Administration Guide
- About This Guide
- I Installation, Setup and Upgrade
- II Configuration and Administration
- 6 Configuration and Administration Basics
- 7 Configuring and Managing Cluster Resources with Hawk2
- 8 Configuring and Managing Cluster Resources (Command Line)
- 9 Adding or Modifying Resource Agents
- 10 Fencing and STONITH
- 11 Storage Protection and SBD
- 12 Access Control Lists
- 13 Network Device Bonding
- 14 Load Balancing
- 15 Geo Clusters (Multi-Site Clusters)
- 16 Executing Maintenance Tasks
- III Storage and Data Replication
- IV Appendix
- Glossary
- E GNU Licenses
6 Configuration and Administration Basics #
Abstract#
The main purpose of an HA cluster is to manage user services. Typical examples of user services are an Apache Web server or a database. From the user's point of view, the services do something specific when ordered to do so. To the cluster, however, they are only resources which may be started or stopped—the nature of the service is irrelevant to the cluster.
In this chapter, we will introduce some basic concepts you need to know when configuring resources and administering your cluster. The following chapters show you how to execute the main configuration and administration tasks with each of the management tools the High Availability Extension provides.
6.1 Use Case Scenarios #
In general, clusters fall into one of two categories:
Two-node clusters
Clusters with more than two nodes. This usually means an odd number of nodes.
Adding also different topologies, different use cases can be derived. The following use cases are the most common:
- Two-node cluster in one location
Configuration: FC SAN or similar shared storage, layer 2 network.
Usage scenario: Embedded clusters that focus on service high availability and not data redundancy for data replication. Such a setup is used for radio stations or assembly line controllers, for example.
- Two-node clusters in two locations (most widely used)
Configuration: Symmetrical stretched cluster, FC SAN, and layer 2 network all across two locations.
Usage scenario: Classic stretched clusters, focus on high availability of services and local data redundancy. For databases and enterprise resource planning. One of the most popular setups during the last few years.
- Odd number of nodes in three locations
Configuration: 2×N+1 nodes, FC SAN across two main locations. Auxiliary third site with no FC SAN, but acts as a majority maker. Layer 2 network at least across two main locations.
Usage scenario: Classic stretched cluster, focus on high availability of services and data redundancy. For example, databases, enterprise resource planning.
6.2 Quorum Determination #
Whenever communication fails between one or more nodes and the rest of the cluster, a cluster partition occurs. The nodes can only communicate with other nodes in the same partition and are unaware of the separated nodes. A cluster partition is defined as having quorum (can “quorate”) if it has the majority of nodes (or votes). How this is achieved is done by quorum calculation. Quorum is a requirement for fencing.
Quorum calculation has changed between SUSE Linux Enterprise High Availability Extension 11 and SUSE Linux Enterprise High Availability Extension 12. For SUSE Linux Enterprise High Availability Extension 11, quorum was calculated by Pacemaker. Starting with SUSE Linux Enterprise High Availability Extension 12, Corosync can handle quorum for two-node clusters directly without changing the Pacemaker configuration.
How quorum is calculated is influenced by the following factors:
- Number of Cluster Nodes
To keep services running, a cluster with more than two nodes relies on quorum (majority vote) to resolve cluster partitions. Based on the following formula, you can calculate the minimum number of operational nodes required for the cluster to function:
N ≥ C/2 + 1 N = minimum number of operational nodes C = number of cluster nodes
For example, a five-node cluster needs a minimum of three operational nodes (or two nodes which can fail).
We strongly recommend to use either a two-node cluster or an odd number of cluster nodes. Two-node clusters make sense for stretched setups across two sites. Clusters with an odd number of nodes can be built on either one single site or might being spread across three sites.
- Corosync Configuration
Corosync is a messaging and membership layer, see Section 6.2.4, “Corosync Configuration for Two-Node Clusters” and Section 6.2.5, “Corosync Configuration for N-Node Clusters”.
6.2.1 Global Cluster Options #
Global cluster options control how the cluster behaves when
confronted with certain situations. They are grouped into sets and can be
viewed and modified with the cluster management tools like Hawk2 and
the crm shell.
The predefined values can usually be kept. However, to make key functions of your cluster work correctly, you need to adjust the following parameters after basic cluster setup:
6.2.2 Global Option no-quorum-policy #
This global option defines what to do when a cluster partition does not have quorum (no majority of nodes is part of the partition).
Allowed values are:
ignoreSetting
no-quorum-policytoignoremakes the cluster behave like it has quorum. Resource management is continued.On SLES 11 this was the recommended setting for a two-node cluster. Starting with SLES 12, this option is obsolete. Based on configuration and conditions, Corosync gives cluster nodes or a single node “quorum”—or not.
For two-node clusters the only meaningful behavior is to always react in case of quorum loss. The first step should always be to try to fence the lost node.
freezeIf quorum is lost, the cluster partition freezes. Resource management is continued: running resources are not stopped (but possibly restarted in response to monitor events), but no further resources are started within the affected partition.
This setting is recommended for clusters where certain resources depend on communication with other nodes (for example, OCFS2 mounts). In this case, the default setting
no-quorum-policy=stopis not useful, as it would lead to the following scenario: Stopping those resources would not be possible while the peer nodes are unreachable. Instead, an attempt to stop them would eventually time out and cause astop failure, triggering escalated recovery and fencing.stop(default value)If quorum is lost, all resources in the affected cluster partition are stopped in an orderly fashion.
suicideIf quorum is lost, all nodes in the affected cluster partition are fenced. This option works only in combination with SBD, see Chapter 11, Storage Protection and SBD.
6.2.3 Global Option stonith-enabled #
This global option defines whether to apply fencing, allowing STONITH
devices to shoot failed nodes and nodes with resources that cannot be
stopped. By default, this global option is set to
true, because for normal cluster operation it is
necessary to use STONITH devices. According to the default value,
the cluster will refuse to start any resources if no STONITH
resources have been defined.
If you need to disable fencing for any reasons, set
stonith-enabled to false, but be
aware that this has impact on the support status for your product.
