|
Ce document a été traduit à l'aide d'une technologie de traduction automatique. Bien que nous nous efforcions de fournir des traductions exactes, nous ne fournissons aucune garantie quant à l'exhaustivité, l'exactitude ou la fiabilité du contenu traduit. En cas de divergence, la version originale anglaise prévaut et fait foi. |
Mettez à niveau de v1.4.0 à v1.4.1
informations générales
Un bouton Upgrade apparaît sur l’écran Dashboard chaque fois qu’une nouvelle version SUSE Virtualization à laquelle vous pouvez mettre à niveau est disponible. Pour plus d’informations, voir Démarrer une mise à niveau.
Pour les environnements isolés physiquement, voir Préparer une mise à niveau isolée physiquement.
|
Vérifiez l’utilisation du disque des images du système d’exploitation sur chaque nœud avant de commencer la mise à niveau. Pour ce faire, accédez au nœud via SSH et exécutez la commande Exemple : Si
|
Mettez à jour l’extension UI de Harvester sur SUSE Rancher Prime v2.10.1
Vous devez utiliser v1.0.3 de l’extension UI de Harvester pour importer des clusters SUSE Virtualization v1.4.1 sur Rancher v2.10.1.
-
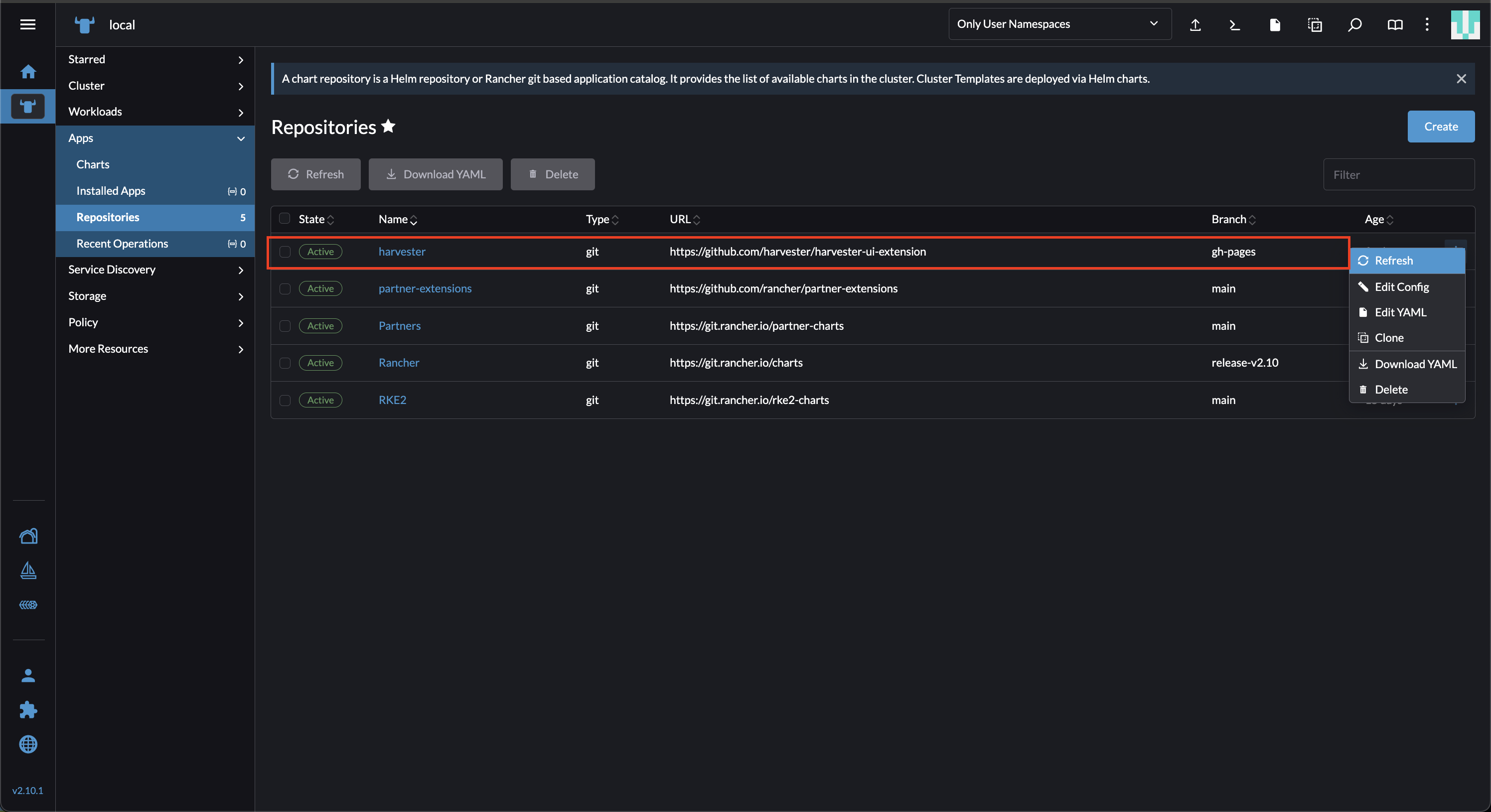
Sur l’interface Rancher, allez à local → Apps → Repositories.
