アップグレード
SUSE Virtualization は、バージョン管理とアップグレードを簡素化する新しいライフサイクル戦略を採用しています。この戦略には、以下が含まれます。
-
4か月ごとのマイナーリリースのサイクル
-
2か月ごとのパッチリリースのサイクル
-
コンポーネント採用ポリシー
|
SUSE Virtualization ではダウングレードはサポートされていません。この制限は、予期しないシステムの動作や機能の非互換性、廃止、削除に関連する問題を防ぐのに役立ちます。 |
アップグレードパス
以下の表は、サポートされているアップグレードパスを示しています。
| インストール済みのバージョン | サポートされているアップグレードバージョン |
|---|---|
v1.6.x |
|
v1.6.x |
v1.6.y (y は x より大きいです) |
v1.5.x |
|
v1.5.0 および v1.5.1 |
|
v1.5.0 |
|
v1.4.2 および v1.4.3 |
|
v1.4.2 および v1.4.3 |
|
v1.4.1 および v1.4.2 |
|
v1.4.1 |
|
v1.4.0 |
|
v1.3.1 |
|
v1.2.2 および v1.3.0 |
|
v1.2.1 |
|
v1.1.2、v1.1.3、および v1.2.0 |
最新の SUSE Virtualization バージョンでは、以下が可能です。
-
1つのマイナー バージョンから次のバージョンへのアップグレード(例:v1.5.2 から v1.6.1 へ)を、2つのバージョンの間にリリースされたパッチをインストールすることなく行うことができます。これは、SUSE Virtualization が基盤となるコンポーネントに対して最大1つのマイナー バージョンのアップグレードを許可しているためです。
-
後のパッチバージョンへのアップグレード(例:v1.6.0 から v1.6.1 へ)が可能であり、特定のマイナー バージョンのリリース間で同じコンポーネントバージョンが使用されていることを前提としています。
以下の表は、これらのバージョンで使用されるコンポーネントを示しています。
| コンポーネント | SUSE Virtualization v1.5.x | SUSE Virtualization v1.6.x | SUSE Virtualization v1.7.x |
|---|---|---|---|
KubeVirt |
v1.4 |
v1.5 |
v1.6 |
SUSE Storage |
v1.8 |
v1.9 |
v1.10 |
SUSE Rancher Prime |
v2.11 |
v2.12 |
v2.13 |
RKE2 |
v1.32 |
v1.33 |
v1.34 |
SUSE Linux Micro |
5.5 |
5.5 |
6.1 |
|
複数のKubernetesマイナーバージョンをスキップすることは、アップストリームではサポートされておらず、限られたアップグレードパスの主な理由です。詳細については、Kubernetesのドキュメントにある バージョンスキュー・ポリシーを参照してください。 |
Rancher アップグレード
もしRancherを使用してSUSE Virtualizationクラスターを管理している場合は、SUSE Virtualizationをアップグレードする前に、 アップグレード Rancherを実行する必要があります。
|
SUSE VirtualizationとRancherのアップグレードプロセスは互いに独立しています。Rancherのアップグレード中は、仮想IPを使用してSUSE Virtualizationクラスターにアクセスできます。SUSE Virtualizationは自動的にアップグレードされません。 |
Rancherバージョンがメンテナンス終了(EOM)日を迎えると、SUSE Virtualizationは統合機能(仮想化管理)に影響を与える重要なセキュリティ関連の問題に対してのみ修正を提供します。詳細については、 サポートマトリックスを参照してください。
