1 製品の概要 #
概要#
SUSE® Linux Enterprise High Availability Extensionは、オープンソースクラスタ化技術の統合スイートで、可用性の高い物理Linuxクラスタと仮想Linuxクラスタを実装し、SPOF (シングルポイント障害)をなくします。データ、アプリケーション、サービスなどの重要なリソースの高度な可用性と管理のしやすさを実現します。その結果、ミッションクリティカルなLinuxワークロードに対してビジネスの継続性維持、データ整合性の保護、予期せぬダウンタイムの削減を行います。
基本的な監視、メッセージング、およびクラスタリソース管理の機能を標準装備し、個々の管理対象クラスタリソースのフェールオーバー、フェールバック、およびマイグレーション(負荷分散)をサポートします。
この章では、High Availability Extensionの主な製品機能と利点を紹介します。ここには、いくつかのクラスタ例が記載されており、クラスタを設定するコンポーネントについて学ぶことができます。最後のセクションでは、アーキテクチャの概要を示し、クラスタ内の個々のアーキテクチャ層とプロセスについて説明します。
High Availabilityクラスタのコンテキストでよく使用される用語については、用語集を参照してください。
1.1 拡張としての提供 #
High Availability Extensionは、SUSE Linux Enterprise Server 12 SP5の拡張として入手できます。Geo Clustering for SUSE Linux Enterprise High Availability Extensionという、High Availability Extensionの個別の拡張として、地理的に離れたクラスタ(Geoクラスタ)に対するサポートが提供されています。
1.2 主な機能 #
SUSE® Linux Enterprise High Availability Extensionでは、ネットワークリソースの可用性を確保し、管理することができます。以降のセクションでは、いくつかの主要機能に焦点を合わせて説明します。
1.2.1 広範なクラスタリングシナリオ #
High Availability Extensionは次のシナリオをサポートしています。
アクティブ/アクティブ設定
アクティブ/パッシブ設定: N+1、N+M、Nから1、NからM
ハイブリッド物理仮想クラスタ。仮想サーバを物理サーバとともにクラスタ化できます。これによって、サービスの可用性とリソースの使用状況が向上します。
ローカルクラスタ
メトロクラスタ(「ストレッチされた」ローカルクラスタ)
Geoクラスタ(地理的に離れたクラスタ)は、追加のGeo拡張がサポートされます。1.2.5項 「ローカル、メトロ、およびGeoクラスタのサポート」を参照してください。
クラスタには、最大32のLinuxサーバを含めることができます。pacemaker_remoteを使用すると、この制限を超えて追加のLinuxサーバを含めるようにクラスタを拡張できます。クラスタ内のどのサーバも、クラスタ内の障害が発生したサーバのリソース(アプリケーション、サービス、IPアドレス、およびファイルシステム)を再起動することができます。
1.2.2 柔軟性 #
High Availability Extensionには、Corosyncメッセージングおよびメンバーシップ層のほか、Pacemakerクラスタリソースマネージャが標準装備されています。Pacemakerの使用によって、管理者は継続的にリソースのヘルスとステータスを監視し、依存関係を管理し、柔軟に設定できるルールとポリシーに基づいてサービスを自動的に開始および停止できます。High Availability Extensionでは、ユーザの組織に適した特定のアプリケーションおよびハードウェアインフラストラクチャに合わせて、クラスタのカスタマイズが可能です。時間依存設定を使用して、サービスを特定の時刻に修復済みのノードに自動的にフェールバック(マイグレート)させることができます。
1.2.3 ストレージとデータレプリケーション #
