Surveillance
La fonctionnalité de surveillance est maintenant implémentée avec un produit complémentaire et est désactivée par défaut dans les nouvelles installations.
Vous pouvez activer et désactiver le rancher-monitoring produit complémentaire après l’installation en utilisant l’interface SUSE Virtualization ou le fichier de configuration.
Métriques du tableau de bord
SUSE Virtualization a fourni une intégration de surveillance intégrée utilisant Prometheus. La surveillance est automatiquement activée lors de l’installation.
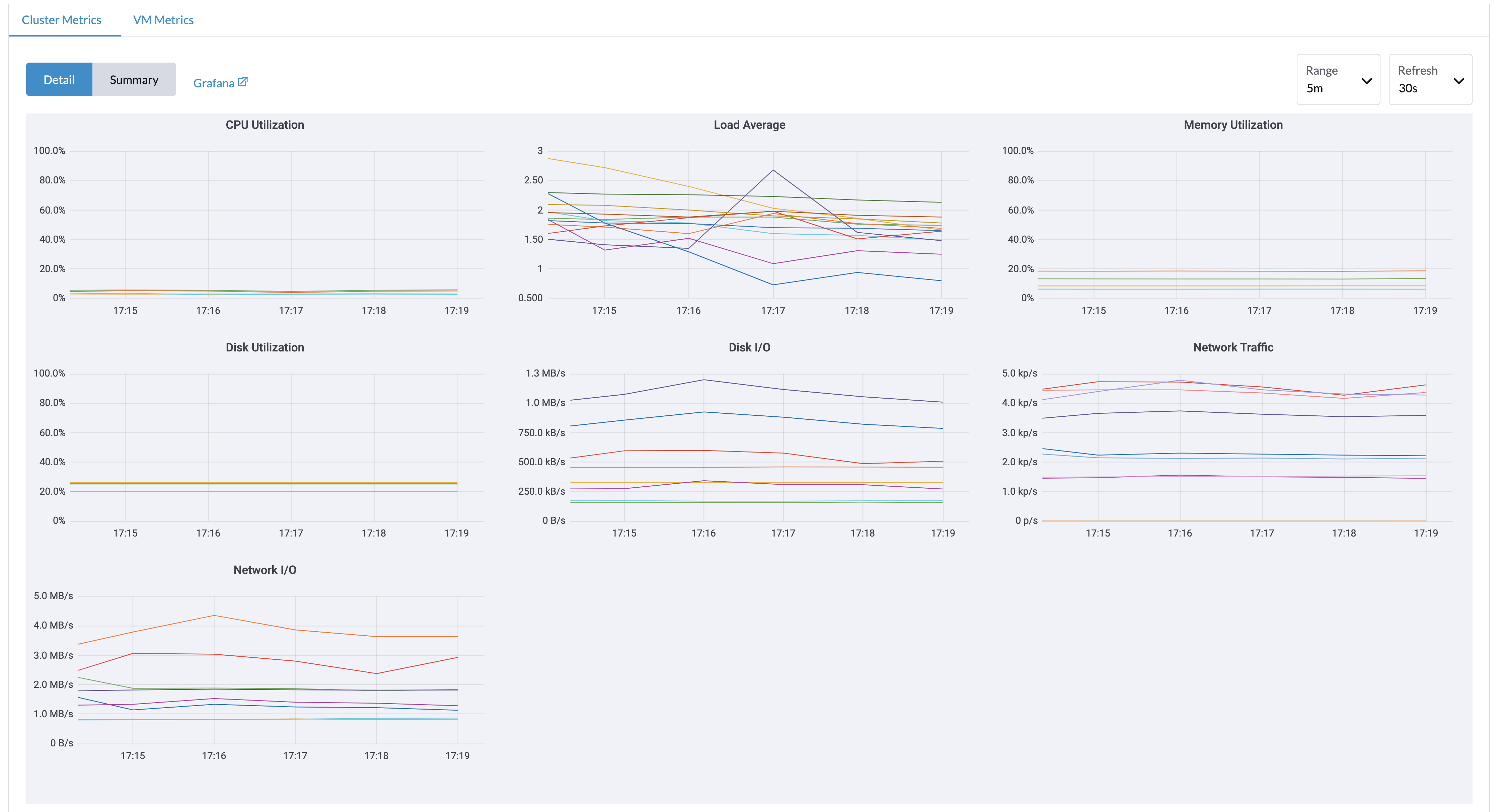
Depuis la page Dashboard, les utilisateurs peuvent voir les métriques du cluster et les 10 métriques de VM les plus utilisées respectivement.
De plus, les utilisateurs peuvent cliquer sur le lien du tableau de bord Grafana pour voir plus de tableaux de bord sur l’interface Grafana.
|
Seuls les utilisateurs administrateurs peuvent voir les métriques du tableau de bord du cluster. De plus, Grafana est fourni par Référence : values.yaml |
Métriques détaillées des VM
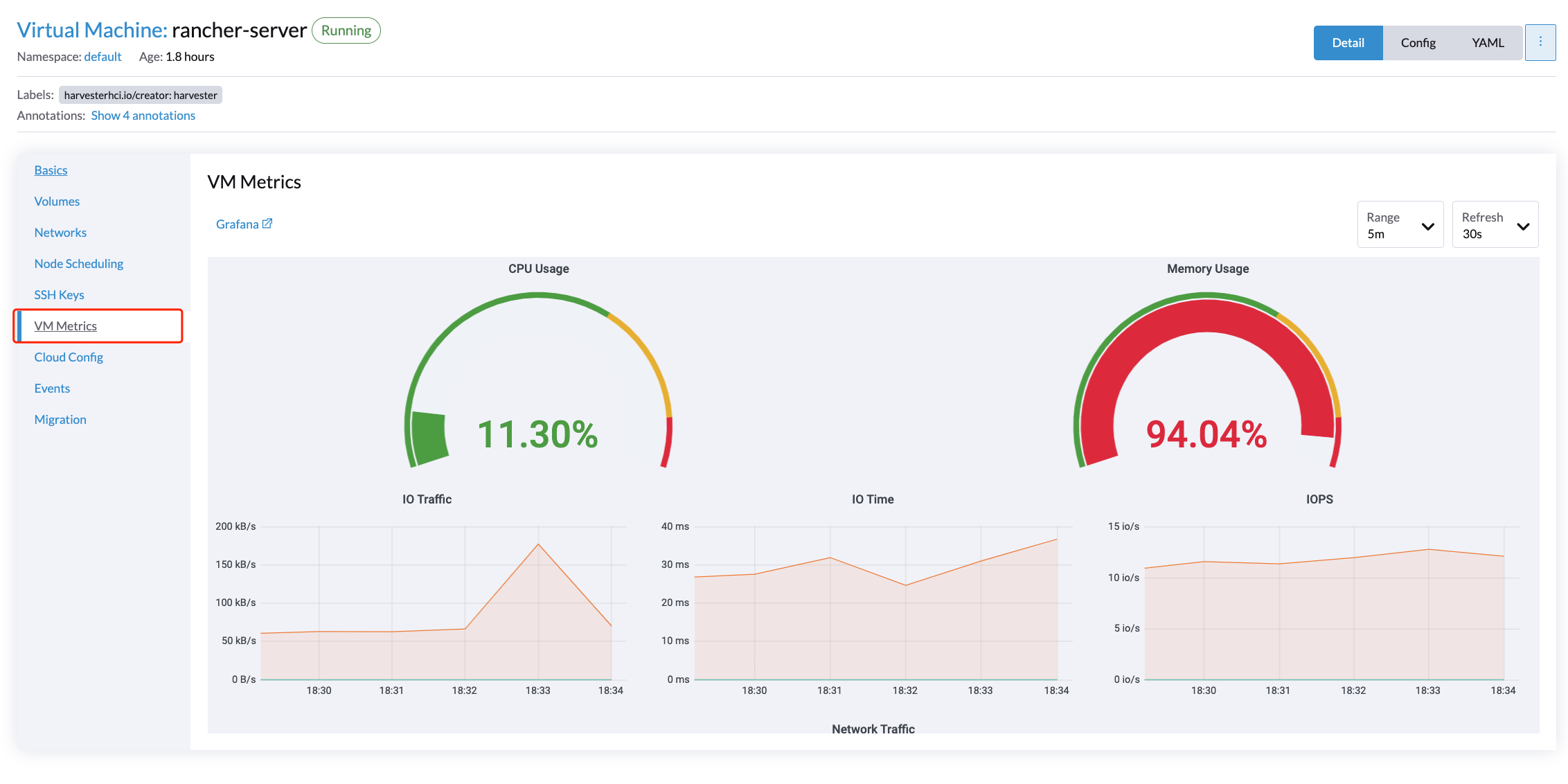
Pour les VM, vous pouvez voir les métriques des VM en cliquant sur le VM details page > VM Metrics.
|
Le |
Par exemple, dans un système d’exploitation Linux, la commande free -h affiche les statistiques de mémoire actuelles comme suit
$ free -h
total used free shared buff/cache available
Mem: 7.7Gi 166Mi 4.6Gi 1.0Mi 2.9Gi 7.2Gi
Swap: 0B 0B 0B
Le Memory Usage correspondant est (1 - 4.6/7.7) * 100%, environ 40%.
Statut et métriques de migration en direct
La migration en direct est une fonctionnalité critique pour garantir la disponibilité des charges de travail. Vous pouvez surveiller l’avancement de la migration en direct de la machine virtuelle directement depuis l’interface Harvester via le rancher-monitoring produit complémentaire.
-
Activez le rancher-monitoring produit complémentaire.
-
Allez à Machines Virtuelles.
-
Localisez la machine virtuelle dans la liste, puis cliquez sur son nom pour afficher ses détails.
-
Allez à l’onglet Migration.
L’onglet Migration est divisé en plusieurs sections :
-
