Mises à niveau
SUSE Virtualization adopte une nouvelle stratégie de cycle de vie qui simplifie la gestion des versions et les mises à niveau. Cette stratégie comprend les éléments suivants :
-
Un rythme de publication mineure de quatre mois
-
Un rythme de publication de correctifs de deux mois
-
Stratégie d’adoption des composants
|
SUSE Virtualization ne prend pas en charge les rétrogradations. Cette restriction aide à prévenir un comportement système inattendu et des problèmes associés à l’incompatibilité des fonctions, à leur dépréciation et à leur suppression. |
Options de mise à jour
Le tableau suivant décrit les chemins de mise à niveau pris en charge.
| Version installée | Versions de mise à niveau prises en charge |
|---|---|
v1.6.x |
|
v1.6.x |
v1.6.y (y est supérieur à x) |
v1.5.x |
|
v1.5.0 et v1.5.1 |
|
v1.5.0 |
|
v1.4.2 et v1.4.3 |
|
v1.4.2 et v1.4.3 |
|
v1.4.1 et v1.4.2 |
|
v1.4.1 |
|
v1.4.0 |
|
v1.3.1 |
|
v1.2.2 et v1.3.0 |
|
v1.2.1 |
|
v1.1.2, v1.1.3 et v1.2.0 |
Les dernières versions de SUSE Virtualization permettent les éléments suivants :
-
Mise à niveau d’une version mineure à la suivante (par exemple, de v1.5.2 à v1.6.1) sans avoir besoin d’installer les correctifs publiés entre les deux versions. Ceci est possible car SUSE Virtualization permet un maximum d’une mise à niveau de version mineure pour les composants sous-jacents.
-
Mise à niveau vers une version de correctif ultérieure (par exemple, de v1.6.0 à v1.6.1), en supposant que les mêmes versions de composants sont utilisées à travers les publications pour une version mineure donnée.
Le tableau suivant présente les composants utilisés dans ces versions :
| Composant | SUSE Virtualization v1.5.x | SUSE Virtualization v1.6.x | SUSE Virtualization v1.7.x |
|---|---|---|---|
KubeVirt |
v1.4 |
v1.5 |
v1.6 |
SUSE Storage |
v1.8 |
v1.9 |
v1.10 |
SUSE Rancher Prime |
v2.11 |
v2.12 |
v2.13 |
RKE2 |
v1.32 |
v1.33 |
v1.34 |
SUSE Linux Micro |
5.5 |
5.5 |
6.1 |
|
Le saut de plusieurs versions mineures de Kubernetes n’est pas pris en charge en amont et constitue une raison clé des chemins de mise à niveau limités. Pour plus d’informations, voir Politique de déséquilibre de version dans la documentation de Kubernetes. |
Rancher mise à niveau
Si vous utilisez Rancher pour gérer votre cluster SUSE Virtualization, vous devez mettre à niveau Rancher avant de mettre à niveau SUSE Virtualization.
|
Les processus de mise à niveau SUSE Virtualization et Rancher sont indépendants l’un de l’autre. Lors d’une mise à niveau Rancher, vous pouvez toujours accéder à votre cluster SUSE Virtualization en utilisant son IP virtuelle. SUSE Virtualization n’est pas automatiquement mis à niveau. |
Lorsqu’une version Rancher atteint sa date d’arrêt de maintenance (EOM), SUSE Virtualization ne fournit que des correctifs pour les problèmes de sécurité critiques qui affectent les fonctions d’intégration (Gestion de la virtualisation). Pour plus d’informations, voir le Matrice de support.
Gestion des machines virtuelles via la mise à niveau
Machines virtuelles migrables en direct
Les machines virtuelles migrables en direct sont automatiquement migrées vers d’autres nœuds via migration par lot avant que le nœud actuel ne soit mis à niveau. Ces machines virtuelles ne subissent aucun temps d’arrêt pendant la migration.
Machines virtuelles non migrables
Lorsqu’une mise à niveau est déclenchée, SUSE Virtualization effectue certaines actions en fonction de la valeur de l’option restoreVM du paramètre upgrade-config.
