Consignation
Il est important de savoir ce qui se passe ou ce qui s’est passé dans le Harvester Cluster.
Harvester collecte le cluster running log, les journaux Kubernetes audit et event juste après que le cluster soit mis en marche, ce qui est utile pour la surveillance, la journalisation, l’audit et le dépannage.
Harvester prend en charge l’envoi de ces journaux vers divers types de serveurs de journaux.
|
La taille des données de journalisation est liée à l’échelle du cluster, à la charge de travail et à d’autres facteurs. |
La fonctionnalité de journalisation est maintenant implémentée avec un produit complémentaire et est désactivée par défaut dans les nouvelles installations.
Les utilisateurs peuvent activer/désactiver le rancher-logging produit complémentaire depuis l’interface utilisateur de Harvester après l’installation.
Les utilisateurs peuvent également activer/désactiver le `rancher-logging`produit complémentaire dans leur installation de Harvester en personnalisant le fichier de configuration.
Pour les clusters Harvester mis à niveau depuis la version v1.1.x, la fonctionnalité de journalisation est automatiquement convertie en produit complémentaire et reste activée comme auparavant.
Architecture générale
Harvester et Rancher utilisent tous deux le Logging Operator pour gérer des composants et des opérations spécifiques de l’infrastructure de journalisation interne.
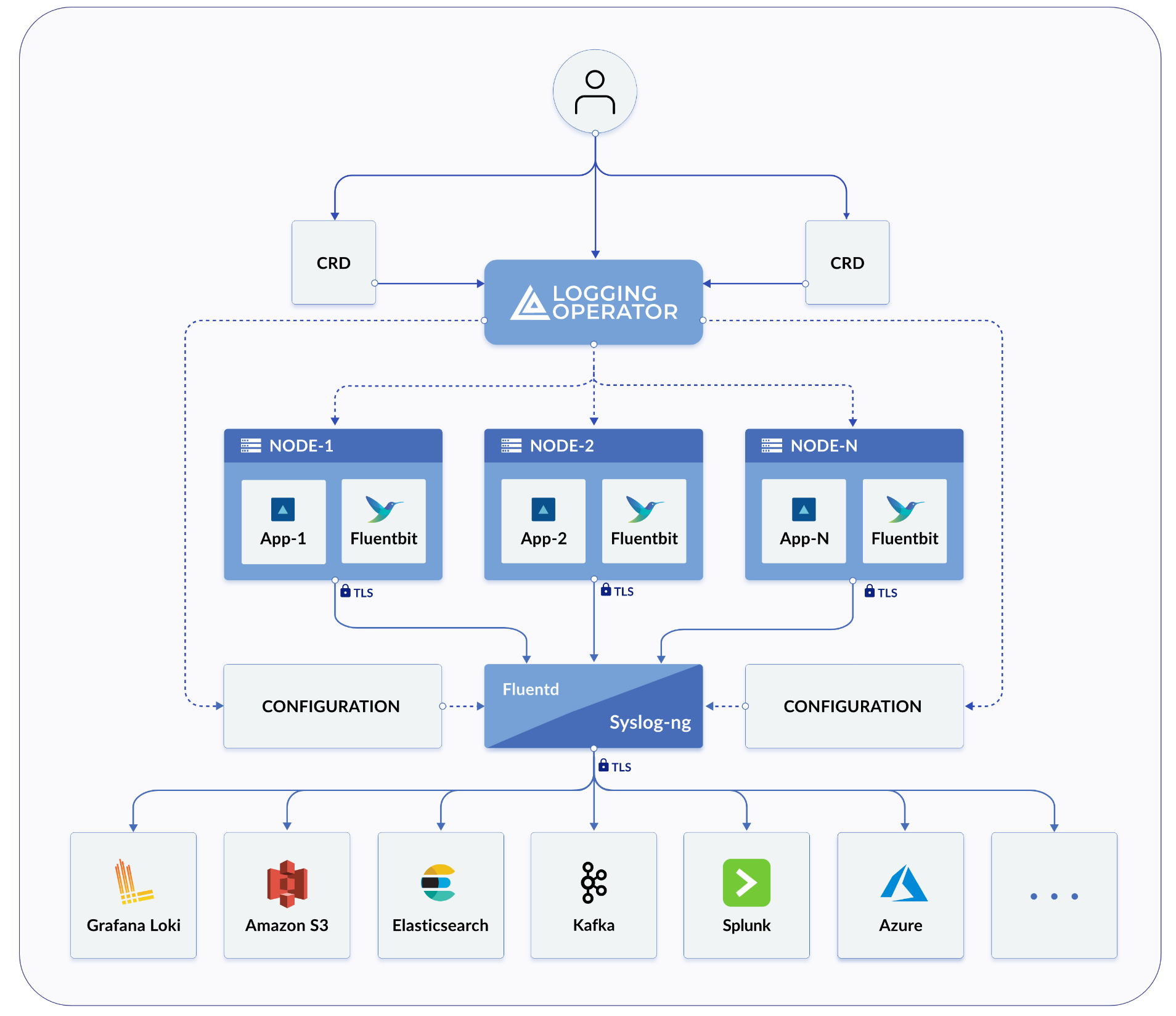
Dans la pratique de Harvester, le Logging, Audit et Event partagent une architecture, le Logging est l’infrastructure, tandis que le Audit et Event sont au-dessus.
Consignation
L’infrastructure de journalisation de Harvester vous permet d’agréger les journaux de Harvester dans un service externe tel que Graylog, Elasticsearch, Splunk, Grafana Loki et d’autres.
Journaux collectés
Voir ci-dessous une liste des journaux qui sont collectés :
-
Journaux de tous les clusters
Pods -
Journaux du noyau Linux de chaque
node -
Journaux de certains services systemd de chaque nœud
-
rke2-server -
rke2-agent -
rancherd -
rancher-system-agent -
NetworkManager -
iscsid
-
|
Les utilisateurs peuvent configurer et modifier où les journaux agrégés sont envoyés, ainsi qu’un filtrage de base. La modification des journaux collectés n’est pas prise en charge. |
Configuration des ressources de journalisation
Sous l’opérateur de journalisation se trouvent Fluentd et Fluent Bit, qui gèrent la collecte et le routage des journaux. Si vous le souhaitez, vous pouvez modifier le nombre de ressources dédiées à ces composants.