Informations générales : Cette section montre la phase actuelle de migration, les nœuds source et cible, ainsi que les heures de début et de fin de migration.
-
Métriques en temps réel : Ces métriques sont générées par Prometheus et sont conservées pendant cinq jours.
Métrique Description Octets de données de migration restantes
Quantité de données du système d’exploitation invité qui n’a pas été migrée
Octets de données de migration traitées
Quantité de données du système d’exploitation invité qui a déjà été migrée
Taux de transfert de mémoire de migration
Taux auquel la mémoire est transférée
Taux de mémoire sale de migration
Taux auquel les données sont modifiées dans la mémoire de l’invité mais ne sont pas synchronisées avec les données sur le disque
Si la valeur Octets de données de migration restantes diminue régulièrement alors que la valeur Octets de données de migration traitées augmente, les données sont migrées avec succès vers la destination.
Si la valeur Octets de données de migration restantes fluctue tandis que le Taux de mémoire sale de migration reste très élevé, la machine virtuelle subit une contrainte importante. Dans certains cas, cela peut empêcher la migration de se terminer.
-
Événements de migration : Ces enregistrements d’événements spécifiques à la machine virtuelle sont générés par le serveur API Kubernetes (kube-apiserver) et sont conservés pendant une heure.
Comment configurer les paramètres de surveillance
La surveillance comprend plusieurs composants qui aident à collecter et agréger les données métriques de tous les nœuds/Pods/VMs. Les ressources nécessaires pour la surveillance dépendent de vos charges de travail et des ressources matérielles. SUSE Virtualization définit des valeurs par défaut basées sur des cas d’utilisation généraux, et vous pouvez les modifier en conséquence.
Actuellement, Resources Settings peut être configuré pour les composants suivants :
-
Prometheus
-
Prometheus Node Exporter
Depuis l’interface utilisateur
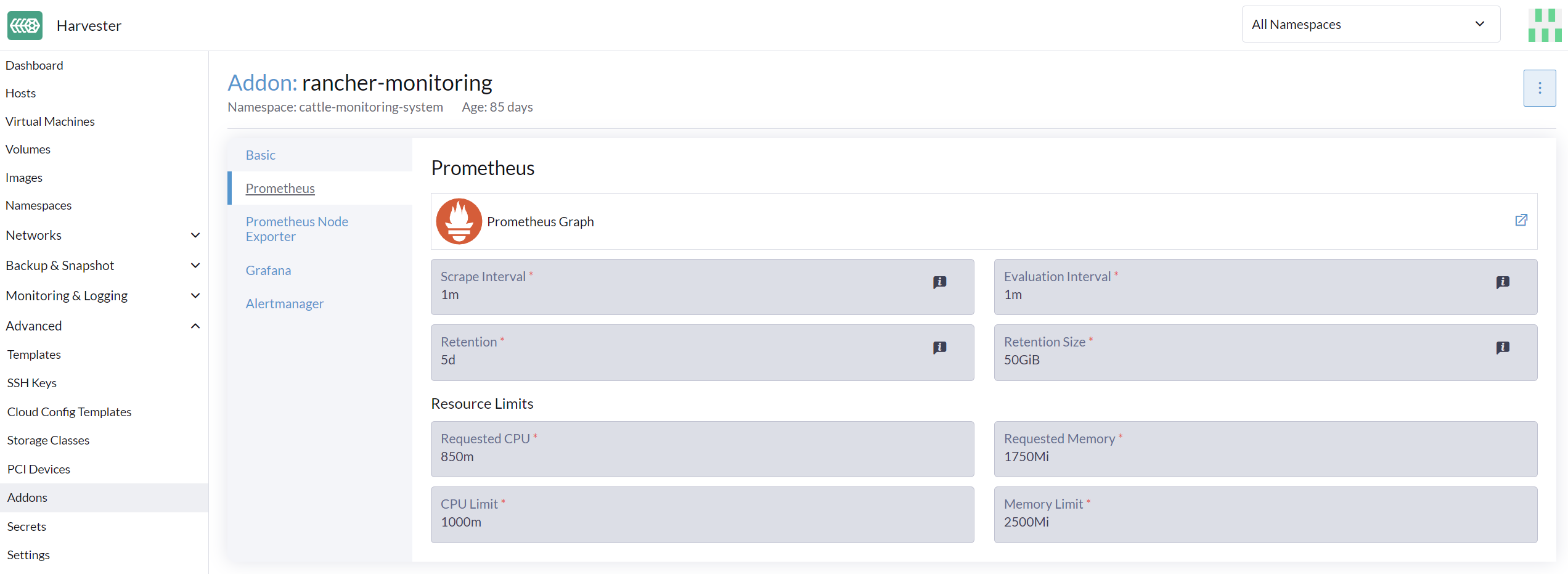
Sur la page Avancé, vous pouvez consulter et modifier les paramètres de ressources comme suit :
-
Allez à la page Avancé > Addons et sélectionnez la page rancher-monitoring.