High Availability Extensionでは必要に応じてサーバストレージを自動的に割り当て、再割り当てすることができます。ファイバチャネルストレージエリアネットワーク(SAN)とネットワーク上のiSCSIストレージをサポートします。共有ディスクシステムもサポートされていますが、必要要件ではありません。SUSE Linux Enterprise High Availability Extensionには、クラスタ対応のファイルシステムとボリュームマネージャ(OCFS2)、cLVM (clustered Logical Volume Manager)も含まれています。データのレプリケーションでは、DRBD*を使用して、High Availabilityサービスのデータをクラスタのアクティブノードからスタンバイノードへミラーリングできます。さらに、SUSE Linux Enterprise High Availability Extensionでは、Sambaクラスタリング技術であるCTDB (Clustered Trivial Database)もサポートしています。
1.2.4 仮想化環境のサポート #
SUSE Linux Enterprise High Availability Extensionは、物理Linuxサーバと仮想Linuxサーバ両方のクラスタリングをサポートしています。両タイプのサーバの混合もサポートしています。SUSE Linux Enterprise Server 12 SP5には、XenおよびKVM (カーネルベースの仮想マシン)が付属しています。両方がオープンソース仮想ハイパーバイザーです。仮想ゲストシステム(VMとも呼ばれる)はクラスタによるサービスとして管理できます。
1.2.5 ローカル、メトロ、およびGeoクラスタのサポート #
SUSE Linux Enterprise High Availability Extensionは、様々な地理的なシナリオをサポートするように拡張されています。Geo Clustering for SUSE Linux Enterprise High Availability Extensionという、High Availability Extensionの個別の拡張として、地理的に離れたクラスタ(Geoクラスタ)に対するサポートが提供されています。
- ローカルクラスタ
1つのロケーション内の単一のクラスタ(たとえば、すべてのノードが1つのデータセンターにある)。クラスタはノード間の通信にマルチキャストまたはユニキャストを使用し、フェールオーバーを内部で管理します。ネットワークの遅延時間は無視できます。ストレージは通常、すべてのノードに同時にアクセスされます。
- メトロクラスタ
複数の建物またはデータセンターにわたってストレッチできる単一のクラスタ。クラスタはノード間の通信に通常ユニキャストを使用し、フェールオーバーを内部で管理します。ネットワークの遅延時間は通常は短くなります(約20マイルの距離で<5ms)。 ストレージは可能な場合はファイバチャネルで接続されます。データレプリケーションは内部でストレージごとに、またはクラスタの管理下でホストベースのミラーリングごとに実行されます。
- Geoクラスタ(マルチサイトクラスタ)
それぞれにローカルクラスタを持つ、複数の地理的に離れたサイト。サイトはIPによって交信します。サイト全体のフェールオーバーはより高いレベルのエンティティによって調整されます。Geoクラスタは限られたネットワーク帯域幅および高レイテンシに対応する必要があります。ストレージは同期的にレプリケートされます。
個々のクラスタノード間の地理的距離が大きいほど、クラスタが提供するサービスの高可用性を妨げる可能性のある要因が多くなります。ネットワークの遅延時間、限られた帯域幅およびストレージへのアクセス が長距離クラスタの課題として残ります。
1.2.6 リソースエージェント #
