仮想マシンの問題
以下のセクションには、SUSE Virtualization VM管理に関連する問題のトラブルシューティングに役立つ情報が含まれています。
VMスタートボタンが表示されない
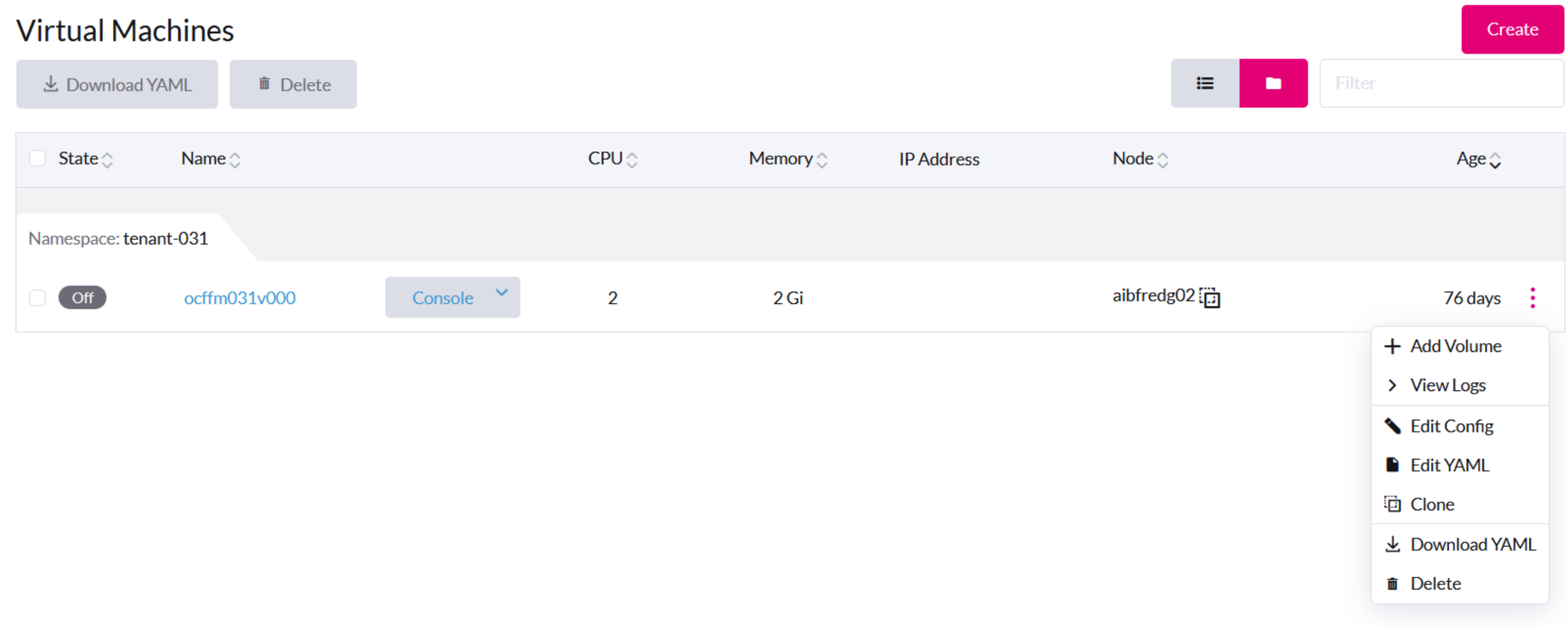
VM一般操作
SUSE Virtualization UI上では、VMが作成され起動した後に*停止*ボタンが表示されます。
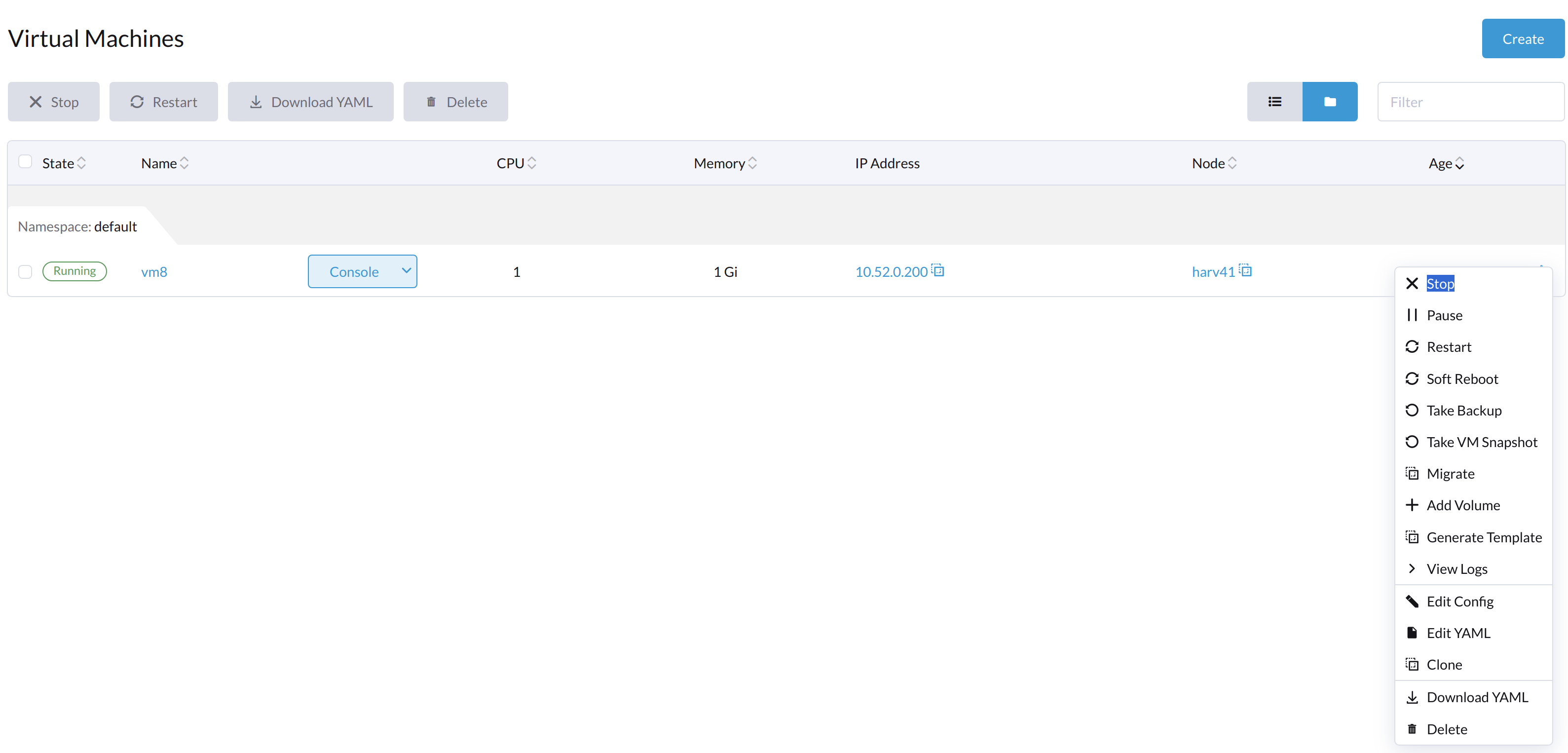
VMが停止した後に*スタート*ボタンが表示されます。
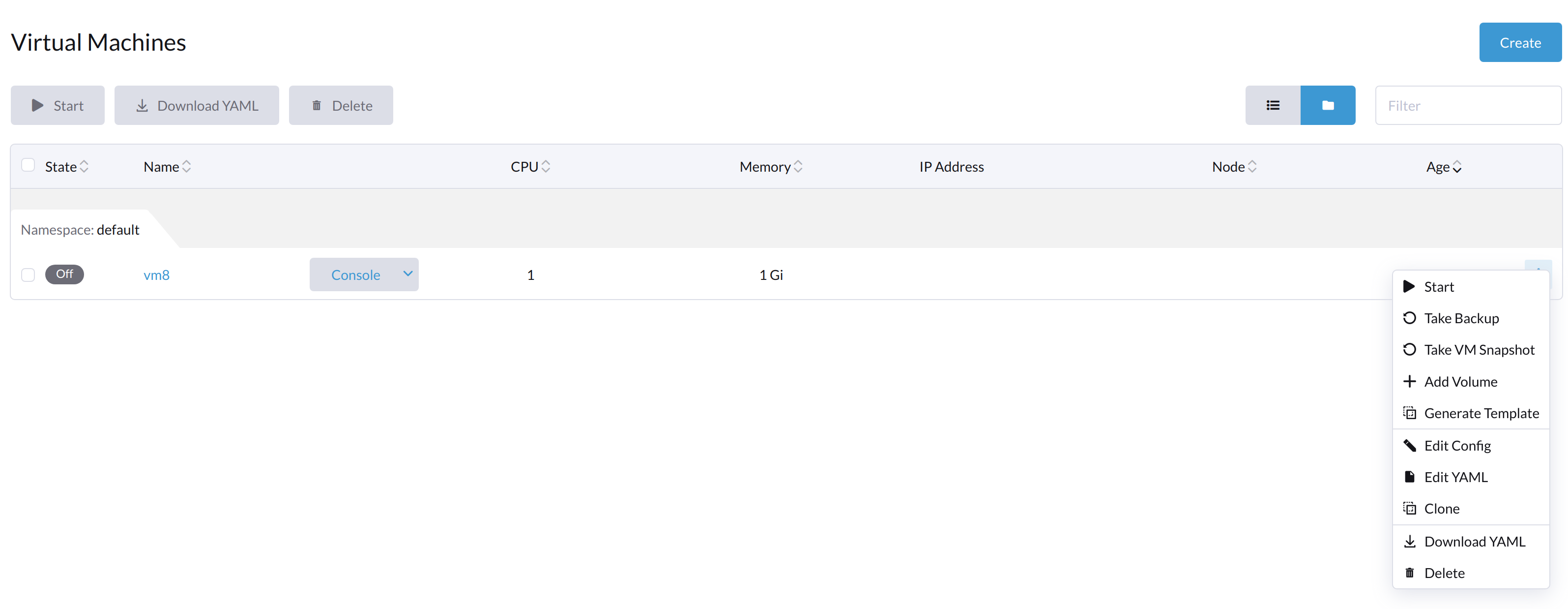
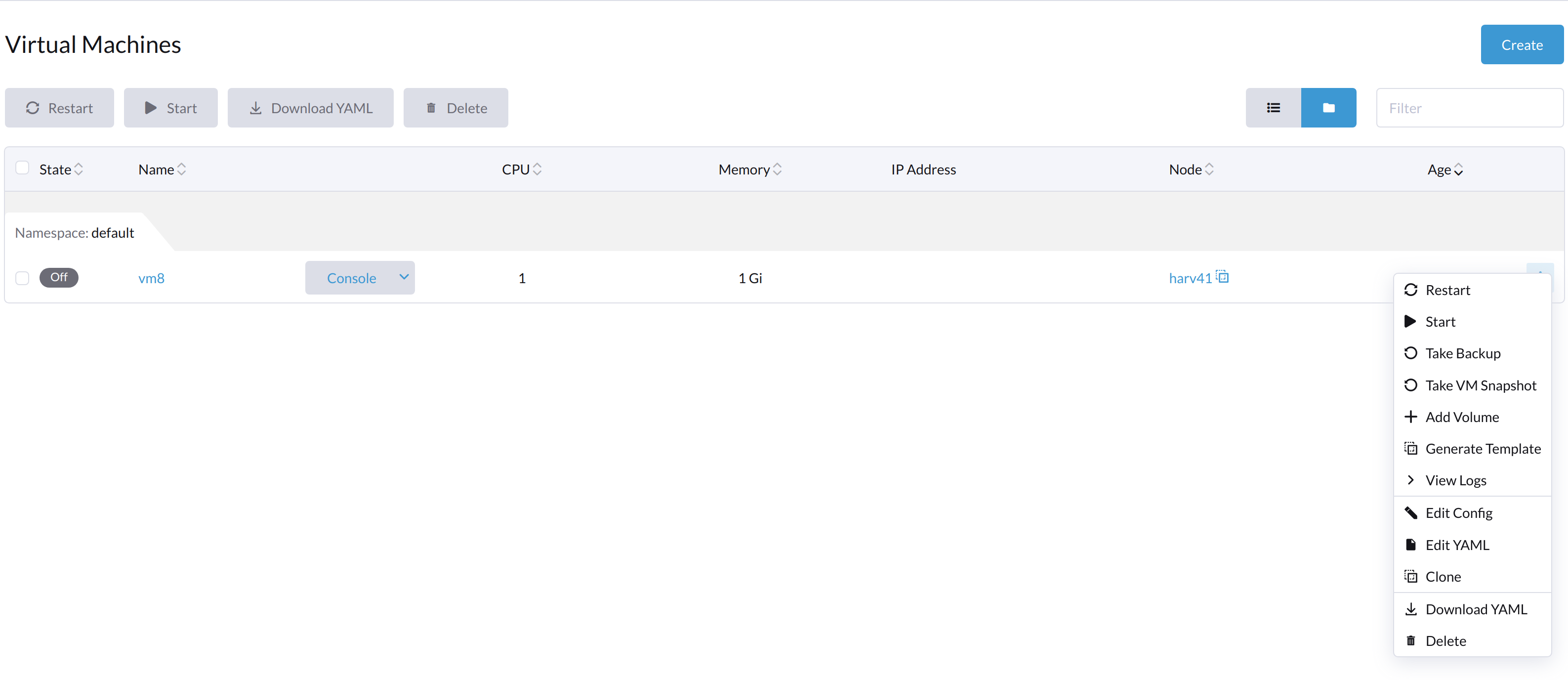
VMが内部から電源オフされた場合、*スタート*ボタンと*再起動*ボタンの両方が表示されます。
一般的なVM関連オブジェクト
稼働中のVM
VMに関連するオブジェクト`vm`、vmi、`pod`が存在します。これら三つのオブジェクトの状態は`Running`です。
# kubectl get vm NAME AGE STATUS READY vm8 7m25s Running True # kubectl get vmi NAME AGE PHASE IP NODENAME READY vm8 78s Running 10.52.0.199 harv41 True # kubectl get pod NAME READY STATUS RESTARTS AGE virt-launcher-vm8-tl46h 1/1 Running 0 80s
SUSE Virtualization UIを使用して停止したVM
オブジェクト`vm`のみが存在し、その状態は`Stopped`です。`vmi`と`pod`の両方が消えます。
# kubectl get vm NAME AGE STATUS READY vm8 123m Stopped False # kubectl get vmi No resources found in default namespace. # kubectl get pod No resources found in default namespace. #
VMの電源オフコマンドを使用して停止したVM
