|
この文書は自動機械翻訳技術を使用して翻訳されています。 正確な翻訳を提供するように努めておりますが、翻訳された内容の完全性、正確性、信頼性については一切保証いたしません。 相違がある場合は、元の英語版 英語 が優先され、正式なテキストとなります。 |
v1.4.2またはv1.4.3からv1.5.0にアップグレードします。
一般情報
新しいSUSE Virtualizationバージョンにアップグレードできるようになると、*ダッシュボード*画面に*アップグレード*ボタンが表示されます。詳細については、アップグレードを開始するを参照してください。
v1.4.2からv1.5.0に直接アップグレードできます。なぜなら、SUSE Virtualizationは基盤コンポーネントに対して最大1つのマイナーバージョンのアップグレードを許可するからです。SUSE Virtualization v1.4.2およびv1.4.3はSUSE® Rancher Prime: RKE2の同じマイナーバージョン(v1.31)を使用していますが、SUSE Virtualization v1.5.0は次のマイナーバージョン(v1.32)を使用しています。
エアギャップ環境でのSUSE Virtualizationのアップグレードに関する情報は、エアギャップアップグレードの準備を参照してください。
SUSE Rancher Prime v2.11.0でハーベスターUI拡張機能を更新します。
Rancher v2.11.0でSUSE Virtualization v1.5.0クラスターをインポートするには、ハーベスターUI拡張機能のv1.5.0を使用する必要があります。
-
Rancher UIで、*ローカル→アプリ→リポジトリ*に移動します。
-
harvester*という名前のリポジトリを見つけて、⋮ →再読み込み*を選択します。
このリポジトリには以下のプロパティがあります:
-
ブランチ: gh-pages
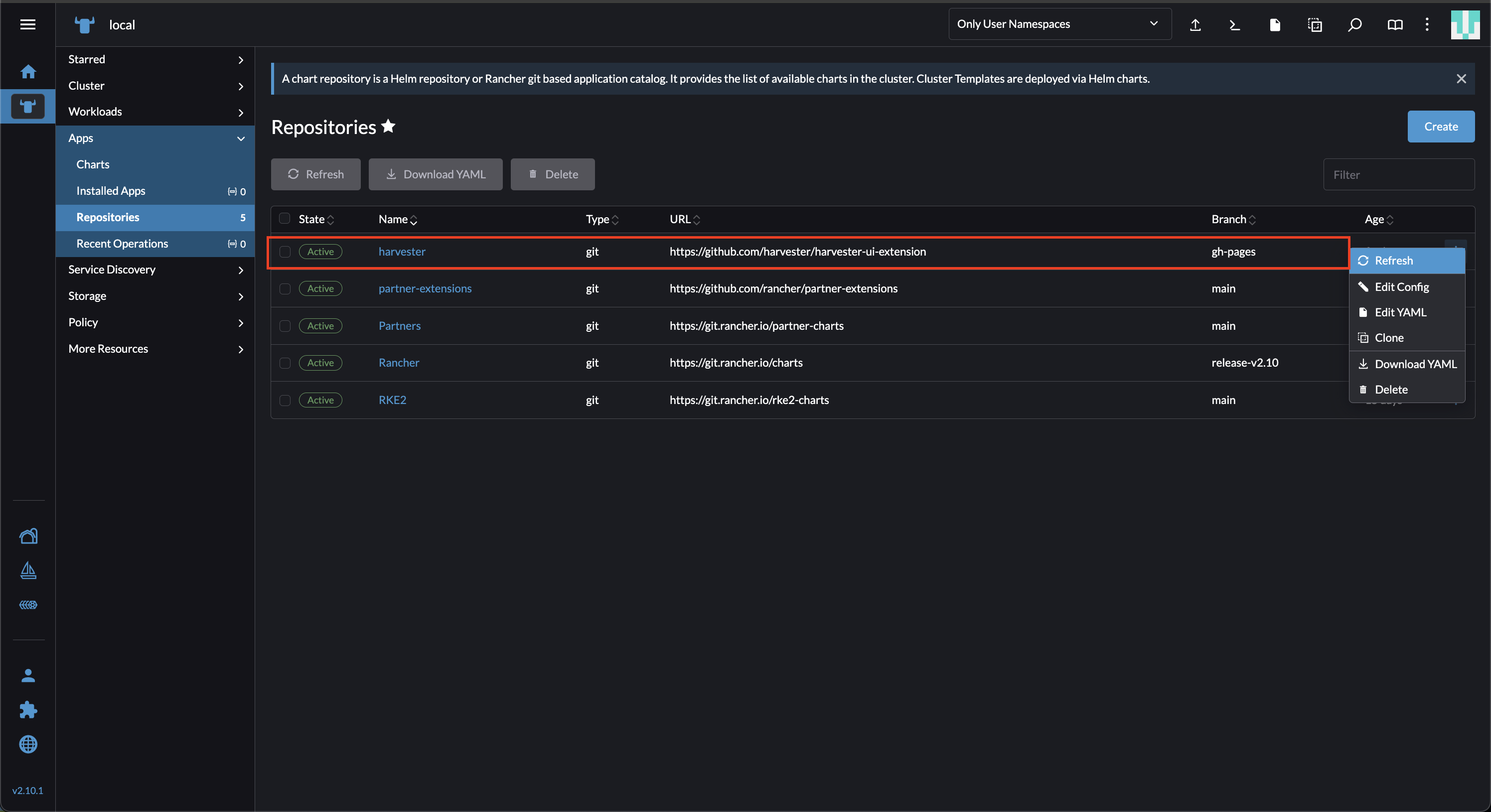
-
*拡張機能*画面に移動します。
-
*ハーベスター*という名前の拡張機能を見つけて、*更新*をクリックします。
-
バージョン*1.5.0*を選択し、*更新*をクリックします。
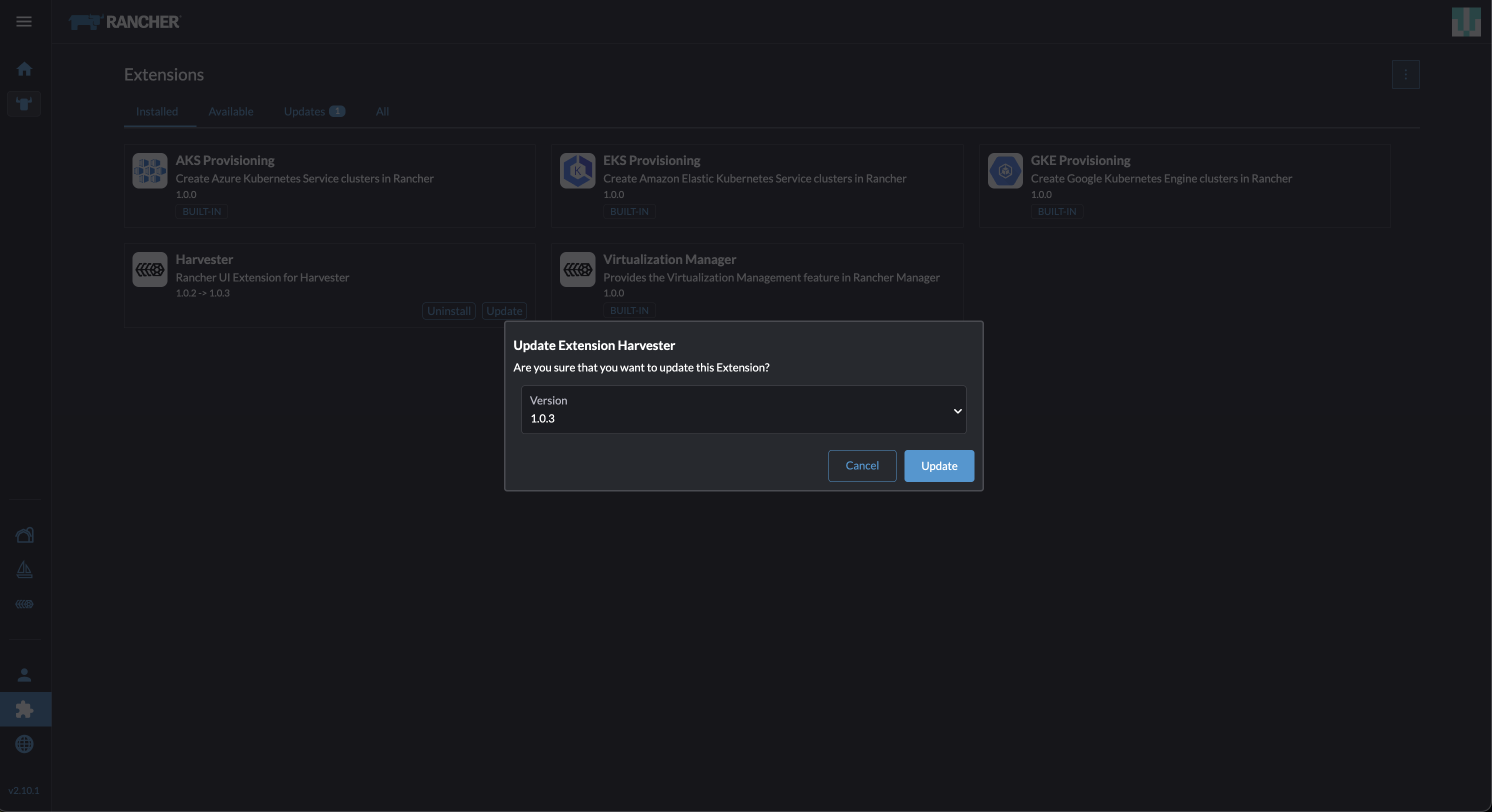
-
拡張機能が更新されるまでしばらくお待ちいただき、画面を再読み込みしてください。
当バージョンの注意事項
1.アップグレード中は管理URLのステータスが「NotReady」です。
アップグレードが進行中の間、一部のノードのSUSE Virtualizationコンソールに`Status: NotReady`が表示される場合があります。
v1.5.0へのアップグレードが完了すると、正しいステータスが表示されます。
関連する問題: #7963
2.エアギャップ(された)アップグレードがFluentdおよびFluent Bitポッドで`ImagePullBackOff`エラーで停止しています。
アップグレードは処理の最初の段階で停止する可能性があり、進行状況が0%で、*アップグレード*ダイアログの*保留中*とマークされた項目がSUSE Virtualization UIに表示されます。
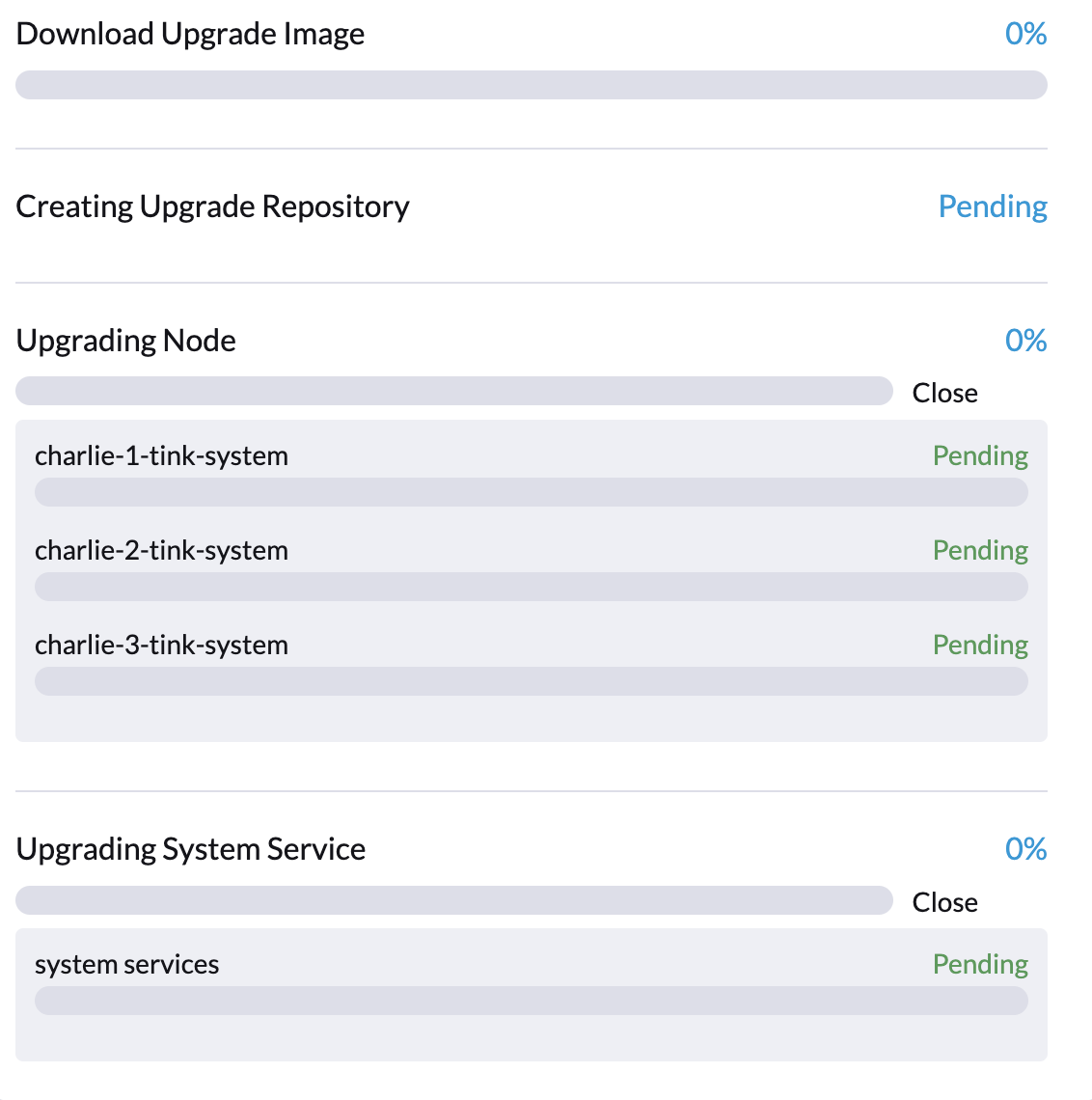
具体的には、FluentdおよびFluent Bitポッドが`ImagePullBackOff`ステータスで停止する可能性があります。ポッドのステータスを確認するには、次のコマンドを実行してください:
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-x2hz8 7m14s
$ kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=hvst-upgrade-x2hz8
NAME UPGRADE
hvst-upgrade-x2hz8-upgradelog hvst-upgrade-x2hz8
$ kubectl -n harvester-system get pods -l harvesterhci.io/upgradeLog=hvst-upgrade-x2hz8-upgradelog
NAME READY STATUS RESTARTS AGE
hvst-upgrade-x2hz8-upgradelog-downloader-6cdb864dd9-6bw98 1/1 Running 0 7m7s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-2nq7q 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-697wf 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-kd8kl 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentd-0 0/2 ImagePullBackOff 0 7m42sこれは、次のコンテナイメージがクラスターのノードに事前にロードされていないか、インターネットからプルされていないために発生します:
-
ghcr.io/kube-logging/fluentd:v1.15-ruby3 -
ghcr.io/kube-logging/config-reloader:v0.0.5 -
fluent/fluent-bit:2.1.8
問題を解決するには、次のいずれかのアクションを実行してください:
-
Logging CRを、クラスターのノードにすでに事前にロードされているイメージを使用するように更新します。これを行うには、クラスターに対して次のコマンドを実行してください:
# Get the Logging CR names OPERATOR_LOGGING_NAME=$(kubectl get loggings -l app.kubernetes.io/name=rancher-logging -o jsonpath="{.items[0].metadata.name}") INFRA_LOGGING_NAME=$(kubectl get loggings -l harvesterhci.io/upgradeLogComponent=infra -o jsonpath="{.items[0].metadata.name}") # Gather image info from operator's Logging CR FLUENTD_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.repository}") FLUENTD_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.tag}") FLUENTBIT_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.repository}") FLUENTBIT_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.tag}") CONFIG_RELOADER_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.repository}") CONFIG_RELOADER_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.tag}") # Patch