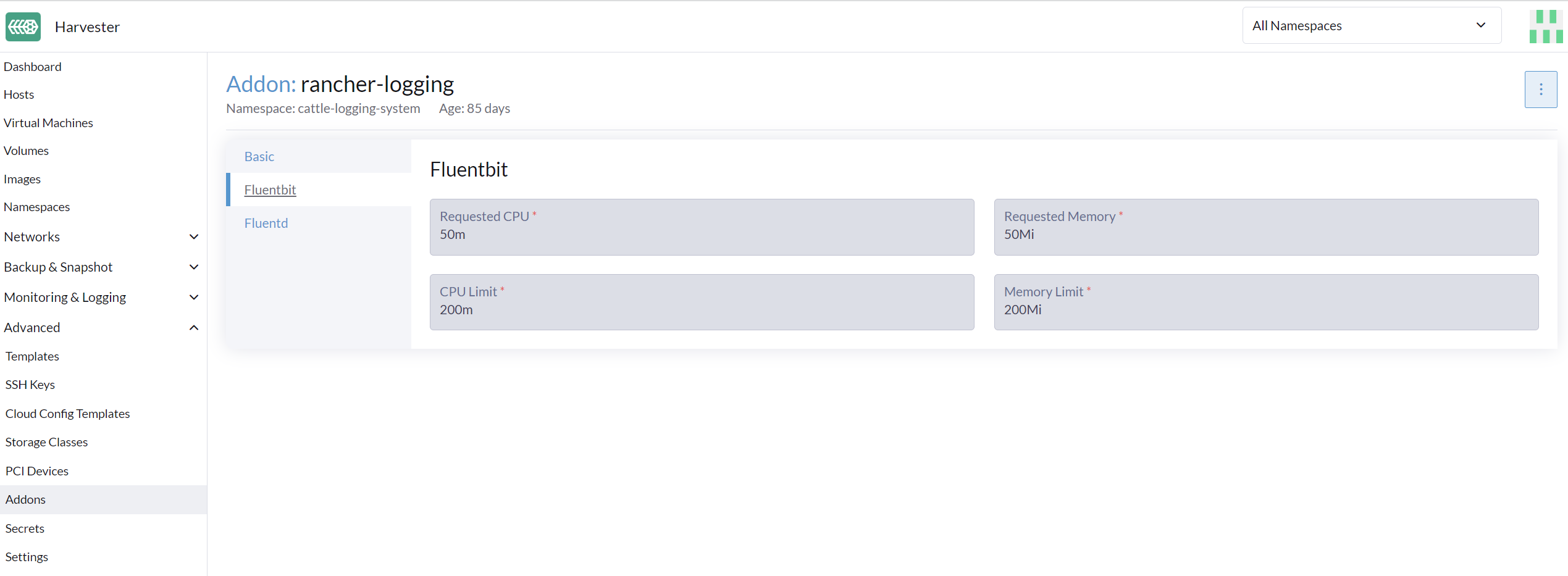
Depuis l’interface utilisateur
-
Allez à la page Avancé > Produits complémentaires et sélectionnez le produit complémentaire rancher-logging.
-
Depuis l’onglet Fluentbit, changez les demandes et limites de ressources.
-
Depuis l’onglet Fluentd, changez les demandes et limites de ressources.
-
Sélectionnez Enregistrer lorsque vous avez terminé de configurer les paramètres pour le produit complémentaire rancher-logging.
|
La configuration de l’interface utilisateur n’est visible que lorsque le produit complémentaire rancher-logging est activé. |
Depuis le CLI
Vous pouvez utiliser la commande suivante kubectl pour changer la configuration des ressources pour le produit complémentaire rancher-logging : kubectl edit addons.harvesterhci.io -n cattle-logging-system rancher-logging.
Le chemin des ressources et les valeurs par défaut sont les suivants.
apiVersion: harvesterhci.io/v1beta1
kind: Addon
metadata:
name: rancher-logging
namespace: cattle-logging-system
spec:
valuesContent: |
fluentbit:
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 50m
memory: 50Mi
fluentd:
resources:
limits:
cpu: 1000m
memory: 800Mi
requests:
cpu: 100m
memory: 200Mi
|
Vous pouvez toujours apporter des ajustements de configuration lorsque le produit complémentaire est désactivé. Cependant, ces changements ne prennent effet que lorsque vous réactivez le produit complémentaire. |
Vérification des ressources pendantes
Lors de l’activation du produit complémentaire rancher-logging, vous pouvez rencontrer l’erreur suivante :
Vous pouvez également observer que les déploiements liés au produit complémentaire ne sont pas entièrement déployés.
Pour éviter que l’erreur ne se reproduise, effectuez les actions suivantes avant d’activer le produit complémentaire :
-
Mettez à jour ou supprimez les ressources pendantes affectées.
-
Ajoutez l’annotation
harvesterhci.io/skipRancherLoggingAddonWebhookCheck: "true"au produit complémentaire.
Configuration des destinations de journalisation
Les opérations de journalisation sont soutenues par le Logging Operator et contrôlées à l’aide des ressources Fluentd, en particulier Flow et ClusterFlow et Output et ClusterOutput. Vous pouvez acheminer et filtrer les journaux en appliquant ces CRD au cluster Harvester.
Lors de l’application de nouveaux Outputs et Flows au cluster, il peut falloir un certain temps pour que l’opérateur de journalisation les applique efficacement. Veuillez donc prévoir quelques minutes pour que les journaux commencent à circuler.
Clusterisé vs en espace de noms
Une chose importante à comprendre lors de l’acheminement des journaux est la différence entre ClusterFlow et Flow ainsi que ClusterOutput et Output. La principale différence entre la version clusterisée et la version non clusterisée de chacune est que les versions non clusterisées sont dans un espace de noms.
La plus grande implication de cela est que Flows ne peut accéder qu’à Outputs qui se trouvent dans le même espace de noms, mais peut toujours accéder à n’importe quel ClusterOutput.
Pour plus d’informations, consultez la documentation :
Depuis l’interface utilisateur
|
Les images de l’interface utilisateur sont pour |
Création de sorties
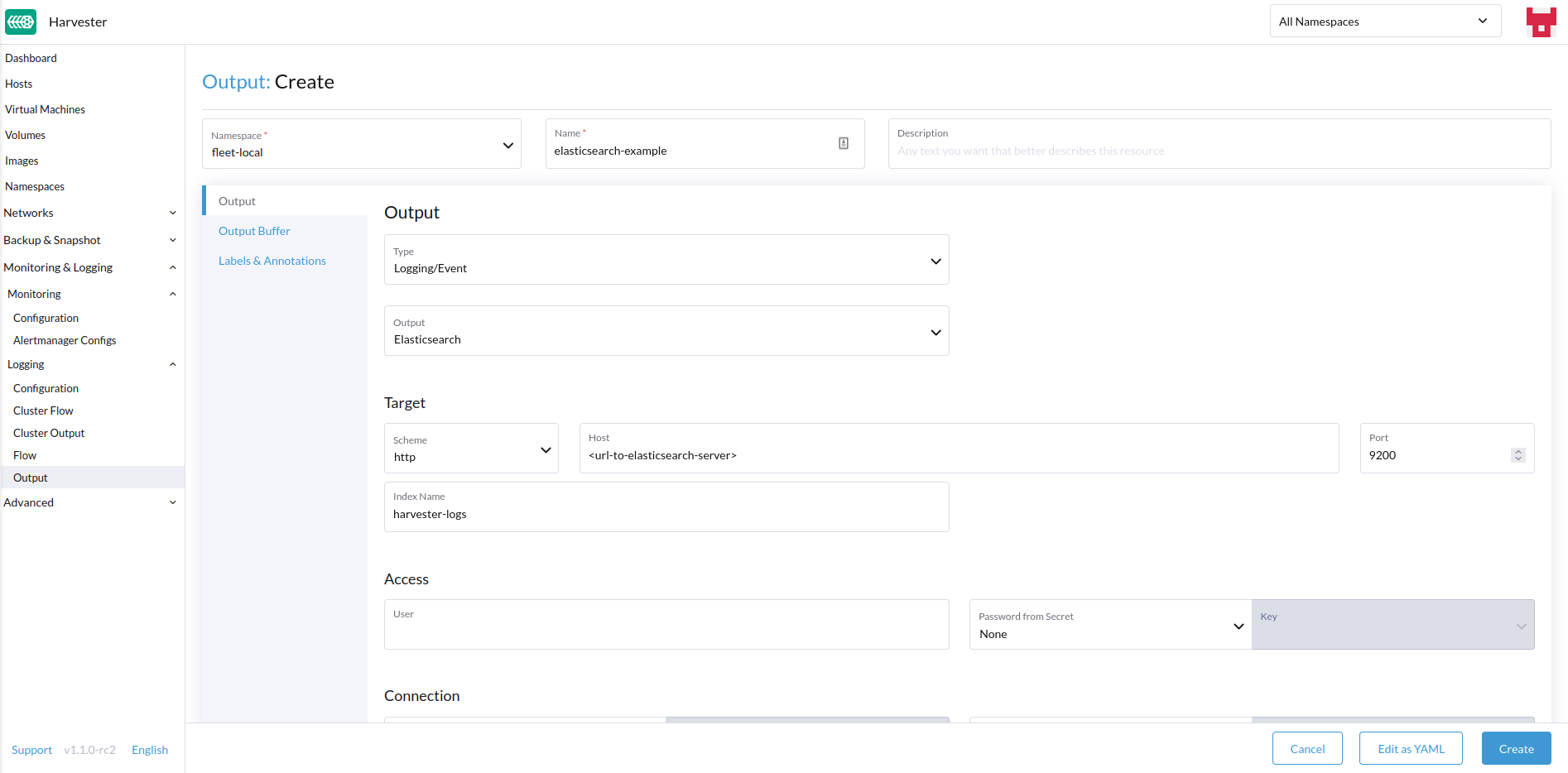
-
Choisissez l’option pour créer un nouveau
OutputouClusterOutput. -
Si vous créez un
Output, sélectionnez l’espace de noms souhaité. -
Ajoutez un nom pour les ressources.
