OR virtual IP address to access Operations Console: Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.2 “Connecting to the Operations Console”, Section 1.2.3 “Optionally use a Hostname OR virtual IP address to access Operations Console”
Operations Console will always be accessed over port 9095.
12.1.1.3.4 For More Information #
For more details about the Operations Console, see Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.1 “Operations Console Overview”.
12.1.1.4 Service Alarm Definitions #
HPE Helion OpenStack comes with some predefined monitoring alarms for the services installed.
Full details of all service alarms can be found here: Section 15.1.1, “Alarm Resolution Procedures”.
Each alarm will have one of the following statuses:
- Open alarms, identified by red indicator.
- Open alarms, identified by yellow indicator.
- Open alarms, identified by gray indicator. Unknown will be the status of an alarm that has stopped receiving a metric. This can be caused by the following conditions:
An alarm exists for a service or component that is not installed in the environment.
An alarm exists for a virtual machine or node that previously existed but has been removed without the corresponding alarms being removed.
There is a gap between the last reported metric and the next metric.
- Complete list of open alarms.
- Complete list of alarms, may include Acknowledged and Resolved alarms.
When alarms are triggered it is helpful to review the service logs.
12.1.2 Configuring the Monitoring Service #
The monitoring service, based on Monasca, allows you to configure an external SMTP server for email notifications when alarms trigger. You also have options for your alarm metrics database should you choose not to use the default option provided with the product.
In HPE Helion OpenStack you have the option to specify a SMTP server for email notifications and a database platform you want to use for the metrics database. These steps will assist in this process.
12.1.2.1 Configuring the Monitoring Email Notification Settings #
The monitoring service, based on Monasca, allows you to configure an external SMTP server for email notifications when alarms trigger. In HPE Helion OpenStack, you have the option to specify a SMTP server for email notifications. These steps will assist in this process.
If you are going to use the email notifiication feature of the monitoring service, you must set the configuration options with valid email settings including an SMTP server and valid email addresses. The email server is not provided by HPE Helion OpenStack, but must be specified in the configuration file described below. The email server must support SMTP.
12.1.2.1.1 Configuring monitoring notification settings during initial installation #
Log in to the Cloud Lifecycle Manager.
To change the SMTP server configuration settings edit the following file:
~/openstack/my_cloud/definition/cloudConfig.yml
Enter your email server settings. Here is an example snippet showing the configuration file contents, uncomment these lines before entering your environment details.
smtp-settings: # server: mailserver.examplecloud.com # port: 25 # timeout: 15 # These are only needed if your server requires authentication # user: # password:This table explains each of these values:
Value Description Server (required) The server entry must be uncommented and set to a valid hostname or IP Address.
Port (optional) If your SMTP server is running on a port other than the standard 25, then uncomment the port line and set it your port.
Timeout (optional) If your email server is heavily loaded, the timeout parameter can be uncommented and set to a larger value. 15 seconds is the default.
User / Password (optional) If your SMTP server requires authentication, then you can configure user and password. Use double quotes around the password to avoid issues with special characters.
To configure the sending email addresses, edit the following file:
~/openstack/ardana/ansible/roles/monasca-notification/defaults/main.yml
Modify the following value to add your sending email address:
email_from_addr

Note
The default value in the file is
email_from_address: notification@exampleCloud.comwhich you should edit.[optional] To configure the receiving email addresses, edit the following file:
~/openstack/ardana/ansible/roles/monasca-default-alarms/defaults/main.yml
Modify the following value to configure a receiving email address:
notification_address
Note
You can also set the receiving email address via the Operations Console. Instructions for this are in the last section.
If your environment requires a proxy address then you can add that in as well:
# notification_environment can be used to configure proxies if needed. # Below is an example configuration. Note that all of the quotes are required. # notification_environment: '"http_proxy=http://<your_proxy>:<port>" "https_proxy=http://<your_proxy>:<port>"' notification_environment: ''Commit your configuration to the local Git repository (see Book “Installing with Cloud Lifecycle Manager”, Chapter 10 “Using Git for Configuration Management”), as follows:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "Updated monitoring service email notification settings"Continue with your installation.
12.1.2.1.2 Monasca and Apache Commons validator #
The Monasca notification uses a standard Apache Commons validator to validate the configured HPE Helion OpenStack domain names before sending the notification over webhook. Monasca notification supports some non-standard domain names, but not all. See the Domain Validator documentation for more information: https://commons.apache.org/proper/commons-validator/apidocs/org/apache/commons/validator/routines/DomainValidator.html
You should ensure that any domains that you use are supported by IETF and IANA. As an example, .local is not listed by IANA and is invalid but .gov and .edu are valid.
Internet Assigned Numbers Authority (IANA): https://www.iana.org/domains/root/db
Failure to use supported domains will generate an unprocessable exception in Monasca notification create:
HTTPException code=422 message={"unprocessable_entity":
{"code":422,"message":"Address https://myopenstack.sample:8000/v1/signal/test is not of correct format","details":"","internal_code":"c6cf9d9eb79c3fc4"}12.1.2.1.3 Configuring monitoring notification settings after the initial installation #
If you need to make changes to the email notification settings after your initial deployment, you can change the "From" address using the configuration files but the "To" address will need to be changed in the Operations Console. The following section will describe both of these processes.
To change the sending email address:
Log in to the Cloud Lifecycle Manager.
To configure the sending email addresses, edit the following file:
~/openstack/ardana/ansible/roles/monasca-notification/defaults/main.yml
Modify the following value to add your sending email address:
email_from_addr
Note
The default value in the file is
email_from_address: notification@exampleCloud.comwhich you should edit.Commit your configuration to the local Git repository (Book “Installing with Cloud Lifecycle Manager”, Chapter 10 “Using Git for Configuration Management”), as follows:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "Updated monitoring service email notification settings"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlUpdate your deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the Monasca reconfigure playbook to deploy the changes:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts monasca-reconfigure.yml --tags notificationNote
You may need to use the
--ask-vault-passswitch if you opted for encryption during the initial deployment.
To change the receiving email address via the Operations Console:
To configure the "To" email address, after installation,
Connect to and log in to the Operations Console. See Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.2 “Connecting to the Operations Console” for assistance.
On the Home screen, click the menu represented by 3 horizontal lines (
 ).
).
From the menu that slides in on the left side, click Home, and then Alarm Explorer.
On the Alarm Explorer page, at the top, click the Notification Methods text.
On the Notification Methods page, find the row with the Default Email notification.
In the Default Email row, click the details icon (
 ), then click
Edit.
), then click
Edit.
On the Edit Notification Method: Default Email page, in Name, Type, and Address/Key, type in the values you want to use.
On the Edit Notification Method: Default Email page, click Update Notification.
Important
Once the notification has been added, using the procedures using the Ansible playbooks will not change it.
12.1.2.2 Managing Notification Methods for Alarms #
12.1.2.2.1 Enabling a Proxy for Webhook or Pager Duty Notifications #
If your environment requires a proxy in order for communications to function then these steps will show you how you can enable one. These steps will only be needed if you are utilizing the webhook or pager duty notification methods.
These steps will require access to the Cloud Lifecycle Manager in your cloud deployment so you may need to contact your Administrator. You can make these changes during the initial configuration phase prior to the first installation or you can modify your existing environment, the only difference being the last step.
Log in to the Cloud Lifecycle Manager.
Edit the
~/openstack/ardana/ansible/roles/monasca-notification/defaults/main.ymlfile and edit the line below with your proxy address values:notification_environment: '"http_proxy=http://<proxy_address>:<port>" "https_proxy=<http://proxy_address>:<port>"'
Note
There are single quotation marks around the entire value of this entry and then double quotation marks around the individual proxy entries. This formatting must exist when you enter these values into your configuration file.
If you are making these changes prior to your initial installation then you are done and can continue on with the installation. However, if you are modifying an existing environment, you will need to continue on with the remaining steps below.
Commit your configuration to the local Git repository (see Book “Installing with Cloud Lifecycle Manager”, Chapter 10 “Using Git for Configuration Management”), as follows:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlGenerate an updated deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the Monasca reconfigure playbook to enable these changes:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts monasca-reconfigure.yml --tags notification
12.1.2.2.2 Creating a New Notification Method #
Log in to the Operations Console. For more information, see Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.2 “Connecting to the Operations Console”.
Use the navigation menu to go to the Alarm Explorer page:
Select the Notification Methods menu and then click the Create Notification Method button:
On the Create Notification Method window you will select your options and then click the Create Notification button.
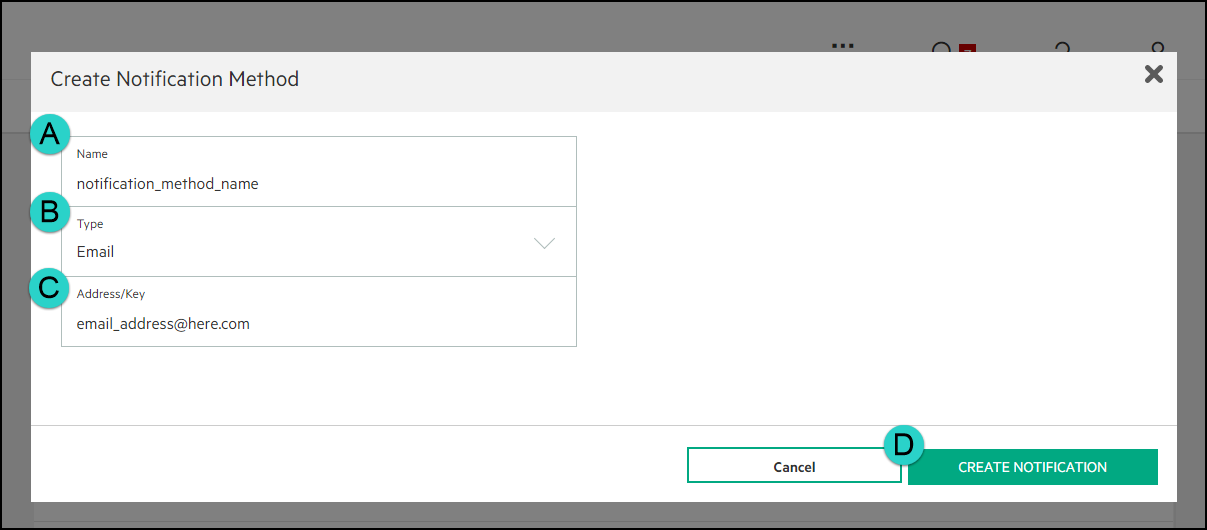
A description of each of the fields you use for each notification method:
Field Description Name Enter a unique name value for the notification method you are creating.
Type Choose a type. Available values are Webhook, Email, or Pager Duty.
Address/Key Enter the value corresponding to the type you chose.
12.1.2.2.3 Applying a Notification Method to an Alarm Definition #
Log in to the Operations Console. For more informalfigure, see Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.2 “Connecting to the Operations Console”.
Use the navigation menu to go to the Alarm Explorer page:
Select the Alarm Definition menu which will give you a list of each of the alarm definitions in your environment.
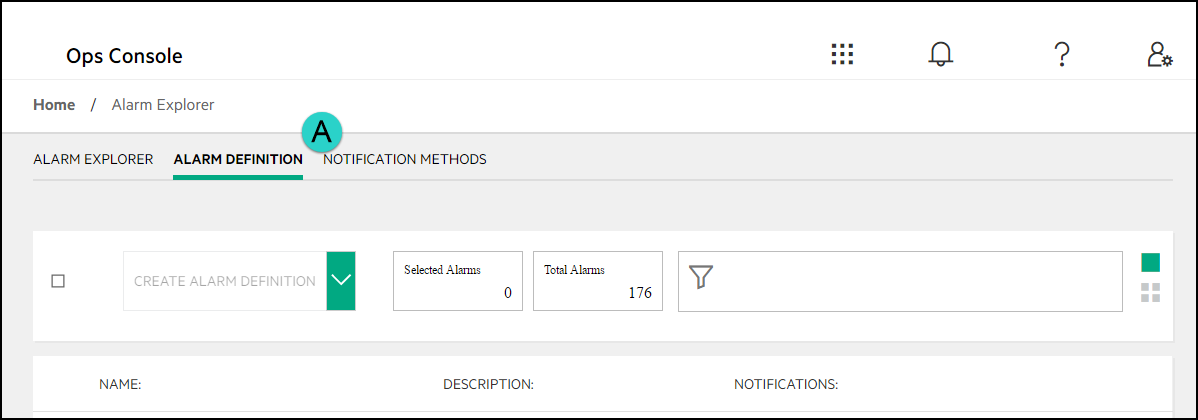
Locate the alarm you want to change the notification method for and click on its name to bring up the edit menu. You can use the sorting methods for assistance.
In the edit menu, scroll down to the Notifications and Severity section where you will select one or more Notification Methods before selecting the Update Alarm Definition button:
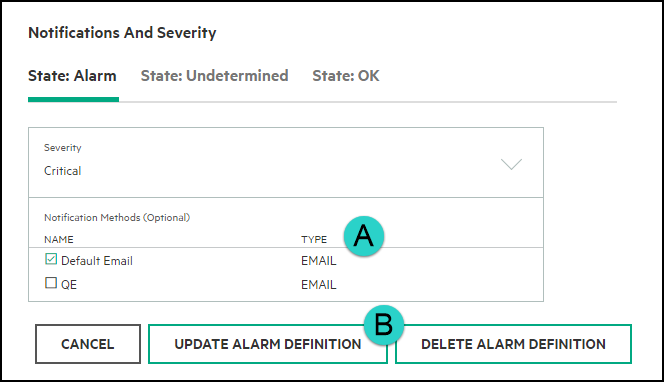
Repeat as needed until all of your alarms have the notification methods you desire.
12.1.2.3 Enabling the RabbitMQ Admin Console #
The RabbitMQ Admin Console is off by default in HPE Helion OpenStack. You can turn on the console by following these steps:
Log in to the Cloud Lifecycle Manager.
Edit the
~/openstack/my_cloud/config/rabbitmq/main.ymlfile. Under therabbit_plugins:line, uncomment- rabbitmq_management
Commit your configuration to the local Git repository (see Book “Installing with Cloud Lifecycle Manager”, Chapter 10 “Using Git for Configuration Management”), as follows:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "Enabled RabbitMQ Admin Console"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlUpdate your deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the RabbitMQ reconfigure playbook to deploy the changes:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts rabbitmq-reconfigure.yml
To turn the RabbitMQ Admin Console off again, add the comment back and repeat steps 3 through 6.
12.1.2.4 Capacity Reporting and Monasca Transform #
Capacity reporting is a new feature in HPE Helion OpenStack which will provide cloud operators overall capacity (available, used, and remaining) information via the Operations Console so that the cloud operator can ensure that cloud resource pools have sufficient capacity to meet the demands of users. The cloud operator is also able to set thresholds and set alarms to be notified when the thresholds are reached.
For Compute
Host Capacity - CPU/Disk/Memory: Used, Available and Remaining Capacity - for the entire cloud installation or by host
VM Capacity - CPU/Disk/Memory: Allocated, Available and Remaining - for the entire cloud installation, by host or by project
For Object Storage
Disk Capacity - Used, Available and Remaining Capacity - for the entire cloud installation or by project
In addition to overall capacity, roll up views with appropriate slices provide views by a particular project, or compute node. Graphs also show trends and the change in capacity over time.
12.1.2.4.1 Monasca Transform Features #
Monasca Transform is a new component in Monasca which transforms and aggregates metrics using Apache Spark
Aggregated metrics are published to Kafka and are available for other monasca components like monasca-threshold and are stored in monasca datastore
Cloud operators can set thresholds and set alarms to receive notifications when thresholds are met.
These aggregated metrics are made available to the cloud operators via Operations Console's new Capacity Summary (reporting) UI
Capacity reporting is a new feature in HPE Helion OpenStack which will provides cloud operators an overall capacity (available, used and remaining) for Compute and Object Storage
Cloud operators can look at Capacity reporting via Operations Console's Compute Capacity Summary and Object Storage Capacity Summary UI
Capacity reporting allows the cloud operators the ability to ensure that cloud resource pools have sufficient capacity to meet demands of users. See table below for Service and Capacity Types.
A list of aggregated metrics is provided in Section 12.1.2.4.4, “New Aggregated Metrics”.
Capacity reporting aggregated metrics are aggregated and published every hour
In addition to the overall capacity, there are graphs which show the capacity trends over time range (for 1 day, for 7 days, for 30 days or for 45 days)
Graphs showing the capacity trends by a particular project or compute host are also provided.
Monasca Transform is integrated with centralized monitoring (Monasca) and centralized logging
Flexible Deployment
Upgrade & Patch Support
| Service | Type of Capacity | Description |
|---|---|---|
| Compute | Host Capacity |
CPU/Disk/Memory: Used, Available and Remaining Capacity - for entire cloud installation or by compute host |
| VM Capacity |
CPU/Disk/Memory: Allocated, Available and Remaining - for entire cloud installation, by host or by project | |
| Object Storage | Disk Capacity |
Used, Available and Remaining Disk Capacity - for entire cloud installation or by project |
| Storage Capacity |
Utilized Storage Capacity - for entire cloud installation or by project |
12.1.2.4.2 Architecture for Monasca Transform and Spark #
Monasca Transform is a new component in Monasca. Monasca Transform uses Spark for data aggregation. Both Monasca Transform and Spark are depicted in the example diagram below.
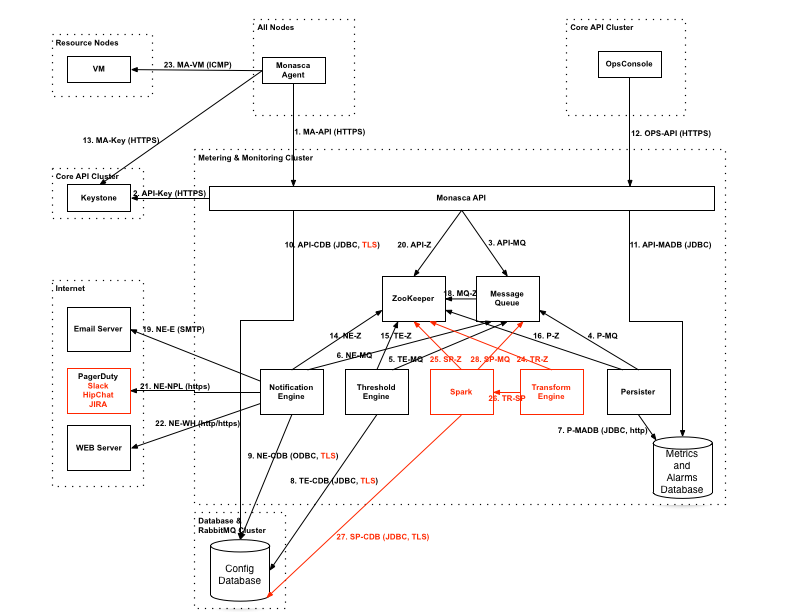
You can see that the Monasca components run on the Cloud Controller nodes, and the Monasca agents run on all nodes in the Mid-scale Example configuration.
12.1.2.4.3 Components for Capacity Reporting #
12.1.2.4.3.1 Monasca Transform: Data Aggregation Reporting #
Monasca-transform is a new component which provides mechanism to aggregate or transform metrics and publish new aggregated metrics to Monasca.
Monasca Transform is a data driven Apache Spark based data aggregation engine which collects, groups and aggregates existing individual Monasca metrics according to business requirements and publishes new transformed (derived) metrics to the Monasca Kafka queue.
Since the new transformed metrics are published as any other metric in Monasca, alarms can be set and triggered on the transformed metric, just like any other metric.
12.1.2.4.3.2 Object Storage and Compute Capacity Summary Operations Console UI #
A new "Capacity Summary" tab for Compute and Object Storage will displays all the aggregated metrics under the "Compute" and "Object Storage" sections.
Operations Console UI makes calls to Monasca API to retrieve and display various tiles and graphs on Capacity Summary tab in Compute and Object Storage Summary UI pages.
12.1.2.4.3.3 Persist new metrics and Trigger Alarms #
New aggregated metrics will be published to Monasca's Kafka queue and will be ingested by monasca-persister. If thresholds and alarms have been set on the aggregated metrics, Monasca will generate and trigger alarms as it currently does with any other metric. No new/additional change is expected with persisting of new aggregated metrics or setting threshold/alarms.
12.1.2.4.4 New Aggregated Metrics #
Following is the list of aggregated metrics produced by monasca transform in HPE Helion OpenStack
Table 12.1: Aggregated Metrics #
| Metric Name | For | Description | Dimensions | Notes | |
|---|---|---|---|---|---|
| 1 |
cpu.utilized_logical_cores_agg | compute summary |
utilized physical host cpu core capacity for one or all hosts by time interval (defaults to a hour) |
aggregation_period: hourly host: all or <host name> project_id: all | Available as total or per host |
| 2 | cpu.total_logical_cores_agg | compute summary |
total physical host cpu core capacity for one or all hosts by time interval (defaults to a hour) |
aggregation_period: hourly host: all or <host name> project_id: all | Available as total or per host |
| 3 | mem.total_mb_agg | compute summary |
total physical host memory capacity by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all | |
| 4 | mem.usable_mb_agg | compute summary |
usable physical host memory capacity by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all | |
| 5 | disk.total_used_space_mb_agg | compute summary |
utilized physical host disk capacity by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all | |
| 6 | disk.total_space_mb_agg | compute summary |
total physical host disk capacity by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all | |
| 7 | nova.vm.cpu.total_allocated_agg | compute summary |
cpus allocated across all VMs by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all | |
| 8 | vcpus_agg | compute summary |
virtual cpus allocated capacity for VMs of one or all projects by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all or <project ID> | Available as total or per project |
| 9 | nova.vm.mem.total_allocated_mb_agg | compute summary |
memory allocated to all VMs by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all | |
| 10 | vm.mem.used_mb_agg | compute summary |
memory utilized by VMs of one or all projects by time interval (defaults to an hour) |
aggregation_period: hourly host: all project_id: <project ID> | Available as total or per project |
| 11 | vm.mem.total_mb_agg | compute summary |
memory allocated to VMs of one or all projects by time interval (defaults to an hour) |
aggregation_period: hourly host: all project_id: <project ID> | Available as total or per project |
| 12 | vm.cpu.utilization_perc_agg | compute summary |
cpu utilized by all VMs by project by time interval (defaults to an hour) |
aggregation_period: hourly host: all project_id: <project ID> | |
| 13 | nova.vm.disk.total_allocated_gb_agg | compute summary |
disk space allocated to all VMs by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all | |
| 14 | vm.disk.allocation_agg | compute summary |
disk allocation for VMs of one or all projects by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all or <project ID> | Available as total or per project |
| 15 | swiftlm.diskusage.val.size_agg | object storage summary |
total available object storage capacity by time interval (defaults to a hour) |
aggregation_period: hourly host: all or <host name> project_id: all | Available as total or per host |
| 16 | swiftlm.diskusage.val.avail_agg | object storage summary |
remaining object storage capacity by time interval (defaults to a hour) |
aggregation_period: hourly host: all or <host name> project_id: all | Available as total or per host |
| 17 | swiftlm.diskusage.rate_agg | object storage summary |
rate of change of object storage usage by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all | |
| 18 | storage.objects.size_agg | object storage summary |
used object storage capacity by time interval (defaults to a hour) |
aggregation_period: hourly host: all project_id: all |
12.1.2.4.5 Deployment #
Monasca Transform and Spark will be deployed on the same control plane nodes along with Logging and Monitoring Service (Monasca).
Security Consideration during deployment of Monasca Transform and Spark
The HPE Helion OpenStack Monitoring system connects internally to the Kafka and Spark technologies without authentication. If you choose to deploy Monitoring, configure it to use only trusted networks such as the Management network, as illustrated on the network diagrams below for Entry Scale Deployment and Mid Scale Deployment.
Entry Scale Deployment
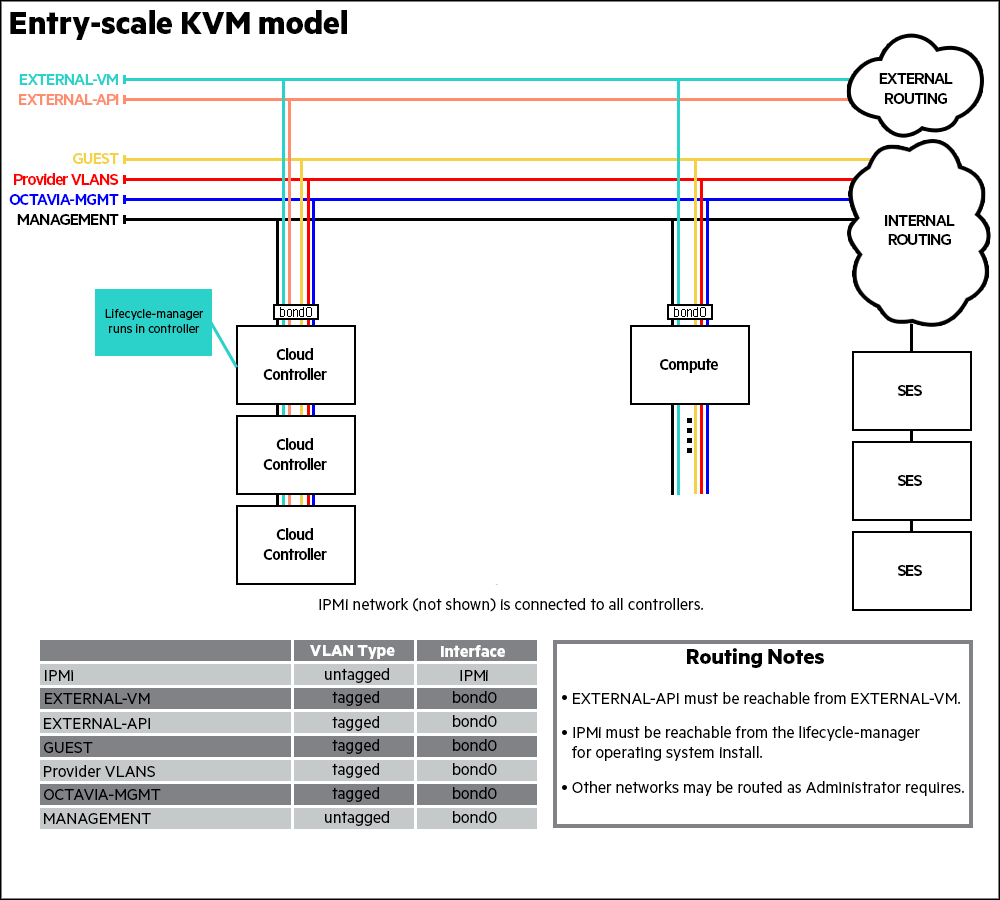
In Entry Scale Deployment Monasca Transform and Spark will be deployed on Shared Control Plane along with other Openstack Services along with Monitoring and Logging
Mid scale Deployment
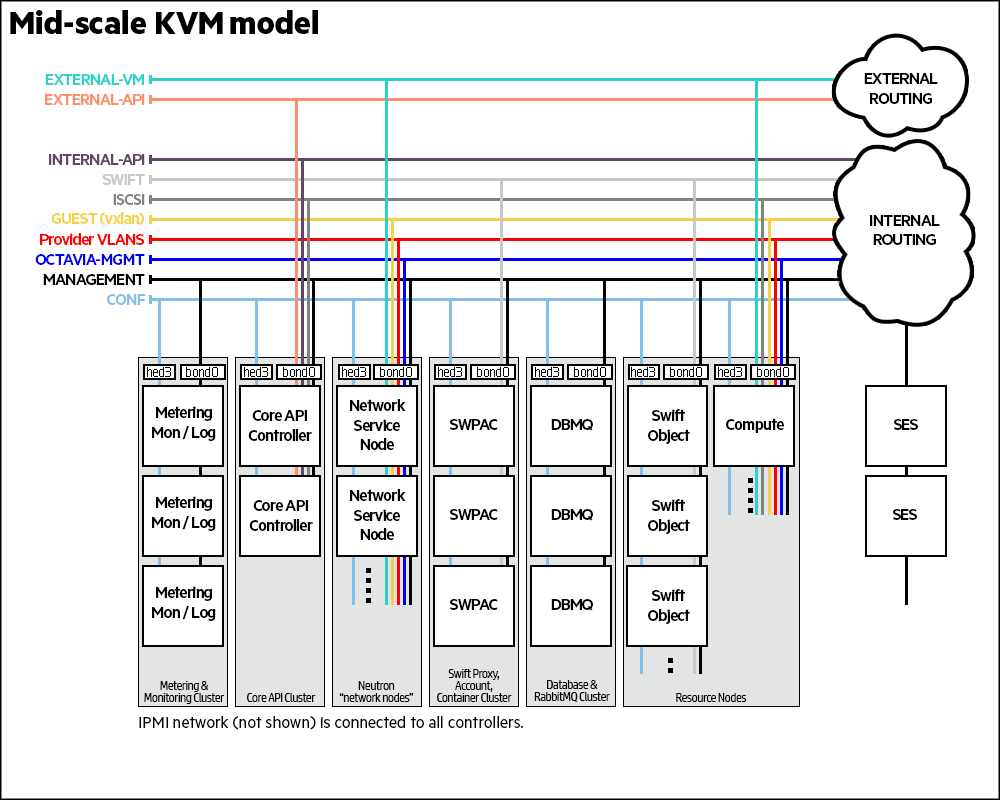
In a Mid Scale Deployment Monasca Transform and Spark will be deployed on dedicated Metering Monitoring and Logging (MML) control plane along with other data processing intensive services like Metering, Monitoring and Logging
Multi Control Plane Deployment
In a Multi Control Plane Deployment, Monasca Transform and Spark will be deployed on the Shared Control plane along with rest of Monasca Components.
Start, Stop and Status for Monasca Transform and Spark processes
The service management methods for monasca-transform and spark follow the convention for services in the OpenStack platform. When executing from the deployer node, the commands are as follows:
Status
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts spark-status.ymlardana >ansible-playbook -i hosts/verb_hosts monasca-transform-status.yml
Start
As monasca-transform depends on spark for the processing of the metrics spark will need to be started before monasca-transform.
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts spark-start.ymlardana >ansible-playbook -i hosts/verb_hosts monasca-transform-start.yml
Stop
As a precaution, stop the monasca-transform service before taking spark down. Interruption to the spark service altogether while monasca-transform is still running can result in a monasca-transform process that is unresponsive and needing to be tidied up.
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts monasca-transform-stop.ymlardana >ansible-playbook -i hosts/verb_hosts spark-stop.yml
12.1.2.4.6 Reconfigure #
The reconfigure process can be triggered again from the deployer. Presuming that changes have been made to the variables in the appropriate places execution of the respective ansible scripts will be enough to update the configuration. The spark reconfigure process alters the nodes serially meaning that spark is never down altogether, each node is stopped in turn and zookeeper manages the leaders accordingly. This means that monasca-transform may be left running even while spark is upgraded.
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts spark-reconfigure.ymlardana >ansible-playbook -i hosts/verb_hosts monasca-transform-reconfigure.yml
12.1.2.4.7 Adding Monasca Transform and Spark to HPE Helion OpenStack Deployment #
Since Monasca Transform and Spark are optional components, the users might elect to not install these two components during their initial HPE Helion OpenStack install. The following instructions provide a way the users can add Monasca Transform and Spark to their existing HPE Helion OpenStack deployment.