-
false: SUSE Virtualization ne réalise pas la mise à niveau lorsque les machines virtuelles non migrables sont encore en cours d’exécution. Vous devez éteindre manuellement les machines virtuelles. -
true: SUSE Virtualization éteint automatiquement les machines virtuelles non migrables lorsque le nœud est mis à niveau, puis les restaure après le redémarrage du nœud.
|
Les machines virtuelles non migrables subissent un temps d’arrêt pendant la migration. |
Pour plus d’informations, reportez-vous à Phase 4 : Mise à niveau des nœuds.
Avant de commencer une mise à niveau
Consultez le paramètre disponible upgrade-config pour ajuster les stratégies et comportements de mise à niveau qui conviennent le mieux à votre environnement de cluster.
Démarrer une mise à niveau
|
|
|
Les NIC qui se connectent à un pont PCI pourraient être renommés après une mise à niveau. Veuillez consulter l’article de la base de connaissances pour plus d’informations. |
|
À partir de la v1.7.0, SUSE Virtualization utilise un dépôt de mise à niveau basé sur le déploiement au lieu d’une approche basée sur une machine virtuelle pour améliorer les performances et la fiabilité. Pour plus d’informations, voir le problème #7101. |
-
Sur l’écran SUSE Virtualization Tableau de bord de l’interface utilisateur, cliquez sur Mettre à niveau.
Le bouton Mettre à niveau apparaît chaque fois qu’une nouvelle version vers laquelle vous pouvez mettre à niveau devient disponible.
Si votre environnement n’a pas d’accès direct à Internet, suivez les instructions dans [Prepare an air-gapped upgrade], qui fournit une approche efficace pour télécharger l’ISO.
-
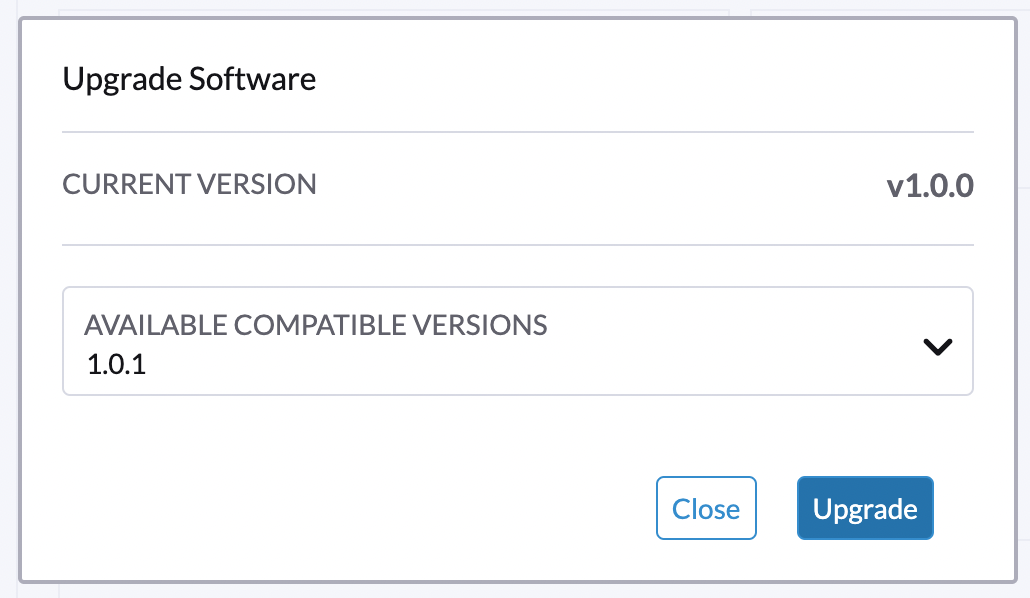
Sélectionnez la version vers laquelle vous souhaitez effectuer la mise à niveau.
Si vous avez besoin de personnalisations, consultez [Customize the version].
-
Cliquez sur l’indicateur de progression (icône circulaire) pour voir l’état de chaque processus associé.
Personnaliser la version
-
Téléchargez le fichier de version (
https://releases.rancher.com/harvester/{version}/version.yaml).Exemple :
Le fichier de version v1.5.0 est téléchargé sous le nom de
v1.5.0.yaml.apiVersion: harvesterhci.io/v1beta1 kind: Version metadata: name: v1.5.0-customized # Changed, to avoid duplicated with the official version name namespace: harvester-system spec: isoChecksum: 'df28e9bf8dc561c5c26dee535046117906581296d633eb2988e4f68390a281b6856a5a0bd2e4b5b988c695a53d0fc86e4e3965f19957682b74317109b1d2fe32' # Don't change isoURL: https://releases.rancher.com/harvester/v1.5.0/harvester-v1.5.0-amd64.iso # Official ISO path by default releaseDate: '20250425' -
Créez la version en utilisant la commande
kubectl create -f v1.5.0.yaml.