-
Sélectionnez le type de journalisation.
-
Sélectionnez le type de sortie de journalisation.
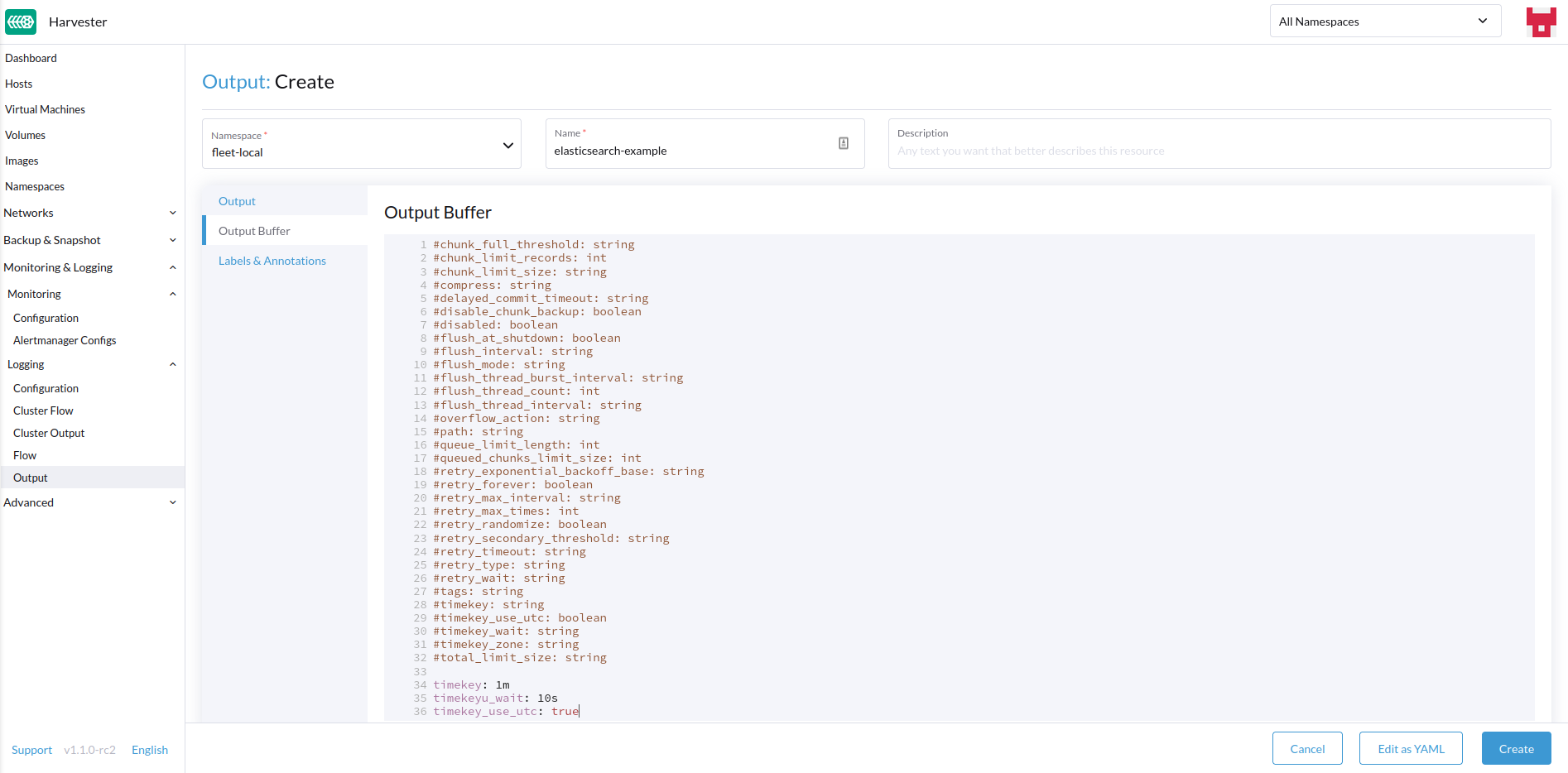
-
Configurez le tampon de sortie si nécessaire.
-
Ajoutez des étiquettes ou des annotations.
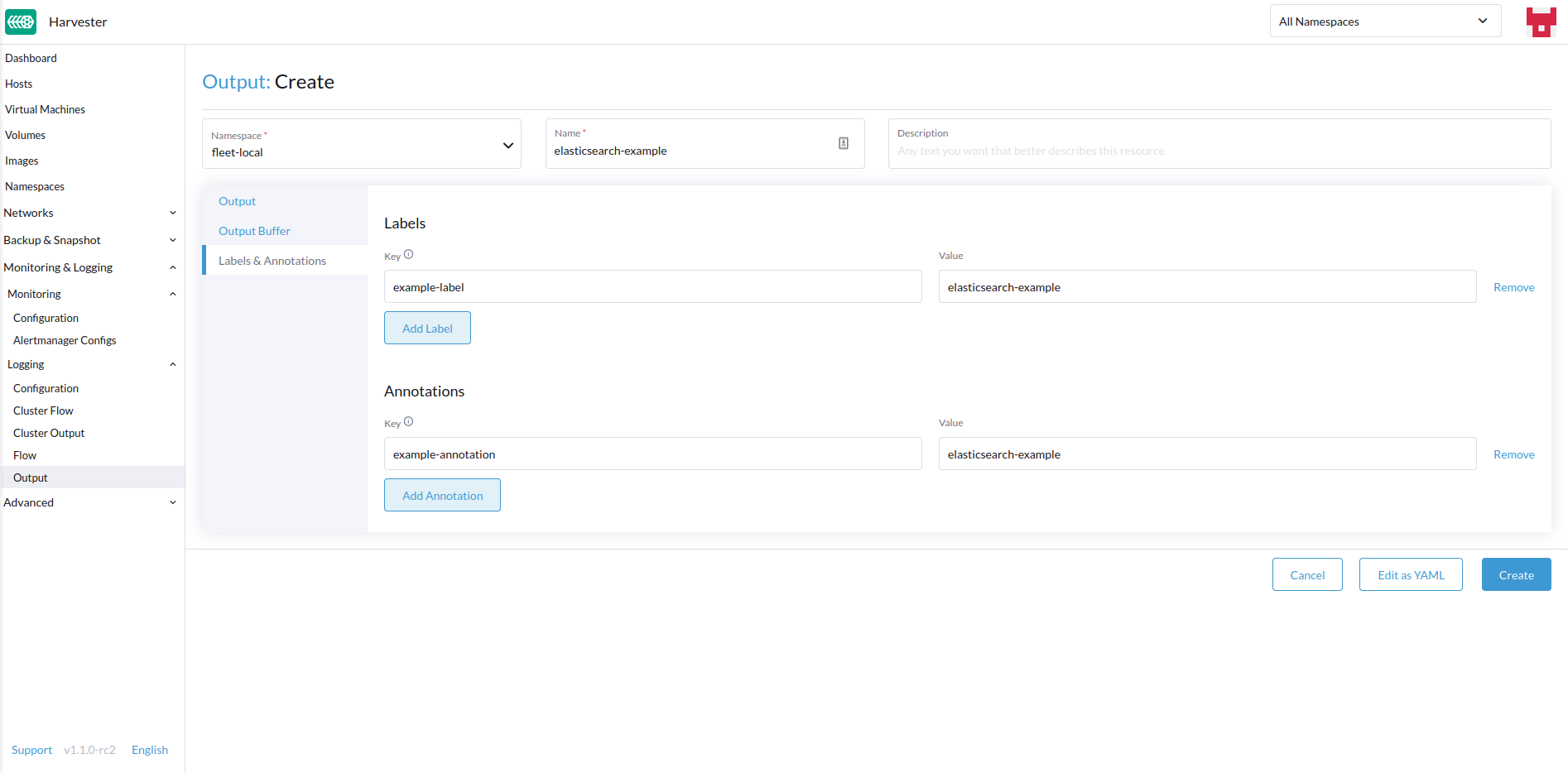
-
Une fois terminé, cliquez sur
Createen bas à droite.
