|
Ce document a été traduit à l'aide d'une technologie de traduction automatique. Bien que nous nous efforcions de fournir des traductions exactes, nous ne fournissons aucune garantie quant à l'exhaustivité, l'exactitude ou la fiabilité du contenu traduit. En cas de divergence, la version originale anglaise prévaut et fait foi. |
Mettez à niveau de v1.4.1 ou v1.4.2 vers v1.4.3
informations générales
Un bouton Mettre à niveau apparaît sur l’écran Panneau de configuration chaque fois qu’une nouvelle version SUSE Virtualization à laquelle vous pouvez mettre à niveau est disponible. Pour plus d’informations, consultez Démarrer une mise à niveau.
Les versions SUSE Virtualization v1.4.2 et v1.4.3 utilisent la même version mineure de SUSE® Rancher Prime: RKE2 (v1.31). Cela vous permet de mettre à niveau directement de v1.4.1 à v1.4.3.
Pour les environnements isolés physiquement, consultez Préparer une mise à niveau isolée physiquement.
Problèmes connus
1. Mise à niveau isolée bloquée avec l’erreur ImagePullBackOff dans les pods Fluentd et Fluent Bit
La mise à niveau peut être bloquée dès le début du processus, comme l’indique un progrès de 0 % et des éléments marqués En attente dans la boîte de dialogue Mise à niveau de l’interface utilisateur SUSE Virtualization.
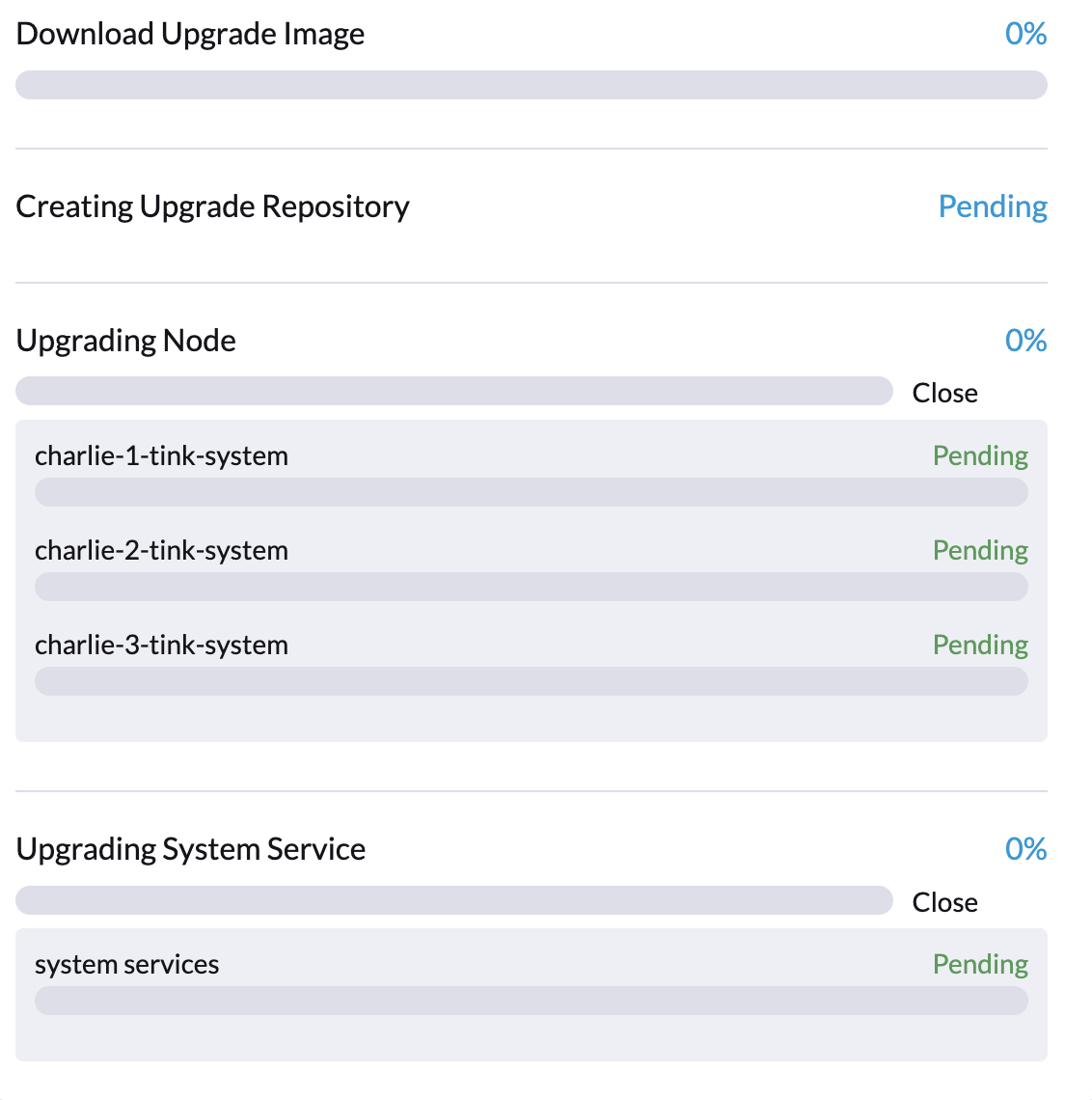
Plus précisément, les pods Fluentd et Fluent Bit peuvent rester bloqués dans l’état ImagePullBackOff. Pour vérifier l’état des pods, exécutez les commandes suivantes :
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-x2hz8 7m14s
$ kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=hvst-upgrade-x2hz8
NAME UPGRADE
hvst-upgrade-x2hz8-upgradelog hvst-upgrade-x2hz8
$ kubectl -n harvester-system get pods -l harvesterhci.io/upgradeLog=hvst-upgrade-x2hz8-upgradelog
NAME READY STATUS RESTARTS AGE
hvst-upgrade-x2hz8-upgradelog-downloader-6cdb864dd9-6bw98 1/1 Running 0 7m7s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-2nq7q 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-697wf 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-kd8kl 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentd-0 0/2 ImagePullBackOff 0 7m42sCela se produit parce que les images de conteneur suivantes ne sont ni préchargées dans les nœuds du cluster ni téléchargées depuis Internet :
-
ghcr.io/kube-logging/fluentd:v1.15-ruby3 -
ghcr.io/kube-logging/config-reloader:v0.0.5 -
fluent/fluent-bit:2.1.8
Pour résoudre le problème, effectuez l’une des actions suivantes :
-
Mettez à jour le CR de journalisation pour utiliser les images qui sont déjà préchargées dans les nœuds du cluster. Pour ce faire, exécutez les commandes suivantes sur le cluster :