Préparez une mise à niveau isolée physiquement
|
Assurez-vous de vérifier d’abord la section [Upgrade paths] concernant les versions pouvant être mises à niveau. |
Préparez le fichier ISO
-
Téléchargez un fichier ISO depuis la page Releases.
-
Enregistrez l’ISO sur un serveur HTTP local.
Supposez que le fichier est hébergé à
http://10.10.0.1/harvester.iso.
Préparez la version
-
Téléchargez le fichier de version (
https://releases.rancher.com/harvester/{version}/version.yaml). -
Remplacez la valeur
isoURLdans le fichier.apiVersion: harvesterhci.io/v1beta1 kind: Version metadata: name: v1.5.0 namespace: harvester-system spec: isoChecksum: <SHA-512 checksum of the ISO> isoURL: http://10.10.0.1/harvester.iso # change to local ISO URL releaseDate: '20250425'Supposez que le fichier est hébergé à
http://10.10.0.1/version.yaml. Si vous avez besoin de personnalisations, consultez [Customize the version]. -
Accédez à l’un des nœuds du plan de contrôle via SSH et connectez-vous en utilisant le compte root.
-
Créez un objet de version.
rancher@node1:~> sudo -i rancher@node1:~> kubectl create -f http://10.10.0.1/version.yaml
Démarrez manuellement une mise à niveau avant que la mise à niveau officielle ne devienne disponible
Le bouton Mettre à niveau n’apparaît pas sur l’interface utilisateur immédiatement après la publication d’une nouvelle version. Si vous souhaitez mettre à niveau votre cluster avant que l’option ne devienne disponible sur l’interface utilisateur, suivez les étapes dans [Prepare an air-gapped upgrade].
|
Dans les environnements de production, il est recommandé de mettre à niveau les clusters via l’interface utilisateur. |
Personnaliser les mises à niveau des nœuds
Les mises à niveau de SUSE Virtualization impliquent plusieurs phases définies. Une phase clé est la mise à niveau des nœuds, au cours de laquelle le système d’exploitation et la distribution Kubernetes sous-jacente (RKE2) sont mis à niveau sur chaque nœud de manière séquentielle et autonome.
Vous avez la possibilité de suspendre les mises à niveau automatiques sur des nœuds spécifiques, ce qui est utile pour des tâches de maintenance manuelle ou de vérification. Après l’achèvement de ces tâches, vous devez explicitement instruire SUSE Virtualization de reprendre la mise à niveau sur les nœuds cibles.
Suspendre les mises à niveau des nœuds
Vous pouvez utiliser l’option nodeUpgradeOption dans le paramètre upgrade-config pour suspendre les mises à niveau des nœuds.
-
Suspendre pour tous les nœuds du cluster : Changez la valeur du champ
modeenmanual. -
Suspendre pour des nœuds spécifiques : Listez les noms des nœuds dans le champ
pauseNodes. Les nœuds non inclus dans la liste sont automatiquement mis à niveau.