Steps
Add Monasca Transform and Spark to the input model. Monasca Transform and Spark on a entry level cloud would be installed on the common control plane, for mid scale cloud which has a MML (Metering, Monitoring and Logging) cluster, Monasca Transform and Spark will should be added to MML cluster.
ardana >cd ~/openstack/my_cloud/definition/data/Add spark and monasca-transform to input model, control_plane.yml
clusters - name: core cluster-prefix: c1 server-role: CONTROLLER-ROLE member-count: 3 allocation-policy: strict service-components: [...] - zookeeper - kafka - cassandra - storm - spark - monasca-api - monasca-persister - monasca-notifier - monasca-threshold - monasca-client - monasca-transform [...]Run the Configuration Processor
ardana >cd ~/openstack/my_cloud/definitionardana >git add -Aardana >git commit -m "Adding Monasca Transform and Spark"ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlRun Ready Deployment
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun Cloud Lifecycle Manager Deploy
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts ardana-deploy.yml
Verify Deployment
Login to each controller node and run
tux >sudo service monasca-transform statustux >sudo service spark-master statustux >sudo service spark-worker status
tux >sudo service monasca-transform status ● monasca-transform.service - Monasca Transform Daemon Loaded: loaded (/etc/systemd/system/monasca-transform.service; disabled) Active: active (running) since Wed 2016-08-24 00:47:56 UTC; 2 days ago Main PID: 7351 (bash) CGroup: /system.slice/monasca-transform.service ├─ 7351 bash /etc/monasca/transform/init/start-monasca-transform.sh ├─ 7352 /opt/stack/service/monasca-transform/venv//bin/python /opt/monasca/monasca-transform/lib/service_runner.py ├─27904 /bin/sh -c export SPARK_HOME=/opt/stack/service/spark/venv/bin/../current && spark-submit --supervise --master spark://omega-cp1-c1-m1-mgmt:7077,omega-cp1-c1-m2-mgmt:7077,omega-cp1-c1... ├─27905 /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /opt/stack/service/spark/venv/lib/drizzle-jdbc-1.3.jar:/opt/stack/service/spark/venv/bin/../current/conf/:/opt/stack/service/spark/v... └─28355 python /opt/monasca/monasca-transform/lib/driver.py Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.tux >sudo service spark-worker status ● spark-worker.service - Spark Worker Daemon Loaded: loaded (/etc/systemd/system/spark-worker.service; disabled) Active: active (running) since Wed 2016-08-24 00:46:05 UTC; 2 days ago Main PID: 63513 (bash) CGroup: /system.slice/spark-worker.service ├─ 7671 python -m pyspark.daemon ├─28948 /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /opt/stack/service/spark/venv/bin/../current/conf/:/opt/stack/service/spark/venv/bin/../current/lib/spark-assembly-1.6.1-hadoop2.6.0... ├─63513 bash /etc/spark/init/start-spark-worker.sh & └─63514 /usr/bin/java -cp /opt/stack/service/spark/venv/bin/../current/conf/:/opt/stack/service/spark/venv/bin/../current/lib/spark-assembly-1.6.1-hadoop2.6.0.jar:/opt/stack/service/spark/ven... Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.tux >sudo service spark-master status ● spark-master.service - Spark Master Daemon Loaded: loaded (/etc/systemd/system/spark-master.service; disabled) Active: active (running) since Wed 2016-08-24 00:44:24 UTC; 2 days ago Main PID: 55572 (bash) CGroup: /system.slice/spark-master.service ├─55572 bash /etc/spark/init/start-spark-master.sh & └─55573 /usr/bin/java -cp /opt/stack/service/spark/venv/bin/../current/conf/:/opt/stack/service/spark/venv/bin/../current/lib/spark-assembly-1.6.1-hadoop2.6.0.jar:/opt/stack/service/spark/ven... Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.
12.1.2.4.8 Increase Monasca Transform Scale #
Monasca Transform in the default configuration can scale up to estimated data for 100 node cloud deployment. Estimated maximum rate of metrics from a 100 node cloud deployment is 120M/hour.
You can further increase the processing rate to 180M/hour. Making the Spark configuration change will increase the CPU's being used by Spark and Monasca Transform from average of around 3.5 to 5.5 CPU's per control node over a 10 minute batch processing interval.
To increase the processing rate to 180M/hour the customer will have to make following spark configuration change.
Steps
Edit /var/lib/ardana/openstack/my_cloud/config/spark/spark-defaults.conf.j2 and set spark.cores.max to 6 and spark.executor.cores 2
Set spark.cores.max to 6
spark.cores.max {{ spark_cores_max }}to
spark.cores.max 6
Set spark.executor.cores to 2
spark.executor.cores {{ spark_executor_cores }}to
spark.executor.cores 2
Edit ~/openstack/my_cloud/config/spark/spark-env.sh.j2
Set SPARK_WORKER_CORES to 2
export SPARK_WORKER_CORES={{ spark_worker_cores }}to
export SPARK_WORKER_CORES=2
Edit ~/openstack/my_cloud/config/spark/spark-worker-env.sh.j2
Set SPARK_WORKER_CORES to 2
export SPARK_WORKER_CORES={{ spark_worker_cores }}to
export SPARK_WORKER_CORES=2
Run Configuration Processor
ardana >cd ~/openstack/my_cloud/definitionardana >git add -Aardana >git commit -m "Changing Spark Config increase scale"ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlRun Ready Deployment
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun spark-reconfigure.yml and monasca-transform-reconfigure.yml
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts spark-reconfigure.ymlardana >ansible-playbook -i hosts/verb_hosts monasca-transform-reconfigure.yml
12.1.2.4.9 Change Compute Host Pattern Filter in Monasca Transform #
Monasca Transform identifies compute host metrics by pattern matching on
hostname dimension in the incoming monasca metrics. The default pattern is of
the form compNNN. For example,
comp001, comp002, etc. To filter for it
in the transformation specs, use the expression
-comp[0-9]+-. In case the compute
host names follow a different pattern other than the standard pattern above,
the filter by expression when aggregating metrics will have to be changed.
Steps
On the deployer: Edit
~/openstack/my_cloud/config/monasca-transform/transform_specs.json.j2Look for all references of
-comp[0-9]+-and change the regular expression to the desired pattern say for example-compute[0-9]+-.{"aggregation_params_map":{"aggregation_pipeline":{"source":"streaming", "usage":"fetch_quantity", "setters":["rollup_quantity", "set_aggregated_metric_name", "set_aggregated_period"], "insert":["prepare_data","insert_data_pre_hourly"]}, "aggregated_metric_name":"mem.total_mb_agg", "aggregation_period":"hourly", "aggregation_group_by_list": ["host", "metric_id", "tenant_id"], "usage_fetch_operation": "avg", "filter_by_list": [{"field_to_filter": "host", "filter_expression": "-comp[0-9]+", "filter_operation": "include"}], "setter_rollup_group_by_list":[], "setter_rollup_operation": "sum", "dimension_list":["aggregation_period", "host", "project_id"], "pre_hourly_operation":"avg", "pre_hourly_group_by_list":["default"]}, "metric_group":"mem_total_all", "metric_id":"mem_total_all"}to
{"aggregation_params_map":{"aggregation_pipeline":{"source":"streaming", "usage":"fetch_quantity", "setters":["rollup_quantity", "set_aggregated_metric_name", "set_aggregated_period"], "insert":["prepare_data", "insert_data_pre_hourly"]}, "aggregated_metric_name":"mem.total_mb_agg", "aggregation_period":"hourly", "aggregation_group_by_list": ["host", "metric_id", "tenant_id"],"usage_fetch_operation": "avg","filter_by_list": [{"field_to_filter": "host","filter_expression": "-compute[0-9]+", "filter_operation": "include"}], "setter_rollup_group_by_list":[], "setter_rollup_operation": "sum", "dimension_list":["aggregation_period", "host", "project_id"], "pre_hourly_operation":"avg", "pre_hourly_group_by_list":["default"]}, "metric_group":"mem_total_all", "metric_id":"mem_total_all"}Note
The filter_expression has been changed to the new pattern.
To change all host metric transformation specs in the same JSON file, repeat Step 2.
Transformation specs will have to be changed for following metric_ids namely "mem_total_all", "mem_usable_all", "disk_total_all", "disk_usable_all", "cpu_total_all", "cpu_total_host", "cpu_util_all", "cpu_util_host"
Run the Configuration Processor:
ardana >cd ~/openstack/my_cloud/definitionardana >git add -Aardana >git commit -m "Changing Monasca Transform specs"ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlRun Ready Deployment:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun Monasca Transform Reconfigure:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts monasca-transform-reconfigure.yml
12.1.2.5 Configuring Availability of Alarm Metrics #
Using the Monasca agent tuning knobs, you can choose which alarm metrics are available in your environment.
The addition of the libvirt and OVS plugins to the Monasca agent provides a number of additional metrics that can be used. Most of these metrics are included by default, but others are not. You have the ability to use tuning knobs to add or remove these metrics to your environment based on your individual needs in your cloud.
We will list these metrics along with the tuning knob name and instructions for how to adjust these.
12.1.2.5.1 Libvirt plugin metric tuning knobs #
The following metrics are added as part of the libvirt plugin:
| Tuning Knob | Default Setting | Admin Metric Name | Project Metric Name |
|---|---|---|---|
| vm_cpu_check_enable | True | vm.cpu.time_ns | cpu.time_ns |
| vm.cpu.utilization_norm_perc | cpu.utilization_norm_perc | ||
| vm.cpu.utilization_perc | cpu.utilization_perc | ||
| vm_disks_check_enable |
True Creates 20 disk metrics per disk device per virtual machine. | vm.io.errors | io.errors |
| vm.io.errors_sec | io.errors_sec | ||
| vm.io.read_bytes | io.read_bytes | ||
| vm.io.read_bytes_sec | io.read_bytes_sec | ||
| vm.io.read_ops | io.read_ops | ||
| vm.io.read_ops_sec | io.read_ops_sec | ||
| vm.io.write_bytes | io.write_bytes | ||
| vm.io.write_bytes_sec | io.write_bytes_sec | ||
| vm.io.write_ops | io.write_ops | ||
| vm.io.write_ops_sec | io.write_ops_sec | ||
| vm_network_check_enable |
True Creates 16 network metrics per NIC per virtual machine. | vm.net.in_bytes | net.in_bytes |
| vm.net.in_bytes_sec | net.in_bytes_sec | ||
| vm.net.in_packets | net.in_packets | ||
| vm.net.in_packets_sec | net.in_packets_sec | ||
| vm.net.out_bytes | net.out_bytes | ||
| vm.net.out_bytes_sec | net.out_bytes_sec | ||
| vm.net.out_packets | net.out_packets | ||
| vm.net.out_packets_sec | net.out_packets_sec | ||
| vm_ping_check_enable | True | vm.ping_status | ping_status |
| vm_extended_disks_check_enable |
True Creates 6 metrics per device per virtual machine. | vm.disk.allocation | disk.allocation |
| vm.disk.capacity | disk.capacity | ||
| vm.disk.physical | disk.physical | ||
|
True Creates 6 aggregate metrics per virtual machine. | vm.disk.allocation_total | disk.allocation_total | |
| vm.disk.capacity_total | disk.capacity.total | ||
| vm.disk.physical_total | disk.physical_total | ||
| vm_disks_check_enable vm_extended_disks_check_enable |
True Creates 20 aggregate metrics per virtual machine. | vm.io.errors_total | io.errors_total |
| vm.io.errors_total_sec | io.errors_total_sec | ||
| vm.io.read_bytes_total | io.read_bytes_total | ||
| vm.io.read_bytes_total_sec | io.read_bytes_total_sec | ||
| vm.io.read_ops_total | io.read_ops_total | ||
| vm.io.read_ops_total_sec | io.read_ops_total_sec | ||
| vm.io.write_bytes_total | io.write_bytes_total | ||
| vm.io.write_bytes_total_sec | io.write_bytes_total_sec | ||
| vm.io.write_ops_total | io.write_ops_total | ||
| vm.io.write_ops_total_sec | io.write_ops_total_sec |
12.1.2.5.1.1 Configuring the libvirt metrics using the tuning knobs #
Use the following steps to configure the tuning knobs for the libvirt plugin metrics.
Log in to the Cloud Lifecycle Manager.
Edit the following file:
~/openstack/my_cloud/config/nova/libvirt-monitoring.yml
Change the value for each tuning knob to the desired setting,
Trueif you want the metrics created andFalseif you want them removed. Refer to the table above for which metrics are controlled by each tuning knob.vm_cpu_check_enable: <true or false> vm_disks_check_enable: <true or false> vm_extended_disks_check_enable: <true or false> vm_network_check_enable: <true or false> vm_ping_check_enable: <true or false>
Commit your configuration to the local Git repository (see Book “Installing with Cloud Lifecycle Manager”, Chapter 10 “Using Git for Configuration Management”), as follows:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "configuring libvirt plugin tuning knobs"Update your deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the Nova reconfigure playbook to implement the changes:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts nova-reconfigure.yml
Note
If you modify either of the following files, then the monasca tuning parameters should be adjusted to handle a higher load on the system.
~/openstack/my_cloud/config/nova/libvirt-monitoring.yml ~/openstack/my_cloud/config/neutron/monasca_ovs_plugin.yaml.j2
Tuning parameters are located in
~/openstack/my_cloud/config/monasca/configuration.yml.
The parameter monasca_tuning_selector_override should be
changed to the extra-large setting.
12.1.2.5.2 OVS plugin metric tuning knobs #
The following metrics are added as part of the OVS plugin:
Note
For a description of each of these metrics, see Section 12.1.4.16, “Open vSwitch (OVS) Metrics”.
| Tuning Knob | Default Setting | Admin Metric Name | Project Metric Name |
|---|---|---|---|
| use_rate_metrics | False | ovs.vrouter.in_bytes_sec | vrouter.in_bytes_sec |
| ovs.vrouter.in_packets_sec | vrouter.in_packets_sec | ||
| ovs.vrouter.out_bytes_sec | vrouter.out_bytes_sec | ||
| ovs.vrouter.out_packets_sec | vrouter.out_packets_sec | ||
| use_absolute_metrics | True | ovs.vrouter.in_bytes | vrouter.in_bytes |
| ovs.vrouter.in_packets | vrouter.in_packets | ||
| ovs.vrouter.out_bytes | vrouter.out_bytes | ||
| ovs.vrouter.out_packets | vrouter.out_packets | ||
| use_health_metrics with use_rate_metrics | False | ovs.vrouter.in_dropped_sec | vrouter.in_dropped_sec |
| ovs.vrouter.in_errors_sec | vrouter.in_errors_sec | ||
| ovs.vrouter.out_dropped_sec | vrouter.out_dropped_sec | ||
| ovs.vrouter.out_errors_sec | vrouter.out_errors_sec | ||
| use_health_metrics with use_absolute_metrics | False | ovs.vrouter.in_dropped | vrouter.in_dropped |
| ovs.vrouter.in_errors | vrouter.in_errors | ||
| ovs.vrouter.out_dropped | vrouter.out_dropped | ||
| ovs.vrouter.out_errors | vrouter.out_errors |
12.1.2.5.2.1 Configuring the OVS metrics using the tuning knobs #
Use the following steps to configure the tuning knobs for the libvirt plugin metrics.
Log in to the Cloud Lifecycle Manager.
Edit the following file:
~/openstack/my_cloud/config/neutron/monasca_ovs_plugin.yaml.j2
Change the value for each tuning knob to the desired setting,
Trueif you want the metrics created andFalseif you want them removed. Refer to the table above for which metrics are controlled by each tuning knob.init_config: use_absolute_metrics: <true or false> use_rate_metrics: <true or false> use_health_metrics: <true or false>
Commit your configuration to the local Git repository (see Book “Installing with Cloud Lifecycle Manager”, Chapter 10 “Using Git for Configuration Management”), as follows:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "configuring OVS plugin tuning knobs"Update your deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the Neutron reconfigure playbook to implement the changes:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts neutron-reconfigure.yml
12.1.3 Integrating HipChat, Slack, and JIRA #
Monasca, the HPE Helion OpenStack monitoring and notification service, includes three default notification methods, email, PagerDuty, and webhook. Monasca also supports three other notification plugins which allow you to send notifications to HipChat, Slack, and JIRA. Unlike the default notification methods, the additional notification plugins must be manually configured.
This guide details the steps to configure each of the three non-default notification plugins. This guide also assumes that your cloud is fully deployed and functional.
12.1.3.1 Configuring the HipChat Plugin #
To configure the HipChat plugin you will need the following four pieces of information from your HipChat system.
The URL of your HipChat system.
A token providing permission to send notifications to your HipChat system.
The ID of the HipChat room you wish to send notifications to.
A HipChat user account. This account will be used to authenticate any incoming notifications from your HPE Helion OpenStack cloud.
Obtain a token
Use the following instructions to obtain a token from your Hipchat system.
Log in to HipChat as the user account that will be used to authenticate the notifications.
Navigate to the following URL:
https://<your_hipchat_system>/account/api. Replace<your_hipchat_system>with the fully-qualified-domain-name of your HipChat system.Select the Create token option. Ensure that the token has the "SendNotification" attribute.
Obtain a room ID
Use the following instructions to obtain the ID of a HipChat room.
Log in to HipChat as the user account that will be used to authenticate the notifications.
Select My account from the application menu.
Select the Rooms tab.
Select the room that you want your notifications sent to.
Look for the API ID field in the room information. This is the room ID.
Create HipChat notification type
Use the following instructions to create a HipChat notification type.
Begin by obtaining the API URL for the HipChat room that you wish to send notifications to. The format for a URL used to send notifications to a room is as follows:
/v2/room/{room_id_or_name}/notificationUse the Monasca API to create a new notification method. The following example demonstrates how to create a HipChat notification type named MyHipChatNotification, for room ID 13, using an example API URL and auth token.
ardana >monasca notification-create NAME TYPE ADDRESSardana >monasca notification-create MyHipChatNotification HIPCHAT https://hipchat.hpe.net/v2/room/13/notification?auth_token=1234567890The preceding example creates a notification type with the following characteristics
NAME: MyHipChatNotification
TYPE: HIPCHAT
ADDRESS: https://hipchat.hpe.net/v2/room/13/notification
auth_token: 1234567890
Note
The Horizon dashboard can also be used to create a HipChat notification type.
12.1.3.2 Configuring the Slack Plugin #
Configuring a Slack notification type requires four pieces of information from your Slack system.
Slack server URL
Authentication token
Slack channel
A Slack user account. This account will be used to authenticate incoming notifications to Slack.
Identify a Slack channel
Log in to your Slack system as the user account that will be used to authenticate the notifications to Slack.
In the left navigation panel, under the CHANNELS section locate the channel that you wish to receive the notifications. The instructions that follow will use the example channel #general.
Create a Slack token
Log in to your Slack system as the user account that will be used to authenticate the notifications to Slack
Navigate to the following URL: https://api.slack.com/docs/oauth-test-tokens
Select the Create token button.
Create a Slack notification type
Begin by identifying the structure of the API call to be used by your notification method. The format for a call to the Slack Web API is as follows:
https://slack.com/api/METHODYou can authenticate a Web API request by using the token that you created in the previous Create a Slack Tokensection. Doing so will result in an API call that looks like the following.
https://slack.com/api/METHOD?token=auth_tokenYou can further refine your call by specifying the channel that the message will be posted to. Doing so will result in an API call that looks like the following.
https://slack.com/api/METHOD?token=AUTH_TOKEN&channel=#channelThe following example uses the
chat.postMessagemethod, the token1234567890, and the channel#general.https://slack.com/api/chat.postMessage?token=1234567890&channel=#general
Find more information on the Slack Web API here: https://api.slack.com/web
Use the CLI on your Cloud Lifecycle Manager to create a new Slack notification type, using the API call that you created in the preceding step. The following example creates a notification type named MySlackNotification, using token 1234567890, and posting to channel #general.
ardana >monasca notification-create MySlackNotification SLACK https://slack.com/api/chat.postMessage?token=1234567890&channel=#general
Note
Notification types can also be created in the Horizon dashboard.
12.1.3.3 Configuring the JIRA Plugin #
Configuring the JIRA plugin requires three pieces of information from your JIRA system.
The URL of your JIRA system.
Username and password of a JIRA account that will be used to authenticate the notifications.
The name of the JIRA project that the notifications will be sent to.
Create JIRA notification type
You will configure the Monasca service to send notifications to a particular JIRA project. You must also configure JIRA to create new issues for each notification it receives to this project, however, that configuration is outside the scope of this document.
The Monasca JIRA notification plugin supports only the following two JIRA issue fields.
PROJECT. This is the only supported “mandatory” JIRA issue field.
COMPONENT. This is the only supported “optional” JIRA issue field.
The JIRA issue type that your notifications will create may only be configured with the "Project" field as mandatory. If your JIRA issue type has any other mandatory fields, the Monasca plugin will not function correctly. Currently, the Monasca plugin only supports the single optional "component" field.
Creating the JIRA notification type requires a few more steps than other notification types covered in this guide. Because the Python and YAML files for this notification type are not yet included in HPE Helion OpenStack 8, you must perform the following steps to manually retrieve and place them on your Cloud Lifecycle Manager.
Configure the JIRA plugin by adding the following block to the
/etc/monasca/notification.yamlfile, under thenotification_typessection, and adding the username and password of the JIRA account used for the notifications to the respective sections.plugins: - monasca_notification.plugins.jira_notifier:JiraNotifier jira: user: password: timeout: 60After adding the necessary block, the
notification_typessection should look like the following example. Note that you must also add the username and password for the JIRA user related to the notification type.notification_types: plugins: - monasca_notification.plugins.jira_notifier:JiraNotifier jira: user: password: timeout: 60 webhook: timeout: 5 pagerduty: timeout: 5 url: "https://events.pagerduty.com/generic/2010-04-15/create_event.json"Create the JIRA notification type. The following command example creates a JIRA notification type named
MyJiraNotification, in the JIRA projectHISO.ardana >monasca notification-create MyJiraNotification JIRA https://jira.hpcloud.net/?project=HISOThe following command example creates a JIRA notification type named
MyJiraNotification, in the JIRA projectHISO, and adds the optional component field with a value ofkeystone.ardana >monasca notification-create MyJiraNotification JIRA https://jira.hpcloud.net/?project=HISO&component=keystoneNote
There is a slash (
/) separating the URL path and the query string. The slash is required if you have a query parameter without a path parameter.Note
Notification types may also be created in the Horizon dashboard.
12.1.4 Alarm Metrics #
You can use the available metrics to create custom alarms to further monitor your cloud infrastructure and facilitate autoscaling features.
For details on how to create customer alarms using the Operations Console, see Book “Operations Console”, Chapter 1 “Alarm Definition”.
12.1.4.1 Apache Metrics #
A list of metrics associated with the Apache service.
| Metric Name | Dimensions | Description |
|---|---|---|
| apache.net.hits |
hostname service=apache component=apache | Total accesses |
| apache.net.kbytes_sec |
hostname service=apache component=apache | Total Kbytes per second |
| apache.net.requests_sec |
hostname service=apache component=apache | Total accesses per second |
| apache.net.total_kbytes |
hostname service=apache component=apache | Total Kbytes |
| apache.performance.busy_worker_count |
hostname service=apache component=apache | The number of workers serving requests |
| apache.performance.cpu_load_perc |
hostname service=apache component=apache |
The current percentage of CPU used by each worker and in total by all workers combined |
| apache.performance.idle_worker_count |
hostname service=apache component=apache | The number of idle workers |
| apache.status |
apache_port hostname service=apache component=apache | Status of Apache port |
12.1.4.2 Ceilometer Metrics #
A list of metrics associated with the Ceilometer service.
| Metric Name | Dimensions | Description |
|---|---|---|
| disk.total_space_mb_agg |
aggregation_period=hourly, host=all, project_id=all | Total space of disk |
| disk.total_used_space_mb_agg |
aggregation_period=hourly, host=all, project_id=all | Total used space of disk |
| swiftlm.diskusage.rate_agg |
aggregation_period=hourly, host=all, project_id=all | |
| swiftlm.diskusage.val.avail_agg |
aggregation_period=hourly, host, project_id=all | |
| swiftlm.diskusage.val.size_agg |
aggregation_period=hourly, host, project_id=all | |
| image |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=image, source=openstack | Existence of the image |
| image.delete |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=image, source=openstack | Delete operation on this image |
| image.size |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=B, source=openstack | Size of the uploaded image |
| image.update |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=image, source=openstack | Update operation on this image |
| image.upload |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=image, source=openstack | Upload operation on this image |
| instance |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=instance, source=openstack | Existence of instance |
| disk.ephemeral.size |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=GB, source=openstack | Size of ephemeral disk on this instance |
| disk.root.size |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=GB, source=openstack | Size of root disk on this instance |
| memory |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=MB, source=openstack | Size of memory on this instance |
| ip.floating |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=ip, source=openstack | Existence of IP |
| ip.floating.create |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=ip, source=openstack | Create operation on this fip |
| ip.floating.update |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=ip, source=openstack | Update operation on this fip |
| mem.total_mb_agg |
aggregation_period=hourly, host=all, project_id=all | Total space of memory |
| mem.usable_mb_agg |
aggregation_period=hourly, host=all, project_id=all | Available space of memory |
| network |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=network, source=openstack | Existence of network |
| network.create |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=network, source=openstack | Create operation on this network |
| network.update |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=network, source=openstack | Update operation on this network |
| network.delete |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=network, source=openstack | Delete operation on this network |
| port |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=port, source=openstack | Existence of port |
| port.create |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=port, source=openstack | Create operation on this port |
| port.delete |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=port, source=openstack | Delete operation on this port |
| port.update |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=port, source=openstack | Update operation on this port |
| router |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=router, source=openstack | Existence of router |
| router.create |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=router, source=openstack | Create operation on this router |
| router.delete |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=router, source=openstack | Delete operation on this router |
| router.update |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=router, source=openstack | Update operation on this router |
| snapshot |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=snapshot, source=openstack | Existence of the snapshot |
| snapshot.create.end |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=snapshot, source=openstack | Create operation on this snapshot |
| snapshot.delete.end |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=snapshot, source=openstack | Delete operation on this snapshot |
| snapshot.size |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=GB, source=openstack | Size of this snapshot |
| subnet |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=subnet, source=openstack | Existence of the subnet |
| subnet.create |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=subnet, source=openstack | Create operation on this subnet |
| subnet.delete |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=subnet, source=openstack | Delete operation on this subnet |
| subnet.update |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=subnet, source=openstack | Update operation on this subnet |
| vcpus |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=vcpus, source=openstack | Number of virtual CPUs allocated to the instance |
| vcpus_agg |
aggregation_period=hourly, host=all, project_id | Number of vcpus used by a project |
| volume |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=volume, source=openstack | Existence of the volume |
| volume.create.end |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=volume, source=openstack | Create operation on this volume |
| volume.delete.end |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=volume, source=openstack | Delete operation on this volume |
| volume.resize.end |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=volume, source=openstack | Resize operation on this volume |
| volume.size |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=GB, source=openstack | Size of this volume |
| volume.update.end |
user_id, region, resource_id, datasource=ceilometer, project_id, type=delta, unit=volume, source=openstack | Update operation on this volume |
| storage.objects |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=object, source=openstack | Number of objects |
| storage.objects.size |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=B, source=openstack | Total size of stored objects |
| storage.objects.containers |
user_id, region, resource_id, datasource=ceilometer, project_id, type=gauge, unit=container, source=openstack | Number of containers |
12.1.4.3 Cinder Metrics #
A list of metrics associated with the Cinder service.
| Metric Name | Dimensions | Description |
|---|---|---|
| cinderlm.cinder.backend.physical.list |
service=block-storage, hostname, cluster, cloud_name, control_plane, component, backends | List of physical backends |
| cinderlm.cinder.backend.total.avail |
service=block-storage, hostname, cluster, cloud_name, control_plane, component, backendname | Total available capacity metric per backend |
| cinderlm.cinder.backend.total.size |
service=block-storage, hostname, cluster, cloud_name, control_plane, component, backendname | Total capacity metric per backend |
| cinderlm.cinder.cinder_services |
service=block-storage, hostname, cluster, cloud_name, control_plane, component | Status of a cinder-volume service |
| cinderlm.hp_hardware.hpssacli.logical_drive |
service=block-storage, hostname, cluster, cloud_name, control_plane, component, sub_component, logical_drive, controller_slot, array The HPE Smart Storage Administrator (HPE SSA) CLI component will have to be installed for SSACLI status to be reported. To download and install the SSACLI utility to enable management of disk controllers, please refer to: https://support.hpe.com/hpsc/swd/public/detail?swItemId=MTX_3d16386b418a443388c18da82f | Status of a logical drive |
| cinderlm.hp_hardware.hpssacli.physical_drive |
service=block-storage, hostname, cluster, cloud_name, control_plane, component, box, bay, controller_slot | Status of a logical drive |
| cinderlm.hp_hardware.hpssacli.smart_array |
service=block-storage, hostname, cluster, cloud_name, control_plane, component, sub_component, model | Status of smart array |
| cinderlm.hp_hardware.hpssacli.smart_array.firmware |
service=block-storage, hostname, cluster, cloud_name, control_plane, component, model | Checks firmware version |
12.1.4.4 Compute Metrics #
A list of metrics associated with the Compute service.
| Metric Name | Dimensions | Description |
|---|---|---|
| nova.heartbeat |
service=compute cloud_name hostname component control_plane cluster |
Checks that all services are running heartbeats (uses nova user and to list services then sets up checks for each. For example, nova-scheduler, nova-conductor, nova-consoleauth, nova-compute) |
| nova.vm.cpu.total_allocated |
service=compute hostname component control_plane cluster | Total CPUs allocated across all VMs |
| nova.vm.disk.total_allocated_gb |
service=compute hostname component control_plane cluster | Total Gbytes of disk space allocated to all VMs |
| nova.vm.mem.total_allocated_mb |
service=compute hostname component control_plane cluster | Total Mbytes of memory allocated to all VMs |
12.1.4.5 Crash Metrics #
A list of metrics associated with the Crash service.
| Metric Name | Dimensions | Description |
|---|---|---|
| crash.dump_count |
service=system hostname cluster | Number of crash dumps found |
12.1.4.6 Directory Metrics #
A list of metrics associated with the Directory service.
| Metric Name | Dimensions | Description |
|---|---|---|
| directory.files_count |
service hostname path | Total number of files under a specific directory path |
| directory.size_bytes |
service hostname path | Total size of a specific directory path |
12.1.4.7 Elasticsearch Metrics #
A list of metrics associated with the Elasticsearch service.
| Metric Name | Dimensions | Description |
|---|---|---|
| elasticsearch.active_primary_shards |
service=logging url hostname |
Indicates the number of primary shards in your cluster. This is an aggregate total across all indices. |
| elasticsearch.active_shards |
service=logging url hostname |
Aggregate total of all shards across all indices, which includes replica shards. |
| elasticsearch.cluster_status |
service=logging url hostname |
Cluster health status. |
| elasticsearch.initializing_shards |
service=logging url hostname |
The count of shards that are being freshly created. |
| elasticsearch.number_of_data_nodes |
service=logging url hostname |
Number of data nodes. |
| elasticsearch.number_of_nodes |
service=logging url hostname |
Number of nodes. |
| elasticsearch.relocating_shards |
service=logging url hostname |
Shows the number of shards that are currently moving from one node to another node. |
| elasticsearch.unassigned_shards |
service=logging url hostname |
The number of unassigned shards from the master node. |
12.1.4.8 HAProxy Metrics #
A list of metrics associated with the HAProxy service.