the Logging CR kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentbit/image\",\"value\":{\"repository\":\"$FLUENTBIT_IMAGE_REPO\",\"tag\":\"$FLUENTBIT_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/image\",\"value\":{\"repository\":\"$FLUENTD_IMAGE_REPO\",\"tag\":\"$FLUENTD_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/configReloaderImage\",\"value\":{\"repository\":\"$CONFIG_RELOADER_IMAGE_REPO\",\"tag\":\"$CONFIG_RELOADER_IMAGE_TAG\"}}]"FluentdおよびFluent Bitポッドのステータスはすぐに`Running`に変更され、Logging CRが更新された後にアップグレードプロセスが続行されるはずです。Fluentdポッドのステータスがまだ`ImagePullBackOff`の場合、ポッドを削除して強制的に再起動させることができます。
UPGRADE_NAME=$(kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o jsonpath='{.items[0].metadata.name}') UPGRADELOG_NAME=$(kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=$UPGRADE_NAME -o jsonpath='{.items[0].metadata.name}') kubectl -n harvester-system delete pods -l harvesterhci.io/upgradeLog=$UPGRADELOG_NAME,harvesterhci.io/upgradeLogComponent=aggregator -
インターネットに接続されたコンピュータで、必要なコンテナイメージをプルし、それをTARファイルにエクスポートします。次に、TARファイルをクラスターのノードに転送し、各ノードで次のコマンドを実行してイメージをインポートします:
# Pull down the three container images docker pull ghcr.io/kube-logging/fluentd:v1.15-ruby3 docker pull ghcr.io/kube-logging/config-reloader:v0.0.5 docker pull fluent/fluent-bit:2.1.8 # Export the images to a tar file docker save \ ghcr.io/kube-logging/fluentd:v1.15-ruby3 \ ghcr.io/kube-logging/config-reloader:v0.0.5 \ fluent/fluent-bit:2.1.8 > upgradelog-images.tar # After transferring the tar file to the cluster nodes, import the images (need to be run on each node) ctr -n k8s.io images import upgradelog-images.tarイメージが事前にロードされた後、アップグレードプロセスは続行されるはずです。
-
(推奨しません)ロギングを無効にしてアップグレードプロセスを再起動します。*ロギングを有効にする*チェックボックスが*アップグレード*ダイアログで選択されていないことを確認してください。
-
関連する問題: #7955
3.アップグレードが`mcc-harvester`バンドルCRの待機中で停止しています
古いSUSE Virtualizationバージョン(v1.0.x、v1.1.x、`v1.2.x`など)からアップグレードすると、アップグレードプロセスが`mcc-harvester`バンドルCRが準備完了になるのを待っている間に停止する可能性があります。
> kubectl get bundles -n fleet-local
NAME BUNDLEDEPLOYMENTS-READY STATUS
mcc-harvester 0/1 Modified(1) [Cluster fleet-local/local]; kubevirt.kubevirt.io harvester-system/kubevirt modified {"spec":{"configuration":{"vmStateStorageClass":"vmstate-persistence"}}}根本的な原因は、最新の`dependency_charts` CRDが適用されなかったことで、これはHelmがSUSE VirtualizationのCRDを管理しないために発生しました。アップグレードを続行できるようにするには、次のスクリプトを実行してください:
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/kubevirt-operator/crds/crd-kubevirt.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/csi-snapshotter/crds/volumesnapshotclasses.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/csi-snapshotter/crds/volumesnapshotcontents.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/csi-snapshotter/crds/volumesnapshots.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/whereabouts/crds/whereabouts.cni.cncf.io_ippools.yaml