SUSE Linux Enterprise High Availability Extensionには、Apache、IPv4、IPv6、その他多数のリソースを管理するための膨大な数のリソースエージェントが含まれています。またIBM WebSphere Application Serverなどの一般的なサードパーティアプリケーション用のリソースエージェントも含まれています。ご利用の製品に含まれているOpen Cluster Framework (OCF)リソースエージェントの概要は、8.1.3項 「OCFリソースエージェントに関する情報の表示」で説明されるcrm raコマンドを使用してください。
1.2.7 ユーザフレンドリな管理ツール #
High Availability Extensionは、クラスタの基本的なインストールとセットアップのほか、効果的な設定および管理に使用できる強力なツールセットを標準装備しています。
- YaST
一般的なシステムインストールおよび管理用グラフィカルユーザインタフェース。『インストールおよびセットアップクイックスタート』で説明されているように、YaSTを使用して、High Availability ExtensionをSUSE Linux Enterprise Server上にインストールします。YaSTでは、クラスタまたは個々のコンポーネントの設定に役立つように、High Availabilityカテゴリ内の次のモジュールも提供しています。
クラスタ: 基本的なクラスタセットアップ。詳細については、第4章 「YaSTクラスタモジュールの使用」を参照してください。
DRBD: Distributed Replicated Block Deviceの設定。
IP負荷分散: Linux仮想サーバまたはHAProxyによる負荷分散の設定。詳細については、第14章 「負荷バランス」を参照してください。
- HA Web Konsole (Hawk2)
Linux以外のマシンから、Linuxクラスタを管理できるWebベースのユーザインタフェース。このインタフェースは、システムにグラフィカルユーザインタフェースがない場合も理想的なソリューションです。リソースの作成と設定の手順を順を追って支援し、リソースの起動、中止、移行などの管理作業を容易にします。詳細については、第7章 「Hawk2を使用したクラスタリソースの設定と管理」を参照してください。
crmシェルリソースを設定し、すべての監視または管理作業を実行する、統合されたパワフルなコマンドラインインタフェースです。詳細については、第8章 「クラスタリソースの設定と管理(コマンドライン)」を参照してください。
1.3 利点 #
High Availability Extensionでは最大 32台のLinuxサーバを可用性の高いクラスタ(HAクラスタ)に設定し、クラスタ内の任意のサーバにリソースをダイナミックに切り替えたり、移動することができます。サーバ障害発生時のリソースの自動マイグレーションの設定ができます。また、ハードウェアのトラブルシューティングやワークロードのバランスをとるために、リソースを手動で移動することもできます。
High Availability Extensionは、コモディティコンポーネントによる高可用性を提供しています。アプリケーションと操作をクラスタに統合することによって、運用コストを削減できます。さらにHigh Availability Extensionでは、クラスタ全体を一元管理し、変化するワークロード要件に応じてリソースを調整することもできます(手動でのクラスタの「負荷分散」)。3ノード以上でクラスタを設定すると、複数のノードが「ホットスペア」を共用できて無駄がありません。
その他にも重要な利点として、予測できないサービス停止を削減したり、ソフトウェアおよびハードウェアの保守やアップグレードのための計画的なサービス停止を削減できる点が挙げられます。
次に、クラスタによるメリットについて説明します。
可用性の向上
パフォーマンスの改善
運用コストの低減
スケーラビリティ
障害回復
データの保護
サーバの集約
ストレージの集約
共有ディスクサブシステムにRAID を導入することによって、共有ディスクの耐障害性を強化できます。
次のシナリオは、High Availability Extensionの利点を紹介するものです。
クラスタシナリオ例#
