Nœud témoin
SUSE VirtualizationLes clusters déployés dans des environnements de production nécessitent un plan de contrôle pour la gestion des nœuds et des pods. Un cluster typique à trois nœuds a trois nœuds de gestion qui contiennent chacun l’ensemble complet des composants du plan de contrôle. Un composant clé est etcd, que Kubernetes utilise pour stocker ses données (configuration, état et métadonnées). Le nombre de nœuds etcd doit toujours être un nombre impair (par exemple, 3 est le nombre par défaut dans SUSE Virtualization) pour garantir qu’un quorum est maintenu.
Certaines situations peuvent nécessiter d’éviter de déployer des charges de travail et des données utilisateur sur les nœuds de gestion. Dans ces situations, un nœud de cluster peut se voir attribuer le rôle de witness, ce qui le limite à fonctionner en tant que membre du cluster etcd. Le nœud témoin est responsable d’établir un quorum de membres (une majorité de nœuds), qui doivent s’accorder sur les mises à jour de l’état du cluster.
Les nœuds témoins ne stockent aucune donnée, mais les recommandations matérielles pour les nœuds etcd doivent tout de même être prises en compte. Utiliser du matériel avec des ressources limitées affecte considérablement les performances du cluster, comme décrit dans l’article Performances lentes d’etcd (tests de performance et optimisation).
SUSE Virtualization prend en charge des clusters avec deux nœuds de gestion et un nœud témoin (et éventuellement, un ou plusieurs nœuds de travail). Pour plus d’informations sur les rôles des nœuds, voir Gestion des rôles.
|
Un nœud ne peut se voir attribuer le rôle de witness qu’au moment où il rejoint un cluster. Chaque cluster ne peut avoir qu’un seul nœud témoin. |
Créer un SUSE Virtualization cluster avec un nœud témoin
Vous pouvez attribuer le rôle de witness à un nœud lorsqu’il rejoint un cluster nouvellement créé.
Dans l’exemple suivant, un cluster avec trois nœuds a été créé et le nœud harvester-node-1 a été attribué le rôle de witness. harvester-node-1 consomme moins de ressources et n’a que des capacités etcd.
NAME↑ STATUS ROLE VERSION PODS CPU MEM %CPU %MEM CPU/A MEM/A AGE harvester-node-0 Ready control-plane,etcd,master v1.27.10+rke2r1 70 1095 10143 10 63 10000 15976 4d13h harvester-node-1 Ready etcd v1.27.10+rke2r1 7 258 2258 2 14 10000 15976 4d13h harvester-node-2 Ready control-plane,etcd,master v1.27.10+rke2r1 36 840 6905 8 43 10000 15976 4d13h
Parce que le cluster doit avoir trois nœuds, le contrôleur de promotion promouvra les deux autres nœuds. Après cela, le cluster aura deux nœuds de plan de contrôle et un nœud témoin.
Charges de travail sur le nœud témoin
Le nœud témoin exécute uniquement les charges de travail essentielles suivantes :
-
harvester-node-manager
-
cloud-controller-manager
-
etcd
-
kube-proxy
-
rke2-canal
-
rke2-multus
Mettre à niveau un cluster avec un nœud témoin
Les exigences et procédures générales de mise à niveau s’appliquent aux clusters avec un nœud témoin. Cependant, l’existence de volumes dégradés dans de tels clusters peut entraîner l’échec des opérations de mise à niveau.
Répliques Longhorn dans des clusters avec un nœud témoin
SUSE Virtualization utilise Longhorn, un système de stockage de blocs distribué, pour la gestion des volumes de dispositifs de bloc. Longhorn est provisionné pour les nœuds de gestion et de travail, mais pas pour les nœuds témoins, qui ne stockent aucune donnée.
Longhorn crée des répliques de chaque volume pour augmenter la disponibilité. Les répliques contiennent une chaîne d’instantanés du volume, chaque instantané stockant la modification par rapport à un instantané précédent. Dans SUSE Virtualization, la StorageClass par défaut harvester-longhorn a une valeur de nombre de répliques de 3.
limites
Les nœuds témoins ne stockent aucune donnée. Cela signifie que dans des clusters à trois nœuds (sans nœuds de travail), seules deux répliques sont créées pour chaque volume Longhorn. Cependant, la StorageClass par défaut harvester-longhorn a une valeur de nombre de répliques de 3 pour une haute disponibilité. Si vous utilisez cette StorageClass pour créer des volumes, Longhorn ne peut pas créer le nombre de répliques configuré. Cela entraîne que les volumes sont marqués comme Dégradés sur l’interface Longhorn.
