Troubleshooting
Overview
Here are certain tips to troubleshoot a failed upgrade:
-
Check version-specific upgrade notes. You can click the version in the support matrix table to see if there are any known issues.
-
Dive into the upgrade design proposal. The following section briefly describes phases within an upgrade and possible diagnostic methods.
Upgrade flow
The upgrade process includes several phases.
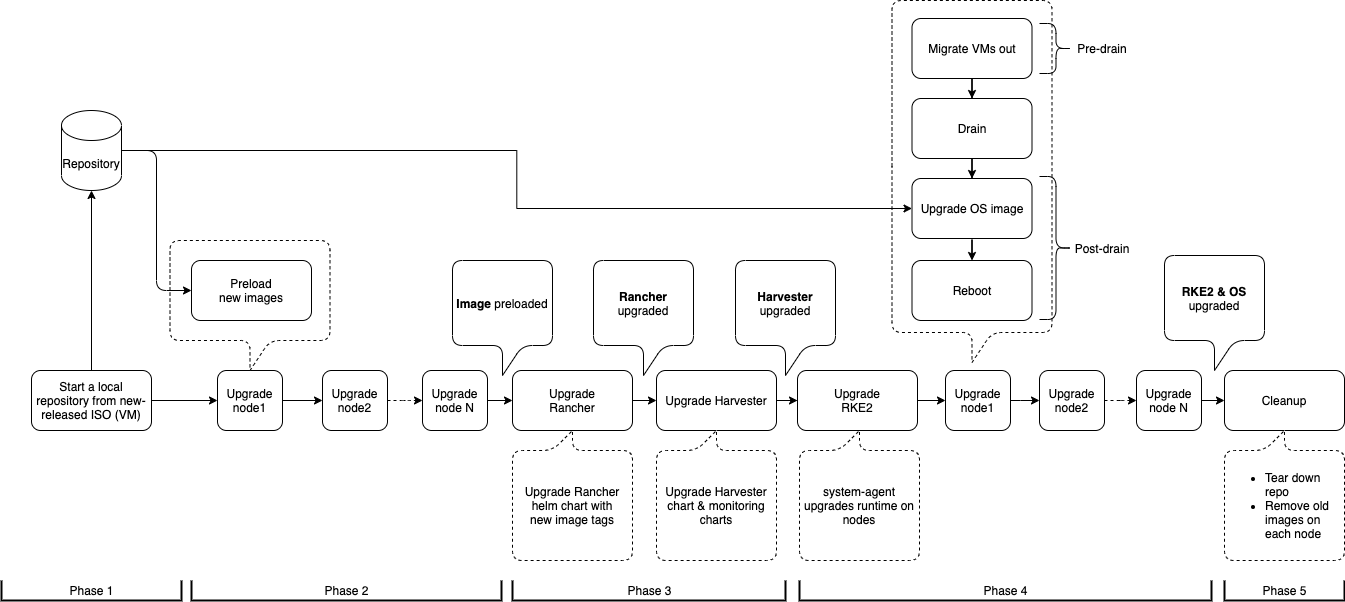
Phase 1: Provision upgrade repository virtual machine
The SUSE Virtualization controller downloads a release ISO file and uses it to provision a repository virtual machine. The virtual machine name uses the format upgrade-repo-hvst-xxxx.
Network speed and cluster resource utilization influence the amount of time required to complete this phase. Upgrades typically fail because of network speed issues.
If the upgrade fails at this point, check the status of the repository virtual machine and its corresponding pod before restarting the upgrade. You can check the status using the command kubectl get vm -n harvester-system.