サーバ3台でクラスタが設定され、それぞれのサーバにWebサーバをインストールしたと仮定します。クラスタ内の各サーバが、2つのWebサイトをホストしています。各Webサイトのすべてのデータ、グラフィックス、Webページコンテンツは、クラスタ内の各サーバに接続された、共有ディスクサブシステムに保存されています。次の図は、このクラスタのセットアップを示しています。
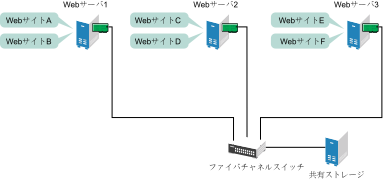
図 1.1: 3サーバクラスタ #
通常のクラスタ操作では、クラスタ内の各サーバが他のサーバと常に交信し、すべての登録済みリソースを定期的にポーリングして、障害を検出します。
Webサーバ1でハードウェアまたはソフトウェアの障害が発生したため、このサーバを利用してインターネットアクセス、電子メール、および情報収集を行っているユーザの接続が切断されたとします。次の図は、Webサーバ1で障害が発生した場合のリソースの移動を表したものです。
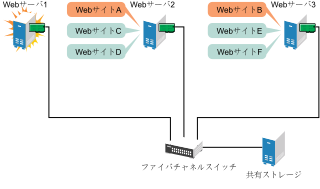
図 1.2: 1台のサーバに障害が発生した後の3サーバクラスタ #
WebサイトAがWebサーバ2に、WebサイトBがWebサーバ3に移動します。IPアドレスと証明書もWebサーバ2とWebサーバ3に移動します。
クラスタを設定するときに、それぞれのWebサーバがホストしているWebサイトについて、障害発生時の移動先を指定します。先に説明した例では、WebサイトAの移動先としてWebサーバ2が、WebサイトBの移動先としてWebサーバ3が指定されています。このようにして、Webサーバ1によって処理されていたワークロードが、残りのクラスタメンバーに均等に分散され、可用性を維持できます。
Webサーバ1で障害が発生すると、High Availability Extensionソフトウェアは次の処理を実行します。
障害を検出し、Webサーバ 1が本当に機能しなくなっていることをSTONITHを使用して検証。STONITHは、「Shoot The Other Node In The Head」(他のノードの頭を撃て)の頭字語であり、誤動作しているノードをダウンさせて、それらがクラスタ内に問題を発生させることを防ぎます。
Webサーバ1にマウントされていた共有データディレクトリを、Webサーバ2およびWebサーバ3に再マウント。
Webサーバ1で動作していたアプリケーションを、Webサーバ2およびWebサーバ3で再起動。
IPアドレスをWebサーバ2およびWebサーバ3に移動。
この例では、フェールオーバープロセスが迅速に実行され、ユーザはWebサイトの情報へのアクセスを数秒程度で回復できます。通常、再度ログインする必要はありません。
ここで、Webサーバ1で発生した問題が解決し、通常に操作できる状態に戻ったと仮定します。WebサイトAおよびWebサイトBは、Webサーバ1に自動的にフェールバック(復帰)することも、そのままの状態を維持することもできます。これは、リソースの設定方法によって決まります。Webサーバ1へのマイグレーションは多少のダウンタイムを伴うため、High Availability Extensionではサービス中断がほとんど、またはまったく発生しないタイミングまでマイグレーションを延期することもできます。いずれの場合でも利点と欠点があります。
High Availability Extensionは、リソースマイグレーション機能も提供します。アプリケーション、Webサイトなどをシステム管理の必要性に応じて、クラスタ内の他のサーバに移動することができます。
たとえば、WebサイトAまたはWebサイトBをWebサーバ1からクラスタ内の他のサーバに手動で移動することができます。これは、Webサーバ1のアップグレードや定期メンテナンスを実施する場合、また、Webサイトのパフォーマンスやアクセスを向上させる場合に有効な機能です。
1.4 クラスタ設定: ストレージ #
