Witness Node
SUSE Virtualization clusters deployed in production environments require a control plane for node and pod management. A typical three-node cluster has three management nodes that each contain the complete set of control plane components. One key component is etcd, which Kubernetes uses to store its data (configuration, state, and metadata). The etcd node count must always be an odd number (for example, 3 is the default count in SUSE Virtualization) to ensure that a quorum is maintained.
Some situations may require you to avoid deploying workloads and user data to management nodes. In these situations, one cluster node can be assigned the witness role, which limits it to functioning as an etcd cluster member. The witness node is responsible for establishing a member quorum (a majority of nodes), which must agree on updates to the cluster state.
Witness nodes do not store any data, but the hardware recommendations for etcd nodes must still be considered. Using hardware with limited resources significantly affects cluster performance, as described in the article Slow etcd performance (performance testing and optimization).
SUSE Virtualization supports clusters with two management nodes and one witness node (and optionally, one or more worker nodes). For more information about node roles, see Role Management.
|
A node can be assigned the witness role only at the time it joins a cluster. Each cluster can have only one witness node. |
Creating a SUSE Virtualization Cluster with a Witness Node
You can assign the witness role to a node when it joins a newly created cluster.
In the following example, a cluster with three nodes was created and the node harvester-node-1 was assigned the witness role. harvester-node-1 consumes less resources and only has etcd capabilities.
NAME↑ STATUS ROLE VERSION PODS CPU MEM %CPU %MEM CPU/A MEM/A AGE harvester-node-0 Ready control-plane,etcd,master v1.27.10+rke2r1 70 1095 10143 10 63 10000 15976 4d13h harvester-node-1 Ready etcd v1.27.10+rke2r1 7 258 2258 2 14 10000 15976 4d13h harvester-node-2 Ready control-plane,etcd,master v1.27.10+rke2r1 36 840 6905 8 43 10000 15976 4d13h
Because the cluster must have three nodes, the promote controller will promote the other two nodes. After that, the cluster will have two control-plane nodes and one witness node.
Workloads on the Witness Node
The witness node only runs the following essential workloads:
-
harvester-node-manager
-
cloud-controller-manager
-
etcd
-
kube-proxy
-
rke2-canal
-
rke2-multus
Upgrade a Cluster with a Witness Node
The general upgrade requirements and procedures apply to clusters with a witness node. However, the existence of degraded volumes in such clusters may cause upgrade operations to fail.
Longhorn Replicas in Clusters with a Witness Node
SUSE Virtualization uses Longhorn, a distributed block storage system, for management of block device volumes. Longhorn is provisioned to management and worker nodes but not to witness nodes, which do not store any data.
Longhorn creates replicas of each volume to increase availability. Replicas contain a chain of snapshots of the volume, with each snapshot storing the change from a previous snapshot. In SUSE Virtualization, the default StorageClass harvester-longhorn has a replica count value of 3.
Limitations
Witness nodes do not store any data. This means that in three-node clusters (no worker nodes), only two replicas are created for each Longhorn volume. However, the default StorageClass harvester-longhorn has a replica count value of 3 for high availability. If you use this StorageClass to create volumes, Longhorn is unable to create the configured number of replicas. This results in volumes being marked as Degraded on the Longhorn UI.
In summary, you must use a StorageClass that matches the cluster configuration.