| Metric Name | Dimensions | Description |
|---|---|---|
| haproxy.backend.bytes.in_rate | ||
| haproxy.backend.bytes.out_rate | ||
| haproxy.backend.denied.req_rate | ||
| haproxy.backend.denied.resp_rate | ||
| haproxy.backend.errors.con_rate | ||
| haproxy.backend.errors.resp_rate | ||
| haproxy.backend.queue.current | ||
| haproxy.backend.response.1xx | ||
| haproxy.backend.response.2xx | ||
| haproxy.backend.response.3xx | ||
| haproxy.backend.response.4xx | ||
| haproxy.backend.response.5xx | ||
| haproxy.backend.response.other | ||
| haproxy.backend.session.current | ||
| haproxy.backend.session.limit | ||
| haproxy.backend.session.pct | ||
| haproxy.backend.session.rate | ||
| haproxy.backend.warnings.redis_rate | ||
| haproxy.backend.warnings.retr_rate | ||
| haproxy.frontend.bytes.in_rate | ||
| haproxy.frontend.bytes.out_rate | ||
| haproxy.frontend.denied.req_rate | ||
| haproxy.frontend.denied.resp_rate | ||
| haproxy.frontend.errors.req_rate | ||
| haproxy.frontend.requests.rate | ||
| haproxy.frontend.response.1xx | ||
| haproxy.frontend.response.2xx | ||
| haproxy.frontend.response.3xx | ||
| haproxy.frontend.response.4xx | ||
| haproxy.frontend.response.5xx | ||
| haproxy.frontend.response.other | ||
| haproxy.frontend.session.current | ||
| haproxy.frontend.session.limit | ||
| haproxy.frontend.session.pct | ||
| haproxy.frontend.session.rate |
12.1.4.9 HTTP Check Metrics #
A list of metrics associated with the HTTP Check service:
Table 12.2: HTTP Check Metrics #
| Metric Name | Dimensions | Description |
|---|---|---|
| http_response_time |
url hostname service component | The response time in seconds of the http endpoint call. |
| http_status |
url hostname service | The status of the http endpoint call (0 = success, 1 = failure). |
For each component and HTTP metric name there are two separate metrics reported, one for the local URL and another for the virtual IP (VIP) URL:
Table 12.3: HTTP Metric Components #
| Component | Dimensions | Description |
|---|---|---|
| account-server |
service=object-storage component=account-server url | swift account-server http endpoint status and response time |
| barbican-api |
service=key-manager component=barbican-api url | barbican-api http endpoint status and response time |
| ceilometer-api |
service=telemetry component=ceilometer-api url | ceilometer-api http endpoint status and response time |
| cinder-api |
service=block-storage component=cinder-api url | cinder-api http endpoint status and response time |
| container-server |
service=object-storage component=container-server url | swift container-server http endpoint status and response time |
| designate-api |
service=dns component=designate-api url | designate-api http endpoint status and response time |
| freezer-api |
service=backup component=freezer-api url | freezer-api http endpoint status and response time |
| glance-api |
service=image-service component=glance-api url | glance-api http endpoint status and response time |
| glance-registry |
service=image-service component=glance-registry url | glance-registry http endpoint status and response time |
| heat-api |
service=orchestration component=heat-api url | heat-api http endpoint status and response time |
| heat-api-cfn |
service=orchestration component=heat-api-cfn url | heat-api-cfn http endpoint status and response time |
| heat-api-cloudwatch |
service=orchestration component=heat-api-cloudwatch url | heat-api-cloudwatch http endpoint status and response time |
| ardana-ux-services |
service=ardana-ux-services component=ardana-ux-services url | ardana-ux-services http endpoint status and response time |
| horizon |
service=web-ui component=horizon url | horizon http endpoint status and response time |
| keystone-api |
service=identity-service component=keystone-api url | keystone-api http endpoint status and response time |
| monasca-api |
service=monitoring component=monasca-api url | monasca-api http endpoint status |
| monasca-persister |
service=monitoring component=monasca-persister url | monasca-persister http endpoint status |
| neutron-server |
service=networking component=neutron-server url | neutron-server http endpoint status and response time |
| neutron-server-vip |
service=networking component=neutron-server-vip url | neutron-server-vip http endpoint status and response time |
| nova-api |
service=compute component=nova-api url | nova-api http endpoint status and response time |
| nova-vnc |
service=compute component=nova-vnc url | nova-vnc http endpoint status and response time |
| object-server |
service=object-storage component=object-server url | object-server http endpoint status and response time |
| object-storage-vip |
service=object-storage component=object-storage-vip url | object-storage-vip http endpoint status and response time |
| octavia-api |
service=octavia component=octavia-api url | octavia-api http endpoint status and response time |
| ops-console-web |
service=ops-console component=ops-console-web url | ops-console-web http endpoint status and response time |
| proxy-server |
service=object-storage component=proxy-server url | proxy-server http endpoint status and response time |
12.1.4.10 Kafka Metrics #
A list of metrics associated with the Kafka service.
| Metric Name | Dimensions | Description |
|---|---|---|
| kafka.consumer_lag |
topic service component=kafka consumer_group hostname | Hostname consumer offset lag from broker offset |
12.1.4.11 Libvirt Metrics #
Note
For information on how to turn these metrics on and off using the tuning knobs, see Section 12.1.2.5.1, “Libvirt plugin metric tuning knobs”.
A list of metrics associated with the Libvirt service.
Table 12.4: Tunable Libvirt Metrics #
| Admin Metric Name | Project Metric Name | Dimensions | Description |
|---|---|---|---|
| vm.cpu.time_ns | cpu.time_ns |
zone service resource_id hostname component | Cumulative CPU time (in ns) |
| vm.cpu.utilization_norm_perc | cpu.utilization_norm_perc |
zone service resource_id hostname component | Normalized CPU utilization (percentage) |
| vm.cpu.utilization_perc | cpu.utilization_perc |
zone service resource_id hostname component | Overall CPU utilization (percentage) |
| vm.io.errors | io.errors |
zone service resource_id hostname component | Overall disk I/O errors |
| vm.io.errors_sec | io.errors_sec |
zone service resource_id hostname component | Disk I/O errors per second |
| vm.io.read_bytes | io.read_bytes |
zone service resource_id hostname component | Disk I/O read bytes value |
| vm.io.read_bytes_sec | io.read_bytes_sec |
zone service resource_id hostname component | Disk I/O read bytes per second |
| vm.io.read_ops | io.read_ops |
zone service resource_id hostname component | Disk I/O read operations value |
| vm.io.read_ops_sec | io.read_ops_sec |
zone service resource_id hostname component | Disk I/O write operations per second |
| vm.io.write_bytes | io.write_bytes |
zone service resource_id hostname component | Disk I/O write bytes value |
| vm.io.write_bytes_sec | io.write_bytes_sec |
zone service resource_id hostname component | Disk I/O write bytes per second |
| vm.io.write_ops | io.write_ops |
zone service resource_id hostname component | Disk I/O write operations value |
| vm.io.write_ops_sec | io.write_ops_sec |
zone service resource_id hostname component | Disk I/O write operations per second |
| vm.net.in_bytes | net.in_bytes |
zone service resource_id hostname component device port_id | Network received total bytes |
| vm.net.in_bytes_sec | net.in_bytes_sec |
zone service resource_id hostname component device port_id | Network received bytes per second |
| vm.net.in_packets | net.in_packets |
zone service resource_id hostname component device port_id | Network received total packets |
| vm.net.in_packets_sec | net.in_packets_sec |
zone service resource_id hostname component device port_id | Network received packets per second |
| vm.net.out_bytes | net.out_bytes |
zone service resource_id hostname component device port_id | Network transmitted total bytes |
| vm.net.out_bytes_sec | net.out_bytes_sec |
zone service resource_id hostname component device port_id | Network transmitted bytes per second |
| vm.net.out_packets | net.out_packets |
zone service resource_id hostname component device port_id | Network transmitted total packets |
| vm.net.out_packets_sec | net.out_packets_sec |
zone service resource_id hostname component device port_id | Network transmitted packets per second |
| vm.ping_status | ping_status |
zone service resource_id hostname component | 0 for ping success, 1 for ping failure |
| vm.disk.allocation | disk.allocation |
zone service resource_id hostname component | Total Disk allocation for a device |
| vm.disk.allocation_total | disk.allocation_total |
zone service resource_id hostname component | Total Disk allocation across devices for instances |
| vm.disk.capacity | disk.capacity |
zone service resource_id hostname component | Total Disk capacity for a device |
| vm.disk.capacity_total | disk.capacity_total |
zone service resource_id hostname component | Total Disk capacity across devices for instances |
| vm.disk.physical | disk.physical |
zone service resource_id hostname component | Total Disk usage for a device |
| vm.disk.physical_total | disk.physical_total |
zone service resource_id hostname component | Total Disk usage across devices for instances |
| vm.io.errors_total | io.errors_total |
zone service resource_id hostname component | Total Disk I/O errors across all devices |
| vm.io.errors_total_sec | io.errors_total_sec |
zone service resource_id hostname component | Total Disk I/O errors per second across all devices |
| vm.io.read_bytes_total | io.read_bytes_total |
zone service resource_id hostname component | Total Disk I/O read bytes across all devices |
| vm.io.read_bytes_total_sec | io.read_bytes_total_sec |
zone service resource_id hostname component | Total Disk I/O read bytes per second across devices |
| vm.io.read_ops_total | io.read_ops_total |
zone service resource_id hostname component | Total Disk I/O read operations across all devices |
| vm.io.read_ops_total_sec | io.read_ops_total_sec |
zone service resource_id hostname component | Total Disk I/O read operations across all devices per sec |
| vm.io.write_bytes_total | io.write_bytes_total |
zone service resource_id hostname component | Total Disk I/O write bytes across all devices |
| vm.io.write_bytes_total_sec | io.write_bytes_total_sec |
zone service resource_id hostname component | Total Disk I/O Write bytes per second across devices |
| vm.io.write_ops_total | io.write_ops_total |
zone service resource_id hostname component | Total Disk I/O write operations across all devices |
| vm.io.write_ops_total_sec | io.write_ops_total_sec |
zone service resource_id hostname component | Total Disk I/O write operations across all devices per sec |
These metrics in libvirt are always enabled and cannot be disabled using the tuning knobs.
Table 12.5: Untunable Libvirt Metrics #
| Admin Metric Name | Project Metric Name | Dimensions | Description |
|---|---|---|---|
| vm.host_alive_status | host_alive_status |
zone service resource_id hostname component |
-1 for no status, 0 for Running / OK, 1 for Idle / blocked, 2 for Paused, 3 for Shutting down, 4 for Shut off or Nova suspend 5 for Crashed, 6 for Power management suspend (S3 state) |
| vm.mem.free_mb | mem.free_mb |
cluster service hostname | Free memory in Mbytes |
| vm.mem.free_perc | mem.free_perc |
cluster service hostname | Percent of memory free |
| vm.mem.resident_mb |
cluster service hostname | Total memory used on host, an Operations-only metric | |
| vm.mem.swap_used_mb | mem.swap_used_mb |
cluster service hostname | Used swap space in Mbytes |
| vm.mem.total_mb | mem.total_mb |
cluster service hostname | Total memory in Mbytes |
| vm.mem.used_mb | mem.used_mb |
cluster service hostname | Used memory in Mbytes |
12.1.4.12 Monitoring Metrics #
A list of metrics associated with the Monitoring service.
| Metric Name | Dimensions | Description |
|---|---|---|
| alarm-state-transitions-added-to-batch-counter |
service=monitoring url hostname component=monasca-persister | |
| jvm.memory.total.max |
service=monitoring url hostname component | Maximum JVM overall memory |
| jvm.memory.total.used |
service=monitoring url hostname component | Used JVM overall memory |
| metrics-added-to-batch-counter |
service=monitoring url hostname component=monasca-persister | |
| metrics.published |
service=monitoring url hostname component=monasca-api | Total number of published metrics |
| monasca.alarms_finished_count |
hostname component=monasca-notification service=monitoring | Total number of alarms received |
| monasca.checks_running_too_long |
hostname component=monasca-agent service=monitoring cluster | Only emitted when collection time for a check is too long |
| monasca.collection_time_sec |
hostname component=monasca-agent service=monitoring cluster | Collection time in monasca-agent |
| monasca.config_db_time |
hostname component=monasca-notification service=monitoring | |
| monasca.created_count |
hostname component=monasca-notification service=monitoring | Number of notifications created |
| monasca.invalid_type_count |
hostname component=monasca-notification service=monitoring | Number of notifications with invalid type |
| monasca.log.in_bulks_rejected |
hostname component=monasca-log-api service=monitoring version | |
| monasca.log.in_logs |
hostname component=monasca-log-api service=monitoring version | |
| monasca.log.in_logs_bytes |
hostname component=monasca-log-api service=monitoring version | |
| monasca.log.in_logs_rejected |
hostname component=monasca-log-api service=monitoring version | |
| monasca.log.out_logs |
hostname component=monasca-log-api service=monitoring | |
| monasca.log.out_logs_lost |
hostname component=monasca-log-api service=monitoring | |
| monasca.log.out_logs_truncated_bytes |
hostname component=monasca-log-api service=monitoring | |
| monasca.log.processing_time_ms |
hostname component=monasca-log-api service=monitoring | |
| monasca.log.publish_time_ms |
hostname component=monasca-log-api service=monitoring | |
| monasca.thread_count |
service=monitoring process_name hostname component | Number of threads monasca is using |
| raw-sql.time.avg |
service=monitoring url hostname component | Average raw sql query time |
| raw-sql.time.max |
service=monitoring url hostname component | Max raw sql query time |
12.1.4.13 Monasca Aggregated Metrics #
A list of the aggregated metrics associated with the Monasca Transform feature.
| Metric Name | For | Dimensions | Description |
|---|---|---|---|
| cpu.utilized_logical_cores_agg | Compute summary |
aggregation_period: hourly host: all or <hostname> project_id: all |
Utilized physical host cpu core capacity for one or all hosts by time interval (defaults to a hour). Available as total or per host |
| cpu.total_logical_cores_agg | Compute summary |
aggregation_period: hourly host: all or <hostname> project_id: all |
Total physical host cpu core capacity for one or all hosts by time interval (defaults to a hour) Available as total or per host |
| mem.total_mb_agg | Compute summary |
aggregation_period: hourly host: all project_id: all |
Total physical host memory capacity by time interval (defaults to a hour) |
| mem.usable_mb_agg | Compute summary |
aggregation_period: hourly host: all project_id: all | Usable physical host memory capacity by time interval (defaults to a hour) |
| disk.total_used_space_mb_agg | Compute summary |
aggregation_period: hourly host: all project_id: all |
Utilized physical host disk capacity by time interval (defaults to a hour) |
| disk.total_space_mb_agg | Compute summary |
aggregation_period: hourly host: all project_id: all | Total physical host disk capacity by time interval (defaults to a hour) |
| nova.vm.cpu.total_allocated_agg | Compute summary |
aggregation_period: hourly host: all project_id: all |
CPUs allocated across all virtual machines by time interval (defaults to a hour) |
| vcpus_agg | Compute summary |
aggregation_period: hourly host: all project_id: all or <project ID> |
Virtual CPUs allocated capacity for virtual machines of one or all projects by time interval (defaults to a hour) Available as total or per host |
| nova.vm.mem.total_allocated_mb_agg | Compute summary |
aggregation_period: hourly host: all project_id: all |
Memory allocated to all virtual machines by time interval (defaults to a hour) |
| vm.mem.used_mb_agg | Compute summary |
aggregation_period: hourly host: all project_id: all or <project ID> |
Memory utilized by virtual machines of one or all projects by time interval (defaults to an hour) Available as total or per host |
| vm.mem.total_mb_agg | Compute summary |
aggregation_period: hourly host: all project_id: all or <project ID> |
Memory allocated to virtual machines of one or all projects by time interval (defaults to an hour) Available as total or per host |
| vm.cpu.utilization_perc_agg | Compute summary |
aggregation_period: hourly host: all project_id: all or <project ID> |
CPU utilized by all virtual machines by project by time interval (defaults to an hour) |
| nova.vm.disk.total_allocated_gb_agg | Compute summary |
aggregation_period: hourly host: all project_id: all |
Disk space allocated to all virtual machines by time interval (defaults to an hour) |
| vm.disk.allocation_agg | Compute summary |
aggregation_period: hourly host: all project_id: all or <project ID> |
Disk allocation for virtual machines of one or all projects by time interval (defaults to a hour) Available as total or per host |
| swiftlm.diskusage.val.size_agg | Object Storage summary |
aggregation_period: hourly host: all or <hostname> project_id: all |
Total available object storage capacity by time interval (defaults to a hour) Available as total or per host |
| swiftlm.diskusage.val.avail_agg | Object Storage summary |
aggregation_period: hourly host: all or <hostname> project_id: all |
Remaining object storage capacity by time interval (defaults to a hour) Available as total or per host |
| swiftlm.diskusage.rate_agg | Object Storage summary |
aggregation_period: hourly host: all project_id: all |
Rate of change of object storage usage by time interval (defaults to a hour) |
| storage.objects.size_agg | Object Storage summary |
aggregation_period: hourly host: all project_id: all |
Used object storage capacity by time interval (defaults to a hour) |
12.1.4.14 MySQL Metrics #
A list of metrics associated with the MySQL service.
| Metric Name | Dimensions | Description |
|---|---|---|
| mysql.innodb.buffer_pool_free |
hostname mode service=mysql |
The number of free pages, in bytes. This value is calculated by
multiplying |
| mysql.innodb.buffer_pool_total |
hostname mode service=mysql |
The total size of buffer pool, in bytes. This value is calculated by
multiplying |
| mysql.innodb.buffer_pool_used |
hostname mode service=mysql |
The number of used pages, in bytes. This value is calculated by
subtracting |
| mysql.innodb.current_row_locks |
hostname mode service=mysql |
Corresponding to current row locks of the server status variable. |
| mysql.innodb.data_reads |
hostname mode service=mysql |
Corresponding to |
| mysql.innodb.data_writes |
hostname mode service=mysql |
Corresponding to |
| mysql.innodb.mutex_os_waits |
hostname mode service=mysql |
Corresponding to the OS waits of the server status variable. |
| mysql.innodb.mutex_spin_rounds |
hostname mode service=mysql |
Corresponding to spinlock rounds of the server status variable. |
| mysql.innodb.mutex_spin_waits |
hostname mode service=mysql |
Corresponding to the spin waits of the server status variable. |
| mysql.innodb.os_log_fsyncs |
hostname mode service=mysql |
Corresponding to |
| mysql.innodb.row_lock_time |
hostname mode service=mysql |
Corresponding to |
| mysql.innodb.row_lock_waits |
hostname mode service=mysql |
Corresponding to |
| mysql.net.connections |
hostname mode service=mysql |
Corresponding to |
| mysql.net.max_connections |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.com_delete |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.com_delete_multi |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.com_insert |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.com_insert_select |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.com_replace_select |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.com_select |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.com_update |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.com_update_multi |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.created_tmp_disk_tables |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.created_tmp_files |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.created_tmp_tables |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.kernel_time |
hostname mode service=mysql |
The kernel time for the databases performance, in seconds. |
| mysql.performance.open_files |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.qcache_hits |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.queries |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.questions |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.slow_queries |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.table_locks_waited |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.threads_connected |
hostname mode service=mysql |
Corresponding to |
| mysql.performance.user_time |
hostname mode service=mysql |
The CPU user time for the databases performance, in seconds. |
12.1.4.15 NTP Metrics #
A list of metrics associated with the NTP service.
| Metric Name | Dimensions | Description |
|---|---|---|
| ntp.connection_status |
hostname ntp_server | Value of ntp server connection status (0=Healthy) |
| ntp.offset |
hostname ntp_server | Time offset in seconds |
12.1.4.16 Open vSwitch (OVS) Metrics #
A list of metrics associated with the OVS service.
Note
For information on how to turn these metrics on and off using the tuning knobs, see Section 12.1.2.5.2, “OVS plugin metric tuning knobs”.
Table 12.6: Per-router metrics #
| Admin Metric Name | Project Metric Name | Dimensions | Description |
|---|---|---|---|
| ovs.vrouter.in_bytes_sec | vrouter.in_bytes_sec |
service=networking resource_id component=ovs router_name port_id |
Inbound bytes per second for the router (if
|
| ovs.vrouter.in_packets_sec | vrouter.in_packets_sec |
service=networking resource_id tenant_id component=ovs router_name port_id |
Incoming packets per second for the router |
| ovs.vrouter.out_bytes_sec | vrouter.out_bytes_sec |
service=networking resource_id component=ovs router_name port_id |
Outgoing bytes per second for the router (if
|
| ovs.vrouter.out_packets_sec | vrouter.out_packets_sec |
service=networking resource_id tenant_id component=ovs router_name port_id |
Outgoing packets per second for the router |
| ovs.vrouter.in_bytes | vrouter.in_bytes |
service=networking resource_id tenant_id component=ovs router_name port_id |
Inbound bytes for the router (if |
| ovs.vrouter.in_packets | vrouter.in_packets |
service=networking resource_id tenant_id component=ovs router_name port_id |
Incoming packets for the router |
| ovs.vrouter.out_bytes | vrouter.out_bytes |
service=networking resource_id tenant_id component=ovs router_name port_id |
Outgoing bytes for the router (if |
| ovs.vrouter.out_packets | vrouter.out_packets |
service=networking resource_id tenant_id component=ovs router_name port_id |
Outgoing packets for the router |
| ovs.vrouter.in_dropped_sec | vrouter.in_dropped_sec |
service=networking resource_id tenant_id component=ovs router_name port_id |
Incoming dropped packets per second for the router |
| ovs.vrouter.in_errors_sec | vrouter.in_errors_sec |
service=networking resource_id component=ovs router_name port_id |
Number of incoming errors per second for the router |
| ovs.vrouter.out_dropped_sec | vrouter.out_dropped_sec |
service=networking resource_id component=ovs router_name port_id |
Outgoing dropped packets per second for the router |
| ovs.vrouter.out_errors_sec | vrouter.out_errors_sec |
service=networking resource_id component=ovs router_name port_id |
Number of outgoing errors per second for the router |
| ovs.vrouter.in_dropped | vrouter.in_dropped |
service=networking resource_id tenant_id component=ovs router_name port_id |
Incoming dropped packets for the router |
| ovs.vrouter.in_errors | vrouter.in_errors |
service=networking resource_id component=ovs router_name port_id |
Number of incoming errors for the router |
| ovs.vrouter.out_dropped | vrouter.out_dropped |
service=networking resource_id component=ovs router_name port_id |
Outgoing dropped packets for the router |
| ovs.vrouter.out_errors | vrouter.out_errors |
service=networking resource_id tenant_id component=ovs router_name port_id |
Number of outgoing errors for the router |
Table 12.7: Per-DHCP port and rate metrics #
| Admin Metric Name | Tenant Metric Name | Dimensions | Description |
|---|---|---|---|
| ovs.vswitch.in_bytes_sec | vswitch.in_bytes_sec |
service=networking resource_id component=ovs router_name port_id |
Incoming Bytes per second on DHCP
port(if |
| ovs.vswitch.in_packets_sec | vswitch.in_packets_sec |
service=networking resource_id tenant_id component=ovs router_name port_id |
Incoming packets per second for the DHCP port |
| ovs.vswitch.out_bytes_sec | vswitch.out_bytes_sec |
service=networking resource_id component=ovs router_name port_id |
Outgoing Bytes per second on DHCP
port(if |
| ovs.vswitch.out_packets_sec | vswitch.out_packets_sec |
service=networking resource_id tenant_id component=ovs router_name port_id |
Outgoing packets per second for the DHCP port |
| ovs.vswitch.in_bytes | vswitch.in_bytes |
service=networking resource_id tenant_id component=ovs router_name port_id |
Inbound bytes for the DHCP port (if |
| ovs.vswitch.in_packets | vswitch.in_packets |
service=networking resource_id tenant_id component=ovs router_name port_id |
Incoming packets for the DHCP port |
| ovs.vswitch.out_bytes | vswitch.out_bytes |
service=networking resource_id tenant_id component=ovs router_name port_id |
Outgoing bytes for the DHCP port (if |
| ovs.vswitch.out_packets | vswitch.out_packets |
service=networking resource_id tenant_id component=ovs router_name port_id |
Outgoing packets for the DHCP port |
| ovs.vswitch.in_dropped_sec | vswitch.in_dropped_sec |
service=networking resource_id tenant_id component=ovs router_name port_id |
Incoming dropped per second for the DHCP port |
| ovs.vswitch.in_errors_sec | vswitch.in_errors_sec |
service=networking resource_id component=ovs router_name port_id |
Incoming errors per second for the DHCP port |
| ovs.vswitch.out_dropped_sec | vswitch.out_dropped_sec |
service=networking resource_id component=ovs router_name port_id |
Outgoing dropped packets per second for the DHCP port |
| ovs.vswitch.out_errors_sec | vswitch.out_errors_sec |
service=networking resource_id component=ovs router_name port_id |
Outgoing errors per second for the DHCP port |
| ovs.vswitch.in_dropped | vswitch.in_dropped |
service=networking resource_id tenant_id component=ovs router_name port_id |
Incoming dropped packets for the DHCP port |
| ovs.vswitch.in_errors | vswitch.in_errors |
service=networking resource_id component=ovs router_name port_id |
Errors received for the DHCP port |
| ovs.vswitch.out_dropped | vswitch.out_dropped |
service=networking resource_id component=ovs router_name port_id |
Outgoing dropped packets for the DHCP port |
| ovs.vswitch.out_errors | vswitch.out_errors |
service=networking resource_id tenant_id component=ovs router_name port_id |
Errors transmitted for the DHCP port |
12.1.4.17 Process Metrics #
A list of metrics associated with processes.
| Metric Name | Dimensions | Description |
|---|---|---|
| process.cpu_perc |
hostname service process_name component | Percentage of cpu being consumed by a process |
| process.io.read_count |
hostname service process_name component | Number of reads by a process |
| process.io.read_kbytes |
hostname service process_name component | Kbytes read by a process |
| process.io.write_count |
hostname service process_name component | Number of writes by a process |
| process.io.write_kbytes |
hostname service process_name component | Kbytes written by a process |
| process.mem.rss_mbytes |
hostname service process_name component | Amount of physical memory allocated to a process, including memory from shared libraries in Mbytes |
| process.open_file_descriptors |
hostname service process_name component | Number of files being used by a process |
| process.pid_count |
hostname service process_name component | Number of processes that exist with this process name |
| process.thread_count |
hostname service process_name component | Number of threads a process is using |
12.1.4.17.1 process.cpu_perc, process.mem.rss_mbytes, process.pid_count and process.thread_count metrics #
| Component Name | Dimensions | Description |
|---|---|---|
| apache-storm |
service=monitoring process_name=monasca-thresh process_user=storm | apache-storm process info: cpu percent, momory, pid count and thread count |
| barbican-api |
service=key-manager process_name=barbican-api | barbican-api process info: cpu percent, momory, pid count and thread count |
| ceilometer-agent-notification |
service=telemetry process_name=ceilometer-agent-notification | ceilometer-agent-notification process info: cpu percent, momory, pid count and thread count |
| ceilometer-api |
service=telemetry process_name=ceilometer-api | ceilometer-api process info: cpu percent, momory, pid count and thread count |
| ceilometer-polling |
service=telemetry process_name=ceilometer-polling | ceilometer-polling process info: cpu percent, momory, pid count and thread count |
| cinder-api |
service=block-storage process_name=cinder-api | cinder-api process info: cpu percent, momory, pid count and thread count |
| cinder-scheduler |
service=block-storage process_name=cinder-scheduler | cinder-scheduler process info: cpu percent, momory, pid count and thread count |
| designate-api |
service=dns process_name=designate-api | designate-api process info: cpu percent, momory, pid count and thread count |
| designate-central |
service=dns process_name=designate-central | designate-central process info: cpu percent, momory, pid count and thread count |
| designate-mdns |
service=dns process_name=designate-mdns | designate-mdns process cpu percent, momory, pid count and thread count |
| designate-pool-manager |
service=dns process_name=designate-pool-manager | designate-pool-manager process info: cpu percent, momory, pid count and thread count |
| freezer-scheduler |
service=backup process_name=freezer-scheduler | freezer-scheduler process info: cpu percent, momory, pid count and thread count |
| heat-api |
service=orchestration process_name=heat-api | heat-api process cpu percent, momory, pid count and thread count |
| heat-api-cfn |
service=orchestration process_name=heat-api-cfn | heat-api-cfn process info: cpu percent, momory, pid count and thread count |
| heat-api-cloudwatch |
service=orchestration process_name=heat-api-cloudwatch | heat-api-cloudwatch process cpu percent, momory, pid count and thread count |
| heat-engine |
service=orchestration process_name=heat-engine | heat-engine process info: cpu percent, momory, pid count and thread count |
| ipsec/charon |
service=networking process_name=ipsec/charon | ipsec/charon process info: cpu percent, momory, pid count and thread count |
| keystone-admin |
service=identity-service process_name=keystone-admin | keystone-admin process info: cpu percent, momory, pid count and thread count |
| keystone-main |
service=identity-service process_name=keystone-main | keystone-main process info: cpu percent, momory, pid count and thread count |
| monasca-agent |
service=monitoring process_name=monasca-agent | monasca-agent process info: cpu percent, momory, pid count and thread count |
| monasca-api |
service=monitoring process_name=monasca-api | monasca-api process info: cpu percent, momory, pid count and thread count |
| monasca-notification |
service=monitoring process_name=monasca-notification | monasca-notification process info: cpu percent, momory, pid count and thread count |
| monasca-persister |
service=monitoring process_name=monasca-persister | monasca-persister process info: cpu percent, momory, pid count and thread count |
| monasca-transform |
service=monasca-transform process_name=monasca-transform | monasca-transform process info: cpu percent, momory, pid count and thread count |
| neutron-dhcp-agent |
service=networking process_name=neutron-dhcp-agent | neutron-dhcp-agent process info: cpu percent, momory, pid count and thread count |
| neutron-l3-agent |
service=networking process_name=neutron-l3-agent | neutron-l3-agent process info: cpu percent, momory, pid count and thread count |
| neutron-lbaasv2-agent |
service=networking process_name:neutron-lbaasv2-agent | neutron-lbaasv2-agent process info: cpu percent, momory, pid count and thread count |
| neutron-metadata-agent |
service=networking process_name=neutron-metadata-agent | neutron-metadata-agent process info: cpu percent, momory, pid count and thread count |
| neutron-openvswitch-agent |
service=networking process_name=neutron-openvswitch-agent | neutron-openvswitch-agent process info: cpu percent, momory, pid count and thread count |
| neutron-rootwrap |
service=networking process_name=neutron-rootwrap | neutron-rootwrap process info: cpu percent, momory, pid count and thread count |
| neutron-server |
service=networking process_name=neutron-server | neutron-server process info: cpu percent, momory, pid count and thread count |
| neutron-vpn-agent |
service=networking process_name=neutron-vpn-agent | neutron-vpn-agent process info: cpu percent, momory, pid count and thread count |
| nova-api |
service=compute process_name=nova-api | nova-api process info: cpu percent, momory, pid count and thread count |
| nova-compute |
service=compute process_name=nova-compute | nova-compute process info: cpu percent, momory, pid count and thread count |
| nova-conductor |
service=compute process_name=nova-conductor | nova-conductor process info: cpu percent, momory, pid count and thread count |
| nova-consoleauth |
service=compute process_name=nova-consoleauth | nova-consoleauth process info: cpu percent, momory, pid count and thread count |
| nova-novncproxy |
service=compute process_name=nova-novncproxy | nova-novncproxy process info: cpu percent, momory, pid count and thread count |
| nova-scheduler |
service=compute process_name=nova-scheduler | nova-scheduler process info: cpu percent, momory, pid count and thread count |
| octavia-api |
service=octavia process_name=octavia-api | octavia-api process info: cpu percent, momory, pid count and thread count |
| octavia-health-manager |
service=octavia process_name=octavia-health-manager | octavia-health-manager process info: cpu percent, momory, pid count and thread count |
| octavia-housekeeping |
service=octavia process_name=octavia-housekeeping | octavia-housekeeping process info: cpu percent, momory, pid count and thread count |
| octavia-worker |
service=octavia process_name=octavia-worker | octavia-worker process info: cpu percent, momory, pid count and thread count |
| org.apache.spark.deploy.master.Master |
service=spark process_name=org.apache.spark.deploy.master.Master | org.apache.spark.deploy.master.Master process info: cpu percent, momory, pid count and thread count |
| org.apache.spark.executor.CoarseGrainedExecutorBackend |
service=monasca-transform process_name=org.apache.spark.executor.CoarseGrainedExecutorBackend | org.apache.spark.executor.CoarseGrainedExecutorBackend process info: cpu percent, momory, pid count and thread count |
| pyspark |
service=monasca-transform process_name=pyspark | pyspark process info: cpu percent, momory, pid count and thread count |
| transform/lib/driver |
service=monasca-transform process_name=transform/lib/driver | transform/lib/driver process info: cpu percent, momory, pid count and thread count |
| cassandra |
service=cassandra process_name=cassandra | cassandra process info: cpu percent, momory, pid count and thread count |
12.1.4.17.2 process.io.*, process.open_file_descriptors metrics #
| Component Name | Dimensions | Description |
|---|---|---|
| monasca-agent |
service=monitoring process_name=monasca-agent process_user=mon-agent | monasca-agent process info: number of reads, number of writes,number of files being used |
12.1.4.18 RabbitMQ Metrics #
A list of metrics associated with the RabbitMQ service.
