|
この文書は自動機械翻訳技術を使用して翻訳されています。 正確な翻訳を提供するように努めておりますが、翻訳された内容の完全性、正確性、信頼性については一切保証いたしません。 相違がある場合は、元の英語版 英語 が優先され、正式なテキストとなります。 |
v1.4.2またはv1.4.3からv1.5.2にアップグレードします
一般情報
新しいSUSE Virtualizationバージョンが利用可能になると、*ダッシュボード*画面に*アップグレード*ボタンが表示されます。詳細については、アップグレードを開始するを参照してください。
v1.4.2からv1.5.2に直接アップグレードできます。なぜなら、SUSE Virtualizationは基盤コンポーネントに対して最大1つのマイナーバージョンのアップグレードを許可するからです。v1.4.2およびv1.4.3はRKE2の同じマイナーバージョン(v1.31)を使用しており、v1.5.0、v1.5.1、およびv1.5.2は次のマイナーバージョン(v1.32)を使用しています。
エアギャップ環境でのSUSE Virtualizationのアップグレードに関する情報は、エアギャップ(された)アップグレードの準備を参照してください。
SUSE Rancher Prime v2.11.0でHarvester UI拡張機能を更新します
Rancher v2.11.0でSUSE Virtualization v1.5.2クラスターをインポートするには、Harvester UI拡張機能のv1.5.2を使用する必要があります。
-
Rancher UIで、*ローカル→アプリ→リポジトリ*に移動します。
-
Harvester*という名前のリポジトリを見つけて、⋮ → 更新*を選択します。
-
*拡張機能*画面に移動します。
-
*Harvester*という名前の拡張機能を見つけて、*更新*をクリックします。
-
バージョン*1.5.2*を選択し、*更新*をクリックします。
-
拡張機能が更新されるまでしばらく時間を置き、その後画面を更新します。
当バージョンの注意事項
エアギャップ(された)アップグレードがFluentdおよびFluent Bitポッドで`ImagePullBackOff`エラーで停止しました
アップグレードは、プロセスの最初の段階で停止する可能性があります。これは、SUSE Virtualization UIの*アップグレード*ダイアログで0%の進行状況と*保留中*とマークされた項目によって示されます。
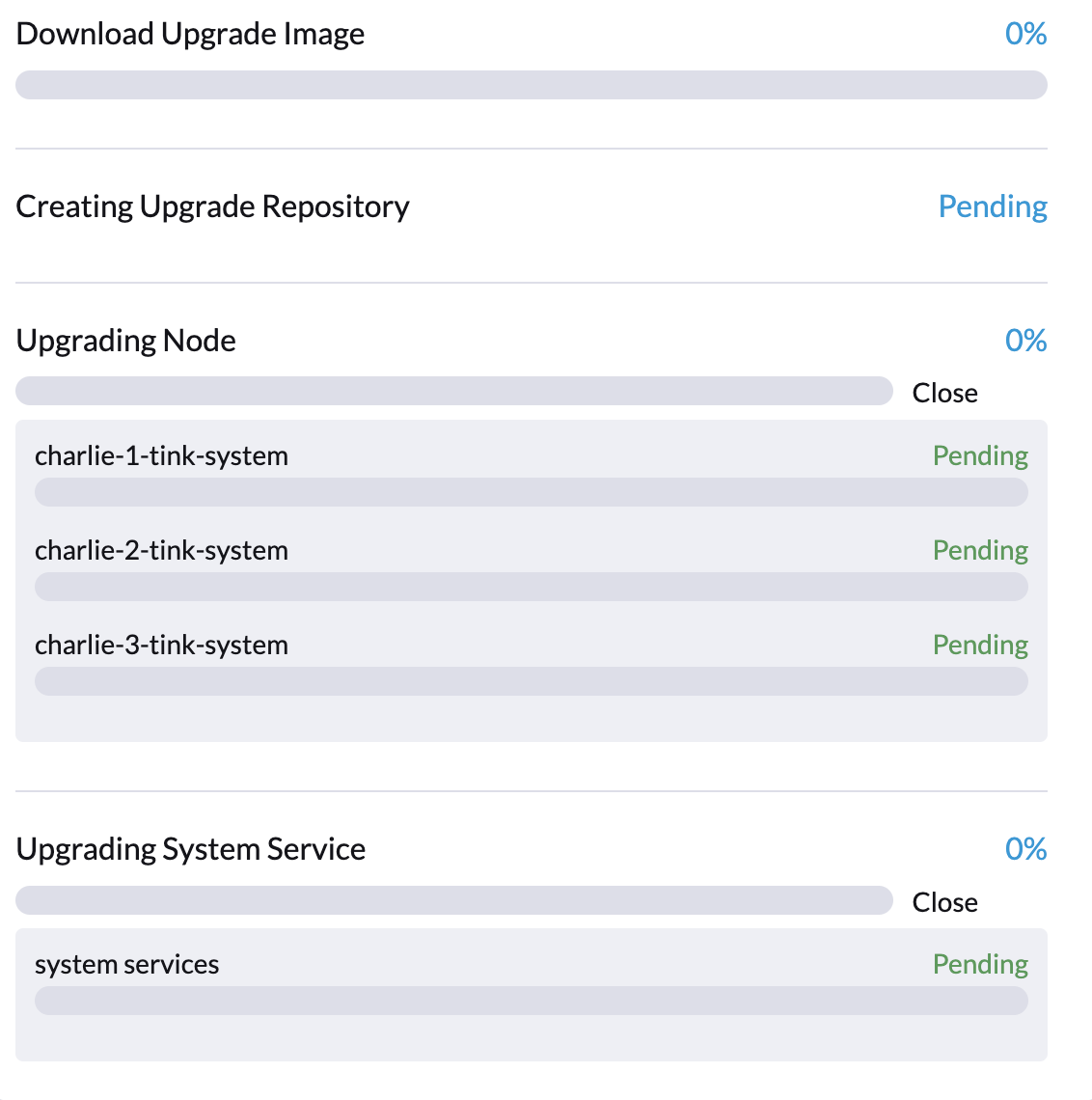
具体的には、FluentdおよびFluent Bitポッドが`ImagePullBackOff`ステータスで停止する可能性があります。ポッドのステータスを確認するには、次のコマンドを実行します:
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-x2hz8 7m14s
$ kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=hvst-upgrade-x2hz8
NAME UPGRADE
hvst-upgrade-x2hz8-upgradelog hvst-upgrade-x2hz8
$ kubectl -n harvester-system get pods -l harvesterhci.io/upgradeLog=hvst-upgrade-x2hz8-upgradelog
NAME READY STATUS RESTARTS AGE
hvst-upgrade-x2hz8-upgradelog-downloader-6cdb864dd9-6bw98 1/1 Running 0 7m7s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-2nq7q 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-697wf 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentbit-kd8kl 0/1 ImagePullBackOff 0 7m42s