-
Dans l’onglet Prometheus, modifiez les demandes et limites de ressources.
-
Sélectionnez Enregistrer lorsque vous avez terminé de configurer les paramètres pour le produit complémentaire rancher-monitoring. Les déploiements Surveillance redémarrent dans quelques secondes. Veuillez noter que le redémarrage peut prendre du temps pour recharger les données précédentes.
|
La configuration de l’interface utilisateur n’est visible que lorsque l’addon rancher-monitoring est activé. |
L’option la plus fréquemment utilisée est le paramètre de mémoire :
-
Le
Requested Memoryest la mémoire minimale requise par la ressourceMonitoring. La valeur recommandée est d’environ 5 % à 10 % de la mémoire système d’un seul nœud de gestion. Une valeur inférieure à 500Mi sera refusée. -
Le
Memory Limitest la mémoire maximale qui peut être allouée à une ressourceMonitoring. La valeur recommandée est d’environ 30 % de la mémoire du système pour un seul nœud de gestion. Lorsque leMonitoringatteint ce seuil, il redémarrera automatiquement.
En fonction des ressources matérielles disponibles et des charges système, vous pouvez modifier les paramètres ci-dessus en conséquence.
|
Si vous avez plusieurs nœuds de gestion avec des ressources matérielles différentes, veuillez définir la valeur de Prometheus en fonction de la plus petite. |
|
Lorsqu’un nombre croissant de machines virtuelles est déployé sur un nœud, le pod |
Depuis l’interface en ligne de commande (CLI)
Vous pouvez utiliser la commande kubectl suivante pour modifier les configurations de ressources pour l’addon rancher-monitoring : kubectl edit addons.harvesterhci.io -n cattle-monitoring-system rancher-monitoring.
Le chemin des ressources et les valeurs par défaut sont les suivants :
apiVersion: harvesterhci.io/v1beta1
kind: Addon
metadata:
name: rancher-monitoring
namespace: cattle-monitoring-system
spec:
valuesContent: |
prometheus:
prometheusSpec:
resources:
limits:
cpu: 1000m
memory: 2500Mi
requests:
cpu: 850m
memory: 1750Mi
|
Vous pouvez toujours apporter des ajustements de configuration lorsque l’addon est désactivé. Cependant, ces changements ne prennent effet que lorsque vous réactivez l’addon. |
Alertmanager
SUSE Virtualization utilise Alertmanager pour collecter et gérer toutes les alertes qui se sont produites/se produisent dans le cluster.
Configuration d’Alertmanager
Activer/Désactiver Alertmanager
Alertmanager est activé par défaut. Vous pouvez le désactiver depuis le chemin de configuration suivant.
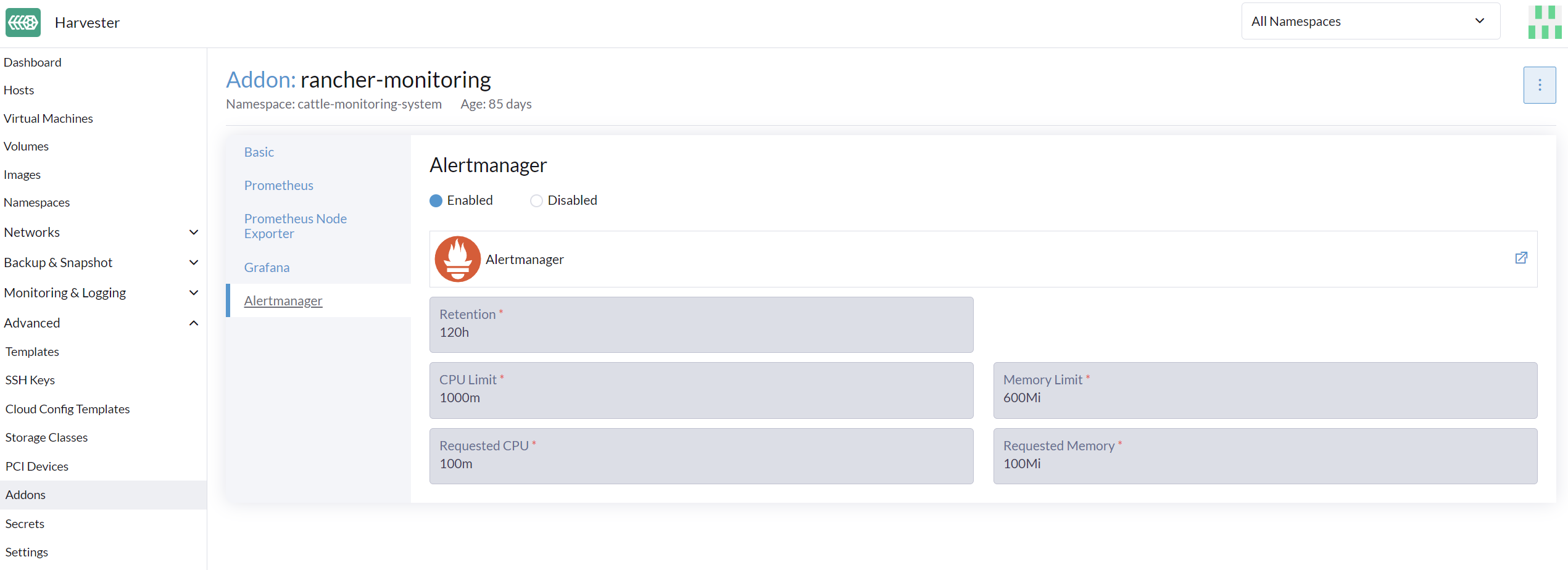
Modifier les paramètres de ressources
Vous pouvez également modifier les paramètres de ressources de Alertmanager comme indiqué dans l’image ci-dessus.