|
En fonction de la sortie sélectionnée (Splunk, Elasticsearch, etc.), il y aura des champs supplémentaires à spécifier dans le formulaire. |
Sortie
Le formulaire affiche les champs disponibles pour la sortie sélectionnée.
Tampon de sortie
L’éditeur vous permet de décrire le comportement préféré du tampon de sortie en utilisant divers champs.
Création de flux
-
Choisissez l’option pour créer un nouveau
FlowouClusterFlow. -
Si vous créez un
Flow, sélectionnez l’espace de noms souhaité. -
Ajoutez un nom pour la ressource.
-
Sélectionnez les nœuds dont vous souhaitez inclure ou exclure les journaux.
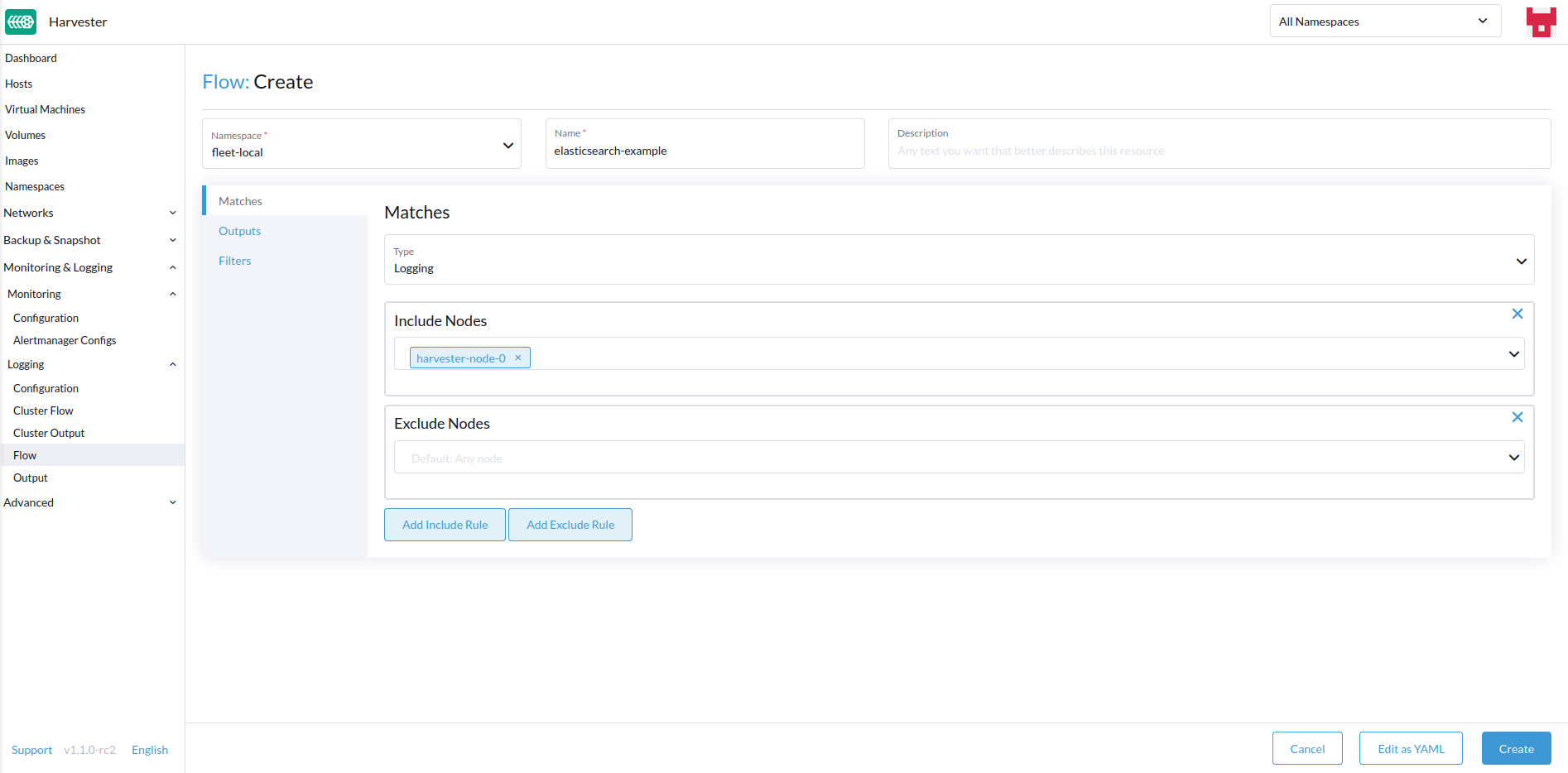
-
Sélectionnez la cible
OutputsetClusterOutputs.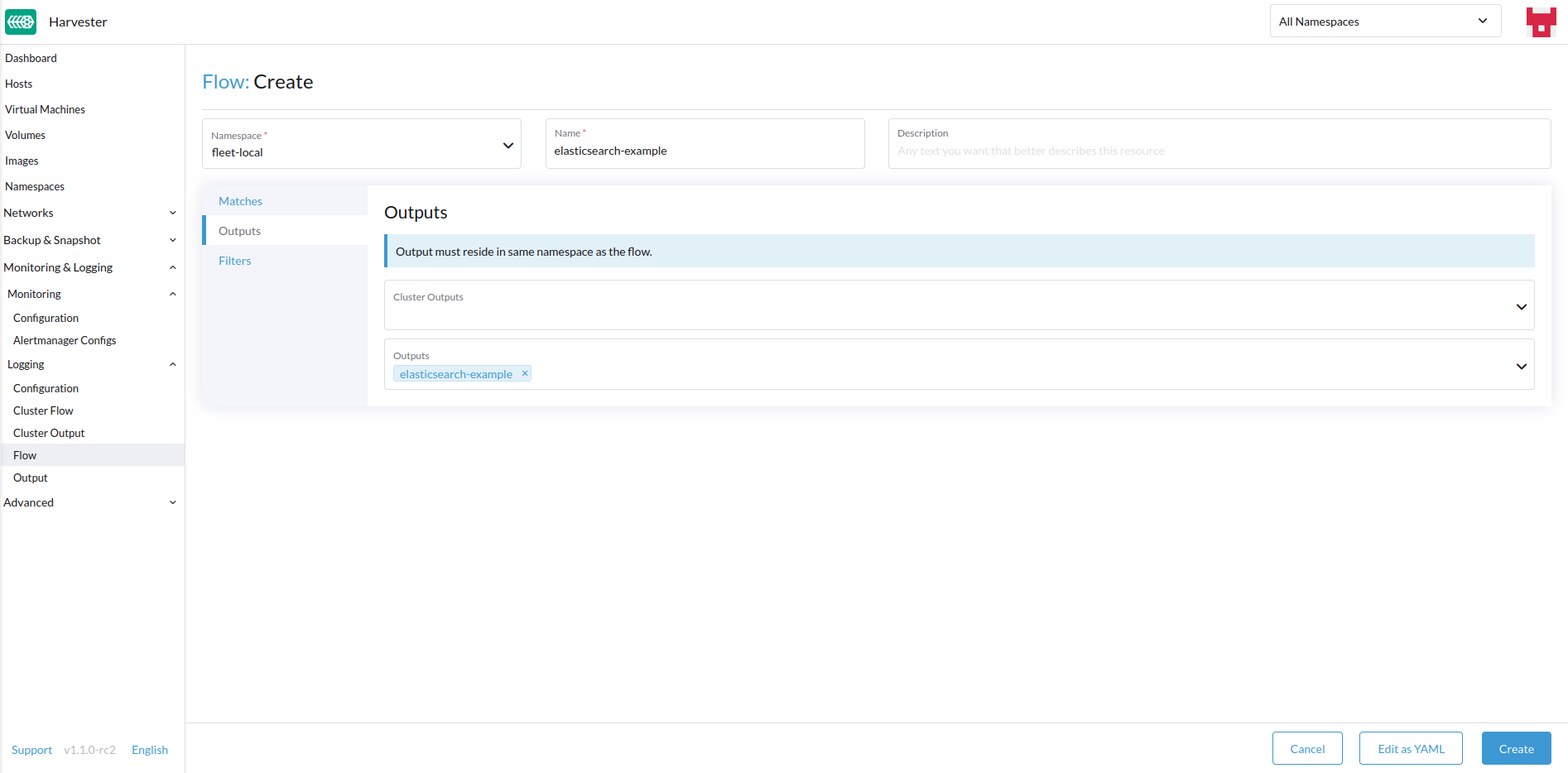
-
Ajoutez des filtres si désiré.
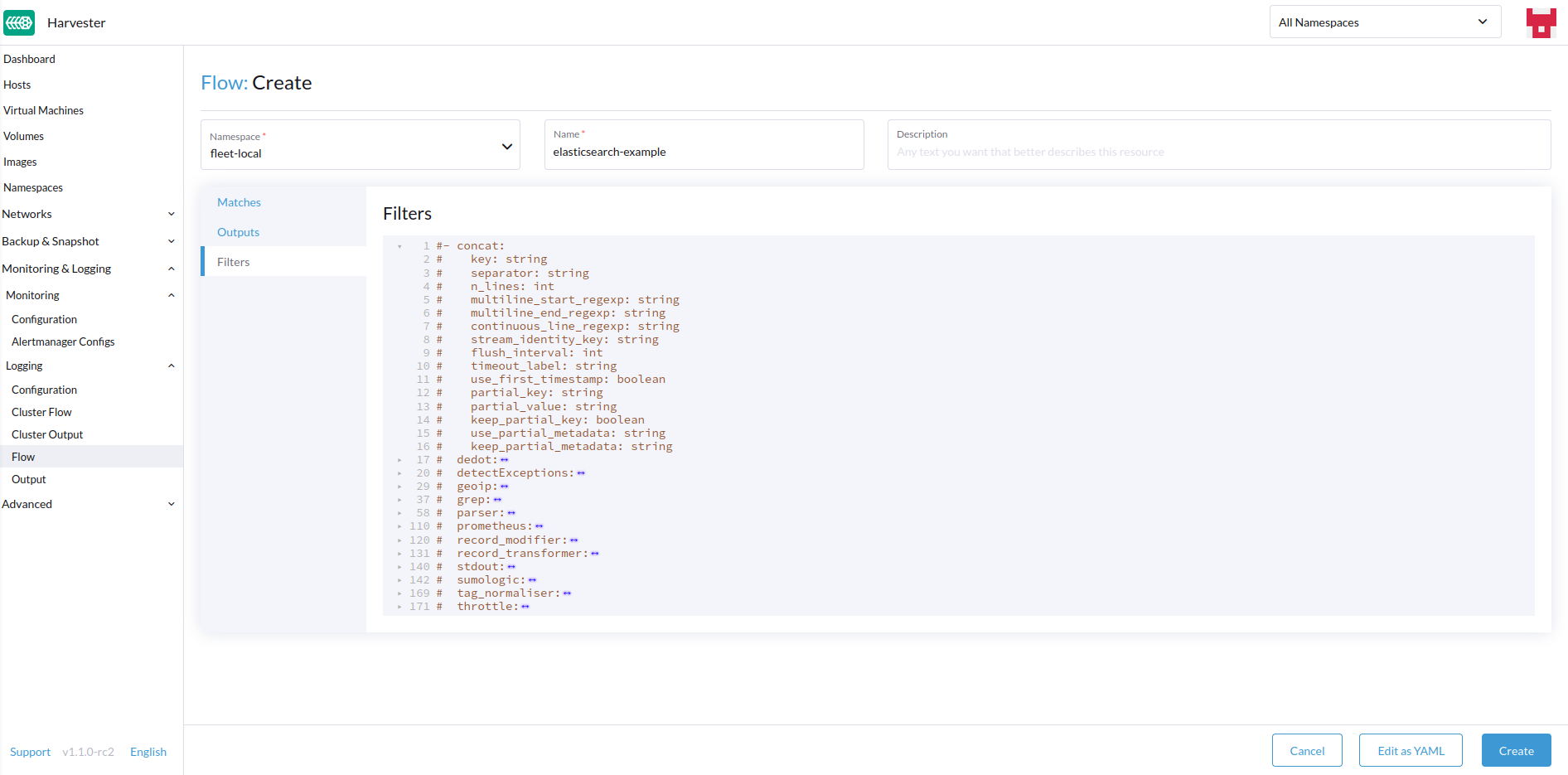
-
Une fois terminé, cliquez sur
Createen bas à gauche.
Correspond à
Les correspondances vous permettent de filtrer les journaux que vous souhaitez inclure dans le Flow. Le formulaire ne vous permet d’inclure ou d’exclure que les journaux des nœuds, mais si nécessaire, vous pouvez ajouter d’autres règles de correspondance prises en charge par la ressource en sélectionnant Edit as YAML.
Pour plus d’informations sur la directive de correspondance, consultez Match statement.
Sorties
Les sorties vous permettent de sélectionner un ou plusieurs OutputRefs pour envoyer les journaux agrégés. Lors de la création ou de la modification d’un Flow / ClusterFlow, il est nécessaire que l’utilisateur sélectionne au moins un Output.
|
Il doit y avoir au moins un |
Filtres
Les filtres vous permettent de transformer, traiter et muter les journaux. Pour plus d’informations, consultez la liste des filtres pris en charge.