Furthermore, with stonith-enabled="false", resources
like the Distributed Lock Manager (DLM) and all services depending on
DLM (such as cLVM, GFS2, and OCFS2) will fail to start.
Important: No Support Without STONITH
A cluster without STONITH is not supported.
6.2.4 Corosync Configuration for Two-Node Clusters #
When using the bootstrap scripts, the Corosync configuration contains
a quorum section with the following options:
Example 6.1: Excerpt of Corosync Configuration for a Two-Node Cluster #
quorum {
# Enable and configure quorum subsystem (default: off)
# see also corosync.conf.5 and votequorum.5
provider: corosync_votequorum
expected_votes: 2
two_node: 1
}
As opposed to SUSE Linux Enterprise 11, the votequorum subsystem in SUSE Linux Enterprise 12 is
powered by Corosync version 2.x. This means that the
no-quorum-policy=ignore option must not be used.
By default, when two_node: 1 is set, the
wait_for_all option is automatically enabled.
If wait_for_all is not enabled, the cluster should be
started on both nodes in parallel. Otherwise the first node will perform
a startup-fencing on the missing second node.
6.2.5 Corosync Configuration for N-Node Clusters #
When not using a two-node cluster, we strongly recommend an odd number of nodes for your N-node cluster. With regard to quorum configuration, you have the following options:
Adding additional nodes with the
ha-cluster-joincommand, orAdapting the Corosync configuration manually.
If you adjust /etc/corosync/corosync.conf manually,
use the following settings:
Example 6.2: Excerpt of Corosync Configuration for an N-Node Cluster #
quorum {
provider: corosync_votequorum 1
expected_votes: N 2
wait_for_all: 1 3
}Use the quorum service from Corosync | |
The number of votes to expect. This parameter can either be
provided inside the | |
Enables the wait for all (WFA) feature.
When WFA is enabled, the cluster will be quorate for the first time
only after all nodes have become visible.
To avoid some start-up race conditions, setting |
6.3 Cluster Resources #
As a cluster administrator, you need to create cluster resources for every resource or application you run on servers in your cluster. Cluster resources can include Web sites, e-mail servers, databases, file systems, virtual machines, and any other server-based applications or services you want to make available to users at all times.
6.3.1 Resource Management #
Before you can use a resource in the cluster, it must be set up. For example, to use an Apache server as a cluster resource, set up the Apache server first and complete the Apache configuration before starting the respective resource in your cluster.
If a resource has specific environment requirements, make sure they are present and identical on all cluster nodes. This kind of configuration is not managed by the High Availability Extension. You must do this yourself.
Note: Do Not Touch Services Managed by the Cluster
When managing a resource with the High Availability Extension, the same resource must not be started or stopped otherwise (outside of the cluster, for example manually or on boot or reboot). The High Availability Extension software is responsible for all service start or stop actions.
If you need to execute testing or maintenance tasks after the services are already running under cluster control, make sure to put the resources, nodes, or the whole cluster into maintenance mode before you touch any of them manually. For details, see Section 16.2, “Different Options for Maintenance Tasks”.
After having configured the resources in the cluster, use the cluster management tools to start, stop, clean up, remove or migrate any resources manually. For details how to do so with your preferred cluster management tool:
6.3.2 Supported Resource Agent Classes #
For each cluster resource you add, you need to define the standard that the resource agent conforms to. Resource agents abstract the services they provide and present an accurate status to the cluster, which allows the cluster to be non-committal about the resources it manages. The cluster relies on the resource agent to react appropriately when given a start, stop or monitor command.
Typically, resource agents come in the form of shell scripts. The High Availability Extension supports the following classes of resource agents:
- Open Cluster Framework (OCF) Resource Agents
OCF RA agents are best suited for use with High Availability, especially when you need multi-state resources or special monitoring abilities. The agents are generally located in
/usr/lib/ocf/resource.d/provider/. Their functionality is similar to that of LSB scripts. However, the configuration is always done with environmental variables which allow them to accept and process parameters easily. The OCF specification (as it relates to resource agents) can be found at https://github.com/ClusterLabs/OCF-spec/blob/master/ra/1.0/resource-agent-api.md. OCF specifications have strict definitions of which exit codes must be returned by actions, see Section 9.3, “OCF Return Codes and Failure Recovery”. The cluster follows these specifications exactly.All OCF Resource Agents are required to have at least the actions
start,stop,status,monitor, andmeta-data. Themeta-dataaction retrieves information about how to configure the agent. For example, if you want to know more about theIPaddragent by the providerheartbeat, use the following command:OCF_ROOT=/usr/lib/ocf /usr/lib/ocf/resource.d/heartbeat/IPaddr meta-data
The output is information in XML format, including several sections (general description, available parameters, available actions for the agent).
Alternatively, use the crmsh to view information on OCF resource agents. For details, see Section 8.1.3, “Displaying Information about OCF Resource Agents”.
- Linux Standards Base (LSB) Scripts
LSB resource agents are generally provided by the operating system/distribution and are found in
/etc/init.d. To be used with the cluster, they must conform to the LSB init script specification. For example, they must have several actions implemented, which are, at minimum,start,stop,restart,reload,force-reload, andstatus. For more information, see http://refspecs.linuxbase.org/LSB_4.1.0/LSB-Core-generic/LSB-Core-generic/iniscrptact.html.The configuration of those services is not standardized. If you intend to use an LSB script with High Availability, make sure that you understand how the relevant script is configured. Often you can find information about this in the documentation of the relevant package in
/usr/share/doc/packages/PACKAGENAME.- Systemd
Starting with SUSE Linux Enterprise 12, systemd is a replacement for the popular System V init daemon. Pacemaker can manage systemd services if they are present. Instead of init scripts, systemd has unit files. Generally the services (or unit files) are provided by the operating system. In case you want to convert existing init scripts, find more information at http://0pointer.de/blog/projects/systemd-for-admins-3.html.