-
Localisez le dépôt nommé harvester, puis sélectionnez ⋮ → Actualiser.
Ce dépôt a les propriétés suivantes :
-
Branche : gh-pages
-
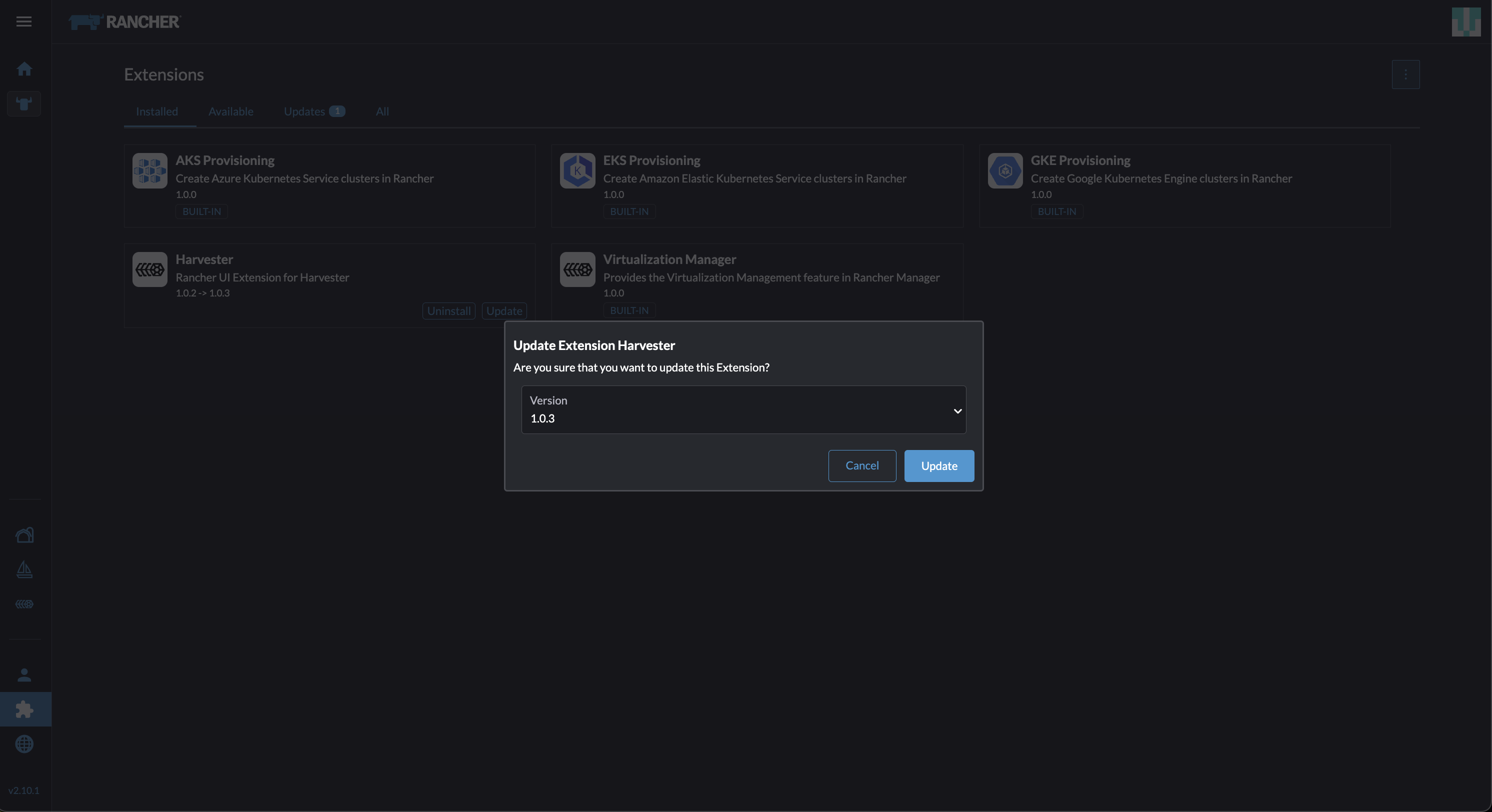
Allez à l’écran Extensions.
