|
本文档采用自动化机器翻译技术翻译。 尽管我们力求提供准确的译文,但不对翻译内容的完整性、准确性或可靠性作出任何保证。 若出现任何内容不一致情况,请以原始 英文 版本为准,且原始英文版本为权威文本。 |
架构
本节介绍了 Rancher Logging 应用程序的架构。
有关 Logging Operator 工作原理的更多详细信息,请参阅官方文档。
Logging Operator 工作原理
Logging Operator 自动部署和配置 Kubernetes 日志流水线。它会在每个节点上部署和配置一个 Fluent Bit DaemonSet,从而收集节点文件系统中的容器和应用程序日志。
Fluent Bit 查询 Kubernetes API 并使用 pod 的元数据来丰富日志,然后将日志和元数据都传输到 Fluentd。Fluentd 会接收和过滤日志并将日志传输到多个Output。
以下自定义资源用于定义了如何过滤日志并将日志发送到 Output:
-
Flow是一个命名空间自定义资源,它使用过滤器和选择器将日志消息路由到对应的Output。 -
ClusterFlow用于路由集群级别的日志消息。 -
Output是一个命名空间资源,用于定义发送日志消息的位置。 -
ClusterOutput定义了一个所有Flow和ClusterFlow都可用的Output。
每个 Flow 都必须引用一个 Output,而每个 ClusterFlow 都必须引用一个 ClusterOutput。
Logging Operator 文档中的下图显示了新的 Logging 架构:
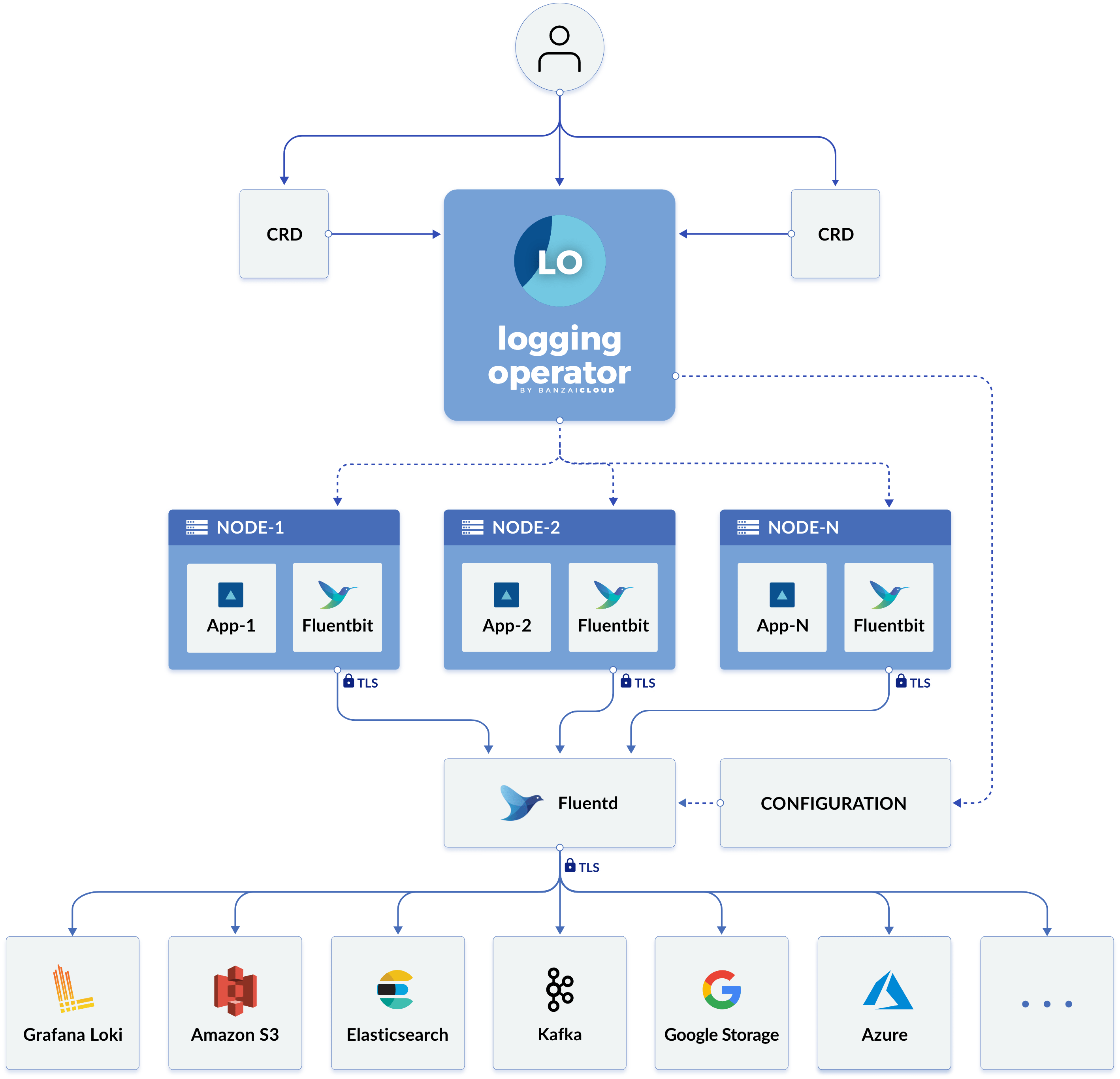
Figure 1. Logging Operator 如何与 Fluentd 和 Fluent Bit 一起使用