|
SUSE Virtualization applique la configuration |
|
Vous pouvez modifier la ressource personnalisée |
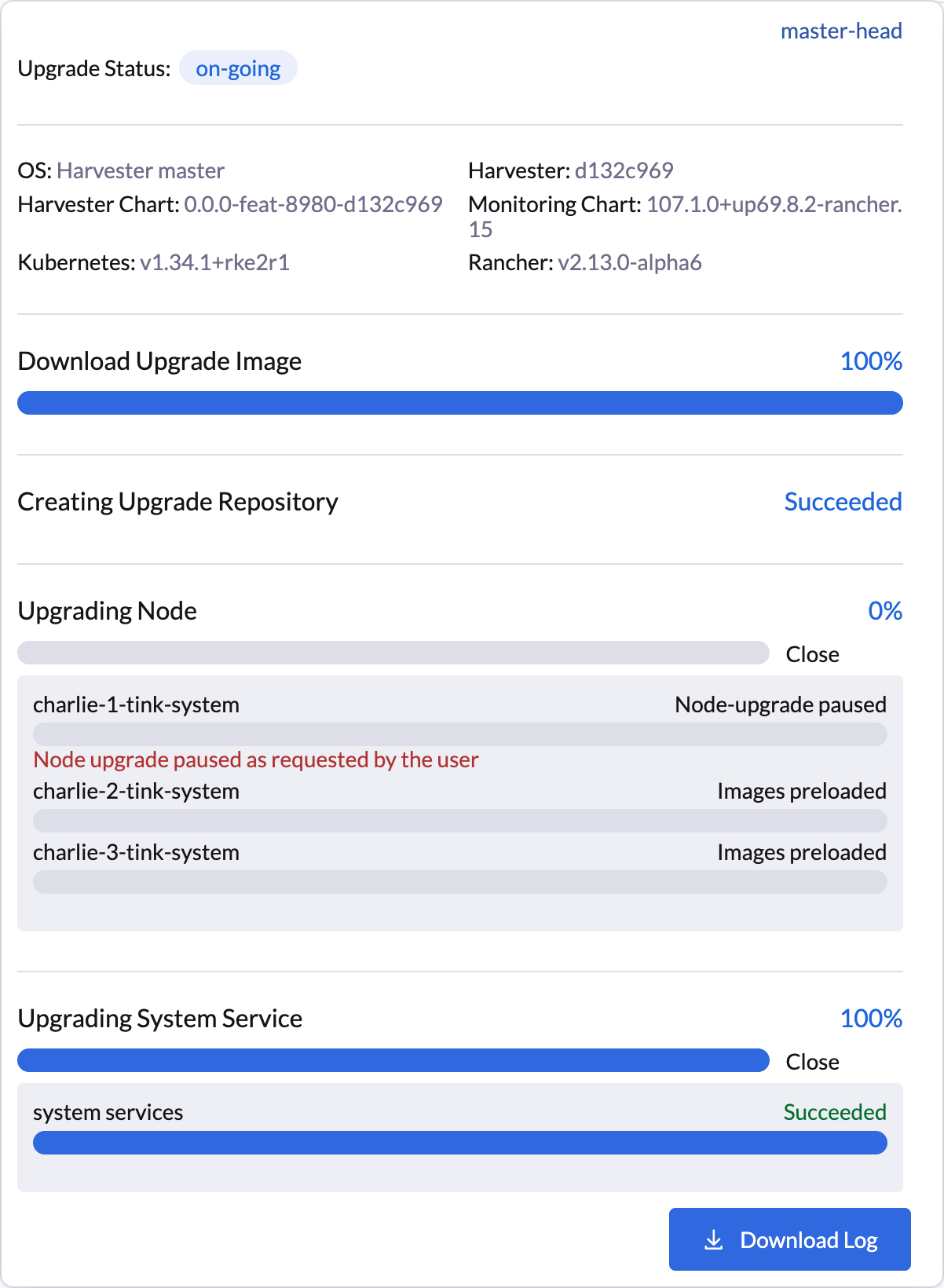
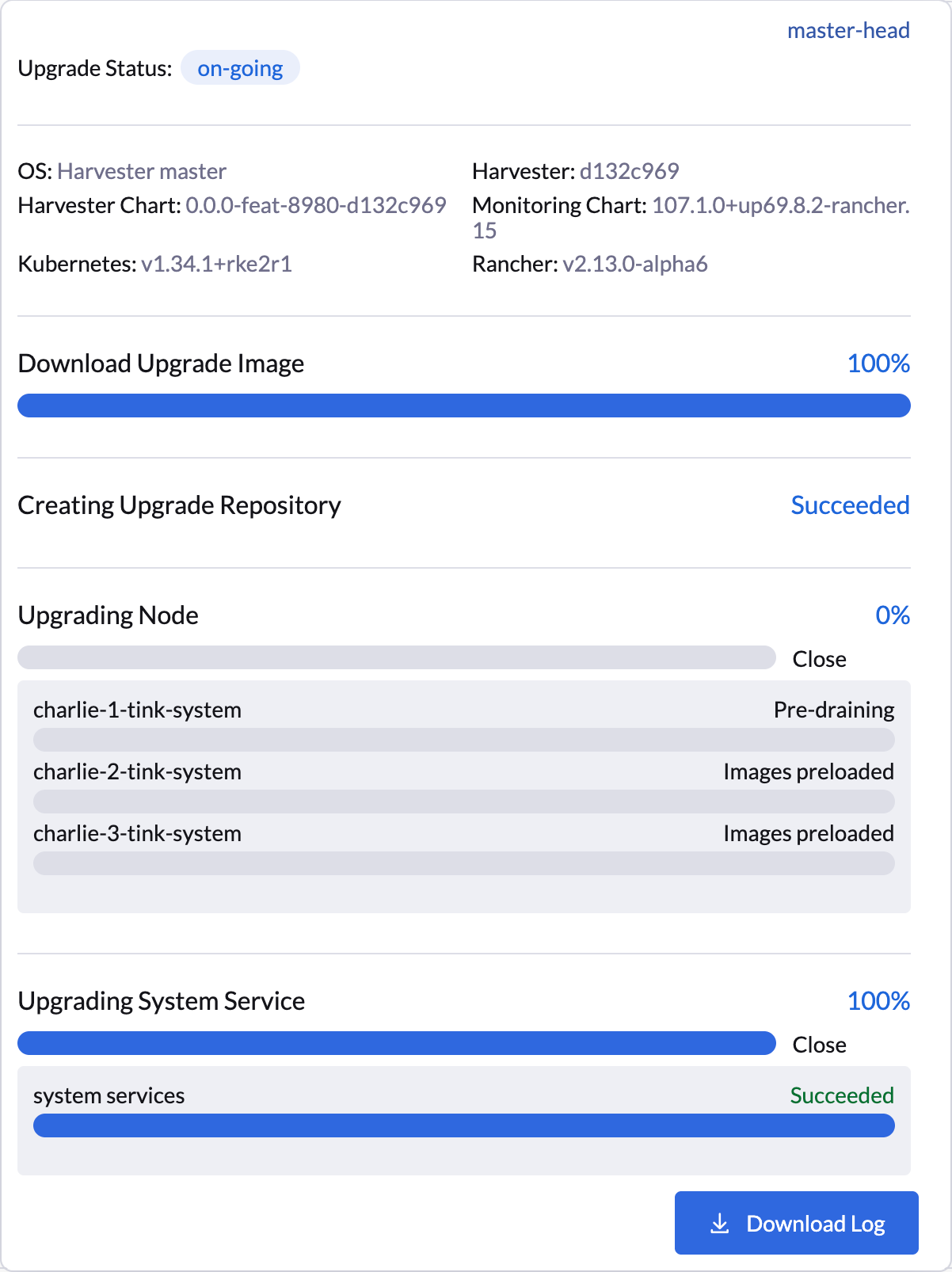
L’interface utilisateur SUSE Virtualization fournit une confirmation visuelle des mises à niveau des nœuds suspendues. Dans l’exemple suivant, la mise à niveau du nœud charlie-1-tink-system est actuellement suspendue.
Vous pouvez également utiliser la commande kubectl suivante pour vérifier les mises à niveau de nœuds suspendues.
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o yaml
...
annotations:
harvesterhci.io/node-upgrade-pause-map: '{"charlie-1-tink-system":"pause","charlie-2-tink-system":"pause","charlie-3-tink-system":"pause"}'
...
nodeStatuses:
charlie-1-tink-system:
message: Node upgrade paused as requested by the user
reason: AdministrativelyPaused
state: Node-upgrade paused
charlie-2-tink-system:
state: Images preloaded
charlie-3-tink-system:
state: Images preloaded
...|
Les travaux de pré-drainage pour les nœuds avec des mises à niveau suspendues n’ont pas été créés. Cependant, ces nœuds sont toujours isolés et vous ne pourrez pas exécuter de nouvelles charges de travail sur eux. Seules les tâches de maintenance, telles que l’arrêt manuel des machines virtuelles, doivent être effectuées sur les nœuds dont les mises à niveau sont suspendues. |
Reprise d’une mise à niveau de nœud suspendue
Vous pouvez reprendre une mise à niveau de nœud suspendue en mettant à jour l’annotation harvesterhci.io/node-upgrade-pause-map sur la ressource personnalisée Upgrade.