VMに関連するオブジェクト`vm`、vmi、`pod`が存在します。`vm`の状態は`Stopped`であり、`pod`の状態は`Completed`です。
# kubectl get vm NAME AGE STATUS READY vm8 134m Stopped False # kubectl get vmi NAME AGE PHASE IP NODENAME READY vm8 2m49s Succeeded 10.52.0.199 harv41 False # kubectl get pod NAME READY STATUS RESTARTS AGE virt-launcher-vm8-tl46h 0/1 Completed 0 2m54s
問題分析
問題が発生したとき、オブジェクト vm、vmi、および pod が存在します。オブジェクトの状態は、VMの電源オフコマンドを使用して停止したVM の状態に似ています。
例:
VM ocffm031v000 は準備ができていません (status: "False")。これは、virt-launcher ポッドが終了中であるためです (reason: "PodTerminating")。
- apiVersion: kubevirt.io/v1
kind: VirtualMachine
...
status:
conditions:
- lastProbeTime: "2023-07-20T08:37:37Z"
lastTransitionTime: "2023-07-20T08:37:37Z"
message: virt-launcher pod is terminating
reason: PodTerminating
status: "False"
type: Ready
同様に、VMI (仮想マシンインスタンス) ocffm031v000 は準備ができていません (status: "False")。これは、virt-launcher ポッドが終了中であるためです (reason: "PodTerminating")。
- apiVersion: kubevirt.io/v1
kind: VirtualMachineInstance
...