| Metric Name | Dimensions | Description |
|---|---|---|
| rabbitmq.exchange.messages.published_count |
hostname exchange vhost type service=rabbitmq |
Value of the "publish_out" field of "message_stats" object |
| rabbitmq.exchange.messages.published_rate |
hostname exchange vhost type service=rabbitmq |
Value of the "rate" field of "message_stats/publish_out_details" object |
| rabbitmq.exchange.messages.received_count |
hostname exchange vhost type service=rabbitmq |
Value of the "publish_in" field of "message_stats" object |
| rabbitmq.exchange.messages.received_rate |
hostname exchange vhost type service=rabbitmq |
Value of the "rate" field of "message_stats/publish_in_details" object |
| rabbitmq.node.fd_used |
hostname node service=rabbitmq |
Value of the "fd_used" field in the response of /api/nodes |
| rabbitmq.node.mem_used |
hostname node service=rabbitmq |
Value of the "mem_used" field in the response of /api/nodes |
| rabbitmq.node.run_queue |
hostname node service=rabbitmq |
Value of the "run_queue" field in the response of /api/nodes |
| rabbitmq.node.sockets_used |
hostname node service=rabbitmq |
Value of the "sockets_used" field in the response of /api/nodes |
| rabbitmq.queue.messages |
hostname queue vhost service=rabbitmq |
Sum of ready and unacknowledged messages (queue depth) |
| rabbitmq.queue.messages.deliver_rate |
hostname queue vhost service=rabbitmq |
Value of the "rate" field of "message_stats/deliver_details" object |
| rabbitmq.queue.messages.publish_rate |
hostname queue vhost service=rabbitmq |
Value of the "rate" field of "message_stats/publish_details" object |
| rabbitmq.queue.messages.redeliver_rate |
hostname queue vhost service=rabbitmq |
Value of the "rate" field of "message_stats/redeliver_details" object |
12.1.4.19 Swift Metrics #
A list of metrics associated with the Swift service.
| Metric Name | Dimensions | Description |
|---|---|---|
| swiftlm.access.host.operation.get.bytes |
service=object-storage |
This metric is the number of bytes read from objects in GET requests processed by this host during the last minute. Only successful GET requests to objects are counted. GET requests to the account or container is not included. |
| swiftlm.access.host.operation.ops |
service=object-storage |
This metric is a count of the all the API requests made to Swift that were processed by this host during the last minute. |
| swiftlm.access.host.operation.project.get.bytes | ||
| swiftlm.access.host.operation.project.ops | ||
| swiftlm.access.host.operation.project.put.bytes | ||
| swiftlm.access.host.operation.put.bytes |
service=object-storage |
This metric is the number of bytes written to objects in PUT or POST requests processed by this host during the last minute. Only successful requests to objects are counted. Requests to the account or container is not included. |
| swiftlm.access.host.operation.status | ||
| swiftlm.access.project.operation.status |
service=object-storage |
This metric reports whether the swiftlm-access-log-tailer program is running normally. |
| swiftlm.access.project.operation.ops |
tenant_id service=object-storage |
This metric is a count of the all the API requests made to Swift that were processed by this host during the last minute to a given project id. |
| swiftlm.access.project.operation.get.bytes |
tenant_id service=object-storage |
This metric is the number of bytes read from objects in GET requests processed by this host for a given project during the last minute. Only successful GET requests to objects are counted. GET requests to the account or container is not included. |
| swiftlm.access.project.operation.put.bytes |
tenant_id service=object-storage |
This metric is the number of bytes written to objects in PUT or POST requests processed by this host for a given project during the last minute. Only successful requests to objects are counted. Requests to the account or container is not included. |
| swiftlm.async_pending.cp.total.queue_length |
observer_host service=object-storage |
This metric reports the total length of all async pending queues in the system. When a container update fails, the update is placed on the async pending queue. An update may fail becuase the container server is too busy or because the server is down or failed. Later the system will “replay” updates from the queue – so eventually, the container listings will show all objects known to the system. If you know that container servers are down, it is normal to see the value of async pending increase. Once the server is restored, the value should return to zero. A non-zero value may also indicate that containers are too large. Look for “lock timeout” messages in /var/log/swift/swift.log. If you find such messages consider reducing the container size or enable rate limiting. |
| swiftlm.check.failure |
check error component service=object-storage |
The total exception string is truncated if longer than 1919 characters and an ellipsis is prepended in the first three characters of the message. If there is more than one error reported, the list of errors is paired to the last reported error and the operator is expected to resolve failures until no more are reported. Where there are no further reported errors, the Value Class is emitted as ‘Ok’. |
| swiftlm.diskusage.cp.avg.usage |
observer_host service=object-storage |
Is the average utilization of all drives in the system. The value is a percentage (example: 30.0 means 30% of the total space is used). |
| swiftlm.diskusage.cp.max.usage |
observer_host service=object-storage |
Is the highest utilization of all drives in the system. The value is a percentage (example: 80.0 means at least one drive is 80% utilized). The value is just as important as swiftlm.diskusage.usage.avg. For example, if swiftlm.diskusage.usage.avg is 70% you might think that there is plenty of space available. However, if swiftlm.diskusage.usage.max is 100%, this means that some objects cannot be stored on that drive. Swift will store replicas on other drives. However, this will create extra overhead. |
| swiftlm.diskusage.cp.min.usage |
observer_host service=object-storage |
Is the lowest utilization of all drives in the system. The value is a percentage (example: 10.0 means at least one drive is 10% utilized) |
| swiftlm.diskusage.cp.total.avail |
observer_host service=object-storage |
Is the size in bytes of available (unused) space of all drives in the system. Only drives used by Swift are included. |
| swiftlm.diskusage.cp.total.size |
observer_host service=object-storage |
Is the size in bytes of raw size of all drives in the system. |
| swiftlm.diskusage.cp.total.used |
observer_host service=object-storage |
Is the size in bytes of used space of all drives in the system. Only drives used by Swift are included. |
| swiftlm.diskusage.host.avg.usage |
hostname service=object-storage |
This metric reports the average percent usage of all Swift filesystems on a host. |
| swiftlm.diskusage.host.max.usage |
hostname service=object-storage |
This metric reports the percent usage of a Swift filesystem that is most used (full) on a host. The value is the max of the percentage used of all Swift filesystems. |
| swiftlm.diskusage.host.min.usage |
hostname service=object-storage |
This metric reports the percent usage of a Swift filesystem that is least used (has free space) on a host. The value is the min of the percentage used of all Swift filesystems. |
| swiftlm.diskusage.host.val.avail |
hostname service=object-storage mount device label |
This metric reports the number of bytes available (free) in a Swift filesystem. The value is an integer (units: Bytes) |
| swiftlm.diskusage.host.val.size |
hostname service=object-storage mount device label |
This metric reports the size in bytes of a Swift filesystem. The value is an integer (units: Bytes) |
| swiftlm.diskusage.host.val.usage |
hostname service=object-storage mount device label |
This metric reports the percent usage of a Swift filesystem. The value is a floating point number in range 0.0 to 100.0 |
| swiftlm.diskusage.host.val.used |
hostname service=object-storage mount device label |
This metric reports the number of used bytes in a Swift filesystem. The value is an integer (units: Bytes) |
| swiftlm.load.cp.avg.five |
observer_host service=object-storage |
This is the averaged value of the five minutes system load average of all nodes in the Swift system. |
| swiftlm.load.cp.max.five |
observer_host service=object-storage |
This is the five minute load average of the busiest host in the Swift system. |
| swiftlm.load.cp.min.five |
observer_host service=object-storage |
This is the five minute load average of the least loaded host in the Swift system. |
| swiftlm.load.host.val.five |
hostname service=object-storage |
This metric reports the 5 minute load average of a host. The value is
derived from |
| swiftlm.md5sum.cp.check.ring_checksums |
observer_host service=object-storage |
If you are in the middle of deploying new rings, it is normal for this to be in the failed state. However, if you are not in the middle of a deployment, you need to investigate the cause. Use “swift-recon –md5 -v” to identify the problem hosts. |
| swiftlm.replication.cp.avg.account_duration |
observer_host service=object-storage |
This is the average across all servers for the account replicator to complete a cycle. As the system becomes busy, the time to complete a cycle increases. The value is in seconds. |
| swiftlm.replication.cp.avg.container_duration |
observer_host service=object-storage |
This is the average across all servers for the container replicator to complete a cycle. As the system becomes busy, the time to complete a cycle increases. The value is in seconds. |
| swiftlm.replication.cp.avg.object_duration |
observer_host service=object-storage |
This is the average across all servers for the object replicator to complete a cycle. As the system becomes busy, the time to complete a cycle increases. The value is in seconds. |
| swiftlm.replication.cp.max.account_last |
hostname path service=object-storage |
This is the number of seconds since the account replicator last completed a scan on the host that has the oldest completion time. Normally the replicators runs periodically and hence this value will decrease whenever a replicator completes. However, if a replicator is not completing a cycle, this value increases (by one second for each second that the replicator is not completing). If the value remains high and increasing for a long period of time, it indicates that one of the hosts is not completing the replication cycle. |
| swiftlm.replication.cp.max.container_last |
hostname path service=object-storage |
This is the number of seconds since the container replicator last completed a scan on the host that has the oldest completion time. Normally the replicators runs periodically and hence this value will decrease whenever a replicator completes. However, if a replicator is not completing a cycle, this value increases (by one second for each second that the replicator is not completing). If the value remains high and increasing for a long period of time, it indicates that one of the hosts is not completing the replication cycle. |
| swiftlm.replication.cp.max.object_last |
hostname path service=object-storage |
This is the number of seconds since the object replicator last completed a scan on the host that has the oldest completion time. Normally the replicators runs periodically and hence this value will decrease whenever a replicator completes. However, if a replicator is not completing a cycle, this value increases (by one second for each second that the replicator is not completing). If the value remains high and increasing for a long period of time, it indicates that one of the hosts is not completing the replication cycle. |
| swiftlm.swift.drive_audit |
hostname service=object-storage mount_point kernel_device |
If an unrecoverable read error (URE) occurs on a filesystem, the error is logged in the kernel log. The swift-drive-audit program scans the kernel log looking for patterns indicating possible UREs. To get more information, log onto the node in question and run: sudoswift-drive-audit/etc/swift/drive-audit.conf UREs are common on large disk drives. They do not necessarily indicate that the drive is failed. You can use the xfs_repair command to attempt to repair the filesystem. Failing this, you may need to wipe the filesystem. If UREs occur very often on a specific drive, this may indicate that the drive is about to fail and should be replaced. |
| swiftlm.swift.file_ownership.config |
hostname path service |
This metric reports if a directory or file has the appropriate owner. The check looks at Swift configuration directories and files. It also looks at the top-level directories of mounted file systems (for example, /srv/node/disk0 and /srv/node/disk0/objects). |
| swiftlm.swift.file_ownership.data |
hostname path service |
This metric reports if a directory or file has the appropriate owner. The check looks at Swift configuration directories and files. It also looks at the top-level directories of mounted file systems (for example, /srv/node/disk0 and /srv/node/disk0/objects). |
| swiftlm.swiftlm_check |
hostname service=object-storage |
This indicates of the Swiftlm Monasca Agent Plug-in is running normally. If the status is failed, it probable that some or all metrics are no longer being reported. |
| swiftlm.swift.replication.account.last_replication |
hostname service=object-storage |
This reports how long (in seconds) since the replicator process last finished a replication run. If the replicator is stuck, the time will keep increasing forever. The time a replicator normally takes depends on disk sizes and how much data needs to be replicated. However, a value over 24 hours is generally bad. |
| swiftlm.swift.replication.container.last_replication |
hostname service=object-storage |
This reports how long (in seconds) since the replicator process last finished a replication run. If the replicator is stuck, the time will keep increasing forever. The time a replicator normally takes depends on disk sizes and how much data needs to be replicated. However, a value over 24 hours is generally bad. |
| swiftlm.swift.replication.object.last_replication |
hostname service=object-storage |
This reports how long (in seconds) since the replicator process last finished a replication run. If the replicator is stuck, the time will keep increasing forever. The time a replicator normally takes depends on disk sizes and how much data needs to be replicated. However, a value over 24 hours is generally bad. |
| swiftlm.swift.swift_services |
hostname service=object-storage |
This metric reports of the process as named in the component dimension and the msg value_meta is running or not.
Use the |
| swiftlm.swift.swift_services.check_ip_port |
hostname service=object-storage component | Reports if a service is listening to the correct ip and port. |
| swiftlm.systems.check_mounts |
hostname service=object-storage mount device label |
This metric reports the mount state of each drive that should be mounted on this node. |
| swiftlm.systems.connectivity.connect_check |
observer_host url target_port service=object-storage |
This metric reports if a server can connect to a VIPs. Currently the following VIPs are checked:
|
| swiftlm.systems.connectivity.memcache_check |
observer_host hostname target_port service=object-storage |
This metric reports if memcached on the host as specified by the hostname dimension is accepting connections from the host running the check. The following value_meta.msg are used: We successfully connected to <hostname> on port <target_port> {
"dimensions": {
"hostname": "ardana-ccp-c1-m1-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"target_port": "11211"
},
"metric": "swiftlm.systems.connectivity.memcache_check",
"timestamp": 1449084058,
"value": 0,
"value_meta": {
"msg": "ardana-ccp-c1-m1-mgmt:11211 ok"
}
}We failed to connect to <hostname> on port <target_port> {
"dimensions": {
"fail_message": "[Errno 111] Connection refused",
"hostname": "ardana-ccp-c1-m1-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"target_port": "11211"
},
"metric": "swiftlm.systems.connectivity.memcache_check",
"timestamp": 1449084150,
"value": 2,
"value_meta": {
"msg": "ardana-ccp-c1-m1-mgmt:11211 [Errno 111] Connection refused"
}
} |
| swiftlm.systems.connectivity.rsync_check |
observer_host hostname target_port service=object-storage |
This metric reports if rsyncd on the host as specified by the hostname dimension is accepting connections from the host running the check. The following value_meta.msg are used: We successfully connected to <hostname> on port <target_port>: {
"dimensions": {
"hostname": "ardana-ccp-c1-m1-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"target_port": "873"
},
"metric": "swiftlm.systems.connectivity.rsync_check",
"timestamp": 1449082663,
"value": 0,
"value_meta": {
"msg": "ardana-ccp-c1-m1-mgmt:873 ok"
}
}We failed to connect to <hostname> on port <target_port>: {
"dimensions": {
"fail_message": "[Errno 111] Connection refused",
"hostname": "ardana-ccp-c1-m1-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"target_port": "873"
},
"metric": "swiftlm.systems.connectivity.rsync_check",
"timestamp": 1449082860,
"value": 2,
"value_meta": {
"msg": "ardana-ccp-c1-m1-mgmt:873 [Errno 111] Connection refused"
}
} |
| swiftlm.umon.target.avg.latency_sec |
component hostname observer_host service=object-storage url |
Reports the average value of N-iterations of the latency values recorded for a component. |
| swiftlm.umon.target.check.state |
component hostname observer_host service=object-storage url |
This metric reports the state of each component after N-iterations of checks. If the initial check succeeds, the checks move onto the next component until all components are queried, then the checks sleep for ‘main_loop_interval’ seconds. If a check fails, it is retried every second for ‘retries’ number of times per component. If the check fails ‘retries’ times, it is reported as a fail instance. A successful state will be reported in JSON: {
"dimensions": {
"component": "rest-api",
"hostname": "ardana-ccp-vip-admin-SWF-PRX-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"url": "http://ardana-ccp-vip-admin-SWF-PRX-mgmt:8080"
},
"metric": "swiftlm.umon.target.check.state",
"timestamp": 1453111805,
"value": 0
},A failed state will report a “fail” value and the value_meta will provide the http response error. {
"dimensions": {
"component": "rest-api",
"hostname": "ardana-ccp-vip-admin-SWF-PRX-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"url": "http://ardana-ccp-vip-admin-SWF-PRX-mgmt:8080"
},
"metric": "swiftlm.umon.target.check.state",
"timestamp": 1453112841,
"value": 2,
"value_meta": {
"msg": "HTTPConnectionPool(host='192.168.245.9', port=8080): Max retries exceeded with url: /v1/AUTH_76538ce683654a35983b62e333001b47 (Caused by NewConnectionError('<requests.packages.urllib3.connection.HTTPConnection object at 0x7fd857d7f550>: Failed to establish a new connection: [Errno 110] Connection timed out',))"
}
} |
| swiftlm.umon.target.max.latency_sec |
component hostname observer_host service=object-storage url |
This metric reports the maximum response time in seconds of a REST call from the observer to the component REST API listening on the reported host A response time query will be reported in JSON: {
"dimensions": {
"component": "rest-api",
"hostname": "ardana-ccp-vip-admin-SWF-PRX-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"url": "http://ardana-ccp-vip-admin-SWF-PRX-mgmt:8080"
},
"metric": "swiftlm.umon.target.max.latency_sec",
"timestamp": 1453111805,
"value": 0.2772650718688965
}A failed query will have a much longer time value: {
"dimensions": {
"component": "rest-api",
"hostname": "ardana-ccp-vip-admin-SWF-PRX-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"url": "http://ardana-ccp-vip-admin-SWF-PRX-mgmt:8080"
},
"metric": "swiftlm.umon.target.max.latency_sec",
"timestamp": 1453112841,
"value": 127.288015127182
} |
| swiftlm.umon.target.min.latency_sec |
component hostname observer_host service=object-storage url |
This metric reports the minimum response time in seconds of a REST call from the observer to the component REST API listening on the reported host A response time query will be reported in JSON: {
"dimensions": {
"component": "rest-api",
"hostname": "ardana-ccp-vip-admin-SWF-PRX-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"url": "http://ardana-ccp-vip-admin-SWF-PRX-mgmt:8080"
},
"metric": "swiftlm.umon.target.min.latency_sec",
"timestamp": 1453111805,
"value": 0.10025882720947266
}A failed query will have a much longer time value: {
"dimensions": {
"component": "rest-api",
"hostname": "ardana-ccp-vip-admin-SWF-PRX-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"url": "http://ardana-ccp-vip-admin-SWF-PRX-mgmt:8080"
},
"metric": "swiftlm.umon.target.min.latency_sec",
"timestamp": 1453112841,
"value": 127.25378203392029
} |
| swiftlm.umon.target.val.avail_day |
component hostname observer_host service=object-storage url |
This metric reports the average of all the collected records in the swiftlm.umon.target.val.avail_minute metric data. This is a walking average data set of these approximately per-minute states of the Swift Object Store. The most basic case is a whole day of successful per-minute records, which will average to 100% availability. If there is any downtime throughout the day resulting in gaps of data which are two minutes or longer, the per-minute availability data will be “back filled” with an assumption of a down state for all the per-minute records which did not exist during the non-reported time. Because this is a walking average of approximately 24 hours worth of data, any outtage will take 24 hours to be purged from the dataset. A 24-hour average availability report: {
"dimensions": {
"component": "rest-api",
"hostname": "ardana-ccp-vip-admin-SWF-PRX-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"url": "http://ardana-ccp-vip-admin-SWF-PRX-mgmt:8080"
},
"metric": "swiftlm.umon.target.val.avail_day",
"timestamp": 1453645405,
"value": 7.894736842105263
} |
| swiftlm.umon.target.val.avail_minute |
component hostname observer_host service=object-storage url |
A value of 100 indicates that swift-uptime-monitor was able to get a token from Keystone and was able to perform operations against the Swift API during the reported minute. A value of zero indicates that either Keystone or Swift failed to respond successfully. A metric is produced every minute that swift-uptime-monitor is running. An “up” minute report value will report 100 [percent]: {
"dimensions": {
"component": "rest-api",
"hostname": "ardana-ccp-vip-admin-SWF-PRX-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"url": "http://ardana-ccp-vip-admin-SWF-PRX-mgmt:8080"
},
"metric": "swiftlm.umon.target.val.avail_minute",
"timestamp": 1453645405,
"value": 100.0
}A “down” minute report value will report 0 [percent]: {
"dimensions": {
"component": "rest-api",
"hostname": "ardana-ccp-vip-admin-SWF-PRX-mgmt",
"observer_host": "ardana-ccp-c1-m1-mgmt",
"service": "object-storage",
"url": "http://ardana-ccp-vip-admin-SWF-PRX-mgmt:8080"
},
"metric": "swiftlm.umon.target.val.avail_minute",
"timestamp": 1453649139,
"value": 0.0
} |
| swiftlm.hp_hardware.hpssacli.smart_array.firmware |
component hostname service=object-storage component model controller_slot |
This metric reports the firmware version of a component of a Smart Array controller. |
| swiftlm.hp_hardware.hpssacli.smart_array |
component hostname service=object-storage component sub_component model controller_slot |
This reports the status of various sub-components of a Smart Array Controller. A failure is considered to have occured if:
|
| swiftlm.hp_hardware.hpssacli.physical_drive |
component hostname service=object-storage component controller_slot box bay |
This reports the status of a disk drive attached to a Smart Array controller. |
| swiftlm.hp_hardware.hpssacli.logical_drive |
component hostname observer_host service=object-storage controller_slot array logical_drive sub_component |
This reports the status of a LUN presented by a Smart Array controller. A LUN is considered failed if the LUN has failed or if the LUN cache is not enabled and working. |
Note
HPE Smart Storage Administrator (HPE SSA) CLI component will have to be installed on all control nodes that are Swift nodes, in order to generate the following Swift metrics:
swiftlm.hp_hardware.hpssacli.smart_array
swiftlm.hp_hardware.hpssacli.logical_drive
swiftlm.hp_hardware.hpssacli.smart_array.firmware
swiftlm.hp_hardware.hpssacli.physical_drive
HPE-specific binaries that are not based on open source are distributed directly from and supported by HPE. To download and install the SSACLI utility, please refer to: https://support.hpe.com/hpsc/swd/public/detail?swItemId=MTX_3d16386b418a443388c18da82f
After the HPE SSA CLI component is installed on the Swift nodes, the metrics will be generated automatically during the next agent polling cycle. Manual reboot of the node is not required.
12.1.4.20 System Metrics #
A list of metrics associated with the System.
Table 12.8: CPU Metrics #
| Metric Name | Dimensions | Description |
|---|---|---|
| cpu.frequency_mhz |
cluster hostname service=system |
Maximum MHz value for the cpu frequency. NoteThis value is dynamic, and driven by CPU governor depending on current resource need. |
| cpu.idle_perc |
cluster hostname service=system |
Percentage of time the CPU is idle when no I/O requests are in progress |
| cpu.idle_time |
cluster hostname service=system |
Time the CPU is idle when no I/O requests are in progress |
| cpu.percent |
cluster hostname service=system |
Percentage of time the CPU is used in total |
| cpu.stolen_perc |
cluster hostname service=system |
Percentage of stolen CPU time, that is, the time spent in other OS contexts when running in a virtualized environment |
| cpu.system_perc |
cluster hostname service=system |
Percentage of time the CPU is used at the system level |
| cpu.system_time |
cluster hostname service=system |
Time the CPU is used at the system level |
| cpu.time_ns |
cluster hostname service=system |
Time the CPU is used at the host level |
| cpu.total_logical_cores |
cluster hostname service=system |
Total number of logical cores available for an entire node (Includes hyper threading). Note:This is an optional metric that is only sent when send_rollup_stats is set to true. |
| cpu.user_perc |
cluster hostname service=system |
Percentage of time the CPU is used at the user level |
| cpu.user_time |
cluster hostname service=system |
Time the CPU is used at the user level |
| cpu.wait_perc |
cluster hostname service=system |
Percentage of time the CPU is idle AND there is at least one I/O request in progress |
| cpu.wait_time |
cluster hostname service=system |
Time the CPU is idle AND there is at least one I/O request in progress |
Table 12.9: Disk Metrics #
| Metric Name | Dimensions | Description |
|---|---|---|
| disk.inode_used_perc |
mount_point service=system hostname cluster device |
The percentage of inodes that are used on a device |
| disk.space_used_perc |
mount_point service=system hostname cluster device |
The percentage of disk space that is being used on a device |
| disk.total_space_mb |
mount_point service=system hostname cluster device |
The total amount of disk space in Mbytes aggregated across all the disks on a particular node. NoteThis is an optional metric that is only sent when send_rollup_stats is set to true. |
| disk.total_used_space_mb |
mount_point service=system hostname cluster device |
The total amount of used disk space in Mbytes aggregated across all the disks on a particular node. NoteThis is an optional metric that is only sent when send_rollup_stats is set to true. |
| io.read_kbytes_sec |
mount_point service=system hostname cluster device |
Kbytes/sec read by an io device |
| io.read_req_sec |
mount_point service=system hostname cluster device |
Number of read requests/sec to an io device |
| io.read_time_sec |
mount_point service=system hostname cluster device |
Amount of read time in seconds to an io device |
| io.write_kbytes_sec |
mount_point service=system hostname cluster device |
Kbytes/sec written by an io device |
| io.write_req_sec |
mount_point service=system hostname cluster device |
Number of write requests/sec to an io device |
| io.write_time_sec |
mount_point service=system hostname cluster device |
Amount of write time in seconds to an io device |
Table 12.10: Load Metrics #
| Metric Name | Dimensions | Description |
|---|---|---|
| load.avg_15_min |
service=system hostname cluster |
The normalized (by number of logical cores) average system load over a 15 minute period |
| load.avg_1_min |
service=system hostname cluster |
The normalized (by number of logical cores) average system load over a 1 minute period |
| load.avg_5_min |
service=system hostname cluster |
The normalized (by number of logical cores) average system load over a 5 minute period |
Table 12.11: Memory Metrics #
| Metric Name | Dimensions | Description |
|---|---|---|
| mem.free_mb |
service=system hostname cluster |
Mbytes of free memory |
| mem.swap_free_mb |
service=system hostname cluster |
Percentage of free swap memory that is free |
| mem.swap_free_perc |
service=system hostname cluster |
Mbytes of free swap memory that is free |
| mem.swap_total_mb |
service=system hostname cluster |
Mbytes of total physical swap memory |
| mem.swap_used_mb |
service=system hostname cluster |
Mbytes of total swap memory used |
| mem.total_mb |
service=system hostname cluster |
Total Mbytes of memory |
| mem.usable_mb |
service=system hostname cluster |
Total Mbytes of usable memory |
| mem.usable_perc |
service=system hostname cluster |
Percentage of total memory that is usable |
| mem.used_buffers |
service=system hostname cluster |
Number of buffers in Mbytes being used by the kernel for block io |
| mem.used_cache |
service=system hostname cluster |
Mbytes of memory used for the page cache |
| mem.used_mb |
service=system hostname cluster |
Total Mbytes of used memory |
Table 12.12: Network Metrics #
| Metric Name | Dimensions | Description |
|---|---|---|
| net.in_bytes_sec |
service=system hostname device |
Number of network bytes received per second |
| net.in_errors_sec |
service=system hostname device |
Number of network errors on incoming network traffic per second |
| net.in_packets_dropped_sec |
service=system hostname device |
Number of inbound network packets dropped per second |
| net.in_packets_sec |
service=system hostname device |
Number of network packets received per second |
| net.out_bytes_sec |
service=system hostname device |
Number of network bytes sent per second |
| net.out_errors_sec |
service=system hostname device |
Number of network errors on outgoing network traffic per second |
| net.out_packets_dropped_sec |
service=system hostname device |
Number of outbound network packets dropped per second |
| net.out_packets_sec |
service=system hostname device |
Number of network packets sent per second |
12.1.4.21 Zookeeper Metrics #
A list of metrics associated with the Zookeeper service.
| Metric Name | Dimensions | Description |
|---|---|---|
| zookeeper.avg_latency_sec |
hostname mode service=zookeeper | Average latency in second |
| zookeeper.connections_count |
hostname mode service=zookeeper | Number of connections |
| zookeeper.in_bytes |
hostname mode service=zookeeper | Received bytes |
| zookeeper.max_latency_sec |
hostname mode service=zookeeper | Maximum latency in second |
| zookeeper.min_latency_sec |
hostname mode service=zookeeper | Minimum latency in second |
| zookeeper.node_count |
hostname mode service=zookeeper | Number of nodes |
| zookeeper.out_bytes |
hostname mode service=zookeeper | Sent bytes |
| zookeeper.outstanding_bytes |
hostname mode service=zookeeper | Outstanding bytes |
| zookeeper.zxid_count |
hostname mode service=zookeeper | Count number |
| zookeeper.zxid_epoch |
hostname mode service=zookeeper | Epoch number |
12.2 Centralized Logging Service #
You can use the Centralized Logging Service to evaluate and troubleshoot your distributed cloud environment from a single location.
12.2.1 Getting Started with Centralized Logging Service #
A typical cloud consists of multiple servers which makes locating a specific log from a single server difficult. The Centralized Logging feature helps the administrator evaluate and troubleshoot the distributed cloud deployment from a single location.
The Logging API is a component in the centralized logging architecture. It works between log producers and log storage. In most cases it works by default after installation with no additional configuration. To use Logging API with logging-as-a-service, you must configure an end-point. This component adds flexibility and supportability for features in the future.