Exemple :
# Find out the latest Upgrade custom resource
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-6mcwv 4h16m
# Update the annotation to unpause the node
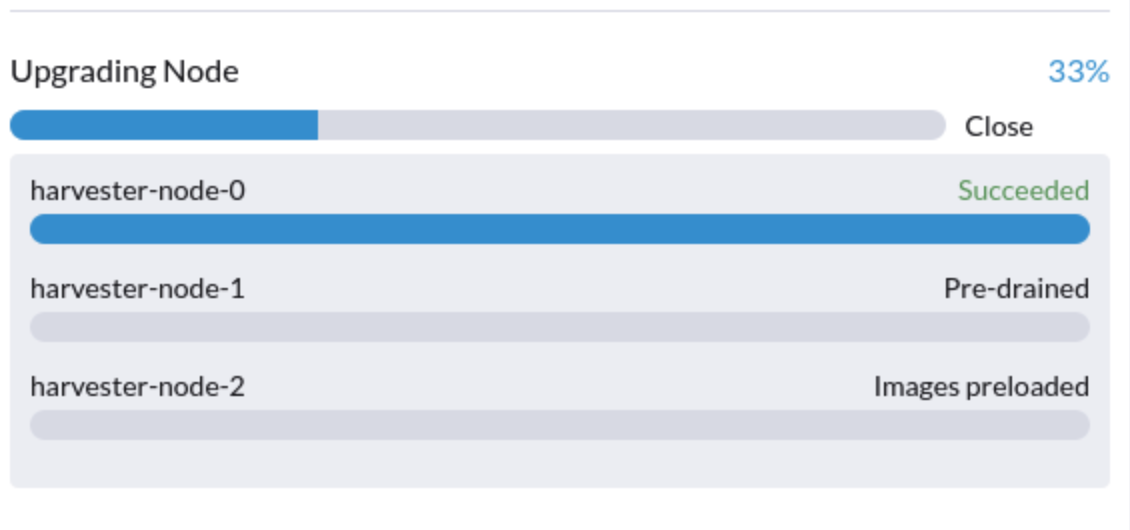
$ kubectl -n harvester-system annotate --overwrite upgrades hvst-upgrade-6mcwv harvesterhci.io/node-upgrade-pause-map='{"charlie-1-tink-system":"unpause","charlie-2-tink-system":"pause","charlie-3-tink-system":"pause"}'Une fois que le nœud cible est annoté dans la ressource personnalisée Upgrade, SUSE Virtualization reprend immédiatement la mise à niveau, l’interface utilisateur affichant des mises à niveau visuelles de progression.
Vous pouvez également utiliser la commande kubectl suivante pour vérifier l’état du nœud cible :
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o yaml
...
annotations:
harvesterhci.io/node-upgrade-pause-map: '{"charlie-1-tink-system":"unpause","charlie-2-tink-system":"pause","charlie-3-tink-system":"pause"}'
...
nodeStatuses:
charlie-1-tink-system:
state: Pre-draining
charlie-2-tink-system:
state: Images preloaded
charlie-3-tink-system:
state: Images preloaded
...En fonction du nombre de nœuds cibles, vous pourriez avoir besoin d’exécuter l’opération de reprise plusieurs fois pendant le processus global de mise à niveau du cluster.
Exigence d’espace libre sur la partition système
SUSE Virtualization charge des images sur chaque nœud pendant les mises à niveau. Lorsque l’utilisation du disque dépasse le seuil de collecte des déchets du kubelet, le kubelet supprime les images inutilisées pour libérer de l’espace. Cela peut causer des problèmes dans des environnements isolés physiquement car les images ne sont pas disponibles sur le nœud.
SUSE Virtualization inclut des vérifications qui garantissent que les nœuds ne déclenchent pas la collecte des déchets après le chargement de nouvelles images.
Lorsque l’espace disque est insuffisant, SUSE Virtualization bloque la mise à niveau et renvoie une erreur similaire à la suivante :
Node "harvester-node-0" will reach 92.84% storage space after loading new images. It's higher than kubelet image garbage collection threshold 85%.Si vous souhaitez essayer de mettre à jour même si l’espace libre sur la partition système est insuffisant sur certains nœuds, vous pouvez mettre à jour l’annotation harvesterhci.io/skipGarbageCollectionThresholdCheck: true de l’objet Upgrade.
apiVersion: harvesterhci.io/v1beta1
kind: Upgrade
metadata:
annotations:
harvesterhci.io/skipGarbageCollectionThresholdCheck: true
generateName: hvst-upgrade-
namespace: harvester-system
spec:
version: "1.6.0"
logEnabled: true|
Définir une valeur inférieure à la valeur prédéfinie peut entraîner l’échec de la mise à niveau et n’est pas recommandé dans un environnement de production. |
Les sections suivantes décrivent des solutions pour les problèmes liés à cette exigence.