- Service
There are currently many “common” types of system services that exist in parallel:
LSB(belonging to System V init),systemd, and (in some distributions)upstart. Therefore, Pacemaker supports a special alias which intelligently figures out which one applies to a given cluster node. This is particularly useful when the cluster contains a mix of systemd, upstart, and LSB services. Pacemaker will try to find the named service in the following order: as an LSB (SYS-V) init script, a systemd unit file, or an Upstart job.- Nagios
Monitoring plug-ins (formerly called Nagios plug-ins) allow to monitor services on remote hosts. Pacemaker can do remote monitoring with the monitoring plug-ins if they are present. For detailed information, see Section 6.6.1, “Monitoring Services on Remote Hosts with Monitoring Plug-ins”.
- STONITH (Fencing) Resource Agents
This class is used exclusively for fencing related resources. For more information, see Chapter 10, Fencing and STONITH.
The agents supplied with the High Availability Extension are written to OCF specifications.
6.3.3 Types of Resources #
The following types of resources can be created:
- Primitives
A primitive resource, the most basic type of resource.
Learn how to create primitive resources with your preferred cluster management tool:
- Groups
Groups contain a set of resources that need to be located together, started sequentially and stopped in the reverse order. For more information, refer to Section 6.3.5.1, “Groups”.
- Clones
Clones are resources that can be active on multiple hosts. Any resource can be cloned, provided the respective resource agent supports it. For more information, refer to Section 6.3.5.2, “Clones”.
- Multi-state Resources (formerly known as Master/Slave Resources)
Multi-state resources are a special type of clone resources that can have multiple modes. For more information, refer to Section 6.3.5.3, “Multi-state Resources”.
6.3.4 Resource Templates #
If you want to create lots of resources with similar configurations, defining a resource template is the easiest way. After having been defined, it can be referenced in primitives—or in certain types of constraints, as described in Section 6.5.3, “Resource Templates and Constraints”.
If a template is referenced in a primitive, the primitive will inherit all operations, instance attributes (parameters), meta attributes, and utilization attributes defined in the template. Additionally, you can define specific operations or attributes for your primitive. If any of these are defined in both the template and the primitive, the values defined in the primitive will take precedence over the ones defined in the template.
Learn how to define resource templates with your preferred cluster configuration tool:
6.3.5 Advanced Resource Types #
Whereas primitives are the simplest kind of resources and therefore easy to configure, you will probably also need more advanced resource types for cluster configuration, such as groups, clones or multi-state resources.
6.3.5.1 Groups #
Some cluster resources depend on other components or resources. They require that each component or resource starts in a specific order and runs together on the same server with resources it depends on. To simplify this configuration, you can use cluster resource groups.
Example 6.3: Resource Group for a Web Server #
An example of a resource group would be a Web server that requires an IP address and a file system. In this case, each component is a separate resource that is combined into a cluster resource group. The resource group would run on one or more servers. In case of a software or hardware malfunction, the group would fail over to another server in the cluster, similar to an individual cluster resource.
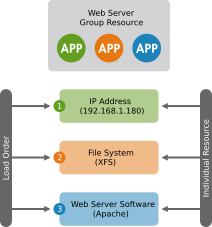
Figure 6.1: Group Resource #
Groups have the following properties:
- Starting and Stopping
Resources are started in the order they appear in and stopped in the reverse order.
- Dependency
If a resource in the group cannot run anywhere, then none of the resources located after that resource in the group is allowed to run.
- Contents
Groups may only contain a collection of primitive cluster resources. Groups must contain at least one resource, otherwise the configuration is not valid. To refer to the child of a group resource, use the child’s ID instead of the group’s ID.
- Constraints
Although it is possible to reference the group’s children in constraints, it is usually preferable to use the group’s name instead.
- Stickiness
Stickiness is additive in groups. Every active member of the group will contribute its stickiness value to the group’s total. So if the default
resource-stickinessis100and a group has seven members (five of which are active), the group as a whole will prefer its current location with a score of500.- Resource Monitoring
To enable resource monitoring for a group, you must configure monitoring separately for each resource in the group that you want monitored.
Learn how to create groups with your preferred cluster management tool:
6.3.5.2 Clones #
You may want certain resources to run simultaneously on multiple nodes in your cluster. To do this you must configure a resource as a clone. Examples of resources that might be configured as clones include cluster file systems like OCFS2. You can clone any resource provided. This is supported by the resource’s Resource Agent. Clone resources may even be configured differently depending on which nodes they are hosted.
There are three types of resource clones:
- Anonymous Clones
These are the simplest type of clones. They behave identically anywhere they are running. Because of this, there can only be one instance of an anonymous clone active per machine.
- Globally Unique Clones
These resources are distinct entities. An instance of the clone running on one node is not equivalent to another instance on another node; nor would any two instances on the same node be equivalent.
- Stateful Clones (Multi-state Resources)
Active instances of these resources are divided into two states, active and passive. These are also sometimes called primary and secondary, or master and slave. Stateful clones can be either anonymous or globally unique. See also Section 6.3.5.3, “Multi-state Resources”.
Clones must contain exactly one group or one regular resource.
When configuring resource monitoring or constraints, clones have different requirements than simple resources. For details, see Pacemaker Explained, available from http://www.clusterlabs.org/doc/. Refer to section Clones - Resources That Get Active on Multiple Hosts.
Learn how to create clones with your preferred cluster management tool:
6.3.5.3 Multi-state Resources #
Multi-state resources are a specialization of clones. They allow the
instances to be in one of two operating modes (called
master or slave, but can mean
whatever you want them to mean). Multi-state resources must contain
exactly one group or one regular resource.
When configuring resource monitoring or constraints, multi-state resources have different requirements than simple resources. For details, see Pacemaker Explained, available from http://www.clusterlabs.org/doc/. Refer to section Multi-state - Resources That Have Multiple Modes.
6.3.6 Resource Options (Meta Attributes) #
For each resource you add, you can define options. Options are used by
the cluster to decide how your resource should behave—they tell
the CRM how to treat a specific resource. Resource options can be set
with the crm_resource --meta command or with
Hawk2 as described in
Procedure 7.5, “Adding a Primitive Resource”.
Table 6.1: Options for a Primitive Resource #
|
Option |
Description |
Default |
|---|---|---|
|
|
If not all resources can be active, the cluster will stop lower priority resources to keep higher priority ones active. |
|
|
|
In what state should the cluster attempt to keep this resource?