Do I need to Configure monasca-log-api? If you are only using Cloud Lifecycle Manager , then the default configuration is ready to use.
Important
If you are using logging in any of the following deployments, then you will need to query Keystone to get an end-point to use.
Logging as a Service
Platform as a Service
The Logging API is protected by Keystone’s role-based access control. To ensure that logging is allowed and Monasca alarms can be triggered, the user must have the monasca-user role. To get an end-point from Keystone:
Log on to Cloud Lifecycle Manager (deployer node).
To list the Identity service catalog, run:
ardana >source ./service.osrcardana >openstack catalog listIn the output, find Kronos. For example:
Name Type Endpoints kronos region0 public: http://myardana.test:5607/v3.0, admin: http://192.168.245.5:5607/v3.0, internal: http://192.168.245.5:5607/v3.0
Use the same port number as found in the output. In the example, you would use port 5607.
In HPE Helion OpenStack, the logging-ansible restart playbook has been updated to manage the start,stop, and restart of the Centralized Logging Service in a specific way. This change was made to ensure the proper stop, start, and restart of Elasticsearch.
Important
It is recommended that you only use the logging playbooks to perform the start, stop, and restart of the Centralized Logging Service. Manually mixing the start, stop, and restart operations with the logging playbooks will result in complex failures.
For more information, see Section 12.2.4, “Managing the Centralized Logging Feature”.
12.2.1.1 For More Information #
For more information about the centralized logging components, see the following sites:
12.2.2 Understanding the Centralized Logging Service #
The Centralized Logging feature collects logs on a central system, rather than leaving the logs scattered across the network. The administrator can use a single Kibana interface to view log information in charts, graphs, tables, histograms, and other forms.
12.2.2.1 What Components are Part of Centralized Logging? #
Centralized logging consists of several components, detailed below:
Administrator's Browser: Operations Console can be used to access logging alarms or to access Kibana's dashboards to review logging data.
Apache Website for Kibana: A standard Apache website that proxies web/REST requests to the Kibana NodeJS server.
Beaver: A Python daemon that collects information in log files and sends it to the Logging API (monasca-log API) over a secure connection.
Cloud Auditing Data Federation (CADF): Defines a standard, full-event model anyone can use to fill in the essential data needed to certify, self-manage and self-audit application security in cloud environments.
Centralized Logging and Monitoring (CLM): Used to evaluate and troubleshoot your HPE Helion OpenStack distributed cloud environment from a single location.
Curator: a tool provided by Elasticsearch to manage indices.
Elasticsearch: A data store offering fast indexing and querying.
HPE Helion OpenStack: Provides public, private, and managed cloud solutions to get you moving on your cloud journey.
JavaScript Object Notation (JSON) log file: A file stored in the JSON format and used to exchange data. JSON uses JavaScript syntax, but the JSON format is text only. Text can be read and used as a data format by any programming language. This format is used by the Beaver and Logstash components.
Kafka: A messaging broker used for collection of HPE Helion OpenStack centralized logging data across nodes. It is highly available, scalable and performant. Kafka stores logs in disk instead of memory and is therefore more tolerant to consumer down times.

Important
Make sure not to undersize your Kafka partition or the data retention period may be lower than expected. If the Kafka partition capacity is lower than 85%, the retention period will increase to 30 minutes. Over time Kafka will also eject old data.
Kibana: A client/server application with rich dashboards to visualize the data in Elasticsearch through a web browser. Kibana enables you to create charts and graphs using the log data.
Logging API (monasca-log-api): HPE Helion OpenStack API provides a standard REST interface to store logs. It uses Keystone authentication and role-based access control support.
Logstash: A log processing system for receiving, processing and outputting logs. Logstash retrieves logs from Kafka, processes and enriches the data, then stores the data in Elasticsearch.
MML Service Node: Metering, Monitoring, and Logging (MML) service node. All services associated with metering, monitoring, and logging run on a dedicated three-node cluster. Three nodes are required for high availability with quorum.
Monasca: OpenStack monitoring at scale infrastructure for the cloud that supports alarms and reporting.
OpenStack Service. An OpenStack service process that requires logging services.
Oslo.log. An OpenStack library for log handling. The library functions automate configuration, deployment and scaling of complete, ready-for-work application platforms. Some PaaS solutions, such as Cloud Foundry, combine operating systems, containers, and orchestrators with developer tools, operations utilities, metrics, and security to create a developer-rich solution.
Text log: A type of file used in the logging process that contains human-readable records.
These components are configured to work out-of-the-box and the admin should be able to view log data using the default configurations.
In addition to each of the services, Centralized Logging also processes logs for the following features:
HAProxy
Syslog
keepalived
The purpose of the logging service is to provide a common logging infrastructure with centralized user access. Since there are numerous services and applications running in each node of a HPE Helion OpenStack cloud, and there could be hundreds of nodes, all of these services and applications can generate enough log files to make it very difficult to search for specific events in log files across all of the nodes. Centralized Logging addresses this issue by sending log messages in real time to a central Elasticsearch, Logstash, and Kibana cluster. In this cluster they are indexed and organized for easier and visual searches. The following illustration describes the architecture used to collect operational logs.
Note
The arrows come from the active (requesting) side to the passive (listening) side. The active side is always the one providing credentials, so the arrows may also be seen as coming from the credential holder to the application requiring authentication.
12.2.2.2 Steps 1- 2 #
Services configured to generate log files record the data. Beaver listens for changes to the files and sends the log files to the Logging Service. The first step the Logging service takes is to re-format the original log file to a new log file with text only and to remove all network operations. In Step 1a, the Logging service uses the Oslo.log library to re-format the file to text-only. In Step 1b, the Logging service uses the Python-Logstash library to format the original audit log file to a JSON file.
- Step 1a
Beaver watches configured service operational log files for changes and reads incremental log changes from the files.
- Step 1b
Beaver watches configured service operational log files for changes and reads incremental log changes from the files.
- Step 2a
The monascalog transport of Beaver makes a token request call to Keystone passing in credentials. The token returned is cached to avoid multiple network round-trips.
- Step 2b
The monascalog transport of Beaver batches multiple logs (operational or audit) and posts them to the monasca-log-api VIP over a secure connection. Failure logs are written to the local Beaver log.
- Step 2c
The REST API client for monasca-log-api makes a token-request call to Keystone passing in credentials. The token returned is cached to avoid multiple network round-trips.
- Step 2d
The REST API client for monasca-log-api batches multiple logs (operational or audit) and posts them to the monasca-log-api VIP over a secure connection.
12.2.2.3 Steps 3a- 3b #
The Logging API (monasca-log API) communicates with Keystone to validate the incoming request, and then sends the logs to Kafka.
- Step 3a
The monasca-log-api WSGI pipeline is configured to validate incoming request tokens with Keystone. The keystone middleware used for this purpose is configured to use the monasca-log-api admin user, password and project that have the required keystone role to validate a token.
- Step 3b
Monasca-log-api sends log messages to Kafka using a language-agnostic TCP protocol.
12.2.2.4 Steps 4- 8 #
Logstash pulls messages from Kafka, identifies the log type, and transforms the messages into either the audit log format or operational format. Then Logstash sends the messages to Elasticsearch, using either an audit or operational indices.
- Step 4
Logstash input workers pull log messages from the Kafka-Logstash topic using TCP.
- Step 5
This Logstash filter processes the log message in-memory in the request pipeline. Logstash identifies the log type from this field.
- Step 6
This Logstash filter processes the log message in-memory in the request pipeline. If the message is of audit-log type, Logstash transforms it from the monasca-log-api envelope format to the original CADF format.
- Step 7
This Logstash filter determines which index should receive the log message. There are separate indices in Elasticsearch for operational versus audit logs.
- Step 8
Logstash output workers write the messages read from Kafka to the daily index in the local Elasticsearch instance.
12.2.2.5 Steps 9- 12 #
When an administrator who has access to the guest network accesses the Kibana client and makes a request, Apache forwards the request to the Kibana NodeJS server. Then the server uses the Elasticsearch REST API to service the client requests.
- Step 9
An administrator who has access to the guest network accesses the Kibana client to view and search log data. The request can originate from the external network in the cloud through a tenant that has a pre-defined access route to the guest network.
- Step 10
An administrator who has access to the guest network uses a web browser and points to the Kibana URL. This allows the user to search logs and view Dashboard reports.
- Step 11
The authenticated request is forwarded to the Kibana NodeJS server to render the required dashboard, visualization, or search page.
- Step 12
The Kibana NodeJS web server uses the Elasticsearch REST API in localhost to service the UI requests.
12.2.2.6 Steps 13- 15 #
Log data is backed-up and deleted in the final steps.
- Step 13
A daily cron job running in the ELK node runs curator to prune old Elasticsearch log indices.
- Step 14
The curator configuration is done at the deployer node through the Ansible role logging-common. Curator is scripted to then prune or clone old indices based on this configuration.
- Step 15
The audit logs are configured to be backed up by the HPE Helion OpenStack Freezer product. For more information about Freezer (and Bura), see Chapter 14, Backup and Restore.
12.2.2.7 How Long are Log Files Retained? #
The logs that are centrally stored are saved to persistent storage as
Elasticsearch indices. These indices are stored in the partition
/var/lib/elasticsearch on each of the Elasticsearch
cluster nodes. Out of the box, logs are stored in one Elasticsearch index
per service. As more days go by, the number of indices stored in this disk
partition grows. Eventually the partition fills up. If they are
open, each of these indices takes up CPU
and memory. If these indices are left unattended they will continue to
consume system resources and eventually deplete them.
Elasticsearch, by itself, does not prevent this from happening.
HPE Helion OpenStack uses a tool called curator that is developed by the Elasticsearch community to handle these situations. HPE Helion OpenStack installs and uses a curator in conjunction with several configurable settings. This curator is called by cron and performs the following checks:
First Check. The hourly cron job checks to see if the currently used Elasticsearch partition size is over the value set in:
curator_low_watermark_percent
If it is higher than this value, the curator deletes old indices according to the value set in:
curator_num_of_indices_to_keep
Second Check. Another check is made to verify if the partition size is below the high watermark percent. If it is still too high, curator will delete all indices except the current one that is over the size as set in:
curator_max_index_size_in_gb
Third Check. A third check verifies if the partition size is still too high. If it is, curator will delete all indices except the current one.
Final Check. A final check verifies if the partition size is still high. If it is, an error message is written to the log file but the current index is NOT deleted.
In the case of an extreme network issue, log files can run out of disk space
in under an hour. To avoid this HPE Helion OpenStack uses a shell script called
logrotate_if_needed.sh. The cron process runs this script
every 5 minutes to see if the size of /var/log has
exceeded the high_watermark_percent (95% of the disk, by default). If it is
at or above this level, logrotate_if_needed.sh runs the
logrotate script to rotate logs and to free up extra
space. This script helps to minimize the chance of running out of disk space
on /var/log.
12.2.2.8 How Are Logs Rotated? #
HPE Helion OpenStack uses the cron process which in turn calls Logrotate to provide rotation, compression, and removal of log files. Each log file can be rotated hourly, daily, weekly, or monthly. If no rotation period is set then the log file will only be rotated when it grows too large.
Rotating a file means that the Logrotate process creates a copy of the log file with a new extension, for example, the .1 extension, then empties the contents of the original file. If a .1 file already exists, then that file is first renamed with a .2 extension. If a .2 file already exists, it is renamed to .3, etc., up to the maximum number of rotated files specified in the settings file. When Logrotate reaches the last possible file extension, it will delete the last file first on the next rotation. By the time the Logrotate process needs to delete a file, the results will have been copied to Elasticsearch, the central logging database.
The log rotation setting files can be found in the following directory
~/scratch/ansible/next/ardana/ansible/roles/logging-common/vars
These files allow you to set the following options:
- Service
The name of the service that creates the log entries.
- Rotated Log Files
List of log files to be rotated. These files are kept locally on the server and will continue to be rotated. If the file is also listed as Centrally Logged, it will also be copied to Elasticsearch.
- Frequency
The timing of when the logs are rotated. Options include:hourly, daily, weekly, or monthly.
- Max Size
The maximum file size the log can be before it is rotated out.
- Rotation
The number of log files that are rotated.
- Centrally Logged Files
These files will be indexed by Elasticsearch and will be available for searching in the Kibana user interface.
As an example, Freezer, the Backup and Restore (BURA) service, may be configured to create log files by setting the Rotated Log Files section to contain:
/var/log/freezer/freezer-scheduler.log
This configuration means that in the /var/log/freezer-agent directory, in a live environment, there should be a file called freezer-scheduler.log. As the log file grows, the cron process runs every hour to check the log file size against the settings in the configuration files. The example freezer-agent settings are described below.
| Service | Node Type | Rotated Log Files | Frequency | Max Size | Rotation | Centrally Logged Files |
|---|---|---|---|---|---|---|
|
Freezer |
Control |
/var/log/freezer/freezer-scheduler.log /var/log/freezer/freezer-agent-json.log |
Daily |
45 MB |
7 |
/var/log/freezer-agent/freezer-agent-json.log |
For the freezer-scheduler.log file specifically, the
information in the table tells the Logrotate process that the log file is to
be rotated daily, and it can have a maximum size of 45 MB. After a week of
log rotation, you might see something similar to this list:
freezer-scheduler.log at 10K freezer-scheduler.log.1 at 123K freezer-scheduler.log.2.gz at 13K freezer-scheduler.log.3.gz at 17K freezer-scheduler.log.4.gz at 128K freezer-scheduler.log.5.gz at 22K freezer-scheduler.log.6.gz at 323K freezer-scheduler.log.7.gz at 123K
Since the Rotation value is set to 7 for this log file, there will never be
a freezer-scheduler.log.8.gz. When the cron process runs
its checks, if the freezer-scheduler.log size is more
than 45 MB, then Logrotate rotates the file.
In this example, the following log files are rotated:
/var/log/freezer/freezer-scheduler.log /var/log/freezer/freezer-agent-json.log
However, in this example, only the following file is centrally logged with Elasticsearch:
/var/log/freezer/freezer-agent-json.log
Only files that are listed in the Centrally Logged Files section are copied to Elasticsearch.
All of the variables for the Logrotate process are found in the following file:
~/scratch/ansible/next/ardana/ansible/roles/logging-ansible/logging-common/defaults/main.yml
Cron runs Logrotate hourly. Every 5 minutes another process is run called "logrotate_if_needed" which uses a watermark value to determine if the Logrotate process needs to be run. If the "high watermark" has been reached, and the /var/log partition is more than 95% full (by default - this can be adjusted), then Logrotate will be run within 5 minutes.
12.2.2.9 Are Log Files Backed-Up To Elasticsearch? #
While centralized logging is enabled out of the box, the backup of these logs is not. The reason is because Centralized Logging relies on the Elasticsearch FileSystem Repository plugin, which in turn requires shared disk partitions to be configured and accessible from each of the Elasticsearch nodes. Since there are multiple ways to setup a shared disk partition, HPE Helion OpenStack allows you to choose an approach that works best for your deployment before enabling the back-up of log files to Elasticsearch.
If you enable automatic back-up of centralized log files, then all the logs collected from the cloud nodes will be backed-up to Elasticsearch. Every hour, in the management controller nodes where Elasticsearch is setup, a cron job runs to check if Elasticsearch is running low on disk space. If the check succeeds, it further checks if the backup feature is enabled. If enabled, the cron job saves a snapshot of the Elasticsearch indices to the configured shared disk partition using curator. Next, the script starts deleting the oldest index and moves down from there checking each time if there is enough space for Elasticsearch. A check is also made to ensure that the backup runs only once a day.
For steps on how to enable automatic back-up, see Section 12.2.5, “Configuring Centralized Logging”.
12.2.3 Accessing Log Data #
All logging data in HPE Helion OpenStack is managed by the Centralized Logging Service and can be viewed or analyzed by Kibana. Kibana is the only graphical interface provided with HPE Helion OpenStack to search or create a report from log data. Operations Console provides only a link to the Kibana Logging dashboard.
The following two methods allow you to access the Kibana Logging dashboard to search log data:
To learn more about Kibana, read the Getting Started with Kibana guide.
12.2.3.1 Use the Operations Console Link #
Operations Console allows you to access Kibana in the same tool that you use to manage the other HPE Helion OpenStack resources in your deployment. To use Operations Console, you must have the correct permissions. For more about permission requirements, see Book “User Guide”, Chapter 1 “Using the Operations Console”, Section 1.2 “Connecting to the Operations Console”.
To use Operations Console:
In a browser, open the Operations Console.
On the login page, enter the user name, and the Password, and then click LOG IN.
On the Home/Central Dashboard page, click the menu represented by 3 horizontal lines (
).
From the menu that slides in on the left, select Home, and then select Logging.
On the Home/Logging page, click View Logging Dashboard.
Important
In HPE Helion OpenStack, Kibana usually runs on a different network than Operations Console. Due to this configuration, it is possible that using Operations Console to access Kibana will result in an “404 not found” error. This error only occurs if the user has access only to the public facing network.
12.2.3.2 Using Kibana to Access Log Data #
Kibana is an open-source, data-visualization plugin for Elasticsearch. Kibana provides visualization capabilities using the log content indexed on an Elasticsearch cluster. Users can create bar and pie charts, line and scatter plots, and maps using the data collected by HPE Helion OpenStack in the cloud log files.
While creating Kibana dashboards is beyond the scope of this document, it is important to know that the dashboards you create are JSON files that you can modify or create new dashboards based on existing dashboards.
Note
Kibana is client-server software. To operate properly, the browser must be able to access port 5601 on the control plane.
| Field | Default Value | Description |
|---|---|---|
| user | kibana |
Username that will be required for logging into the Kibana UI. |
| password | random password is generated |
Password generated during installation that is used to login to the Kibana UI. |
12.2.3.3 Logging into Kibana #
To log into Kibana to view data, you must make sure you have the required login configuration.
Verify login credentials: Section 12.2.3.3.1, “Verify Login Credentials”
Find the randomized password: Section 12.2.3.3.2, “Find the Randomized Password”
Access Kibana using a direct link: Section 12.2.3.3.3, “Access Kibana Using a Direct Link:”
12.2.3.3.1 Verify Login Credentials #
During the installation of Kibana, a password is automatically set and it is randomized. Therefore, unless an administrator has already changed it, you need to retrieve the default password from a file on the control plane node.
12.2.3.3.2 Find the Randomized Password #
To find the Kibana password, run:
ardana >grep kibana ~/scratch/ansible/next/my_cloud/stage/internal/CloudModel.yaml
12.2.3.3.3 Access Kibana Using a Direct Link: #
This section helps you verify the Horizon virtual IP (VIP) address that you should use.
To find hostname, run:
ardana >grep -i log-svr /etc/hostsNavigate to the following directory:
ardana >~/openstack/my_cloud/definition/dataNote
The file
network_groups.ymlin the~/openstack/my_cloud/definition/datadirectory is the input model file that may be copied automatically to other directories.Open the following file for editing:
network_groups.yml
Find the following entry:
external-name
If your administrator set a hostname value in the EXTERNAL_NAME field during the configuration process for your cloud, then Kibana will be accessed over port 5601 on that hostname.
If your administrator did not set a hostname value, then to determine which IP address to use, from your Cloud Lifecycle Manager, run:
ardana >grep HZN-WEB /etc/hostsThe output of the grep command should show you the virtual IP address for Kibana that you should use.
Important
If nothing is returned by the grep command, you can open the following file to look for the IP address manually:
/etc/hosts
Access to Kibana will be over port 5601 of that virtual IP address. Example:
https://VIP:5601
12.2.4 Managing the Centralized Logging Feature #
No specific configuration tasks are required to use Centralized Logging, as it is enabled by default after installation. However, you can configure the individual components as needed for your environment.
12.2.4.1 How Do I Stop and Start the Logging Service? #
Although you might not need to stop and start the logging service very often, you may need to if, for example, one of the logging services is not behaving as expected or not working.
You cannot enable or disable centralized logging across all services unless you stop all centralized logging. Instead, it is recommended that you enable or disable individual log files in the <service>-clr.yml files and then reconfigure logging. You would enable centralized logging for a file when you want to make sure you are able to monitor those logs in Kibana.
In HPE Helion OpenStack, the logging-ansible restart playbook has been updated to manage the start,stop, and restart of the Centralized Logging Service in a specific way. This change was made to ensure the proper stop, start, and restart of Elasticsearch.
Important
It is recommended that you only use the logging playbooks to perform the start, stop, and restart of the Centralized Logging Service. Manually mixing the start, stop, and restart operations with the logging playbooks will result in complex failures.
The steps in this section only impact centralized logging. Logrotate is an essential feature that keeps the service log files from filling the disk and will not be affected.
Important
These playbooks must be run from the Cloud Lifecycle Manager.
To stop the Logging service:
To change to the directory containing the ansible playbook, run
ardana >cd ~/scratch/ansible/next/ardana/ansibleTo run the ansible playbook that will stop the logging service, run:
ardana >ansible-playbook -i hosts/verb_hosts logging-stop.yml
To start the Logging service:
To change to the directory containing the ansible playbook, run
ardana >cd ~/scratch/ansible/next/ardana/ansibleTo run the ansible playbook that will stop the logging service, run:
ardana >ansible-playbook -i hosts/verb_hosts logging-start.yml
12.2.4.2 How Do I Enable or Disable Centralized Logging For a Service? #
To enable or disable Centralized Logging for a service you need to modify the configuration for the service, set the enabled flag to true or false, and then reconfigure logging.
Important
There are consequences if you enable too many logging files for a service. If there is not enough storage to support the increased logging, the retention period of logs in Elasticsearch is decreased. Alternatively, if you wanted to increase the retention period of log files or if you did not want those logs to show up in Kibana, you would disable centralized logging for a file.
To enable Centralized Logging for a service:
Use the documentation provided with the service to ensure it is not configured for logging.
To find the HPE Helion OpenStack file to edit, run:
ardana >find ~/openstack/my_cloud/config/logging/vars/ -name "*service-name*"Edit the file for the service for which you want to enable logging.
To enable Centralized Logging, find the following code and change the enabled flag to true, to disable, change the enabled flag to false:
logging_options: - centralized_logging: enabled: true format: jsonSave the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To reconfigure logging, run:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts kronos-reconfigure.ymlardana >cd ~/openstack/ardana/ansible/ardana >ansible-playbook -i hosts/localhost config-processor-run.ymlardana >ansible-playbook -i hosts/localhost ready-deployment.yml
Sample of a Freezer file enabled for Centralized logging:
---
sub_service:
hosts: FRE-AGN
name: freezer-agent
service: freezer
monitoring:
enabled: true
external_name: backup
logging_dir: /var/log/freezer
logging_options:
- files:
- /var/log/freezer/freezer-agent.log
- /var/log/freezer/freezer-scheduler.log
- centralized_logging:
enabled: true
format: json12.2.5 Configuring Centralized Logging #
You can adjust the settings for centralized logging when you are troubleshooting problems with a service or to decrease log size and retention to save on disk space. For steps on how to configure logging settings, refer to the following tasks:
12.2.5.1 Configuration Files #
Centralized Logging settings are stored in the configuration files in the
following directory on the Cloud Lifecycle Manager:
~/openstack/my_cloud/config/logging/
The configuration files and their use are described below:
| File | Description |
|---|---|
| main.yml | Main configuration file for all centralized logging components. |
| elasticsearch.yml.j2 | Main configuration file for Elasticsearch. |
| elasticsearch-default.j2 | Default overrides for the Elasticsearch init script. |
| kibana.yml.j2 | Main configuration file for Kibana. |
| kibana-apache2.conf.j2 | Apache configuration file for Kibana. |
| logstash.conf.j2 | Logstash inputs/outputs configuration. |
| logstash-default.j2 | Default overrides for the Logstash init script. |
| beaver.conf.j2 | Main configuration file for Beaver. |
| vars | Path to logrotate configuration files. |
12.2.5.2 Planning Resource Requirements #
The Centralized Logging service needs to have enough resources available to it to perform adequately for different scale environments. The base logging levels are tuned during installation according to the amount of RAM allocated to your control plane nodes to ensure optimum performance.
These values can be viewed and changed in the
~/openstack/my_cloud/config/logging/main.yml file, but you
will need to run a reconfigure of the Centralized Logging service if changes
are made.
Warning
The total process memory consumption for Elasticsearch will be the above
allocated heap value (in
~/openstack/my_cloud/config/logging/main.yml) plus any Java
Virtual Machine (JVM) overhead.
Setting Disk Size Requirements
In the entry-scale models, the disk partition sizes on your controller nodes
for the logging and Elasticsearch data are set as a percentage of your total
disk size. You can see these in the following file on the Cloud Lifecycle Manager
(deployer):
~/openstack/my_cloud/definition/data/<controller_disk_files_used>
Sample file settings:
# Local Log files. - name: log size: 13% mount: /var/log fstype: ext4 mkfs-opts: -O large_file # Data storage for centralized logging. This holds log entries from all # servers in the cloud and hence can require a lot of disk space. - name: elasticsearch size: 30% mount: /var/lib/elasticsearch fstype: ext4
Important
The disk size is set automatically based on the hardware configuration. If you need to adjust it, you can set it manually with the following steps.
To set disk sizes:
Log in to the Cloud Lifecycle Manager (deployer).
Open the following file:
~/openstack/my_cloud/definition/data/disks.yml
Make any desired changes.
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -A gitardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the logging reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts kronos-reconfigure.yml
12.2.5.3 Backing Up Elasticsearch Log Indices #
The log files that are centrally collected in HPE Helion OpenStack are stored by
Elasticsearch on disk in the /var/lib/elasticsearch
partition. However, this is distributed across each of the Elasticsearch
cluster nodes as shards. A cron job runs periodically to see if the disk
partition runs low on space, and, if so, it runs curator to delete the old
log indices to make room for new logs. This deletion is permanent and the
logs are lost forever. If you want to backup old logs, for example to comply
with certain regulations, you can configure automatic backup of
Elasticsearch indices.
Important
If you need to restore data that was archived prior to HPE Helion OpenStack 8 and used the older versions of Elasticsearch, then this data will need to be restored to a separate deployment of Elasticsearch.
This can be accomplished using the following steps:
Deploy a separate distinct Elasticsearch instance version matching the version in HPE Helion OpenStack.
Configure the backed-up data using NFS or some other share mechanism to be available to the Elasticsearch instance matching the version in HPE Helion OpenStack.
Before enabling automatic back-ups, make sure you understand how much disk space you will need, and configure the disks that will store the data. Use the following checklist to prepare your deployment for enabling automatic backups:
| ☐ | Item |
|---|---|
| ☐ |
Add a shared disk partition to each of the Elasticsearch controller nodes. The default partition name used for backup is /var/lib/esbackup You can change this by:
|
| ☐ |
Ensure the shared disk has enough storage to retain backups for the desired retention period. |
To enable automatic back-up of centralized logs to Elasticsearch:
Log in to the Cloud Lifecycle Manager (deployer node).
Open the following file in a text editor:
~/openstack/my_cloud/config/logging/main.yml
Find the following variables:
curator_backup_repo_name: "es_{{host.my_dimensions.cloud_name}}" curator_es_backup_partition: /var/lib/esbackupTo enable backup, change the curator_enable_backup value to true in the curator section:
curator_enable_backup: true
Save your changes and re-run the configuration processor:
ardana >cd ~/openstackardana >git add -A # Verify the added filesardana >git statusardana >git commit -m "Enabling Elasticsearch Backup" $ cd ~/openstack/ardana/ansible $ ansible-playbook -i hosts/localhost config-processor-run.yml $ ansible-playbook -i hosts/localhost ready-deployment.ymlTo re-configure logging:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts kronos-reconfigure.ymlTo verify that the indices are backed up, check the contents of the partition:
ardana >ls /var/lib/esbackup
12.2.5.4 Restoring Logs From an Elasticsearch Backup #
To restore logs from an Elasticsearch backup, see https://www.elastic.co/guide/en/elasticsearch/reference/2.4/modules-snapshots.html.
Note
We do not recommend restoring to the original HPE Helion OpenStack Centralized Logging cluster as it may cause storage/capacity issues. We rather recommend setting up a separate ELK cluster of the same version and restoring the logs there.
12.2.5.5 Tuning Logging Parameters #
When centralized logging is installed in HPE Helion OpenStack, parameters for Elasticsearch heap size and logstash heap size are automatically configured based on the amount of RAM on the system. These values are typically the required values, but they may need to be adjusted if performance issues arise, or disk space issues are encountered. These values may also need to be adjusted if hardware changes are made after an installation.
These values are defined at the top of the following file
.../logging-common/defaults/main.yml. An example of the
contents of the file is below:
1. Select heap tunings based on system RAM
#-------------------------------------------------------------------------------
threshold_small_mb: 31000
threshold_medium_mb: 63000
threshold_large_mb: 127000
tuning_selector: " {% if ansible_memtotal_mb < threshold_small_mb|int %}
demo
{% elif ansible_memtotal_mb < threshold_medium_mb|int %}
small
{% elif ansible_memtotal_mb < threshold_large_mb|int %}
medium
{% else %}
large
{%endif %}
"
logging_possible_tunings:
2. RAM < 32GB
demo:
elasticsearch_heap_size: 512m
logstash_heap_size: 512m
3. RAM < 64GB
small:
elasticsearch_heap_size: 8g
logstash_heap_size: 2g
4. RAM < 128GB
medium:
elasticsearch_heap_size: 16g
logstash_heap_size: 4g
5. RAM >= 128GB
large:
elasticsearch_heap_size: 31g
logstash_heap_size: 8g
logging_tunings: "{{ logging_possible_tunings[tuning_selector] }}"This specifies thresholds for what a small, medium, or large system would look like, in terms of memory. To see what values will be used, see what RAM your system uses, and see where it fits in with the thresholds to see what values you will be installed with. To modify the values, you can either adjust the threshold values so that your system will change from a small configuration to a medium configuration, for example, or keep the threshold values the same, and modify the heap_size variables directly for the selector that your system is set for. For example, if your configuration is a medium configuration, which sets heap_sizes to 16 GB for Elasticsearch and 4 GB for logstash, and you want twice as much set aside for logstash, then you could increase the 4 GB for logstash to 8 GB.
12.2.6 Configuring Settings for Other Services #
When you configure settings for the Centralized Logging Service, those changes impact all services that are enabled for centralized logging. However, if you only need to change the logging configuration for one specific service, you will want to modify the service's files instead of changing the settings for the entire Centralized Logging service. This topic helps you complete the following tasks:
12.2.6.1 Setting Logging Levels for Services #
When it is necessary to increase the logging level for a specific service to troubleshoot an issue, or to decrease logging levels to save disk space, you can edit the service's config file and then reconfigure logging. All changes will be made to the service's files and not to the Centralized Logging service files.
Messages only appear in the log files if they are the same as or more severe than the log level you set. The DEBUG level logs everything. Most services default to the INFO logging level, which lists informational events, plus warnings, errors, and critical errors. Some services provide other logging options which will narrow the focus to help you debug an issue, receive a warning if an operation fails, or if there is a serious issue with the cloud.
For more information on logging levels, see the OpenStack Logging Guidelines documentation.
12.2.6.2 Configuring the Logging Level for a Service #
If you want to increase or decrease the amount of details that are logged by a service, you can change the current logging level in the configuration files. Most services support, at a minimum, the DEBUG and INFO logging levels. For more information about what levels are supported by a service, check the documentation or Website for the specific service.