Depuis l’interface en ligne de commande
Pour configurer les routes de journaux via la ligne de commande, vous devez simplement définir les fichiers YAML pour les ressources pertinentes :
# elasticsearch-logging.yaml
apiVersion: logging.banzaicloud.io/v1beta1
kind: Output
metadata:
name: elasticsearch-example
namespace: fleet-local
labels:
example-label: elasticsearch-example
annotations:
example-annotation: elasticsearch-example
spec:
elasticsearch:
host: <url-to-elasticsearch-server>
port: 9200
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: elasticsearch-example
namespace: fleet-local
spec:
match:
- select: {}
globalOutputRefs:
- elasticsearch-exampleEt ensuite les appliquer :
kubectl apply -f elasticsearch-logging.yamlRéférencer les Secrets
Vous pouvez définir des valeurs secrètes (au format YAML) en utilisant l’une des méthodes suivantes :
La plus simple est d’utiliser la clé value, qui est une valeur de chaîne simple pour le secret souhaité. Cette méthode ne doit être utilisée que pour les tests et jamais en production :
aws_key_id:
value: "secretvalue"La suivante est d’utiliser valueFrom, qui permet de référencer une valeur spécifique d’un secret par une paire nom et clé :
aws_key_id:
valueFrom:
secretKeyRef:
name: <kubernetes-secret-name>
key: <kubernetes-secret-key>Certains plugins nécessitent un fichier à lire plutôt que de simplement recevoir une valeur du secret (c’est souvent le cas pour les fichiers de certificats CA). Dans ces cas, vous devez utiliser mountFrom, qui montera le secret en tant que fichier dans le déploiement fluentd sous-jacent et pointera le plugin vers le fichier. Les objets valueFrom et mountFrom se ressemblent :
tls_cert_path:
mountFrom:
secretKeyRef:
name: <kubernetes-secret-name>
key: <kubernetes-secret-key>Pour plus d’informations, consultez Définition du secret.
Exemple Outputs
-
Elasticsearch
-
Graylog
-
Splunk
-
Loki
Pour le déploiement le plus simple, vous pouvez déployer Elasticsearch sur votre système local en utilisant docker :
sudo docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e xpack.security.enabled=false -e node.name=es01 -e discovery.type=single-node -it docker.elastic.co/elasticsearch/elasticsearch:8.16.6|
Pour utiliser Elasticsearch avec SUSE Virtualization v1.5.0, assurez-vous que le serveur Elasticsearch exécute la version 8.11.0 ou ultérieure. Vous devez mettre à niveau Elasticsearch lorsque le |
Assurez-vous que vous avez défini vm.max_map_count pour être >= 262144, sinon la commande docker ci-dessus échouera. Une fois que le serveur Elasticsearch est opérationnel, vous pouvez créer le fichier yaml pour le ClusterOutput et le ClusterFlow :
cat << EOF > elasticsearch-example.yaml
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: elasticsearch-example
namespace: cattle-logging-system
spec:
elasticsearch:
host: 192.168.0.119
port: 9200
buffer:
timekey: 1m
timekey_wait: 30s
timekey_use_utc: true
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: elasticsearch-example
namespace: cattle-logging-system
spec:
match:
- select: {}
globalOutputRefs:
- elasticsearch-example
EOFEt appliquez le fichier :
kubectl apply -f elasticsearch-example.yamlAprès avoir laissé un certain temps au gestionnaire de journaux pour appliquer les ressources, vous pouvez tester que les journaux circulent :
$ curl localhost:9200/fluentd/_search
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 11603,
"max_score": 1,
"hits": [
{
"_index": "fluentd",
"_type": "fluentd",
"_id": "yWHr0oMBXcBggZRJgagY",
"_score": 1,
"_source": {
"stream": "stderr",
"logtag": "F",
"message": "I1013 02:29:43.020384 1 csi_handler.go:248] Attaching \"csi-974b4a6d2598d8a7a37b06d06557c428628875e077dabf8f32a6f3aa2750961d\"",
"kubernetes": {
"pod_name": "csi-attacher-5d4cc8cfc8-hd4nb",
"namespace_name": "longhorn-system",
"pod_id": "c63c2014-9556-40ce-a8e1-22c55de12e70",
"labels": {
"app": "csi-attacher",
"pod-template-hash": "5d4cc8cfc8"
},
"annotations": {
"cni.projectcalico.org/containerID": "857df09c8ede7b8dee786a8c8788e8465cca58f0b4d973c448ed25bef62660cf",
"cni.projectcalico.org/podIP": "10.52.0.15/32",
"cni.projectcalico.org/podIPs": "10.52.0.15/32",
"k8s.v1.cni.cncf.io/network-status": "[{\n \"name\": \"k8s-pod-network\",\n \"ips\": [\n \"10.52.0.15\"\n ],\n \"default\": true,\n \"dns\": {}\n}]",
"k8s.v1.cni.cncf.io/networks-status": "[{\n \"name\": \"k8s-pod-network\",\n \"ips\": [\n \"10.52.0.15\"\n ],\n \"default\": true,\n \"dns\": {}\n}]",
"kubernetes.io/psp": "global-unrestricted-psp"
},
"host": "harvester-node-0",
"container_name": "csi-attacher",
"docker_id": "f10e4449492d4191376d3e84e39742bf077ff696acbb1e5f87c9cfbab434edae",
"container_hash": "sha256:03e115718d258479ce19feeb9635215f98e5ad1475667b4395b79e68caf129a6",
"container_image": "docker.io/longhornio/csi-attacher:v3.4.0"
}
}
},
...
]
}
}Vous pouvez suivre les instructions ici pour déployer et visualiser les journaux du cluster via Graylog :
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: "all-logs-gelf-hs"
namespace: "cattle-logging-system"
spec:
globalOutputRefs:
- "example-gelf-hs"
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: "example-gelf-hs"
namespace: "cattle-logging-system"
spec:
gelf:
host: "192.168.122.159"
port: 12202
protocol: "udp"Vous pouvez suivre les instructions ici pour déployer et visualiser les journaux du cluster via Splunk.
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: harvester-logging-splunk
namespace: cattle-logging-system
spec:
splunkHec:
hec_host: 192.168.122.101
hec_port: 8088
insecure_ssl: true
index: harvester-log-index
hec_token:
valueFrom:
secretKeyRef:
key: HECTOKEN
name: splunk-hec-token2
buffer:
chunk_limit_size: 3MB
timekey: 2m
timekey_wait: 1m
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: harvester-logging-splunk
namespace: cattle-logging-system
spec:
filters:
- tag_normaliser: {}
match:
globalOutputRefs:
- harvester-logging-splunkVous pouvez suivre les instructions dans le logging HEP sur le déploiement et la visualisation des journaux du cluster via Grafana Loki.
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: harvester-loki
namespace: cattle-logging-system
spec:
match:
- select: {}
globalOutputRefs:
- harvester-loki
---
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: harvester-loki
namespace: cattle-logging-system
spec:
loki:
url: http://loki-stack.cattle-logging-system.svc:3100
extra_labels:
logOutput: harvester-lokiAudit
Harvester collecte les Kubernetes audit et est capable d’envoyer les audit à divers types de serveurs de journaux.
Le fichier de stratégie pour guider kube-apiserver est ici.
Définition de l’audit
Dans kubernetes, les données audit sont générées par kube-apiserver selon la stratégie définie.
... Audit policy Audit policy defines rules about what events should be recorded and what data they should include. The audit policy object structure is defined in the audit.k8s.io API group. When an event is processed, it's compared against the list of rules in order. The first matching rule sets the audit level of the event. The defined audit levels are: None - don't log events that match this rule. Metadata - log request metadata (requesting user, timestamp, resource, verb, etc.) but not request or response body. Request - log event metadata and request body but not response body. This does not apply for non-resource requests. RequestResponse - log event metadata, request and response bodies. This does not apply for non-resource requests.