name: ocffm031v000
...
status:
activePods:
ec36a1eb-84a5-4421-b57b-2c14c1975018: aibfredg02
conditions:
- lastProbeTime: "2023-07-20T08:37:37Z"
lastTransitionTime: "2023-07-20T08:37:37Z"
message: virt-launcher pod is terminating
reason: PodTerminating
status: "False"
type: Ready
一方、ポッド virt-launcher-ocffm031v000-rrkss は準備ができていません (status: "False")。これは、ポッドが完了したためです (reason: "PodCompleted")。
基盤となるコンテナ 0d7a0f64f91438cb78f026853e6bebf502df1bdeb64878d351fa5756edc98deb は終了しており、exitCode は 0 です。
- apiVersion: v1
kind: Pod
...
name: virt-launcher-ocffm031v000-rrkss
...
ownerReferences:
- apiVersion: kubevirt.io/v1
...
kind: VirtualMachineInstance
name: ocffm031v000
uid: 8d2cf524-7e73-4713-86f7-89e7399f25db
uid: ec36a1eb-84a5-4421-b57b-2c14c1975018
...
status:
conditions:
- lastProbeTime: "2023-07-18T13:48:56Z"
lastTransitionTime: "2023-07-18T13:48:56Z"
message: the virtual machine is not paused
reason: NotPaused
status: "True"
type: kubevirt.io/virtual-machine-unpaused
- lastProbeTime: "null"