En résumé, vous devez utiliser une StorageClass qui correspond à la configuration du cluster.
-
2 nœuds de gestion + 1 nœud témoin : Créez une nouvelle StorageClass par défaut avec le paramètre Nombre de réplicas défini sur 2. Cela garantit que seulement deux réplicas sont créés pour chaque volume Longhorn.
-
2 nœuds de gestion + 1 nœud témoin + 1 ou plusieurs nœuds de travail : Vous pouvez utiliser la StorageClass par défaut existante.
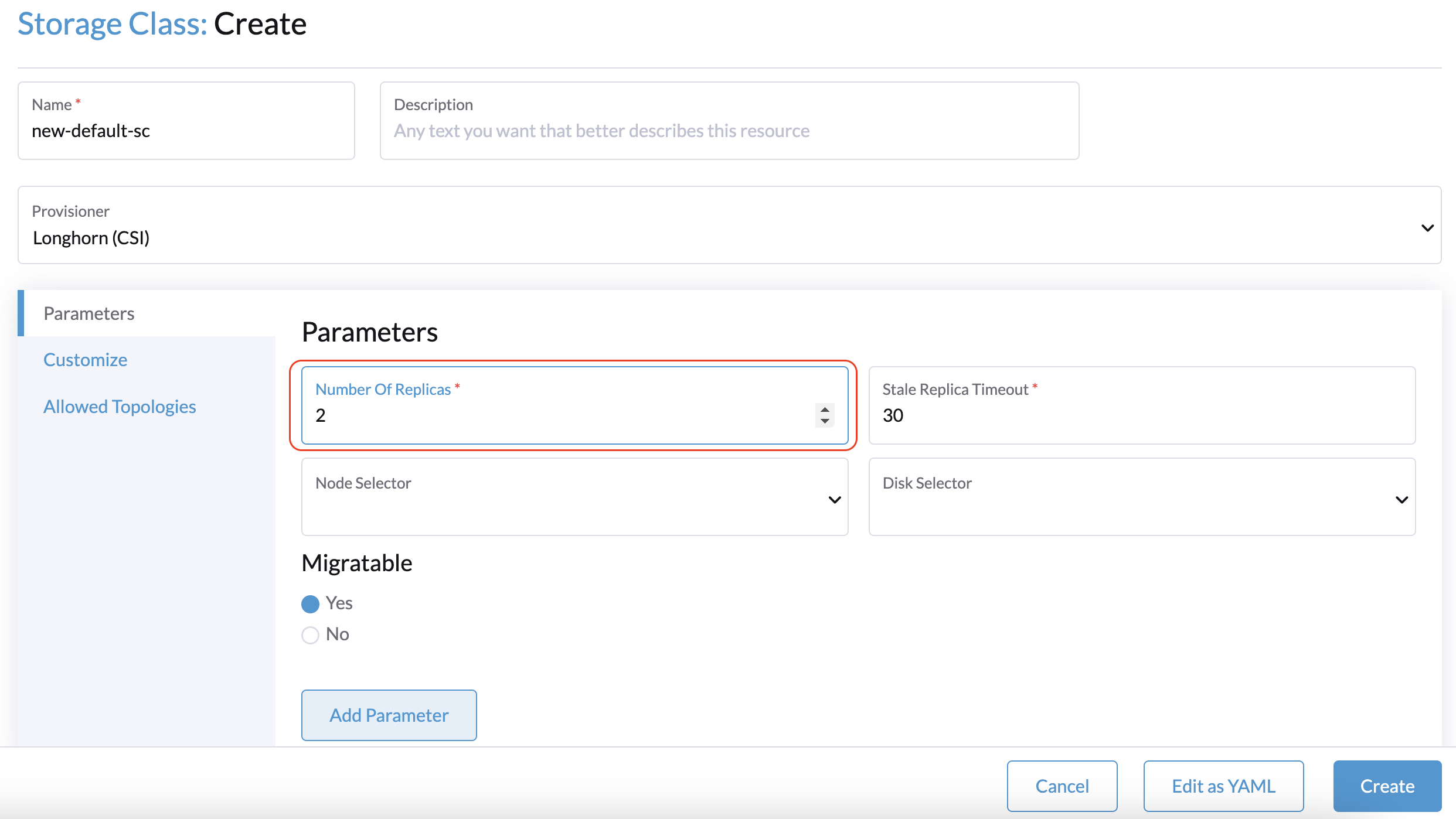