High Availability Extensionでのクラスタ構成には、共有ディスクサブシステムが含まれる場合と含まれない場合があります。共有ディスクサブシステムの接続には、高速ファイバチャネルカード、ケーブル、およびスイッチを使用でき、また設定にはiSCSIを使用することができます。サーバの障害時には、クラスタ内の別の指定されたサーバが、障害の発生したサーバにマウントされていた共有ディスクディレクトリを自動的にマウントします。この機能によって、ネットワークユーザは、共有ディスクサブシステム上のディレクトリに対するアクセスを中断することなく実行できます。
一般的なリソースの例としては、データ、アプリケーション、およびサービスなどがあります。次の図は、一般的なファイバチャネルクラスタの設定を表したものです。
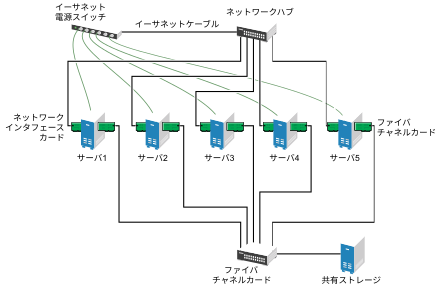
図 1.3: 一般的なファイバチャネルクラスタの設定 #
ファイバチャネルは最も高いパフォーマンスを提供しますが、iSCSIを利用するようにクラスタを設定することもできます。iSCSIは低コストなストレージエリアネットワーク(SAN)を作成するための方法として、ファイバチャネルの代わりに使用できます。次の図は、一般的なiSCSIクラスタの設定を表したものです。
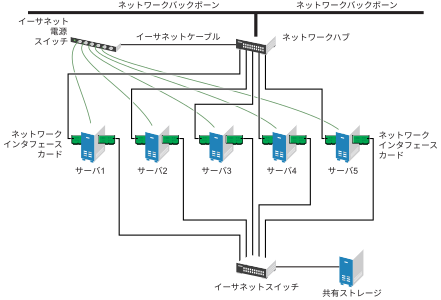
図 1.4: 一般的なiSCSIクラスタの設定 #
ほとんどのクラスタには共有ディスクサブシステムが含まれていますが、共有ディスクサブシステムなしのクラスタを作成することもできます。次の図は、共有ディスクサブシステムなしのクラスタを表したものです。
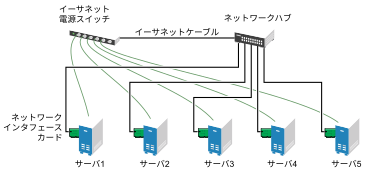
図 1.5: 共有ストレージなしの一般的なクラスタ設定 #
1.5 アーキテクチャ #
このセクションでは、High Availability Extensionアーキテクチャの概要を説明します。アーキテクチャコンポーネントと、その相互運用方法について説明します。
1.5.1 アーキテクチャ層 #
High Availability Extensionのアーキテクチャは層化されています。図1.6「アーキテクチャ」に異なる層と関連するコンポーネントを示します。
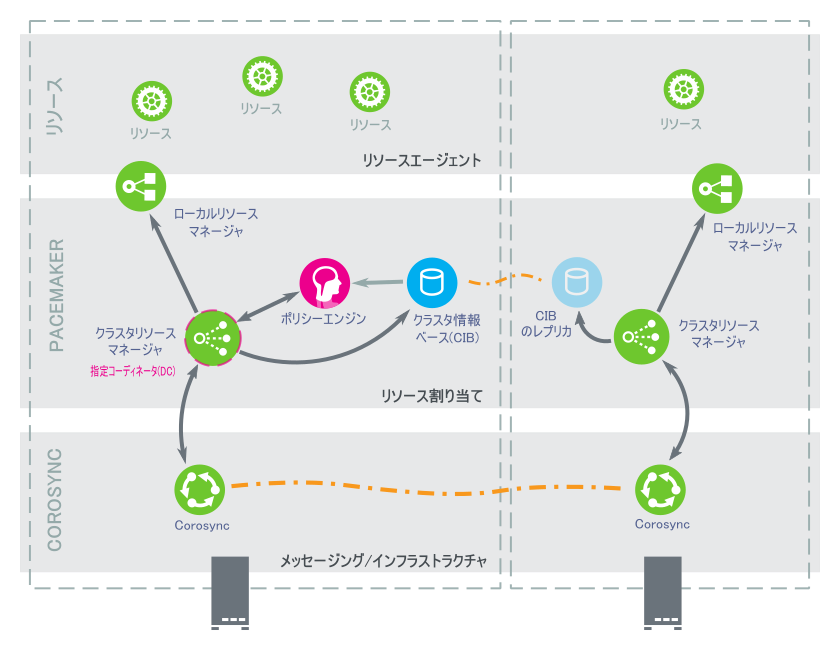
図 1.6: アーキテクチャ #
1.5.1.1 メッセージングおよびインフラストラクチャ層 #
プライマリまたは最初の層は、メッセージングおよびインフラストラクチャの層で、Corosync層とも呼ばれます。この層には、「I am alive」信号やその他の情報を含むメッセージを送信するコポーネントが含まれます。
1.5.1.2 リソース割り当て層 #
次の層はリソース割り当て層です。この層は最も複雑で、次のコンポーネントから設定されていいます。
- CRM (クラスターリソースマネージャ)
リソース割り当て層のすべてのアクションは、クラスターリソースマネージャを通過します。リソース割り当て層の他のコンポーネント(または上位層のコンポーネント)による通信の必要性が発生した場合は、ローカルCRM経由で行います。すべてのノードで、CRMはCIB (クラスタ情報ベース)を維持しています。
- CIB (クラスタ情報ベース)
クラスタ情報ベースは、メモリ内でクラスタ全体の設定や現在のステータスをXML形式で表すものです。すべてのクラスタオプション、ノード、リソース、制約、相互関係の定義が含まれます。CIBはすべてのクラスタノードへの更新の同期化も行います。指定コーディネータ(DC)が維持するマスタCIBがクラスタ内に1つあります。他のすべてのノードにはCIBのレプリカが含まれます。
- 指定コーディネータ(DC)
クラスタ内のCRMはDCとして選択されます。DCは、ノードのフェンシングやリソースの移動など、クラスタ全体におよぶ変更が必要かどうかを判断できる、クラスタ内で唯一のエンティティです。DCは、CIBのマスターコピーが保持されるノードでもあります。その他すべてのノードは、現在のDCから設定とリソース割り当て情報を取得します。DCは、メンバーシップの変更後、クラスタ内のすべてのノードから選抜されます。
- PE (ポリシーエンジン)