12.2.6.3 Barbican #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| Barbican | barbican-api |
INFO (default) DEBUG |
To change the Barbican logging level:
Log in to the Cloud Lifecycle Manager (deployer).
Open the following file:
ardana >cd ~/openstack/my_cloud/config/barbican/barbican_deploy_config.ymlTo change the logging level, use ALL CAPS to set the desired level in the following lines:
barbican_loglevel: {{ openstack_loglevel | default('INFO') }} barbican_logstash_loglevel: {{ openstack_loglevel | default('INFO') }}Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts barbican-reconfigure.yml
12.2.6.4 Block Storage (Cinder) #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| Cinder |
cinder-local cinder-logstash |
INFO DEBUG (default) |
To enable Cinder logging:
On each Control Node, edit
/opt/stack/service/cinder-volume-CURRENT_VENV/etc/volume-logging.confIn the
Writes to disksection, changeWARNINGtoDEBUG.# Writes to disk [handler_watchedfile] class: handlers.WatchedFileHandler args: ('/var/log/cinder/cinder-volume.log',) formatter: context # level: WARNING level: DEBUGOn the Cloud Lifecycle Manager (deployer) node, edit
/var/lib/ardana/openstack/my_cloud/config/cinder/volume.conf.j2, adding a linedebug = TRUEto the default section.[DEFAULT] log_config_append={{cinder_volume_conf_dir }}/volume-logging.conf debug = TrueRun the following commands:
ardana >cd ~/openstack/ardana/ansible/ardana >git commit -am "Enable Cinder Debug"ardana >ansible-playbook config-processor-run.ymlardana >ansible-playbook ready-deployment.ymlardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook cinder-reconfigure.ymlardana >sudo grep -i debug /opt/stack/service/cinder-volume-CURRENT_VENV/etc/volume.confdebug = True
Important
Leaving debugs enabled is not recommended. After collecting necessary logs, disable debug with the following steps:
On the Cloud Lifecycle Manager (deployer) node, edit
/var/lib/ardana/openstack/my_cloud/config/cinder/volume.conf.j2, comment the linedebug = TRUEin the default section.[DEFAULT] log_config_append={{cinder_volume_conf_dir }}/volume-logging.conf #debug = TrueRun the following commands:
ardana >cd ~/openstack/ardana/ansible/ardana >git commit -am "Disable Cinder Debug"ardana >ansible-playbook config-processor-run.ymlardana >ansible-playbook ready-deployment.ymlardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook cinder-reconfigure.ymlardana >sudo grep -i debug /opt/stack/service/cinder-volume-CURRENT_VENV/etc/volume.conf#debug = True
12.2.6.5 Ceilometer #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| Ceilometer |
ceilometer-api ceilometer-collector ceilometer-agent-notification ceilometer-agent-central ceilometer-expirer |
INFO (default) DEBUG |
To change the Ceilometer logging level:
Log in to the Cloud Lifecycle Manager (deployer).
Open the following file:
~/openstack/ardana/ansible/roles/_CEI-CMN/defaults/main.yml
To change the logging level, use ALL CAPS to set the desired level in the following lines:
ceilometer_loglevel: INFO ceilometer_logstash_loglevel: INFO
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts ceilometer-reconfigure.yml
12.2.6.6 Compute (Nova) #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| nova |
INFO (default) DEBUG |
To change the Nova logging level:
Log in to the Cloud Lifecycle Manager.
The Neutron service component logging can be changed by modifying the following files:
~/openstack/my_cloud/config/nova/novncproxy-logging.conf.j2 ~/openstack/my_cloud/config/nova/api-logging.conf.j2 ~/openstack/my_cloud/config/nova/compute-logging.conf.j2 ~/openstack/my_cloud/config/nova/conductor-logging.conf.j2 ~/openstack/my_cloud/config/nova/consoleauth-logging.conf.j2 ~/openstack/my_cloud/config/nova/scheduler-logging.conf.j2
To change the logging level, use ALL CAPS to set the desired level in the following line in the [handler_logstash] section:
level: INFO
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts nova-reconfigure.yml
12.2.6.7 Designate #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| Designate |
designate-api designate-central designate-mdns designate-pool-manager designate-zone-manager designate-api-json designate-central-json designate-mdns-json designate-pool-manager-json designate-zone-manager-json |
INFO (default) DEBUG |
12.2.6.8 Freezer #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| Freezer |
freezer-agent freezer-api freezer-scheduler |
INFO (default) |
Important
Currently the freezer service does not support any level other than INFO.
12.2.6.9 ARDANA-UX-Services #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| ARDANA-UX-Services |
INFO (default) DEBUG |
To change the ARDANA-UX-Services logging level:
Log in to the Cloud Lifecycle Manager (deployer).
Open the following file:
~/openstack/ardana/ansible/roles/HUX-SVC/defaults/main.yml
To change the logging level, set the desired level in the following line:
hux_svc_default_log_level: info
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts ardana-ux-services-reconfigure.yml
12.2.6.10 Identity (Keystone) #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| Keystone | key-api |
INFO (default) DEBUG WARN ERROR |
To change the Keystone logging level:
Log in to the Cloud Lifecycle Manager (deployer).
Open the following file:
~/openstack/my_cloud/config/keystone/keystone_deploy_config.yml
To change the logging level, use ALL CAPS to set the desired level in the following lines:
keystone_loglevel: INFO keystone_logstash_loglevel: INFO
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts keystone-reconfigure.yml
12.2.6.11 Image (Glance) #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| Glance |
glance-api glance-registry |
INFO (default) DEBUG |
To change the Glance logging level:
Log in to the Cloud Lifecycle Manager (deployer).
Open the following file:
~/openstack/my_cloud/config/glance/glance-[api,registry]-logging.conf.j2
To change the logging level, use ALL CAPS to set the desired level in the following line in the [handler_logstash] section:
level: INFO
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts glance-reconfigure.yml
12.2.6.12 Ironic #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| ironic |
ironic-api-logging.conf.j2 ironic-conductor-logging.conf.j2 |
INFO (default) DEBUG |
To change the Ironic logging level:
Log in to the Cloud Lifecycle Manager (deployer).
Change to the following directory:
~/openstack/my_cloud/config/ironic
To change the logging for one of the sub-components, open one of the following files:
ironic-api-logging.conf.j2 ironic-conductor-logging.conf.j2
To change the logging level, use ALL CAPS to set the desired level in the following line in the [handler_logstash] section:
level: INFO
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts ironic-reconfigure.yml
12.2.6.13 Monitoring (Monasca) #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| monasca |
monasca-persister zookeeper storm monasca-notification monasca-api kafka monasca-agent |
WARN (default) INFO |
To change the Monasca logging level:
Log in to the Cloud Lifecycle Manager (deployer).
Monitoring service component logging can be changed by modifying the following files:
~/openstack/ardana/ansible/roles/monasca-persister/defaults/main.yml ~/openstack/ardana/ansible/roles/zookeeper/defaults/main.yml ~/openstack/ardana/ansible/roles/storm/defaults/main.yml ~/openstack/ardana/ansible/roles/monasca-notification/defaults/main.yml ~/openstack/ardana/ansible/roles/monasca-api/defaults/main.yml ~/openstack/ardana/ansible/roles/kafka/defaults/main.yml ~/openstack/ardana/ansible/roles/monasca-agent/defaults/main.yml (For this file, you will need to add the variable)
To change the logging level, use ALL CAPS to set the desired level in the following line:
monasca_log_level: WARN
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts monasca-reconfigure.yml
12.2.6.14 Networking (Neutron) #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| neutron |
neutron-server dhcp-agent l3-agent lbaas-agent metadata-agent openvswitch-agent vpn-agent |
INFO (default) DEBUG |
To change the Neutron logging level:
Log in to the Cloud Lifecycle Manager.
The Neutron service component logging can be changed by modifying the following files:
~/openstack/ardana/ansible/roles/neutron-common/templates/dhcp-agent-logging.conf.j2 ~/openstack/ardana/ansible/roles/neutron-common/templates/l3-agent-logging.conf.j2 ~/openstack/ardana/ansible/roles/neutron-common/templates/lbaas-agent-logging.conf.j2 ~/openstack/ardana/ansible/roles/neutron-common/templates/metadata-agent-logging.conf.j2 ~/openstack/ardana/ansible/roles/neutron-common/templates/openvswitch-agent-logging.conf.j2 ~/openstack/ardana/ansible/roles/neutron-common/templates/vpn-agent-logging.conf.j2
To change the logging level, use ALL CAPS to set the desired level in the following line in the [handler_logstash] section:
level: INFO
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansible git add -A git commit -m "My config or other commit message"To run the configuration processor:
cd ~/openstack/ardana/ansible
ardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts neutron-reconfigure.yml
12.2.6.15 Object Storage (Swift) #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| swift |
INFO (default) DEBUG |
Note
Currently it is not recommended to log at any level other than INFO.
12.2.6.16 Octavia #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| octavia |
Octavia-api Octavia-worker Octavia-hk Octavia-hm |
INFO (default) DEBUG |
To change the Octavia logging level:
Log in to the Cloud Lifecycle Manager.
The Octavia service component logging can be changed by modifying the following files:
~/openstack/my_cloud/config/octavia/octavia-api.conf.j2 ~/openstack/my_cloud/config/octavia/octavia-worker.conf.j2 ~/openstack/my_cloud/config/octavia/octavia-hk-logging.conf.j2 ~/openstack/my_cloud/config/octavia/Octavia-hm-logging.conf.j2
To change the logging level, use ALL CAPS to set the desired level in the following line in the [handler_logstash] section:
level: INFO
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts octavia-reconfigure.yml
12.2.6.17 Operations Console #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| opsconsole |
ops-web ops-mon |
INFO (default) DEBUG |
To change the Operations Console logging level:
Log in to the Cloud Lifecycle Manager.
Open the following file:
~/openstack/ardana/ansible/roles/OPS-WEV/defaults/main.yml
To change the logging level, use ALL CAPS to set the desired level in the following line:
ops_console_loglevel: "{{ openstack_loglevel | default('INFO') }}"To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts ops-console-reconfigure.yml
12.2.6.18 Orchestration (Heat) #
| Service | Sub-component | Supported Logging Levels |
|---|---|---|
| heat |
api-cfn api-cloudwatch api-logging engine |
INFO (default) DEBUG |
To change the Heat logging level:
Log in to the Cloud Lifecycle Manager (deployer).
Open the following file:
~/openstack/my_cloud/config/heat/*-logging.conf.j2
To change the logging level, use ALL CAPS to set the desired level in the following line in the [handler_logstash] section:
level: INFO
Save the changes to the file.
To commit the changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"To run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlTo create a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlTo run the reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts heat-reconfigure.yml
12.2.6.19 Selecting Files for Centralized Logging #
As you use HPE Helion OpenStack, you might find a need to redefine which log files are rotated on disk or transferred to centralized logging. These changes are all made in the centralized logging definition files.
HPE Helion OpenStack uses the logrotate service to provide rotation, compression, and
removal of log files. All of the tunable variables for the logrotate process
itself can be controlled in the following file:
~/openstack/ardana/ansible/roles/logging-common/defaults/main.yml
You can find the centralized logging definition files for each service in
the following directory:
~/openstack/ardana/ansible/roles/logging-common/vars
You can change log settings for a service by following these steps.
Log in to the Cloud Lifecycle Manager.
Open the *.yml file for the service or sub-component that you want to modify.
Using Freezer, the Backup, Restore, and Archive service as an example:
ardana >vi ~/openstack/ardana/ansible/roles/logging-common/vars/freezer-agent-clr.ymlConsider the opening clause of the file:
sub_service: hosts: FRE-AGN name: freezer-agent service: freezer
The hosts setting defines the role which will trigger this logrotate definition being applied to a particular host. It can use regular expressions for pattern matching, that is, NEU-.*.
The service setting identifies the high-level service name associated with this content, which will be used for determining log files' collective quotas for storage on disk.
Verify logging is enabled by locating the following lines:
centralized_logging: enabled: true format: rawjson
Note
When possible, centralized logging is most effective on log files generated using logstash-formatted JSON. These files should specify format: rawjson. When only plaintext log files are available, format: json is appropriate. (This will cause their plaintext log lines to be wrapped in a json envelope before being sent to centralized logging storage.)
Observe log files selected for rotation:
- files: - /var/log/freezer/freezer-agent.log - /var/log/freezer/freezer-scheduler.log log_rotate: - daily - compress - missingok - notifempty - copytruncate - maxsize 80M - rotate 14
Note
With the introduction of dynamic log rotation, the frequency (that is, daily) and file size threshold (that is, maxsize) settings no longer have any effect. The rotate setting may be easily overridden on a service-by-service basis.
Commit any changes to your local git repository:
ardana >cd ~/openstack/ardana/ansibleardana >git add -Aardana >git commit -m "My config or other commit message"Run the configuration processor:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost config-processor-run.ymlCreate a deployment directory:
ardana >cd ~/openstack/ardana/ansibleardana >ansible-playbook -i hosts/localhost ready-deployment.ymlRun the logging reconfigure playbook:
ardana >cd ~/scratch/ansible/next/ardana/ansibleardana >ansible-playbook -i hosts/verb_hosts kronos-reconfigure.yml
12.2.6.20 Controlling Disk Space Allocation and Retention of Log Files #
Each service is assigned a weighted allocation of the
/var/log filesystem's capacity. When all its log files'
cumulative sizes exceed this allocation, a rotation is triggered for that
service's log files according to the behavior specified in the
/etc/logrotate.d/* specification.
These specification files are auto-generated based on YML sources delivered with the Cloud Lifecycle Manager codebase. The source files can be edited and reapplied to control the allocation of disk space across services or the behavior during a rotation.
Disk capacity is allocated as a percentage of the total weighted value of all services running on a particular node. For example, if 20 services run on the same node, all with a default weight of 100, they will each be granted 1/20th of the log filesystem's capacity. If the configuration is updated to change one service's weight to 150, all the services' allocations will be adjusted to make it possible for that one service to consume 150% of the space available to other individual services.
These policies are enforced by the script
/opt/kronos/rotate_if_exceeded_quota.py, which will be
executed every 5 minutes via a cron job and will rotate the log files of any
services which have exceeded their respective quotas. When log rotation
takes place for a service, logs are generated to describe the activity in
/var/log/kronos/check_if_exceeded_quota.log.
When logrotate is performed on a service, its existing log files are compressed and archived to make space available for fresh log entries. Once the number of archived log files exceeds that service's retention thresholds, the oldest files are deleted. Thus, longer retention thresholds (that is, 10 to 15) will result in more space in the service's allocated log capacity being used for historic logs, while shorter retention thresholds (that is, 1 to 5) will keep more space available for its active plaintext log files.
Use the following process to make adjustments to services' log capacity allocations or retention thresholds:
Navigate to the following directory on your Cloud Lifecycle Manager:
~/stack/scratch/ansible/next/ardana/ansible
Open and edit the service weights file:
ardana >vi roles/kronos-logrotation/vars/rotation_config.ymlEdit the service parameters to set the desired parameters. Example:
cinder: weight: 300 retention: 2
Note
The retention setting of default will use recommend defaults for each services' log files.
Run the kronos-logrotation-deploy playbook:
ardana >ansible-playbook -i hosts/verb_hosts kronos-logrotation-deploy.ymlVerify the changes to the quotas have been changed:
Login to a node and check the contents of the file /opt/kronos/service_info.yml to see the active quotas for that node, and the specifications in /etc/logrotate.d/* for rotation thresholds.
12.2.6.21 Configuring Elasticsearch for Centralized Logging #
Elasticsearch includes some tunable options exposed in its configuration. HPE Helion OpenStack uses these options in Elasticsearch to prioritize indexing speed over search speed. HPE Helion OpenStack also configures Elasticsearch for optimal performance in low RAM environments. The options that HPE Helion OpenStack modifies are listed below along with an explanation about why they were modified.
These configurations are defined in the
~/openstack/my_cloud/config/logging/main.yml file and are
implemented in the Elasticsearch configuration file
~/openstack/my_cloud/config/logging/elasticsearch.yml.j2.
12.2.6.22 Safeguards for the Log Partitions Disk Capacity #
Because the logging partitions are at a high risk of filling up over time, a condition which can cause many negative side effects on services running, it is important to safeguard against log files consuming 100 % of available capacity.
This protection is implemented by pairs of low/high
watermark thresholds, with values
established in
~/stack/scratch/ansible/next/ardana/ansible/roles/logging-common/defaults/main.yml
and applied by the kronos-logrotation-deploy playbook.
var_log_low_watermark_percent (default: 80) sets a capacity level for the contents of the
/var/logpartition beyond which alarms will be triggered (visible to administrators in Monasca).var_log_high_watermark_percent (default: 95) defines how much capacity of the
/var/logpartition to make available for log rotation (in calculating weighted service allocations).var_audit_low_watermark_percent (default: 80) sets a capacity level for the contents of the
/var/auditpartition beyond which alarm notifications will be triggered.var_audit_high_watermark_percent (default: 95) sets a capacity level for the contents of the
/var/auditpartition which will cause log rotation to be forced according to the specification in/etc/auditlogrotate.conf.
12.2.7 Audit Logging Overview #
Existing OpenStack service logging varies widely across services. Generally, log messages do not have enough detail about who is requesting the application program interface (API), or enough context-specific details about an action performed. Often details are not even consistently logged across various services, leading to inconsistent data formats being used across services. These issues make it difficult to integrate logging with existing audit tools and processes.
To help you monitor your workload and data in compliance with your corporate, industry or regional policies, HPE Helion OpenStack provides auditing support as a basic security feature. The audit logging can be integrated with customer Security Information and Event Management (SIEM) tools and support your efforts to correlate threat forensics.
The HPE Helion OpenStack audit logging feature uses Audit Middleware for Python services. This middleware service is based on OpenStack services which use the Paste Deploy system. Most OpenStack services use the paste deploy mechanism to find and configure WSGI servers and applications. Utilizing the paste deploy system provides auditing support in services with minimal changes.
By default, audit logging as a post-installation feature is disabled in the cloudConfig file on the Cloud Lifecycle Manager and it can only be enabled after HPE Helion OpenStack installation or upgrade.
The tasks in this section explain how to enable services for audit logging in your environment. HPE Helion OpenStack provides audit logging for the following services:
Nova
Barbican
Keystone
Cinder
Ceilometer
Neutron
Glance
Heat
For audit log backup information see Section 14.13, “Backing up and Restoring Audit Logs”
12.2.7.1 Audit Logging Checklist #
Before enabling audit logging, make sure you understand how much disk space you will need, and configure the disks that will store the logging data. Use the following table to complete these tasks:
12.2.7.1.1 Frequently Asked Questions #
- How are audit logs generated?
The audit logs are created by services running in the cloud management controller nodes. The events that create auditing entries are formatted using a structure that is compliant with Cloud Auditing Data Federation (CADF) policies. The formatted audit entries are then saved to disk files. For more information, see the Cloud Auditing Data Federation Website.
- Where are audit logs stored?
We strongly recommend adding a dedicated disk volume for
/var/audit.If the disk templates for the controllers are not updated to create a separate volume for
/var/audit, the audit logs will still be created in the root partition under the folder/var/audit. This could be problematic if the root partition does not have adequate space to hold the audit logs.
Warning
We recommend that you do not store audit logs in the
/var/logvolume. The/var/logvolume is used for storing operational logs and logrotation/alarms have been preconfigured for various services based on the size of this volume. Adding audit logs here may impact these causing undesired alarms. This would also impact the retention times for the operational logs.- Are audit logs centrally stored?
Yes. The existing operational log profiles have been configured to centrally log audit logs as well, once their generation has been enabled. The audit logs will be stored in separate Elasticsearch indices separate from the operational logs.
- How long are audit log files retained?
By default, audit logs are configured to be retained for 7 days on disk. The audit logs are rotated each day and the rotated files are stored in a compressed format and retained up to 7 days (configurable). The backup service has been configured to back up the audit logs to a location outside of the controller nodes for much longer retention periods.
- Do I lose audit data if a management controller node goes down?
Yes. For this reason, it is strongly recommended that you back up the audit partition in each of the management controller nodes for protection against any data loss.
12.2.7.1.2 Estimate Disk Size #
The table below provides estimates from each service of audit log size generated per day. The estimates are provided for environments with 100 nodes, 300 nodes, and 500 nodes.
| Service |
Log File Size: 100 nodes |
Log File Size: 300 nodes |
Log File Size: 500 nodes |
|---|---|---|---|
| Barbican | 2.6 MB | 4.2 MB | 5.6 MB |
| Keystone | 96 - 131 MB | 288 - 394 MB | 480 - 657 MB |
| Nova | 186 (with a margin of 46) MB | 557 (with a margin of 139) MB | 928 (with a margin of 232) MB |
| Ceilometer | 12 MB | 12 MB | 12 MB |
| Cinder | 2 - 250 MB | 2 - 250 MB | 2 - 250 MB |
| Neutron | 145 MB | 433 MB | 722 MB |
| Glance | 20 (with a margin of 8) MB | 60 (with a margin of 22) MB | 100 (with a margin of 36) MB |
| Heat | 432 MB (1 transaction per second) | 432 MB (1 transaction per second) | 432 MB (1 transaction per second) |
| Swift | 33 GB (700 transactions per second) | 102 GB (2100 transactions per second) | 172 GB (3500 transactions per second) |
12.2.7.1.3 Add disks to the controller nodes #
You need to add disks for the audit log partition to store the data in a secure manner. The steps to complete this task will vary depending on the type of server you are running. Please refer to the manufacturer’s instructions on how to add disks for the type of server node used by the management controller cluster. If you already have extra disks in the controller node, you can identify any unused one and use it for the audit log partition.
12.2.7.1.4 Update the disk template for the controller nodes #
Since audit logging is disabled by default, the audit volume groups in the disk templates are commented out. If you want to turn on audit logging, the template needs to be updated first. If it is not updated, there will be no back-up volume group. To update the disk template, you will need to copy templates from the examples folder to the definition folder and then edit the disk controller settings. Changes to the disk template used for provisioning cloud nodes must be made prior to deploying the nodes.
To update the disk controller template:
Log in to your Cloud Lifecycle Manager.
To copy the example templates folder, run the following command:
Important
If you already have the required templates in the definition folder, you can skip this step.
ardana >cp -r ~/openstack/examples/entry-scale-esx/* ~/openstack/my_cloud/definition/To change to the data folder, run:
ardana >cd ~/openstack/my_cloud/definition/To edit the disks controller settings, open the file that matches your server model and disk model in a text editor:
Model File entry-scale-kvm disks_controller_1TB.yml
disks_controller_600GB.yml
mid-scale disks_compute.yml
disks_control_common_600GB.yml
disks_dbmq_600GB.yml
disks_mtrmon_2TB.yml
disks_mtrmon_4.5TB.yml
disks_mtrmon_600GB.yml
disks_swobj.yml
disks_swpac.yml
To update the settings and enable an audit log volume group, edit the appropriate file(s) listed above and remove the '#' comments from these lines, confirming that they are appropriate for your environment.
- name: audit-vg physical-volumes: - /dev/sdz logical-volumes: - name: audit size: 95% mount: /var/audit fstype: ext4 mkfs-opts: -O large_file
12.2.7.1.5 Save your changes #
To save your changes you will use the GIT repository to add the setup disk files.
To save your changes:
To change to the openstack directory, run:
ardana >cd ~/openstackTo add the new and updated files, run:
ardana >git add -ATo verify the files are added, run:
ardana >git statusTo commit your changes, run:
ardana >git commit -m "Setup disks for audit logging"
12.2.7.2 Enable Audit Logging #
To enable audit logging you must edit your cloud configuration settings, save your changes and re-run the configuration processor. Then you can run the playbooks to create the volume groups and configure them.
In the ~/openstack/my_cloud/definition/cloudConfig.yml file,
service names defined under enabled-services or disabled-services override
the default setting.
The following is an example of your audit-settings section:
# Disc space needs to be allocated to the audit directory before enabling
# auditing.
# Default can be either "disabled" or "enabled". Services listed in
# "enabled-services" and "disabled-services" override the default setting.
audit-settings:
default: disabled
#enabled-services:
# - keystone
# - barbican
disabled-services:
- nova
- barbican
- keystone
- cinder
- ceilometer
- neutronIn this example, although the default setting for all services is set to disabled, keystone and barbican may be explicitly enabled by removing the comments from these lines and this setting overrides the default.
12.2.7.2.1 To edit the configuration file: #
Log in to your Cloud Lifecycle Manager.
To change to the cloud definition folder, run:
ardana >cd ~/openstack/my_cloud/definitionTo edit the auditing settings, in a text editor, open the following file:
cloudConfig.yml
To enable audit logging, begin by uncommenting the "enabled-services:" block.
enabled-service:
any service you want to enable for audit logging.
For example, Keystone has been enabled in the following text:
Default cloudConfig.yml file Enabling Keystone audit logging audit-settings: default: disabled enabled-services: # - keystone
audit-settings: default: disabled enabled-services: - keystone
To move the services you want to enable, comment out the service in the disabled section and add it to the enabled section. For example, Barbican has been enabled in the following text:
cloudConfig.yml file Enabling Barbican audit logging audit-settings: default: disabled enabled-services: - keystone disabled-services: - nova # - keystone - barbican - cinder
audit-settings: default: disabled enabled-services: - keystone - barbican disabled-services: - nova # - barbican # - keystone - cinder
12.2.7.2.2 To save your changes and run the configuration processor: #
To change to the openstack directory, run:
ardana >cd ~/openstackTo add the new and updated files, run:
ardana >git add -ATo verify the files are added, run:
ardana >git statusTo commit your changes, run:
ardana >git commit -m "Enable audit logging"To change to the directory with the ansible playbooks, run:
ardana >cd ~/openstack/ardana/ansibleTo rerun the configuration processor, run:
ardana >ansible-playbook -i hosts/localhost config-processor-run.ymlardana >ansible-playbook -i hosts/localhost ready-deployment.yml
12.2.7.2.3 To create the volume group: #
To change to the directory containing the osconfig playbook, run:
ardana >cd ~/scratch/ansible/next/ardana/ansibleTo remove the stub file that osconfig uses to decide if the disks are already configured, run:
ardana >ansible -i hosts/verb_hosts KEY-API -a 'sudo rm -f /etc/hos/osconfig-ran'Important
The osconfig playbook uses the stub file to mark already configured disks as "idempotent." To stop osconfig from identifying your new disk as already configured, you must remove the stub file /etc/hos/osconfig-ran before re-running the osconfig playbook.
To run the playbook that enables auditing for a service, run:
ardana >ansible-playbook -i hosts/verb_hosts osconfig-run.yml --limit KEY-APIImportant
The variable KEY-API is used as an example to cover the management controller cluster. To enable auditing for a service that is not run on the same cluster, add the service to the –limit flag in the above command. For example:
ardana >ansible-playbook -i hosts/verb_hosts osconfig-run.yml --limit KEY-API:NEU-SVR
12.2.7.2.4 To Reconfigure services for audit logging: #
To change to the directory containing the service playbooks, run:
ardana >cd ~/scratch/ansible/next/ardana/ansibleTo run the playbook that reconfigures a service for audit logging, run:
ardana >ansible-playbook -i hosts/verb_hosts SERVICE_NAME-reconfigure.ymlFor example, to reconfigure Keystone for audit logging, run:
ardana >ansible-playbook -i hosts/verb_hosts keystone-reconfigure.ymlRepeat steps 1 and 2 for each service you need to reconfigure.
Important
You must reconfigure each service that you changed to be enabled or disabled in the cloudConfig.yml file.
12.2.8 Troubleshooting #
For information on troubleshooting Central Logging, see Section 15.7.1, “Troubleshooting Centralized Logging”.
12.3 Metering Service (Ceilometer) Overview #
The HPE Helion OpenStack metering service collects and provides access to OpenStack usage data that can be used for billing reporting such as showback, and chargeback. The metering service can also provide general usage reporting. Ceilometer acts as the central collection and data access service to the meters provided by all the OpenStack services. The data collected is available both through the Monasca API and the Ceilometer V2 API.
Important
Ceilometer V2 API has been deprecated in Pike release upstream. Although the Ceilometer V2 API is still available with HPE Helion OpenStack, to prepare for eventual removal of Ceilometer V2 API in next release we recommend that users switch to the Monasca API to access data.
12.3.1 Metering Service New Functionality #
12.3.1.1 New Metering Functionality in HPE Helion OpenStack 8 #
Ceilometer is now integrated with Monasca to use it as the datastore. Ceilometer API also now queries the Monasca datastore using the Monasca API (query) instead of the MySQL database
The default meters and other items configured for the Ceilometer API can now be modified and additional meters can be added. It is highly recommended that customers test overall HPE Helion OpenStack performance prior to deploying any Ceilometer modifications to ensure the addition of new notifications or polling events does not negatively affect overall system performance.
Ceilometer Central Agent (pollster) is now called Polling Agent and is configured to support HA (Active-Active)
Notification Agent has built-in HA (Active-Active) with support for pipeline transformers, but workload partitioning has been disabled in HPE Helion OpenStack
SWIFT Poll-based account level meters will be enabled by default with an hourly collection cycle.
Integration with centralized monitoring (Monasca) and centralized logging
Support for upgrade and reconfigure operations
12.3.1.2 Limitations #
The Ceilometer Post Meter API is disabled by default.
The Ceilometer Events and Traits API is not supported and disabled by default.
The Number of metadata attributes that can be extracted from resource_metadata has a maximum of 16. This is the number of fields in the metadata section of the monasca_field_definitions.yaml file for any service. It is also the number that is equal to fields in metadata.common and fields in metadata.<service.meters> sections. The total number of these fields cannot be more than 16.
Several network-related attributes are accessible using a colon ":" but are returned as a period ".". For example, you can access a sample list using the following command:
ardana >source ~/service.osrcardana >ceilometer --debug sample-list network -q "resource_id=421d50a5-156e-4cb9-b404- d2ce5f32f18b;resource_metadata.provider.network_type=flat"However, in response you will see the following:
provider.network_type
instead of
provider:network_type
This limitation is known for the following attributes:
provider:network_type provider:physical_network provider:segmentation_id
Ceilometer Expirer is unsupported. Data retention expiration is now handled by Monasca with a default retention period of 45 days.
Ceilometer Collector is unsupported.
The Ceilometer Alarms API is disabled by default. HPE Helion OpenStack 8 provides an alternative operations monitoring service that will provide support for operations monitoring, alerts, and notifications use cases.
12.3.2 Understanding the Metering Service Concepts #
12.3.2.1 Ceilometer Introduction #
Before configuring the Ceilometer Metering Service, make sure you understand how it works.
12.3.2.1.1 Metering Architecture #
HPE Helion OpenStack automatically configures Ceilometer to use Logging and Monitoring Service (Monasca) as its backend. Ceilometer is deployed on the same control plane nodes as Monasca.
The installation of Celiometer creates several management nodes running different metering components.
Ceilometer Components on Controller nodes
This controller node is the first of the High Available (HA) cluster. In this node there is an instance of the Ceilometer API running under the HA Proxy Virtual IP address.
Ceilometer Sample Polling
Sample Polling is part of the Polling Agent. Now that Ceilometer API uses Monasca API (query) instead of the MySQL database, messages are posted by Notification Agent directly to Monasca API.