# Get the Logging CR names OPERATOR_LOGGING_NAME=$(kubectl get loggings -l app.kubernetes.io/name=rancher-logging -o jsonpath="{.items[0].metadata.name}") INFRA_LOGGING_NAME=$(kubectl get loggings -l harvesterhci.io/upgradeLogComponent=infra -o jsonpath="{.items[0].metadata.name}") # Gather image info from operator's Logging CR FLUENTD_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.repository}") FLUENTD_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.tag}") FLUENTBIT_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.repository}") FLUENTBIT_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.tag}") CONFIG_RELOADER_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.repository}") CONFIG_RELOADER_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.tag}") # Patch the Logging CR kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentbit/image\",\"value\":{\"repository\":\"$FLUENTBIT_IMAGE_REPO\",\"tag\":\"$FLUENTBIT_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/image\",\"value\":{\"repository\":\"$FLUENTD_IMAGE_REPO\",\"tag\":\"$FLUENTD_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/configReloaderImage\",\"value\":{\"repository\":\"$CONFIG_RELOADER_IMAGE_REPO\",\"tag\":\"$CONFIG_RELOADER_IMAGE_TAG\"}}]"L’état des pods Fluentd et Fluent Bit devrait changer en
Runningdans un instant et le processus de mise à niveau devrait se poursuivre après la mise à jour du CR de journalisation. Si l’état du pod Fluentd est toujoursImagePullBackOff, vous pouvez supprimer le pod pour forcer son redémarrage.UPGRADE_NAME=$(kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o jsonpath='{.items[0].metadata.name}') UPGRADELOG_NAME=$(kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=$UPGRADE_NAME -o jsonpath='{.items[0].metadata.name}') kubectl -n harvester-system delete pods -l harvesterhci.io/upgradeLog=$UPGRADELOG_NAME,harvesterhci.io/upgradeLogComponent=aggregator -
Sur un ordinateur avec accès à Internet, téléchargez les images de conteneur requises, puis exportez-les dans un fichier TAR. Ensuite, transférez le fichier TAR vers les nœuds du cluster, puis importez les images en exécutant les commandes suivantes sur chaque nœud :
# Pull down the three container images docker pull ghcr.io/kube-logging/fluentd:v1.15-ruby3 docker pull ghcr.io/kube-logging/config-reloader:v0.0.5 docker pull fluent/fluent-bit:2.1.8 # Export the images to a tar file docker save \ ghcr.io/kube-logging/fluentd:v1.15-ruby3 \ ghcr.io/kube-logging/config-reloader:v0.0.5 \ fluent/fluent-bit:2.1.8 > upgradelog-images.tar # After transferring the tar file to the cluster nodes, import the images (need to be run on each node) ctr -n k8s.io images import upgradelog-images.tarLe processus de mise à niveau devrait se poursuivre après que les images soient préchargées.