Allowed values: |
|
|
|
Is the cluster allowed to start and stop the resource? Allowed
values: |
|
|
|
Can the resources be touched manually? Allowed values:
|
|
|
|
How much does the resource prefer to stay where it is? |
calculated |
|
|
How many failures should occur for this resource on a node before making the node ineligible to host this resource? |
|
|
|
What should the cluster do if it ever finds the resource active on
more than one node? Allowed values: |
|
|
|
How many seconds to wait before acting as if the failure had not occurred (and potentially allowing the resource back to the node on which it failed)? |
|
|
|
Allow resource migration for resources which support
|
|
|
|
The name of the remote node this resource defines. This both
enables the resource as a remote node and defines the unique name
used to identify the remote node. If no other parameters are set,
this value will also be assumed as the host name to connect to at
Warning: Use Unique IDsThis value must not overlap with any existing resource or node IDs. |
none (disabled) |
|
|
Custom port for the guest connection to pacemaker_remote. |
|
|
|
The IP address or host name to connect to if the remote node’s name is not the host name of the guest. |
|
|
|
How long before a pending guest connection will time out. |
|
6.3.7 Instance Attributes (Parameters) #
The scripts of all resource classes can be given parameters which
determine how they behave and which instance of a service they control.
If your resource agent supports parameters, you can add them with the
crm_resource command or with
Hawk2 as described in
Procedure 7.5, “Adding a Primitive Resource”. In the
crm command line utility and in Hawk2, instance
attributes are called params or
Parameter, respectively. The list of instance
attributes supported by an OCF script can be found by executing the
following command as root:
root #crmra info [class:[provider:]]resource_agent
or (without the optional parts):
root #crmra info resource_agent
The output lists all the supported attributes, their purpose and default values.
For example, the command
root #crmra info IPaddr
returns the following output:
Manages virtual IPv4 addresses (portable version) (ocf:heartbeat:IPaddr)
This script manages IP alias IP addresses
It can add an IP alias, or remove one.
Parameters (* denotes required, [] the default):
ip* (string): IPv4 address
The IPv4 address to be configured in dotted quad notation, for example
"192.168.1.1".
nic (string, [eth0]): Network interface
The base network interface on which the IP address will be brought
online.
If left empty, the script will try and determine this from the
routing table.
Do NOT specify an alias interface in the form eth0:1 or anything here;
rather, specify the base interface only.
cidr_netmask (string): Netmask
The netmask for the interface in CIDR format. (ie, 24), or in
dotted quad notation 255.255.255.0).
If unspecified, the script will also try to determine this from the
routing table.
broadcast (string): Broadcast address
Broadcast address associated with the IP. If left empty, the script will
determine this from the netmask.
iflabel (string): Interface label
You can specify an additional label for your IP address here.
lvs_support (boolean, [false]): Enable support for LVS DR
Enable support for LVS Direct Routing configurations. In case a IP
address is stopped, only move it to the loopback device to allow the
local node to continue to service requests, but no longer advertise it
on the network.
local_stop_script (string):
Script called when the IP is released
local_start_script (string):
Script called when the IP is added
ARP_INTERVAL_MS (integer, [500]): milliseconds between gratuitous ARPs
milliseconds between ARPs
ARP_REPEAT (integer, [10]): repeat count
How many gratuitous ARPs to send out when bringing up a new address
ARP_BACKGROUND (boolean, [yes]): run in background
run in background (no longer any reason to do this)
ARP_NETMASK (string, [ffffffffffff]): netmask for ARP
netmask for ARP - in nonstandard hexadecimal format.
Operations' defaults (advisory minimum):
start timeout=90
stop timeout=100
monitor_0 interval=5s timeout=20sNote: Instance Attributes for Groups, Clones or Multi-state Resources
Note that groups, clones and multi-state resources do not have instance attributes. However, any instance attributes set will be inherited by the group's, clone's or multi-state resource's children.
6.3.8 Resource Operations #
By default, the cluster will not ensure that your resources are still healthy. To instruct the cluster to do this, you need to add a monitor operation to the resource’s definition. Monitor operations can be added for all classes or resource agents. For more information, refer to Section 6.4, “Resource Monitoring”.
Table 6.2: Resource Operation Properties #
|
Operation |
Description |
|---|---|
|
|
Your name for the action. Must be unique. (The ID is not shown). |
|
|
The action to perform. Common values: |
|
|
How frequently to perform the operation. Unit: seconds |
|
|
How long to wait before declaring the action has failed. |
|
|
What conditions need to be satisfied before this action occurs.
Allowed values: |
|
|
The action to take if this action ever fails. Allowed values:
|
|
|
If |
|
|
Run the operation only if the resource has this role. |
|
|
Can be set either globally or for individual resources. Makes the CIB reflect the state of “in-flight” operations on resources. |
|
|
Description of the operation. |
6.3.9 Timeout Values #
Timeouts values for resources can be influenced by the following parameters:
op_defaults(global timeout for operations),a specific timeout value defined in a resource template,
a specific timeout value defined for a resource.
Note: Priority of Values
If a specific value is defined for a resource, it takes precedence over the global default. A specific value for a resource also takes precedence over a value that is defined in a resource template.
Getting timeout values right is very important. Setting them too low will result in a lot of (unnecessary) fencing operations for the following reasons:
If a resource runs into a timeout, it fails and the cluster will try to stop it.
If stopping the resource also fails (for example, because the timeout for stopping is set too low), the cluster will fence the node. It considers the node where this happens to be out of control.
You can adjust the global default for operations and set any specific timeout values with both crmsh and Hawk2. The best practice for determining and setting timeout values is as follows:
Procedure 6.1: Determining Timeout Values #
Check how long it takes your resources to start and stop (under load).
If needed, add the
op_defaultsparameter and set the (default) timeout value accordingly:For example, set
op_defaultsto60seconds:crm(live)configure#op_defaults timeout=60For resources that need longer periods of time, define individual timeout values.
When configuring operations for a resource, add separate
startandstopoperations. When configuring operations with Hawk2, it will provide useful timeout proposals for those operations.