Configurer AlertmanagerConfig depuis l’interface Web
Pour envoyer les alertes à des serveurs tiers, configurez AlertmanagerConfig.
-
Dans l’interface utilisateur, allez à Surveillance & Journalisation → Surveillance → Configurations d’Alertmanager.
-
Sur le Configuration d’Alertmanager : Créez un écran, spécifiez un espace de noms et un nom, puis cliquez sur Créer.
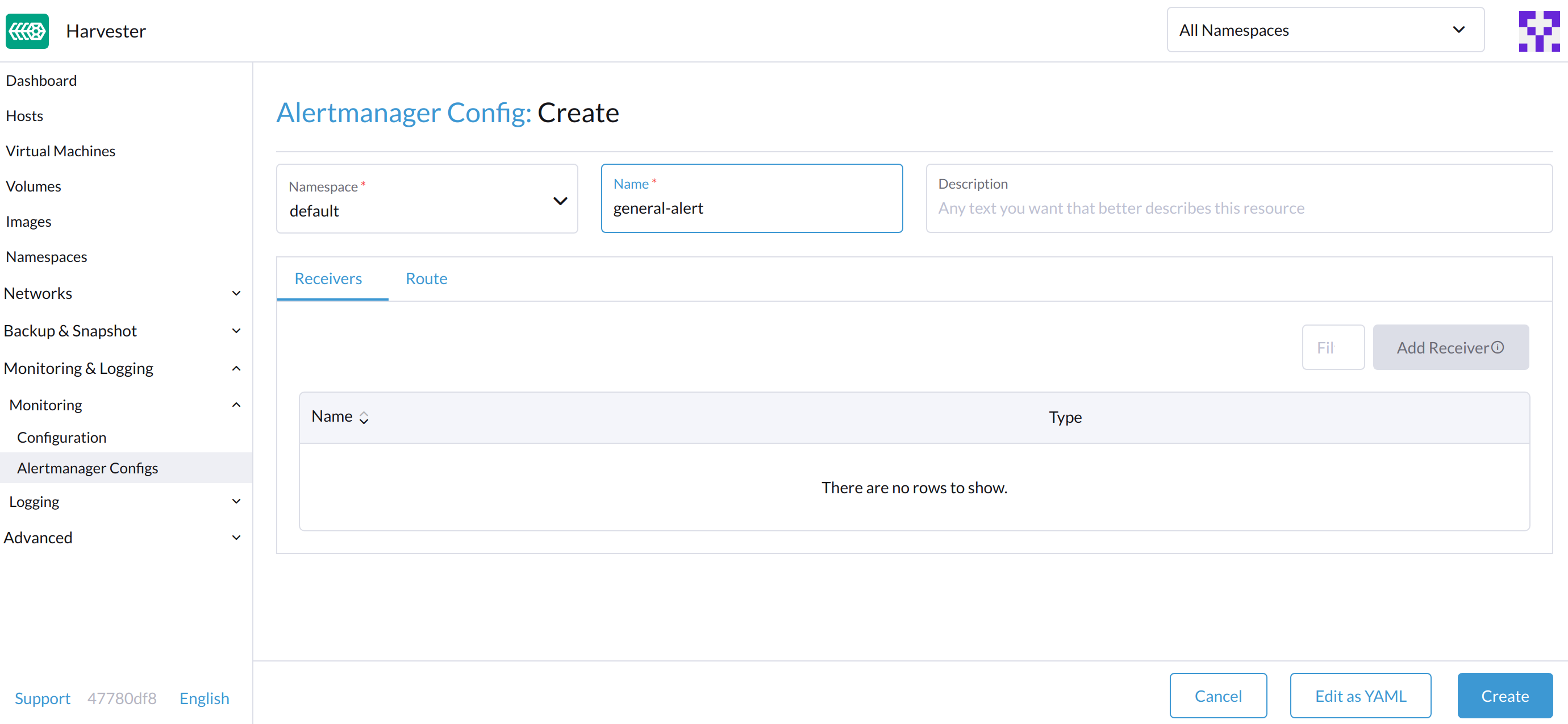
-
Cliquez sur le nom de la configuration que vous venez de créer.
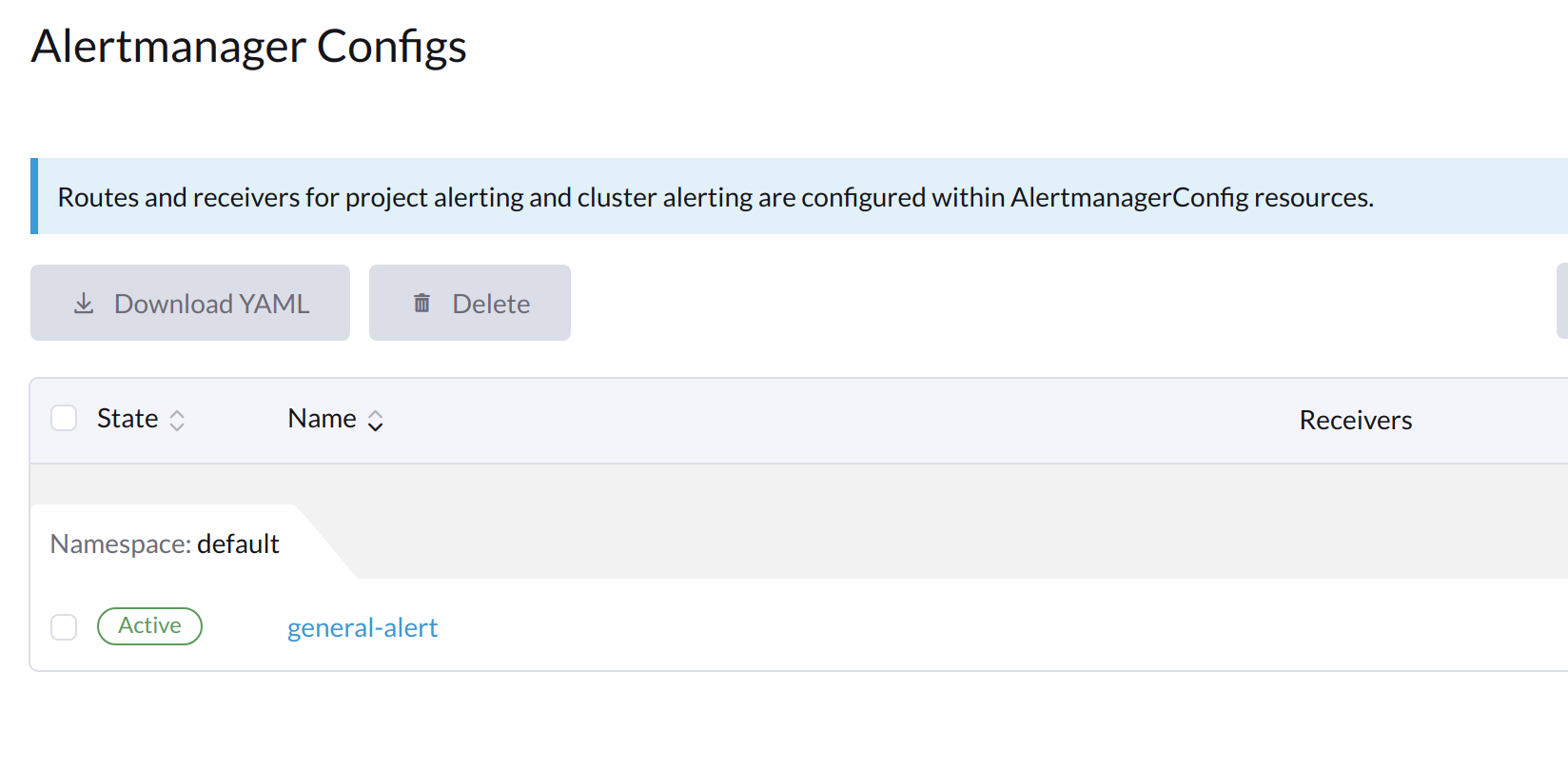
-
Cliquez sur Ajouter un récepteur.
