|
Este documento ha sido traducido utilizando tecnología de traducción automática. Si bien nos esforzamos por proporcionar traducciones precisas, no ofrecemos garantías sobre la integridad, precisión o confiabilidad del contenido traducido. En caso de discrepancia, la versión original en inglés prevalecerá y constituirá el texto autorizado. |
Actualiza de v1.4.2 o v1.4.3 a v1.5.2
Información general
Un botón de actualizar versión aparece en la pantalla Panel de control cada vez que hay una nueva SUSE Virtualization versión a la que puedes actualizar. Para más información, consulta Iniciar una actualización de versión.
Puedes actualizar directamente de v1.4.2 a v1.5.2 porque SUSE Virtualization permite un máximo de una actualización menor para los componentes subyacentes. v1.4.2 y v1.4.3 utilizan la misma versión menor de RKE2 (v1.31), mientras que v1.5.0, v1.5.1 y v1.5.2 utilizan la siguiente versión menor (v1.32).
Para obtener información sobre cómo actualizar SUSE Virtualization en entornos aislados, consulta Preparar una actualización en entorno aislado.
Actualiza la Extensión de UI de Harvester en SUSE Rancher Prime v2.11.0
Debes usar v1.5.2 de la Extensión de UI de Harvester para importar clústeres de SUSE Virtualization v1.5.2 en Rancher v2.11.0.
-
En la UI de Rancher, ve a local → Apps → Repositorios.
-
Localiza el repositorio llamado harvester, y luego selecciona ⋮ → Actualizar.
-
Ve a la pantalla Extensiones.
-
Localiza la extensión llamada Harvester, y luego haz clic en Actualizar.
-
Selecciona la versión 1.5.2, y luego haz clic en Actualizar.
-
Permite un tiempo para que la extensión se actualice, y luego actualiza la pantalla.
Problemas conocidos
La actualización en entorno aislado se queda atascada con el error ImagePullBackOff en los pods de Fluentd y Fluent Bit.
La actualización puede quedar atascada al principio del proceso, como indica el 0% de progreso y los elementos marcados como Pendiente en el diálogo de Actualización de la UI de SUSE Virtualization.
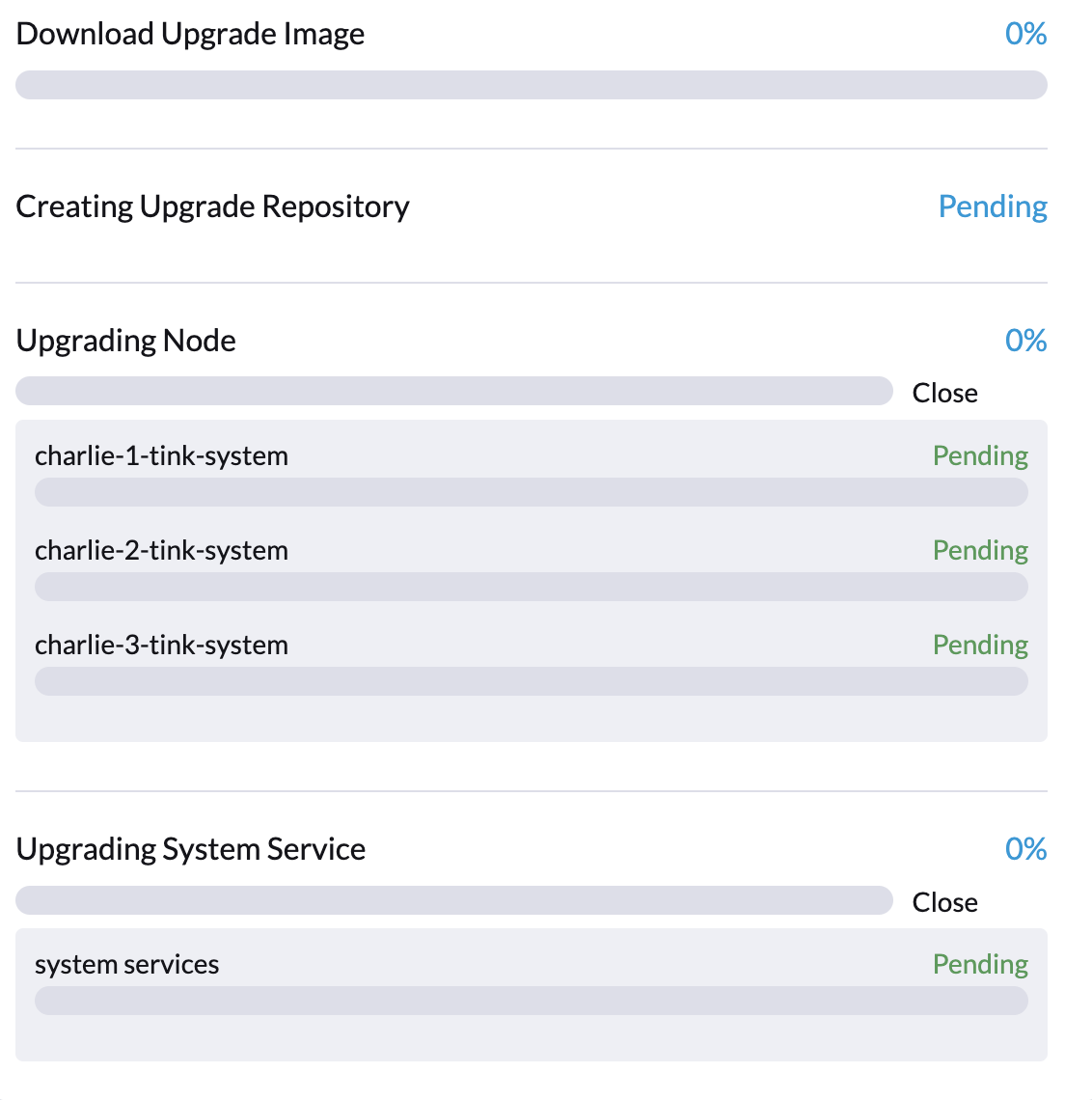
Específicamente, los pods de Fluentd y Fluent Bit pueden quedar atascados en el estado ImagePullBackOff. Para comprobar el estado de los pods, ejecuta los siguientes comandos:
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-x2hz8 7m14s
$ kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=hvst-upgrade-x2hz8
NAME UPGRADE
hvst-upgrade-x2hz8-upgradelog hvst-upgrade-x2hz8
$ kubectl -n harvester-system get pods -l harvesterhci.io/upgradeLog=hvst-upgrade-x2hz8-upgradelog
NAME READY STATUS RESTARTS AGE
hvst-upgrade-x2hz8-upgradelog-downloader-6cdb864dd9-6bw98 1/1 Running 0 7m7s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-2nq7q 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-697wf 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-kd8kl 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentd-0 0/2 ImagePullBackOff 0 7m42sEsto ocurre porque las siguientes imágenes de contenedor no están precargadas en los nodos del clúster ni se han descargado de internet:
-
ghcr.io/kube-logging/fluentd:v1.15-ruby3 -
ghcr.io/kube-logging/config-reloader:v0.0.5 -
fluent/fluent-bit:2.1.8
Para solucionar el problema, realiza cualquiera de las siguientes acciones:
-
Actualiza el CR de Logging para utilizar las imágenes que ya están precargadas en los nodos del clúster. Para hacer esto, ejecuta los siguientes comandos contra el clúster:
# Get the Logging CR names OPERATOR_LOGGING_NAME=$(kubectl get loggings -l app.kubernetes.io/name=rancher-logging -o jsonpath="{.items[0].metadata.name}") INFRA_LOGGING_NAME=$(kubectl get loggings -l harvesterhci.io/upgradeLogComponent=infra -o jsonpath="{.items[0].metadata.name}") # Gather image info from operator's Logging CR FLUENTD_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.repository}") FLUENTD_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.tag}") FLUENTBIT_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.repository}") FLUENTBIT_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.tag}") CONFIG_RELOADER_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.repository}") CONFIG_RELOADER_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.tag}") # Patch the Logging CR kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentbit/image\",\"value\":{\"repository\":\"$FLUENTBIT_IMAGE_REPO\",\"tag\":\"$FLUENTBIT_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/image\",\"value\":{\"repository\":\"$FLUENTD_IMAGE_REPO\",\"tag\":\"$FLUENTD_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/configReloaderImage\",\"value\":{\"repository\":\"$CONFIG_RELOADER_IMAGE_REPO\",\"tag\":\"$CONFIG_RELOADER_IMAGE_TAG\"}}]"El estado de los pods de Fluentd y Fluent Bit debería cambiar a
Runningen un momento y el proceso de actualización debería continuar después de que se actualice el CR de Logging. Si el estado del pod de Fluentd sigue siendoImagePullBackOff, puedes eliminar el pod para forzar su reinicio.UPGRADE_NAME=$(kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o jsonpath='{.items[0].metadata.name}') UPGRADELOG_NAME=$(kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=$UPGRADE_NAME -o jsonpath='{.items[0].metadata.name}') kubectl -n harvester-system delete pods -l harvesterhci.io/upgradeLog=$UPGRADELOG_NAME,harvesterhci.io/upgradeLogComponent=aggregator -
En un ordenador con acceso a internet, descarga las imágenes de contenedor requeridas y luego expórtalas a un archivo TAR. A continuación, transfiere el archivo TAR a los nodos del clúster y luego importa las imágenes ejecutando los siguientes comandos en cada nodo:
# Pull down the three container images docker pull ghcr.io/kube-logging/fluentd:v1.15-ruby3 docker pull ghcr.io/kube-logging/config-reloader:v0.0.5 docker pull fluent/fluent-bit:2.1.8 # Export the images to a tar file docker save \ ghcr.io/kube-logging/fluentd:v1.15-ruby3 \ ghcr.io/kube-logging/config-reloader:v0.0.5 \ fluent/fluent-bit:2.1.8 > upgradelog-images.tar # After transferring the tar file to the cluster nodes, import the images (need to be run on each node) ctr -n k8s.io images import upgradelog-images.tarEl proceso de actualización debería continuar después de que las imágenes estén precargadas.
-
(No recomendado) Reinicia el proceso de actualización con el registro deshabilitado. Asegúrate de que la casilla Habilitar Registro en el diálogo Actualización no esté seleccionada.
-
Problema relacionado: #7955
Las máquinas virtuales que utilizan volúmenes RWX migrables se reinician inesperadamente.
Las máquinas virtuales que utilizan volúmenes RWX migrables se reinician inesperadamente cuando se reinician los pods del plugin CSI. Este problema afecta a SUSE Virtualization v1.4.x, v1.5.0 y v1.5.1.
La solución alternativa es deshabilitar la configuración Eliminar automáticamente el pod de carga de trabajo cuando el volumen se desconecta inesperadamente en el UI SUSE Storage antes de comenzar la actualización. Debes habilitar la configuración nuevamente una vez que se complete la actualización.
El problema se solucionará en SUSE Storage v1.8.3, v1.9.1 y versiones posteriores. SUSE Virtualization v1.6.0 incluirá SUSE Storage v1.9.1.