Format de Journal d’Audit
Format de Journal d’Audit dans Kubernetes
Les journaux du serveur API Kubernetes enregistrent l’audit avec le format JSON suivant dans un fichier local.
{
"kind":"Event",
"apiVersion":"audit.k8s.io/v1",
"level":"Metadata",
"auditID":"13d0bf83-7249-417b-b386-d7fc7c024583",
"stage":"RequestReceived",
"requestURI":"/apis/flowcontrol.apiserver.k8s.io/v1beta2/prioritylevelconfigurations?fieldManager=api-priority-and-fairness-config-producer-v1",
"verb":"create",
"user":{"username":"system:apiserver","uid":"d311c1fe-2d96-4e54-a01b-5203936e1046","groups":["system:masters"]},
"sourceIPs":["::1"],
"userAgent":"kube-apiserver/v1.24.7+rke2r1 (linux/amd64) kubernetes/e6f3597",
"objectRef":{"resource":"prioritylevelconfigurations",
"apiGroup":"flowcontrol.apiserver.k8s.io",
"apiVersion":"v1beta2"},
"requestReceivedTimestamp":"2022-10-19T18:55:07.244781Z",
"stageTimestamp":"2022-10-19T18:55:07.244781Z"
}Sortie de Journal d’Audit/Sortie de Cluster
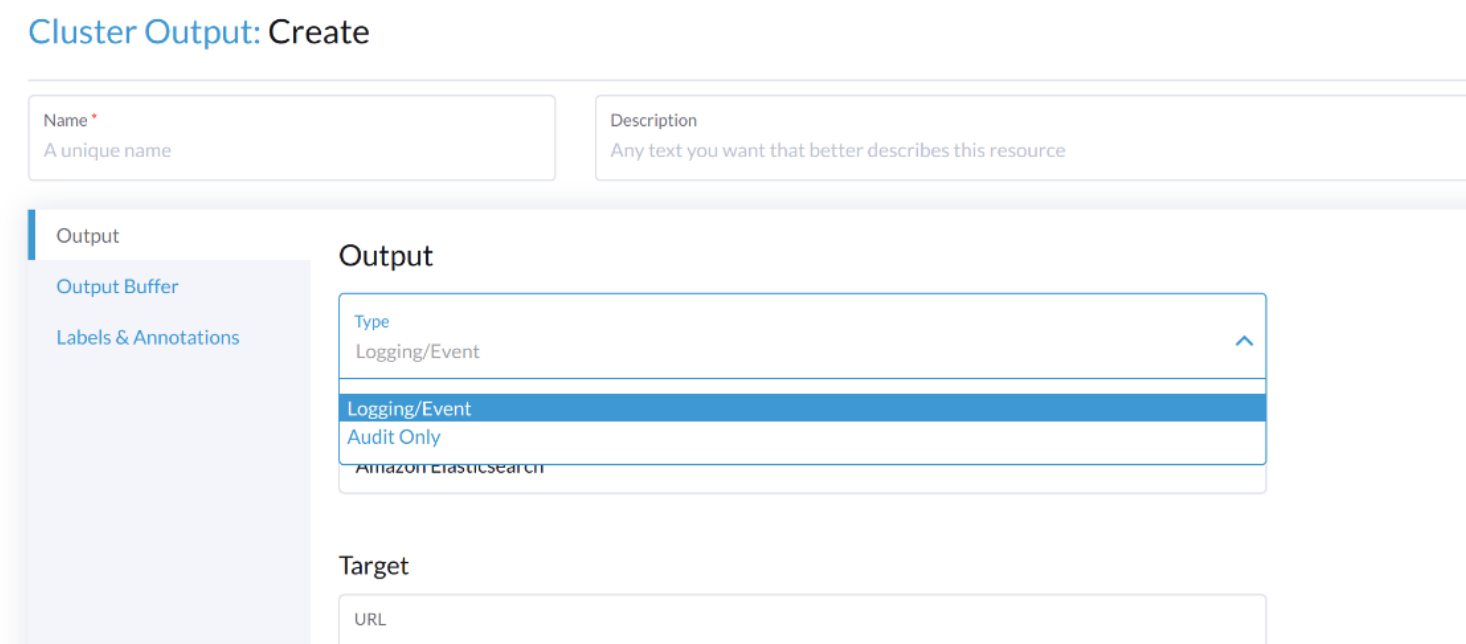
Pour produire un journal lié à l’audit, le Output/ClusterOutput nécessite que la valeur de loggingRef soit harvester-kube-audit-log-ref.
Lorsque vous configurez depuis le tableau de bord Harvester, le champ est ajouté automatiquement.
Sélectionnez le type Audit Only dans la liste déroulante Type.
Lorsque vous configurez depuis la CLI, veuillez ajouter le champ manuellement.
Exemple :
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: "harvester-audit-webhook"
namespace: "cattle-logging-system"
spec:
http:
endpoint: "http://192.168.122.159:8096/"
open_timeout: 3
format:
type: "json"
buffer:
chunk_limit_size: 3MB
timekey: 2m
timekey_wait: 1m
loggingRef: harvester-kube-audit-log-ref # this reference is fixed and must be here
Flux de journal d’audit/ClusterFlow
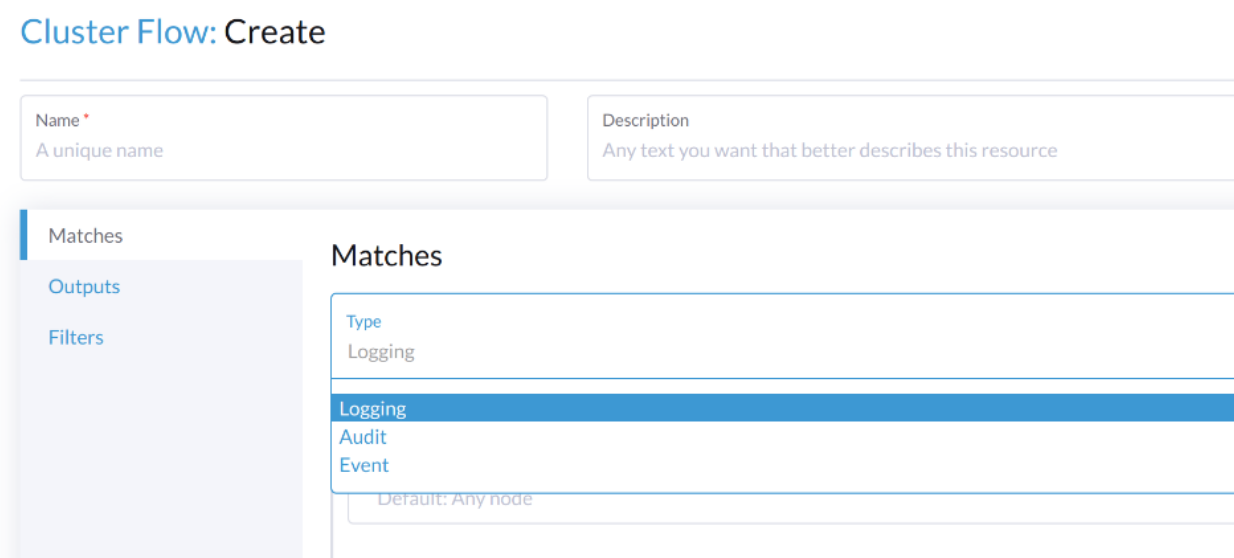
Pour acheminer les journaux liés à l’audit, le Flow/ClusterFlow nécessite que la valeur de loggingRef soit harvester-kube-audit-log-ref.