Example:
$ kubectl get vm -n harvester-system
NAME AGE STATUS READY
upgrade-repo-hvst-upgrade-9gmg2 101s Starting False
$ kubectl get pods -n harvester-system | grep upgrade-repo-hvst
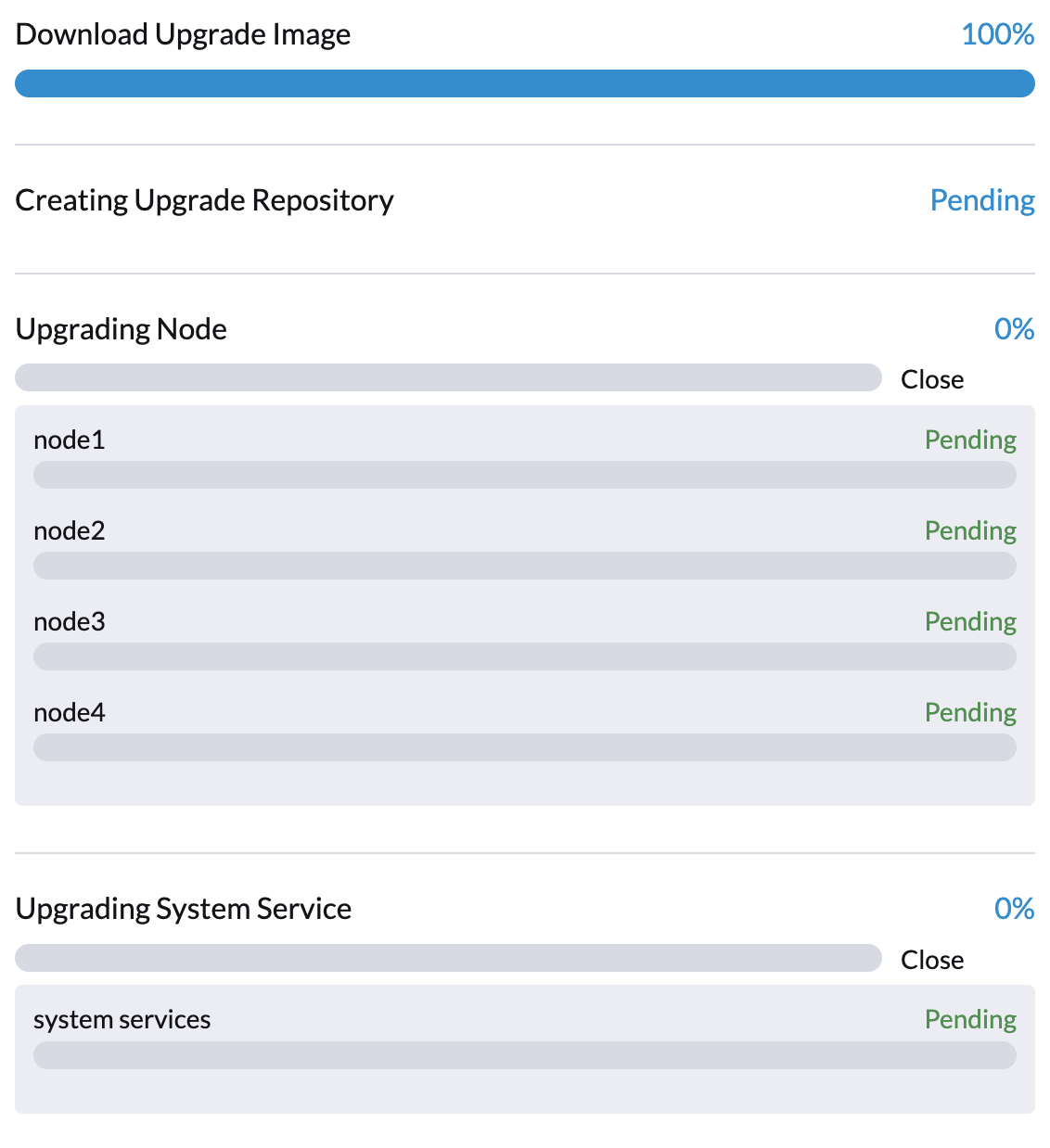
virt-launcher-upgrade-repo-hvst-upgrade-9gmg2-4mnmq 1/1 Running 0 4m44sPhase 2: Preload container images
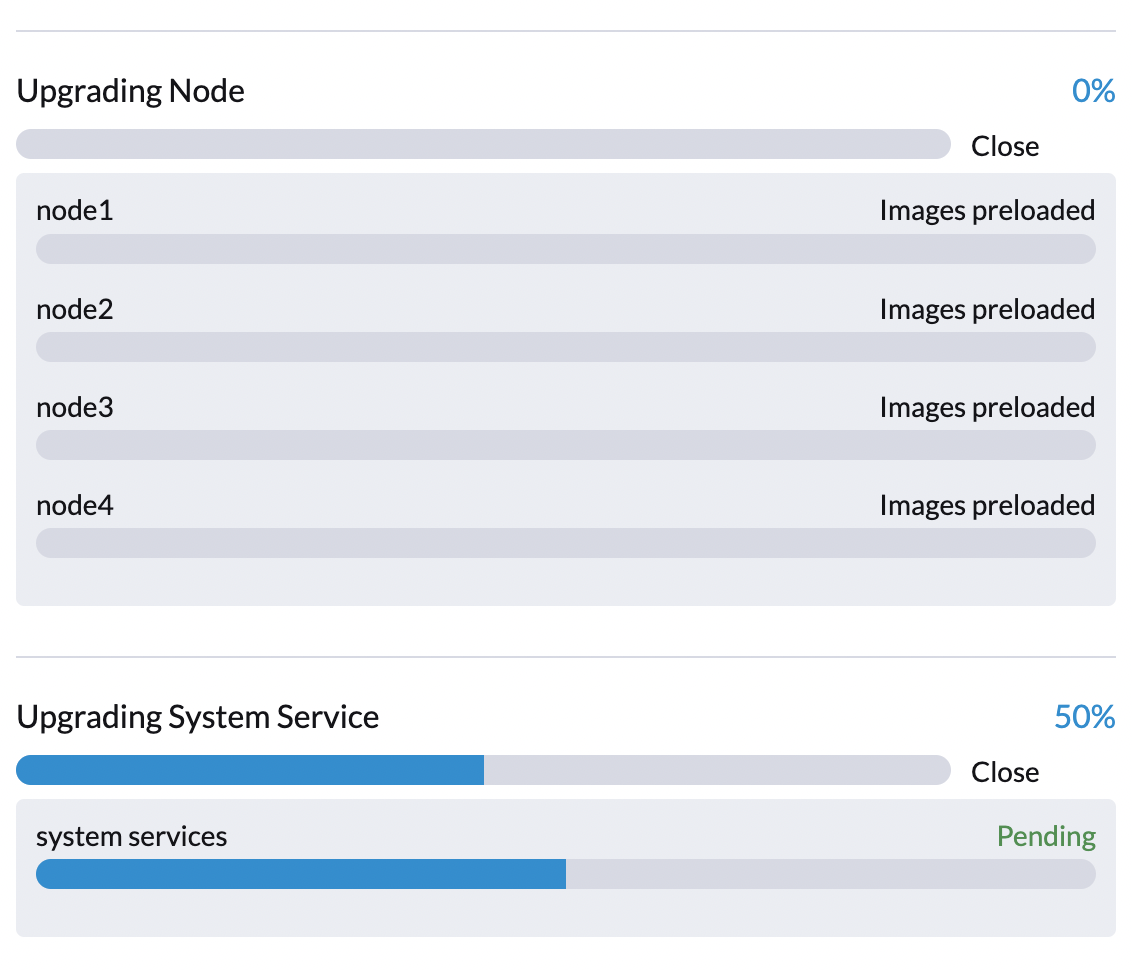
The SUSE Virtualization controller creates jobs that download and preload container images from the repository virtual machine. These images are required for the next release.
Allow some time for the images to be downloaded and preloaded on all nodes.

If the upgrade fails at this point, check the job logs in the cattle-system namespace before restarting the upgrade. You can check the logs using the command kubectl get jobs -n cattle-system | grep prepare.