アップグレードによる仮想マシン管理
ライブマイグレーション可能な仮想マシン
ライブマイグレーション可能な仮想マシンは、現在のノードがアップグレードされる前に、バッチマイグレーションを介して他のノードに自動的に移行されます。これらの仮想マシンは、移行中にダウンタイムが発生しません。
非マイグレーション可能な仮想マシン
アップグレードがトリガーされると、SUSE Virtualizationはupgrade-config設定の`restoreVM`オプションの値に応じて特定のアクションを実行します。
-
false: SUSE Virtualizationは、移行不可能な仮想マシンがまだ稼働しているときにアップグレードを実行しません。仮想マシンを手動でシャットダウンする必要があります。 -
true: SUSE Virtualizationは、ノードがアップグレードされるときに移行不可能な仮想マシンを自動的にシャットダウンし、その後ノードが再起動された後に復元します。
|
移行不可能な仮想マシンは、移行中にダウンタイムを経験します。 |
詳細については、フェーズ4を参照してください。ノードのアップグレード。
アップグレードを開始する前に
クラスタ環境に最適なアップグレード戦略と動作を調整するために、利用可能な`upgrade-config`設定を確認してください。
アップグレードを開始する
|
|
|
PCIブリッジに接続されているNICは、アップグレード後に名前が変更される可能性があります。さらなる情報については、 ナレッジベースの記事を確認してください。 |
|
v1.7.0以降、SUSE Virtualizationはパフォーマンスと信頼性を向上させるために、仮想マシンベースのアプローチの代わりにデプロイメントベースのアップグレードリポジトリを使用します。詳細については、 問題 #7101を参照してください。 |
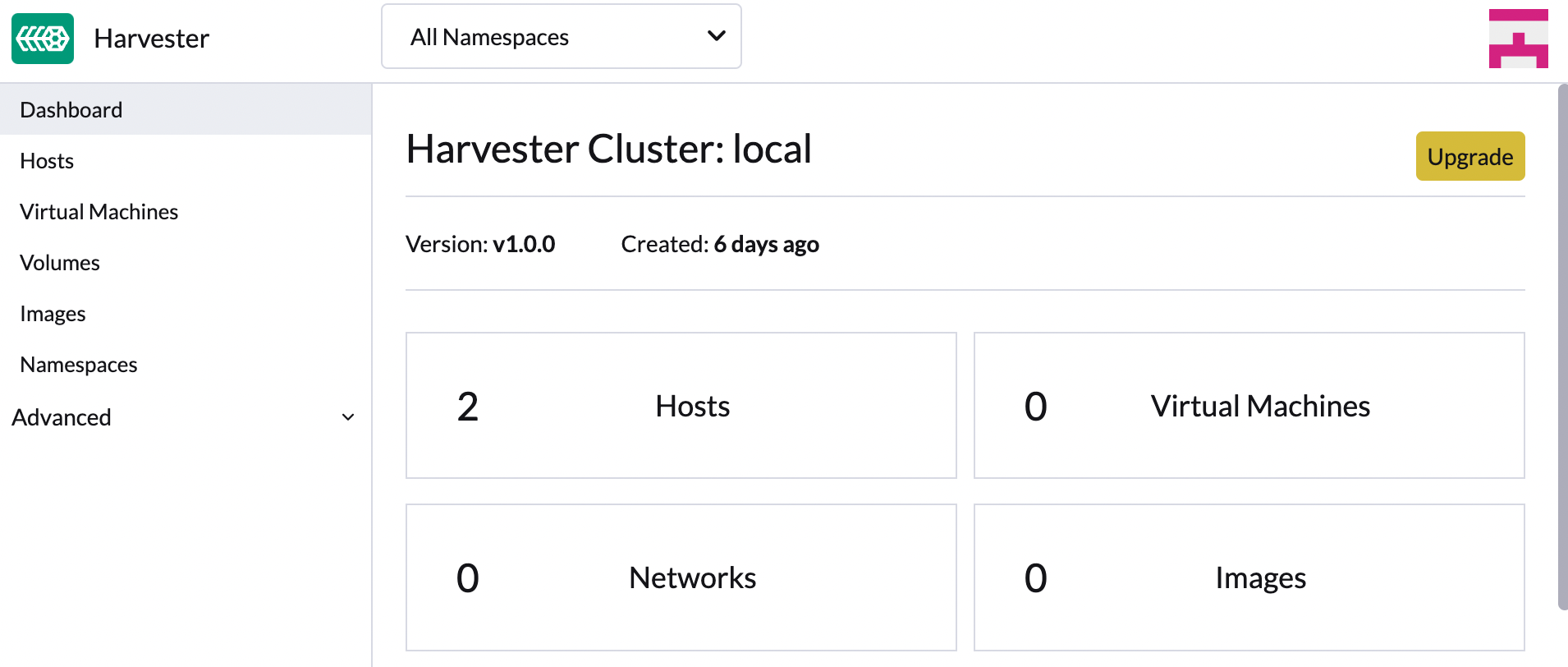
-
SUSE Virtualization UIの*ダッシュボード*画面で、*アップグレード*をクリックします。
新しいバージョンにアップグレードできるようになると、*アップグレード*ボタンが表示されます。
環境に直接インターネットアクセスがない場合は、ISOのダウンロードに効率的なアプローチを提供する[Prepare an air-gapped upgrade]の指示に従ってください。
-
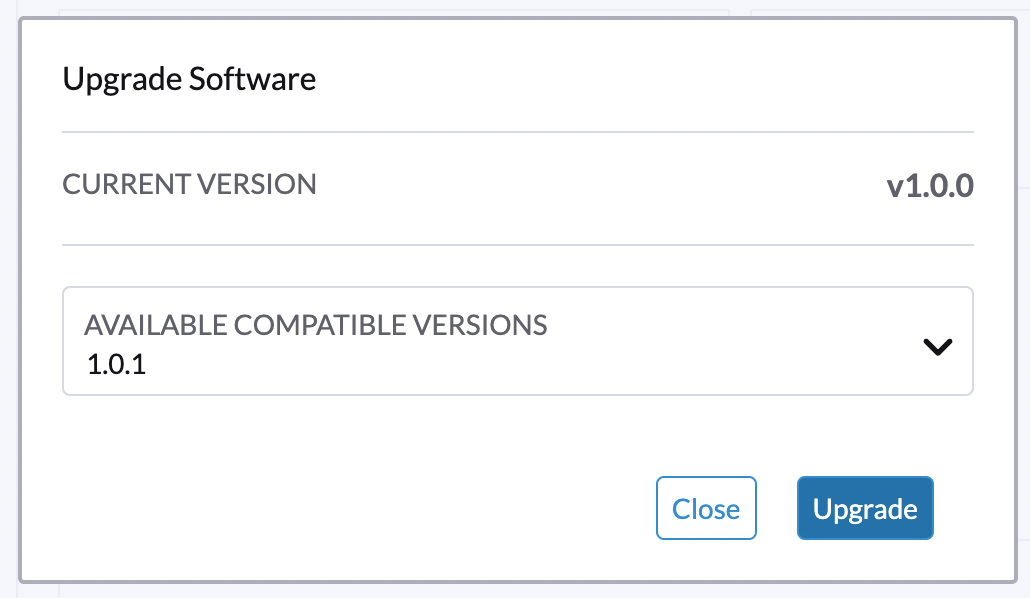
アップグレードしたいバージョンを選択してください。
カスタマイズが必要な場合は、[Customize the version]を参照してください。
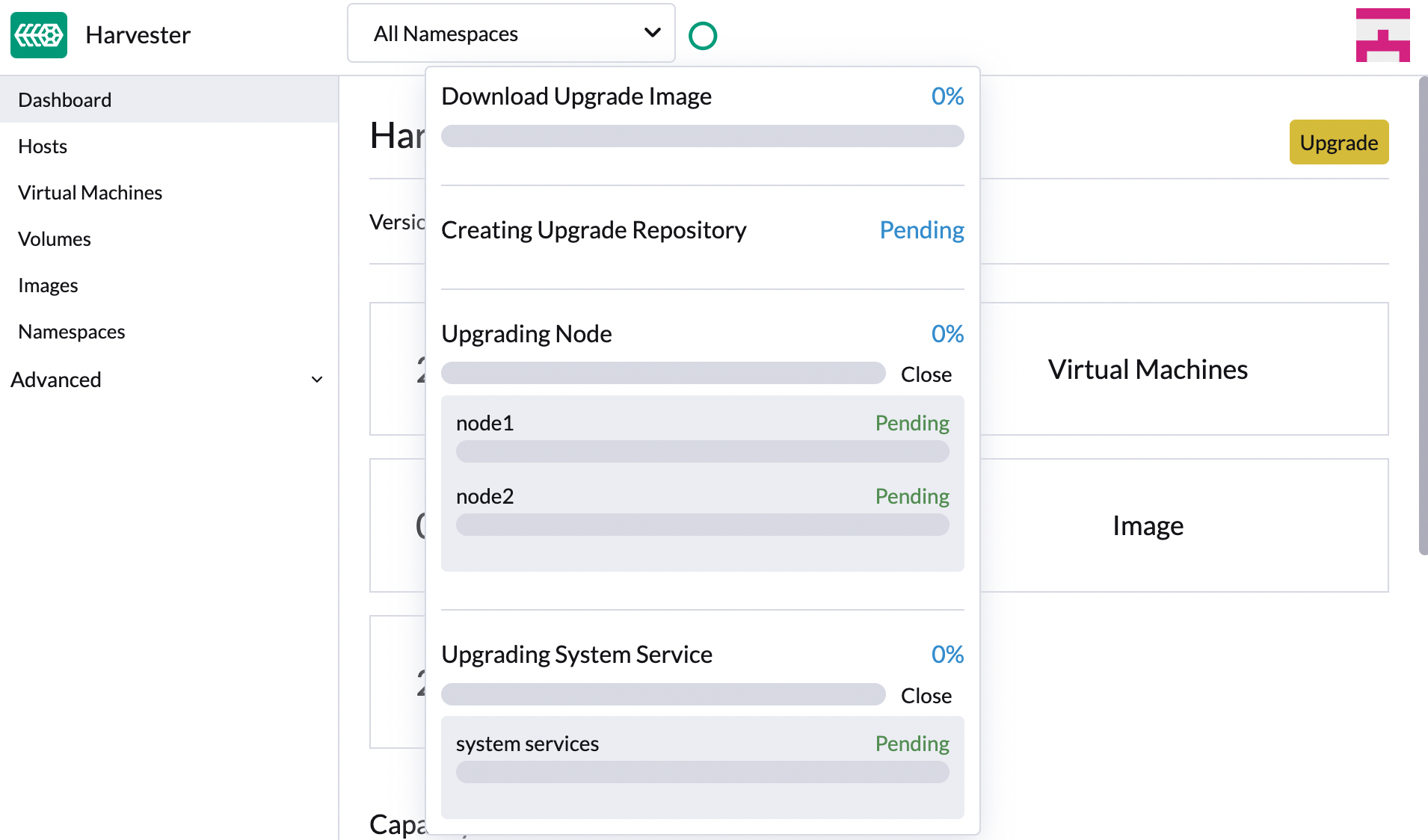
-
進行状況インジケーター(円形アイコン)をクリックして、各関連プロセスのステータスを表示します。
バージョンをカスタマイズする
-
バージョンファイルをダウンロードします(
https://releases.rancher.com/harvester/{version}/version.yaml)。例:
v1.5.0バージョンファイルは`v1.5.0.yaml`としてダウンロードされます。
apiVersion: harvesterhci.io/v1beta1 kind: Version metadata: name: v1.5.0-customized # Changed, to avoid duplicated with the official version name namespace: harvester-system spec: isoChecksum: 'df28e9bf8dc561c5c26dee535046117906581296d633eb2988e4f68390a281b6856a5a0bd2e4b5b988c695a53d0fc86e4e3965f19957682b74317109b1d2fe32' # Don't change isoURL: https://releases.rancher.com/harvester/v1.5.0/harvester-v1.5.0-amd64.iso # Official ISO path by default releaseDate: '20250425' -