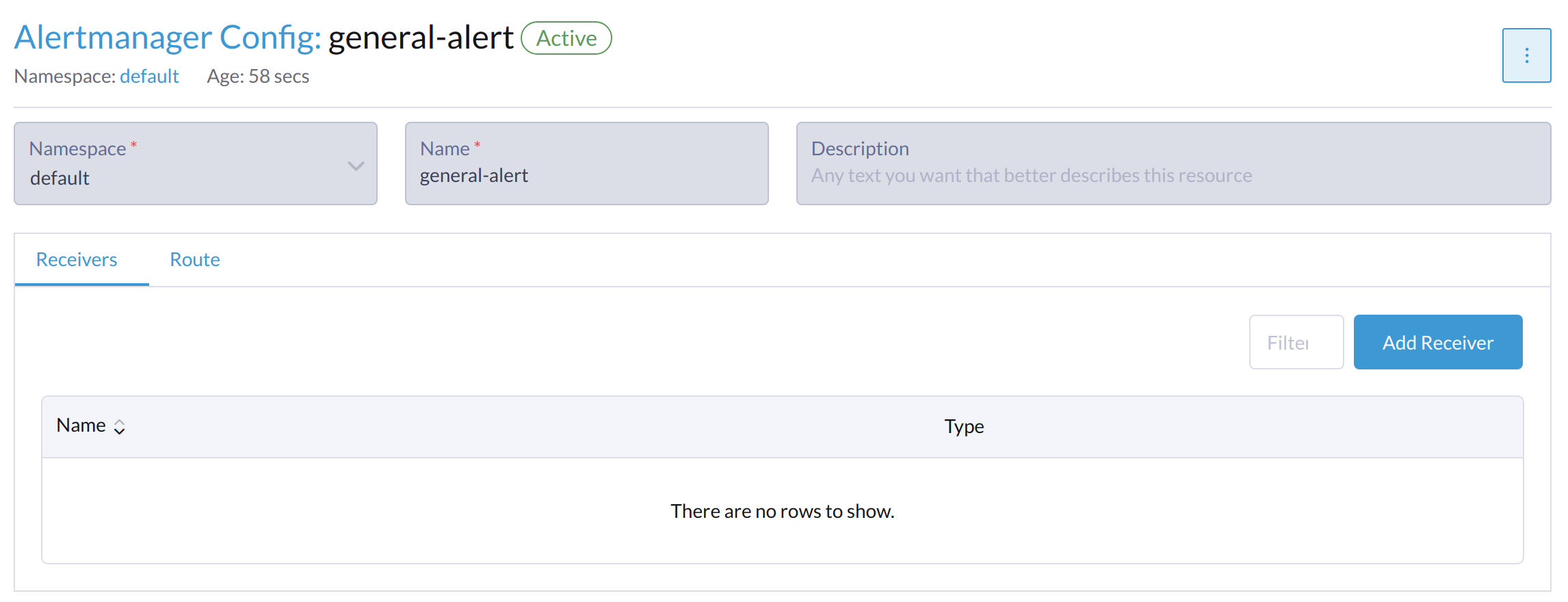
-
Spécifiez un nom pour le récepteur, puis sélectionnez un type de récepteur.
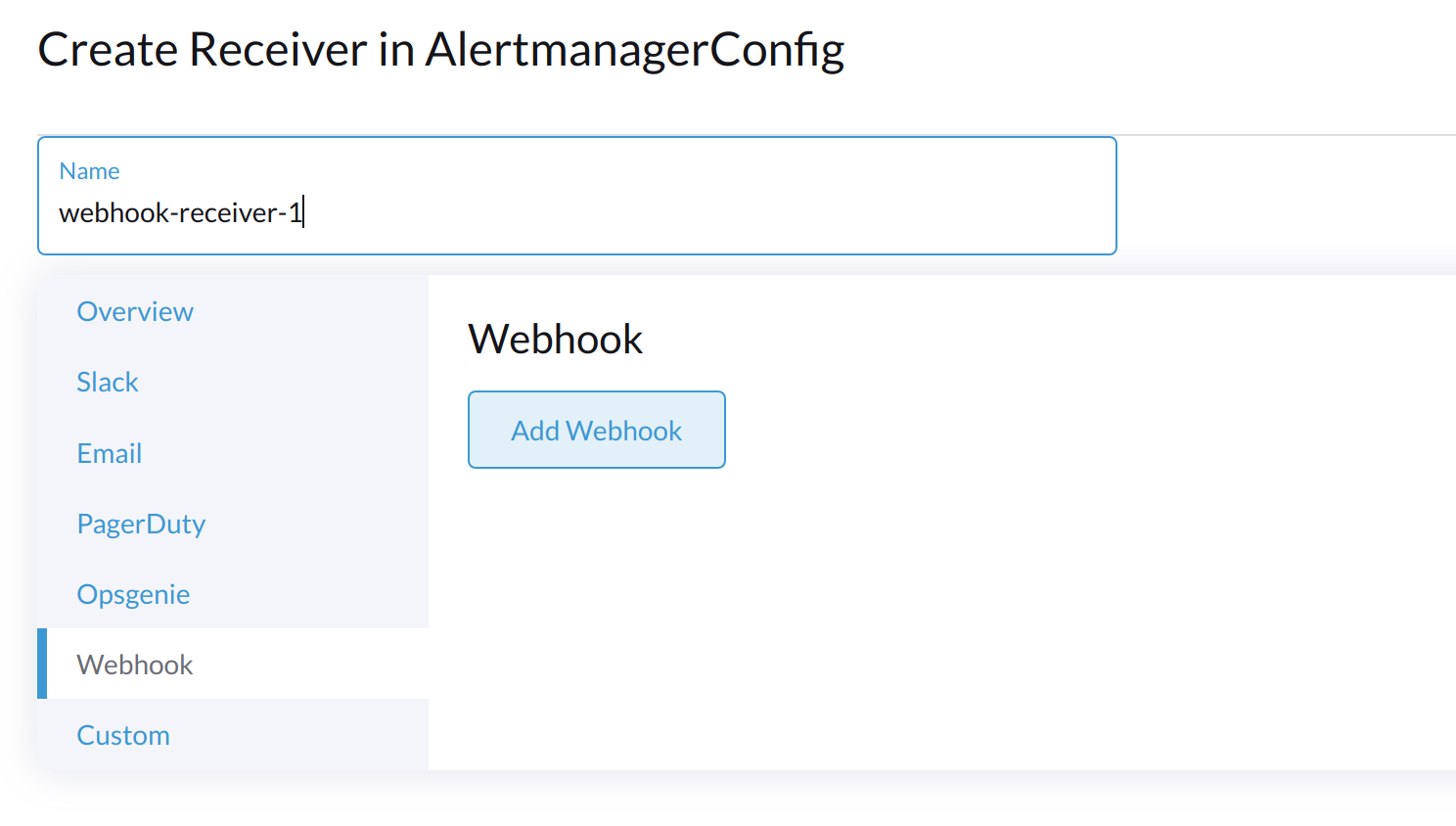
-
Configurez les paramètres requis, puis cliquez sur Créer.