hvst-upgrade-x2hz8-upgradelog-infra-fluentd-0 0/2 ImagePullBackOff 0 7m42sこれは、次のコンテナイメージがクラスターのノードに事前にロードされていないか、インターネットからプルされていないために発生します:
-
ghcr.io/kube-logging/fluentd:v1.15-ruby3 -
ghcr.io/kube-logging/config-reloader:v0.0.5 -
fluent/fluent-bit:2.1.8
問題を修正するには、次のいずれかのアクションを実行します:
-
クラスターのノードにすでに事前にロードされているイメージを使用するようにLogging CRを更新します。これを行うには、クラスターに対して次のコマンドを実行してください。
# Get the Logging CR names OPERATOR_LOGGING_NAME=$(kubectl get loggings -l app.kubernetes.io/name=rancher-logging -o jsonpath="{.items[0].metadata.name}") INFRA_LOGGING_NAME=$(kubectl get loggings -l harvesterhci.io/upgradeLogComponent=infra -o jsonpath="{.items[0].metadata.name}") # Gather image info from operator's Logging CR FLUENTD_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.repository}") FLUENTD_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.image.tag}") FLUENTBIT_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.repository}") FLUENTBIT_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentbit.image.tag}") CONFIG_RELOADER_IMAGE_REPO=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.repository}") CONFIG_RELOADER_IMAGE_TAG=$(kubectl get loggings $OPERATOR_LOGGING_NAME -o jsonpath="{.spec.fluentd.configReloaderImage.tag}") # Patch the Logging CR kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentbit/image\",\"value\":{\"repository\":\"$FLUENTBIT_IMAGE_REPO\",\"tag\":\"$FLUENTBIT_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/image\",\"value\":{\"repository\":\"$FLUENTD_IMAGE_REPO\",\"tag\":\"$FLUENTD_IMAGE_TAG\"}}]" kubectl patch logging $INFRA_LOGGING_NAME --type=json -p="[{\"op\":\"replace\",\"path\":\"/spec/fluentd/configReloaderImage\",\"value\":{\"repository\":\"$CONFIG_RELOADER_IMAGE_REPO\",\"tag\":\"$CONFIG_RELOADER_IMAGE_TAG\"}}]"FluentdおよびFluent Bitポッドのステータスは、しばらくすると`Running`に変わり、Logging CRが更新された後にアップグレードプロセスが続行されるはずです。