Libérez manuellement l’espace sur la partition système
SUSE Virtualization tente de supprimer les images de conteneurs inutiles après qu’une mise à niveau soit terminée. Cependant, ce nettoyage automatique des images peut ne pas être effectué pour diverses raisons. Vous pouvez utiliser un script pour supprimer manuellement les images. Pour plus d’informations, voir le problème #6620.
Configurez un registre de conteneurs privé et évitez le préchargement des images.
La partition système peut encore manquer d’espace libre même après avoir supprimé des images. Pour y remédier, configurez un registre de conteneurs privé pour les images actuelles et nouvelles, et configurez le paramètre upgrade-config avec la valeur suivante :
{"imagePreloadOption":{"strategy":{"type":"skip"}}, "restoreVM": false}SUSE Virtualization ignore le processus de préchargement des images de mise à niveau. Lorsque les déploiements sur les nœuds sont mis à niveau, l’environnement d’exécution des conteneurs charge les images stockées dans le registre de conteneurs privé.
|
Ne comptez pas sur le registre de conteneurs public. Notez toute interruption potentielle du service Internet et à quel point vous êtes proche d’atteindre votre limite de taux Docker Hub. L’échec de téléchargement de l’une des images requises peut entraîner l’échec de la mise à niveau et laisser le cluster dans un état intermédiaire. |
Vérification de l’expiration des certificats
SUSE Virtualization vérifie la période de validité des certificats sur chaque nœud. Cette vérification élimine la possibilité que des certificats expirent pendant que la mise à niveau est en cours. Si un certificat doit expirer dans les 7 jours, une erreur est renvoyée. Ce comportement peut être remplacé en définissant l’annotation harvesterhci.io/minCertsExpirationInDay.
Exemple :
apiVersion: harvesterhci.io/v1beta1
kind: Upgrade
metadata:
annotations:
harvesterhci.io/minCertsExpirationInDay: "14"
generateName: hvst-upgrade-
namespace: harvester-system
spec:
version: "1.6.0"
logEnabled: trueLorsque cette annotation est ajoutée à l’objet Upgrade, SUSE Virtualization renvoie une erreur lorsqu’il détecte un certificat qui expirera dans les 14 jours.
Pour plus d’informations, voir auto-rotate-rke2-certs.
Compatibilité de la sauvegarde de machine virtuelle
Vous pouvez rencontrer certaines limitations lors de la création et de la restauration de sauvegardes impliquant un stockage externe.
Les plantages de Longhorn Manager dus à l’éviction de l’image de sauvegarde
|
Lors de la mise à niveau vers SUSE Virtualization v1.4.x, Longhorn Manager peut planter si le drapeau Pour éviter que le problème ne se produise, assurez-vous que le drapeau |
Réactivez les webhooks d’admission ingress-nginx RKE2 (CVE-2025-1974)
Si vous avez désactivé les webhooks d’admission ingress-nginx RKE2 pour atténuer CVE-2025-1974, vous devez réactiver le webhook après la mise à niveau vers SUSE Virtualization v1.5.0 ou une version ultérieure.
-
Vérifiez que SUSE Virtualization utilise nginx-ingress v1.12.1 ou une version ultérieure.
$ kubectl -n kube-system get po -l"app.kubernetes.io/name=rke2-ingress-nginx" -ojsonpath='{.items[].spec.containers[].image}' rancher/nginx-ingress-controller:v1.12.1-hardened1 -
Exécutez
kubectl -n kube-system edit helmchartconfig rke2-ingress-nginxpour supprimer les configurations suivantes de la ressourceHelmChartConfig.-
.spec.valuesContent.controller.admissionWebhooks.enabled: false -
.spec.valuesContent.controller.extraArgs.enable-annotation-validation: true
-
-
Vérifiez que la nouvelle configuration
.spec.ValuesContentest similaire à l’exemple suivant.apiVersion: helm.cattle.io/v1 kind: HelmChartConfig metadata: name: rke2-ingress-nginx namespace: kube-system spec: valuesContent: |- controller: admissionWebhooks: port: 8444 extraArgs: default-ssl-certificate: cattle-system/tls-rancher-internal config: proxy-body-size: "0" proxy-request-buffering: "off" publishService: pathOverride: kube-system/ingress-exposeSi la ressource
HelmChartConfigcontient d’autres configurations personnaliséesingress-nginx, vous devez les conserver lors de l’édition de la ressource. -
Quittez l’exécution de la commande
kubectl editpour enregistrer la configuration.SUSE Virtualization applique automatiquement le changement une fois le contenu enregistré.