lastTransitionTime: "2023-07-18T13:48:55Z"
reason: PodCompleted
status: "True"
type: Initialized
- lastProbeTime: "null"
lastTransitionTime: "2023-07-20T08:38:56Z"
reason: PodCompleted
status: "False"
type: Ready
- lastProbeTime: "null"
lastTransitionTime: "2023-07-20T08:38:56Z"
reason: PodCompleted
status: "False"
type: ContainersReady
...
containerStatuses:
- containerID: containerd://0d7a0f64f91438cb78f026853e6bebf502df1bdeb64878d351fa5756edc98deb
image: registry.suse.com/suse/sles/15.4/virt-launcher:0.54.0-150400.3.3.2
imageID: sha256:43bb08efdabb90913534b70ec7868a2126fc128887fb5c3c1b505ee6644453a2
lastState: {}
name: compute
ready: false
restartCount: 0
started: false
state:
terminated:
containerID: containerd://0d7a0f64f91438cb78f026853e6bebf502df1bdeb64878d351fa5756edc98deb
exitCode: 0
finishedAt: "2023-07-20T08:38:55Z"
reason: Completed
startedAt: "2023-07-18T13:50:17Z"
重要な違いは、Stop および Start のアクションが stateChangeRequests プロパティの vm に表示されることです。
status:
conditions:
...
