Administration Guide
- About This Guide
- I Installation, Setup and Upgrade
- II Configuration and Administration
- 6 Configuration and Administration Basics
- 7 Configuring and Managing Cluster Resources with Hawk2
- 8 Configuring and Managing Cluster Resources (Command Line)
- 9 Adding or Modifying Resource Agents
- 10 Fencing and STONITH
- 11 Storage Protection and SBD
- 12 Access Control Lists
- 13 Network Device Bonding
- 14 Load Balancing
- 15 Geo Clusters (Multi-Site Clusters)
- 16 Executing Maintenance Tasks
- III Storage and Data Replication
- IV Appendix
- Glossary
- E GNU Licenses
1 Product Overview #
Abstract#
SUSE® Linux Enterprise High Availability Extension is an integrated suite of open source clustering technologies that enables you to implement highly available physical and virtual Linux clusters, and to eliminate single points of failure. It ensures the high availability and manageability of critical resources including data, applications, and services. Thus, it helps you maintain business continuity, protect data integrity, and reduce unplanned downtime for your mission-critical Linux workloads.
It ships with essential monitoring, messaging, and cluster resource management functionality (supporting failover, failback, and migration (load balancing) of individually managed cluster resources).
This chapter introduces the main product features and benefits of the High Availability Extension. Inside you will find several example clusters and learn about the components making up a cluster. The last section provides an overview of the architecture, describing the individual architecture layers and processes within the cluster.
For explanations of some common terms used in the context of High Availability clusters, refer to Glossary.
1.1 Availability as Extension #
The High Availability Extension is available as an extension to SUSE Linux Enterprise Server 12 SP5. Support for geographically dispersed clusters (Geo clusters) is available as a separate extension to the High Availability Extension, called Geo Clustering for SUSE Linux Enterprise High Availability Extension.
1.2 Key Features #
SUSE® Linux Enterprise High Availability Extension helps you ensure and manage the availability of your network resources. The following sections highlight some of the key features:
1.2.1 Wide Range of Clustering Scenarios #
The High Availability Extension supports the following scenarios:
Active/active configurations
Active/passive configurations: N+1, N+M, N to 1, N to M
Hybrid physical and virtual clusters, allowing virtual servers to be clustered with physical servers. This improves service availability and resource usage.
Local clusters
Metro clusters (“stretched” local clusters)
Geo clusters (geographically dispersed clusters) are supported with the additional Geo extension, see Section 1.2.5, “Support of Local, Metro, and Geo Clusters”.
Your cluster can contain up to 32 Linux servers. Using
pacemaker_remote, the cluster can be extended to include
additional Linux servers beyond this limit.
Any server in the cluster can restart resources (applications, services, IP
addresses, and file systems) from a failed server in the cluster.
1.2.2 Flexibility #
The High Availability Extension ships with Corosync messaging and membership layer and Pacemaker Cluster Resource Manager. Using Pacemaker, administrators can continually monitor the health and status of their resources, manage dependencies, and automatically stop and start services based on highly configurable rules and policies. The High Availability Extension allows you to tailor a cluster to the specific applications and hardware infrastructure that fit your organization. Time-dependent configuration enables services to automatically migrate back to repaired nodes at specified times.
1.2.3 Storage and Data Replication #
With the High Availability Extension you can dynamically assign and reassign server storage as needed. It supports Fibre Channel storage area networks (SAN) and iSCSI storage on networks. Thus, shared disk systems are supported, but they are not a requirement. SUSE Linux Enterprise High Availability Extension also comes with a cluster-aware file system and volume manager (OCFS2) and the clustered Logical Volume Manager (cLVM). For replication of your data, you can use DRBD* to mirror the data of a High Availability service from the active node of a cluster to its standby node. Furthermore, SUSE Linux Enterprise High Availability Extension also supports CTDB (Clustered Trivial Database), a technology for Samba clustering.