Ceilometer Polling Agent
The Polling Agent is responsible for coordinating the polling activity. It parses the pipeline.yml configuration file and identifies all the sources that need to be polled. The sources are then evaluated using a discovery mechanism and all the sources are translated to resources where a dedicated pollster can retrieve and publish data. At each identified interval the discovery mechanism is triggered, the resource list is composed, and the data is polled and sent to the queue.
Ceilometer Collector No Longer Required
In previous versions, the collector was responsible for getting the samples/events from the RabbitMQ service and storing it in the main database. The Ceilometer Collector is no longer enabled. Now that Notification Agent posts the data directly to Monasca API, the collector is no longer required
12.3.2.1.2 Meter Reference #
The Ceilometer API collects basic information grouped into categories known as meters. A meter is the unique resource-usage measurement of a particular OpenStack service. Each OpenStack service defines what type of data is exposed for metering.
Each meter has the following characteristics:
| Attribute | Description |
|---|---|
| Name | Description of the meter |
| Unit of Measurement | The method by which the data is measured. For example: storage meters are defined in Gigabytes (GB) and network bandwidth is measured in Gigabits (Gb). |
| Type | The origin of the meter's data. OpenStack defines the following origins:
|
A meter is defined for every measurable resource. A meter can exist beyond the actual existence of a particular resource, such as an active instance, to provision long-cycle use cases such as billing.
Important
For a list of meter types and default meters installed with HPE Helion OpenStack, see Section 12.3.3, “Ceilometer Metering Available Meter Types”
The most common meter submission method is notifications. With this method, each service sends the data from their respective meters on a periodic basis to a common notifications bus.
Ceilometer, in turn, pulls all of the events from the bus and saves the notifications in a Ceilometer-specific database. The period of time that the data is collected and saved is known as the Ceilometer expiry and is configured during Ceilometer installation. Each meter is collected from one or more samples, gathered from the messaging queue or polled by agents. The samples are represented by counter objects. Each counter has the following fields:
| Attribute | Description |
|---|---|
| counter_name | Description of the counter |
| counter_unit | The method by which the data is measured. For example: data can be defined in Gigabytes (GB) or for network bandwidth, measured in Gigabits (Gb). |
| counter_typee |
The origin of the counter's data. OpenStack defines the following origins:
|
| counter_volume | The volume of data measured (CPU ticks, bytes transmitted, etc.). Not used for gauge counters. Set to a default value such as 1. |
| resource_id | The identifier of the resource measured (UUID) |
| project_id | The project (tenant) ID to which the resource belongs. |
| user_id | The ID of the user who owns the resource. |
| resource_metadata | Other data transmitted in the metering notification payload. |
12.3.2.1.3 Role Based Access Control (RBAC) #
A user with the admin role can access all API functions across all projects by default. Ceilometer also supports the ability to assign access to a specific API function by project and UserID. User access is configured in the Ceilometer policy file and enables you to grant specific API functions to specific users for a specific project.
For instructions on how to configure role-based access, see Section 12.3.7, “Ceilometer Metering Setting Role-based Access Control”.
12.3.3 Ceilometer Metering Available Meter Types #
The Metering service contains three types of meters:
- Cumulative
A cumulative meter measures data over time (for example, instance hours).
- Gauge
A gauge measures discrete items (for example, floating IPs or image uploads) or fluctuating values (such as disk input or output).
- Delta
A delta measures change over time, for example, monitoring bandwidth.
Each meter is populated from one or more samples, which are gathered from the messaging queue (listening agent), polling agents, or push agents. Samples are populated by counter objects.
Each counter contains the following fields:
- name
the name of the meter
- type
the type of meter (cumulative, gauge, or delta)
- amount
the amount of data measured
- unit
the unit of measure
- resource
the resource being measured
- project ID
the project the resource is assigned to
- user
the user the resource is assigned to.
Note: The metering service shares the same High-availability proxy, messaging, and database clusters with the other Information services. To avoid unnecessarily high loads, Section 12.3.9, “Optimizing the Ceilometer Metering Service”.
12.3.3.1 HPE Helion OpenStack Default Meters #
These meters are installed and enabled by default during an HPE Helion OpenStack installation.
Detailed information on the Ceilometer API can be found on the following page:
12.3.3.2 Compute (Nova) Meters #
| Meter | Type | Unit | Resource | Origin | Note |
|---|---|---|---|---|---|
| vcpus | Gauge | vcpu | Instance ID | Notification | Number of virtual CPUs allocated to the instance |
| memory | Gauge | MB | Instance ID | Notification | Volume of RAM allocated to the instance |
| memory.resident | Gauge | MB | Instance ID | Pollster | Volume of RAM used by the instance on the physical machine |
| memory.usage | Gauge | MB | Instance ID | Pollster | Volume of RAM used by the instance from the amount of its allocated memory |
| cpu | Cumulative | ns | Instance ID | Pollster | CPU time used |
| cpu_util | Gauge | % | Instance ID | Pollster | Average CPU utilization |
| disk.read.requests | Cumulative | request | Instance ID | Pollster | Number of read requests |
| disk.read.requests.rate | Gauge | request/s | Instance ID | Pollster | Average rate of read requests |
| disk.write.requests | Cumulative | request | Instance ID | Pollster | Number of write requests |
| disk.write.requests.rate | Gauge | request/s | Instance ID | Pollster | Average rate of write requests |
| disk.read.bytes | Cumulative | B | Instance ID | Pollster | Volume of reads |
| disk.read.bytes.rate | Gauge | B/s | Instance ID | Pollster | Average rate of reads |
| disk.write.bytes | Cumulative | B | Instance ID | Pollster | Volume of writes |
| disk.write.bytes.rate | Gauge | B/s | Instance ID | Pollster | Average rate of writes |
| disk.root.size | Gauge | GB | Instance ID | Notification | Size of root disk |
| disk.ephemeral.size | Gauge | GB | Instance ID | Notification | Size of ephemeral disk |
| disk.device.read.requests | Cumulative | request | Disk ID | Pollster | Number of read requests |
| disk.device.read.requests.rate | Gauge | request/s | Disk ID | Pollster | Average rate of read requests |
| disk.device.write.requests | Cumulative | request | Disk ID | Pollster | Number of write requests |
| disk.device.write.requests.rate | Gauge | request/s | Disk ID | Pollster | Average rate of write requests |
| disk.device.read.bytes | Cumulative | B | Disk ID | Pollster | Volume of reads |
| disk.device.read.bytes .rate | Gauge | B/s | Disk ID | Pollster | Average rate of reads |
| disk.device.write.bytes | Cumulative | B | Disk ID | Pollster | Volume of writes |
| disk.device.write.bytes .rate | Gauge | B/s | Disk ID | Pollster | Average rate of writes |
| disk.capacity | Gauge | B | Instance ID | Pollster | The amount of disk that the instance can see |
| disk.allocation | Gauge | B | Instance ID | Pollster | The amount of disk occupied by the instance on the host machine |
| disk.usage | Gauge | B | Instance ID | Pollster | The physical size in bytes of the image container on the host |
| disk.device.capacity | Gauge | B | Disk ID | Pollster | The amount of disk per device that the instance can see |
| disk.device.allocation | Gauge | B | Disk ID | Pollster | The amount of disk per device occupied by the instance on the host machine |
| disk.device.usage | Gauge | B | Disk ID | Pollster | The physical size in bytes of the image container on the host per device |
| network.incoming.bytes | Cumulative | B | Interface ID | Pollster | Number of incoming bytes |
| network.outgoing.bytes | Cumulative | B | Interface ID | Pollster | Number of outgoing bytes |
| network.incoming.packets | Cumulative | packet | Interface ID | Pollster | Number of incoming packets |
| network.outgoing.packets | Cumulative | packet | Interface ID | Pollster | Number of outgoing packets |
12.3.3.3 Compute Host Meters #
| Meter | Type | Unit | Resource | Origin | Note |
|---|---|---|---|---|---|
| compute.node.cpu.frequency | Gauge | MHz | Host ID | Notification | CPU frequency |
| compute.node.cpu.kernel.time | Cumulative | ns | Host ID | Notification | CPU kernel time |
| compute.node.cpu.idle.time | Cumulative | ns | Host ID | Notification | CPU idle time |
| compute.node.cpu.user.time | Cumulative | ns | Host ID | Notification | CPU user mode time |
| compute.node.cpu.iowait.time | Cumulative | ns | Host ID | Notification | CPU I/O wait time |
| compute.node.cpu.kernel.percent | Gauge | % | Host ID | Notification | CPU kernel percentage |
| compute.node.cpu.idle.percent | Gauge | % | Host ID | Notification | CPU idle percentage |
| compute.node.cpu.user.percent | Gauge | % | Host ID | Notification | CPU user mode percentage |
| compute.node.cpu.iowait.percent | Gauge | % | Host ID | Notification | CPU I/O wait percentage |
| compute.node.cpu.percent | Gauge | % | Host ID | Notification | CPU utilization |
12.3.3.4 Image (Glance) Meters #
| Meter | Type | Unit | Resource | Origin | Note |
|---|---|---|---|---|---|
| image.size | Gauge | B | Image ID | Notification | Uploaded image size |
| image.update | Delta | Image | Image ID | Notification | Number of uploads of the image |
| image.upload | Delta | Image | image ID | notification | Number of uploads of the image |
| image.delete | Delta | Image | Image ID | Notification | Number of deletes on the image |
12.3.3.5 Volume (Cinder) Meters #
| Meter | Type | Unit | Resource | Origin | Note |
|---|---|---|---|---|---|
| volume.size | Gauge | GB | Vol ID | Notification | Size of volume |
| snapshot.size | Gauge | GB | Snap ID | Notification | Size of snapshot's volume |
12.3.3.6 Storage (Swift) Meters #
| Meter | Type | Unit | Resource | Origin | Note |
|---|---|---|---|---|---|
| storage.objects | Gauge | Object | Storage ID | Pollster | Number of objects |
| storage.objects.size | Gauge | B | Storage ID | Pollster | Total size of stored objects |
| storage.objects.containers | Gauge | Container | Storage ID | Pollster | Number of containers |
The resource_id for any Ceilometer query is the
tenant_id for the Swift object because Swift usage is
rolled up at the tenant level.
12.3.4 Metering API Reference #
Ceilometer uses a polling agent to communicate with an API to collect information at a regular interval, as shown in the diagram below.
Ceilometer query APIs can put a significant load on the database leading to unexpected results or failures. Therefore it is important to understand how the Ceilometer API works and how to change the configuration to protect against failures.
12.3.4.1 Ceilometer API Changes #
The following changes have been made in the latest release of Ceilometer for HPE Helion OpenStack:
Ceilometer API supports a default of 100 queries. This limit is configurable in the ceilometer.conf configuration file. The option is in the
DEFAULTsection and is nameddefault_api_return_limit.Flexible configuration for pollster and notifications has been added. Ceilometer can now list different event types differently for these services.
Query-sample API is now supported in HPE Helion OpenStack.
Meter-list API can now return a unique list of meter names with no duplicates. To create this list, when running the list command, use the
--uniqueoption.
The following limitations exist in the latest release of Ceilometer for HPE Helion OpenStack:
Event API is disabled by default and is unsupported in HPE Helion OpenStack.
Trait API is disabled by default and is unsupported in HPE Helion OpenStack.
Post Sample API is disabled by default and is unsupported in HPE Helion OpenStack.
Alarm API is disabled by default and is unsupported in HPE Helion OpenStack.
Sample-Show API is unsupported in HPE Helion OpenStack.
Meter-List API does not support filtering with metadata.
Query-Sample API (Complex query) does not support using the following operators in the same query:
order by argument NOT
Query-Sample API requires you to specify a meter name. Complex queries will be analyzed as several simple queries according to the AND/OR logic. As meter-list is a constraint, each simple query must specify a meter name. If this condition is not met, you will receive a detailed 400 error.
Due to a Monasca API limitation, microsecond is no longer supported. In the Resource-List API, Sample-List API, Statistics API and Query-Samples API, the
timestampfield now only supports measuring down to the millisecond.Sample-List API does not support
message_idas a valid search parameter. This parameter is also not included in the output.Sample-List API now requires the meter name as a positional parameter.
Sample-List API returns a sample with an empty
message_signaturefield.
12.3.4.2 Disabled APIs #
The following Ceilometer metering APIs are disabled in this release:
Event API
Trait API
Ceilometer Alarms API
Post Samples API
These APIs are disabled through a custom rule called
hp_disabled_rule:not_implemented. This rule is added to
each disabled API in Ceilometer's policy.json file
/etc/ceilometer/policy.json on controller
nodes. Attempts to access any of the disabled APIs will result in an HTTP
response 501 Not Implemented.
To manually enable any of the APIs, remove the corresponding rule and restart Apache
{
"context_is_admin": "role:admin",
"context_is_project": "project_id:%(target.project_id)s",
"context_is_owner": "user_id:%(target.user_id)s",
"segregation": "rule:context_is_admin",
"telemetry:create_samples": "hp_disabled_rule:not_implemented",
"telemetry:get_alarm": "hp_disabled_rule:not_implemented",
"telemetry:change_alarm": "hp_disabled_rule:not_implemented",
"telemetry:delete_alarm": "hp_disabled_rule:not_implemented",
"telemetry:alarm_history": "hp_disabled_rule:not_implemented",
"telemetry:change_alarm_state": "hp_disabled_rule:not_implemented",
"telemetry:get_alarm_state": "hp_disabled_rule:not_implemented",
"telemetry:create_alarm": "hp_disabled_rule:not_implemented",
"telemetry:get_alarms": "hp_disabled_rule:not_implemented",
"telemetry:query_sample":"hp_disabled_rule:not_implemented",
"default": ""
}The following Alarm APIs are disabled
POST /v2/alarms
GET /v2/alarms
GET /v2/alarms/(alarm_id)
PUT /v2/alarms/(alarm_id)
DELETE /v2/alarms/(alarm_id)
GET /v2/alarms/(alarm_id)/history
PUT /v2/alarms/(alarm_id)/state
GET /v2/alarms/(alarm_id)/state
POST /v2/query/alarms
POST /v2/query/alarms/history
In addition, these APIs are disabled:
Post Samples API: POST /v2/meters/(meter_name)
Query Sample API: POST /v2/query/samples
12.3.4.3 Improving Reporting API Responsiveness #
Reporting APIs are the main access to the Metering data stored in Ceilometer. These APIs are accessed by Horizon to provide basic usage data and information. However, Horizon Resources Usage Overview / Stats panel shows usage metrics with the following limitations:
No metric option is available until you actually create a resource (such as an instance, Swift container, etc).
Only specific meters are displayed for a selection after resources have been created. For example, only the Cinder volume and volume.size meters are displayed if only a Cinder volume has been created (for example, if no compute instance or Swift containers were created yet)
Only the top 20 meters associated with the sample query results are displayed.
Period duration selection should be much less than the default retention period (currently 7 days), to get statistics for multiple groups.
HPE Helion OpenStack uses the Apache2 Web Server to provide API access. It is possible to tune performance to optimize the front end as well as the back-end database. Experience indicates that an excessive increase of concurrent access to the front-end tends to put a strain in the database.
12.3.4.4 Reconfiguring Apache2, Horizon and Keystone #
The ceilometer-api is now running as part of the Apache2 service together with Horizon and Keystone. To remove them from the active list so that changes can be made and then re-instate them, use the following commands.
Disable the Ceilometer API on the active sites.
tux >sudo rm /etc/apache2/vhosts.d/ceilometer_modwsgi.conftux >sudo systemctl reload apache2.servicePerform all necessary changes. The Ceilometer API will not be served until it is re-enabled.
Re-enable the Ceilometer API on the active sites.
tux >sudo ln -s /etc/apache2/vhosts.d/ceilometer_modwsgi.vhost /etc/apache2/vhosts.d/ceilometer_modwsgi.conftux >sudo systemctl reload apache2.serviceThe new changes need to be picked up by Apache2. If possible, force a reload rather than a restart. Unlike a restart, the reload waits for currently active sessions to gracefully terminate or complete.
tux >sudo systemctl reload apache2.service
12.3.4.5 Data Access API #
Ceilometer provides a complete API for data access only and not for data visualization or aggregation. These functions are provided by external, downstream applications that support various use cases like usage billing and software license policy adherence.
Each application calls the specific Ceilometer API needed for their use case. The resulting data is then aggregated and visualized based on the unique functions provided by each application.
For more information, see the OpenStack Developer documentation for V2 Web API.
12.3.4.6 Post Samples API #
The Post Sample API is disabled by default in HPE Helion OpenStack 8 and it requires a separate pipeline.yml for Ceilometer. This is because it uses a pipeline configuration different than the agents. Also by default, the API pipeline has no meters enabled. When the Post Samples API is enabled, you need to configure the meters.
Important
Use caution when adding meters to the API pipeline. Ensure that only meters already present in the notification agent and the polling agent pipeline are added to the Post Sample API pipeline.
The Ceilometer API pipeline configuration file is located in the following directory:
/opt/stack/service/ceilometer-api/etc/pipeline-api.yml
Sample API pipeline file:
---
sources:
- name: meter_source
interval: 30
meters:
- "instance"
- "ip.floating"
- "network"
- "network.create"
- "network.update"
sinks:
- meter_sink
- name: image_source
interval: 30
meters:
- "image"
- "image.size"
- "image.upload"
- "image.delete"
sinks:
- meter_sink
- name: volume_source
interval: 30
meters:
- "volume"
- "volume.size"
- "snapshot"
- "snapshot.size"
sinks:
- meter_sink
- name: swift_source
interval: 3600
meters:
- "storage.objects"
- "storage.objects.size"
- "storage.objects.containers"
sinks:
- meter_sink
sinks:
- name: meter_sink
transformers:
publishers:
- notifier://12.3.4.7 Resource API #
The Ceilometer Resource API provides a list of resources associated with meters that Ceilometer polls. By default, all meter links are generated for each resource.
Important
Be aware that this functionality has a high cost. For a large deployment, in order to reduce the response time, it is recommended that you do not return meter links. You can disable links in the output using the following filter in your query: (for the REST API only)
meter_links=0
The resource-list (/v2/resources) API can be filtered by
the following parameters:
project_id
user_id
source
resource_id
timestamp
metadata
Important
It is highly recommended that you use one or both of the following query filters to get a quick response in a scaled deployment:
project_id
timestamp
Example Query:
ardana > ceilometer resource-list -q "project_id=7aa0fe3f02ff4e11a70a41e97d0db5e3;timestamp>=2015-10-22T15:44:00;timestamp<=2015-10-23T15:44:00"12.3.4.8 Sample API #
Ceilometer Sample has two APIs:
ceilometer sample-list(/v2/samples)
ceilometer query-sample (/v2/query/samples)
Sample-list API allows querying based on the following values:
meter name
user_id
project_id
sample source
resource_id
sample timestamp (range)
sample message_id
resource metadata attributes
Sample-list API uses the AND operator implicitly. However, the query-sample API allows for finer control over the filter expression. This is because query-sample API allows the use of AND, OR, and NOT operators over any of the sample, meter or resource attributes.
Limitations:
Ceilometer query-sample API does not support the JOIN operator for stability of the system. This is due to the fact that query-sample API uses an anonymous/alias table to cache the JOIN query results and concurrent requests to this API. This can use up the disk space quickly and cause service interruptions.
Ceilometer sample-list API uses the AND operator implicitly for all queries. However, sample-list API does allow you to query on resource metadata field of samples.
Sample queries from the command line:
ardana > ceilometer sample-list -m METER_NAME -q '<field1><operator1><value1>;...;<field_n><operator_n><value_n>'where operators can be: <, <=, =, !=, >= >
Important
All the key value pairs will be combined with the implicit AND operator.
Example usage for the sample-list API
ardana > ceilometer sample-list --meter image.serve -q 'resource_id=a1ec2585'ardana > ceilometer sample-list --meter instance -q 'resource_id=<ResourceID>;metadata.event_type=<eventType>'12.3.4.9 Statistics API #
Ceilometer Statistics is an open-ended query API that performs queries on the table of data collected from a meter. The Statistics API obtains the minimum and maximum timestamp for the meter that is being queried.
The Statistics API also provides a set of statistical functions. These functions perform basic aggregation for meter-specific data over a period of time. Statistics API includes the following functions:
- Count
the number of discrete samples collected in each period
- Maximum
the sample with the maximum value in a selected time period
- Minimum
the sample with the minimum value in a selected time period
- Average
the average value of a samples within a selected time period
- Sum
the total value of all samples within a selected time period added together
Important
The Statistics API can put a significant load on the database leading to unexpected results and or failures. Therefore, you should be careful about restricting your queries.
Limitations of Statistics-list API
filtering with metadata is not supported
the
groupbyoption is only supported with only one parameter. That single parameter has to be one of the following:user_id project_id resource_id source
only the following are supported as aggregate functions: average, minimum, maximum, sum, and count
when no time period is specified in the query, a default period of 300 seconds is used to aggregate measurements (samples)
the meter name is a required positional parameter
when a closed time range is specified, results may contain an extra row with duration, duration start, duration end assigned with a value of None. This row has a start and end time period that fall outside the requested time range and can be ignored. Ceilometer does not remove this row because it is by design inside the back-end Monasca.
Statistical Query Best Practices
By default, the Statistics API will return a limited number of statistics. You can control the output using the period "." parameter.
- Without a period parameter
only a few statistics: minimum, maximum, avgerage and sum
- With a period parameter "."
the range is divided into equal periods and Statistics API finds the count, minimum, maximum, average, and sum for each of the periods
Important
It is recommended that you provide a timestamp parameter
with every query, regardless of whether a period paramter is used. For
example:
timestamp>={$start-timestamp} and timestamp<{$end-timestamp}It is also recommended that you query a period of time that covers at most 1 day (24 hours).
Examples
- Without period parameter
ardana >ceilometer statistics -q "timestamp>=2014-12-11T00:00:10;timestamp<2014-12-11T23:00:00" -m "instance"- With the period parameter "."
ardana >ceilometer statistics -q "timestamp>=2014-12-11T00:00:10;timestamp<2014-12-11T23:00:00" -m "instance" -p 3600
If the query and timestamp parameters are not provided, all records in the database will be queried. This is not recommended. Use the following recommended values for query (-q) parameter and period (-p) parameters:
- -q
Always provide a timestamp range, with the following guidelines:
recommended maximum time period to query is one day (24 hours)
do not set the timestamp range to greater than a day
it is better to provide no time stamp range than to set the time period for more than 1 day
example of an acceptable range:
-q "timestamp>=2014-12-11T00:00:10;timestamp<2014-12-11T23:00:00"
- -p
Provide a large number in seconds, with the following guidelines:
recommended minimum value is 3600 or more (1 hour or more)
providing a period of less than 3600 is not recommended
Use this parameter to divide the overall time range into smaller intervals. A small period parameter value will translate into a very large number of queries against the database.
Example of an acceptable range:
-p 3600
12.3.5 Configure the Ceilometer Metering Service #
HPE Helion OpenStack 8 automatically deploys Ceilometer to use the Monasca database. Ceilometer is deployed on the same control plane nodes along with other OpenStack services such as Keystone, Nova, Neutron, Glance, and Swift.
The Metering Service can be configured using one of the procedures described below.
12.3.5.1 Run the Upgrade Playbook #
Follow Standard Service upgrade mechanism available in the Cloud Lifecycle Manager distribution. For Ceilometer, the playbook included with HPE Helion OpenStack is ceilometer-upgrade.yml
12.3.5.2 Configure Apache2 for the Ceilometer API #
Reporting APIs provide access to the metering data stored in Ceilometer. These APIs are accessed by Horizon to provide basic usage data and information.HPE Helion OpenStack uses Apache2 Web Server to provide the API access.
Important
To improve API responsiveness you can increase the number of threads and processes in the Ceilometer configuration file. The Ceilometer API runs as an WSGI processes. Each process can have a certain amount of threads managing the filters and applications, which can comprise the processing pipeline.
To configure Apache:
Edit the Ceilometer configuration files.
Reload and verify Apache2.
Edit the Ceilometer Configuration Files
To create a working file for Ceilometer with the correct settings:
To add the configuration file to the correct folder, copy the following file:
ceilometer.conf
to the following directory:
/etc/apache2/vhosts.d/
To verify the settings, in a text editor, open the
ceilometer_modwsgi.vhostfile.The ceilometer_modwsgi.conf file should have the following data. If it does not exist, add it to the file.
Listen <ipaddress>:8777 <VirtualHost *:8777> WSGIScriptAlias / /srv/www/ceilometer/ceilometer-api WSGIDaemonProcess ceilometer user=ceilometer group=ceilometer processes=4 threads=5 socket-timeout=600 python-path=/opt/stack/service/ceilometer-api/venv:/opt/stack/service/ceilometer-api/venv/lib/python2.7/site-packages/ display-name=ceilometer-api WSGIApplicationGroup %{GLOBAL} WSGIProcessGroup ceilometer ErrorLog /var/log/ceilometer/ceilometer_modwsgi.log LogLevel INFO CustomLog /var/log/ceilometer/ceilometer_access.log combined <Directory /opt/stack/service/ceilometer-api/venv/lib/python2.7/site-packages/ceilometer> Options Indexes FollowSymLinks MultiViews Require all granted AllowOverride None Order allow,deny allow from all LimitRequestBody 102400 </Directory> </VirtualHost>Note
The WSGIDaemon Recommended Settings are to use four processes running in parallel:
processes=4
Five threads for each process is also recommended:
threads=5
To add a softlink for the ceilometer.conf, run:
tux >sudo ln -s /etc/apache2/vhosts.d/ceilometer_modwsgi.vhost /etc/apache2/vhosts.d/ceilometer_modwsgi.conf
Reload and Verify Apache2
For the changes to take effect, the Apache2 service needs to be reloaded. This ensures that all the configuration changes are saved and the service has applied them. The system administrator can change the configuration of processes and threads and experiment if alternative settings are necessary.
Once the Apache2 service has been reloaded you can verify that the Ceilometer APIs are running and able to receive incoming traffic. The Ceilometer APIs are listening on port 8777.
To reload and verify the Apache2 service:
To reload Apache2, run:
tux >sudo systemctl reload apache2.serviceTo verify the service is running, run:
tux >sudo systemctl status apache2.serviceImportant
In a working environment, the list of entries in the output should match the number of processes in the configuration file. In the example configuration file, the recommended number of 4 is used, and the number of Running Instances is also 4.
You can also verify that Apache2 is accepting incoming traffic using the following procedure:
To verify traffic on port 8777, run:
tux >sudo netstat -tulpn | grep 8777Verify your output is similar to the following example:
tcp6 0 0 :::8777 :::* LISTEN 8959/apache2
Important
If Ceilometer fails to deploy:
check the proxy setting
unset the https_proxy, for example:
unset http_proxy HTTP_PROXY HTTPS_PROXY
12.3.5.3 Enable Services for Messaging Notifications #
After installation of HPE Helion OpenStack, the following services are enabled by default to send notifications:
Nova
Cinder
Glance
Neutron
Swift
The list of meters for these services are specified in the Notification Agent or Polling Agent's pipeline configuration file.
For steps on how to edit the pipeline configuration files, see: Section 12.3.6, “Ceilometer Metering Service Notifications”
12.3.5.4 Restart the Polling Agent #
The Polling Agent is responsible for coordinating the polling activity. It parses the pipeline.yml configuration file and identifies all the sources where data is collected. The sources are then evaluated and are translated to resources that a dedicated pollster can retrieve. The Polling Agent follows this process:
At each identified interval, the pipeline.yml configuration file is parsed.
The resource list is composed.
The pollster collects the data.
The pollster sends data to the queue.
Metering processes should normally be operating at all times. This need is addressed by the Upstart event engine which is designed to run on any Linux system. Upstart creates events, handles the consequences of those events, and starts and stops processes as required. Upstart will continually attempt to restart stopped processes even if the process was stopped manually. To stop or start the Polling Agent and avoid the conflict with Upstart, using the following steps.
To restart the Polling Agent:
To determine whether the process is running, run:
tux >sudo systemctl status ceilometer-agent-notification #SAMPLE OUTPUT: ceilometer-agent-notification.service - ceilometer-agent-notification Service Loaded: loaded (/etc/systemd/system/ceilometer-agent-notification.service; enabled; vendor preset: disabled) Active: active (running) since Tue 2018-06-12 05:07:14 UTC; 2 days ago Main PID: 31529 (ceilometer-agen) Tasks: 69 CGroup: /system.slice/ceilometer-agent-notification.service ├─31529 ceilometer-agent-notification: master process [/opt/stack/service/ceilometer-agent-notification/venv/bin/ceilometer-agent-notification --config-file /opt/stack/service/ceilometer-agent-noti... └─31621 ceilometer-agent-notification: NotificationService worker(0) Jun 12 05:07:14 ardana-qe201-cp1-c1-m2-mgmt systemd[1]: Started ceilometer-agent-notification Service.To stop the process, run:
tux >sudo systemctl stop ceilometer-agent-notificationTo start the process, run:
tux >sudo systemctl start ceilometer-agent-notification
12.3.5.5 Replace a Logging, Monitoring, and Metering Controller #
In a medium-scale environment, if a metering controller has to be replaced or rebuilt, use the following steps:
If the Ceilometer nodes are not on the shared control plane, to implement the changes and replace the controller, you must reconfigure Ceilometer. To do this, run the ceilometer-reconfigure.yml ansible playbook without the limit option
12.3.5.6 Configure Monitoring #
The Monasca HTTP Process monitors the Ceilometer API service. Ceilometer's notification and polling agents are also monitored. If these agents are down, Monasca monitoring alarms are triggered. You can use the notification alarms to debug the issue and restart the notifications agent. However, for Central-Agent (polling) and Collector the alarms need to be deleted. These two processes are not started after an upgrade so when the monitoring process checks the alarms for these components, they will be in UNDETERMINED state. HPE Helion OpenStack does not monitor these processes anymore so the best option to resolve this issue is to manually delete alarms that are no longer used but are installed.
To resolve notification alarms, first check the ceilometer-agent-notification logs for errors in the /var/log/ceilometer directory. You can also use the Operations Console to access Kibana and check the logs. This will help you understand and debug the error.
To restart the service, run the ceilometer-start.yml. This playbook starts the ceilometer processes that has stopped and only restarts during install, upgrade or reconfigure which is what is needed in this case. Restarting the process that has stopped will resolve this alarm because this Monasca alarm means that ceilometer-agent-notification is no longer running on certain nodes.
You can access Ceilometer data through Monasca. Ceilometer publishes samples to Monasca with credentials of the following accounts:
ceilometer user
services
Data collected by Ceilometer can also be retrieved by the Monasca REST API. Make sure you use the following guidelines when requesting data from the Monasca REST API:
Verify you have the monasca-admin role. This role is configured in the monasca-api configuration file.
Specify the
tenant idof the services project.
For more details, read the Monasca API Specification.
To run Monasca commands at the command line, you must be have the admin role. This allows you to use the Ceilometer account credentials to replace the default admin account credentials defined in the service.osrc file. When you use the Ceilometer account credentials, Monasca commands will only return data collected by Ceilometer. At this time, Monasca command line interface (CLI) does not support the data retrieval of other tenants or projects.
12.3.6 Ceilometer Metering Service Notifications #
Ceilometer uses the notification agent to listen to the message queue, convert notifications to Events and Samples, and apply pipeline actions.