printableStatus: Stopped
stateChangeRequests:
- action: Stop
uid: 8d2cf524-7e73-4713-86f7-89e7399f25db
- action: Start
原因分析
この問題の根本原因は調査中です。
ソースコード が vm の状態をチェックし、オブジェクトが起動中であると仮定することは注目に値します。オブジェクトに対して Start および Restart の操作は追加されていません。
func (vf *vmformatter) canStart(vm *kubevirtv1.VirtualMachine, vmi *kubevirtv1.VirtualMachineInstance) bool {
if vf.isVMStarting(vm) {
return false
}
..
}
func (vf *vmformatter) canRestart(vm *kubevirtv1.VirtualMachine, vmi *kubevirtv1.VirtualMachineInstance) bool {
if vf.isVMStarting(vm) {
return false
}
...
}
func (vf *vmformatter) isVMStarting(vm *kubevirtv1.VirtualMachine) bool {
for _, req := range vm.Status.StateChangeRequests {
if req.Action == kubevirtv1.StartRequest {
return true
}
}
return false
}
エラーメッセージ not a device node で VM が起動状態に固まっています。
影響を受けるバージョン: v1.3.0
問題の説明
クラスタまたはいくつかのノードが再起動された後、一部の VM が起動に失敗し、その後応答しなくなることがあります。SUSE Virtualization UI の ダッシュボード 画面で、影響を受けた VM の状態は 起動中 に固まっています。
問題分析
影響を受けた VM に関連するポッドの状態は CreateContainerError です。
$ kubectl get pods NAME READY STATUS RESTARTS AGE virt-launcher-vm1-w9bqs 0/2 CreateContainerError 0 9m39s
フレーズ failed to generate spec: not a device node は以下に見つかります:
$kubectl get pods -oyaml
apiVersion: v1
items:
apiVersion: v1
kind: Pod
metadata:
...
containerStatuses:
- image: registry.suse.com/suse/sles/15.5/virt-launcher:1.1.0-150500.8.6.1
imageID: ""
lastState: {}
name: compute
ready: false
restartCount: 0
started: false
state:
waiting:
message: 'failed to generate container "50f0ec402f6e266870eafb06611850a5a03b2a0a86fdd6e562959719ccc003b5"
spec: failed to generate spec: not a device node'
reason: CreateContainerError
kubelet.log ファイル:
file path: /var/lib/rancher/rke2/agent/logs/kubelet.log E0205 20:44:31.683371 2837 pod_workers.go:1294] "Error syncing pod, skipping" err="failed to \"StartContainer\" for \"compute\" with CreateContainerError: \"failed t o generate container \\\"255d42ec2e01d45b4e2480d538ecc21865cf461dc7056bc159a80ee68c411349\\\" spec: failed to generate spec: not a device node\"" pod="default/virt-laun cher-caddytest-9tjzj" podUID=d512bf3e-f215-4128-960a-0658f7e63c7c
containerd.log ファイル:
file path: /var/lib/rancher/rke2/agent/containerd/containerd.log
time="2024-02-21T11:24:00.140298800Z" level=error msg="CreateContainer within sandbox \"850958f388e63f14a683380b3c52e57db35f21c059c0d93666f4fdaafe337e56\" for &ContainerMetadata{Name:compute,Attempt:0,} failed" error="failed to generate container \"5ddad240be2731d5ea5210565729cca20e20694e364e72ba14b58127e231bc79\" spec: failed to generate spec: not a device node"
デバッグ情報を`containerd`に追加した後、エラーメッセージ`not a device node`がファイル`pvc-3c1b28fb-*`にあることを特定します。
time="2024-02-22T15:15:08.557487376Z" level=error msg="CreateContainer within sandbox \"d23af3219cb27228623cf8168ec27e64e836ed44f2b2f9cf784f0529a7f92e1e\" for &ContainerMetadata{Name:compute,Attempt:0,} failed" error="failed to generate container \"e4ed94fb5e9145e8716bcb87aae448300799f345197d52a617918d634d9ca3e1\" spec: failed to generate spec: get device path: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-3c1b28fb-683e-4bf5-9869-c9107a0f1732/20291c6b-62c3-4456-be8a-fbeac118ec19 containerPath: /dev/disk-0 error: not a device node"
これはCSI関連のファイルですが、期待されるデバイスファイルではなく、空のファイルです。その後、containerdは`CreateContainer`のリクエストを拒否しました。
$ ls /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-3c1b28fb-683e-4bf5-9869-c9107a0f1732/ -alth
total 8.0K
drwxr-x--- 2 root root 4.0K Feb 22 15:10 .