1.2.4 Support for Virtualized Environments #
SUSE Linux Enterprise High Availability Extension supports the clustering of both physical and virtual Linux servers. Mixing both types of servers is supported as well. SUSE Linux Enterprise Server 12 SP5 ships with Xen and KVM (Kernel-based Virtual Machine). Both are open source virtualization hypervisors. Virtualization guest systems (also known as VMs) can be managed as services by the cluster.
1.2.5 Support of Local, Metro, and Geo Clusters #
SUSE Linux Enterprise High Availability Extension has been extended to support different geographical scenarios. Support for geographically dispersed clusters (Geo clusters) is available as a separate extension to High Availability Extension, called Geo Clustering for SUSE Linux Enterprise High Availability Extension.
- Local Clusters
A single cluster in one location (for example, all nodes are located in one data center). The cluster uses multicast or unicast for communication between the nodes and manages failover internally. Network latency can be neglected. Storage is typically accessed synchronously by all nodes.
- Metro Clusters
A single cluster that can stretch over multiple buildings or data centers. The cluster usually uses unicast for communication between the nodes and manages failover internally. Network latency is usually low (<5 ms for distances of approximately 20 miles). Storage is preferably connected by fibre channel. Data replication is done by storage internally, or by host based mirror under control of the cluster.
- Geo Clusters (Multi-Site Clusters)
Multiple, geographically dispersed sites with a local cluster each. The sites communicate via IP. Failover across the sites is coordinated by a higher-level entity. Geo clusters need to cope with limited network bandwidth and high latency. Storage is replicated asynchronously.
The greater the geographical distance between individual cluster nodes, the more factors may potentially disturb the high availability of services the cluster provides. Network latency, limited bandwidth and access to storage are the main challenges for long-distance clusters.
1.2.6 Resource Agents #
SUSE Linux Enterprise High Availability Extension includes a huge number of resource agents to manage
resources such as Apache, IPv4, IPv6 and many more. It also ships with
resource agents for popular third party applications such as IBM
WebSphere Application Server. For an overview of Open Cluster Framework
(OCF) resource agents included with your product, use the crm
ra command as described in
Section 8.1.3, “Displaying Information about OCF Resource Agents”.
1.2.7 User-friendly Administration Tools #
The High Availability Extension ships with a set of powerful tools for basic installation and setup of your cluster, effective configuration and administration:
- YaST
A graphical user interface for general system installation and administration. Use it to install the High Availability Extension on top of SUSE Linux Enterprise Server as described in the Installation and Setup Quick Start. YaST also provides the following modules in the High Availability category to help configure your cluster or individual components:
Cluster: Basic cluster setup. For details, refer to Chapter 4, Using the YaST Cluster Module.
DRBD: Configuration of a Distributed Replicated Block Device.
IP Load Balancing: Configuration of load balancing with Linux Virtual Server or HAProxy. For details, refer to Chapter 14, Load Balancing.
- HA Web Konsole (Hawk2)
A Web-based user interface with which you can administer your Linux cluster from non-Linux machines. It is also an ideal solution in case your system does not provide a graphical user interface. It guides you through the creation and configuration of resources and lets you execute management tasks like starting, stopping or migrating resources. For details, refer to Chapter 7, Configuring and Managing Cluster Resources with Hawk2.
crmShellA powerful unified command line interface to configure resources and execute all monitoring or administration tasks. For details, refer to Chapter 8, Configuring and Managing Cluster Resources (Command Line).
1.3 Benefits #
The High Availability Extension allows you to configure up to 32 Linux servers into a high-availability cluster (HA cluster), where resources can be dynamically switched or moved to any server in the cluster. Resources can be configured to automatically migrate if a server fails, or they can be moved manually to troubleshoot hardware or balance the workload.
The High Availability Extension provides high availability from commodity components. Lower costs are obtained through the consolidation of applications and operations onto a cluster. The High Availability Extension also allows you to centrally manage the complete cluster and to adjust resources to meet changing workload requirements (thus, manually “load balance” the cluster). Allowing clusters of more than two nodes also provides savings by allowing several nodes to share a “hot spare”.
An equally important benefit is the potential reduction of unplanned service outages as well as planned outages for software and hardware maintenance and upgrades.