コマンド`kubectl create -f v1.5.0.yaml`を使用してバージョンを作成します。
エアギャップ(された)アップグレードを準備します。
|
最初に[Upgrade paths]セクションでアップグレード可能なバージョンを確認してください。 |
ISOファイルを準備してください。
-
リリースページからISOファイルをダウンロードしてください。
-
ISOをローカルHTTPサーバーに保存してください。
ファイルが`http://10.10.0.1/harvester.iso`にホストされていると仮定します。
バージョンを準備してください。
-
バージョンファイルをダウンロードしてください(
https://releases.rancher.com/harvester/{version}/version.yaml)。 -
ファイル内の`isoURL`の値を置き換えてください。
apiVersion: harvesterhci.io/v1beta1 kind: Version metadata: name: v1.5.0 namespace: harvester-system spec: isoChecksum: <SHA-512 checksum of the ISO> isoURL: http://10.10.0.1/harvester.iso # change to local ISO URL releaseDate: '20250425'ファイルが`http://10.10.0.1/version.yaml`にホストされていると仮定してください。カスタマイズが必要な場合は、[Customize the version]を参照してください。
-
SSHを介してコントロールプレーンノードの1つにアクセスし、ルートアカウントを使用してログインしてください。
-
バージョンオブジェクトを作成してください。
rancher@node1:~> sudo -i rancher@node1:~> kubectl create -f http://10.10.0.1/version.yaml
公式のアップグレードが利用可能になる前に手動でアップグレードを開始してください。
新しいバージョンがリリースされた直後には、UIに*アップグレード*ボタンが表示されません。UIでオプションが利用可能になる前にクラスターをアップグレードしたい場合は、[Prepare an air-gapped upgrade]の手順に従ってください。
|
本番環境では、UIを介してクラスターをアップグレードすることが推奨されます。 |
ノードのアップグレードをカスタマイズしてください。
SUSE Virtualizationのアップグレードには、いくつかの定義されたフェーズが含まれます。重要なフェーズはノードのアップグレードであり、この間に各ノードのオペレーティングシステムと基盤となるKubernetesディストリビューション(RKE2)が順次自律的にアップグレードされます。
特定のノードで自動アップグレードを一時停止するオプションがあり、手動メンテナンスや検証作業に便利です。これらの作業が完了した後、SUSE Virtualizationに対してターゲットノードのアップグレードを再開するよう明示的に指示する必要があります。
ノードのアップグレードを一時停止する
ノードのアップグレードを一時停止するには、upgrade-config設定の`nodeUpgradeOption`オプションを使用できます。
-