Example:
$ kubectl get jobs -n cattle-system | grep prepare
apply-hvst-upgrade-9gmg2-prepare-on-node1-with-2bbea1599a-f0e86 0/1 47s 47s
apply-hvst-upgrade-9gmg2-prepare-on-node4-with-2bbea1599a-041e4 1/1 2m3s 2m50s
$ kubectl logs jobs/apply-hvst-upgrade-9gmg2-prepare-on-node1-with-2bbea1599a-f0e86 -n cattle-system
...Phase 3: Upgrade system services
The SUSE Virtualization controller creates a job that upgrades component Helm charts.
You can check the apply-manifest job using the command $ kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=manifest.
Example:
$ kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=manifest
NAME COMPLETIONS DURATION AGE
hvst-upgrade-9gmg2-apply-manifests 0/1 46s 46s
$ kubectl logs jobs/hvst-upgrade-9gmg2-apply-manifests -n harvester-system
...|
If the upgrade fails at this point, you must generate a support bundle before restarting the upgrade. The support bundle contains logs and resource manifests that can help identify the cause of the failure. |
Phase 4: Upgrade nodes
The SUSE Virtualization controller creates the following jobs on each node:
-
Multi-node clusters:
-
pre-drainjob: Live-migrates or shuts down virtual machines on the node. Once completed, the embedded Rancher service upgrades the RKE2 runtime on the node. -
post-drainjob: Upgrades and reboots the operating system.
-
-
Single-node clusters:
-
single-node-upgradejob: Upgrades the operating system and RKE2 runtime. The job name uses the formathvst-upgrade-xxx-single-node-upgrade-<hostname>.
-

You can check the jobs running on each node by running the command kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=node.
Example:
$ kubectl get jobs -n harvester-system -l harvesterhci.io/upgradeComponent=node
NAME COMPLETIONS DURATION AGE
hvst-upgrade-9gmg2-post-drain-node1 1/1 118s 6m34s
hvst-upgrade-9gmg2-post-drain-node2 0/1 9s 9s
hvst-upgrade-9gmg2-pre-drain-node1 1/1 3s 8m14s
hvst-upgrade-9gmg2-pre-drain-node2 1/1 7s 85s
$ kubectl logs -n harvester-system jobs/hvst-upgrade-9gmg2-post-drain-node2
...|
If the upgrade fails at this point, do not restart the upgrade unless instructed by SUSE Support. |
Common operations
Restart the upgrade
|
If the ongoing upgrade fails or becomes stuck at Phase 4: Upgrade nodes, do not restart the upgrade unless instructed by SUSE Support. |
-
Generate a support bundle.
-
Click the Upgrade button on the Dashboard screen.
If you customized the version, you might need to create the version object again.
Stop the ongoing upgrade
|
If an ongoing upgrade fails or becomes stuck at Phase 4: Upgrade nodes, identify the cause first. |
You can stop the upgrade by performing the following steps:
-
Log in to a control plane node.
-
Retrieve a list of
UpgradeCRs in the cluster.# become root $ sudo -i # list the on-going upgrade $ kubectl get upgrade.harvesterhci.io -n harvester-system -l harvesterhci.io/latestUpgrade=true NAME AGE hvst-upgrade-9gmg2 10m -
Delete the
UpgradeCR.$ kubectl delete upgrade.harvesterhci.io/hvst-upgrade-9gmg2 -n harvester-system -
Resume the paused ManagedCharts.
ManagedCharts are paused to avoid a data race between the upgrade and other processes. You must manually resume all paused ManagedCharts.
cat > resumeallcharts.sh << 'FOE' resume_all_charts() { local patchfile="/tmp/charttmp.yaml" cat >"$patchfile" << 'EOF' spec: paused: false EOF echo "the to-be-patched file" cat "$patchfile" local charts="harvester harvester-crd rancher-monitoring-crd rancher-logging-crd" for chart in $charts; do echo "unapuse managedchart $chart" kubectl patch managedcharts.management.cattle.io $chart -n fleet-local --patch-file "$patchfile" --type merge || echo "failed, check reason" done rm "$patchfile" } resume_all_charts FOE chmod +x ./resumeallcharts.sh ./resumeallcharts.sh
Download upgrade logs
SUSE Virtualization automatically collects all the upgrade-related logs and display the upgrade procedure. By default, this is enabled. You can also choose to opt out of such behavior.