6.4 Resource Monitoring #
If you want to ensure that a resource is running, you must configure resource monitoring for it.
If the resource monitor detects a failure, the following takes place:
Log file messages are generated, according to the configuration specified in the
loggingsection of/etc/corosync/corosync.conf.The failure is reflected in the cluster management tools (Hawk2,
crm status), and in the CIB status section.The cluster initiates noticeable recovery actions which may include stopping the resource to repair the failed state and restarting the resource locally or on another node. The resource also may not be restarted, depending on the configuration and state of the cluster.
If you do not configure resource monitoring, resource failures after a successful start will not be communicated, and the cluster will always show the resource as healthy.
- Monitoring Stopped Resources
Usually, resources are only monitored by the cluster as long as they are running. However, to detect concurrency violations, also configure monitoring for resources which are stopped. For example:
primitive dummy1 ocf:heartbeat:Dummy \ op monitor interval="300s" role="Stopped" timeout="10s" \ op monitor interval="30s" timeout="10s"This configuration triggers a monitoring operation every
300seconds for the resourcedummy1when it is inrole="Stopped". When running, it will be monitored every30seconds.- Probing
The CRM executes an initial monitoring for each resource on every node, the so-called
probe. A probe is also executed after the cleanup of a resource. If multiple monitoring operations are defined for a resource, the CRM will select the one with the smallest interval and will use its timeout value as default timeout for probing. If no monitor operation is configured, the cluster-wide default applies. The default is20seconds (if not specified otherwise by configuring theop_defaultsparameter). If you do not want to rely on the automatic calculation or theop_defaultsvalue, define a specific monitoring operation for the probing of this resource. Do so by adding a monitoring operation with theintervalset to0, for example:crm(live)configure#primitiversc1 ocf:pacemaker:Dummy \ op monitor interval="0" timeout="60"The probe of
rsc1will time out in60s, independent of the global timeout defined inop_defaults, or any other operation timeouts configured. If you did not setinterval="0"for specifying the probing of the respective resource, the CRM will automatically check for any other monitoring operations defined for that resource and will calculate the timeout value for probing as described above.
Learn how to add monitor operations to resources with your preferred cluster management tool:
6.5 Resource Constraints #
Having all the resources configured is only part of the job. Even if the cluster knows all needed resources, it might still not be able to handle them correctly. Resource constraints let you specify which cluster nodes resources can run on, what order resources will load, and what other resources a specific resource is dependent on.
6.5.1 Types of Constraints #
There are three different kinds of constraints available:
- Resource Location
Locational constraints that define on which nodes a resource may be run, may not be run or is preferred to be run.
- Resource Colocation
Colocational constraints that tell the cluster which resources may or may not run together on a node.
- Resource Order
Ordering constraints to define the sequence of actions.
Important: Restrictions for Constraints and Certain Types of Resources
Do not create colocation constraints for members of a resource group. Create a colocation constraint pointing to the resource group as a whole instead. All other types of constraints are safe to use for members of a resource group.
Do not use any constraints on a resource that has a clone resource or a multi-state resource applied to it. The constraints must apply to the clone or multi-state resource, not to the child resource.
6.5.1.1 Resource Sets #
6.5.1.1.1 Using Resource Sets for Defining Constraints #
As an alternative format for defining location, colocation or ordering
constraints, you can use resource sets, where
primitives are grouped together in one set. Previously this was
possible either by defining a resource group (which could not always
accurately express the design), or by defining each relationship as an
individual constraint. The latter caused a constraint explosion as the
number of resources and combinations grew. The configuration via
resource sets is not necessarily less verbose, but is easier to
understand and maintain, as the following examples show.
Example 6.4: A Resource Set for Location Constraints #
For example, you can use the following configuration of a resource
set (loc-alice) in the crmsh to place
two virtual IPs (vip1 and vip2)
on the same node, alice:
crm(live)configure#primitivevip1 ocf:heartbeat:IPaddr2 params ip=192.168.1.5crm(live)configure#primitivevip1 ocf:heartbeat:IPaddr2 params ip=192.168.1.6crm(live)configure#locationloc-alice { vip1 vip2 } inf: alice
To use resource sets to replace a configuration of colocation constraints, consider the following two examples:
Example 6.5: A Chain of Colocated Resources #
<constraints>
<rsc_colocation id="coloc-1" rsc="B" with-rsc="A" score="INFINITY"/>
<rsc_colocation id="coloc-2" rsc="C" with-rsc="B" score="INFINITY"/>
<rsc_colocation id="coloc-3" rsc="D" with-rsc="C" score="INFINITY"/>
</constraints>The same configuration expressed by a resource set:
<constraints>
<rsc_colocation id="coloc-1" score="INFINITY" >
<resource_set id="colocated-set-example" sequential="true">
<resource_ref id="A"/>
<resource_ref id="B"/>
<resource_ref id="C"/>
<resource_ref id="D"/>
</resource_set>
</rsc_colocation>
</constraints>If you want to use resource sets to replace a configuration of ordering constraints, consider the following two examples:
Example 6.6: A Chain of Ordered Resources #
<constraints>
<rsc_order id="order-1" first="A" then="B" />
<rsc_order id="order-2" first="B" then="C" />
<rsc_order id="order-3" first="C" then="D" />
</constraints>The same purpose can be achieved by using a resource set with ordered resources:
Example 6.7: A Chain of Ordered Resources Expressed as Resource Set #
<constraints>
<rsc_order id="order-1">
<resource_set id="ordered-set-example" sequential="true">
<resource_ref id="A"/>
<resource_ref id="B"/>
<resource_ref id="C"/>
<resource_ref id="D"/>
</resource_set>
</rsc_order>
</constraints>
Sets can be either ordered (sequential=true) or
unordered (sequential=false). Furthermore, the
require-all attribute can be used to switch between
AND and OR logic.
6.5.1.1.2 Resource Sets for Colocation Constraints Without Dependencies #
Sometimes it is useful to place a group of resources on the same node
(defining a colocation constraint), but without having hard
dependencies between the resources. For example, you want two
resources to be placed on the same node, but you do
not want the cluster to restart the other one if
one of them fails. This can be achieved on the crm shell by using
the weak bond command.