Lorsque vous configurez depuis le tableau de bord Harvester, le champ est ajouté automatiquement.
Sélectionnez le type Audit.
Lorsque vous configurez depuis la CLI, veuillez ajouter le champ manuellement.
Exemple :
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: "harvester-audit-webhook"
namespace: "cattle-logging-system"
spec:
globalOutputRefs:
- "harvester-audit-webhook"
loggingRef: harvester-kube-audit-log-ref # this reference is fixed and must be here
Événement
Harvester collecte les Kubernetes event et est capable d’envoyer les event à divers types de serveurs de journaux.
Définition de l’événement
Les Kubernetes events sont des objets qui vous montrent ce qui se passe à l’intérieur d’un cluster, comme les décisions prises par le planificateur ou pourquoi certains pods ont été évincés du nœud. Tous les composants du noyau et les extensions (opérateurs/contrôleurs) peuvent créer des événements via l’API Server.
Les événements n’ont pas de relation directe avec les messages de journal générés par les différents composants et ne sont pas affectés par le niveau de verbosité des journaux. Lorsqu’un composant crée un événement, il émet souvent un message de journal correspondant. Les événements sont collectés par l’API Server après un court laps de temps (généralement après une heure), ce qui signifie qu’ils peuvent être utilisés pour comprendre les problèmes qui se produisent, mais vous devez les collecter pour enquêter sur les événements passés.
Les événements sont la première chose à examiner pour les applications, ainsi que pour les opérations d’infrastructure lorsque quelque chose ne fonctionne pas comme prévu. Les conserver pendant une période plus longue est essentiel si l’échec est le résultat d’événements antérieurs, ou lors de l’analyse post-mortem.
Format du journal d’événements
Format du journal d’événements dans Kubernetes
Un exemple de kubernetes event :
{
"apiVersion": "v1",
"count": 1,
"eventTime": null,
"firstTimestamp": "2022-08-24T11:17:35Z",
"involvedObject": {
"apiVersion": "kubevirt.io/v1",
"kind": "VirtualMachineInstance",
"name": "vm-ide-1",
"namespace": "default",
"resourceVersion": "604601",
"uid": "1bd4133f-5aa3-4eda-bd26-3193b255b480"
},
"kind": "Event",
"lastTimestamp": "2022-08-24T11:17:35Z",
"message": "VirtualMachineInstance defined.",
"metadata": {
"creationTimestamp": "2022-08-24T11:17:35Z",
"name": "vm-ide-1.170e43cbdd833b62",
"namespace": "default",
"resourceVersion": "604626",
"uid": "0114f4e7-1d4a-4201-b0e5-8cc8ede202f4"
},
"reason": "Created",
"reportingComponent": "",
"reportingInstance": "",
"source": {
"component": "virt-handler",
"host": "harv1"
},
"type": "Normal"
},
Format du journal d’événements avant d’être envoyé aux serveurs de journaux
Chaque event log a le format suivant : {"stream":"","logtag":"F","message":"","kubernetes":{""}}. Le kubernetes event est dans le champ message.
{
"stream":"stdout",
"logtag":"F",
"message":"{
\\"verb\\":\\"ADDED\\",
\\"event\\":{\\"metadata\\":{\\"name\\":\\"vm-ide-1.170e446c3f890433\\",\\"namespace\\":\\"default\\",\\"uid\\":\\"0b44b6c7-b415-4034-95e5-a476fcec547f\\",\\"resourceVersion\\":\\"612482\\",\\"creationTimestamp\\":\\"2022-08-24T11:29:04Z\\",\\"managedFields\\":[{\\"manager\\":\\"virt-controller\\",\\"operation\\":\\"Update\\",\\"apiVersion\\":\\"v1\\",\\"time\\":\\"2022-08-24T11:29:04Z\\"}]},\\"involvedObject\\":{\\"kind\\":\\"VirtualMachineInstance\\",\\"namespace\\":\\"default\\",\\"name\\":\\"vm-ide-1\\",\\"uid\\":\\"1bd4133f-5aa3-4eda-bd26-3193b255b480\\",\\"apiVersion\\":\\"kubevirt.io/v1\\",\\"resourceVersion\\":\\"612477\\"},\\"reason\\":\\"SuccessfulDelete\\",\\"message\\":\\"Deleted PodDisruptionBudget kubevirt-disruption-budget-hmmgd\\",\\"source\\":{\\"component\\":\\"disruptionbudget-controller\\"},\\"firstTimestamp\\":\\"2022-08-24T11:29:04Z\\",\\"lastTimestamp\\":\\"2022-08-24T11:29:04Z\\",\\"count\\":1,\\"type\\":\\"Normal\\",\\"eventTime\\":null,\\"reportingComponent\\":\\"\\",\\"reportingInstance\\":\\"\\"}
}",
"kubernetes":{"pod_name":"harvester-default-event-tailer-0","namespace_name":"cattle-logging-system","pod_id":"d3453153-58c9-456e-b3c3-d91242580df3","labels":{"app.kubernetes.io/instance":"harvester-default-event-tailer","app.kubernetes.io/name":"event-tailer","controller-revision-hash":"harvester-default-event-tailer-747b9d4489","statefulset.kubernetes.io/pod-name":"harvester-default-event-tailer-0"},"annotations":{"cni.projectcalico.org/containerID":"aa72487922ceb4420ebdefb14a81f0d53029b3aec46ed71a8875ef288cde4103","cni.projectcalico.org/podIP":"10.52.0.178/32","cni.projectcalico.org/podIPs":"10.52.0.178/32","k8s.v1.cni.cncf.io/network-status":"[{\\n \\"name\\": \\"k8s-pod-network\\",\\n \\"ips\\": [\\n \\"10.52.0.178\\"\\n ],\\n \\"default\\": true,\\n \\"dns\\": {}\\n}]","k8s.v1.cni.cncf.io/networks-status":"[{\\n \\"name\\": \\"k8s-pod-network\\",\\n \\"ips\\": [\\n \\"10.52.0.178\\"\\n ],\\n \\"default\\": true,\\n \\"dns\\": {}\\n}]","kubernetes.io/psp":"global-unrestricted-psp"},"host":"harv1","container_name":"harvester-default-event-tailer-0","docker_id":"455064de50cc4f66e3dd46c074a1e4e6cfd9139cb74d40f5ba00b4e3e2a7ab2d","container_hash":"docker.io/banzaicloud/eventrouter@sha256:6353d3f961a368d95583758fa05e8f4c0801881c39ed695bd4e8283d373a4262","container_image":"docker.io/banzaicloud/eventrouter:v0.1.0"}
}
Sortie du journal des événements/Sortie du cluster
Les événements partagent le Output/ClusterOutput avec Logging.
Sélectionnez Logging/Event dans la liste déroulante Type.
Flux du journal des événements/Flux du cluster
Comparé au journal normal Flow/ClusterFlow, le Event lié Flow/ClusterFlow a un champ de correspondance supplémentaire avec la valeur de event-tailer.
Lorsque vous configurez depuis le tableau de bord Harvester, le champ est ajouté automatiquement.
Sélectionnez Event dans la liste déroulante Type.
Lorsque vous configurez depuis la CLI, veuillez ajouter le champ manuellement.
Exemple :
apiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: harvester-event-webhook
namespace: cattle-logging-system
spec:
filters:
- tag_normaliser: {}
match:
- select:
labels:
app.kubernetes.io/name: event-tailer
globalOutputRefs:
- harvester-event-webhook