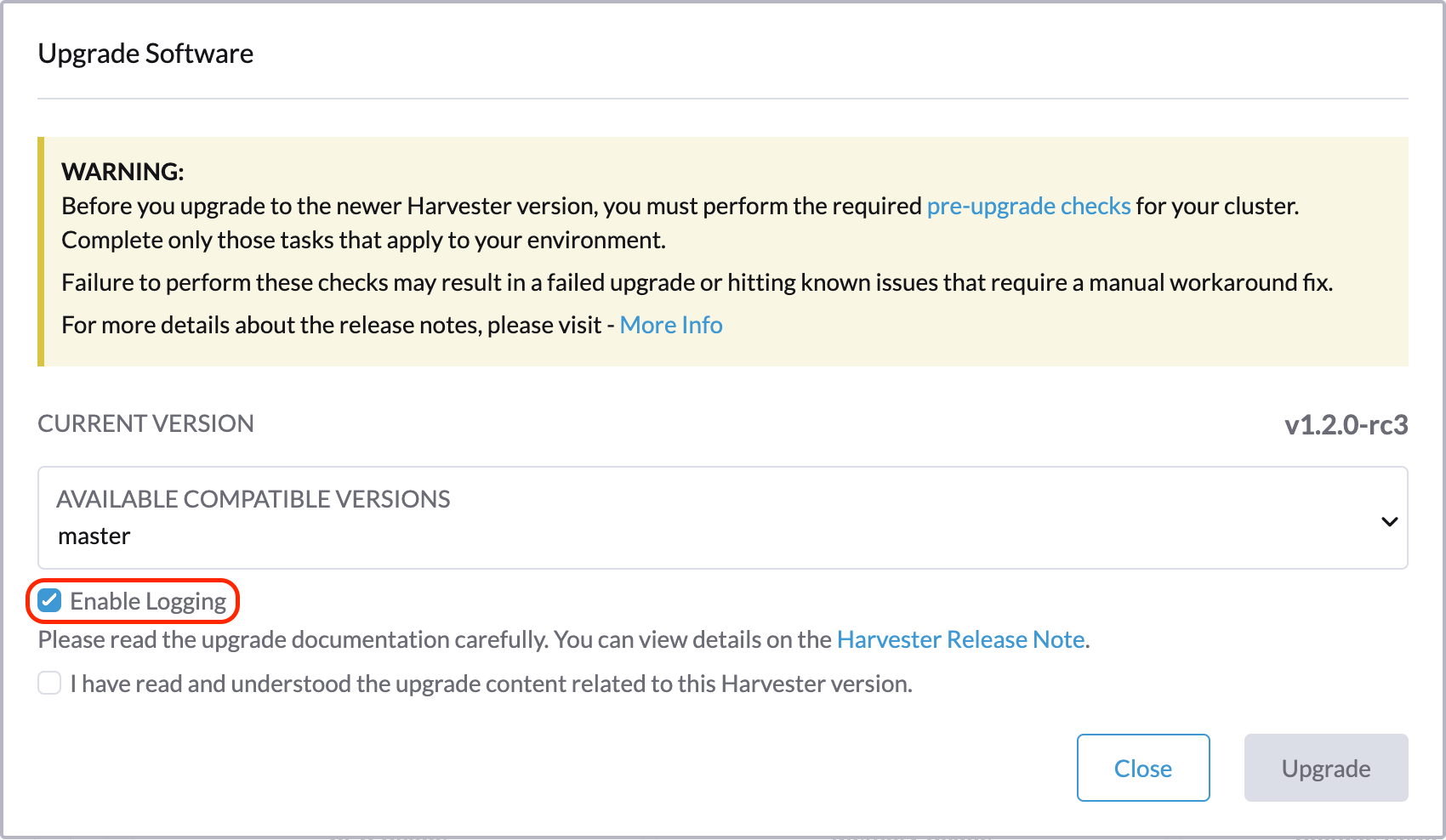
You can click the Download Log button to download the log archive during an upgrade.