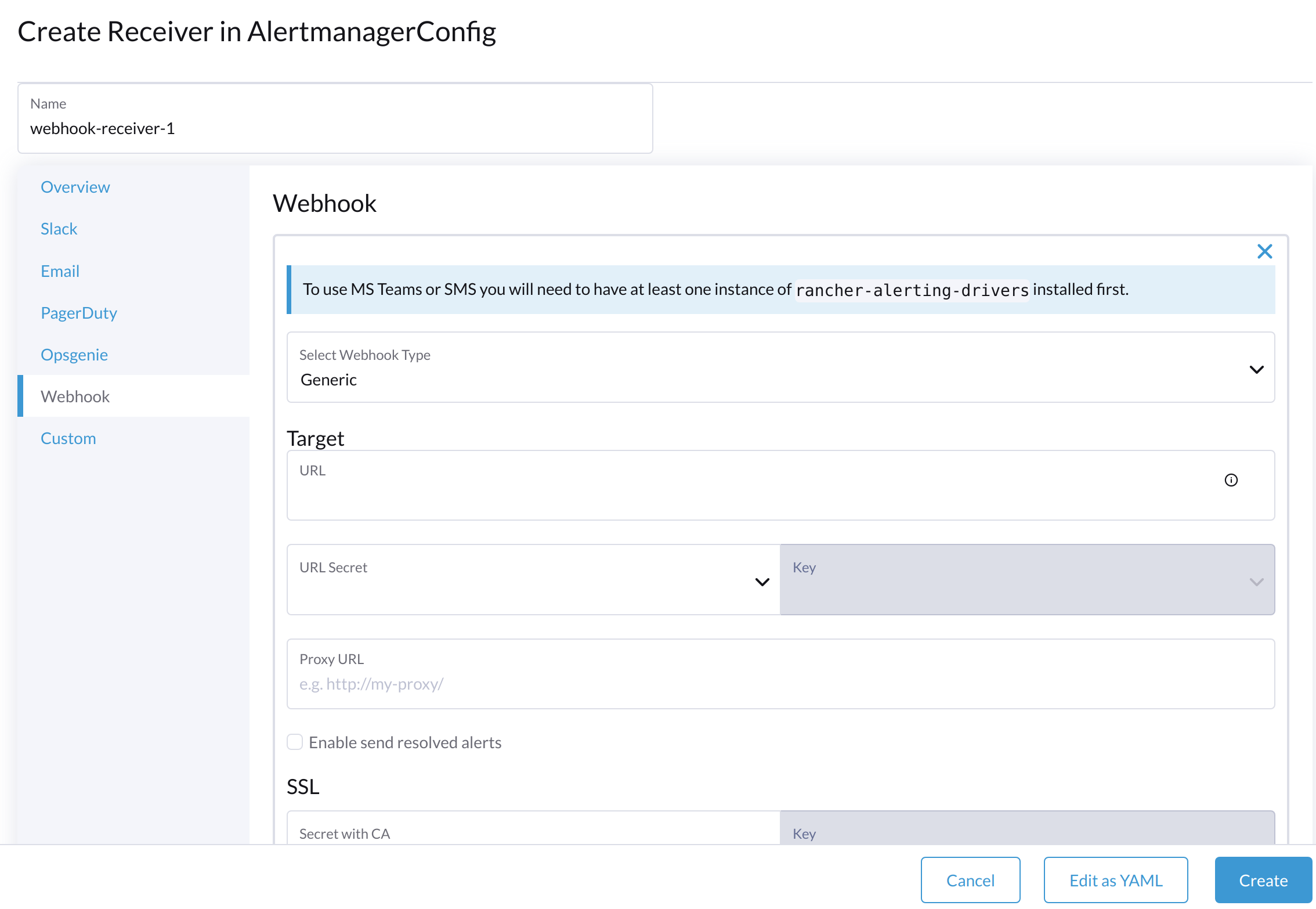
Pour configurer les webhooks Microsoft Teams ou SMS, installez d’abord l’application rancher-alerting-drivers en utilisant les commandes suivantes :
helm repo add rancher-charts https://charts.rancher.io/
helm repo update
helm install rancher-charts/rancher-alerting-drivers \
--set sachet.enabled=false \ # Set to true if you want to use SMS Webhook
--set prom2teams.enabled=true \ # Set to true if you want to use MS Teams Webhook
--namespace cattle-monitoring-system \
--generate-namePour des instructions de configuration détaillées, consultez Configuration du récepteur dans la documentation Rancher.
Si votre environnement n’a pas d’accès direct à Internet (isolé physiquement), vous devez télécharger manuellement le chart Helm et les images de conteneur associées, puis les télécharger sur le cluster SUSE Virtualization.
-
Téléchargez le chart Helm rancher-alerting-drivers et empaquetez-le.
helm pull rancher-charts/rancher-alerting-drivers --version <VERSION>
-
Téléchargez les images requises.
docker save -o sachet.tar rancher/mirrored-messagebird-sachet:<VERSION> docker save -o prom2teams.tar rancher/mirrored-idealista-prom2teams:<VERSION>
-
Téléversez le chart et les images sur le cluster SUSE Virtualization.