クラスタ内のすべてのノードを一時停止:`mode`フィールドの値を`manual`に変更してください。
-
特定のノードを一時停止:ノード名を`pauseNodes`フィールドにリストしてください。リストに含まれていないノードは自動的にアップグレードされます。
|
SUSE Virtualizationはアップグレード初期化フェーズ中に`nodeUpgradeOption`設定を適用します。初期化後にこれらのフィールドに加えられた変更は、現在のアップグレードには無視され、次のアップグレードサイクルでのみ有効になります。 |
|
ノードがアップグレードされていない限り、アノテーションにノードを追加または削除するために`Upgrade`カスタムリソースを変更できます。ノードアップグレード一時停止機能は、アノテーションを唯一の情報源として使用します。 |
SUSE Virtualization UIは、一時停止されたノードのアップグレードの視覚的確認を提供します。次の例では、ノード`charlie-1-tink-system`のアップグレードが現在一時停止されています。
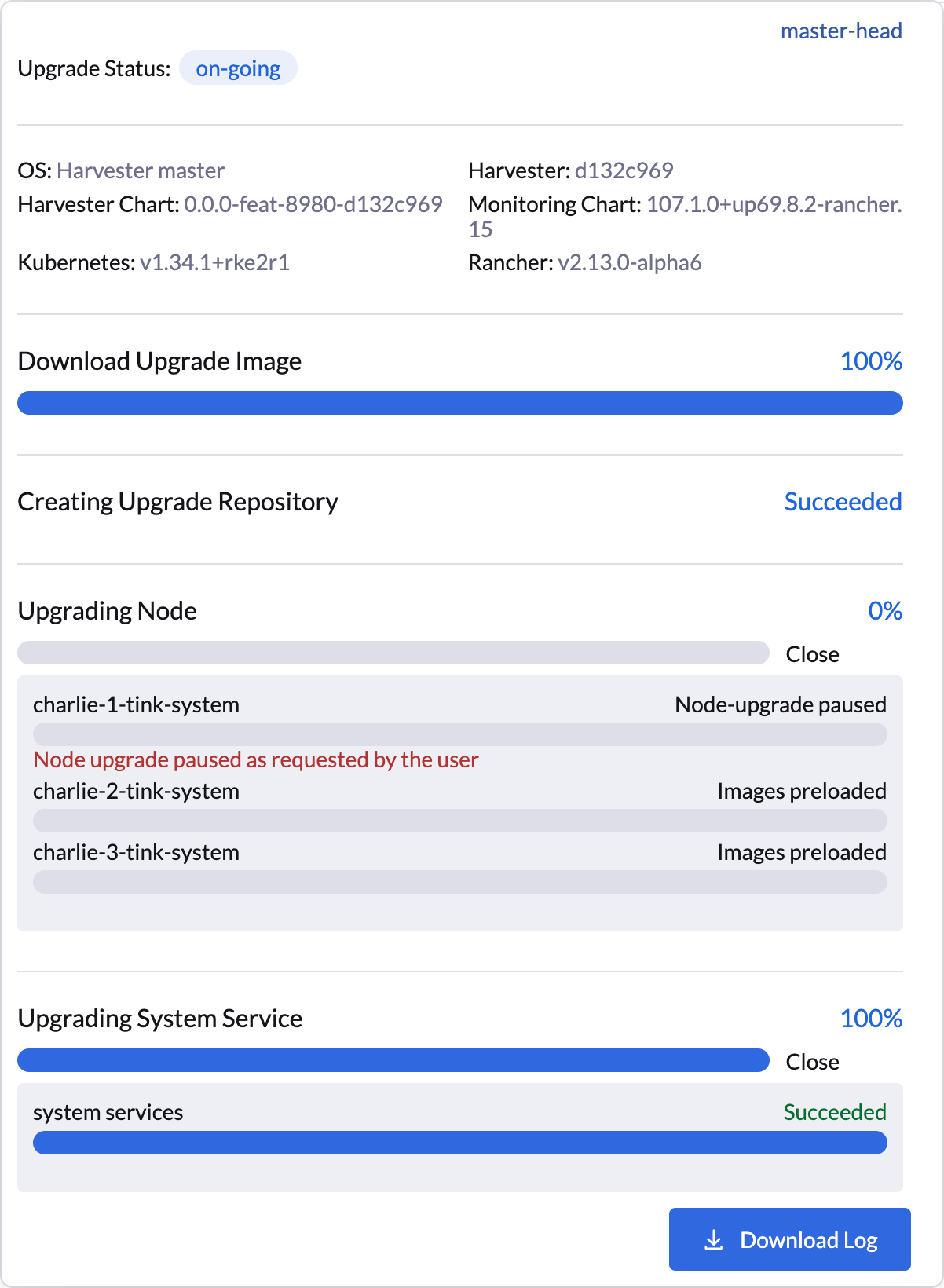
一時停止されたノードのアップグレードを確認するために、次の`kubectl`コマンドも使用できます。
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o yaml
...
annotations:
harvesterhci.io/node-upgrade-pause-map: '{"charlie-1-tink-system":"pause","charlie-2-tink-system":"pause","charlie-3-tink-system":"pause"}'
...
nodeStatuses:
charlie-1-tink-system:
message: Node upgrade paused as requested by the user
reason: AdministrativelyPaused
state: Node-upgrade paused
charlie-2-tink-system:
state: Images preloaded
charlie-3-tink-system:
state: Images preloaded
...|
アップグレードが一時停止されているノードのためのプレドレインジョブは作成されていません。しかし、これらのノードは依然として cordon 状態にあり、新しいワークロードを実行することはできません。アップグレードが一時停止されているノードでは、仮想マシンを手動でシャットダウンするなどのメンテナンスタスクのみを実行する必要があります。 |
一時停止したノードのアップグレードを再開する
harvesterhci.io/node-upgrade-pause-map アノテーションを Upgrade カスタムリソースで更新することで、一時停止したノードのアップグレードを再開できます。
例:
# Find out the latest Upgrade custom resource
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true
NAME AGE
hvst-upgrade-6mcwv 4h16m
# Update the annotation to unpause the node
$ kubectl -n harvester-system annotate --overwrite upgrades hvst-upgrade-6mcwv harvesterhci.io/node-upgrade-pause-map='{"charlie-1-tink-system":"unpause","charlie-2-tink-system":"pause","charlie-3-tink-system":"pause"}'ターゲットノードが Upgrade カスタムリソースにアノテーションされると、SUSE Virtualization はすぐにアップグレードを再開し、UIに視覚的な進捗更新が表示されます。