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/whereabouts/crds/whereabouts.cni.cncf.io_overlappingrangeipreservations.yaml5分後に、`mcc-harvester`の`bundle.fleet.cattle.io/v1alpha1`バンドルCRのステータスを確認してください。同じエラーがまだ表示されている場合は、次のスクリプトを使用してバンドルCRを再同期する必要があります:
#!/bin/bash
patch_fleet_bundle() {
local bundleName=$1
local generation=$(kubectl get -n fleet-local bundle ${bundleName} -o jsonpath='{.spec.forceSyncGeneration}')
local new_generation=$((generation+1))
patch_manifest="$(mktemp)"
cat > "$patch_manifest" <<EOF
{
"spec": {
"forceSyncGeneration": $new_generation
}
}
EOF
echo "patch bundle to new generation: $new_generation"
kubectl patch -n fleet-local bundle ${bundleName} --type=merge --patch-file $patch_manifest
rm -f $patch_manifest
}
for bundle in mcc-harvester
do
patch_fleet_bundle ${bundle}
donecdi CRDが存在することも確認する必要があります。
> kubectl get bundle -n fleet-local
NAMESPACE NAME BUNDLEDEPLOYMENTS-READY STATUS
fleet-local mcc-harvester 0/1 Modified(1) [Cluster fleet-local/local]; cdi.cdi.kubevirt.io cdi missingcdi CRDが存在する場合は、mcc-harvester`バンドルCRを再同期するために`patch_fleet_bundle`スクリプトを実行してください。そうでない場合は、次のスクリプトを実行して`cdi CRDを作成してください:
kubectl apply -f https://raw.githubusercontent.com/harvester/harvester/refs/tags/v1.5.0/deploy/charts/harvester/dependency_charts/cdi/crds/cdi.yaml関連する問題: #8163
4.移行可能なRWXボリュームを使用する仮想マシンが予期せず再起動します。
CSIプラグインポッドが再起動されると、移行可能なRWXボリュームを使用する仮想マシンが予期せず再起動します。この問題は、SUSE Virtualization v1.4.x、v1.5.0、およびv1.5.1に影響します。
回避策は、アップグレードを開始する前にSUSE Storage UIで設定 ボリュームが予期せず切り離されたときにワークロードポッドを自動的に削除するを無効にすることです。アップグレードが完了したら、再度設定を有効にする必要があります。
この問題は、SUSE Storage v1.8.3、v1.9.1、およびそれ以降のバージョンで修正されます。SUSE Virtualization v1.6.0にはSUSE Storage v1.9.1が含まれます。