-rw-r--r-- 1 root root 0 Feb 22 14:28 aa851da3-cee1-45be-a585-26ae766c16ca
-rw-r--r-- 1 root root 0 Feb 22 14:07 20291c6b-62c3-4456-be8a-fbeac118ec19
drwxr-x--- 4 root root 4.0K Feb 22 14:06 ..
-rw-r--r-- 1 root root 0 Feb 21 15:48 4333c9fd-c2c8-4da2-9b5a-1a310f80d9fd
-rw-r--r-- 1 root root 0 Feb 21 09:18 becc0687-b6f5-433e-bfb7-756b00deb61b
$file /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-3c1b28fb-683e-4bf5-9869-c9107a0f1732/20291c6b-62c3-4456-be8a-fbeac118ec19
: empty上記の出力は、実行中のVMの期待されるデバイスファイルを示す以下の例と直接対照的です。
$ ls /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-732f8496-103b-4a08-83af-8325e1c314b7/ -alth total 8.0K drwxr-x--- 2 root root 4.0K Feb 21 10:53 . drwxr-x--- 4 root root 4.0K Feb 21 10:53 .. brw-rw---- 1 root root 8, 16 Feb 21 10:53 4883af80-c202-4529-a2c6-4e7f15fe5a9b
解決策
クラスタレベルの操作:
-
影響を受けたVMのバックエンドポッドおよび関連するLonghornボリュームを見つけます。
$ kubectl get pods NAME READY STATUS RESTARTS AGE virt-launcher-vm1-nxfm4 0/2 CreateContainerError 0 7m11s $ kubectl get pvc -A NAMESPACE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE default vm1-disk-0-9gc6h Bound pvc-f1798969-5b72-4d76-9f0e-64854af7b59c 1Gi RWX longhorn-image-fxsqr 7d22h
-
停止 影響を受けたVMをSUSE Virtualization UIから。
VMは`Stopping`にスタックする可能性があるため、次のステップに進んでください。
-
バックエンドポッドを強制的に削除します。
$ kubectl delete pod virt-launcher-vm1-nxfm4 --force Warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "virt-launcher-vm1-nxfm4" force deleted
VMは現在オフです。
ノードレベルの操作、ノードごとに:
-
コーデン ノードを。
-
このノードの影響を受けたすべてのLonghornボリュームのマウントを解除します。
このノードにSSHで接続し、
sudo -i umount pathコマンドを実行する必要があります。$ umount /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/* umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/4b2ab666-27bd-4e3c-a218-fb3d48a72e69: not mounted. umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/6aaf2bbe-f688-4dcd-855a-f9e2afa18862: not mounted. umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/91488f09-ff22-45f4-afc0-ca97f67555e7: not mounted. umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/bb4d0a15-737d-41c0-946c-85f4a56f072f: not mounted. umount: /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/dev/d2a54e32-4edc-4ad8-a748-f7ef7a2cacab: not mounted.
-
アンコーデン このノードを。
-
スタート 影響を受けたVMをHarvester UIから。
しばらく待ってください。VMは正常に実行されます。
新しく生成されたcsiファイルは期待されるデバイスファイルです。
$ ls /var/lib/kubelet/plugins/kubernetes.io/csi/volumeDevices/publish/pvc-f1798969-5b72-4d76-9f0e-64854af7b59c/ -alth ... brw-rw---- 1 root root 8, 64 Mar 6 11:47 7beb531d-a781-4775-ba5e-8773773d77f1
仮想マシンのIPアドレスが表示されない
`qemu-guest-agent`パッケージがインストールされていません
分析
この問題は通常、仮想マシンに`qemu-guest-agent`パッケージがインストールされていないときに発生します。これが根本原因かどうかを判断するには、`VirtualMachineInstance`オブジェクトの状態を確認してください。
$ kubectl get vmi -n <NAMESPACE> <NAME> -ojsonpath='{.status.interfaces[0].infoSource}'`qemu-guest-agent`パッケージがインストールされていない場合、出力には`guest-agent`という文字列が含まれません。
解決策
仮想マシンの設定を編集することで、QEMUゲストエージェントをインストールすることができます。
-
SUSE Virtualization UIで、*仮想マシン*に移動します。
-
影響を受けた仮想マシンを見つけて、*⋮ → 設定を編集*を選択します。
-
*詳細オプション*タブの*クラウド設定*の下で、*ゲストエージェントをインストール*を選択します。