-
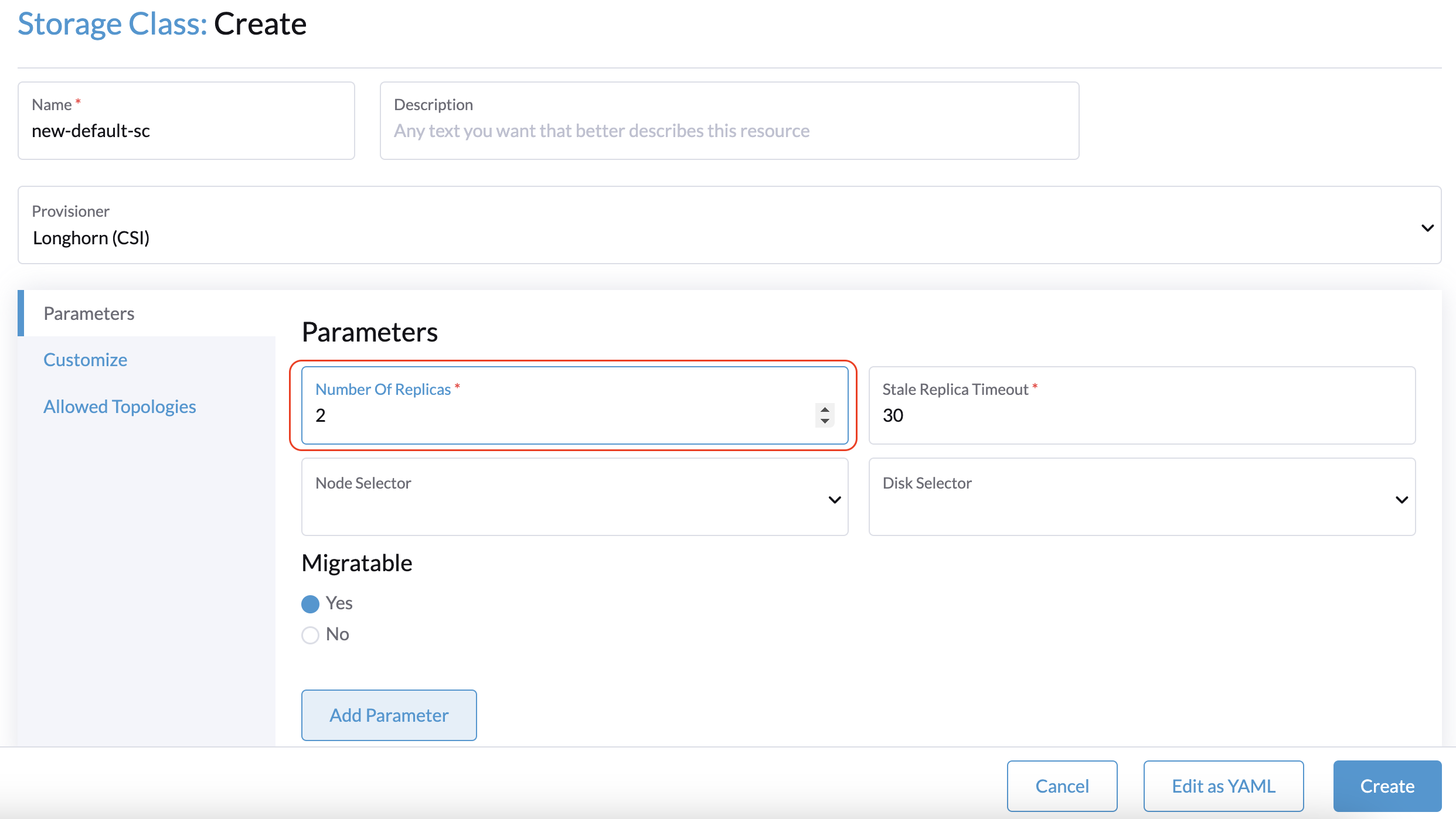
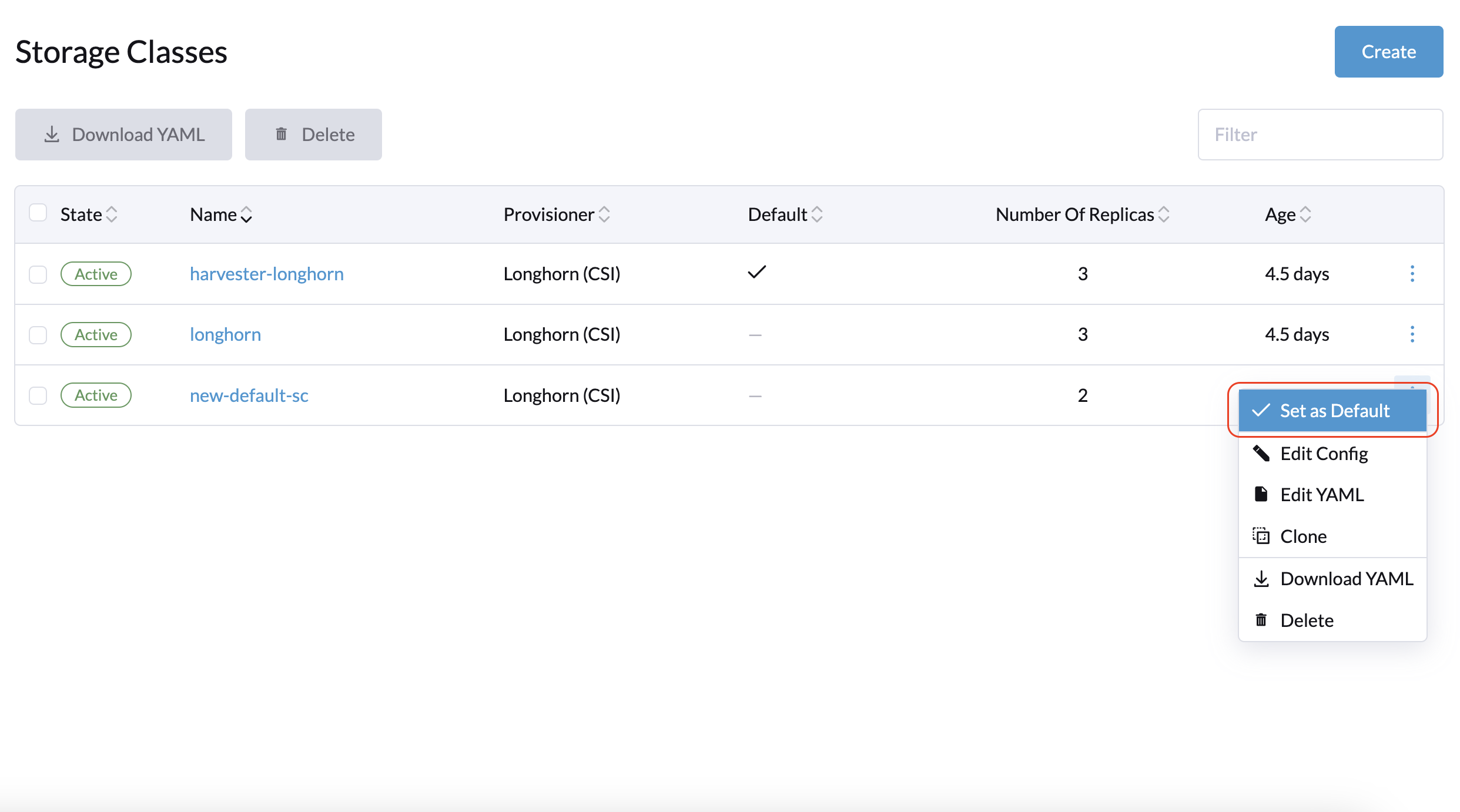
2 management nodes + 1 witness node: Create a new default StorageClass with the Number of Replicas parameter set to 2. This ensures that only two replicas are created for each Longhorn volume.