-
Chargez les images sur tous les nœuds SUSE Virtualization.
docker load -i sachet.tar docker load -i prom2teams.tar
-
Installez rancher-alerting-drivers sur le cluster SUSE Virtualization.
|
SUSE Virtualization ne gère pas les mises à jour de l’application |
Configurez AlertmanagerConfig depuis la CLI.
Vous pouvez également ajouter AlertmanagerConfig depuis la CLI.
Exemple : un récepteur Webhook dans l’espace de noms default.
cat << EOF > a-single-receiver.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: amc-example
# namespace: your value
labels:
alertmanagerConfig: example
spec:
route:
continue: true
groupBy:
- cluster
- alertname
receiver: "amc-webhook-receiver"
receivers:
- name: "amc-webhook-receiver"
webhookConfigs:
- sendResolved: true
url: "http://192.168.122.159:8090/"
EOF
# kubectl apply -f a-single-receiver.yaml
alertmanagerconfig.monitoring.coreos.com/amc-example created
# kubectl get alertmanagerconfig -A
NAMESPACE NAME AGE
default amc-example 27s
Exemple d’une alerte reçue par Webhook.
Les alertes envoyées au serveur webhook seront au format suivant :
{
'receiver': 'longhorn-system-amc-example-amc-webhook-receiver',
'status': 'firing',
'alerts': [],
'groupLabels': {},
'commonLabels': {'alertname': 'LonghornVolumeStatusWarning', 'container': 'longhorn-manager', 'endpoint': 'manager', 'instance': '10.52.0.83:9500', 'issue': 'Longhorn volume is Degraded.',
'job': 'longhorn-backend', 'namespace': 'longhorn-system', 'node': 'harv2', 'pod': 'longhorn-manager-r5bgm', 'prometheus': 'cattle-monitoring-system/rancher-monitoring-prometheus',
'service': 'longhorn-backend', 'severity': 'warning'},
'commonAnnotations': {'description': 'Longhorn volume is Degraded for more than 5 minutes.', 'runbook_url': 'https://longhorn.io/docs/1.3.0/monitoring/metrics/',