-
Localisez l’extension nommée Harvester, puis cliquez sur Mettre à jour.
-
Sélectionnez la version 1.0.3, puis cliquez sur Mettre à jour.
-
Laissez un certain temps pour que l’extension soit mise à jour, puis actualisez l’écran.
|
L’interface utilisateur Rancher affiche un message d’erreur après la mise à jour de l’extension. Le message d’erreur disparaît lorsque vous actualisez l’écran. Ce problème, qui existe dans Rancher v2.10.0 et v2.10.1, sera corrigé dans v2.10.2. |
Problèmes connus
1. Mise à niveau bloquée dans l’état "Pré-drainé"
Le processus de mise à niveau peut être bloqué dans l’état "Pré-drainé". Kubernetes est censé drainer la charge de travail sur le nœud, mais certains facteurs peuvent provoquer un blocage du processus.
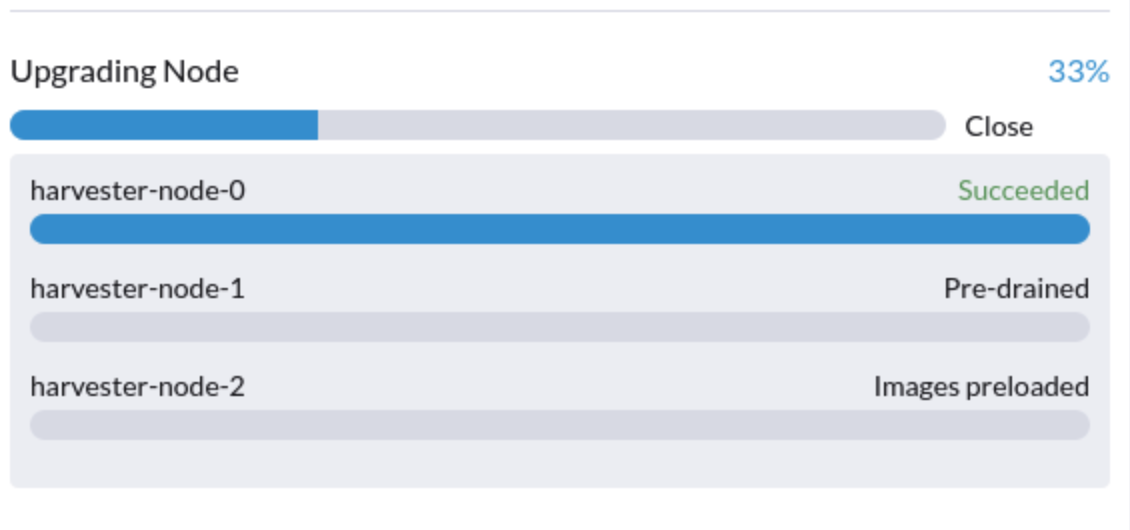
Une cause possible est des processus liés aux moteurs orphelins du Longhorn Instance Manager. Pour déterminer si cela s’applique à votre situation, effectuez les étapes suivantes :
-
Vérifiez le nom du pod
instance-managersur le nœud bloqué.Exemple :
Le nœud bloqué est
harvester-node-1, et le nom du pod Instance Manager estinstance-manager-d80e13f520e7b952f4b7593fc1883e2a.$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager instance-manager-d80e13f520e7b952f4b7593fc1883e2a 1/1 Running 0 3d8h -
Vérifiez les journaux du Longhorn Manager pour des messages d’information.