-
2 management nodes + 1 witness node + 1 or more worker nodes: You can use the existing default StorageClass.
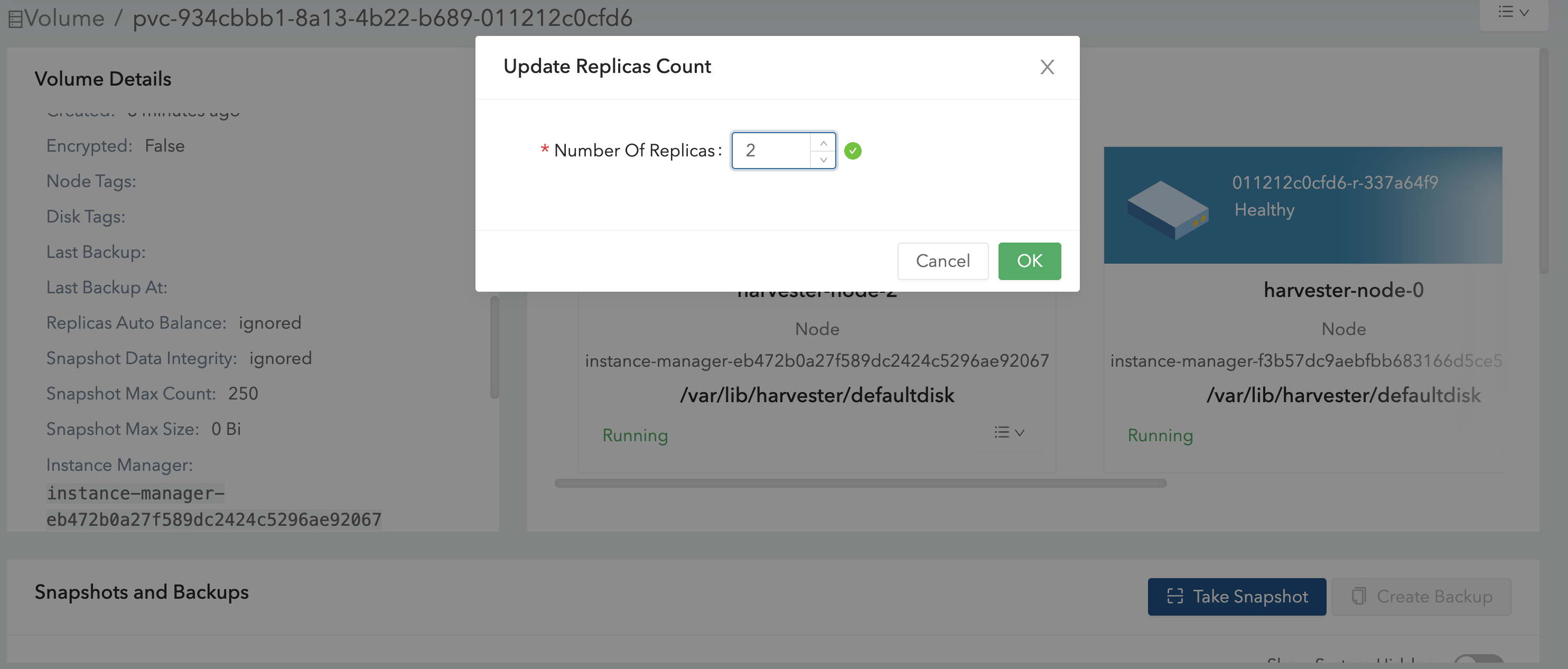
If you already created volumes using the original default