12.3.6.1 Manage Whitelisting and Polling #
HPE Helion OpenStack is designed to reduce the amount of data that is stored. HPE Helion OpenStack's use of a SQL-based cluster, which is not recommended for big data, means you must control the data that Ceilometer collects. You can do this by filtering (whitelisting) the data or by using the configuration files for the Ceilometer Polling Agent and the Ceilometer Notificfoation Agent.
Whitelisting is used in a rule specification as a positive filtering parameter. Whitelist is only included in rules that can be used in direct mappings, for identity service issues such as service discovery, provisioning users, groups, roles, projects, domains as well as user authentication and authorization.
You can run tests against specific scenarios to see if filtering reduces the amount of data stored. You can create a test by editing or creating a run filter file (whitelist). For steps on how to do this, see: Book “Installing with Cloud Lifecycle Manager”, Chapter 27 “Cloud Verification”, Section 27.1 “API Verification”.
Ceilometer Polling Agent (polling agent) and Ceilometer Notification Agent (notification agent) use different pipeline.yaml files to configure meters that are collected. This prevents accidentally polling for meters which can be retrieved by the polling agent as well as the notification agent. For example, glance image and image.size are meters which can be retrieved both by polling and notifications.
In both of the separate configuration files, there is a setting for
interval. The interval attribute determines the
frequency, in seconds, of how often data is collected. You can use this
setting to control the amount of resources that are used for notifications
and for polling. For example, you want to use more resources for
notifications and less for polling. To accomplish this you would set the
interval in the polling configuration file to a large
amount of time, such as 604800 seconds, which polls only once a week. Then
in the notifications configuration file, you can set the
interval to a higher amount, such as collecting data
every 30 seconds.
Important
Swift account data will be collected using the polling mechanism in an hourly interval.
Setting this interval to manage both notifications and polling is the recommended procedure when using a SQL cluster back-end.
Sample Ceilometer Polling Agent file:
#File: ~/opt/stack/service/ceilometer-polling/etc/pipeline-polling.yaml
---
sources:
- name: swift_source
interval: 3600
meters:
- "storage.objects"
- "storage.objects.size"
- "storage.objects.containers"
resources:
discovery:
sinks:
- meter_sink
sinks:
- name: meter_sink
transformers:
publishers:
- notifier://Sample Ceilometer Notification Agent(notification agent) file:
#File: ~/opt/stack/service/ceilometer-agent-notification/etc/pipeline-agent-notification.yaml
---
sources:
- name: meter_source
interval: 30
meters:
- "instance"
- "image"
- "image.size"
- "image.upload"
- "image.delete"
- "volume"
- "volume.size"
- "snapshot"
- "snapshot.size"
- "ip.floating"
- "network"
- "network.create"
- "network.update"
resources:
discovery:
sinks:
- meter_sink
sinks:
- name: meter_sink
transformers:
publishers:
- notifier://Both of the pipeline files have two major sections:
- Sources
represents the data that is collected either from notifications posted by services or through polling. In the Sources section there is a list of meters. These meters define what kind of data is collected. For a full list refer to the Ceilometer documentation available at: Telemetry Measurements
- Sinks
represents how the data is modified before it is published to the internal queue for collection and storage.
You will only need to change a setting in the Sources section to control the data collection interval.
For more information, see Telemetry Measurements
To change the Ceilometer Polling Agent interval setting:
To find the polling agent configuration file, run:
cd ~/opt/stack/service/ceilometer-polling/etc
In a text editor, open the following file:
pipeline-polling.yaml
In the following section, change the value of
intervalto the desired amount of time:--- sources: - name: swift_source interval: 3600 meters: - "storage.objects" - "storage.objects.size" - "storage.objects.containers" resources: discovery: sinks: - meter_sink sinks: - name: meter_sink transformers: publishers: - notifier://In the sample code above, the polling agent will collect data every 600 seconds, or 10 minutes.
To change the Ceilometer Notification Agent (notification agent) interval setting:
To find the notification agent configuration file, run:
cd /opt/stack/service/ceilometer-agent-notification
In a text editor, open the following file:
pipeline-agent-notification.yaml
In the following section, change the value of
intervalto the desired amount of time:sources: - name: meter_source interval: 30 meters: - "instance" - "image" - "image.size" - "image.upload" - "image.delete" - "volume" - "volume.size" - "snapshot" - "snapshot.size" - "ip.floating" - "network" - "network.create" - "network.update"In the sample code above, the notification agent will collect data every 30 seconds.
Note
The pipeline-agent-notification.yaml file needs to be changed on all
controller nodes to change the white-listing and polling strategy.
12.3.6.2 Edit the List of Meters #
The number of enabled meters can be reduced or increased by editing the pipeline configuration of the notification and polling agents. To deploy these changes you must then restart the agent. If pollsters and notifications are both modified, then you will have to restart both the Polling Agent and the Notification Agent. Ceilometer Collector will also need to be restarted. The following code is an example of a compute-only Ceilometer Notification Agent (notification agent) pipeline-agent-notification.yaml file:
---
sources:
- name: meter_source
interval: 86400
meters:
- "instance"
- "memory"
- "vcpus"
- "compute.instance.create.end"
- "compute.instance.delete.end"
- "compute.instance.update"
- "compute.instance.exists"
sinks:
- meter_sink
sinks:
- name: meter_sink
transformers:
publishers:
- notifier://Important
If you enable meters at the container level in this file, every time the polling interval triggers a collection, at least 5 messages per existing container in Swift are collected.
The following table illustrates the amount of data produced hourly in different scenarios:
| Swift Containers | Swift Objects per container | Samples per Hour | Samples stored per 24 hours |
| 10 | 10 | 500 | 12000 |
| 10 | 100 | 5000 | 120000 |
| 100 | 100 | 50000 | 1200000 |
| 100 | 1000 | 500000 | 12000000 |
The data in the table shows that even a very small Swift storage with 10 containers and 100 files will store 120,000 samples in 24 hours, generating a total of 3.6 million samples.
Important
The size of each file does not have any impact on the number of samples collected. As shown in the table above, the smallest number of samples results from polling when there are a small number of files and a small number of containers. When there are a lot of small files and containers, the number of samples is the highest.
12.3.6.3 Add Resource Fields to Meters #
By default, not all the resource metadata fields for an event are recorded and stored in Ceilometer. If you want to collect metadata fields for a consumer application, for example, it is easier to add a field to an existing meter rather than creating a new meter. If you create a new meter, you must also reconfigure Ceilometer.
Important
Consider the following information before you add or edit a meter:
You can add a maximum of 12 new fields.
Adding or editing a meter causes all non-default meters to STOP receiving notifications. You will need to restart Ceilometer.
New meters added to the
pipeline-polling.yaml.j2file must also be added to thepipeline-agent-notification.yaml.j2file. This is due to the fact that polling meters are drained by the notification agent and not by the collector.After HPE Helion OpenStack is installed, services like compute, cinder, glance, and neutron are configured to publish Ceilometer meters by default. Other meters can also be enabled after the services are configured to start publishing the meter. The only requirement for publishing a meter is that the
originmust have a value ofnotification. For a complete list of meters, see the OpenStack documentation on Measurements.Not all meters are supported. Meters collected by Ceilometer Compute Agent or any agent other than Ceilometer Polling are not supported or tested with HPE Helion OpenStack.
Identity meters are disabled by Keystone.
To enable Ceilometer to start collecting meters, some services require you enable the meters you need in the service first before enabling them in Ceilometer. Refer to the documentation for the specific service before you add new meters or resource fields.
To add Resource Metadata fields:
Log on to the Cloud Lifecycle Manager (deployer node).
To change to the Ceilometer directory, run:
ardana >cd ~/openstack/my_cloud/config/ceilometerIn a text editor, open the target configuration file (for example, monasca-field-definitions.yaml.j2).
In the metadata section, either add a new meter or edit an existing one provided by HPE Helion OpenStack.
Include the metadata fields you need. You can use the
instance meterin the file as an example.Save and close the configuration file.
To save your changes in HPE Helion OpenStack, run:
ardana >cd ~/openstackardana >git add -Aardana >git commit -m "My config"If you added a new meter, reconfigure Ceilometer:
ardana >cd ~/openstack/ardana/ansible/ # To run the config-processor playbook:ardana >ansible-playbook -i hosts/localhost config-processor-run.yml #To run the ready-deployment playbook:ardana >ansible-playbook -i hosts/localhost ready-deployment.ymlardana >cd ~/scratch/ansible/next/ardana/ansible/ardana >ansible-playbook -i hosts/verb_hosts ceilometer-reconfigure.yml
12.3.6.4 Update the Polling Strategy and Swift Considerations #
Polling can be very taxing on the system due to the sheer volume of data thtyat the system may have to process. It also has a severe impact on queries since the database will now have a very large amount of data to scan to respond to the query. This consumes a great amount of cpu and memory. This can result in long wait times for query responses, and in extreme cases can result in timeouts.
There are 3 polling meters in Swift:
storage.objects
storage.objects.size
storage.objects.containers
Here is an example of pipeline.yml in which
Swift polling is set to occur hourly.
---
sources:
- name: swift_source
interval: 3600
meters:
- "storage.objects"
- "storage.objects.size"
- "storage.objects.containers"
resources:
discovery:
sinks:
- meter_sink
sinks:
- name: meter_sink
transformers:
publishers:
- notifier://With this configuration above, we did not enable polling of container based meters and we only collect 3 messages for any given tenant, one for each meter listed in the configuration files. Since we have 3 messages only per tenant, it does not create a heavy load on the MySQL database as it would have if container-based meters were enabled. Hence, other APIs are not hit because of this data collection configuration.
12.3.7 Ceilometer Metering Setting Role-based Access Control #
Role Base Access Control (RBAC) is a technique that limits access to resources based on a specific set of roles associated with each user's credentials.
Keystone has a set of users that are associated with each project. Each user has one or more roles. After a user has authenticated with Keystone using a valid set of credentials, Keystone will augment that request with the Roles that are associated with that user. These roles are added to the Request Header under the X-Roles attribute and are presented as a comma-separated list.
12.3.7.1 Displaying All Users #
To discover the list of users available in the system, an administrator can run the following command using the Keystone command-line interface:
ardana >source ~/service.osrcardana >openstack user list
The output should resemble this response, which is a list of all the users currently available in this system.
+----------------------------------+-----------------------------------------+----+ | id | name | enabled | email | +----------------------------------+-----------------------------------------+----+ | 1c20d327c92a4ea8bb513894ce26f1f1 | admin | True | admin.example.com | | 0f48f3cc093c44b4ad969898713a0d65 | ceilometer | True | nobody@example.com | | 85ba98d27b1c4c8f97993e34fcd14f48 | cinder | True | nobody@example.com | | d2ff982a0b6547d0921b94957db714d6 | demo | True | demo@example.com | | b2d597e83664489ebd1d3c4742a04b7c | ec2 | True | nobody@example.com | | 2bd85070ceec4b608d9f1b06c6be22cb | glance | True | nobody@example.com | | 0e9e2daebbd3464097557b87af4afa4c | heat | True | nobody@example.com | | 0b466ddc2c0f478aa139d2a0be314467 | neutron | True | nobody@example.com | | 5cda1a541dee4555aab88f36e5759268 | nova | True | nobody@example.com || | 5cda1a541dee4555aab88f36e5759268 | nova | True | nobody@example.com | | 1cefd1361be8437d9684eb2add8bdbfa | swift | True | nobody@example.com | | f05bac3532c44414a26c0086797dab23 | user20141203213957|True| nobody@example.com | | 3db0588e140d4f88b0d4cc8b5ca86a0b | user20141205232231|True| nobody@example.com | +----------------------------------+-----------------------------------------+----+
12.3.7.2 Displaying All Roles #
To see all the roles that are currently available in the deployment, an administrator (someone with the admin role) can run the following command:
ardana >source ~/service.osrcardana >openstack role list
The output should resemble the following response:
+----------------------------------+-------------------------------------+ | id | name | +----------------------------------+-------------------------------------+ | 507bface531e4ac2b7019a1684df3370 | ResellerAdmin | | 9fe2ff9ee4384b1894a90878d3e92bab | _member_ | | e00e9406b536470dbde2689ce1edb683 | admin | | aa60501f1e664ddab72b0a9f27f96d2c | heat_stack_user | | a082d27b033b4fdea37ebb2a5dc1a07b | service | | 8f11f6761534407585feecb5e896922f | swiftoperator | +----------------------------------+-------------------------------------+
12.3.7.3 Assigning a Role to a User #
In this example, we want to add the role ResellerAdmin to the demo user who has the ID d2ff982a0b6547d0921b94957db714d6.
Determine which Project/Tenant the user belongs to.
ardana >source ~/service.osrcardana >openstack user show d2ff982a0b6547d0921b94957db714d6The response should resemble the following output:
+---------------------+----------------------------------+ | Field | Value | +---------------------+----------------------------------+ | domain_id | default | | enabled | True | | id | d2ff982a0b6547d0921b94957db714d6 | | name | admin | | options | {} | | password_expires_at | None | +---------------------+----------------------------------+We need to link the ResellerAdmin Role to a Project/Tenant. To start, determine which tenants are available on this deployment.
ardana >source ~/service.osrcardana >openstack project listThe response should resemble the following output:
+----------------------------------+-------------------------------+--+ | id | name | enabled | +----------------------------------+-------------------------------+--+ | 4a8f4207a13444089a18dc524f41b2cf | admin | True | | 00cbaf647bf24627b01b1a314e796138 | demo | True | | 8374761f28df43b09b20fcd3148c4a08 | gf1 | True | | 0f8a9eef727f4011a7c709e3fbe435fa | gf2 | True | | 6eff7b888f8e470a89a113acfcca87db | gf3 | True | | f0b5d86c7769478da82cdeb180aba1b0 | jaq1 | True | | a46f1127e78744e88d6bba20d2fc6e23 | jaq2 | True | | 977b9b7f9a6b4f59aaa70e5a1f4ebf0b | jaq3 | True | | 4055962ba9e44561ab495e8d4fafa41d | jaq4 | True | | 33ec7f15476545d1980cf90b05e1b5a8 | jaq5 | True | | 9550570f8bf147b3b9451a635a1024a1 | service | True | +----------------------------------+-------------------------------+--+
Now that we have all the pieces, we can assign the ResellerAdmin role to this User on the Demo project.
ardana >openstack role add --user d2ff982a0b6547d0921b94957db714d6 --project 00cbaf647bf24627b01b1a314e796138 507bface531e4ac2b7019a1684df3370This will produce no response if everything is correct.
Validate that the role has been assigned correctly. Pass in the user and tenant ID and request a list of roles assigned.
ardana >openstack role list --user d2ff982a0b6547d0921b94957db714d6 --project 00cbaf647bf24627b01b1a314e796138Note that all members have the _member_ role as a default role in addition to any other roles that have been assigned.
+----------------------------------+---------------+----------------------------------+----------------------------------+ | id | name | user_id | tenant_id | +----------------------------------+---------------+----------------------------------+----------------------------------+ | 507bface531e4ac2b7019a1684df3370 | ResellerAdmin | d2ff982a0b6547d0921b94957db714d6 | 00cbaf647bf24627b01b1a314e796138 | | 9fe2ff9ee4384b1894a90878d3e92bab | _member_ | d2ff982a0b6547d0921b94957db714d6 | 00cbaf647bf24627b01b1a314e796138 | +----------------------------------+---------------+----------------------------------+----------------------------------+
12.3.7.4 Creating a New Role #
In this example, we will create a Level 3 Support role called L3Support.
Add the new role to the list of roles.
ardana >openstack role create L3SupportThe response should resemble the following output:
+----------+----------------------------------+ | Property | Value | +----------+----------------------------------+ | id | 7e77946db05645c4ba56c6c82bf3f8d2 | | name | L3Support | +----------+----------------------------------+
Now that we have the new role's ID, we can add that role to the Demo user from the previous example.
ardana >openstack role add --user d2ff982a0b6547d0921b94957db714d6 --project 00cbaf647bf24627b01b1a314e796138 7e77946db05645c4ba56c6c82bf3f8d2This will produce no response if everything is correct.
Verify that the user Demo has both the ResellerAdmin and L3Support roles.
ardana >openstack role list --user d2ff982a0b6547d0921b94957db714d6 --project 00cbaf647bf24627b01b1a314e796138The response should resemble the following output. Note that this user has the L3Support role, the ResellerAdmin role, and the default member role.
+----------------------------------+---------------+----------------------------------+----------------------------------+ | id | name | user_id | tenant_id | +----------------------------------+---------------+----------------------------------+----------------------------------+ | 7e77946db05645c4ba56c6c82bf3f8d2 | L3Support | d2ff982a0b6547d0921b94957db714d6 | 00cbaf647bf24627b01b1a314e796138 | | 507bface531e4ac2b7019a1684df3370 | ResellerAdmin | d2ff982a0b6547d0921b94957db714d6 | 00cbaf647bf24627b01b1a314e796138 | | 9fe2ff9ee4384b1894a90878d3e92bab | _member_ | d2ff982a0b6547d0921b94957db714d6 | 00cbaf647bf24627b01b1a314e796138 | +----------------------------------+---------------+----------------------------------+----------------------------------+
12.3.7.5 Access Policies #
Before introducing RBAC, Ceilometer had very simple access control. There were two types of user: admins and users. Admins will be able to access any API and perform any operation. Users will only be able to access non-admin APIs and perform operations only on the Project/Tenant where they belonged.
12.3.7.6 New RBAC Policy File #
This is the policy file for Ceilometer without RBAC (etc/ceilometer/policy.json)
{
"context_is_admin": "role:admin"
}With the RBAC-enhanced code it is possible to control access to each API command. The new policy file (rbac_policy.json) looks like this.
{
"context_is_admin": "role:admin",
"telemetry:get_samples": "rule:context_is_admin",
"telemetry:get_sample": "rule:context_is_admin",
"telemetry:query_sample": "rule:context_is_admin",
"telemetry:create_samples": "rule:context_is_admin",
"telemetry:compute_statistics": "rule:context_is_admin",
"telemetry:get_meters": "rule:context_is_admin",
"telemetry:get_resource": "rule:context_is_admin",
"telemetry:get_resources": "rule:context_is_admin",
"telemetry:get_alarm": "rule:context_is_admin",
"telemetry:query_alarm": "rule:context_is_admin",
"telemetry:get_alarm_state": "rule:context_is_admin",
"telemetry:get_alarms": "rule:context_is_admin",
"telemetry:create_alarm": "rule:context_is_admin",
"telemetry:set_alarm": "rule:service_role",
"telemetry:delete_alarm": "rule:context_is_admin",
"telemetry:alarm_history": "rule:context_is_admin",
"telemetry:change_alarm_state": "rule:context_is_admin",
"telemetry:query_alarm_history": "rule:context_is_admin"
}Note that the API action names are namespaced using the telemetry: prefix. This avoids potential confusion if other services have policies with the same name.
12.3.7.7 Applying Policies to Roles #
Copy the rbac_policy.json file over the policy.json file and make any required changes.
12.3.7.8 Apply a policy to multiple roles #
For example, the ResellerAdmin role could also be permitted to access compute_statistics. This change would require the following changes in the rbac_policy.json policy file:
{
"context_is_admin": "role:admin",
"i_am_reseller": "role:ResellerAdmin",
"telemetry:get_samples": "rule:context_is_admin",
"telemetry:get_sample": "rule:context_is_admin",
"telemetry:query_sample": "rule:context_is_admin",
"telemetry:create_samples": "rule:context_is_admin",
"telemetry:compute_statistics": "rule:context_is_admin or rule:i_am_reseller",
...
}After a policy change has been made all the API services will need to be restarted .
12.3.7.9 Apply a policy to a non-default role only #
Another example: assign the L3Support role to the get_meters API and exclude all other roles.
{
"context_is_admin": "role:admin",
"i_am_reseller": "role:ResellerAdmin",
"l3_support": "role:L3Support",
"telemetry:get_samples": "rule:context_is_admin",
"telemetry:get_sample": "rule:context_is_admin",
"telemetry:query_sample": "rule:context_is_admin",
"telemetry:create_samples": "rule:context_is_admin",
"telemetry:compute_statistics": "rule:context_is_admin or rule:i_am_reseller",
"telemetry:get_meters": "rule:l3_support",
...
}12.3.7.10 Writing a Policy #
The Policy Engine capabilities are as expressible using a set of rules and guidelines. For a complete reference, please see the OSLO policy documentation.
Policies can be expressed in one of two forms: A list of lists, or a string written in the new policy language.
In the list-of-lists representation, each check inside the innermost list is combined with an and conjunction - for that check to pass, all the specified checks must pass. These innermost lists are then combined as with an or conjunction.
As an example, take the following rule, expressed in the list-of-lists representation:
[["role:admin"], ["project_id:%(project_id)s", "role:projectadmin"]]
In the policy language, each check is specified the same way as in the list-of-lists representation: a simple [a:b] pair that is matched to the correct class to perform that check.
User's Role
role:admin
Rules already defined on policy
rule:admin_required
Against a URL (URL checking must return TRUE to be valid)
http://my-url.org/check
User attributes (obtained through the token: user_id, domain_id, project_id)
project_id:%(target.project.id)s
Strings
<variable>:'xpto2035abc' 'myproject':<variable>
Literals
project_id:xpto2035abc domain_id:20 True:%(user.enabled)s
Conjunction operators are also available, allowing for more flexibility in crafting policies. So, in the policy language, the previous check in list-of-lists becomes:
role:admin or (project_id:%(project_id)s and role:projectadmin)
The policy language also has the NOT operator, allowing for richer policy rules:
project_id:%(project_id)s and not role:dunce
Attributes sent along with API calls can be used by the policy engine (on the right side of the expression), by using the following syntax:
<some_value>:%(user.id)s
Note: two special policy checks should be mentioned; the policy check @ will always accept an access, and the policy check ! will always reject an access.
12.3.8 Ceilometer Metering Failover HA Support #
In the HPE Helion OpenStack environment, the Ceilometer metering service supports native Active-Active high-availability (HA) for the notification and polling agents. Implementing HA support includes workload-balancing, workload-distribution and failover.
Tooz is the coordination engine that is used to coordinate workload among multiple active agent instances. It also maintains the knowledge of active-instance-to-handle failover and group membership using hearbeats (pings).
Zookeeper is used as the coordination backend. Zookeeper uses Tooz to expose the APIs that manage group membership and retrieve workload specific to each agent.
The following section in the configuration file is used to implement high-availability (HA):
[coordination] backend_url = <IP address of Zookeeper host: port> (port is usually 2181 as a zookeeper default) heartbeat = 1.0 check_watchers = 10.0
For the notification agent to be configured in HA mode, additional configuration is needed in the configuration file:
[notification] workload_partitioning = true
The HA notification agent distributes workload among multiple queues that are created based on the number of unique source:sink combinations. The combinations are configured in the notification agent pipeline configuration file. If there are additional services to be metered using notifications, then the recommendation is to use a separate source for those events. This is recommended especially if the expected load of data from that source is considered high. Implementing HA support should lead to better workload balancing among multiple active notification agents.
Ceilometer-expirer is also an Active-Active HA. Tooz is used to pick an expirer process that acquires a lock when there are multiple contenders and the winning process runs. There is no failover support, as expirer is not a daemon and is scheduled to run at pre-determined intervals.
Important
You must ensure that a single expirer process runs when multiple processes are scheduled to run at the same time. This must be done using cron-based scheduling. on multiple controller nodes
The following configuration is needed to enable expirer HA:
[coordination] backend_url = <IP address of Zookeeper host: port> (port is usually 2181 as a zookeeper default) heartbeat = 1.0 check_watchers = 10.0
The notification agent HA support is mainly designed to coordinate among notification agents so that correlated samples can be handled by the same agent. This happens when samples get transformed from other samples. The HPE Helion OpenStack Ceilometer pipeline has no transformers, so this task of coordination and workload partitioning does not need to be enabled. The notification agent is deployed on multiple controller nodes and they distribute workload among themselves by randomly fetching the data from the queue.
To disable coordination and workload partitioning by OpenStack, set the following value in the configuration file:
[notification]
workload_partitioning = FalseImportant
When a configuration change is made to an API running under the HA Proxy, that change needs to be replicated in all controllers.
12.3.9 Optimizing the Ceilometer Metering Service #
You can improve API and database responsiveness by configuring metering to store only the data you are require. This topic provides strategies for getting the most out of metering while not overloading your resources.
12.3.9.1 Change the List of Meters #
The list of meters can be easily reduced or increased by editing the pipeline.yaml file and restarting the polling agent.
Sample compute-only pipeline.yaml file with the daily poll interval:
---
sources:
- name: meter_source
interval: 86400
meters:
- "instance"
- "memory"
- "vcpus"
- "compute.instance.create.end"
- "compute.instance.delete.end"
- "compute.instance.update"
- "compute.instance.exists"
sinks:
- meter_sink
sinks:
- name: meter_sink
transformers:
publishers:
- notifier://Note
This change will cause all non-default meters to stop receiving notifications.
12.3.9.2 Enable Nova Notifications #
You can configure Nova to send notifications by enabling the setting in the configuration file. When enabled, Nova will send information to Ceilometer related to its usage and VM status. You must restart Nova for these changes to take effect.
The Openstack notification daemon, also known as a polling agent, monitors
the message bus for data being provided by other OpenStack components such
as Nova. The notification daemon loads one or more listener plugins, using
the ceilometer.notification namespace. Each plugin can
listen to any topic, but by default it will listen to the
notifications.info topic. The listeners grab messages off
the defined topics and redistribute them to the appropriate plugins
(endpoints) to be processed into Events and Samples. After the Nova service
is restarted, you should verify that the notification daemons are receiving
traffic.
For a more in-depth look at how information is sent over openstack.common.rpc, refer to the OpenStack Ceilometer documentation.
Nova can be configured to send following data to Ceilometer:
| Name | Unit | Type | Resource | Note |
| instance | g | instance | inst ID | Existence of instance |
instance: type
| g | instance | inst ID | Existence of instance of type (Where
type is a valid OpenStack type.) |
| memory | g | MB | inst ID | Amount of allocated RAM. Measured in MB. |
| vcpus | g | vcpu | inst ID | Number of VCPUs |
| disk.root.size | g | GB | inst ID | Size of root disk. Measured in GB. |
| disk.ephemeral.size | g | GB | inst ID | Size of ephemeral disk. Measured in GB. |
To enable Nova to publish notifications:
In a text editor, open the following file:
nova.conf
Compare the example of a working configuration file with the necessary changes to your configuration file. If there is anything missing in your file, add it, and then save the file.
notification_driver=messaging notification_topics=notifications notify_on_state_change=vm_and_task_state instance_usage_audit=True instance_usage_audit_period=hour
Important
The
instance_usage_audit_periodinterval can be set to check the instance's status every hour, once a day, once a week or once a month. Every time the audit period elapses, Nova sends a notification to Ceilometer to record whether or not the instance is alive and running. Metering this statistic is critical if billing depends on usage.To restart Nova service, run:
tux >sudo systemctl restart nova-api.servicetux >sudo systemctl restart nova-conductor.servicetux >sudo systemctl restart nova-scheduler.servicetux >sudo systemctl restart nova-novncproxy.serviceImportant
Different platforms may use their own unique command to restart nova-compute services. If the above command does not work, please refer to the documentation for your specific platform.
To verify successful launch of each process, list the service components:
ardana >source ~/service.osrcardana >nova service-list +----+------------------+------------+----------+---------+-------+----------------------------+-----------------+ | Id | Binary | Host | Zone | Status | State | Updated_at | Disabled Reason | +----+------------------+------------+----------+---------+-------+----------------------------+-----------------+ | 1 | nova-conductor | controller | internal | enabled | up | 2014-09-16T23:54:02.000000 | - | | 2 | nova-consoleauth | controller | internal | enabled | up | 2014-09-16T23:54:04.000000 | - | | 3 | nova-scheduler | controller | internal | enabled | up | 2014-09-16T23:54:07.000000 | - | | 4 | nova-cert | controller | internal | enabled | up | 2014-09-16T23:54:00.000000 | - | | 5 | nova-compute | compute1 | nova | enabled | up | 2014-09-16T23:54:06.000000 | - | +----+------------------+------------+----------+---------+-------+----------------------------+-----------------+
12.3.9.3 Improve Reporting API Responsiveness #
Reporting APIs are the main access to the metering data stored in Ceilometer. These APIs are accessed by Horizon to provide basic usage data and information.
HPE Helion OpenStack uses Apache2 Web Server to provide the API access. This topic provides some strategies to help you optimize the front-end and back-end databases.
To improve the responsiveness you can increase the number of threads and processes in the ceilometer configuration file. The Ceilometer API runs as an WSGI processes. Each process can have a certain amount of threads managing the filters and applications, which can comprise the processing pipeline.
To configure Apache2 to use increase the number of threads, use the steps in Section 12.3.5, “Configure the Ceilometer Metering Service”
Warning
The resource usage panel could take some time to load depending on the number of metrics selected.
12.3.9.4 Update the Polling Strategy and Swift Considerations #
Polling can put an excessive amount of strain on the system due to the amount of data the system may have to process. Polling also has a severe impact on queries since the database can have very large amount of data to scan before responding to the query. This process usually consumes a large amount of CPU and memory to complete the requests. Clients can also experience long waits for queries to come back and, in extreme cases, even timeout.
There are 3 polling meters in Swift:
storage.objects
storage.objects.size
storage.objects.containers
Sample section of the pipeline.yaml configuration file with Swift polling on an hourly interval:
---
sources:
- name: swift_source
interval: 3600
sources:
meters:
- "storage.objects"
- "storage.objects.size"
- "storage.objects.containers"
sinks:
- name: meter_sink
transformers:
publishers:
- notifier://Every time the polling interval occurs, at least 3 messages per existing object/container in Swift are collected. The following table illustrates the amount of data produced hourly in different scenarios:
| Swift Containers | Swift Objects per container | Samples per Hour | Samples stored per 24 hours |
| 10 | 10 | 500 | 12000 |
| 10 | 100 | 5000 | 120000 |
| 100 | 100 | 50000 | 1200000 |
| 100 | 1000 | 500000 | 12000000 |
Looking at the data we can see that even a very small Swift storage with 10 containers and 100 files will store 120K samples in 24 hours, bringing it to a total of 3.6 million samples.
Note
The file size of each file does not have any impact on the number of samples collected. In fact the smaller the number of containers or files, the smaller the sample size. In the scenario where there a large number of small files and containers, the sample size is also large and the performance is at its worst.
12.3.10 Metering Service Samples #
Samples are discrete collections of a particular meter or the actual usage data defined by a meter description. Each sample is time-stamped and includes a variety of data that varies per meter but usually includes the project ID and UserID of the entity that consumed the resource represented by the meter and sample.
In a typical deployment, the number of samples can be in the tens of thousands if not higher for a specific collection period depending on overall activity.
Sample collection and data storage expiry settings are configured in Ceilometer. Use cases that include collecting data for monthly billing cycles are usually stored over a period of 45 days and require a large, scalable, back-end database to support the large volume of samples generated by production OpenStack deployments.
Example configuration:
[database] metering_time_to_live=-1
In our example use case, to construct a complete billing record, an external billing application must collect all pertinent samples. Then the results must be sorted, summarized, and combine with the results of other types of metered samples that are required. This function is known as aggregation and is external to the Ceilometer service.
Meter data, or samples, can also be collected directly from the service APIs by individual Ceilometer polling agents. These polling agents directly access service usage by calling the API of each service.
OpenStack services such as Swift currently only provide metered data through this function and some of the other OpenStack services provide specific metrics only through a polling action.