Exemple :
$ kubectl -n longhorn-system logs daemonsets/longhorn-manager ... time="2025-01-14T00:00:01Z" level=info msg="Node instance-manager-d80e13f520e7b952f4b7593fc1883e2a is marked unschedulable but removing harvester-node-1 PDB is blocked: some volumes are still attached InstanceEngines count 1 pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0" func="controller.(*InstanceManagerController).syncInstanceManagerPDB" file="instance_manager_controller.go:823" controller=longhorn-instance-manager node=harvester-node-1Le pod
instance-managerne peut pas être drainé en raison du moteurpvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0. -
Vérifiez si le moteur fonctionne toujours sur le nœud bloqué.
Exemple :
$ kubectl -n longhorn-system get engines.longhorn.io pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0 -o jsonpath='{"Current state: "}{.status.currentState}{"\nNode ID: "}{.spec.nodeID}{"\n"}' Current state: stopped Node ID:Le problème existe probablement si la sortie montre que le moteur n’est pas en cours d’exécution ou introuvable.
-
Vérifiez si tous les volumes sont sains.
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'Tous les volumes doivent être marqués
healthy. Si ce n’est pas le cas, signalez le problème. -
Supprimez le PodDisruptionBudget (PDB) du pod
instance-manager.Exemple :
kubectl delete pdb instance-manager-d80e13f520e7b952f4b7593fc1883e2a -n longhorn-system
2. Mettez à niveau avec une StorageClass par défaut qui n’est pas harvester-longhorn
Le Harvester ajoute l’annotation storageclass.kubernetes.io/is-default-class: "true" à harvester-longhorn, qui est la StorageClass par défaut d’origine. Lorsque vous remplacez harvester-longhorn par une autre StorageClass, les éléments suivants se produisent :
-
Le ManagedChart du Harvester affiche le message d’erreur
cannot patch "harvester-longhorn" with kind StorageClass: admission webhook "validator.harvesterhci.io" denied the request: default storage class %!s(MISSING) already exists, please reset it first. -