'summary': 'Longhorn volume is Degraded'},
'externalURL': 'https://192.168.122.200/api/v1/namespaces/cattle-monitoring-system/services/http:rancher-monitoring-alertmanager:9093/proxy',
'version': '4',
'groupKey': '{}/{namespace="longhorn-system"}:{}',
'truncatedAlerts': 0
}
|
Différents récepteurs peuvent présenter les alertes dans différents formats. Pour plus de détails, veuillez vous référer aux documents associés. |
Limitation connue
Le AlertmanagerConfig est appliqué par le namespace. Le AlertmanagerConfig au niveau global sans un espace de noms n’est pas pris en charge.
Nous avons déjà créé un problème GitHub pour suivre les changements en amont. Une fois la fonctionnalité disponible, SUSE Virtualization l’adoptera.
Afficher et gérer les alertes
Depuis le tableau de bord Alertmanager
Vous pouvez visiter le tableau de bord original de Alertmanager via le lien ci-dessous. Notez que vous devez remplacer the-cluster-vip par le cluster-vip réel :
La vue d’ensemble du tableau de bord Alertmanager est la suivante.
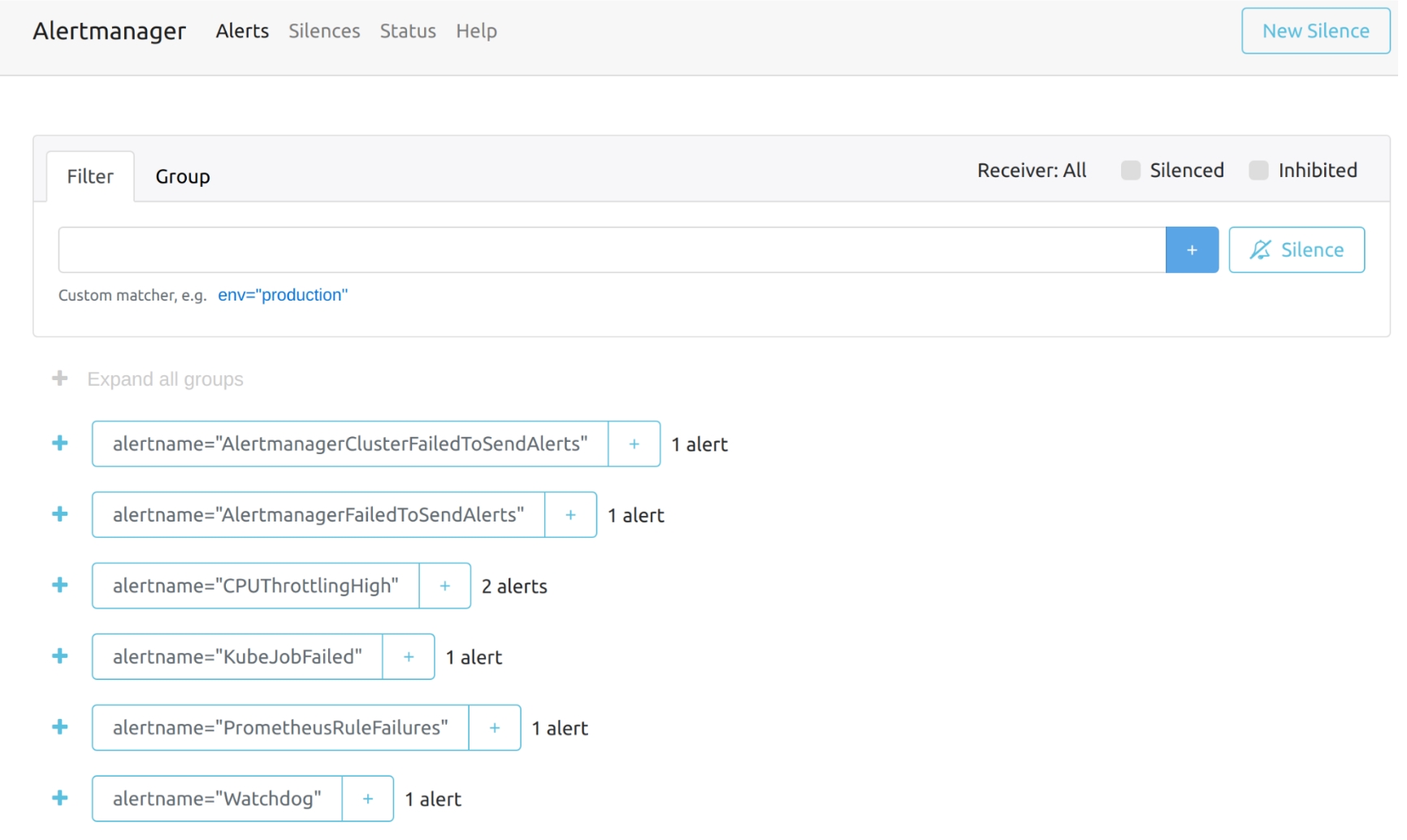
Vous pouvez voir les détails d’une alerte :
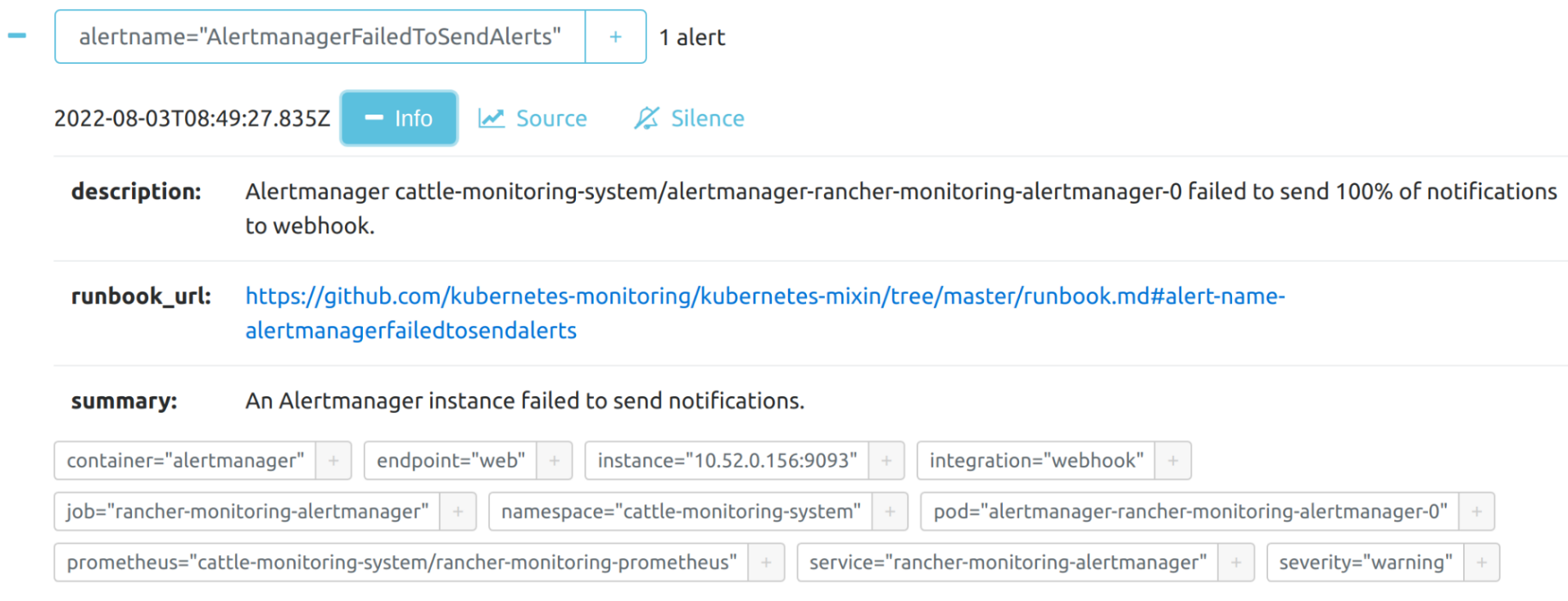
Depuis le tableau de bord Prometheus
Vous pouvez visiter le tableau de bord original de Prometheus via le lien ci-dessous. Notez que vous devez remplacer the-cluster-vip par le cluster-vip réel :
Le menu Alerts dans la barre de navigation supérieure affiche toutes les règles définies dans Prometheus. Vous pouvez utiliser les filtres Inactive, Pending et Firing pour trouver rapidement les informations dont vous avez besoin.
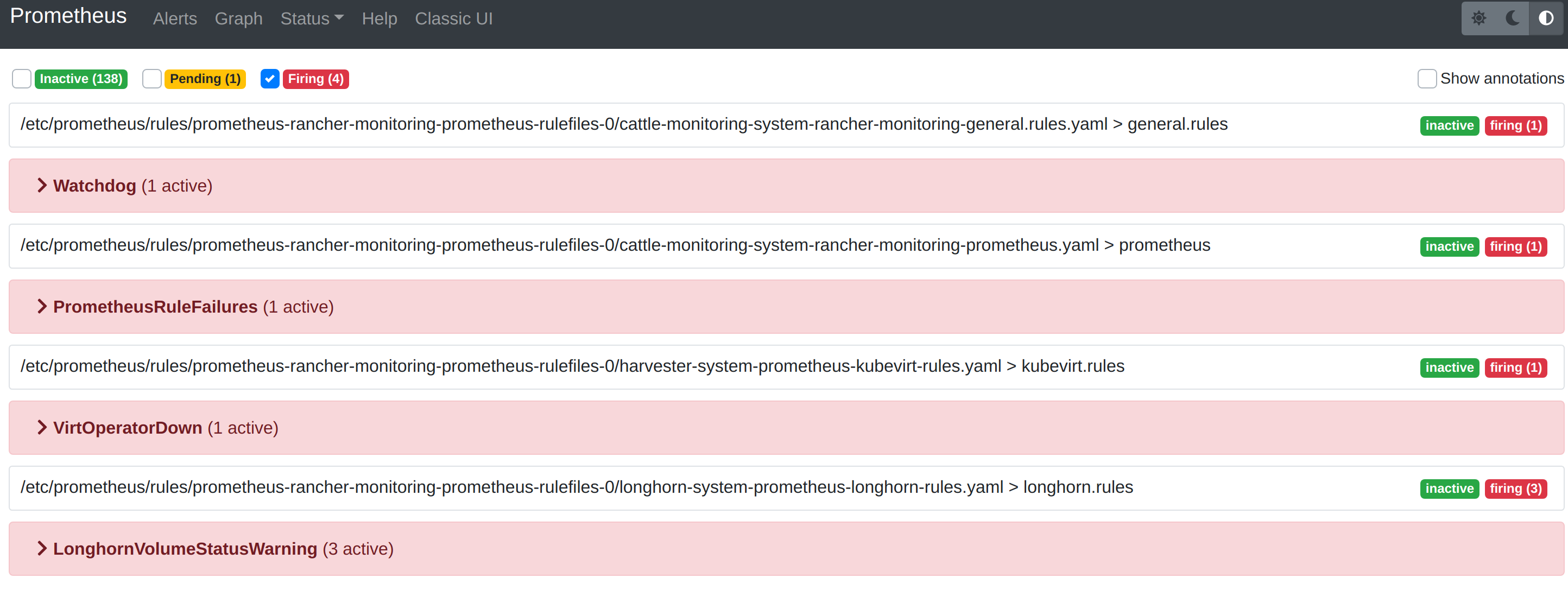
Dépannage
Pour le support de surveillance et le dépannage, veuillez vous référer à la page de dépannage.