-
[保存]をクリックします。
ただし、cloud-initは一度だけ実行されます(仮想マシンが初めて起動されたとき)。新しい*クラウド設定*を適用するには、仮想マシン内のcloud-initディレクトリを削除する必要があります。
$ sudo rm -rf /var/lib/cloud/*ディレクトリを削除した後、cloud-initが再度実行され、`qemu-guest-agent`パッケージがインストールされるように仮想マシンを再起動する必要があります。
virt-launcher Podとゲストオペレーティングシステム間のIPv6レースコンディション
説明
SUSE Virtualization UIは、`virt-launcher`ポッドのネットワークインタフェースがIPv6リンクローカルアドレスを取得するたびに、仮想マシンのIPアドレスを表示しません。
分析
QEMUゲストエージェントは、インターフェースの詳細を含むゲストオペレーティングシステムに関する情報を報告する責任があります。これらの情報は、SUSE Virtualization UIに表示されるために仮想マシンインスタンスに送信されます。この問題は、仮想マシンのポッドインターフェースがIPv6リンクローカルアドレスを取得し、QEMUゲストエージェントが自分の情報を提供する前にそれを仮想マシンインスタンスに報告する場合に発生します。これが発生すると、KubeVirtのバグのためにQEMUゲストエージェントからのIPv4アドレスは報告されません。
以下の手順を使用して、ポッドインターフェースと仮想マシンインスタンスのIPアドレスを確認できます:
-
仮想マシンインスタンスのIPアドレスを取得します:
$ kubectl get vmi -n <NAMESPACE> <NAME> -ojsonpath='{.status.interfaces[0].ipAddress}'
出力にはIPv6リンクローカルアドレスのみが表示されます。
-
ポッドインターフェースのIPアドレスを取得します:
$ kubectl exec -it -n <namespace> <pod-name> -- /bin/bash -c "ip a show label pod\*"
出力は仮想マシンインスタンスのIPv6アドレスと一致します。
-
割り当てられたIPv4アドレスを取得するには、仮想マシンのシリアルコンソールを開き、ゲストオペレーティングシステム内で`ip a`を実行します。
|
この問題は、一般的に仮想マシンの動作およびアップタイムに影響しません。ネットワークインターフェースのIPv4アドレスを使用して、SSH経由で仮想マシンにアクセスすることができます。特定のケースでは、この問題がRancher統合に影響を与え、ゲストクラスター内のノードのプロビジョニングや参加がタイムアウトすることがあります。 |
解決策
回避策は、カーネルパラメータのSUSE VirtualizationIPv6を無効にすることです。
上記の例では、`ipv6.disable=1`を追加し、ノードを再起動して仮想マシンポッドインターフェースがIPv6リンクローカルアドレスを取得しないようにします。
仮想マシンのIPアドレスが断続的に表示されない
分析
QEMUゲストエージェントは、インターフェースの詳細を含むゲストオペレーティングシステムに関する情報を報告する責任があります。これらの情報は、SUSE Virtualization UIに表示されるために仮想マシンインスタンスに送信されます。この問題は、空のネットワークインターフェースを含むドメインデータで仮想マシンインスタンスが更新されると発生します。これは、アップストリームのKubeVirtの問題によるものです。
この動作は、Alma Linux 9およびRocky Linux 9でより一般的に観察され、QEMUゲストエージェントが仮想マシンインスタンスにファイルシステム情報を頻繁に更新します。
環境にこの問題が存在するかどうかを確認するには、異なる時間に次のコマンドを実行します:
$ kubectl get vmi -n <NAMESPACE> <NAME> -ojsonpath='{.status.interfaces[0].ipAddress}'
コマンドを実行すると、`ipAddress`フィールドが空である可能性があります。
割り当てられたIPv4アドレスを取得するには、仮想マシンのシリアルコンソールを開き、ゲストオペレーティングシステム内で`ip a`を実行します。
| この問題は、一般的に仮想マシンの動作およびアップタイムに影響しません。ネットワークインターフェースのIPv4アドレスを使用して、SSH経由で仮想マシンにアクセスすることができます。 |
解決策
この問題に対する直接的な回避策はありませんが、[アップストリームの修正](https://github.com/kubevirt/kubevirt/pull/13624)により、QEMUゲストエージェントからの不要な更新を減らすためにコードが最適化されました。この機能強化により、問題が発生するのを防ぐことができる場合があります。
スケジュールできない仮想マシン
仮想マシンは、満たされていないアフィニティルールのために Unschedulable としてマークされる場合があります。
具体的には、VirtualMachine オブジェクトには次のようなアフィニティルールが含まれています:
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: vm100
namespace: default
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: network.harvesterhci.io/cn2
operator: In
values:
- 'true'ポッドの状態は Pending であり、エラーメッセージは、どのノードもアフィニティルールの基準を満たしていないことを示しています。
例:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
virt-launcher-vm100-f4nh4 0/2 Pending 0 5m12s
$ kubectl get pods virt-launcher-vm100-f4nh4 -oyaml
apiVersion: v1
kind: Pod
metadata:
name: virt-launcher-vm100-f4nh4
namespace: default
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: network.harvesterhci.io/cn2
operator: In
values:
- "true"
...