Le webhook refuse la demande de mise à niveau.
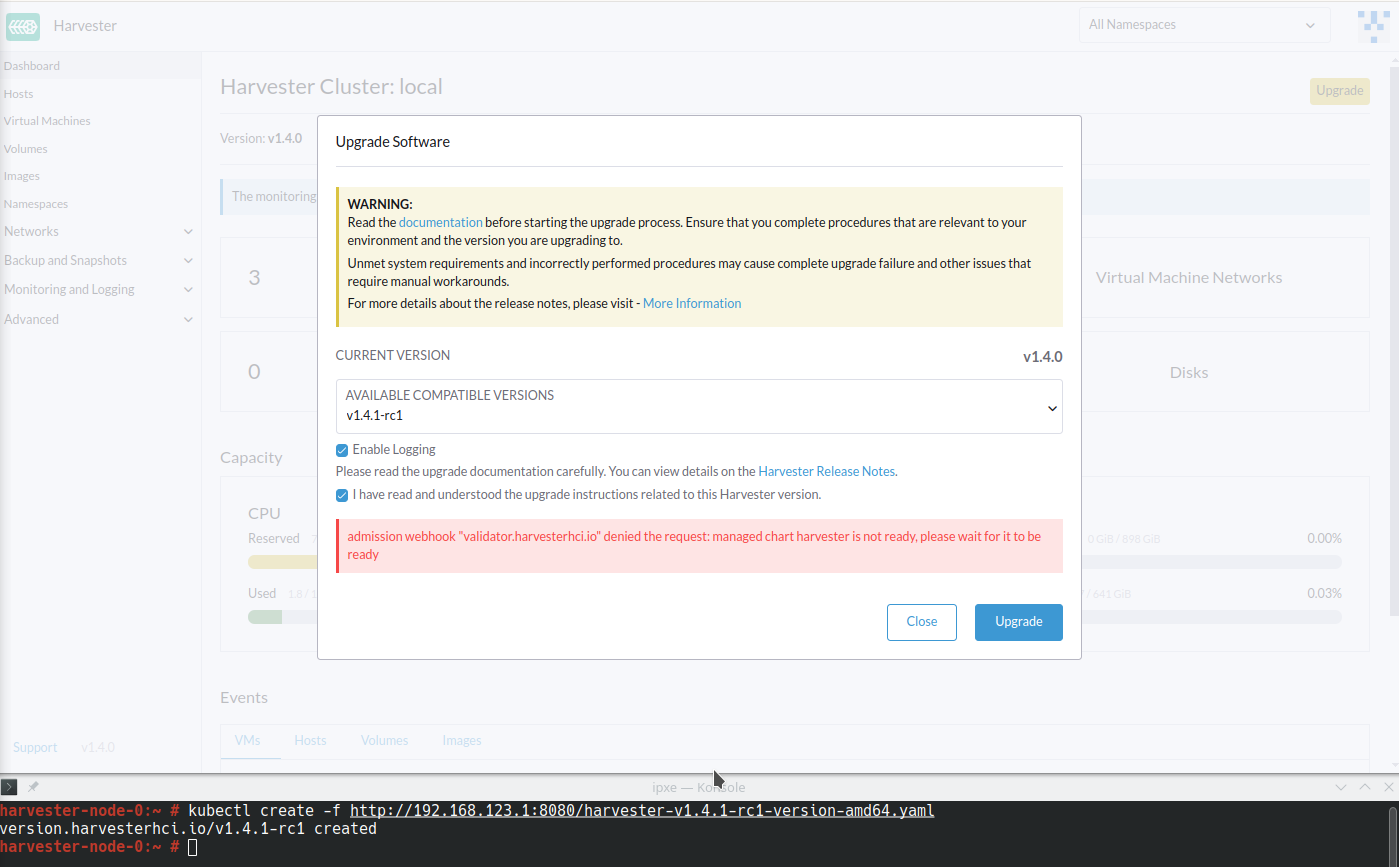
Vous pouvez effectuer l’une des solutions de contournement suivantes :
-
Définissez
harvester-longhorncomme la StorageClass par défaut. -
Ajoutez
spec.values.storageClass.defaultStorageClass: falseau ManagedChartharvester.kubectl edit managedchart harvester -n fleet-local -
Ajoutez
timeoutSeconds: 600à la spécification du ManagedChart du Harvester.kubectl edit managedchart harvester -n fleet-local
Problème lié : #7375
3. Mise à niveau bloquée dans l’état "En attente de redémarrage"
Le processus de mise à niveau peut rester bloqué dans l’état "En attente de redémarrage" après que l’image Harvester v1.4.1 a été installée sur un nœud et qu’un redémarrage a été initié. À ce stade, le contrôleur de mise à niveau observe si le système d’exploitation Harvester v1.4.1 est en cours d’exécution.
Si l’image Harvester v1.4.1 (ci-après dénommée active.img) ne parvient pas à démarrer pour une raison quelconque, le nœud redémarre automatiquement en mode de secours et démarre l’image Harvester v1.4.0 précédemment installée (ci-après dénommée passive.img). Le contrôleur de mise à niveau ne parvient pas à détecter le système d’exploitation attendu, donc la mise à niveau reste bloquée jusqu’à ce qu’un administrateur résolve le problème avec active.img.
active.img peut devenir corrompu et non amorçable en raison d’un espace disque insuffisant dans la partition COS_STATE pendant la mise à niveau. Cela se produit si Harvester v1.4.0 a été initialement installé sur le nœud et que le système a été configuré pour utiliser un disque de données séparé. Le problème ne se produit pas dans les situations suivantes :
-
Le système dispose d’un seul disque partagé par le système d’exploitation et les données.
-
Une version antérieure de Harvester a été installée puis mise à niveau vers la v1.4.0.