Reasons that you would want to implement a cluster include:
Increased availability
Improved performance
Low cost of operation
Scalability
Disaster recovery
Data protection
Server consolidation
Storage consolidation
Shared disk fault tolerance can be obtained by implementing RAID on the shared disk subsystem.
The following scenario illustrates some benefits the High Availability Extension can provide.
Example Cluster Scenario#
Suppose you have configured a three-server cluster, with a Web server installed on each of the three servers in the cluster. Each of the servers in the cluster hosts two Web sites. All the data, graphics, and Web page content for each Web site are stored on a shared disk subsystem connected to each of the servers in the cluster. The following figure depicts how this setup might look.
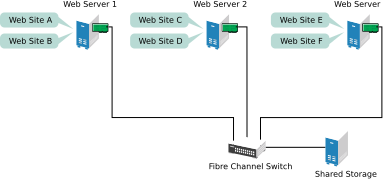
Figure 1.1: Three-Server Cluster #
During normal cluster operation, each server is in constant communication with the other servers in the cluster and performs periodic polling of all registered resources to detect failure.
Suppose Web Server 1 experiences hardware or software problems and the users depending on Web Server 1 for Internet access, e-mail, and information lose their connections. The following figure shows how resources are moved when Web Server 1 fails.
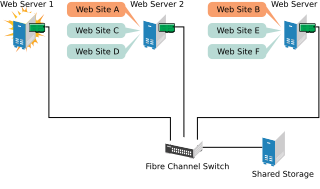
Figure 1.2: Three-Server Cluster after One Server Fails #
Web Site A moves to Web Server 2 and Web Site B moves to Web Server 3. IP addresses and certificates also move to Web Server 2 and Web Server 3.
When you configured the cluster, you decided where the Web sites hosted on each Web server would go should a failure occur. In the previous example, you configured Web Site A to move to Web Server 2 and Web Site B to move to Web Server 3. This way, the workload once handled by Web Server 1 continues to be available and is evenly distributed between any surviving cluster members.
When Web Server 1 failed, the High Availability Extension software did the following:
Detected a failure and verified with STONITH that Web Server 1 was really dead. STONITH is an acronym for “Shoot The Other Node In The Head” and is a means of bringing down misbehaving nodes to prevent them from causing trouble in the cluster.
Remounted the shared data directories that were formerly mounted on Web server 1 on Web Server 2 and Web Server 3.
Restarted applications that were running on Web Server 1 on Web Server 2 and Web Server 3.
Transferred IP addresses to Web Server 2 and Web Server 3.
In this example, the failover process happened quickly and users regained access to Web site information within seconds, usually without needing to log in again.
Now suppose the problems with Web Server 1 are resolved, and Web Server 1 is returned to a normal operating state. Web Site A and Web Site B can either automatically fail back (move back) to Web Server 1, or they can stay where they are. This depends on how you configured the resources for them. Migrating the services back to Web Server 1 will incur some down-time, so the High Availability Extension also allows you to defer the migration until a period when it will cause little or no service interruption. There are advantages and disadvantages to both alternatives.
The High Availability Extension also provides resource migration capabilities. You can move applications, Web sites, etc. to other servers in your cluster as required for system management.
For example, you could have manually moved Web Site A or Web Site B from Web Server 1 to either of the other servers in the cluster. Use cases for this are upgrading or performing scheduled maintenance on Web Server 1, or increasing performance or accessibility of the Web sites.
1.4 Cluster Configurations: Storage #
Cluster configurations with the High Availability Extension might or might not include a shared disk subsystem. The shared disk subsystem can be connected via high-speed Fibre Channel cards, cables, and switches, or it can be configured to use iSCSI. If a server fails, another designated server in the cluster automatically mounts the shared disk directories that were previously mounted on the failed server. This gives network users continuous access to the directories on the shared disk subsystem.
Typical resources might include data, applications, and services. The following figure shows how a typical Fibre Channel cluster configuration might look.