StorageClass, you can modify the replica count on the Volume screen of the embedded Longhorn UI.

Known Issues
1. When creating a cluster with a witness node, the Network Config: Create screen on the SUSE Virtualization UI is unable to identify any NICs that can be used with all nodes.
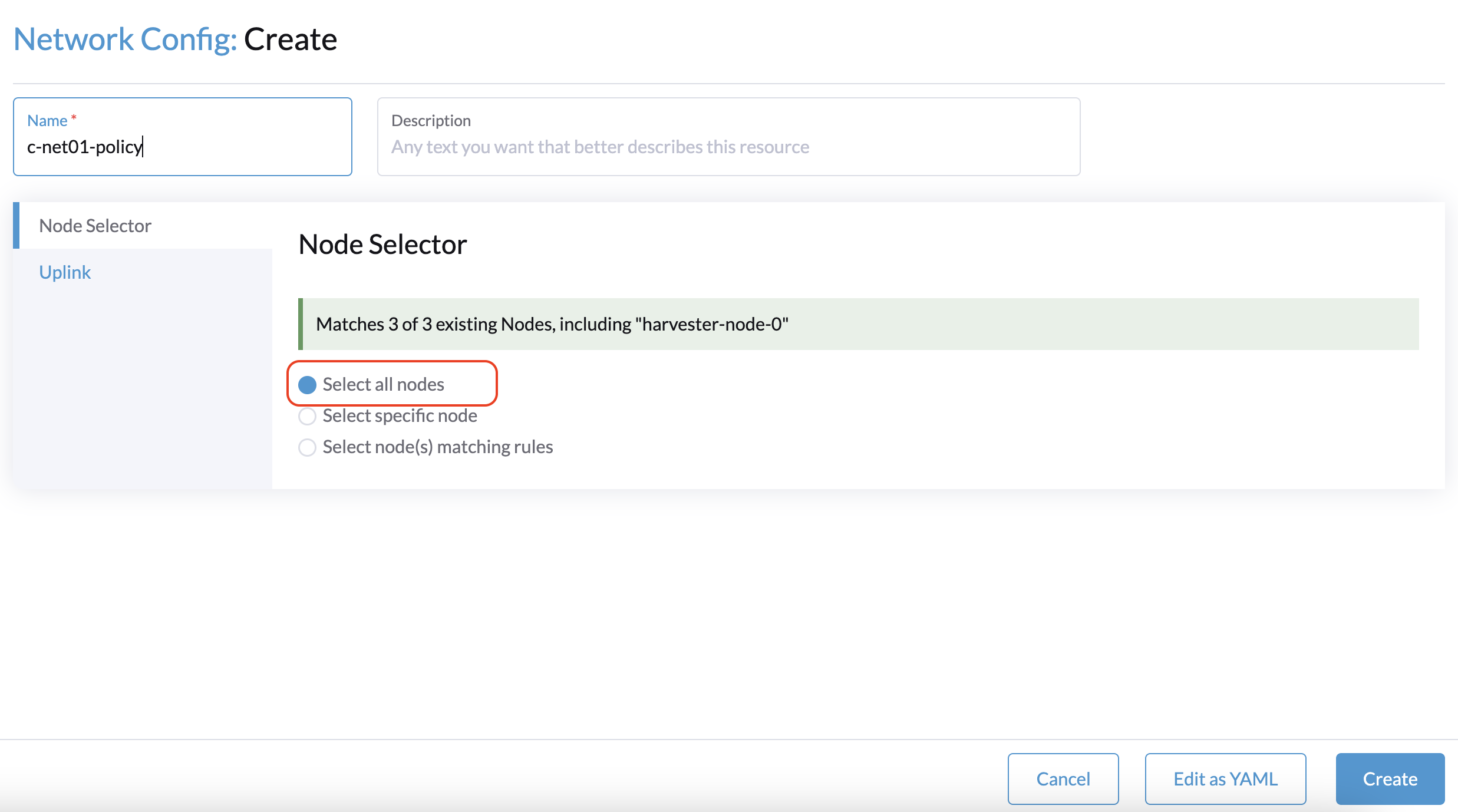
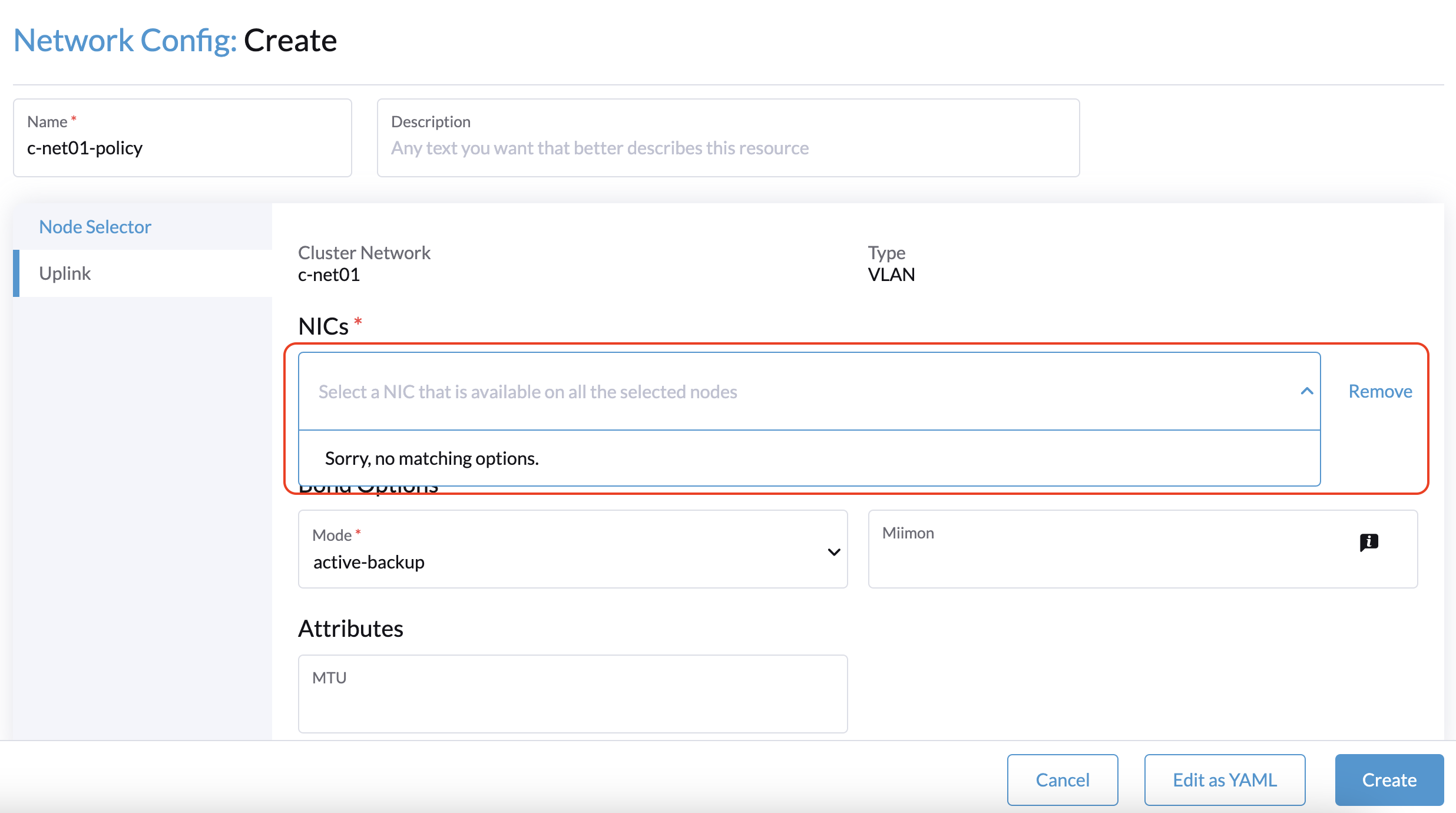
The workaround is to select a non-witness node and then select a NIC that can be used with that specific node.