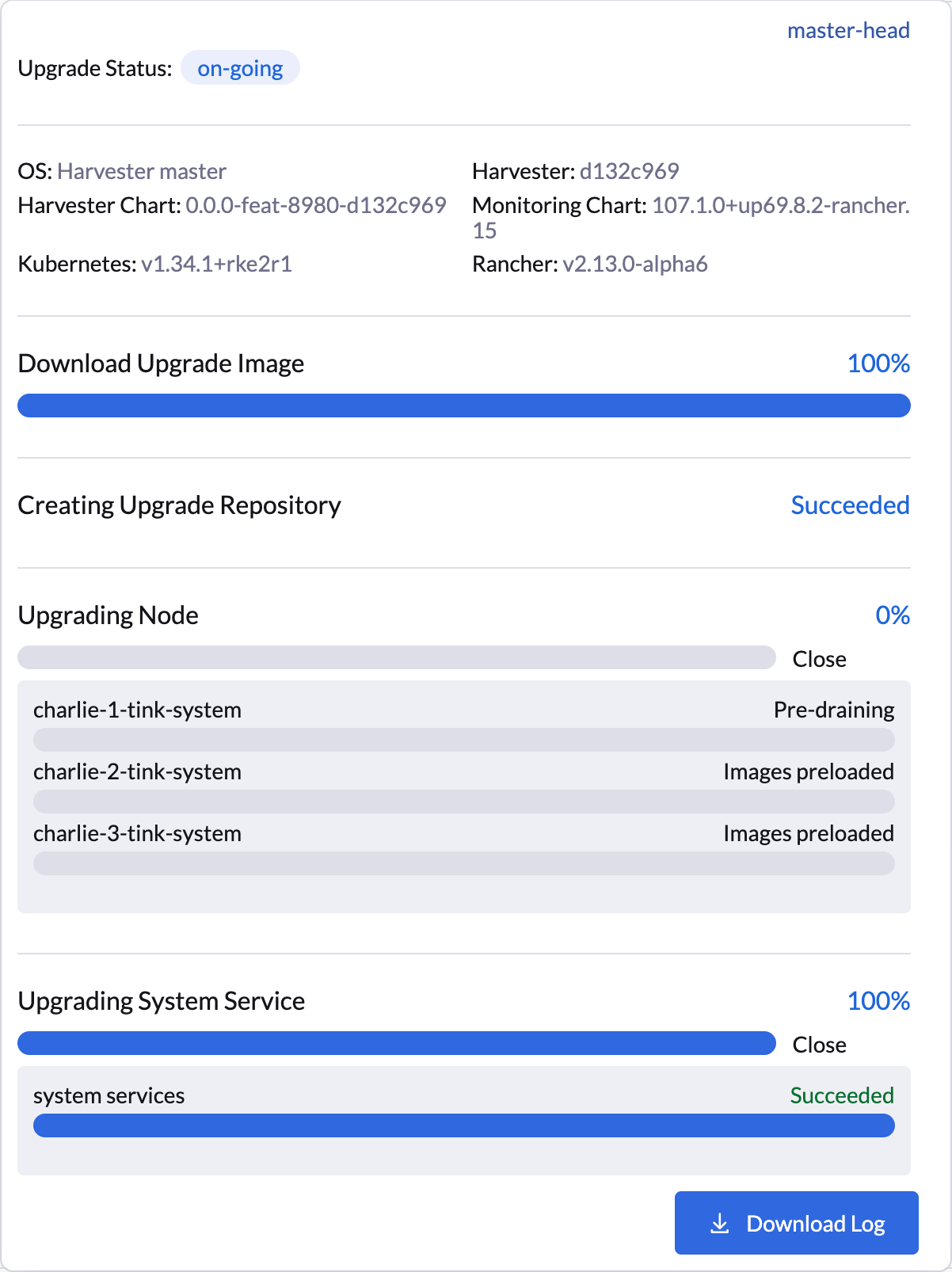
次の kubectl コマンドを使用して、ターゲットノードの状態を確認することもできます:
$ kubectl -n harvester-system get upgrades -l harvesterhci.io/latestUpgrade=true -o yaml
...
annotations:
harvesterhci.io/node-upgrade-pause-map: '{"charlie-1-tink-system":"unpause","charlie-2-tink-system":"pause","charlie-3-tink-system":"pause"}'
...
nodeStatuses:
charlie-1-tink-system:
state: Pre-draining
charlie-2-tink-system:
state: Images preloaded
charlie-3-tink-system:
state: Images preloaded
...ターゲットノードの数に応じて、全体のクラスターアップグレードプロセス中に一時解除操作を複数回実行する必要がある場合があります。
空きシステムパーティションスペースの要件
SUSE Virtualization はアップグレード中に各ノードにイメージをロードします。ディスク使用量が kubelet のガーベジコレクションの閾値を超えると、kubelet は未使用のイメージを削除してスペースを確保します。これは、ノード上でイメージが利用できないため、エアギャップ(された)環境で問題を引き起こす可能性があります。
SUSE Virtualization には、新しいイメージをロードした後にノードがガーベジコレクションをトリガーしないことを保証するチェックが含まれています。
ディスクスペースが不足している場合、SUSE Virtualization はアップグレードをブロックし、次のようなエラーを返します:
Node "harvester-node-0" will reach 92.84% storage space after loading new images. It's higher than kubelet image garbage collection threshold 85%.一部のノードで空きシステムパーティションスペースが不足していてもアップグレードを試みたい場合は、Upgrade オブジェクトの harvesterhci.io/skipGarbageCollectionThresholdCheck: true アノテーションを更新できます。
apiVersion: harvesterhci.io/v1beta1
kind: Upgrade
metadata:
annotations:
harvesterhci.io/skipGarbageCollectionThresholdCheck: true
generateName: hvst-upgrade-
namespace: harvester-system
spec:
version: "1.6.0"
logEnabled: true|
事前定義された値よりも小さい値を設定すると、アップグレードが失敗する可能性があり、運用環境では推奨されません。 |
以下のセクションでは、この要件に関連する問題の解決策について説明します。
プライベートコンテナレジストリを設定し、イメージの事前ロードをスキップします。
システムパーティションは、イメージを削除した後でも空きスペースが不足している可能性があります。これに対処するために、現在のイメージと新しいイメージの両方のためにプライベートコンテナレジストリを設定し、設定upgrade-configを次の値で構成します:
{"imagePreloadOption":{"strategy":{"type":"skip"}}, "restoreVM": false}SUSE Virtualizationはアップグレードイメージの事前ロードプロセスをスキップします。ノードのデプロイメントがアップグレードされると、コンテナランタイムはプライベートコンテナレジストリに保存されたイメージをロードします。
|
パブリックコンテナレジストリに依存しないでください。インターネットサービスの中断の可能性や、 Docker Hub のレート制限にどれだけ近づいているかに注意してください。必要なイメージのいずれかをダウンロードできないと、アップグレードが失敗し、クラスターが中間状態になる可能性があります。 |
証明書の有効期限チェック
SUSE Virtualizationは各ノードの証明書の有効期間をチェックします。このチェックにより、アップグレードが進行中に証明書が期限切れになる可能性が排除されます。証明書が7日以内に期限切れになる場合、エラーが返されます。この動作は、`harvesterhci.io/minCertsExpirationInDay`アノテーションを設定することでオーバーライドできます。
例:
apiVersion: harvesterhci.io/v1beta1
kind: Upgrade
metadata:
annotations:
harvesterhci.io/minCertsExpirationInDay: "14"
generateName: hvst-upgrade-
namespace: harvester-system
spec:
version: "1.6.0"
logEnabled: trueこのアノテーションが`Upgrade`オブジェクトに追加されると、SUSE Virtualizationは14日以内に期限切れになる証明書を検出した場合にエラーを返します。
詳細については、auto-rotate-rke2-certsを参照してください。
バックイメージの排出によるLonghorn Managerのクラッシュ
|
SUSE Virtualization *v1.4.x*にアップグレードする際、`EvictionRequested`フラグが任意のノードまたはディスクで`true`に設定されている場合、Longhorn Managerがクラッシュする可能性があります。この問題は、バックイメージ仕様内のディスクの削除とそのステータスの更新との間の 競合状態によって引き起こされます。 問題が発生しないように、アップグレードプロセスを開始する前に、 |
RKE2 ingress-nginx アドミッションウェブホック (CVE-2025-1974) を再有効化してください。
RKE2 ingress-nginx アドミッションウェブホック を無効にして CVE-2025-1974 を軽減した場合、SUSE Virtualization v1.5.0 以降にアップグレードした後にウェブホックを再有効化する必要があります。
-
SUSE Virtualization が nginx-ingress v1.12.1 以降を使用していることを確認してください。
$ kubectl -n kube-system get po -l"app.kubernetes.io/name=rke2-ingress-nginx" -ojsonpath='{.items[].spec.containers[].image}' rancher/nginx-ingress-controller:v1.12.1-hardened1 -
kubectl -n kube-system edit helmchartconfig rke2-ingress-nginxを実行して 以下の構成をHelmChartConfigリソースから削除します。-
.spec.valuesContent.controller.admissionWebhooks.enabled: false -