Pour vérifier si le problème existe dans votre environnement, effectuez les étapes suivantes :
-
Accédez au nœud via SSH et connectez-vous en utilisant le compte [Root].
-
Exécutez les commandes
cat /proc/cmdlineethead -n1 /etc/harvester-release.yaml.Exemple :
# cat /proc/cmdline BOOT_IMAGE=(loop0)/boot/vmlinuz console=tty1 root=LABEL=COS_STATE cos-img/filename=/cOS/passive.img panic=0 net.ifnames=1 rd.cos.oemlabel=COS_OEM rd.cos.mount=LABEL=COS_OEM:/oem rd.cos.mount=LABEL=COS_PERSISTENT:/usr/local rd.cos.oemtimeout=120 audit=1 audit_backlog_limit=8192 intel_iommu=on amd_iommu=on iommu=pt multipath=off upgrade_failure # head -n1 /etc/harvester-release.yaml harvester: v1.4.0La présence de
cos-img/filename=/cOS/passive.imgetupgrade_failuredans la sortie indique que le système a démarré en mode de secours. La version de Harvester dans/etc/harvester-release.yamlconfirme que le système utilise actuellement l’image v1.4.0. -
Vérifiez si
active.imgest corrompu en exécutant la commandefsck.ext2 -nf /run/initramfs/cos-state/cOS/active.img.Exemple :
# fsck.ext2 -nf /run/initramfs/cos-state/cOS/active.img e2fsck 1.46.4 (18-Aug-2021) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure [...a list of various different errors may appear here...] e2fsck: aborted COS_ACTIVE: ********** WARNING: Filesystem still has errors ********** -
Vérifiez les tailles des partitions en exécutant la commande
lsblk -o NAME,LABEL,SIZE.Exemple :
# lsblk -o NAME,LABEL,SIZE NAME LABEL SIZE loop0 COS_ACTIVE 3G sr0 1024M vda 250G ├─vda1 COS_GRUB 64M ├─vda2 COS_OEM 64M ├─vda3 COS_RECOVERY 4G ├─vda4 COS_STATE 8G └─vda5 COS_PERSISTENT 237.9G vdb HARV_LH_DEFAULT 128GLa sortie dans l’exemple montre une partition
COS_STATEde 8 Go. Dans ce cas spécifique, qui implique une tentative de mise à niveau infructueuse et unactive.imgcorrompu, la partition n’avait probablement pas assez d’espace libre pour que la mise à niveau réussisse.
Pour résoudre le problème, effectuez les étapes suivantes :
-
Si votre cluster a deux nœuds ou plus, accédez aux nœuds restants via SSH et vérifiez l’utilisation du disque de
active.imgetpassive.img.# du -sh /run/initramfs/cos-state/cOS/* 1.7G /run/initramfs/cos-state/cOS/active.img 3.1G /run/initramfs/cos-state/cOS/passive.imgSi
passive.imgconsomme 3,1 Go d’espace disque, exécutez la commande suivante en utilisant le compte [Root] :# mount -o remount,rw /run/initramfs/cos-state # fallocate --dig-holes /run/initramfs/cos-state/cOS/passive.img # mount -o remount,ro /run/initramfs/cos-statepassive.imgest converti en un fichier sparse, qui ne devrait consommer que 1.7G d’espace disque (le même queactive.img). Cela garantit que les autres nœuds disposent de suffisamment d’espace libre, empêchant le processus de mise à niveau de se bloquer à nouveau. -
Accédez au nœud bloqué via SSH, puis exécutez la commande suivante en utilisant le compte [Root] :
# mount -o remount,rw /run/initramfs/cos-state # cp /run/initramfs/cos-state/cOS/passive.img \ /run/initramfs/cos-state/cOS/active.img # tune2fs -L COS_ACTIVE /run/initramfs/cos-state/cOS/active.img # mount -o remount,ro /run/initramfs/cos-stateLe
passive.imgexistant (propre) est copié sur leactive.imgcorrompu, et l’étiquette est correctement définie. -
Redémarrez le nœud bloqué, puis sélectionnez la première entrée (Harvester v1.4.1) sur l’écran de démarrage GRUB.