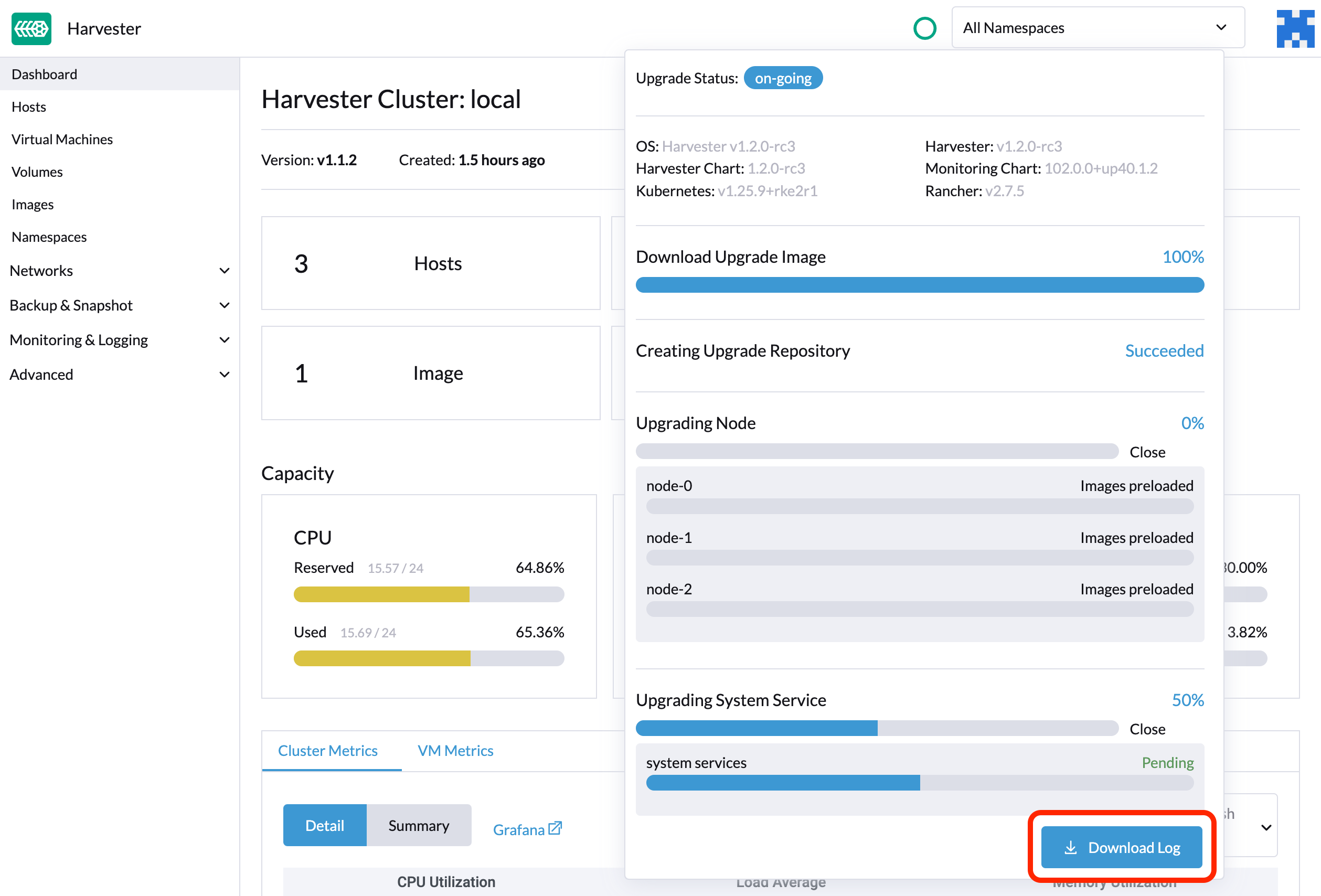
Log entries will be collected as files for each upgrade-related Pod, even for intermediate Pods. The support bundle provides a snapshot of the current state of the cluster, including logs and resource manifests, while the upgrade log preserves any logs generated during an upgrade. By combining these two, you can further investigate the issues during upgrades.