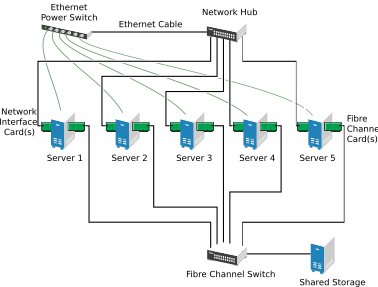
Figure 1.3: Typical Fibre Channel Cluster Configuration #
Although Fibre Channel provides the best performance, you can also configure your cluster to use iSCSI. iSCSI is an alternative to Fibre Channel that can be used to create a low-cost Storage Area Network (SAN). The following figure shows how a typical iSCSI cluster configuration might look.
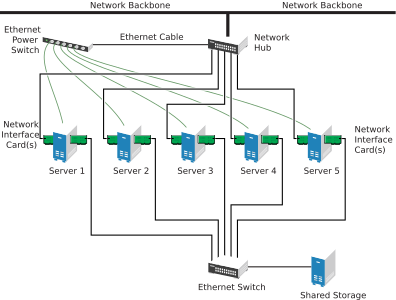
Figure 1.4: Typical iSCSI Cluster Configuration #
Although most clusters include a shared disk subsystem, it is also possible to create a cluster without a shared disk subsystem. The following figure shows how a cluster without a shared disk subsystem might look.
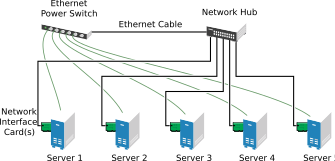
Figure 1.5: Typical Cluster Configuration Without Shared Storage #
1.5 Architecture #
This section provides a brief overview of the High Availability Extension architecture. It identifies and provides information on the architectural components, and describes how those components interoperate.
1.5.1 Architecture Layers #
The High Availability Extension has a layered architecture. Figure 1.6, “Architecture” illustrates the different layers and their associated components.
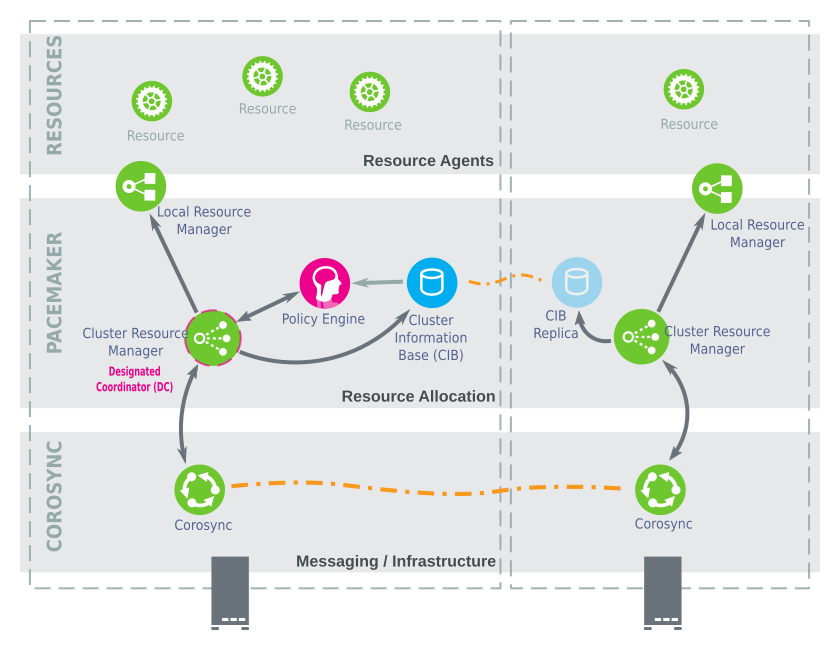
Figure 1.6: Architecture #
1.5.1.1 Messaging and Infrastructure Layer #
The primary or first layer is the messaging/infrastructure layer, also known as the Corosync layer. This layer contains components that send out the messages containing “I am alive” signals, as well as other information.