Learn how to set these “weak bonds” with your preferred cluster management tool:
6.5.1.2 For More Information #
Learn how to add the various kinds of constraints with your preferred cluster management tool:
For more information on configuring constraints and detailed background information about the basic concepts of ordering and colocation, refer to the following documents. They are available at http://www.clusterlabs.org/doc/:
Pacemaker Explained, chapter Resource Constraints
Colocation Explained
Ordering Explained
6.5.2 Scores and Infinity #
When defining constraints, you also need to deal with scores. Scores of all kinds are integral to how the cluster works. Practically everything from migrating a resource to deciding which resource to stop in a degraded cluster is achieved by manipulating scores in some way. Scores are calculated on a per-resource basis and any node with a negative score for a resource cannot run that resource. After calculating the scores for a resource, the cluster then chooses the node with the highest score.
INFINITY is currently defined as
1,000,000. Additions or subtractions with it stick to
the following three basic rules:
Any value + INFINITY = INFINITY
Any value - INFINITY = -INFINITY
INFINITY - INFINITY = -INFINITY
When defining resource constraints, you specify a score for each constraint. The score indicates the value you are assigning to this resource constraint. Constraints with higher scores are applied before those with lower scores. By creating additional location constraints with different scores for a given resource, you can specify an order for the nodes that a resource will fail over to.
6.5.3 Resource Templates and Constraints #
If you have defined a resource template (see Section 6.3.4, “Resource Templates”), it can be referenced in the following types of constraints:
order constraints,
colocation constraints,
rsc_ticket constraints (for Geo clusters).
However, colocation constraints must not contain more than one reference to a template. Resource sets must not contain a reference to a template.
Resource templates referenced in constraints stand for all primitives which are derived from that template. This means, the constraint applies to all primitive resources referencing the resource template. Referencing resource templates in constraints is an alternative to resource sets and can simplify the cluster configuration considerably. For details about resource sets, refer to Procedure 7.17, “Using a Resource Set for Constraints”.
6.5.4 Failover Nodes #
A resource will be automatically restarted if it fails. If that cannot
be achieved on the current node, or it fails N times
on the current node, it will try to fail over to another node. Each time
the resource fails, its failcount is raised. You can define a number of
failures for resources (a migration-threshold), after
which they will migrate to a new node. If you have more than two nodes
in your cluster, the node a particular resource fails over to is chosen
by the High Availability software.
However, you can specify the node a resource will fail over to by
configuring one or several location constraints and a
migration-threshold for that resource.
Learn how to specify failover nodes with your preferred cluster management tool:
Example 6.8: Migration Threshold—Process Flow #
For example, let us assume you have configured a location constraint
for resource rsc1 to preferably run on
alice. If it fails there,
migration-threshold is checked and compared to the
failcount. If failcount >= migration-threshold then the resource is
migrated to the node with the next best preference.
After the threshold has been reached, the node will no longer be
allowed to run the failed resource until the resource's failcount is
reset. This can be done manually by the cluster administrator or by
setting a failure-timeout option for the resource.
For example, a setting of migration-threshold=2 and
failure-timeout=60s would cause the resource to
migrate to a new node after two failures. It would be allowed to move
back (depending on the stickiness and constraint scores) after one
minute.
There are two exceptions to the migration threshold concept, occurring when a resource either fails to start or fails to stop:
Start failures set the failcount to
INFINITYand thus always cause an immediate migration.Stop failures cause fencing (when
stonith-enabledis set totruewhich is the default).In case there is no STONITH resource defined (or
stonith-enabledis set tofalse), the resource will not migrate.
For details on using migration thresholds and resetting failcounts with your preferred cluster management tool:
6.5.5 Failback Nodes #
A resource might fail back to its original node when that node is back online and in the cluster. To prevent a resource from failing back to the node that it was running on, or to specify a different node for the resource to fail back to, change its resource stickiness value. You can either specify resource stickiness when you are creating a resource or afterward.
Consider the following implications when specifying resource stickiness values:
- Value is
0: This is the default. The resource will be placed optimally in the system. This may mean that it is moved when a “better” or less loaded node becomes available. This option is almost equivalent to automatic failback, except that the resource may be moved to a node that is not the one it was previously active on.
- Value is greater than
0: The resource will prefer to remain in its current location, but may be moved if a more suitable node is available. Higher values indicate a stronger preference for a resource to stay where it is.
- Value is less than
0: The resource prefers to move away from its current location. Higher absolute values indicate a stronger preference for a resource to be moved.
- Value is
INFINITY: The resource will always remain in its current location unless forced off because the node is no longer eligible to run the resource (node shutdown, node standby, reaching the
migration-threshold, or configuration change). This option is almost equivalent to completely disabling automatic failback.- Value is
-INFINITY: The resource will always move away from its current location.
6.5.6 Placing Resources Based on Their Load Impact #
Not all resources are equal. Some, such as Xen guests, require that the node hosting them meets their capacity requirements. If resources are placed such that their combined need exceed the provided capacity, the resources diminish in performance (or even fail).
To take this into account, the High Availability Extension allows you to specify the following parameters:
The capacity a certain node provides.
The capacity a certain resource requires.
An overall strategy for placement of resources.
Learn how to configure these settings with your preferred cluster management tool:
A node is considered eligible for a resource if it has sufficient free capacity to satisfy the resource's requirements. The nature of the capacities is completely irrelevant for the High Availability Extension; it only makes sure that all capacity requirements of a resource are satisfied before moving a resource to a node.
To manually configure the resource's requirements and the capacity a node provides, use utilization attributes. You can name the utilization attributes according to your preferences and define as many name/value pairs as your configuration needs. However, the attribute's values must be integers.
If multiple resources with utilization attributes are grouped or have colocation constraints, the High Availability Extension takes that into account. If possible, the resources will be placed on a node that can fulfill all capacity requirements.
Note: Utilization Attributes for Groups
It is impossible to set utilization attributes directly for a resource group. However, to simplify the configuration for a group, you can add a utilization attribute with the total capacity needed to any of the resources in the group.