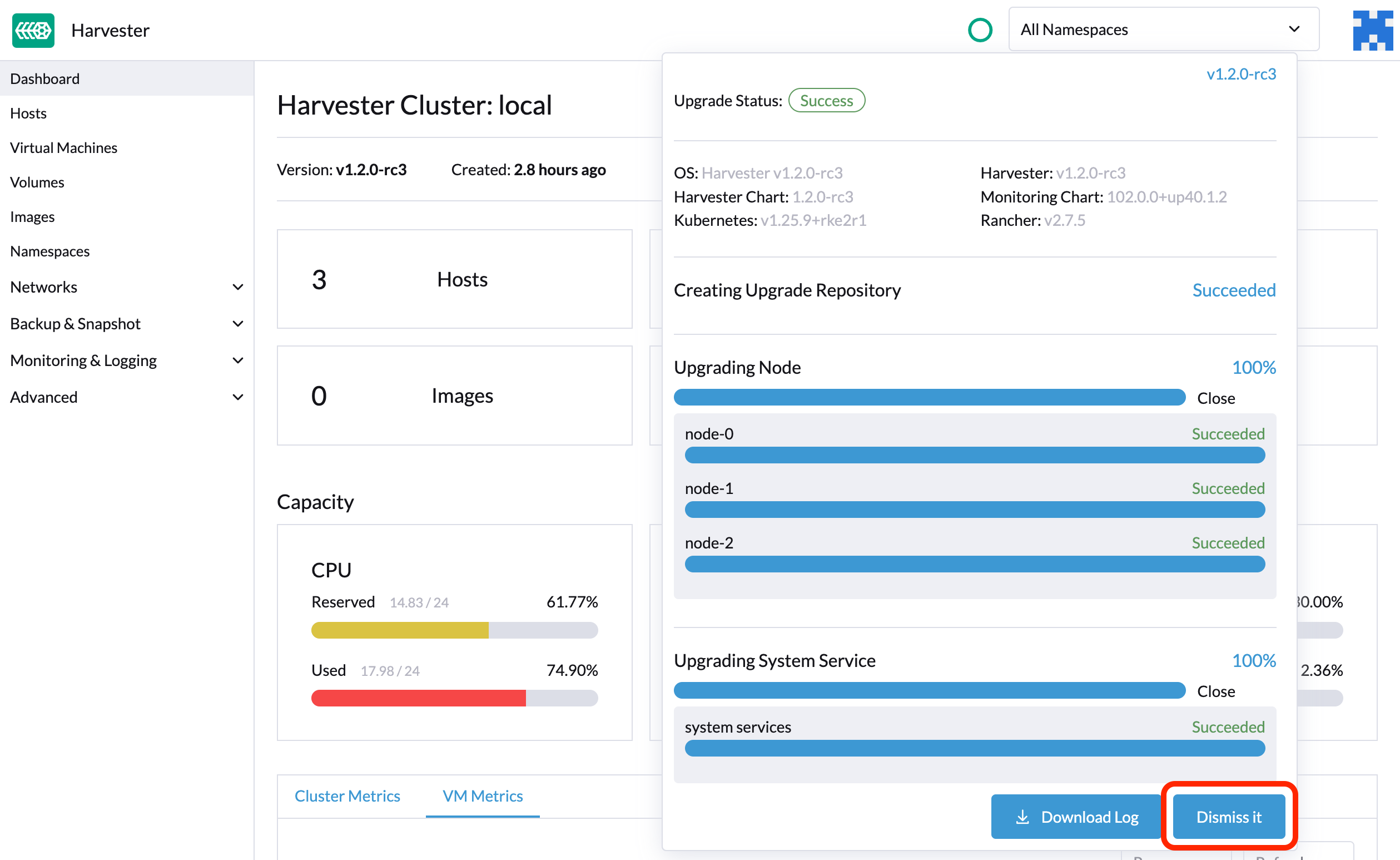
After the upgrade ends, SUSE Virtualization stops collecting the upgrade logs to avoid occupying the disk space. In addition, you can click the Dismiss it button to purge the upgrade logs.