-
Vérifiez que la configuration du webhook
rke2-ingress-nginx-admissionest réactivée.$ kubectl get validatingwebhookconfiguration rke2-ingress-nginx-admission NAME WEBHOOKS AGE rke2-ingress-nginx-admission 1 6s -
Vérifiez que les pods
ingress-nginxsont redémarrés avec succès.kubectl -n kube-system get po -lapp.kubernetes.io/instance=rke2-ingress-nginx NAME READY STATUS RESTARTS AGE rke2-ingress-nginx-controller-l2cxz 1/1 Running 0 94s
La mise à niveau est bloquée dans l’état "Pré-drainé"
Le processus de mise à niveau peut être bloqué dans l’état "Pré-drainé". Kubernetes est censé drainer la charge de travail sur le nœud, mais certains facteurs peuvent provoquer un blocage du processus.
Une cause possible est les processus liés aux moteurs orphelins du gestionnaire d’instances Longhorn. Pour déterminer si cela s’applique à votre situation, effectuez les étapes suivantes :
-
Vérifiez le nom du pod
instance-managersur le nœud bloqué.Exemple :
Le nœud bloqué est
harvester-node-1, et le nom du pod Instance Manager estinstance-manager-d80e13f520e7b952f4b7593fc1883e2a.$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager instance-manager-d80e13f520e7b952f4b7593fc1883e2a 1/1 Running 0 3d8h -
Vérifiez les journaux du Longhorn Manager pour des messages d’information.
Exemple :
$ kubectl -n longhorn-system logs daemonsets/longhorn-manager ... time="2025-01-14T00:00:01Z" level=info msg="Node instance-manager-d80e13f520e7b952f4b7593fc1883e2a is marked unschedulable but removing harvester-node-1 PDB is blocked: some volumes are still attached InstanceEngines count 1 pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0" func="controller.(*InstanceManagerController).syncInstanceManagerPDB" file="instance_manager_controller.go:823" controller=longhorn-instance-manager node=harvester-node-1Le pod
instance-managerne peut pas être drainé en raison du moteurpvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0. -
Vérifiez si le moteur fonctionne toujours sur le nœud bloqué.
Exemple :
$ kubectl -n longhorn-system get engines.longhorn.io pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0 -o jsonpath='{"Current state: "}{.status.currentState}{"\nNode ID: "}{.spec.nodeID}{"\n"}' Current state: stopped Node ID:Le problème existe probablement si la sortie montre que le moteur n’est pas en cours d’exécution ou introuvable.
-
Vérifiez si tous les volumes sont sains.
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'Tous les volumes doivent être marqués
healthy. Si ce n’est pas le cas, signalez le problème. -
Supprimez le PodDisruptionBudget (PDB) du pod
instance-manager.Exemple :
kubectl delete pdb instance-manager-d80e13f520e7b952f4b7593fc1883e2a -n longhorn-system
Problèmes connexes :
Échec de la migration en direct dans l’état "Pré-drainé"
La migration en direct des machines virtuelles peut échouer lorsque le nœud en cours de mise à niveau est isolé pendant l’état pré-drainé. Une cause courante est le manque de nœuds cibles compatibles en raison de règles d’anti-affinité strictes.
Lorsque cela se produit, SUSE Virtualization éteint automatiquement ces machines virtuelles pour débloquer la mise à niveau et empêcher le processus de redémarrer de manière non sécurisée.
Les instantanés et sauvegardes récurrents SUSE Storage ne sont pas pris en charge
Les instantanés et sauvegardes récurrents SUSE Storage ne sont pas intégrés dans SUSE Virtualization. Si vous décidez d’utiliser cette fonctionnalité, vous devez désactiver tous les travaux d’instantanés et de sauvegardes récurrents dans SUSE Storage avant de commencer la mise à niveau.
Pour plus d’informations sur l’incompatibilité, voir Sauvegardes et instantanés programmés des machines virtuelles.