L’écran de démarrage GRUB affiche initialement Harvester v1.4.1 (fallback) par défaut. Malgré la version affichée, le système démarre sur Harvester v1.4.0.
-
Copiez
rootfs.squashfsde l’ISO de Harvester v1.4.1 vers un emplacement pratique sur le nœud bloqué.L’ISO peut être monté soit sur le nœud bloqué, soit sur un autre système. Vous pouvez copier le fichier en utilisant la commande
scp. -
Accédez au nœud bloqué via SSH, puis exécutez la commande suivante en utilisant le compte [Root] :
# mkdir /tmp/manual-os-upgrade # mkdir /tmp/manual-os-upgrade/config # mkdir /tmp/manual-os-upgrade/rootfs # mount -o loop rootfs.squashfs /tmp/manual-os-upgrade/rootfs # cat > /tmp/manual-os-upgrade/config/config.yaml <<EOF upgrade: system: size: 3072 EOF # elemental upgrade \ --logfile /tmp/manual-os-upgrade/upgrade.log \ --directory /tmp/manual-os-upgrade/rootfs \ --config-dir /tmp/manual-os-upgrade/config \ --debugVous devez remplacer le chemin d’exemple dans la quatrième ligne par le chemin réel du
rootfs.squashfscopié.Un nouveau
active.img(propre) est généré à partir de l’image racine de l’ISO Harvester v1.4.1.Si des erreurs se produisent, sauvegardez une copie de
/tmp/manual-os-upgrade/upgrade.log. -
Exécutez les commandes suivantes :
# umount /tmp/manual-os-upgrade/rootfs # rebootLe nœud doit démarrer avec succès sur Harvester v1.4.1, et la mise à niveau doit se poursuivre comme prévu.
4. La mise à niveau redémarre de manière inattendue après avoir cliqué sur le bouton "Ignorer".
Lorsque vous utilisez Rancher pour mettre à niveau SUSE Virtualization, l’interface utilisateur Rancher affiche une boîte de dialogue avec un bouton étiqueté "Ignorer". Cliquer sur ce bouton peut entraîner les problèmes suivants :
-
La section
statusdu CRharvesterhci.io/v1beta1/upgradeest effacée, entraînant la perte de toutes les informations importantes concernant la mise à niveau. -
Le processus de mise à niveau redémarre de manière inattendue.
Ce problème affecte Rancher v2.10.x, qui utilise v1.0.2, v1.0.3 et v1.0.4 de la Harvester UI Extension. Toutes les versions de l’interface utilisateur SUSE Virtualization ne sont pas affectées. Le problème est corrigé dans Harvester UI Extension v1.0.5 et v1.5.0.
Pour éviter ce problème, effectuez l’une des actions suivantes :
-
Utilisez l’interface utilisateur SUSE Virtualization pour mettre à niveau. Cliquer sur le bouton "Ignorer" dans l’interface utilisateur SUSE Virtualization ne provoque pas de comportement inattendu.
-
Au lieu de cliquer sur le bouton dans l’interface utilisateur Rancher, exécutez la commande suivante contre le cluster :
kubectl -n harvester-system label upgrades -l harvesterhci.io/latestUpgrade=true harvesterhci.io/read-message=true
Problème lié : #7791
5. Les machines virtuelles qui utilisent des volumes RWX migrables redémarrent de manière inattendue
Les machines virtuelles qui utilisent des volumes RWX volumes migrables redémarrent de manière inattendue lorsque les pods du plugin CSI sont redémarrés. Ce problème affecte SUSE Virtualization v1.4.x, v1.5.0 et v1.5.1.
La solution de contournement consiste à désactiver le paramètre Supprimer automatiquement le pod de charge de travail lorsque le volume est détaché de manière inattendue sur l’interface utilisateur SUSE Storage avant de commencer la mise à niveau. Vous devez réactiver le paramètre une fois la mise à niveau terminée.
Le problème sera corrigé dans SUSE Storage v1.8.3, v1.9.1 et les versions ultérieures. SUSE Virtualization v1.6.0 inclura SUSE Storage v1.9.1.