|
The However, these components continue to consume cluster resources and may block certain operations, such as updating storage network settings (see issue #9599). To free up resources and unblock operations, perform either of the following actions:
|
For more details, please refer to the upgrade log HEP.
|
The default size of the volume that stores upgrade-related logs is 1 GB. When errors occur, these logs may completely consume the volume’s available space. To work around this issue, you can perform the following steps:
|
Clean up unused images
The default value of imageGCHighThresholdPercent in KubeletConfiguration is 85. When disk usage exceeds 85%, the kubelet attempts to remove unused images.
New images are loaded to each SUSE Virtualization node during upgrades. When disk usage exceeds 85%, these new images may be marked for cleanup because they are not used by any containers. In air-gapped environments, removal of new images from the cluster may break the upgrade process.
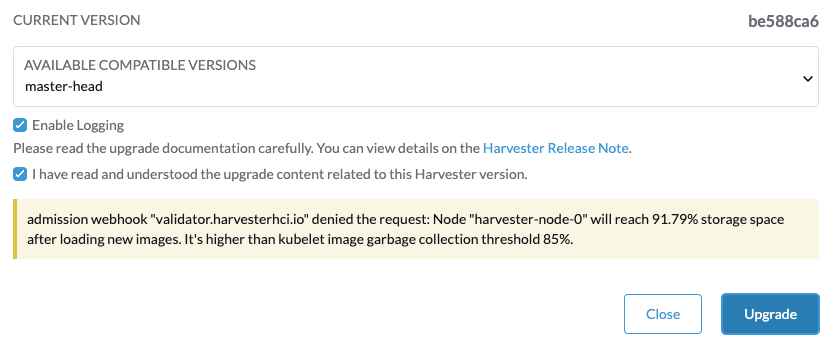
If you encounter the error message Node xxx will reach xx.xx% storage space after loading new images. It’s higher than kubelet image garbage collection threshold 85%., run crictl rmi --prune to clean up unused images before starting a new upgrade.
Check the status of a stuck upgrade
If the upgrade becomes stuck and the SUSE Virtualization UI does not display any error messages, perform the following steps:
-
Check the pods that were created during the upgrade process using the command
kubectl get pods -n harvester-system | grep upgrade.The main script is in the
hvst-upgrade-xxxxx-apply-manifests-xxxxxpod. If the log records include the following messages, themanagedChartCR might be causing issues.Current version: x.x.x, Current state: WaitApplied, Current generation: x Sleep for 5 seconds to retry -
Retrieve information about the
bundleCR using the commandkubectl get bundles -A.Example:
NAMESPACE NAME BUNDLEDEPLOYMENTS-READY STATUS fleet-local fleet-agent-local 1/1 fleet-local local-managed-system-agent 1/1 fleet-local mcc-harvester 0/1 Modified(1) [Cluster fleet-local/local]; kubevirt.kubevirt.io harvester-system/kubevirt modified {"spec":{"configuration":{"vmStateStorageClass":"vmstate-persistence"}}} fleet-local mcc-harvester-crd 1/1 fleet-local mcc-local-managed-system-upgrade-controller 1/1 fleet-local mcc-rancher-logging-crd 1/1 fleet-local mcc-rancher-monitoring-crd 1/1