Fluentdポッドのステータスがまだ`ImagePullBackOff`の場合は、ポッドを削除して強制的に再起動させることができます。
UPGRADE_NAME=$(kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o jsonpath='{.items[0].metadata.name}') UPGRADELOG_NAME=$(kubectl -n harvester-system get upgradelogs -l harvesterhci.io/upgrade=$UPGRADE_NAME -o jsonpath='{.items[0].metadata.name}') kubectl -n harvester-system delete pods -l harvesterhci.io/upgradeLog=$UPGRADELOG_NAME,harvesterhci.io/upgradeLogComponent=aggregator -
インターネットに接続されたコンピュータで、必要なコンテナイメージをプルし、それをtarファイルにエクスポートします。次に、tarファイルをクラスターのノードに転送し、各ノードで次のコマンドを実行してイメージをインポートします。
# Pull down the three container images docker pull ghcr.io/kube-logging/fluentd:v1.15-ruby3 docker pull ghcr.io/kube-logging/config-reloader:v0.0.5 docker pull fluent/fluent-bit:2.1.8 # Export the images to a tar file docker save \ ghcr.io/kube-logging/fluentd:v1.15-ruby3 \ ghcr.io/kube-logging/config-reloader:v0.0.5 \ fluent/fluent-bit:2.1.8 > upgradelog-images.tar # After transferring the tar file to the cluster nodes, import the images (need to be run on each node) ctr -n k8s.io images import upgradelog-images.tarイメージがプリロードされた後、アップグレードプロセスは続行されるはずです。
-
(推奨しません)ロギングを無効にしてアップグレードプロセスを再起動します。*ロギングを有効にする*チェックボックスが*アップグレード*ダイアログで選択されていないことを確認してください。
-
関連する問題: #7955
移行可能なRWXボリュームを使用する仮想マシンが予期せず再起動します。
CSIプラグインポッドが再起動されると、移行可能なRWXボリュームを使用する仮想マシンが予期せず再起動します。この問題はSUSE Virtualization v1.4.x、v1.5.0、およびv1.5.1に影響します。
回避策は、アップグレードを開始する前にSUSE Storage UIで設定 ボリュームが予期せず切り離されたときにワークロードポッドを自動的に削除するを無効にすることです。アップグレードが完了したら、設定を再度有効にする必要があります。
この問題はSUSE Storage v1.8.3、v1.9.1、およびそれ以降のバージョンで修正されます。SUSE Virtualization v1.6.0にはSUSE Storage v1.9.1が含まれます。