The High Availability Extension also provides means to detect and configure both node capacity and resource requirements automatically:
The NodeUtilization resource agent checks the
capacity of a node (regarding CPU and RAM).
To configure automatic detection, create a clone resource of the
following class, provider, and type:
ocf:pacemaker:NodeUtilization. One instance of the
clone should be running on each node. After the instance has started, a
utilization section will be added to the node's configuration in CIB.
For automatic detection of a resource's minimal requirements (regarding
RAM and CPU) the Xen resource agent has been
improved. Upon start of a Xen resource, it will
reflect the consumption of RAM and CPU. Utilization attributes will
automatically be added to the resource configuration.
Note: Different Resource Agents for Xen and libvirt
The ocf:heartbeat:Xen resource agent should not be
used with libvirt, as libvirt expects
to be able to modify the machine description file.
For libvirt, use the
ocf:heartbeat:VirtualDomain resource agent.
Apart from detecting the minimal requirements, the High Availability Extension also allows
to monitor the current utilization via the
VirtualDomain resource agent. It detects CPU
and RAM use of the virtual machine. To use this feature, configure a
resource of the following class, provider and type:
ocf:heartbeat:VirtualDomain. The following instance
attributes are available: autoset_utilization_cpu and
autoset_utilization_hv_memory. Both default to
true. This updates the utilization values in the CIB
during each monitoring cycle.
Independent of manually or automatically configuring capacity and
requirements, the placement strategy must be specified with the
placement-strategy property (in the global cluster
options). The following values are available:
default(default value)Utilization values are not considered. Resources are allocated according to location scoring. If scores are equal, resources are evenly distributed across nodes.
utilizationUtilization values are considered when deciding if a node has enough free capacity to satisfy a resource's requirements. However, load-balancing is still done based on the number of resources allocated to a node.
minimalUtilization values are considered when deciding if a node has enough free capacity to satisfy a resource's requirements. An attempt is made to concentrate the resources on as few nodes as possible (to achieve power savings on the remaining nodes).
balancedUtilization values are considered when deciding if a node has enough free capacity to satisfy a resource's requirements. An attempt is made to distribute the resources evenly, thus optimizing resource performance.
Note: Configuring Resource Priorities
The available placement strategies are best-effort—they do not yet use complex heuristic solvers to always reach optimum allocation results. Ensure that resource priorities are properly set so that your most important resources are scheduled first.
Example 6.9: Example Configuration for Load-Balanced Placing #
The following example demonstrates a three-node cluster of equal nodes, with four virtual machines.
node alice utilization memory="4000"
node bob utilization memory="4000"
node charlie utilization memory="4000"
primitive xenA ocf:heartbeat:Xen utilization hv_memory="3500" \
params xmfile="/etc/xen/shared-vm/vm1"
meta priority="10"
primitive xenB ocf:heartbeat:Xen utilization hv_memory="2000" \
params xmfile="/etc/xen/shared-vm/vm2"
meta priority="1"
primitive xenC ocf:heartbeat:Xen utilization hv_memory="2000" \
params xmfile="/etc/xen/shared-vm/vm3"
meta priority="1"
primitive xenD ocf:heartbeat:Xen utilization hv_memory="1000" \
params xmfile="/etc/xen/shared-vm/vm4"
meta priority="5"
property placement-strategy="minimal"
With all three nodes up, resource xenA will be
placed onto a node first, followed by xenD.
xenB and xenC would either be
allocated together or one of them with xenD.
If one node failed, too little total memory would be available to host
them all. xenA would be ensured to be allocated, as
would xenD. However, only one of the remaining
resources xenB or xenC could
still be placed. Since their priority is equal, the result would still
be open. To resolve this ambiguity as well, you would need to set a
higher priority for either one.
6.5.7 Grouping Resources by Using Tags #
Tags are a new feature that has been added to Pacemaker recently. Tags
are a way to refer to multiple resources at once, without creating any
colocation or ordering relationship between them. This can be useful for
grouping conceptually related resources. For example, if you have
several resources related to a database, create a tag called
databases and add all resources related to the
database to this tag. This allows you to stop or start them all with a
single command.
Tags can also be used in constraints. For example, the following
location constraint loc-db-prefer applies to the set
of resources tagged with databases:
location loc-db-prefer databases 100: alice
Learn how to create tags with your preferred cluster management tool:
6.6 Managing Services on Remote Hosts #
The possibilities for monitoring and managing services on remote hosts
has become increasingly important during the last few years.
SUSE Linux Enterprise High Availability Extension 11 SP3 offered fine-grained monitoring of services on
remote hosts via monitoring plug-ins. The recent addition of the
pacemaker_remote service now allows SUSE Linux Enterprise High Availability Extension
12 SP5 to fully manage and monitor resources on remote hosts
just as if they were a real cluster node—without the need to
install the cluster stack on the remote machines.
6.6.1 Monitoring Services on Remote Hosts with Monitoring Plug-ins #
Monitoring of virtual machines can be done with the VM agent (which only checks if the guest shows up in the hypervisor), or by external scripts called from the VirtualDomain or Xen agent. Up to now, more fine-grained monitoring was only possible with a full setup of the High Availability stack within the virtual machines.
By providing support for monitoring plug-ins (formerly named Nagios plug-ins), the High Availability Extension now also allows you to monitor services on remote hosts. You can collect external statuses on the guests without modifying the guest image. For example, VM guests might run Web services or simple network resources that need to be accessible. With the Nagios resource agents, you can now monitor the Web service or the network resource on the guest. In case these services are not reachable anymore, the High Availability Extension will trigger a restart or migration of the respective guest.
If your guests depend on a service (for example, an NFS server to be used by the guest), the service can either be an ordinary resource, managed by the cluster, or an external service that is monitored with Nagios resources instead.
To configure the Nagios resources, the following packages must be installed on the host:
monitoring-pluginsmonitoring-plugins-metadata
YaST or Zypper will resolve any dependencies on further packages, if required.