指定コーディネータがクラスタ全体におよぶ変更を行う(新しいCIBに対応する)ことが必要になるたびに、ポリシーエンジンは現在の状態と設定に基づき、クラスタの次の状態を計算します。PEは(リソース)アクションのリストと、次のクラスタ状態に移るために必要な依存性を含む遷移グラフも作成します。PEは常にDC上で実行されます。
- LRM(ローカルリソースマネージャ)
LRMはCRMに代わってローカルリソースエージェントを呼び出します(1.5.1.3項 「リソース層」を参照)。そのため、操作の開始、停止、監視を行い、結果をCRMに報告します。LRMはそのローカルノード上のすべてのリソース関連情報の信頼できるソースです。
1.5.1.3 リソース層 #
最も上位の層はリソース層です。リソース層には1つ以上のリソースエージェント(RA)が含まれます。リソースエージェントは、一定の種類のサービス(リソース)を開始、停止、監視するために作成されたプログラム(通常はシェルスクリプト)です。リソースエージェントの呼び出しはLRMだけが行います。サードパーティはファイルシステム内の定義された場所に独自のエージェントを配置して、自社ソフトウェア用に、すぐに使えるクラスタ統合機能を提供することができます。
1.5.2 プロセスフロー #
SUSE Linux Enterprise High Availability Extensionでは、PacemakerをCRMとして使用します。CRMは各クラスタノード上にインスタンスを持つデーモン(crmd)として実装されます。Pacemakerは、マスタとして動作するcrmdインスタンスを1つ選択することにより、クラスタのすべての意思決定を一元化します。選択したcrmdプロセス(またはその下のノード)で障害が発生したら、新しいcrmdプロセスが確立されます。
クラスタの設定とクラスタ内のすべてのリソースの現在の状態を反映したCIBが、各ノードに保存されます。CIBのコンテンツはクラスタ全体で自動的に同期化されます。
クラスタ内で実行するアクションの多くは、クラスタ全体におよぶ変更を伴います。これらのアクションにはクラスタリソースの追加や削除、リソース制約の変更などがあります。このようなアクションを実行する場合は、クラスタ内でどのような変化が発生するのかを理解することが重要です。
たとえば、クラスタIPアドレスリソースを追加するとします。そのためには、コマンドラインツールかWebインタフェースを使用してCIBを変更できます。DC上でアクションを実行する必要はなく、クラスタ内の任意のノードでいずれかのツールを使用すれば、DCに反映されます。そして、DCがすべてのクラスタノードにCIBの変更を複製します。
CIBの情報に基づき、PEがクラスタの理想的な状態と実行方法を計算し、指示リストをDCに送ります。DCはメッセージング/インフラストラクチャ層を介してコマンドを送信し、他のノードのcrmdピアがこれらのコマンドを受信します。各crmdはLRM(lrmdとして実装)を使用してリソースを変更します。lrmdはクラスタに対応しておらず、リソースエージェント(スクリプト)と直接通信します。
すべてのピアノードは操作結果をDCに返送します。DCが、すべての必要な操作がクラスタ内で成功したことを確認すると、クラスタはアイドル状態に戻り、次のイベントを待機します。予定通り実行されなかった操作があれば、CIBに記録された新しい情報を元に、PEを再度呼び出します。
場合によっては、共有データの保護や完全なリソース復旧のためにノードの電源を切らなければならないことがあります。このPacemakerにはフェンシングサブシステムとしてstonithdが内蔵されています。STONITHは「Shoot The Other Node In The Head」の略です。通常は、STONITH共有ブロックデバイス、リモート管理ボード、またはリモートパワースイッチを使用して実装されます。Pacemakerで、STONITHデバイスはリソースとしてモデル化されており(そしてCIBで設定されており)、簡単に使用することができます。ただし、stonithdがSTONITHトポロジの把握を担うため、そのクライアントはノードのフェンシングを要求し、残りをstonithdが行います。