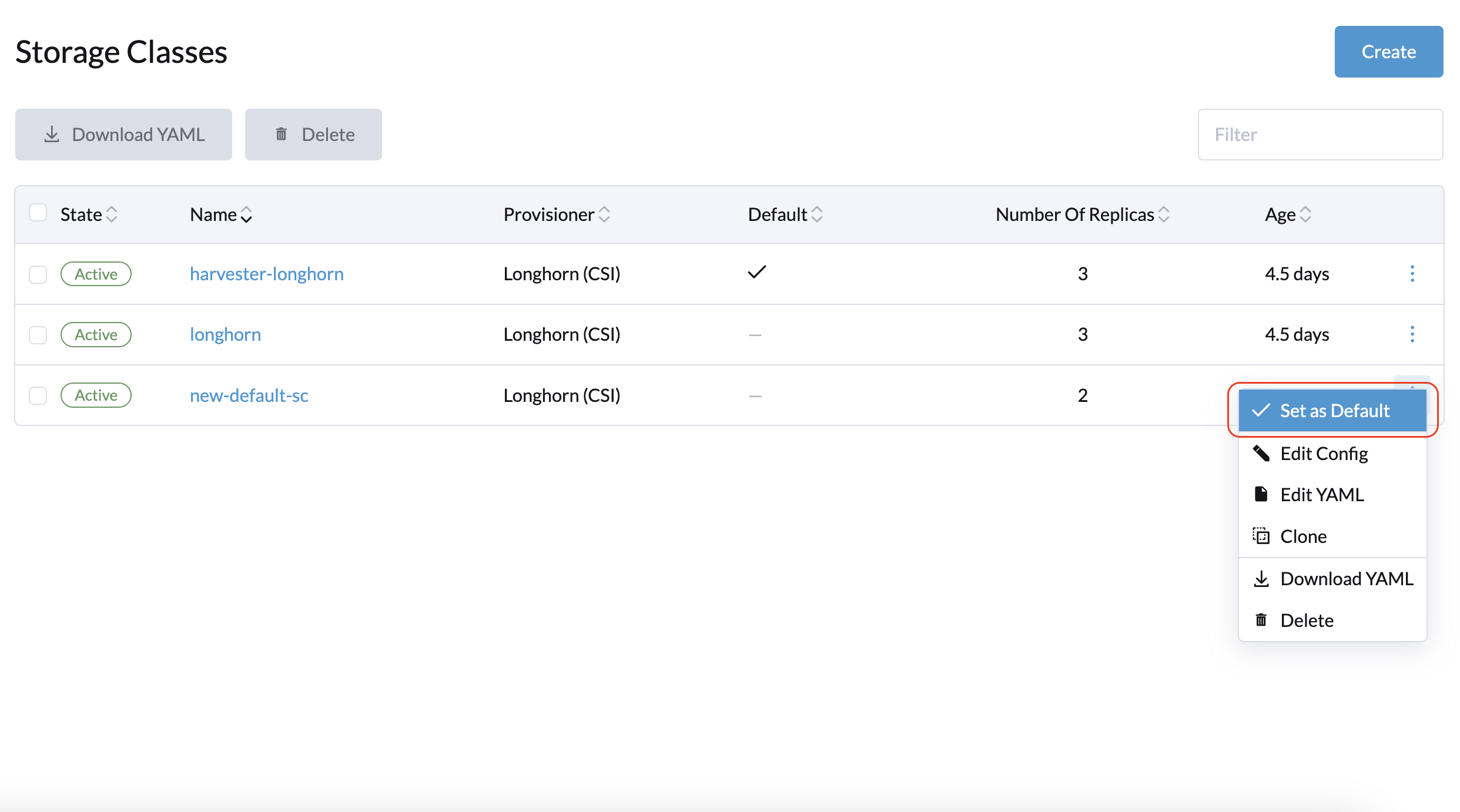
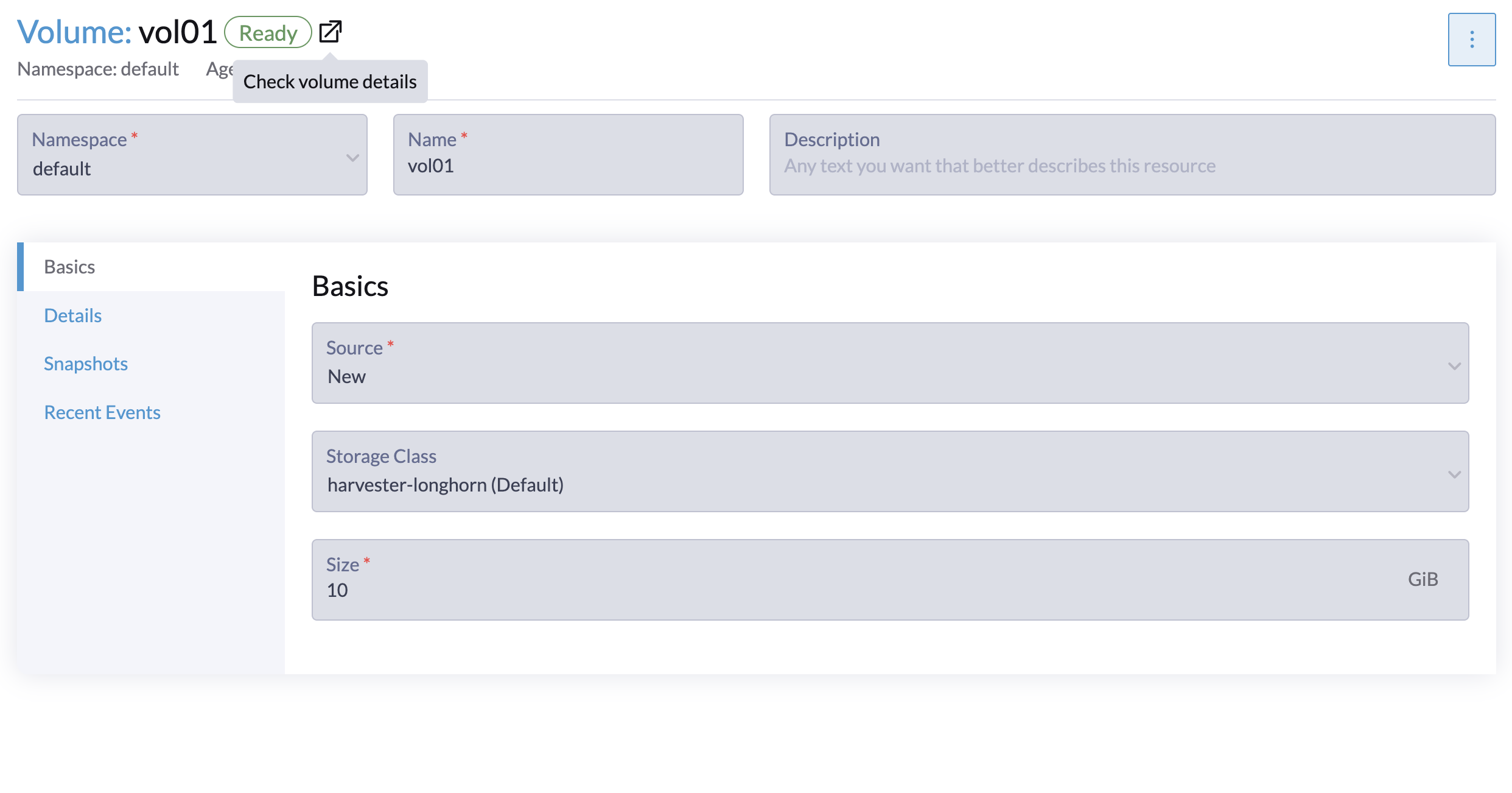
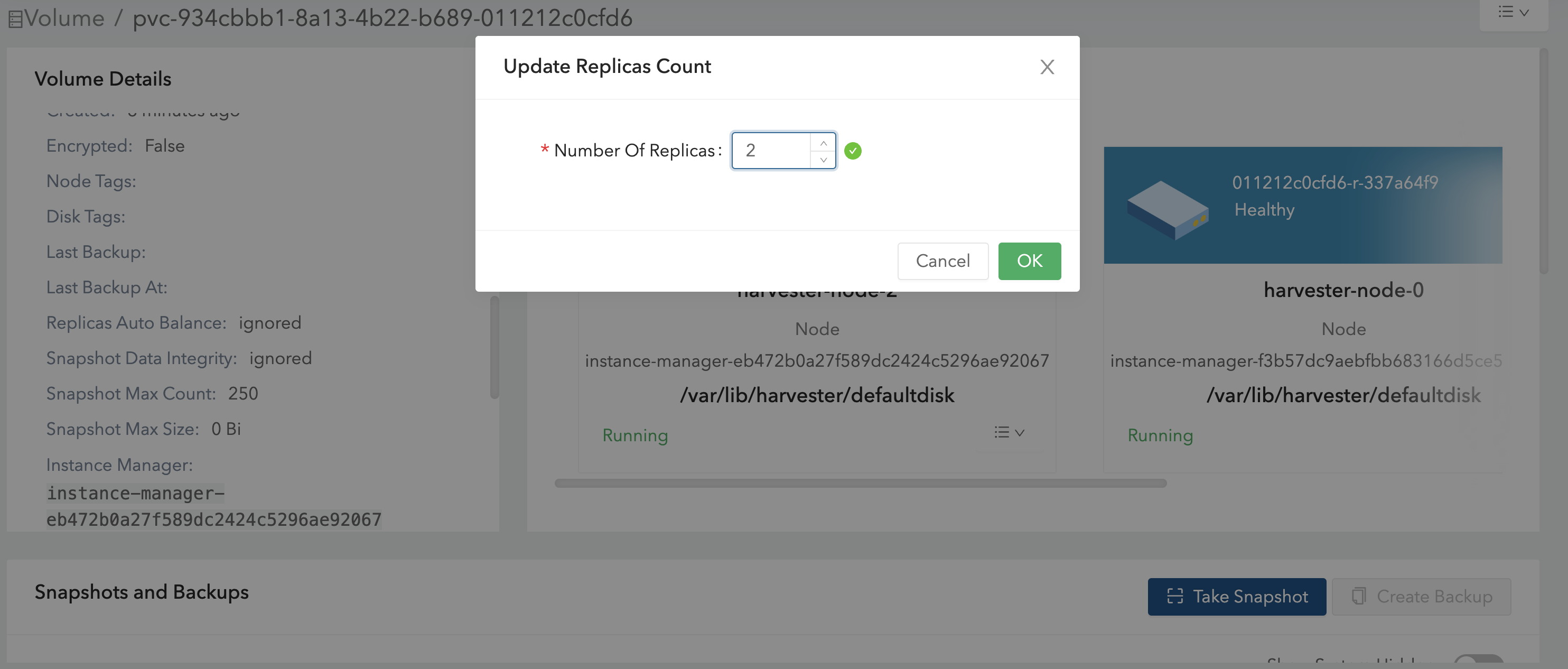
Si vous avez déjà créé des volumes en utilisant la StorageClass par défaut originale, vous pouvez modifier le nombre de réplicas sur l’écran Volume