A typical use case is to configure the monitoring plug-ins as resources belonging to a resource container, which usually is a VM. The container will be restarted if any of its resources has failed. Refer to Example 6.10, “Configuring Resources for Monitoring Plug-ins” for a configuration example. Alternatively, Nagios resource agents can also be configured as ordinary resources if you want to use them for monitoring hosts or services via the network.
Example 6.10: Configuring Resources for Monitoring Plug-ins #
primitive vm1 ocf:heartbeat:VirtualDomain \
params hypervisor="qemu:///system" config="/etc/libvirt/qemu/vm1.xml" \
op start interval="0" timeout="90" \
op stop interval="0" timeout="90" \
op monitor interval="10" timeout="30"
primitive vm1-sshd nagios:check_tcp \
params hostname="vm1" port="22" \ 1
op start interval="0" timeout="120" \ 2
op monitor interval="10"
group g-vm1-and-services vm1 vm1-sshd \
meta container="vm1" 3
The supported parameters are the same as the long options of a
monitoring plug-in. Monitoring plug-ins connect to services with the
parameter | |
As it takes some time to get the guest operating system up and its services running, the start timeout of the monitoring resource must be long enough. | |
A cluster resource container of type
|
The example above contains only one resource for the
check_tcpplug-in, but multiple resources for
different plug-in types can be configured (for example,
check_http or check_udp).
If the host names of the services are the same, the
hostname parameter can also be specified for the
group, instead of adding it to the individual primitives. For example:
group g-vm1-and-services vm1 vm1-sshd vm1-httpd \
meta container="vm1" \
params hostname="vm1"
If any of the services monitored by the monitoring plug-ins fail within
the VM, the cluster will detect that and restart the container resource
(the VM). Which action to take in this case can be configured by
specifying the on-fail attribute for the service's
monitoring operation. It defaults to
restart-container.
Failure counts of services will be taken into account when considering the VM's migration-threshold.
6.6.2 Managing Services on Remote Nodes with pacemaker_remote #
With the pacemaker_remote service, High Availability clusters
can be extended to virtual nodes or remote bare-metal machines. They do
not need to run the cluster stack to become members of the cluster.
The High Availability Extension can now launch virtual environments (KVM and LXC), plus the resources that live within those virtual environments without requiring the virtual environments to run Pacemaker or Corosync.
For the use case of managing both virtual machines as cluster resources plus the resources that live within the VMs, you can now use the following setup:
The “normal” (bare-metal) cluster nodes run the High Availability Extension.
The virtual machines run the
pacemaker_remoteservice (almost no configuration required on the VM's side).The cluster stack on the “normal” cluster nodes launches the VMs and connects to the
pacemaker_remoteservice running on the VMs to integrate them as remote nodes into the cluster.
As the remote nodes do not have the cluster stack installed, this has the following implications:
Remote nodes do not take part in quorum.
Remote nodes cannot become the DC.
Remote nodes are not bound by the scalability limits (Corosync has a member limit of 32 nodes).
Find more information about the remote_pacemaker
service, including multiple use cases with detailed setup instructions
in Pacemaker Remote—Extending High Availability into
Virtual Nodes, available at
http://www.clusterlabs.org/doc/.
6.7 Monitoring System Health #
To prevent a node from running out of disk space and thus being unable to
manage any resources that have been assigned to it, the High Availability Extension
provides a resource agent,
ocf:pacemaker:SysInfo. Use it to monitor a
node's health with regard to disk partitions.
The SysInfo RA creates a node attribute named
#health_disk which will be set to
red if any of the monitored disks' free space is below
a specified limit.
To define how the CRM should react in case a node's health reaches a
critical state, use the global cluster option
node-health-strategy.
Procedure 6.2: Configuring System Health Monitoring #
To automatically move resources away from a node in case the node runs out of disk space, proceed as follows:
Configure an
ocf:pacemaker:SysInforesource:primitive sysinfo ocf:pacemaker:SysInfo \ params disks="/tmp /var"1 min_disk_free="100M"2 disk_unit="M"3 \ op monitor interval="15s"Which disk partitions to monitor. For example,
/tmp,/usr,/var, and/dev. To specify multiple partitions as attribute values, separate them with a blank.
Note:
/File System Always MonitoredYou do not need to specify the root partition (
/) indisks. It is always monitored by default.The minimum free disk space required for those partitions. Optionally, you can specify the unit to use for measurement (in the example above,
Mfor megabytes is used). If not specified,min_disk_freedefaults to the unit defined in thedisk_unitparameter.The unit in which to report the disk space.
To complete the resource configuration, create a clone of
ocf:pacemaker:SysInfoand start it on each cluster node.Set the
node-health-strategytomigrate-on-red:property node-health-strategy="migrate-on-red"
In case of a
#health_diskattribute set tored, the policy engine adds-INFto the resources' score for that node. This will cause any resources to move away from this node. The STONITH resource will be the last one to be stopped but even if the STONITH resource is not running anymore, the node can still be fenced. Fencing has direct access to the CIB and will continue to work.
After a node's health status has turned to red, solve
the issue that led to the problem. Then clear the red
status to make the node eligible again for running resources. Log in to
the cluster node and use one of the following methods:
Execute the following command:
root #crmnode status-attr NODE delete #health_diskRestart Pacemaker on that node.
Reboot the node.
The node will be returned to service and can run resources again.
6.8 For More Information #
- http://crmsh.github.io/
Home page of the crm shell (crmsh), the advanced command line interface for High Availability cluster management.
- http://crmsh.github.io/documentation
Holds several documents about the crm shell, including a Getting Started tutorial for basic cluster setup with crmsh and the comprehensive Manual for the crm shell. The latter is available at http://crmsh.github.io/man-2.0/. Find the tutorial at http://crmsh.github.io/start-guide/.
- http://clusterlabs.org/
Home page of Pacemaker, the cluster resource manager shipped with the High Availability Extension.
- http://www.clusterlabs.org/doc/
Holds several comprehensive manuals and some shorter documents explaining general concepts. For example:
Pacemaker Explained: Contains comprehensive and very detailed information for reference.
Configuring Fencing with crmsh: How to configure and use STONITH devices.
Colocation Explained
Ordering Explained
- https://clusterlabs.org
Home page of the High Availability Linux Project.