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2025-07-28T16:21:56Z"
message: '0/2 nodes are available: 1 node(s) didn''t match Pod''s node affinity/selector,
1 node(s) had untolerated taint {node.kubernetes.io/unreachable: }. preemption:
0/2 nodes are available: 2 Preemption is not helpful for scheduling.'
reason: Unschedulable
status: "False"
type: PodScheduled
...根本原因
SUSE Virtualization は、仮想マシンの構成に基づいて アフィニティルールを自動的に適用する ことがあります。この例では、仮想マシン vm100 がクラスタネットワーク cn2 に接続し、SUSE Virtualization がアフィニティルール network.harvesterhci.io/cn2 を適用します。しかし、どのノードもルールの基準を満たしていないため、仮想マシンはスケジュールできません。
クラウド構成 YAML を介した意図しない仮想マシンテンプレートの変更
テンプレートを使用して仮想マシンを作成し、その後 YAML として編集 機能を使用してその仮想マシンのユーザーデータを変更すると、変更を保存すると元のテンプレートが意図せず変更される可能性があります。
この問題は、システムが構成の継承を適切に切り離さないために発生します。新しい構成が元のテンプレートにリンクされたままになるため、変更を保存すると自動的にテンプレートのデータが上書きされます。
|
特にテンプレートを使用して仮想マシンを作成する際には、YAML として編集 機能の使用を避けてください。代わりに、*仮想マシンの利用可能な専用フィールドとオプションを使用してください:作成*画面。 |
この問題を軽減するには、次の手順を実行してください:
-
影響を受けた仮想マシンの名前とネームスペースを特定します。
-
影響を受けた仮想マシンに関連付けられたCloud Configの秘密を特定します。
# Get the current Secret name linked to the VM's cloudInitNoCloud volume source: VM_NAME=<VM_NAME> VM_NAMESPACE=<VM_NAMESPACE> SECRET=$(kubectl get vm $VM_NAME -n $VM_NAMESPACE -o jsonpath='{.spec.template.spec.volumes[?(@.cloudInitNoCloud)].cloudInitNoCloud.secretRef.name}') SECRET_NAMESPACE=$(kubectl get secret -A | grep $SECRET | awk '{print $1}') echo "Current Secret: $SECRET_NAMESPACE -> $SECRET" -
秘密の独立したコピーを作成します。
現在の秘密をエクスポートし、識別メタデータを削除し、一意の名前を付けてから、秘密を適用します。
# Define a new, unique name for the secret NEW_SECRET="$VM_NAME-$(date +%s)" # Export, clean, rename, and create the new Secret kubectl get secret $SECRET -n $SECRET_NAMESPACE -o json | \ jq 'del(.metadata.creationTimestamp, .metadata.resourceVersion, .metadata.uid, .metadata.ownerReferences, .metadata.annotations["kubectl.kubernetes.io/last-applied-configuration"], .metadata.selfLink)' | \ jq '.metadata.name = "'"$NEW_SECRET"'"' | \ jq '.metadata.namespace = "'"$VM_NAMESPACE"'"' | \ kubectl apply -n $VM_NAMESPACE -f - -
仮想マシンの設定を更新して新しい秘密を使用します。
仮想マシンの`cloudInitNoCloud`ボリュームソースを新しい秘密にポイントします。
# Patch the VM to replace the secretRef name VOLUME_INDEX=$(kubectl get vm $VM_NAME -n $NAMESPACE -o json | jq '.spec.template.spec.volumes | to_entries[] | select(.value.cloudInitNoCloud != null) | .key') kubectl patch vm $VM_NAME -n $VM_NAMESPACE --type='json' \ -p='[{"op": "replace", "path": "/spec/template/spec/volumes/'$VOLUME_INDEX'/cloudInitNoCloud/secretRef/name", "value": "'"$NEW_SECRET"'"}, {"op": "replace", "path": "/spec/template/spec/volumes/'$VOLUME_INDEX'/cloudInitNoCloud/networkDataSecretRef/name", "value": "'"$NEW_SECRET"'"}]'
Cloud Configが一意の秘密でバックアップされると、SUSE Virtualization UIのYAMLエディタを使用して、ソーステンプレートに影響を与えることなく仮想マシンの設定を編集できます。
関連する問題: #9207