de l’interface utilisateur Longhorn intégrée.
Problèmes connus
1. Lors de la création d’un cluster avec un nœud témoin, la Configuration réseau : L’écran de création sur l’SUSE Virtualization UI ne parvient pas à identifier de NIC pouvant être utilisés avec tous les nœuds.
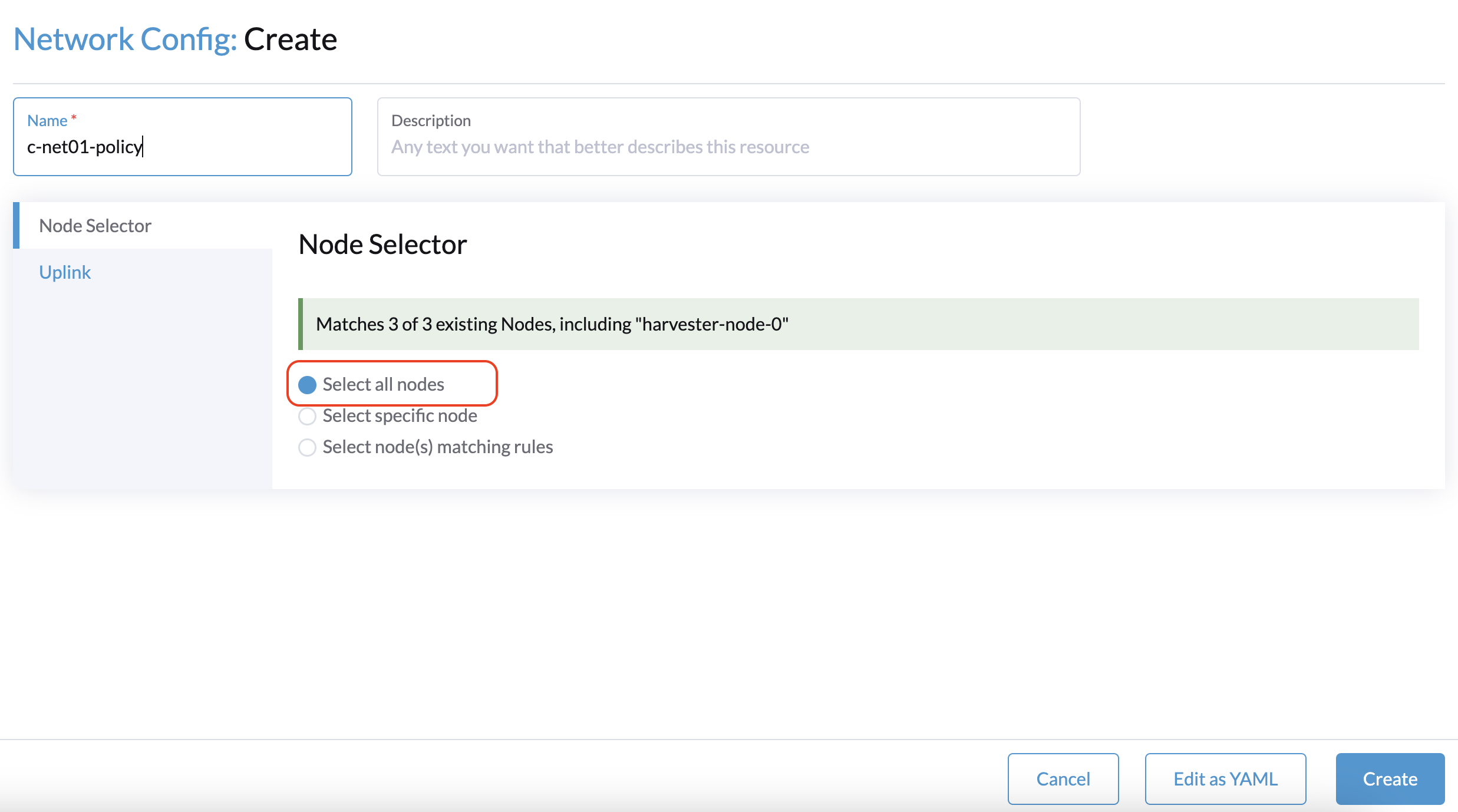
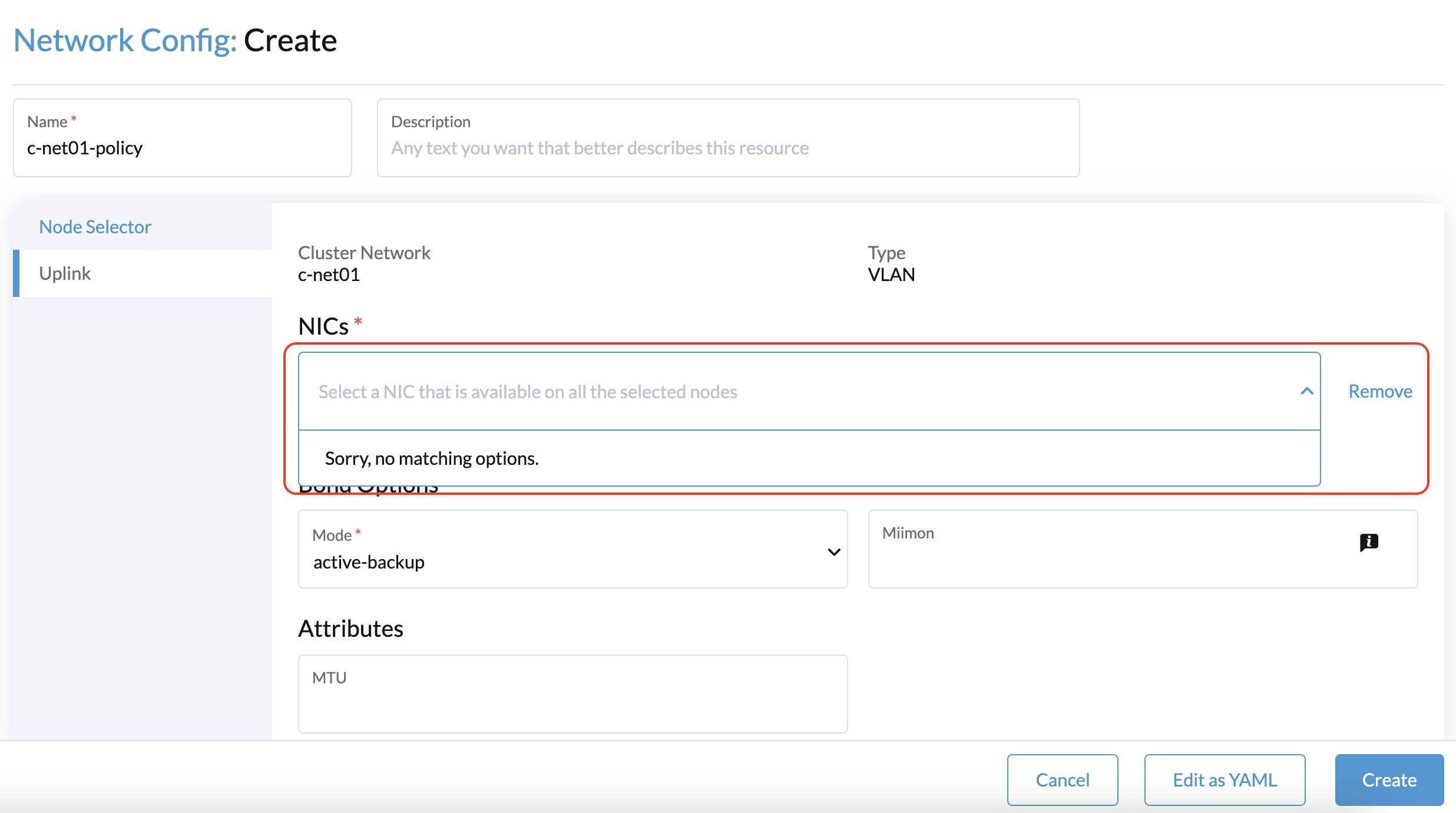
La solution de contournement consiste à sélectionner un nœud non témoin, puis à sélectionner un NIC qui peut être utilisé avec ce nœud spécifique.