-
(Non recommandé) Redémarrez le processus de mise à niveau avec la journalisation désactivée. Assurez-vous que la case à cocher Activer la journalisation dans la boîte de dialogue Mise à niveau n’est pas sélectionnée.
-
Problème connexe : #7955
2. Volumes surdimensionnés
Dans SUSE Virtualization v1.4.3, qui utilise SUSE Storage v1.7.3, les volumes surdimensionnés (par exemple, 999999 Gi de taille) sont marqués Non prêt et ne peuvent pas être supprimés.
Pour résoudre ce problème, procédez comme suit :
-
Supprimez temporairement la règle de webhook PVC.
RULE_INDEX=$(kubectl get \ validatingwebhookconfiguration longhorn-webhook-validator -o json \ | jq '.webhooks[0].rules | map(.resources[0] == "persistentvolumeclaims") | index(true)') if [ -n "$RULE_INDEX" -a "$RULE_INDEX" != "null" ]; then kubectl patch validatingwebhookconfiguration longhorn-webhook-validator \ --type='json' \ -p="[{'op': 'remove', 'path': '/webhooks/0/rules/$RULE_INDEX'}]" fi -
Attendez que le PVC connexe soit supprimé.
-
Restaurez la règle de webhook PVC pour réactiver la validation.
kubectl patch validatingwebhookconfiguration longhorn-webhook-validator \ --type='json' \ -p='[{"op": "add", "path": "/webhooks/0/rules/-", "value": {"apiGroups":[""],"apiVersions":["v1"],"operations":["UPDATE"],"resources":["persistentvolumeclaims"],"scope":"Namespaced"}}]'
Le problème sera résolu dans SUSE Storage v1.8.2, qui sera probablement inclus dans SUSE Virtualization v1.5.1.
3. Les utilisateurs non-root sur les clusters invités ne peuvent pas accéder aux volumes RWX
Les utilisateurs non-root sur les clusters invités rencontrent des erreurs inattendues "autorisation refusée" lors de l’accès aux volumes RWX. Cela est causé par un problème de régression dans nfs-ganesha v6.0+, qui affecte v1.7.3 de l’image longhorn-share-manager.
Vous pouvez résoudre le problème en remplaçant longhorn-share-manager:v1.7.3 par l’image corrigée longhorn-share-manager:v1.7.3-hotfix-1.
|
N’utilisez pas l’image corrigée si vous n’êtes pas affecté par le problème. |
-
Modifiez le
longhorn-managerDaemonSet en exécutant la commande suivante :kubectl -n longhorn-system edit daemonset/longhorn-manager -
Dans le champ
spec.containers.command, changez le--share-manager-imageenlonghornio/longhorn-share-manager:v1.7.3-hotfix-1.... spec: containers: - command: - longhorn-manager - -d - daemon - --engine-image - longhornio/longhorn-engine:v1.7.3 - --instance-manager-image - longhornio/longhorn-instance-manager:v1.7.3 - --share-manager-image - longhornio/longhorn-share-manager:v1.7.3-hotfix-1 - --backing-image-manager-image - longhornio/backing-image-manager:v1.7.3 - --support-bundle-manager-image - longhornio/support-bundle-kit:v0.0.51 - --manager-image - longhornio/longhorn-manager:v1.7.3 - --service-account - longhorn-service-account - --upgrade-version-check ... -
Une fois la mise à jour appliquée, redémarrez les charges de travail utilisant des volumes RWX.
|
Si vous utilisez l’image corrigée et souhaitez mettre à niveau SUSE Virtualization v1.5.x, vous devez modifier le |
4. Les machines virtuelles qui utilisent des volumes RWX migrables redémarrent de manière inattendue
Les machines virtuelles qui utilisent des volumes RWX migrables redémarrent de manière inattendue lorsque les pods du plugin CSI sont redémarrés. Ce problème affecte SUSE Virtualization v1.4.x, v1.5.0 et v1.5.1.
La solution de contournement consiste à désactiver le paramètre Supprimer automatiquement le pod de charge de travail lorsque le volume est détaché de manière inattendue sur l’interface utilisateur SUSE Storage avant de commencer la mise à niveau. Vous devez réactiver le paramètre une fois la mise à niveau terminée.
Le problème sera corrigé dans SUSE Storage v1.8.3, v1.9.1 et les versions ultérieures. SUSE Virtualization v1.6.0 inclura SUSE Storage v1.9.1.