.spec.valuesContent.controller.extraArgs.enable-annotation-validation: true
-
-
新しい
.spec.ValuesContent設定が以下の例に似ていることを確認してください。apiVersion: helm.cattle.io/v1 kind: HelmChartConfig metadata: name: rke2-ingress-nginx namespace: kube-system spec: valuesContent: |- controller: admissionWebhooks: port: 8444 extraArgs: default-ssl-certificate: cattle-system/tls-rancher-internal config: proxy-body-size: "0" proxy-request-buffering: "off" publishService: pathOverride: kube-system/ingress-exposeHelmChartConfigリソースに他のカスタムingress-nginx設定が含まれている場合、リソースを編集する際にそれらを保持する必要があります。 -
構成を保存するために
kubectl editコマンドの実行を終了してください。SUSE Virtualization は、内容が保存されると自動的に変更を適用します。
-
rke2-ingress-nginx-admissionウェブホック構成が再有効化されていることを確認してください。$ kubectl get validatingwebhookconfiguration rke2-ingress-nginx-admission NAME WEBHOOKS AGE rke2-ingress-nginx-admission 1 6s -
ingress-nginxポッドが正常に再起動されていることを確認してください。kubectl -n kube-system get po -lapp.kubernetes.io/instance=rke2-ingress-nginx NAME READY STATUS RESTARTS AGE rke2-ingress-nginx-controller-l2cxz 1/1 Running 0 94s
アップグレードが「プレドレイン」状態でスタックしています。
アップグレードプロセスが「プレドレイン」状態でスタックする可能性があります。Kubernetes はノード上のワークロードを排出することになっていますが、いくつかの要因がプロセスを停止させる可能性があります。
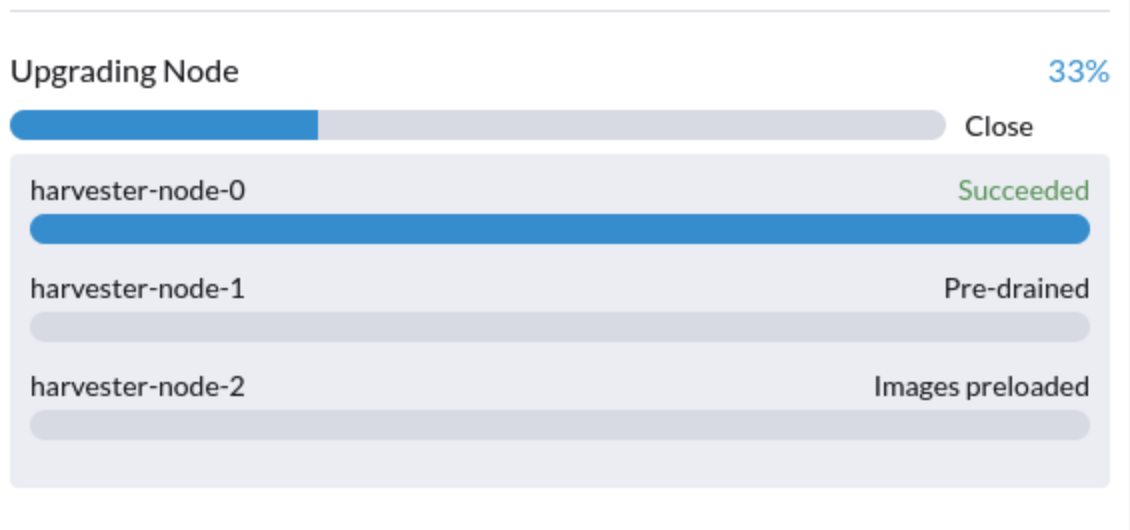
考えられる原因は、Longhorn インスタンスマネージャーの孤児エンジンに関連するプロセスです。これがあなたの状況に当てはまるかどうかを判断するために、以下の手順を実行してください:
-
スタックしているノードの
instance-managerポッドの名前を確認してください。例:
スタックしているノードは
harvester-node-1で、インスタンスマネージャーポッドの名前はinstance-manager-d80e13f520e7b952f4b7593fc1883e2aです。$ kubectl get pods -n longhorn-system --field-selector spec.nodeName=harvester-node-1 | grep instance-manager instance-manager-d80e13f520e7b952f4b7593fc1883e2a 1/1 Running 0 3d8h -
Longhorn マネージャーログに情報メッセージがあるか確認してください。
例:
$ kubectl -n longhorn-system logs daemonsets/longhorn-manager ... time="2025-01-14T00:00:01Z" level=info msg="Node instance-manager-d80e13f520e7b952f4b7593fc1883e2a is marked unschedulable but removing harvester-node-1 PDB is blocked: some volumes are still attached InstanceEngines count 1 pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0" func="controller.(*InstanceManagerController).syncInstanceManagerPDB" file="instance_manager_controller.go:823" controller=longhorn-instance-manager node=harvester-node-1エンジン
pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0のため、instance-managerポッドは排出できません。 -
エンジンがスタックしたノードでまだ動作しているか確認してください。
例:
$ kubectl -n longhorn-system get engines.longhorn.io pvc-9ae0e9a5-a630-4f0c-98cc-b14893c74f9e-e-0 -o jsonpath='{"Current state: "}{.status.currentState}{"\nNode ID: "}{.spec.nodeID}{"\n"}' Current state: stopped Node ID:出力にエンジンが動作していないか、見つからないと表示されている場合、問題が存在する可能性があります。
-
すべてのボリュームが正常であるか確認してください。
kubectl get volumes -n longhorn-system -o yaml | yq '.items[] | select(.status.state == "attached")| .status.robustness'すべてのボリュームは`healthy`としてマークされている必要があります。これが当てはまらない場合は、問題を報告してください。
-
`instance-manager`ポッドのPodDisruptionBudget (PDB)を削除してください。
例:
kubectl delete pdb instance-manager-d80e13f520e7b952f4b7593fc1883e2a -n longhorn-system
関連する問題:
「プレドレイン」状態でのライブマイグレーションに失敗しました。
仮想マシンのライブマイグレーションは、アップグレード中のノードがプレドレイン状態でコーデンされていると失敗することがあります。一般的な原因は、厳格なアンチアフィニティルールのために互換性のあるターゲットノードが不足していることです。
このような場合、SUSE Virtualizationは自動的にこれらの仮想マシンをシャットダウンし、アップグレードの進行を妨げることなく、プロセスが安全でない状態で再起動するのを防ぎます。
定期的なSUSE Storageスナップショットとバックアップはサポートされていません。
定期的なSUSE StorageスナップショットとバックアップはSUSE Virtualizationに統合されていません。この機能を使用することに決めた場合、アップグレードを開始する前に、すべての*定期的なスナップショットおよびバックアップジョブをSUSE Storage*無効にする必要があります。
互換性の問題に関する詳細は、スケジュールされた仮想マシンのバックアップとスナップショットを参照してください。