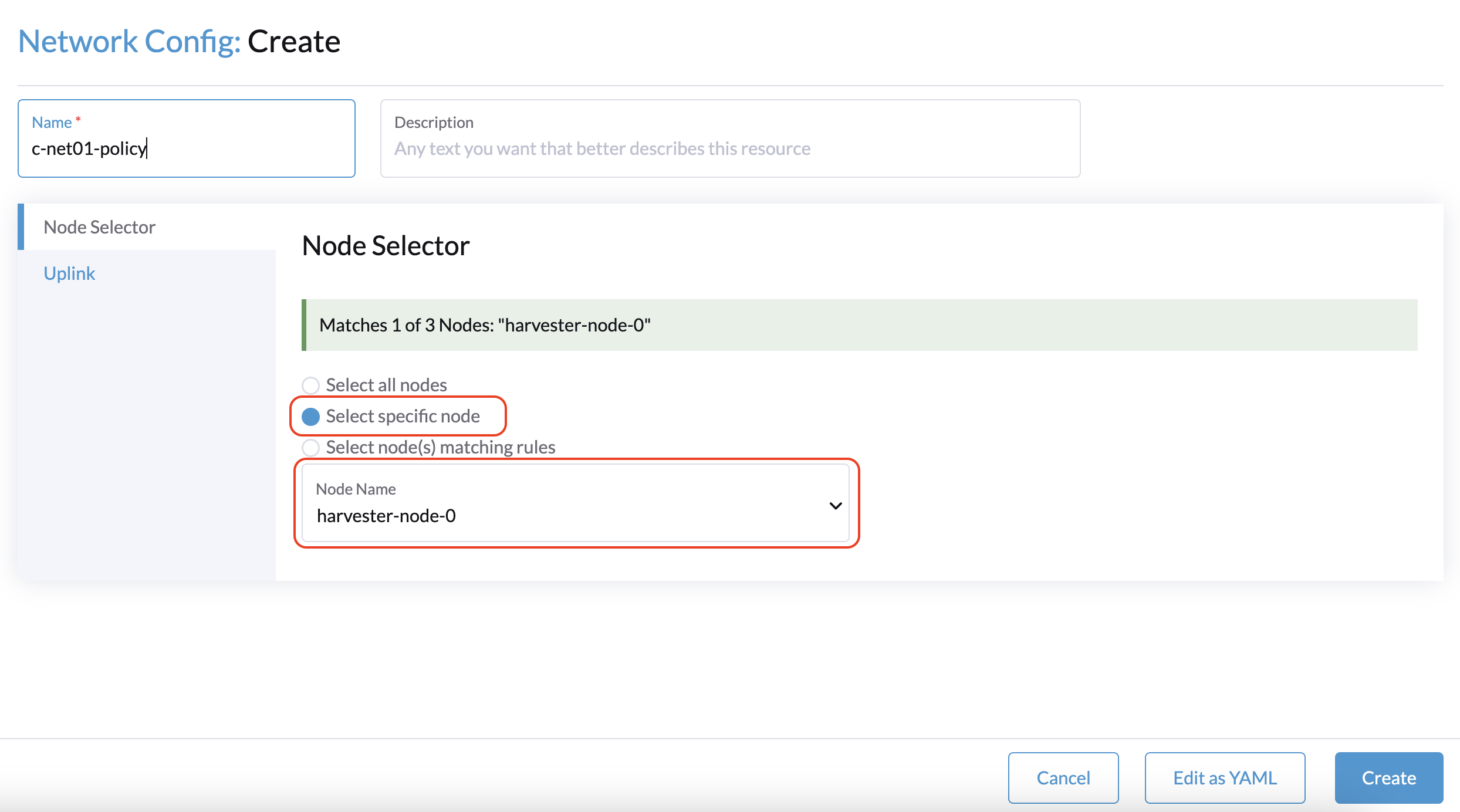
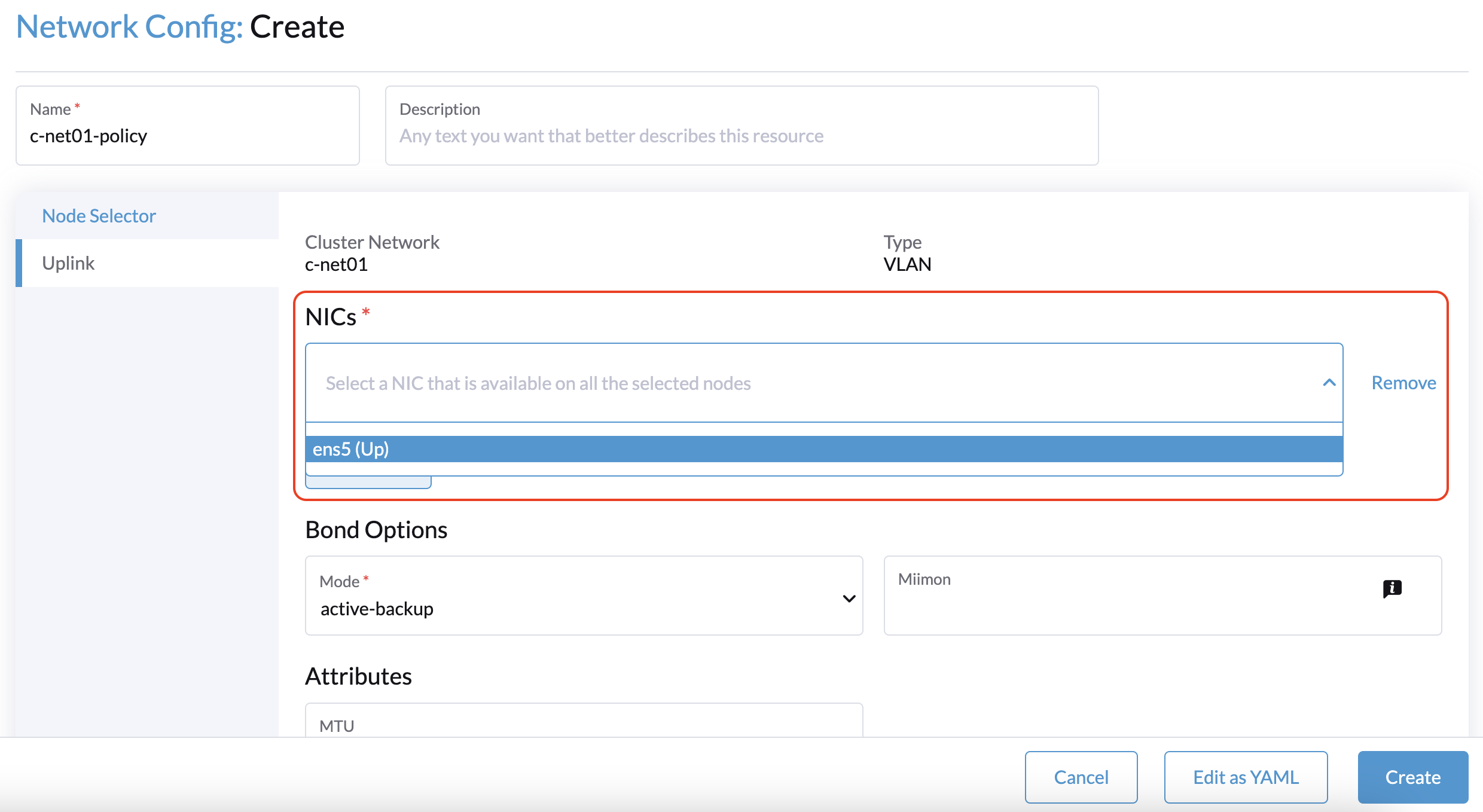
Vous devez répéter cette procédure pour chaque nœud non témoin dans le cluster. Les mêmes paramètres de lien monté peuvent être utilisés sur tous les nœuds.
2. Lors de la sélection d’un nœud cible pour la migration de VM, la liste des cibles inclut le nœud témoin.
Ne sélectionnez pas le nœud témoin comme cible de migration. Si vous le faites, la migration de la VM échouera.
Problème connexe : [BUG] Le nœud témoin ne doit pas être sélectionné comme cible de migration