1.5.1.2 Resource Allocation Layer #
The next layer is the resource allocation layer. This layer is the most complex, and consists of the following components:
- Cluster Resource Manager (CRM)
Every action taken in the resource allocation layer passes through the Cluster Resource Manager. If other components of the resource allocation layer (or components which are in a higher layer) need to communicate, they do so through the local CRM. On every node, the CRM maintains the Cluster Information Base (CIB).
- Cluster Information Base (CIB)
The Cluster Information Base is an in-memory XML representation of the entire cluster configuration and current status. It contains definitions of all cluster options, nodes, resources, constraints and the relationship to each other. The CIB also synchronizes updates to all cluster nodes. There is one master CIB in the cluster, maintained by the Designated Coordinator (DC). All other nodes contain a CIB replica.
- Designated Coordinator (DC)
One CRM in the cluster is elected as DC. The DC is the only entity in the cluster that can decide that a cluster-wide change needs to be performed, such as fencing a node or moving resources around. The DC is also the node where the master copy of the CIB is kept. All other nodes get their configuration and resource allocation information from the current DC. The DC is elected from all nodes in the cluster after a membership change.
- Policy Engine (PE)
Whenever the Designated Coordinator needs to make a cluster-wide change (react to a new CIB), the Policy Engine calculates the next state of the cluster based on the current state and configuration. The PE also produces a transition graph containing a list of (resource) actions and dependencies to achieve the next cluster state. The PE always runs on the DC.
- Local Resource Manager (LRM)
The LRM calls the local Resource Agents (see Section 1.5.1.3, “Resource Layer”) on behalf of the CRM. It can thus perform start / stop / monitor operations and report the result to the CRM. The LRM is the authoritative source for all resource-related information on its local node.
1.5.1.3 Resource Layer #
The highest layer is the Resource Layer. The Resource Layer includes one or more Resource Agents (RA). Resource Agents are programs (usually shell scripts) that have been written to start, stop, and monitor a certain kind of service (a resource). Resource Agents are called only by the LRM. Third parties can include their own agents in a defined location in the file system and thus provide out-of-the-box cluster integration for their own software.
1.5.2 Process Flow #
SUSE Linux Enterprise High Availability Extension uses Pacemaker as CRM. The CRM is implemented as daemon
(crmd) that has an instance on each cluster node.
Pacemaker centralizes all cluster decision-making by electing one of the
crmd instances to act as a master. Should the elected crmd process (or
the node it is on) fail, a new one is established.
A CIB, reflecting the cluster’s configuration and current state of all resources in the cluster is kept on each node. The contents of the CIB are automatically kept synchronous across the entire cluster.
Many actions performed in the cluster will cause a cluster-wide change. These actions can include things like adding or removing a cluster resource or changing resource constraints. It is important to understand what happens in the cluster when you perform such an action.
For example, suppose you want to add a cluster IP address resource. To do this, you can use one of the command line tools or the Web interface to modify the CIB. It is not required to perform the actions on the DC, you can use either tool on any node in the cluster and they will be relayed to the DC. The DC will then replicate the CIB change to all cluster nodes.
Based on the information in the CIB, the PE then computes the ideal state of the cluster and how it should be achieved and feeds a list of instructions to the DC. The DC sends commands via the messaging/infrastructure layer which are received by the crmd peers on other nodes. Each crmd uses its LRM (implemented as lrmd) to perform resource modifications. The lrmd is not cluster-aware and interacts directly with resource agents (scripts).
All peer nodes report the results of their operations back to the DC. After the DC concludes that all necessary operations are successfully performed in the cluster, the cluster will go back to the idle state and wait for further events. If any operation was not carried out as planned, the PE is invoked again with the new information recorded in the CIB.
In some cases, it may be necessary to power off nodes to protect shared data or complete resource recovery. For this Pacemaker comes with a fencing subsystem, stonithd. STONITH is an acronym for “Shoot The Other Node In The Head”. It is usually implemented with a STONITH shared block device, remote management boards, or remote power switches. In Pacemaker, STONITH devices are modeled as resources (and configured in the CIB) to enable them to be easily used. However, stonithd takes care of understanding the STONITH topology such that its clients request a node be fenced and it does the rest.