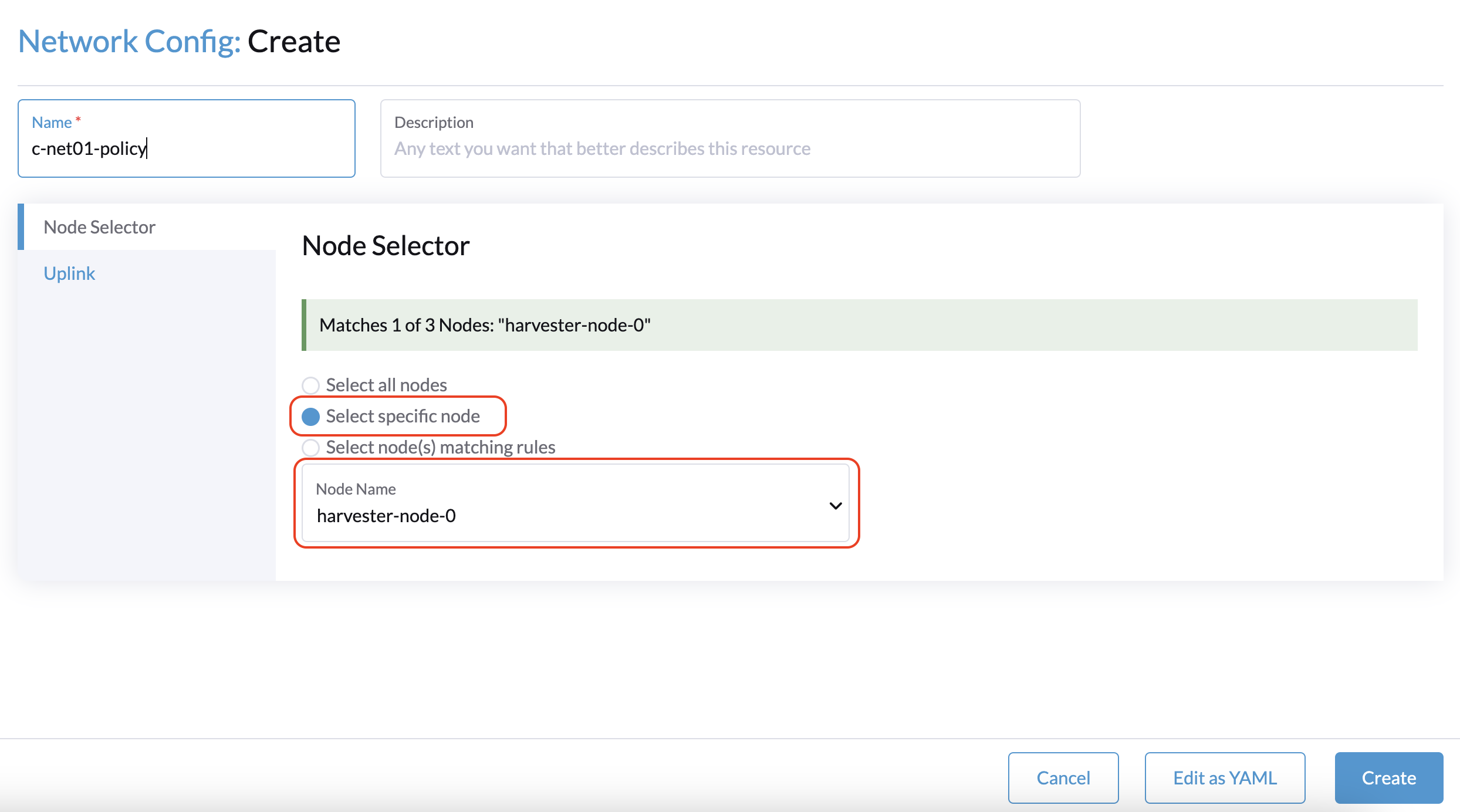
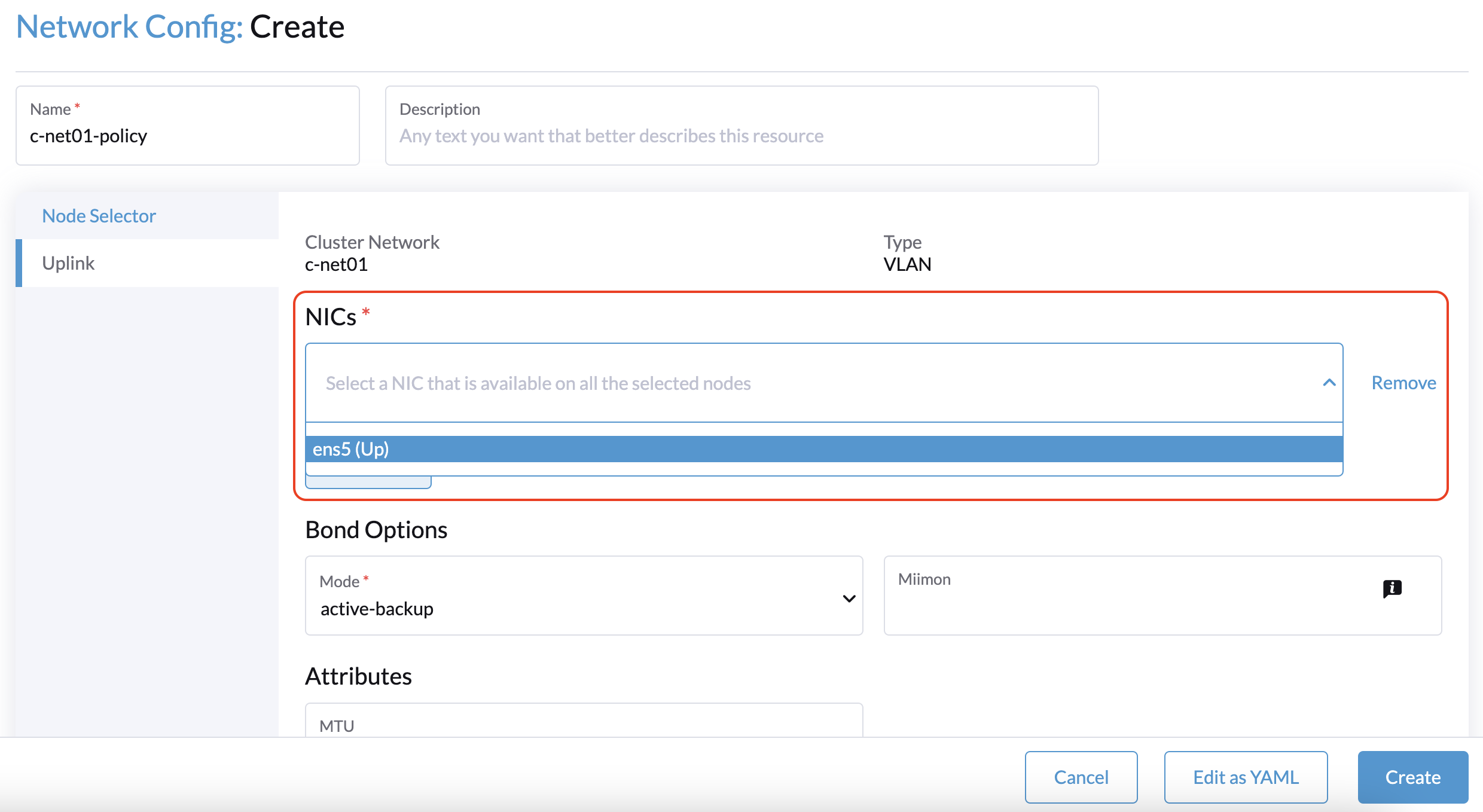
You must repeat this procedure for every non-witness node in the cluster. The same uplink settings can be used across nodes.